# Sound field reconstruction in rooms: inpainting meets super-resolution
**Authors**: Francesc Lluís, Pablo Martínez-Nuevo, Martin Bo Møller, Sven Ewan Shepstone
## Sound field reconstruction in rooms: inpainting meets super-resolution
Francesc Llu´ ıs, 1, a Pablo Mart´ ınez-Nuevo, 2 Martin Bo Møller, 2 and Sven Ewan Shepstone 2 1 Department of Music Acoustics, University of Music and Performing Arts Vienna, Austria 2 R&D Acoustics, Bang & Olufsen, Struer, 7600, Denmark
(Dated: 7 August 2020)
In this paper, a deep-learning-based method for sound field reconstruction is proposed. It is shown the possibility to reconstruct the magnitude of the sound pressure in the frequency band 30-300 Hz for an entire room by using a very low number of irregularly distributed microphones arbitrarily arranged. Moreover, the approach is agnostic to the location of the measurements in the Euclidean space. In particular, the presented approach uses a limited number of arbitrary discrete measurements of the magnitude of the sound field pressure in order to extrapolate this field to a higher-resolution grid of discrete points in space with a low computational complexity. The method is based on a U-net-like neural network with partial convolutions trained solely on simulated data, which itself is constructed from numerical simulations of Green's function across thousands of common rectangular rooms. Although extensible to three dimensions and different room shapes, the method focuses on reconstructing a two-dimensional plane of a rectangular room from measurements of the three-dimensional sound field. Experiments using simulated data together with an experimental validation in a real listening room are shown. The results suggest a performance which may exceed conventional reconstruction techniques for a low number of microphones and computational requirements.
c © 2020 Acoustical Society of America.
[XYZ]
## I. INTRODUCTION
The functions describing sound propagation, such as sound pressure or particle velocity, operate scalar and vector values respectively which vary across the temporal and spatial dimensions. There are many applications where knowledge of the spatial variation of the sound field is of paramount interest, for example, sound field navigation for virtual reality environments 1,2 , accurate spatial sound field reproduction over predefined regions of space 3-5 , or sound field control in reverberant environments 6,7 .
The different reconstruction scenarios are determined by the type of information gathered from the sound field. Depending on the type of acquisition, several techniques are used, ranging for example, from acoustic holography 8 , acousto-optic methods 9,10 , or traditional discrete sets of spatial samples 11 . The latter is particularly convenient in practice since it requires simple microphones.
In the case of sound field reconstruction in rooms, there exist several methods in the literature. In particular, model-based approaches based on samples of the sound pressure at a discrete set of locations tend to dominate the area. Results using classical sampling 11 , i.e. based on bandwidth analysis, build upon the image
a lluis-salvado@mdw.ac.at
[https://doi.org(DOI number)]
Pages: 1-12
source method to characterize the sound field in a room in order to derive bounds on the aliasing error for a given sampling density. This leads to an impractically high density of microphones for an acceptable reconstruction error. Another approach to simplify the model and the number of measurements is based on parameterizing the room impulse response as a pole-zero system 12 .
Compressive sensing approaches have been effective in reducing the number of measurements compared to these previous methods. They inherently require an underlying assumption of the sparsity of the chosen room acoustics model. Utilizing modal theory, it is possible to consider a plane wave approximation of the sound field 13 in a room in order to describe it spatially as a sparse linear combination of damped complex exponentials 14-16 . Dictionaries tend to be large, performance degrades at high frequencies, and the interpolated location should be, in general, in the far field with respect to the source. Under the image source method, estimation of the early part of the room impulse response is also possible assuming a few dominant image sources 17 . These techniques are in general sensitive to the choice of sampling scheme used in order to guarantee meaningful solutions and wellconditioned problems. Empirical methods for the latter are commonly adopted leading to some restrictions in the arrangement of microphones. Exploiting information about the modal frequencies may allow a more general microphone arrangement 18 at the expense of sensitivity to source location, modal density, and accurate modal
frequencies estimation. Additionally, finding solutions to these sparse inverse problems is typically computationally demanding 19 .
In this paper, we adopt a data-driven approach to the problem of sound field sampling and reconstruction, which, for the present application, appears to be unexplored. For clarity of exposition, we focus on a twodimensional horizontal plane of three-dimensional rectangular rooms. We consider a very low number of irregularly and arbitrarily distributed measurements to recover the magnitude of the sound pressure in a room across the spatial dimension for the frequency range 30-300 Hz. In contrast to previous methods, our approach is location agnostic in the sense that it does not require knowledge of the microphone positions or the interpolation points in the Euclidean space. These characteristics can contribute to designing more practical sampling and reconstruction procedures. The goal of the paper is then threefold: use a very low number of microphones, accommodate irregular and location agnostic microphone distributions, and carry out inference that is computationally efficient.
We first view the sound field as a two-dimensional discrete signal. The acquisition step can be interpreted as producing a low-resolution signal with missing samples. Then, the recovery step consists of filling the missing data of a high-resolution two-dimensional signal. We show how this process can be viewed as jointly performing inpainting 20,21 and super-resolution 22,23 , both wellknown techniques in image processing with a good performance using deep learning methods. In particular, we use a U-net neural network 24 with partial convolutions 21 trained on simulated data that simultaneously performs inpainting and super-resolution. Under this framework, we show how it is possible to recover a high-resolution field from a very low number of irregular and locationagnostic measurements with low computational complexity in the inference process.
The paper is organized as follows: Section II establishes the conceptual framework under which the reconstruction problem is addressed, i.e. as a learning algorithm drawing upon inpainting and super-resolution techniques. The details about the neural network architecture and the training procedure used for recovery are explained in Section III. Section IV presents results concerning the reconstruction accuracy of the proposed algorithm both in simulated and experimental settings, i.e. in real rooms.
## II. PROBLEM DESCRIPTION
We frame the problem of sound field reconstruction within a data-driven approach, i.e. we aim at developing a recovery algorithm that directly and progressively learns from raw sound field data. The machine learning methods that have been particularly successful in this regard fall under deep learning systems. These have significantly outperformed model-based approaches in tasks such as, but not limited to, image classification, analysis, and restoration 25,26 ; or speech recognition and synthesis 27,28 .
The novelty of the present approach lies in the observation that the magnitude of the sound pressure in a room can be interpreted as a two-dimensional discrete function defined on a rectangular grid of points in space, i.e. in the same way a raster image is represented by a rectangular grid of pixels. This allows us to exploit the effectiveness of deep learning techniques in image processing. Although the principles governing the proposed algorithm can, in principle, be extended to three-dimensional regions, we focus on reconstructing the three-dimensional field in a two-dimensional plane for the sake of simplicity. We further assume that the enclosures of interest consist of rectangular rooms corresponding to domestic standards 29 . Note that the method described here could also be extended to different room shapes.
In particular, the function that we sample and reconstruct is a discrete version of the magnitude of the Fourier transform of the sound field in a given frequency band. We show in the following how reconstructing this function is connected to the well-known concepts of image inpainting and super-resolution. Let us first denote the spatio-temporal sound field in a three-dimensional rectangular room as p ( r , t ) where R = (0 , l x ) × (0 , l y ) × (0 , l z ) for some l x , l y , l z > 0 and r ∈ R . The magnitude of its Fourier transform is given by
<!-- formula-not-decoded -->
for ω ∈ R and r ∈ R .
Initially, given a room, we can define the following rectangular grid as a set on an arbitrary two-dimensional plane, i.e.
<!-- formula-not-decoded -->
for z o ∈ (0 , l z ), i = 0 , . . . , I -1, j = 0 , . . . , J -1, and some integers I, J ≥ 2. Then, the available spatial sample points, denoted as S o , consist of a subset of D o . It is important to observe that there is no constraint whatsoever with regard to the pattern that S o has to form within D o . This allows us to have, for example, irregularly distributed spatial sample points within the room. For a given excitation frequency, the available samples can then be expressed as follows
<!-- formula-not-decoded -->
Note that the problem of interpolating s ( r , ω ) to the entire domain D o from known values in S o can be viewed as image inpainting, i.e. filling in the missing holes of a raster image. This is motivated by the irregular nature of the sampling pattern.
However, we are interested in reconstruction on an even finer rectangular grid in order to capture the smallscale spatial variations of the sound field. In order to do so, we eventually interpolate the sound field to a grid of
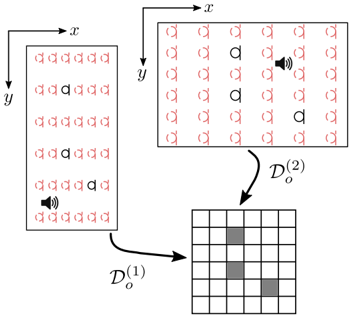
FIG. 1. Illustration of the spatial points considered for reconstruction of the function s ( r , ω ) for a given frequency. The set D o consists of the solid black and gray circles where the former, for example, can be interpreted as S o . The set D L,P o is then given by all the points depicted where inpainting and super-resolution is jointly performed from knowledge of the function in S o . Note that here L = P = 4. (Color online.)
<details>
<summary>Image 1 Details</summary>

### Visual Description
\n
## Grid: Dot Pattern
### Overview
The image presents a grid of circles, most of which are white (empty). A small number of circles are filled with black or gray. The arrangement appears non-random, potentially representing a pattern or data visualization. There are no explicit axes or labels.
### Components/Axes
There are no axes or labels present in the image. The components are simply the grid of circles and the filled circles.
### Detailed Analysis or Content Details
The grid appears to be approximately 11 rows by 13 columns, resulting in roughly 143 total circles.
* **Black Circles:** There are 4 black circles. Their approximate locations are:
* Row 1, Column 1 (top-left)
* Row 4, Column 7 (center-left)
* Row 7, Column 11 (center-right)
* Row 10, Column 2 (bottom-left)
* **Gray Circles:** There are 4 gray circles. Their approximate locations are:
* Row 1, Column 4 (top-center)
* Row 3, Column 2 (upper-center)
* Row 7, Column 13 (center-right)
* Row 10, Column 11 (bottom-right)
* **White Circles:** The remaining circles are white, representing the majority of the grid. Approximately 135 circles are white.
There is no apparent numerical data associated with the image beyond the counts of each color.
### Key Observations
The black and gray circles are sparsely distributed across the grid. There doesn't appear to be a clear, simple geometric pattern (e.g., diagonal, checkerboard). The distribution seems somewhat irregular.
### Interpretation
Without additional context, it's difficult to definitively interpret the meaning of this grid. It could represent:
* **A simple visual pattern:** The arrangement might be designed to test visual perception or pattern recognition.
* **Data visualization:** The black and gray circles could represent data points, with the grid representing a two-dimensional space. The positions of the colored circles would then indicate the location of specific data points.
* **A code or cipher:** The arrangement could be part of a code or cipher, where the positions of the colored circles represent letters or numbers.
* **A representation of a network:** The circles could represent nodes in a network, and the colored circles could represent nodes with specific properties.
The limited number of colored circles suggests that the data or pattern being represented is relatively sparse. The lack of axes or labels makes it impossible to determine the meaning of the grid without further information. The image is a visual representation, but lacks the factual data to draw concrete conclusions.
</details>
points corresponding to an upsampled version of the set D o , i.e.
<!-- formula-not-decoded -->
where i = 0 , . . . , ( I -1) L , j = 0 , . . . , ( J -1) P , and some integers L, P ≥ 1. In the signal processing community, reconstructing a function on the domain D L,P o (the high resolution signal) from knowledge of the function on D o (the low resolution signal) is known as super-resolution. Fig. 1 illustrates how the different sets D o , D L,P o , and S o are placed under the inpainting and super-resolution framework.
In summary, we aim at designing an estimator g w with the structure of a neural network where its parameters are real-valued weights w learned from simulated data. In particular, for a given set of frequencies of interest { ω k } K k =1 , the estimator is defined as follows
<!-- formula-not-decoded -->
The goal is then that the error
<!-- formula-not-decoded -->
is reduced for each frequency point.
It is important to note that the actual input to the neural network will represent the values { s ( r , ω k ) } r ∈D o ,k in the rectangular grid D o as a tensor-the missing values will be included by means of a mask on the original grid. For each frequency, this can be seen as a matrix. This implies that there is no information whatsoever provided at the input about the location of these values in the Euclidean coordinate system, i.e. the algorithm is location agnostic. In other words, irrespective of the room dimensions, we assume that our algorithm accepts measurements from a rectangular grid, whose absolute size
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Convolutional Neural Network Illustration
### Overview
The image depicts a simplified illustration of a convolutional neural network (CNN) process. It shows an input matrix, a convolutional operation with a filter, and the resulting output feature map. The diagram highlights the effect of a filter sliding across the input, producing a smaller output matrix with activated regions.
### Components/Axes
The diagram consists of three main components:
1. **Input Matrix (D⁽¹⁾o):** A rectangular grid labeled with 'x' and 'y' axes. The grid is populated with the character 'd' repeated multiple times. A small speaker icon with sound waves emanating from it is present in the bottom-right corner.
2. **Convolutional Filter (D⁽²⁾o):** A smaller rectangular grid, also labeled with 'x' and 'y' axes. This grid is populated with the character 'α' repeated multiple times, with a few 'd' characters interspersed. A small speaker icon with sound waves emanating from it is present in the top-right corner.
3. **Output Feature Map:** A grid of squares, with some squares shaded in gray. This represents the result of the convolution operation. An arrow labeled "D⁽²⁾o" points from the convolutional filter to this output. An arrow labeled "D⁽¹⁾o" points from the input matrix to the convolutional filter.
### Detailed Analysis or Content Details
The input matrix (D⁽¹⁾o) appears to be approximately 5x6 in size. The character 'd' is the dominant element.
The convolutional filter (D⁽²⁾o) appears to be approximately 4x5 in size. The character 'α' is the dominant element, with a few 'd' characters.
The output feature map is approximately 2x2 in size. Four squares are shaded gray, indicating activation. The positions of the gray squares suggest the filter detected the 'd' character in those locations of the input matrix.
### Key Observations
The diagram illustrates how a convolutional filter slides across the input matrix, performing element-wise multiplication and summation. The speaker icons suggest that the filter is detecting a specific feature (represented by the 'd' character). The gray squares in the output feature map indicate the locations where the filter detected this feature. The filter appears to be designed to detect the 'd' character, as it activates when it encounters it in the input.
### Interpretation
This diagram demonstrates the core principle of convolution in CNNs. The filter acts as a feature detector, scanning the input for specific patterns. The output feature map highlights the presence and location of these patterns. The use of 'd' and 'α' characters is symbolic, representing any input data and the filter's learned weights, respectively. The diagram simplifies the process, omitting details like stride, padding, and multiple filters, but effectively conveys the fundamental concept of feature extraction through convolution. The speaker icons suggest that the detected feature is significant or noteworthy. The diagram is a visual aid for understanding how CNNs learn to identify patterns in data.
</details>
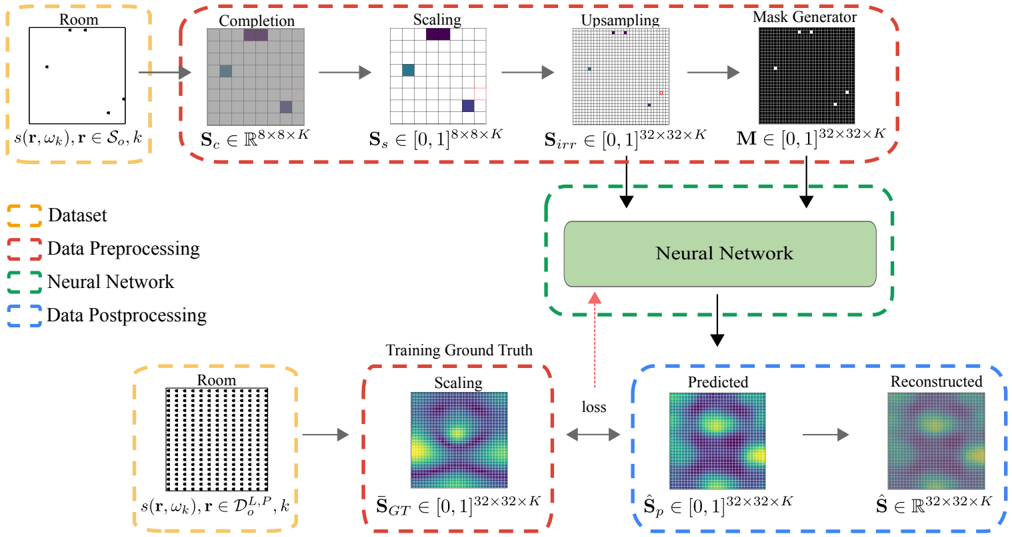
FIG. 2. Example of the location agnostic property. Two rooms with different sizes lead to different rectangular grids in the Euclidean space, i.e. D (1) o = D (2) o . For a given frequency, we use a matrix to represent the input to the network. However, the measured and missing values in both cases (in black and red respectively) are placed at the same matrix entries. This essentially disregards any information about their locations in the Euclidean space. Similarly, the source location is considered unknown. (Color online.)
depends on the room size. In the same way an image reconstruction algorithm would learn to recover images that have been stretched, shrunk, or zoomed in or out (see Fig. 2). Thus, the absolute separation of points along each dimension is not the same. For example, in a room with dimensions l x × l y , input points will be at distance of l x I and l y J .
We will occasionally use tensors in order to represent function values on discrete spatial and frequency domains and as the data structure for the neural network operations. In particular, tensors, irrespective of their order, are denoted by bold uppercase letters, e.g. matrices can be denoted by A ∈ R n 1 × n 2 for n 1 , n 2 ∈ N . Regarding function values, we interchangeably use the tensor representation. For example, consider { s ( r , ω k ) } r ∈D L,P o ,k , then it possible to arrange its values into a tensor S ∈ R IL × JP × K whose elements are given by
<!-- formula-not-decoded -->
## III. APPROACH
We propose a learning algorithm capable of estimating the magnitude of the spatial sound field, for a given frequency range, at a predefined number of locations based on very few measurements from irregularly distributed microphones. The microphones are assumed to provide the room transfer functions (RTFs) at those particular locations for a given frequency range. It is assumed that these microphones are located in a rectangular grid with a predefined number of points irrespective of the room size (see Fig. 2). Note that the source location
is also considered unknown. The prediction algorithm then provides an estimate of the corresponding RTFs at the desired locations.
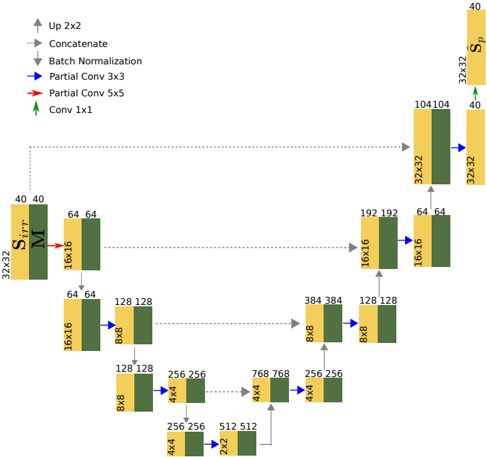
The approach is to train an artificial neural network that learns the structure of these sound fields from thousands of different examples of common domestic rectangular rooms. The main parts of the algorithm, which we describe in detail in the following sections, and illustrate in Fig. 3, can be briefly summarized as follows:
- Dataset: we simulate three-dimensional sound fields, in the frequency band [30,300] Hz, for thousands of common rectangular rooms. The magnitude of the pressure in the available spatial sample points S o serves as input to the network after a preprocessing step. The magnitude of the pressure in the finer rectangular grid, i.e. { s ( r , ω k ) } r ∈D L,P o ,k , is then used to train the network in a supervised manner.
- Data Preprocessing: from { s ( r , ω k ) } r ∈S o ,k , we generate a grid version, defined on D L,P o , consisting of the observed samples and a mask that encodes the information about the locations of these measurements. This preprocessing step involves completion, scaling, and upsampling operations.
- Neural Network: The architecture learns to predict a scaled version of the two-dimensional function { s ( r , ω k ) } r ∈D L,P o ,k from the preprocessed observed sample values { s ( r , ω k ) } r ∈S o ,k and the mask.
- Data Postprocessing: Estimates the appropriate scaling in order to restore the predicted values to the range of the source data.
The data and code of the proposed algorithm is freely available online 30 .
## A. Dataset
The sound field in a lightly damped rectangular room can be approximated using Green's function expressing the solution as an infinite summation of room modes (or standing waves) in the x-,y-, and z-dimension of the room 31
<!-- formula-not-decoded -->
Here, for compactness ∑ N denotes a triple summation across the modal order in each dimension of the room i.e. ∑ N = ∑ ∞ n x =0 ∑ ∞ n y =0 ∑ ∞ n z =0 and correspondingly N represents the triplet of integers n x , n y , n z . The volume of the room is denoted V , ψ N ( · ) is the mode shape associated with a specific N , ω N is the angular resonance frequency of the mode, τ N is the time constant of the mode, and c is the speed of sound. The room shape is here determined assuming rigid boundaries leading to the expression
<!-- formula-not-decoded -->
where Λ N = √ n x n y n z are normalization constants with 0 = 1, 1 = 2 = . . . = 2.
Throughout this work, the focus is to predict the variation of the sound field in a single xy -plane, hence, we seek to train a model which can predict the variation of the sound pressure in the plane. With the purpose to generalize for any xy -plane, we remove the height variation in the Dataset by setting n z = 0. The time constants of each mode are determined from the absorption coefficient calculated using Sabine's equation and assuming a reverberation time T 60 of 0.6 s and uniform distribution of absorption on the surfaces of the room.
We use this model to simulate point source radiation in 5 000 rectangular rooms. Room size and room proportions are randomly created following the recommendation for listening room dimensions for audio reproduction in the standard ITU - R BS.1116 - 3 29 . The floor area ranges from 20 m 2 to 60 m 2 and the dimension ratios follow:
<!-- formula-not-decoded -->
where l x , l y , and l z correspond to length, width, and height respectively. In addition, the source is placed at a random xy -location, i.e. ( x o , y o , 0) for x o ∈ (0 , l x ) and y o ∈ (0 , l y ). Both the dimensions and source location are sampled uniformly.
The magnitude of the sound field pressure is acquired in the finer rectangular grid D L,P o with L = P = 4 and I = J = 8. This essentially divides the room into a grid of 32 by 32 uniformly-spaced points independently of its dimensions. We analyze the results with 1/12th octave frequency resolution in the range [30, 300] Hz including all room modes with a resonance frequency below 400 Hz. This gives K = 40 frequency points. The sound fields generated using this technique are referred to as ground truth sound fields, i.e. s GT ( r , ω k ) := s ( r , ω k ) for r ∈ D L,P o and k = 1 , . . . K . A subset of s GT ( r , ω k ) containing the observed samples captured by the microphones, { s GT ( r , ω k ) } r ∈S o ,k , is used in the preprocessing part.
## B. Preprocessing
This part addresses the processing stage necessary to handle the arbitrary nature of the sampling distribution. In particular, the raw input data is allowed to be variable in size and sampling location. In order to address this, we complete the input data to take values on D o . This is followed by a scaling operation in order to generalize the predictions for arbitrary sources and receivers. The actual information of where the samples are located within D L,P o is encoded into a mask-like function. An upsampled version of this processed input data together with this mask comprises the final input to the network.
FIG. 3. Diagram showing the different steps of the algorithm design. The data is assumed to be represented as third-order tensors in order to include the frequency dimension and the spatial dimensions; however, for the sake of illustration, the former is not shown. The preprocessing stage generates the input mask together with an upsampled and scaled version of the observed samples. The training examples are also scaled. For our choice of parameters, the two input tensors and the training examples take values in [0 , 1] 32 × 32 × 40 . During training, the observed sample values are drawn from our simulated dataset of sound fields in rooms. (Color online.)
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Neural Network for Room Completion
### Overview
This diagram illustrates a neural network pipeline for completing a room scene from a partial observation. The process involves data preprocessing, a neural network core, and data postprocessing, with a training loop for optimization. The diagram shows the flow of data through these stages, along with the mathematical notation representing the dimensions of the data at each step.
### Components/Axes
The diagram is divided into two main sections: the forward pass (top row) and the training loop (bottom row). Each section is further divided into stages: Room, Completion, Scaling, Upsampling, Mask Generator (top row) and Room, Scaling, Predicted, Reconstructed (bottom row). A central "Neural Network" block connects the two sections.
The legend, located in the bottom-left corner, defines the color-coding for different data types:
- Yellow dashed line: Dataset
- Red dashed line: Data Preprocessing
- Green solid line: Neural Network
- Blue dashed line: Data Postprocessing
Mathematical notations are used to define the dimensions of the data at each stage.
### Detailed Analysis or Content Details
**Forward Pass (Top Row):**
1. **Room:** Input is `s(r, ωk)`, where `r ∈ S0, k`. The output is a visual representation of a room scene.
2. **Completion:** The output `Sc ∈ ℝ8x8xK` represents the completed scene.
3. **Scaling:** The completed scene is scaled to `Ss ∈ [0, 1]8x8xK`.
4. **Upsampling:** The scaled scene is upsampled to `Sirr ∈ [0, 1]32x32xK`.
5. **Mask Generator:** A mask is generated `M ∈ [0, 1]32x32xK`.
**Training Loop (Bottom Row):**
1. **Room:** Input is `s(r, ωk)`, where `r ∈ D0, P, k`. The output is a visual representation of a room scene.
2. **Scaling:** The ground truth is scaled to `SGT ∈ [0, 1]32x32xK`.
3. **Predicted:** The neural network predicts the completed scene `Sp ∈ [0, 1]32x32xK`.
4. **Reconstructed:** The reconstructed scene is `S ∈ ℝ32x32xK`.
**Central Neural Network:**
The "Neural Network" block receives the upsampled image and the training ground truth as inputs. It outputs the predicted scene, which is then compared to the ground truth to calculate a "loss" value. This loss is used to update the network's weights during training.
**Data Flow:**
Arrows indicate the flow of data between stages. Dashed arrows represent data flow associated with the legend's color-coding.
### Key Observations
The diagram highlights the key stages involved in room completion using a neural network. The use of mathematical notation emphasizes the quantitative nature of the process. The training loop demonstrates how the network learns to minimize the difference between its predictions and the ground truth. The diagram clearly separates the preprocessing, network core, and postprocessing stages.
### Interpretation
The diagram illustrates a supervised learning approach to room completion. The neural network is trained to predict a complete scene given a partial observation. The scaling and upsampling stages suggest that the network operates on normalized and resized images. The mask generator likely plays a role in identifying and filling in missing parts of the scene. The loss function quantifies the error between the predicted and ground truth scenes, guiding the network's learning process. The overall goal is to develop a neural network that can accurately and realistically complete room scenes from incomplete data. The use of mathematical notation suggests a focus on precise control and optimization of the network's performance. The diagram is a high-level overview and does not provide details about the specific architecture or training procedure of the neural network.
</details>
## 1. Completion
We assume that the possible observed pressure values correspond to locations within the coarser grid D o , which also covers the whole room area. In this paper, the choice of parameters results in D o being a grid of 8 by 8 points. The samples observed are then given by { s GT ( r , ω k ) } r ∈S o ,k . Irrespective of the structure of S o , i.e. the number and pattern of observed samples, the neural network is designed so that the size of the input data is fixed. In order to address this, we introduce a function defined on D o that, in a sense, completes the acquired data, i.e.
<!-- formula-not-decoded -->
for each ω k . In other words, for the locations where no samples are provided, i.e. no microphone is present, s c is chosen arbitrarily to take the maximum value.
## 2. Scaling
We want the proposed method to be independent of the gain in the measurement equipment and the reproduction system. Thus, we introduce a scaling for the sample values s c in such a way that the range is restricted to [0,1], i.e.
<!-- formula-not-decoded -->
for each ω k . Consequently, the neural network will learn to predict the sound field values in [0,1]. A postprocessing stage will be added so that the predictions are restored to the original range.
## 3. Upsampling
Since we are interested in predicting values in the finer rectangular grid, D L,P o , we transform s s ∈ R 8 × 8 × 40 to a function s irr ∈ R 32 × 32 × 40 by means of an upsampling operation. This new function s irr consists of a scaled version of the irregularly-distributed microphone measurements. In particular, we have that
<!-- formula-not-decoded -->
for each ω k . The original measurements are incorporated into s c , however, the actual input values to the network are given by s irr . Note that the value of s irr for r ∈
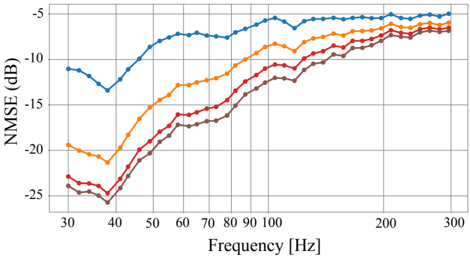
FIG. 4. Schematic diagram of the neural network architecture proposed in this paper. This diagram is not exhaustive in terms of all the operations involved. For further details, the reader can refer to the text. (Color online.)
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: U-Net Architecture Block
### Overview
This diagram depicts a block of a U-Net architecture, a common convolutional neural network used for image segmentation. The diagram illustrates the flow of data through a series of convolutional and upsampling layers, showing the changes in feature map size and channel depth. The diagram is oriented vertically, with input on the left and output on the right.
### Components/Axes
The diagram uses several visual cues to represent different operations:
* **Arrows:** Indicate the direction of data flow. Different arrow styles represent different operations (Up 2x2, Concatenate, Batch Normalization, Partial Conv 3x3, Partial Conv 5x5, Conv 1x1).
* **Rectangles:** Represent feature maps, with dimensions (height x width) and channel depth indicated within the rectangle. Colors differentiate input (green) and output (yellow).
* **Labels:** Text labels identify the operations and feature maps.
* **S<sub>irr</sub><sup>T</sup>:** Represents the input feature map.
* **S<sub>p</sub>:** Represents the output feature map.
* **M:** Indicates the Mask.
### Detailed Analysis
The diagram shows a series of operations starting from a 32x32x64 input feature map (S<sub>irr</sub><sup>T</sup>).
1. **Initial Block:** A 32x32x64 feature map (green) is the input.
2. **Downsampling Path:**
* A 16x16x128 feature map (green) is produced.
* A 8x8x256 feature map (yellow) is produced.
* A 4x4x512 feature map (green) is produced.
* A 2x2x512 feature map (green) is produced.
3. **Upsampling Path:**
* A 4x4x256 feature map (yellow) is produced.
* A 8x8x128 feature map (yellow) is produced.
* A 16x16x64 feature map (yellow) is produced.
4. **Concatenation and Final Output:**
* A 32x32x104 feature map (yellow) is produced.
* A 32x32x40 feature map (green) is produced.
The operations between these feature maps are as follows:
* From 32x32x64 to 16x16x128: Partial Conv 3x3
* From 16x16x128 to 8x8x256: Partial Conv 3x3
* From 8x8x256 to 4x4x512: Partial Conv 3x3
* From 4x4x512 to 2x2x512: Partial Conv 3x3
* From 2x2x512 to 4x4x256: Up 2x2
* From 4x4x256 to 8x8x128: Up 2x2
* From 8x8x128 to 16x16x64: Up 2x2
* From 16x16x64 to 32x32x104: Up 2x2
* From 32x32x104 to 32x32x40: Conv 1x1
The diagram also shows concatenation operations between the upsampled feature maps and the corresponding feature maps from the downsampling path.
### Key Observations
* The diagram illustrates a symmetrical structure, characteristic of U-Net architectures.
* The channel depth increases as the spatial resolution decreases in the downsampling path and decreases as the spatial resolution increases in the upsampling path.
* The use of "Partial Conv" suggests a specific type of convolutional layer that handles irregular shapes or missing data.
* The final Conv 1x1 layer reduces the channel depth from 104 to 40.
### Interpretation
This diagram represents a key building block of a U-Net architecture, commonly used for image segmentation tasks. The U-Net's architecture is designed to capture both local and global context by combining a contracting path (downsampling) to extract features and an expanding path (upsampling) to reconstruct the segmentation map. The skip connections (concatenation) between the downsampling and upsampling paths help to preserve fine-grained details that might be lost during the downsampling process. The use of partial convolutions suggests that the network is designed to handle images with irregular boundaries or missing data. The diagram provides a clear visual representation of the data flow and the transformations applied at each layer, aiding in understanding the network's functionality. The overall structure suggests a focus on preserving spatial information while extracting high-level features for accurate segmentation.
</details>
D L,P o \ D o can be arbitrarily chosen due to the maskrelated operation that follows.
## 4. Mask generator
The function s irr does not provide any information about which values have been originally observed. Thus, we simultaneously generate a mask, defined on the finer grid D L,P o , that carries information about the spatial locations of the measurements. This mask takes the value 1 at each available spatial sample point and 0 otherwise, i.e.
<!-- formula-not-decoded -->
for all ω k . Clearly, the mask must be the same for every frequency point.
## 5. Input
The input data to the network consists of thirdorder tensors representing the frequency dimension and the two spatial dimensions, i.e. M ∈ [0 , 1] 32 × 32 × 40 and S irr ∈ [0 , 1] 32 × 32 × 40 . It is important to emphasize that the network performs convolutions considering the three dimensions in order to learn the relationships within and between frequency and space.
## C. Neural Network
## 1. Architecture
We propose a U-Net-like deep neural network 24 with partial convolutions 21 in order to predict the magnitude of the sound field pressure in a room. U-Net was first introduced for the task of biomedical image segmentation and since then it has been successfully used in many cases.
The U-Net encoder-decoder structure can learn multi-resolution features of the sound field in the frequency-space domain, i.e. it can capture the sound field variations at different scales in both domains. This is carried out by the encoder which halves the feature maps by using a stride of 2 and doubling the filter size in each partial convolution. The decoder then reverses this procedure by upsampling the feature maps and reducing by 2 the filter size. After each partial convolution, the encoder uses a ReLU activation while the decoder uses a Leaky ReLU activation with a negative slope coefficient of 0.2. Furthermore, the decoder, through concatenation, incorporates at the same hierarchical level the feature maps and masks computed by the encoder. In other words, the features from different resolutions in the frequency-space domain are also utilized as an input in the upsampling layers of the decoder. Finally, a 1 × 1 convolution with a sigmoid activation projects the last feature map to generate the predicted sound field ˆ S p . Fig. 4 shows a schematic diagram of the architecture.
Although there are similarities between U-Net and a standard encoder-decoder architecture, their skip connections are paramount in order to attain better performance. This has been shown by ablation studies in image segmentation 32 and label-to-image 33 tasks. Skip connections allow U-Net to access low-level information that may be lost when propagated through the network. In the current case, skip connections help to recover spatial information lost during downsampling which corresponds to the initial arrangement of measurements.
## 2. Partial Convolutions
Unlike traditional convolutions, partial convolutions 21 allow us to compute the output feature maps based solely on the available spatial sample points from the input feature maps. This provides the necessary flexibility to use any number of microphones at irregularly distributed locations. Let w be the sliding convolutional window with size k h × k t . Consider further I w ∈ R k h × k t × C and M w ∈ [0 , 1] k h × k t × C as corresponding to the C -channel input feature maps and mask within w respectively. The tensor W ∈ R k h × k t × C ′ × C respresents the filter weights and b ∈ R C ′ is the bias. Partial convolution computes each spatial location value o ′ w ∈ R C ′ in the C ′ -channel output feature maps as
<!-- formula-not-decoded -->
where sum( · ) receives a tensor as an argument and provides the summation of its elements, is the Hadamard product, and · is a combination, in different dimensions, of matrix dot products and element-wise summations 21 . The scaling factor sum( 1 ) sum( M w ) can be interpreted as a measure of the amount of known information in the input feature maps. Then, the mask M w is updated at each spatial location m ′ ∈ R C ′ as follows:
<!-- formula-not-decoded -->
## 3. Loss Function
In order to train the model in a supervised manner, we also use a scaled version of the ground truth in order to be consistent with the output data before postprocessing. The assumption is that this process may also assist the learning process. The scaling is given by
<!-- formula-not-decoded -->
for r ∈ D L,P o and k = 1 , . . . , K . It is clear then that ¯ s GT ( r , ω k ) ∈ [0 , 1].
As a loss function, we use two terms in order to distinguish between predicted values in the available spatial sample points S o and its complement under D L,P o . We first define
<!-- formula-not-decoded -->
and then
<!-- formula-not-decoded -->
where 1 ∈ R 32 × 32 × 40 with all entries equal to 1, and sum( | · | ) acting on a tensor is the summation of the absolute value of its elements. The combined loss function finally takes the form
<!-- formula-not-decoded -->
The factors in (20) were chosen as the best performing ones after analyzing the performance on 1 000 validation rooms.
## 4. Training Procedure
The model is trained in two different stages using supervised learning. We use 75% of the dataset for training purposes and the remaining 25% is used for validation. For both stages, the model is trained during 400 epochs and the weights with less validation loss are selected. In the first stage, the learning rate is set to 2 · 10 -4 and batch normalization is enabled in all layers. For the second stage, the learning rate is set to 5 · 10 -5 with batch normalization disabled in all encoding layers. Training the model in multiple stages helps to overcome the error generated by batch normalization when computing, in the first stage, the mean and variance for all input values, corresponding to known and unknown locations. In addition, faster convergence is achieved.
## D. Postprocessing
We use linear regression to restore the output of the neural network ˆ s p to its original range. Thus, the rescaled version takes the form
<!-- formula-not-decoded -->
for all r ∈ D L,P o and k = 1 , . . . , K , where the values a k , b k ∈ R are determined through the following optimization problem
<!-- formula-not-decoded -->
for each k = 1 , . . . , K . Note that the rescaling operation could be implemented as another neural network that learns the mapping function. However, experiments showed that linear regression provided reasonable performance.
## IV. RESULTS
## A. Evaluation Metrics
We use two different measures of performance for the proposed method. First, we consider the normalized mean square error (NMSE) computed for each frequency point, i.e.
<!-- formula-not-decoded -->
The NMSE mainly provides an average absolute squared error over all locations between the reconstructed and the original signals. As a consequence, a high NMSE value may result from a poor performance locally while performing individually well in the remaining spatial locations.
Therefore, we use the concept of mean structural similarity 34 (MSSIM) from image processing. This evaluates how the model predicts the overall shape of the pressure distribution for each frequency point. Moreover, it also provides a measure of performance that is independent of the scaling chosen. Let us first introduce the structural similarity index (SSIM) between two matrices A , B ∈ R n × n as follows
<!-- formula-not-decoded -->
where µ is the mean of the corresponding matrix entries, σ 2 the estimate of the variance of the entries, and σ AB is the covariance estimate between the entries of A and B . The constants c 1 = ( h 1 R ) 2 and c 2 = ( h 2 R ) 2 , where
FIG. 5. Normalized mean squared error (NMSE) estimated from simulated data. The results are reported for different number of microphone observations n mic , i.e. ( ): n mic = 5, ( ): n mic = 15, ( ): n mic = 35, and ( ): n mic = 55. (Color online.)
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Line Chart: NMSE vs. Frequency
### Overview
The image presents a line chart illustrating the relationship between Frequency (in Hertz) and Normalized Mean Squared Error (NMSE) in decibels (dB). Four distinct data series are plotted, each represented by a different colored line. The chart appears to be evaluating the performance of a system or algorithm across a range of frequencies.
### Components/Axes
* **X-axis:** Frequency [Hz], ranging from approximately 30 Hz to 300 Hz. Markers are present at 30, 40, 50, 60, 70, 80, 90, 100, 200, and 300 Hz.
* **Y-axis:** NMSE (dB), ranging from approximately -25 dB to -5 dB. Markers are present at -5, -10, -15, -20, and -25 dB.
* **Data Series:** Four lines, visually distinguishable by color:
* Blue
* Orange
* Red
* Dark Red/Brown
### Detailed Analysis
Let's analyze each line individually, noting trends and approximate data points.
* **Blue Line:** This line exhibits an upward sloping trend, starting at approximately -12 dB at 30 Hz and reaching approximately -4 dB at 300 Hz. It initially dips to around -14 dB at 40 Hz before steadily increasing.
* **Orange Line:** This line also slopes upward, but starts at a lower NMSE value of approximately -20 dB at 30 Hz. It reaches approximately -6 dB at 300 Hz. It shows a more consistent upward trend than the blue line.
* **Red Line:** This line begins at approximately -24 dB at 30 Hz and rises to approximately -10 dB at 300 Hz. It shows a relatively steep upward slope, particularly between 40 Hz and 100 Hz.
* **Dark Red/Brown Line:** This line starts at approximately -25 dB at 30 Hz and increases to approximately -9 dB at 300 Hz. It has a similar upward trend to the red line, but consistently remains slightly below it.
Here's a table summarizing approximate data points:
| Frequency (Hz) | Blue Line (dB) | Orange Line (dB) | Red Line (dB) | Dark Red/Brown Line (dB) |
|---|---|---|---|---|
| 30 | -12 | -20 | -24 | -25 |
| 40 | -14 | -16 | -18 | -19 |
| 50 | -9 | -13 | -15 | -16 |
| 60 | -7 | -11 | -13 | -14 |
| 80 | -6 | -9 | -11 | -12 |
| 100 | -5 | -8 | -10 | -10 |
| 200 | -4 | -6 | -8 | -9 |
| 300 | -4 | -6 | -10 | -9 |
### Key Observations
* All four lines demonstrate a positive correlation between frequency and NMSE – as frequency increases, NMSE increases.
* The dark red/brown line consistently exhibits the lowest performance (highest NMSE) at lower frequencies, but converges with the red line at higher frequencies.
* The blue line consistently exhibits the best performance (lowest NMSE) across the entire frequency range.
* The orange line falls between the blue and red lines in terms of performance.
### Interpretation
The chart likely represents the performance of different noise reduction or signal processing algorithms across a range of frequencies. The NMSE metric indicates the error between the original signal and the processed signal. A lower NMSE value indicates better performance.
The upward trend of all lines suggests that the algorithms become less effective at higher frequencies. The differences in performance between the lines indicate that some algorithms are more robust to frequency variations than others. The blue line's consistently lower NMSE suggests it is the most effective algorithm overall.
The convergence of the red and dark red/brown lines at higher frequencies suggests that the performance difference between those algorithms diminishes as frequency increases. This could be due to limitations in the algorithms' ability to handle high-frequency components or due to the nature of the signal being processed.
The data suggests that the choice of algorithm should be based on the frequency content of the signal. If the signal contains primarily low frequencies, the dark red/brown line algorithm might be sufficient. However, if the signal contains significant high-frequency components, the blue line algorithm would be the preferred choice.
</details>
R is the dynamic range of the entry values, are meant to stabilize the division with a weak denominator. We set h 1 and h 2 to the standard values 0.01 and 0.03 respectively.
In our scenario, we consider the individual matrices S k ∈ R IL × JP , i.e. the k -th matrix of tensor S ∈ R IL × JP × K . Now, let { S n k ( η ) } N n =1 denote the set of all possible windowed versions of S k of size η × η . The mean structural similarity is then given by
<!-- formula-not-decoded -->
for each frequency point. In the results presented, we have used η = 7.
## B. Simulated Data
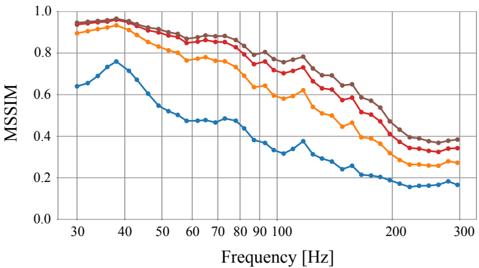
We asses the reconstruction performance of the proposed method, i.e. the generalization error, by using sound fields in 30 different rooms. These have been simulated identically to the training data and have not been previously seen by the network. We are interested in evaluating the performance with regard to the number of irregularly placed microphones, denoted by n mic . Thus, given n mic , we analyze the reconstruction in each room placing the microphones in 10 000 different arrangements, i.e. each realization corresponds to a different S o . Figures 5 and 6 show, as a function of frequency, the average NMSE in dB and MSSIM for all rooms and locations tested and different number of available microphones.
Results show a general improved performance in sound field reconstruction as the number of available microphones is increased. At the same time, performance degrades as the frequency increases. This is in agreement with theoretical results that, given a maximum frequency content, require a higher sampling density for a more robust reconstruction and, given a reconstruction error, the sampling density constraints also increase whenever higher frequency content is available 11,35 . This suggests
FIG. 6. Mean structural similarity index (MSSIM) estimated from simulated data. The results are reported for different number of microphone observations n mic , i.e. ( ): n mic = 5, ( ): n mic = 15, ( ): n mic = 35, and ( ): n mic = 55. (Color online.)
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Line Chart: MSIM vs. Frequency
### Overview
The image presents a line chart illustrating the relationship between Frequency (in Hertz) and MSIM (likely referring to a metric for image similarity or quality). Four distinct data series are plotted, each represented by a different colored line. The chart spans a frequency range from approximately 30 Hz to 300 Hz, with MSIM values ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis:** Frequency [Hz]. Scale ranges from 30 to 300 Hz, with markings at 30, 40, 50, 60, 70, 80, 90, 100, 200, and 300.
* **Y-axis:** MSIM. Scale ranges from 0.0 to 1.0, with markings at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Data Series:** Four lines, visually distinguishable by color:
* Dark Blue
* Orange
* Red
* Brown
### Detailed Analysis
* **Dark Blue Line:** This line exhibits a decreasing trend. Starting at approximately 0.65 at 30 Hz, it rises to a peak of around 0.72 at 40 Hz, then steadily declines to approximately 0.15 at 300 Hz.
* **Orange Line:** This line also shows a decreasing trend, but starts at a higher MSIM value than the dark blue line. It begins at approximately 0.85 at 30 Hz, decreases to around 0.45 at 200 Hz, and continues to approximately 0.3 at 300 Hz.
* **Red Line:** This line demonstrates a relatively stable, decreasing trend. It starts at approximately 0.9 at 30 Hz, gradually decreases to around 0.4 at 200 Hz, and continues to approximately 0.35 at 300 Hz.
* **Brown Line:** This line is similar to the red line, showing a decreasing trend. It begins at approximately 0.9 at 30 Hz, decreases to around 0.4 at 200 Hz, and continues to approximately 0.35 at 300 Hz.
Approximate Data Points (read from the chart):
| Frequency (Hz) | Dark Blue MSIM | Orange MSIM | Red MSIM | Brown MSIM |
|---|---|---|---|---|
| 30 | 0.65 | 0.85 | 0.90 | 0.90 |
| 40 | 0.72 | 0.82 | 0.87 | 0.87 |
| 50 | 0.68 | 0.80 | 0.85 | 0.85 |
| 60 | 0.62 | 0.76 | 0.80 | 0.80 |
| 70 | 0.58 | 0.72 | 0.76 | 0.76 |
| 80 | 0.55 | 0.69 | 0.73 | 0.73 |
| 90 | 0.52 | 0.66 | 0.70 | 0.70 |
| 100 | 0.50 | 0.64 | 0.68 | 0.68 |
| 200 | 0.25 | 0.45 | 0.40 | 0.40 |
| 300 | 0.15 | 0.30 | 0.35 | 0.35 |
### Key Observations
* All four data series exhibit a general decreasing trend as frequency increases.
* The dark blue line consistently has the lowest MSIM values across the entire frequency range.
* The red and brown lines are nearly identical, suggesting they represent the same or very similar data.
* The orange line starts with the highest MSIM values but decreases more rapidly than the red and brown lines.
### Interpretation
The chart likely demonstrates how the similarity or quality (as measured by MSIM) of an image or signal degrades as the frequency content increases. The different lines could represent different algorithms, processing methods, or image types. The consistent decline in MSIM suggests that higher frequencies introduce more distortion or loss of information. The fact that the red and brown lines are almost identical suggests that two different methods yield very similar results. The dark blue line's lower MSIM values could indicate a less robust or less accurate method. The initial high MSIM values for the orange line, followed by a rapid decline, might indicate a method that performs well at lower frequencies but struggles with higher frequency components. This data could be used to evaluate the performance of different image processing techniques or to understand the limitations of a particular system in handling high-frequency signals.
</details>
that the neural network capacity is subject to the same physical limitations as classical methods when learning the spatial variations of the pressure distribution. In other words, at high frequencies it is hindered by undersampling and also requires more observations to improve robustness. For example, the relative improvement as the number of microphones increase is higher at lower frequencies as opposed to the high-frequency range. It is at this high frequency range where more observations do not provide a big impact on performance. However, the requirements in terms of sampling density for a particular performance seem to be less stringent than other methods present in the literature. For example, only n mic = 5 microphones are able to provide an NMSE below -5 dB for the frequency range considered in common domestic rooms.
It is also important to observe that the loss functions defined in Eq. 18 and Eq. 19 are suitable for prediction at low frequencies but they underperform at high frequencies. These commonly result in predictions that emphasize the median value in order to reduce the overall error. This can explain, in the frequency range 100-300 Hz, the more abrupt changes in performance of the MSSIM as opposed to the NMSE.
## C. Experimental Data
We test the model optimized for simulated data in a real listening room. The RTFs are estimated for two different source locations on a two-dimensional grid consisting of 32 by 32 points uniformly spaced along the corresponding dimensions. In particular, impulse response measurements were conducted from two 10' loudspeakers on a grid one meter above the floor in a rectangular room of dimensions 4 . 16 × 6 . 46 × 2 . 3 m. The measurements were performed using 4-second duration exponential sweeps from 0.1 Hz to 24 kHz at a sampling frequency of 48 kHz 36 . These measurements were performed with
FIG. 7. Normalized mean square error (NMSE) in dB estimated from experimental data. Top and bottom plots correspond to different source locations. The results are reported for different number of microphone observations n mic , i.e. ( ): n mic = 5, ( ): n mic = 15, ( ): n mic = 35, and ( ): n mic = 55. (Color online.)
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Chart: NMSE vs. Frequency
### Overview
The image presents two identical line charts displaying Normalized Mean Squared Error (NMSE) in decibels (dB) as a function of Frequency in Hertz (Hz). Both charts show multiple lines representing different conditions or algorithms, with the NMSE generally decreasing with increasing frequency up to a certain point, then stabilizing or slightly increasing. The charts are stacked vertically, with the second chart directly below the first.
### Components/Axes
* **X-axis:** Frequency [Hz], ranging from approximately 30 Hz to 300 Hz. The axis is marked with tick labels at 30, 40, 50, 60, 70, 80, 90, 100, 200, and 300 Hz.
* **Y-axis:** NMSE [dB], ranging from approximately -20 dB to 0 dB. The axis is marked with tick labels at -20, -15, -10, -5, and 0 dB.
* **Lines:** Four distinct lines are present in each chart, each with a different color. There is no explicit legend, but the colors appear consistent between the two charts.
* Blue Line
* Orange Line
* Red Line
* Dark Red/Brown Line
### Detailed Analysis or Content Details
**Chart 1 (Top)**
* **Blue Line:** Starts at approximately -13 dB at 30 Hz, decreases to a minimum of approximately -18 dB around 45 Hz, then increases to approximately -3 dB at 300 Hz. There is a noticeable peak around 70-80 Hz, reaching approximately -1 dB.
* **Orange Line:** Starts at approximately -10 dB at 30 Hz, decreases to a minimum of approximately -16 dB around 45 Hz, then increases to approximately -5 dB at 300 Hz. It exhibits a peak around 70-80 Hz, reaching approximately -2 dB.
* **Red Line:** Starts at approximately -15 dB at 30 Hz, decreases to a minimum of approximately -20 dB around 45 Hz, then increases to approximately -8 dB at 300 Hz. It has a peak around 70-80 Hz, reaching approximately -4 dB.
* **Dark Red/Brown Line:** Starts at approximately -12 dB at 30 Hz, decreases to a minimum of approximately -17 dB around 45 Hz, then increases to approximately -7 dB at 300 Hz. It shows a peak around 70-80 Hz, reaching approximately -3 dB.
**Chart 2 (Bottom)**
The lines in the second chart follow the same trends as the first chart, with very similar values.
* **Blue Line:** Starts at approximately -13 dB at 30 Hz, decreases to a minimum of approximately -18 dB around 45 Hz, then increases to approximately -3 dB at 300 Hz. There is a noticeable peak around 70-80 Hz, reaching approximately -1 dB.
* **Orange Line:** Starts at approximately -10 dB at 30 Hz, decreases to a minimum of approximately -16 dB around 45 Hz, then increases to approximately -5 dB at 300 Hz. It exhibits a peak around 70-80 Hz, reaching approximately -2 dB.
* **Red Line:** Starts at approximately -15 dB at 30 Hz, decreases to a minimum of approximately -20 dB around 45 Hz, then increases to approximately -8 dB at 300 Hz. It has a peak around 70-80 Hz, reaching approximately -4 dB.
* **Dark Red/Brown Line:** Starts at approximately -12 dB at 30 Hz, decreases to a minimum of approximately -17 dB around 45 Hz, then increases to approximately -7 dB at 300 Hz. It shows a peak around 70-80 Hz, reaching approximately -3 dB.
### Key Observations
* All four lines exhibit a similar U-shaped curve, indicating a common behavior across the different conditions.
* The minimum NMSE values are achieved around 45 Hz for all lines.
* The lines generally converge at higher frequencies (around 200-300 Hz).
* The orange and blue lines consistently have lower NMSE values (better performance) than the red and dark red/brown lines across most of the frequency range.
* The two charts are nearly identical, suggesting the results are consistent.
### Interpretation
The charts likely represent the performance of different signal processing algorithms or noise reduction techniques at varying frequencies. The NMSE metric quantifies the difference between the original signal and the processed signal, with lower values indicating better performance.
The U-shaped curve suggests that the algorithms perform best at lower frequencies (around 45 Hz) and their performance degrades at very low and very high frequencies. The peak around 70-80 Hz could indicate a resonance or a frequency range where the algorithms struggle to accurately process the signal.
The consistent difference between the orange/blue lines and the red/dark red lines suggests that the algorithms represented by those lines are inherently more effective than the others. The fact that the two charts are nearly identical suggests that the results are robust and not sensitive to minor variations in the experimental setup.
The data suggests that the choice of algorithm should be tailored to the frequency content of the signal being processed. For signals dominated by low frequencies, the orange or blue algorithms would be preferred. For signals with a broader frequency spectrum, the performance differences may be less significant.
</details>
two microphones, each covering roughly half of the grid. The microphones were a Br¨ uel & Kjær (B&K) 4192 and a B&K4133 1 2 ' condenser microphone connected to a B&K Nexus conditioning amplifier and recorded with an RME Fireface UFX+ sound card. Both microphones were level calibrated at 1 kHz using a B&K 4231 calibrator prior to the measurements. The reverberation time of the room, specified as the arithmetic average of the 1/3 octave T 20 estimates 37 in the range of 32 Hz to 316 Hz, was 0.46 s.
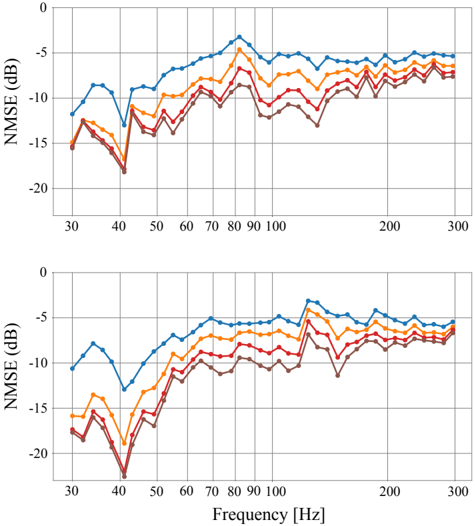
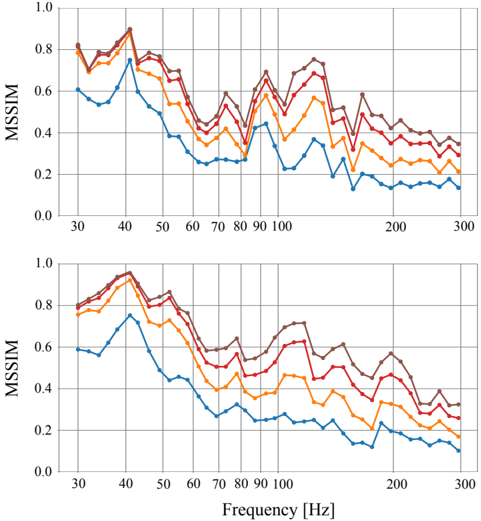
Similar to the previous scenario, we investigate the performance of the model with regard to the number of microphones placed in the room. We are particularly interested in assessing the performance when using very few observations. Thus, for each predefined source location, we also use here 5, 15, 35, and 55 microphones in 10 000 different arrangements and analyze the mean performance with a 95% confidence interval. These results are reported in Figures 7 and 8.
It is important to emphasize that the model was trained using simulated data. Moreover, the simulations were simplified by assuming mode shapes equal to rigid walls and removing all room modes including height variation, neither of which is true for the experimental data. It can be observed that, given n mic , the NMSE improves for decreasing frequencies as a general trend although
FIG. 8. Mean structural similarity (MSSIM) estimated from experimental data. Top and bottom plots correspond to different source locations. The results are reported for different number of microphone observations n mic , i.e. ( ): n mic = 5, ( ): n mic = 15, ( ): n mic = 35, and ( ): n mic = 55. (Color online.)
<details>
<summary>Image 8 Details</summary>
### Visual Description
\n
## Line Chart: MSIM vs Frequency
### Overview
The image presents two identical line charts displaying the relationship between MSIM (likely a metric for image similarity) and Frequency in Hertz (Hz). Each chart contains five distinct lines, each representing a different data series. The charts share the same axes and scale.
### Components/Axes
* **X-axis:** Frequency [Hz], ranging from approximately 30 Hz to 300 Hz. Marked at intervals of 10 Hz (30, 40, 50, 60, 70, 80, 90, 100, 200, 300).
* **Y-axis:** MSIM, ranging from 0.0 to 1.0. Marked at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Lines:** Five distinct lines are present in each chart, each with a different color. No explicit legend is provided, but the colors are consistent across both charts. The colors are approximately:
* Dark Blue
* Light Blue
* Orange
* Reddish-Orange
* Dark Red
### Detailed Analysis or Content Details
**Chart 1 (Top):**
* **Dark Blue Line:** Starts at approximately 0.78 at 30 Hz, dips to around 0.3 at 40 Hz, fluctuates between 0.3 and 0.6 until 100 Hz, then gradually decreases to approximately 0.25 at 300 Hz.
* **Light Blue Line:** Starts at approximately 0.65 at 30 Hz, dips to around 0.35 at 40 Hz, fluctuates between 0.35 and 0.55 until 100 Hz, then gradually decreases to approximately 0.2 at 300 Hz.
* **Orange Line:** Starts at approximately 0.75 at 30 Hz, dips to around 0.4 at 40 Hz, fluctuates between 0.4 and 0.7 until 100 Hz, then gradually decreases to approximately 0.3 at 300 Hz.
* **Reddish-Orange Line:** Starts at approximately 0.7 at 30 Hz, dips to around 0.35 at 40 Hz, fluctuates between 0.35 and 0.65 until 100 Hz, then gradually decreases to approximately 0.25 at 300 Hz.
* **Dark Red Line:** Starts at approximately 0.8 at 30 Hz, dips to around 0.45 at 40 Hz, fluctuates between 0.45 and 0.75 until 100 Hz, then gradually decreases to approximately 0.35 at 300 Hz.
**Chart 2 (Bottom):**
The lines in the second chart follow the same trends as the first chart, with slight variations in the exact values.
* **Dark Blue Line:** Starts at approximately 0.78 at 30 Hz, dips to around 0.3 at 40 Hz, fluctuates between 0.3 and 0.6 until 100 Hz, then gradually decreases to approximately 0.25 at 300 Hz.
* **Light Blue Line:** Starts at approximately 0.65 at 30 Hz, dips to around 0.35 at 40 Hz, fluctuates between 0.35 and 0.55 until 100 Hz, then gradually decreases to approximately 0.2 at 300 Hz.
* **Orange Line:** Starts at approximately 0.75 at 30 Hz, dips to around 0.4 at 40 Hz, fluctuates between 0.4 and 0.7 until 100 Hz, then gradually decreases to approximately 0.3 at 300 Hz.
* **Reddish-Orange Line:** Starts at approximately 0.7 at 30 Hz, dips to around 0.35 at 40 Hz, fluctuates between 0.35 and 0.65 until 100 Hz, then gradually decreases to approximately 0.25 at 300 Hz.
* **Dark Red Line:** Starts at approximately 0.8 at 30 Hz, dips to around 0.45 at 40 Hz, fluctuates between 0.45 and 0.75 until 100 Hz, then gradually decreases to approximately 0.35 at 300 Hz.
### Key Observations
* All lines exhibit a significant drop in MSIM between 30 Hz and 40 Hz.
* All lines generally fluctuate between approximately 0.3 and 0.7 from 40 Hz to 100 Hz.
* All lines show a gradual decrease in MSIM from 100 Hz to 300 Hz.
* The Dark Red line consistently has the highest MSIM values across the entire frequency range.
* The Dark Blue line consistently has the lowest MSIM values across the entire frequency range.
* The two charts are nearly identical, suggesting the data represents a consistent phenomenon.
### Interpretation
The charts likely represent the performance of an image processing or compression algorithm at different frequencies. The MSIM metric indicates the similarity between the original and processed images. The significant drop in MSIM around 40 Hz suggests that the algorithm struggles to preserve image quality at this frequency. The gradual decrease in MSIM at higher frequencies (above 100 Hz) indicates a general loss of detail as frequency increases.
The consistent ranking of the lines (Dark Red highest, Dark Blue lowest) suggests that different parameters or configurations of the algorithm are being tested. The Dark Red line represents the most effective configuration, while the Dark Blue line represents the least effective.
The fact that the two charts are nearly identical suggests that the observed behavior is robust and not dependent on specific data or conditions. This could indicate a fundamental limitation of the algorithm or a characteristic of the type of images being processed. Further investigation would be needed to determine the root cause of the observed trends and to identify ways to improve the algorithm's performance.
</details>
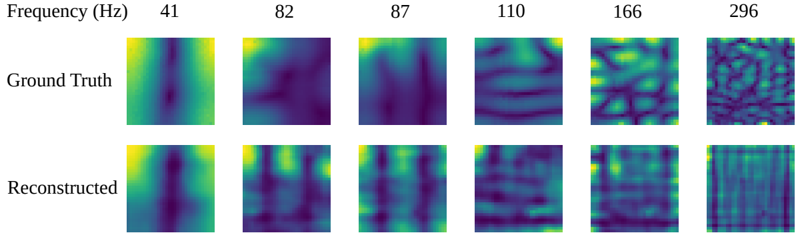
there exist inconsistencies at a local level, i.e. adjacent frequencies may present abrupt changes in performance. The same interpretation applies to the MSSIM. In particular, there are two specific frequencies acting as outliers, i.e. 82 Hz and 157 Hz for the two different source locations. In this case, this is likely to be caused by the sources being positioned at nulls of the room modes. Fig. 9 depicts a representation of the magnitude of the sound field when the reconstruction is performed using only 5 microphones.
## D. Computational Complexity
Apart from the reduced number of microphones used, another advantage of the proposed method is the computational complexity regarding the inference operation. The training stage is usually time consuming, but it can often be run offline. The model size is relatively small with 3.9 million parameters resulting in a deterministic inference time of approximately 0.05 s on a Nvidia GeForce GTX 1080 Ti GPU (value estimated from 100 different room predictions).
Microphone Distribution
<details>
<summary>Image 9 Details</summary>

### Visual Description
\n
## Diagram: Scattered "a" Characters
### Overview
The image presents a white background within a black border. Five instances of the lowercase letter "a" are scattered across the white space. There are no axes, legends, or other graphical elements beyond the letter "a" itself. The image does not contain any numerical data or quantifiable information.
### Components/Axes
There are no axes or legends present. The sole component is the repeated character "a".
### Detailed Analysis or Content Details
The letter "a" appears five times. Their approximate positions are as follows (relative to the bottom-left corner):
1. Approximately 1/8th of the way across and 7/8th of the way up.
2. Approximately 1/8th of the way across and 5/8th of the way up.
3. Approximately 1/2 way across and 1/2 way up.
4. Approximately 7/8th of the way across and 3/8th of the way up.
5. Approximately 7/8th of the way across and 1/8th of the way up.
The size of each "a" appears to be consistent.
### Key Observations
The "a" characters are distributed somewhat randomly across the space, with no apparent pattern or clustering.
### Interpretation
The image appears to be a simple visual arrangement of the letter "a". Without further context, it's difficult to determine its purpose or meaning. It could be a placeholder, a test image, or a component of a larger design. The lack of data or structure suggests it is not intended to convey specific information beyond the presence and arrangement of the character "a". There is no underlying data to interpret. It is a purely visual element.
</details>
FIG. 9. Visualization of the model reconstruction when using 5 microphones arbitrarily placed. The results are shown for different frequencies in a real room where the source location is the same as the top plots in Figures 7 and 8. (Color online.)
<details>
<summary>Image 10 Details</summary>
### Visual Description
\n
## Heatmap: Ground Truth vs. Reconstructed Spectrograms
### Overview
The image presents a comparison between "Ground Truth" and "Reconstructed" spectrograms across six different frequencies. Each spectrogram is represented as a heatmap, with color intensity indicating signal strength. The arrangement is a 2x6 grid, with "Ground Truth" spectrograms in the top row and corresponding "Reconstructed" spectrograms in the bottom row.
### Components/Axes
* **X-axis:** Not explicitly labeled, but represents time or a similar temporal dimension.
* **Y-axis:** Not explicitly labeled, but represents frequency or a similar spectral dimension.
* **Frequency (Hz):** Labels above each column indicate the frequency for that spectrogram: 41 Hz, 82 Hz, 87 Hz, 110 Hz, 166 Hz, and 296 Hz.
* **Rows:** Two rows are present, labeled "Ground Truth" (top) and "Reconstructed" (bottom).
* **Color Scale:** The heatmap uses a color gradient, ranging from dark purple (low signal strength) to yellow (high signal strength).
### Detailed Analysis
The image displays six pairs of heatmaps, one "Ground Truth" and one "Reconstructed" for each frequency.
* **41 Hz:**
* Ground Truth: A strong vertical signal, predominantly yellow, with a gradual fade to purple.
* Reconstructed: Similar vertical signal, but with more pronounced purple areas and less distinct yellow.
* **82 Hz:**
* Ground Truth: A more diffuse signal, with a mix of yellow and purple, appearing somewhat blurred.
* Reconstructed: A more structured signal, with a grid-like pattern of yellow and purple squares.
* **87 Hz:**
* Ground Truth: A complex pattern with horizontal bands of yellow and purple.
* Reconstructed: A similar pattern, but with more defined and regular horizontal bands.
* **110 Hz:**
* Ground Truth: A complex pattern with wavy horizontal bands of yellow and purple.
* Reconstructed: A similar pattern, but with more pronounced and regular wavy bands.
* **166 Hz:**
* Ground Truth: A highly complex and chaotic pattern with a mix of yellow and purple.
* Reconstructed: A similar complex pattern, but with a more grid-like structure.
* **296 Hz:**
* Ground Truth: A highly complex and chaotic pattern with a mix of yellow and purple, appearing almost random.
* Reconstructed: A highly structured grid-like pattern of yellow and purple squares.
### Key Observations
* At lower frequencies (41 Hz, 82 Hz), the reconstructed spectrograms show some deviation from the ground truth, with less distinct signal and more purple areas.
* As the frequency increases (87 Hz, 110 Hz, 166 Hz, 296 Hz), the reconstructed spectrograms tend to exhibit a more grid-like structure, even when the ground truth is more chaotic.
* The reconstructed spectrograms consistently show a more structured appearance than the ground truth spectrograms, particularly at higher frequencies.
### Interpretation
The image demonstrates the results of a signal reconstruction process. The "Ground Truth" spectrograms represent the original signal, while the "Reconstructed" spectrograms represent the signal after being processed through a reconstruction algorithm.
The differences between the ground truth and reconstructed spectrograms suggest that the reconstruction algorithm introduces some artifacts or limitations. The increasing grid-like structure in the reconstructed spectrograms at higher frequencies could indicate that the algorithm is struggling to accurately capture the complexity of the original signal at those frequencies, and instead is imposing a regular pattern.
The fact that the reconstructed spectrograms are not identical to the ground truth spectrograms suggests that there is some information loss during the reconstruction process. The amount of information loss appears to increase with frequency. This could be due to limitations in the algorithm itself, or to the quality of the input signal.
The image provides a visual assessment of the performance of the reconstruction algorithm, highlighting its strengths and weaknesses. It suggests that the algorithm may be more effective at reconstructing signals at lower frequencies than at higher frequencies.
</details>
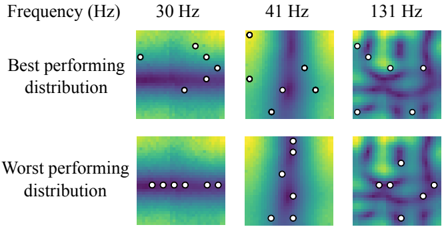
FIG. 10. Best and worst performing sampling distributions for 6 microphones in terms of NMSE performance. The results are shown for different frequencies in a real room where the source location is the same as the top plots in Figures 7 and 8. Symbol ( ◦ ) represents the microphone locations. (Color online.)
<details>
<summary>Image 11 Details</summary>
### Visual Description
\n
## Heatmap: Frequency Response Distributions
### Overview
The image presents a 2x3 grid of heatmaps, visualizing the distribution of some metric (likely signal strength or activation) at different frequencies (30 Hz, 41 Hz, and 131 Hz) for two different performance levels: "Best performing distribution" and "Worst performing distribution". Each heatmap is overlaid with a series of circular markers, presumably indicating specific data points or locations of interest.
### Components/Axes
* **Title:** "Frequency (Hz)" positioned at the top-left corner.
* **Rows:** Two rows labeled "Best performing distribution" (top row) and "Worst performing distribution" (bottom row).
* **Columns:** Three columns labeled with frequencies: "30 Hz", "41 Hz", and "131 Hz".
* **Heatmap Color Scale:** The heatmaps use a color gradient, ranging from dark purple (low values) to yellow (high values), with intermediate shades of blue and green.
* **Markers:** Each heatmap contains approximately 9-10 circular markers with a black outline and a white fill.
### Detailed Analysis or Content Details
The heatmaps show spatial distributions of values, represented by color. The markers are overlaid on these distributions.
**30 Hz:**
* **Best Performing:** The heatmap shows a predominantly green and blue distribution with some yellow areas. Markers are scattered across the heatmap, with a concentration in the upper-left and lower-right quadrants. The values at the marker locations appear to be moderate to high, based on the color.
* **Worst Performing:** The heatmap is predominantly blue and green, with less yellow than the "Best Performing" distribution. Markers are more evenly distributed, and the values at the marker locations appear generally lower than in the "Best Performing" distribution.
**41 Hz:**
* **Best Performing:** The heatmap shows a strong vertical gradient, with yellow bands running vertically. Markers are aligned with these yellow bands, suggesting a strong response at those locations.
* **Worst Performing:** The heatmap shows a more diffuse distribution, with less pronounced vertical banding. Markers are scattered, and the values at the marker locations appear lower than in the "Best Performing" distribution.
**131 Hz:**
* **Best Performing:** The heatmap shows a complex pattern with multiple areas of high and low intensity. Markers are scattered across the heatmap, with some concentration in the upper-left quadrant.
* **Worst Performing:** The heatmap shows a more uniform distribution, with less contrast than the "Best Performing" distribution. Markers are scattered, and the values at the marker locations appear generally lower.
It is difficult to provide precise numerical values without a color scale legend. However, we can qualitatively assess the relative values based on the color gradient.
### Key Observations
* The "Best Performing" distributions generally exhibit higher intensity (yellow) and more localized peaks compared to the "Worst Performing" distributions.
* At 41 Hz, the "Best Performing" distribution shows a clear vertical banding pattern, which is absent in the "Worst Performing" distribution.
* The marker locations appear to be correlated with areas of high intensity in the "Best Performing" distributions, suggesting that these locations are more responsive at those frequencies.
* The distributions change significantly with frequency, indicating that the system's response is frequency-dependent.
### Interpretation
The data suggests that the system's performance is highly dependent on both frequency and the spatial distribution of the input signal. The "Best Performing" distributions indicate that certain frequencies and spatial patterns elicit a stronger response than others. The vertical banding observed at 41 Hz in the "Best Performing" distribution may represent a resonant frequency or a preferred mode of operation. The "Worst Performing" distributions suggest that the system is less sensitive to certain frequencies or spatial patterns.
The markers likely represent locations where a specific measurement is taken, and their placement on the heatmaps indicates the corresponding value at that location. The difference in marker values between the "Best Performing" and "Worst Performing" distributions highlights the importance of optimizing the input signal to maximize performance.
The image provides a qualitative comparison of different frequency response distributions, but a quantitative analysis would require a color scale legend and the actual numerical values at the marker locations.
</details>
## E. Microphone Distribution
In our analysis, we have mainly focused on the performance based on the number of observations. However, we are also interested in studying the impact that particular microphone distributions have on the performance. Fig. 10 shows an illustration of the best and worst performing microphone distributions in terms of the NMSE. It can be observed that a better reconstruction at a specific frequency is achieved when the microphones capture the maximum variation of the pressure values. On the contrary, if the observations consist solely of the dip-like part of the room modes, the reconstruction degrades significantly. Evidently, this effect is frequency dependent, thus there is not a microphone setup that performs well across all frequencies. However, this also suggests that an unstructured microphone arrangement may be more likely to avoid these sampling issues caused by the modal structure.
## V. DISCUSSION
The work presented here indicates the potential for applying neural networks to predict sound field variations in an entire room from few microphone observations in a location agnostic manner. The training data was based on simplifying assumptions e.g. near-rigid walls, no room modes with height variation, and perfectly rectangular room shape. Despite the mismatch between the training and test scenarios, the network shows promising results under unseen data. This can be understood in relation to the literature where it has been shown that the structure of convolutional neural networks represents a prior which conditions the network to perform well for imagelike signals 38 . The magnitude of the spatial sound field naturally fits the latter. Further, the results can be interpreted as a transfer learning 39 approach where the architecture itself helps to generalize well in the experimental scenario from weights only learned with simulated data.
Despite the discrepancy between training data and the experimental measurements, the extrapolation results are encouraging. It is, therefore, expected that the method could be extended to more complicated scenarios like non-rectangular rooms with complex boundary conditions given the appropriate training data.
## VI. CONCLUSIONS
In this paper, a deep-learning-based method for sound field reconstruction in rectangular rooms has been proposed and examined. The method jointly performs inpainting and super-resolution in order to reconstruct the magnitude of the sound pressure in a two-dimensional plane of a three-dimensional room. The focus of this work is threefold: use a very low number of microphones, accommodate irregular and location agnostic microphone distributions, and carry out inference that is computationally efficient. The results suggest a performance which offers advantages in these three directions, e.g. even using 5 microphones arbitrarily placed the method provides an acceptable reconstruction error with a low inference time.
Regarding future work, the study of generative adversarial networks as discriminators may help to increase the performance at high frequencies. In addition, using more complex acoustic simulation models during the training stage could overcome performance inconsistencies at a local level as well as providing a lower generalization error when using experimental data.
## ACKNOWLEDGMENTS
This project has received funding from the European Union's Horizon 2020 research and innovation programme under the Marie Sk lodowska-Curie grant agreement No 812719.
- 1 J. G. Tylka and E. Choueiri, 'Comparison of techniques for binaural navigation of higher-order ambisonic soundfields,' in Audio Engineering Society Convention 139 , Audio Engineering Society (2015).
- 2 J. G. Tylka and E. Choueiri, 'Soundfield navigation using an array of higher-order ambisonics microphones,' in Audio Engineering Society Conference: 2016 AES International Conference on Audio for Virtual and Augmented Reality , Audio Engineering Society (2016).
- 3 A. J. Berkhout, D. de Vries, and P. Vogel, 'Acoustic control by wave field synthesis,' The Journal of the Acoustical Society of America 93 (5), 2764-2778 (1993).
- 4 W. Druyvesteyn and J. Garas, 'Personal sound,' Journal of the Audio Engineering Society 45 (9), 685-701 (1997).
- 5 D. B. Ward and T. D. Abhayapala, 'Reproduction of a planewave sound field using an array of loudspeakers,' IEEE Transactions on speech and audio processing 9 (6), 697-707 (2001).
- 6 T. Betlehem and T. D. Abhayapala, 'Theory and design of sound field reproduction in reverberant rooms,' The Journal of the Acoustical Society of America 117 (4), 2100-2111 (2005).
- 7 B. D. Radlovic, R. C. Williamson, and R. A. Kennedy, 'Equalization in an acoustic reverberant environment: Robustness results,' IEEE Transactions on Speech and Audio Processing 8 (3), 311-319 (2000).
- 8 E. G. Williams, Fourier acoustics: sound radiation and nearfield acoustical holography (Elsevier, 1999).
- 9 A. Torras-Rosell, S. Barrera-Figueroa, and F. Jacobsen, 'Sound field reconstruction using acousto-optic tomography,' The Journal of the Acoustical Society of America 131 (5), 3786-3793 (2012).
- 10 E. Fernandez-Grande, A. Torras-Rosell, and F. Jacobsen, 'Holographic reconstruction of sound fields based on the acoustooptic effect,' in INTER-NOISE and NOISE-CON Congress and Conference Proceedings , Institute of Noise Control Engineering (2013), Vol. 247, pp. 3181-3190.
- 11 T. Ajdler, L. Sbaiz, and M. Vetterli, 'The plenacoustic function and its sampling,' IEEE transactions on Signal Processing 54 (10), 3790-3804 (2006).
- 12 Y. Haneda, Y. Kaneda, and N. Kitawaki, 'Common-acousticalpole and residue model and its application to spatial interpolation and extrapolation of a room transfer function,' IEEE Transactions on Speech and Audio Processing 7 (6), 709-717 (1999).
- 13 A. Moiola, R. Hiptmair, and I. Perugia, 'Plane wave approximation of homogeneous helmholtz solutions,' Zeitschrift f¨ ur angewandte Mathematik und Physik 62 (5), 809 (2011).
- 14 R. Mignot, G. Chardon, and L. Daudet, 'Low frequency interpolation of room impulse responses using compressed sensing,' IEEE/ACM Transactions on Audio, Speech, and Language Processing 22 (1), 205-216 (2013).
- 15 N. Antonello, E. De Sena, M. Moonen, P. A. Naylor, and T. van Waterschoot, 'Room impulse response interpolation us-
- ing a sparse spatio-temporal representation of the sound field,' IEEE/ACM Transactions on Audio, Speech, and Language Processing 25 (10), 1929-1941 (2017).
- 16 S. A. Verburg and E. Fernandez-Grande, 'Reconstruction of the sound field in a room using compressive sensing,' The Journal of the Acoustical Society of America 143 (6), 3770-3779 (2018).
- 17 R. Mignot, L. Daudet, and F. Ollivier, 'Room reverberation reconstruction: Interpolation of the early part using compressed sensing,' IEEE Transactions on Audio, Speech, and Language Processing 21 (11), 2301-2312 (2013).
- 18 E. F. Grande, 'Sound field reconstruction in a room from spatially distributed measurements,' in 23rd International Congress on Acoustics , German Acoustical Society (DEGA) (2019), pp. 4961-68.
- 19 S.-J. Kim, K. Koh, M. Lustig, S. Boyd, and D. Gorinevsky, 'An interior-point method for large-scale 1 -regularized least squares,' IEEE journal of selected topics in signal processing 1 (4), 606-617 (2007).
- 20 M. Bertalmio, G. Sapiro, V. Caselles, and C. Ballester, 'Image inpainting,' in Proceedings of the 27th annual conference on Computer graphics and interactive techniques , ACM Press/AddisonWesley Publishing Co. (2000), pp. 417-424.
- 21 G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro, 'Image inpainting for irregular holes using partial convolutions,' in Proceedings of the European Conference on Computer Vision (ECCV) (2018), pp. 85-100.
- 22 W. T. Freeman, T. R. Jones, and E. C. Pasztor, 'Examplebased super-resolution,' IEEE Computer graphics and Applications 22 (2), 56-65 (2002).
- 23 Y. Zhang, Y. Tian, Y. Kong, B. Zhong, and Y. Fu, 'Residual dense network for image super-resolution,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), pp. 2472-2481.
- 24 O. Ronneberger, P. Fischer, and T. Brox, 'U-net: Convolutional networks for biomedical image segmentation,' in International Conference on Medical image computing and computer-assisted intervention , Springer (2015), pp. 234-241.
- 25 K. He, X. Zhang, S. Ren, and J. Sun, 'Deep residual learning for image recognition,' in Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770-778.
- 26 F. Chollet, 'Xception: Deep learning with depthwise separable convolutions,' in Proceedings of the IEEE conference on computer vision and pattern recognition (2017), pp. 1251-1258.
- 27 A. B. Nassif, I. Shahin, I. Attili, M. Azzeh, and K. Shaalan, 'Speech recognition using deep neural networks: A systematic review,' IEEE Access 7 , 19143-19165 (2019).
- 28 Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio, et al. , 'Tacotron: Towards end-to-end speech synthesis,' Proc. Interspeech 2017 4006-4010 (2017).
- 29 I. T. Union, 'Recommendation itu-r bs. 1116-3: Methods for the subjective assessment of small impairments in audio systems' (2015).
- 30 See supplementary material at github.com/francesclluis/ sound-field-neural-network .
- 31 F. Jacobsen and P. M. Juhl, Fundamentals of general linear acoustics (John Wiley & Sons, 2013).
- 32 M. Drozdzal, E. Vorontsov, G. Chartrand, S. Kadoury, and C. Pal, 'The importance of skip connections in biomedical image segmentation,' in Deep Learning and Data Labeling for Medical Applications (Springer, 2016), pp. 179-187.
- 33 P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, 'Image-to-image translation with conditional adversarial networks,' in Proceedings of the IEEE conference on computer vision and pattern recognition (2017), pp. 1125-1134.
- 34 Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, et al. , 'Image quality assessment: from error visibility to structural similarity,' IEEE transactions on image processing 13 (4), 600-612 (2004).
- 35 H. J. Landau, 'Necessary density conditions for sampling and interpolation of certain entire functions,' Acta Mathematica 117 (1), 37-52 (1967).
- 36 A. Farina, 'Simultaneous measurement of impulse response and distortion with a swept-sine technique,' in Audio Engineering Society Convention 108 , Audio Engineering Society (2000).
- 37 I. 3382-2, 'Acoustics measurement of room acoustic parameters part 2: Reverberation time in ordinary rooms' (2008).
- 38 D. Ulyanov, A. Vedaldi, and V. Lempitsky, 'Deep image prior,' in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), pp. 9446-9454.
- 39 I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning (MIT Press, 2016) http://www.deeplearningbook.org .