# Attention Is All You Need
**Authors**:
- Ashish Vaswani (Google Brain)
- &Noam Shazeer (Google Brain)
- &Niki Parmar (Google Research)
- &Jakob Uszkoreit (Google Research)
- &Llion Jones (Google Research)
- &Aidan N. Gomez (University of Toronto)
- &Łukasz Kaiser (Google Brain)
- &Illia Polosukhin
> Equal contribution. Listing order is random. Jakob proposed replacing RNNs with self-attention and started the effort to evaluate this idea. Ashish, with Illia, designed and implemented the first Transformer models and has been crucially involved in every aspect of this work. Noam proposed scaled dot-product attention, multi-head attention and the parameter-free position representation and became the other person involved in nearly every detail. Niki designed, implemented, tuned and evaluated countless model variants in our original codebase and tensor2tensor. Llion also experimented with novel model variants, was responsible for our initial codebase, and efficient inference and visualizations. Lukasz and Aidan spent countless long days designing various parts of and implementing tensor2tensor, replacing our earlier codebase, greatly improving results and massively accelerating our research. Work performed while at Google Brain.Work performed while at Google Research.
Provided proper attribution is provided, Google hereby grants permission to reproduce the tables and figures in this paper solely for use in journalistic or scholarly works.
## Abstract
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
## 1 Introduction
Recurrent neural networks, long short-term memory [13] and gated recurrent [7] neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation [35, 2, 5]. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures [38, 24, 15].
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states $h_t$ , as a function of the previous hidden state $h_t-1$ and the input for position $t$ . This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks [21] and conditional computation [32], while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences [2, 19]. In all but a few cases [27], however, such attention mechanisms are used in conjunction with a recurrent network.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
## 2 Background
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU [16], ByteNet [18] and ConvS2S [9], all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions [12]. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations [4, 27, 28, 22].
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks [34].
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as [17, 18] and [9].
## 3 Model Architecture
<details>
<summary>Figures/ModalNet-21.png Details</summary>
### Visual Description
## Diagram: Transformer Architecture (Encoder-Decoder)
### Overview
This image is a technical schematic diagram illustrating the architecture of the Transformer model, a neural network architecture primarily used for sequence-to-sequence tasks like machine translation. The diagram is presented in a vertical, flowchart-style layout on a light gray background. It clearly separates the model into two main stacks: an **Encoder** on the left and a **Decoder** on the right, which are connected. The flow of data is from the bottom (Inputs/Outputs) to the top (Output Probabilities).
### Components/Axes
The diagram is composed of labeled rectangular blocks, circles, and directional arrows indicating data flow. There are no traditional chart axes. The key components and their spatial relationships are:
**1. Input Pathway (Bottom-Left):**
* **Inputs**: Text label at the very bottom left.
* **Input Embedding**: A pink rectangular block directly above "Inputs".
* **Positional Encoding**: A circular icon with a sine wave symbol, located to the left of the Input Embedding block. An arrow points from this circle to a summation symbol (`+`) above the Input Embedding.
* **Summation (`+`)**: A circle with a plus sign, indicating the addition of the Input Embedding and Positional Encoding.
**2. Encoder Stack (Left, labeled "Nx"):**
* A large rounded rectangle enclosing a repeating block (indicated by "Nx" to its left).
* **Multi-Head Attention**: An orange rectangular block. It receives three arrows from below (representing Queries, Keys, Values).
* **Add & Norm**: A yellow rectangular block directly above the Multi-Head Attention block. A residual connection (curved arrow) bypasses the Multi-Head Attention and Add & Norm blocks, feeding into the Add & Norm block.
* **Feed Forward**: A light blue rectangular block above the first Add & Norm.
* **Add & Norm**: A second yellow rectangular block above the Feed Forward block. Another residual connection bypasses the Feed Forward and this Add & Norm block.
* The output of this entire Encoder block is fed into the Decoder stack.
**3. Decoder Stack (Right, labeled "Nx"):**
* A larger rounded rectangle enclosing a repeating block (indicated by "Nx" to its right).
* **Masked Multi-Head Attention**: An orange rectangular block at the bottom of the decoder stack. It receives arrows from below.
* **Add & Norm**: A yellow rectangular block above the Masked Multi-Head Attention. A residual connection bypasses both.
* **Multi-Head Attention**: A second orange rectangular block. This block receives two sets of inputs: one from the Add & Norm block below it, and another from the output of the Encoder stack (indicated by a long arrow coming from the left).
* **Add & Norm**: A yellow rectangular block above this Multi-Head Attention. A residual connection bypasses it.
* **Feed Forward**: A light blue rectangular block.
* **Add & Norm**: The final yellow rectangular block at the top of the decoder stack. A residual connection bypasses the Feed Forward and this block.
**4. Output Pathway (Bottom-Right to Top):**
* **Outputs (shifted right)**: Text label at the very bottom right.
* **Output Embedding**: A pink rectangular block above the "Outputs" label.
* **Positional Encoding**: A circular icon with a sine wave symbol, located to the right of the Output Embedding. An arrow points to a summation symbol (`+`).
* **Summation (`+`)**: Adds the Output Embedding and Positional Encoding.
* The result is fed into the bottom of the Decoder stack.
* **Linear**: A light purple rectangular block above the Decoder stack.
* **Softmax**: A light green rectangular block above the Linear block.
* **Output Probabilities**: Text label at the very top, with an arrow pointing up from the Softmax block.
### Detailed Analysis
The diagram meticulously details the data flow and internal operations of the Transformer:
* **Flow Direction**: The process is strictly bottom-up. Data enters at the bottom ("Inputs" and "Outputs (shifted right)"), passes through embedding and positional encoding layers, then through multiple identical encoder/decoder layers (Nx times), and finally through a linear and softmax layer to produce output probabilities at the top.
* **Encoder-Decoder Connection**: A critical connection is shown by a long, curved arrow originating from the output of the Encoder stack (left) and feeding into the **Multi-Head Attention** block within the Decoder stack (right). This is how the decoder accesses the encoded representation of the input sequence.
* **Residual Connections**: Every major sub-layer (Multi-Head Attention, Feed Forward) is followed by an "Add & Norm" block. The diagram shows this with a primary arrow going into the sub-layer and a parallel, curved "residual" arrow that bypasses the sub-layer and connects directly to the "Add & Norm" block. This visualizes the residual connection and layer normalization step.
* **Masking**: The first attention block in the decoder is specifically labeled **"Masked"** Multi-Head Attention, indicating it prevents positions from attending to subsequent positions, preserving the auto-regressive property.
* **Repetition**: The "Nx" labels next to the encoder and decoder stacks signify that the entire block within the rounded rectangle is repeated N times (a hyperparameter).
### Key Observations
1. **Symmetry and Asymmetry**: The encoder and decoder stacks are structurally similar (both have attention and feed-forward sub-layers with residual connections) but not identical. The decoder has an additional cross-attention layer and uses masking in its first attention layer.
2. **Color Coding**: Components are consistently color-coded:
* Pink: Embedding layers.
* Orange: Attention mechanisms (Multi-Head, Masked Multi-Head).
* Light Blue: Feed Forward networks.
* Yellow: Add & Norm (Residual connection + Layer Normalization).
* Light Purple: Linear transformation.
* Light Green: Softmax activation.
3. **Positional Encoding**: Represented by identical sine wave icons added to both input and output embeddings, emphasizing that the model requires explicit information about token position, as it contains no recurrence or convolution.
4. **Data Flow Clarity**: The arrows are unambiguous. For example, the three arrows into each Multi-Head Attention block clearly represent the Query (Q), Key (K), and Value (V) inputs.
### Interpretation
This diagram is the foundational blueprint for the Transformer architecture. It visually explains the key innovations that enabled its success:
* **Parallelization**: Unlike recurrent neural networks (RNNs), the encoder and decoder stacks process all input tokens simultaneously via the **Multi-Head Attention** mechanism, allowing for highly parallel computation.
* **Contextual Understanding**: The **Multi-Head Attention** blocks allow the model to weigh the importance of different words in the input sequence when processing a given word, capturing long-range dependencies effectively.
* **Sequence-to-Sequence Mapping**: The architecture is explicitly designed for tasks where an input sequence (e.g., an English sentence) must be transformed into an output sequence (e.g., its French translation). The encoder creates a rich representation of the input, and the decoder generates the output one token at a time, attending to both this encoded representation and the previously generated tokens (via masked self-attention).
* **Modularity and Depth**: The "Nx" repetition indicates the model's depth, which is crucial for learning complex patterns. The clear separation of sub-layers (attention, feed-forward, normalization) makes the architecture modular and easier to analyze and scale.
The diagram is not a data chart but a precise technical schematic. It contains no numerical data or trends but provides complete structural information about one of the most influential models in modern machine learning.
</details>
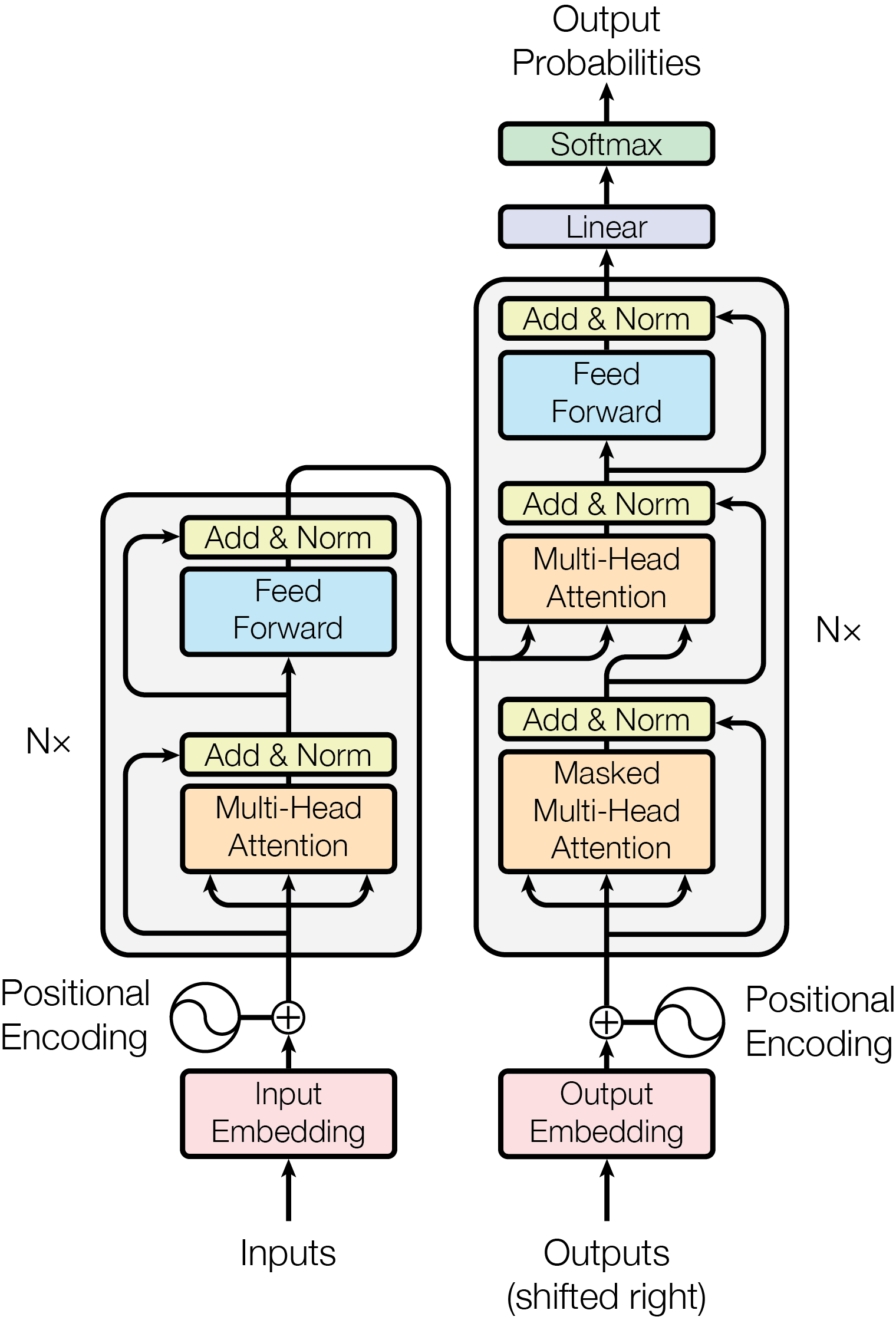
Figure 1: The Transformer - model architecture.
Most competitive neural sequence transduction models have an encoder-decoder structure [5, 2, 35]. Here, the encoder maps an input sequence of symbol representations $(x_1,...,x_n)$ to a sequence of continuous representations $z=(z_1,...,z_n)$ . Given $z$ , the decoder then generates an output sequence $(y_1,...,y_m)$ of symbols one element at a time. At each step the model is auto-regressive [10], consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
### 3.1 Encoder and Decoder Stacks
Encoder:
The encoder is composed of a stack of $N=6$ identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection [11] around each of the two sub-layers, followed by layer normalization [1]. That is, the output of each sub-layer is $LayerNorm(x+Sublayer(x))$ , where $Sublayer(x)$ is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $d_model=512$ .
Decoder:
The decoder is also composed of a stack of $N=6$ identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$ .
### 3.2 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
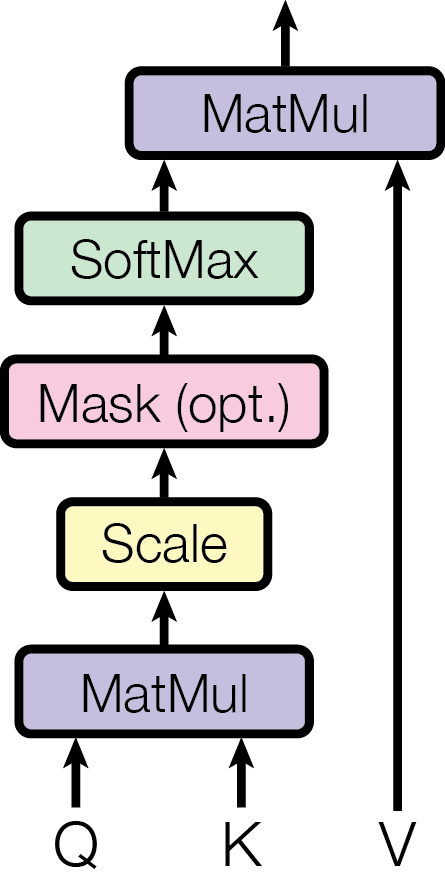
#### 3.2.1 Scaled Dot-Product Attention
We call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries and keys of dimension $d_k$ , and values of dimension $d_v$ . We compute the dot products of the query with all keys, divide each by $√{d_k}$ , and apply a softmax function to obtain the weights on the values.
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix $Q$ . The keys and values are also packed together into matrices $K$ and $V$ . We compute the matrix of outputs as:
$$
Attention(Q,K,V)=softmax(\frac{QK^T}{√{d_k}})V \tag{1}
$$
The two most commonly used attention functions are additive attention [2], and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of $\frac{1}{√{d_k}}$ . Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
While for small values of $d_k$ the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of $d_k$ [3]. We suspect that for large values of $d_k$ , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients To illustrate why the dot products get large, assume that the components of $q$ and $k$ are independent random variables with mean $0$ and variance $1$ . Then their dot product, $q· k=∑_i=1^d_kq_ik_i$ , has mean $0$ and variance $d_k$ .. To counteract this effect, we scale the dot products by $\frac{1}{√{d_k}}$ .
#### 3.2.2 Multi-Head Attention
Scaled Dot-Product Attention
<details>
<summary>Figures/ModalNet-19.png Details</summary>
### Visual Description
## Diagram: Scaled Dot-Product Attention Mechanism
### Overview
The image is a technical flowchart illustrating the computational steps of the scaled dot-product attention mechanism, a core component of transformer architectures in machine learning. It depicts a sequential data flow from inputs (Q, K, V) through several processing blocks to a final output.
### Components/Axes
The diagram consists of labeled rectangular blocks connected by directional arrows, indicating the flow of data. The components are arranged vertically from bottom to top.
**Inputs (Bottom of Diagram):**
* **Q**: Positioned at the bottom-left. Represents the Query matrix.
* **K**: Positioned at the bottom-center. Represents the Key matrix.
* **V**: Positioned at the bottom-right. Represents the Value matrix.
**Processing Blocks (from bottom to top):**
1. **MatMul** (Purple box): First matrix multiplication block. Receives inputs from **Q** and **K**.
2. **Scale** (Yellow box): Scaling operation block. Receives input from the first **MatMul**.
3. **Mask (opt.)** (Pink box): Optional masking operation block. Receives input from **Scale**.
4. **SoftMax** (Green box): Softmax normalization block. Receives input from **Mask (opt.)**.
5. **MatMul** (Purple box): Second matrix multiplication block. Receives input from **SoftMax** and directly from **V**.
**Output (Top of Diagram):**
* An upward-pointing arrow from the final **MatMul** block indicates the output of the attention mechanism.
### Detailed Analysis
The diagram explicitly details the sequence of operations for scaled dot-product attention:
1. **Initial Computation**: The Query (**Q**) and Key (**K**) matrices are multiplied together in the first **MatMul** operation. This computes the raw attention scores.
2. **Scaling**: The result is passed to the **Scale** block. This typically involves dividing the scores by the square root of the key dimension (`√d_k`) to stabilize gradients.
3. **Optional Masking**: The scaled scores then pass through the **Mask (opt.)** block. This step is optional and is used to prevent attention to certain positions (e.g., future tokens in causal language modeling).
4. **Normalization**: The (potentially masked) scores are processed by the **SoftMax** block, which converts them into a probability distribution (attention weights).
5. **Final Aggregation**: The attention weights from the **SoftMax** are multiplied with the Value (**V**) matrix in the final **MatMul** operation. This produces the weighted sum of values, which is the output of the attention layer.
**Spatial Grounding & Flow Verification:**
* The flow is strictly bottom-to-top, as indicated by the arrows.
* The **V** input has a direct, long arrow bypassing the intermediate scaling/masking/softmax steps to connect only to the final **MatMul** block. This is a critical architectural detail.
* The two **MatMul** blocks are visually identical (purple) but perform different functions in the sequence: the first computes scores, the second applies weights to values.
### Key Observations
* **Modularity**: The diagram presents the mechanism as a clear pipeline of discrete, functional modules.
* **Optionality**: The "Mask (opt.)" label explicitly notes that this step is not always required, highlighting a configurable aspect of the architecture.
* **Color Coding**: Blocks are color-coded by function type (purple for matrix operations, yellow for scaling, pink for masking, green for normalization), aiding visual parsing.
* **Input Separation**: The three distinct inputs (Q, K, V) are clearly labeled and enter the pipeline at different points, emphasizing their separate roles.
### Interpretation
This diagram is a canonical representation of the scaled dot-product attention function, mathematically expressed as:
`Attention(Q, K, V) = softmax( (QK^T) / √d_k ) V`
It visually answers the question: "How do Query, Key, and Value matrices interact to produce a context-aware output?" The flow demonstrates how raw compatibility scores (Q·K) are refined through scaling and normalization to create attention weights, which then selectively aggregate information from the Value matrix. The optional mask component reveals the mechanism's adaptability for tasks like autoregressive generation, where future information must be hidden. This process allows a model to dynamically focus on relevant parts of an input sequence when producing each part of the output, which is the foundational innovation of the transformer model.
</details>
Multi-Head Attention
<details>
<summary>Figures/ModalNet-20.png Details</summary>
### Visual Description
\n
## Diagram: Multi-Head Attention Mechanism (Transformer Architecture)
### Overview
This image is a technical diagram illustrating the architecture of the Multi-Head Attention mechanism, a core component of the Transformer neural network model. It depicts the flow of data through parallel attention heads and the subsequent combination of their outputs. The diagram is presented on a light gray background with black outlines and text.
### Components/Axes
The diagram is structured as a data flow graph with the following labeled components, arranged from bottom to top:
**Inputs (Bottom):**
* **V**: Value input vector/matrix.
* **K**: Key input vector/matrix.
* **Q**: Query input vector/matrix.
**Processing Layers (Middle):**
* **Linear**: Three separate, parallel "Linear" transformation blocks. Each receives one of the inputs (V, K, Q). The diagram shows stacked, semi-transparent layers behind each primary "Linear" box, visually representing multiple parallel heads (`h`).
* **Scaled Dot-Product Attention**: A central, prominent purple block. It receives the outputs from all the parallel "Linear" layers. A bracket labeled **`h`** on the right side of this block indicates that this operation is performed across `h` parallel attention heads.
* **Concat**: A yellow block positioned above the attention block. It receives the outputs from all `h` attention heads (indicated by multiple upward arrows) and concatenates them.
**Output (Top):**
* **Linear**: A final "Linear" transformation block that processes the concatenated output from the previous layer.
* An upward-pointing arrow from the final "Linear" block indicates the output of the entire Multi-Head Attention sub-layer.
### Detailed Analysis
The diagram details the precise data flow and transformation steps:
1. **Input Projection:** The input vectors **V**, **K**, and **Q** each feed into their own dedicated **Linear** layer. The stacked, shadowed boxes behind each "Linear" label indicate that this projection is not singular but is performed `h` times in parallel, once for each attention head. This creates `h` different sets of projected V, K, and Q vectors.
2. **Parallel Attention Calculation:** Each of the `h` sets of projected vectors is processed independently by the **Scaled Dot-Product Attention** mechanism. The bracket labeled **`h`** confirms this parallelism. The core operation within this block (not visually detailed) is: `Attention(Q, K, V) = softmax(QK^T / √d_k)V`.
3. **Output Aggregation:** The outputs from all `h` attention heads (each being a vector/matrix) are gathered by the **Concat** block. The multiple arrows entering this block from below represent the `h` separate outputs being combined into a single, larger vector/matrix.
4. **Final Projection:** The concatenated vector/matrix is passed through a final **Linear** layer. This layer projects the combined multi-head representation back to the model's expected dimensionality, producing the final output of the Multi-Head Attention sub-layer.
### Key Observations
* **Visualizing Parallelism:** The diagram's most salient feature is its use of stacked, semi-transparent layers behind the "Linear" and "Scaled Dot-Product Attention" components. This is a direct visual metaphor for the `h` parallel attention heads, making the "multi-head" concept explicit.
* **Spatial Flow:** The layout is strictly vertical, emphasizing a bottom-up data flow from inputs (V, K, Q) to the final output. The central placement of the "Scaled Dot-Product Attention" block highlights it as the core computational unit.
* **Color Coding:** A minimal color scheme is used for functional distinction: light purple for the core attention operation, pale yellow for the concatenation operation, and white for linear transformations.
* **Label Precision:** All text labels are clear, using a sans-serif font. The critical parameter `h` (number of heads) is explicitly labeled with a bracket, linking the visual metaphor to a concrete hyperparameter.
### Interpretation
This diagram is a canonical representation of the Multi-Head Attention mechanism introduced in the "Attention Is All You Need" paper (Vaswani et al., 2017). It demonstrates the architectural innovation that allows the Transformer model to jointly attend to information from different representation subspaces at different positions.
* **What it demonstrates:** The diagram shows how a single attention mechanism is decomposed into `h` parallel, independent "heads." Each head can learn to focus on different aspects of the input (e.g., syntactic relationships, semantic roles, long-range dependencies) simultaneously. The final linear layer learns to combine these diverse attentional perspectives.
* **Relationships:** The flow illustrates a "split-transform-merge" strategy. The input is split via linear projections into multiple subspaces (`h` heads), processed independently by the same attention function, and then merged via concatenation and a final linear projection. This is more efficient and expressive than applying a single, large attention mechanism.
* **Significance:** This parallel structure is key to the Transformer's performance and scalability. It allows for more nuanced understanding of sequences than single-head attention, as different heads can specialize. The diagram effectively communicates this complex, parallel computational graph in an intuitive, spatial format. The presence of `h` as a labeled parameter underscores that this is a configurable hyperparameter of the model.
</details>
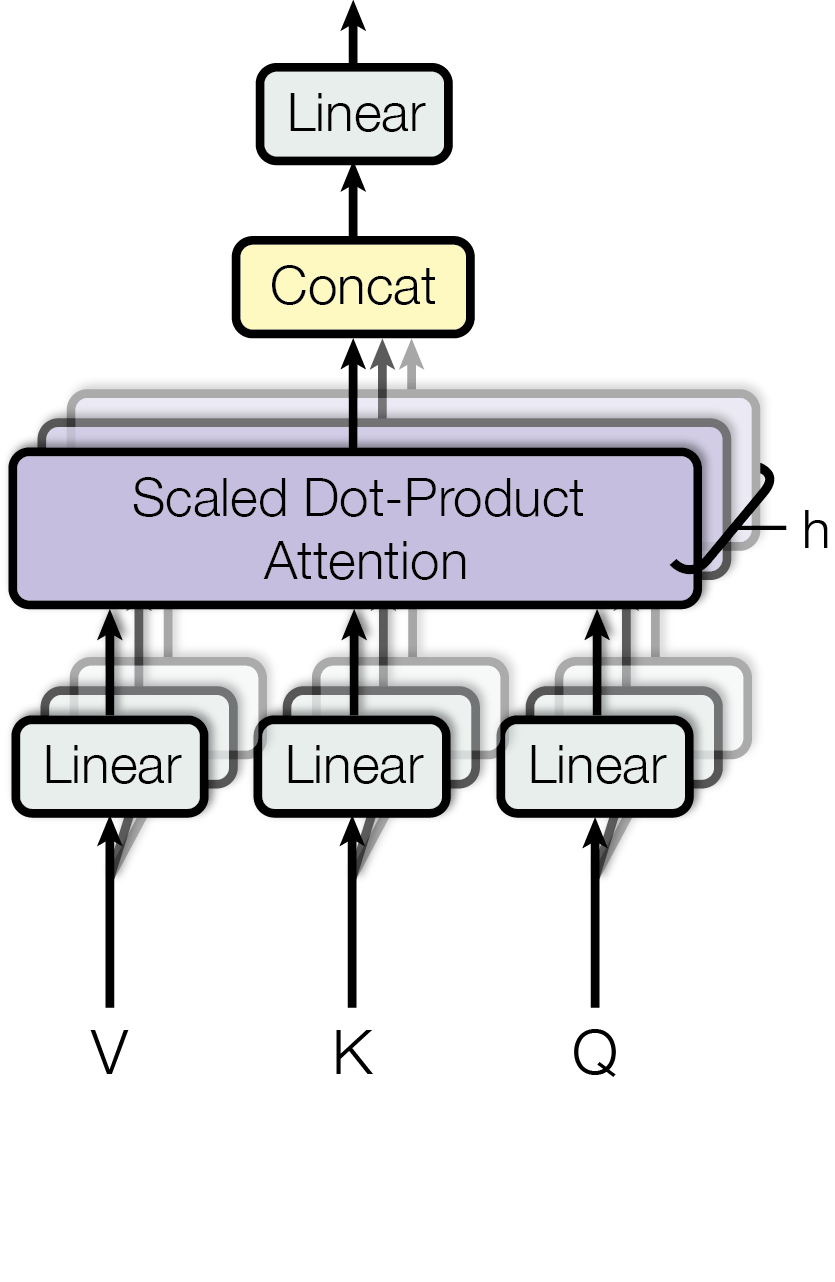
Figure 2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.
Instead of performing a single attention function with $d_model$ -dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values $h$ times with different, learned linear projections to $d_k$ , $d_k$ and $d_v$ dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding $d_v$ -dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure 2.
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
| | $\displaystyleMultiHead(Q,K,V)$ | $\displaystyle=Concat(head_1,...,head_h)W^O$ | |
| --- | --- | --- | --- |
Where the projections are parameter matrices $W^Q_i∈ℝ^d_model× d_k$ , $W^K_i∈ℝ^d_model× d_k$ , $W^V_i∈ℝ^d_model× d_v$ and $W^O∈ℝ^hd_v× d_model$ .
In this work we employ $h=8$ parallel attention layers, or heads. For each of these we use $d_k=d_v=d_model/h=64$ . Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
#### 3.2.3 Applications of Attention in our Model
The Transformer uses multi-head attention in three different ways:
- In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [38, 2, 9].
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
- Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to $-∞$ ) all values in the input of the softmax which correspond to illegal connections. See Figure 2.
### 3.3 Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
$$
FFN(x)=\max(0,xW_1+b_1)W_2+b_2 \tag{2}
$$
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is $d_model=512$ , and the inner-layer has dimensionality $d_ff=2048$ .
### 3.4 Embeddings and Softmax
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension $d_model$ . We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [30]. In the embedding layers, we multiply those weights by $√{d_model}$ .
### 3.5 Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension $d_model$ as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed [9].
In this work, we use sine and cosine functions of different frequencies:
| | $\displaystyle PE_(pos,2i)=sin(pos/10000^2i/d_model)$ | |
| --- | --- | --- |
where $pos$ is the position and $i$ is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from $2π$ to $10000· 2π$ . We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset $k$ , $PE_pos+k$ can be represented as a linear function of $PE_pos$ .
We also experimented with using learned positional embeddings [9] instead, and found that the two versions produced nearly identical results (see Table 3 row (E)). We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
## 4 Why Self-Attention
In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations $(x_1,...,x_n)$ to another sequence of equal length $(z_1,...,z_n)$ , with $x_i,z_i∈ℝ^d$ , such as a hidden layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we consider three desiderata.
One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
The third is the path length between long-range dependencies in the network. Learning long-range dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network. The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies [12]. Hence we also compare the maximum path length between any two input and output positions in networks composed of the different layer types.
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. $n$ is the sequence length, $d$ is the representation dimension, $k$ is the kernel size of convolutions and $r$ the size of the neighborhood in restricted self-attention.
$$
O(n^2· d) O(1) O(1) O(n· d^2) O(n) O(n) O(k· n· d^2) O(1) O(log_k(n)) O(r· n· d) O(1) O(n/r) \tag{1}
$$
As noted in Table 1, a self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires $O(n)$ sequential operations. In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length $n$ is smaller than the representation dimensionality $d$ , which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece [38] and byte-pair [31] representations. To improve computational performance for tasks involving very long sequences, self-attention could be restricted to considering only a neighborhood of size $r$ in the input sequence centered around the respective output position. This would increase the maximum path length to $O(n/r)$ . We plan to investigate this approach further in future work.
A single convolutional layer with kernel width $k<n$ does not connect all pairs of input and output positions. Doing so requires a stack of $O(n/k)$ convolutional layers in the case of contiguous kernels, or $O(log_k(n))$ in the case of dilated convolutions [18], increasing the length of the longest paths between any two positions in the network. Convolutional layers are generally more expensive than recurrent layers, by a factor of $k$ . Separable convolutions [6], however, decrease the complexity considerably, to $O(k· n· d+n· d^2)$ . Even with $k=n$ , however, the complexity of a separable convolution is equal to the combination of a self-attention layer and a point-wise feed-forward layer, the approach we take in our model.
As side benefit, self-attention could yield more interpretable models. We inspect attention distributions from our models and present and discuss examples in the appendix. Not only do individual attention heads clearly learn to perform different tasks, many appear to exhibit behavior related to the syntactic and semantic structure of the sentences.
## 5 Training
This section describes the training regime for our models.
### 5.1 Training Data and Batching
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding [3], which has a shared source-target vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary [38]. Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
### 5.2 Hardware and Schedule
We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models,(described on the bottom line of table 3), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
### 5.3 Optimizer
We used the Adam optimizer [20] with $β_1=0.9$ , $β_2=0.98$ and $ε=10^-9$ . We varied the learning rate over the course of training, according to the formula:
$$
lrate=d_model^-0.5·\min({step\_num}^-0.5,{step\_num}·{warmup\_steps}^-1.5) \tag{3}
$$
This corresponds to increasing the learning rate linearly for the first $warmup\_steps$ training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used $warmup\_steps=4000$ .
### 5.4 Regularization
We employ three types of regularization during training:
Residual Dropout
We apply dropout [33] to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of $P_drop=0.1$ .
Label Smoothing
During training, we employed label smoothing of value $ε_ls=0.1$ [36]. This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
## 6 Results
### 6.1 Machine Translation
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
| Model | BLEU | | Training Cost (FLOPs) | | |
| --- | --- | --- | --- | --- | --- |
| EN-DE | EN-FR | | EN-DE | EN-FR | |
| ByteNet [18] | 23.75 | | | | |
| Deep-Att + PosUnk [39] | | 39.2 | | | $1.0· 10^20$ |
| GNMT + RL [38] | 24.6 | 39.92 | | $2.3· 10^19$ | $1.4· 10^20$ |
| ConvS2S [9] | 25.16 | 40.46 | | $9.6· 10^18$ | $1.5· 10^20$ |
| MoE [32] | 26.03 | 40.56 | | $2.0· 10^19$ | $1.2· 10^20$ |
| Deep-Att + PosUnk Ensemble [39] | | 40.4 | | | $8.0· 10^20$ |
| GNMT + RL Ensemble [38] | 26.30 | 41.16 | | $1.8· 10^20$ | $1.1· 10^21$ |
| ConvS2S Ensemble [9] | 26.36 | 41.29 | | $7.7· 10^19$ | $1.2· 10^21$ |
| Transformer (base model) | 27.3 | 38.1 | | $3.3· 10^18$ | |
| Transformer (big) | 28.4 | 41.8 | | $2.3· 10^19$ | |
On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) in Table 2) outperforms the best previously reported models (including ensembles) by more than $2.0$ BLEU, establishing a new state-of-the-art BLEU score of $28.4$ . The configuration of this model is listed in the bottom line of Table 3. Training took $3.5$ days on $8$ P100 GPUs. Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of any of the competitive models.
On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of $41.0$ , outperforming all of the previously published single models, at less than $1/4$ the training cost of the previous state-of-the-art model. The Transformer (big) model trained for English-to-French used dropout rate $P_drop=0.1$ , instead of $0.3$ .
For the base models, we used a single model obtained by averaging the last 5 checkpoints, which were written at 10-minute intervals. For the big models, we averaged the last 20 checkpoints. We used beam search with a beam size of $4$ and length penalty $α=0.6$ [38]. These hyperparameters were chosen after experimentation on the development set. We set the maximum output length during inference to input length + $50$ , but terminate early when possible [38].
Table 2 summarizes our results and compares our translation quality and training costs to other model architectures from the literature. We estimate the number of floating point operations used to train a model by multiplying the training time, the number of GPUs used, and an estimate of the sustained single-precision floating-point capacity of each GPU We used values of 2.8, 3.7, 6.0 and 9.5 TFLOPS for K80, K40, M40 and P100, respectively..
### 6.2 Model Variations
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
| | $N$ | $d_model$ | $d_ff$ | $h$ | $d_k$ | $d_v$ | $P_drop$ | $ε_ls$ | train | PPL | BLEU | params |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| steps | (dev) | (dev) | $× 10^6$ | | | | | | | | | |
| base | 6 | 512 | 2048 | 8 | 64 | 64 | 0.1 | 0.1 | 100K | 4.92 | 25.8 | 65 |
| (A) | | | | 1 | 512 | 512 | | | | 5.29 | 24.9 | |
| 4 | 128 | 128 | | | | 5.00 | 25.5 | | | | | |
| 16 | 32 | 32 | | | | 4.91 | 25.8 | | | | | |
| 32 | 16 | 16 | | | | 5.01 | 25.4 | | | | | |
| (B) | | | | | 16 | | | | | 5.16 | 25.1 | 58 |
| 32 | | | | | 5.01 | 25.4 | 60 | | | | | |
| (C) | 2 | | | | | | | | | 6.11 | 23.7 | 36 |
| 4 | | | | | | | | | 5.19 | 25.3 | 50 | |
| 8 | | | | | | | | | 4.88 | 25.5 | 80 | |
| 256 | | | 32 | 32 | | | | 5.75 | 24.5 | 28 | | |
| 1024 | | | 128 | 128 | | | | 4.66 | 26.0 | 168 | | |
| 1024 | | | | | | | 5.12 | 25.4 | 53 | | | |
| 4096 | | | | | | | 4.75 | 26.2 | 90 | | | |
| (D) | | | | | | | 0.0 | | | 5.77 | 24.6 | |
| 0.2 | | | 4.95 | 25.5 | | | | | | | | |
| 0.0 | | 4.67 | 25.3 | | | | | | | | | |
| 0.2 | | 5.47 | 25.7 | | | | | | | | | |
| (E) | | positional embedding instead of sinusoids | | 4.92 | 25.7 | | | | | | | |
| big | 6 | 1024 | 4096 | 16 | | | 0.3 | | 300K | 4.33 | 26.4 | 213 |
To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013. We used beam search as described in the previous section, but no checkpoint averaging. We present these results in Table 3.
In Table 3 rows (A), we vary the number of attention heads and the attention key and value dimensions, keeping the amount of computation constant, as described in Section 3.2.2. While single-head attention is 0.9 BLEU worse than the best setting, quality also drops off with too many heads.
In Table 3 rows (B), we observe that reducing the attention key size $d_k$ hurts model quality. This suggests that determining compatibility is not easy and that a more sophisticated compatibility function than dot product may be beneficial. We further observe in rows (C) and (D) that, as expected, bigger models are better, and dropout is very helpful in avoiding over-fitting. In row (E) we replace our sinusoidal positional encoding with learned positional embeddings [9], and observe nearly identical results to the base model.
### 6.3 English Constituency Parsing
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)
To evaluate if the Transformer can generalize to other tasks we performed experiments on English constituency parsing. This task presents specific challenges: the output is subject to strong structural constraints and is significantly longer than the input. Furthermore, RNN sequence-to-sequence models have not been able to attain state-of-the-art results in small-data regimes [37].
We trained a 4-layer transformer with $d_model=1024$ on the Wall Street Journal (WSJ) portion of the Penn Treebank [25], about 40K training sentences. We also trained it in a semi-supervised setting, using the larger high-confidence and BerkleyParser corpora from with approximately 17M sentences [37]. We used a vocabulary of 16K tokens for the WSJ only setting and a vocabulary of 32K tokens for the semi-supervised setting.
We performed only a small number of experiments to select the dropout, both attention and residual (section 5.4), learning rates and beam size on the Section 22 development set, all other parameters remained unchanged from the English-to-German base translation model. During inference, we increased the maximum output length to input length + $300$ . We used a beam size of $21$ and $α=0.3$ for both WSJ only and the semi-supervised setting.
Our results in Table 4 show that despite the lack of task-specific tuning our model performs surprisingly well, yielding better results than all previously reported models with the exception of the Recurrent Neural Network Grammar [8].
In contrast to RNN sequence-to-sequence models [37], the Transformer outperforms the BerkeleyParser [29] even when training only on the WSJ training set of 40K sentences.
## 7 Conclusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
The code we used to train and evaluate our models is available at https://github.com/tensorflow/tensor2tensor.
Acknowledgements
We are grateful to Nal Kalchbrenner and Stephan Gouws for their fruitful comments, corrections and inspiration.
## References
- [1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014.
- [3] Denny Britz, Anna Goldie, Minh-Thang Luong, and Quoc V. Le. Massive exploration of neural machine translation architectures. CoRR, abs/1703.03906, 2017.
- [4] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
- [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. CoRR, abs/1406.1078, 2014.
- [6] Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357, 2016.
- [7] Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014.
- [8] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. Recurrent neural network grammars. In Proc. of NAACL, 2016.
- [9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
- [10] Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- [12] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001.
- [13] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [14] Zhongqiang Huang and Mary Harper. Self-training PCFG grammars with latent annotations across languages. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 832–841. ACL, August 2009.
- [15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
- [16] Łukasz Kaiser and Samy Bengio. Can active memory replace attention? In Advances in Neural Information Processing Systems, (NIPS), 2016.
- [17] Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. In International Conference on Learning Representations (ICLR), 2016.
- [18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2, 2017.
- [19] Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. Structured attention networks. In International Conference on Learning Representations, 2017.
- [20] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [21] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint arXiv:1703.10722, 2017.
- [22] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
- [23] Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. Multi-task sequence to sequence learning. arXiv preprint arXiv:1511.06114, 2015.
- [24] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
- [25] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
- [26] David McClosky, Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In Proceedings of the Human Language Technology Conference of the NAACL, Main Conference, pages 152–159. ACL, June 2006.
- [27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. In Empirical Methods in Natural Language Processing, 2016.
- [28] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
- [29] Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein. Learning accurate, compact, and interpretable tree annotation. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, pages 433–440. ACL, July 2006.
- [30] Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859, 2016.
- [31] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909, 2015.
- [32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- [33] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1):1929–1958, 2014.
- [34] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 2440–2448. Curran Associates, Inc., 2015.
- [35] Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems, pages 3104–3112, 2014.
- [36] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. CoRR, abs/1512.00567, 2015.
- [37] Vinyals & Kaiser, Koo, Petrov, Sutskever, and Hinton. Grammar as a foreign language. In Advances in Neural Information Processing Systems, 2015.
- [38] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
- [39] Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu. Deep recurrent models with fast-forward connections for neural machine translation. CoRR, abs/1606.04199, 2016.
- [40] Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu. Fast and accurate shift-reduce constituent parsing. In Proceedings of the 51st Annual Meeting of the ACL (Volume 1: Long Papers), pages 434–443. ACL, August 2013.
## Attention Visualizations
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Linguistic Dependency/Attention Visualization
### Overview
The image displays a visualization of linguistic relationships or attention weights between words in a sentence. It consists of two horizontal rows of text. The top row contains a complete sentence, while the bottom row repeats the sentence with colored, numbered blocks overlaid on specific words. Lines connect a single word in the top row to multiple words in the bottom row, with the line colors corresponding to the colored blocks. This is characteristic of a dependency parse tree or an attention mechanism visualization from a natural language processing model.
### Components/Axes
* **Primary Text (Top Row):** A single English sentence: "It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult . <EOS> <pad> <pad> <pad> <pad> <pad>"
* **Secondary Text (Bottom Row):** The same sentence repeated: "It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult . <EOS> <pad> <pad> <pad> <pad> <pad>"
* **Connecting Lines:** Multiple lines originate from the word "**making**" in the top row and connect to various words in the bottom row. The lines are colored (purple, brown, green, red, blue).
* **Colored Blocks & Legend:** Small, colored rectangular blocks with numerical values are placed on or near specific words in the bottom row. A legend in the bottom-right corner maps colors to numerical values:
* **Blue:** 0.2
* **Green:** 0.3
* **Red:** 0.1
* **Brown:** 0.2
* **Purple:** 0.2
* **Spatial Grounding:** The legend is positioned in the bottom-right quadrant of the image. The connecting lines fan out downwards and to the right from the source word "making" (top row, center-right) to the target words in the bottom row.
### Detailed Analysis
**Word-by-Word Mapping & Connection Analysis:**
The diagram isolates the verb "**making**" as the central node. Lines connect it to the following words in the bottom row, with associated weights from the legend:
1. **"registration"**: Connected by a **green** line. A **green block** with the value **0.3** is placed on this word.
2. **"or"**: Connected by a **red** line. A **red block** with the value **0.1** is placed on this word.
3. **"voting"**: Connected by a **blue** line. A **blue block** with the value **0.2** is placed on this word.
4. **"process"**: Connected by a **brown** line. A **brown block** with the value **0.2** is placed on this word.
5. **"more"**: Connected by a **purple** line. A **purple block** with the value **0.2** is placed on this word.
6. **"difficult"**: Connected by a **purple** line. A **purple block** with the value **0.2** is placed on this word.
**Trend Verification:** The visual trend shows a focused distribution of connection weights from "making" to the noun phrase "registration or voting process" and its modifiers "more difficult." The highest weight (0.3) is on the noun "registration," suggesting it is the most strongly linked object of the verb "making" in this context.
**Text Transcription (Complete):**
The full sentence, including special tokens, is:
`It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult . <EOS> <pad> <pad> <pad> <pad> <pad>`
* `<EOS>`: Likely denotes "End Of Sequence."
* `<pad>`: Denotes padding tokens, used to fill sequence length in machine learning models.
### Key Observations
1. **Focused Attention:** The visualization explicitly shows that the model's attention or the syntactic dependency for the verb "making" is concentrated on the subsequent noun phrase and its modifiers, not on the subject or earlier parts of the sentence.
2. **Weight Distribution:** The weights are not evenly distributed. "Registration" (0.3) carries 50% more weight than "voting," "process," "more," or "difficult" (each 0.2), and three times the weight of "or" (0.1).
3. **Structural Tokens:** The presence of `<EOS>` and `<pad>` tokens confirms this is a visualization from a computational model's processing pipeline, not a purely linguistic diagram.
### Interpretation
This diagram is a technical visualization, likely from a neural network model (e.g., a Transformer-based model) performing a task like dependency parsing, semantic role labeling, or machine translation. It demonstrates how the model assigns importance or establishes a syntactic link between the verb "making" and its complex object.
**What the data suggests:** The model identifies "making" as the pivotal action that connects the main clause ("governments have passed new laws") to the purpose or result clause ("making the registration... more difficult"). The higher weight on "registration" versus "voting" could imply the model interprets the laws as primarily targeting the registration process, with voting being a secondary, coordinated element. The low weight on the conjunction "or" is logical, as it is a functional word with less semantic content.
**Why it matters:** Such visualizations are crucial for model interpretability. They allow researchers to "see inside" the model's decision-making process, verifying that it is focusing on linguistically plausible relationships. This builds trust in the model's outputs and helps diagnose errors if the attention weights were assigned to irrelevant words.
**Notable Anomaly:** The connection to the word "more" (an adverb) is interesting. It suggests the model is linking "making" not just to the head nouns ("registration," "voting process") but also to the comparative modifier "more," which is essential for understanding the *nature* of the change being described (making things *more* difficult). This indicates a nuanced capture of the phrase's meaning.
</details>
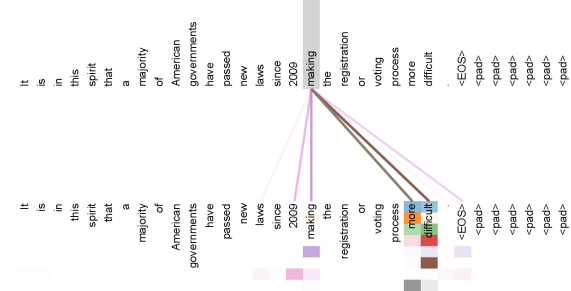
Figure 3: An example of the attention mechanism following long-distance dependencies in the encoder self-attention in layer 5 of 6. Many of the attention heads attend to a distant dependency of the verb ‘making’, completing the phrase ‘making…more difficult’. Attentions here shown only for the word ‘making’. Different colors represent different heads. Best viewed in color.
<details>
<summary>x2.png Details</summary>

### Visual Description
\n
## Text Alignment Visualization: Attention Weights Between Identical Sequences
### Overview
The image is a visualization of word-level alignment or attention weights between two identical sequences of text. It displays two parallel lines of text, one positioned above the other, with a network of connecting lines (edges) between corresponding words. The visualization likely represents the output of an attention mechanism from a natural language processing model, showing how strongly each word in the top sequence "attends to" or aligns with each word in the bottom sequence.
### Components/Axes
* **Text Sequences:** Two identical lines of English text are displayed.
* **Top Sequence (Source):** "The Law will never be perfect, but its application should be just. This is what we are missing, in my opinion. <EOS> <pad>"
* **Bottom Sequence (Target):** "The Law will never be perfect, but its application should be just. This is what we are missing, in my opinion. <EOS> <pad>"
* **Connecting Lines (Edges):** A dense network of purple lines connects words from the top sequence to words in the bottom sequence.
* **Color:** All connecting lines are a shade of purple/violet.
* **Opacity/Thickness:** The lines vary significantly in opacity (transparency). Darker, more opaque lines indicate a stronger alignment or higher attention weight between the connected words. Lighter, more transparent lines indicate weaker connections.
* **Spatial Layout:**
* The source text is aligned horizontally across the top third of the image.
* The target text is aligned horizontally across the bottom third of the image.
* The network of connecting lines occupies the central third of the image, creating a complex web between the two text lines.
### Detailed Analysis
* **Text Transcription:** The complete, identical text in both sequences is:
`The Law will never be perfect, but its application should be just. This is what we are missing, in my opinion. <EOS> <pad>`
* **Language:** English.
* **Special Tokens:** The sequence ends with `<EOS>` (End Of Sequence) and `<pad>` (padding token), which are standard in machine learning text processing.
* **Connection Pattern Analysis:**
* **Self-Alignment Dominance:** The strongest, darkest purple lines connect each word in the top sequence directly to the *same* word in the bottom sequence (e.g., "The" to "The", "Law" to "Law"). This creates a strong, near-vertical line for each word pair.
* **Cross-Alignment Weaker Connections:** Lighter, more transparent lines connect words to other, non-identical words in the opposite sequence. For example, there are faint connections from "perfect" to "application" or from "missing" to "opinion".
* **Token Connections:** The special tokens `<EOS>` and `<pad>` at the end of each sequence show strong self-alignment and also have multiple weaker connections fanning out to various words in the opposite sequence, particularly to the final content words like "opinion".
### Key Observations
1. **Perfect Diagonal:** The primary visual feature is a strong, dark purple diagonal line formed by the self-alignments, indicating the model assigns the highest attention weight to matching words.
2. **Attention Diffusion:** Despite the strong self-attention, there is a significant amount of "diffuse" attention, represented by the web of lighter lines. This shows the model is also considering relationships between different words, albeit with lower confidence.
3. **End-Token Behavior:** The `<EOS>` and `<pad>` tokens act as sinks or hubs, receiving and sending out many weak connections, which is typical as these tokens often aggregate sequence-level information.
4. **Symmetry:** The connection pattern appears largely symmetrical around the central horizontal axis, which is expected since the two sequences are identical.
### Interpretation
This visualization demonstrates the behavior of a **self-attention mechanism** (likely from a Transformer model) applied to a single sentence. The data suggests:
* **Primary Function:** The model's core task here is to reconstruct or align the sequence with itself. The dominant dark diagonal confirms that the most important relationship for each token is its own position in the sequence.
* **Contextual Understanding:** The presence of weaker cross-connections indicates the model is not merely copying. It is building a contextual representation where each word's meaning is informed by its relationship to other words in the sentence (e.g., "application" is weakly connected to "just," its descriptor). This is the foundation for understanding syntax and semantics.
* **Model Confidence:** The variance in line opacity provides a visual proxy for the model's "confidence" or the magnitude of the attention weights. The stark contrast between the dark self-connections and the faint cross-connections implies a model that is highly certain about token identity but still performs broad, low-magnitude contextual integration.
* **Technical Context:** The inclusion of `<EOS>` and `<pad>` tokens frames this as a technical output from a neural network's processing pipeline, not a human-made diagram. It reveals the internal "reasoning" steps of the model as it processes the input text.
**In essence, the image is a window into how a neural network "reads" a sentence: it focuses first and foremost on each word itself, while simultaneously, more faintly, weaving a web of connections between all words to build a unified understanding.**
</details>
<details>
<summary>x3.png Details</summary>
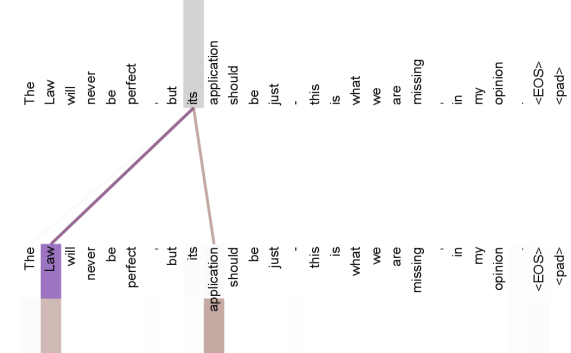
### Visual Description
## Diagram: Syntactic Dependency Visualization
### Overview
The image displays a diagram visualizing the syntactic or semantic relationships between words in a single English sentence. The sentence is presented twice in a spaced-out, horizontal format. Colored lines connect specific words, indicating a grammatical or conceptual dependency between them. The background is a plain, light gray.
### Components/Axes
* **Text Content:** The identical sentence is displayed in two parallel rows.
* **Connecting Lines:** Two colored lines form a V-shape, originating from words in the bottom row and converging on a word in the top row.
* **Purple Line:** Connects the word "Law" (bottom row) to the word "its" (top row).
* **Brown/Taupe Line:** Connects the word "application" (bottom row) to the same word "its" (top row).
* **Spatial Layout:** The text is centered. The connecting lines are drawn in the space between the two rows of text. The word "its" in the top row is the focal point of the connections.
### Detailed Analysis
**1. Text Transcription:**
The sentence, with exact spacing and punctuation, is:
`The Law will never be perfect , but its application should be just . this is what we are missing . in my opinion <EOS> <pad>`
* **Language:** English.
* **Note:** The tags `<EOS>` (End Of Sequence) and `<pad>` (padding) at the end are common in natural language processing (NLP) contexts, indicating this text may be from a model's input or output sequence.
**2. Connection Mapping:**
* **Source Word 1:** "Law" (bottom row, 2nd word). A purple line extends upward and rightward from this word.
* **Source Word 2:** "application" (bottom row, 9th word). A brown line extends upward and leftward from this word.
* **Target Word:** "its" (top row, 7th word). Both the purple and brown lines terminate at this word.
* **Visual Trend:** The lines create a clear visual dependency, suggesting that both "Law" and "application" are antecedents or modifiers for the possessive pronoun "its."
### Key Observations
1. **Dual Presentation:** The sentence is shown twice, which is atypical for a simple text display. This could be for visual clarity in showing the connections or might represent two different states (e.g., input vs. output, or original vs. annotated).
2. **Specific Word Focus:** The diagram isolates and highlights the relationship between three specific words: "Law," "application," and "its." All other words in the sentence are present but not annotated.
3. **NLP Artifacts:** The presence of `<EOS>` and `<pad>` tokens strongly suggests this image is a visualization from a computational linguistics or machine learning context, likely illustrating how a model parses or attends to relationships within a sentence.
4. **Color Coding:** The use of distinct colors (purple and brown) for the two connecting lines clearly differentiates the two separate dependency relationships being shown, even though they share the same target word.
### Interpretation
This diagram is a **dependency parse visualization**. It illustrates the grammatical structure of the sentence by showing that the possessive pronoun "its" refers back to two distinct nouns: "Law" and "application."
* **What it demonstrates:** The core message is that the "application" of "the Law" is the subject of critique. The diagram makes explicit that "its" is not ambiguous; it possesses both the Law and the application of the Law. This reinforces the sentence's argument: while the Law itself may be unattainably perfect, the practical *application* of it is where justice is (or is not) enacted.
* **Why it matters:** In NLP, accurately resolving such pronoun references (coreference resolution) is crucial for understanding meaning. This visualization likely serves as an explanatory tool or a debug output from a model, showing that it has correctly identified the antecedents for "its."
* **Notable Insight:** The diagram emphasizes the sentence's central contrast between an abstract ideal ("the Law will never be perfect") and a concrete action ("its application should be just"). By graphically linking "application" to "its," it underscores that the responsibility for justice lies in human action and interpretation, not in the theoretical text of the law alone.
</details>
Figure 4: Two attention heads, also in layer 5 of 6, apparently involved in anaphora resolution. Top: Full attentions for head 5. Bottom: Isolated attentions from just the word ‘its’ for attention heads 5 and 6. Note that the attentions are very sharp for this word.
<details>
<summary>x4.png Details</summary>

### Visual Description
\n
## Text Visualization Diagram: Attention/Connection Map Between Two Identical Text Sequences
### Overview
The image displays a visualization of connections between two identical sequences of text tokens, arranged in parallel horizontal rows. The visualization appears to be a form of bipartite graph or parallel coordinates plot, commonly used in natural language processing (NLP) to illustrate attention weights, alignment, or relationships between tokens in a sequence. The primary visual elements are the text tokens themselves and the green connecting lines of varying opacity/thickness between them.
### Components/Axes
* **Text Sequences:** Two identical rows of text tokens are present.
* **Top Row (Source/Sequence 1):** "The", "Law", "will", "never", "be", "perfect", ",", "but", "its", "application", "should", "be", "just", ".", "this", "is", "what", "we", "are", "missing", ".", "in", "my", "opinion", "<EOS>", "<pad>"
* **Bottom Row (Target/Sequence 2):** "The", "Law", "will", "never", "be", "perfect", ",", "but", "its", "application", "should", "be", "just", ".", "this", "is", "what", "we", "are", "missing", ".", "in", "my", "opinion", "<EOS>", "<pad>"
* **Connections:** Green lines connect tokens from the top row to tokens in the bottom row. The lines vary significantly in opacity (from very faint to solid dark green) and apparent thickness.
* **Special Tokens:** The sequences end with `<EOS>` (End Of Sequence) and `<pad>` (padding token), standard in machine learning text processing.
* **Layout:** The tokens are spaced horizontally. The connecting lines create a dense web between the two rows, with some lines running nearly vertically and others crossing diagonally.
### Detailed Analysis
* **Connection Pattern:** Every token in the top row appears to have at least one connection to a token in the bottom row. The most prominent (darkest/thickest) connections are not strictly vertical (i.e., connecting a token to its identical counterpart). For example:
* The token "Law" (top) has a very strong connection to "Law" (bottom).
* The token "application" (top) has a very strong connection to "application" (bottom).
* The token "missing" (top) has a very strong connection to "missing" (bottom).
* The token "opinion" (top) has a very strong connection to "opinion" (bottom).
* **Cross-Token Connections:** Numerous fainter lines connect tokens to non-identical tokens. For instance, there are visible connections from "The" (top) to several tokens in the bottom row, and from "perfect" (top) to various tokens. This suggests a model is attending to or relating multiple words within the sentence when processing each word.
* **Token Density:** The central portion of the sentence ("application should be just . this is what we are missing") shows a particularly dense cluster of connections, indicating high interrelatedness or attention among these tokens.
* **Special Token Connections:** The `<EOS>` token (top) has strong connections to `<EOS>` (bottom) and also to several preceding tokens like "opinion" and "my". The `<pad>` token has very faint connections.
### Key Observations
1. **Self-Attention Dominance:** The strongest connections are between identical tokens in the two rows (self-alignment). This is a common pattern in self-attention mechanisms where a token's strongest relationship is often with itself.
2. **Semantic Core:** The words "Law," "application," "missing," and "opinion" exhibit the most intense self-connections, suggesting they are treated as key semantic anchors in the sentence.
3. **Dense Interconnection:** The visualization reveals a complex web of relationships, not just a simple one-to-one mapping. This indicates the underlying model considers a broad context when representing each word.
4. **Structural Tokens:** Punctuation (",", ".") and function words ("the", "be", "is") are integrated into the connection web, showing they are not ignored in the relational analysis.
### Interpretation
This diagram is a technical visualization of **attention weights or alignment scores** from a neural network model (likely a Transformer-based model) processing the given English sentence. The sentence expresses a normative opinion about law: "The Law will never be perfect, but its application should be just this is what we are missing in my opinion."
* **What it Demonstrates:** It maps how the model internally relates different parts of the sentence to itself. The strong self-connections confirm the model's focus on individual word meaning. The web of cross-connections illustrates the model's mechanism for capturing syntactic dependencies (e.g., "its" referring to "Law") and semantic relationships (linking "application" to "just" and "missing").
* **Relationship Between Elements:** The two text rows represent the same sequence, likely the input and output of an attention layer or the query and key sequences in a self-attention operation. The lines quantify the strength of association the model assigns between each pair of tokens.
* **Notable Patterns:** The high connectivity around "application should be just . this is what we are missing" visually underscores the core argument of the sentence—the gap between the ideal of just application and the current reality. The model's attention architecture mirrors the human reading process, where understanding a sentence involves continuously relating words to each other and to the overall context.
* **Purpose:** Such visualizations are used in AI research and development to interpret model behavior, debug attention patterns, and understand how linguistic information is processed and represented within the network. It provides a "look inside the black box" of a language model's reasoning process for this specific sentence.
</details>
<details>
<summary>x5.png Details</summary>

### Visual Description
## Diagram: Word Alignment Visualization
### Overview
The image displays a visualization of word alignment or attention between two sequences of text. It consists of two horizontal rows of words, with red lines connecting corresponding words between the top and bottom rows. The diagram appears to illustrate a natural language processing (NLP) concept, such as sequence-to-sequence alignment, attention mechanisms, or error analysis in text generation.
### Components/Axes
* **Top Row (Source/Reference Sequence):** A complete English sentence with punctuation and special tokens.
* **Bottom Row (Target/Hypothesis Sequence):** A similar but incomplete sequence, missing some words from the top row.
* **Connecting Lines:** Red lines of varying thickness and opacity connect words from the top row to the bottom row. Thicker, more opaque lines indicate a stronger or more direct alignment.
* **Special Tokens:** Both sequences end with `<EOS>` (End Of Sequence) and `<pad>` (padding token), which are standard in machine learning for text processing.
### Detailed Analysis
**Text Transcription:**
* **Top Row (Left to Right):**
`The` `Law` `will` `never` `be` `perfect` `,` `but` `its` `application` `should` `be` `just` `.` `this` `is` `what` `we` `are` `missing` `.` `in` `my` `opinion` `<EOS>` `<pad>`
* **Bottom Row (Left to Right):**
`The` `Law` `will` `be` `perfect` `,` `but` `its` `application` `should` `be` `.` `this` `is` `what` `we` `are` `missing` `.` `in` `my` `opinion` `<EOS>` `<pad>`
**Alignment & Missing Words:**
The primary difference is that the bottom row is missing two words present in the top row:
1. The word **"never"** (4th token in top row) has no corresponding word or connection in the bottom row.
2. The word **"just"** (13th token in top row) has no corresponding word or connection in the bottom row.
**Connection Pattern:**
* Most words have a direct, one-to-one alignment shown by a red line (e.g., "The" to "The", "Law" to "Law").
* The lines for the missing words ("never", "just") are absent.
* The punctuation marks (`,`, `.`) are aligned.
* The special tokens (`<EOS>`, `<pad>`) are aligned at the end.
### Key Observations
1. **Omission Errors:** The diagram clearly highlights two specific omission errors in the bottom sequence compared to the top reference sequence.
2. **Structural Fidelity:** Despite the omissions, the overall grammatical structure and the majority of the content words are preserved and correctly aligned.
3. **NLP Context:** The use of `<EOS>` and `<pad>` tokens strongly suggests this is a visualization from a machine learning model's output, likely showing the alignment between a reference text and a model-generated hypothesis.
4. **Visual Emphasis:** The red lines draw immediate attention to the correspondences, making the missing links (the omissions) visually apparent by their absence.
### Interpretation
This diagram is a diagnostic tool used in natural language processing, specifically for tasks like machine translation, text summarization, or grammar correction. It visually answers the question: "How well does the generated text (bottom) match the reference text (top)?"
* **What it demonstrates:** It shows that the model or process generating the bottom text successfully captured most of the semantic content and structure but failed to include two key modifiers: "never" (which negates the perfection of the law) and "just" (which qualifies the desired nature of its application). These omissions significantly alter the meaning and nuance of the original statement.
* **Relationship between elements:** The top row serves as the ground truth. The bottom row is the output being evaluated. The lines represent the model's "attention" or the evaluation metric's alignment between the two sequences. The absence of lines is as informative as their presence.
* **Notable anomaly:** The most critical anomaly is the omission of "just." Its absence changes the sentence from "its application should be just" (a positive assertion about fairness) to "its application should be ." which is grammatically incomplete and semantically void. This suggests a potential failure mode in the generation process.
* **Underlying message:** The diagram argues that while the core message ("The Law will be perfect, but its application should be. this is what we are missing.") is partially conveyed, the precise, qualified argument of the original ("The Law will **never** be perfect, but its application should be **just**.") is lost. It visually underscores the importance of function words and modifiers in preserving meaning.
</details>
Figure 5: Many of the attention heads exhibit behaviour that seems related to the structure of the sentence. We give two such examples above, from two different heads from the encoder self-attention at layer 5 of 6. The heads clearly learned to perform different tasks.