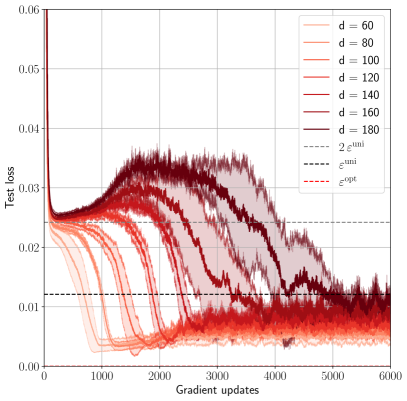
## Line Chart: Test Loss vs. Gradient Updates
### Overview
The image is a line chart displaying the test loss of a model as a function of gradient updates, with different lines representing different values of 'd' (likely a model parameter). The chart also includes horizontal lines representing theoretical error bounds.
### Components/Axes
* **X-axis:** Gradient updates, ranging from 0 to 6000.
* **Y-axis:** Test loss, ranging from 0.00 to 0.06.
* **Legend (Top-Right):**
* d = 60 (lightest tan color)
* d = 80 (light tan color)
* d = 100 (light brown color)
* d = 120 (brown color)
* d = 140 (dark brown color)
* d = 160 (darker brown color)
* d = 180 (darkest brown color)
* 2 ε<sup>uni</sup> (dashed black line)
* ε<sup>uni</sup> (dashed black line)
* ε<sup>opt</sup> (dashed red line)
### Detailed Analysis
* **General Trend:** All lines start at approximately the same test loss value (around 0.055) and initially decrease rapidly. After the initial drop, the behavior diverges based on the value of 'd'.
* **d = 60 (lightest tan):** The test loss decreases rapidly to approximately 0.005 around 1000 gradient updates, then remains relatively stable with some fluctuations.
* **d = 80 (light tan):** The test loss decreases rapidly to approximately 0.008 around 1200 gradient updates, then remains relatively stable with some fluctuations.
* **d = 100 (light brown):** The test loss decreases rapidly to approximately 0.015 around 1500 gradient updates, then remains relatively stable with some fluctuations.
* **d = 120 (brown):** The test loss decreases rapidly to approximately 0.02 around 1700 gradient updates, then remains relatively stable with some fluctuations.
* **d = 140 (dark brown):** The test loss decreases rapidly to approximately 0.025 around 2000 gradient updates, then increases to approximately 0.032 around 3000 gradient updates, then decreases to approximately 0.02 around 4000 gradient updates, then increases to approximately 0.025 around 5000 gradient updates.
* **d = 160 (darker brown):** The test loss decreases rapidly to approximately 0.025 around 2200 gradient updates, then increases to approximately 0.035 around 3500 gradient updates, then decreases to approximately 0.022 around 4500 gradient updates, then increases to approximately 0.028 around 5500 gradient updates.
* **d = 180 (darkest brown):** The test loss decreases rapidly to approximately 0.025 around 2500 gradient updates, then increases to approximately 0.038 around 3800 gradient updates, then decreases to approximately 0.025 around 5000 gradient updates, then increases to approximately 0.03 around 6000 gradient updates.
* **Horizontal Lines:**
* 2 ε<sup>uni</sup> (dashed black line): Located at approximately 0.024.
* ε<sup>uni</sup> (dashed black line): Located at approximately 0.012.
* ε<sup>opt</sup> (dashed red line): Located at approximately 0.024.
### Key Observations
* As 'd' increases, the initial decrease in test loss becomes less steep, and the final test loss value tends to be higher.
* For larger values of 'd' (140, 160, 180), the test loss exhibits a more pronounced increase after the initial decrease, suggesting potential overfitting or instability.
* The lines for d=60, d=80, d=100, and d=120 appear to converge to a stable, low test loss value.
* The horizontal lines represent error bounds, with the test loss for smaller 'd' values eventually falling below these bounds.
### Interpretation
The chart illustrates the impact of the parameter 'd' on the training process and the final test loss. Smaller values of 'd' lead to faster convergence and lower final test loss, suggesting better generalization performance. Larger values of 'd' may lead to overfitting or instability, as indicated by the increase in test loss after the initial decrease. The error bounds provide a theoretical benchmark for the performance of the model, and the results suggest that smaller 'd' values achieve performance close to or better than these bounds. The optimal value of 'd' would likely be a trade-off between convergence speed and final test loss, potentially lying in the range of 60-120.