## Neural Turing Machines
Alex Graves Greg Wayne Ivo Danihelka gravesa@google.com gregwayne@google.com danihelka@google.com
Google DeepMind, London, UK
## Abstract
We extend the capabilities of neural networks by coupling them to external memory resources, which they can interact with by attentional processes. The combined system is analogous to a Turing Machine or Von Neumann architecture but is differentiable end-toend, allowing it to be efficiently trained with gradient descent. Preliminary results demonstrate that Neural Turing Machines can infer simple algorithms such as copying, sorting, and associative recall from input and output examples.
## 1 Introduction
Computer programs make use of three fundamental mechanisms: elementary operations (e.g., arithmetic operations), logical flow control (branching), and external memory, which can be written to and read from in the course of computation (Von Neumann, 1945). Despite its wide-ranging success in modelling complicated data, modern machine learning has largely neglected the use of logical flow control and external memory.
Recurrent neural networks (RNNs) stand out from other machine learning methods for their ability to learn and carry out complicated transformations of data over extended periods of time. Moreover, it is known that RNNs are Turing-Complete (Siegelmann and Sontag, 1995), and therefore have the capacity to simulate arbitrary procedures, if properly wired. Yet what is possible in principle is not always what is simple in practice. We therefore enrich the capabilities of standard recurrent networks to simplify the solution of algorithmic tasks. This enrichment is primarily via a large, addressable memory, so, by analogy to Turing's enrichment of finite-state machines by an infinite memory tape, we
dub our device a 'Neural Turing Machine' (NTM). Unlike a Turing machine, an NTM is a differentiable computer that can be trained by gradient descent, yielding a practical mechanism for learning programs.
In human cognition, the process that shares the most similarity to algorithmic operation is known as 'working memory.' While the mechanisms of working memory remain somewhat obscure at the level of neurophysiology, the verbal definition is understood to mean a capacity for short-term storage of information and its rule-based manipulation (Baddeley et al., 2009). In computational terms, these rules are simple programs, and the stored information constitutes the arguments of these programs. Therefore, an NTM resembles a working memory system, as it is designed to solve tasks that require the application of approximate rules to 'rapidly-created variables.' Rapidly-created variables (Hadley, 2009) are data that are quickly bound to memory slots, in the same way that the number 3 and the number 4 are put inside registers in a conventional computer and added to make 7 (Minsky, 1967). An NTM bears another close resemblance to models of working memory since the NTMarchitecture uses an attentional process to read from and write to memory selectively. In contrast to most models of working memory, our architecture can learn to use its working memory instead of deploying a fixed set of procedures over symbolic data.
The organisation of this report begins with a brief review of germane research on working memory in psychology, linguistics, and neuroscience, along with related research in artificial intelligence and neural networks. We then describe our basic contribution, a memory architecture and attentional controller that we believe is well-suited to the performance of tasks that require the induction and execution of simple programs. To test this architecture, we have constructed a battery of problems, and we present their precise descriptions along with our results. We conclude by summarising the strengths of the architecture.
## 2 Foundational Research
## 2.1 Psychology and Neuroscience
The concept of working memory has been most heavily developed in psychology to explain the performance of tasks involving the short-term manipulation of information. The broad picture is that a 'central executive' focuses attention and performs operations on data in a memory buffer (Baddeley et al., 2009). Psychologists have extensively studied the capacity limitations of working memory, which is often quantified by the number of 'chunks' of information that can be readily recalled (Miller, 1956). 1 These capacity limitations lead toward an understanding of structural constraints in the human working memory system, but in our own work we are happy to exceed them.
In neuroscience, the working memory process has been ascribed to the functioning of a system composed of the prefrontal cortex and basal ganglia (Goldman-Rakic, 1995). Typ-
1 There remains vigorous debate about how best to characterise capacity limitations (Barrouillet et al., 2004).
ical experiments involve recording from a single neuron or group of neurons in prefrontal cortex while a monkey is performing a task that involves observing a transient cue, waiting through a 'delay period,' then responding in a manner dependent on the cue. Certain tasks elicit persistent firing from individual neurons during the delay period or more complicated neural dynamics. A recent study quantified delay period activity in prefrontal cortex for a complex, context-dependent task based on measures of 'dimensionality' of the population code and showed that it predicted memory performance (Rigotti et al., 2013).
Modeling studies of working memory range from those that consider how biophysical circuits could implement persistent neuronal firing (Wang, 1999) to those that try to solve explicit tasks (Hazy et al., 2006) (Dayan, 2008) (Eliasmith, 2013). Of these, Hazy et al.'s model is the most relevant to our work, as it is itself analogous to the Long Short-Term Memory architecture, which we have modified ourselves. As in our architecture, Hazy et al.'s has mechanisms to gate information into memory slots, which they use to solve a memory task constructed of nested rules. In contrast to our work, the authors include no sophisticated notion of memory addressing, which limits the system to storage and recall of relatively simple, atomic data. Addressing, fundamental to our work, is usually left out from computational models in neuroscience, though it deserves to be mentioned that Gallistel and King (Gallistel and King, 2009) and Marcus (Marcus, 2003) have argued that addressing must be implicated in the operation of the brain.
## 2.2 Cognitive Science and Linguistics
Historically, cognitive science and linguistics emerged as fields at roughly the same time as artificial intelligence, all deeply influenced by the advent of the computer (Chomsky, 1956) (Miller, 2003). Their intentions were to explain human mental behaviour based on information or symbol-processing metaphors. In the early 1980s, both fields considered recursive or procedural (rule-based) symbol-processing to be the highest mark of cognition. The Parallel Distributed Processing (PDP) or connectionist revolution cast aside the symbol-processing metaphor in favour of a so-called 'sub-symbolic' description of thought processes (Rumelhart et al., 1986).
Fodor and Pylyshyn (Fodor and Pylyshyn, 1988) famously made two barbed claims about the limitations of neural networks for cognitive modeling. They first objected that connectionist theories were incapable of variable-binding , or the assignment of a particular datum to a particular slot in a data structure. In language, variable-binding is ubiquitous; for example, when one produces or interprets a sentence of the form, 'Mary spoke to John,' one has assigned 'Mary' the role of subject, 'John' the role of object, and 'spoke to' the role of the transitive verb. Fodor and Pylyshyn also argued that neural networks with fixedlength input domains could not reproduce human capabilities in tasks that involve processing variable-length structures . In response to this criticism, neural network researchers including Hinton (Hinton, 1986), Smolensky (Smolensky, 1990), Touretzky (Touretzky, 1990), Pollack (Pollack, 1990), Plate (Plate, 2003), and Kanerva (Kanerva, 2009) investigated specific mechanisms that could support both variable-binding and variable-length
structure within a connectionist framework. Our architecture draws on and potentiates this work.
Recursive processing of variable-length structures continues to be regarded as a hallmark of human cognition. In the last decade, a firefight in the linguistics community staked several leaders of the field against one another. At issue was whether recursive processing is the 'uniquely human' evolutionary innovation that enables language and is specialized to language, a view supported by Fitch, Hauser, and Chomsky (Fitch et al., 2005), or whether multiple new adaptations are responsible for human language evolution and recursive processing predates language (Jackendoff and Pinker, 2005). Regardless of recursive processing's evolutionary origins, all agreed that it is essential to human cognitive flexibility.
## 2.3 Recurrent Neural Networks
Recurrent neural networks constitute a broad class of machines with dynamic state; that is, they have state whose evolution depends both on the input to the system and on the current state. In comparison to hidden Markov models, which also contain dynamic state, RNNs have a distributed state and therefore have significantly larger and richer memory and computational capacity. Dynamic state is crucial because it affords the possibility of context-dependent computation; a signal entering at a given moment can alter the behaviour of the network at a much later moment.
A crucial innovation to recurrent networks was the Long Short-Term Memory (LSTM) (Hochreiter and Schmidhuber, 1997). This very general architecture was developed for a specific purpose, to address the 'vanishing and exploding gradient' problem (Hochreiter et al., 2001a), which we might relabel the problem of 'vanishing and exploding sensitivity.' LSTM ameliorates the problem by embedding perfect integrators (Seung, 1998) for memory storage in the network. The simplest example of a perfect integrator is the equation x ( t + 1) = x ( t ) + i ( t ) , where i ( t ) is an input to the system. The implicit identity matrix I x ( t ) means that signals do not dynamically vanish or explode. If we attach a mechanism to this integrator that allows an enclosing network to choose when the integrator listens to inputs, namely, a programmable gate depending on context, we have an equation of the form x ( t + 1) = x ( t ) + g ( context ) i ( t ) . We can now selectively store information for an indefinite length of time.
Recurrent networks readily process variable-length structures without modification. In sequential problems, inputs to the network arrive at different times, allowing variablelength or composite structures to be processed over multiple steps. Because they natively handle variable-length structures, they have recently been used in a variety of cognitive problems, including speech recognition (Graves et al., 2013; Graves and Jaitly, 2014), text generation (Sutskever et al., 2011), handwriting generation (Graves, 2013) and machine translation (Sutskever et al., 2014). Considering this property, we do not feel that it is urgent or even necessarily valuable to build explicit parse trees to merge composite structures greedily (Pollack, 1990) (Socher et al., 2012) (Frasconi et al., 1998).
Other important precursors to our work include differentiable models of attention (Graves,
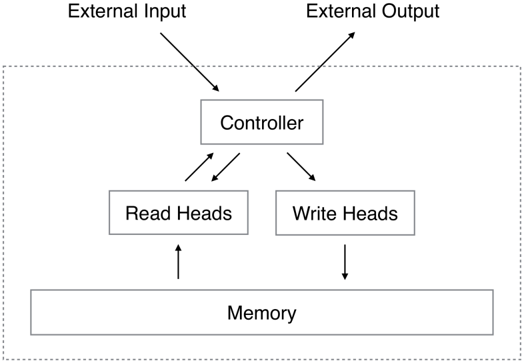
Figure 1: Neural Turing Machine Architecture. During each update cycle, the controller network receives inputs from an external environment and emits outputs in response. It also reads to and writes from a memory matrix via a set of parallel read and write heads. The dashed line indicates the division between the NTM circuit and the outside world.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Memory Access Flow
### Overview
The image is a diagram illustrating the flow of data and control in a memory access system. It shows the interaction between external input/output, a controller, read/write heads, and memory. The diagram uses arrows to indicate the direction of data flow and control signals.
### Components/Axes
* **External Input:** Located at the top-left of the diagram.
* **External Output:** Located at the top-right of the diagram.
* **Controller:** Located centrally at the top of the diagram.
* **Read Heads:** Located centrally on the left side of the diagram.
* **Write Heads:** Located centrally on the right side of the diagram.
* **Memory:** Located at the bottom of the diagram.
* A dashed rectangle surrounds all components except "External Input" and "External Output".
### Detailed Analysis
* **External Input** has an arrow pointing downwards to the **Controller**.
* **External Output** has an arrow pointing upwards and away from the **Controller**.
* The **Controller** has two arrows pointing downwards, one to **Read Heads** and one to **Write Heads**.
* The **Controller** has two arrows pointing upwards and to the left, towards the **Read Heads**.
* **Read Heads** has an arrow pointing upwards from **Memory**.
* **Write Heads** has an arrow pointing downwards to **Memory**.
### Key Observations
* The diagram illustrates a system where external input is processed by a controller, which then directs read and write operations to memory via read and write heads.
* The controller receives input and provides output, and also controls the read and write heads.
* The read heads retrieve data from memory, while the write heads store data into memory.
* The dashed rectangle likely represents the boundary of the system or a specific module.
### Interpretation
The diagram represents a simplified model of a memory access system. The controller acts as the central processing unit, receiving external input and generating external output. It manages the flow of data between memory and the external environment by controlling the read and write heads. The two-way arrows between the controller and read heads suggest that the controller receives feedback or status information from the read heads. The dashed rectangle likely represents the boundary of the memory subsystem or a specific hardware component. This diagram is useful for understanding the basic architecture and data flow within a memory system.
</details>
2013) (Bahdanau et al., 2014) and program search (Hochreiter et al., 2001b) (Das et al., 1992), constructed with recurrent neural networks.
## 3 Neural Turing Machines
A Neural Turing Machine (NTM) architecture contains two basic components: a neural network controller and a memory bank. Figure 1 presents a high-level diagram of the NTM architecture. Like most neural networks, the controller interacts with the external world via input and output vectors. Unlike a standard network, it also interacts with a memory matrix using selective read and write operations. By analogy to the Turing machine we refer to the network outputs that parametrise these operations as 'heads.'
Crucially, every component of the architecture is differentiable, making it straightforward to train with gradient descent. We achieved this by defining 'blurry' read and write operations that interact to a greater or lesser degree with all the elements in memory (rather than addressing a single element, as in a normal Turing machine or digital computer). The degree of blurriness is determined by an attentional 'focus' mechanism that constrains each read and write operation to interact with a small portion of the memory, while ignoring the rest. Because interaction with the memory is highly sparse, the NTM is biased towards storing data without interference. The memory location brought into attentional focus is determined by specialised outputs emitted by the heads. These outputs define a normalised weighting over the rows in the memory matrix (referred to as memory 'locations'). Each weighting, one per read or write head, defines the degree to which the head reads or writes
at each location. A head can thereby attend sharply to the memory at a single location or weakly to the memory at many locations.
## 3.1 Reading
Let M t be the contents of the N × M memory matrix at time t, where N is the number of memory locations, and M is the vector size at each location. Let w t be a vector of weightings over the N locations emitted by a read head at time t . Since all weightings are normalised, the N elements w t ( i ) of w t obey the following constraints:
<!-- formula-not-decoded -->
The length M read vector r t returned by the head is defined as a convex combination of the row-vectors M t ( i ) in memory:
<!-- formula-not-decoded -->
which is clearly differentiable with respect to both the memory and the weighting.
## 3.2 Writing
Taking inspiration from the input and forget gates in LSTM, we decompose each write into two parts: an erase followed by an add .
Given a weighting w t emitted by a write head at time t , along with an erase vector e t whose M elements all lie in the range (0 , 1) , the memory vectors M t -1 ( i ) from the previous time-step are modified as follows:
<!-- formula-not-decoded -->
where 1 is a row-vector of all 1 -s, and the multiplication against the memory location acts point-wise. Therefore, the elements of a memory location are reset to zero only if both the weighting at the location and the erase element are one; if either the weighting or the erase is zero, the memory is left unchanged. When multiple write heads are present, the erasures can be performed in any order, as multiplication is commutative.
Each write head also produces a length M add vector a t , which is added to the memory after the erase step has been performed:
<!-- formula-not-decoded -->
Once again, the order in which the adds are performed by multiple heads is irrelevant. The combined erase and add operations of all the write heads produces the final content of the memory at time t . Since both erase and add are differentiable, the composite write operation is differentiable too. Note that both the erase and add vectors have M independent components, allowing fine-grained control over which elements in each memory location are modified.
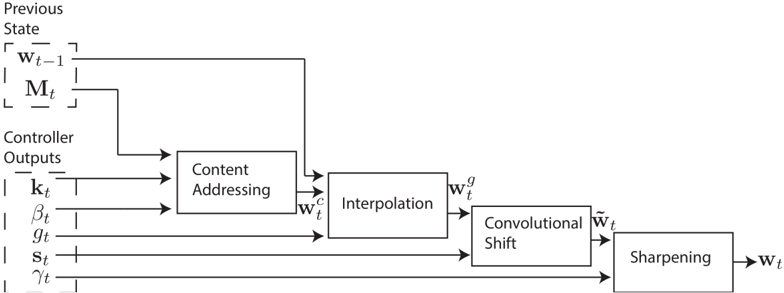
Figure 2: Flow Diagram of the Addressing Mechanism. The key vector , k t , and key strength , β t , are used to perform content-based addressing of the memory matrix, M t . The resulting content-based weighting is interpolated with the weighting from the previous time step based on the value of the interpolation gate , g t . The shift weighting , s t , determines whether and by how much the weighting is rotated. Finally, depending on γ t , the weighting is sharpened and used for memory access.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Neural Turing Machine Addressing Mechanism
### Overview
The image is a block diagram illustrating the addressing mechanism within a Neural Turing Machine (NTM). It shows the flow of information from previous states and controller outputs through several processing stages to determine the current weight vector.
### Components/Axes
* **Previous State (Top-Left)**:
* `w_{t-1}` (Weight vector at time t-1) - enclosed in a dashed box.
* `M_t` (Memory matrix at time t) - enclosed in a dashed box.
* **Controller Outputs (Left)**:
* `k_t` (Key vector at time t)
* `β_t` (Key strength at time t)
* `g_t` (Interpolation gate at time t)
* `s_t` (Shift weighting at time t)
* `γ_t` (Sharpening factor at time t)
* **Processing Blocks (Center)**:
* Content Addressing
* Interpolation
* Convolutional Shift
* Sharpening
* **Intermediate Weight Vectors**:
* `w_t^c` (Content-based weight vector)
* `w_t^g` (Gated weight vector)
* `\tilde{w}_t` (Shifted weight vector)
* **Output (Right)**:
* `w_t` (Weight vector at time t)
### Detailed Analysis
1. **Previous State**: The weight vector from the previous time step (`w_{t-1}`) and the memory matrix (`M_t`) are inputs to the Content Addressing block.
2. **Controller Outputs**: The controller outputs (`k_t`, `β_t`, `g_t`, `s_t`, `γ_t`) are used to modulate the addressing process.
3. **Content Addressing**: The `k_t` and `β_t` controller outputs, along with `w_{t-1}` and `M_t` are inputs to the "Content Addressing" block, which outputs `w_t^c`.
4. **Interpolation**: The `g_t` controller output and `w_t^c` are inputs to the "Interpolation" block, which outputs `w_t^g`.
5. **Convolutional Shift**: The `s_t` controller output and `w_t^g` are inputs to the "Convolutional Shift" block, which outputs `\tilde{w}_t`.
6. **Sharpening**: The `γ_t` controller output and `\tilde{w}_t` are inputs to the "Sharpening" block, which outputs `w_t`.
7. **Feedback Loop**: The output of the "Content Addressing" block, `w_t^c`, is fed back into the "Interpolation" block.
### Key Observations
* The diagram illustrates a sequential process where the weight vector is refined through multiple stages.
* Controller outputs play a crucial role in modulating each stage of the addressing mechanism.
* The previous state (`w_{t-1}` and `M_t`) influences the current weight vector (`w_t`).
### Interpretation
The diagram represents the addressing mechanism of a Neural Turing Machine, which allows the NTM to selectively read from and write to its external memory. The process starts with the previous state and controller outputs, which are then used to compute a content-based weight vector (`w_t^c`). This vector is then interpolated, shifted, and sharpened to produce the final weight vector (`w_t`), which determines the focus of attention on the memory. The feedback loop from the "Content Addressing" block to the "Interpolation" block suggests that the content-based weight vector influences the subsequent interpolation process. The controller outputs (`k_t`, `β_t`, `g_t`, `s_t`, `γ_t`) provide the NTM with the flexibility to dynamically adjust its addressing strategy based on the current task.
</details>
## 3.3 Addressing Mechanisms
Although we have now shown the equations of reading and writing, we have not described how the weightings are produced. These weightings arise by combining two addressing mechanisms with complementary facilities. The first mechanism, 'content-based addressing,' focuses attention on locations based on the similarity between their current values and values emitted by the controller. This is related to the content-addressing of Hopfield networks (Hopfield, 1982). The advantage of content-based addressing is that retrieval is simple, merely requiring the controller to produce an approximation to a part of the stored data, which is then compared to memory to yield the exact stored value.
However, not all problems are well-suited to content-based addressing. In certain tasks the content of a variable is arbitrary, but the variable still needs a recognisable name or address. Arithmetic problems fall into this category: the variable x and the variable y can take on any two values, but the procedure f ( x, y ) = x × y should still be defined. A controller for this task could take the values of the variables x and y , store them in different addresses, then retrieve them and perform a multiplication algorithm. In this case, the variables are addressed by location, not by content. We call this form of addressing 'location-based addressing.' Content-based addressing is strictly more general than location-based addressing as the content of a memory location could include location information inside it. In our experiments however, providing location-based addressing as a primitive operation proved essential for some forms of generalisation, so we employ both mechanisms concurrently.
Figure 2 presents a flow diagram of the entire addressing system that shows the order of operations for constructing a weighting vector when reading or writing.
## 3.3.1 Focusing by Content
For content-addressing, each head (whether employed for reading or writing) first produces a length M key vector k t that is compared to each vector M t ( i ) by a similarity measure K [ · , · ] . The content-based system produces a normalised weighting w c t based on the similarity and a positive key strength , β t , which can amplify or attenuate the precision of the focus:
<!-- formula-not-decoded -->
In our current implementation, the similarity measure is cosine similarity:
<!-- formula-not-decoded -->
## 3.3.2 Focusing by Location
The location-based addressing mechanism is designed to facilitate both simple iteration across the locations of the memory and random-access jumps. It does so by implementing a rotational shift of a weighting. For example, if the current weighting focuses entirely on a single location, a rotation of 1 would shift the focus to the next location. A negative shift would move the weighting in the opposite direction.
Prior to rotation, each head emits a scalar interpolation gate g t in the range (0 , 1) . The value of g is used to blend between the weighting w t -1 produced by the head at the previous time-step and the weighting w c t produced by the content system at the current time-step, yielding the gated weighting w g t :
<!-- formula-not-decoded -->
If the gate is zero, then the content weighting is entirely ignored, and the weighting from the previous time step is used. Conversely, if the gate is one, the weighting from the previous iteration is ignored, and the system applies content-based addressing.
After interpolation, each head emits a shift weighting s t that defines a normalised distribution over the allowed integer shifts. For example, if shifts between -1 and 1 are allowed, s t has three elements corresponding to the degree to which shifts of -1, 0 and 1 are performed. The simplest way to define the shift weightings is to use a softmax layer of the appropriate size attached to the controller. We also experimented with another technique, where the controller emits a single scalar that is interpreted as the lower bound of a width one uniform distribution over shifts. For example, if the shift scalar is 6.7, then s t (6) = 0 . 3 , s t (7) = 0 . 7 , and the rest of s t is zero.
If we index the N memory locations from 0 to N -1 , the rotation applied to w g t by s t can be expressed as the following circular convolution:
<!-- formula-not-decoded -->
where all index arithmetic is computed modulo N . The convolution operation in Equation (8) can cause leakage or dispersion of weightings over time if the shift weighting is not sharp. For example, if shifts of -1, 0 and 1 are given weights of 0.1, 0.8 and 0.1, the rotation will transform a weighting focused at a single point into one slightly blurred over three points. To combat this, each head emits one further scalar γ t ≥ 1 whose effect is to sharpen the final weighting as follows:
<!-- formula-not-decoded -->
The combined addressing system of weighting interpolation and content and locationbased addressing can operate in three complementary modes. One, a weighting can be chosen by the content system without any modification by the location system. Two, a weighting produced by the content addressing system can be chosen and then shifted. This allows the focus to jump to a location next to, but not on, an address accessed by content; in computational terms this allows a head to find a contiguous block of data, then access a particular element within that block. Three, a weighting from the previous time step can be rotated without any input from the content-based addressing system. This allows the weighting to iterate through a sequence of addresses by advancing the same distance at each time-step.
## 3.4 Controller Network
The NTM architecture architecture described above has several free parameters, including the size of the memory, the number of read and write heads, and the range of allowed location shifts. But perhaps the most significant architectural choice is the type of neural network used as the controller. In particular, one has to decide whether to use a recurrent or feedforward network. A recurrent controller such as LSTM has its own internal memory that can complement the larger memory in the matrix. If one compares the controller to the central processing unit in a digital computer (albeit with adaptive rather than predefined instructions) and the memory matrix to RAM, then the hidden activations of the recurrent controller are akin to the registers in the processor. They allow the controller to mix information across multiple time steps of operation. On the other hand a feedforward controller can mimic a recurrent network by reading and writing at the same location in memory at every step. Furthermore, feedforward controllers often confer greater transparency to the network's operation because the pattern of reading from and writing to the memory matrix is usually easier to interpret than the internal state of an RNN. However, one limitation of
a feedforward controller is that the number of concurrent read and write heads imposes a bottleneck on the type of computation the NTM can perform. With a single read head, it can perform only a unary transform on a single memory vector at each time-step, with two read heads it can perform binary vector transforms, and so on. Recurrent controllers can internally store read vectors from previous time-steps, so do not suffer from this limitation.
## 4 Experiments
This section presents preliminary experiments on a set of simple algorithmic tasks such as copying and sorting data sequences. The goal was not only to establish that NTM is able to solve the problems, but also that it is able to do so by learning compact internal programs. The hallmark of such solutions is that they generalise well beyond the range of the training data. For example, we were curious to see if a network that had been trained to copy sequences of length up to 20 could copy a sequence of length 100 with no further training.
For all the experiments we compared three architectures: NTM with a feedforward controller, NTM with an LSTM controller, and a standard LSTM network. Because all the tasks were episodic, we reset the dynamic state of the networks at the start of each input sequence. For the LSTM networks, this meant setting the previous hidden state equal to a learned bias vector. For NTM the previous state of the controller, the value of the previous read vectors, and the contents of the memory were all reset to bias values. All the tasks were supervised learning problems with binary targets; all networks had logistic sigmoid output layers and were trained with the cross-entropy objective function. Sequence prediction errors are reported in bits-per-sequence. For more details about the experimental parameters see Section 4.6.
## 4.1 Copy
The copy task tests whether NTM can store and recall a long sequence of arbitrary information. The network is presented with an input sequence of random binary vectors followed by a delimiter flag. Storage and access of information over long time periods has always been problematic for RNNs and other dynamic architectures. We were particularly interested to see if an NTM is able to bridge longer time delays than LSTM.
The networks were trained to copy sequences of eight bit random vectors, where the sequence lengths were randomised between 1 and 20. The target sequence was simply a copy of the input sequence (without the delimiter flag). Note that no inputs were presented to the network while it receives the targets, to ensure that it recalls the entire sequence with no intermediate assistance.
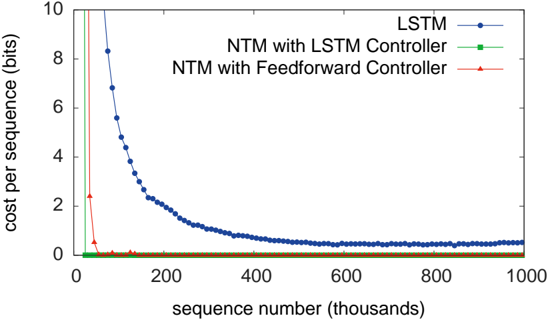
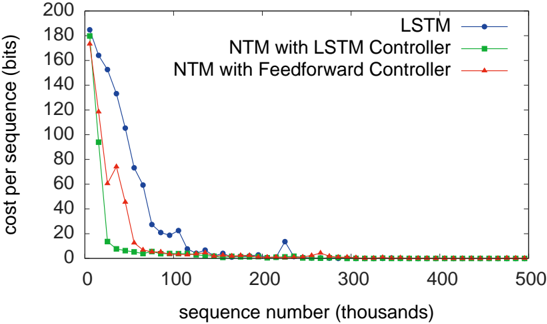
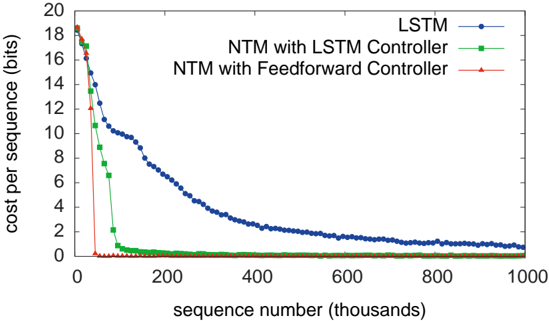
As can be seen from Figure 3, NTM (with either a feedforward or LSTM controller) learned much faster than LSTM alone, and converged to a lower cost. The disparity between the NTM and LSTM learning curves is dramatic enough to suggest a qualitative,
Figure 3: Copy Learning Curves.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart: Cost per Sequence vs. Sequence Number
### Overview
The image is a line chart comparing the cost per sequence (in bits) for three different models: LSTM, NTM with LSTM Controller, and NTM with Feedforward Controller, as a function of the sequence number (in thousands). The chart shows how the cost changes as the models process more sequences.
### Components/Axes
* **X-axis:** Sequence number (thousands), ranging from 0 to 1000. Axis markers are present at intervals of 200 (0, 200, 400, 600, 800, 1000).
* **Y-axis:** Cost per sequence (bits), ranging from 0 to 10. Axis markers are present at intervals of 2 (0, 2, 4, 6, 8, 10).
* **Legend (top-right):**
* Blue line with circles: LSTM
* Green line with squares: NTM with LSTM Controller
* Red line with triangles: NTM with Feedforward Controller
### Detailed Analysis
* **LSTM (Blue):** The cost per sequence starts high (around 8.3 bits at sequence number 50) and rapidly decreases as the sequence number increases. The curve flattens out after approximately 400,000 sequences, approaching a cost of approximately 0.3 bits.
* Sequence 50: ~8.3 bits
* Sequence 100: ~4.7 bits
* Sequence 200: ~1.8 bits
* Sequence 400: ~0.4 bits
* Sequence 600: ~0.3 bits
* Sequence 800: ~0.3 bits
* Sequence 1000: ~0.3 bits
* **NTM with LSTM Controller (Green):** The cost per sequence starts high (around 9.8 bits at sequence number 10) and quickly drops to near zero. It remains consistently low (approximately 0.05 bits) throughout the entire range of sequence numbers.
* Sequence 10: ~9.8 bits
* Sequence 50: ~0.05 bits
* Sequence 100: ~0.05 bits
* Sequence 200: ~0.05 bits
* Sequence 400: ~0.05 bits
* Sequence 600: ~0.05 bits
* Sequence 800: ~0.05 bits
* Sequence 1000: ~0.05 bits
* **NTM with Feedforward Controller (Red):** The cost per sequence starts high (around 2.5 bits at sequence number 10) and quickly drops to near zero. It remains consistently low (approximately 0.05 bits) throughout the entire range of sequence numbers.
* Sequence 10: ~2.5 bits
* Sequence 50: ~0.05 bits
* Sequence 100: ~0.05 bits
* Sequence 200: ~0.05 bits
* Sequence 400: ~0.05 bits
* Sequence 600: ~0.05 bits
* Sequence 800: ~0.05 bits
* Sequence 1000: ~0.05 bits
### Key Observations
* The LSTM model initially has a much higher cost per sequence compared to the NTM models.
* The cost per sequence for the LSTM model decreases significantly as the sequence number increases, eventually approaching a similar level to the NTM models.
* The NTM models (both with LSTM and Feedforward controllers) exhibit a very low and stable cost per sequence across all sequence numbers.
* The NTM with LSTM Controller and NTM with Feedforward Controller perform almost identically.
### Interpretation
The chart suggests that NTM models, regardless of the controller type (LSTM or Feedforward), are more efficient in terms of cost per sequence compared to a standalone LSTM model, especially at the beginning of the learning process. The LSTM model, however, improves with more training data (larger sequence numbers) and eventually approaches the performance of the NTM models. This indicates that NTM models may be better suited for tasks where quick learning and consistent performance are crucial, while LSTM models may require more training to achieve comparable results. The near-identical performance of the two NTM models suggests that the choice of controller (LSTM or Feedforward) has minimal impact on the overall performance of the NTM architecture in this specific scenario.
</details>
rather than quantitative, difference in the way the two models solve the problem.
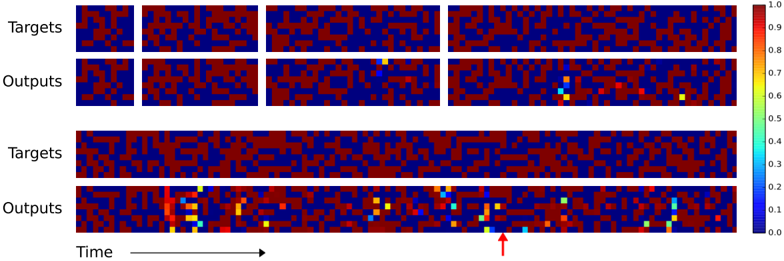
We also studied the ability of the networks to generalise to longer sequences than seen during training (that they can generalise to novel vectors is clear from the training error). Figures 4 and 5 demonstrate that the behaviour of LSTM and NTM in this regime is radically different. NTM continues to copy as the length increases 2 , while LSTM rapidly degrades beyond length 20.
The preceding analysis suggests that NTM, unlike LSTM, has learned some form of copy algorithm. To determine what this algorithm is, we examined the interaction between the controller and the memory (Figure 6). We believe that the sequence of operations performed by the network can be summarised by the following pseudocode:
```
```
## end while
This is essentially how a human programmer would perform the same task in a low-
2 The limiting factor was the size of the memory (128 locations), after which the cyclical shifts wrapped around and previous writes were overwritten.
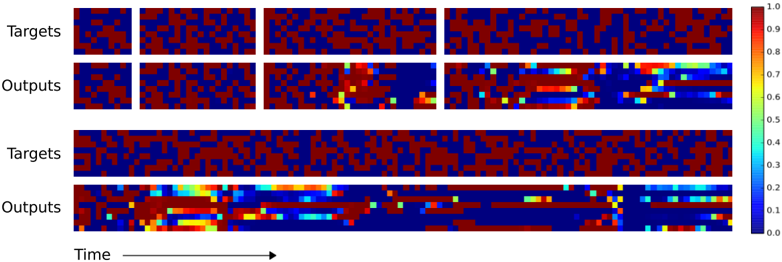
Figure 4: NTM Generalisation on the Copy Task. The four pairs of plots in the top row depict network outputs and corresponding copy targets for test sequences of length 10, 20, 30, and 50, respectively. The plots in the bottom row are for a length 120 sequence. The network was only trained on sequences of up to length 20. The first four sequences are reproduced with high confidence and very few mistakes. The longest one has a few more local errors and one global error: at the point indicated by the red arrow at the bottom, a single vector is duplicated, pushing all subsequent vectors one step back. Despite being subjectively close to a correct copy, this leads to a high loss.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Heatmap: Targets vs. Outputs Over Time
### Overview
The image presents a series of heatmaps comparing "Targets" and "Outputs" over time. The heatmaps are arranged in pairs, with "Targets" above "Outputs" in each pair. The color intensity represents a value, ranging from 0.0 (dark blue) to 1.0 (dark red), as indicated by the colorbar on the right. The x-axis represents time, and an arrow points to a specific time point in the last "Outputs" heatmap.
### Components/Axes
* **Y-Axis Labels:** "Targets", "Outputs" (repeated twice)
* **X-Axis:** "Time" (with an arrow indicating direction)
* **Colorbar:** Ranges from 0.0 (dark blue) to 1.0 (dark red), with intermediate values labeled (0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9).
* **Heatmap Structure:** Each heatmap is a grid of cells, with color indicating the value at that time point.
### Detailed Analysis or ### Content Details
**First Pair (Top):**
* **Targets:** The first "Targets" heatmap shows two distinct white blocks, indicating a value of 1.0. The rest of the heatmap is a mix of red and blue, indicating values close to 0.0 and 1.0.
* **Outputs:** The first "Outputs" heatmap shows a similar pattern to the "Targets" heatmap, but with less distinct blocks. There are some scattered yellow and green pixels, indicating values between 0.6 and 0.8.
**Second Pair (Bottom):**
* **Targets:** The second "Targets" heatmap shows a more dispersed pattern of red and blue, with no distinct blocks.
* **Outputs:** The second "Outputs" heatmap shows a more structured pattern, with a concentration of yellow, green, and light blue pixels at the beginning, indicated by the red arrow. This suggests a higher output value at that time point.
**Colorbar Values:**
* 1. 0: Dark Red
* 0.9: Red
* 0.8: Orange
* 0.7: Yellow-Orange
* 0.6: Yellow
* 0.5: Light Green
* 0.4: Green
* 0.3: Light Blue
* 0.2: Blue
* 0.1: Dark Blue
* 0.0: Very Dark Blue
### Key Observations
* The "Targets" heatmaps show a mix of high and low values, with some distinct blocks in the first heatmap.
* The "Outputs" heatmaps show a more dispersed pattern, with a concentration of higher values at the beginning of the second heatmap.
* The color intensity varies across the heatmaps, indicating different values at different time points.
### Interpretation
The heatmaps likely represent the target and output values of a system over time. The first pair of heatmaps shows a more distinct pattern in the "Targets" heatmap, suggesting a clear input signal. The second pair of heatmaps shows a more dispersed pattern in the "Targets" heatmap, suggesting a more complex input signal. The concentration of higher values at the beginning of the second "Outputs" heatmap suggests that the system is responding to the input signal at that time point. The red arrow highlights a specific time point where the output is particularly high. The data suggests that the system is learning or adapting over time, as the output pattern changes between the first and second pairs of heatmaps.
</details>
level programming language. In terms of data structures, we could say that NTM has learned how to create and iterate through arrays. Note that the algorithm combines both content-based addressing (to jump to start of the sequence) and location-based addressing (to move along the sequence). Also note that the iteration would not generalise to long sequences without the ability to use relative shifts from the previous read and write weightings (Equation 7), and that without the focus-sharpening mechanism (Equation 9) the weightings would probably lose precision over time.
## 4.2 Repeat Copy
The repeat copy task extends copy by requiring the network to output the copied sequence a specified number of times and then emit an end-of-sequence marker. The main motivation was to see if the NTM could learn a simple nested function. Ideally, we would like it to be able to execute a 'for loop' containing any subroutine it has already learned.
The network receives random-length sequences of random binary vectors, followed by a scalar value indicating the desired number of copies, which appears on a separate input channel. To emit the end marker at the correct time the network must be both able to interpret the extra input and keep count of the number of copies it has performed so far. As with the copy task, no inputs are provided to the network after the initial sequence and repeat number. The networks were trained to reproduce sequences of size eight random binary vectors, where both the sequence length and the number of repetitions were chosen randomly from one to ten. The input representing the repeat number was normalised to have mean zero and variance one.
Figure 5: LSTM Generalisation on the Copy Task. The plots show inputs and outputs for the same sequence lengths as Figure 4. Like NTM, LSTM learns to reproduce sequences of up to length 20 almost perfectly. However it clearly fails to generalise to longer sequences. Also note that the length of the accurate prefix decreases as the sequence length increases, suggesting that the network has trouble retaining information for long periods.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Heatmap: Targets vs. Outputs Over Time
### Overview
The image presents a series of heatmaps comparing "Targets" and "Outputs" over time. The heatmaps use a color gradient from blue (0.0) to red (1.0) to represent the magnitude of values. There are two sets of "Targets" and "Outputs" heatmaps displayed. The x-axis represents "Time," and the y-axis is not explicitly labeled but represents different data points or features.
### Components/Axes
* **Y-Axis Labels:** "Targets", "Outputs" (repeated twice)
* **X-Axis Label:** "Time" (with an arrow indicating direction)
* **Color Scale:** A vertical color bar on the right side of the image, ranging from 0.0 (blue) to 1.0 (red), with increments of 0.1.
### Detailed Analysis
The image is divided into two main sections, each containing a "Targets" heatmap and a corresponding "Outputs" heatmap.
**First Section (Top):**
* **Targets:** The "Targets" heatmap shows a seemingly random distribution of high (red) and low (blue) values. There are two distinct blocks separated by a white vertical line.
* **Outputs:** The "Outputs" heatmap shows a similar random distribution initially, but as "Time" progresses, there are regions where the values become more consistently high (red and yellow). There are also two distinct blocks separated by a white vertical line.
**Second Section (Bottom):**
* **Targets:** The "Targets" heatmap again shows a seemingly random distribution of high (red) and low (blue) values.
* **Outputs:** The "Outputs" heatmap shows a similar pattern to the first section. Initially, there is a random distribution, but as "Time" progresses, there are regions where the values become more consistently high (red and yellow).
**Color Scale Values:**
* Red: 1.0
* Orange-Red: ~0.8-0.9
* Yellow: ~0.6-0.7
* Green: ~0.4-0.5
* Light Blue: ~0.2-0.3
* Dark Blue: 0.0-0.1
### Key Observations
* The "Targets" heatmaps appear to be relatively static and random across both sections.
* The "Outputs" heatmaps show a change over "Time," with some regions transitioning from low (blue) to high (red/yellow) values.
* The two sections seem to represent different trials or instances of the same process.
* The white vertical lines in the first section of "Targets" and "Outputs" suggest a break or separation in the data.
### Interpretation
The image likely represents the comparison of desired "Targets" with the actual "Outputs" of a system or model over time. The "Targets" represent the desired state, while the "Outputs" represent the actual state achieved by the system. The change in the "Outputs" heatmaps over time suggests that the system is learning or adapting to match the "Targets." The differences between the two sections indicate that the system's performance may vary across different trials or initial conditions. The presence of high values (red) in the "Outputs" heatmaps indicates that the system is successfully matching the "Targets" in those regions. The white lines in the first section could indicate a reset or change in the input data.
</details>
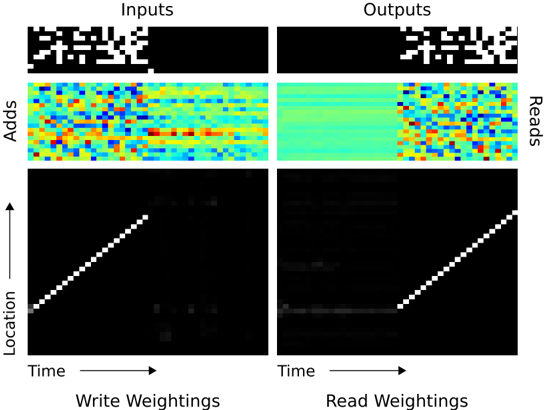
Figure 6: NTM Memory Use During the Copy Task. The plots in the left column depict the inputs to the network (top), the vectors added to memory (middle) and the corresponding write weightings (bottom) during a single test sequence for the copy task. The plots on the right show the outputs from the network (top), the vectors read from memory (middle) and the read weightings (bottom). Only a subset of memory locations are shown. Notice the sharp focus of all the weightings on a single location in memory (black is weight zero, white is weight one). Also note the translation of the focal point over time, reflects the network's use of iterative shifts for location-based addressing, as described in Section 3.3.2. Lastly, observe that the read locations exactly match the write locations, and the read vectors match the add vectors. This suggests that the network writes each input vector in turn to a specific memory location during the input phase, then reads from the same location sequence during the output phase.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Neural Turing Machine Visualization: Inputs, Outputs, Adds, Reads, Write Weightings, Read Weightings
### Overview
The image presents a visualization of the internal operations of a Neural Turing Machine (NTM). It shows the inputs and outputs, the memory additions and reads, and the write and read weightings over time and memory location. The visualization is split into two columns, representing the write and read operations respectively.
### Components/Axes
* **Top Row:**
* Left: "Inputs" - A binary matrix representing the input data.
* Right: "Outputs" - A binary matrix representing the output data.
* **Middle Row:**
* Left: "Adds" - A heatmap showing the values added to memory over time. The color scale ranges from blue (low values) to red (high values).
* Right: "Reads" - A heatmap showing the values read from memory over time. The color scale ranges from blue (low values) to red (high values).
* **Bottom Row:**
* Left: "Write Weightings" - A grayscale image representing the weights assigned to each memory location during the write operation over time.
* X-axis: "Time" (arrow pointing right)
* Y-axis: "Location" (arrow pointing up)
* Right: "Read Weightings" - A grayscale image representing the weights assigned to each memory location during the read operation over time.
* X-axis: "Time" (arrow pointing right)
* Y-axis: "Location" (arrow pointing up)
### Detailed Analysis
**1. Inputs and Outputs:**
* **Inputs (Top-Left):** The input data is represented as a sparse binary matrix. The left portion of the matrix contains a pattern of white and black squares, while the right portion is entirely black.
* **Outputs (Top-Right):** The output data is also represented as a sparse binary matrix. The left portion is entirely black, while the right portion contains a pattern of white and black squares.
**2. Adds and Reads:**
* **Adds (Middle-Left):** The "Adds" heatmap shows significant activity in the memory. There are fluctuations across the memory locations over time. The heatmap shows a range of values, with blue indicating lower values and red indicating higher values.
* **Reads (Middle-Right):** The "Reads" heatmap shows relatively low activity in the memory initially, followed by increased activity in the later time steps. The color intensity increases from left to right, indicating more significant read operations towards the end.
**3. Write and Read Weightings:**
* **Write Weightings (Bottom-Left):** The "Write Weightings" plot shows a diagonal line of high weights (white) moving from the bottom-left to the top-right. This indicates that the write operation is sequentially addressing memory locations. There are also some scattered, lower-intensity weights outside the main diagonal.
* **Read Weightings (Bottom-Right):** The "Read Weightings" plot also shows a diagonal line of high weights (white) moving from the bottom-left to the top-right. This indicates that the read operation is sequentially addressing memory locations. There are also some horizontal lines of lower intensity, suggesting that certain memory locations are being read repeatedly over time.
### Key Observations
* The input pattern appears to be "copied" to the output, but shifted in time.
* The "Adds" heatmap shows more initial activity compared to the "Reads" heatmap.
* Both "Write Weightings" and "Read Weightings" show a diagonal pattern, indicating sequential memory access.
### Interpretation
The visualization provides insights into how the NTM processes information. The sequential access patterns in the "Write Weightings" and "Read Weightings" suggest that the NTM is using a form of addressing mechanism to interact with its memory. The shift in the input and output patterns suggests a time-dependent transformation or processing of the data. The "Adds" and "Reads" heatmaps show how the NTM is modifying and retrieving information from its memory during the computation. The difference in activity between the "Adds" and "Reads" heatmaps may indicate a phase of writing followed by a phase of reading.
</details>
Figure 7: Repeat Copy Learning Curves.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Line Chart: Cost per Sequence vs. Sequence Number
### Overview
The image is a line chart comparing the cost per sequence (in bits) for three different models: LSTM, NTM with LSTM Controller, and NTM with Feedforward Controller, as a function of the sequence number (in thousands). The chart shows how the cost decreases as the sequence number increases, indicating learning or optimization over time.
### Components/Axes
* **X-axis:** Sequence number (thousands). The axis ranges from 0 to 500, with tick marks at intervals of 100.
* **Y-axis:** Cost per sequence (bits). The axis ranges from 0 to 200, with tick marks at intervals of 20.
* **Legend (top-right):**
* Blue line with circle markers: LSTM
* Green line with square markers: NTM with LSTM Controller
* Red line with triangle markers: NTM with Feedforward Controller
### Detailed Analysis
* **LSTM (Blue):** The LSTM line starts at approximately 185 bits and rapidly decreases to around 20 bits by a sequence number of 100 (thousands). It then continues to decrease, but at a slower rate, reaching a cost of approximately 2 bits by a sequence number of 300 (thousands), and remains relatively constant thereafter.
* (0, 185)
* (20, 130)
* (40, 105)
* (60, 75)
* (80, 22)
* (100, 18)
* (220, 10)
* (300, 2)
* (500, 1)
* **NTM with LSTM Controller (Green):** The NTM with LSTM Controller line starts at approximately 180 bits and decreases very rapidly to below 5 bits by a sequence number of 50 (thousands). It then remains relatively constant at around 1-2 bits for the rest of the sequence numbers.
* (0, 180)
* (20, 10)
* (40, 3)
* (60, 2)
* (500, 1)
* **NTM with Feedforward Controller (Red):** The NTM with Feedforward Controller line starts at approximately 130 bits and decreases rapidly to around 5 bits by a sequence number of 75 (thousands). It then remains relatively constant at around 1-2 bits for the rest of the sequence numbers.
* (0, 130)
* (20, 60)
* (40, 75)
* (60, 50)
* (80, 3)
* (500, 1)
### Key Observations
* All three models show a significant decrease in cost per sequence as the sequence number increases, indicating learning.
* The NTM with LSTM Controller and NTM with Feedforward Controller models converge to a low cost much faster than the LSTM model.
* After an initial rapid decrease, the cost for all models stabilizes at a low level (around 1-2 bits).
* The LSTM model has a slower initial learning rate compared to the other two models.
### Interpretation
The data suggests that the NTM models, especially those with LSTM or Feedforward controllers, are more efficient in reducing the cost per sequence compared to the standalone LSTM model. This could be due to the memory capabilities of the NTM architecture, which allows it to learn and generalize more effectively from the sequences. The rapid convergence of the NTM models indicates that they can quickly adapt to the task and achieve a low cost, while the LSTM model requires more training sequences to reach a similar level of performance. The stabilization of the cost at a low level for all models suggests that they eventually reach a point where further learning provides minimal improvement in cost reduction.
</details>
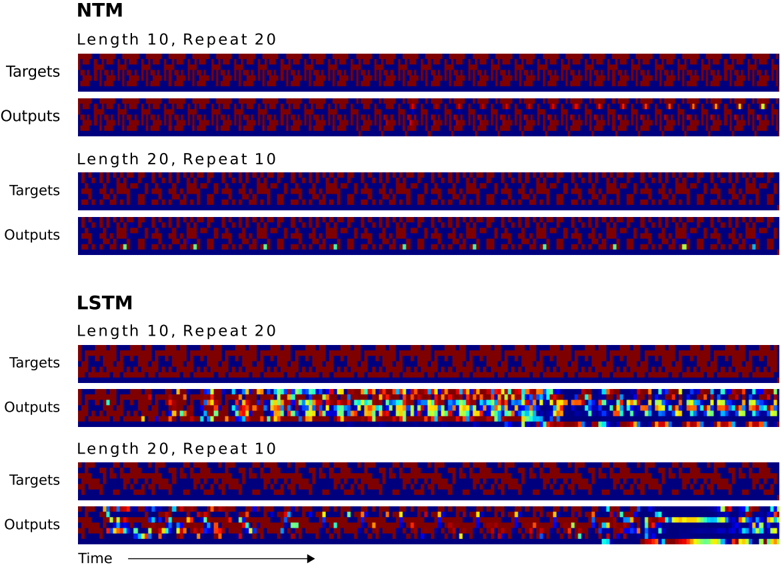
Figure 7 shows that NTM learns the task much faster than LSTM, but both were able to solve it perfectly. 3 The difference between the two architectures only becomes clear when they are asked to generalise beyond the training data. In this case we were interested in generalisation along two dimensions: sequence length and number of repetitions. Figure 8 illustrates the effect of doubling first one, then the other, for both LSTM and NTM. Whereas LSTM fails both tests, NTM succeeds with longer sequences and is able to perform more than ten repetitions; however it is unable to keep count of of how many repeats it has completed, and does not predict the end marker correctly. This is probably a consequence of representing the number of repetitions numerically, which does not easily generalise beyond a fixed range.
Figure 9 suggests that NTM learns a simple extension of the copy algorithm in the previous section, where the sequential read is repeated as many times as necessary.
## 4.3 Associative Recall
The previous tasks show that the NTM can apply algorithms to relatively simple, linear data structures. The next order of complexity in organising data arises from 'indirection'-that is, when one data item points to another. We test the NTM's capability for learning an instance of this more interesting class by constructing a list of items so that querying with one of the items demands that the network return the subsequent item. More specifically, we define an item as a sequence of binary vectors that is bounded on the left and right by delimiter symbols. After several items have been propagated to the network, we query by showing a random item, and we ask the network to produce the next item. In our experiments, each item consisted of three six-bit binary vectors (giving a total of 18 bits
3 It surprised us that LSTM performed better here than on the copy problem. The likely reasons are that the sequences were shorter (up to length 10 instead of up to 20), and the LSTM network was larger and therefore had more memory capacity.
Figure 8: NTM and LSTM Generalisation for the Repeat Copy Task. NTM generalises almost perfectly to longer sequences than seen during training. When the number of repeats is increased it is able to continue duplicating the input sequence fairly accurately; but it is unable to predict when the sequence will end, emitting the end marker after the end of every repetition beyond the eleventh. LSTM struggles with both increased length and number, rapidly diverging from the input sequence in both cases.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Heatmap: NTM vs LSTM Performance
### Overview
The image presents a comparison of the performance of two neural network models, NTM (Neural Turing Machine) and LSTM (Long Short-Term Memory), on a sequence learning task. The performance is visualized as heatmaps, where each row represents either the target sequence or the model's output sequence. Two different sequence configurations are tested: "Length 10, Repeat 20" and "Length 20, Repeat 10". The heatmaps use color to indicate the activation level or the presence of a specific element in the sequence.
### Components/Axes
* **Models:** NTM (top) and LSTM (bottom)
* **Sequence Configurations:**
* Length 10, Repeat 20
* Length 20, Repeat 10
* **Rows:**
* Targets: The desired output sequence.
* Outputs: The sequence generated by the model.
* **X-axis:** Represents "Time" (indicated by an arrow pointing right).
* **Color Scale:** The heatmap uses a color scale, where blue likely represents a low activation or absence of an element, and colors progressing towards red, yellow, and potentially white represent increasing activation levels or presence.
### Detailed Analysis
**NTM:**
* **Length 10, Repeat 20:**
* **Targets:** The target sequence shows a repeating pattern of length 10. The pattern consists of alternating blocks of red and blue.
* **Outputs:** The output sequence closely matches the target sequence, with a similar repeating pattern of red and blue blocks. There are some minor deviations, indicated by slightly different color intensities.
* **Length 20, Repeat 10:**
* **Targets:** The target sequence shows a repeating pattern of length 20, with alternating blocks of red and blue.
* **Outputs:** The output sequence mostly matches the target sequence, but there are some errors. There are a few isolated pixels of a different color (likely green or yellow) scattered throughout the output.
**LSTM:**
* **Length 10, Repeat 20:**
* **Targets:** The target sequence shows a repeating pattern of length 10, with alternating blocks of red and blue.
* **Outputs:** The output sequence is significantly different from the target sequence. It shows a more complex pattern with a wider range of colors, including blue, cyan, yellow, and red. The repeating pattern is not as clear as in the target sequence.
* **Length 20, Repeat 10:**
* **Targets:** The target sequence shows a repeating pattern of length 20, with alternating blocks of red and blue.
* **Outputs:** The output sequence shows some resemblance to the target sequence, but it also contains significant errors. The repeating pattern is less clear, and there are regions with different colors, including blue, cyan, yellow, and red. Towards the end of the sequence, the output seems to align better with the target.
### Key Observations
* NTM performs better than LSTM on this sequence learning task, especially for the "Length 10, Repeat 20" configuration.
* LSTM struggles to accurately reproduce the target sequences, particularly for the "Length 10, Repeat 20" configuration.
* Both models show some errors in the "Length 20, Repeat 10" configuration, but NTM's errors are less pronounced.
* The color variations in the LSTM outputs suggest that the model is not confident in its predictions and is exploring a wider range of possibilities.
### Interpretation
The heatmaps provide a visual representation of the performance of NTM and LSTM on a sequence learning task. The results suggest that NTM is better suited for learning simple repeating patterns than LSTM. LSTM's struggle to accurately reproduce the target sequences may be due to its more complex architecture, which can lead to overfitting or difficulty in learning simple patterns. The errors in both models' outputs for the "Length 20, Repeat 10" configuration suggest that longer sequences are more challenging to learn. The color variations in the LSTM outputs indicate that the model is less confident in its predictions and is exploring a wider range of possibilities. This could be due to the model's internal state being less stable or its inability to capture the underlying structure of the sequence.
</details>
per item). During training, we used a minimum of 2 items and a maximum of 6 items in a single episode.
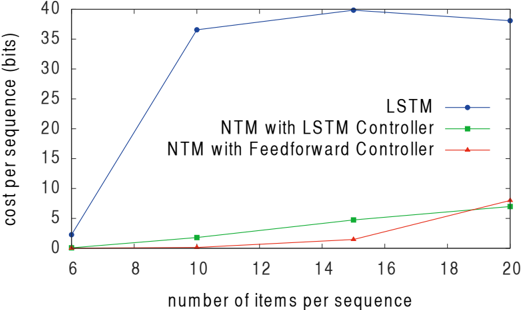
Figure 10 shows that NTM learns this task significantly faster than LSTM, terminating at near zero cost within approximately 30 , 000 episodes, whereas LSTM does not reach zero cost after a million episodes. Additionally, NTM with a feedforward controller learns faster than NTM with an LSTM controller. These two results suggest that NTM's external memory is a more effective way of maintaining the data structure than LSTM's internal state. NTM also generalises much better to longer sequences than LSTM, as can be seen in Figure 11. NTM with a feedforward controller is nearly perfect for sequences of up to 12 items (twice the maximum length used in training), and still has an average cost below 1 bit per sequence for sequences of 15 items.
In Figure 12, we show the operation of the NTM memory, controlled by an LSTM with one head, on a single test episode. In 'Inputs,' we see that the input denotes item delimiters as single bits in row 7. After the sequence of items has been propagated, a
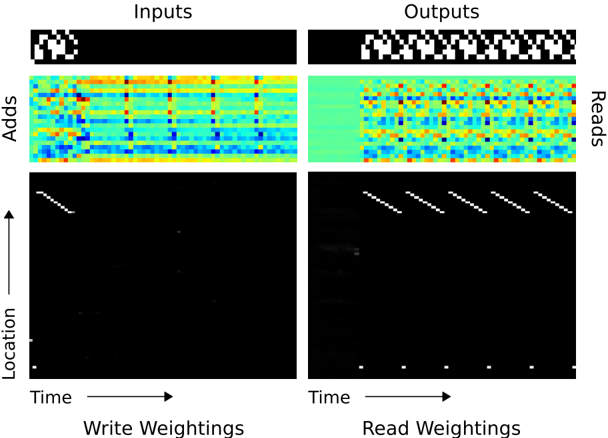
Figure 9: NTM Memory Use During the Repeat Copy Task. As with the copy task the network first writes the input vectors to memory using iterative shifts. It then reads through the sequence to replicate the input as many times as necessary (six in this case). The white dot at the bottom of the read weightings seems to correspond to an intermediate location used to redirect the head to the start of the sequence (The NTM equivalent of a goto statement).
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Diagram: Neural Network Memory Analysis
### Overview
The image presents a visualization of the internal operations of a neural network, specifically focusing on memory access patterns during write and read operations. It displays input and output patterns, memory addition patterns, and write/read weighting distributions over time and location.
### Components/Axes
* **Titles:** "Inputs" (top-left), "Outputs" (top-right)
* **Y-axis (left side):** "Adds", "Location" (with an upward-pointing arrow indicating direction)
* **X-axis (bottom):** "Time" (with a rightward-pointing arrow indicating direction)
* **Bottom Labels:** "Write Weightings" (left), "Read Weightings" (right)
### Detailed Analysis
The image is divided into two main sections: "Inputs" (left) and "Outputs" (right). Each section contains three sub-sections:
1. **Input/Output Patterns (Top Row):**
* **Inputs:** A small, black square with a white pattern.
* **Outputs:** A horizontal sequence of repeating black and white patterns.
2. **Memory Addition Patterns (Middle Row):**
* **Adds (Inputs):** A heatmap-like representation showing memory addition patterns over time. The color scheme ranges from blue to red, indicating different levels of addition. There are vertical bands of varying color intensity.
* **Reads (Outputs):** A heatmap-like representation showing memory read patterns over time. The color scheme ranges from blue to red, indicating different levels of reading. There are vertical bands of varying color intensity.
3. **Write/Read Weightings (Bottom Row):**
* **Write Weightings:** A black background with sparse white pixels. There are diagonal lines of white pixels that appear to move from top-left to bottom-right. There are also a few scattered white pixels.
* **Read Weightings:** A black background with sparse white pixels. There are diagonal lines of white pixels that appear to move from top-left to bottom-right. There are also a few scattered white pixels and a row of white dots at the bottom.
### Key Observations
* The input pattern is static, while the output pattern is dynamic and repetitive.
* The memory addition patterns (Adds/Reads) show distinct temporal structures, with the "Reads" section exhibiting more regular patterns than the "Adds" section.
* The write and read weightings show diagonal patterns, suggesting sequential memory access. The read weightings show more activity than the write weightings.
### Interpretation
The diagram visualizes how a neural network interacts with its memory during processing. The "Inputs" and "Outputs" sections show the data being fed into and produced by the network. The "Adds" and "Reads" sections reveal how the network modifies and retrieves information from its memory. The "Write Weightings" and "Read Weightings" sections illustrate the specific memory locations being accessed during these operations.
The diagonal patterns in the weightings suggest that the network is sequentially accessing memory locations. The differences between the "Adds" and "Reads" sections indicate that the network's memory access patterns are different for writing and reading. The repetitive nature of the output pattern is reflected in the regular patterns observed in the "Reads" section.
</details>
Figure 10: Associative Recall Learning Curves for NTM and LSTM.
<details>
<summary>Image 10 Details</summary>
### Visual Description
## Line Chart: Cost per Sequence vs. Sequence Number
### Overview
The image is a line chart comparing the cost per sequence (in bits) for three different models: LSTM, NTM with LSTM Controller, and NTM with Feedforward Controller, across a sequence number ranging from 0 to 1000 (thousands). The chart illustrates how the cost decreases as the sequence number increases, indicating learning or optimization over time.
### Components/Axes
* **X-axis:** Sequence number (thousands). Scale ranges from 0 to 1000, with tick marks at 0, 200, 400, 600, 800, and 1000.
* **Y-axis:** Cost per sequence (bits). Scale ranges from 0 to 20, with tick marks at 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, and 20.
* **Legend (Top-Right):**
* Blue line with circle markers: LSTM
* Green line with square markers: NTM with LSTM Controller
* Red line with triangle markers: NTM with Feedforward Controller
### Detailed Analysis
* **LSTM (Blue):** The cost starts at approximately 18 bits and decreases rapidly until around sequence number 200 (thousands), where it begins to level off. By sequence number 1000 (thousands), the cost is approximately 1 bit.
* At sequence number 0: ~18 bits
* At sequence number 100: ~10 bits
* At sequence number 200: ~4 bits
* At sequence number 500: ~1.5 bits
* At sequence number 1000: ~1 bit
* **NTM with LSTM Controller (Green):** The cost starts at approximately 17 bits and decreases very rapidly, reaching a cost of approximately 0 bits by sequence number 150 (thousands).
* At sequence number 0: ~17 bits
* At sequence number 50: ~7 bits
* At sequence number 100: ~1 bits
* At sequence number 150: ~0 bits
* At sequence number 1000: ~0 bits
* **NTM with Feedforward Controller (Red):** The cost starts at approximately 12 bits and decreases very rapidly, reaching a cost of approximately 0 bits by sequence number 50 (thousands).
* At sequence number 0: ~18 bits
* At sequence number 50: ~0 bits
* At sequence number 1000: ~0 bits
### Key Observations
* The NTM with Feedforward Controller converges to a low cost much faster than the other two models.
* The NTM with LSTM Controller also converges quickly, but not as fast as the Feedforward Controller.
* The LSTM model has the slowest convergence rate.
### Interpretation
The chart demonstrates the learning curves of three different neural network models. The NTM with Feedforward Controller appears to be the most efficient in terms of reducing the cost per sequence, followed by the NTM with LSTM Controller. The LSTM model, while still effective, requires a significantly larger number of sequences to achieve a comparable cost reduction. This suggests that the architecture of the NTM models, particularly when paired with a Feedforward Controller, is better suited for this specific task, leading to faster learning and optimization. The rapid initial decrease in cost for all models indicates a quick initial learning phase, followed by a slower refinement as the models approach their optimal performance.
</details>
Figure 11: Generalisation Performance on Associative Recall for Longer Item Sequences. The NTM with either a feedforward or LSTM controller generalises to much longer sequences of items than the LSTM alone. In particular, the NTM with a feedforward controller is nearly perfect for item sequences of twice the length of sequences in its training set.
<details>
<summary>Image 11 Details</summary>
### Visual Description
## Line Chart: Cost per Sequence vs. Number of Items per Sequence
### Overview
The image is a line chart comparing the cost per sequence (in bits) for three different models: LSTM, NTM with LSTM Controller, and NTM with Feedforward Controller, as the number of items per sequence increases. The x-axis represents the number of items per sequence, ranging from 6 to 20. The y-axis represents the cost per sequence in bits, ranging from 0 to 40.
### Components/Axes
* **X-axis:** "number of items per sequence" with markers at 6, 8, 10, 12, 14, 16, 18, and 20.
* **Y-axis:** "cost per sequence (bits)" with markers at 0, 5, 10, 15, 20, 25, 30, 35, and 40.
* **Legend:** Located on the right side of the chart, it identifies the three models:
* Blue line with circle markers: LSTM
* Green line with square markers: NTM with LSTM Controller
* Red line with triangle markers: NTM with Feedforward Controller
### Detailed Analysis
* **LSTM (Blue):** The cost per sequence increases sharply from approximately 2 bits at 6 items to approximately 36 bits at 10 items. From 10 items to 14 items, the cost increases slightly to approximately 39 bits, and then plateaus, remaining around 39 bits at 20 items.
* (6, ~2)
* (10, ~36)
* (14, ~39)
* (20, ~39)
* **NTM with LSTM Controller (Green):** The cost per sequence starts near 0 bits at 6 items and increases gradually to approximately 2 bits at 10 items, approximately 4.5 bits at 14 items, and approximately 7 bits at 20 items.
* (6, ~0)
* (10, ~2)
* (14, ~4.5)
* (20, ~7)
* **NTM with Feedforward Controller (Red):** The cost per sequence starts near 0 bits at 6 items and increases gradually to approximately 0.5 bits at 10 items, approximately 1 bit at 14 items, and approximately 7.5 bits at 20 items.
* (6, ~0)
* (10, ~0.5)
* (14, ~1)
* (20, ~7.5)
### Key Observations
* The LSTM model has a significantly higher cost per sequence compared to the two NTM models, especially for sequences with 10 or more items.
* The cost per sequence for the LSTM model increases rapidly initially and then plateaus.
* The cost per sequence for both NTM models increases gradually and almost linearly with the number of items per sequence.
* The NTM with Feedforward Controller has a slightly lower cost than the NTM with LSTM Controller until the number of items reaches 20, where they are approximately equal.
### Interpretation
The chart demonstrates that the LSTM model is more expensive in terms of cost per sequence (bits) than the NTM models, particularly as the sequence length increases. This suggests that for longer sequences, the NTM models with either LSTM or Feedforward controllers are more efficient. The initial sharp increase in cost for the LSTM model indicates a higher overhead or complexity in processing the initial items of the sequence. The plateauing of the LSTM cost suggests a saturation point where adding more items does not significantly increase the cost. The gradual increase in cost for the NTM models indicates a more linear relationship between sequence length and cost. The similar performance of the two NTM models suggests that the choice of controller (LSTM or Feedforward) has a relatively minor impact on the cost per sequence.
</details>
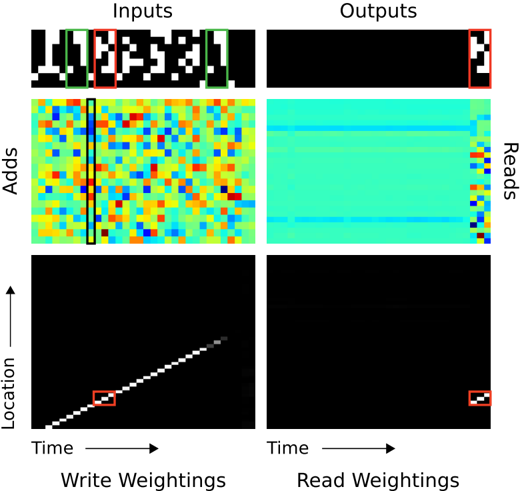
delimiter in row 8 prepares the network to receive a query item. In this case, the query item corresponds to the second item in the sequence (contained in the green box). In 'Outputs,' we see that the network crisply outputs item 3 in the sequence (from the red box). In 'Read Weightings,' on the last three time steps, we see that the controller reads from contiguous locations that each store the time slices of item 3. This is curious because it appears that the network has jumped directly to the correct location storing item 3. However we can explain this behaviour by looking at 'Write Weightings.' Here we see that the memory is written to even when the input presents a delimiter symbol between items. One can confirm in 'Adds' that data are indeed written to memory when the delimiters are presented (e.g., the data within the black box); furthermore, each time a delimiter is presented, the vector added to memory is different. Further analysis of the memory reveals that the network accesses the location it reads after the query by using a content-based lookup that produces a weighting that is shifted by one. Additionally, the key used for content-lookup corresponds to the vector that was added in the black box. This implies the following memory-access algorithm: when each item delimiter is presented, the controller writes a compressed representation of the previous three time slices of the item. After the query arrives, the controller recomputes the same compressed representation of the query item, uses a content-based lookup to find the location where it wrote the first representation, and then shifts by one to produce the subsequent item in the sequence (thereby combining content-based lookup with location-based offsetting).
## 4.4 Dynamic N-Grams
The goal of the dynamic N-Grams task was to test whether NTM could rapidly adapt to new predictive distributions. In particular we were interested to see if it were able to use its
Figure 12: NTM Memory Use During the Associative Recall Task. In 'Inputs,' a sequence of items, each composed of three consecutive binary random vectors is propagated to the controller. The distinction between items is designated by delimiter symbols (row 7 in 'Inputs'). After several items have been presented, a delimiter that designates a query is presented (row 8 in 'Inputs'). A single query item is presented (green box), and the network target corresponds to the subsequent item in the sequence (red box). In 'Outputs,' we see that the network correctly produces the target item. The red boxes in the read and write weightings highlight the three locations where the target item was written and then read. The solution the network finds is to form a compressed representation (black box in 'Adds') of each item that it can store in a single location. For further analysis, see the main text.
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Neural Network Visualization: Inputs and Outputs
### Overview
The image presents a visualization of the internal workings of a neural network, specifically focusing on the inputs, outputs, adds, reads, write weightings, and read weightings. The visualization is structured as a 3x2 grid, with "Inputs" on the left and "Outputs" on the right. Each row represents a different aspect of the network's operation: the first row shows the raw input and output data, the second row shows the "Adds" and "Reads" operations, and the third row shows the "Write Weightings" and "Read Weightings" over time and location.
### Components/Axes
* **Titles:**
* Top: "Inputs" (left), "Outputs" (right)
* Left Column: "Adds", "Location" (with an upward-pointing arrow)
* Bottom Row: "Time" (with a rightward-pointing arrow), "Write Weightings" (left), "Read Weightings" (right)
* Right Column: "Reads"
* **Axes:**
* The "Adds" and "Reads" visualizations appear to be heatmaps, with no explicit axes labels.
* The "Location" vs. "Time" plots have axes labeled "Location" (vertical) and "Time" (horizontal).
* **Annotations:**
* There are red, green, and black rectangular boxes highlighting specific regions in the visualizations.
### Detailed Analysis
**Row 1: Inputs and Outputs**
* **Inputs (Top-Left):** A binary image consisting of black and white pixels. The image appears to contain a pattern or character. A red box highlights a small section of the input, and a green box highlights a larger section.
* **Outputs (Top-Right):** A mostly black image with a small section of white pixels in the bottom-right corner. A red box highlights this section, and a green box highlights a larger section.
**Row 2: Adds and Reads**
* **Adds (Middle-Left):** A heatmap with a color gradient ranging from blue to red. The distribution of colors appears random, with no clear pattern. A black box highlights a vertical section of the heatmap.
* **Reads (Middle-Right):** A heatmap with a color gradient ranging from blue to red. The heatmap is predominantly cyan, with some vertical stripes of other colors on the right side.
**Row 3: Write Weightings and Read Weightings**
* **Write Weightings (Bottom-Left):** A black image with a diagonal line of white pixels extending from the bottom-left to the top-right. The line represents the weights being written over time and location. A red box highlights a small section of the diagonal line.
* **Read Weightings (Bottom-Right):** A mostly black image with a small cluster of white pixels in the bottom-right corner. A red box highlights this cluster.
### Key Observations
* The input image contains a distinct pattern, while the output image is mostly black with a small, localized activation.
* The "Adds" heatmap shows a seemingly random distribution of values, while the "Reads" heatmap shows a more structured pattern.
* The "Write Weightings" plot shows a clear diagonal pattern, indicating a sequential writing process.
* The "Read Weightings" plot shows a localized activation, suggesting that the network is reading from a specific location.
### Interpretation
The image provides a glimpse into the internal operations of a neural network, likely a memory-augmented neural network (MANN) or a similar architecture. The "Adds" and "Reads" heatmaps likely represent the memory content being written to and read from, respectively. The "Write Weightings" and "Read Weightings" plots show how the network is accessing its memory over time.
The fact that the output is mostly black suggests that the network is either still learning or that the input pattern is not strongly associated with any particular output. The localized activation in the "Read Weightings" plot suggests that the network is focusing on a specific memory location to produce the output.
The diagonal line in the "Write Weightings" plot indicates that the network is sequentially writing information to memory. This could be related to how the network is processing the input sequence or how it is storing information for later use.
</details>
memory as a re-writable table that it could use to keep count of transition statistics, thereby emulating a conventional N-Gram model.
We considered the set of all possible 6-Gram distributions over binary sequences. Each 6-Gram distribution can be expressed as a table of 2 5 = 32 numbers, specifying the probability that the next bit will be one, given all possible length five binary histories. For each training example, we first generated random 6-Gram probabilities by independently drawing all 32 probabilities from the Beta ( 1 2 , 1 2 ) distribution.
We then generated a particular training sequence by drawing 200 successive bits using the current lookup table. 4 The network observes the sequence one bit at a time and is then asked to predict the next bit. The optimal estimator for the problem can be determined by
4 The first 5 bits, for which insufficient context exists to sample from the table, are drawn i.i.d. from a Bernoulli distribution with p = 0 . 5 .
Figure 13: Dynamic N-Gram Learning Curves.
<details>
<summary>Image 13 Details</summary>
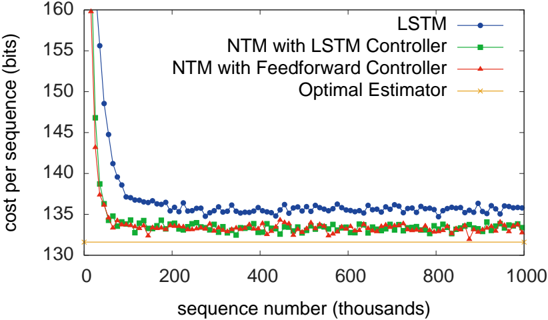
### Visual Description
## Line Chart: Cost per Sequence vs. Sequence Number
### Overview
The image is a line chart comparing the cost per sequence (in bits) for different models (LSTM, NTM with LSTM Controller, NTM with Feedforward Controller, and Optimal Estimator) over a sequence number ranging from 0 to 1000 (thousands). The chart illustrates the performance of these models as the sequence number increases.
### Components/Axes
* **X-axis:** Sequence number (thousands), ranging from 0 to 1000 in increments of 200.
* **Y-axis:** Cost per sequence (bits), ranging from 130 to 160 in increments of 5.
* **Legend (Top-Right):**
* Blue line with circles: LSTM
* Green line with squares: NTM with LSTM Controller
* Red line with triangles: NTM with Feedforward Controller
* Yellow line with crosses: Optimal Estimator
### Detailed Analysis
* **LSTM (Blue):** The LSTM line starts at approximately 159 bits and rapidly decreases to around 136 bits by sequence number 200 (thousands). After that, it fluctuates between 134 and 137 bits, remaining relatively stable.
* (0, 159)
* (200, 136)
* (1000, 135)
* **NTM with LSTM Controller (Green):** The NTM with LSTM Controller line starts at approximately 159 bits and decreases to around 133 bits by sequence number 100 (thousands). It then fluctuates between 132 and 134 bits for the rest of the sequence.
* (0, 159)
* (100, 133)
* (1000, 133)
* **NTM with Feedforward Controller (Red):** The NTM with Feedforward Controller line starts at approximately 159 bits and decreases to around 133 bits by sequence number 100 (thousands). It then fluctuates between 132 and 134 bits for the rest of the sequence.
* (0, 159)
* (100, 133)
* (1000, 133)
* **Optimal Estimator (Yellow):** The Optimal Estimator line remains constant at approximately 131 bits throughout the entire sequence.
* (0, 131)
* (1000, 131)
### Key Observations
* The LSTM model has a higher initial cost per sequence but stabilizes after the sequence number reaches 200 (thousands).
* The NTM with LSTM Controller and NTM with Feedforward Controller models have similar performance, with a lower cost per sequence than LSTM after the initial drop.
* The Optimal Estimator consistently has the lowest cost per sequence.
* All models show a significant decrease in cost per sequence in the initial phase (sequence number < 200 thousands).
### Interpretation
The chart demonstrates the learning curves of different models in terms of cost per sequence. The LSTM model initially performs worse but converges to a stable cost. The NTM models with LSTM and Feedforward controllers perform similarly and better than LSTM after the initial phase. The Optimal Estimator provides a baseline with the lowest cost, indicating the theoretical limit of performance. The initial drop in cost for all models suggests a rapid learning phase, after which the models stabilize. The data suggests that NTM with either LSTM or Feedforward controllers are more efficient than LSTM for this particular task, but none can outperform the Optimal Estimator.
</details>
Bayesian analysis (Murphy, 2012):
<!-- formula-not-decoded -->
where c is the five bit previous context, B is the value of the next bit and N 0 and N 1 are respectively the number of zeros and ones observed after c so far in the sequence. We can therefore compare NTM to the optimal predictor as well as LSTM. To assess performance we used a validation set of 1000 length 200 sequences sampled from the same distribution as the training data. As shown in Figure 13, NTM achieves a small, but significant performance advantage over LSTM, but never quite reaches the optimum cost.
The evolution of the two architecture's predictions as they observe new inputs is shown in Figure 14, along with the optimal predictions. Close analysis of NTM's memory usage (Figure 15) suggests that the controller uses the memory to count how many ones and zeros it has observed in different contexts, allowing it to implement an algorithm similar to the optimal estimator.
## 4.5 Priority Sort
This task tests whether the NTM can sort data-an important elementary algorithm. A sequence of random binary vectors is input to the network along with a scalar priority rating for each vector. The priority is drawn uniformly from the range [-1, 1]. The target sequence contains the binary vectors sorted according to their priorities, as depicted in Figure 16.
Each input sequence contained 20 binary vectors with corresponding priorities, and each target sequence was the 16 highest-priority vectors in the input. 5 Inspection of NTM's
5 We limited the sort to size 16 because we were interested to see if NTM would solve the task using a binary heap sort of depth 4.
Figure 14: Dynamic N-Gram Inference. The top row shows a test sequence from the N-Gram task, and the rows below show the corresponding predictive distributions emitted by the optimal estimator, NTM, and LSTM. In most places the NTM predictions are almost indistinguishable from the optimal ones. However at the points indicated by the two arrows it makes clear mistakes, one of which is explained in Figure 15. LSTM follows the optimal predictions closely in some places but appears to diverge further as the sequence progresses; we speculate that this is due to LSTM 'forgetting' the observations at the start of the sequence.
<details>
<summary>Image 14 Details</summary>

### Visual Description
\n
## Heatmap: Sequence Comparison of Input, Optimal, NTM, and LSTM
### Overview
The image is a heatmap-like representation comparing the sequences generated by different models (NTM and LSTM) against an "Optimal" sequence, given a specific "Input" sequence. The sequences are represented as rows, with each column representing a time step or element in the sequence. The color intensity indicates the value or state at each step.
### Components/Axes
* **Rows (from top to bottom):**
* Input: A binary sequence (black and white).
* Optimal: A grayscale sequence.
* NTM: A grayscale sequence generated by a Neural Turing Machine.
* LSTM: A grayscale sequence generated by a Long Short-Term Memory network.
* **Columns:** Represent the sequence elements or time steps. There are approximately 30-40 columns.
* **Color Scale:** Grayscale, where darker shades likely represent higher values or activation.
* **Annotations:** Two red upward-pointing arrows are present near the bottom, indicating a specific point of interest in the LSTM sequence.
### Detailed Analysis
* **Input:** The input sequence consists of alternating black and white bars, indicating a binary input. The pattern is irregular, with varying widths of black and white segments.
* **Optimal:** The "Optimal" sequence shows a more graded response, with varying shades of gray. It appears to follow the general pattern of the input but with smoothed transitions.
* **NTM:** The NTM sequence shows a similar pattern to the "Optimal" sequence, but with some differences in the intensity of the gray shades. In some regions, it closely matches the "Optimal" sequence, while in others, it deviates.
* **LSTM:** The LSTM sequence also attempts to replicate the "Optimal" sequence. The red arrows point to a specific location where the LSTM sequence seems to have a distinct response compared to the other sequences.
### Key Observations
* The "Optimal" sequence serves as a target or ground truth for the NTM and LSTM models.
* Both NTM and LSTM models attempt to approximate the "Optimal" sequence, but with varying degrees of accuracy.
* The red arrows highlight a specific point where the LSTM model's behavior is of particular interest, possibly indicating a point of divergence or error.
### Interpretation
The heatmap visually compares the performance of NTM and LSTM models in generating a sequence that matches a desired "Optimal" sequence, given a specific input. The differences in the grayscale patterns indicate the models' varying abilities to capture the underlying dynamics of the sequence generation task. The red arrows suggest a specific area where the LSTM model's performance warrants further investigation. The image suggests that both NTM and LSTM models can approximate the optimal sequence, but there are differences in their performance, with specific areas where one model might outperform the other. The analysis of these differences can provide insights into the strengths and weaknesses of each model architecture for sequence generation tasks.
</details>
Figure 15: NTM Memory Use During the Dynamic N-Gram Task. The red and green arrows indicate point where the same context is repeatedly observed during the test sequence ('00010' for the green arrows, '01111' for the red arrows). At each such point the same location is accessed by the read head, and then, on the next time-step, accessed by the write head. We postulate that the network uses the writes to keep count of the fraction of ones and zeros following each context in the sequence so far. This is supported by the add vectors, which are clearly anti-correlated at places where the input is one or zero, suggesting a distributed 'counter.' Note that the write weightings grow fainter as the same context is repeatedly seen; this may be because the memory records a ratio of ones to zeros, rather than absolute counts. The red box in the prediction sequence corresponds to the mistake at the first red arrow in Figure 14; the controller appears to have accessed the wrong memory location, as the previous context was '01101' and not '01111.'
<details>
<summary>Image 15 Details</summary>
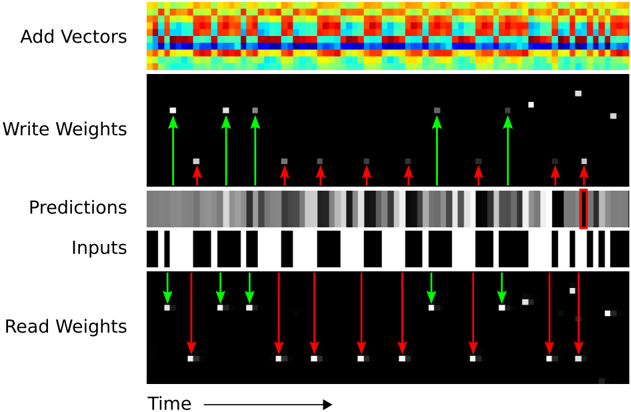
### Visual Description
## Neural Network Diagram: Memory Access Visualization
### Overview
The image is a visualization of memory access patterns in a neural network over time. It shows how vectors are added, weights are written and read, and how these actions relate to the network's inputs and predictions. The diagram is structured vertically, with time progressing horizontally from left to right.
### Components/Axes
* **Vertical Sections (Top to Bottom):**
* Add Vectors
* Write Weights
* Predictions
* Inputs
* Read Weights
* **Horizontal Axis:**
* Labeled "Time" with an arrow indicating the direction of time's progression.
* **Arrows:**
* Green arrows indicate successful or positive actions.
* Red arrows indicate unsuccessful or negative actions.
### Detailed Analysis or ### Content Details
1. **Add Vectors:**
* A heatmap-like representation showing the addition of vectors over time. The colors range from blue to red, potentially indicating the magnitude or frequency of vector additions. The pattern appears somewhat periodic.
* The heatmap consists of a grid of colored squares. The colors vary from blue to green to yellow to red. The pattern is complex, but there are some repeating elements.
2. **Write Weights:**
* A black background with white/gray squares representing the weights being written.
* Green arrows point upwards from the "Inputs" section to the "Write Weights" section, indicating when a weight is successfully written.
* Red arrows point upwards from the "Inputs" section to the "Write Weights" section, indicating when a weight write fails.
* The squares vary in intensity, with some being brighter than others.
3. **Predictions:**
* A grayscale bar representing the network's predictions over time. The intensity of the gray likely corresponds to the confidence or value of the prediction.
* The predictions vary in intensity, with some being darker than others.
4. **Inputs:**
* A binary representation of the input data over time, with black representing 0 and white representing 1.
* The inputs are represented as black and white bars. The pattern of black and white bars represents the input data.
5. **Read Weights:**
* A black background with white/gray squares representing the weights being read.
* Green arrows point downwards from the "Inputs" section to the "Read Weights" section, indicating when a weight is successfully read.
* Red arrows point downwards from the "Inputs" section to the "Read Weights" section, indicating when a weight read fails.
* The squares vary in intensity, with some being brighter than others.
### Key Observations
* The "Add Vectors" section shows a complex, potentially periodic pattern of vector additions.
* The "Write Weights" and "Read Weights" sections show sparse activity, with only a few weights being written or read at any given time.
* The "Predictions" section shows a continuous stream of predictions, with varying levels of confidence.
* The "Inputs" section shows a binary input pattern, with alternating sequences of 0s and 1s.
* The green and red arrows indicate the success or failure of weight writes and reads, providing insight into the network's learning process.
### Interpretation
The diagram provides a visual representation of the internal workings of a neural network, specifically focusing on memory access patterns. By visualizing the addition of vectors, the writing and reading of weights, the network's predictions, and the input data, the diagram offers insights into how the network learns and makes decisions. The green and red arrows highlight the success or failure of weight operations, which can be used to diagnose potential issues in the network's training process. The periodic pattern in the "Add Vectors" section may indicate a cyclical process within the network. The varying intensities in the "Predictions" section suggest different levels of confidence in the network's outputs. The diagram could be used to optimize the network's architecture or training process by identifying bottlenecks or inefficiencies in memory access.
</details>
Figure 16: Example Input and Target Sequence for the Priority Sort Task. The input sequence contains random binary vectors and random scalar priorities. The target sequence is a subset of the input vectors sorted by the priorities.
<details>
<summary>Image 16 Details</summary>
### Visual Description
## Diagram: Input Transformation with Priority
### Overview
The image illustrates a transformation process where an input matrix is converted into a target matrix based on a priority system. The priority is represented by a line graph above the input matrix, with numerical labels indicating the priority order. The transformation from input to target is visually indicated by an arrow.
### Components/Axes
* **Priority:** A line graph indicating the priority of transformation. The x-axis is implicitly the order of transformation (1 to 7). The y-axis represents the priority level.
* **Inputs:** A black and white matrix representing the initial state.
* **Targets:** A black and white matrix representing the final state after transformation.
* **Arrow:** An arrow pointing from the "Inputs" matrix to the "Targets" matrix, indicating the direction of the transformation.
* **Numerical Labels:** Numbers 1 through 7 are placed above the priority line, indicating the order of priority.
### Detailed Analysis
* **Priority Line Graph:**
* The line graph starts at priority 5, then goes to 7, then drops to 4, then rises to 6, then drops to 3, then rises to 2, and finally rises to 1.
* The priority order is explicitly labeled as 1, 2, 3, 4, 5, 6, 7.
* **Input Matrix:**
* The input matrix is a 7x7 grid of black and white squares.
* The arrangement of black and white squares appears random.
* **Target Matrix:**
* The target matrix is also a 7x7 grid of black and white squares.
* The arrangement of black and white squares is different from the input matrix, indicating a transformation.
* The numbers 1234567... are written above the target matrix.
* **Transformation Arrow:**
* The arrow indicates the transformation process from the input matrix to the target matrix.
### Key Observations
* The priority line graph suggests that the transformation process is not sequential but rather based on a specific order of priority.
* The input and target matrices are different, indicating that a transformation has occurred.
* The numbers above the target matrix likely correspond to the priority order used in the transformation.
### Interpretation
The diagram illustrates a process where an input matrix is transformed into a target matrix based on a defined priority. The priority line graph dictates the order in which elements of the input matrix are processed to generate the target matrix. The specific algorithm or method used for the transformation is not explicitly defined, but the diagram suggests that it is influenced by the priority order. The black and white matrices could represent binary data, pixel values, or any other discrete information. The transformation could represent a sorting, filtering, or re-arrangement process based on the priority assigned to each element.
</details>
Figure 17: NTM Memory Use During the Priority Sort Task. Left: Write locations returned by fitting a linear function of the priorities to the observed write locations. Middle: Observed write locations. Right: Read locations.
<details>
<summary>Image 17 Details</summary>
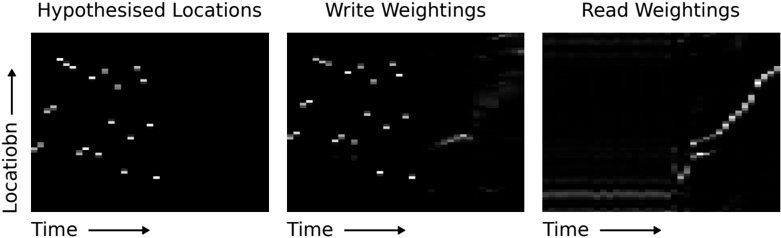
### Visual Description
## Heatmaps: Hypothesized, Write, and Read Weightings
### Overview
The image presents three heatmaps side-by-side, visualizing "Hypothesized Locations," "Write Weightings," and "Read Weightings." Each heatmap displays data points as varying shades of gray against a black background, with axes representing "Locationbn" (vertical) and "Time" (horizontal). The intensity of the gray indicates the magnitude or weighting at each location and time point.
### Components/Axes
* **Titles:**
* Left: "Hypothesised Locations"
* Center: "Write Weightings"
* Right: "Read Weightings"
* **Axes:**
* Vertical (all three heatmaps): "Locationbn" with an arrow pointing upwards.
* Horizontal (all three heatmaps): "Time" with an arrow pointing to the right.
* **Color Scale:** The heatmaps use a grayscale color scheme, where darker shades represent lower values and lighter shades represent higher values. The background is black.
### Detailed Analysis
**1. Hypothesised Locations**
* **Trend:** The heatmap shows scattered, discrete points of activity. These points appear as small, light-gray or white rectangles against the black background.
* **Data Points:**
* There are approximately 15-20 distinct points visible.
* The points are distributed across the "Locationbn" axis, with some clustering in the middle and lower regions.
* The points appear at various "Time" intervals, suggesting activity at different time steps.
* The intensity of the points varies, indicating different levels of "weighting" or "activity" at each location and time.
**2. Write Weightings**
* **Trend:** Similar to "Hypothesised Locations," this heatmap also shows discrete points of activity, but with some blurring or smearing, indicating a spread of weighting.
* **Data Points:**
* The number of distinct points is similar to "Hypothesised Locations," around 15-20.
* The points are less sharply defined, with a gradual fade from light gray to black.
* There is a concentration of activity in the lower-right portion of the heatmap.
* The intensity of the points varies, with some points appearing brighter than others.
**3. Read Weightings**
* **Trend:** This heatmap shows a more structured pattern compared to the other two. There is a distinct diagonal band of activity, suggesting a sequential reading process.
* **Data Points:**
* A prominent diagonal line of light-gray/white points extends from the top-right to the bottom-left.
* There are also some horizontal lines of activity, particularly in the lower half of the heatmap.
* The intensity of the diagonal line varies, with some points appearing brighter than others.
* The lower portion of the heatmap shows a more continuous, less discrete pattern of activity.
### Key Observations
* The "Hypothesised Locations" heatmap shows sparse, discrete activity, representing potential locations of interest.
* The "Write Weightings" heatmap shows a similar pattern, but with some blurring, suggesting the assignment of weights to these locations.
* The "Read Weightings" heatmap shows a more structured pattern, with a diagonal line indicating a sequential reading process and horizontal lines indicating activity at specific locations.
### Interpretation
The three heatmaps likely represent different stages in a memory or attention mechanism. "Hypothesised Locations" could represent potential locations to attend to. "Write Weightings" could represent the assignment of importance or relevance to these locations. "Read Weightings" could represent the process of retrieving information from these locations, with the diagonal line indicating a sequential reading process. The horizontal lines in "Read Weightings" might indicate specific locations that are being actively read. The blurring in "Write Weightings" suggests a distribution of attention or weighting around the hypothesized locations. The data suggests a system that first identifies potential locations, assigns weights to them, and then reads from them in a structured manner.
</details>
memory use led us to hypothesise that it uses the priorities to determine the relative location of each write. To test this hypothesis we fitted a linear function of the priority to the observed write locations. Figure 17 shows that the locations returned by the linear function closely match the observed write locations. It also shows that the network reads from the memory locations in increasing order, thereby traversing the sorted sequence.
The learning curves in Figure 18 demonstrate that NTM with both feedforward and LSTM controllers substantially outperform LSTM on this task. Note that eight parallel read and write heads were needed for best performance with a feedforward controller on this task; this may reflect the difficulty of sorting vectors using only unary vector operations (see Section 3.4).
## 4.6 Experimental Details
For all experiments, the RMSProp algorithm was used for training in the form described in (Graves, 2013) with momentum of 0.9. Tables 1 to 3 give details about the network configurations and learning rates used in the experiments. All LSTM networks had three stacked hidden layers. Note that the number of LSTM parameters grows quadratically with
Figure 18: Priority Sort Learning Curves.
<details>
<summary>Image 18 Details</summary>
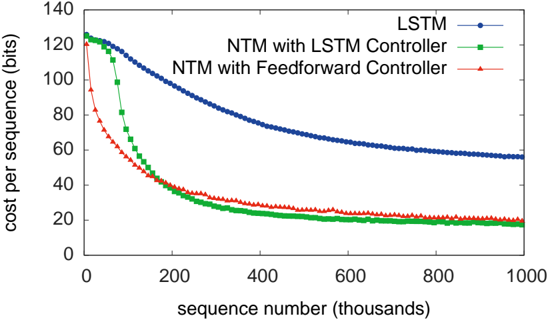
### Visual Description
## Line Chart: Cost per Sequence vs. Sequence Number
### Overview
The image is a line chart comparing the cost per sequence (in bits) for three different models: LSTM, NTM with LSTM Controller, and NTM with Feedforward Controller, across a range of sequence numbers (in thousands). The chart illustrates how the cost per sequence changes as the sequence number increases for each model.
### Components/Axes
* **X-axis:** Sequence number (thousands), ranging from 0 to 1000 in increments of 200.
* **Y-axis:** Cost per sequence (bits), ranging from 0 to 140 in increments of 20.
* **Legend (top-right):**
* Blue line with circular markers: LSTM
* Green line with square markers: NTM with LSTM Controller
* Red line with triangular markers: NTM with Feedforward Controller
### Detailed Analysis
* **LSTM (Blue):** The blue line, representing LSTM, starts at approximately 125 bits and gradually decreases as the sequence number increases. The line flattens out around 60 bits after a sequence number of 600, indicating a slower rate of cost reduction.
* At sequence number 0, cost is ~125 bits.
* At sequence number 200, cost is ~95 bits.
* At sequence number 400, cost is ~75 bits.
* At sequence number 600, cost is ~65 bits.
* At sequence number 800, cost is ~60 bits.
* At sequence number 1000, cost is ~57 bits.
* **NTM with LSTM Controller (Green):** The green line, representing NTM with LSTM Controller, starts at approximately 125 bits and rapidly decreases until a sequence number of around 200. After that, the line flattens out around 20 bits, indicating a stable cost per sequence.
* At sequence number 0, cost is ~125 bits.
* At sequence number 100, cost is ~80 bits.
* At sequence number 200, cost is ~35 bits.
* At sequence number 300, cost is ~25 bits.
* At sequence number 400, cost is ~22 bits.
* At sequence number 1000, cost is ~17 bits.
* **NTM with Feedforward Controller (Red):** The red line, representing NTM with Feedforward Controller, starts at approximately 125 bits and rapidly decreases until a sequence number of around 200. After that, the line flattens out around 20 bits, indicating a stable cost per sequence.
* At sequence number 0, cost is ~125 bits.
* At sequence number 100, cost is ~65 bits.
* At sequence number 200, cost is ~35 bits.
* At sequence number 300, cost is ~25 bits.
* At sequence number 400, cost is ~22 bits.
* At sequence number 1000, cost is ~17 bits.
### Key Observations
* Both NTM models (with LSTM and Feedforward controllers) exhibit a significantly faster initial decrease in cost per sequence compared to the LSTM model.
* The NTM models converge to a lower cost per sequence (around 20 bits) compared to the LSTM model (around 60 bits).
* The NTM models with LSTM and Feedforward controllers perform almost identically.
### Interpretation
The data suggests that NTM models, regardless of whether they use an LSTM or Feedforward controller, are more efficient in reducing the cost per sequence compared to a standalone LSTM model. The rapid initial decrease in cost for the NTM models indicates a faster learning rate or better adaptation to the sequence data. The convergence to a lower cost per sequence suggests that NTM models are better at minimizing the resources required to process the sequences. The similarity in performance between the NTM models with LSTM and Feedforward controllers indicates that the choice of controller may not significantly impact the overall efficiency of the NTM architecture in this specific scenario. The LSTM model, while initially having a similar cost, plateaus at a higher cost, suggesting it may not be as effective at long-term sequence processing or optimization.
</details>
Table 1: NTM with Feedforward Controller Experimental Settings
| Task | #Heads | Controller Size | Memory Size | Learning Rate | #Parameters |
|---------------|----------|-------------------|---------------|-----------------|---------------|
| Copy | 1 | 100 | 128 × 20 | 10 - 4 | 17 , 162 |
| Repeat Copy | 1 | 100 | 128 × 20 | 10 - 4 | 16 , 712 |
| Associative | 4 | 256 | 128 × 20 | 10 - 4 | 146 , 845 |
| N-Grams | 1 | 100 | 128 × 20 | 3 × 10 - 5 | 14 , 656 |
| Priority Sort | 8 | 512 | 128 × 20 | 3 × 10 - 5 | 508 , 305 |
the number of hidden units (due to the recurrent connections in the hidden layers). This contrasts with NTM, where the number of parameters does not increase with the number of memory locations. During the training backward pass, all gradient components are clipped elementwise to the range (-10, 10).
## 5 Conclusion
We have introduced the Neural Turing Machine, a neural network architecture that takes inspiration from both models of biological working memory and the design of digital computers. Like conventional neural networks, the architecture is differentiable end-to-end and can be trained with gradient descent. Our experiments demonstrate that it is capable of learning simple algorithms from example data and of using these algorithms to generalise well outside its training regime.
Table 2: NTM with LSTM Controller Experimental Settings
| Task | #Heads | Controller Size | Memory Size | Learning Rate | #Parameters |
|---------------|----------|-------------------|---------------|-----------------|---------------|
| Copy | 1 | 100 | 128 × 20 | 10 - 4 | 67 , 561 |
| Repeat Copy | 1 | 100 | 128 × 20 | 10 - 4 | 66 , 111 |
| Associative | 1 | 100 | 128 × 20 | 10 - 4 | 70 , 330 |
| N-Grams | 1 | 100 | 128 × 20 | 3 × 10 - 5 | 61 , 749 |
| Priority Sort | 5 | 2 × 100 | 128 × 20 | 3 × 10 - 5 | 269 , 038 |
Table 3: LSTM Network Experimental Settings
| Task | Network Size | Learning Rate | #Parameters |
|---------------|----------------|-----------------|---------------|
| Copy | 3 × 256 | 3 × 10 - 5 | 1 , 352 , 969 |
| Repeat Copy | 3 × 512 | 3 × 10 - 5 | 5 , 312 , 007 |
| Associative | 3 × 256 | 10 - 4 | 1 , 344 , 518 |
| N-Grams | 3 × 128 | 10 - 4 | 331 , 905 |
| Priority Sort | 3 × 128 | 3 × 10 - 5 | 384 , 424 |
## 6 Acknowledgments
Many have offered thoughtful insights, but we would especially like to thank Daan Wierstra, Peter Dayan, Ilya Sutskever, Charles Blundell, Joel Veness, Koray Kavukcuoglu, Dharshan Kumaran, Georg Ostrovski, Chris Summerfield, Jeff Dean, Geoffrey Hinton, and Demis Hassabis.
## References
Baddeley, A., Eysenck, M., and Anderson, M. (2009). Memory . Psychology Press.
- Bahdanau, D., Cho, K., and Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. abs/1409.0473.
- Barrouillet, P., Bernardin, S., and Camos, V. (2004). Time constraints and resource sharing in adults' working memory spans. Journal of Experimental Psychology: General , 133(1):83.
- Chomsky, N. (1956). Three models for the description of language. Information Theory, IEEE Transactions on , 2(3):113-124.
- Das, S., Giles, C. L., and Sun, G.-Z. (1992). Learning context-free grammars: Capabilities and limitations of a recurrent neural network with an external stack memory. In Proceedings of The Fourteenth Annual Conference of Cognitive Science Society. Indiana University .
- Dayan, P. (2008). Simple substrates for complex cognition. Frontiers in neuroscience , 2(2):255.
- Eliasmith, C. (2013). How to build a brain: A neural architecture for biological cognition . Oxford University Press.
- Fitch, W., Hauser, M. D., and Chomsky, N. (2005). The evolution of the language faculty: clarifications and implications. Cognition , 97(2):179-210.
- Fodor, J. A. and Pylyshyn, Z. W. (1988). Connectionism and cognitive architecture: A critical analysis. Cognition , 28(1):3-71.
- Frasconi, P., Gori, M., and Sperduti, A. (1998). A general framework for adaptive processing of data structures. Neural Networks, IEEE Transactions on , 9(5):768-786.
- Gallistel, C. R. and King, A. P. (2009). Memory and the computational brain: Why cognitive science will transform neuroscience , volume 3. John Wiley & Sons.
- Goldman-Rakic, P. S. (1995). Cellular basis of working memory. Neuron , 14(3):477-485.
- Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 .
- Graves, A. and Jaitly, N. (2014). Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the 31st International Conference on Machine Learning (ICML-14) , pages 1764-1772.
- Graves, A., Mohamed, A., and Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on , pages 6645-6649. IEEE.
- Hadley, R. F. (2009). The problem of rapid variable creation. Neural computation , 21(2):510-532.
- Hazy, T. E., Frank, M. J., and O'Reilly, R. C. (2006). Banishing the homunculus: making working memory work. Neuroscience , 139(1):105-118.
- Hinton, G. E. (1986). Learning distributed representations of concepts. In Proceedings of the eighth annual conference of the cognitive science society , volume 1, page 12. Amherst, MA.
- Hochreiter, S., Bengio, Y., Frasconi, P., and Schmidhuber, J. (2001a). Gradient flow in recurrent nets: the difficulty of learning long-term dependencies.
- Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural computation , 9(8):1735-1780.
- Hochreiter, S., Younger, A. S., and Conwell, P. R. (2001b). Learning to learn using gradient descent. In Artificial Neural Networks?ICANN 2001 , pages 87-94. Springer.
- Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences , 79(8):25542558.
- Jackendoff, R. and Pinker, S. (2005). The nature of the language faculty and its implications for evolution of language (reply to fitch, hauser, and chomsky). Cognition , 97(2):211225.
- Kanerva, P. (2009). Hyperdimensional computing: An introduction to computing in distributed representation with high-dimensional random vectors. Cognitive Computation , 1(2):139-159.
- Marcus, G. F. (2003). The algebraic mind: Integrating connectionism and cognitive science . MIT press.
- Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychological review , 63(2):81.
- Miller, G. A. (2003). The cognitive revolution: a historical perspective. Trends in cognitive sciences , 7(3):141-144.
- Minsky, M. L. (1967). Computation: finite and infinite machines . Prentice-Hall, Inc.
- Murphy, K. P. (2012). Machine learning: a probabilistic perspective . MIT press.
- Plate, T. A. (2003). Holographic Reduced Representation: Distributed representation for cognitive structures . CSLI.
- Pollack, J. B. (1990). Recursive distributed representations. Artificial Intelligence , 46(1):77-105.
- Rigotti, M., Barak, O., Warden, M. R., Wang, X.-J., Daw, N. D., Miller, E. K., and Fusi, S. (2013). The importance of mixed selectivity in complex cognitive tasks. Nature , 497(7451):585-590.
- Rumelhart, D. E., McClelland, J. L., Group, P. R., et al. (1986). Parallel distributed processing , volume 1. MIT press.
- Seung, H. S. (1998). Continuous attractors and oculomotor control. Neural Networks , 11(7):1253-1258.
- Siegelmann, H. T. and Sontag, E. D. (1995). On the computational power of neural nets. Journal of computer and system sciences , 50(1):132-150.
- Smolensky, P. (1990). Tensor product variable binding and the representation of symbolic structures in connectionist systems. Artificial intelligence , 46(1):159-216.
- Socher, R., Huval, B., Manning, C. D., and Ng, A. Y. (2012). Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning , pages 1201-1211. Association for Computational Linguistics.
- Sutskever, I., Martens, J., and Hinton, G. E. (2011). Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11) , pages 1017-1024.
- Sutskever, I., Vinyals, O., and Le, Q. V . (2014). Sequence to sequence learning with neural networks. arXiv preprint arXiv:1409.3215 .
- Touretzky, D. S. (1990). Boltzcons: Dynamic symbol structures in a connectionist network. Artificial Intelligence , 46(1):5-46.
- Von Neumann, J. (1945). First draft of a report on the edvac.
- Wang, X.-J. (1999). Synaptic basis of cortical persistent activity: the importance of nmda receptors to working memory. The Journal of Neuroscience , 19(21):9587-9603.