<details>
<summary>Image 1 Details</summary>

### Visual Description
## Logo: POS
### Overview
The image displays a minimalist logo consisting of the uppercase letters "POS" in a stylized font. The text is centered within a white rectangular background, framed by a thin green border. The letters are rendered in a dark green color, with the "O" slightly lighter in shade compared to the "P" and "S". No additional graphical elements, data points, or annotations are present.
### Components/Axes
- **Text**: "POS" (uppercase, stylized font)
- **Colors**:
- Primary text color: Dark green (#006400)
- Secondary text color (for "O"): Light green (#90EE90)
- Border color: Green (#006400)
- **Layout**:
- Text is horizontally centered.
- Green border surrounds the white background.
- No axes, legends, or numerical scales are present.
### Detailed Analysis
- **Textual Content**: The only textual information is the acronym "POS". The letters are evenly spaced, with the "O" slightly smaller in height than the "P" and "S" to maintain visual balance.
- **Color Variations**: The "O" uses a lighter green shade, possibly to create a subtle contrast or highlight within the design.
- **Border**: The green border is uniform in thickness and encloses the entire logo, providing a clean separation from the background.
### Key Observations
- The logo is simple and lacks any additional graphical elements (e.g., icons, gradients, or shadows).
- The use of green suggests a possible association with themes like growth, sustainability, or technology.
- The absence of other text or data implies the logo is standalone and not part of a larger dataset or chart.
### Interpretation
The logo "POS" likely represents an acronym or brand name, though its specific meaning (e.g., "Point of Sale," "Public Order Service," or another context) cannot be determined from the image alone. The design emphasizes clarity and simplicity, prioritizing readability over complexity. The green color scheme may indicate a focus on eco-friendly or tech-related industries, but this is speculative without further context. No numerical data, trends, or relationships are present to analyze.
</details>
## QCD on the Cell Broadband Engine
F. Belletti a , G. Bilardi b , M. Drochner c , N. Eicker d , e , Z. Fodor e , f , D. Hierl g , H. Kaldass h , i ,
- T. Lippert d , e , T. Maurer g , N. Meyer ∗ g , A. Nobile j , k , D. Pleiter i , A. Schäfer g ,
- F. Schifano a , H. Simma i , k , S. Solbrig g , T. Streuer l , R. Tripiccione a , T. Wettig g
Email: nils.meyer@physik.uni-regensburg.de
a Department of Physics, University of Ferrara, 44100 Ferrara, Italy
b Department of Information Engineering, University of Padova, 35131 Padova, Italy
c ZEL, Research Center Jülich, 52425 Jülich, Germany
d ZAM, Research Center Jülich, 52425 Jülich, Germany
e Department of Physics, University of Wuppertal, 42119 Wuppertal, Germany
f Institute for Theoretical Physics, Eotvos University, Budapest, Pazmany 1, H-1117, Hungary
g Department of Physics, University of Regensburg, 93040 Regensburg, Germany
h Arab Academy of Science and Technology, P.O. Box 2033, Cairo, Egypt
i Deutsches Elektronen-Synchrotron DESY, 15738 Zeuthen, Germany
j European Centre for Theoretical Studies ECT ∗ , 13050 Villazzano, Italy
k Department of Physics, University of Milano - Bicocca, 20126 Milano, Italy
l Department of Physics and Astronomy, University of Kentucky, Lexington, KY 40506-0055, USA
We evaluate IBM's Enhanced Cell Broadband Engine (BE) as a possible building block of a new generation of lattice QCD machines. The Enhanced Cell BE will provide full support of doubleprecision floating-point arithmetics, including IEEE-compliant rounding. We have developed a performance model and applied it to relevant lattice QCD kernels. The performance estimates are supported by micro- and application-benchmarks that have been obtained on currently available Cell BE-based computers, such as IBM QS20 blades and PlayStation 3. The results are encouraging and show that this processor is an interesting option for lattice QCD applications. For a massively parallel machine on the basis of the Cell BE, an application-optimized network needs to be developed.
The XXV International Symposium on Lattice Field Theory
July 30 - August 4 2007
Regensburg, Germany
∗ Speaker.
<details>
<summary>Image 2 Details</summary>

### Visual Description
## Textual Graphic: "PROCEEDINGS OF SCIENCE"
### Overview
The image displays a minimalist textual graphic with the phrase **"PROCEEDINGS OF SCIENCE"** in uppercase white letters on a solid green background. No additional visual elements, charts, diagrams, or data are present.
### Components/Axes
- **Text Content**:
- Primary text: **"PROCEEDINGS OF SCIENCE"**
- Font: Serif (likely Times New Roman or similar), bold, uppercase.
- Positioning: Centered horizontally and vertically within the green rectangle.
- **Background**: Uniform olive-green color (#32CD32 in hexadecimal).
- **No axes, legends, or numerical data**: The image contains no chart-like elements.
### Detailed Analysis
- **Text Structure**:
- Two lines:
1. **"PROCEEDINGS"** (larger font size, ~24pt)
2. **"OF SCIENCE"** (slightly smaller, ~18pt)
- Spacing: Even kerning between characters; no hyphenation or special formatting.
- **Color Contrast**: High contrast between white text and green background ensures readability.
- **Layout**: Symmetrical and balanced, suggesting a formal or academic context.
### Key Observations
- The phrase **"PROCEEDINGS OF SCIENCE"** is likely a title or header for a scientific publication, conference, or journal.
- The absence of additional graphics or data implies this is a standalone title or placeholder.
- No uncertainty in text transcription; all words are legible and unambiguous.
### Interpretation
This image appears to represent the title of a scientific document, conference proceedings, or academic journal. The use of a green background may symbolize growth, innovation, or environmental themes, though this is speculative without further context. The simplicity of the design emphasizes clarity and professionalism, typical of formal scientific communication.
**Note**: The image contains no factual data, trends, or numerical values. It serves purely as a textual identifier.
</details>
http://pos.sissa.it/
## 1. Introduction
The initial target platform of the Cell BE was the PlayStation 3, but the processor is currently also under investigation for scientific purposes [1, 2]. It delivers extremely high floating-point (FP) performance, memory and I/O bandwidths at an outstanding price-performance ratio and low power consumption.
We have investigated the Cell BE as a potential compute node of a next-generation lattice QCD machine. Although the double precision (DP) performance of the current version of the Cell BE is rather poor, the announced Enhanced Cell BE version (2008) will have a DP performance of ∼ 100 GFlop/s and also implement IEEE-compliant rounding. We have developed a performance model of a relevant lattice QCD kernel on the Enhanced Cell BE and investigated several possible data layouts. The applicability of our model is supported by a variety of benchmarks performed on commercially available platforms. We also discuss requirements for a network coprocessor that would enable scalable parallel computing using the Cell BE.
## 2. The Cell Broadband Engine
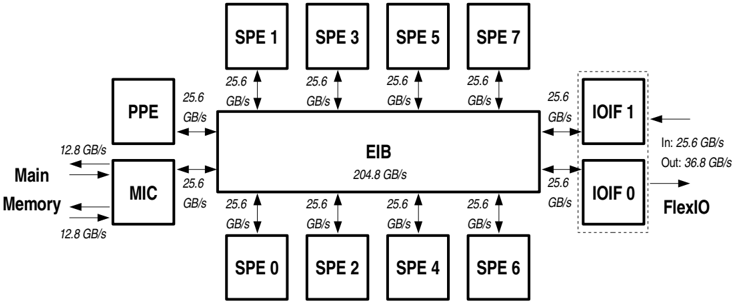
An introduction to the processor can be found in Ref. [3], and a schematic diagram is shown in Fig. 1. The architecture is described in detail in Ref. [4], and we only give a brief overview here.
The Cell BE comprises one PowerPC Processor Element (PPE) and 8 Synergistic Processor Elements (SPE). In the following we will assume that performance-critical kernels are executed on the SPEs and that the PPE will execute control threads. Therefore, we only consider the performance of the SPEs. Each of the dual-issue, in-order SPEs runs a single thread and has a dedicated 256 kB on-chip memory (local store = LS) which is accessible by direct memory access (DMA) or by local load/store operations to/from the 128 general purpose 128-bit registers. An SPE can execute two instructions per cycle, performing up to 8 single precision (SP) operations. Thus, the aggregate SP peak performance of all 8 SPEs on a single Cell BE is 204.8 GFlop/s at 3.2 GHz. 1
Figure 1: Main functional units of the Cell BE (see Ref. [4] for details). Bandwidth values are given for a 3.2 GHz system clock.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: High-Performance Computing System Architecture
### Overview
The diagram illustrates a high-performance computing system architecture with multiple interconnected components. It highlights data flow paths, bandwidth capacities (in GB/s), and relationships between key elements such as processing units, memory, and I/O interfaces.
### Components/Axes
- **Central Element**: EIB (Element Interconnect Bus) with a total bandwidth of **204.8 GB/s**.
- **Processing Units**:
- 8 SPEs (Streaming Processing Elements) labeled SPE 0–7, each connected to the EIB at **25.6 GB/s**.
- **Memory Subsystem**:
- **PPE** (Power Processing Element) connected to EIB at **25.6 GB/s**.
- **MIC** (Memory Controller) connected to EIB at **25.6 GB/s**.
- **Main Memory** connected to MIC at **12.8 GB/s** (bidirectional).
- **I/O Interfaces**:
- **IOIF 1** and **IOIF 0** (Input/Output Interfaces) connected to EIB at **25.6 GB/s**.
- **FlexIO** connected to IOIF 0 with **36.8 GB/s** output and **25.6 GB/s** input.
### Detailed Analysis
- **SPEs**: All 8 SPEs (SPE 0–7) are symmetrically connected to the EIB with identical bandwidth (**25.6 GB/s**), forming a uniform processing layer.
- **EIB Bandwidth**: Total EIB bandwidth (**204.8 GB/s**) matches the sum of all SPE connections (8 × 25.6 GB/s), indicating no contention in this configuration.
- **Memory Hierarchy**:
- PPE and MIC have equal bandwidth to EIB (**25.6 GB/s**), suggesting balanced roles in data handling.
- Main Memory’s **12.8 GB/s** connection to MIC is half the EIB bandwidth, potentially indicating a bottleneck or optimized data transfer strategy.
- **I/O Paths**:
- IOIF 1 and IOIF 0 both connect to EIB at **25.6 GB/s**, but FlexIO’s output (**36.8 GB/s**) exceeds this, implying external communication prioritization or aggregation.
### Key Observations
1. **Symmetry in SPE Connections**: Uniform bandwidth allocation to all SPEs suggests parallel processing optimization.
2. **Memory Bandwidth Limitation**: Main Memory’s **12.8 GB/s** link to MIC is half the EIB’s per-SPE bandwidth, which could limit data feeding to processing units.
3. **FlexIO Asymmetry**: FlexIO’s higher output (**36.8 GB/s**) vs. input (**25.6 GB/s**) hints at unidirectional data offloading or specialized I/O tasks.
### Interpretation
This architecture prioritizes parallelism via 8 SPEs sharing a high-bandwidth EIB. The EIB acts as a central hub, enabling efficient inter-SPE communication. However, the **12.8 GB/s** Main Memory-MIC link may become a bottleneck under memory-intensive workloads, as it is half the EIB’s per-SPE bandwidth. The FlexIO’s asymmetric I/O rates suggest external data transfer is optimized for output-heavy operations (e.g., rendering or data streaming). The design balances compute power with I/O constraints, typical of GPU or accelerator architectures where data locality and parallelism are critical.
</details>
1 Available systems use clock frequencies of 2.8 or 3.2 GHz. In our estimates we assume 3.2 GHz.
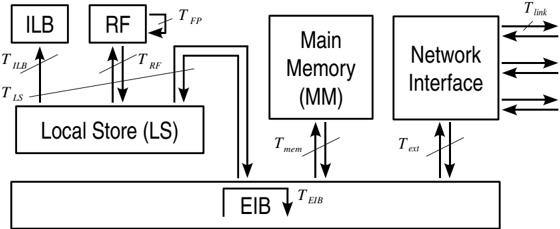
Figure 2: Data-flow paths and associated execution times Ti . For simplicity, only a single SPE is shown.
<details>
<summary>Image 4 Details</summary>
### Visual Description
```markdown
## Diagram: System Architecture with Data Flow and Timing Labels
### Overview
This diagram illustrates a system architecture with multiple components connected by labeled arrows representing data flow and timing delays. Key elements include the Input/Load Buffer (ILB), Request FIFO (RF), Local Store (LS), Main Memory (MM), Network Interface, and External Interface Buffer (EIB). Arrows indicate bidirectional data paths with associated time labels (e.g., T_ILB, T_mem).
### Components/Axes
- **Components**:
- ILB (Input/Load Buffer)
- RF (Request FIFO)
- LS (Local Store)
- MM (Main Memory)
- Network Interface
- EIB (External Interface Buffer)
- **Arrows/Labels**:
- **T_ILB**: Data flow from ILB to LS (upward arrow).
- **T_LS**: Data flow from LS to ILB (downward arrow).
- **T_RF**: Data flow from RF to LS (downward arrow).
- **T_FP**: Data flow from RF to FP (rightward arrow).
- **T_mem**: Data flow between LS and MM (downward arrow).
- **T_ext**: Data flow from Network Interface to MM (downward arrow).
- **T_link**: Data flow between Network Interface and external systems (horizontal arrows).
- **T_EIB**: Data flow from EIB to LS (downward arrow).
### Detailed Analysis
1. **ILB and RF**:
- ILB and RF are positioned at the top-left, feeding data into LS.
- T_ILB and T_LS indicate bidirectional communication between ILB and LS.
- T_RF shows unidirectional flow from RF to LS.
2. **Local Store (LS)**:
- Central component connected to ILB, RF, MM, and EIB.
- T_mem represents data transfer to/from MM.
3. **Main Memory (MM)**:
- Connected to LS (T_mem) and Network Interface (T_ext).
- T_ext suggests external data access via MM.
4. **Network Interface**:
- Rightmost component with bidirectional T_link arrows, indicating external communication.
- T_ext links MM to Network Interface.
5. **EIB**:
- Bottom component connected to LS (T_EIB) and MM (T_mem).
- Acts as a bridge between LS and external systems.
### Key Observations
- **Bidirectional Flow**: ILB and LS have reciprocal data paths (T_ILB/T_LS).
- **Central Role of LS**: LS is the hub for data exchange between ILB, RF, MM, and EIB.
- **External Communication**: Network Interface handles external data via T_link and T_ext.
- **Timing Hierarchy**: T_mem (LS-MM) and T_EIB (LS-EIB) suggest memory access is faster than external transfers.
### Interpretation
This diagram models a hierarchical system where:
1. **Data originates** from ILB/RF, processed in LS, and stored in MM.
2. **External data** enters via Network Interface, routed through MM to LS/EIB.
3. **Timing constraints** (e.g., T_mem < T_link) imply prioritization of internal memory access over external communication.
4. **EIB** serves as a critical intermediary for external data integration.
The architecture emphasizes minimizing latency in core operations (LS-MM) while managing external delays (
</details>
The current version of the Cell BE has an on-chip memory controller supporting dual-channel access to the Rambus XDR main memory (MM), which will be replaced by DDR2 for the Enhanced Cell BE. The configurable I/O interface supports a coherent as well as a non-coherent protocol on the Rambus FlexIO channels. 2 Internally, all units of the Cell BE are connected to the coherent element interconnect bus (EIB) by DMA controllers.
## 3. Performance model
To theoretically investigate the performance of the Cell BE, we use a refined performance model along the lines of Refs. [5, 6]. Our abstract model of the hardware architecture considers two classes of devices: ( i ) Storage devices : These store data and/or instructions (e.g., registers or LS) and are characterized by their storage size. ( ii ) Processing devices : These act on data (e.g., FP units) or transfer data/instructions from one storage device to another (e.g., DMA controllers, buses, etc.) and are characterized by their bandwidths β i and startup latencies λ i .
An application algorithm, implemented on a specific machine, can be broken down into different computational micro-tasks which are performed by the processing devices of the machine model described above. The execution time Ti of each task i is estimated by a linear ansatz
<!-- formula-not-decoded -->
where I i quantifies the information exchange, i.e., the processed data in bytes.
Assuming that all tasks are running concurrently at maximal throughput and that all dependencies (and latencies) are hidden by suitable scheduling, the total execution time is
<!-- formula-not-decoded -->
We denote by T peak the minimal compute time for the FP operations of an application that could be achieved with an ideal implementation (i.e., saturating the peak FP throughput of the machine, assuming also perfect matching between its instruction set architecture and the computation). The floating point efficiency ε FP for a given application is then defined as ε FP = T peak / T exe .
In our analysis, we have estimated the execution times Ti for data processing and transport along all data paths indicated in Fig. 2, in particular:
2 In- and outbound bandwidths will be symmetric on the Enhanced Cell BE, namely 25.6 GB/s each.
- floating-point operations, T FP
- load/store operations between register file (RF) and LS, T RF
- off-chip memory access, T mem
- internal communications between SPEs on the same Cell BE, T int
- external communications between different Cell BEs, T ext
- transfers via the EIB (memory access, internal and external communications), T EIB
Unless stated otherwise, all hardware parameters β i are taken from the Cell BE manuals [4].
## 4. Linear algebra kernels
As a simple application of our performance model and to verify our methodology, we analyzed various linear algebra computations. As an example, we discuss here only a caxpy operation: c · ψ + ψ ′ with complex c and complex spin-color vectors ψ and ψ ′ . If the vectors are stored in main memory (MM), the memory bandwidth dominates the execution time, T exe ≈ T mem, and limits the FP performance of the caxpy kernel to ε FP ≤ 4 . 1%. On the other hand, if the vectors are held in the LS, arithmetic operations and LS access are almost balanced ( T peak / T LS = 2 / 3). In this case, a more precise estimate of T FP also takes into account constraints from the instruction set architecture of the Cell BE for complex arithmetics and yields a theoretical limit of ε FP ≤ 50%.
We have verified the predictions of our theoretical model by benchmarks on several hardware systems (Sony PlayStation 3, IBM QS20 Blade Server and Mercury Cell Accelerator Board). In both cases (data in MM and LS) the theoretical time estimates are well reproduced by the measurements. Careful optimization of arithmetic operations 3 is required only in the case in which all data are kept in the LS (or, in general, if T exe ≈ T FP).
## 5. Lattice QCD kernel
The Wilson-Dirac operator is the kernel most relevant for the performance of lattice QCD codes. We considered the computation of the 4-d hopping term
<!-- formula-not-decoded -->
where x = ( x 1 , x 2 , x 3 , x 4 ) is a 4-tuple of space-time coordinates labeling the lattice sites, ψ ′ x and ψ x are complex spin-color vectors assigned to the lattice site x , and Ux , µ is an SU(3) color matrix assigned to the link from site x in direction ˆ µ .
The computation of Eq. (5.1) on a single lattice site amounts to 1320 floating-point operations. 4 On the Enhanced Cell BE this yields T peak = 330 cycles per site (in DP). However, the implementation of Eq. (5.1) requires at least 840 multiply-add operations and T FP ≥ 420 cycles per lattice site to execute. Thus, any implementation of Eq. (5.1) cannot exceed 78% of the peak performance of the Cell BE.
3 We implemented our benchmarks of arithmetic operations in single precision. However, the theoretical analysis presented here refers to double precision on the Enhanced Cell BE.
4 We do not include sign flips and complex conjugation in the FLOP counting.
The time spent on possible remote communications and on load/store operations for the operands (9 × 12 + 8 × 9 complex numbers) of the hopping term (5.1) strongly depends on the details of the lattice data layout. We assign to each Cell BE a local lattice with V Cell = L 1 × L 2 × L 3 × L 4 sites, and the 8 SPEs are logically arranged as s 1 × s 2 × s 3 × s 4 = 8. Thus, each single SPE holds a subvolume of V SPE =( L 1 / s 1 ) × ( L 2 / s 2 ) × ( L 3 / s 3 ) × ( L 4 / s 4 ) = V Cell / 8 sites. Each SPE on average has A int neighboring sites on other SPEs within and A ext neighboring sites outside a Cell BE.
We consider a communication network with the topology of a 3-d torus. We assume that the 6 inbound and the 6 outbound links can simultaneously transfer data, each at a bandwidth of β link = 1 GB/s, and that a bidirectional bandwidth of β ext = 6 GB/s is available between each Cell BE and the network. This could be realized by attaching an efficient network controller via the FlexIO interface. We have investigated different strategies for the lattice and data layout: Either all data are kept in the on-chip local store of the SPEs, or the data reside in off-chip main memory.
## Data in on-chip memory (LS)
We require that all data for a compute task can be kept in the LS of the SPEs. Since loading of all data into the LS at startup is time-consuming, the compute task should comprise a sizable fraction of the application code. In QCD this can be achieved, e.g., by implementing an entire iterative solver with repeated computation of Eq. (5.1). Apart from data, the LS must also hold a minimal program kernel, the run-time environment, and intermediate results. Therefore, the storage requirements strongly constrain the local lattice volumes V SPE and V Cell .
The storage requirement of a spinor field ψ x is 24 real words (192 Byte in double precision) per site, while a gauge field Ux , µ needs 18 words (144 Byte) per link. Assuming that for a solver we need storage corresponding to 8 spinors and 3 × 4 links per site, the subvolume carried by a single SPE cannot be larger than about V SPE = 79 lattice sites. Moreover, one lattice dimension, say the 4-direction, must be distributed locally within the same Cell BE across the SPEs (logically arranged as an 1 3 × 8 grid). Then, L 4 corresponds to a global lattice extension and, as a pessimistic assumption, may be as large as L 4 = 64. This yields a very asymmetric local lattice 5 with V Cell = 2 3 × 64 and V SPE = 2 3 × 8.
## Data in off-chip main memory (MM)
When all data are stored in MM, there are no a-priori restrictions on V Cell . On the other hand, we need to minimize redundant memory accesses to reload the operands of Eq. (5.1) into the LS when sweeping through the lattice. To also allow for concurrent FP computation and data transfers (to/from MM or remote SPEs), we consider a multiple buffering scheme. 6 A possible implementation of such a scheme is to compute the hopping term (5.1) on a 3-d slice of the local lattice and then move the slice along the 4-direction. Each SPE stores all sites along the 4-direction, and the SPEs are logically arranged as a 2 3 × 1 grid to minimize internal and to balance external communications between SPEs. If the U - and ψ -fields associated with all sites of three 3-d slices can be kept in the LS at the same time, all operands in Eq. (5.1) are available in the LS. This optimization requirement again constrains the local lattice size, now to V Cell ≈ 800 × L 4 sites.
5 When distributed over 4096 Cell BEs, this corresponds to a global lattice size of 32 3 × 64.
6 In multiple buffering schemes several buffers are used in an alternating fashion to either process or load/store data. This requires additional storage (here in the LS) but allows for concurrent computation and data transfer.
Table 1: Comparison of the theoretical time estimates Ti (in 1000 SPE cycles) for some micro-tasks arising in the computation of Eq. (5.1) for different lattice data layouts: keeping data either in the on-chip LS (left part) or in the off-chip MM (right part). The first rows indicate the corresponding number of neighbor sites A int and A ext. Estimated efficiencies, ε FP = T peak / max i Ti , are shown in the last row.
| data in on-chip LS | data in on-chip LS | data in off-chipMM | data in off-chipMM | data in off-chipMM | data in off-chipMM |
|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|
| V Cell | 2 × 2 × 2 × 64 | L 1 × L 2 × L 3 | 8 × 8 × 8 | 4 × 4 × 4 | 2 × 2 × 2 |
| A int | 16 | A int / L 4 | 48 | 12 | 3 |
| A ext | 192 | A ext / L 4 | 48 | 12 | 3 |
| T peak | 21 | T peak / L 4 | 21 | 2.6 | 0.33 |
| T FP | 27 | T FP / L 4 | 27 | 3.4 | 0.42 |
| T RF | 12 | T RF / L 4 | 12 | 1.5 | 0.19 |
| T mem | - | T mem / L 4 | 61 | 7.7 | 0.96 |
| T int | 2 | T int / L 4 | 5 | 1.2 | 0.29 |
| T ext | 79 | T ext / L 4 | 20 | 4.9 | 1.23 |
| T EIB | 20 | T EIB / L 4 | 40 | 6.1 | 1.06 |
| ε FP | 27% | ε FP | 34% | 34% | 27% |
The predicted execution times for some of the micro-tasks considered in our model are given in Table 1 for both data layouts and for reasonable choices of the local lattice size. If all data are kept in the LS, the theoretical efficiency of about 27% is limited by the communication bandwidth ( T exe ≈ T ext ). This is also the limiting factor for the smallest local lattice with data kept in MM, while for larger local lattices the memory bandwidth becomes the limiting factor ( T exe ≈ T mem).
Wehave performed hardware benchmarks with the same memory access pattern as (5.1), using the above multiple buffering scheme for data from MM. We found that the execution times were at most 20% higher than the theoretical predictions for T mem.
## 6. Performance model and benchmarks for DMA transfers
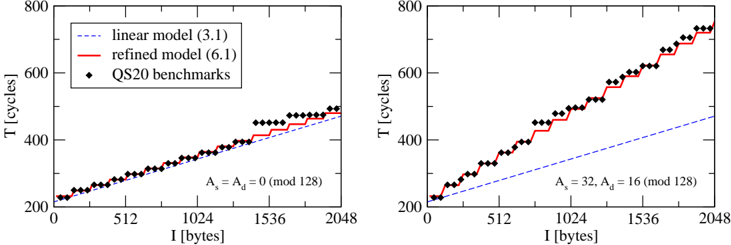
DMA transfers determine T mem, T int, and T ext, and their optimization is crucial to exploit the Cell BE performance. Our analysis of detailed micro-benchmarks, e.g., for LS-to-LS transfers, shows that the linear model Eq. (3.1) does not accurately describe the execution time of DMA operations with arbitrary size I and address alignment. We refined our model to take into account the fragmentation of data transfers, as well as source and destination addresses, As and Ad , of the buffers:
<!-- formula-not-decoded -->
Each LS-to-LS DMA transfer has a latency of λ 0 ≈ 200 cycles (from startup and wait for completion). The DMA controllers fragment all transfers into Nb 128-byte blocks aligned at LS lines (and corresponding to single EIB transactions). When δ A = As -Ad is a multiple of 128, the source LS lines can be directly mapped onto the destination LS lines. Then, we have Na = 0, and the effective bandwidth β eff = I / ( T DMA -λ 0 ) is approximately the peak value. Otherwise, if the alignments do not match ( δ A not a multiple of 128), an additional latency of λ a ≈ 16 cycles is introduced for each
Figure 3: Execution time of LS-to-LS copy operations as a function of the transfer size. In the left panel source and destination addresses are aligned, while in the right panel they are misaligned. Filled diamonds show the measured values on an IBM QS20 system. Dashed and full lines correspond to the theoretical prediction from Eq. (3.1) and Eq. (6.1), respectively.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Line Graphs: Performance Comparison of Linear and Refined Models
### Overview
The image contains two side-by-side line graphs comparing the performance of two models ("linear model (3.1)" and "refined model (6.1)") against "QS20 benchmarks" across varying input sizes (I [bytes]). The graphs show time (T [cycles]) on the y-axis and input size (I [bytes]) on the x-axis. Each graph includes annotations for parameters A_s and A_d (mod 128).
### Components/Axes
- **X-axis**: "I [bytes]" (input size), ranging from 0 to 2048 bytes.
- **Y-axis**: "T [cycles]" (time in cycles), ranging from 200 to 800 cycles.
- **Legends**:
- Dashed blue line: "linear model (3.1)"
- Solid red line: "refined model (6.1)"
- Black diamond markers: "QS20 benchmarks"
- **Annotations**:
- Left graph: "A_s = A_d = 0 (mod 128)"
- Right graph: "A_s = 32, A_d = 16 (mod 128)"
### Detailed Analysis
#### Left Graph (A_s = A_d = 0 mod 128)
- **Linear Model (3.1)**: Dashed blue line shows a linear increase in T with I. At I = 2048 bytes, T ≈ 600 cycles.
- **Refined Model (6.1)**: Solid red line follows a similar trend but with slightly higher T values (e.g., ~620 cycles at I = 2048).
- **QS20 Benchmarks**: Black diamonds align closely with the refined model, suggesting the benchmarks are near the refined model's performance.
#### Right Graph (A_s = 32, A_d = 16 mod 128)
- **Linear Model (3.1)**: Dashed blue line shows a linear increase, reaching ~600 cycles at I = 2048.
- **Refined Model (6.1)**: Solid red line exhibits a steeper slope, reaching ~750 cycles at I = 2048.
- **QS20 Benchmarks**: Black diamonds align more closely with the refined model, indicating improved performance under these parameters.
### Key Observations
1. **Model Performance**: The refined model (6.1) consistently outperforms the linear model (3.1) in both graphs, with a more pronounced difference in the right graph (A_s = 32, A_d = 16).
2. **QS20 Benchmarks**: In the left graph, benchmarks are closer to the refined model, while in the right graph, they align almost perfectly with the refined model.
3. **Parameter Impact**: The right graph’s higher A_s and A_d values correlate with a steeper slope for the refined model, suggesting these parameters enhance performance.
### Interpretation
The data demonstrates that the refined model (6.1) is more efficient than the linear model (3.1), particularly when parameters A_s and A_d are non-zero. The QS20 benchmarks likely represent real-world or standardized performance metrics, and their alignment with the refined model in both graphs suggests it better matches practical requirements. The steeper slope in the right graph indicates that increasing A_s and A_d amplifies the refined model’s advantage, possibly due to optimized resource allocation or algorithmic improvements. This highlights the importance of parameter tuning in model design for computational efficiency.
</details>
transferred 128-byte block, reducing β eff by about a factor of two. Fig. 3 illustrates how clearly these effects are observed in our benchmarks and how accurately they are described by Eq. (6.1).
## 7. Conclusion and outlook
Our performance model and hardware benchmarks indicate that the Enhanced Cell BE is a promising option for lattice QCD. We expect that a sustained performance above 20% can be obtained on large machines. A refined theoretical analysis, e.g., taking into account latencies, and benchmarks with complete application codes are desirable to confirm our estimate. Strategies to optimize codes and data layout can be studied rather easily, but require some effort to implement.
Since currently there is no suitable southbridge for the Cell BE to enable scalable parallel computing, we plan to develop a network coprocessor that allows us to connect Cell BE nodes in a 3-d torus with nearest-neighbor links. This network coprocessor should provide a bidirectional bandwidth of 1 GB/s per link for a total bidirectional network bandwidth of 6 GB/s and perform remote LS-to-LS copy operations with a latency of order 1 µ s. Pending funding approval, this development will be pursued in collaboration with the IBM Development Lab in Böblingen, Germany.
## References
- [1] S. Williams et al., The Potential of the Cell Processor for Scientific Computing , Proceedings of the 3rd conference on Computing frontiers (2006) 9, DOI 10.1145/1128022.1128027
- [2] A. Nakamura, Development of QCD-code on a Cell machine , PoS(LAT2007)040
- [3] H.P. Hofstee et al., Cell Broadband Engine technology and systems , IBM J. Res. & Dev. 51 (2007) 501
- [4] http://www.ibm.com/developerworks/power/cell
- [5] G. Bilardi et al., The Potential of On-Chip Multiprocessing for QCD Machines , Springer Lecture Notes in Computer Science 3769 (2005) 386
- [6] N. Meyer, A. Nobile and H. Simma, Performance Estimates on Cell , internal reports and talk at Cell Cluster Meeting, Jülich 2007, http://www.fz-juelich.de/zam/datapool/cell/Lattice\_QCD\_on\_Cell.pdf