## Interpreting Finite Automata for Sequential Data
## Christian Albert Hammerschmidt
SnT
University of Luxembourg christian.hammerschmidt@uni.lu
Qin Lin
Department of Intelligent Systems Delft University of Technology q.lin@tudelft.nl
## Abstract
Automaton models are often seen as interpretable models. Interpretability itself is not well defined: it remains unclear what interpretability means without first explicitly specifying objectives or desired attributes. In this paper, we identify the key properties used to interpret automata and propose a modification of a state-merging approach to learn variants of finite state automata. We apply the approach to problems beyond typical grammar inference tasks. Additionally, we cover several use-cases for prediction, classification, and clustering on sequential data in both supervised and unsupervised scenarios to show how the identified key properties are applicable in a wide range of contexts.
## 1 Introduction
The demand for explainable machine learning is increasing, driven by the spread of machine learning techniques to sensitive domains like cyber-security, medicine, and smart infrastructure among others. Often, the need is abstract but nevertheless a requirement, e.g., in the recent EU regulation [Goodman and Flaxman, 2016].
Approaches to explanations range from post-hoc explanation systems like Turner [2015], which provide explanations of decisions taken by black-box systems to the use of linear or specialized whitebox systems [Fiterau et al., 2012] that generate models seen as simple enough for non-expert humans to interpret and understand. Lipton [2016] outlines how different motivations and requirements for interpretations lead different notions of interpretable models in supervised learning.
Automata models, such as (probabilistic) deterministic finite state automata ((P)DFA) and timed automata (RA) have long been studied (Hopcroft et al. [2013]) and are often seen as interpretable models. Moreover, they are learnable from data samples, both in supervised and unsupervised (see Higuera [2010]) fashion. But which properties make these models interpretable, and how can we get the most benefit from them? We argue that-especially in the case of unsupervised learningautomata models have a number of properties that make it easy for humans to understand the learned model and project knowledge into it: a graphical representation, transparent computation, generative nature, and our good understanding of their theory.
## Sicco Verwer
Department of Intelligent Systems Delft University of Technology s.e.verwer@tudelft.nl
Radu State SnT University of Luxembourg radu.state@uni.lu
## 2 Preliminaries
Finite automata. The models we consider are variants of deterministic finite state automata, or finite state machines. These have long been key models for the design and analysis of computer systems [Lee and Yannakakis, 1996]. We provide a conceptual introduction here, and refer to Section B in the appendix for details. An automaton consists of a set of states, connected by transitions labeled over an alphabet. It is said to accept a word (string) over the alphabet in a computation if there exists a path of transitions from a predefined start state to one of the predefined final states, using transitions labeled with the letters of the word. Automata are called deterministic when there exists exactly one such path for every possible string. Probabilistic automata include probability values on transitions and compute word probabilities using the product of these values along a path, similar to hidden Markov models (HMMs).
Learning approaches. As learning finite state machines has long been of interest in the field of grammar induction, different approaches ranging from active learning algorithms [Angluin, 1987] to algorithms based on the method of moments [Balle et al., 2014] have been proposed. Process mining [Van Der Aalst et al., 2012] can also be seen as a type of automaton learning, focusing on systems that display a large amount of concurrency, such as business processes, represented as interpretable Petri-nets. We are particularly interested in state-merging approaches, based on Oncina and Garcia [1992]. While Section C in the appendix provides formal details, we provide a conceptual introduction here.
The starting point for state-merging algorithms is the construction of a tree-shaped automaton from the input sample, called augmented prefix tree acceptor (APTA). It contains all sequences from the input sample, with each sequence element as a directed labeled transition. Two samples share a path if they share a prefix. The state-merging algorithm reduces the size of the automaton iteratively by reducing the tree through merging pairs of states in the model, and forcing the result to be deterministic. The choice of the pairs, and the evaluation of a merge is made heuristically: Each possible merge is evaluated and scored, and the highest scoring merge is executed. This process is repeated and stops if no merges with high scores are possible. These merges generalize the model beyond the samples from the training set: the starting prefix tree is already an a-cyclic finite automaton. It has a finite set of computations, accepting all words from the training set. Merges can make the resulting automaton cyclic. Automata with cycles accept an infinite set of words. State-merging algorithms generalize by identifying repetitive patterns in the input sample and creating appropriate cycles via merges. Intuitively, the heuristic tries to accomplish this generalization by identifying pairs of states that have similar future behaviors. In a probabilistic setting, this similarity might be measured by similarity of the empirical probability distributions over the outgoing transition labels. In grammar inference, heuristics rely on occurrence information and the identity of symbols, or use global model selection criteria to calculate merge scores.
## 3 Flexible State-Merging
The key step in state-merging algorithms is the identification of good merges. A merge of two states is considered good if the possible futures of the two states are very similar. By focusing on application-driven notions of similarity of sequences and sequence elements, we modify the statemerging algorithm as follows: For each possible merge, a heuristic can evaluate an application-driven similarity measure to obtain the merge score. Optionally, each symbol of the words is enriched with addition data, e.g. real values. This information can be aggregated in each state, e.g. by averaging. It is used to guide the heuristic in reasoning about the similarity of transitions and therefore the inferred latent states, or guide a model selection criterion, e.g. by using mean-squared-error minimization as an objective function. It effectively separates the symbolic description connecting the latent variables from the objective (function) used to reason about the similarity. An implementation in C++ is available 1 . The importance of combining data with symbolic data is getting renewed attention, c.f. recent works such as Garnelo et al. [2016]. In Section 5, we outline regression automata as a use case of our approach.
1 https://bitbucket.org/chrshmmmr/dfasat
## 4 Aspects of Interpretability in Automata
To understand how a particular model works as well as how to go beyond the scope of the model and combing foreground knowledge about the application with the model itself, we now focus on which aspects of automata enable interpretations:
1. Automata have an easy graphical representation as cyclic, directed, labeled graphs, offering a hierarchical view of sequential data.
2. Computation is transparent . Each step of the computation is the same for each symbol w i of an input sample w . It can be verified manually (e.g. visually), and compared to other computation paths through the latent state space. This makes it possible to analyze training samples and their contribution to the final model.
3. Automata are generative . Sampling from the model helps to understand what it describes. Tools like model checkers to query properties in a formal way, e.g. using temporal logic, can help to analyze the properties of the model.
4. Automata are well studied in theory and practice, including composition and closure properties, sub-classes and related equally expressive formalisms. This makes it easy for humans to transfer their knowledge onto it: The model is frequently used in system design as a way to describe system logic, and are accessible to a wide audience.
The intention behind using either of these aspects depends on the purpose of the interpretation, e.g. trust, transparency, or generalizing beyond the input sample. Especially for unsupervised learning, we believe that knowledge transfer and exploratory knowledge discovery are common motivations, e.g. in (software) process discovery.
## 5 Application Case Studies
In the following we present some use cases of automata models and how they are interpreted and how the properties identified in Section 4 contribute to it. While this is by no means an exhaustive literature study, we hope that it helps to illustrate how the different aspects of interpretability are used in practice. In unsupervised learning, the data is observations without labels or counter-examples to the observed events. Often, there is no ground-truth to be used in an objective function. Methods for learning such systems typically use statistical assumptions to compute state similarity.
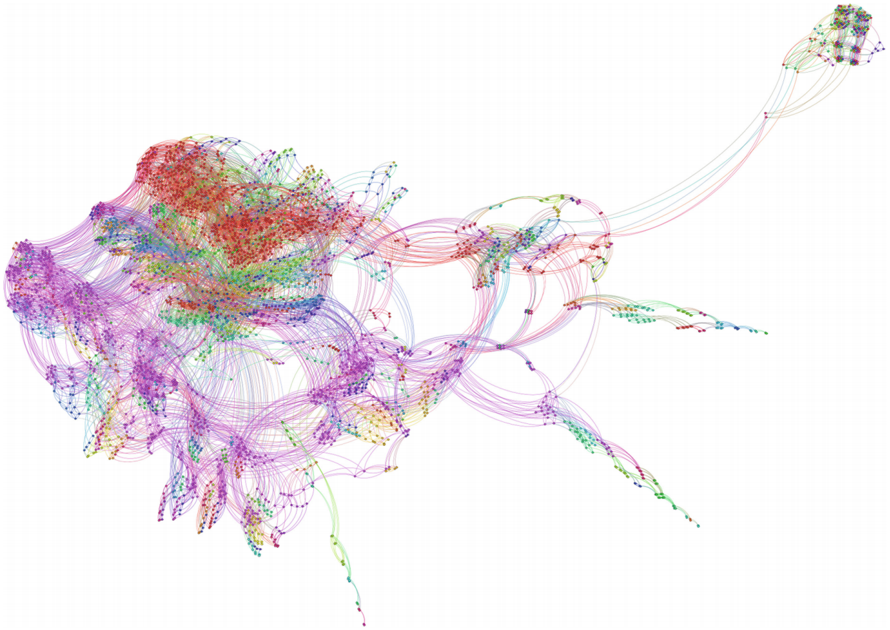
Software systems. Automata models are often used to infer models of software in an unsupervised fashion, e.g. Walkinshaw et al. [2007]. In these cases, the generative property of automaton models is see as interpretable: It is possible to ask queries using a temporal logic like LTL [Clarke et al., 2005] to answer questions regarding the model, e.g. whether a certain condition will eventually be true, or analyze at what point a computation path deviated from the expected outcome. In Smetsers et al. [2016], the authors use this property to test and validate properties of code by first fuzzing the code to obtain execution paths and the associated inputs and then learn a model to check LTL queries on. Additionally, we can transfer human expert knowledge on system design [Wagner et al., 2006] to inspect the model, e.g. to identify the function of substructures identified. An example can be found in Smeenk et al. [2015], where the authors infer a state machine for a printer via active learning. Through visual inspection alone it is possible to identify deadlocks that are otherwise hard to see in the raw data. The visual analysis helped to identify bugs in the software the developers were unaware of. The appendix shows the final model in Figure 3.
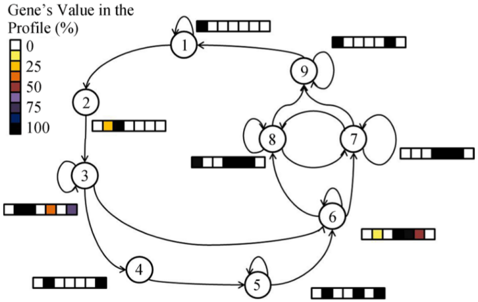
Biological systems. In Schmidt and Kramer [2014], timed automata are used to infer the cell cycle of yeast based on sequences of gene expression activity. The graphical model obtained (c.f. Figure 4) can be visually compared to existing models derived using other methods and combined with a-priori knowledge in biology.
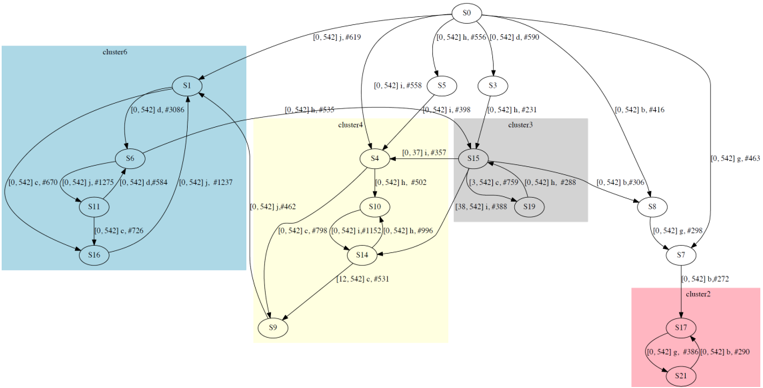
Driver behavior. In our ongoing work using the RTI+ state-merging algorithm for timed automata [Verwer et al., 2008], we analyze car following behavior of human drivers. The task is to relate driver actions like changes of vehicle speed (and thus distance and relative speed to a lead vehicle) to a response action, e.g. acceleration. The inferred automaton model is inspected visually like a software controller. Different driving behaviors are distinguished by clustering the states of the automaton, i.e. the latent state space. The discovered distinct behaviors form control loops within the model. Figure 2 in the appendix shows an example with the discovered clusters highlighted.
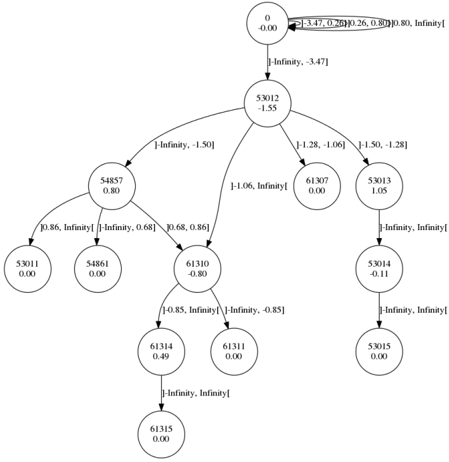
Wind speed prediction. In our own work, we applied automata learning in different ways to a problem not related to grammar inference, predicting short-term changes in wind speeds. We take two different approaches to obtain models that tell us more about the data than just a minimizer of the objective function: In one approach, [Pellegrino et al., 2016], we discover structure in the data by using by inferring transition guards over a potentially infinite alphabet, effectively discovering a clustering as transition labels from the sequences automatically. The only constraint and objective used here is the similarity of future behaviors. The learned model can be seen as a structure like a decision tree built in a bottom-up fashion, but allowing loops for repetitive patterns. Figure 1 in the appendix shows an example of such an automaton. In another approach [Lin et al., 2016], we use our flexible state-merging framework to impose structure through parameter choices. We derive discrete events from the physical wind speed observations by using clustering approaches to obtain a small alphabet of discrete events as a symbolic representation that fits the underlying data well. Using a heuristic that scores merges based on minimizing a mean squared error measure, the automata model has a good objective function for regression, as well as discovers latent variables in terms of the given discretization. In practice, other choices of discretization can be used. By using thresholds of the turbine used in wind mills, e.g. the activation point, one could infer a model whose latent states relate to the physical limitations of the application. We are planning to analyze this approach in future work. As with the previous example, the learned model can be seen as a description of decision paths taken in the latent state-space. If the model makes predictions that are difficult to believe for human experts, the computation and the model prediction can be visually analyzed to see which factors contributed to it, and how the situation relates to similar sets of features.
## 6 Discussion
The applications surveyed in Section 5 show that interpreting finite state automata as models takes many forms and serves different goals. As such, this interpretation is not a feature inherent in the models or the algorithms themselves. Rather, interpretations are defined by the need and intention of the user. But yet, interpretations of automata models draw from a core set of properties as identified in Section 4: graphical representations, transparent computation, generative nature, and our understanding of their theory.
We note that automata models are particularly useful in unsupervised learning: Applications of automata models often aim at easing the transfer of knowledge about the subject, or related subjects, to the data generating process. In this case, machine learning serves as a tool for exploration, to deal with epistemic uncertainty in observed systems. The goal is not only to obtain a more compact view of the data, but learn how to generalize from the observed data. Often, it is often unclear what the a-priori knowledge is as users rely on experience. This makes it very difficult to formalize a clear objective function. A visual model with a traceable computation helps to guide the users, and helps to iterate over multiple models.
Flexible state-merging allows to obtain automata models in new domains: in our flexible state-merging framework presented in Section 3, we try to separate the symbolic representation from the objective function and heuristic. We hope that this will help to guide discovery by stating the model parameters, e.g. the symbols, independently form the heuristic that guides the discovery of latent variables. In this fashion, it is possible to learn models with interpretable aspects without having to sacrifice the model performance on the intended task.
Future work. We hope that this discussion will help to build a bridge between practitioners and experts in applied fields on one side, and the grammar inference and machine learning community on other side. As probabilistic deterministic automata models are almost as expressive as HMMs, the models and techniques described here are applicable to a wide range of problems with decent performance metrics. We see a lot of promise in combining symbolic data with numeric or other data via a flexible state-merging approach to bring automata learning to fields beyond grammatical inference.
## Acknowledgments
I would like to thank, in no particular order, my colleagues, Joshua Moermann, Rick Smeters, Nino Pellegrino, Sara Messelaar, Corina Grigore, and Mijung Park for their time and feedback on this work. This work is partially funded by the FNR AFR grant PAULINE and Technologiestichting STW VENI project 13136 (MANTA) and NWO project 62001628 (LEMMA).
## References
- Dana Angluin. Learning Regular Sets from Queries and Counterexamples. Information and Computation , 75(2): 87-106, 1987. URL http://dx.doi.org/10.1016/0890-5401(87)90052-6 .
- Borja Balle, Xavier Carreras, Franco M. Luque, and Ariadna Quattoni. Spectral Learning of Weighted Automata. Machine Learning , 96(1-2):33-63, 2014. URL http://link.springer.com/article/10.1007/ s10994-013-5416-x .
- Edmund Clarke, Ansgar Fehnker, Sumit Kumar Jha, and Helmut Veith. Temporal Logic Model Checking. In Handbook of Networked and Embedded Control Systems , Control Engineering, pages 539-558. Birkhäuser Boston, 2005. ISBN 978-0-8176-3239-7 978-0-8176-4404-8. URL http://link.springer. com/chapter/10.1007/0-8176-4404-0\_23 .
- Madalina Fiterau, Artur Dubrawski, Jeff Schneider, and Geoff Gordon. Trade-offs in Explanatory Model Learning. 2012. URL http://www.ml.cmu.edu/research/dap-papers/dap\_fiterau.pdf .
- Marta Garnelo, Kai Arulkumaran, and Murray Shanahan. Towards Deep Symbolic Reinforcement Learning. arXiv:1609.05518 [cs] , September 2016. URL http://arxiv.org/abs/1609.05518 . arXiv: 1609.05518.
- Bryce Goodman and Seth Flaxman. European Union Regulations on Algorithmic Decision-making and a "Right to Explanation". arXiv:1606.08813 [cs, stat] , June 2016. URL http://arxiv.org/abs/1606.08813 . arXiv: 1606.08813.
- Colin de la Higuera. Grammatical Inference: Learning Automata and Grammars . Cambridge University Press, April 2010. ISBN 978-0-521-76316-5.
- John E. Hopcroft, Rajeev Motwani, and Jeffrey D. Ullman. Introduction to Automata Theory, Languages, and Computation . Pearson, Harlow, Essex, Pearson New International Edition edition, November 2013. ISBN 978-1-292-03905-3.
- D. Lee and M. Yannakakis. Principles and Methods of Testing Finite State Machines-a Survey. Proceedings of the IEEE , 84(8):1090-1123, August 1996. ISSN 0018-9219. doi: 10.1109/5.533956.
- Qin Lin, Christian Hammerschmidt, Gaetano Pellegrino, and Sicco Verwer. Short-term Time Series Forecasting with Regression Automata. In MiLeTS Workshop at KDD 2016 , 2016. URL http://www-bcf.usc.edu/ ~liu32/milets16/paper/MiLeTS\_2016\_paper\_17.pdf .
- Zachary C. Lipton. The Mythos of Model Interpretability. arXiv:1606.03490 [cs, stat] , June 2016. URL http://arxiv.org/abs/1606.03490 . arXiv: 1606.03490.
- Jose Oncina and Pedro Garcia. Identifying Regular Languages In Polynomial Time. In Advances in Structural and Syntactic Pattern Recognition , pages 99-108. World Scientific, 1992.
- Gaetano Pellegrino, Christian Albert Hammerschmidt, Qin Lin, and Sicco Verwer. Learning Deterministic Finite Automata from Infinite Alphabets. In Proceedings of The 13th International Conference on Grammatical Inference , Delft, October 2016.
- Jana Schmidt and Stefan Kramer. Online Induction of Probabilistic Real-Time Automata. Journal of Computer Science and Technology , 29(3):345-360, May 2014. ISSN 1000-9000, 1860-4749. doi: 10.1007/ s11390-014-1435-8. URL http://link.springer.com/article/10.1007/s11390-014-1435-8 .
- Wouter Smeenk, Joshua Moerman, Frits Vaandrager, and David N. Jansen. Applying Automata Learning to Embedded Control Software. In Formal Methods and Software Engineering , number 9407 in Lecture Notes in Computer Science, pages 67-83. November 2015. URL http://link.springer.com/chapter/10. 1007/978-3-319-25423-4\_5 .
- Rick Smetsers, Joshua Moerman, Mark Janssen, and Sicco Verwer. Complementing Model Learning with Mutation-Based Fuzzing. arXiv:1611.02429 [cs] , 2016. URL http://arxiv.org/abs/1611.02429 . arXiv: 1611.02429.
- Ryan Turner. A Model Explanation System. In Black Box Learning and Inference NIPS Workshop , 2015. URL http://www.blackboxworkshop.org/pdf/Turner2015\_MES.pdf .
- Wil Van Der Aalst, Arya Adriansyah, Ana Karla Alves de Medeiros, Franco Arcieri, Thomas Baier, Tobias Blickle, Jagadeesh Chandra Bose, Peter van den Brand, Ronald Brandtjen, Joos Buijs, and others. Process Mining Manifesto. In Business Process Management Workshops , pages 169-194. Springer, 2012. URL http://link.springer.com/chapter/10.1007/978-3-642-28108-2\_19 .
- Sicco Verwer, Mathijs de Weerdt, and Cees Witteveen. Efficiently Learning Simple Timed Automata. Induction of Process Models , pages 61-68, 2008. URL http://www.cs.ru.nl/~sicco/papers/ipm08.pdf .
- Ferdinand Wagner, Ruedi Schmuki, Thomas Wagner, and Peter Wolstenholme. Modeling Software with Finite State Machines: A Practical Approach . CRC Press, May 2006. ISBN 978-1-4200-1364-1.
- N. Walkinshaw, K. Bogdanov, M. Holcombe, and S. Salahuddin. Reverse Engineering State Machines by Interactive Grammar Inference. In 14th Working Conference on Reverse Engineering (WCRE 2007) , 2007.
## A Visualizations of Automata
Figure 1: Auto-regressive model of short-term average wind speeds using the approach presented by Lin et al. [2016]. The ranges on the transitions indicate for which speed they activate, the number in the nodes is the predicted change in speed. The top node models persistent behavior (i.e. no change in speed for the next period), whereas the lower part denotes exceptions to this rule.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Decision Tree / State Diagram
### Overview
The image depicts a directed acyclic graph, resembling a decision tree or state diagram. Nodes are represented as circles containing numerical identifiers and associated values. Arrows indicate transitions between nodes, with associated interval values labeled on the arrows. The diagram appears to represent a branching process, potentially a classification or decision-making algorithm.
### Components/Axes
The diagram consists of nodes and directed edges. Each node has:
* **Identifier:** A numerical value (e.g., 0, 53012, 54857).
* **Value:** A decimal number (e.g., 0.00, -1.55, 0.80).
Each edge has:
* **Interval:** A pair of values enclosed in square brackets, representing a range (e.g., [-Infinity, -1.50], [-1.28, 0.68]).
### Detailed Analysis / Content Details
The diagram can be described level by level, starting from the root node:
* **Node 0:** Identifier 0, Value 0.00. Has two outgoing edges.
* Edge 1: Interval [-3.47, 0.26] leads to Node 53012.
* Edge 2: Interval [0.80, Infinity] leads to Node 54857.
* **Node 53012:** Identifier 53012, Value -1.55. Has one outgoing edge.
* Edge 3: Interval [-Infinity, -1.50] leads to Node 54857.
* **Node 54857:** Identifier 54857, Value 0.80. Has two outgoing edges.
* Edge 4: Interval [0.86, Infinity] leads to Node 53011.
* Edge 5: Interval [-Infinity, 0.68] leads to Node 61310.
* **Node 61307:** Identifier 61307, Value 0.00. Has one outgoing edge.
* Edge 6: Interval [-1.28, Infinity] leads to Node 53013.
* **Node 53013:** Identifier 53013, Value 1.05. Has one outgoing edge.
* Edge 7: Interval [-Infinity, Infinity] leads to Node 53014.
* **Node 53014:** Identifier 53014, Value -0.11. Has one outgoing edge.
* Edge 8: Interval [-Infinity, Infinity] leads to Node 53015.
* **Node 53015:** Identifier 53015, Value 0.00.
* **Node 61310:** Identifier 61310, Value -0.80. Has two outgoing edges.
* Edge 9: Interval [0.68, 0.86] leads to Node 61314.
* Edge 10: Interval [-Infinity, -0.85] leads to Node 61311.
* **Node 61311:** Identifier 61311, Value 0.00.
* **Node 61314:** Identifier 61314, Value 0.49. Has one outgoing edge.
* Edge 11: Interval [-Infinity, Infinity] leads to Node 61315.
* **Node 61315:** Identifier 61315, Value 0.00.
* **Node 53011:** Identifier 53011, Value 0.00.
* **Node 54861:** Identifier 54861, Value 0.00.
### Key Observations
* The diagram is a tree structure, starting from node 0 and branching out.
* The interval values on the edges define the conditions for transitioning between nodes.
* Several nodes have a value of 0.00, suggesting they might represent terminal states or default values.
* The intervals often include -Infinity or Infinity, indicating unbounded ranges.
* Node 54857 appears as a convergence point, being reached from both node 0 and node 53012.
### Interpretation
This diagram likely represents a decision-making process or a classification algorithm. The nodes represent states or decisions, and the edges represent transitions based on certain conditions (defined by the intervals). The values associated with the nodes could represent probabilities, scores, or other relevant metrics.
The presence of -Infinity and Infinity in the intervals suggests that the algorithm can handle a wide range of input values. The convergence of paths at node 54857 indicates that different initial conditions can lead to the same state. The terminal nodes (with values of 0.00) likely represent the final outcomes or classifications.
Without further context, it's difficult to determine the specific purpose of this diagram. However, it provides a clear visual representation of a branching process with well-defined conditions and outcomes. The diagram could be used to model a variety of real-world scenarios, such as medical diagnosis, financial risk assessment, or machine learning classification. The values associated with each node could be used to quantify the confidence or certainty of each decision.
</details>
Figure 2: Car-following controller model with highlighted clusters. Each color denotes one distinct cluster. The loop in cluster 6 (colored light blue), e.g. state sequence: 1-6-11-16-1 with symbolic transitions loop: d (keep short distance and slower than lead vehicle)-j (keep short distance and same speed to lead vehicle)-c (keep short distance and faster than lead vehicle))-j, can be interpreted as the car-following behavior at short distances , i.e. adapting the speed difference with the lead vehicle around 0 and bounding the relative distance in small zone. Similarly interesting and significant loops can be also seen in cluster 2 (colored pink) and cluster 4 (colored light yellow), which are long distance and intermediate distance car-following behaviors respectively. The intermediate state like S 15 in cluster 3 (colored light grey) explains how to switch between clusters.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: State Transition Diagram with Clustering
### Overview
The image depicts a state transition diagram with nodes representing states (labeled S0 through S21) and directed edges representing transitions between states. The diagram is visually organized into four distinct clusters, highlighted with different background colors: light blue (cluster6), pale yellow (cluster4), gray (cluster3), and light red (cluster2). Each transition edge is labeled with a tuple of the form `(probability, uncertainty)`.
### Components/Axes
The diagram consists of:
* **Nodes:** Represented by circles labeled S0 to S21.
* **Edges:** Directed arrows connecting the nodes, labeled with probability and uncertainty values.
* **Clusters:** Colored regions grouping related states.
* Cluster 2 (Light Red)
* Cluster 3 (Gray)
* Cluster 4 (Pale Yellow)
* Cluster 6 (Light Blue)
* **Labels:** State labels (S0-S21), edge labels (probability, uncertainty), and cluster labels (cluster2, cluster3, cluster4, cluster6).
### Detailed Analysis
**Cluster 2 (Light Red - Bottom Right):**
* S17 transitions to S21 with a probability of approximately 0.542 and an uncertainty of 272.
* S21 transitions to S17 with a probability of approximately 0.542 and an uncertainty of 290.
**Cluster 3 (Gray - Center Right):**
* S3 transitions to S15 with a probability of approximately 0.542 and an uncertainty of 231.
* S8 transitions to S15 with a probability of approximately 0.542 and an uncertainty of 3306.
* S15 transitions to S3 with a probability of approximately 0.542 and an uncertainty of 759.
* S15 transitions to S8 with a probability of approximately 0.542 and an uncertainty of 928.
* S15 transitions to S10 with a probability of approximately 0.888 and an uncertainty of 38.
**Cluster 4 (Pale Yellow - Center):**
* S0 transitions to S5 with a probability of approximately 0.542 and an uncertainty of 4556.
* S0 transitions to S3 with a probability of approximately 0.542 and an uncertainty of 490.
* S5 transitions to S15 with a probability of approximately 0.542 and an uncertainty of 898.
* S4 transitions to S10 with a probability of approximately 0.37 and an uncertainty of 1357.
* S10 transitions to S9 with a probability of approximately 0.542 and an uncertainty of 4462.
* S10 transitions to S14 with a probability of approximately 1.11 and an uncertainty of 999.
* S14 transitions to S9 with a probability of approximately 12.542 and an uncertainty of 351.
* S9 transitions to S4 with a probability of approximately 0.542 and an uncertainty of 444.
**Cluster 6 (Light Blue - Left):**
* S1 transitions to S6 with a probability of approximately 0.542 and an uncertainty of 4670.
* S6 transitions to S11 with a probability of approximately 0.542 and an uncertainty of 1275.
* S11 transitions to S16 with a probability of approximately 0.542 and an uncertainty of 4584.
* S16 transitions to S11 with a probability of approximately 0.726 and an uncertainty of 26.
**Inter-Cluster Transitions:**
* S1 transitions to S0 with a probability of approximately 0.619 and an uncertainty of 0.
* S4 transitions to S5 with a probability of approximately 0.542 and an uncertainty of 888.
### Key Observations
* The probabilities are consistently around 0.542, suggesting a relatively uniform transition probability within most of the network.
* The uncertainty values vary significantly, ranging from 0 to 3306. This suggests varying degrees of confidence in the transition probabilities.
* Cluster 2 (S17, S21) is isolated, indicating a self-contained sub-system.
* S15 is a central node, receiving transitions from S3, S8, and S5, and transitioning to S3, S8, and S10.
* S10 is a hub within Cluster 4, receiving transitions from S4 and S14, and transitioning to S9 and S14.
### Interpretation
This diagram represents a Markov chain or a similar probabilistic state transition model. The clusters likely represent different functional modules or states of a system. The probabilities represent the likelihood of transitioning from one state to another. The high uncertainty values in some transitions suggest that these transitions are less predictable or based on less data.
The clustering suggests that the system can be decomposed into relatively independent sub-systems (e.g., Cluster 2). The central nodes (S15, S10) act as key intermediaries, connecting different parts of the system. The diagram could represent a variety of systems, such as a control system, a biological pathway, or a user interaction model. The consistent probability of 0.542 could indicate a balanced system or a simplification of a more complex model. The isolated cluster 2 could represent a stable state or a rarely accessed part of the system. The diagram provides a visual representation of the system's dynamics and potential pathways.
</details>
Figure 3: Visualization of a state machine learned from a printer controller using an active learning approach. Each state, represented as a dot, represents a state in the controller software and each transition, represened as an edge, a state-change upon receiving input. Using knowledge about the controller design, it is possible to identify the sparsely connected protrusions of states at the bottom as deadlock situations. Taken from Smeenk et al. [2015]
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Network Graph: Complex Interconnection Visualization
### Overview
The image presents a complex network graph, visually representing interconnected nodes with varying degrees of connection. The graph is densely populated, particularly in the left and center regions, with connections represented by curved lines of varying colors. There are no explicit axes, labels, or legends present within the image itself. The visualization appears to be a force-directed graph, where nodes repel each other and connections act as springs, resulting in a layout that attempts to minimize edge crossings and maximize clarity.
### Components/Axes
There are no explicit axes or labels. The components are:
* **Nodes:** Represented by small colored circles.
* **Edges:** Represented by curved lines connecting the nodes. The edges vary in color.
* **Color Coding:** The nodes and edges are color-coded, but the meaning of the colors is not provided.
### Detailed Analysis or Content Details
Due to the lack of labels and a legend, precise data extraction is impossible. However, we can describe the visual characteristics:
* **Node Density:** The left side of the image exhibits the highest node density, forming a large, somewhat amorphous cluster. There is a smaller, more defined cluster in the upper-right corner.
* **Edge Density:** The central region has a very high edge density, with numerous lines crisscrossing. The edges become sparser towards the periphery.
* **Color Distribution:**
* **Purple/Violet:** Dominates the left cluster. Approximately 40% of the nodes are shades of purple.
* **Red/Orange:** Concentrated in the upper-center region. Roughly 20% of the nodes are red or orange.
* **Green/Teal:** Predominantly found in the lower-right tail of the graph. About 15% of the nodes are green or teal.
* **Blue:** Scattered throughout, but more prevalent in the upper-right cluster. Approximately 10% of the nodes are blue.
* **Yellow/Brown:** Less frequent, appearing as isolated nodes or within the denser clusters. About 15% of the nodes are yellow or brown.
* **Edge Colors:** The edges exhibit a similar color distribution to the nodes, suggesting a possible correlation between node color and the color of its connections. However, there are many edges connecting nodes of different colors.
* **Connection Patterns:** Many nodes have multiple connections, indicating a high degree of interconnectedness. Some nodes appear to be "hubs" with a significantly larger number of connections than others.
### Key Observations
* **Clustering:** The graph clearly exhibits clustering, with distinct groups of nodes forming identifiable regions.
* **Hubs:** The presence of hub nodes suggests that certain entities within the network have a disproportionate influence or play a central role in information flow.
* **Color Correlation:** While not definitive, there appears to be a tendency for nodes of similar colors to connect with each other.
* **Asymmetry:** The graph is not symmetrical. The left side is much denser and more complex than the right side.
### Interpretation
This visualization likely represents a complex system of relationships, such as a social network, a biological network (e.g., protein interactions), or a communication network. The lack of labels makes it difficult to determine the specific entities represented by the nodes and the nature of the connections.
The clustering suggests that the system is organized into distinct communities or groups. The hub nodes likely represent key individuals or entities that bridge these communities. The color coding could represent different categories or attributes of the nodes, but without a legend, this is speculative.
The asymmetry of the graph suggests that the system is not uniformly connected. The denser left side may represent a more established or influential part of the network, while the sparser right side may represent a newer or less developed area.
Without further information, it is impossible to draw definitive conclusions about the meaning of this graph. However, the visualization provides a valuable overview of the network's structure and highlights key patterns and relationships. The image is a visual representation of data, but does not provide the underlying data itself. It is a descriptive visualization, not a quantitative one.
</details>
.
Figure 4: The yeast cell cycle learned in Schmidt and Kramer [2014] using a passive online learning algorithm for timed automata. The colored bars indicate gene activities. The model corresponds to the well-known yeast cycle.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Gene Value Profile Flow
### Overview
The image depicts a directed graph representing a flow or process with nine nodes (numbered 1 through 9). Each node is associated with a visual representation of a "Gene's Value in the Profile (%)" using a color-coded bar. The diagram illustrates transitions between these nodes, indicated by arrows.
### Components/Axes
* **Nodes:** Numbered 1-9, represented as circles.
* **Arrows:** Indicate the direction of flow between nodes.
* **Legend:** Located in the top-left corner, defining the color scale for "Gene's Value in the Profile (%)":
* White: 0%
* Light Yellow: 25%
* Orange: 50%
* Dark Blue: 75%
* Darkest Blue: 100%
* **Gene Value Bars:** Horizontal bars associated with each node, representing the gene value percentage.
### Detailed Analysis or Content Details
Let's analyze each node and its associated gene value:
* **Node 1:** The bar is mostly white with a small dark section. Approximately 10-15% value.
* **Node 2:** The bar is predominantly light yellow with a small orange section. Approximately 30-40% value.
* **Node 3:** The bar is a mix of dark blue, orange, and light yellow. Approximately 70-80% value.
* **Node 4:** The bar is mostly white with a few dark sections. Approximately 10-20% value.
* **Node 5:** The bar is mostly dark gray with a few white sections. Approximately 20-30% value.
* **Node 6:** The bar is a mix of light yellow and dark red. Approximately 30-40% value.
* **Node 7:** The bar is mostly white with a few dark sections. Approximately 10-20% value.
* **Node 8:** The bar is mostly dark gray with a few white sections. Approximately 20-30% value.
* **Node 9:** The bar is mostly white with a few dark sections. Approximately 10-20% value.
**Flow Analysis:**
* Node 1 flows to Node 9.
* Node 1 flows to Node 2.
* Node 2 flows to Node 3.
* Node 3 flows to Node 4.
* Node 4 flows to Node 5.
* Node 5 flows to Node 6.
* Node 6 flows to Node 7 and Node 8.
* Node 7 flows to Node 9.
* Node 8 flows to Node 9.
### Key Observations
* The gene values vary significantly between nodes.
* Node 3 has the highest gene value (approximately 70-80%).
* Nodes 1, 4, 5, 7, 8, and 9 have relatively low gene values (approximately 10-30%).
* The flow converges at Node 9, suggesting a final state or outcome.
* Node 6 splits the flow into two paths, leading to Nodes 7 and 8.
### Interpretation
This diagram likely represents a biological pathway or a state transition diagram for a gene expression process. The nodes represent different states or stages in the process, and the arrows indicate the transitions between these states. The "Gene's Value in the Profile (%)" represents the expression level of a particular gene at each stage.
The high value at Node 3 suggests a key regulatory step or a point of significant gene expression. The convergence at Node 9 indicates a final outcome or a stable state. The split at Node 6 suggests a branching point where the process can follow different paths depending on certain conditions.
The varying gene values suggest that the gene expression is dynamically regulated throughout the process. The diagram provides a visual representation of this regulation and the flow of information within the system. The diagram does not provide any quantitative data beyond the approximate percentages indicated by the color bars. It is a qualitative representation of a process.
</details>
## B Finite State Automata
In this section, we give a formal introduction to deterministic finite state automata as the most basic model considered in the related work. For other variants like probabilistic automata, timed and real time automata, and regression automata, we refer to the cited papers for formal introductions. A deterministic finite state automaton (DFA) is one of the basic and most commonly used finite state machines. Below, we provide a concise description of DFAs, the reader is referred to Hopcroft et al. [2013] for a more elaborate overview. A DFA A = 〈 Q,T, Σ , q 0 , Q + 〉 is a directed graph consisting of a set of states Q (nodes) and labeled transitions T (directed edges). An example is shown in Figure 6. The start state q 0 ∈ Q is a specific state of the DFA and any state can be an accepting state (final state) in Q + ⊆ Q . The labels of transitions are all members of a given alphabet Σ . A DFA A can be used to generate or accept sequences of symbols (strings) using a process called DFA computation . This process begins in q 0 , and iteratively activates (or fires ) an outgoing transition t i = 〈 q i -1 , q i , l i 〉 ∈ T with label l i ∈ Σ from the source state it is in q i -1 , moving the process to the target state q i pointed to by t i . A computation q 0 t 1 q 1 t 2 q 2 . . . t n q n is accepting if the state it ends in (its last state) is an accepting state q n ∈ Q + , otherwise it is rejecting . The labels of the activated transitions form a string l 1 . . . l n . A DFA accepts exactly those strings formed by the labels of accepting computations, it rejects all others. Since a DFA is deterministic there exists exactly one computation for every string, implying that for every state q and every label l there exists at most one outgoing transition from q with label l . A string s is said to reach all the states contained in the computation that forms s , s is said to end in the last state q n of such a computation. The set of all strings accepted by a DFA A is called the language L ( A ) of A .
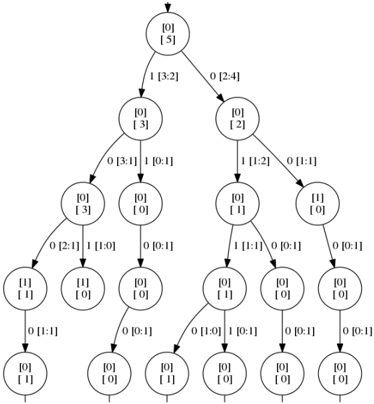
Figure 5: The initial part of the prefix tree, built from the input sample as shown in Figure 7. The square brackets indicate occurrence counts of positive data.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Diagram: Binary Tree Representation
### Overview
The image depicts a binary tree diagram. Each node in the tree contains two values enclosed in square brackets. Arrows indicate the direction of flow from parent to child nodes. The diagram appears to represent a hierarchical structure, potentially related to data partitioning or decision-making processes.
### Components/Axes
The diagram consists of nodes connected by directed edges (arrows). Each node displays two numerical values: the first value is enclosed in square brackets, and the second value is enclosed in square brackets. The edges are labeled with values in the format "0 [x:y]" or "1 [x:y]", indicating a binary choice or split.
### Detailed Analysis or Content Details
The tree structure unfolds as follows, starting from the root:
* **Root Node:** \[0] \[5]
* **Level 1 (Left Branch):** \[0] \[3] - Connected by arrow labeled "0 [2:4]"
* **Level 1 (Right Branch):** \[0] \[2] - Connected by arrow labeled "1 [2:4]"
* **Level 2 (Left-Left Branch):** \[0] \[3] - Connected by arrow labeled "0 [3:1]"
* **Level 2 (Left-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [0:1]"
* **Level 2 (Right-Left Branch):** \[0] \[1] - Connected by arrow labeled "1 [1:2]"
* **Level 2 (Right-Right Branch):** \[1] \[0] - Connected by arrow labeled "0 [1:1]"
* **Level 3 (Left-Left-Left Branch):** \[1] \[1] - Connected by arrow labeled "0 [2:1]"
* **Level 3 (Left-Left-Right Branch):** \[0] \[1] - Connected by arrow labeled "1 [1:0]"
* **Level 3 (Left-Right-Left Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 3 (Left-Right-Right Branch):** \[0] \[1] - Connected by arrow labeled "1 [0:1]"
* **Level 3 (Right-Left-Left Branch):** \[1] \[1] - Connected by arrow labeled "1 [1:1]"
* **Level 3 (Right-Left-Right Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 3 (Right-Right-Left Branch):** \[0] \[1] - Connected by arrow labeled "0 [0:1]"
* **Level 3 (Right-Right-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [0:1]"
* **Level 4 (Left-Left-Left-Left Branch):** \[1] \[1] - Connected by arrow labeled "0 [1:1]"
* **Level 4 (Left-Left-Left-Right Branch):** \[0] \[1] - Connected by arrow labeled "1 [1:1]"
* **Level 4 (Left-Left-Right-Left Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 4 (Left-Left-Right-Right Branch):** \[0] \[1] - Connected by arrow labeled "1 [0:1]"
* **Level 4 (Left-Right-Left-Left Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 4 (Left-Right-Left-Right Branch):** \[0] \[1] - Connected by arrow labeled "1 [0:1]"
* **Level 4 (Left-Right-Right-Left Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 4 (Left-Right-Right-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [0:1]"
* **Level 4 (Right-Left-Left-Left Branch):** \[1] \[1] - Connected by arrow labeled "0 [1:1]"
* **Level 4 (Right-Left-Left-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [1:1]"
* **Level 4 (Right-Left-Right-Left Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 4 (Right-Left-Right-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [0:1]"
* **Level 4 (Right-Right-Left-Left Branch):** \[0] \[1] - Connected by arrow labeled "0 [0:1]"
* **Level 4 (Right-Right-Left-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [0:1]"
* **Level 4 (Right-Right-Right-Left Branch):** \[0] \[0] - Connected by arrow labeled "0 [0:1]"
* **Level 4 (Right-Right-Right-Right Branch):** \[0] \[0] - Connected by arrow labeled "1 [0:1]"
### Key Observations
The values within the nodes consistently alternate between 0 and 1. The labels on the edges follow a consistent pattern of "0 [x:y]" or "1 [x:y]". The tree expands in a balanced manner, with each node having at most two children. The values of 'x' and 'y' in the edge labels appear to define a range or interval.
### Interpretation
This diagram likely represents a decision tree or a partitioning of data based on binary choices. The "0" and "1" labels on the edges could represent "true" or "false" conditions, or simply two distinct categories. The values within the square brackets, \[x:y], likely represent the range of data or the number of elements associated with that branch. The root node \[0] \[5] suggests an initial dataset of size 5, which is then recursively divided into smaller subsets based on the binary decisions represented by the edges. The consistent presence of 0 and 1 suggests a binary classification or partitioning scheme. The diagram could be used to visualize a search algorithm, a classification model, or a data compression technique. The depth of the tree indicates the number of decision levels or partitioning steps involved.
</details>
Figure 6: An automaton learned from the input sample. The numbers in square brackets indicate occurrence counts of positive and negative samples.
<details>
<summary>Image 6 Details</summary>

### Visual Description
\n
## Diagram: State Transition Diagram
### Overview
The image depicts a state transition diagram. It shows a series of states represented by ovals, connected by arrows indicating transitions. Each transition is labeled with a '0' or '1' input, followed by a time duration in the format `[hours:minutes]`. The diagram appears to model a system with a sequence of states and time-based transitions triggered by binary inputs.
### Components/Axes
The diagram consists of the following components:
* **States:** Represented by ovals.
* **Transitions:** Represented by arrows connecting states.
* **Transition Labels:** Each arrow is labeled with a binary input (0 or 1) and a time duration.
* **Initial State:** The topmost oval labeled "1".
### Detailed Analysis or Content Details
The diagram can be described as a sequence of states and transitions as follows:
1. **Initial State:** Oval labeled "1".
2. **Transition 1:** From "1" to "[1:5:0]", triggered by input "0" with duration "[3:7]". A loop back to "[1:5:0]" is triggered by input "1" with duration "[7:5]".
3. **Transition 2:** From "[1:5:0]" to "[0:11]", triggered by input "1" with duration "[1:3]". A loop back to "[0:11]" is triggered by input "0" with duration "[17:4]".
4. **Transition 3:** From "[0:11]" to "[0:0]", triggered by input "0" with duration "[17:4]".
5. **Transition 4:** From "[0:0]" to "[3:0]", triggered by input "0" with duration "[4:3]". A loop back to "[3:0]" is triggered by input "1" with duration "[3:1]".
6. **Transition 5:** From "[3:0]" to "[10:11]", triggered by input "0" with duration "[8:5]". A loop back to "[10:11]" is triggered by input "1" with duration "[4:1]".
7. **Transition 6:** From "[10:11]" to "[4:0]", triggered by input "0" with duration "[4:5]". A loop back to "[4:0]" is triggered by input "1" with duration "[0:2]".
8. **Transition 7:** From "[4:0]" to "[0:3]", triggered by input "0" with duration "[13:10]". A loop back to "[0:3]" is triggered by input "1" with duration "[3:7]".
### Key Observations
* The diagram represents a deterministic finite automaton (DFA) or a state machine.
* The time durations associated with transitions vary significantly, ranging from seconds to hours.
* Each state has at least one incoming and one outgoing transition.
* The diagram does not have a clear "final" or "accepting" state. It appears to be a continuous loop.
### Interpretation
The diagram likely models a system that responds to binary inputs ("0" and "1") and transitions between different states over time. The time durations associated with each transition could represent the amount of time the system remains in a particular state before responding to the next input. The absence of a final state suggests that the system operates continuously, cycling through its states based on the input sequence. The varying time durations could represent different processing times or delays within the system. The diagram could represent a control system, a communication protocol, or a behavioral model of a complex system. Without further context, it is difficult to determine the specific application of this state transition diagram. The durations are likely in the format `hours:minutes`.
</details>
## C State-Merging Algorithms
The idea of a state-merging algorithm is to first construct a tree-shaped DFA A from the input sample S , and then to merge the states of A . This DFA A is called an augmented prefix tree acceptor (APTA). An example is shown in Figure 5. For every state q of A , there exists exactly one computation that ends in q . This implies that the computations of two strings s and s ′ reach the same state q if and only if s and s ′ share the same prefix until they reach q . Furthermore, an APTA A is constructed to be consistent with the input sample S , i.e., S + ⊆ L ( A ) and S -∩ L ( A ) = ∅ . Thus a state q is accepting only if there exists a string s ∈ S + such that the computation of s ends in q . Similarly, it is rejecting only if the computation of a string s ∈ S -ends in q . As a consequence, A can contain states that are neither accepting nor rejecting. No computation of any string from S ends in such a state. Therefore, the rejecting states are maintained in a separate set Q -⊆ Q , with Q -∪ Q + = ∅ . Whether a state q ∈ Q \ ( Q + ∪ Q -) should be accepting or rejecting is determined by merging the states of the APTA and trying to find a DFA that is as small as possible.
1 9 1 0 0 0 0 0 0 0 0 1 15 0 1 1 0 0 0 1 0 1 0 1 0 1 0 0 0 5 0 1 0 0 0 1 2 0 0 0 12 1 1 0 0 0 0 0 0 0 1 0 0 1 5 1 0 1 0 0 1 3 1 0 0 0 6 0 0 0 0 0 1 1 3 1 0 1 0 20 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 1 1 0 0 0 0 13 0 1 1 1 0 1 0 0 0 0 0 0 0 1 3 1 0 1 1 7 1 0 0 0 0 0 0
Figure 7: Input sample for the APTA in Figure 5 and the learned model in Figure 6. The first column indicates whether the sample is positive or negative (i.e. a counter-example), the second column indicates the length of the word. The following symbols form the word, with each symbol separated by a space. This input format is commonly used in tools in the grammar induction community.
A merge of two states q and q ′ combines the states into one: it creates a new state q ′′ that has the incoming and outgoing transitions of both q and q ′ , i.e., replace all 〈 q, q t , l 〉 , 〈 q ′ , q t , l 〉 ∈ T by 〈 q ′′ , q t , l 〉 and all 〈 q s , q, l 〉 , 〈 q s , q ′ , l 〉 ∈ T by 〈 q s , q ′′ , l 〉 . Such a merge is only allowed if the states are consistent , i.e., it is not the case that q is accepting while q ′ is rejecting or vice versa. When a merge introduces a non-deterministic choice, i.e., q ′′ is now the source of two transitions 〈 q ′′ , q 1 , l 〉 and 〈 q ′′ , q 2 , l 〉 in T with the same label l , the target states of these transitions q 1 and q 2 are merged as well. This is called the determinization process (c.f. the while-loop in Algorithm 2), and is continued until there are no non-deterministic choices left. However, if this process at some point merges two inconsistent states, the original states q and q ′ are also considered inconsistent and the merge will fail. The result of a successful merge is a new DFA that is smaller than before, and still consistent with the input sample S . A state-merging algorithm iteratively applies this state merging process until no more consistent merges are possible. The general algorithm is outlined in Algorithm 1. Figure 6 shows an automaton obtained from the input given in Figure 7, which is also depicted as an APTA in Figure 5.
```
<loc_0><loc_0><loc_500><loc_499><_FORTRAN_>Algorithm 1 State-merging in the red-blue framework
Require: an input sample S
Ensure: A is a DFA that is consistent with S
A = apta(S) {construct the APTA A}
R = {q0} {color the start state of A red}
B = {q \ Q \ R | \exists \ q0, q, l \ } T {color all its children blue}
while B # 0 do {while A contains blue states}
if \b \in B s.t. \r \in R holds merge (A, r, b) = FALSE then {if there is a blue state inconsistent
with every red state}
R := R \{ b}
B := B \{ q \in Q \ R | \exists \langle b, q, l \rangle \ } T {color all its children blue}
else
for all b \in B and r \in R do {forall red-blue pair of states}
compute the evidence (A, q, q') of merge (A, r, b) {find the best performing merge}
end for
A := merge (A, r, b) with highest evidence {perform the best merge}
let q'' be resulting state
R := R \{q''} {color the resulting state red}
R := R \{r} {uncolor the merged red state}
B := {q \ Q \ R | \exists r \in R and \langle r, q, l \rangle \ } T {recompute the set of blue states}
end if
end while
return A
```
```
```
```
end if
end while
return A
```