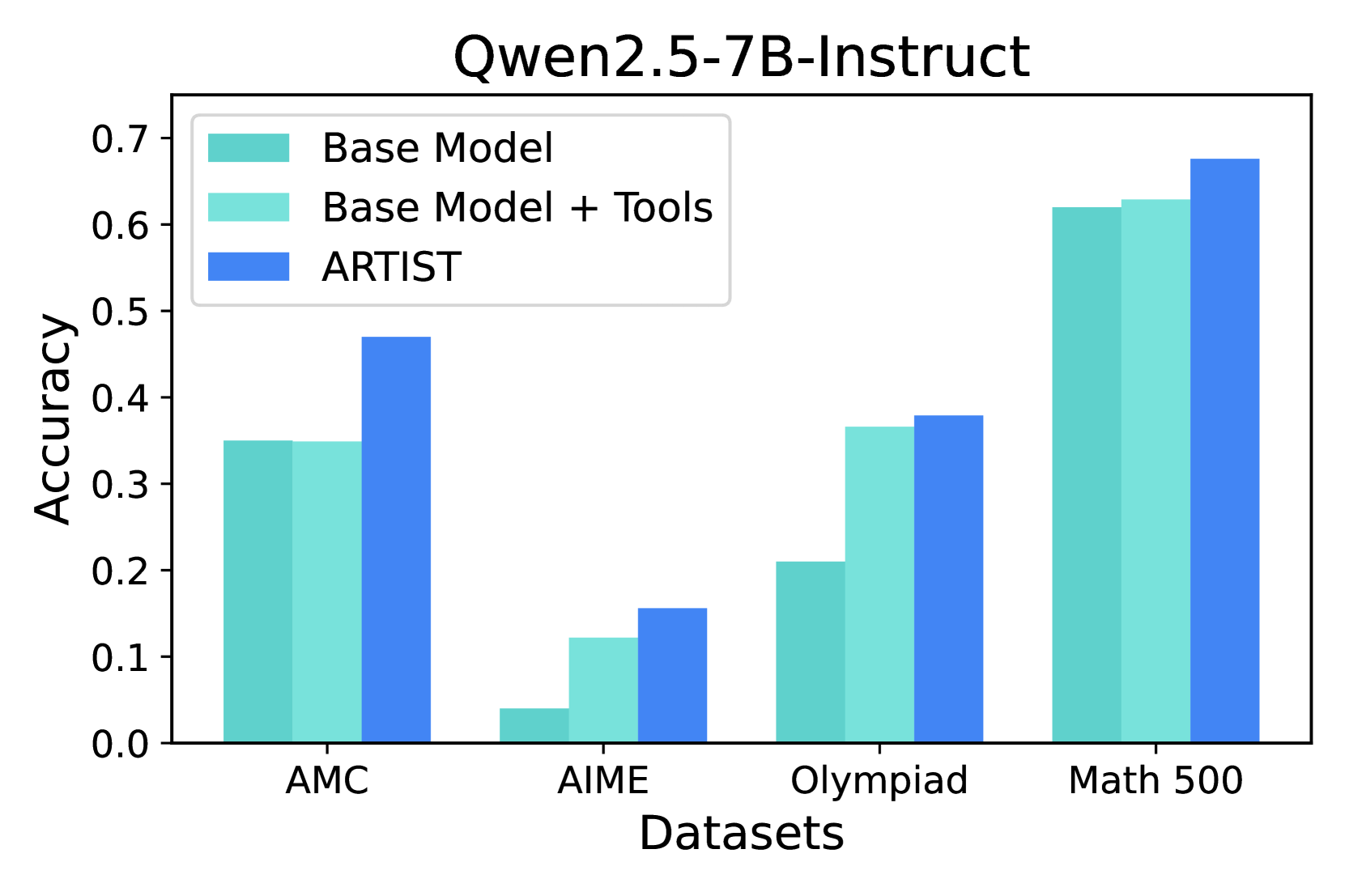
## Bar Chart: Qwen2.5-7B-Instruct Model Performance Across Datasets
### Overview
The chart compares the accuracy of three model configurations (Base Model, Base Model + Tools, ARTIST) across four datasets (AMC, AIME, Olympiad, Math 500). Accuracy values range from 0.0 to 0.7 on the y-axis, with datasets labeled on the x-axis.
### Components/Axes
- **X-axis (Datasets)**: AMC, AIME, Olympiad, Math 500 (categorical, evenly spaced)
- **Y-axis (Accuracy)**: 0.0 to 0.7 (linear scale, increments of 0.1)
- **Legend**:
- Teal: Base Model
- Light Teal: Base Model + Tools
- Blue: ARTIST
- **Bar Groups**: Each dataset has three adjacent bars representing the three model configurations.
### Detailed Analysis
1. **AMC Dataset**:
- Base Model: ~0.35
- Base Model + Tools: ~0.35
- ARTIST: ~0.47
- *Trend*: ARTIST shows a significant (~12%) improvement over Base Model configurations.
2. **AIME Dataset**:
- Base Model: ~0.05
- Base Model + Tools: ~0.12
- ARTIST: ~0.16
- *Trend*: All configurations underperform, but ARTIST achieves ~33% higher accuracy than Base Model.
3. **Olympiad Dataset**:
- Base Model: ~0.21
- Base Model + Tools: ~0.37
- ARTIST: ~0.38
- *Trend*: Base Model + Tools shows a ~76% improvement over Base Model, with ARTIST adding marginal gains.
4. **Math 500 Dataset**:
- Base Model: ~0.62
- Base Model + Tools: ~0.63
- ARTIST: ~0.68
- *Trend*: ARTIST achieves ~8% higher accuracy than Base Model + Tools, maintaining the highest performance.
### Key Observations
- **ARTIST Consistency**: ARTIST outperforms all other configurations across all datasets, with the largest gap in AMC (~12%) and smallest in Math 500 (~8%).
- **Tool Impact**: Base Model + Tools improves upon Base Model in all datasets except AMC (where they are equal).
- **Dataset Difficulty**: AIME shows the lowest accuracies overall (~0.05–0.16), while Math 500 achieves the highest (~0.62–0.68).
### Interpretation
The data suggests that the ARTIST configuration (likely enhanced with specialized tools or training) demonstrates superior performance across diverse tasks. The Base Model + Tools configuration shows meaningful improvements over the Base Model, particularly in Olympiad (~76% gain), indicating that tool integration significantly aids performance. The Math 500 dataset’s high baseline accuracy (~0.62) implies the model may have been optimized for mathematical reasoning, while AIME’s low performance (~0.05–0.16) highlights challenges with complex problem-solving tasks. The consistent ARTIST advantage across datasets suggests it incorporates critical enhancements (e.g., reasoning pipelines, external knowledge integration) that generalize well.