## FPGA-Based CNN Inference Accelerator Synthesized from Multi-Threaded C Software
†
Samsung Semiconductor Inc., San Jose, CA, USA
Jin Hee Kim, Brett Grady, Ruolong Lian, John Brothers , Jason H. Anderson Dept. of Electrical and Computer Engineering, University of Toronto, Toronto, ON, Canada †
Email:
{ kimjin14, bgrady, janders } @ece.utoronto.ca
Abstract -A deep-learning inference accelerator is synthesized from a C -language software program parallelized with Pthreads. The software implementation uses the well-known producer/consumer model with parallel threads interconnected by FIFO queues. The LegUp high-level synthesis (HLS) [1] tool synthesizes threads into parallel FPGA hardware, translating software parallelism into spatial parallelism. A complete system is generated where convolution, pooling and padding are realized in the synthesized accelerator, with remaining tasks executing on an embedded ARM processor. The accelerator incorporates reduced precision, and a novel approach for zero-weight-skipping in convolution. On a mid-sized Intel Arria 10 SoC FPGA, peak performance on VGG-16 is 138 effective GOPS.
## I. INTRODUCTION
State-of-the-art accuracy results in image recognition, language translation, image-caption generation, and many other tasks are being achieved with deep convolutional neural networks (CNNs) (e.g. [2], [3], [4]). CNN training is very compute intensive, requiring hours, days or weeks of time using state-of-the-art graphics processing units (GPUs). Applying a trained CNN to a recognition task, inference , can involve billions of operations. Hardware acceleration is particularly desirable for inference, as training is typically done once offline, whereas inference with a trained network is applied repeatedly. Moreover, there is increased emphasis on performing CNN inference in an embedded-computing context (e.g. mobile handsets, self-driving cars), where low-power and low latency are important metrics. In this paper, we focus on acceleration of CNN inference.
CNN inference has been accelerated with GPUs, custom ASICs, and recently, field-programmable gate arrays (FPGAs). At present, it is unclear which IC media will ultimately prevail as best for CNN inference acceleration. However, the speed at which CNN research is evolving, as well as recent research on low-precision CNNs [5] bodes well for FPGA technology. With FPGAs, the accelerator architecture and its datapath widths can be precisely tailored to the target CNN, whereas an ASIC or GPU are necessarily over-engineered with fixed-sized datapaths to handle a broad set of precisions. Moreover, the reconfigurability of FPGAs permits an accelerator design to be adapted to incorporate new research findings as they arise, for example, the ability to achieve high recognition accuracy with 2-bit precision [6]. Lastly, high-level synthesis (HLS) is a relatively mature design methodology for FPGAs [7], permitting a software specification of the accelerator to be synthesized into hardware. HLS lowers NRE costs by allowing design and debugging to proceed at a higher level of abstraction vs. manual RTL design.
We apply HLS and use an FPGA to realize a CNN inference accelerator. The accelerator is described in C and synthesized with the LegUp HLS framework [1]. A unique aspect of LegUp is its ability to synthesize software parallelized with the Pthreads standard into parallel hardware [8]. We leverage the Pthreads synthesis to exploit spatial parallelism on the FPGA. Specifically, we specify the accelerator in software using the producer/consumer parallelization idiom, well known to software engineers. 20 parallel software threads are synthesized by LegUp HLS into streaming hardware comprising compute kernels interconnected by FIFO queues.
The inference accelerator performs key compute-intensive operations: convolution, subsampling (pooling), and padding. Software executing on an embedded on-die ARM processor performs remaining operations to provide a complete end-toend embedded solution. The accelerator architecture incorporates novel features for tiling, data-reuse, and zero-weightskipping, as many CNNs can be pruned without significant loss of accuracy [9]. The accelerator's computations are realized in reduced precision, specifically 8-bit magnitude + sign format. We demonstrate our accelerator on the VGG-16 CNN for image recognition (ImageNet database). Our contributions are as follows:
- An FPGA-based CNN accelerator synthesized from multi-threaded (Pthreads) C software. The software behavior closely resembles the synthesized hardware, easing design and debugging by allowing it to proceed in software.
- Generation and exploration of accelerator architectural variants via software/constraint changes alone.
- Analysis of the efficiency of the HLS implementation, in terms of cycles spent, compared to the theoretical minimum for the architecture.
- A novel architecture for zero-skipping; use of reducedprecision arithmetic.
- A complete end-to-end solution for CNN inference, integrated with Caffe for network training.
- 138 GOPS peak effective performance implementing the VGG-16 CNN for image recognition on a midsized Arria 10 SoC SX660 20 n m FPGA.
## II. BACKGROUND
## A. LegUp High-Level Synthesis
The Pthreads synthesis flow of LegUp HLS is used to synthesize parallel software threads into parallel hardware. The multi-threaded software is written using the producer/consumer paradigm, where threads represent computational kernels and communicate with one another through FIFO queues [8]. Producer threads deposit computed partial results into output queues, which are then retrieved by concurrently running consumer threads, which perform further processing. Note that a given thread can be both a producer and a consumer, receiving inputs from FIFO queues, computing on those inputs, and depositing results to output FIFO queues. The support in LegUp HLS for hardware synthesis of the producer/consumer parallel model is well-aligned with the computational and communication requirements of deep CNN inference.
FIFO queues that interconnect kernels are realized with a LegUp HLS-provided LEGUP\_PTHREAD\_FIFO structure and API, and can be created with user-provided lengths and bitwidths. To illustrate the coding style (used heavily throughout our implementation), the example below shows a function with one input queue, inQ , and one output queue, outQ . The function body contains an infinite while loop that reads an input, inputData from inQ , performs computation to produce output outData , and deposits into outQ . pthread\_fifo\_read and pthread\_fifo\_write are API functions to read-from and write-to queues, respectively. The while loop is pipelined in hardware by LegUp to realize a streaming kernel that accepts new input each clock cycle.
```
void prodCons(LEGUP_PTHREAD_FIFO *inQ, LEGUP_PTHREAD_FIFO *outQ) {
...
while (1) {
inputData = pthread_fifo_read(inQ);
outputData = compute(inputData);
pthread_fifo_write(outQ, outputData);
}
}
```
## B. VGG-16 CNN
The VGG-16 CNN [3] is used as the test vehicle for our accelerator. The input to the CNN is a 224 × 224 RGB image drawn from the 1000-category ImageNet database. The image is first passed through 13 convolution layers interspersed with occasional max-pooling layers, ending with 3 fully connected layers. All convolutional filters are 3 × 3 pixels in dimension. Before each convolutional layer, the input feature maps are padded with 0 s around the perimeter. Max-pooling is done for 2 × 2 regions with a stride of 2. ReLU activation is applied in all cases ( y = max (0 , x ) , where x is the neuron output). The VGG-16 network has over 130M parameters and the reader is referred to [3] for complete details.
## III. ARCHITECTURE
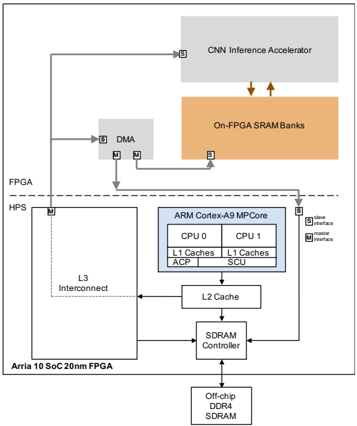
Fig. 1 depicts the system-on-chip (SoC) architecture, consisting of a Cortex A9 hard processor system (HPS), accelerator, DMA controller, and SRAM banks within the Arria 10 FPGA fabric. The on-FPGA banks are backed by offchip DDR4 RAM. The components are connected to one another using Avalon, Intel's on-chip memory mapped bus interface (discussed below). Bus masters are designated with M in the figure; slaves are designated with S. The processor issues instructions to the DMA and accelerator by writing to the memory mapped address (connected through the L3 interconnect). DMA transfers between the off-chip DRAM and FPGA are realized by a direct connection from the DMA unit to the SDRAM controller.
## A. Accelerator Architecture
We first introduce the data representation, as it is necessary to understand the zero-skipping approach. Feature maps are organized into tiles of 4 × 4 values, as shown on the left side of Fig. 2. The center of the figure shows a 16 × 16 feature map, comprising 4 × 4 tiles. These tiles are stored
X0
X4
X8
X1
X5
X9
X2
X6
XA
X3
X7
XB
XC
XD
XE
XF
!"#$%&'%()(%*+#,$-
Fig. 1. System architecture.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## System Diagram: Arria 10 SoC FPGA Architecture
### Overview
The image is a system diagram illustrating the architecture of an Arria 10 SoC (System on Chip) 20nm FPGA. It depicts the interconnection of various components, including a CNN Inference Accelerator, On-FPGA SRAM Banks, DMA (Direct Memory Access), an ARM Cortex-A9 MPCore, L3 Interconnect, L2 Cache, SDRAM Controller, and Off-chip DDR4 SDRAM. The diagram highlights the data flow and interfaces between these components within the FPGA and HPS (Hard Processor System) domains.
### Components/Axes
* **FPGA:** Field Programmable Gate Array section of the SoC.
* **HPS:** Hard Processor System section of the SoC.
* **CNN Inference Accelerator:** A block for accelerating Convolutional Neural Network inference.
* **On-FPGA SRAM Banks:** On-chip Static Random-Access Memory.
* **DMA:** Direct Memory Access controller.
* **ARM Cortex-A9 MPCore:** A multi-core ARM processor. Contains:
* CPU 0
* CPU 1
* L1 Caches (for both CPUs)
* ACP (Accelerator Coherency Port)
* SCU (Snoop Control Unit)
* **L3 Interconnect:** Interconnect fabric for the HPS.
* **L2 Cache:** Level 2 cache memory.
* **SDRAM Controller:** Controller for external SDRAM.
* **Off-chip DDR4 SDRAM:** External Dynamic Random-Access Memory.
* **Arria 10 SoC 20nm FPGA:** Label for the overall chip.
* **Slave Interface (S):** Denoted by the letter 'S' in a square.
* **Master Interface (M):** Denoted by the letter 'M' in a square.
### Detailed Analysis
* **CNN Inference Accelerator:** Located at the top of the diagram, within the FPGA domain. It has a slave interface.
* **On-FPGA SRAM Banks:** Located below the CNN Inference Accelerator, within the FPGA domain. It has a slave interface. Data flows between the CNN Inference Accelerator and the On-FPGA SRAM Banks, indicated by two downward-pointing arrows.
* **DMA:** Located to the left of the On-FPGA SRAM Banks, within the FPGA domain. It has both slave and master interfaces.
* **FPGA/HPS Boundary:** A dashed line separates the FPGA and HPS domains.
* **ARM Cortex-A9 MPCore:** Located within the HPS domain. It has a slave interface.
* **CPU 0 and CPU 1:** Each CPU has its own L1 Cache.
* **ACP and SCU:** Are also components within the ARM Cortex-A9 MPCore.
* **L3 Interconnect:** Located to the left of the ARM Cortex-A9 MPCore, within the HPS domain. It has a master interface.
* **L2 Cache:** Located below the ARM Cortex-A9 MPCore.
* **SDRAM Controller:** Located below the L2 Cache.
* **Off-chip DDR4 SDRAM:** Located at the bottom of the diagram.
* **Data Flow:**
* The CNN Inference Accelerator connects to the DMA via a line.
* The DMA connects to the On-FPGA SRAM Banks via two lines.
* The L3 Interconnect connects to the SDRAM Controller.
* The L2 Cache connects to the L3 Interconnect and the SDRAM Controller.
* The SDRAM Controller connects to the Off-chip DDR4 SDRAM.
### Key Observations
* The diagram illustrates a typical data processing pipeline, where the CNN Inference Accelerator processes data stored in the On-FPGA SRAM Banks.
* The DMA facilitates data transfer between the CNN Inference Accelerator and the On-FPGA SRAM Banks.
* The ARM Cortex-A9 MPCore interacts with the L2 Cache and SDRAM Controller to access external memory.
* The FPGA and HPS domains are clearly separated, indicating the partitioning of functionality between the programmable logic and the hard processor system.
### Interpretation
The diagram provides a high-level overview of the Arria 10 SoC FPGA architecture, emphasizing the data flow and interconnection of key components. It highlights the integration of a CNN Inference Accelerator, which suggests the device is designed for applications involving machine learning and image processing. The presence of both on-chip SRAM and off-chip DDR4 SDRAM indicates a memory hierarchy optimized for performance and capacity. The separation of the FPGA and HPS domains allows for flexible hardware acceleration and software control. The master and slave interfaces indicate the direction of data flow and control between the different components. Overall, the architecture is designed to support a wide range of embedded applications requiring high performance and low power consumption.
</details>
-/0"2$
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
XC
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
XC
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XD
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
XE
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
X3
X0
X1
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X3
X7
XB
XF
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
XC
X0
X4
X8
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XC
XD
XE
XF
XC
XD
XE
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XD
X1
X5
X9
XD
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
XE
X2
X6
XA
XE
.$+/,0$%1+2
Fig. 2. Tile concept, feature map, stripe, data layout.
in memory in row-major order, depicted on the right, where colors of tiles correspond to those in the center image. Fig. 2 also introduces the notion of a stripe , which is a region of tiles spanning the entire width of a feature map. Striping is used to subdivide large convolutional layers into smaller ones that can be accommodated in on-chip memory.
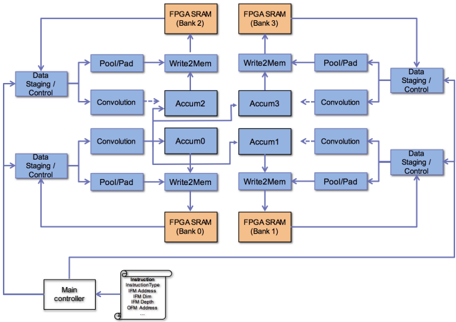
A block diagram of the accelerator is shown in Fig. 3. Four banks of on-FPGA SRAM are shown in orange. An entire tile of data (16 values) can be read from an SRAM bank in a single cycle. The on-FPGA SRAM banks are dual-port: reads are from port A; writes are to port B. The primary computing
Fig. 3. Accelerator block diagram (each blue module is synthesized from a software thread to hardware).
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: FPGA Data Flow
### Overview
The image is a block diagram illustrating the data flow within an FPGA-based system, likely for image processing or similar applications. It shows the interconnection of various processing blocks, memory banks, and a main controller.
### Components/Axes
* **Blocks:** The diagram consists of rectangular blocks representing functional units. These blocks are colored blue, except for the FPGA SRAM blocks, which are orange.
* **Arrows:** Blue arrows indicate the direction of data flow between the blocks. Dashed arrows are also present.
* **Text Labels:** Each block is labeled with its function (e.g., "Data Staging/Control", "Convolution", "Pool/Pad", "Write2Mem", "Accum").
* **Memory Banks:** Four FPGA SRAM blocks are labeled as Bank 0, Bank 1, Bank 2, and Bank 3.
* **Main Controller:** A block labeled "Main controller" is present at the bottom-left.
* **Instruction Box:** A box near the main controller contains the word "Instruction" and the following parameters: "InstructionType", "IFM Address", "IFM Dim", "IFM Depth", "OFM Address".
### Detailed Analysis
* **Data Staging/Control:** There are four "Data Staging/Control" blocks, one at each corner of the central processing array.
* **Convolution:** There are two pairs of "Convolution" blocks.
* **Pool/Pad:** There are two pairs of "Pool/Pad" blocks.
* **Write2Mem:** There are two pairs of "Write2Mem" blocks.
* **Accum:** There are four "Accum" blocks, labeled Accum0, Accum1, Accum2, and Accum3.
* **FPGA SRAM:** The four FPGA SRAM blocks are positioned at the top and bottom of the diagram. Bank 2 and Bank 3 are at the top, while Bank 0 and Bank 1 are at the bottom.
* **Data Flow:**
* Data flows from the "Data Staging/Control" blocks to "Pool/Pad" and "Convolution" blocks.
* "Pool/Pad" blocks feed into "Write2Mem" blocks.
* "Convolution" blocks feed into "Accum" blocks.
* "Write2Mem" blocks write to the FPGA SRAM banks.
* Data flows from the FPGA SRAM banks back to the "Data Staging/Control" blocks.
* The "Main controller" connects to all "Data Staging/Control" blocks.
* Dashed arrows connect the "Convolution" blocks to the "Accum" blocks.
### Key Observations
* The diagram represents a parallel processing architecture.
* The data flow is cyclical, with data being processed and stored in memory before being fed back into the processing pipeline.
* The "Main controller" likely manages the overall operation of the system.
### Interpretation
The diagram illustrates a hardware architecture implemented on an FPGA for performing a series of operations, likely related to image processing or deep learning. The "Convolution" blocks suggest convolutional neural network processing. The "Pool/Pad" blocks suggest pooling and padding operations commonly used in CNNs. The data flow indicates that data is staged, processed, stored in memory, and then reused. The parallel structure suggests that the architecture is designed for high-throughput processing. The instruction box suggests that the main controller is responsible for configuring the processing pipeline.
</details>
!"!"!
3&451+6&0%/"#$%1$1&07%#+7&,/
units are shown in blue - each is a software thread in the software implementation. Observe that there are 4 instances of 5 different compute units: 20 units (threads) in total. Edges in the figure represent multiple FIFO queues for communication of data/control between the units; queues are not shown for clarity.
The high-level behavior is as follows: The datastaging/control units receive an instruction from the ARM processor to perform convolution, padding, or max-pooling. We do not focus on fully connected layers, since it is essentially matrix multiplication and most CNN computational work comprises convolution. Although the padding and subsampling operations can be performed by a processor fairly efficiently, in most CNNs, they are tightly interleaved with convolution operations. Supporting them in hardware minimizes memory traffic between the FPGA and HPS.
For a convolution instruction, four tiles from different output feature maps (OFMs) are computed simultaneously. The four concurrently computed OFM tiles are at the same x/y location. Each data-staging/control unit loads a subset of input feature maps (IFMs) from an on-FPGA SRAM bank, as well as corresponding filter weight data from four filters. On each clock cycle weights and IFM data are injected into the convolution units. Each convolution unit performs 64 multiply operations each clock cycle, thus the entire accelerator performs 256 multiplication operations per cycle. Products from the convolution units are sent to the accumulator units (center of the figure). Each accumulator unit is responsible for maintaining the values of one tile (16 values) in an OFM. In the figure, for clarity, some edges between convolution units and accumulator units are omitted. When an OFM tile is completed, it is sent to the write-to-memory unit and written to an on-FPGA SRAM bank.
For a padding or max-pooling instruction, the datastaging/control units send IFM data and instructions to the pool/pad units, capable of performing any style of padding/max-pooling, described below. Pooled/padded tiles are then forwarded to the write-to-memory units and written to SRAM banks. Padding/pooling of four OFM tiles is done concurrently.
## B. Convolution and Zero-Weight Skipping
OFMs are computed on a tile-by-tile basis to completion without any intermediate swap-out to off-chip memory in an output-stationary manner. This style allows us to keep a fixed datapath width and not compromise accuracy by rounding partial sums. The convolution unit contains a computational sub-module that multiplies one weight per clock cycle to 16 IFM values and accumulates the resulting 16 products to the corresponding 16 OFM values in an OFM tile being computed.
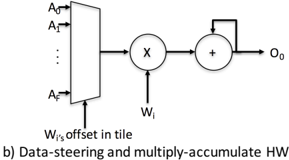
Fig. 4(a) shows an OFM tile (lower right), a weight tile (upper right), and four contiguous IFM tiles. For this example, assume that the upper-left IFM tile is x/y aligned with the OFM tile being computed and that the filter dimensions are smaller than 4 × 4 (the tile size). In a given clock cycle, a weight in the weight tile is selected and multiplied by 16 IFM values. The example illustrates, with a dotted rectangle, the region of 16 IFM values with which the weight W 5 is multiplied. Observe that the intra-tile x/y offset of W 5 defines the region of IFM values which with it is multiplied. This produces 16 products: W 5 · A 5 , W 5 · A 6 . . . W 5 · D 0 . The products are accumulated to the corresponding OFM values: O 0 , O 1 , . . . , O F , respectively.
| A 0 A 4 A 8 | A 1 3 5 6 7 B | A 2 A 0 B 1 B 2 B 3 4 |
|---------------|-----------------------|-------------------------|
| | A A A B B 5 B 6 | B 7 |
| | A 9 A A A B B B A | 8 B 9 B B |
| A C | A D A E A F B B E | C B D B F |
| C 0 | C 1 C 2 C 3 D D 2 | 0 D 1 D 3 |
| C 4 | C 5 C 6 C 7 D D 6 | 4 D 5 D 7 |
| C 8 | C 9 C A C B D 8 D 9 D | A D B |
| C C | C D C E C F D D D D E | C D F |
)(&*+%$%&'(
| W 0 | W 1 | W 2 | W 3 |
|-------|-------|-------|-------|
| W 4 | W 5 | W 6 | W 7 |
| W 8 | W 9 | W A | W B |
| W C | W D | W E | W F |
,"#$./'0(-$/--12&/%(3$4&%+ /55'&2/%&16$17$)8
| O 0 | O 1 | O 2 | O 3 |
|-------|-------|-------|-------|
| O 4 | O 5 | O 6 | O 7 |
| O 8 | O 9 | O A | O B |
| O C | O D | O E | O F |
!"#$%&'(
/@$,"#A$4(&*+%$/63$!"#$%&'(-$71B$216.1'0%&16$
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Data-steering and Multiply-Accumulate Hardware
### Overview
The image presents a block diagram illustrating data-steering and multiply-accumulate hardware. It shows how input data is selected, multiplied by a weight, and then accumulated to produce an output.
### Components/Axes
* **Inputs:** A0, A1, ..., Af (representing multiple input data lines)
* **Multiplexer:** A block that selects one of the input data lines based on the "Wi's offset in tile" signal.
* **Multiplier:** Represented by a circle with an "X" inside. It multiplies the selected input data with the weight Wi.
* **Accumulator:** Represented by a circle with a "+" inside. It adds the result of the multiplication to the previous accumulated value.
* **Weight Input:** Wi (representing the weight value)
* **Offset Input:** Wi's offset in tile (controls the multiplexer)
* **Output:** O0 (representing the final output)
* **Feedback Loop:** A loop connecting the output of the accumulator back to its input, enabling accumulation.
### Detailed Analysis
1. **Input Selection:** The inputs A0, A1, up to Af are fed into a multiplexer. The multiplexer selects one of these inputs based on the "Wi's offset in tile" signal.
2. **Multiplication:** The selected input from the multiplexer is then multiplied by the weight Wi using the multiplier.
3. **Accumulation:** The result of the multiplication is added to the previous accumulated value using the accumulator. The accumulator's output is fed back into its input, creating a feedback loop.
4. **Output:** The final accumulated value is output as O0.
### Key Observations
* The diagram illustrates a common hardware architecture used in neural networks and digital signal processing for performing multiply-accumulate operations.
* The "Wi's offset in tile" signal is crucial for selecting the appropriate input data for processing.
* The feedback loop in the accumulator enables the accumulation of multiple multiplication results.
### Interpretation
The diagram demonstrates how data-steering and multiply-accumulate operations are implemented in hardware. The multiplexer selects the appropriate input data, which is then multiplied by a weight and accumulated. This architecture is commonly used in applications such as neural networks, where multiple inputs need to be processed and combined to produce an output. The "Wi's offset in tile" signal allows for flexible data selection, while the feedback loop in the accumulator enables the accumulation of multiple multiplication results.
</details>
Fig. 4. Data and architecture for convolution and zero-weight skipping.
Fig. 4(b) shows steering and multiply-accumulate hardware for value O 0 -the top-left value in an OFM tile being computed. Registers are omitted for clarity. When a weight W i is selected from the weight tile, the specific IFM value with which the weight W i is multiplied depends on W i 's offset within the weight tile. For the OFM value O 0 , this may be any of the IFM values A 0 , A 1 , . . . , A F , shown on the data inputs of the multiplexer, while the select inputs receive the weight's offset within the weight tile.
With the proposed tiling and convolution approach, zeroweight skipping is straightforward. For a given neural network model, the non-zero weights and their intra-tile offsets are 'packed' offline in advance in software. The packing procedure only needs to be done once for a given CNN model such as VGG-16. During inference, the accelerator receives the weight values and their intra-tile offsets in a packed format that is read directly into scratchpad memory. One non-zero weight is applied per clock cycle; no cycles are spent on weights having a value of 0.
1) Scaling Out Convolution: Each of the four datastaging/control units in Fig. 3 manages one quarter of the IFMs and corresponding weights. Every clock cycle, a datastaging/control unit injects IFM data and four weights (from four different filters) and their respective weight offsets into a convolution unit. Each of the four weights is multiplied by 16 IFM values, as described above. Thus, each convolution unit performs 4 × 16 = 64 multiplications/cycle. While the weights from a tile are being applied to (i.e. multiplied with) IFM data, the next required tiles of IFM data are simultaneously preloaded from the on-FPGA SRAM banks. Fig. 4 shows that four IFM tiles are needed to apply a weight tile and hence, since one tile/cycle can be loaded from an SRAM bank, at least four clock cycles must be spent processing a weight tile. This restriction implies that the upper-bound cycle-count reduction from zero-skipping is (16 -4) / 16 = 75% in our implementation. Moreover, note that OFMs being computed simultaneously may have different numbers of nonzero weights in their filters, causing pipeline bubbles and reduced efficiency. The completion of all four OFM tiles at a
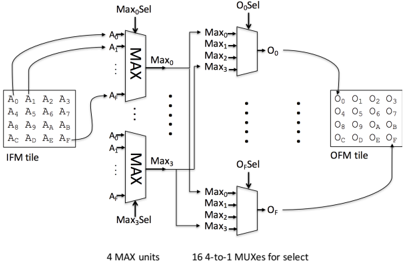
Fig. 5. Hardware architecture of padding/pooling unit.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: MAX Unit and MUX Network
### Overview
The image depicts a diagram of a system involving MAX units and multiplexers (MUXes) for selection, likely in a hardware or computational context. It shows data flow from an Input Feature Map (IFM) tile through MAX units to a network of MUXes, and finally to an Output Feature Map (OFM) tile.
### Components/Axes
* **IFM tile:** A 4x4 grid labeled with `A0` to `AF`. This represents the input data.
* **MAX Units:** Four MAX units are shown, each taking multiple inputs (`A0` to `AF`) from the IFM tile and producing a single output (`Max0` to `Max3`). Each MAX unit has a selection input labeled `Max_i Sel`, where `i` is the index of the MAX unit (0 to 3).
* **16 4-to-1 MUXes:** A network of 16 multiplexers, each selecting one of four inputs (`Max0` to `Max3`). Each MUX has a selection input labeled `O_i Sel`, where `i` is the index of the MUX (0 to F).
* **OFM tile:** A 4x4 grid labeled with `O0` to `OF`. This represents the output data.
### Detailed Analysis
* **IFM Tile:** The IFM tile is a 4x4 grid with elements labeled `A0`, `A1`, `A2`, `A3`, `A4`, `A5`, `A6`, `A7`, `A8`, `A9`, `AA`, `AB`, `AC`, `AD`, `AE`, `AF`.
* **MAX Units:**
* The first MAX unit takes inputs `A0` and `A1` from the IFM tile.
* The last MAX unit takes input `AF` from the IFM tile.
* The outputs of the MAX units are labeled `Max0`, `Max1`, `Max2`, and `Max3`.
* **MUX Network:**
* Each MUX takes `Max0`, `Max1`, `Max2`, and `Max3` as inputs.
* The outputs of the MUXes are labeled `O0` to `OF`.
* **OFM Tile:** The OFM tile is a 4x4 grid with elements labeled `O0`, `O1`, `O2`, `O3`, `O4`, `O5`, `O6`, `O7`, `O8`, `O9`, `OA`, `OB`, `OC`, `OD`, `OE`, `OF`.
* **Connections:** The output `O0` of the first MUX is connected to the `O0` element of the OFM tile. The output `OF` of the last MUX is connected to the `OF` element of the OFM tile.
### Key Observations
* The IFM tile provides input to the MAX units.
* The MAX units perform a maximum operation on their inputs.
* The outputs of the MAX units are fed into the MUX network.
* The MUX network selects one of the MAX unit outputs for each output element.
* The outputs of the MUX network form the OFM tile.
### Interpretation
The diagram illustrates a system for feature extraction and selection. The IFM tile represents the input features. The MAX units likely perform a max-pooling operation, selecting the maximum value from a set of input features. The MUX network then selects specific max-pooled features to form the OFM tile, which represents the output features. The `Max_i Sel` and `O_i Sel` signals control the selection process, allowing for different feature combinations to be chosen. This architecture could be used in convolutional neural networks or other machine learning models for feature extraction and dimensionality reduction.
</details>
given x/y tile position is synchronized using a Pthreads barrier.
## C. Padding and Pooling
Fig. 5 shows the padding/max-pooling unit. The controller/data-staging unit injects an IFM tile (shown on the left), as well as an instruction that specifies the desired padding/max-pooling behavior. There are four MAX units that, based on the instruction, select the maximum of any of the 16 IFM values in the input tile. The MAX units feed 16 multiplexers: one for each value of the OFM tile being computed. Based on the instruction, each value in the OFM tile may be updated with one of the MAX unit outputs, or alternately, may retain its old value.
To implement padding, which does not involve taking the maximum of multiple IFM values, the MAX units return a single value from the IFM (i.e. find the maximum among a single value). The specific number of MAX units (four in this case), is inspired by the needs of VGG-16, which requires 2 × 2 max-pooling regions with a stride of 2. However, with just a few instructions, the padding/max-pooling unit is capable of realizing any padding/max-pooling layer (e.g. a variety of max-pooling region sizes or strides). Moreover, since all units are described in software, it is straightforward to increase the number of MAX functional units within the padding/maxpooling unit.
## IV. IMPLEMENTATION
## A. High-Level Synthesis
Use of the LegUp HLS Pthreads flow permitted accelerator design, development and debugging to proceed in software. Debug and test were simplified, as the parallel software execution aligns closely with the target hardware architecture.
The primary HLS constraints applied were loop pipelining, if-conversion, automated bitwidth minimization [10], and clock-period constraints. To achieve optimized loop pipelines (initiation interval [II] = 1), it was necessary to remove control flow from the C code to the extent possible by making use of the ternary operator ( <cond> ? <val1> : <val2> ) to implement MUX'ing instead of using conditionals. The C specification of the accelerator is ∼ 5,600 LOC. The Verilog RTL automatically produced by LegUp was modified (using a script) in three ways: 1) pragmas were added to direct the Intel synthesis tools to implement the FIFO queues using LUT RAM instead of block RAM (saving precious block-RAM resources); 2) the on-FPGA SRAM banks were brought to the top-level of the hierarchy, making them accessible to the DMA
unit for writing/reading; and 3) the port assignment for the onFPGA RAM banks was altered so that reads and writes have exclusive ports, reducing contention/arbitration. Our design goal was skewed towards maximizing performance; however, it is possible to apply directives in LegUp that lower resource utilization at the expense of some performance.
A challenge with HLS is the disconnect between the software source code and the generated hardware -it can be difficult for one to know how to change the source code to effect desired changes in the hardware. In this work, this issue arose in the context of the controller/data-staging unit, which synthesized to a module with a large number of FSM states (hundreds), and consequent high-fanout signals (e.g. the FSM stall logic). To mitigate this, we split the unit into two C functions, one for convolution instructions and one for padding/max-pooling instructions, each having a simpler FSM than the original monolithic controller.
With reference to Fig. 3, the pool/pad, convolution, writeto-memory, and accumulator units are all streaming kernels generated by LegUp HLS that can accept new inputs every clock cycle (II = 1). The data-staging/control unit is capable of injecting data into the compute units every cycle. We reinforce that the entire accelerator, including the compute pipelines and the relatively complex control as described in Section III-A, is synthesized to Verilog RTL from parallel C software. Manual RTL design was used solely for the DMA unit. While streaming audio/video applications are typically emblematic as being 'ideal' for the use of HLS, here, we show that HLS can effectively be used to generate sophisticated control and data-staging for streaming hardware.
## B. VGG-16 Reduced Precision and Pruning
Beginning with the pre-trained VGG-16 model [3], we increased the sparsity by pruning and reduced the precision to 8-bit magnitude-plus-sign representation by scaling. Pruning and precision reduction were done using Caffe, in a manner similar to [9]. We consider two VGG-16 models: 1) with reduced precision and 2) with reduced precision and pruning. With variant #2, inference accuracy in validation was within 2% of the original unpruned floating point, which can be improved further through training.
## C. Software
Software executing on the on-chip ARM processor handles the loading and pre-processing of network weights, biases and test images. Pre-processing includes the reordering of data into tiled format for our accelerator. The framework sends the instruction and calls the hardware driver for inference.
## D. System Integration, Accelerator Scale-Out
The accelerator core, DMA controller, and host processor communicate via an interconnect network synthesized using Intel's Qsys System Integration tool. Two separate systems are instantiated: System I is a high bandwidth 256-bit bus that performs DMA to and from system DRAM to the accelerator banks. System II is a set of Avalon Memory-Mapped (AMM) interfaces between the host ARM processor and control and status registers on the accelerator core and DMA unit. The accelerator and DMA unit are controlled using System II by the host ARM processor.
We target a mid-range-sized Intel Arria 10 SX660 FPGA, whose size permits us to instantiate two instances of the
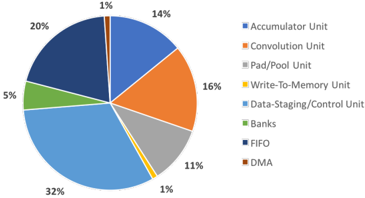
Fig. 6. ALM usage by each unit in the accelerator.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Pie Chart: Unit Distribution
### Overview
The image is a pie chart illustrating the distribution of different units within a system. Each slice represents a unit, and the size of the slice corresponds to its percentage contribution. The legend on the right identifies each unit by color.
### Components/Axes
* **Chart Type**: Pie Chart
* **Units**:
* Accumulator Unit (Blue)
* Convolution Unit (Orange)
* Pad/Pool Unit (Gray)
* Write-To-Memory Unit (Yellow)
* Data-Staging/Control Unit (Light Blue)
* Banks (Green)
* FIFO (Dark Blue)
* DMA (Brown)
* **Percentages**: Represented by the size of each slice.
### Detailed Analysis
* **Accumulator Unit**: 14% (Blue slice in the top-right quadrant)
* **Convolution Unit**: 16% (Orange slice in the right quadrant)
* **Pad/Pool Unit**: 11% (Gray slice in the bottom-right quadrant)
* **Write-To-Memory Unit**: 1% (Yellow slice in the bottom-right quadrant)
* **Data-Staging/Control Unit**: 32% (Light Blue slice in the bottom quadrant)
* **Banks**: 5% (Green slice in the left quadrant)
* **FIFO**: 20% (Dark Blue slice in the top-left quadrant)
* **DMA**: 1% (Brown slice in the top quadrant)
### Key Observations
* The Data-Staging/Control Unit constitutes the largest portion of the system, accounting for 32%.
* FIFO (20%) and Convolution Unit (16%) also represent significant portions.
* Write-To-Memory Unit and DMA each contribute only 1%.
### Interpretation
The pie chart provides a clear visual representation of the relative importance of different units within the system. The Data-Staging/Control Unit's large share suggests it plays a central role in the system's operation. The relatively small contributions of the Write-To-Memory Unit and DMA might indicate that these functions are less resource-intensive or are optimized in some way. The distribution of units can inform design decisions and resource allocation within the system.
</details>
accelerator shown in Fig. 3, where each instance operates concurrently on separate stripes of FMs (see Fig. 2). The overall multi-accelerator system is capable of 512 MACs/cycle.
## V. EXPERIMENTAL STUDY
A unique advantage of HLS is that one can synthesize multiple architecture variants from software and constraint changes alone. We analyze area, power and performance for four architecture variants running the two VGG-16 CNN models mentioned above: reduced precision without and with pruning (higher fraction of zero weights). The four architecture variants considered are as follows (labels in brackets):
- 1) A non-optimized simplified accelerator variant with a single convolution sub-module capable of performing at most 16 MACs/cycle (16-unopt).
- 2) A non-performance-optimized variant with one instance of the accelerator in Fig. 3 capable of performing at most 256 MACs/cycle (256-unopt).
- 3) A performance-optimized variant of Fig. 3 (256-opt).
- 4) A variant with two instances of the accelerator in Fig. 3 capable of performing at most 512 MACs/cycle (512-opt).
The 16-unopt architecture computes a single OFM tile at a time, and consequently requires no synchronization among multiple control/data-staging units. Analysis of the 16-unopt architectures gives insight into the HLS hardware quality in the absence of synchronization overhead. Both the 16unopt and the 256-unopt architectures were not performanceoptimized and as such, they consume minimal area and, to verify functional correctness, were clocked at 55MHz. To produce higher-performance variants, we tightened the clockperiod constraint supplied to the LegUp HLS tool, and also invoked performance optimizations in the Intel RTL-synthesis tool: retiming, physical synthesis, higher place/route effort. The 256-opt and 512-opt architectures were clocked at 150 MHz and 120 MHz, respectively. Routing of the 512-opt architecture failed at higher performance targets due to high congestion.
Intel FPGAs have 3 main types of resources: Adaptive Logic Modules (ALMs - lookup-table-based logic), DSP and RAM blocks. Our 256-opt accelerator uses 44% of the ALM logic, 25% of the DSP and 49% of the RAM blocks. Fig. 6 shows the breakdown of ALM usage for each module. The convolution, accumulator and data-staging/control modules take up most of the area, due to the heavy MUX'ing required in these units. Most of the DSP blocks are used in the convolution and accumulator modules. We adjust the RAM block usage to maximize our bank size given the number of available RAMs.
We consider the efficiency of the HLS-generated hardware by comparing the experimentally observed throughput
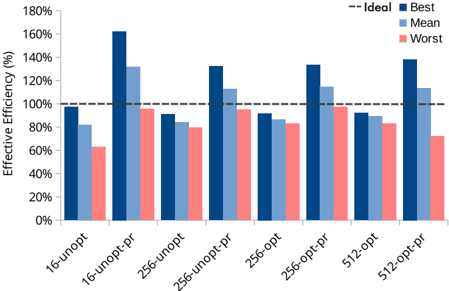
Fig. 7. Efficiency of each accelerator variant for VGG-16 inference.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Bar Chart: Effective Efficiency Comparison
### Overview
The image is a bar chart comparing the effective efficiency (%) of different configurations. The x-axis represents various configurations (16-unopt, 16-unopt-pr, 256-unopt, 256-unopt-pr, 256-opt, 256-opt-pr, 512-opt, 512-opt-pr), and the y-axis represents the effective efficiency in percentage, ranging from 0% to 180%. For each configuration, there are three bars representing the "Best", "Mean", and "Worst" efficiency. A dashed horizontal line indicates the "Ideal" efficiency at 100%.
### Components/Axes
* **X-axis:** Configuration types: 16-unopt, 16-unopt-pr, 256-unopt, 256-unopt-pr, 256-opt, 256-opt-pr, 512-opt, 512-opt-pr.
* **Y-axis:** Effective Efficiency (%), ranging from 0% to 180% in increments of 20%.
* **Legend (top-right):**
* "-- Ideal": Dashed black line at 100% efficiency.
* "Best": Dark blue bars.
* "Mean": Light blue bars.
* "Worst": Light red bars.
### Detailed Analysis
Here's a breakdown of the efficiency values for each configuration:
* **16-unopt:**
* Best: ~98%
* Mean: ~82%
* Worst: ~63%
* **16-unopt-pr:**
* Best: ~160%
* Mean: ~132%
* Worst: ~95%
* **256-unopt:**
* Best: ~92%
* Mean: ~84%
* Worst: ~82%
* **256-unopt-pr:**
* Best: ~132%
* Mean: ~112%
* Worst: ~92%
* **256-opt:**
* Best: ~92%
* Mean: ~88%
* Worst: ~82%
* **256-opt-pr:**
* Best: ~132%
* Mean: ~102%
* Worst: ~78%
* **512-opt:**
* Best: ~92%
* Mean: ~90%
* Worst: ~72%
* **512-opt-pr:**
* Best: ~134%
* Mean: ~114%
* Worst: ~94%
### Key Observations
* The "Best" efficiency is consistently higher than the "Mean" and "Worst" efficiencies for all configurations.
* Configurations with "-pr" (likely indicating a specific optimization or parameter) generally show significantly higher "Best" and "Mean" efficiencies compared to their counterparts without "-pr".
* The "Worst" efficiency is generally the lowest across all configurations.
* The "16-unopt-pr" configuration has the highest "Best" efficiency, exceeding 160%.
* The "Best" efficiency for "16-unopt-pr", "256-unopt-pr", "256-opt-pr", and "512-opt-pr" exceeds the "Ideal" efficiency of 100%.
### Interpretation
The data suggests that the "-pr" configurations provide a significant boost in effective efficiency, as evidenced by the higher "Best" and "Mean" values. This indicates that the optimization or parameter represented by "-pr" is highly effective in improving performance. The "Worst" efficiency values highlight the variability in performance, even with the "-pr" optimization. The "16-unopt-pr" configuration stands out as the most efficient, achieving the highest "Best" efficiency among all configurations. The configurations without "-pr" hover around the ideal efficiency, with the "Worst" case being significantly lower.
</details>
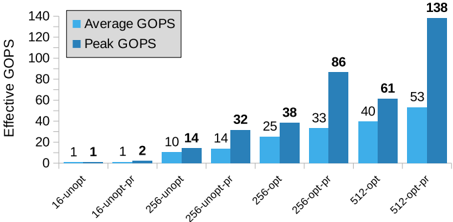
Fig. 8. Absolute GOPS/s across accelerator variants for VGG-16.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Bar Chart: Effective GOPS Comparison
### Overview
The image is a bar chart comparing the "Average GOPS" and "Peak GOPS" for different configurations. The x-axis represents the configurations, and the y-axis represents "Effective GOPS". The chart compares performance across different configurations, including unoptimized (unopt) and optimized (opt) versions, with and without a "pr" setting, for 16, 256, and 512 configurations.
### Components/Axes
* **Y-axis:** "Effective GOPS" ranging from 0 to 140, with tick marks at intervals of 20.
* **X-axis:** Configurations: 16-unopt, 16-unopt-pr, 256-unopt, 256-unopt-pr, 256-opt, 256-opt-pr, 512-opt, 512-opt-pr.
* **Legend (top-left):**
* Light Blue: "Average GOPS"
* Dark Blue: "Peak GOPS"
### Detailed Analysis
Here's a breakdown of the data for each configuration:
* **16-unopt:**
* Average GOPS: 1
* Peak GOPS: 1
* **16-unopt-pr:**
* Average GOPS: 1
* Peak GOPS: 2
* **256-unopt:**
* Average GOPS: 10
* Peak GOPS: 14
* **256-unopt-pr:**
* Average GOPS: 14
* Peak GOPS: 32
* **256-opt:**
* Average GOPS: 25
* Peak GOPS: 38
* **256-opt-pr:**
* Average GOPS: 33
* Peak GOPS: 86
* **512-opt:**
* Average GOPS: 40
* Peak GOPS: 61
* **512-opt-pr:**
* Average GOPS: 53
* Peak GOPS: 138
**Trend Verification:**
Both "Average GOPS" and "Peak GOPS" generally increase as we move from left to right across the configurations. The "pr" setting appears to improve performance, especially in the "256" and "512" configurations. The "opt" setting also improves performance. The 512-opt-pr configuration has the highest "Peak GOPS" by a significant margin.
### Key Observations
* The "Peak GOPS" is always higher than the "Average GOPS" for each configuration.
* The "512-opt-pr" configuration shows a significantly higher "Peak GOPS" compared to all other configurations.
* The "unopt" configurations have very low GOPS values compared to the "opt" configurations.
* Adding "pr" generally improves both "Average GOPS" and "Peak GOPS".
### Interpretation
The data suggests that optimization ("opt") and the "pr" setting significantly improve the performance (GOPS) of the system. The "512-opt-pr" configuration is the most effective, indicating that a combination of optimization and the "pr" setting at the "512" level yields the best results. The "unopt" configurations perform poorly, highlighting the importance of optimization. The "pr" setting seems to have a more pronounced effect on the "Peak GOPS" than on the "Average GOPS", suggesting it allows for higher burst performance.
</details>
( ops/elapsed time ) with the theoretically minimum ideal throughput numbers. Ideal throughput is defined as peak throughput * total number of computations . We add an overhead ( ∼ 15% but varies by layer) for the increased number of MAC operation due to limited on-FPGA SRAM bank size 'striping'. Results in Fig. 7 illustrate the efficiency of various architectures with the pruned and unpruned VGG-16 model. Results obtained using a pruned network are labeled as '-pr'. 'Best' and 'worst' refer to the highest and lowest throughput for any single convolutional layer of VGG-16, respectively. Mean refers to the average throughput across all VGG-16 layers. The ideal throughput value is indicated as a dotted line on Fig. 7.
The underlying reason for differences between best, worst, and mean is that, for deeper layers of VGG-16, the ratio of weight data to FM data increases, imposing a higher overhead for unpacking weights and offsets in our accelerator, reducing effective throughput. Using the pruned network we see greater than 100% efficiency, due to the zero-skipping avoiding some multiply-accumulates altogether. For the non-pruned VGG-16, we are not far from the ideal throughput -usually within ∼ 10%. This analysis shows the HLS-generated hardware is quite efficient; overhead from HLS is minimal from the cycle latency perspective.
Secondly, we look at our results in terms of absolute performance (GOPS). Fig. 8 shows that our 512-opt accelerator achieved the highest average (peak) throughput of 39.5 GOPS (61 GOPS), and with the pruned network, the effective average (peak) performance increases to 53.3 GOPS (138 GOPS). We can clearly see the effects of zero-skipping in these results. By pruning the network, we were able to increase our performance by ∼ 1.3 × , on average, and ∼ 2.2 × in the
TABLE I. POWER CONSUMPTION
| Accelerator Variant | Peak Power (mW) | GOPS/W | GOPS/W (peak) |
|-----------------------|-------------------|----------|-----------------|
| 256-opt (FPGA) | 2300 (500) | 13.4 | 37.4 |
| 512-opt (FPGA) | 3300 (800) | 13.9 | 41.8 |
| 256-opt (Board) | 9500 | 3.5 | 9.05 |
| 512-opt (Board) | 10800 | 5.6 | 12.7 |
*dynamic power is parenthesized peak case. The peak performance numbers are considerably higher than the average in the pruned case, as peak throughput requires uniformly sparse filters applied concurrently for even workload balancing. Future work could include grouping filters in advance according to similarity in non-zero-entry counts to maximize available zero skipping and balance the work.
While the absolute performance numbers are relatively modest and in line with prior work (cf. Section VI), the results in Fig. 8 underscore a key advantage of HLS, namely, a wide range of architectures with distinct performance/area trade-offs can be produced by software and HLS constraint changes alone. For example, in the opt vs. unopt variants, the clock-period constraint applied in HLS impacts the degree of pipelining in the compute units and control. It would be expensive and time-consuming to produce hand-written RTL for all architecture variants considered. Finally, we note that on a larger Arria 10 FPGA family member (e.g. GT1150), with nearly double the capacity, software changes alone would allow us to scale out the design further.
Power consumption measurements are given in Table I. All measurements are peak power measured while running the accelerator on the worst-case VGG-16 layer. A board -level power measurement is provided, alongside the power consumption of the FPGA by itself. Power numbers in parentheses are dynamic power; numbers outside parentheses are static + dynamic power.
## VI. RELATED WORK
Recent years have seen considerable research on custom hardware accelerators for deep CNN inference designed in manual RTL, realized in ASICs (e.g. [11], [12]) and FPGAs (e.g. [13]). The works most comparable to ours use HLS and target FPGAs. [14] applied Xilinx's Vivado HLS to synthesize an accelerator for the convolution operation, achieving 61 GFLOPS peak performance. Suda et al. [15] synthesized a CNN accelerator from OpenCL, achieving peak performance of 136 GOPS for convolution. In [16], Intel synthesized a CNN accelerator from OpenCL that incorporates the Winograd transform, half-precision floating point, and achieves over 1 TFLOPS performance. In [17], Xilinx synthesized significant parts of a binarized CNN accelerator with Vivado HLS. In binarized CNNs, both weights and activations are represented by 1-bit values. OpenCL along with Xilinx's SDAccel OpenCL HLS tool was also used in [18] to synthesize a single-precision floating-point CNN accelerator incorporating Winograd and achieving 50 GFLOPS performance. The latter work also provides integration with the Caffe framework.
Generally, the OpenCL implementations above use PCIe connectivity with a host processor and are more suited for data center applications; whereas, our system is intended for embedded. To the best of the authors' knowledge, our work is the first to synthesize a CNN accelerator from parallelized C -language software that incorporates a novel zero-skipping approach and reduced precision, and illustrates how, beginning with a software-parallelized C specification of the architecture, constraints to the HLS and RTL synthesis tools can be applied to generate a variety of accelerator architectures with different performance/area trade-offs.
## VII. CONCLUSIONS AND FUTURE WORK
An FPGA-based CNN inference accelerator was synthesized from parallel C software using the LegUp HLS tool, incorporating a zero-weight skipping architecture and reducedprecision arithmetic. The end-to-end system contains a dualcore ARM processor, the accelerator, on-FPGA memories (backed by DDR4) and DMA. Software running on the ARM issues instructions to the accelerator for convolution, padding and pooling. Complex datapath and control logic was synthesized entirely from C , and the use of HLS permitted a range of architectures to be evaluated, through software and constraint changes alone. Future work involves the use of HLS to synthesize accelerators for other neural network styles, including binarized, ternary and recurrent networks.
## REFERENCES
- [1] A. Canis, J. Choi, M. Aldham, V. Zhang, A. Kammoona, T. Czajkowski, S. D. Brown, , and J. H. anderson, 'LegUp: An open source high-level synthesis tool for FPGA-based processor/accelerator systems,' ACM Tranasactions on Embedded Computing Systems , 2013.
- [2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, 'ImageNet classification with deep convolutional neural networks,' in Neural Information Processing Systems , 2012, pp. 1106-1114.
- [3] K. Simonyan and A. Zisserman, 'Very deep convolutional networks for large-scale image recognition,' CoRR , vol. abs/1409.1556, 2014.
- [4] C. Szegedy and et al., 'Going deeper with convolutions,' in IEEE CVPR , 2015, pp. 1-9.
- [5] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, 'Binarized neural networks,' in NIPS , 2016, pp. 4107-4115.
- [6] G. Venkatesh, E. Nurvitadhi, and D. Marr, 'Accelerating deep convolutional networks using low-precision and sparsity,' CoRR , vol. abs/1610.00324, 2016. [Online]. Available: http://arxiv.org/abs/1610. 00324
- [7] J. Cong, B. Liu, S. Neuendorffer, J. Noguera, K. A. Vissers, and Z. Zhang, 'High-level synthesis for FPGAs: From prototyping to deployment,' IEEE TCAD , vol. 30, no. 4, pp. 473-491, 2011.
- [8] J. Choi, R. Lian, S. D. Brown, and J. H. Anderson, 'A unified software approach to specify pipeline and spatial parallelism in FPGA hardware,' in IEEE ASAP , 2016, pp. 75-82.
- [9] S. Han, H. Mao, and W. J. Dally, 'Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding,' CoRR , vol. abs/1510.00149, 2015.
- [10] M. Gort and J. H. Anderson, 'Range and bitmask analysis for hardware optimization in high-level synthesis,' in IEEE/ACM ASP-DAC , 2013, pp. 773-779.
- [11] Y. Chen, T. Krishna, J. S. Emer, and V. Sze, 'Eyeriss: An energyefficient reconfigurable accelerator for deep convolutional neural networks,' J. Solid-State Circuits , vol. 52, no. 1, pp. 127-138, 2017.
- [12] T. Chen, Z. Du, N. Sun, J. Wang, C. Wu, Y. Chen, and O. Temam, 'DianNao: A small-footprint high-throughput accelerator for ubiquitous machine-learning,' in ACM ASPLOS , 2014, pp. 269-284.
- [13] E. Nurvitadhi and et al., 'Can FPGAs beat GPUs in accelerating nextgeneration deep neural networks?' in ACM FPGA , 2017, pp. 5-14.
- [14] C. Zhang, P. Li, G. Sun, Y. Guan, B. Xiao, and J. Cong, 'Optimizing FPGA-based accelerator design for deep convolutional neural networks,' in ACM FPGA , 2015, pp. 161-170.
- [15] N. Suda, V. Chandra, G. Dasika, A. Mohanty, Y. Ma, S. Vrudhula, J.-s. Seo, and Y. Cao, 'Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks,' in ACM FPGA , 2016.
- [16] U. Aydonat, S. O'Connell, D. Capalija, A. C. Ling, and G. R. Chiu, 'An OpenCL Deep Learning Accelerator on Arria 10,' ArXiv e-prints , Jan. 2017.
- [17] Y. Umuroglu, N. J. Fraser, G. Gambardella, M. Blott, P. Leong, M. Jahre, and K. Vissers, 'FINN: A Framework for Fast, Scalable Binarized Neural Network Inference,' ArXiv e-prints , 2016.
- [18] R. DiCecco, G. Lacey, J. Vasiljevic, P. Chow, G. W. Taylor, and S. Areibi, 'Caffeinated FPGAs: FPGA framework for convolutional neural networks,' CoRR , vol. abs/1609.09671, 2016.