## Bar Chart: Types of errors made by a 62B language model
### Overview
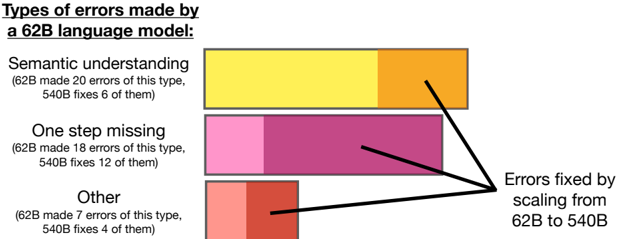
The chart compares error types in a 62B language model (62B) versus a scaled-up 540B model (540B), showing errors made and fixed. Three error categories are analyzed: "Semantic understanding," "One step missing," and "Other." Each category includes two data points: errors made by 62B and errors fixed by 540B. An arrow highlights the "Errors fixed by scaling from 62B to 540B" metric.
### Components/Axes
- **Title**: "Types of errors made by a 62B language model"
- **X-axis**: "Errors fixed by scaling from 62B to 540B" (no numerical scale, categorical)
- **Y-axis**: Error categories (Semantic understanding, One step missing, Other)
- **Legend**:
- Yellow: 62B errors made
- Orange: 540B errors fixed (Semantic understanding)
- Pink: 62B errors made (One step missing)
- Purple: 540B errors fixed (One step missing)
- Red: 62B errors made (Other)
- Dark red: 540B errors fixed (Other)
- **Arrow**: Points to the "Errors fixed by scaling" metric, connecting the 540B fixed errors to the 62B errors made.
### Detailed Analysis
1. **Semantic understanding**:
- 62B made 20 errors (yellow bar).
- 540B fixed 6 of these errors (orange bar).
2. **One step missing**:
- 62B made 18 errors (pink bar).
- 540B fixed 12 of these errors (purple bar).
3. **Other**:
- 62B made 7 errors (red bar).
- 540B fixed 4 of these errors (dark red bar).
### Key Observations
- The 540B model fixes a subset of errors made by the 62B model across all categories.
- "One step missing" errors show the highest number of fixes (12/18), suggesting this category is most amenable to scaling improvements.
- "Semantic understanding" errors have the largest gap between errors made (20) and fixed (6), indicating persistent challenges in this area.
- "Other" errors show minimal improvement (4/7 fixed).
### Interpretation
The data demonstrates that scaling from 62B to 540B reduces errors, particularly in "One step missing" scenarios, where 67% of errors are resolved. However, "Semantic understanding" errors remain largely unresolved (only 30% fixed), highlighting a critical limitation in the larger model's capabilities. The "Other" category's low fix rate (57%) suggests these errors may stem from fundamentally different causes. This pattern implies that while model scaling improves performance, it does not universally address all error types, pointing to the need for targeted architectural or training improvements for specific error categories.