\n
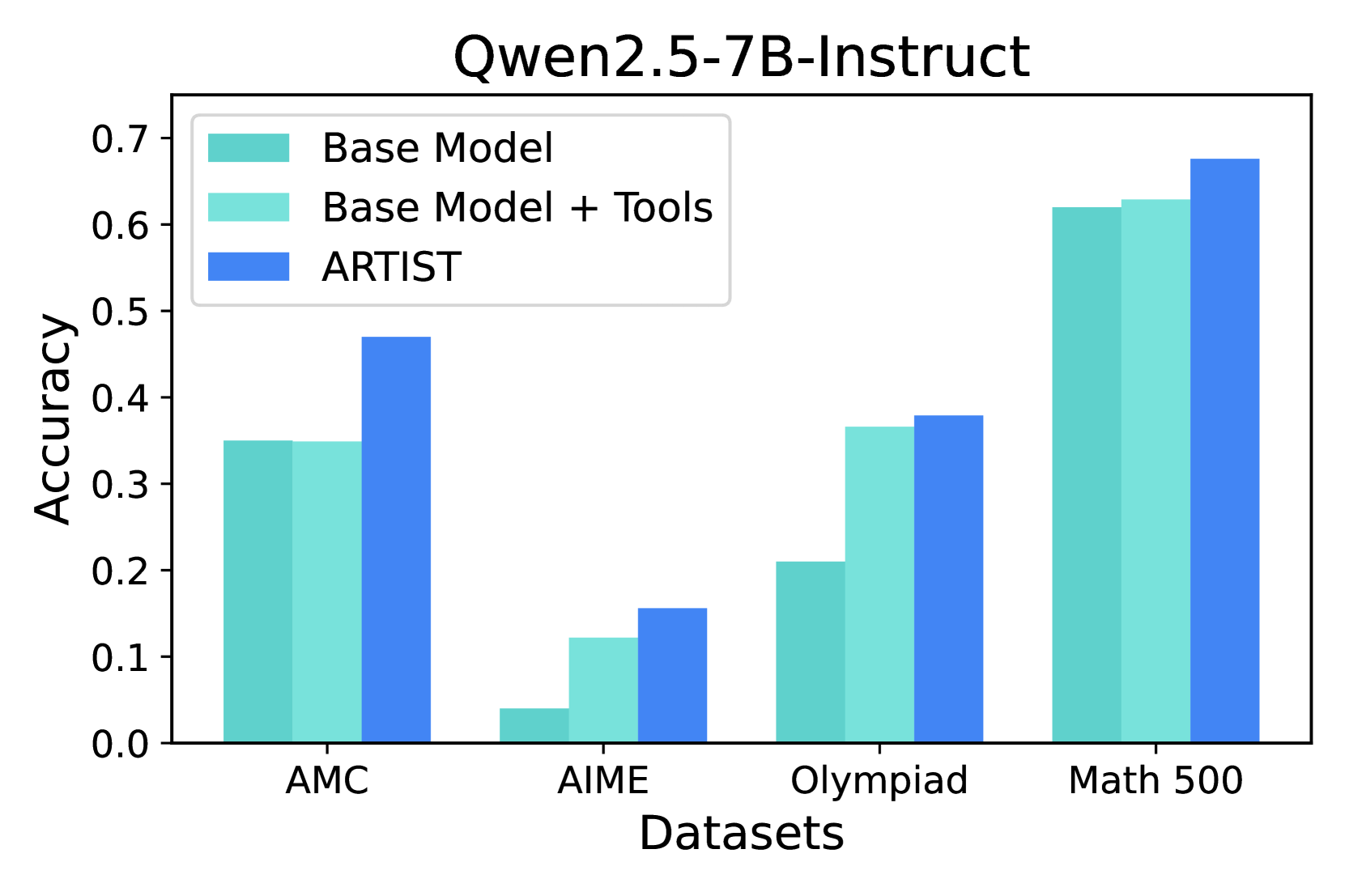
## Bar Chart: Qwen2.5-7B-Instruct Accuracy on Math Datasets
### Overview
This bar chart compares the accuracy of three different models – Base Model, Base Model + Tools, and ARTIST – on four math datasets: AMC, AIME, Olympiad, and Math 500. The accuracy is measured on the y-axis, ranging from 0.0 to 0.7, while the datasets are listed on the x-axis.
### Components/Axes
* **Title:** Qwen2.5-7B-Instruct
* **X-axis Label:** Datasets
* **Y-axis Label:** Accuracy
* **Datasets (X-axis):** AMC, AIME, Olympiad, Math 500
* **Models (Legend):**
* Base Model (Light Blue)
* Base Model + Tools (Turquoise)
* ARTIST (Blue)
### Detailed Analysis
The chart consists of grouped bar plots for each dataset, representing the accuracy of each model.
**AMC Dataset:**
* Base Model: Approximately 0.34
* Base Model + Tools: Approximately 0.48
* ARTIST: Approximately 0.46
**AIME Dataset:**
* Base Model: Approximately 0.08
* Base Model + Tools: Approximately 0.14
* ARTIST: Approximately 0.09
**Olympiad Dataset:**
* Base Model: Approximately 0.21
* Base Model + Tools: Approximately 0.34
* ARTIST: Approximately 0.38
**Math 500 Dataset:**
* Base Model: Approximately 0.61
* Base Model + Tools: Approximately 0.64
* ARTIST: Approximately 0.68
**Trends:**
* For all datasets, ARTIST generally outperforms the Base Model.
* Adding tools to the Base Model consistently improves performance.
* The largest performance difference between models is observed on the Math 500 dataset.
* The Base Model + Tools and ARTIST models show similar performance on the AMC dataset.
### Key Observations
* The ARTIST model achieves the highest accuracy across all datasets.
* The Base Model performs relatively poorly on the AIME and Olympiad datasets.
* The Math 500 dataset shows the highest overall accuracy scores for all models.
* The addition of tools significantly boosts the performance of the Base Model, particularly on the AMC and Olympiad datasets.
### Interpretation
The data suggests that the ARTIST model is the most effective at solving problems from these math datasets, followed by the Base Model with added tools. The Base Model alone exhibits lower accuracy, especially on more challenging datasets like AIME and Olympiad. The consistent improvement observed when tools are added to the Base Model indicates that these tools provide valuable assistance in problem-solving. The higher accuracy scores on the Math 500 dataset may be due to the dataset's characteristics, potentially being less complex or more aligned with the models' training data. The differences in performance across datasets highlight the varying difficulty levels and the models' ability to generalize to different types of math problems. The chart demonstrates the effectiveness of model enhancement through tool integration and the potential for further improvement in AI-driven math problem-solving.