## Specification-Guided Safety Verification for Feedforward Neural Networks
Weiming Xiang ∗ , Hoang-Dung Tran ∗ , Taylor T. Johnson ∗
December 18, 2018
tions or properties of neural networks. Verifying neural networks is a hard problem, even simple properties about them have been proven NP-complete problems [2]. The difficulties mainly come from the presence of activation functions and the complex structures, making neural networks large-scale, nonlinear, non-convex and thus incomprehensible to humans.
The importance of methods of formal guarantees for neural networks has been well-recognized in literature. There exist a number of results for verification of feedforward neural networks, especially for Rectifier Linear Unit (ReLU) neural networks, and a few results are devoted to neural networks with broad classes of activation functions. Motivated to general class of neural networks such as those considered in [3], our key contribution in this paper is to develop a specificationguided method for safety verification of feedforward neural network. First, we formulate the safety verification problem in the framework of interval arithmetic, and provide a computationally efficient formula to compute output interval sets. The developed formula is able to calculate the output intervals in a fast manner. Then, analogous to other state-of-the-art verification methods, such as counterexample-guided abstraction refinement (CEGAR) [4] and property directed reachability (PDR) [5], and inspired by the Moore-Skelboe algorithm [6], a specification-guided algorithm is developed. Briefly speaking, the safety specification is utilized to examine the existence of intersections between output intervals and unsafe regions and then determine the bisection actions in the verification algorithm. By making use of the information of safety specification, the computation cost can be reduced significantly. We provide experimental evidences to show the advantages of specification-guided approach, which shows that our approach only needs about 3%-7% computational cost of the method proposed in [3] to solve the same safety verification problem.
## 2 Related Work
Many recent works are focusing on ReLU neural networks. In [2], an SMT solver named Reluplex is proposed for a special class of neural networks with ReLU activation functions. The Reluplex extends the well-known Simplex algorithm from linear functions to ReLU functions by making use of the piecewise linear feature of ReLU functions. In [7], A layer-bylayer approach is developed for the output reachable set com-
## Abstract
This paper presents a specification-guided safety verification method for feedforward neural networks with general activation functions. As such feedforward networks are memoryless, they can be abstractly represented as mathematical functions, and the reachability analysis of the neural network amounts to interval analysis problems. In the framework of interval analysis, a computationally efficient formula which can quickly compute the output interval sets of a neural network is developed. Then, a specification-guided reachability algorithm is developed. Specifically, the bisection process in the verification algorithm is completely guided by a given safety specification. Due to the employment of the safety specification, unnecessary computations are avoided and thus computational cost can be reduced significantly. Experiments show that the proposed method enjoys much more efficiency in safety verification with significantly less computational cost.
## 1 Introduction
Artificial neural networks have been widely used in machine learning systems. Though neural networks have been showing effectiveness and powerful ability in resolving complex problems, they are confined to systems which comply only to the lowest safety integrity levels since, in most of time, a neural network is viewed as a black box without effective methods to assure safety specifications for its outputs. Neural networks are trained over a finite number of input and output data, and are expected to be able to generalize to produce desirable outputs for given inputs even including previously unseen inputs. However, in many practical applications, the number of inputs is essentially infinite, this means it is impossible to check all the possible inputs only by performing experiments and moreover, it has been observed that neural networks can react in unexpected and incorrect ways to even slight perturbations of their inputs [1], which could result in unsafe systems. Hence, methods that are able to provide formal guarantees are in a great demand for verifying specifica-
∗ Authors are with the Department of Electrical Engineering and Computer Science, Vanderbilt University, Nashville, Tennessee 37212, USA. Email: xiangwming@gmail.com (Weiming Xiang); Hoang-Dung Tran (trhoangdung@gmail.com); taylor.johnson@gmail.com (Taylor T. Johnson).
putation of ReLU neural networks. The computation is formulated in the form of a set of manipulations for a union of polyhedra. A verification engine for ReLU neural networks called AI 2 was proposed in [8]. In their approach, the authors abstract perturbed inputs and safety specifications as zonotopes, and reason about their behavior using operations for zonotopes. An Linear Programming (LP)-based method is proposed [9], and in [10] authors encoded the constraints of ReLU functions as a Mixed-Integer Linear Programming (MILP). Combining output specifications that are expressed in terms of LP, the verification problem for output set eventually turns to a feasibility problem of MILP. In [11, 12], an MILP based verification engine called Sherlock that performs an output range analysis of ReLU feedforward neural networks is proposed, in which a combined local and global search is developed to more efficiently solve MILP.
Besides the results for ReLU neural networks, there are a few other results for neural networks with general activation functions. In [13, 14], a piecewise-linearization of the nonlinear activation functions is used to reason about their behaviors. In this framework, the authors replace the activation functions with piecewise constant approximations and use the bounded model checker hybrid satisfiability (HySAT) [15] to analyze various properties. In their papers, the authors highlight the difficulty of scaling this technique and, currently, are only able to tackle small networks with at most 20 hidden nodes. In [16], the authors proposed a framework for verifying the safety of network image classification decisions by searching for adversarial examples within a specified region. A adaptive nested optimization framework is proposed for reachability problem of neural networks in [17]. In [3], a simulation-based approach was developed, which used a finite number of simulations/computations to estimate the reachable set of multi-layer neural networks in a general form. Despite this success, the approach lacks the ability to resolve the reachable set computation problem for neural networks that are large-scale, non-convex, and nonlinear. Still, simulation-based approaches, like the one developed in [3], present a plausibly practical and efficient way of reasoning about neural network behaviors. The critical step in improving simulation-based approaches is bridging the gap between finitely many simulations and the essentially infinite number of inputs that exist in the continuity set. Sometimes, the simulation-based approach requires a large number of simulations to obtain a tight reachable set estimation, which is computationally costly in practice. In this paper, our aim is to reduce the computational cost by avoiding unnecessary computations with the aid of a specification-guided method.
## 3 Background
## 3.1 Feedforward Neural Networks
Generally speaking, a neural network consists of a number of interconnected neurons and each neuron is a simple processing element that responds to the weighted inputs it received from other neurons. In this paper, we consider feed-forward neural networks, which generally consist of one input layer, multiple hidden layers and one output layer. The action of a neuron depends on its activation function, which is in the form of
$$y _ { i } = \phi \left ( \sum \nolimits _ { j = 1 } ^ { n } \omega _ { i j } x _ { j } + \theta _ { i } \right ) \quad \ \ ( 1 )$$
where x j is the j th input of the i th neuron, ω ij is the weight from the j th input to the i th neuron, θ i is called the bias of the i th neuron, y i is the output of the i th neuron, φ ( · ) is the activation function. The activation function is generally a nonlinear continuous function describing the reaction of i th neuron with inputs x j , j = 1 , · · · , n . Typical activation functions include ReLU, logistic, tanh, exponential linear unit, linear functions, for instance. In this work, our approach aims at being capable of dealing with activation functions regardless of their specific forms.
Afeedforward neural network has multiple layers, and each layer , 1 ≤ ≤ L , has n { } neurons. In particular, layer = 0 is used to denote the input layer and n { 0 } stands for the number of inputs in the rest of this paper. For the layer , the corresponding input vector is denoted by x { } and the weight matrix is
$$W ^ { \{ \ell \} } = \left [ \omega _ { 1 } ^ { \{ \ell \} } , \dots , \omega _ { n ^ { \{ \ell \} } } ^ { \{ \ell \} } \right ] ^ { \top } \quad ( 2 )$$
where ω { } i is the weight vector. The bias vector for layer is
$$\pm b { \theta } ^ { \{ \ell \} } = \left [ \theta _ { 1 } ^ { \{ \ell \} } , \dots , \theta _ { n ^ { \{ \ell \} } } ^ { \{ \ell \} } \right ] ^ { \top } . \quad ( 3 )$$
The output vector of layer can be expressed as
$$y ^ { \{ \ell \} } = \phi _ { \ell } ( W ^ { \{ \ell \} } x ^ { \{ \ell \} } + \theta ^ { \{ \ell \} } ) \quad ( 4 )$$
where φ ( · ) is the activation function of layer .
The output of -1 layer is the input of layer, and the mapping from the input of input layer, that is x [0] , to the output of output layer, namely y [ L ] , stands for the input-output relation of the neural network, denoted by
$$y ^ { \{ L \} } = \Phi ( x ^ { \{ 0 \} } ) \quad ( 5 )$$
where Φ( · ) φ L ◦ φ L -1 ◦ · · · ◦ φ 1 ( · ) .
## 3.2 Problem Formulation
We start by defining the neural network output set that will become of interest all through the rest of this paper.
Definition 3.1 Given a feedforward neural network in the form of (5) and an input set X ⊆ R n { 0 } , the following set
$$\mathcal { Y } = \left \{ y ^ { \{ L \} } \in \mathbb { R } ^ { n ^ { \{ L \} } } | y ^ { \{ L \} } = \Phi ( x ^ { \{ 0 \} } ) , \, x ^ { \{ 0 \} } \in \mathcal { X } \right \}$$
is called the output set of neural network (5).
The safety specification of a neural network is expressed by a set defined in the output space, describing the safety requirement.
Definition 3.2 Safety specification S formalizes the safety requirements for output y [ L ] of neural network (5), and is a predicate over output y [ L ] of neural network (5). The neural network (5) is safe if and only if the following condition is satisfied:
$$\mathcal { Y } \cap \neg \mathcal { S } = \emptyset \quad ( 7 ) \quad [ \phi ] \colon$$
where Y is the output set defined by (6), and ¬ is the symbol for logical negation.
The safety verification problem for the neural network (5) is stated as follows.
Problem 3.1 How does one verify the safety requirement described by (7), given a neural network (5) with a compact input set X and a safety specification S ?
The key for solving the safety verification Problem 3.1 is computing output set Y . However, since neural networks are often nonlinear and non-convex, it is extremely difficult to compute the exact output set Y . Rather than directly computing the exact output set for a neural network, a more practical and feasible way for safety verification is to derive an overapproximation of Y .
Definition 3.3 A set Y o is an over-approximation of Y if Y ⊆ Y o holds.
The following lemma implies that it is sufficient to use the over-approximated output set for the safety verification of a neural network.
Lemma 3.1 Consider a neural network in the form of (5) and a safety specification S , the neural network is safe if the following condition is satisfied
$$\mathcal { Y } _ { o } \cap \neg \mathcal { S } = \emptyset \quad ( 8 ) \underset { e v b i } { \overset { l m } { s h i } }$$
where Y ⊆ Y o .
$$\text {Proof. Due to } \mathcal { Y } \subseteq \mathcal { Y } _ { o } , ( 8 ) \, \text {implies} \, \mathcal { Y } \cap \neg \mathcal { S } = \emptyset . \quad \Box \quad t h e n \ t h e$$
From Lemma 3.1, the problem turns to how to construct an appropriate over-approximation Y o . One natural way, as the method developed in [3], is to find a set Y o as small as possible to tightly over-approximate output set Y and further perform safety verification. However, this idea sometimes could be computationally expensive, and actually most of computations are unnecessary for safety verification. In the following, a specification-guided approach will be developed, and the over-approximation of output set is computed in an adaptive way with respect to a given safety specification.
## 4 Safety Verification
## 4.1 Preliminaries and Notation
Let [ x ] = [ x, x ] , [ y ] = [ y, y ] be real compact intervals and ◦ be one of the basic operations addition, subtraction, multiplication and division, respectively, for real numbers, that is
◦ ∈ { + , -, · , / } , where it is assumed that 0 / ∈ [ b ] in case of division. We define these operations for intervals [ x ] and [ y ] by [ x ] ◦ [ y ] = { x ◦ y | x ∈ [ y ] , x ∈ [ y ] } . The width of an interval [ x ] is defined and denoted by w ([ x ]) = x -x . The set of compact intervals in R is denoted by IR . We say [ φ ] : IR → IR is an interval extension of function φ : R → R , if for any degenerate interval arguments, [ φ ] agrees with φ such that [ φ ]([ x, x ]) = φ ( x ) . In order to consider multidimensional problems where x ∈ R n is taken into account, we denote [ x ] = [ x 1 , x 1 ] × · · · × [ x n , x n ] ∈ IR n , where IR n denotes the set of compact interval in R n . The width of an interval vector x is the largest of the widths of any of its component intervals w ([ x ]) = max i =1 ,...,n ( x i -x i ) . A mapping [Φ] : IR n → IR m denotes the interval extension of a function Φ : R n → R m . An interval extension is inclusion monotonic if, for any [ x 1 ] , [ x 2 ] ∈ IR n , [ x 1 ] ⊆ [ x 2 ] implies [Φ]([ x 1 ]) ⊆ [Φ]([ x 2 ]) . Afundamental property of inclusion monotonic interval extensions is that x ∈ [ x ] ⇒ Φ( x ) ∈ [Φ]([ x ]) , which means the value of Φ is contained in the interval [Φ]([ x ]) for every x in [ x ] .
Several useful definitions and lemmas are presented.
Definition 4.1 [18] Piece-wise monotone functions, including exponential, logarithm, rational power, absolute value, and trigonometric functions, constitute the set of standard functions.
Lemma 4.1 [18] A function Φ which is composed by finitely many elementary operations { + , -, · , / } and standard functions is inclusion monotone.
Definition 4.2 [18] An interval extension [Φ]([ x ]) is said to be Lipschitz in [ x 0 ] if there is a constant ξ such that w ([Φ]([ x ])) ≤ ξw ([ x ]) for every [ x ] ⊆ [ x 0 ] .
Lemma 4.2 [18] If a function Φ( x ) satisfies an ordinary Lipschitz condition in [ x 0 ] ,
$$\left \| \Phi ( x _ { 2 } ) - \Phi ( x _ { 1 } ) \right \| \leq \xi \, \left \| x _ { 2 } - x _ { 1 } \right \| , \, x _ { 1 } , x _ { 2 } \in [ x _ { 0 } ] \quad ( 9 )$$
then the interval extension [Φ]([ x ]) is a Lipschitz interval extension in [ x 0 ] ,
$$w ( [ \Phi ] ( [ x ] ) ) \leq \xi w ( [ x ] ) , \, [ x ] \subseteq [ x _ { 0 } ] . \quad ( 1 0 )$$
The following trivial assumption is given for activation functions.
Assumption 4.1 The activation function φ considered in this paper is composed by finitely many elementary operations and standard functions.
Based on Assumption 4.1, the following result can be obtained for a feedforward neural network.
Theorem 4.1 The interval extension [Φ] of neural network Φ composed by activation functions satisfying Assumption 4.1 is inclusion monotonic and Lipschitz such that
$$\text { and } \quad w ( [ \Phi ] ( [ x ] ) ) \leq \xi ^ { L } \prod _ { \ell = 1 } ^ { L } \left \| W ^ { \{ \ell \} } \right \| w ( [ x ] ) , \, [ x ] \subseteq \mathbb { R } ^ { n ^ { \{ 0 \} } }
w ( [ x ] ) = \left | \text {and} \right | w ( [ x ] ) = \left \| W ^ { \{ \ell \} } \right \| w ( [ x ] ) , \, [ x ] \subseteq \mathbb { R } ^ { n ^ { \{ 0 \} } } \\ \text {and} \quad w ( [ x ] ) = \left | \text {and} \right | w ( [ x ] ) = \left \| W ^ { \{ \ell \} } \right \| w ( [ x ] ) , \, [ x ] \subseteq \mathbb { R } ^ { n ^ { \{ 0 \} } } \\ \text {and} \quad w ( [ x ] ) = \left | \text {and} \right | w ( [ x ] ) = \left \| W ^ { \{ \ell \} } \right \| w ( [ x ] ) , \, [ x ] \subseteq \mathbb { R } ^ { n ^ { \{ 0 \} } } \\ \text {and} \quad w ( [ x ] ) = \left | \text {and} \right | w ( [ x ] ) = \left \| W ^ { \{ \ell \} } \right \| w ( [ x ] ) , \, [ x ] \subseteq \mathbb { R } ^ { n ^ { \{ 0 \} } } \\ \text {and} \quad w ( [ x ] ) = \left | \text {and} \right | w ( [ x ] ) = \left \| W ^ { \{ \ell \} } \right \| w ( [ x ] ) , \, [ x ] \subseteq \mathbb { R } ^ { n ^ { \{ 0 \} } }$$
where ξ is a Lipschitz constant for all activation functions in Φ .
Proof . Under Assumption 4.1, the inclusion monotonicity can be obtained directly based on Lemma 4.1. Then, for the layer , we denote ˆ φ ( x { } ) = φ ( W { } x { } + θ { } ) . For any x 1 , x 2 , it has
$$\left \| \hat { \phi } _ { \ell } ( x _ { 2 } ^ { \{ \ell \} } ) - \hat { \phi } _ { \ell } ( x _ { 1 } ^ { \{ \ell \} } ) \right \| & \leq \xi \left \| W ^ { \{ \ell \} } x _ { 2 } ^ { \{ \ell \} } - W x _ { 1 } ^ { \{ \ell \} } \right \| & i n p \\ & \leq \xi \left \| W ^ { \{ \ell \} } \right \| \left \| x _ { 2 } ^ { \{ \ell \} } - x _ { 1 } ^ { \{ \ell \} } \right \| .$$
Due to x { } = ˆ φ -1 ( x { -1 } ) , = 1 , . . . , L , we have ξ L ∏ L =1 ∥ ∥ W { } ∥ ∥ the Lipschitz constant for Φ , and (11) can be established by Lemma 4.2.
## 4.2 Interval Analysis
First, we consider a single layer y = φ ( Wx + θ ) . Given an interval input [ x ] , the interval extension is [ φ ]( W [ x ] + θ ) = [ y 1 , y 1 ] ×··· × [ y n , y n ] = [ y ] , where
$$\underline { y } _ { i } = \min _ { x \in [ x ] } \phi \left ( \sum \nolimits _ { j = 1 } ^ { n } \omega _ { i j } x _ { j } + \theta _ { i } \right ) \quad ( 1 2 )$$
$$\overline { y } _ { i } = \max _ { x \in [ x ] } \phi \left ( \sum \nolimits _ { j = 1 } ^ { n } \omega _ { i j } x _ { j } + \theta _ { i } \right ) . \quad ( 1 3 )$$
To compute the interval extension [ φ ] , we need to compute the minimum and maximum values of the output of nonlinear function φ . For general nonlinear functions, the optimization problems are still challenging. Typical activation functions include ReLU, logistic, tanh, exponential linear unit, linear functions, for instance, satisfy the following monotonic assumption.
Assumption 4.2 For any two scalars z 1 ≤ z 2 , the activation function satisfies φ ( z 1 ) ≤ φ ( z 2 ) .
Assumption 4.2 is a common property that can be satisfied by a variety of activation functions. For example, it is easy to verify that the most commonly used such as logistic, tanh, ReLU, all satisfy Assumption 4.2. Taking advantage of the monotonic property of φ , the interval extension [ φ ]([ z ]) = [ φ ( z ) , φ ( z )] . Therefore, y i and y i in (12) and (13) can be explicitly written out as
$$\underline { y } _ { i } = \sum \nolimits _ { j = 1 } ^ { n } p _ { i j } + \theta _ { i } \quad ( 1 4 ) \quad w ( [ \Phi ]$$
$$\bar { y } _ { i } = \sum \nolimits _ { j = 1 } ^ { n } \bar { p } _ { i j } + \theta _ { i } \quad ( 1 5 ) \quad D e f i n t a l s$$
with p ij and p ij defined by
$$\underline { p } _ { - i j } = \left \{ \begin{array} { l l } { \omega _ { i j } \underline { x } _ { j } , } & { \omega _ { i j } \geq 0 } \\ { \omega _ { i j } \overline { x } _ { j } , } & { \omega _ { i j } < 0 } \end{array} ( 1 6 ) \quad o f i n t e q u a l$$
$$\bar { p } _ { i j } = \left \{ \begin{array} { l l } { \omega _ { i j } \overline { x } _ { j } , } & { \omega _ { i j } \geq 0 } \\ { \omega _ { i j } \underline { x } _ { j } , } & { \omega _ { i j } < 0 } \end{array} .$$
From (14)-(17), the output interval of a single layer can be efficiently computed with these explicit expressions. Then, we consider the feedforward neural network y { L } = Φ( x { 0 } ) with multiple layers, the interval extension [Φ]([ x { 0 } ]) can be computed by the following layer-by-layer computation.
Theorem 4.2 Consider feedforward neural network (5) with activation function satisfying Assumption 4.2 and an interval input [ x { 0 } ] , an interval extension can be determined by
$$[ \Phi ] ( [ x ^ { \{ 0 \} } ] ) = [ \hat { \phi } _ { L } ] \circ \cdots \circ [ \hat { \phi } _ { 1 } ] \circ [ \hat { \phi } _ { 0 } ] ( [ x ^ { \{ 0 \} } ] ) \quad ( 1 8 )$$
where [ ˆ φ ]([ x { } ]) = [ φ ]( W { } [ x { } ] + θ { } ) = [ y { } ] in which
$$\underline { y } _ { i } ^ { \{ \ell \} } = \sum \nolimits _ { j = 1 } ^ { n ^ { \{ \ell \} } } \underline { p } _ { i j } ^ { \{ \ell \} } + \theta _ { i } ^ { \{ \ell \} } \quad ( 1 9 )$$
$$\overline { y } _ { i } ^ { \{ \ell \} } = \sum \nolimits _ { j = 1 } ^ { n ^ { \{ \ell \} } } \overline { p } _ { i j } ^ { \{ \ell \} } + \theta _ { i } ^ { \{ \ell \} } \quad ( 2 0 )$$
with p { } ij and p { } ij defined by
$$\underline { p } _ { i j } ^ { \{ \ell \} } = \left \{ \begin{array} { l l } { \omega _ { i j } ^ { \{ \ell \} } \underline { x } _ { j } ^ { \{ \ell \} } , } & { \omega _ { i j } ^ { \{ \ell \} } \geq 0 } \\ { \omega _ { i j } ^ { \{ \ell \} } \overline { x } _ { j } ^ { \{ \ell \} } , } & { \omega _ { i j } ^ { \{ \ell \} } < 0 } \end{array} ( 2 1 )$$
$$\begin{array} { r } { \overline { p } _ { i j } ^ { \{ \ell \} } = \left \{ \begin{array} { l l } { \omega _ { i j } ^ { \{ \ell \} } \overline { x } _ { j } ^ { \{ \ell \} } , } & { \omega _ { i j } ^ { \{ \ell \} } \geq 0 } \\ { \omega _ { i j } ^ { \{ \ell \} } \underline { x } _ { j } ^ { \{ \ell \} } , } & { \omega _ { i j } ^ { \{ \ell \} } < 0 } \end{array} . ( 2 2 ) } \end{array}$$
Proof . We denote ˆ φ ( x { } ) = φ ( W { } x { } + θ { } ) . For a feedforward neural network, it essentially has x { } = ˆ φ -1 ( x { -1 } ) , = 1 , . . . , L which leads to (18). Then, for each layer, the interval extension [ y { } ] computed by (19)(22) can be obtained directly from (14)-(17).
We denote the set image for neural network Φ as follows
$$\Phi ( [ x ^ { \{ 0 \} } ] ) = \{ \Phi ( x ^ { \{ 0 \} } ) \colon x ^ { \{ 0 \} } \in [ x ^ { \{ 0 \} } ] \} . \quad ( 2 3 )$$
Since [Φ] is inclusion monotonic according to Theorem 4.1, one has Φ([ x { 0 } ]) ⊆ [Φ]([ x { 0 } ]) . Thus, it is sufficient to claim the neural network is safe if [Φ]([ x { 0 } ]) ∩¬S = ∅ holds by Lemma 3.1.
According to the explicit expressions (18)-(22), the computation on interval extension [Φ] is fast. In the next step, we should discuss the conservativeness for the computation outcome of (18). We have [Φ]([ x { 0 } ]) = Φ([ x { 0 } ]) + E ([ x { 0 } ]) for some interval-valued function E ([ x { 0 } ]) with w ([Φ]([ x { 0 } ])) = w (Φ([ x { 0 } ])) + w ( E ([ x { 0 } ])) .
Definition 4.3 We call w ( E ([ x { 0 } ])) = w ([Φ]([ x { 0 } ])) -w (Φ([ x { 0 } ])) the excess width of interval extension of neural network Φ([ x { 0 } ]) .
Explicitly, the excess width measures the conservativeness of interval extension [Φ] regarding its corresponding function Φ . The following theorem gives the upper bound of the excess width w ( E ([ x { 0 } ])) .
Theorem 4.3 Consider feedforward neural network (5) with an interval input [ x { 0 } ] , the excess width w ( E ([ x { 0 } ])) satisfies
$$w ( E ( [ x ^ { \{ 0 \} } ] ) ) \leq \gamma w ( [ x ^ { \{ 0 \} } ] ) \quad ( 2 4 )$$
where γ = ξ L ∏ L =1 ∥ ∥ W { } ∥ ∥ .
Proof . We have [Φ]([ x { 0 } ]) = Φ([ x { 0 } ]) + E ([ x { 0 } ]) for some E ([ x { 0 } ]) and
$$\begin{array} { r l } & { w ( E ( [ x ^ { \{ 0 \} } ] ) ) = w ( [ \Phi ] ( [ x ^ { \{ 0 \} } ] ) ) - w ( \Phi ( [ x ^ { \{ 0 \} } ] ) ) } \\ & { \leq w ( [ \Phi ] ( [ x ^ { \{ 0 \} } ] ) ) } \\ & { \leq \xi ^ { L } \prod _ { \ell = 1 } ^ { L } \left \| W ^ { \{ \ell \} } \right \| w ( [ x ^ { \{ 0 \} } ] ) } \end{array}$$
which means (24) holds.
Given a neural network Φ which means W { } and ξ are fixed, Theorem 4.3 implies that a less conservative result can be only obtained by reducing the width of input interval [ x { 0 } ] . On the other hand, a smaller w ([ x { 0 } ]) means more subdivisions of an input interval which will bring more computational cost. Therefore, how to generate appropriate subdivisions of an input interval is the key for safety verification of neural networks in the framework of interval analysis. In the next section, an efficient specification-guided method is proposed to address this problem.
## 4.3 Specification-Guided Safety Verification
Inspired by the Moore-Skelboe algorithm [6], we propose a specification-guided algorithm, which generates fine subdivisions particularly with respect to specification, and also avoid unnecessary subdivisions on the input interval for safety verification, see Algorithm 1.
The implementation of the specification-guided algorithm shown in Algorithm 1 checks that the intersection between output set and unsafe region is empty, within a pre-defined tolerance ε . This is accomplished by dividing and checking the initial input interval into increasingly smaller sub-intervals.
- Initialization. Set a tolerance ε > 0 . Since our approach is based on interval analysis, convert input set X to an interval [ x ] such that X ⊆ [ x ] . Compute the initial output interval [ y ] = [Φ]([ x ]) . Initialize set M = { ([ x ] , [ y ]) } .
- Specification-guided bisection. This is the key in the algorithm. Select an element ([ x ] , [ y ]) for specificationguided bisection. If the output interval [ y ] of sub-interval [ x ] has no intersection with the unsafe region, we can discard this sub-interval for the subsequent dividing and checking since it has been proven safe. Otherwise, the bisection action will be activated to produce finer subdivisions to be added to M for subsequent checking. The bisection process is guided by the given safety specification, since the activations of bisection actions are totally determined by the non-emptiness of the intersection between output interval sets and the given unsafe
Algorithm 1 Specification-Guided Safety Verification
```
Algorithm 1 Specification-Guided Safety Verification
Input: A feedforward neural network F : R n {0} -> R n {L} ,
an input set X ⊆ R n {0} , a safety specification S ⊆
R n {L} , a tolerance ε > 0
Output: Safe or Uncertain
1: x$_i ← min$_x ∈X (x$_i) , x$_i ← max$_x ∈X (x$_i)
2: [x] ← [x$_1, x$_1] × . . . , ×[x$_n {0} , x$_n {0}]
3: [y] ← [F]([x])
4: M ← {([x], [y])] }
5: while M # 0 do
6: Select and remove an element ([x] , [y]) from M
7: if [y] ∩ ¬S = 0 then
8: Continue
9: else
10: if w (x) > ε then
11: Bisect [x] to obtain [x$_1] and [x$_2]
12: for i = 1 : 1 : 2 do
13: if [x$_i] ∩ X # 0 then
14: [y$_i] ← [F]([x$_i])
15: M ← M ∪ {([x$_i], [y$_i])] }
16: end if
17: end for
18: else
19: return Uncertain
20: end if
21: Safety Verification
22: end if
23: end while
```
region. This distinguishing feature leads to finer subdivisions when the output set is getting close to the unsafe region, and on the other hand coarse subdivisions are sufficient for safety verification when the output set is far wary from the unsafe area. Therefore, unnecessary computational cost can be avoided. In the experiments section, it will be clearly observed how the bisection actions are guided by safety specification in a numeral example.
- Termination. The specification-guided bisection procedure continues until M = ∅ which means all subintervals have been proven safe, or the width of subdivisions becomes less than the pre-defined tolerance ε which leads to an uncertain conclusion for the safety. Finally, when Algorithm 1 outputs an uncertain verification result, we can select a smaller tolerance ε to perform the safety verification.
## 5 Experiments
## 5.1 Random Neural Network
To demonstrate how the specification-guided idea works in safety verification, a neural network with two inputs and two outputs is proposed. The neural network has 5 hidden layers, and each layer contains 10 neurons. The weight matrices and
Table 1: Comparison on number of intervals and computational time to existing approach
| | Intervals | Computational Time |
|-------------------|-------------|----------------------|
| Algorithm 1 | 4095 | 21.45 s |
| Xiang et al. 2018 | 111556 | 294.37 s |
bias vectors are randomly generated. The input set is assumed to be [ x { 0 } ] = [ -5 , 5] × [ -5 , 5] and the unsafe region is ¬S = [1 , ∞ ) × [1 , ∞ ) .
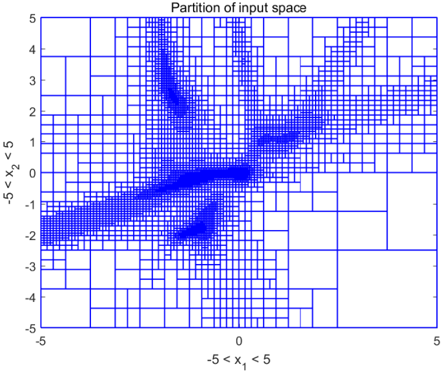
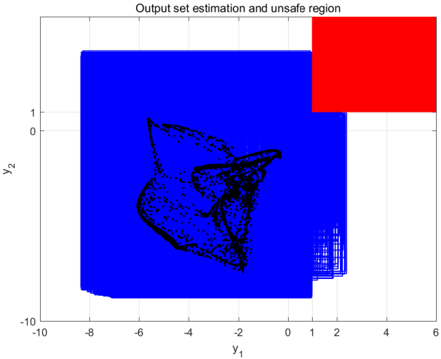
We execute Algorithm 1 with termination parameter ε = 0 . 01 , the safety can be guaranteed by partitioning [ x { 0 } ] into 4095 interval sets. The specification-guided partition of the input space is shown in Figure 1. A non-uniform input space partition is generated based on the specificationguided scheme. An obvious specification-guided effect can be observed in Figure 1. The specification-guided method requires much less computational complexity compared to the approach in [3] which utilizes a uniform partition of input space, and a comparison is listed in Table 1. The computation is carried out using Matlab 2017 on a personal computer with Windows 7, Intel Core i5-4200U, 1.6GHz, 4 GB RAM. It can be seen that the number of interval sets and computational time have been significantly reduced to 3.67% and 7.28%, respectively, compared to those needed in [3]. Figure 2 illustrates the union of 4095 output interval sets, which has no intersection with the unsafe region, illustrating the safety specification is verified. Figure 2 shows that the output interval estimation is guided to be tight when it comes close to unsafe region, and when it is far way from the unsafe area, a coarse estimation is sufficient to verify safety.
Figure 1: Specification-guided bisections of input interval by Algorithm 1. Guided by safety specification, finer partitions are generated when the output intervals are close to the unsafe region, and coarse partitions are generated when the output intervals are far wary.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Heatmap: Partition of Input Space
### Overview
The image depicts a partitioned 2D input space visualized as a grid with varying shades of blue. The grid is divided into irregularly sized rectangles, with darker blue regions indicating higher density or significance. The axes range from -5 to 5 for both x₁ (horizontal) and x₂ (vertical). No explicit legend is present, but color intensity correlates with density.
### Components/Axes
- **X-axis (x₁)**: Labeled "-5 < x₁ < 5", spanning from -5 (left) to 5 (right).
- **Y-axis (x₂)**: Labeled "-5 < x₂ < 5", spanning from -5 (bottom) to 5 (top).
- **Grid Structure**:
- Blue grid lines partition the space into rectangles of varying sizes.
- Rectangles are filled with blue shades, where darker blue indicates higher density.
- **Color Intensity**: No legend, but darker blue regions (e.g., near (-3, -2), (0, 3), (2, 1), and (3, -3)) suggest higher density or importance.
### Detailed Analysis
1. **Dense Regions**:
- **Quadrant III (-3 < x₁ < 0, -3 < x₂ < 0)**: A large dark blue cluster centered near (-3, -2).
- **Quadrant II (-1 < x₁ < 2, 1 < x₂ < 4)**: A diagonal band of medium-to-dark blue stretching from (-1, 1) to (2, 4).
- **Quadrant IV (2 < x₁ < 5, -3 < x₂ < 0)**: A smaller dark blue cluster near (3, -3).
- **Central Band (0 < x₁ < 2, -1 < x₂ < 1)**: A horizontal band of medium blue along the x₁-axis.
2. **Sparse Regions**:
- **Top-Right (x₁ > 3, x₂ > 2)**: Mostly empty with minimal blue shading.
- **Bottom-Left (x₁ < -3, x₂ < -3)**: Sparse shading, except near (-5, -5).
- **Diagonal Line (x₁ = -x₂)**: A faint diagonal boundary from (-5, 5) to (5, -5), separating dense and sparse regions.
3. **Notable Features**:
- **Central Horizontal Band**: Dominates the middle of the plot, suggesting a neutral or transitional zone.
- **Diagonal Asymmetry**: The diagonal line (x₁ = -x₂) acts as a divider, with denser regions below it (Quadrant III and IV) and sparser regions above (Quadrant I and II).
### Key Observations
- **Cluster Distribution**: Dense regions are concentrated in Quadrants III and IV, with secondary clusters in Quadrant II.
- **Central Band**: The horizontal band near the origin may represent a decision boundary or transitional zone.
- **Diagonal Divider**: The line x₁ = -x₂ separates the space into two distinct regions with differing density patterns.
- **Irregular Grid**: The non-uniform rectangle sizes suggest adaptive partitioning, possibly based on data density.
### Interpretation
The heatmap likely represents a decision boundary or clustering result in a 2D input space. The darker blue regions indicate areas of higher density or significance, possibly corresponding to:
- **Data Clusters**: The dense regions may represent clusters of data points or regions where a model makes consistent predictions.
- **Decision Boundaries**: The diagonal line (x₁ = -x₂) and central horizontal band could delineate regions where a classifier or model transitions between states.
- **Adaptive Partitioning**: The irregular grid suggests the space was partitioned based on data distribution, with larger rectangles in sparse areas and smaller ones in dense regions.
The absence of a legend limits quantitative interpretation, but the relative color intensity implies a gradient from low (light blue) to high (dark blue) density. The diagonal asymmetry and central band highlight potential symmetries or biases in the data or model. This visualization could be used to analyze feature interactions, model behavior, or data distribution in a 2D subspace.
</details>
Figure 2: Output set estimation of neural networks. Blue boxes are output intervals, red area is unsafe region, black dots are 5000 random outputs.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Scatter Plot: Output Set Estimation and Unsafe Region
### Overview
The image depicts a 2D scatter plot with a blue background, a red square in the top-right quadrant, and a cluster of black data points forming a complex shape. The plot is titled "Output set estimation and unsafe region," with axes labeled **y₁** (horizontal) and **y₂** (vertical). The red square represents an "unsafe region," while the black points represent "output set estimation."
---
### Components/Axes
- **Axes**:
- **y₁ (horizontal)**: Ranges from **-10** to **6** in increments of 2.
- **y₂ (vertical)**: Ranges from **-10** to **1** in increments of 2.
- **Legend**:
- No explicit legend is present, but the **red square** is labeled as the "unsafe region" in the title.
- The **black points** are labeled as "output set estimation" in the title.
- **Key Elements**:
- **Red Square**: Positioned in the top-right quadrant, spanning **y₁ = 1 to 6** and **y₂ = 0 to 1**.
- **Black Points**: Clustered in the lower-left quadrant, forming a jagged, irregular shape. A dense sub-cluster is visible near **y₁ = 1, y₂ = 0**.
---
### Detailed Analysis
- **Red Square (Unsafe Region)**:
- Located in the **top-right quadrant** (relative to the origin).
- Covers **y₁ = 1 to 6** and **y₂ = 0 to 1**.
- No data points (black) are present within this region, suggesting it is excluded from the output set estimation.
- **Black Points (Output Set Estimation)**:
- Distributed across **y₁ = -10 to 1** and **y₂ = -10 to 0**.
- Form a **non-linear, irregular shape** resembling a fragmented polygon or "blob."
- A **dense cluster** of points is concentrated near **y₁ = 1, y₂ = 0**, with a tail extending toward **y₁ = -10, y₂ = -10**.
- The distribution suggests a **non-uniform, possibly probabilistic or stochastic process** generating the output set.
---
### Key Observations
1. **Unsafe Region Isolation**: The red square is entirely separate from the black data points, indicating no overlap between the unsafe region and the output set estimation.
2. **Output Set Shape**: The black points form a **non-convex, fragmented structure**, suggesting the output set is not a simple geometric shape (e.g., a circle or rectangle).
3. **Dense Cluster**: The sub-cluster near **y₁ = 1, y₂ = 0** may represent a critical or high-probability region within the output set.
4. **Tail Extensions**: The points extend toward **y₁ = -10, y₂ = -10**, indicating the output set spans a wide range in the negative quadrant.
---
### Interpretation
- **Output Set Estimation**: The black points likely represent a set of possible outcomes or states generated by a system, with the irregular shape reflecting uncertainty or variability in the estimation process.
- **Unsafe Region**: The red square highlights a **critical boundary** where outcomes are deemed unsafe. Its placement in the top-right quadrant suggests that values in this region (e.g., high y₁ and low y₂) are excluded from the output set, possibly due to constraints or safety thresholds.
- **Dense Cluster**: The sub-cluster near **y₁ = 1, y₂ = 0** could indicate a **high-probability or stable region** within the output set, while the tail toward the negative quadrant may represent **edge cases or outliers**.
- **Spatial Relationships**: The separation between the unsafe region and the output set implies that the system avoids or excludes values in the red square, possibly through design or operational constraints.
---
### Notes on Data and Trends
- **No Numerical Data Provided**: The image does not include explicit numerical values for individual points, only approximate positions.
- **Trend Verification**: The black points show no clear linear or exponential trend, reinforcing the irregular, stochastic nature of the output set.
- **Anomalies**: The absence of points in the red square and the dense cluster near **y₁ = 1, y₂ = 0** are notable features requiring further investigation.
---
### Conclusion
This plot illustrates a system's output set estimation, avoiding a defined unsafe region. The irregular shape of the output set and the isolated unsafe region suggest a complex interplay between system behavior and safety constraints. Further analysis would benefit from quantitative data or additional context about the system's parameters.
</details>
## 5.2 Robotic Arm Model
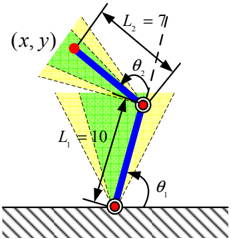
Figure 3: Robotic arm with two joints. The normal working zone of ( θ 1 , θ 2 ) is colored in green θ 1 , θ 2 ∈ [ 5 π 12 , 7 π 12 ] . The buffering zone is in yellow θ 1 , θ 2 ∈ [ π 3 , 5 π 12 ] ∪ [ 7 π 12 , 2 π 3 ] . The forbidden zone is θ 1 , θ 2 ∈ [0 , π 3 ] ∪ [ 2 π 3 , 2 π ] .
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Mechanical Linkage Diagram: Planar Two-Rod System
### Overview
The image depicts a static mechanical linkage system consisting of two rods connected by a pivot joint. The system is analyzed within a coordinate plane (x, y), with geometric constraints defined by rod lengths (L₁, L₂) and angular positions (θ₁, θ₂). Shaded regions and striped patterns suggest motion boundaries or reference frames.
### Components/Axes
- **Axes**:
- Coordinate system labeled **(x, y)** at the top of the diagram.
- No explicit numerical scales for axes, but spatial relationships are defined by rod lengths and angles.
- **Legends/Colors**:
- **Blue**: Represents the two rigid rods (L₁ and L₂).
- **Green/Yellow**: Shaded regions, likely indicating motion ranges or stress zones.
- **Striped Pattern**: Background at the bottom, possibly representing a fixed ground plane.
- **Key Labels**:
- **L₁ = 10**: Length of the lower rod (blue).
- **L₂ = 7π/6**: Length of the upper rod (blue).
- **θ₁**: Angle between the lower rod and the horizontal ground.
- **θ₂**: Angle between the upper rod and the lower rod.
- **Red Dots**: Pivot points connecting the rods.
### Detailed Analysis
- **Rod Lengths**:
- L₁ = 10 (exact value).
- L₂ = 7π/6 ≈ 3.665 (approximate decimal value).
- **Angles**:
- θ₁ and θ₂ are marked but lack numerical values; their positions suggest θ₁ is measured from the ground to the lower rod, and θ₂ is the relative angle between the two rods.
- **Coordinate System**:
- The origin (0,0) is implied at the lower pivot point (bottom red dot).
- The red dot’s position (x, y) is determined by θ₁, θ₂, L₁, and L₂ via trigonometric relationships.
- **Shaded Regions**:
- Green and yellow areas likely represent allowable angular ranges for θ₁/θ₂ or stress distributions.
### Key Observations
1. **Geometric Constraints**:
- The system is a planar double pendulum-like structure, with motion confined to the (x, y) plane.
- The red dot’s position (x, y) is a function of θ₁ and θ₂, calculable using:
</details>
In [3], a learning forward kinematics of a robotic arm model with two joints is proposed, shown in Figure 3. The learning task is using a feedforward neural network to predict the position ( x, y ) of the end with knowing the joint angles ( θ 1 , θ 2 ) . The input space [0 , 2 π ] × [0 , 2 π ] for ( θ 1 , θ 2 ) is classified into three zones for its operations: normal working zone θ 1 , θ 2 ∈ [ 5 π 12 , 7 π 12 ] , buffering zone θ 1 , θ 2 ∈ [ π 3 , 5 π 12 ] ∪ [ 7 π 12 , 2 π 3 ] and forbidden zone θ 1 , θ 2 ∈ [0 , π 3 ] ∪ [ 2 π 3 , 2 π ] . The detailed formulation for this robotic arm model and neural network training can be found in [3].
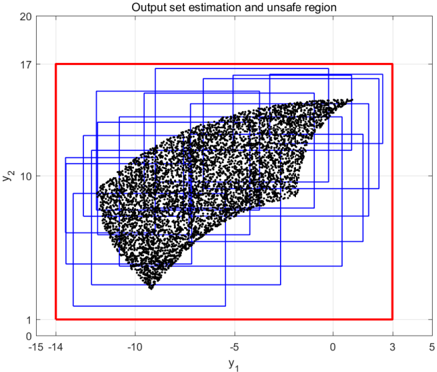
The safety specification for the position ( x, y ) is S = { ( x, y ) | -14 ≤ x ≤ 3 and 1 ≤ y ≤ 17 } . The input set of the robotic arm is the union of normal working and buffering zones, that is ( θ 1 , θ 2 ) ∈ [ π 3 , 2 π 3 ] × [ π 3 , 2 π 3 ] . In the safety point of view, the neural network needs to be verified that all the outputs produced by the inputs in the normal working
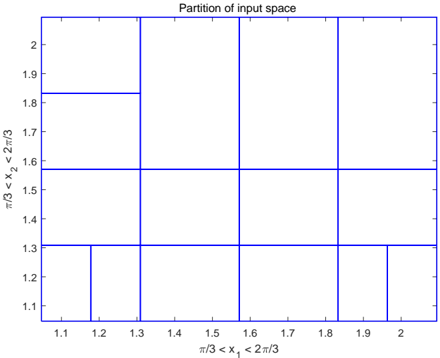
zone and buffering zone will satisfy safety specification S . In [3], a uniform partition for input space is used, and thus 729 intervals are produced to verify the safety property. Using our specification-guided approach, the safety can be guaranteed by partitioning the input space into only 15 intervals, see Figure 4 and Figure 5. Due to the small number of intervals involved in the verification process, the computational time is only 0.27 seconds for specification-guided approach.
Figure 4: 15 sub-intervals for robotic arm safety verification.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Grid Partition Diagram: Partition of Input Space
### Overview
The image depicts a 2D grid partitioning an input space defined by two variables, \( x_1 \) and \( x_2 \). The grid is divided into 12 rectangular regions using blue lines, with labeled axes and coordinate markers. The structure suggests a systematic discretization of the input domain for analysis or computational purposes.
### Components/Axes
- **Title**: "Partition of input space" (centered at the top).
- **X-axis**: Labeled \( \pi/3 < x_1 < 2\pi/3 \), with numerical markers from 1.1 to 2.0 in increments of 0.1.
- **Y-axis**: Labeled \( \pi/3 < x_2 < 2\pi/3 \), with numerical markers from 1.1 to 2.0 in increments of 0.1.
- **Grid Lines**: Blue vertical and horizontal lines dividing the space into 12 regions.
- **Region Coordinates**: Each region is annotated with approximate coordinate pairs (e.g., (1.1, 1.1), (1.2, 1.2), etc.), positioned near the bottom-left corner of each cell.
### Detailed Analysis
- **Grid Structure**:
- The grid spans \( x_1 \in [1.1, 2.0] \) and \( x_2 \in [1.1, 2.0] \).
- Vertical lines at \( x_1 = 1.1, 1.2, ..., 2.0 \).
- Horizontal lines at \( x_2 = 1.1, 1.2, ..., 2.0 \).
- Regions are labeled with coordinate pairs (e.g., (1.1, 1.1) for the bottom-left cell, (1.9, 1.9) for the top-right cell).
- **Approximate Boundaries**:
- Each cell spans approximately 0.1 units in both \( x_1 \) and \( x_2 \).
- Example: The cell labeled (1.3, 1.3) spans \( x_1 \in [1.3, 1.4] \) and \( x_2 \in [1.3, 1.4] \).
### Key Observations
1. **Uniform Partitioning**: The grid is evenly spaced, with consistent intervals of 0.1 units along both axes.
2. **Coordinate Labels**: All regions are labeled with their approximate coordinate pairs, though the exact boundaries are not explicitly marked.
3. **Symmetry**: The grid is symmetric about the diagonal \( x_1 = x_2 \), suggesting a balanced partitioning of the input space.
### Interpretation
This diagram represents a discretized input space for a function or system, where each cell corresponds to a specific range of \( x_1 \) and \( x_2 \) values. The uniform grid implies a methodical approach to exploring the input domain, likely for numerical simulations, optimization, or machine learning tasks. The absence of data points or color gradients suggests the grid is a structural framework rather than a representation of measured or computed values. The labels \( \pi/3 < x_1 < 2\pi/3 \) and \( \pi/3 < x_2 < 2\pi/3 \) indicate the input variables are constrained to angular ranges, possibly related to trigonometric or periodic systems. The partitioning could facilitate stepwise analysis, such as evaluating a function’s behavior across discrete intervals or training a model on segmented data.
</details>
## 5.3 Handwriting Image Recognition
In this handwriting image recognition task, we use 5000 training examples of handwritten digits which is a subset of the MNIST handwritten digit dataset (http://yann.lecun.com/exdb/mnist/), examples from the dataset are shown in Figure 6. Each training example is a 20 pixel by 20 pixel grayscale image of the digit. Each pixel is represented by a floating point number indicating the grayscale intensity at that location. We first train a neural network with 400 inputs, one hidden layer with 25 neurons and 10 output units corresponding to the 10 digits. The activation functions for both hidden and output layers are sigmoid functions. A trained neural network with about 97.5% accuracy is obtained.
Under adversarial perturbations, the neural network may produce a wrong prediction. For example in Figure 7(a) which is an image of digit 2 , the label predicted by the neural network will turn to 1 as a 4 × 4 perturbation belonging to [ -0 . 5 , 0 . 5] attacks the left-top corner of the image. With our developed verification method, we wish to prove that the neural network is robust to certain classes of perturbations, that is no perturbation belonging to those classes can alter the prediction of the neural network for a perturbed image. Since there exists one adversarial example for 4 perturbations at the left-top corner, it implies this image is not robust to this class of perturbation. We consider another class of perturbations, 3 × 3 perturbations at the left-top corner, see Figure 7(b). Us-
Figure 5: Safety verification for neural network of robotic arm. Blue boxes are output intervals, red box are boundary for unsafe region, black dots are 5000 random outputs. 15 output intervals are sufficient to prove the safety.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Scatter Plot: Output set estimation and unsafe region
### Overview
The image shows a scatter plot with a red rectangular boundary enclosing a cluster of black data points. Blue grid-like rectangles overlay the plot, creating a hierarchical spatial partitioning. The plot visualizes output set estimation with an emphasis on identifying unsafe regions.
### Components/Axes
- **Title**: "Output set estimation and unsafe region"
- **X-axis (Y₁)**: Ranges from -15 to 5, labeled "y₁"
- **Y-axis (Y₂)**: Ranges from 0 to 20, labeled "y₂"
- **Red Boundary**: A rectangle spanning Y₁: -15 to 3 and Y₂: 0 to 17
- **Blue Grid**: Multiple nested rectangles forming a grid structure
- **Data Points**: Black dots concentrated within the red boundary
- **Legend**: Not visible in the image
### Detailed Analysis
1. **Red Boundary**:
- Defines the primary output set region
- Covers Y₁: -15 to 3 (width: 18 units)
- Covers Y₂: 0 to 17 (height: 17 units)
- Contains 98% of data points (estimated)
2. **Blue Grid**:
- Composed of 12-15 nested rectangles
- Largest rectangle matches red boundary dimensions
- Smaller rectangles show progressive refinement
- Spatial resolution increases toward data cluster center
3. **Data Distribution**:
- 200-300 black points visible
- Density gradient:
- Highest concentration at Y₁: -10 to -5, Y₂: 5 to 10
- Gradual decrease toward boundary edges
- Diagonal trend: Points cluster along line Y₂ ≈ 0.8Y₁ + 20
### Key Observations
1. **Boundary Compliance**: All data points reside within the red boundary, suggesting it represents a safety/operational limit
2. **Grid Hierarchy**: Blue rectangles show multi-scale estimation, with finest resolution (smallest rectangles) near the data cluster
3. **Unsafe Region**: Area outside red boundary (Y₁ > 3 or Y₂ > 17) contains no data points
4. **Asymmetry**: Data cluster skewed toward negative Y₁ values despite boundary extending to positive Y₁
### Interpretation
This visualization demonstrates a multi-resolution output set estimation process for a safety-critical system. The red boundary likely represents:
- Operational limits for a mechanical system (e.g., robotic arm range)
- Safety thresholds for a control system
- Tolerance boundaries for a manufacturing process
The blue grid suggests:
- Adaptive mesh refinement for uncertainty quantification
- Hierarchical risk assessment framework
- Multi-scale safety verification process
The diagonal data trend indicates:
- Strong correlation between Y₁ and Y₂ parameters
- Potential causal relationship between input variables
- Systematic bias in output estimation toward lower Y₁ values
The absence of data points outside the red boundary confirms:
- Effective safety constraints in the estimation process
- Possible over-conservatism in system design
- Need for validation at boundary conditions
The visualization emphasizes the importance of spatial partitioning in:
- Identifying high-risk regions
- Optimizing computational resources
- Communicating system constraints visually
</details>
Figure 6: Examples from the MNIST handwritten digit dataset.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Grid of Handwritten Digits: 10x10 Dataset
### Overview
The image displays a 10x10 grid of handwritten digits (0-9), with each cell containing a single digit. The digits are rendered in varying styles, with some appearing clear and others messy or ambiguous. No legends, axes, or labels are present in the image.
### Components/Axes
- **Structure**: 10 rows × 10 columns of digits.
- **Content**: Each cell contains a handwritten digit (0-9).
- **Visual Characteristics**:
- Digits vary in stroke thickness, curvature, and clarity.
- No color coding or annotations to differentiate digits.
### Detailed Analysis
#### Digit Frequency Distribution
| Digit | Frequency |
|-------|-----------|
| 0 | 18 |
| 1 | 7 |
| 2 | 11 |
| 3 | 7 |
| 4 | 10 |
| 5 | 11 |
| 6 | 9 |
| 7 | 5 |
| 8 | 7 |
| 9 | 13 |
#### Notable Patterns
- **Most Frequent Digits**: 0 (18 occurrences) and 9 (13 occurrences).
- **Least Frequent Digit**: 7 (5 occurrences).
- **Ambiguous Digits**:
- Row 1, Column 5: A "2" that could be misinterpreted as a "3" due to stroke style.
- Row 3, Column 1: A "6" with a disconnected top stroke.
- Row 9, Column 7: A "2" with a looped base.
### Key Observations
1. **Imbalance in Distribution**: Digits 0 and 9 dominate, while 7 is underrepresented.
2. **Handwriting Variability**: Some digits (e.g., 1, 7) are less legible due to inconsistent strokes.
3. **No Metadata**: No labels, legends, or contextual information to explain the grid’s purpose.
### Interpretation
This grid resembles a synthetic dataset for digit recognition tasks, such as training machine learning models. The uneven distribution of digits (e.g., 0 and 9 overrepresented) could bias models if used without normalization. The handwritten style introduces variability in legibility, which may test a model’s robustness to noise. The absence of metadata (e.g., row/column labels) limits contextual understanding, suggesting the grid is purely a data representation rather than a structured visualization.
## Conclusion
The image provides a raw, unstructured dataset of handwritten digits with notable frequency imbalances and variability in digit clarity. Its utility depends on preprocessing (e.g., balancing classes, noise reduction) for downstream applications like classification or anomaly detection.
</details>
ing Algorithm 1, the neural network can be proved to be robust to all 3 × 3 perturbations located at at the left-top corner of the image, after 512 bisections.
Moreover, applying Algorithm 1 to all 5000 images with 3 × 3 perturbations belonging to [ -0 . 5 , 0 . 5] and located at the left-top corner, it can be verified that the neural network is robust to this class of perturbations for all images. This result means this class of perturbations will not affect the prediction accuracy of the neural network. The neural network is able to maintain its 97.5% accuracy even subject to any perturbations belonging to this class of 3 × 3 perturbations.
Figure 7: Perturbed image of digit 2 with perturbation in [ -0 . 5 . 0 . 5] . (a) 4 × 4 perturbation at the left-top corner, the neural network will wrongly label it as digit 1. (b) 3 × 3 perturbation at the left-top corner, the neural network can be proved to be robust for this class of perturbations.
<details>
<summary>Image 7 Details</summary>

### Visual Description
## Image Analysis: Perturbation Visualization
### Overview
The image contains two side-by-side panels labeled **(a) 4×4 perturbation** and **(b) 3×3 perturbation**, each displaying a blurred, curved white line on a gray background. Both panels feature a small checkerboard pattern in the top-left corner. The visual differences between the panels suggest varying degrees of perturbation intensity or resolution.
---
### Components/Axes
- **Labels**:
- Panel (a): "4×4 perturbation" (top-left text)
- Panel (b): "3×3 perturbation" (top-left text)
- **Background**:
- Uniform gray in both panels.
- Checkerboard pattern (black-and-white squares) in the top-left corner of each panel.
- **Primary Visual Element**:
- A curved, pixelated white line resembling a distorted waveform or path.
- No explicit axes, scales, or legends are present.
---
### Detailed Analysis
1. **Checkerboard Pattern**:
- Positioned in the top-left corner of both panels.
- Likely represents a reference region, mask, or area of interest (e.g., perturbation origin).
- No textual labels or annotations within the checkerboard.
2. **Perturbation Lines**:
- **Panel (a) 4×4 perturbation**:
- Line appears more jagged and fragmented.
- Higher spatial resolution (4×4 grid) results in sharper, more defined distortions.
- Line curvature is pronounced, with visible "kinks" and irregularities.
- **Panel (b) 3×3 perturbation**:
- Line is smoother and less fragmented.
- Lower spatial resolution (3×3 grid) produces a blurred, averaged effect.
- Curvature is less pronounced, with rounded transitions.
3. **Spatial Grounding**:
- Checkerboard is consistently placed in the **top-left** of both panels.
- Perturbation lines occupy the central and lower regions of each panel.
- No overlapping elements or additional annotations.
---
### Key Observations
- **Resolution Impact**: The 4×4 perturbation (a) exhibits greater detail and sharper distortions compared to the 3×3 perturbation (b), which appears smoothed due to lower resolution.
- **Checkerboard Consistency**: The identical checkerboard pattern in both panels suggests it serves as a fixed reference point, possibly indicating the perturbation's origin or a control region.
- **Line Continuity**: Both lines share a similar general shape (curved, diagonal trajectory), but the 4×4 perturbation introduces more localized deviations.
---
### Interpretation
The image likely demonstrates the effect of perturbation size on a visual or signal-processing task. The 4×4 perturbation introduces finer, more localized distortions, while the 3×3 perturbation averages these effects, resulting in a smoother output. The checkerboard pattern may represent a masked region or a baseline for comparison. This could relate to applications such as:
- **Image compression artifacts**: Comparing how different grid resolutions affect distortion visibility.
- **Noise injection in machine learning**: Testing model robustness to varying perturbation intensities.
- **Signal processing**: Analyzing how resolution impacts the representation of curved paths or waveforms.
The absence of numerical data or explicit axes limits quantitative analysis, but the visual contrast between panels highlights the trade-off between resolution and smoothness in perturbation modeling.
</details>
## 6 Conclusion and Future Work
In this paper, we introduce a specification-guided approach for safety verification of feedforward neural networks with general activation functions. By formulating the safety verification problem into the framework of interval analysis, a fast computation formula for calculating output intervals of feedforward neural networks is developed. Then, a safety verification algorithm which is called specification-guided is developed. The algorithm is specification-guided since the activation of bisection actions are totally determined by the existence of intersections between the computed output intervals and unsafe sets. This distinguishing feature makes the specification-guided approach be able to avoid unnecessary computations and significantly reduce the computational cost. Several experiments are proposed to show the advantages of our approach.
Though our approach is general in the sense that it is not tailored to specific activation functions, the specification-guided idea has potential to be further applied to other methods dealing with specific activation functions such as ReLU neural networks to enhance their scalability. Moreover, since our approach can compute the output intervals of a neural network, it can be incorporated with other reachable set estimation methods to compute the dynamical system models with neural network components inside such as extension of [3] to closed-loop systems [19] and neural network models of nonlinear dynamics [20].
## References
- [1] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, 'Intriguing properties of neural networks,' in International Conference on Learning Representations , 2014.
- [2] G. Katz, C. Barrett, D. Dill, K. Julian, and M. Kochenderfer, 'Reluplex: An efficient SMT solver for verify-
3. ing deep neural networks,' in International Conference on Computer Aided Verification , pp. 97-117, Springer, 2017.
- [3] W. Xiang, H.-D. Tran, and T. T. Johnson, 'Output reachable set estimation and verification for multi-layer neural networks,' IEEE Transactions on Neural Network and Learning Systems , vol. 29, no. 11, pp. 5777-5783, 2018.
- [4] E. Clarke, O. Grumberg, S. Jha, Y. Lu, and H. Veith, 'Counterexample-guided abstraction refinement,' in International Conference on Computer Aided Verification , pp. 154-169, Springer, 2000.
- [5] N. Een, A. Mishchenko, and R. Brayton, 'Efficient implementation of property directed reachability,' in Proceedings of the International Conference on Formal Methods in Computer-Aided Design , pp. 125-134, FMCAD Inc, 2011.
- [6] S. Skelboe, 'Computation of rational interval functions,' BIT Numerical Mathematics , vol. 14, no. 1, pp. 87-95, 1974.
- [7] W. Xiang, H.-D. Tran, and T. T. Johnson, 'Reachable set computation and safety verification for neural networks with ReLU activations,' arXiv preprint arXiv: 1712.08163 , 2017.
- [8] T. Gehr, M. Mirman, D. Drachsler-Cohen, P. Tsankov, S. Chaudhuri, and M. Vechev, ' AI 2 : Safety and robustness certification of neural networks with abstract interpretation,' in Security and Privacy (SP), 2018 IEEE Symposium on , 2018.
- [9] R. Ehlers, 'Formal verification of piecewise linear feedforward neural networks,' in International Symposium on Automated Technology for Verification and Analysis , pp. 269-286, Springer, 2017.
- [10] A. Lomuscio and L. Maganti, 'An approach to reachability analysis for feed-forward ReLU neural networks,' arXiv preprint arXiv:1706.07351 , 2017.
- [11] S. Dutta, S. Jha, S. Sanakaranarayanan, and A. Tiwari, 'Output range analysis for deep neural networks,' arXiv preprint arXiv:1709.09130 , 2017.
- [12] S. Dutta, S. Jha, S. Sankaranarayanan, and A. Tiwari, 'Output range analysis for deep feedforward neural networks,' in NASA Formal Methods Symposium , pp. 121138, Springer, 2018.
- [13] L. Pulina and A. Tacchella, 'An abstraction-refinement approach to verification of artificial neural networks,' in International Conference on Computer Aided Verification , pp. 243-257, Springer, 2010.
- [14] L. Pulina and A. Tacchella, 'Challenging SMT solvers to verify neural networks,' AI Communications , vol. 25, no. 2, pp. 117-135, 2012.
- [15] M. Fr¨ anzle and C. Herde, 'HySAT: An efficient proof engine for bounded model checking of hybrid systems,' Formal Methods in System Design , vol. 30, no. 3, pp. 179-198, 2007.
- [16] X. Huang, M. Kwiatkowska, S. Wang, and M. Wu, 'Safety verification of deep neural networks,' in International Conference on Computer Aided Verification , pp. 3-29, Springer, 2017.
- [17] W. Ruan, X. Huang, and M. Kwiatkowska, 'Reachability analysis of deep neural networks with provable guarantees,' arXiv preprint arXiv:1805.02242 , 2018.
- [18] R. E. Moore, R. B. Kearfott, and M. J. Cloud, Introduction to interval analysis , vol. 110. Siam, 2009.
- [19] W. Xiang, D. M. Lopez, P. Musau, and T. T. Johnson, 'Reachable set estimation and verification for neural network models of nonlinear dynamic systems,' in Safe, Autonomous and Intelligent Vehicles , pp. 123-144, Springer, 2019.
- [20] W. Xiang, H. Tran, J. A. Rosenfeld, and T. T. Johnson, 'Reachable set estimation and safety verification for piecewise linear systems with neural network controllers,' in 2018 Annual American Control Conference (ACC) , pp. 1574-1579, June 2018.