## Memristors - from In-memory computing, Deep Learning Acceleration, Spiking Neural Networks, to the Future of Neuromorphic and Bio-inspired Computing
Adnan Mehonic * , Abu Sebastian, Bipin Rajendran, Osvaldo Simeone, Eleni Vasilaki, Anthony J. Kenyon
Dr. Adnan Mehonic, Prof Anthony J. Kenyon
Department of Electronic & Electrical Engineering, UCL, Torrington Place, London WC1E 7JE, United Kingdom
E-mail: adnan.mehonic.09@ucl.ac.uk
Dr. Abu Sebastian
IBM Research - Zurich, 8803 Rüschlikon, Switzerland
Dr. Bipin Rajendran, Prof Osvaldo Simeone
Centre for Telecommunications Research, Department of Engineering, King's College London, WC2R 2LS, United Kingdom
Prof. Eleni Vasilaki
Department of Computer Science, University of Sheffield, Sheffield, South Yorkshire, United Kingdom
Keywords: memristor, neuromorphic, AI, deep learning, spiking neural networks, in-memory computing
## Abstract
Machine learning, particularly in the form of deep learning, has driven most of the recent fundamental developments in artificial intelligence. Deep learning is based on computational models that are, to a certain extent, bio-inspired, as they rely on networks of connected simple computing units operating in parallel. Deep learning has been successfully applied in areas such as object/pattern recognition, speech and natural language processing, self-driving vehicles, intelligent self-diagnostics tools, autonomous robots, knowledgeable personal assistants, and monitoring. These successes have been mostly supported by three factors: availability of vast amounts of data, continuous growth in computing power, and algorithmic innovations. The approaching demise of Moore's law, and the consequent expected modest improvements in computing power that can be achieved by scaling, raise the question of whether the described progress will be slowed or halted due to hardware limitations. This paper reviews the case for a novel beyond-CMOS hardware technology - memristors - as a potential solution for the implementation of power-efficient in-memory computing, deep learning accelerators, and spiking neural networks. Central themes are the reliance on nonvon-Neumann computing architectures and the need for developing tailored learning and inference algorithms. To argue that lessons from biology can be useful in providing directions for further progress in artificial intelligence, we briefly discuss an example based reservoir computing. We conclude the review by speculating on the 'big picture' view of future neuromorphic and brain-inspired computing systems.
## 1. Introduction
The three factors are currently driving the main developments in artificial intelligence (AI): availability of vast amounts of data, continuous growth in computing power, and algorithmic innovations. Graphics processing units (GPUs) have been demonstrated as effective coprocessors for the implementation of machine learning (ML) algorithms based on deep learning (DL). Solutions based on deep learning and GPU implementations have led to massive improvements in many AI tasks, but have also caused an exponential increase in demand for computing power. Recent analyses show that the demand for computing power has increased by a factor of 300,000 since 2012, and the estimate is that this demand will double every 3.4 months - at a much faster rate than improvements made historically through Moore's scaling (a 7-fold improvement over the same period of time) [1] . At the same time, Moore's law has been slowing down significantly for the last few years [2] , as there are strong indications that we will not be able to continue scaling down CMOS transistors. This calls for the exploration of alternative technology roadmaps for the development of scalable and efficient AI solutions.
Transistor scaling is not the only way to improve computing performance. Architectural innovations such as GPUs, field-programmable arrays (FPGAs), and application-specific integrated circuits (ASICs), have all significantly advanced the ML field 3 . A common aspect of modern computing architectures for ML is a move away from the classical von Neumann architecture that physically separates memory and computing. This approach yields a performance bottleneck that is often the main reason for both energy and speed inefficiency of ML implementations on conventional hardware platforms due to costly data movements. However, architectural developments alone are not likely to be sufficient. In fact, standard digital CMOS components are inherently not well suited for the implementation of a massive number of continuous weights/synapses in artificial neural networks (ANNs).
1.1. The promise of memristors. There is a strong case to be made for the exploration of alternative technologies. Although the memristor technology is currently still in development, it is a strong candidate for future non-CMOS and beyond von-Neumann computing solutions [4] . Since its early development in 2008 [5] , or even earlier under different names [6] , memristor technology expanded remarkably to include many different materials solutions, physical mechanisms, and novel computing approaches [4] . A single progress report cannot cover all different approaches and fast-growing developments in the field. The evaluation of state of the art in memristor-based electronics can be found elsewhere [7] . Instead, in this paper, we present and discuss a few representative case studies, showcasing the potential role of memristors in the expanding field of AI hardware. We present examples of how memristors are used for in-memory computing systems, deep learning accelerators, and spike-based computing. Finally, we discuss and speculate on the future of neuromorphic and bio-inspired computing paradigms and provide reservoir computing as an example.
For the last 15 years, memristors have been a focal point for many different research communities - mathematicians, solid-state physicists, experimental material scientists, electrical engineers and, more recently, computer scientists and computational neuroscientists. The concept of memristor was introduced almost 50 years ago, back in 1971 [8] , was nearly forgotten for almost four decades. It is now experiencing a rebirth with a vibrant and very active research community. There are many different flavours of memristive technologies. Still, in their most popular implementation, memristors are simple two-terminal devices with the extraordinary property that their resistance depends on their history of electrical stimuli. In other words, memristors are resistors with memory. They promise high levels of integration, stable non-volatile resistance states, fast resistance switching, excellent energy efficiency - all very desirable properties for next generation of memory technologies.
The physical implementations of memristors are broad and arguably include many different technologies such as redox-based resistive random-access memory (ReRAM), phase change memories (PCM), magnetoresistive random-access memory (MRAM). Further differentiations within larger classes can be made, depending on physical mechanisms that govern the resistance change. Many excellent reviews cover the principles and switching mechanisms of memristor devices. Here, we will briefly mention two extensively studied types of memristive devices, namely redox-based random access memory (ReRAM) and phase-change memory (PCM).
Resistance switching is one of the most explored properties of memristive devices. A thin insulating film reversibly changes its electrical resistance - between an insulating state and a conducting state - under the application of an external electrical stimulus. For binary memory devices, two stable states are sought, typically called the high resistance state (HRS), and the low resistance state (LRS). The transition from the HRS to the LRS is called a SET process, while a RESET process describes the transition from the LRS to the HRS.
Basic memory cells of both types, in their most straightforward implementation, have three layers - two conductive electrodes and a thin switching layer sandwiched in-between. Local redox processes govern resistance switching in ReRAM devices. A broad classification can be made based on a distinction between the switching that happens as a result of intrinsic properties of the switching material (typically oxides), and switching that is the result of indiffusion of metal ions (typically from one of the metallic electrodes). The former type is called intrinsic switching, and the latter is called extrinsic switching [9] . Alternatively, a classification can be made depending on the main driving force for the redox process (thermal or electrical), or the type of ions that move. The main three classes are electrochemical metallization cells (or conductive bridge) ReRAMs (ECM), valence change ReRAMs (VCM) and thermochemical ReRAMs (TCM) [4] .
Many ReRAM devices require an electroforming step prior to resistance switching. This can be considered a soft breakdown of the insulating material. A conductive filament is produced inside the insulating film as a result of the applied electrical bias. Modification of conductive filaments, led by a local redox process, leads to the change of resistance. The diameter of the conductive filament is typically of the order of a few nanometers to a few tens of nanometers, and it does not depend on the size of the electrodes. Another, less common type is interfacetype switching, which does not depend on creation and modification of conductive filaments, but can be driven by the formation of a tunnel or Schottky barrier across the whole interface between electrode and switching layer.
In the case of PCMs, the change of resistance due to the crystallisation and amorphisation processes of phase change materials. Amplitude and duration of applied voltage pulses control the phase transitions - the SET process changes the amorphous to a crystalline phase (HRS to LRS transition), and the RESET process changes the crystalline to an amorphous phase (LRS to HRS transition).
For many computing tasks, more than two states are required, and for most memristive devices, including ReRAMs and PCMs, many resistance states can be achieved. However, benchmarking of memristive devices for different applications, beyond pure digital memory, can be challenging and relies on many different parameters other than the number of different resistance states. We will discuss the main device properties in the context of different applications.
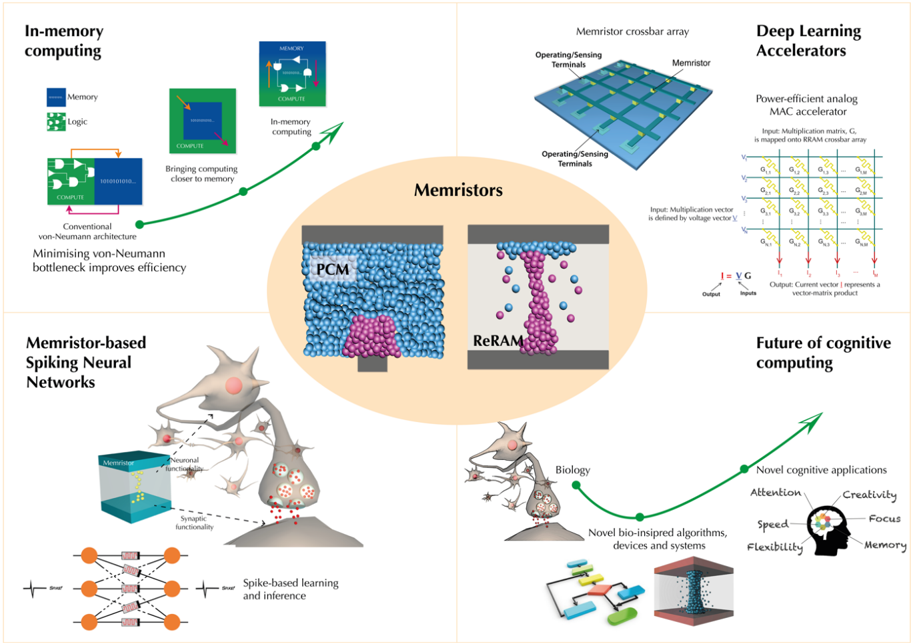
1.2 The landscape of different approaches and applications. In the context of this paper, memristors can be used in applications beyond simple memory devices [10] . A 'big picture' landscape of memristor-based approaches for AI is shown in Figure 1. There is more than one way that memristors can perform computing. A unique feature of memristor devices is the ability to co-locate memory and computing and to break the von Neumann bottleneck at the lowest, nanometre-scale level. One such approach is the concept of in-memory computing, which uses memory not only to store the data but also to perform computation at the same physical location. Furthermore, memristors have long been considered for deep learning acceleration. Specifically, memristive crossbar arrays physically represent weights in artificial neural networks as conductances at each crosspoint. When voltages are applied at one side of the crossbar and current sensed on the orthogonal terminals, the array provides vector-matrix multiplication in constant time step using Kirchhoff's and Ohm's laws. Vector-matrix multiplications dominate most DL algorithms - hundreds of thousands are often needed during training and inference. When weights are implemented as memristor conductances, there is no need for the extensive power-hungry data movement required by conventional digital systems based on the von Neumann architecture.
Other more bio-realistic concepts are also being explored. These include schemes relying on spike-based communication. The central premise of this approach can be summarised with the motto 'computing with time, not in time'. It has been shown that memristors can directly implement some functions of biological neurons and synapses, most importantly, synapse-like plasticity, and neuron-like integration and spiking. In these solutions, the information is encoded and transferred in the form of voltage or current spikes. Memristor resistances are used as proxies for synaptic strengths. More importantly, adjustment of the resistances is controlled according to local learning rules. One popular local learning rule is spike-timingdependent plasticity (STDP), which adjust a local state variable such as conductance dynamically based on the relative timing of spikes. In a simple example, the conductance of a memristive 'synapse' can be increased or decreased depending on the degree of overlap between pre- and post-synaptic voltage pulses. There also exist implementations that do not require overlapping pulses, instead utilising the volatile internal dynamics of memristive devices. Spike-based computing promises further improvements in power-efficiency, taking the inspiration from the remarkable efficiency of the human brain.
Finally, we speculate that, for future developments in AI, new knowledge and computational models from the fields of computational neuroscience could play a crucial role. Virtually all recent developments in ML and DL are driven by the field of computer science. At the same time, the algorithmic inspiration from neuroscience is mostly based on old models established as early as the 1950s. Although we are still at the infancy of understanding the full working principles of the biological brain, novel brain-inspired architectural principles, beyond simple probabilistic deep learning approaches, could lead to higher-level cognitive functionalities. One such example is the concept of reservoir computing, which we discuss briefly in the paper. It is unlikely that current digital CMOS transistor technology can be optimized for the implementation of much more dynamic and adaptive systems in an efficient way. In contrast, memristor-based systems, with their rich switching dynamics and many state variables, may provide a perfect substrate to build a new class of intelligent and efficient neuromorphic systems.
Figure 1. The landscape of memristor-based systems for Artificial Intelligence. In-memory computing aims to eliminate the von-Neumann bottleneck by implementing compute directly within the memory. Deep learning accelerators based on memristive crossbars are used to implement vector-matrix multiplication directly using Ohm's and Kirchhoff's laws. Spiking neural networks, a type of artificial neural networks, are biologically more plausible and do not operate with continuous signals, but use spikes to process and transfer data. Memristor systems could provide a hardware platform to implement spike-based learning and inference. More complex functionalities (neuromorphic), beyond simple digital switching CMOS paradigm, directly implemented in memristive hardware primitives, might fuel the next wave of higher cognitive systems.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Memristor Applications
### Overview
The image presents a diagram showcasing various applications of memristors in computing, including in-memory computing, deep learning accelerators, spiking neural networks, and future cognitive computing. It illustrates the evolution from conventional von-Neumann architecture to memristor-based systems, highlighting their potential to improve efficiency and enable novel computing paradigms.
### Components/Axes
* **Central Theme:** Memristors
* **Applications:**
* In-memory computing
* Memristor crossbar array
* Deep Learning Accelerators
* Memristor-based Spiking Neural Networks
* Future of cognitive computing
* **Key Concepts:**
* Conventional von-Neumann architecture
* Spike-based learning and inference
* Novel bio-inspired algorithms, devices, and systems
* Novel cognitive applications
### Detailed Analysis
**1. In-memory computing (Top-Left)**
* Diagram shows a transition from separate memory and compute units to integrated in-memory computing.
* **Legend:**
* Blue: Memory
* Green: Logic
* **Text:**
* "Bringing computing closer to memory"
* "Conventional von-Neumann architecture"
* "Minimising von-Neumann bottleneck improves efficiency"
* A green arrow indicates the progression towards in-memory computing.
**2. Memristors (Center)**
* Illustrations of two types of memristors: PCM (Phase Change Memory) and ReRAM (Resistive Random-Access Memory).
* **PCM:** Shows a structure with a blue region and a pink region.
* **ReRAM:** Shows a structure with blue and pink particles moving within a channel.
**3. Memristor crossbar array (Top-Center)**
* Diagram of a memristor crossbar array with operating/sensing terminals.
* **Labels:**
* "Memristor crossbar array"
* "Operating/Sensing Terminals"
* "Memristor"
**4. Deep Learning Accelerators (Top-Right)**
* Diagram of a power-efficient analog MAC (Multiply-Accumulate) accelerator using an RRAM crossbar array.
* **Labels:**
* "Deep Learning Accelerators"
* "Power-efficient analog MAC accelerator"
* "Input: Multiplication matrix, G, is mapped onto RRAM crossbar array"
* "Input: Multiplication vector is defined by voltage vector V"
* "Output: Current vector I represents a vector-matrix product"
* "I = VG"
* "Output"
* "Inputs"
* The diagram shows a matrix representation of the multiplication process.
**5. Memristor-based Spiking Neural Networks (Bottom-Left)**
* Diagram illustrating the use of memristors in spiking neural networks.
* **Labels:**
* "Memristor-based Spiking Neural Networks"
* "Memristor"
* "Neuronal functionality"
* "Synaptic functionality"
* "Spike-based learning and inference"
* The diagram shows a neuron with synaptic connections and a simplified representation of a spiking neural network.
**6. Future of cognitive computing (Bottom-Right)**
* Diagram representing the future of cognitive computing enabled by memristors.
* **Labels:**
* "Future of cognitive computing"
* "Biology"
* "Novel bio-inspired algorithms, devices and systems"
* "Novel cognitive applications"
* A mind map shows key cognitive attributes: Attention, Creativity, Focus, Memory, Speed, Flexibility.
### Key Observations
* The diagram emphasizes the shift from traditional computing architectures to memristor-based systems.
* Memristors are presented as a key enabler for advanced computing paradigms like in-memory computing, deep learning, and cognitive computing.
* The diagram highlights the bio-inspired nature of memristor-based systems, particularly in spiking neural networks and cognitive computing.
### Interpretation
The diagram illustrates the potential of memristors to revolutionize computing by overcoming the limitations of conventional von-Neumann architectures. By integrating memory and processing, memristors offer significant advantages in terms of speed, energy efficiency, and scalability. The applications showcased in the diagram demonstrate the versatility of memristors and their potential to enable advanced computing paradigms such as artificial intelligence, cognitive computing, and neuromorphic computing. The emphasis on bio-inspired approaches suggests a trend towards developing computing systems that mimic the structure and function of the human brain.
</details>
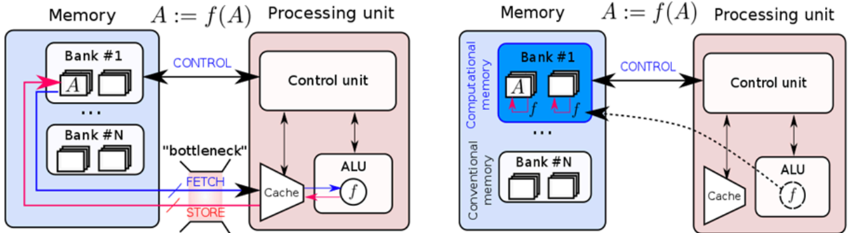
## 2. In-memory computing
In the von Neumann architecture, which dates back to the 1940s, memory and processing units are physically separated and large amounts of data need to be shuttled back and forth between them during the execution of various computational tasks. The latency and energy associated with accessing data from the memory units are key performance bottlenecks for a range of applications, in particular for the increasingly prominent artificial intelligence related workloads [11] . The energy cost associated with moving data is a key challenge for both severely energy constrained mobile and edge computing as well as high performance computing in a cloud environment due to cooling constraints. The current approaches, such as using hundreds of processors in parallel [12] or application-specific processors [13] , are not likely to fully overcome the challenge of data movement. It is getting increasingly clear that novel architectures need to be explored where memory and processing are better collocated. In-memory computing is one such non-von Neumann approach where certain computational tasks are performed in place in the memory itself organized as a computational memory unit [14,15 ,16, 17]. As schematically illustrated in Figure 2, in-memory computing obviates the need to move data into a processing unit. Computing is performed by exploiting the physical attributes of the memory devices, their array-level organization, the peripheral circuitry as well as the control logic. In this paradigm, the memory is an active participant in the computational task. Besides reducing latency and energy cost associated with data movement, in-memory computing also has the potential to improve the computational time complexity associated with certain tasks due to the massive parallelism afforded by a dense array of millions of nanoscale memory devices serving as compute units. By introducing physical coupling between the memory devices, there is also a potential for further reduction in computational time complexity [18, 19]. Memristive devices such as PCM, ReRAM and MRAM [20, 21] are particularly well suited for in-memory computing.
## Processing unit & Conventional memory Processing unit & Computational memory
Figure 2. In-memory computing. In a conventional computing system, when an operation f is performed on data D, D has to be moved into a processing unit. This incurs significant latency and energy cost and creates the well-known von Neumann bottleneck. With in-memory computing, f(D) is performed within a computational memory unit by exploiting the physical attributes of the memory devices. This obviates the need to move D to the processing unit. (Adapted and reproduced with permission [14] , Copyright 2017, Nature Research)
<details>
<summary>Image 2 Details</summary>
### Visual Description
## System Architecture Diagram: Memory and Processing Unit Interaction
### Overview
The image presents two diagrams illustrating the interaction between memory and a processing unit. The left diagram depicts a conventional memory architecture, while the right diagram shows a computational memory architecture. Both diagrams highlight the flow of data and control signals between the memory banks and the processing unit components.
### Components/Axes
**Left Diagram (Conventional Memory):**
* **Memory:** Labeled "Memory" at the top. Contains two memory banks: "Bank #1" and "Bank #N". Each bank contains multiple memory locations represented by small rectangles.
* The memory banks are enclosed in a light blue rounded rectangle.
* **Processing Unit:** Labeled "Processing unit" at the top. Contains a "Control unit", "ALU" (Arithmetic Logic Unit), and "Cache".
* The processing unit is enclosed in a light red rounded rectangle.
* **Data Flow:**
* **FETCH:** Data is fetched from memory to the cache via a "bottleneck". The "FETCH" label is associated with a red arrow pointing from the memory to the cache.
* **STORE:** Data is stored from the cache to memory. The "STORE" label is associated with a pink arrow pointing from the cache to the memory.
* **Control:** Control signals are sent from the control unit to the memory. The "CONTROL" label is associated with a blue arrow pointing from the control unit to Bank #1.
* Data flows between Bank #1 and Bank #N via pink and blue arrows.
* **Equation:** "A := f(A)" is displayed above the processing unit, indicating that the processing unit applies a function 'f' to data 'A'.
**Right Diagram (Computational Memory):**
* **Memory:** Labeled "Memory" at the top. Contains two memory banks: "Bank #1" and "Bank #N". Each bank contains multiple memory locations represented by small rectangles.
* Bank #1 is labeled as "Computational memory" and is enclosed in a blue rounded rectangle.
* Bank #N is labeled as "Conventional memory" and is enclosed in a white rounded rectangle.
* **Processing Unit:** Labeled "Processing unit" at the top. Contains a "Control unit", "ALU" (Arithmetic Logic Unit), and "Cache".
* The processing unit is enclosed in a light red rounded rectangle.
* **Data Flow:**
* The function 'f' is applied directly within the computational memory bank (Bank #1), indicated by small pink arrows and 'f' labels within the bank.
* **Control:** Control signals are sent from the control unit to the memory. The "CONTROL" label is associated with a blue arrow pointing from the control unit to Bank #1.
* A dashed black arrow indicates a potential data flow path from the computational memory to the cache.
* **Equation:** "A := f(A)" is displayed above the processing unit, indicating that the processing unit applies a function 'f' to data 'A'.
### Detailed Analysis or ### Content Details
**Left Diagram (Conventional Memory):**
* Data 'A' is stored in Bank #1.
* The "bottleneck" suggests a limitation in the data transfer rate between memory and cache.
* The ALU performs the function 'f' on data fetched from memory.
* The control unit manages the data flow and operations.
**Right Diagram (Computational Memory):**
* Data 'A' is stored in Bank #1 (Computational Memory).
* The function 'f' is applied directly within the memory bank, reducing the need to transfer data to the ALU for processing.
* The dashed arrow suggests that the processed data can be sent to the cache if needed.
* Bank #N (Conventional Memory) operates similarly to the memory banks in the left diagram.
### Key Observations
* The primary difference between the two diagrams is the location where the function 'f' is applied. In the conventional memory architecture, 'f' is applied in the ALU within the processing unit. In the computational memory architecture, 'f' is applied directly within the memory bank.
* The "bottleneck" label in the conventional memory diagram highlights a potential performance limitation.
* The computational memory architecture aims to improve performance by reducing data transfer between memory and the processing unit.
### Interpretation
The diagrams illustrate the evolution from a conventional memory architecture to a computational memory architecture. The conventional architecture requires data to be transferred to the processing unit for computation, which can be a bottleneck. The computational memory architecture aims to overcome this bottleneck by performing computations directly within the memory bank. This reduces data transfer, potentially leading to improved performance and energy efficiency. The dashed arrow in the computational memory diagram suggests that the processed data can still be accessed by the processing unit if needed, providing flexibility in the system design.
</details>
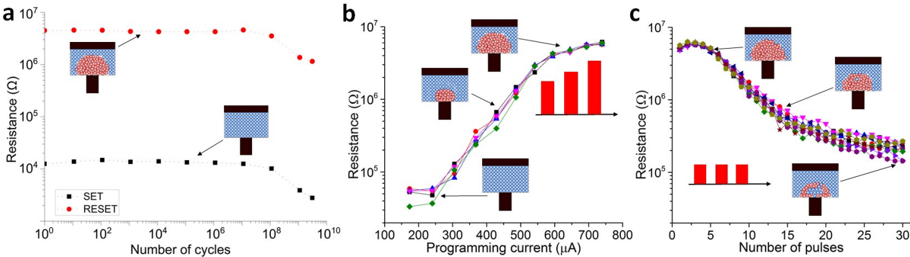
Figure 3. The key physical attributes of memristive devices that facilitate in- memory computing . a) Binary storage capability whereby the devices can be switched between high and low resistance values in a repeatable manner (Adapted and reproduced with permission [22] . Copyright 2019, IOP Publishing). b) Multi- level storage capability whereby the devices can be programmed to a continuum of resistance values by the application of appropriate programming pulses (Adapted and reproduced with permission [23] . Copyright 2018, American Institute of Physics) c) The accumulative behavior whereby the resistance of a device can be progressively decreased by the successive application of identical programming pulses (Adapted and reproduced with permission [23] . Copyright 2018, American Institute of Physics).
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart/Diagram Type: Multiple Line Graphs and Schematics
### Overview
The image presents three line graphs (a, b, c) showing the resistance of a device under different conditions. Each graph is accompanied by schematic diagrams illustrating the device's state.
### Components/Axes
**Graph a:**
* **X-axis:** Number of cycles (logarithmic scale from 10^0 to 10^10)
* **Y-axis:** Resistance (Ω) (logarithmic scale from 10^4 to 10^7)
* **Legend:**
* SET (black squares)
* RESET (red circles)
* **Schematics:** Two schematics are present, one showing a high-resistance state (RESET) and the other showing a low-resistance state (SET).
**Graph b:**
* **X-axis:** Programming current (µA) (linear scale from 100 to 800)
* **Y-axis:** Resistance (Ω) (logarithmic scale from 10^4 to 10^7)
* **Data Series:** Multiple overlapping lines, distinguished by color and marker shape (green diamonds, blue circles, black squares, pink triangles, purple inverted triangles).
* **Schematics:** Three schematics are present, showing the device's state at different programming currents. A bar graph is also present, showing increasing resistance with increasing current.
**Graph c:**
* **X-axis:** Number of pulses (linear scale from 0 to 30)
* **Y-axis:** Resistance (Ω) (logarithmic scale from 10^5 to 10^7)
* **Data Series:** Multiple overlapping lines, distinguished by color and marker shape (green diamonds, blue circles, black squares, pink triangles, purple inverted triangles).
* **Schematics:** Two schematics are present, showing the device's state after different numbers of pulses. A pulse diagram is also present, showing three pulses.
### Detailed Analysis or ### Content Details
**Graph a:**
* **SET (black squares):** The resistance remains relatively constant around 10^4 Ω across the entire range of cycles.
* **RESET (red circles):** The resistance remains relatively constant around 10^7 Ω across the entire range of cycles.
**Graph b:**
* All data series show a similar trend: a sharp increase in resistance as the programming current increases from 200 µA to 800 µA.
* At 200 µA, the resistance is approximately 2 * 10^4 Ω to 5 * 10^4 Ω.
* At 800 µA, the resistance is approximately 5 * 10^6 Ω to 8 * 10^6 Ω.
**Graph c:**
* All data series show a similar trend: a decrease in resistance as the number of pulses increases from 0 to 30.
* At 0 pulses, the resistance is approximately 5 * 10^6 Ω to 8 * 10^6 Ω.
* At 30 pulses, the resistance is approximately 1 * 10^5 Ω to 3 * 10^5 Ω.
### Key Observations
* **Graph a:** The device exhibits stable SET and RESET resistance values over a large number of cycles.
* **Graph b:** The programming current significantly affects the resistance of the device.
* **Graph c:** The number of pulses significantly affects the resistance of the device.
### Interpretation
The data suggests that the device is a resistive switching memory element. Graph a demonstrates the endurance of the device, showing that it can maintain its SET and RESET states over many cycles. Graph b shows that the resistance can be modulated by applying different programming currents. Graph c shows that the resistance can be modulated by applying different numbers of pulses. The schematics provide a visual representation of the device's state during these processes. The bar graph in (b) and the pulse diagram in (c) visually reinforce the trends observed in the line graphs.
</details>
There are several key physical attributes that enable in-memory computing using memristive devices. First of all, the ability to store two levels of resistance/conductance values in a nonvolatile manner and to reversibly switch from one level to the other (binary storage capability) can be exploited for computing. Figure 3 a shows the resistance values achieved upon repeated switching of a representative PCM device between low resistance SET states and high resistance RESET states. Due to the SET and RESET states, resistance could serve as an additional logic state variable. In conventional CMOS, voltage serves as the single logic state variable. The input signals are processed as voltage signals and are output as voltage signals. By combining CMOS circuitry with memristive devices, it is possible to exploit the additional resistance state variable. For example, the RESET state could indicate logic '0' and the SET state could denote logic '1'. This enables logical operations that rely on the interaction between the voltage and resistance state variables and could enable the seamless integration of processing and storage. This is the essential idea behind memristive logic, which is an active area of research [24, 25, 26] . Memristive logic has the potential to impact application areas such as image processing [27] , encryption and database query [28] . Brain-inspired hyperdimensional computing that involves the manipulation of large binary vectors has recently emerged as another promising application area for in-memory logic [29, 30] . Going beyond binary storage, certain memristive devices can also be programmed to a continuum of resistance or conductance values (analog storage capability). For example, Figure 3 b shows a continuum of resistance levels in a PCM device achieved by the application of programming pulses with varying amplitude. The device is first programmed to the fully crystalline state, after which RESET pulses are applied with progressively increasing amplitude. The device resistance is measured after the application of each RESET pulse. Due to this property, it is possible to program a memristive device to a certain desired resistance value through iterative programming by applying several pulses in a closed-loop manner [31] . Yet another physical attribute that enables in-memory computing is the accumulative behavior exhibited by certain memristive devices. In these devices, it is possible to progressively reduce the device resistance by the successive application of SET pulses with the same amplitude. And in certain cases, it is possible to progressively increase the resistance by the successive application of RESET pulses. Experimental measurement of this accumulative behavior in a
PCM device is shown in Figure 3 c . This accumulative behavior is central to applications such as training deep neural networks which is described later. The intrinsic stochasticity associated with the switching behavior in memristive devices can also be exploited for inmemory computing [32] . Applications include stochastic computing [33] and physically unclonable functions [34] .
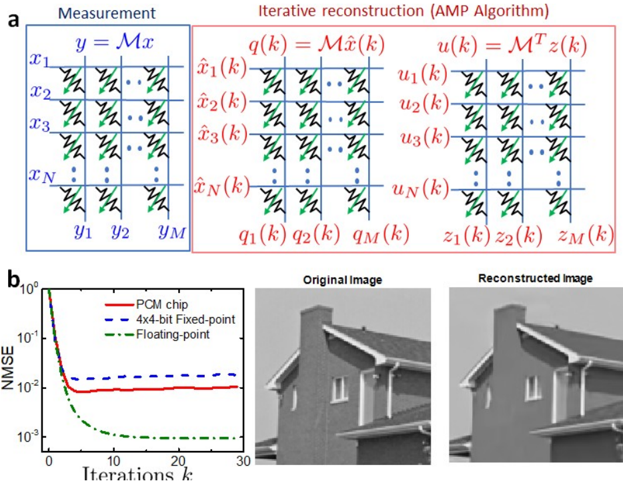
× Figure 4. a) Compressed sensing involves one matrix-vector multiplication. Data recovery is performed via an iterative scheme, using several matrix-vector multiplications on the very same measurement matrix and its transpose. b) An experimental illustration of compressed sensing recovery in the context of image compression is presented, showing 50% compression of a 128x128 pixel image. The normalized mean square error (NMSE) associated with the reconstructed signal is plotted against the number of iterations. Adapted and reproduced with permission [35] , Copyright 2018, IEEE.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Chart/Diagram Type: Composite Figure - System Diagram, Line Plot, and Image Comparison
### Overview
The image presents a composite figure consisting of three parts: (a) a system diagram illustrating a measurement and iterative reconstruction process using the AMP algorithm, (b) a line plot comparing the NMSE (Normalized Mean Squared Error) performance of three different methods (PCM chip, 4x4-bit Fixed-point, and Floating-point) over iterations, and (c) a visual comparison of an original image and its reconstructed version.
### Components/Axes
**Part (a): System Diagram**
* **Title:** Measurement (left, blue box) and Iterative reconstruction (AMP Algorithm) (right, red box)
* **Measurement Block:**
* Equation: y = Mx (blue)
* Input variables: x1, x2, x3, ..., xN (left side)
* Output variables: y1, y2, ..., yM (bottom)
* Diagram: A grid structure with arrows indicating the flow from x_i to y_j.
* **Iterative Reconstruction Block:**
* Equations: q(k) = M x̂(k) and u(k) = M^T z(k) (red)
* Variables: x̂1(k), x̂2(k), x̂3(k), ..., x̂N(k) (left side of first equation)
* Variables: q1(k), q2(k), ..., qM(k) (bottom of first equation)
* Variables: u1(k), u2(k), u3(k), ..., uN(k) (top of second equation)
* Variables: z1(k), z2(k), ..., zM(k) (bottom of second equation)
* Diagram: Similar grid structure with arrows indicating flow.
**Part (b): Line Plot**
* **Title:** None explicitly given, but it's implied to be a comparison of NMSE vs. Iterations for different methods.
* **Y-axis:** NMSE (Normalized Mean Squared Error), logarithmic scale from 10^-3 to 10^0.
* **X-axis:** Iterations k, linear scale from 0 to 30.
* **Legend:** (top-right)
* Red solid line: PCM chip
* Blue dashed line: 4x4-bit Fixed-point
* Green dash-dotted line: Floating-point
**Part (c): Image Comparison**
* **Titles:** Original Image (left) and Reconstructed Image (right)
* Images: Grayscale images of a house.
### Detailed Analysis or ### Content Details
**Part (a): System Diagram**
* The diagram illustrates a measurement process where the input vector 'x' is transformed into the output vector 'y' using a matrix 'M'.
* The iterative reconstruction process uses the AMP (Approximate Message Passing) algorithm to estimate 'x' from 'y'.
* The variables x̂(k), q(k), u(k), and z(k) represent intermediate values in the iterative process at iteration 'k'.
**Part (b): Line Plot**
* **PCM chip (Red solid line):** Starts at approximately 0.2 NMSE, quickly decreases to around 0.01 NMSE within the first 5 iterations, and then plateaus around 0.01 NMSE for the remaining iterations.
* **4x4-bit Fixed-point (Blue dashed line):** Starts at approximately 0.8 NMSE, decreases to around 0.02 NMSE within the first 5 iterations, and then plateaus around 0.02 NMSE for the remaining iterations.
* **Floating-point (Green dash-dotted line):** Starts at approximately 1 NMSE, rapidly decreases to below 0.001 NMSE within the first 10 iterations, and continues to decrease slightly for the remaining iterations.
**Part (c): Image Comparison**
* The original image shows a clear, detailed view of a house.
* The reconstructed image shows a slightly blurred version of the same house, indicating some loss of detail during the reconstruction process.
### Key Observations
* The Floating-point method achieves the lowest NMSE and converges the fastest.
* The PCM chip method performs better than the 4x4-bit Fixed-point method in terms of NMSE.
* The iterative reconstruction process reduces the NMSE over iterations for all three methods.
* The reconstructed image is visually similar to the original image, but with some loss of detail.
### Interpretation
The composite figure demonstrates the performance of different methods for reconstructing an image using an iterative algorithm. The line plot shows that the Floating-point method is the most accurate and efficient, while the PCM chip and 4x4-bit Fixed-point methods have higher NMSE values. The image comparison visually confirms that the reconstruction process introduces some level of distortion, but the overall structure of the image is preserved. The system diagram provides a high-level overview of the measurement and reconstruction process, highlighting the key variables and equations involved. The data suggests that the choice of method significantly impacts the accuracy and efficiency of the image reconstruction process.
</details>
× × A very useful in-memory computing primitive enabled by the binary and analog nonvolatile storage capability is matrix-vector multiplication (MVM) [36, 37] . The physical laws that are exploited to perform this operation are Ohm's law and Kirchhoff's current summation laws. For example, to perform the operation Ax = b , the elements of A are mapped linearly to the conductance values of memristive devices organized in a crossbar configuration. The x values are mapped linearly to the amplitudes of read voltages and are applied to the crossbar along the rows. The result of the computation, b , will be proportional to the resulting current measured along the columns of the array. Compressed sensing and recovery are one of the applications that could benefit from an in-memory computing unit that performs matrix-vector multiplications. The objective behind compressed sensing is to acquire a large signal at subNyquist sampling rate and to subsequently reconstruct that signal accurately. Unlike most other compression schemes, sampling and compression are done simultaneously, with the signal getting compressed as it is sampled. Such techniques have widespread applications in the domain of medical imaging, security systems, and camera sensors. The compressed measurements can be thought of as a mapping of a signal x of length N to a measurement vector y of length M < N. If this process is linear, then it can be modeled by an M N measurement matrix M. The idea is to store this measurement matrix in the in-memory computing unit, with memristive devices organized in a cross-bar configuration (see Figure 4(a)). In this manner the compression operation can be performed in O(1) time complexity.
To recover the original signal from the compressed measurements, an approximate message passing algorithm (AMP) can be used, using an iterative algorithm that involves several matrix-vector multiplications on the very same measurement matrix and its transpose. In this way the same matrix that was coded in the in-memory computing unit can also be used for the reconstruction, reducing reconstruction complexity from O( MN) to O( N ). An experimental illustration of compressed sensing recovery in the context of image compression is shown in Figure 4(b). A 128x128-pixel image was compressed by 50% and recovered using the measurement matrix elements encoded in a PCM array. The normalized mean square error associated with the recovered signal is plotted as a function of the number of iterations. A remarkable property of AMP is that its convergence rate is independent of the precision of the matrix-vector multiplications. The lack of precision only results in a higher error floor, which may be considered acceptable for many applications. Note that, in this application, the measurement matrix remains fixed and hence the property of PCM that is exploited is the multi-level storage capability.
## 3. Deep learning accelerators
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Diagram: Neural Network and Memristor Crossbar Array
### Overview
The image depicts a neural network architecture and its implementation using a memristor crossbar array. The diagram illustrates the flow of information from an input image (a dog) through the neural network layers to an output classification ("dog"). The neural network's connections are then mapped onto a physical memristor crossbar array for hardware implementation.
### Components/Axes
* **Input:** Image of a dog (top-left)
* **Neural Network:** A multi-layered neural network with interconnected nodes (circles). The connections between layers are represented by lines.
* **Output:** "dog" (top-right), indicating the classification result.
* **Memristor Crossbar Array:** A grid-like structure composed of horizontal and vertical lines, with memristors (represented by resistor symbols) at the intersections.
* **Digital Interface:** A blue block labeled "Digital interface" on the left.
* **Control Unit:** A blue block labeled "Control unit" below the digital interface.
* **Peripheral Circuits:** Green blocks labeled "Peripheral circuits" surrounding the memristor arrays.
* **Communication Network:** A dotted red line labeled "Communication network" at the bottom.
* **Arrows:** Arrows indicate the flow of information from the neural network layers to the memristor arrays.
### Detailed Analysis
* **Neural Network Structure:** The neural network consists of multiple layers of interconnected nodes. The connections between nodes represent the weights of the neural network. A red arrow highlights a specific path through the network, leading to the "dog" output.
* **Memristor Array Mapping:** The connections of the neural network are mapped onto the memristor crossbar array. Each memristor represents a synaptic weight in the neural network. The peripheral circuits provide the necessary control and read/write operations for the memristor array.
* **Digital Interface and Control Unit:** The digital interface provides the input to the neural network and receives the output. The control unit manages the operation of the memristor array.
* **Communication Network:** The communication network facilitates data transfer between the different components of the system.
* **Array Structure:** Each memristor array is connected to peripheral circuits on the top and right sides. A control unit is connected to the bottom of the peripheral circuits. The digital interface is connected to the control unit.
### Key Observations
* The diagram illustrates the concept of implementing a neural network using memristor technology.
* The memristor crossbar array provides a compact and energy-efficient way to implement the synaptic weights of the neural network.
* The peripheral circuits and control unit are essential for managing the operation of the memristor array.
### Interpretation
The diagram demonstrates how a neural network can be physically realized using a memristor crossbar array. This approach offers potential advantages in terms of power consumption, speed, and scalability compared to traditional software-based implementations. The memristor array acts as a hardware accelerator for the neural network, enabling faster and more efficient processing of data. The diagram highlights the key components and their interactions in this type of system, showcasing the integration of neural network algorithms with emerging hardware technologies. The use of memristors to represent synaptic weights allows for a dense and energy-efficient implementation of neural networks, which is particularly relevant for applications in edge computing and artificial intelligence.
</details>
Communicationnetwork
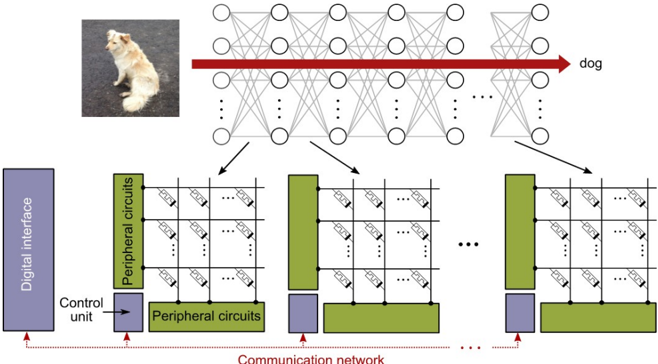
Figure 5. Deep learning based on in-memory computing. The various layers of a neural network are mapped to a computational memory unit where memristive devices are organized in a crossbar configuration. The synaptic weights are stored in the conductance state of the memristive devices. A global communication network is used to send data from one array to another. Adapted and reproduced with permission [17] , Copyright 2020, Nature Research.
Deep neural networks (DNNs), loosely inspired by biological neural networks, consist of parallel processing units called neurons interconnected by plastic synapses. By tuning the weights of these interconnections using millions of labelled examples, these networks are able to perform certain supervised learning tasks remarkably well. These networks are typically trained via a supervised learning algorithm based on gradient descent. During the training phase, the input data is forward propagated through the neuron layers with the synaptic networks performing multiply-accumulate operations. The final layer responses are compared with input data labels and the errors are back-propagated. Both steps involve sequences of matrix-vector multiplications. Subsequently, the synaptic weights are updated to reduce the error. This optimization approach can take multiple days or weeks to train state-of-the-art networks on conventional computers. Hence, there is a significant effort towards the design of custom ASICs based on reduced precision arithmetic and highly optimized dataflow [13, 38] . However, the need to shuttle millions of synaptic weight values between the memory and processing unit remains a key performance bottleneck and hence in-memory computing is being explored as an alternative approach for both inference and training of DNNs [39, 40] . The essential idea is to map the various layers of a neural network to an in-memory computing unit where memristive devices are organized in a crossbar configuration (see Figure 5). The synaptic weights are stored in the conductance state of the memristive devices and the propagation of data through each layer is performed in a single step by inputting the data to the crossbar rows and deciphering the results at the columns.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Neural Network Architecture and Performance Chart
### Overview
The image presents a diagram of a convolutional neural network (CNN) architecture, followed by a chart comparing the test accuracy of different training methods over time. The CNN architecture consists of convolutional layers and ResNet blocks, while the chart compares the performance of a floating-point baseline, custom training, and direct mapping of FP32 weights.
### Components/Axes
**Top: CNN Architecture Diagram**
* **Header:** "6 conv layers" is repeated above each ResNet block.
* **Input:** "Cifar10 image" followed by "Conv" block.
* The input image is represented by a small image of a red car.
* The "Conv" block has dimensions "3x3x16".
* **ResNet Blocks:** There are three ResNet blocks labeled "ResNet block 1", "ResNet block 2", and "ResNet block 3".
* ResNet block 1: Contains convolutional layers with dimensions "3x3x16".
* ResNet block 2: Contains convolutional layers with dimensions "3x3x28" and a "1x1x28" layer.
* ResNet block 3: Contains convolutional layers with dimensions "3x3x56" and a "1x1x56" layer.
* **Output:** "Softmax" layer with dimensions "56x10" leading to "Label".
* **Connections:** Blocks are connected by arrows indicating the flow of data. Small yellow circles are present at the end of each block.
**Bottom: Test Accuracy Chart**
* **Y-axis:** "Test Accuracy (%)", ranging from 60 to 100. Markers at 70, 80, 90, and 100.
* **X-axis:** "Time (s)" on a logarithmic scale, ranging from 10<sup>-5</sup> to 10<sup>5</sup>. Markers at 10<sup>-5</sup>, 10<sup>-3</sup>, 10<sup>-1</sup>, 10<sup>1</sup>, 10<sup>3</sup>, and 10<sup>5</sup>.
* **Legend (bottom-left):**
* "-- Floating point (FP32) baseline" (dashed black line)
* "Experiments: Custom training" (solid blue line with square markers)
* "Experiments: Direct mapping of FP32 weights" (solid red line with diamond markers)
### Detailed Analysis
**CNN Architecture:**
* The network processes a Cifar10 image through an initial convolutional layer.
* The image then passes through three ResNet blocks, each containing multiple convolutional layers.
* The dimensions of the convolutional layers increase through the network (16 -> 28 -> 56).
* The output of the final ResNet block is fed into a Softmax layer to produce a label.
**Test Accuracy Chart:**
* **Floating point (FP32) baseline (dashed black line):** The baseline accuracy is approximately constant at 92%.
* **Experiments: Custom training (solid blue line with square markers):** The accuracy starts at approximately 90% at 10<sup>-5</sup> seconds, decreases slightly to approximately 89% at 10<sup>1</sup> seconds, and then remains relatively stable around 89-90% until 10<sup>5</sup> seconds.
* **Experiments: Direct mapping of FP32 weights (solid red line with diamond markers):** The accuracy starts at approximately 89% at 10<sup>-5</sup> seconds, decreases to approximately 75% at 10<sup>1</sup> seconds, and then fluctuates between 75% and 85% from 10<sup>1</sup> to 10<sup>5</sup> seconds.
### Key Observations
* The custom training method (blue line) maintains a relatively stable accuracy over time, close to the FP32 baseline.
* The direct mapping of FP32 weights (red line) initially performs similarly to the custom training, but its accuracy degrades significantly over time and exhibits more fluctuation.
* The x-axis is logarithmic, indicating that the performance is being evaluated over a wide range of time scales.
### Interpretation
The data suggests that custom training is a more effective approach than direct mapping of FP32 weights for maintaining accuracy over time. The direct mapping method may suffer from issues related to weight quantization or adaptation, leading to the observed performance degradation and fluctuations. The FP32 baseline provides a benchmark for the maximum achievable accuracy, and the custom training method comes close to achieving this level of performance. The chart highlights the importance of proper training techniques when dealing with different weight representations or hardware constraints.
</details>
Time (s)
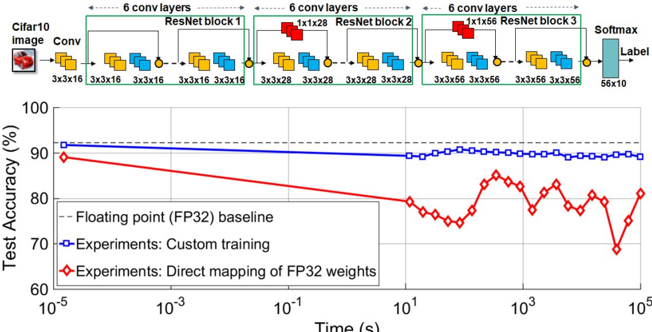
Figure 6. Deep learning inference. Experimental results on ResNet-32 using the CIFAR-10 dataset. The classification accuracies obtained via the direct mapping and custom training approaches are compared to the floating-point baseline. Adapted and reproduced with permission [40] , Copyright 2019, IEEE.
Deep learning inference refers to just the forward propagation in a DNN once the weights have been learned. Both binary and analogue storage capability of memristive devices can be exploited for the MVM operations associated with the inference operation. The key challenges are the inaccuracies associated with programming the devices to a specified synaptic weight as well as drift, noise etc. associated with the conductance values [41] . Due to these reasons, the synaptic weights that are obtained by training in high precision arithmetic (e.g. 32-bit floating point) cannot be mapped directly to computational memory. However, it can be shown that by customizing the training procedure to make it aware of these devicelevel nonidealities, it is possible to obtain synaptic weights that are suitable for being mapped to an in-memory computing unit [42,40] . A more recent approach is to use the committee machines of multiple smaller neural networks. The approach shows the promise of increasing inference accuracy without increasing the number of devices by using a committee of smaller neural networks [43] . Figure 6 shows mixed hardware/software experimental results using a prototype multi-level PCM chip. The synaptic weights are mapped to PCM devices organized in a 2-PCM differential configuration (723,444 PCM devices in total). It can be seen that the custom training scheme approaches the floating-point base-line, whereas the direct mapping approach fails to deliver sufficient accuracy. The slight temporal decline in accuracy is attributed to the conductance drift exhibited by PCM devices [44] . However, in spite of the drift, a classification accuracy of close to 90% is maintained over a significant duration of time.
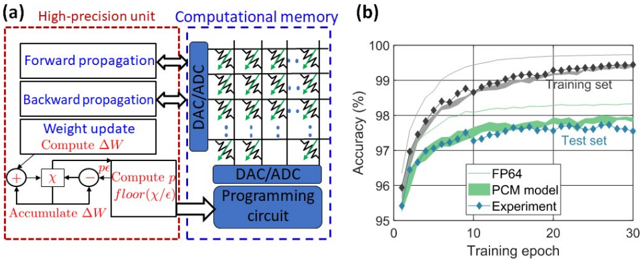
Figure 7. Deep learning training. a) Schematic illustration of the mixed-precision architecture for training DNNs. b) The synaptic weight distributions and classification accuracies are compared between the experiments and floating point baseline [45] .
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Diagram and Chart: High-Precision Unit and Accuracy vs. Training Epoch
### Overview
The image consists of two parts: (a) a diagram illustrating the architecture of a high-precision unit connected to computational memory, and (b) a chart showing the accuracy of different models (FP64, PCM model, and Experiment) over training epochs.
### Components/Axes
#### Part (a): Diagram of High-Precision Unit and Computational Memory
* **Title:** (a) High-precision unit Computational memory
* **Regions:**
* **High-precision unit:** Enclosed in a red dashed rectangle. Contains the following components:
* Forward propagation (blue text)
* Backward propagation (blue text)
* Weight update (red text): Compute ΔW
* Mathematical operations: A series of interconnected symbols representing addition (+), multiplication (X), and subtraction (-). The operations are labeled as "Compute p floor(χ/ε)" (red text) and "Accumulate ΔW" (red text).
* **Computational memory:** Enclosed in a blue dashed rectangle. Contains the following components:
* DAC/ADC (Digital-to-Analog Converter/Analog-to-Digital Converter) (blue text)
* Memory array: A grid-like structure with symbols resembling resistors or memory cells.
* DAC/ADC (Digital-to-Analog Converter/Analog-to-Digital Converter) (blue text)
* Programming circuit (blue text)
* **Flow:** Arrows indicate the flow of data and control signals between the high-precision unit and the computational memory.
#### Part (b): Accuracy vs. Training Epoch Chart
* **Title:** (b)
* **Axes:**
* X-axis: Training epoch (labeled from 0 to 30 in increments of 10)
* Y-axis: Accuracy (%) (labeled from 95 to 100 in increments of 1)
* **Legend:** Located in the bottom-right corner of the chart.
* FP64 (light gray line)
* PCM model (green shaded region)
* Experiment (blue line with diamond markers)
* **Data Series:**
* Training set (black line with diamond markers): Located near the top of the chart.
* Test set (blue text): Located near the middle of the chart.
### Detailed Analysis
#### Part (a): Diagram
The diagram illustrates a system where a high-precision unit interacts with computational memory. The high-precision unit performs forward and backward propagation, updates weights, and performs mathematical operations. The computational memory stores data and is controlled by a programming circuit. DAC/ADC converters facilitate communication between the analog memory and the digital processing unit.
#### Part (b): Chart
* **FP64 (light gray line):** The accuracy starts at approximately 95.8% at epoch 0 and increases rapidly, reaching approximately 99.5% by epoch 10. It then plateaus and remains relatively constant until epoch 30.
* **PCM model (green shaded region):** The accuracy starts at approximately 95.5% at epoch 0 and increases, reaching approximately 97.8% by epoch 15. It then fluctuates slightly around this value until epoch 30. The shaded region indicates the variability or uncertainty in the PCM model's accuracy.
* **Experiment (blue line with diamond markers):** The accuracy starts at approximately 95.3% at epoch 0 and increases, reaching approximately 97.3% by epoch 15. It then fluctuates slightly around this value until epoch 30.
* **Training set (black line with diamond markers):** The accuracy starts at approximately 95.8% at epoch 0 and increases rapidly, reaching approximately 98.5% by epoch 10. It then increases slowly, reaching approximately 99.5% by epoch 30.
### Key Observations
* The FP64 model achieves the highest accuracy, followed by the training set.
* The PCM model and the Experiment data have similar accuracy trends, with the Experiment data showing slightly lower accuracy.
* All models show a rapid increase in accuracy during the initial training epochs, followed by a plateau or slower increase.
### Interpretation
The diagram in part (a) illustrates the hardware architecture used for the experiment. The chart in part (b) demonstrates the performance of different models in terms of accuracy over training epochs. The FP64 model serves as a benchmark, achieving the highest accuracy. The PCM model and the Experiment data represent alternative approaches, with the Experiment data likely representing the actual hardware implementation. The results suggest that the PCM model and the Experiment data achieve comparable accuracy, but are lower than the FP64 model. The initial rapid increase in accuracy indicates that the models are learning effectively during the early stages of training. The subsequent plateau suggests that the models are approaching their maximum performance or that further training is needed to improve accuracy.
</details>
In-memory computing can also be used in the context of supervised training of DNNs with backpropagation. When performing training of a DNN encoded in crossbar arrays, forward propagation is performed in the same way as inference described above. Next, backward propagation is performed by inputting the error gradient from the subsequent layer onto the columns of the current layer and deciphering the result from the rows. Subsequently the error gradient is computed. Finally, the weight update is performed based on the outer product of activations and error gradients of each layer. This weight update relies on the accumulative behaviour of memristive devices. Recent deep learning research shows that when training DNNs, it is possible to perform the forward and backward propagations rather imprecisely while the gradients need to be accumulated in high precision [ 46 ] . This observation makes the DL training problem amenable to the mixed-precision in-memory computing approach that was recently proposed [ 47 ] . The in-memory compute unit is used to store the synaptic weights and to perform the forward and backward passes, while the weight changes are accumulated in high precision (Figure 7(a)) [ 48 , 49 ] . When the accumulated weight exceeds a certain threshold, pulses are applied to the corresponding memory devices to alter the synaptic weights. This approach was tested using the handwritten digit classification problem based on the MNIST data set. A two-layered neural network was employed with 2-PCM devices in differential configuration (approx. 400,000 devices) representing the synaptic weights. Resulting test accuracy after 20 epochs of training was approx. 98% (Figure 7(b)). After training, inference on this network was performed for over a year with marginal reduction in the test accuracy. The crossbar topology also facilitates the estimation of the gradient and the in-place update of the resulting synaptic weight all in O(1) time complexity [ 50 , 39] . By obviating the need to perform gradient accumulation externally, this approach could yield better performance than the mixed-precision approach. However, significant improvements to the memristive technology, in particular the accumulative behavior, is needed to apply this to a wide range of DNNs [ 51 , 52 ] .
Compared to the charge-based memory devices that are also used for in-memory computing [53, 54, 55] , a key advantage of memristive devices is the potential to be scaled to dimensions of a few nanometers [56, 57, 58, 59,60] . Most of the memristive devices are also suitable for back end of line integration, thus enabling their integration with a wide range of front-end CMOS technologies. Another key advantage is the non-volatility of these devices that would obviate the need for computing systems to be constantly connected to a power supply. However, there are also challenges that need to be overcome. The significant intra-device and intra-device variability associated with the SET and RESET states is a key challenge for applications where memristive devices are used for logical operations. For applications that rely on analogue storage capability, a significant challenge is programming variability that captures the inaccuracies associated with programming an array of devices to desired conductance values. In ReRAM, this variability is attributed mostly to the stochastic nature of filamentary switching and one prominent approach to counter this is that of establishing preferential paths for CF formation [ 61 , 62 ] . Representing single computational elements by using multiple memory devices is another promising approach [ 63 ] . Yet another challenge is the temporal and temperature-induced variations of the programmed conductance values. The resistance 'drift' in PCM devices, which is attributed to the intrinsic structural relaxation of the amorphous phase, is an example. The concept of projected phase change memory is a promising approach towards tackling 'drift' [ 64 , 65 ] . The requirements that the memristive devices need to fulfil when employed for computational memory are heavily application dependant. For memristive logic, high cycling endurance ( > 10 12 cycles) and low device-to-device variability of the SET/RESET resistance values are critical. For computational tasks involving read-only operations, such as matrix-vector multiplication, it is required that the conductance states remain relatively unchanged during their execution. It is also desirable to have a gradual analogue-type switching characteristic for programming a continuum of resistance values in a single device. A linear and symmetric accumulative behaviour is also required in applications where the device conductance needs to be incrementally updated such as in deep learning training [ 66 ] . For stochastic computing applications, random device variability is not problematic, but graceful device degradation is highly desirable, as described in [ 67 ].
## 4. Spiking Neural Networks and Memristors
As opposed to the deep learning networks discussed above, spiking neural networks (SNNs) can more naturally incorporate the notion of time in signal encoding and processing. SNNs are typically modelled on the integrate-and-fire behaviour of neurons in the brain. In this framework, neurons communicate with each other using binary signals or spikes. The arrival of a spike at a synapse triggers a current flow into the downstream neuron, with the magnitude of the current weighted by the effective conductance of the synapse. The incoming currents are integrated by the neuron to determine its membrane potential and a spike is issued when the potential exceeds a threshold. This spiking behaviour can be triggered in a deterministic or probabilistic manner. Once a spike is issued, the membrane potential is reset to a resting potential or decreased according to some predetermined rule. The integration is limited to a specific time window, or else a leak factor is incorporated in the integration, endowing the neuron model with a finite memory of past spiking events.
Compared to the realization of second-generation deep neural networks (DNNs discussed in the previous section), SNNs can potentially have significant improvements in efficiency. The first reason for this comes from the underlying signal encoding mechanism. The calculation of the output of a neuron involves the determination of the weighted sum of synaptic weights with real-valued neuronal outputs of the previous layer. For a fully connected second generation DNN with 𝑁 neurons in each layer, this requires 𝑁 ! multiplications of real valued numbers, typically stored in low precision representations. In contrast, the forward propagation operation in an SNN only requires addition operations, as the input neuronal signals are binary spike signals. To elaborate, assume that the input signal is encoded as a spike train with duration 𝑇 , with a minimum inter-spike interval of ∆𝑡 . If the probability of a spike at any instant of time is 𝑝 , then on an average 𝑁𝑝𝑇/∆𝑡 spikes have to be propagated through the synapses, and this requires 𝑁 ! 𝑝𝑇/∆𝑡 addition operations. In most modern processors, the cost of multiplication, 𝐶 " , is 3-4 times higher than that of addition, 𝐶 # . Hence, provided the neuronal and synaptic variables required for computation are available in the processor, SNNs offer a path to more efficient computation if the inequality
$$C _ { a } p \left ( \frac { T } { \Delta t } \right ) < C _ { m }$$
holds. Hence, it is important to develop algorithms for SNNs that minimize 𝑝 and (𝑇/∆𝑡) to improve computational efficiency. This requires the use of sparse binary signal encoding schemes that go beyond rate coding that is typically used in SNNs today. The following section will discuss strategies to develop general-purpose learning rules for SNNs that satisfy such constraints.
The second potential for efficiency improvement of SNNs as compared to second-generation networks arises thanks to novel memory-processor architectures based on memristive devices. While SNNs can be implemented using Si CMOS SRAM or DRAM technologies, the advent of novel nanoscale memristive devices provides opportunities for significant improvements in overall computational efficiency.
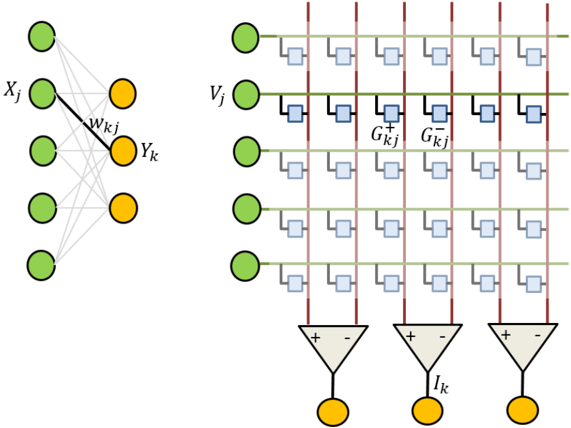
Figure 8. A cross-bar array based representation of an SNN. Each synaptic weight is represented by the differential conductance of two nanoscale devices in the crossbar.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Neural Network Diagram: Conceptual Model and Hardware Implementation
### Overview
The image presents a conceptual diagram of a neural network and a corresponding hardware implementation. The left side illustrates the weighted connections between input and output neurons, while the right side depicts a potential hardware architecture using memristors to represent synaptic weights.
### Components/Axes
**Left Side (Conceptual Model):**
* **Nodes:** Green circles represent input neurons (labeled Xj), and orange circles represent output neurons (labeled Yk).
* **Connections:** Gray lines represent connections between input and output neurons. A thicker black line represents a specific connection with weight wkj.
**Right Side (Hardware Implementation):**
* **Input Neurons:** Green circles represent input neurons (labeled Vj).
* **Output Neurons:** Orange circles represent output neurons (labeled Ik).
* **Memristor Array:** A grid of light blue squares represents memristors, which store the synaptic weights.
* **Horizontal Lines:** Green lines represent the input lines.
* **Vertical Lines:** Red lines represent the output lines.
* **Differential Amplifiers:** Gray triangles represent differential amplifiers.
* **Conductances:** G+kj and G-kj represent positive and negative conductances, respectively.
### Detailed Analysis
**Left Side (Conceptual Model):**
* There are four input neurons (Xj) and two output neurons (Yk).
* Each input neuron is connected to each output neuron.
* The weight of the connection between input neuron j and output neuron k is denoted as wkj.
**Right Side (Hardware Implementation):**
* There are five input neurons (Vj) and three output neurons (Ik).
* Each input neuron is connected to each output neuron through a memristor.
* Each memristor is connected to a differential amplifier.
* The differential amplifier sums the currents from the memristors and produces an output current Ik.
* The memristors are arranged in a grid, with each row corresponding to an input neuron and each column corresponding to an output neuron.
* The memristors are connected to the input and output lines through switches.
* The switches are used to program the memristor conductances.
* The positive and negative conductances (G+kj and G-kj) are used to represent both positive and negative synaptic weights.
### Key Observations
* The left side of the image shows a simplified neural network with weighted connections.
* The right side of the image shows a potential hardware implementation of the neural network using memristors.
* The memristors are used to store the synaptic weights.
* The differential amplifiers are used to sum the currents from the memristors and produce an output current.
### Interpretation
The image illustrates the mapping of a conceptual neural network model onto a physical hardware architecture. The left side represents the abstract mathematical relationships between neurons and their connections, while the right side demonstrates how these relationships can be implemented using memristors and differential amplifiers. This type of hardware implementation offers potential advantages in terms of power consumption, speed, and scalability compared to traditional software-based neural networks. The use of memristors allows for the efficient storage and processing of synaptic weights, while the differential amplifiers enable the summation of currents to produce the output signals. The diagram highlights the potential for building energy-efficient and high-performance neural networks using emerging memristor technology.
</details>
Memristive devices can be integrated at the junctions of crossbar arrays to represent the weights of synapses, and CMOS circuits at the periphery can be designed to implement the neuronal integration and learning logic. As mentioned above, this architecture enables the computation of spike propagation operation in an efficient manner based on Kirchhoff's law as:
$$I _ { k } = \sum _ { j } \left ( G _ { k j } ^ { + } - G _ { k j } ^ { - } \right ) V _ { j }$$
In this formula, 𝑉 % denotes the applied voltage pulses that are triggered when an input neuron spikes and are applied to the line connected to the 𝑗 th input neuron, 𝐺 $% & and 𝐺 $% ' are the conductances of the devices configured in a differential configuration to represent the synaptic weight, and 𝐼 $ is the total incoming current into the 𝑘 th output neuron. The small form factor of the devices, coupled with the scalability of operating voltages and currents beyond what is possible with conventional CMOS, suggests that these architectures can have several orders of magnitude efficiency improvement over Silicon based implementations [68,69] .
However, apart from the already mentioned non-idealities of memritive devices, crossbar arrays with more than 2048x2048 devices cannot be fabricated and operated reliably due to the resistance drop on the wires and the sneak-paths that corrupt the measurement and programming of synaptic states. One approach to mitigate these issues is to design neurosynaptic cores with smaller crossbars and associated neuron circuits, tile these cores on a 2D array, and provide communication fabrics between the cores [70] . Such tiled neurosynaptic core-based designs are particularly amenable for realizing SNNs, as only binary spikes corresponding to intermittently active spiking neurons need to be transported between cores, as opposed to real-valued neuronal variables that are active for all the neurons in the core in the case of deep learning networks. This is the second inherent advantage that SNNs have over DNNs for computational efficiency improvement.
Overcoming the reliability challenges mentioned above is essential for building reliable systems, and would require the co-optimization of algorithms and architectures that are designed to mitigate or leverage these non-ideal behaviours for computation. Two kinds of systems can be visualized based on the application mode. Inference engines, which do not support on-chip learning, can be designed based on memristive devices integrated on crossbars, where the devices are programmed to the desired conductance states based on the weights obtained from software training. However, as memristive devices support incremental conductance changes by the application of suitable electrical programming pulses, it is also possible to design learning systems where network weight updates are implemented on-chip in an event-driven manner [82] . There are also many recent examples where these devices have been engineered to mimic the integration and fire characteristics of biological neurons [71, 72,73], potentially enabling the realization of all-memristor implementations of spiking neural networks [74] . The field is still in its infancy, and so far, has only witnessed small proof-ofconcept demonstrations. We now discuss some of the approaches that have been explored towards realizing memristive based inference-only spiking networks as well as learning networks with SNNs.
4.1. Memristive SNNs for inference . A common approach to develop SNNs is to start with a second-generation ANN trained using traditional backpropagation-based methods, and then convert the resulting network to a spiking network in software. These solutions are based on weight-normalization schemes so that the spike rates of the neurons in the SNN are proportional to the activations of the neurons in the ANN [75, 76] . While this should in principle result in SNNs with comparable accuracies as their second-generation counterparts, some device-aware re-training would typically be necessary when the network is implemented in hardware due to the non-linearity and limited dynamic ranges of nanoscale devices.
One of the differentiating features of inference engines is that the nanoscale devices storing state variables are programmed only rarely, compared to the number of reads (potentially at every inference cycle). Since higher-energy programming cycles have a stronger effect in degrading device lifetimes compared to the lower-energy read cycles, this mode of operation can have better overall system reliability compared to that of learning systems.
In a preliminary hardware demonstration leveraging this approach, R. Midya et al. used memristors based on SiOxNy:Ag to implement compact oscillatory neurons whose output voltage oscillation frequency is proportional to the input current [77] . In this proof-of-concept demonstration of a 3-layer network, ANN to SNN conversion was limited to the last layer alone, but the approach could be extended to hidden layers as well.
4.2. Memristive SNNs for unsupervised learning and adaptation. Most hardware demonstrations of SNNs using memristive devices have focused on the unsupervised learning paradigm, where the synaptic weights are modified in an unsupervised manner according to the biologically inspired spike timing dependent plasticity (STDP) rule [78] . The rule captures the experimental observation that when a synapse experiences multiple pre-before-post pairings, the effective synaptic strength increases, and conversely, multiple post-before-pre spike pairs result in an effective decrease of synaptic conductance.
It should be noted that while other biological mechanisms may also play a key role in learning and memory formation in the brain, as have been observed experimentally [79, 80] , STDP is a simple local learning rule which is especially straight-forward to implement in hardware. While it is possible to implement timing dependent plasticity rules using many-transistor CMOS circuits [81] , it was experimentally demonstrated early on that memristive devices can exhibit STDP-like weight adaptation behaviours upon the application of suitable waveforms [82, 83,84] . Going beyond individual device demonstrations, IBM has also demonstrated an integrated neuromorphic core with 256x256 phase change memory synapses fabricated along with Si CMOS neuron circuits capable of on-chip learning based on a simplified model of STDP for auto-associative pattern learning tasks [85] .
Boybat et al. used phase change memristive synapses to demonstrate temporal correlation detection through unsupervised learning based on a simplified form of STDP [86] as shown in Figure 9. In their experiment, a multi-memristive architecture was introduced, where 𝑁 PCM devices are used to represent one synapse, with all devices within a synapse read during spike transmission, but only one of the devices, selected through an arbitration scheme, is programmed to update the synaptic weight. Software equivalent accuracies could be obtained in the experiment with this scheme, although the individual devices are plagued by several common non-ideal effects such as programming non-linearity, read noise, and conductance drift. Note that with 𝑁 = 1 device representing a synapse, the network accuracy was significantly lower than the software baseline; 𝑁 = 7 devices were necessary to obtain close to ideal performance.
Spiking networks can also be used for other unsupervised learning [87] and adaptation tasks. Recently, Y. Fang et al. demonstrated that certain optimization problems could be solved driven by the coupled dynamics of ferroelectric field-effect transistor (FeFET) based spiking neurons [88] . While there was no synaptic weight adaptation in this approach, the optimal solution to the problem is determined by the coupled interactions between the neurons which modulate each other's membrane potentials in an event-driven manner.
Figure 9 . a) Unsupervised learning demonstration using multi-memristive PCM architecture. The network consists of an integrate and fire neuron receiving inputs from 1000 multi-PCM synapses, with each synapse being excited by Poisson generated binary spike streams. 10% of the synapses receive correlated inputs, while the rest receive uncorrelated inputs. The weights evolve based on the simplified STDP rule shown. b) With N=7 PCM device per synapse, the correlated and uncorrelated synaptic weights evolve to well-separated values, while with N=1, the separation is corrupted due to programming noise. Adapted with permission [86], Copyright 2018, Nature Research.
<details>
<summary>Image 9 Details</summary>
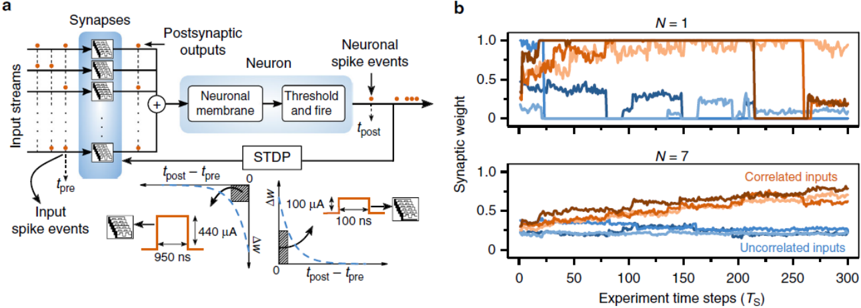
### Visual Description
## Diagram and Charts: Synaptic Weight Dynamics
### Overview
The image presents a diagram illustrating the process of spike-timing-dependent plasticity (STDP) in a neuron, coupled with two charts showing the synaptic weight changes over time under different input correlation conditions (N=1 and N=7).
### Components/Axes
**Part A: STDP Diagram**
* **Title:** Synapses, Neuron
* **Components:**
* **Input Streams:** Represented by vertical lines with dots, feeding into synapses.
* **Synapses:** An array of synaptic connections.
* **Postsynaptic Outputs:** The combined output from the synapses.
* **Neuronal Membrane:** A processing unit receiving the postsynaptic outputs.
* **Threshold and Fire:** A module that generates neuronal spike events when a threshold is reached.
* **Neuronal Spike Events:** Output of the neuron, represented by dots.
* **STDP (Spike-Timing-Dependent Plasticity):** A block representing the STDP mechanism.
* **tpre:** Time of the presynaptic spike.
* **tpost:** Time of the postsynaptic spike.
* **ΔW:** Change in synaptic weight.
* **STDP Timing Diagrams:**
* **Left Diagram:** Shows the change in synaptic weight (ΔW) as a function of the time difference (tpost - tpre). When tpost precedes tpre, there is a negative change in weight.
* Vertical axis: ΔW
* Horizontal axis: tpost - tpre
* **Right Diagram:** Shows the change in synaptic weight (ΔW) as a function of the time difference (tpost - tpre). When tpre precedes tpost, there is a positive change in weight.
* Vertical axis: ΔW
* Horizontal axis: tpost - tpre
* **Pulse Diagrams:**
* Left: A pulse with amplitude 440 μA and duration 950 ns.
* Right: A pulse with amplitude 100 μA and duration 100 ns.
**Part B: Synaptic Weight Charts**
* **Y-axis:** Synaptic weight (ranging from 0 to 1.0).
* **X-axis:** Experiment time steps (Ts) (ranging from 0 to 300).
* **Top Chart:** N = 1
* **Bottom Chart:** N = 7
* **Legend (Bottom Chart):**
* **Correlated inputs:** Represented by brown/orange lines.
* **Uncorrelated inputs:** Represented by blue lines.
### Detailed Analysis
**Part A: STDP Diagram**
* The diagram illustrates how input streams are processed through synapses, combined, and fed into a neuron. The neuron integrates these inputs via its neuronal membrane. If the integrated signal exceeds a threshold, the neuron fires, producing spike events. The STDP mechanism adjusts the synaptic weights based on the timing difference between pre- and postsynaptic spikes.
* The timing diagrams show the relationship between the timing difference (tpost - tpre) and the change in synaptic weight (ΔW). If the postsynaptic spike occurs before the presynaptic spike, the synaptic weight decreases (long-term depression, LTD). Conversely, if the presynaptic spike occurs before the postsynaptic spike, the synaptic weight increases (long-term potentiation, LTP).
**Part B: Synaptic Weight Charts**
* **Top Chart (N = 1):**
* The brown/orange lines representing correlated inputs show a high synaptic weight, close to 1.0, for most of the experiment. One line drops to 0 at approximately time step 250.
* The blue lines representing uncorrelated inputs show a low synaptic weight, close to 0, for most of the experiment. One line increases to approximately 0.75 at time step 50, then drops back to 0 at approximately time step 250.
* **Bottom Chart (N = 7):**
* The brown/orange lines representing correlated inputs show a gradual increase in synaptic weight over time, reaching values between 0.4 and 0.6 by the end of the experiment.
* The blue lines representing uncorrelated inputs show a low synaptic weight, remaining close to 0.2 for most of the experiment.
### Key Observations
* **STDP Mechanism:** The diagram clearly illustrates the STDP mechanism, showing how the timing of pre- and postsynaptic spikes influences synaptic weight changes.
* **Input Correlation Impact:** The charts demonstrate that correlated inputs lead to higher synaptic weights compared to uncorrelated inputs, especially when N = 7.
* **N = 1 vs. N = 7:** The synaptic weight dynamics differ significantly between N = 1 and N = 7. When N = 1, the synaptic weights tend to be more binary (either high or low), while when N = 7, the synaptic weights show a more gradual change over time.
### Interpretation
The data suggests that the STDP mechanism plays a crucial role in shaping synaptic connections based on the correlation of input signals. Correlated inputs strengthen synaptic connections, while uncorrelated inputs weaken them. The number of correlated inputs (N) influences the dynamics of synaptic weight changes. When N is small (N = 1), the synaptic weights exhibit more abrupt transitions, potentially indicating a winner-take-all scenario where only the most correlated input dominates. When N is larger (N = 7), the synaptic weights show a more gradual and distributed change, suggesting a more balanced integration of multiple correlated inputs. This highlights the importance of input correlation and the number of correlated inputs in shaping neuronal circuits and learning.
</details>
4.3. Memristive SNNs for supervised learning. Compared to the previous two approaches, implementing supervised learning in SNNs is a more challenging tasks, as the algorithm and the network must generate spikes at precise time instants based on the input excitation. As opposed to the backpropagation algorithm that is highly successful in training ANNs, supervised learning algorithms for SNNs are not well developed yet, due to the inherent difficulty in applying gradient descent methods for spiking neuron models with infinite discontinuities at the instants of spikes. Nevertheless, there have been several demonstrations of supervised learning algorithms for SNNs based on approximate forms of gradient descent for simple fully-connected networks [89,90,91] .
Figure 10 . a) SNN supervised learning experiment. A two-layer network is tasked with generating 1000ms long spike streams from the 168 neurons at the output corresponding to the images of the spoken characters. The inputs to the network are 132 spike streams representing the characters subsampled from the output of a Silicon cochlea chip. The weights are modified based on the NormAD learning rule. b) Using multi-PCM synapses, the accuracy of spike placement at the output is about 80%, compared to the FP64 accuracy of close to 98%. [92]
<details>
<summary>Image 10 Details</summary>
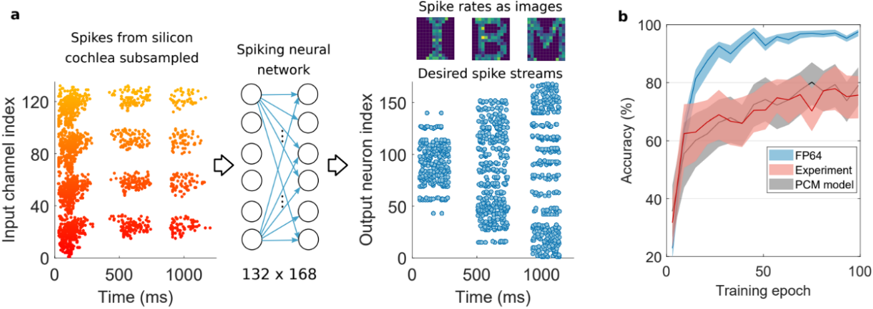
### Visual Description
## Diagram and Chart: Spiking Neural Network Performance
### Overview
The image presents a diagram of a spiking neural network processing data from a silicon cochlea, along with a chart comparing the accuracy of different models (FP64, Experiment, PCM model) during training.
### Components/Axes
**Part a (Left Side):**
* **Title:** Spikes from silicon cochlea subsampled
* **X-axis:** Time (ms), ranging from 0 to 1000.
* **Y-axis:** Input channel index, ranging from 0 to 120.
* **Data:** A scatter plot showing spike events over time, with the color of the points varying from red (at lower channel indices) to yellow/orange (at higher channel indices). The spikes are clustered in four vertical bands, each containing three sub-bands.
* **Title:** Spiking neural network
* **Description:** A diagram of a neural network with an input layer of 6 nodes, and an output layer of 6 nodes. The dimensions of the network are labeled as "132 x 168".
* **Title:** Desired spike streams
* **X-axis:** Time (ms), ranging from 0 to 1000.
* **Y-axis:** Output neuron index, ranging from 0 to 150.
* **Data:** A scatter plot showing spike events over time. The spikes are clustered in three vertical bands.
* **Title:** Spike rates as images
* **Description:** Three images depicting the letters "I", "B", and "M".
**Part b (Right Side):**
* **Title:** Accuracy vs. Training Epoch
* **X-axis:** Training epoch, ranging from 0 to 100.
* **Y-axis:** Accuracy (%), ranging from 20 to 100.
* **Legend:** Located in the bottom-right corner.
* **FP64:** Blue line with a blue shaded region indicating variance.
* **Experiment:** Red line with a red shaded region indicating variance.
* **PCM model:** Gray line with a gray shaded region indicating variance.
### Detailed Analysis
**Part a (Left Side):**
* **Spikes from silicon cochlea subsampled:** The spike events appear to increase in frequency over time within each of the four main bands. The color gradient suggests that lower channel indices (red) are activated earlier than higher channel indices (yellow/orange).
* **Spiking neural network:** The diagram shows a fully connected network.
* **Desired spike streams:** The spike events are clustered into three distinct vertical bands, corresponding to the three letters "I", "B", and "M".
**Part b (Right Side):**
* **FP64 (Blue):** The accuracy increases rapidly from approximately 20% to nearly 95% within the first 20 training epochs, then plateaus.
* **Experiment (Red):** The accuracy increases from approximately 20% to around 70% within the first 20 training epochs, then fluctuates between 70% and 80% for the remaining epochs.
* **PCM model (Gray):** The accuracy increases from approximately 20% to around 80% within the first 50 training epochs, then plateaus.
### Key Observations
* The FP64 model achieves the highest accuracy and converges faster than the other two models.
* The Experiment and PCM models have similar performance, with the PCM model showing a slightly smoother learning curve.
* The silicon cochlea data is processed by the spiking neural network to produce desired spike streams that represent the letters "I", "B", and "M".
### Interpretation
The data suggests that the FP64 model is the most effective for this particular task, achieving higher accuracy with fewer training epochs. The spiking neural network is successfully processing the input from the silicon cochlea to generate spike streams that correspond to specific letters. The experiment and PCM models show comparable performance, indicating that they may be viable alternatives, although not as efficient as the FP64 model. The diagram illustrates the flow of information from the silicon cochlea, through the spiking neural network, and into the desired output spike streams.
</details>
Recently, Nandakumar et al., demonstrated a proof-of-concept realization of supervised learning in a 2-layer SNN implemented using nanoscale phase change memory synapses based on the Normalized Approximate Descent Algorithm [89] . In the experiment, 132 spikestreams representing spoken audio signals generated using a Silicon cochlea chip was used as the input, and the network was trained to generate 168 spike-streams whose arrival times indicate the pixel intensity corresponding to the spoken characters [92] . Compared to normal classification problems in deep networks where the accuracy depends only on the relative magnitude of the response of the output neurons, the SNN problem is harder as the network is tasked with generating close to 1000 spikes at specific time instances over a period of 1250 ms from 168 spiking neurons that are excited by 132 input spike streams. The accuracy for spike placement obtained in the experiment was about 80% compared to the software baseline accuracy of over 98%, despite using the same multi-memristive architecture described earlier. This experiment is hence illustrative of the need for developing more robust and event-driven learning algorithms for SNNs that can mitigate or even leverage the device non-idealities for designing computational systems.
## 4.4. Harnessing Randomness for Learning Noise - from impairment to asset . As
discussed in the previous section, the implementation of standard deterministic learning rules, such as STDP or gradient-based schemes like NormAD [89] , may be severely impaired in hardware implementations whose components are inherently noisy. In this section, we explore the idea that, if properly harnessed, native hardware randomness can be an asset for the deployment of training algorithms for SNNs [93, 94] . The gist of the argument is that randomness enables the native implementation of probabilistic models, which otherwise would require the deployment of additional, potentially costly, components. As we elaborate on next, probabilistic models have several advantages over their conventional deterministic counterparts. We focus the discussion on the problem of training, but we will also mention some of the advantages in terms of inference.
4.5. Training deterministic SNN models. Standard Artificial Neural Network (ANN)-based models only account for uncertainty at their inputs or outputs, while the process transforming inputs to outputs is deterministic. While limiting their expressiveness and their capacity to model structured uncertainty [95] , this modelling choice does not cause a problem in the development of learning rules for ANNs. This is because deterministic ANN models define a differentiable input-output mapping as a function of the model weights, enabling the direct derivation of gradient-based learning rules through backpropagation and automatic differentiation.
Not so for SNNs. In fact, deterministic spiking neuron models such as Leaky Integrate and Fire (LIF) define non-differentiable functions of the synaptic weights: Increasing or decreasing the synaptic weights of a spiking neuron may cause the membrane potential to cross or step back from the spiking threshold, causing an abrupt change in the output. The derivative with respect to the weights is hence zero except around the firing threshold, where it is undefined. As a result, standard gradient-based learning rules cannot be directly derived for deterministic models of SNNs.
A second important issue with conventional gradient-based methods when applied to deterministic SNN models concerns the problem of credit assignment. Discrete-time deterministic SNN models can be interpreted as Recurrent Neural Networks (RNNs) with state defined by the neurons' membrane potential, input currents, and previous spiking behaviours [91] . Accordingly, the outputs and the state transition produced as a function of exogeneous inputs and state depend on the learnable synaptic weights. Therefore, a synaptic weight affects the loss function being optimized via changes that are propagated through the neurons and through time. Assigning credit for changes in the output - which is what is needed to compute the gradient - hence requires to either backpropagate per-output changes through neurons and time or to keep track of per-weight changes in a forward manner through neurons and time [96,97,91] . Both solutions come with significant drawbacks: Backpropagation requires keeping track of forward activations and flowing information backward through time, while forward methods entail the need to memorize per-weight quantities across all neurons.
Given the two challenges discussed above - non-differentiability and credit assignment state-of-the-art training methods for SNNs based on deterministic, typically LIF, models follow various heuristic approaches. As discussed in the previous section, the most common class of methods sidesteps both challenges by carrying out an offline conversion from a pretrained ANNs. This makes it impossible to implement online on-chip learning, and it also limits information processing to rate encoding, which encodes information in the spike frequency (e.g. see [75]). A second, popular, approach is to implement biologically inspired local synaptic update rules, such as STDP, that do not require credit assignment. The main downside of these approaches is that they do not optimize specific objective functions sidestepping the problem of non-differentiability - and hence they are difficult to generalize to a variety of tasks and requirements. When focusing on rate encoding, it is possible to overcome to problem of non-differentiability, but not that of credit assignment, by removing non-linearities and working directly with spiking rates, for example with low-pass filtered spike trains [98,89] .
In contrast to standard rate encoding, SNNs enable a novel type of information processing that computes with time, rather than merely over it as for ANNs. In order to make use of this unique capability of SNNs, it is necessary to derive learning rules that are capable of processing information encoded in the timing of the spikes and not only in their frequency. The simplest way to do this is to limit the number of spikes per neuron to one, so as to assign a continuous-valued output to each neuron. This allows the derivation of backpropagationbased rules as for ANNs, whereby the neurons' (differentiable) non-linearities capture the relationship between input and output spike timings [99] .
More sophisticated methods, allowing for multiple spikes per neuron, are either based on soft non-linearity models [100] or on surrogate gradient methods [91] . The first type of approaches tackles the problem of non-differentiability by approximating the threshold activation function with a differentiable function [100] . As a result, these methods do not preserve the key feature of SNNs of processing and communicating binary spikes. The second class of techniques approximates the derivative of the threshold activation function (but not the function itself) when computing gradients [91] . Both types of methods require backward or forward propagation or the implementation of heuristic credit assignment methods such as random backpropagation [101] . As an example, SuperSpike uses forward propagation to carry out credit assignment over time coupled with random backpropagation for spatial credit assignment [90,91] .
We emphasize again that the discussion above focused on the role of randomness in facilitating training. Randomness in SNNs can also be useful in the inference phase to enable Gibbs sampling-based Bayesian inference strategies [93, 102] .
4.6. Probabilistic SNN models. Among their key advantages, probabilistic models allow the direct encoding of domain knowledge in the graph of connections among the constituent variables - a key feature of so-called expert systems - and the modelling of uncertainty [103] .
They can also account for complex multi-modal distributions, unlike their deterministic counterparts [104] . Finally, stochastic models, even for ANNs, can both improve generalization, as in dropout regularization, and facilitate exploration of the training space [105] .
Training of probabilistic models is generally conceptually more complex than for deterministic models due to the need to account for the exponentially large space of values that the hidden stochastic units can take. Note, however, that probabilistic models have provided the framework used to develop the first deep learning algorithms for ANNs in [106] through Boltzmann machines. Early training methods for general (undirected) models used Gibbs sampling or mean-field approximation, requiring an expensive cycling through the variables one at a time [107,108] . More modern approaches leverage advanced forms of approximate learning and inference via (Generalized) Expectation Maximization, Monte Carlo methods, and variational inference [106,104,109,110] .
Probabilistic models for SNNs can be thought as direct extensions of the belief networks studied in [107,106,105] from static to dynamic models. As in belief networks, a neuron spikes probabilistically with a probability that increases with its membrane potential. In belief networks, the membrane potential of a neuron is an instantaneous function of the current spikes emitted by the incoming neurons in neuron's fan-in. In contrast, in an SNN, the membrane potential of a neuron evolves over time as for LIF models as a function of the past spiking behaviour of the neuron itself and of the neurons in its fan-in (see [111] for a review).
4.7. Training probabilistic SNN models. For the development of training rules, probabilistic SNN models have the fundamental advantage over their deterministic counterparts that the probability of the neurons' outputs is a differentiable function of the model parameters, including the synaptic weights. Many learning criteria can be formulated as the average over such distribution of a given loss or reward function. Specifically, in supervised and unsupervised learning, the learning problem can be formulated as the minimization of a loss function averaged over the joint distribution of data and of specific neurons in a read-out layer [112,111] ; and in reinforcement learning, the goal is to minimize an average reward function dependent on the behaviour of the neurons in the readout layer [113] . Unlike deterministic SNN models, probabilistic SNN models hence allow naturally for the definition of differentiable learning criteria.
Once a learning criterion is determined based on the problem under study, training can be carried out via stochastic gradient-based rules. The key novel challenge in deriving such rules is the need to differentiate over the distribution of the neurons' outputs. Mathematically, with deterministic models, one needs to differentiate a training criterion of the type
$$L _ { d } ( \theta ) = E _ { X \sim D } [ f _ { \theta } ( X ) ] ,$$
where the expectation is taken over the empirical distribution 𝐷 of the data and the model parameter 𝜃 directly affects the learning criterion 𝑓 , (𝑋) through the input-output function of the network. In contrast, with probabilistic models, the relevant learning criterion is of the type
$$L _ { p } ( \theta ) = E _ { X \sim D } [ E _ { Y \sim P _ { \theta } } [ f ( X , Y ) ] ] ,$$
in which 𝑌 represents the random output of the neurons. Note that unlike the standard deterministic approach, the model parameters affect the learning performance through the distribution of the random output of the neurons.
Maximization of the criterion above can be in principle carried out via Expectation Maximization. In practice, the intractability of Bayesian inference of the hidden neurons entails the need for approximate solutions based on sampling methods and gradient-based techniques [104] . Computing stochastic gradients of 𝐿 -(𝜃) requires a double empirical expectation, one over the data distribution 𝐷 and one over the output distribution 𝑃 , . Estimators based on such samples can be derived by following one of a variety of principles, yielding different statistical properties in terms of, e.g., bias and variance [114] .
While a number of techniques attempt to reuse the standard backpropagation algorithm, e.g., the 'Straight-Through' estimator [105] , an approach that is more suitable for the implementation of SNNs is obtained via the score, or log-likelihood, or REINFORCE method and variations thereof (see [104,109,110]). Accordingly, for given data and neurons' output samples the gradient with respect to a synaptic weight can be estimated through the correlation between the accrued loss function over time and the log-probability of the realized output for a given sample (𝑋, 𝑌) , i.e., (somewhat informally)
$$\nabla _ { \theta } L _ { p } ( \theta ) \approx f ( X , Y ) \nabla _ { \theta } \log ( P _ { \theta } ( Y ) ) .$$
Intuitively, the higher the loss is, the more the negative gradient should push away from output distributions that generate such disadvantageous samples 𝑌 . Various improvements of the statistical properties of this estimator are reviewed in [114].
The REINFORCE gradient estimate ∇ , 𝐿 -(𝜃) highlights not only the direct differentiability of generic learning criteria but also the fact that probabilistic learning rules solve the credit assignment problem by not requiring any form of backpropagation [105] . In contrast, a gradient-based rule that uses ∇ , 𝐿 -(𝜃) only requires all nodes to receive a global feedback signal 𝑓(𝑋, 𝑌), which may be computed by a central node [111] . The resulting learning procedure follows the standard three-factor rule from theoretical computer science, whereby the synaptic weights are modified based on pre- and post-synaptic recent spikes, which are locally available at each neuron, and on a global feedback signal [111] . Accordingly, the rule can be easily implemented in an online streaming fashion.
4.8. Generalized probabilistic SNN models. Apart from the advantages described above in terms of differentiability and credit assignment, probabilistic models can be directly extended with minor conceptual and algorithmic difficulties in various directions. First, it is possible to directly derive - technically, by selecting a categorical instead of a Bernoulli distribution in a Generalized Linear Model (GLM) for SNNs - training rules that allow for multi-valued spikes or inter-neuron instantaneous connections or, equivalently, Winner Take All (WTA) circuits [115, 102] . This is particularly important since data produced by some neuromorphic sensors incorporates a sign to indicate a positive or negative change [116] . Multi-valued spikes can also be used for time compression [117] . Second, various decoding rules, such as first-to-spike, can be directly optimized for, instead of having to rely on surrogate target spiking sequences [118] . Third, probabilistic models can provide an estimate of the uncertainty on the trained weights by means of Bayesian Monte Carlo methods [115] .
Before describing some applications of the models and learning rules reviewed above, we mention briefly here alternative probabilistic formulations for SNNs. In the models discussed above, randomness is defined at the level of neurons' outputs. Alternative models introduce randomness at the level of synapses or thresholds [119,120] .
4.9. Examples. Once an SNN is trained, it can be used as a sequence-to-sequence mapper in order to solve supervised, unsupervised, and reinforcement learning problems. Alternatively, with specific choices of the synaptic kernels and memory, the SNN can be used as a Gibbs sampler to carry out Bayesian inference with outputs encoded in the spiking rates [93, 102] . We now briefly discuss three applications that fall in the first category, one concerning supervised learning, one reinforcement learning, and one federated learning.
<details>
<summary>Image 11 Details</summary>
### Visual Description
## Line Charts: Encoding Performance Comparison
### Overview
The image contains two line charts comparing the performance of rate encoding and time encoding methods. The left chart shows the error (MAE - Mean Absolute Error) as a function of ΔT, while the right chart shows the number of spikes as a function of ΔT.
### Components/Axes
**Left Chart:**
* **Title:** error (MAE)
* **Y-axis:** error (MAE), ranging from 0.04 to 0.1.
* **X-axis:** ΔT, with values 3, 5, 7, 10, and 15.
* **Data Series:**
* Rate encoding (blue line with diamond markers)
* Time encoding (orange line with circle markers)
**Right Chart:**
* **Title:** number of spikes
* **Y-axis:** number of spikes, ranging from 0 to 4.
* **X-axis:** ΔT, with values 3, 5, 7, 10, and 15.
* **Data Series:**
* Rate encoding (blue line with diamond markers)
* Time encoding (orange line with circle markers)
### Detailed Analysis
**Left Chart (Error vs. ΔT):**
* **Rate Encoding (blue):** The error starts at approximately 0.085 at ΔT = 3, decreases slightly to approximately 0.082 at ΔT = 5, then decreases further to approximately 0.077 at ΔT = 7, and remains relatively constant at approximately 0.078 at ΔT = 10 and ΔT = 15.
* **Time Encoding (orange):** The error starts at approximately 0.09 at ΔT = 3, decreases to approximately 0.082 at ΔT = 5, then decreases significantly to approximately 0.064 at ΔT = 7, and continues to decrease to approximately 0.052 at ΔT = 10 and remains relatively constant at approximately 0.05 at ΔT = 15.
**Right Chart (Number of Spikes vs. ΔT):**
* **Rate Encoding (blue):** The number of spikes increases from approximately 1.2 at ΔT = 3 to approximately 2.7 at ΔT = 7, and continues to increase to approximately 3.7 at ΔT = 15.
* **Time Encoding (orange):** The number of spikes remains relatively constant at approximately 1.0 at ΔT = 3, approximately 1.1 at ΔT = 5, approximately 1.1 at ΔT = 7, approximately 1.2 at ΔT = 10, and approximately 1.3 at ΔT = 15.
### Key Observations
* In the left chart, the error for time encoding decreases more significantly with increasing ΔT compared to rate encoding.
* In the right chart, the number of spikes for rate encoding increases significantly with increasing ΔT, while the number of spikes for time encoding remains relatively constant.
### Interpretation
The data suggests that time encoding is more effective in reducing error (MAE) as ΔT increases, while rate encoding requires a higher number of spikes to achieve similar or slightly higher error rates. The relationship between ΔT and the number of spikes differs significantly between the two encoding methods. Rate encoding's performance seems to improve with more spikes (higher ΔT), while time encoding maintains a relatively stable number of spikes and achieves lower error rates at higher ΔT values. This could indicate that time encoding is more efficient in terms of spike usage for the same level of accuracy, especially as ΔT increases.
</details>
△T
△T
Figure 11. Test error and number of spikes as a function of the time expansion parameter defining source encoding from natural signals to spikes. Reproduced with permission [ 111 ] , Copyright 2019, IEEE .
In order to first illustrate the potential of probabilistic SNNs trained to process time-encoded information, in Figure 11, we consider an online sequence prediction problem in which samples of a discrete-time source are converted into spiking signals with ∆𝑇 time instants for each sample of the input source. We consider two types of encoding, one based on standard quantization and rate encoding, and one based on the time encoding via Gaussian receptive fields. The figures, fully detailed in [111], demonstrate that time encoding can vastly outperform rate encoding both in terms of accuracy and in terms of number of spikes, which is a proxy for energy consumption.
Second, we consider a standard reinforcement learning task, in which a probabilistic SNN is used as a stochastic policy. Figure 12 compares the performance as a function of the resolution of the input grid representation for a policy directly trained with a first-to-spike decoder and one that is instead converted using state-of-the-art methods from a pre-trained ANN. The results clearly validate the intuition that directly training the stochastic policy as an SNN is more efficient than using ANN-to-SNN conversion.
Figure 12 Time steps to reach goal and spikes per episode for a grid world reinforcement learning task. Reproduced with permission [113], Copyright 2019, IEEE.
<details>
<summary>Image 12 Details</summary>
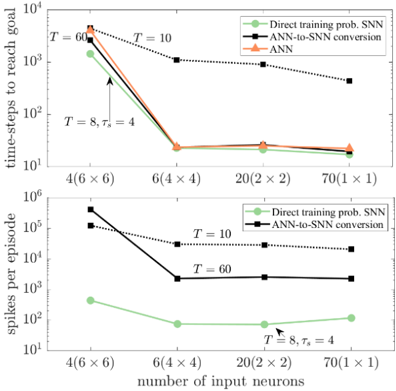
### Visual Description
## Line Charts: Performance Comparison of Different Neural Network Training Methods
### Overview
The image contains two line charts comparing the performance of different neural network training methods. The top chart shows the number of time-steps required to reach a goal, while the bottom chart shows the number of spikes per episode. Both charts compare "Direct training prob. SNN", "ANN-to-SNN conversion", and "ANN" methods across different numbers of input neurons.
### Components/Axes
**Top Chart:**
* **Title:** time-steps to reach goal
* **Y-axis:** time-steps to reach goal (Logarithmic scale, base 10). Axis markers at 10<sup>1</sup>, 10<sup>2</sup>, 10<sup>3</sup>, 10<sup>4</sup>.
* **X-axis:** number of input neurons. Axis markers at 4(6x6), 6(4x4), 20(2 x 2), 70(1 x 1).
* **Legend (Top-Right):**
* Green line with circle markers: Direct training prob. SNN
* Black dotted line with square markers: ANN-to-SNN conversion
* Orange line with triangle markers: ANN
**Bottom Chart:**
* **Title:** spikes per episode
* **Y-axis:** spikes per episode (Logarithmic scale, base 10). Axis markers at 10<sup>1</sup>, 10<sup>2</sup>, 10<sup>4</sup>, 10<sup>5</sup>, 10<sup>6</sup>.
* **X-axis:** number of input neurons. Axis markers at 4(6x6), 6(4x4), 20(2 x 2), 70(1 x 1).
* **Legend (Top-Right):**
* Green line with circle markers: Direct training prob. SNN
* Black dotted line with square markers: ANN-to-SNN conversion
### Detailed Analysis
**Top Chart: Time-steps to reach goal**
* **Direct training prob. SNN (Green):** The line starts at approximately 1200 at 4(6x6), decreases sharply to about 20 at 6(4x4), remains relatively constant at approximately 18 at 20(2x2), and then decreases slightly to approximately 15 at 70(1x1).
* **ANN-to-SNN conversion (Black, dotted):** The line starts at approximately 5000 at 4(6x6), decreases sharply to approximately 900 at 6(4x4), then decreases to approximately 25 at 20(2x2), and finally decreases to approximately 400 at 70(1x1).
* **ANN (Orange):** The line starts at approximately 2500 at 4(6x6), decreases sharply to approximately 20 at 6(4x4), remains relatively constant at approximately 20 at 20(2x2), and then decreases slightly to approximately 18 at 70(1x1).
**Bottom Chart: Spikes per episode**
* **Direct training prob. SNN (Green):** The line starts at approximately 300 at 4(6x6), decreases to approximately 80 at 6(4x4), remains relatively constant at approximately 70 at 20(2x2), and then decreases slightly to approximately 60 at 70(1x1).
* **ANN-to-SNN conversion (Black, dotted):** The line starts at approximately 500000 at 4(6x6), decreases sharply to approximately 25000 at 6(4x4), then decreases to approximately 15000 at 20(2x2), and finally decreases to approximately 10000 at 70(1x1).
### Key Observations
* In the top chart, the "Direct training prob. SNN" and "ANN" methods show similar performance, requiring significantly fewer time-steps to reach the goal compared to "ANN-to-SNN conversion" for lower numbers of input neurons. However, as the number of input neurons increases, the performance gap narrows.
* In the bottom chart, "Direct training prob. SNN" consistently requires significantly fewer spikes per episode compared to "ANN-to-SNN conversion". The difference is several orders of magnitude.
* Both charts show a general trend of decreasing time-steps/spikes per episode as the number of input neurons increases, up to a point, after which the performance plateaus or even slightly degrades.
### Interpretation
The data suggests that "Direct training prob. SNN" and "ANN" are more efficient in terms of time-steps to reach the goal, especially when the number of input neurons is low. However, "ANN-to-SNN conversion" requires significantly more spikes per episode, indicating a higher computational cost. The choice of method depends on the specific application and the trade-off between time-steps, spikes, and the number of input neurons. The annotations "T=60", "T=10", and "T = 8, τs = 4" likely refer to different parameter settings used during the training or conversion process, and their impact on performance varies depending on the method and the number of input neurons.
</details>
Finally, we consider the potential of SNN for on-mobile training via Federated Learning (FL). The approach is motivated by the fact that training on a device is limited by the amount of data available at it. Cooperative training can be carried out through FL as explored in [121], where an online FL-based learning rule is introduced for networked on-mobile probabilistic SNNs. As seen in the Figure 13 through sufficiently frequent inter-device communication, with a communication round occurring every 𝜏 iterations, the scheme demonstrates significant advantages over separate on-mobile training.
Figure 13 Test loss versus number of training iterations with inter-device communication taking place every 𝜏 iterations.
<details>
<summary>Image 13 Details</summary>
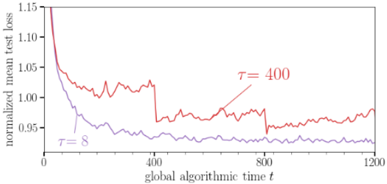
### Visual Description
## Line Chart: Normalized Mean Test Loss vs. Global Algorithmic Time
### Overview
The image is a line chart comparing the normalized mean test loss over global algorithmic time for two different parameter settings, denoted as τ = 8 and τ = 400. The chart illustrates how the test loss changes as the algorithm progresses, with each line representing a different configuration.
### Components/Axes
* **X-axis:** "global algorithmic time t". The scale ranges from 0 to 1200, with tick marks at 0, 400, 800, and 1200.
* **Y-axis:** "normalized mean test loss". The scale ranges from 0.90 to 1.15, with tick marks at 0.95, 1.00, 1.05, 1.10, and 1.15.
* **Legend:**
* τ = 8 (purple line) - Located on the left side of the chart, near the middle.
* τ = 400 (red line) - Located in the upper-middle part of the chart.
### Detailed Analysis
* **τ = 8 (purple line):**
* Trend: The line starts at approximately 1.05 and slopes downward rapidly initially, then gradually decreases and stabilizes around 0.92 after approximately 400 units of global algorithmic time.
* Data Points:
* t = 0, loss ≈ 1.05
* t = 400, loss ≈ 0.93
* t = 1200, loss ≈ 0.92
* **τ = 400 (red line):**
* Trend: The line starts at approximately 1.15 and slopes downward rapidly initially, then fluctuates between 0.95 and 1.03 after approximately 400 units of global algorithmic time. There are noticeable jumps in the loss around t = 400 and t = 800.
* Data Points:
* t = 0, loss ≈ 1.15
* t = 400, loss ≈ 1.03
* t = 800, loss ≈ 0.95
* t = 1200, loss ≈ 0.97
### Key Observations
* The normalized mean test loss decreases over time for both parameter settings.
* The parameter setting τ = 8 results in a lower and more stable test loss compared to τ = 400.
* The parameter setting τ = 400 exhibits more fluctuation and instability in the test loss.
### Interpretation
The chart demonstrates the impact of different parameter settings (τ = 8 and τ = 400) on the performance of a machine learning algorithm, as measured by the normalized mean test loss. The lower and more stable test loss achieved with τ = 8 suggests that this parameter setting leads to better convergence and generalization performance. The fluctuations and jumps observed with τ = 400 indicate potential instability or sensitivity to the training data. The initial rapid decrease in test loss for both settings indicates that the algorithm is learning effectively at the beginning of the training process. The stabilization of the test loss after a certain point suggests that the algorithm has reached a point of diminishing returns, where further training does not significantly improve performance.
</details>
4.10. Algorithmic and hardware co-design. To sum up the discussion in this section, spikebased learning and inference are promising facets of the neuromorphic computing paradigm. Unlike conventional machine learning models, spike-based processing "computes with time, not in time". As we have discussed, the main advantage is a potentially massive increase in power efficiency. In this section, we have presented a review of algorithmic models that leverage stochastic behavior for the implementation of SNNs. While it is true that spike-based computing can be implemented in CMOS technology, there is a great deal to be gained from compact nano-scale implementations of fundamental functional blocks - spiking neurons and adjustable synapses-- in terms of scalability and power-efficiency. Memristors are much better suited to emulate, and not merely simulate many of the sought functionalities. Moreover, the implementation of probabilistic models on current hardware platforms is made difficult by the lack of randomness sources in such systems. In contrast, the inherent randomness of switching processes in memristive devices could provide a source of randomness "for free". Research in spike-based computing is a fast-growing field. We believe that developing better-suited hardware platforms would accelerate the progress of co-designed spike-based learning and inference machines. Memristors may be the missing piece that will unlock the potential of spike-based computing.
## 5. Future of neuromorphic and bio-inspired computing systems
Taking a 'big picture' view, current AI, and machine learning methods in particular, have achieved astonishing results in every field they have been applied to and have become or are becoming standard tools for nearly every type of industry one can think of. This impressive invasion was mainly propelled by deep learning which is loosely inspired by biological neural networks.
Deep learning primarily refers to learning with artificial neural networks of many layers, and fundamentally is not different to what we know about that field in the 90's. Indeed, the key algorithm underlining the success of deep learning, backpropagation, is an old story: 'Learning with back-propagating errors' by Rumelhart, Hinton and Williams was published in 1986 [122] . The most commonly used neural networks are feedforward neural networks, and, convolutional neural networks used for image processing can be seen as inspired by our visual system, and both of these are not very new concepts.
Backpropagation is perhaps the most fundamental method we can think of for parameter optimisation. It is derived by differentiating an error function with respect to the learnable parameters, so in some ways it is not entirely surprising that the algorithm existed for many years. What might be somehow surprising is that we have not been able to move away much from this idea. While there has been recent progress, much of it consisted of relatively small additions and tweaks, for instance new ways to address the so called 'problem of the vanishing gradient', the deterioration of the error signal as is backpropagated from the output to the input of the network. Undoubtedly, there were some fundamentally different architectures, smart techniques and novel analyses but arguably, the key factor behind such a success seems to be the vast availability of data and computational power.
In fact, recent advances of the neuroscience community are not present in the neural networks. We do not want to argue that this, per se, is either good or bad, or to suggest that the next super-algorithms will be copying nature. We only want to underline that though inspired only, artificial neural networks had their basis on neuroscience concepts and that there are many phenomena that have, perhaps, not been sufficiently explored within an AI context. For instance, biological neural networks have different learning rules for positive and negative connections, connections change in multiple time scales and show reversable dynamic behavior (known as short-term plasticity), and the brain itself has a structure where specific areas play different roles, just to name a few.
Instead, our progress was mainly based on hardware improvements that made this success possible by allowing long training phases; an amount of training unrealistic for any human. While it is true that human intelligence also develops over years and that human learning involves many trials, for comparison AlphaGoZero, which surpass human performance in the game of Go, was trained over 4.9 Million games 123 . To match this number of games would require a human that lives for 90 years to complete one Go game every 10 minutes from the moment they are born. This realization tells us two things: (1) our machines do not learn the same way that humans do, and even if we think our methods as bioinspired, we likely still miss some key ingredients and (2) executing that many games certainly require considerable computational power and energy consumption.
As a consequence, training algorithms often require a high energy footprint due to excessive training times and hyper parameter tuning involved. Hyper-parameters are parameters of the system that are not (usually) adapted via the learning method itself, one such example is the learning rate, which indicate how fast the network should update its 'knowledge'. Before rushing to say that a high learning rate is obviously desirable, such a learning rate could lead to oscillations as, for instance, optimal solutions could be overlooked, or it could lead to forgetting previously obtained knowledge. Setting the learning rate right is not always trivial. In fact, the tuning of hyper-parameters was what originally made the machine learning community to turn away from artificial neural networks, and it was the performance of deep learning that brought the focus back. One may then wonder, at the end of the day how much energy inefficient could deep learning systems be? The reply is perhaps surprising: estimated carbon emissions for training standard natural language processing models is approximately five times higher than running a car for a lifetime [124] . This realization suggests there is an urgent need to improve on both current hardware and learning models.
Given such energy concerns, systems based on low-power memristive devices are a highly promising alternative [125,126] . Besides having a low carbon footprint, there is numerus work demonstrating devices that mimic neurons, synapses, and plasticity phenomena. Often such approaches work well for offline training. However, some of these attempts, particularly where plasticity is involved, are opportunistic (including own work) and how scaling to larger networks could happen is not always obvious. Faithfully reproducing the brain functionality, when neuroscience has already so many open questions is challenging for any technology. Moreover, using technologies that potentially allow less possibilities for engineering in comparison to traditional methods (such as CMOS) might well be mission impossible. How far can we go by reconstructing neuron by neuron and synapse by synapse in terms of scalability remains unclear. A more promising way might be to achieve a deeper understanding of the physics of the relevant materials and based on this understanding codevelop the technology and the required learning methods for achieving Artificial Intelligence.
<details>
<summary>Image 14 Details</summary>
### Visual Description
## Diagram: Reservoir Computing Network
### Overview
The image is a diagram illustrating the architecture of a reservoir computing network. It consists of three main layers: an input layer, a dynamic reservoir layer, and an output layer. The diagram shows the connections between these layers and highlights the fixed and trainable weights within the network.
### Components/Axes
* **Input Layer:** Located on the left side of the diagram. Contains a series of purple nodes. Labeled "Input layer" at the top and "Input x(t)" at the bottom.
* **Dynamic Reservoir Layer:** Located in the center of the diagram. Contains a network of interconnected orange nodes within a shaded orange region. Labeled "Dynamic reservoir layer" at the top and "Internal states r(t)" at the bottom.
* **Output Layer:** Located on the right side of the diagram. Contains a series of teal nodes. Labeled "Output layer" at the top and "Output y(t)" at the bottom.
* **Connections:** Arrows indicate the flow of information between the layers. Connections from the input layer to the reservoir layer and from the reservoir layer to the output layer. The reservoir layer also contains internal connections.
* **Weights:** The connections between the input layer and the reservoir layer are labeled as "Fixed". The connections between the reservoir layer and the output layer are labeled as "Trainable weights".
### Detailed Analysis
* **Input Layer:** The input layer consists of at least 3 purple nodes, with an ellipsis indicating that there may be more. Each node in the input layer has connections to multiple nodes in the dynamic reservoir layer.
* **Dynamic Reservoir Layer:** The dynamic reservoir layer is the core of the network. It consists of approximately 10 orange nodes interconnected in a complex, recurrent manner. The connections within the reservoir are represented by curved arrows, indicating feedback loops. The entire reservoir is contained within a shaded orange region.
* **Output Layer:** The output layer consists of at least 3 teal nodes, with an ellipsis indicating that there may be more. Each node in the output layer receives input from multiple nodes in the dynamic reservoir layer.
* **Connections:** The connections between the input layer and the reservoir layer appear to be randomly distributed. The connections between the reservoir layer and the output layer are also distributed.
* **Weights:** The diagram explicitly labels the weights between the input and reservoir layers as "Fixed," implying that these connections are not adjusted during training. The weights between the reservoir and output layers are labeled as "Trainable weights," indicating that these connections are adjusted during the training process.
### Key Observations
* The dynamic reservoir layer is a complex, recurrent network.
* The connections between the input layer and the reservoir layer are fixed.
* The connections between the reservoir layer and the output layer are trainable.
### Interpretation
The diagram illustrates the fundamental architecture of a reservoir computing network. The key idea behind reservoir computing is to use a fixed, randomly connected recurrent neural network (the dynamic reservoir layer) to map the input signal into a higher-dimensional space. The output layer is then trained to read out the desired output from this high-dimensional representation.
The fixed weights between the input and reservoir layers allow the reservoir to act as a non-linear feature extractor. The trainable weights between the reservoir and output layers allow the network to learn the mapping from the reservoir's internal states to the desired output.
The recurrent connections within the reservoir allow the network to process temporal data, making it suitable for tasks such as speech recognition, time series prediction, and control. The complexity of the reservoir's internal connections is crucial for its ability to capture the dynamics of the input signal.
</details>
Fixed
Figure 14 Reservoir Computing maps inputs x(t) to higher-dimensional space, defined by the reservoir states r (t). Only weights connecting reservoir states r (t) and output y (t) need to be trained.
In the meantime, in parallel, we can immediately explore simple bio-inspired approaches that harness the dynamics of the material and could be proven useful for particular sets of problems. Here we present one such example which stems from the area of reservoir computing, an idea invented separately by Herbert Jeager for the machine learning community [ 127 ] , under the name of echo state networks, and by Wolfgang Mass [ 128 ] for the computational neuroscience community, under the name of liquid state machines. We strongly suspect that both these methods were very much motivated by the difficulty of training recurrent networks with a generalization of backpropagation known as backpropagation through time. While feedforward networks can perform many tasks successfully, recurrences are required for memory and, moreover, the brain is clearly not only feedforward. If recurrences exist and are required, there must be a way to efficiently train such structures. As a side note, it is very difficult to imagine how a biological neural network would be able to implement backpropagation through time, and for this alternative approaches have recently made their appearance [ 129 ] .
Reservoir computing methods came up with a workaround to the problem of training recurrent networks: they do not train them but instead harness their properties. Common in the approaches of echo state networks and liquid state machines is the idea of using a randomly recurrent network with fixed connectivity, hence no need to resort to backpropagation through time. This recurrent network is called a reservoir. It provides memory and at the same time transforms the input data to a spatiotemporal representation of higher dimensionality. This enhanced representation can be used as an input to single-layer perceptrons, that are trained with a very simple learning method, so the only learnable parameters are the feedforward weights between the reservoir neurons and the output neurons. The key difference between the echo state networks and liquid state machines, is that the first approach uses recurrent artificial neuron dynamics while the second uses recurrent spiking neural networks, reflecting the mindset in their corresponding communities. The main principle of reservoir computing is shown in Figure 14. The input x (t) is projected into the higher dimensional feature space r (t) by using the dynamical reservoir system. Only the weights connecting the internal states r (t) with the output y (t) need to be trained, while the rest of the system is fixed. The advantage of this approach is that it only requires a simple training method, while the ability to process complex and temporal data is retained.
Indeed, it might be surprising how much randomness can do from the point of computation: a random network can enrich data representations sufficiently so that a linear method can separate the data into the desirable classes. This approach is conceptually similar to the wellknown method of support vector machines, which uses kernels to augment the dimensionality of the data, so that again only a simple linear method is sufficient to achieve data classification. In fact, a link between the purely statistical technique of support vector machines and the bioinspired technique of reservoir computing has been formally built [130] . We can perhaps think of this link as a demonstration that biological inspiration and purely mathematical methodology might also solve problems in a similar manner.
We claim that reservoir computing would benefit from appropriate hardware. When simulating, the convergence of the recurrent network requires time, because the continuous system will be discretized and sequentially run on the CPU. If instead we replace the reservoir with an appropriate material, this step could become both fast and energy efficient: the material could compute effortlessly using its physical properties. Reservoirs do not need overengineering, since no specific structure is required; we only need to produce dynamics that are complex enough but not chaotic. In fact, there has already been work exploiting memristors in this direction [131] .
Could ideas from biology still add value to existing methods? A recent augmentation of the echo state networks [132] , inspired by the fruitfly brain, explores the concept of sparseness in order to improve learning performance of reservoirs. In brains, contrary to the typical artificial neural networks, only few neurons fire at a time, a fact that has been linked to memory capacity. Neuronal thresholds, appropriately initialized and updated with a slower time constant than that of the feedforward learnable weights can modulate sparseness and lead to better performance in comparison to the non-sparse reservoir, but also in comparison to stateof-the-art methods in a set of benchmark problems. Due to the sparseness leading to taskspecific neurons, this bio-inspired technique can alleviate the problem of catastrophic forgetting. Machine learning methods often suffer from the fact that once they learn a new task they have forgotten the previous one. Since in the space reservoir network a new task will likely recruit previously unused neurons, leaning a new skill does not completely override those previously learned. This simple method competes and surpasses more complicated methods that are built specifically to address catastrophic forgetting. Most importantly, the formulation of the specific rule allows for completely replacing the network dynamics with any other dynamics, including material dynamics, that are suitable for the purpose (i.e. highly nonlinear and not chaotic). Perhaps there are more such lessons to be learned from biology.
So, what can be done right now? To us it is clear that a better understanding of the physics behind memristive devices is key for the progress of the field [133] . A deeper understanding will allow us to harness the properties of the system for brain-like computation rather trying to fabricate some arbitrary brain behavior that may or may not be important in the context of a specific application, or worse may not scale up. Instead of thinking at the level of mimicking neurons and synapses, we can instead take inspiration from the biological systems, consider the dynamics required for neuronal processing and use the material physics to reproduce them.
## 6. Conclusion
Memristor technologies are still to realise their full potential that has been promoted over the last 15 years. Although predominantly seen as candidates to replace or augment our current digital memory technologies, the impact of memristor technologies on the broader fields of artificial intelligence and cognitive computing platforms are likely to be even more significant. As discussed in this progress report, the versatility of memristor technologies has resulted in their use across a range of applications: from in-memory computing, deep learning accelerators, spiking neural networks, to more futuristic bio-inspired computing paradigms. These approaches should not be seen as solutions to the same problem, nor as technologies that are in direct competition among themselves or with current, very successful, CMOS systems. Additionally, it is crucial to recognise that many of the discussed research areas are still at the very beginning of their development. Of these, more mature approaches will likely produce industrially relevant solutions sooner. For example, greater power-efficiency is an essential utility and a pressing issue that many engineers are trying to address. In-memory computing and deep learning accelerators based on memristors represent an attractive proposition for extreme power-efficiency.
There is also significant scope for more fundamental work. Development of new generations of bio-inspired algorithms would further boost advancements in hardware systems and platforms. The challenge and opportunity lie in the interdisciplinary nature of the research and the necessity to understand distinct methodologies and approaches. We believe that the community will benefit from the next generation of researchers being well educated across different traditional disciplines. For example, there is an undeniable link between the fields of computer science, more specifically machine learning, and computational neuroscience. The two disciplines could co-exist separately and act independently with distinct goals; however, there are great benefits to be gained from a more holistic approach. A strong case for closer collaboration has been made recently [134] . Collaborations should be expanded to include researchers in solid-state physics, materials science, nanoelectronics, circuit/architecture design and information theory. Memristors show great promise to be a fabric for producing brain-inspired building blocks [135] , and this progress report showcases different types of memristor-based applications. Memristor technologies are versatile enough to provide the perfect platform for different disciplines to strive together in pushing the frontiers of our current technologies in the most fundamental way.
## Acknowledgements
A.M. acknowledges funding and support from the Royal Academy of Engineering under the Research Fellowship scheme. A.S. acknowledges funding from the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement number 682675). B.R. acknowledges partial support from IBM and Cisco. O. S. acknowledges funding from the European Research Council (ERC) under the European Union Horizon 2020 research and innovation program (grant agreement 725731). E.V. would like to acknowledge a Google Faculty Research Award (2017). AJK acknowledges funding from the Engineering and Physical Sciences Research Council (EPSRC).
## References
- 1 Dario Amodei and Danny Hernandez, AI and Compute, https://openai.com/blog/ai-and-compute/, Access: March 2020
2 M. M. Waldrop, Nature 2016 , 530 , 144.
3 V. Sze, Y.-H. Chen, T.-J. Yang, J. S. Emer, Proc. IEEE 2017 , 105 , 2295.
- 4 D. Ielmini, R. Waser, Eds. , Resistive Switching: From Fundamentals of Nanoionic Redox Processes to Memristive Device Applications , Wiley-VCH Verlag GmbH & Co. KGaA, Weinheim, 2016 .
- 5 D. B. Strukov, G. S. Snider, D. R. Stewart, R. S. Williams, Nature 2008 , 453 , 80.
- 6 K. Szot, W. Speier, G. Bihlmayer, R. Waser, Nature Mater 2006 , 5 , 312.
- 7 M. A. Zidan, J. P. Strachan, W. D. Lu, Nat Electron 2018 , 1 , 22.
- 8 L. Chua, IEEE Trans. Circuit Theory 1971 , 18 , 507.
- 9 A. Mehonic, A. J. Kenyon, in Defects at Oxide Surfaces (Eds.: J. Jupille, G. Thornton), Springer International Publishing, Cham, 2015 , pp. 401-428.
- 10 S. Yu, Neuro-Inspired Computing Using Resistive Synaptic Devices , Springer Science+Business Media, New York, NY, 2017 .
- 11 O. Mutlu, S. Ghose, J. Gómez-Luna, R. Ausavarungnirun, Microprocessors and Microsystems 2019 , 67 , 28.
- 12 S. W. Keckler, W. J. Dally, B. Khailany, M. Garland, D. Glasco, IEEE Micro 2011 , 31 , 7.
- 13 N. P. Jouppi, A. Borchers, R. Boyle, P. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, C. Young, T. V. Ghaemmaghami, R. Gottipati, W. Gulland, R. Hagmann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, N. Patil, A. Jaffey, A. Jaworski, A. Kaplan, H. Khaitan, D. Killebrew, A. Koch, N. Kumar, S. Lacy, J. Laudon, J. Law, D. Patterson, D. Le, C. Leary, Z. Liu, K. Lucke, A. Lundin, G. MacKean, A. Maggiore, M. Mahony, K. Miller, R. Nagarajan, G. Agrawal, R. Narayanaswami, R. Ni, K. Nix, T. Norrie, M. Omernick, N. Penukonda, A. Phelps, J. Ross, M. Ross, A. Salek, R. Bajwa, E. Samadiani, C. Severn, G. Sizikov, M. Snelham, J. Souter, D. Steinberg, A. Swing, M. Tan, G. Thorson, B. Tian, S. Bates, H. Toma, E. Tuttle, V. Vasudevan, R. Walter, W. Wang, E. Wilcox, D. H. Yoon, S. Bhatia, N. Boden, in Proceedings of the 44th Annual International Symposium on Computer Architecture - ISCA '17 , ACM Press, Toronto, ON, Canada, 2017 , pp. 1-12.
- 14 A. Sebastian, T. Tuma, N. Papandreou, M. Le Gallo, L. Kull, T. Parnell, E. Eleftheriou, Nat Commun 2017 , 8 , 1115.
- 15 J. J. Yang, D. B. Strukov, D. R. Stewart, Nature Nanotech 2013 , 8 , 13.
- 16 D. Ielmini, H.-S. P. Wong, Nat Electron 2018 , 1 , 333.
- 17 A. Sebastian, M. Le Gallo, R. Khaddam-Aljameh, E. Eleftheriou, Nat. Nanotechnol. 2020 , DOI 10.1038/s41565-020-0655-z.
- 18 M. Di Ventra, Y. V. Pershin, Nature Phys 2013 , 9 , 200.
- 19 Z. Sun, G. Pedretti, E. Ambrosi, A. Bricalli, W. Wang, D. Ielmini, Proc Natl Acad Sci USA 2019 , 116 , 4123.
- 20 L. Chua, Appl. Phys. A 2011 , 102 , 765.
- 21 H.-S. P. Wong, S. Salahuddin, Nature Nanotech 2015 , 10 , 191.
- 22 A. Sebastian, M. Le Gallo, E. Eleftheriou, J. Phys. D: Appl. Phys. 2019 , 52 , 443002.
- 23 A. Sebastian, M. Le Gallo, G. W. Burr, S. Kim, M. BrightSky, E. Eleftheriou, Journal of Applied Physics 2018 , 124 , 111101.
- 24 J. Borghetti, G. S. Snider, P. J. Kuekes, J. J. Yang, D. R. Stewart, R. S. Williams, Nature 2010 , 464 , 873.
- 25 I. Vourkas, G. Ch. Sirakoulis, IEEE Circuits Syst. Mag. 2016 , 16 , 15.
- 26 S. Kvatinsky, D. Belousov, S. Liman, G. Satat, N. Wald, E. G. Friedman, A. Kolodny, U. C. Weiser, IEEE Trans. Circuits Syst. II 2014 , 61 , 895.
- 27 A. Haj-Ali, R. Ben-Hur, N. Wald, R. Ronen, S. Kvatinsky, IEEE Trans. Circuits Syst. I 2018 , 65 , 4258.
- 28 S. Hamdioui, H. A. Du Nguyen, M. Taouil, A. Sebastian, M. L. Gallo, S. Pande, S. Schaafsma, F. Catthoor, S. Das, F. G. Redondo, G. Karunaratne, A. Rahimi, L. Benini, in 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE) , IEEE, Florence, Italy, 2019 , pp. 486-491.
- 29 A. Rahimi, S. Datta, D. Kleyko, E. P. Frady, B. Olshausen, P. Kanerva, J. M. Rabaey, IEEE Trans. Circuits Syst. I 2017 , 64 , 2508.
- 30 G. Karunaratne, M. L. Gallo, G. Cherubini, L. Benini, A. Rahimi, A. Sebastian, arXiv:1906.01548 [physics] 2020 .
- 31 N. Papandreou, H. Pozidis, A. Pantazi, A. Sebastian, M. Breitwisch, C. Lam, E. Eleftheriou, in 2011 IEEE International Symposium of Circuits and Systems (ISCAS) , IEEE, Rio de Janeiro, Brazil, 2011 , pp. 329-332.
R. Carboni, D. Ielmini,
Adv. Electron. Mater.
,
, 1900198.
- 33 Y. Shim, S. Chen, A. Sengupta, K. Roy, Sci Rep 2017 , 7 , 14101.
- 34 H. Nili, G. C. Adam, B. Hoskins, M. Prezioso, J. Kim, M. R. Mahmoodi, F. M. Bayat, O. Kavehei, D. B. Strukov, Nat Electron 2018 , 1 , 197.
- 35 M. Le Gallo, A. Sebastian, G. Cherubini, H. Giefers, E. Eleftheriou, IEEE Trans. Electron Devices 2018 , 65 , 4304.
- 36 G. W. Burr, R. M. Shelby, A. Sebastian, S. Kim, S. Kim, S. Sidler, K. Virwani, M. Ishii, P. Narayanan, A. Fumarola, L. L. Sanches, I. Boybat, M. Le Gallo, K. Moon, J. Woo, H. Hwang, Y. Leblebici, Advances in Physics: X 2017 , 2 , 89.
- 37 M. A. Zidan, J. P. Strachan, W. D. Lu, Nat Electron 2018 , 1 , 22.
- 38 B. Fleischer, S. Shukla, M. Ziegler, J. Silberman, J. Oh, V. Srinivasan, J. Choi, S. Mueller, A. Agrawal, T. Babinsky, N. Cao, C.-Y. Chen, P. Chuang, T. Fox, G. Gristede, M. Guillorn, H. Haynie, M. Klaiber, D. Lee, S.H. Lo, G. Maier, M. Scheuermann, S. Venkataramani, C. Vezyrtzis, N. Wang, F. Yee, C. Zhou, P.-F. Lu, B. Curran, L. Chang, K. Gopalakrishnan, in 2018 IEEE Symposium on VLSI Circuits , IEEE, Honolulu, HI, 2018 , pp. 35-36.
- 39 G. W. Burr, R. M. Shelby, S. Sidler, C. di Nolfo, J. Jang, I. Boybat, R. S. Shenoy, P. Narayanan, K. Virwani, E. U. Giacometti, B. N. Kurdi, H. Hwang, IEEE Trans. Electron Devices 2015 , 62 , 3498.
- 40 A. Sebastian, I. Boybat, M. Dazzi, I. Giannopoulos, V. Jonnalagadda, V. Joshi, G. Karunaratne, B. Kersting,
- R. Khaddam-Aljameh, S. R. Nandakumar, A. Petropoulos, C. Piveteau, T. Antonakopoulos, B. Rajendran, M. L. Gallo, E. Eleftheriou, in 2019 Symposium on VLSI Technology , IEEE, Kyoto, Japan, 2019 , pp. T168-T169.
- 41 A. Mehonic, D. Joksas, W. H. Ng, M. Buckwell, A. J. Kenyon, Front. Neurosci. 2019 , 13 , 593.
- 42 V. Joshi, M. L. Gallo, I. Boybat, S. Haefeli, C. Piveteau, M. Dazzi, B. Rajendran, A. Sebastian, E. Eleftheriou, arXiv:1906.03138 [cs] 2019 .
- 43 D. Joksas, P. Freitas, Z. Chai, W. H. Ng, M. Buckwell, W. D. Zhang, A. J. Kenyon, A. Mehonic, arXiv:1909.06658 [cs] 2019 .
- 44 M. Le Gallo, D. Krebs, F. Zipoli, M. Salinga, A. Sebastian, Adv. Electron. Mater. 2018 , 4 , 1700627.
- 45 S. R. Nandakumar, M. L. Gallo, C. Piveteau, V. Joshi, G. Mariani, I. Boybat, G. Karunaratne, R. KhaddamAljameh, U. Egger, A. Petropoulos, T. Antonakopoulos, B. Rajendran, A. Sebastian, E. Eleftheriou, arXiv:2001.11773 [cs] 2020 .
- 46 I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, Y. Bengio, arXiv:1609.07061 [cs] 2016 .
- 47 M. Le Gallo, A. Sebastian, R. Mathis, M. Manica, H. Giefers, T. Tuma, C. Bekas, A. Curioni, E. Eleftheriou, Nat Electron 2018 , 1 , 246.
- 48 S. R. Nandakumar, M. Le Gallo, I. Boybat, B. Rajendran, A. Sebastian, E. Eleftheriou, in 2018 IEEE International Symposium on Circuits and Systems (ISCAS) , IEEE, Florence, 2018 , pp. 1-5.
- 49 E. Eleftheriou, G. Karunaratne, B. Kersting, M. Stanisavljevic, V. P. Jonnalagadda, N. Ioannou, K. Kourtis, P. A. Francese, A. Sebastian, M. L. Gallo, S. R. Nandakumar, C. Piveteau, I. Boybat, V. Joshi, R. KhaddamAljameh, M. Dazzi, I. Giannopoulos, IBM J. Res. & Dev. 2019 , 63 , 7:1.
- 50 F. Alibart, E. Zamanidoost, D. B. Strukov, Nat Commun 2013 , 4 , 2072.
- 51 T. Gokmen, Y. Vlasov, Front. Neurosci. 2016 , 10 , DOI 10.3389/fnins.2016.00333
- 52 S. Ambrogio, P. Narayanan, H. Tsai, R. M. Shelby, I. Boybat, C. di Nolfo, S. Sidler, M. Giordano, M. Bodini, N. C. P. Farinha, B. Killeen, C. Cheng, Y. Jaoudi, G. W. Burr, Nature 2018 , 558 , 60.
- 53 V. Seshadri, T. C. Mowry, D. Lee, T. Mullins, H. Hassan, A. Boroumand, J. Kim, M. A. Kozuch, O. Mutlu, P. B. Gibbons, in Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture MICRO-50 '17 , ACM Press, Cambridge, Massachusetts, 2017 , pp. 273-287.
- 54 S. Aga, S. Jeloka, A. Subramaniyan, S. Narayanasamy, D. Blaauw, R. Das, in 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA) , IEEE, Austin, TX, 2017 , pp. 481-492.
- 55 N. Verma, H. Jia, H. Valavi, Y. Tang, M. Ozatay, L.-Y. Chen, B. Zhang, P. Deaville, IEEE Solid-State Circuits Mag. 2019 , 11 , 43.
- 56 F. Xiong, A. D. Liao, D. Estrada, E. Pop, Science 2011 , 332 , 568.
Kai-Shin Li, C. Ho, Ming-Taou Lee, Min-Cheng Chen, Cho-Lun Hsu, J. M. Lu, C. H. Lin, C. C. Chen, B. W.
Wu, Y. F. Hou, C. Yi. Lin, Y. J. Chen, T. Y. Lai, M. Y. Li, I. Yang, C. S. Wu, Fu-Liang Yang, in
- Symposium on VLSI Technology (VLSI-Technology): Digest of Technical Papers , IEEE, Honolulu, HI, USA, 2014 , pp. 1-2.
- 58 M. Salinga, B. Kersting, I. Ronneberger, V. P. Jonnalagadda, X. T. Vu, M. Le Gallo, I. Giannopoulos, O. Cojocaru-Mirédin, R. Mazzarello, A. Sebastian, Nature Mater 2018 , 17 , 681.
- 59 S. Pi, C. Li, H. Jiang, W. Xia, H. Xin, J. J. Yang, Q. Xia, Nature Nanotech 2019 , 14 , 35.
- 60 M. Buckwell, L. Montesi, S. Hudziak, A. Mehonic, A. J. Kenyon, Nanoscale 2015 , 7 , 18030.
- 61 S. Brivio, J. Frascaroli, S. Spiga, Nanotechnology 2017 , 28 , 395202.
- 62 S. Choi, S. H. Tan, Z. Li, Y. Kim, C. Choi, P.-Y. Chen, H. Yeon, S. Yu, J. Kim, Nature Mater 2018 , 17 , 335.
- 63 I. Boybat, M. Le Gallo, S. R. Nandakumar, T. Moraitis, T. Parnell, T. Tuma, B. Rajendran, Y. Leblebici, A. Sebastian, E. Eleftheriou, Nat Commun 2018 , 9 , 2514.
- 64 W. W. Koelmans, A. Sebastian, V. P. Jonnalagadda, D. Krebs, L. Dellmann, E. Eleftheriou, Nat Commun 2015 , 6 , 8181.
I. Giannopoulos, A. Sebastian, M. Le Gallo, V. P. Jonnalagadda, M. Sousa, M. N. Boon, E. Eleftheriou, in
2018 IEEE International Electron Devices Meeting (IEDM)
- 66 S. Yu, Proc. IEEE 2018 , 106 , 260.
, IEEE, San Francisco, CA,
, pp. 27.7.1-27.7.4.
- 67 M. Le Gallo, T. Tuma, F. Zipoli, A. Sebastian, E. Eleftheriou, in 2016 46th European Solid-State Device Research Conference (ESSDERC) , IEEE, Lausanne, Switzerland, 2016 , pp. 373-376.
- 68 S. Yu, B. Gao, Z. Fang, H. Yu, J. Kang, H.-S. P. Wong, in 2012 International Electron Devices Meeting , IEEE, San Francisco, CA, USA, 2012 , pp. 10.4.1-10.4.4.
- 69 P. Yao, H. Wu, B. Gao, J. Tang, Q. Zhang, W. Zhang, J. J. Yang, H. Qian, Nature 2020 , 577 , 641.
- 70 P. A. Merolla, J. V. Arthur, R. Alvarez-Icaza, A. S. Cassidy, J. Sawada, F. Akopyan, B. L. Jackson, N. Imam, C. Guo, Y. Nakamura, B. Brezzo, I. Vo, S. K. Esser, R. Appuswamy, B. Taba, A. Amir, M. D. Flickner, W. P. Risk, R. Manohar, D. S. Modha, Science 2014 , 345 , 668.
- 71 M. Jerry, W. Tsai, B. Xie, X. Li, V. Narayanan, A. Raychowdhury, S. Datta, in 2016 74th Annual Device Research Conference (DRC) , IEEE, Newark, DE, USA, 2016 , pp. 1-2.
- 72 T. Tuma, A. Pantazi, M. L. Gallo, A. Sebastian, E. Eleftheriou, Nat. Nanotechnol. 2016 , 11, 693.
73 A. Mehonic, A. J. Kenyon, Front. Neurosci. 2016 , 10 , DOI 10.3389/fnins.2016.00057
- 74 A. Sengupta, A. Ankit, K. Roy, in 2017 International Joint Conference on Neural Networks (IJCNN) , IEEE, Anchorage, AK, USA, 2017 , pp. 4557-4563.
- 75 P. U. Diehl, D. Neil, J. Binas, M. Cook, S.-C. Liu, M. Pfeiffer, in 2015 International Joint Conference on Neural Networks (IJCNN) , IEEE, Killarney, Ireland, 2015 , pp. 1-8.
- 76 A. Sengupta, Y. Ye, R. Wang, C. Liu, K. Roy, Front. Neurosci . 2019 13, 95.
- 77 R. Midya, Z. Wang, S. Asapu, S. Joshi, Y. Li, Y. Zhuo, W. Song, H. Jiang, N. Upadhay, M. Rao, P. Lin, C. Li, Q. Xia, J. J. Yang, Adv. Electron. Mater. 2019 , 5, 1900060.
- 78 G. Bi, M. Poo, J. Neurosci. 1998 , 18 , 10464.
- 79 H. Shouval, Front. Comput. Neurosci. 2010 , DOI 10.3389/fncom.2010.00019.
- 80 Z. Brzosko, S. B. Mierau, O. Paulsen, Neuron 2019 , 103 , 563.
- 81 J. Seo, B. Brezzo, Y. Liu, B. D. Parker, S. K. Esser, R. K. Montoye, B. Rajendran, J. A. Tierno, L. Chang, D.
- S. Modha, D. J. Friedman, in 2011 IEEE Custom Integrated Circuits Conference (CICC) , IEEE, San Jose, CA, USA, 2011 , pp. 1-4.
- 82 D. Kuzum, R. G. D. Jeyasingh, B. Lee, H.-S. P. Wong, Nano Lett. 2012 , 12 , 2179.
- 83 S. Kim, C. Du, P. Sheridan, W. Ma, S. Choi, W. D. Lu, Nano Lett. 2015 , 15 , 2203.
- 84 K. Zarudnyi, A. Mehonic, L. Montesi, M. Buckwell, S. Hudziak, A. J. Kenyon, Front. Neurosci. 2018 , 12 , 57.
- 85 S. Kim, M. Ishii, S. Lewis, T. Perri, M. BrightSky, W. Kim, R. Jordan, G. W. Burr, N. Sosa, A. Ray, J.-P. Han, C. Miller, K. Hosokawa, C. Lam, in 2015 IEEE International Electron Devices Meeting (IEDM) , IEEE, Washington, DC, USA, 2015 , pp. 17.1.1-17.1.4.
- 86 I. Boybat, M. Le Gallo, S. R. Nandakumar, T. Moraitis, T. Parnell, T. Tuma, B. Rajendran, Y. Leblebici, A. Sebastian, E. Eleftheriou, Nat Commun 2018 , 9 , 2514.
- 87 A. Serb, J. Bill, A. Khiat, R. Berdan, R. Legenstein, T. Prodromakis, Nat Commun 2016 , 7 , 12611.
- 88 Y. Fang, Z. Wang, J. Gomez, S. Datta, A. I. Khan, A. Raychowdhury, Front. Neurosci. 2019 , 13 , 855.
- 89 N. Anwani, B. Rajendran, Neurocomputing 2020 , 380 , 67.
- 90 F. Zenke, S. Ganguli, Neural Computation 2018 , 30 , 1514.
- 91 E. O. Neftci, H. Mostafa, F. Zenke, IEEE Signal Process. Mag. 2019 , 36 , 51.
- 92 S. R. Nandakumar, I. Boybat, M. L. Gallo, E. Eleftheriou, A. Sebastian, B. Rajendran, arXiv:1905.11929 [cs] 2019 .
- 93 W. Maass, Proc. IEEE 2014 , 102 , 860.
- 94 M. Payvand, M. V. Nair, L. K. Müller, G. Indiveri, Faraday Discuss. 2019 , 213 , 487.
- 95 D. Koller, N. Friedman, Probabilistic Graphical Models: Principles and Techniques , MIT Press, Cambridge, MA, 2009 .
- 96 R. J. Williams, D. Zipser, Neural Computation 1989 , 1 , 270.
- 97 A. Griewank, A. Walther, Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation , Society For Industrial And Applied Mathematics, Philadelphia, PA, 2008 .
- 98 J. H. Lee, T. Delbruck, M. Pfeiffer, Front. Neurosci. 2016 , 10 , DOI 10.3389/fnins.2016.00508.
- 99 H. Mostafa, IEEE Trans. Neural Netw. Learning Syst. 2017 , 1.
- 100 D. Huh, T. J. Sejnowski, arXiv:1706.04698 [cs, q-bio, stat] 2017 .
- 101 E. O. Neftci, C. Augustine, S. Paul, G. Detorakis, Front. Neurosci. 2017 , 11 , 324.
- 102 B. Nessler, M. Pfeiffer, L. Buesing, W. Maass, PLoS Comput Biol 2013 , 9 , e1003037
- 103 R. M. Neal, Artificial Intelligence 1992 , 56 , 71.
- 104 Y. Tang, R. Salakhutdinov, Advances In Neural Information Processing Systems 2013 (Pp. 530-538).
- 105 Y. Bengio, N. Léonard, A. Courville, arXiv:1308.3432 [cs] 2013 .
- 106 G. E. Hinton, S. Osindero, Y.-W. Teh, Neural Computation 2006 , 18 , 1527
- 107 R. M. Neal, Artificial Intelligence 1992 , 56 , 71.
- 108 D. Barber, P. Sollich, in Advances In Neural Information Processing Systems 2000 (Pp. 393-399).
- 109 T. Raiko, M. Berglund, G. Alain, L. Dinh, arXiv:1406.2989 [cs, stat] 2015 .
- 110 S. Gu, S. Levine, I. Sutskever, A. Mnih, arXiv:1511.05176 [cs] 2016 .
- 111 H. Jang, O. Simeone, B. Gardner, A. Gruning, IEEE Signal Process. Mag. 2019 , 36 , 64.
- 112 J. Brea, W. Senn, J.-P. Pfister, Journal of Neuroscience 2013 , 33 , 9565
B. Rosenfeld, O. Simeone, B. Rajendran, in
2019 IEEE 20th International Workshop on Signal Processing
Advances in Wireless Communications (SPAWC)
, IEEE, Cannes, France,
S. Mohamed, M. Rosca, M. Figurnov, A. Mnih,
H. Jang, O. Simeone, in
, pp. 1-5.
arXiv:1906.10652 [cs, math, stat]
.
ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal
Processing (ICASSP)
, IEEE, Brighton, United Kingdom,
, pp. 3382-3386.
S.-C. Liu, B. Rueckauer, E. Ceolini, A. Huber, T. Delbruck,
C. Xu, W. Zhang, Y. Liu, P. Li,
Front. Neurosci.
,
IEEE Signal Process. Mag.
, 104.
118 A. Bagheri, O. Simeone, B. Rajendran, in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , IEEE, Calgary, AB, 2018 , pp. 2986-2990.
N. Kasabov,
Neural Networks
,
23 , 16
120 H. Mostafa, G. Cauwenberghs, Neural Computation 2018 , 30 , 1542.
N. Skatchkovsky, H. Jang, O. Simeone, arXiv:1910.09594 [cs, eess, stat]
D. E. Rumelhart, G. E. Hinton, R. J. Williams,
,
, 533.
Nature
123 D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, D. Hassabis, Nature 2017 , 550 , 354.
E. Strubell, A. Ganesh, A. McCallum,
Q. Xia, J. J. Yang,
Nat. Mater.
arXiv:1906.02243 [cs]
,
, 309.
M. Rahimi Azghadi, Y.-C. Chen, J. K. Eshraghian, J. Chen, C.-Y. Lin, A. Amirsoleimani, A. Mehonic, A. J.
Kenyon, B. Fowler, J. C. Lee, Y.-F. Chang,
Advanced Intelligent Systems
, 1900189.
The 'echo State' approach to Analysing and Training Recurrent Neural Networks
H. Jaeger,
German National Research Institute For Computer Science,
W. Maass, T. Natschläger, H. Markram,
.
Neural Computation
L. Manneschi, E. Vasilaki,
Nat Mach Intell
,
M. Hermans, B. Schrauwen,
, 155
Neural Computation
,
C. Du, F. Cai, M. A. Zidan, W. Ma, S. H. Lee, W. D. Lu,
, 104.
Nat Commun
L. Manneschi, A. C. Lin, E. Vasilaki, arXiv:1912.08124 [cs, stat]
,
.
M. Lanza, H.-S. P. Wong, E. Pop, D. Ielmini, D. Strukov, B. C. Regan, L. Larcher, M. A. Villena, J. J. Yang,
L. Goux, A. Belmonte, Y. Yang, F. M. Puglisi, J. Kang, B. Magyari-Köpe, E. Yalon, A. Kenyon, M. Buckwell,
A. Mehonic, A. Shluger, H. Li, T.-H. Hou, B. Hudec, D. Akinwande, R. Ge, S. Ambrogio, J. B. Roldan, E.
Miranda, J. Suñe, K. L. Pey, X. Wu, N. Raghavan, E. Wu, W. D. Lu, G. Navarro, W. Zhang, H. Wu, R. Li, A.
Holleitner, U. Wurstbauer, M. C. Lemme, M. Liu, S. Long, Q. Liu, H. Lv, A. Padovani, P. Pavan, I. Valov, X.
Jing, T. Han, K. Zhu, S. Chen, F. Hui, Y. Shi,
Adv. Electron. Mater.
Commun. ACM
J. B. Aimone,
J. D. Kendall, S. Kumar,
,
, 110.
Applied Physics Reviews
,
, 011305.
, 1800143.
.
,
,
.
14 , 2531.
, 2204.
,
36 , 29.
, GMD -