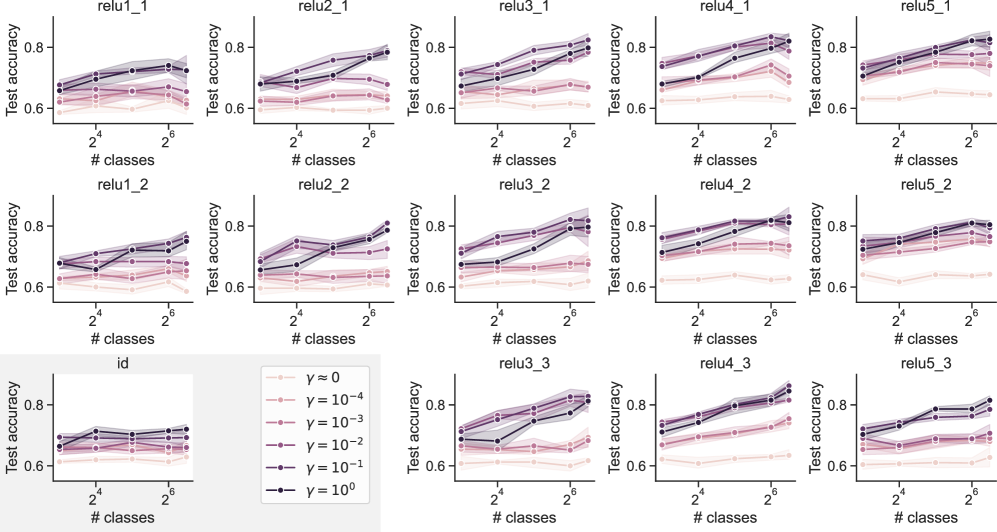
## Line Graph Grid: Test Accuracy vs. Number of Classes Across ReLU Configurations
### Overview
The image displays a 5x3 grid of line graphs comparing test accuracy across different numbers of classes (2⁴ to 2⁶) for various ReLU configurations (relu1_1 to relu5_3) and an "id" category. Each graph includes multiple data series differentiated by gamma (γ) values (0, 10⁻⁴, 10⁻³, 10⁻², 10⁻¹, 10⁰), with trends showing how accuracy evolves as class complexity increases.
---
### Components/Axes
- **X-axis**: "# classes" (logarithmic scale: 2⁴ to 2⁶)
- **Y-axis**: "Test accuracy" (linear scale: 0.6 to 0.8)
- **Legend**:
- γ = 0 (light pink)
- γ = 10⁻⁴ (pink)
- γ = 10⁻³ (light purple)
- γ = 10⁻² (purple)
- γ = 10⁻¹ (dark purple)
- γ = 10⁰ (black)
- **Labels**:
- Top row: relu1_1, relu2_1, relu3_1, relu4_1, relu5_1
- Middle row: relu1_2, relu2_2, relu3_2, relu4_2, relu5_2
- Bottom row: id (no ReLU configuration specified)
---
### Detailed Analysis
1. **Test Accuracy Trends**:
- **Higher γ values** (e.g., γ = 10⁰, black lines) generally show **steeper upward slopes** in test accuracy as class count increases, particularly in relu4_1, relu4_2, and relu5_1.
- **Lower γ values** (e.g., γ = 0, light pink) exhibit **flatter trajectories**, with minimal improvement across class counts.
- **Relu4 configurations** (e.g., relu4_1, relu4_2) demonstrate the **highest peak accuracies** (up to ~0.85 for γ = 10⁰ at 2⁶ classes).
- **Relu1/Relu2** graphs show **moderate gains**, while **Relu3** and **id** categories lag behind.
2. **Data Points**:
- **relu1_1**:
- γ = 10⁰: 0.72 (2⁴) → 0.78 (2⁶)
- γ = 0: 0.65 (2⁴) → 0.67 (2⁶)
- **relu4_2**:
- γ = 10⁰: 0.82 (2⁴) → 0.85 (2⁶)
- γ = 10⁻¹: 0.75 (2⁴) → 0.79 (2⁶)
- **id**:
- γ = 10⁰: 0.68 (2⁴) → 0.70 (2⁶)
- γ = 0: 0.63 (2⁴) → 0.64 (2⁶)
3. **Color Consistency**:
- All γ values are consistently mapped to their legend colors across graphs (e.g., γ = 10⁰ is always black).
---
### Key Observations
- **γ = 10⁰** (black lines) consistently outperforms other γ values, especially in high-complexity scenarios (2⁶ classes).
- **Relu4 configurations** achieve the highest accuracy, suggesting architectural advantages in handling class complexity.
- The **id category** underperforms all ReLU variants, indicating ReLU activation functions improve generalization.
- **γ = 0** (light pink) shows the least sensitivity to class count, implying minimal regularization effect.
---
### Interpretation
The data suggests that:
1. **Gamma (γ) acts as a regularization parameter**: Higher γ values (closer to 1) improve model robustness to class complexity, likely by reducing overfitting.
2. **ReLU configuration impacts performance**: Relu4 variants outperform others, possibly due to deeper or more optimized architectures.
3. **Diminishing returns**: Accuracy gains plateau at higher class counts (2⁶), suggesting practical limits to scalability.
4. **Baseline weakness**: The "id" category’s low accuracy highlights the necessity of ReLU activation for competitive performance.
Notably, relu4_1 and relu5_1 show **non-monotonic trends** (e.g., slight dips at 2⁵ classes), which may indicate overfitting or architectural trade-offs. Further investigation into γ’s interaction with specific ReLU configurations could reveal optimal hyperparameter settings for complex datasets.