## How citation boosts promote scientific paradigm shifts and Nobel Prizes
Amin Mazloumian, 1 Young-Ho Eom, 2 Dirk Helbing, 1 Sergi Lozano, 1 and Santo Fortunato 2
ETH Z¨ urich, CLU E1, Clausiusstrasse 50, 8092 Z¨ urich, Switzerland 2 Complex Networks & Systems Lagrange Laboratory, ISI Foundation, Turin, Italy
Nobel Prizes are commonly seen to be among the most prestigious achievements of our times. Based on mining several million citations, we quantitatively analyze the processes driving paradigm shifts in science. We find that groundbreaking discoveries of Nobel Prize Laureates and other famous scientists are not only acknowledged by many citations of their landmark papers. Surprisingly, they also boost the citation rates of their previous publications. Given that innovations must outcompete the rich-gets-richer effect for scientific citations, it turns out that they can make their way only through citation cascades. A quantitative analysis reveals how and why they happen. Science appears to behave like a self-organized critical system, in which citation cascades of all sizes occur, from continuous scientific progress all the way up to scientific revolutions, which change the way we see our world. Measuring the 'boosting effect' of landmark papers, our analysis reveals how new ideas and new players can make their way and finally triumph in a world dominated by established paradigms. The underlying 'boost factor' is also useful to discover scientific breakthroughs and talents much earlier than through classical citation analysis, which by now has become a widespread method to measure scientific excellence, influencing scientific careers and the distribution of research funds. Our findings reveal patterns of collective social behavior, which are also interesting from an attention economics perspective. Understanding the origin of scientific authority may therefore ultimately help to explain, how social influence comes about and why the value of goods depends so strongly on the attention they attract.
PACS numbers: 89.75.-k
## I. INTRODUCTION
Ground-breaking papers are extreme events [1] in science. They can transform the way in which researchers do science in terms of the subjects they choose, the methods they use, and the way they present their results. The related spreading of ideas has been described as an epidemic percolation process in a social network [2]. However, the impact of most innovations is limited. There are only a few ideas, which gain attention all over the world and across disciplinary boundaries [3]. Typical examples are elementary particle physics, the theory of evolution, superconductivity, neural networks, chaos theory, systems biology, nanoscience, or network theory.
It is still a puzzle, however, how a new idea and its proponent can be successful, given that they must beat the rich-gets-richer dynamics of already established ideas and scientists. According to the Matthew effect [4-7], famous scientists receive an amount of credit that may sometimes appear disproportionate to their actual contributions, to the detriment of younger or less known scholars. This implies a great authority of a small number of scientists, which is reflected by the big attention received by their work and ideas, and of the scholars working with them [8].
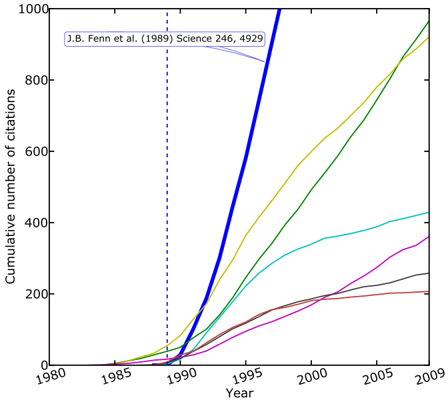
Therefore, how can a previously unknown scientist establish at all a high scientific reputation and authority, if those who get a lot of citations receive even more over time? Here we shed light on this puzzle. The following results for 124 Nobel Prize Laureates in chemistry, economics, medicine and physics suggest that innovators can gain reputation and innovations can successfully spread, mainly because a scientist's body of work overall enjoys a greater impact after the publication of a landmark paper. Not only do colleagues notice the ground-breaking paper, but the latter also attracts the attention to older publications of the same author (see Fig. 1). Consequently, future papers have an impact on past papers, as their relevance is newly weighted.
We focus here on citations as indicator of scientific impact [9-13], studying data from the ISI Web of Science, but the use of click streams [14] would be conceivable as well. It is well-known that the relative number of citations correlates with research quality [15-17]. Citations are now regularly used in university rankings [18], in academic recruitments and for the distribution of funds among scholars and scientific institutions [19].
## II. RESULTS
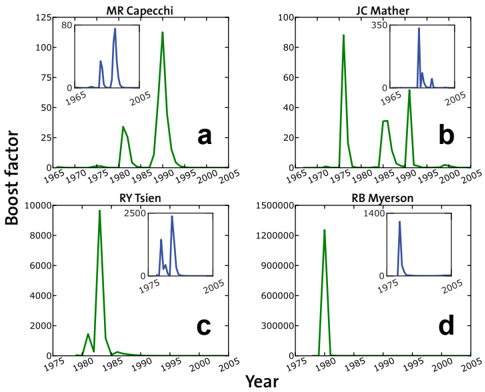
We evaluated data for 124 Nobel Prize Laureates that were awarded in the last two decades (1990-2009), which include an impressive number of about 2 million citations. For all of them and other internationally established experts as well, we find peaks in the changes of their citation rates (Figs. 2 and 3).
Moreover, it is always possible to attribute to these peaks landmark papers (Fig. 4), which have reached hundreds of citations over the period of a decade. Such landmark papers are rare even in the lives of the most excellent scientists, but some authors have several such peaks.
Technically, we detect a groundbreaking article a published at time t = t a by comparing the citation rates
Figure 1: Illustration of the boosting effect. Typical citation trajectories of papers, here for Nobel Prize Laureate John Bennett Fenn, who received the award in chemistry in 2002 for the development of the electrospray ionization technique used to analyze biological macromolecules. The original article, entitled Electrospray ionization for mass spectrometry of large biomolecules , coauthored by M. Mann, C. K. Meng, S. F. Wong and C. M. Whitehouse, was published in Science in 1989 and is the most cited work of Fenn, with currently over 3 , 000 citations. The diagram reports the growth in time of the total number of citations received by this landmark paper (blue solid line) and by six older papers. The diagram indicates that the number of citations of the landmark paper has literally exploded in the first years after its appearance. However, after its publication in 1989, a number of other papers also enjoyed a much higher citation rate. Thus, a sizeable part of previous scientific work has reached a big impact after the publication of the landmark paper. We found that the occurrence of this boosting effect is characteristic for successful scientific careers.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Cumulative Citations Over Time
### Overview
The image is a line chart showing the cumulative number of citations over time for several unspecified publications or research areas. The x-axis represents the year, ranging from 1980 to 2009. The y-axis represents the cumulative number of citations, ranging from 0 to 1000. There are multiple lines, each representing a different publication or research area, showing how citations accumulate over time. A vertical dashed line marks the year 1989, and a text box references "J.B. Fenn et al. (1989) Science 246, 4929".
### Components/Axes
* **X-axis:** Year, ranging from 1980 to 2009, with markers at 1980, 1985, 1990, 1995, 2000, 2005, and 2009.
* **Y-axis:** Cumulative number of citations, ranging from 0 to 1000, with markers at 0, 200, 400, 600, 800, and 1000.
* **Lines:** Multiple lines representing different publications or research areas. The colors are blue, yellow, green, cyan, purple, brown, and black.
* **Vertical Dashed Line:** A blue dashed line at the year 1989.
* **Text Box:** A text box in the top-left corner containing the text "J.B. Fenn et al. (1989) Science 246, 4929". An arrow points from the text box to the blue line.
### Detailed Analysis
* **Blue Line:** This line starts at approximately 0 citations in 1988 and increases linearly to approximately 900 citations by 1996. It then continues linearly to 1000 citations by 1997.
* **Yellow Line:** This line starts at approximately 0 citations in 1987 and increases to approximately 700 citations by 2009.
* **Green Line:** This line starts at approximately 0 citations in 1988 and increases to approximately 900 citations by 2009.
* **Cyan Line:** This line starts at approximately 0 citations in 1988 and increases to approximately 400 citations by 2009.
* **Purple Line:** This line starts at approximately 0 citations in 1988 and increases to approximately 250 citations by 2009.
* **Brown Line:** This line starts at approximately 0 citations in 1988 and increases to approximately 200 citations by 2009.
* **Black Line:** This line starts at approximately 0 citations in 1988 and increases to approximately 250 citations by 2009.
### Key Observations
* The blue line, associated with the "J.B. Fenn et al. (1989)" publication, shows the most rapid increase in citations in the early years.
* The other lines show a more gradual increase in citations over the entire period.
* All lines start accumulating citations around the late 1980s.
### Interpretation
The chart illustrates the cumulative impact of different publications or research areas over time, as measured by the number of citations they receive. The steep initial rise of the blue line suggests that the "J.B. Fenn et al. (1989)" publication had a significant and immediate impact on the field. The other lines represent publications or research areas that have had a more gradual and sustained impact. The vertical line at 1989 may indicate a significant event or publication that influenced the citation trends. The data suggests that the publication by J.B. Fenn et al. was a seminal work that rapidly gained recognition and influence.
</details>
before and after t a for the earlier papers. The analysis proceeds as follows: Given a year t and a time window w , we take all papers of the studied author that were published since the beginning of his/her career until year t . The citation rate R <t,w measures the average number of citations received per paper per year in the period from t -w + 1 to t . Similarly, the citation rate R >t,w measures the average number of citations received by the same publications per paper per year between t +1 and t + w (or 2009, if t + w exceeds 2009). The ratio R w ( t ) = R >t,w /R <t,w , which we call the 'boost factor', is a variable that detects critical events in the life of a scientist: sudden increases in the citation rates (as illustrated by Fig. 1) show up as peaks in the time-dependent plot of R w ( t ).
In our analysis we used the generalized boost factor R ′ w ( t ), which reduces the influence of random variations
Figure 2: Typical time evolutions of the boost factor. Temporal dependence of R ′ w ( t ) for Nobel Laureates [here for (a) Mario R. Capecchi (Medicine, 2007), (b) John C. Mather (Physics, 2006), (c) Roger Y. Tsien (Chemistry, 2008) and (d) Roger B. Myerson (Economics, 2007)]. Sharp peaks indicate citation boosts in favor of older papers, triggered by the publication and recognition of a landmark paper. Insets: The peaks even persist (though somewhat smaller), if in the determination of the citation counts c p,t , the landmark paper is skipped (which is defined as the paper that produces the largest reduction in the peak size, when excluded from the computation of the boost factor). We conclude that the observed citation boosts are mostly due to a collective effect involving several publications rather than due to the high citation rate of the landmark paper itself.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Chart: Boost Factor vs. Year for Four Individuals
### Overview
The image presents four separate line graphs (a, b, c, d), each displaying a "Boost factor" over time (Year) for a different individual: MR Capecchi, JC Mather, RY Tsien, and RB Myerson. Each graph also includes a smaller inset graph showing a zoomed-in view of a specific time period. The main graphs show a spike in the boost factor around the 1980s for all individuals, with varying magnitudes.
### Components/Axes
* **Main Graphs:**
* **Y-axis (Boost factor):**
* Graph a (MR Capecchi): Scale from 0 to 125.
* Graph b (JC Mather): Scale from 0 to 100.
* Graph c (RY Tsien): Scale from 0 to 10000.
* Graph d (RB Myerson): Scale from 0 to 1500000.
* **X-axis (Year):** All main graphs share the same x-axis scale, ranging from approximately 1965/1975 to 2005.
* **Titles:**
* Graph a: "MR Capecchi"
* Graph b: "JC Mather"
* Graph c: "RY Tsien"
* Graph d: "RB Myerson"
* **Labels:** Each graph is labeled with a lowercase letter: a, b, c, and d, located in the bottom right corner of each graph.
* **Inset Graphs:**
* All inset graphs have the same X-axis (Year) ranging from 1965/1975 to 2005.
* Y-axis scales vary.
* Graph a (MR Capecchi): Scale from 0 to 80.
* Graph b (JC Mather): Scale from 0 to 350.
* Graph c (RY Tsien): Scale from 0 to 2500.
* Graph d (RB Myerson): Scale from 0 to 1400.
* **Data Series:** Each graph contains one data series represented by a green line in the main graphs and a blue line in the inset graphs.
### Detailed Analysis
* **Graph a (MR Capecchi):**
* **Trend:** The green line shows a small peak around 1980, followed by a larger peak around 1990, then decreases.
* **Data Points:**
* Approximately 0 around 1970.
* Approximately 30 around 1980.
* Peak of approximately 110 around 1990.
* Decreases to approximately 0 by 2000.
* **Inset Graph:** Shows two peaks, one around 1995 and another around 2000.
* **Graph b (JC Mather):**
* **Trend:** The green line shows a peak around 1975, followed by a smaller peak around 1990, then decreases.
* **Data Points:**
* Approximately 0 around 1970.
* Peak of approximately 90 around 1975.
* Approximately 40 around 1990.
* Decreases to approximately 0 by 2000.
* **Inset Graph:** Shows two peaks, one around 1995 and another around 2000.
* **Graph c (RY Tsien):**
* **Trend:** The green line shows a large peak around 1980, then decreases.
* **Data Points:**
* Approximately 0 around 1975.
* Peak of approximately 8000 around 1980.
* Decreases to approximately 0 by 1990.
* **Inset Graph:** Shows two peaks, one around 1995 and another around 2000.
* **Graph d (RB Myerson):**
* **Trend:** The green line shows a very large peak around 1980, then decreases.
* **Data Points:**
* Approximately 0 around 1975.
* Peak of approximately 1200000 around 1980.
* Decreases to approximately 0 by 1990.
* **Inset Graph:** Shows a single peak around 1995.
### Key Observations
* All four individuals show a significant spike in the "Boost factor" around the 1975-1990 period.
* The magnitude of the "Boost factor" varies greatly between individuals, with RB Myerson having a significantly higher peak value than the others.
* The inset graphs show activity in the later years (1995-2005), which is not as prominent in the main graphs.
### Interpretation
The graphs likely represent some form of impact or recognition (indicated by the "Boost factor") over time for each individual. The peak around the 1980s could indicate a period of significant achievement or influence. The varying magnitudes suggest different levels of impact for each individual. The inset graphs might represent a secondary period of recognition or a different type of impact that is less pronounced than the initial peak. The data suggests that each individual experienced a period of heightened activity or recognition, with the timing and magnitude varying across individuals.
</details>
in the citation rates (see Materials and Methods).
Figure 2 shows typical plots of the boost factors R ′ w ( t ) of four Nobel Prize Laureates. Interestingly, peaks are even found, when those papers, which mostly contribute to them, are excluded from the analysis (see insets of Fig. 2). That is, the observed increases in the citation rates are not just due to the landmark papers themselves, but rather to a collective effect, namely an increase in the citation rates of previously published papers. This results from the greater visibility that the body of work of the corresponding scientist receives after the publication of a landmark paper and establishes an increased scientific impact ('authority'). From the perspective of attention economics [20], it may be interpreted as a herding effect resulting from the way in which relevant information is collectively discovered in an information-rich environment. Interestingly, we have found that older papers receiving a boost are not always works related to the topic of the landmark paper.
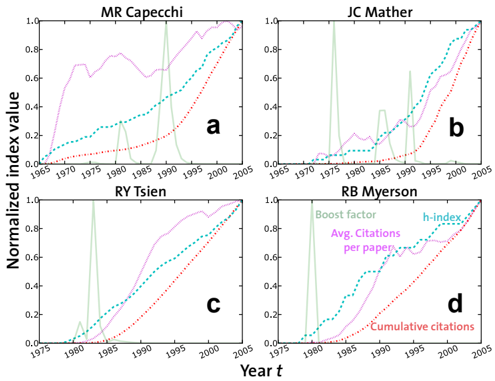
Traditional citation analysis does not reveal such crucial events in the life of a scientist very well. Figure 3 shows the time history of three classical citation indices: the average number of citations per paper 〈 c ( t ) 〉 , the cumulative number C ( t ) of citations, and the Hirsch in-
Figure 3: Dynamics of the boost factor R ′ w ( t ) versus traditional citation variables. Each panel displays the time histories of four variables: the boost factor R ′ w ( t ), the average number of citations per paper 〈 c ( t ) 〉 , the cumulative number of citations C ( t ), and the H -index earned until year t [21]. The panels refer to the same Nobel Laureates as displayed in Fig. 2. The classical indices have relatively smooth profiles, i.e. they are not very sensitive to extreme events in the life of a scientist like the publication of landmark papers. An advantage of the boost factor is that its peaks allow one to identify scientific breakthroughs earlier.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Multiple Line Charts: Citation Metrics Over Time for Four Researchers
### Overview
The image presents four line charts (arranged in a 2x2 grid) showing citation metrics over time for four researchers: MR Capecchi, JC Mather, RY Tsien, and RB Myerson. Each chart displays the "Boost factor", "Avg. Citations per paper", "h-index", and "Cumulative citations" as functions of time (Year t). The y-axis represents a normalized index value.
### Components/Axes
* **Titles:**
* Top-left: MR Capecchi
* Top-right: JC Mather
* Bottom-left: RY Tsien
* Bottom-right: RB Myerson
* **X-axis (Year t):**
* MR Capecchi and JC Mather: 1965 to 2005, with markers every 5 years.
* RY Tsien and RB Myerson: 1975 to 2005, with markers every 5 years.
* **Y-axis (Normalized index value):** 0.0 to 1.0, with markers every 0.2.
* **Legend (Bottom-right chart):**
* Green: Boost factor
* Pink: Avg. Citations per paper
* Teal: h-index
* Red: Cumulative citations
* **Chart Labels:**
* a (Top-left)
* b (Top-right)
* c (Bottom-left)
* d (Bottom-right)
### Detailed Analysis
**Chart a: MR Capecchi**
* **Boost factor (Green):** A sharp spike around 1990, with values near 0 for the rest of the time. Peak value is approximately 0.7.
* **Avg. Citations per paper (Pink):** Starts around 0 in 1965, rises to approximately 0.7 by 1975, fluctuates between 0.6 and 1.0 until 2000, then drops slightly to approximately 0.9 by 2005.
* **h-index (Teal):** Starts at 0 in 1965, increases steadily to approximately 0.3 by 1980, then increases more slowly to approximately 0.4 by 2005.
* **Cumulative citations (Red):** Starts at 0 in 1965, increases steadily to approximately 0.2 by 2005.
**Chart b: JC Mather**
* **Boost factor (Green):** A sharp spike around 1970 and another around 1990, with values near 0 for the rest of the time. Peak values are approximately 0.9.
* **Avg. Citations per paper (Pink):** Starts around 0 in 1965, fluctuates between 0 and 0.3 until 1990, then increases to approximately 1.0 by 2005.
* **h-index (Teal):** Starts at 0 in 1965, increases steadily to approximately 0.4 by 1990, then increases more rapidly to approximately 1.0 by 2005.
* **Cumulative citations (Red):** Starts at 0 in 1965, increases steadily to approximately 0.9 by 2005.
**Chart c: RY Tsien**
* **Boost factor (Green):** A sharp spike around 1982, with values near 0 for the rest of the time. Peak value is approximately 1.0.
* **Avg. Citations per paper (Pink):** Starts around 0 in 1975, remains near 0 until 1980, then increases to approximately 1.0 by 2005.
* **h-index (Teal):** Starts at 0 in 1975, increases steadily to approximately 0.4 by 2005.
* **Cumulative citations (Red):** Starts at 0 in 1975, increases steadily to approximately 0.2 by 2005.
**Chart d: RB Myerson**
* **Boost factor (Green):** A sharp spike around 1980, with values near 0 for the rest of the time. Peak value is approximately 0.8.
* **Avg. Citations per paper (Pink):** Starts around 0 in 1975, fluctuates between 0 and 0.7 until 2005.
* **h-index (Teal):** Starts at 0 in 1975, increases steadily to approximately 0.8 by 2005.
* **Cumulative citations (Red):** Starts at 0 in 1975, increases steadily to approximately 0.7 by 2005.
### Key Observations
* The "Boost factor" (Green) consistently shows sharp spikes at specific years for all researchers, indicating periods of high impact.
* The "Avg. Citations per paper" (Pink) varies significantly between researchers, with some showing a steady increase and others showing fluctuations.
* The "h-index" (Teal) generally increases steadily over time for all researchers.
* The "Cumulative citations" (Red) also increases steadily over time, but at different rates for each researcher.
### Interpretation
The charts provide a visual representation of the citation impact of four researchers over time. The "Boost factor" highlights specific years where their work had a particularly high impact. The "Avg. Citations per paper" and "h-index" reflect the overall quality and quantity of their publications. The "Cumulative citations" show the total impact of their work over their careers.
The data suggests that each researcher has a unique citation profile. For example, JC Mather's "Avg. Citations per paper" and "h-index" show a rapid increase in later years, while MR Capecchi's "Avg. Citations per paper" remains relatively high throughout the period. RY Tsien and RB Myerson have different patterns, with RY Tsien showing a later increase in "Avg. Citations per paper" and RB Myerson showing a more gradual increase in "h-index" and "Cumulative citations".
The spikes in "Boost factor" could be related to specific publications or events that significantly increased the researchers' visibility and impact. The differences in the other metrics could be due to various factors, such as the field of research, the number of publications, and the citation practices in their respective fields.
</details>
dex [21] ( h -index) H ( t ) in year t . For comparison, the evolution of the boost factor R ′ w ( t ) is depicted as well. All indices were divided by their maximum value, in order to normalize them and to use the same scale for all. The profiles of the classical indices are rather smooth in most cases, and it is often very hard to see any significant effects of landmark papers. However, this is not surprising, as the boost factor is designed to capture abrupt variations in the citation rates, while both C ( t ) and H ( t ) reflect the overall production of a scientist and are therefore less sensitive to extreme events.
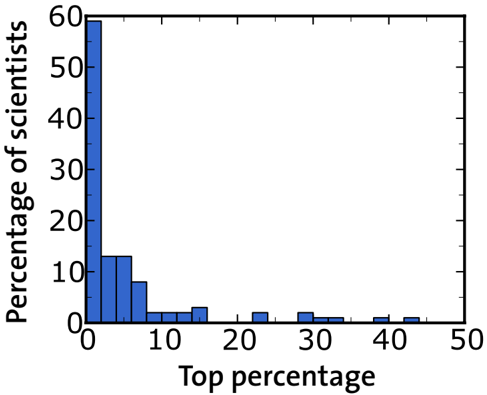
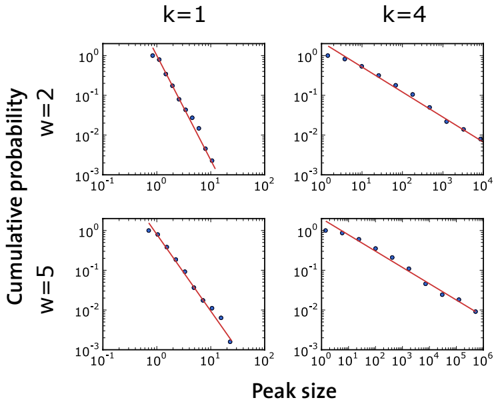
To gain a better understanding of our findings, Figs. 4 and 5 present a statistical analysis of the boosts observed for Nobel Prize Laureates. Figure 4 demonstrates that pronounced peaks are indeed related to highly cited papers. Furthermore, Fig. 5 analyzes the size distribution of peaks. The distribution looks like a power law for all choices of the parameters w and k (at least within the relevant range of small values). This suggests that the bursts are produced by citation cascades as they would occur in a self-organized critical system [22]. In fact, power laws were found to result from human interactions also in other contexts [23-25].
The mechanism underlying citation cascades is the discovery of new ideas, which colleagues refer to in the references of their papers. Moreover, according to the rich-gets-richer effect, successful papers are more often cited, also to raise their own success. Innovations may
Figure 4: Correlation between papers and the local maxima ('peaks') of R ′ w ( t ). We first determined the ranks of all papers of an author based on the total number of citations received until the year 2009 inclusively. We then determined the rank of that particular publication, which had the greatest contribution to the peak. This was done by measuring the reduction in the height of the peak, when the paper was excluded from the calculation of the boost factor (as in the insets of Fig. 2). The distribution of the ranks of 'landmark papers' is dominated by low values, implying that they are indeed among the top publications of their authors.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Histogram: Distribution of Scientists by Top Percentage
### Overview
The image is a histogram showing the distribution of scientists based on their "Top percentage". The y-axis represents the percentage of scientists, and the x-axis represents the top percentage. The histogram bars are blue.
### Components/Axes
* **Y-axis:** "Percentage of scientists", ranging from 0 to 60. Increments of 10 are marked.
* **X-axis:** "Top percentage", ranging from 0 to 50. Increments of 10 are marked.
### Detailed Analysis
The histogram bars represent the frequency of scientists within specific "Top percentage" ranges.
* **0-1%:** Approximately 58% of scientists.
* **1-2%:** Approximately 13% of scientists.
* **2-3%:** Approximately 10% of scientists.
* **3-4%:** Approximately 8% of scientists.
* **4-5%:** Approximately 2% of scientists.
* **5-6%:** Approximately 2% of scientists.
* **6-7%:** Approximately 2% of scientists.
* **7-8%:** Approximately 1% of scientists.
* **8-9%:** Approximately 1% of scientists.
* **9-10%:** Approximately 1% of scientists.
* **10-11%:** Approximately 3% of scientists.
* **11-12%:** Approximately 3% of scientists.
* **12-13%:** Approximately 1% of scientists.
* **13-14%:** Approximately 1% of scientists.
* **14-15%:** Approximately 1% of scientists.
* **24-25%:** Approximately 2% of scientists.
* **29-30%:** Approximately 2% of scientists.
* **30-31%:** Approximately 1% of scientists.
* **31-32%:** Approximately 1% of scientists.
* **39-40%:** Approximately 2% of scientists.
* **40-41%:** Approximately 1% of scientists.
* **41-42%:** Approximately 1% of scientists.
### Key Observations
* The distribution is heavily skewed to the left, indicating that a large percentage of scientists fall within the lower "Top percentage" ranges.
* The highest percentage of scientists is in the 0-1% range.
* The frequency of scientists decreases significantly as the "Top percentage" increases.
### Interpretation
The histogram suggests that a majority of scientists are clustered within the lower end of the "Top percentage" metric. This could indicate that the metric being measured is one where high performance is relatively rare, or that the population being measured is one where most individuals are not considered top performers. The rapid decline in the percentage of scientists as the "Top percentage" increases suggests a power-law or exponential decay relationship.
</details>
even cause scientists to change their research direction or approach. Apparently, such feedback effects can create citation cascades, which are ultimately triggered by landmark papers.
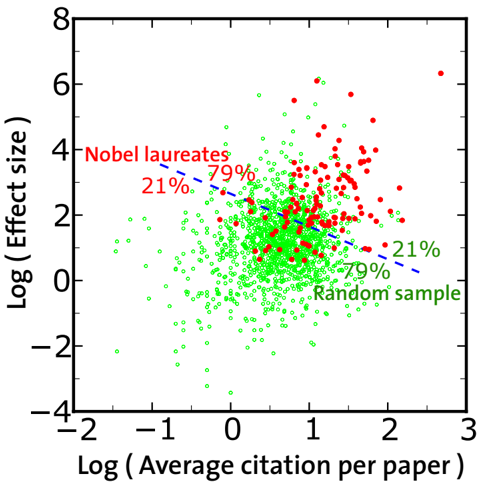
Finally, it is important to check whether the boost factor is able to distinguish exceptional scientists from average ones. Since any criteria used to define 'normal scientists' may be questioned, we have assembled a set of scientists taken at random. Scientists were chosen among those who published at least one paper in the year 2000. We selected 400 names for each of four fields: Medicine, Physics, Chemistry and Economy. After discarding those with no citations, we ended up with 1361 scientists. In Fig. 6 we draw on a bidimensional plane each scientist of our random sample (empty circles), together with the Nobel Prize Laureates considered (full circles). The two dimensions are the value of the boost factor and the average number of citations of a scientist. A cluster analysis separates the populations in the proportions of 79% to 21%. The separation is significant but there is an overlap of the two datasets, mainly because of two reasons. First, by picking a large number of scientists at random, as we did, there is a finite probability to choose also outstanding scholars. We have verified that this is the case. Therefore, some of the empty circles deserve to sit on the top-right part of the diagram, like many Nobel Prize Laureates. The second reason is that we are considering
Figure 5: Cumulative probability distribution of peak heights in the boost factor curves of Nobel Prize Laureates. The four panels correspond to different choices of the parameters k and w . The power law fits (lines) are performed with the maximum likelihood method [26]. The exponents for the direct distribution (of which the cumulative distribution is the integral) are: 3 . 63 ± 0 . 16 (top left), 2 . 93 ± 0 . 16 (bottom left), 1 . 63 ± 0 . 05 (top right), 1 . 41 ± 0 . 05 (bottom right). The best fits have the following lower cutoffs and values of the KolmogorovSmirnov (KS) statistics: 1 . 06, 0 . 0289 (top left), 1 . 15, 0 . 0264 (bottom left), 13 . 1, 0 . 038 (top right), 24 . 7, 0 . 0462 (bottom right). The KS values support the power law ansatz for the shape of the curves. Still, we point out that on the left plots the data span just one decade in the variable, so one has to be careful about the existence of power laws here.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Chart: Cumulative Probability vs. Peak Size
### Overview
The image presents four scatter plots arranged in a 2x2 grid. Each plot displays the relationship between "Cumulative probability" (y-axis) and "Peak size" (x-axis) under different conditions, specified by the parameters 'k' and 'w'. Both axes are logarithmically scaled. The plots show a decreasing trend, with a red line of best fit overlaid on the blue scatter points.
### Components/Axes
* **Title:** The plots are implicitly titled by the parameters 'k' and 'w' displayed above and to the left of each plot, respectively.
* **X-axis:** "Peak size" with a logarithmic scale ranging from approximately 10<sup>-1</sup> to 10<sup>2</sup> for k=1 and from 10<sup>0</sup> to 10<sup>6</sup> for k=4.
* **Y-axis:** "Cumulative probability" with a logarithmic scale ranging from 10<sup>-3</sup> to 10<sup>0</sup>.
* **Data Points:** Blue scatter points representing the data.
* **Trend Line:** A red line of best fit is plotted through the data points in each graph.
* **Parameters:**
* k = 1 (top left and bottom left plots)
* k = 4 (top right and bottom right plots)
* w = 2 (top left and top right plots)
* w = 5 (bottom left and bottom right plots)
### Detailed Analysis
**Top-Left Plot (k=1, w=2):**
* X-axis: Peak size ranges from 10<sup>-1</sup> to 10<sup>2</sup>.
* Y-axis: Cumulative probability ranges from 10<sup>-3</sup> to 10<sup>0</sup>.
* Trend: The blue data points show a decreasing trend. The red line of best fit confirms this downward slope.
* Data Points:
* At Peak size ≈ 0.1, Cumulative probability ≈ 1
* At Peak size ≈ 1, Cumulative probability ≈ 0.1
* At Peak size ≈ 10, Cumulative probability ≈ 0.01
**Top-Right Plot (k=4, w=2):**
* X-axis: Peak size ranges from 10<sup>0</sup> to 10<sup>4</sup>.
* Y-axis: Cumulative probability ranges from 10<sup>-3</sup> to 10<sup>0</sup>.
* Trend: The blue data points show a decreasing trend. The red line of best fit confirms this downward slope.
* Data Points:
* At Peak size ≈ 1, Cumulative probability ≈ 1
* At Peak size ≈ 10, Cumulative probability ≈ 0.2
* At Peak size ≈ 100, Cumulative probability ≈ 0.05
* At Peak size ≈ 1000, Cumulative probability ≈ 0.01
* At Peak size ≈ 10000, Cumulative probability ≈ 0.002
**Bottom-Left Plot (k=1, w=5):**
* X-axis: Peak size ranges from 10<sup>-1</sup> to 10<sup>2</sup>.
* Y-axis: Cumulative probability ranges from 10<sup>-3</sup> to 10<sup>0</sup>.
* Trend: The blue data points show a decreasing trend. The red line of best fit confirms this downward slope.
* Data Points:
* At Peak size ≈ 0.1, Cumulative probability ≈ 1
* At Peak size ≈ 1, Cumulative probability ≈ 0.1
* At Peak size ≈ 10, Cumulative probability ≈ 0.01
**Bottom-Right Plot (k=4, w=5):**
* X-axis: Peak size ranges from 10<sup>0</sup> to 10<sup>6</sup>.
* Y-axis: Cumulative probability ranges from 10<sup>-3</sup> to 10<sup>0</sup>.
* Trend: The blue data points show a decreasing trend. The red line of best fit confirms this downward slope.
* Data Points:
* At Peak size ≈ 1, Cumulative probability ≈ 1
* At Peak size ≈ 10, Cumulative probability ≈ 0.2
* At Peak size ≈ 100, Cumulative probability ≈ 0.05
* At Peak size ≈ 1000, Cumulative probability ≈ 0.01
* At Peak size ≈ 10000, Cumulative probability ≈ 0.002
* At Peak size ≈ 100000, Cumulative probability ≈ 0.0005
* At Peak size ≈ 1000000, Cumulative probability ≈ 0.0001
### Key Observations
* All four plots exhibit a power-law relationship between peak size and cumulative probability, as indicated by the linear trend on the log-log scale.
* The parameter 'k' influences the range of peak sizes considered, with k=4 extending to larger peak sizes than k=1.
* The parameter 'w' seems to have a minor effect on the slope of the trend line, but this is difficult to quantify precisely without further analysis.
### Interpretation
The plots suggest that the cumulative probability of observing a certain peak size decreases as the peak size increases. This is a common characteristic of many natural phenomena, often modeled by power-law distributions. The different values of 'k' and 'w' likely represent different system parameters or conditions that affect the range and distribution of peak sizes. The fact that the relationship is linear on a log-log scale indicates a power-law relationship, which is often associated with scale-free phenomena. The parameter 'k' seems to control the range of peak sizes observed, while 'w' may influence the rate at which the cumulative probability decreases with increasing peak size. Further analysis would be needed to determine the exact functional relationship and the physical meaning of 'k' and 'w'.
</details>
scholars from different disciplines, which generally have different citation frequencies. This affects particularly the average number of citations of a scientist, but also the value of the boost factor. In this way, the position in the diagram is affected by the specific research topic, and the distribution of the points in the diagram of Fig. 6 is a superposition of field-specific distributions. Nevertheless, the two datasets, though overlapping, are clearly distinct. Adding further dimensions could considerably improve the result. In this respect, the boost factor can be used together with other measures to better specify the performance of scientists.
## III. DISCUSSION
In summary, groundbreaking scientific papers have a boosting effect on previous publications of their authors, bringing them to the attention of the scientific community and establishing their 'authority'. We have provided the first quantitative characterization of this phenomenon by introducing a new variable, the 'boost factor', which is sensitive to sudden changes in the citation
Figure 6: Two-dimensional representation of our collection of Nobel Prize Laureates and a set of 1361 scientists, which were randomly selected. On the x-axis we report the average number of citations of a scientist, on the y-axis his/her boost factor. It can be seen that, on average, Nobel Prize winners clearly perform better. However a Nobel Prize is not solely determined by the average number of citations and the boost factor, but also by further factors. These may be the degree of innovation or quality, which are hard to quantify.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Scatter Plot: Effect Size vs. Average Citation per Paper for Nobel Laureates and a Random Sample
### Overview
The image is a scatter plot comparing the logarithmic effect size and logarithmic average citation per paper for Nobel laureates (represented by red dots) and a random sample (represented by green dots). The plot also includes a dashed blue line indicating a separation between the two groups, with percentages indicating the proportion of each group above and below the line.
### Components/Axes
* **X-axis:** Log (Average citation per paper). The axis ranges from approximately -2 to 3, with tick marks at every integer value.
* **Y-axis:** Log (Effect size). The axis ranges from approximately -4 to 8, with tick marks at every integer value.
* **Data Series 1:** Nobel laureates (red dots).
* **Data Series 2:** Random sample (green dots).
* **Separation Line:** A dashed blue line that slopes downward from left to right.
* **Percentages:** "79%" and "21%" are associated with each side of the separation line for both Nobel laureates and the random sample.
### Detailed Analysis
* **Nobel Laureates (Red Dots):**
* The red dots representing Nobel laureates are concentrated in the upper-right quadrant of the plot, indicating a tendency for higher effect sizes and higher average citations per paper.
* The distribution is somewhat scattered, but there is a noticeable cluster around the region where Log (Average citation per paper) is between 0.5 and 1.5, and Log (Effect size) is between 2 and 4.
* Above the dashed blue line, 21% of the Nobel laureates are located.
* Below the dashed blue line, 79% of the Nobel laureates are located.
* **Random Sample (Green Dots):**
* The green dots representing the random sample are more widely distributed across the plot, with a higher concentration in the lower-left quadrant.
* The distribution appears more uniform compared to the Nobel laureates, with a larger spread in both effect size and average citation per paper.
* Above the dashed blue line, 79% of the random sample is located.
* Below the dashed blue line, 21% of the random sample is located.
* **Separation Line (Dashed Blue):**
* The dashed blue line visually separates the two groups, with a higher proportion of Nobel laureates located below the line and a higher proportion of the random sample located above the line.
* The line starts at approximately (x=-1, y=4) and ends at approximately (x=2, y=0).
### Key Observations
* Nobel laureates tend to have higher effect sizes and average citations per paper compared to the random sample.
* The distributions of the two groups are distinct, with the Nobel laureates showing a more concentrated pattern.
* The dashed blue line provides a visual separation between the two groups, highlighting the differences in their distributions.
### Interpretation
The scatter plot suggests a correlation between receiving a Nobel Prize and having both a higher effect size and a higher average citation per paper. The concentration of Nobel laureates in the upper-right quadrant indicates that their work tends to have a greater impact and is more frequently cited compared to the random sample. The dashed blue line and the associated percentages provide a quantitative measure of the separation between the two groups, indicating that a significant proportion of Nobel laureates have higher values for both metrics compared to the random sample. This could imply that Nobel laureates, on average, produce more influential and impactful research. The percentages near the dashed line indicate the proportion of each group that falls on either side of the line, further emphasizing the distinction between the two groups.
</details>
rates. The fact that landmark papers trigger the collective discovery of older papers amplifies their impact and tends to generate pronounced spikes long before the paper receives full recognition. The boosting factor can therefore serve to discover new breakthroughs and talents more quickly than classical citation indices. It may also help to assemble good research teams, which have a pivotal role in modern science [27-29].
The power law behavior observed in the distribution of peak sizes suggests that science progresses through phase transitions [30] with citation avalanches on all scales-from small cascades reflecting quasi-continuous scientific progress all the way up to scientific revolutions, which fundamentally change our perception of the world. While this provides new evidence for sudden paradigm shifts [31], our results also give a better idea of why and how they happen.
It is noteworthy that similar feedback effects may determine the social influence of politicians, or prices of stocks and products (and, thereby, the value of companies). In fact, despite the long history of research on these subjects, such phenomena are still not fully understood. There is evidence, however, that the power of a person or the value of a company increase with the level
of attention they enjoy. Consequently, our study of scientific impact is likely to shed new light on these scientific puzzles as well.
## IV. MATERIALS AND METHODS
The basic goal is to improve the signal-to-noise ratio in the citation rates, in order to detect sudden changes in them. An effective method to reduce the influence of papers with largely fluctuating citation rates is to weight highly cited papers more. This can be achieved by raising the number of cites to the power k , where k > 1. Therefore, our formula to compute R ′ w ( t ) looks as follows:
$$R _ { w } ^ { \prime } ( t ) = \frac { \sum _ { p } \sum _ { t ^ { \prime } = t + 1 } ^ { t + w } ( c _ { p , t ^ { \prime } } ) ^ { k } } { \sum _ { p } \sum _ { t ^ { \prime } = t - w + 1 } ^ { t } ( c _ { p , t ^ { \prime } } ) ^ { k } } .$$
Here, c p,t ′ is the number of cites received by paper p in year t ′ . The sum over p includes all papers published
- [1] Albeverio S, Jentsch V, Kantz H, eds. (2006) Extreme Events in Nature and Society. Berlin, Germany: Springer.
- [2] Bettencourt LM, Cintr´ on-Arias A, Kaiser DI, CastilloCh´ avez C (2006) The power of a good idea: Quantitative modeling of the spread of ideas from epidemiological models. Physica A 364: 513 - 536.
- [3] Davenport TH, Beck JC (2001) The Attention Economy : Understanding the New Currency of Business Boston, USA: Harvard Business School Press.
- [4] Merton RK (1968) The Matthew effect in science: The reward and communication systems of science are considered. Science 159: 56-63.
- [5] Merton RK (1988) The Matthew effect in science, ii: Cumulative advantage and the symbolism of intellectual property. ISIS 79: 606-623.
- [6] Scharnhorst A (1997) Characteristics and impact of the matthew effect for countries. Scientometrics 40: 407-422.
- [7] Petersen AM, Jung WS, Yang JS, Stanley HE (2011) Quantitative and empirical demonstration of the Matthew effect in a study of career longevity. Proc Natl Acad Sci USA 108: 18-23.
- [8] Malmgren RD, Ottino JM, Nunes Amaral LA (2010) The role of mentorship in protege performance. Nature 465: 622-626.
- [9] Garfield E (1955) Citation Indexes for Science: A New Dimension in Documentation through Association of Ideas. Science 122: 108-111.
- [10] Garfield E (1979) Citation Indexing. Its Theory and Applications in Science, Technology, and Humanities. New York, USA: Wiley.
- [11] Egghe L, Rousseau R (1990) Introduction to Informetrics: Quantitative Methods in Library, Documentation and Information Science. Amsterdam, The Netherlands: Elsevier.
- [12] Amsterdamska O, Leydesdorff L (1989) Citations: indicators of significance. Scientometrics 15: 449-471.
before the year t ; w is the time window selected to compute the boosting effect. For k = 1 we recover the original definition of R w ( t ) (see main text). For the analysis presented in the paper we have used k = 4 and w = 5, but our conclusions are not very sensitive to the choice of smaller values of k and w .
## V. ACKNOWLEDGMENTS
We acknowledge the use of ISI Web of Science data of Thomson Reuters for our citation analysis. A.M., S.L. and D.H. were partially supported by the Future and Emerging Technologies programme FP7-COSI-ICT of the European Commission through the project QLectives (grant no.: 231200). Y.-H. E. and S. F. gratefully acknowledge ICTeCollective, grant 238597 of the European Commission.
- [13] Petersen AM, Wang F, Stanley HE (2010) Methods for measuring the citations and productivity of scientists across time and discipline. Phys Rev E 81: 036114.
- [14] Bollen J, de Sompel HV, Smith JA, Luce R (2005) Toward alternative metrics of journal impact: A comparison of download and citation data. Information Processing & Management 41: 1419 - 1440.
- [15] Trajtenberg M (1990) A penny for your quotes: Patent citations and the value of innovations. RAND Journal of Economics 21: 172-187.
- [16] Aksnes DW (2006) Citation rates and perceptions of scientific contribution. J Am Soc Inf Sci Technol 57: 169185.
- [17] Moed HF (2005) Citation Analysis in Research Evaluation. Berlin, Germany: Springer.
- [18] Van Raan AJF (2005) Fatal attraction: Conceptual and methodological problems in the ranking of universities by bibliometric methods. Scientometrics 62: 133-143.
- [19] Boyack KW, B¨ orner K (2003) Indicator-assisted evaluation and funding of research: visualizing the influence of grants on the number and citation counts of research papers. J Am Soc Inf Sci Technol 54: 447-461.
- [20] Wu F, Huberman BA (2007) Novelty and collective attention. Proc Natl Acad Sci USA 104: 17599-17601.
- [21] Hirsch JE (2005) An index to quantify an individual's scientific research output. Proc Natl Acad Sci USA 102: 16569-16572.
- [22] Bak P, Tang C, Wiesenfeld K (1987) Self-organized criticality: An explanation of the 1/f noise. Phys Rev Lett 59: 381-384.
- [23] Barab´ asi AL (2005) The origin of bursts and heavy tails in human dynamics. Nature 435: 207-211.
- [24] Oliveira JG, Barab´ asi AL (2005) Human dynamics: The correspondence patterns of Darwin and Einstein. Nature 437: 1251.
- [25] Malmgren RD, Stouffer DB, Campanharo ASLO, Amaral LAN (2009) On Universality in Human Correspondence
Activity. Science 325: 1696-1700.
- [26] Clauset A, Shalizi CR, Newman MEJ (2007) Power-law distributions in empirical data. SIAM Reviews 51: 661703.
- [27] Guimer` a R, Uzzi B, Spiro J, Amaral LAN (2005) Team Assembly Mechanisms Determine Collaboration Network Structure and Team Performance. Science 308: 697-702.
- [28] Wuchty S, Jones BF, Uzzi B (2007) The Increasing Dominance of Teams in Production of Knowledge. Science 316: 1036-1039.
- [29] Jones BF, Wuchty S, Uzzi B (2008) Multi-University Research Teams: Shifting Impact, Geography, and Stratification in Science. Science 322: 1259-1262.
- [30] Stanley HE (1987) Introduction to Phase Transitions and Critical Phenomena. New York, USA: Oxford University Press.
- [31] Kuhn TS (1962) The Structure of Scientific Revolutions. Chicago, USA: University of Chicago Press.