2004.03573
Model: gemini-2.0-flash
## Neural Analogical Matching
Maxwell Crouse 1 * , Constantine Nakos 1 , Ibrahim Abdelaziz 2 , Kenneth Forbus 1
1 Qualitative Reasoning Group, Northwestern University
2 IBM Research, IBM T.J. Watson Research Center
{ mvcrouse, cnakos } @u.northwestern.edu, ibrahim.abdelaziz1@ibm.com, forbus@northwestern.edu
## Abstract
Analogy is core to human cognition. It allows us to solve problems based on prior experience, it governs the way we conceptualize new information, and it even influences our visual perception. The importance of analogy to humans has made it an active area of research in the broader field of artificial intelligence, resulting in data-efficient models that learn and reason in human-like ways. While cognitive perspectives of analogy and deep learning have generally been studied independently of one another, the integration of the two lines of research is a promising step towards more robust and efficient learning techniques. As part of a growing body of research on such an integration, we introduce the Analogical Matching Network: a neural architecture that learns to produce analogies between structured, symbolic representations that are largely consistent with the principles of Structure-Mapping Theory.
## 1 Introduction
Analogical reasoning is a form of inductive reasoning that cognitive scientists consider to be one of the cornerstones of human intelligence (Gentner 2003; Hofstadter 2001, 1995). Analogy shows up at nearly every level of human cognition, from low-level visual processing (Sagi, Gentner, and Lovett 2012) to abstract conceptual change (Gentner et al. 1997). Problem solving using analogy is common, with past solutions forming the basis for dealing with new problems (Holyoak, Junn, and Billman 1984; Novick 1988). Analogy also facilitates learning and understanding by allowing people to generalize specific situations into increasingly abstract schemas (Gick and Holyoak 1983).
Many different theories have been proposed for how humans perform analogy (Mitchell 1993; Chalmers, French, and Hofstadter 1992; Gentner 1983; Holyoak, Holyoak, and Thagard 1996). One of the most influential theories is StructureMapping Theory (SMT) (Gentner 1983), which posits that analogy involves the alignment of structured representations of objects or situations subject to certain constraints. Key characteristics of SMT are its use of symbolic representations and its emphasis on relational structure, which allow the same principles to apply to a wide variety of domains.
* Correspondence to mvcrouse@u.northwestern.edu , code available at https://github.com/mvcrouse/NeuralAnalogy.
Copyright © 2021, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved.
Until now, the symbolic, structured nature of SMT has made it a poor fit for deep learning. The representations produced by deep learning techniques are incompatible with offthe-shelf SMT implementations like the Structure-Mapping Engine (SME) (Falkenhainer, Forbus, and Gentner 1989; Forbus et al. 2017), while the symbolic graphs that SMT assumes as input are challenging to encode with traditional neural methods. In this work, we describe how recent advances in graph representation learning can be leveraged to create deep learning systems that can learn to produce structural analogies consistent with SMT.
Contributions: We introduce the Analogical Matching Network (AMN), a neural architecture that learns to produce analogies between symbolic representations. AMN is trained on purely synthetic data and is demonstrated over a diverse set of analogy problems drawn from structure-mapping literature to produce outputs that are largely consistent with SMT. With AMN, we aim to push the boundaries of deep learning and extend them to an important area of human cognition; in particular, by showing how to design a deep learning system that conforms to a cognitive theory of analogical reasoning. It is our hope that future generations of neural architectures can reap the same benefits from analogy that symbolic reasoning systems and humans currently do.
## 2 Related Work
Many different computational models of analogy have been proposed (Mitchell 1993; Holyoak and Thagard 1989; O'Donoghue and Keane 1999; Forbus et al. 2017), each instantiating a different cognitive theory of analogy. The differences between them are compounded by the computational costs of analogical reasoning, a provably NP-Hard problem (Veale and Keane 1997). While these computational models are often used to test cognitive theories of human behavior, they are also useful tools for applied tasks. For instance, the Structure-Mapping Engine (SME) has been used in questionanswering (Ribeiro et al. 2019), computer vision (Chen et al. 2019), and machine reasoning (Klenk et al. 2005).
Many of the early approaches to analogy were connectionist (Gentner and Markman 1993). The STAR architecture of (Halford et al.) used tensor product representations of structured data to perform simple analogies of the form R ( x, y ) ⇒ S ( f ( x ) , f ( y )) . Drama (Eliasmith and Thagard
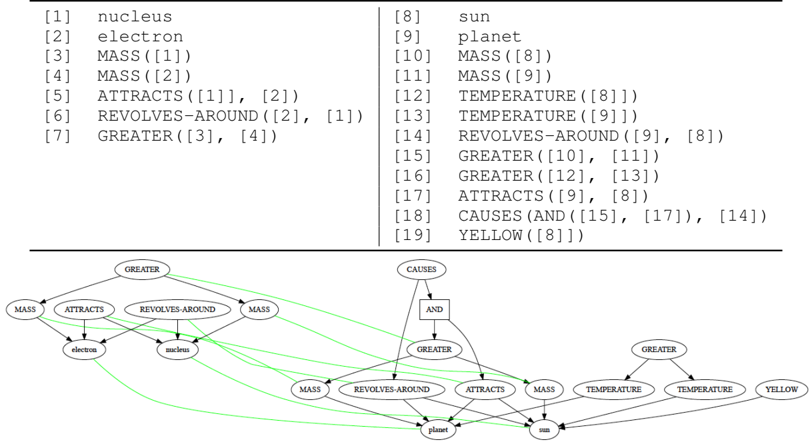
Figure 1: Relational and graph representations for models of the atom (left) and Solar System (right). Light green edges indicate the set of correspondences between the two graphs.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Knowledge Graph Diagram: Atomic and Solar System Relationships
### Overview
The image presents a knowledge graph illustrating relationships between atomic components (nucleus, electron) and solar system objects (sun, planet). The graph uses nodes to represent entities and edges to represent relationships between them. The top portion of the image is a textual representation of the relationships, while the bottom portion is a visual diagram of the same relationships.
### Components/Axes
* **Nodes:** Represent entities such as "nucleus", "electron", "sun", "planet", "MASS", "ATTRACTS", "REVOLVES-AROUND", "GREATER", "TEMPERATURE", "YELLOW", and "CAUSES". The "AND" node is represented as a square, while all other nodes are represented as ovals.
* **Edges:** Represent relationships between entities. Edges are directed, indicating the direction of the relationship. Some edges are black, while others are green.
* **Textual Representation:** A numbered list of relationships, where each number corresponds to an entity or relationship. For example, "[1] nucleus" defines node 1 as "nucleus".
* **Spatial Arrangement:** The diagram is arranged with higher-level concepts (e.g., "GREATER", "CAUSES") at the top and specific entities (e.g., "electron", "nucleus", "planet", "sun") at the bottom.
### Detailed Analysis or Content Details
**Textual Representation (Top Portion):**
* \[1] nucleus
* \[2] electron
* \[3] MASS(\[1]) - Mass of the nucleus
* \[4] MASS(\[2]) - Mass of the electron
* \[5] ATTRACTS(\[1], \[2]) - Nucleus attracts electron
* \[6] REVOLVES-AROUND(\[2], \[1]) - Electron revolves around nucleus
* \[7] GREATER(\[3], \[4]) - Mass of nucleus is greater than mass of electron
* \[8] sun
* \[9] planet
* \[10] MASS(\[8]) - Mass of the sun
* \[11] MASS(\[9]) - Mass of the planet
* \[12] TEMPERATURE(\[8]) - Temperature of the sun
* \[13] TEMPERATURE(\[9]) - Temperature of the planet
* \[14] REVOLVES-AROUND(\[9], \[8]) - Planet revolves around the sun
* \[15] GREATER(\[10], \[11]) - Mass of the sun is greater than mass of the planet
* \[16] GREATER(\[12], \[13]) - Temperature of the sun is greater than temperature of the planet
* \[17] ATTRACTS(\[9], \[8]) - Planet attracts the sun
* \[18] CAUSES(AND(\[15], \[17]), \[14]) - Mass and attraction cause revolution
* \[19] YELLOW(\[8]) - The sun is yellow
**Diagram (Bottom Portion):**
* **Atomic Level (Left Side):**
* "GREATER" node connects to "MASS" (nucleus) and "MASS" (electron).
* "MASS" (nucleus) connects to "nucleus".
* "MASS" (electron) connects to "electron".
* "ATTRACTS" connects to "nucleus" and "electron".
* "REVOLVES-AROUND" connects to "electron" and "nucleus".
* Green edges connect "MASS" (nucleus) to "planet", "ATTRACTS" to "planet", and "REVOLVES-AROUND" to "planet".
* **Solar System Level (Right Side):**
* "CAUSES" node connects to "AND" node and "REVOLVES-AROUND" (planet, sun).
* "AND" node connects to "GREATER" (mass) and "ATTRACTS" (planet, sun).
* "GREATER" (mass) connects to "MASS" (sun) and "MASS" (planet).
* "ATTRACTS" (planet, sun) connects to "planet" and "sun".
* "REVOLVES-AROUND" (planet, sun) connects to "planet" and "sun".
* "MASS" (sun) connects to "sun".
* "MASS" (planet) connects to "planet".
* "GREATER" (temperature) connects to "TEMPERATURE" (sun) and "TEMPERATURE" (planet).
* "TEMPERATURE" (sun) connects to "sun".
* "TEMPERATURE" (planet) connects to "planet".
* "YELLOW" connects to "sun".
### Key Observations
* The diagram visually represents the relationships described in the textual list.
* The green edges seem to connect concepts from the atomic level to the solar system level, suggesting an analogy or parallel between the two systems.
* The "CAUSES" node links the concepts of mass, attraction, and revolution, indicating a causal relationship.
* The "AND" node suggests that both "GREATER" (mass) and "ATTRACTS" (planet, sun) are necessary for the "CAUSES" relationship.
### Interpretation
The knowledge graph illustrates the structural similarities between an atom and a solar system. The nucleus and sun are both central bodies with significantly greater mass, around which smaller bodies (electrons and planets, respectively) revolve due to attractive forces. The green edges highlight this analogy, suggesting that the same fundamental principles govern both systems. The "CAUSES" node emphasizes that the revolution of planets around the sun is caused by a combination of the sun's greater mass and the attractive force between the sun and the planets. The diagram effectively visualizes complex relationships and highlights underlying similarities between seemingly disparate systems.
</details>
2001) was an implementation of the multi-constraint theory of analogy (Holyoak, Holyoak, and Thagard 1996) that used holographic representations similar to tensor products to embed structure. LISA (Hummel and Holyoak 1997, 2005) was a hybrid symbolic connectionist approach to analogy. It staged the mapping process temporally, generating mappings from elements that were activated at the same time.
Cognitive perspectives of analogy have gone relatively unexplored in deep learning research, with only a few recent works that address them (Hill et al. 2019; Zhang et al. 2019; Lu et al. 2019). Most prior deep learning works have considered analogies involving perceptual data (Mikolov, Yih, and Zweig 2013; Reed et al. 2015; Bojanowski et al. 2017; Zhou et al. 2019; Benaim et al. 2020). Such problems differ from those seen in the structure-mapping literature in that they typically do not require explicit graph matching and they involve only one relation which is unobserved.
Our approach is conceptually related to recent work on neural graph matching (Emami and Ranka 2018; Georgiev and Li´ o 2020; Wang, Yan, and Yang 2019). Such works generally focus on finding unconstrained maximum weight matchings and often interleave their networks with hardcoded algorithms (e.g., (Emami and Ranka 2018) applies the Hungarian algorithm to coerce its outputs into a permutation matrix). These considerations make them less applicable here, as 1) SMT is subject to unique constraints that make standard bipartite matching techniques insufficient and 2) we wish to explore the extent to which SMT is purely learnable.
## 3 Structure-Mapping Theory
In Structure-Mapping Theory (SMT) (Gentner 1983), analogy centers around the structural alignment of relational representations (see Figure 1). A relational representation is a set of logical expressions constructed from entities (e.g., sun ), attributes (e.g., YELLOW ), functions (e.g., TEMPERATURE ), and relations (e.g., GREATER ). Structural alignment is the process of producing a mapping between two relational representations (referred to as the base and target ). A mapping is a triple 〈 M,C,S 〉 , where M is a set of correspondences between the base and target, C is a set of candidate inferences (i.e., inferences about the target that can be made from the structure of the base), and S is a structural evaluation score that measures the quality of M . Correspondences are pairs of elements between the base and target (i.e., expressions or entities) that are identified as matching with one another. While entities can be matched together irrespective of their labels, there are more rigorous criteria for matching expressions. SMT asserts that matches should satisfy the following:
1. One-to-One : Each element of the base and target can be a part of at most one correspondence.
2. Parallel Connectivity : Two expressions can be in a correspondence with each other only if their arguments are also in correspondences with each other.
3. Tiered Identicality : Relations of expressions in a correspondence must match identically, but functions need not if their correspondence supports parallel connectivity.
4. Systematicity : Preference should be given to mappings with more deeply nested expressions.
To understand these properties, we use a classic analogy (see Figure 1) from (Gentner 1983; Falkenhainer, Forbus, and Gentner 1989), which draws an analogy between the Solar System and the Rutherford model of the atom. A set of correspondences M between the base (Solar System) and target (Rutherford atom) is a set of pairs of elements from both sets, e.g., { 〈 [1] , [8] 〉 , 〈 [2] , [9] 〉 } . The one-to-one constraint
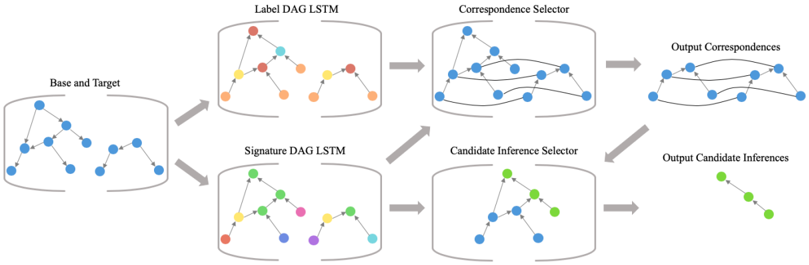
Figure 2: An overview of the model pipeline
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: DAG LSTM Workflow
### Overview
The image illustrates a workflow using Directed Acyclic Graph (DAG) Long Short-Term Memory (LSTM) networks for correspondence and inference selection. It shows the progression from base and target graphs through label and signature DAG LSTMs, followed by correspondence and candidate inference selectors, and finally, the output correspondences and candidate inferences.
### Components/Axes
* **Base and Target:** Initial input graphs, consisting of blue nodes connected by lines.
* **Label DAG LSTM:** Processes the base and target graphs, assigning different colors to the nodes (red, cyan, orange, yellow).
* **Signature DAG LSTM:** Processes the base and target graphs, assigning different colors to the nodes (green, yellow, red, pink, purple).
* **Correspondence Selector:** Selects correspondences between nodes in the graphs, represented by blue nodes and connecting lines.
* **Candidate Inference Selector:** Selects candidate inferences from the graphs, represented by blue and green nodes connected by lines.
* **Output Correspondences:** The final output of the correspondence selection process, consisting of blue nodes and connecting lines.
* **Output Candidate Inferences:** The final output of the candidate inference selection process, consisting of green nodes and connecting lines.
* **Arrows:** Gray arrows indicate the flow of data between the different stages of the workflow.
### Detailed Analysis or ### Content Details
1. **Base and Target:**
* Two separate graphs are shown, both consisting of blue nodes connected by lines.
* The graph on the left has more nodes and a more complex structure than the graph on the right.
2. **Label DAG LSTM:**
* The input graphs are processed, and the nodes are assigned different colors.
* The colors used are red, cyan, orange, and yellow.
* The structure of the graphs remains similar to the base and target graphs.
3. **Signature DAG LSTM:**
* The input graphs are processed, and the nodes are assigned different colors.
* The colors used are green, yellow, red, pink, and purple.
* The structure of the graphs remains similar to the base and target graphs.
4. **Correspondence Selector:**
* The graphs are transformed into a new representation with blue nodes and connecting lines.
* The lines connecting the nodes appear to represent correspondences between nodes in the original graphs.
5. **Candidate Inference Selector:**
* The graphs are transformed into a new representation with blue and green nodes connected by lines.
* The green nodes appear to represent candidate inferences.
6. **Output Correspondences:**
* The final output is a graph of blue nodes connected by lines, representing the selected correspondences.
7. **Output Candidate Inferences:**
* The final output is a graph of green nodes connected by lines, representing the selected candidate inferences.
### Key Observations
* The workflow involves processing base and target graphs using DAG LSTM networks.
* The label and signature DAG LSTMs assign different colors to the nodes, possibly representing different features or attributes.
* The correspondence and candidate inference selectors extract relevant information from the processed graphs.
* The final outputs are graphs representing the selected correspondences and candidate inferences.
### Interpretation
The diagram illustrates a method for identifying correspondences and inferences between two graphs using DAG LSTM networks. The label and signature DAG LSTMs likely encode information about the structure and features of the graphs, which are then used by the selectors to extract relevant information. The use of different colors in the intermediate stages suggests that the LSTMs are learning to represent different aspects of the graphs. The final outputs represent the results of the correspondence and inference selection processes, which could be used for various downstream tasks such as graph matching or knowledge graph completion.
</details>
restricts each element to be a member of at most one correspondence. Thus, if 〈 [7] , [15] 〉 was a member of M , then 〈 [7] , [16] 〉 could not be added to M . Parallel connectivity enforces correspondence between arguments if the parents are in correspondence. In this example, if 〈 [7] , [15] 〉 was a member of M , then both 〈 [3] , [10] 〉 and 〈 [4] , [11] 〉 would need to be members of M . Parallel connectivity also respects argument order when dealing with ordered relations. Tiered identicality is not relevant in this example; however, if [10] used the label WEIGHT instead of MASS , tiered identicality could be used to match [3] and [10] , since such a correspondence would allow for a match between their parents. The last property, systematicity, results in larger correspondence sets being preferred over smaller ones. Note that the singleton set { 〈 [1] , [8] 〉 } satisfies SMT's constraints, but it is clearly not useful by itself. Systematicity captures the natural preference for larger, more interesting matches.
Candidate inferences are statements from the base that are projected into the target to fill in missing structure (Bowdle and Gentner 1997; Gentner and Markman 1998). Given a set of correspondences M , candidate inferences are created from statements in the base that are supported by expressions in M but are not part of M themselves. In Figure 1, one candidate inference would be CAUSES(AND([7],[5]),[6]) , derived from [18] by substituting its arguments with the expressions they correspond to in the target. In this work, we adopt SME's default criteria for computing candidate inferences. Valid candidate inferences are all statements that have some dependency that is included in the correspondences or an ancestor that is a candidate inference (e.g., an expression whose parent has arguments in the correspondences).
The concepts above carry over naturally into graphtheoretic notions. The base and target are considered semiordered directed-acyclic graphs (DAGs) G B = 〈 V B , E B 〉 and G T = 〈 V T , E T 〉 , where V B and V T are sets of nodes and E B and E T are sets of edges. Each node corresponds to some expression and has a label given by its relation, function, attribute, or entity name. Structural alignment is the process of finding a maximum weight bipartite matching M ⊆ V B × V T , where M satisfies the pairwise-disjunctive constraints imposed by parallel connectivity. Finding candidate inferences is then determining the subset of nodes from
V B \ { b i : 〈 b i , t j 〉 ∈ M } with support in M .
## 4 Model
## 4.1 Model Components
Given a base G B = 〈 V B , E B 〉 and target G T = 〈 V T , E T 〉 , AMN produces a set of correspondences M ⊆ V B × V T and a set of candidate inferences I ∈ V B \ { b i : 〈 b i , t j 〉 ∈ M } . A key design choice of this work was to avoid using rules or architectures that force particular outputs whenever possible. AMN is not forced to output correspondences that satisfy the constraints of SMT; instead, conformance with SMT is reinforced through performance on training data. Our architecture uses Transformers (Vaswani et al. 2017) and pointer networks (Vinyals, Fortunato, and Jaitly 2015) and takes inspiration from the work of (Kool, Van Hoof, and Welling 2018). A high-level overview is given in Figure 2, which shows how each of the three main components (graph embedding, correspondence selection, and candidate inference selection) interact with one another.
Representing Structure: When embedding the nodes of G B and G T , there are representational concerns to keep in mind. First, as matching should be done on the basis of structure, the labels of entities should not be taken into account during the alignment process. Second, because SMT's constraints require AMN to be able to recognize when a node is part of multiple correspondences, AMN should maintain distinguishable representations for distinct nodes, even if those nodes have the same labels. Last, the architecture should not be vocabulary dependent, i.e., AMN should generalize to symbols it has never seen before. To achieve each of these, AMNfirst parses the original input into two separate graphs, a label graph and a signature graph (see Figure 3).
The label graph will be used to get an estimate of structural similarities. To generate the label graph, AMN substitutes each entity node's label with a generic entity token. This is intentional, as it reflects that entity labels have no inherent utility for producing matchings according to SMT. Then, each function and predicate node is assigned a randomly chosen generic label (from a fixed set of such labels) based off its arity and orderedness. Assignments are made consistently across the entire graph, e.g., every instance of MASS in both
Figure 3: Original graph (left), its label graph (middle), and its signature graph (right)
<details>
<summary>Image 3 Details</summary>

### Visual Description
## Diagram: Semantic Network
### Overview
The image presents a semantic network diagram composed of three distinct sub-graphs. Each sub-graph illustrates relationships between concepts using nodes (ovals) and directed edges (arrows). The nodes represent entities, attributes, or relationships, while the arrows indicate the direction of the relationship.
### Components/Axes
* **Nodes:** Represented as ovals containing text labels.
* **Edges:** Represented as arrows indicating the direction of the relationship between nodes.
* **Sub-graphs:** Three distinct sub-graphs, each representing a different set of relationships.
### Detailed Analysis
**Sub-graph 1 (Left):**
* Nodes: "GREATER", "MASS", "ATTRACTS", "REVOLVES-AROUND", "MASS", "electron", "nucleus"
* Relationships:
* "GREATER" points to "MASS"
* "MASS" points to "electron"
* "ATTRACTS" points to "electron" and "nucleus"
* "REVOLVES-AROUND" points to "nucleus"
* "MASS" points to "nucleus"
**Sub-graph 2 (Middle):**
* Nodes: "rp_7", "rp_9", "rp_12", "rf_7", "entity", "entity"
* Relationships:
* "rp_7" points to "rp_9" and "rp_12"
* "rp_9" points to "entity"
* "rp_12" points to "entity"
* "rf_7" points to "entity"
**Sub-graph 3 (Right):**
* Nodes: "p_2", "f_1", "p_2", "p_2", "f_1", "id_87", "id_13"
* Relationships:
* "p_2" points to "f_1"
* "p_2" points to "p_2" and "f_1"
* "p_2" points to "id_87" and "id_13"
### Key Observations
* The diagram uses a consistent visual style for nodes and edges.
* The sub-graphs are disconnected, indicating separate sets of relationships.
* Some nodes have generic labels like "entity," while others have more specific labels like "electron" or "nucleus."
* The naming convention for some nodes includes prefixes like "rp_", "rf_", "p_", "f_", and "id_", suggesting different categories or types of entities.
### Interpretation
The diagram represents a semantic network, visually illustrating relationships between concepts. The first sub-graph appears to describe basic physics concepts related to atomic structure, with "electron" and "nucleus" being central entities. The other two sub-graphs are more abstract, possibly representing relationships within a knowledge base or a system of logical rules. The prefixes in the node labels suggest a structured organization of the concepts within the network. The diagram could be used to visualize knowledge representation, inference rules, or semantic relationships in a specific domain.
</details>
the base and target would be assigned the same generic replacement label. This substitution means the original label is not used in the matching process, which allows AMN to generalize to new symbols.
The label graph is not sufficient to produce representations that can be used for matching, as it represents a node by only label-based features which are shared amongst different nodes, an issue known as the type-token distinction (Kahneman, Treisman, and Gibbs 1992; Wetzel 2006). To contend with this, a signature graph is constructed that represents nodes in a way that respects object identity. To construct the signature graph, AMN replaces each distinct entity with a unique identifier (drawn from a fixed set of possible identifiers). It then assigns each function and predicate a new label based solely on its arity and orderedness, ignoring the original symbol. For instance, ATTRACTS and REVOLVES-AROUND would be assigned the same label as they are both ordered binary predicates.
As all input graphs will be DAGs, AMN uses two separate DAG LSTMs (Crouse et al. 2019) to embed the nodes of the label and signature graphs (equations detailed in Appendix 7.4). Each node embedding is computed as a function of its complete set of dependencies in the original graph. The set of label structure embeddings is written as L V = { l v : v ∈ V } and the set of signature embeddings is written as S V = { s v : v ∈ V } . Before passing these embeddings to the next step, each element of S V is scaled to unit length, i.e. each s v becomes s v / ‖ s v ‖ , which gives our network an efficiently checkable criterion for whether or not two nodes are likely to be equal, i.e., when the dot product of two signature embeddings is 1.
Correspondence Selector: The graph embedding procedure yields two sets of node embeddings (label structure and signature embeddings) for the base and target. We utilize the set of embedding pairs for each node of V B and V T , writing l v to denote the label structure embedding of node v from L V and s v the signature embedding of node v from S V . We first define the set of unprocessed correspondences C (0)
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
where [ · ; · ] denotes vector concatenation, is the tiered identicality threshold that governs how much the subgraphs rooted at two nodes may differ and still be considered for correspondence (in this work, we set = 1e -5 ). The first element of each correspondence in C (0) , i.e., h c = [ l b ; l t ; s b ; s t ] , is then passed through an N -layered Transformer encoder (equations detailed in Appendix 7.4) to produce a set of encoded
<!-- formula-not-decoded -->
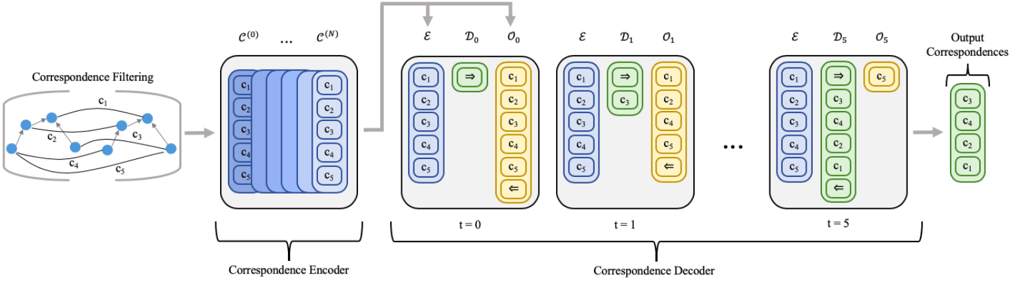
The Transformer decoder selects a subset of correspondences that constitutes the best analogical match (see Figure 4). The attention-based transformations are only performed on the initial element of each tuple, i.e., h d in 〈 h d , s b , s t 〉 . We let D t be the processed set of all selected correspondences at timestep t (after the N attention layers) and O t be the set of all remaining correspondences (with D 0 = { START-TOK } and O 0 = E ∪ { END-TOK } ). The decoder generates compatibility scores α od between each pair of elements, i.e., 〈 o, d 〉 ∈ O t ×D t . These are combined with the signature embedding similarities to produce a final compatibility π od
<!-- formula-not-decoded -->
where FFN is a two layer feed-forward network with ELU activations (Clevert, Unterthiner, and Hochreiter 2015). Recall that the signature components, i.e. s b and s t , were scaled to unit length. Thus, we would expect closeness in the original graph to be reflected by dot-product similarity and identicality to be indicated by a maximum value dot-product, i.e. s b o s b d = 1 or s t o s t d = 1 . Once each pair has been scored, AMNselects an element of O t to be added to D t +1 . For each o ∈ O t , we compute its value to be
<!-- formula-not-decoded -->
where FFN is a two layer feed-forward network with ELU activations. A softmax is applied to these scores and the highest valued element is added to D t +1 . The use of maximum, minimum, and average is intended to let the network capture both individual and aggregate evidence. Individual evidence is given by a pairwise interaction between two correspondences (e.g., two correspondences that together violate the one-toone constraint). Conversely, aggregate evidence is given by the interaction of a correspondence with everything selected thus far (e.g., a correspondence needed for several parallel connectivity constraints). When END-TOK is selected, the set of correspondences M returned is the set of node pairs from V B and V T associated with elements in D .
Candidate Inference Selector: The output of the correspondence selector is a set of correspondences M . The candidate inferences associated with M are drawn from the nodes of the base graph V B that were not used in M . Let V in and V out be the subsets of V B that were / were not used in M , respectively. We first extract all signature embeddings for both sets, i.e., S in = { s b : b ∈ V in } and S out = { s b : b ∈ V out } . In this module there are no Transformer components, with AMNoperating directly on S in and S out .
Figure 4: The correspondence selection process, where ⇒ and ⇐ are the start and stop tokens and E , D t , and O t are the sets of encoded, selected, and remaining correspondences
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: Correspondence Filtering and Encoding/Decoding
### Overview
The image is a diagram illustrating a process of correspondence filtering, encoding, and decoding. It shows how initial correspondences are filtered, encoded into a latent representation, and then decoded over several time steps to produce output correspondences.
### Components/Axes
* **Correspondence Filtering:** A network of nodes labeled c1, c2, c3, c4, and c5, connected by lines with arrows indicating direction.
* **Correspondence Encoder:** Takes the filtered correspondences and encodes them into a series of representations, denoted as C^(0) to C^(N). Each representation contains c1, c2, c3, c4, and c5.
* **Correspondence Decoder:** Decodes the encoded representation over time (t=0, t=1, ..., t=5) to produce output correspondences.
* **Epsilon (E):** Represents the encoded state at each time step. Contains c1, c2, c3, c4, and c5.
* **D_t:** Represents the decoder's state at time t. Contains c1, c2, c3, c4, and c5.
* **O_t:** Represents the output at time t. Contains c1, c2, c3, c4, and c5.
* **Output Correspondences:** The final output of the decoder, containing c1, c2, c3, c4, and c5.
### Detailed Analysis
The diagram can be broken down into three main stages:
1. **Correspondence Filtering:**
* The initial stage involves filtering correspondences. A network of nodes (c1 to c5) is shown, with connections between them.
2. **Correspondence Encoder:**
* The filtered correspondences are then encoded. The encoder takes the initial filtered correspondences and transforms them into a series of encoded representations, denoted as C^(0) to C^(N). Each representation contains the elements c1, c2, c3, c4, and c5.
3. **Correspondence Decoder:**
* The encoded representation is then decoded over several time steps (t=0, t=1, ..., t=5).
* At each time step, the decoder takes the encoded state (Epsilon), the decoder's state (D\_t), and produces an output (O\_t).
* The decoder's state (D\_t) contains elements c1, c2, c3, c4, and c5, which are represented by green rounded rectangles.
* The output (O\_t) contains elements c1, c2, c3, c4, and c5, which are represented by yellow rounded rectangles.
* Arrows between the decoder's state and the output indicate the transformation or mapping of correspondences.
* At t=0, the arrow points from D0 to c1 in O0.
* At t=1, the arrow points from D1 to c3 in O1, and an arrow points from c5 in D1 to D1.
* At t=5, the arrow points from D5 to c5 in O5, and an arrow points from c1 in D5 to D5.
* The final output of the decoder is the "Output Correspondences," which contains the elements c1, c2, c3, c4, and c5, represented by green rounded rectangles.
### Key Observations
* The diagram illustrates a sequential process of filtering, encoding, and decoding correspondences.
* The decoder operates over multiple time steps, refining the output at each step.
* The arrows between the decoder's state and the output indicate the transformation or mapping of correspondences.
### Interpretation
The diagram represents a system for processing correspondences, likely in a machine learning context. The correspondence filtering stage could represent an initial selection or weighting of potential matches. The encoder compresses this information into a latent representation, and the decoder then reconstructs the correspondences over time, potentially refining them or resolving ambiguities. The arrows within the decoder suggest a dynamic process where the decoder's state influences the output at each time step. The final "Output Correspondences" represent the system's best estimate of the true correspondences.
</details>
AMNwill select elements from S out to return. Like before, we let D t be the set of all selected elements from S out and O t be the set of all remaining elements from S out at timestep t . AMNcomputes compatibility scores between pairs of output options with candidate inference and previously selected nodes, i.e. α od for each 〈 o, d 〉 ∈ O t × ( D t ∪S in ) . The compatibility scores are given by a simple single-headed attention computation (see Appendix 7.4). Unlike the correspondence encoder-decoder, there are no other values to combine these scores with, so they are used directly to compute a value v o for each element of O t . AMNcomputes this value as
<!-- formula-not-decoded -->
A softmax is used and the highest valued element is added to D t +1 . Once the end token is selected, decoding stops and the set of nodes associated with elements in D is returned.
Loss Function: As both the correspondence and candidate inference components use a softmax, the loss function is categorical cross entropy. Teacher forcing is used to guide the decoder to select the correct choices during training. With L corr the loss for correspondence selection and L ci the loss for candidate inference selection, the final loss is given as L = L corr + λ L ci (with λ a hyperparameter), which is minimized with Adam (Kingma and Ba 2014).
## 4.2 Model Scoring
Structural Match Scoring: In order to avoid counting erroneous correspondence predictions towards the score of the output correspondences M , we first identify all correspondences that are either degenerate or violate the constraints of SMT. Degenerate correspondences are correspondences between constants that have no higher-order structural support in M (i.e., if either has no parent that participates in a correspondence in M ). To determine if a correspondence 〈 b, t 〉 violates SMT, we check whether the subgraphs of the base and target rooted at b and t satisfy the one-to-one matching, parallel connectivity, and tiered identicality constraints (see Section 3). The check can be computed in time linear with the size of the corresponding subgraphs. Let the valid subset of M be M val . A correspondence m is considered a root correspondence if there does not exist another correspondence m ′ such that m ′ ∈ M val and a node in m ′ is an ancestor of a node in m . We define M root ⊆ M val to be the set of all such root correspondences. For a correspondence m = 〈 b, t 〉 in M val , its score s ( m ) is given as the size of the subgraph rooted at b in the base. The structural match score for M is then sum of scores for all correspondences in M root , i.e., s ( M ) = ∑ m ∈ M root s ( m ) . This repeatedly counts nodes that appear in the dependencies of multiple correspondences, which leads to higher scores for more interconnected matchings (in keeping with the systematicity preference of SMT).
Structural Evaluation Maximization: Dynamically assigning labels to each example allows AMN to handle neverbefore-seen symbols, but its inherent randomness can lead to significant variability in terms of outputs. AMN combats this by running each test problem r times and returning the mapping M = arg max M i ∑ j J ( M i , M j ) , where J ( M i , M j ) is the Jaccard index (intersection over union) between the correspondence sets produced by the i -th and j -th runs. Intuitively, this is the run that shared the most correspondences with other runs and had the fewest unshared extra correspondences.
## 5 Experiments
## 5.1 Data Generation and Training
AMN was trained on 100,000 synthetic analogy examples, with the hyperparameters used for AMN provided in Appendix 7.1 (in the supplementary material). A single example consisted of base and target graphs, a set of correspondences, and a set of nodes from the base to be candidate inferences. Construction of synthetic examples begins with generating DAGs. Each DAG consists of a set of k ∈ [2 , 7] layers (with the particular k for a graph chosen at random). Each node is assigned an arity a , with the maximum arity being a = 3 . Nodes at layer i can be connected to a nodes from lower layers (i.e., layer j with j < i ) selected at random. Nodes with arity a = 0 are considered entities and nodes with non-zero
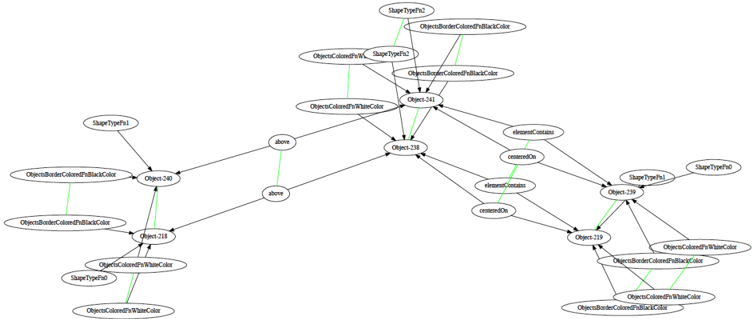
Figure 5: AMN output correspondences for an example from the Geometric Analogies domain
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Diagram: Object Relationship Diagram
### Overview
The image is a directed graph diagram illustrating relationships between different objects and their properties. The nodes represent objects or properties, and the edges represent relationships between them. Black arrows indicate a general relationship, while green lines indicate a more specific or defined relationship.
### Components/Axes
* **Nodes:** Represented as rounded rectangles or ovals containing text labels.
* **Edges:** Represented as black arrows indicating the direction of the relationship. Green lines indicate a more specific relationship.
* **Labels:** Text within the nodes describes the object or property. Examples include "ShapeTypePn1", "Object-240", "above", "elementContains", etc.
### Detailed Analysis
The diagram can be broken down into three main clusters: left, center, and right.
**Left Cluster:**
* "ShapeTypePn1" at the top-left connects to "Object-240" with a black arrow.
* "ObjectBorderColoredPnBlackColor" is below "ShapeTypePn1" and connects to "Object-240" with a black arrow.
* "Object-240" connects to "Object-238" with a black arrow.
* "Object-240" connects to "Object-218" with a black arrow.
* "ObjectsBorderColoredPnBlackColor" is below "ObjectBorderColoredPnBlackColor" and connects to "Object-218" with a green line.
* "Object-218" connects to "ObjectColoredPnWhiteColor" and "ShapeTypePn0" with black arrows.
* "ObjectColoredPnWhiteColor" connects to "ObjectColoredPnWhiteColor" with a green line.
**Center Cluster:**
* "ShapeTypePn2" at the top connects to "Object-241" with a black arrow.
* "ObjectsBorderColoredPnBlackColor" is below "ShapeTypePn2" and connects to "Object-241" with a green line.
* "ObjectsColoredPnWhiteColor" is to the left of "ShapeTypePn2" and connects to "Object-241" with a black arrow.
* "ShapeTypeP2" is to the right of "ObjectsColoredPnWhiteColor" and connects to "Object-241" with a green line.
* "ObjectsBorderColoredPnBlackColor" is to the right of "ShapeTypeP2" and connects to "Object-241" with a black arrow.
* "Object-241" connects to "Object-238" with a black arrow.
* "ObjectColoredPnWhiteColor" is below "Object-241" and connects to "Object-238" with a black arrow.
* "Object-238" connects to "Object-219" with a black arrow.
* "above" is to the left of "Object-238" and connects to "Object-238" with a green line.
* "above" is below "above" and connects to "Object-238" with a green line.
* "elementContains" is to the right of "Object-238" and connects to "Object-238" with a black arrow.
* "centeredOn" is below "elementContains" and connects to "Object-238" with a black arrow.
* "elementContains" is below "centeredOn" and connects to "Object-239" with a green line.
* "centeredOn" is below "elementContains" and connects to "Object-239" with a green line.
**Right Cluster:**
* "ShapeTypePn1" at the top-right connects to "Object-239" with a black arrow.
* "ShapeTypePn0" is to the right of "ShapeTypePn1" and connects to "Object-239" with a black arrow.
* "Object-239" connects to "Object-219" with a black arrow.
* "ObjectColoredPnWhiteColor" is below "ShapeTypePn1" and connects to "Object-239" with a black arrow.
* "ObjectsBorderColoredPnBlackColor" is below "ObjectColoredPnWhiteColor" and connects to "Object-219" with a green line.
* "ObjectsColoredPnWhiteColor" is below "ObjectsBorderColoredPnBlackColor" and connects to "Object-219" with a black arrow.
* "ObjectsBorderColoredPnBlackColor" is below "ObjectsColoredPnWhiteColor" and connects to "Object-219" with a green line.
### Key Observations
* "Object-238" appears to be a central node, receiving connections from multiple other nodes.
* The green lines seem to indicate a more direct or specific relationship than the black arrows.
* The diagram shows relationships between object types, properties, and specific object instances (e.g., "Object-240").
### Interpretation
The diagram likely represents a system or model where objects have properties and relationships with each other. The "Object-XXX" nodes could represent specific instances of objects, while the other nodes represent properties or types. The diagram could be used to visualize dependencies or relationships within a software system, knowledge graph, or other complex system. The "above", "elementContains", and "centeredOn" labels suggest spatial or containment relationships between objects. The diagram is a visual representation of a complex network of relationships between different entities.
</details>
arities (i.e., a > 0 ) are randomly assigned as predicates or functions and randomly designated as ordered or unordered.
To generate a training example, we first generate a set of random DAGs C , which will later become the correspondences. Next, we construct the base B by generating graphs above C . As each DAG is constructed in layers, this simply means that C is considered the lowest layers of B . Likewise, for the target T we build another set of graphs above C . The nodes of C are thus shared with both B and T . Each node of C is duplicated, producing one node for B and one node for T , and the resulting pair of nodes becomes a correspondence. Any element in B that was an ancestor of a node from C or a descendent of such an ancestor was considered a candidate inference. In Appendix 7.2 we provide a figure showing each component of a training example. During training, each generated example was turned into a batch of 8 inputs by repeatedly running the encoding procedure (which dynamically assigns node labels) over the original base and target.
## 5.2 Experimental Domains
Though training was done with synthetic data, we evaluated the effectiveness of AMN on both synthetic data and data used in previous analogy experiments. The corpus of previous analogy examples was taken from the public release of SME 1 . Importantly, AMN was not trained on the corpus of existing analogy examples (AMN never learned from a real-world analogy example). In fact, there was no overlap between the symbols (i.e., entities, functions, and predicates) used in that corpus and the symbols used for the synthetic data. We briefly describe each of the domains AMN was evaluated on below (detailed descriptions can be found in (Forbus et al. 2017)).
1. Synthetic : this domain consisted of 1000 examples generated with the same parameters as the training data (useful as a sanity check for AMN's performance).
2. Visual Oddity : this problem setting was initially proposed to explore cultural differences to geometric reasoning in (Dehaene et al. 2006). The work of (Lovett and Forbus 2011) modeled the findings of the original experiment
1 http://www.qrg.northwestern.edu/software/sme4/index.html
- computationally with qualitative visual representations and analogy. We extracted 3405 analogical comparisons from the computational experiment.
3. Moral Decision Making : this domain was taken from (Dehghani et al. 2008a), which introduced a computational model of moral decision making that used SME to reason through moral dilemmas. From the works of (Dehghani et al. 2008a,b), we extracted 420 analogical comparisons.
4. Geometric Analogies : this domain is from one of the first computational analogy experiments (Evans 1964). Each problem was an incomplete analogy of the form A : B :: C : ? , where each of A , B , and C were manually encoded geometric figures and the goal was to select the figure that best completed the analogy from an encoded set of possible answers. While in the original work all figures had to be manually encoded, in (Lovett et al. 2009; Lovett and Forbus 2012) it was shown that the analogy problems could be solved with structure-mapping over automatic encodings (produced by the CogSketch system (Forbus et al. 2011)). From that work we extracted 866 analogies.
## 5.3 Results and Discussion
Table 1a shows the results for AMN across different values of r , where r denotes the re-run hyperparameter detailed in Section 4.2. When evaluating on the synthetic data, the comparison set of correspondences was given by the data generator; whereas when evaluating on the three other analogy domains, the comparison set of correspondences was given by the output of SME. It is important to note that we are using SME as our stand-in for SMT (as it is the most widely accepted computational model of SMT). Thus, we do not want significantly different results from SME in the correspondence selection experiments (e.g., substantially higher or lower structural evaluation scores). Matching SME's performance (i.e., not producing higher or lower values) gives evidence that we are modeling SMT.
In the Struct. Perf. column, the numbers reflect the average across examples of the structural evaluation score of AMN divided by that of the comparison correspondence sets. For the other columns of Table 1a, the numbers represent average
(a) AMN correspondence prediction results for performance ratio (left), solution type rate (middle, ↑ better), and error rate (right, ↓ better)
| Domain | r | Struct. Perf. | Larger | Equiv. | Err. Free | 1-to-1 Err. | PC Err. | Degen. Err. |
|-----------|-----|-----------------|----------|----------|-------------|---------------|-----------|---------------|
| Synthetic | 1 | 0.713 | 0 | 0.313 | 0.346 | 0.007 | 0.102 | 0.02 |
| Synthetic | 16 | 0.952 | 0.001 | 0.683 | 0.695 | 0.005 | 0.02 | 0.011 |
| Oddity | 1 | 0.774 | 0.061 | 0.404 | 0.484 | 0.153 | 0.225 | 0 |
| Oddity | 16 | 0.955 | 0.074 | 0.485 | 0.564 | 0.131 | 0.139 | 0 |
| MoralDM | 1 | 0.61 | 0.014 | 0.021 | 0.093 | 0.002 | 0.17 | 0.03 |
| MoralDM | 16 | 0.958 | 0.081 | 0.164 | 0.329 | 0 | 0.041 | 0.016 |
| Geometric | 1 | 0.871 | 0.064 | 0.533 | 0.649 | 0.039 | 0.116 | 0 |
| Geometric | 16 | 1.04 | 0.069 | 0.714 | 0.788 | 0.029 | 0.043 | 0 |
(b) AMN candidate inference prediction results
| Domain | r | Avg. CI F1 | Avg. CI Prec. | Avg. CI Rec. | Avg. CI Acc. | Avg. CI Spec. |
|-----------|-----|--------------|-----------------|----------------|----------------|-----------------|
| Synthetic | 16 | 0.9 | 0.867 | 0.967 | 0.861 | 0.735 |
| Oddity | 16 | 0.992 | 0.995 | 0.994 | 0.991 | 0.911 |
| MoralDM | 16 | 0.899 | 0.834 | 0.985 | 0.832 | 0.439 |
| Geometric | 16 | 0.958 | 0.955 | 0.99 | 0.951 | 0.917 |
Table 1: AMN experimental results
fractions of examples or correspondences (e.g., 0.684 should be interpreted as 68.4%). Candidate inference prediction performance was measured relative to the set of correspondences AMNgenerated, i.e., all candidate inferences were computed from the predicted correspondences, and treated as the true positives. In many problems from the non-synthetic domains, every non-correspondence node was a candidate inference (which can lead to inflated precision and recall values). Thus, we also report the specificity (i.e., true negative rate) of AMN for only problems with non-candidate inference nodes.
the same / larger structural evaluation score as compared to gold set of correspondences. The Equiv. column provides the best indication that AMN could model SMT. It shows that 50% of AMN's outputs were SMT-satisfying, error-free analogical matches with the exact same structural score as SME (the lead computational model of SMT) in two of the non-synthetic analogy domains.
In addition to our main results, we also provide qualitative examples of AMN's outputs on real analogy problems and ablation studies for various aspects of AMN's design. Both the matching shown in Figure 5 as well as the solar system analogy shown in Figure 1 were produced by AMN. Further examples of AMN's outputs can be found in Appendix 7.5. Ablation experiments regarding the impact of both the signature graph and unit normalization of signature embeddings (each detailed in Section 4.1) are given in Appendix 7.3.
Analysis: The left side of Table 1a shows the average ratio of AMN's performance (labeled Struct. Perf.), as measured by structural evaluation score, against the comparison method's performance (i.e., data generator correspondences or SME). As can be seen, AMN produced matches with structural evaluation scores at 95-104% the level of SME on the non-synthetic domains, which indicates that it was finding similar structural matches. This is ideal as it shows that AMN matches SME's systematicity preference, and thus likely conforms fairly well to SMT in terms of systematicity.
The middle of Table 1a gives us the best sense of how well AMN modeled SMT. We observe AMN's performance in terms of the proportion of larger , equivalent , and error-free matches it produces (labeled Larger, Equiv., and Err. Free, respectively). Error-free matches do not contain degenerate correspondences or SMT constraint violations, whereas equivalent and larger matches are both error-free and have
The right side of Table 1a shows the frequency of the different types of errors, including violations of the one-to-one / parallel connectivity constraints, and degenerate correspondences (labeled 1-to-1 Err., PC Err., and Degen. Err.). It shows that AMN had fairly low error rates across domains (except for Visual Oddity). Importantly, degenerate correspondences were very infrequent, which is significant because it verifies that AMN leveraged higher-order relational structure.
Table 1b shows that AMN was fairly effective in predicting candidate inferences. The high accuracy (labeled Avg. CI Acc.) scores for both the Visual Oddity and Geometric Analogies domains indicate that AMN was able to capture the notion of structural support when determining candidate inferences. The non-zero specificity (labeled Avg. CI Spec.) results show that, while it more often classified nodes as candidate inferences, it was capable of distinguishing noncandidate inference nodes as well.
## 6 Conclusions
In this paper, we introduced the Analogical Matching Network, a neural approach that learned to produce analogies consistent with Structure-Mapping Theory. AMN was trained on completely synthetic data and was capable of performing well on a varied set of analogies drawn from previous work involving analogical reasoning. AMN demonstrated renaming invariance, structural sensitivity, and the ability to find solutions in a combinatorial search space, all of which are key properties of symbolic reasoners and are known to be important to human reasoning.
Ba, J. L.; Kiros, J. R.; and Hinton, G. E. 2016. Layer normalization. arXiv preprint arXiv:1607.06450 .
Benaim, S.; Mokady, R.; Bermano, A.; Cohen-Or, D.; and Wolf, L. 2020. Structural-analogy from a Single Image Pair. arXiv preprint arXiv:2004.02222 .
Bojanowski, P.; Grave, E.; Joulin, A.; and Mikolov, T. 2017. Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics 5: 135-146.
Bowdle, B. F.; and Gentner, D. 1997. Informativity and asymmetry in comparisons. Cognitive Psychology 34(3): 244-286.
Chalmers, D. J.; French, R. M.; and Hofstadter, D. R. 1992. High-level perception, representation, and analogy: A critique of artificial intelligence methodology. Journal of Experimental & Theoretical Artificial Intelligence 4(3): 185-211.
Chen, K.; Rabkina, I.; McLure, M. D.; and Forbus, K. D. 2019. Human-Like Sketch Object Recognition via Analogical Learning. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, 1336-1343.
Clevert, D.-A.; Unterthiner, T.; and Hochreiter, S. 2015. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289 .
Crouse, M.; Abdelaziz, I.; Cornelio, C.; Thost, V.; Wu, L.; Forbus, K.; and Fokoue, A. 2019. Improving Graph Neural Network Representations of Logical Formulae with Subgraph Pooling. arXiv preprint arXiv:1911.06904 .
Dehaene, S.; Izard, V.; Pica, P.; and Spelke, E. 2006. Core knowledge of geometry in an Amazonian indigene group. Science 311(5759): 381-384.
Dehghani, M.; Tomai, E.; Forbus, K.; Iliev, R.; and Klenk, M. 2008a. MoralDM: A Computational Modal of Moral Decision-Making. In Proceedings of the Annual Meeting of the Cognitive Science Society .
Dehghani, M.; Tomai, E.; Forbus, K. D.; and Klenk, M. 2008b. An Integrated Reasoning Approach to Moral Decision-Making. In AAAI , 1280-1286.
Eliasmith, C.; and Thagard, P. 2001. Integrating structure and meaning: A distributed model of analogical mapping. Cognitive Science 25(2): 245-286.
Emami, P.; and Ranka, S. 2018. Learning permutations with sinkhorn policy gradient. arXiv preprint arXiv:1805.07010 .
Evans, T. G. 1964. A program for the solution of a class of geometric-analogy intelligence-test questions. Technical report, AIR FORCE CAMBRIDGE RESEARCH LABS LG HANSCOM FIELD MASS.
Falkenhainer, B.; Forbus, K. D.; and Gentner, D. 1989. The structure-mapping engine: Algorithm and examples. Artificial Intelligence 41(1): 1-63.
Forbus, K.; Usher, J.; Lovett, A.; Lockwood, K.; and Wetzel, J. 2011. CogSketch: Sketch understanding for cognitive science research and for education. Topics in Cognitive Science 3(4): 648-666.
Forbus, K. D.; Ferguson, R. W.; Lovett, A.; and Gentner, D. 2017. Extending SME to handle large-scale cognitive modeling. Cognitive Science 41(5): 1152-1201.
Gentner, D. 1983. Structure-mapping: A theoretical framework for analogy. Cognitive Science 7(2): 155-170.
Gentner, D. 2003. Why we're so smart. Language in mind: Advances in the study of language and thought 195235.
Gentner, D.; Brem, S.; Ferguson, R. W.; Markman, A. B.; Levidow, B. B.; Wolff, P.; and Forbus, K. D. 1997. Analogical reasoning and conceptual change: A case study of Johannes Kepler. The Journal of the Learning Sciences 6(1): 3-40.
Gentner, D.; and Markman, A. B. 1993. Analogy-Watershed or Waterloo? Structural alignment and the development of connectionist models of analogy. In Advances in Neural Information Processing Systems , 855-862.
Gentner, D.; and Markman, A. B. 1998. Analogy-based reasoning. In The handbook of brain theory and neural networks , 91-93. MIT Press.
Georgiev, D.; and Li´ o, P. 2020. Neural Bipartite Matching. arXiv preprint arXiv:2005.11304 .
Gick, M. L.; and Holyoak, K. J. 1983. Schema induction and analogical transfer .
Halford, G. S.; Wilson, W. H.; Guo, J.; Gayler, R. W.; Wiles, J.; and Stewart, J. ???? Connectionist implications for processing capacity limitations in analogies .
Hill, F.; Santoro, A.; Barrett, D. G.; Morcos, A. S.; and Lillicrap, T. 2019. Learning to make analogies by contrasting abstract relational structure. International Conference on Learning Representations .
Hofstadter, D. 1995. Fluid concepts and creative analogies: Computer models of the fundamental mechanisms of thought. Basic books.
Hofstadter, D. R. 2001. Analogy as the core of cognition. The Analogical Mind: Perspectives from Cognitive Science 499-538.
Holyoak, K. J.; Holyoak, K. J.; and Thagard, P. 1996. Mental leaps: Analogy in creative thought .
Holyoak, K. J.; Junn, E. N.; and Billman, D. O. 1984. Development of analogical problem-solving skill. Child Development 2042-2055.
Holyoak, K. J.; and Thagard, P. 1989. Analogical mapping by constraint satisfaction. Cognitive Science 13(3): 295-355.
Hummel, J. E.; and Holyoak, K. J. 1997. Distributed representations of structure: A theory of analogical access and mapping. Psychological Review 104(3): 427.
Hummel, J. E.; and Holyoak, K. J. 2005. Relational reasoning in a neurally plausible cognitive architecture: An overview of the LISA project. Current Directions in Psychological Science 14(3): 153-157.
Kahneman, D.; Treisman, A.; and Gibbs, B. J. 1992. The reviewing of object files: Object-specific integration of information. Cognitive Psychology 24(2): 175-219.
Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 .
Klenk, M.; Forbus, K. D.; Tomai, E.; Kim, H.; and Kyckelhahn, B. 2005. Solving everyday physical reasoning problems by analogy using sketches. In AAAI Conference on Artificial Intelligence .
Kool, W.; Van Hoof, H.; and Welling, M. 2018. Attention, learn to solve routing problems! arXiv preprint arXiv:1803.08475 .
Lovett, A.; and Forbus, K. 2011. Cultural commonalities and differences in spatial problem-solving: A computational analysis. Cognition 121(2): 281-287.
Lovett, A.; and Forbus, K. 2012. Modeling multiple strategies for solving geometric analogy problems. In Proceedings of the Annual Meeting of the Cognitive Science Society , volume 34.
Lovett, A.; Tomai, E.; Forbus, K.; and Usher, J. 2009. Solving geometric analogy problems through two-stage analogical mapping. Cognitive Science 33(7): 1192-1231.
Lu, H.; Liu, Q.; Ichien, N.; Yuille, A. L.; and Holyoak, K. J. 2019. Seeing the Meaning: Vision Meets Semantics in Solving Pictorial Analogy Problems. In CogSci , 2201-2207.
Mikolov, T.; Yih, W.-t.; and Zweig, G. 2013. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , 746-751.
Mitchell, M. 1993. Analogy-making as perception: A computer model .
Novick, L. R. 1988. Analogical transfer, problem similarity, and expertise. Journal of Experimental Psychology: Learning, memory, and cognition 14(3): 510.
O'Donoghue, T. V. D.; and Keane, M. 1999. Computability as a limiting cognitive constraint: Complexity concerns in metaphor comprehension about which cognitive linguists should be aware. In Cultural, Psychological and Typological Issues in Cognitive Linguistics: Selected papers of the biannual ICLA meeting in Albuquerque, July 1995 , volume 152, 129. John Benjamins Publishing.
Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. 2019. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems , 8024-8035.
Reed, S. E.; Zhang, Y.; Zhang, Y.; and Lee, H. 2015. Deep visual analogy-making. In Advances in Neural Information Processing Systems , 1252-1260.
Ribeiro, D.; Hinrichs, T.; Crouse, M.; Forbus, K.; Chang, M.; and Witbrock, M. 2019. Predicting State Changes in Procedural Text using Analogical Question Answering .
Sagi, E.; Gentner, D.; and Lovett, A. 2012. What difference reveals about similarity. Cognitive Science 36(6): 1019-1050.
Tai, K. S.; Socher, R.; and Manning, C. D. 2015. Improved Semantic Representations From Tree-Structured Long ShortTerm Memory Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , 1556-1566.
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In Advances in Neural Information Processing Systems , 5998-6008.
Veale, T.; and Keane, M. T. 1997. The competence of suboptimal theories of structure mapping on hard analogies. In IJCAI , 232-237.
Vinyals, O.; Fortunato, M.; and Jaitly, N. 2015. Pointer networks. In Advances in Neural Information Processing Systems , 2692-2700.
Wang, R.; Yan, J.; and Yang, X. 2019. Learning combinatorial embedding networks for deep graph matching. In Proceedings of the IEEE International Conference on Computer Vision , 3056-3065.
Wetzel, L. 2006. Types and tokens .
Zhang, C.; Gao, F.; Jia, B.; Zhu, Y.; and Zhu, S.-C. 2019. Raven: A dataset for relational and analogical visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 5317-5327.
Zhou, L.; Cui, P.; Yang, S.; Zhu, W.; and Tian, Q. 2019. Learning to learn image classifiers with visual analogy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 11497-11506.
## 7 Appendix
## 7.1 Model Details
In the DAG LSTM, the node embeddings were 32dimensional vectors and the edge embeddings were 16dimensional vectors. For all Transformer components, our model used multi-headed attention with 2 attention layers each having 4 heads. In each multi-headed attention layer, the query and key vectors were projected to 128-dimensional vectors. The feed forward networks used in the Transformer components had one hidden layer with a dimensionality twice that of the input vector size. The feed forward networks used to compute the values in the correspondence selector used two 64-dimensional hidden layers. The λ parameter applied to the candidate inference loss L ci was set to λ = 0 . 1 in our experiments. The models were constructed with the Pytorch (Paszke et al. 2019) library.
## 7.2 Training Data Generation
In Figure 6, the dark green nodes indicate the initial random graphs C after being copied into the base and target. The red and blue nodes show the graphs built around B and T . The light green edges indicate the gold set of correspondences generated from C . On average, each example consisted of 26.9 expressions and 14.3 entities in the base (41.2 distinct items in total), 27.0 expressions and 14.3 entities in the target (41.3 distinct items in total), and 26.8 correspondences.
Figure 6: Synthetic example with a base (red), target (blue), and shared subgraphs (green)
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Diagram: Relationship Diagram of Entities
### Overview
The image is a relationship diagram depicting connections between different entities labeled with prefixes "rel_ord_", "rel_unord_", and "const". The diagram uses colored lines (red, blue, green) to represent relationships between these entities. The shapes of the nodes (rectangles, ovals) also seem to carry meaning.
### Components/Axes
* **Nodes:**
* Rectangles: Represent entities with the prefix "rel_unord_".
* Ovals: Represent entities with the prefixes "rel_ord_" and "const".
* **Edges (Connections):**
* Red Arrows: Connect "rel_ord_" entities to "const" entities and "rel_unord_" entities.
* Blue Arrows: Connect "rel_unord_" entities to "const" entities and "rel_unord_" entities.
* Green Arrows: Connect "rel_unord_" entities to "const" entities.
* **Labels:**
* `rel_ord_c_2` (Red oval, top-left)
* `rel_ord_o_2` (Red oval, top-left)
* `rel_unord_a_2` (Red rectangle, top-center)
* `rel_ord_a_2` (Red oval, top-center)
* `rel_ord_a_3` (Red oval, top-center)
* `rel_unord_e_3` (Green rectangle, top-center)
* `rel_ord_r_2` (Blue oval, center)
* `rel_unord_a_2` (Blue rectangle, center)
* `rel_unord_a_1` (Blue rectangle, center)
* `rel_unord_e_3` (Green rectangle, center)
* `rel_unord_e_3` (Green rectangle, bottom)
* `rel_unord_b_1` (Blue rectangle, bottom)
* `const` (Green ovals, bottom row, and scattered throughout)
### Detailed Analysis or Content Details
* **Top Row (Left to Right):**
* `rel_ord_c_2` (Red oval) connects to a `const` (Green oval) below it with a red arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_ord_o_2` (Red oval) connects to a `const` (Green oval) below it with a red arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_unord_a_2` (Red rectangle) connects to a `const` (Green oval) below it with a red arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_ord_a_2` (Red oval) connects to a `const` (Green oval) below it with a red arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_ord_a_3` (Red oval) connects to a `const` (Green oval) below it with a red arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_unord_e_3` (Green rectangle) connects to three `const` (Green ovals) below it with green arrows. These `const` ovals are in the bottom row.
* **Middle Row (Left to Right):**
* `rel_ord_r_2` (Blue oval) connects to a `const` (Blue oval) below it with a blue arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_unord_a_2` (Blue rectangle) connects to a `const` (Blue oval) below it with a blue arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_unord_a_1` (Blue rectangle) connects to a `const` (Blue oval) below it with a blue arrow. This `const` then connects to another `const` (Green oval) at the bottom with a green arrow.
* `rel_unord_e_3` (Green rectangle) connects to three `const` (Green ovals) below it with green arrows. These `const` ovals are in the bottom row.
* **Bottom Row:**
* `rel_unord_b_1` (Blue rectangle) connects to a `const` (Blue oval) below it with a blue arrow.
### Key Observations
* Entities prefixed with "rel_ord_" are represented by red ovals.
* Entities prefixed with "rel_unord_" are represented by rectangles (red, blue, or green).
* "const" entities are represented by green ovals, except when directly connected to a "rel_ord_" or "rel_unord_" entity, in which case they are the same color as the connecting arrow.
* All entities eventually connect to a "const" entity in the bottom row.
* "rel_unord_e_3" is a central node, connecting to multiple "const" entities.
### Interpretation
The diagram illustrates relationships between different types of entities, possibly representing data dependencies or a hierarchical structure. The "rel_ord_" entities might represent ordered relations, while "rel_unord_" entities represent unordered relations. The "const" entities likely represent constant values or terminal nodes in the graph. The colors and shapes of the nodes and edges likely encode additional information about the nature of these relationships. The diagram suggests a flow of information or dependency from the top-level entities down to the "const" entities at the bottom. The central role of "rel_unord_e_3" suggests it is a key component in this system.
</details>
## 7.3 Additional Experiments
Unit Normalization for Signature Embeddings: In Section 4.1, we described how signature embeddings were scaled to unit length to provide a simple criterion for whether two nodes were likely the same node (i.e., they have a dot product of 1). Intuitively, this feature would be most important for allowing AMN to follow SMT's one-to-one constraint, as it gives AMN the ability to determine which nodes have already been selected for correspondence. To measure the importance of this feature, we performed a simple experiment where we did not scale the signature embeddings to unit length (keeping all other components of AMN the same). We retrained AMN following the same training methodology as before, and tested AMN on the synthetic domain.
Interestingly, we found that performance in all categories (not just conformance to SMT's one-to-one constraint) became significantly worse. The structural performance of AMNdropped from 0.948 to 0.750, indicating that systematicity was impacted. The fraction of problems that were equivalent to the gold standard correspondence set (i.e., no SMT errors and the same structural evaluation score as the gold standard) dropped from 0.671 to 0.278. In terms of errors, the percent of correspondences that violated one-to-one increased from 0.6% to 1.6% and those violating parallel connectivity increased from 2.1% to 12.0%. Degenerate errors remained about the same, increasing from 0.9% to 1.2%, likely reflecting that the dot product of two signature embeddings still incorporates their shared descendants.
Value of the Signature Graph: Given that label graph captures almost all of the graph structure, it is natural to question whether the signature graph is necessary for producing SMT-conforming matchings. To determine the value of the signature graph, we performed an experiment where we completely excised the signature embeddings from AMN, leaving only the label graph for correspondence and candidate inference selection. We retrained this ablated version of AMN with the standard training methodology and tested it on the synthetic set of analogy problems.
Without the signature graph, AMN's performance plummeted in all categories. The one-to-one error rate increased from 0.6% to 92.4% and the parallel connectivity error rate increased from 1.2% to 99.4%. Consequently, the number of error free matches dropped to 0. This matches our intuitions, that without a distinction between the labels of objects and the objects themselves, AMN is incapable of modeling SMT.
## 7.4 Background
DAG LSTMs: DAG LSTMs extend Tree LSTMs (Tai, Socher, and Manning 2015) to DAG-structured data. As with Tree LSTMs, DAG LSTMs compute each node embedding as the aggregated information of all their immediate predecessors (the equations for the DAG LSTM are identical to those of the Tree LSTM). The difference between the two is that DAG LSTMs stage the computation of a node's embedding based on the order given by a topological sort of the input graph. Batching of computations is done by grouping together updates of independent nodes (where two nodes are independent if they are neither ancestors nor predecessors of one another). As in (Crouse et al. 2019), for a node, v , its initial node embedding, s v , is assigned based on its label and arity. The DAG LSTM then computes the final embedding h v to be
<!-- formula-not-decoded -->
where is element-wise multiplication, σ is the sigmoid function, P is the predecessor function that returns the arguments for a node, U ( e vw ) i , U ( e vw ) o , U ( e vw ) c , and U ( e vw ) f are learned matrices per edge type. i and o represent input and output gates, c and ˆ c are memory cells, and f is a forget gate.
Multi-Headed Attention: The multi-headed attention (MHA) mechanism of (Vaswani et al. 2017) is used in our work to compare correspondences against one another. In this work, MHA is given two inputs, a query vector q and a list of key vectors to compare the query vector against 〈 k 1 , . . . , k n 〉 . In N -headed attention, N separate attention transformations are computed. For transformation i we have
<!-- formula-not-decoded -->
where each of W ( q ) i , W ( k ) i , and W ( v ) i are learned matrices and b ˆ q is the dimensionality of ˆ q i . The final output vector q ′ for input q is then given as a combination of its N transformations
<!-- formula-not-decoded -->
where each W ( o ) i is a distinct learned matrix for each i . In implementation, the comparisons of query and key vectors are batched together and performed as efficient matrix multiplications.
Transformer Encoder-Decoder: The Transformer-based encoder-decoder is given two inputs, a comparison set C and an output set O . At a high level, C will be encoded into a new set E , which will inform a selection process that picks elements of O to return. In the context of pointer networks, the set O begins as the encoded input set, i.e., O = E .
Encoder: First, the elements of C , i.e. h c ∈ C , are passed through N layers of an attention-based transformation. For element h c in the i -th layer (i.e., h ( i -1) c ) this is performed as follows
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
where LN denotes the use of layer normalization (Ba, Kiros, and Hinton 2016), MHA ( i ) C (Appendix 7.4) denotes the use of self multi-headed attention for layer i (i.e., attention between h ( i ) c and the other elements of C ( i -1) ), and FFN ( i ) is a two-layer feed-forward neural network with ELU (Clevert, Unterthiner, and Hochreiter 2015) activations. After N layers of processing, the set of encoded inputs E is given by E = C ( N )
Decoder: With encoded comparison elements E and a set of potential outputs O , the objective of the decoder is to use E to inform the selection of some subset of output options D ⊆ O to return. Decoding happens sequentially; at each timestep t ∈ { 1 , . . . , n } the decoder selects an element from O ∪ { END-TOK } (where END-TOK is a learned triple) to add to D . If END-TOK is chosen, the decoding procedure stops and D is returned.
Let D t be the set of elements that have been selected by timestep t and O t be the remaining unselected elements at timetstep t . First, D t is processed with an N -layered attention-based transformation. For an element h ( i -1) d this is given by
<!-- formula-not-decoded -->
where MHA ( i ) D denotes the use of self multi-headed attention, MHA ( i ) E denotes the use of multi-headed attention against elements of E , and FFN ( i ) is a two-layer feed-forward neural network with ELU activations. We will consider the already selected outputs to be the transformed selected outputs, i.e., D t = D ( N ) t . For a pair, 〈 h o , h d 〉 ∈ O t × D t , we compute their compatibility as α od
<!-- formula-not-decoded -->
where W q and W k are learned matrices, b o is the dimensionality of h o , and FFN is a two layer feed-forward network with ELU activations. This defines a matrix H ∈ R |O t |×|D t | of compatibility scores. One can then apply some operation (e.g., max pooling) to produce a vector of values v t ∈ R |O t | which can be fed into a softmax to produce a distribution over options from O t . The highest probability element δ ∗ from the distribution is then added to the set of selected outputs, i.e., D = D t ∪ { δ ∗ } .
## 7.5 AMNExample Outputs
For the outputs from the non-synthetic domains (all but the first figure), only small subgraphs of the original graphs are shown (the original graphs were too large to be displayed)
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Directed Acyclic Graph: Dependency Network
### Overview
The image is a directed acyclic graph (DAG) representing a dependency network. Nodes in the graph are labeled with strings like "rel_ord_g_2", "rel_unord_s_2", and "const". Edges, represented by arrows, indicate dependencies between nodes. Some edges are black, while others are green. Nodes with rounded rectangles are labeled "rel_ord_...", while nodes with square rectangles are labeled "rel_unord_...". The "const" nodes appear to be terminal nodes.
### Components/Axes
* **Nodes:** Represented by ovals and rectangles.
* Ovals: Labeled as "rel_ord_..."
* Rectangles: Labeled as "rel_unord_..."
* Ovals: Labeled as "const"
* **Edges:** Represented by arrows, indicating the direction of dependency.
* Black Arrows: Standard dependency flow.
* Green Arrows: Represent a different type of dependency or relationship.
* **Labels:** Text strings within the nodes, identifying the type and specific instance of the relationship or constant.
### Detailed Analysis or Content Details
**Left Branch:**
* Top: "rel_unord_s_2" (rectangle)
* Below "rel_unord_s_2": "rel_ord_g_2" (oval) and "rel_ord_n_2" (oval)
* Below "rel_ord_g_2" and "rel_ord_n_2": "rel_ord_d_3" (oval) and "rel_ord_n_2" (oval)
* Below "rel_ord_d_3" and "rel_ord_n_2": "rel_ord_r_3" (oval)
* Bottom: Three "const" nodes (ovals).
**Middle Branch:**
* Top: "rel_ord_l_2" (oval)
* Below "rel_ord_l_2": "rel_ord_k_3" (oval), "rel_unord_c_2" (rectangle), "rel_ord_n_2" (oval), and "rel_ord_d_3" (oval)
* Below: "rel_unord_f_2" (rectangle), "rel_ord_b_1" (oval), "rel_ord_r_3" (oval), and "rel_ord_s_1" (oval)
* Bottom: Four "const" nodes (ovals).
**Right Branch:**
* Top: "rel_ord_t_3" (oval) and "rel_ord_l_2" (oval)
* Below "rel_ord_t_3": "rel_unord_f_1" (rectangle) and "rel_ord_j_3" (oval) and "rel_ord_d_3" (oval)
* Below "rel_ord_l_2": "rel_unord_i_1" (rectangle) and "rel_ord_n_2" (oval)
* Below: "rel_ord_n_2" (oval), "rel_ord_d_3" (oval), and "rel_ord_r_3" (oval) and "rel_unord_o_1" (rectangle)
* Bottom: Four "const" nodes (ovals).
**Edge Types:**
* Black edges indicate a standard dependency.
* Green edges connect nodes across different branches, suggesting a more complex relationship. For example, a green edge connects "rel_ord_g_2" to one of the "const" nodes in the middle branch.
### Key Observations
* The graph has a hierarchical structure, with nodes at the top influencing nodes below.
* The "const" nodes are terminal nodes, indicating the end of a dependency chain.
* The "rel_unord_..." nodes appear to act as connectors or aggregators, influencing multiple downstream nodes.
* The green edges suggest cross-dependencies or relationships between different parts of the graph.
### Interpretation
The DAG represents a complex system of dependencies, likely within a software or data processing pipeline. The "rel_ord_..." nodes represent ordered relationships, while "rel_unord_..." nodes represent unordered relationships. The "const" nodes likely represent constant values or final outputs. The green edges indicate a more complex interaction between different parts of the system, possibly representing data flow or control signals. The structure of the graph suggests a modular design, with different branches representing different components or modules. The interconnections between these modules, represented by the green edges, are crucial for the overall system behavior.
</details>
Figure 7: AMN output for an example from the Synthetic domain
Figure 8: AMN output for an example from the Visual Oddity domain
<details>
<summary>Image 8 Details</summary>
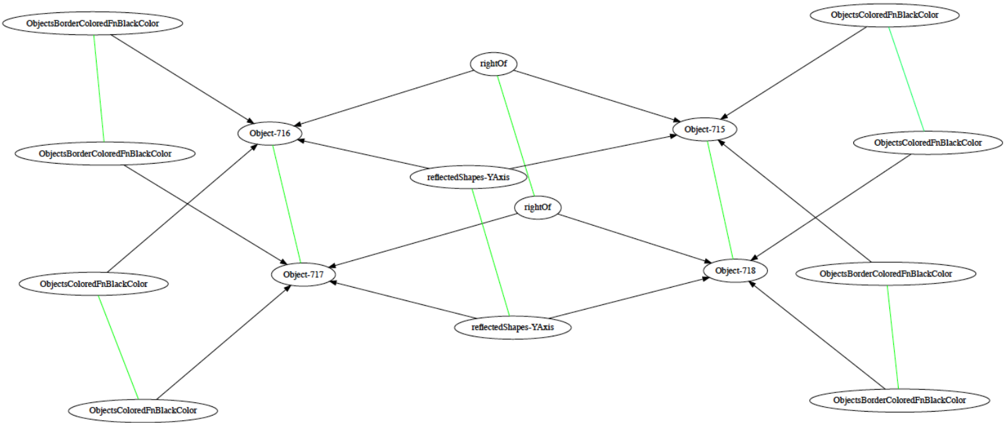
### Visual Description
## Diagram: Object Relationship Diagram
### Overview
The image is a diagram illustrating relationships between different objects. The objects are represented by ovals containing text labels, and the relationships are represented by black and green lines connecting these ovals. The diagram appears to show connections between objects, their properties, and spatial relationships like "rightOf" and "reflectedShapes-YAxis".
### Components/Axes
* **Nodes:** The nodes are ovals containing text. The text labels identify the objects and their properties.
* Object-716
* Object-717
* Object-715
* Object-718
* ObjectsBorderColoredFnBlackColor (appears 4 times)
* ObjectsColoredFnBlackColor (appears 4 times)
* rightOf (appears 2 times)
* reflectedShapes-YAxis (appears 2 times)
* **Edges:** The edges are lines connecting the nodes, indicating relationships between them.
* Black lines: Represent general relationships.
* Green lines: Represent specific relationships.
* **Spatial Arrangement:** The diagram is arranged with Object-716 and Object-715 at the top, Object-717 and Object-718 at the bottom, and "rightOf" and "reflectedShapes-YAxis" in the middle.
### Detailed Analysis or Content Details
* **Object-716:**
* Connected to "ObjectsBorderColoredFnBlackColor" (top-left) via a black line.
* Connected to "ObjectsBorderColoredFnBlackColor" (mid-left) via a black line.
* Connected to "Object-717" via a black line.
* Connected to "rightOf" (top-center) via a black line.
* Connected to "ObjectsColoredFnBlackColor" (top-left) via a green line.
* Connected to "Object-718" via a green line.
* **Object-717:**
* Connected to "ObjectsColoredFnBlackColor" (bottom-left) via a black line.
* Connected to "ObjectsColoredFnBlackColor" (mid-left) via a black line.
* Connected to "Object-716" via a black line.
* Connected to "reflectedShapes-YAxis" (bottom-center) via a black line.
* Connected to "Object-716" via a green line.
* Connected to "ObjectsColoredFnBlackColor" (bottom-left) via a green line.
* **Object-715:**
* Connected to "ObjectsColoredFnBlackColor" (top-right) via a black line.
* Connected to "ObjectsColoredFnBlackColor" (mid-right) via a black line.
* Connected to "Object-718" via a black line.
* Connected to "rightOf" (top-center) via a black line.
* Connected to "Object-718" via a green line.
* Connected to "ObjectsBorderColoredFnBlackColor" (top-right) via a green line.
* **Object-718:**
* Connected to "ObjectsBorderColoredFnBlackColor" (bottom-right) via a black line.
* Connected to "ObjectsBorderColoredFnBlackColor" (mid-right) via a black line.
* Connected to "Object-715" via a black line.
* Connected to "reflectedShapes-YAxis" (bottom-center) via a black line.
* Connected to "Object-715" via a green line.
* Connected to "ObjectsBorderColoredFnBlackColor" (bottom-right) via a green line.
* **rightOf:**
* Connected to "Object-716" via a black line.
* Connected to "Object-715" via a black line.
* Connected to "Object-715" via a green line.
* Connected to "Object-716" via a green line.
* **reflectedShapes-YAxis:**
* Connected to "Object-717" via a black line.
* Connected to "Object-718" via a black line.
* Connected to "Object-718" via a green line.
* Connected to "Object-717" via a green line.
* **ObjectsBorderColoredFnBlackColor:** These nodes are connected to Object-716, Object-715, Object-718, and are also connected to Object-715 and Object-718 via green lines.
* **ObjectsColoredFnBlackColor:** These nodes are connected to Object-716, Object-717, Object-715, and are also connected to Object-716 and Object-717 via green lines.
### Key Observations
* The diagram shows a network of relationships between objects and their properties.
* The "rightOf" and "reflectedShapes-YAxis" nodes seem to represent spatial relationships between the objects.
* The green lines might indicate a specific type of relationship or a direction of influence.
* ObjectsBorderColoredFnBlackColor and ObjectsColoredFnBlackColor appear to be properties or attributes of the objects.
### Interpretation
The diagram likely represents a system where objects have properties and spatial relationships with each other. The "rightOf" and "reflectedShapes-YAxis" relationships suggest a geometric or spatial context. The green lines could indicate a specific type of dependency or influence between the objects. The diagram could be used to model a scene, a data structure, or any system where objects have relationships with each other. The specific meaning of "ObjectsBorderColoredFnBlackColor" and "ObjectsColoredFnBlackColor" would depend on the context of the diagram, but they likely represent visual or functional attributes of the objects.
</details>
Figure 9: AMN output for an example from the Moral Decision Making domain
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Diagram: Decision Flow Network
### Overview
The image is a directed graph representing a decision flow network. It shows various states or actions connected by arrows, indicating the flow of decisions or processes. The nodes are labeled with descriptive names, and some connections are highlighted in green, possibly indicating a specific path or outcome.
### Components/Axes
* **Nodes:** Represented by ovals, each containing a label describing a state, action, or choice. Examples include "SelectingSomething," "OpeningOrNotOpeningTheDam," "Inaction131950," "you128898," and "preventingExtinctionRiver1FishGroup1."
* **Edges:** Represented by arrows, indicating the direction of flow or relationship between nodes.
* **Highlighted Edges:** Some edges are colored green, possibly indicating a specific path or outcome.
* **Labels:** Each node is labeled with a descriptive name. Some nodes have numbers appended to them, such as "SelectingSomething131949" and "Inaction131950."
* **Keywords:** Several nodes contain keywords like "choices," "chosenItem," and "performedBy," suggesting the nature of the decisions or actions being represented.
### Detailed Analysis or ### Content Details
**Node Details (Left Side):**
* "SelectingSomething" (top-left) has a green edge leading to "SelectingSomething131949."
* "SelectingSomething" (below the first) has a black edge leading to "OpeningOrNotOpeningTheDam."
* "SelectingSomething131949" has edges leading to "OpeningOrNotOpeningTheDam," "choices," and "notOpen8135."
* "OpeningOrNotOpeningTheDam" has edges leading to "choices" and "open8135."
* A cluster of nodes labeled "choices" and "chosenItem" are interconnected with "SelectingSomething131949" and "OpeningOrNotOpeningTheDam."
* "open8135" has an edge leading to "performedBy."
* "order131049" has a green edge leading to "open8135."
**Node Details (Center):**
* "Inaction131950" is connected to "notOpen8135" and "performedBy."
* "notOpen8135" has an edge leading to "you128898."
* "you8131" has an edge leading to "you128898."
* "you8131" has a green edge leading to "performedBy."
* "performedBy" nodes connect "Inaction131950," "notOpen8135," "you128898," "you8131," and "open8135."
**Node Details (Right Side):**
* "save128937" has an edge leading to "performedBy," which then leads to "you128898."
* "you128898" has an edge leading to "performedBy."
* "PreventingSomething131948" has a green edge leading to "preventingExtinctionRiver1FishGroup1."
* "PreventingSomething131948" has an edge leading to "PreventingSomething."
* "PreventingSomething" has an edge leading to "preventingExtinctionRiver1FishGroup1."
* "PreventingSomething" (bottom) has an edge leading to "preventingExtinctionRiver1FishGroup2."
### Key Observations
* The graph is highly interconnected, with multiple paths leading to and from various nodes.
* The "you128898" node appears to be a central point, receiving connections from multiple "performedBy" nodes.
* The green edges highlight specific paths, possibly indicating successful or preferred outcomes.
* The presence of nodes related to "preventingExtinctionRiver1FishGroup" suggests a focus on environmental or ecological concerns.
### Interpretation
The diagram likely represents a decision-making process or a flow of actions related to a specific scenario, possibly involving environmental management or resource allocation. The nodes represent different states or actions, and the edges represent the flow of decisions or processes. The green edges may indicate optimal or preferred paths within the decision network. The "you128898" node could represent a key decision-maker or a central point in the process. The diagram suggests a complex interplay of choices and actions, with potential consequences for the "preventingExtinctionRiver1FishGroup." The numbers appended to some nodes might represent specific instances or iterations of the action.
</details>