## Hierarchical Human Parsing with Typed Part-Relation Reasoning
Wenguan Wang 1 , 2 ∗ , Hailong Zhu 3 ∗ , Jifeng Dai 4 , Yanwei Pang 3 † , Jianbing Shen 2 , Ling Shao 2
ETH Zurich, Switzerland 2 Inception Institute of Artificial Intelligence, UAE
3 Tianjin Key Laboratory of Brain-inspired Intelligence Technology, School of Electrical and Information Engineering, Tianjin University, China 4 SenseTime Research
{ wenguanwang.ai,hlzhu2009 } @gmail.com https://github.com/hlzhu09/Hierarchical-Human-Parsing
## Abstract
Human parsing is for pixel-wise human semantic understanding. As human bodies are underlying hierarchically structured, how to model human structures is the central theme in this task. Focusing on this, we seek to simultaneously exploit the representational capacity of deep graph networks and the hierarchical human structures. In particular, we provide following two contributions. First, three kinds of part relations, i.e ., decomposition, composition, and dependency, are, for the first time, completely and precisely described by three distinct relation networks. This is in stark contrast to previous parsers, which only focus on a portion of the relations and adopt a type-agnostic relation modeling strategy. More expressive relation information can be captured by explicitly imposing the parameters in the relation networks to satisfy the specific characteristics of different relations. Second, previous parsers largely ignore the need for an approximation algorithm over the loopy human hierarchy, while we instead address an iterative reasoning process, by assimilating generic message-passing networks with their edgetyped, convolutional counterparts. With these efforts, our parser lays the foundation for more sophisticated and flexible human relation patterns of reasoning. Comprehensive experiments on five datasets demonstrate that our parser sets a new state-of-the-art on each.
## 1. Introduction
Human parsing involves segmenting human bodies into semantic parts, e.g ., head, arm, leg, etc . It has attracted tremendous attention in the literature, as it enables finegrained human understanding and finds a wide spectrum of human-centric applications, such as human behavior analysis [50, 14], human-robot interaction [16], and many others.
Human bodies present a highly structured hierarchy and body parts inherently interact with each other. As
∗ The first two authors contribute equally to this work.
† Corresponding author: Yanwei Pang .
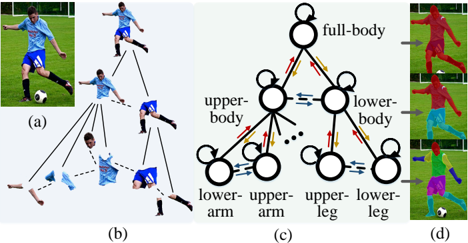
Figure 1: Illustration of our hierarchical human parser. (a) Input image. (b) The human hierarchy in (a), where indicates dependency relations and is de-/compositional relations. (c) In our parser, three distinct relation networks are designed for addressing the specific characteristics of different part relations, i.e ., , , and stand for decompositional, compositional, and dependency relation networks, respectively. Iterative inference ( ) is performed for better approximation. For visual clarity, some nodes are omitted. (d) Our hierarchical parsing results.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Image Analysis: Human Pose Decomposition and Representation
### Overview
The image presents a visual representation of human pose decomposition and modeling, likely related to computer vision or machine learning. It shows a soccer player's image broken down into hierarchical components and represented as a state diagram.
### Components/Axes
* **(a):** Original image of a soccer player kicking a ball.
* **(b):** Hierarchical decomposition of the soccer player's image into body parts. The full body is at the top, branching down to upper and lower body, and further down to individual limbs. Dashed lines indicate less certain connections.
* **(c):** State diagram representing the relationships between body parts. Nodes represent body parts (full-body, upper-body, lower-body, lower-arm, upper-arm, upper-leg, lower-leg). Arrows indicate transitions or relationships between states. The arrows are colored blue, red, and yellow.
* **(d):** Visualization of the body part segmentation. The original image is overlaid with different colors representing different body parts.
### Detailed Analysis
**Section (a):**
* Shows a soccer player in action, kicking a soccer ball.
**Section (b):**
* The full image is at the top.
* It branches into the upper and lower body.
* The upper body branches into the upper arms.
* The lower body branches into the upper and lower legs.
* The arms and legs are further broken down into their respective parts.
**Section (c):**
* **Nodes:**
* full-body (at the top)
* upper-body (left side, below full-body)
* lower-body (right side, below full-body)
* lower-arm (bottom-left)
* upper-arm (left-center, below upper-body)
* upper-leg (right-center, below lower-body)
* lower-leg (bottom-right)
* **Arrows:**
* Self-loops on each node.
* Bi-directional arrows between upper-body and lower-body (blue).
* Arrows from upper-body to upper-arm (red/orange).
* Arrows from lower-body to upper-leg (red/orange).
* Bi-directional arrows between upper-arm and lower-arm (blue).
* Bi-directional arrows between upper-leg and lower-leg (blue).
* Arrows from full-body to upper-body and lower-body (red/orange).
**Section (d):**
* The original image is segmented into different body parts, each colored differently.
* The colors appear to correspond to the body parts identified in the state diagram.
* The segmentation is not perfect, but it provides a visual representation of the body part decomposition.
### Key Observations
* The image demonstrates a hierarchical approach to representing human pose.
* The state diagram captures the relationships between different body parts.
* The segmentation provides a visual representation of the body part decomposition.
### Interpretation
The image illustrates a method for representing human pose using a hierarchical decomposition and a state diagram. This approach could be used in computer vision applications such as pose estimation, action recognition, and human-computer interaction. The hierarchical decomposition allows for a coarse-to-fine representation of the human body, while the state diagram captures the relationships between different body parts. The segmentation provides a visual representation of the body part decomposition, which can be used for training and evaluation. The use of different colored arrows in the state diagram likely indicates different types of relationships or probabilities of transitions between states. The dashed lines in the hierarchical decomposition might indicate weaker or less certain relationships between body parts.
</details>
shown in Fig. 1(b), there are different relations between parts [42, 59, 49]: decompositional and compositional relations (full line: ) between constituent and entire parts ( e.g ., { upper body , lower body } and full body ), and dependency relations (dashed line: ) between kinematically connected parts ( e.g ., hand and arm ). Thus the central problem in human parsing is how to model such relations. Recently, numerous structured human parsers have been proposed [64, 15, 22, 63, 47, 73, 60, 20]. Their notable successes indeed demonstrate the benefit of exploiting the structure in this problem. However, three major limitations in human structure modeling are still observed. (1) The structural information utilized is typically weak and relation types studied are incomplete. Most efforts [64, 15, 22, 63, 47] directly encode human pose information into the parsing model, causing them to suffer from trivial structural information, not to mention the need of extra pose annotations. In addition, previous structured parsers focus on only one or two of the aforementioned part relations, not all of them. For example, [20] only considers
dependency relations, and [73] relies on decompositional relations. (2) Only a single relation model is learnt to reason different kinds of relations, without considering their essential and distinct geometric constraints. Such a relation modeling strategy is over-general and simple; do not seem to characterize well the diverse part relations. (3) According to graph theory, as the human body yields a complex, cyclic topology, an iterative inference is desirable for optimal result approximation. However, current arts [22, 63, 47, 73, 60] are primarily built upon an immediate, feed-forward prediction scheme.
To respond to the above challenges and enable a deeper understanding of human structures, we develop a unified, structured human parser that precisely describes a more complete set of part relations, and efficiently reasons structures with the prism of a message-passing, feed-back inference scheme. To address the first two issues, we start with an in-depth and comprehensive analysis on three essential relations, namely decomposition, composition, and dependency. Three distinct relation networks ( , , and in Fig. 1(c)) are elaborately designed and imposed to explicitly satisfy the specific, intrinsic relation constraints. Then, we construct our parser as a tree-like, end-to-end trainable graph model, where the nodes represent the human parts, and edges are built upon the relation networks. For the third issue, a modified, relation-typed convolutional message passing procedure ( in Fig. 1(c)) is performed over the human hierarchy, enabling our method to obtain better parsing results from a global view. All components, i.e ., the part nodes, edge (relation) functions, and message passing modules, are fully differentiable, enabling our whole framework to be end-to-end trainable and, in turn, facilitating learning about parts, relations, and inference algorithms.
More crucially, our structured human parser can be viewed as an essential variant of message passing neural networks (MPNNs) [19, 56], yet significantly differentiated in two aspects. (1) Most previous MPNNs are edge-typeagnostic, while ours addresses relation-typed structure reasoning with a higher expressive capability. (2) By replacing the Multilayer Perceptron (MLP) based MPNN units with convolutional counterparts, our parser gains a spatial information preserving property, which is desirable for such a pixel-wise prediction task.
We extensively evaluate our approach on five standard human parsing datasets [22, 63, 44, 31, 45], achieving stateof-the-art performance on all of them ( § 4.2). In addition, with ablation studies for each essential component in our parser ( § 4.3), three key insights are found: (1) Exploring different relations reside on human bodies is valuable for human parsing. (2) Distinctly and explicitly modeling different types of relations can better support human structure reasoning. (3) Message passing based feed-back inference is able to reinforce parsing results.
## 2. Related Work
Human parsing: Over the past decade, active research has been devoted towards pixel-level human semantic understanding. Early approaches tended to leverage image regions [35, 67, 68], hand-crafted features [57, 7], part templates [2, 11, 10] and human keypoints [66, 35, 67, 68], and typically explored certain heuristics over human body configurations [3, 11, 10] in a CRF [66, 28], structured model [67, 11], grammar model [3, 42, 10], or generative model [13, 51] framework. Recent advance has been driven by the streamlined designs of deep learning architectures. Some pioneering efforts revisit classic template matching strategy [31, 36], address local and global cues [34], or use tree-LSTMs to gather structure information [32, 33]. However, due to the use of superpixel [34, 32, 33] or HOG feature [44], they are fragmentary and time-consuming. Consequent attempts thus follow a more elegant FCN architecture, addressing multi-level cues [5, 62], feature aggregation [45, 71, 38], adversarial learning [70, 46, 37], or crossdomain knowledge [37, 65, 20]. To further explore inherent structures, numerous approaches [64, 71, 22, 63, 15, 47] choose to straightforward encode pose information into the parsers, however, relying on off-the-shelf pose estimators [18, 17] or additional annotations. Some others consider top-down [73] or multi-source semantic [60] information over hierarchical human layouts. Though impressive, they ignore iterative inference and seldom address explicit relation modeling, easily suffering from weak expressive ability and risk of sub-optimal results.
With the general success of these works, we make a further step towards more precisely describing the different relations residing on human bodies, i.e ., decomposition, composition, and dependency, and addressing iterative, spatialinformation preserving inference over human hierarchy.
Graph neural networks (GNNs): GNNshave a rich history (dating back to [53]) and became a veritable explosion in research community over the last few years [23]. GNNs effectively learn graph representations in an end-to-end manner, and can generally be divided into two broad classes: Graph Convolutional Networks (GCNs) and Message Passing Graph Networks (MPGNs). The former [12, 48, 27] directly extend classical CNNs to non-Euclidean data. Their simple architecture promotes their popularity, while limits their modeling capability for complex structures [23]. MPGNs [19, 72, 56, 58] parameterize all the nodes, edges, and information fusion steps in graph learning, leading to more complicated yet flexible architectures.
Our structured human parser, which falls in the second category, can be viewed as an early attempt to explore GNNs in the area of human parsing. In contrast to conventional MPGNs, which are mainly MLP-based and edgetype-agnostic, we provide a spatial information preserving and relation-type aware graph learning scheme.
O
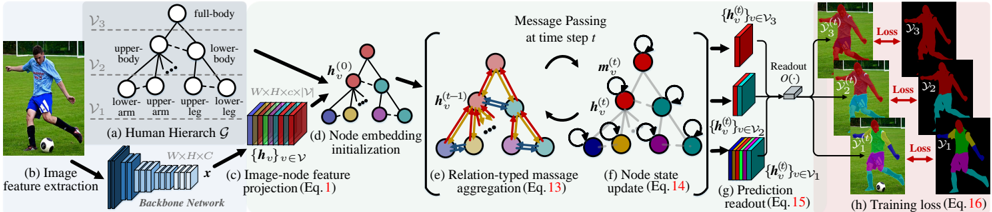
Figure 2: Illustration of our structured human parser for hierarchical human parsing during the training phase. The main components in the flowchart are marked by (a)-(h). Please refer to § 3 for more details. Best viewed in color.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Human Pose Estimation Pipeline
### Overview
The image illustrates a pipeline for human pose estimation using a hierarchical graph-based approach. It starts with image feature extraction, projects these features onto a human hierarchy graph, performs message passing on the graph, and finally predicts the pose and calculates the training loss.
### Components/Axes
* **(a) Human Hierarchy G:** A hierarchical graph representing the human body. It has three levels:
* V3: full-body
* V2: upper-body, lower-body
* V1: lower-arm, upper-arm, upper-leg, lower-leg
* **(b) Image feature extraction:** An image of a person playing soccer is fed into a backbone network.
* **(c) Image-node feature projection (Eq. 1):** The extracted features (x) are projected to node features {h\_v}, where v belongs to V. The dimensions are WxHxC.
* **(d) Node embedding initialization:** The initial node embeddings h\_v^(0) are created.
* **(e) Relation-typed message aggregation (Eq. 13):** Messages are passed between nodes based on their relationships. The node embeddings at time t-1, h\_v^(t-1), are used to aggregate messages.
* **(f) Node state update (Eq. 14):** The node states h\_v^(t) are updated based on the aggregated messages m\_v^(t).
* **(g) Prediction readout (Eq. 15):** The node states at different levels of the hierarchy {h\_v^(t)}, where v belongs to V3, V2, and V1, are used to predict the pose through a readout function O().
* **(h) Training loss (Eq. 16):** The predicted pose is compared to the ground truth, and a loss is calculated for each level of the hierarchy (y3, y2, y1).
### Detailed Analysis
* **Human Hierarchy (a):** The human body is represented as a tree-like structure. The root node represents the full body, which is then divided into upper and lower body. These are further divided into limbs (lower-arm, upper-arm, upper-leg, lower-leg).
* **Image Feature Extraction (b):** A convolutional neural network (Backbone Network) extracts features from the input image.
* **Image-node feature projection (c):** The extracted image features are projected onto the nodes of the human hierarchy graph. The dimensions of the feature representation are W x H x C x |V|.
* **Node embedding initialization (d):** Each node in the graph is initialized with an embedding vector h\_v^(0).
* **Relation-typed message aggregation (e):** Nodes exchange messages with their neighbors based on the relationships defined in the hierarchy. The arrows indicate the direction of message passing.
* **Node state update (f):** Each node updates its state based on the received messages. Self-loops indicate that the node also considers its previous state.
* **Prediction readout (g):** The final node states are used to predict the pose. The readout function O() takes the node states from different levels of the hierarchy as input.
* **Training loss (h):** The predicted pose is compared to the ground truth pose, and a loss is calculated. The loss is computed at each level of the hierarchy (V3, V2, V1).
### Key Observations
* The pipeline uses a hierarchical graph to represent the human body, which allows for structured reasoning about the pose.
* Message passing is used to propagate information between nodes in the graph.
* The loss is computed at multiple levels of the hierarchy, which encourages the model to learn a consistent representation of the pose.
### Interpretation
The diagram illustrates a sophisticated approach to human pose estimation that leverages a hierarchical graph structure. By representing the human body as a graph and using message passing, the model can effectively reason about the relationships between different body parts. The multi-level loss function ensures that the model learns a consistent and accurate representation of the pose. This approach is likely to be more robust to occlusions and variations in pose compared to traditional methods. The use of a backbone network for feature extraction allows the model to leverage pre-trained knowledge from large image datasets.
</details>
## 3. Our Approach
## 3.1. Problem Definition
Formally, we represent the human semantic structure as a directed, hierarchical graph G = ( V , E , Y ) . As show in Fig. 2(a), the node set V = ∪ 3 l =1 V l represents human parts in three different semantic levels, including the leaf nodes V 1 ( i.e ., the most fine-grained parts: head, arm, hand , etc .) which are typically considered in common human parsers, two middle-level nodes V 2 = { upper-body, lower-body } and one root V 3 = { full-body } 1 . The edge set E∈ ( V 2 ) represents the relations between human parts (nodes), i.e ., the directed edge e =( u, v ) ∈E links node u to v : u → v . Each node v and each edge ( u, v ) are associated with feature vectors: h v and h u,v , respectively. y v ∈Y indicates the groundtruth segmentation map of part (node) v and the groundtruth maps Y are also organized in a hierarchical manner: Y = ∪ 3 l =1 Y l .
Our human parser is trained in a graph learning scheme, using the full supervision from existing human parsing datasets. For a test sample, it is able to effectively infer the node and edge representations by reasoning human structures at the levels of individual parts and their relations, and iteratively fusing the information over the human structures.
## 3.2. Structured Human Parsing Network
Node embedding: As an initial step, a learnable projection function is used to map the input image representation into node (part) features, in order to obtain sufficient expressive power. Formally, let us denote the input image feature as x ∈ R W × H × C , which comes from a DeepLabV3 [6]-like backbone network ( in Fig.2(b)), and the projection function as P : R W × H × C ↦→ R W × H × c ×|V| , where |V| indicates the number of nodes. The node embeddings { h v ∈ R W × H × c } v ∈V are initialized by (Fig.2(d)):
<!-- formula-not-decoded -->
where each node embedding h v is a ( W , H , c )-dimensional tenor that encodes full spatial details ( in Fig.2(c)).
1 As the classic settings of graph models, there is also a 'dummy' node in V , used for interpreting the background class. As it does not interact with other semantic human parts (nodes), we omit this node for concept clarity.
Typed human part relation modeling: Basically, an edge embedding h u,v captures the relations between nodes u and v . Most previous structured human parsers [73, 60] work in an edge-type-agnostic manner, i.e ., a unified, shared relation network R : R W × H × c × R W × H × c ↦→ R W × H × c is used to capture all the relations: h u,v = R ( h u , h v ) . Such a strategy may lose the discriminability of individual relation types and does not have an explicit bias towards modeling geometric and anatomical constraints. In contrast, we formulate h u,v in a relation-typed manner R r :
<!-- formula-not-decoded -->
where r ∈ { dec , com , dep } . F r ( · ) is an attention-based relation-adaption operation, which is used to enhance the original node embedding h u by addressing geometric characteristics in relation r . The attention mechanism is favored here as it allows trainable and flexible feature enhancement and explicitly encodes specific relation constraints. From the view of information diffusion mechanism in the graph theory [53], if there exists an edge ( u, v ) that links a starting node u to a destination v , this indicates v should receive incoming information ( i.e ., h u,v ) from u . Thus, we use F r ( · ) to make h u better accommodate the target v . R r is edgetype specific, employing the more tractable feature F r ( h u ) in place of h u , so more expressive relation feature h u,v for v can be obtained and further benefit the final parsing results. In this way, we learn more sophisticated and impressive relation patterns within human bodies.
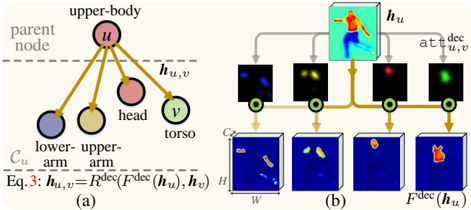
1) Decompositional relation modeling: Decompositional relations (full line: in Fig. 2(a)) are represented by those vertical edges starting from parent nodes to corresponding child nodes in the human hierarchy G . For example, a parent node full-body can be separated into { upper-body , lowerbody } , and upper-body can be decomposed into { head , torso , upper-arm , lower-arm } . Formally, for a node u , let us denote its child node set as C u . Our decompositional relation network R dec aims to learn the rule for 'breaking down' u into its constituent parts C u (Fig.3):
<!-- formula-not-decoded -->
de feature
(e) Relation-typed massage
(f) Node state aggregation
update
upper-leg lower-body v u Figure 3: Illustration of our decompositional relation modeling. (a) Decompositional relations between the upper-body node ( u ) and its constituents ( C u ). (b) With the decompositional attentions { att dec u,v ( h u ) } v ∈C u , F dec learns how to 'break down' the upper-body node and generates more tractable features for its constituents. In the relation adapted feature F dec ( h u ) , the responses from the background and other irrelevant parts are suppressed.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Hierarchical Body Part Decomposition
### Overview
The image presents a diagram illustrating a hierarchical decomposition of the human body into parts, likely within the context of a computer vision or machine learning system. It shows a parent node representing the "upper-body" and its connections to child nodes representing "lower-arm", "upper-arm", "head", and "torso". The diagram also depicts a process involving feature extraction and attention mechanisms.
### Components/Axes
**Part (a): Hierarchical Tree Structure**
* **Parent Node:** Labeled "parent node" with a dashed horizontal line indicating the level. The node itself is labeled "u" and "upper-body".
* **Child Nodes:** Four child nodes connected to the parent node "u" via gold-colored arrows. These nodes represent:
* "lower-arm" (blue circle)
* "upper-arm" (yellow circle)
* "head" (pink circle)
* "torso" (green circle)
* **Edge Labels:** The edges connecting the parent node to the child nodes are labeled "h<sub>u,v</sub>".
* **Node Labels:** The nodes are labeled with "C<sub>u</sub>" below the lower-arm and upper-arm nodes.
* **Equation:** "Eq. 3: h<sub>u,v</sub> = R<sup>dec</sup>(F<sup>dec</sup>(h<sub>u</sub>), h<sub>v</sub>)"
**Part (b): Feature Extraction and Attention**
* **Top Row:**
* A 3D representation of a person with a heat map overlay, labeled "h<sub>u</sub>".
* Four feature maps, each connected to the "h<sub>u</sub>" representation via gray arrows.
* Each feature map is connected to a green circle.
* The connection between the "h<sub>u</sub>" representation and the feature maps is labeled "att<sup>dec</sup><sub>u,v</sub>".
* **Bottom Row:**
* Four 3D representations of feature maps, each connected to the green circles above via gold-colored arrows.
* The final 3D representation is labeled "F<sup>dec</sup>(h<sub>u</sub>)".
* Dimensions of the 3D representations are labeled "W", "H", and "C".
### Detailed Analysis
**Part (a): Hierarchical Tree Structure**
* The diagram represents a tree-like structure where the "upper-body" is the root, and the other body parts are its children.
* The arrows indicate a flow of information or dependency from the parent node to the child nodes.
* The equation "h<sub>u,v</sub> = R<sup>dec</sup>(F<sup>dec</sup>(h<sub>u</sub>), h<sub>v</sub>)" likely describes the computation of features or relationships between the parent node "u" and its child nodes "v".
**Part (b): Feature Extraction and Attention**
* The "h<sub>u</sub>" representation shows a person with a heat map, indicating areas of interest or activation.
* The feature maps in the top row likely represent different features extracted from the "h<sub>u</sub>" representation.
* The "att<sup>dec</sup><sub>u,v</sub>" label suggests an attention mechanism is used to focus on relevant features.
* The bottom row shows the processed feature maps, with the final representation "F<sup>dec</sup>(h<sub>u</sub>)" potentially representing a refined or decoded feature representation.
### Key Observations
* The diagram combines a hierarchical representation of body parts with a feature extraction and attention mechanism.
* The equation in part (a) and the labels in part (b) suggest a complex computation involving feature decoding and attention.
* The heat map on the person in part (b) indicates a focus on specific body regions.
### Interpretation
The diagram illustrates a system for analyzing human body pose or activity. The hierarchical decomposition allows for a structured representation of the body, while the feature extraction and attention mechanisms enable the system to focus on relevant features and relationships between body parts. The equation suggests a recursive or iterative process for refining the feature representation. This approach could be used for tasks such as pose estimation, action recognition, or human-computer interaction.
</details>
lower-leg
C
H W ' ' indicates the attention-based feature enhancement operation, and att dec u,v ( h u ) ∈ [0 , 1] W × H produces an attention map.Foreachsub-node v ∈C u of u , att dec u,v ( h u ) is defined as:
<!-- formula-not-decoded -->
where PSM( · ) stands for pixel-wise soft-max , '[ · ]' represents the channel-wise concatenation, and φ dec v ( h u ) ∈ R W × H computes a specific significance map for v . By making ∑ v ∈C u att dec u,v = 1 , { att dec u,v ( h u ) } v ∈C u forms a decompositional attention mechanism, i.e ., allocates disparate attentions over h u . To recap, the decompositional attention , conditioned on h u , lets u pass separate high-level information to different child nodes C u (see Fig. 3(b)). Here att dec u,v ( · ) is node-specific and separately learnt for the three entire nodes in V 2 ∪V 3 , namely full-body , upper-body and lowerbody . A subscript u,v is added to address this point. In addition, for each parent node u , the groundtruth maps Y C u = { y v } v ∈C u ∈{ 0 , 1 } W × H ×|C u | of all the child nodes C u can be used as supervision signals to train its decompositional attention { att dec u,v ( h u ) } v ∈C u ∈ [0 , 1] W × H ×|C u | :
<!-- formula-not-decoded -->
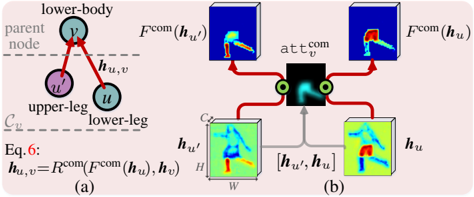
where L CE represents the standard cross-entropy loss. 2) Compositional relation modeling: In the human hierarchy G , compositional relations are represented by vertical, downward edges. To address this type of relations, we design a compositional relation network R com as (Fig.4):
<!-- formula-not-decoded -->
Here att com v : R W × H × c ×|C v | ↦→ [0 , 1] W × H is a compositional attention , implemented by a 1 × 1 convolutional layer. The rationale behind such a design is that, for a parent node v , att com v gathers statistics of all the child nodes C v and is used to enhance each sub-node feature h u . As att com v is compositional in nature, its enhanced feature F com ( h u ) is lower-
(g) Prediction upper-
arm arm
readout torso
C
(h) Training loss
H
W
Figure 4: Illustration of our compositional relation modeling. (a) Compositional relations between the lower-body node ( v ) and its constituents ( C v ). (b) The compositional attention att com v ([ h u ′ , h u ]) gathers information from all the constituents C v and lets F com enhance all the lower-body related features of C v .
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: Hierarchical Compositional Reasoning
### Overview
The image presents a diagram illustrating a hierarchical compositional reasoning process, likely within a computer vision or machine learning context. It shows how features from different parts of an object (e.g., body parts) are combined to form a higher-level representation. The diagram is split into two parts: (a) a graph representation of the hierarchy and (b) a visual representation of the feature combination process.
### Components/Axes
**Part (a): Graph Representation**
* **Nodes:**
* `v`: Labeled "lower-body", representing a parent node.
* `u'`: Labeled "upper-leg", representing a child node.
* `u`: Labeled "lower-leg", representing a child node.
* **Edges:** Red arrows indicating the flow of information from child nodes to the parent node. The edges are labeled `h_u,v`.
* **Labels:**
* "parent node" (horizontal dashed line)
* "C_v" (horizontal dashed line)
* **Equation:**
* `Eq. 6: h_u,v = R^{com}(F^{com}(h_u'), h_v)`
**Part (b): Feature Combination Process**
* **Input Features:**
* `h_u'`: A 3D block labeled with dimensions `C`, `H`, and `W`, showing a human figure.
* `h_u`: A 3D block showing a human figure.
* **Feature Transformation:**
* `F^{com}(h_u')`: A 3D block showing a transformed representation of the human figure.
* `F^{com}(h_u)`: A 3D block showing a transformed representation of the human figure.
* **Attention Mechanism:**
* `att_v^{com}`: A block representing an attention mechanism, taking `[h_u', h_u]` as input.
* **Connections:** Red arrows indicate the flow of information. Gray arrows indicate the concatenation of `h_u'` and `h_u`.
### Detailed Analysis
**Part (a): Graph Representation**
The graph shows a hierarchical structure where the "lower-body" node (`v`) receives information from the "upper-leg" (`u'`) and "lower-leg" (`u`) nodes. The equation `h_u,v = R^{com}(F^{com}(h_u'), h_v)` describes how the features from the child nodes are combined to form a representation for the parent node. `R^{com}` likely represents a combination function, and `F^{com}` likely represents a feature transformation function.
**Part (b): Feature Combination Process**
The feature combination process visually demonstrates how the input features `h_u'` and `h_u` are transformed using `F^{com}`. The attention mechanism `att_v^{com}` takes the concatenated features `[h_u', h_u]` as input and likely assigns weights to the transformed features `F^{com}(h_u')` and `F^{com}(h_u)` before combining them.
The 3D blocks representing the features show human figures, suggesting that the process is related to human pose estimation or action recognition. The color gradients within the blocks likely represent feature activations or importance.
### Key Observations
* The diagram illustrates a hierarchical approach to feature representation.
* An attention mechanism is used to weigh the contributions of different features.
* The process is likely applied to human pose estimation or action recognition.
### Interpretation
The diagram demonstrates a hierarchical compositional reasoning process where features from different parts of an object are combined to form a higher-level representation. The use of an attention mechanism allows the model to focus on the most relevant features when combining them. This approach is likely to be more robust and accurate than simply concatenating the features. The hierarchical structure allows the model to capture relationships between different parts of the object, which is important for understanding complex scenes. The equation in part (a) provides a mathematical description of the feature combination process, while the visual representation in part (b) provides a more intuitive understanding of how the process works.
</details>
more 'friendly' to the parent node v , compared to h u . Thus, R com is able to generate more expressive relation features by considering compositional structures (see Fig.4(b)).
For each parent node v ∈ V 2 ∪ V 3 , with its groundtruth map y v ∈{ 0 , 1 } W × H , the compositional attention for all its child nodes C v is trained by minimizing the following loss:
<!-- formula-not-decoded -->
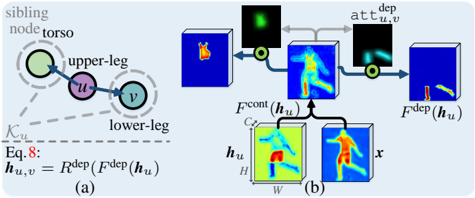
3) Dependency relation modeling: In G , dependency relations are represented as horizontal edges (dashed line: in Fig. 2(a)), describing pairwise, kinematic connections between human parts, such as ( head , torso ), ( upper-leg , lowerleg ), etc . Two kinematically connected human parts are spatially adjacent, and their dependency relation essentially addresses the context information. For a node u , with its kinematically connected siblings K u , a dependency relation network R dep is designed as (Fig. 5):
<!-- formula-not-decoded -->
where F cont ( h u ) ∈ R W × H × c is used to extract the context of u , and att dep u,v ( F cont ( h u ) ) ∈ [0 , 1] W × H is a dependency attention that produces an attention for each sibling node v , conditioned on u 's context F cont ( h u ) . Specifically, inspired by the non-local self-attention [55, 61], the context extraction module F cont is designed as:
<!-- formula-not-decoded -->
where h ′ u ∈ R ( c +8) × ( WH ) and x ′ ∈ R ( C +8) × ( WH ) are node (part) and image representations augmented with spatial information, respectively, flattened into matrix formats. The last eight channels of h ′ u and x ′ encode spatial coordinate information [25], where the first six dimensions are the normalized horizontal and vertical positions, and the last two dimensions are the normalized width and height information of the feature, 1/ W and 1/ H . W ∈ R ( c +8) × ( C +8) is learned as a linear transformation based node-to-context projection
Attention based feature enhancem
Decomposition relation adaptio
H
W
Figure 5: Illustration of our dependency relation modeling. (a) Dependency relations between the upper-body node ( u ) and its siblings ( K u ). (b) The dependency attention { att dep u,v ( F cont ( h u ) ) } v ∈K u , derived from u 's contextual information F cont ( h u ) , gives separate importance for different siblings K u .
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Diagram: Dependency Parsing
### Overview
The image presents a diagram illustrating a dependency parsing process, likely within a computer vision or machine learning context. It shows the relationships between different body parts (torso, upper-leg, lower-leg) and the flow of information between them, represented by feature maps and attention mechanisms. The diagram is divided into two parts: (a) a graph representation of the body part dependencies and (b) a visual representation of the feature processing steps.
### Components/Axes
* **Part (a): Graph Representation**
* Nodes:
* "torso" (top-left, green circle)
* "upper-leg" (center, purple circle labeled "u")
* "lower-leg" (bottom-right, teal circle labeled "v")
* Edges:
* Directed edge from "torso" to "upper-leg"
* Directed edge from "upper-leg" to "lower-leg"
* Other:
* "sibling node" label above "torso"
* "K\_u" label below the graph
* Equation: h\_u,v = R^(dep)(F^(dep)(h\_u))
* Label: (a)
* **Part (b): Feature Processing**
* Input:
* Two 3D feature maps labeled "h\_u" and "x" (bottom-left and bottom-center)
* Dimensions of "h\_u": W (width), H (height), C (channels)
* Processing Steps:
* F^(cont)(h\_u): Combination of "h\_u" and "x" to produce a feature map.
* Feature map with a heat map of the upper leg.
* Attention map "att^(dep)\_{u,v}" (top-center, black square with a teal blob).
* F^(dep)(h\_u): Final feature map after applying the attention mechanism.
* Labels: (b)
### Detailed Analysis
* **Graph Representation (Part a):**
* The graph shows a hierarchical relationship between body parts. The torso is the parent node, the upper-leg is a child node, and the lower-leg is a child node of the upper-leg.
* The equation h\_u,v = R^(dep)(F^(dep)(h\_u)) describes the computation of a feature vector h\_u,v based on the feature vector h\_u and a dependency function F^(dep) and a relation function R^(dep).
* **Feature Processing (Part b):**
* The feature maps "h\_u" and "x" likely represent different types of information about the body part "u" (upper-leg).
* F^(cont)(h\_u) combines these features.
* The attention map "att^(dep)\_{u,v}" highlights the relevant regions in the feature map for the dependency between "u" and "v" (upper-leg and lower-leg).
* F^(dep)(h\_u) represents the final feature map after applying the attention mechanism, focusing on the dependency between the upper and lower leg.
### Key Observations
* The diagram illustrates a dependency parsing approach for understanding the relationships between body parts.
* Attention mechanisms are used to focus on the relevant regions in the feature maps for each dependency.
* The diagram shows the flow of information from the input feature maps to the final feature map, highlighting the key processing steps.
### Interpretation
The diagram presents a method for modeling the dependencies between body parts using feature maps and attention mechanisms. The graph representation captures the hierarchical relationships between body parts, while the feature processing steps show how these dependencies are used to refine the feature representations. This approach is likely used for tasks such as pose estimation or action recognition, where understanding the relationships between body parts is crucial. The use of attention mechanisms allows the model to focus on the most relevant regions in the feature maps, improving the accuracy and efficiency of the parsing process.
</details>
function. The node feature h ′ u , used as a query term, retrieves the reference image feature x ′ for its context information. As a result, the affinity matrix A stores the attention weight between the query and reference at a certain spatial location, accounting for both visual and spatial information. Then, u 's context is collected as a weighted sum of the original image feature x with column-wise normalized weight matrix A : xA ∈ R C × ( WH ) . A 1 × 1 convolution based linear embedding function ρ : R W × H × C ↦→ R W × H × c is applied for feature dimension compression, i.e ., to make the channel dimensions of different edge embeddings consistent.
For each sibling node v ∈K u of u , att dep u,v is defined as:
<!-- formula-not-decoded -->
Here φ dep v ( · ) ∈ R W × H gives an importance map for v , using a 1 × 1 convolutional layer. Through the pixel-wise soft-max operation PSM( · ), we enforce ∑ v ∈K u att dep u,v = 1 , leading to a dependency attention mechanism which assigns exclusive attentions over F cont ( h u ) , for the corresponding sibling nodes K u . Such a dependency attention is learned via:
<!-- formula-not-decoded -->
where Y K u ∈ [0 , 1] W × H ×|K u | stands for the groundtruth maps { y v } v ∈K u of all the sibling nodes K u of u .
Iterative inference over human hierarchy: Humanbodies present a hierarchical structure. According to graph theory, approximate inference algorithms should be used for such a loopy structure G . However, previous structured human parsers directly produce the final node representation h v by either simply accounting for the information from the parent node u [73]: h v ← R ( h u , h v ) , where v ∈ C u ; or from its neighbors N v [60]: h v ← ∑ u ∈N v R ( h u , h v ) . They ignore the fact that, in such a structured setting, information is organized in a complex system. Iterative algorithms offer a more favorable solution, i.e ., the node representation should be updated iteratively by aggregating the messages from its neighbors; after several iterations, the representation can approximate the optimal results [53]. In graph theory parlance, the iterative algorithm can be achieved by a parametric message passing process, which is defined in terms of a message function M and node update function U , and runs T steps. For each node v , the message passing process recursively collects information (messages) m v from the neighbors N v to enrich the node embedding h v :
<!-- formula-not-decoded -->
where h ( t ) v stands for v 's state in the t -th iteration. Recurrent neural networks are typically used to address the iterative nature of the update function U .
Inspired by previous message passing algorithms, our iterative algorithm is designed as (Fig.2(e)-(f)):
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
where the initial state h (0) v is obtained by Eq. 1. Here, the message aggregation step (Eq. 13) is achieved by per-edge relation function terms, i.e ., node v updates its state h v by absorbing all the incoming information along different relations. As for the update function U in Eq. 14, we use a convGRU [54], which replaces the fully-connected units in the original MLP-based GRU with convolution operations, to describe its repeated activation behavior and address the pixel-wise nature of human parsing, simultaneously. Compared to previous parsers, which are typically based on feedforward architectures, our massage-passing inference essentially provides a feed-back mechanism, encouraging effective reasoning over the cyclic human hierarchy G .
Loss function: In each step t , to obtain the predictions ˆ Y ( t ) l = { ˆ y ( t ) v ∈ [0 , 1] W × H } v ∈V l of the l -th layer nodes V l , we apply a convolutional readout function O : R W × H × c ↦→ R W × H over { h ( t ) v } v ∈V ( in Fig. 2(g)), and pixel-wise soft-max (PSM) for normalization:
<!-- formula-not-decoded -->
Given the hierarchical human parsing results { ˆ Y ( t ) l } 3 l =1 and corresponding groundtruths {Y l } 3 l =1 , the learning task in the iterative inference can be posed as the minimization of the following loss (Fig.2(h)):
<!-- formula-not-decoded -->
Considering Eqs.5,7,11,and16, the overall loss is defined as:
<!-- formula-not-decoded -->
where the coefficient α is empirically set as 0 . 1 . We set the total inference time T =2 and study how the performance changes with the number of inference iterations in § 4.3.
## 3.3. Implementation Details
Node embedding: A DeepLabV3 network [6] serves as the backbone architecture, resulting in a 256-channel image representation whose spatial dimensions are 1/8 of the input image. The projection function P : R W × H × C ↦→ R W × H × c ×|V| in Eq.1 is implemented by a 3 × 3 convolutional layer with ReLU nonlinearity, where C =256 and |V| ( i.e ., the number of nodes) is set according to the settings in different human parsing datasets. We set the channel size of node features c =64 to maintain high computational efficiency.
Relation networks: Each typed relation network R r in Eq.2 concatenates the relation-adapted feature F r ( h u ) from the source node u and the destination node v 's feature h v as the input, and outputs the relation representations: h u,v = R r ([ F r ( h u ) , h v ]) . R r : R W × H × 2 c ↦→ R W × H × c is implemented by a 3 × 3 convolutional layer with ReLU nonlinearity.
Iterative inference: In Eq.14, the update function U convGRU is implemented by a convolutional GRU with 3 × 3 convolution kernels. The readout function O in Eq. 15 applies a 1 × 1 convolution operation on the feature-prediction projection. In addition, before sending a node feature h ( t ) v into O , we use a light-weight decoder (built using a principle of upsampling the node feature and merging it with the low-level feature of the backbone network) that outputs the segmentation mask with 1/4 the spatial resolution of the input image.
As seen, all the units of our parser are built on convolution operations, leading to spatial information preservation.
## 4. Experiments
## 4.1. Experimental Settings
Datasets: 2 Five standard benchmark datasets [22, 63, 44, 31, 45] are used for performance evaluation. LIP [22] contains 50,462 single-person images, which are collected from realistic scenarios and divided into 30,462 images for training, 10,000 for validation and 10,000 for test. The pixelwise annotations cover 19 human part categories ( e.g ., face , left-/right-arms , left-/right-legs , etc .). PASCAL-PersonPart [63] includes 3,533 multi-person images with challenging poses and viewpoints. Each image is pixel-wise annotated with six classes ( i.e ., head, torso, upper-/lower-arms , and upper-/lower-legs ). It is split into 1,716 and 1,817 images for training and test. ATR [31] is a challenging human parsing dataset, which has 7,700 single-person images with dense annotations over 17 categories ( e.g ., face, upperclothes, left-/right-arms, left-/right-legs , etc .). There are 6,000, 700 and 1,000 images for training, validation, and test, respectively. PPSS [44] is a collection of 3,673 singlepedestrian images from 171 surveillance videos and provides pixel-wise annotations for hair, face, upper-/lowerclothes, arm , and leg . It presents diverse real-word chal-
2 As the datasets provide different human part labels, we make proper modifications of our human hierarchy. For some labels that do not deliver human structures, such as hat , sun-glasses , we treat them as isolate nodes.
Table 1: Comparison of pixel accuracy, mean accuracy and mIoU on LIP val [22]. † indicates extra pose information used.
| Method | pixAcc. | Mean Acc. | Mean IoU |
|----------------------|-----------|-------------|------------|
| SegNet [1] | 69.04 | 24.00 | 18.17 |
| FCN-8s [41] | 76.06 | 36.75 | 28.29 |
| DeepLabV2 [4] | 82.66 | 51.64 | 41.64 |
| Attention [5] | 83.43 | 54.39 | 42.92 |
| † Attention+SSL [22] | 84.36 | 54.94 | 44.73 |
| DeepLabV3+ [6] | 84.09 | 55.62 | 44.8 |
| ASN [43] | - | - | 45.41 |
| † SSL [22] | - | - | 46.19 |
| MMAN[46] | 85.24 | 57.60 | 46.93 |
| † SS-NAN [71] | 87.59 | 56.03 | 47.92 |
| HSP-PRI [26] | 85.07 | 60.54 | 48.16 |
| † MuLA [47] | 88.5 | 60.5 | 49.3 |
| PSPNet [69] | 86.23 | 61.33 | 50.56 |
| CE2P [39] | 87.37 | 63.20 | 53.1 |
| BraidNet [40] | 87.60 | 66.09 | 54.42 |
| CNIF [60] | 88.03 | 68.80 | 57.74 |
| Ours | 89.05 | 70.58 | 59.25 |
lenges, e.g ., pose variations, illumination changes, and occlusions. There are 1,781 and 1,892 images for training and testing, respectively. Fashion Clothing [45] has 4,371 images gathered from Colorful Fashion Parsing [35], Fashionista [67], and Clothing Co-Parsing [68]. It has 17 clothing categories ( e.g ., hair, pants, shoes, upper-clothes , etc .) and the data split follows 3,934 for training and 437 for test.
Training: ResNet101 [24], pre-trained on ImageNet [52], is used to initialize our DeepLabV3 [6] backbone. The remaining layers are randomly initialized. We train our model on the five aforementioned datasets with their respective training samples, separately. Following the common practice [39, 21, 60], we randomly augment each training sample with a scaling factor in [0.5, 2.0], crop size of 473 × 473 , and horizontal flip. For optimization, we use the standard SGD solver, with a momentum of 0.9 and weight decay of 0.0005. To schedule the learning rate, we employ the polynomial annealing procedure [4, 69], where the learning rate is multiplied by (1 -iter total iter ) power with power as 0 . 9 .
Testing: For each test sample, we set the long side of the image to 473 pixels and maintain the original aspect ratio. As in [69, 47], we average the parsing results over five-scale image pyramids of different scales with flipping, i.e ., the scaling factor is 0.5 to 1.5 (with intervals of 0.25).
Reproducibility: Our method is implemented on PyTorch and trained on four NVIDIA Tesla V100 GPUs (32GB memory per-card). All the experiments are performed on one NVIDIA TITAN Xp 12GB GPU. To provide full details of our approach, our code will be made publicly available.
Evaluation: For fair comparison, we follow the official evaluation protocols of each dataset. For LIP, following [71], we report pixel accuracy, mean accuracy and mean Intersection-over-Union (mIoU). For PASCAL-Person-Part and PPSS, following [62, 63, 46], the performance is evaluated in terms of mIoU. For ATR and Fashion Clothing, as
| Method | Head | Torso | U-Arm | L-Arm | U-Leg | L-Leg | B.G. | Ave. |
|---------------------|--------|---------|---------|---------|---------|---------|--------|--------|
| HAZN [62] | 80.79 | 59.11 | 43.05 | 42.76 | 38.99 | 34.46 | 93.59 | 56.11 |
| Attention [5] | 81.47 | 59.06 | 44.15 | 42.50 | 38.28 | 35.62 | 93.65 | 56.39 |
| LG-LSTM [33] | 82.72 | 60.99 | 45.40 | 47.76 | 42.33 | 37.96 | 88.63 | 57.97 |
| Attention+SSL [22] | 83.26 | 62.40 | 47.80 | 45.58 | 42.32 | 39.48 | 94.68 | 59.36 |
| Attention+MMAN [46] | 82.58 | 62.83 | 48.49 | 47.37 | 42.80 | 40.40 | 94.92 | 59.91 |
| Graph LSTM [32] | 82.69 | 62.68 | 46.88 | 47.71 | 45.66 | 40.93 | 94.59 | 60.16 |
| SS-NAN [71] | 86.43 | 67.28 | 51.09 | 48.07 | 44.82 | 42.15 | 97.23 | 62.44 |
| Structure LSTM [30] | 82.89 | 67.15 | 51.42 | 48.72 | 51.72 | 45.91 | 97.18 | 63.57 |
| Joint [63] | 85.50 | 67.87 | 54.72 | 54.30 | 48.25 | 44.76 | 95.32 | 64.39 |
| DeepLabV2 [4] | - | - | - | - | - | - | - | 64.94 |
| MuLA [47] | 84.6 | 68.3 | 57.5 | 54.1 | 49.6 | 46.4 | 95.6 | 65.1 |
| PCNet [73] | 86.81 | 69.06 | 55.35 | 55.27 | 50.21 | 48.54 | 96.07 | 65.9 |
| Holistic [29] | 86.00 | 69.85 | 56.63 | 55.92 | 51.46 | 48.82 | 95.73 | 66.34 |
| WSHP [15] | 87.15 | 72.28 | 57.07 | 56.21 | 52.43 | 50.36 | 97.72 | 67.6 |
| DeepLabV3+ [6] | 87.02 | 72.02 | 60.37 | 57.36 | 53.54 | 48.52 | 96.07 | 67.84 |
| SPGNet [8] | 87.67 | 71.41 | 61.69 | 60.35 | 52.62 | 48.80 | 95.98 | 68.36 |
| PGN [21] | 90.89 | 75.12 | 55.83 | 64.61 | 55.42 | 41.57 | 95.33 | 68.4 |
| CNIF [60] | 88.02 | 72.91 | 64.31 | 63.52 | 55.61 | 54.96 | 96.02 | 70.76 |
Ours
89.73
75.22
66.87
66.21
58.69
58.17
96.94
73.12
Table 2: Per-class comparison of mIoU on PASCAL-PersonPart test [63].
| Method | pixAcc. | F.G. Acc. | Prec. | Recall | F-1 |
|----------------|-----------|-------------|---------|----------|-------|
| Yamaguchi [67] | 84.38 | 55.59 | 37.54 | 51.05 | 41.8 |
| Paperdoll [66] | 88.96 | 62.18 | 52.75 | 49.43 | 44.76 |
| M-CNN [36] | 89.57 | 73.98 | 64.56 | 65.17 | 62.81 |
| ATR [31] | 91.11 | 71.04 | 71.69 | 60.25 | 64.38 |
| DeepLabV2 [4] | 94.42 | 82.93 | 78.48 | 69.24 | 73.53 |
| PSPNet [69] | 95.2 | 80.23 | 79.66 | 73.79 | 75.84 |
| Attention [5] | 95.41 | 85.71 | 81.3 | 73.55 | 77.23 |
| DeepLabV3+ [6] | 95.96 | 83.04 | 80.41 | 78.79 | 79.49 |
| Co-CNN [34] | 96.02 | 83.57 | 84.95 | 77.66 | 80.14 |
| LG-LSTM [33] | 96.18 | 84.79 | 84.64 | 79.43 | 80.97 |
| TGPNet [45] | 96.45 | 87.91 | 83.36 | 80.22 | 81.76 |
| CNIF [60] | 96.26 | 87.91 | 84.62 | 86.41 | 85.51 |
| Ours | 96.84 | 89.23 | 86.17 | 88.35 | 87.25 |
Table 3: Comparison of accuracy, foreground accuracy, average precision, recall and F1-score on ATR test [31].
in [45, 60], we report pixel accuracy, foreground accuracy, average precision, average recall, and average F1-score.
## 4.2. Quantitative and Qualitative Results
LIP [22]: LIP is a gold standard benchmark for human parsing. Table1 reports the comparison results with 16 state-ofthe-arts on LIP val . Wefirst find that general semantic segmentation methods [1, 41, 4, 6] tend to perform worse than human parsers. This indicates the importance of reasoning human structures in this problem. In addition, though recent human parsers gain impressive results, our model still outperforms all the competitors by a large margin. For instance, in terms of pixAcc., mean Acc., and mean IoU, our parser dramatically surpasses the best performing method, CNIF [60], by 1.02%, 1.78% and 1.51%, respectively. We would also like to mention that our parser does not use additional pose [22, 71, 47] or edge [39] information.
PASCAL-Person-Part [63]: In Table 2, we compare our method against 18 recent methods on PASCAL-Person-Part test using IoU score. From the results, we can again see that our approach achieves better performance compared to all other methods; specially, 73.12% vs 70.76%
| Method | pixAcc. | F.G. Acc. | Prec. | Recall | F-1 |
|----------------|-----------|-------------|---------|----------|-------|
| Yamaguchi [67] | 81.32 | 32.24 | 23.74 | 23.68 | 22.67 |
| Paperdoll [66] | 87.17 | 50.59 | 45.8 | 34.2 | 35.13 |
| DeepLabV2 [4] | 87.68 | 56.08 | 35.35 | 39 | 37.09 |
| Attention [5] | 90.58 | 64.47 | 47.11 | 50.35 | 48.68 |
| TGPNet [45] | 91.25 | 66.37 | 50.71 | 53.18 | 51.92 |
| CNIF [60] | 92.2 | 68.59 | 56.84 | 59.47 | 58.12 |
| Ours | 93.12 | 70.57 | 58.73 | 61.72 | 60.19 |
Table 4: Comparison of pixel accuracy, foreground pixel accuracy, average precision, average recall and average f1-score on Fashion Clothing test [45].
| Method | Head | Face | U-Cloth | Arms | L-Cloth | Legs | B.G. | Ave. |
|-----------|--------|--------|-----------|--------|-----------|--------|--------|--------|
| DL [44] | 22 | 29.1 | 57.3 | 10.6 | 46.1 | 12.9 | 68.6 | 35.2 |
| DDN [44] | 35.5 | 44.1 | 68.4 | 17 | 61.7 | 23.8 | 80 | 47.2 |
| ASN [43] | 51.7 | 51 | 65.9 | 29.5 | 52.8 | 20.3 | 83.8 | 50.7 |
| MMAN[46] | 53.1 | 50.2 | 69 | 29.4 | 55.9 | 21.4 | 85.7 | 52.1 |
| LCPC [9] | 55.6 | 46.6 | 71.9 | 30.9 | 58.8 | 24.6 | 86.2 | 53.5 |
| CNIF [60] | 67.6 | 60.8 | 80.8 | 46.8 | 69.5 | 28.7 | 90.6 | 60.5 |
| Ours | 68.8 | 63.2 | 81.7 | 49.3 | 70.8 | 32 | 91.4 | 65.3 |
Table 5: Comparison of mIoU on PPSS test [44].
of CNIF [60] and 68.40% of PGN [21], in terms of mIoU . Such a performance gain is particularly impressive considering that improvement on this dataset is very challenging.
ATR [31]: Table 3 presents comparisons with 14 previous methods on ATR test . Our approach sets new state-ofthe-arts for all five metrics, outperforming all other methods by a large margin. For example, our parser provides a considerable performance gain in F-1 score, i.e ., 1.74% and 5.49% higher than the current top-two performing methods, CNIF [60] and TGPNet [45], respectively.
Fashion Clothing [45]: The quantitative comparison results with six competitors on Fashion Clothing test are summarized in Table 4. Our model yields an F-1 score of 60.19%, while those for Attention [5], TGPNet [45], and CNIF [60] are 48.68%, 51.92%, and 58.12%, respectively. This again demonstrates our superior performance.
PPSS [44]: Table 5 compares our method against six famous methods on PPSS test set. The evaluation results demonstrate that our human parser achieves 65.3% mIoU, with substantial gains over the second best, CNIF [60], and third best, LCPC [9], of 4.8% and 11.8%, respectively.
Runtime comparison: As our parser does not require extra pre-/post-processing steps ( e.g ., human pose used in [63], over-segmentation in [32, 30], and CRF in [63]), it achieves a high speed of 12fps (on PASCAL-Person-Part), faster than most of the counterparts, such as Joint [63] (0.1fps), Attention+SSL [22] (2.0fps), MMAN [46] (3.5fps), SSNAN [71] (2.0fps), and LG-LSTM [33] (3.0fps).
Qualitative results: Some qualitative comparison results on PASCAL-Person-Part test are depicted in Fig. 6. We can see that our approach outputs more precise parsing results than other competitors [6, 21, 71, 60], despite the existence of rare pose (2 nd row) and occlusion (3 rd row). In addition, with its better understanding of human structures,
Figure 6: Visual comparison on PASCAL-Person-Part test . Our model (c) generates more accurate predictions, compared to other famous methods [6, 21, 71, 60] (d-g). The improved labeled results by our parser are denoted in red boxes. Best viewed in color.
<details>
<summary>Image 6 Details</summary>

### Visual Description
## Semantic Segmentation Results
### Overview
The image presents a comparison of semantic segmentation results on three different scenes. The first column shows the original images, followed by the ground truth segmentation, and then the results of four different models: "Ours", "DeepLabV3+ [6]", "PGN [21]", "SS-NAN [71]", and "CNIF [60]". Each row represents a different scene. The segmentation results are visualized using different colors to represent different semantic categories. Red bounding boxes highlight regions of interest in the segmentation results.
### Components/Axes
* **Columns:**
* (a) Image: Original image
* (b) Ground-truth: Manually labeled segmentation
* (c) Ours: Segmentation result from the model "Ours"
* (d) DeepLabV3+ [6]: Segmentation result from the DeepLabV3+ model, with citation [6]
* (e) PGN [21]: Segmentation result from the PGN model, with citation [21]
* (f) SS-NAN [71]: Segmentation result from the SS-NAN model, with citation [71]
* (g) CNIF [60]: Segmentation result from the CNIF model, with citation [60]
* **Rows:**
* Row 1: Scene with people on a beach
* Row 2: Scene with a person and a dog indoors
* Row 3: Scene with a cyclist on a road
### Detailed Analysis or ### Content Details
**Row 1: Beach Scene**
* **(a) Image:** Two people are standing on a beach, with a body of water and boats in the background. One person is handing the other a green object.
* **(b) Ground-truth:** The people, water, and boats are segmented with different colors.
* **(c) Ours:** The segmentation is similar to the ground truth, but with some differences in the boundaries. A red bounding box highlights the torso and arm of one of the people.
* **(d) DeepLabV3+ [6]:** Similar segmentation to "Ours", with a red bounding box around the torso and arm of one of the people.
* **(e) PGN [21]:** Similar segmentation to "Ours" and "DeepLabV3+ [6]", with a red bounding box around the torso and arm of one of the people.
* **(f) SS-NAN [71]:** Similar segmentation to "Ours", "DeepLabV3+ [6]", and "PGN [21]", with a red bounding box around the torso and arm of one of the people.
* **(g) CNIF [60]:** Similar segmentation to "Ours", "DeepLabV3+ [6]", "PGN [21]", and "SS-NAN [71]", with a red bounding box around the torso and arm of one of the people.
**Row 2: Indoor Scene**
* **(a) Image:** A person is lying on a couch with a dog.
* **(b) Ground-truth:** The person, dog, couch, and blanket are segmented with different colors.
* **(c) Ours:** The segmentation is similar to the ground truth, but with some differences in the boundaries. A red bounding box highlights the person's arm and the blanket.
* **(d) DeepLabV3+ [6]:** Similar segmentation to "Ours", with a red bounding box around the person's arm and the blanket.
* **(e) PGN [21]:** Similar segmentation to "Ours" and "DeepLabV3+ [6]", with a red bounding box around the person's arm and the blanket.
* **(f) SS-NAN [71]:** Similar segmentation to "Ours", "DeepLabV3+ [6]", and "PGN [21]", with a red bounding box around the person's arm and the blanket.
* **(g) CNIF [60]:** Similar segmentation to "Ours", "DeepLabV3+ [6]", "PGN [21]", and "SS-NAN [71]", with a red bounding box around the person's arm and the blanket.
**Row 3: Road Scene**
* **(a) Image:** A cyclist is riding on a road.
* **(b) Ground-truth:** The cyclist, road, and surrounding environment are segmented with different colors.
* **(c) Ours:** The segmentation is similar to the ground truth, but with some differences in the boundaries. A red bounding box highlights the cyclist.
* **(d) DeepLabV3+ [6]:** Similar segmentation to "Ours", with a red bounding box around the cyclist.
* **(e) PGN [21]:** Similar segmentation to "Ours" and "DeepLabV3+ [6]", with a red bounding box around the cyclist.
* **(f) SS-NAN [71]:** Similar segmentation to "Ours", "DeepLabV3+ [6]", and "PGN [21]", with a red bounding box around the cyclist.
* **(g) CNIF [60]:** Similar segmentation to "Ours", "DeepLabV3+ [6]", "PGN [21]", and "SS-NAN [71]", with a red bounding box around the cyclist.
### Key Observations
* The image compares the performance of different semantic segmentation models on different scenes.
* The red bounding boxes highlight regions where the segmentation results may be of particular interest or where there are differences between the models.
* The models "Ours", "DeepLabV3+ [6]", "PGN [21]", "SS-NAN [71]", and "CNIF [60]" produce generally similar segmentation results.
### Interpretation
The image demonstrates the capabilities of different semantic segmentation models in various scenarios. The comparison with the ground truth allows for a visual assessment of the accuracy of each model. The highlighted regions draw attention to areas where the models may struggle or where their performance differs. The overall similarity in the results suggests that these models are relatively robust and can effectively segment different types of scenes. The citations ([6], [21], [71], [60]) indicate that these are established models in the field of semantic segmentation.
</details>
our parser gets more robust results and eliminates the interference from the background (1 st row). The last row gives a challenging case, where our parser still correctly recognizes the confusing parts of the person in the middle.
Overall, our human parser attains strong performance across all the five datasets. We believe this is due to our typed relation modeling and iterative algorithm, which enable more trackable part features and better approximations.
## 4.3. Diagnostic Experiments
To demonstrate how each component in our parser contributes to the performance, a series of ablation experiments are conducted on PASCAL-Person-Part test .
Type-specific relation modeling: We first investigate the necessity of comprehensively exploring different relations, and discuss the effective of our type-specific relation modeling strategy. Concretely, we studied six variant models, as listed in Table 6: (1) 'Baseline' denotes the approach only using the initial node embeddings { h (0) v } v ∈V without any relation information; (2) 'Type-agnostic' shows the performance when modeling different human part relations in a type-agnostic manner: h u,v = R ([ h u , h v ]) ; (3) 'Typespecific w/o F r ' gives the performance without the relationadaption operation F r in Eq. 2: h u,v = R r ([ h u , h v ]) ; (4-6) 'Decomposition relation', 'Composition relation' and 'Dependency relation' are three variants that only consider the corresponding single one of the three kinds of relation categories, using our type-specific relation modeling strategy (Eq.2). Four main conclusions can be drawn: (1) Structural information are essential for human parsing, as all the structured models outperforms 'Baseline'. (2) Typed relation modeling leads to more effective human structure learning, as 'Type-specific w/o F r ' improves 'Type-agnostic' by 1.28%. (3) Exploring different kinds of relations are meaningful, as the variants using individual relation types outperform 'Baseline' and our full model considering all the three kinds of relations achieves the best performance. (4) Encoding relation-specific constrains helps with relation pattern learning as our full model is better than the one without
Table 6: Ablation study ( § 4.3) on PASCAL-Person-Part test .
| Component | Module | mIoU | | time (ms) |
|-------------|---------------------------|--------|-------------------|-------------|
| Reference | Full model (2 iterations) | 73.12 | - | 81 |
| | Baseline | 68.84 | -4.28 | 46 |
| | Type-agnostic | 70.37 | -2.75 | 55 |
| Relation | Type-specific w/o F r | 71.65 | -1.47 | 55 |
| modeling | Decomposition relation | 71.38 | -1.74 | 50 |
| | Composition relation | 69.35 | -3.77 | 49 |
| | Dependency relation | 69.43 | -3.69 | 52 |
| | 0 iteration | 68.84 | -4.28 | 46 |
| | 1 iterations | 72.17 | -0.95 | 59 |
| Iterative | 3 iterations | 73.19 | +0.07 | 93 |
| Inference T | 4 iterations | 73.22 | +0.10 | 105 |
| | 5 iterations | 73.23 | +0.11 | 116 |
relation-adaption, 'Type-specific w/o F r '.
Iterative inference: Table 6 shows the performance of our parser with regard to the iteration step t as denoted in Eq.13 and Eq.14. Note that, when t =0 , only the initial node feature is used. It can be observed that setting T =2 or T =3 provided a consistent boost in accuracy of 4 ∼ 5%, on average, compared to T = 0 ; however, increasing T beyond 3 gave marginal returns in performance (around 0.1%). Accordingly, we choose T =2 for a better trade-off between accuracy and computation time.
## 5. Conclusion
In the human semantic parsing task, structure modeling is an essential, albeit inherently difficult, avenue to explore. This work proposed a hierarchical human parser that addresses this issue in two aspects. First, three distinct relation networks are designed to precisely describe the compositional/decompositional relations between constituent and entire parts and help with the dependency learning over kinetically connected parts. Second, to address the inference over the loopy human structure, our parser relies on a convolutional, message passing based approximation algorithm, which enjoys the advantages of iterative optimization and spatial information preservation. The above designs enable strong performance across five widely adopted bench- mark datasets, at times outperforming all other competitors.
## References
- [1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE TPAMI , 39(12):2481-2495, 2017.
- [2] Yihang Bo and Charless C Fowlkes. Shape-based pedestrian parsing. In CVPR , 2011.
- [3] Hong Chen, Zi Jian Xu, Zi Qiang Liu, and Song Chun Zhu. Composite templates for cloth modeling and sketching. In CVPR , 2006.
- [4] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE TPAMI , 40(4):834-848, 2018.
- [5] Liang-Chieh Chen, Yi Yang, Jiang Wang, Wei Xu, and Alan L Yuille. Attention to scale: Scale-aware semantic image segmentation. In CVPR , 2016.
- [6] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV , 2018.
- [7] Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu, Sanja Fidler, Raquel Urtasun, and Alan Yuille. Detect what you can: Detecting and representing objects using holistic models and body parts. In CVPR , 2014.
- [8] Bowen Cheng, Liang-Chieh Chen, Yunchao Wei, Yukun Zhu, Zilong Huang, Jinjun Xiong, Thomas Huang, Wen-Mei Hwu, and Honghui Shi. Spgnet: Semantic prediction guidance for scene parsing. In ICCV , 2019.
- [9] Kang Dang and Junsong Yuan. Location constrained pixel classifiers for image parsing with regular spatial layout. In BMVC , 2014.
- [10] Jian Dong, Qiang Chen, Xiaohui Shen, Jianchao Yang, and Shuicheng Yan. Towards unified human parsing and pose estimation. In CVPR , 2014.
- [11] Jian Dong, Qiang Chen, Wei Xia, Zhongyang Huang, and Shuicheng Yan. A deformable mixture parsing model with parselets. In ICCV , 2013.
- [12] David K Duvenaud, Dougal Maclaurin, Jorge Iparraguirre, Rafael Bombarell, Timothy Hirzel, Al´ an Aspuru-Guzik, and Ryan P Adams. Convolutional networks on graphs for learning molecular fingerprints. In NIPS , 2015.
- [13] S Eslami and Christopher Williams. A generative model for parts-based object segmentation. In NIPS , 2012.
- [14] Lifeng Fan, Wenguan Wang, Siyuan Huang, Xinyu Tang, and Song-Chun Zhu. Understanding human gaze communication by spatio-temporal graph reasoning. In ICCV , 2019.
- [15] Hao-Shu Fang, Guansong Lu, Xiaolin Fang, Jianwen Xie, Yu-Wing Tai, and Cewu Lu. Weakly and semi supervised human body part parsing via pose-guided knowledge transfer. In CVPR , 2018.
- [16] Hao-Shu Fang, Chenxi Wang, Minghao Gou, and Cewu Lu. Graspnet: A large-scale clustered and densely annotated datase for object grasping. arXiv preprint arXiv:1912.13470 , 2019.
- [17] Hao-Shu Fang, Shuqin Xie, Yu-Wing Tai, and Cewu Lu.
18. Rmpe: Regional multi-person pose estimation. In ICCV , 2017.
- [18] Hao-Shu Fang, Yuanlu Xu, Wenguan Wang, Xiaobai Liu, and Song-Chun Zhu. Learning pose grammar to encode human body configuration for 3d pose estimation. In AAAI , 2018.
- [19] Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In ICML , 2017.
- [20] Ke Gong, Yiming Gao, Xiaodan Liang, Xiaohui Shen, Meng Wang, and Liang Lin. Graphonomy: Universal human parsing via graph transfer learning. In CVPR , 2019.
- [21] Ke Gong, Xiaodan Liang, Yicheng Li, Yimin Chen, Ming Yang, and Liang Lin. Instance-level human parsing via part grouping network. In ECCV , 2018.
- [22] Ke Gong, Xiaodan Liang, Dongyu Zhang, Xiaohui Shen, and Liang Lin. Look into person: Self-supervised structuresensitive learning and a new benchmark for human parsing. In CVPR , 2017.
- [23] William L Hamilton, Rex Ying, and Jure Leskovec. Representation learning on graphs: Methods and applications. arXiv preprint arXiv:1709.05584 , 2017.
- [24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR , 2016.
- [25] Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. In ECCV , 2016.
- [26] Mahdi M. Kalayeh, Emrah Basaran, Muhittin Gokmen, Mustafa E. Kamasak, and Mubarak Shah. Human semantic parsing for person re-identification. In CVPR , 2018.
- [27] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR , 2017.
- [28] Lubor Ladicky, Philip HS Torr, and Andrew Zisserman. Human pose estimation using a joint pixel-wise and part-wise formulation. In CVPR , 2013.
- [29] Qizhu Li, Anurag Arnab, and Philip HS Torr. Holistic, instance-level human parsing. In BMVC , 2017.
- [30] Xiaodan Liang, Liang Lin, Xiaohui Shen, Jiashi Feng, Shuicheng Yan, and Eric P Xing. Interpretable structureevolving lstm. In CVPR , 2017.
- [31] Xiaodan Liang, Si Liu, Xiaohui Shen, Jianchao Yang, Luoqi Liu, Jian Dong, Liang Lin, and Shuicheng Yan. Deep human parsing with active template regression. IEEE TPAMI , 37(12):2402-2414, 2015.
- [32] Xiaodan Liang, Xiaohui Shen, Jiashi Feng, Liang Lin, and Shuicheng Yan. Semantic object parsing with graph lstm. In ECCV , 2016.
- [33] Xiaodan Liang, Xiaohui Shen, Donglai Xiang, Jiashi Feng, Liang Lin, and Shuicheng Yan. Semantic object parsing with local-global long short-term memory. In CVPR , 2016.
- [34] Xiaodan Liang, Chunyan Xu, Xiaohui Shen, Jianchao Yang, Si Liu, Jinhui Tang, Liang Lin, and Shuicheng Yan. Human parsing with contextualized convolutional neural network. In ICCV , 2015.
- [35] Si Liu, Jiashi Feng, Csaba Domokos, Hui Xu, Junshi Huang, Zhenzhen Hu, and Shuicheng Yan. Fashion parsing with weak color-category labels. TMM , 16(1):253-265, 2014.
- [36] Si Liu, Xiaodan Liang, Luoqi Liu, Xiaohui Shen, Jianchao Yang, Changsheng Xu, Liang Lin, Xiaochun Cao, and
38. Shuicheng Yan. Matching-cnn meets knn: Quasi-parametric human parsing. In CVPR , 2015.
- [37] Si Liu, Yao Sun, Defa Zhu, Guanghui Ren, Yu Chen, Jiashi Feng, and Jizhong Han. Cross-domain human parsing via adversarial feature and label adaptation. In AAAI , 2018.
- [38] Si Liu, Changhu Wang, Ruihe Qian, Han Yu, Renda Bao, and Yao Sun. Surveillance video parsing with single frame supervision. In CVPR , 2017.
- [39] Ting Liu, Tao Ruan, Zilong Huang, Yunchao Wei, Shikui Wei, Yao Zhao, and Thomas Huang. Devil in the details: Towards accurate single and multiple human parsing. arXiv preprint arXiv:1809.05996 , 2018.
- [40] Xinchen Liu, Meng Zhang, Wu Liu, Jingkuan Song, and Tao Mei. Braidnet: Braiding semantics and details for accurate human parsing. In ACMMM , 2019.
- [41] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR , 2015.
- [42] Long Zhu, Yuanhao Chen, Yifei Lu, Chenxi Lin, and A. Yuille. Max margin and/or graph learning for parsing the human body. In CVPR , 2008.
- [43] Pauline Luc, Camille Couprie, Soumith Chintala, and Jakob Verbeek. Semantic segmentation using adversarial networks. In NIPS-workshop , 2016.
- [44] Ping Luo, Xiaogang Wang, and Xiaoou Tang. Pedestrian parsing via deep decompositional network. In ICCV , 2013.
- [45] Xianghui Luo, Zhuo Su, Jiaming Guo, Gengwei Zhang, and Xiangjian He. Trusted guidance pyramid network for human parsing. In ACMMM , 2018.
- [46] Yawei Luo, Zhedong Zheng, Liang Zheng, Tao Guan, Junqing Yu, and Yi Yang. Macro-micro adversarial network for human parsing. In ECCV , 2018.
- [47] Xuecheng Nie, Jiashi Feng, and Shuicheng Yan. Mutual learning to adapt for joint human parsing and pose estimation. In ECCV , 2018.
- [48] Mathias Niepert, Mohamed Ahmed, and Konstantin Kutzkov. Learning convolutional neural networks for graphs. In ICML , 2016.
- [49] Seyoung Park, Bruce Xiaohan Nie, and Song-Chun Zhu. Attribute and-or grammar for joint parsing of human pose, parts and attributes. IEEE TPAMI , 40(7):1555-1569, 2018.
- [50] Siyuan Qi, Wenguan Wang, Baoxiong Jia, Jianbing Shen, and Song-Chun Zhu. Learning human-object interactions by graph parsing neural networks. In ECCV , 2018.
- [51] Ingmar Rauschert and Robert T Collins. A generative model for simultaneous estimation of human body shape and pixellevel segmentation. In ECCV , 2012.
- [52] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Fei-Fei Li. Imagenet large scale visual recognition challenge. IJCV , 115(3):211-252, 2015.
- [53] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks , 20(1):61-80, 2008.
- [54] Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In NIPS , 2015.
- [55] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS , 2017.
- [56] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. In ICLR , 2018.
- [57] Nan Wang and Haizhou Ai. Who blocks who: Simultaneous clothing segmentation for grouping images. In ICCV , 2011.
- [58] Wenguan Wang, Xiankai Lu, Jianbing Shen, David J Crandall, and Ling Shao. Zero-shot video object segmentation via attentive graph neural networks. In ICCV , 2019.
- [59] Wenguan Wang, Yuanlu Xu, Jianbing Shen, and Song-Chun Zhu. Attentive fashion grammar network for fashion landmark detection and clothing category classification. In CVPR , 2018.
- [60] Wenguan Wang, Zhijie Zhang, Siyuan Qi, Jianbing Shen, Yanwei Pang, and Ling Shao. Learning compositional neural information fusion for human parsing. In ICCV , 2019.
- [61] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR , 2018.
- [62] Fangting Xia, Peng Wang, Liang-Chieh Chen, and Alan L Yuille. Zoom better to see clearer: Human and object parsing with hierarchical auto-zoom net. In ECCV , 2016.
- [63] Fangting Xia, Peng Wang, Xianjie Chen, and Alan L Yuille. Joint multi-person pose estimation and semantic part segmentation. In CVPR , 2017.
- [64] Fangting Xia, Jun Zhu, Peng Wang, and Alan L Yuille. Poseguided human parsing by an and/or graph using pose-context features. In AAAI , 2016.
- [65] Wenqiang Xu, Yonglu Li, and Cewu Lu. Srda: Generating instance segmentation annotation via scanning, reasoning and domain adaptation. In ECCV , 2018.
- [66] Kota Yamaguchi, M Hadi Kiapour, and Tamara L Berg. Paper doll parsing: Retrieving similar styles to parse clothing items. In ICCV , 2013.
- [67] Kota Yamaguchi, M Hadi Kiapour, Luis E Ortiz, and Tamara L Berg. Parsing clothing in fashion photographs. In CVPR , 2012.
- [68] Wei Yang, Ping Luo, and Liang Lin. Clothing co-parsing by joint image segmentation and labeling. In CVPR , 2014.
- [69] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR , 2017.
- [70] Jian Zhao, Jianshu Li, Yu Cheng, Terence Sim, Shuicheng Yan, and Jiashi Feng. Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing. In ACMMM , 2018.
- [71] Jian Zhao, Jianshu Li, Xuecheng Nie, Fang Zhao, Yunpeng Chen, Zhecan Wang, Jiashi Feng, and Shuicheng Yan. Selfsupervised neural aggregation networks for human parsing. In CVPR-workshop , 2017.
- [72] Zilong Zheng, Wenguan Wang, Siyuan Qi, and Song-Chun Zhu. Reasoning visual dialogs with structural and partial observations. In CVPR , 2019.
- [73] Bingke Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. Progressive cognitive human parsing. In AAAI , 2018.