## Parallelized Kendall's Tau Coefficient Computation via SIMD Vectorized Sorting On Many-Integrated-Core Processors
Yongchao Liu a, ∗ , Tony Pan a , Oded Green a , Srinivas Aluru a, ∗
a School of Computational Science & Engineering, Georgia Institute of Technology, Atlanta, GA 30332, USA
## Abstract
Pairwise association measure is an important operation in data analytics. Kendall's tau coefficient is one widely used correlation coefficient identifying non-linear relationships between ordinal variables. In this paper, we investigated a parallel algorithm accelerating all-pairs Kendall's tau coefficient computation via single instruction multiple data (SIMD) vectorized sorting on Intel Xeon Phis by taking advantage of many processing cores and 512-bit SIMD vector instructions. To facilitate workload balancing and overcome on-chip memory limitation, we proposed a generic framework for symmetric all-pairs computation by building provable bijective functions between job identifier and coordinate space. Performance evaluation demonstrated that our algorithm on one 5110P Phi achieves two orders-of-magnitude speedups over 16-threaded MATLAB and three ordersof-magnitude speedups over sequential R, both running on high-end CPUs. Besides, our algorithm exhibited rather good distributed computing scalability with respect to number of Phis. Source code and datasets are publicly available at http://lightpcc.sourceforge.net .
Keywords: Pairwise correlation; Kendall's tau coefficient; all-pairs computation; many integrated core; Xeon Phi
## 1. Introduction
Identifying interesting pairwise association between variables is an important operation in data analytics. In bioinformatics and computational biology, one typical application is to mine gene co-expression relationship via gene expression data, which can be realized by query-based gene expression database search [1]
∗ Corresponding author
Email addresses: yliu@cc.gatech.edu (Yongchao Liu), tpan7@gatech.edu (Tony Pan), ogreen@gatech.edu (Oded Green), aluru@cc.gatech.edu (Srinivas Aluru)
1 Preliminary work was presented in the 28th International Symposium on Computer Architecture and High Performance Computing, Los Angeles, USA, 2016
or gene co-expression network analysis [2]. For gene expression database search, it targets to select the subject genes in the database that are co-expressed with the query gene. One approach is to first define some pairwise correlation/dependence measure over gene expression profiles across multiple samples (gene expression profiles for short) and then rank query-subject gene pairs by their scores. For gene co-expression networks, nodes usually correspond to genes and edges represent significant gene interactions inferred from the association of gene expression profiles. To construct a gene co-expression network, allpairs computation over gene expression profiles is frequently conducted based on linear (e.g. [3] [4] [5]) or non-linear (e.g. [6] [7] [8]) co-expression measures. A variety of correlation/dependence measures have been proposed in the literature and among them, Pearson's product-moment correlation coefficient [9] (or Pearson's r correlation) is the most widely used correlation measure [10]. However, this correlation coefficient is only applicable to linear correlations. In contrast, Spearman's rank correlation coefficient [11] (or Spearman's ρ coefficient) and Kendall's rank correlation coefficient [12] (or Kendall's τ coefficient) are two commonly used measures for non-linear correlations [13]. Spearman's ρ coefficient is based on Pearson's r coefficient but applies to ranked variables, while Kendall's τ coefficient tests the association between ordinal variables. These two rank-based coefficients were shown to play complementary roles in the cases when Pearson's r is not effective [14]. Among other non-linear measures, mutual information [15] [16] [17], Euclidean distance correlation [18] [19], Hilbert-Schmidt information criterion [20], and maximal information criterion [21] are frequently used as well. In addition, some unified frameworks for pairwise dependence assessments were proposed in the literature (e.g. [22]).
/negationslash
Kendall's τ coefficient ( τ coefficient for short) measures the ordinal correlation between two vectors of ordinal variables. Given two ordinal vectors u = { u 1 , u 2 , ..., u n } and v = { v 1 , v 2 , ..., v n } , where variables u i and v i are both ordinal (0 ≤ i < n ), the τ coefficient computes the correlation by counting the number of concordant pairs n c and the number of discordant pairs n d by treating u i and v i as a joint ordinal variable ( u i , v i ). For the τ coefficient, a pair of observations ( u i , v i ) and ( u j , v j ), where i = j , is deemed as concordant if u i > u j and v i > v j or u i < u j and v i < v j , and discordant if u i > u j and v i < v j or u i < u j and v i > v j . Note that if u i = u j or v i = v j , this pair is considered neither concordant nor discordant.
In our study, we will consider two categories of τ coefficient, namely Tau-a (denoted as τ A ) and Tau-b (denoted as τ B ). τ A does not take into account tied elements in each vector and is defined as
<!-- formula-not-decoded -->
where n 0 = n ( n -1) / 2. If all elements in each vector are distinct, we have n c + n d = n 0 and can therefore re-write Equation (1) as
<!-- formula-not-decoded -->
As opposed to τ A , τ B makes adjustments for ties and is computed as
<!-- formula-not-decoded -->
where n 1 = ∑ i u ′ i ( u ′ i -1) / 2 and n 2 = ∑ i v ′ i ( v ′ i -1) / 2. u ′ i ( v ′ i ) denotes the cardinality of the i -th group of ties for vector u ( v ). Within a vector, each distinct value defines one tie group and this value acts as the identifier of the corresponding group. The cardinality of a tie group is equal to the number of elements in the vector whose values are identical to the identifier of the tie group. If all elements in either vector are distinct, τ B will equal τ A as n 1 = n 2 = 0. This indicates τ A is a special case of τ B and an implementation of τ B will cover τ A inherently. In addition, from the definitions of τ A and τ B , we can see that the computation of the τ coefficient between u and v is commutable.
Besides the values of correlation coefficients, some applications need to calculate P -value statistics to infer statistical significance between variables. For this purpose, one approach is permutation test [23]. However, a permutation test may need a substantial number of pairwise τ coefficient computation [24] even for moderately large n , thus resulting in prohibitively long times for sequential execution. In the literature, parallelizing pairwise τ coefficient computation has not yet been intensively explored. One recent work is from Wang et al . [25], which accelerated the sequential τ coefficient computation in R [26] based on Hadoop MapReduce [27] parallel programming model. In [25], the sequential all-pairs τ coefficient implementation in R was shown extremely slow on largescale datasets. In our study, we further confirmed this observation through our performance assessment (refer to section 5.2).
In this paper, we parallelized all-pairs τ coefficient computation on Intel Xeon Phis based on Many-Integrated-Core (MIC) architecture, the first work accelerating all-pairs τ coefficient computation on MIC processors to the best of our knowledge. This work is a continuation from our previous parallelization of all-pairs Pearson's r coefficient on Phi clusters [28] and further enriches our LightPCC library ( http://lightpcc.sourceforge.net ) targeting parallel pairwise association measures between variables in big data analytics. In this work, we have investigated three variants, namely the na¨ ıve variant, the generic sorting-enabled (GSE) variant and the vectorized sorting-enabled (VSE) variant, built upon three pairwise τ coefficient kernels, i.e. the na¨ ıve kernel, the GSE kernel and the VSE kernel, respectively. Given two ordinal vectors u and v of n elements each, the na¨ ıve kernel enumerates all possible pairs of joint variables ( u i , v i ) (0 ≤ i < n ) to obtain n c and n d , resulting in O ( n 2 ) time complexity. In contrast, both the GSE and VSE kernels take sorting as the core and manage to reduce the time complexity to O ( n log n ).
Given m vectors of n elements each, the overall time complexity would be O ( m 2 n 2 ) for the na¨ ıve variant and O ( m 2 n log n ) for the GSE and VSE variants. The VSE variant enhances the GSE one by exploiting 512-bit wide single instruction multiple data (SIMD) vector instructions in MIC processors to implement fast SIMD vectorized pairwise merge of sorted subarrays. Furthermore,
to facilitate workload balancing and overcome on-chip memory limitation, we investigated a generic framework for symmetric all-pairs computation by pioneering to build a provable, reversible and bijective relationship between job identifier and coordinate space in a job matrix.
The performance of our algorithm was assessed using a collection of real whole human genome gene expression datasets. Our experimental results demonstrates that the VSE variant performs best on both the multi-threaded CPU and Phi systems, compared to the other two variants. We further compared our algorithm with the all-pairs τ coefficient implementations in the widely used MATLAB [29] and R [26], revealing that our algorithm on a single 5110P Phi achieves up to 812 speedups over 16-threaded MATLAB and up to 1,166 speedups over sequential R, both of which were benchmarked on high-end CPUs. In addition, our algorithm exhibited rather good distributed computing scalability with respect to number of Phis.
## 2. Intel Many-Integrated-Core (MIC) Architecture
Intel MIC architecture targets to combine many Intel processor cores onto a single chip and has already led to the release of two generations of MIC processors. The first generation is code named as Knights Corner (KNC) and the second generation code named as Knights Landing (KNL) [30]. KNC is a PCI Express (PCIe) connected coprocessor that must be paired with Intel Xeon CPUs. KNC is actually a shared-memory computer [31] with full cache coherency over the entire chip and running a specialized Linux operating system over many cores. Each core adopts an in-order micro-architecture and has four hardware threads offering four-way simultaneous multithreading. Besides scalar processing, each core is capable of vectorized processing from a newly designed vector processing unit (VPU) featuring 512-bit wide SIMD instruction set architecture (ISA). For KNC, each core has only one VPU and this VPU is shared by all active hardware threads running on the same core. Each 512-bit vector register can be split to either 8 lanes with 64 bits each or 16 lanes with 32 bits each. Note that the VPU does not support legacy SIMD ISAs such as the Streaming SIMD extensions (SSE) series. As for caches, each core has separate L1 instruction and data caches of size 32 KB each, and a 512 KB L2 cache interconnected via a bidirectional ring bus with the L2 caches of all other cores to form a unified shared L2 cache over the chip. The cache line size is 64 bytes. In addition, two usage models can be used to invoke KNC: offload model and native model, where the former relies on compiler pragmas/directives to offload highly-parallel parts of an application to KNC, while the latter treats KNC as symmetric multiprocessing computers. While primarily focusing on KNC Phis in this work, we note that our KNC-based implementations can be easily ported onto KNL processors, as KNL implements a superset of KNC instruction sets. We expect that our implementations will be portable to future Phis as well.
Table 1: A list of notions used
| Notion | Description |
|-------------------|------------------------------------------------------------------------------|
| m | number of vectors |
| n | number of elements per vector |
| u | vector u of n elements, likewise for v |
| u i | i -th element of vector u , likewise for v i |
| n c | number of concordant variable pairs |
| n d | number of discordant variable pairs |
| n 0 | n ( n - 1) / 2 |
| n 1 | i u ′ i ( u ′ i - 1) / 2, u ′ i is size of the i -th tie group in u |
| n 2 | ∑ ∑ i v ′ i ( v ′ i - 1) / 2, v ′ i is size of the i -th tie group in v |
| n 3 | ∑ i w i ( w i - 1) / 2, w i is size of the i -th joint tie group for u and v |
| τ A | ( n c - n d ) /n 0 |
| τ B | ( n c - n d ) / √ ( n 0 - n 1 )( n 0 - n 2 ) |
| S X | a sorted subarray |
| | S X | | length of the sorted subarray S X |
| vX | a 512-bit SIMD vector with 16 32-bit integer lanes |
## 3. Pairwise Correlation Coefficient Kernels
For the τ coefficient, we have investigated three pairwise τ coefficient kernels: the na¨ ıve kernel, the GSE kernel and the VSE kernel. From its definition, it can be seen that the Kendall's τ coefficient only depends on the order of variable pairs. Hence, given two ordinal vectors, we can first order all elements in each vector, then replace the original value of every element with its rank in each vector, and finally conduct the τ coefficient computation on the rank transformed new vectors. This rank transformation does not affect the resulting coefficient value, but could streamline the computation, especially for ordinal variables in complex forms of representation. Moreover, this transformation needs to be done only once beforehand for each vector. Hence, we will assume that all ordinal vectors have already been rank transformed in the following discussions. For the convenience of discussion, Table 1 shows a list of notions used across our study.
## 3.1. Na¨ ıve Kernel
The na¨ ıve kernel enumerates all possible combinations of joint variables ( u i , v i ) (0 ≤ i < n ) and counts the number of concordant pairs n c as well as the number of discordant pairs n d . As mentioned above, given two joint variable pairs ( u i , v i ) and ( u j , v j ) ( i = j ), they are considered concordant if u i > u j and v i > v j or u i < u j and v i < v j , discordant if u i > u j and v i < v j or u i < u j and v i > v j , and neither concordant nor discordant if u i = u j or v i = v j . Herein, we can observe that the two joint variables are concordant if and only if the value of ( u i -u j ) × ( v i -v j ) is positive; discordant if and only if the value of ( u i -u j ) × ( v i -v j ) is negative; and neither concordant nor
/negationslash
discordant if and only if the value of ( u i -u j ) × ( v i -v j ) is equal to zero. In this case, in order to avoid branching in execution paths (particularly important for processors without hardware branch prediction units), we compute the value of n c -n d by examining the sign bit of the product of u i -u j and v i -v j (refer to lines 2 and 11 in Algorithm 1).
## Algorithm 1 Pseudocode of our na¨ ıve kernel
```
```
Algorithm 1 shows the pseudocode of the na¨ ıve kernel. From the code, the na¨ ıve kernel has a quadratic time complexity in a function of n , but its runtime is independent of the actual content of u and v , due to the use of function calc sign . Meanwhile, the space complexity is O (1). Note that this na¨ ıve kernel is only used to compute τ A .
## 3.2. Generic Sorting-enabled Kernel
Considering the close relationship between calculating τ and ordering a list of variables, Knight [32] proposed a merge-sort-like divide-and-conquer approach with O ( n log n ) time complexity, based on the assumption that no element tie exists within any vector. As this assumption is not always the case, Knight did mention this drawback and suggested an approximation method by averaging counts, rather than propose an exact solution. In this subsection, we investigate an exact sorting-enabled solution to address both cases: with or without element ties within any vector, together in a unified manner.
Given two ordinal vectors u and v , this GSE kernel generally works in the following five steps.
- Step1 sorts the list of joint variables ( u i , v i ) (0 ≤ i < n ) in ascending order, where the joint variables are sorted first by the first element u i and secondarily by the second element v i . In this step, we used quicksort via the standard qsort library routine, resulting in O ( n log n ) time complexity.
- Step2 performs a linear-time scan over the sorted list to compute n 1 (refer to Equation (3)) by counting the number of groups consisting of tied values as well as the number of tied values in each group. Meanwhile, we compute a new value n 3 for joint ties, with respect to the pair ( u i , v i ), as
∑ i w i ( w i -1) / 2, where w i represents the number of jointly tied values in the i -th group of joint ties for u and v .
- Step3 counts the number of discordant pairs n d by re-sorting the sorted list obtained in Step1 in ascending order of all elements in v via a merge sort procedure that can additionally accumulate the number of discordant joint variable pairs each time two adjacent sorted subarrays are merged. The rationale is as follows. Firstly, when merging two adjacent sorted subarrays, we count the number of discordant pairs by only performing pairwise comparison between joint variables from distinct subarrays. In this way, we can ensure that every pair of joint variables will be enumerated once and only once during the whole Step3 execution. Secondly, given two adjacent sorted subarrays to merge, it is guaranteed that the first value (corresponding to u ) of every joint variable in the left subarray (with the smaller indices) is absolutely less than or equal to the first value of every joint variable in the right subarray (with the larger indices), due to the sort conducted in Step1. In particular, when the first value is identical for the two joint variables from distinct subarrays, the second value (corresponding to v ) of the joint variable from the left subarray is also absolutely less than or equal to the second value of the joint variable from the left subarray. This means that discordance occurs only if the second value of a joint variable from the right subarray is less than the second value of a joint variable from the left subarray. Therefore, the value of n d can be gained by accumulating the number of occurrences of the aforementioned discordance in every pairwise merge of subarrays. Algorithm 2 shows the pseudocode of counting discordant pairs with out-of-place pairwise merge of adjacent sorted subarrays, where the time complexity is O ( n log n ) and the space complexity is O ( n ).
- Step4 performs a linear-time scan over the sorted list obtained in Step3 to compute n 2 (see Equation (3)) in a similar way to Step2. This works because the sorted list actually corresponds to a sorted list of all elements in v .
- Step 5 computes the numerator n c -n d in Equations (1) and (3) as n 0 -n 1 -n 2 + n 3 -2 n d . Note that if there is no tie in each vector, n 1 , n 2 and n 3 will all be zero. In this case, n c -n d will be equal to n 0 -2 n d as shown in Equation (2).
From the above workflow, we can see that the GSE kernel takes into account tied elements within each vector. Unlike the na¨ ıve kernel that computes τ A , the GSE kernel targets the computation of τ B . As mentioned above, τ A is actually a special case of τ B and an algorithm for τ B will inherently cover τ A . Therefore, our GSE kernel is able to calculate both τ A and τ B in a unified manner. In addition, the GSE kernel has O ( n log n ) time complexity, since the time complexity is O ( n log n ) for both Step1 and Step3, O ( n ) for both Step2 and Step4, and O (1) for Step 5.
## Algorithm 2 Pseudocode of Step3 of our GSE kernel
```
```
## 3.3. Vectorized Sorting-enabled Kernel
The VSE kernel enhances the GSE kernel by employing 512-bit SIMD vector instructions on MIC processors to implement vectorized pairwise merge of sorted subarrays. In contrast with the GSE kernel, the VSE kernel has made the following algorithmic changes. The first is packing a rank variable pair ( u i , v i ) into a signed 32-bit integer. In this packed format, each variable is represented by 15 bits in the 32-bit integer, with u i taking the most significant 16 bits and v i the least significant 16 bits. In this case, the VSE kernel limits the maximum allowable vector size n to 2 15 -1 = 32 , 767. The second is that due to packing, we replace the generic variable pair quicksort in Step1 with an integer sorting method, and re-implement the discordant pair counting algorithm in Step3 (see Algorithm 2) based on integer representation. In Step1, sorting packed integers is equivalent to sorting generic variable pairs ( u i , v i ), since within any packed integer u i sits in higher bits and v i in lower bits. In Step3, an additional preprocessing procedure is needed to reset to zero the most significant 16 bits of each packed integer (corresponding to u ). In our implementation, we split a 512-bit SIMD vector into a 16-lane 32-bit-integer vector and then investigated a vectorized merge sort for Step1 and a vectorized discordant pair counting algorithm for Step3, both of which use the same pairwise merge method and also follow a very similar procedure. Algorithm 3 shows the pseudocode of Step3 of our VSE kernel.
In the literature, some research has been done to accelerate sorting algorithms by means of SIMD vectorized pairwise merge of sorted subarrays. Hiroshi et al. [33] employed a SSE vectorized odd-even merge network [34] to merge sorted subarrays in an out-of-core way. Chhugan et al. [35] adopted
## Algorithm 3 Pseudocode of Step3 our VSE kernel
```
```
Figure 1: 16-way bitonic merge network: (1) input data are stored in two 16-lane vectors and (2) pipelining from left-to-right
<details>
<summary>Image 1 Details</summary>

### Visual Description
## Diagram: Hierarchical Node Network with Layered Connections
### Overview
The image depicts a complex, layered network diagram with interconnected nodes and directional lines. It features two primary sections: a left section labeled with "u" nodes (u0–u15) and a right section labeled with "a" nodes (a0–a15). Each node contains a box labeled "L" or "H," and lines connect these nodes in a structured, grid-like pattern. The diagram appears to represent a hierarchical or process-oriented system with multiple layers of interaction.
### Components/Axes
- **Nodes**:
- **Left Section**:
- **u0–u15**: Nodes labeled with "u" followed by a number (e.g., u0, u1, ..., u15). Each node contains a box labeled "L" (e.g., "L H" in the box).
- **a0–a15**: Nodes labeled with "a" followed by a number (e.g., a0, a1, ..., a15). Each node contains a box labeled "H" (e.g., "L H" in the box).
- **Right Section**:
- **b0–b15**: Nodes labeled with "b" followed by a number (e.g., b0, b1, ..., b15). Each node contains a box labeled "H" (e.g., "L H" in the box).
- **Lines**:
- Lines connect "L" nodes (left section) to "H" nodes (middle and right sections).
- Lines also connect "H" nodes (middle section) to "H" nodes (right section).
- **Labels**:
- All nodes have labels (e.g., u0, a0, b0).
- Boxes within nodes contain "L" or "H" (e.g., "L H" in the box).
### Detailed Analysis
- **Left Section (u0–u15)**:
- Each "u" node (e.g., u0) connects to multiple "a" nodes (e.g., a0, a1, a2, etc.) via lines.
- The "L" box in "u" nodes suggests a "Low" or "Left" state, while the "H" box in "a" nodes suggests a "High" or "Right" state.
- **Middle Section (a0–a15)**:
- "a" nodes connect to "b" nodes (right section) via lines.
- The "H" box in "a" nodes indicates a transition or output state.
- **Right Section (b0–b15)**:
- "b" nodes are the final layer, with "H" boxes indicating a terminal or output state.
### Key Observations
1. **Many-to-Many Connections**: Each "L" node (e.g., u0) connects to multiple "H" nodes (e.g., a0, a1, a2), and vice versa.
2. **Layered Structure**: The diagram is divided into three layers: "u" (left), "a" (middle), and "b" (right).
3. **Directional Flow**: Lines flow from left to right, suggesting a process or transformation from "u" to "a" to "b."
4. **Repetitive Pattern**: The connections follow a consistent grid-like structure, with each node linked to multiple nodes in the next layer.
### Interpretation
This diagram likely represents a **hierarchical or layered system** with interconnected components. The "L" and "H" labels may denote **states** (e.g., "Low" vs. "High") or **roles** (e.g., "Left" vs. "Right") within the network. The many-to-many connections suggest **complex dependencies** or **data flow** between layers. For example:
- **u nodes** (left) act as inputs or initial states, connecting to **a nodes** (middle) as intermediate states.
- **a nodes** then connect to **b nodes** (right) as final outputs or terminal states.
- The repetition of "L H" in boxes implies a **binary or dual-state system** (e.g., active/inactive, high/low).
The diagram’s structure resembles a **neural network**, **decision tree**, or **process flow diagram**, where nodes represent entities and lines represent interactions. The absence of numerical data or explicit labels for the lines suggests the focus is on **topological relationships** rather than quantitative metrics.
### Notable Patterns
- **Symmetry**: The left and right sections mirror each other in structure (u/a/b nodes with "L H" boxes).
- **Density**: The left section has the highest density of connections, indicating a critical role in the system’s flow.
- **Terminal Nodes**: The "b" nodes (right section) have no outgoing lines, suggesting they are endpoints.
### Conclusion
This diagram illustrates a **multi-layered, interconnected system** with a clear directional flow from "u" to "a" to "b." The "L" and "H" labels likely represent states or roles, while the lines define the relationships between components. The complexity of connections highlights the system’s **interdependence** and **hierarchical organization**.
</details>
similar ideas to [33], but combined a SSE vectorized in-register odd-even merge sort [34] with an in-memory bitonic merge network. Chen et al. [36] absorbed the merge-path idea of [37, 38] and extended the SSE vectorized work of [35] to take advantage of 512-bit SIMD VPUs on KNC Phis and used a vectorized in-register bitonic merge sort, instead of the in-register odd-even merge sort. In our VSE kernel, we engineered a 512-bit SIMD vectorized in-register bitonic merge network as the core of our pairwise merge procedure for sorted subarrays, which is similar to [36], and further proposed a predict-and-skip mechanism to reduce the number of comparisons during pairwise merge.
## 3.3.1. In-register bitonic merge network
The in-register bitonic merge network is the core of our vectorized pairwise merge of sorted subarrays. In our algorithm, this network has 16 ways and merges two sorted vectors vMin and vMax (Figure 1 shows the computation layout of the network), where all elements in each vector are placed in ascending order from lane 0 to lane 15. In this case, to generate an input bitonic sequence from the two vectors, we need to reverse the order of all elements in one and only one vector (reverse vMax in our case) and this order reversal is realized by one permutation instruction, i.e. mm512 permutevar epi32( · ). Having completed the order reversal, we can complete the sorting of vectors vMin and vMax in log 2 (32) = 5 steps. Algorithm 4 shows the pseudocode for our 16-way in-register bitonic merge network. From the code, the function bitonic merge 16way is
composed of a fixed number of vector instructions and thus has a constant time complexity.
```
```
Algorithm 4 Pseudocode of our 16-way in-register bitonic merge network
## 3.3.2. Vectorized pairwise merge of sorted subarrays
Our vectorized pairwise merge of sorted subarrays relies on the aforementioned 16-way in-register bitonic merge network and adopted a very similar procedure to [33]. Given two sorted subarrays S A and S B , we assume that they are aligned to 64 bytes and their lengths | S A | and | S B | are multiples of 16, for the convenience of discussion. In this way, the vectorized pairwise merge works as follows.
1. loads the smallest 16 elements of S A and S B to vMin and vMax , respectively, and advances the pointer of each subarray.
2. invokes bitonic merge 16way( · ) to sort vectors vMin and vMax , and then stores the content of vMin , the smallest 16 elements, to the resulting output array.
## Algorithm 5 Pseudocode of processing the leftovers in both subarrays
```
```
3. compares the next element of S A and S B and loads 16 elements into vMin from the subarray whose next element is the smaller, followed by pointer advancing for the subarray.
4. jumps back to the second step and repeats the procedure until all elements in both subarrays have been processed.
5. completes the merge of S A and S B by writing the content of vMax to the output array.
Note that if | S A | or | S B | is not a multiple of 16, we will have to implement some special treatment to deal with the leftovers in S A and S B . This special treatment is implemented as Algorithm 5 and invoked by Algorithm 3 (see line 46). From the above procedure, we can see that the time complexity of merging S A and S B is linear and thus the VSE kernel has a time complexity of O ( n log n ).
As assumed that both S A and S B are aligned to 64 bytes, we can therefore use only one mm512 load epi32( · ) instruction to load 16 integer elements from memory to a vector and only one mm512 store epi32( · ) instruction to store 16 elements in a vector to memory. This is because memory address is guaranteed to keep aligned to 64 bytes during pairwise merge. Defining T rd to denote the latency of memory load (in clock cycles) and T wt to denote the latency of memory store, the number of clock cycles per element load from memory can be estimated as ( T rd +16) / 16 = T rd / 16 + 1 clock cycles and the number of clocks cycles per element store to memory as ( T wt +16) / 16 = T wt / 16+1 clock cycles. Moreover, bitonic merge 16way( · ) is composed of 27 vector instructions (see lines 7 ∼ 33 in Algorithm 4) and each of its invocations leads to the output of 16 elements. In these regards, the average number of instructions per element can be estimated as 27 / 16 ≈ 1 . 69. Considering that we only used simple integer and single-source permutation instructions, each of which has a two clock cycle latency according to the Intel Xeon Phi processor software optimization manual [39], the average computational cost per element can be estimated as /ceilingleft 2 × 27 / 16 /ceilingright = 4 clock cycles in the worst cases where consecutive instructions always have data dependency. In order to reduce inter-instruction latency caused by data dependency, we have manually tuned the order of instructions by means of interleaving. Since each instruction has a latency of two clock cycles, this interleaving could enable to execute one instruction in only one clock cycle, thus further reducing the cost per element to /ceilingleft 1 × 27 / 16 /ceilingright = 2 clock cycles optimistically. In sum, the overall cost per element can be favorably estimated to be ( T rd + T wr ) / 16 + 4 clock cycles.
We have proposed a predict-and-skip scheme to determine ( i ) whether we need to invoke the 16-way bitonic merge network and ( ii ) whether we should load two vectors of new elements from S A and S B , respectively. For cases ( i ), the rationale is if the minimum value in vMin ( vMax ) is ≥ the maximum value in vMax ( vMin ), every value in vMin ( vMax ) will be ≥ to all values in vMin ( vMax ). In this case, there is no need of invoking the bitonic merge network (lines 23 ∼ 26 in Algorithm 3), since the order of all elements in both vectors is already deterministic. For cases ( ii ), we compare the maximum value C in vMax with both the smallest element A in the rest of S A and the one B in
the rest of S B (lines 34 ∼ 38 in Algorithm 3). If C ≤ A and C ≤ B , none of the elements in vMax will be greater than any element in the rest of S A and S B , indicating that the absolute order of all vMax elements has already been determined. In this case, we write vMax to the resulting output array and load two vectors of new elements from S A and S B to vMin and vMax , respectively. The updates in vMin and vMax will be used for the next iteration of comparison.
It is worth mentioning that we also developed a 32-way bitonic merge network to implement the VSE kernel. Unfortunately, this new kernel based on 32-way merge network yielded slightly inferior performance to the kernel with the 16-way network through our tests. In this regard, we adopted the 16-way merge network in our VSE kernel.
## 4. Parallel All-Pairs Computation
## 4.1. All-Pairs Computation Framework
We consider the m × m job matrix to be a 2-dimensional coordinate space on the Cartesian plane, and define the left-top corner to be the origin, the horizontal x -axis (corresponding to columns) in left-to-right direction and the vertical y -axis (corresponding to rows) in top-to-bottom direction. For nonsymmetric all-pairs computation (non-commutative pairwise computation), the workload distribution over processing elements (PEs), e.g. threads, processes, cores and etc., would be relatively straightforward. This is because coordinates in the 2-dimensional matrix corresponds to distinct jobs. Unlike non-symmetric all-pairs computation, it suffices by only computing the upper-triangle (or lowertriangle) of the job matrix for symmetric all-pairs computation (commutative pairwise computation). In this case, balanced workload distribution could be more complex than non-symmetric all-pairs computation.
In this paper, we propose a generic framework for workload balancing in symmetric all-pairs computation, since the computation of the τ coefficient between any u and v is commutable as mentioned above. This framework works by assigning each job a unique identifier and then building a bijective relationship between a job identifier J m ( y, x ) and its corresponding coordinate ( y, x ). We refer to this as direct bijective mapping . While facilitating balanced workload distribution, this mapping merely relies on bijective functions, which is a prominent feature distinguished from existing methods. To the best of our knowledge, in the literature bijective functions have not ever been proposed for workload balancing in symmetric all-pairs computation. In [40], the authors used a very similar job numbering approach to ours (shown in this study), but did not derive a bijective function for symmetric all-pairs computation. Our framework can be applied to cases with identical (e.g. using static workload distribution) or varied workload per job (e.g. using a shared integer counter to realize dynamic workload distribution via remote memory access operations in MPI [41] and Unified Parallel C (UPC) programming models [42] [43]) and is also particularly useful for parallel computing architectures with hardware
!
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Grid and Function Graphs: Mathematical Representation
### Overview
The image consists of three components:
1. A numerical grid (a) with shaded cells
2. Two function graphs (b and c) depicting Fₘ(y) with mathematical equations
3. Vertical dashed lines and shaded regions indicating specific mathematical relationships
### Components/Axes
**Grid (a):**
- **Rows:** Labeled 0–7 (vertical axis)
- **Columns:** Labeled 8–35 (horizontal axis)
- **Shaded Cells:**
- Row 0: Columns 8–14
- Row 1: Columns 15–20
- Row 2: Columns 21–25
- Row 3: Columns 26–29
- Row 4: Columns 30–32
- Row 5: Columns 33–34
- Row 6: Column 35
**Graphs (b and c):**
- **Y-axis:** Fₘ(y) (function value)
- **X-axis:** y (variable)
- **Vertical Dashed Line:** y = m (critical threshold)
- **Legend:** Shaded region labeled "Fₘ(y)"
### Detailed Analysis
**Grid (a):**
- Shaded cells form a stepped pattern, increasing in column count per row until row 3, then decreasing.
- Total shaded cells: 35 (matches column 35 in row 6).
**Graph (b):**
- **Equations:**
- Upper boundary: y = m + 0.5 + √(m² + m + 0.25 − 2J)
- Lower boundary: y = m + 0.5 − √(m² + m + 0.25 − 2J)
- **Shaded Region:** Between the two curves, symmetric about y = m + 0.5.
- **Vertical Dashed Line:** At y = m, intersecting the shaded region.
**Graph (c):**
- **Equations:**
- Upper boundary: y = m − 0.5 + √(m² + m + 0.25 − 2(J + 1))
- Lower boundary: y = m − 0.5 − √(m² + m + 0.25 − 2(J + 1))
- **Shaded Region:** Between the two curves, symmetric about y = m − 0.5.
- **Vertical Dashed Line:** At y = m, intersecting the shaded region.
### Key Observations
1. **Grid Pattern:** Shaded cells suggest a hierarchical or tiered structure, with diminishing density in higher rows.
2. **Graph Symmetry:** Both graphs exhibit parabolic symmetry around their respective midlines (y = m ± 0.5).
3. **Parameter Sensitivity:**
- Graph (b) uses J, while graph (c) uses J + 1, shifting the curves downward.
- The square root terms imply constraints on J (e.g., m² + m + 0.25 − 2J ≥ 0).
### Interpretation
- **Grid (a):** Likely represents a matrix or heatmap where shaded cells encode specific values (e.g., active states, thresholds). The stepped pattern may reflect a decay or prioritization mechanism.
- **Graphs (b and c):** Model a function Fₘ(y) with parameter-dependent bounds. The shaded regions could represent allowable ranges or confidence intervals.
- Graph (b) corresponds to J, while graph (c) adjusts for J + 1, suggesting iterative or incremental analysis.
- The vertical dashed line (y = m) acts as a reference point, possibly a mean or critical value.
- **Mathematical Relationships:** The equations highlight dependencies on m and J, with the square root terms introducing nonlinear constraints.
This structure suggests a system where grid-based data (a) informs parameter choices (m, J) in the function graphs (b, c), with shaded regions visualizing solution spaces or valid ranges.
</details>
!
)
)
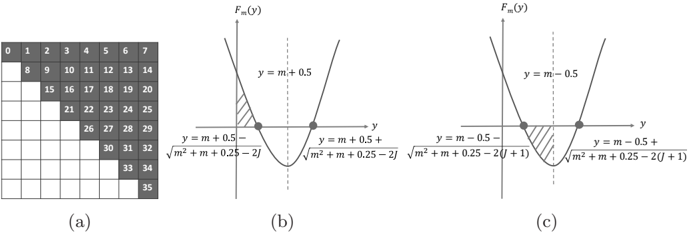
Figure 2: (a) an example direct bijective mapping between job identifier and coordinate space, (b) solution region for Equation (7), and (c) solution region for Equation (8)
schedulers such as GPUs and FPGAs. In the following, without loss of generality, we will interpret our framework relative to the upper triangle of the job matrix by counting in the major diagonal. Nonetheless, this framework can be easily adapted to the cases excluding the major diagonal.
Direct bijective mapping. Given a job ( y, x ) in the upper triangle, we compute its integer job identifier J m ( y, x ) as
<!-- formula-not-decoded -->
for dimension size m . In this equation, F m ( y ) is the total number of cells preceding row y in the upper triangle and is computed as
<!-- formula-not-decoded -->
where y varies in [0 , m ]. In this way, we have defined Equation (4) based on our job numbering policy, i.e. all job identifiers vary in [0 , m ( m +1) / 2) and jobs are sequentially numbered left-to-right and top-to-bottom in the upper triangle (see Fig. 2a for an example).
Reversely, given a job identifier J = J m ( y, x ) (0 ≤ J < m ( m +1) / 2), we need to compute the coordinate ( y, x ) in order to locate the corresponding variable pair. As per our definition, we have
<!-- formula-not-decoded -->
By solving J ≥ F m ( y ) (see Figure 2b), we get
<!-- formula-not-decoded -->
while getting
<!-- formula-not-decoded -->
by solving J ≤ F m ( y + 1) -1 (see Figure 2c). In this case, by defining ∆ = √ m 2 + m +0 . 25 -2( J +1), ∆ ′ = √ m 2 + m +0 . 25 -2 J and z = m -0 . 5 -√ m 2 + m +0 . 25 -2( J +1), we can reformulate Equations (7) and (8) to be z ≤ y ≤ z + 1 + ∆ -∆ ′ . Because ∆ < ∆ ′ , we know that [ z, z +1 + ∆ -∆ ′ ] is a sub-range of [ z, z +1) and thereby have z ≤ y < z +1. Based on our job numbering policy stated before, as a function of integer y , Equation (6) definitely has y solutions, meaning that at least one integer exists in [ z, z +1+∆ -∆ ′ ], which satisfies Equation (6). Meanwhile, it is known that there always exists one and only one integer in [ z, z + 1) (can be easily proved) and this integer equals /ceilingleft z /ceilingright , regardless of the value of z . Since [ z, z +1+∆ -∆ ′ ] is a sub-range of [ z, z +1), we can conclude that Equation (6) has a unique solution y that is computed as
<!-- formula-not-decoded -->
Having got y , we can compute the coordinate x as
<!-- formula-not-decoded -->
based on Equation (4).
## 4.2. Tiled Computing
Based on the direct bijective mapping, we adopted tiled computing with the intention to benefit from L1/L2 caches. The rationale behind the tiled computing is loading into cache a small subset of the bigger dataset and reusing this block of data in cache for multiple passes. This technique partitions a matrix into a non-overlapping set of equal-sized q × q tiles. In our case, we partition the job matrix and produce a tile matrix of size w × w tiles, where w = /ceilingleft m/q /ceilingright . In this way, all jobs in the upper triangle of the job matrix are still fully covered by the upper triangle of the tile matrix. By treating a tile as a unit, we can assign a unique identifier to each tile in the upper triangle of the tile matrix and then build bijective functions between tile identifiers and tile coordinates in the tile matrix, similarly as we do for the job matrix.
Because the tile matrix has an identical structure to the original job matrix, we can directly apply our bijective mapping to the tile matrix. In this case, given a coordinate ( y q , x q ) (0 ≤ y q ≤ x q < w ) in the upper triangle of the tile matrix, we can compute a unique tile identifier J w ( y q , x q ) as
<!-- formula-not-decoded -->
where F w ( y q ) is defined similar to Equation (5) as
<!-- formula-not-decoded -->
Likewise, given a tile identifier J w , such that 0 ≤ J w < w ( w + 1) / 2, we can
reversely compute its unique vertical coordinate y q as
<!-- formula-not-decoded -->
and subsequently its unique horizontal coordinate x q as
<!-- formula-not-decoded -->
As title size is subject to cache sizes and input data, tuning tile size is believed to be important for gaining high performance. This tuning process, however, is tedious and has to be conducted case-by-case. For convenience, we empirically set q to 8 for CPUs and to 4 for Phis. Nevertheless, users can feel free to tune tile sizes to meet their needs.
## 4.3. Multithreading
## 4.3.1. Asynchronous kernel execution
When m is large, we may not have sufficient memory to reside the resulting m × m correlation matrix M τ entirely in memory. To overcome memory limitation, we adopted a multi-pass kernel execution model which partitions the tile identifier range [0 , w ( w +1) / 2) into a set of non-overlapping sub-ranges (equalsized in our case) and finishes the computation one sub-range after another. In this way, we do not need to allocate the whole memory for matrix M τ . Instead, we only need to allocate a small amount of memory to store the computing results of one sub-range, thus considerably reducing memory footprint.
When using the KNC Phi, we need to transfer the newly computed results from the Phi to the host after having completed each pass of kernel execution. If kernel execution and data transfer is conducted in sequential, the Phi will be kept idle during the interim of device-to-host data transfer. In this regard, a more preferable solution would be to employ asynchronous kernel execution by enabling concurrent execution of host-side tasks and accelerator-side kernel execution. Fortunately, KNC Phis enable such a kind of asynchronous data transfer and kernel execution associated with the offload model. This asynchronous execution can be realized by coupling the signal and wait clauses, both of which are associated with each other via a unique identifier. That is, a signal clause initiates an asynchronous operation such as data transfer and kernel execution, while a wait clause blocks the current execution until the associated asynchronous operation is completed. Refer to our previous work [28] for more details about the host-side asynchronous execution workflow proposed.
## 4.3.2. Workload balancing
For the variant using the na¨ ıve kernel, all jobs have the same amount of computation (refer to Algorithm 1). Thus, given a fixed number of threads, we evenly distribute jobs over the set of threads by assigning a thread to process one tile at a time. In contrast, for the two variants using the sorting-enabled kernels, different jobs may have different amount of computation because of
the two rounds of sort used in Step1 and Step3. Typically, an OpenMP dynamic scheduling policy is supposed to be in favor to address workload irregularity, albeit having relatively heavier workload distribution overhead than static scheduling. However, it is observed that dynamic scheduling produces slightly inferior performance to static scheduling through our tests. In this regard, we adopted static scheduling in our two sorting-enabled variants and assigned one thread to process one tile at a time, same as the na¨ ıve variant.
## 4.4. Distributed Computing
On KNC Phi clusters, we used MPI offload model which launches MPI processes just as an ordinary CPU cluster does. In this model, one or more Phis will be associated to a parental MPI process, which utilizes offload pragmas/directives to interact with the affiliated Phis, and inter-Phi communications need to be explicitly managed by parental processes. In this sense, Phis may not perceive the existence of remote inter-process communications. Our distributed implementations require one-to-one correspondence between MPI processes and Phis, and adopted a static workload distribution scheme based on tiled computation. This static distribution is inspired by our practice in multithreading on single Phis. In our implementation, given p processes, we evenly distribute tiles onto the p processes with the i -th (0 ≤ i < p ) process assigned to compute the tiles whose identifiers are in [ i ×/ceilingleft w ( w +1) 2 p /ceilingright , ( i +1) ×/ceilingleft w ( w +1) 2 p /ceilingright ). Within each process, we adopted asynchronous execution workflow as well.
## 5. Performance Evaluation
We assessed the performance of our algorithm from four aspects: ( i ) comparison between our three variants, ( ii ) comparison with widely used counterparts: MATLAB (version R2015b) and R (version 3.2.0), ( iii ) multithreading scalability on a single Phi, and ( iv ) distributed computing scalability on Phi clusters. In these tests, we used four real whole human genome gene expression datasets (refer to Table 2) produced by Affymetrix Human Genome U133 Plus 2.0 Array. These datasets are publicly available in the GPL570 data collection of SEEK [1], a query-based computational gene co-expression search engine over large transcriptomic databases. In this study, unless otherwise specified, we compute τ coefficients between genes, meaning that m is equal to the number of genes and n equal to the number of samples for each dataset.
All tests are conducted on 8 compute nodes in CyEnce HPC Cluster (Iowa State University), where each node has two high-end Intel E5-2650 8-core 2.0 GHz CPUs, two 5110P Phis (each has 60 cores and 8 GB memory) and 128 GB memory. Our algorithm is compiled by Intel C++ compiler v15.0.1 with option -fast enabled. In addition, for distributed computing scalability assessment, when two processes are launched into the same node, we used the environment variable I MPI PIN PROCESSOR LIST to guide Intel MPI runtime system to pin the two processes within the node to distinct CPUs (recall that one node has two CPUs).
Table 2: Information of whole human genome gene expression datasets used
| Name | No. of Genes | No. of Samples | Platform |
|---------|----------------|------------------|------------|
| DS21050 | 17,941 | 310 | Affymetrix |
| DS19784 | 17,941 | 320 | Affymetrix |
| DS13070 | 17,941 | 324 | Affymetrix |
| DS3526 | 17,941 | 353 | Affymetrix |
## 5.1. Assessment of Our Three Variants
All of the three variants work on CPUs, Phis and their clusters. For the na¨ ıve and GSE variants, they both used the same C++ core code for CPUand MIC-oriented instances. For the VSE variant, its 512-bit SIMD vectorization is only applicable to Phis. In this regard, to support CPUs, we further developed a non-vectorized merge sort in Step1 and a non-vectorized discordant pair counting algorithm in Step3 instead, based on the aforementioned packed integer representation. Considering that this non-vectorized version also works on Phis, we have examined how much our 512-bit SIMD vectorization contributes to speed improvement by comparing the vectorized version with the non-vectorized one on the same 5110P Phi. Interestingly, by measuring the correlation between genes using the datasets in Table 2, we observed that the non-vectorized version is on a par with the vectorized one. This may be due to the relatively small value of n , which is only 353 at maximum. Based on this consideration, we further evaluated both versions by measuring the correlation between samples, where m will be equal to the number of samples and n equal to the number of genes. In this case, n becomes 17,941 for each dataset, more than 50 × larger than before. In this context, our performance assessment exposed that the vectorized version is consistently superior to the non-vectorized one, yielding very stable speedups averaged to be 1.87 for all datasets. This result was exciting, proving that our 512-bit SIMD vectorization did boost speed even for moderately large n values. Hence, we have used the vectorized version of the VSE variant for performance measurement all throughout our study.
## 5.1.1. On CPU
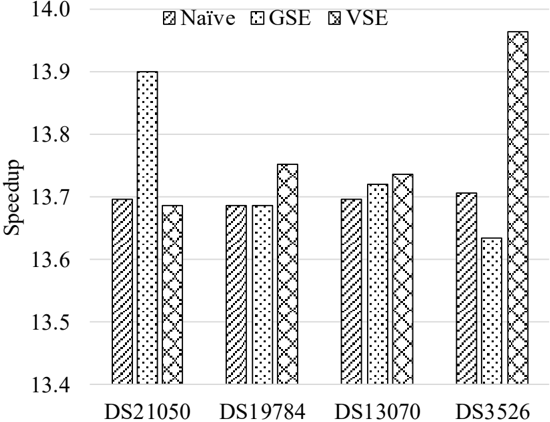
We first compared the performance of our three variants on multiple CPU cores. Table 3 shows the performance of each variant on 16 CPU cores and Figure 3 shows the speedup of the 16-threaded instance of each variant over its single-threaded one.
For the na¨ ıve variant, its 16-threaded instance achieves a roughly constant speedup of 13.70 over its single-threaded one. This observation is consistent with our expectation, as the runtime of the na¨ ıve kernel is subject to the vector size n but independent of actual vector content (refer to the implementation shown in Algorithm 1). In contrast, the speed of the two sorting-enabled kernels are sensitive to vector content to some degree. This can be explained by the following three factors: variable pair sorting in Step1, discordant pair counting based on pairwise merge of sorted subarrays in Step3, and linear-time scans
Figure 3: Speedups of 16-threaded instances over single-thread ones on multiple CPU cores
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Bar Chart: Speedup Comparison Across Datasets
### Overview
The chart compares speedup values for three computational methods (Naïve, GSE, VSE) across four datasets (DS21050, DS19784, DS13070, DS3526). Speedup is measured on a y-axis from 13.4 to 14.0, with grouped bars representing each method per dataset.
### Components/Axes
- **X-axis**: Datasets labeled as DS21050, DS19784, DS13070, DS3526.
- **Y-axis**: Speedup values ranging from 13.4 to 14.0.
- **Legend**:
- Naïve (striped pattern)
- GSE (dotted pattern)
- VSE (crosshatched pattern)
- **Bar Patterns**: Each method is visually distinct via hatching styles.
### Detailed Analysis
1. **DS21050**:
- Naïve: ~13.7
- GSE: ~13.9 (highest in this group)
- VSE: ~13.7
2. **DS19784**:
- Naïve: ~13.7
- GSE: ~13.7
- VSE: ~13.8
3. **DS13070**:
- Naïve: ~13.7
- GSE: ~13.7
- VSE: ~13.7
4. **DS3526**:
- Naïve: ~13.7
- GSE: ~13.6
- VSE: ~14.0 (highest overall)
### Key Observations
- **VSE Dominance**: VSE achieves the highest speedup in DS3526 (14.0) and consistently outperforms Naïve in all datasets.
- **GSE Peaks**: GSE shows the highest speedup in DS21050 (13.9) but underperforms VSE in DS3526.
- **Naïve Consistency**: Naïve maintains a stable speedup (~13.7) across all datasets, indicating minimal variability.
- **DS3526 Anomaly**: VSE's speedup in DS3526 (14.0) is notably higher than other datasets, suggesting a potential optimization or dataset-specific efficiency.
### Interpretation
The data demonstrates that **VSE** is the most effective method for speedup, particularly in the DS3526 dataset, where it achieves a 14.0 speedup. This suggests VSE may leverage optimizations or parallelism better suited to certain workloads. **GSE** performs comparably to Naïve in most cases but lags behind VSE in DS3526. The **Naïve** method shows no significant improvement across datasets, highlighting its limitations. The stark contrast in VSE's performance in DS3526 warrants further investigation into why this dataset yields such a high speedup, potentially revealing insights into algorithmic efficiency or hardware utilization.
</details>
for determining tie groups in Step2 and Step4. Nevertheless, for both sortingenabled variants, their 16-threaded instances yield relatively consistent speedups over their single-threaded ones, respectively. For the GSE (VSE) variant, its 16threaded instance runs 13 . 74 × (13 . 79 × ) faster than its single-threaded one on average, with a minimum speedup 13.63 (13.69) and a maximum speedup 13.90 (13.97). For each case, the two sorting-enabled variants both yield superior performance to the na¨ ıve variant, where the average speedup is 1.60 for the GSE kernel and 2.72 for the VSE kernel.
Table 3: Performance comparison of three variants on multiple CPU cores
| Instance | Dataset | Time (s) | Time (s) | Time (s) | Speedup | Speedup |
|-----------------|-----------|------------|------------|------------|-----------|-----------|
| Instance | Dataset | Na¨ ıve | GSE | VSE | GSE | VSE |
| Single-threaded | DS21050 | 10,052 | 6,609 | 3,758 | 1.52 | 2.67 |
| Single-threaded | DS19784 | 10,690 | 6,776 | 3,938 | 1.58 | 2.71 |
| Single-threaded | DS13070 | 10,975 | 6,920 | 4,041 | 1.59 | 2.72 |
| Single-threaded | DS3526 | 12,993 | 7,619 | 4,742 | 1.71 | 2.74 |
| | DS21050 | 734 | 475 | 275 | 1.54 | 2.67 |
| | DS19784 | 781 | 495 | 286 | 1.58 | 2.73 |
| | DS13070 | 801 | 504 | 294 | 1.59 | 2.72 |
| | DS3526 | 948 | 559 | 340 | 1.70 | 2.79 |
Table 4: Performance comparison of the three variants on Phi
| Dataset | Time (s) | Time (s) | Time (s) | Speedup | Speedup |
|-----------|------------|------------|------------|-----------|-----------|
| Dataset | Na¨ ıve | GSE | VSE | GSE | VSE |
| DS21050 | 400 | 419 | 261 | 0.95 | 1.53 |
| DS19784 | 424 | 434 | 266 | 0.98 | 1.59 |
| DS13070 | 433 | 459 | 276 | 0.94 | 1.57 |
| DS3526 | 506 | 488 | 296 | 1.04 | 1.71 |
## 5.1.2. On Xeon Phi
Subsequently, we evaluated the three variants on a single 5110P Phi (see Table 4). From Table 4, the VSE variant outperforms the na¨ ıve variant for each dataset by yielding an average speedup of 1.60 with the minimum speedup 1.53 and the maximum speedup 1.71. The GSE variant is superior to the na¨ ıve one on the DS3526 dataset, but inferior to the latter on the remaining three datasets. Interestingly, by revisiting the CPU results shown in Table 3, we recalled that the former actually performs consistently better than the latter for each dataset on CPU. Since both the na¨ ıve and the GSE variants use the same pairwise τ coefficient kernel code for their corresponding CPU- and MIC-oriented implementations, this discordant performance ranking between the two variants could owe to the architectural differences of the two types of processing unit (PU). For instance, by enabling auto-vectorization, the na¨ ıve kernel (see Algorithm 1) can concurrently process 16 integer elements by one 512-bit SIMD vector instruction, in contrast with 4 integer elements by one 128-bit SSE instruction on CPU. This fourfold increase in parallelism would enable the na¨ ıve kernel to further boost performance.
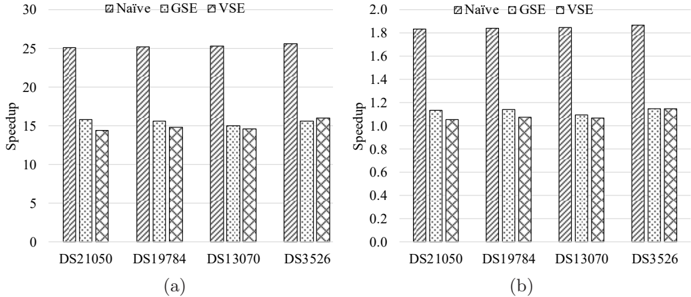
Figure 4 shows the speedups of each variant on the Phi over on multiple CPU cores for each dataset. From Figure 4, it is observed that the Phi instance of each variant outperforms its corresponding single-threaded and 16-threaded CPU instances for each dataset. Specifically, the Phi instance of the na¨ ıve variant runs 25 . 34 × faster on average than its single-threaded CPU instance, with the maximum speedup 25.67, and 1 . 85 × faster on average than the 16threaded CPU instance, with the maximum speedup 1.87. Compared to their single-threaded CPU instances, the Phi instances of the GSE and VSE variants produce the average speedups of 15.52 and 14.96 and the maximum speedups of 15.77 and 16.00, respectively. Meanwhile, in comparison to their 16-threaded CPU instances, their Phi instances performs 1 . 13 × and 1 . 08 × better on average and 1 . 15 × and 1 . 15 × better at maximum, respectively.
## 5.2. Comparison With MATLAB and R
Secondly, we compared our algorithm with all-pairs τ coefficient implementations in the widely used MATLAB (version R2015b) and R (version 3.2.0). MATLAB and R are executed in one 16-core compute node mentioned above, where MATLAB runs 16 threads as it supports multithreading and R runs in sequential. For fair comparison, both MATLAB and R merely compute all-pairs
Figure 4: Speedups of each variant on Phi over on CPU: (a) speedups over one CPU core and (b) speedups over 16 CPU cores.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Bar Chart: Speedup Comparison Across Datasets and Methods
### Overview
The image contains two side-by-side bar charts (subplots a and b) comparing speedup values for four datasets (DS21050, DS19784, DS13070, DS3526) across three computational methods: Naïve, GSE, and VSE. The charts use grayscale patterns (striped, dotted, crosshatched) to differentiate methods. Subplot (a) shows absolute speedup values (0–30), while subplot (b) shows normalized speedup (0–2.0).
### Components/Axes
- **X-axis**: Datasets (DS21050, DS19784, DS13070, DS3526), labeled sequentially from left to right.
- **Y-axis (a)**: Speedup (0–30), with gridlines at 5-unit intervals.
- **Y-axis (b)**: Speedup (0–2.0), with gridlines at 0.2-unit intervals.
- **Legend**: Positioned at the top of each subplot, with labels:
- Naïve (striped pattern)
- GSE (dotted pattern)
- VSE (crosshatched pattern)
- **Subplot Titles**: None explicitly labeled, but subplot (a) has higher magnitude values than (b).
### Detailed Analysis
#### Subplot (a) (Absolute Speedup)
- **DS21050**:
- Naïve: ~25
- GSE: ~15
- VSE: ~14
- **DS19784**:
- Naïve: ~25
- GSE: ~15
- VSE: ~14
- **DS13070**:
- Naïve: ~25
- GSE: ~15
- VSE: ~14
- **DS3526**:
- Naïve: ~25
- GSE: ~15
- VSE: ~16
#### Subplot (b) (Normalized Speedup)
- **DS21050**:
- Naïve: ~1.8
- GSE: ~1.1
- VSE: ~1.0
- **DS19784**:
- Naïve: ~1.8
- GSE: ~1.1
- VSE: ~1.0
- **DS13070**:
- Naïve: ~1.8
- GSE: ~1.1
- VSE: ~1.0
- **DS3526**:
- Naïve: ~1.8
- GSE: ~1.1
- VSE: ~1.1
### Key Observations
1. **Method Consistency**: Naïve consistently shows the highest speedup in both subplots, followed by GSE and VSE.
2. **Dataset Variance**: All datasets exhibit similar trends, with no significant outliers between datasets.
3. **Normalization Impact**: Subplot (b) values are ~1/20th of subplot (a), suggesting normalization or unit conversion between subplots.
4. **Pattern Accuracy**: Legend patterns (striped/dotted/crosshatched) align perfectly with bar styles in both subplots.
### Interpretation
The data suggests that the Naïve method achieves the highest speedup across all datasets, while GSE and VSE perform comparably but with lower efficiency. The near-identical trends across datasets imply that method performance is independent of dataset characteristics. The drastic reduction in subplot (b) values (vs. subplot (a)) indicates a potential normalization factor (e.g., baseline speedup subtracted) or a unit conversion (e.g., from absolute to relative speedup). The slight advantage of VSE over GSE in DS3526 (subplot a) may reflect dataset-specific optimizations, but the small difference (~1 unit) suggests minimal practical impact. This analysis highlights the Naïve method as the most efficient choice in this context, though further investigation into the normalization methodology is warranted.
</details>
Table 5: Performance comparison with MATLAB and R
| Dataset | Time (s) | Time (s) | Speedup over MLAB | Speedup over MLAB | Speedup over MLAB | Speedup over R | Speedup over R | Speedup over R |
|-----------|------------|------------|---------------------|---------------------|---------------------|------------------|------------------|------------------|
| Dataset | MLAB | R | Na¨ ıve | GSE | VSE | Na¨ ıve | GSE | VSE |
| DS21050 | 182,343 | 266,001 | 456 | 435 | 699 | 665 | 635 | 1,019 |
| DS19784 | 205,181 | 284,215 | 484 | 473 | 772 | 671 | 655 | 1,069 |
| DS13070 | 205,063 | 287,635 | 473 | 446 | 743 | 664 | 626 | 1,042 |
| DS3526 | 240,778 | 345,668 | 476 | 494 | 812 | 683 | 709 | 1,166 |
τ coefficient values, without conducting statistical tests, same as our algorithm does. Table 5 shows the runtimes of the 16-threaded MATLAB and sequential R instances as well as their comparison with our three variants that execute on the 5110P Phi. From the table, each variant demonstrates excellent speedups, i.e. two orders-of-magnitude over 16-threaded MATLAB and three orders-ofmagnitude over sequential R. Compared to 16-threaded MATLAB, the average and maximum speedups are 472 and 484 for the na¨ ıve variant, 462 and 494 for the GSE variant and 756 and 812 for the VSE variant, respectively. In contrast, the average and maximum speedups over sequential R are 671 and 683 for the na¨ ıve variant, 656 and 709 for the GSE variant and 1,074 and 1,166 for the VSE variant, respectively.
## 5.3. Parallel Scalability Assessment
## 5.3.1. Multithreading
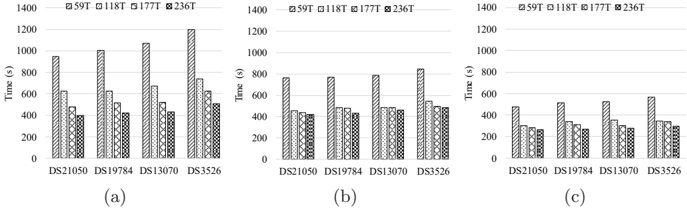
Thirdly, we evaluated the multithreading scalability of our variants on the Phi with respect to number of threads. Figure 5 shows the parallel scalability of the three variants. In this test, we used balanced thread affinity to ensure that thread allocation is balanced over the cores and the threads allocated to the same core have consecutive identifiers (i.e. neighbors of each other). This
Figure 5: Multithreading scalability of different variants: (a) the na¨ ıve variant, (b) the GSE variant and (c) the VSE variant.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Bar Charts: Time Comparison Across DS Labels and T Categories
### Overview
The image contains three bar charts (a, b, c) comparing time values (in seconds) across four categories (59T, 118T, 177T, 236T) for four datasets (DS21050, DS19784, DS13070, DS3526). Each chart uses distinct bar patterns and colors to differentiate categories, with consistent axis labels and a shared legend.
### Components/Axes
- **X-axis**: Labeled "DS21050", "DS19784", "DS13070", "DS3526" (repeated across all charts).
- **Y-axis**: Labeled "Time (s)" with a scale from 0 to 1400.
- **Legend**: Located on the right, mapping categories to patterns/colors:
- **59T**: Square (■), Gray
- **118T**: Diamond (◇), Light Gray
- **177T**: Triangle (▲), Dark Gray
- **236T**: Circle (●), Black
### Detailed Analysis
#### Chart (a)
- **59T (■)**:
- DS21050: ~950s
- DS19784: ~1000s
- DS13070: ~1050s
- DS3526: ~1200s
- **118T (◇)**:
- DS21050: ~650s
- DS19784: ~600s
- DS13070: ~650s
- DS3526: ~700s
- **177T (▲)**:
- DS21050: ~700s
- DS19784: ~650s
- DS13070: ~700s
- DS3526: ~750s
- **236T (●)**:
- DS21050: ~450s
- DS19784: ~420s
- DS13070: ~440s
- DS3526: ~480s
#### Chart (b)
- **59T (■)**:
- DS21050: ~780s
- DS19784: ~780s
- DS13070: ~790s
- DS3526: ~840s
- **118T (◇)**:
- DS21050: ~480s
- DS19784: ~480s
- DS13070: ~490s
- DS3526: ~500s
- **177T (▲)**:
- DS21050: ~490s
- DS19784: ~490s
- DS13070: ~490s
- DS3526: ~500s
- **236T (●)**:
- DS21050: ~440s
- DS19784: ~440s
- DS13070: ~440s
- DS3526: ~480s
#### Chart (c)
- **59T (■)**:
- DS21050: ~500s
- DS19784: ~500s
- DS13070: ~500s
- DS3526: ~580s
- **118T (◇)**:
- DS21050: ~320s
- DS19784: ~320s
- DS13070: ~320s
- DS3526: ~340s
- **177T (▲)**:
- DS21050: ~330s
- DS19784: ~330s
- DS13070: ~330s
- DS3526: ~340s
- **236T (●)**:
- DS21050: ~280s
- DS19784: ~280s
- DS13070: ~280s
- DS3526: ~300s
### Key Observations
1. **Consistent Trends**: Across all charts, **59T** consistently has the highest time, while **236T** has the lowest. This inverse relationship holds for all datasets.
2. **Magnitude Differences**:
- In chart (a), time values for 59T are ~2–3x higher than 236T.
- In chart (c), the gap narrows (59T ~1.7x higher than 236T).
3. **Dataset Variability**:
- DS3526 generally shows higher time values than other datasets, especially in chart (a) (1200s for 59T).
- DS21050 and DS19784 exhibit similar trends across charts.
### Interpretation
The data suggests a **negative correlation between T values and time**: higher T values (e.g., 236T) correspond to shorter processing times. This could indicate:
- **Efficiency Gains**: Larger T values (possibly representing computational resources or iterations) reduce processing time.
- **Scalability**: The system scales better with increased T, though diminishing returns are observed in chart (c).
- **Dataset-Specific Factors**: DS3526’s higher baseline times may reflect inherent complexity or larger data size.
Notably, chart (c) shows the smallest time differences between categories, implying potential optimization or saturation effects at higher T values. The consistency across datasets reinforces the reliability of this trend.
</details>
thread affinity configuration is attained by setting the environment variable KMP AFFINITY to balanced .
From the figures, it is observed that each variant gets performance improved as the number of active threads per core grows from 1, via 2 and 3, to 4 (corresponding to 59, 118, 177 and 236 threads, respectively). As each core is dual issue and employs in-order execution, at least two threads per core are required in order to saturate the compute capacity of each core. Meanwhile, when moving from one thread per core to two threads per core, we expect that the speedup could be close to 2. In this regard, we investigated the speedup of the instance with two threads per core over the one with one thread per core for each variant, and found that the average speedups are 1.58, 1.61 and 1.56 for the na¨ ıve, GSE and VSE variants, respectively. This finding is close to our expectation largely. Furthermore, since all threads per core share the dual in-order execution pipeline, deploying three or four threads per core may further improve performance but normally with decreased parallel efficiency (with respect to threads rather than cores). Note that for the 5110P Phi, only 59 out of 60 cores are used for computing as one core is reserved for the operating system running inside. Since each variant reaches peak performance at 236 threads, we used this number of threads for performance evaluation in all tests, unless otherwise stated.
## 5.3.2. Distributed computing
Finally, we measured the parallel scalability of our algorithm by varying the number of Phis used in a distributed environment (see Figure 6). This test is conducted in a cluster that consists of 16 Phis and is constituted by the aforementioned 8 compute nodes. Each variant used 236 threads, since this setting leads to the best performance as mentioned above. From Figure 6, the na¨ ıve variant demonstrates nearly constant speedups for all datasets on a specific number of Phis, while the two sorting-enabled variants exposed slight fluctuations under the same hardware configuration. This can be explained by the fact that the runtime of our na¨ ıve variant is independent of vector content, whereas that of each sorting-enabled variant is sensitive to actual vector content to some degree. Moreover, for each dataset, it is observed that every variant has demon-
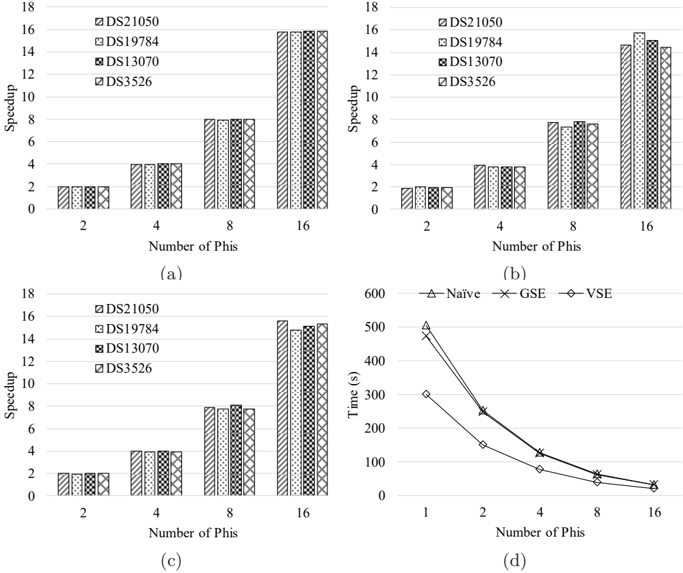
Figure 6: Distributed computing scalability: (a) the na¨ ıve variant, (b) the GSE variant and (c) the VSE variant and (d) runtimes of each variant on the DS3526 dataset.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Bar Charts and Line Graphs: Speedup and Time Analysis Across Datasets and Methods
### Overview
The image contains four subplots analyzing computational performance metrics. Subplots (a), (b), and (c) are bar charts comparing speedup and time across datasets (DS21050, DS19784, DS13070, DS3526) at varying numbers of PHIs (2, 4, 8, 16). Subplot (d) is a line graph comparing time efficiency of three methods (Naïve, GSE, VSE) across PHI counts. All values are approximate with visual uncertainty.
---
### Components/Axes
#### Subplot (a)
- **X-axis**: Number of PHIs (2, 4, 8, 16)
- **Y-axis**: Speedup (0–18)
- **Legend**:
- DS21050 (solid black)
- DS19784 (dotted black)
- DS13070 (crosshatch black)
- DS3526 (diagonal stripes black)
- **Legend Position**: Top-right
#### Subplot (b)
- **X-axis**: Number of PHIs (2, 4, 8, 16)
- **Y-axis**: Speedup (0–18)
- **Legend**: Same as (a)
- **Legend Position**: Top-right
#### Subplot (c)
- **X-axis**: Number of PHIs (2, 4, 8, 16)
- **Y-axis**: Time (s) (0–600)
- **Legend**: Same as (a)
- **Legend Position**: Top-right
#### Subplot (d)
- **X-axis**: Number of PHIs (1, 2, 4, 8, 16)
- **Y-axis**: Time (s) (0–600)
- **Legend**:
- Naïve (triangle)
- GSE (cross)
- VSE (diamond)
- **Legend Position**: Top-right
---
### Detailed Analysis
#### Subplot (a)
- **DS21050**: Speedup increases from ~2 (2 PHIs) to ~16 (16 PHIs).
- **DS19784**: Speedup peaks at ~14 (16 PHIs), with ~4 at 4 PHIs.
- **DS13070**: Speedup rises to ~12 (16 PHIs), ~3 at 4 PHIs.
- **DS3526**: Speedup plateaus at ~2 across all PHI counts.
#### Subplot (b)
- **DS21050**: Speedup reaches ~14 (16 PHIs), ~2 at 2 PHIs.
- **DS19784**: Speedup peaks at ~16 (16 PHIs), ~3 at 4 PHIs.
- **DS13070**: Speedup ~12 (16 PHIs), ~4 at 8 PHIs.
- **DS3526**: Speedup ~8 (16 PHIs), ~2 at 2 PHIs.
#### Subplot (c)
- **DS21050**: Time ~200s (2 PHIs) to ~140s (16 PHIs).
- **DS19784**: Time ~400s (2 PHIs) to ~120s (16 PHIs).
- **DS13070**: Time ~300s (2 PHIs) to ~100s (16 PHIs).
- **DS3526**: Time ~500s (2 PHIs) to ~80s (16 PHIs).
#### Subplot (d)
- **Naïve**: Time decreases from ~500s (1 PHI) to ~50s (16 PHIs).
- **GSE**: Time drops from ~450s (1 PHI) to ~40s (16 PHIs).
- **VSE**: Time reduces from ~400s (1 PHI) to ~30s (16 PHIs).
---
### Key Observations
1. **Speedup Trends**:
- DS21050 and DS19784 show the highest speedup gains with increasing PHIs.
- DS3526 exhibits minimal speedup improvement, suggesting inefficiency or saturation.
2. **Time Efficiency**:
- All methods improve time efficiency with more PHIs, but VSE outperforms others consistently.
- Naïve method has the highest time overhead, especially at low PHI counts.
3. **Dataset Variability**:
- DS3526 underperforms in speedup but achieves the lowest time in (c), indicating potential trade-offs.
---
### Interpretation
- **Speedup vs. Time Trade-off**: Higher PHI counts generally improve speedup but reduce time, except for DS3526, which shows inconsistent behavior.
- **Method Efficiency**: VSE is the most efficient method, reducing time by ~90% compared to Naïve at 16 PHIs.
- **Dataset-Specific Behavior**: DS21050 and DS19784 benefit most from PHI scaling, while DS3526 may have architectural or algorithmic limitations.
- **Anomalies**: DS3526’s low speedup in (a) contrasts with its low time in (c), suggesting it may prioritize throughput over latency or vice versa.
This analysis highlights the importance of method selection (VSE) and dataset characteristics in optimizing computational performance.
</details>
strated rather good scalability with respect to number of Phis. Concretely, the na¨ ıve variant achieves an average speedup of 2.00, 3.99, 7.96 and 15.81, the GSE one yields an average speedup of 1.93, 3.82, 7.63 and 14.97, and the VSE one produces an average speedup of 1.99, 3.94, 7.86 and 15.23, on 2, 4, 8 and 16 Phis, respectively.
## 6. Conclusion
Pairwise association measure is an important operation in searching for meaningful insights within a dataset by examining potentially interesting relationships between data variables of the dataset. However, all-pairs association computation are computationally demanding for a large volume of data and may take a prohibitively long sequential runtime. This computational challenge for big data motivated us to use parallel/high-performance computing architectures to accelerate its execution.
In this paper, we have investigated the parallelization of all-pairs Kendall's τ coefficient computation using MIC processors as the accelerator. To the best of our knowledge, this is for the first time that all-pairs τ coefficient computation
has been parallelized on MIC processors. For the τ coefficient, we have developed three variants, namely the na¨ ıve variant, the GSE variant and the VSE variant, based on three pairwise τ coefficient kernels, i.e. the na¨ ıve kernel, the GSE kernel and the VSE kernel. The three variants all can execute on CPUs, Phis and their clusters. The na¨ ıve kernel has a time complexity of O ( n 2 ), while the other two sorting-enabled kernels have an improved time complexity of O ( n log n ). Furthermore, we have proposed a generic framework for workload balancing in symmetric all-pairs computation and overcoming memory limitation on the host or accelerator side. This framework assigns unique identifiers to jobs in the upper triangle of the job matrix and builds provable bijective functions between job identifier and coordinate space.
The performance of the three variants was evaluated using a collection of real gene expression datasets produced from whole human genomes. Our experimental results demonstrated that on one 5110P Phi, the na¨ ıve variant runs up to 25 . 67 × faster than its execution on a single CPU core, and up to 1 . 87 × faster than on 16 CPU cores. On the same Phi, the GSE and VSE variants run up to 15 . 77 × and 16 . 00 × faster than their executions on a single CPU core, and up to 1 . 15 × and 1 . 15 × faster than on 16 CPU cores, respectively. Meanwhile, on the same CPU/Phi hardware configuration, the VSE variant achieves superior performance to the na¨ ıve and GSE variants. Interestingly, the na¨ ıve variant was observed to be inferior to the GSE variant on CPUs for both single-threaded and 16-threaded settings, but became superior to the latter on the 5110P Phi for most benchmarking datasets used. As both variants use the same core C++ code for their corresponding CPU- and MIC-oriented implementations as mentioned above, this observation suggests that the architectural differences between different types of PUs may make substantial impact on the resulting performance. Subsequently, we compared our algorithm with the third-party counterparts implemented in the popular MATLAB and R, observing that our algorithm on a single 5110P Phi runs up to 812 × faster than 16-threaded MATLAB and up to 1 , 166 × faster than sequential R, both of which are executed on high-end Intel E5-2650 CPUs. We further assessed the parallel scalability of our algorithm with respect to number of Phis in a distributed environment, exposing that our algorithm demonstrated rather good distributed computing scalability.
Finally, it is worth mentioning that the current version of our VSE kernel constrains the largest n value to 2 15 -1, due to 32-bit integer packing. One solution to overcome this constraint is packing a variable pair ( u i , v i ) into a 64-bit integer with each variable occupying 32 bits. In this case, we can split a 512-bit vector into 8 lanes with each lane representing a 64-bit integer, and then implement vectorized pairwise merge of sorted subarrays based on 64-bit integers. Nonetheless, it should be noted that this 64-bit solution has twice less parallelism than 32-bit. In the future, we plan to combine this non-linear measure with other linear or non-linear correlation/dependence measures to generate fused co-expression networks for genome-wide gene expression data analysis at population level. In addition, since R programming language is frequently used in data analytics and the R implementation of all-pairs τ coefficient computation
is extremely slow for large-scale datasets, we also plan to release a R package for public use based on our research in this study.
## Acknowledgment
This research is supported in part by US National Science Foundation under IIS-1416259 and an Intel Parallel Computing Center award. Conflict of interest : none declared.
## References
## References
- [1] Q. Zhu, A. K. Wong, A. Krishnan, M. R. Aure, A. Tadych, R. Zhang, D. C. Corney, C. S. Greene, L. A. Bongo, V. N. Kristensen, et al., Targeted exploration and analysis of large cross-platform human transcriptomic compendia, Nature Methods 12 (3) (2015) 211-214.
- [2] R. Steuer, J. Kurths, C. O. Daub, J. Weise, J. Selbig, The mutual information: detecting and evaluating dependencies between variables, Bioinformatics 18 (suppl 2) (2002) S231-S240.
- [3] A. J. Butte, I. S. Kohane, Unsupervised knowledge discovery in medical databases using relevance networks., in: Proceedings of the AMIA Symposium, American Medical Informatics Association, 1999, p. 711.
- [4] M. Mutwil, S. Klie, T. Tohge, F. M. Giorgi, O. Wilkins, M. M. Campbell, A. R. Fernie, B. Usadel, Z. Nikoloski, S. Persson, Planet: combined sequence and expression comparisons across plant networks derived from seven species, The Plant Cell 23 (3) (2011) 895-910.
- [5] A. Gobbi, G. Jurman, A null model for pearson coexpression networks, PloS One 10 (6) (2015) e0128115.
- [6] A. A. Margolin, I. Nemenman, K. Basso, C. Wiggins, G. Stolovitzky, R. D. Favera, A. Califano, ARACNE: an algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context, BMC Bioinformatics 7 (Suppl 1) (2006) S7.
- [7] M. Aluru, J. Zola, D. Nettleton, S. Aluru, Reverse engineering and analysis of large genome-scale gene networks, Nucleic Acids Research 41 (1) (2013) e24.
- [8] A. Lachmann, F. M. Giorgi, G. Lopez, A. Califano, Aracne-ap: gene network reverse engineering through adaptive partitioning inference of mutual information, Bioinformatics 32 (14) (2016) 2233-2235.
- [9] J. Lee Rodgers, W. A. Nicewander, Thirteen ways to look at the correlation coefficient, The American Statistician 42 (1) (1988) 59-66.
- [10] L. Song, P. Langfelder, S. Horvath, Comparison of co-expression measures: mutual information, correlation, and model based indices, BMC Bioinformatics 13 (1) (2012) 328.
- [11] C. Spearman, Spearmans rank correlation coefficient, Amer J Psychol 15 (1904) 72-101.
- [12] M. G. Kendall, Rank correlation methods, Griffin, 1948.
- [13] Y. Wang, Y. Li, H. Cao, M. Xiong, Y. Y. Shugart, L. Jin, Efficient test for nonlinear dependence of two continuous variables, BMC Bioinformatics 16 (1) (2015) 1.
- [14] W. Xu, Y. Hou, Y. Hung, Y. Zou, A comparative analysis of spearman's rho and kendall's tau in normal and contaminated normal models, Signal Processing 93 (1) (2013) 261-276.
- [15] G. A. Darbellay, I. Vajda, et al., Estimation of the information by an adaptive partitioning of the observation space, IEEE Transactions on Information Theory 45 (4) (1999) 1315-1321.
- [16] C. O. Daub, R. Steuer, J. Selbig, S. Kloska, Estimating mutual information using b-spline functions-an improved similarity measure for analysing gene expression data, BMC Bioinformatics 5 (1) (2004) 1.
- [17] K.-C. Liang, X. Wang, Gene regulatory network reconstruction using conditional mutual information, EURASIP Journal on Bioinformatics and Systems Biology 2008 (1) (2008) 1-14.
- [18] G. J. Sz´ ekely, M. L. Rizzo, N. K. Bakirov, et al., Measuring and testing dependence by correlation of distances, The Annals of Statistics 35 (6) (2007) 2769-2794.
- [19] M. R. Kosorok, On brownian distance covariance and high dimensional data, The Annals of Applied Statistics 3 (4) (2009) 1266.
- [20] A. Gretton, O. Bousquet, A. Smola, B. Sch¨ olkopf, Measuring statistical dependence with hilbert-schmidt norms, in: International Conference on Algorithmic Learning Theory, Springer, 2005, pp. 63-77.
- [21] D. N. Reshef, Y. A. Reshef, H. K. Finucane, S. R. Grossman, G. McVean, P. J. Turnbaugh, E. S. Lander, M. Mitzenmacher, P. C. Sabeti, Detecting novel associations in large data sets, Science 334 (6062) (2011) 1518-1524.
- [22] L. Song, A. Smola, A. Gretton, J. Bedo, K. Borgwardt, Feature selection via dependence maximization, Journal of Machine Learning Research 13 (May) (2012) 1393-1434.
- [23] B. H. W. Chang, W. Tian, Gsa-lightning: ultra-fast permutation-based gene set analysis, Bioinformatics 32 (19) (2016) 3029-3031.
- [24] H. Abdi, The kendall rank correlation coefficient, Encyclopedia of Measurement and Statistics. Sage, Thousand Oaks, CA (2007) 508-510.
- [25] S. Wang, I. Pandis, D. Johnson, I. Emam, F. Guitton, A. Oehmichen, Y. Guo, Optimising parallel R correlation matrix calculations on gene expression data using mapreduce, BMC Bioinformatics 15 (1) (2014) 1.
- [26] R. C. Team, et al., R: A language and environment for statistical computing, R Foundation for Statistical Computing, 2013.
- [27] J. Dean, S. Ghemawat, Mapreduce: simplified data processing on large clusters, Communications of the ACM 51 (1) (2008) 107-113.
- [28] Y. Liu, T. Pan, S. Aluru, Parallel pairwise correlation computation on intel xeon phi clusters, in: 28th International Symposium on Computer Architecture and High Performance Computing, IEEE, 2016, pp. 141-149.
- [29] Mathworks, https://www.mathworks.com/products/matlab.html (2015).
- [30] A. Sodani, R. Gramunt, J. Corbal, H.-S. Kim, K. Vinod, S. Chinthamani, S. Hutsell, R. Agarwal, Y.-C. Liu, Knights landing: Second-generation intel xeon phi product, IEEE Micro 36 (2) (2016) 34-46.
- [31] J. Jeffers, J. Reinders, Intel Xeon Phi coprocessor high-performance programming, Morgan Kaufmann, 2013.
- [32] W. R. Knight, A computer method for calculating kendall's tau with ungrouped data, Journal of the American Statistical Association 61 (314) (1966) 436-439.
- [33] H. Inoue, T. Moriyama, H. Komatsu, T. Nakatani, Aa-sort: A new parallel sorting algorithm for multi-core simd processors, in: Proceedings of the 16th International Conference on Parallel Architecture and Compilation Techniques, IEEE Computer Society, 2007, pp. 189-198.
- [34] K. E. Batcher, Sorting networks and their applications, in: Proceedings of the April 30-May 2, 1968, spring joint computer conference, ACM, 1968, pp. 307-314.
- [35] J. Chhugani, A. D. Nguyen, V. W. Lee, W. Macy, M. Hagog, Y.-K. Chen, A. Baransi, S. Kumar, P. Dubey, Efficient implementation of sorting on multi-core simd cpu architecture, Proceedings of the VLDB Endowment 1 (2) (2008) 1313-1324.
- [36] T. Xiaochen, K. Rocki, R. Suda, Register level sort algorithm on multicore simd processors, in: Proceedings of the 3rd Workshop on Irregular Applications: Architectures and Algorithms, ACM, 2013, p. 9.
- [37] S. Odeh, O. Green, Z. Mwassi, O. Shmueli, Y. Birk, Merge path-cacheefficient parallel merge and sort, Tech. rep., Technical report, CCIT Report (2012).
- [38] O. Green, R. McColl, D. A. Bader, Gpu merge path: a gpu merging algorithm, in: Proceedings of the 26th ACM international conference on Supercomputing, ACM, 2012, pp. 331-340.
- [39] Intel, Intel xeon phi processor software optimization guide, https://software.intel.com/en-us/articles/intel-xeon-phi-processorsoftware-optimization-guide (2016).
- [40] T. Kiefer, P. B. Volk, W. Lehner, Pairwise element computation with MapReduce, in: Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, ACM, 2010, pp. 826-833.
- [41] W. Gropp, T. Hoefler, R. Thakur, E. Lusk, Using advanced MPI: Modern features of the message-passing interface, MIT Press, 2014.
- [42] T. El-Ghazawi, L. Smith, Upc: unified parallel c, in: Proceedings of the 2006 ACM/IEEE conference on Supercomputing, ACM, 2006, p. 27.
- [43] J. Gonz´ alez-Dom´ ınguez, Y. Liu, B. Schmidt, Parallel and scalable shortread alignment on multi-core clusters using upc++, PLoS ONE 11 (1) (2016) e0145490.