## Bar Chart: Types of Errors Made by a 62B Language Model
### Overview
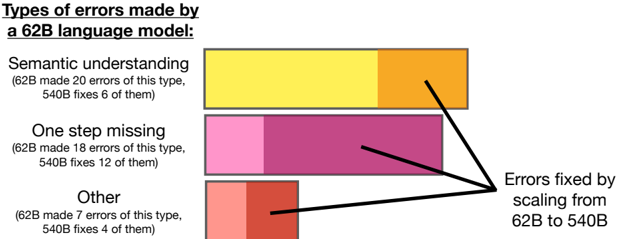
The image presents a bar chart illustrating the types of errors made by a 62B language model and the number of those errors fixed by scaling to a 540B model. The chart categorizes errors into "Semantic understanding," "One step missing," and "Other." Each category is represented by a horizontal bar, with the bar divided into two sections representing the number of errors made by the 62B model and the number fixed by the 540B model.
### Components/Axes
* **Title:** Types of errors made by a 62B language model:
* **Categories (Y-axis):**
* Semantic understanding
* One step missing
* Other
* **Bar Segments:** Each bar is divided into two segments:
* Left segment: Represents the number of errors made by the 62B model.
* Right segment: Represents the number of errors fixed by scaling to the 540B model.
* **Annotation:** "Errors fixed by scaling from 62B to 540B" with arrows pointing to the right segments of each bar.
### Detailed Analysis
* **Semantic understanding:**
* 62B model made 20 errors (yellow segment).
* 540B model fixed 6 errors (orange segment).
* **One step missing:**
* 62B model made 18 errors (pink segment).
* 540B model fixed 12 errors (purple segment).
* **Other:**
* 62B model made 7 errors (light red segment).
* 540B model fixed 4 errors (red segment).
### Key Observations
* The "Semantic understanding" category has the highest number of errors made by the 62B model (20).
* The "One step missing" category has the highest number of errors fixed by the 540B model (12).
* The "Other" category has the lowest number of errors made by the 62B model (7) and the lowest number of errors fixed by the 540B model (4).
* The proportion of errors fixed is highest for "One step missing" (12 out of 18) compared to "Semantic understanding" (6 out of 20) and "Other" (4 out of 7).
### Interpretation
The chart demonstrates the impact of scaling a language model from 62B to 540B parameters on different types of errors. Scaling the model appears to be most effective in reducing "One step missing" errors, suggesting that the larger model is better at handling sequential reasoning or procedural tasks. While scaling also reduces "Semantic understanding" and "Other" errors, the improvement is less pronounced. This could indicate that these types of errors are more complex and require different approaches beyond simply increasing model size. The data suggests that model scaling has a varying degree of effectiveness depending on the nature of the error.