## Inapproximability of Nash Equilibrium
∗
Aviad Rubinstein September 9, 2016
## Abstract
We prove that finding an -approximate Nash equilibrium is PPAD -complete for constant and a particularly simple class of games: polymatrix, degree 3 graphical games, in which each player has only two actions.
As corollaries, we also prove similar inapproximability results for Bayesian Nash equilibrium in a two-player incomplete information game with a constant number of actions, for relative -Well Supported Nash Equilibrium in a two-player game, for market equilibrium in a non-monotone market, for the generalized circuit problem defined by Chen et al [CDT09], and for approximate competitive equilibrium from equal incomes with indivisible goods.
## 1 Introduction
Nash equilibrium is the central concept in Game Theory. Much of its importance and attractiveness comes from its universality : by Nash's Theorem [Nas51], every finite game has at least one. The result that finding a Nash equilibrium is PPAD -complete, and therefore intractable [DGP09, CDT09] casts this universality in doubt, since it suggests that there are games whose Nash equilibria, though existent, are in any practical sense inaccessible.
∗ UC Berkeley. I am grateful to Christos Papadimitriou for inspiring discussions, comments, and advice. I also thank Yang Cai for suggesting the connection to Bayesian Nash equilibrium in two-player games. Additional thanks go to Constantinos Daskalakis, Karthik C.S., and anonymous reviewers for helpful comments. This research was supported by NSF grants CCF0964033 and CCF1408635, and by Templeton Foundation grant 3966. This work was done in part at the Simons Institute for the Theory of Computing.
Can approximation repair this problem? Chen et al [CDT09] proved that it is also hard to find an -approximate Nash equilibrium for any that is polynomially small - even for two-player games. The only remaining hope is a PTAS, i.e. an approximation scheme for any constant > 0 . Whether there is a PTAS for the Nash equilibrium problem is the most important remaining open question in equilibrium computation.
For a constant number of players, we are unlikely to prove PPAD -hardness since a quasi-polynomial time approximation algorithm exists [LMM03] 1 . We therefore shift our attention to games with a large number of players. For such games, there is a question of representation: the normal form representation is exponential in the number of the players. Instead, we consider two natural and well-studied concise representations:
- Polymatrix games In a polymatrix game, each pair of players simultaneously plays a separate two-player game. Every player has to play the same strategy in every two-player subgame, and her utility is the sum of her subgame utilities. The game is given in the form of the payoff matrix for each two-player game.
- Graphical games In a graphical game [Kea07], the utility of each player depends only on the action chosen by a few other players. This game now naturally induces a directed graph: we say that ( i, j ) ∈ E if the utility of player j depends on the strategy chosen by player i . When the maximal incoming degree is bounded, the game has a representation polynomial in the number of players and strategies.
## Our results
We prove that even for games that are both polymatrix and graphical (for particularly simple graphs) finding an -approximate Nash equilibrium is intractable.
Theorem 1. There exists a constant > 0 , such that given a degree 3 , bipartite, polymatrix game where each player has two actions, finding an -approximate Nash equilibrium is PPAD -complete.
In previous works [CDT09, DGP09], hardness of Nash equilibrium in twoplayer games was obtained from hardness of a bipartite polymatrix game. Roughly
1 In followup work [Rub16] we prove that assuming the 'Exponential Time Hypothesis (ETH) for PPAD ', quasi-polynomial running time of [LMM03]'s algorithm is indeed necessary.
speaking, the reduction lets each of the two players choose the strategies for the vertices on one side of the bipartite graphical game. This reduction incurs a polynomial blowup in the error - and indeed, as discussed earlier, we do not expect to obtain PPAD -hardness for -approximate Nash equilibrium in two-player games. Nevertheless, in Section 8 we show that a similar technique yields an interesting corollary for -approximate Bayesian Nash equilibrium in two-player games with incomplete information.
Corollary 1 ( -Bayesian Nash equilibrium) . There exists a constant > 0 , such that given a two-player game with incomplete information where each player has a constant number of actions, finding an -approximate Bayesian Nash equilibrium is PPAD -complete.
In two-player complete information games, Daskalakis [Das13] circumvents Lipton et al's quasi-polynomial time algorithm by studying a notion of relative (sometimes also called multiplicative [HdRS08], as opposed to the more standard additive) -Well Supported Nash Equilibrium (relative -WSNE). Daskalakis proves that in two player games with payoffs in [ -1 , 1] , finding a relative -WSNE is PPAD -complete. One caveat of this result is that the gain from deviation is large compared to the expected payoff because the latter is small due to cancellation of positive and negative payoffs. Namely, the gain from deviation may be very small compared to the expected magnitude of the payoff. Here we answer an open question from [Das13] by proving that finding a relative -WSNE continues to be PPAD -complete even when all the payoffs are positive.
Corollary 2 (Relative -WSNE) . There exists a constant > 0 such that finding a relative -Well Supported Nash Equilibrium in a bimatrix game with positive payoffs is PPAD-complete.
The computation of Nash equilibrium is tightly related to computation of equilibrium in markets. In particular, Chen, Paparas, and Yannakakis [CPY13] use a reduction from polymatrix games to prove PPAD -hardness for the computation of equilibrium for every family of utility functions from a very general class, which they call non-monotone families of utility functions . In Section 10 we prove the following hardness of approximation for market equilibrium.
Corollary 3 (Non-monotone markets) . Let U be any non-monotone family of utility functions. There exists a constant U > 0 such that given a market M
where the utility of each trader is either linear or taken from U , finding an U -tight approximate market equilibrium is PPAD -hard.
Although our inapproximability factor is stronger than that showed by Chen et al, the results are incomparable as ours only holds for the stronger notion of 'tight' approximate equilibrium, by which we mean the more standard definition which bounds the two-sided error of the market equilibrium. Chen et al, in contrast, prove that even if we allow arbitrary excess supply, finding a (1 /n ) -approximate equilibrium is PPAD -hard. Furthermore, for the interesting case of CES utilities with parameter ρ < 0 , they show that there exist markets where every (1 / 2) -tight equilibrium requires prices that are doubly-exponentially large (and thus require an exponential-size representation). Indeed, for a general non-monotone family U , the problem of computing a (tight or not) approximate equilibrium may not belong to PPAD . Nevertheless, the important family of additively separable, concave piecewise-linear utilities is known to satisfy the non-monotone condition [CPY13], and yet the computation of (exact) market equilibrium is in PPAD [VY11]. Therefore,
Corollary 4 (SPLC markets) . There exists a constant > 0 , such that finding an -tight approximate market equilibrium with additively separable, concave piecewise-linear utilities is PPAD -complete.
En route to proving our main result, we also prove hardness of approximation for the generalized circuit problem. Generalized circuits are similar to standard algebraic circuits, the main difference being that generalized circuits contain cycles, which allow them to verify fixed points of continuous functions. A generalized circuit induces a constraint satisfaction problem, -Gcircuit [CDT09]: find an assignment for the values on the lines of the circuit, that simultaneously -approximately satisfies all the constraints imposed by the gates (see Section 3.2 for a formal definition). -Gcircuit was implicitly proven PPAD -complete for exponentially small by Daskalakis et al [DGP09], and explicitly for polynomially small by Chen et al [CDT09]. Here we prove that it continues to be PPAD -complete for some constant .
Theorem 2 (Generalized circuit) . There exists a constant > 0 such that -Gcircuit with fan-out 2 is PPAD -complete.
The -Gcircuit problem has already proven useful in several works in recent years (e.g [CDT09, Das13, CPY13, OPR14]). We believe that Theorem 2
will lead to stronger hardness results in many applications in algorithmic game theory and economics. For example, competitive equilibrium with equal incomes (CEEI) is a well-known fair allocation mechanism [Fol67, Var74, TV85]; however, for indivisible resources a CEEI may not exist. It was shown by Budish [Bud11] that in the case of indivisible resources there is always an allocation, called ACEEI, that is approximately fair, approximately truthful, and approximately efficient, for some favorable approximation parameters. This approximation is used in practice to assign business school students to classes [Oth14].
The approximation of CEEI is characterized by two parameters: α , which is a measure of the market clearing error, and β , which quantifies the inequality in initial endowments. Budish's proof guarantees the existence of an ( α ∗ , β ) -CEEI for any β > 0 (and some parameter α ∗ that depends on the input). Othman et al [OPR14] reduced Θ( β log (1 /β )) -Gcircuit with fan-out 2 to the problem of finding the guaranteed approximation, ( α ∗ , β ) -CEEI. Theorem 2 now gives the following corollary:
Corollary 5 (A-CEEI) . There exists a constant β > 0 such that finding an ( α ∗ , β ) -CEEI is PPAD -complete.
## 1.1 Related works
This work extends [DGP09, CDT09, CPY13, OPR14] where similar hardness results were established for 1 / poly ( n ) -approximation. It also extends our own [Rub14], where we proved PPAD -hardness of -Well Supported Nash equilibrium ( -WSNE), for constant and a constant number of actions per player, over a larger class of games called succinct games . Succinct games can have much more complex utilities than polymatrix or graphical games of bounded degree: any utility function that can be computed in polynomial time is allowed.
We improve over the results of [Rub14] in three ways: (1) simplicity: our new hardness result holds for a much simpler and more natural definition of games; (2) -ANE vs -WSNE: thanks to the transformation to bounded degree graphical games our result extends to the weaker concept (thus stronger hardness) of -approximate Nash equilibrium (see Section 3.1 for precise definitions); and (3) completeness: finding an approximate Nash equilibrium in a bounded-degree graphical game is not only PPAD -hard - it also belongs to PPAD [DGP09]. For succinct games, in contrast, -WSNE is unlikely to belong to PPAD since it is also known to be BPP -hard [SV12].
On the technical side, our current construction of hard instances of Brouwer fixed points is identical to [Rub14]. The main technical contribution in this paper is the adaptation of the equiangle sampling gadget of Chen et al [CDT09] to this particular Brouwer function.
Query complexity There are several interesting results on the query complexity of approximate Nash equilibria, where the algorithm is assumed to have black-box access to the exponential-size payoff function.
Hart and Nisan [HN13] prove that any deterministic algorithm needs to query at least an exponential number of queries to compute any -Well Supported Nash Equilibrium - and even for any -correlated equilibrium. For -correlated equilibrium, on the other hand, Hart and Nisan show a randomized algorithm that uses a number of queries polynomial in n and -1 .
Babichenko [Bab14] showed that any randomized algorithm requires an exponential number of queries to find an -Well Supported Nash Equilibrium. Our proof is inspired by Babichenko's work and builds on some of his techniques. Babichenko's query complexity lower bound was eventually extended to -Approximate Nash Equilibrium [CCT15, Rub16] and later also to communication complexity [BR16].
Goldberg and Roth [GR14] characterize the query complexity of approximate coarse correlated equilibrium in games with many players. More important for our purpose is their polynomial upper bound on the query complexity of -WSNE for any family of games that have any concise representation. This result is to be contrasted with (a) Babichenko's query complexity lower bound, which uses a larger family of games, and (b) [Rub14] which applies exactly to this setting and gives a lower bound on the computational complexity .
A much older yet very interesting and closely related result is that of Hirsch, Papadimitriou, and Vavasis [HPV89]. Hirsch et al show that any deterministic algorithm for computing a Brouwer fixed point in the oracle model must make an exponential -in the dimension n and the approximation - number of queries for values of the function. The techniques in [HPV89] have proven particularly useful both in [Bab14, Rub14] and here.
Approximation algorithms In any polymatrix game and for any constant δ > 0 , Deligkas et al [DFSS14] give a polynomial time algorithm for finding a
(1 / 2 + δ ) -ANE. For the special case of polymatrix graphical games on a tree graph, Barman et al [BLP15] give a PTAS.
Followup work on PCP for PPAD Following our work, [BPR16] conjecture the following robust strengthening of our main theorem: given a polymatrix, graphical game, it is PPAD -hard to find a strategy profile where a (1 -δ ) -fraction of the players are playing -approximate best response, for some constants , δ > 0 . (Our Theorem 1 corresponds to the case of δ = 1 / poly ( n ) .) [BPR16] prove that this so-called 'PCP for PPAD ' is equivalent to a robust variant of our Theorem 2, and implies robust versions of Corollaries 2 and 5. This conjecture remains an open problem.
[Rub16] uses related ideas to prove that the quasi-polynomial time algorithm of Lipton et al [LMM03] for -ANE in two-player games is essentially tight: improving to polynomial time would imply an unlikely subexponentialtime algorithm for EndOfTheLine .
## 2 Proof overview
Webegin our proof of Theorem 1 with the EndOfTheLine problem over { 0 , 1 } n [DGP09]. Our first step (Section 4) is to reduce this problem to the problem of finding an approximate fixed point of a particular continuous function, inspired by the work of Hirsch et al [HPV89] (this reduction also appeared in [Rub14]). Our second step (Section 5) is to reduce the problem of finding an approximate fixed point of this particular function to that of finding an approximate solution to a generalized circuit. In Section 6, we further reduce to a generalized circuit with fan-out 2 . Our final step (Section 7) is to reduce the problem of finding an approximate solution to a circuit with fan-out 2 to that of finding an approximate Nash equilibrium. This reduction follows directly from the game gadgets of Daskalakis et al [DGP09] which establishes the result for -WSNE. We complete the proof by pointing out that for bounded degree graphical games, finding an -WSNE reduces to finding a Θ( 2 ) -ANE.
Our main technical contribution is in the second step, which reduces finding an approximate fixed point of a particular continuous function, to finding an approximate solution to [CDT09]'s generalized circuit problem. We provide further details below (see also Section 5).
## Obtaining a constant hardness of -Gcircuit
A key idea that enables us to improve over previous hardness of approximation for -Gcircuit (and Nash equilibrium) [DGP09, CDT09] is that we start from a better instance of Brouwer function due to [HPV89]. The first advantage is that our instance is simply harder to approximate: finding an -approximate fixed point (i.e. x such that ‖ f ( x ) -x ‖ ∞ ≤ ) is PPAD -hard for = Ω(1) (as opposed to = 1 / exp ( n ) for [DGP09] and = 1 / poly ( n ) in [CDT09]). This advantage of the Hirsch et al construction was used before by Babichenko [Bab14] and also in [Rub14].
A simpler averaging gadget Our construction of hard instances of Brouwer functions, as do the ones form previous works, partitions the (continuous) hypercube into subcubes, and define the function separately on each subcube. When we construct a circuit that approximately simulates such a Brouwer function, we have a problem near the facets of the subcubes: using approximate gates and brittle comparators (both defined formally in Section 3.2), one cannot determine to which subcube the input belongs. This is the most challenging part of our reduction, as was also the case in [DGP09, CDT09].
Originally, Daskalakis et al [DGP09] tackled this obstacle by approximating f ( x ) as the average over a ball around x . The key observation is that even if x is close to a facet between subcubes, most of the points in its neighborhoods will be sufficiently far. Yet if f is Lipschitz they are mapped approximately to the same point as x . This works fine in O (1) dimensions, but then the inapproximability parameter is inherently exponentially small (in constant dimensions, it is easy to construct a 1 / poly ( n ) -net over the unit hypercube). For poly ( n ) dimensions, the (discretization of the) ball around x contains exponentially many points.
Chen et al [CDT09] overcome this problem using equiangle sampling : consider many translations of the input vector by adding small multiples of the all-ones vector; compute the displacement for each translation, and average. Since each translation may be close to a facet in a different dimension, Chen et al consider a polynomial number of translations. Thus, all translations must be polynomially close to each other - otherwise they will be too far to approximate the true input.
We avoid this problem by observing another nice property of the [HPV89]'s construction: when the input vector lies near two or more facets, the displace-
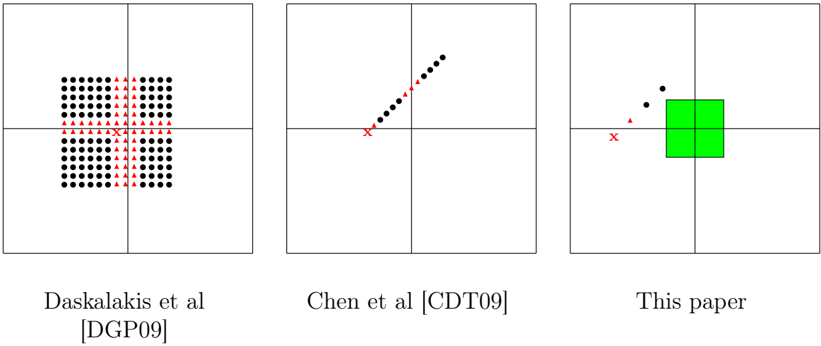
Figure 1: Comparison of averaging gadgets
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Comparison of Algorithms
### Overview
The image presents three diagrams, each representing the performance or behavior of a different algorithm. Each diagram is contained within a square divided into four quadrants. The diagrams use black dots, red triangles, and a red 'X' to represent data points or markers. The third diagram also includes a green square. The diagrams are labeled with the names of the algorithms or their corresponding publications.
### Components/Axes
Each diagram is contained within a square divided into four quadrants by horizontal and vertical lines.
* **Markers:**
* Black dots: Represent data points.
* Red triangles: Represent data points.
* Red 'X': Represents a specific point or origin.
* Green square: Represents an area or region.
* **Labels:**
* Left Diagram: "Daskalakis et al [DGP09]"
* Middle Diagram: "Chen et al [CDT09]"
* Right Diagram: "This paper"
### Detailed Analysis
**Left Diagram: Daskalakis et al [DGP09]**
* A grid of black dots fills the top-left, top-right, bottom-left, and bottom-right quadrants, leaving a vertical space in the center.
* Red triangles are positioned vertically in the center of the square, forming a line.
* A red 'X' is located at the intersection of the horizontal and vertical lines, in the center of the square.
**Middle Diagram: Chen et al [CDT09]**
* Black dots form a line that slopes upwards from the center towards the top-right quadrant.
* Red triangles are positioned along the lower part of the line of black dots, closer to the center.
* A red 'X' is located at the intersection of the horizontal and vertical lines, in the center of the square.
**Right Diagram: This paper**
* A green square is positioned in the center of the square, spanning across all four quadrants.
* Two black dots are located in the top-left quadrant, above the green square.
* One red triangle is located in the bottom-left quadrant, below the black dots.
* A red 'X' is located at the intersection of the horizontal and vertical lines, in the center of the square.
### Key Observations
* The Daskalakis et al diagram shows a clustered distribution of data points with a clear separation in the center.
* The Chen et al diagram shows a linear relationship between data points.
* The "This paper" diagram shows a concentrated area (green square) with a few scattered data points.
### Interpretation
The diagrams likely represent the performance or results of different algorithms in a specific context. The Daskalakis et al algorithm seems to have a clustered behavior, while the Chen et al algorithm shows a linear trend. "This paper" algorithm appears to have a concentrated result, possibly indicating a more focused or localized outcome. The red 'X' likely represents a starting point or a reference point for the algorithms. The red triangles may represent a specific type of data point or a threshold. The green square in the "This paper" diagram could represent a target area or a region of optimal performance.
</details>
A comparison of the averaging gadgets of [DGP09], [CDT09], and this paper. x is the point whose displacement we would like to estimate using imprecise gates and brittle comparators. Points that are too close to a facet between subcubes are denoted by triangles, while points that are sufficiently far are denoted by circles. Finally, in this paper we have a 'safe' zone (shaded) around the corner where we don't need to parse the subcube; thus we only need to avoid one facet.
ment is (approximately) the same, regardless of the subcube. Once we rule out such points, it suffices to sample only a constant number of points (as at most one of them may be too close to a facet). See also illustration in Figure 2.
Completing the proof Given a point x ′ ≈ x which is safely in the interior of one subcube, we can parse the corresponding binary vector, use logical operator gates to simulate the EndOfTheLine circuit, and then approximately compute f ( x ′ ) . This is tedious, but mostly straightforward.
One particular challenge that nevertheless arises is preventing the error from accumulating when concatenating approximate gates. Of course this is more difficult in our setting where each gate may err by a constant > 0 . Fortunately, the definition of -Gcircuit provides logical operator gates that round the output to { 0 , 1 } before introducing new error. As long as the inputs are unambiguous bits, approximate logical operator gates can be concatenated without accumulating errors.
In order to carry out the reduction to Nash equilibrium (Section 7), we must first ensure that every gate in our generalized circuit has a constant fan-out
(Section 6). We can replace each logical operator gate with a binary tree of fan-out 2 , alternating negation gates (that do not accumulate error). Given an arithmetic gate with large fan-out, we convert its output to unary representation 2 using a constant number of (fan-out 2 ) gates. Then we copy the unary representation using a binary tree of negation gates. Finally, we convert each copy back to a real number using a constant number of gates.
## 2.1 Alternative proofs
We informally sketch a couple of different approaches that could lead to our main theorem or similar results.
## No averaging gadget
The simpler averaging gadget was perhaps the main breakthrough that enabled us to improve on the results in [Rub14]. In hindsight it seems that we could completely avoid the use of averaging gadgets. As we discuss in the previous subsection, reducing from the Hirsch et al Brouwer function allows us to treat corners , i.e. the intersection of two or more facets, differently. In particular, near corners we don't need to determine to which subcube our input vector belongs because the displacement is always the same. The simpler averaging gadget is used when we are close to one facet.
Alternatively, one could construct a gadget that determines that the input is close to a particular facet -without deciding on which side of the facetand compute the Hirsch et al displacement on that facet. Thus, no averaging gadget is needed, but some care is necessary when stitching together the corner gadget (which would be the same as this paper), the facet gadget, and the interior point gadget.
## A richer set of gates
There is also a simpler and more intuitive reduction that gives somewhat weaker results, namely: PPAD -completeness for degree 3 graphical games with a constant number of actions per player.
2 Unary representation of numbers with constant precision is prevalent throughout our implementation of the generalized circuit. We prefer unary representation over binary, because in the former at most one bit can be ambiguous due to the use of brittle comparators.
The most arduous part in our proof is the second step, which takes us from the Hirsch et al Brouwer function to a generalized circuit. In order to prove this reduction, we must design a circuit (or an algorithm) that implements the equiangle sampling and the Hirsch et al Brouwer function using the limited set of gates allowed in Chen et al's definition of -Gcircuit . This part could be simplified using a more expressive set of gates.
A recent reduction that appeared in Eran Shmaya's blog [Shm12] would essentially allow us to to replace the -Gcircuit gates with any gates of bounded fan-in and fan-out that compute c -Lipschitz functions for any constant c . We briefly sketch here this reduction from an arbitrary generalized circuit to a graphical game:
Each line in the circuit corresponds to a player, and we connect all players that share a common gate. The pure strategies of each player correspond to an O ( ) -discretization of [0 , 1] . When the player that corresponds to the output of gate G plays strategy b , and the input players play strategies a 1 and a 2 , the utility to the output player is given by
$$loc_40>loc_1><loc_460>loc_50>u \left ( b , a _ { 1 } , a _ { 2 } \right ) = - \left | b - G \left ( a _ { 1 } , a _ { 2 } \right ) \right | ^ { 2 }$$
It can be shown that in any O ( 2 ) -WSNE of this game, the output player only uses the strategy 3 b ∗ which is closest to E a 1 ,a 2 [ G ( a 1 , a 2 )] (i.e. the expectation of G ( a 1 , a 2 ) over the mixed strategies of the input players).
## 3 Preliminaries
Throughout this paper we use the max-norm as the default measure of distance. In particular, when we say that f is M -Lipschitz we mean that for every x and y in the domain of f , ‖ f ( x ) -f ( y ) ‖ ∞ ≤ M ‖ x -y ‖ ∞ .
A large part of our paper deals with approximate solutions to equations. We adopt the notation of writing x = y ± to imply that x ∈ ( y -, y + ) .
We use ξ i to denote the i -th standard basis vector, and 0 n to denote the all-zeros vector.
3 There may be two strategies which are equally close to E a 1 ,a 2 [ G ( a 1 , a 2 )] , in which case the output player may use a mixed strategy.
## The EndOfTheLine problem
Our reduction starts from the EndOfTheLine problem. This problem was implicit in [Pap94], and explicitly defined in [DGP09].
Definition 1. EndOfTheLine : ([DGP09]) Given two circuits S and P , with n input bits and n output bits each, such that P (0 n ) = 0 n = S (0 n ) , find an input x ∈ { 0 , 1 } n such that P ( S ( x )) = x or S ( P ( x )) = x = 0 n .
We like to interpret EndOfTheLine as a problem over a graph which is implicitly defined by circuits S and P : every vertex x ∈ { 0 , 1 } n has one incoming edge from P ( x ) , and one outgoing edge to S ( x ) . The only exceptions are sources, for which P ( x ) = x , and sinks, for which S ( x ) = x . The special vertex 0 n has an odd degree (no incoming edge), so by a parity argument, there must be at least one more vertex with an odd degree. The goal is to find such a vertex. For technical reasons, we also allow the solution to point out inconsistencies in the graph definition (i.e. x thinks it has an incoming edge from y , but y doesn't have an outgoing edge to x ).
Theorem. (Essentially [Pap94]) EndOfTheLine is PPAD -complete.
## 3.1 -Well Supported Nash Equilibrium vs -Approximate Nash Equilibrium
A mixed strategy of player i is a distribution over i 's set of actions, denoted x i ∈ ∆ A i . We say that a vector of mixed strategies x ∈ × j ∆ A j is a Nash equilibrium if every strategy a i in the support of x i is a best response to the actions of the mixed strategies of the rest of the players, x -i . Formally,
$$\begin{array} { r } { \forall a _ { i } \in S u p p \left ( x _ { i } \right ) \, \mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a _ { i } , a _ { - i } \right ) \right ] = \max _ { a ^ { \prime } \in A _ { i } } \mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a ^ { \prime } , a _ { - i } \right ) \right ] \, . } \end{array}$$
Equivalently, x is a Nash equilibrium if each mixed strategy x i is a best mixed response to x -i :
$$\mathbb { E } _ { a \sim x } \left [ u _ { i } \left ( a \right ) \right ] = \max _ { x _ { i } ^ { \prime } \in \Delta A _ { i } } \mathbb { E } _ { a \sim \left ( x _ { i } ^ { \prime } ; x _ { - i } \right ) } \left [ u _ { i } \left ( a \right ) \right ] \, .$$
Each of those equivalent definitions can be generalized to include approximation in a different way. (Of course, there are also other interesting generalizations
of Nash equilibria to approximate settings.) We say that x is an -approximate Nash equilibrium ( -ANE ) if each x i is an -best mixed response to x -i :
$$\mathbb { E } _ { a \sim x } \left [ u _ { i } \left ( a \right ) \right ] \geq \max _ { x _ { i } ^ { \prime } \in \Delta A _ { i } } \mathbb { E } _ { a \sim \left ( x _ { i } ^ { \prime } ; x _ { - i } \right ) } \left [ u _ { i } \left ( a \right ) \right ] - \epsilon \, .$$
On the other hand, we generalize the first definition of Nash equilibrium by saying that x is a -Well Supported Nash Equilibrium ( -WSNE ; sometimes also just -Nash Equilibrium [Das13]) if each a i in the support of x i is an -best response to x -i :
$$\forall a _ { i } \in S u p p \left ( x _ { i } \right ) \, \mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a _ { i } , a _ { - i } \right ) \right ] \geq \max _ { a ^ { ^ { \prime } } \in A _ { i } } \mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a ^ { ^ { \prime } } , a _ { - i } \right ) \right ] - \epsilon \, .$$
It is easy to see that every -WSNE is also an -ANE, but the converse is false. In Lemma 5 we prove that given an -ANE in a graphical game with incoming degree d in , it is possible to find a Θ( √ d in ) -WSNE. We note that this approach is unlikely to give a lower bound on the query complexity for -ANE: graphical games of bounded incoming degree can be learned in a polynomial number of queries; furthermore, due to [GR14], for any concisely represented game, it is possible to find an -WSNE (and hence also -ANE) in a polynomial number of queries.
## 3.2 The -Gcircuit problem
Generalized circuits are similar to the standard algebraic circuits, the main difference being that generalized circuits contain cycles, which allow them to verify fixed points of continuous functions. We restrict the class of generalized circuits to include only a particular list of gates described below. Formally,
Definition 2. [Generalized circuits, [CDT09]] A generalized circuit S is a pair ( V, T ) , where V is a set of nodes and T is a collection of gates. Every gate T ∈ T is a 5-tuple T = G ( ζ | v 1 , v 2 | v ) , in which G ∈ { G ζ , G × ζ , G = , G + , G -, G < , G ∨ , G ∧ , G ¬ } is the type of the gate; ζ ∈ R ∪{ nil } is a real parameter; v 1 , v 2 ∈ V ∪{ nil } are the first and second input nodes of the gate; and v ∈ V is the output node.
The collection T of gates must satisfy the following important property: For every two gates T = G ( ζ | v 1 , v 2 | v ) and T ′ = G ′ ( ζ ′ | v ′ 1 , v ′ 2 | v ′ ) in T , v = v ′ .
Alternatively, we can think of each gate as a constraint on the values on the incoming and outgoing wires. We are interested in the following constraint
satisfaction problem: given a generalized circuit, find an assignment to all the wires that simultaneously satisfies all the gates. When every gate computes a continuous function of the incoming wires (with inputs and output in [0 , 1] ), a solution must exist by Brouwer's fixed point theorem.
In particular, we are interested in the approximate version of this CSP, where we must approximately satisfy every constraint.
Definition 3. Given a generalized circuit S = ( V, T ) , we say that an assignment x : V → [0 , 1] -approximately satisfies S if for each of the following gates, x satisfies the corresponding constraints:
| Gate | Constraint |
|-------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| G ζ ( α || a ) | x [ a ] = α ± |
| G × ζ ( α | a | b ) | x [ b ] = α · x [ a ] ± |
| G = ( | a | b ) | x [ b ] = x [ a ] ± |
| G + ( | a, b | c ) | x [ c ] = min( x [ a ]+ x [ b ] , 1) ± |
| G - ( | a, b | c ) | x [ c ] = max( x [ a ] - x [ b ] , 0) ± |
| G < ( | a, b | c ) | x [ c ] = 1 ± x [ a ] < x [ b ] - 0 ± x [ a ] > x [ b ]+ |
| G ∨ ( | a, b | c ) | [ c ] = 1 ± x [ a ] = 1 ± or x [ b ] = 1 ± 0 ± x [ a ] = 0 ± and x [ b ] = 0 ± |
| G ∧ ( | a, b | c ) | [ c ] = 1 ± x [ a ] = 1 ± and x [ b ] = 1 ± 0 ± x [ a ] = 0 ± or x [ b ] = 0 ± |
| G ¬ ( | a | b ) | x [ b ] = 1 ± x [ a ] = 0 ± 0 ± x [ a ] = 1 ± |
(Where G ζ and G × ζ also take a parameter α ∈ [0 , 1] .)
Given a generalized circuit S = ( V, T ) , -Gcircuit is the problem of finding an assignment that -approximately satisfies it.
Brittle comparators Intuitively, in order for (approximate) solutions to the circuit problem to correspond to (approximate) equilibria, all our gates should implement continuous (Lipschitz) functions. The gate G < ( | a, b | c ) , for exam-
ple, approximates that the function c ( a, b ) = 1 a < b 0 a ≥ b , which is not contin- uous. To overcome this problem, Daskalakis et al [DGP09] defined the brittle comparator : when a is ( -) larger than b , it outputs 0 ; when b is ( -) larger than a , it outputs 1 . However, when a and b are ( -approximately) equal, its behavior is undefined.
Brittleness introduces difficulties in the transition from continuous to discrete solutions. This challenge is overcome by an averaging gadget, which is described in detail in Section 5.
## 3.3 Max-norm Geometry
As we mentioned earlier, throughout this paper we work with the max-norm. This has some implications that may contradict our geometric intuition. For example: in a max-norm world, a circle is a square .
Max-norm interpolation Given coordinates x, y ≥ 0 , we define the maxnorm angle 4 that point ( x, y ) forms with the X -axis (in the XY -plane) as
$$\theta _ { \max } \left ( x , y \right ) = \frac { y } { x + y }$$
The max-norm angle is useful for interpolation. Given the values of f : [0 , 1] n → [0 , 1] n on two neighboring facets of the hypercube, we can extend f to all points of the hypercube by angular interpolation : interpolate according to the maxnorm angle θ max ( x i , x j ) where x i and x j are the respective distances from the two facets. When f is defined on two opposite facets, we can simply use Cartesian interpolation , which again means to interpolate according to the distance from each facet.
Max-norm local polar coordinates Given a point z ∈ R n we define a new local max-norm polar coordinate system around z . Every x ∈ R n is transformed into 〈 r, p 〉 z ∈ R × R n where r = ‖ x -z ‖ is the max-norm radius, and p = ( x -z ) /r is the max-norm unit vector that points from z in the direction of x .
4 Our max-norm angle was called unit in [HPV89].
## 4 Finding an approximate Brouwer fixed point is PPAD -hard
In the first step of the proof, we show that finding an approximate Brouwer fixed point is PPAD -hard. Essentially the same reduction also appeared in [Rub14], and it heavily relies on techniques of Hirsch et al [HPV89].
Theorem 3. (Essentially [Rub14]) There exists a constant > 0 such that, given an arithmetic circuit that computes an M -Lipschitz function f : [0 , 1] n → [0 , 1] n , finding an -fixed point of f (an x such that ‖ f ( x ) -x ‖ ≤ ) is PPAD -hard.
Theorem 3 by itself does not quite suffice for proving our main theorem. In Section 5 we use the specific properties of our construction, in particular those detailed in Fact 1.
Proof. In the first step (Subsection 4.1), we embed the EndOfTheLine problem (over { 0 , 1 } n ) as a collection H of vertex-disjoint paths over the (2 n +1) -dimensional hypercube graph. Given H , our second step (Subsection 4.2) is to construct a continuous mapping f : [0 , 1] 2 n +2 → [0 , 1] 2 n +2 whose fixed points correspond to ends of paths in H . This step generalizes a construction of Hirsch et al [HPV89] for embedding a single path.
## 4.1 Embedding the EndOfTheLine graph as paths in { 0 , 1 } 2 n +1
Our first step in the reduction is to embed an EndOfTheLine graph as vertexdisjoint paths on the (2 n +1) -dimensional hypercube graph. We first recall that the input to the EndOfTheLine problem is given as two circuits S and P , which define a directed graph over G over { 0 , 1 } n . Given S and P , we construct a collection H of vertex-disjoint paths and cycles over the (2 n +1) -dimensional hypercube graph, such that there is a 1-to-1 correspondence between starting and end points of paths in H and starting and end points of lines in G .
In order to construct our embedding we divide the 2 n + 1 coordinates as follows: the first n coordinates store the current vertex u , the next n coordinates for the next vertex in the line, v , and finally, the last coordinate b stores a compute-next vs copy bit. When b = 0 , the path proceeds to update v ← S ( u ) , bit-by-bit. When this update is complete, the value of b is changed to 1 . Whenever b = 1 , the path proceeds by copying u ← v bit-by-bit, and then
changes that value of b again. Finally, when u = v = S ( u ) and b = 0 , the path reaches an end point. For example, the edge x → y maps into the path:
$$( x , x , 0 ) \rightarrow \cdots \rightarrow ( x , y , 0 ) \rightarrow ( x , y , 1 ) \rightarrow \cdots \rightarrow ( y , y , 1 ) \rightarrow ( y , y , 0 ) \, .$$
Notice that the paths in H do not intersect. Furthermore, given a vector in p ∈ { 0 , 1 } 2 n +1 , we can output in polynomial time whether p belongs to a path in H , and if so which are the previous and consecutive vectors in the path. It is therefore PPAD -hard to find a starting or end point of any path in H other than 0 2 n +1 .
## 4.2 Continuous mapping on [0 , 1] 2 n +2
In order to construct a hard instance of Brouwer function, we use techniques introduced by Hirsch, Papadimitriou, and Vavasis [HPV89]. [HPV89] showed that the number of deterministic value-oracle queries required to find a Brouwer fixed point is exponential in the number of precision digits, the Lipschitz constant of the function, and -most important to us- the dimension of the domain. Our construction is almost identical, with the exception that [HPV89] embed a single path, whereas we embed H which is a collection of paths and cycles.
The continuous Brouwer function is denoted by f : [0 , 1] 2 n +2 → [0 , 1] 2 n +2 , while the associated displacement function is denoted by g ( x ) = f ( x ) -x . The following lemma (proven below) completes the proof of Theorem 3.
## Lemma 1. The displacement g satisfies:
1. g is O (1) -Lipschitz (thus, f is also O (1) -Lipschitz)
2. ‖ g ( x ) ‖ ∞ = Ω(1) for every x that does not correspond to the endpoint of the path
3. The value of g at each point x can be computed in polynomial time using S and P .
## 4.2.1 Overview of the construction
The domain of f is the 2 n +2 -dimensional (solid) hypercube. The hypercube is divided into subcubes, of side length h (we fix h = 1 / 4 ). We define f separately
on each subcube such that it agrees on the intersections (no interpolation is needed in this sense).
The last ( (2 n +2) -th) dimension is special; we use 'up' (resp. 'down') to refer to the positive (negative) (2 n +2) -th direction. All the action takes place in the second-from-bottom (2 n +1) -dimensional layer of subcubes; this layer is called the slice . Within the slice, we also ignore the subcubes that are near the boundary of the hypercube (those compose the frame ); we are left with the subcubes in the center of the slice, which we call the picture . We identify between the vertices of the (2 n +1) -dimensional hypercube graph (over which H was defined) and the 2 2 n +1 subcubes of the picture.
In [HPV89], a single path is embedded inside the picture; this embedded path is called the tube . The home subcube , the subcube that corresponds to the beginning of the path, is special: all the flow from all subcubes that do not belong to the tube leads to this subcube. For our purposes, we consider many tubes, corresponding to the paths and cycles of H . The home subcube continues to be special in the sense described above, and it corresponds to the vertex 0 2 n +1 .
Below we define the displacement in the following regions, and argue that it satisfies the desiderata of Lemma 1:
- Inside the picture, but not in any tube;
- inside a tube; and
- outside the picture.
## 4.2.2 Default displacement
Most of the slice has the same default displacement : directly upward, i.e. g ( x ) = δ ξ 2 n +2 , where ξ 2 n +2 is the (2 n +2) -unit vector, and δ > 0 is a small constant. Formally,
Fact 1. g ( x ) = δ ξ 2 n +2 , for every x such that at least one of the following holds:
1. x lies on a corner, i.e. the intersection of two or more facets of a subcube;
2. x lies on an outer facet of a tube subcube, i.e. a facet other than the two facets that continue the path; or
3. x lies in a subcube that does not belong to any tube.
Intuitively, Property 2 implies that all subcubes -whether they belong to the tube or notlook the same from the outside (except for the two facets that continue the path). In particular, the displacement on both sides of each facet is the same; so if the displacement is O (1) -Lipschitz on each subcube, it is also O (1) -Lipschitz on the entire hypercube.
Property 1, stating that all corners look the same , is key to the sampling gadget in Section (5), because it liberates us from having to disambiguate the position of a point near the corners (that is, deciding exactly to which subcube it belongs). This is useful because those points that are close to corners, are precisely the ones that are hard to determine using 'noisy' gates.
## 4.2.3 Displacement at a tube
The mapping is defined so that in the center of the tube, the flow goes along the direction of the path; slightly outside the center, the flow points towards the center of the tube; further away from the center, the flow goes against the direction of the path; at the outer boundary of the tube, as we previously described, the flows goes upwards.
We first define g on facets. Let 〈 r, p 〉 z be a point on the facet centered at z , and suppose that the tube enters the subcube through z , advancing in the positive i -th coordinate. We define
$$g \left ( \langle r , p \rangle _ { z } \right ) = \begin{cases} \delta \boldsymbol \xi _ { i } & r = 0 \\ - \delta p & r = h / 8 \\ - \delta \boldsymbol \xi _ { i } & r = h / 4 \\ \delta \boldsymbol \xi _ { 2 n + 2 } & r = h / 2 \end{cases}$$
$$( 1 )$$
(Recall that h is the subcube side length, and δ is some small constant.) Notice that at each r , the displacement g is O (1) -Lipschitz and has magnitude ‖ g ( x ) ‖ ∞ = Ω(1) (thus satisfying the first two desiderata of Lemma 1).
For r ∈ (0 , h/ 8) , interpolate between δ ξ i and -δ p ([HPV89] call this radial interpolation ), and similarly for r ∈ ( h/ 8 , h/ 4) and r ∈ ( h/ 4 , h/ 2) . See also illustration in Figure 2. It is easy to see that the O (1) -Lipschitz property is preserved. Notice also that ξ i is orthogonal to p and ξ 2 n +2 ; this guarantees that the interpolation does not lead to cancellation, i.e. we still have ‖ g ( x ) ‖ ∞ = Ω(1) .
In the last couple of paragraphs we defined g on two facets for each subcube that belongs to the tubes; for all other points in the tubes we interpolate (angular interpolation) between those two facets: Consider a point x in the tube, and assume (w.l.o.g.) that x i , x j > 1 / 2 , and suppose that the value of f ( · ) on the y i = 1 / 2 and y j = 1 / 2 facets of the subcube containing x is determined by (1). Let
$$\begin{array} { r l r } { x ^ { i } } & { = } & { \left ( x _ { - i , j } , \frac { 1 } { 2 } , \max \left \{ x _ { i } , x _ { j } \right \} \right ) } \\ { x ^ { j } } & { = } & { \left ( x _ { - i , j } , \max \left \{ x _ { i } , x _ { j } \right \} , \frac { 1 } { 2 } \right ) } \end{array}$$
denote the corresponding 'max-norm projections' to the respective y i = 1 / 2 and y j = 1 / 2 facets. We set
$$g \left ( x \right ) \ = \ \theta _ { \max } \left ( x _ { i } - \frac { 1 } { 2 } , x _ { j } - \frac { 1 } { 2 } \right ) g \left ( x ^ { i } \right ) + \left ( 1 - \theta _ { \max } \left ( x _ { i } - \frac { 1 } { 2 } , x _ { j } - \frac { 1 } { 2 } \right ) \right ) g \left ( x ^ { j } \right ) .$$
Notice that x i and x j are at the same distance from the respective facet centers, i.e. they have they correspond to the same r . For each case of (1), the ( i, j ) -components of the displacements at x i and x j are orthogonal, and for the rest of the components they are aligned. Therefore, when we interpolate between g ( x i ) and g ( x j ) there is again no cancellation, i.e. ‖ g ( x ) ‖ ∞ = Ω( ‖ g ( x i ) ‖ ∞ ) = Ω (1) . Finally, recall that the displacement on each facet is O (1) -Lipschitz, and the displacements agree on the intersection of the facets. Therefore the interpolated displacement is O (1) -Lipschitz over the entire subcube by a triangle-inequality argument.
The home subcube is defined using (1) as if the tube enters from above, i.e. coming down the (2 n +2) -dimension, and exits through another facet (in one of the first (2 n +1) dimensions) in the direction of the path (here again we have ‖ g ( x ) ‖ ∞ = Ω(1) ). For all other starting and end points, we define g ( x ) = δ ξ 2 n +2 on the facet opposite the one that continues the tube, and interpolate between the opposite facets using Cartesian interpolation. Notice that this gives a fixed point when the interpolation cancels the default displacement at the opposite facet, with the displacement -δ ξ 2 n +2 at the point on the tube facet which is at distance h/ 8 above the path.
Figure 2: A facet of the Hirsch et al construction
<details>
<summary>Image 2 Details</summary>

### Visual Description
## Vector Field Diagram: Radial Flow
### Overview
The image depicts a 2D vector field on a grid. Each grid point has a colored sphere and an arrow indicating the direction and, qualitatively, the magnitude of the vector at that point. The color of the sphere changes radially from the center, with the colors transitioning from pink at the center, to purple, blue, gray, yellow, and finally green at the edges. The arrows generally point away from the center, indicating a radial flow.
### Components/Axes
* **Grid:** A 11x11 grid of points.
* **Vectors:** Each point has an associated vector represented by an arrow.
* **Color Gradient:** The color of the sphere at each point varies radially from the center. The colors are:
* Pink (center)
* Purple
* Blue
* Gray
* Yellow
* Green (outer edges)
* **Arrow Direction:** The arrows generally point radially outward from the center.
### Detailed Analysis
* **Center:** The central point is pink. The arrow at the center is short and points in a random direction.
* **Purple Region:** The points immediately surrounding the center are purple. The arrows point outwards from the center.
* **Blue Region:** The next layer of points is blue. The arrows point outwards from the center.
* **Gray Region:** The next layer of points is gray. The arrows point outwards from the center.
* **Yellow Region:** The next layer of points is yellow. The arrows point outwards from the center.
* **Green Region:** The outermost points are green. The arrows point outwards from the center.
* **Arrow Length:** The length of the arrows appears to increase as the distance from the center increases, suggesting that the magnitude of the vector field increases with distance from the center.
### Key Observations
* The vector field is approximately radially symmetric.
* The magnitude of the vector field increases with distance from the center.
* The color gradient provides a visual representation of the distance from the center.
### Interpretation
The diagram likely represents a physical phenomenon where something is emanating from a central point. The color gradient could represent a scalar field (e.g., temperature, pressure, concentration) that decreases with distance from the center. The arrows represent the direction and magnitude of a vector field (e.g., velocity, force) that is driven by the scalar field. The diagram could be used to visualize fluid flow, heat transfer, or diffusion processes.
</details>
An illustration of the displacement on a facet between two subcubes in a tube; the direction of the path is into the paper. In the center, the displacement points into the paper; slightly further outside, the displacement points towards the center; further outside, the displacement points out of the paper; finally in the outer layer, the displacements points in the special 2 n +2 dimension.
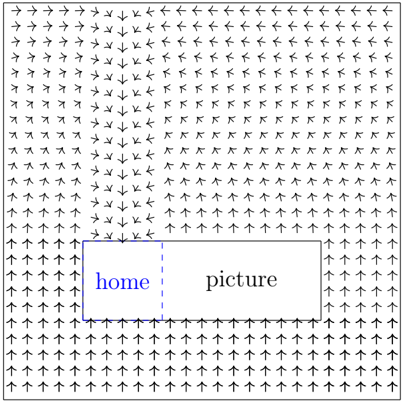
## 4.2.4 Outside the picture
For all points in the frame and below the slice, the displacement points directly upward, i.e. g ( x ) = δ ξ 2 n +2 . Moving above the slice, let z [ top ] be the point on the top facet of the hypercube which is directly above the center of the home subcube. For all points 〈 r, p 〉 z [ top ] on the top facet of the hypercube, define the displacement as follows:
$$g \left ( \langle r , p \rangle _ { z [ t o p ] } \right ) = \begin{cases} - \delta \xi _ { 2 n + 2 } & r = 0 \\ - \delta p & r \geq h / 8 \end{cases}$$
and interpolate for r ∈ (0 , h/ 8) . Notice that this displacement is O (1) -Lipschitz and has Ω(1) magnitude for each r , and this is preserved after interpolation.
Notice that the definition of g on the slice from the previous subsection, implies that all the points in the top facet of the slice, except for the top of the home subcube, point directly upwards. Let z [ home ] denote the center of the top facet of the home subcube. We therefore have that for any 〈 r, p 〉 z [ home ] in the top facet of the slice,
$$g \left ( \langle r , p \rangle _ { z [ h o m e ] } \right ) = \begin{cases} - \delta \xi _ { 2 n + 2 } & r = 0 \\ - \delta p & r = h / 8 \\ \delta \xi _ { 2 n + 2 } & r \geq h / 4 \end{cases}$$
where we again interpolate radially for r in (0 , h/ 8) and ( h/ 8 , h/ 4) .
Finally, to complete the construction above the slice, simply interpolate (using Cartesian interpolation) between the top facets of the slice and the hypercube. See also illustration in Figure 3.
## 5 From Brouwer to -Gcircuit
Proposition 1. There exists a constant > 0 such that -Gcircuit is PPAD -complete.
Proof. We continue to denote the hard Brouwer function by f : [0 , 1] 2 n +2 → [0 , 1] 2 n +2 , and its associated displacement by g ( y ) = f ( y ) -y . We design a generalized circuit S that computes f , and verifies that the output is equal to
Figure 3: Outside the picture
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Vector Field Diagram: Home vs. Picture
### Overview
The image is a vector field diagram illustrating the directional flow around two adjacent rectangular regions labeled "home" and "picture". The arrows indicate the direction of the field at various points in the space. The "home" region is distinguished by a blue outline and text, while the "picture" region has a gray outline and black text.
### Components/Axes
* **Vectors:** Black arrows indicating direction.
* **Regions:** Two adjacent rectangles, "home" (left, blue outline) and "picture" (right, gray outline).
* **Labels:** "home" (blue text) and "picture" (black text).
* **Boundary:** The entire diagram is enclosed within a square boundary.
### Detailed Analysis
* **Vector Field:** The arrows generally point upwards at the bottom of the diagram and downwards at the top. There is a convergence of arrows towards the top edge of the "home" region and a divergence of arrows from the bottom edge of the "home" region. A similar, but less pronounced, pattern is observed around the "picture" region.
* **"home" Region:** The "home" region is located on the left side of the diagram. It is enclosed by a blue rectangle. The word "home" is written in blue inside the rectangle. The left, top, and bottom borders are solid blue lines, while the right border is a dashed blue line.
* **"picture" Region:** The "picture" region is located on the right side of the diagram. It is enclosed by a gray rectangle. The word "picture" is written in black inside the rectangle.
* **Arrow Orientation:**
* **Top:** Arrows point predominantly downwards.
* **Bottom:** Arrows point predominantly upwards.
* **Left:** Arrows point predominantly to the right.
* **Right:** Arrows point predominantly to the left.
* **Around "home":** Arrows tend to converge towards the top of the "home" region and diverge from the bottom.
* **Around "picture":** Arrows tend to converge towards the top of the "picture" region and diverge from the bottom, but less strongly than around "home".
### Key Observations
* The vector field appears to be influenced by the presence of the "home" and "picture" regions, with a more pronounced effect around the "home" region.
* The arrows generally flow from bottom to top, but are redirected around the rectangular regions.
### Interpretation
The diagram likely represents a potential field or a flow field, where the arrows indicate the direction of force or movement. The "home" region seems to have a stronger influence on the field than the "picture" region, possibly indicating a higher "potential" or "attraction". The convergence and divergence of arrows around the regions suggest that they act as sources or sinks in the field. The diagram could be used to visualize concepts such as electric fields, fluid flow, or even abstract concepts like user navigation on a website (where "home" might represent a more attractive destination).
</details>
An illustration of the displacement outside the picture.
the input. We show that every -approximate solution to S corresponds to an O ( 1 / 4 ) -approximate fixed point of f .
Recall that the construction from Section (4) divides the hypercube into equal-sized subcubes (of length 1 / 4 ). Furthermore, all the paths in H are embedded in the 2 2 n +1 subcubes that belong to the picture. For ease of exposition, we present a construction that only works for points in the picture, i.e. y ∈ [1 / 4 , 3 / 4] 2 n +1 × [1 / 4 , 1 / 2] . It is straightforward how to use the same ideas to extend the circuit to deal with all y ∈ [0 , 1] 2 n +2 .
The most challenging part of the construction is the extraction of the information about the local subcube: is it part of a tube? if so, which are the entrance and exit facets? This is done by extracting the binary representation of the current subcube, and feeding it to the (Boolean) circuit that computes H (recall that H is our collection of paths and cycles from Section (4.1)). Notice that whenever we have valid logic bits, i.e. x [ b ] < or x [ b ] > 1 - , we can perform logic operations on them without increasing the error.
Once we know the behavior of the path on the current subcube, we simply have to locally implement the mapping from the previous section, for which we have a closed form description, using the available gates in the definition of generalized circuits. Since this definition does not include multiplication and
division, we implement multiplication and division in Algorithms 2 and 3 in Subsection 5.1.
Our construction has four parts: (1) equiangle sampling segment, (2) computing the displacement, (3) summing the displacement vectors, and (4) closing the loop. The first part contains a new idea introduced in this paper: using a constant size sample. The second part is a more technical but straightforward description of the implementation of the closed-form mapping by approximate gates. The third and fourth parts are essentially identical to [CDT09].
## 5.1 Subroutines
In this subsection we show how to implement a few useful subroutines using the gates in the definition of -Gcircuit .
## 5.1.1 If-Else
We begin by describing how to implement a simple if-else. Similar ideas can be used to implement more involved cases such as (1).
Claim 1 . In any -approximate solution to If-Else ( | a, b, c | d ) ,
$$x \left [ d \right ] = \begin{cases} x \left [ c \right ] \pm O \left ( \epsilon \right ) & \text {if } x \left [ a \right ] < \sqrt { \epsilon } \\ x \left [ b \right ] \pm O \left ( \epsilon \right ) & \text {if } x \left [ a \right ] > 1 - \sqrt { \epsilon } \end{cases} .$$
## Algorithm 1 If-Else ( | a, b, c | d )
1. G ¬ ( | a | a ) # a is the negation of a
2. G -( | b, a | b ′ ) # b ′ is (approximately) equal to b iff a = 1
3. G ¬ ( | a | a ) # a is the roudning of a to { 0 , 1 }
4. G -( | c, a | c ′ ) # c ′ is (approximately) equal to c iff a = 0
5. G -( | b ′ , c ′ | d )
Proof. By definition of G ¬ , we have that
$$x \left [ \overline { a } \right ] = \begin{cases} 1 \pm \epsilon & i f $ x \left [ a \right ] < \sqrt { \epsilon } \\ 0 \pm \epsilon & i f $ x \left [ a \right ] > 1 - \sqrt { \epsilon } \end{cases} .$$
Therefore by definition of G -,
$$x \left [ b ^ { \prime } \right ] = \begin{cases} 0 \pm O \left ( \epsilon \right ) & i f x \left [ a \right ] < \sqrt { \epsilon } \\ x \left [ b \right ] \pm O \left ( \epsilon \right ) & i f x \left [ a \right ] > 1 - \sqrt { \epsilon } \end{cases} .$$
$$x \left [ c ^ { \prime } \right ] = \begin{cases} x \left [ c \right ] \pm O \left ( \epsilon \right ) & i f $ x \left [ a \right ] < \sqrt { \epsilon } $ \\ 0 \pm O \left ( \epsilon \right ) & i f $ x \left [ a \right ] > 1 - \sqrt { \epsilon } $ . \end{cases}$$
Similarly,
Finally, the claim follows by definition of G + .
## 5.1.2 Multiply
Claim 2 . In any -approximate solution to Multiply ( | a, b | c ) ,
$$x \left [ c \right ] = x \left [ a \right ] \cdot x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
Proof. For any k , the first gate implies that
$$x \left [ \zeta _ { k } \right ] = k \sqrt { \epsilon } \pm \epsilon .$$
The second gate thus gives
$$x \left [ \overline { a _ { k } } \right ] = \begin{cases} 0 \pm \epsilon & \text {if $x\left[a]\geq k\sqrt{\epsilon}$} + O \left ( \epsilon \right ) \\ 1 \pm \epsilon & \text {if $x\left[a]\leq k\sqrt{\epsilon}-O\left( \epsilon\right)$} . \end{cases}$$
Notice that the above equation is ambiguous for at most one value of k . In particular,
We also have
$$\sum _ { k } \left ( 1 - x \left [ \overline { a _ { k } } \right ] \right ) \sqrt { \epsilon } = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
$$x \left [ d _ { k } \right ] = x \left [ b \right ] \cdot \sqrt { \epsilon } \pm \epsilon .$$
## Algorithm 2 Multiply ( | a, b | c )
1. G ζ (0 || h 0 )
2. for each k ∈ [1 / √ ] :
3. (a) G ζ ( k √ || ζ k ) , G < ( | a, ζ k | a k )
# The vector ( a k ) is the unary representation of a
$$\sum _ { k \colon X [ \overline { a _ { k } } ] < \epsilon } \sqrt { \epsilon } = \max _ { k \colon X [ \overline { a _ { k } } ] < \epsilon } k \sqrt { \epsilon } = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
- (b) G × ζ ( √ | b | d k )
# The vector ( d k ) is simply equal to b · √ everywhere.
$$\sum _ { k \colon X [ \overline { a _ { k } } ] < \epsilon } x \left [ d _ { k } \right ] = \left ( \sum _ { k \colon X [ \overline { a _ { k } } ] < 1 - \epsilon } \sqrt { \epsilon } \right ) \cdot x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right ) = x \left [ a \right ] \cdot x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
- (c) G -( | d k , a k | e k )
# The vector ( e k ) is b · √ only when ( a k ) < .
$$\sum _ { k \colon X [ \overline { a _ { k } } ] < \epsilon } x \left [ e _ { k } \right ] = x \left [ a \right ] \cdot x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
- (d) G + ( | h k -1 , e k | h k )
# Finally, we sum the e k 's to get a · b
$$x \left [ h _ { 1 / \sqrt { \epsilon } } \right ] = x \left [ a \right ] \cdot x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
3. G = ( | h 1 / √ | c )
The subtraction gate zeros x [ d k ] for all k such that x [ a ] < k √ -O ( ) , and has negligible effect for k such that x [ a ] > k √ + O ( ) :
$$x \left [ e _ { k } \right ] = \begin{cases} x \left [ b \right ] \cdot \sqrt { \epsilon } \pm 2 \epsilon & \text {if $x\left[a]\geq k\sqrt{\epsilon}+O(\epsilon)$} \\ 0 \pm 2 \epsilon & \text {if $x\left[a]\leq k\sqrt{\epsilon}-O(\epsilon)\,.$} \end{cases}$$
The sum of the x [ e k ] 's satisfies:
$$\sum _ { k } x \left [ e _ { k } \right ] = x \left [ a \right ] \cdot x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right ) ,$$
where we have an error of ± O ( √ ) arising from aggregating ± 2 for 1 / √ distinct k 's, and another ± O ( √ ) from (3).
By induction, each h k is approximately equal to the sum of the first x [ e j ] 's:
$$x \left [ h _ { k } \right ] = \sum _ { j = 1 } ^ { k } x \left [ e _ { j } \right ] \pm k \epsilon .$$
In particular, we have
$$\begin{array} { r c l } \mathbf x \left [ h _ { 1 / \sqrt { \epsilon } } \right ] & = & \sum _ { k } \mathbf x \left [ e _ { k } \right ] \pm \sqrt { \epsilon } \\ & = & \mathbf x \left [ a \right ] \cdot \mathbf x \left [ b \right ] \pm O \left ( \sqrt { \epsilon } \right ) . \end{array}$$
## 5.1.3 Divide
Claim 3 . In any -approximate solution to Divide ( | a, b | c ) ,
$$x \left [ c \right ] \cdot x \left [ b \right ] = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
Notice that for Algorithm 3, in any -approximate solution, x [ c ] = x [ a ] / x [ b ] ± O ( √ ) / x [ b ] ; when x [ b ] and are bounded away from 0 , this is only a constant factor increase in the error.
Proof. For each k , we have
$$x \left [ b _ { k } \right ] = k \sqrt { \epsilon } \cdot x \left [ b \right ] \pm \epsilon .$$
## Algorithm 3 Divide ( | a, b | c )
1. G ζ (0 || h 0 )
2. for each k ∈ [1 / √ ] :
3. (a) G × ζ ( k √ | b | b k ) , G < ( | b k , a | d k )
# The vector ( d k ) is the unary representation of a/b
$$\left ( \sum _ { k \colon X [ d _ { k } ] > \epsilon } \sqrt { \epsilon } \right ) \cdot x \, [ b ] = \left ( \max _ { k \colon X [ d _ { k } ] > \epsilon } k \sqrt { \epsilon } \right ) \cdot x \, [ b ] = x \, [ a ] \pm O \left ( \sqrt { \epsilon } \right )$$
- (b) G × ζ ( √ | d k | e k
# The vector ( e k ) is a ( ) -scaled version of ( d k
- ) √ )
$$\left ( \sum x \left [ e _ { k } \right ] \right ) \cdot x \left [ b \right ] = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
e 's
- (c) G + ( | h k -1 , e k | h k ) # Finally, we sum the k
$$x \left [ h _ { 1 / \sqrt { \epsilon } } \right ] \cdot x \left [ b \right ] = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
3. G = ( | h 1 / √ | c )
Thus also
$$x \left [ d _ { k } \right ] = \begin{cases} 1 \pm \epsilon & i f x \left [ a \right ] > k \sqrt { \epsilon } \cdot x \left [ b \right ] + O \left ( \epsilon \right ) \\ 0 \pm \epsilon & i f x \left [ a \right ] < k \sqrt { \epsilon } \cdot x \left [ b \right ] - O \left ( \epsilon \right ) . \end{cases}$$
Notice that x [ d k ] is ambiguous for at most k . Furthermore, aggregating the ± error over 1 / √ distinct k 's, we have:
$$\sum x \left [ d _ { k } \right ] \cdot \sqrt { \epsilon } x \left [ b \right ] = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
x [ e k ] 's are a step closer to what we need:
$$x \left [ e _ { k } \right ] = x \left [ d _ { k } \right ] \sqrt { \epsilon } \pm \epsilon ,$$
$$\sum x \left [ e _ { k } \right ] \cdot x \left [ b \right ] = x \left [ a \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
and therefore also
Finally, by induction
$$x \left [ h _ { 1 / \sqrt { \epsilon } } \right ] = \sum x \left [ e _ { k } \right ] \pm \sqrt { \epsilon } ,$$
and the claim follows by plugging into (4).
## 5.1.4 Max
Claim 4 . In any -approximate solution to Max ( | a 1 , . . . a n | b ) ,
$$x \left [ b \right ] = \max x \left [ a _ { i } \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
Proof. Similarly to (2), we have that for each i, k
$$x \left [ c _ { k , i } \right ] = \begin{cases} 0 \pm \epsilon & \text {if} \, x \left [ a _ { i } \right ] < k \sqrt { \epsilon } - O \left ( \epsilon \right ) \\ 1 \pm \epsilon & \text {if} \, x \left [ a _ { i } \right ] > k \sqrt { \epsilon } + O \left ( \epsilon \right ) . \end{cases}$$
For each k , taking OR of all the c k,i 's gives (approximately) 1 iff any of the x [ a i ] 's is sufficiently large; in particular if the maximum is:
$$x \left [ d _ { k , n } \right ] = \begin{cases} 0 \pm \epsilon & i f m a x _ { i } x \left [ a _ { i } \right ] < k \sqrt { \epsilon } - O \left ( \epsilon \right ) \\ 1 \pm \epsilon & i f m a x _ { i } x \left [ a _ { i } \right ] > k \sqrt { \epsilon } + O \left ( \epsilon \right ) . \end{cases}$$
## Algorithm 4 Max ( | a 1 , . . . a n | b )
1. G ζ (0 || h 0 )
2. for each k ∈ [1 / √ ] :
3. (a) G ζ ( k √ || ζ k )
4. (b) G ζ (0 || d k, 0 )
5. (c) for each i ∈ [ n ] :
# The vector ( c k,i ) is the unary representation of a i :
- i. G < ( | ζ k , a i | c k,i ) k
$$\forall i \quad \left ( \max _ { k \colon X [ c _ { k , i } ] > \epsilon } k \sqrt { \epsilon } \right ) = x \, [ a _ { i } ] \pm O \left ( \sqrt { \epsilon } \right )$$
- ii. G ∨ ( | d k,i -1 , c k,i | d k,i )
# The vector ( d k,n ) is the unary representation of max a i :
$$\left ( \max _ { k \colon X [ d _ { k , n } ] > \epsilon } k \sqrt { \epsilon } \right ) = \max x \, [ a _ { i } ] \pm O \left ( \sqrt { \epsilon } \right )$$
(d) G × ζ ( √ | d k,n | e k ) # The vector ( e k ) is a ( √ ) -scaled version of ( d k ) (∑ √ )
$$\left ( \sum x \left [ e _ { k } \right ] \right ) = \max x \left [ a _ { i } \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
- (e) G + ( | h k -1 , e k | h k ) # Finally, we sum the
e 's
$$x \left [ h _ { 1 / \sqrt { \epsilon } } \right ] = \max x \, [ a _ { i } ] \pm O \left ( \sqrt { \epsilon } \right )$$
$$= \max x [ a _ { i } ] \pm O ( \sqrt { \epsilon } )$$
3. G = ( | h 1 / √ | b )
Therefore also (similarly to (3)),
$$\sum _ { k } x \left [ d _ { k , n } \right ] \sqrt { \epsilon } = \max _ { i } x \left [ a _ { i } \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
The x [ e k ] take care of scaling by √ :
$$\sum _ { k } x \left [ e _ { k } \right ] = \underset { i } { \max } x \left [ a _ { i } \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
Finally, by induction,
$$x \left [ h _ { 1 / \sqrt { \epsilon } } \right ] = \max x \left [ a _ { i } \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
## 5.1.5 Interpolate
Claim 5 . In any -approximate solution to Interpolate ( a, w a , b, w b | c ) ,
$$x \left [ c \right ] \left ( x \left [ w _ { a } \right ] + x \left [ w _ { b } \right ] \right ) = \left ( x \left [ w _ { a } \right ] \cdot x \left [ a \right ] + x \left [ w _ { b } \right ] \cdot x \left [ b \right ] \right ) \pm O \left ( \sqrt { \epsilon } \right ) .$$
Proof. By Claim 3, we have
$$\mathbf x \left [ \overline { w _ { a } } \right ] \cdot \left ( \mathbf x \left [ w _ { a } \right ] + \mathbf x \left [ w _ { b } \right ] \right ) & \ = \ \mathbf x \left [ w _ { a } \right ] \pm O \left ( \sqrt { \epsilon } \right ) \\ \mathbf x \left [ \overline { w _ { b } } \right ] \cdot \left ( \mathbf x \left [ w _ { a } \right ] + \mathbf x \left [ w _ { b } \right ] \right ) & \ = \ \mathbf x \left [ w _ { b } \right ] \pm O \left ( \sqrt { \epsilon } \right ) .$$
Therefore, by Claim 2,
$$\begin{array} { r c l } \mathbf x \left [ c _ { a } \right ] \cdot \left ( \mathbf x \left [ w _ { a } \right ] + \mathbf x \left [ w _ { b } \right ] \right ) & = & \mathbf x \left [ w _ { a } \right ] \cdot \mathbf x \left [ c \right ] \pm O \left ( \sqrt { \epsilon } \right ) \\ \mathbf x \left [ c _ { b } \right ] \cdot \left ( \mathbf x \left [ w _ { a } \right ] + \mathbf x \left [ w _ { b } \right ] \right ) & = & \mathbf x \left [ w _ { b } \right ] \cdot \mathbf x \left [ c \right ] \pm O \left ( \sqrt { \epsilon } \right ) . \end{array}$$
The claim follows by definition of G + .
$$\left ( \sqrt { \epsilon } \right ) .$$
$$r$$
## Algorithm 5 Interpolate ( a, w a , b, w b | c )
1. G × ζ ( 1 / 2 | w a | w a/ 2 ) and G × ζ ( 1 / 2 | w b | w b/ 2 ) # We divide by 2 before adding in order to stay in [0 ,
1]
2. G + ( | w a/ 2 , w b/ 2 | w a/ 2+ b/ 2 ) Add the weights
3. Divide ( | w a/ 2 , w a/ 2+ b/ 2 | w a ) and Divide ( | w b/ 2 , w a/ 2+ b/ 2 | w b ) # w a and w b are the normalized weights:
$$x \left [ \overline { w _ { a } } \right ] \cdot \left ( x \left [ w _ { a } \right ] + x \left [ w _ { b } \right ] \right ) = x \left [ w _ { a } \right ] \pm O \left ( \sqrt { \epsilon } \right )$$
4. Multiply ( | w a , a | c a ) and Multiply ( | w b , b | c b )
# c a and c b are the a and b components, respectively, of c :
$$x \left [ c _ { a } \right ] = x \left [ w _ { a } \right ] \cdot x \left [ a \right ] / \left ( x \left [ w _ { a } \right ] + x \left [ w _ { b } \right ] \right ) \pm O \left ( \sqrt { \epsilon } \right ) / \left ( x \left [ w _ { a } \right ] + x \left [ w _ { b } \right ] \right )$$
5. G + ( | c a , c b | c )
2. # Finally, c is the interpolation of a and b :
$$\begin{array} { r c l } { x \left [ c \right ] } & { = } & { \left ( x \left [ w _ { a } \right ] \cdot x \left [ a \right ] + x \left [ w _ { b } \right ] \cdot x \left [ b \right ) \right ) / \left ( x \left [ w _ { a } \right ] + x \left [ w _ { b } \right ] \right ) } \\ & { \quad \pm O \left ( \sqrt { \epsilon } \right ) / \left ( x \left [ w _ { a } \right ] + x \left [ w _ { b } \right ] \right ) } \end{array}$$
- ,
## 5.2 Equiangle sampling segment
The first information we require in order to compute the Hirsch et al mapping f ( y ) is about the subcube to which y belongs: is it part of the tube? if so, which are the entrance and exit facets? In order to answer those questions, we extract the binary representation of the cube. Recall that our circuit uses brittle comparators; thus when y is close to a facet between subcubes, the behaviour of the brittle comparators may be unpredictable. We start with the easy case, where y is actually far from every facet:
Definition 4. We say that y is an interior point if for every i , | y i -1 / 2 | > ; otherwise, we say that y is a boundary point .
A very nice property of the Hirsch et al construction is that whenever y is at the intersection of two or more facets, the displacement is the same: g ( y ) = δ ξ 2 n +2 . Thus, by the Lipschitz property of g , whenever y is close to the intersection of two or more facets, the displacement is approximately δ ξ 2 n +2 . For such y 's, we don't care to which subcube they belong.
Definition 5. Wesay that y is a corner point if there exist distinct i, j ∈ [2 n +2] such that | y i -1 / 2 | < 1 / 4 and | y j -1 / 2 | < 1 / 4 .
(Notice that y may be an interior point and a corner point at the same time.) We still have a hard time handling y 's which are neither an interior point nor a corner point. To mitigate the effect of such y 's we use an equiangle averaging scheme. Namely we consider the set:
$$E ^ { \epsilon } \left ( y \right ) = \left \{ y ^ { l } = y + \left ( 6 l \cdot \epsilon \right ) 1 \colon 0 \leq l < 1 / \sqrt { \epsilon } \right \}$$
where 1 denotes the all-ones vector. Notice that since g is λ -Lipschitz for constant λ , g ( y l ) will be approximately the same for all y l ∈ E ( y ) .
Fact 2. If any y l ∈ E ( y ) is not a corner point, then at most one y l ′ ∈ E ( y ) is a boundary point.
Proof. For each dimension, at most one element in E ( y ) can be -close to the (1 / 2) facet. Thus if two elements in E ( y ) are boundary points, it must be because of distinct dimensions - and therefore every y l is a corner point.
Given input y , we compute the displacement g ( · ) separately and in parallel for each y l ∈ E , and average at the end. Since at most one y l is a boundary point, this will incur an error of at most √ .
In the generalized circuit we can construct E using (1 / √ ) auxiliary nodes and G ζ and G + gates:
$$x \left [ y _ { i } ^ { l } \right ] = \min \left \{ x \left [ y _ { i } ^ { 0 } \right ] + \left ( 6 l \cdot \epsilon \right ) , 1 \right \} \pm 2 \epsilon$$
## 5.3 Computing the displacement
For each y l ∈ E , we construct a disjoint circuit that approximates the displacement g ( y l ) . In the description of the circuit below we omit the index l .
Lemma 2. The circuit below O ( √ ) -approximately simulates the computation of the Hirsch et al displacement:
1. Whenever ( x [ y i ]) i ∈ [2 n +2] is an interior point,
$$x \left [ g _ { i } ^ { + } \right ] - x \left [ g _ { i } ^ { - } \right ] = g _ { i } \left ( x \left [ y \right ] \right ) \pm O \left ( \epsilon ^ { 1 / 4 } \right )$$
2. Furthermore, whenever ( x [ y i ]) i ∈ [2 n +2] is a corner point,
$$x \left [ g _ { 2 n + 2 } ^ { + } \right ] - x \left [ g _ { 2 n + 2 } ^ { - } \right ] = \delta \pm O \left ( \sqrt { \epsilon } \right )$$
$$x \left [ g _ { i } ^ { + } \right ] - x \left [ g _ { i } ^ { - } \right ] = 0 \pm O \left ( \sqrt { \epsilon } \right )$$
and ∀ i < 2 n +2 :
Proof. We construct the circuit in five stages: (1) given y , we extract b , that is the binary representation of the corresponding subcube in { 0 , 1 } 2 n +2 ; (2) we then compute whether b belongs to a path in H , and if so which are the previous and next vertices; (3) we compute the centers of the coordinate systems corresponding to the entrance and exit facets, and label them z in and z out ; (4) we project y to each facet, and transform this projection to the local polar coordinate systems -( r in , p in ) ; and (5) finally, we use all the information above to compute the displacement g = g ( y ) .
The correctness of Lemma 2 follows from Claims 6-12.
$$E x t r a c t \, b \in \{ 0 , 1 \} ^ { 2 n + 2 }$$
Our first step is to extract the binary vector b which represents the subcube to which y belongs. In other words we want b i to be the indicator of y i < 1 / 2 . We do that by adding the following gadgets: G ζ ( 1 / 2 || c 1 / 2 ) and, for each i , G < ( | y i , c 1 / 2 | b i ) . Observe that now
$$x \left [ b _ { i } \right ] \ = \ \begin{cases} 0 \pm \epsilon & x \left [ y _ { i } \right ] < x \left [ c _ { 1 / 2 } \right ] - \epsilon \\ 1 \pm \epsilon & x \left [ y _ { i } \right ] > x \left [ c _ { 1 / 2 } \right ] + \epsilon \end{cases}$$
Claim 6 . If x [ y ] is an interior point, x [ b ] is the correct representation (up to error) of the corresponding bits in { 0 , 1 } 2 n +2 .
## Neighbors in H
Given x [ b ] we can construct, using G ∧ 's and G ¬ 's and a polynomial number of unused nodes, the circuits S H and P H that give the next and previous vertex visited by our collection of paths, H . The output of each circuit is represented by 2 n +2 unused nodes { P H i ( b ) } and { S H i ( b ) } .
Recall that H is defined in { 0 , 1 } 2 n +1 , so the last input bit is simply ignored (inside the picture it is always 0 ); the last output bit is used as follows. Our convention is that starting points and end points correspond to P H ( b ) = b and S H ( b ) = b , respectively, and likewise for points that do not belong to any path. An exception to this is the 0 starting point, which will correspond to P H ( 0 ) = (0 2 n +1 ; 1) : This is in accordance with the Hirsch et al construction, where the home subcube is constructed as if it continues a path from the subcube above it.
Claim 7 . If x [ b ] is an -approximate binary vector, i.e. x [ b ] ∈ ([0 , ] ∪ [1 -, 1]) 2 n +2 , then x [ P H ( b ) ] and x [ S H ( b ) ] correctly represent (up to error) the previous vertex and next vertex in H .
## Entrance and exit facets
Let b + in i = b i ∧ ¬ P H i ( b ) , i.e. b + in i is 1 if the path enters the current subcube via the positive i -th direction; define b -in i analogously. Let b in i denote the OR of b + in i and b -in i .
The center of the entrance facet is constructed via G ζ , G × ζ , G + , and G -according to the formula:
$$z _ { i } ^ { i n } = \begin{cases} 1 / 2 - h / 2 & b _ { i } ^ { i n } = 0 \ A N D b _ { i } = 0 \\ 1 / 2 + h / 2 & b _ { i } ^ { i n } = 0 \ A N D b _ { i } = 1 \\ 1 / 2 & b _ { i } ^ { i n } = 1 \end{cases}$$
Construct z out analogously.
Notice that if we know on which coordinate the path enters, in { 0 , 1 } 2 n +2 it has only one possible direction; in the Hirsch et al hypercube this corresponds to always entering from the center (i.e. from the y i = 1 / 2 facet). Also, if b corresponds to a non-trivial starting point b in = 0 and z in is simply the center of the subcube (and similarly for b out , z out when b is an end point).
Claim 8 . If x [ b ] , x [ P H ( b ) ] , and x [ S H ( b ) ] are -approximate binary vectors, then x [ z in ] and x [ z out ] are O ( ) -approximations to the centers of the entrance facet and exit facets, respectively.
## Max-norm polar coordinates
We are now ready to compute the local max-norm polar coordinates of the projections of y on the entrance and exit facets.
The max-norm radius is given by
$$r ^ { i n } = \max _ { i \colon b _ { i } ^ { i n } = 0 } \left | z _ { i } ^ { i n } - y _ { i } \right |$$
Finding the maximum of a (length 2 n +1 ) vector requires some care when on each gate we can incur a constant error, the details are described in Algorithm 4.
The direction (max-norm) unit-vector, p , is given by
$$p _ { i } ^ { i n } = \left ( z _ { i } ^ { i n } - y _ { i } \right ) / r ^ { i n }$$
Division is computed using Divide , introducing an error of O ( √ /r in ) ; this approximation suffices because for r in < h/ 8 , we multiply p in i by r in when we interpolate. Also, we will use two nodes for each p in i to represent the positive and negative values. We do the same for ( r out , p out ) .
√
Claim 9 . If x [ y ] is an interior point, then x [ r in ] and x [ r out ] are O ( ) -approximations to the distances of x [ y ] from x [ z in ] and x [ z out ] , respectively. Furthermore, x [ p in ] and x [ p out ] are O ( √ / x [ r in ]) - and O ( √ / x [ r out ]) -to the unit-length vectors that point from x [ y ] in the directions of x [ z in ] and x [ z out ] , respectively.
## The final displacement
Given p in and b in , we can compute g in for the special values of r in . Recall that
$$g ^ { i n } \left ( \left \langle r ^ { i n } , p ^ { i n } \right \rangle \right ) = \begin{cases} \delta \left ( b ^ { + i n } - b ^ { - i n } \right ) & r ^ { i n } = 0 \\ - \delta p ^ { i n } & r ^ { i n } = h / 8 \\ \delta \left ( b ^ { - i n } - b ^ { + i n } \right ) & r ^ { i n } = h / 4 \\ \delta \xi _ { 2 n + 2 } & r ^ { i n } = h / 2 \end{cases}$$
We use Algorithm 5 to interpolate for intermediate values of r in . We also need to interpolate between g in and g out . The ratio at which we interpolate is exactly the ratio between the distance of y from the entrance and exit facets. We label the positive and negative components of this last interpolation g ( interior )+ and g ( interior ) -, respectively.
When y is close to both facets, the interpolation may be inaccurate; however, in this case it is a corner point. (We remark that this seems to be the only part of the proof which requires us to set the threshold for a corner point and the final error at Θ ( 1 / 4 ) rather than Θ( √ ) ; this issue may be avoidable by a more careful construction of Algorithms 3 and 5.)
Claim 10 . If x [ y ] is an interior point of an intermediate subcube in the tube, and it is not a corner point, then ( x [ g ( interior )+ ] -x [ g ( interior ) -]) is a O ( 1 / 4 ) -approximation of the Hirsch et al displacement g ( x [ y ]) .
Corner points We must ensure that if y is a corner point, we set g ( corner )+ = δ ξ 2 n +2 and g ( corner ) -= 0 : check over all pairs of coordinates whether | x [ y i ] -1 / 2 | < 2 1 / 4 and | x [ y j ] -1 / 2 | < 2 1 / 4 . Let z be the variable representing the OR of those ( 2 n +2 2 ) indicators. Interpolate (e.g. using Algorithm 5) between the ( g ( interior )+ , g ( interior ) -) we computed earlier and δ ξ 2 n +2 with weights z and ¬ z . Label the result of the interpolation ( g ( tube )+ , g ( tube ) -) .
Weremark that whenever z is ambiguous, i.e. the second smallest | x [ y i ] -1 / 2 | is very close to 2 1 / 4 , then we cannot predict the value of x [ z ] ; it can take any
value in [0 , 1] . Nevertheless, in this case x [ y ] is not a corner point, thus for most y l ∈ E , x [ y l ] is an interior point. This means that by Claim 10, we would compute the (approximately) correct interior displacement ( x [ g ( interior )+ ] -x [ g ( interior ) -]) . Since x [ y ] is close to a corner point, this value is very close to δ ξ 2 n +2 = ( x [ g ( corner )+ ] -x [ g ( corner ) -]) . Therefore, although we don't know the value of x [ z ] , we use it to interpolate between two (approximately) equal vectors - so the result is guaranteed to be (approximately) correct regardless of the value of x [ z ] .
Claim 11 . If x [ y ] is a corner point, then ( x [ g ( tube )+ ] -x [ g ( tube ) -]) is a O ( √ ) -approximation of δ ξ 2 n +2 , and thus also a O ( 1 / 4 ) -approximation of the Hirsch et al displacement g ( x [ y ]) . Furthermore, Claim 10 continues to hold for ( g ( tube )+ , g ( tube ) -) .
Start/end subcubes and subcubes outside the tube For start/end subcubes (except the home subcube) we use a slightly different (Cartesian) interpolation that yields a fixed point in the center of the subcube, and a displacement of δ ξ 2 n +2 on all facets but the exit/entrance facet, respectively. For subcubes in the picture but outside the tube, we again set g = δ ξ 2 n +2 .
Notice that we can infer the type of subcube from the following two-bits vector:
$$T = \left ( \vee _ { i } b _ { i } ^ { i n } , \vee _ { i } b _ { i } ^ { o u t } \right )$$
If T = (0 , 0) , the subcube is outside the tube; when T = (0 , 1) , we are at a start subcube, while T = (1 , 0) corresponds to an end subcube; T = (1 , 1) is an intermediate subcube in the tube. Finally, interpolate between the displacement for each type of subcube using T and ¬ T ; label the result of the interpolation ( g + , g -) .
Claim 12 . If x [ y ] is either an interior point or a corner point, of any subcube in the slice, then ( x [ g + ] -x [ g -]) is an O ( 1 / 4 ) -approximation of the Hirsch et al displacement g ( x [ y ]) .
## 5.4 Summing the displacement vectors
We are now ready to average over the displacement vectors we computed for each y l . Using G × ζ and G + we have that
$$\mathbf x \left [ g _ { i } ^ { + } \right ] = \sum _ { l = 1 } ^ { 1 / \sqrt { \epsilon } } \left ( \sqrt { \epsilon } \mathbf x \left [ g _ { i } ^ { l + } \right ] \right ) \pm O \left ( \sqrt { \epsilon } \right ) \quad a n d \quad \mathbf x \left [ g _ { i } ^ { - } \right ] = \sum _ { l = 1 } ^ { 1 / \sqrt { \epsilon } } \left ( \sqrt { \epsilon } \mathbf x \left [ g _ { i } ^ { l - } \right ] \right ) \pm O \left ( \sqrt { \epsilon } \right )$$
Lemma 3. For every input x [ y ] and every i ∈ [2 n +2] ,
$$x \left [ g _ { i } ^ { + } \right ] - x \left [ g _ { i } ^ { - } \right ] = g _ { i } \left ( x \left [ y \right ] \right ) \pm O \left ( \epsilon ^ { 1 / 4 } \right )$$
Proof. By Fact 2, every y l ∈ E , except at most one, is either an interior point or a corner point. By Lemma 2, for all those y l , ( x [ g + l i ] -x [ g -l i ]) is at most O ( 1 / 4 ) -far from the right displacement. The single point which is neither an interior point nor a corner point increases the error by at most O ( √ ) , as does the summation above. Finally, because g is λ -Lipschitz for constant λ , the error added due to the distance between the y l 's is again at most O ( √ ) .
## 5.5 Closing the loop
Finally, for each i ∈ [2 n +2] : G + ( | y 1 i , g + i | y ′ i ) , G + ( | y ′ i , g -i | y ′′ i ) and G = ( | y ′′ i | y 1 i ) .
## 6 -Gcircuit with fan-out 2
In the previous section, we proved that -Gcircuit is PPAD -complete for some constant > 0 . Each generalized circuit gate has fan-in at most 2 , which would eventually correspond to a bound on the incoming degree of each player in the graphical game. In order to bound the total degree (as well as for the application to A-CEEI), we need to also bound fan-out of each gate.
Theorem 2 (Generalized circuit) . There exists a constant > 0 such that -Gcircuit with fan-out 2 is PPAD -complete.
Proof. We present a black-box reduction that converts a general ′ -Gcircuit instance to an instance of -Gcircuit with fan-out 2 , for ′ = Θ( √ ) . Daskalakis et al [DGP09] bound the fan-out of the generalized circuit by introducing a binary tree of G = gates. Unfortunately, this blows up the error: each G = gate
## Algorithm 6 Real2Unary ( | a | b 1 , . . . b 4 / ′ )
1. G = ( | a | c 0 )
2. for each k ∈ [4 / ′ ] :
3. (a) G = ( | c k -1 | c k )
#The c k 's are simply copies of a , ensuring that each gate has fan-out at most 2 :
$$\forall k \ x [ c _ { k } ] = x [ a ] \pm ( k + 1 ) \, \epsilon$$
- (b) G ζ ( k ′ / 4 || ζ k )
- (c) G < ( | ζ k , c k | b k )
# The vector ( b k ) is the unary representation of a :
$$\forall i \quad \left ( \max _ { k \colon X [ b _ { k } ] > \epsilon } k \epsilon ^ { \prime } / 4 \right ) = x \, [ a ] \pm \epsilon ^ { \prime } / 2$$
introduces an additive error of , so the increase is proportional to the depth of the tree, i.e. Θ( · log n ) . While this was acceptable for [DGP09] who used an exponentially small , it clearly fails in our setting.
We overcome this obstacle by resorting to logical gates ( G < , G ∨ , G ∧ , and in particular G ¬ ). Recall that the logical gates are at most ′ -far from the correct Boolean value. Therefore, concatenating multiple logical gates does not amplify the error. In particular, if any logical gate has a large fan-out, we can distribute its output using a binary tree of G ¬ gates (we use trees of even depth). When the gate is arithmetic ( G ζ , G × ζ , G = , G + , or G -), we convert its output to unary representation over Θ( ′ ) logical gates (Algorithm 6). Then, we copy the unary representation using trees of G ¬ gates. Finally, we use G × ζ and G + gates to convert each copy of the unary representation back to a real value in [0 , 1] (Algorithm 7).
It is interesting to note that for constant and ′ , the unary representation has constant size, so the number of new gates is proportional to the original fan-out (i.e. the number of leaves of the binary tree that copies the unary representation). In particular this reduction increases the size of the circuit by a factor of Θ(1 / ′ ) .
## Algorithm 7 Unary2Real ( | b 1 , . . . b 4 / ′ | a ′ )
1. G ζ (0 || d 0 )
2. for each k ∈ [4 / ′ ] :
(a) G × ζ ( ′ / 4 | b k | c k ) # The sum of the c k 's is approximately a :
$$\sum x \left [ c _ { k } \right ] = x \left [ a \right ] \pm \left ( \epsilon ^ { \prime } / 2 + \epsilon \cdot 4 / \epsilon ^ { \prime } \right )$$
$$( b ) \, G _ { + } \left ( | \ d _ { k - 1 } , c _ { k } | \ d _ { k } \right )$$
3. G = ( | d k | a ′ )
# a ′ approximately recovers the original a :
$$x \left [ a ^ { \prime } \right ] = x \left [ a \right ] \pm \epsilon ^ { \prime }$$
## 7 From -Gcircuit to 2 -ANE
The last step in our proof is to reduce the problem of finding an -approximate solution to the generalized circuit to that of finding an Θ( 2 ) -ANE. First, we reduce to the problem of finding an -WSNE in a (polymatrix, degree 3) graphical game. This reduction is implicit in Daskalakis et al [DGP09] 5 .
Definition 6. Given a polymatrix game over a degree d graph with k actions for each player, -WSNE-Polymatrix ( d, k ) is the problem of finding an -Well Supported Nash Equilibrium.
Theorem. (Essentially [DGP09]) 2 -Gcircuit with fan-out 2 ≤ P -WSNEPolymatrix (3 , 2)
Daskalakis et al construct a different gadget for each type of gate. For example, we describe their gadget for the G × ζ gate below.
5 In [DGP09], polymatrix games are called games with additive utility functions .
## Lemma 4. ( G × ζ gadget, [DGP09])
Let v 1 , v 2 , and w be players in a graphical game, and suppose that the payoffs of v 2 and w are as follows.
| | w plays | 0 | w plays 1 |
|------------------|-------------|-----|-------------|
| Payoff for v 2 : | v 2 plays 0 | 0 | 1 |
| Payoff for v 2 : | v 2 plays 1 | 1 | 0 |
Payoffs for w :
| | | v 1 plays 0 | v 1 plays 1 |
|-----------------|-----------|---------------|---------------|
| game with v 1 : | w plays 0 | 0 | ζ |
| game with v 1 : | w plays 1 | 0 | 0 |
| game with v 1 : | | v 2 plays 0 | v 2 plays 1 |
| game with v 2 : | w plays 0 | 0 | 0 |
| game with v 2 : | w plays 1 | 0 | 1 |
Then, in every -WSNE p [ v 2 ] = min( ζ p [ v 1 ] , 1) ± , where p [ u ] denotes the probability that u assigns to strategy 1 .
Proof. (Sketch) If p [ v 2 ] > ζ p [ v 1 ] + , then in every -WSNE p [ w ] = 1 , which contradicts p [ v 2 ] > . Similarly, if p [ v 2 ] < min( ζ p [ v 1 ] , 1) - , then p [ w ] = 0 , which yields a contradiction when p [ v 2 ] < 1 - .
## 7.1 From √ -WSNE to Θ( ) -ANE
The reduction above shows hardness for the slightly stronger notion (therefore weaker hardness) of -WSNE. Daskalakis et al [DGP09] show a reduction from √ -WSNE to Θ( ) -ANE for games with a constant number of players. It is easy to see that the same reduction holds for graphical games with constant degree. We sketch the proof below.
Lemma 5. (Essentially [DGP09]) Given an -ANE of a graphical game with payoffs in [0 , 1] and incoming degree d in , we can construct in polynomial time a √ · ( √ +1+4 d in ) -WSNE.
Proof. Let V be the set of players, where each v ∈ V has utility U v and action set A v . Let x = ( x v a ) ∈ ∆( × v A v ) be an -ANE. Let U v a ( x -v ) denote the expected payoff for playing a when all other players play according to x . Note that
U v a ( x -v ) = U v a ( x N in ( v ) ) depends only on the distributions of the players in the incoming neighborhood of v , which we denote N in ( v ) . Finally, let U v max ( x -v ) = max a ∈ A v U v a ( x -v ) .
Let k = k ( ) > 0 be some large number do be specified later. We construct our new approximate equilibrium by taking, for each player only the strategies that are within k of the optimum:
$$\hat { x } _ { a } ^ { v } = \begin{cases} \frac { x _ { a } ^ { v } } { 1 - z ^ { v } } & U _ { a } ^ { v } \left ( x ^ { - v } \right ) \geq U _ { \max } ^ { v } \left ( x ^ { - v } \right ) - \epsilon k \\ 0 & o t h e r w i s e \end{cases}$$
where z v is the total probability that player v assigns to strategies that are more than k away from the optimum.
The above division is well-defined because for k > 1 , z v is bounded away from 1 . Moreover, the following claim from [DGP09] formalizes the intuition that when k is sufficiently large, the total weight on actions removed is small, so ˆ x v is close to x v :
Claim 13 . (Claim 6 of [DGP09])
$$\forall v \in V \ \sum _ { a \in A ^ { v } } | \hat { x } _ { a } ^ { v } - x _ { a } ^ { v } | \leq \frac { 2 } { k - 1 }$$
Now, the total change to the expected payoff to player v for each action a , is bounded by the total change in mixed strategies of its incoming neighbors :
$$\begin{array} { r l } { \left | U _ { a } ^ { v } \left ( x ^ { - v } \right ) - U _ { a } ^ { v } \left ( \hat { x } ^ { - v } \right ) \right | } & { = } & { \left | U _ { a } ^ { v } \left ( x ^ { \mathcal { N } _ { i n } ( v ) } \right ) - U _ { a } ^ { v } \left ( \hat { x } ^ { \mathcal { N } _ { i n } ( v ) } \right ) \right | } \\ & { \leq } & { \sum _ { a \in A ^ { \mathcal { N } ( v ) } } \left | \hat { x } _ { a } ^ { \mathcal { N } _ { i n } ( v ) } - x _ { a } ^ { \mathcal { N } _ { i n } ( v ) } \right | \leq \sum _ { w \in \mathcal { N } ( v ) } \sum _ { a \in A ^ { w } } \left | \hat { x } _ { a } ^ { w } - x _ { a } ^ { w } \right | \leq \frac { 2 d _ { i n } } { k - 1 } } \end{array}$$
It follows that ˆ x v a is a ( k + 4 d in k -1 ) -WSNE:
$$U _ { a } ^ { v } \left ( \hat { x } ^ { - v } \right ) \geq U _ { a } ^ { v } \left ( x ^ { - v } \right ) - \frac { 2 d _ { i n } } { k - 1 } \geq U _ { \max } ^ { v } \left ( x ^ { - v } \right ) - \epsilon k - \frac { 2 d _ { i n } } { k - 1 } \geq U _ { \max } ^ { v } \left ( \hat { x } ^ { - v } \right ) - \epsilon k - \frac { 4 d _ { i n } } { k - 1 }$$
Finally, take k = 1 + 1 / √ to get that
$$k \epsilon + { \frac { 4 d _ { i n } } { k - 1 } } \leq { \sqrt { \epsilon } } \cdot \left ( { \sqrt { \epsilon } } + 1 + 4 d _ { i n } \right )$$
## 8 -approximate Bayesian Nash equilibrium
In this section we formally introduce and prove our corollary for -approximate Bayesian Nash equilibrium in two-player games with incomplete information.
In a game with incomplete information, each player i has a type t i known only to her, and the players' types t = ( t 1 , t 2 ) are drawn from a joint distribution which is known to everyone. The payoff for player i is a function u i ( a , t i ) of her own type and all the players' actions.
## Definition 7. (e.g. [SSW04])
In a Bayesian Nash equilibrium , for every player i and every type t i , the mixed strategy x i ( t i ) must be a best response in expectation over the other players' types and actions:
$$\mathbb { E } _ { t | t _ { i } } \left [ \mathbb { E } _ { a \sim ( x _ { i } ( t _ { i } ) , x _ { - i } ( t _ { - i } ) ) } \left [ u _ { i } \left ( a ; t _ { i } \right ) \right ] \right ] \geq \max _ { x _ { i } ^ { \prime } ( t _ { i } ) \in \Delta A _ { i } } \mathbb { E } _ { t | t _ { i } } \left [ \mathbb { E } _ { a \sim \left ( x _ { i } ^ { \prime } ( t _ { i } ) , x _ { - i } ( t _ { - i } ) \right ) } \left [ u _ { i } \left ( a ; t _ { i } \right ) \right ] \right ] .$$
Similarly, in an -approximate Bayesian Nash equilibrium , for every player i and every type t i , the mixed strategy x i ( t i ) must be an -best response in expectation over the other players' types and actions:
$$\mathbb { E } _ { t | t _ { i } } \left [ \mathbb { E } _ { a \sim ( x _ { i } ( t _ { i } ) , x _ { - i } ( t _ { - i } ) ) } \left [ u _ { i } \left ( a ; t _ { i } \right ) \right ] \right ] \geq \max _ { x _ { i } ^ { \prime } ( t _ { i } ) \in \Delta A _ { i } } \mathbb { E } _ { t | t _ { i } } \left [ \mathbb { E } _ { a \sim \left ( x _ { i } ^ { \prime } ( t _ { i } ) , x _ { - i } ( t _ { - i } ) \right ) } \left [ u _ { i } \left ( a ; t _ { i } \right ) \right ] \right ] - \epsilon .$$
Before we prove our main corollary for incomplete information games, it is helpful to prove the following slightly weaker statement, for two players with many strategies.
Lemma 6. There exists a constant > 0 , such that given a two-player game with incomplete information where each player has n actions, finding an -approximate Bayesian Nash equilibrium is PPAD -complete.
Proof. We reduce from a bipartite polymatrix game, and let the typeset for each of the two players in the incomplete information game correspond to one side of the bipartite graph. The utility of player i on edge ( i, j ) of the polymatrix game depends on her identity ( i ), as well as the identity ( j ) of the vertex on the other side of that edge. We use the types of the incomplete information game, to encode i . We encode j using the strategies of the second player in the incomplete information game.
In more detail, consider a bipartite polymatrix game for which it is PPAD -hard to compute a 4 -approximate Nash equilibrium. Use an affine transformation to change all the payoffs from [0 , 1] to [1 / 2 , 1] . It is PPAD -hard to find a 2 -approximate Nash equilibrium in the transformed game.
We now construct the two-player incomplete information game: As we hinted before, we let the typeset of each player correspond to the vertices on one side of the bipartite graphical game. Player i has | T i | types and 2 | T i | strategies, where each strategy corresponds to a pair of vertex and strategy for that vertex. If a player plays a strategy whose vertex does not match her type, her payoff is 0 . Therefore in every -approximate Bayesian Nash equilibrium, every player, on every type, plays the two strategies that correspond to her type with probability at least 1 -2 .
Let the joint distribution over types be as follows: pick a random edge in the bipartite graph, and assign the types corresponding to its vertices. Whenever both players play strategies that match their respective types, their payoffs are the payoffs in the (transformed) bimatrix game on that edge. In every -approximate Bayesian Nash equilibrium, every player, on every type, plays a mixed strategy which is -best response. Since the other player plays strategies that correspond to the correct vertex with probability at least 1 -2 , the same mixture must be a 2 -best response for the vertex player in the bipartite game.
In order to prove the main corollary, we need to reduce the number of actions in the above construction. Observe that we don't need each player to choose an action that uniquely identifies her type. Rather, it suffices to specify which neighbor of the other player's vertex is chosen. This can be done concisely via a coloring of the vertices such that every pair of vertices of distance exactly two have different colors; i.e. a coloring of the square of the polymatrix game's graph. The squared graph has degree 3 · (3 -1) = 6 , and therefore we can efficiently find a 7 -coloring. It suffices for each player to specify one of 7 colors, together with one of 2 strategies for the vertex with that color. Therefore we can encode this choice using only 14 strategies.
Corollary 1. There exists a constant > 0 , such that given a two-player game with incomplete information where each player has 14 actions, finding an -approximate Bayesian Nash equilibrium is PPAD -complete.
## 9 Relative -Well Supported Nash equilibrium
In this section we formally introduce and prove our result for relative -Well Supported Nash Equilibrium in two-player games.
As we mentioned in Section 3.1, we say that a vector of mixed strategies x ∈ × j ∆ A j is a Nash equilibrium if every strategy a i in the support of x i is a best response to the actions of the mixed strategies of the rest of the players, x -i ;
$$\mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a _ { i } , a _ { - i } \right ) \right ] = \underset { a ^ { \prime } \in A _ { i } } { \max } \mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a ^ { \prime } , a _ { - i } \right ) \right ] .$$
In this section, we study the multiplicative relaxation of this condition. Namely,
Definition 8. We say that x is a relative -Well Supported Nash Equilibrium ( relative -WSNE ) if each a i in the support of x i is a relative -best response to x -i . I.e. ∀ a i ∈ Supp( x i ) ,
$$\mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a _ { i } , a _ { - i } \right ) \right ] \geq ( 1 - \epsilon ) \max _ { a ^ { ^ { \prime } } \in A _ { i } } \mathbb { E } _ { a _ { - i } \sim x _ { - i } } \left [ u _ { i } \left ( a ^ { ^ { \prime } } , a _ { - i } \right ) \right ] .$$
Corollary 2 (Relative -WSNE) . There exists a constant > 0 such that finding a relative -Well Supported Nash Equilibrium in a bimatrix game with positive payoffs is PPAD-complete.
Proof. We reduce from a bipartite, degree 3 , polymatrix game (Theorem 1). The payoff bimatrix is the sum of a main game that simulates the polymatrix game and an imitation game that forces the two players to randomize (approximately) uniformly across all the polymatrix game nodes.
Main game As in the reduction to games of incomplete information, let each player 'control' the nodes on one side of the bipartite game graph. Namely, let n be the number nodes on each side of the graph; each player has 2 n actions, each corresponding to a choice of a node and an action for that node. (We assume without loss of generality that the number of nodes is equal and every node has exactly 3 neighbors.) When the players play strategies that correspond to adjacent nodes in the graphs, they receive the payoffs of the corresponding nodes, scaled by a small positive constant, e.g. η = 0 . 01 , to fit in [0 , η ] . If the nodes played do not share an edge in the bipartite game graph, the utility for both players is zero.
- Imitation game We also let the players play a hide-and-seek game with payoffs in { 0 , 1 } over a space of n actions. Fix an arbitrary ordering over the nodes on each side of the polymatrix game; action i in the imitation game corresponds to the two rows (respectively, two columns) for node i in the main game. The row player tries to imitate the column player; namely her payoff is 1 if they both play their respective node i , and 0 otherwise. The column player tries to imitate the row player +1 ; her payoff is 1 if the row player plays node i , and she plays node i +1 (mod n ) (we henceforth drop the (mod n ) for simplicity of notation).
## Structure and value of a relative -WSNE
We first claim that in every relative -WSNE ( x, y ) , the two players randomize approximately uniformly across all their nodes. Let x ( i ) denote the total probability that the row player assigns to node i , and analogously for y ( i ) .
Lemma 7. In every ( x, y ) relative -WSNE, x ( i ) , y ( i ) ∈ [(1 -4 η ) /n, (1 + 5 η ) /n ] ∀ i .
Proof. Let t R = max i x ( i ) and i ∗ R = arg max i x ( i ) ; we first observe that if x ( j ) ≤ (1 -4 η ) t R < (1 - -3 η ) t R , then y ( j +1) = 0 . The column player's payoff from the imitation game, when playing node j +1 , is at most x ( j ) , while from the main game she can gain at most x ( k ) · η for each row player's node k in the neighborhood of the column player's j +1 . Since each node has only three neighbors and they all satisfy x ( k ) ≤ t R , her payoff for playing either strategy of node j + 1 is bounded by x ( j ) + 3 t R · η < (1 - ) t R . However, she can guarantee a payoff of at least t R by playing node i ∗ R ; therefore by the well-supported condition, y ( j +1) = 0 . Similarly, if we let t C = max i y ( i ) , then whenever y ( j ) ≤ (1 -4 η ) t C , x ( j ) = 0 .
Next, we claim that both players have full support in the imitation game, i.e. x ( i ) , y ( i ) > 0 ∀ i ∈ [ n ] . Assume by contradiction that this is false, and let, without loss of generality, x ( i ) = 0 . Since x ( i ) < (1 -4 η ) /n ≤ (1 -4 η ) t R , we also have y ( i +1) = 0 . However, this implies x ( i +1) = 0 , which in turn implies y ( i +2) = 0 , and so forth. By induction we get that x ( i ) , y ( i ) = 0 ∀ i ∈ [ n ] , which of course cannot be true as their sum is 1 .
Therefore, for every i ∈ [ n ] , we also have that
$$locate ( i ) > ( 1 - 4 \eta ) \, t _ { R } \geq ( 1 - 4 \eta ) \, E _ { j } x \left ( j \right ) = ( 1 - 4 \eta ) / n ,$$
and similarly y ( i ) > (1 -4 η ) /n .
Finally, we claim that the maximum probability assigned to any node is at most t R , t C ≤ 1 / ((1 -4 η ) n ) < (1 + 5 η ) /n . Otherwise, E i x ( i ) < (1 -4 η ) t R , which in particular implies that for some i ∈ [ n ] , x ( i ) < (1 -4 η ) t R , violating (5)
Corollary 6. In every ( x, y ) relative -WSNE, the expected utilities of both players for playing any strategy is in [(1 -4 η ) /n, (1 + 9 η ) /n ] .
## Completing the proof of Corollary 2
Given a relative -WSNE ( x, y ) , we can take, for each node i , the mixed strategy induced by the probabilities x ( i : 1) /x ( i ) and x ( i : 2) /x ( i ) that the row player assigns to each action (respectively, y ( j : 1) /y ( j ) and y ( j : 2) /y ( j ) assigned by the column player). We claim that this strategy profile is an ′ -approximate equilibrium for the polymatrix game for some small constant ′ = Θ( ) (which is PPAD -hard to find by Theorem 1).
Assume by contradiction that this is not the case. Then without loss of generality there exists a node i which is controlled by the row player, and, under the induced strategy profile, can improve her payoff by ′ by deviating from strategy 1 to strategy 2 . Therefore in the two player game, the expected payoff to the row player from playing x ( i : 2) is greater than the payoff from playing x ( i : 1) by at least ′ · η · 1 n · (1 -O ( η )) . (We multiply ′ by the scaling factor η and the probability 1 n · (1 -O ( η )) of observing any of its neighbors.) Yet, by Corollary 6 the total payoff from playing x ( i : 2) is at most (1 + 9 η ) /n . Therefore, the row player improves her expected payoff by a factor of 1 + Ω ( ′ · η ) ≥ 1 + 2 when deviating from x ( i : 1) to x ( i : 2) - but this contradicts our assumption that ( x, y ) is a relative -WSNE.
## 10 Non-monotone markets
In this section we formally introduce our result for non-monotone markets, discuss it, and compare it to the original result of Chen, Paparas, and Yannakakis [CPY13]. A sketch of the proof appears in Appendix A.
Intuitively, a market is monotone if increasing the price of some good, while fixing the rest of the prices, never increases the excess demand for that good. Formally, we have the following definition by Chen et al:
Definition 9. ([CPY13]) Let M be a market with k ≥ 2 goods. We say that M is non-monotone at price vector π if there exist c > 0 , and a good g 1 such that:
- the excess demand Z 1 ( y 1 , . . . y k ) is a continuous function (rather than correspondence) over y ∈ B ( π , c ) ;
- Z 1 ( π ) > 0 ;
- the partial derivative of ∂Z 1 /∂y 1 exists and is continuous over B ( π , c ) ;
- and ∂Z 1 /∂y 1 ( π ) > 0 .
We say that a market M is non-monotone if there exists such a rational price vector π ≥ 0 , and Z 1 ( π ) is moderately computable ; i.e. for any γ > 0 , Z 1 ( π ) can be approximated to within γ in time polynomial in 1 /γ .
In general we want to talk about non-monotone families of utility functions, i.e. ones that support non-monotone markets. Formally,
Definition 10. ([CPY13]) We say that a family U of utility functions is nonmonotone if:
- U is countable;
- if u : [0 , ∞ ) k → R is in U , then so is u ′ ( x 1 , . . . x m ) = a · u ( x l 1 /b 1 , . . . x l k /b k ) for any indices l 1 , . . . , l k ∈ [ m ] and positive (rational) a, b 1 , . . . , b k ;
- u ( x ) = g ∗ ( x i ) is in U for some strictly increasing g : [0 , ∞ ) → R ; and
- there exists a non-monotone market M U with utilities from U .
We need to include one more definition: that of -tight market equilibrium.
Definition 11. A price vector π is an -tight approximate market equilibrium of M if there exists a z ∈ Z ( π ) (the excess demand at π ) such that for every good j , | z j | ≤ W j , where W j is the sum of the endowments of good j .
Our main result for non-monotone markets equilibria is now formally defined:
Corollary 3 (Non-monotone markets) . Let U be any non-monotone family of utility functions. There exists a constant U > 0 such that given a market M where the utility of each trader is either linear or taken from U , finding an U -tight approximate market equilibrium is PPAD -hard.
## 10.1 Why are non-monotone markets hard?
Before delving into the details of the construction, we attempt to reach some intuition: why should we expect equilibrium computation to be hard in nonmonotone markets? Probably the most intuitive algorithm for finding market equilibrium is via tatonnement: raise the prices of over-demanded goods, and decrease the prices of under-demanded goods. For many markets, the tatonnement process is also computationally efficient [CMV05]. One obvious problem is that when the market is non-monotone, the tatonnement step actually takes us further away from equilibrium. However, the non-monotonicity is only local: if we set the (relative) price of the non-monotone good high enough, even the most enthusiastic traders can only afford a small amount.
The 'real' reason that tatonnement fails to converge efficiently for nonmonotone markets is a little more subtle. What happens when the demand for the non-monotone good g increases by a factor of (1 + δ ) for some small δ ? The tatonnement increases the price of g , which further increases the demand. Eventually, the price is high enough, and the demand is reduced; but due to the non-monotonicity we may have to increase the price by larger factor, i.e. (1 + δ ′ ) for δ ′ > δ . Now, another trader with a positive endowment of g has increased her spending budget by (1 + δ ′ ) , further increasing the demand for yet another good (by a larger factor). Thus a small change in the demand for one good may cause a much larger change in the demand for another good. Exploiting this 'butterfly effect' lies at the heart of Chen et al's construction.
## 10.2 High-level structure of the proof
Our reduction from polymatrix games to non-monotone markets closely follows the footsteps of [CPY13]. To gain some intuition, consider two goods g 2 i -1 and g 2 i for each player i , corresponding to her two available strategies (soon each of those goods will become a subset of goods). Let π ( g 2 i -1 ) and π ( g 2 i ) denote their corresponding prices; those prices correspond to the probabilities that player i assigns to her respective strategies. For every i, j ∈ [ n ] , we add a trader who is interested in selling g 2 i -1 and buying g 2 j -1 (and similarly for (2 i, 2 j -1) , (2 i -1 , 2 j ) , and (2 i, 2 j ) ). This trader has an endowment of g 2 i -1 that is proportional to P 2 i -1 , 2 j -1 , the utility of player j in the bimatrix game with player i , when they both play the first strategy. Qualitatively, if the price π ( g 2 i -1 ) is high (player i assigns a high probability to her first strategy), and
P 2 i -1 , 2 j -1 is high (player j receives a high utility from playing her first strategy to i 's first strategy), then the demand for good g 2 j -1 is high - implying a high price in every approximate market equilibrium (i.e. player j indeed assigns a high probability to her first strategy).
In order to turn this qualitative intuition into a proof we use a more complex construction. The main difficulty comes from the need to amplify the effect of a higher income for one trader on the incomes of other traders. To this end we consider, for each i ∈ [ n ] , two sequences of goods: g 2 i -1 = g 2 i -1 , 0 , g 2 i -1 , 1 , . . . , g 2 i -1 , 4 t = h 2 i -1 and g 2 i = g 2 i, 0 , g 2 i, 1 , . . . , g 2 i, 4 t = h 2 i . The trader mentioned in the previous paragraph actually owns P 2 i -1 , 2 j -1 units of good h 2 i -1 ; she is still interested in good g 2 j -1 . Now we construct (Lemma 14) a chain of gadgets that use copies of the non-monotone markets in U to amplify the small gap guaranteed between π ( g 2 j -1 ) and π ( g 2 j ) to a larger gap between π ( h 2 j -1 ) and π ( h 2 j ) .
Additionally, we want to bound the range that these prices may take. In Lemma 11 we use a price regulating gadget [CDDT09, VY11] to control the relative prices of π ( g 2 i -1 ,j ) and π ( g 2 i,j ) . In Lemma 13 we show that the sums π i,j = π ( g 2 i -1 ,j ) + π ( g 2 i,j ) are approximately equal. Finally, in Section A.5 we combine these lemmata to formalize a quantitative version of the qualitative intuition described above.
## 10.3 Adaptations for constant factor inapproximability
As mentioned in the introduction, Corollary 3 has a weakness in comparison to the results of Chen et al [CPY13]: it only applies to tight approximate market equilibrium.
Maintaining the constant hardness of approximation through most of [CPY13]'s proof is rather straightforward, but there are a few hurdles along the way. To understand the first obstacle, we must consider a subtle issue of normalization. Chen et al normalize the bimatrix game between every pair of players to have an average value of 1 / 2 . While this does not change the absolute utility gained from any deviation, the relative utility from deviation is now divided by a factor of Θ( n ) . In contrast, in Theorem 1 we prove hardness for a constant when normalizing with respect to a constant degree ( 3 ), i.e. each player participates in only a constant number of bimatrix games. We overcome this difficulty by using a different normalization: only edges (i.e. bimatrix games) that belong to the game graph will have an average utility of 1 / 2 , while the utilities on other
edges remains 0 . Since we proved hardness for a degree 3 graphical game, the normalization only costs us a constant factor.
More serious complications arise when trying to prove [CPY13]'s Lemma 3 6 for a constant . This lemma says that certain prices (in fact, these are sums of prices), denoted π i, 0 for i ∈ [ n ] , are approximately equal. A key step in the proof of [CPY13] is to show, roughly, that in every ( n ) -approximate market equilibrium,
$$loc_1>loc_2>loc_5>loc_7>\pi _ { i , 0 } \geq \frac { 1 } { n } \sum _ { j \in [ n ] } \pi _ { j , 0 } - O \left ( \epsilon \left ( n \right ) \right )$$
When ( n ) is polynomially small, this immediately implies that min i ∈ [ n ] π i, 0 is within O ( ( n )) of the average, and therefore it must also be that max i ∈ [ n ] π i, 0 is within O ( n · ( n )) of the average. When taking a larger ( n ) , this reasoning breaks. The first modification we make to overcome this obstacle, is to require ( n ) -tight approximate market equilibrium. This gives a two-sided bound:
$$\left | \pi _ { i , 0 } - \frac { 1 } { n } \sum _ { j \in [ n ] } \pi _ { j , 0 } \right | = O \left ( \epsilon \left ( n \right ) \right )$$
A second issue that arises in the same inequality, is that with our new normalization, which depends on the game graph G , we can only prove that π i, 0 approximates the values of its neighbors, denoted N G ( i ) . In other words, (6) becomes
$$\left | \pi _ { i , 0 } - \frac { 1 } { \left | \mathcal { N } _ { G } \left ( i \right ) \right | } \sum _ { j \in \mathcal { N } _ { G } \left ( i \right ) } \pi _ { j , 0 } \right | = O \left ( \epsilon \left ( n \right ) \right )$$
In order to relate the value of π i, 0 to the corresponding values of the neighboring vertices, π j, 0 's, we consider T consecutive applications of (7): π i, 0 is O ( T · ) -close to the expectation over π j, 0 where j is taken from the distribution of a T -steps random walk on G starting from i . For example, if G is a constant degree expander, the random walk converges in O (log n ) steps, yielding a (1 / log n ) -inapproximability result.
6 Compare with our Lemma 13. The reader may also want to refer to Lemma 6 in the full version of [CPY13].
## Achieving constant hardness
Finally, in order to achieve hardness for a constant , we want a graph with constant mixing time - and this clearly cannot be done with a constant degree 7 . Instead, in Section A.2 we construct a normalized game whose graph has a constant mixing time, each vertex has degree O ( √ n ) , and yet approximating Nash equilibrium is hard for a constant . In short, we take n copies of the original n -player game (our new game has n 2 players). For any pair of players that play a (non-trivial) bimatrix game in the original game, we have a copy of the same bimatrix game between all ( n 2 ) pairs of their respective copies. We also add a trivial bimatrix game between every pair of players that belong to the same copy of the original game. In Section A.2 we argue that these newly added trivial edges are only a constant fraction of all edges in the new game graph, yet this graph has a constant mixing time.
## References
- [Bab14] Yakov Babichenko. Query complexity of approximate nash equilibria. In STOC , pages 535-544, 2014.
- [BLP15] Siddharth Barman, Katrina Ligett, and Georgios Piliouras. Approximating nash equilibria in tree polymatrix games. In Algorithmic Game Theory - 8th International Symposium, SAGT 2015, Saarbrücken, Germany, September 28-30, 2015, Proceedings , pages 285296, 2015.
- [BPR16] Yakov Babichenko, Christos H. Papadimitriou, and Aviad Rubinstein. Can almost everybody be almost happy? In Proceedings of the 2016 ACM Conference on Innovations in Theoretical Computer Science, Cambridge, MA, USA, January 14-16, 2016 , pages 1-9, 2016.
- [BR16] Yakov Babichenko and Aviad Rubinstein. CoRR , abs/1608.06580, 2016.
7 In fact, it seems that a graph where the random walks starting from any pair of neighbors converge in constant time would suffice. We do not know whether such graphs can be constructed with constant degree.
- [Bud11] Eric Budish. The combinatorial assignment problem: Approximate competitive equilibrium from equal incomes. Journal of Political Economy , 119(6):1061 - 1103, 2011.
- [CCT15] Xi Chen, Yu Cheng, and Bo Tang. Well-supported versus approximate nash equilibria: Query complexity of large games. CoRR , abs/1511.00785, 2015.
- [CDDT09] Xi Chen, Decheng Dai, Ye Du, and Shang-Hua Teng. Settling the Complexity of Arrow-Debreu Equilibria in Markets with Additively Separable Utilities. In FOCS , pages 273-282, 2009.
- [CDT09] Xi Chen, Xiaotie Deng, and Shang-Hua Teng. Settling the complexity of computing two-player Nash equilibria. J. ACM , 56(3), 2009.
- [CMV05] Bruno Codenotti, Benton McCune, and Kasturi Varadarajan. Market equilibrium via the excess demand function. In Proceedings of the Thirty-seventh Annual ACM Symposium on Theory of Computing , STOC '05, pages 74-83, New York, NY, USA, 2005. ACM.
- [CPY13] Xi Chen, Dimitris Paparas, and Mihalis Yannakakis. The complexity of non-monotone markets. In STOC , pages 181-190, 2013. Preprint of full version is available at http://arxiv.org/abs/1211.4918v1.
- [Das13] Constantinos Daskalakis. On the complexity of approximating a nash equilibrium. ACM Transactions on Algorithms , 9(3):23, 2013.
- [DFSS14] Argyrios Deligkas, John Fearnley, Rahul Savani, and Paul G. Spirakis. Computing Approximate Nash Equilibria in Polymatrix Games. In Web and Internet Economics - 10th International Conference, WINE 2014, Beijing, China, December 14-17, 2014. Proceedings , pages 58-71, 2014.
- [DGP09] Constantinos Daskalakis, Paul W. Goldberg, and Christos H. Papadimitriou. The complexity of computing a Nash equilibrium. Commun. ACM , 52(2):89-97, 2009.
- [Fol67] D.K. Foley. Resource Allocation and the Public Sector. Yale Economic Essays , 7(1):45-98, 1967.
- [GR14] Paul W. Goldberg and Aaron Roth. Bounds for the query complexity of approximate equilibria. In EC , pages 639-656, 2014.
- [HdRS08] Sébastien Hémon, Michel de Rougemont, and Miklos Santha. Approximate Nash Equilibria for Multi-player Games. In SAGT , pages 267-278, 2008.
- [HN13] Sergiu Hart and Noam Nisan. The query complexity of correlated equilibria. CoRR , abs/1305.4874, 2013.
- [HPV89] Michael D. Hirsch, Christos H. Papadimitriou, and Stephen A. Vavasis. Exponential lower bounds for finding brouwer fix points. J. Complexity , 5(4):379-416, 1989.
- [Kea07] Michael Kearns. Graphical games , chapter 7, pages 159-180. Cambridge University Press, 2007.
- [LMM03] Richard J. Lipton, Evangelos Markakis, and Aranyak Mehta. Playing large games using simple strategies. In EC , pages 36-41, 2003.
- [Max97] R. R. Maxfield. General equilibrium and the theory of directed graphs. Journal of Mathematical Economics , 27(1):23-51, 1997.
- [Nas51] John Nash. Non-cooperative games. The Annals of Mathematics , 54:286-295, 1951.
- [OPR14] Abraham Othman, Christos H. Papadimitriou, and Aviad Rubinstein. The complexity of fairness through equilibrium. In EC , pages 209-226, 2014.
- [Oth14] Abraham Othman. Course Match User Manual , 1.3 edition, 2014.
- [Pap94] Christos H. Papadimitriou. On the complexity of the parity argument and other inefficient proofs of existence. J. Comput. Syst. Sci. , 48(3):498-532, 1994.
- [Rub14] Aviad Rubinstein. Computational complexity of approximate nash equilibrium in large games. CoRR , abs/1405.0524, 2014.
- [Rub16] Aviad Rubinstein. Settling the complexity of computing approximate two-player nash equilibria. In To appear in FOCS , 2016.
- [Shm12] Eran Shmaya. Brouwer Implies Nash Implies Brouwer. http://theoryclass.wordpress.com/2012/01/05/brouwer-impliesnash-implies-brouwer/, 2012.
- [SSW04] Satinder P. Singh, Vishal Soni, and Michael P. Wellman. Computing approximate bayes-nash equilibria in tree-games of incomplete information. In EC , pages 81-90, 2004.
- [SV12] Grant Schoenebeck and Salil P. Vadhan. The computational complexity of nash equilibria in concisely represented games. TOCT , 4(2):4, 2012.
- [TV85] W. Thomson and H.R. Varian. Theories of justice based on symmetry. Social Goals and Social Organizations: Essays in Memory of Elisha Pazner , 1985.
- [Var74] H. Varian. Equity, envy, and efficiency. Journal of Economic Theory , 9(1):63-91, 1974.
- [VY11] Vijay V. Vazirani and Mihalis Yannakakis. Market equilibrium under separable, piecewise-linear, concave utilities. J. ACM , 58(3):10, 2011.
## A Non-monotone markets: proof of inapproximability
In this section we prove our main inapproximability result for non-monotone markets:
Corollary 3 (Non-monotone markets) . Let U be any non-monotone family of utility functions. There exists a constant U > 0 such that given a market M where the utility of each trader is either linear or taken from U , finding an U -tight approximate market equilibrium is PPAD -hard.
## A.1 Normalized polymatrix games
We identify n -player, 2 -strategy polymatrix graphical games with 2 n × 2 n matrices by letting the ( i, j ) -th 2 × 2 block correspond to the payoff matrix of player j in the bimatrix game with player i .
Given a game G , let P ′ be the 2 n × 2 n induced payoff matrix. We normalize P ′ as follows:
$$P _ { 2 i , 2 j - 1 } = \begin{cases} 1 / ( 2 \Delta ) + \left ( P ^ { \prime } _ { 2 i , 2 j - 1 } - P ^ { \prime } _ { 2 i , 2 j } \right ) / ( 2 \Delta ) & ( i , j ) \in E \\ 0 & \text {otherwise} \end{cases}$$
where E is the edge set for the graphical game 8 and ∆ is the maximum degree. We define P 2 i, 2 j , P 2 i -1 , 2 j -1 , P 2 i -1 , 2 j analogously. Notice that P and P ′ have the same -WSNE, up to the normalization by the degree ∆ . In particular finding an ( / ∆) -WSNE in P continues to be PPAD -complete.
Observe that in this formulation, finding an -WSNE is equivalent to finding a vector x ∈ [0 , 1] 2 n s.t. x 2 i -1 + x 2 i = 1 and
$$\begin{array} { r l } { x ^ { \top } \cdot P _ { 2 i - 1 } > x ^ { \top } \cdot P _ { 2 i } + \epsilon } & { \implies x _ { 2 i } = 0 } \\ { x ^ { \top } \cdot P _ { 2 i - 1 } < x ^ { \top } \cdot P _ { 2 i } - \epsilon } & { \implies x _ { 2 i - 1 } = 0 } \end{array}$$
## A.2 Games on graphs with a constant mixing time
Given the correspondence defined above between n -player games and 2 n × 2 n matrices, we see that the structure of the game graph plays a non-trivial role in the construction. In particular, adding trivial edges between vertices, i.e. adding zero-utility bimatrix games between players, has no affect on the utility of the players, but changes the corresponding normalized matrix. For reasons that will become clear much later in the proof, we would like our game graph to have a constant mixing time.
Indeed, a trivial candidate with very fast mixing is the complete graph. However, such a blowup in the degree would dilute our inapproximability factor in the normalized game . Instead, we consider n copies ( v 1 , . . . , v n ) of each player v ∈ V in the original game. If players u and v play a bimatrix game G u,v in the original game G , then for every i, j ∈ [ n ] , we construct the same bimatrix game G u,v between u i and v j . Our game graph now consists of n 2 vertices, each with degree 9 3 n . Finally, within each copy V i , we add trivial edges between all the vertices not otherwise connected (including self-loops). Normalize this game using (8). We use G to denote the new game and G for the new game graph; we
8 Notice that this definition allows self-loops in the game graph.
9 Theorem 1 promises a graphical game of degree at most 3 . It is not hard to extend to a 3 -regular graph game with only a constant loss in the approximation factor.
henceforth let ∆ = 4 n -3 denote the degree. In the next two lemmata we show that this game satisfies the two properties we need: finding an -WSNE of G is PPAD -complete, and the mixing time of G is constant.
Lemma 8. Given an -WSNE in G , we can (efficiently) construct a (4 / 3) -WSNE for G .
Proof. For each player v , we take the average of the mixed strategies of v 1 , . . . , v n . The utility of v is the same as the average of utilities of v 1 , . . . , v n , and if v has a (4 / 3) -improving deviation, then at least one of the copies v i has an -improving deviation. (The (4 / 3) factor comes from the change in the degree.)
Lemma 9. Let π v i ,T be the distribution of a random walk on G after T steps, starting from v i , and let π ∗ be the uniform distribution on the vertices of G . Then
$$\left \| \pi _ { v ^ { i } , T } - \pi ^ { * } \right \| _ { 1 } \leq \left ( \frac { 1 } { 4 } \right ) ^ { T / 2 } + \left ( \frac { 3 } { 4 } \right ) ^ { T / 2 } = 2 ^ { - O ( T ) }$$
Proof. At each step of the random walk, there is a constant probability (greater than 3 / 4 ) of walking on a non-trivial edge, which takes us to another (uniformly random) copy of the original game; thereafter the copy of the game remains uniformly random. Similarly, at each step there is a constant probability (greater than 1 / 4 ) of moving to a vertex within the same copy (again, uniformly random). Thus conditioned on having walked on a non-trivial edge, and then on an edge within the same copy, the distribution is uniform. Since all vertices have the same degree, this is also the stationary distribution, and we never leave it.
For simplicity, in the following we redefine n to be the size of G (and hence ∆ ≈ 4 √ n ).
## A.3 Construction
Let N be a sufficiently large constant, and let t = log N . Note that N depends on the parameters of the non-monotone market in U , but not on the size n of our construction. We use the notation O N ( · ) to denote the asymptotic behavior when N goes to infinity (but arbitrarily slower than n ). We prove that it is PPAD -hard to find an η -tight approximate market clearing equilibrium for η = N -8 , where is the inapproximability factor from Lemma 8.
For each vertex i ∈ [ n ] we construct a series of 4 t + 1 gadgets R i,j , for j ∈ [0 : 4 t ] . Each gadget is composed of:
Main goods g 2 i -1 ,j and g 2 i,j are the main goods in the reduction. They are used to encode the weights assigned to strategies x 2 i -1 and x 2 i , respectively.
Non-monotone gadget For each j ∈ [4 t ] , we include additional goods s i,j, 3 , . . . , s i,j,k and a non-monotone gadget
$$N M \left ( \mu , \gamma , g _ { 2 i - 1 , j } , g _ { 2 i , j } , s _ { i , j , 3 } , \dots , s _ { i , j , k } \right )$$
This means that we scale the non-monotone market guaranteed to exist in U according to parameters γ and µ such that when all the prices are approximately the same, the excess demand of g 2 i -1 ,j increases linearly with its price. Formally, we have the following lemma by Chen et al.
Lemma 10. (Lemma 3.1 of [CPY13]) There exist two (not necessarily rational) positive constants c and d with the following property. Given any γ > 0 , one can build a market M γ with utilities from U and goods g 2 i -1 ,j , g 2 i,j , s i,j, 3 , . . . , s i,j,k in polynomial time in 1 /γ such that:
Let f γ,µ ( x ) denote the excess demand function of g 2 i -1 ,j when the price of g 2 i -1 is 1 + x , and the prices of all other k -1 goods are 1 -x . Then f γ,µ is well defined over [ -c, c ] with | f γ,µ (0) | ≤ µγ and its derivative f ′ γ,µ (0) = d > 0 . For any x ∈ [ -c, c ] , f γ,µ ( x ) also satisfies
$$\left | f _ { \gamma , \mu } \left ( x \right ) - f _ { \gamma , \mu } \left ( 0 \right ) - \mu d x \right | \leq \left | \mu x / D \right | , \, w h e r e \ D = \max \left \{ 2 0 , 2 0 / d \right \} .$$
Finally, we would like to set µ = ∆ /d ; in particular, this would imply that f γ,µ ( x ) ≈ ∆ x . However, as mentioned above, d may be irrational. Instead, let d ∗ be a positive rational constant that satisfies
$$1 - 1 / D \leq d ^ { * } \cdot d \leq 1$$
We set the parameters µ = d ∗ ∆ and γ = 1 /N 6 .
Price regulating gadget For j ∈ [4 t ] , we include a price regulating gadget
$$\begin{array} { r } { P R \left ( \tau , \alpha _ { j } , g _ { 2 i - 1 , j } , g _ { 2 i , j } , s _ { i , j , 3 } , \dots s _ { i , j , k } \right ) , } \end{array}$$
whereas for j = 0 , we don't have goods s i, 0 , 3 , . . . s i, 0 ,k , and simply include
the gadget
$$\begin{array} { r } { P R \left ( \tau , \alpha _ { 0 } , g _ { 2 i - 1 , 0 } , g _ { 2 i , 0 } \right ) . } \end{array}$$
The parameters are set to τ = N ∆ and α i = 2 i /N 5 . Notice that α 0 = N -5 and α 4 t = N -1 = β .
This gadget ensures that in any approximate equilibrium, the price ratio π ( g 2 i -1 ,j ) /π ( g 2 i,j ) is always in the range [ 1 -α j 1+ α j , 1+ α j 1 -α j ] . Furthermore, within each gadget R i,j , the prices of all the goods besides g 2 i -1 ,j are exactly equal:
$$\pi \left ( g _ { 2 i } , j \right ) = \pi \left ( s _ { i , j , 3 } \right ) = \cdots = \pi \left ( s _ { i , j , k } \right ) .$$
More specifically, we have two traders T 1 and T 2 with endowments ( k -1) τ of g 2 i -1 ,j , for T 1 and τ of each of the other goods for T 2 . The utilities are defined as
$$\begin{array} { r c l } u _ { 1 } & = & ( 1 + \alpha _ { j } ) \, x \left ( g _ { 2 i - 1 , j } \right ) + ( 1 - \alpha _ { j } ) \left ( x \left ( g _ { 2 i , j } \right ) + \sum _ { l = 3 } ^ { k } x \left ( s _ { i , j , l } \right ) \right ) \\ u _ { 2 } & = & ( 1 - \alpha _ { j } ) \, x \left ( g _ { 2 i - 1 , j } \right ) + ( 1 + \alpha _ { j } ) \left ( x \left ( g _ { 2 i , j } \right ) + \sum _ { l = 3 } ^ { k } x \left ( s _ { i , j , l } \right ) \right ) . \end{array}$$
In particular, T 1 and T 2 do not trade whenever π ( g 2 i -1 ,j ) /π ( g 2 i,j ) ∈ ( 1 -α j 1+ α j , 1+ α j 1 -α j ) .
- Auxiliary goods For j = 0 , we also include an auxiliary good aux i . Its eventual purpose is to disentangle the price of g 2 i -1 , 0 and g 2 i, 0 from the utility that the actions of player i causes to other players.
## Single-minded traders graph
Weconnect the groups of goods ( R i,j 's) using the following single-minded traders. We use ( w, g 1 : g 2 ) to denote a trader with endowment w of good g 1 who only wants good g 2 . Similarly, we use ( w, g 1 , g 2 : g 3 ) to denote a trader who has an endowment w of each of g 1 and g 2 , and only wants g 3 .
1. For each i ∈ [ n ] and j ∈ [0 : 4 t -1] , we add two traders from R i,j to R i,j +1 : (∆ , g 2 i -1 ,j : g 2 i -1 ,j +1 ) and (∆ , g 2 i,j : g 2 i,j +1 ) . These traders help propagate price discrepancies from g i, 0 to g i, 4 t .
2. Recall that we use g i as short for g i, 0 and h i for g i, 4 t . For each pair ( i, j ) ∈ E we add the following four traders: (∆ P 2 i -1 , 2 j -1 , h 2 i -1 : g 2 j -1 ) , (∆ P 2 i, 2 j -1 , h 2 i : g 2 j -1 ) , (∆ P 2 i -1 , 2 j , h 2 i -1 : g 2 j ) , (∆ P 2 i, 2 j , h 2 i : g 2 j ) . Since P is normalized, we have
$$\Delta P _ { 2 i - 1 , 2 j - 1 } + \Delta P _ { 2 i - 1 , 2 j } = \Delta P _ { 2 i , 2 j - 1 } + \Delta P _ { 2 i , 2 j } = 1$$
These traders will enforce the approximate Nash equilibrium.
3. Connect the auxiliary goods: We let
$$r _ { 2 j - 1 } = 2 \Delta - \Delta \sum _ { i \in \mathcal { N } ( j ) } \left ( P _ { 2 i - 1 , 2 j - 1 } + P _ { 2 i , 2 j - 1 } \right ) > 0$$
$$r _ { 2 j } = 2 \Delta - \Delta \sum _ { i \in \mathcal { N } ( j ) } \left ( P _ { 2 i - 1 , 2 j } + P _ { 2 i , 2 j } \right ) > 0$$
note that r 2 j -1 + r 2 j = 2∆ .
Weadd the following traders: ((1 -β ) r 2 j -1 , aux j : g 2 j -1 ) , ((1 -β ) r 2 j , aux j : g 2 j ) , and ((1 -β ) ∆ , g 2 j -1 , g 2 j : aux j ) .
Notice that the economy graph is strongly connected (because G is strongly connected); therefore an equilibrium always exists [Max97]. The supplies and demands for each good are summarized in Table 1.
## A.4 Structure of a market equilibrium
We now prove some properties that every η -tight approximate equilibrium π must satisfy. Recall that η = N -8 , where is the inapproximability factor for the polymatrix game.
We begin with the application of the price regulating markets:
Lemma 11. For every i ∈ [ n ] and j ∈ [0 : 4 t ] ,
$$\frac { 1 - \alpha _ { j } } { 1 + \alpha _ { j } } \leq \frac { \pi \left ( g _ { 2 i - 1 } , j \right ) } { \pi \left ( g _ { 2 i } , j \right ) } \leq \frac { 1 + \alpha _ { j } } { 1 - \alpha _ { j } }$$
$$\pi \left ( g _ { 2 i } , j \right ) = \pi \left ( s _ { i , j , 3 } \right ) = \cdots = \pi \left ( s _ { i , j , k } \right )$$
and
Table 1: Goods and traders
| good [total supply] | supplied by | demanded by |
|-------------------------------------------|------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| g 2 i - 1 , g 2 i [ N ∆(1+ o N (1)) ] | pr trader; (∆ , g 2 i - 1 : g 2 i - 1 , 1 ) , (∆ , g 2 i : g 2 i, 1 ) ; ((1 - β )∆ , g 2 i - 1 , g 2 i : aux i ) | pr traders; (∆ P 2 j - 1 , 2 i - 1 ,h 2 j - 1 : g 2 i - 1 ) , . . . (∆ P 2 j, 2 i ,h 2 j : g 2 i ) ; ((1 - β ) r 2 i - 1 , aux i : g 2 i - 1 ) , ((1 - β ) r 2 i , aux i : g 2 i ) |
| h 2 i - 1 [ | pr trader; nm traders; (∆ P 2 i - 1 , 2 j - 1 ,h 2 i - 1 : g 2 j - 1 ) | pr traders; nm traders; (∆ , g 2 i - 1 , 4 t - 1 : h 2 i - 1 ) |
| ( k - 1) N ∆(1+ o N (1)) ] | , (∆ P 2 i - 1 , 2 j ,h 2 i - 1 : g 2 j ) pr trader; nm traders; | pr traders; nm traders; |
| h 2 i [ N ∆(1+ o N (1)) ] | (∆ P 2 i, 2 j - 1 ,h 2 i : g 2 j - 1 ) , (∆ P 2 i, 2 j ,h 2 i : g 2 j ) | (∆ , g 2 i, 4 t - 1 : h 2 i ) |
| g 2 i - 1 ,j [ ( k - 1) N ∆(1+ o N (1)) ] | pr trader; nm traders; (∆ , g 2 i - 1 ,j : g 2 i - 1 ,j +1 ) | pr traders; nm traders; (∆ , g 2 i - 1 ,j - 1 : g 2 i - 1 ,j ) pr traders; |
| g 2 i,j [ N ∆(1+ o N (1)) ] | pr trader; nm traders; (∆ , g 2 i,j : g 2 i,j +1 ) | nm traders; (∆ , g 2 i,j - 1 : g 2 i,j ) |
| s i,j,l [ N ∆(1+ o N (1)) ] | pr trader; nm traders; | pr traders; nm traders; |
| aux i [ N ∆(1+ o N (1)) ] | ((1 - β ) r 2 i - 1 , aux i : g 2 i - 1 ) , ((1 - β ) r 2 i , aux i : g 2 i ) | ((1 - β )∆ , g 2 i - 1 , g 2 i : aux i ) |
Proof. Follows from the construction of the price regulating markets. For more details see the proof 10 of Lemma 6 in the full version of [CPY13], or previous works that use similar gadgets [CDDT09, VY11].
We henceforth use π i,j to denote the sum of the ( i, j ) -th main goods: π i,j = π ( g 2 i -1 ,j ) + π ( g 2 i,j ) .
## Lemma 12.
$$locate ( 1 - O _ { N } \left ( \eta \right ) ) \, \pi _ { i , 0 } / 2 \leq \pi \left ( A U X _ { i } \right ) \leq \left ( 1 + O _ { N } \left ( \eta \right ) \right ) \pi _ { i , 0 } / 2$$
Proof. The total supply of aux i is 2 (1 -β ) ∆ , yet the demand from the singleminded trader ((1 -β ) ∆ , g 2 i -1 , g 2 i : aux i ) is (1 -β ) ∆ π i, 0 π ( aux i ) . (For the upper bound we use the fact that π is a tight approximate market equilibrium.)
We are now ready to prove that the cost of every pair of main goods is approximately the same. Let δ = N 2 η .
Lemma 13. Let π max = max i,j π i,j and π min = min i,j π i,j , then
$$\pi _ { \max } / \pi _ { \min } \leq 1 + O _ { N } \left ( \delta \right ) .$$
Proof. The proof of this lemma is the main obstacle which requires the tightness assumption of the market equilibrium, as well as our bound on the mixing time from Lemma 9.
Recall that by Lemma 11, the prices of all the goods in each gadget R i,j are approximately equal. Thus, using our bound on the clearing error, we have that for each ( i, j ) ∈ [ n ] × [0 : 4 t ] ,
$$\left | \text {total spent on } \mathcal { R } _ { i , j } - \text {total worth of } \mathcal { R } _ { i , j } \right | \leq O _ { N } \left ( \eta \cdot k N \Delta \right ) \pi _ { i , j } = O _ { N } \left ( \eta \cdot N \Delta \right ) \pi _ { i , j }$$
By Walras' Law, the traders within each R i,j (i.e. the price regulating and non-monotone gadgets) contribute the same to both quantities in (9). Similarly, by Lemma 12, the auxiliary traders contribute O N ( η ∆ π i, 0 ) -approximately the same (for j = 0 ). Therefore the money spent on R i,j by the single minded traders is approximately the same as the total worth of endowments in R i,j of single minded traders:
10 In their statement, Chen et al require an -additively approximate equilibrium, and for a much smaller . However their proof continues to hold with our parameters.
- For each ( i, j ) ∈ [ n ] × [4 t ] , the restriction of (9) to the single-minded traders gives
$$\left | \Delta \pi _ { i , j - 1 } - \Delta \pi _ { i , j } \right | = O _ { N } \left ( \eta \cdot N \Delta \right ) \pi _ { i , j } \quad \ \ ( 1 0 )$$
- Similarly, for each group R i, 0 , we have
$$\left | \sum _ { l \in \mathcal { N } ( i ) } \pi _ { l , 4 t } - \Delta \pi _ { i , 0 } \right | = O _ { N } \left ( \eta \cdot N \Delta \right ) \pi _ { i , 0 } \quad \ \ ( 1 1 )$$
Applying (10) inductively, we have that for any i ∈ [ n ] and for any j, l ∈ [0: 4 t ] ,
$$\left | \pi _ { i , j } - \pi _ { i , l } \right | = O _ { N } \left ( \eta \cdot N t \right ) \pi _ { i , l }$$
Combining, with (11) we have,
$$\left | \pi _ { i , 0 } - \frac { 1 } { \Delta } \sum _ { l \in \mathcal { N } _ { G ^ { G } } ( i ) } \pi _ { l , 0 } \right | = O \left ( \eta \cdot N t \right ) \pi _ { i , 0 }$$
Thus for each i , π i, 0 is O ( η · Nt ) -approximately equal to the average of its neighbors in G . Repeating this argument T times, we have that π i, 0 is O N ( Tη · Nt ) -approximately equal to the expectation over a T -step random walk in G starting from i . By Lemma 9, after T = O (log δ ) steps the random walk δ -approximately converges to the uniform distribution, and we have
$$\begin{array} { r l } { \left | \pi _ { i , 0 } - \frac { 1 } { n } \sum _ { l \in [ n ] } \pi _ { l , 0 } \right | } & { = } & { O _ { N } \left ( T \eta \cdot N t \right ) \frac { 1 } { n } \sum _ { l \in [ n ] } \pi _ { l , 0 } + \delta \max _ { l \in [ n ] } \pi _ { l , 0 } } \\ & { = } & { O _ { N } \left ( \delta \right ) \max _ { l \in [ n ] } \pi _ { l , 0 } } \end{array}$$
Finally, we have the following lemma which describes the action of the nonmonotone gadgets.
Lemma 14. (Lemma 6 of [CPY13])
$$\begin{array} { r l } { \frac { 1 + \alpha _ { j - 1 } } { \pi \left ( g _ { 2 i - 1 , j - 1 } \right ) } = \frac { 1 - \alpha _ { j - 1 } } { \pi \left ( g _ { 2 i , j - 1 } \right ) } } & { \Longrightarrow } & { \frac { 1 + \alpha _ { j } } { \pi \left ( g _ { 2 i - 1 , j } \right ) } = \frac { 1 - \alpha _ { j } } { \pi \left ( g _ { 2 i , j } \right ) } a n d } \\ { \frac { 1 - \alpha _ { j - 1 } } { \pi \left ( g _ { 2 i - 1 , j - 1 } \right ) } = \frac { 1 + \alpha _ { j - 1 } } { \pi \left ( g _ { 2 i , j - 1 } \right ) } } & { \Longrightarrow } & { \frac { 1 - \alpha _ { j } } { \pi \left ( g _ { 2 i - 1 , j } \right ) } = \frac { 1 + \alpha _ { j } } { \pi \left ( g _ { 2 i , j } \right ) } } \end{array}$$
Proof. The demand for g 2 i -1 ,j and g 2 i,j comes from three sources: the singleminded traders, (∆ , g 2 i -1 ,j -1 : g 2 i -1 ,j ) and (∆ , g 2 i,j -1 : g 2 i,j ) ; the non-monotone gadget; and the price regulating gadget. Assume without loss of generality that the first premise holds, i.e. 1+ α j -1 π ( g 2 i -1 ,j -1 ) = 1 -α j -1 π ( g 2 i,j -1 ) . When the prices of g 2 i -1 ,j and g 2 i,j are equal, the demand from (∆ , g 2 i -1 ,j -1 : g 2 i -1 ,j ) is larger since she has more income from g 2 i -1 ,j -1 . In order to account for this difference, π ( g 2 i -1 ,j ) must be higher - but then the demand from the traders in the non-monotone market increases. Thus we further have to increase π ( g 2 i -1 ,j ) , until we reach the threshold of the price regulating traders: (1 + α j ) / (1 -α j ) .
Formally, normalize π such that π i,j = π ( g 2 i -1 ,j ) + π ( g 2 i,j ) = 2 . Thus by Lemma 13, π i,j -1 is also O N ( δ ) -close to 2 . Let f ( x ) denote the excess demand from the traders in the non-monotone gadget when π ( g 2 i -1 ,j ) = 1 + x and π ( g 2 i -1 ,j ) = π ( s i,j, 3 ) = · · · = π ( s i,j,k ) = 1 -x (recall from Lemma 11 that the latter prices are always equal to each other). By Lemma 10, we have that | f (0) | ≤ µγ , and for all x ∈ [ -c, c ] :
$$\left | f \left ( x \right ) - f \left ( 0 \right ) - \mu d x \right | \leq \left | \mu x / D \right | .$$
Now, let π ( g 2 i -1 ,j -1 ) = 1 + y ; notice that by Lemma 13, y = α j -1 ± O N ( δ ) . Let h ( x, y ) excess demand from all traders besides the two that belong to the price regulating gadget. Then,
$$h \left ( x , y \right ) = f \left ( x \right ) + { \frac { \Delta \left ( 1 + y \right ) } { 1 + x } } - \Delta = f \left ( x \right ) - { \frac { \Delta x } { 1 + x } } + { \frac { \Delta y } { 1 + x } }$$
For small x , we show that f ( x ) ≈ ∆ x/ (1 + x ) . More precisely,
$$\begin{array} { r c l } | f \left ( x \right ) - \Delta x / \left ( 1 + x \right ) | & \leq & | f \left ( x \right ) - \mu d x | + | \mu d x - \Delta x | + \Delta | x - x / \left ( 1 + x \right ) | \\ & \leq & | f \left ( 0 \right ) | + 2 | \mu x / D | + 2 \Delta x ^ { 2 } \\ & \leq & \Delta \cdot \left ( d ^ { * } \cdot \gamma + 2 x / 2 0 + 2 x ^ { 2 } \right ) \\ & \leq & \frac { \Delta y } { 3 } \end{array}$$
where the first inequality follows from the triangle inequality; the second follows by application of Lemma 10 for the first difference and the definitions of µ and d ∗ for the second; the third inequality applies the Lemma 10 again; finally the last inequality holds because for sufficiently large constant N , the parameters γ and x are sufficiently small.
Therefore, the excess demand must be balanced by the demand from the price regulating traders, implying that indeed 1+ α j π ( g 2 i -1 ,j ) = 1 -α j π ( g 2 i,j ) .
## A.5 From market equilibrium to Nash equilibrium
To complete the proof of Corollary 3, we must construct an -WSNE from any η -tight approximate market equilibrium.
For each i ∈ [ n ] , let θ i = ( π ( h 2 i -1 ) + π ( h 2 i )) / 2 . We define
$$x _ { 2 i - 1 } = \frac { \pi \left ( h _ { 2 i - 1 } \right ) / \theta _ { i } - \left ( 1 - \beta \right ) } { 2 \beta } a n d x _ { 2 i } = \frac { \pi \left ( h _ { 2 i } \right ) / \theta _ { i } - \left ( 1 - \beta \right ) } { 2 \beta } \quad \ \ ( 1 2 )$$
Observe that x 2 i -1 + x 2 i = 1 .
Suppose that
$$x ^ { \top } \cdot P _ { 1 } \geq x ^ { \top } \cdot P _ { 2 } + \epsilon$$
We show that this forces x 1 = 1 and x 2 = 0 ; by the discussion in Section A.1 this implies that x is indeed an -WSNE.
The following traders spend money on g 1 :
1. For each i ∈ N G (1) , there is a (∆ P i, 1 , h i ; g 1 ) trader. The total money these traders spend on g 1 is
$$\sum \Delta P _ { i , 1 } \cdot \pi \left ( h _ { 1 } \right ) = \sum \Delta P _ { i , 1 } \left ( 1 - \beta + 2 \beta \cdot x _ { i } \right ) \theta _ { \lceil i / 2 \rceil }$$
2. For each i ∈ N G (2) , there is a (∆ P i, 2 , h i ; g 2 ) trader. The total money these traders spend on g 2 is
$$\sum \Delta P _ { i , 2 } \cdot \pi \left ( h _ { 2 } \right ) = \sum \Delta P _ { i , 2 } \left ( 1 - \beta + 2 \beta \cdot x _ { i } \right ) \theta _ { \lceil i / 2 \rceil }$$
3. ((1 -β ) r 1 , aux 1 : g 1 ) and ((1 -β ) r 2 , aux 1 : g 2 ) traders
Let M 1 be the total amount that these traders spend on g 1 . Then
$$M _ { 1 } \ = \ \sum _ { i \in \mathcal { N } _ { \overline { G } } ( 1 ) } \Delta P _ { i , 1 } \left ( 1 - \beta + 2 \beta \cdot x _ { i } \right ) \theta _ { \lceil i / 2 \rceil } + \left ( 1 - \beta \right ) r _ { 1 } \pi \left ( A U X _ { 1 } \right )$$
Normalizing the prices such that 1 n ∑ n i =1 θ i = 1 / ∆ , this means that
$$M _ { 1 } \geq 2 \left ( 1 - \beta \right ) + 2 \beta x ^ { \top } \cdot P _ { 1 } - O _ { N } \left ( \delta \right )$$
$$M _ { 2 } \leq 2 \left ( 1 - \beta \right ) + 2 \beta x ^ { \top } \cdot P _ { 2 } + O _ { N } \left ( \delta \right )$$
$$M _ { 1 } \geq M _ { 2 } + 2 \beta \epsilon - O _ { N } \left ( \delta \right ) = M _ { 2 } + \Theta _ { N } \left ( \beta \epsilon \right )$$
so the difference between the demands for g 1 and g 2 from these traders is
$$\frac { M _ { 1 } } { \pi \left ( g _ { 1 } \right ) } - \frac { M _ { 2 } } { \pi \left ( g _ { 2 } \right ) } \geq \frac { M _ { 2 } + \Theta _ { N } \left ( \beta \epsilon \right ) } { \pi \left ( g _ { 1 } \right ) } - \frac { M _ { 2 } \left ( 1 + \alpha _ { 0 } \right ) } { \pi \left ( g _ { 1 } \right ) \left ( 1 - \alpha _ { 0 } \right ) } = \Theta _ { N } \left ( \beta \epsilon \right )$$
Thus the price regulating traders T 1 and T 2 must have different demands for g 1 and g 2 - but this can only happen when
$$\frac { 1 + \alpha _ { 0 } } { \pi \left ( g _ { 1 } \right ) } = \frac { 1 - \alpha _ { 0 } } { \pi \left ( g _ { 2 } \right ) }$$
Therefore, by consecutive applications of Lemma 14,
$$\frac { 1 + \beta } { \pi \left ( h _ { 1 } \right ) } = \frac { 1 - \beta } { \pi \left ( h _ { 2 } \right ) }$$
Finally, by (12) this implies that x 1 = 1 and x 2 = 0 .
Similarly,
Therefore,