# Technical Document Extraction: LLM Evaluation Methods Flowchart
## Diagram Overview
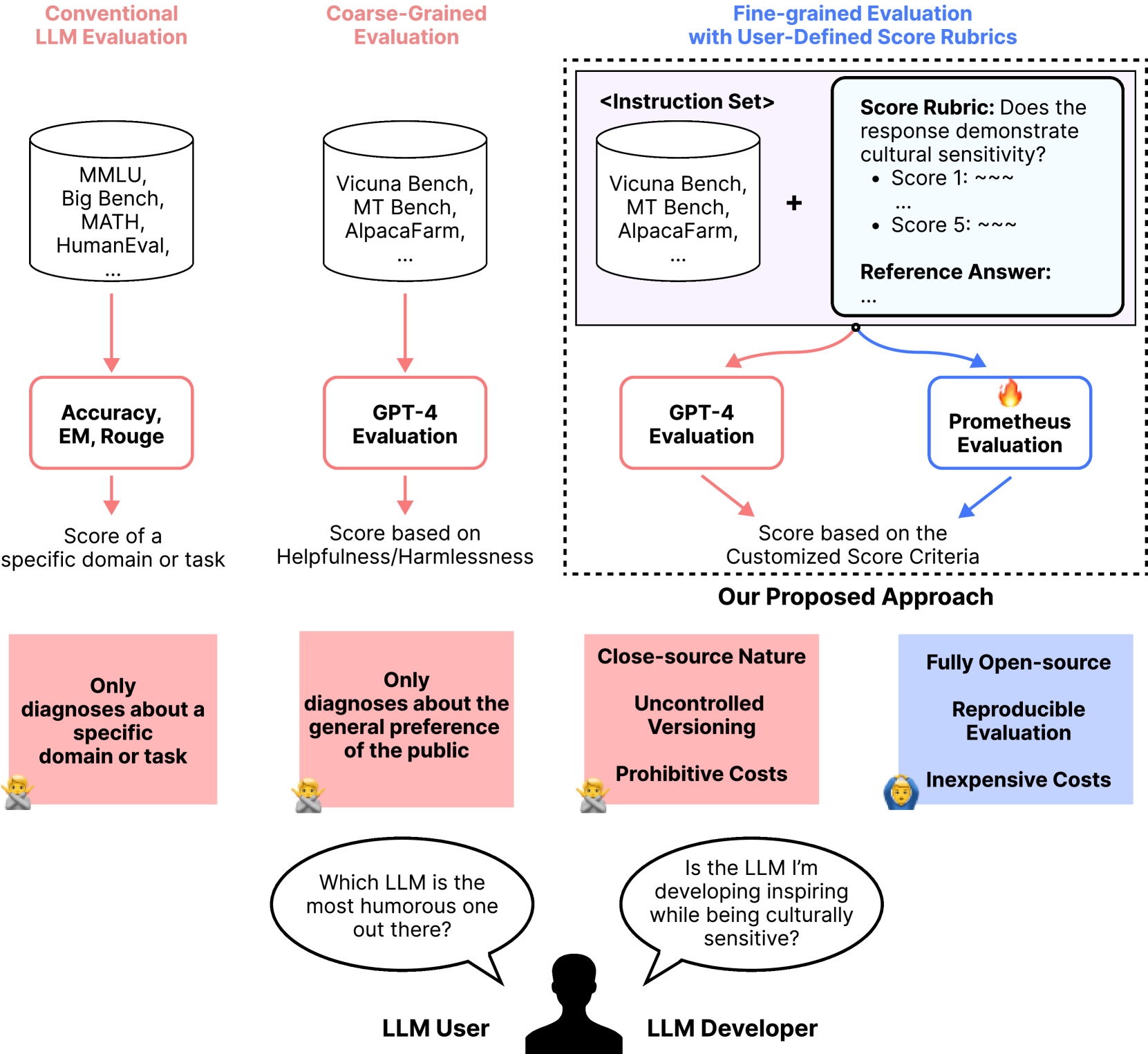
The image presents a comparative analysis of Large Language Model (LLM) evaluation methodologies through a multi-section flowchart. Key components include conventional benchmarks, coarse-grained evaluations, fine-grained evaluations with custom rubrics, and a proposed evaluation approach.
---
## Section 1: Conventional LLM Evaluation
**Title**: Conventional LLM Evaluation
**Components**:
- **Benchmarks**: MMLU, Big Bench, MATH, HumanEval
- **Evaluation Metrics**: Accuracy, EM (Exact Match), Rouge
- **Output**: Score for specific domain/task
**Flow**:
```
Benchmarks → Accuracy/EM/Rouge → Domain-specific Score
```
---
## Section 2: Coarse-Grained Evaluation
**Title**: Coarse-Grained Evaluation
**Components**:
- **Benchmarks**: Vicuna Bench, MT Bench, AlpacaFarm
- **Evaluation Method**: GPT-4 Evaluation
- **Output**: Score based on Helpfulness/Harmlessness
**Flow**:
```
Benchmarks → GPT-4 Evaluation → Helpfulness/Harmlessness Score
```
---
## Section 3: Fine-grained Evaluation with User-Defined Score Rubrics
**Title**: Fine-grained Evaluation with User-Defined Score Rubrics
**Components**:
- **Instruction Set**: Vicuna Bench, MT Bench, AlpacaFarm
- **Score Rubric**: Cultural sensitivity assessment (1-5 scale)
- Score 1: `~~~` (Low sensitivity)
- Score 5: `~~~` (High sensitivity)
- **Reference Answer**: Placeholder for ground truth
- **Evaluation Methods**:
- GPT-4 Evaluation → Customized Criteria
- Prometheus Evaluation (🔥 icon) → Customized Criteria
**Flow**:
```
Instruction Set + Score Rubric → GPT-4 Evaluation → Customized Criteria
Instruction Set + Score Rubric → Prometheus Evaluation → Customized Criteria
```
---
## Section 4: Proposed Approach
**Components**:
1. **Domain-specific Diagnostics**
- 🤔 Emoji: "Only diagnoses about a specific domain or task"
- Limitation: Narrow focus
2. **General Preference Diagnostics**
- 🤔 Emoji: "Only diagnoses about the general preference of the public"
- Limitation: Public bias
3. **Close-source Nature**
- 🤔 Emoji: "Uncontrolled Versioning"
- 💸 Emoji: "Prohibitive Costs"
4. **Fully Open-source**
- 🤔 Emoji: "Reproducible Evaluation"
- 💸 Emoji: "Inexpensive Costs"
---
## Dialogue Bubble Analysis
**LLM User**:
"Which LLM is the most humorous one out there?"
**LLM Developer**:
"Is the LLM I’m developing inspiring while being culturally sensitive?"
---
## Key Observations
1. **Color Coding**:
- Red: Conventional/Coarse-grained evaluations
- Blue: Fine-grained evaluations
- Purple: Proposed approach
2. **Evaluation Philosophy**:
- Traditional methods focus on accuracy metrics
- Modern approaches emphasize cultural sensitivity and user-defined criteria
- Proposed method advocates for open-source reproducibility and cost efficiency
3. **Critical Gaps**:
- Conventional methods lack cultural sensitivity assessment
- Coarse-grained evaluations depend on third-party models (GPT-4)
- Close-source systems face versioning and cost challenges
---
## Diagram Structure
```
[Conventional LLM Evaluation]
↓
[Accuracy/EM/Rouge]
↓
[Domain-specific Score]
[Coarse-Grained Evaluation]
↓
[GPT-4 Evaluation]
↓
[Helpfulness/Harmlessness Score]
[Fine-grained Evaluation]
↓
[GPT-4 Evaluation]
↓
[Customized Criteria]
[Proposed Approach]
├─ Domain-specific Diagnostics
├─ General Preference Diagnostics
├─ Close-source Nature (Uncontrolled Versioning, Prohibitive Costs)
└─ Fully Open-source (Reproducible Evaluation, Inexpensive Costs)
```
---
## Language Notes
- **Primary Language**: English
- **Emojis**: Used as visual indicators (no translation required)
- **Special Characters**:
- `~~~` (tilde symbols) for score representation
- `🔥` (fire emoji) for Prometheus Evaluation
---
## Conclusion
The flowchart illustrates the evolution of LLM evaluation from traditional accuracy metrics to culturally sensitive, user-defined frameworks. The proposed approach emphasizes open-source reproducibility and cost efficiency while addressing limitations in existing methods.