## ABDUCTIVE COMMONSENSE REASONING
Chandra Bhagavatula ♦ , Ronan Le Bras ♦ , Chaitanya Malaviya ♦ , Keisuke Sakaguchi ♦ , Ari Holtzman ♦ , Hannah Rashkin ♦ , Doug Downey ♦ , Scott Wen-tau Yih ♣ , Yejin Choi ♦♥
♦ ♣
{ scottyih } @fb.com
Allen Institute for AI, Seattle, WA, USA, Facebook AI, Seattle, WA, USA ♥ Paul G. Allen School of Computer Science & Engineering, WA, USA { chandrab,ronanlb,chaitanyam,keisukes } @allenai.org { arih,hannahr,dougd } @allenai.org { yejin } @cs.washington.edu ∗
## ABSTRACT
Abductive reasoning is inference to the most plausible explanation . For example, if Jenny finds her house in a mess when she returns from work, and remembers that she left a window open, she can hypothesize that a thief broke into her house and caused the mess, as the most plausible explanation. While abduction has long been considered to be at the core of how people interpret and read between the lines in natural language (Hobbs et al., 1988), there has been relatively little research in support of abductive natural language inference and generation.
We present the first study that investigates the viability of language-based abductive reasoning. We introduce a challenge dataset, ART , that consists of over 20k commonsense narrative contexts and 200k explanations. Based on this dataset, we conceptualize two new tasks - (i) Abductive NLI : a multiple-choice question answering task for choosing the more likely explanation, and (ii) Abductive NLG : a conditional generation task for explaining given observations in natural language. On Abductive NLI , the best model achieves 68.9% accuracy, well below human performance of 91.4%. On Abductive NLG , the current best language generators struggle even more, as they lack reasoning capabilities that are trivial for humans. Our analysis leads to new insights into the types of reasoning that deep pre-trained language models fail to perform-despite their strong performance on the related but more narrowly defined task of entailment NLI-pointing to interesting avenues for future research.
## 1 INTRODUCTION
The brain is an abduction machine, continuously trying to prove abductively that the observables in its environment constitute a coherent situation.
- Jerry Hobbs, ACL 2013 Lifetime Achievement Award 1
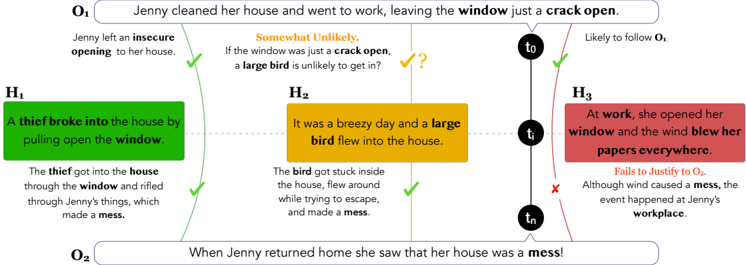
Abductive reasoning is inference to the most plausible explanation for incomplete observations (Peirce, 1965a). Figure 1 illustrates an example. Given the incomplete observations about the world that O 1 : 'Jenny cleaned her house and went to work, leaving the window just a crack open.' and sometime later O 2 : 'When Jenny returned home, she saw her house was a mess.', we can hypothesize different potential explanations and reason about which is the most likely. We can readily rule out H 3 since it fails to justify the observation O 2 . While H 1 and H 2 are both plausible, the most likely explanation based on commonsense is H 1 as H 2 is somewhat implausible given O 1 .
One crucial observation Peirce makes about abductive reasoning is that abduction is 'the only logical operation which introduces any new ideas' , which contrasts with other types of inference such as entailment, that focuses on inferring only such information that is already provided in the premise.
∗ Work done while at AI2
1 The full transcript of his award speech is available at https://www.mitpressjournals.org/ doi/full/10.1162/COLI\_a\_00171
Figure 1: Example of Abductive Reasoning. Given observations O 1 and O 2 , the α NLI task is to select the most plausible explanatory hypothesis. Since the number of hypotheses is massive in any given situation, we make a simplifying assumption in our ART dataset to only choose between a pair of explanations.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Causal Reasoning & Hypothesis Evaluation
### Overview
This diagram illustrates a causal reasoning process, evaluating different hypotheses (H1, H2, H3) to explain an observation (O2) given an initial condition (O1). It uses a timeline (t0, t1, t2) and visual cues (checkmarks, crosses, question marks) to indicate the likelihood and justification of each hypothesis.
### Components/Axes
The diagram consists of the following components:
* **O1 (Observation 1):** "Jenny cleaned her house and went to work, leaving the window just a crack open." – Located at the top center.
* **O2 (Observation 2):** "When Jenny returned home she saw that her house was a mess!" – Located at the bottom center.
* **H1 (Hypothesis 1):** A green box stating "A thief broke into the house by pulling open the window." with supporting text: "The thief got into the house through the window and rifled through Jenny’s things, which made a mess." – Located on the left side.
* **H2 (Hypothesis 2):** A yellow box stating "It was a breezy day and a large bird flew into the house." with supporting text: "The bird got stuck inside the house, flew around while trying to escape, and made a mess." – Located in the center.
* **H3 (Hypothesis 3):** A red box stating "At work, she opened her window and the wind blew her papers everywhere." with supporting text: "Although wind caused a mess, the event happened at Jenny’s workplace." – Located on the right side.
* **Timeline:** t0, t1, t2 – Representing sequential points in time. Located on the right side.
* **Arrows:** Connecting O1 to H1, H2, and H3, and connecting H1, H2, and H3 to O2. Arrows are colored to indicate likelihood (green = likely, red = unlikely, orange = somewhat unlikely).
* **Visual Cues:** Checkmarks (✓) indicate justification, crosses (✗) indicate failure to justify, and question marks (?) indicate uncertainty.
### Detailed Analysis or Content Details
* **O1 to H1:** A curved green arrow indicates that H1 is likely to follow from O1. A checkmark confirms justification.
* **O1 to H2:** A curved orange arrow indicates that H2 is "Somewhat Unlikely" to follow from O1. A question mark indicates uncertainty. The text above the question mark asks: "If the window was just a crack open, a large bird is unlikely to get in?".
* **O1 to H3:** A curved red arrow indicates that H3 is unlikely to follow from O1.
* **H1 to O2:** A green arrow from H1 to O2 with a checkmark indicates that H1 justifies O2.
* **H2 to O2:** A green arrow from H2 to O2 with a checkmark indicates that H2 justifies O2.
* **H3 to O2:** A red arrow from H3 to O2 with a cross indicates that H3 fails to justify O2. The text below the cross states: "Although wind caused a mess, the event happened at Jenny’s workplace."
* **Timeline Connections:**
* H1 is connected to t0 with a green arrow.
* H2 is connected to t1 with a green arrow.
* H3 is connected to t2 with a red arrow.
### Key Observations
* H1 and H2 are both considered plausible explanations for O2, given O1.
* H3 is deemed unlikely as it doesn't explain the mess at Jenny's *home*.
* The timeline suggests a sequence of events, with H1 occurring earliest (t0), followed by H2 (t1), and H3 latest (t2).
* The diagram emphasizes the importance of justification in evaluating hypotheses.
### Interpretation
This diagram demonstrates a process of abductive reasoning – inferring the best explanation for an observation. The diagram highlights that multiple hypotheses can be consistent with the available evidence (O1 and O2). The use of color-coded arrows and visual cues effectively communicates the degree of likelihood and justification for each hypothesis. The timeline suggests a possible order of events, but it's not necessarily a strict causal chain. The rejection of H3 is based on a spatial mismatch – the mess occurred at home, not at work. The diagram is a visual representation of a logical argument, illustrating how to evaluate competing explanations and arrive at the most plausible conclusion. The question mark above H2 indicates that the plausibility of a large bird entering through a small crack is being questioned, suggesting a need for further investigation or evidence.
</details>
Abductive reasoning has long been considered to be at the core of understanding narratives (Hobbs et al., 1988), reading between the lines (Norvig, 1987; Charniak & Shimony, 1990), reasoning about everyday situations (Peirce, 1965b; Andersen, 1973), and counterfactual reasoning (Pearl, 2002; Pearl & Mackenzie, 2018). Despite the broad recognition of its importance, however, the study of abductive reasoning in narrative text has very rarely appeared in the NLP literature, in large part because most previous work on abductive reasoning has focused on formal logic, which has proven to be too rigid to generalize to the full complexity of natural language.
In this paper, we present the first study to investigate the viability of language-based abductive reasoning. This shift from logic -based to language -based reasoning draws inspirations from a significant body of work on language-based entailment (Bowman et al., 2015; Williams et al., 2018b), language-based logic (Lakoff, 1970; MacCartney & Manning, 2007), and language-based commonsense reasoning (Mostafazadeh et al., 2016; Zellers et al., 2018). In particular, we investigate the use of natural language as the representation medium, and probe deep neural models on language-based abductive reasoning.
More concretely, we propose Abductive Natural Language Inference ( α NLI) and Abductive Natural Language Generation ( α NLG) as two novel reasoning tasks in narrative contexts. 2 We formulate α NLI as a multiple-choice task to support easy and reliable automatic evaluation: given a context, the task is to choose the more likely explanation from a given pair of hypotheses choices. We also introduce a new challenge dataset, ART , that consists of 20K narratives accompanied by over 200K explanatory hypothesis. 34 We then establish comprehensive baseline performance based on state-of-the-art NLI and language models. The best baseline for α NLI based on BERT achieves 68.9% accuracy, with a considerable gap compared to human performance of 91.4%( § 5.2). The best generative model, based on GPT2, performs well below human performance on the α NLG task ( § 5.2). Our analysis leads to insights into the types of reasoning that deep pre-trained language models fail to perform - despite their strong performance on the closely related but different task of entailment NLI - pointing to future research directions.
## 2 TASK DEFINITION
Abductive Natural Language Inference We formulate α NLI as multiple choice problems consisting of a pair of observations as context and a pair of hypothesis choices. Each instance in ART is defined as follows:
- O 1 : The observation at time t 1 .
2 α NLI and α NLG are pronounced as alpha -NLI and alpha -NLG, respectively
3 ART : A bductive R easoning in narrative T ext.
4 Data available to download at http://abductivecommonsense.xyz
- O 2 : The observation at time t 2 > t 1 .
- h + : A plausible hypothesis that explains the two observations O 1 and O 2 .
- h -: An implausible (or less plausible) hypothesis for observations O 1 and O 2 .
Given the observations and a pair of hypotheses, the α NLI task is to select the most plausible explanation (hypothesis).
Abductive Natural Language Generation α NLG is the task of generating a valid hypothesis h + given the two observations O 1 and O 2 . Formally, the task requires to maximize P ( h + | O 1 , O 2 ) .
## 3 MODELS FOR ABDUCTIVE COMMONSENSE REASONING
## 3.1 ABDUCTIVE NATURAL LANGUAGE INFERENCE
A Probabilistic Framework for α NLI: A distinct feature of the α NLI task is that it requires jointly considering all available observations and their commonsense implications, to identify the correct hypothesis. Formally, the α NLI task is to select the hypothesis h ∗ that is most probable given the observations.
$$h ^ { * } = \arg \max _ { h ^ { i } } P ( H = h ^ { i } | O _ { 1 } , O _ { 2 } ) \quad ( 1 )$$
Rewriting the objective using Bayes Rule conditioned on O 1 , we have:
$$P ( h ^ { i } | O _ { 1 } , O _ { 2 } ) \varpropto P ( O _ { 2 } | h ^ { i } , O _ { 1 } ) P ( h ^ { i } | O _ { 1 } ) & & ( 2 )$$
We formulate a set of probabilistic models for α NLI that make various independence assumptions on Equation 2 - starting from a simple baseline that ignores the observations entirely, and building up to a fully joint model. These models are depicted as Bayesian Networks in Figure 2.
Figure 2: Illustration of the graphical models described in the probabilistic framework. The 'Fully Connected' model can, in theory, combine information from both available observations.
<details>
<summary>Image 2 Details</summary>

### Visual Description
\n
## Diagram: Network Models of Observation
### Overview
The image presents five distinct diagrams, labeled a through e, illustrating different network models of observation. Each diagram depicts a series of rounded rectangles representing entities (H, O1, O2) connected by arrows indicating relationships or flow. The diagrams are arranged horizontally.
### Components/Axes
The diagrams are labeled as follows:
* a) Hypothesis-Only
* b) First Observation Only
* c) Second Observation Only
* d) Linear Chain
* e) Fully Connected
The entities represented are:
* H
* O1
* O2
The arrows represent relationships between the entities.
### Detailed Analysis or Content Details
**a) Hypothesis-Only:**
* Contains a single rounded rectangle labeled "H".
* No connections or arrows are present.
**b) First Observation Only:**
* Contains three rounded rectangles labeled "O1", "H", and "O1" from left to right.
* An arrow points from the first "O1" to "H".
**c) Second Observation Only:**
* Contains three rounded rectangles labeled "H", "O2", and "O2" from left to right.
* An arrow points from "H" to the first "O2".
**d) Linear Chain:**
* Contains three rounded rectangles labeled "O1", "H", and "O2" from left to right.
* An arrow points from "O1" to "H".
* An arrow points from "H" to "O2".
**e) Fully Connected:**
* Contains three rounded rectangles labeled "O1", "O2", and "H".
* An arrow points from "O1" to "H".
* An arrow points from "O2" to "H".
* An arrow points from "O1" to "O2".
### Key Observations
The diagrams demonstrate increasing complexity in network connections. Diagram (a) represents a baseline with no connections. Diagrams (b) and (c) show simple, unidirectional relationships. Diagram (d) introduces a linear sequence of observations. Diagram (e) represents a fully interconnected network where all entities are directly related to each other.
### Interpretation
These diagrams likely represent different models for how observations are made and related to a hypothesis.
* **(a) Hypothesis-Only:** Represents a starting point where only a hypothesis exists, without any observational data.
* **(b) First Observation Only:** Shows the initial observation (O1) influencing the hypothesis (H).
* **(c) Second Observation Only:** Shows a second observation (O2) influencing the hypothesis (H).
* **(d) Linear Chain:** Represents a sequential process where one observation leads to another, mediated by the hypothesis.
* **(e) Fully Connected:** Suggests a more complex, iterative process where observations influence each other and the hypothesis simultaneously.
The progression from (a) to (e) could illustrate a learning process or the development of a more refined understanding of a phenomenon through repeated observation and analysis. The diagrams are conceptual and do not contain numerical data, but they visually represent different relationships between a hypothesis and observations. The use of "O1" and "O2" suggests multiple observations are being considered. The diagrams are a visual representation of a conceptual framework, rather than a presentation of empirical data.
</details>
Hypothesis Only: Our simplest model makes the strong assumption that the hypothesis is entirely independent of both observations, i.e. ( H ⊥ O 1 , O 2 ) , in which case we simply aim to maximize the marginal P ( H ) .
First (or Second) Observation Only: Our next two models make weaker assumptions: that the hypothesis depends on only one of the first O 1 or second O 2 observation.
Linear Chain: Our next model uses both observations, but considers each observation's influence on the hypothesis independently , i.e. it does not combine information across the observations. Formally, the model assumes that the three variables 〈 O 1 , H, O 2 〉 form a linear Markov chain, where the second observation is conditionally independent of the first, given the hypothesis (i.e. ( O 1 ⊥ O 2 | H ) ). Under this assumption, we aim to maximize a somewhat simpler objective than Equation 2:
$$h ^ { * } = \arg \max _ { h ^ { i } } P ( O _ { 2 } | h ^ { i } ) P ( h ^ { i } | O _ { 1 } ) w h e r e \left ( O _ { 1 } \perp O _ { 2 } | H \right ) \quad ( 3 )$$
Fully Connected: Finally, our most sophisticated model jointly models all three random variables as in Equation 2, and can in principle combine information across both observations to choose the correct hypothesis.
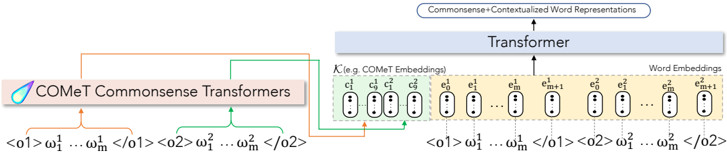
Figure 3: Overview of an α NLG model that integrates commonsense representations obtained from COMeT(Bosselut et al., 2019) with GPT2. Each observation is input to the COMeT model to obtain nine embeddings, each associated with one commonsense inference type.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: CoMeT Commonsense Transformers Architecture
### Overview
The image depicts a diagram illustrating the architecture of CoMeT (Commonsense Transformers). It shows how input tokens are processed through the CoMeT model to generate embeddings, which are then fed into a Transformer to produce contextualized word representations. The diagram highlights the input token sequences, CoMeT embeddings, and the final output.
### Components/Axes
The diagram consists of the following key components:
* **CoMeT Commonsense Transformers:** A purple rectangular block labeled "CoMeT Commonsense Transformers".
* **Input Token Sequences:** Two sequences of tokens represented as `<01> ω₁¹ ... ωₘ¹ <02>` and `<02> ω₁² ... ωₘ² <02>`.
* **CoMeT Embeddings:** A series of oval shapes labeled `c₁`, `c₂`, ..., `cₘ`, `cₘ+1`, `e₁`, `e₂`, ..., `eₘ`, `eₘ+1`. These are grouped under the label "K (e.g. CoMeT Embeddings)".
* **Word Embeddings:** A series of oval shapes labeled `e₁`, `e₂`, ..., `eₘ`, `eₘ+1`.
* **Transformer:** A large light blue rectangular block labeled "Transformer".
* **Output:** A rectangular block labeled "Commonsense + Contextualized Word Representations".
* **Arrows:** Arrows indicating the flow of data between the components.
### Detailed Analysis or Content Details
The diagram illustrates the following process:
1. **Input:** Two sequences of tokens, `<01> ω₁¹ ... ωₘ¹ <02>` and `<02> ω₁² ... ωₘ² <02>`, are provided as input. The `<01>` and `<02>` likely represent start and end tokens, and ω represents the individual tokens.
2. **CoMeT Processing:** These input sequences are fed into the "CoMeT Commonsense Transformers" block.
3. **Embedding Generation:** The CoMeT model generates a series of embeddings, represented as `c₁`, `c₂`, ..., `cₘ`, `cₘ+1` and `e₁`, `e₂`, ..., `eₘ`, `eₘ+1`. The `c` embeddings are labeled as "CoMeT Embeddings" and the `e` embeddings are labeled as "Word Embeddings".
4. **Transformer Input:** The CoMeT embeddings are then fed into the "Transformer" block.
5. **Contextualization:** The Transformer processes the embeddings to generate "Commonsense + Contextualized Word Representations" as output.
The diagram shows a parallel processing of two input sequences, with the CoMeT model generating embeddings for both. The embeddings are then combined and fed into the Transformer. The number of embeddings (m+1) is consistent across both input sequences.
### Key Observations
* The diagram emphasizes the role of CoMeT in generating embeddings that capture commonsense knowledge.
* The Transformer is depicted as a central component for contextualizing the embeddings.
* The use of two input sequences suggests that CoMeT may be designed to handle multiple perspectives or contexts.
* The diagram does not provide specific details about the internal workings of the CoMeT model or the Transformer.
### Interpretation
The diagram illustrates a pipeline for incorporating commonsense knowledge into word representations. The CoMeT model acts as a knowledge encoder, transforming input tokens into embeddings that capture relevant commonsense information. These embeddings are then fed into a Transformer, which leverages its attention mechanism to contextualize the embeddings and generate more informative word representations. This approach aims to improve the performance of downstream NLP tasks that require commonsense reasoning. The parallel processing of two input sequences suggests that CoMeT may be capable of handling ambiguous or multi-faceted inputs, allowing it to generate more robust and nuanced representations. The diagram is a high-level overview and does not delve into the specific algorithms or parameters used in the CoMeT model or the Transformer. It serves as a conceptual illustration of the overall architecture and data flow.
</details>
To help illustrate the subtle distinction between how the Linear Chain and Fully Connected models consider both observations, consider the following example. Let observation O 1 : 'Carl went to the store desperately searching for flour tortillas for a recipe.' and O 2 : 'Carl left the store very frustrated.'. Then consider two distinct hypotheses, an incorrect h 1 : 'The cashier was rude' and the correct h 2 : 'The store had corn tortillas, but not flour ones.'. For this example, a Linear Chain model could arrive at the wrong answer, because it reasons about the observations separately-taking O 1 in isolation, both h 1 and h 2 seem plausible next events, albeit each a priori unlikely. And for O 2 in isolation-i.e. in the absence of O 1 , as for a randomly drawn shopper-the h 1 explanation of a rude cashier seems a much more plausible explanation of Carl's frustration than are the details of the store's tortilla selection. Combining these two separate factors leads the Linear Chain to select h 1 as the more plausible explanation. It is only by reasoning about Carl's goal in O 1 jointly with his frustration in O 2 , as in the Fully Connected model, that we arrive at the correct answer h 2 as the more plausible explanation.
In our experiments, we encode the different independence assumptions in the best performing neural network model. For the hypothesis-only and single observation models, we can enforce the independencies by simply restricting the inputs of the model to only the relevant variables. On the other hand, the Linear Chain model takes all three variables as input, but we restrict the form of the model to enforce the conditional independence. Specifically, we learn a discriminative classifier:
$$P _ { L i n e a r C h a i n } ( h | O _ { 1 } , O _ { 2 } ) \, \infty \, e ^ { \phi ( O _ { 1 } , h ) + \phi ^ { \prime } ( h , O _ { 2 } ) }$$
where φ and φ ′ are neural networks that produce scalar values.
## 3.2 ABDUCTIVE NATURAL LANGUAGE GENERATION
Given h + = { w h 1 . . . w h l } , O 1 = { w o 1 1 . . . w o 1 m } and O 2 = { w o 2 1 . . . w o 2 n } as sequences of tokens, the α NLG task can be modeled as P ( h + | O 1 , O 2 ) = ∏ P ( w h i | w h <i , w o 1 1 . . . w o 1 m , w o 2 1 . . . w o 2 n ) Optionally, the model can also be conditioned on background knowledge K . Parameterized models can then be trained to minimize the negative log-likelihood over instances in ART :
$$\mathcal { L } = - \sum _ { i = 1 } ^ { N } \log P ( w _ { i } ^ { h } | w _ { < i } ^ { h } , w _ { 1 } ^ { o 1 } \dots w _ { m } ^ { o 1 } , w _ { 1 } ^ { o 2 } \dots w _ { n } ^ { o 2 } , \mathcal { K } )$$
## 4 ART DATASET: ABDUCTIVE REASONING IN NARRATIVE TEXT
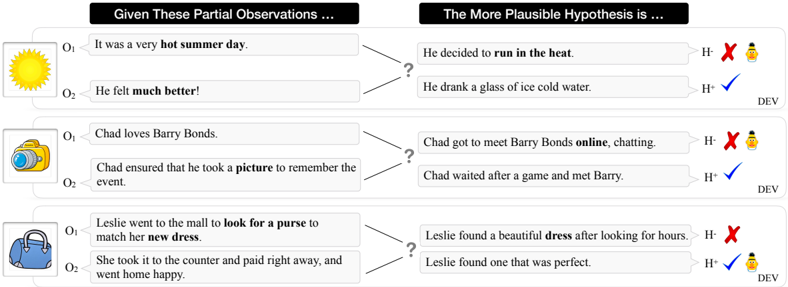
ART is the first large-scale benchmark dataset for studying abductive reasoning in narrative texts. It consists of ∼ 20K narrative contexts (pairs of observations 〈 O 1 , O 2 〉 ) with over 200K explanatory hypotheses. Table 6 in the Appendix summarizes corpus-level statistics of the ART dataset. 5 Figure 4 shows some illustrative examples from ART (dev split). The best model based on BERT fails to correctly predict the first two dev examples.
5 We will publicly release the ART dataset upon acceptance.
Figure 4: Examples from ART (dev split). The best model based on BERT fails to correctly predict the first two examples.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Plausible Hypothesis Selection
### Overview
The image presents a diagram illustrating the process of selecting a more plausible hypothesis given partial observations. It consists of three distinct scenarios, each with two observations (O1, O2) and two competing hypotheses (H1, H2). Each hypothesis is evaluated and marked as either supported (H+) or refuted (H-), accompanied by visual cues (icons of a person and a beverage).
### Components/Axes
The diagram is structured into three horizontal sections, each representing a different scenario. Each section is divided into two columns: "Given These Partial Observations..." and "The More Plausible Hypothesis is...".
- **Observations Column:** Contains two observations labeled O1 and O2, accompanied by a small illustrative icon.
- **Hypotheses Column:** Presents two hypotheses (H1 and H2) with a question mark connecting them to the observations. Each hypothesis is marked with either a red "X" (H-) indicating refutation or a green checkmark (H+) indicating support. A small icon of a person and a beverage is also present next to each hypothesis.
### Detailed Analysis or Content Details
**Scenario 1: Hot Summer Day**
- **O1:** "It was a very hot summer day." (Icon: Sun)
- **O2:** "He felt much better!" (No Icon)
- **H1:** "He decided to run in the heat." (Marked H- with red "X" and person/beverage icon)
- **H2:** "He drank a glass of ice cold water." (Marked H+ with green checkmark and person/beverage icon)
**Scenario 2: Chad and Barry Bonds**
- **O1:** "Chad loves Barry Bonds." (Icon: Camera)
- **O2:** "Chad ensured that he took a picture to remember the event." (No Icon)
- **H1:** "Chad got to meet Barry Bonds online, chatting." (Marked H- with red "X" and person/beverage icon)
- **H2:** "Chad waited after a game and met Barry." (Marked H+ with green checkmark and person/beverage icon)
**Scenario 3: Leslie's Purse**
- **O1:** "Leslie went to the mall to look for a purse to match her new dress." (Icon: Handbag)
- **O2:** "She took it to the counter and paid right away, and went home." (No Icon)
- **H1:** "Leslie found a beautiful dress after looking for hours." (Marked H- with red "X" and person/beverage icon)
- **H2:** "Leslie found one that was perfect." (Marked H+ with green checkmark and person/beverage icon)
### Key Observations
- In all three scenarios, one hypothesis is consistently marked as more plausible (H+) while the other is refuted (H-).
- The icons accompanying the hypotheses (person and beverage) appear consistently across all scenarios, suggesting they represent a general indicator of plausibility or a specific element within the evaluation process.
- The observations are presented as factual statements, while the hypotheses are interpretations of those observations.
### Interpretation
The diagram demonstrates a simplified model of Bayesian reasoning or abductive inference. Given a set of observations, the diagram illustrates how to evaluate competing hypotheses and select the one that best explains the available evidence. The "H+" and "H-" markings represent the outcome of this evaluation. The consistent presence of the person/beverage icon suggests it might be a visual cue representing a positive outcome or a reward for selecting the correct hypothesis. The scenarios themselves are designed to be relatable and intuitive, making the concept of hypothesis selection more accessible. The diagram highlights the importance of considering multiple explanations and using evidence to determine the most plausible one. The question mark connecting the observations to the hypotheses visually represents the uncertainty inherent in the process of inference. The diagram is a pedagogical tool for illustrating the core principles of scientific reasoning and critical thinking.
</details>
Collecting Observations: The pairs O 1 , O 2 in ART are drawn from the ROCStories dataset (Mostafazadeh et al., 2016). ROCStories is a large collection of short, manually curated fivesentence stories. It was designed to have a clear beginning and ending for each story, which naturally map to the first ( O 1 ) and second ( O 2 ) observations in ART .
Collecting Hypotheses Options: We crowdsourced the plausible and implausible hypotheses options on Amazon Mechanical Turk (AMT) in two separate tasks 6 :
1. Plausible Hypothesis Options: We presented O 1 and O 2 as narrative context to crowdworkers who were prompted to fill in 'What happened in-between?' in natural language. The design of the task motivates the use of abductive reasoning to hypothesize likely explanations for the two given observations.
2. Implausible Hypothesis Options: In this task, we presented workers with observations O 1 , O 2 and one plausible hypothesis option h + ∈ H + collected from the previous task. Crowdworkers were instructed to make minimal edits (up to 5 words) to a given h + to create implausible hypothesis variations for each plausible hypothesis.
A significant challenge in creating datasets is avoiding annotation artifacts - unintentional patterns in the data that leak information about the target label - that several recent studies (Gururangan et al., 2018; Poliak et al., 2018; Tsuchiya, 2018) have reported on crowdsourced datasets . To tackle this challenge, we collect multiple plausible and implausible hypotheses for each 〈 O 1 , O 2 〉 pair (as described above) and then apply an adversarial filtering algorithm to retain one challenging pair of hypotheses that are hard to distinguish between. We describe our algorithm in detail in Appendix A.5. While our final dataset uses BERT as the adversary, preliminary experiments that used GPT as an adversary resulted in similar drops in performance of all models, including all BERT variants. We compare the results of the two adversaries in Table 1.
## 5 EXPERIMENTS AND RESULTS
We now present our evaluation of finetuned state-of-the-art pre-trained language models on the ART dataset, and several other baseline systems for both α NLI and α NLG. Since α NLI is framed as a binary classification problem, we choose accuracy as our primary metric. For α NLG, we report performance on automated metrics such as BLEU (Papineni et al., 2002), CIDEr (Vedantam et al., 2015), METEOR (Banerjee & Lavie, 2005) and also report human evaluation results.
## 5.1 ABDUCTIVE NATURAL LANGUAGE INFERENCE
6 Both crowdsourcing tasks are complex and require creative writing. Along with the ART dataset, we will publicly release templates and the full set of instructions for all crowdsourcing tasks to facilitate future data collection and research in this direction.
Despite strong performance on several other NLP benchmark datasets, the best baseline model based on BERT achieves an accuracy of just 68.9% on ART compared to human performance of 91.4%. The large gap between human performance and that of the best system provides significant scope for development of more sophisticated abductive reasoning models. Our experiments show that introducing the additional independence assumptions described in Section 3.1 over the fully connected model tends to degrade system performance (see Table 1) in general.
Human Performance We compute human performance using AMT. Each instance (two observations and two hypothesis choices) is shown to three workers who were prompted to choose the more plausible hypothesis choice. 7 We compute majority vote on the labels assigned which
Table 1: Performance of baselines and finetuned-LM approaches on the test set of ART . Test accuracy is reported as the mean of five models trained with random seeds, with the standard deviation in parenthesis.
| Model | GPT AF Acc. (%) | ART Acc. (%) |
|----------------------------------|-------------------|----------------|
| Random ( 2 -way choice) | 50.1 | 50.4 |
| Majority (from dev set) | 50.1 | 50.8 |
| Infersent (Conneau et al., 2017) | 50.9 | 50.8 |
| ESIM+ELMo (Chen et al., 2017) | 58.2 | 58.8 |
| Finetuning Pre-trained LMs | | |
| GPT-ft | 52.6 (0.9) | 63.1 (0.5) |
| BERT-ft [ h i Only] | 55.9 (0.7) | 59.5 (0.2) |
| BERT-ft [ O 1 Only] | 63.9 (0.8) | 63.5 (0.7) |
| BERT-ft [ O 2 Only] | 68.1 (0.6) | 66.6 (0.2) |
| BERT-ft [Linear Chain] | 65.3 (1.4) | 68.9 (0.5) |
| BERT-ft [Fully Connected] | 72.0 (0.5) | 68.6 (0.5) |
| Human Performance | - | 91.4 |
leads to a human accuracy of 91.4% on the ART test set.
Baselines We include baselines that rely on simple features to verify that ART is not trivially solvable due to noticeable annotation artifacts, observed in several crowdsourced datasets. The accuracies of all simple baselines are close to chance-performance on the task - indicating that the dataset is free of simple annotation artifacts.
A model for the related but distinct task of entailment NLI (e.g. SNLI) forms a natural baseline for α NLI. We re-train the ESIM+ELMo (Chen et al., 2017; Peters et al., 2018) model as its performance on entailment NLI ( 88 . 9% ) is close to state-of-the-art models (excluding pre-trained language models). This model only achieves an accuracy of 58 . 8% highlighting that performing well on ART requires models to go far beyond the linguistic notion of entailment.
Pre-trained Language Models BERT (Devlin et al., 2018) and GPT (Radford, 2018) have recently been shown to achieve state-of-the-art results on several NLP benchmarks (Wang et al., 2018). We finetune both BERT-Large and GPT as suggested in previous work and we present each instance in their natural narrative order. BERT-ft (fully connected) is the best performing model achieving 68.9% accuracy, compared to GPT's 63 . 1% . 8 Our AF approach was able to reduce BERT performance from over 88% by 20 points.
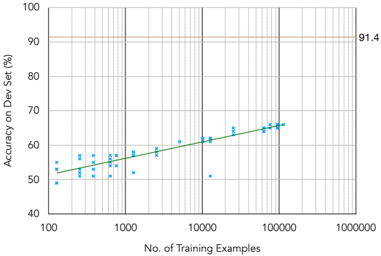
Learning Curve and Dataset Size While there is enough scope for considerably scaling up the dataset based on ROCStories, the learning curve in Figure 5 shows that the performance of the best
Figure 5: BERT learning curve on the dev set of ART . For each point on the x-axis, we fine-tune BERT with five random seeds. Human performance is 91.4%.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Chart: Learning Curves - Accuracy vs. Training Examples
### Overview
The image presents a learning curve chart illustrating the relationship between the number of training examples and the accuracy achieved on a development (dev) set. The chart displays a scatter plot of individual data points, along with a green line representing a trendline. A horizontal line indicates a maximum accuracy level.
### Components/Axes
* **X-axis:** "No. of Training Examples" - Logarithmic scale, ranging from 100 to 1000000 (1 million). Tick marks are present at 100, 1000, 10000, 100000, and 1000000.
* **Y-axis:** "Accuracy on Dev Set (%)" - Linear scale, ranging from 40% to 100%. Tick marks are present at 40%, 50%, 60%, 70%, 80%, 90%, and 100%.
* **Data Points:** Blue 'x' markers representing individual accuracy measurements for different numbers of training examples.
* **Trendline:** A solid green line representing the overall trend of accuracy as the number of training examples increases.
* **Horizontal Line:** A thin, tan horizontal line at approximately 91.4% accuracy.
* **Gridlines:** Vertical gridlines are present to aid in reading values on the x-axis. Horizontal gridlines are present to aid in reading values on the y-axis.
### Detailed Analysis
The trendline slopes upward, indicating that as the number of training examples increases, the accuracy on the dev set generally increases.
* **Data Point Distribution:**
* At 100 training examples, accuracy ranges from approximately 48% to 56%.
* At 1000 training examples, accuracy ranges from approximately 54% to 64%.
* At 10000 training examples, accuracy ranges from approximately 58% to 68%.
* At 100000 training examples, accuracy ranges from approximately 62% to 70%.
* At 1000000 training examples, accuracy ranges from approximately 64% to 68%.
* **Trendline Approximation:**
* At 100 training examples, the trendline indicates an accuracy of approximately 53%.
* At 1000 training examples, the trendline indicates an accuracy of approximately 58%.
* At 10000 training examples, the trendline indicates an accuracy of approximately 62%.
* At 100000 training examples, the trendline indicates an accuracy of approximately 65%.
* At 1000000 training examples, the trendline indicates an accuracy of approximately 67%.
* **Maximum Accuracy:** The horizontal line at 91.4% represents an upper bound on the achievable accuracy, potentially indicating the performance of a more complex model or the theoretical limit of the dataset.
### Key Observations
* The accuracy increases rapidly with the initial increase in training examples (from 100 to 10000).
* The rate of accuracy increase slows down as the number of training examples continues to grow (from 100000 to 1000000). This suggests diminishing returns from adding more data.
* The accuracy appears to be approaching an asymptote, as it plateaus around 67% even with a million training examples.
* There is significant variance in the accuracy for a given number of training examples, as evidenced by the spread of the blue 'x' markers.
### Interpretation
This learning curve suggests that the model is data-limited. Increasing the number of training examples initially leads to significant improvements in accuracy, but eventually, the gains become marginal. The horizontal line at 91.4% suggests that the model may be underfitting, or that the dataset itself has inherent limitations preventing it from reaching higher accuracy levels. Further improvements might require more complex models, feature engineering, or a larger, more diverse dataset. The diminishing returns observed at higher training example counts indicate that simply adding more data may not be the most effective strategy for improving performance. The spread of data points suggests that the model's performance is sensitive to the specific training data used.
</details>
model plateaus after ∼ 10 , 000 instances. In addition, there is still a wide gap ( ∼ 23% ) between the performance of the best model and human performance.
7 Additional crowdsourcing details in the Appendix A.1
8 The input format for the GPT model and BERT variants is described in the Appendix A.4.
Table 2: Performance of generative models on the test set of ART . All models except GPT2-Fixed are finetuned on ART .
| Model | BLEU | METEOR | ROUGE | CIDEr | BERT-Score | Human |
|--------------------------|--------|----------|---------|---------|--------------|---------|
| GPT2-Fixed | 0 | 9.29 | 9.99 | 3.34 | 36.69 | - |
| O 1 - O 2 - Only | 2.23 | 16.71 | 22.83 | 33.54 | 48.74 | 42.26 |
| COMeT-Txt+GPT2 | 2.29 | 16.73 | 22.51 | 31.99 | 48.46 | 38.28 |
| COMeT-Emb+GPT2 | 3.03 | 17.66 | 22.93 | 32 | 48.52 | 44.56 |
| Human-written Hypotheses | 8.25 | 26.71 | 30.4 | 53.56 | 53.3 | 96.03 |
GPT Adversary Table 1 also includes results of our experiments where GPT was used as the adversary. Notably, in this case, adversarially filtering the dataset brings down GPT performance under 53%. On the other hand, the best BERT model, that encodes the fully connected bayesian network performs significantly better than the BERT model that encodes the linear chain assumptions - 72% compared to 65%. Therefore, we use the BERT fully connected model as the adversary in ART . The gap between the linear chain and fully connected BERT models diminishes when BERT is used as an adversary - in spite of being a more powerful model - which indicates that adversarial filtering disproportionately impacts the model used as the adversary. However, the dataset also becomes more difficult for the other models that were not used as adversaries. For example, before any filtering, BERT scores 88% and OpenGPT gets 80% , which is much higher than either model achieves in Table 1 when the other model is used for filtering. This result is a reasonable indicator, albeit not a guarantee, that ART will remain challenging for new models released in the future.
## 5.2 ABDUCTIVE NATURAL LANGUAGE GENERATION
Generative Language Models As described in Equation 4, we train GPT2 conditioned on the tokens of the two observations O 1 and O 2 . Both observations are enclosed with field-specific tags. ATOMIC (Sap et al., 2019), a repository of inferential if-then knowledge is a natural source of background commonsense required to reason about narrative contexts in ART . Yet, there is no straightforward way to include such knowledge into a neural model as ATOMIC's nodes are not canonicalized and are represented as short phrases of text. Thus, we rely on COMeT - a transformer model trained on ATOMIC that generates nine commonsense inferences of events in natural language. 9 Specifically, we experiment with two ways of integrating information from COMeT in GPT2: (i) as textual phrases , and (ii) as embeddings .
Figure 3 shows how we integrate COMeT representations. Concretely, after the input tokens are embedded by the word-embedding layer, we append eighteen (corresponding to nine relations for each observation) embeddings to the sequence before passing through the layers of the Transformer architecture. This allows the model to learn each token's representation while attending to the COMeT embeddings - effectively integrating background commonsense knowledge into a language model. 10
Discussion Table 2 reports results on the α NLGtask. Among automatic metrics, we report BLEU4 (Papineni et al., 2002), METEOR (Banerjee & Lavie, 2005), ROUGE (Lin, 2004), CIDEr (Vedantam et al., 2015) and BERT-Score (Zhang et al., 2019) (with the bert-base-uncased model). We establish human performance through crowdsourcing on AMT. Crowdworkers are shown pairs of observations and a generated hypothesis and asked to label whether the hypothesis explains the given observations. The last column reports the human evaluation score. The last row reports the score of a held-out human-written hypothesis and serves as a ceiling for model performance. Human-written hypotheses are found to be correct for 96% of instances, while our best generative models, even when enhanced with background commonsense knowledge, only achieve 45% indicating that the α NLG generation task is especially challenging for current state-of-the-art text generators.
9 Please see Appendix A.6 for a full list of the nine relations.
10 We describe the format of input for each model in Appendix A.7.
## 6 ANALYSIS
## 6.1 α NLI
Commonsense reasoning categories We investigate the categories of commonsense-based abductive reasoning that are challenging for current systems and the ones where the best model over-performs. While there have been previous attempts to categorize commonsense knowledge required for entailment (LoBue & Yates, 2011; Clark et al., 2007), crowdsourcing this task at scale with high fidelity and high agreement across annotators remains challenging. Instead, we aim to probe the model with soft categories identified by matching lists of category-specific keywords to the hypothesis choices.
| Category | Human Accuracy | BERT Accuracy | ∆ |
|------------------|------------------|-----------------|------|
| All ( 1 , 000 ) | 91.4 | 68.8 | 22.6 |
| Numerical ( 44 ) | 88.6 | 56.8 | 21.8 |
| Spatial ( 130 ) | 91.5 | 65.4 | 26.1 |
| Emotional ( 84 ) | 86.9 | 72.6 | 14.3 |
Table 3: BERT's performance and human evaluation on categories for 1,000 instances from the test set, based on commonsense reasoning domains (Numerical, Spatial, Emotional). The number in parenthesis indicates the size of the category.
Table 3 shows the accuracy of the best model (BERT-ft) across various categories of commonsense knowledge. BERT-ft significantly underperforms on instances involving Numerical ( 56 . 8% ) and Spatial ( 65 . 4% ) commonsense. These two categories include reasoning about numerical quantities and the spatial location of agents and objects, and highlight some of the limitations of the language models. In contrast, it significantly overperforms on the Emotional category ( 72 . 6% ) where the hypotheses exhibit strong textual cues about emotions and sentiments.
Implausible transitions A model for an instance of the ART dataset should discard implausible hypotheses in the context of the two given observations. In narrative contexts, there are three main reasons for an implausible hypothesis to be labeled as such:
1. O 1 → h -: h -is unlikely to follow after the first observation O 1 .
2. h -→ O 2 : h -is plausible after O 1 but unlikely to precede the second observation O 2 .
3. Plausible: 〈 O 1 , h -, O 2 〉 is a coherent narrative and forms a plausible alternative, but it is less plausible than 〈 O 1 , h + , O 2 〉 .
| Story Transition | %of Dataset | BERT-ft Fully Connected Acc. (%) | BERT-ft Linear Chain Acc. (%) |
|-------------------------------|---------------|------------------------------------|---------------------------------|
| O 1 → h - | 32.5 | 73.6 | 71.6 |
| h - → O 2 | 45.3 | 69 | 70.5 |
| Plausible | 22.2 | 62.5 | 58.5 |
| All (1,000) | 100 | 69.1 | 68.2 |
Table 4: Fraction of dataset for which a particular transition in the story is broken for the negative hypothesis, for 1,000 random instances from the test set.
We analyze the prevalence of each of these reasons in ART . We design a crowdsourcing task in which we show the implausible option along with the narrative context 〈 O 1 , O 2 〉 and get labels for which transition ( O 1 → h -, h -→ O 2 or neither) in the narrative chain is broken. Table 4 shows the proportion of each category from a subset of 1 , 000 instances from the test set. While h -→ O 2 accounts for almost half of the implausible transitions in ART , all three categories are substantially present in the dataset. BERT performance on each of these categories indicates that the model finds it particularly hard when the narrative created by the incorrect hypothesis is plausible, but less plausible than the correct hypothesis. On that subset of the test set, the fully connected model performs better than the linear chain model where it is important to consider both observations jointly to arrive at the more likely hypothesis.
## 6.2 α NLG
Figure 6 shows some examples of generations from the trained models compared to human-written generations. The example on the left is an example of an instance that only humans could get correct, while for the one on the right, COMeT-Emb+GPT2 also generates the correct explanation for the observations.
Figure 6: Examples of generated hypotheses from different models and human-written hypothesis for 2 instances from ART .
<details>
<summary>Image 6 Details</summary>

### Visual Description
\n
## Generated Hypotheses: Comparison of AI-Generated Text
### Overview
The image presents a comparison of hypotheses generated by different AI models regarding two separate scenarios: Larry's yard covered in leaves and Junior, a 20-year-old turtle. Each hypothesis is accompanied by a validation check (red 'X' for incorrect, blue checkmark for correct). The models being compared are GPT2, O1-O2-Only, COMET-Txt+GPT2, COMET-Emb+GPT2, and Human-written.
### Components/Axes
The image is divided into two main sections, one for Larry's yard and one for Junior the turtle. Each section contains a table of hypotheses.
* **Top Header:** "Generated Hypotheses"
* **Left Section Header:** "Larry's yard was covered in dead leaves."
* **Right Section Header:** "Junior is the name of our 20+ year old turtle."
* **Bottom Left:** "Larry decided to give up for the day and went back inside."
* **Bottom Right:** "Junior is still going strong."
* **Validation Symbols:** Red 'X' (incorrect), Blue Checkmark (correct).
* **Model Labels:** GPT2, O1-O2-Only, COMET-Txt+GPT2, COMET-Emb+GPT2, Human-written. These are positioned vertically along the right side of the table.
### Detailed Analysis or Content Details
**Larry's Yard Section (Left):**
1. **GPT2:** "by accident, he spent a year living in his mother's basement, he..." - Incorrect (Red 'X')
2. **O1-O2-Only:** "Larry wondered what he could do with the leaves." - Incorrect (Red 'X')
3. **COMET-Txt+GPT2:** "Larry decided to pull the dirt off his lawn." - Incorrect (Red 'X')
4. **COMET-Emb+GPT2:** "Larry threw the leaves out." - Incorrect (Red 'X')
5. **Human-written:** "He spent hours trying to clean the yard." - Correct (Blue Checkmark)
**Junior the Turtle Section (Right):**
1. **GPT2:** "actually, that turtle can't bite you" - Incorrect (Red 'X')
2. **O1-O2-Only:** "Junior made a giant jump rope." - Incorrect (Red 'X')
3. **COMET-Txt+GPT2:** "Junior will have surgery to heal and her internal organs are broken." - Incorrect (Red 'X')
4. **COMET-Emb+GPT2:** "Junior has been swimming in the pool with her friends." - Correct (Blue Checkmark)
5. **Human-written:** "We took Junior to the vet to check on him." - Correct (Blue Checkmark)
### Key Observations
* The Human-written hypotheses are the only ones that are validated as correct in both scenarios.
* All hypotheses generated by GPT2 and O1-O2-Only are incorrect.
* COMET-Txt+GPT2 and COMET-Emb+GPT2 have a mixed performance, with one correct and one incorrect hypothesis each.
* The generated hypotheses vary significantly in their plausibility and relevance to the initial scenarios.
### Interpretation
This image demonstrates a comparison of the quality of hypotheses generated by different AI models. The results suggest that the Human-written hypotheses are the most accurate and relevant, which is expected. The AI models, particularly GPT2 and O1-O2-Only, struggle to generate plausible hypotheses. The COMET models show some improvement, but still fall short of human-level performance.
The image highlights the challenges of natural language understanding and generation, and the need for further research in this area. The discrepancies between the generated hypotheses and the actual scenarios suggest that the AI models lack a deep understanding of the world and common sense reasoning abilities. The image also suggests that combining different AI techniques (e.g., COMET-Txt+GPT2, COMET-Emb+GPT2) may lead to improved performance, but further investigation is needed. The presence of images of a leaf pile and a turtle on the left and right respectively, are likely used to provide context to the models.
</details>
## 7 TRANSFER LEARNING FROM ART
ART contains a large number of questions for the novel abductive reasoning task. In addition to serving as a benchmark, we investigate if ART can be used as a resource to boost performance on other commonsense tasks. We apply transfer learning by first training a model on ART , and subsequently training on four target datasets - WinoGrande Sakaguchi et al. (2020), WSC Levesque et al. (2011), DPR Rahman & Ng (2012) and HellaSwag Zellers et al. (2019). We show that compared to a model that is only trained on the target dataset, a model that is sequentially trained on ART first and then on the target dataset can perform better. In particular, pre-training on ART consistently improves performance on related datasets when they have relatively few training examples.
On the other hand, for target datasets with large amounts of training data, pre-training on ART does not provide a significant improvement.
## 8 RELATED WORK
Cloze-Style Task vs. Abductive Reasoning Since abduction is fundamentally concerned with plausible chains of cause-and-effect, our work draws inspiration from previous works that deal with narratives such as script learning
Table 5: Transfer Learning from ART
| Dataset | BERT-ft(D) | BERT-ft( ART ) → BERT-ft(D) |
|----------------------------------------------|--------------|-------------------------------|
| WinoGrande Sakaguchi et al. (2020) | 65.8% | 67.2 % |
| WSC | 70.0% | 74.0 % |
| Levesque et al. (2011) DPR Rahman &Ng (2012) | 72.5% | 86.0 % |
| Hellaswag Zellers et al. (2019) | 46.7 % | 46.1% |
(Schank & Abelson, 1975) and the narrative cloze test (Chambers & Jurafsky, 2009; Jans et al., 2012; Pichotta & Mooney, 2014; Rudinger et al., 2015). Rather than learning prototypical scripts or narrative chains, we instead reason about the most plausible events conditioned on observations. We make use of the ROCStories dataset (Mostafazadeh et al., 2016), which was specifically designed for the narrative cloze task. But, instead of reasoning about plausible event sequences, our task requires reasoning about plausible explanations for narrative omissions.
Entailment vs. Abductive Reasoning The formulation of α NLI is closely related to entailment NLI, but there are two critical distinctions that make abductive reasoning uniquely challenging. First, abduction requires reasoning about commonsense implications of observations (e.g., if we observe that the 'grass is wet', a likely hypothesis is that 'it rained earlier') which go beyond the linguistic notion of entailment (also noted by Josephson (2000)). Second, abduction requires non-monotonic reasoning about a set of commonsense implications collectively, to check the potential contradictions against multiple observations and to compare the level of plausibility of different hypotheses. This makes abductive reasoning distinctly challenging compared to other forms of reasoning such as induction and deduction (Shank, 1998). Perhaps more importantly, abduction is closely related to the kind of reasoning humans perform in everyday situations, where information is incomplete and definite inferences cannot be made.
Generative Language Modeling Recent advancements in the development of large-scale pretrained language models (Radford, 2018; Devlin et al., 2018; Radford et al., 2019) have improved the quality and coherence of generated language. Although these models have shown to generate reasonably coherent text when condition on a sequence of text, our experiments highlight the limitations of these models to 1) generate language non-monotonically and 2) adhere to commonsense knowledge. We attempt to overcome these limitations with the incorporation of a generative commonsense model during hypothesis generation.
Related Datasets Our new resource ART complements ongoing efforts in building resources for natural language inference (Dagan et al., 2006; MacCartney & Manning, 2009; Bowman et al., 2015; Williams et al., 2018a; Camburu et al., 2018). Existing datasets have mostly focused on textual entailment in a deductive reasoning set-up (Bowman et al., 2015; Williams et al., 2018a) and making inferences about plausible events (Maslan et al., 2015; Zhang et al., 2017). In their typical setting, these datasets require a system to deduce the logically entailed consequences of a given premise . In contrast, the nature of abduction requires the use of commonsense reasoning capabilities, with less focus on lexical entailment. While abductive reasoning has been applied to entailment datasets (Raina et al., 2005), they have been applied in a logical theorem-proving framework as an intermediate step to perform textual entailment - a fundamentally different task than α NLI.
## 9 CONCLUSION
We present the first study that investigates the viability of language-based abductive reasoning. We conceptualize and introduce Abductive Natural Language Inference ( α NLI) - a novel task focused on abductive reasoning in narrative contexts. The task is formulated as a multiple-choice questionanswering problem. We also introduce Abductive Natural Language Generation ( α NLG) - a novel task that requires machines to generate plausible hypotheses for given observations. To support these tasks, we create and introduce a new challenge dataset, ART , which consists of 20,000 commonsense narratives accompanied with over 200,000 explanatory hypotheses. In our experiments, we establish comprehensive baseline performance on this new task based on state-of-the-art NLI and language models, which leads to 68.9% accuracy with a considerable gap with human performance (91.4%). The α NLG task is significantly harder - while humans can write a valid explanation 96% of times, the best generator models can only achieve 45%. Our analysis leads to new insights into the types of reasoning that deep pre-trained language models fail to perform - despite their strong performance on the closely related but different task of entailment NLI - pointing to interesting avenues for future research. We hope that ART will serve as a challenging benchmark for future research in languagebased abductive reasoning and the α NLI and α NLG tasks will encourage representation learning that enables complex reasoning capabilities in AI systems.
## ACKNOWLEDGMENTS
We thank the anonymous reviewers for their insightful feedback. This research was supported in part by NSF (IIS-1524371), the National Science Foundation Graduate Research Fellowship under Grant No. DGE 1256082, DARPA CwC through ARO (W911NF15-1- 0543), DARPA MCS program through NIWC Pacific (N66001-19-2-4031), and the Allen Institute for AI. Computations on beaker.org were supported in part by credits from Google Cloud.
## REFERENCES
Henning Andersen. Abductive and deductive change. Language , pp. 765-793, 1973. URL https: //www.jstor.org/stable/pdf/412063.pdf .
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pp. 65-72, 2005.
- Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chaitanya Malaviya, Asli Celikyilmaz, and Yejin Choi. Comet: Commonsense transformers for automatic knowledge graph construction. arXiv preprint arXiv:1906.05317 , 2019.
- Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP) . Association for Computational Linguistics, 2015. URL https://nlp.stanford.edu/pubs/snli\_paper.pdf .
- Oana-Maria Camburu, Tim Rockt¨ aschel, Thomas Lukasiewicz, and Phil Blunsom. e-snli: Natural language inference with natural language explanations. In Advances in Neural Information Processing Systems , pp. 9560-9572, 2018. URL https://papers.nips.cc/paper/ 8163-e-snli-natural-language-inference-with-natural-language-explanations. pdf .
- Nathanael Chambers and Dan Jurafsky. Unsupervised learning of narrative schemas and their participants. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP , pp. 602-610, Suntec, Singapore, August 2009. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/P/P09/P09-1068 .
- Eugene Charniak and Solomon Eyal Shimony. Probabilistic semantics for cost based abduction . Brown University, Department of Computer Science, 1990. URL https://www.aaai.org/ Papers/AAAI/1990/AAAI90-016.pdf .
- Qian Chen, Xiao-Dan Zhu, Zhen-Hua Ling, Si Wei, Hui Jiang, and Diana Inkpen. Enhanced lstm for natural language inference. In ACL , 2017. URL https://www.aclweb.org/anthology/ P17-1152 .
- Peter E. Clark, Philip Harrison, John A. Thompson, William R. Murray, Jerry R. Hobbs, and Christiane Fellbaum. On the role of lexical and world knowledge in rte3. In ACL-PASCAL@ACL , 2007. URL https://www.aclweb.org/anthology/W07-1409 .
- Alexis Conneau, Douwe Kiela, Holger Schwenk, Lo¨ ıc Barrault, and Antoine Bordes. Supervised learning of universal sentence representations from natural language inference data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pp. 670680, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/D17-1070. URL https://www.aclweb.org/anthology/D17-1070 .
- Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment , pp. 177-190. Springer, 2006. URL http: //u.cs.biu.ac.il/˜dagan/publications/RTEChallenge.pdf .
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 , 2018. URL https://arxiv.org/abs/1810.04805 .
- Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith. Annotation artifacts in natural language inference data. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pp. 107-112, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18-2017. URL https://www.aclweb.org/anthology/N18-2017 .
- Jerry R. Hobbs, Mark Stickel, Paul Martin, and Douglas Edwards. Interpretation as abduction. In Proceedings of the 26th Annual Meeting of the Association for Computational Linguistics , pp. 95-103, Buffalo, New York, USA, June 1988. Association for Computational Linguistics. doi: 10.3115/982023.982035. URL https://www.aclweb.org/anthology/P88-1012 .
- Bram Jans, Steven Bethard, Ivan Vuli´ c, and Marie-Francine Moens. Skip n-grams and ranking functions for predicting script events. In Proceedings of the 13th Conference of the European Chapter
of the Association for Computational Linguistics , pp. 336-344, Avignon, France, April 2012. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/ E12-1034 .
- Susan G. Josephson. Abductive inference: Computation , philosophy , technology. 2000. URL https://philpapers.org/rec/JOSAIC .
- George Lakoff. Linguistics and natural logic. Synthese , 22(1-2):151-271, 1970. URL https: //link.springer.com/article/10.1007/BF00413602 .
- Hector J. Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In KR , 2011.
- Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. Text Summarization Branches Out , 2004.
- Peter LoBue and Alexander Yates. Types of common-sense knowledge needed for recognizing textual entailment. In ACL , 2011. URL https://www.aclweb.org/anthology/ P11-2057 .
- Bill MacCartney and Christopher D. Manning. Natural logic for textual inference. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing , pp. 193-200, Prague, June 2007. Association for Computational Linguistics. URL https://www.aclweb.org/ anthology/W07-1431 .
- Bill MacCartney and Christopher D. Manning. An extended model of natural logic. In Proceedings of the Eight International Conference on Computational Semantics , pp. 140-156, Tilburg, The Netherlands, January 2009. Association for Computational Linguistics. URL https://www. aclweb.org/anthology/W09-3714 .
- Nicole Maslan, Melissa Roemmele, and Andrew S. Gordon. One hundred challenge problems for logical formalizations of commonsense psychology. In AAAI Spring Symposia , 2015. URL http://people.ict.usc.edu/˜gordon/publications/AAAI-SPRING15.PDF .
- Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL) , pp. 839-849. Association for Computational Linguistics, 2016. doi: 10.18653/v1/N16-1098. URL http://aclweb.org/anthology/N16-1098 .
- Peter Norvig. Inference in text understanding. In AAAI , pp. 561-565, 1987. URL http:// norvig.com/aaai87.pdf .
- Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In ACL , 2002.
- Judea Pearl. Reasoning with cause and effect. AI Magazine , 23(1):95, 2002. URL https:// ftp.cs.ucla.edu/pub/stat\_ser/r265-ai-mag.pdf .
- Judea Pearl and Dana Mackenzie. The Book of Why: The New Science of Cause and Effect . Basic Books, Inc., New York, NY, USA, 1st edition, 2018. ISBN 046509760X, 9780465097609. URL https://dl.acm.org/citation.cfm?id=3238230 .
- Charles Sanders Peirce. Collected papers of Charles Sanders Peirce , volume 5. Harvard University Press, 1965a. URL http://www.hup.harvard.edu/catalog.php?isbn= 9780674138001 .
- Charles Sanders Peirce. Pragmatism and pragmaticism , volume 5. Belknap Press of Harvard University Press, 1965b. URL https://www.jstor.org/stable/224970 .
- Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 1532-1543, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1162. URL https://www.aclweb.org/anthology/ D14-1162 .
- Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pp. 2227-2237, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18-1202. URL https://www.aclweb.org/anthology/N18-1202 .
- Karl Pichotta and Raymond Mooney. Statistical script learning with multi-argument events. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics , pp. 220-229, Gothenburg, Sweden, April 2014. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/E14-1024 .
- Adam Poliak, Jason Naradowsky, Aparajita Haldar, Rachel Rudinger, and Benjamin Van Durme. Hypothesis only baselines in natural language inference. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics , pp. 180-191, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/S18-2023. URL https: //www.aclweb.org/anthology/S18-2023 .
- Alec Radford. Improving language understanding by generative pre-training. 2018.
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog , 1(8), 2019.
- Altaf Rahman and Vincent Ng. Resolving complex cases of definite pronouns: The winograd schema challenge. In EMNLP-CoNLL , 2012.
- Rajat Raina, Andrew Y Ng, and Christopher D Manning. Robust textual inference via learning and abductive reasoning. In AAAI , pp. 1099-1105, 2005. URL https://nlp.stanford.edu/ ˜manning/papers/aaai05-learnabduction.pdf .
- Rachel Rudinger, Pushpendre Rastogi, Francis Ferraro, and Benjamin Van Durme. Script induction as language modeling. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pp. 1681-1686, Lisbon, Portugal, September 2015. Association for Computational Linguistics. URL http://aclweb.org/anthology/D15-1195 .
- Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. In AAAI , 2020.
- Maarten Sap, Ronan Le Bras, Emily Allaway, Chandra Bhagavatula, Nicholas Lourie, Hannah Rashkin, Brendan Roof, Noah A Smith, and Yejin Choi. Atomic: an atlas of machine commonsense for if-then reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, pp. 3027-3035, 2019.
- Roger C. Schank and Robert P. Abelson. Scripts, plans, and knowledge. In Proceedings of the 4th International Joint Conference on Artificial Intelligence - Volume 1 , IJCAI'75, pp. 151-157, San Francisco, CA, USA, 1975. Morgan Kaufmann Publishers Inc. URL http://dl.acm.org/ citation.cfm?id=1624626.1624649 .
- Gary Shank. The extraordinary ordinary powers of abductive reasoning. Theory & Psychology , 8(6):841-860, 1998. URL https://journals.sagepub.com/doi/10.1177/ 0959354398086007 .
- Masatoshi Tsuchiya. Performance impact caused by hidden bias of training data for recognizing textual entailment. CoRR , abs/1804.08117, 2018. URL http://www.lrec-conf.org/ proceedings/lrec2018/pdf/786.pdf .
- Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition , pp. 4566-4575, 2015.
- Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pp. 353-355, Brussels, Belgium, November 2018. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/W18-5446 .
- Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pp. 1112-1122. Association for Computational Linguistics, 2018a. URL http://aclweb.org/anthology/N18-1101 .
- Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pp. 1112-1122, New Orleans, Louisiana, June 2018b. Association for Computational Linguistics. doi: 10.18653/v1/N18-1101. URL https://www.aclweb. org/anthology/N18-1101 .
- Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. Swag: A large-scale adversarial dataset for grounded commonsense inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2018. URL https://aclweb. org/anthology/D18-1009 .
- Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In ACL , 2019.
- Sheng Zhang, Rachel Rudinger, Kevin Duh, and Benjamin Van Durme. Ordinal common-sense inference. Transactions of the Association for Computational Linguistics , 5:379-395, 2017. doi: 10.1162/tacl a 00068. URL https://www.aclweb.org/anthology/Q17-1027 .
- Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 , 2019.
## A APPENDICES
## A.1 DATA COLLECTION DETAILS
We describe the crowdsourcing details of our data collection method.
Task 1 - Plausible Hypothesis Options In this task, participants were presented an incomplete three-part story, which consisted of the first observation ( O 1 ) and the second observation ( O 2 ) of the story. They were then asked to complete the story by writing a probable middle sentence that explains why the second observation should follow after the first one. We instructed participants to make sure that the plausible middle sentence (1) is short (fewer than 10 words) and (2) simple as if narrating to a child, (3) avoids introducing any extraneous information, and (4) uses names instead of pronouns (e.g., he/she) wherever possible.
All participants were required to meet the following qualification requirements: (1) their location is in the US, (2) HIT approval rate is greater than 95(%), and (3) Number of HITs approved is greater than 5,000. The reward of this task was set to be $0.07 per question ($14/hour in average), and each HIT was assigned to five different workers (i.e., 5-way redundancy).
Task 2 - Implausible Hypothesis Options In this task, participants were presented a three-part story, which consisted of the first observation ( O 1 ), a middle sentence ( h + ) collected in Task 1, and the second observation ( O 2 ) of the story. They were then asked to rewrite the middle sentence ( h + ) with minimal changes , so that the story becomes unlikely, implausible or inconsistent ( h -). We asked participants to add or remove at most four words to h + , while ensuring that the new middle sentence is grammatical. In addition, we asked them to stick to the context in the given story. For example, if the story talks about 'doctors', they are welcome to talk about 'health' or 'diagnosis', but not mention 'aliens'. Finally, we also asked workers to verify if the given middle ( h + ) makes a plausible story, in order to confirm the plausibility of h + collected in Task 1.
With respect to this task's qualification, participants were required to fulfill the following requirements: (1) their location is the US or Canada, (2) HIT approval rate is greater than or equal to 99(%), and (3) number of HITs approved is greater than or equal to 10 , 000 . Participants were paid $0.1 per question ($14/hour in average), and each HIT was assigned to three different participants (i.e., 3-way redundancy).
Task 3 α NLI Human Performance Human performance was evaluated by asking participants to answer the α NLI questions. Given a narrative context 〈 O 1 , O 2 〉 and two hypotheses, they were asked to choose the more plausible hypothesis. They were also allowed to choose 'None of the above' when neither hypothesis was deemed plausible.
We asked each question to seven participants with the following qualification requirements: (1) their location is either in the US, UK, or Canada, (2) HIT approval rate is greater than 98(%), (3) Number of HITs approved is greater than 10 , 000 . The reward was set to $0.05 per HIT. We took the majority vote among the seven participants for every question to compute human performance.
## A.2 ART DATA STATISTICS
Table 6 shows some statistics of the ART dataset.
## A.3 FINE-TUNING BERT
We fine-tuned the BERT model using a grid search with the following set of hyper-parameters:
- batch size: { 3 , 4 , 8 }
- number of epochs: { 3 , 4 , 10 }
- learning rate: { 1e-5, 2e-5, 3e-5, 5e-5 }
The warmup proportion was set to 0 . 2 , and cross-entropy was used for computing the loss. The best performance was obtained with a batch size of 4 , learning rate of 5e-5, and number of epochs equal to 10 . Table 7 describes the input format for GPT and BERT (and its variants).
| | Train | Dev | Test |
|--------------------------|---------|-------|--------|
| Total unique occurrences | | | |
| Contexts 〈 O 1 , O 2 〉 | 17,801 | 1,532 | 3,059 |
| Plausible hyp. h + | 72,046 | 1,532 | 3,059 |
| Implausible hyp. h - | 166,820 | 1,532 | 3,059 |
| Avg. size per context | | | |
| Plausible hyp. h + | 4.05 | 1 | 1 |
| Implausible hyp. h - | 9.37 | 1 | 1 |
| Avg. word length | | | |
| Plausible hyp. h + | 8.34 | 8.62 | 8.54 |
| Implausible hyp. h - | 8.28 | 8.55 | 8.53 |
| First observation O 1 | 8.09 | 8.07 | 8.17 |
| Second observation O 2 | 9.29 | 9.3 | 9.31 |
Table 6: Some statistics summarizing the ART dataset. The train set includes all plausible and implausible hypotheses collected via crowdsourcing, while the dev and test sets include the hypotheses selected through the Adversarial Filtering algorithm.
## A.4 BASELINES
The SVM classifier is trained on simple features like word length, overlap and sentiment features to select one of the two hypothesis choices. The bag-of-words baseline computes the average of GloVe (Pennington et al., 2014) embeddings for words in each sentence to form sentence embeddings. The sentence embeddings in a story (two observations and a hypothesis option) are concatenated and passed through fully-connected layers to produce a score for each hypothesis. The accuracies of both baselines are close to 50% (SVM: 50.6; BOW: 50.5).
Specifically, we train an SVM classifier and a bag-of-words model using GLoVE embeddings. Both models achieve accuracies close to 50%. An Infersent (Conneau et al., 2017) baseline that uses sentences embedded by max-pooling over Bi-LSTM token representations achieves only 50.8% accuracy.
Table 7: Input formats for GPT and BERT fine-tuning.
| Model | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format | Input Format |
|--------------------------------------------------------------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| GPT | [START] | O 1 + | h i | [SEP] | | O | 2 | [SEP] | | | | | |
| BERT-ft [Hypothesis Only] | [CLS] | h i | [SEP] | | | | | | | | | | |
| BERT-ft [First Observation Only] BERT-ft [Second Observation Only] | [CLS] [CLS] | O 1 h i | [SEP] [SEP] | O | h i 2 | [SEP] | [SEP] | | | | O 2 | | |
| BERT-ft [Linear Chain] | [CLS] | O 1 | [SEP] | | h i | [SEP] | ; | [CLS] | h i | [SEP] | | [SEP] | |
| BERT-ft [Fully Connected] | [CLS] | O 1 | + O 2 | | [SEP] | h i | | [SEP] | | | | | |
## A.5 ADVERSARIAL FILTERING OF HYPOTHESES CHOICES
Given an observation pair and sets of plausible and implausible hypotheses 〈 O 1 , O 2 , H + , H -〉 , our adversarial filtering algorithm selects one plausible and one implausible hypothesis 〈 O 1 , O 2 , h + , h -〉 such that h + and h -are hard to distinguish between. We make three key improvements over the previously proposed Adversarial Filtering (AF) approach in Zellers et al. (2018). First, Instead of a single positive sample, we exploit a pool H + of positive samples to choose from (i.e. plausible hypotheses). Second, Instead of machine generated distractors, the pool H -of negative samples (i.e. implausible hypotheses) is human-generated. Thus, the distractors share stylistic features of the positive samples as well as that of the context (i.e. observations O 1 and O 2 ) - making the negative samples harder to distinguish from positive samples. Finally, We use BERT (Devlin et al., 2018) as
the adversary and introduce a temperature parameter that controls the maximum number of instances that can be modified in each iteration of AF. In later iterations, fewer instances get modified resulting in a smoother convergence of the AF algorithm (described in more detail below).
Algorithm 1 provides a formal description of our approach. In each iteration i , we train an adversarial model M i on a random subset T i of the data and update the validation set V i to make it more challenging for M i . For a pair ( h + k , h -k ) of plausible and implausible hypotheses for an instance k , we denote δ = ∆ M i ( h + k , h -k ) the difference in the model evaluation of h + k and h -k . Apositive value of δ indicates that the model M i favors the plausible hypothesis h + k over the implausible one h -k . With probability t i , we update instance k that M i gets correct with a pair ( h + , h -) ∈ H + k × H -k of hypotheses that reduces the value of δ , where H + k (resp. H -k ) is the pool of plausible (resp. implausible) hypotheses for instance k .
We ran AF for 50 iterations and the temperature t i follows a sigmoid function, parameterized by the iteration number, between t s = 1 . 0 and t e = 0 . 2 . Our final dataset, ART , is generated using BERT as the adversary in Algorithm 1.
## Algorithm 1: Dual Adversarial Filtering
```
Algorithm 1: Dual Adversarial Filtering
input : dataset D$_{0}$ , plausible & implausible hypothesis sets (H $^{+}$, H$^{-}$) , number of iterations n ,
initial & final temperatures (t$_s$, t$_e)
output: dataset D$_n
1 for iteration i : 0..n - 1 do
2 t$_i = t$_e + t$_s-t$_e 1+e^0.3(i-3n $_{4}$)
3 Randomly partition D$_i into (T$_i$, V$_i).
4 Train model M$_i on T$_i$.
5 S$_i = , the selected hypotheses for V$_i .
6 for (h + k, h - $_{k}$) 2 \in V$_i do
7 Pick r uniformly at random in [0,1].
8 if r > t$_i or \Delta$_{M}$(h + k, h - $_{k}$) < 0 then
9 Add (h + k, h - $_{k}$) to S$_i.
10 else
11 Pick (h $^{+}$, h$^{-}$) \in H + k \times H - k s.t. \Delta$_{M}$(h $^{+}$, h$^{-}$) < \Delta$_{M}$(h + $_{k}$, h - $_{k}$)
12 Add (h $^{+}$, h$^{-}$) to S$_i.
13 end
14 end
15 D$_i+1 = T$_i \cup S$_i
```
## A.6 ATOMIC RELATIONS
ATOMIC (Sap et al., 2019) represents commonsense knowledge as a graph with events are nodes and the following nine relations as edges:
1. xIntent: Why does X cause an event? 2. xNeed: What does X need to do before the event? 3. xAttr: How would X be described? 4. xEffect: What effects does the event have on X? 5. xWant: What would X likely want to do after the event? 6. xReaction: How does X feel after the event? 7. oReact: How do others' feel after the event? 8. oWant: What would others likely want to do after the event? 9. oEffect: What effects does the event have on others?
Table 8: Input format used to training and generated text from various GPT2 based models. c j i refers to the COMeTembeddings obtained using a separate transformer model for relation i and observation j . Similarly, T j i is the textual phrase for relation i , observation j . Where appropriate, field specific start and end-tags are added to the sequence of inputs.
| Model | Input Format |
|-----------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| GPT2-Fixed O 1 - O 2 - Only COMeT-Txt+GPT2 COMeT-Emb+GPT2 | w 1 1 ...w 1 n w 2 1 ...w 2 n Because, 〈 o 1 〉 w 1 1 ...w 1 n 〈 /o 1 〉〈 o 2 〉 w 2 1 ...w 2 n 〈 /o 2 〉〈 h 〉 〈 p 1 1 〉 T 1 1 . ..T 1 9 〈 p 1 9 〉〈 p 2 1 〉 T 2 1 . ..T 2 9 〈 p 2 9 〉〈 o 1 〉 w 1 1 ...w 1 n 〈 /o 1 〉〈 o 2 〉 w 2 1 ...w 2 n 〈 /o 2 〉〈 h 〉 c 1 1 . . . c 1 9 ; c 2 1 . . . c 2 9 〈 o 1 〉 w 1 1 ...w 1 n 〈 /o 1 〉〈 o 2 〉 w 2 1 ...w 2 n 〈 /o 2 〉〈 h 〉 |
## A.7 GENERATION MODELS INPUT FORMAT
Table 8 describes the format of input to each variation of the generative model evaluated.