# Unknown Title
## QUANTUM ANNEALING: FROM VIEWPOINTS OF STATISTICAL PHYSICS, CONDENSED MATTER PHYSICS, AND COMPUTATIONAL PHYSICS
## SHU TANAKA
Department of Chemistry, University of Tokyo, 7-3-1, Hongo, Bunkyo-ku, Tokyo, 113-0033, Japan E-mail: shu-t@chem.s.u-tokyo.ac.jp
## RYO TAMURA
Institute for Solid State Physics, University of Tokyo, 5-1-5, Kashiwanoha, Kashiwa-shi, Chiba, 277-8501, Japan
International Center for Young Scientists, National Institute for Materials Science, 1-2-1, Sengen, Tsukuba-shi, Ibaraki, 305-0047, Japan E-mail: tamura.ryo@nims.go.jp
In this paper, we review some features of quantum annealing and related topics from viewpoints of statistical physics, condensed matter physics, and computational physics. We can obtain a better solution of optimization problems in many cases by using the quantum annealing. Actually the efficiency of the quantum annealing has been demonstrated for problems based on statistical physics. Then the quantum annealing has been expected to be an efficient and generic solver of optimization problems. Since many implementation methods of the quantum annealing have been developed and will be proposed in the future, theoretical frameworks of wide area of science and experimental technologies will be evolved through studies of the quantum annealing.
Keywords : Quantum annealing; Quantum information; Ising model; Optimization problem
## 1. Introduction
Optimization problems are present almost everywhere, for example, designing of integrated circuit, staff assignment, and selection of a mode of transportation. To find the best solution of optimization problems is difficult in general. Then, it is a significant issue to propose and to develop a method for obtaining the best solution (or a better solution) of optimiza-
tion problems in information science. In order to obtain the best solution, a couple of algorithms according to type of optimization problems have been formulated in information science and these methods have yielded practical applications. Furthermore, since optimization problem is to find the state where a real-valued function takes the minimum value, it can be regarded as problem to obtain the ground state of the corresponding Hamiltonian. Thus, if we can map optimization problem to well-defined Hamiltonian, we can use knowledge and methodologies of physics. Actually, in computational physics, generic and powerful algorithms which can be adopted for wide application have been proposed. One of famous methods is simulated annealing which was proposed by Kirkpatrick et al. 1,2 In the simulated annealing, we introduce a temperature (thermal fluctuation) in the considered optimization problems. We can obtain a better solution of the optimization problem by decreasing temperature gradually since thermal fluctuation effect facilitates transition between states. It is guaranteed that we can obtain the best solution definitely if we decrease temperature slow enough. 3 Then, the simulated annealing has been used in many cases because of easy implementation and guaranty.
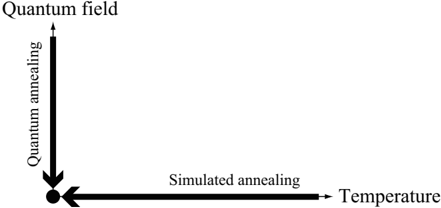
The quantum annealing was proposed as an alternative method of the simulated annealing. 4-11 In the quantum annealing, we introduce a quantum field which is appropriate for the considered Hamiltonian. For instance, if the considered optimization problem can be mapped onto the Ising model, the simplest form of the quantum fluctuation is transverse field. In the quantum annealing, we gradually decrease quantum field (quantum fluctuation) instead of temperature (thermal fluctuation). The efficiency of the quantum annealing has been demonstrated by a number of researchers, and it has been reported that a better solution can be obtained by the quantum annealing comparison with the simulated annealing in many cases. Figure 1 shows schematic picture of the simulated annealing and the quantum annealing. In optimization problems, our target is to obtain the stable state at zero temperature and zero quantum field, which is indicated by the solid circle in Fig. 1.
Recently, methods in which we decrease temperature and quantum field simultaneously have been proposed and as a result, we can obtain a better solution than the simulated annealing and the simple quantum annealing. 12-14 Moreover, as an another example of methods in which we use both thermal fluctuation and quantum fluctuation, novel quantum annealing method with the Jarzynski equality 15,16 was also proposed, 17 which is based on nonequilibrium statistical physics.
Fig. 1. Schematic picture of the simulated annealing and the quantum annealing. Our purpose is to obtain the ground state at the point indicated by the solid circle.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Quantum Annealing vs. Simulated Annealing Conceptual Relationship
### Overview
The image is a conceptual diagram illustrating the relationship between two optimization methods—Quantum Annealing and Simulated Annealing—and their associated domains. It uses a simple two-axis layout with directional arrows to show how each method originates from a distinct conceptual space and converges toward a common point.
### Components/Axes
The diagram consists of two perpendicular axes forming an L-shape, with text labels and directional arrows.
1. **Vertical Axis (Left Side):**
* **Label:** "Quantum annealing" (written vertically, reading from bottom to top).
* **Direction:** A thick black arrow points **downward** along this axis.
* **Origin Label:** At the top of this axis, the text "Quantum field" is placed.
2. **Horizontal Axis (Bottom):**
* **Label:** "Simulated annealing" (written horizontally).
* **Direction:** A thick black arrow points **leftward** along this axis.
* **Origin Label:** At the right end of this axis, the text "Temperature" is placed.
3. **Convergence Point:**
* The downward arrow from "Quantum annealing" and the leftward arrow from "Simulated annealing" meet at a single, solid black dot located at the bottom-left corner of the diagram (the intersection of the two axes).
### Detailed Analysis
* **Spatial Grounding:** The "Quantum field" label is positioned top-center relative to the vertical axis. The "Temperature" label is positioned center-right relative to the horizontal axis. The convergence dot is at the absolute bottom-left of the graphical elements.
* **Flow and Direction:** The diagram establishes two distinct pathways:
1. A vertical flow from the abstract "Quantum field" down through the process of "Quantum annealing."
2. A horizontal flow from the classical parameter "Temperature" leftward through the process of "Simulated annealing."
* **Text Transcription:** All text is in English. The precise labels are: "Quantum field", "Quantum annealing", "Simulated annealing", and "Temperature".
### Key Observations
* The diagram is purely conceptual and contains **no numerical data, scales, or quantitative values**. It is a schematic, not a chart.
* The use of thick, bold arrows emphasizes directionality and process flow.
* The convergence at a single point is the central visual metaphor, suggesting a common goal, outcome, or operational point reached by both methods.
* The layout is asymmetric, with the vertical axis on the left and the horizontal axis on the bottom, creating a focused point of interest in the lower-left quadrant.
### Interpretation
This diagram visually hypothesizes a relationship between quantum and classical annealing techniques. It suggests that:
1. **Distinct Origins:** Quantum annealing is fundamentally rooted in or driven by principles of a "Quantum field," while simulated annealing is classically governed by the parameter of "Temperature."
2. **Convergent Process:** Despite their different foundations, both processes are depicted as directional pathways (annealing) that lead to the same destination or solution state (the black dot). This implies that for a given problem, both methods might be applicable or aim for a similar optimal result.
3. **Conceptual Mapping:** The diagram serves as a high-level conceptual map, likely used to frame a discussion comparing the two optimization strategies. It abstracts away all technical details to highlight their philosophical or methodological origins and their potential equivalence in outcome. The lack of data indicates its purpose is to illustrate a relationship or model, not to present empirical results.
</details>
In this paper, we review the quantum annealing method which is the generic and powerful tool for obtaining the best solution of optimization problems from viewpoints of statistical physics, condensed matter physics, and computational physics. The organization of this paper is as follows. In Sec. 2, we review the Ising model which is a fundamental model of magnetic systems. The realization method of the Ising model by nuclear magnetic resonance is also explained. In Sec. 3, we show a couple of implementation methods of the quantum annealing. In Sec. 4, we explain two optimization problems - traveling salesman problem and clustering problem. The quantum annealing based on the Monte Carlo method for the traveling salesman problem is also demonstrated. In Sec. 5, we review related topics of the quantum annealing - Kibble-Zurek mechanism of the Ising spin chain and order by disorder in frustrated systems. In Sec. 6, we summarize this paper briefly and give some future perspectives of the quantum annealing.
## 2. Ising Model
In this section we introduce the Ising model which is a fundamental model in statistical physics. A century ago, the Ising model was proposed to explain cooperative nature in strongly correlated magnetic systems from a microscopic viewpoint. 18 The Hamiltonian of the Ising model is given by
$$H _ { 1 } = - \sum _ { i , j } J _ { ij } o _ { i z } o _ { j z } - \sum _ { i = 1 } ^ { N } h _ { i }$$
where the summation of the first term runs over all interactions on the defined graph and N represents the number of spins. If the sign of J ij is positive/negative, the interaction is called ferromagnetic/antiferromagnetic
interaction. Spins which are connected by ferromagnetic/antiferromagnetic interaction tend to be the same/opposite direction. The second term of the Hamiltonian denotes the site-dependent longitudinal magnetic fields. Although the Ising model is quite simple, this model exhibits inherent rich properties e.g. phase transition and dynamical behavior such as melting process and slow relaxation. For instance, the ferromagnetic Ising model with homogeneous interaction ( J ij = J for ∀ i, j ) and no external magnetic fields ( h i = 0 for ∀ i ) on square lattice exhibits the second-order phase transition, whereas no phase transition occurs in the Ising model on onedimensional lattice. Onsager first succeeded to obtain explicitly free energy of the Ising model without external magnetic field on square lattice. 19 After that, a couple of calculation methods were proposed. Furthermore, these calculation methods have been improved day by day, and the new techniques which were developed in these methods have been applied for other more complicated problems. Since the Ising model is quite simple, we can easily generalize the Ising model in diverse ways such as the Blume-Capel model, 20,21 the clock model, 22,23 and the Potts model. 24,25 By analyzing these models, relation between nature of phase transition and the symmetry which breaks at the transition point has been investigated. Then, it is not too much to say that the Ising model has opened up a new horizon for statistical physics.
The Ising model can be adopted for not only magnetic systems but also systems in wide area of science such as information science. Optimization problem is one of important topics in information science. As we mention in Sec. 4, optimization problem can be mapped onto the Ising model and its generalized models in many cases. Then some methods which were developed in statistical physics often have been used for optimization problem. In Sec. 2.1, we show a couple of magnetic systems which can be well represented by the Ising model. In Sec. 2.2, we review how to create the Ising model by Nuclear Magnetic Resonance (NMR) technique as an example of experimental realization of the Ising model.
## 2.1. Magnetic Systems
In many cases, the Hamiltonian of magnetic systems without external magnetic field is given by
$$\hat { H } = - \sum _ { i , j } J _ { ij } ( \sigma ^ { i } _ { j } \cdot \sigma ^ { j } _ { i } )$$
where ˆ σ α i denotes the α -component of the Pauli matrix at the i -th site. The form of this interaction is called Heisenberg interaction. The definitions of Pauli matrices are
$$\sigma ^ { x } = ( 0 , 1 ) , \sigma ^ { y } = ( 0 - i , 0 )$$
where the bases are defined by
$$\begin{array}{c}
n = \left\{ 0 \right\}, \\
1 \geq n = \left\{ 1 \right\}, \\
1 + = \left\{ 4 \right\}.
\end{array}$$
In this case, magnetic interactions are isotropic. However, they become anisotropic depending on the surrounded ions in real magnetic materials. In general, the Hamiltonian of magnetic systems should be replaced by
$$a ^ { i } - \sum _ { i , j } J _ { i , j } ( c x _ { i } ^ { 2 } o ^ { 2 } f _ { j } + c y _ { i } ^ { 2 } o ^ { 2 } f _ { j } )$$
When | c x | , | c y | > | c z | , the xy -plane is easy-plane and the Hamiltonian becomes XY-like Hamiltonian. On the contrary, when | c z | > | c x | , | c y | , the z -axis is easy-axis and the Hamiltonian becomes Ising-like Hamiltonian. Such anisotropy comes from crystal structure, spin-orbit coupling, and dipoledipole coupling. Moreover, even if there is almost no anisotropy in magnetic interactions, magnetic systems can be regarded as the Ising model when the number of electrons in the magnetic ion is odd and the total spin is halfinteger. In this case, doubly degenerated states exist because of the Kramers theorem. These states are called the Kramers doublet. When the energy difference between the ground states and the first-excited states ∆ E is large enough, these doubly-degenerated ground states can be well represented by the S = 1 / 2 Ising spins. Table 1 shows examples of the magnetic materials which can be well represented by the Ising model on one-dimensional chain, two-dimensional square lattice, and three-dimensional cubic lattice.
Table 1. Examples of magnetic materials which can be represented by the Ising model on chain (one-dimension), square lattice (two-dimension), and cubic lattice (three-dimension).
| Material | Spatial dimension | Total spin | Type of interaction | J/k B | References |
|-------------------------------|---------------------|--------------|-----------------------|-------------|--------------|
| K 3 Fe(CN) 6 | One (chain) | 1 2 | Antiferromagnetic | - 0 . 23 K | 26-28 |
| CsCoCl 3 | One (chain) | 1 2 | Antiferromagnetic | - 100 K | 29,30 |
| Dy(C 2 H 5 SO 4 ) 2 · 9 H 2 O | One (chain) | 1 2 | Ferromagnetic | 0 . 2 K | 31-33 |
| CoCl 2 · 2NC 5 H 5 | One (chain) | 1 2 | Ferromagnetic | 9 . 5 K | 34,35 |
| CoCs 3 Br 5 | Two (square) | 1 2 | Antiferromagnetic | - 0 . 23 K | 36-38 |
| Co(HCOO) 2 · 2 H 2 O | Two (square) | 1 2 | Antiferromagnetic | - 4 . 3 K | 39-42 |
| Rb 2 CoF 4 | Two (square) | 1 2 | Antiferromagnetic | - 91 K | 43,44 |
| FeCl 2 | Two (square) | 1 | Ferromagnetic | 3 . 4 K | 45,46 |
| DyPO 4 | Three (cubic) | 1 2 | Antiferromagnetic | - 2 . 5 K | 47-50 |
| Dy 3 Al 5 O 12 | Three (cubic) | 1 2 | Antiferromagnetic | - 1 . 85 K | 51-53 |
| CoRb 3 Cl 5 | Three (cubic) | 1 2 | Antiferromagnetic | - 0 . 511 K | 54,55 |
| FeF 2 | Three (cubic) | 2 | Antiferromagnetic | - 2 . 69 K | 56-59 |
## 2.2. Nuclear Magnetic Resonance
In condensed matter physics, Nuclear Magnetic Resonance (NMR) has been used for decision of the structure of organic compounds and for analysis of the state in materials by using resonance induced by electromagnetic wave. The NMR can create the Ising model with transverse fields, which is expected to become an element of quantum information processing. In this processing, we use molecules where the coherence times are long compared with typical gate operations. Actually a couple of molecules which have nuclear spins were used for demonstration of quantum computing. 60-75 In this section we explain how to create the Ising model by NMR.
The setup of the NMR spectrometer as a tool of quantum computing is as follows. We first put molecules which contain nuclear spins under the strong magnetic field B 0 . Next we apply radio frequency ω (rf) magnetic field which is perpendicular to the strong magnetic field B 0 . For simplicity, we here consider a molecule which contains two spins. We also assume that the considered molecule can be well described by the Heisenberg Hamiltonian. Then the Hamiltonian of this system is given by
$$\frac { \hat { H } } { 6 } = \hat { H } _ { m o l } + \hat { H } _ { 1 ^ { r t } } + \hat { H } _ { 2 ^ { r f } }$$
where ˆ H mol , ˆ H (rf) 1 , and ˆ H (rf) 2 are defined by
$$\sigma _ { 2 } + \sigma _ { 1 } \cdot \sigma _ { 2 } + \sigma _ { 1 } \cdot \sigma _ { 3 } , ( 7 )$$
$$\frac { 1 } { 2 } ( t ) = - I _ { 2 } \cos ( w ( t ) + \phi _ { 2 } ) ( r ^ { 2 } )$$
$$\gamma ( t ) = - I _ { 1 } \cos ( w ( t ) + \phi _ { 1 } ( t ^ { 2 } )$$
respectively. We take the natural unit in which /planckover2pi1 = 1. The values of φ 1 and φ 2 are the phases at the time t = 0 of the first spin and that of the second spin, respectively. The quantities of h i are defined by h i := γ i B 0 , where γ i denotes the gyromagnetic ratio of the i -th spin ( i = 1 , 2). The values of h 1 and h 2 represent energy differences between |↑〉 and |↓〉 of the first spin and the second spin, respectively. The coefficients Γ 1 and Γ 2 in ˆ H (rf) 1 and ˆ H (rf) 2 are the effective amplitudes of the ac magnetic field, whose definitions are Γ i := γ i B ac , where B ac is amplitude of the ac magnetic field. The value of γ ′ is defined by the ratio of the gyromagnetic ratios γ ′ := γ 2 /γ 1 .
We define the following unitary transformation:
$$\int ( R ) : = e ^ { - i h _ { 1 } \phi _ { 1 } t } . e ^ { - i h _ { 2 } \phi _ { 2 } t }$$
We can change from the laboratory frame to a frame rotating with h i around the z -axis by using the above unitary transformation. The dynamics of a
density matrix can be calculated by
$$\frac { i \phi } { d t } = [ H , \phi ].$$
The density matrix on the rotating frame is given by
$$\rho ^ { ( R ) } : = U ^ { ( R ) } \dot { p } U ^ { ( R ) } t .$$
To be the same form as Eq. (11) on the rotating frame, the Hamiltonian on the rotating frame should be
$$\frac { \hat { U } ( R ) } { d t } = \hat { U } ( R ) \hat { H } U ^ { \prime } ( R ) + - i \hat { U } ^ { \prime } ( R )$$
Here we decompose the Hamiltonian on the rotating frame as
$$\frac { h ( R ) } { 2 } = \frac { h _ { mol } ( R ) } { 2 } + \frac { h _ { 1 } ( R ) ( f ) } { 2 } + r$$
where the three terms are defined by
$$\frac { H ( R ) } { \frac { d U ^ { \prime } ( R ) t } { d t } } , ( 1 5 )$$
$$\sum _ { i = 1 } ^ { n } \frac { 1 } { n } H _ { i } ( R ) = \sum _ { i = 1 } ^ { n } \frac { 1 } { n } H _ { i } ( t ) \tilde { H } ( R + t )$$
$$H _ { 2 } ^ { ( R ) ( r f ) } = \bar { U } ( R ) H _ { 2 } ^ { ( R ) ( r f ) } U ( R + t ) .$$
The intramolecular magnetic interaction Hamiltonian on the rotating frame ˆ H (R) mol can be calculated as
$$\hat { r } ( R ) = J \left\{ \begin{array}{ll} 0 & 0 & 0 \\ 0 & e ^ { - i ( h _ { 2 } - h _ { 1 } ) t } & 0 \\ 0 & 0 & 0 \end{array} \right.$$
The approximation is valid when | h 2 -h 1 | τ /greatermuch 1, where τ is a characteristic time scale since the exponential terms are averaged to vanish. The radio frequency magnetic field Hamiltonian on the rotating frame ˆ H (R)(rf) 1 under the resonance condition ω (rf) = h i can be calculated as
$$\begin{array}{ll}
\eta _ { 1 } ( R ) ( r ) = - \Gamma _ { 1 } \left[ \left\{ \begin{array}{l}
0 & 0 & e^{-i \theta _ { 1 } } \\
0 & 0 & 0 \\
e^{i \theta _ { 1 } } & 0 & 0 \\
0 & 0 & e^{i \theta _ { 1 } }
\end{array} \right. \right]
,
where a_{-1} := e^{-i ( h _ { 2 } - h ) t + \phi _ { 1 } } + e^{-i \theta _ { 1 } } .
\end{array}$$
$$\rho ^ { 1 } ( R ) ( r f ) = - \Gamma _ { 1 } ( \cos \phi _ { 1 } \hat { r } + s )$$
where a --:= e -i ( h 2 -h 1 ) t + φ 1 +e -i ( h 1 + h 2 ) t -φ 1 and a ++ := e i ( h 2 -h 1 ) t + φ 1 + e i ( h 1 + h 2 ) t -φ 1 . The second term of ˆ H (R)(rf) 1 vanishes when | h 1 + h 2 | τ, | h 2 -h 1 | τ /greatermuch 1. Then under these conditions, the Hamiltonian becomes
In the same way, the Hamiltonian ˆ H (R)(rf) 2 can be calculated as
$$\frac { x _ { 2 } ( R ) ( r f ) } { \sin ^ { 6 } \phi _ { 2 } \phi _ { 2 } } = - I _ { 2 } ( \cos \phi _ { 2 } \phi _ { 2 } + s )$$
By taking the rotation operators on the individual sites, we can rewrite the Hamiltonians ˆ H (R)(rf) 1 and ˆ H (R)(rf) 2 by only the x -component of the Pauli matrix:
$$\sum _ { i = 1 } ^ { \infty } \sum _ { j = 1 } ^ { \infty } H _ { 1 } ( R ) ( r f ) - i \sigma _ { 1 } ^ { 2 } i = - 1$$
$$e ^ { i \phi _ { 2 } \alpha _ { 2 } } H _ { 2 } ( R ) ( r f ) - i e ^ { i \phi _ { 2 } \alpha _ { 2 } } = -$$
Then, the total Hamiltonian can be represented by the Ising model with site-dependent transverse fields:
$$H ^ { ( R ) } = - J _ { 0 } ^ { i } \dot { I } _ { 0 } ^ { j } - I _ { 1 } ^ { k }$$
It should be noted that the above procedure is not restricted for two spin system. Then, the NMR technique can be create the Ising model with sitedependent transverse fields in general.
## 3. Implementation Methods of Quantum Annealing
As stated in Sec. 1, the quantum annealing method is expected to be a powerful tool to obtain the best solution of optimization problems in a generic way. The quantum annealing methods can be categorized according to how to treat time-development. One is a stochastic method such as the Monte Carlo method which will be shown in Sec. 3.1. Other is a deterministic method such as mean-field type method and real-time dynamics. We will explain the mean-field type method and the method based on real-time dynamics in Secs. 3.2 and 3.3. Although in the Monte Carlo method and the mean-field type method, we introduce time-development in an artificial way, the merit of these methods is to be able to treat large-scale systems. The methods based on the Schr¨ odinger equation can follow up real-time dynamics which occurs in real experimental systems. However, these methods can be used for very small systems and/or limited lattice geometries because of limited computer resources and characters of algorithms. Each method has strengths and limitations based on its individuality. Then when we use the quantum annealing, we have to choose implementation methods according to what we want to know. In this section, we explain three types of theoretical methods for the quantum annealing and some experimental results which relate to the quantum annealing.
## 3.1. Monte Carlo Method
In this section we review the Monte Carlo method as an implementation method of the quantum annealing. In physics, the Monte Carlo method is widely adopted for analysis of equilibrium properties of strongly correlated systems such as spin systems, electric systems, and bosonic systems. Originally the Monte Carlo method is used in order to calculate integrated value of given function. The simplest example is 'calculation of π '. Suppose we consider a square in which -1 ≤ x, y ≤ 1 and a circle whose radius is unity and center is ( x, y ) = (0 , 0). We generate pair of uniform random numbers ( -1 ≤ x i , y i ≤ 1) many times and calculate the following quantity:
$$\frac { \sqrt { x ^ { 2 } + 1 } } { \text { number of steps } } \cdot ( 2 4 )$$
Hereafter we refer to the denominator as Monte Carlo step. The quantity should converge to π/ 4 in the limit of infinite Monte Carlo step. This is a pedagogical example of the Monte Carlo method. We first explain how to implement and theoretical background of the Monte Carlo method which is used in physics.
In equilibrium statistical physics, we would like to know the equilibrium value at given temperature T . The equilibrium value of the physical quantity which is represented by the operator O is defined as
$$( O ) ^ { ( eq ) } T : = \frac { T _ { r } O e ^ { - 3 H } } { T _ { r } e ^ { - 8 H } } ,$$
where Tr means the trace of matrix and β denotes the inverse temperature β = ( k B T ) -1 . Hereafter we set the Boltzmann constant k B to be unity. For small systems, we can obtain the equilibrium value by taking sum analytically, on the contrary, it is difficult to obtain the equilibrium value for large systems except few solvable models. Then in order to evaluate equilibrium value of the physical quantity, we often use the Monte Carlo method.
We consider the Ising model given by
$$H _ { 1 } \sigma i = - \sum _ { ( j , i ) } ^ { N } J _ { ij } o _ { i j } - \sum _ { i = 1 } ^ { N } h _ { i }$$
The Ising model without transverse field can be expressed as a diagonal matrix by using 'trivial' bit representation |↑〉 and |↓〉 which were introduced in Sec. 2. Then, in this case, we can easily calculate the eigenenergy once the eigenstate is specified.
We can use the Monte Carlo method for obtaining the equilibrium value defined by Eq. (25) as well as the calculation of π :
$$\sum _ { S \in O } ( \Sigma e ^ { - \beta E ( \Sigma ) } \rightarrow 0 ) ^ { q } ,$$
where O (Σ) and E (Σ) denote the physical value of O and the eigenenergy of the eigenstate Σ, respectively. Here the eigenstate Σ is generated by uniform random number and ∑ Σ 1 is equal to Monte Carlo step. In the limit of infinite Monte Carlo step, LHS of Eq. (27) should be converge to the equilibrium value. Equilibrium statistical physics says that the probability distribution at equilibrium state can be described by the Boltzmann distribution which is proportional to e -βE (Σ) . In this case, since we know the form of the probability distribution, it is better to use the distribution function to generate a state according to the Boltzmann distribution instead of uniform random number. This scheme is called importance sampling. When we use the importance sampling, we can obtain the equilibrium value as follows:
$$\sum _ { \Sigma 1 } ^ { \Sigma 0 } ( \Sigma ) \rightarrow ( O ) ( e a ) .$$
In order to generate a state according to the Boltzmann distribution, we use the Markov chain Monte Carlo method. Let P (Σ a , t ) be the probability of the a -th state at time t . In this method, time-evolution of probability distribution is given by the master equation:
/negationslash
/negationslash where w (Σ a | Σ b ) represents the transition probability from the b -th state to the a -th state in unit time. The transition probability w (Σ a | Σ b ) obeys
$$\sum _ { S _ { e } } w ( \Sigma _ { a } | \Sigma _ { b } ) = 1 ( n \geqslant$$
For convenience, let P ( t ) be a vector-representation of probability distribution { P (Σ a , t ) } . Then the master equation can be represented by
$$P ( t + \Delta t ) = C P ( t ) ,$$
where L is the transition matrix whose elements are defined as
$$\int _ { \sqrt { 2 } } ^ { \infty } w ( \sum b | z | ) d t ,$$
/negationslash
$$\sum _ { b \neq a } L _ { b a } = 1 - \sum _ { b \neq a } L _ { b a }$$
/negationslash
Here the matrix L is a non-negative matrix and does not depend on time. Then this time-evolution is the Markovian.
If the transition matrix L is prepared appropriately, which satisfies the detailed balance condition and the ergordicity, we can obtain the equilibrium probability distribution in the limit of infinite Monte Carlo step regardless of choice of the initial state because of the Perron-Frobenius theorem.
We can perform the Monte Carlo method easily as following process.
- Step 1 We prepare a initial state arbitrary.
- Step 2 We choose a spin randomly.
- Step 3 We calculate the molecular field at the chosen site in Step 2. The molecular field at the chosen site i is defined as
$$h _ { i } ^ { ( eff ) } = \sum _ { j } ^ { \prime } J _ { ij } o ^ { 2 } j + h _ { i }$$
where the summation takes over the nearest neighbor sites of the i -th site.
- Step 4 We flip the chosen spin in Step 2 according to a probability defined by some way.
- Step 5 We continue from Step 2 to Step 4 until physical quantities such as magnetization converge.
In this Monte Carlo method, we only update the chosen single spin, and thus we refer to this method as single-spin-flip method. There is an ambiguity how to define w (Σ a | Σ b ) in Step 4. Here we explain two famous choices of w (Σ a | Σ b ) as follows. Transition probability in the heat-bath method is given by
$$\frac { w H B ( \sigma _ { i } ^ { - } - \sigma _ { f } ^ { + } ) } { 2 \cos h ( \beta _ { i } ^ { 2 } ) } = \frac { e ^ { - 8 h _ { i } ^ { 2 } } } { 2 \cos h ( \beta _ { i } ^ { 2 } ) } .$$
Transition probability in the Metropolis method is given by
$$\omega _ { M P } ( \sigma ^ { z } _ { i } - \sigma ^ { z } _ { j } ) = \{ 1 e^{-2 \beta h _ { i } ( e t ) } ,$$
Since both two transition probabilities satisfy the detailed balance condition, the equilibrium state can be obtained definitely in the limit of infinite Monte Carlo step a . It is important to select how to choice the transition probability since it is known that a couple of methods can sample states in an efficient fashion. 76-83
So far we considered the Monte Carlo method for systems where there is no off-diagonal matrix element. To perform the Monte Carlo method, in a precise mathematical sense, we only have to know how to choice the basis or appropriate transformation so as to diagonalize the given Hamiltonian. However, it is difficult to obtain equilibrium values of physical quantities of quantum systems, since we have to calculate the exponential of the given Hamiltonian e -β ˆ H in general. If we know all eigenvalues and the corresponding eigenvectors of the given Hamiltonian, we can easily calculate e -β ˆ H by the unitary transformation which diagonalizes the Hamiltonian ˆ H . In contrast, if we do not know all eigenvalues and eigenvectors, we have to calculate any power of the Hamiltonian ˆ H m since the matrix exponential is given by
$$e ^ { A } = \sum _ { m = 0 } ^ { \infty } \frac { 1 } { m ! } A ^ { m }$$
It is difficult to calculate the matrix exponential in general. Then we have to consider the following procedure in order to use the framework of the Monte Carlo method for quantum systems.
In many cases, the Hamiltonian of quantum systems can be represented as
$$H = H _ { c } + H _ { q } .$$
Hereafter we refer to ˆ H c and ˆ H q as classical Hamiltonian and quantum Hamiltonian, respectively. The classical Hamiltonian ˆ H c is a diagonal matrix. Here we assume that ˆ H q can be easily diagonalized b . This is a key of the quantum Monte Carlo method as will be shown later. Since ˆ H c and ˆ H q cannot commute in general: [ ˆ H c , ˆ H q ] = 0, then e -β ˆ H = e -β ˆ H c e -β ˆ H q . We
/negationslash
/negationslash
a Recently, the algorithm which does not use the detailed balance condition was proposed. 76,77 It should be noted that the detailed balance condition is just a necessary condition. This novel algorithm is efficient for general spin systems.
b This fact does not seem to be general. However we can prepare the matrices which can be easily diagonalized by the decomposition as ˆ H q = ∑ /lscript ˆ H ( /lscript ) q in many cases.
decompose the matrix exponential by introducing large integer m ,
$$\exp ( - \frac { b } { m } H _ { c } ) = \exp [ - \frac { b } { m } ( H _ { c } + i \alpha ) ]$$
This is a concrete representation of the Trotter formula. 84 From now on, we refer to m as Trotter number. By using this relation, we can perform the Monte Carlo method for quantum systems. To illustrate it, we consider the Ising model with longitudinal and transverse magnetic fields. The considered Hamiltonian is given as
$$\sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { N } \sum _ { k = 1 } ^ { N } H _ { ij } o _ { i j } - \sum _ { i = 1 } ^ { N } H _ { i } o _ { i }$$
$$H _ { c } = - \sum _ { i = 1 } ^ { N } J _ { i j } o _ { i } o _ { j } - \sum _ { i = 1 } ^ { N } h _ { i j } o _ { i }$$
where optimization problems often can be expressed by this classical Hamiltonian ˆ H c . The partition function of the Hamiltonian at temperature T (= β -1 ) is given by
$$z = T _ { r } e ^ { - b ^ { 2 } h } = \sum _ { z } \{ e ^ { - b ( c ) } \} .$$
Using Eq. (39) we obtain
$$z = \lim _ { n \rightarrow \infty } \sum _ { k = 1 , n } ^ { n - 1 } \{ \Sigma _ { m } | e ^ { - \beta H _ { a } / m } | \Sigma _ { m } \} \{ \Sigma _ { k } | e ^ { - \beta H _ { a } / m } | \Sigma _ { k } \}$$
∣ ∣ ∣ ∣ where | Σ k 〉 represents the direct-product space of N spins:
$$\sum _ { k = 1 } ^ { \infty } | o _ { i , k } | \circ | o _ { 2 , k } | \circ \cdots$$
where the first and the second subscripts of | σ z i,k 〉 indicate coordinates of the real space and the Trotter axis, respectively. Here | σ z i,k 〉 = |↑〉 or |↓〉 . Equation (42) consists of two elements 〈 Σ k | e -β ˆ H c /m | Σ ′ k 〉 and
〈 Σ ′ k | e -β ˆ H q /m | Σ k +1 〉 . Since the classical Hamiltonian ˆ H c is a diagonal matrix, the former is easily calculated:
$$= \exp [ \frac { \beta } { m } ( \sum _ { i = 1 } ^ { N } j _ { i } \sigma _ { i } ^ { 2 } , \sigma _ { i } ^ { k } + \sum _ { i = 1 } ^ { N } h _ { i } \sigma _ { i } ^ { 2 } ) ]$$
$$\begin{aligned}
& = \frac { 1 } { 2 } \sinh ( \frac { 2 p T } { m } ) ^ { N / 2 } \exp [ - \frac { 1 } { 2 } ln ( \frac { 1 } { m } ) ] \\
& = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { N } o _ { i , k } o _ { i , k + 1 } | . (46)$$
where σ z i,k = ± 1. On the other hand, the latter 〈 Σ ′ k ∣ ∣ ∣ e -β ˆ H q /m ∣ ∣ ∣ Σ k +1 〉 is calculated as
Then the partition function given by Eq. (43) can be represented as
$$Z = \lim _ { m \rightarrow \infty } A _ { ( r ^{i}, k ^{j}) } \sum _ { i=1}^m exp \left\{ \sum _ { k=1}^n \left( \beta J_{ij} \sigma ^{i,k}\sigma ^{j,k} \right) + \sum _ { m=1}^n \theta ^{i,k} \sigma ^{i,k} \right\}$$
where A is just a parameter which does not affect physical quantities. It should be noted that the partition function of the d -dimensional Ising model with transverse field ˆ H is equivalent to that of the ( d +1)-dimensional Ising model without transverse field H eff which is given by
$$\begin{aligned}
H_{eff} &= - \sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { m } J _ { i , j } o _ { i , k } o _ { j , k } - \\
&= - \frac { 1 } { B } \sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { m } - 1 in coth ( \frac { 3 T } { m } o _ { i , k } o _ { i + 1 , k + 1 } ) \\
&= (48)
\end{aligned}$$
The coefficient of the third term of RHS is always negative, and thus the interaction along the Trotter axis is always ferromagnetic. This ferromagnetic interaction becomes strong as the value of Γ decreases. This is called the Suzuki-Trotter decomposition. 84,85
So far we explained the Monte Carlo method as a tool for obtaining the equilibrium state. However we can also use this method to investigate stochastic dynamics of strongly correlated systems, since the Monte Carlo
method is originally based on the master equation. In terms of optimization problem, our purpose is to obtain the ground state of the given Hamiltonian. Then we decrease transverse field gradually and obtain a solution. There are many Monte Carlo studies in which the quantum annealing succeeds to obtain a better solution than that by the simulated annealing. 5,8-10,12,14,86
## 3.2. Deterministic Method Based on Mean-Field Approximation
In the previous section, we considered the Monte Carlo method in which time-evolution is treated as stochastic dynamics. In this section, on the other hand, we explain a deterministic method based on mean-field approximation according to Refs. [87,88]. Before we consider the quantum annealing based on the mean-field approximation, we treat the Ising model with random interactions and site-dependent longitudinal fields given by
$$H _ { l , i s i n g } = - \sum _ { ( i , j ) } ^ { N } J _ { i j } o ^ { z } i o ^ { z } - \sum _ { ( i = 1 } ^ { N } } h _ { i o ^ { z } }$$
When the transverse field is absent, the molecular field of the i -th spin is given by Eq. (34). Then an equation which determines expectation value of the i -th spin at temperature T (= β -1 ) is given by
$$m ^ { 2 } _ { i } = \frac { e ^ { - B h _ { i } ( e f ) } + e ^ { - B h _ { i } ( c e f ) } } { e ^ { B h _ { i } ( e f ) } + e ^ { B h _ { i } ( c e f ) } } = t a$$
In the mean-field level, we approximate that the state σ z j is equal to the expectation value m z j in Eq. (34), and we obtain
$$m _ { i } = \tanh [ \beta ( \sum _ { j } ^ { i } J _ { i , j } m _ { j } ) ] .$$
which is often called self-consistent equation.
We can obtain equilibrium value in the mean-field level by iterating the following equation until convergence:
$$\sum _ { j } ^ { i } ( t + 1 ) = \tan h ( B _ { H } ^ { i } ( e f ) ( t ) ) .$$
In order to judge the convergence, we introduce a distance which represents difference between the state at t -th step and that at ( t +1)-th step as follows:
$$d ( t ) = - \sum _ { i = 1 } ^ { N } [ m _ { i } ^ { z } ( t + 1 ) -$$
When the quantity d ( t ) is less than a given small value (typically ∼ 10 -8 or more smaller value), we judge that the calculation is converged. We summarize this method:
- Step 1 We prepare a initial state arbitrary.
- Step 2 We choose a spin randomly.
- Step 3 We calculate the molecular field given by Eq. (34) at the chosen site in Step 2.
- Step 4 We change the value of the chosen spin in Step 2 according to the obtained molecular field in Step 3.
- Step 5 We continue from Step 2 to Step 4 until the distance d ( t ) converges to small value.
The differences between the Monte Carlo method and this method are Step 4 and Step 5. We can perform the simulated annealing by decreasing temperature and using the state obtained in Step 5 as the initial state in Step 1 at the time changing temperature c .
Next we explain a quantum version of this method. Here we apply transverse field as a quantum field. We consider the Hamiltonian given by
$$\sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { N } \sum _ { k = 1 } ^ { N } h _ { i , j , k }$$
The density matrix of the equilibrium state is
$$\rho = \frac { e _ { n } ( - \beta ^ { H } ) Tr \exp ( - \beta ^ { H } ) } { \sum _ { n = 1 } ^ { N } e _ { n } ^ { 2 n } \sum _ { n = 1 } ^ { N } e _ { n } ^ { - 2 n } } ,$$
where /epsilon1 n and | λ n 〉 denote the n -th eigenenergy and the corresponding eigenvector. The density matrix satisfies the variational principle that minimizes free energy:
$$F = \min _ { p } \{ T r ( H + \beta ^ { - 1 } l n \hat { p } ) \} ,$$
where the logarithm of the matrix is defined by the series expansion as well as the definition of the matrix exponential (see Eq. (37)). Since it is difficult to obtain the density matrix, we have to consider alternative strategy as follows.
c If we want to decrease temperature rapidly, we choose not so small value for judgement of convergence.
A reduced density matrix is defined as
$$\rho _ { i } = T r ^ { \prime } \rho = \frac { 1 } { 2 } ( i + m _ { z } ^ { 2 } o ^ { 2 } +$$
where Tr ′ indicates trace over spin states except the i -th spin. The values m z i and m x i are calculated by
$$m _ { i } = T ( \sigma ^ { i } _ { j } \phi ) , m _ { i } = T$$
The reduced density matrix satisfies the following relations:
$$Tr ( \sigma ^ { i } \rho _ { j } ) = m _ { i } .$$
Here we assume that the density matrix can be represented by direct products of the reduced density matrices:
$$\rho = \sum _ { i = 1 } ^ { N } p _ { i }$$
which is mean-field approximation (in other words, decoupling approximation). Then, the free energy is expressed as
$$F \leq \min F ( \phi _ { i } ) ,$$
$$\begin{aligned}
F ( \rho _ { i } ) & = - \sum _ { i = 1 } ^ { N } J _ { i , m _ { i } } ^ { n _ { i } } - \sum _ { i = 1 } ^ { N } h _ { i , m _ { i } } ^ { n _ { i } } \\
& + b ^ { - 1 } \sum _ { i = 1 } ^ { N } T _ { r ( \rho _ { i } ) } ln \rho _ { i } .
\end{aligned}$$
From the variation of F ( { ˆ ρ i } ) under the normalization condition, we obtain the following relations:
$$\rho _ { i } = \frac { e x p ( - \beta ^ { 3 } H _ { i } ) } { T _ { r } [ e x p ( - \beta ^ { 3 } H _ { i } ) ] ^ { \prime } }$$
Then the reduced density matrix is represented by using the n -th ( n = 1 , 2) eigenvalues /epsilon1 ( i ) n and the corresponding eigenvectors | λ ( i ) n 〉 of ˆ H i :
$$\hat { h _ { i } } = ( - h _ { i } - \sum _ { j = 1 } ^ { n } J _ { ij } m _ { i j } ) + h _ { i }$$
$$\rho _ { i } = \frac { e p ( - \beta e ^ { i } ) | x _ { i } | + e ^ { i } } { e p ( - \beta e ^ { i } ) + e ^ { i } } .$$
We can also obtain the equilibrium values of physical quantities as well as the case for Γ = 0:
$$n _ { i } ( t + 1 ) = T _ { r } ( \sigma ^ { i } _ { p } ( t ) ) ,$$
$$\dot { \alpha } ( t ) = \frac { e ^ { - \beta H _ { i } ( t ) } } { T _ { r } e ^ { - \beta H _ { i } ( t ) } }$$
We continue the above self-consistent equation until the following distance converges:
$$h _ { i } ( t ) = ( - h _ { i } - \sum _ { j = 1 } ^ { n } J _ { ij } m _ { i j } ( t ) +$$
$$d ( t ) = \frac { 1 } { 2 N } \sum _ { i = 1 } ^ { N } ( | m _ { i } z _ { i } ( t + 1 ) - m _ { i } z _ { i } ( t ) | .$$
If the temperature is zero, the reduced density matrix should be
$$\rho _ { i } = \vert \lambda _ { 1 } ^ { ( 2 ) } \vert \langle \lambda _ { 1 } ^ { ( 2 ) } \vert ,$$
where we consider the case for /epsilon1 ( i ) 1 < /epsilon1 ( i ) 2 . Note that if and only if -h i -∑ ′ j J ij m z j = Γ = 0, /epsilon1 ( i ) 1 = /epsilon1 ( i ) 2 is satisfied. Then if we perform the quantum annealing at T = 0, we have to know only the ground state of the local Hamiltonian ˆ H i . The procedure is the same as the case for finite temperature. By using the method, we can obtain a better solution than that obtained by the simulated annealing for some optimization problems. Recently, other type of implementation method based on mean-field approximation was proposed. 13 The method is a quantum version of the variational Bayes inference. 89 We can also obtain a better solution than the conventional variational Bayes inference.
## 3.3. Real-Time Dynamics
In Sec. 3.1 and Sec. 3.2, we considered artificial time-development rules such as the Markov chain Monte Carlo method and mean-field dynamics. In this section, we explain real-time dynamics which is expressed by the time-dependent Schr¨ odinger equation:
where ˆ H ( t ) and | ψ ( t ) 〉 denote the time-dependent Hamiltonian and the wave function at time t , respectively. The solution of this equation is given
by
If we use the time-dependent Hamiltonian including time-dependent quantum field, we can perform the quantum annealing by decreasing the quantum field gradually. To obtain the solution, it is necessary to decide the initial state for Eq. (72). Since our purpose is to obtain the ground state of the given Hamiltonian which represents the optimization problem, we have no way to know the preferable initial state that leads to the ground state definitely in the adiabatic limit. However, in general, we often use a 'trivial state' as the initial state. Actually, it goes well in many cases. For instance, when we consider the Ising model with time-dependent transverse field which is given by
we set the ground state for large Γ as the initial state, hence the initial state is set as
where |→〉 denotes the eigenstate of ˆ σ x :
In real-time dynamics, in order to obtain the ground state by using given initial condition, it is important whether there is level crossing. If there is no level crossing, the system can necessarily reach the ground state by the quantum annealing in the adiabatic limit. To show this fact, we first consider a single spin system under time-dependent longitudinal magnetic field. The Hamiltonian is given by
Suppose we set | ψ (0) 〉 = |↓〉 as the initial state. For arbitrary sweeping schedules, the state at arbitrary positive t is obtained by
This is because the state |↓〉 is the eigenstate of the instantaneous Hamiltonian for arbitrary time t . In general, when there is a good quantum number
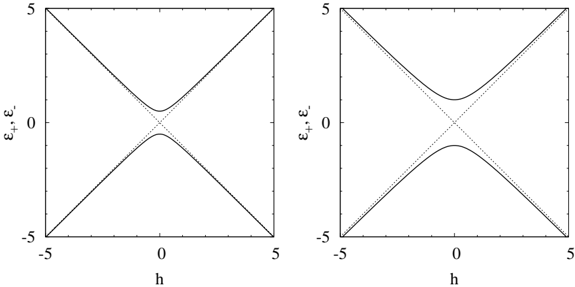
Fig. 2. Eigenenergies of the single spin system under longitudinal and transverse magnetic fields for Γ = 0 . 5 (left panel) and Γ = 1 (right panel). The dotted lines represent eigenenergies for Γ = 0.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Mathematical Plot Pair: Energy Dispersion Relations
### Overview
The image displays two side-by-side, square-format mathematical plots. Each plot shows two curves (one solid, one dashed) on a 2D Cartesian coordinate system. The plots appear to represent energy dispersion relations or eigenvalue solutions as a function of a parameter `h`. The left plot exhibits an "avoided crossing" behavior, while the right plot shows a direct crossing of the two curves.
### Components/Axes
**Common to Both Plots:**
* **Y-axis:** Labeled with the Greek letters `ε₊` (epsilon plus) and `ε₋` (epsilon minus). The axis scale ranges from -5 to 5, with major tick marks at -5, 0, and 5.
* **X-axis:** Labeled with the letter `h`. The axis scale ranges from -5 to 5, with major tick marks at -5, 0, and 5.
* **Data Series:** Each plot contains two data series differentiated by line style:
1. A **solid black line**.
2. A **dashed black line**.
* **Plot Frame:** Each graph is enclosed in a square box with tick marks on all four sides.
**Spatial Layout:**
* The two plots are arranged horizontally, side-by-side.
* The y-axis labels (`ε₊, ε₋`) are positioned to the left of each plot's vertical axis.
* The x-axis label (`h`) is centered below each plot's horizontal axis.
### Detailed Analysis
**Left Plot Analysis:**
* **Trend Verification:** Both curves are symmetric about the vertical line `h=0`. As `|h|` increases (moving left or right from the center), both curves move away from the horizontal axis (`ε=0`) in opposite directions. The solid line trends upward, and the dashed line trends downward.
* **Key Feature:** The curves approach each other near `h=0` but do not intersect. They reach a point of closest approach (a minimum gap) at `h=0`. At this point, the solid line is at a positive `ε` value (approximately `ε ≈ 0.8`), and the dashed line is at a negative `ε` value (approximately `ε ≈ -0.8`).
* **Behavior at Extremes:** At `h = -5` and `h = 5`, the solid line reaches `ε ≈ 5`, and the dashed line reaches `ε ≈ -5`.
**Right Plot Analysis:**
* **Trend Verification:** Both curves are also symmetric about `h=0`. As `|h|` increases, both curves move away from `ε=0` in opposite directions, similar to the left plot.
* **Key Feature:** The two curves intersect directly at the origin point `(h=0, ε=0)`. This is a crossing point, not an avoided crossing.
* **Behavior at Extremes:** At `h = -5` and `h = 5`, the solid line reaches `ε ≈ 5`, and the dashed line reaches `ε ≈ -5`, identical to the left plot.
### Key Observations
1. **Symmetry:** Both plots exhibit perfect symmetry about the `h=0` axis.
2. **Line Style Consistency:** The solid line represents the upper branch (positive `ε`) for `h>0` and the lower branch (negative `ε`) for `h<0` in both plots. The dashed line does the opposite.
3. **Critical Difference:** The fundamental distinction between the two plots is the behavior at `h=0`. The left plot shows a **finite energy gap** (avoided crossing), while the right plot shows a **zero energy gap** (crossing).
4. **Identical Asymptotes:** Far from `h=0` (at `|h| = 5`), the numerical values of the curves are identical in both plots, suggesting the same underlying linear relationship dominates at large `|h|`.
### Interpretation
These plots are characteristic of a two-level quantum system or a coupled oscillator model, where `ε` represents energy or frequency and `h` represents a tuning parameter like a magnetic field or detuning.
* **Left Plot (Avoided Crossing):** This demonstrates the effect of a **coupling** or interaction between the two states. The interaction prevents the energy levels from crossing, creating a minimum gap at the resonance point (`h=0`). This is a signature of hybridization, where the original states mix to form new eigenstates with separated energies. The size of the gap at `h=0` is proportional to the coupling strength.
* **Right Plot (Crossing):** This represents the **uncoupled** or degenerate case. The two states are independent, and their energies cross linearly as the parameter `h` is varied. There is no interaction to lift the degeneracy at the crossing point.
* **Relationship:** The pair of plots likely illustrates a comparison between a system with interaction (left) and without interaction (right). The identical behavior at large `|h|` indicates that the coupling is a local effect near resonance (`h=0`), while the far-detuned behavior is governed by the bare, uncoupled energies.
* **Underlying Model:** The linear dependence of `ε` on `h` at large `|h|` suggests a Hamiltonian of the form `H ~ hσ_z` (where `σ_z` is a Pauli matrix), with an additional coupling term `~ σ_x` present only in the left plot. The avoided crossing gap is `2 * |coupling strength|`.
</details>
and the initial state is set to be the corresponding eigenstate, the good quantum number is conserved. Then when we perform the quantum annealing method based on the real-time dynamics, we should take care of the symmetries of the considered Hamiltonian. From this, we can obtain the ground state of the considered system in the adiabatic limit if there is no level crossing. In practice, however, since we change magnetic field with finite speed, a nonadiabatic transition is inevitable. To show this fact, we consider a single spin system under longitudinal and transverse magnetic fields. The Hamiltonian of this system is given by
Since the eigenenergies are /epsilon1 ± = ± √ h 2 +Γ 2 , the smallest value of the energy difference between the ground state and the excited state is 2Γ at h = 0 as shown in Fig. 2.
Suppose we consider the single spin system under time-dependent longitudinal magnetic field and fixed transverse magnetic field. The Hamiltonian is given by
where we adopt h ( t ) = vt as time-dependent longitudinal field. Here we set t = -∞ as the initial time. The initial state is set to be the ground
state of the Hamiltonian at the initial time | ψ ( t = -∞ ) 〉 = |↓〉 . The ground state at t = + ∞ in the adiabatic limit is | ψ (ad) ( t = + ∞ ) 〉 = |↑〉 . Then a characteristic value which represents the nature of this dynamics is a probability of staying in the ground state at t = + ∞ which is defined by
∣ ∣ The probability of staying in the ground state should depend on the sweeping speed v and the characteristic energy gap and can be obtained by the Landau-Zener-St¨ uckelberg formula: 90-92
where ∆ E and ∆ m represent the energy gap at the avoided level-crossing point and the difference of the magnetizations in the adiabatic limit, respectively. In this case ∆ E = 2Γ and ∆ m = 2.
In many cases, typical shape of energy structure can be approximated by simple systems such as the single spin system. Then the knowledge of the simple transitions such as the Landau-Zener-St¨ ukelberg transition and the Rosen-Zener transition 93 is useful to analyze the efficiency of the quantum annealing based on the real-time dynamics.
## 3.4. Experiments
Transverse field response of the Ising model has been also established in experimentally. 94-103 A dipolar-coupled disordered magnet LiHo x Y 1 -x F 4 has easy-axis anisotropy and can be represented by the Ising model. 104,105 If we apply the longitudinal magnetic field (in other words, the magnetic field is parallel to the easy-axis), phase transition does not take place. 106,107 However, when we apply the transverse magnetic field (in other words, the magnetic field is perpendicular to the easy-axis), phase transitions occur and interesting dynamical properties shown in Ref.[ 6] were observed. In the phase diagram of this material, there are three phases. The ferromagnetic phase appears at intermediate temperature and low transverse magnetic field, whereas at low temperature and low transverse magnetic field, the glassy critical phase 108 appears. The paramagnetic phase exists at the other region. The glassy critical phase exhibits slow relaxation in general. It found that the characteristic relaxation time obtained by ac field susceptibility for
quantum cooling in which we decrease transverse field after temperature is decreased is lower than that for temperature cooling case. 6 From this result, it has been expected that the effect of the quantum fluctuation helps us to obtain the best solution of the optimization problem.
## 4. Optimization Problems
Optimization problems are defined by composition elements of the considered problem and real-valued cost/gain function. They are problems to obtain the best solution such that the cost/gain function takes the minimum/maximum value. In general, the number of candidate solutions increases exponentially with the number of composition elements in optimization problems. Although we can obtain the best solution by a brute force in principle, it is difficult to obtain the best solution by such a naive method in practice. Then we have to invent an innovative method for obtaining the best solution in a practical time and limited computational resource. Optimization problems can be expressed by the Ising model in many cases. Once optimization problems are mapped onto the Ising model, we can use methods that have been considered in statistical physics and computational physics such as the quantum annealing.
In the anterior half of this section, we explain the correspondence between the Ising model and the traveling salesman problem which is one of famous optimization problems. We demonstrate the quantum annealing based on the quantum Monte Carlo simulation for this problem. In the posterior half, we explain the clustering problem as the example expressed by the Potts model which is a straightforward extension of the Ising model.
## 4.1. Traveling Salesman Problem
In this section, we consider the traveling salesman problem which is one of famous optimization problems. The setup of the traveling salesman problem is as follows:
- There are N cities.
- We move from the i -th city to the j -th city where the distance between them is /lscript i,j .
- We can pass through a city only once.
- We return the initial city after we pass through all the cities.
The traveling salesman problem is to find the minimum path under above conditions. The length of a path is given by
where c a denotes the city where we pass through at the a -th step. In the traveling salesman problem, the length of a path is a cost function. From the fourth condition, the following relation should be satisfied:
In terms of mathematics, the traveling salesman problem is to find { c a } N a =1 so as to minimize the path L under the above four conditions.
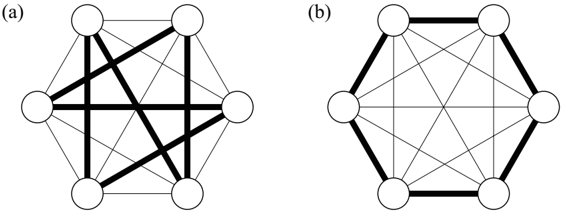
If the number of cities N is small, it is easy to obtain the shortest path by a brute force. We can easily find the best solution of the traveling salesman problem for N = 6 shown in Fig. 3. Figure 3 (a) and (b) represent a bad solution and the best solution where the length of the path L is minimum, respectively. As the number of cities increases, the traveling salesman problem becomes seriously difficult since the number of candidate solutions is ( N -1)! / 2. Then if we want to deal with the traveling salesman problem with large N , we have to adopt smart and easy practical methods such as the simulated annealing instead of a brute force. To use the simulated annealing, we map the traveling salesman problem onto the Ising model with a couple of constraints as follows.
We consider N × N two-dimensional lattice. Let n i,a be the microscopic state which represents the state at the i -th city at the a -th step. The value of n i,a can be taken either 0 or 1. If we pass through the i -th city at the
Fig. 3. Traveling salesman problem for N = 6. Thin lines and thick lines denote the permitted paths and selected paths, respectively. (a) Bad solution. (b) The best solution in which the length of the path is minimum.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Network Diagram: Hexagonal Node Connectivity Patterns
### Overview
The image displays two side-by-side network diagrams, labeled (a) and (b), each depicting a hexagonal arrangement of six nodes (represented as white circles) connected by lines of two distinct thicknesses. The diagrams illustrate different patterns of connectivity within the same set of nodes.
### Components/Axes
* **Nodes:** Six identical white circles arranged at the vertices of a regular hexagon in both diagrams.
* **Connections (Edges):** Lines connecting the nodes. Two visual types are present:
* **Thick Black Lines:** Indicate a primary or emphasized connection.
* **Thin Gray Lines:** Indicate a secondary or background connection.
* **Labels:**
* `(a)`: Positioned in the top-left corner, labeling the left diagram.
* `(b)`: Positioned in the top-left corner, labeling the right diagram.
* **Legend:** No explicit legend is present. The distinction between thick and thin lines is implied visually.
### Detailed Analysis
The analysis isolates each diagram and describes the connections based on node position. For spatial reference, nodes are described as: Top-Left (TL), Top-Right (TR), Right (R), Bottom-Right (BR), Bottom-Left (BL), Left (L).
**Diagram (a):**
* **Thick Line Connections (6 total):**
* TL to R
* TL to BR
* TR to BL
* TR to L
* R to BL
* L to BR
* **Thin Line Connections:** All other possible connections between nodes not listed above (forming a complete graph, K₆, when combined with thick lines).
* **Visual Pattern:** The thick lines form a complex, intersecting web that connects each node to two non-adjacent nodes, creating a star-like pattern within the hexagon. No two thick lines share a common endpoint on the hexagon's perimeter.
**Diagram (b):**
* **Thick Line Connections (6 total):**
* TL to TR
* TR to R
* R to BR
* BR to BL
* BL to L
* L to TL
* **Thin Line Connections:** All other possible connections between nodes not listed above (again, forming a complete graph, K₆, when combined with thick lines).
* **Visual Pattern:** The thick lines exclusively connect adjacent nodes, perfectly outlining the perimeter of the hexagon. All internal, non-adjacent connections are thin.
### Key Observations
1. **Identical Node Set:** Both diagrams use the exact same six-node hexagonal layout.
2. **Complete Underlying Graph:** In both (a) and (b), every node is connected to every other node by either a thick or thin line. The diagrams do not show missing connections; they only vary the *emphasis* (line thickness) on specific subsets of edges.
3. **Contrasting Emphasis Patterns:**
* Diagram (a) emphasizes a set of **non-adjacent, cross-hexagon connections**.
* Diagram (b) emphasizes the set of **adjacent, perimeter connections**.
4. **Symmetry:** Both patterns exhibit rotational symmetry. Rotating either diagram by 60 degrees would result in an identical visual pattern.
### Interpretation
These diagrams are abstract representations likely used to illustrate concepts in **graph theory, network science, or combinatorial design**. They demonstrate how the same set of elements (nodes) can have different structural properties based on which relationships (edges) are prioritized.
* **Diagram (a)** represents a network where long-range, cross-cluster connections are highlighted. This could model a system where communication or interaction bypasses immediate neighbors, potentially indicating a **small-world network** property or a specific **matching** within the graph.
* **Diagram (b)** represents a network where local, nearest-neighbor connections are highlighted. This models a system with strong **local clustering** or a **ring lattice** topology, where interactions are primarily with adjacent units.
* **The Juxtaposition:** Placing them side-by-side invites comparison. It visually argues that network function and resilience depend critically on *which* connections are active or strong, not just on the existence of connections. The thick lines in (a) might represent shortcuts that reduce path length, while the thick lines in (b) represent the robust local backbone. The thin lines in both indicate that all other potential pathways exist but are weaker or latent.
**Language Declaration:** The only text present consists of the English labels "(a)" and "(b)". No other language is detected.
</details>
a -th step, n i,a is unity whereas n i,a = 0 if we do not pass through the i -th city at the a -th step. The third condition can be represented by
Furthermore, since it is obvious that we can pass through only one city at the a -th step, this constraint is expressed by
Then the length of the path L can be rewritten as
where the Ising spin variable σ z i,a = ± 1 is defined by
Here we used the following relation derived by Eqs. (84) and (85):
Then the length of the path can be represented by the Ising spin Hamiltonian on N × N two-dimensional lattice. In general, it is difficult to obtain the stable state of the Ising model with some constraints regarded as some kind of frustration which will be shown in Sec. 5.2.
## 4.1.1. Monte Carlo Method
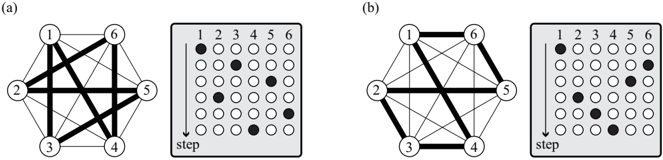
We explain how to implement the Monte Carlo method in the traveling salesman problem. We cannot use the single-spin-flip method which was explained in Sec. 3.1 because of existence of two constraints given by Eqs. (84) and (85). The simplest way of transition between states is realized by flipping four spins simultaneously as shown in Fig. 4.
Suppose we consider the case that we pass through at the i -th city at the a -th step and pass through at the j -th city at the a ′ -th step, which is described as
Fig. 4. The simplest way of flipping method in traveling salesman problem. Transition between the state depicted in (a) and that depicted in (b) occurs. In this case, i = 3, j = 6, a = 2, and a ′ = 5.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## [Diagram/Graph Pair]: Network Graphs and Adjacency Matrices
### Overview
The image displays two side-by-side panels, labeled (a) and (b). Each panel contains a pair of related diagrams: a **network graph** on the left and a corresponding **adjacency matrix** (or step matrix) on the right. The diagrams appear to represent connectivity or relationships between six numbered nodes (1 through 6) in two different states or configurations.
### Components/Axes
**Panel (a):**
* **Left - Network Graph:**
* **Nodes:** Six circles numbered 1, 2, 3, 4, 5, 6 arranged in a hexagonal pattern.
* **Edges:** Lines connecting the nodes. The lines have two distinct thicknesses: **thick** and **thin**.
* **Spatial Layout:** Node 1 is at the top. Nodes 2 and 6 are at the upper left and right. Nodes 3 and 5 are at the lower left and right. Node 4 is at the bottom.
* **Right - Adjacency Matrix:**
* **Structure:** A 6x6 grid of circles.
* **Axes Labels:**
* **Top (Columns):** Numbers 1, 2, 3, 4, 5, 6.
* **Left (Rows):** The word "step" written vertically, with an arrow pointing downward. This implies the rows represent sequential steps or time.
* **Data Points:** Circles within the grid are either **filled (black)** or **empty (white outline)**. A filled circle indicates an active connection or relationship between the column node and the row step.
**Panel (b):**
* **Left - Network Graph:**
* **Nodes:** Same hexagonal arrangement of nodes 1-6.
* **Edges:** Lines connecting nodes, again with **thick** and **thin** lines. The pattern of thick lines is different from panel (a).
* **Right - Adjacency Matrix:**
* **Structure:** Identical 6x6 grid layout as in (a).
* **Axes Labels:** Identical to (a): Column numbers 1-6, and a vertical "step" label with a downward arrow on the left.
* **Data Points:** A different pattern of filled (black) and empty (white) circles compared to panel (a).
### Detailed Analysis
**Panel (a) Analysis:**
* **Graph Connectivity (Thick Lines):** The thick edges form a specific subgraph. They connect:
* Node 1 to Node 3
* Node 1 to Node 4
* Node 1 to Node 5
* Node 2 to Node 4
* Node 2 to Node 5
* Node 3 to Node 6
* Node 4 to Node 6
* Node 5 to Node 6
* **Matrix Data (Filled Circles):** The filled circles in the matrix correspond to the following (Row "step" / Column Node):
* Step 1: Node 1
* Step 2: Node 3
* Step 3: Node 2
* Step 4: Node 5
* Step 5: Node 4
* Step 6: Node 6
* **Mapping:** The matrix does not directly show the graph's adjacency. Instead, it seems to show a **sequence or activation order** of the nodes over 6 steps. The pattern of filled circles is a single filled circle per row, moving down the steps.
**Panel (b) Analysis:**
* **Graph Connectivity (Thick Lines):** The thick edges form a different subgraph. They connect:
* Node 1 to Node 6
* Node 2 to Node 5
* Node 3 to Node 4
* Node 3 to Node 6
* Node 4 to Node 5
* **Matrix Data (Filled Circles):** The filled circles show a different pattern:
* Step 1: Node 1
* Step 2: Node 2
* Step 3: Node 3
* Step 4: Node 4
* Step 5: Node 5
* Step 6: Node 6
* **Mapping:** Similar to (a), this matrix shows a node activation sequence. The sequence here is a simple diagonal: Node 1 at step 1, Node 2 at step 2, etc., through Node 6 at step 6.
### Key Observations
1. **Different Graph Topologies:** The two graphs have distinct sets of "thick" edges, indicating two different network structures or states.
2. **Different Activation Sequences:** The matrices show two different temporal patterns. Panel (a) shows a non-sequential, seemingly random order of node activation (1, 3, 2, 5, 4, 6). Panel (b) shows a perfectly sequential order (1, 2, 3, 4, 5, 6).
3. **Matrix Interpretation:** The matrices are not standard adjacency matrices (which would show all connections at once). The "step" axis and single filled circle per row strongly suggest they represent a **time series** or **process flow** where one node is active or selected at each discrete step.
4. **Potential Relationship:** The thick edges in the graph might represent the **available or strong connections** at the start, while the matrix shows the **actual path or activation sequence** taken through the network over time.
### Interpretation
This figure likely illustrates a concept in **network science, graph theory, or dynamic systems**. It contrasts two scenarios:
* **Scenario (a):** A network with a complex, highly interconnected structure (many thick edges) is traversed in a non-intuitive, non-sequential order. The path (1→3→2→5→4→6) jumps across the network, possibly following a rule like "activate the node with the strongest connection to the currently active node" or representing a stochastic process.
* **Scenario (b):** A network with a simpler, more linear or ring-like structure of thick edges (1-6, 2-5, 3-4, plus 3-6 and 4-5) is traversed in a perfectly sequential order (1→2→3→4→5→6). This suggests a more predictable, perhaps rule-based or spatially-ordered process.
The core message is the relationship between **network structure** (the graph) and **dynamic behavior** (the sequence in the matrix). The same set of nodes can exhibit vastly different temporal patterns depending on the underlying connectivity. The thick lines may represent "highways" or preferred pathways that constrain or guide the sequential activation shown in the matrices. The figure demonstrates how structural properties of a network influence its functional dynamics over time.
</details>
The trial state generated by flipping four spins is as follows:
The heat-bath method and the Metropolis method can be adopted for the transition probability between the present state and the trial state. In Fig. 4, i = 3, j = 6, a = 2, and a ′ = 5.
It should be noted that without loss of generality the initial condition can be set as
/negationslash and thus we can fix the states at the first step ( a = 1) during calculation. The number of interactions in which we try to flip all spins in each Monte Carlo step is ( N -1)( N -2) / 2.
## 4.1.2. Quantum Annealing
In order to perform the quantum annealing, we introduce the transverse field as the quantum fluctuation effect as shown in Sec. 3. The quantum Hamiltonian is given by
where the first-term corresponds to the length of path and the second-term denotes the transverse field. We can map this quantum Hamiltonian on N × N two-dimensional lattice onto N × N × m three-dimensional Ising model as well as the case which was considered in Sec. 3.1. The effective classical
Hamiltonian derived by the Suzuki-Trotter decomposition is written as
In the quantum annealing procedure, we have to take care of the constraints given by Eqs. (84) and (85) as stated before. Then the simplest way of changing state is to flip simultaneously four spins on the same layer ( m is fixed) along the Trotter axis.
## 4.1.3. Comparison with Simulated Annealing and Quantum Annealing
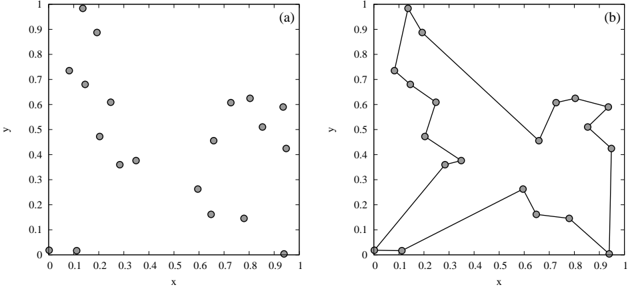
In order to demonstrate the comparison with the simulated annealing and the quantum annealing, we perform the Monte Carlo simulation for the traveling salesman problem. As an example, we consider N = 20 cities depicted in Fig. 5 (a). The positions of these cities were generated by pair of uniform random numbers (0 ≤ x i , y i ≤ 1). The time schedules of temperature T ( t ) for the simulated annealing and transverse field Γ( t ) for the
Fig. 5. Traveling salesman problem for N = 20. (a) Positions of cities. (b) The best solution in which the length of the path is minimum.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Scatter Plot Comparison: Unstructured vs. Structured Data
### Overview
The image displays two side-by-side scatter plots, labeled (a) and (b), sharing identical axes. Plot (a) shows a set of discrete, unconnected data points. Plot (b) shows the same set of points, but with a subset of them connected by straight lines, forming a continuous, non-intersecting path or tour. The image appears to be a figure from a technical or scientific document, likely illustrating a concept in data analysis, optimization (e.g., Traveling Salesman Problem), or graph theory.
### Components/Axes
* **Chart Type:** Two-panel scatter plot with an overlay of connecting lines in panel (b).
* **Panel Labels:** "(a)" in the top-right corner of the left plot; "(b)" in the top-right corner of the right plot.
* **Axes (Both Panels):**
* **X-axis:** Labeled "x". Scale ranges from 0 to 1. Major tick marks and labels at 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.
* **Y-axis:** Labeled "y". Scale ranges from 0 to 1. Major tick marks and labels at 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.
* **Data Points:** Represented by gray-filled circles with black outlines. The same set of points appears in both panels.
* **Legend:** None present.
* **Spatial Layout:** The two plots are arranged horizontally. Plot (a) occupies the left half, Plot (b) the right half. The axes frames are identical in size and position within their respective halves.
### Detailed Analysis
**Panel (a): Unconnected Scatter Points**
* **Trend:** No inherent order or connection is shown. The points appear to be distributed in a somewhat clustered but irregular pattern across the unit square.
* **Data Point Extraction (Approximate Coordinates):**
* (0.00, 0.00)
* (0.10, 0.00)
* (0.10, 0.73)
* (0.15, 1.00)
* (0.18, 0.68)
* (0.20, 0.47)
* (0.25, 0.61)
* (0.30, 0.36)
* (0.35, 0.38)
* (0.60, 0.26)
* (0.62, 0.45)
* (0.65, 0.16)
* (0.75, 0.14)
* (0.75, 0.61)
* (0.80, 0.62)
* (0.85, 0.51)
* (0.90, 0.59)
* (0.95, 0.42)
* (0.95, 0.00)
**Panel (b): Connected Path**
* **Trend:** A single, continuous path is drawn connecting 18 of the 19 points from panel (a). The path does not intersect itself. It starts at (0.00, 0.00), traverses the points in a specific order, and ends at (0.95, 0.00). The point at (0.10, 0.00) is **not** included in the path.
* **Path Sequence (Approximate Order):** The visual path suggests the following connection order:
1. (0.00, 0.00) → (0.10, 0.73)
2. (0.10, 0.73) → (0.15, 1.00)
3. (0.15, 1.00) → (0.18, 0.68)
4. (0.18, 0.68) → (0.25, 0.61)
5. (0.25, 0.61) → (0.20, 0.47)
6. (0.20, 0.47) → (0.30, 0.36)
7. (0.30, 0.36) → (0.35, 0.38)
8. (0.35, 0.38) → (0.62, 0.45)
9. (0.62, 0.45) → (0.60, 0.26)
10. (0.60, 0.26) → (0.65, 0.16)
11. (0.65, 0.16) → (0.75, 0.14)
12. (0.75, 0.14) → (0.95, 0.00)
13. (0.95, 0.00) → (0.95, 0.42)
14. (0.95, 0.42) → (0.90, 0.59)
15. (0.90, 0.59) → (0.85, 0.51)
16. (0.85, 0.51) → (0.80, 0.62)
17. (0.80, 0.62) → (0.75, 0.61)
18. (0.75, 0.61) → (0.10, 0.73) *[This closes a loop back to the second point, but the path continues from here to the start? Re-examination shows the path from (0.75, 0.61) connects to (0.10, 0.73), and the initial segment from (0.00, 0.00) to (0.10, 0.73) is part of the same continuous line. The path is a single open tour, not a closed loop.]*
### Key Observations
1. **Point Consistency:** All points in plot (b) correspond exactly in position to points in plot (a).
2. **Excluded Point:** The point at (0.10, 0.00) in plot (a) is the only one not incorporated into the path in plot (b).
3. **Path Characteristics:** The path in (b) is a Hamiltonian path (visits each selected point exactly once) but not a cycle. It is non-self-intersecting. The longest straight-line segment connects (0.75, 0.14) to (0.95, 0.00).
4. **Spatial Distribution:** The points are not uniformly random; there are clusters in the top-left quadrant and the right-center region, with a notable gap in the center of the plot.
### Interpretation
This figure visually demonstrates the transformation of unstructured spatial data into a structured sequence. Panel (a) presents raw data—locations without relationship. Panel (b) imposes a specific order, creating a narrative or a solution.
* **What it Suggests:** The most likely interpretation is an illustration of a **path-finding or optimization algorithm**. It could represent:
* A solution (or a step) to a **Traveling Salesman Problem (TSP)**, where the goal is to find the shortest possible route visiting all points. The path shown is likely not the optimal solution but a feasible one.
* A **minimum spanning tree** or a similar graph structure, though the path is a single line, not a branching tree.
* The output of a **clustering or ordering algorithm** that sequences data points based on proximity.
* **Relationship Between Elements:** The core relationship is between the set of points (the problem space) and the connecting lines (the solution or structure). The axes provide the coordinate system that defines the "distance" between points, which is fundamental to any such algorithm.
* **Notable Anomalies:** The exclusion of the point at (0.10, 0.00) is significant. It implies that either the algorithm in (b) was not required to visit all points, or that point was considered an outlier and deliberately omitted from the structured set. The path's specific order, which creates a long "return" segment from the right side back to the top-left cluster, may indicate a non-greedy or globally optimized approach rather than a simple nearest-neighbor heuristic.
**In essence, the image contrasts chaos (a) with imposed order (b), serving as a pedagogical tool to show how algorithms can derive structure from scattered information.**
</details>
quantum annealing are defined as
where T 0 and Γ 0 are temperature and transverse field at the final time ( t = τ ), and T 0 + T 1 and Γ 0 +Γ 1 are temperature and transverse field at the initial time ( t = 0). The value of τ -1 indicates the annealing speed, and the annealing speed becomes slow as the value of τ increases. In our simulations, we adopt T 0 = Γ 0 = 0 . 01 and T 1 = Γ 1 = 5. Furthermore, we fix the transverse field as Γ = 0 during the simulation in the simulated annealing and the temperature as T = 0 . 01 during the simulation in the quantum annealing.
We execute 100 independent simulations of simulated annealing based on the heat-bath type Monte Carlo method where each initial state generated by the uniform random number is different. To compare the efficiency of the simulated annealing and quantum annealing in an equitable manner, in the quantum annealing, the Trotter number is putted as m = 10, and we execute 10 independent simulations. We also calculate the minimum length of path L min ( t ) := min { L ( t ′ ) | 0 ≤ t ′ ≤ t } . It should be noted that L min ( t ) is a monotonic decreasing function. The upper panel of Fig. 6 shows the time dependence of minimum length of path L min ( t ) for various τ . From the upper panel of Fig. 6, we can see that the convergence of minimum length of path in the quantum annealing is faster than that in the simulated annealing. We also show the sweeping time τ dependence of the minimum length of path at the final state L min ( τ ) in the lower panel of Fig. 6. This figure indicates that the obtained solution in the quantum annealing is always better than that in the simulated annealing. Figure 5 (b) shows the obtained best solution in both the simulated annealing and the quantum annealing with slow schedule.
In this way, we can obtain a better solution (in this case, the best solution) by both annealing methods with slow schedule. Moreover, in our calculation, the convergence of solution in the quantum annealing is faster than that in the simulated annealing, and the obtained solution in the quantum annealing is better than that in the simulated annealing regardless of sweeping time τ . Thus, we can say that the quantum annealing method is appropriate as the annealing method for the traveling salesman problem in comparison with the simulated annealing. This fact has been confirmed in some researches. 86,109
Fig. 6. (Upper panel) Time dependence of minimum length of path L min ( t ) for τ = 10, 100, and 1000 obtained by the simulated annealing (SA) and the quantum annealing (QA). (Lower panel) Sweeping-time τ dependence of minimum length of path at the final state L min ( τ ) obtained by the simulated annealing indicated by squares and the quantum annealing indicated by circles.
<details>
<summary>Image 6 Details</summary>
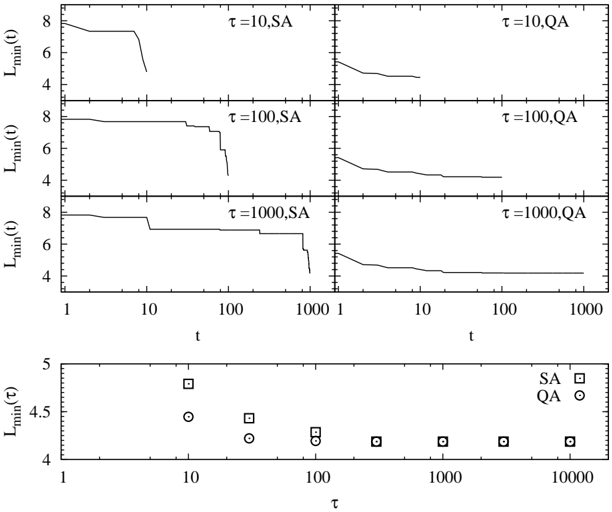
### Visual Description
## Line Graphs and Scatter Plot: Comparison of SA and QA Optimization Methods
### Overview
The image is a technical figure containing seven plots that compare the performance of two methods, labeled **SA** and **QA**, across different parameter values. The top section consists of six line graphs arranged in a 3x2 grid, showing the time evolution of a minimum value metric, \( L_{\text{min}}(t) \), for three distinct values of a parameter \( \tau \). The bottom section is a single scatter plot summarizing the final minimum value, \( L_{\text{min}}(\tau) \), as a function of \( \tau \) for both methods. The overall purpose is to analyze and contrast the convergence behavior and final solution quality of the two methods.
### Components/Axes
**Top Section (Six Line Graphs):**
* **Layout:** 3 rows × 2 columns.
* **Y-axis (All plots):** Label is **\( L_{\text{min}}(t) \)**. Scale is linear, with major tick marks at 4, 6, and 8.
* **X-axis (All plots):** Label is **\( t \)** (time or iteration). Scale is logarithmic, with major tick marks at 1, 10, 100, and 1000.
* **Panel Labels (Top-right corner of each subplot):**
* Top-Left: **\( \tau=10, SA \)**
* Top-Right: **\( \tau=10, QA \)**
* Middle-Left: **\( \tau=100, SA \)**
* Middle-Right: **\( \tau=100, QA \)**
* Bottom-Left: **\( \tau=1000, SA \)**
* Bottom-Right: **\( \tau=1000, QA \)**
* **Data Series:** Each plot contains a single black line representing the trajectory of \( L_{\text{min}}(t) \) for the specified method and \( \tau \).
**Bottom Section (Scatter Plot):**
* **Y-axis:** Label is **\( L_{\text{min}}(\tau) \)**. Scale is linear, with major tick marks at 4, 4.5, and 5.
* **X-axis:** Label is **\( \tau \)**. Scale is logarithmic, with major tick marks at 1, 10, 100, 1000, and 10000.
* **Legend (Top-right corner):**
* **SA** is represented by a **square (□)** symbol.
* **QA** is represented by a **circle (○)** symbol.
* **Data Points:** Discrete symbols plotted at specific \( \tau \) values (10, 100, 1000, 10000, and possibly 100000, though the axis ends at 10000).
### Detailed Analysis
**Top Line Graphs - SA Method (Left Column):**
* **Trend:** The lines exhibit a **stepwise, descending pattern**. They remain flat for periods before making abrupt, near-vertical drops.
* **\( \tau=10, SA \):** Starts near \( L_{\text{min}} \approx 8 \). Shows a sharp drop just before \( t=10 \), ending at \( L_{\text{min}} \approx 5 \) at \( t \approx 10 \). The line terminates early.
* **\( \tau=100, SA \):** Starts near 8. Shows a small drop around \( t=10 \), a plateau, then a major drop between \( t=100 \) and \( t=200 \), ending near \( L_{\text{min}} \approx 4.5 \) at \( t=1000 \).
* **\( \tau=1000, SA \):** Starts near 8. Shows a drop around \( t=10 \), a long plateau, another drop near \( t=500 \), and a final drop near \( t=1000 \), ending near \( L_{\text{min}} \approx 4.2 \).
**Top Line Graphs - QA Method (Right Column):**
* **Trend:** The lines show a **smoother, more continuous decay**. The descent is more gradual compared to SA.
* **\( \tau=10, QA \):** Starts lower than SA, around \( L_{\text{min}} \approx 5.5 \). Decays smoothly, flattening out near \( L_{\text{min}} \approx 4.5 \) by \( t=100 \).
* **\( \tau=100, QA \):** Starts around 5.5. Decays smoothly and steadily, approaching \( L_{\text{min}} \approx 4.2 \) by \( t=1000 \).
* **\( \tau=1000, QA \):** Starts around 5.5. Shows a very smooth, asymptotic decay, approaching \( L_{\text{min}} \approx 4.1 \) by \( t=1000 \).
**Bottom Scatter Plot - \( L_{\text{min}}(\tau) \):**
* **SA (Squares):** At \( \tau=10 \), \( L_{\text{min}} \approx 4.8 \). At \( \tau=100 \), \( L_{\text{min}} \approx 4.4 \). At \( \tau=1000 \), \( L_{\text{min}} \approx 4.2 \). At \( \tau=10000 \), \( L_{\text{min}} \approx 4.15 \). The value decreases with increasing \( \tau \).
* **QA (Circles):** At \( \tau=10 \), \( L_{\text{min}} \approx 4.45 \). At \( \tau=100 \), \( L_{\text{min}} \approx 4.25 \). At \( \tau=1000 \), \( L_{\text{min}} \approx 4.15 \). At \( \tau=10000 \), \( L_{\text{min}} \approx 4.15 \). The value also decreases with \( \tau \) but starts lower than SA and appears to converge to a similar floor.
### Key Observations
1. **Convergence Behavior:** SA converges via discrete, large improvements (steps), while QA converges via a continuous, smooth process.
2. **Initial Performance:** For a given \( \tau \), QA consistently starts at a lower (better) \( L_{\text{min}}(t) \) value than SA at early times (\( t \approx 1 \)).
3. **Final Performance:** Both methods approach similar final \( L_{\text{min}} \) values for large \( t \) and large \( \tau \), though QA may achieve slightly lower values marginally faster.
4. **Parameter \( \tau \) Effect:** Increasing \( \tau \) allows both methods to reach lower final \( L_{\text{min}} \) values. For SA, larger \( \tau \) delays the major drops but leads to a lower final value. For QA, larger \( \tau \) results in a smoother and slightly lower asymptotic curve.
5. **Data Density:** The scatter plot shows data points at \( \tau = 10, 100, 1000, 10000 \). The points for both methods converge closely at \( \tau=1000 \) and \( \tau=10000 \).
### Interpretation
This figure likely compares two optimization algorithms—**SA** (commonly Simulated Annealing) and **QA** (commonly Quantum Annealing)—on a minimization problem where \( L_{\text{min}} \) is the cost or energy to be minimized.
* **What the data suggests:** The stepwise descent of SA is characteristic of a stochastic process that occasionally finds significantly better solutions after periods of stagnation. The smooth decay of QA suggests a more deterministic or guided optimization path. QA's advantage in early-time performance implies it finds good solutions faster initially.
* **Relationship between elements:** The top plots show the *process* of optimization over time for fixed \( \tau \), while the bottom plot summarizes the *outcome* (final solution quality) as a function of the control parameter \( \tau \). The parameter \( \tau \) could represent a time scale, a temperature schedule, or a problem difficulty parameter.
* **Notable trends/anomalies:** The most striking trend is the fundamental difference in convergence dynamics (stepwise vs. smooth). The convergence of both methods to similar final values at high \( \tau \) suggests that given sufficient resources (time or parameter tuning), both can find comparable solutions, but their paths and efficiency differ. The early termination of the \( \tau=10, SA \) plot might indicate the algorithm got stuck or the run was shorter.
</details>
## 4.2. Clustering Problem
In Sec. 4.1, we explained the traveling salesman problem which can be mapped onto the Ising model with some constraints. Many optimization problems can also be mapped onto the Ising model. However, there are a number of optimization problems that can be described by the other models which are straightforward extensions of the Ising model. In this section, we review the concept of clustering problem as such an example.
Clustering problem is also one of important optimization problems in information science and engineering. 12-14 We need to categorize much data in the real world according to its contents in various situations. For instance, suppose we play stock market. In order to see the socioeconomic situation, we want to extract efficiently important information related to
stock market from an enormous quantity of information in news sites and newspapers. In this case, it is better to categorize many articles in news sites and newspapers according to their contents. This is an example of clustering problem which is adopted for many applications in wide area of science such as cognitive science, social science, and psychology. The clustering problem is to divide the whole set into a couple of subsets. Here we refer to the subsets as 'cluster'.
Figure 7 shows schematic picture of the clustering problem. Suppose we consider much data in the whole set which represents the square frame in Fig. 7 (a). The points in Fig. 7 denote individual data. In the clustering problem, our target is to find which the best division is. Figure 7 (b), (c), and (d) represent typical clustering states Σ 1 , Σ 2 , and Σ ∗ , respectively. The states Σ 1 and Σ 2 are an unstable solution and a metastable solution, respectively. The state Σ ∗ denotes the best solution of clustering problem.
In order to consider how to implement the quantum annealing, the clustering problem can be described by the Potts model with random interac-
Fig. 7. Schematic pictures of clustering problem. The points represent data and the square denote the whole set. (a) Data set. (b) Unstable solution Σ 1 . (c) Metastable solution Σ 2 . (d) The best solution Σ ∗ .
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Diagram: Dot Clustering and Grouping Variations
### Overview
The image displays four rectangular panels, labeled (a) through (d), each containing an identical arrangement of black dots. The panels demonstrate different ways to group or segment these dots using dotted-line rectangles. The underlying dot pattern is constant across all panels, but the proposed groupings (represented by the dotted boundaries) vary, illustrating different interpretations of spatial clustering or data segmentation.
### Components/Axes
* **Panels:** Four distinct panels arranged in a 2x2 grid.
* Top-left: Panel (a)
* Top-right: Panel (b)
* Bottom-left: Panel (c)
* Bottom-right: Panel (d)
* **Primary Elements:** Black dots of uniform size.
* **Grouping Elements:** Dotted-line rectangles (present in panels b, c, and d).
* **Labels:** Each panel is labeled with a lowercase letter in parentheses: `(a)`, `(b)`, `(c)`, `(d)`. These labels are positioned at the top-left corner outside each panel's border.
* **Axes:** None. This is a conceptual diagram, not a quantitative chart.
### Detailed Analysis
The core data (the dot arrangement) is identical in all four panels. The variation is in the applied grouping logic.
**Common Dot Pattern (All Panels):**
The dots form four primary clusters within the rectangular frame:
1. **Top-Left Cluster:** A dense, roughly rectangular group of dots.
2. **Top-Right Cluster:** A smaller, rectangular group.
3. **Bottom-Left Cluster:** A smaller, rectangular group.
4. **Bottom-Center/Right Cluster:** A more elongated, irregular group.
**Panel-Specific Grouping (Dotted Rectangles):**
* **Panel (a):** No grouping rectangles are present. Only the raw dot pattern is shown.
* **Panel (b):** Three dotted rectangles are used.
* **Top-Left Rectangle:** Encloses the top-left cluster but is split internally by a vertical dotted line, creating two subgroups within the same main cluster.
* **Top-Right Rectangle:** Encloses the top-right cluster.
* **Bottom Rectangle:** A single, wide rectangle that encloses both the bottom-left and bottom-center/right clusters together.
* **Panel (c):** Four dotted rectangles are used, each isolating one of the four primary clusters.
* **Top-Left Rectangle:** Encloses the top-left cluster.
* **Top-Right Rectangle:** Encloses the top-right cluster.
* **Bottom-Left Rectangle:** Encloses the bottom-left cluster.
* **Bottom-Right Rectangle:** Encloses the bottom-center/right cluster.
* **Panel (d):** Three dotted rectangles are used, with a different logic than panel (b).
* **Top-Left Rectangle:** Encloses the top-left cluster and is split internally by a vertical dotted line, creating two subgroups (similar to panel b).
* **Top-Right Rectangle:** Encloses the top-right cluster.
* **Bottom-Right Rectangle:** Encloses only the bottom-center/right cluster.
* **Note:** The bottom-left cluster is **not** enclosed by any dotted rectangle in this panel.
### Key Observations
1. **Identical Underlying Data:** The spatial distribution of dots is a constant control variable across all four examples.
2. **Grouping Subjectivity:** The diagrams visually argue that the same dataset can be meaningfully segmented in multiple, conflicting ways.
3. **Hierarchy and Division:** Panels (b) and (d) introduce the concept of subdividing a single dense cluster (top-left) into two subgroups, suggesting a hierarchical or finer-grained analysis.
4. **Inclusion vs. Exclusion:** Panel (d) is notable for leaving one cluster (bottom-left) completely ungrouped, which could represent an outlier, noise, or a cluster that doesn't meet a specific grouping criterion.
5. **Granularity Contrast:** Panel (c) represents the most granular grouping (one box per natural cluster), while panel (b) represents a coarser grouping (merging two bottom clusters).
### Interpretation
This diagram is a classic illustration of the **cluster analysis** or **segmentation problem** in fields like data science, pattern recognition, computer vision, and geography. It demonstrates that "grouping" is not an intrinsic property of the data but an interpretive act dependent on the chosen algorithm, parameters, or human perspective.
* **What it suggests:** There is no single "correct" way to partition this set of points. The choice involves trade-offs:
* **Panel (c)** prioritizes **purity** and separation of distinct visual masses.
* **Panel (b)** suggests a **hierarchical** view (main clusters and sub-clusters) and may prioritize **continuity** by merging the two bottom clusters.
* **Panel (d)** might represent an algorithm with a **minimum cluster size** or **density threshold**, causing the smaller bottom-left cluster to be excluded or classified as noise.
* **Why it matters:** This concept is foundational for understanding how machines and humans find patterns. It warns against assuming a single "true" structure in unsupervised learning tasks. The diagram could be used to explain concepts like:
* The difference between **flat** (c) and **hierarchical** (b, d) clustering.
* The impact of **distance metrics** and **linkage criteria** in algorithms like K-means or DBSCAN.
* The subjectivity involved in defining **regions of interest** in image processing or **sales territories** in business analytics.
**Language Declaration:** The only text present is the English labels `(a)`, `(b)`, `(c)`, `(d)`. No other language is present in the image.
</details>
tions d . The Hamiltonian of the Potts model is given by
where the summation runs over all pairs of the i -th and j -th data. The spin variable σ i represents individual data. Here the value of Q represents the number of clusters. When σ i = σ j , the i -th and j -th data are in the same cluster. It is natural to adopt ferromagnetic/antiferromagnetic interaction between data in the same/different cluster. It should be noted that the Potts model is a straightforward extension of the Ising model since the Potts model is equivalent to the Ising model if Q = 2. Then the clustering problem is a problem to obtain the ground state of the Hamiltonian of the Potts model with given random interactions. Here we assume that the number of clusters is fixed.
Next we explain how to introduce quantum field in order to perform the quantum annealing. In optimization problems which can be represented by the Ising model, we can use transverse field as the quantum fluctuation which is represented as -Γ ∑ i σ x i . However, we cannot use this transverse field -Γ ∑ i σ x i for the clustering problem directly, since the matrix which represents the state is Q × Q matrix. Thus, we generalize the x -component of the Pauli matrix of the Ising model as follows:
where E Q and I Q represent the Q × Q unit matrix and the Q × Q matrix whose all elements are unity. By using this generalized Pauli matrix, we can apply the quantum annealing for clustering problem. 12-14 Here we consider the following Hamiltonian:
d In practice, we do not know { J ij } and have to estimate interactions when we consider the clustering problem. However, we assume the Hamiltonian for simple explanation. As shown in this section, the implementation method does not depend on the specific form of interactions.
where N is the number of individual data. As well as the case for the Ising model, we can calculate the partition function of the Hamiltonian:
∣ ∣ ∣ ∣ where | Σ k 〉 represents the direct-product space of N spins:
$$\sum _ { k = 1 } ^ { \infty } ( o _ { 1 , k } ) \otimes ( o _ { 2 , k } ) \otimes \cdots$$
There are two elements 〈 Σ k | e -β ˆ H Potts /m | Σ ′ k 〉 and 〈 Σ ′ k | e -β ˆ H (Potts) q /m | Σ k +1 〉 . These factors are calculated as follows:
$$( \sum _ { j } e ^ { - \beta H_P ( t s , m ) } | z _ { k } | ^ { 2 } ) = \exp ( \frac { \sum _ { i = 1 } ^ { N } z _ { i } } { m } \sum _ { i = 1 } ^ { N } \left[ e ^ { - \beta H_P ( t s , m ) } + \frac { 1 } { e ^ { - \beta H_P ( t s , m ) } ( 1 - q ) } \right] .$$
$$\sum _ { m = 1 } ^ { N } \sum _ { k = 1 } ^ { m } [ e ^ { - g x ( Potts ) / m } \sum _ { i = 1 } ^ { k } \left | e ^ { - g x ( - q ) - 1 } \right | ] .$$
By using the above expressions, we can perform the quantum Monte Carlo simulation as well as the Ising model with transverse field. If the spin variable is not S = 1 / 2 Ising spin as in the case just described, we can implement the quantum annealing by considering appropriate quantum field. There are some studies that the quantum annealing succeeds to obtain the better solution than the simulated annealing for clustering problems. 12-14
## 5. Relationship between Quantum Annealing and Statistical Physics
In the preceding sections we explained the Ising model, a couple of implementation methods of the quantum annealing, and the optimization problems. There are a couple of studies that clarify the efficiency and feature of the quantum annealing in terms of statistical physics. In this section we take two examples which display relationship between quantum annealing and statistical physics focusing on the thermal fluctuation effect and the quantum fluctuation effect for ordering phenomena. In the first half, we
review the Kibble-Zurek mechanism which characterizes the efficiency of the quantum annealing for systems where a second-order phase transition occurs comparing with the efficiency of the simulated annealing. In the last half, we show similarities and differences between thermal fluctuation and quantum fluctuation for frustrated Ising spin systems.
## 5.1. Kibble-Zurek Mechanism
In statistical physics, it has been an important topic to investigate the ordering process in systems where a phase transition takes place. 110-116 Especially, dynamical properties during changing control variables such as temperature and external fields are interesting. 111,113,115 Recently, the Kibble-Zurek mechanism has been drawing attention not only in statistical physics and condensed matter physics but also for the quantum annealing. In this section, we explain the Kibble-Zurek mechanism relating to a dynamics which passes across a second-order phase transition point. The Kibble-Zurek mechanism can make clear what happens in systems where the second-order phase transition occurs during the simulated annealing and the quantum annealing from a viewpoint of statistical physics. Before we consider the efficiency of the quantum annealing comparing with the simulated annealing by using the Kibble-Zurek mechanism, we show the general feature of the Kibble-Zurek mechanism.
As an example, we consider the Kibble-Zurek mechanism in the ferromagnetic system where the second-order phase transition occurs at finite temperature. At the second-order phase transition point, the correlation length diverges in the equilibrium state, and thus the relaxation time should be infinite. Hence, the system cannot reach the equilibrium state, when we decrease temperature to the transition temperature with finite speed. Furthermore, since the relaxation time is long around the transition temperature, it is difficult to equilibrate the system. Here, we assume that growth of correlation length stops at the temperature where the system is less able to reach the equilibrium state. If we decrease temperature slow enough, the system can reach the equilibrium state even near the transition point. Thus, it is expected that the value of stopped correlation length because of the long relaxation time depends on the annealing speed. As we will see below, the value of stopped correlation length can be scaled by the annealing speed.
To consider the second-order phase transition at finite temperature in
the ferromagnetic systems, we define the dimensionless temperature g as
$$g = \frac { T - T _ { c } } { T _ { c } } ,$$
where T c is the phase transition temperature. When the absolute value of g is small, it is believed that the scaling ansatz is valid. By the scaling ansatz, the temperature-dependent correlation length ξ ( g ) is given as 117
$$\{ g \} \times \{ g \} ^ { - 1 } ,$$
where ν is one of the critical exponents. Moreover, the relaxation time τ rel is scaled by the following relation: 117
$$T _ { rel } ( g ) \times [ \{ ( g ) \} ^ { 2 } \times | g | ^ { - 2 v }$$
where z is the dynamical critical exponent. Here, we decrease the temperature T ( t ) against the time t as following schedule:
$$\rho ( t ) = \rho _ { c } ( 1 - \frac { t } { T Q } )$$
The value of τ -1 Q corresponds to the annealing speed. When the value of τ Q is large/small, the system is annealed to low temperature slowly/quickly. At t = 0, the temperature is the phase transition temperature ( T (0) = T c ), and the temperature is zero ( T ( τ Q ) = 0) at t = τ Q . From Eq. (106), the dimensionless temperature g becomes the time-dependent function as follows:
$$g ( t ) = \frac { T ( t ) - T _ { c } } { T _ { c } } = - \frac { t } { T Q }$$
In the Kibble-Zurek mechanism, we assume the following situation:
$$\left\{ \begin{array}{ll} t _ { rel } ( g ( t ) ) < | t | : system can reach equilibrium state \\ t _ { rel } ( g ( t ) ) > | t | : system cannot reach equilibrium state \end{array} \right.$$
where | t | is a remaining time to transition temperature. That is, when a remaining time | t | is longer/shorter than the relaxation time τ rel ( g ( t )), the system can/cannot reach the equilibrium state. Note that the value of considered t should be negative since the relaxation time diverges before the temperature reaches the transition temperature ( t = 0). From this assumption, the time ˜ t at which the system is less able to reach the equilibrium state is defined by following relation:
$$\tau _ { rel } ( g ( t ) ) = [ t ].$$
Furthermore, since we have assumed that the growth of correlation length stops at t = ˜ t , the value of correlation length is always ξ ( g ( ˜ t )) below T ( ˜ t ) as shown in Fig. 8. Moreover, the dimensionless temperature at ˜ t is expressed as
$$g ( t ) = \frac { | t | } { r _ { Q } } = \frac { T _ { re } ( g ( t ) ) } { r _ { Q } }$$
From this relation, g ( ˜ t ) is scaled by the annealing speed, and from Eqs. (104) and (110), the correlation length at t = ˜ t is scaled as follows:
$$g ( t ) x ^ { - \frac { 1 } { Q } } , g ( g ( t ) )$$
Furthermore, the density of domain wall n ( t ) is written as
$$( 1 1 2 )$$
where d is the spatial dimension, and n ( ˜ t ) at t = ˜ t is scaled as follows:
$$n ( t ) \times T _ { Q } ^ { - \frac { d v } { dt } + z v } .$$
For instance, in the ferromagnetic Ising model on two-dimensional lattice ( d = 2, ν = 1) when we adopt the Monte Carlo dynamics based on the single-spin-flip method ( z = 2 . 132), 118 the correlation length and the density of domain wall at t = ˜ t are naively obtained as
$$\frac { - 0 . 3 1 9 } { 7 Q ^ { \circ } } , n ( i ) \approx$$
In this way, in the dynamics which passes across the second-order phase transition point at finite temperature, the correlation length and the density of domain wall (topological defect) are scaled by the annealing speed.
Fig. 8. Schematic of the annealing speed dependence of correlation length ξ ( g ( t )). τ -1 Q is annealing speed and τ Q 1 > τ Q 2 > τ Q 3 . We define ˜ T i := T c (1 + | ˜ t | /τ Q i ) and ˜ ξ i := ξ ( | ˜ t | /τ Q i ). The dotted curve represents correlation length in the equilibrium state.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Line Graphs: Temperature-Dependent Decay of ξ under Different τ_Q Conditions
### Overview
The image displays three horizontally arranged line graphs, each plotting a variable ξ (vertical axis) against temperature T (horizontal axis). Each graph represents a different condition labeled τ_Q1, τ_Q2, and τ_Q3. The graphs illustrate a common pattern: ξ remains constant at an initial value (ξ̃_i) until a specific temperature (T̄_i), after which it decays. The rate of decay increases from the left graph (τ_Q1) to the right graph (τ_Q3).
### Components/Axes
* **Vertical Axis (Y-axis):** Labeled with the Greek letter **ξ** (xi). This represents the dependent variable.
* **Horizontal Axis (X-axis):** Labeled with the letter **T**, representing temperature.
* **Key Temperature Markers:**
* **T_c:** A critical temperature marked by a vertical dashed line in all three graphs. It is positioned to the left of T̄_i.
* **T̄_i:** The temperature at which the decay of ξ begins, marked by a vertical solid line. The subscript `i` corresponds to the graph number (1, 2, 3).
* **Initial Value Labels:** The constant value of ξ before decay is labeled on the y-axis as **ξ̃_1**, **ξ̃_2**, and **ξ̃_3** for the left, middle, and right graphs, respectively.
* **Graph Titles/Conditions:** Each graph is labeled in its top-right corner with a condition: **τ_Q1** (left), **τ_Q2** (middle), and **τ_Q3** (right).
* **Spatial Layout:** The three graphs are placed side-by-side. The legend/condition label (τ_Qi) is consistently in the top-right of each plot area. The axis labels (ξ, T) are at the ends of their respective axes.
### Detailed Analysis
1. **Graph 1 (τ_Q1 - Left):**
* **Trend:** The line is horizontal at value **ξ̃_1** from T=0 until temperature **T̄_1**. After T̄_1, the line curves downward in a gradual, convex decay.
* **Spatial Relationship:** The dashed line at **T_c** is located to the left of the solid line at **T̄_1**. The decay begins at T̄_1, which is greater than T_c.
2. **Graph 2 (τ_Q2 - Middle):**
* **Trend:** The line is horizontal at value **ξ̃_2** until temperature **T̄_2**. After T̄_2, the line decays. The curvature of the decay is steeper than in the τ_Q1 graph.
* **Spatial Relationship:** Similar to the first graph, **T_c** (dashed) is left of **T̄_2** (solid). The initial value ξ̃_2 appears visually lower than ξ̃_1.
3. **Graph 3 (τ_Q3 - Right):**
* **Trend:** The line is horizontal at value **ξ̃_3** until temperature **T̄_3**. After T̄_3, the line decays with the steepest slope of the three graphs.
* **Spatial Relationship:** **T_c** (dashed) is left of **T̄_3** (solid). The initial value ξ̃_3 appears visually lower than both ξ̃_1 and ξ̃_2.
### Key Observations
* **Common Structure:** All three graphs share an identical qualitative structure: a constant plateau followed by a decay phase initiated at a temperature T̄_i > T_c.
* **Variable Decay Rate:** The primary difference between the graphs is the steepness of the decay curve after T̄_i. The decay becomes progressively faster from τ_Q1 to τ_Q3.
* **Variable Initial Value:** The initial constant value ξ̃_i appears to decrease from the left graph to the right graph (ξ̃_1 > ξ̃_2 > ξ̃_3).
* **Fixed Critical Temperature:** The marker **T_c** is in the same relative position (left of the decay onset) in all plots, suggesting it is a fixed reference point, possibly a critical temperature for a phase transition.
* **No Numerical Scales:** The axes lack numerical tick marks, so all values (ξ̃_i, T_c, T̄_i) are symbolic. Relationships are inferred from visual positioning.
### Interpretation
These graphs likely model a physical quantity (ξ) that is stable below a certain temperature threshold (T̄_i) but becomes unstable and decays above it. The parameter **τ_Q** (possibly a relaxation time, coupling constant, or quenching rate) controls two key aspects of this behavior:
1. **The Onset Temperature (T̄_i):** A higher τ_Q (from 1 to 3) corresponds to a lower initial value ξ̃_i and a decay that begins at a higher temperature (T̄_3 > T̄_2 > T̄_1, visually).
2. **The Decay Rate:** A higher τ_Q leads to a much more rapid collapse of ξ once the threshold temperature is exceeded.
The fixed marker **T_c** may represent a fundamental critical temperature of the system (e.g., a phase transition point). The fact that decay onset (T̄_i) always occurs at a temperature higher than T_c suggests that the τ_Q parameter modifies the system's response, delaying the onset of decay relative to this critical point but making the subsequent decay more severe. This could be relevant in contexts like non-equilibrium thermodynamics, quantum quenches, or material science, where a system's response to a temperature change is governed by an internal timescale or coupling strength.
</details>
This argument is called the Kibble-Zurek mechanism. Since the KibbleZurek mechanism explains the creation of topological defects induced by cooling of the system which takes place the second-order phase transition, this relates to the evolution of cosmic strings by spontaneous symmetry breaking in the Big Bang theory. 119-121 The Kibble-Zurek mechanism can also describe the creation of topological defects in magnetic models, 122,123 superfluid helium systems, 124,125 and Bose-Einstein condensations. 126,127 Next we consider the efficiency of the simulated annealing and the quantum annealing using the Kibble-Zurek mechanism by taking examples which can be treated analytically.
## 5.1.1. Efficiency of Simulated Annealing and Quantum Annealing
Next, we consider the efficiency of the simulated annealing and the quantum annealing according to the Kibble-Zurek mechanism. As an example, we treat the case where the non-domain wall state is the best solution. In this case, the value of n ( ˜ t ) approximately represents the difference between the obtained solution and the best solution. Thus, by using the Kibble-Zurek mechanism, we can compare the efficiency of annealing methods from the behavior of n ( ˜ t ) against the annealing speed. Suppose we solve optimization problems by using annealing methods, we would like to obtain a better solution as fast as possible, in other words, as small τ Q as possible. Then, the comparison obtained by the Kibble-Zurek mechanism is expected to become an useful information for the optimization problems.
As an example, we consider the efficiency of the simulated annealing and the quantum annealing for the random ferromagnetic Ising chain in terms of the Kibble-Zurek mechanism according to Refs. [128,129].
## 5.1.2. Simulated Annealing for Random Ferromagnetic Ising Chain
The model Hamiltonian of the random ferromagnetic Ising chain is given as
$$H = - \sum _ { i } j _ { 0 } ^ { z } o _ { i + 1 } , o _ { i }$$
where J i is the interaction between the i -th site and the ( i +1)-th site. The value of J i is given by the uniform distribution between 0 < J i ≤ 1. The distribution function P (u) ( J i ) is given by
$$p ^ { ( w ) } ( j _ { 1 } ) = \begin{cases} 1 & \text{for } 0 < J_ { 1 } < 1 \\ 0 & \text{otherwise} \end{cases}$$
Since the interaction J i is always positive value, the ground state spin configuration is the all-up spin state or the all-down spin state. In this model, the ferromagnetic transition occurs at zero temperature.
The correlation function between two sites where the distance is r is written as
$$\vert \sigma _ { i } \sigma _ { i + 1 } \vert _ { av } = ( \frac { 1 } { B } \ln \cos h ^ { r } ) ^ { r } , \ldots ( 1 1 7 )$$
where 〈· · · 〉 and [ · · · ] av denote the thermal average and the random average. Physical quantities should depend on the specific spatial pattern of the random interactions { J i } . Then, these averages are defined by
$$( 0 ( J _ { 3 } ) ) : = \frac { T _ { r } O ( ( J _ { 1 } ) ) e ^ { - R } } { T _ { r } e ^ { - B H } } ,$$
$$\int \limits _ { 0 } ^ { ( J ) } O ( \{ J \} ) d J p ^ { ( u ) } i = f I _ { d , J , p ^ { ( u ) } }$$
respectively. We omit the argument ( { J i } ) for simplicity. The relationship between the correlation function and the correlation length ξ is given by
$$( \sigma _ { i } \sigma _ { i + r } ) l _ { v } = e ^ { - r / s } .$$
Here we mainly focus on the low-temperature limit, since the correlation length grows as temperature decreases. Then the correlation length is given as
$$\zeta = \frac { 1 } { \ln ( \beta - 1 ) \ln \cos h \beta ) ^ { 2 } }$$
Here, we adopt the Glauber dynamics 130 as the time development, and thus the relaxation time τ rel can be written as
$$\tau _ { rel } = \frac { 1 } { 1 - \tan h 2 \beta ^ { 2 } } \approx 1 . 4 8 ^ { 3 }$$
As we can see, in this model, the correlation length ξ and the relaxation time τ rel are not the power function of temperature unlike the case of the systems where the second-order phase transition occurs at finite temperature (Eqs. (104) and (105)). This is because properties are different between phase transition which exhibits at finite temperature and that occurs at zero temperature.
We decrease temperature T ( t ) against the time t as following schedule:
$$T ( t ) = - \frac { t } { r _ { 0 } } ( - \infty < t$$
Here T c = 0 in this system. According to the Kibble-Zurek mechanism, we define ˜ t by following relation:
$$\tau _ { rel } ( T ( t ) = | t | ,$$
$$T ( t ) = \frac { I _ { Q } } { T _ { Q } } = \frac { T _ { rel } ( T ( t ) ) } { T ( t ) } .$$
By using Eqs. (121) and (122), low-temperature limit of Eq. (125) is written as
$$\frac { 1 } { \frac { 1 } { ( T ( t ) ) ^ { 2 } m ^ { 2 } - 2 r _ { c } q } } = \frac { 1 } { 2 r _ { c } q } e ^ { 4 s ( T ( t ) ) }$$
and, we obtain and, we obtain
$$\frac { \ln r _ { 0 } + l n ^ { 2 } - l n ( g ( Z ) ) } { 4 l n ^ { 2 } } x = \frac { l n r _ { 0 } } { 4 l n ^ { 2 } }$$
The approximation of RHS is valid in the case of τ Q /greatermuch 1 which indicates very slow annealing speed. Thus, we can estimate the density of domain wall n SA ( ˜ t ) at t = ˜ t as follows:
$$\frac { 4 n ^ { 2 } } { \ln r _ { 0 } }$$
## 5.1.3. Quantum Annealing for Random Ferromagnetic Ising Chain
We study the Kibble-Zurek mechanism for the random ferromagnetic Ising chain with transverse field Γ. The model Hamiltonian is given as
$$h = - \sum _ { i } J _ { i 0 ^ { z _ { i } } } o _ { i + 1 } - I ^ { \lambda _ { i } }$$
where the value of J i is given by the uniform distribution between 0 < J i ≤ 1 as well as the case of simulated annealing. In this model, the quantum phase transition from the paramagnetic phase to the ferromagnetic phase occurs at Γ c = exp([ln J i ] av ). 131 Here, we define the dimensionless transverse field g as
$$g = \frac { F - T _ { c } } { F _ { c } } .$$
When | g | /lessmuch 1, it has been known that the correlation length obtained by the renormalization group analysis 132 is scaled by the following relation:
Moreover, a coherence time τ coh is scaled by
where the dynamical exponent z is scaled as
which is also obtained by the renormalization group analysis. 132 This means that the dynamical exponent diverges at the transition point, and this behavior is a qualitative difference between the random system and the pure system ( z = 1). From this fact, τ coh cannot be expressed by the power function of g unlike the case of the second-order phase transition at finite temperature.
We decrease transverse field Γ( t ) against the time t as following schedule:
According to the Kibble-Zurek mechanism, we define ˜ t by following relation:
By using Eqs. (131), (132), and (133), Eq. (136) is written as
and, we obtain
In the limit of τ Q /greatermuch 1, since the value of ξ ( g ( ˜ t )) is very large, and we obtain 133
$$g ( g ( t ) ) \times ( \frac { l n r _ { 0 } } { l _ { n } \{ g ( t ) \} } ) ^ { 2 }$$
and we obtain
Moreover, since the change of ln ξ ( g ( ˜ t )) is gradual in comparison with that of ξ ( g ( ˜ t )), we neglect ln ξ ( g ( ˜ t )) and obtain
$$\{ g ( t ) \} \times ( 1 n r q ) ^ { 2 } .$$
From this relation, we can estimate the density of domain wall n QA ( ˜ t ) at t = ˜ t as follows:
$$( 1 4 2 )$$
## 5.1.4. Comparison between Simulated and Quantum Annealing Methods
We have shown analysis of the domain wall density in the random ferromagnetic Ising chain during the simulated annealing and the quantum annealing by the Kibble-Zurek mechanism. The obtained densities of domain wall are
$$\frac { n s A ( t ) } { 2 } \times ( m r _ { 0 } ) ^ { - 1 } : \sinul$$
From these relations, it is clear that the decay of n QA ( ˜ t ) is faster than that of n SA ( ˜ t ) against the value of τ Q . Thus, from the Kibble-Zurek mechanism, it is concluded that the quantum annealing method is appropriate as the annealing method for the random ferromagnetic Ising chain in comparison with the simulated annealing method. Suppose we consider the ferromagnetic Ising chain with homogeneous interaction ( J i = 1 for all i ). In this case, both the domain wall density in the simulated annealing and that in the quantum annealing are obtained as
$$\sum _ { n = 0 } ^ { \infty } ( t ) x ( in r _ { 0 } ) ^ { - 2 } : q u a n t$$
$$\frac { 1 } { \sqrt { \pi } }$$
This relation for the simulated annealing can be obtained by a simple calculation as well as the case of the random Ising spin chain. On top of that, the relation for the quantum annealing can be derived by Eq. (113). Here the critical exponent ν of the transverse Ising chain with homogeneous interaction is ν = 1 and the dynamical exponent of this system is z = 1. Then there is no difference between the simulated annealing and the quantum annealing in the case of the homogeneous ferromagnetic Ising chain. However, since the optimization problem has some kind of randomness, the abovementioned result encourages that the quantum annealing is better than the simulated annealing for optimization problems.
In general, the existence of the phase transition in optimization problems negatively influences performance of annealing methods. Here, we have
introduced the Kibble-Zurek mechanism relating to the dynamics which passes across the second-order phase transition point. As the specific example, we have analyzed the efficiencies of the simulated annealing and the quantum annealing for the random ferromagnetic Ising chain according to the Kibble-Zurek mechanism. For this model, the efficiency of the quantum annealing is better than that of the simulated annealing. Of course, since the efficiency of annealing methods depends on the details of optimization problems, it is not to say that the quantum annealing is always appropriate as the annealing method for general optimization problems in comparison with the simulated annealing. Moreover, we have to develop a theory based on the Kibble-Zurek mechanism itself, 134 since we assume the growth of the correlation length stops at t > ˜ t . For example, if we adapt the Kibble-Zurek mechanism to two- or three-dimensional models and more complicated models, it is difficult to estimate the correlation length analytically, and thus we should execute numerical simulations such as the Monte Carlo simulation. For example, in the two-dimensional Ising model with random interactions, it has been shown that the efficiency of the quantum annealing is better than that of the simulated annealing by Monte Carlo simulation. 129 Although the efficiency of annealing methods for a number of optimization problems has been clarified by the Kibble-Zurek mechanism, it remains to be an open problem to investigate when to use the quantum annealing exhaustively.
In the above-mentioned argument, the phase transition under consideration is of the second order. What happens if we adapt the same argument for the other type phase transitions such as first-order phase transition and Kosterlitz-Thouless (KT) transition? In these phase transitions, the behaviors of correlation length are different from that in systems where a secondorder phase transition occurs: the finite-correlation length at the first-order phase transition point and the quasi-long-range correlation length at the KTtransition point. Thus, it is an interesting problem to clarify relationship between behaviors of correlation length and the generalized Kibble-Zurek mechanism. By considering dynamical nature of the optimization problems in terms of non-equilibrium statistical physics in a deeper way, we believe that the quantum annealing method will become a central part of practical method for optimization problems.
## 5.2. Frustration Effects for Simulated Annealing and Quantum Annealing
In many cases optimization problems can be represented by the Ising model with random interactions and magnetic fields as mentioned before. The Hamiltonian of this system is given by
$$H = - \sum _ { i , j } J _ { i j } g ^ { 2 } r _ { i j } - \sum _ { i = 1 } ^ { N } h _ { i j } r _ { i j }$$
When all interactions are ferromagnetic as the previous example in Sec. 5.1, the ground state is the all-up or the all-down states. However, if there are antiferromagnetic interactions in the system, the situation becomes different. In order to show the difference between ferromagnetic interaction and antiferromagnetic interaction, we first consider three spin system on triangle cluster as shown in Fig. 9. In this section, we treat the case for h i = 0 for all i . The dotted and solid lines in Fig. 9 represent ferromagnetic and antiferromagnetic interactions, respectively.
The considered Hamiltonian is written as
$$H _ { \triangle } = - J ( o ^ { 2 } i o ^ { 2 } + o ^ { 3 } i o ^ { 3 } )$$
Here we set the all interactions are the same value for simplicity. The ground states for positive J (ferromagnetic interaction) are the all-up or the alldown states shown in Fig. 9 (a). In these states, all spins between all interactions are energetically favorable states. In the case of negative J (antiferromagnetic interaction), while on the other hand, six states shown in Fig. 9 (b) are ground states. These ground states have unfavorable interactions
Fig. 9. Three spin system on triangle cluster. The dotted and solid lines represent ferromagnetic and antiferromagnetic interactions, respectively. The open and solid circles are the +1-state and the -1-state, respectively. The crosses indicate the positions of unfavorable interactions. (a) Ground states for ferromagnetic case. (b) Ground states for antiferromagnetic case.
<details>
<summary>Image 9 Details</summary>
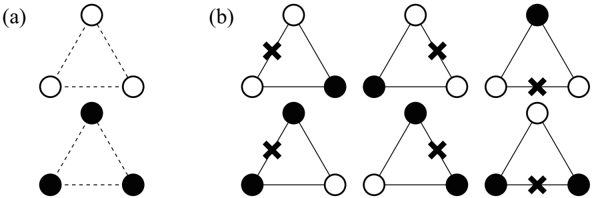
### Visual Description
## Diagram: Triangular Graph Structures with Node States and Edge Constraints
### Overview
The image displays a technical diagram consisting of two main sections, labeled **(a)** and **(b)**, each containing schematic representations of triangular graphs. The graphs consist of nodes (circles) connected by edges (lines). Nodes are either unfilled (white) or filled (black). Some edges are marked with a bold "X". The diagram appears to illustrate different states or configurations of a three-node system, possibly related to graph theory, network motifs, constraint satisfaction, or spin systems.
### Components/Axes
* **Labels:** The only textual labels are the section identifiers **(a)** and **(b)**, positioned at the top-left of their respective sections.
* **Graph Elements:**
* **Nodes:** Represented as circles. Two states are shown: **White (unfilled)** and **Black (filled)**.
* **Edges:** Represented as lines connecting nodes. Two styles are shown: **Dashed lines** and **Solid lines**.
* **Constraint Markers:** A bold **"X"** is placed over certain solid edges.
* **Spatial Layout:**
* Section **(a)** is on the left side of the image. It contains two triangular diagrams stacked vertically.
* Section **(b)** is on the right side of the image. It contains six triangular diagrams arranged in a 2x3 grid (two rows, three columns).
### Detailed Analysis
#### Section (a)
This section shows two "pure" or homogeneous states.
1. **Top Triangle:**
* **Nodes:** All three nodes are **white**.
* **Edges:** All three edges are **dashed lines**.
* **Constraints:** No edges are marked with an "X".
2. **Bottom Triangle:**
* **Nodes:** All three nodes are **black**.
* **Edges:** All three edges are **dashed lines**.
* **Constraints:** No edges are marked with an "X".
#### Section (b)
This section shows six "mixed" or heterogeneous states, where nodes can be black or white. Solid edges with an "X" are introduced.
* **Top Row (Left to Right):**
1. **Triangle 1:** Nodes (clockwise from top): White, Black, White. The edge between the top (White) and bottom-left (White) node is **solid with an "X"**. The other two edges are solid without marks.
2. **Triangle 2:** Nodes: White, White, Black. The edge between the top (White) and bottom-right (Black) node is **solid with an "X"**.
3. **Triangle 3:** Nodes: Black, White, White. The edge between the two bottom (White) nodes is **solid with an "X"**.
* **Bottom Row (Left to Right):**
1. **Triangle 4:** Nodes: Black, Black, White. The edge between the top (Black) and bottom-left (Black) node is **solid with an "X"**.
2. **Triangle 5:** Nodes: Black, White, Black. The edge between the top (Black) and bottom-right (Black) node is **solid with an "X"**.
3. **Triangle 6:** Nodes: White, Black, Black. The edge between the two bottom (Black) nodes is **solid with an "X"**.
### Key Observations
1. **State Contrast:** Section (a) depicts uniform node states (all white or all black) with dashed, unconstrained connections. Section (b) depicts all possible mixed states (two nodes of one color, one of the other) with solid connections, one of which is always constrained (marked with an "X").
2. **Constraint Pattern:** In every triangle in section (b), exactly one of the three edges is marked with an "X". The marked edge always connects the two nodes that share the same color.
3. **Symmetry:** The six configurations in (b) represent all unique permutations of a triangle with two nodes of one color and one of the other, considering rotational symmetry. The "X" consistently marks the edge between the like-colored pair.
4. **Edge Style Correlation:** Dashed lines are exclusively used in the homogeneous states of (a). Solid lines are exclusively used in the heterogeneous states of (b).
### Interpretation
This diagram likely illustrates a fundamental principle in a system where connections (edges) between similar entities (nodes of the same color) are forbidden, unstable, or carry a different interaction energy.
* **What it suggests:** The system favors or only allows connections between *dissimilar* nodes (black-white). The "X" on the edge connecting two similar nodes (white-white or black-black) in section (b) visually represents a **constraint, frustration, or forbidden interaction**. The homogeneous states in (a) might represent ground states or idealized configurations where this constraint is avoided because all nodes are identical, hence the different (dashed) edge representation.
* **Relationship between elements:** The progression from (a) to (b) shows the introduction of heterogeneity and the resulting necessary constraint. The diagram systematically enumerates all ways a three-node cluster can be "frustrated" by having one pair of like neighbors.
* **Potential Contexts:** This is a classic representation found in:
* **Statistical Physics/Ising Models:** Illustrating "frustration" in spin systems where antiferromagnetic interactions (preferring opposite spins) cannot be satisfied on a triangle with an odd number of nodes.
* **Graph Theory/Network Science:** Showing a "forbidden triad" or a motif where a specific edge type is disallowed.
* **Constraint Satisfaction Problems:** Visualizing a basic unit where a binary constraint (nodes connected by an edge must be different) is violated.
* **Social Network Analysis:** Representing the "balance theory" principle that "the enemy of my enemy is my friend," where a triangle with an odd number of hostile edges (the "X") is unbalanced.
The diagram's power lies in its exhaustive and clear visual proof that any triangle containing both black and white nodes *must* contain at least one "frustrated" or constrained edge between like nodes.
</details>
indicated by the crosses in Fig. 9 (b). This situation is called frustration. In the homogeneous antiferromagnetic Ising spin systems on lattices based on triangle such as triangular lattice and kagom´ e lattice, frustration appears in all triangles. Since such frustration comes from lattice geometry, this is called geometrical frustration. It should be noted that the homogeneous antiferromagnetic Ising spin systems on square lattice and hexagonal lattice have no frustration. Since these systems are bipartite systems which can be decomposed by two sublattices, these systems can be transformed on the ferromagnetic systems by local gauge transformation of all spins belonging to one of the sublattices.
Frustration appears in also inhomogeneous systems as shown in Fig. 10. The squares pointed by stars in Fig. 10 represent frustration plaquettes which are satisfied following relation:
$$k _ { k } = \sum _ { i , j \in O _ { k } } J _ { ij } < 0 ,$$
where /square k indicates the smallest square plaquette at the position k . If κ k for all k is positive, the system is not frustrated.
In general, frustration prevents the system from conventional magnetic ordering such as ferromagnetic order and N´ eel order, since there is no state where all interactions are satisfied energetically in frustrated systems. Frustration makes peculiar density of states which induces unconventional phase transition and slow dynamics. 112,115,135-144 Although many optimization problems can be represented by the Ising model with random interactions and magnetic fields, here we focus on the frustration effect which comes
Fig. 10. A ground state of the Ising spin system with random interactions. The dotted and solid lines represent ferromagnetic and antiferromagnetic interactions, respectively. The open and solid circles are the +1-state and the -1-state, respectively. The stars and crosses indicate frustration plaquettes and unfavorable interactions, respectively.
<details>
<summary>Image 10 Details</summary>
### Visual Description
## Diagram: 5x5 Grid Network with State Indicators
### Overview
The image displays a 5x5 grid of circular nodes connected by two types of lines (solid and dashed). Interspersed within the grid cells are two types of symbols (stars and crosses). The diagram appears to represent a network, state machine, or grid-based system where nodes have binary states (black/white) and connections or relationships are indicated by line styles and symbols. There is no textual information, labels, titles, or numerical data present in the image.
### Components/Axes
* **Nodes:** 25 circles arranged in a 5x5 grid. Each node is either filled black or white (outlined).
* **Connections:**
* **Solid Lines:** Connect certain adjacent nodes horizontally and vertically.
* **Dashed Lines:** Connect certain adjacent nodes horizontally and vertically.
* **Symbols:**
* **Stars (☆):** Five-pointed star outlines placed in the spaces between some nodes.
* **Crosses (×):** 'X' marks placed in the spaces between some nodes.
* **Layout:** The grid is perfectly regular. Symbols are placed in the "cells" formed by four adjacent nodes (e.g., between row 1 col 1, row 1 col 2, row 2 col 1, row 2 col 2).
### Detailed Analysis
**Node State Distribution (Row by Row, Left to Right):**
* **Row 1:** Black, White, White, White, White
* **Row 2:** Black, White, White, White, Black
* **Row 3:** Black, White, White, White, Black
* **Row 4:** Black, White, White, Black, White
* **Row 5:** White, Black, Black, Black, White
**Connection Pattern (Between Adjacent Nodes):**
* **Horizontal Connections (Left to Right):**
* Row 1: Solid, Dashed, Dashed, Dashed
* Row 2: Solid, Solid, Dashed, Solid
* Row 3: Solid, Dashed, Dashed, Solid
* Row 4: Solid, Dashed, Solid, Dashed
* Row 5: Solid, Solid, Solid, Dashed
* **Vertical Connections (Top to Bottom):**
* Column 1: Dashed, Dashed, Dashed, Dashed
* Column 2: Dashed, Solid, Dashed, Solid
* Column 3: Dashed, Dashed, Dashed, Solid
* Column 4: Dashed, Solid, Solid, Solid
* Column 5: Dashed, Solid, Dashed, Dashed
**Symbol Placement (In the cell between four nodes):**
* **Stars (☆):** Located in cells at approximate grid coordinates (using top-left as 1,1):
* (1,1), (1,2), (1,4), (2,1), (2,3), (3,1), (3,3), (4,4)
* **Crosses (×):** Located in cells at approximate grid coordinates:
* (1,3), (2,2), (2,4), (3,2), (4,3)
### Key Observations
1. **Node State Clustering:** Black nodes are concentrated on the left edge (Column 1, Rows 1-4) and in a cluster in the bottom-center (Row 5, Columns 2-4). White nodes dominate the top-right and center.
2. **Connection Type Correlation:** There is a visible, though not absolute, correlation between node state and connection type. For example, the solid vertical line in Column 4 connects a sequence of Black, White, Black, Black nodes.
3. **Symbol Distribution:** Stars and crosses are distributed throughout the grid without an immediately obvious simple pattern relative to node colors or line types. They appear to mark specific relationships or conditions between groups of four nodes.
4. **Asymmetry:** The diagram is not symmetrical horizontally, vertically, or diagonally.
### Interpretation
This diagram likely represents a **state diagram for a grid-based system**, a **network topology map**, or a **visualization of a cellular automaton or constraint satisfaction problem**.
* **Binary Node States:** The black/white nodes most likely represent two possible states (e.g., on/off, active/inactive, true/false, occupied/empty).
* **Dual Connection Types:** The solid and dashed lines suggest two different kinds of relationships or pathways between nodes. This could indicate strong vs. weak links, different types of communication channels, or permitted vs. forbidden transitions.
* **Symbolic Annotations:** The stars and crosses are critical annotations. They likely denote specific properties, rules, or outcomes for the 2x2 node clusters they occupy. For instance, a star might indicate a "stable" or "valid" configuration, while a cross might indicate an "unstable" or "conflict" state. Their placement seems deliberate and is key to understanding the system's logic.
* **Overall Function:** The diagram does not show a simple flow from start to end. Instead, it presents a **system state snapshot**. The combination of node states, connection types, and cell symbols defines a complex set of conditions. To fully interpret it, one would need the accompanying legend or rulebook that defines the meaning of each element (black node, white node, solid line, dashed line, star, cross). Without that key, the diagram is a precise but cryptic map of a structured system.
</details>
from non-random interactions. In terms of statistical physics, this is a firststep study to investigate similarities and differences between thermal fluctuation and quantum fluctuation for frustrated systems. Furthermore, it is important topic for the optimization problems to consider the thermal fluctuation and quantum fluctuation effects for frustrated systems. To obtain the ground state of frustrated systems is to find how to put the unsatisfied bonds represented by the crosses. Since the unsatisfied bonds are regarded as some kind of constraints, this situation is similar with the traveling salesman problem in which there are some constraints as mentioned before. We explain two topics in this section. In the first half, we consider the order by disorder effect in fully-frustrated systems. In the last half, we explain non-monotonic dynamics in decorated bond systems.
## 5.2.1. Thermal Fluctuation and Quantum Fluctuation Effect of Geometrical Frustrated Systems
In general, there are many degenerated ground states in geometrical frustrated systems such as triangular antiferromagnetic Ising spin systems and kagom´ e antiferromagnetic Ising spin systems. In these cases, non-zero residual entropy which is entropy at zero temperature exists. Typical configurations of ground states of the triangular antiferromagnetic Ising spin systems are shown in Fig. 11. The residual entropy per spin of this system is S (tri) res /similarequal 0 . 323 k B , 145-148 where k B is the Boltzmann constant. Since the total entropy per spin is k B ln 2 /similarequal 0 . 693 k B , 46 . 6% of the total entropy remains even at zero temperature. In other words, there are macroscopic degenerated ground states in this system. In the antiferromagnetic Ising spin system on kagom´ e lattice, there are also macroscopic degenerated ground states. The residual entropy per spin of this system is S (kag) res /similarequal 0 . 502 k B , which is 72 . 4% of the total entropy. 149
Suppose we apply the simulated annealing or the quantum annealing with slow schedule for geometrical frustrated spin systems. Since there are macroscopically degenerated ground states in these systems, our purpose is to clarify whether all ground states are obtained with the same probabilities or biased probabilities. We first consider the obtained ground states in the case of the simulated annealing with slow schedule. If we decrease temperature slow enough, the obtained state should satisfy the equilibrium probability distribution. When the temperature is k B T /lessmuch | J | , the equilibrium probabilities of the ground states are dominant and that of any excited states can be neglected. The principle of equal weight which is the keystone in the equilibrium statistical physics says that if the eigenenergies of the
Fig. 11. Typical configurations of ground states of antiferromagnetic Ising spin system on triangular lattice. The open and solid circles are the +1-state and the -1-state, respectively. The dotted circles indicate free spin where the molecular field is zero.
<details>
<summary>Image 11 Details</summary>
### Visual Description
## Diagram: Hexagonal Lattice Network with Binary Node States
### Overview
The image displays two distinct hexagonal lattice structures, presented side-by-side. Each lattice is composed of nodes (circles) connected by edges (lines), forming a honeycomb pattern. The nodes exist in one of two states: solid black or white with a black outline. Some white nodes are further distinguished by a dashed circular outline. The diagram appears to illustrate two different configurations or states of a network, possibly representing a physical system (like atoms in a crystal), a computational model, or a graph theory concept. There is no textual information, labels, axes, or legends present in the image.
### Components/Axes
* **Primary Structure:** Two separate hexagonal (honeycomb) lattices.
* **Nodes:** Circles representing vertices in the lattice.
* **State 1:** Solid black circles.
* **State 2:** White circles with a solid black outline.
* **Sub-State:** A subset of the white nodes features an additional dashed circular outline concentric with the solid outline.
* **Edges:** Straight lines connecting adjacent nodes, forming the hexagonal grid.
* **Layout:** The two lattices are positioned horizontally, with the left lattice slightly offset vertically relative to the right one. Each lattice is a parallelogram-shaped section of an infinite hexagonal grid.
### Detailed Analysis
**Left Lattice:**
* **Structure:** A 5-row (by the slanted vertical axis) section of a hexagonal grid.
* **Node Distribution:** Contains a mixture of black and white nodes. The distribution does not follow an immediately obvious simple repeating pattern across the entire section.
* **Dashed Nodes:** Several white nodes have dashed outlines. Their placement appears scattered. For example, in the top row, the 2nd and 4th nodes from the left are dashed. In the bottom row, the 2nd node from the left is dashed.
**Right Lattice:**
* **Structure:** Also a 5-row section of a hexagonal grid, similar in overall shape to the left lattice.
* **Node Distribution:** Also contains a mixture of black and white nodes. The specific arrangement of black and white nodes differs from the left lattice.
* **Dashed Nodes:** Similarly, several white nodes have dashed outlines. Their positions are different from those in the left lattice. For instance, in the top row, the 1st and 5th nodes from the left are dashed.
**Spatial Grounding & Pattern Verification:**
* **Trend/Pattern Check:** There is no numerical data or continuous trend to verify. The "data" is the categorical state (black/white/dashed) of each discrete node at a fixed position.
* **Component Isolation:** The image can be segmented into two independent regions: the Left Lattice and the Right Lattice. Each must be analyzed separately to avoid mixing their distinct configurations.
* **Cross-Reference:** Without a legend, the meaning of the node states (black, white, dashed-white) is undefined. The analysis can only describe their visual presence and relative positions.
### Key Observations
1. **Binary State with a Marker:** The system has a primary binary state (black vs. white), with a secondary marker (dashed outline) applied to a subset of the white nodes.
2. **Distinct Configurations:** The left and right lattices show two different specific arrangements of these node states. They are not simple translations or rotations of each other.
3. **No Obvious Long-Range Order:** In both lattices, the black nodes do not form a perfectly alternating (checkerboard) pattern nor large uniform clusters. The pattern appears somewhat disordered or complex.
4. **Absence of Text:** The diagram is purely graphical. All information is encoded in the visual properties of the nodes and their connections.
### Interpretation
This diagram is a structural illustration, not a data chart. It does not provide quantitative facts or trends but rather presents two qualitative states of a networked system.
* **What it Demonstrates:** The image likely serves to compare two different configurations of a system modeled on a hexagonal lattice. This could represent:
* **Physics/Chemistry:** Two possible arrangements of atoms (e.g., different spin states in a magnetic material, or different types of atoms in an alloy) on a crystal lattice. The dashed circles might indicate defects, impurities, or atoms in an excited state.
* **Computer Science/Graph Theory:** Two different colorings or states of nodes in a graph, potentially illustrating concepts like graph coloring, network percolation, or cellular automata states.
* **Network Science:** Two snapshots of a network where nodes can be active (black) or inactive (white), with dashed nodes representing a special status (e.g., recently changed state, or under observation).
* **Relationship Between Elements:** The connections (edges) define the neighborhood and interaction pathways between nodes. The state of any given node (black/white/dashed) is likely influenced by or related to the states of its immediate neighbors in the lattice.
* **Notable Anomalies:** The key "anomaly" or point of interest is the specific, non-random-looking yet complex pattern of black nodes and dashed nodes in each lattice. The purpose of the diagram is almost certainly to draw attention to these specific patterns and invite comparison between the two. The lack of a key means the viewer must infer the meaning from the context in which the diagram appears (e.g., a scientific paper caption).
</details>
microscopic state Σ A and Σ B are the same, the equilibrium probability of Σ A and that of Σ B are also the same. Then we obtain all macroscopic degenerated ground states with the same probability after the simulated annealing with slow schedule.
Next we consider the obtained ground states in the case of the quantum annealing where the transverse field decreases slow enough. Here we assume that the initial state is set to be the ground state of the Hamiltonian at the initial time. In order to capture the feature of the ground states in a graphical way, it is convenient to introduce the concept of free spin where the molecular field is zero. The molecular field at the i -th site is given by
$$h _ { i } ^ { ( eff ) } = \sum _ { j } ^ { ' } o _ { j } ^ { 2 }$$
where the summation runs over the nearest-neighbor sites of the i -th site. For instance, in Fig. 11, spins indicated by dotted circles are free spins. Here, the transverse field is expressed as
$$\sum _ { i = 1 } ^ { n } \sigma _ { i } ^ { - 1 } - \sum _ { i = 1 } ^ { n } ( \sigma _ { i } + 1 )$$
where ˆ σ + i and ˆ σ -i denote the raising and lowering operators at the i -th site, respectively. They are defined by
$$\sigma ^ { + } = ( 0 , 1 ) , \sigma ^ { - } = ( 0 , 0 ) .$$
The x -component of the Pauli matrix corresponds to the operator which flips the considered spin:
$$\sigma ^ { 2 } ( t ) = \langle t \rangle , \sigma ^ { 2 } ( t ) =$$
From this, the states which have large number of free spins are expected to become stable at the limit of Γ → 0+ and T = 0. Actually, in the adiabatic limit, the amplitudes of the states which have the maximum number of free spins are larger than the others. 150-154 When we decrease the transverse field slow enough, the state at each time can be well approximated by the ground state of the instantaneous Hamiltonian. Then we obtain specific ground states with high probability after the quantum annealing with slow schedule.
In this section, we considered the thermal fluctuation effect and the quantum fluctuation effect in the adiabatic limit. The simulated annealing can obtain all the ground states with the same probability, while on the other hand, the quantum annealing can obtain specific ground states in this limit. The biased probability distribution can be explained by the character of the quantum Hamiltonian. The selected states should depend on how to choice the quantum Hamiltonian. When we adopt the exchange type interaction as the quantum field, the states that have the maximum value of the 'free spin pair' should be selected. Moreover, it is an interesting topic to investigate differences between the simulated annealing and the quantum annealing with finite speed not only in terms of the quantum annealing but also in nonequilibrium statistical physics and condensed matter physics. At the present stage, to consider dynamic phenomena in strongly correlated systems is difficult, since a small number of theoretical methods for obtaining dynamic phenomena have been developed. If the technology of the artificial lattices develops more than ever, real-time dynamics and time-dependent phenomena of frustrated spin systems can be observed in real experiments.
## 5.2.2. Non-Monotonic Behavior of Correlation Function in Decorated Bond System
In the ferromagnetic Ising spin systems, the correlation function behaves monotonic against the temperature and transverse field. However, the behavior of the correlation function is non-monotonic as a function of temperature in some frustrated spin systems. As an example of non-monotonic correlation function, we introduce equilibrium properties of the correlation function in decorated bond systems in which the frustration exists. The Hamiltonian of the decorated bond systems where the number of system
spins is two shown in Fig. 12 is given by
$$H = - J _ { dir } ^ { 0 } \sigma _ { z } ^ { 2 } - J \sum _ { i = 1 } ^ { N d } s _ { i } ^ { z } ( σ _ { i } + σ _ { j } ) ,$$
where σ z i = ± 1 and s z i = ± 1 are, respectively, called system spins and decorated spins, and N d is the number of decorated spins. The circles and the squares in Fig. 12 represent the system spins and the decorated spins, respectively.
When the direct interaction between system spins J dir is zero and the decorated bond J is positive, the correlation function between system spins 〈 σ z 1 σ z 2 〉 is always positive and monotonic decaying function against the temperature. When the direct interaction between system spins J dir is negative and the decorated bond J is zero, on the other hand, the correlation function 〈 σ z 1 σ z 2 〉 is always negative and monotonic increasing function against the temperature. From this, the correlation function 〈 σ z 1 σ z 2 〉 is expected to behave non-monotonic in some cases for negative J dir and positive J or positive J dir and negative J . In order to obtain temperature dependence of the correlation function between system spins, we trace over spin states except the system spins:
$$T _ { r } ( s ; j ) e ^ { - B H } = A e K _ { e r t o i ^ { 2 } }$$
where A is just a constant which does not affect any physical quantities and the effective coupling K eff is given by
$$K _ { dir } = \frac { N d } { 2 } I n \cos h ( 2 \beta J ) +$$
Temperature dependence of the correlation function between system spins
Fig. 12. Decorated bond system where the number of system spins is two and the number of decorated spins is four ( N d = 4). The circles and squares represent system spins and decorated spins, respectively. The dotted and solid lines indicate the direct interaction between system spins and the decorated bonds, respectively.
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Diagram: Network Topology with Two Central Nodes
### Overview
The image displays a simple network or relationship diagram consisting of geometric shapes (nodes) connected by lines (edges). There is no textual information, labels, titles, or annotations present in the image. The diagram is purely graphical.
### Components/Axes
* **Nodes:**
* Two circles, positioned vertically on the left side of the diagram. One is at the top-left, the other at the bottom-left.
* Four squares, arranged in a horizontal row extending from the center to the right side of the diagram.
* **Edges (Connections):**
* A single **dashed line** connects the two circles vertically.
* Multiple **solid lines** connect each square to both circles. Each square has two solid lines emanating from it: one leading to the top circle and one to the bottom circle.
### Detailed Analysis
* **Spatial Layout:** The diagram has a clear left-to-right flow. The two circles act as primary hubs or central points on the left. The four squares are secondary nodes distributed to the right.
* **Connection Pattern:** The connectivity is dense and uniform. Every square node is connected to every circle node, creating a complete bipartite graph structure between the set of circles {C1, C2} and the set of squares {S1, S2, S3, S4}.
* **Line Types:** The use of a dashed line between the two circles suggests a different type of relationship (e.g., potential, secondary, or logical connection) compared to the solid lines connecting circles to squares (e.g., primary, physical, or active connections).
### Key Observations
1. **Symmetry and Repetition:** The diagram is highly symmetrical. The connection pattern from each square to the two circles is identical.
2. **Visual Hierarchy:** The circles, placed at the left origin point and connected by a unique dashed line, are visually emphasized as the primary elements. The squares are uniform and subordinate.
3. **Absence of Text:** The diagram contains zero textual data. All information is conveyed through shape, position, and line style.
### Interpretation
This diagram is an abstract representation of a system with two central controllers, sources, or categories (the circles) and four peripheral units, items, or sub-categories (the squares). The solid lines indicate that each peripheral unit interacts with or is dependent on both central nodes. The dashed line between the central nodes implies they are related to each other, but this relationship is of a different nature than their relationship with the peripherals.
**Possible Contexts:**
* **Network Topology:** Could represent a simple network where two core switches (circles) are connected to each other (dashed line for a trunk or backup link) and each connects to four access-layer devices (squares).
* **Organizational Chart:** Might depict two managers (circles) who both oversee the same four team members or projects (squares). The dashed line could indicate the managers are peers.
* **Data Model:** Could illustrate a database schema where two primary tables (circles) have a many-to-many relationship with a set of child tables (squares).
* **Conceptual Map:** May show two core concepts that are interrelated, with four sub-concepts each linked to both cores.
**Conclusion:** The diagram's primary function is to visualize a specific relational structure: a **complete bipartite connection (K₂,₄)** between two central nodes and four peripheral nodes, with an additional intra-group connection between the central nodes. The lack of labels makes it a generic template for such relationships.
</details>
is represented by using K eff :
$$C ^ { ( 0 ) } ( T ) = ( \sigma _ { i } ^ { 2 } j _ { 2 } ) = \frac { T _ { r } j _ { 2 } ^ { 3 } e ^ { - \beta H } } { T _ { r } e ^ { - \beta H } } = \frac { tanh K _ { eff } } { ( 156 ) }$$
Hereafter we set J as the energy unit and J is positive. In order to compare the effect of the direct interaction J dir fairly, we assume the form such as J dir = -xN d J . This is because the effective coupling K eff is proportional to the number of decorated spins N d under the assumption.
Figure 13 shows temperature dependence of correlation function between the system spins for N d = 1 and N d = 10 for several x . For small x and large x , the correlation function C (c) ( T ) is monotonic decreasing and increasing functions, respectively, against the temperature. However, the correlation function C (c) ( T ) behaves non-monotonic as a function of temperature for intermediate x . At the temperatures where the effective coupling K eff is larger than the critical value of the ferromagnetic Ising spin system on square lattice 19 K (square) c = 1 2 ln(1 + √ 2), ferromagnetic phase appears. On the other hand, at the temperature where K eff is less than -K (square) c , antiferromagnetic phase appears. In this case, successive
Fig. 13. The correlation function between system spins C (c) ( T ) as a function of temperature for N d = 1 (left panel) and for N d = 10 (right panel) in the cases of x = 0 . 1, 0 . 2, 0 . 5, 1 . 0, and 2 . 0.
<details>
<summary>Image 13 Details</summary>
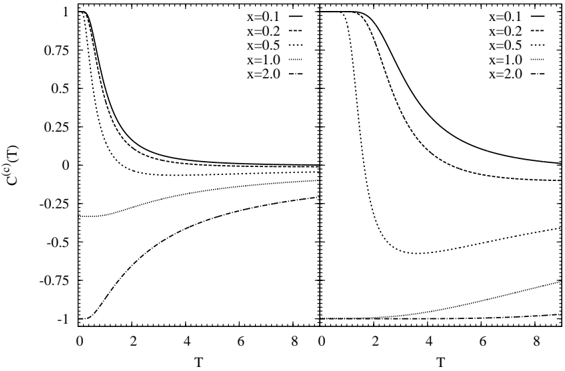
### Visual Description
## Line Chart: Two-Panel Plot of C^(θ)(T) vs. T for Various x Values
### Overview
The image displays a two-panel scientific line chart. Each panel plots the same set of five curves, representing the function C^(θ)(T) against the variable T. The two panels appear to show the same data but with different vertical scaling or focus, as the curves in the right panel exhibit more pronounced features in the negative region. The overall purpose is to illustrate how the behavior of C^(θ)(T) changes as the parameter x varies.
### Components/Axes
* **Chart Type:** Two-panel line chart (side-by-side).
* **X-Axis (Both Panels):**
* **Label:** `T`
* **Scale:** Linear, ranging from 0 to 8.
* **Major Ticks:** 0, 2, 4, 6, 8.
* **Y-Axis (Both Panels):**
* **Label:** `C^(θ)(T)`
* **Scale:** Linear, ranging from -1 to 1.
* **Major Ticks:** -1, -0.75, -0.5, -0.25, 0, 0.25, 0.5, 0.75, 1.
* **Legend (Present in both panels, top-right corner):**
* **Location:** Top-right corner within each plot area.
* **Entries (with corresponding line styles):**
* `x=0.1` — Solid line
* `x=0.2` — Dashed line (long dashes)
* `x=0.05` — Dotted line (short dots)
* `x=1.0` — Dash-dot line
* `x=2.0` — Dash-dot-dot line (long dash followed by two dots)
### Detailed Analysis
**Left Panel:**
* **Trend Verification:** All curves start at or near C^(θ)(T) = 1 when T=0. As T increases, they decay towards an asymptotic value near 0, but at different rates and with different intermediate behaviors.
* **Data Series Analysis:**
* `x=0.1` (Solid): Starts at 1, decays rapidly, approaches 0 from above. At T=2, C^(θ)(T) ≈ 0.1.
* `x=0.2` (Dashed): Starts at 1, decays slower than x=0.1, approaches 0 from above. At T=2, C^(θ)(T) ≈ 0.2.
* `x=0.05` (Dotted): Starts at 1, decays the fastest, dips slightly below 0 around T=1.5, then approaches 0 from below. At T=2, C^(θ)(T) ≈ -0.05.
* `x=1.0` (Dash-dot): Starts at 1, decays quickly, crosses zero around T=1, reaches a minimum of approximately -0.3 near T=1.5, then slowly rises towards 0. At T=2, C^(θ)(T) ≈ -0.25.
* `x=2.0` (Dash-dot-dot): Starts at 1, decays very rapidly, crosses zero near T=0.5, reaches a deep minimum of approximately -1.0 near T=1, then rises steadily towards 0. At T=2, C^(θ)(T) ≈ -0.75.
**Right Panel:**
* **Trend Verification:** This panel appears to be a "zoomed-in" or differently scaled view emphasizing the negative region. The curves for x=0.05, 1.0, and 2.0 show more detailed structure below zero.
* **Data Series Analysis:**
* `x=0.1` (Solid): Similar to left panel, decays from 1 towards 0.
* `x=0.2` (Dashed): Similar to left panel, decays from 1 towards 0.
* `x=0.05` (Dotted): Shows a pronounced dip, reaching a minimum of approximately -0.55 near T=3, before rising slowly. This feature is much more visible here than in the left panel.
* `x=1.0` (Dash-dot): Starts at 1, decays, crosses zero, and reaches a minimum of approximately -1.0 near T=2.5, then begins a slow rise.
* `x=2.0` (Dash-dot-dot): Starts at 1, decays almost vertically to -1.0 by T=0.5, remains flat at -1.0 until about T=3, then begins a very gradual rise.
### Key Observations
1. **Parameter Dependence:** The parameter `x` dramatically influences the dynamics. Lower `x` values (0.05, 0.1, 0.2) lead to monotonic or slightly undershooting decay towards zero. Higher `x` values (1.0, 2.0) cause a sharp drop into negative values, with a subsequent slow recovery.
2. **Non-Monotonic Behavior:** For `x >= 0.05`, the function C^(θ)(T) is non-monotonic, exhibiting a minimum before trending back towards zero.
3. **Asymptotic Behavior:** All curves appear to approach an asymptote of C^(θ)(T) = 0 as T becomes large (T > 8).
4. **Panel Comparison:** The right panel provides a clearer view of the minima for the `x=0.05`, `x=1.0`, and `x=2.0` curves, suggesting the left panel may be clipped or use a different vertical perspective that compresses these features.
### Interpretation
This chart likely represents the time evolution (where T is time) of a correlation function, response function, or order parameter C^(θ) in a physical or mathematical system, with `x` being a control parameter (e.g., coupling strength, temperature, disorder).
* **What the data suggests:** The system exhibits two distinct dynamical regimes based on `x`. For small `x`, the system relaxes smoothly to equilibrium (C^(θ)=0). For larger `x`, the system undergoes an "overshoot" or "anti-correlation" phase (C^(θ) becomes negative) before slowly relaxing. The depth and duration of this negative phase increase with `x`.
* **How elements relate:** The parameter `x` controls the strength of an effect that drives the system past its equilibrium point. The initial condition at T=0 is the same for all `x` (C^(θ)=1), indicating a common starting state. The subsequent divergence in paths highlights the parameter's critical role.
* **Notable anomalies:** The curve for `x=2.0` in the right panel is striking—it saturates at the minimum value of -1.0 for a significant duration (T≈0.5 to 3). This could indicate a pinned state, a saturation limit of the model, or a phase where the system is maximally anti-correlated.
* **Underlying Investigation (Peircean):** The chart is an **abductive** stimulus, prompting the question: "What kind of system produces this family of curves?" It suggests a system with inertia or memory, where a strong perturbation (high `x`) causes an overcompensation. The negative region implies an active opposing force or a reversal of the measured quantity. The slow recovery for high `x` points to a slow relaxation mechanism. This is characteristic of systems near a critical point, in glassy dynamics, or in certain non-equilibrium statistical mechanics models.
</details>
phase transitions such as paramagnetic → antiferromagnetic → paramagnetic → ferromagnetic phases occur. Such phase transitions are called reentrant phase transitions which are sometimes appeared in frustrated systems. 115,139,155-160
We consider transverse field response of the decorated bond systems in the ground state. The Hamiltonian of the decorated bond system with transverse field is expressed as
$$H = - J _ { di } \sigma ^ { z } i σ _ { j } + \sum _ { i = 1 } ^ { N _ { d } } s _ { i } ( \sigma _ { i } + o _ { i } )$$
where ˆ s α i denotes the α -component of the Pauli matrix of the i -th decorated spin. Here we consider transverse-field dependence of the correlation function in the ground state given by
$$( g s ) ( T ) , \quad ( 1 5 8 )$$
where | ψ (gs) (Γ) 〉 denotes the ground state at the transverse field Γ. Figure 14 shows transverse-field dependence of C (q) (Γ) for N d = 1 and N d = 10 for several x .
Fig. 14. The correlation function between system spins C (q) (Γ) as a function of transverse field for N d = 1 (left panels) and for N d = 10 (right panels) in the cases of x = 0 . 1, 0 . 2, 0 . 5, 1 . 0, and 2 . 0.
<details>
<summary>Image 14 Details</summary>
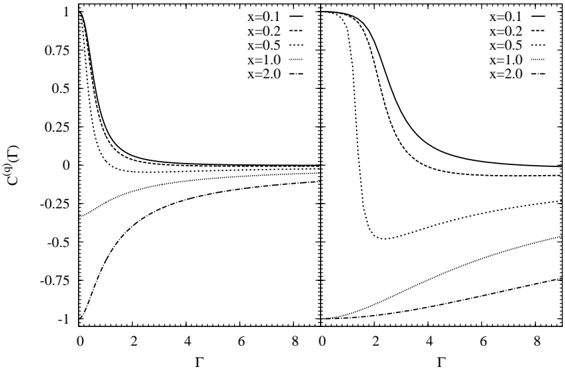
### Visual Description
## Scientific Plot: Dual-Panel Function Analysis
### Overview
The image displays a two-panel scientific plot, likely from a physics or engineering context, showing the behavior of a function denoted as `C^(0)(Γ)` against a variable `Γ`. Each panel contains multiple curves corresponding to different values of a parameter `x`. The left panel shows curves that generally decay or rise towards zero, while the right panel shows more complex, non-monotonic behavior with curves that dip and then recover.
### Components/Axes
* **Layout:** Two rectangular plot panels arranged side-by-side, sharing a common x-axis label.
* **Left Panel:**
* **Y-axis Label:** `C^(0)(Γ)` (vertical text, left side).
* **Y-axis Scale:** Linear, ranging from -1.0 to 1.0, with major ticks at intervals of 0.25 (-1, -0.75, -0.5, -0.25, 0, 0.25, 0.5, 0.75, 1).
* **X-axis Label:** `Γ` (centered below the axis).
* **X-axis Scale:** Linear, ranging from 0 to 8, with major ticks at 0, 2, 4, 6, 8.
* **Right Panel:**
* **Y-axis Label:** Not explicitly labeled. It shares the same scale and range as the left panel.
* **X-axis Label:** `Γ` (centered below the axis).
* **X-axis Scale:** Linear, ranging from 0 to 8, with major ticks at 0, 2, 4, 6, 8.
* **Legend:** Located in the top-right corner of each panel. It defines five curves by the parameter `x` and their corresponding line styles:
* `x=0.1` - Solid line
* `x=0.2` - Dashed line (long dashes)
* `x=0.5` - Dotted line (short dots)
* `x=1.0` - Solid line (thinner weight than x=0.1)
* `x=2.0` - Dash-dot line
### Detailed Analysis
**Left Panel Analysis:**
* **Trend:** All curves originate at `Γ=0` and approach the horizontal axis (`C^(0)(Γ) = 0`) as `Γ` increases, suggesting a decay or relaxation process.
* **Data Series & Approximate Points:**
* **x=0.1 (Solid):** Starts at `C^(0)(0) ≈ 1.0`. Decays rapidly, crossing `C^(0) ≈ 0.25` near `Γ ≈ 0.5`, and approaches zero asymptotically.
* **x=0.2 (Dashed):** Starts at `C^(0)(0) ≈ 1.0`. Decays slower than x=0.1, crossing `C^(0) ≈ 0.25` near `Γ ≈ 1.0`.
* **x=0.5 (Dotted):** Starts at `C^(0)(0) ≈ 1.0`. Decays more slowly, crossing `C^(0) ≈ 0.25` near `Γ ≈ 2.0`.
* **x=1.0 (Thin Solid):** Starts at `C^(0)(0) ≈ -0.3`. Rises monotonically, approaching zero from below.
* **x=2.0 (Dash-Dot):** Starts at `C^(0)(0) ≈ -1.0`. Rises monotonically, approaching zero from below, but remains more negative than the x=1.0 curve for all `Γ`.
**Right Panel Analysis:**
* **Trend:** Curves exhibit non-monotonic behavior. They start at extreme values (`1` or `-1`), undergo a significant dip or rise, and then trend back towards zero or a negative asymptote.
* **Data Series & Approximate Points:**
* **x=0.1 (Solid):** Starts at `C^(0)(0) ≈ 1.0`. Remains near 1 until `Γ ≈ 1`, then decays smoothly, crossing `C^(0) ≈ 0.5` near `Γ ≈ 2.5`, and approaches zero.
* **x=0.2 (Dashed):** Starts at `C^(0)(0) ≈ 1.0`. Begins decaying earlier than x=0.1, crossing `C^(0) ≈ 0.5` near `Γ ≈ 1.5`, and approaches zero.
* **x=0.5 (Dotted):** Starts at `C^(0)(0) ≈ 1.0`. Drops sharply, reaching a minimum of `C^(0) ≈ -0.5` near `Γ ≈ 2.5`, then rises, crossing zero near `Γ ≈ 5.5` and approaching a small positive value.
* **x=1.0 (Thin Solid):** Starts at `C^(0)(0) ≈ -1.0`. Rises steadily, crossing `C^(0) ≈ -0.5` near `Γ ≈ 3.0` and `C^(0) ≈ 0` near `Γ ≈ 7.0`.
* **x=2.0 (Dash-Dot):** Starts at `C^(0)(0) ≈ -1.0`. Rises more slowly than x=1.0, crossing `C^(0) ≈ -0.75` near `Γ ≈ 4.0`.
### Key Observations
1. **Parameter `x` Controls Dynamics:** The parameter `x` dramatically alters the functional form. Low `x` (0.1, 0.2) leads to simple decay from a positive initial condition. Intermediate `x` (0.5) causes an undershoot below zero before recovery. High `x` (1.0, 2.0) leads to growth from a negative initial condition.
2. **Initial Condition Split:** There is a clear bifurcation at `x=1.0`. For `x < 1`, `C^(0)(0) = 1`. For `x ≥ 1`, `C^(0)(0) = -1` (or near -1 for x=1.0).
3. **Asymptotic Behavior:** In the left panel, all curves converge to 0. In the right panel, curves for `x ≤ 0.2` converge to 0, while curves for `x ≥ 0.5` appear to converge to different negative or near-zero values.
4. **Crossing Points:** The `x=0.5` curve in the right panel is notable for crossing from positive to negative and back to positive, indicating a complex underlying process.
### Interpretation
This plot likely illustrates the solution to a differential equation or a response function where `x` is a critical control parameter (e.g., coupling strength, damping coefficient, or a ratio of timescales). The left panel might represent a standard or baseline response, showing how perturbations (`C^(0)`) decay over time (`Γ`). The right panel could represent a different regime or a related but distinct quantity, where the system exhibits resonant or oscillatory-like behavior (the dip and recovery) for intermediate `x`.
The sharp change in initial condition at `x=1.0` suggests a phase transition or a bifurcation point in the system's dynamics. The non-monotonic response for `x=0.5` is particularly significant, as it indicates the system can temporarily overshoot its equilibrium state. The divergence in asymptotic behavior in the right panel implies that the parameter `x` not only affects the transient response but also the final steady state of the system. This type of analysis is fundamental in fields like control theory, statistical mechanics, or signal processing to understand system stability and parameter sensitivity.
</details>
For small x and large x , the correlation function C (q) (Γ) behaves monotonic decreasing and increasing, respectively as a function of transverse field, whereas for intermediate x , transverse-field dependence of the correlation function behaves nonmonotonic as well as the case of thermal fluctuation. Then, the reentrant phase transition also occurs by changing the transverse field. However there is a difference between the thermal fluctuation effect and the quantum fluctuation effect for decorated bond system. The temperature where C (c) ( T ) = 0 is satisfied is the same when we change the number of decorated spins N d , whereas the transverse field at C (q) (Γ) = 0 is different when N d is changed.
The thermal fluctuation and the quantum fluctuation have similar properties for the phase transition phenomena in general. Indeed, the reentrant phase transitions occur by changing the thermal fluctuation and also the quantum fluctuation as shown in this section. However as described in Sec. 5.1, in order to obtain the best solution of optimization problems, it is better to erase phase transition. By dealing with thermal and quantum fluctuation effects for frustrated systems exhaustively, we can construct the best form of the adding fluctuation which erases phase transition e .
## 6. Conclusion
In this paper, we described some aspects of the quantum annealing from viewpoints of statistical physics, condensed matter physics, and computational physics. Originally, the quantum annealing has been proposed as a method which can solve efficiently optimization problems in a generic way. Since many optimization problems can be mapped onto the Ising model or generalized Ising model such as the clock model and the Potts model, it has been considered that we can obtain a better solution by using methods which were developed in computational physics. For instance, we can obtain a better solution by decreasing temperature (thermal fluctuation) gradually in the simulated annealing which is one of the most famous practical methods. In the quantum annealing, we decrease an introduced quantum field (quantum fluctuation) instead of temperature (thermal fluctuation). In many studies, it was reported that a better solution can be obtained
e It is not necessary that the adding fluctuation is restricted in quantum physics. From a viewpoint of optimization problems, we can arbitrary form adding term. Furthermore, it has studied that other novel fluctuation which may be able to erase phase transition as an alternative to thermal and quantum fluctuations. 14,116,161,162 Of course, if we want to realize experimentally, it is better that the added fluctuation term should be some kind of quantum fluctuation.
by the quantum annealing efficiently in comparison with the simulated annealing as we explained in Sec. 4. Thus, the quantum annealing method is expected to be a generic and powerful solver of optimization problems as an alternative to the simulated annealing.
The quantum annealing has become a milestone of some related fields under the situation in which the quantum annealing itself has been studied exhaustively. Since we use the quantum fluctuation in the quantum annealing with ingenuity, to obtain a better solution by using the quantum annealing is a kind of quantum information processing. Thus, many implementation methods of the quantum annealing in theoretical and experimental ways have been proposed by many researchers. A number of theoretical implementation methods are proposed based on knowledge of statistical physics. As we shown in Sec. 5, question of what are differences between the simulated annealing and the quantum annealing and question of which is efficient in the given optimization problem are catalysts to investigate differences between the thermal fluctuation and the quantum fluctuation in a deeper way. On top of that, studies on the quantum annealing are expected to open the door to consider equilibrium and nonequilibrium statistical physics. Recently, preparation methods of intended Hamiltonian have been established in some experimental systems such as artificial lattices and nuclear magnetic resonance because of recent development of experimental techniques. As long as we use classical computer and our present knowledge, there are a huge number of problems where to obtain the best solution is difficult without any and every approximation in theoretical methods. However if we prepare the Hamiltonian which expresses our intended problem, we can calculate experimentally the stable state of the prepared Hamiltonian in near future.
The quantum annealing transcends just a method for obtaining the best solution of optimization problems and it will make a development in wide area of science. Although it seems that studies on the quantum annealing itself have been well established, we believe that the quantum annealing plays a role as a bridge with the abovementioned area of science and the quantum information.
## Acknowledgement
The authors are grateful to Bernard Barbara, Bikas K. Charkrabarti, Naomichi Hatano, Masaki Hirano, Naoki Kawashima, Kenichi Kurihara, Yoshiki Matsuda, Seiji Miyashita, Hiroshi Nakagawa, Mikio Nakahara, Hidetoshi Nishimori, Masayuki Ohzeki, Hans de Raedt, Per Arne Rikvold,
Issei Sato, Sei Suzuki, Eric Vincent, and Yoshihisa Yamamoto for their valuable comments. S.T. acknowledges Keisuke Fujii, Yoshifumi Nakada, and Takahiro Sagawa for their useful discussion during the lecture. S.T. is partly supported by Grand-in-Aid for JSPS Fellows (23-7601). R.T. is partly supported financially by National Institute for Materials Science (NIMS). The computation in the present work was performed on computers at the Suprecomputer Center, Institute for Solid State Physics, University of Tokyo.
## References
1. S. Kirkpatrick, C. D. Gelatt Jr., and M. P. Vecchi, Science 220 , 671 (1983).
2. S. Kirkpatrick, J. Stat. Phys. 34 , 975 (1984).
3. S. Geman and D. Geman, IEEE Transactions on Pattern Analysis and Machine Intelligence 6 , 721 (1984).
4. A. B. Finnila, M. A. Gomez, C. Sebenik, C. Stenson, and J. D. Doll, Chem. Phys. Lett. 219 , 343 (1994).
5. T. Kadowaki and H. Nishimori, Phys. Rev. E 58 , 5355 (1998).
6. J. Brooke, D. Bitko, T. F. Rosenbaum, and G. Aeppli, Science 284 , 779 (1999).
7. E. Farhi, J. Goldstone, S. Gutmann, J. Lapan, A. Lundgren, and D. Preda, Science 292 , 472 (2001).
8. G. E. Santoro, R. Martoˇ n´ ak, E. Tosatti, and R. Car, Science 295 , 2427 (2002).
9. A. Das and B. K. Chakrabarti, Quantum Annealing and Related Optimization Methods (Springer, Heidelberg, 2005).
10. A. Das and B. K. Chakrabarti, Rev. Mod. Phys. 80 , 1061 (2008).
11. M. Ohzeki and H. Nishimori, J. Comp. and Theor. Nanoscience 8 , 963 (2011).
12. K. Kurihara, S. Tanaka, and S. Miyashita, Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (2009).
13. I. Sato, K. Kurihara, S. Tanaka, H. Nakagawa, and S. Miyashita, Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (2009).
14. S. Tanaka, R. Tamura, I. Sato, and K. Kurihara, to appear in Kinki University Quantum Computing Series: 'Summer School on Diversities in Quantum Computation/Information' .
15. C. Jarzynski, Phys. Rev. Lett. 78 , 2690 (1997).
16. C. Jarzynski, Phys. Rev. E 56 , 5018 (1997).
17. M. Ohzeki, Phys. Rev. Lett. 105 , 050401 (2010).
18. E. Ising, Z. Phys. 31 , 253 (1925).
19. L. Onsager, Phys. Rev. 65 , 117 (1944).
20. M. Blume, Phys. Rev. 141 , 517 (1966).
21. H. W. Capel, Phys. Lett. 23 , 327 (1966).
22. J. Tobochnik, Phys. Rev. B 26 , 6201 (1982).
23. M. S. S. Challa and D. P. Landau, Phys. Rev. B 33 , 437 (1986).
24. R. B. Potts, Proc. Cambridge Philos. Soc. 48 , 106 (1952).
25. F. Y. Wu, Rev. Mod. Phys. 54 , 235 (1982).
26. T. Ohtsuka, J. Phys. Soc. Jpn. 16 , 1549 (1961).
27. M. Rayl, O. E. Vilches, and J. C. Wheatley, Phys. Rev. 165 , 698 (1968).
28. K. ˆ Ono, M. Shinohara, A. Ito, N. Sakai, and M. Suenaga, Phys. Rev. Lett. 24 , 770 (1970).
29. N. Achiwa, J. Phys. Soc. Jpn. 27 , 561 (1969).
30. M. Mekata and K. Adachi, J. Phys. Soc. Jpn. 44 , 806 (1978).
31. A. H. Cooke, D. T. Edmonds, F. R. McKim, and W. P. Wolf, Proc. Roy. Soc. London Ser. A 252 , 246 (1959).
32. A. H. Cooke, D. T. Edmonds, C. B. P. Finn, and W. P. Wolf, Proc. Roy. Soc. London Ser. A 306 , 313 (1968).
33. A. H. Cooke, D. T. Edmonds, C. B. P. Finn, and W. P. Wolf, Proc. Roy. Soc. London Ser. A 306 , 335 (1968).
34. K. Takeda, M. Matsuura, S. Matsukawa, Y. Ajiro, and T. Haseda, Proc. 12th Int. Conf. Low Temp. Phys., Kyoto 803 (1970).
35. K. Takeda, S. Matsukawa, and T. Haseda, J. Phys. Soc. Jpn. 30 , 1330 (1971).
36. B. N. Figgis, M. Gerloch, and R. Mason, Acta. Crystallogr. 17 , 506 (1964).
37. R. F. Wielinga, H. W. J. Blote, J. A. Roest, and W. J. Huiskamp, Physica 34 , 223 (1967).
38. K. W. Mess, E. Lagendijk, D. A. Curtis, and W. J. Huiskamp, Physica 34 , 126 (1967).
39. G. R. Hoy and F. de S. Barros, Phys. Rev. 139 , A929 (1965).
40. M. Matsuura, H. W. J. Blote, and W. J. Huiskamp, Physica 50 , 444 (1970).
41. R. D. Pierce and S. A. Friedberg, Phys. Rev. B 3 , 934 (1971).
42. K. Takeda and S. Matsukawa, J. Phys. Soc. Jpn. 30 , 887 (1971).
43. E. Stryjewski and N. Giordano, Adv. Phys. 26 , 487 (1977).
44. D. J. Breed, K. Gilijamse, and A. R. Miedema, Physica 45 , 205 (1969).
45. K. ˆ Ono, A. Ito, and T. Fujita, J. Phys. Soc. Jpn. 19 , 2119 (1964).
46. R. J. Birgeneau, W. B. Yelon, E. Cohen, and J. Makovsky, Phys. Rev. B 5 , 2607 (1972).
47. J. C. Wright, H. W. Moos, J. H. Colwell, B. W. Magnum, and D. D. Thornton, Phys. Rev. B 3 , 843 (1971).
48. G. T. Rado, Phys. Rev. Lett. 23 , 644 (1969).
49. W. Scharenberg and G. Will, Int. J. Magnetism 1 , 277 (1971).
50. H. Fuess, A. Kallel, and F. Tch´ eou, Solid State Commun. 9 , 1949 (1971).
51. M. Ball, M. J. M. Leask, W. P. Wolf, and A. F. G. Wyatt, J. Appl. Phys. 34 , 1104 (1963).
52. J. C. Norvell, W. P. Wolf, L. M. Corliss, J. M. Hastings, and R. Nathans, Phys. Rev. 186 , 557 (1969).
53. J. C. Norvell, W. P. Wolf, L. M. Corliss, J. M. Hastings, and R. Nathans, Phys. Rev. 186 , 567 (1969).
54. G. A. Baker, Jr., Phys. Rev. 129 , 99 (1963).
55. M. F. Sykes, D. L. Hunter, D. S. McKenzie, and B. R. Heap, J. Phys. A: Gen. Phys. 5 , 667 (1972).
56. J. W. Stout and E. Catalano, J. Chem. Phys. 23 , 2013 (1955).
57. C. Domb and A. R. Miedema, Progress in low Temperature Physics, Vol. 4, edited by C. J. Gorter (North-Holland, Amsterdam, 1964).
58. G. K. Wertheim and D. N. E. Buchanan, Phys. Rev. 161 , 478 (1967).
59. Y. Shapira, Phys. Rev. B 2 , 2725 (1970).
60. M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press, Cambridge, 2000).
61. M. Nakahara and T. Ohmi, Quantum Computing: From Linear Algebra to Physical Realizations (Taylor & Francis, London, 2008).
62. D. G. Cory, A. F. Fahmy, and T. F. Havel, Proc. Natl. Acad. Sci. USA 94 , 1634 (1997).
63. D. G. Cory, M. D. Price, W. Maas, E. Knill, R. Laflamme, W. H. Zurek, T. F. Havel, and S. S. Somaroo, Phys. Rev. Lett. 81 , 2152 (1998).
64. N. A. Gershenfeld and I. L. Chuang, Science 275 , 350 (1997).
65. I. L. Chuang, L. M. K. Vandersypen, X. Zhou, D. W. Leung, and S. Lloyd, Nature 393 , 143 (1998).
66. J. A. Jones and M. Mosca, J. Chem. Phys. 109 , 1648 (1998).
67. E. Knill, I. Chuang, and R. Laflamme, Phys. Rev. A 57 , 3348 (1998).
68. R. Laflamme, E. Knill, W. H. Zurek, P. Catasti, and S. V. S. Mariappan, Phil. Trans. R. Soc. Lond. A 356 , 1941 (1998).
69. J. A. Jones and M. Mosca, Phys. Rev. Lett. 83 , 1050 (1999).
70. M. D. Price, S. S. Somaroo, A. E. Dunlop, T. F. Havel, and D. G. Cory, Phys. Rev. A 60 , 2777 (1999).
71. L. M. K. Vandersypen, C. S. Yannoni, M. H. Sherwood, and I. L. Chuang, Phys. Rev. Lett. 83 , 3085 (1999).
72. L. M. K. Vandersypen, M. Steffen, G. Breyta, C. S. Yannoni, R. Cleve, and I. L. Chuang, Phys. Rev. Lett. 85 , 5452 (2000).
73. L. M. K. Vandersypen, M. Steffen, G. Breyta, C. S. Yannoni, M. H. Sherwood, and I. L. Chuang, Nature (London) 414 , 883 (2001).
74. M. Nakahara, Y. Kondo, K. Hata, and S. Tanimura, Phys. Rev. A 70 , 052319 (2004).
75. Y. Kondo, J. Phys. Soc. Jpn. 76 , 104004 (2007).
76. H. Suwa and S. Todo, Phys. Rev. Lett. 105 , 120603 (2010).
77. H. Suwa and S. Todo, arXiv :1106.3562.
78. R. H. Swendsen and J. S. Wang, Phys. Rev. Lett. 58 , 86 (1987).
79. U. Wolff, Phys. Rev. Lett. 62 , 361 (1989).
80. K. Hukushima and K. Nemoto, J. Phys. Soc. Jpn. 65 , 1604 (1996).
81. N. Kawashima and K. Harada, J. Phys. Soc. Jpn. 73 , 1379 (2004).
82. T. Nakamura, Phys. Rev. Lett. 101 , 210602 (2008).
83. S. Morita, S. Suzuki, and T. Nakamura, Phys. Rev. E 79 , 065701(R) (2009).
84. H. F. Trotter, Proc. Am. Math. Soc. 10 , 545 (1959).
85. M. Suzuki, Prog. Theor. Phys. 56 , 1454 (1976).
86. T. Kadowaki, Ph. D thesis, Tokyo Institute of Technology (1998).
87. K. Tanaka and T. Horiguchi, Electronics and Communications in Japan, Part 3: Fundamental Electronic Science 83 , 84 (2000).
88. K. Tanaka and T. Horiguchi, Interdisciplinary Information Science 8 , 33 (2002).
89. H. Attias, Proceedings of the 15th Conference on Uncertainly in Artificial Intelligence 21 (1999).
90. L. Landau, Phys. Z. Sowjetunion 2 , 46 (1932).
91. C. Zener, Proc. R. Soc. London Ser. A 137 , 696 (1932).
92. E. C. G. St¨ uckelberg, Helv. Phys. Acta 5 , 369 (1932).
93. N. Rosen and C. Zener, Phys. Rev. 40 , 502 (1932).
94. B. K. Chakrabarti, A. Dutta, and P. Sen, Quantum Ising Phases and Transitions in Transverse Ising Models (Springer Verlag, Berlin, 1996).
95. G. T. Trammel, J. Appl. Phys. 31 , 362S (1960).
96. A. H. Cooke, D. T. Edmonds, C. B. P. Finn, and W. P. Wolf, J. Phys. Soc. Jpn. 17 , Suppl. B1 481 (1962).
97. J. W. Stout and R. C. Chisolm, J. Chem. Phys. 36 , 979 (1962).
98. V. L. Moruzzi and D. T. Teaney, Sol. State. Comm. 1 , 127 (1963).
99. A. Narath and J. E. Schriber, J. Appl. Phys. 37 , 1124 (1966).
100. R. F. Wielinga and W. J. Huiskamp, Physica 40 , 602 (1969).
101. W. P. Wolf, J. Phys. (Paris) 32 Suppl. C1 26 (1971).
102. W. Wu, B. Ellman, T. F. Rosenbaum, G. Aeppli, and D. H. Reich, Phys. Rev. Lett. 67 , 2076 (1991).
103. W. Wu, D. Bitko, T. F. Rosenbaum, and G. Aeppli, Phys. Rev. Lett. 71 , 1919 (1993).
104. D. H. Reich, B. Ellman, J. Yang, T. F. Rosenbaum, G. Aeppli, and D. P. Belanger, Phys. Rev. B 42 , 4631 (1990).
105. T. F. Rosenbaum, J. Phys.: Condens. Matter 8 , 9759 (1996).
106. D. H. Reich, T. F. Rosenbaum, G. Aeppli, and H. Guggenheim, Phys. Rev. B 34 , 4956 (1986).
107. J. A. Mydosh, Spin Glasses: An Experimental Introduction (Taylor & Francis, London, 1993).
108. P. Bak, C. Tang, and K. Wiesenfeld, Phys. Rev. Lett. 59 , 381 (1987).
109. R. Martoˇ n´ ak, G. E. Santoro, and E. Tosatti, Phys. Rev. E 70 , 057701 (2004).
110. S. Tanaka and S. Miyashita, J. Phys.: Condens. Matter 19 , 145256 (2007).
111. H. Takayama and K. Hukushima, J. Phys. Soc. Jpn. 76 , 013702 (2007).
112. S. Tanaka and S. Miyashita, J. Phys. Soc. Jpn. 76 , 103001 (2007).
113. S. Miyashita, S. Tanaka, and M. Hirano, J. Phys. Soc. Jpn. 76 , 083001 (2007).
114. S. Tanaka and S. Miyashita, J. Phys. Soc. Jpn. 78 , 084002 (2009).
115. S. Tanaka and S. Miyashita, Phys. Rev. E 81 , 051138 (2010), Virtual Journal of Quantum Information 10 , (2010).
116. S. Tanaka and R. Tamura, J. Phys.: Conf. Ser. 320 , 012025 (2011).
117. H. Nishimori and G. Ortiz, Elements of Phase Transitions and Critical Phenomena (Oxford Univ Press, Oxford, 2010).
118. N. Ito, M. Taiji, and M. Suzuki, J. Phys. Soc. Jpn. 56 , 4218 (1987).
119. T. W. B. Kibble, J. Phys. A 9 , 1387 (1976).
120. T. W. B. Kibble, Phys. Rep. 67 , 183 (1980).
121. W. H. Zurek, Nature (London) 317 , 505 (1985).
122. B. Damski, Phys. Rev. Lett. 95 , 035701 (2005).
123. W. H. Zurek, U. Dorner, and P. Zoller, Phys. Rev. Lett. 95 , 105701 (2005).
124. V. M. H. Ruutu, V. B. Eltsov, A. J. Gill, T. W. B. Kibble, M. Krusius, Y. G. Makhlin, B. Placais, G. E. Volovik, and W. Xu, Nature (London) 382 , 334 (1996).
125. V. B. Eltsov, T. W. B. Kibble, M. Krusius, V. M. H. Ruutu, and G. E. Volovik, Phys. Rev. Lett. 85 , 4739 (2000).
126. H. Saito, Y. Kawaguchi, and M. Ueda, Phys. Rev. A 76 , 043613 (2007).
127. C. N. Weiler, T. W. Neely, D. R. Scherer, A. S. Bradley, M. J. Davis, and B. P. Anderson, Nature (London) 455 , 948 (2008).
128. S. Suzuki, J. Stat. Mech. P03032 (2009).
129. S. Suzuki, J. Phys.: Conf. Ser. 302 , 012046 (2011).
130. R. J. Glauber, J. Math. Phys. 4 , 294 (1963).
131. R. Shankar and G. Murthy, Phys. Rev. B 36 , 536 (1987).
132. D. S. Fisher, Phys. Rev. B 51 , 6411 (1995).
133. J. Dziarmaga, Phys. Rev. B 74 , 064416 (2006).
134. G. Biroli, L. F. Cugliandolo, and A. Sicilia, Phys. Rev. E 81 , 050101(R) (2010).
135. G. Toulouse, Commun. Phys. (London) 2 , 115 (1977).
136. R. Liebmann, Statistical Mechanics of Periodic Frustrated Ising Systems (Springer-Verlag, Berlin/Heidelberg, GmbH, Heidelberg, 1986).
137. H. Kawamura, J. Phys.: Condens. Matter 10 , 4707 (1998).
138. H. T. Diep (ed.), Frustrated Spin Systems (World Scientific, Singapore, 2005).
139. S. Tanaka and S. Miyashita, Prog. Theor. Phys. Suppl. 157 , 34 (2005).
140. S. Tanaka and S. Miyashita, J. Phys. Soc. Jpn. 76 , 103001 (2007).
141. R. Tamura and N. Kawashima, J. Phys. Soc. Jpn. 77 , 103002 (2008).
142. S. Tanaka and S. Miyashita, J. Phys. Soc. Jpn. 78 , 084002 (2009).
143. R. Tamura and N. Kawashima, J. Phys. Soc. Jpn. 80 , 074008 (2011).
144. R. Tamura, N. Kawashima, T. Yamamoto, C. Tassel, and H. Kageyama, Phys. Rev. B 84 , 214408 (2011).
145. K. Husimi and I. Syozi, Prog. Theor. Phys. 5 , 177 (1950).
146. R. M. F. Houtappel, Physica 16 , 425 (1950).
147. G. H. Wannier, Phys. Rev. 79 , 357 (1950).
148. G. H. Wannier, Phys. Rev. B 7 , 5017 (1973).
149. K. Kano and S. Naya, Prog. Theor. Phys. 10 , 158 (1953).
150. Y. Matsuda, H. Nishimori, and H. G. Katzgraber, J. Phys.: Conf. Ser. 143 , 012003 (2009).
151. Y. Matsuda, H. Nishimori, and H. G. Katzgraber, New J. Phys. 11 , 073021 (2009).
152. S. Tanaka, M. Hirano, and S. Miyashita, Lecture Note in Physics 'Quantum Quenching, Annealing, and Computation' (Springer) 802 , 215 (2010).
153. S. Tanaka, to appear in proceedings of Kinki University Quantum Computing Series: 'Symposium on Quantum Information and Quantum Computing' (2011).
154. S. Tanaka and R. Tamura, in preparation .
155. E. H. Fradkin and T. P. Eggarter, Phys. Rev. A 14 , 495 (1976).
156. S. Miyashita, Prog. Theor. Phys. 69 , 714 (1983).
157. H. Kitatani, S. Miyashita, and M. Suzuki, Phys. Lett. 108A , 45 (1985).
158. H. Kitatani, S. Miyashita, and M. Suzuki, J. Phys. Soc. Jpn. 55 , 865 (1986).
159. P. Azaria, H. T. Diep, and H. Giacomini, Phys. Rev. Lett. 59 , 1629 (1987).
160. S. Miyashita and E. Vincent, Eur. Phys. J. B 22 , 203 (2001).
161. R. Tamura, S. Tanaka, and N. Kawashima, Prog. Theor. Phys. 124 , 381 (2010).
162. S. Tanaka and R. Tamura, and N. Kawashima, J. Phys.: Conf. Ser. 297 , 012022 (2011).