# Cognitive Science in the era of Artificial Intelligence: A roadmap for reverse-engineering the infant language-learner
## Cognitive Science in the era of Artificial Intelligence: A roadmap for reverse-engineering the infant language-learner
Emmanuel Dupoux
EHESS, ENS, PSL Research University, LSCP, CNRS
emmanuel.dupoux@gmail.com, www.syntheticlearner.net
## Short Abstract
Advances in machine learning and wearable sensors make it possible to envision the construction of systems that would reproduce infant's early language acquisition based on the totality of their sensory input. We propose a series of methodological steps to be taken to make such a reverse engineering approach scientifically useful, and discuss its benefits and shortcomings in relation to experimental and theoretical work in this area.
## Long Abstract
During their first years of life, infants learn the language(s) of their environment at an amazing speed despite large cross cultural variations in amount and complexity of the available language input. Understanding this simple fact still escapes current cognitive and linguistic theories. Recently, spectacular progress in the engineering science, notably, machine learning and wearable technology, o er the promise of revolutionizing the study of cognitive development. Machine learning o ers powerful learning algorithms that can achieve human-like performance on many linguistic tasks. Wearable sensors can capture vast amounts of data, which enable the reconstruction of the sensory experience of infants in their natural environment. The project of 'reverse engineering' language development, i.e., of building an e ective system that mimics infant's achievements appears therefore to be within reach.
Here, we analyze the conditions under which such a project can contribute to our scientific understanding of early language development. We argue that instead of defining a sub-problem or simplifying the data, computational models should address the full complexity of the learning situation, and take as input the raw sensory signals available to infants. This implies that (1) accessible but privacypreserving repositories of home data be setup and widely shared, and (2) models be evaluated at di erent linguistic levels through a benchmark of psycholinguist tests that can be passed by machines and humans alike, (3) linguistically and psychologically plausible learning architectures be scaled up to real data using probabilistic / optimization principles from machine learning. We discuss the feasibility of this approach and present preliminary results.
## Keywords
artificial intelligence, big data, computational modeling, corpus analysis, early language acquisition, infant development, language bootstrapping, machine learning, phonetic learning
## 1 Introduction
In recent years, Artificial Intelligence (AI) has been hitting the headlines with impressive achievements at matching or even beating humans in cognitive tasks (playing go or video games: Mnih et al., 2015; Silver et al., 2016; processing natural language: Ferrucci, 2012; recognizing objects and faces: He, Zhang, Ren, & Sun, 2015; Lu & Tang, 2014) and promising a revolution in manufacturing processes and human society at large. These successes rest both on improvement in computer hardware and on statistical learning techniques, which enable to mimic cognitive functions through the training of machine learning algorithms on large amounts of data. Can AI also revolutionize cognitive science by bringing new insights to the scientific study of human cognition? Can machine learning techniques be used to also shed light on human learning? Within the area of human learning, language has always occupied a special place. It has been at the very core of heated debates and controversies related to the nature / nurture debate (rationalism vs. empiricism, biology vs. culture) and the structure of cognitive processes (connexions vs symbols). Three factors can explain why language is so important within cognitive science. First, the linguistic system is uniquely complex : mastering a language implies mastering a combinatorial sound system (phonetics and phonology), an open ended morphologically structured lexicon, and a compositional syntax and semantics (e.g., Jackendo , 1997). No other animal communication system uses such a complex multilayered organization. On this basis, it has been claimed that humans have evolved (or acquired through a mutation) a dedicated computational architecture to process language (see Chomsky, 1965; Hauser, Chomsky, & Fitch, 2002; Steedman, 2014). Second, the overt manifestations of this system are extremely variable across languages and cultures. Language can be expressed through the oral or manual modality. In the oral modality, some languages use only 3 vowels, other more than 20. Con-
sonants inventories vary from 6 to more than 100. Words can be mostly composed of a single syllable (as in Chinese) or long strings of stems and a xes (as in Turkish). Semantic roles can be identified through fixed positions within constituents, or be identified through functional morphemes, etc. (see Song, 2010, for a typology of language variation). Evidently, infants acquire the relevant variant through learning, not genetic transmission. Third, the human language capacity can be viewed as a finite computational system with the ability to generate a (virtual) infinity of utterances. This turns into a learnability problem for infants: on the basis of finite evidence, they have to induce the (virtual) infinity corresponding to their language. As has been repeatedly discussed since Aristotle, such induction problems do not have a generally valid solution. Therefore, language is simultaneously a human-specific biological trait and a highly variable cultural production, and it poses a di cult learnability problem. Here, we investigate the possibility of using machine learning techniques to shed some light on language acquisition. Specifically, we propose the following approach:
The reverse engineering approach to the study of infant language acquisition consists in constructing computational systems that can, when fed with the same input data, reproduce language acquisition as it is observed in infants.
The idea of using machine learning or AI techniques as a means to study child's language learning is not new (to name a few: Kelley, 1967; Anderson, 1975; Berwick, 1985; Rumelhart & McClelland, 1987; Langley & Carbonell, 1987) although relatively few studies have concentrated on the early phases of language learning (see Brent, 1996b, for a review). What is new, however, is that whereas previous AI approaches were limited to proofs of principle on toy or miniature languages, modern AI techniques have scaled up so much that end-to-end language processing systems working with real inputs are now deployed commercially. This paper examines whether and how such unprecedented change in scale could be put to use to address lingering scientific questions in the field of language development. The structure of the paper is as follows: In Section 2, we present two deep puzzles that modeling approaches should address in order to have a scientific impact: solving the bootstrapping problem, accounting for developmental trajectories. In Section 3, we review past theoretical or modeling work, showing that these puzzles have not, so far, received an adequate answer. In Section 4, we argue that to answer them with reverse engineering, three requirements have to be addressed: modeling should be done on real data, model performance should be compared with that of humans, modeling should be computationally e ective. In Section 5, we argue that within a simplifying framework, these requirements can be reached given current technology, although specific roadblocks need to be lifted. In Section 6 we show that even before these roadblocks are lifted, interesting results can be obtained. In Section 7 we show how the reverse engineering approach can be generalized beyond the simplifying framework presented in Section 5, and we conclude in Section 8.
## 2 Two puzzles of early language development
Most infants spontaneously learn their native(s) language(s) in a matter of a few years of immersion in a linguistic environment. The more we know about this simple fact, the more puzzling it appears. Specifically, we outline two central puzzles that a reverse engineering approach could, in principle help to solve: the bootstrapping problem and developmental trajectories.
## 2.1 The bootstrapping problem
As pointed out in the Introduction, language is a multilayered system comprising several components: phonetics, phonology, morphology, syntax, semantics, pragmatics. The di erent components of language appear interdependent from a learning point of view. For instance, the phoneme inventory of a language is defined through pairs of words that di er minimally in sounds (e.g., "light" vs "right"). This would suggest that to learn phonemes, infants need to first learn words. However, from a processing viewpoint, words are recognized through their phonological constituents (e.g., Cutler, 2012), suggesting that infants should learn phonemes before words. Similar paradoxical co-dependency issues have been noted between other linguistic levels (for instance, syntax and semantics: Pinker, 1987, prosody and syntax: Morgan & Demuth, 1996). In order to learn any one component of the language faculty, many others need to be learned first, creating what has been dubbed a bootstrapping problem. The bootstrapping problem is compounded by the fact that infants do not have to be taught formal linguistics language courses to learn their native language(s). As in other cases of animal communication, infants spontaneously acquire the language(s) of their community by merely being immersed in that community (Pinker, 1994). Experimental and observational studies have revealed that infants start acquiring elements of their language (phonetics, phonology, lexicon, syntax and semantics) even before they can talk (Jusczyk, 1997; Hollich et al., 2000; Werker & Curtin, 2005), and therefore before parents can give them much feedback about their progress into language learning. This suggests that language learning (at least the initial bootstrapping steps) occurs largely without supervisory feedback . 1 Areverse engineering approach has the potential of solving this puzzle by providing a system that can
1 Even in later acquisitions, the nature, universality and e ectiveness of corrective feedback of children's outputs has been debated (see Brown, 1973; Pinker, 1989; Marcus, 1993; Chouinard & Clark, 2003; Saxton, 1997; Clark & Lappin, 2011).
demonstrably bootstrap into language when fed with similar, supervisory poor, inputs.
## 2.2 Accounting for developmental trajectories
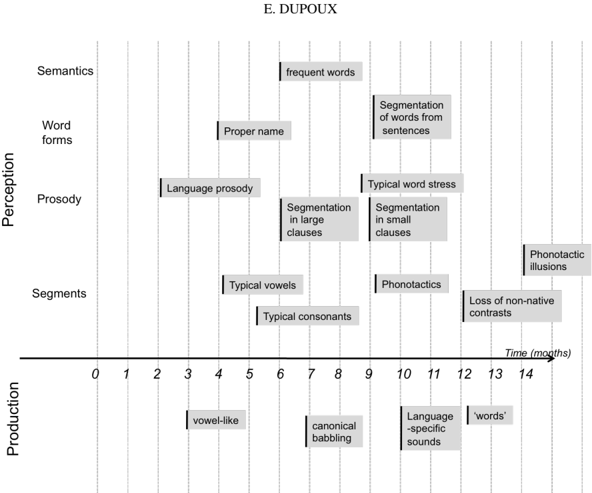
In the last forty years, a large body of empirical work has been collected regarding infant's language achievements during their first years of life. This work has only added more puzzlement. First, given the multi-layered structure of language, one could expect a stage-like developmental tableau where acquisition would proceed as a discrete succession of learning phases organized logically or hierarchically (e.g., building linguistic structure from the low level to the high levels). This is not what is observed (see Figure 1). For instance, infants start di erentiating native from foreign consonants and vowels at 6 months, but continue to fine tune their phonetic categories well after the first year of life (e.g., Sundara, Polka, & Genesee, 2006). However, they start learning about the sequential structure of phonemes (phonotactics, see Jusczyk, Friederici, Wessels, Svenkerud, & Jusczyk, 1993) way before they are done acquiring the phoneme inventory (Werker & Tees, 1984). Even before that, they start acquiring the meaning of a small set of common words (e.g. Bergelson & Swingley, 2012). In other words, instead of a stage-like developmental tableau, the evidence shows that acquisition takes places at all levels more or less simultaneously, in a gradual and largely overlapping fashion. Second, observational studies have revealed considerable variations in the amount of language input to infants across cultures (Shneidman & Goldin-Meadow, 2012) and across socio-economic strata (Hart & Risley, 1995), some of which can exceed an order of magnitude (Weisleder & Fernald, 2013, p. 2146). These variations do impact language achievement as measured by vocabulary size and syntactic complexity (Ho , 2003; Huttenlocher, Waterfall, Vasilyeva, Vevea, & Hedges, 2010; Pan, Rowe, Singer, & Snow, 2005; Rowe & Goldin-Meadow, 2009, among others), but at least for some markers of language achievement, the di erences in outcome are much less extreme than the variations in input. For canonical babbling, for instance, an order of magnitude would mean that some children start to babble at 6 months, and others at 5 years! The observed range is between 6 and 10 months, less than a 1 to 2 ratio. Similarly, reduced range of variations are found for the onset of word production and the onset of word combinations. This suggests a surprising level of resilience to language learning, i.e., some minimal amount of input is su cient to trigger certain landmarks. A reverse engineering approach has the potential of accounting for this otherwise perplexing developmental tableau, and provide quantitative predictions both across linguistic levels (gradual overlapping pattern), and cultural or individual variations in input (resilience).
## 3 Past work
Early language acquisition is primarily an empirical field of research. Much of what we know has been obtained thanks to the patient accumulation of data in two lines of work. The first one is devoted to the collection and manual transcription of parents and infants interactions. A large number of datasets across languages have been collected and organized into repositories that have proved immensely useful to the research community. One prominent example of this is the CHILDES repository (MacWhinney, 2000), which has enabled more than 5000 research papers (according to a google scholar search as of 2016). The other line consists in measuring the linguistic knowledge of infants of various ages across di erent languages through the administration of experimental tests (see Jusczyk, 1997; Bornstein & TamisLeMonda, 2010 for reviews). Besides this impressive activity in data gathering, the field of language development is also actively pursuing theoretical work. Here, we briefly review three major strands related to psycholinguistics, formal linguistics and machine learning, respectively, and argue that even though this work has provided important insights into the acquisition process, it still falls short of accounting for the two puzzles presented in Section 2.
## 3.1 Conceptual frameworks and learning mechanisms
Within developmental psycholinguistics, conceptual frameworks have been proposed to account for key aspects of the developmental trajectories (the competition model: Bates & MacWhinney, 1987; MacWhinney, 1987 ; WRAPSA: Jusczyk, 1997; the emergentist coalition model: Hollich et al., 2000; PRIMIR: Werker & Curtin, 2005; the usage-based theory: Tomasello, 2003; among others). These frameworks present overarching architectures or scenarios that integrate many empirical results. WRAPSA (Jusczyk, 1997) focuses on phonetic learning and lexical segmentation during the first year of life. PRIMIR (Werker & Curtin, 2005) extends WRAPSA by incorporating phonetic and speaker-related categories at an early stage, and meaning and phonemic categories at a later stage. The emergentist coalition model (Hollich et al., 2000) focuses on the attentional, social and linguistic factors that modulate the association between lexical forms and meanings at di erent ages. The competition model (Bates & MacWhinney, 1987; MacWhinney, 1987) and the usage-based theory (Tomasello, 2003) focus on grammar learning; the former is lexicon-based and focuses on mechanisms of competitive learning. The latter is construction-based and focuses on social and pragmatic learning mechanisms. While these conceptual framework are very useful in summarizing and organizing a vast amount of empirical results, and could serve as sources of inspiration for computational models, they are not specific enough to demonstrate that their core
Figure 1 . Sample studies illustrating infant's language development. The left edge of each box is aligned to the earliest age at which the result has been documented.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Timeline Diagram: Stages of Language Development
### Overview
This diagram presents a timeline illustrating the development of language skills in infants, categorized by perception and production. The x-axis represents time in months (0-14), and the y-axis lists different aspects of language development: Semantics, Word Forms, Prosody, Segments, and Production. Each stage is represented by a grey rectangular bar indicating the approximate age range when that skill emerges.
### Components/Axes
* **X-axis:** Time (months), ranging from 0 to 14, with markings at intervals of 1 month.
* **Y-axis:** Language Development Aspects, including:
* Semantics
* Word Forms
* Prosody
* Segments
* Production
* **Title:** "E. DUPOUX" at the top center.
* **Bars:** Grey rectangular bars representing the approximate time frame for each language skill.
### Detailed Analysis or Content Details
The diagram shows the following stages and their approximate timing:
* **Production:**
* "vowel-like" sounds: approximately 0-4 months.
* "canonical babbling": approximately 6-8 months.
* "Language-specific sounds": approximately 10-12 months.
* "words": approximately 12-14 months.
* **Segments:**
* "Typical vowels": approximately 4-5 months.
* "Typical consonants": approximately 5-6 months.
* "Phonotactics": approximately 10-11 months.
* "Loss of non-native contrasts": approximately 12-14 months.
* "Phonotactic illusions": approximately 13-14 months.
* **Prosody:**
* "Language prosody": approximately 2-4 months.
* "Segmentation in large clauses": approximately 7-9 months.
* "Segmentation in small clauses": approximately 10-11 months.
* "Typical word stress": approximately 11-12 months.
* **Word Forms:**
* "Proper name": approximately 4-5 months.
* "Segmentation of words from sentences": approximately 11-12 months.
* **Semantics:**
* "frequent words": approximately 12-14 months.
### Key Observations
* The diagram suggests a hierarchical development of language skills, starting with basic production of sounds (vowel-like) and progressing to more complex skills like semantics and word segmentation.
* There is overlap between the stages, indicating that language development is not strictly linear.
* The diagram highlights the early emergence of prosodic features (language prosody around 2-4 months) before more complex segmental features (typical vowels around 4-5 months).
* The later stages (12-14 months) show a convergence of skills related to word recognition and meaning.
### Interpretation
This diagram provides a simplified model of language acquisition, likely intended for educational or research purposes. It illustrates the developmental sequence of language skills, emphasizing the interplay between perception and production. The timeline suggests that infants initially focus on producing basic sounds and perceiving prosodic features, gradually developing the ability to segment speech, recognize words, and understand their meanings. The diagram's author, E. Dupoux, likely used this visualization to communicate a specific theoretical framework regarding language development. The diagram does not provide specific data points or statistical analysis, but rather a qualitative overview of the typical stages and their approximate timing. The overlapping bars suggest that these stages are not discrete but rather represent a continuous process of development. The diagram is a useful tool for understanding the general trajectory of language acquisition, but it should be noted that individual children may develop at different rates.
</details>
principles can e ectively solve the language bootstrapping problem. Nor do they provide quantitative predictions about the observed resilience in developmental trajectories and their variations as a function of language input at the individual, linguistic or cultural level. Psycholinguists often supplement conceptual frameworks with propositions for specific learning mechanisms which are tested using an artificial language paradigm. As an example, a mechanism based on the tracking of statistical modes in phonetic space has been proposed to underpin phonetic category learning in infancy. It was tested in infants through the presentation of a simplified language (a continuum of syllables between / da / and / ta / ) where the statistical distribution of acoustic tokens was controlled (Maye, Werker, & Gerken, 2002). It was also modeled computationally using unsupervised clustering algorithms and tested using simplified corpora or synthetic data (Vallabha, McClelland, Pons, Werker, & Amano, 2007; McMurray, Aslin, & Toscano, 2009). A similar double-pronged approach (experimental and modeling evidence) has been conducted for other mechanisms: word segmentation based on transition probability (Sa ran, Aslin, & Newport, 1996; Daland & Pierrehumbert, 2011), word meaning learning based on cross situational statistics (Yu & Smith, 2007; K. Smith, Smith, & Blythe, 2011; Siskind, 1996), semantic role learning based on syntactic cues (Connor, Fisher, & Roth, 2013), etc. Although studies with artificial languages are useful to discover candidate learning algorithms which could be incorporated in a global architecture, the algorithms proposed have only been tested on toy or artificial languages; there is therefore no guarantee that they would actually work when faced with real corpora that are both very large and very noisy. In fact, as discussed in section 6.1, some of these algorithms do not scale up. In addition, it remains to be shown that taken collectively, such learning mechanisms (or scaled up versions) would work synergistically to solve the bootstrapping problem.
## 3.2 Formal linguistic models
Even though much of current theoretical linguistics is devoted to the study of the language competence as it pertains to the human adults, very interesting work has also be conducted in the area of formal models of grammar induction . These models propose algorithms that are provably powerful enough to learn a fragment of grammar given certain assumptions about the input. For instance, Tesar and Smolensky (1998) proposed an algorithm that provided pairs of surface and underlying word forms can learn the phonological grammar (see also Magri, 2015). Similar learnability assumptions and results have been obtained for stress systems (Dresher & Kaye, 1990; Tesar & Smolensky, 2000). For learnability results of syntax, see the review in Clark and Lappin (2011). These models establish important learnability results, and in particular, demonstrate that under certain hypotheses, a particular class of grammar is learnable. What they do not demonstrate however is that these hypotheses are met for infants. In particular, most grammar induction studies assume that infants have an error-free, adult-like symbolic representation of linguistic entities (e.g., phonemes, phonological features, grammatical categories, etc). Yet, perception is certainly not error-free, and it is not clear that infants have adult-like symbols, and if they do, how they acquired them.
In other words, even though these models are more advanced than psycholinguistic models in formally addressing the effectiveness of the proposed learning algorithms, it is not clear that they are solving the same bootstrapping problem than the one faced by infants. In addition, they typically lack a connection with empirical data on developmental trajectories. 2
## 3.3 Machine learning
The idea of using computational modeling to shed light on language acquisition is as old as the field of cognitive science itself, and a complete review would be beyond the scope of this paper. We mention some of the landmarks, separating three learning subproblems: syntax, lexicon, and speech. Computational models of syntax learning in infants can be roughly classified into two strands, one that learns from strings of words alone, and one that additionally uses a conceptual representation of the utterance meaning. The first strand is illustrated by Kelley (1967). The proposed computational model performed hypothesis testing and constructed more and more complex syntactic rules to account for the distribution of words in the input. The input itself was artificial (generated by a context free grammar) and part of speech tags (nouns, verbs, etc.) were provided as side information. Since then, manual tagging has been replaced by automatic tagging using a variety of approaches (see Christodoulopoulos, Goldwater, & Steedman, 2010 for a review), and artificial datasets have been replaced by naturalistic ones (see D'Ulizia, Ferri, & Grifoni, 2011, for a review). This strand views grammar induction as a problem of representing the input corpus with a grammar in the most compact fashion, using both a priori constraints on the shape and complexity of the grammars and a measure of fitness of the grammar to the data (see de Marcken, 1996 for a probabilistic view). The second strand can be traced back to Siklossy (1968), and makes the radically di erent hypothesis that language learning is essentially a translation problem: children are provided with a parallel corpus of speech in an unknown language, and a conceptual representation of the corresponding meaning. The Language Acquisition System (LAS) of Anderson (1975) is a good illustration of this approach. It learns context-free parsers when provided with pairs of representations of meaning (viewed as logical form trees) and sentences (viewed as a string of words, whose meaning are known). Since then, algorithms have been proposed to learn directly the meaning of words (e.g., cross-situational learning, see Siskind, 1996), context-free grammars have been replaced by more powerful ones (e.g. probabilistic Combinatorial Categorical Grammar), and sentence meaning has been replaced by sets of candidate meanings with noise (although still generated from linguistic annotations) (e.g., Kwiatkowski, Goldwater, Zettlemoyer, & Steedman, 2012). Note that all of these models take textual input, and therefore make the (incorrect) assumption that infants are able to represent their input in terms of an error-free segmented string of words.
The problem of word learning itself has been addressed using two main ideas. One main idea is to use distributional properties that distinguish within word and between word phoneme sequences (Harris, 1954; Elman, 1990; Christiansen, Conway, & Curtin, 2005). A second idea, is to simultaneously build a lexicon and segment sentences into words (Olivier, 1968; de Marcken, 1996; Goldwater, 2007). These ideas are now frequently combined (Brent, 1996a; M. Johnson, 2008). In addition, segmentation models have been augmented by jointly learning the lexicon and morphological decomposition (M. Johnson, 2008; Botha & Blunsom, 2013), or tackling phonological variation through the use of a noisy channel model (Elsner, Goldwater, & Eisenstein, 2012). Note that all of these studies assume that speech is represented as an error-free string of adult-like phonemes, an assumption which cannot apply to early language learners. Finally, some studies have addressed language learning from raw speech. These have either concerned the discovery of phoneme-sized units, the discovery of words, or both. Several ideas have been proposed to discover phonemes from the speech signal (self organizing maps: Kohonen, 1988; clustering: Pons, Anguera, & Binefa, 2013; auto-encoders: Badino, Canevari, Fadiga, & Metta, 2014; HMMs: Siu, Gish, Chan, Belfield, & Lowe, 2013; etc.). Regarding words, D. K. Roy and Pentland (2002) proposed a model that learn both to segment continuous speech into words and map them to visual categories (through cross situational learning). This was one of the first models to work from a real speech corpus (parents interacting with their infants in a semi-directed fashion), although the model used the output of a supervised phoneme recognizer. The ACORNS project (Boves, Ten Bosch, & Moore, 2007) used real speech as input to discover candidate words (Ten Bosch & Cranen, 2007, see also Park & Glass, 2008; Muscariello, Gravier, & Bimbot, 2009, etc.), or to learn word-meaning associations (see a review in Räsänen, 2012). Only a small number of papers combined learning of both phonemes and word units (Ying, 2005; Jansen, Thomas, &Hermansky, 2013; Lee, O'Donnell, & Glass, 2015; Thiollière, Dunbar, Synnaeve, Versteegh, & Dupoux, 2015). In sum, machine learning models represent the clearest attempt so far of addressing the full bootstrapping problem. Yet, although one can see a clear progression, from simple models and toy datasets, towards more integrative algorithms and more realistic datasets, there is no single proposition yet that handles the entire speech processing pipeline, i.e., from signal to semantics. In addition, the progression has been very discontinuous across studies, and in our view, hampered by
2 A particular di culty of formal models which lack of a processing component is the observed discrepancies between the developmental trajectories in perception (e.g. early phonotactic learning in 8-month-olds) and production (slow phonotactic learning in one to 3-year-olds).
the complete lack of cumulativity in algorithm, evaluation method and corpora, overall making it impossible to compare the merits of the di erent ideas and register progress. Finally, even though most of these studies mention infants as a source of inspiration of the models, almost none of them try to account for developmental trajectories.
## 3.4 Summing up
Each of the above reviewed approach is evidently valid, has brought a wealth of interesting results and will continue to do so. Our main point is that, in isolation, these approaches do not enable to answer the developmental puzzles outlined in Section 2. They need to be combined, and the proper way to achieve this combination is examined next.
## 4 Four requirements
Here, we examine four requirements about how to conduct reverse engineering in order to answer the two scientific puzzles. They are: using real data, comparing humans and machines, constructing e ective computational models, open-sourcing data, evaluation and models.
## 4.1 Using real data
One of the most serious limitations of past theoretical work is the tendency to focus either on a simplified learning situation, a small corpus, or both, thereby failing to address the language leaning problem in its full complexity. Of course, simplification is the hallmark of the scientific enterprise, but we claim that in the present case, simplifications often result in the learning problem itself being modified beyond recognition. We therefore argue that to address the bootstrapping problem, one has to use real data as input. Formal learning theory provides us with many examples where idealizing assumptions about the learning situation (regarding the input to the learner or the set of target languages to be learned) have extreme consequences on what can be learned or not. For instance, if the environment presents only positive instances of grammatical sentences presented in any possible order, then even simple classes of grammars (e.g., finite state or context free grammars, Gold, 1967) are unlearnable. In contrast, if the environment presents sentences according to processes that can be recursively enumerated (an apparently innocuous requirement), then even the most complex classes of grammars (recursive grammars) 3 become learnable. This result extends to a probabilistic scenario where the input sentences are sampled according to a statistical distribution, constraints about the shape of the distribution radically changes the di culty of the learning problem (see Angluin, 1988). In addition, the presence of side information can make a substantial di erence: providing the syntactic trees along with the phonological form can turn an unlearnable problem into a learnable one (Sakakibara, 1992). The scale of the dataset can also have drastic e ects, even when real data is used. This is illustrated by the history of automatic speech recognition systems. This field started to construct systems aimed at recognizing a small vocabulary for a single speaker (single digits) in the 50's, and nowadays handles multiple speakers with large vocabularies in continuous speech. By moving from small scale to big scale problems the field did not only use bigger models and more powerful machines, but had to build systems based on completely di erent principles (in order of appearance, formant based pattern matching, dynamic programming, statistical modeling, neural networks). Such heavy dependence on the scale and realism of the dataset is even more apparent in with models of learning. For instance, dramatically di erent performances are found when word segmentation algorithms (which attempt to recover word boundaries from continuous speech) are fed with a phoneme transcription or when they are fed with raw speech signals (Jansen, Dupoux, et al., 2013; Ludusan, Versteegh, et al., 2014). Addressing the data scalability problem can be done according to two approaches. The approach followed by formal learning theory consists in starting with simple assumptions and progressively making them more realistic. While perfectly valid, this approach has to face the fact that the class of formal grammars that characterizes human languages is still a matter of debate (e.g., Jäger & Rogers, 2012), and that the way inputs are made available to the children (the caretaker's speech and associated side information) is not formally characterized. As a result the researcher runs the risk of making wrong assumptions and solving a learning problem that is di erent from the one faced by infants in the real world. The second approach, which we promote as "reverse engineering" takes a radical step: instead of relying on formal descriptions of possible inputs, it uses actual, attested, raw data as input. We discuss three important consequences of this proposed solution: qualitative, quantitative, and cross-linguistic. On the qualitative side, the input has to be defined as the total sensory experience of the learner, not a predefined subset nor a pre-formatted linguistic 'channel'. The reason for this is that the linguistic signals emitted by the parents are typically mixed with a variety of non linguistic signals in a culture dependent way. In addition, the physical medium of linguistic signals also vary from culture to culture. In the audio channel for instance, speech sounds are heard by infants mixed with all manners of background noise, music, and non linguistic vocal sounds. Within vocal sounds, click noises are considered non linguistic in many languages, but some languages use them phonologically (Best, McRoberts, & Sithole, 1988). In the visual channel, some amount of linguistic / communicative signals (ges-
3 The problem of unrestricted presentations is that, for each learner, there always exists a 'nemesis', an evil environment that will trick the learner into converging on the wrong grammar (see Clark & Lappin, 2011 for a detailed explanation).
Table 1 Four studies used to estimate infant's speech input
| study | reference | mode of acquisition;age | population |
|---------|-----------------------------------------------------|----------------------------------------|-------------------------------------------------|
| H&R | Hart and Risley (1995) | observer, 1h every month; 12-36 months | urban high, mid & low SES, English |
| SALG | Shneidman, Arroyo, Levine, and Goldin-Meadow (2013) | observer, 1h every month; 12-36 months | urban high SES, English & ru- ral low SES, Maya |
| W&F | Weisleder and Fernald (2013) | daylong recording; 19 months | low SES, Spanish |
| VdW | van de Weijer (2002) | daylong recording; 6-9 months | high SES, Dutch |
Table 2 Estimates of yearly input, in total, and restricted to Child Directed Speech (CDS) , in number of hours and words (millions) per year in four studies (see the references in Table 1) as a function of sociolinguistic group (SES: Socio Economic Status). The numbers between brackets provide the range [min, max] of these numbers across families. t uses a wake time estimate of 9 hours per day. w uses a word duration estimate of 400ms. c uses SALG's estimate of
| | Yearly total | Yearly total | Yearly total | Yearly total | Yearly CDS | Yearly CDS | Yearly CDS | Yearly CDS |
|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|
| | Hours | Hours | Words (M) | Words (M) | Hours | Hours | Words (M) | Words (M) |
| Urban, high SES | Urban, high SES | Urban, high SES | Urban, high SES | Urban, high SES | Urban, high SES | Urban, high SES | Urban, high SES | Urban, high SES |
| H&R (N = 13) t | 1221 w,c | [578,1987] | 11.0 c | [5.20, 17.9] | 786 w | [372, 1279] | 7.07 | [3.35, 11.5] |
| SALG (N = 6) t | 2023 w,m | [1243, 2858] | 18.2 m | [11.2, 25.7] | 1223 w,m | [853, 1574] | 11.0 m | [7.7, 14.2] |
| VdW (N = 1) | 931 | | 9.28 | | 140 | | 1.39 | |
| Urban, low SES | Urban, low SES | Urban, low SES | Urban, low SES | Urban, low SES | Urban, low SES | Urban, low SES | Urban, low SES | Urban, low SES |
| H&R (N = 6) t | 363 w,d | [136, 558] | 3.26 d | [1.22, 5.02] | 225 w | [84, 346] | 2.02 | [0.76., 3.11] |
| W&F(N = 29) t | 363 w | [52, 1049] | 3.27 | [0.46., 9.44] | 225 w | [32, 650] | 2.03 | [0.29, 5.85] |
| Rural, low SES | Rural, low SES | Rural, low SES | Rural, low SES | Rural, low SES | Rural, low SES | Rural, low SES | Rural, low SES | Rural, low SES |
| SALG (N = 6) t | 503 w,m | [365, 640] | 4.53 m | [3.28, 5.76] | 234 w,m | [132, 322] | 2.10 m | [1.19, 2.90] |
tures, mouth movements) is present in all cultures (Fowler & Dekle, 1991; Goldin-Meadow, 2005), but it becomes the dominant language channel in deaf communities using sign language (Poizner, Klima, & Bellugi, 1987). However, sign language can be used as native language even in hearing children, provided they are raised in mixed hearing / deaf communities (Van Cleve, 2004). Cross-cultural variation makes it impossible to innately specify a fixed way of unmixing these signals or selecting a language channel. It is therefore part of the language learning problem to separate the linguistic signals from the non-linguistic background. Using real inputs, instead of idealized ones, could be said to set up an impossibly di cult task for computational models. In the real world, the linguistic signal is often corrupted or partially masked by non-linguistic signals. Dysfluencies or speech errors at many levels (Fromkin, 1984), as well as individuallevel sources of variability, added to structural ambiguity at all linguistic levels (e.g., homophony: Ke, 2006) may make the learning problem orders of magnitude more di cult than in simplified situations. Yet, real inputs may also bring about potential benefits in the shape of side information. As an example, syntax learning could be helped through the detec- tion of prosodic information present in the signal. Prosodic boundaries may not always be coincidental with syntactic boundaries, but they could provide to the learner useful side information for the purpose of syntax and lexical acquisition (e.g. Christophe, Millotte, Bernal, & Lidz, 2008; Ludusan, Gravier, & Dupoux, 2014). Similarly, semantic information in the form of visually perceived objects or scenes and afferent social signals may help lexical learning (D. K. Roy &Pentland, 2002) and help bootstrap syntactic learning (the semantic bootstrapping hypothesis, see Pinker, 1984). On the quantitative side, it is important that the totality of the input is being considered for the following reasons. First, it sets up boundary conditions for the learning algorithms. Algorithms that require more input than is generally available to infants can be ruled out. As an example, current distributional semantic models use between 3 and 100 billion words to learn vector representations for the meaning of words or short phrases based on adjacent words (Mikolov, Sutskever, Chen, Corrado, & Dean, 2013; Word2vec Google Project Page , 2013). This is between 30 and 1000 times more data than infants are typically exposed to during their first 4 years of life, in fact, more than most people get in a lifetime, and
therefore not plausible as the sole mechanism for meaning learning. Vice versa, an algorithm that would require only 10 On the cross-linguistic side, a successful model of the learner should not demonstrate learning for only one input dataset, but it should learn for any input dataset in any possible human language in any modality (see the equipotentiality criterion in Pinker, 1987). Since, as we argued above, the class of all possible language inputs it still not formally characterized, one could take the approach of sampling from a finite but ever expanding set of existing linguistic communities. An adequate sampling procedure would insure that, statistically speaking, a given computational model is (or is not) able to learn from any possible input. Practically speaking, it may be interesting to sample typologies and sociolinguistic groups in a stratified fashion to avoid over-fitting the learning model to a restricted set of learning situations. To sum up, using real input is the only way to make sure that modelers are addressing the right learning problem. This has significant consequences regarding the size of the dataset that has to be collected : complete sensory coverage over the first 3 or 4 years of life, for a representative sample of children over a representative sample of languages. Before such a dataset is available, of course, it is still interesting to use as proxy a variety of smaller or simplified datasets, provided that one keeps in mind the important caveat that the conclusions may not scale up when put to test with real data.
## 4.2 Evaluating systems through human-machine comparison
For a modeling enterprise of any sort, it is important to specify a success criterion. A lingering limitation of past theoretical work is that too many distinct success criteria have been used. In fact, the diversity is so great that it is nearly impossible to compare the di erent propositions across research fields (and sometimes even within field), and to reach the same standards as cumulative science. For psycholinguistic conceptual frameworks, the primary success criterion is the ability to account for developmental trajectories. Note, however, that because of the verbal nature of these frameworks, it can only be checked at an intuitive and qualitative level. It can then be di cult to validate, refute or compare these frameworks. For linguistic formal learning models, the main focus is the learnability puzzle and is usually defined in terms of learnability in the limit (Gold, 1967): A learner is said to learn a target grammar in the limit, if after some amount of time, his own grammar becomes equivalent to the target grammar. This standard formulation has been criticized as too lax (K. Johnson, 2004). Since there is no time limit on convergence, a learner that needs a million year's worth of data to converge would still be deemed successful. We know that most children converge on an adult grammar in a fixed number of years, which is bounded by puberty. Therefore, our learnability criterion should be stronger and require the system to converge on a grammar after the same amount of input that it takes for children to converge. In addition the standard criterion assumes that one can determine when two grammars are equivalent, which is not always simple. 4 Finally, for the machine learning models that we reviewed, system evaluation was not their strong selling point. Many provided only qualitative evaluations, but for those that did provide a numeric one, they were typically defined in relation to a so called gold standard , i.e. human annotations (like phoneme transcriptions, part of speech annotations, parse trees, etc). The success of the learning algorithm is then measured as a distance between the machine annotation and the gold one. Of course, these evaluations are only valid to the extent that the gold standard reflects the state of the human language competence. This is not necessarily the case for adult-machine comparisons, as linguists may disagree on some of the annotations, and certainly not the case for children-machine comparisons, as the infant's grammar is probably di erent from that of the linguisticallytrained adult. We therefore claim that for the reverse engineering approach, none of these criteria, taken individually, are satisfactory. Prior advocates of the use of machine learning to model language acquisition have proposed a number of ways to combine these criteria. To quote a few, MacWhinney (1978) proposed 9 criteria, Berwick (1985), 9 criteria (di erent ones), Pinker (1987) 6 criteria, Yang (2002) 3 criteria, M. C. Frank, Goldwater, Gri ths, and Tenenbaum (2010) 2 criteria. These can be sorted into conditions about e ective modeling (being able to generate a prediction), about the input (being as realistic as possible), about the end product of learning (being adult-like) and about the plausibility of the computational mechanisms. In our proposed reverse engineering approach, we would like to integrate within a single operational criterion, the cognitive indistinguishability criterion , the insights of the psycholinguistic theories with the quantitative evaluations of the formal and algorithmic models:
A human and a machine are cognitively indistinguishable with respect to a given set of tests when they yield numerically similar results when ran on these tests.
The proposal, therefore, is that, a computational model of language learning is successful, when it yields a system that is cognitively indistinguishable from a human (adult or child) after having been fed with the same input data. Such a success criterion enables both to address the learnability puzzle and to account for developmental trajectories. Note,
4 Two grammars are said to be weakly equivalent if they generate the same utterances. In the case of context free grammars, this is an undecidable problem. More generally, for many learning algorithms (e.g., neural networks), it is not even clear what has been learned, and therefore the criterion cannot be verified.
however, that cognitive indistinguishability is not an absolute criterion but depends on a set of tests. Constructing an agreed upon set of such tests (a cognitive benchmark ) becomes therefore part of the reverse engineering project by integrating tests that linguists and psycholinguists agree upon as being relevant to characterizing grammatical competence in humans. This benchmark can of course be revised as new and more subtle experimental protocols for language competence are discovered and can set the human and machine apart. Here, we present three conditions that such tests must satisfy to achieve our scientific objectives: they should be administrable (to adults, children and computers alike), valid (measure the construct under study as opposed to something else), and reliable (with a good signal to noise ratio). The last two conditions are common in psychometrics and psychophysics (e.g., Gregory, 2004). Test validity refers to whether a test, both theoretically and empirically, is sensitive to the psychological construct (state or process) it is supposed to measure. For instance, in an influential paper, Turing (1950) proposed to test whether machines can 'think' using the so-called imitation game , where it had to persuade a human observer that it was a female human through an online keyboard conversation. The machine succeeds if it fools the observer as often as a human male participant would. This test is evidently not valid, as theoretically, 'thinking' is not a well defined psychological construct, but rather a polysemous folk psychology concept, and empirically, it is rather easy to fool human observers using rather simplistic text manipulation rules (see ELIZA, Weizenbaum, 1966). Fortunately, since the 50's, cognitive psychology has progressed tremendously and can o er a rich set of valid tests for the evaluation of language-related cognitive components (see Section 5.2). Test reliability refers to the signal to noise ratio of the measure. It can be evaluated by rerunning the same tests over the same or di erent participants for humans, or over di erent initial conditions for the machines. Typically, test reliability is not thought to be a real issue for machines, to the extent that many algorithms are deterministic or assumed to be quite stable. Yet, it is important to assess this reliability empirically, for instance, by running the same algorithm over di erent samples of a large corpus. As for humans, test reliability is a very important issue, and even more so, for children and infants. Evidently, we cannot ask that the match between humans and machines be larger that the match within population. Test administrability does not belong to standard psychometrics, but it is especially important in the case both of infants and machines. Human adults have metalinguistic abilities which allow the experimenter to explain to them how to perform a particular test, in simple words. Such a strategy is not directly applicable to human infants nor to machines. In infants, a testing apparatus has to be constructed, i.e., a rather artificial environment whereby everything is controlled so that the response to test stimuli arises naturally and is measured using spontaneous tendencies of the participants (preference methods, habituation methods, etc; see Ho , 2012, for a review). 5 In machines, there is also an issue of administrability. Typically, learning algorithms are not constructed to run linguistic tests, but to learn based on their input. Therefore, they need to be supplemented with particular task interfaces for each of the proposed tests in order to extract a response that would be equivalent to the response generated by humans. 6 In both cases, administering the task has to be made so as not to compromise the test's validity. Biases or knowledge of the desired response has to be removed from the testing apparatus (for the infants) and from the interface (for the machine). To sum up, to evaluate computational models, the reverse engineering approach proposes to build a revisable benchmark of valid and reliable tests measuring the various components of the human language faculty, and that can be administered to humans of various ages and machines alike. Models will be compared on their ability to mimic the results of these tests.
## 4.3 Constructing scalable computational models
As discussed in Section 3, past work in psycholinguistics and formal linguistics was not centered on the task of building e ective systems which would work with real data at scale. In contrast, speech and language engineering systems are typically constructed to perform complex functions like converting speech to text, or conducting a simple question / answer dialogue. Importantly, engineering systems do work impressively well with large scale noisy data. The main design feature of these systems is that even though they are often constructed using components that are similar to the ones envisioned by psycholinguistic and linguistic models (for instance with phonetic, phonological, lexical, and syntactico-semantic components), it is not assumed that each of these levels is errorless. On the contrary, the handling of errors and ambiguity is acknowledged from the ground up, through a statistical or parallel processing architecture. Within such an architecture, multiple interpretations are passed from one level to the next along with their probabilities, enabling the errors and ambiguities to be resolved in a holistic and optimal fashion (for a statistical framework in speech processing, see Jelinek, 1997). Where engineering systems fall short of the reverse engineering objectives, is that they do not care about mimicking the learning process that takes place in infants. Instead, they are constructed as
5 In animals, before tests can be run, an extensive period of training is often necessary, in order for the animal to comply with the protocol. Such procedures are not possible in human infants.
6 A task interface can be viewed as a function which takes as input the internal state of the algorithm generated by the stimuli and delivers a binary or real valued response.
full-blown adult systems, using a substantial amount of expert knowledge regarding the language and the tasks that the systems should perform. Early systems were heavily engineered, with each subcomponent crafted and tuned by hand using expert knowledge. Nowadays, experts only specify a general architecture, and all of the parameters are tuned automatically using numerical optimization techniques run on very large datasets of human annotated speech or text. For instance, a typical state-of-the-art speech recognition component is trained with hours of hand transcribed speech (10000 hours or more), with a large pronunciation dictionary, and a few billion words of text. A language understanding component is trained with a bank of sentences annotated with part of speech and parse trees. All of these expert language resources are unfortunately not available to infants learning their native language(s). In brief, on the one hand, the psycholinguistic and linguistic approaches propose plausible candidate learning mechanisms, which may not scale up. On the other hand, engineering approaches propose scalable processing systems, but even though they are based on statistical learning, they do not use cognitively plausible learning mechanisms. The idea of the reverse engineering approach is, therefore, to use as a source of inspiration the conceptual frameworks and the psychologically validated learning mechanisms, and incorporate them into scalable and noiseresistant processing architectures from speech and language technology, which have to be modified to rely only on the inputs available to infants (i.e. raw sensory data, but no expert annotation). Technically, learning mechanisms that only use raw signals (or sparse and errorful human 'labels') are called unsupervised (or weakly supervised). This class of machine learning problems is unfortunately less well studied and understood than the supervised learning ones (classification, regression, etc). Learning without external labels is obviously more di cult than learning with labels. Humans labels provide simultaneously a target representation that the machine has to compute given its input, and an error function (the difference between the human provided and machine computed labels) that can be optimized using numerical methods in order to reach this objective. With unsupervised problems, everything changes: the machine is only given inputs, and has to construct on its own (so-called latent) representations of the input. This can also be written as an optimization problem, but the error function is defined with respect to the input only (typically, the system's objective is to model its input, for instance, it has to be able to predict future inputs based on past ones). Therefore the problem is much more underdetermined, and it is not clear that the latent representations will succeed in capturing anything useful at all (for humans or for the rest of the system). Before closing, let us discuss briefly one issue which often comes up when engineering systems are used as models of human processing: the issue of biological plausibility . This term means that the computa- tions done in the models should be compatible with what we know about the biological systems that underlie these computations in human infants / adults. This constraint, while reasonable, may be tricky to apply because of the existence of space-time trade-o s, i.e., the possibility of rewriting algorithms that require a lot of compute time and little memory (hence biologically implausible) into algorithms that require less time and more memory (hence biologically plausible). In addition, the computational power of a human brain is currently unknown. Current supercomputers can simulate at a synapse level only a fraction of a brain and several orders of magnitude slower than real time (Kunkel et al., 2014). If this is so, all computational models run in 2016 are still massively underpowered compared to a child's brain. Still, biological plausibility can be invoked to discard at least some of the most unrealistic propositions, and this in two ways. One is through algorithmic complexity . A learning algorithms that requires an exponential amount of memory or compute time as a function of input size will quickly exhaust the computing resources of the universe and can be therefore discarded or replaced by less demanding ones. A second way relates to system complexity at the initial state , i.e., before any learning has taken place, which has to be bounded by what is encoded in the human genome regarding the language faculty. This allows to rule out, for instance, a 100 Apart from these extreme examples, the biological plausibility constraint may not a ect much the modeling approach, which therefore could result in models that some would judge are not neurologically plausible. One way to deal with such criticism is to claim that reverse engineering aims at characterizing the learner at the level of the information and computation that are needed in order to solve the learning problem (Marr & Poggio, 1976). Another way would be to enrich the cognitive benchmark with processing-related or neurologicallyrelated tests that have to be passed both by the models and the humans, as we defined above. To sum up, the best available option for constructing a scalable computational model of language learning comes from machine learning systems of speech and language processing, which needs to be refactored to work without expert supervision (no linguistic labels) in a weakly or unsupervised fashion.
## 4.4 Open sourcing data, benchmarks and models
As any scientific endeavor, the reverse engineering approach proposed adheres to standard in transparency of process and replicability. As was noted above, many of the earlier attempts to bring machine learning to bear to issues of language development were not set up in order to allow cumulative science to proceed. It is therefore central for this proposal to share language datasets, test benchmarks and reference systems in an open source format to enable comparison of di erent models and enable new players to try their own ideas. Open source benchmarks, datasets and models
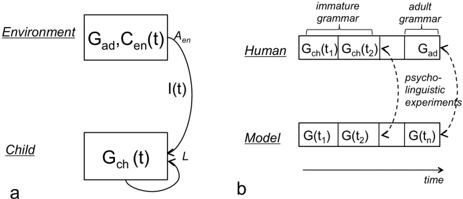
Figure 2 . a. The (simplified) learning situation: The Child's internal state is a grammar Gch ( t ) that can be updated through the learning function L based on input I ( t ). The environment's internal state is a constant adult grammar Gad and a variable context Cen , which produces the input to the child. b. Method to test the empirical adequacy of the model by comparing the outcome of psycholinguistic experiments with that of children and adults.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Language Acquisition Model
### Overview
The image presents two diagrams (labeled 'a' and 'b') illustrating a model of language acquisition. Diagram 'a' depicts the interaction between a child and their environment, while diagram 'b' shows a parallel model using a computational approach. Both diagrams represent a process evolving over time, with the goal of transitioning from an immature grammar to an adult grammar.
### Components/Axes
**Diagram a:**
* **Labels:** "Environment", "Child"
* **Variables within boxes:**
* Environment: `G_ad`, `C_en(t)`, `A_en`
* Child: `G_ch(t)`
* **Arrows & Labels:**
* Arrow from Environment to Child: `L` (likely representing learning)
* Arrow from Child to Environment: `I(t)` (likely representing input/output)
* Arrow from Environment to Child (curved): `A_en`
**Diagram b:**
* **Labels:** "Human", "Model"
* **Labels above Human:** "immature grammar", "adult grammar"
* **Labels above Model:** No labels
* **Variables within boxes:**
* Human: `G_ch(t_1)`, `G_ch(t_2)`, `G_ad`
* Model: `G(t_1)`, `G(t_2)`, `G(t_n)`
* **Arrows & Labels:**
* Arrow from `G_ch(t_2)` to `G_ad` (dashed): "psycho-linguistic experiments"
* Arrow from `G(t_2)` to `G(t_n)` (dashed): "psycho-linguistic experiments"
* **Horizontal Axis:** "time" (indicated by an arrow)
### Detailed Analysis / Content Details
**Diagram a:**
The diagram shows a child interacting with their environment. The environment is characterized by `G_ad` (adult grammar), `C_en(t)` (environmental constraints at time t), and `A_en` (environmental actions). The child possesses `G_ch(t)` (child's grammar at time t). The child receives input `I(t)` from the environment and provides output `L` (learning) back to the environment. The curved arrow `A_en` suggests a feedback loop from the environment influencing the child.
**Diagram b:**
This diagram parallels 'a' with a computational model. The "Human" row represents the development of grammar from an immature state (`G_ch(t_1)`, `G_ch(t_2)`) to an adult state (`G_ad`). The "Model" row represents a similar progression (`G(t_1)`, `G(t_2)`, `G(t_n)`). The dashed arrows labeled "psycho-linguistic experiments" indicate a connection between the human and model development, suggesting that experiments are used to inform or validate the model. The time axis indicates that the grammar evolves over time.
### Key Observations
* Both diagrams represent a similar process of grammatical development.
* The model in diagram 'b' is intended to mimic the human process in diagram 'a'.
* The use of time-dependent variables (`t`, `t_1`, `t_2`, `t_n`) emphasizes the dynamic nature of language acquisition.
* The dashed arrows in diagram 'b' suggest a validation or feedback loop between the model and human data.
* The variables are not defined numerically, so no quantitative analysis is possible.
### Interpretation
The diagrams illustrate a cognitive science approach to modeling language acquisition. Diagram 'a' presents a high-level conceptual framework of a child learning from their environment. Diagram 'b' proposes a computational model that attempts to replicate this process. The "psycho-linguistic experiments" link suggests that the model is grounded in empirical data. The use of variables like `G_ad` and `G_ch` implies that the model focuses on the structure of grammar itself. The diagrams suggest a cyclical process where the child's grammar evolves through interaction with the environment, and the model's grammar evolves through experimentation and validation. The diagrams do not provide specific data or numerical values, but rather a conceptual framework for understanding language acquisition. The use of mathematical notation (`G`, `C`, `I`, `L`) suggests a formal, potentially mathematical, representation of the model. The diagrams are a qualitative representation of a theoretical model.
</details>
are very common in many areas of machine learning, prominently in vision (e.g. the Imagenet dataset http: // www.imagenet.org). This is less the case in speech and language, as many speech resources are protected or proprietary, thereby slowing down progress. Yet, this is changing quickly as open source speech databases are being constructed (for instance, open SLR http: // www.openslr.org for datasets, and kaldi http: // kaldi-asr.org for speech tools).
## 5 Feasibility and Challenges
To address the feasibility of the reverse engineering approach as applied to early language acquisition, we first limit ourselves to the following simplifying framework: the total input available to a particular child provides enough information to acquire the grammar of the language present in the environment. This may seem an innocuous assumption, but it essentially puts us in the open loop situation described in Figure 2), where the environment delivers a fixed curriculum of inputs (utterances and their sensory contexts) and the learner recovers the grammar that generated the utterances. In this framework, the output of the child is not modeled, and the environment does not modify its inputs according to her behavior or inferred internal states. We come back to this simplifying assumption in Section 7. Within this framework, we discuss how the four requirements can be met using current technology. We also discuss possible roadblocks that arise in the process of deploying this technology. We address each of the three pillars of the reverse engineering approach (data collection, computational modeling and empirical validation) in turn.
## 5.1 Data Collection and Privacy
The requirement of using real data as input to the learner raises two issues, one technological and one ethical. At the technological level, it has become relatively easy to record virtually unlimited amounts of good quality audio and video data in children's environments. Perhaps the most ambitious data collection e ort so far has been done within the Speechome project (D. Roy, 2009), where video and audio equipment was installed in each room of an apartment, recording 3 years' worth of data around one infant. Wearable recorders (see for instance the LENA system, Xu et al., 2008) enable recording the infant's sound environment for a full day at a time, even outside the home. These can be supplemented with position sensors to categorize activities (Sangwan, Hansen, Irvin, Crutchfield, & Greenwood, 2015), or Life logging wearable devices to capture images every 30 seconds in order to reconstruct the context of speech interactions (Casillas, 2016). Of course, part of the technological challenge is not only to record raw data, but also to reconstruct the infant's sensory experience, from a first person point of view. In this context, head-mounted cameras can be useful to estimate the infant's head (and therefore average gaze) direction (L. B. Smith, Yu, Yoshida, & Fausey, 2015). Recent progress in 3D reconstruction, especially when using multi-view and / or depth sensors make it possible to go further in sensory reconstruction (e.g., Mustafa, Kim, Guillemaut, & Hilton, 2016) although this has not yet been done with infant data. Finally, even raw sensory data is di cult to use if it not supplemented with reliable linguistic / high level annotations. For instance, a large part of the Speechome corpus's audio track has been transcribed using semi-automatized means, enabling the search for linguistic characteristics of both the input to the child and its output (B. C. Roy, Frank, DeCamp, Miller, & Roy, 2015). Continuous progress in machine learning (speech recognition: Amodei et al., 2015; object recognition: Girshick, Donahue, Darrell, & Malik, 2016; action recognition: Rahmani, Mian, & Shah, 2016; emotion recognition: Kahou et al., 2015) will enable to lower the burden on high-level annotation of large amounts of data. The technological aspect of massive data collection, however, appears relatively simple when compared with the ethical challenges raised by the need to make this data accessible to the research community. There is a tension between the requirement of sharability and open scientific data (see Section 4.4), and the need of protecting individual privacy when it comes to personal and sensitive data. Up to now, the response of the scientific community has been dichotomous: either make everything public (as in the open access repositories like CHILDES, MacWhinney, 2000), or completely close o the corpora to anybody outside the institution that has recorded the data (as in the Riken corpus, Mazuka, Igarashi, & Nishikawa, 2006, or the Speechome corpus D. Roy, 2009). The first strategy sacrifices privacy and is impossible to scale up to dense recordings. The second strategy puts such an obstacle to the scientific use of the corpora that it almost defeats
the purpose of conducting the recording in the first place. A number of alternative strategies are being considered by the research community. The Homebank repository contains raw and transcribed audio, with a restricted case by case access to researchers (VanDam et al., 2016). Databrary has a similar system for video recordings (https: // nyu.databrary.org). Progress in cryptographic techniques would make it possible to envision preserving privacy while enabling more open exploitation of the data. For instance, the raw data could be locked on secure servers, thereby remaining accessible and revokable by the infants' families. Researchers' access would be restricted to anonymized meta-data or aggregate results extracted by automatic annotation algorithms. Di erential privacy techniques enable outside participants to make queries on databases while providing a level of guarantee on the amount of private information that can be extracted (Dwork, 2006). The specifics of such a new type of linguistic data repository would have to be worked out before dense speech and video home recordings can become a mainstream tool for infant research.
## 5.2 Cognitive Benchmarking and Experimental Reliability
Our second requirement, the construction of a cognitive benchmark for language processing, can be considered a done thing in the case of the human adult. The linguistic and psycholinguistic communities have indeed constructed relatively easy-to-administer, valid and reliable tests of the main components of linguistic competence in perception / comprehension (see Table 3). These tests are easy to administer because they are conceptually simple and can be administered to naive participants; most of them are of two kinds: goodness judgments (say whether a sequence of sound, a sentence, or a piece of discourse, is 'acceptable', or 'weird') and matching judgments (say whether two words mean the same thing or whether an utterance is true of a given situation, which can be described in language, picture or other means). The validity of linguistic tests often stems from the fact that they are used within a minimal set design . Such design selects examples where only one linguistic construct is manipulated while every other variable is kept constant (for instance: 'the dog eats the cat' and 'the eats dog the cat' only di er in word order). Regarding test reliability, as it turns out, many linguistic tests are quite reliable, as 97 Given the simplicity of these tasks, it is relatively straightforward to apply them to machines. Indeed, matching judgments between stimulus A and stimulus B can be derived by extracting from the machine the representations triggered by stimulus A and B, and compute a similarity score between these two representations. Goodness judgments are perhaps more tricky; they can easily be done by generative algorithms that assign a probability score , a reconstruction error , or a prediction error to individual stimuli. As seen in Table 3, some of these tests are already being used quite standardly in the evaluation of unsupervised learning systems, in particular, in the evaluation of phonetic and semantic levels) while for others they are less widespread. 7 Of course, in order to evaluate the ability of models to account for developmental trajectories (second puzzle) we must also compare machines with children. This is where the di cult challenge lies. The younger the child, the more di cult it is to construct reliable tests. The replicability crisis (see Ioannidis, 2012; Open Science Collaboration, 2015) has barely hit developmental psychology yet because there are so few replications in the first place (although, see the Many Babies project, M. Frank, 2015). Addressing this challenge would require improving substantially the reliability of the experimental techniques. Existing meta-analyses highlight large di erences in e ect sizes across experimental methods (community-augmented meta-analyses: Tsuji, Bergmann, & Cristia, 2014, metalab: http: // metalab.stanford.edu / ), which point to ways to improve the methods. If the method's signal-to-noise reach a plateau, there is the possibility to increase the number of participants through collaborative testing, as in genome-wide association studies, where low power requires a consortium to run very large number of participants (e.g., around 200,000 participants in Ehret, Munroe, Rice, & al., 2011) or increase the number of data points per child (perhaps using home-based experiments: L. Shultz, 2014, https: // lookit.mit.edu / , or V. Izard, 2016, https: // www.mybabylab.fr). In brief, some of the most fine grained predictions of reverse engineering models may have to wait for progress in experimental methods in infants.
## 5.3 Unsupervised learning of speech and language understanding
The third requirement comes down to 'desupervising' machine learning algorithms, i.e. to have them learn latent linguistic representations instead of force-feeding these representations through expert annotations. Two main, non exclusive, ideas are being explored to address this challenge. One idea could be referred to under the generic name of prior information . It is the idea that one can replace some of the missing labels (expert information) by innate knowledge about the structure of the problem. With strong prior knowledge, some logically impossible induction problems become solvable. 8 The reasoning here is that evolution might
7 Regarding the evaluation of word discovery systems, see the proposition by Ludusan, Versteegh, et al. (2014) but see Pearl and Phillips (2016) for a counter proposal and a discussion in (Dupoux, 2016).
8 One good illustration is the following: can you tell the colors of 1000 balls in an urn by just selecting one ball? The task is impossible without any prior knowledge about the distribution of colors in the urn, but very easy if you know that all the balls have the same color.
Table 3 Example of tasks that could be used for a Cognitive Benchmark.
| Task description in human adults | Linguistic level | Equivalent task in children | Equivalent task in machines |
|-----------------------------------------------------------------------------|--------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------|
| Well-formedness judgement does utterance S sound good? | phonetic, prosody, phonology, morphology, syntax | preferential looking (9-month-olds: Jusczyk, 1997), acceptability judgment (2-year-olds: de Villiers and de Villiers, 1972; Gleitman, Gleit- man, and Shipley, 1972) | reconstruction error (Allen & Seiden- berg, 1999), probability (Hayes & Wilson, 2008), mean or min log probability (Clark, Giorgolo, &Lappin, 2013) |
| Same-Di erent judgment is X the same sound / word / meaning as Y? | phonetic, phonology, semantics | habituation / deshabituation (newborns, 4-month- olds: Eimas, Siqueland, Jusczyk, & Vigorito, 1971; Bertoncini, Bijeljac-Babic, Blumstein, & Mehler, 1987), oddball (3-month-olds: Dehaene- Lambertz, Dehaene, et al., 1994) | AX / ABX discrimination (Carlin, Thomas, Jansen, & Hermansky, 2011; Schatz et al., 2013), cosine similarity (Landauer & Du- mais, 1997) |
| Part-Whole judgment is word X part of sentence S? | phonology, mor- phology | Word spotting (8-month-olds: Jusczyk, Houston, &Newsome, 1999) | spoken web search (Fiscus, Ajot, Garofolo, &Doddingtion, 2007) |
| Reference judgment does word X (in sent S) refer to meaning M? | semantics, prag- matics | intermodal preferential looking (16-month-olds: Golinko , Hirsh-Pasek, Cauley, & Gordon, 1987), picture-word matching (11-month-olds: Thomas, Campos, Shucard, Ramsay, & Shucard, 1981) | picture / video captioning (e.g., Devlin, Gupta, Girshick, Mitchell, & Zitnick, 2015), Winograd's schemas (Levesque, Davis, &Morgenstern, 2011) |
| Truth / Entailment judgment is sent S true (in context C)? | semantics | Truth Judgment Task (3-year-olds: Abrams, Chiarello, Cress, Green, & Ellett, 1978; Lidz & Musolino, 2002) | visual question answering (Antol et al., 2015) |
| Felicity judgement would people say S to meanM (in context C) ? | pragmatics | Ternary reward task (5-year-olds: Katsos & Bishop, 2011), Felicity judgment task (5 years olds: Foppolo, Guasti, &Chierchia, 2012). | ? |
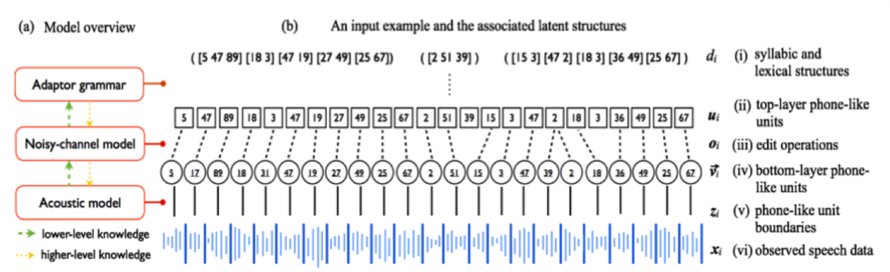
Figure 3 . Outline of a generative architecture learning jointly words and phonemes from raw speech (from Lee, O'Donnell & Glass, 2015).
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Model Overview and Input Example with Latent Structures
### Overview
The image presents a diagram illustrating a model overview and an input example with associated latent structures. The diagram consists of two main parts: (a) a block diagram representing the model architecture, and (b) a visualization of an input example and its corresponding latent structures. The diagram uses arrows to indicate the flow of information and the levels of knowledge.
### Components/Axes
The diagram includes the following components:
* **Model Overview (a):**
* Adaptor grammar (rectangle)
* Noisy-channel model (rectangle)
* Acoustic model (rectangle)
* Arrows indicating lower-level knowledge (dashed green arrows)
* Arrows indicating higher-level knowledge (solid yellow arrows)
* **Input Example and Latent Structures (b):**
* Observed speech data (xₜ) - represented as a waveform
* Phone-like unit boundaries (zₜ) - a series of numbers above the waveform
* Lower-layer phone-like units (vₜ) - a series of numbers above zₜ
* Edit operations (θₜ) - a series of numbers above vₜ
* Top-layer phone-like units (μₜ) - a series of numbers above θₜ
* Syllabic and lexical structures (dₜ) - a series of numbers above μₜ
* **Labels:**
* (a) Model overview
* (b) An input example and the associated latent structures
* xₜ: (vi) observed speech data
* zₜ: (v) phone-like unit boundaries
* vₜ: (iv) lower-layer phone-like units
* θₜ: (iii) edit operations
* μₜ: (ii) top-layer phone-like units
* dₜ: (i) syllabic and lexical structures
* **Numerical Data:**
* Observed speech data (xₜ): A complex waveform, no specific values are discernible.
* Phone-like unit boundaries (zₜ): 5, 47, 89, 18, 3, 47, 19, 27, 49, 25, 67
* Lower-layer phone-like units (vₜ): 5, 17, 18, 11, 12, 19, 22, 25, 47, 42, 51, 15, 3, 32, 39, 22, 18, 36, 49, 25, 67
* Edit operations (θₜ): 15, 3, 11, 47, 2, 18, 3, 36, 49, 25, 67
* Top-layer phone-like units (μₜ): 39, 15, 3, 47, 2, 39
* Syllabic and lexical structures (dₜ): 5, 47, 89, 18, 3, 47, 19, 27, 49, 25, 67
### Detailed Analysis or Content Details
The model overview (a) shows a hierarchical structure with the acoustic model at the bottom, the noisy-channel model in the middle, and the adaptor grammar at the top. The acoustic model receives lower-level knowledge, while the adaptor grammar receives higher-level knowledge. The noisy-channel model acts as an intermediary, receiving input from both the acoustic model and the adaptor grammar.
The input example (b) demonstrates how observed speech data (xₜ) is transformed into a series of latent structures. The observed speech data is represented as a waveform. Above the waveform are the phone-like unit boundaries (zₜ), followed by the lower-layer phone-like units (vₜ), edit operations (θₜ), top-layer phone-like units (μₜ), and finally, the syllabic and lexical structures (dₜ). The numbers associated with each layer represent the corresponding latent units. The arrows indicate the flow of information from the lower layers to the higher layers.
### Key Observations
The diagram illustrates a hierarchical model for speech recognition or processing. The model uses a series of latent structures to represent the input speech data at different levels of abstraction. The use of both lower-level and higher-level knowledge suggests a combination of acoustic and linguistic information is used in the model. The numerical data in the input example provides a concrete illustration of how the model processes speech data.
### Interpretation
The diagram depicts a probabilistic model for speech recognition, likely based on Hidden Markov Models (HMMs) or a related framework. The "noisy-channel model" suggests a Bayesian approach where the observed speech data is considered a noisy version of the underlying linguistic structure. The adaptor grammar likely allows for customization or adaptation of the model to specific speakers or domains. The latent structures represent the hidden states of the model, which are inferred from the observed speech data. The hierarchical structure allows the model to capture both the acoustic and linguistic properties of speech. The diagram suggests a bottom-up approach to speech recognition, starting with the acoustic signal and gradually building up to the syllabic and lexical levels. The numerical data in the input example provides a snapshot of the model's internal representation of a particular utterance. The diagram is a conceptual illustration of the model's architecture and does not provide specific details about the model's parameters or training procedure.
</details>
have given the learning system strong prior knowledge about some universal regularities of language, such that only few data points are necessary to learn the relevant system. Such ideas have been proposed in the acquisition of syntax under the name of principles and parameters. Under this theory, a single sentence (called a trigger) is su cient to decide on one parameter (Gibson & Wexler, 1994; Sakas & Fodor, 2012). An illustration of such a system for learning phonemes and words from raw speech uses a very specific generative architecture to guide the learning process (Lee & Glass, 2012; Lee et al., 2015, see Figure 3). The second idea is that of soft constraints coming from a large interconnected system. Instead of trying to learn each subcomponent of language in isolation, the idea is to integrate these subsystems in a general language processing architecture, and let the subcomponent constrain each other. Because each subcomponent is solv-
Figure 4 . Architecture illustrating a top-down synergy between learning phonemes and words. Auditory spectrograms (speech features) are computed from the raw speech signal. Then, protowords are extracted using Spoken Term Discovery; these words are then used to learn a more invariant speech representation using discriminative learning in a siamese Deep Neural Network architecture (from Thiolliere et al., 2015).
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Spoken Term Discovery Flow
### Overview
The image depicts a diagram illustrating the flow of information in a spoken term discovery process. It shows a series of processing steps, starting from a raw audio signal and culminating in a lexicon of protowords. The diagram uses boxes to represent processing stages and arrows to indicate the flow of data.
### Components/Axes
The diagram consists of the following components:
* **Raw Audio Signal:** Represented by a waveform at the bottom of the diagram.
* **Speech Coding:** A rectangular box labeled "speech coding" connected to the audio signal.
* **Speech Features:** A label indicating the output of the speech coding stage.
* **Siamese DNN:** A rectangular box labeled "Siamese DNN".
* **Proto-phonemes:** A label indicating the output of the Siamese DNN stage.
* **Spoken Term Discovery:** A rectangular box labeled "Spoken Term Discovery".
* **Lexicon of Protowords:** An oval shape labeled "lexicon of protowords" at the top of the diagram.
* **Arrows:** Solid and dashed arrows indicating the direction of data flow between components.
### Detailed Analysis or Content Details
The diagram shows the following flow:
1. **Audio Signal to Speech Coding:** A waveform representing the raw audio signal feeds into the "speech coding" stage.
2. **Speech Coding to Speech Features:** The "speech coding" stage outputs "speech features".
3. **Speech Features to Siamese DNN:** The "speech features" are input to the "Siamese DNN".
4. **Siamese DNN to Proto-phonemes:** The "Siamese DNN" outputs "proto-phonemes".
5. **Proto-phonemes to Spoken Term Discovery:** The "proto-phonemes" are input to the "Spoken Term Discovery" stage.
6. **Spoken Term Discovery to Lexicon of Protowords:** The "Spoken Term Discovery" stage outputs to the "lexicon of protowords".
7. **Lexicon of Protowords to Spoken Term Discovery:** There is a feedback loop from the "lexicon of protowords" back to the "Spoken Term Discovery" stage.
8. **Spoken Term Discovery to Siamese DNN:** There is a dashed arrow from the "Spoken Term Discovery" stage to the "Siamese DNN", labeled "proto-phonemes".
### Key Observations
The diagram illustrates a cyclical process where the discovered protowords influence the subsequent term discovery process. The dashed arrow suggests a feedback mechanism where the "Spoken Term Discovery" stage provides "proto-phonemes" back to the "Siamese DNN", potentially for refinement or adaptation.
### Interpretation
This diagram represents a system for automatically discovering spoken terms from raw audio. The "speech coding" stage likely converts the audio signal into a more manageable representation (e.g., spectrograms, MFCCs). The "Siamese DNN" is used to learn similarities between speech segments, potentially identifying proto-phonemes – basic sound units. The "Spoken Term Discovery" stage then uses these proto-phonemes to identify and categorize spoken terms, building a "lexicon of protowords". The feedback loop suggests an iterative refinement process, where the lexicon influences the identification of new terms. The use of a Siamese DNN implies a learning-based approach focused on similarity and comparison of speech segments. The diagram does not provide any quantitative data, but rather a conceptual overview of the system's architecture and data flow.
</details>
ing a di erent optimization problem, they are providing the other subsystems their own view of what has to be learned. For instance, in the domain of phonetic learning it has been shown that even an imperfect, automatically discovered lexicon can help improving on subword representations using allophonic representations (Martin, Peperkamp, & Dupoux, 2013; Fourtassi & Dupoux, 2014) or the raw speech signal (Jansen, Thomas, & Hermansky, 2013; Thiollière et al., 2015, see Figure 4). This idea has been discussed under different guises (multitask learning: Caruana, 1997; multi-cue integration: Christiansen et al., 2005), but is perhaps best expressed under the notion of learning synergies (M. Johnson, 2008). Synergies correspond to the fact that jointly learning two aspects of language is easier than learning either one alone. 9 They have been documented among others, between phonemes and words inventories (Feldman, Myers, White, Gri ths, & Morgan, 2011), syllables and words segmentation (M. Johnson, 2008), referential intentions and word meanings (M. C. Frank, Goodman, & Tenenbaum, 2009). Note that the envisioned solutions address squarely the puzzles mentioned in the introduction: learning takes place without supervisory signals (the unsupervised / weakly supervised setting), all levels are learned simultaneously (joint modeling), and language learning is resilient. This last point can be viewed as a correlate of the soft constraint idea: a (reasonable) limitation in some input can be compensated for by strong priors and / or information coming from another linguistic or non linguistic level. Even though this challenge is di cult, there is a growing interest for the study of unsupervised algorithms. This opens up a window of opportunity for collaborations between the cognitive science and machine learning communities.
## 6 Preliminary results
Evidently, achieving the goals of the reverse engineering approach is a long-term project, requiring us to overcome the challenges listed in the preceding section. This means that we will have to contend with partial realizations for many years. Yet, even partial realizations would provide useful benefits in the area of cognitive and linguistic theories, corpus studies, experimental studies and machine learning. We illustrate these benefits next, through a selection of examples.
## 6.1 Challenging intuitions and psychological theories
Õ referential intentions to model early cross-situational word learning. Psychological Science, 20, 579-585. As shown in Section 3, cognitive theories of the language learner typically come under the shape of conceptual frameworks , sometimes supplemented with a list of psychologically validated learning mechanisms . Conceptual frameworks refer to potential mechanisms using verbal descriptions ( statistical learning , rule learning , abstraction , grammaticalization , analogy ) or boxes and arrows which may be intuitive, but also vague; refer to many potentially distinct mechanisms; and are therefore di cult to put to empirical test. The reverse engineering approach may nudge these theories into providing more detailed algorithmic specification, so that they can derive testable predictions. Regarding the proposed learning mechanisms, implementing and testing them at scale can be useful to assess the e ectiveness of these mechanisms and their relative strength in real life situations. We briefly illustrate this with three examples. The first example is the learning of phonetic categories by infant through 'distributional learning' which can be viewed as a mechanism of unsupervised clustering. Even though this mechanism was validated in infants (Maye et al., 2002), and several implemented algorithms were tested (Vallabha et al., 2007; McMurray et al., 2009, , among others), it appears that none of these tests were run on real continuous speech datasets. Most papers used either fake data (points in formant space generated from a Gaussian distribution), or worked from measurements made on manually segmented speech. When tested on continuous speech, clustering algorithms yield a very di erent result.
9 Interestingly, the idea of synergies turn the bootstrapping problem on its head: instead of being a liability, the codependancies between linguistic components become an asset.
For instance, Varadarajan, Khudanpur, and Dupoux (2008) have shown that a clustering algorithm based on Hidden Markov Models and Gaussian mixtures does not converge on phonetic segments, but rather, on much shorter (30 ms), highly context-sensitive acoustic events. To find phonemesized units would seem to require a di erent algorithm with strong priors on the acoustic structure of phonemes (Lee & Glass, 2012). This example reveals that contrary to the hypothesis in Maye et al. (2002), finding phonetic units is not only a problem of constructing categories (clustering), it is also a problem of segmenting continuous speech. Furthermore, the two problems are not independent and have therefore to be addressed jointly by the learning algorithms. This, in turn, would yield specific predictions to be tested in infants. The second example is word segmentation using transition probabilities. Even though a lot of work has been devoted to study the importance of transition probabilities as a possibly cue to signal word boundaries in infants (Romberg &Sa ran, 2010, for a review), it turns out that this cue alone yields disappointingly poor segmentation performance in a real corpus. In contrast, algorithms based on totally di erent principles which directly learn a lexicon, and obtain a segmentation as a by-product fare a lot better (Cristia et al. in preparation). Unfortunately, such lexical-based algorithms which could potentially be much more useful for language acquisition, have been little studied empirically in infants. The third example shows that computational models may suggest new types of mechanisms that were not thought before or may seem implausible from an intuitive point of view. The received wisdom is that the meaning of words may be acquired in infants through the coocurrence patterns of verbal material with contextual cues in other modalities (for instance, the presence of a dog when hearing the word 'dog'). Yet, Fourtassi and Dupoux (2014) has shown that coocurrence patterns within the verbal material alone can provide an approximate representation of the meaning of words, which can then provide a useful top-down feedback on how to cluster phonetic information into phonemes.
## 6.2 Grounding formal linguistic theories
Every linguistic theory relies on a core list of representations and symbols that are supposed universal. For instance, Optimality Theory relies on a list of universal phonetic features and constraints. The same goes with syntactic and semantic theories (part of speech, types of grammatical relations or computations, quantifiers, etc.). Where do these symbols come from and how they are grounded in the signal remains unspecified. Reverse Engineering o ers the possibility to give an account of the developmental emergence of these elements. For instance, in the domain of phonology, Dunbar, Synnaeve, and Dupoux (2015) has proposed that phonological features could emerge from a joint auditory and articulation space. In the domain of lexical semantics, distri- butional accounts have emerged which ground the meaning of words into the unsupervised learning of patterns of concurrence (Landauer & Dumais, 1997). These patterns correlate well with judgments of semantic proximity (although see Linzen, Dupoux, & Spector, 2016; Gladkova, Drozd, Center, & Matsuoka, 2016). Similarly, in the domain of syntax, systems of automatically derived part of speech tags through unsupervised distributional learning finding work as well, and on some occasion better than those tags provided by experts (e.g., Prins & Van Noord, 2001). The potential consequences of these results for foundational issues in formal linguistic theories remain to be explored.
## 6.3 Characterizing the input
Corpus studies characterize the input to the child in terms of various measures of linguistic complexity (mean length of utterance, lexical diversity, etc). What reverse engineering can o er is a new set of tools to quantify linguistic complexity with respect to its e ect on the language learner . We briefly give two examples, one cross linguistic, one that regards the so-called hyperspeech hypothesis. Regarding cross-linguistic variation, languages di er in great extent in the complexity of their surface features. How much do these variations matter to the learner? This can be explored by systematically running language learning algorithms through corpora of di erent languages. For instance, Fourtassi, Boerschinger, Johnson, and Dupoux (2013) have replicated in a controlled fashion the often noted finding that word segmentation models make a lot more errors in some languages than others (e.g., Japanese versus English). They showed that the di erence in performance was not specific to the algorithm that they used, but was related an intrinsic di erence in segmentation ambiguity between the two languages, which is itself based on their di ering syllabic structure. Conducting similar studies cross-linguistically would help to derive a new learnability-based linguistic typology, which could then be related to potential cross-linguistic di erences in learning trajectories in infants. As for the hyperspeech hypothesis, it was proposed that parents adapt their pattern of speech to infants in order to facilitate learning (see Fernald, 2000 for a discussion). Consistent with this, Kuhl (1997) observed that parents tend to increase the separation between point vowels in child directed speech, possibly making them more distinctive. Yet, Ludusan, Seidl, Dupoux, and Cristia (2015) ran a word discovery algorithm on raw speech and failed to find any di erence in word learning between child and adult directed speech; if anything, the former was slightly more di cult. This paradoxical result can be explained by the fact that parents tend to increase phonetic variability when addressing their infants, which results in a net decrease in category discriminability (Martin et al., 2015; see also McMurray, Kovack-Lesh, Goodwin, & McEchron, 2013). Scalable computational models are therefore useful to
assess the net functional role of otherwise disparate linguistic and phonetic e ects. More topics could be explored following the same approach. For instance, some studies have proposed that parents provide informative feedback even on preverbal vocalization (Gros-Louis, West, Goldstein, & King, 2006; Plummer, 2012; Warlaumont, Richards, Gilkerson, & Oller, 2014). A modeling approach would help to determine whether such behavior truly helps language learning in a naturalistic environment. The same goes for other forms of weak parental supervision like referential pointing, joint attention, etc.
## 6.4 Errors as predictions
Before a full model of the learner is available, even a partial model would enable to provide useful predictions. For instance, even the best unsupervised segmentation mechanisms fed with errorless phonemic transcriptions make systematic errors: under-segmentations for frequent pairs of words (like "readit" instead of "read" + "it") or over-segmentations (which would be "butterfly" being segmented into "butter" + "fly") (see Peters, 1983). Instead of viewing these errors are inadequacies of the models, one could view them as reflecting areas of the target language that are intrinsically di cult to segment in the absence of other information (syntactic, semantic, etc). Therefore, it is reasonable to expect that infants would make the same errors, at least at an age where the assumptions of the models are met (after having stabilized their phonetic representations, but before much semantic / syntactic learning). These 'errors' could then be presented into infants and tested for recognition. If infants are making the same errors as the proposed mechanism, this would count as evidence in favor of this mechanism. Ngon et al. (2013) tested the prediction of a very simple model of word segmentation (an ngram model) run on a CHILDES corpus. Eleven month olds preferred to listen to some frequent mis-segmentations of the model, and did not distinguish them from real words of the same frequency. The logic could be extended by running di erent models on the same data, and generating diagnostic patterns that distinguish between the competing models, allowing to separate them empirically. In principle, such diagnostic patterns could be generated, cross-linguistically, within a language, or even within a given individual infant (to the extent that the input data can be collected individually). The diagnostic pattern technique opens up therefore a whole arena for comparing implemented models and theories.
## 6.5 Collaborations with the Machine Learning community
As the reverse engineering approach develops cognitive benchmarks, this can provide new playgrounds (problem sets) for developing architectures and algorithms that can work with little or no supervision, with a moderate amount of data. Infants provide a proof of principle that
Figure 5 . The learning situation in the interactive scenario, viewed as two coupled dynamic systems: the Child and the Environment.
<details>
<summary>Image 5 Details</summary>
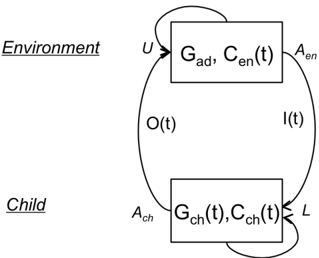
### Visual Description
\n
## Diagram: Dynamic Systems Model - Adult-Child Interaction
### Overview
The image depicts a diagram illustrating a dynamic systems model of interaction between an adult and a child within an environment. It shows two rectangular blocks representing the "Adult" and "Child" systems, connected by several bidirectional arrows representing information and action flows. The diagram emphasizes the reciprocal influence between the two systems and their environment.
### Components/Axes
The diagram consists of the following labeled components:
* **Environment:** Labelled on the left side of the diagram.
* **Child:** Labelled on the bottom left side of the diagram.
* **Adult:** Represented by the top rectangular block. Contains the label "G<sub>ad</sub>, C<sub>en</sub>(t)".
* **Child:** Represented by the bottom rectangular block. Contains the label "G<sub>ch</sub>(t), C<sub>ch</sub>(t)".
* **U:** Input from the environment to the adult.
* **A<sub>en</sub>:** Output from the adult to the environment.
* **I(t):** Input from the environment to the child.
* **O(t):** Output from the child to the environment.
* **A<sub>ch</sub>:** Output from the child to the adult.
* **L:** Output from the adult to the child.
The arrows indicate the direction of influence or information flow. The arrows are curved, suggesting a continuous and dynamic interaction.
### Detailed Analysis or Content Details
The diagram represents a closed-loop system. The Adult system (G<sub>ad</sub>, C<sub>en</sub>(t)) receives input 'U' from the Environment and produces output 'A<sub>en</sub>' back into the Environment. The Child system (G<sub>ch</sub>(t), C<sub>ch</sub>(t)) receives input 'I(t)' from the Environment and produces output 'O(t)' back into the Environment. The Adult and Child systems also interact directly with each other via outputs 'A<sub>ch</sub>' and 'L' respectively.
The labels within the blocks suggest the following:
* **G<sub>ad</sub>:** Likely represents the "gain" or amplification factor for the Adult system.
* **C<sub>en</sub>(t):** Likely represents the "context" or state of the Environment at time 't' as perceived by the Adult.
* **G<sub>ch</sub>(t):** Likely represents the "gain" or amplification factor for the Child system at time 't'.
* **C<sub>ch</sub>(t):** Likely represents the "context" or state of the Environment at time 't' as perceived by the Child.
The arrows indicate a continuous feedback loop. The Adult's actions (A<sub>en</sub>) influence the Environment, which in turn influences the Child (I(t)). The Child's actions (O(t)) influence the Environment, which in turn influences the Adult (U). The direct interaction between Adult and Child (A<sub>ch</sub> and L) creates another feedback loop.
### Key Observations
The diagram highlights the interconnectedness of the Adult, Child, and Environment. It emphasizes that each system's behavior is influenced by, and influences, the others. The use of time-dependent variables (C<sub>en</sub>(t), C<sub>ch</sub>(t), G<sub>ch</sub>(t)) suggests that the system is dynamic and changes over time. The bidirectional arrows indicate reciprocal causality.
### Interpretation
This diagram illustrates a systems thinking approach to understanding adult-child interactions. It moves beyond a simple linear cause-and-effect model and recognizes the complex interplay of factors. The diagram suggests that interventions aimed at changing behavior in either the Adult or Child system must consider the broader context of the Environment and the reciprocal influences between the systems. The use of 'gain' and 'context' suggests that the system's response is not simply proportional to the input, but is also shaped by internal states and sensitivities. This model is useful for understanding how patterns of interaction can emerge and become self-sustaining, and how small changes in one part of the system can have cascading effects throughout the entire system. The diagram does not provide specific data or numerical values, but rather a conceptual framework for analyzing the dynamics of the interaction.
</details>
such systems can be constructed. One example of this is the zero resource speech challenge (Versteegh et al., 2015) which explores the unsupervised discovery of sublexical and lexical linguistic units from raw speech. Such a challenge, set up with open-source datasets and baselines (see www.zerospeech.com) attracted considerable interest in the community of speech technology (Versteegh, Anguera, Jansen, & Dupoux, 2016). Such so-called zero-resource algorithms (Glass, 2012; Jansen, Dupoux, et al., 2013) are not only interesting models of infant early phonetic and lexical acquisition, they can also provide technical solutions for the construction of speech services in languages with scarce linguistic resources, or in languages with no or unreliable orthography.
## 7 Extensions
The feasibility section (Section 5) endorsed a set of simplifying assumptions encapsulated in Figure 2a. This framework does not take into consideration the child's output, nor the possible feedback loops from the parents based on this output. Many researchers would see this as a major, if not fatal, limitation of the approach. In real learning situations, infants are also agents, and the environment reacts to their outputs creating feedback loops (Bruner, 1975, 1983; MacWhinney, 1987; Snow, 1972; Tamis-LeMonda & Rodriguez, 2008). The most general description of the learning situation is therefore as in Figure 5. Here, the child is able to generate observable actions (some linguistic, some not) that will modify the internal state of the environment (through the monitoring function). The environment is able to generate the input to the child as a function of his internal state. In this most general form, the learning situation consists therefore in two coupled dynamic systems . 10 Could such a complex situation be addressed within the reverse engineering approach? We would like to answer with a cautious yes, to the extent
10 We thank Thomas Schatz, personal communication, for proposing this general formulation.
that it is possible to adhere to the same four requirements, i.e., realistic data (as opposed to simplified ones), explicit criteria of success (based on cognitive indistinguishability), scalable modeling (as opposed to verbal theories or toy models) and sharable resources. While none of these requirements seem out of reach, we would like to pinpoint some of the di culties, which are the source of our caution. Regarding the data, the interactive scenario would require accessing the full (linguistic and non linguistic) output of the infant, not only her input. While this is not intrinsically harder to collect than the input, and is already been done in many corpora for older children, the issue of what to categorize as linguistic and non linguistic output and how to annotate it is not completely trivial. Regarding computational modeling, instead of focusing on only one component (the learner) of one agent (the child), in the full interactive framework, one has to model a total of 4 components (the learner, the infant generator, the caretaker monitor, and the caretaker generator) in 2 agents (adult, child). Furthermore, the internal states of each agent has to be split into linguistic states (grammars) and non-linguistic (cognitive) states to represent the communicative aspects of the interaction (e.g., communicative intent, emotional / reinforcement signals). This, in turn, causes the split of each processing component into linguistic and cognitive subcomponents. Although this is clearly a di -cult endeavor, many of the individual ingredients needed for constructing such a system are already available in the following research areas. First, within speech technology, there are available components to build a language generator, as well as the perception and comprehension components in the adult caretaker. Second, within linguistics, psycholinguistics and neuroscience, there are interesting theoretical models of the learning of speech production and articulation in young children (Tomasello, 2003; W. Johnson & Reimers, 2010; Guenther & Vladusich, 2012). Third, within machine learning, great progress has been made recently on reinforcement learning, a powerful class of learning algorithms which assume that besides raw sensory data, the environment only provides sporadic positive or negative feedback (Sutton & Barto, 1998). This could be adapted to model the e ect of the feedback loops on the learning components of the caretaker and the infant. Fourth, developmental robotics studies have developed the notion of intrinsic motivation, where the agent actively seek new information by being reinforced by its own learning rate (Oudeyer, Kaplan, & Hafner, 2007). This notion could be used to model the dynamics of learning in the child, and the adaptive e ects of the caretaker-child feedback loops. The most di cult part of this enterprise would perhaps concern the evaluation of the models. Indeed, each of these new components and subcomponents would have to be evaluated on their own in the same spirit as before, i.e., by running them on scalable data and testing them using humanvalidated tasks. For instance, the child language generator should be tested by comparing its output to age appropriate children's outputs, which requires the development of appropriate metrics (sentence length, complexity, etc) or human judgments. The cognitive subcomponents would have to be tested against experiments studying children and adults in experimentally controlled interactive loops (e.g., N. A. Smith & Trainor, 2008; Goldstein, 2008). In addition, because a complex system is more than the sum of its parts, individual component validation would not su cient, and the entire system would have to be evaluated. 11 Fully specifying the methodological requirements for the reverse engineering of the interactive scenario would be a project of its own. It is not clear at present how much of the complications introduced by this scenario are necessary, at least to understand the first steps of language bootstrapping. To the extent that there are cultures where the direct input to the child is severely limited and / or the interactive character of that input circumscribed, it would seem that a fair amount of bootstrap can take place outside of interactive feedback loops. This is of course entirely an empirical issue, one that the reverse engineering approach should help to clarify.
## 8 Conclusion
During their first years of life, infants learn a vast array of cognitive competences at an amazing speed; studying this development is a major scientific challenge for cognitive science in that it requires the cooperation of a wide variety of approaches and methods. Here, we proposed to add to the existing arsenal of experimental and theoretical methods the reverse engineering approach, which consists in building an e ective system that mimics infant's achievements. The idea of constructing an e ective system that mimics an object in order to gain more knowledge about that object is of course a very general one, which can be applied beyond language (for instance, in the modeling of the acquisition of naive physics or naive psychology) and even beyond development. Related work exist in the area of computational neuroscience, which attempts to use machine learning architectures (deep learning) and bring it to bear to the analysis of neural representations for visual inputs (Cadieu et al., 2014; Isik, Tacchetti, & Poggio, 2016; Leibo, Liao, Anselmi, & Poggio, 2015). The computational rationality framework uses bayesian modeling to bring together the field of Artificial Intelligence and studies of human abilities like reasoning or decision making (Gershman, Horvitz, & Tenenbaum, 2015). Returning to language acquisition, we have defined four methodological requirements for this combined approach to work: using real data as input (which implies setting up sharable and privately
11 For instance, a combined learner / caretaker system should be able to converge on a similar grammar as a learner ran on real data. In addition, their interactions should not di er in 'naturalness' compared to what can be recorded in natural situations, see (Bornstein &Tamis-LeMonda, 2010).
safe repositories of dense reconstructions of the sensory experience of many infants), constructing a computational system at scale (which implies de-supervising machine learning systems to turn them into models of infant learning), assessing success by running tests derived from linguistics on both humans and machines (which implies setting up cumulative benchmarks of cognitive and linguistic tests) and sharing all of these resources. We've argued that even before the challenges are all met, such an approach can help to understand how language bootstrap can take place in a resilient fashion, and can provide an e ective way to derive quantitative predictions that are of interest both practically and theoretically. The reverse engineering approach we propose does not endorse a particular model, theory or view of language acquisition. For instance, it does not take a position on the rationalist versus empiricist debate (e.g., Chomsky, 1965, vs. Harman, 1967). Our proposal is more of a methodological one: it specifies what needs to be done such that the machine learning tools can be used to address scientific questions that are relevant for such a debate. It strives at constructing at least one e ective model that can learn language. Any such model will both have an initial architecture (nature), and feed on real data (nurture). It is only through the comparison of several such models that it will be possible to assess the minimal amount of information that the initial architecture has to have, in order to perform well. Such a comparison would give a quantitative estimate of the number of bits required in the genome to construct this architecture, and therefore the relative weight of these two sources of information. In other words, our roadmap does not start o with a given position on the rationalist / empiricist debate, rather, a position in this debate will be an outcome of this enterprise.
## Acknowledgments
This paper benefited immensely from comments from and discussion with Alex Cristia and Paul Smolensky as well as with all the members of the 'Bootphon' team. This work was supported by the European Research Council (ERC-2011AdG-295810 BOOTPHON), the Agence Nationale pour la Recherche (ANR-10-LABX-0087 IEC, ANR-10-IDEX0001-02 PSL*), the Fondation de France, the Ecole de Neurosciences de Paris, and the Region Ile de France (DIM cerveau et pensée).
## References
- Abrams, K., Chiarello, C., Cress, K., Green, S., & Ellett, N. (1978). Recent advances in the psychology of language. In R. Campbell & P. Smith (Eds.), (Vol. 4a, chap. The relation between mother-to-child speech and word-order comprehension strategies in children). New York: Plenum Press.
- Allen, J., & Seidenberg, M. S. (1999). The emergence of grammaticality in connectionist networks. In B. MacWhinney (Ed.), Emergentist approaches to language: proceedings of the 28th
- carnegie symposium on cognition (p. 115-151). Lawrence Earlbaum Associates.
- Amodei, D., Anubhai, R., Battenberg, E., Case, C., Casper, J., Catanzaro, B., . . . others (2015). Deep speech 2: End-toend speech recognition in english and mandarin. arXiv preprint arXiv:1512.02595 .
- Anderson, J. R. (1975). Computer simulation of a language acquisition system: A first report. In R. Solso (Ed.), Information processing and cognition. Hillsdale, N.J.: Lawrence Erlbaum.
- Angluin, D. (1988). Identifying Languages from Stochastic Examples [Technical Report 614. New Haven, CT: Yale University].
- Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Lawrence Zitnick, C., & Parikh, D. (2015). Vqa: Visual question answering. In Proceedings of the ieee international conference on computer vision (pp. 2425-2433).
- Badino, L., Canevari, C., Fadiga, L., & Metta, G. (2014). An Autoencoder based approach to unsupervised learning of subword units. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
- Bates, E., & MacWhinney, B. (1987). Competition, Variation and Language learning. In B. MacWhinney (Ed.), Mechanisms of Language Acquisition (pp. 157-193). Hillsdale, N.J.: Lawrence Erlbaum.
- Bergelson, E., & Swingley, D. (2012, February). At 6-9 months, human infants know the meanings of many common nouns. Proceedings of the National Academy of Sciences , 109 (9), 32533258.
- Bertoncini, J., Bijeljac-Babic, R., Blumstein, S. E., & Mehler, J. (1987). Discrimination in neonates of very short cvs. The Journal of the Acoustical Society of America , 82 (1), 31-37.
- Berwick, R. (1985). The acquisition of syntactic knowledge . MIT Press.
- Best, C. T., McRoberts, G. W., & Sithole, N. M. (1988). Examination of perceptual reorganization for nonnative speech contrasts: Zulu click discrimination by English-speaking adults and infants. Journal of Experimental Psychology: Human perception and performance , 14 (3), 345.
- Bornstein, M. H., & Tamis-LeMonda, C. S. (2010). The wileyblackwell handbook of infant development. In J. G. Bremner & T. D. Wachs (Eds.), (pp. 458-482). Wiley-Blackwell.
- Botha, J. A., & Blunsom, P. (2013). Adaptor grammars for learning non-concatenative morphology. In Emnlp (pp. 345-356).
- Boves, L., Ten Bosch, L., & Moore, R. K. (2007). ACORNS- Towards computational modeling of communication and recognition skills. In 6th IEEE International Conference on In Cognitive Informatics (pp. 349-356). IEEE.
- Brent, M. R. (1996a). Advances in the computational study of language acquisition. Cognition , 61 (1), 1-38.
- Brent, M. R. (1996b). Computational approaches to language acquisition . MIT Press.
- Brown, R. (1973). A first language; the early stages . Cambridge, Mass: Harvard University Press.
- Bruner, J. S. (1975, April). The ontogenesis of speech acts. Journal of Child Language , 2 (01).
- Bruner, J. S. (1983). Child's Talk: Learning to Use Language . New York, N.Y.: Norton.
- Cadieu, C. F., Hong, H., Yamins, D. L., Pinto, N., Ardila, D., Solomon, E. A., . . . DiCarlo, J. J. (2014). Deep Neural Net-
- works Rival the Representation of Primate IT Cortex for Core Visual Object Recognition. arXiv preprint arXiv:1406.3284 .
Carlin, M. A., Thomas, S., Jansen, A., & Hermansky, H. (2011). Rapid evaluation of speech representations for spoken term discovery. In Proceedings of Interspeech.
Caruana, R. (1997). Multitask learning. Machine learning , 28 (1), 41-75.
Casillas, M. (2016). Age and turn type in mayan children's predictions about conversational turn-taking. to be presented at. In Boston university child language development. Boston, USA.
Chomsky, N. (1965). Aspects of the Theory of Syntax . MIT press.
Chouinard, M. M., & Clark, E. V. (2003). Adult reformulations of child errors as negative evidence. Journal of child language , 30 (03), 637-669.
Christiansen, M. H., Conway, C. M., & Curtin, S. (2005). Multiplecue integration in language acquisition: A connectionist model of speech segmentation and rule-like behavior. Language acquisition, change and emergence: Essay in evolutionary linguistics , 205-249.
Christodoulopoulos, C., Goldwater, S., & Steedman, M. (2010). Two Decades of Unsupervised POS induction: How far have we come? In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing (pp. 575-584). Association for Computational Linguistics.
Christophe, A., Millotte, S., Bernal, S., & Lidz, J. (2008). Bootstrapping lexical and syntactic acquisition. Language and Speech , 51 (1-2), 61-75.
Clark, A., Giorgolo, G., & Lappin, S. (2013). Statistical representation of grammaticality judgements: the limits of n-gram models. In Proceedings of the fourth annual workshop on cognitive modeling and computational linguistics (cmcl) (pp. 28-36).
Clark, A., & Lappin, S. (2011). Linguistic Nativism and the poverty of the stimulus . Wiley and sons.
Connor, M., Fisher, C., & Roth, D. (2013). Starting from scratch in semantic role labeling: Early indirect supervision. In T. Poibeau, A. Villavicencio, A. Korhonen, & A. Alishahi (Eds.), Cognitive aspects of computational language acquisition (pp. 257-296). Springer.
Cutler, A. (2012). Native listening: Language experience and the recognition of spoken words . Mit Press.
Daland, R., & Pierrehumbert, J. B. (2011). Learning DiphoneBased Segmentation. Cognitive Science , 35 (1), 119-155.
Dehaene-Lambertz, G., Dehaene, S., et al. (1994). Speed and cerebral correlates of syllable discrimination in infants. Nature , 370 (6487), 292-295.
de Marcken, C. G. (1996). Unsupervised Language Acquisition (Unpublished doctoral dissertation). MIT.
Devlin, J., Gupta, S., Girshick, R., Mitchell, M., & Zitnick, C. L. (2015). Exploring nearest neighbor approaches for image captioning. arXiv preprint arXiv:1505.04467 .
Dresher, B. E., & Kaye, J. D. (1990). A computational learning model for metrical phonology. Cognition , 34 (2), 137-195.
D'Ulizia, A., Ferri, F., & Grifoni, P. (2011). A survey of grammatical inference methods for natural language learning. Artificial Intelligence Review , 36 (1), 1-27. doi: 10.1007 / s10462010-9199-1
Dunbar, E., Synnaeve, G., & Dupoux, E. (2015). On the origin of features: Quantitative methods for comparing representations.
In Abstract in glow-2015.
Dupoux, E. (2016). Evaluating models of language acquisition: are utility metrics useful? Retrieved from http://bootphon.blogspot.fr/2015/05/ models-of-language-acquisition-machine.html
Dwork, C. (2006). Di erential privacy. In Automata, languages and programming (pp. 1-12). Springer.
Ehret, G., Munroe, P., Rice, K., & al. (2011). Genetic variants in novel pathways influence blood pressure and cardiovascular disease risk. Nature , 478 (7367), 103-9.
Eimas, P. D., Siqueland, E. R., Jusczyk, P., & Vigorito, J. (1971). Speech perception in infants. Science , 171 (3968), 303-306.
Elman, J. L. (1990). Finding structure in time. Cognitive science , 14 (2), 179-211.
Elsner, M., Goldwater, S., & Eisenstein, J. (2012). Bootstrapping a Unified Model of Lexical and Phonetic Acquisition. In Proceedings of the 50th Annual Meeting of the Association of Computational Linguistics.
Feldman, N., Myers, E., White, K., Gri ths, T., & Morgan, J. (2011). Learners use word-level statistics in phonetic category acquisition. In Proceedings of the 35th Annual Boston University Conference on Language Development (pp. 197-209).
Fernald, A. (2000). Speech to infants as hyperspeech: Knowledgedriven processes in early word recognition. Phonetica , 57 (2-4), 241-254.
Ferrucci, D. A. (2012). Introduction to 'this is watson'. IBM Journal of Research and Development , 56 (3.4), 1-1.
Fiscus, J. G., Ajot, J., Garofolo, J. S., & Doddingtion, G. (2007). Results of the 2006 spoken term detection evaluation. In Proc. sigir (Vol. 7, pp. 51-57).
Foppolo, F., Guasti, M. T., & Chierchia, G. (2012). Scalar implicatures in child language: Give children a chance. Language learning and development , 8 (4), 365-394.
Fourtassi, A., Boerschinger, B., Johnson, M., & Dupoux, E. (2013). Whyisenglishsoeasytosegment. In Proceedings of the 4th workshop on cognitive modeling and computational linguistics (cmcl 2013) (p. 1-10). Sofia, Bulgaria.
Fourtassi, A., & Dupoux, E. (2014). A rudimentary lexicon and semantics help bootstrap phoneme acquisition. In Proceedings of the 18th conference on computational natural language learning (conll).
Fowler, C. A., & Dekle, D. J. (1991). Listening with eye and hand: cross-modal contributions to speech perception. Journal of Experimental Psychology: Human Perception and Performance , 17 (3), 816.
Frank, M. (2015, December). The manybabies project. Retrieved from http://babieslearninglanguage.blogspot.fr/2015/ 12/the-manybabies-project.html
Frank, M. C., Goldwater, S., Gri ths, T. L., & Tenenbaum, J. B. (2010, November). Modeling human performance in statistical word segmentation. Cognition , 117 (2), 107-125.
Frank, M. C., Goodman, N. D., & Tenenbaum, J. B. (2009). Using speakers' referential intentions to model early cross-situational word learning. Psychological Science , 20 (5), 578-585.
Fromkin, V. A. (1984). Speech errors as linguistic evidence . Walter de Gruyter.
- Gershman, S. J., Horvitz, E. J., & Tenenbaum, J. B. (2015). Computational rationality: A converging paradigm for intelligence in brains, minds, and machines. Science , 349 (6245), 273-278.
- Gibson, E., & Wexler, K. (1994). Triggers. Linguistic Inquiry , 25 (3), 407-454.
- Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2016). Regionbased convolutional networks for accurate object detection and segmentation. Pattern Analysis and Machine Intelligence, IEEE Transactions on , 38 (1), 142-158.
- Gladkova, A., Drozd, A., Center, C., & Matsuoka, S. (2016). Analogy-based detection of morphological and semantic relations with word embeddings: What works and what doesn't. In Proceedings of naacl-hlt (pp. 8-15).
- Glass, J. (2012). Towards unsupervised speech processing. In Information Science, Signal Processing and their Applications (ISSPA), 2012 11th International Conference on (pp. 1-4). IEEE.
- Gold, E. M. (1967). Language identification in the limit. Information and control , 10 (5), 447-474.
- Goldin-Meadow, S. (2005). Hearing Gesture: How Our Hands Help Us Think . Belknap Press of Harvard University Press.
- Goldstein, M. H. (2008). Social Feedback to Babbling Facilitates Vocal Learning Michael H. Goldstein and Jennifer A. Schwade. Psychological Science .
- Goldwater, S. J. (2007). Nonparametric Bayesian models of lexical acquisition (Unpublished doctoral dissertation). Brown.
- Golinko , R. M., Hirsh-Pasek, K., Cauley, K. M., & Gordon, L. (1987). The eyes have it: Lexical and syntactic comprehension in a new paradigm. Journal of child language , 14 (01), 23-45.
- Gregory, R. J. (2004). Psychological testing: History, principles, and applications. Allyn & Bacon.
- Gros-Louis, J., West, M. J., Goldstein, M. H., & King, A. P. (2006, November). Mothers provide di erential feedback to infants' prelinguistic sounds. International Journal of Behavioral Development , 30 (6), 509-516. doi: 10.1177 / 0165025406071914
- Guenther, F. H., & Vladusich, T. (2012, September). A neural theory of speech acquisition and production. Journal of Neurolinguistics , 25 (5), 408-422. doi: 10.1016 / j.jneuroling.2009.08.006
- Harris, Z. S. (1954). Distributional structure. Word , 10 (2-3), 146162.
- Hart, B., & Risley, T. R. (1995). Meaningful di erences in the everyday experience of young american children. Paul H Brookes Publishing.
- Hauser, M. D., Chomsky, N., & Fitch, W. T. (2002). The faculty of language: what is it, who has it, and how did it evolve? science , 298 (5598), 1569-1579.
- Hayes, B., & Wilson, C. (2008). A maximum entropy model of phonotactics and phonotactic learning. Linguistic inquiry , 39 (3), 379-440.
- He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the ieee international conference on computer vision (pp. 1026-1034).
- Ho , E. (2003). The specificity of environmental influence: Socioeconomic status a ects early vocabulary development via maternal speech. Child development , 74 (5), 1368-1378.
- Ho , E. (Ed.). (2012). Research methods in child language: a practical guide . Malden, MA: Wiley-Blackwell.
- Hollich, G. J., Hirsh-Pasek, K., Golinko , R. M., Brand, R. J., Brown, E., Chung, H. L., . . . Bloom, L. (2000). Breaking the language barrier: An emergentist coalition model for the origins of word learning. Monographs of the society for research in child development , i-135.
- Huttenlocher, J., Waterfall, H., Vasilyeva, M., Vevea, J., & Hedges, L. V. (2010). Sources of variability in children's language growth. Cognitive psychology , 61 (4), 343-365.
- Ioannidis, J. P. (2012). Why science is not necessarily selfcorrecting. Perspectives on Psychological Science , 7 (6), 645654.
- Isik, L., Tacchetti, A., & Poggio, T. (2016). Fast, invariant representation for human action in the visual system. arXiv preprint arXiv:1601.01358 .
- Jackendo , R. (1997). The architecture of the language faculty (No. 28). MIT Press.
- Jäger, G., & Rogers, J. (2012). Formal language theory: refining the chomsky hierarchy. Philosophical Transactions of the Royal Society B: Biological Sciences , 367 (1598), 1956-1970.
- Jansen, A., Dupoux, E., Goldwater, S., Johnson, M., Khudanpur, S., Church, K., . . . others (2013). A summary of the 2012 JHU CLSP workshop on zero resource speech technologies and models of early language acquisition. In ICASSP (pp. 8111-8115).
- Jansen, A., Thomas, S., & Hermansky, H. (2013). Weak top-down constraints for unsupervised acoustic model training. In ICASSP (pp. 8091-8095).
- Jelinek, F. (1997). Statistical methods for speech recognition . MIT press.
- Johnson, K. (2004). Gold's theorem and cognitive science*. Philosophy of Science , 71 (4), 571-592.
- Johnson, M. (2008). Using Adaptor Grammars to Identify Synergies in the Unsupervised Acquisition of Linguistic Structure. In ACL (pp. 398-406).
- Johnson, W., & Reimers, P. (2010). Patterns in child phonology . Edinburgh University Press.
- Jusczyk, P. W. (1997). The discovery of spoken language . Cambridge, Mass.: MIT Press.
- Jusczyk, P. W., Friederici, A. D., Wessels, J. M., Svenkerud, V. Y., & Jusczyk, A. M. (1993). Infantsâ ˘ Aš sensitivity to the sound patterns of native language words. Journal of memory and language , 32 (3), 402-420.
- Jusczyk, P. W., Houston, D. M., & Newsome, M. (1999). The beginnings of word segmentation in English-learning infants. Cognitive psychology , 39 (3), 159-207.
- Kahou, S. E., Bouthillier, X., Lamblin, P., Gulcehre, C., Michalski, V., Konda, K., . . . others (2015). Emonets: Multimodal deep learning approaches for emotion recognition in video. Journal on Multimodal User Interfaces , 1-13.
- Katsos, N., & Bishop, D. V. (2011). Pragmatic tolerance: Implications for the acquisition of informativeness and implicature. Cognition , 120 (1), 67-81.
- Ke, J. (2006). A cross-linguistic quantitative study of homophony*. Journal of Quantitative Linguistics , 13 (01), 129-159.
- Kelley, K. (1967). Early syntactic acquisition (Tech. Rep. No. P3719). Santa Monica, California: Rand Corp.
- Kohonen, T. (1988). The 'neural' phonetic typewriter. Computer , 21 (3), 11-22.
- Kuhl, P. K. (1997, August). Cross-Language Analysis of Phonetic Units in Language Addressed to Infants. Science , 277 (5326), 684-686. doi: 10.1126 / science.277.5326.684
- Kuhl, P. K., Conboy, B. T., Co ey-Corina, S., Padden, D., RiveraGaxiola, M., & Nelson, T. (2008, March). Phonetic learning as a pathway to language: new data and native language magnet theory expanded (NLM-e). Philosophical Transactions of the Royal Society B: Biological Sciences , 363 (1493), 979-1000. doi: 10.1098 / rstb.2007.2154
- Kunkel, S., Schmidt, M., Eppler, J. M., Plesser, H. E., Masumoto, G., Igarashi, J., . . . others (2014). Spiking network simulation code for petascale computers. Frontiers in neuroinformatics , 8 (78).
- Kwiatkowski, T., Goldwater, S., Zettlemoyer, L., & Steedman, M. (2012). A probabilistic model of syntactic and semantic acquisition from child-directed utterances and their meanings. EACL 2012 , 234.
- Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato's problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological review , 104 (2), 211. Retrieved 2016-03-23, from http://psycnet.apa.org/journals/rev/104/2/211/
- Langley, P., & Carbonell, J. G. (1987). Language acquisition and machine learning. In B. MacWhinney (Ed.), Mechanisms of language acquisition (pp. 115-155). Hillsdale, N.J.: Lawrence Erlbaum.
- Lee, C.-y., & Glass, J. (2012). A nonparametric Bayesian approach to acoustic model discovery. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1 (pp. 40-49).
- Lee, C.-y., O'Donnell, T. J., & Glass, J. (2015). Unsupervised lexicon discovery from acoustic input. Transactions of the Association for Computational Linguistics , 3 , 389-403.
- Leibo, J. Z., Liao, Q., Anselmi, F., & Poggio, T. (2015). The invariance hypothesis implies domain-specific regions in visual cortex. PLoS Comput Biol , 11 (10), e1004390.
- Levesque, H. J., Davis, E., & Morgenstern, L. (2011). The winograd schema challenge. In Aaai spring symposium: Logical formalizations of commonsense reasoning.
- Lidz, J., & Musolino, J. (2002). Children's command of quantification. Cognition , 84 (2), 113-154.
- Linzen, T., Dupoux, E., & Spector, B. (2016). Quantificational features in distributional word representations. In Proceedings of the fifth joint conference on lexical and computational semantics (* sem 2016).
- Lu, C., & Tang, X. (2014). Surpassing human-level face verification performance on lfw with gaussianface. arXiv preprint arXiv:1404.3840 .
- Ludusan, B., Gravier, G., & Dupoux, E. (2014). Incorporating Prosodic Boundaries in Unsupervised Term Discovery. In Proc. of Speech Prosody.
- Ludusan, B., Seidl, A., Dupoux, E., & Cristia, A. (2015). Motif discovery in infant-and adult-directed speech. In Conference on empirical methods in natural language processing (emnlp) (p. 93).
- Ludusan, B., Versteegh, M., Jansen, A., Gravier, G., Cao, X.-N.,
- Johnson, M., & Dupoux, E. (2014). Bridging the gap between speech technology and natural language processing: an evaluation toolbox for term discovery systems. In Proceedings of LREC.
- MacWhinney, B. (1978). Conditions on acquisitional models. In Proceedings of the ACM annual conference (pp. 421-427). ACM.
- MacWhinney, B. (1987). The Competition model. In B. MacWhinney (Ed.), (pp. 249-308). Hillsdale, N.J.: Lawrence Erlbaum.
- MacWhinney, B. (2000). The childes project: Tools for analyzing talk: Volume i: Transcription format and programs, volume ii: The database. Computational Linguistics , 26 (4), 657-657.
- Magri, G. (2015). Noise robustness and stochastic tolerance of OT error-driven ranking algorithms. Journal of Logic and Computation .
- Marcus, G. F. (1993). Negative evidence in language acquisition. Cognition , 46 (1), 53-85.
- Marr, D., & Poggio, T. (1976). From Understanding Computation to Understanding Neural Circuitry (Tech. Rep. No. AIM-357.) Brighton, England: Massachusetts Institute of Technology.
- Martin, A., Peperkamp, S., & Dupoux, E. (2013). Learning phonemes with a proto-lexicon. Cognitive Science , 37 , 103124.
- Martin, A., Schatz, T., Versteegh, M., Miyazawa, K., Mazuka, R., Dupoux, E., & Cristia, A. (2015). Mothers speak less clearly to infants: A comprehensive test of the hyperarticulation hypothesis. Psychological Science , 26 (3), 341-347.
- Maye, J., Werker, J. F., & Gerken, L. (2002). Infant sensitivity to distributional information can a ect phonetic discrimination. Cognition , 82 (3), B101-B111.
- Mazuka, R., Igarashi, Y., & Nishikawa, K. (2006). Input for learning japanese: Riken japanese mother-infant conversation corpus (Vol. 106(165); Tech. Rep. No. TL 2006-16).
- McMurray, B., Aslin, R. N., & Toscano, J. C. (2009). Statistical learning of phonetic categories: insights from a computational approach. Developmental Science , 12 (3), 369-378.
- McMurray, B., Kovack-Lesh, K. A., Goodwin, D., & McEchron, W. (2013, November). Infant directed speech and the development of speech perception: Enhancing development or an unintended consequence? Cognition , 129 (2), 362-378.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., . . . others (2015). Human-level control through deep reinforcement learning. Nature , 518 (7540), 529533.
- Morgan, J., & Demuth, K. (1996). Signal to Syntax: Bootstrapping from Speech to Grammar in Early Acquisition . L. Erlbaum Associates.
- Muscariello, A., Gravier, G., & Bimbot, F. (2009). Audio keyword extraction by unsupervised word discovery. In INTERSPEECH 2009: 10th Annual Conference of the International Speech Communication Association.
- Mustafa, A., Kim, H., Guillemaut, J.-Y., & Hilton, A. (2016). Temporally coherent 4d reconstruction of complex dynamic scenes. arXiv preprint arXiv:1603.03381 .
- Ngon, C., Martin, A., Dupoux, E., Cabrol, D., Dutat, M., & Peperkamp, S. (2013). (Non)words, (non)words, (non)words: evidence for a protolexicon during the first year of life. Developmental Science , 16 (1), 24-34.
- Olivier, D. C. (1968). Stochastic grammars and language acquisition mechanisms (Unpublished doctoral dissertation). Harvard University Doctoral dissertation.
- Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science , 349 (6251), aac4716.
- Oudeyer, P.-Y., Kaplan, F., & Hafner, V. V. (2007, April). Intrinsic Motivation Systems for Autonomous Mental Development. IEEE Transactions on Evolutionary Computation , 11 (2), 265286.
- Pan, B. A., Rowe, M. L., Singer, J. D., & Snow, C. E. (2005). Maternal correlates of growth in toddler vocabulary production in low-income families. Child development , 76 (4), 763-782.
- Park, A. S., & Glass, J. R. (2008, January). Unsupervised Pattern Discovery in Speech. IEEE Transactions on Audio, Speech, and Language Processing , 16 (1), 186-197.
- Pearl, L., & Phillips, L. (2016). Language, cognition, and computational models. In A. Villavicencio & T. Poibeau (Eds.), (chap. Evaluating language acquisition models: A utility-based look at Bayesian segmentation). Cambridge Univ Press.
- Peters, A. M. (1983). The units of language acquisition (Vol. 1). Cambridge University Press Archive.
- Pinker, S. (1984). Language learnability and language development . Cambridge, Mass: Harvard University Press.
- Pinker, S. (1987). The bootstrapping problem in language acquisition. In B. MacWhinney (Ed.), Mechanisms of language acquisition (pp. 399-441). Lawrence Erlbaum.
- Pinker, S. (1989). Learnability and cognition: the acquisition of argument structure . MIT Press.
- Pinker, S. (1994). The language instinct . Harper.
- Plummer, A., R. (2012). Aligning manifolds to model the earliest phonological abstraction in infant-caretaker vocal imitation. In Interspeech (pp. 2482-2485).
- Poizner, H., Klima, E., & Bellugi, U. (1987). What the hand reveals about the brain. MIT Press Cambridge, MA.
- Pons, C. G., Anguera, X., & Binefa, X. (2013). Two-Level Clustering towards Unsupervised Discovery of Acoustic Classes. In Machine Learning and Applications (ICMLA), 2013 12th International Conference on (Vol. 2, pp. 299-302). IEEE.
- Prins, R., & Van Noord, G. (2001). Unsupervised pos-tagging improves parsing accuracy and parsing e ciency. In Iwpt.
- Rahmani, H., Mian, A., & Shah, M. (2016). Learning a deep model for human action recognition from novel viewpoints. arXiv preprint arXiv:1602.00828 .
- Räsänen, O. (2012). Computational modeling of phonetic and lexical learning in early language acquisition: Existing models and future directions. Speech Communication , 54 (9), 975-997. doi: 10.1016 / j.specom.2012.05.001
- Romberg, A. R., & Sa ran, J. R. (2010). Statistical learning and language acquisition. Wiley Interdisciplinary Reviews: Cognitive Science , 1 (6), 906-914.
- Rowe, M. L., & Goldin-Meadow, S. (2009). Di erences in early gesture explain ses disparities in child vocabulary size at school entry. Science , 323 (5916), 951-953.
- Roy, B. C., Frank, M. C., DeCamp, P., Miller, M., & Roy, D. (2015). Predicting the birth of a spoken word. Proceedings of the National Academy of Sciences , 112 (41), 12663-12668.
- Roy, D. (2009). New horizons in the study of child language acquisition. In Proceedings of interspeech. Brighton, England.
- Roy, D. K., & Pentland, A. P. (2002). Learning words from sights and sounds: A computational model. Cognitive science , 26 (1), 113-146.
- Rumelhart, D. E., & McClelland, J. L. (1987). Mechanisms of language acquisition. In B. MacWhinney (Ed.), (pp. 195-248). Erlbaum Hillsdale, NJ.
- Sa ran, J. R., Aslin, R. N., & Newport, E. L. (1996). Statistical learning by 8-month-old infants. Science , 274 , 1926-1928.
- Sakakibara, Y. (1992). E cient learning of context-free grammars from positive structural examples. Information and Computation , 97 (1), 23-60.
- Sakas, W. G., & Fodor, J. D. (2012). Disambiguating syntactic triggers. Language Acquisition , 19 (2), 83-143.
- Sangwan, A., Hansen, J., Irvin, D., Crutchfield, S., & Greenwood, C. (2015). Studying the relationship between physical and language environments of children: Who's speaking to whom and where? In Signal processing and signal processing education workshop (sp / spe), 2015 ieee (pp. 49-54).
- Saxton, M. (1997). The contrast theory of negative input. Journal of child language , 24 (01), 139-161.
- Schatz, T., Peddinti, V., Bach, F., Jansen, A., Hermansky, H., & Dupoux, E. (2013). Evaluating speech features with the minimal-pair abx task: Analysis of the classical mfc / plp pipeline. In INTERSPEECH-2013 (p. 1781-1785). Lyon, France.
- Shneidman, L. A., Arroyo, M. E., Levine, S. C., & Goldin-Meadow, S. (2013, June). What counts as e ective input for word learning? Journal of Child Language , 40 (03), 672-686.
- Shneidman, L. A., & Goldin-Meadow, S. (2012, September). Language input and acquisition in a Mayan village: how important is directed speech?: Mayan village. Developmental Science , 15 (5), 659-673.
- Siklossy, L. (1968). Natural language learning by computer (Tech. Rep.). DTIC Document.
- Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., . . . others (2016). Mastering the game of go with deep neural networks and tree search. Nature , 529 (7587), 484-489.
- Siskind, J. M. (1996). A computational study of cross-situational techniques for learning word-to-meaning mappings. Cognition , 61 (1), 39-91.
- Siu, M.-h., Gish, H., Chan, A., Belfield, W., & Lowe, S. (2013). Unsupervized training of an HMM-based self-organizing recognizer with applications to topic classification and keyword discovery. Computer Speech & Language .
- Smith, K., Smith, A. D., & Blythe, R. A. (2011). Cross-situational learning: An experimental study of word-learning mechanisms. Cognitive Science , 35 (3), 480-498.
- Smith, L. B., Yu, C., Yoshida, H., & Fausey, C. M. (2015). Contributions of head-mounted cameras to studying the visual environments of infants and young children. Journal of Cognition and Development , 16 (3), 407-419.
- Smith, N. A., & Trainor, L. J. (2008). Infant-directed speech is modulated by infant feedback. Infancy , 13 (4), 410-420.
- Snow, C. E. (1972, June). Mothers' Speech to Children Learning Language. Child Development , 43 (2), 549.
- Song, J. J. (2010). The oxford handbook of linguistic typology . Oxford Univ. Press.
- Steedman, M. (2014). Evolutionary basis for human language: Comment on "Toward a computational framework for cognitive biology: Unifying approaches from cognitive neuroscience and comparative cognition" by tecumseh fitch. Physics of life reviews , 11 (3), 382-388.
- Sundara, M., Polka, L., & Genesee, F. (2006). Language-experience facilitates discrimination of / d-/ in monolingual and bilingual acquisition of english. Cognition , 100 (2), 369-388.
- Sutton, R. S., & Barto, A. G. (1998). Reinforcement Learning: An Introduction . MIT Press, Cambridge, MA.
- Tamis-LeMonda, C. S., & Rodriguez, E. T. (2008). Parents' role in fostering young children's learning and language development. In (pp. 1-11).
- Ten Bosch, L., & Cranen, B. (2007). A computational model for unsupervised word discovery. In INTERSPEECH (pp. 14811484).
- Tesar, B., & Smolensky, P. (1998). Learnability in optimality theory. Linguistic Inquiry , 29 (2), 229-268.
- Tesar, B., & Smolensky, P. (2000). Learnability in optimality theory . Mit Press.
- Thiollière, R., Dunbar, E., Synnaeve, G., Versteegh, M., & Dupoux, E. (2015). A hybrid dynamic time warping-deep neural network architecture for unsupervised acoustic modeling. In INTERSPEECH-2015.
- Thomas, D. G., Campos, J. J., Shucard, D. W., Ramsay, D. S., & Shucard, J. (1981). Semantic comprehension in infancy: A signal detection analysis. Child development , 798-803.
- Tomasello, M. (2003). Constructing a language: a usage-based theory of language acquisition . Cambridge, Mass: Harvard University Press.
- Tsuji, S., Bergmann, C., & Cristia, A. (2014). Communityaugmented meta-analyses toward cumulative data assessment. Perspectives on Psychological Science , 9 (6), 661-665.
- Turing, A. M. (1950). Computing machinery and intelligence. Mind , 59 (236), 433-460.
- Vallabha, G. K., McClelland, J. L., Pons, F., Werker, J. F., & Amano, S. (2007). Unsupervised learning of vowel categories from infant-directed speech. Proceedings of the National Academy of Sciences , 104 (33), 13273-13278.
- Van Cleve, J. V. (2004). Genetics, disability, and deafness . Gallaudet University Press.
- VanDam, M., Warlaumont, A. S., Bergelson, E., Cristia, A., Soderstrom, M., De Palma, P., & MacWhinney, B. (2016). Homebank: An online repository of daylong child-centered audio recordings. In Seminars in speech and language (Vol. 37, pp. 128142).
- van de Weijer, J. (2002). How much does an infant hear in a day. In GALA 2001 Conference on Language Acquisition, Lisboa.
- Varadarajan, B., Khudanpur, S., & Dupoux, E. (2008). Unsupervised learning of acoustic subword units. In Proceedings of acl08: Hlt (p. 165-168).
- Versteegh, M., Anguera, X., Jansen, A., & Dupoux, E. (2016). The zero resource speech challenge 2015: Proposed approaches and results. In SLTU-2016.
- Versteegh, M., Thiollière, R., Schatz, T., Cao, X.-N., Anguera, X., Jansen, A., & Dupoux, E. (2015). The zero resource speech challenge 2015. In INTERSPEECH-2015.
- Warlaumont, A. S., Richards, J. A., Gilkerson, J., & Oller, D. K. (2014). A social feedback loop for speech development and its reduction in autism. Psychological science , 25 (7), 1314-1324.
- Weisleder, A., & Fernald, A. (2013, November). Talking to Children Matters: Early Language Experience Strengthens Processing and Builds Vocabulary. Psychological Science , 24 (11), 2143-2152.
- Weizenbaum, J. (1966). Eliza-a computer program for the study of natural language communication between man and machine. Communications of the ACM , 9 (1), 36-45.
- Werker, J. F., & Curtin, S. (2005). PRIMIR: A developmental framework of infant speech processing. Language learning and development , 1 (2), 197-234.
- Werker, J. F., & Tees, R. C. (1984). Cross-language Speech perception: evidence for perceptual reorganization during the first year of life. Infant Behavior and Development , 7 , 49-63.
- Word2vec google project page. (2013, july). Retrieved from https://code.google.com/archive/p/word2vec/
- Xu, D., Yapanel, U. H., Gray, S. S., Gilkerson, J., Richards, J. A., & Hansen, J. H. (2008). Signal processing for young child speech language development. In Wocci (p. 20).
- Yang, C. D. (2002). Knowledge and learning in natural language . Oxford University Press.
- Ying, L. (2005). Learning Features and Segments from Waveforms: A Statistical Model of Early Phonological Acquisition (Unpublished doctoral dissertation). University of California, Los Angeles.
- Yu, C., & Smith, A. (2007). Rapid word learning under uncertainty via cross-situational statistics. Psychological Science , 18 (5), 414-420.