## Modeling the dynamics of dissent
Eun Lee a , Petter Holme a,b , Sang Hoon Lee c,1, ∗
a Department of Energy Science, Sungkyunkwan University, Suwon 16419, Republic of Korea b Institute of Innovative Research, Tokyo Institute of Technology, Yokohama, Kanagawa 226-8503, Japan c School of Physics, Korea Institute for Advanced Study, Seoul 02455, Republic of Korea
## Abstract
We investigate the formation of opinion against authority in an authoritarian society composed of agents with different levels of authority. We explore a 'dissenting' opinion, held by lower-ranking, obedient, or less authoritative people, spreading in an environment of an 'affirmative' opinion held by authoritative leaders. A real-world example would be a corrupt society where people revolt against such leaders, but it can be applied to more general situations. In our model, agents can change their opinion depending on their authority relative to their neighbors and their own confidence level. In addition, with a certain probability, agents can override the affirmative opinion to take the dissenting opinion of a neighbor. Based on analytic derivation and numerical simulations, we observe that both the network structure and heterogeneity in authority, and their correlation, significantly affect the possibility of the dissenting opinion to spread through the population. In particular, the dissenting opinion is suppressed when the authority distribution is very heterogeneous and there exists a positive correlation between the authority and the number of neighbors of people (degree). Except for such an extreme case, though, spreading of the dissenting opinion takes place when people have the tendency to override the authority to hold the dissenting opinion, but the dissenting opinion can take a
∗ Corresponding author
Email address: lshlj82@gntech.ac.kr (Sang Hoon Lee)
1 Present address: Department of Liberal Arts, Gyeongnam National University of Science and Technology, Jinju 52725, Republic of Korea
long time to spread to the entire society, depending on the model parameters. We argue that the internal social structure of agents sets the scale of the time to reach consensus, based on the analysis of the underlying structural properties of opinion spreading.
Keywords: Opinion dynamics, Complex network, Authoritarian society
## 1. Introduction
How much an opinion against a firmly established authority can spread in a population is an important estimate of the population's adaptability [1], in particular when there exists a strong heterogeneity in the distribution of influential power regarding opinion formation. The topic of opinion formation has been studied widely to reveal the hidden mechanisms of a collective opinion dynamics on social networks [2-5]. There has been a wide variety of opinion formation models, such as the voter model [6, 7], the majority rule model [8], the bounded confidence model [9], and the Sznajd model [10]. Many opinion formation models have focused on the effect of heterogeneity in a network structure for a global consensus [11] and considered heterogeneous distributions of personal characteristics-gender, age, job, economic level, personal interests [12, 13], and so on, as those two areas of heterogeneity are important for opinion dynamics on networks [14, 15].
However, most of those opinion formation models mix the concept of heterogeneity in the individual level with the heterogeneity in social structures, even though structural and individual heterogeneity can be independent of each other [16, 17]. Previous studies derive the personal heterogeneity in influential power from the structural heterogeneity, such as the number of neighbors (or 'degree,' in the terminology of network science) [11] or PageRank (or 'eigenvector centrality') [18, 19]. There have been other attempts to highlight heterogeneity in individual attributes [20-23], as well as in authority dispersion and in asymmetric options. [24] and asymmetric opinions [25]. Nevertheless, all these are different from the genuine authority dispersion, so we are still lack
understanding of the transmission of opinions held by non-influential agents, grounded in the heterogeneity of both network-structural properties and influential power or authority. To address this need, in this paper, we investigate the following questions: when a population is composed of different levels of authority of agents, how can an opinion held by obedient agents with less influential power be spread to the whole population? How do the structure and authority collectively contribute to the spreading process?
To answer these questions, we introduce a stylized opinion formation model in a population with the prescribed authority scores assigned to its agents, who are connected via networks [26]. We assume heterogeneously distributed authority scores assigned to the agents, and each agent additionally has two essential characteristics: the willingness to uphold a dissenting opinion against authority and the confidence level for their own opinion. The probability of dissent is characterized by the parameter hinted at in the experiment of Milgram [27], which exemplifies the obedient tendency to an authoritative person's injustice order for the individual level, along with the tendency to resist the authority when there exist companions who would do so together. The agents apply the social comparison process to judge the relative authority level [28]. An illustrative case is a corrupt society where authoritative agents have an agreement on a certain immoral decision, and a less influential population has a dissenting opinion against it. As the results of our analysis, we present the crucial role of the correlation between network structure and authority, via intrinsic social relations representing the authority comparison process.
## 2. Model
To model the society presented in Sec. 1, for each individual we take heterogeneous degree distributions representing heterogeneous networks structures where individuals reside, heterogeneous authority levels of the individuals, and the correlation between them. In addition, we also incorporate individuals' inner characteristics for the confidence to their own opinion and willingness to follow
the dissenting opinion. For heterogeneous structures, we construct a network composed of N agents as nodes; thus, we use the terms 'agent' and 'node' interchangeably in this paper. The edges between the nodes represent the relationship between the nodes on which the authority comparison and the opinion spreading are based.
For network generation, we use an unweighted and undirected scale-free network (SFN) without self-loop and multiple edges, from the configuration model [29]. The degree distribution follows the power-law, p ( k ) ∼ k -λ , which yields a degree sequence { k i } for node i ∈ { 0 , 1 , · · · , N -1 } (thus there exist N nodes in total). We set the minimum degree k min = 2 for the initial network construction. To keep the overall connectivity, we use the largest connected component from the initially constructed network for the dynamics of our model. We verify that the change of network sizes in terms of the number of nodes and edges due to this selection process is negligible. Given the resultant connected network, we adjust the degree exponent λ to control the degree heterogeneity, where the smaller λ results in more heterogeneous degree distributions. When λ = 2, the average degree 〈 k 〉 9, and the maximum degree k max 306. For λ = 3, 〈 k 〉 4 and k max 100. As the control group compared to such heterogeneous structures, we also take the fully connected network to simulate the well-mixed population, which is expected to more accurately follow the result of the analytic derivation based on the mean-field approximation in Sec. 3.
For the authoritarian structure, we assign an intrinsic authority score { s i } to each node i ∈ { 0 , 1 , · · · , N -1 } . To generate heterogeneous authority scores, we extract random numbers (real numbers, in contrast to the natural numbers for the degree sequence { k i } by definition) from the power-law distribution p ( s ) ∼ s -γ with the minimum value of unity. The setup is inspired by the Pareto distribution [30] of wealth and income, which are indirect representatives of authority. Therefore, in general, we have two sets of power-law distributed values: λ for the degrees { k i } and γ for the authority scores { s i } . For simplicity, however, we use the same power-law exponent for the authority score and degree, i.e., λ = γ in our model, assuming that the same power-law exponent controls
both structural and authoritarian heterogeneities. The set of authority scores { s i } for agents i ∈ { 0 , 1 , · · · , N -1 } will be correlated with the agents' degree with different types of correlations. In addition, we take the two representative cases for the degree exponent to see the effect of the heterogeneity of degree distribution: relatively heterogeneous γ = 2 and relative homogeneous γ = 3.
To investigate the effect of the correlation between authority and network structures [16, 17], we take three types of correlations: positive, no (uncorrelated), and negative correlations. The positive correlation implies that agents with higher authority scores have larger degree values. To control the correlation in practice, we sort both { s i } and { k i } from the smallest to the largest and match the indices of the sorted { s i } with the sorted { k i } in their exact order (as a result, the rank-based correlations such as Spearman's r or Kendall's τ = 1). The negative correlation is achieved by the opposite way of ordering, i.e., matching the indices using the ascending order for { s i } and the descending order for { k i } (the rank-based correlations = -1). The uncorrelated case corresponds to the random matching (the rank-based correlations 0 on average).
Each agent in the model selectively accepts her neighbor's opinion or keeps her own opinion, depending on the result of the authority comparison [28]. In addition, she also has an intrinsically biased probability toward the dissenting opinion. We consider two personal characteristics for the comparison process: the confidence parameter α and the acceptance probability of the dissenting opinion p . Here, α and p are global variables at a societal level, i.e., every agent has the same α and p , for simplification. Each agent i has the time-dependent binary opinion variable σ i ( t ) ∈ { 0 , 1 } at time t , where 0 represents the authoritative opinion and 1 represents the dissenting opinion in our convention. If we assume a corrupt society where an immoral opinion of the dominant authority prevails, the dissenting opinion of less influential people would be a desirable choice. Throughout the paper, therefore, we use the expression 'dissenting' or 'opposing' opinion for the less influential people's opinion, as the opposite of the 'authoritative' or 'affirmative' opinion held by authoritative people.
For the temporal evolution of the agents' opinion, at each time step, we
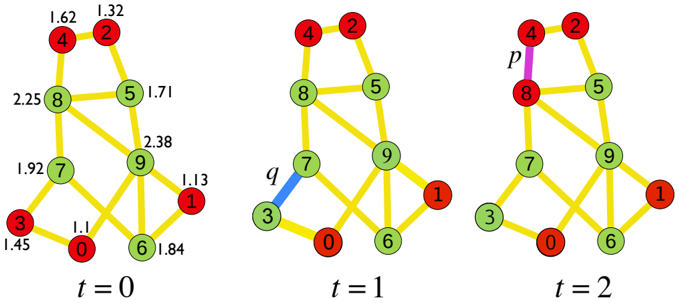
Figure 1: Snapshots of the opinion change in our model. The numbers inside the nodes indicate the relative rank i ∈ { 0 , 1 , . . . 9 } for authority, where the larger values correspond to higher authority, which are used as the node indices in our description. The color of the nodes represents their opinion: red for the dissenting opinion ( σ i = 1) and green for the affirmative ( σ i = 0) opinions. The numbers outside the nodes indicate the authority scores { s i | i = 0 , 1 , . . . 9 } . The nodes compare their authority scores by Eq. (1). For instance, node 3 chooses node 7 for the comparison (the blue edge), and takes node 7's opinion ( σ 3 = 0 → 1 at t = 1, because σ 7 ( t = 0) = 0 and q ( s 3 , s 7 ; α ) < 0 (corresponding to the ' q ' process as denoted in the figure) in Eq. (1) when node 7 has a larger authority score than that of node 3. At t = 2, node 8 chooses node 4 (the purple edge), and with the probability p (corresponding to the ' p ' process as denoted in the figure), regardless of their authority scores, node 8 takes the dissenting ( σ 4 = 1) opinion of node 4 ( σ 8 = 0 → 1).
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Network Evolution over Time
### Overview
The image presents a series of three network diagrams illustrating the evolution of a network over three time steps (t=0, t=1, and t=2). The network consists of nine nodes, labeled 1 through 9, connected by edges. Each edge is labeled with a numerical value, presumably representing a weight or distance. The diagrams show how the network connections change over time, with some edges appearing, disappearing, or changing their weights.
### Components/Axes
The diagrams do not have traditional axes. They consist of nodes (circles) and edges (lines) connecting the nodes. Each edge has a numerical label. The time step is indicated below each diagram (t=0, t=1, t=2). At t=2, two edges are highlighted in different colors: a purple edge labeled 'p' and a blue edge labeled 'q'.
### Detailed Analysis or Content Details
**t = 0:**
* Nodes: 1, 2, 3, 4, 5, 6, 7, 8, 9
* Edges and Weights:
* 1-6: 1.84
* 1-9: 1.13
* 2-4: 1.62
* 2-8: 1.32
* 3-1: 1.45
* 3-7: 1.92
* 4-2: 1.62
* 4-8: 2.25
* 5-8: 1.71
* 5-9: 2.38
* 6-1: 1.84
* 7-3: 1.92
* 7-9: 2.38
* 8-2: 1.32
* 8-4: 2.25
* 8-5: 1.71
* 9-5: 2.38
* 9-7: 2.38
* 9-1: 1.13
**t = 1:**
* Nodes: 1, 2, 3, 4, 5, 6, 7, 8, 9
* Edges and Weights:
* 1-6: 1.84
* 1-9: 1.13
* 2-4: 1.62
* 2-8: 1.32
* 3-7: 1.92
* 4-2: 1.62
* 4-8: 2.25
* 5-8: 1.71
* 5-9: 2.38
* 6-1: 1.84
* 7-3: 1.92
* 7-9: 2.38
* 8-2: 1.32
* 8-4: 2.25
* 8-5: 1.71
* 9-5: 2.38
* 9-7: 2.38
* 3-7: 1.92 (new edge)
* 3-7: 1.92
* 3-7: 1.92
* Highlighted Edge:
* 3-7: q (blue)
**t = 2:**
* Nodes: 1, 2, 3, 4, 5, 6, 7, 8, 9
* Edges and Weights:
* 1-6: 1.84
* 1-9: 1.13
* 2-4: 1.62
* 2-8: 1.32
* 3-1: 1.45
* 4-2: 1.62
* 4-8: 2.25
* 5-8: 1.71
* 5-9: 2.38
* 6-1: 1.84
* 7-3: 1.92
* 7-9: 2.38
* 8-2: 1.32
* 8-4: 2.25
* 8-5: 1.71
* 9-5: 2.38
* 9-7: 2.38
* Highlighted Edges:
* 3-7: q (blue)
* 4-8: p (purple)
### Key Observations
* The network appears to be relatively stable between t=0 and t=1, with only the addition of the edge 3-7.
* At t=2, the network returns to a configuration similar to t=0, but with the edges 3-7 and 4-8 highlighted.
* The edge weights remain constant throughout the three time steps.
* The highlighted edges 'p' and 'q' at t=2 suggest these edges are of particular interest or are involved in a specific process.
### Interpretation
The diagrams likely represent a dynamic network where connections are formed and potentially broken over time. The edge weights could represent distances, costs, or strengths of relationships between nodes. The evolution from t=0 to t=1 shows the addition of a connection between nodes 3 and 7. The return to a similar configuration at t=2, with the highlighting of edges 'p' and 'q', could indicate a cyclical process or a specific path being emphasized.
The highlighting of edges 'p' and 'q' at t=2 suggests these edges are important for a particular analysis. They might represent critical paths, bottlenecks, or edges involved in a specific event. The network's evolution could be modeling a communication network, a transportation system, or a social network, where connections represent interactions or relationships. The cyclical nature of the changes suggests a dynamic equilibrium or a repeating pattern. The diagram is a visual representation of a network's state at different points in time, allowing for the analysis of its evolution and the identification of key features.
</details>
Table 1: The decision table for σ i ( t +1), where Θ[ q ] with q ≡ q ( s i , s j ; α ) in Eq. (1) is the Heaviside step function.
| | σ j ( t ) = 1 | σ j ( t ) = 0 |
|-------|---------------------------|-----------------|
| p | 1 | σ i ( t )Θ[ q ] |
| 1 - p | 1 - [1 - σ i ( t )]Θ[ q ] | σ i ( t )Θ[ q ] |
select a node (denoted by i ) uniformly at random and also choose one of its neighbors, denoted by j , uniformly at random. Then, node i first checks node j 's opinion. If σ j ( t ) = 1 (the dissenting opinion), with the probability p (denoted by the ' p ' process in Fig. 1), she accepts the dissenting opinion of node j , i.e., σ i ( t +1) = 1, regardless of her current opinion σ i ( t ) and their relative authority scores s i and s j . With the complementary probability 1 -p when σ j ( t ) = 1, or when σ j ( t ) = 0, node i compares her authority score with that of node j and decides whether or not she follows node j 's opinion, regardless of the current σ j ( t ) value (denoted by the ' q ' process in Fig. 1). The criterion is calculated based on their authority scores s i and s j , and the confidence level α . It is based on the impact function
<!-- formula-not-decoded -->
If q ( s i , s j ; α ) ≥ 0, node i keeps her opinion, i.e., σ i ( t +1) = σ i ( t ). Otherwise, if q ( s i , s j ; α ) < 0, node i follows node j 's opinion, i.e., σ i ( t +1) = σ j ( t ). Therefore, large values of α represent a stronger tendency to keep the nodes' own opinion. We believe that this rule captures an aspect of human psychology revealed by the experiment of Milgram [27]-the existence of a companion who raises the dissenting opinion is crucial for an individual's objection to the immoral authority. Note that the present model includes the conventional voter model as a limiting case when p = α = 0. Table 1 summarizes the rule, and Fig. 1 illustrates an example case of the opinion evolution.
## 3. Results
In this section, we present the numerical simulation results supported by the analytic calculation on the stability condition of the dissenting opinion, in regard to the correlation between the degree and the authority score with different degree heterogeneity, namely, γ = 2 and 3. We mainly focus on the final or steady-state fraction of the dissenting opinion in the network and the time to reach a consensus or steady state. The opinion averaged over agents and network realizations is expressed as
<!-- formula-not-decoded -->
where ν ∈ { 0 , 1 , · · · , n -1 } is the index of independent realization of a network sample and σ ν ; i ( t ) ∈ { 0 , 1 } (recall that 0 is the affirmative opinion and 1 is the dissenting opinion) is the opinion of agent i at time t , for the particular realization ν . In the simulations, we take N = 1000 and n = 2000, unless otherwise stated.
The average opinion m ( t ) eventually reaches the consensus m ( t ) = 0 or m ( t ) = 1 (which are the two absorbing states in our model, as no further change of opinion is possible once the network reaches one of the consensus states by the rule of our model) for a finite-size network, if we do not consider the practical time limitation. However, for finite-time simulations, there could be a steady state without reaching the consensus. When the average opinion m ( t ) only slightly fluctuates around a specific finite value (0 < m ( t ) < 1) for a sufficient period, we consider the state as the balanced point for the opinion change from 0 to 1 and from 1 to 0, which we denote by the nontrivial steady state.
We assume that the system reaches the nontrivial steady state if m ( t ) fluctuates within a given range (denoted by f ) for at least t c consecutive time steps, which is required for finite-size systems in finite-time numerical simulations. For practical simulations, we first wait for t max = 1000 time steps (we use the Monte Carlo time steps where N trials of opinion changes correspond to a single unit
of time, for numerical simulations) to check if the system reaches the absorbing states m ( t ) = 0 or m ( t ) = 1. When m ( t < t max ) = 0 or m ( t < t max ) = 1, we halt the simulation and record the consensus time denoted by τ . If the system does not reach the absorbing states until t = t max , we wait for the nontrivial steady state satisfying | m ν ( t -u +1) -m ν ( t -u ) | < f ∀ u ∈ { 0 , 1 , · · · , t c -2 , t c -1 } for t c consecutive times (we set f = 0 . 05 and t c = 1000 based on the fluctuation in our observation). When m ( t ) meets the nontrivial steady state criterion for the first time, we denote the time for reaching the nontrivial steady state by τ s = t . With N = 1000, the system always reaches the steady state with the given f value, if it does not reach the consensus before t max . Note that the consensus states m ( t ) = 0 and m ( t ) = 1 are also (denoted by 'trivial,' in that case) steady states, so τ s = τ for such cases. In other words, we denote both trivial and nontrivial steady states by τ s , and τ exclusively refers to the former case: consensus or absorbing states. With this setting, we explore the equally spaced parameter ranges α ∈ { 0 . 00 , 0 . 05 , ..., 0 . 95 , 1 . 00 } and p ∈ { 0 . 00 , 0 . 05 , ..., 0 . 95 , 1 . 00 } .
## 3.1. The fully connected network and the SFN without correlations
First, let us check the effects of authority heterogeneity only, by taking the fully connected network structure. Figure 2 shows m ( τ s ) in the fully connected network in which the authority scores of individual nodes keep the unique heterogeneity. To understand the result analytically, we derive the stability condition for the steady state of opinions. Basically, at time t , node i [with the authority score s i and opinion σ i ( t )] interacts with its random neighbor j [with s j and σ j ( t )]. Then, node i 's opinion at time t +1 is determined as Table 1.
In this case, all of the agents are statistically equivalent and the neighbors are chosen uniformly at random (well-mixed population). If we denote the fraction of agents with the opinion 1 at time t by m ( t ), the probability of σ i ( t ) = 1 and that of σ j ( t ) = 1 are also m ( t ) = 〈 σ i ( t ) 〉 , where the angular bracket denotes the agent-and-ensemble-averaged quantity and m ( t ) becomes equivalent to the definition in Eq. (2). According to Table 1, with the shorthand notation q ≡ q ( s i , s j ; α ) in Eq. (1) and m ≡ m ( t ), the probability of σ i ( t +1) = 1,
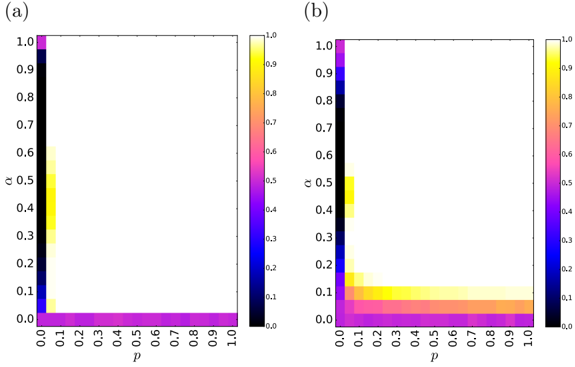
Figure 2: The average opinion m ( τ s ) at the steady state in Eq. (2) with N = 1000, averaged over n = 2000 realizations for the fully connected network case, with the authority heterogeneity exponents (a) γ = 2 and (b) γ = 3.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Heatmaps: Parameter Space Analysis
### Overview
The image presents two heatmaps, labeled (a) and (b), visualizing a two-dimensional parameter space defined by 'p' and 'q'. The color intensity represents a value associated with each (p, q) pair. Both heatmaps share the same axes scales, but display different distributions of color intensity.
### Components/Axes
Both heatmaps share the following components:
* **X-axis:** Labeled 'p', ranging from 0.0 to 1.0 with increments of approximately 0.1.
* **Y-axis:** Labeled 'q', ranging from 0.0 to 1.0 with increments of approximately 0.1.
* **Colorbar:** A vertical colorbar on the right side of each heatmap, ranging from approximately 0.0 (dark purple) to 1.0 (yellow). The colorbar indicates the value corresponding to each color.
### Detailed Analysis or Content Details
**Heatmap (a):**
* The heatmap shows a strong vertical gradient.
* The left side of the heatmap (low 'p' values) is predominantly purple, indicating values close to 0.0.
* As 'p' increases, the color transitions through shades of magenta, pink, yellow, and finally to a bright yellow at p=1.0 for q values between 0.3 and 0.7.
* For p values close to 1.0, the color is predominantly yellow, indicating values close to 1.0.
* The top-right corner (p=1.0, q=1.0) is yellow.
* The bottom-left corner (p=0.0, q=0.0) is dark purple.
**Heatmap (b):**
* The heatmap shows a more complex distribution of color intensity.
* The top-left corner (p=0.0, q=1.0) is dark purple, indicating values close to 0.0.
* There is a yellow region around (p=0.1, q=0.2), indicating a value close to 1.0.
* A diagonal band of yellow extends from approximately (p=0.2, q=0.2) to (p=0.6, q=0.6), indicating values close to 1.0.
* The bottom-right corner (p=1.0, q=0.0) is yellow, indicating values close to 1.0.
* The top-right corner (p=1.0, q=1.0) is dark purple, indicating values close to 0.0.
### Key Observations
* Heatmap (a) exhibits a clear dependence on the 'p' parameter, with 'q' having a minimal effect.
* Heatmap (b) shows a more complex relationship between 'p' and 'q', with regions of high and low values distributed across the parameter space.
* The color scales are identical, allowing for direct comparison of the values represented in each heatmap.
* The presence of distinct color regions in both heatmaps suggests that the underlying function is not smooth or continuous.
### Interpretation
The heatmaps likely represent the results of a simulation or calculation where 'p' and 'q' are input parameters. The color intensity indicates the value of some output variable or metric.
* **Heatmap (a)** suggests that the output is primarily determined by 'p', with 'q' having little influence. The output increases monotonically with 'p', reaching a maximum value of approximately 1.0 when 'p' is close to 1.0. This could represent a threshold effect, where the output only becomes significant when 'p' exceeds a certain value.
* **Heatmap (b)** indicates a more complex relationship between 'p' and 'q'. The presence of a diagonal band of high values suggests that the output is maximized when 'p' and 'q' are approximately equal. The isolated yellow region at (p=0.1, q=0.2) could represent a specific condition or scenario where the output is particularly high. The dark purple top-right corner suggests that the output is suppressed when both 'p' and 'q' are close to 1.0.
The difference between the two heatmaps suggests that the underlying model or system has been modified or that different parameters have been used in the two calculations. Further investigation would be needed to determine the specific meaning of 'p' and 'q' and the nature of the output variable.
</details>
or equivalently the average opinion of i is
<!-- formula-not-decoded -->
where we assume the independence of the current opinion and (static) authority and Pr[ q ≥ 0] denotes the probability that the inequality q ≥ 0 holds. Rearranging all of the terms and imposing the steady state condition 〈 σ i ( t +1) 〉 = 〈 σ i ( t ) 〉 = m , we obtain
<!-- formula-not-decoded -->
where replacing the instantaneous opinions σ i ( t ) and σ i ( t +1) with the averaged opinions 〈 σ i ( t ) 〉 = m ( t ) and 〈 σ i ( t +1) 〉 = m ( t +1) corresponds to our mean-field assumption.
For the network without any correlation between the degree and the authority score as the simplest case, which corresponds to both the fully connected
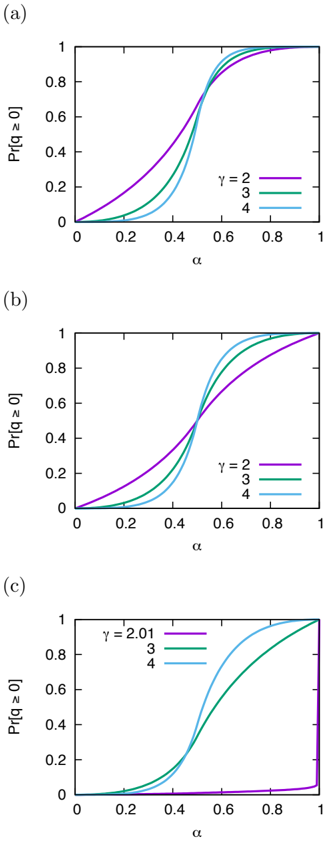
Figure 3: Pr[ q ≥ 0] for (a) the negatively correlated network case [Eq. (10)], (b) uncorrelated network case [Eq. (11)], and (c) positively correlated network case [Eq. (12)].
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Charts: Cumulative Distribution Functions (CDFs) for Different Gamma Values
### Overview
The image presents three separate charts (labeled a, b, and c) displaying cumulative distribution functions (CDFs). Each chart plots Pr(α > 0) against α, with different values of γ (gamma) represented by different colored lines. The charts appear to illustrate how the probability of α being greater than 0 changes as α increases, for varying γ values.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Labeled "α" (alpha), ranging from 0 to 1.
* **Y-axis:** Labeled "Pr(α > 0)" (Probability that alpha is greater than 0), ranging from 0 to 1.
* **Legend:** Located in the top-right corner of each chart, indicating the γ (gamma) values corresponding to each line color. The γ values are 2, 3, and 4.
* **Chart Labels:** Each chart is labeled with a letter: (a), (b), and (c) in the top-left corner.
### Detailed Analysis or Content Details
**Chart (a):**
* **Cyan Line (γ = 2):** The line starts at approximately Pr(α > 0) = 0.1 at α = 0, and rises steadily, crossing Pr(α > 0) = 0.5 at approximately α = 0.35, and reaching Pr(α > 0) = 0.9 at α = 0.75.
* **Magenta Line (γ = 3):** The line starts at approximately Pr(α > 0) = 0.05 at α = 0, and rises more steeply than the cyan line, crossing Pr(α > 0) = 0.5 at approximately α = 0.25, and reaching Pr(α > 0) = 0.9 at α = 0.65.
* **Green Line (γ = 4):** The line starts at approximately Pr(α > 0) = 0.02 at α = 0, and rises even more steeply than the magenta line, crossing Pr(α > 0) = 0.5 at approximately α = 0.2, and reaching Pr(α > 0) = 0.9 at α = 0.6.
**Chart (b):**
* **Cyan Line (γ = 2):** The line starts at approximately Pr(α > 0) = 0.1 at α = 0, and rises steadily, crossing Pr(α > 0) = 0.5 at approximately α = 0.35, and reaching Pr(α > 0) = 0.9 at α = 0.75.
* **Magenta Line (γ = 3):** The line starts at approximately Pr(α > 0) = 0.05 at α = 0, and rises more steeply than the cyan line, crossing Pr(α > 0) = 0.5 at approximately α = 0.25, and reaching Pr(α > 0) = 0.9 at α = 0.65.
* **Green Line (γ = 4):** The line starts at approximately Pr(α > 0) = 0.02 at α = 0, and rises even more steeply than the magenta line, crossing Pr(α > 0) = 0.5 at approximately α = 0.2, and reaching Pr(α > 0) = 0.9 at α = 0.6.
**Chart (c):**
* **Cyan Line (γ = 2.01):** The line starts at approximately Pr(α > 0) = 0.1 at α = 0, and rises steadily, crossing Pr(α > 0) = 0.5 at approximately α = 0.35, and reaching Pr(α > 0) = 0.9 at α = 0.75.
* **Magenta Line (γ = 3):** The line starts at approximately Pr(α > 0) = 0.05 at α = 0, and rises more steeply than the cyan line, crossing Pr(α > 0) = 0.5 at approximately α = 0.25, and reaching Pr(α > 0) = 0.9 at α = 0.65.
* **Green Line (γ = 4):** The line starts at approximately Pr(α > 0) = 0.02 at α = 0, and rises even more steeply than the magenta line, crossing Pr(α > 0) = 0.5 at approximately α = 0.2, and reaching Pr(α > 0) = 0.9 at α = 0.6.
### Key Observations
* In all three charts, the lines representing higher γ values (3 and 4) exhibit steeper slopes than the line representing the lower γ value (2 or 2.01). This indicates that for higher γ values, the probability of α being greater than 0 increases more rapidly as α increases.
* The charts (a) and (b) are identical.
* The curves are all sigmoid in shape, characteristic of cumulative distribution functions.
### Interpretation
These charts demonstrate the effect of the γ parameter on the cumulative distribution of α. The γ parameter likely controls the shape of the underlying probability distribution. A higher γ value results in a distribution where the probability of α being greater than 0 increases more quickly with increasing α. This suggests that higher γ values correspond to distributions with a more concentrated probability mass at higher α values. The identical nature of charts (a) and (b) suggests a potential redundancy or a deliberate repetition for emphasis. The data suggests a relationship between the gamma value and the distribution of alpha, where a higher gamma value leads to a faster increase in the probability of alpha being greater than zero. This could be indicative of a more skewed or concentrated distribution for higher gamma values.
</details>
network and the SFN without any correlation between the degree and the authority scores, let us consider the explicit form of Pr[ q ≥ 0]. We give the power-law form of the authority distribution p ( s ) = ( γ -1) s -γ with s min = 1 [for the proper normalization ∫ ∞ 1 ds p ( s ) = 1]. Then, because p ( s i ) and p ( s j ) are independent to each other, we express Pr[ q ≥ 0] as
<!-- formula-not-decoded -->
where Θ( q ) is the Heaviside step function (= 1 when q ≥ 0 and = 0 when q < 0). When α ≤ 1 / 2 [thus (1 -α ) /α ≥ 1],
<!-- formula-not-decoded -->
always, as s i ≥ 1. Therefore, the integral in Eq. (5) becomes
<!-- formula-not-decoded -->
When α > 1 / 2 [thus (1 -α ) /α < 1],
<!-- formula-not-decoded -->
so we have to split the integration range for s j in Eq. (5) as
<!-- formula-not-decoded -->
Combining the two cases, we obtain
<!-- formula-not-decoded -->
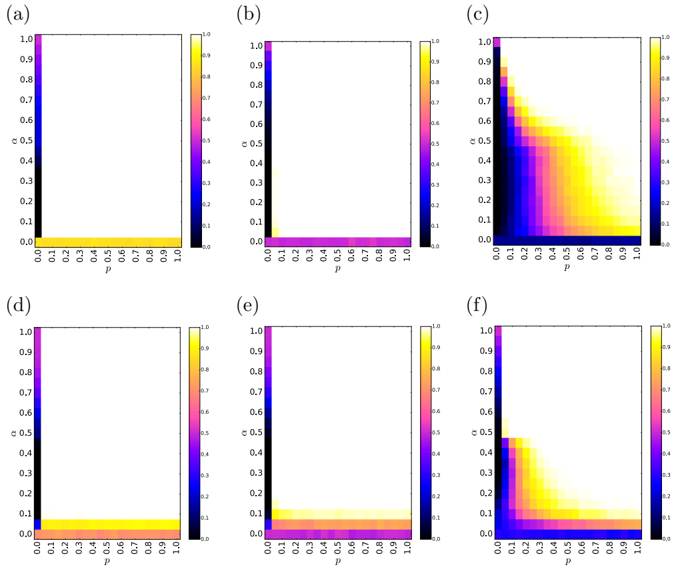
Figure 4: The average opinion m ( τ s ) at the steady state in Eq. (2) with N = 1000, averaged over n = 2000 realizations with different correlations between degree k and authority score s in different power-law exponents for authority and degree distribution. The upper panels are the γ = 2 cases with (a) negative, (b) no, and (c) positive correlations. The lower panels are the γ = 3 cases with (d) negative, (e) no, and (f) positive correlations.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Heatmaps: Correlation Matrices
### Overview
The image presents six heatmaps, labeled (a) through (f). Each heatmap appears to represent a correlation matrix, visualizing the relationship between two variables, 'p' and 'q', across a range of values from 0.0 to 1.0. The color intensity represents the correlation strength, with a colorbar indicating the mapping between color and correlation value.
### Components/Axes
Each heatmap shares the following components:
* **X-axis:** Labeled 'p', ranging from 0.0 to 1.0 with markers at 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0.
* **Y-axis:** Labeled 'q', ranging from 0.0 to 1.0 with markers at 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0.
* **Colorbar:** Located to the right of each heatmap, ranging from approximately 0.0 (dark purple) to 1.0 (yellow). The colorbar is labeled with numerical values representing correlation strength.
### Detailed Analysis or Content Details
Each heatmap displays a different correlation pattern. I will describe each individually:
**(a)**: The heatmap shows a strong positive correlation along the diagonal (where p = q). Values are approximately 1.0 along the diagonal. Correlation decreases as the difference between 'p' and 'q' increases. Values near 0.0 are observed in the bottom-left and top-right corners.
**(b)**: Similar to (a), a strong positive correlation is present along the diagonal (values around 1.0). However, the correlation drops off more rapidly as 'p' and 'q' diverge. Values near 0.0 are more prominent than in (a).
**(c)**: Again, a strong positive correlation along the diagonal (values around 1.0). The correlation decreases more gradually than in (b), but still shows a clear trend of decreasing correlation with increasing difference between 'p' and 'q'.
**(d)**: This heatmap exhibits a different pattern. While there's still a positive correlation along the diagonal (values around 1.0), the correlation remains relatively high even when 'p' and 'q' are different. The lower-left corner shows values around 0.2-0.3, indicating some positive correlation even at p=0.0 and q=0.0.
**(e)**: Similar to (d), a relatively high correlation is maintained across a wider range of 'p' and 'q' values. The diagonal shows values around 1.0, and the lower-left corner has values around 0.3-0.4.
**(f)**: This heatmap shows a pattern similar to (c) and (a), with a strong diagonal correlation (values around 1.0) and a decrease in correlation as 'p' and 'q' diverge. The lower-left corner shows values around 0.1-0.2.
### Key Observations
* All heatmaps exhibit a strong positive correlation when 'p' equals 'q' (diagonal).
* The rate at which correlation decreases as 'p' and 'q' diverge varies significantly between the heatmaps.
* Heatmaps (d) and (e) show a more sustained positive correlation even when 'p' and 'q' are different, suggesting a stronger underlying relationship between the variables.
* The color scales are consistent across all heatmaps, allowing for direct visual comparison of correlation strengths.
### Interpretation
These heatmaps likely represent the correlation between two parameters, 'p' and 'q', under different conditions or for different datasets. The variations in correlation patterns suggest that the relationship between 'p' and 'q' is not static and is influenced by external factors.
The strong diagonal correlation in all heatmaps indicates that when 'p' and 'q' are equal, they are highly related. The differences in the off-diagonal correlations suggest that the strength of this relationship depends on the specific context represented by each heatmap.
Heatmaps (d) and (e) suggest a more robust relationship between 'p' and 'q', as they maintain a relatively high correlation even when the values differ. This could indicate a fundamental connection between the variables that is not easily disrupted.
The variations between the heatmaps could be due to different experimental conditions, different datasets, or different stages of a process. Further investigation would be needed to determine the specific factors that contribute to these differences.
</details>
When α = 1 / 2, Eq. (10) gives Pr[ q ≥ 0] = 1 / 2 guaranteeing the continuity of the function. Another limiting case is α = 1, where Pr[ q ≥ 0] = 1 (agent i always beats agent j ). Figure 3(a) shows the functional form of Pr[ q ≥ 0] given by Eq. (10). If we substitute Pr[ q ≥ 0] in Eq. (10) into Eq. (4), as we usually consider γ > 1, the steady-state with 0 < m < 1 is possible for α = 0 or p = 0.
Therefore, when p > 0 and Pr[ q ≥ 0] > 0, for the system to reach the steady state, m should be either 0 or 1 (in practice, due to the intrinsic asymmetry between 0 and 1 for p > 0, the simulation results almost always converge to
m = 1) or the consensus. The nontrivial steady-state with 0 < m < 1 is possible only for Pr[ q ≥ 0] = 0 or p = 0. From the results, we confirm the clear L -shaped boundary on α = 0 , p = 0 axes, and it matches well with the numerical result shown in Fig. 2. In the α > 0 and p > 0 regime, there is a successful transmission of the dissenting opinion initially held by lower-ranked nodes in terms of authority. The result m ( τ s ) 0 . 5 at α = p = 0 is also consistent with the conventional voter model at that point. The only difference between γ = 2 and γ = 3 (Fig. 2) is a larger strap for nonzero m values near the p = 0 axis for the γ = 3 case [Fig. 2(b)] than that of the γ = 2 case [Fig. 2(a)].
Again, we would like to emphasize that the analytic derivation up to this point applies not only to the fully connected network, but also to the SFN without any correlation between the degrees and authority scores, as shown in Figs. 4(b) and 4(e), because the probability of choosing node j (proportional to her degree k j [16, 17]) is independent of her authority score s j for both cases. To be more precise, all of the elements of { k j | j = 0 , 1 , · · · , N -1 } themselves are identical for the fully connected network, and k j is independent of s j for the SFN without any correlation between k j and s j . Therefore, as expected, the same L -shaped nontrivial steady-state regions appear as in the fully connected network case (Fig. 2). The results of the SFN cases in general show the same L -shaped nontrivial steady state in Figs. 4(a), 4(b), 4(d), and 4(e) except for Figs. 4(c) and 4(f) for the positive correlation between the degree and the authority score. We explore such a possibility of nontrivial steady states with α > 0 and p > 0 values in the next section.
## 3.2. The SFN with positive correlation between authority scores and degrees
The nontrivial steady state in the positive correlation case when γ = 2 in Fig. 4(c) confirms the existence of the nontrivial steady state (0 < m ( τ s ) < 1) with the positive correlation. It confirms that the positive correlation between the heterogeneous network structures and the authority scores effectively blocks the spreading of the opposing opinion with the authoritarian suppression. Considering the parameter p forces the nodes to be biased toward the dissenting
opinion, it is clear that the positively correlated degrees and authority scores makes the spreading difficult. Since the probability p represents the willingness to accept a neighbor's dissenting opinion against the authority, the increment of m ( τ s ) with it in Fig. 4(c) reflects the crucial role of inner motivation p in the spreading of the dissent opinion. Without it (when p = 0), the system can be dominated by the affirmative opinion.
We can understand the nontriviality of the positive correlation with the analytic approach in the following. For simplicity, we assume the completely positively correlated case, i.e., the case that the authority and degree coincide (or at least they are described by the same power-law exponent as mentioned in Sec. 2). In addition, p ( s j ) = ( γ -1) s -γ j for the uncorrelated network should be replaced with p ( s j ) = ( γ -2) s 1 -γ j because the probability of being a neighbor will be proportional to the neighbor's authority (= degree) and the exponent for the power-law distribution is modified by 1 (the celebrated 'friendship paradox' [16, 17]). In that case, the probability becomes
<!-- formula-not-decoded -->
One can also check the continuity of Eq. (11) at α = 1 / 2. Figure 3(b) shows the functional form of Pr[ q ≥ 0] given by Eq. (11). The stability condition for 0 < m < 1 requiring α = 0 or p = 0, therefore, is not affected by the correlated network, as long as γ > 2.
For γ ≤ 2, things get tricky as the distribution p ( s j ) itself cannot be properly normalized (so we will need an extra cutoff, such as an exponential tail). For instance, as γ → 2 + , Pr[ q ≥ 0] → 0 according to Eq. (11) [ γ = 2 . 01 in Fig. 3(b)], implying that the 0 < m < 1 stable state is possible for any α ( < 1) and p values. This illustrates the situation that spreading of the dissenting opinion can be severely suppressed by dominating hubs (with large degree and authority at the same time) as we confirm with Fig. 4(c).
Figure 4(c) also displays the crucial role of the confidence level α as a lead-
ing factor for the transmission of the dissent opinion. Specifically, α should be larger than a certain threshold α max ,γ [as shown in Figs. 4(c) and 4(f)], e.g., α max ,γ =2 0 . 6, and α max ,γ =3 0 . 5. When α is very small ( α 0 . 1), the system has a barrier that prevents reaching the consensus of the opposing opinion [see Figs. 4(c) and 4(f), and Eq. (11)]. With γ = 2, Pr[ q ≥ 0] = 0 in Eq. (11), so the system is able to deliver the dissenting opinion to the entire system more easily, compared to the case of γ = 3 [Fig. 3(c) versus Fig. 3(f)] where Pr[ q ≥ 0] > 0 in Eq. (11). Only when α α max ,γ , the successful spreading of the dissenting opinion is possible. The point is closely related to the segregated opinion spreading groups that will be discussed later in Sec. 3.4. Another notable thing is that the heterogeneous degree distribution, γ = 2 in this case, with the positive correlation requires a higher confidence level for the spreading of the opposing opinion than the γ = 3 case, i.e., α max ,γ =2 > α max ,γ =3 .
## 3.3. The SFN with negative correlation between authority scores and degrees
For the negative correlation, let us consider the case s i ∝ 1 /k i where k i is the degree of node i . Then, p ( s j ) = γs -1 -γ j (the probability of being chosen as one's neighbor is inversely proportional to the neighbor's authority), which gives
<!-- formula-not-decoded -->
In this case, Pr[ q ≥ 0] > 1 / 2 for α = 1 / 2, implying that 'your neighbor is weaker than you' (the 'inverse' friendship paradox [16, 17]). Figure 3(c) shows the functional form of Pr[ q ≥ 0] given by Eq. (12). Unlike the positive correlation case, Pr[ q ≥ 0] = 0 only at α = 0 as γ > 1, so the stability condition is the same as the uncorrelated network case ( α = 0 or p = 0 for the 0 < m < 1 stability) as shown in Figs. 4(a) and 4(d).
So far, we have shown that γ ≤ 2 with the positive correlation is the only possible nontrivial steady state condition regardless of α and p . In other correlations, α = 0 or p = 0 is the only possible case allowing nontrivial steady states
for γ > 2. We also find that finite-size effects are more severe for α 1 with large γ , where the α value small enough to make Pr[ q ≥ 0] 0, which is indeed observable from the results in Fig. 4: a wider stripe near the horizontal axis. Note that the assumption s i ∝ 1 /k i is technically different from our negative correlation case in Sec. 2, where we just use the inverse order between { s i } and { k i } . However, we believe that the stability condition will be the same, based on the robustness of the condition from the uncorrelated to inversely correlated cases described in this section.
## 3.4. Effects of underlying network topology
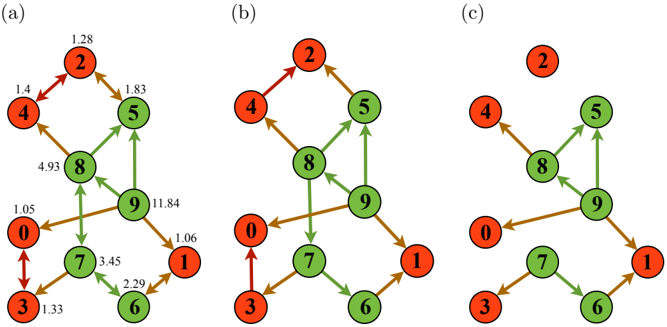
For a closer examination of the microscopic dynamics of opinion spreading, we focus on the directionality of opinion adoption represented by the directed followship network on top of the undirected substrate network, as illustrated in Fig. 5. The topological change of the followship network is caused by the sign change of q in Eq. (1) which is a function of α . Consider nodes 2 and 5 whose authority scores s 2 = 1 . 28 and s 5 = 1 . 83, respectively, in Fig. 5(a). As q ( s 2 , s 5 ; α = 0 . 3) < 0 and q ( s 5 , s 2 ; α = 0 . 3) < 0 from Eq. (1), the opinion can spread in both directions (node 2 → node 5 and node 5 → node 2) for α = 0 . 3, represented as a bidirectional edge between the two nodes in Fig. 5(b). In contrast, q ( s 2 , s 5 ; α = 0 . 6) > 0 and q ( s 5 , s 2 ; α = 0 . 6) > 0, so no opinion can spread between the two nodes in any direction for α = 0 . 6, represented as the absence of an edge between the two nodes in Fig. 5(c). Note that it is also possible for the dissenting opinion to spread from node i to j even if i and j are not connected in the followship network (as long as i and j are connected in the original network), since there exists the adoption of a neighbor's dissenting opinion regardless of q (the ' p ' process in Fig. 1), with the probability p .
This simple example shows that a disjoint group from the giant component (GC) of such a directed followship network can appear depending on the α value, which corresponds to the percolation transition occurring somewhere in between Figs. 5(b) and 5(c). In that example, node 2 becomes isolated on the authority comparison level, so there is no way to change its opinion to
Figure 5: (a) An example of the followship structure representing the comparison process. The red (green) nodes correspond to the agents with the opinion 1 (0), respectively. The red (green) edges connect the two agents with the same opinion = 1 (= 0), respectively, and the brown edges connect the two agents with different opinions. The authority rank inside the nodes and the actual authority scores outside the nodes are denoted as in Fig. 1. The followship structure is shown for (b) α = 0 . 3 and (c) α = 0 . 6.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Diagram: Network Graphs (a, b, c)
### Overview
The image presents three distinct network graphs, labeled (a), (b), and (c). Each graph consists of ten nodes numbered 0 through 9, represented as colored circles (red or green). Arrows connect these nodes, indicating directed edges, and each arrow is labeled with a numerical value representing a weight or cost associated with that connection. The graphs appear to illustrate different configurations of a network with varying edge weights.
### Components/Axes
Each graph shares the same node set: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
Nodes are colored either red or green.
Edges are represented by arrows with associated numerical labels.
There are no explicit axes or legends beyond the node numbers and edge weights.
### Detailed Analysis or Content Details
**Graph (a):**
* Node 0 (green) connects to Node 7 (green) with a weight of 1.05.
* Node 0 also connects to Node 3 (red) with a weight of 1.05.
* Node 1 (red) connects to Node 6 (green) with a weight of 1.06.
* Node 2 (red) connects to Node 4 (red) with a weight of 1.4.
* Node 2 also connects to Node 5 (green) with a weight of 1.83.
* Node 3 (red) connects to Node 0 (green) with a weight of 1.33.
* Node 4 (red) connects to Node 8 (green) with a weight of 4.93.
* Node 5 (green) connects to Node 8 (green) with a weight of 1.83.
* Node 6 (green) connects to Node 7 (green) with a weight of 2.29.
* Node 6 also connects to Node 1 (red) with a weight of 3.45.
* Node 7 (green) connects to Node 0 (green) with a weight of 1.05.
* Node 7 also connects to Node 6 (green) with a weight of 2.29.
* Node 8 (green) connects to Node 9 (green) with a weight of 11.84.
* Node 9 (green) connects to Node 1 (red) with a weight of 1.06.
**Graph (b):**
* Node 0 (green) connects to Node 3 (red) with a weight of 1.05.
* Node 1 (red) connects to Node 6 (green) with a weight of 1.06.
* Node 2 (red) connects to Node 4 (red) with a weight of 1.4.
* Node 2 also connects to Node 5 (green) with a weight of 1.83.
* Node 3 (red) connects to Node 0 (green) with a weight of 1.33.
* Node 4 (red) connects to Node 8 (green) with a weight of 4.93.
* Node 5 (green) connects to Node 8 (green) with a weight of 1.83.
* Node 6 (green) connects to Node 7 (green) with a weight of 2.29.
* Node 7 (green) connects to Node 0 (green) with a weight of 1.05.
* Node 7 also connects to Node 6 (green) with a weight of 2.29.
* Node 8 (green) connects to Node 9 (green) with a weight of 11.84.
* Node 9 (green) connects to Node 1 (red) with a weight of 1.06.
**Graph (c):**
* Node 0 (green) connects to Node 3 (red) with a weight of 1.05.
* Node 1 (red) connects to Node 6 (green) with a weight of 1.06.
* Node 2 (red) connects to Node 4 (red) with a weight of 1.4.
* Node 2 also connects to Node 5 (green) with a weight of 1.83.
* Node 3 (red) connects to Node 0 (green) with a weight of 1.33.
* Node 4 (red) connects to Node 8 (green) with a weight of 4.93.
* Node 5 (green) connects to Node 8 (green) with a weight of 1.83.
* Node 6 (green) connects to Node 7 (green) with a weight of 2.29.
* Node 7 (green) connects to Node 0 (green) with a weight of 1.05.
* Node 7 also connects to Node 6 (green) with a weight of 2.29.
* Node 8 (green) connects to Node 9 (green) with a weight of 11.84.
* Node 9 (green) connects to Node 1 (red) with a weight of 1.06.
### Key Observations
All three graphs have the same node connections and edge weights. The only difference is the arrangement of the nodes. The red nodes are consistently 2, 4, 1, and 3. The green nodes are consistently 0, 5, 6, 7, 8, and 9.
### Interpretation
The three diagrams likely represent different layouts or visualizations of the same underlying network. The consistent edge weights and connections across all three graphs suggest that the network's structure remains unchanged, only its visual representation differs. This could be for purposes of clarity, aesthetic preference, or to highlight different aspects of the network. The color coding of the nodes (red and green) might represent different categories or roles within the network, but without further context, the meaning of the colors remains speculative. The high weight on the edge connecting node 8 to node 9 (11.84) suggests a strong or important connection between these two nodes. The diagrams could be illustrating different algorithms for network layout or different stages of a network optimization process.
</details>
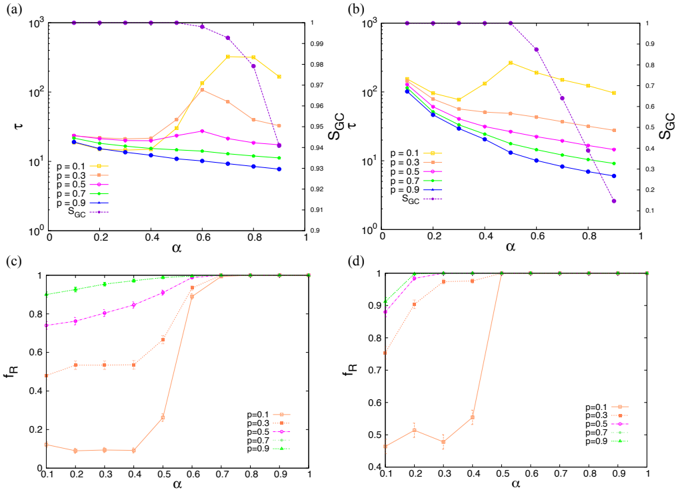
the dissenting opinion by the comparison process. Only the adoption process of a neighbor's dissenting opinion regardless of the authority scores with the probability p allows the opinion change of this isolated node. In this way, the transmission of the dissenting opinion is related to the structural change for the comparison process. Figure 6 displays the effect of GC on the consensus time τ for different α and γ values. We use the fraction of nodes in the GC, denoted by S GC = n GC /n where n GC is the number of nodes in the giant component and n is the total number of nodes. For simplicity, we neglect the directionality for the connected component analysis, or in other words, we take the weakly connected component. Even though the overall scales of S GC are different between Figs. 6(a) and 6(b), the location of α max ,γ (the α value when the maximum value of τ occurs for given γ ) marks the segregation of the cluster in p ≤ 0 . 5 except for p = 0 . 1 at γ = 2 ( α max ,γ =2 0 . 6 and α max ,γ =3 0 . 5).
In general, the consensus time τ increases with α until it reaches the maxi- a06
Figure 6: The consensus time τ (the symbols with the solid lines) and the fraction of giant component S GC (the symbols with the dashed lines), averaged over n = 2000 realizations, are presented in the upper panels. Panel (a) is for γ = 2, and panel (b) is for γ = 3. Panels (c) and (d) display the fraction of realizations with the consensus to the dissenting opinion f R as a function of α . Panel (c) is for γ = 2 and panel (d) is for γ = 3. The fraction f R is plotted only when the system reaches to the consensus by t max among the 2000 ensembles ( N = 1000). The lines are the guide to the eyes. The symbols are located at the mean values, and the corresponding error bars represent the standard error of the mean (the error bars of τ are smaller than the symbols).
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Charts: Parameter Variation Analysis
### Overview
The image contains four separate charts (labeled a, b, c, and d) displaying the relationship between a parameter α (ranging from 0 to 1) and various metrics: τ, SGC, rR, and fR. Each chart also shows the impact of varying a parameter 'p' (with values 0.1, 0.3, 0.5, 0.7, and 0.9) on these metrics. Charts (a) and (b) have a dual y-axis, one linear and one logarithmic. Charts (b) and (d) also include a secondary y-axis representing SGC.
### Components/Axes
* **X-axis (all charts):** α (Alpha), ranging from 0 to 1.
* **Y-axis (a):** τ (Tau), logarithmic scale from 10^0 to 10^3.
* **Y-axis (b):** SGC (left axis), logarithmic scale from 10^0 to 10^3; α (right axis), linear scale from 0.9 to 1.
* **Y-axis (c):** rR (R squared), linear scale from 0 to 1.
* **Y-axis (d):** fR (F measure), linear scale from 0.4 to 1.
* **Legend (all charts):** p = 0.1 (blue), p = 0.3 (green), p = 0.5 (red), p = 0.7 (orange), p = 0.9 (purple), SGC (dashed black).
### Detailed Analysis or Content Details
**Chart (a): τ vs. α**
* **p = 0.1 (blue):** Line is relatively flat, starting at approximately τ = 20 and ending at approximately τ = 25.
* **p = 0.3 (green):** Line starts at approximately τ = 20, dips to approximately τ = 15 at α = 0.2, then rises to approximately τ = 25 at α = 1.
* **p = 0.5 (red):** Line starts at approximately τ = 20, rises to approximately τ = 40 at α = 0.4, then decreases to approximately τ = 25 at α = 1.
* **p = 0.7 (orange):** Line starts at approximately τ = 20, rises to approximately τ = 100 at α = 0.8, then drops to approximately τ = 25 at α = 1.
* **p = 0.9 (purple):** Line is relatively flat, starting at approximately τ = 20 and ending at approximately τ = 20.
* **SGC (dashed black):** Line is relatively flat, starting at approximately SGC = 0.99 and ending at approximately SGC = 0.99.
**Chart (b): SGC vs. α**
* **p = 0.1 (blue):** Line slopes downward, starting at approximately SGC = 0.98 and ending at approximately SGC = 0.92.
* **p = 0.3 (green):** Line slopes downward, starting at approximately SGC = 0.98 and ending at approximately SGC = 0.93.
* **p = 0.5 (red):** Line slopes downward, starting at approximately SGC = 0.98 and ending at approximately SGC = 0.92.
* **p = 0.7 (orange):** Line slopes downward, starting at approximately SGC = 0.98 and ending at approximately SGC = 0.91.
* **p = 0.9 (purple):** Line slopes downward, starting at approximately SGC = 0.98 and ending at approximately SGC = 0.91.
* **SGC (dashed black):** Line is relatively flat, starting at approximately SGC = 100 and ending at approximately SGC = 100.
**Chart (c): rR vs. α**
* **p = 0.1 (blue):** Line is relatively flat, starting at approximately rR = 0.2 and ending at approximately rR = 0.2.
* **p = 0.3 (green):** Line increases steadily, starting at approximately rR = 0.2 and ending at approximately rR = 0.8.
* **p = 0.5 (red):** Line increases steadily, starting at approximately rR = 0.2 and ending at approximately rR = 0.9.
* **p = 0.7 (orange):** Line increases rapidly, starting at approximately rR = 0.2 and ending at approximately rR = 0.8.
* **p = 0.9 (purple):** Line increases rapidly, starting at approximately rR = 0.2 and ending at approximately rR = 0.9.
**Chart (d): fR vs. α**
* **p = 0.1 (blue):** Line is relatively flat, starting at approximately fR = 0.5 and ending at approximately fR = 0.5.
* **p = 0.3 (green):** Line increases rapidly, starting at approximately fR = 0.4 and ending at approximately fR = 0.9.
* **p = 0.5 (red):** Line increases rapidly, starting at approximately fR = 0.4 and ending at approximately fR = 0.9.
* **p = 0.7 (orange):** Line increases slowly, starting at approximately fR = 0.4 and ending at approximately fR = 0.6.
* **p = 0.9 (purple):** Line increases rapidly, starting at approximately fR = 0.4 and ending at approximately fR = 0.9.
### Key Observations
* In charts (a) and (b), the SGC remains relatively constant, while τ decreases with increasing α for p > 0.1.
* Charts (c) and (d) show a clear trend of increasing rR and fR with increasing α, particularly for higher values of p (0.5, 0.7, and 0.9).
* The parameter 'p' significantly influences the behavior of τ, SGC, rR, and fR.
* The behavior of τ is most sensitive to changes in α when p is 0.5 and 0.7.
### Interpretation
These charts likely represent the performance of a model or algorithm as its parameters (α and p) are varied. α could represent a regularization parameter, while p might control some aspect of the data or model complexity.
* **Charts (a) and (b):** The relatively constant SGC suggests that the model's overall structure or stability is maintained across different values of α. The decrease in τ with increasing α (for p > 0.1) could indicate a reduction in model complexity or overfitting.
* **Charts (c) and (d):** The increasing rR and fR with increasing α suggest that the model's predictive power and accuracy improve as α increases, especially for higher values of p. This could be because higher α values allow the model to better capture the underlying patterns in the data.
* The different behaviors observed for different values of p suggest that the optimal value of α depends on the specific context or data being used.
The combination of these observations suggests that there is a trade-off between model complexity and performance. Increasing α can improve predictive power, but it may also lead to overfitting if p is too low. The optimal value of α depends on the specific characteristics of the data and the desired level of model complexity. The SGC metric appears to be a measure of model stability, and its relatively constant value suggests that the model is robust to changes in α.
</details>
mum point τ max at α = α max ,γ , and it starts to decrease again when α > α max ,γ . The result implies that the segregation of opinion-spreading groups affects the dynamics considerably. The sharp increase of τ near α = α max ,γ stems from the fragmented components in the opinion-spreading network, while the decrease of τ for α > α max ,γ is the effect of increment on the viability of the dissenting opinion by the increased confidence parameter α . As a substantial fraction of the dissenting opinion survives, the consensus can speed up when α > α max ,γ overcoming the authoritarian force suppressing the dissenting opinion. This trend of τ is similar for both γ = 2 and γ = 3 cases, but the reduction of τ and the prevalence of the dissenting opinion for the γ = 2 case is much more prominent than that for γ = 3. The exceptional result of τ at p = 0 . 1 for γ = 2 might come from the relatively large size of GC with small p 0 . 1. As we explained before, the obvious functional segregation should protect the initial opinion more in the comparison process. However, a number of beholders of the dissenting opinion still has to face the social comparison process due to the small value of p , so the system experiences large fluctuations until it reaches the consensus and consumes more time. Nevertheless, the maximum time for the consensus τ max occurs at α = α max ,γ =2 by the structural segregation in the comparison process.
So far, we have seen the segregation in the opinion spreading depending on α in terms of consensus time, but it also affects the type of a consensus (whether m = 1 or m = 0) manifestly [see Figs. 6(c) and 6(d)]. In particular, we focus on the fraction of consensus to the dissenting opinion, denoted by f R . As we can observe in Figs. 6(c) and 6(d), a drastic increase of f R occurs at α max ,γ =2 0 . 6 and α max ,γ =3 0 . 5, and f R 1 for α α max ,γ . It is caused by the increased viability of the dissenting opinion, as we have explained so far. Given the condition, the main factor responsible for the successful spreading of the dissenting opinion is the existence of isolated groups of agents in the followship network and the type of opinion they protect. As shown in Fig. 5(c), the separated nodes are generally less influential, so they are initially likely to have the dissenting opinion. Therefore, the isolation can effectively protect
the dissenting opinion during the comparison process. We also confirm it by measuring the probability of isolation for each node.
In summary, the system reaches the opinion consensus more rapidly in the γ = 2 case which is a more heterogeneous system regarding degree and authority. On the contrary, a more homogeneous structure ( γ = 3) promotes the spreading of the dissenting opinion more, even though it takes longer time, compared to the γ = 2 case. For the spreading of the dissenting opinion, a confidence level exceeding a certain threshold confidence level is required, i.e., α > α max ,γ , and it can lead the successful spreading of the dissenting opinion with low values of p < 0 . 1.
## 4. Summary and conclusions
We have introduced a stylized opinion formation model to understand the spreading of the less influential agents' opinion by setting the correlation between the degree and the authority score, with personal characteristics such as the confidence level and the willingness to accept the dissenting opinion. First of all, nonzero amount of willingness to accept the dissenting opinion, albeit small, drastically promotes the spreading of the dissenting opinion in most cases. Nontrivial steady states, or the coexistence of different opinions, is possible when the degree and the authority score are positively correlated in the case of severe heterogeneity, namely, when the power-law exponent γ ≤ 2. It implies that the strong authoritarian structure, combined with its correlation to the number of neighbors, efficiently suppresses the acceptance of the opposing opinion from less influential people.
For given heterogeneity and correlation, the confidence level α toward the agents' own opinion is the major factor deciding the prevalence of the dissenting opinion, even though it may take a long time. In particular, the parameter α controls the viability of the dissenting opinion, via the segregation of the opinionspreading subgroups in the comparison process. By incorporating the personal factors in the model, we have learned two things. First, if a population has
the willingness to hear the dissenting opinion held by less influential people, there is a large chance for the effective spreading of their opinion. Second, from the critical role of the confidence level, we infer that if the confidence of each agent is strong enough, the opinion of less influential people can be spread to the entire population even in the case of severely heterogeneous authority and degree distribution. Since our model is a highly simplified one, it may not capture all of the details in the real opinion formation processes in our society. For example, the assumption of the same power-law exponent for the authority and degree distribution could be a limitation of the model. In spite of the limitations, though, the results suggest a possibility of the crucial impact on the correlations between the network and authority structures in opinion formation. For future studies, with the necessity of studies with a spreading of misinformation [31, 32] from the authorities, the model could be applied to figure out effects of the authority and a correlated network on the spreading of misinformation in a hierarchical structure.
## Acknowledgements
This work was supported by the Human Resources Development program (No. 20124010203270) of the Korea Institute of Energy Technology Evaluation and Planning (KETEP) grant funded by the Korea government Ministry of Trade, Industry and Energy. We thank Heetae Kim, Minjin Lee, Hang-Hyun Jo, and Jinhyuk Yun for helpful discussions and suggestions, and Jimin Hwang for linguistic advice. Computation was partially carried out using a server in Complex Systems and Statistical Physics Lab, Korea Advanced Institute of Science and Technology.
## References
- [1] A. Sen, Development as Freedom (Oxford University Press, Oxford, 1999).
- [2] C. Castellano, S. Fortunato, and V. Loreto, Statistical physics of social dynamics, Rev. Mod. Phys. 81 , 591 (2009).
- [3] S. Galam, Majority rule, hierarchical structures, and democratic totalitarianism: A statistical approach, J. Math. Psych. 30 , 426 (1986).
- [4] S. Galam, Sociophysics: A review of Galam models, Internat. J. Modern Phys. C 19 , 409 (2008).
- [5] P. Sen and B. K. Chakrabarti, Sociophysics: An introduction (Oxford University Press, Oxford, 2013).
- [6] V. Sood and S. Redner, Voter model on heterogeneous graphs, Phys. Rev. Lett. 94 , 178701 (2005).
- [7] K. Suchecki, V. M. Egu´ ıluz, and M. San Miguel, Voter model dynamics in complex networks: Role of dimensionality, disorder, and degree distribution, Phys. Rev. E 72 , 036132 (2005).
- [8] S. Galam, Minority opinion spreading in random geometry, Eur. Phys. J. B 25 , 403 (2002).
- [9] G. Deffuant, D. Neau, F. Amblard, and G. Weisbuch, Mixing beliefs among interacting agents, Adv. Complex Syst. 3 , 87 (2001).
- [10] K. Sznajd-Weron and J. Sznajd, Opinion evolution in closed community, Internat. J. Modern Phys. C 11 , 1157 (2000).
- [11] H.X. Yang, Z. X. Wu, C. Zhou, T. Zhou, and B.-H. Wang, Effects of social diversity on the emergence of global consensus in opinion dynamics, Phys. Rev. E 80 046108 (2009).
- [12] J. Park and A.-L. Barab´ asi, Distribution of node characteristics in complex networks, Proc. Natl. Acad. Sci. USA 104 , 17916 (2007).
- [13] J. H. Fowler, C. T. Dawes, and N. A. Christakis, Model of genetic variation in human social networks, Proc. Natl. Acad. Sci. USA 106 , 1720 (2008).
- [14] S. Aral, L. Muchnik, and A. Sundararajan, Distinguishing influence-based contagion from homophily driven diffusion in dynamic networks, Proc. Natl. Acad. Sci. USA 106 , 21544 (2009).
- [15] M. Ramos, J. Shao, S. D. S. Reis, C. Anteneodo, J. S. Andrade, S. Havlin, and H. A. Makse, How does public opinion become extreme?, Sci. Rep. 5 , 10032 (2015).
- [16] Y.-H. Eom and H.-H. Jo, Generalized friendship paradox in complex networks: The case of scientific collaboration, Sci. Rep. 4 , 4603 (2014).
- [17] H.-H. Jo and Y.-H. Eom, Generalized friendship paradox in networks with tunable degree-attribute correlation, Phys. Rev. E 90 , 022809 (2014).
- [18] V. Kandiah and D. L. Shepelyansky, PageRank model of opinion formation on social networks, Physica A 391 , 5779 (2012).
- [19] L. Chakhmakhchyana and D.L. Shepelyansky, PageRank model of opinion formation on Ulam networks, Phys. Lett. A 377 , 3119 (2013).
- [20] M. Mobilia, Nonlinear q -voter model with inflexible zealots, Phys. Rev. E 92 , 012803 (2015).
- [21] A.C.R. Martins and S. Galam, Building up of individual inflexibility in opinion dynamics, Phys. Rev. E 87 , 042807 (2013).
- [22] M. Mobilia and I. T. Georgiev, Voting and catalytic processes with inhomogeneities, Phys. Rev. E 71 , 046102 (2005).
- [23] N. Crokidakis, C. Anteneodo, Role of conviction in nonequilibrium models of opinion formation, Phys. Rev. E 86 , 061127 (2012).
- [24] M.F. Laguna, S. Risau Gusman, G. Abramson, S. Gon¸ calves, J. R. Iglesias, The dynamics of opinion in hierarchical organizations, Physica A 351 , 580 (2005).
- [25] M.F. Laguna, G. Abramson, S. Risau Gusman, J. R. Iglesias, Do the right thing, J. Stat. Mech. 2010 , P05001 (2010).
- [26] M.E.J. Newman, Networks: An Introduction (Oxford University Press, Oxford, 2010).
- [27] S. Milgram, Behavioral study of obedience, J. Abnorm. Psychol. 67 , 371 (1963).
- [28] K. Corcoran, J. Crusius, and T. Mussweiler, Social Comparison: Motives, Standards, and Mechanisms (Wiley-Blackwell, Oxford, 2011)
- [29] M.E.J. Newman, S.H. Strogatz, and D. J. Watts, Random graphs with arbitrary degree distributions and their applications, Phys. Rev. E 64 , 026118 (2001).
- [30] M.O. Lorenz, Methods of measuring the concentration of wealth, J. Am. Stat. Assoc. 9 , 691 (2016).
- [31] M. Del Vicario, A. Bessi, F. Zollo, F. Petroni, A. Scala, G. Caldarelli, H. E. Stanley, W. Quattrociocchi, The spreading of misinformation online, Proc. Natl. Acad. Sci. USA 113 , 554 (2016).
- [32] A.L. Schmidt, F. Zollo, M. Del Vicario, A. Bessi, A. Scala, G. Caldarelli, H.E. Stanley, and W. Quattrociocchi, Anatomy of news consumption on Facebook, Proc. Natl. Acad. Sci. USA 114 , 3035 (2017).