## Tunneling Neural Perception and Logic Reasoning through Abductive Learning
Wang-Zhou Dai † , Qiu-Ling Xu † , Yang Yu † , Zhi-Hua Zhou ∗
National Key Laboratory for Novel Software Technology Nanjing University, Nanjing 210093, China
## Abstract
Perception and reasoning are basic human abilities that are seamlessly connected as part of human intelligence. However, in current machine learning systems, the perception and reasoning modules are incompatible. Tasks requiring joint perception and reasoning ability are difficult to accomplish autonomously and still demand human intervention. Inspired by the way language experts decoded Mayan scripts by joining two abilities in an abductive manner, this paper proposes the abductive learning framework. The framework learns perception and reasoning simultaneously with the help of a trial-and-error abductive process. We present the Neural-Logical Machine as an implementation of this novel learning framework. We demonstrate that-using human-like abductive learning-the machine learns from a small set of simple hand-written equations and then generalises well to complex equations, a feat that is beyond the capability of state-of-the-art neural network models. The abductive learning framework explores a new direction for approaching human-level learning ability.
Key words: Machine Learning, logic, neural network, perception, abduction, reasoning
Mayan scripts were a complete mystery to modern humanity until its numerical systems and calendars were first successfully deciphered in the late 19th century. As described by historians, the number recognition was derived from a handful of images that show mathematical regularity [16]. The decipherment was not trivial because the Mayan numerical system is vigesimal (base twenty), totally different from the decimal system currently in common use. The successful deciphering
∗ Corresponding author. Email: zhouzh@nju.edu.cn
† These authors contributed equally to this work
of Mayan numbers reflects two remarkable human intelligence capabilities: 1) visually perceiving individual characters from images and 2) reasoning symbolically based on mathematical background knowledge during perception. These two abilities function at the same time and affect each other. Moreover, the two abilities are often joined subconsciously by humans, which is key in many real-life learning problems.
Modern artificial intelligence (AI) systems exhibit both these abilities-but only in isolation. Deep neural networks have achieved extraordinary performance levels in recognizing human faces [44], objects [25, 43], and speech [13]; meanwhile, logic-based AI systems have achieved human-level abilities in proving mathematical theorems [33, 5] and in performing inductive reasoning concerning relations [31]. However, recognition systems can hardly exploit complex domain knowledge in symbolic forms, perceived information is difficult to include in reasoning systems, and a reasoning system usually requires semantic-level knowledge, which involves human input [35]. Even in recent neural network models with enhanced memories [12], the ability to focus on relations [36], and differentiable knowledge representations [14, 17, 10, 2], full logical reasoning ability is still missing-as an example, consider the difficulties of understanding natural language [19]. To glue together perception and reasoning, it is crucial to answer the question: How should perception and reasoning affect one another in a single system?
## Mayan Hieroglyph Decipherment
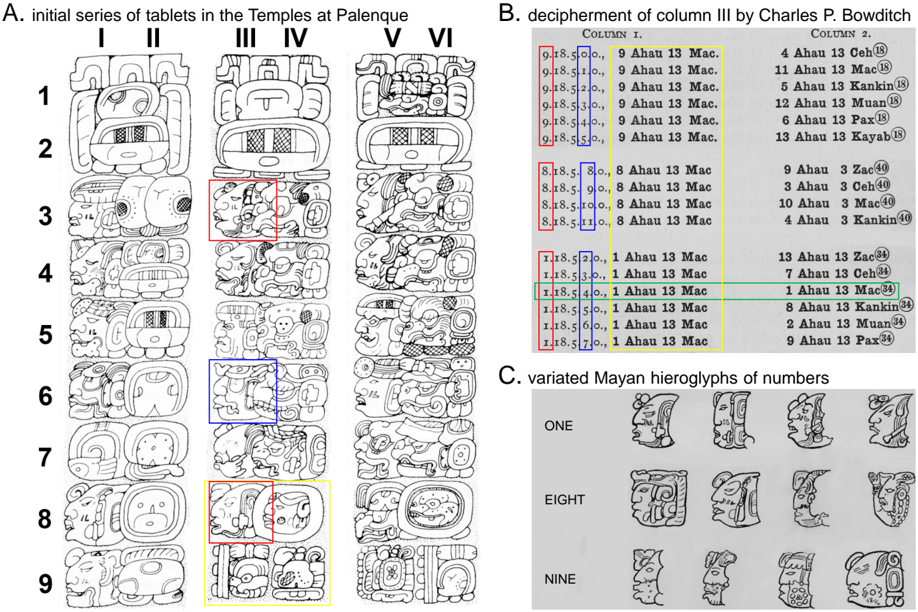
In a quest for the answer, we return to the process by which Charles P. Bowditch deciphered Mayan numbers, which were inscribed as the heads of gods (now known as head variants of numbers) [3]. Figure 1 illustrates this process. Figure 1(A) displays parts of three tablets discovered at Palenque. The first tablet (columns I-II) uses standard hieroglyphs to represent Mayan time units, e.g., 'Tun' (360 days) at II5 and as parts of the initials in row 2 on all three tablets. Columns IV and VI draw the units in a totally different way, but Bowditch conjectured that they were identical to column II based on their positions. Moreover, although the Mayan numeral system is vigesimal, the unit 'Tun' is just 18 times its predecessor, 'Winal' (row 6 in all the even columns), making the decipherment even more difficult. Bowditch verified this through calculations and by evaluating the consistency of the relationships in these tablets. Then, he started to decipher the numbers in column III. As illustrated in Figure 1(B), by mapping the
Figure 1: Illustration of Mayan hieroglyph decipherment. (A) In rows 3-9, the odd columns represent numbers and the even columns represent calendar time units. Column II shows the standard representations for the units; columns IV and VI are identical unit representations but in different drawings. Rows 1-2 are initials, rows 3-6 represent time spans, and rows 8-9 are dates computed from the time spans. The hieroglyphs marked by boxes correspond to the numbers and units in the same colored boxes in subfigure (B). (B) Column 1 lists possible interpretations from Column III of subfigure (A), and Column 2 lists the results calculated from the numbers in Column 1. Bowditch first identified the hieroglyphs at III4, III5, III7 and III9 in (A) and then confirmed that III3 and III9 represent the same numbers. Initially, he abduced III3 as 9 based on his past experience with Mayan calendars; however, that was impossible because the calculated results were inconsistent with the dates. Then, he tried substituting those positions with numbers that have similar hieroglyphs. Finally, he confirmed that the interpretation '1.18.5.4.0 1 Ahau 13 Mac' (in the green box) should be correct. It is very unusual for 1 to be attached to the unit in row 3, but its presence there is confirmed by its consistency with subsequent passages in the same tablet. (C) The highly varied character representations and unusual calendar system cause the decipherment of Mayan hieroglyphs to require both sensitive vision and a logical mind. Credits: subfigure (A) is reproduced from [42]; subfigures (B) and (C) are reproduced from [3].
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Mayan Calendar Glyphs and Decipherment
### Overview
The image presents a collection of Mayan hieroglyphs and their decipherment, focusing on calendar-related glyphs. It is divided into three sections: A) Initial series of tablets at the Temples at Palenque, showing glyphs in columns; B) Decipherment of column III by Charles P. Bowditch, providing interpretations of the glyphs; and C) Varied Mayan hieroglyphs of numbers.
### Components/Axes
**Section A: Initial Series of Tablets**
* **Title:** "A. initial series of tablets in the Temples at Palenque"
* **Columns:** Labeled I, II, III, IV, V, VI.
* **Rows:** Numbered 1 through 9.
* **Content:** Each cell contains a Mayan glyph, seemingly representing calendar dates or events.
* **Annotations:** Red, blue, and yellow boxes highlight specific glyphs in column III.
**Section B: Decipherment of Column III**
* **Title:** "B. decipherment of column III by Charles P. Bowditch"
* **Columns:** Labeled "COLUMN I." and "COLUMN 2."
* **Content:** Column I lists dates in the Mayan Long Count calendar and their corresponding names. Column 2 lists other dates and names.
* **Annotations:** Red, blue, yellow, and green boxes highlight specific entries.
**Section C: Varied Mayan Hieroglyphs of Numbers**
* **Title:** "C. variated Mayan hieroglyphs of numbers"
* **Labels:** "ONE", "EIGHT", "NINE"
* **Content:** Each label is followed by a series of Mayan glyphs representing the corresponding number.
### Detailed Analysis or Content Details
**Section A: Initial Series of Tablets**
The glyphs in each column appear to have a consistent style, possibly indicating a specific time period or location. The glyphs are complex and detailed, featuring various symbols and figures.
* **Column I:** Glyphs are vertically stacked.
* **Column II:** Glyphs are vertically stacked.
* **Column III:** Glyphs are vertically stacked.
* Row 3: Highlighted with a red box.
* Row 6: Highlighted with a blue box.
* Row 8: Highlighted with a yellow box.
* **Column IV:** Glyphs are vertically stacked.
* Row 3: Highlighted with a red box.
* Row 6: Highlighted with a blue box.
* Row 8: Highlighted with a red box.
* **Column V:** Glyphs are vertically stacked.
* **Column VI:** Glyphs are vertically stacked.
**Section B: Decipherment of Column III**
Column I lists dates and names, with the dates formatted as "X.18.5.Y.0." where X and Y are integers.
* **9.18.5.0.0.:** 9 Ahau 13 Mac. (Red box)
* **9.18.5.1.0.:** 9 Ahau 13 Mac. (Red box)
* **9.18.5.2.0.:** 9 Ahau 13 Mac. (Red box)
* **9.18.5.3.0.:** 9 Ahau 13 Mac. (Red box)
* **9.18.5.4.0.:** 9 Ahau 13 Mac. (Red box)
* **9.18.5.5.0.:** 9 Ahau 13 Mac. (Red box)
* **8.18.5.8.0.:** 8 Ahau 13 Mac (Red box)
* **8.18.5.9.0.:** 8 Ahau 13 Mac (Red box)
* **8.18.5.10.0.:** 8 Ahau 13 Mac (Red box)
* **8.18.5.11.0.:** 8 Ahau 13 Mac (Red box)
* **1.18.5.2.0.:** 1 Ahau 13 Mac (Red box)
* **1.18.5.3.0.:** 1 Ahau 13 Mac (Red box)
* **1.18.5.4.0.:** 1 Ahau 13 Mac (Green box)
* **1.18.5.5.0.:** 1 Ahau 13 Mac (Red box)
* **1.18.5.6.0.:** 1 Ahau 13 Mac (Red box)
* **1.18.5.7.0.:** 1 Ahau 13 Mac (Red box)
Column 2 lists dates and names, with numbers in parentheses.
* 4 Ahau 13 Ceh (18)
* 11 Ahau 13 Mac (18)
* 5 Ahau 13 Kankin (18)
* 12 Ahau 13 Muan (18)
* 6 Ahau 13 Pax (18)
* 13 Ahau 13 Kayab (18)
* 9 Ahau 3 Zac (40)
* 3 Ahau 3 Ceh (40)
* 10 Ahau 3 Mac (40)
* 4 Ahau 3 Kankin (40)
* 13 Ahau 13 Zac (34)
* 7 Ahau 13 Ceh (34)
* 1 Ahau 13 Mac (34) (Green box)
* 8 Ahau 13 Kankin (34)
* 2 Ahau 13 Muan (34)
* 9 Ahau 13 Pax (34)
**Section C: Varied Mayan Hieroglyphs of Numbers**
This section shows different glyphic representations for the numbers one, eight, and nine. Each number has multiple glyph variations.
### Key Observations
* Section A presents a visual representation of Mayan glyphs, while Section B provides a textual decipherment of a specific column from Section A.
* The dates in Section B follow a pattern, with variations in the "X" and "Y" values of the "X.18.5.Y.0." format.
* Section C demonstrates the variability in Mayan number glyphs.
### Interpretation
The image provides insight into the Mayan calendar system and the process of deciphering Mayan glyphs. The initial series of tablets likely represents a chronological record of events or dates. The decipherment by Charles P. Bowditch attempts to correlate the glyphs with specific dates in the Mayan Long Count calendar. The varied hieroglyphs of numbers highlight the complexity and flexibility of the Mayan writing system. The annotations (colored boxes) likely indicate specific areas of interest or comparison within the glyphs and decipherments.
</details>
hieroglyphs to different numbers and checking whether these numbers were consistent under the mathematical rules, Bowditch finally decoded the numbers and proved their correctness [3].
Bowditch's decipherment of the Mayan hieroglyphs explicitly illustrates the key aspect of joint visual perception and logical reasoning: in this case, a tunnel between perception and reasoning was established through a trial-and-error process of the hieroglyphic interpretations as shown in Column 1 in Figure 1(B). The trial step perceives, interprets the picture, and passes the interpreted symbols for consistency checking, while the error step evaluates the consistency, uses reasoning to find errors in the interpretation, and provides error feedback to correct the perception.
This problem-solving process was called 'abduction' by Charles S. Peirce [34] and termed 'retroproduction' by Herbert A. Simon [39]; it refers to the process of selectively inferring certain facts and hypotheses that explain phenomena and observations based on background knowledge [30, 20]. In Bowditchs Mayan number decipherment, the background knowledge involved arithmetic and some basic facts about Mayan calendars; the hypotheses involved a recognition model for mapping hieroglyphs to meaningful symbols and a more complete understanding of the Mayan calendar system. Finally, the validity of the hypotheses was ensured by trial-and-error searches and consistency checks.
## Overview of the Abductive Learning Framework
Inspired by the human abductive problem-solving process, we propose the Abductive Learning framework to enable knowledge-involved joint perception and reasoning capability in machine learning.
Generally, machine learning is a process that involves searching for an optimal model within a large hypothesis space. Constraints are used to reduce the search space. Most of the machine learning algorithms exploit constraints expressed explicitly through mathematical formulations. However, as was the case with the domain knowledge used in Mayan language decipherment, many complex constraints in real-world tasks take the form of symbolic rules. Moreover, such symbolic knowledge can be incomplete or even inaccurate. Abductive Learning uses logical abduction [20] to handle the imperfect symbolic inference problem. Given domain knowledge written as firstorder logical rules, Abductive Learning can abduce multiple hypotheses as possible explanations
to observed facts, just as Bowditch made guesses about the unknown hieroglyphs based on his knowledge of arithmetic and Mayan language during his 'trial' steps.
To exploit domain knowledge written as first-order logical rules, traditional logic-based AI uses the rules to make logical inferences based on input logical groundings, which are logical facts about the relations between objects in the domain. This, in fact, implicitly assumes the absolute existence of both the objects and the relations. However, as Stuart Russell commented, 'real objects seldom wear unique identifiers or pre-announce their existence like the cast of a play' [35]. Therefore, abductive learning adopts neural perception to automatically abstract symbols from data; then, the logic abduction is applied to the generalized results of neural perception.
The key to abductive learning is to discover how logical abduction and neural perception can be trained together. More concretely, when a differentiable neural perception module is coupled to a non-differentiable logical abduction module, learning system optimization becomes extremely difficult: the traditional gradient-based methods are inapplicable. In analogy to Bowditchs decipherment, abductive learning combines the two functionalities using a heuristic trial-and-error search approach.
Logical abduction, as a discrete reasoning system, can easily address a set of symbolic inputs. The neural layers involved in perception should output symbols that make the symbolic hypotheses consistent with each other. When the hypotheses are inconsistent, the logical abduction module finds incorrect output from the neural perception module and corrects it. This process is exactly the trial-and-error process that Bowditch followed in Figure 1(B). The corrections function as the supervised signals to train the neural perception.
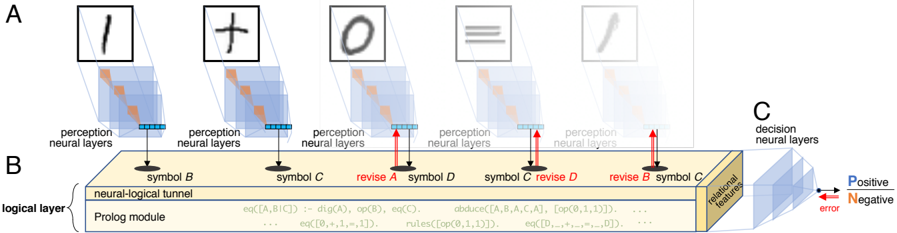
To verify the effectiveness of abductive learning , we implemented a Neural Logical Machine (NLM) as a demonstration of the abductive learning framework. The architecture of an NLM for classifying handwritten equations is shown in Figure 2. The equations consist of sequential pictures of characters, as in the examples shown in Figure 4. An equation is associated with a label (positive or negative) that indicates whether the equation is correct or incorrect. A machine is tasked with learning from a training set of labeled equations, and the trained model is expected to predict future equations correctly. This task simulates Mayan hieroglyph decipherment: the machine does not know the meaning of the character pictures or the calculation rules in advance.
Figure 2: The architecture of a neural-logical machine . (A) Perception neural layers (such as convolutional layers) accomplish the perception task. (B) The perception results are the input for the logical layer, which consists of the neural-logical tunnel, Prolog module, and relational features. The Prolog module checks the input consistency and produces relational features; the neural logical tunnel corrects the perception output based on consistency with the hypotheses; and the relational features expose the logical process outcomes. (C) The decision neural layers transform the relational features into the final output.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Neural-Logical Reasoning Diagram
### Overview
The image illustrates a neural-logical reasoning system, processing visual input through perception neural layers, integrating it with a Prolog module via a neural-logical tunnel, and making decisions based on relational features. The diagram shows how visual symbols are processed and revised using logical rules.
### Components/Axes
* **A:** Represents the input layer with handwritten symbols (1, +, 0, =, /). Each symbol is processed by perception neural layers.
* **Labels:** "perception neural layers"
* **B:** Represents the logical layer, consisting of a "neural-logical tunnel" and a "Prolog module". This layer processes the symbols and revises them based on logical rules.
* **Labels:** "symbol B", "symbol C", "revise A", "symbol D", "revise D", "revise B", "symbol C", "neural-logical tunnel", "Prolog module", "logical layer"
* **C:** Represents the decision neural layers, which output a decision based on relational features.
* **Labels:** "decision neural layers", "relational features", "Positive", "Negative", "error"
* **Arrows:** Red arrows indicate error signals or revisions. Black arrows indicate the flow of information.
### Detailed Analysis or ### Content Details
* **Input Symbols (A):**
* The diagram shows five handwritten symbols: '1', '+', '0', '=', and '/'.
* Each symbol is fed into a stack of "perception neural layers", represented as a cube.
* The output of these layers is a set of features, represented as a row of blue squares.
* **Logical Layer (B):**
* The "neural-logical tunnel" connects the perception neural layers to the "Prolog module".
* The Prolog module contains logical rules, such as:
* `eq([A,B,C]) :- dig(A), op(B), eq(C).`
* `eq([0,+,1,-,1]).`
* `abduce([A, B, A,C,A], [op(0,1,1)]).`
* `rules([op(0,1,1)]).`
* `eq([D]).`
* `eq([D,+,*,=,D]).`
* The symbols are processed and potentially revised based on these rules. For example, "revise A", "revise B", and "revise D" are explicitly labeled.
* **Decision Layer (C):**
* The "decision neural layers" receive "relational features" from the logical layer.
* Based on these features, the system makes a decision, indicated by the "Positive" and "Negative" outputs.
* An "error" signal is shown as a red arrow pointing back into the decision layer.
### Key Observations
* The diagram illustrates a hybrid system combining neural networks for perception and logical reasoning using Prolog.
* The "revise" labels indicate that the system can correct or refine its understanding of the input symbols based on logical rules.
* The error signal suggests a feedback loop for learning or adaptation.
### Interpretation
The diagram demonstrates a system that integrates visual perception with logical reasoning. The neural networks handle the initial processing of visual input, while the Prolog module applies logical rules to interpret and revise the symbols. This approach allows the system to handle noisy or ambiguous input by leveraging logical constraints. The error signal suggests that the system can learn from its mistakes and improve its performance over time. The system is designed to process and understand symbolic information, potentially for tasks such as mathematical problem-solving or logical inference.
</details>
Thus, this task demands the same ability as a human jointly utilizing perceptual and reasoning abilities.
Deep neural networks have been demonstrated to have incomparable perception performance on images [25]. Our implementation of NLM employs a convolutional neural network (CNN) [28] as the perception neural layers. The CNN takes image pixels as input and is expected to output the symbols in the image. The symbol output forms the input to the logical layer. To process the symbols logically and efficiently, the core of the logical layer is a Prolog module. Prolog is a powerful general-purpose logic programming language rooted in first-order logic. A common limitation of logic-based learning is its lack of flexibility when dealing with the uncertainty (such as noise and system errors) that exists in the real-world. Thus, we do not require the logical layer to output the final prediction directly. Instead, the logical layer outputs the values of some relational features that reflect the deductions made inside the Prolog module. Finally, the relational feature values are fed into the decision neural layers, which are implemented as a fully-connected multilayer feedforward neural network. The decision neural layers handle the uncertainty that exists between the logical outcomes and the labels.
The heuristic trial-and-error search is implemented using derivative-free optimization [47] in the neural-logical tunnel. Although the logical layer can find inconsistencies between the logic rules and the perceived symbols, it cannot find the positions of the incorrectly perceived symbols.
NLM employs a derivative-free optimization method [47] to intelligently guess the positions at which the symbols appear incorrectly. For each guess, the Prolog module runs the abductive logical programming (ALP) [21] process that abduces whether the correct symbols appear at the indicated positions, making the logical hypotheses more consistent. We further accelerate the NLM by feeding it only a sample of the available training data during each training iteration. From a dataset sample, we can obtain only locally consistent hypotheses. Finally, the NLM transforms the locally consistent hypotheses into relational features using the propositionalization technique [24].
As an analogy to human abductive problem-solving, NLM works as follows. Before training, domain knowledge-written as a first-order logic program-is provided to the Prolog module. In our implementation, this background knowledge involves only the logic structure rules, as shown in Figure 5. After training starts, a sample of the training data will be interpreted to candidate primitive symbols pre-defined in the neural-logical tunnel. Because the perception neural layer is initially a random network, the interpreted symbols are typically wrong and form inconsistent hypotheses. The logical layer starts to revise the interpreted symbols and search for the most consistent logical hypothesis in the training data sample. The hypotheses are stored as relational features in the logical layer, while the symbol revisions are used to train the perception neural layer in a straightforward supervised manner. When the training of these two subparts is complete (e.g., the perception layer converges or reaches an iteration limit), all the training examples are processed again by the NLM to obtain their feature vectors with regard to the abduced relational features. Finally, the decision neural layer is trained with these feature vectors from the whole dataset. The decision neural layer learning process will automatically filter ill-performing perception neural layer, hypotheses, and relational features. Moreover, due to the high complexity of symbolic abduction, we adopt the curriculum learning paradigm for training NLM (i.e., it begins learning from easier examples, and the difficulty of the learning tasks is gradually increased [1].
## Preliminaries
Logic Programming is a type of programming paradigm that is largely based on formal logic. It is designed for symbolic computation and is especially well suited for solving problems that involve objects and the relations between them [22].
One of the most widely used logic programming language is Prolog [4], which is designed based on first-order logic. A Prolog program consists of a set of logical facts and rules. For example, the fact that 'Adam is the father of Bob' can be written in Prolog as:
father(adam, bob).
Here the father is the name of a property, called as predicate ; adam and bob
A Rule stating that 'if father of is , then is also a parent of are its arguments. B A A B ' can be written as:
```
parent(A, B) :- father(A, B).
```
Here the ' :-' denotes logical implication; A and B are logical variables.
By using Selective Linear Definite (SLD) clause resolution [23], Prolog can perform first-order logical inferences. For example, given the above facts and rules as a logical program, the following question could be asked of the Prolog system:
```
?- parent(X, bob).
```
Having access to the previously asserted fact, Prolog will answer:
```
X = adam.
```
However, if the query is:
```
?- parent(eve, bob).
```
Prolog will answer
## false.
because the previous program does not specify any relation between eve and bob .
Owing to its comprehensibility and the power of performing first-order logical inferences, logic programming is widely used in symbolic AI systems such as expert systems [5], inductive logic programming [31], abductive logic programming [21], and so on.
Derivative-free optimization , as a counterpart of gradient-based optimization methods, solves optimization tasks without requiring the derivative information of the optimization function. Instead, it uses sampling methods to draw samples from the solution space and learns a potential region from which further samples will be drawn. Recent studies have shown that derivative-free optimization algorithms can solve a range of sophisticated optimization functions at a guaranteed level [32, 37, 47]. This work thus employs a state-of-the-art derivative-free optimization approach to solve the raised non-differentiable functions.
## Problem Setting
The input of abductive learning consists of a set of labeled training data X = {〈 x 1 , y 1 〉 , . . . , 〈 x n , y n 〉} about target concept C and domain knowledge T , where x i ∈ R m is a raw feature space, y i ∈ { 0 , 1 } is the label for x i on target concept C , and T is a logical theory expressed by a set of first-order logical formulas.
In contrast to ordinary statistical machine learning problems, the target concept C describes a certain relationship between a set of primitive concepts P = { p 1 , . . . , p r } in the domain; thus, it can hardly be directly induced from the raw feature space R m using statistical models. Therefore, learning the target concept requires symbolic reasoning based on the set of primitive concepts P in the logical theory T . However, although the primitive concepts P are defined in T , the mapping of p ( x ) : R m ↦→ P from the raw feature space to the primitive concepts is unknown. Furthermore, the domain knowledge in T is incomplete, i.e., it is some missing logic formulas ∆ C that describe the relations between primitive concepts P that are required as complements to T to define the target concept. The target output of abductive learning is to learn the mapping for p ( x ) and the symbolic knowledge ∆ C simultaneously from the data X , where p ( x ) and ∆ C are respectively called the perception model and the reasoning model in this paper.
For example, in the binary additive equation learning problem in Figure 4: X consists of images of equations and their labels; T contains basic arithmetic knowledge but no specific calculation rules for calculating 'addition'; the primitive concepts of P are the digit and operator symbols { 0 , 1 , + , = } . The goal is to learn a perception model p mapping images to the symbols, and a reasoning model ∆ C of addition rules for calculating '+' operations, such as arithmetic calculations or logical exclusive-or operations.
## Neural-Logical Machine Implementation
Abductive logic programming. Abduction refers to a reasoning process of forming a hypothesis that explains given observed phenomena according to domain knowledge [34]. For example,
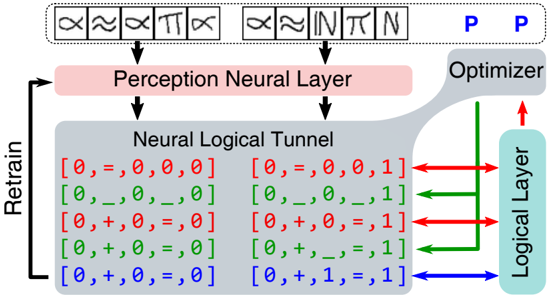
Figure 3: Example of using logical abduction to correct the perception layer . First, the perception neural layer incorrectly interprets the two images of positive examples and feeds them to the neural logical tunnel (the downward black arrows). Then, the logical layer finds them inconsistent (red arrows) and makes a request to the derivative-free optimization to substitute some digits into blank variables (green arrows). Finally, the logical layer successfully abduces a consistent interpretation for the two images (the blue arrow) and uses them as labels of the two images to retrain the perception neural layer (the upward black arrow).
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Neural Network Diagram: Perception and Logical Layers
### Overview
The image is a diagram illustrating a neural network architecture, focusing on the interaction between a perception neural layer, a neural logical tunnel, and a logical layer. It shows how input symbols are processed through these layers, with an optimizer and a retraining loop involved.
### Components/Axes
* **Top:** Input symbols enclosed in a dashed box. The symbols include mathematical symbols like alpha (α), approximately equal to (≈), pi (π), and the letters I and N. There are two "P" labels to the right of the symbols.
* **Perception Neural Layer:** A red block labeled "Perception Neural Layer" receives input from the symbols.
* **Neural Logical Tunnel:** A grey area labeled "Neural Logical Tunnel" receives input from the Perception Neural Layer. Inside this tunnel are several bracketed expressions containing numbers (0, 1) and symbols (=, +, \_). These expressions are color-coded in red, green, and blue.
* **Logical Layer:** A light blue block labeled "Logical Layer" interacts with the Neural Logical Tunnel and an "Optimizer" block.
* **Optimizer:** A grey block labeled "Optimizer" interacts with the Logical Layer.
* **Retrain:** A black arrow labeled "Retrain" loops from the output of the Neural Logical Tunnel back to the input of the Perception Neural Layer.
* **Arrows:** Red, green, and blue arrows indicate the flow of information between the Neural Logical Tunnel and the Logical Layer.
### Detailed Analysis
* **Input Symbols:** The input consists of a sequence of symbols: α, ≈, α, π, α, ≈, I, N, π, N. These symbols are fed into the Perception Neural Layer.
* **Perception Neural Layer:** This layer processes the input symbols and passes the information to the Neural Logical Tunnel.
* **Neural Logical Tunnel:** This layer contains a series of expressions. The expressions are arranged in two columns.
* **Left Column:**
* `[0, =, 0, 0, 0]` (Red)
* `[0, _, 0, _, 0]` (Red)
* `[0, +, 0, =, 0]` (Red)
* `[0, +, 0, =, 0]` (Green)
* `[0, +, 0, =, 0]` (Blue)
* **Right Column:**
* `[0, =, 0, 0, 1]` (Red)
* `[0, _, 0, _, 1]` (Red)
* `[0, +, 0, =, 1]` (Red)
* `[0, +, _, =, 1]` (Green)
* `[0, +, 1, =, 1]` (Blue)
* **Logical Layer:** This layer receives input from the Neural Logical Tunnel and interacts with the Optimizer.
* **Optimizer:** The Optimizer likely adjusts the parameters of the network based on the output of the Logical Layer.
* **Retrain Loop:** The "Retrain" arrow indicates that the network is trained iteratively, with the output of the Neural Logical Tunnel influencing the Perception Neural Layer in subsequent iterations.
* **Color-Coded Arrows:**
* Red arrows connect the first three expressions in each column of the Neural Logical Tunnel to the Logical Layer.
* Green arrows connect the fourth expression in each column to the Logical Layer.
* Blue arrows connect the fifth expression in each column to the Logical Layer.
### Key Observations
* The diagram illustrates a complex interaction between different layers of a neural network.
* The Neural Logical Tunnel appears to be a key component, processing information and providing feedback for retraining.
* The color-coding suggests different pathways or types of information flow within the network.
### Interpretation
The diagram depicts a neural network designed to process symbolic input, potentially for tasks involving logical reasoning or pattern recognition. The Perception Neural Layer likely extracts features from the input symbols, while the Neural Logical Tunnel performs some form of logical inference or transformation. The Logical Layer then makes a decision or prediction based on this processed information. The Optimizer and Retrain loop enable the network to learn and improve its performance over time. The color-coding could represent different logical pathways or confidence levels associated with different inferences. The specific meaning of the expressions within the Neural Logical Tunnel would depend on the details of the network's implementation and training data.
</details>
consider the following knowledge written as first-order logical formulas:
$$w e t r a g s \colon - r a i n _ { \ } l a s t \, n i g h t .$$
$$\ w e t { \text grass} \colon = \ s p r i n k l e r _ { \ } w a s \, o n .$$
$$w e t \, s h o e s \colon = w e t \, g r a s s .$$
$$\text {false} \colon - \ r a i n \, l a s t \, n i g h t , s p r i k l e r \, w a s \, o n .$$
where the first three formulas state the causes for grass and shoes being wet, and the last formula specifies that the given two conditions cannot be true at the same time. When an observation of wet shoes is true, formula 3 is regarded as an explanation, indicating wet grass should also be true. Continuing this process, both rain last night and sprinkler was on are other possible explanations. If it is observed that no rain occurred last night, according to the constraint in Formula 4, sprinkler was on would be the only explanation.
A declarative framework in Logic Programming that formalizes this process is Abductive Logic Programming (ALP) [21]. In this framework, an abductive logic theory T is a triple ( KB,A,IC ), where KB is a knowledge base of domain knowledge, A is a set of abducible predicates or propositions, and IC is the integrity constraints of the theory. The logic program KB consists of a set of first-order logic formulas that describes the domain, including complete definitions for a
set of observable predicates or propositions, and a set of abducible predicates or propositions A that have no definitive rules in T . For the above example, KB involves Formulas 1 to 3, A consists of the two propositions without any definitive formula: { rain last night , sprinkler was on } , and Formula 4 is the integrity constraint. Formally, an abductive logic program can be defined as follows [21]:
Definition 1 Given an abductive logic theory T = ( KB,A,IC ) , an abductive explanation for observed data X , is a set, ∆ , of ground abducibles of A , such that:
- KB ∪ ∆ | = X
- KB ∪ ∆ | = IC
- KB ∪ ∆ is consistent.
where | = denotes the logical entailment relation.
Intuitively, the abductive explanation ∆ serves as a hypothesis that explains how an observation X could hold according to the logical theory T .
In the binary additive learning tasks shown in Figure 4, the abductive theory T contains a set of first-order logical rules for parsing symbol lists into equations and performing bitwise calculations, as shown in Figure 5. Specifically, the components are listed as follows.
The domain knowledge KB first contains rules for parsing a list of symbols to an equation. By assuming that all the equations in the data have the form X+Y=Z , this piece of domain knowledge can be expressed with a Prolog DCG formula:
$$\begin{array} { r l } & { \ e q \, \rightarrow \, d i g t i s , [ + ] , d i g t i s , [ = ] , d i g t i s . } \end{array}$$
where eq is a list of symbols such as [1,+,1,0,1,=,1,1,0] , digits represents a list of digital symbols, for example [0] and [1,0,0,1] . This parser can parse the list eq into a Prolog term calc(X,Y,Z) , where the variables correspond to the parsed digits .
To enable arithmetic calculation in logical layer, the domain knowledge KB also include certain rules for calculating a parsed equation, e.g., calc(X,Y,Z) . We implemented it using a bitwise
additive calculator with the following Prolog formula:
$$\begin{array} { r l } & { c a l c ( X , Y , Z ) \, \colon - \, o p _ { \ } r u l e s ( R ) , b i t w i s e _ { C a l c ( R , X , Y , Z ) } . } \end{array}$$
where op rules is a predicate that declares a list of unknown bitwise operations as addition rules that can be applied to bitwise calc to perform calculations.
One type of abducibles is the bitwise operations described with the predicate my op(D1,D2, [D3]) , which represents a bitwise addition rule D1+D2=D3 . For example, a logical exclusive-or operation can be defined with a list of bitwise operations [my op(0,0,[0]),my op(1,0,[1]), my op(0,1,1),my op(1,1,[0])] , and the carry rule for arithmetic addition can be written as my op(1,1,[1,0]) . Note that these bitwise addition rules are not included in the domain knowledge-they will be abduced as explanatory hypotheses for the training data during learning process.
Another type of abducibles involves the lists of symbols eq in Formula 5, which are the input to the logic layer through the neural-logical tunnel. Typically, the original eq 0 =[l 1 , . . . ,l s ] interpreted by initial perception model would contain mistakes and cause failures when attempting to abduce consistent hypotheses. Therefore, the neural-logical tunnel will try to substitute some l i with a Prolog variable ' ' as blanks in the equation. ALP will then abduce symbols that satisfy the consistency constraints to fill in these blanks. For example, when the perception model is under-trained, the neural-logical tunnel is highly likely to receive an eq 0 =[1,1,1,1,1] , i.e., the perception model interprets the image of the equation as '11111', which is definitely inconsistent with any arithmetic rules. Observing that ALP cannot abduce a consistent hypothesis, the neural logical tunnel will begin substituting some of the values in eq 0 with blank Prolog variables, e.g., eq 1 =[1, ,1, ,1] . Then, ALP can abduce a consistent hypothesis involving the additive rule my op(1,1,[1]) and eq ′ 1 =[1,+,1,=,1] . Finally, the abduced eq ′ 1 can be used as a supervised signal to train the perception model, helping it distinguish images of '+' and '=' from other symbols. An example of this process is illustrated in Figure 3.
The abduced answer ∆ contains hypotheses of the previous two abducibles (i.e., a list of my op rules for the op rules predicate in Formula 6 as the reasoning model ∆ C , and a list of (modified) digit and operator symbols eq ′ for retraining the perception model).
The integrity constraint IC simply addresses the consistency of the abduced hypotheses. For
example, the bitwise operations my op(1,0,[1]) and my op(1,0,[0]) cannot be valid bitwise addition rules at the same time; my op(1,0,[0]) and eq ′ =[1,+,0,=,1] cannot be both be abduced output as an explanatory hypothesis.
The observed fact X is the entire training dataset, which consists of all the images of equations and the labels indicating their correctness. However, in first-order logic, evaluating the consistency of a set of formulas on given facts is NP-hard. Hence, during the abduction process it will be difficult to evaluate the consistency of an abduced hypothesis on the entire training set. Therefore, NLM performs abduction on subsampled data over multiple iterations, where each subsample contains only 5-10 equation images. The abduced locally consistent hypotheses in each subsample are saved as relational features.
Optimization . The learning target of NLMs abduction is to find a hypothesis ∆ that maximizes its consistency Con (∆ , X ) on a set of observed examples X = { x 1 , . . . , x n } . This objective can be written as follows:
$$\begin{smallmatrix} \arg \max & C o n ( \Delta , X ) \\ \Delta & \end{smallmatrix}$$
where the consistency Con (∆ , X ) is defined by the size of the maximum consistent subset X C ⊆ X derived from ∆, which can be formalized as follows:
$$\underset { X _ { c } \subseteq X } { \arg \max } & \quad | X _ { c } | \\ s . t . & \quad K B \wedge \Delta \models X _ { c } . \\ & P \wedge \Delta \models I C .$$
where KB and IC are the domain knowledge and integrity constraints, respectively, defined in the abductive logic program of the logical layer. The optimization problem in objective 8 is a subset-selection problem, which is also generally NP-hard. Therefore, we approximately solve objectives 7 an 8 with greedy algorithms.
As shown in Figure 3, when the perception model is under-trained, the perceived symbols eq 0 from X might contain mistakes, causing the abduction of sufficiently consistent hypotheses to fail. NLM tries to solve this problem by substituting some possibly incorrectly perceived symbols in eq 0 to blank variable ' ' and lets ALP abduce a symbol list eq ′ 1 that ensures a maximally
consistent ∆ on dataset X ; then, it retrains the perception model. The substitution vector can be represented by S = { 0 , 1 } l , where l is the length of the interpreted symbol list eq 0 from X . When S i = 1 then the i -th interpreted symbol in eq 0 will be replaced with a blank variable ' '. When abducing hypotheses that are too far away from the perceived symbols and obtaining trivial solutions, the number of substituted variables should be constrained. Thus, the objective can be formalized as follows:
$$\max _ { S \in \{ 0 , 1 \} ^ { l } } & \max _ { \Delta ( S ) } C o n ( \Delta ( S ) , X ) \\$$
where ∆( S ) is a hypothesis abduced by ALP whose symbolic interpretations eq 0 are modified with the substitution vector S , and k is the limit on the number of modified perceived symbols. In the experiments we set k = 2.
The optimization problem in 9 is a binary vector optimization problem in an extremely complex hypothesis space, popular gradient-based optimization techniques can hardly be applied to this scenario. Therefore, we adopt a derivative-free optimization technique, RACOS [47], to solve it. RACOS is a randomized derivative-free optimization method implemented by a classification model that discriminates good solutions from bad ones, and it achieves good performance on complex optimization problems.
Making decisions . The high complexity of the optimization objective in Equation 9 makes it infeasible for the NLM to evaluate the entire training set X during optimization. Therefore, NLM performs abduction and optimization for T times, using a small observed dataset X t ⊆ X subsampled from the original dataset X each time. While the perception model p is iteratively trained from t = 1 to T , the locally consistent reasoning model ∆ t C in each iteration cannot be simply replaced or merged to construct the final output reasoning model ∆ C . Because the training data in each iteration X t = X , there is no guarantee that ∆ t C will be consistent for all training examples x ∈ X . In fact, some sets of examples (such as the arithmetic equations '1+10=11, 11+100=111') can achieve maximum consistency using just one bitwise addition rule my op(1,0,[1]) , which results in an incomplete ∆ t C for defining the target concept. Moreover, when the perception model p t in the t -th turn is under-trained, ALP might abduce incorrect bitwise addition rules.
To solve this problem, inspired by the propositionalization technique in Inductive Logic Programming [24], we retain the reasoning models abduced in each iteration as a relational feature . Before the perception model is well-trained, NLM uses a buffer that retains only the latest R -learned ∆ t C , and-based on their performances-some of these will be discarded during the training of the decision neural layer.
When an equation x i is input into NLM, its symbolic interpretation eq t mapped by the perception model will be evaluated by all the relational features to produce a binary vector r i = [ r i 1 , . . . , r iR ], where
$$r _ { i j } = \begin{cases} 1 , & K B \wedge \Delta _ { C } ^ { j } \models x _ { i } , \\ 0 , & K B \wedge \Delta _ { C } ^ { j } \not \equiv x _ { i } . \end{cases}$$
This vector of relational features transforms the original dataset X = {〈 x i , y i 〉} into a new dataset X ′ = {〈 r i , y i 〉} , from which a decision model is learned by the decision layer in Figure 2.
On one hand, the retained relational features are still first-order logical rules serving as a reasoning model with good human comprehensibility. On the other hand, using the propositionalization technique in the decision learning process reduces the impact of the noise introduced by the random subsampling of the training data.
## Experiment: Handwritten Equations Decipherment
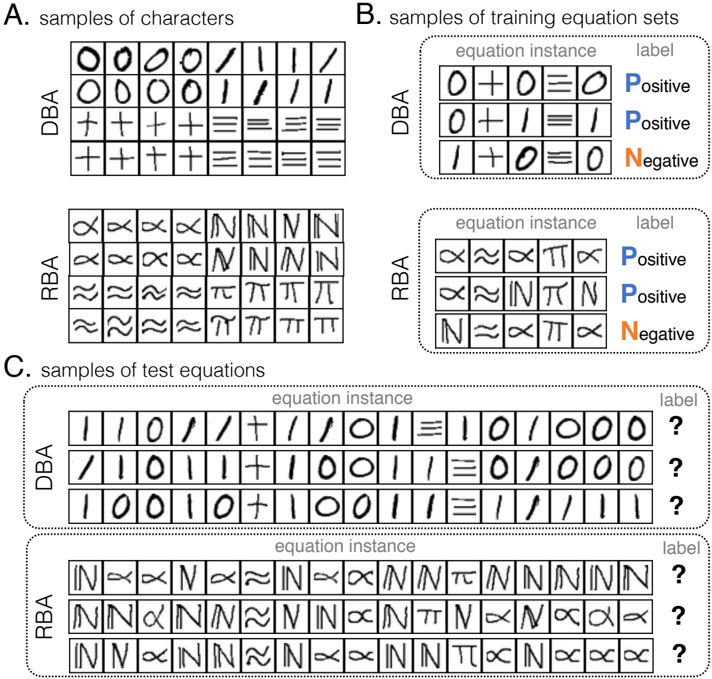
We constructed two image sets of symbols to build the equations shown in Figure 4. The Digital Binary Additive (DBA) equations were created with images from benchmark handwritten character datasets [29, 46], while the Random Binary Additive (RBA) equations were constructed from randomly selected character sets and shared isomorphic structure with the equations in the DBA tasks. Each equation is input as a sequence of raw images of digits and operators. As an analogy to the Mayan hieroglyph decipherment by historians, we provided NLM with background domain knowledge of arithmetic structure rules as shown in Figure 5(A) and 5(B). Note that this knowledge does not specify the type of calculation in the equations; instead, NLM needs to learn that from the data. Examples appear in Figure 5.
In the NLM implemented for this task, the perception layers consist of a two-layer CNN and a twolayer multiple-layer perceptron (MLP) followed by a softmax layer; the logical layer will abduce
Figure 4: Dataset illustrations . Our datasets are constructed from images of symbols ('0', '1', '+' and '='). (A) Samples of the two types of characters corresponding to those symbols: The Digital Binary Additive (DBA) set and the Random Binary Additive (RBA) set. (B) Samples of training equation sets of length 5, where each equation is associated with a label: positive or negative . A learning algorithm is required to learn from a set of equations and their labels and then predict the labels of testing equations with different lengths. (C) Samples of test equations of length 17, where labels are not shown to the algorithms; the labels are used only to calculate the accuracy of the predictions.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Character and Equation Samples: DBA vs. RBA
### Overview
The image presents samples of characters and equations processed using two different methods, DBA and RBA. It's divided into three sections: A) samples of characters, B) samples of training equation sets, and C) samples of test equations. Each section compares the output of DBA and RBA.
### Components/Axes
* **Section A Title:** samples of characters
* **Y-Axis Labels:** DBA, RBA
* **Characters:** The characters displayed are numerical digits (0, 1), mathematical symbols (+, =), and Greek letters (α, ≈, π, N).
* **Section B Title:** samples of training equation sets
* **Column Labels:** equation instance, label
* **Y-Axis Labels:** DBA, RBA
* **Labels:** Positive (Blue), Negative (Orange)
* **Section C Title:** samples of test equations
* **Column Labels:** equation instance, label
* **Y-Axis Labels:** DBA, RBA
* **Labels:** ?
### Detailed Analysis
**Section A: samples of characters**
* **DBA:**
* The DBA method displays the characters 0, 1, +, and =.
* The characters are arranged in a grid format.
* The characters are relatively clear and distinct.
* **RBA:**
* The RBA method displays the characters α, ≈, π, and N.
* The characters are arranged in a grid format.
* The characters are relatively clear and distinct.
**Section B: samples of training equation sets**
* **DBA:**
* Equation instances: 0+0=0 (Positive), 0+1=1 (Positive), 1+0=0 (Negative)
* The equations use numerical digits and basic mathematical operators.
* The labels indicate whether the equation is mathematically correct (Positive) or incorrect (Negative).
* **RBA:**
* Equation instances: α≈απ α (Positive), α≈Nπ N (Positive), N≈απ α (Negative)
* The equations use Greek letters and the approximation symbol.
* The labels indicate whether the equation is consistent with a defined rule set (Positive) or inconsistent (Negative).
**Section C: samples of test equations**
* **DBA:**
* Equation instances: Three rows of equations using 1, 0, +, =, and /.
* The labels are all marked with a question mark (?).
* **RBA:**
* Equation instances: Three rows of equations using N, α, ≈, π.
* The labels are all marked with a question mark (?).
### Key Observations
* The image compares the performance of DBA and RBA in processing characters and equations.
* Section A shows the basic character recognition capabilities of each method.
* Section B demonstrates the ability of each method to classify equations as positive or negative based on training data.
* Section C presents test equations for which the correct classification is unknown, indicated by the question mark labels.
### Interpretation
The image likely illustrates a comparison of two different algorithms (DBA and RBA) for optical character recognition (OCR) and equation solving. DBA seems to focus on numerical and basic mathematical symbols, while RBA focuses on Greek letters and approximation-based equations. The training sets in Section B are used to teach the algorithms to recognize patterns and classify equations. The test sets in Section C are used to evaluate the performance of the trained algorithms on unseen data. The question marks indicate that the expected outputs for these test equations are not provided in the image, implying that the algorithms are being tested for their ability to generalize and predict the correct answers.
</details>
20 bitwise operations set as relational features; The decision neural layer is a two-layer MLP. We test the learning performance of NLM by comparing it with the Bidirectional Long Short-Term Memory network (BiLSTM) [15] and the Differentiable Neural Computer (DNC) [12], because both are state-of-the-art benchmark models capable of solving tasks from sequential input such as arithmetic equations. In particular, the DNC has shown its potential on symbolic computing tasks [12] because it is associated with memory. To handle the image inputs, BiLSTM and DNC also use a CNN as their input layers. The training data prepared for BiLSTM and DNC contains equations with lengths from 5 to 26, but for NLM, we used only equations with lengths from 5 to 8, where each length contains 300 random sampled equations. In the testing stage, all the methods are tasked with predicting 6,600 equations whose lengths range from 5 to 26, where each length contains 300 examples.
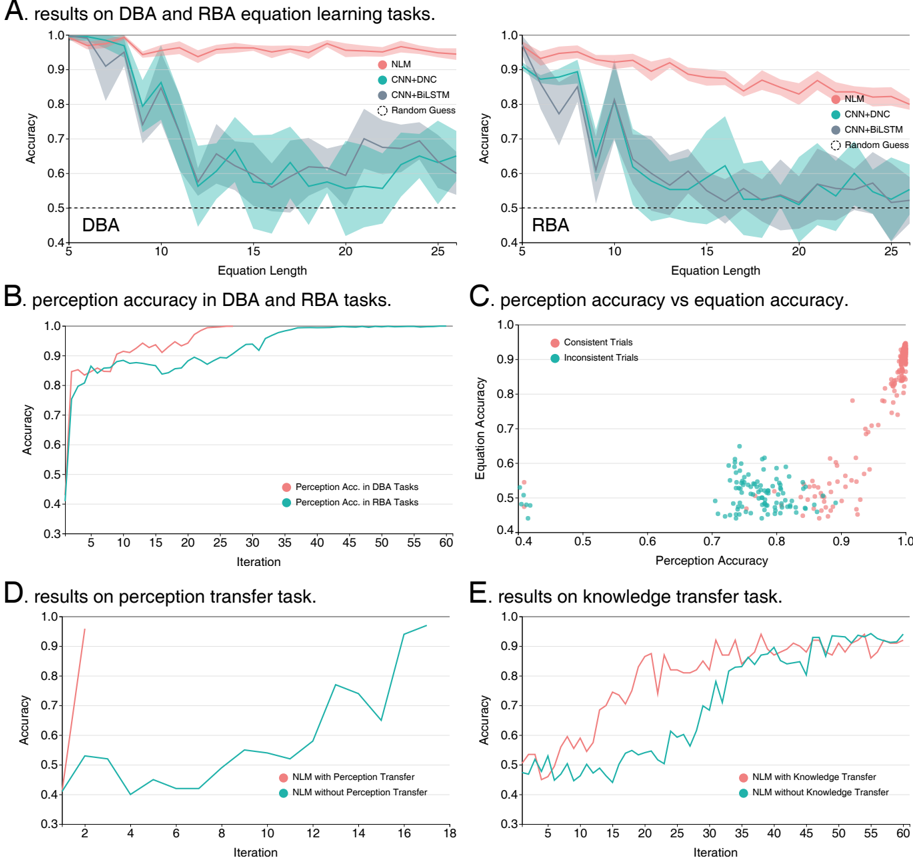
Figure 6(A) shows that on both tasks, the NLMs significantly outperform the compared methods while using far fewer training equations with lengths of at most 8. All the methods performed better on the DBA task than on the RBA task, because the symbol images in the DBA task are more easily distinguished. The performance of BiLSTM and DNC degenerates quickly toward the random-guess line as the length of the testing equations grows, while the performance of NLM degenerates much more slowly and maintains an accuracy above 80%. These results verify that NLM has learned the correct rules from the data. The logical layer benefits considerably from its ability to handle first-order logic; thus, it naturally exploits the definitions of the symbolic primitives and the background knowledge when solving the task. Note that the background knowledge exploited by NLM in this task involves no more than the logic structure rules, which alone cannot define the target concept; however, only the symbolic rules must be learned from data. The learned rules are shown in Figure 5(C). As a result, NLM generalizes well from the training data distribution, exhibiting a learning ability closer to that of humans.
Inside the learning process of NLM, although no labels exist for the images of digits and operators, the perception accuracy did increase during the learning process, as shown by Figure 6(B). The results verified that logic consistency can be very useful for providing a surrogate supervised signal and that, through logical abduction, NLM can correct incorrect neural perceptions. Figure 6(C) shows the relationship between the overall equation classification accuracy and the image perception accuracy during NLM training on the RBA tasks, where each dot in the figure represents a trial of abducing a consistent hypothesis from a subsample of equations; the red dots
## A. domain knowledge for parsing equations
```
1 % predicate for parsing symbol list
2 parse_eq(X, Y, Z, Eq) :- phrase(eq(X, Y, Z), Eq).
4 % definition of "digits" and "equation"
5 digit(0).
6 digit(1).
7 digits([D]) --> [D], { digit(D) }.
8 digits([D | T]) --> [D], !, digits(T), { digit(D) }.
9 eq(X, Y, Z) --> digits(X), [+], digits(Y), [=], digits(Z).
10 digits(X) :- phrase(digits(X), X).
```
## B. domain knowledge for bitwise calculation
```
B. domain knowledge for bitwise calculation
1% rule for calculation when bitwise addition rules available
2 calc(X, Y, Z) :- op_rules(R), bitwise_calc(R, X, Y, Z).
4% bitwise calculation that handles carrying
5 bitwise_calc(R, X, Y, Z) :-
6 reverse(X, X1), reverse(Y, Y1), reverse(Z, Z1),
7 bitwise_calc_r(R, X1, Y1, Z1), !.
8 bitwise_calc_r(_, [], Y, Y).
9 bitwise_calc_r(_, X, [], X).
10 bitwise_calc_r(R, [D1 | X], [D2 | Y], [D3 | Z]) :-
11 op_Rule = my_op(D1, D2, Sum),
12 member(Op_Rule, R),
13 ((Sum = [D3], Carry = []); (Sum = [C, D3], Carry = [C])),
14 bitwise_calc_r(R, X, Carry, X_carried),
15 bitwise_calc_r(R, X_carried, Y, Z).
```
- C. symbolic models learned in experiments
```
1 % symbolic hypothesis abduced from arithmetic addition tasks.
2 R_art = [my_op(0, 0, [0]), my_op(1, 0, [1]),
my_op(0, 1, [1]), my_op(1, 1, [1, 0])].
4 % symbolic hypothesis abduced from exclusive-or tasks.
6 R_xor = [my_op(0, 0, [0]), my_op(1, 0, [1]),
my_op(0, 1, [1]), my_op(1, 1, [0])].
```
Figure 5: Domain knowledge as Prolog programs used in the logical layer . The blue and green words are user-defined and system predicates, respectively, while the yellow words are abducibles that can be derived from the observed data. (A) A Prolog program that can parse and abduce a list of symbols as equations. For example, when Eq=[1, ,1, ,1] (the ' ' is a Prolog 'blank' variable that can be filled with an abduced symbol), using ALP ' parse eq ' can abduce ' X=Y=Z=1 ' and ' Eq=[1,+,1,=,1] '. (B) A Prolog program for making bitwise calculations and abducing bitwise operations as learned reasoning models. When a positive example perceived as ' [1,1,+,1,=,1,0,0] ' is provided, using ALP it can abduce two bitwise addition rules ' op rules([my op(1,1,[1,0]),my op(1,0,[1])]) '). (C) Examples of output reasoning models (relational features) abduced by NLM from data; different hypotheses can be learned from different tasks.
indicate successful abductions and the green dots signify failures. From the results, it is apparent that a better perception accuracy indeed contributed to better equation classification accuracy.
## Experiment: Cross-task Transfer
Just as when Bowditch used his past knowledge about Mayan hieroglyphs and calendar units to decipher unknown scripts, human learning features the ability of cross-domain transfer. We further investigate whether NLM, with its improved learning ability, also has an improved transfer capability. The first task investigates the transferability of the perception model to domains with different symbolic structures. We created logical exclusive-or equations as training examples using the DBA characters; the size of the dataset was equal to that used for the binary additive equation learning tasks.
To transfer the perception model to the exclusive-or domain, the perception layers used in the NLM are a direct copy of those trained on the DBA task. During the learning process, the parameters of those layers are fixed, ensuring that the NLM learns only reasoning models. As a comparison, another NLM was trained on the exclusive-or task from scratch. The results are shown in Figure 6(D), and the learned reasoning model is shown in Figure 5(C). As we can observe from the result, the final performances of NLMs with and without perception transfer are comparable. However, the convergence of the NLM with perception transfer is much faster than that without the transfer. This is consistent with the results in Figure 6(C) and shows that a good perception model dramatically reduces the difficulty of learning reasoning models.
The second task attempted to evaluate the capability of NLMs for transferring learned symbolic knowledge. We did this by setting the source and target domain as the RBA and DBA tasks, respectively. The knowledge transferred is in the form of both the logical layer and the decision neural layer. The NLM with knowledge transfer copied the relational features and the decision MLP parameters from a well-trained RBA NLM, therefore it only needed to train its perception CNN, in which the list of symbols abduced by the logical layer are regarded as labels to the input images. Similar to the previous experiment, the compared NLM learns the entire model from scratch. From the results depicted in Figure 6(E), we can observe that the NLMs eventually reach the same level of accuracy; however, the NLM with knowledge transfer converged significantly faster than the compared method. This result verifies that well-built domain knowledge makes
A. results on DBA and RBA equation learning tasks.
Figure 6: Experimental results : (A) Performances of the NLM and the compared methods on the DBA and RBA equation classification tasks, respectively. The values on the x-axis show the lengths of the test equations; the shadowed areas represent standard deviations. (B) The average training accuracy of the perception neural network vs. the number of iterations on the DBA and RBA tasks. (C) The relationship between the accuracy of character perception and equation classification during training. Each dot represents an abductive problem-solving trial with subsampled data: the red dots are trials where the NLM successfully found consistent symbolic hypotheses. (D) and (E) Performances of the NLMs on the perception and knowledge transfer tasks.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Combined Results: Equation Learning, Perception Accuracy, and Transfer Tasks
### Overview
The image presents a series of five plots (A-E) that analyze the performance of different models on equation learning tasks, perception accuracy, and transfer learning tasks. The plots compare the accuracy of Neural Language Models (NLM) against other models like CNN+DNC and CNN+BiLSTM, and also examine the impact of perception and knowledge transfer on model performance.
### Components/Axes
**Plot A: Results on DBA and RBA equation learning tasks (Left)**
* **Title:** results on DBA and RBA equation learning tasks.
* **X-axis:** Equation Length (5 to 25)
* **Y-axis:** Accuracy (0.4 to 1.0)
* **Legend (Top-Right):**
* NLM (Red)
* CNN+DNC (Teal)
* CNN+BiLSTM (Dark Gray)
* Random Guess (Dashed Black)
* **Subplot Label:** DBA (Bottom-Left)
**Plot A: Results on DBA and RBA equation learning tasks (Right)**
* **Title:** results on DBA and RBA equation learning tasks.
* **X-axis:** Equation Length (5 to 25)
* **Y-axis:** Accuracy (0.4 to 1.0)
* **Legend (Top-Right):**
* NLM (Red)
* CNN+DNC (Teal)
* CNN+BiLSTM (Dark Gray)
* Random Guess (Dashed Black)
* **Subplot Label:** RBA (Bottom-Left)
**Plot B: Perception accuracy in DBA and RBA tasks.**
* **Title:** perception accuracy in DBA and RBA tasks.
* **X-axis:** Iteration (5 to 60, increments of 5)
* **Y-axis:** Accuracy (0.3 to 1.0)
* **Legend (Bottom):**
* Perception Acc. in DBA Tasks (Red)
* Perception Acc. in RBA Tasks (Teal)
**Plot C: Perception accuracy vs equation accuracy.**
* **Title:** perception accuracy vs equation accuracy.
* **X-axis:** Perception Accuracy (0.4 to 1.0)
* **Y-axis:** Equation Accuracy (0.4 to 1.0)
* **Legend (Top-Right):**
* Consistent Trials (Red)
* Inconsistent Trials (Teal)
**Plot D: Results on perception transfer task.**
* **Title:** results on perception transfer task.
* **X-axis:** Iteration (2 to 18, increments of 2)
* **Y-axis:** Accuracy (0.3 to 1.0)
* **Legend (Bottom):**
* NLM with Perception Transfer (Red)
* NLM without Perception Transfer (Teal)
**Plot E: Results on knowledge transfer task.**
* **Title:** results on knowledge transfer task.
* **X-axis:** Iteration (5 to 60, increments of 5)
* **Y-axis:** Accuracy (0.3 to 1.0)
* **Legend (Bottom):**
* NLM with Knowledge Transfer (Red)
* NLM without Knowledge Transfer (Teal)
### Detailed Analysis
**Plot A (DBA):**
* **NLM (Red):** Starts at approximately 1.0 accuracy, drops sharply to around 0.8 at equation length 7, then fluctuates between 0.8 and 0.9 with increasing equation length.
* **CNN+DNC (Teal):** Starts at approximately 0.95 accuracy, drops sharply to around 0.55 at equation length 7, then gradually increases to around 0.65 with increasing equation length.
* **CNN+BiLSTM (Dark Gray):** Data not clearly visible.
* **Random Guess (Dashed Black):** Constant accuracy at approximately 0.5.
**Plot A (RBA):**
* **NLM (Red):** Starts at approximately 0.95 accuracy, gradually decreases to around 0.85 with increasing equation length.
* **CNN+DNC (Teal):** Starts at approximately 0.9 accuracy, drops sharply to around 0.5 at equation length 7, then gradually increases to around 0.55 with increasing equation length.
* **CNN+BiLSTM (Dark Gray):** Data not clearly visible.
* **Random Guess (Dashed Black):** Constant accuracy at approximately 0.5.
**Plot B:**
* **Perception Acc. in DBA Tasks (Red):** Starts at approximately 0.8 accuracy, increases sharply to around 0.95 by iteration 10, and then plateaus at approximately 1.0.
* **Perception Acc. in RBA Tasks (Teal):** Starts at approximately 0.4 accuracy, increases sharply to around 0.9 by iteration 15, and then plateaus at approximately 1.0.
**Plot C:**
* **Consistent Trials (Red):** Clusters in two regions: one around (0.4, 0.5) and another along the upper-right corner, showing a positive correlation between perception accuracy and equation accuracy.
* **Inconsistent Trials (Teal):** Clusters primarily in the region where perception accuracy is between 0.7 and 0.9, and equation accuracy is between 0.5 and 0.7.
**Plot D:**
* **NLM with Perception Transfer (Red):** Starts at approximately 0.95 accuracy, drops sharply to around 0.4 at iteration 2.
* **NLM without Perception Transfer (Teal):** Starts at approximately 0.4 accuracy, fluctuates between 0.4 and 0.8, and then increases sharply to around 1.0 at iteration 16.
**Plot E:**
* **NLM with Knowledge Transfer (Red):** Starts at approximately 0.5 accuracy, increases gradually to around 0.9 by iteration 35, and then fluctuates between 0.9 and 1.0.
* **NLM without Knowledge Transfer (Teal):** Starts at approximately 0.5 accuracy, increases gradually to around 0.9 by iteration 40, and then fluctuates between 0.9 and 1.0.
### Key Observations
* In equation learning tasks (Plot A), NLM generally outperforms CNN+DNC, especially for longer equations.
* Perception accuracy in both DBA and RBA tasks (Plot B) improves significantly with iteration, eventually reaching near-perfect accuracy.
* Plot C shows a positive correlation between perception accuracy and equation accuracy for consistent trials.
* Perception transfer (Plot D) initially hinders performance but eventually leads to higher accuracy.
* Knowledge transfer (Plot E) improves the learning rate and overall accuracy of the NLM.
### Interpretation
The data suggests that NLM is a more effective model for equation learning tasks compared to CNN+DNC, particularly as equation length increases. The improvement in perception accuracy with iteration indicates that the models are learning to better interpret the input data. The positive correlation between perception and equation accuracy highlights the importance of accurate perception for successful equation solving. The impact of perception and knowledge transfer on model performance demonstrates the potential for transfer learning to enhance the learning process. The initial dip in accuracy with perception transfer may indicate an initial adjustment period as the model integrates the transferred knowledge.
</details>
learning easier. However, comparing the results between knowledge transfer and perception transfer, we can see that providing the learning perception model without explicitly providing the labels is considerably more difficult-which indeed caused considerable trouble when historians were trying to decipher the Mayan language.
## Conclusion and Discussion
The experimental results verified that abductive learning can perform human-like abductive problem-solving that combines neural perception and symbolic reasoning. Abductive learning works even when the given symbolic background knowledge is incomplete for learning the target concepts. The proposed NLM approach can exploit symbolic domain knowledge while processing sub-symbolic data such as raw pixel images. In our experiments, the only supervision exploited by NLM involves labels of high-level concepts such as the 'correctness of an equation'. For mid-level concepts such as the digits and operator symbols that serve as primitives for high-level reasoning, NLM learns a recognition model without requiring image labels.
To the best of the authors' knowledge, abductive learning is the first framework designed for simultaneously learning both reasoning and perception models. To accomplish this goal, the AI system must be able to simultaneously manipulate symbolic learning and sub-symbolic learning. In past AI research, these two abilities have been developed only separately.
Symbolic AI has been considered as a fundamental solution to artificial intelligence since the dawn of AI. Symbolic AI refers to a set of methods based on high-level 'symbolic' problem representations and its goal is to define intelligent systems in an explicit way that is understandable by humans. In this branch of AI research, a series of important steps has been achieved, e.g., automatic theorem proving [33, 5], propositional rule learning [9], expert systems [18], automated planning [8] and inductive logic programming [31], and so on.
By formalizing the problem-solving process using symbolic representations such as a first-order logic language, symbolic AI imitates human reasoning through symbolic computation-based mainly on heuristic and selective search. Owing to the computers high efficiency in solving searching problems, symbolic AIs can deal with many tasks that are difficult for humans [40]. For example, recent progress in playing the game of Go verified that learning algorithms taught
by heuristically searched examples perform even better than those trained from demonstrations involving human expertise [38]. In fact, the success of symbolic AI over the last century has already shown the advantages of using computers to solve many symbolic reasoning tasks as compared to humans.
Most of the current mainstream machine learning methods, such as statistical learning and deep neural networks, focus on problems that have continuous and sub-symbolic hypothesis space representations to which gradient-based optimization techniques can be easily applied. Consequently, these methods have achieved great success on perception-like tasks such as image recognition [25, 43], speech recognition [13] and so on. However, due to the limited expressive power of sub-symbolic representation, most of these machine learning methods are incapable of performing secondary reasoning on learned data. For example, although deep neural networks have achieved near-human performance on some simple natural language processing tasks, a recent empirical study noted that they cannot address reading comprehension problems [19]. Moreover, the gap between symbolic and sub-symbolic representations causes them to fail to make use of domain knowledge that can only be expressed through first-order logic; thus, they miss an opportunity for exploiting the great inventions in the fruitful symbolic AI research.
A natural approach to fix these problems is to combine symbolic and sub-symbolic AI systems. Fuzzy logic [48], probabilistic logic programming [7] and statistical relational learning [11] have been proposed to empower traditional logic-based methods to handle probability distributions; however, most of them still require human-defined symbols as input similar to traditional symbolic AI systems. Probabilistic programming is then proposed as an analogy to human cognition to enable probabilistic reasoning with sub-symbolic primitives [45, 27, 26], yet the correspondence between the sub-symbolic primitives and their symbolic representations used in programming is assumed to already exist rather than assuming that it should be automatically learned [27, 26]. Differential programming methods such as DNC attempt to emulate symbolic computing using differentiable functional calculations [12, 10, 2], but they can hardly reproduce genuine logical inferences, and they require large amounts of training data to learn even simple logical operations. LASIN is a work that also uses logical abduction to introduce general human knowledge into statistical learning [6]; however, the exploited symbolic knowledge is required to be complete and correct. In short, few AI systems exist that can perform symbolic and sub-symbolic learning at the same time.
As shown in the Mayan digits decipherment example, humans can easily combine knowledgebased symbolic reasoning and sensory-based sub-symbolic perception, and these two components affect each other simultaneously [41]. This fact has been verified in cognitive psychology. The most representative evidence is visual illusions, which illustrate that the way we understand the world is greatly influenced by the complicated interactions between our sensations and our past knowledge that lend abundant meaning to sensed stimuli [41]. It has been suggested that abduction is the key to the entangled relationship between sub-symbolic perception and symbolic reasoning connections [30]. In a sense, we believe that the proposed abductive learning can be regarded as a verification of this theory.
Inspired by the trial-and-error approach of Bowditch's decipherment (Figure 1(B)), abductive learning connects symbolic reasoning with sub-symbolic perception. Owing to the expressive power of first-order logic, abductive learning is capable of directly exploiting general domain knowledge. The differentiable structure of neural perception enables abductive learning to conveniently create the mappings between raw data and its symbolic representations. Finally, the background knowledge based heuristic search allows abductive learning to automatically infer the existence of primitive objects from raw data.
Many improvements can be made to abductive learning in the future. Ideally, an AI system should be able to learn the background knowledge by itself; in addition, the learned knowledge should be reusable in other tasks. In this work, we verified that both perception model and reasoning model can be directly reused in different but similar tasks; however, a general paradigm for reusing more complicated knowledge is required. Moreover, loss of the learning system is currently back-propagated through its logical module by searching, abduction and optimization in a naive way. Methods for improving the efficiency of these operations are worth studying and can make abductive learning more practical for real applications.
## References
- [1] Bengio, Y., Louradour, J., Collobert, R., and Weston, J. Curriculum learning. Journal of the American Podiatry Association 60 , 60 (2009), 6.
- [2] Boˇ snjak, M., Rockt¨ aschel, T., Naradowsky, J., and Riedel, S. Programming with a differentiable forth interpreter. In Proceedings of the 34th International Conference on Machine Learning (Sydney, Australia, 2017), pp. 547-556.
- [3] Bowditch, C. P. The numeration, calendar systems and astronomical knowledge of the mayas . Cambridge University Press, 1910.
- [4] Bratko, I. Prolog Programming for Artificial Intelligence . Addison-Wesley Longman Publishing, Boston, MA, 1990.
- [5] Chang, C.-L., and Lee, R. C.-T. Symbolic logic and mechanical theorem proving . Academic Press, Orlando, FL, 1997.
- [6] Dai, W.-Z., and Zhou, Z.-H. Combining logical abduction and statistical induction: Discovering written primitives with human knowledge. In Proceedings of the 31st AAAI Conference on Artificial Intelligence (San Francisco, CA, 2017), pp. 4392-4398.
- [7] De Raedt, L., Frasconi, P., Kersting, K., and Muggleton, S. H. Probabilistic inductive logic programming . Springer-Verlag, Berlin, 2008. LNAI 4911.
- [8] Fikes, R., and Nilsson, N. J. STRIPS: A new approach to the application of theorem proving to problem solving. Artificial Intelligence 2 , 3/4 (1971), 189-208.
- [9] F¨ urnkranz, J., Gamberger, D., and Lavraˇ c, N. Foundations of rule learning . Cognitive Technologies. Springer, 2012.
- [10] Gaunt, A. L., Brockschmidt, M., Kushman, N., and Tarlow, D. Differentiable programs with neural libraries. In Proceedings of the 34th International Conference on Machine Learning (Sydney, Australia, 2017), pp. 1213-1222.
- [11] Getoor, L., and Taskar, B. , Eds. Introduction to statistical relational learning . MIT Press, Cambridge, Massachusetts, 2007.
- [12] Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., GrabskaBarwiska, A., Colmenarejo, S. G., Grefenstette, E., Ramalho, T., and Agapiou, J. Hybrid computing using a neural network with dynamic external memory. Nature 538 , 7626 (2016), 471.
- [13] Hinton, G., Deng, L., Yu, D., Dahl, G. E., Mohamed, A., Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., and Sainath, T. N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Processing Magazine 29 , 6 (2012), 82-97.
- [14] Hinton, G. E. Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society (1986), Hillsdale, NJ: Erlbaum, pp. 1-12.
- [15] Hochreiter, S., and Schmidhuber, J. Long short-term memory. Neural Computation 9 , 8 (1997), 1735-1780.
- [16] Houston, S. D., Mazariegos, O. C., and Stuart, D. , Eds. The decipherment of ancient maya writing . University of Oklahoma Press, Norman, OK, 2001.
- [17] Hu, Z., Ma, X., Liu, Z., Hovy, E., and Xing, E. Harnessing deep neural networks with logic rules. arXiv preprint arXiv:1603.06318 (2016).
- [18] Jackson, P. Introduction to Expert Systems , 3rd ed. Addison-Wesley, 1999.
- [19] Jia, R., and Liang, P. Adversarial examples for evaluating reading comprehension systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP'17) (Copenhagen, Denmark, 2017), pp. 2011-2021.
- [20] Kakas, A. C., and Flach, P. A. Abduction and induction in artificial intelligence. Jounal of Applied Logic 7 , 3 (2009), 251.
- [21] Kakas, A. C., Kowalski, R. A., and Toni, F. Abductive logic programming. Journal of Logic Computation 2 , 6 (1992), 719-770.
- [22] Kowalski, R. A. Predicate logic as programming language. In Proceedings of IFIP Congress 74 (1974), pp. 569-574.
- [23] Kowalski, R. A., and Kuehner, D. Linear resolution with selection function. Artificial Intelligence 2 , 3/4 (1971), 227-260.
- [24] Kramer, S., Lavraˇ c, N., and Flach, P. Propositionalisation approaches to Relational Data Mining. In Relational Data Mining , S. Dˇ zeroski and N. Larac, Eds. Springer, Berlin, 2001, pp. 262-291.
- [25] Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25 (NIPS'12) (2012), pp. 1097-1105.
- [26] Kulkarni, T. D., Kohli, P., Tenenbaum, J. B., and Mansinghka, V. Picture: A probabilistic programming language for scene perception. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (2015), pp. 4390-4399.
- [27] Lake, B. M., Salakhutdinov, R., and Tenenbaum, J. B. Human-level concept learning through probabilistic program induction. Science 350 , 6266 (2015), 1332-1338.
- [28] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE 86 , 11 (1998), 2278-2324.
- [29] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE 86 , 11 (2001), 2278-2324.
- [30] Magnani, L. Abductive Cognition: The Epistemological and Eco-Cognitive Dimensions of Hypothetical Reasoning , 1st ed. Springer, 2009.
- [31] Muggleton, S. H. Inductive logic programming. New Generation Computing 8 , 4 (1991), 295-318.
- [32] Munos, R. From bandits to Monte-Carlo Tree Search: The optimistic principle applied to optimization and planning. Foundations and Trends in Machine Learning 7 , 1 (2014), 1-130.
- [33] Newell, A., and Simon, H. A. The logic theory machine - A complex information processing system. IRE Transactions on Information Theory 2 , 3 (1956), 61-79.
- [34] Peirce, S. C. Abduction and induction. In Philosophical writings of peirce , J. Buchler, Ed. Dover Publications, 1955.
- [35] Russell, S. J. Unifying logic and probability. Communications of the ACM 58 , 7 (2015), 88-97.
- [36] Santoro, A., Raposo, D., Barrett, D. G., Malinowski, M., Pascanu, R., Battaglia, P., and Lillicrap, T. A simple neural network module for relational reasoning. CoRR abs/1706.01427 (2017).
- [37] Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and de Freitas, N. Taking the human out of the loop: A review of bayesian optimization. Proceedings of the IEEE 104 , 1 (2016), 148-175.
- [38] Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Gue, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., and Hassabis, D. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. CoRR abs/1712.01815 (2017).
- [39] Simon, H. A. The logic of rational decision. British Journal for the Philosophy of Science (1965), 169-186.
- [40] Simon, H. A., and Newell, A. Human problem solving: The state of the theory in 1970. American Psychologist 26 , 2 (1971), 145.
- [41] Solso, R. L., MacLin, O. H., and MacLin, M. K. Cognitive Psychology , 8th ed. Pearson/Allyn and Bacon, 2008.
- [42] Stuart, D. Sourcebook for the 30th Maya Meetings Part II: The Malenque Mythology: Inscriptions from the Cross Group at Palenque . University of Texas Austin Press, 2006.
- [43] Szegedy, C., Toshev, A., and Erhan, D. Deep neural networks for object detection. In Advances in Neural Information Processing Systems 26 (NIPS'13) . Curran Associates, 2014, pp. 2553-2561.
- [44] Taigman, Y., Yang, M., Ranzato, M., and Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2014).
- [45] Tenenbaum, J. B., Kemp, C., Griffiths, T. L., and Goodman, N. D. How to grow a mind: Statistics, structure, and abstraction. Science 331 , 6022 (2011), 1279-1285.
- [46] Thoma, M. The HASYv2 dataset. CoRR abs/1701.08380 (2017).
- [47] Yu, Y., Qian, H., and Hu, Y. Q. Derivative-free optimization via classification. In Proceedings of the 30th AAAI Conference on Artificial Intelligence (2016), pp. 2286-2292.
- [48] Zadeh, L. A. Fuzzy sets. Information and Control 8 , 3 (1965), 338-353.