## Probabilistic Reasoning via Deep Learning: Neural Association Models
Quan Liu † , Hui Jiang ‡ , Andrew Evdokimov ‡ , Zhen-Hua Ling † , Xiaodan Zhu , Si Wei § , Yu Hu †§
†
National Engineering Laboratory for Speech and Language Information Processing
University of Science and Technology of China, Hefei, Anhui, China
‡ Department of Electrical Engineering and Computer Science, York University, Canada
National Research Council Canada, Ottawa, Canada
§ iFLYTEK Research, Hefei, China emails: quanliu@mail.ustc.edu.cn, hj@cse.yorku.ca, ae2718@cse.yorku.ca, zhling@ustc.edu.cn xiaodan@cse.yorku.ca, siwei@iflytek.com, yuhu@iflytek.com
## Abstract
In this paper, we propose a new deep learning approach, called neural association model (NAM), for probabilistic reasoning in artificial intelligence. We propose to use neural networks to model association between any two events in a domain. Neural networks take one event as input and compute a conditional probability of the other event to model how likely these two events are to be associated. The actual meaning of the conditional probabilities varies between applications and depends on how the models are trained. In this work, as two case studies, we have investigated two NAM structures, namely deep neural networks (DNN) and relation-modulated neural nets (RMNN), on several probabilistic reasoning tasks in AI, including recognizing textual entailment, triple classification in multi-relational knowledge bases and commonsense reasoning. Experimental results on several popular datasets derived from WordNet, FreeBase and ConceptNet have all demonstrated that both DNNs and RMNNs perform equally well and they can significantly outperform the conventional methods available for these reasoning tasks. Moreover, compared with DNNs, RMNNs are superior in knowledge transfer, where a pre-trained model can be quickly extended to an unseen relation after observing only a few training samples. To further prove the effectiveness of the proposed models, in this work, we have applied NAMs to solving challenging Winograd Schema (WS) problems. Experiments conducted on a set of WS problems prove that the proposed models have the potential for commonsense reasoning.
## Introduction
Reasoning is an important topic in artificial intelligence (AI), which has attracted considerable attention and research effort in the past few decades (McCarthy 1986; Minsky 1988; Mueller 2014). Besides the traditional logic reasoning, probabilistic reasoning has been studied as another typical genre in order to handle knowledge uncertainty in reasoning based on probability theory (Pearl 1988; Neapolitan 2012). The probabilistic reasoning can be used to predict conditional probability Pr( E 2 | E 1 ) of one event E 2 given another event E 1 . State-of-the-art methods for probabilistic reasoning include Bayesian Networks (Jensen 1996), Markov Logic Networks (Richardson and Domingos 2006) and other graphical models (Koller and Friedman 2009). Taking Bayesian networks as an example, the conditional
Copyright 2015-2016.
probabilities between two associated events are calculated as posterior probabilities according to Bayes theorem, with all possible events being modeled by a pre-defined graph structure. However, these methods quickly become intractable for most practical tasks where the number of all possible events is usually very large.
In recent years, distributed representations that map discrete language units into continuous vector space have gained significant popularity along with the development of neural networks (Bengio et al. 2003; Collobert et al. 2011; Mikolov et al. 2013). The main benefit of embedding in continuous space is its smoothness property, which helps to capture the semantic relatedness between discrete events, potentially generalizable to unseen events. Similar ideas, such as knowledge graph embedding, have been proposed to represent knowledge bases (KB) in low-dimensional continuous space (Bordes et al. 2013; Socher et al. 2013; Wang et al. 2014; Nickel et al. 2015). Using the smoothed KB representation, it is possible to reason over the relations among various entities. However, human-like reasoning remains as an extremely challenging problem partially because it requires the effective encoding of world knowledge using powerful models. Most of the existing KBs are quite sparse and even recently created large-scale KBs, such as YAGO, NELL and Freebase, can only capture a fraction of world knowledge. In order to take advantage of these sparse knowledge bases, the state-of-the-art approaches for knowledge graph embedding usually adopt simple linear models, such as RESCAL (Nickel, Tresp, and Kriegel 2012), TransE (Bordes et al. 2013) and Neural Tensor Networks (Socher et al. 2013; Bowman 2013).
Although deep learning techniques achieve great progresses in many domains, e.g. speech and image (LeCun, Bengio, and Hinton 2015), the progress in commonsense reasoning seems to be slow. In this paper, we propose to use deep neural networks, called neural association model (NAM) , for commonsense reasoning. Different from the existing linear models, the proposed NAM model uses multilayer nonlinear activations in deep neural nets to model the association conditional probabilities between any two possible events. In the proposed NAM framework, all symbolic events are represented in low-dimensional continuous space and there is no need to explicitly specify any dependency structure among events as required in Bayesian networks.
Deep neural networks are used to model the association between any two events, taking one event as input to compute a conditional probability of another event. The computed conditional probability for association may be generalized to model various reasoning problems, such as entailment inference, relational learning, causation modelling and so on. In this work, we study two model structures for NAM. The first model is a standard deep neural networks (DNN) and the second model uses a special structure called relation modulated neural nets (RMNN). Experiments on several probabilistic reasoning tasks, including recognizing textual entailment, triple classification in multi-relational KBs and commonsense reasoning, have demonstrated that both DNNs and RMNNs can outperform other conventional methods. Moreover, the RMNN model is shown to be effective in knowledge transfer learning, where a pre-trained model can be quickly extended to a new relation after observing only a few training samples.
Furthermore, we also apply the proposed NAM models to more challenging commonsense reasoning problems, i.e., the recently proposed Winograd Schemas (WS) (Levesque, Davis, and Morgenstern 2011). The WS problems has been viewed as an alternative to the Turing Test (Turing 1950). To support the model training for NAM, we propose a straightforward method to collect associated cause-effect pairs from large unstructured texts. The pair extraction procedure starts from constructing a vocabulary with thousands of common verbs and adjectives. Based on the extracted pairs, this paper extends the NAM models to solve the Winograd Schema problems and achieves a 61% accuracy on a set of causeeffect examples. Undoubtedly, to realize commonsense reasoning, there is still much work be done and many problems to be solved. Detailed discussions would be given at the end of this paper.
## Motivation: Association between Events
This paper aims to model the association relationships between events using neural network methods. To make clear our main work, we will first describe the characteristics of events and all the possible association relationships between events. Based on the analysis of event association, we present the motivation for the proposed neural association models. In commonsense reasoning, the main characteristics of events are the following:
- Massive : In most natural situations, the number of events is massive, which means that the association space we will model is very large.
- Sparse : All the events occur in our dialy life are very sparse. It is a very challenging task to ideally capture the similarities between all those different events.
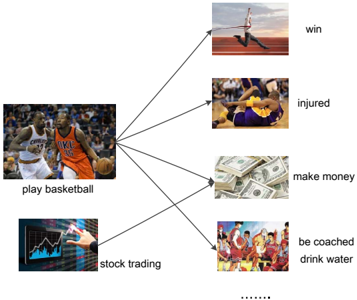
At the same time, association between events appears everywhere. Consider a single event play basketball for example, shown in Figure 1. This single event would associate with many other events. A person who plays basketball would win a game. Meanwhile, he would be injured in some cases. The person could make money by playing basketball as well. Moreover, we know that a person who plays basketball should be coached during a regular game. Those are all typical associations between events. However, we need to recognize that the task of modeling event association is not identical to performing classification . In classification, we typically map an event from its feature space into one of pre-defined finite categories or classes. In event association, we need to compute the association probability between two arbitrary events, each of which may be a sample from a possibly infinite set. The mapping relationships in event association would be many-to-many ; e.g., not only playing basketball could support us to make money, someone who makes stock trading could make money as well. More specifically, the association relationships between events include causeeffect, spatial, temporal and so on. This paper treats them as a general relation considering the sparseness of useful KBs.
Figure 1: Example of association between events.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Sports and Activities Association
### Overview
The image is a diagram showing associations between different activities and their potential outcomes or related concepts. A central image of people playing basketball is linked to several other images representing various outcomes or related activities.
### Components/Axes
* **Central Image:** Two basketball players in action, labeled "play basketball".
* **Associated Images (clockwise from top-right):**
* A pole vaulter, labeled "win".
* An injured basketball player, labeled "injured".
* A pile of money, labeled "make money".
* A group of basketball players, labeled "be coached drink water".
* A stock trading chart, labeled "stock trading".
* **Connecting Lines:** Arrows connecting the central image to the associated images, indicating a relationship or association.
### Detailed Analysis
* **Play Basketball -> Win:** The image of a pole vaulter winning is associated with playing basketball, suggesting the possibility of winning in sports.
* **Play Basketball -> Injured:** The image of an injured basketball player is associated with playing basketball, suggesting the risk of injury.
* **Play Basketball -> Make Money:** The image of money is associated with playing basketball, suggesting the possibility of earning money through the sport.
* **Play Basketball -> Be Coached Drink Water:** The image of a basketball team is associated with playing basketball, suggesting the need for coaching and hydration.
* **Play Basketball -> Stock Trading:** The image of a stock trading chart is associated with playing basketball, suggesting the possibility of investing money earned from the sport.
### Key Observations
* The diagram illustrates various potential outcomes and related activities associated with playing basketball.
* The associations range from positive outcomes (winning, making money) to negative outcomes (injury) and related activities (coaching, stock trading).
### Interpretation
The diagram demonstrates the multifaceted nature of playing basketball, highlighting not only the potential for success and financial gain but also the risks involved and the need for support and related activities. The association with stock trading suggests a potential avenue for managing earnings from the sport. The diagram provides a visual representation of the various aspects and consequences associated with engaging in the activity of playing basketball.
</details>
In this paper, we believe that modeling the the association relationships between events is a fundamental work for commonsense reasoning. If we could model the event associations very well, we may have the ability to solve many commonsense reasoning problems. Considering the main characteristics of discrete event and event association , two reasons are given for describing our motivation.
- The advantage of distributed representation methods: representing discrete events into continuous vector space provides a good way to capture the similarities between discrete events.
- The advantage of neural network methods: neural networks could perform universal approximation while linear models cannot easily do this (Hornik, Stinchcombe, and White 1990).
At the same time, this paper takes into account that both distributed representation and neural network methods are data-hungry. In Artificial Intelligence (AI) research, mining large sizes of useful data (or knowledge) for model learning is always challenging. In the following section, this paper presents a preliminary work on data collection and the corresponding experiments we have made for solving commonsense reasoning problems.
## Neural Association Models (NAM)
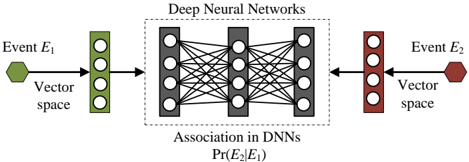
In this paper, we propose to use a nonlinear model, namely neural association model, for probabilistic reasoning. Our main goal is to use neural nets to model the association probability for any two events E 1 and E 2 in a domain, i.e., Pr( E 2 | E 1 ) of E 2 conditioning on E 1 . All possible events in the domain are projected into continuous space without specifying any explicit dependency structure among them. In the following, we first introduce neural association models (NAM) as a general modeling framework for probabilistic reasoning. Next, we describe two particular NAM structures for modeling the typical multi-relational data.
## NAMin general
Figure 2: The NAM framework in general.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Deep Neural Network Association
### Overview
The image is a diagram illustrating the association between two events, E1 and E2, using a deep neural network (DNN). It shows the flow of information from Event E1 through a vector space into the DNN, and then from the DNN through another vector space to Event E2.
### Components/Axes
* **Title:** Deep Neural Networks
* **Left Side:**
* Event E1 (represented by a green hexagon)
* Vector space (text label)
* A green column of 4 circles
* Arrow pointing from the hexagon to the column of circles, and another arrow pointing from the column of circles to the DNN.
* **Center:**
* Deep Neural Network (DNN) - Represented by three gray columns of 4 circles each, fully connected by lines.
* Association in DNNs (text label below the DNN)
* Pr(E2|E1) (Probability of E2 given E1, text label below "Association in DNNs")
* **Right Side:**
* Event E2 (represented by a red hexagon)
* Vector space (text label)
* A red column of 4 circles
* Arrow pointing from the DNN to the column of circles, and another arrow pointing from the column of circles to the hexagon.
### Detailed Analysis or ### Content Details
* **Event E1:** Represented by a green hexagon on the left.
* **Vector Space (Left):** Located between Event E1 and the first layer of the DNN.
* **Input Layer:** A green column of 4 circles, representing the input layer of the DNN.
* **Deep Neural Network:** Consists of three gray columns of 4 circles each, representing the layers of the DNN. Each circle represents a neuron. The layers are fully connected, meaning each neuron in one layer is connected to every neuron in the next layer.
* **Association in DNNs:** The text "Association in DNNs" is located below the DNN, indicating that the DNN is used to model the association between the two events.
* **Pr(E2|E1):** The text "Pr(E2|E1)" represents the conditional probability of Event E2 occurring given that Event E1 has occurred. This is the output of the DNN.
* **Output Layer:** A red column of 4 circles, representing the output layer of the DNN.
* **Vector Space (Right):** Located between the last layer of the DNN and Event E2.
* **Event E2:** Represented by a red hexagon on the right.
### Key Observations
* The diagram illustrates a process where Event E1 is transformed into a vector representation, processed by a DNN, and then transformed back into Event E2.
* The DNN models the association between the two events, and the output is the conditional probability Pr(E2|E1).
* The color coding (green for E1, red for E2) visually distinguishes the input and output events.
### Interpretation
The diagram represents a system that uses a deep neural network to learn the relationship between two events, E1 and E2. The DNN takes a vector representation of E1 as input and outputs the probability of E2 occurring, given that E1 has occurred. This type of system could be used for various applications, such as predicting the outcome of an event based on the occurrence of another event, or for identifying patterns and relationships between events. The use of vector spaces allows for the representation of complex events in a format that can be processed by the DNN.
</details>
Figure 2 shows the general framework of NAM for associating two events, E 1 and E 2 . In the general NAM framework, the events are first projected into a low-dimension continuous space. Deep neural networks with multi-layer nonlinearity are used to model how likely these two events are to be associated. Neural networks take the embedding of one event E 1 (antecedent) as input and compute a conditional probability Pr( E 2 | E 1 ) of the other event E 2 (consequent). If the event E 2 is binary (true or false), the NAM models may use a sigmoid node to compute Pr( E 2 | E 1 ) . If E 2 takes multiple mutually exclusive values, we use a few softmax nodes for Pr( E 2 | E 1 ) , where it may need to use multiple embeddings for E 2 (one per value). NAMs do not explicitly specify how different events E 2 are actually related; they may be mutually exclusive, contained, intersected. NAMs are only used to separately compute conditional probabilities, Pr( E 2 | E 1 ) , for each pair of events, E 1 and E 2 , in a task. The actual physical meaning of the conditional probabilities Pr( E 2 | E 1 ) varies between applications and depends on how the models are trained. Table 1 lists a few possible applications.
Table 1: Some applications for NAMs.
| Application | E 1 | E 2 |
|------------------------------------|---------------|-------------|
| language modeling causal reasoning | h | w e j W 2 D |
| | cause | effect |
| knowledge triple classification | { e i , r k } | |
| lexical entailment | W 1 | |
| textual entailment | D 1 | 2 |
In language modeling, the antecedent event is the representation of historical context, h , and the consequent event is the next word w that takes one out of K values. In causal reasoning, E 1 and E 2 represent cause and effect respectively. For example, we have E 1 = 'eating cheesy cakes' and E 2 = 'being happy' , where Pr( E 2 | E 1 ) indicates how likely it is that E 1 may cause the binary (true or false) event E 2 . In the same model, we may add more nodes to model different effects from the same E 1 , e.g., E ′ 2 = 'growing fat' . Moreover, we may add 5 softmax nodes to model a multi-valued event, e.g., E ′′ 2 = 'happiness' (scale from 1 to 5) . Similarly, for knowledge triple classification of multi-relation data, given one triple ( e i , r k , e j ) , E 1 consists of the head entity ( subject ) e i and relation ( predicate ) r k , and E 2 is a binary event indicating whether the tail entity ( object ) e j is true or false. Finally, in the applications of recognizing lexical or textual entailment, E 1 and E 2 may be defined as premise and hypothesis . More generally, NAMs can be used to model an infinite number of events E 2 , where each point in a continuous space represents a possible event. In this work, for simplicity, we only consider NAMs for a finite number of binary events E 2 but the formulation can be easily extended to more general cases.
Compared with traditional methods, like Bayesian networks, NAMs employ neural nets as a universal approximator to directly model individual pairwise event association probabilities without relying on explicit dependency structure. Therefore, NAMs can be end-to-end learned purely from training samples without strong human prior knowledge, and are potentially more scalable to real-world tasks.
Learning NAMs Assume we have a set of N d observed examples (event pairs { E 1 , E 2 } ), D , each of which is denoted as x n . This training set normally includes both positive and negative samples. We denote all positive samples ( E 2 = true ) as D + and all negative samples ( E 2 = false ) as D -. Under the same independence assumption as in statistical relational learning (SRL) (Getoor 2007; Nickel et al. 2015), the log likelihood function of a NAM model can be expressed as follows:
$$\mathcal { L } ( \Theta ) = \sum _ { x _ { n } ^ { + } \in \mathcal { D } ^ { + } } \ln f ( x _ { n } ^ { + } ; \Theta ) + \sum _ { x _ { n } ^ { - } \in \mathcal { D } ^ { - } } \ln ( 1 - f ( x _ { n } ^ { - } ; \Theta ) )$$
where f ( x n ; Θ ) denotes a logistic score function derived by the NAM for each x n , which numerically computes the conditional probability Pr( E 2 | E 1 ) . More details on f ( · ) will be given later in the paper. Stochastic gradient descent (SGD) methods may be used to maximize the above likelihood function, leading to a maximum likelihood estimation (MLE) for NAMs.
In the following, as two case studies, we consider two NAM structures with a finite number of output nodes to model Pr( E 2 | E 1 ) for any pair of events, where we have only a finite number of E 2 and each E 2 is binary. The first model is a typical DNN that associates antecedent event ( E 1 ) at input and consequent event ( E 2 ) at output. We then present another model structure, called relation-modulated neural nets, which is more suitable for multi-relational data.
xisted Relations
(
L
)
……
(2)
(1)
(head)
ector
Event
Vector space
E
Head entity vector
Tail entity vector
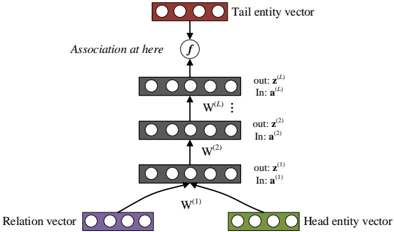
## DNN for NAMs
Event
E
Head entity vector
Event
E
The first NAM structure is a traditional DNN as shown in Figure 3. Here we use multi-relational data in KB for illustration. Given a KB triple x n = ( e i , r k , e j ) and its corresponding label y n (true or false), we cast E 1 = ( e i , r k ) and E 2 = e j to compute Pr( E 2 | E 1 ) as follows. Vector space Vector space Association in DNNs P( E 2 | E 1 )
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Neural Network for Relation Extraction
### Overview
The image depicts a neural network architecture designed for relation extraction between entities. It illustrates the flow of information from input vectors representing a relation and a head entity, through multiple layers of the network, to an output vector representing the tail entity.
### Components/Axes
* **Input Layer:**
* **Relation vector:** Located at the bottom-left, represented by a purple rectangle containing four circles.
* **Head entity vector:** Located at the bottom-right, represented by a green rectangle containing four circles.
* **Hidden Layers:** Three layers of nodes, each represented by a gray rectangle containing four circles.
* Layer 1: Labeled with "out: z^(1)" and "In: a^(1)" to the right.
* Layer 2: Labeled with "out: z^(2)" and "In: a^(2)" to the right.
* Layer L: Labeled with "out: z^(L)" and "In: a^(L)" to the right.
* **Output Layer:**
* **Tail entity vector:** Located at the top, represented by a brown rectangle containing four circles.
* **Weights:**
* W^(1): Connects the input layer to the first hidden layer.
* W^(2): Connects the first hidden layer to the second hidden layer.
* W^(L): Connects the second hidden layer to the output layer.
* **Association Function:** A circle containing the letter "f" is positioned between the last hidden layer and the output layer, labeled "Association at here".
### Detailed Analysis
The diagram shows a feedforward neural network. The relation vector and head entity vector are fed into the network. These vectors are then passed through multiple hidden layers. Each layer applies a weight matrix (W^(1), W^(2), W^(L)) and an activation function (implicitly) to the input from the previous layer. The output of the final hidden layer is then passed through an association function "f" to produce the tail entity vector.
* **Relation vector:** Purple rectangle, bottom-left.
* **Head entity vector:** Green rectangle, bottom-right.
* **Hidden Layers:** Three gray rectangles, stacked vertically.
* **Tail entity vector:** Brown rectangle, top.
* **Connections:** Arrows indicate the flow of information between layers.
* **Weights:** W^(1), W^(2), and W^(L) are labeled on the arrows connecting the layers.
* **Association Function:** "f" is labeled above the arrow connecting the last hidden layer to the tail entity vector.
### Key Observations
* The network architecture is a multi-layer perceptron (MLP).
* The input consists of two vectors: a relation vector and a head entity vector.
* The output is a tail entity vector.
* The network learns to associate the relation and head entity with the tail entity.
### Interpretation
This diagram illustrates a neural network model for predicting the tail entity given a head entity and the relation between them. The network learns to represent the relationships between entities in a vector space. The multiple hidden layers allow the network to learn complex, non-linear relationships between the input and output vectors. The association function "f" likely represents a final transformation or classification step to produce the tail entity vector. The model can be used for tasks such as knowledge graph completion, where the goal is to predict missing relationships between entities.
</details>
V (head)
Tail entity vector
Figure 3: The DNN structure for NAMs.
Tail entity vector f Association at here W (2) W ( L ) … out: z ( L ) In: a ( L ) out: z (2) In: a (2) … B (2) B ( L ) B ( L+ 1) Firstly, we represent head entity phrase e i and tail entity phrase e j by two embedding vectors v (1) i ( ∈ V (1) ) and v (2) j ( ∈ V (2) ) . Similarly, relation r k is also represented by a low-dimensional vector c k ∈ C , which we call a relation code hereafter. Secondly, we combine the embeddings of the head entity e i and the relation r k to feed into an ( L + 1) -layer DNN as input. The DNN consists of L rectified linear (ReLU) hidden layers (Nair and Hinton 2010). The input is z (0) = [ v (1) i , c k ] . During the feedforward process, we have
$$a ^ { ( \ell ) } = W ^ { ( \ell ) } z ^ { ( \ell - 1 ) } + b ^ { \ell } \quad ( \ell = 1 , \cdots , L ) \quad ( 2 )$$
W (1)
$$z ^ { ( \ell ) } = h \left ( a ^ { ( \ell ) } \right ) = \max \left ( 0 , a ^ { ( \ell ) } \right ) \quad ( \ell = 1 , \cdots , L ) \quad ( 3 )$$
where W ( ) and b represent the weight matrix and bias for layer respectively.
Finally, we propose to calculate a sigmoid score for each triple x n = ( e i , r k , e j ) as the association probability using the last hidden layer's output and the tail entity vector v (2) j :
$$f ( x _ { n } ; \Theta ) = \sigma \left ( z ^ { ( L ) } \cdot v _ { j } ^ { ( 2 ) } \right ) \quad ( 4 )$$
-x where σ ( · ) is the sigmoid function, i.e., σ ( x ) = 1 / (1+ e ) . All network parameters of this NAM structure, represented as Θ = { W , V (1) , V (2) , C } , may be jointly learned by maximizing the likelihood function in eq. (1).
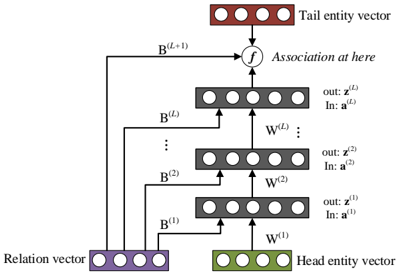
## Relation-modulated Neural Networks (RMNN)
Particularly for multi-relation data, following the idea in (Xue et al. 2014), we propose to use the so-called relationmodulated neural nets (RMNN), as shown in Figure 4.
The RMNN uses the same operations as DNNs to project all entities and relations into low-dimensional continuous space. As shown in Figure 4, we connect the knowledgespecific relation code c ( k ) to all hidden layers in the network.
New Relation
Deep Neural Networks
Tail entity vector
Figure 4: The relation-modulated neural networks (RMNN).
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Neural Network Diagram: Entity and Relation Vector Association
### Overview
The image depicts a neural network architecture designed to associate relation vectors with head and tail entity vectors. The network consists of multiple layers, each processing input from the previous layer and relation vectors. The final layer outputs an association between the head and tail entities.
### Components/Axes
* **Input Layers:**
* **Relation vector:** Represented by a row of four purple circles at the bottom-left.
* **Head entity vector:** Represented by a row of four green circles at the bottom-right.
* **Hidden Layers:**
* A stack of L layers, each represented by a row of five gray circles. The layers are indexed from 1 to L.
* Each layer receives input from the layer below and the relation vector.
* **Output Layer:**
* **Tail entity vector:** Represented by a row of four red circles at the top.
* **Connections:**
* **W^(l):** Represents the weights connecting layer l-1 to layer l. These are represented by arrows pointing upwards between layers.
* **B^(l):** Represents the weights connecting the relation vector to layer l. These are represented by arrows pointing from the relation vector to each layer.
* **B^(L+1):** Represents the weights connecting the relation vector to the association function.
* **Association Function:**
* Represented by a circle containing the letter "f" at the top, which combines the output of the last hidden layer and the relation vector.
* **Layer Outputs:**
* Each layer l has an output z^(l) and an input a^(l).
### Detailed Analysis
* **Bottom Layer (l=1):**
* Input: a^(1)
* Output: z^(1)
* Receives input from the Head entity vector via W^(1) and the Relation vector via B^(1).
* **Intermediate Layers (l=2 to L-1):**
* Input: a^(2)
* Output: z^(2)
* Receives input from the previous layer via W^(2) and the Relation vector via B^(2).
* **Top Layer (l=L):**
* Input: a^(L)
* Output: z^(L)
* Receives input from the previous layer via W^(L) and the Relation vector via B^(L).
* **Association Layer:**
* The output of the top layer z^(L) and the Relation vector are fed into the association function "f".
* The Relation vector is connected to the association function via B^(L+1).
* The output of the association function is the Tail entity vector.
### Key Observations
* The Relation vector is used as input to every layer of the network, suggesting it plays a crucial role in determining the association between the head and tail entities.
* The network architecture is a feed-forward neural network with skip connections from the Relation vector to each layer.
* The association function "f" is a key component that combines the output of the final hidden layer and the Relation vector to produce the Tail entity vector.
### Interpretation
This diagram illustrates a neural network model designed to learn relationships between entities. The model takes a head entity vector and a relation vector as input and predicts the corresponding tail entity vector. The use of skip connections from the relation vector to each layer allows the model to incorporate relational information at multiple levels of abstraction. The association function "f" likely performs a non-linear transformation to combine the outputs of the hidden layers and the relation vector, enabling the model to capture complex relationships between entities. The model could be used for tasks such as knowledge graph completion, relation extraction, and question answering.
</details>
As shown later, this structure is superior in knowledge transfer learning tasks. Therefore, for each layer of RMNNs, instead of using eq.(2), its linear activation signal is computed from the previous layer z ( -1) and the relation code c ( k ) as follows:
$$a ^ { ( \ell ) } = W ^ { ( \ell ) } z ^ { ( \ell - 1 ) } + B ^ { ( \ell ) } c ^ { ( k ) } , \quad ( \ell = 1 \cdots L ) \quad ( 5 )$$
where W ( ) and B represent the normal weight matrix and the relation-specific weight matrix for layer . At the topmost layer, we calculate the final score for each triple x n = ( e i , r k , e j ) using the relation code as:
$$f ( x _ { n } ; \Theta ) = \sigma \left ( z ^ { ( L ) } \cdot v _ { j } ^ { ( 2 ) } + B ^ { ( L + 1 ) } \cdot c ^ { ( k ) } \right ) . \quad ( 6 )$$
In the same way, all RMNN parameters, including Θ = { W , B , V (1) , V (2) , C } , can be jointly learned based on the above maximum likelihood estimation.
The RMNN models are particularly suitable for knowledge transfer learning , where a pre-trained model can be quickly extended to any new relation after observing a few samples from that relation. In this case, we may estimate a new relation code based on the available new samples while keeping the whole network unchanged. Due to its small size, the new relation code can be reliably estimated from only a small number of new samples. Furthermore, model performance in all original relations will not be affected since the model and all original relation codes are not changed during transfer learning.
## Experiments
In this section, we evaluate the proposed NAM models for various reasoning tasks. We first describe the experimental setup and then we report the results from several reasoning tasks, including textual entailment recognition, triple classification in multi-relational KBs, commonsense reasoning and knowledge transfer learning.
## Experimental setup
Here we first introduce some common experimental settings used for all experiments: 1) For entity or sentence representations, we represent them by composing from their
word vectors as in (Socher et al. 2013). All word vectors are initialized from a pre-trained skip-gram (Mikolov et al. 2013) word embedding model, trained on a large English Wikipedia corpus. The dimensions for all word embeddings are set to 100 for all experiments; 2) The dimensions of all relation codes are set to 50. All relation codes are randomly initialized; 3) For network structures, we use ReLU as the nonlinear activation function and all network parameters are initialized according to (Glorot and Bengio 2010). Meanwhile, since the number of training examples for most probabilistic reasoning tasks is relatively small, we adopt the dropout approach (Hinton et al. 2012) during the training process to avoid the over-fitting problem; 4) During the learning process of NAMs, we need to use negative samples, which are automatically generated by randomly perturbing positive KB triples as D -= { ( e i , r k , e ) | e = e j ∧ ( e i , r k , e j ) ∈ D + } .
For each task, we use the provided development set to tune for the best training hyperparameters. For example, we have tested the number of hidden layers among { 1, 2, 3 } , the initial learning rate among { 0.01, 0.05, 0.1, 0.25, 0.5 } , dropout rate among { 0, 0.1, 0.2, 0.3, 0.4 } . Finally, we select the best setting based on the performance on the development set: the final model structure uses 2 hidden layers, and the learning rate and the dropout rate are set to be 0.1 and 0.2, respectively, for all the experiments. During model training, the learning rate is halved once the performances in the development set decreases. Both DNNs and RMNNs are trained using the stochastic gradient descend (SGD) algorithm. We notice that the NAM models converge quickly after 30 epochs.
## Recognizing Textual Entailment
Understanding entailment and contradiction is fundamental to language understanding. Here we conduct experiments on a popular recognizing textual entailment (RTE) task, which aims to recognize the entailment relationship between a pair of English sentences. In this experiment, we use the SNLI dataset in (Bowman et al. 2015) to conduct 2-class RTE experiments (entailment or contradiction). All instances that are not labelled as 'entailment' are converted to contradiction in our experiments. The SNLI dataset contains hundreds of thousands of training examples, which is useful for training a NAM model. Since this data set does not include multirelational data, we only investigate the DNN structure for this task. The final NAM result, along with the baseline performance provided in (Bowman et al. 2015), is listed in Table 2.
Table 2: Experimental results on the RTE task.
| Model | Accuracy (%) |
|----------------------------------------|----------------|
| Edit Distance (Bowman et al. 2015) | 71.9 |
| Classifier (Bowman et al. 2015) | 72.2 |
| Lexical Resources (Bowman et al. 2015) | 75 |
| DNN | 84.7 |
From the results, we can see the proposed DNN based
NAM model achieves considerable improvements over various traditional methods. This indicates that we can better model entailment relationship in natural language by representing sentences in continuous space and conducting probabilistic reasoning with deep neural networks.
## Triple classification in multi-relational KBs
In this section, we evaluate the proposed NAM models on two popular knowledge triple classification datasets, namely WN11andFB13in(Socher et al. 2013) (derived from WordNet and FreeBase), to predict whether some new triple relations hold based on other training facts in the database. The WN11 dataset contains 38,696 unique entities involving 11 different relations in total while the FB13 dataset covers 13 relations and 75,043 entities. Table 3 summarizes the statistics of these two datasets.
Table 3: The statistics for KBs triple classification datasets. #R is the number of relations. #Ent is the size of the entity set.
| Dataset | # R | # Ent | # Train | # Dev | # Test |
|-----------|-------|---------|-----------|---------|----------|
| WN11 | 11 | 38,696 | 112,581 | 2,609 | 10,544 |
| FB13 | 13 | 75,043 | 316,232 | 5,908 | 23,733 |
The goal of knowledge triple classification is to predict whether a given triple x n = ( e i , r k , e j ) is correct or not. We first use the training data to learn NAM models. Afterwards, we use the development set to tune a global threshold T to make a binary decision: the triple is classified as true if f ( x n ; Θ ) ≥ T ; otherwise it is false. The final accuracy is calculated based on how many triplets in the test set are classified correctly.
Experimental results on both WN11 and FB13 datasets are given in Table 4, where we compare the two NAM models with all other methods reported on these two datasets. The results clearly show that the NAM methods (DNNs and RMNNs) achieve comparable performance on these triple classification tasks, and both yield consistent improvement over all existing methods. In particular, the RMNN model yields 3.7% and 1.9% absolute improvements over the popular neural tensor networks (NTN) (Socher et al. 2013) on WN11 and FB13 respectively. Both DNN and RMNN models are much smaller than NTN in the number of parameters and they scale well as the number of relation types increases. For example, both DNN and RMNN models for WN11 have about 7.8 millions of parameters while NTN has about 15 millions. Although the RESCAL and TransE models have about 4 millions of parameters for WN11, their size goes up quickly for other tasks of thousands or more relation types. In addition, the training time of DNN and RMNN is much shorter than that of NTN or TransE since our models converge much faster. For example, we have obtained at least a 5 times speedup over NTN in WN11.
## Commonsense Reasoning
Similar to the triple classification task (Socher et al. 2013), in this work, we use the ConceptNet KB (Liu and Singh 2004) to construct a new commonsense data set, named as
Table 4: Triple classification accuracy in WN11 and FB13.
| Model | WN11 | FB13 | Avg. |
|-----------------------------|--------|--------|--------|
| SME (Bordes et al. 2012) | 70 | 63.7 | 66.9 |
| TransE (Bordes et al. 2013) | 75.9 | 81.5 | 78.7 |
| TransH (Wang et al. 2014) | 78.8 | 83.3 | 81.1 |
| TransR (Lin et al. 2015) | 85.9 | 82.5 | 84.2 |
| NTN (Socher et al. 2013) | 86.2 | 90 | 88.1 |
| DNN | 89.3 | 91.5 | 90.4 |
| RMNN | 89.9 | 91.9 | 90.9 |
CN14 hereafter. When building CN14, we first select all facts in ConceptNet related to 14 typical commonsense relations, e.g., UsedFor , CapableOf . (see Figure 5 for all 14 relations.) Then, we randomly divide the extracted facts into three sets, Train, Dev and Test. Finally, in order to create a test set for classification, we randomly switch entities (in the whole vocabulary) from correct triples and get a total of 2 × #Test triples (half are positive samples and half are negative examples). The statistics of CN14 are given in Table 5.
Table 5: The statistics for the CN14 dataset.
| Dataset | # R | # Ent. | # Train | # Dev | # Test |
|-----------|-------|----------|-----------|---------|----------|
| CN14 | 14 | 159,135 | 200,198 | 5,000 | 10,000 |
The CN14 dataset is designed for answering commonsense questions like Is a camel capable of journeying across desert? The proposed NAM models answer this question by calculating the association probability Pr( E 2 | E 1 ) where E 1 = { camel , capable of } and E 2 = journey across desert . In this paper, we compare two NAM methods with the popular NTN method in (Socher et al. 2013) on this data set and the overall results are given in Table 6. We can see that both NAM methods outperform NTN in this task, and the DNN and RMNN models obtain similar performance.
Table 6: Accuracy (in %) comparison on CN14.
| Model | Positive | Negative | total |
|---------|------------|------------|---------|
| NTN | 82.7 | 86.5 | 84.6 |
| DNN | 84.5 | 86.9 | 85.7 |
| RMNN | 85.1 | 87.1 | 86.1 |
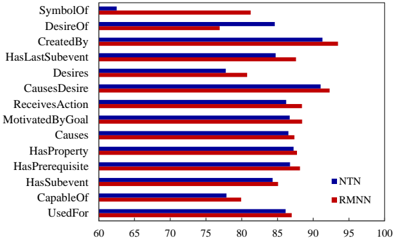
Furthermore, we show the classification accuracy of all 14 relations in CN14 for RMNN and NTN in Figure 5, which show that the accuracy of RMNN varies among different relations from 80.1% ( Desires ) to 93.5% ( CreatedBy ). We notice some commonsense relations (such as Desires , CapableOf ) are harder than the others (like CreatedBy , CausesDesire ). RMNN overtakes NTN in almost all relations.
## Knowledge Transfer Learning
Knowledge transfer between various domains is a characteristic feature and crucial cornerstone of human learning. In this section, we evaluate the proposed NAM models for a
Figure 5: Accuracy of different relations in CN14.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Horizontal Bar Chart: Comparison of NTN and RMNN Performance
### Overview
The image is a horizontal bar chart comparing the performance of two models, NTN (blue bars) and RMNN (red bars), across various relation types. The x-axis represents performance, ranging from 60 to 100. The y-axis lists different relation types.
### Components/Axes
* **X-axis:** Performance (ranging from 60 to 100)
* **Y-axis:** Relation Types (SymbolOf, DesireOf, CreatedBy, HasLastSubevent, Desires, CausesDesire, ReceivesAction, MotivatedByGoal, Causes, HasProperty, HasPrerequisite, HasSubevent, CapableOf, UsedFor)
* **Legend:** Located in the bottom-right corner.
* Blue square: NTN
* Red square: RMNN
### Detailed Analysis
Here's a breakdown of the performance of each model for each relation type:
* **SymbolOf:** NTN ~62, RMNN ~82
* **DesireOf:** NTN ~87, RMNN ~88
* **CreatedBy:** NTN ~92, RMNN ~93
* **HasLastSubevent:** NTN ~87, RMNN ~90
* **Desires:** NTN ~78, RMNN ~80
* **CausesDesire:** NTN ~85, RMNN ~86
* **ReceivesAction:** NTN ~87, RMNN ~88
* **MotivatedByGoal:** NTN ~87, RMNN ~88
* **Causes:** NTN ~87, RMNN ~88
* **HasProperty:** NTN ~86, RMNN ~87
* **HasPrerequisite:** NTN ~85, RMNN ~87
* **HasSubevent:** NTN ~83, RMNN ~84
* **CapableOf:** NTN ~78, RMNN ~80
* **UsedFor:** NTN ~85, RMNN ~86
### Key Observations
* RMNN consistently performs slightly better than NTN across most relation types.
* The largest performance difference is observed in "SymbolOf," where RMNN significantly outperforms NTN.
* The performance difference between the two models is minimal for relation types like "DesireOf", "ReceivesAction", "MotivatedByGoal", and "Causes".
* Both models generally achieve higher performance on relation types like "CreatedBy" and "HasLastSubevent" compared to "SymbolOf" and "Desires".
### Interpretation
The data suggests that RMNN is generally a more effective model than NTN for the tested relation types. The significant difference in performance for "SymbolOf" indicates that RMNN may be better at handling symbolic relationships. The relatively consistent performance across other relation types suggests that both models have similar strengths and weaknesses in those areas. The high performance on "CreatedBy" and "HasLastSubevent" could indicate that both models are particularly well-suited for handling relationships involving creation and event sequencing.
</details>
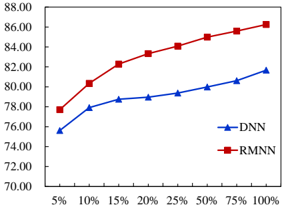
Figure 6: Accuracy (in %) on the test set of a new relation CausesDesire is shown as a function of used training samples from CausesDesire when updating the relation code only. (Accuracy on the original relations remains as 85.7%.)
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Chart: DNN vs RMNN Performance
### Overview
This image is a line chart comparing the performance of two models, DNN and RMNN, across different data percentages. The chart shows the accuracy of each model as the percentage of data used increases from 5% to 100%.
### Components/Axes
* **X-axis:** Data Percentage (5%, 10%, 15%, 20%, 25%, 50%, 75%, 100%)
* **Y-axis:** Accuracy (from 70.00 to 88.00)
* **Legend:**
* Blue line with triangle markers: DNN
* Red line with square markers: RMNN
### Detailed Analysis
* **DNN (Blue Line):**
* Trend: The DNN accuracy generally increases as the data percentage increases.
* Data Points:
* 5%: ~75.5
* 10%: ~78.0
* 15%: ~78.7
* 20%: ~79.0
* 25%: ~79.3
* 50%: ~79.9
* 75%: ~81.0
* 100%: ~81.8
* **RMNN (Red Line):**
* Trend: The RMNN accuracy also increases as the data percentage increases, and it consistently outperforms DNN.
* Data Points:
* 5%: ~77.7
* 10%: ~80.3
* 15%: ~82.3
* 20%: ~82.8
* 25%: ~83.8
* 50%: ~85.0
* 75%: ~85.6
* 100%: ~86.2
### Key Observations
* RMNN consistently outperforms DNN across all data percentages.
* Both models show increasing accuracy with more data.
* The rate of increase in accuracy appears to slow down as the data percentage approaches 100%.
### Interpretation
The chart demonstrates that the RMNN model is more accurate than the DNN model for the given task, regardless of the amount of data used. Both models benefit from increased data, but the RMNN model maintains a higher level of performance. The diminishing returns observed as the data percentage increases suggest that there may be a point beyond which adding more data yields only marginal improvements in accuracy. This information is valuable for model selection and resource allocation, indicating that RMNN is the preferred choice and that focusing on data acquisition beyond a certain point may not be cost-effective.
</details>
knowledge transfer learning scenario, where we adapt a pretrained model to an unseen relation with only a few training samples from the new relation. Here we randomly select a relation, e.g., CausesDesire in CN14 for this experiment. This relation contains only 4800 training samples and 480 test samples. During the experiments, we use all of the other 13 relations in CN14 to train baseline NAM models (both DNN and RMNN). During the transfer learning, we freeze all NAM parameters, including all weights and entity representations, and only learn a new relation code for CausesDesire from the given samples. At last, the learned relation code (along with the original NAM models) is used to classify the new samples of CausesDesire in the test set. Obviously, this transfer learning does not affect the model performance in the original 13 relations because the models are not changed. Figure 6 shows the results of knowledge transfer learning for the relation CausesDesire as we increase the training samples gradually. The result shows that RMNN performs much better than DNN in this experiment, where we can significantly improve RMNN for the new relation with only 5-20% of the total training samples for CausesDesire . This demonstrates that the structure to connect the relation code to all hidden layers leads to more effective learning of new relation codes from a relatively small number of training samples.
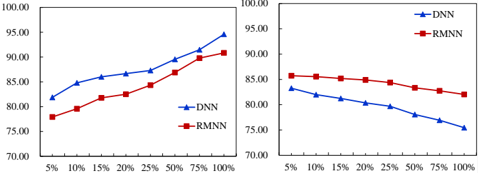
Next, we also test a more aggressive learning strategy for this transfer learning setting, where we simultaneously update all the network parameters during the learning of the new relation code. The results are shown in Figure 7. This strategy can obviously improve performance more on the new relation, especially when we add more training samples. However, as expected, the performance on the original 13 relations deteriorates. The DNN improves the performance on the new relation as we use all training samples (up to 94.6%). However, the performance on the remaining 13 original relations drops dramatically from 85.6% to 75.5%. Once again, RMNN shows an advantage over DNN in this transfer learning setting, where the accuracy on the new relation increases from 77.9% to 90.8% but the accuracy on the original 13 relations only drop slightly from 85.9% to 82.0%.
Figure 7: Transfer learning results by updating all network parameters. The left figure shows results on the new relation while the right figure shows results on the original relations.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Chart Type: Comparative Line Graphs
### Overview
The image presents two line graphs comparing the performance of two models, DNN (Deep Neural Network) and RMNN (Recurrent Memory Neural Network), across varying data percentages. The left graph shows performance increasing with data percentage, while the right graph shows performance decreasing with data percentage.
### Components/Axes
* **Y-axis (both graphs):** Performance, ranging from 70.00 to 100.00. Increments of 5.00 are marked.
* **X-axis (both graphs):** Data percentage, with markers at 5%, 10%, 15%, 20%, 25%, 50%, 75%, and 100%.
* **Legend (both graphs):**
* Blue line with triangle markers: DNN
* Red line with square markers: RMNN
### Detailed Analysis
**Left Graph (Increasing Performance):**
* **DNN (Blue):** The DNN line slopes upward.
* 5%: ~82.00
* 10%: ~84.50
* 15%: ~86.00
* 20%: ~86.50
* 25%: ~87.00
* 50%: ~88.00
* 75%: ~92.00
* 100%: ~95.00
* **RMNN (Red):** The RMNN line also slopes upward, but generally remains below the DNN line.
* 5%: ~78.00
* 10%: ~80.00
* 15%: ~82.00
* 20%: ~83.00
* 25%: ~83.00
* 50%: ~87.00
* 75%: ~90.00
* 100%: ~91.00
**Right Graph (Decreasing Performance):**
* **DNN (Blue):** The DNN line slopes downward.
* 5%: ~83.00
* 10%: ~82.00
* 15%: ~81.50
* 20%: ~81.00
* 25%: ~80.50
* 50%: ~78.00
* 75%: ~77.00
* 100%: ~76.00
* **RMNN (Red):** The RMNN line also slopes downward, but generally remains above the DNN line.
* 5%: ~86.00
* 10%: ~85.50
* 15%: ~85.50
* 20%: ~85.00
* 25%: ~85.00
* 50%: ~83.50
* 75%: ~83.00
* 100%: ~82.00
### Key Observations
* In the left graph, DNN consistently outperforms RMNN. Both models improve as the data percentage increases.
* In the right graph, RMNN consistently outperforms DNN. Both models degrade as the data percentage increases.
* The performance difference between DNN and RMNN is more pronounced in the left graph than in the right graph.
### Interpretation
The two graphs likely represent performance under different conditions or tasks. The left graph suggests a scenario where more data benefits both models, with DNN being more efficient at leveraging the increased data. The right graph suggests a scenario where more data introduces noise or complexity that degrades performance, with RMNN being more robust to this degradation. The specific nature of these conditions or tasks would require additional context.
</details>
## Extending NAMs for Winograd Schema Data Collection
In the previous experiments sections, all the tasks already contained manually constructed training data for us. However, in many cases, if we want to realize flexible commonsense reasoning under the real world conditions, obtaining the training data can also be very challenging. More specifically, since the proposed neural association model is a typical deep learning technique, lack of training data would make it difficult for us to train a robust model. Therefore, in this paper, we make some efforts and try to mine useful data for model training. As a very first step, we are now working on collecting the cause-effect relationships between a set of common words and phrases. We believe this type of knowledge would be a key component for modeling the association relationships between discrete events.
This section describes the idea for automatic cause-effect pair collection as well as the data collection results. We will first introduce the common vocabulary we created for query generation. After that, the detailed algorithm for cause-effect pair collection will be presented. Finally, the following section will present the data collection results.
## Common Vocabulary and Query Generation
To avoid the data sparsity problem, we start our work by constructing a vocabulary of very common words. In our current investigations, we construct a vocabulary which contains 7500 verbs and adjectives. As shown in Table 7, this vocabulary includes 3000 verb words, 2000 verb phrases and 2500 adjective words. The procedure for constructing this vocabulary is straightforward. We first extract all words and phrases (divided by part-of-speech tags) from WordNet (Miller 1995). After conducting part-of-speech tagging on a large corpus, we then get the occurrence frequencies for all those words and phrases by scanning over the tagged corpus. Finally, we sort those words and phrases by frequency and then select the top N results.
Table 7: Common vocabulary constructed for mining causeeffect event pairs.
| Set | Category | Size |
|-------|-----------------|--------|
| 1 | Verb words | 3000 |
| 2 | Verb phrases | 2000 |
| 3 | Adjective words | 2500 |
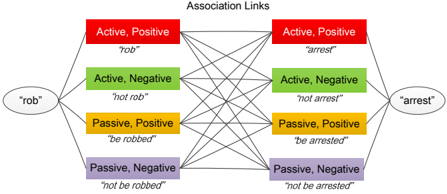
Query Generation Based on the common vocabulary, we generate search queries by pairing any two words (or phrases). Currently we only focus on extracting the association relationships between verbs and adjectives. Even for this small vocabulary, the search space is very large (7.5K by 7.5K leads to tens of millions pairs). In this work, we define several patterns for each word or phrase based on two popular semantic dimensions: 1) positive-negative, 2) activepassive (Osgood 1952). Using the verbs rob and arrest for example, each of them contains 4 patterns, i.e. (active, positive), (active, negative), (passive, positive) and (passive, negative). Therefore, the query formed by rob and arrest would contain 16 possible dimensions, as shown in Figure 8. The task of mining the cause-effect relationships for any two words or phrases then becomes the task of getting the number of occurrences for all the possible links. Text corpus Vocab Sentences Results
Figure 8: Typical 16 dimensions for a typical query.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Association Diagram: "rob" to "arrest"
### Overview
The image is a diagram illustrating association links between the words "rob" and "arrest". It shows how these words can be connected through active/passive and positive/negative associations. The diagram uses colored rectangles to represent these associations, with lines connecting the initial word "rob" to these associations and then to the final word "arrest".
### Components/Axes
* **Title:** Association Links
* **Nodes:**
* Left Node: "rob" (oval shape)
* Right Node: "arrest" (oval shape)
* **Association Blocks (Left Side):**
* Red: Active, Positive; "rob"
* Green: Active, Negative; "not rob"
* Orange: Passive, Positive; "be robbed"
* Purple: Passive, Negative; "not be robbed"
* **Association Blocks (Right Side):**
* Red: Active, Positive; "arrest"
* Green: Active, Negative; "not arrest"
* Orange: Passive, Positive; "be arrested"
* Purple: Passive, Negative; "not be arrested"
* **Links:** Lines connecting "rob" to each of the four association blocks on the left, and lines connecting each of those blocks to each of the four association blocks on the right, and lines connecting each of the four association blocks on the right to "arrest".
### Detailed Analysis
The diagram visually represents the different ways the words "rob" and "arrest" can be associated. Each association block is defined by two attributes: Active/Passive and Positive/Negative.
* **Left Side ("rob"):**
* **Red (Active, Positive):** The action of robbing is actively performed, and the outcome is positive (from the perspective of the robber). The associated word is "rob".
* **Green (Active, Negative):** The action of robbing is actively performed, and the outcome is negative (from the perspective of the victim). The associated phrase is "not rob".
* **Orange (Passive, Positive):** The subject is passively receiving the action of being robbed, and the outcome is positive (perhaps in a twisted sense, like insurance payout). The associated phrase is "be robbed".
* **Purple (Passive, Negative):** The subject is passively receiving the action of being robbed, and the outcome is negative. The associated phrase is "not be robbed".
* **Right Side ("arrest"):**
* **Red (Active, Positive):** The action of arresting is actively performed, and the outcome is positive (from the perspective of law enforcement). The associated word is "arrest".
* **Green (Active, Negative):** The action of arresting is actively performed, and the outcome is negative (from the perspective of the person being arrested). The associated phrase is "not arrest".
* **Orange (Passive, Positive):** The subject is passively receiving the action of being arrested, and the outcome is positive (perhaps in a sense of justice being served). The associated phrase is "be arrested".
* **Purple (Passive, Negative):** The subject is passively receiving the action of being arrested, and the outcome is negative. The associated phrase is "not be arrested".
The lines connecting the blocks show all possible combinations of associations between "rob" and "arrest".
### Key Observations
* The diagram highlights the multifaceted relationships between two seemingly straightforward words.
* The use of Active/Passive and Positive/Negative attributes provides a structured way to analyze these relationships.
* The diagram demonstrates how a single action (robbery) can lead to different outcomes and perspectives, ultimately connecting to another action (arrest).
### Interpretation
The diagram illustrates the complex web of associations that can exist between words, going beyond simple definitions. It demonstrates how actions can be viewed from different perspectives (active vs. passive) and with varying outcomes (positive vs. negative). The connections between "rob" and "arrest" are not direct but are mediated by these different associations, showing the potential for nuanced understanding of language and events. The diagram suggests that understanding the context and perspective is crucial for interpreting the relationship between actions and their consequences.
</details>
## Automatic Cause-Effect Pair Collection
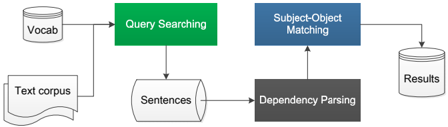
Based on the created queries, in this section, we present the procedures for extracting cause-effect pairs from large unstructured texts. The overall system framework is shown in Figure 9.
Query Searching The goal of query searching is to find all the possible sentences that may contain the input queries. Since the number of queries is very large, we structure all the queries as a hashmap and conduct string matching during text scanning. In detail, the searching program starts by
Figure 9: Automatic pair collection system framework.
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Diagram: Text Processing Workflow
### Overview
The image is a diagram illustrating a text processing workflow. It shows the flow of data and processes involved in extracting relationships between subjects and objects from a text corpus. The workflow includes steps such as query searching, dependency parsing, and subject-object matching.
### Components/Axes
The diagram consists of the following components:
* **Vocab:** A database-like structure containing vocabulary.
* **Text corpus:** A collection of text documents.
* **Query Searching:** A green rectangular block representing the query searching process.
* **Sentences:** A database-like structure containing sentences extracted from the text corpus.
* **Dependency Parsing:** A dark gray rectangular block representing the dependency parsing process.
* **Subject-Object Matching:** A blue rectangular block representing the subject-object matching process.
* **Results:** A database-like structure containing the results of the subject-object matching.
* **Arrows:** Arrows indicate the flow of data between the components.
### Detailed Analysis or ### Content Details
1. **Vocab** and **Text corpus** feed into **Query Searching**.
2. **Query Searching** outputs to **Sentences**.
3. **Text corpus** also feeds into **Dependency Parsing**.
4. **Sentences** and **Dependency Parsing** feed into **Subject-Object Matching**.
5. **Subject-Object Matching** outputs to **Results**.
### Key Observations
The diagram illustrates a pipeline where a text corpus is processed to extract subject-object relationships. The vocabulary and text corpus are used for query searching, which results in sentences. The text corpus is also used for dependency parsing. The sentences and dependency parsing results are then used for subject-object matching, which produces the final results.
### Interpretation
The diagram represents a typical natural language processing (NLP) pipeline for extracting structured information from unstructured text. The process starts with a text corpus and a vocabulary. Query searching is performed to identify relevant sentences. Dependency parsing is used to analyze the grammatical structure of the sentences. Finally, subject-object matching is performed to extract relationships between subjects and objects. The results of this process can be used for various applications, such as knowledge graph construction, information retrieval, and question answering.
</details>
conducting lemmatizing, part-of-speech tagging and dependency parsing on the source corpus. After it, we scan the corpus from the begining to end. When dealing with each sentence, we will try to find the matched words (or phrases) using the hashmap. This strategy help us to reduce the search complexity to be linear with the size of corpus, which has been proved to be very efficient in our experiments.
Association Links
'rob' Active, Positive Active, Negative Passive, Positive Passive, Negative 'arrest' Active, Positive Active, Negative Passive, Positive Passive, Negative Subject-Object Matching Based on the dependency parsing results, once we find one phrase of a query, we would check whether that phrase is associated with at least one subject or object in the corresponding sentence or not. At the same time, we record whether the phrase was positive or negative, active or passive. Moreover, for helping us to decide the cause-effect relationships, we would check whether the phrase is linked with some connective words or not. Typical connective words used in this work are because and if . To finally extract the cause-effect pairs, we design a simple subject-object matching rule, which is similar to the work of (Peng, Khashabi, and Roth 2015). 1) If the two phrases in one query share the same subject , the relationship between them is then straightforward; 2) If the subject of one phrase is the object of the other phrase, then we need to apply the passive pattern to the phrase related to the object . This subject-object matching idea is similar to the work proposed in (Peng, Khashabi, and Roth 2015). Using query ( arrest , rob ) as an example. Once we find sentence 'Tom was arrested because Tom robbed the man' , we obtain its dependency parsing result as shown in Figure 10. The verb arrest and rob share a same subject, and the pattern for arrest is passive, we will add the occurrence of the corresponding association link, i.e. link from the (active,positive) pattern of rob to the (passive,positive) pattern of arrest , by 1.
Figure 10: Dependency parsing result of sentence 'Tom was arrested because Tom robbed the man' .
<details>
<summary>Image 10 Details</summary>

### Visual Description
Icon/Small Image (393x59)
</details>
## Data Collection Results
Table 8 shows the corpora we used for collecting the causeeffect pairs and the corresponding data collection results. We extract approximately 240,000 pairs from different corpora.
Table 8: Data collection results on different corpora.
| Corpus | # Result pairs |
|------------------------------|------------------|
| Gigaword (Graff et al. 2003) | 117,938 |
| Novels (Zhu et al. 2015) | 129,824 |
| CBTest (Hill et al. 2015) | 4,167 |
| BNC (Burnard 1995) | 2,128 |
## Winograd Schema Challenge
Based on all the experiments described in the previous sections, we could conclude that the neural association model has the potential to be effective in commonsense reasoning. To further evaluate the effectiveness of the proposed neural association model, in this paper, we conduct experiments on solving the complex Winograd Schema challenge problems (Levesque, Davis, and Morgenstern 2011; Morgenstern, Davis, and Ortiz Jr 2016). Winograd Schema is a commonsense reasoning task proposed in recent years, which has been treated as an alternative to the Turing Test (Turing 1950). This is a new AI task and it would be very interesting to see whether neural network methods are suitable for solving this problem. This section then describes the progress we have made in attempting to meet the Winograd Schema Challenge. For making clear what is the main task of the Winograd Schema , we will firstly introduce it at a high level. Afterwards, we will introduce the system framework as well as all the corresponding modules we proposed to automatically solve the Winograd Schema problems. Finally, experiments and discussions on a human annotated causeeffect dataset and discussion will be presented.
## Winograd Schema
The Winograd Schema (WS) evaluates a system's commonsense reasoning ability based on a traditional, very difficult natural language processing task: coreference resolution (Levesque, Davis, and Morgenstern 2011; Saba 2015). The Winograd Schema problems are carefully designed to be a task that cannot be easily solved without commonsense knowledge. In fact, even the solution of traditional coreference resolution problems relies on semantics or world knowledge (Rahman and Ng 2011; Strube 2016). For describing the WS in detail, here we just copy some words from (Levesque, Davis, and Morgenstern 2011). A WS is a small reading comprehension test involving a single binary question. Here are two examples:
- The trophy would not fit in the brown suitcase because it was too big. What was too big?
- -Answer 0: the trophy
- -Answer 1: the suitcase
- Joan made sure to thank Susan for all the help she had given. Who had given the help?
- -Answer 0: Joan
- -Answer 1: Susan
The correct answers here are obvious for human beings. In each of the questions, the corresponding WS has the following four features:
1. Two parties are mentioned in a sentence by noun phrases. They can be two males, two females, two inanimate objects or two groups of people or objects.
2. A pronoun or possessive adjective is used in the sentence in reference to one of the parties, but is also of the right sort for the second party. In the case of males, it is 'he/him/his'; for females, it is 'she/her/her' for inanimate object it is 'it/it/its,' and for groups it is 'they/them/their.'
3. The question involves determining the referent of the pronoun or possessive adjective. Answer 0 is always the first party mentioned in the sentence (but repeated from the sentence for clarity), and Answer 1 is the second party.
4. There is a word (called the special word) that appears in the sentence and possibly the question. When it is replaced by another word (called the alternate word), everything still makes perfect sense, but the answer changes.
Solving WS problems is not easy since the required commonsense knowledge is quite difficult to collect. In the following sections, we are going to describe our work on solving the Winograd Schema problems via neural network methods.
## System Framework
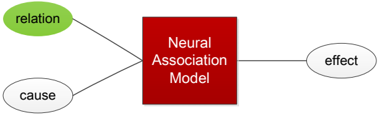
In this paper, we propose that the commonsense knowledge required in many Winograd Schema problems could be formulized as some association relationships between discrete events. Using sentence ' Joan made sure to thank Susan for all the help she had given ' as an example, the commonsense knowledge is that the man who receives help should thank to the man who gives help to him. We believe that by modeling the association between event receive help and thank , give help and thank , we can make the decision by comparing the association probability Pr( thank | receive help ) and Pr( thank | give help ) . If the models are well trained, we should get the inequality Pr( thank | receive help ) > Pr( thank | give help ) . Following this idea, we propose to utilize the data constructed from the previous section and extend the NAM models for solving WS problems. Here we design two frameworks for training NAM models. relation
- TransMat -NAM: We design to apply four linear transformation matrices, i.e., matrices of (active, positive), (active, negative), (passive, positive) and (passive, negative), for transforming both the cause event and the effect event. After it, we then use NAM for model the causeeffect association relationship between any cause and effect events. cause effect Neural Association Model
- RelationVec -NAM: On the other hand, in this configuration, we treat all the typical 16 dimensions shown in Figure 8 as distinct relations. So there are 16 relation vectors
Figure 11: The model framework for TransMat -NAM.
<details>
<summary>Image 11 Details</summary>

### Visual Description
## Diagram: Neural Association Model
### Overview
The image is a diagram illustrating a Neural Association Model. It shows a flow from "cause" to "effect" with "Transform" steps before and after the "Neural Association Model" block.
### Components/Axes
* **Nodes:**
* "cause" (white oval)
* "effect" (white oval)
* **Processes:**
* "Transform" (yellow rectangle, appears twice)
* "Neural Association Model" (red square)
* **Connectors:** Lines connecting the nodes and processes, indicating flow.
### Detailed Analysis or ### Content Details
1. **Cause Node:** A white oval labeled "cause" is located on the left.
2. **First Transform:** A yellow rectangle labeled "Transform" is connected to the "cause" node via a line.
3. **Neural Association Model:** A red square labeled "Neural Association Model" is connected to the first "Transform" block.
4. **Second Transform:** Another yellow rectangle labeled "Transform" is connected to the "Neural Association Model" block.
5. **Effect Node:** A white oval labeled "effect" is connected to the second "Transform" block.
### Key Observations
* The diagram represents a linear flow from cause to effect.
* The "Neural Association Model" is central to the diagram, suggesting it is the core process.
* "Transform" blocks are used before and after the "Neural Association Model," indicating pre-processing and post-processing steps.
### Interpretation
The diagram illustrates a simplified model of how a cause leads to an effect through a neural association model. The "Transform" blocks likely represent data transformation or feature extraction steps necessary for the model to process the input ("cause") and generate the output ("effect"). The model suggests that the relationship between cause and effect is not direct but mediated by transformations and the neural association model itself.
</details>
in the corresponding NAM models. Currently we use the RMNN structure for NAM.
Figure 12: The model framework for RelationVec -NAM.
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Diagram: Neural Association Model
### Overview
The image is a diagram illustrating a Neural Association Model. It shows the relationship between "relation", "cause", and "effect" through the model.
### Components/Axes
* **Nodes:**
* "relation" (green oval, top-left)
* "cause" (white oval, bottom-left)
* "effect" (white oval, right)
* **Model:** "Neural Association Model" (red square, center)
* **Connections:** Lines connecting the nodes to the model.
### Detailed Analysis
* The "relation" node on the top-left is connected to the "Neural Association Model" in the center.
* The "cause" node on the bottom-left is connected to the "Neural Association Model" in the center.
* The "Neural Association Model" in the center is connected to the "effect" node on the right.
### Key Observations
* The diagram shows a flow from "relation" and "cause" to the "Neural Association Model", and then from the model to "effect".
* The "relation" node is colored green, while the "cause" and "effect" nodes are white. The "Neural Association Model" is red.
### Interpretation
The diagram represents a system where "relation" and "cause" are inputs to a "Neural Association Model", which then produces an "effect". The diagram suggests that the model uses the relationship and cause to determine the effect. The different colors of the nodes and the model might indicate different types or roles within the system. The diagram illustrates a basic causal relationship mediated by a neural association model.
</details>
cause effect Neural Association Model Transform Transform Training the NAM models based on these two configurations is straightforward. All the network parameters, including the relation vectors and the linear transformation matrices, are learned by the standard stochastic gradient descend algorithm.
## Experiments
In this section, we will introduce our current experiments on solving the Winograd Schema problems. We will first select a cause-effect dataset constructed from the standard WS dataset. Subsequently, experimental setup will be described in detail. After presenting the experimental results, discussions would be made at the end of this section.
Cause-Effect Dataset Labelling In this paper, based on the WS dataset available at http: //www.cs.nyu.edu/faculty/davise/papers/ WinogradSchemas/WS.html , we labelled 78 causeeffect problems among all 278 available WS questions for our experiments. Table 9 shows some typical examples. For each WS problem, we label three verb (or adjective) phrases for the corresponding two parities and the pronoun. In the labelled phrases, we also record the corresponding patterns for each word respectively. Using word lift for example, we will generate lift for its active and positive pattern, not lift for its active and negative pattern, be lifted for its passive and positive pattern, and not be lifted for its passive and negative pattern. For example, in sentence ' The man couldn't lift his son because he was so weak ', we identify weak , not lift and not be lifted for he , the man and son resspectively. The commonsense is that somebody who is weak would more likely to has the effect not lift rather than not be lifted . The main work of NAM for solving this problem is to calculate the association probability between these phrases.
Experimental setup The setup for NAM on this causeeffect task is similar to the settings on the previous tasks. For representing the phrases in neural association models, we use the bag-of-word (BOW) approach for composing phrases from pre-trained word vectors. Since the vocabulary we use in this experiment contains only 7500 common verbs and adjectives, there are some out-of-vocabulary (OOV) words in some phrases. Based on the BOW method, a phrase would be useless if all the words it contains are OOV. In this paper, we remove all the testing samples with useless phrases which results in 70 testing cause-effect samples. For network settings, we set the embedding size to 50 and the
Table 9: Examples of the Cause-Effect dataset labelled from the Winograd Schema Challenge.
| Schema texts | Verb/Adjective 1 | Verb/Adjective 2 | Verb/Adjective 3 |
|---------------------------------------------------------------------------------|--------------------|--------------------|--------------------|
| The man couldn't lift his son because he was so weak | weak | not lift | not be lifted |
| The man couldn't lift his son because he was so heavy | heavy | not lift | not be lifted |
| The fish ate the worm. it was tasty | tasty | eat | be eaten |
| The fish ate the worm. it was hungry | hungry | eat | be eaten |
| Mary tucked her daughter Anne into bed, so that she could sleep | tuck into bed | be tucked into bed | sleep |
| Mary tucked her daughter Anne into bed, so that she could work | tuck into bed | be tucked into bed | work |
| Tom threw his schoolbag down to ray after he reached the top of the stairs | reach top | throw down | be thrown down |
| Tom threw his schoolbag down to ray after he reached the bottom of the stairs | reach bottom | throw down | be thrown down |
| Jackson was greatly influenced by Arnold, though he lived two centuries earlier | live earlier | influence | be influenced |
| Jackson was greatly influenced by Arnold, though he lived two centuries later | live later | influence | be influenced |
dimension of relation vectors to 50. We set 2 hidden layers for the NAM models and all the hidden layer sizes are set to 100. The learning rate is set to 0.01 for all the experiments. At the same time, to better control the model training, we set the learning rates for learning all the embedding matrices and the relation vectors to 0.025.
Negative sampling is very important for model training for this task. In the TransMat -NAM system, we generate negative samples by randomly selecting different patterns with respect to the pattern of the effect event in the positive samples. For example, if the positive training sample is ' hungry (active, positive) causes eat (active, positive) ', we may generate negative samples like ' hungry (active, positive) causes eat (passive, positive) ', or ' hungry (active, positive) causes eat (active, negative) '. In the RelationVec -NAM system, the negative sampling method is much more straightforward, i.e., we will randomly select a different effect event from the whole vocabulary. In the example shown here, the possible negative sample would be ' hungry (active, positive) causes happy (active, positive) ', or ' hungry (active, positive) causes talk (active, positive) ' and so on.
Results The experimental results are shown in Table 10. From the results, we find that the proposed NAM models achieve about 60% accuracy on the cause-effect dataset constructed from Winograd Schemas . More specifically, the RelationVec -NAM system performs slightly better than the TransMat -NAM system.
Table 10: Results of NAMs on the Winograd Schema CauseEffect dataset.
| Model | Accuracy (%) |
|------------------|----------------|
| TransMat -NAM | 58.6 (41 / 70) |
| RelationVec -NAM | 61.4 (43 / 70) |
In the testing results, we find the NAM performs well on some testing examples. For instance, in the call phone scenario, the proposed NAM generates the corresponding association probabilities as follows.
- Paul tried to call George on the phone, but he wasn't successful. Who was not successful?
- Paul tried to call George on the phone, but he wasn't available. Who was not available?
- Paul: Pr( not successful | call ) = 0.7299
- George: Pr( not successful | be called ) = 0.5430
- Answer: Paul
- Paul: Pr( not available | call ) = 0.6859
- George: Pr( not available | be called ) = 0.8306
- Answer: George
For these testing examples, we find our model can answer the questions by correctly calculating the association probabilities. The probability Pr( not successful | call ) is larger than Pr( not successful | be called ) while the probability Pr( not available | call ) is smaller than Pr( not available | be called ) . Those simple inequality relationships between the association probabilities are very reasonable in our commonsense. Here are some more examples:
- Jim yelled at Kevin because he was so upset. Who was upset?
- -Jim: Pr( yell | be upset ) = 0.9296
- -Kevin: Pr( be yelled | be upset ) = 0.8785
- -Answer: Jim
- Jim comforted Kevin because he was so upset. Who was upset?
- -Answer: Kevin
- Jim: Pr( comfort | be upset ) = 0.0282
- Kevin: Pr( be comforted | be upset ) = 0.5657
This example also conveys some commonsense knowledge in our daily life. We all know that somebody who is upset would be more likely to yell at other people. Meanwhile, it is also more likely that they would be be comforted by other people.
## Conclusions
In this paper, we have proposed neural association models (NAM) for probabilistic reasoning. We use neural networks to model association probabilities between any two events in a domain. In this work, we have investigated two model structures, namely DNN and RMNN, for NAMs. Experimental results on several reasoning tasks have shown that both DNNs and RMNNs can outperform the existing methods. This paper also reports some preliminary results to use NAMs for knowledge transfer learning. We have found that the proposed RMNN model can be quickly adapted to a new relation without sacrificing the performance in the original relations. After proving the effectiveness of the NAM models, we apply it to solve more complex commonsense reasoning problems, i.e., the Winograd Schemas (Levesque, Davis, and Morgenstern 2011). To support model training in this task, we propose a straightforward method to collect associative phrase pairs from text corpora. Experiments conducted on a set of Winograd Schema problems have indicated the neural association model does solve some problems successfully. However, it is still a long way to finally achieving automatic commonsense reasoning.
## Acknowledgments
We want to thank Prof. Gary Marcus of New York University for his useful comments on commonsense reasoning. Wealso want to thank Prof. Ernest Davis, Dr. Leora Morgenstern and Dr. Charles Ortiz for their wonderful organizations for making the first Winograd Schema Challenge happen. This paper was supported in part by the Science and Technology Development of Anhui Province, China (Grants No. 2014z02006), the Fundamental Research Funds for the Central Universities (Grant No. WK2350000001) and the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant No. XDB02070006).
## References
- [Bengio et al. 2003] Bengio, Y.; Ducharme, R.; Vincent, P.; and Janvin, C. 2003. A neural probabilistic language model. The Journal of Machine Learning Research 3:1137-1155.
- [Bordes et al. 2012] Bordes, A.; Glorot, X.; Weston, J.; and Bengio, Y. 2012. Joint learning of words and meaning representations for open-text semantic parsing. In Proceedings of AISTATS , 127-135.
- [Bordes et al. 2013] Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; and Yakhnenko, O. 2013. Translating embeddings for modeling multi-relational data. In Proceedings of NIPS , 2787-2795.
- [Bowman et al. 2015] Bowman, S. R.; Angeli, G.; Potts, C.; and Manning, C. D. 2015. A large annotated corpus for learning natural language inference. arXiv preprint arXiv:1508.05326 .
- [Bowman 2013] Bowman, S. R. 2013. Can recursive neural tensor networks learn logical reasoning? arXiv preprint arXiv:1312.6192 .
- [Burnard 1995] Burnard, L. 1995. Users reference guide british national corpus version 1.0.
- [Collobert et al. 2011] Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; and Kuksa, P. 2011. Natural language processing (almost) from scratch. The Journal of Machine Learning Research 12:2493-2537.
- [Getoor 2007] Getoor, L. 2007. Introduction to statistical relational learning . MIT press.
- [Glorot and Bengio 2010] Glorot, X., and Bengio, Y. 2010. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of AISTATS , 249-256.
- [Graff et al. 2003] Graff, D.; Kong, J.; Chen, K.; and Maeda, K. 2003. English gigaword. Linguistic Data Consortium, Philadelphia .
- [Hill et al. 2015] Hill, F.; Bordes, A.; Chopra, S.; and Weston, J. 2015. The goldilocks principle: Reading children's books with explicit memory representations. arXiv preprint arXiv:1511.02301 .
- [Hinton et al. 2012] Hinton, G. E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; and Salakhutdinov, R. R. 2012. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580 .
- [Hornik, Stinchcombe, and White 1990] Hornik, K.; Stinchcombe, M.; and White, H. 1990. Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks. Neural networks 3(5):551-560.
- [Jensen 1996] Jensen, F. V. 1996. An introduction to Bayesian networks , volume 210. UCL press London.
- [Koller and Friedman 2009] Koller, D., and Friedman, N. 2009. Probabilistic graphical models: principles and techniques . MIT press.
- [LeCun, Bengio, and Hinton 2015] LeCun, Y.; Bengio, Y.; and Hinton, G. 2015. Deep learning. Nature 521(7553):436-444.
- [Levesque, Davis, and Morgenstern 2011] Levesque, H. J.; Davis, E.; and Morgenstern, L. 2011. The winograd schema challenge. In AAAI Spring Symposium: Logical Formalizations of Commonsense Reasoning .
- [Lin et al. 2015] Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; and Zhu, X. 2015. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of AAAI .
- [Liu and Singh 2004] Liu, H., and Singh, P. 2004. Conceptnet: a practical commonsense reasoning toolkit. BT technology journal 22(4):211-226.
- [McCarthy 1986] McCarthy, J. 1986. Applications of circumscription to formalizing common-sense knowledge. Artificial Intelligence 28(1):89-116.
- [Mikolov et al. 2013] Mikolov, T.; Chen, K.; Corrado, G.; and Dean, J. 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 .
- [Miller 1995] Miller, G. A. 1995. Wordnet: a lexical database for english. Communications of the ACM 38(11):39-41.
- [Minsky 1988] Minsky, M. 1988. Society of mind . Simon and Schuster.
- [Morgenstern, Davis, and Ortiz Jr 2016] Morgenstern, L.; Davis, E.; and Ortiz Jr, C. L. 2016. Planning, executing, and evaluating the winograd schema challenge. AI Magazine 37(1):50-54.
- [Mueller 2014] Mueller, E. T. 2014. Commonsense Reasoning: An Event Calculus Based Approach . Morgan Kaufmann.
- [Nair and Hinton 2010] Nair, V., and Hinton, G. E. 2010. Rectified linear units improve restricted boltzmann machines. In Proceedings of ICML , 807-814.
- [Neapolitan 2012] Neapolitan, R. E. 2012. Probabilistic reasoning in expert systems: theory and algorithms . CreateSpace Independent Publishing Platform.
- [Nickel et al. 2015] Nickel, M.; Murphy, K.; Tresp, V.; and Gabrilovich, E. 2015. A review of relational machine learning for knowledge graphs. arXiv preprint arXiv:1503.00759 .
- [Nickel, Tresp, and Kriegel 2012] Nickel, M.; Tresp, V.; and Kriegel, H.-P. 2012. Factorizing YAGO: scalable machine learning for linked data. In Proceedings of WWW , 271-280. ACM.
- [Osgood 1952] Osgood, C. E. 1952. The nature and measurement of meaning. Psychological bulletin 49(3):197.
- [Pearl 1988] Pearl, J. 1988. Probabilistic reasoning in intelligent systems: Networks of plausible reasoning.
- [Peng, Khashabi, and Roth 2015] Peng, H.; Khashabi, D.; and Roth, D. 2015. Solving hard coreference problems. Urbana 51:61801.
- [Rahman and Ng 2011] Rahman, A., and Ng, V. 2011. Coreference resolution with world knowledge. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language TechnologiesVolume 1 , 814-824. Association for Computational Linguistics.
- [Richardson and Domingos 2006] Richardson, M., and Domingos, P. 2006. Markov logic networks. Machine learning 62(1-2):107-136.
- [Saba 2015] Saba, W. 2015. On the winograd schema challenge.
- [Socher et al. 2013] Socher, R.; Chen, D.; Manning, C. D.; and Ng, A. 2013. Reasoning with neural tensor networks for knowledge base completion. In Proceedings of NIPS , 926-934.
- [Strube 2016] Strube, M. 2016. The (non) utility of semantics for coreference resolution (corbon remix). In NAACL 2016 workshop on Coreference Resolution Beyond OntoNotes .
- [Turing 1950] Turing, A. M. 1950. Computing machinery and intelligence. Mind 59(236):433-460.
- [Wang et al. 2014] Wang, Z.; Zhang, J.; Feng, J.; and Chen, Z. 2014. Knowledge graph embedding by translating on hyperplanes. In Proceedings of AAAI , 1112-1119. Citeseer.
- [Xue et al. 2014] Xue, S.; Abdel-Hamid, O.; Jiang, H.; Dai, L.; and Liu, Q. 2014. Fast adaptation of deep neural network based on discriminant codes for speech recognition. Audio, Speech, and Language Processing, IEEE/ACM Trans. on 22(12):1713-1725.
- [Zhu et al. 2015] Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; and Fidler, S. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision , 19-27.