# Unknown Title
## Bayesian Online Changepoint Detection
## Ryan Prescott Adams
Cavendish Laboratory Cambridge CB3 0HE United Kingdom
## Abstract
Changepoints are abrupt variations in the generative parameters of a data sequence. Online detection of changepoints is useful in modelling and prediction of time series in application areas such as finance, biometrics, and robotics. While frequentist methods have yielded online filtering and prediction techniques, most Bayesian papers have focused on the retrospective segmentation problem. Here we examine the case where the model parameters before and after the changepoint are independent and we derive an online algorithm for exact inference of the most recent changepoint. We compute the probability distribution of the length of the current 'run,' or time since the last changepoint, using a simple message-passing algorithm. Our implementation is highly modular so that the algorithm may be applied to a variety of types of data. We illustrate this modularity by demonstrating the algorithm on three different real-world data sets.
## 1 INTRODUCTION
Changepoint detection is the identification of abrupt changes in the generative parameters of sequential data. As an online and offline signal processing tool, it has proven to be useful in applications such as process control [1], EEG analysis [5, 2, 17], DNA segmentation [6], econometrics [7, 18], and disease demographics [9].
Frequentist approaches to changepoint detection, from the pioneering work of Page [22, 23] and Lorden [19] to recent work using support vector machines [10], offer online changepoint detectors. Most Bayesian approaches to changepoint detection, in contrast, have been offline and retrospective [24, 4, 26, 13, 8]. With a
David J.C. MacKay Cavendish Laboratory
Cambridge CB3 0HE United Kingdom few exceptions [16, 20], the Bayesian papers on changepoint detection focus on segmentation and techniques to generate samples from the posterior distribution over changepoint locations.
In this paper, we present a Bayesian changepoint detection algorithm for online inference. Rather than retrospective segmentation, we focus on causal predictive filtering; generating an accurate distribution of the next unseen datum in the sequence, given only data already observed. For many applications in machine intelligence, this is a natural requirement. Robots must navigate based on past sensor data from an environment that may have abruptly changed: a door may be closed now, for example, or the furniture may have been moved. In vision systems, the brightness change when a light switch is flipped or when the sun comes out.
We assume that a sequence of observations x 1 , x 2 , . . . , x T may be divided into non-overlapping product partitions [3]. The delineations between partitions are called the changepoints. We further assume that for each partition ρ , the data within it are i.i.d. from some probability distribution P ( x t | η ρ ). The parameters η ρ , ρ = 1 , 2 , . . . are taken to be i.i.d. as well. We denote the contiguous set of observations between time a and b inclusive as x a : b . The discrete a priori probability distribution over the interval between changepoints is denoted as P gap ( g ).
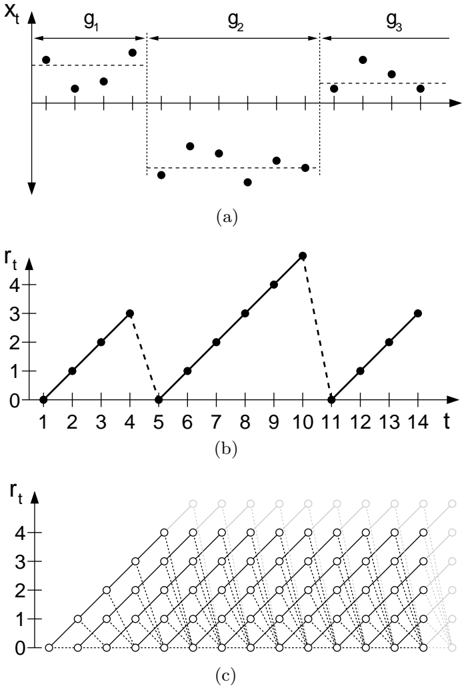
We are concerned with estimating the posterior distribution over the current 'run length,' or time since the last changepoint, given the data so far observed. We denote the length of the current run at time t by r t . We also use the notation x ( r ) t to indicate the set of observations associated with the run r t . As r may be zero, the set x ( r ) may be empty. We illustrate the relationship between the run length r and some hypothetical univariate data in Figures 1(a) and 1(b).
Figure 1: This figure illustrates how we describe a changepoint model expressed in terms of run lengths. Figure 1(a) shows hypothetical univariate data divided by changepoints on the mean into three segments of lengths g 1 = 4, g 2 = 6, and an undetermined length g 3 . Figure 1(b) shows the run length r t as a function of time. r t drops to zero when a changepoint occurs. Figure 1(c) shows the trellis on which the messagepassing algorithm lives. Solid lines indicate that probability mass is being passed 'upwards,' causing the run length to grow at the next time step. Dotted lines indicate the possibility that the current run is truncated and the run length drops to zero.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Charts/Graphs: Time Series Diagrams
### Overview
The image presents three separate time series diagrams, labeled (a), (b), and (c). Diagram (a) shows a scatter plot with grouped data points. Diagram (b) displays a step-like function with discrete jumps. Diagram (c) shows a grid of points representing a two-dimensional time series.
### Components/Axes
* **Diagram (a):**
* X-axis: Labeled with `g1`, `g2`, and `g3` indicating groupings or time intervals. No numerical scale is present.
* Y-axis: Labeled `Xt`. The scale ranges from approximately 0 to 4, with markings at 0, 1, 2, 3, and 4.
* Data Points: Black dots scattered across the plot.
* **Diagram (b):**
* X-axis: Labeled `t`. The scale ranges from 1 to 14, with markings at each integer value.
* Y-axis: Labeled `rt`. The scale ranges from 0 to 5, with markings at 0, 1, 2, 3, 4, and 5.
* Data Line: A black line connecting discrete points, forming a step function.
* **Diagram (c):**
* X-axis: Labeled `t`. The scale ranges from 1 to 14, with markings at each integer value.
* Y-axis: Labeled `rt`. The scale ranges from 0 to 5, with markings at 0, 1, 2, 3, 4, and 5.
* Data Points: Light gray circles forming a grid pattern.
### Detailed Analysis or Content Details
* **Diagram (a):**
* Group `g1`: Contains approximately 5 data points, with Y-values ranging from approximately 1 to 3.
* Group `g2`: Contains approximately 6 data points, with Y-values ranging from approximately 0 to 2.
* Group `g3`: Contains approximately 5 data points, with Y-values ranging from approximately 0 to 3.
* **Diagram (b):**
* The line starts at (1, 0).
* It increases linearly to (3, 2).
* It decreases linearly to (5, 0).
* It increases linearly to (8, 2).
* It increases linearly to (10, 4).
* It decreases linearly to (12, 0).
* It increases linearly to (14, 3).
* **Diagram (c):**
* The diagram shows a grid of points where the x-coordinate ranges from 1 to 14 and the y-coordinate ranges from 0 to 5.
* Each point (t, rt) is represented by a light gray circle.
* The points form a regular grid, indicating a possible representation of all possible combinations of `t` and `rt` within the specified ranges.
### Key Observations
* Diagram (a) shows clustered data, potentially representing observations grouped by time or condition.
* Diagram (b) represents a piecewise linear function with distinct steps, suggesting a system that changes state at specific time points.
* Diagram (c) represents a complete set of possible states for the system defined by `t` and `rt`.
### Interpretation
The three diagrams likely represent different aspects of a time series analysis or a state-space representation of a dynamic system. Diagram (a) could be raw data, diagram (b) a simplified model of the system's behavior, and diagram (c) a visualization of the system's possible states. The step function in diagram (b) suggests a system with discrete transitions, while the grid in diagram (c) provides a complete picture of the system's state space. The lack of numerical scales on the x-axis of diagram (a) suggests that the groupings `g1`, `g2`, and `g3` are categorical rather than quantitative. The diagrams together suggest an attempt to model or understand a system that evolves over time with discrete changes in state.
</details>
## 2 RECURSIVE RUN LENGTH ESTIMATION
We assume that we can compute the predictive distribution conditional on a given run length r t . We then integrate over the posterior distribution on the current run length to find the marginal predictive distribution:
$$P ( x _ { t + 1 } | x _ { t } ) = \sum _ { r _ { t } } P ( x _ { t } )$$
To find the posterior distribution
$$P ( r _ { t } | x _ { 1 : t } ) = \frac { P ( r _ { t } , x _ { 1 : t } ) } { P ( x _ { 1 : t } ) } ,$$
we write the joint distribution over run length and observed data recursively.
$$= \sum _ { t = 1 } ^ { n } P ( r _ { t } - 1 , x _ { 1 } : t - 1 )$$
Note that the predictive distribution P ( x t | r t -1 , x 1: t ) depends only on the recent data x ( r ) t . We can thus generate a recursive message-passing algorithm for the joint distribution over the current run length and the data, based on two calculations: 1) the prior over r t given r t -1 , and 2) the predictive distribution over the newly-observed datum, given the data since the last changepoint.
## 2.1 THE CHANGEPOINT PRIOR
The conditional prior on the changepoint P ( r t | r t -1 ) gives this algorithm its computational efficiency, as it has nonzero mass at only two outcomes: the run length either continues to grow and r t = r t -1 +1 or a changepoint occurs and r t = 0.
$$P ( r _ { t } | r _ { t - 1 } ) = \begin{cases} H ( r _ { t - 1 } + 1 ) & \text{if } r _ { t } = 0 \\ 1 - H ( r _ { t } + 1 ) & \text{if } r _ { t } = r _ { t - 1 } + 1 \\ 0 & \text{otherwise} \end{cases}$$
The function H ( τ ) is the hazard function . [11].
$$H ( r ) = \frac { P _ { gap } ( g = t ) } { \sum _ { l = r } ^ { \infty } P _ { gap } ( g = t ) }$$
In the special case is where P gap ( g ) is a discrete exponential (geometric) distribution with timescale λ , the process is memoryless and the hazard function is constant at H ( τ ) = 1 /λ .
Figure 1(c) illustrates the resulting message-passing algorithm. In this diagram, the circles represent runlength hypotheses. The lines between the circles show recursive transfer of mass between time steps. Solid lines indicate that probability mass is being passed 'upwards,' causing the run length to grow at the next time step. Dotted lines indicate that the current run is truncated and the run length drops to zero.
## 2.2 BOUNDARY CONDITIONS
A recursive algorithm must not only define the recurrence relation, but also the initialization conditions. We consider two cases: 1) a changepoint occurred a priori before the first datum, such as when observing a game. In such cases we place all of the probability mass for the initial run length at zero, i.e. P ( r 0 =0) = 1. 2) We observe some recent subset of the data, such as when modelling climate change. In this case the prior over the initial run length is the normalized survival function [11]
$$P ( n = r ) = \frac { 1 } { 2 ^ { r } } S ( r , . . . , . . )$$
where Z is an appropriate normalizing constant, and
$$S ( r ) = \sum _ { t = r + 1 } ^ { \infty } P _ { g a p } ( g = t ).$$
## 2.3 CONJUGATE-EXPONENTIAL MODELS
Conjugate-exponential models are particularly convenient for integrating with the changepoint detection scheme described here. Exponential family likelihoods allow inference with a finite number of sufficient statistics which can be calculated incrementally as data arrives. Exponential family likelihoods have the form
$$P ( x \vert n ) = h ( x ) e p ( n )$$
where
$$A ( n ) = \log \int d n h ( x )$$
The strength of the conjugate-exponential representation is that both the prior and posterior take the form of an exponential-family distribution over η that can be summarized by succinct hyperparameters ν and χ .
$$P ( n | x , v ) = \hat { h } ( n ) exp ( \tilde { n } - \vec { A } ( n ) - \vec { A } ( x , v ) )$$
We wish to infer the parameter vector η associated with the data from a current run length r t . We denote this run-specific model parameter as η ( r ) t . After finding the posterior distribution P ( η ( r ) t | r t , x ( r ) t ), we can marginalize out the parameters to find the predictive distribution, conditional on the length of the current run.
$$P ( x _ { t + 1 } \vert r _ { t } ) = \int d n P ( x _ { t } )$$
<!-- formula-not-decoded -->
Algorithm 1: The online changepoint algorithm with prediction. An additional optimization not shown is to truncate the per-timestep vectors when the tail of P ( r t | x 1: t ) has mass beneath a threshold.
This marginal predictive distribution, while generally not itself an exponential-family distribution, is usually a simple function of the sufficient statistics. When exact distributions are not available, compact approximations such as that described by Snelson and Ghahramani [25] may be useful. We will only address the exact case in this paper, where the predictive distribution associated with a particular current run length is parameterized by ν ( r ) t and χ ( r ) t .
$$v _ { t } ^ { r } = v _ { prior } + r t$$
$$x ^ { ( r ) } = x _ { p i o r } + \sum t ^ { ( r ) } e _ { r }$$
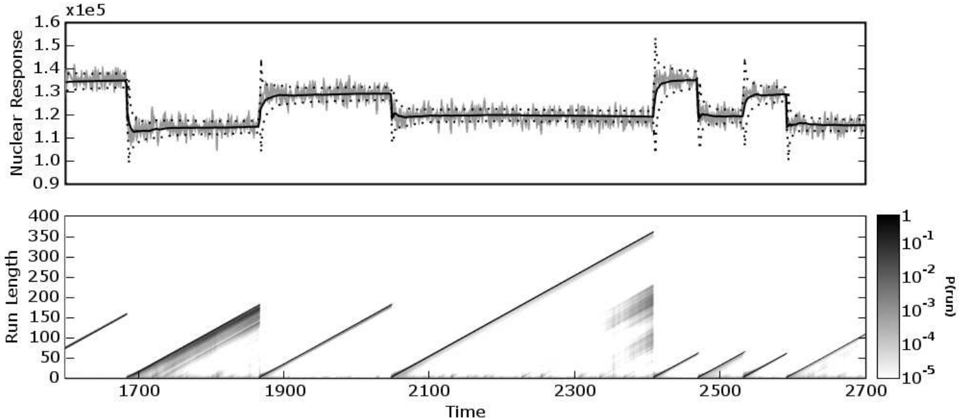
Figure 2: The top plot is a 1100-datum subset of nuclear magnetic response during the drilling of a well. The data are plotted in light gray, with the predictive mean (solid dark line) and predictive 1σ error bars (dotted lines) overlaid. The bottom plot shows the posterior probability of the current run P ( r t | x 1: t ) at each time step, using a logarithmic color scale. Darker pixels indicate higher probability.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Chart: Nuclear Response and Run Length over Time
### Overview
The image presents two charts stacked vertically. The top chart displays a time series of "Nuclear Response" with associated variability, indicated by grey lines. The bottom chart shows a heatmap-like representation of "Run Length" over "Time", with color intensity representing the value of "Prnm" (likely a unit of measurement). Both charts share a common x-axis representing "Time".
### Components/Axes
* **Top Chart:**
* **Y-axis:** "Nuclear Response" (scale from approximately 0.9 x 10^5 to 1.6 x 10^5).
* **X-axis:** "Time" (unspecified units, ranging from approximately 1600 to 2700).
* **Data Series:** A thick black line representing the average "Nuclear Response" over time, with numerous thin grey lines indicating individual data points or variability.
* **Markers:** Vertical dotted lines are present at approximately Time = 1850, 2150, 2450, and 2650.
* **Bottom Chart:**
* **Y-axis:** "Run Length" (scale from 0 to 350).
* **X-axis:** "Time" (same scale as the top chart, approximately 1600 to 2700).
* **Color Scale (Legend):** Located in the top-right corner, representing "Prnm" values. The scale ranges from 1 (darkest color) to 10^-5 (lightest color). The color gradient is as follows:
* 1 (darkest)
* 10^-1
* 10^-2
* 10^-3
* 10^-4
* 10^-5 (lightest)
### Detailed Analysis or Content Details
* **Top Chart:** The "Nuclear Response" line starts at approximately 1.45 x 10^5 at Time = 1600. It decreases to a minimum of approximately 1.15 x 10^5 around Time = 1750. The line then fluctuates between approximately 1.2 x 10^5 and 1.4 x 10^5 with several peaks and valleys. There are noticeable spikes in "Nuclear Response" around Time = 1850, 2150, 2450, and 2650, indicated by the dotted lines. The final value at Time = 2700 is approximately 1.18 x 10^5.
* **Bottom Chart:** The chart displays a diagonal pattern, indicating a relationship between "Time" and "Run Length". The color intensity varies across the chart. Darker shades (higher "Prnm" values) are concentrated in the lower-left region (early times, short run lengths) and along a diagonal band. Lighter shades (lower "Prnm" values) are present in the upper-right region (later times, longer run lengths). There are areas of higher "Prnm" values (darker colors) around Time = 1850, 2150, 2450, and 2650, corresponding to the spikes in the top chart. The color intensity decreases as "Run Length" increases.
### Key Observations
* The spikes in "Nuclear Response" in the top chart correlate with areas of higher "Prnm" values in the bottom chart.
* The "Run Length" generally increases with "Time".
* The "Prnm" values are highest at shorter "Run Lengths" and earlier "Times".
* The grey lines in the top chart show significant variability in the "Nuclear Response" around the average line.
### Interpretation
The data suggests a dynamic system where "Nuclear Response" fluctuates over time, with occasional spikes. The "Run Length" appears to be related to the duration of these fluctuations or events. The "Prnm" value, whatever unit it represents, seems to be a measure of the intensity or frequency of these events. The correlation between the spikes in "Nuclear Response" and the higher "Prnm" values in the bottom chart indicates that these spikes are significant events within the system. The decreasing "Prnm" values with increasing "Run Length" could suggest that events become less intense or frequent as they persist over time. The variability in the "Nuclear Response" (shown by the grey lines) indicates that the system is not entirely predictable and is subject to random fluctuations. The dotted lines likely mark specific events or interventions that trigger changes in the system's behavior. Without knowing the context of this data, it's difficult to provide a more specific interpretation, but it appears to represent a complex system with dynamic behavior and measurable events.
</details>
## 2.4 COMPUTATIONAL COST
The complete algorithm, assuming exponential-family likelihoods, is shown in Algorithm 1. The space- and time-complexity per time-step are linear in the number of data points so far observed. A trivial modification of the algorithm is to discard the run length probability estimates in the tail of the distribution which have a total mass less than some threshold, say 10 -4 . This yields a constant average complexity per iteration on the order of the expected run length E [ r ], although the worst-case complexity is still linear in the data.
## 3 EXPERIMENTAL RESULTS
In this section we demonstrate several implementations of the changepoint algorithm developed in this paper. We examine three real-world example datasets. The first case is a varying Gaussian mean from welllog data. In the second example we consider abrupt changes of variance in daily returns of the Dow Jones Industrial Average. The final data are the intervals between coal mining disasters, which we model as a Poisson process. In each of the three examples, we use a discrete exponential prior over the interval between changepoints.
## 3.1 WELL-LOG DATA
These data are 4050 measurements of nuclear magnetic response taken during the drilling of a well. The data are used to interpret the geophysical structure of the rock surrounding the well. The variations in mean reflect the stratification of the earth's crust. These data have been studied in the context of changepoint detection by ´ O Ruanaidh and Fitzgerald [21], and by Fearnhead and Clifford [12].
The changepoint detection algorithm was run on these data using a univariate Gaussian model with prior parameters µ = 1 . 15 × 10 5 and σ = 1 × 10 4 . The rate of the discrete exponential prior, λ gap , was 250. A subset of the data is shown in Figure 2, with the predictive mean and standard deviation overlaid on the top plot. The bottom plot shows the log probability over the current run length at each time step. Notice that the drops to zero run-length correspond well with the abrupt changes in the mean of the data. Immediately after a changepoint, the predictive variance increases, as would be expected for a sudden reduction in data.
## 3.2 1972-75 DOW JONES RETURNS
During the three year period from the middle of 1972 to the middle of 1975, several major events occurred that had potential macroeconomic effects. Significant among these are the Watergate affair and the OPEC oil embargo. We applied the changepoint detection algorithm described here to daily returns of the Dow Jones Industrial Average from July 3, 1972 to June 30, 1975. We modelled the returns
$$R _ { t } = \frac { p _ { 0 } } { p _ { - 1 } } - 1 ,$$
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart: Time Series of Daily Return and Run Length Heatmap
### Overview
The image presents two charts stacked vertically. The top chart is a time series plot of daily returns, while the bottom chart is a heatmap showing the probability (Pr(run)) as a function of run length and time. The bottom chart includes vertical lines marking significant historical events: the involvement of former Nixon aides (January 30, 1973), the beginning of the OPEC embargo (October 19, 1973), and Nixon's resignation (August 9, 1974).
### Components/Axes
**Top Chart:**
* **Y-axis:** Daily Return (ranging approximately from -0.04 to 0.04).
* **X-axis:** Time (unlabeled, but spanning approximately 1973 to 1975).
* **Data Series:** A single line representing the daily return. A shaded area around the line indicates variability.
**Bottom Chart:**
* **Y-axis:** Run Length (ranging from 0 to 500).
* **X-axis:** Time (labeled with years 1973, 1974, and 1975).
* **Color Scale (Right):** Probability (Pr(run)) on a logarithmic scale, ranging from 10<sup>-5</sup> to 10<sup>1</sup>. Darker shades represent higher probabilities.
* **Vertical Lines:** Marking events: "30 January 1973: Former Nixon Aides Committed", "19 October 1973: OPEC Embargo Begins", "9 August 1974: Nixon Resigns".
### Detailed Analysis or Content Details
**Top Chart:**
The daily return line fluctuates around a slightly positive value. Initially, around 1973, the line oscillates with a relatively small amplitude (approximately +/- 0.01). Around October 1973, the volatility increases significantly, with larger positive and negative excursions. After 1974, the volatility decreases again, and the line settles into a more stable pattern, still fluctuating but with a smaller amplitude. The average daily return appears to be around 0.015.
**Bottom Chart:**
The heatmap shows the probability of a run of a given length at a given time.
* **1973:** The probability of runs is generally low (lighter shades) across all run lengths. There is a slight increase in probability for shorter runs (below 100) around the time of the Nixon aides event.
* **1973-1974 (OPEC Embargo):** A significant brightening (increase in probability) is visible for runs of intermediate length (approximately 100-300) starting around October 1973. This indicates a higher probability of sustained positive or negative trends during this period. The peak probability appears to be around a run length of 200, with a probability of approximately 10<sup>-2</sup> to 10<sup>-1</sup>.
* **1974-1975 (Post-Embargo):** The probability of longer runs (above 300) increases gradually, reaching higher values (darker shades) by 1975. The probability of runs of length 400-500 is approximately 10<sup>-3</sup> to 10<sup>-2</sup>.
### Key Observations
* The OPEC embargo in October 1973 coincides with a marked increase in the probability of intermediate-length runs in the bottom chart, suggesting increased market persistence during that period.
* The volatility in the daily return (top chart) is highest around the time of the OPEC embargo, corroborating the increased persistence observed in the heatmap.
* The probability of longer runs increases over time, indicating a trend towards more sustained market movements in the post-embargo period.
* The Nixon Resignation event does not appear to have a strong immediate impact on the run length probabilities.
### Interpretation
The charts suggest that the OPEC embargo of 1973 was a significant disruptive event for the market. The increased volatility in daily returns and the higher probability of intermediate-length runs indicate that the market became more prone to sustained trends during and immediately after the embargo. The gradual increase in the probability of longer runs in the post-embargo period may reflect a shift towards more stable, long-term market dynamics. The heatmap provides a visual representation of the market's tendency to exhibit runs of consecutive positive or negative returns, and how this tendency changed over time in response to major historical events. The data suggests that external shocks, like the OPEC embargo, can significantly alter market behavior and increase the likelihood of sustained trends. The lack of a strong signal around the Nixon Resignation suggests that this event, while politically significant, had a less direct impact on market persistence.
</details>
Convicted
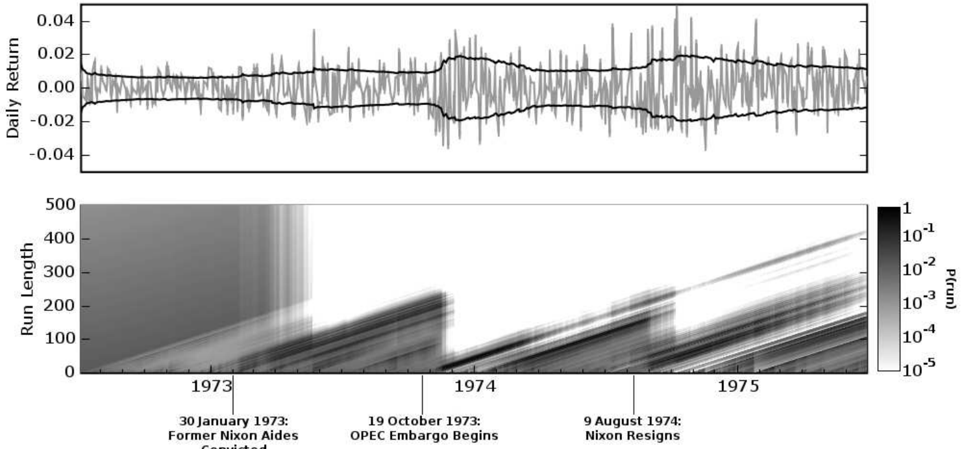
Figure 3: The top plot shows daily returns on the Dow Jones Industrial Average, with an overlaid plot of the predictive volatility. The bottom plot shows the posterior probability of the current run length P ( r t | x 1: t ) at each time step, using a logarithmic color scale. Darker pixels indicate higher probability. The time axis is in business days, as this is market data. Three events are marked: the conviction of G. Gordon Liddy and James W. McCord, Jr. on January 30, 1973; the beginning of the OPEC embargo against the United States on October 19, 1973; and the resignation of President Nixon on August 9, 1974.
(where p close is the daily closing price) with a zeromean Gaussian distribution and piecewise-constant variance. Hsu [14] performed a similar analysis on a subset of these data, using frequentist techniques and weekly returns.
We used a gamma prior on the inverse variance, with a = 1 and b = 10 -4 . The exponential prior on changepoint interval had rate λ gap = 250. In Figure 3, the top plot shows the daily returns with the predictive standard deviation overlaid. The bottom plot shows the posterior probability of the current run length, P ( r t | x 1: t ). Three events are marked on the plot: the conviction of Nixon re-election officials G. Gordon Liddy and James W. McCord, Jr., the beginning of the oil embargo against the United States by the Organization of Petroleum Exporting Countries (OPEC), and the resignation of President Nixon.
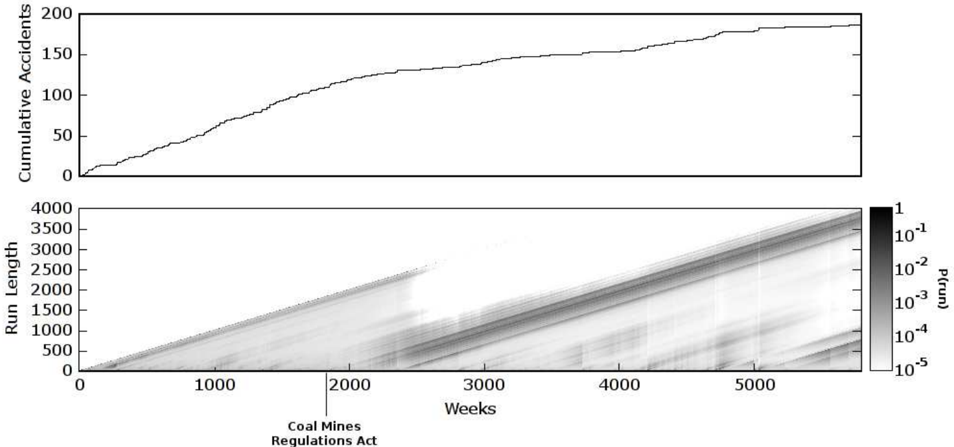
## 3.3 COAL MINE DISASTER DATA
These data from Jarrett [15] are dates of coal mining explosions that killed ten or more men between March 15, 1851 and March 22, 1962. We modelled the data as an Poisson process by weeks, with a gamma prior on the rate with a = b = 1. The rate of the exponential prior on the changepoint inverval was λ gap = 1000. The data are shown in Figure 4. The top plot shows the cumulative number of accidents. The rate of the
Possion process determines the local average of the slope. The posterior probability of the current run length is shown in the bottom plot. The introduction of the Coal Mines Regulations Act in 1887 (corresponding to weeks 1868 to 1920) is also marked.
## 4 DISCUSSION
This paper contributes a predictive, online interpetation of Bayesian changepoint detection and provides a simple and exact method for calculating the posterior probability of the current run length. We have demonstrated this algorithm on three real-world data sets with different modelling requirements.
Additionally, this framework provides convenient delineation between the implementation of the changepoint algorithm and the implementation of the model. This modularity allows changepoint-detection code to use an object-oriented, 'pluggable' type architecture.
## Acknowledgements
The authors would like to thank Phil Cowans and Marian Frazier for valuable discussions. This work was funded by the Gates Cambridge Trust.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Chart: Cumulative Accidents vs. Run Length over Time
### Overview
The image presents a combined chart visualizing the relationship between cumulative accidents, run length, and time (in weeks) in coal mines, likely following the implementation of the Coal Mines Regulations Act. The chart consists of a line graph showing cumulative accidents over time, and a heatmap illustrating run length as a function of weeks, with color intensity representing the probability density (Pr(um)).
### Components/Axes
* **Top Chart (Line Graph):**
* X-axis: Weeks (ranging from 0 to approximately 5500)
* Y-axis: Cumulative Accidents (ranging from 0 to approximately 200)
* Data Series: A single dark-blue line representing cumulative accidents.
* **Bottom Chart (Heatmap):**
* X-axis: Weeks (ranging from 0 to approximately 5500)
* Y-axis: Run Length (ranging from 0 to approximately 4000)
* Color Scale (right side): Probability Density (Pr(um)) on a logarithmic scale from 10<sup>-5</sup> to 1.
* **Text Label (bottom-center):** "Coal Mines Regulations Act"
### Detailed Analysis or Content Details
**Top Chart (Cumulative Accidents):**
The dark-blue line representing cumulative accidents exhibits a generally upward trend, indicating an increasing number of accidents over time. The slope of the line is steeper in the initial period (0-1000 weeks) and gradually flattens out as time progresses.
* At approximately 500 weeks, the cumulative accidents are around 75.
* At approximately 2000 weeks, the cumulative accidents are around 120.
* At approximately 5000 weeks, the cumulative accidents are around 170.
**Bottom Chart (Heatmap - Run Length vs. Weeks):**
The heatmap displays a gradient of gray shades representing the probability density of run length at different weeks.
* The heatmap shows a generally increasing trend in run length with increasing weeks.
* The darkest shades (highest probability density, around Pr(um) = 1) are concentrated in the upper-right corner of the heatmap (high run length and high weeks).
* The lightest shades (lowest probability density, around Pr(um) = 10<sup>-5</sup>) are concentrated in the lower-left corner (low run length and low weeks).
* There are several darker bands running diagonally across the heatmap, suggesting periods where certain run lengths were more common.
* The heatmap shows a relatively uniform distribution of run lengths in the early weeks (0-1000 weeks), with a gradual increase in the range of run lengths as weeks progress.
* The heatmap shows a concentration of run lengths between 1000 and 2500 for weeks between 2000 and 5000.
### Key Observations
* The cumulative accident rate increases over time, but the rate of increase slows down.
* Run length generally increases with time, indicating that mines are operating for longer periods.
* The probability density of run length varies over time, suggesting that certain periods are associated with specific run length distributions.
* The heatmap shows a positive correlation between weeks and run length.
### Interpretation
The data suggests that while the Coal Mines Regulations Act may have been implemented to improve safety, the cumulative number of accidents still increased over time, albeit at a decreasing rate. This could indicate that the regulations were partially effective in mitigating accident risk, but further improvements were needed. The increasing run length suggests that mines were becoming more efficient or were operating for longer durations, potentially due to technological advancements or economic factors. The heatmap provides insights into the distribution of run lengths over time, revealing periods where certain run lengths were more prevalent. The diagonal bands in the heatmap could represent specific operational cycles or changes in mining practices. The logarithmic scale of the probability density highlights the relative rarity of shorter run lengths at later weeks.
The combination of the line graph and heatmap provides a comprehensive view of the safety and operational characteristics of coal mines over time, allowing for a deeper understanding of the impact of the Coal Mines Regulations Act and the evolving dynamics of the mining industry.
</details>
RegulationsAct
Figure 4: These data are the weekly occurrence of coal mine disasters that killed ten or more people between 1851 and 1962. The top plot is the cumulative number of accidents. The accident rate determines the local average slope of the plot. The introduction of the Coal Mines Regulations Act in 1887 is marked. The year 1887 corresponds to weeks 1868 to 1920 on this plot. The bottom plot shows the posterior probability of the current run length at each time step, P ( r t | x 1: t ).
## References
- [1] Leo A. Aroian and Howard Levene. The effectiveness of quality control charts. Journal of the American Statistical Association , 45(252):520529, 1950.
- [2] J. S. Barlow, O. D. Creutzfeldt, D. Michael, J. Houchin, and H. Epelbaum. Automatic adaptive segmentation of clinical EEGs,. Electroencephalography and Clinical Neurophysiology , 51(5):512-525, May 1981.
- [3] D. Barry and J. A. Hartigan. Product partition models for change point problems. The Annals of Statistics , 20:260-279, 1992.
- [4] D. Barry and J. A. Hartigan. A Bayesian analysis of change point problems. Journal of the American Statistical Association , 88:309-319, 1993.
- [5] G. Bodenstein and H. M. Praetorius. Feature extraction from the electroencephalogram by adaptive segmentation. Proceedings of the IEEE , 65(5):642-652, 1977.
- [6] J. V. Braun, R. K. Braun, and H. G. M¨ uller. Multiple changepoint fitting via quasilikelihood, with application to DNA sequence segmentation. Biometrika , 87(2):301-314, June 2000.
- [7] Jie Chen and A. K. Gupta. Testing and locating variance changepoints with application to stock prices. Journal of the American Statistical Association , 92(438):739-747, June 1997.
- [8] Siddhartha Chib. Estimation and comparison of multiple change-point models. Journal of Econometrics , 86(2):221-241, October 1998.
- [9] D. Denison and C. Holmes. Bayesian partitioning for estimating disease risk, 1999.
- [10] F. Desobry, M. Davy, and C. Doncarli. An online kernel change detection algorithm. IEEE Transactions on Signal Processing , 53(8):29612974, August 2005.
- [11] Merran Evans, Nicholas Hastings, and Brian Peacock. Statistical Distributions . WileyInterscience, June 2000.
- [12] Paul Fearnhead and Peter Clifford. On-line inference for hidden Markov models via particle filters. Journal of the Royal Statistical Society B , 65(4):887-899, 2003.
- [13] P. Green. Reversible jump Markov chain Monte Carlo computation and Bayesian model determination, 1995.
- [14] D. A. Hsu. Tests for variance shift at an unknown time point. Applied Statistics , 26(3):279284, 1977.
- [15] R. G. Jarrett. A note on the intervals between coal-mining disasters. Biometrika , 66(1):191-193, 1979.
- [16] Timothy T. Jervis and Stuart I. Jardine. Alarm system for wellbore site. United States Patent 5,952,569, October 1997.
- [17] A. Y. Kaplan and S. L. Shishkin. Application of the change-point analysis to the investigation of the brain's electrical activity. In B. E. Brodsky and B. S. Darkhovsky, editors, Non-Parametric Statistical Diagnosis : Problems and Methods , pages 333-388. Springer, 2000.
- [18] Gary M. Koop and Simon M. Potter. Forecasting and estimating multiple change-point models with an unknown number of change points. Technical report, Federal Reserve Bank of New York, December 2004.
- [19] G. Lorden. Procedures for reacting to a change in distribution. The Annals of Mathematical Statistics , 42(6):1897-1908, December 1971.
- [20] J. J. ´ O Ruanaidh, W. J. Fitzgerald, and K. J. Pope. Recursive Bayesian location of a discontinuity in time series. In Acoustics, Speech, and Signal Processing, 1994. ICASSP-94., 1994 IEEE International Conference on , volume iv, pages IV/513-IV/516 vol.4, 1994.
- [21] Joseph J. K. ´ O Ruanaidh and William J. Fitzgerald. Numerical Bayesian Methods Applied to Signal Processing (Statistics and Computing) . Springer, February 1996.
- [22] E. S. Page. Continuous inspection schemes. Biometrika , 41(1/2):100-115, June 1954.
- [23] E. S. Page. A test for a change in a parameter occurring at an unknown point. Biometrika , 42(3/4):523-527, 1955.
- [24] A. F. M. Smith. A Bayesian approach to inference about a change-point in a sequence of random variables. Biometrika , 62(2):407-416, 1975.
- [25] Edward Snelson and Zoubin Ghahramani. Compact approximations to Bayesian predictive distributions. In ICML '05: Proceedings of the 22nd international conference on Machine learning , pages 840-847, New York, NY, USA, 2005. ACM Press.
- [26] D. A. Stephens. Bayesian retrospective multiplechangepoint identification. Applied Statistics , 43:159-178, 1994.