## Causal inference via algebraic geometry: feasibility tests for functional causal structures with two binary observed variables
## Ciar´ an M. Lee ∗
Department of Computer Science, University of Oxford, Oxford, UK OX1 3QD
## Abstract
We provide a scheme for inferring causal relations from uncontrolled statistical data based on tools from computational algebraic geometry, in particular, the computation of Groebner bases. We focus on causal structures containing just two observed variables, each of which is binary. We consider the consequences of imposing different restrictions on the number and cardinality of latent variables and of assuming different functional dependences of the observed variables on the latent ones (in particular, the noise need not be additive). We provide an inductive scheme for classifying functional causal structures into distinct observational equivalence classes. For each observational equivalence class, we provide a procedure for deriving constraints on the joint distribution that are necessary and sufficient conditions for it to arise from a model in that class. We also demonstrate how this sort of approach provides a means of determining which causal parameters are identifiable and how to solve for these. Prospects for expanding the scope of our scheme, in particular to the problem of quantum causal inference, are also discussed.
## 1 Introduction
Causal relationships, unlike statistical dependences, support inferences about the effects of interventions and the truths of counterfactuals. While a randomised controlled experiment can be used to determine causal relationships, these may not be available for various reasons: they could be restrictively expensive, technologically infeasible, unethical (e.g., assessing the effect of smoking on lung cancer), or indeed physically impossible (e.g., for variables describing properties of distant astronomical bodies). Therefore, inferring causal relationships from uncontrolled statistical data is an important problem, with broad applicability across scientific disciplines. Over the past-twenty
∗ Electronic address: ciaran.lee@cs.ox.ac.uk.
† Electronic address: rspekkens@perimeterinstitute.ca.
## Robert W. Spekkens †
Perimeter Institute for Theoretical Physics, Waterloo, Ontario, Canada N2L 2Y5
five years, there has been much progress in developing methods to solve this problem [1, 2, 3, 4, 5].
As has become standard practice, we formalize the notion of causal structure using directed acyclic graphs (DAGs) with random variables as nodes and arrows representing direct causal influence [1, 2]. A more refined description of causal dependences specifies not only what causes what, but also, for every variable, its functional dependence on its causal parents. We shall use the term functional causal structure to refer to the specification of the set of functions, which includes a specification of the DAG. As is standard, the variables that are not observed are termed latent , and the DAG does not include any latent variables that act as causal mediaries, so that all the latent variables are parentless. We shall use the term causal model to describe the functional causal structure together with a specification, for each latent variable, of a probability distribution over its values. Each causal model associated to a given functional causal structure defines a possible joint probability distribution over the observed variables. We are interested in the set of possible joint distributions over the observed variables for a given functional causal structure, that is, those that can arise from some set of distributions on the latent variables. We will say that two functional causal structures are observationally equivalent if they are characterized by the same set of distributions over the observed variables. 1
Many causal inference algorithms, such as those of [1] and [2], only make use of conditional independence relations among the observed variables. If two causal structures are such that the same set of conditional independence relations are faithful to them, then they are said to be Markov equivalent. Note that Markov equivalence can be decided purely on the basis of the DAG (i.e., the causal structure), while the notion of observational equivalence of interest here depends on the functional dependences (i.e., the functional causal structure ). In the case of just two observed variables, which is the one we consider here, the set of all causal structures are partitioned into just two Markov equivalence classes: those wherein the variables are causally connected, and those wherein they are not. As we show, however, the joint distribution over the observed variables supports many more inferences about the
1 This should not be confused with the notion of observational equivalence as applied to DAGs [1].
functional causal structure, thereby providing a more finegrained classification than is provided by Markov equivalence.
In recent years, several methods have been suggested that make use not only of conditional independences, but also other properties of the joint statistical distribution between the observed variables [3, 4, 5, 6] (See also the works discussed in Secs. 6.2 and 6.3). These newer methods also have limitations in the sense that they impose restrictions on the number of latent variables allowed in the underlying causal model and also on the mechanisms by which these latent variables influence the observed ones.
In the present work, we restrict attention to the causal inference problem where there are just two observed variables, each of which is binary (that is, discrete with just two possible values). We allow any functional causal structure involving latent variables that are discrete (with a finite number of values), and we impose no restriction on the number of latent variables or the mechanisms by which these influence the observed ones.
We provide an inductive scheme for characterizing the observational equivalence classes of functional causal structures. This scheme has a few steps. First we show that, in each observational class, there is a functional causal structure wherein all of the latent variables are binary. Restricting ourselves to the latter sort of functional causal structure, we show that one can inductively build up any functional causal structure from a pair of others having fewer latent variables. Thus, starting with functional causal structures with no latent variables, we can recursively build up all functional causal structures, and therefore all observational equivalence classes of these, by applying our inductive scheme.
Using this scheme, we catalogue all observational equivalence classes generated by functional causal structures with four or fewer binary latent variables. We have evidence, but no proof yet, that our catalogue is complete in the sense that a functional causal structure with any number of binary latent variables-and hence, by the connection described above, any functional causal structure with discrete latent variables-belongs to one of the classes we have identified.
We also describe a procedure for deriving, for each class, the set of necessary and sufficient conditions on the joint distribution over observed variables for it to be possible to generate it from functional causal structures in this class. We call such a set of conditions a feasibility test for the class. The procedure for deriving these is as follows. We start with a particular functional causal structure within the class, express the parameters in the joint probability distribution over the observed variables in terms of the parameters in the probability distributions over the latent variables, then eliminate the latter using techniques from algebraic geometry.
Finally, we consider applications to the problem of identifying causal parameters. For the parameters describing the probability distributions over the latent variables, we note that our technique allows one to find expressions for these
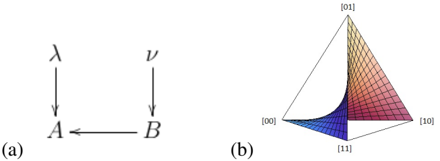
Fig. 1: (a) DAG for causal model defined by A = B ⊕ λ and B = ν (b) Joint distributions that can be generated by this causal model.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Representation of a Phase Diagram
### Overview
The image presents two diagrams, labeled (a) and (b). Diagram (a) is a 2D representation with labeled axes, while diagram (b) is a 3D surface plot. Both appear to relate to a phase diagram, likely in materials science or physics. The diagrams are positioned side-by-side, with (a) on the left and (b) on the right.
### Components/Axes
**Diagram (a):**
* **Axes:**
* Vertical axis labeled "λ" (lambda).
* Horizontal axis labeled "ν" (nu).
* **Points:** Two points are labeled "A" and "B".
* **Arrows:** Arrows indicate the direction of increasing values along each axis.
**Diagram (b):**
* **Axes:** The axes are represented by the corners of the triangular base of the plot.
* One corner is labeled "[00]".
* Another corner is labeled "[01]".
* The final corner is labeled "[10]".
* The third dimension (height) is not explicitly labeled, but represents a value dependent on the two base axes.
* **Surface:** A colored surface plot is displayed, with color gradients indicating varying values.
### Detailed Analysis or Content Details
**Diagram (a):**
This diagram is a simple 2D coordinate system. The points A and B are positioned within this space. The axes λ and ν likely represent parameters defining a system's state. Without further context, the specific meaning of these parameters is unknown.
**Diagram (b):**
The 3D plot shows a surface that appears to be a minimum. The surface is colored with a gradient, transitioning from blue at the lower values to red at the higher values. The plot is bounded by a triangle with vertices at [00], [01], and [10]. The surface is lowest near the center of the triangle and rises towards the edges. The color gradient suggests a continuous variation in the value represented by the height of the surface.
### Key Observations
* Diagram (a) provides a basic coordinate system, while diagram (b) visualizes a function of two variables.
* The surface in diagram (b) has a minimum, suggesting a stable state or optimal condition.
* The axes in diagram (b) are labeled with bracketed numbers, which could represent composition or other material properties.
* The color gradient in diagram (b) is consistent, with blue representing lower values and red representing higher values.
### Interpretation
These diagrams likely represent a phase diagram or a potential energy surface. Diagram (a) could be a simplified representation of the parameters influencing the system, while diagram (b) shows the resulting behavior. The minimum in diagram (b) could correspond to the most stable phase or configuration of the system. The axes [00], [01], and [10] likely represent the composition of different components in a mixture. The color gradient indicates the energy or stability of different compositions.
Without additional context, it is difficult to determine the specific system being represented. However, the diagrams suggest a relationship between parameters λ and ν (in diagram a) and the composition of a material (in diagram b), and how these factors influence the system's stability. The diagrams are likely used to predict the behavior of the system under different conditions.
</details>
in terms of the observational data for each observational equivalence classes that we have considered. For the parameters describing the functional relations, we note that the limits to what one can infer about these, which may be different for different points in the space of possible joint distributions over the observed variables, can be inferred from our feasibility tests.
## 2 Setting up the problem
Consider the causal model of Fig.1(a). From the DAG, it is clear that B is a cause of A , while λ is noise local to A and ν is noise local to B . The functional dependences are given by A = B ⊕ λ and B = ν . Amodel with this sort of functional dependence is referred to as an additive noise model (ANM) in Refs. [3, 4, 5, 6]. The values of A , for different values of B and λ , are given in the table below.
| ν | λ | B | A = B ⊕ λ |
|-----|-----|-----|-------------|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 |
In Ref. [5], it was shown that one can distinguish between the causal model of Fig.1(a) and the causal models depicted in Fig. 2(a) and Fig. 2(c), except for special cases of the distributions over the noise variables, such as, for instance, when λ and ν are uniformly distributed. Thus if we are promised that the causal model is an ANM, then (except for the special cases) we can distinguish between B causing A , A causing B and A and B being causally disconnected. To see how this works we will need to determine the correlations generated by this model.
To describe the correlations we adopt the following notational convention.
<!-- formula-not-decoded -->
Let q 1 be the probability that ν = 0 and q 2 be the probability that λ = 0 , then the correlations for the above causal model are
<!-- formula-not-decoded -->
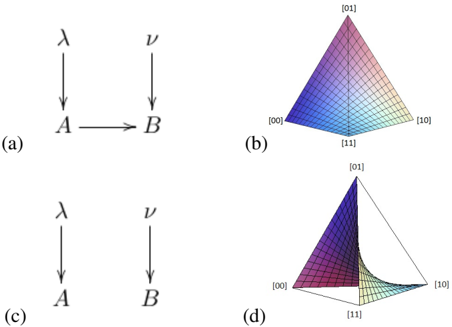
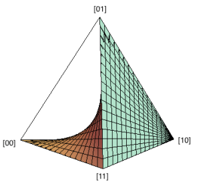
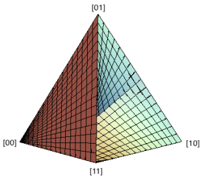
Fig. 2: (a) DAG for causal model defined by A = λ and B = A ⊕ ν . (b) Joint distributions that can be generated by the model of (a). Note that this is a head-on view of a fan shape of the same type as is depicted in (d). (c) DAG for causal model defined by A = λ and B = ν . (d) Joint distributions that can be generated by the model of (c).
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Quantum State Transitions and Bloch Sphere Representations
### Overview
The image presents four diagrams illustrating concepts related to quantum mechanics, specifically focusing on state transitions and their representation on the Bloch sphere. Diagrams (a) and (c) depict state transitions between two levels, labeled A and B, influenced by external factors represented by λ and ν. Diagrams (b) and (d) show 3D representations resembling Bloch spheres, with coordinate labels indicating specific quantum states.
### Components/Axes
* **Diagram (a) & (c):**
* Labels: λ, ν, A, B
* Arrows: Downward arrows labeled λ and ν, and a horizontal arrow from A to B.
* **Diagram (b) & (d):**
* Coordinate Labels: [00], [01], [10], [11] are labeled on the vertices of the triangular shape.
* Surface: A 3D surface with color gradients.
### Detailed Analysis or Content Details
* **Diagram (a):** Shows a transition from state A to state B. A downward arrow labeled "λ" points towards A, and another downward arrow labeled "ν" points towards B. An arrow connects A to B, indicating a transition.
* **Diagram (c):** Similar to (a), shows a transition from state A to state B. A downward arrow labeled "λ" points towards A, and another downward arrow labeled "ν" points towards B. An arrow connects A to B, indicating a transition.
* **Diagram (b):** Displays a triangular surface with coordinate labels at the vertices: [00], [01], [10], and [11]. The surface exhibits a color gradient, transitioning from red to blue. The shape resembles a Bloch sphere representation.
* **Diagram (d):** Similar to (b), displays a triangular surface with coordinate labels at the vertices: [00], [01], [10], and [11]. The surface exhibits a color gradient, transitioning from red to blue. The shape resembles a Bloch sphere representation.
### Key Observations
* Diagrams (a) and (c) are structurally identical, suggesting they represent the same physical process or scenario.
* Diagrams (b) and (d) are also structurally identical, representing the same Bloch sphere configuration.
* The coordinate labels [00], [01], [10], and [11] likely represent the basis states of a two-qubit system.
* The color gradients in (b) and (d) likely represent the probability amplitude or some other quantum property associated with each state.
### Interpretation
The diagrams likely illustrate the effect of external influences (λ and ν) on the transition between two quantum states (A and B). Diagrams (b) and (d) provide a visual representation of the resulting quantum state on the Bloch sphere. The coordinate labels indicate the basis states, and the color gradients represent the probability amplitudes or other quantum properties.
The similarity between (a) and (c), and (b) and (d) suggests that the diagrams are presenting different perspectives of the same underlying quantum phenomenon. The diagrams could be used to explain concepts such as quantum state manipulation, decoherence, or entanglement.
The diagrams do not provide specific numerical data, but rather a qualitative representation of quantum processes. The absence of numerical values limits the extent to which detailed quantitative analysis can be performed. However, the diagrams are valuable for visualizing and understanding the fundamental principles of quantum mechanics.
</details>
This means P ( A = 0 , B = 0) = q 1 q 2 , P ( A = 0 , B = 1) = (1 -q 1 )(1 -q 2 ) and so on. From now on, we will use the shorthand q i ≡ 1 -q i to simplify expressions.
Note that if a latent variable were to take one of its values with probability 1, then it would be trivial and could be eliminated from the functional causal structure. We therefore consider only functional causal structures with nontrivial latent variables, that is, latent variables that have some statistical variation in their value, so that the probability of any value is bounded away from 0 and 1. In the present example, therefore, 0 < q 1 , q 2 < 1 .
For a general causal model we have P ( A,B ) = p 00 [00] + p 01 [01]+ p 10 [10]+ p 11 [11] , where P ( A = i, B = j ) = p ij . We note that p 00 + p 01 + p 10 + p 11 = 1 . As we only need three real parameters to specify P ( A,B ) , we can plot it in R 3 . It is easy to see that the points { P ( A = i, B = j ) = 1 : i, j ∈ Z 2 } form the vertices of a tetrahedron in R 3 and so the plot of P ( A,B ) must lie within this tetrahedron.
We can rewrite P ( A,B ) for our current example as
<!-- formula-not-decoded -->
So, if we fix the value of q 2 in the range (0 , 1) and vary q 1 over the interval (0 , 1) , the plot of P ( A,B ) consists of the line passing through a point on the edge of the tetrahedron containing the vertices { [00] , [10] } and a point on the edge containing the vertices { [11] , [01] } (but excluding these points). The full plot of P ( A,B ) , as q 1 and q 2 each range over the interval (0 , 1) , is depicted in Fig. 1(b) (where the boundary points are excluded). We refer to this shape as a fan . Fig. 2(b) and Fig. 2(d) depict the set of joint distributions for the ANM where A causes B and the causal structure where A and B are causally disconnected.
Given some joint distribution, P ( A,B ) , how do we determine if it lies on one of the fans of Fig. 1(b), Fig. 2(b) or Fig. 2(d)? Recall that, because the latent variables are un- observed, we do not have access to the q i 's directly, only the observed p ij 's. Thus, the problem can be posed as follows: what are the defining equations of the fans in terms of the observed p ij 's?
This problem was solved for the example of Fig. 1 in Ref. [5] using the following technique. First, it was noted that the DAG implies that λ is marginally independent of B , and therefore P ( λ | B = 0) = P ( λ | B = 1) . Given that λ is a binary variable, this is true if and only if P ( λ = 1 | B = 0) = P ( λ = 1 | B = 1) . We wish to eliminate λ from this condition. Recall from the definition of conditional probability that P ( λ = 1 | B = b ) = P ( λ = 1 , B = b ) / P ( B = b ) . The functional dependence A = B ⊕ λ can be used to conclude that P ( λ = 1 , B = b ) = P ( A = b ⊕ 1 , B = b ) . Note that this last step is only possible because the noise is additive, so that one can infer λ from A and B . Therefore, reverting to our notational conventions, where P ( A = 1 ⊕ b, B = b ) = p 1 ⊕ b,b and P ( B = b ) = p 0 ,b + p 1 ,b , the condition becomes
<!-- formula-not-decoded -->
which can be rewritten as:
<!-- formula-not-decoded -->
This equation, together with the open-interval constraints ,
<!-- formula-not-decoded -->
defines the fan in Fig. 1(b). Using similar techniques, one can show that Figs. 2(b) and 2(d) are defined by equation
<!-- formula-not-decoded -->
respectively
<!-- formula-not-decoded -->
together with the open-interval constraint.
The question is: how can one find feasibility tests for generic causal models? In particular, how does one treat models where the noise is not additive? Consider, for instance, the causal model that has the same DAG as in Fig. 1(a), but where the noise is multiplicative, that is, A = Bλ . In this case, the value of λ cannot be inferred from A and B (given that these could be zero), and consequently one cannot use the approach of Ref. [5]. It is also unclear how one can characterize the possibilities for the joint distribution when the causal model involves an arbitrary number of latent variables. We will show that these questions can be answered using powerful tools from algebraic geometry, which we describe in the next section.
## 3 Deriving the feasibility tests
We begin with an introduction to some of the main concepts of algebraic geometry following the presentation given in [7]. For a more detailed discussion, see appendix A.
Denote the set of all polynomials in variables x 1 , . . . , x n with coefficients in some field k by k [ x 1 , . . . , x n ] . When dealing with polynomials, we are mainly interested in the solution set of systems of polynomial equations. This leads us to the main geometrical objects studied in algebraic geometry, algebraic varieties and semi-algebraic sets.
An algebraic variety 2 V ( f 1 , . . . , f s ) ⊂ k n is the solution set of the system of polynomial equations f 1 ( x 1 , . . . , x n ) = · · · = f s ( x 1 , . . . , x n ) = 0 . A basic semi-algebraic set is defined to be the solution set of a system of polynomial equalities and inequalities, that is, { x ∈ R n : g i ( x ) 0 , ∀ i = 1 , . . . , m } , where g 1 , . . . , g n ∈ R [ x 1 , . . . , x n ] are polynomials ove the reals 3 and where corresponds to either ≥ , = , or ≤ . Note that algebraic varieties are examples of basic semi-algebraic sets. A semi-algebraic set is formed by taking finite combinations of unions, intersections, or complements of basic semi-algebraic sets. For instance, the fan in Fig.1(b) is the semi-algebraic set that results from the intersection of the algebraic variety defined by the single polynomial equation p 00 p 01 -p 11 p 10 = 0 and the set of inequalities that define the interior of the tetrahedral probability simplex (requiring each probability to be in the interval (0 , 1) ).
More generally, for any causal model, the set of possible joint distributions that can be generated by it are represented by a semi-algebraic set. It follows that two causal models are observationally equivalent if and only if they generate the same semi-algebraic set.
We now define ideals , the main algebraic object studied in algebraic geometry. A subset I ⊂ k [ x 1 , . . . , x n ] is an ideal if it satisfies: (1) 0 ∈ I , (2) If f, g ∈ I , then f + g ∈ I , and (3) If f ∈ I and h ∈ k [ x 1 , . . . , x n ] , then hf ∈ I .
A natural example of an ideal is the ideal generated by a finite number of polynomials, defined as follows. Let f 1 , . . . , f s be polynomials in k [ x 1 , . . . , x n ] , then the ideal generated by f 1 , . . . , f s is:
<!-- formula-not-decoded -->
The polynomials f 1 , . . . , f s are called the basis of the ideal.
Studying the relations between certain ideals and varieties forms one of the main areas of study in algebraic geometry. One can even define the algebraic variety V ( I ) defined by the ideal I ⊂ k [ x 1 , . . . , x n ] , where
<!-- formula-not-decoded -->
Interestingly, it can also be shown that if I = 〈 f 1 , . . . , f s 〉 , then V ( I ) = V ( f 1 , . . . , f s ) , which is to say that the variety defined by a set of polynomials is the same as the variety defined by the ideal generated by those polynomials. Hence, varieties are determined by ideals .
We can now use the language of algebraic geometry to restate the question asked at the end of the last section. Let
2 Also called an affine variety or an algebraic set .
3 Note that one can replace the real field R used in the last definition with any ordered field.
V ⊆ k n be an algebraic variety given parametrically as
<!-- formula-not-decoded -->
where the g i are polynomials in q 1 , . . . , q m . The conjunction of the above equalities with the inequalities ensuring that the variables q 1 , . . . , q m are in the interval (0 , 1) (probabilities bounded away from 0 and 1) defines a semialgebraic set on p 1 , . . . , p n , q 1 , . . . , q m . We seek to infer which values of p 1 , . . . , p n are possible for some values of the q 1 , . . . , q m in their allowed intervals. By the TarskiSeidenberg theorem [8], the solution to this problem is also a semi-algebraic set. We determine the latter as follows. First, we eliminate the variables q 1 , . . . , q m to find a system of polynomial equations in p 1 , . . . , p n ,. These define the smallest algebraic variety on p 1 , . . . , p n , q 1 , . . . , q m that contains the semi-algebraic set that we seek to characterize. This problem is known as implicitization . The second step is to determine which points in this algebraic variety can be extended to a solution of the equalities and inequalities of the original parametric characterization.
For example, consider the algebraic variety that is defined parametrically by the polynomial equations
<!-- formula-not-decoded -->
We would like to characterize the semi-algebraic set that this variety defines on the observed variables p 00 , p 01 , p 10 , p 11 alone when one eliminates the parameters q 1 and q 2 while enforcing that they are probabilities in (0 , 1) . In Sec. 2, it was shown how one can do so, and that the resulting semi-algebraic set is the one depicted in Fig.1(b). However, the technique was not generalizable to arbitrary functional causal structures. Here, we reconsider this example using techniques that are generally applicable.
The problem can be solved by employing a specific choice of basis for the ideal generated by the system of polynomial equations that define the variety (3.0.1). The basis that achieves this feat is known as the Groebner basis .
Groebner bases simplify many calculations in algebraic geometry and they have many interesting properties [7]. There are efficient algorithms for calculating Groebner bases and many software packages that one can use to implement them.
We discovered in this section that the fan of Fig. 1(b) is in fact the intersection of the algebraic variety defined by the ideal
<!-- formula-not-decoded -->
with the tetrahedron.The Groebner basis 4 of this ideal is
4 with respect to the lex order q 1 > q 2 > p 00 > p 10 > p 01 > p 11 , see appendix A
found to be
<!-- formula-not-decoded -->
Solutions to g 1 = · · · = g 4 = 0 provide solutions to
<!-- formula-not-decoded -->
which define our algebraic variety. Looking more closely at the Groebner basis we note that the variables q 1 , q 2 have been eliminated from the polynomials g 3 and g 4 . The solution of g 3 = p 00 + p 01 + p 10 + p 11 -1 = 0 is exactly the normalisation condition. The solution of g 4 = 0 gives us the following
<!-- formula-not-decoded -->
which, using the normalization condition, then gives us
<!-- formula-not-decoded -->
Ondemanding 0 < p 00 , p 01 , p 10 , p 11 < 1 and p ij ∈ R , ∀ ij (i.e. on taking the intersection of this algebraic variety with the tetrahedron), we obtain the semi-algebraic set corresponding to the fan of Fig.1(b), which we derived in section 2. This is a special case of a general result, known as the elimination theorem , which provides us with a way of using Groebner bases to systematically eliminate certain variables from a system of polynomial equations and, thus, to solve the implicitization problem.
The general procedure for finding the semi-algebraic set is as follows. First, given the system of polynomial equations defining the implicitization problem, as in Eq. (3.0.1), form the ideal generated by these polynomials and compute 5 its Groebner basis. The elements of this basis that do not contain the variables q 1 , . . . , q m constitute constraints on the variables p 1 , . . . , p n alone. These constraints consitute polynomial equalities, and therefore define an algebraic variety on the variables p 1 , . . . , p n . Second, we determine which points on this variety correspond to solutions of the original equalities and inequalities on q 1 , . . . , q n and p 1 , . . . , p m . This will result in inequality constraints. The equality constraints from the first step and the inequality constraints from the second step together characterize the semi-algebraic set on p 1 , . . . , p n that is compatible with the given functional causal structure. We note that one trivial consequence of the fact that each of the q 1 , . . . , q m is in the interval (0 , 1) is that each of the p 1 , . . . , p n is in the interval (0 , 1) . As such, the semialgebraic set we seek to characterize is always a subset of the geometric intersection of the algebraic variety we find in the first step and the probability simplex on p 1 , . . . , p n . Note, however, that it is generically a strict subset of this intersection.
These inequality constraints manifest themselves in different ways. We present an example of one such manifestation below and leave the remaining examples to appendix B.
5 with respect to the lexicographic order q 1 > q 2 > · · · > q m > p 1 > · · · > p n .
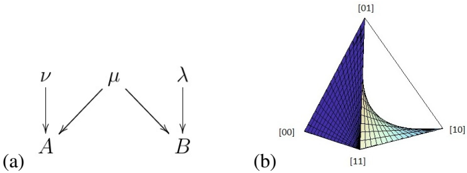
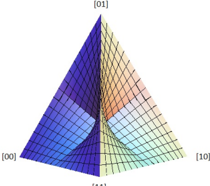
Fig. 3: (a) A = µν and B = µλ . (b) p 00 p 11 ≥ p 01 p 10 .
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Representation of a Parameter Space
### Overview
The image presents two diagrams, labeled (a) and (b). Diagram (a) is a directed graph illustrating relationships between parameters, while diagram (b) is a 3D representation of a parameter space, likely related to the relationships shown in (a). The diagrams appear to be related to a mathematical or physics context, potentially concerning decay processes or branching ratios.
### Components/Axes
**Diagram (a):**
* Nodes: A, B
* Edges:
* ν → A
* μ → A
* λ → B
* Labels: ν, μ, λ, A, B
**Diagram (b):**
* Axes: The diagram is a 3D representation, but the axes are not explicitly labeled. The coordinates are indicated by the markings [00], [01], [10], and [11] along the edges of the triangular prism.
* Surface: A curved surface is depicted within a triangular prism.
* Coloring: The surface is colored with a gradient, transitioning from dark blue to light green.
### Detailed Analysis or Content Details
**Diagram (a):**
This diagram shows a directed graph. The parameters ν (nu), μ (mu), and λ (lambda) all point to node A. Parameter λ also points to node B. This suggests that A is influenced by ν, μ, and λ, while B is influenced by λ. The diagram does not provide any quantitative information.
**Diagram (b):**
The diagram shows a 3D space defined by the coordinates [00], [01], [10], and [11]. The curved surface within the triangular prism suggests a relationship between these coordinates. The color gradient indicates a variation in some property across the surface, with darker blue representing lower values and lighter green representing higher values. The surface appears to be concave, with the lowest values concentrated near the [11] coordinate. The shape suggests a constraint or boundary within the parameter space.
### Key Observations
* Diagram (a) provides a qualitative representation of relationships between parameters.
* Diagram (b) visualizes a parameter space with a curved surface, potentially representing a constraint or optimization problem.
* The coordinates [00], [01], [10], and [11] likely represent binary combinations of two underlying parameters.
* The color gradient in diagram (b) suggests a continuous variation in some property within the parameter space.
### Interpretation
The diagrams likely represent a system with three input parameters (ν, μ, λ) that influence two output variables (A, B). Diagram (a) shows the dependencies, while diagram (b) visualizes the possible values of the system within a defined parameter space. The curved surface in diagram (b) could represent a constraint on the system, or a region of optimal performance. The color gradient suggests that certain combinations of parameters lead to more favorable outcomes.
The use of [00], [01], [10], and [11] suggests a binary representation of two parameters, potentially representing probabilities or fractions. The overall system could be related to particle physics, where decay channels are governed by branching ratios and constraints. The parameters ν, μ, and λ could represent coupling constants or decay rates.
Without further context, it is difficult to determine the exact meaning of the diagrams. However, they provide a visual representation of a complex system with interconnected parameters and constraints.
</details>
Consider the causal model of Fig. 3(a). Defining q 1 , q 2 and q 3 to be the probabilities for µ = 0 , ν = 0 and λ = 0 respectively, the joint distribution generated by this model is
<!-- formula-not-decoded -->
We begin by providing an intuitive account of the semialgebraic set describing such joint distributions. Note first that P ( A,B ) can be rewritten as
<!-- formula-not-decoded -->
implying that it is the convex combination, with weight q 1 , of the point distribution [00] , and with weight q 1 , of the distribution arising from the functional causal structure of Fig. 2(c), shown above to be characterized by the equality p 00 p 11 = p 10 p 01 . It follows that the semi-algebraic set defined by P ( A,B ) contains all interior points on any line extending from the vertex [00] to a point on the fan depicted in Fig. 2(d); this variety is depicted in Fig. 3(b).
Reading off the expressions for p 00 , p 01 , p 10 , and p 11 from Eq. (3.0.2), we obtain the set of polynomials that define the full algebraic variety. The ideal generated by these is:
<!-- formula-not-decoded -->
To implement the first step of the general procedure outlined above, we derive the Groebner basis for this ideal 6 :
<!-- formula-not-decoded -->
Now g 5 = 0 is just the normalisation condition and g 6 = 0 gives the following:
<!-- formula-not-decoded -->
6 with respect to the lex order q 1 > q 2 > q 3 > p 00 > p 01 > p 10 > p 11
which, using the normalisation condition, results in
<!-- formula-not-decoded -->
To implement the second step of our procedure, we begin by enforcing q 1 > 0 . This results in the following inequality
<!-- formula-not-decoded -->
None of the remaining constraints 0 < q i < 1 , for i ∈ { 2 , 3 } result in nontrivial relations among the p ij 's, so the latter inequality is the only nontrivial constraint. Together with the open-interval constraints 0 < p 00 , p 01 , p 10 , p 11 < 1 , it describes the necessary and sufficient conditions for the distribution on observed variables to be compatible with the functional causal structure of Fig. 3(a). These conditions define the semi-algebraic set depicted in Fig. 3(b).
## 4 Characterizing the observational equivalence classes
In this section, we will provide a scheme for inductively characterizing all observational equivalence classes. As noted in the introduction, we consider only causal models where there is a pair of binary observed variables, which we denote by A and B .
## 4.1 Sufficiency of considering purely common-cause models
A causal model having no directed causal influences between the observed variables will be termed purely common-cause .
Lemma 4.1.1. Every causal model wherein there is a directed causal influence between A and B (either A → B or B → A ) is observationally equivalent to one that is purely common-cause.
The proof is as follows. Suppose that there is a directed causal influence B → A . If the collection of all latent variables is denoted by λ , then a general causal model can be specified by the functional dependences B = f ( λ ) and A = g ( λ, B ) for some functions f and g . But this is observationally equivalent to the causal model that is purely common-cause with functional dependences B = f ( λ ) and A = g ′ ( λ ) where g ′ ( λ ) ≡ g ( λ, f ( λ )) . In characterizing the distinct observational equivalence classes, therefore, it suffices for us to consider the models that are purely common-cause, and therefore we restrict our attention to these henceforth.
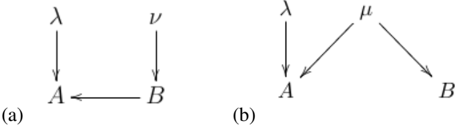
An explicit example serves to illustrate this equivalence. The causal model depicted in Fig. 4(a), with functional dependences A = λ ⊕ B and B = ν , involving a directed causal influence from B to A , is observationally equivalent to the causal model depicted in Fig. 4(b), with functional dependences A = λ ⊕ µ and B = µ , which is purely common-cause. To see this, note that one can express the functional dependences of the first causal model
Fig. 4: (a) DAG for causal model defined by A = λ ⊕ B and B = ν (b) DAG for causal model defined by A = λ ⊕ µ and B = µ .
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Decay Schemes
### Overview
The image presents two diagrams, labeled (a) and (b), illustrating decay schemes. Both diagrams depict transitions between energy levels or particles, represented by letters and arrows. The diagrams appear to represent nuclear or particle physics decay processes.
### Components/Axes
The diagrams consist of the following components:
* **Labels:** λ (lambda), ν (nu), μ (mu), A, B.
* **Arrows:** Represent transitions or decays. The arrows indicate the direction of the decay process.
* **Diagram (a):** Shows a sequential decay where λ decays to A, ν decays to A, and A decays to B.
* **Diagram (b):** Shows a branching decay where λ decays to A, μ decays to B, and both A and B are reached from a common starting point.
### Detailed Analysis or Content Details
**Diagram (a):**
* λ decays to A.
* ν decays to A.
* A decays to B.
* The arrow between A and B is bidirectional, suggesting a reversible process or an equilibrium.
**Diagram (b):**
* λ decays to A.
* μ decays to B.
* A and B are terminal states.
* The arrows from λ to A and μ to B indicate direct decays.
### Key Observations
* Diagram (a) represents a cascade decay, where one particle decays into another, which then decays further.
* Diagram (b) represents a branching decay, where a particle can decay into one of two possible states.
* The symbols λ, ν, and μ likely represent different decay modes or particles involved in the decay process.
* A and B likely represent different energy levels or final states.
### Interpretation
These diagrams illustrate fundamental concepts in decay processes, commonly encountered in nuclear physics and particle physics. Diagram (a) shows a sequential decay, where a particle undergoes multiple decay steps. Diagram (b) shows a branching decay, where a particle has multiple possible decay pathways. The use of Greek letters (λ, ν, μ) suggests these represent specific decay constants or particles. The letters A and B likely represent different states or isotopes. The diagrams are simplified representations of complex physical processes, focusing on the transitions between states rather than the details of the decay mechanisms. The bidirectional arrow in diagram (a) could indicate an equilibrium between A and B, or a reversible process. Without further context, it is difficult to determine the specific physical system being represented.
</details>
as A = g ( λ, ν, B ) = λ ⊕ B and B = f ( λ, ν ) = ν. Performing the substitution described in the previous paragraph yields A = g ( λ, ν, f ( λ, ν )) = g ′ ( λ, ν ) = λ ⊕ ν , which on identifying ν with µ , results in the second causal model.
## 4.2 Sufficiency of considering models with binary latents
We call a causal model where all the latent variables are binary a causal model with binary latents . If there are n binary latent variables, it is called an n -latent-bit causal model .
Theorem 4.2.1. Consider the family of causal models where the latent variables are discrete and finite, but not necessarily binary. Every such model is observationally equivalent to one with binary latents. Equivalently, there is a causal model with binary latents in each observational equivalence class.
The proof is provided in appendix C, but we now present a simple example which illustrates the main idea of the proof.
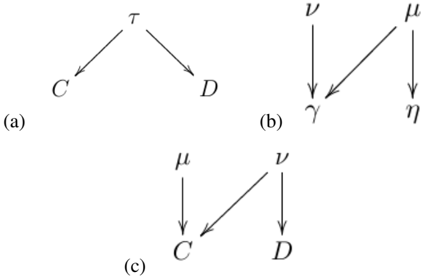
Consider the causal model of Fig. 5(a), where C, D are binary, but τ is a three-valued variable, i.e., a trit. Suppose the functional relationships are as follows: C = τ mod 2 and D = ( 2( τ ⊕ 3 1) ) mod 2 , where ⊕ k means addition modulo k . The values of C, D for different values of τ are given in the table below.
| τ | C | D |
|-----|-----|-----|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 0 | 1 |
One can see that the distributions over C, D that can be generated by this model correspond to the face of the tetrahedron that contains the vertices { [00] , [11] , [01] } .
The trick to simulating this model using a 2 -latent-bit model is to replace the latent three-valued variable τ with a pair of binary variables γ and η and to imagine that these are causally related in the manner depicted in Fig. 5(b). That is, we imagine a latent bit ν acting locally on γ and a latent bit µ acting as a common cause of γ and η with the functional dependence γ = µν and η = µ . This causal model can generate any distribution over γ and η that has support only on the values ( γ, η ) ∈ { (0 , 1) , (0 , 0) , (1 , 1) } , as can be seen by consulting the row containing class
Fig. 5: Example of how to reduce a causal model with a latent trit to one involving only latent bits. (a) The original causal model, with functional dependences C = τ mod 2 , and D = ( 2( τ ⊕ 3 1) ) mod 2 . (b) the trit τ is replaced by two bits, γ and η , which are presumed to be determined by a causal model having the depicted causal structure with functional dependences γ = µν , and η = µ . (c) The causal model with binary latents that simulates the original model; the functional dependences are C = νµ ⊕ 2 ν , and D = ν .
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Diagram: Causal Diagrams
### Overview
The image presents three directed acyclic graphs (DAGs), labeled (a), (b), and (c). These diagrams represent causal relationships between variables. Each diagram consists of nodes representing variables and arrows indicating the direction of causal influence.
### Components/Axes
The variables represented in the diagrams are:
* τ (Tau)
* C
* D
* ν (Nu)
* μ (Mu)
* γ (Gamma)
* η (Eta)
The diagrams themselves do not have axes in the traditional sense of a chart or graph. They are composed of nodes and directed edges.
### Detailed Analysis or Content Details
**(a)**
This diagram shows a root node labeled 'τ' with arrows pointing to nodes 'C' and 'D'. This indicates that τ is a cause of both C and D.
**(b)**
This diagram shows a chain of causal relationships. 'ν' points to 'γ', which in turn points to 'μ', and 'μ' points to 'η'. This suggests a causal pathway: ν → γ → μ → η.
**(c)**
This diagram shows 'μ' pointing to 'C' and 'ν' pointing to 'D'. Additionally, there is an arrow from 'C' to 'D', indicating that C is a cause of D.
### Key Observations
The diagrams are simple causal models. Diagram (a) represents a common cause scenario. Diagram (b) represents a chain of causation. Diagram (c) represents a more complex relationship with potential confounding or mediation effects.
### Interpretation
These diagrams are likely used to illustrate causal inference concepts. They are tools for representing assumptions about the relationships between variables in a statistical model.
* **Diagram (a)** illustrates a situation where a common cause (τ) influences two variables (C and D). This is important in understanding spurious correlations.
* **Diagram (b)** shows a simple causal chain. Understanding the direction of causality is crucial for interventions and predictions.
* **Diagram (c)** is more complex and suggests that the relationship between ν and D might be mediated by C, or that C and D are causally related.
The diagrams are abstract representations and do not contain numerical data. They are conceptual tools for reasoning about causality. The use of Greek letters suggests a mathematical or theoretical context. The diagrams are likely part of a larger discussion on causal modeling, statistical inference, or related fields.
</details>
(2 , 1 , b ) Id from the 3 -page table appearing later in this paper, where A and B play the role of γ and η .
If we take γ and η to be related to τ by τ = ( γ mod 3) ⊕ 3 ( η mod 3) , so that the values (0 , 0) , (0 , 1) and (1 , 1) of ( γ, η ) map respectively to the values 0 , 1 and 2 of τ , then any distribution over τ can be emulated by some distribution over the values (0 , 0) , (0 , 1) and (1 , 1) of ( γ, η ) and hence some distribution over µ and ν . Finally, we can express C and D explicitly in terms of µ and ν by eliminating γ and η , obtaining the causal model depicted in Fig. 5(c) with dependences C = νµ ⊕ 2 ν and D = ν . By construction, we must obtain precisely the same semi-algebraic set for C and D in the model of Fig. 5(c) as one does in the model of Fig. 5(a). We have therefore defined a 2 -latent-bit model that simulates our latent trit model.
The key ingredient of the above example was that we were able find a causal model which could-by appropriately varying over the distribution of its latent variablesgenerate any distribution over a given face of the tetrahedron, and hence any distribution on a trit. In the case of an m -valued latent variable however, one would need to find a k -latent-bit model which could generate any distribution on an m -simplex. We provide an inductive procedure for constructing such a latent-bit model in appendix C.
Theorem 4.2.1 implies that for the project of determining the observational equivalence classes, it suffices to consider models with binary latents. and so we restrict our attention to these henceforth.
## 4.3 Inductive scheme
Next, we define a scheme for composing pairs of n -latentbit causal models into a single ( n + 1) -latent bit causal model, such that if we start with all possible pairs of n -latent-bit causal models, and apply the composition oper- ation, we generate all possible ( n + 1) -latent-bit causal models.
Denote the n latent binary variables by λ ≡ ( λ 1 , . . . , λ n ) . A general n -latent-bit causal model is then defined by the functional dependences
<!-- formula-not-decoded -->
where λ α is shorthand for the monomial λ α 1 1 . . . λ α n n for some set of exponents α ≡ ( α 1 , . . . α n ) , and a α , b α ∈ Z 2 are parameters that specify the nature of the functional dependences.
We assume that the first causal model is defined by parameters { a (0) α } and { b (0) α } , and the second is defined by parameters { a (1) α } and { b (1) α } . The additional binary latent variable, which supplements the n binary variables of the original two models is denoted δ . The ( n + 1) -latent-bit model which is the composition of the two models is defined by the functional dependences
<!-- formula-not-decoded -->
This construction has been chosen such that δ acts as a switch variable: if we set δ = 0 in the resulting ( n + 1) -latent-bit model, we recover the first n -latent-bit model, while if we set δ = 1 , we recover the second n -latent-bit model.
With these definitions, our composition result can be summarized as follows.
Theorem 4.3.1. Consider the map that takes a pair of n -latent-bit causal models defined by the functional dependences of Eq. (4.3.1) with parameters { a (0) α } ∪ { b (0) α } for the first model, and parameters { a (1) α }∪{ b (1) α } for the second model, and returns the ( n +1) -latent-bit causal model defined by the functional dependences of Eq. (4.3.2). Under this map, the image of the set of all pairs of n -latentbit causal models is the set of all ( n +1) -latent-bit causal models.
Proof. The functional dependences of Eq. (4.3.2) can equivalently be expressed as polynomials in λ and δ as
<!-- formula-not-decoded -->
It now suffices to note that as one varies over all possible joint values for the variables in the set { a (0) α } ∪ { a (1) α } (there are 2 2 n +1 possibilities), one necessarily varies over all possible joint values for the variables in the set { a (0) α }∪ { a (0) α ⊕ a (1) α } , which in turn implies that one is varying over all possible polynomials in λ 1 , . . . , λ n and δ in the expresson for A . By a similar argument, as one varies over all possible joint values for the variables in the set { b (0) α }∪{ b (1) α } , one varies over all possible polynomials in λ 1 , . . . , λ n and δ in the expression for B . It follows that as one varies over all possible joint values for the variables in the set { a (0) α } ∪ { a (1) α } ∪ { b (0) α } ∪ { b (1) α } , one obtains all possible manners in which A and B might be functionally dependent on the latent variables in the ( n +1) -latent-bit causal model. Thus as one varies over all possible pairs of n -latent-bit causal models in our switch-variable construction, one varies over all possible ( n +1) -latent-bit causal models.
We can therefore generate all causal models with binary latents by this inductive rule starting from the 0 -latent-bit causal models.
## 4.4 Catalogue of observational equivalence classes
Recall that two causal models are observationally equivalent if they define the same semi-algebraic set. Thus, to characterize the observational equivalence classes, we proceed as follows. For each new causal model that we generate by the inductive scheme, we determine the corresponding semi-algebraic set. Every time one obtains a variety that has not appeared previously, one adds it to the catalogue of observational equivalence classes.
Note that if a causal model has been obtained from two simpler models via our composition scheme, then the semi-algebraic set associated to it necessarily includes as subsets both of the semi-algebraic sets of the simpler models (note that this semi-algebraic set is generally not the convex hull of the semi-algebraic sets of the two simpler models). It follows that if the semi-algebraic set of a given causal model is found to be the entire tetrahedron, then composing this model with any other will also yield the tetrahedron. In this case, there are no new observational equivalence classes to be found among the descendants of this causal model in the inductive scheme.
In particular, if it were to occur that at some level of the inductive scheme, every newly generated causal model could be shown either to reduce to a previously generated causal model or to yield a semi-algebraic set that is the entire tetrahedron, then one could conclude that one's catalogue of the observational equivalence classes of causal models was complete in the sense that any n -latent bit causal model belongs to one of these classes.
We have used our inductive scheme to construct all observational equivalence classes generated by causal models with four or fewer binary latent variables. We have also considered a large number of causal models with five binary latent variables and found no new observational equivalence classes. This suggests that our catalogue may already be complete, although we do not have a proof of this. Above, we noted circumstances in which our inductive scheme would terminate, which provides one strategy for attempting to settle the question. Even in the absence of a proof of completeness, the inductive scheme presented here for classifying observational equivalence classes may be of independent interest to researchers in the field.
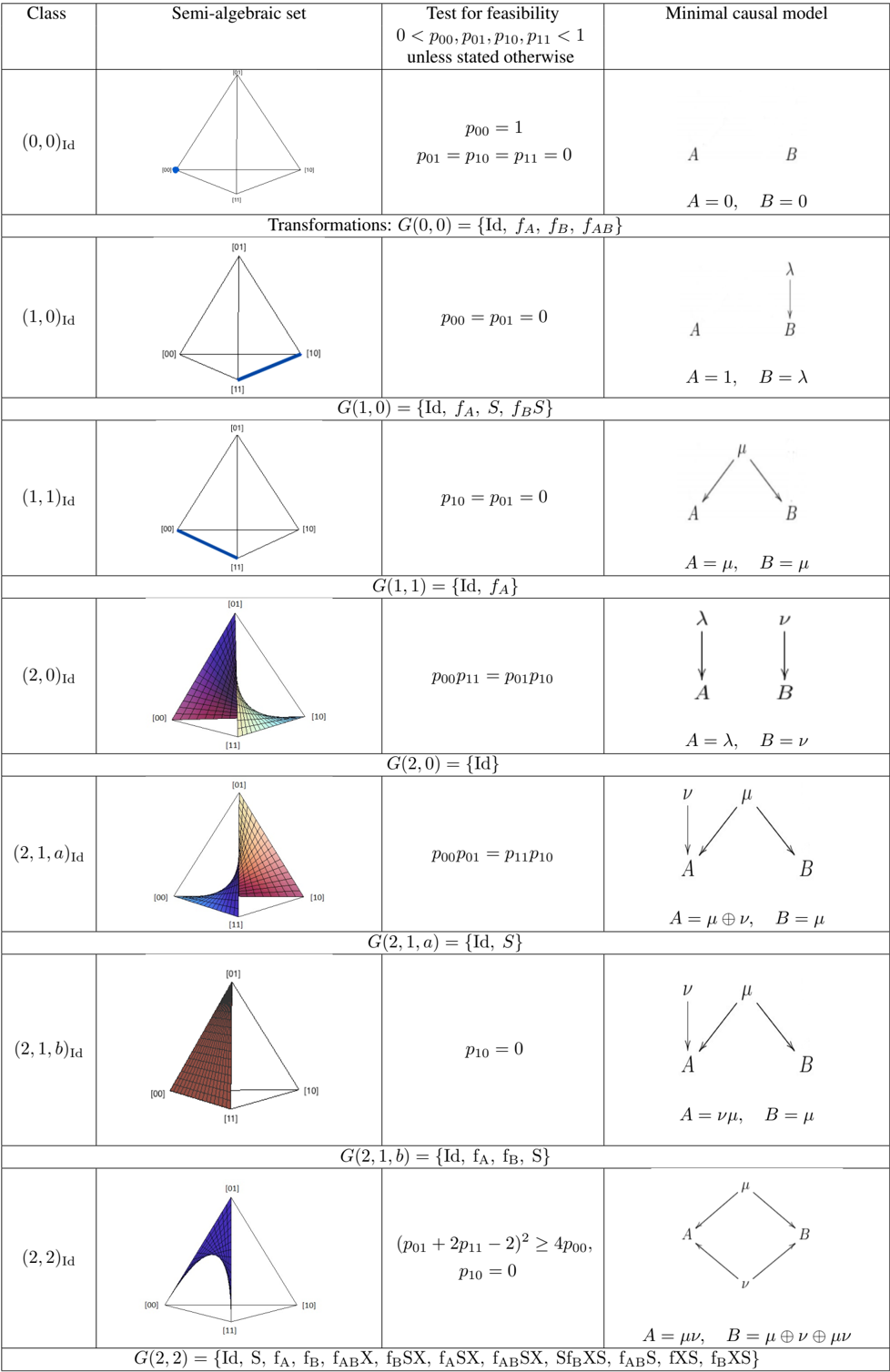
The observational equivalence classes of causal models that we have obtained (which cover all causal models with four or fewer binary latent variables) are presented in the table covering the next three pages. For each class, we depict the semi-algebraic set that defines the class, the feasibility test for the class, and a representative causal model from the class. Note that the open-interval constraints 0 < p 00 , p 01 , p 10 , p 11 < 1 are part of every feasibility test unless explicitly stated otherwise. The corresponding constraint on the affine varieties is that those varieties confined to the edges exclude the vertices, those confined to the faces exclude the edges, and those in the bulk exclude the faces.
The task of describing the catalogue is simplified by the fact that many of the observational equivalence classes are related to one another by simple symmetries. We therefore organize the classes into orbits, where an orbit is a set of classes whose elements are related to one another by a set of symmetry transformations. For one of the classes in the orbit (which we term the 'fiducial' class), we provide a full description, and below this description, we specify the set of symmetry transformations that must be applied to it to obtain the other elements of the orbit. Formally, this is a set of representatives of the right cosets of the subgroup of symmetries of the semi-algebraic set in the full symmetry group of the tetrahedron.
We express these representatives as compositions of the following set of symmetry transformations, which we define below: { Id , f A , f B , S, X } . For each of the five, we specify both their action on the causal model, i.e., their action on the functional dependences, from which their action on the DAG can be inferred, and on the elements of the joint distribution { p ab : a, b ∈ Z 2 } , from which their action on the feasibility test can be inferred. Each symmetry transformation also defines an action on the tetrahedron in an obvious manner. Id is the identity transformation, leaving the model and p ab invariant; f A is the bit flip on A , replacing the functional dependence A = f ( λ ) with A = f ( λ ) ⊕ 1 and mapping p ab → p a ⊕ 1 ,b ; f B is the bit flip on B , defined analogously to f A ; S is the swap transformation, replacing the functional dependences A = f ( λ ) , B = g ( λ ) with A = g ( λ ) , B = f ( λ ) , and mapping p ab → p ba ; X is the 'add B to A ' transformation, replacing the functional dependences A = f ( λ ) , B = g ( λ ) with A = f ( λ ) ⊕ g ( λ ) , B = g ( λ ) and mapping p ab → p a ⊕ b,b . We denote a composition of two symmetry transformations by a right-to-left product: for instance, a bit flip on A followed by a swap is denoted Sf A . The conjunction of a bit flip on A and a bit flip on B yields the same transformation regardless of the order in which they are implemented and is denoted f AB .
Finally, a given observational equivalence class will be distinguished by a label of the form ( n, m, x ) g . Here, n is the number of binary latent variables in the causal model, m is the number of these that act as common causes, x is an optional label that is used for distinguishing functional dependences that are consistent with a given ( n, m ) but are observationally inequivalent, and g labels the symmetry transformation that relates the class to the fiducial class
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Diagram: Causal Models and Semi-Algebraic Sets
### Overview
The image presents a series of diagrams illustrating different causal models, their corresponding semi-algebraic sets, tests for feasibility, and minimal causal models. The diagram is organized into six rows, each representing a different class of causal model. Each row contains a 3D plot (semi-algebraic set), a feasibility test, and a simplified causal diagram.
### Components/Axes
The diagram is structured in columns:
* **Class:** Labels the causal model type (e.g., (0,0)<sub>Id</sub>, (1,1)<sub>Id</sub>, etc.).
* **Semi-algebraic set:** A 3D plot with axes labeled [00], [01], and [11] (or [10] in some cases). The plots appear to represent regions defined by inequalities.
* **Test for feasibility:** Mathematical conditions that must be met for the model to be valid. These conditions involve probabilities denoted as p<sub>00</sub>, p<sub>01</sub>, p<sub>10</sub>, and p<sub>11</sub>.
* **Minimal causal model:** A simplified diagram showing the causal relationships between variables A and B, often with Greek letters representing causal effects.
### Detailed Analysis or Content Details
**Row 1: (0,0)<sub>Id</sub>**
* **Semi-algebraic set:** A flat plane.
* **Test for feasibility:** 0 < p<sub>00</sub>, p<sub>01</sub>, p<sub>10</sub>, p<sub>11</sub> < 1 unless stated otherwise. p<sub>00</sub> = 1 and p<sub>01</sub> = p<sub>10</sub> = p<sub>11</sub> = 0.
* **Transformations:** G(0,0) = {Id, f<sub>A</sub>, f<sub>B</sub>, f<sub>AB</sub>}
* **Minimal causal model:** A and B are independent, represented by two unconnected nodes labeled A and B. A = 0, B = 0.
**Row 2: (1,0)<sub>Id</sub>**
* **Semi-algebraic set:** A triangular region.
* **Test for feasibility:** p<sub>00</sub> = p<sub>01</sub> = 0.
* **Transformations:** G(1,0) = {Id, f<sub>A</sub>, S, f<sub>B</sub>S}
* **Minimal causal model:** A causes B, represented by an arrow from A to B. A = 1, B = λ.
**Row 3: (1,1)<sub>Id</sub>**
* **Semi-algebraic set:** A triangular region.
* **Test for feasibility:** p<sub>10</sub> = p<sub>01</sub> = 0.
* **Transformations:** G(1,1) = {Id, f<sub>A</sub>}
* **Minimal causal model:** A causes B, represented by an arrow from A to B. A = μ, B = μ.
**Row 4: (2,0)<sub>Id</sub>**
* **Semi-algebraic set:** A more complex 3D shape.
* **Test for feasibility:** p<sub>00</sub>p<sub>11</sub> = p<sub>01</sub>p<sub>10</sub>.
* **Transformations:** G(2,0) = {Id}
* **Minimal causal model:** A and B are independent, represented by two unconnected nodes labeled A and B. A = λ, B = ν.
**Row 5: (2,1,α)<sub>Id</sub>**
* **Semi-algebraic set:** A more complex 3D shape.
* **Test for feasibility:** p<sub>00</sub>p<sub>01</sub> = p<sub>11</sub>p<sub>10</sub>.
* **Transformations:** G(2,1,α) = {Id, S}
* **Minimal causal model:** A causes B, represented by an arrow from A to B. A = μ + ρυ, B = μ.
**Row 6: (2,2)<sub>Id</sub>**
* **Semi-algebraic set:** A complex 3D shape.
* **Test for feasibility:** (p<sub>01</sub> + 2p<sub>11</sub> - 2)<sup>2</sup> ≥ 4p<sub>00</sub>, p<sub>10</sub> = 0.
* **Transformations:** G(2,2) = {Id, S, f<sub>A</sub>, f<sub>AB</sub>X, f<sub>BS</sub>X, f<sub>AS</sub>X, f<sub>AB</sub>XS, S<sub>fB</sub>XS, f<sub>XS</sub>, f<sub>fXS</sub>}
* **Minimal causal model:** A causes B, and B causes A, represented by bidirectional arrows between A and B. A = μ, B = μ + ρυ.
### Key Observations
* The complexity of the semi-algebraic set generally increases with the complexity of the causal model.
* The feasibility tests provide mathematical constraints on the probabilities that define the relationships between variables.
* The minimal causal models offer a simplified visual representation of the causal relationships.
* The transformations (G(x,y,z)) appear to represent operations or functions applied to the variables.
### Interpretation
This diagram illustrates the connection between causal models, their mathematical representation as semi-algebraic sets, and their simplified visual representation as causal diagrams. The feasibility tests define the conditions under which these models are valid, based on probabilistic constraints. The transformations suggest the operations that can be performed on the variables within each model. The diagram demonstrates how complex causal relationships can be represented and analyzed using mathematical and graphical tools. The use of Greek letters (λ, μ, ν, ρ) in the minimal causal models likely represents specific causal parameters or effects. The notation "Id" likely refers to the identity transformation. The "S" transformation is not explicitly defined but appears to represent some form of intervention or manipulation. The increasing complexity of the transformations with each row suggests a growing level of intervention or manipulation required to define the causal relationships. The diagram is a formalization of causal inference, linking mathematical conditions to graphical representations of causal structures.
</details>
| Class | Semi-algebraic set | Test for feasibility 0 < p 00 , p 01 , p 10 , p 11 < 1 unless stated otherwise | Minimal causal model |
|--------------------------------------------------------|--------------------------------------------------------|----------------------------------------------------------------------------------|--------------------------------------------------------|
| (0 , 0) Id | p 00 = 1 p 01 = p 10 = p 11 = 0 | | A = 0 , B = 0 |
| Transformations: G (0 , 0) = { Id , f A , f B , f AB } | Transformations: G (0 , 0) = { Id , f A , f B , f AB } | Transformations: G (0 , 0) = { Id , f A , f B , f AB } | Transformations: G (0 , 0) = { Id , f A , f B , f AB } |
| (1 , 0) Id p 00 = p 01 = | 0 | A = 1 , B = λ | G (1 , 0) = { Id , f A , S, f B S } |
| p 10 = p 01 | p 10 = p 01 | p 10 = p 01 | p 10 = p 01 |
| (1 , 1) Id = 0 | | A = µ, B = µ G (1 , 1) = { Id , f A } | (2 , 0) Id |
| 00 11 G (2 | p p = p 01 p 10 , | A = λ, B = ν = { Id } | 0) (2 , 1 ,a ) Id |
| p 00 p 01 = p | p 00 p 01 = p | p 00 p 01 = p | p 00 p 01 = p |
| 11 p 10 G (2 , 1 | = µ ⊕ ν, B = µ ,a | A ) = { Id , S } (2 , 1 , b ) Id | p 10 |
| = 0 | = 0 | = 0 | = 0 |
| A = νµ, B = µ G (2 , 1 , b ) | = (2 , 2) Id | { Id , f A , f B , S } ( p 01 +2 | p 11 - 2) 2 ≥ 4 p 00 , p 10 = 0 |
| A = µν, B = µ ⊕ ν ⊕ µν AB S , fXS , f B XS } | A = µν, B = µ ⊕ ν ⊕ µν AB S , fXS , f B XS } | A = µν, B = µ ⊕ ν ⊕ µν AB S , fXS , f B XS } | A = µν, B = µ ⊕ ν ⊕ µν AB S , fXS , f B XS } |
Class
(3 , 1 , a ) Id
(3 , 1 , b ) Id
(3 , 1 , c ) Id
(3 , 2 , a ) Id
(3 , 2 , b ) Id
(3 , 2 , c ) Id
[00]
[11]
Semi-algebraic set
[01]
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## 3D Surface Plot: Triangular Pyramid with Curved Surface
### Overview
The image depicts a 3D surface plot resembling a triangular pyramid with a curved surface replacing one of its faces. The plot is rendered with a grid-like mesh, and labeled with numerical values at the vertices. The surface appears to be defined by a mathematical function, creating a smooth, curved shape.
### Components/Axes
The plot is defined by three axes, labeled with the following values:
* **X-axis:** [1]
* **Y-axis:** [4]
* **Z-axis:** [10]
* **Base:** [4]
The plot is a triangular pyramid with a curved surface. The apex of the pyramid is at the point (1, 4, 10). The base of the pyramid is a triangle with vertices at approximately (1, 0, 0), (0, 4, 0), and (0, 0, 0). The curved surface replaces the face connecting the points (1, 0, 0), (0, 4, 0), and (0, 0, 0).
### Detailed Analysis or Content Details
The surface is a smooth curve that starts at a maximum height at the apex (1, 4, 10) and descends towards the base. The curvature is not uniform; it appears to be steeper near the x-axis and more gradual near the y-axis. The grid lines on the surface indicate a regular sampling of the function defining the surface.
The numerical labels at the vertices provide coordinate information. The apex is labeled as [1, 4, 10]. The base vertices are labeled as [1], [4], and [10].
### Key Observations
The plot demonstrates a surface that is defined by a function of two variables (likely x and y), with the height (z) being determined by the function's value at each point (x, y). The shape suggests a non-linear relationship between the input variables and the output height. The surface is smooth and continuous, indicating that the function is differentiable.
### Interpretation
The image represents a visualization of a mathematical function in three dimensions. The triangular pyramid shape with a curved surface suggests a function that is constrained by certain boundaries (the edges of the pyramid) but exhibits a smooth, continuous variation within those boundaries. The function could represent a variety of phenomena, such as a probability distribution, a physical surface, or a mathematical landscape. The specific shape of the curve would depend on the exact form of the function.
The plot is a visual representation of a mathematical concept, and its interpretation requires understanding the underlying function and its properties. Without knowing the function itself, it is difficult to draw definitive conclusions about the data it represents. However, the image provides a clear and intuitive visualization of a complex mathematical relationship.
</details>
<details>
<summary>Image 8 Details</summary>
### Visual Description
\n
## 3D Surface Plot: Triangular Surface
### Overview
The image depicts a 3D surface plot resembling a cone or a triangular pyramid with a curved surface. The surface is colored with a gradient, transitioning from purple to yellow/orange. The plot is defined by three axes labeled [00], [01], and [11], [10]. The surface appears to be a function of two variables, with the height of the surface changing as you move along the x and y axes.
### Components/Axes
* **Axes:** Three axes are visible, labeled as follows:
* X-axis: [00] to [10]
* Y-axis: [00] to [01]
* Z-axis: Implied vertical axis representing the function's value.
* **Surface:** A curved surface defined by a grid of points.
* **Color Gradient:** The surface is colored with a gradient:
* Purple: Represents lower values of the function.
* Yellow/Orange: Represents higher values of the function.
### Detailed Analysis
The surface rises from a minimum value at approximately [00, 00] and reaches a maximum value along the line connecting [11] and [10]. The surface is symmetrical along the line connecting [00] and [10].
* **[00] to [10] axis:** The surface starts at a low point near [00] and gradually increases in height as it moves towards [10]. The height reaches a maximum around [10].
* **[00] to [01] axis:** The surface starts at a low point near [00] and gradually increases in height as it moves towards [01]. The height reaches a maximum around [01].
* **[11] point:** The surface reaches a peak at the [11] point.
* **Color Distribution:** The purple color dominates the lower left portion of the surface (near [00]), while the yellow/orange color dominates the upper right portion (near [10] and [01]).
It is difficult to extract precise numerical values from the image without a scale on the Z-axis. However, we can observe the relative heights of the surface at different points.
### Key Observations
* The surface is smooth and continuous.
* The surface is symmetrical along the line connecting [00] and [10].
* The maximum value of the function occurs along the line connecting [11] and [10].
* The minimum value of the function occurs near [00].
### Interpretation
The plot likely represents a function of two variables, where the x and y axes represent the input variables and the z-axis represents the output variable. The shape of the surface suggests that the function has a maximum value at [11] and [10] and a minimum value at [00]. The color gradient provides a visual representation of the function's values, with purple representing lower values and yellow/orange representing higher values.
The triangular shape of the plot suggests that the input variables may be constrained to a specific region, such as a triangle. The function may represent a physical quantity, such as energy or probability, that is defined within this region.
Without more information about the function and the axes, it is difficult to provide a more specific interpretation. However, the plot provides a clear visual representation of the function's behavior and its key features. The plot is a visualization of a surface defined by a mathematical function, likely representing a constraint or optimization problem within a triangular domain. The color gradient helps to understand the distribution of values across the surface.
</details>
<details>
<summary>Image 9 Details</summary>
### Visual Description
\n
## 3D Surface Plot: Ternary Diagram
### Overview
The image depicts a 3D surface plot representing a ternary diagram. The diagram is a triangular pyramid with vertices labeled [00], [01], and [10]. The surface within the pyramid is colored to represent varying values, with a clear division between a blue/purple region and a yellow/orange/pink region. A grid is overlaid on the surface.
### Components/Axes
* **Axes:** The diagram represents a ternary plot, meaning the axes represent proportions of three components that sum to 1. The axes are labeled as follows:
* [00] - Bottom-left corner
* [01] - Top corner
* [10] - Bottom-right corner
* The third axis, implicitly defined, would complete the equilateral triangle base.
* **Surface:** The surface represents a function of the three components. The color of the surface indicates the value of the function at that point.
* **Grid:** A regular grid is overlaid on the surface, aiding in visualizing the shape and values.
### Detailed Analysis
The surface is divided into two distinct regions:
* **Left Region (Blue/Purple):** This region, extending from [00] towards [01], exhibits a generally concave shape. The color transitions from deep blue near [00] to a lighter purple as it approaches the dividing line. The surface appears relatively flat near [01].
* **Right Region (Yellow/Orange/Pink):** This region, extending from [00] towards [10], shows a more complex curvature. The color transitions from yellow near [00] to orange and then pink as it approaches [10]. The surface appears to rise more steeply than the left region.
* **Dividing Line:** A sharp boundary separates the two regions, running approximately from [01] to [10]. This line suggests a discontinuity or a significant change in the function being represented.
Due to the nature of the plot, precise numerical values cannot be extracted without knowing the function being plotted. However, we can describe the relative values based on color:
* The lowest values are likely represented by the deep blue color near [00] in the left region.
* The highest values are likely represented by the pink color near [10] in the right region.
* The dividing line represents a point of inflection or a significant change in value.
### Key Observations
* The diagram demonstrates a clear asymmetry between the two regions. The right region exhibits more curvature and a wider range of colors, suggesting a more complex relationship between the components.
* The sharp dividing line indicates a potential threshold or a significant change in the underlying process.
* The grid provides a visual reference for the relative values of the surface.
### Interpretation
This ternary diagram likely represents a compositional system where the proportions of three components determine a certain property or outcome. The color-coded surface illustrates how this property changes as the composition varies. The sharp dividing line suggests a critical composition where the property undergoes a significant shift.
The asymmetry between the two regions indicates that the system is more sensitive to changes in composition on the right side of the diagram (towards [10]). This could be due to a non-linear relationship between the components and the property being measured.
Without knowing the specific context of the diagram, it is difficult to provide a more detailed interpretation. However, the diagram suggests a complex interplay between the three components and a potential threshold effect. This type of diagram is commonly used in fields such as materials science, chemistry, and ecology to represent compositional data and understand the relationships between different variables.
</details>
[11]
<details>
<summary>Image 10 Details</summary>
### Visual Description
\n
## 3D Surface Plot: Triangular Surface
### Overview
The image depicts a 3D surface plot resembling a saddle or hyperbolic paraboloid, constrained within a triangular region. The surface is rendered as a grid of intersecting lines, with color differentiation indicating varying z-values. The plot is oriented such that the apex of the triangle points upwards.
### Components/Axes
The plot is defined by three axes, labeled as follows:
* **X-axis:** [0] to [10] - Located at the bottom-left corner of the triangular base.
* **Y-axis:** [0] to [11] - Located at the bottom-right corner of the triangular base.
* **Z-axis:** [0] to [11] - Located at the apex of the triangle.
The surface itself is the primary component, displaying a curved shape. The grid lines represent constant values along the x and y axes. The surface is colored with a gradient, transitioning from a brownish-orange hue to a light green.
### Detailed Analysis or Content Details
The surface exhibits a saddle-like shape. Starting from the x-axis ([0] to [10]), the surface initially descends, reaching a minimum value around x = 5, y = 5. Then, it rises again towards the y-axis ([0] to [11]). The z-values appear to be negative in the region near x = 5 and y = 5, and positive elsewhere.
The grid lines are approximately evenly spaced. The surface is relatively smooth, with no sharp discontinuities visible.
* **X = 0:** Z values range from approximately 0 to 11.
* **X = 10:** Z values range from approximately 0 to 11.
* **Y = 0:** Z values range from approximately 0 to 11.
* **Y = 11:** Z values range from approximately 0 to 11.
* **Minimum Z value:** Approximately -1 to -2, located around x = 5, y = 5.
* **Maximum Z value:** Approximately 11, located along the edges of the triangle.
### Key Observations
The most notable feature is the saddle shape, indicating a hyperbolic paraboloid function. The minimum z-value is located near the center of the triangular base. The surface is symmetrical along both the x and y axes.
### Interpretation
This plot likely represents a visualization of a mathematical function of two variables, z = f(x, y). The hyperbolic paraboloid shape suggests a function with a saddle point. The triangular domain indicates that the function is only defined within this specific region. The color gradient provides a visual representation of the z-values, allowing for a quick understanding of the function's behavior. The plot demonstrates a function that changes sign within its domain, having both positive and negative z-values. The function is likely defined as something like z = x*y, or a similar quadratic form. The plot is a visual aid for understanding the function's characteristics, such as its saddle point, symmetry, and range of values.
</details>
<details>
<summary>Image 11 Details</summary>
### Visual Description
\n
## 3D Diagram: Triangular Pyramid
### Overview
The image depicts a triangular pyramid rendered in a 3D perspective. The pyramid's surface is divided into three distinct colored regions: reddish-brown, light blue, and pale yellow. The coordinate axes are labeled, indicating a three-dimensional space. The diagram appears to be a visual representation of a mathematical or geometric concept, potentially related to a simplex or a constraint region.
### Components/Axes
The diagram features the following components:
* **Pyramid Structure:** A triangular pyramid with a triangular base and three sloping sides.
* **Coordinate Axes:** Three axes are labeled as follows:
* X-axis: Labeled "[0, 10]" and positioned horizontally.
* Y-axis: Not explicitly labeled, but implied to be the vertical axis.
* Z-axis: Labeled "[0, 11]" and positioned at an angle.
* **Colored Regions:** The pyramid's surface is divided into three regions:
* Reddish-Brown: Occupies the left side of the pyramid.
* Light Blue: Occupies the upper-right side of the pyramid.
* Pale Yellow: Occupies the lower-right side of the pyramid.
* **Apex:** The top point of the pyramid is labeled "[0,1]".
* **Base:** The base of the pyramid is defined by the coordinate axes.
### Detailed Analysis or Content Details
The diagram does not contain specific numerical data points beyond the axis labels. The colored regions visually represent different areas within the three-dimensional space defined by the pyramid. The pyramid's dimensions are approximately:
* X-axis range: 0 to 10 units.
* Z-axis range: 0 to 11 units.
* Y-axis range: 0 to 1 unit (based on the apex label).
The pyramid's base is a right triangle with vertices at (0,0,0), (10,0,0), and (0,0,11). The apex is located at (0,1,0).
### Key Observations
The diagram is a geometric representation rather than a data visualization. The color coding of the pyramid's faces does not appear to be associated with any specific values or quantities. The diagram's primary purpose is to illustrate the shape and spatial arrangement of a triangular pyramid within a three-dimensional coordinate system.
### Interpretation
The diagram likely represents a constraint region or a simplex in a three-dimensional space. The pyramid's shape defines the boundaries of a feasible region, and the colored regions may represent different sub-regions or categories within that space. The coordinate axes provide a framework for defining the position and extent of the pyramid. The diagram could be used to illustrate concepts in linear programming, optimization, or geometry. The lack of specific data points suggests that the diagram is intended to be a general illustration rather than a precise representation of a particular dataset. The apex label "[0,1]" suggests a possible normalization or scaling factor applied to the y-axis.
</details>
>
>
Test for feasibility p 00 p 11 > p 01 p 10
## G (3 , 1 , a ) = { Id , f A }
( p 01 -p 11 )( p 00 p 11 -p 01 p 10 ) < 0 ( p 01 -p 11 )( p 10 p 11 -p 01 p 00 ) < 0
## G (3 , 1 , b ) = { Id , f AB }
p
p
p
-
>
p
p
+
p
p
p
p
-
+
p
p
-
p
-
p
p
-
p
p
p
+
p
-
## G (3 , 1 , c ) = { Id }
p 10 p 11 > p 01 p 00
## G (3 , 2 , a ) = { Id, Sf A , f A , f A XS }
( p 01 -p 10 )( p 11 p 10 -p 01 p 00 ) < 0 ( p 01 -p 10 )( p 00 p 10 -p 01 p 11 ) < 0
## G (3 , 2 , b ) = { Id, f AB XS, f B XS, f A }
<details>
<summary>Image 12 Details</summary>
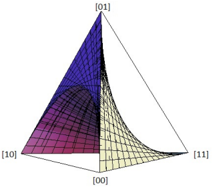
### Visual Description
\n
## 3D Surface Plot: Triangular Surface
### Overview
The image depicts a 3D surface plot resembling a triangular pyramid or cone. The surface is a mesh of grid lines, colored with a gradient transitioning from purple to yellow. The axes are labeled with coordinate pairs in square brackets.
### Components/Axes
* **X-axis:** Labeled "[10]" at the left base and "[11]" at the right base.
* **Y-axis:** Labeled "[00]" at the base.
* **Z-axis:** Implicitly represented by the height of the surface, with the apex labeled "[01]".
* **Surface:** A mesh of grid lines forming a curved surface. The surface is colored with a gradient: purple on the left side, transitioning to yellow on the right side.
### Detailed Analysis
The surface appears to be defined by a function of two variables, x and y, where x ranges approximately from 10 to 11 and y is fixed at 0. The height (z-value) of the surface increases from 0 at the base to a maximum at the apex [01].
The surface is divided into two distinct regions by a vertical plane. The left region (x values closer to 10) is colored purple, and the right region (x values closer to 11) is colored yellow. The gradient suggests a continuous change in the function's value as x changes.
The surface is not a simple cone or pyramid. It has a curvature that suggests a more complex mathematical function. The surface is highest at the apex [01] and decreases towards the base along both the x and y axes.
### Key Observations
* The surface is symmetrical about the y-axis.
* The color gradient indicates a change in the function's value along the x-axis.
* The surface is smooth and continuous, with no sharp edges or discontinuities.
* The apex of the surface is located at [01].
### Interpretation
The plot likely represents a mathematical function of two variables, possibly a quadratic or polynomial function. The triangular shape suggests that the function is constrained by the x and y axes. The color gradient could represent the value of the function, with purple indicating lower values and yellow indicating higher values.
The division of the surface into two regions by a vertical plane could indicate a discontinuity or a change in the function's behavior. Alternatively, it could be a visual representation of a boundary condition or a constraint on the function.
Without knowing the specific function that defines the surface, it is difficult to provide a more detailed interpretation. However, the plot suggests a relationship between the x and y variables and the height (z-value) of the surface. The shape and color gradient provide clues about the nature of this relationship. The plot could be used to visualize and analyze the behavior of the function, identify critical points, and explore its properties.
</details>
A
Minimal causal model
V
μ
入
A
B
A = µν, B = µλ
μ
入
W
人
A
B
A = µ ⊕ ν, B = µλ
V
μ
入
W
A
B
A = µ ⊕ ν, B = µ ⊕ λ
入
μ
A
B
## A = µν ⊕ µλ ⊕ 1 , B = µν ⊕ 1
入
μ
A
B
V
A = µ ⊕ ν ⊕ µλ ⊕ 1 , B = µ ⊕ ν ⊕ 1
μ
A
=
µν,
## G (3 , 2 , c ) = { Id , S, f A , f AB SX, f B XS, XS, f A XS, f A X, f AB X, f A SXS, X }
B
⊕
ν
| 4( p 10 -p 11 )( p 00 p 10 -p 01 p 11 ) | ≤ ( p 11 (2 p 01 +2 p 10 + p 00 ) -p 10 (2 p 00 +2 p 11 + p 01 ) ) 2
,
,
.
V
B
=
µ
⊕
δ
<details>
<summary>Image 13 Details</summary>
### Visual Description
\n
## Diagram: Causal Models and Semi-Algebraic Sets
### Overview
The image presents a series of diagrams illustrating different causal models alongside their corresponding semi-algebraic sets and tests for feasibility. Each row represents a different class of causal model, visually depicting the model and providing a mathematical test to determine its feasibility. The diagram is organized in a grid-like structure, with each row containing four columns: "Class", "Semi-algebraic set", "Test for feasibility", and "Minimal causal model".
### Components/Axes
The diagram consists of the following components:
* **Class:** Labels indicating the type of causal model (e.g., (3,2,d)₁ₐ, (3,3)₁ₐ, (4,2,a)₁ₐ).
* **Semi-algebraic set:** 3D plots representing the semi-algebraic set associated with each causal model. The axes of these plots are labeled [100], [110], and [111].
* **Test for feasibility:** Mathematical inequalities that must be satisfied for the corresponding causal model to be feasible.
* **Minimal causal model:** Diagrams illustrating the causal relationships between variables A and B, with arrows indicating the direction of causality. The variables A and B are often expressed in terms of μ and ν, and δ.
### Detailed Analysis / Content Details
Here's a breakdown of each row, extracting the key information:
**1. (3,2,d)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** (p₀₁ + 2p₁₀ + 2p₁₁) ² ≥ 4p₀₀
* **Minimal causal model:** A → B, where A = μν, B = μνδ
**2. (3,2,e)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** 4(p₁₀ - p₁₁)(p₀₀p₁₀ - p₀₁p₁₁) ≤ (p₁₁(2p₀₁ + p₁₁) - p₁₀(2p₀₀ + p₁₀))²
* **Minimal causal model:** A → B, where A = μ + ∅, B = μν + δ
**3. (3,2,f)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** [4(p₁₀ - p₁₁)(p₀₀p₁₀ - p₀₁p₁₁)]² ≤ (p₁₁(2p₀₁ + 2p₁₀ + p₁₁) - p₁₀(2p₀₀ + p₁₀))²
* **Minimal causal model:** A → B, where A = νμ, B = μνδ
**4. (3,2,g)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** p₀₀p₁₁ > p₀₁p₁₀
* **Minimal causal model:** A → B, where A = μ + 1, B = μνδ + ν
**5. (3,3)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** (2p₁₀ + 2p₁₁) ² ≥ 4(1 - p₀₀)p₁₀
* **Minimal causal model:** A ↔ B, where A = δμ + δν, B = δμν + δ
**6. (4,2,a)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** p₁₁ > p₀₁
* **Minimal causal model:** A → B, where A = νμ + γ, B = μνδ + γ
**7. (4,2,a)₁ₐ**
* **Semi-algebraic set:** 3D plot with axes [100], [110], [111].
* **Test for feasibility:** p₁₁ > p₀₁
* **Minimal causal model:** A → B, where A = νμ + γ, B = μνδ + γ
### Key Observations
* The semi-algebraic sets are consistently represented as 3D plots with the same axes ([100], [110], [111]).
* The tests for feasibility are mathematical inequalities involving probabilities (p₀₀, p₀₁, p₁₀, p₁₁).
* The minimal causal models are simple diagrams showing the relationship between variables A and B, often involving bidirectional or unidirectional causality.
* The variables A and B are frequently expressed in terms of μ, ν, δ, and γ.
* The notation "₁ₐ" appears consistently after the class label, potentially indicating a specific parameterization or condition.
### Interpretation
This diagram explores the relationship between causal models, their geometric representation as semi-algebraic sets, and the mathematical conditions required for their feasibility. Each row represents a specific causal structure, and the diagram demonstrates how to translate that structure into a mathematical test. The 3D plots likely visualize the space of possible probability distributions that satisfy the causal constraints.
The tests for feasibility provide a way to determine whether a given causal model is consistent with observed data. The minimal causal models offer a simplified representation of the causal relationships, highlighting the essential connections between variables.
The consistent use of variables like μ, ν, and δ suggests a common underlying framework for representing these causal models. The notation "₁ₐ" might indicate a specific assumption or constraint within that framework. The diagram serves as a visual and mathematical tool for understanding and analyzing causal relationships in probabilistic systems. The diagram is a theoretical exploration of causal inference, and does not present empirical data. It is a demonstration of the mathematical relationships between causal structures and their feasibility conditions.
</details>
for the particular n, m and x . The set of possibilities for g for a given n, m, and x is a subgroup of the group closure of { Id, f A , f B , S, X } , which we denote by G ( n, m, x ) . Note that n, m ∈ N , m ≤ n , and we take x ∈ { a, b, c, . . . } .
The first few steps of our iterative procedure for the construction of causal models proceed as follows.
The semi-algebraic sets associated to the four 0 -latent-bit causal models are the four vertices of the tetrahedron, labelled by the deterministic assignments to A and B , that is, as [00] , [10] , [01] and [11] . These correspond to the classes { (0 , 0) g : g ∈ { Id , f A , f B , f AB }} , depicted in the first row of the table (because there is only one observational equivalence class with n = 0 and m = 0 , the label x is not necessary in this case and so it is not excluded from the name of the class).
One finds that by composing these with one another into 1 -latent-bit causal models, one arrives at six new observational equivalence classes. Four of these correspond to models with a single latent bit that acts locally, and their semi-algebraic sets are the four edges of the tetrahedron with endpoints { [00] , [01] } , { [10] , [11] } , { [00] , [10] } , { [01] , [11] } , which we might call the AB -uncorrelated edges ; these correspond to the classes { (1 , 0) g : g ∈ { Id , f A , S, f B S }} , depicted in the second row of the table. Two of these correspond to models with a single latent bit acting as a common cause and their semi-algebraic sets are the [00] -[11] and [01] -[10] edges of the tetrahedron, which we might call the AB -correlated edges , corresponding to the classes { (1 , 1) g : g ∈ { Id , f A }} , depicted in the third row of the table.
Next, one constructs all of the 2 -latent-bit causal models and finds their semi-algebraic sets. This set includes the model of Fig. 2(c), where both latent bits act locally, and whose semi-algebraic set is the fan of Fig. 2(d), which touches each of the AB -uncorrelated edges of the tetrahedron, corresponding to the single class (2 , 0) Id , depicted in the fourth row of the table. This set also includes the models of Fig. 1(a) and Fig. 2(a) where one of the latent bits acts as a common cause and whose semi-algebraic sets are the fans of Fig. 1(b) and Fig. 2(b), which touch the AB -correlated edges of the tetrahedron. They correspond to the pair of classes { (2 , 1 , a ) g : g ∈ { Id , S }} , depicted in the fifth row of the table. There is also a second type of 2 -latent-bit causal model where one latent bit acts as a common cause which yield the semi-algebraic sets corresponding to the four faces of the tetrahedron. These are the four classes { (2 , 1 , b ) g : g ∈ { Id , f A , f B , S }} in the table. When both of the latent variables act as common causes, one obtains semi-algebraic sets that are subsets of a face of the tetrahedron and which have the appearance of the StarFleet insignia from Star Trek, of which there are twelve in total. These are the classes labelled (2 , 2) g in the table. The construction of 3 -latent-bit and 4 -latentbit causal models proceeds similarly and the new observational equivalence classes one thereby obtains are depicted in the rest of the table.
## 5 Identification of parameters in the causal model
Our results also have applications for the identification problem, that is, the problem of determining which parameters in a causal model can be identified or bounded using observational data.
Consider the problem of identifying the probability distributions over the latent variables (our q j parameters) in a causal model associated to a given functional causal structure. From the description of our algorithm, it is clear that the q j parameters are generally identifiable because the Groebner basis provides a means of computing expressions for them in terms of our p i parameters (the observational data). Indeed, we often must compute the explicit expressions for one or more of the q j s in terms of the p i s as an intermediate step on the way to deriving our feasibility tests. Eq. (3.0.3) is an example of such an identification formula.
The other sort of parameter of a causal model that one may wish to identify is the nature of the functional dependences (assuming the model is indeed functional). For the sorts of models we consider, this problem is also solved by our results.
Consider the problem where the causal structure is given, but where there is uncertainty over the nature of the functional dependences thereon. For instance, suppose that it is known that the functional causal structure is either the minimal structure associated to the class (2 , 1 , a ) Id in our table or the one associated to (2 , 1 , b ) Id . Because the semialgebraic sets defining these two classes do not intersect 7 , it is clear that one can settle this decision problem on the basis of the observational data.
As another, more nuanced example, suppose that it is known that the functional causal structure is the minimal structure associated to one of the three classes (3 , 1 , a ) Id , (3 , 1 , b ) Id , and (3 , 1 , c ) Id in our table. Here, one finds that certain points in the space of distributions over the observed variables pass the feasibility test for just one of these functional causal structures, other points pass the test for two of them, while still others pass the test for all three.
More generally, one might know only the causal structure. For instance, the set of possible functional causal structures might be the minimal ones in each of the classes in the set { (2 , 1 , a ) g : g ∈ { Id , S }} ∪ { (2 , 1 , b) g : g ∈ { Id , f A , f B , S }} . The feasibility tests we have derived provide a means of determining, for any given point in the space of distributions over the observed variables, precisely which of these functional causal structures is compatible with that observational data.
7 Recall our convention of demanding the probabilities for latent variable to be bounded away from 0 and 1, so that all of our semi-algebraic sets are confined to the interior of the tetrahedron.
## 6 Discussion
## 6.1 Future directions
The restriction to pairs of binary observed variables is a limitation of our analysis. In future work, we hope to extend our approach to cases where the observed variables have an arbitrary number of values and where the number of observed variables is also arbitrary. While the tools from algebraic geometry employed in this paper provide a procedure for deriving feasibility tests for such functional causal structures in principle, in practice it is unlikely that such procedures will be scalable. Indeed, calculating Groebner bases is an EXPSPACE -complete problem [9]. Nevertheless, it may still be possible to develop new tools for causal inference in these cases using the approach described here.
It also remains an open problem to decide, for any given functional causal structure, which observational equivalence class it belongs to. That is, even if our catalogue of classes is complete, it merely establishes that every functional causal structure falls into one of these classes, but it does not provide a means of deciding, for a given functional causal structure, having an arbitrary number of latent variables and functional dependences, which class it is a member of. Of course, if one supplements a given functional causal structure with distributions over the latent variables, then one obtains a joint distribution over the observed variables and this can be subjected to the feasibility tests for different observational equivalence classes. It is likely, however, that there are better ways of solving the classification problem, for instance, by determining how the functional dependences can be simplified. Solving this classification problem would allow one to find common features of all of the functional causal structures in a given class, for instance, features of the topology of the causal structure.
We have here made the idealization that the uncontrolled statistical data is given as a joint distribution whereas in practice it is a finite sample from this distribution. To contend with this idealization, one should in practice evaluate causal models by considering how well the finite statistical data can be fit to them.
## 6.2 Relevance to quantum foundations
One of the motivations of the current work was the prospect of new insights into the interplay between causal structure and observed correlations in quantum theory. In particular, for a pair of quantum systems-each subjected to one of a set of possible measurements-a Bell inequality [10, 11, 12] is a constraint on the joint probability distribution over the outcomes of each possible choice of the local measurements (that is, for every combination of local measurement settings ). It has recently been noted [13, 14] that one can understand the assumptions required to derive a Bell inequality as the standard assumptions for causal inference together with a particular hypothesis about the underlying causal structure, namely, that each local outcome depends causally on the corresponding local setting and on a latent common cause between the two systems. This causal structure is illustrated in Fig.6, where A and B are the measurement outcomes for each quantum system, X and Y are the local choices of measurement, and µ is the latent common cause. The complete set of Bell inequalities for this scenario, therefore, can be understood as a feasibility test for such a causal model.
The problem considered in the current work is different from that of deriving the complete set of Bell inequalities in a couple of ways: (i) The observational input to our causal inference problem is different; there are no setting variables in our problem-that is to say, any variable distinct from the observed A,B appearing in a causal structure must be latent-and therefore our input is a single joint distribution over two observed binary variables rather than a set of such distributions, one for each choice of the setting variables. (ii) The hypotheses whose feasibility we are testing are different; while the set of all Bell inequalities provides a test of the feasibility of the causal structure illustrated in Fig. 6, we here seek to assess the feasibility of a causal structure for a given choice of cardinalities for the latent variables appearing therein (e.g., whether a given latent variable consists of a single bit, two bits, etcetera) and for a given choice of the precise form of the functional dependence of the observed variables on the latent variables.
Consider the Bell scenario of Fig. 6 where A,B,X, and Y are binary variables. To define a functional causal structure, one must supplement this causal structure with a hypothesis about the cardinality of µ and a hypothesis about the function f that maps X,µ to A and the function g that maps Y, µ to B . (Given that there are only 16 possible values of A,B,X, and Y , a µ of cardinality 16 is sufficient to simulate any other case.) The conditional distributions P ( A,B | X,Y ) compatible with this functional causal structure are
<!-- formula-not-decoded -->
where q µ denotes a probability distribution over the latent variable µ . To determine the semi-algebraic set of possibilities for P ( A,B | X,Y ) that are compatible with this functional causal structure, one could use the techniques of the present article. From the polynomial equalities that hold between the P ( A,B | X,Y ) and the q µ (those given in Eq. (6.2.1)), one seeks to obtain constraints on the P ( A,B | X,Y ) alone by eliminating the q µ . Because the variables to be eliminated appear linearly, to eliminate the q µ , it suffices to use quantifier elimination techniques that are less computationally demanding than implicitization, such as Fourier-Motzkin elimination.
Note that if some observed correlations violate an inequality derived in this fashion, it only establishes the infeasibility of a given classical functional causal structure. Violation of Bell inequalities, on the other hand, rule out the feasibility of the causal structure, regardless of the cardinality of the latent variables and the nature of the functional dependences. In this sense, deriving Bell inequali-
?
<details>
<summary>Image 14 Details</summary>
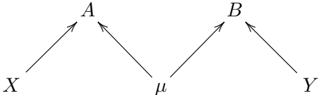
### Visual Description
\n
## Diagram: Directed Acyclic Graph
### Overview
The image depicts a directed acyclic graph (DAG) with five nodes labeled X, A, B, Y, and μ (mu). Arrows indicate the direction of relationships between the nodes. The graph appears to represent a causal or probabilistic model.
### Components/Axes
The diagram consists of the following components:
* **Nodes:** X, A, B, Y, μ
* **Edges (Arrows):**
* X → A
* A → μ
* B → μ
* B → Y
### Detailed Analysis or Content Details
The graph shows the following relationships:
* X influences A.
* A influences μ.
* B influences μ.
* B influences Y.
* μ is influenced by both A and B.
* Y is influenced by B.
There are no numerical values or scales present in the diagram. The diagram is purely structural, representing relationships rather than quantitative data.
### Key Observations
* μ acts as a common effect of A and B, suggesting a potential confounding variable or a point of interaction.
* B has two outgoing edges, influencing both μ and Y, making it a central node in the graph.
* X and Y are terminal nodes, only having outgoing edges.
* The graph is acyclic, meaning there are no closed loops or cycles.
### Interpretation
This diagram likely represents a causal model or a Bayesian network. The nodes represent variables, and the arrows represent direct dependencies. The structure suggests that X and B are independent causes influencing μ, and B also directly influences Y. The graph could be used to model the relationships between these variables and to make inferences about their probabilities. The symbol μ (mu) is often used to represent a mean or expected value in statistics, suggesting that it might represent a central tendency or summary statistic. The diagram does not provide any information about the strength of the relationships or the nature of the variables themselves, only their structural dependencies. It is a qualitative representation of relationships, not a quantitative one.
</details>
?
\_
\_
?
?
\_
\_
Fig. 6: In the Bell scenario, one is interested in the conditional distribution P ( A,B | X,Y ) . This is equivalent to a set of distributions over A,B , { P ( X,Y ) ( A,B ) } , one for each choice of measurement setting.
ties is more challenging than deriving feasibility tests for functional causal structures. However, in another sense, deriving Bell inequalities is more straightforward because the semi-algebraic set defined by Eq. (6.2.1) is a polytope, whereas for a general funcational causal structure this is not the case. The mathematical tools that have been used to derive Bell-type inequalities-which include semi-definite [15] and linear programming [16] as well as Fourier-Motzkin elimination [17, 18]-are therefore quite different from those used here.
Bell inequalities are significant to the foundations of quantum theory because they are found to be violated in experiments on pairs of separated quantum systems, implying that the predictions of quantum theory cannot be explained by a classical causal model with the causal structure that one expects to hold for the experiment (that of Fig. 6) without fine-tuning [13].
Researchers in the field of quantum foundations have now begun to apply insights obtained from the study of Bell inequalities to the problem of deriving constraints on observed correlations in more general causal scenarios [14, 19, 20, 21, 22, 23], and the current work constitutes another contribution in this direction.
More importantly, there are now a few proposals for how to generalize the standard notion of a causal model to the quantum realm. Ref. [24], for instance, proposes a definition of a quantum causal model in terms of a noncommutative generalization of conditional probability, while Refs. [19, 25, 26] follow a more operational approach. With a notion of quantum causal model in hand, one can explore the problem of inferring facts about the quantum causal model from observed correlations. This is the problem of quantum causal inference .
In the case of Bell-type experiments, for instance, one expects a quantum causal model with the natural causal structure (that of Fig. 6) to be feasible only if the observed correlations satisfy the so-called Cirel'son bound, which is a generalization of a Bell inequality [27]. A simple case of quantum causal inference that has been investigated recently is the problem of distinguishing a cause-effect relation from a common-cause relation. Here, it has been shown that the quantum correlations can distinguish the two cases even in uncontrolled experiments, implying a quantum advantage for causal inference [28].
In quantum causal models, variables are replaced by sys- tems, each represented by a Hilbert space, and one makes a distinction between observed systems, upon which a measurement is made, and latent systems. Sets of systems are described by joint quantum states (as opposed to the joint probability distributions that describe sets of variables), and the functional dependences are specified by unitary maps. A natural analogue of the classical causal inference problem is to make inferences about the causal structure and the parameters of the causal model given a joint quantum state on the observed systems. The natural analogue of the functional causal structures considered in this article are quantum causal structures together with a specification of the dimensions of the latent systems and the unitaries that describe the functional dependences. To derive a feasibility test for a functional causal structure, one must eliminate the real-valued parameters that specify the quantum state of the latent systems. For example, if a given latent system is 2-dimensional (the quantum analogue of a binary latent variable), there are three real-valued parameters needed to specify the state completely (as opposed to the one real parameter needed to completely specify a distribution over a classical bit). The expectation values of the three Pauli operators, for instance, suffice to do so. Nonetheless, one can still take advantage of the techniques from algebraic geometry employed in this work to eliminate these parameters and determine constraints on the quantum state of the observed systems. In this way, we ought to be able to derive feasability tests for functional causal structures in the quantum sphere.
## 6.3 Related work
The extent to which the mathematical tools associated to quantifier elimination are well-suited to problems of causal inference has been previously emphasized by Geiger and Meek [29]. Many authors have noted, in particular, the applicability of quantifier elimination to the problem of deriving tests for the feasibility of a causal structure when the cardinality of the latent variables is known. Ref. [29], for instance, used Cylindrical Algebraic Decomposition to derive equality and inequality constraints for a particular causal model. However the computational complexity of such brute-force quantifier elimination (doubly exponential in the number of parameters) means that its applications are limited to very simple examples.
Many previous works have appealed to implicitization procedures using Groebner bases to obtain equality constraints for causal models. Geiger and Meek [30], Garcia, Stillman and Sturmfels [31], and Garcia [32] have used implicitization to obtain the smallest algebraic variety that contains the semi-algebraic set of joint distributions over observed variables for various causal structures with known cardinalities of latent variables. This yields polynomial equalities on the joint distribution whose satisfaction are necessary conditions for compatibility with the causal structure. Kang and Tian [33] have also applied implicitization techniques to the problem of identifying polynomial equality constraints on observational and interventional distributions (using the framework supplied by Refs. [34, 35]).
Our work goes beyond these treatments insofar as it uses implicitization as one step in an algorithm that finds the semi-algebraic set itself rather than the smallest algebraic variety containing it. The second step is to use the extension theorem (described in Appendix A) to find inequality constraints on the joint probability distribution over observed variables from knowledge of the Groebner basis. To illustrate the difference, consider the observational equivalence class labelled (2 , 2) Id in our classification. This corresponds to a semi-algebraic set for which the smallest algebraic variety containing it is the plane p 10 = 0 . The intersection of this variety with the tetrahedral probability simplex is its p 10 = 0 facet. The semi-algebraic set, however, is a strict subset of this, the one satisfying the additional inequality ( p 01 +2 p 11 -2) 2 ≥ 4 p 00 .
One novel feature of our approach which distinguishes it from previous uses of implicitization is that we focus on deriving feasibility constraints for a causal structure with specific functional dependences. In previous approaches, the set of variables that needed to be eliminated included both the parameters describing the probability distributions for the root variables and the parameters describing the conditional probability distributions for each non-root variable. In our approach, the second sort of parameter is fixed and not in need of elimination. The restriction to binary variables ensures that the number of distinct possible functional dependences is relatively modest.
Finally, the use of Groebner bases in identifying or bounding parameters in a causal model has also been highlighted in previous work such as Garcia-Puente et al. [36].
After the completion of this work, we became aware of related independent works by Chaves [37] and Rossett et al. [38] which also derive nonlinear inequalities for determining the feasibility of certain causal structures. These authors consider structures which, like Bell scenarios, have multiple pairs of observed variables that are related as cause and effect (understood as setting-outcome pairs) but which, unlike Bell scenarios, can have more than one latent common cause acting on the outcome variables. Chaves simplifies the quantifier elimination problem that must be solved using a round of Fourier-Motzkin elimination, while Rossett et al. provide an inductive approach for deriving new inequalities from given inequalities for subgraphs of the causal network under consideration. Combining our approach with these other methods constitutes an interesting direction for future work.
## Acknowledgements
This research began while CML was completing the Perimeter Scholars International Masters program at Perimeter Institute. Research at Perimeter Institute is supported by the Government of Canada through Industry Canada and by the Province of Ontario through the Ministry of Research and Innovation.
## References
- [1] Judea Pearl, Causality (2nd edition) , Cambridge University Press, 2009.
- [2] P. Sprites and C. Glymour and R. Scheines, Causation, Prediction and Search , The MIT press, 2nd edition, 2000.
- [3] Dominik Janzing and Joris Mooij and Jonas Peters and Bernhard Scholkopf, Identifying counfounders using additive noise models , Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, 2009.
- [4] Patrick Hoyer and Dominik Janzing and Joris Mooij and Jonas Peters and Bernhard Scholkopf, Nonlinear causal discovery with additive noise models Neural Information Processing Systems Foundation , 2009.
- [5] J. Peters and D. Janzing and B. Scholkopf, Causal inference on Discrete Data using Additive Noise Models , IEEE TPAMI vol. 33 no. 12 2436-2450, 2011.
- [6] J. Peters and J. M. Mooij and D. Janzing and B. Scholkopf, Causal discovery with continuous additive noise models , Journal of Machine Learning Research 15:2009-2053, 2014.
- [7] D. Cox and J. Little and D. O'Shea, Ideals, Varieties and Algorithms: An Introduction to Computational Algebraic Geometry and Commutative Algebra , Springer Verlag, New York, 2007.
- [8] B. Mishra, Algorithmic algebra , Springer Verlag, New York, 2012.
- [9] Magali Bardet, On the complexity of a Groebner basis algorithm , Algorithms Seminar, 20022004. 2005.
- [10] John S. Bell, Speakable and Unspeakable in Quantum Mechanics , Cambridge University Press, 1964.
- [11] John F. Clauser, Michael A. Horne, Abner Shimony, and Richard A. Holt, Proposed Experiment to Test Local Hidden-Variable Theories , Phys. Rev. Lett. 23 880, 1969.
- [12] Nicolas Brunner, Daniel Cavalcanti, Stefano Pironio, Valerio Scarani, and Stephanie Wehner, Bell nonlocality , Rev. Mod. Phys. 86, 419, 2014.
- [13] Christopher J. Wood and Robert W. Spekkens, The lesson of causal discovery algorithms for quantum correlations: Causal explanations of Bell-inequality violations require fine-tuning , New J. Phys. 17, 033002, 2015.
- [14] T. Fritz, Beyond Bell's theorem: Correlation scenarios New J. Phys. 14 103001, 2012
- [15] Greg Ver Steeg, Aram Galstyan, A Sequence of Relaxations Constraining Hidden Variable Models , Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence, UAI 2011.
- [16] Blai Bonet, Instrumentality Tests Revisited Proceedings of the 17th Conference on Uncertainty in Artificial Intelligence, 2001.
- [17] Costantino Budroni, and Adan Cabello, Bell inequalities from variable elimination methods , J. Phys. A: Math. Theor. 45 (2012) 385304.
- [18] Tobias Fritz, and Rafael Chaves, Entropic Inequalities and Marginal Problems , IEEE Trans. on Information Theory, vol. 59, pages 803 - 817 (2013).
- [19] T. Fritz, Beyond Bell's theorem II: Scenarios with arbitrary causal structure , Comm. Math. Phys. 341(2), 391-434, 2016.
- [20] R. Chaves and R. Kuen and J. Brask and D. Gross, A unifying framework for relaxations of the causal assumptions in Bell's theorem Phys. Rev. Lett. 114, 140403, 2015.
- [21] R. Chaves and C. Majenz and D. Gross, InformationTheoretic implications of Quantum Causal Structures , Nature Communications 6, 5766, 2015.
- [22] A. Tavakoli and P. Skrzypczyk and D. Cavalcanti and A. Acin, Non-local correlations in the star-network configuration , Phys. Rev. A 90, 062109, 2014.
- [23] C. Branciard and D. Rosset and N. Gisin and S. Pironio, Bilocal versus nonbilocal correlations in entanglement swapping , Phys. Rev. A 85, 032129, 2012.
- [24] M. S. Leifer and R. W. Spekkens, Formulating quantum theory as a causally neutral theory of bayesian inference , Phys. Rev. A 88, 052130 (2013).
- [25] J. Hensen and R. Lal and M. F. Pusey, Theoryindependent limits on correlations from generalised bayesian networks , New J. Phys. 16, 113043, 2014.
- [26] J. Pienaar and C. Brukner, A graph-separation theorem for quantum causal models New J. Phys. 17 073020, 2015.
- [27] B. S. Cirel'son, Quantum generalisations of Bell's inequality Lett. Math. Phys. Volume 4, Issue 2, 1980.
- [28] K. Ried and M. Agnew and L. Vermeyden and D. Janzing and R. W. Spekkens and K. Resch, A quantum advantage for inferring causal structure , Nature Physics 11, 414 2015.
- [29] D. Geiger and C. Meek, Quantifier elimination for statistical problems , Proceedings of the 15th Conference on Uncertainty in artificial intelligence, 1999.
- [30] D. Geiger and C. Meek, Graphical models and exponential families , Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence, 1998.
- [31] L. D. Garcia, M. Stillman, and B. Sturmfels, Algebraic geometry of bayesian networks. Journal of Symbolic Computation, 39(34):331355, 2005.
- [32] Luis David Garcia, Algebraic Statistics in Model Selection , Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, 2004.
- [33] Changsung Kang, and Jin Tian , Polynomial Constraints in Causal Bayesian Networks , Proceedings of the 23rd Conference on Uncertainty in Artificial Intelligence, 2007.
- [34] Jin Tian, Judea Pearl, On the Testable Implications of Causal Models with Hidden Variables , Proceedings of the 18th Conference on Uncertainty in Artificial Intelligence, 2002.
- [35] Changsung Kang, and Jin Tian , Inequality Constraints in Causal Models with Hidden Variables , Proceedings of the 22nd Conference on Uncertainty in Artificial Intelligence, 2006.
- [36] L. D. Garc´ ıa-Puente and S. Spielvogel and Seth Sullivant, Identifying causal effects with computer algebra , Proceedings of the 26th Conference on Uncertainty in Artificial Intelligence, 2010.
- [37] R. Chaves, Polynomial Bell inequalities , Phys. Rev. Lett. 116, 010402 (2016)
- [38] D. Rosset, C. Branciard, T. J. Barnea, G. Ptz, N. Brunner, and N. Gisin, Nonlinear Bell Inequalities Tailored for Quantum Networks , Phys. Rev. Lett. 116, 010403 (2016)
## Appendices
## A Ideals, varieties and Groebner bases
We now introduce useful concepts and tools from algebraic geometry that we will make use of in solving the problem mentioned in section 2 of the main text. We will follow the presentation given in [7].
We define a monomial in x 1 , . . . , x n to be a product of the form x α 1 1 x α 2 2 . . . x α n n , where the exponents are non-negative integers, α i ∈ Z ≥ 0 for i = 1 , . . . , n . We can simplify our notation slightly by letting α = ( α 1 , . . . , α n ) and setting
<!-- formula-not-decoded -->
We can now define a polynomial over a field k .
Definition A.0.1. A polynomial f in x 1 , . . . , x n with coefficients in a field k is a finite linear combination of monomials. We write f as
<!-- formula-not-decoded -->
where the sum is taken over a finite number of α 's.
The set of all polynomials in x 1 , . . . , x n with coefficients in k is denoted k [ x 1 , . . . , x n ] . When we deal with polynomials we are mainly interested in the solution set of systems of polynomial equations. This leads us to the main geometrical objects studied in algebraic geometry, algebraic varieties and semi-algebraic sets, which we now define.
Definition A.0.2. Let k be a field and let f 1 , . . . , f s be polynomials in k [ x 1 , . . . , x n ] . Then we set
<!-- formula-not-decoded -->
We call V ( f 1 , . . . , f s ) the algebraic variety (also called the affine variety ) defined by f 1 , . . . , f s .
Thus, an algebraic variety V ( f 1 , . . . , f s ) ⊂ k n is the solution set of the system of polynomial equations f 1 ( x 1 , . . . , x n ) = · · · = f s ( x 1 , . . . , x n ) = 0 . A basic semi-algebraic set is defined to be the solution set of a system of polynomial equalities and in equalities, that is:
Definition A.0.3. A basic semi-algebraic set is defined by { x ∈ R n : g i ( x ) 0 , ∀ i = 1 , . . . , m } , where g 1 , . . . , g n ∈ R [ x 1 , . . . , x n ] are polynomials over the reals 8 and where corresponds to either ≥ , = , or ≤ .
Note that algebraic varieties are examples of basic semi-algebraic sets.
Definition A.0.4. A semi-algebraic set is formed by taking finite combinations of unions, intersections, or complements of basic semi-algebraic sets.
For any causal model, the set of possible joint distributions that can be generated by it are represented by a semi-algebraic set. It follows that two causal models are observationally equivalent if and only if they generate the same semi-algebraic set.
We now introduce and define ideals , the main algebraic object studied in algebraic geometry.
Definition A.0.5. A subset I ⊂ k [ x 1 , . . . , x n ] is an ideal if it satisfies:
1. 0 ∈ I ,
2. If f, g ∈ I , then f + g ∈ I ,
3. If f ∈ I and h ∈ k [ x 1 , . . . , x n ] , then hf ∈ I .
A natural example of an ideal is the ideal generated by a finite number of polynomials.
Definition A.0.6. Let f 1 , . . . , f s be polynomials in k [ x 1 , . . . , x n ] . Then we set
<!-- formula-not-decoded -->
It is not hard to show that 〈 f 1 , . . . , f s 〉 is an ideal. We call it the ideal generated by f 1 , . . . , f s and we call f 1 , . . . , f s the basis of the ideal.
8 Note that one can replace the real field R used in the last definition with any ordered field.
Studying the relations between certain ideals and varieties forms one of the main areas of study in algebraic geometry. One can even define the algebraic variety V ( I ) defined by the ideal I ⊂ k [ x 1 , . . . , x n ] , where
<!-- formula-not-decoded -->
The proof that V ( I ) forms an algebraic variety can be found in [7]. Interestingly, it can also be shown that if I = 〈 f 1 , . . . , f s 〉 , then V ( I ) = V ( f 1 , . . . , f s ) . That is to say that varieties are determined by ideals . This will have interesting consequences for us, as we will see shortly.
To find a general solution to the implicitization problem introduced in the main text we need to introduce monomial orderings and Groebner bases.
First, note that we can reconstruct the monomial x α 1 1 . . . x α n n from the n -tuple of exponents ( α 1 , . . . , α n ) ∈ Z n ≥ 0 . This establishes a one-to-one correspondence between Z n ≥ 0 and monomials in k [ x 1 , . . . , x n ] . It follows that any ordering > on the space Z n ≥ 0 will induce an ordering on monomials: if α > β according to this ordering, then we will also say that x α > x β .
Now, we want the induced ordering to be 'compatible' with the algebraic structure of the polynomial ring that our monomials live in. This requirement leads us to the following definition.
Definition A.0.7. A monomial ordering on k [ x 1 , . . . , x n ] is any relation > on Z n ≥ 0 satisfying:
1. > is a total ordering on Z n ≥ 0 . That is to say that, for every α, β ∈ Z n ≥ 0 either α > β , β > α or α = β .
2. If α > β and γ ∈ Z n ≥ 0 , then α + γ > β + γ .
3. > is a well ordering on Z n ≥ 0 . This means that every non-empty subset of Z n ≥ 0 has a smallest element under > .
The main monomial ordering we will make use of here is the lexicographic order , which we define as follows.
Definition A.0.8 (Lexicographic order) . Let α = ( α 1 , . . . , α n ) and β = ( β 1 , . . . , β n ) ∈ Z n ≥ 0 . We say α > lex β if, in the vector difference α -β ∈ Z n , the leftmost non-zero entry is positive. We will write x α > lex x β if α > lex β .
Once we fix a monomial order, each f ∈ k [ x 1 , . . . , x n ] has a unique leading term LT ( f ) relative to this order. We denote by LT ( I ) the set of leading terms of elements of the ideal I . We can then define 〈 LT ( I ) 〉 to be the ideal generated by the elements of LT ( I ) . Consider a finitely generated ideal I = 〈 f 1 , . . . , f s 〉 , it is interesting to note that 〈 LT ( f 1 ) , . . . , LT ( f s ) 〉 and 〈 LT ( I ) 〉 may in general be different ideals. But surprisingly there always exists [7] a choice of basis g 1 , . . . , g t ∈ I such that 〈 LT ( g 1 ) , . . . , LT ( g t ) 〉 = 〈 LT ( I ) 〉 . These bases are know as Groebner bases .
Definition A.0.9. Fix a monomial ordering. A finite subset G = { g 1 , . . . , g t } of an ideal I is said to be a Groebner basis if
<!-- formula-not-decoded -->
More informally, a set G = { g 1 , . . . , g t } ⊂ I is a Groebner basis for I if and only if the leading term of any element of I is divisible by (at least) one of the LT ( g i ) . Groebner bases simplify performing many calculations in algebraic geometry and they have many interesting properties, some of which we will see shortly. There are efficient algorithms for calculating Groebner bases and many software packages that one can use to implement them. An example of a Groebner basis was given in the main text. Our use of the Groebner basis in that example was a special case of a general result, known as the elimination theorem , which provides us with a way of using Groebner bases to systematically eliminate certain variables from a system of polynomial equations and thereby solve the implicitization problem. We will state the elimination theorem shortly. First, we require the following definition.
Definition A.0.10. Given I = 〈 g 1 , . . . , g t 〉 ⊂ k [ x 1 , . . . , x n ] , the l th elimination ideal I l is the ideal of k [ x 1 , . . . , x n ] defined by
<!-- formula-not-decoded -->
Thus I l consists of all consequences of g 1 = · · · = g t = 0 which eliminate the variables x 1 , . . . , x l . Using this language, we see that eliminating x 1 , . . . , x l means finding non-zero polynomials in the l th elimination ideal of k [ x l +1 , . . . , x n ] . With the proper ordering, Groebner bases allow us to do this instantly. We can now state the elimination theorem (for a proof, see [7]).
Theorem A.0.11 (Elimination theorem) . Let I ⊂ k [ x 1 , . . . , x n ] be an ideal and let G be a Groebner basis for I with respect to the lex order where x 1 > x 2 > · · · > x n . Then, for every 0 ≤ l ≤ n , the set
<!-- formula-not-decoded -->
is a Groeber basis of the l th elimination ideal.
Fig. 7: (a) A = µν and B = µ ⊕ ν ⊕ µν .
<details>
<summary>Image 15 Details</summary>
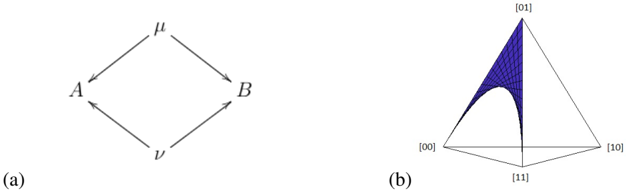
### Visual Description
\n
## Diagram: Relationship and Ternary Plot
### Overview
The image presents two diagrams: (a) a directed graph illustrating relationships between elements A, B, and ν, and (b) a ternary plot representing a compositional space.
### Components/Axes
**(a) Directed Graph:**
* Nodes: A, B, ν (nu)
* Edges: A → μ, μ → B, B → ν, ν → A
* Label: μ (placed above the edge connecting A and B)
**(b) Ternary Plot:**
* Axes: Represented by corner labels [00], [10], and [11].
* Plot Surface: A triangular surface filled with a grid of lines.
* Color: The surface is colored in a dark blue.
### Detailed Analysis or Content Details
**(a) Directed Graph:**
The diagram shows a cyclic relationship between A, B, and ν. The arrows indicate the direction of influence or transformation. The element μ appears to be an intermediate state or process connecting A and B. The cycle is A -> μ -> B -> ν -> A.
**(b) Ternary Plot:**
The ternary plot represents a three-component system. The corners of the triangle represent pure compositions of each component. The coordinates [00], [10], and [11] likely represent the proportions of these components. The plot surface shows a distribution or relationship within this compositional space. The grid lines indicate specific compositional ratios. The dark blue color suggests a region of interest or a specific property associated with those compositions. The plot is a 3D representation of a triangular coordinate system.
### Key Observations
**(a) Directed Graph:**
The graph demonstrates a closed-loop system where each element influences the next in a cyclical manner.
**(b) Ternary Plot:**
The ternary plot shows a concentration of the grid lines towards the center of the triangle, suggesting a preference for intermediate compositions. The plot is symmetrical along the line connecting [10] and [11].
### Interpretation
**(a) Directed Graph:**
This diagram could represent a chemical reaction, a biological pathway, or a system of interacting agents. The element μ could be a catalyst or an intermediate product. The cyclic nature suggests a self-sustaining process.
**(b) Ternary Plot:**
The ternary plot is commonly used in materials science, geochemistry, and other fields to visualize the composition of mixtures. The plot suggests that the system favors compositions that are not purely one component but rather a blend of two or more. The specific shape of the distribution on the plot would reveal more about the properties of the system. The plot is a visual representation of a compositional space, where each point within the triangle represents a unique combination of three components. The plot is a 3D representation of a triangular coordinate system.
</details>
(b)
(
p
+2
p
)
≥
p
.
So, in our example with the fan depicted in Fig.1(b)-discussed in the main textg 3 and g 4 form a Groebner basis of the 2 nd elimination ideal and this is what allowed us to eliminate the variables q 1 and q 2 .
How do we know that we can extend solutions from the l th elimination ideal to the ( l -1) th ? More concretely, in our specific example of the fan, how do we know that the equation p 00 p 01 = p 10 p 11 defines the entire algebraic variety and not just some part of it? The following result shows us the conditions under which we can extent partial solutions to full ones.
Theorem A.0.12 (Extension theorem) . Let I ⊂ C [ x 1 , . . . , x n ] and let I 1 be the first elimination ideal of I . For each 1 ≤ i ≤ s , write f i in the form
<!-- formula-not-decoded -->
where N i ≥ 0 and g i ∈ C [ x 1 , . . . , x n ] is non-zero. Suppose we had a partial solution ( a 2 , . . . , a n ) ∈ V ( I 1 ) . If ( a 2 , . . . , a n ) / ∈ V ( g 1 , . . . , g s ) , then there exists a 1 ∈ C such that ( a 1 , . . . , a n ) ∈ V ( I ) .
When we work over (0 , 1) ⊂ R we also, in conjunction with the conditions of the above theorem, need to ensure that at every extension step the new solution is real and lies in (0 , 1) .
We can apply the above theorem to our example to see that, indeed, the equation p 00 p 01 = p 10 p 11 defines the smallest algebraic variety that contains the semi-algebraic set depicted in Fig.1(b) in the main text.
## B More examples of deriving tests for feasibility
Consider the functional causal structure of Fig. 7(a). The joint distributions that can arise from it are of the form
<!-- formula-not-decoded -->
The semi-algebraic set defined by P ( A,B ) is shown in Fig. 7(b). We refer to this variety as a StarFleet insignia . The Groebner basis for the ideal
<!-- formula-not-decoded -->
with respect to the lex order q 1 > q 2 > p 00 > p 01 > p 11 , is
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
The equation g 2 = 0 defines an equality constraint that restricts the joint probability distribution to the plane p 10 = 0 and therefore to the face of the tetrahedron containing the vertices [00] , [01] and [11] . In order to extend the partial solution { p 00 , p 01 , p 11 } to a full solution { q 1 , q 2 , p 00 , p 01 , p 11 } using the extension theorem, we must ensure that all the solutions are real. Now the equation g 3 = 0 allows us to write q 2 in terms of the p ij 's as follows
<!-- formula-not-decoded -->
So in order to ensure that q 2 ∈ R , we must set ( p 01 + 2 p 11 -2) 2 + 4( p 11 + p 01 -1) ≥ 0 . Using the normalisation condition and rearranging gives us
<!-- formula-not-decoded -->
which defines the semi-algebraic set depicted in Fig. 7(b). None of the remaining constraints 0 ≤ q i ≤ 1 , for i = 1 , 2 , 3 result in non-trivial relations among the p ij 's.
Fig. 8: (a) A = µν and B = µ ⊕ ν ⊕ δ . (b) | 4( p 10 -p 11 )( p 00 p 10 -p 01 p 11 ) | ≤ ( p 11 (2 p 01 +2 p 10 + p 00 ) -p 10 (2 p 00 + 2 p 11 + p 01 ) ) 2
<details>
<summary>Image 16 Details</summary>
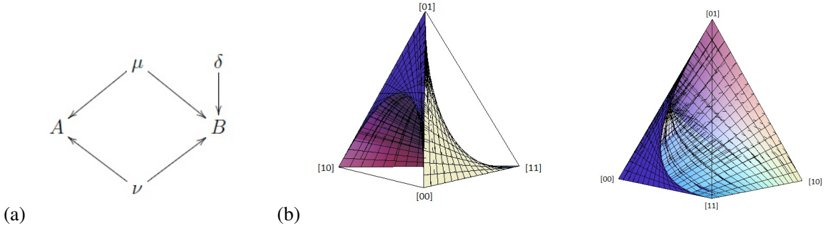
### Visual Description
\n
## Diagram: Ternary Diagram and Associated Flow
### Overview
The image presents three related diagrams. Diagram (a) is a directed graph illustrating a flow between elements A and B. Diagrams (b) and (c) are ternary diagrams, visually representing compositions of three components. The diagrams appear to be related to a system where components are transformed or related through the flow depicted in (a).
### Components/Axes
* **Diagram (a):**
* Nodes: A, B, ν (nu)
* Directed Edges: A → ν, ν → B, A → B, B → ν.
* Edge Labels: μ (mu), δ (delta)
* **Diagrams (b) & (c):**
* Axes: Represented by coordinates [00], [01], [10], and [11]. These likely represent proportions or concentrations of three components.
* The diagrams are triangular, with the corners representing 100% concentration of one component and 0% of the others.
* The diagrams are shaded to indicate varying values or concentrations within the triangle.
### Detailed Analysis or Content Details
* **Diagram (a):**
* The diagram shows a flow from A to ν, from ν to B, and directly from A to B and B to ν.
* The edge from A to ν is labeled 'μ', and the edge from ν to B is labeled 'δ'. The other edges are unlabeled.
* The diagram suggests a system with interconnected transformations or relationships between A, B, and ν.
* **Diagram (b):**
* The diagram is a ternary plot. The color gradient ranges from dark red/purple at the [00] corner to light yellow/white at the [11] corner, and blue at the [10] corner.
* The surface appears to be a curved plane within the ternary space.
* The diagram shows a gradient of values, with higher values concentrated towards the [11] corner and lower values towards the [00] corner.
* **Diagram (c):**
* Similar to (b), this is a ternary plot with a color gradient.
* The color gradient ranges from dark purple at the [00] corner to light blue/white at the [10] corner, and yellow/red at the [11] corner.
* The surface is also a curved plane, but with a different shape and gradient compared to diagram (b).
* The diagram shows a gradient of values, with higher values concentrated towards the [10] corner and lower values towards the [00] corner.
### Key Observations
* The ternary diagrams (b) and (c) represent different states or conditions within the same compositional space.
* The color gradients in the ternary diagrams indicate a continuous variation in the value or concentration of the components.
* The flow diagram (a) may represent the processes that lead to the different states shown in the ternary diagrams.
* The diagrams are visually connected, suggesting a relationship between the flow and the compositional changes.
### Interpretation
The image likely represents a system where components A, B, and ν interact. The flow diagram (a) illustrates the possible transformations or relationships between these components, with 'μ' and 'δ' potentially representing rates or probabilities of these transformations. The ternary diagrams (b) and (c) show the resulting compositions of the three components under different conditions or after different transformations.
The differences between diagrams (b) and (c) suggest that the system can reach different equilibrium states or exhibit different behaviors depending on the initial conditions or the specific parameters of the flow. The curved surfaces in the ternary diagrams indicate that the relationships between the components are not linear.
Without further context, it is difficult to determine the specific meaning of the components and the flow. However, the image suggests a complex system with interconnected elements and dynamic behavior. The diagrams could represent a chemical reaction, a biological process, or any other system where the composition of three components is important. The diagrams are likely used to visualize and analyze the behavior of the system under different conditions.
</details>
Consider the functional causal structure of Fig. 8(a). The joint distributions that can arise from it are of the form
<!-- formula-not-decoded -->
The semi-algebraic set defined by P ( A,B ) is shown from different angles in Fig. 8(b). We note that conditioning on the variable δ being equal to 0 or 1 reduces this variety to one of the star trek symbols depicted on the faces. Similarly conditioning on ν = 1 (or µ = 1 ) reduces this variety to a fan.
The Groebner basis for the ideal
<!-- formula-not-decoded -->
with respect to the usual lex order, is given by
<!-- formula-not-decoded -->
The equation g 2 = 0 is just the usual normalisation condition restricting the joint probability distribution to the tetrahedron.In order to use the extension theorem to extend a partial solution { p 00 , p 01 , p 10 , p 11 } to a full solution { q 1 , q 2 , q 3 , p 00 , p 01 , p 10 , p 11 } , we must ensure that each solution is real. The only situations in which we need to impose this is in the case of q 2 . The equation g 7 = 0 is a quadratic in q 2 and in order for its solutions to be real, we must stipulate that
<!-- formula-not-decoded -->
Using g 1 = 0 to write q 3 in terms of p 10 and p 11 and substituting this into g 5 = 0 gives us another quadratic in q 2 . For the solutions of this quadratic to be real we must enforce that
<!-- formula-not-decoded -->
Combining these two inequalities we get
<!-- formula-not-decoded -->
where | . | denotes the absolute value. None of the remaining constraints 0 ≤ q i ≤ 1 , for i = 1 , 2 , 3 result in non-trivial relations among the p ij 's.
Examining this inequality more closely, we see that setting p 10 = 0 reduces it to the inequality defining the StarFleet insignia, 4 p 01 ≤ (2 p 01 + p 00 ) 2 , on the face spanned by { [00] , [01] , [11] } , as it should (this is visible in Fig. 8(b)). Similarly, for p 11 = 0 we get the StarFleet insignia on the face { [00] , [01] , [10] } (also visible in Fig. 8(b)). The appearance of the term p 00 p 10 -p 01 p 11 is also noteworthy. Recall that the equation p 00 p 10 = p 01 p 11 defines the fan depicted in Fig.2(b) in the main text, so the above inequality quantitatively bounds the deviation from the surface of this fan by an amount proportional to the two star trek symbols discussed above. This is intuitively what we would expect from looking at the semi-algebraic set depicted in Fig. 8(b).
These examples cover all the different situations one may encounter while using algebraic geometry techniques to derive tests for feasibility of the causal models we are considering in this work. The remaining tests are derived in an analogous fashion.
## C Sufficiency of n -latent-bit models
We here present the proof of Theorem 4.2.1.
The example presented in section 4.2 suggests a general procedure for replacing an m -valued latent variable with some finite number of binary latent variables. Replace the m -valued variable with a number of substitute variables-the analogues of γ and η above, but which now can take an arbitrary number of values-such that any distribution over the m -valued variable can be simulated using a k -latent-bit causal model-the analogue of the causal model containing µ and ν above-underlying the substitute variables. By eliminating the intermediary variables, the dependence of the observed variables on the m -valued latent variable is replaced with a dependence on k binary latent variables.
We now describe a procedure for replacing an m -valued variable, for any m , by two variables γ and η in such a way that any distribution over the m -valued variable is obtained by some k -latent-bit causal model underlying γ and η .
Recall that for a 3-valued variable, we can take γ and η to be bits and use the fiducial model from class (2 , 1 , c ) Id , whose distribution is the convex combination of an edge of the tetrahedron and a vertex not contained in that edge. Similarly, for a 4-valued variable, we can take γ and η to be bits and use the fiducial model from class (3 , 2 , g ) Id , whose distribution is the convex combination of a face and vertex not contained in that face.
For a 5-valued variable, we can take γ to be a trit and η to be a bit. For any causal model underlying γ and η , the semialgebraic set generated by this model is now a subset of a simplex with six vertices, [ γη ] ∈ { [00] , [01] , [10] , [11] , [20] , [21] } We now construct a causal model underlying γ and η by combining two simpler models, using the procedure described in section 4 in the main text: the first model is one whose semi-algebraic set is the tetrahedron (considered as the subset of the six-simplex having [ γη ] ∈ { [00] , [01] , [10] , [11] } ) and the second is one whose semi-algebraic set is a vertex of the six-simplex not contained in the tetrahedron. A binary switch variable toggles between these two simpler models. Given the geometry, the semi-algebraic set defined by the model is clearly the convex combination of the tetrahedron and the vertex outside the tetrahedron. In particular, we can take the first model to be the fiducial model from class (3 , 3) Id (where γ is replaced by a trit but its dependence on its causal parents is unchanged) and the second model to be a deterministic model that sets γ = 2 and η = 0 . Denoting the switch variable by ρ , and the other latent bits by µ , ν , δ (as in the row containing class (3 , 3) Id ), we obtain the following functional dependences by the switch-variable construction: γ = ρ ( µν ⊕ 2 1) ⊕ 3 2( ρ ⊕ 2 1) and η = ρ ( µνδ ⊕ 2 ν ) . One easily verified that if ρ = 1 , one recovers the fiducial model of class (3 , 3) Id and hence the tetrahedron spanned by [ γη ] ∈ { [00] , [01] , [10] , [11] } , while if ρ = 0 , one obtains the point [ γη ] = [20] .
By increasing the number of values that γ and η can take, one can ensure that the number of vertices in the space of distributions over γ and η is at least m , such that one can simulate an m -valued latent variable by finding a causal model underlying γ and η whose semi-algebraic set is an m -simplex. To construct such a model, we apply the switch-variable construction to a pair of simpler models, one of which has an semi-algebraic set corresponding to an ( m -1) -simplex, and the other of which is a deterministic model corresponding to a vertex outside of this ( m -1) -simplex. In this way, we can recursively build up a causal model involving only binary latent variables whose semi-algebraic set is an m -simplex for any m .