## Scaling Laws for Neural Language Models
## Jared Kaplan ∗
Johns Hopkins University, OpenAI jaredk@jhu.edu
Sam McCandlish
## ∗
OpenAI sam@openai.com
Tom Henighan OpenAI henighan@openai.com
Tom B. Brown OpenAI tom@openai.com
Benjamin Chess OpenAI bchess@openai.com
Rewon Child OpenAI rewon@openai.com
Scott Gray OpenAI scott@openai.com
Alec Radford OpenAI alec@openai.com
Jeffrey Wu OpenAI jeffwu@openai.com
Dario Amodei OpenAI damodei@openai.com
## Abstract
Westudy empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. Other architectural details such as network width or depth have minimal effects within a wide range. Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. These relationships allow us to determine the optimal allocation of a fixed compute budget. Larger models are significantly more sampleefficient, such that optimally compute-efficient training involves training very large models on a relatively modest amount of data and stopping significantly before convergence.
∗ Equal contribution.
Contributions: Jared Kaplan and Sam McCandlish led the research. Tom Henighan contributed the LSTM experiments. Tom Brown, Rewon Child, and Scott Gray, and Alec Radford developed the optimized Transformer implementation. Jeff Wu, Benjamin Chess, and Alec Radford developed the text datasets. Dario Amodei provided guidance throughout the project.
## Contents
| 1 | Introduction | 2 |
|------------|--------------------------------------------------|-----|
| 2 | Background and Methods | 6 |
| 3 | Empirical Results and Basic Power Laws | 7 |
| 4 | Charting the Infinite Data Limit and Overfitting | 10 |
| 5 | Scaling Laws with Model Size and Training Time | 12 |
| 6 | Optimal Allocation of the Compute Budget | 14 |
| 7 | Related Work | 18 |
| 8 | Discussion | 18 |
| Appendices | Appendices | 20 |
| A | Summary of Power Laws | 20 |
| B | Empirical Model of Compute-Efficient Frontier | 20 |
| C | Caveats | 22 |
| D | Supplemental Figures | 23 |
## 1 Introduction
Language provides a natural domain for the study of artificial intelligence, as the vast majority of reasoning tasks can be efficiently expressed and evaluated in language, and the world's text provides a wealth of data for unsupervised learning via generative modeling. Deep learning has recently seen rapid progress in language modeling, with state of the art models [RNSS18, DCLT18, YDY + 19, LOG + 19, RSR + 19] approaching human-level performance on many specific tasks [WPN + 19], including the composition of coherent multiparagraph prompted text samples [RWC + 19].
One might expect language modeling performance to depend on model architecture, the size of neural models, the computing power used to train them, and the data available for this training process. In this work we will empirically investigate the dependence of language modeling loss on all of these factors, focusing on the Transformer architecture [VSP + 17, LSP + 18]. The high ceiling and low floor for performance on language tasks allows us to study trends over more than seven orders of magnitude in scale.
Throughout we will observe precise power-law scalings for performance as a function of training time, context length, dataset size, model size, and compute budget.
## 1.1 Summary
Our key findings for Transformer language models are are as follows:
2 Here we display predicted compute when using a sufficiently small batch size. See Figure 13 for comparison to the purely empirical data.
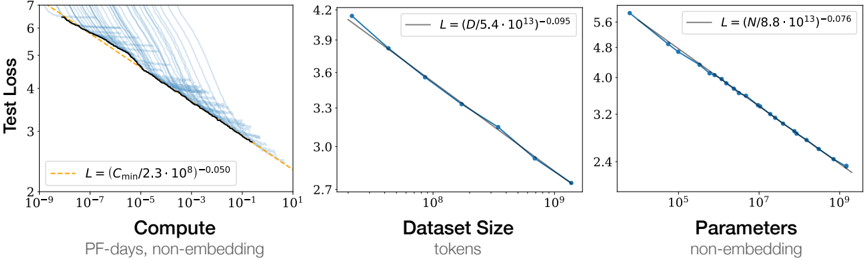
Figure 1 Language modeling performance improves smoothly as we increase the model size, datasetset size, and amount of compute 2 used for training. For optimal performance all three factors must be scaled up in tandem. Empirical performance has a power-law relationship with each individual factor when not bottlenecked by the other two.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Charts: Scaling Laws for Neural Network Training
### Overview
The image presents three charts illustrating scaling laws for neural network training. Each chart explores the relationship between "Test Loss" and a different factor: "Compute", "Dataset Size", and "Parameters". The charts show how test loss decreases as these factors increase, with each chart also including a fitted power law curve.
### Components/Axes
* **Common Y-axis:** "Test Loss" ranging from approximately 2 to 7.
* **Chart 1 (Left):**
* X-axis: "Compute" (PF-days, non-embedding) on a logarithmic scale from 10<sup>-6</sup> to 10<sup>1</sup>.
* Data Series 1 (Blue, faint lines): Multiple individual training runs showing test loss vs. compute.
* Data Series 2 (Orange, bold line): A fitted curve representing the scaling law: L = (C<sub>min</sub>/(2.3 * 10<sup>9</sup>))<sup>-0.050</sup>
* **Chart 2 (Center):**
* X-axis: "Dataset Size" (tokens) on a logarithmic scale from 10<sup>7</sup> to 10<sup>10</sup>.
* Data Series 1 (Blue, bold line): A fitted curve representing the scaling law: L = (D/(5.4 * 10<sup>43</sup>))<sup>-0.095</sup>
* **Chart 3 (Right):**
* X-axis: "Parameters" (non-embedding) on a logarithmic scale from 10<sup>5</sup> to 10<sup>9</sup>.
* Data Series 1 (Blue, bold line): A fitted curve representing the scaling law: L = (N/(8.8 * 10<sup>13</sup>))<sup>-0.076</sup>
### Detailed Analysis or Content Details
* **Chart 1 (Compute):** The blue lines represent individual training runs, showing a wide range of test loss values for a given compute level. The orange line, representing the scaling law, slopes downward, indicating that as compute increases, test loss decreases.
* At Compute = 10<sup>-6</sup>, Test Loss ≈ 6.5
* At Compute = 10<sup>-1</sup>, Test Loss ≈ 3.0
* At Compute = 10<sup>1</sup>, Test Loss ≈ 2.2
* **Chart 2 (Dataset Size):** The blue line slopes downward, indicating that as dataset size increases, test loss decreases.
* At Dataset Size = 10<sup>7</sup>, Test Loss ≈ 4.2
* At Dataset Size = 10<sup>9</sup>, Test Loss ≈ 2.8
* At Dataset Size = 10<sup>10</sup>, Test Loss ≈ 2.7
* **Chart 3 (Parameters):** The blue line slopes downward, indicating that as the number of parameters increases, test loss decreases.
* At Parameters = 10<sup>5</sup>, Test Loss ≈ 5.6
* At Parameters = 10<sup>7</sup>, Test Loss ≈ 3.5
* At Parameters = 10<sup>9</sup>, Test Loss ≈ 2.5
### Key Observations
* All three charts demonstrate a clear inverse relationship between the input factor (Compute, Dataset Size, Parameters) and Test Loss.
* The scaling laws (orange/blue lines) provide a general trend, but individual training runs (blue lines in Chart 1) exhibit significant variance.
* The rate of decrease in test loss appears to diminish as the input factor increases in all three charts.
### Interpretation
These charts illustrate the scaling laws governing the performance of neural networks. They demonstrate that increasing compute, dataset size, and the number of parameters generally leads to lower test loss, and thus improved model performance. The fitted power law curves provide a quantitative relationship between these factors and test loss, allowing for predictions about the performance of models with different configurations. The variance observed in Chart 1 suggests that other factors, beyond compute, also influence model performance. The diminishing returns observed in all charts indicate that there are limits to the benefits of simply scaling up these factors. The specific exponents in the power laws (e.g., -0.050, -0.095, -0.076) quantify the sensitivity of test loss to changes in each factor. These findings are crucial for efficient resource allocation and model design in machine learning.
</details>
Performance depends strongly on scale, weakly on model shape: Model performance depends most strongly on scale, which consists of three factors: the number of model parameters N (excluding embeddings), the size of the dataset D , and the amount of compute C used for training. Within reasonable limits, performance depends very weakly on other architectural hyperparameters such as depth vs. width. (Section 3)
Smooth power laws: Performance has a power-law relationship with each of the three scale factors N,D,C when not bottlenecked by the other two, with trends spanning more than six orders of magnitude (see Figure 1). We observe no signs of deviation from these trends on the upper end, though performance must flatten out eventually before reaching zero loss. (Section 3)
Universality of overfitting: Performance improves predictably as long as we scale up N and D in tandem, but enters a regime of diminishing returns if either N or D is held fixed while the other increases. The performance penalty depends predictably on the ratio N 0 . 74 /D , meaning that every time we increase the model size 8x, we only need to increase the data by roughly 5x to avoid a penalty. (Section 4)
Universality of training: Training curves follow predictable power-laws whose parameters are roughly independent of the model size. By extrapolating the early part of a training curve, we can roughly predict the loss that would be achieved if we trained for much longer. (Section 5)
Transfer improves with test performance: When we evaluate models on text with a different distribution than they were trained on, the results are strongly correlated to those on the training validation set with a roughly constant offset in the loss - in other words, transfer to a different distribution incurs a constant penalty but otherwise improves roughly in line with performance on the training set. (Section 3.2.2)
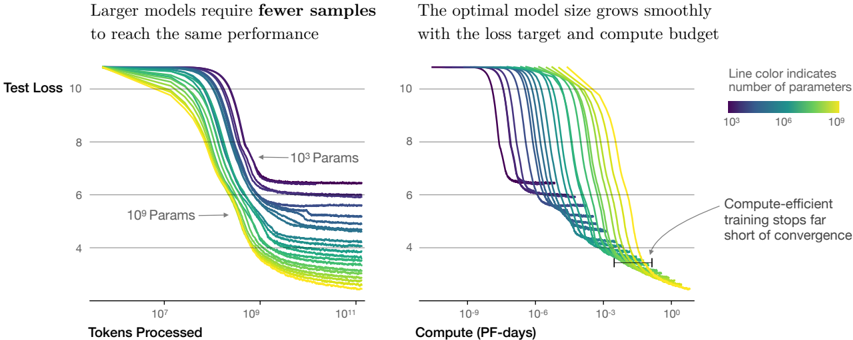
Sample efficiency: Large models are more sample-efficient than small models, reaching the same level of performance with fewer optimization steps (Figure 2) and using fewer data points (Figure 4).
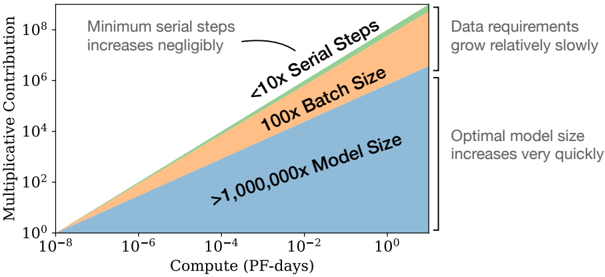
Convergence is inefficient: When working within a fixed compute budget C but without any other restrictions on the model size N or available data D , we attain optimal performance by training very large models and stopping significantly short of convergence (see Figure 3). Maximally compute-efficient training would therefore be far more sample efficient than one might expect based on training small models to convergence, with data requirements growing very slowly as D ∼ C 0 . 27 with training compute. (Section 6)
Optimal batch size: The ideal batch size for training these models is roughly a power of the loss only, and continues to be determinable by measuring the gradient noise scale [MKAT18]; it is roughly 1-2 million tokens at convergence for the largest models we can train. (Section 5.1)
Taken together, these results show that language modeling performance improves smoothly and predictably as we appropriately scale up model size, data, and compute. We expect that larger language models will perform better and be more sample efficient than current models.
Figure 2 We show a series of language model training runs, with models ranging in size from 10 3 to 10 9 parameters (excluding embeddings).
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Charts: Model Performance vs. Data & Compute
### Overview
The image presents two charts comparing the performance of machine learning models with varying numbers of parameters. The left chart shows Test Loss as a function of Tokens Processed, while the right chart shows Test Loss as a function of Compute (in PF-days). Both charts aim to demonstrate the relationship between model size, data usage, compute resources, and performance (measured by Test Loss).
### Components/Axes
* **Left Chart:**
* **Title:** "Larger models require fewer samples to reach the same performance"
* **X-axis:** "Tokens Processed" (logarithmic scale, ranging approximately from 10<sup>6</sup> to 10<sup>11</sup>)
* **Y-axis:** "Test Loss" (linear scale, ranging approximately from 4 to 10)
* **Data Series:** Multiple lines representing different model sizes.
* **Labels:** "10<sup>3</sup> Params" and "10<sup>9</sup> Params" are indicated with arrows pointing to representative lines.
* **Right Chart:**
* **Title:** "The optimal model size grows smoothly with the loss target and compute budget"
* **X-axis:** "Compute (PF-days)" (logarithmic scale, ranging approximately from 10<sup>-9</sup> to 10<sup>1</sup>)
* **Y-axis:** "Test Loss" (linear scale, ranging approximately from 4 to 10)
* **Data Series:** Multiple lines representing different model sizes.
* **Legend:** Located on the right side, indicating that "Line color indicates number of parameters". The legend shows a color gradient from purple (10<sup>3</sup>) to green (10<sup>9</sup>).
* **Annotation:** "Compute-efficient training stops far short of convergence" with an arrow pointing to a line that plateaus at a higher loss value.
### Detailed Analysis or Content Details
**Left Chart (Test Loss vs. Tokens Processed):**
* **Trend:** All lines generally slope downwards, indicating that Test Loss decreases as more tokens are processed. The lines representing larger models (green) reach lower loss values faster than those representing smaller models (purple).
* **Data Points (approximate):**
* **10<sup>3</sup> Params (purple):** Starts around Test Loss = 9.5, reaches approximately Test Loss = 5.5 at 10<sup>11</sup> Tokens Processed.
* **10<sup>9</sup> Params (green):** Starts around Test Loss = 9.5, reaches approximately Test Loss = 4.0 at 10<sup>9</sup> Tokens Processed.
* **Observation:** The lines are densely packed at the beginning (low token count) and spread out as the token count increases, suggesting diminishing returns for larger models.
**Right Chart (Test Loss vs. Compute):**
* **Trend:** Similar to the left chart, all lines slope downwards. Larger models (green) achieve lower loss values with less compute.
* **Data Points (approximate):**
* **10<sup>3</sup> Params (purple):** Starts around Test Loss = 9.5, reaches approximately Test Loss = 5.5 at 10<sup>1</sup> PF-days.
* **10<sup>9</sup> Params (green):** Starts around Test Loss = 9.5, reaches approximately Test Loss = 4.0 at 10<sup>-3</sup> PF-days.
* **Annotation:** The annotated line (yellowish-green) plateaus around Test Loss = 6.0, indicating that further compute investment does not significantly reduce loss.
**Color Mapping:** The color gradient in the legend (purple to green) corresponds to increasing model size (10<sup>3</sup> to 10<sup>9</sup> parameters). This color mapping is consistent across both charts.
### Key Observations
* Larger models converge faster (reach lower loss values) with both increased data (tokens processed) and increased compute.
* The relationship between model size, data, and compute appears smooth and predictable.
* Compute-efficient training can lead to suboptimal results, as indicated by the plateauing line in the right chart.
* The logarithmic scales on the x-axes highlight the significant differences in scale between the two charts.
### Interpretation
The data strongly suggests that increasing model size is an effective strategy for improving performance, but it comes with increased computational cost. The charts demonstrate a trade-off between model size, data requirements, and compute resources. Larger models can achieve the same level of performance as smaller models with less data and compute. However, the annotation on the right chart warns against prematurely stopping training, as this can result in a model that has not fully converged and therefore performs suboptimally. The smooth growth of the optimal model size with loss target and compute budget suggests a predictable scaling relationship that can be leveraged for efficient model development. The use of logarithmic scales indicates that the benefits of increased data and compute diminish as these resources become larger, suggesting that there may be a point of diminishing returns.
</details>
Figure 3 As more compute becomes available, we can choose how much to allocate towards training larger models, using larger batches, and training for more steps. We illustrate this for a billion-fold increase in compute. For optimally compute-efficient training, most of the increase should go towards increased model size. A relatively small increase in data is needed to avoid reuse. Of the increase in data, most can be used to increase parallelism through larger batch sizes, with only a very small increase in serial training time required.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Chart: Multiplicative Contribution vs. Compute
### Overview
The image presents a chart illustrating the relationship between compute (measured in PF-days) and multiplicative contribution, with different regions representing the impact of serial steps, batch size, and model size. The chart uses a logarithmic scale for both axes. The chart is divided into three colored regions: blue, orange, and light blue. Annotations highlight trends related to minimum serial steps, data requirements, and optimal model size.
### Components/Axes
* **X-axis:** Compute (PF-days), ranging from 10<sup>-8</sup> to 10<sup>0</sup> (logarithmic scale).
* **Y-axis:** Multiplicative Contribution, ranging from 10<sup>0</sup> to 10<sup>8</sup> (logarithmic scale).
* **Legend/Regions:**
* Blue: >1,000,000x Model Size
* Orange: 100x Batch Size
* Light Blue: <10x Serial Steps
* **Annotations:**
* "Minimum serial steps increases negligibly" - pointing to the light blue region.
* "Data requirements grow relatively slowly" - pointing to the light blue region.
* "Optimal model size increases very quickly" - pointing to the blue region.
### Detailed Analysis
The chart shows three distinct regions, each representing a different factor influencing multiplicative contribution as compute increases.
* **Light Blue Region (<10x Serial Steps):** This region occupies the lower-left portion of the chart. The line representing this region starts at approximately 10<sup>0</sup> on the Y-axis when the compute is at 10<sup>-8</sup> and rises relatively slowly to approximately 10<sup>3</sup> on the Y-axis when the compute is at 10<sup>0</sup>. This indicates that increasing compute in this regime yields diminishing returns in multiplicative contribution. The annotation suggests that minimum serial steps increase negligibly and data requirements grow relatively slowly in this region.
* **Orange Region (100x Batch Size):** This region is positioned above and to the right of the light blue region. The line starts at approximately 10<sup>2</sup> on the Y-axis when the compute is at 10<sup>-6</sup> and rises to approximately 10<sup>5</sup> on the Y-axis when the compute is at 10<sup>0</sup>. This region shows a steeper slope than the light blue region, indicating a more significant increase in multiplicative contribution for a given increase in compute.
* **Blue Region (>1,000,000x Model Size):** This region occupies the upper-right portion of the chart. The line starts at approximately 10<sup>3</sup> on the Y-axis when the compute is at 10<sup>-4</sup> and rises very steeply to approximately 10<sup>8</sup> on the Y-axis when the compute is at 10<sup>0</sup>. This indicates that increasing compute in this regime leads to a very rapid increase in multiplicative contribution. The annotation suggests that the optimal model size increases very quickly in this region.
### Key Observations
* The multiplicative contribution increases more rapidly with compute as the model size increases (blue region) compared to increasing batch size (orange region) or minimizing serial steps (light blue region).
* The light blue region demonstrates the least sensitivity to compute increases.
* The chart highlights a trade-off between compute, model size, batch size, and serial steps in achieving multiplicative contribution.
### Interpretation
The chart demonstrates the scaling behavior of machine learning models with respect to compute. It suggests that, initially, optimizing for serial steps and data efficiency (light blue region) provides modest gains. As compute resources increase, increasing batch size (orange region) becomes more effective. However, beyond a certain point, the most significant gains are achieved by increasing model size (blue region), albeit at a rapidly increasing compute cost. The annotations emphasize that while minimizing serial steps and data requirements are important, the optimal model size is the primary driver of multiplicative contribution when sufficient compute is available. This implies that scaling model size is the most impactful strategy for improving performance, but it requires substantial computational resources. The logarithmic scales suggest that the benefits of increasing compute diminish as compute increases, but the rate of diminishing returns varies depending on which factor (serial steps, batch size, or model size) is being optimized.
</details>
## 1.2 Summary of Scaling Laws
The test loss of a Transformer trained to autoregressively model language can be predicted using a power-law when performance is limited by only either the number of non-embedding parameters N , the dataset size D , or the optimally allocated compute budget C min (see Figure 1):
1. For models with a limited number of parameters, trained to convergence on sufficiently large datasets:
$$L ( N ) = ( N _ { c } / N ) ^ { \alpha _ { N } } \, ; \quad \alpha _ { N } \sim 0 . 0 7 6 , \quad N _ { c } \sim 8 . 8 \times 1 0 ^ { 1 3 } \, ( n o n - e m b d i n g p a r a m e t e r s ) \quad ( 1 . 1 )$$
2. For large models trained with a limited dataset with early stopping:
$$L ( D ) = \left ( D _ { c } / D \right ) ^ { \alpha _ { D } } ; \, \alpha _ { D } \sim 0 . 0 9 5 , \quad D _ { c } \sim 5 . 4 \times 1 0 ^ { 1 3 } \left ( t o k e n s \right ) \quad \ \ ( 1 . 2 )$$
3. When training with a limited amount of compute, a sufficiently large dataset, an optimally-sized model, and a sufficiently small batch size (making optimal 3 use of compute):
$$\begin{array} { r l } & { L ( C _ { \min } ) = \left ( C _ { c } ^ { \min } / C _ { \min } \right ) ^ { \alpha _ { c } ^ { \min } } ; \, \alpha _ { C } ^ { \min } \sim 0 . 0 5 0 , \quad C _ { c } ^ { \min } \sim 3 . 1 \times 1 0 ^ { 8 } \left ( P F - d a y s \right ) \quad ( 1 . 3 ) } \end{array}$$
3 We also observe an empirical power-law trend with the training compute C (Figure 1) while training at fixed batch size, but it is the trend with C min that should be used to make predictions. They are related by equation (5.5).
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Charts: Loss vs Model and Dataset Size
### Overview
The image presents two charts visualizing the relationship between loss and model/dataset size. The left chart shows Loss vs. Tokens in Dataset, while the right chart shows Loss vs. Estimated S_min (likely a measure of training steps). Both charts use color to represent the number of parameters in the model.
### Components/Axes
**Left Chart:**
* **Title:** Loss vs Model and Dataset Size
* **X-axis:** Tokens in Dataset (log scale, ranging from approximately 10^7 to 10^10)
* **Y-axis:** Loss (ranging from approximately 2.5 to 4.5)
* **Legend:** Params (color-coded)
* 708M (Yellow)
* 302M (Green)
* 85M (Light Blue)
* 3M (Dark Blue)
* 25M (Orange)
* 393.2K (Purple)
**Right Chart:**
* **Title:** Loss vs Model Size and Training Steps
* **X-axis:** Estimated S_min (log scale, ranging from approximately 10^4 to 10^5)
* **Y-axis:** Loss (ranging from approximately 2.4 to 4.4)
* **Colorbar:** Parameters (non-embedded) (log scale, ranging from approximately 10^6 to 10^8) - This serves as the legend.
### Detailed Analysis or Content Details
**Left Chart:**
* **708M (Yellow):** The line starts at approximately Loss = 4.2 with Tokens = 10^7 and decreases rapidly to approximately Loss = 2.6 with Tokens = 10^10.
* **302M (Green):** The line starts at approximately Loss = 4.0 with Tokens = 10^7 and decreases to approximately Loss = 3.0 with Tokens = 10^10.
* **85M (Light Blue):** The line starts at approximately Loss = 4.1 with Tokens = 10^7 and decreases to approximately Loss = 3.4 with Tokens = 10^10.
* **3M (Dark Blue):** The line starts at approximately Loss = 4.3 with Tokens = 10^7 and decreases to approximately Loss = 3.8 with Tokens = 10^10.
* **25M (Orange):** The line starts at approximately Loss = 4.1 with Tokens = 10^7 and decreases to approximately Loss = 3.2 with Tokens = 10^10.
* **393.2K (Purple):** The line starts at approximately Loss = 4.3 with Tokens = 10^7 and remains relatively flat, ending at approximately Loss = 4.2 with Tokens = 10^10.
**Right Chart:**
The chart displays a heatmap-like representation of loss as a function of estimated S_min and model parameters. The color intensity corresponds to the number of parameters.
* **General Trend:** For all parameter sizes, the loss generally decreases as S_min increases.
* **Parameter Impact:** Higher parameter counts (yellow/orange) generally exhibit lower loss values for a given S_min compared to lower parameter counts (blue/purple).
* **Specific Observations:**
* The highest parameter models (yellow) show the most significant loss reduction with increasing S_min, reaching a loss of approximately 2.4 at S_min = 10^5.
* The lowest parameter models (purple) show a less pronounced loss reduction, remaining around a loss of 3.8-4.0 even at S_min = 10^5.
### Key Observations
* In the left chart, increasing the dataset size consistently reduces loss across all model sizes.
* Larger models (708M, 302M) consistently achieve lower loss values than smaller models (3M, 393.2K) for a given dataset size.
* The right chart confirms that increasing training steps (S_min) reduces loss, and this effect is more pronounced for larger models.
* The 393.2K model shows minimal improvement with increased dataset size in the left chart, suggesting it may be underparameterized.
### Interpretation
The data strongly suggests that both model size and dataset size are critical factors in achieving low loss. Increasing either of these factors leads to improved performance. The right chart reinforces this by showing that increased training (S_min) also contributes to lower loss, particularly for larger models. The consistent trend of decreasing loss with increasing parameters and dataset size indicates a clear scaling relationship. The relatively flat curve for the 393.2K model in the left chart suggests that this model has reached its capacity and cannot benefit further from increased data. This highlights the importance of model capacity in effectively utilizing larger datasets. The colorbar on the right chart provides a continuous representation of parameter size, allowing for a more nuanced understanding of the relationship between model size, training steps, and loss. The logarithmic scales on both axes are appropriate for visualizing the wide range of values involved.
</details>
⋂}⌋˜{√(]{(〈∐√∐√˜√
min
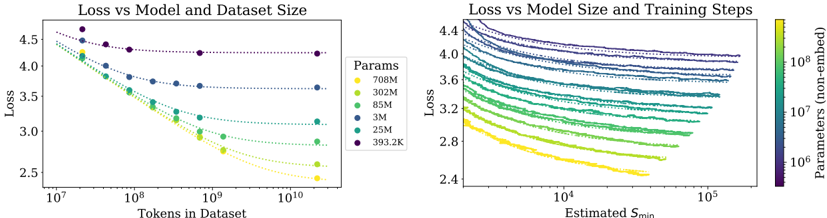
Figure 4 Left : The early-stopped test loss L ( N,D ) varies predictably with the dataset size D and model size N according to Equation (1.5). Right : After an initial transient period, learning curves for all model sizes N can be fit with Equation (1.6), which is parameterized in terms of S min , the number of steps when training at large batch size (details in Section 5.1).
These relations hold across eight orders of magnitude in C min , six orders of magnitude in N , and over two orders of magnitude in D . They depend very weakly on model shape and other Transformer hyperparameters (depth, width, number of self-attention heads), with specific numerical values associated with the Webtext2 training set [RWC + 19]. The power laws α N , α D , α min C specify the degree of performance improvement expected as we scale up N , D , or C min ; for example, doubling the number of parameters yields a loss that is smaller by a factor 2 -α N = 0 . 95 . The precise numerical values of N c , C min c , and D c depend on the vocabulary size and tokenization and hence do not have a fundamental meaning.
The critical batch size, which determines the speed/efficiency tradeoff for data parallelism ([MKAT18]), also roughly obeys a power law in L :
<!-- formula-not-decoded -->
Equation (1.1) and (1.2) together suggest that as we increase the model size, we should increase the dataset size sublinearly according to D ∝ N α N α D ∼ N 0 . 74 . In fact, we find that there is a single equation combining (1.1) and (1.2) that governs the simultaneous dependence on N and D and governs the degree of overfitting:
$$L ( N , D ) = \left [ \left ( \frac { N _ { c } } { N } \right ) ^ { \frac { \alpha _ { N } } { \alpha _ { D } } } + \frac { D _ { c } } { D } \right ] ^ { \alpha _ { D } }$$
with fits pictured on the left in figure 4. We conjecture that this functional form may also parameterize the trained log-likelihood for other generative modeling tasks.
When training a given model for a finite number of parameter update steps S in the infinite data limit, after an initial transient period, the learning curves can be accurately fit by (see the right of figure 4)
$$L ( N , S ) = \left ( \frac { N _ { c } } { N } \right ) ^ { \alpha _ { N } } + \left ( \frac { S _ { c } } { S _ { \min } ( S ) } \right ) ^ { \alpha _ { S } }$$
where S c ≈ 2 . 1 × 10 3 and α S ≈ 0 . 76 , and S min ( S ) is the minimum possible number of optimization steps (parameter updates) estimated using Equation (5.4).
When training within a fixed compute budget C , but with no other constraints, Equation (1.6) leads to the prediction that the optimal model size N , optimal batch size B , optimal number of steps S , and dataset size D should grow as
$$\begin{array} { r } { N \, \infty \, C ^ { \alpha _ { C } ^ { \min } / \alpha _ { N } } , \quad B \, \infty \, C ^ { \alpha _ { C } ^ { \min } / \alpha _ { B } } , \quad S \, \infty \, C ^ { \alpha _ { C } ^ { \min } / \alpha _ { S } } , \quad D = B \cdot S \quad ( 1 . 7 ) } \end{array}$$
with
<!-- formula-not-decoded -->
which closely matches the empirically optimal results N ∝ C 0 . 73 min , B ∝ C 0 . 24 min , and S ∝ C 0 . 03 min . As the computational budget C increases, it should be spent primarily on larger models, without dramatic increases in training time or dataset size (see Figure 3). This also implies that as models grow larger, they become increasingly sample efficient. In practice, researchers typically train smaller models for longer than would
be maximally compute-efficient because of hardware constraints. Optimal performance depends on total compute as a power law (see Equation (1.3)).
We provide some basic theoretical motivation for Equation (1.5), an analysis of learning curve fits and their implications for training time, and a breakdown of our results per token. We also make some brief comparisons to LSTMs and recurrent Transformers [DGV + 18].
## 1.3 Notation
We use the following notation:
- L - the cross entropy loss in nats. Typically it will be averaged over the tokens in a context, but in some cases we report the loss for specific tokens within the context.
- N - the number of model parameters, excluding all vocabulary and positional embeddings
- C ≈ 6 NBS - an estimate of the total non-embedding training compute, where B is the batch size, and S is the number of training steps (ie parameter updates). We quote numerical values in PF-days, where one PF-day = 10 15 × 24 × 3600 = 8 . 64 × 10 19 floating point operations.
- D - the dataset size in tokens
- B crit - the critical batch size [MKAT18], defined and discussed in Section 5.1. Training at the critical batch size provides a roughly optimal compromise between time and compute efficiency.
- C min - an estimate of the minimum amount of non-embedding compute to reach a given value of the loss. This is the training compute that would be used if the model were trained at a batch size much less than the critical batch size.
- S min - an estimate of the minimal number of training steps needed to reach a given value of the loss. This is also the number of training steps that would be used if the model were trained at a batch size much greater than the critical batch size.
- α X - power-law exponents for the scaling of the loss as L ( X ) ∝ 1 /X α X where X can be any of N,D,C,S,B,C min .
## 2 Background and Methods
We train language models on WebText2, an extended version of the WebText [RWC + 19] dataset, tokenized using byte-pair encoding [SHB15] with a vocabulary size n vocab = 50257 . We optimize the autoregressive log-likelihood (i.e. cross-entropy loss) averaged over a 1024-token context, which is also our principal performance metric. We record the loss on the WebText2 test distribution and on a selection of other text distributions. We primarily train decoder-only [LSP + 18, RNSS18] Transformer [VSP + 17] models, though we also train LSTM models and Universal Transformers [DGV + 18] for comparison.
## 2.1 Parameter and Compute Scaling of Transformers
We parameterize the Transformer architecture using hyperparameters n layer (number of layers), d model (dimension of the residual stream), d ff (dimension of the intermediate feed-forward layer), d attn (dimension of the attention output), and n heads (number of attention heads per layer). We include n ctx tokens in the input context, with n ctx = 1024 except where otherwise noted.
We use N to denote the model size, which we define as the number of non-embedding parameters
<!-- formula-not-decoded -->
where we have excluded biases and other sub-leading terms. Our models also have n vocab d model parameters in an embedding matrix, and use n ctx d model parameters for positional embeddings, but we do not include these when discussing the 'model size' N ; we will see that this produces significantly cleaner scaling laws.
Evaluating a forward pass of the Transformer involves roughly
$$C _ { f o r w a r d } \approx 2 N + 2 n _ { l a y e r } n _ { c t x } d _ { m o d e l } \quad ( 2 . 2 )$$
add-multiply operations, where the factor of two comes from the multiply-accumulate operation used in matrix multiplication. A more detailed per-operation parameter and compute count is included in Table 1.
Table 1 Parameter counts and compute (forward pass) estimates for a Transformer model. Sub-leading terms such as nonlinearities, biases, and layer normalization are omitted.
| Operation | Parameters | FLOPs per Token |
|-----------------------|------------------------------------------|-----------------------------------------|
| Embed | ( n vocab + n ctx ) d model | 4 d model |
| Attention: QKV | n layer d model 3 d attn | 2 n layer d model 3 d attn |
| Attention: Mask | - | 2 n layer n ctx d attn |
| Attention: Project | n layer d attn d model | 2 n layer d attn d embd |
| Feedforward | n layer 2 d model d ff | 2 n layer 2 d model d ff |
| De-embed | - | 2 d model n vocab |
| Total (Non-Embedding) | N = 2 d model n layer (2 d attn + d ff ) | C forward = 2 N +2 n layer n ctx d attn |
For contexts and models with d model > n ctx / 12 , the context-dependent computational cost per token is a relatively small fraction of the total compute. Since we primarily study models where d model n ctx / 12 , we do not include context-dependent terms in our training compute estimate. Accounting for the backwards pass (approximately twice the compute as the forwards pass), we then define the estimated non-embedding compute as C ≈ 6 N floating point operators per training token.
## 2.2 Training Procedures
Unless otherwise noted, we train models with the Adam optimizer [KB14] for a fixed 2 . 5 × 10 5 steps with a batch size of 512 sequences of 1024 tokens. Due to memory constraints, our largest models (more than 1B parameters) were trained with Adafactor [SS18]. We experimented with a variety of learning rates and schedules, as discussed in Appendix D.6. We found that results at convergence were largely independent of learning rate schedule. Unless otherwise noted, all training runs included in our data used a learning rate schedule with a 3000 step linear warmup followed by a cosine decay to zero.
## 2.3 Datasets
We train our models on an extended version of the WebText dataset described in [RWC + 19]. The original WebText dataset was a web scrape of outbound links from Reddit through December 2017 which received at least 3 karma. In the second version, WebText2, we added outbound Reddit links from the period of January to October 2018, also with a minimum of 3 karma. The karma threshold served as a heuristic for whether people found the link interesting or useful. The text of the new links was extracted with the Newspaper3k python library. In total, the dataset consists of 20.3M documents containing 96 GB of text and 1 . 62 × 10 10 words (as defined by wc ). We then apply the reversible tokenizer described in [RWC + 19], which yields 2 . 29 × 10 10 tokens. We reserve 6 . 6 × 10 8 of these tokens for use as a test set, and we also test on similarlyprepared samples of Books Corpus [ZKZ + 15], Common Crawl [Fou], English Wikipedia, and a collection of publicly-available Internet Books.
## 3 Empirical Results and Basic Power Laws
To characterize language model scaling we train a wide variety of models, varying a number of factors including:
- Model size (ranging in size from 768 to 1.5 billion non-embedding parameters)
- Dataset size (ranging from 22 million to 23 billion tokens)
- Shape (including depth, width, attention heads, and feed-forward dimension)
- Context length (1024 for most runs, though we also experiment with shorter contexts)
- Batch size ( 2 19 for most runs, but we also vary it to measure the critical batch size)
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Charts: Performance Impact of Architectural Choices
### Overview
The image presents three separate charts comparing the impact of different architectural choices on model loss increase. Each chart focuses on a different parameter: Feed-Forward Ratio, Aspect Ratio, and Attention Head Dimension. Each chart also displays results for different model sizes (parameter counts).
### Components/Axes
Each chart shares the following components:
* **Y-axis:** "Loss Increase" (percentage), ranging from 0% to 10%.
* **X-axis:** Varies depending on the chart, representing the architectural parameter being tested. The X-axis is on a logarithmic scale.
* **Legends:** Each chart has a legend indicating the different model sizes (parameter counts) and/or model dimensions used in the experiment.
**Chart 1: Feed-Forward Ratio (df / dmodel)**
* X-axis label: "Feed-Forward Ratio (df / dmodel)"
* Legend:
* Orange: 50M Params
* Blue: 27M Params
* Yellow: 1.5B Params
**Chart 2: Aspect Ratio (dmodel / nlayer)**
* X-axis label: "Aspect Ratio (dmodel / nlayer)"
* Legend:
* Orange: 50M Params
* Blue: 27M Params
* Yellow: 1.5B Params
* Text Overlay: "A wide range of architectures achieve similar performance"
**Chart 3: Attention Head Dimension (dmodel / nhead)**
* X-axis label: "Attention Head Dimension (dmodel / nhead)"
* Legend:
* Blue: dmodel = 256
* Green: dmodel = 512
* Purple: dmodel = 1024
* Annotation: "22% additional compute compensates for 1% loss increase"
### Detailed Analysis or Content Details
**Chart 1: Feed-Forward Ratio**
* **50M Params (Orange):** Starts at approximately 1.5% loss increase at a ratio of 10^0 (1). Decreases to approximately 0.5% at a ratio of 10^1 (10). Then sharply increases to approximately 9% at a ratio of 10^2 (100).
* **27M Params (Blue):** Starts at approximately 1.5% loss increase at a ratio of 10^0 (1). Decreases to approximately 0.2% at a ratio of 10^1 (10). Then sharply increases to approximately 8% at a ratio of 10^2 (100).
* **1.5B Params (Yellow):** Remains relatively flat around 0.5% loss increase across the entire range of feed-forward ratios.
**Chart 2: Aspect Ratio**
* **50M Params (Orange):** Starts at approximately 3% loss increase at a ratio of 10^0 (1). Decreases to approximately 1% at a ratio of 10^1 (10). Then sharply increases to approximately 8% at a ratio of 10^2 (100).
* **27M Params (Blue):** Starts at approximately 2% loss increase at a ratio of 10^0 (1). Decreases to approximately 0.5% at a ratio of 10^1 (10). Then increases to approximately 4% at a ratio of 10^2 (100).
* **1.5B Params (Yellow):** Remains relatively flat around 0.5% loss increase across the entire range of aspect ratios.
**Chart 3: Attention Head Dimension**
* **dmodel = 256 (Blue):** Starts at approximately 1.5% loss increase at a ratio of 10^0 (1). Remains relatively flat around 1.5% to 2% loss increase across the entire range.
* **dmodel = 512 (Green):** Starts at approximately 0.5% loss increase at a ratio of 10^0 (1). Decreases to approximately 0.2% at a ratio of 10^1 (10). Then increases to approximately 1.5% at a ratio of 10^2 (100).
* **dmodel = 1024 (Purple):** Starts at approximately 0.5% loss increase at a ratio of 10^0 (1). Remains relatively flat around 0.5% to 1% loss increase across the entire range.
### Key Observations
* **Feed-Forward Ratio & Aspect Ratio:** Larger models (1.5B Params) are less sensitive to changes in Feed-Forward Ratio and Aspect Ratio, maintaining a low and stable loss increase. Smaller models (50M and 27M Params) exhibit a significant loss increase at higher ratios.
* **Attention Head Dimension:** The loss increase is relatively stable across different attention head dimensions, with slight variations.
* **Scale Sensitivity:** The charts consistently demonstrate that smaller models are more sensitive to architectural choices than larger models.
* **Logarithmic Scale:** The X-axis is logarithmic, meaning that equal distances represent multiplicative changes in the parameter values.
### Interpretation
These charts demonstrate the impact of different architectural choices on model performance, specifically measured by loss increase. The key takeaway is that larger models (1.5B parameters) are more robust to variations in Feed-Forward Ratio and Aspect Ratio. This suggests that larger models have a greater capacity to learn and adapt to different configurations.
The annotation on the Attention Head Dimension chart indicates a trade-off between computational cost and performance. A 22% increase in compute can compensate for a 1% loss increase, suggesting that increasing computational resources can improve model accuracy.
The text overlay on the Aspect Ratio chart ("A wide range of architectures achieve similar performance") reinforces the idea that there is not a single optimal architecture, and that a variety of configurations can achieve comparable results. This is particularly true for larger models.
The consistent trend across the charts highlights the importance of model size in determining robustness to architectural choices. Smaller models require more careful tuning of hyperparameters to achieve optimal performance, while larger models are more forgiving. The logarithmic scale on the x-axis suggests that the impact of these parameters is not linear, and that there may be diminishing returns to increasing their values beyond a certain point.
</details>
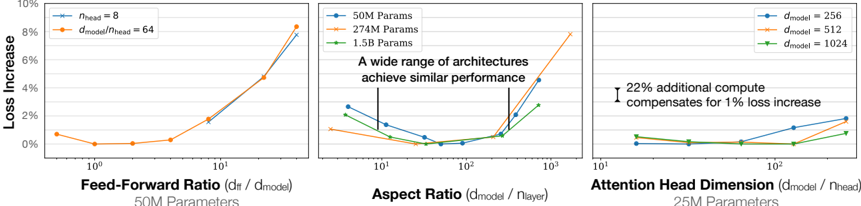
50M Parameters
25M Parameters
Figure 5 Performance depends very mildly on model shape when the total number of non-embedding parameters N is held fixed. The loss varies only a few percent over a wide range of shapes. Small differences in parameter counts are compensated for by using the fit to L ( N ) as a baseline. Aspect ratio in particular can vary by a factor of 40 while only slightly impacting performance; an ( n layer , d model ) = (6 , 4288) reaches a loss within 3% of the (48 , 1600) model used in [RWC + 19].
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Chart: Test Loss vs. Parameters for Different Layer Depths
### Overview
The image presents two line charts comparing the test loss of models with varying numbers of layers against the number of parameters. The left chart shows results for models *with embedding*, while the right chart shows results for models *without embedding*. Both charts use a logarithmic scale for the x-axis (Parameters).
### Components/Axes
* **X-axis (Both Charts):** Parameters. The left chart's scale ranges from approximately 10<sup>6</sup> to 10<sup>9</sup>. The right chart's scale ranges from approximately 10<sup>3</sup> to 10<sup>9</sup>.
* **Y-axis (Both Charts):** Test Loss. The scale ranges from approximately 2 to 7.
* **Left Chart Legend (Top-Left):**
* 0 Layer (Blue)
* 1 Layer (Purple)
* 2 Layers (Dark Red)
* 3 Layers (Orange)
* 6 Layers (Yellow)
* > 6 Layers (Brown)
* **Right Chart Legend (Top-Right):**
* 1 Layer (Purple)
* 2 Layers (Dark Red)
* 3 Layers (Orange)
* 6 Layers (Yellow)
* > 6 Layers (Brown)
### Detailed Analysis or Content Details
**Left Chart (With Embedding):**
* **0 Layer (Blue):** Starts at approximately 6.8 and remains relatively flat, decreasing slightly to around 6.2 at 10<sup>9</sup> parameters.
* **1 Layer (Purple):** Starts at approximately 6.8 and decreases steadily to around 3.8 at 10<sup>9</sup> parameters.
* **2 Layers (Dark Red):** Starts at approximately 6.5 and decreases more rapidly than the 1-layer model, reaching around 3.2 at 10<sup>9</sup> parameters.
* **3 Layers (Orange):** Starts at approximately 6.2 and decreases rapidly, reaching around 2.8 at 10<sup>9</sup> parameters.
* **6 Layers (Yellow):** Starts at approximately 5.5 and decreases very rapidly, reaching around 2.4 at 10<sup>9</sup> parameters.
* **> 6 Layers (Brown):** Starts at approximately 5.2 and decreases most rapidly, reaching around 2.2 at 10<sup>9</sup> parameters.
**Right Chart (Non-Embedding):**
* **1 Layer (Purple):** Starts at approximately 6.8 and decreases steadily to around 3.7 at 10<sup>9</sup> parameters.
* **2 Layers (Dark Red):** Starts at approximately 6.5 and decreases more rapidly than the 1-layer model, reaching around 3.1 at 10<sup>9</sup> parameters.
* **3 Layers (Orange):** Starts at approximately 6.2 and decreases rapidly, reaching around 2.7 at 10<sup>9</sup> parameters.
* **6 Layers (Yellow):** Starts at approximately 5.5 and decreases very rapidly, reaching around 2.3 at 10<sup>9</sup> parameters.
* **> 6 Layers (Brown):** Starts at approximately 5.2 and decreases most rapidly, reaching around 2.1 at 10<sup>9</sup> parameters.
### Key Observations
* In both charts, increasing the number of layers consistently reduces the test loss.
* The rate of loss reduction appears to diminish as the number of parameters increases, especially for models with more layers.
* The models with embedding (left chart) generally exhibit slightly higher test loss values compared to the models without embedding (right chart) for the same number of layers and parameters.
* The 0-layer model (left chart) shows minimal improvement in test loss with increasing parameters, suggesting it is not benefiting from increased model capacity.
### Interpretation
The data demonstrates a clear relationship between model complexity (number of layers) and performance (test loss). Increasing the number of layers generally leads to lower test loss, indicating improved model accuracy. However, the diminishing returns observed at higher parameter counts suggest that there is a point of saturation where adding more layers does not significantly improve performance.
The difference between the "with embedding" and "non-embedding" models suggests that embedding may provide a slight advantage in terms of test loss, but this advantage is not substantial. The 0-layer model's lack of improvement highlights the importance of model capacity for learning complex patterns.
The logarithmic scale on the x-axis emphasizes the impact of increasing parameters, particularly at lower values. The charts provide valuable insights into the trade-offs between model complexity, parameter count, and performance, which can inform model design and optimization strategies. The consistent downward trend for all layer counts suggests that increasing model size is generally beneficial, but careful consideration should be given to the point of diminishing returns and the potential benefits of embedding techniques.
</details>
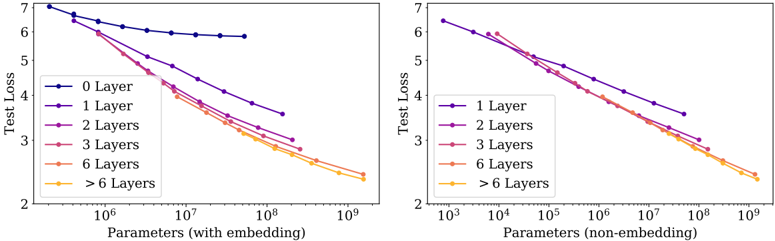
Figure 6 Left: When we include embedding parameters, performance appears to depend strongly on the number of layers in addition to the number of parameters. Right: When we exclude embedding parameters, the performance of models with different depths converge to a single trend. Only models with fewer than 2 layers or with extreme depth-to-width ratios deviate significantly from the trend.
In this section we will display data along with empirically-motivated fits, deferring theoretical analysis to later sections.
## 3.1 Approximate Transformer Shape and Hyperparameter Independence
Transformer performance depends very weakly on the shape parameters n layer , n heads , and d ff when we hold the total non-embedding parameter count N fixed. To establish these results we trained models with fixed size while varying a single hyperparameter. This was simplest for the case of n heads . When varying n layer , we simultaneously varied d model while keeping N ≈ 12 n layer d 2 model fixed. Similarly, to vary d ff at fixed model size we also simultaneously varied the d model parameter, as required by the parameter counts in Table 1. Independence of n layers would follow if deeper Transformers effectively behave as ensembles of shallower models, as has been suggested for ResNets [VWB16]. The results are shown in Figure 5.
## 3.2 Performance with Non-Embedding Parameter Count N
In Figure 6 we display the performance of a wide variety of models, ranging from small models with shape ( n layer , d model ) = (2 , 128) through billion-parameter models, ranging in shape from (6 , 4288) through (207 , 768) . Here we have trained to near convergence on the full WebText2 dataset and observe no overfitting (except possibly for the very largest models).
As shown in Figure 1, we find a steady trend with non-embedding parameter count N , which can be fit to the first term of Equation (1.5), so that
<!-- formula-not-decoded -->
Figure 7
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## Charts: Transformer vs LSTM Performance
### Overview
The image presents two charts comparing the performance of Transformer and LSTM models. The left chart shows Test Loss versus Parameters (non-embedding), demonstrating how Transformers asymptotically outperform LSTMs as the number of parameters increases. The right chart shows Per-token Test Loss versus Token Index in Context, illustrating that LSTMs plateau after approximately 100 tokens, while Transformers continue to improve with increasing context length.
### Components/Axes
**Left Chart:**
* **Title:** "Transformers asymptotically outperform LSTMs due to improved use of long contexts"
* **X-axis:** "Parameters (non-embedding)" - Logarithmic scale from approximately 10<sup>5</sup> to 10<sup>9</sup>.
* **Y-axis:** "Test Loss" - Scale from approximately 3.0 to 5.4.
* **Data Series:**
* "Transformers" (Blue line)
* "LSTMs" (Red lines)
* "1 Layer" (Dark Red)
* "2 Layers" (Light Red)
* "4 Layers" (Very Light Red)
**Right Chart:**
* **Title:** "LSTM plateaus after <100 tokens Transformer improves through the whole context"
* **X-axis:** "Token Index in Context" - Logarithmic scale from approximately 10<sup>0</sup> to 10<sup>3</sup>.
* **Y-axis:** "Per-token Test Loss" - Scale from approximately 2.0 to 6.0.
* **Legend:** "Parameters:"
* "400K" (Darkest Red)
* "2M" (Red)
* "3M" (Light Red)
* "200M" (Very Light Red)
* "300M" (Lightest Red)
### Detailed Analysis or Content Details
**Left Chart:**
* **Transformers (Blue Line):** The line slopes downward consistently, indicating a decrease in Test Loss as the number of parameters increases.
* At approximately 10<sup>5</sup> parameters, Test Loss is around 5.0.
* At approximately 10<sup>7</sup> parameters, Test Loss is around 3.8.
* At approximately 10<sup>9</sup> parameters, Test Loss is around 3.0.
* **LSTMs (Red Lines):** The lines initially decrease, but the rate of decrease slows down and eventually plateaus.
* **1 Layer (Dark Red):** Starts around 5.2, plateaus around 4.2.
* **2 Layers (Light Red):** Starts around 5.0, plateaus around 3.9.
* **4 Layers (Very Light Red):** Starts around 4.8, plateaus around 3.7.
**Right Chart:**
* **400K (Darkest Red):** Starts around 5.8, decreases to approximately 4.0, then plateaus.
* **2M (Red):** Starts around 5.6, decreases to approximately 3.8, then plateaus.
* **3M (Light Red):** Starts around 5.4, decreases to approximately 3.6, then plateaus.
* **200M (Very Light Red):** Starts around 5.2, decreases to approximately 3.2, then plateaus.
* **300M (Lightest Red):** Starts around 5.0, decreases to approximately 2.8, then plateaus.
* All lines show a decrease in Test Loss up to approximately 10<sup>2</sup> (100) Token Index in Context, after which they plateau.
### Key Observations
* Transformers consistently outperform LSTMs across all parameter sizes in the left chart.
* LSTMs exhibit diminishing returns with increasing parameters, while Transformers continue to improve.
* LSTMs show a clear plateau effect in the right chart, indicating limited ability to leverage longer contexts.
* Transformers continue to improve with increasing context length in the right chart.
* Increasing the number of parameters in both models generally leads to lower Test Loss, but the effect is more pronounced for Transformers.
### Interpretation
The data strongly suggests that Transformers are superior to LSTMs, particularly when dealing with long-range dependencies in data. The asymptotic improvement of Transformers with increasing parameters indicates a greater capacity to model complex relationships. The plateauing of LSTMs, both in terms of parameters and context length, highlights their limitations in handling long sequences. The right chart visually demonstrates the core advantage of Transformers: their ability to effectively utilize information from a wider context window, leading to improved performance. The logarithmic scales on both axes suggest that the benefits of Transformers are particularly significant at larger scales (more parameters, longer contexts). The difference in performance is not merely a matter of scale; the fundamental architecture of Transformers allows them to overcome the vanishing gradient problem that plagues LSTMs when processing long sequences.
</details>
To observe these trends it is crucial to study performance as a function of N ; if we instead use the total parameter count (including the embedding parameters) the trend is somewhat obscured (see Figure 6). This suggests that the embedding matrix can be made smaller without impacting performance, as has been seen in recent work [LCG + 19].
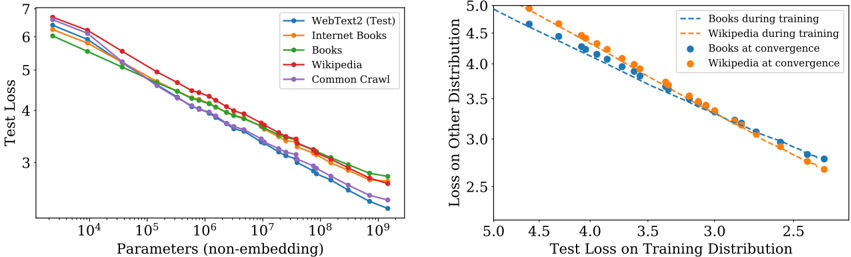
Although these models have been trained on the WebText2 dataset, their test loss on a variety of other datasets is also a power-law in N with nearly identical power, as shown in Figure 8.
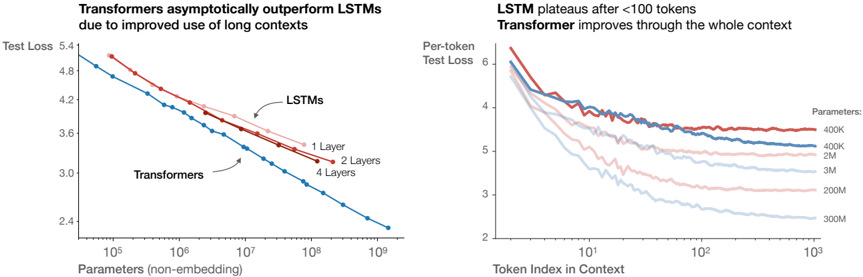
## 3.2.1 Comparing to LSTMs and Universal Transformers
In Figure 7 we compare LSTM and Transformer performance as a function of non-embedding parameter count N . The LSTMs were trained with the same dataset and context length. We see from these figures that the LSTMs perform as well as Transformers for tokens appearing early in the context, but cannot match the Transformer performance for later tokens. We present power-law relationships between performance and context position Appendix D.5, where increasingly large powers for larger models suggest improved ability to quickly recognize patterns.
We also compare the performance of standard Transformers to recurrent Transformers [DGV + 18] in Figure 17 in the appendix. These models re-use parameters, and so perform slightly better as a function of N , at the cost of additional compute per-parameter.
## 3.2.2 Generalization Among Data Distributions
We have also tested our models on a set of additional text data distributions. The test loss on these datasets as a function of model size is shown in Figure 8; in all cases the models were trained only on the WebText2 dataset. We see that the loss on these other data distributions improves smoothly with model size, in direct parallel with the improvement on WebText2. We find that generalization depends almost exclusively on the in-distribution validation loss, and does not depend on the duration of training or proximity to convergence. We also observe no dependence on model depth (see Appendix D.8).
## 3.3 Performance with Dataset Size and Compute
We display empirical trends for the test loss as a function of dataset size D (in tokens) and training compute C in Figure 1.
For the trend with D we trained a model with ( n layer , n embd ) = (36 , 1280) on fixed subsets of the WebText2 dataset. We stopped training once the test loss ceased to decrease. We see that the resulting test losses can be fit with simple power-law
<!-- formula-not-decoded -->
in the dataset size. The data and fit appear in Figure 1.
The total amount of non-embedding compute used during training can be estimated as C = 6 NBS , where B is the batch size, S is the number of parameter updates, and the factor of 6 accounts for the forward and backward passes. Thus for a given value of C we can scan over all models with various N to find the model
using three principles:
1. Changes in vocabulary size or tokenization are expected to rescale the loss by an overall factor. The parameterization of L ( N,D ) (and all models of the loss) must naturally allow for such a rescaling.
2. Fixing D and sending N → ∞ , the overall loss should approach L ( D ) . Conversely, fixing N and sending D →∞ the loss must approach L ( N ) .
3. L ( N,D ) should be analytic at D = ∞ , so that it has a series expansion in 1 /D with integer powers. Theoretical support for this principle is significantly weaker than for the first two.
Our choice of L ( N,D ) satisfies the first requirement because we can rescale N c , D c with changes in the vocabulary. This also implies that the values of N c , D c have no fundamental meaning.
<details>
<summary>Image 8 Details</summary>
### Visual Description
\n
## Charts: Training Loss vs. Parameters & Loss Distribution
### Overview
The image presents two charts. The left chart depicts the relationship between the number of parameters (non-embedding) and the test loss for different datasets. The right chart shows the loss on another distribution plotted against the test loss on the training distribution, for Books and Wikipedia datasets during training and at convergence.
### Components/Axes
**Left Chart:**
* **X-axis:** Parameters (non-embedding), logarithmic scale from approximately 10<sup>4</sup> to 10<sup>9</sup>.
* **Y-axis:** Test Loss, linear scale from approximately 2.5 to 7.
* **Data Series:**
* WebText2 (Test) - Blue line
* Internet Books - Orange line
* Books - Green line
* Wikipedia - Yellow line
* Common Crawl - Purple line
**Right Chart:**
* **X-axis:** Test Loss on Training Distribution, linear scale from approximately 2.0 to 5.0.
* **Y-axis:** Loss on Other Distribution, linear scale from approximately 2.5 to 5.0.
* **Data Series:**
* Books during training - Light blue dashed line
* Wikipedia during training - Orange dashed line
* Books at convergence - Blue dots
* Wikipedia at convergence - Orange dots
### Detailed Analysis or Content Details
**Left Chart:**
* **WebText2 (Test):** The blue line starts at approximately 6.2 at 10<sup>4</sup> parameters and decreases steadily to approximately 2.7 at 10<sup>9</sup> parameters.
* **Internet Books:** The orange line starts at approximately 6.0 at 10<sup>4</sup> parameters and decreases to approximately 3.2 at 10<sup>9</sup> parameters.
* **Books:** The green line starts at approximately 6.1 at 10<sup>4</sup> parameters and decreases to approximately 3.0 at 10<sup>9</sup> parameters.
* **Wikipedia:** The yellow line starts at approximately 6.1 at 10<sup>4</sup> parameters and decreases to approximately 3.1 at 10<sup>9</sup> parameters.
* **Common Crawl:** The purple line starts at approximately 6.3 at 10<sup>4</sup> parameters and decreases to approximately 3.3 at 10<sup>9</sup> parameters.
* All lines exhibit a decreasing trend, indicating that increasing the number of parameters generally reduces the test loss. The rate of decrease slows down as the number of parameters increases.
**Right Chart:**
* **Books during training:** The light blue dashed line starts at approximately (4.8, 4.8) and decreases to approximately (2.5, 3.0).
* **Wikipedia during training:** The orange dashed line starts at approximately (4.8, 4.6) and decreases to approximately (2.5, 3.1).
* **Books at convergence:** The blue dots are at approximately (3.0, 3.0), (3.2, 2.8), (3.5, 2.6), (4.0, 2.5), (4.5, 2.4).
* **Wikipedia at convergence:** The orange dots are at approximately (3.0, 3.2), (3.2, 2.9), (3.5, 2.7), (4.0, 2.6), (4.5, 2.5).
* Both datasets show a negative correlation between test loss on the training distribution and loss on the other distribution.
### Key Observations
* In the left chart, WebText2 consistently exhibits the lowest test loss across all parameter ranges.
* The rate of loss reduction diminishes as the number of parameters increases for all datasets.
* In the right chart, the training curves (dashed lines) are relatively linear, while the convergence points (dots) show a slight curvature.
* The convergence points for Books and Wikipedia are close to each other, suggesting similar performance at convergence.
### Interpretation
The left chart demonstrates the scaling behavior of language models with varying dataset sizes. The consistent lower loss of WebText2 suggests that this dataset is more effective for training, potentially due to its quality or diversity. The diminishing returns of increasing parameters indicate a point of saturation where adding more parameters yields less significant improvements in performance.
The right chart illustrates the concept of generalization. The negative correlation between loss on the training distribution and loss on another distribution suggests that models performing well on the training data also tend to generalize better to unseen data. The convergence points indicate that both Books and Wikipedia datasets can achieve comparable performance when trained to convergence. The difference between the training curves and convergence points highlights the impact of training on model generalization. The fact that the convergence points are not perfectly aligned suggests that the datasets have different characteristics that affect their generalization performance.
</details>
∑∐√∐⌉˜√˜√√({{}{∖˜⌉̂˜̂̂]{˜}
}}⌋√(̂√√]{˜(√√∐]{]{˜
∨]⌋]√˜̂]∐(̂√√]{˜(√√∐]{]{˜
∨]⌋]√˜̂]∐(∐√(̂}{√˜√˜˜{̂˜
⋂˜√√(⊕}√√(}{(⋂√∐]{]{˜(〈]√√√]̂√√]}{
Figure 8 Left: Generalization performance to other data distributions improves smoothly with model size, with only a small and very slowly growing offset from the WebText2 training distribution. Right: Generalization performance depends only on training distribution performance, and not on the phase of training. We compare generalization of converged models (points) to that of a single large model (dashed curves) as it trains.
with the best performance on step S = C 6 BS . Note that in these results the batch size B remains fixed for all models , which means that these empirical results are not truly optimal. We will account for this in later sections using an adjusted C min to produce cleaner trends.
The result appears as the heavy black line on the left-hand plot in Figure 1. It can be fit with
<!-- formula-not-decoded -->
The figure also includes images of individual learning curves to clarify when individual models are optimal. Wewill study the optimal allocation of compute more closely later on. The data strongly suggests that sample efficiency improves with model size, and we also illustrate this directly in Figure 19 in the appendix.
## 4 Charting the Infinite Data Limit and Overfitting
In Section 3 we found a number of basic scaling laws for language modeling performance. Here we will study the performance of a model of size N trained on a dataset with D tokens while varying N and D simultaneously. We will empirically demonstrate that the optimally trained test loss accords with the scaling law of Equation (1.5). This provides guidance on how much data we would need to train models of increasing size while keeping overfitting under control.
## 4.1 Proposed L ( N,D ) Equation
We have chosen the parameterization (1.5) (repeated here for convenience):
<!-- formula-not-decoded -->
⊕}√√(}{(⊗√[˜√(〈]√√√]̂√√]}{
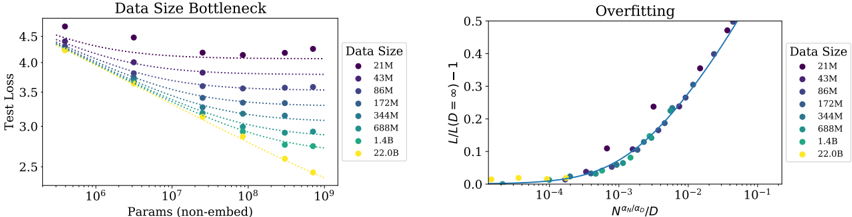
Figure 9 The early-stopped test loss L ( N,D ) depends predictably on the dataset size D and model size N according to Equation (1.5). Left : For large D , performance is a straight power law in N . For a smaller fixed D , performance stops improving as N increases and the model begins to overfit. (The reverse is also true, see Figure 4.) Right : The extent of overfitting depends predominantly on the ratio N α N α D /D , as predicted in equation (4.3). The line is our fit to that equation.
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Charts: Data Size Bottleneck & Overfitting
### Overview
The image presents two charts side-by-side. The left chart, titled "Data Size Bottleneck", depicts the relationship between the number of parameters (non-embedding) and test loss for various data sizes. The right chart, titled "Overfitting", shows the relationship between L/(L-1) and N<sub>val</sub>/D<sub>0</sub>, also for different data sizes. Both charts aim to illustrate how data size impacts model performance, specifically concerning the bottleneck effect and overfitting.
### Components/Axes
**Left Chart (Data Size Bottleneck):**
* **X-axis:** Params (non-embed) - Logarithmic scale, ranging from approximately 10<sup>6</sup> to 10<sup>9</sup>.
* **Y-axis:** Test Loss - Linear scale, ranging from approximately 2.4 to 4.6.
* **Legend:** Data Size, with the following categories:
* 21M (Purple)
* 43M (Dark Blue)
* 86M (Light Blue)
* 172M (Teal)
* 344M (Green)
* 688M (Dark Green)
* 1.4B (Yellow)
* 22.08 (Gold)
**Right Chart (Overfitting):**
* **X-axis:** N<sub>val</sub>/D<sub>0</sub> - Logarithmic scale, ranging from approximately 10<sup>-5</sup> to 10<sup>-1</sup>.
* **Y-axis:** L/(L-1) - 1 - Linear scale, ranging from approximately 0 to 0.5.
* **Legend:** Data Size, with the same categories as the left chart:
* 21M (Purple)
* 43M (Dark Blue)
* 86M (Light Blue)
* 172M (Teal)
* 344M (Green)
* 688M (Dark Green)
* 1.4B (Yellow)
* 22.08 (Gold)
### Detailed Analysis or Content Details
**Left Chart (Data Size Bottleneck):**
* **21M (Purple):** The line starts at approximately 4.5 and decreases slowly, leveling off around 3.8.
* **43M (Dark Blue):** The line starts at approximately 4.3 and decreases more rapidly than the 21M line, reaching around 3.2.
* **86M (Light Blue):** The line starts at approximately 4.1 and decreases rapidly, reaching around 2.8.
* **172M (Teal):** The line starts at approximately 3.9 and decreases rapidly, reaching around 2.7.
* **344M (Green):** The line starts at approximately 3.6 and decreases rapidly, reaching around 2.6.
* **688M (Dark Green):** The line starts at approximately 3.3 and decreases rapidly, reaching around 2.5.
* **1.4B (Yellow):** The line starts at approximately 3.1 and decreases rapidly, reaching around 2.4.
* **22.08 (Gold):** The line starts at approximately 2.9 and decreases very rapidly, reaching around 2.3.
**Right Chart (Overfitting):**
* **21M (Purple):** The line starts at approximately 0 and increases rapidly, reaching 0.45 at approximately 10<sup>-2</sup>.
* **43M (Dark Blue):** The line starts at approximately 0 and increases rapidly, reaching 0.35 at approximately 10<sup>-2</sup>.
* **86M (Light Blue):** The line starts at approximately 0 and increases rapidly, reaching 0.25 at approximately 10<sup>-2</sup>.
* **172M (Teal):** The line starts at approximately 0 and increases rapidly, reaching 0.18 at approximately 10<sup>-2</sup>.
* **344M (Green):** The line starts at approximately 0 and increases rapidly, reaching 0.12 at approximately 10<sup>-2</sup>.
* **688M (Dark Green):** The line starts at approximately 0 and increases rapidly, reaching 0.08 at approximately 10<sup>-2</sup>.
* **1.4B (Yellow):** The line starts at approximately 0 and increases rapidly, reaching 0.05 at approximately 10<sup>-2</sup>.
* **22.08 (Gold):** The line starts at approximately 0 and increases rapidly, reaching 0.03 at approximately 10<sup>-2</sup>.
### Key Observations
* In the "Data Size Bottleneck" chart, increasing the data size consistently lowers the test loss, indicating improved model performance. The rate of decrease slows down as the data size increases, suggesting a diminishing return.
* In the "Overfitting" chart, larger data sizes (smaller values on the x-axis) result in lower values of L/(L-1) - 1, indicating less overfitting. The curves show a steep increase for smaller data sizes, demonstrating a higher susceptibility to overfitting.
* The lines for larger data sizes (yellow and gold) are more flattened in both charts, suggesting that they are less sensitive to changes in parameters and less prone to overfitting.
### Interpretation
These charts demonstrate the crucial role of data size in training machine learning models. The "Data Size Bottleneck" chart illustrates that increasing data size reduces test loss, but there's a point of diminishing returns. The "Overfitting" chart shows that larger datasets mitigate overfitting, as evidenced by the lower L/(L-1) - 1 values.
The relationship between the two charts is that the bottleneck effect (limited improvement with more parameters) is exacerbated by overfitting when the data size is small. As the data size increases, the model can leverage more parameters without overfitting, leading to better performance.
The gold line (22.08) consistently performs best across both charts, indicating that this data size provides a good balance between model capacity and generalization ability. The purple line (21M) consistently performs worst, highlighting the challenges of training models with limited data. The logarithmic scales on the x-axes suggest that the relationships are not linear, and that the benefits of increasing data size or parameters may saturate at some point.
</details>
Since we stop training early when the test loss ceases to improve and optimize all models in the same way, we expect that larger models should always perform better than smaller models. But with fixed finite D , we also do not expect any model to be capable of approaching the best possible loss (ie the entropy of text). Similarly, a model with fixed size will be capacity-limited. These considerations motivate our second principle. Note that knowledge of L ( N ) at infinite D and L ( D ) at infinite N fully determines all the parameters in L ( N,D ) .
The third principle is more speculative. There is a simple and general reason one might expect overfitting to scale ∝ 1 /D at very large D . Overfitting should be related to the variance or the signal-to-noise ratio of the dataset [AS17], and this scales as 1 /D . This expectation should hold for any smooth loss function, since we expect to be able to expand the loss about the D →∞ limit. However, this argument assumes that 1 /D corrections dominate over other sources of variance, such as the finite batch size and other limits on the efficacy of optimization. Without empirical confirmation, we would not be very confident of its applicability.
Our third principle explains the asymmetry between the roles of N and D in Equation (1.5). Very similar symmetric expressions 4 are possible, but they would not have a 1 /D expansion with integer powers, and would require the introduction of an additional parameter.
In any case, we will see that our equation for L ( N,D ) fits the data well, which is the most important justification for our L ( N,D ) ansatz.
## 4.2 Results
We regularize all our models with 10% dropout, and by tracking test loss and stopping once it is no longer decreasing. The results are displayed in Figure 9, including a fit to the four parameters α N , α D , N c , D c in Equation (1.5):
Table 2 Fits to L ( N,D )
| Parameter | α N | α D | N c | D c |
|-------------|---------|---------|---------------|---------------|
| Value | 0 . 076 | 0 . 103 | 6 . 4 × 10 13 | 1 . 8 × 10 13 |
We obtain an excellent fit, with the exception of the runs where the dataset has been reduced by a factor of 1024 , to about 2 × 10 7 tokens. With such a small dataset, an epoch consists of only 40 parameter updates. Perhaps such a tiny dataset represents a different regime for language modeling, as overfitting happens very early in training (see Figure 16). Also note that the parameters differ very slightly from those obtained in Section 3, as here we are fitting the full L ( N,D ) rather than just L ( N, ∞ ) or L ( ∞ , D ) .
To chart the borderlands of the infinite data limit, we can directly study the extent of overfitting. For all but the largest models, we see no sign of overfitting when training with the full 22B token WebText2 dataset, so we can take it as representative of D = ∞ . Thus we can compare finite D to the infinite data limit by
4 For example, one might have used L ( N,D ) = [( N c N ) α N + ( D c D ) α D ] β , but this does not have a 1 /D expansion.
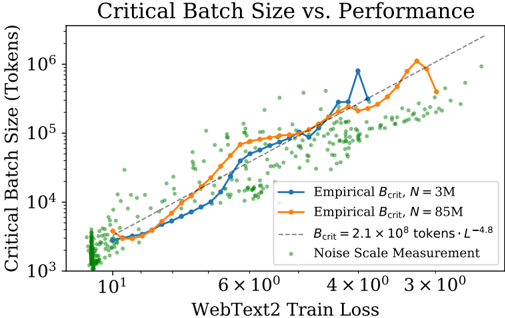
Figure 10 The critical batch size B crit follows a power law in the loss as performance increase, and does not depend directly on the model size. We find that the critical batch size approximately doubles for every 13% decrease in loss. B crit is measured empirically from the data shown in Figure 18, but it is also roughly predicted by the gradient noise scale, as in [MKAT18].
<details>
<summary>Image 10 Details</summary>
### Visual Description
\n
## Chart: Critical Batch Size vs. Performance
### Overview
The image presents a chart illustrating the relationship between Critical Batch Size (in tokens) and WebText2 Train Loss. The chart displays two empirical curves representing different dataset sizes (N = 3M and N = 85M), a theoretical curve, and a scatter plot representing noise scale measurements. The chart aims to demonstrate how critical batch size scales with training loss and dataset size.
### Components/Axes
* **Title:** "Critical Batch Size vs. Performance" (Top-center)
* **X-axis:** "WebText2 Train Loss" (Bottom-center). Scale is logarithmic, with markers at 10<sup>1</sup>, 6 x 10<sup>0</sup>, 4 x 10<sup>0</sup>, 3 x 10<sup>0</sup>.
* **Y-axis:** "Critical Batch Size (Tokens)" (Left-center). Scale is logarithmic, with markers at 10<sup>3</sup>, 10<sup>4</sup>, 10<sup>5</sup>, 10<sup>6</sup>.
* **Legend:** Located in the top-right corner.
* "Empirical B<sub>crit</sub>, N = 3M" (Solid blue line)
* "Empirical B<sub>crit</sub>, N = 85M" (Solid orange line)
* "B<sub>crit</sub> = 2.1 x 10<sup>8</sup> tokens · L<sup>-4.8</sup>" (Gray dashed line)
* "Noise Scale Measurement" (Green dotted points)
### Detailed Analysis
The chart displays the following data:
* **Empirical B<sub>crit</sub>, N = 3M (Blue Line):** This line shows an upward trend, initially steep, then leveling off.
* At WebText2 Train Loss ≈ 10<sup>1</sup>, Critical Batch Size ≈ 2 x 10<sup>3</sup> tokens.
* At WebText2 Train Loss ≈ 6 x 10<sup>0</sup>, Critical Batch Size ≈ 1 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 4 x 10<sup>0</sup>, Critical Batch Size ≈ 3 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 3 x 10<sup>0</sup>, Critical Batch Size ≈ 5 x 10<sup>4</sup> tokens.
* There is a peak around WebText2 Train Loss ≈ 2 x 10<sup>0</sup>, with Critical Batch Size ≈ 8 x 10<sup>4</sup> tokens.
* **Empirical B<sub>crit</sub>, N = 85M (Orange Line):** This line also shows an upward trend, but it is generally higher than the blue line.
* At WebText2 Train Loss ≈ 10<sup>1</sup>, Critical Batch Size ≈ 5 x 10<sup>3</sup> tokens.
* At WebText2 Train Loss ≈ 6 x 10<sup>0</sup>, Critical Batch Size ≈ 2 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 4 x 10<sup>0</sup>, Critical Batch Size ≈ 6 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 3 x 10<sup>0</sup>, Critical Batch Size ≈ 1 x 10<sup>6</sup> tokens.
* **B<sub>crit</sub> = 2.1 x 10<sup>8</sup> tokens · L<sup>-4.8</sup> (Gray Dashed Line):** This line represents a theoretical relationship. It shows a generally upward trend, but is less sensitive to the loss values than the empirical lines.
* At WebText2 Train Loss ≈ 10<sup>1</sup>, Critical Batch Size ≈ 2 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 6 x 10<sup>0</sup>, Critical Batch Size ≈ 4 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 4 x 10<sup>0</sup>, Critical Batch Size ≈ 6 x 10<sup>4</sup> tokens.
* At WebText2 Train Loss ≈ 3 x 10<sup>0</sup>, Critical Batch Size ≈ 8 x 10<sup>4</sup> tokens.
* **Noise Scale Measurement (Green Points):** These points are scattered throughout the chart, generally concentrated at lower loss values and lower batch sizes. They appear to represent the inherent noise in the system.
### Key Observations
* The critical batch size increases with decreasing WebText2 Train Loss for both empirical curves.
* The 85M dataset (orange line) requires a larger critical batch size than the 3M dataset (blue line) for the same level of training loss.
* The empirical curves deviate from the theoretical curve, particularly at lower loss values.
* The noise scale measurements are relatively consistent across the range of loss values, but they are more densely populated at lower loss values.
### Interpretation
The chart demonstrates the relationship between critical batch size, training loss, and dataset size. The increasing trend of critical batch size with decreasing loss suggests that as the model learns (loss decreases), a larger batch size is needed to maintain stability and prevent divergence. The difference between the two empirical curves highlights the impact of dataset size on the optimal batch size. Larger datasets generally require larger batch sizes. The deviation between the empirical curves and the theoretical curve suggests that the theoretical model may not fully capture the complexities of the training process. The noise scale measurements provide insight into the inherent variability of the system, which can influence the optimal batch size. The chart suggests that choosing an appropriate batch size is crucial for effective training, and that the optimal batch size depends on both the dataset size and the current training loss. The logarithmic scales suggest that the relationship is not linear, and that small changes in loss can have a significant impact on the required batch size.
</details>
defining
$$\delta L ( N , D ) \equiv \frac { L ( N , D ) } { L ( N , \infty ) } - 1 \quad ( 4 . 2 )$$
and studying it as a function of N,D . In fact, we see empirically that δL depends only a specific combination of N and D , as shown in Figure 16. This follows from the scaling law of Equation (1.5), which implies
<!-- formula-not-decoded -->
Note that at large D this formula also has a series expansion in powers of 1 /D .
We estimate that the variation in the loss with different random seeds is roughly 0 . 02 , which means that to avoid overfitting when training to within that threshold of convergence we require
<!-- formula-not-decoded -->
With this relation, models smaller than 10 9 parameters can be trained with minimal overfitting on the 22B token WebText2 dataset, but our largest models will encounter some mild overfitting. More generally, this relation shows that dataset size may grow sub-linearly in model size while avoiding overfitting. Note however that this does not typically represent maximally compute-efficient training. We should also emphasize that we have not optimized regularization (eg the dropout probability) while varying dataset and model size.
## 5 Scaling Laws with Model Size and Training Time
In this section we will demonstrate that a simple scaling law provides a good description for the loss as a function of model size N and training time. First we will explain how to use the results of [MKAT18] to define a universal training step S min , which accounts for the fact that most of our models have not been trained at an optimal batch size. Then we will demonstrate that we can fit the model size and training time dependence of the loss using Equation (1.6). Later we will use these results to predict the optimal allocation of training compute between model size and training time, and then confirm that prediction.
## 5.1 Adjustment for Training at B crit ( L )
A simple empirical theory for the batch size dependence of training was developed in [MKAT18] (see also [SLA + 18, ZLN + 19]). It was argued that there is a critical batch size B crit for training; for B up to B crit the batch size can be increased with very minimal degradation in compute-efficiency, whereas for B > B crit increases in B result in diminishing returns. It was also argued that the gradient noise scale provides a simple
prediction for B crit , and that neither depends directly on model size except through the value of the loss that has been attained. These results can be used to predict how training time and compute will vary with the batch size. To utilize both training time and compute as effectively as possible, it is best to train with a batch size B ≈ B crit . Training at B B crit minimizes the number of training steps, while B B crit minimizes the use of compute.
More specifically, it was demonstrated that for a wide variety of neural network tasks, the number of training steps S and the number of data examples processed E = BS satisfy the simple relation
$$\left ( { \frac { S } { S _ { \min } } } - 1 \right ) \left ( { \frac { E } { E _ { \min } } } - 1 \right ) = 1 \quad ( 5 . 1 )$$
when training to any fixed value of the loss L . Here S min is the minimum number of steps necessary to reach L , while E min is the minimum number of data examples that must be processed.
We demonstrate the relation (5.1) for Transformers in Figure 18 in the appendix. This relation defines the critical batch size
<!-- formula-not-decoded -->
which is a function of the target value of the loss. Training at the critical batch size makes a roughly optimal time/compute tradeoff, requiring 2 S min training steps and processing E = 2 E min data examples.
In Figure 10 we have plotted the critical batch size and gradient noise scale 5 as a function of training loss for two different models. We see that B crit ( L ) is independent of model size, and only depends on the loss L . So the predictions of [MKAT18] continue to hold for Transformer language models. The critical batch size can be fit with a power-law in the loss
<!-- formula-not-decoded -->
where B ∗ ≈ 2 × 10 8 and α B ≈ 0 . 21 .
We have chosen this parameterization for B crit ( L ) because as the loss approaches its minimum value L min , the gradient noise scale is expected to diverge, and we expect B crit to track this noise scale. We do not know L min , as we see no sign that our models are approaching it, but L min > 0 since the entropy of natural language is non-zero. Since apparently L min is much smaller than the values of L we have achieved, we used a parameterization where B crit diverges as L → 0 .
We will use B crit ( L ) to estimate the relation between the number of training steps S while training at batch size B = 2 19 tokens and the number of training steps while training at B B crit . This is simply
<!-- formula-not-decoded -->
for any given target value L for the loss. This also defines a critical value of the compute needed to train to L with a model of size N if we were to train at B B crit ( L ) . This is
<!-- formula-not-decoded -->
where C = 6 NBS estimates the (non-embedding) compute used at batch size B .
## 5.2 Results for L ( N,S min ) and Performance with Model Size and Compute
Now we will use S min defined in Equation (5.4) to obtain a simple and universal fit for the dependence of the loss on model size and training time in the infinite data limit. We will fit the stable, Adam-optimized training runs using Equation (1.6), repeated here for convenience:
<!-- formula-not-decoded -->
for the loss. We include all training steps after the warmup period of the learning rate schedule, and find a fit to the data with the parameters:
5 Although the critical batch size roughly matches the gradient noise scale, we are using a direct measurements of B crit from Figures 18 and 10 for all our later analyses.
Figure 11 When we hold either total compute or number of training steps fixed, performance follows L ( N,S ) from Equation (5.6). Each value of compute budget has an associated optimal model size that maximizes performance. Mediocre fits at small S are unsurprising, as the power-law equation for the learning curves breaks down very early in training.
<details>
<summary>Image 11 Details</summary>
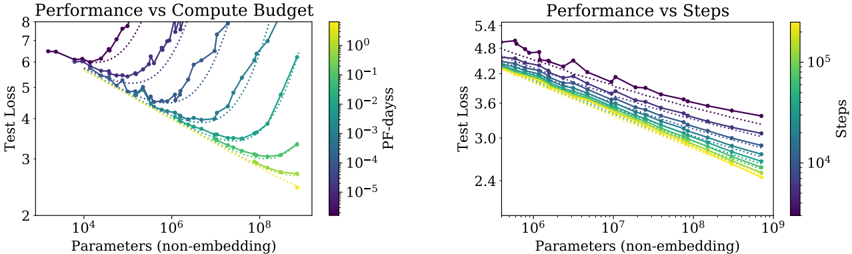
### Visual Description
\n
## Charts: Performance vs Compute Budget & Performance vs Steps
### Overview
The image contains two charts, both depicting performance (Test Loss) against model size (Parameters (non-embedding)). The left chart shows performance against compute budget (PF-days), while the right chart shows performance against training steps. Both charts use color to represent a third variable, allowing for a multi-dimensional view of the data.
### Components/Axes
**Common Elements:**
* **Y-axis Label:** "Test Loss" (Scale ranges from approximately 2 to 8 in the left chart and 2.4 to 5.4 in the right chart).
* **X-axis Label:** "Parameters (non-embedding)" (Logarithmic scale. Left chart ranges from approximately 10<sup>4</sup> to 10<sup>9</sup>. Right chart ranges from approximately 10<sup>6</sup> to 10<sup>9</sup>).
**Left Chart:**
* **Title:** "Performance vs Compute Budget"
* **Colorbar Label:** "PF-days" (Logarithmic scale, ranging from approximately 10<sup>-5</sup> to 10<sup>0</sup>).
* **Lines:** Multiple lines representing different models or configurations.
**Right Chart:**
* **Title:** "Performance vs Steps"
* **Colorbar Label:** "Steps" (Logarithmic scale, ranging from approximately 10<sup>4</sup> to 10<sup>5</sup>).
* **Lines:** Multiple lines representing different models or configurations.
### Detailed Analysis or Content Details
**Left Chart: Performance vs Compute Budget**
The chart displays several lines, each representing a different model or training configuration. The lines generally show a decreasing trend in Test Loss as the number of Parameters increases, indicating improved performance. The color of each line corresponds to the compute budget (PF-days) used for training, as indicated by the colorbar on the right.
* **Dark Purple Line:** Starts at approximately 7.2 Test Loss at 10<sup>4</sup> Parameters, fluctuates, and ends at approximately 3.2 Test Loss at 10<sup>9</sup> Parameters. Represents a high compute budget (PF-days ≈ 10<sup>0</sup>).
* **Blue Line:** Starts at approximately 6.5 Test Loss at 10<sup>4</sup> Parameters, decreases steadily, and ends at approximately 2.8 Test Loss at 10<sup>9</sup> Parameters. Represents a medium-high compute budget (PF-days ≈ 10<sup>-1</sup>).
* **Green Line:** Starts at approximately 5.5 Test Loss at 10<sup>4</sup> Parameters, decreases steadily, and ends at approximately 2.5 Test Loss at 10<sup>9</sup> Parameters. Represents a medium compute budget (PF-days ≈ 10<sup>-2</sup>).
* **Yellow Line:** Starts at approximately 4.5 Test Loss at 10<sup>4</sup> Parameters, decreases rapidly, and ends at approximately 2.3 Test Loss at 10<sup>9</sup> Parameters. Represents a low compute budget (PF-days ≈ 10<sup>-3</sup>).
* **Light Yellow Line:** Starts at approximately 3.8 Test Loss at 10<sup>4</sup> Parameters, decreases rapidly, and ends at approximately 2.2 Test Loss at 10<sup>9</sup> Parameters. Represents a very low compute budget (PF-days ≈ 10<sup>-4</sup>).
**Right Chart: Performance vs Steps**
This chart shows a similar trend, with Test Loss decreasing as the number of Parameters increases. The color of each line corresponds to the number of training steps taken, as indicated by the colorbar on the right.
* **Dark Purple Line:** Starts at approximately 4.9 Test Loss at 10<sup>6</sup> Parameters, fluctuates, and ends at approximately 3.8 Test Loss at 10<sup>9</sup> Parameters. Represents a low number of steps (Steps ≈ 10<sup>4</sup>).
* **Blue Line:** Starts at approximately 4.7 Test Loss at 10<sup>6</sup> Parameters, decreases steadily, and ends at approximately 3.4 Test Loss at 10<sup>9</sup> Parameters. Represents a medium-low number of steps (Steps ≈ 2 x 10<sup>4</sup>).
* **Green Line:** Starts at approximately 4.5 Test Loss at 10<sup>6</sup> Parameters, decreases steadily, and ends at approximately 3.2 Test Loss at 10<sup>9</sup> Parameters. Represents a medium number of steps (Steps ≈ 4 x 10<sup>4</sup>).
* **Yellow Line:** Starts at approximately 4.3 Test Loss at 10<sup>6</sup> Parameters, decreases rapidly, and ends at approximately 3.0 Test Loss at 10<sup>9</sup> Parameters. Represents a medium-high number of steps (Steps ≈ 6 x 10<sup>4</sup>).
* **Light Yellow Line:** Starts at approximately 4.1 Test Loss at 10<sup>6</sup> Parameters, decreases rapidly, and ends at approximately 2.8 Test Loss at 10<sup>9</sup> Parameters. Represents a high number of steps (Steps ≈ 8 x 10<sup>4</sup>).
### Key Observations
* In both charts, increasing the number of Parameters generally leads to lower Test Loss.
* In the left chart, higher compute budgets (PF-days) tend to result in slightly higher initial Test Loss but potentially more stable training.
* In the right chart, a higher number of training steps generally leads to lower Test Loss.
* The lines representing lower compute budgets (left chart) and higher steps (right chart) show the most rapid decrease in Test Loss.
* There is some variation in performance between different models or configurations, even with similar compute budgets or training steps.
### Interpretation
These charts demonstrate the trade-offs between model size, compute budget, training steps, and performance. Increasing model size (Parameters) generally improves performance (lower Test Loss). However, the optimal balance depends on the available compute resources and training time.
The left chart suggests that while higher compute budgets don't necessarily guarantee the lowest Test Loss, they can lead to more stable training and potentially better generalization. The right chart highlights the importance of sufficient training steps to achieve optimal performance.
The color gradients in both charts provide valuable insights into the relationship between these factors. For example, the left chart shows that models trained with lower compute budgets can achieve comparable performance to those trained with higher budgets, but they may require more careful tuning or regularization. The right chart shows that increasing the number of steps can improve performance, but there may be diminishing returns beyond a certain point.
The variation between the lines suggests that other factors, such as model architecture or hyperparameter settings, also play a significant role in determining performance. Further investigation would be needed to understand these factors and optimize model training for specific applications.
</details>
Table 3 Fits to L ( N,S )
| Parameter | α N | α S | N c | S c |
|-------------|---------|--------|---------------|--------------|
| Value | 0 . 077 | 0 . 76 | 6 . 5 × 10 13 | 2 . 1 × 10 3 |
With these parameters, we obtain the learning curve fits in Figure 4. Though the fits are imperfect, we believe they are quite compelling given the simplicity of Equation (5.6).
The data and fits can be visualized in a different and more interesting way, as shown in Figure 11. There we study the test loss as a function of model size while fixing either the total non-embedding compute C used in training, or the number of steps S . For the fits we use Equation (5.5) and (5.4) along with the parameters above and Equation (5.6).
The power-law dependence of the loss on S min reflects the interplay of optimizer dynamics and the loss landscape. Since the fits are best late in training, when the loss may be approximately quadratic, the powerlaw should provide information about the spectrum of the Hessian of the loss. Its universality suggests that the Hessian eigenvalue density is roughly independent of model size.
## 5.3 Lower Bound on Early Stopping Step
The results for L ( N,S min ) can be used to derive a lower-bound (and rough estimate) of the step at which early stopping should occur when training is data limited. It is motivated by the idea that finite and infinite D learning curves for a given model will be very similar until we reach S min ≈ S stop . Thus overfitting should be proportional to the correction from simply ending training at S stop . This will underestimate S stop , because in reality the test loss will decrease more slowly when we have a finite D , and therefore we will require more training steps to reach the optimal test loss at finite D . This line of reasoning leads to the inequality
$$S _ { s t o p } ( N , D ) \gtrsim \frac { S _ { c } } { [ L ( N , D ) - L ( N , \infty ) ] ^ { 1 / \alpha _ { S } } }$$
where L ( N, ∞ ) is the converged loss, evaluated with infinite available data. This inequality and its comparison to the empirical data is displayed in Figure 16 in the appendix. In that figure, the values of S stop and L ( N,D ) are empirical (though S stop is adjusted to mimic training at B B crit ), while L ( N, ∞ ) is computed from the fit to L ( N,D ) evaluated at D = ∞ .
## 6 Optimal Allocation of the Compute Budget
We displayed the empirical trend of performance as a function of the computation used during training in the top-right of Figure 1. However, this result involved training at a fixed batch size B , whereas we know
Figure 12 Left: Given a fixed compute budget, a particular model size is optimal, though somewhat larger or smaller models can be trained with minimal additional compute. Right: Models larger than the computeefficient size require fewer steps to train, allowing for potentially faster training if sufficient additional parallelism is possible. Note that this equation should not be trusted for very large models, as it is only valid in the power-law region of the learning curve, after initial transient effects.
<details>
<summary>Image 12 Details</summary>
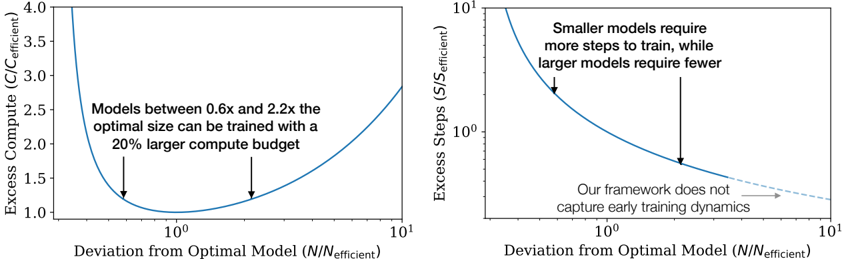
### Visual Description
\n
## Charts: Model Size vs. Compute & Steps
### Overview
The image presents two charts illustrating the relationship between model size and computational resources. The left chart shows the excess compute required as a function of deviation from the optimal model size, while the right chart shows the excess steps required for training as a function of the same deviation. Both charts use a logarithmic scale on the x-axis.
### Components/Axes
**Left Chart:**
* **X-axis:** Deviation from Optimal Model (N/N<sub>efficient</sub>). Scale is logarithmic, ranging from approximately 0.1 to 10.
* **Y-axis:** Excess Compute (C/C<sub>efficient</sub>). Scale is linear, ranging from approximately 1.0 to 4.0.
* **Curve:** A single blue curve representing the relationship between deviation and excess compute.
* **Annotations:** Two downward-pointing arrows indicating minima on the curve. Text annotation: "Models between 0.6x and 2.2x the optimal size can be trained with a 20% larger compute budget."
**Right Chart:**
* **X-axis:** Deviation from Optimal Model (N/N<sub>efficient</sub>). Scale is logarithmic, ranging from approximately 0.1 to 10.
* **Y-axis:** Excess Steps (S/S<sub>efficient</sub>). Scale is logarithmic, ranging from approximately 10<sup>1</sup> to 10<sup>3</sup>.
* **Curve:** A single blue curve representing the relationship between deviation and excess steps.
* **Annotations:** Two downward-pointing arrows indicating a steep decline in steps required. Text annotation: "Smaller models require more steps to train, while larger models require fewer." Text annotation: "Our framework does not capture early training dynamics" with an arrow pointing to the right side of the curve.
### Detailed Analysis or Content Details
**Left Chart:**
The blue curve exhibits a U-shaped trend. It starts at approximately 1.6 at a deviation of 0.1, decreases to a minimum of approximately 1.1 at a deviation of around 1, and then increases again to approximately 3.8 at a deviation of 10. The two minima are located around deviations of 0.6 and 2.2.
**Right Chart:**
The blue curve shows a steep downward slope initially, then flattens out. It starts at approximately 100 at a deviation of 0.1, rapidly decreases to approximately 10 at a deviation of 1, and then continues to decrease to approximately 2 at a deviation of 10. The curve appears to level off after a deviation of approximately 3.
### Key Observations
* Both charts demonstrate a trade-off between model size and computational resources.
* The left chart shows that deviating from the optimal model size increases compute requirements, but within a certain range (0.6x to 2.2x), the increase is manageable (20%).
* The right chart shows that smaller models require significantly more training steps than larger models.
* The right chart's annotation suggests limitations in the framework's ability to model early training dynamics.
### Interpretation
The data suggests that there is an optimal model size that balances computational efficiency and training time. Deviating from this optimal size incurs costs in either compute or training steps. The left chart indicates a tolerance for model size variation, while the right chart highlights the substantial cost of using smaller models in terms of training time. The logarithmic scales on the x-axes emphasize the non-linear relationship between model size and resources. The annotation on the right chart suggests that the observed trend may not hold for the very early stages of training, indicating a potential area for further investigation or model refinement. The two charts together provide a holistic view of the resource implications of model size selection.
</details>
Figure 13 When adjusting performance to simulate training far below the critical batch size, we find a somewhat altered power law for L ( C min ) when compared with the fully empirical results. The conspicuous lump at 10 -5 PF-days marks the transition from 1-layer to 2-layer networks; we exclude 1-layer networks in the power-law fits. It is the L ( C min ) trend that we expect to provide a reliable extrapolation for larger compute.
<details>
<summary>Image 13 Details</summary>
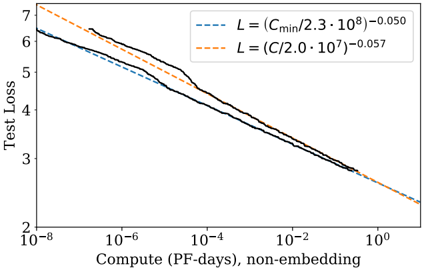
### Visual Description
\n
## Line Chart: Test Loss vs. Compute (PF-days, non-embedding)
### Overview
This image presents a line chart illustrating the relationship between "Compute (PF-days, non-embedding)" on the x-axis and "Test Loss" on the y-axis. Two different loss functions, denoted by equations, are compared. The chart displays the trend of test loss as compute increases, with shaded areas representing confidence intervals around each line.
### Components/Axes
* **X-axis Title:** "Compute (PF-days, non-embedding)"
* **X-axis Scale:** Logarithmic, ranging from 10<sup>-8</sup> to 10<sup>0</sup> (1).
* **Y-axis Title:** "Test Loss"
* **Y-axis Scale:** Linear, ranging from 2 to 7.
* **Legend:** Located in the top-right corner.
* **Line 1:** Dashed blue line labeled "L = (C<sub>min</sub>/2.3 ⋅ 10<sup>8</sup>)<sup>-0.050</sup>"
* **Line 2:** Dashed orange line labeled "L = (C/2.0 ⋅ 10<sup>7</sup>)<sup>-0.057</sup>"
### Detailed Analysis
**Line 1 (Blue, Dashed): L = (C<sub>min</sub>/2.3 ⋅ 10<sup>8</sup>)<sup>-0.050</sup>**
The blue line shows a decreasing trend in test loss as compute increases. The line starts at approximately 6.4 at a compute value of 10<sup>-8</sup> and decreases to approximately 2.6 at a compute value of 10<sup>0</sup>. The shaded area around the line indicates a confidence interval, with the upper bound generally around 0.3-0.5 above the line and the lower bound around 0.2-0.4 below the line.
**Line 2 (Orange, Dashed): L = (C/2.0 ⋅ 10<sup>7</sup>)<sup>-0.057</sup>**
The orange line also exhibits a decreasing trend in test loss with increasing compute. It begins at approximately 6.7 at a compute value of 10<sup>-8</sup> and descends to approximately 2.3 at a compute value of 10<sup>0</sup>. The shaded area around this line is similar in width to the blue line's, with the upper bound generally around 0.3-0.5 above the line and the lower bound around 0.2-0.4 below the line.
**Trend Comparison:**
Both lines demonstrate a similar decreasing trend, indicating that increasing compute generally leads to lower test loss for both loss functions. The orange line appears to consistently be slightly above the blue line across the entire range of compute values, suggesting that the loss function represented by the blue line may perform slightly better.
### Key Observations
* Both loss functions show diminishing returns as compute increases. The rate of decrease in test loss slows down as compute gets larger.
* The confidence intervals suggest that the observed trends are statistically significant, but there is still some variability in the test loss for each compute value.
* The difference between the two loss functions is relatively small, but consistent.
### Interpretation
The chart demonstrates the impact of compute on model performance, as measured by test loss. The decreasing trend in test loss with increasing compute suggests that more computational resources can lead to improved model accuracy. The comparison of two different loss functions allows for an evaluation of their relative effectiveness. The slightly better performance of the loss function represented by the blue line (L = (C<sub>min</sub>/2.3 ⋅ 10<sup>8</sup>)<sup>-0.050</sup>) suggests that it may be a more suitable choice for this particular task. The logarithmic scale on the x-axis highlights the importance of even small increases in compute at very low compute values. The confidence intervals provide a measure of the uncertainty associated with the observed trends, indicating that the results should be interpreted with caution. The chart suggests that there is a point of diminishing returns, where further increases in compute yield progressively smaller improvements in test loss.
</details>
that in fact we could train more efficiently 6 by training at the batch size B crit discussed in Section 5.1. Large and small values of the loss could have been achieved with fewer samples or fewer steps, respectively, and correcting for this inefficiency by standardizing to the critical batch size results in cleaner and more predictable trends.
In this section we will adjust for this oversight. More importantly, we will use the results of Section 5 to determine the optimal allocation of compute between model size N and the quantity of data processed during training, namely 2 B crit S min . We will determine this allocation both empirically and theoretically, by using the equation for L ( N,S min ) , and we will demonstrate that these methods agree.
## 6.1 Optimal Performance and Allocations
Let us first study the loss as a function of the optimally allocated compute from Equation (5.5). The result is plotted in Figure 13, along with a power-law fit. We see that as compared to the compute plot of Figure 1, the new fit with C min is somewhat improved.
Given L ( C min ) , it is natural to ask for the optimal model size N ( C min ) that provides the minimal loss with a given quantity of training compute. The optimal model size is shown in Figure 14. We observe that N ( C min )
6 One might ask why we did not simply train at B crit in the first place. The reason is that it depends not only on the model but also on the target value of the loss we wish to achieve, and so is a moving target.
Figure 14 Left: Each value of the compute budget C min has an associated optimal model size N . Optimal model size grows very rapidly with C min , increasing by 5x for each 10x increase in compute. The number of data examples processed makes up the remainder of the increase, growing relatively modestly by only 2x. Right: The batch-adjusted number of optimization steps also grows very slowly, if at all, meaning that most of the growth in data examples processed can be used for increased batch sizes.
<details>
<summary>Image 14 Details</summary>
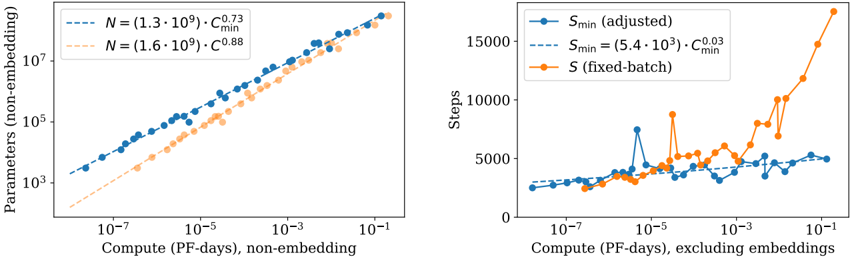
### Visual Description
## Chart: Scaling of Parameters and Steps with Compute
### Overview
The image presents two charts side-by-side, both examining the relationship between compute (measured in PF-days) and either the number of parameters (left chart) or the number of steps (right chart). Both charts display data for different configurations, indicated by different colored lines and associated equations. The left chart focuses on parameter scaling, while the right chart focuses on step scaling.
### Components/Axes
**Left Chart:**
* **X-axis:** Compute (PF-days), non-embedding. Scale is logarithmic, ranging from approximately 10<sup>-7</sup> to 10<sup>-1</sup>.
* **Y-axis:** Parameters (non-embedding). Scale is logarithmic, ranging from approximately 10<sup>3</sup> to 10<sup>5</sup>.
* **Lines/Legends:**
* Blue dashed line: N = (1.3 * 10<sup>9</sup>) * C<sub>min</sub><sup>0.73</sup>
* Orange dashed line: N = (1.6 * 10<sup>9</sup>) * C<sub>min</sub><sup>0.88</sup>
**Right Chart:**
* **X-axis:** Compute (PF-days), excluding embeddings. Scale is logarithmic, ranging from approximately 10<sup>-7</sup> to 10<sup>-1</sup>.
* **Y-axis:** Steps. Scale is linear, ranging from 0 to 15000.
* **Lines/Legends:**
* Blue dashed line: S<sub>min</sub> (adjusted) = (5.4 * 10<sup>3</sup>) * C<sub>min</sub><sup>0.03</sup>
* Orange solid line: S (fixed-batch)
### Detailed Analysis or Content Details
**Left Chart (Parameters vs. Compute):**
* The blue line (N = (1.3 * 10<sup>9</sup>) * C<sub>min</sub><sup>0.73</sup>) starts at approximately 10<sup>3.2</sup> parameters at 10<sup>-7</sup> PF-days and rises to approximately 10<sup>4.8</sup> parameters at 10<sup>-1</sup> PF-days. The line exhibits a generally upward trend, with a slight concavity.
* The orange line (N = (1.6 * 10<sup>9</sup>) * C<sub>min</sub><sup>0.88</sup>) starts at approximately 10<sup>3</sup> parameters at 10<sup>-7</sup> PF-days and rises to approximately 10<sup>5</sup> parameters at 10<sup>-1</sup> PF-days. This line also exhibits an upward trend, but is steeper than the blue line, especially at higher compute values.
**Right Chart (Steps vs. Compute):**
* The blue line (S<sub>min</sub> (adjusted) = (5.4 * 10<sup>3</sup>) * C<sub>min</sub><sup>0.03</sup>) starts at approximately 2000 steps at 10<sup>-7</sup> PF-days, dips to around 1500 steps at 10<sup>-5</sup> PF-days, then rises to approximately 4000 steps at 10<sup>-1</sup> PF-days. The line is relatively flat initially, then shows some fluctuations before a slight increase.
* The orange line (S (fixed-batch)) starts at approximately 2500 steps at 10<sup>-7</sup> PF-days, remains relatively stable until approximately 10<sup>-3</sup> PF-days, then increases sharply to approximately 14000 steps at 10<sup>-1</sup> PF-days. This line shows a much more pronounced increase in steps at higher compute values.
### Key Observations
* Both charts demonstrate a positive correlation between compute and the respective metrics (parameters and steps).
* The parameter scaling (left chart) shows that the orange configuration (higher coefficient) requires more parameters than the blue configuration for a given compute value.
* The step scaling (right chart) shows a significant divergence between the adjusted (blue) and fixed-batch (orange) approaches at higher compute values, with the fixed-batch approach requiring substantially more steps.
* The adjusted step scaling (blue line, right chart) exhibits a dip in steps around 10<sup>-5</sup> PF-days, suggesting a potential optimization or efficiency gain at that compute level.
### Interpretation
The data suggests that increasing compute leads to increased model size (parameters) and training effort (steps). The two parameter scaling curves (left chart) indicate different scaling efficiencies, with the orange curve representing a configuration that requires more parameters for a given compute budget. The right chart highlights the trade-offs between different step scaling strategies. The fixed-batch approach (orange line) becomes significantly more expensive in terms of steps as compute increases, while the adjusted approach (blue line) maintains a more moderate increase. The dip in the adjusted step scaling curve around 10<sup>-5</sup> PF-days could indicate a point where algorithmic optimizations become effective, reducing the number of steps needed for a given level of compute. The equations provided suggest that both parameters and steps scale with C<sub>min</sub> to some power, indicating that the minimum compute unit plays a role in determining the overall resource requirements. The difference in exponents (0.73 vs 0.88 for parameters, and 0.03 for steps) suggests that parameters are more sensitive to changes in C<sub>min</sub> than steps.
</details>
can be fit very well with a power-law where
$$N ( C _ { \min } ) \circ ( C _ { \min } ) ^ { 0 . 7 3 } .$$
In Figure 12, we show the effect of training models of sub-optimal sizes (see Appendix B.4).
By definition C min ≡ 6 NB crit S , and so we can use N ( C min ) to extract further results. In particular, since prior fits show B ∝ L -4 . 8 and L ∝ C -0 . 05 min , we can conclude that B crit ∝ C 0 . 24 min . This leads us to conclude that the optimal number of steps will only grow very slowly with compute, as
$$S _ { \min } \, \infty \left ( C _ { \min } \right ) ^ { 0 . 0 3 } , \quad ( 6 . 2 )$$
matching the empirical results in Figure 14. In fact the measured exponent is sufficiently small that our results may even be consistent with an exponent of zero.
Thus we conclude that as we scale up language modeling with an optimal allocation of computation, we should predominantly increase the model size N , while simultaneously scaling up the batch size via B ∝ B crit with negligible increase in the number of serial steps. Since compute-efficient training uses relatively few optimization steps, additional work on speeding up early training dynamics may be warranted.
## 6.2 Predictions from L ( N,S min )
The results for L ( C min ) and the allocations can be predicted from the L ( N,S min ) equation obtained in Section 5. Given our equation for L ( N,S min ) , we can substitute S min = C min 6 NB and then find the minimum of the loss as a function of N , while fixing the training compute. We carry out this procedure in detail in Appendix B, where we also provide some additional predictions.
For the loss as a function of training compute, we predict that
$$L ( C _ { \min } ) = \left ( \frac { C _ { c } ^ { \min } } { C _ { \min } } \right ) ^ { \alpha _ { C } ^ { \min } }$$
$$\alpha _ { C } ^ { \min } \equiv \frac { 1 } { 1 / \alpha _ { S } + 1 / \alpha _ { B } + 1 / \alpha _ { N } } \approx 0 . 0 5 4 \quad ( 6 . 4 )$$
in excellent agreement with the exponent of Figure 13. We also predict that
$$N ( C _ { \min } ) \, \infty \, ( C _ { \min } ) ^ { \alpha _ { C } ^ { \min } / \alpha _ { N } } \approx ( C _ { \min } ) ^ { 0 . 7 1 } \quad ( 6 . 5 )$$
which also matches the scaling of Figure 14 to within a few percent. Our scaling laws provide a predictive framework for the performance of language modeling.
Figure 15 Far beyond the model sizes we study empirically, we find a contradiction between our equations for L ( C min ) and L ( D ) due to the slow growth of data needed for compute-efficient training. The intersection marks the point before which we expect our predictions to break down. The location of this point is highly sensitive to the precise exponents from our power-law fits.
<details>
<summary>Image 15 Details</summary>
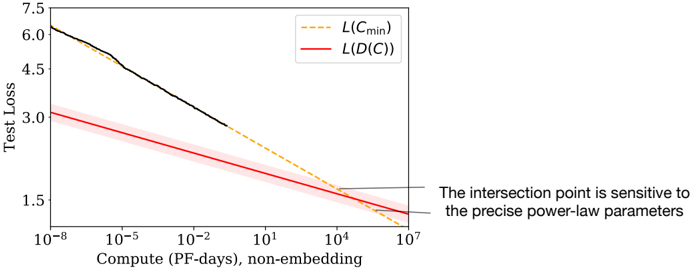
### Visual Description
\n
## Chart: Test Loss vs. Compute (PF-days)
### Overview
The image presents a line chart comparing two loss functions, L(Cmin) and L(D(C)), against the compute cost measured in PF-days (non-embedding). The chart aims to illustrate the relationship between computational effort and test loss for two different approaches. Shaded regions around each line indicate uncertainty or variance.
### Components/Axes
* **X-axis:** "Compute (PF-days), non-embedding" - Logarithmic scale from 10^-8 to 10^7.
* **Y-axis:** "Test Loss" - Linear scale from 1.5 to 7.5.
* **Legend:** Located in the top-right corner.
* `L(Cmin)` - Represented by a dashed orange line.
* `L(D(C))` - Represented by a solid red line.
* **Annotation:** Located on the right side of the chart: "The intersection point is sensitive to the precise power-law parameters".
### Detailed Analysis
**L(Cmin) - Dashed Orange Line:**
The orange line starts at approximately 7.0 at 10^-8 compute and slopes downward, becoming relatively flat around 10^2 compute.
* At 10^-8 compute: Test Loss ≈ 7.0
* At 10^-5 compute: Test Loss ≈ 5.0
* At 10^-2 compute: Test Loss ≈ 3.0
* At 10^0 compute: Test Loss ≈ 2.0
* At 10^4 compute: Test Loss ≈ 1.6
* At 10^7 compute: Test Loss ≈ 1.5
**L(D(C)) - Solid Red Line:**
The red line begins at approximately 6.0 at 10^-8 compute and exhibits a steeper downward slope than the orange line. It intersects with the orange line around 10^2 compute.
* At 10^-8 compute: Test Loss ≈ 6.0
* At 10^-5 compute: Test Loss ≈ 4.0
* At 10^-2 compute: Test Loss ≈ 2.0
* At 10^0 compute: Test Loss ≈ 1.7
* At 10^4 compute: Test Loss ≈ 1.3
* At 10^7 compute: Test Loss ≈ 1.2
**Shaded Regions:**
Both lines are surrounded by shaded regions, indicating uncertainty. The shaded regions are wider at lower compute values and become narrower as compute increases. This suggests greater uncertainty in the loss values at lower compute levels.
### Key Observations
* The red line (L(D(C))) consistently shows lower test loss values compared to the orange line (L(Cmin)) across the entire range of compute values.
* The intersection point of the two lines is around 10^2 compute, where the test loss is approximately 2.0.
* The annotation highlights the sensitivity of this intersection point to the specific power-law parameters used in the model.
* The uncertainty (represented by the shaded regions) is higher at lower compute values, indicating less confidence in the loss estimates in that region.
### Interpretation
The chart suggests that the approach represented by L(D(C)) generally achieves lower test loss for a given compute cost compared to L(Cmin). However, the optimal choice between the two approaches depends on the specific compute budget and the sensitivity of the intersection point to the power-law parameters. The intersection point represents a potential trade-off point where the benefits of L(D(C)) may no longer outweigh the additional computational cost. The higher uncertainty at lower compute values suggests that more data or analysis may be needed to accurately assess the performance of both approaches in that region. The annotation implies that the precise shape of the curves, and therefore the intersection point, is dependent on the underlying model parameters, and careful calibration is required.
</details>
## 6.3 Contradictions and a Conjecture
We observe no signs of deviation from straight power-law trends at large values of compute, data, or model size. Our trends must eventually level off, though, since natural language has non-zero entropy.
Indeed, the trends for compute-efficient training described in this section already contain an apparent contradiction. At scales several orders of magnitude above those documented here, the performance predicted by the L ( C min ) scaling law decreases below what should be possible given the slow growth in training data with compute. This implies that our scaling laws must break down before this point, but we conjecture that the intersection point has a deeper meaning: it provides an estimate of the point at which Transformer language models reach maximal performance.
Since the amount of data used by compute-efficient training grows slowly with the compute budget, the performance predicted by L ( C min ) eventually hits a lower bound set by the L ( D ) power law (see Figure 15). Let us work this out in more detail.
To keep overfitting under control, the results of Section 4 imply that we should scale the dataset size as
$$D \varpropto N ^ { 0 . 7 4 } \varpropto C _ { \min } ^ { 0 . 5 4 }$$
where we have used the compute-efficient N ( C min ) from Figure 14.
Let us compare this to the data requirements of compute-efficient training. If we train at the critical batch size (i.e. C = 2 C min ) and never re-use data during training, we find that data usage grows with compute as
$$D ( C _ { \min } ) = \frac { 2 C _ { \min } } { 6 N ( C _ { \min } ) } \approx \left ( 4 \times 1 0 ^ { 1 0 } t o k e n s \right ) ( C _ { \min } / P F - D a y ) ^ { 0 . 2 6 } \quad ( 6 . 7 )$$
This is the maximum rate at which the dataset size can productively grow with compute, since it means that we are only training for a single epoch. But it grows the dataset much more slowly than in Equation (6.6). It appears to imply that compute-efficient training will eventually run into a problem with overfitting, even if the training process never re-uses any data!
According to Figure 1, we expect that when we are bottlenecked by the dataset size (ie by overfitting), the loss should scale as L ( D ) ∝ D -0 . 095 . This implies that the loss would scale with compute as L ( D ( C min )) ∝ C -0 . 03 min once we are data-limited. Once again, we have a contradiction, as this will eventually intersect with our prediction for L ( C min ) from Figure 13, where we found a scaling L ( C min ) ∝ C -0 . 050 min .
The intersection point of L ( D ( C min )) and L ( C min ) occurs at
$$C ^ { * } \sim 1 0 ^ { 4 } \, P F \text {-Days} \quad N ^ { * } \sim 1 0 ^ { 1 2 } \, \text {parameters} , \quad D ^ { * } \sim 1 0 ^ { 1 2 } \, \text {tokens} , \quad L ^ { * } \sim 1 . 7 \, \text {nats/token} \quad ( 6 . 8 )$$
though the numerical values are highly uncertain, varying by an order or magnitude in either direction depending on the precise values of the exponents from the power-law fits. The most obvious interpretation is that our scaling laws break down at or before we reach this point, which is still many orders of magnitude away in both compute and model size.
One might also conjecture that this intersection point has a deeper meaning. If we cannot increase the model size beyond N ∗ without qualitatively different data requirements, perhaps this means that once we reach C ∗ min and N ∗ , we have extracted all of the reliable information available in natural language data. In this interpretation, L ∗ would provide a rough estimate for the entropy-per-token 7 of natural language. In this scenario, we would expect the loss trend to level off at or before L ∗ .
We can guess at the functional form of L ( C min ) as it levels off by considering a version of our training dataset with added noise. For example, we could append a random string of tokens to each context shown to the model to artificially boost the loss by a constant additive factor. Then, the distance from the noise floor L -L noise would be a more meaningful performance metric, with even a small decrease in this distance potentially representing a significant boost in qualitative performance. Since the artificial noise would affect all of our trends equally, the critical point of 6.8 would not change (aside from the absolute value of L ∗ ), and may be meaningful even if it occurs after the leveling off.
## 7 Related Work
Power laws can arise from a wide variety of sources [THK18]. Power-law scalings with model and dataset size in density estimation [Was06] and in random forest models [Bia12] may be connected with our results. These models suggest that power-law exponents may have a very rough interpretation as the inverse of the number of relevant features in the data.
Some early [BB01, Goo01] work found power-law scalings between performance and dataset size. More recent work [HNA + 17, HAD19] also investigated scaling between model size and data size; their work is perhaps the closest to ours in the literature 8 . Note, however, that [HNA + 17] found super-linear scaling of dataset size with model size, whereas we find a sub-linear scaling. There are some parallels between our findings on optimal allocation of compute and [Kom19], including power-law learning curves. EfficientNets [TL19] also appear to obey an approximate power-law relation between accuracy and model size. Very recent work [RRBS19b] studies scaling with both dataset size and model size for a variety of datasets, and fits an ansatz similar to ours.
EfficientNet [TL19] advocates scaling depth and width exponentially (with different coefficients) for optimal performance of image models, resulting in a power-law scaling of width as a function of depth. We find that for language models this power should be roughly one when scaling up (as width/depth should remain fixed). But more importantly, we find that the precise architectural hyperparameters are unimportant compared to the overall scale of the language model. In [VWB16] it was argued that deep models can function as ensembles of shallower models, which could potentially explain this finding. Earlier work [ZK16] has compared width and depth, and found that wide ResNets can outperform deep ResNets on image classification. Some studies fix computation per data example, which tends to scale in proportion to the number of model parameters, whereas we investigate scaling with both model size and the quantity of training computation.
Various works [AS17, BHMM18] have investigated generalization in highly overparameterized models, finding a 'jamming transition' [GJS + 19] when the model size reaches the dataset size (this may require training many orders of magnitude beyond typical practice, and in particular does not use early stopping). We do not observe such a transition, and find that the necessary training data scales sublinearly in the model size. Expansions in the model size, particularly at large width [JGH18, LXS + 19], may provide a useful framework for thinking about some of our scaling relations. Our results on optimization, such as the shape of learning curves, can likely be explained using a noisy quadratic model, which can provide quite accurate predictions [ZLN + 19] in realistic settings. Making this connection quantitative will require a characterization of the Hessian spectrum [Pap18, GKX19, GARD18].
## 8 Discussion
We have observed consistent scalings of language model log-likelihood loss with non-embedding parameter count N , dataset size D , and optimized training computation C min , as encapsulated in Equations (1.5) and (1.6). Conversely, we find very weak dependence on many architectural and optimization hyperparameters. Since scalings with N,D,C min are power-laws, there are diminishing returns with increasing scale.
7 Defining words using the wc utility, the WebText2 dataset has 1 . 4 tokens per word and 4 . 3 characters per token.
8 After this work was completed, [RRBS19a] also appeared, which makes similar predictions for the dependence of loss on both model and dataset size.
We were able to precisely model the dependence of the loss on N and D , and alternatively on N and S , when these parameters are varied simultaneously. We used these relations to derive the compute scaling, magnitude of overfitting, early stopping step, and data requirements when training large language models. So our scaling relations go beyond mere observation to provide a predictive framework. One might interpret these relations as analogues of the ideal gas law, which relates the macroscopic properties of a gas in a universal way, independent of most of the details of its microscopic consituents.
It is natural to conjecture that the scaling relations will apply to other generative modeling tasks with a maximum likelihood loss, and perhaps in other settings as well. To this purpose, it will be interesting to test these relations on other domains, such as images, audio, and video models, and perhaps also for random network distillation. At this point we do not know which of our results depend on the structure of natural language data, and which are universal. It would also be exciting to find a theoretical framework from which the scaling relations can be derived: a 'statistical mechanics' underlying the 'thermodynamics' we have observed. Such a theory might make it possible to derive other more precise predictions, and provide a systematic understanding of the limitations of the scaling laws.
In the domain of natural language, it will be important to investigate whether continued improvement on the loss translates into improvement on relevant language tasks. Smooth quantitative change can mask major qualitative improvements: 'more is different'. For example, the smooth aggregate growth of the economy provides no indication of the specific technological developments that underwrite it. Similarly, the smooth improvements in language model loss may hide seemingly qualitative changes in capability.
Our results strongly suggest that larger models will continue to perform better, and will also be much more sample efficient than has been previously appreciated. Big models may be more important than big data. In this context, further investigation into model parallelism is warranted. Deep models can be trained using pipelining [HCC + 18], which splits parameters depth-wise between devices, but eventually requires increased batch sizes as more devices are used. Wide networks on the other hand are more amenable to parallelization [SCP + 18], since large layers can be split between multiple workers with less serial dependency. Sparsity [CGRS19, GRK17] or branching (e.g. [KSH12]) may allow for even faster training of large networks through increased model parallelism. And using methods like [WRH17, WYL19], which grow networks as they train, it might be possible to remain on the compute-efficient frontier for an entire training run.
## Acknowledgements
We would like to thank Shan Carter, Paul Christiano, Jack Clark, Ajeya Cotra, Ethan Dyer, Jason Eisner, Danny Hernandez, Jacob Hilton, Brice Menard, Chris Olah, and Ilya Sutskever for discussions and for feedback on drafts of this work.
## Appendices
## A Summary of Power Laws
For easier reference, we provide a summary below of the key trends described throughout the paper.
Table 4
| Parameters | Data | Compute | Batch Size | Equation |
|--------------|--------|------------|--------------------------|-----------------------------------------------------|
| N | ∞ | ∞ | Fixed | L ( N ) = ( N c /N ) α N |
| ∞ | D | Early Stop | Fixed | L ( D ) = ( D c /D ) α D |
| Optimal | ∞ | C | Fixed | L ( C ) = ( C c /C ) α C (naive) |
| N opt | D opt | C min | B B crit | L ( C min ) = ( C min c /C min ) α min C |
| N | D | Early Stop | Fixed | L ( N,D ) = [ ( N c N ) αN αD + D c D ] α D |
| N | ∞ | S steps | B | L ( N,S ) = ( N c N ) α N + ( S c S min ( S,B ) ) α |
The empirical fitted values for these trends are:
Table 5
| Power Law | Scale (tokenization-dependent) |
|-------------------|----------------------------------------|
| α N = 0 . 076 | N c = 8 . 8 × 10 13 params (non-embed) |
| α D = 0 . 095 | D c = 5 . 4 × 10 13 tokens |
| α C = 0 . 057 | C c = 1 . 6 × 10 7 PF-days |
| α min C = 0 . 050 | C min c = 3 . 1 × 10 8 PF-days |
| α B = 0 . 21 | B ∗ = 2 . 1 × 10 8 tokens |
| α S = 0 . 76 | S c = 2 . 1 × 10 3 steps |
The optimal parameters for compute efficient training are given by:
Table 6
| Compute-Efficient Value | Power Law | Scale |
|--------------------------------------------------------|--------------|---------------------------|
| N opt = N e · C p N min | p N = 0 . 73 | N e = 1 . 3 · 10 9 params |
| B B crit = B ∗ L 1 /αB = B e C p B min | p B = 0 . 24 | B e = 2 . 0 · 10 6 tokens |
| S min = S e · C p S min (lower bound) | p S = 0 . 03 | S e = 5 . 4 · 10 3 steps |
| D opt = D e · C p D min (1 epoch) | p D = 0 . 27 | D e = 2 · 10 10 tokens |
## B Empirical Model of Compute-Efficient Frontier
Throughout this appendix all values of C, S, and α C are adjusted for training at the critical batch size B crit . We have left off the 'adj' label to avoid cluttering the notation.
## B.1 Defining Equations
The power-law fit to the learning curves implies a simple prescription for compute-efficient training. In this appendix, we will derive the optimal performance, model size, and number of training steps as a function of
the compute budget. We start with the Equation (1.6), repeated here for convenience:
$$L \left ( N , S \right ) = \left ( \frac { N _ { c } } { N } \right ) ^ { \alpha _ { N } } + \left ( \frac { S _ { c } } { S } \right ) ^ { \alpha _ { S } } .$$
Here, S represents the number of parameter updates when training at the critical batch size [MKAT18], which was defined in Equation (5.2) 9 :
$$B \left ( L \right ) = \frac { B _ { * } } { L ^ { 1 / \alpha _ { B } } } .$$
We would like to determine optimal training parameters for a fixed compute budget, so we replace S = C/ (6 NB ( L )) , where C is the number of FLOPs used in the training run:
$$L \left ( N , C \right ) = \left ( \frac { N _ { c } } { N } \right ) ^ { \alpha _ { N } } + \left ( 6 B _ { * } S _ { c } \frac { N } { L ^ { 1 / \alpha _ { B } C } } \right ) ^ { \alpha _ { S } } .$$
Now, we set ∂ N L ∣ ∣ C = 0 to find the condition for optimality:
$$0 & = \frac { \partial L } { \partial N } | _ { C } \\ & = - \frac { \alpha _ { N } } { N } \left ( \frac { N _ { c } } { N } \right ) ^ { \alpha _ { N } } + \frac { \alpha _ { S } } { N } \left ( 6 B _ { * } S _ { c } \frac { N } { L ^ { 1 / \alpha _ { B } } C } \right ) ^ { \alpha _ { S } } \left ( 1 - 5 \frac { N } { L } \frac { \partial L } { \partial N } \right ) \\ \Rightarrow & \, \frac { \alpha _ { N } } { \alpha _ { S } } \left ( \frac { N _ { c } } { N } \right ) ^ { \alpha _ { N } } = \left ( 6 B _ { * } S _ { c } \frac { N } { L ^ { 1 / \alpha _ { B } } C } \right ) ^ { \alpha _ { S } } \\$$
Equation (B.3) and (B.4) together determine the compute-efficient frontier.
## B.2 Efficient Training
Now we assemble the implications of (B.3) and (B.4). First, note that inserting (B.4) into (B.3) yields
$$L \left ( N _ { e f f } \left ( C \right ) , C \right ) = \left ( 1 + \frac { \alpha _ { N } } { \alpha _ { S } } \right ) L \left ( N _ { e f f } , \infty \right ) , \quad ( B . 5 )$$
which implies that for compute-efficient training, we should train to a fixed percentage α N α S ≈ 10% above the converged loss. Next, let's determine how the optimal loss depends on the compute budget. Eliminating N yields a power-law dependence of performance on compute:
$$L \left ( C \right ) = \left ( \frac { C _ { c } } { C } \right ) ^ { \alpha _ { c } }$$
$$\alpha _ { C } = 1 / \left ( 1 / \alpha _ { S } + 1 / \alpha _ { B } + 1 / \alpha _ { N } \right ) \approx 0 . 0 5 2$$
<!-- formula-not-decoded -->
Similarly, we can eliminate L to find N ( C ) :
$$\frac { N \left ( C \right ) } { N _ { c } } = \left ( \frac { C } { C _ { c } } \right ) ^ { \alpha _ { C } / \alpha _ { N } } \left ( 1 + \frac { \alpha _ { N } } { \alpha _ { S } } \right ) ^ { 1 / \alpha _ { N } }$$
$$S \left ( C \right ) = \frac { C _ { c } } { 6 N _ { c } B _ { * } } \left ( 1 + \frac { \alpha _ { N } } { \alpha _ { S } } \right ) ^ { - 1 / \alpha _ { N } } \left ( \frac { C } { C _ { c } } \right ) ^ { \alpha _ { C } / \alpha _ { S } } \quad \text {(B.10)}$$
9 There is a slight ambiguity here: we can imagine training either at a constant batch size B ( L target ) , or we could instead train at a variable batch size ˜ B ( L ) , where ˜ B is the instantaneous critical batch size (as opposed to B , which is the averaged version). These two prescriptions result in the same number of steps, so we can ignore this subtlety (see [MKAT18]).
where we defined and
## B.3 Comparison to Inefficient
Typically, researchers train models until they appear to be close to convergence. In this section, we compare the efficient training procedure described above to this more typical setup. We define a the convergence factor f as the percent deviation from the converged loss:
$$L \left ( N , C \right ) = \left ( 1 + f \right ) L \left ( N , \infty \right ) .$$
For compute-efficient training we have f = α N /α S ≈ 10% from the previous section, but researchers typically use a much smaller value. Here, we choose f ′ = 2% as an estimate. For a fixed value of the loss, we predict:
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
So that compute-efficient training uses 7.7x fewer parameter updates, 2.7x more parameters, and 65% less compute to reach the same loss.
## B.4 Suboptimal Model Sizes
We can solve A.1 to find an expression for the amount of compute needed to reach a given value of the loss L with a model of size N :
<!-- formula-not-decoded -->
Using A.6 and A.9, we can eliminate L in favor of N eff ( L ) , the model size which reaches L most efficiently. From there, we find an expression for the excess compute needed as a consequence of using a suboptimal model size:
<!-- formula-not-decoded -->
The result is shown in Figure X. Models between 0.6x and 2.2x the optimal size can be used with only a 20% increase in compute budget. Using a smaller model is useful when accounting for the cost inference. A larger model can be trained the the same level of performance in fewer steps, allowing for more parallelism and faster training if sufficient harware is available (see Figure Y):
<!-- formula-not-decoded -->
A2.2x larger model requires 45% fewer steps at a cost of 20% more training compute. Note that this equation should not be trusted for very large models, as it is only valid in the power-law region of the learning curve after initial transient effects.
## C Caveats
In this section we list some potential caveats to our analysis.
- At present we do not have a solid theoretical understanding for any of our proposed scaling laws. The scaling relations with model size and compute are especially mysterious. It may be possible to understand scaling at very large D holding model size fixed [AS17], and also the shape of learning curves late in training, by modeling the loss with a noisy quadratic. But the scaling with D at very large model size still remains mysterious. Without a theory or a systematic understanding of the corrections to our scaling laws, it's difficult to determine in what circumstances they can be trusted.
Figure 16 Left: We characterize the step on which early stopping occurs, as a function of the extent of overfitting. The red line indicates a lower bound for early stopping that is derived in Section 5.3. Right: We display train and test loss for a series of 300M parameter models trained on different sized dataset subsamples. The test loss typically follows that of a run done with unrestricted data until diverging. Note that the degree of overfitting (as compared to the infinite data limit) is significantly overestimated by L test -L train (denoted by a black bar for each run).
<details>
<summary>Image 16 Details</summary>
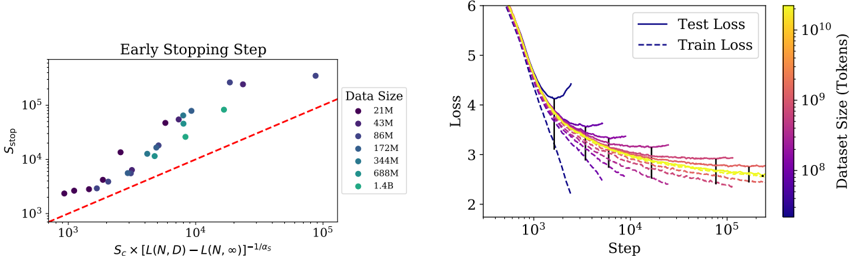
### Visual Description
\n
## Charts: Early Stopping Step & Loss vs. Step
### Overview
The image contains two charts. The left chart shows the relationship between the early stopping step (S_stop) and a calculated value related to loss function (L) and dataset size (N, D). The right chart displays the training and test loss as a function of the training step, with a heatmap indicating dataset size.
### Components/Axes
**Left Chart:**
* **Title:** "Early Stopping Step"
* **X-axis:** S_c x (L(N, D) - L(N, ∞))^-1/α. Scale is logarithmic from approximately 10^2 to 10^5.
* **Y-axis:** S_stop. Scale is logarithmic from approximately 10^1 to 10^5.
* **Legend:** "Data Size" with the following categories and corresponding colors:
* 21M (Dark Blue)
* 43M (Blue)
* 86M (Medium Blue)
* 172M (Light Blue)
* 344M (Yellow)
* 688M (Orange)
* 1.4B (Green)
* **Trendline:** A dashed red line is fitted through the data points.
**Right Chart:**
* **Title:** None explicitly stated, but implied to be "Loss vs. Step"
* **X-axis:** Step. Scale is logarithmic from approximately 10^2 to 10^5.
* **Y-axis:** Loss. Scale is linear from approximately 2 to 6.
* **Legend:**
* Test Loss (Solid Purple)
* Train Loss (Dashed Purple)
* **Colorbar:** "Dataset Size (Tokens)" ranging from approximately 10^8 to 10^10, with a gradient from blue to red. The colorbar is positioned vertically on the right side of the chart.
### Detailed Analysis or Content Details
**Left Chart:**
The data points generally follow an upward trend, aligning with the dashed red trendline. As the value on the x-axis increases, the S_stop value also increases.
* 21M: Points cluster around (10^2, 10^2) to (10^3, 10^3).
* 43M: Points cluster around (10^3, 10^3) to (10^4, 10^4).
* 86M: Points cluster around (10^3, 10^3) to (10^4, 10^4).
* 172M: Points cluster around (10^4, 10^4) to (10^5, 10^5).
* 344M: Points cluster around (10^4, 10^4) to (10^5, 10^5).
* 688M: Points cluster around (10^4, 10^4) to (10^5, 10^5).
* 1.4B: Points cluster around (10^4, 10^4) to (10^5, 10^5).
**Right Chart:**
Both the train and test loss curves decrease as the step increases. The test loss is generally higher than the train loss. The color of each line corresponds to the dataset size, with blue representing smaller datasets and red representing larger datasets.
* **Smallest Dataset (Blue):** Loss starts around 5.5 and decreases to approximately 2.8.
* **Medium Dataset (Yellow/Orange):** Loss starts around 4.5 and decreases to approximately 2.5.
* **Largest Dataset (Red):** Loss starts around 4.0 and decreases to approximately 2.3.
The lines representing larger datasets (redder colors) tend to have lower loss values at each step.
### Key Observations
* The early stopping step (S_stop) increases with the calculated value on the x-axis of the left chart, and appears to be correlated with dataset size.
* Larger datasets generally lead to lower loss values during training (right chart).
* The gap between train and test loss decreases as the training progresses.
* The rate of loss decrease slows down as the step increases, indicating diminishing returns from further training.
### Interpretation
The charts likely illustrate the impact of dataset size on the training process of a machine learning model. The left chart suggests that as the complexity of the loss function (related to dataset size) increases, the early stopping step also increases, meaning more training steps are required to reach an optimal stopping point. The right chart confirms that larger datasets generally result in better model performance (lower loss), but also shows that the benefits of increasing dataset size may diminish beyond a certain point. The color mapping on the right chart provides a visual representation of how dataset size influences the loss curves. The convergence of the train and test loss curves suggests that the model is generalizing well to unseen data, but the persistent gap indicates some degree of overfitting. The diminishing rate of loss decrease suggests that further training may not yield significant improvements in performance.
</details>
- We are not especially confident in the prediction of B crit ( L ) for values of the loss far outside the range we have explored. Changes in B crit could have a significant impact on trade-offs between data parallelism and the number of serial training steps required, which would have a major impact on training time.
- We did not thoroughly investigate the small data regime, and our fits for L ( N,D ) were poor for the smallest values of D (where an epoch corresponded to only 40 steps). Furthermore, we did not experiment with regularization and data augmentation. Improvements in these could alter our results, quantitatively or qualitatively.
- We used the estimated training compute C ≈ 6 NBS , which did not include contributions proportional to n ctx (see Section 2.1). So our scalings with compute may be confounded in practice in the regime of very large n ctx , specifically where n ctx 12 d model .
- We tuned learning rates, and we experimented with learning rate schedules. But we may have neglected to tune some hyperparameter (e.g. intialization scale or momentum) that have an important effect on scaling.
- The optimal choice of learning rate is sensitive to the target loss. When training close to convergence, it may be necessary to use a smaller learning rate to avoid divergences. But when conducting a short training run (eg due to compute limitations), it may be possible to use a larger learning rate. We did not experiment with higher learning rates for training runs that did not proceed to convergence.
## D Supplemental Figures
## D.1 Early Stopping and Test vs Train
In section 5.3 we described the result shown in Figure 16, which provides a prediction for a lower bound on the early stopping step. We also show the train and test loss for a given model size when training on different sized datasets.
## D.2 Universal Transformers
We compare the performance of standard Transformers to recurrent Transformers [DGV + 18] in Figure 17. These models re-use parameters, and so perform slightly better as a function of N , but slightly worse as a function of compute C . We include several different different possibilities for parameter re-use.
## D.3 Batch Size
We measure the critical batch size using the data displayed in figure 18. This made it possible to estimate B crit ( L ) in figure 10.
Figure 17 We compare recurrent Transformers [DGV + 18], which re-use parameters, to standard Transformers. Recurrent Transformers perform slightly better when comparing models with equal parameter count, but slightly worse when accounting for reuse and comparing per FLOP.
<details>
<summary>Image 17 Details</summary>
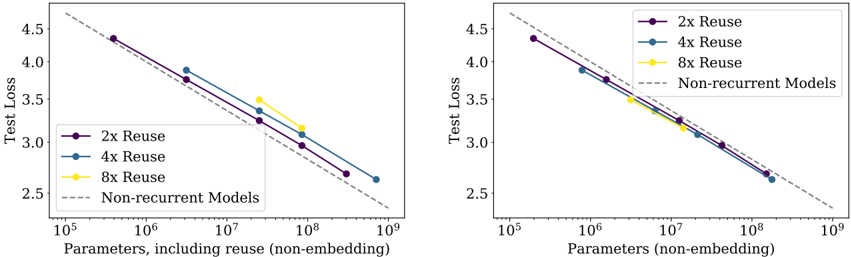
### Visual Description
## Chart: Test Loss vs. Parameters with Reuse
### Overview
The image presents two identical line charts comparing the test loss of machine learning models with different levels of parameter reuse against non-recurrent models. Both charts plot "Test Loss" on the y-axis against "Parameters, including reuse (non-embedding)" on the x-axis, using a logarithmic scale for the x-axis. The charts aim to demonstrate the impact of parameter reuse on model performance as the number of parameters increases.
### Components/Axes
* **X-axis Title:** "Parameters, including reuse (non-embedding)" - Scale is logarithmic, ranging from 10<sup>5</sup> to 10<sup>9</sup>.
* **Y-axis Title:** "Test Loss" - Scale ranges from 2.5 to 4.5.
* **Legend:** Located in the top-right corner of each chart.
* "2x Reuse" - Purple line with circular markers.
* "4x Reuse" - Blue line with circular markers.
* "8x Reuse" - Yellow line with circular markers.
* "Non-recurrent Models" - Brown dashed line.
* **Data Series:** Four lines representing different reuse configurations and non-recurrent models.
* **Gridlines:** Dashed grey lines providing visual reference.
### Detailed Analysis or Content Details
**Chart 1 (Left):**
* **2x Reuse (Purple):** The line slopes downward consistently. Approximate data points:
* (10<sup>5</sup>, ~4.3)
* (10<sup>6</sup>, ~3.9)
* (10<sup>7</sup>, ~3.4)
* (10<sup>8</sup>, ~3.0)
* (10<sup>9</sup>, ~2.6)
* **4x Reuse (Blue):** The line slopes downward consistently, slightly steeper than the 2x Reuse line. Approximate data points:
* (10<sup>5</sup>, ~4.3)
* (10<sup>6</sup>, ~3.7)
* (10<sup>7</sup>, ~3.2)
* (10<sup>8</sup>, ~2.8)
* (10<sup>9</sup>, ~2.4)
* **8x Reuse (Yellow):** The line initially slopes downward, but flattens out between 10<sup>7</sup> and 10<sup>8</sup>. Approximate data points:
* (10<sup>5</sup>, ~4.3)
* (10<sup>6</sup>, ~3.6)
* (10<sup>7</sup>, ~3.4)
* (10<sup>8</sup>, ~3.2)
* (10<sup>9</sup>, ~3.0)
* **Non-recurrent Models (Brown Dashed):** The line slopes downward consistently, but is less steep than the 2x and 4x Reuse lines. Approximate data points:
* (10<sup>5</sup>, ~4.4)
* (10<sup>6</sup>, ~4.0)
* (10<sup>7</sup>, ~3.6)
* (10<sup>8</sup>, ~3.2)
* (10<sup>9</sup>, ~2.8)
**Chart 2 (Right):**
* **2x Reuse (Purple):** The line slopes downward consistently. Approximate data points:
* (10<sup>5</sup>, ~4.4)
* (10<sup>6</sup>, ~4.0)
* (10<sup>7</sup>, ~3.5)
* (10<sup>8</sup>, ~3.0)
* (10<sup>9</sup>, ~2.6)
* **4x Reuse (Blue):** The line slopes downward consistently, slightly steeper than the 2x Reuse line. Approximate data points:
* (10<sup>5</sup>, ~4.4)
* (10<sup>6</sup>, ~3.8)
* (10<sup>7</sup>, ~3.3)
* (10<sup>8</sup>, ~2.8)
* (10<sup>9</sup>, ~2.4)
* **8x Reuse (Yellow):** The line initially slopes downward, but flattens out between 10<sup>7</sup> and 10<sup>8</sup>. Approximate data points:
* (10<sup>5</sup>, ~4.4)
* (10<sup>6</sup>, ~3.7)
* (10<sup>7</sup>, ~3.4)
* (10<sup>8</sup>, ~3.2)
* (10<sup>9</sup>, ~3.0)
* **Non-recurrent Models (Brown Dashed):** The line slopes downward consistently, but is less steep than the 2x and 4x Reuse lines. Approximate data points:
* (10<sup>5</sup>, ~4.5)
* (10<sup>6</sup>, ~4.1)
* (10<sup>7</sup>, ~3.7)
* (10<sup>8</sup>, ~3.3)
* (10<sup>9</sup>, ~2.9)
### Key Observations
* Parameter reuse generally leads to lower test loss compared to non-recurrent models.
* Increasing the reuse factor (from 2x to 4x) consistently improves performance.
* The benefit of 8x reuse appears to diminish at higher parameter counts (around 10<sup>7</sup> - 10<sup>8</sup>), where its performance plateaus.
* Both charts show very similar trends, suggesting the results are consistent.
### Interpretation
The charts demonstrate the effectiveness of parameter reuse in reducing test loss for machine learning models. The steeper slopes of the 2x and 4x reuse lines indicate that increasing the number of parameters while reusing them leads to more significant performance gains than simply increasing parameters without reuse (as seen in the non-recurrent models). The flattening of the 8x reuse line suggests a point of diminishing returns, where further increasing reuse does not yield substantial improvements. This could be due to factors like overfitting or limitations in the model architecture. The consistency between the two charts strengthens the validity of these observations. The logarithmic scale on the x-axis highlights the impact of parameter scaling, particularly at larger parameter counts. The data suggests that parameter reuse is a valuable technique for improving model performance, but careful consideration should be given to the optimal reuse factor and the potential for diminishing returns.
</details>
Figure 18 These figures demonstrate fits to Equation (5.1) for a large number of values of the loss L , and for two different Transformer model sizes. These fits were used to measure B crit ( L ) for Figure 10.
<details>
<summary>Image 18 Details</summary>
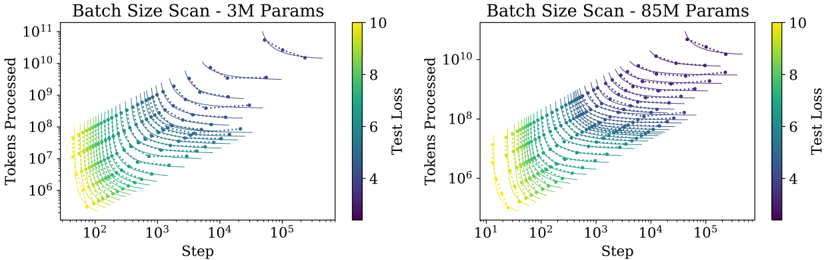
### Visual Description
\n
## Chart: Batch Size Scan - Training Loss Curves
### Overview
The image presents two scatter plots visualizing the relationship between 'Step' (x-axis) and 'Tokens Processed' (y-axis), colored by 'Test Loss'. The plots compare training dynamics for two model sizes: 3M parameters (left) and 85M parameters (right). Each plot displays multiple curves, likely representing different batch sizes. The color gradient indicates the 'Test Loss' value, ranging from approximately 4 to 10.
### Components/Axes
* **X-axis:** 'Step' - Logarithmic scale, ranging from approximately 10<sup>1</sup> to 10<sup>5</sup>.
* **Y-axis:** 'Tokens Processed' - Logarithmic scale, ranging from approximately 10<sup>6</sup> to 10<sup>11</sup>.
* **Colorbar:** 'Test Loss' - Linear scale, ranging from approximately 4 to 10.
* **Title (Left):** "Batch Size Scan - 3M Params"
* **Title (Right):** "Batch Size Scan - 85M Params"
* **Data Points:** Scatter plots with varying colors representing different 'Test Loss' values. Each line represents a different batch size.
### Detailed Analysis or Content Details
**Left Plot (3M Params):**
* **Trend:** The curves generally slope downwards, indicating decreasing loss as the number of steps and tokens processed increases. The initial slope is steeper for some curves than others.
* **Data Points (Approximate):**
* Several curves start around Step = 10<sup>1</sup> and Tokens Processed = 10<sup>6</sup> with a Test Loss of approximately 9-10 (yellow/red).
* As Step increases to 10<sup>2</sup>, Tokens Processed increases to around 10<sup>7</sup>-10<sup>8</sup>, and Test Loss decreases to approximately 6-8 (orange/yellow).
* At Step = 10<sup>3</sup>, Tokens Processed reaches approximately 10<sup>8</sup>-10<sup>9</sup>, and Test Loss decreases to approximately 4-6 (green/yellow).
* By Step = 10<sup>4</sup>-10<sup>5</sup>, Tokens Processed reaches 10<sup>9</sup>-10<sup>10</sup>, and Test Loss stabilizes around 4-5 (blue/green).
* A few curves exhibit a more rapid initial decrease in loss, suggesting potentially larger batch sizes.
**Right Plot (85M Params):**
* **Trend:** Similar to the 3M parameter plot, the curves generally slope downwards. However, the initial slopes are generally less steep, and the curves appear more spread out.
* **Data Points (Approximate):**
* Curves start around Step = 10<sup>1</sup> and Tokens Processed = 10<sup>6</sup> with a Test Loss of approximately 9-10 (yellow/red).
* As Step increases to 10<sup>2</sup>, Tokens Processed increases to around 10<sup>7</sup>-10<sup>8</sup>, and Test Loss decreases to approximately 6-8 (orange/yellow).
* At Step = 10<sup>3</sup>, Tokens Processed reaches approximately 10<sup>8</sup>-10<sup>9</sup>, and Test Loss decreases to approximately 4-6 (green/yellow).
* By Step = 10<sup>4</sup>-10<sup>5</sup>, Tokens Processed reaches 10<sup>9</sup>-10<sup>10</sup>, and Test Loss stabilizes around 4-5 (blue/green).
* There is a greater variance in the final Test Loss values across different batch sizes in this plot.
### Key Observations
* The 85M parameter model appears to require more steps and tokens processed to achieve a similar level of loss reduction compared to the 3M parameter model.
* The spread of curves in the 85M parameter plot suggests a greater sensitivity to batch size.
* The colorbar consistently maps lower Test Loss values to cooler colors (blue/green) and higher values to warmer colors (yellow/red) in both plots.
* The logarithmic scales on both axes are crucial for visualizing the wide range of values.
### Interpretation
These plots demonstrate the impact of batch size on the training dynamics of neural networks with different parameter counts. The 'Test Loss' color coding allows for a visual assessment of how different batch sizes affect the model's generalization performance. The 85M parameter model's greater sensitivity to batch size suggests that careful tuning of this hyperparameter is particularly important for larger models. The slower initial loss reduction in the 85M parameter model could be attributed to the increased complexity and the need for more data to effectively train the larger number of parameters. The plots suggest that, for both model sizes, increasing the number of steps and tokens processed generally leads to lower test loss, but the optimal batch size varies and impacts the training trajectory. The use of a logarithmic scale is essential to visualize the data effectively, as the ranges of 'Step' and 'Tokens Processed' are quite large.
</details>
## D.4 Sample Efficiency vs Model Size
It is easy to see from figure 2 that larger models train faster, and are therefore more sample efficient. We provide another way of looking at this phenomenon in figure 19, which shows when different models reach various fixed values of the loss.
Figure 19 The number of minimum serial steps needed to reach any fixed value of the test loss decreases precipitously with model size. Sample efficiency (show here for training far below the critical batch size) improves greatly as well, improving by a factor of almost 100 when comparing the smallest possible model to a very large one.
<details>
<summary>Image 19 Details</summary>
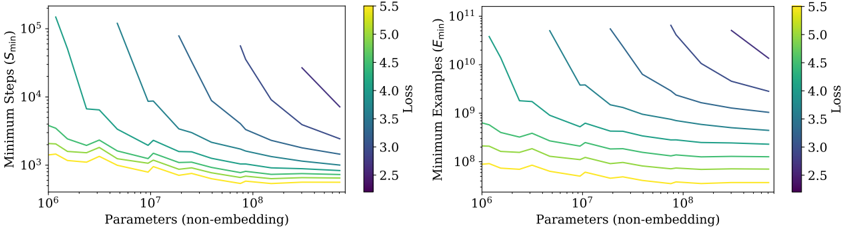
### Visual Description
\n
## Chart: Scaling Laws for Minimum Steps and Minimum Examples
### Overview
The image presents two scatter plots illustrating scaling laws. The left plot shows the relationship between the number of parameters (non-embedding) and the minimum steps (S<sub>min</sub>) required, while the right plot shows the relationship between the number of parameters and the minimum examples (E<sub>min</sub>) needed. Both plots use color to represent the loss value.
### Components/Axes
Both charts share the following components:
* **X-axis:** Parameters (non-embedding) - Logarithmic scale from 10<sup>6</sup> to 10<sup>9</sup>.
* **Colorbar:** Loss - Scale from 2.5 to 5.5. The colorbar is positioned on the right side of each chart.
* **Legend:** Implicitly represented by the colorbar.
The left chart has:
* **Y-axis:** Minimum Steps (S<sub>min</sub>) - Logarithmic scale from 10<sup>4</sup> to 10<sup>5</sup>.
The right chart has:
* **Y-axis:** Minimum Examples (E<sub>min</sub>) - Logarithmic scale from 10<sup>10</sup> to 10<sup>11</sup>.
### Detailed Analysis or Content Details
**Left Chart (Minimum Steps vs. Parameters):**
There are approximately 7 data series represented by different colored lines. The lines generally slope downwards, indicating that as the number of parameters increases, the minimum steps required decrease.
* **Dark Blue Line:** Starts at approximately (10<sup>6</sup>, 5.0 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 2.5 x 10<sup>4</sup>).
* **Light Blue Line:** Starts at approximately (10<sup>6</sup>, 4.5 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 2.0 x 10<sup>4</sup>).
* **Green Line:** Starts at approximately (10<sup>6</sup>, 4.0 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 1.5 x 10<sup>4</sup>).
* **Yellow Line:** Starts at approximately (10<sup>6</sup>, 3.5 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 1.0 x 10<sup>4</sup>).
* **Light Yellow Line:** Starts at approximately (10<sup>6</sup>, 3.0 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 5.0 x 10<sup>3</sup>).
* **Orange Line:** Starts at approximately (10<sup>6</sup>, 3.0 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 2.0 x 10<sup>3</sup>).
* **Red Line:** Starts at approximately (10<sup>6</sup>, 3.5 x 10<sup>4</sup>) and decreases to approximately (10<sup>9</sup>, 1.0 x 10<sup>3</sup>).
**Right Chart (Minimum Examples vs. Parameters):**
Similar to the left chart, there are approximately 7 data series represented by different colored lines. These lines also generally slope downwards, indicating that as the number of parameters increases, the minimum examples needed decrease.
* **Dark Blue Line:** Starts at approximately (10<sup>6</sup>, 8.0 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 2.0 x 10<sup>10</sup>).
* **Light Blue Line:** Starts at approximately (10<sup>6</sup>, 7.0 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 1.5 x 10<sup>10</sup>).
* **Green Line:** Starts at approximately (10<sup>6</sup>, 6.0 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 1.0 x 10<sup>10</sup>).
* **Yellow Line:** Starts at approximately (10<sup>6</sup>, 5.0 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 5.0 x 10<sup>9</sup>).
* **Light Yellow Line:** Starts at approximately (10<sup>6</sup>, 4.0 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 2.0 x 10<sup>9</sup>).
* **Orange Line:** Starts at approximately (10<sup>6</sup>, 3.5 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 1.0 x 10<sup>9</sup>).
* **Red Line:** Starts at approximately (10<sup>6</sup>, 4.0 x 10<sup>10</sup>) and decreases to approximately (10<sup>9</sup>, 5.0 x 10<sup>8</sup>).
### Key Observations
* Both charts exhibit a clear negative correlation between the number of parameters and both minimum steps and minimum examples.
* The loss value (indicated by color) generally decreases as the number of parameters increases, suggesting improved performance with larger models.
* The lines representing different data series are relatively close together, indicating a consistent trend across different configurations.
* The red line consistently shows the lowest values for both minimum steps and minimum examples, suggesting it represents the most efficient configuration.
### Interpretation
These charts demonstrate scaling laws in a machine learning context. They suggest that increasing the number of parameters in a model leads to a reduction in both the number of training steps required to achieve a certain level of performance and the amount of training data needed. The color-coding by loss indicates that larger models generally achieve lower loss values, implying better accuracy or generalization ability.
The consistent downward trends across the different data series suggest that these scaling laws are robust and apply to a range of model configurations. The red line's consistently lower values may indicate a particularly effective architecture or training strategy.
These findings are important for understanding the trade-offs between model size, training cost, and performance. They can guide the design and training of machine learning models, helping to optimize resource allocation and achieve desired levels of accuracy. The logarithmic scales on both axes suggest that the relationships are not linear, and that the benefits of increasing model size may diminish at very large scales.
</details>
Figure 20 This figure provides information about the performance per token as a function of model size and training time. Left: Loss per token as a function of its position T in the 1024-token context. Loss scales predictably as a power-law in T . Right: Test loss per token as a function of training step.
<details>
<summary>Image 20 Details</summary>
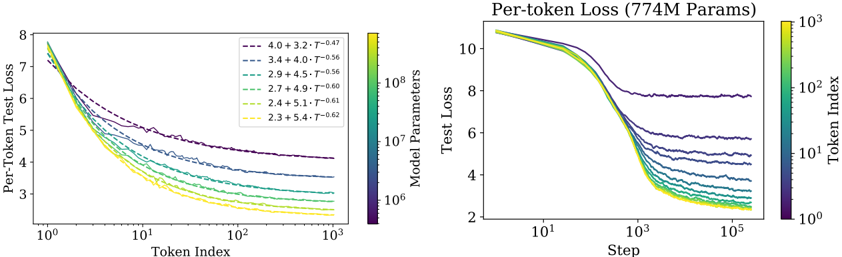
### Visual Description
## Chart: Per-Token Loss vs. Token Index & Step
### Overview
The image presents two charts displaying per-token loss as a function of token index (left) and step (right). Both charts show multiple lines representing different model parameter sizes, with a color gradient indicating the token index or step. The right chart has a title indicating the model size is 774M parameters.
### Components/Axes
**Left Chart:**
* **X-axis:** Token Index (logarithmic scale, ranging from approximately 10^2 to 10^3).
* **Y-axis:** Per-Token Test Loss (ranging from approximately 3 to 8).
* **Lines:** Represent different model parameter configurations. Each line is labeled with a parameter configuration (e.g., "4.0 + 3.2 • T^-0.47").
* **Colorbar:** Located on the right, representing Token Index with a gradient from green to yellow to red.
**Right Chart:**
* **X-axis:** Step (logarithmic scale, ranging from approximately 10^1 to 10^5).
* **Y-axis:** Test Loss (ranging from approximately 2 to 10).
* **Lines:** Represent different model parameter configurations. Each line is labeled with a parameter configuration (e.g., "4.0 + 3.2 • T^-0.47").
* **Colorbar:** Located on the right, representing Token Index with a gradient from green to yellow to red.
* **Title:** "Per-token Loss (774M Params)"
### Detailed Analysis or Content Details
**Left Chart:**
* **Line 1 (Purple):** 4.0 + 3.2 • T^-0.47. Starts at approximately 7.5 and decreases to approximately 4.5. The line exhibits some oscillation.
* **Line 2 (Dark Blue):** 3.4 + 4.0 • T^-0.56. Starts at approximately 7.0 and decreases to approximately 4.0. The line exhibits some oscillation.
* **Line 3 (Green):** 2.9 + 4.5 • T^-0.56. Starts at approximately 6.5 and decreases to approximately 3.5. The line exhibits some oscillation.
* **Line 4 (Light Green):** 2.7 + 4.9 • T^-0.60. Starts at approximately 6.0 and decreases to approximately 3.2. The line exhibits some oscillation.
* **Line 5 (Yellow):** 2.4 + 5.1 • T^-0.61. Starts at approximately 5.5 and decreases to approximately 3.0. The line exhibits some oscillation.
* **Line 6 (Orange):** 2.3 + 5.4 • T^-0.62. Starts at approximately 5.0 and decreases to approximately 2.8. The line exhibits some oscillation.
**Right Chart:**
* **Line 1 (Purple):** 4.0 + 3.2 • T^-0.47. Starts at approximately 9.0 and decreases rapidly to approximately 4.5, then plateaus with some oscillation.
* **Line 2 (Dark Blue):** 3.4 + 4.0 • T^-0.56. Starts at approximately 8.5 and decreases rapidly to approximately 4.0, then plateaus with some oscillation.
* **Line 3 (Green):** 2.9 + 4.5 • T^-0.56. Starts at approximately 8.0 and decreases rapidly to approximately 3.5, then plateaus with some oscillation.
* **Line 4 (Light Green):** 2.7 + 4.9 • T^-0.60. Starts at approximately 7.5 and decreases rapidly to approximately 3.2, then plateaus with some oscillation.
* **Line 5 (Yellow):** 2.4 + 5.1 • T^-0.61. Starts at approximately 7.0 and decreases rapidly to approximately 3.0, then plateaus with some oscillation.
* **Line 6 (Orange):** 2.3 + 5.4 • T^-0.62. Starts at approximately 6.5 and decreases rapidly to approximately 2.8, then plateaus with some oscillation.
### Key Observations
* In both charts, the lines generally trend downwards, indicating decreasing loss as token index or step increases.
* The lines with larger initial parameter values (e.g., 4.0 + 3.2) start with higher loss but decrease more slowly.
* The lines with smaller initial parameter values (e.g., 2.3 + 5.4) start with lower loss and decrease more rapidly.
* All lines exhibit some degree of oscillation, suggesting instability or fluctuations in the learning process.
* The color gradient on the colorbar does not appear to be directly correlated with the line colors.
### Interpretation
The charts demonstrate the relationship between model parameters, token index/step, and per-token loss during training. The different lines represent models with varying parameter configurations. The decreasing loss indicates that the models are learning and improving their performance as they process more tokens or steps. The parameter configurations influence the initial loss and the rate of learning. The oscillations suggest that the training process is not perfectly smooth and may require adjustments to hyperparameters or optimization algorithms. The right chart, specifically, shows how the loss converges as the model progresses through training steps. The 774M parameter size indicates the scale of the models being evaluated. The data suggests that there is a trade-off between initial loss and learning rate, with larger parameter values leading to higher initial loss but potentially slower learning. The colorbar, while present, doesn't seem to provide additional information about the data itself, and may be a visual artifact or represent a different dimension not directly displayed on the charts.
</details>
Figure 21 In addition to the averaged loss, individual tokens within the 1024-token context also improve smoothly as model size increases. Training runs with shorter context n ctx = 8 (dashed lines) perform better on early tokens, since they can allocate all of their capacity to them.
<details>
<summary>Image 21 Details</summary>
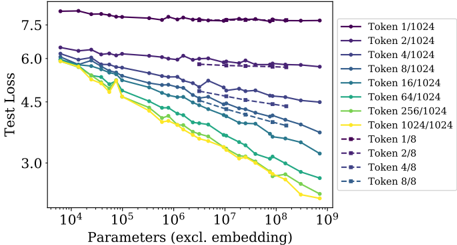
### Visual Description
## Line Chart: Test Loss vs. Parameters (excl. embedding)
### Overview
This image presents a line chart illustrating the relationship between "Test Loss" and "Parameters (excl. embedding)" for various "Token" configurations. The chart displays how test loss changes as the number of parameters increases, with different lines representing different token sizes.
### Components/Axes
* **X-axis:** "Parameters (excl. embedding)" - Logarithmic scale, ranging from approximately 10<sup>4</sup> to 10<sup>9</sup>.
* **Y-axis:** "Test Loss" - Linear scale, ranging from approximately 3.0 to 7.5.
* **Legend:** Located in the top-right corner, listing the following data series:
* Token 1/1024 (Purple)
* Token 2/1024 (Dark Blue)
* Token 4/1024 (Light Blue)
* Token 8/1024 (Teal)
* Token 16/1024 (Green)
* Token 64/1024 (Olive Green)
* Token 256/1024 (Yellow)
* Token 1024/1024 (Gold)
* Token 1/8 (Dark Purple)
* Token 2/8 (Navy)
* Token 4/8 (Dark Teal)
* Token 8/8 (Sky Blue)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points. Note that due to the chart's resolution, values are estimates.
* **Token 1/1024 (Purple):** The line is relatively flat, hovering around a test loss of approximately 7.3-7.5 across the entire parameter range.
* **Token 2/1024 (Dark Blue):** Starts at approximately 6.1 at 10<sup>4</sup> parameters, gradually decreasing to around 5.5 at 10<sup>9</sup> parameters.
* **Token 4/1024 (Light Blue):** Begins at approximately 6.0 at 10<sup>4</sup> parameters, decreasing to around 4.8 at 10<sup>9</sup> parameters.
* **Token 8/1024 (Teal):** Starts at approximately 6.0 at 10<sup>4</sup> parameters, decreasing to around 4.5 at 10<sup>9</sup> parameters.
* **Token 16/1024 (Green):** Begins at approximately 6.0 at 10<sup>4</sup> parameters, decreasing to around 4.0 at 10<sup>9</sup> parameters.
* **Token 64/1024 (Olive Green):** Starts at approximately 5.5 at 10<sup>4</sup> parameters, decreasing to around 3.5 at 10<sup>9</sup> parameters.
* **Token 256/1024 (Yellow):** Begins at approximately 5.0 at 10<sup>4</sup> parameters, decreasing to around 3.0 at 10<sup>9</sup> parameters.
* **Token 1024/1024 (Gold):** Starts at approximately 4.8 at 10<sup>4</sup> parameters, decreasing sharply to around 2.5 at 10<sup>9</sup> parameters. This line exhibits the steepest decline.
* **Token 1/8 (Dark Purple):** Similar to Token 1/1024, it remains relatively flat, around 7.3-7.5.
* **Token 2/8 (Navy):** Starts at approximately 6.0 at 10<sup>4</sup> parameters, decreasing to around 5.5 at 10<sup>9</sup> parameters.
* **Token 4/8 (Dark Teal):** Begins at approximately 5.8 at 10<sup>4</sup> parameters, decreasing to around 4.8 at 10<sup>9</sup> parameters.
* **Token 8/8 (Sky Blue):** Starts at approximately 6.0 at 10<sup>4</sup> parameters, decreasing to around 4.5 at 10<sup>9</sup> parameters.
### Key Observations
* The "Token 1024/1024" configuration consistently exhibits the lowest test loss across all parameter values.
* The "Token 1/1024" and "Token 1/8" configurations show minimal improvement in test loss as the number of parameters increases.
* Generally, increasing the number of parameters leads to a decrease in test loss, but the rate of decrease varies significantly depending on the token configuration.
* The lines representing larger token sizes (e.g., 256/1024, 1024/1024) show a more pronounced downward trend.
### Interpretation
The chart demonstrates the impact of token size on model performance (as measured by test loss) as model capacity (number of parameters) increases. The data suggests that larger token sizes, particularly 1024/1024, are more effective at leveraging increased model capacity to reduce test loss. This implies that the model benefits from having a richer representation of the input data when the number of parameters is sufficiently large.
The relatively flat lines for smaller token sizes (1/1024, 1/8) indicate that these configurations may be limited by their representational capacity, regardless of the number of parameters. The model is unable to effectively utilize the additional parameters to improve performance.
The logarithmic scale on the x-axis highlights the diminishing returns of adding parameters. While increasing parameters initially leads to significant reductions in test loss, the rate of improvement slows down as the number of parameters grows very large. This suggests that there is a point of diminishing returns where adding more parameters provides only marginal improvements in performance.
The differences between the 1024 and 8 token sizes are more pronounced than the differences between the 1, 2, and 4 token sizes. This suggests that the relationship between token size and performance is not linear.
</details>
## D.5 Context Dependence
The trends for loss as a function of model size are displayed for different tokens in the context in Figure 21. We see that models trained on n ctx = 1024 show steady improvement with model size on all but the first token.
Fixing model size, it appears that the loss scales as a power-law as a function of position T in the context, see Figure 20. This may be a consequence of underlying power-law correlations in language [EP94, ACDE12, LT16], or a more general feature of the model architecture and optimization. It provides some suggestion for the potential benefits (or lack thereof) from training on larger contexts. Not only do larger models converge to better performance at T = 1024 , but they also improve more quickly at early tokens, suggesting that larger models are more efficient at detecting patterns with less contextual information. In the right-hand plot we show how per-token performance varies for a fixed model as a function of the training step. The model begins by learning short-range information, and only learns longer-range correlations later in training.
We have also included models trained with a tiny context n ctx = 8 in order to compare with our longer context models. Even modestly sized models trained on n ctx = 8 can dominate our largest n ctx = 1024 models on very early tokens. This also suggests that further improvements should be possible with much larger models trained on large contexts.
## D.6 Learning Rate Schedules and Error Analysis
We experimented with a variety of learning rates and schedules. A host of schedules and resulting test performances for a small language model are plotted in Figure 22. We conclude that the choice of learning rate schedule is mostly irrelevant, as long as the total summed learning rate is sufficiently large, and the schedule includes a warmup period and a final decay to near-vanishing learning rate. Variations among
Figure 22 We test a variety of learning rate schedules including cosine decay, linear decay, as well as other faster/slower decays schedules on a 3 million parameter model, shown on the left. For these experiments we do not decay to zero, since we find that this tends to give a fixed improvement close to the end of training. We find that, as long as the learning rate is not too small and does not decay too quickly, performance does not depend strongly on learning rate. Run-to-run variation is at the level of 0.05 in the loss, so averaging multiple runs is necessary to validate performance changes smaller than this level.
<details>
<summary>Image 22 Details</summary>
### Visual Description
\n
## Charts: Learning Rate Schedule and Loss vs. LR Summed Over Steps
### Overview
The image presents two charts side-by-side. The left chart depicts a learning rate schedule over training steps, showing multiple lines representing different learning rate trajectories. The right chart shows the loss function value plotted against the sum of learning rates over steps.
### Components/Axes
**Left Chart:**
* **X-axis:** "Step" ranging from 0 to 250000.
* **Y-axis:** "Learning Rate" ranging from 0.0000 to 0.00010.
* **Data Series:** Multiple lines, each representing a different learning rate schedule. No explicit labels are provided for each line.
**Right Chart:**
* **X-axis:** "LR Summed Over Steps" ranging from approximately 50 to 250.
* **Y-axis:** "Loss" ranging from approximately 3.65 to 3.90.
* **Data Series:** A scatter plot of individual data points.
### Detailed Analysis or Content Details
**Left Chart:**
The chart shows a collection of learning rate decay curves. All curves start at a relatively high learning rate (approximately 0.00009) at Step 0 and decrease over time. The decay is initially rapid, then slows down as the step number increases.
* The first ~50,000 steps show a steep decline in learning rate for all lines.
* Between 50,000 and 150,000 steps, the rate of decline slows significantly.
* After 150,000 steps, the learning rate plateaus, with most lines converging to a very low learning rate (approximately 0.00001).
* There is significant variation in the decay rates and final learning rates among the different lines.
**Right Chart:**
The chart displays a scatter plot showing the relationship between the sum of learning rates over steps and the corresponding loss value.
* The trend is generally downward, indicating that as the sum of learning rates increases, the loss decreases.
* The initial points (LR Summed Over Steps ~50) have a loss of approximately 3.85.
* Around LR Summed Over Steps ~150, the loss reaches a minimum of approximately 3.72.
* After LR Summed Over Steps ~150, the loss fluctuates around 3.75, with some points reaching as low as 3.70 and as high as 3.78.
* The points appear somewhat scattered, suggesting a noisy relationship between the sum of learning rates and the loss.
### Key Observations
* The learning rate schedule exhibits a decaying behavior, which is common in training deep learning models.
* The variation in learning rate decay curves suggests that different parts of the model or different batches of data may be learning at different rates.
* The loss function initially decreases with increasing learning rate sum, but then plateaus and fluctuates, indicating that the model may be approaching convergence or getting stuck in a local minimum.
* The scatter in the loss vs. LR sum plot suggests that the relationship is not perfectly deterministic and may be influenced by other factors.
### Interpretation
The data suggests a typical training process where the learning rate is gradually reduced to fine-tune the model and prevent oscillations. The initial rapid decay allows for quick progress, while the later slow decay enables precise adjustments. The plateau in the loss function indicates that the model has likely converged to a reasonable solution, but further training may not yield significant improvements. The scatter in the loss plot could be due to the stochastic nature of the training process, the presence of noisy data, or the complexity of the model. The relationship between the learning rate and loss is not linear, and there is a point where increasing the learning rate sum no longer leads to a significant reduction in loss. This is expected as the model approaches its optimal parameters. The multiple lines in the left chart could represent different layers or parameters within the model, each with its own learning rate schedule.
</details>
Figure 23 The trend for performance as a function of parameter count, L ( N ) , is fit better by a power law than by other functions such as a logarithm at a qualitative level.
<details>
<summary>Image 23 Details</summary>
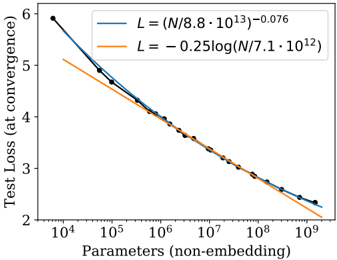
### Visual Description
\n
## Chart: Test Loss vs. Parameters
### Overview
The image presents a line chart illustrating the relationship between the number of parameters in a model (non-embedding) and the test loss achieved at convergence. Two different loss functions, represented by blue and orange lines, are compared. The x-axis is on a logarithmic scale.
### Components/Axes
* **X-axis Title:** Parameters (non-embedding)
* **X-axis Scale:** Logarithmic scale, ranging from approximately 10<sup>4</sup> to 10<sup>9</sup>. Markers are present at 10<sup>4</sup>, 10<sup>5</sup>, 10<sup>6</sup>, 10<sup>7</sup>, 10<sup>8</sup>, and 10<sup>9</sup>.
* **Y-axis Title:** Test Loss (at convergence)
* **Y-axis Scale:** Linear scale, ranging from approximately 2 to 6. Markers are present at 2, 3, 4, 5, and 6.
* **Legend:** Located in the top-right corner.
* **Blue Line:** L = (N/8.8 * 10<sup>13</sup>)<sup>-0.076</sup>
* **Orange Line:** L = -0.25log(N/7.1 * 10<sup>12</sup>)
* **Data Points:** Black circular markers are plotted along both lines, indicating specific data points.
### Detailed Analysis
**Blue Line (L = (N/8.8 * 10<sup>13</sup>)<sup>-0.076</sup>):**
The blue line exhibits a decreasing trend, indicating that as the number of parameters increases, the test loss decreases.
* At approximately 10<sup>4</sup> parameters, the test loss is around 5.8.
* At approximately 10<sup>5</sup> parameters, the test loss is around 5.1.
* At approximately 10<sup>6</sup> parameters, the test loss is around 4.4.
* At approximately 10<sup>7</sup> parameters, the test loss is around 3.8.
* At approximately 10<sup>8</sup> parameters, the test loss is around 3.2.
* At approximately 10<sup>9</sup> parameters, the test loss is around 2.7.
**Orange Line (L = -0.25log(N/7.1 * 10<sup>12</sup>)):**
The orange line also shows a decreasing trend, but it appears to be slightly steeper than the blue line, especially at lower parameter counts.
* At approximately 10<sup>4</sup> parameters, the test loss is around 5.4.
* At approximately 10<sup>5</sup> parameters, the test loss is around 4.7.
* At approximately 10<sup>6</sup> parameters, the test loss is around 4.0.
* At approximately 10<sup>7</sup> parameters, the test loss is around 3.4.
* At approximately 10<sup>8</sup> parameters, the test loss is around 2.8.
* At approximately 10<sup>9</sup> parameters, the test loss is around 2.3.
The black data points closely follow both lines, suggesting a strong correlation between the model and the predicted loss functions.
### Key Observations
* Both loss functions demonstrate diminishing returns as the number of parameters increases. The rate of loss reduction slows down as the model size grows.
* The orange loss function appears to predict slightly lower test losses than the blue loss function, particularly at lower parameter counts.
* The data points are very close to the lines, indicating a good fit between the model's performance and the theoretical loss functions.
### Interpretation
The chart illustrates the scaling behavior of test loss with respect to model size (number of parameters). The two loss functions provide theoretical predictions for how the loss should decrease as the model becomes larger. The close alignment between the lines and the data points suggests that these loss functions are reasonable approximations of the model's actual performance.
The logarithmic scale on the x-axis highlights the importance of considering relative changes in parameter count. The diminishing returns observed at higher parameter counts suggest that simply increasing model size indefinitely may not lead to significant improvements in performance. The difference between the two loss functions could indicate different assumptions about the model's capacity or the complexity of the data. The chart provides valuable insights for model design and optimization, helping to determine the appropriate model size for a given task.
</details>
schedules appear to be statistical noise, and provide a rough gauge for the scale of variation between different training runs. Experiments on larger models suggest that the variation in the final test loss between different random seeds is roughly constant in magnitude for different model sizes.
We found that larger models require a smaller learning rate to prevent divergence, while smaller models can tolerate a larger learning rate. To implement this, the following rule of thumb was used for most runs:
<!-- formula-not-decoded -->
We expect that this formula could be improved. There may be a dependence on network width, likely set by the initialization scale. The formula also breaks down for N > 10 10 parameters. Nevertheless, we found that it works sufficiently well for the models we considered.
## D.7 Fit Details and Power Law Quality
We experimented with a number of functional forms for the fits to L ( N ) , L ( C ) , and L ( D ) ; the power-law fits were qualitatively much more accurate than other functions such as logarithms (see Figure 23).
For L ( C ) , we do not include small models with only 1 layer in the fit, as the transition from 1 to 2 layers causes a noticable lump in the data. For L ( N ) we also do not include very small models with only 1 layer in the fit, and we exclude the largest models that have not trained fully to convergence. Fit parameters change marginally if we do include them, and the trend extrapolates well in both directions regardless.
## D.8 Generalization and Architecture
In figure 24 we show that generalization to other data distributions does not depend on network depth when we hold the total parameter count fixed. It seems to depend only on the performance on the training distribution.
Figure 24 We show evaluations on a series of datasets for models with approximately 1.5 Billion parameters. We observe no effect of depth on generalization; generalization performance depends primarily on training distribution performance. The 12-layer model overfit the Internet Books dataset and we show the early-stopped performance; we have not seen this surprising result in other experiments.
<details>
<summary>Image 24 Details</summary>
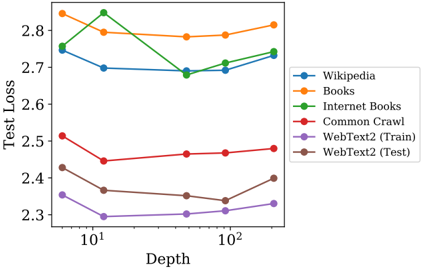
### Visual Description
## Line Chart: Test Loss vs. Depth for Different Datasets
### Overview
This line chart depicts the relationship between 'Depth' (on a logarithmic scale) and 'Test Loss' for six different datasets: Wikipedia, Books, Internet Books, Common Crawl, WebText2 (Train), and WebText2 (Test). The chart aims to illustrate how the test loss changes as the depth of a model or process increases for each dataset.
### Components/Axes
* **X-axis:** 'Depth', ranging from approximately 10<sup>1</sup> to 10<sup>2</sup> (logarithmic scale).
* **Y-axis:** 'Test Loss', ranging from approximately 2.3 to 2.9.
* **Legend:** Located in the top-right corner, identifying each line with a corresponding color:
* Blue: Wikipedia
* Orange: Books
* Green: Internet Books
* Red: Common Crawl
* Purple: WebText2 (Train)
* Brown: WebText2 (Test)
### Detailed Analysis
Here's a breakdown of each data series and their trends:
* **Wikipedia (Blue):** The line starts at approximately 2.73 at Depth 10<sup>1</sup>, dips slightly to around 2.70, and then rises to approximately 2.75 at Depth 10<sup>2</sup>. The trend is relatively flat with a slight upward slope.
* **Books (Orange):** The line begins at approximately 2.86 at Depth 10<sup>1</sup>, decreases to around 2.78, and then increases to approximately 2.88 at Depth 10<sup>2</sup>. This line shows a slight dip followed by an increase.
* **Internet Books (Green):** This line exhibits the most pronounced dip. It starts at approximately 2.92 at Depth 10<sup>1</sup>, drops sharply to around 2.68 at an intermediate depth, and then rises to approximately 2.80 at Depth 10<sup>2</sup>.
* **Common Crawl (Red):** The line starts at approximately 2.53 at Depth 10<sup>1</sup>, decreases slightly to around 2.48, and then remains relatively stable, ending at approximately 2.50 at Depth 10<sup>2</sup>. This line shows a slight decrease and then plateaus.
* **WebText2 (Train) (Purple):** The line begins at approximately 2.38 at Depth 10<sup>1</sup>, decreases to around 2.33, and then increases to approximately 2.37 at Depth 10<sup>2</sup>. This line shows a slight decrease followed by a slight increase.
* **WebText2 (Test) (Brown):** The line starts at approximately 2.44 at Depth 10<sup>1</sup>, remains relatively flat around 2.40, and then increases to approximately 2.45 at Depth 10<sup>2</sup>. This line is mostly flat with a slight upward trend.
### Key Observations
* The 'Internet Books' dataset shows the most significant decrease in test loss as depth increases, suggesting it benefits the most from increased depth within the observed range.
* 'WebText2 (Train)' consistently exhibits the lowest test loss across all depths.
* 'Wikipedia' and 'Books' show relatively stable test loss values with minor fluctuations.
* 'Common Crawl' shows a slight initial decrease in test loss, followed by stabilization.
* 'WebText2 (Test)' shows a slight increase in test loss.
### Interpretation
The chart suggests that increasing the 'Depth' of a model or process does not consistently lead to lower 'Test Loss' across all datasets. The impact of depth is dataset-dependent. The 'Internet Books' dataset appears to be particularly sensitive to depth, experiencing a substantial reduction in test loss. The relatively low and stable test loss for 'WebText2 (Train)' indicates that this dataset may be well-suited for the model or process being evaluated. The divergence between 'WebText2 (Train)' and 'WebText2 (Test)' at higher depths suggests potential overfitting on the training data. The logarithmic scale of the x-axis implies that the benefits of increasing depth may diminish as depth increases further. The chart provides insights into the optimal depth for different datasets, helping to guide model or process design and tuning. The data suggests that a one-size-fits-all approach to depth is not optimal, and dataset-specific considerations are crucial.
</details>
## List of Figures
| 1 | Summary of simple power laws. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 3 |
|-----|-------------------------------------------------------------------------------------------------|-----|
| 2 | Illustration of sample efficiency and compute efficiency. . . . . . . . . . . . . . . . . . . | 4 |
| 3 | How to scale up model size, batch size, and serial steps . . . . . . . . . . . . . . . . . . | 4 |
| 4 | Performance when varying model and data size, or model and training steps, simultaneously | 5 |
| 5 | Weak dependence of performance on hyperparameter tuning . . . . . . . . . . . . . . . | 8 |
| 6 | Comparison of performance trend when including or excluding embeddings . . . . . . . | 8 |
| 7 | LSTM and Transformer performance comparison . . . . . . . . . . . . . . . . . . . . . | 9 |
| 8 | Generalization to other test datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 10 |
| 9 | Universality of overfitting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 11 |
| 10 | Critical batch size . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 12 |
| 11 | Performance versus compute budget or number of parameter updates . . . . . . . . . . . | 14 |
| 12 | Training on suboptimal models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 15 |
| 13 | Comparison between empirical and adjusted compute trends . . . . . . . . . . . . . . . | 15 |
| 14 | Optimal model size and serial number of steps versus compute budget . . . . . . . . . . | 16 |
| 15 | Contradiction between compute and data trends . . . . . . . . . . . . . . . . . . . . . . | 17 |
| 16 | Early stopping lower bound and training curves for overfit models . . . . . . . . . . . . | 23 |
| 17 | Universal transformers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 24 |
| 18 | Batch size scans . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 24 |
| 19 | Another look at sample efficiency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 24 |
| 20 | Power-law dependence of performance on position in context . . . . . . . . . . . . . . . | 25 |
| 21 | Performance at different context positions versus model size . . . . . . . . . . . . . . . | 25 |
| 22 | Learning rate schedule scan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 26 |
| 23 | Comparison of Power-Law and Logarithmic Fits . . . . . . . . . . . . . . . . . . . . . | 26 |
| 24 | Generalization versus depth . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . | 27 |
## List of Tables
| 1 | Parameter and compute counts for Transformer | Parameter and compute counts for Transformer | 7 |
|------------|------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 2 | Fits to L ( N,D ) . | Fits to L ( N,D ) . | 11 |
| 3 | Fits to L ( N,S ) . . . . . | Fits to L ( N,S ) . . . . . | 14 |
| 4 | Key trend equations . | Key trend equations . | 20 |
| 5 | Key parameters to trend fits . | Key parameters to trend fits . | 20 |
| 6 | Trends for compute-efficient training . . . | Trends for compute-efficient training . . . | 20 |
| References | References | References | References |
| [ACDE12] | [ACDE12] | Eduardo G Altmann, Giampaolo Cristadoro, and Mirko Degli Esposti. On the origin of long- range correlations in texts. Proceedings of the National Academy of Sciences , 109(29):11582- 11587, 2012. 25 | Eduardo G Altmann, Giampaolo Cristadoro, and Mirko Degli Esposti. On the origin of long- range correlations in texts. Proceedings of the National Academy of Sciences , 109(29):11582- 11587, 2012. 25 |
| [AS17] | [AS17] | Madhu S. Advani and Andrew M. Saxe. High-dimensional dynamics of generalization error in neural networks. arXiv , 2017, 1710.03667. 11, 18, 22 | Madhu S. Advani and Andrew M. Saxe. High-dimensional dynamics of generalization error in neural networks. arXiv , 2017, 1710.03667. 11, 18, 22 |
| [BB01] | [BB01] | Michele Banko and Eric Brill. Scaling to very very large corpora for natural language disam- biguation. In Proceedings of the 39th annual meeting on association for computational linguis- tics , pages 26-33. Association for Computational Linguistics, 2001. 18 | Michele Banko and Eric Brill. Scaling to very very large corpora for natural language disam- biguation. In Proceedings of the 39th annual meeting on association for computational linguis- tics , pages 26-33. Association for Computational Linguistics, 2001. 18 |
| [BHMM18] | [BHMM18] | Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling modern machine learning and the bias-variance trade-off. arXiv , 2018, 1812.11118. 18 | Mikhail Belkin, Daniel Hsu, Siyuan Ma, and Soumik Mandal. Reconciling modern machine learning and the bias-variance trade-off. arXiv , 2018, 1812.11118. 18 |
| [Bia12] | [Bia12] | GÊrard Biau. Analysis of a random forests model. Journal of Machine Learning Research , 13(Apr):1063-1095, 2012. 18 | GÊrard Biau. Analysis of a random forests model. Journal of Machine Learning Research , 13(Apr):1063-1095, 2012. 18 |
| [CGRS19] | [CGRS19] | Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. CoRR , abs/1904.10509, 2019, 1904.10509. URL http://arxiv.org/ abs/1904.10509 . 19 | Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. CoRR , abs/1904.10509, 2019, 1904.10509. URL http://arxiv.org/ abs/1904.10509 . 19 |
| [DCLT18] | [DCLT18] | Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2018, arXiv:1810.04805. 2 | Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2018, arXiv:1810.04805. 2 |
| [DGV + 18] | [DGV + 18] | Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers. CoRR , abs/1807.03819, 2018, 1807.03819. URL http://arxiv.org/ abs/1807.03819 . 6, 9, 23, 24 | Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers. CoRR , abs/1807.03819, 2018, 1807.03819. URL http://arxiv.org/ abs/1807.03819 . 6, 9, 23, 24 |
| [EP94] | [EP94] | Werner Ebeling and Thorsten Pöschel. Entropy and long-range correlations in literary english. EPL (Europhysics Letters) , 26(4):241, 1994. 25 | Werner Ebeling and Thorsten Pöschel. Entropy and long-range correlations in literary english. EPL (Europhysics Letters) , 26(4):241, 1994. 25 |
| [Fou] | [Fou] | The Common Crawl Foundation. Common crawl. URL http://commoncrawl.org . 7 | The Common Crawl Foundation. Common crawl. URL http://commoncrawl.org . 7 |
| [GARD18] | [GARD18] | Guy Gur-Ari, Daniel A. Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. 2018, arXiv:1812.04754. 18 | Guy Gur-Ari, Daniel A. Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. 2018, arXiv:1812.04754. 18 |
| [GJS + 19] | [GJS + 19] | Mario Geiger, Arthur Jacot, Stefano Spigler, Franck Gabriel, Levent Sagun, Stéphane d'Ascoli, Giulio Biroli, Clément Hongler, and Matthieu Wyart. Scaling description of generalization with number of parameters in deep learning. arXiv , 2019, 1901.01608. 18 | Mario Geiger, Arthur Jacot, Stefano Spigler, Franck Gabriel, Levent Sagun, Stéphane d'Ascoli, Giulio Biroli, Clément Hongler, and Matthieu Wyart. Scaling description of generalization with number of parameters in deep learning. arXiv , 2019, 1901.01608. 18 |
| [GKX19] | [GKX19] | Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net op- timization via hessian eigenvalue density. CoRR , abs/1901.10159, 2019, 1901.10159. URL http://arxiv.org/abs/1901.10159 . 18 | Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net op- timization via hessian eigenvalue density. CoRR , abs/1901.10159, 2019, 1901.10159. URL http://arxiv.org/abs/1901.10159 . 18 |
| [Goo01] | [Goo01] | Joshua Goodman. A bit of progress in language modeling. CoRR , cs.CL/0108005, 2001. URL http://arxiv.org/abs/cs.CL/0108005 . 18 | Joshua Goodman. A bit of progress in language modeling. CoRR , cs.CL/0108005, 2001. URL http://arxiv.org/abs/cs.CL/0108005 . 18 |
| [GRK17] | [GRK17] | Scott Gray, Alec Radford, and Diederik P Kingma. Gpu kernels for block-sparse weights. ope- nai.com , 2017. 19 | Scott Gray, Alec Radford, and Diederik P Kingma. Gpu kernels for block-sparse weights. ope- nai.com , 2017. 19 |
| [HAD19] | [HAD19] | Joel Hestness, Newsha Ardalani, and Gregory Diamos. Beyond human-level accuracy: Compu- tational challenges in deep learning. In Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming , PPoPP '19, pages 1-14, New York, NY, USA, 2019. ACM. doi:10.1145/3293883.3295710. 18 | Joel Hestness, Newsha Ardalani, and Gregory Diamos. Beyond human-level accuracy: Compu- tational challenges in deep learning. In Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming , PPoPP '19, pages 1-14, New York, NY, USA, 2019. ACM. doi:10.1145/3293883.3295710. 18 |
- [HCC + 18] Yanping Huang, Yonglong Cheng, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, and Zhifeng Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism. CoRR , abs/1811.06965, 2018, 1811.06965. URL http://arxiv.org/abs/1811.06965 . 19
- [HNA + 17] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically, 2017, 1712.00409. 18
- [JGH18] Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in neural information processing systems , pages 8571-8580, 2018. 18
- [KB14] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2014, 1412.6980. 7
- [Kom19] Aran Komatsuzaki. One epoch is all you need, 2019, arXiv:1906.06669. 18
- [KSH12] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1 , NIPS'12, pages 1097-1105, USA, 2012. Curran Associates Inc. URL http://dl.acm.org/citation.cfm?id=2999134.2999257 . 19
- [LCG + 19] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations, 2019, 1909.11942. 9
- [LOG + 19] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR , abs/1907.11692, 2019, 1907.11692. URL http://arxiv.org/abs/ 1907.11692 . 2
- [LSP + 18] Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. Generating wikipedia by summarizing long sequences. arXiv:1801.10198 [cs] , 2018, 1801.10198. URL http://arxiv.org/abs/1801.10198 . 2, 6
- [LT16] Henry W Lin and Max Tegmark. Criticality in formal languages and statistical physics. arXiv preprint arXiv:1606.06737 , 2016. 25
- [LXS + 19] Jaehoon Lee, Lechao Xiao, Samuel S. Schoenholz, Yasaman Bahri, Roman Novak, Jascha SohlDickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent, 2019, arXiv:1902.06720. 18
- [MKAT18] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training, 2018, arXiv:1812.06162. 3, 5, 6, 12, 13, 21
- [Pap18] Vardan Papyan. The full spectrum of deep net hessians at scale: Dynamics with sample size. CoRR , abs/1811.07062, 2018, 1811.07062. URL http://arxiv.org/abs/1811.07062 . 18
- [RNSS18] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openaiassets/research-covers/languageunsupervised/language understanding paper. pdf , 2018. 2, 6
- [RRBS19a] Jonathan S. Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. A constructive prediction of the generalization error across scales, 2019, 1909.12673. 18
- [RRBS19b] Jonathan S. Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. A constructive prediction of the generalization error across scales, 2019, arXiv:1909.12673. 18
- [RSR + 19] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2019, arXiv:1910.10683. 2
- [RWC + 19] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. openai.com , 2019. 2, 5, 6, 7, 8
- [SCP + 18] Noam Shazeer, Youlong Cheng, Niki Parmar, Dustin Tran, Ashish Vaswani, Penporn Koanantakool, Peter Hawkins, HyoukJoong Lee, Mingsheng Hong, Cliff Young, Ryan Sepassi, and Blake Hechtman. Mesh-tensorflow: Deep learning for supercomputers, 2018, 1811.02084. 19
- [SHB15] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. CoRR , 2015, 1508.07909. 6
- [SLA + 18] Christopher J. Shallue, Jaehoon Lee, Joe Antognini, Jascha Sohl-Dickstein, Roy Frostig, and George E. Dahl. Measuring the effects of data parallelism on neural network training, 2018, arXiv:1811.03600. 12
- [SS18] Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. CoRR , abs/1804.04235, 2018, 1804.04235. URL http://arxiv.org/abs/1804.04235 . 7
- [THK18] Stefan Thurner, Rudolf Hanel, and Peter Klimek. Introduction to the theory of complex systems . Oxford University Press, 2018. 18
- [TL19] Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. CoRR , abs/1905.11946, 2019, 1905.11946. URL http://arxiv.org/abs/1905. 11946 . 18
- [VSP + 17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30 , pages 5998-6008. Curran Associates, Inc., 2017. URL http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf . 2, 6
- [VWB16] Andreas Veit, Michael Wilber, and Serge Belongie. Residual networks behave like ensembles of relatively shallow networks, 2016, arXiv:1605.06431. 8, 18
- [Was06] Larry Wasserman. All of nonparametric statistics . Springer Science & Business Media, 2006. 18
- [WPN + 19] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems, 2019, 1905.00537. 2
- [WRH17] Yu-Xiong Wang, Deva Ramanan, and Martial Hebert. Growing a brain: Fine-tuning by increasing model capacity. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , Jul 2017. doi:10.1109/cvpr.2017.323. 19
- [WYL19] Wei Wen, Feng Yan, and Hai Li. Autogrow: Automatic layer growing in deep convolutional networks, 2019, 1906.02909. 19
- [YDY + 19] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. Xlnet: Generalized autoregressive pretraining for language understanding, 2019, arXiv:1906.08237. 2
- [ZK16] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. Procedings of the British Machine Vision Conference 2016 , 2016. doi:10.5244/c.30.87. 18
- [ZKZ + 15] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. 2015 IEEE International Conference on Computer Vision (ICCV) , Dec 2015. doi:10.1109/iccv.2015.11. 7
- [ZLN + 19] Guodong Zhang, Lala Li, Zachary Nado, James Martens, Sushant Sachdeva, George E. Dahl, Christopher J. Shallue, and Roger B. Grosse. Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model. CoRR , abs/1907.04164, 2019, 1907.04164. URL http://arxiv.org/abs/1907.04164 . 12, 18