## Learning Graph Structure With A Finite-State Automaton Layer
## Daniel D. Johnson, Hugo Larochelle, Daniel Tarlow
Google Research
{ddjohnson, hugolarochelle, dtarlow}@google.com
## Abstract
Graph-based neural network models are producing strong results in a number of domains, in part because graphs provide flexibility to encode domain knowledge in the form of relational structure (edges) between nodes in the graph. In practice, edges are used both to represent intrinsic structure (e.g., abstract syntax trees of programs) and more abstract relations that aid reasoning for a downstream task (e.g., results of relevant program analyses). In this work, we study the problem of learning to derive abstract relations from the intrinsic graph structure. Motivated by their power in program analyses, we consider relations defined by paths on the base graph accepted by a finite-state automaton. We show how to learn these relations end-to-end by relaxing the problem into learning finite-state automata policies on a graph-based POMDP and then training these policies using implicit differentiation. The result is a differentiable Graph Finite-State Automaton (GFSA) layer that adds a new edge type (expressed as a weighted adjacency matrix) to a base graph. We demonstrate that this layer can find shortcuts in grid-world graphs and reproduce simple static analyses on Python programs. Additionally, we combine the GFSA layer with a larger graph-based model trained end-to-end on the variable misuse program understanding task, and find that using the GFSA layer leads to better performance than using hand-engineered semantic edges or other baseline methods for adding learned edge types.
## 1 Introduction
Determining exactly which relationships to include when representing an object as a graph is not always straightforward. As a motivating example, consider a dataset of source code samples. One natural way to represent these as graphs is to use the abstract syntax tree (AST), a parsed version of the code where each node represents a logical component. 1 But one can also add additional edges to each graph in order to better capture program behaviors. Indeed, adding additional edges to represent control flow or data dependence has been shown to improve performance on code-understanding tasks when compared to a AST-only or token-sequence representation [1, 19].
An interesting observation is that these additional edges are fully determined by the AST, generally by using hand-coded static analysis algorithms. This kind of program abstraction is reminiscent of temporal abstraction in reinforcement learning (e.g., action repeats or options [30, 38]). In both cases, derived higher-level relationships allow reasoning more abstractly and over longer distances (in program locations or time).
In this work, we construct a differentiable neural network layer by combining two ideas: program analyses expressed as reachability problems on graphs [34], and mathematical tools for analyzing temporal behaviors of reinforcement learning policies [13]. This layer, which we call a Graph
1 For instance, the AST for print(x + y) contains nodes for print , x , y , x + y , and the call as a whole.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Code Flowchart: Execution Path Visualization
### Overview
The image contains three components:
1. **Left**: A Python function `example_fn(x, y)` with annotations (arrows, colors) indicating execution flow.
2. **Center**: A modified version of the same function with additional annotations (green circles, orange dashed lines).
3. **Right**: A flowchart visualizing the control flow using colored arrows (green, red, blue, orange).
### Components/Axes
#### Left Code Snippet
- **Function Definition**: `def example_fn(x, y):`
- **Print Statements**:
- `print(x, y)` (annotated with yellow and blue boxes).
- `print(x, y)` inside `while` loop (yellow box).
- `print(x, y)` after `break` (blue box).
- **Loop Structure**:
- `while x > 0:` (annotated with green arrow).
- `x = x - 1` (dashed orange line).
- **Conditional Break**:
- `if y > 10:` (green arrow).
- `break` (red arrow).
- **Post-Loop Print**: `print(x, y)` (blue box).
#### Center Code Snippet
- **Annotations**:
- Green circles around `print(x, y)` and `while x > 0:`.
- Orange dashed lines connecting `print(x, y)` to `break`.
- Blue wavy line connecting `y = y + 1` to final `print(x, y)`.
#### Right Flowchart
- **Nodes**:
- `print(x, y)` (start node, green arrow).
- `while x > 0:` (loop condition, green arrow).
- `x = x - 1` (dashed orange line).
- `if y > 10:` (conditional, green arrow).
- `break` (red arrow).
- `y = y + 1` (blue arrow).
- **Edges**:
- Green arrows for primary flow.
- Red arrow for `break`.
- Blue arrow for post-loop execution.
- Orange dashed lines for conditional paths.
### Detailed Analysis
#### Left Code Snippet
- **Execution Flow**:
1. Initial `print(x, y)` (yellow box).
2. Enter `while x > 0:` loop (green arrow).
3. Decrement `x` by 1 (dashed orange line).
4. Check `if y > 10:` (green arrow).
- If true: Execute `break` (red arrow).
- If false: Continue loop.
5. After loop, execute final `print(x, y)` (blue box).
6. Increment `y` by 1 (`y = y + 1`).
#### Center Code Snippet
- **Annotations**:
- Green circles emphasize repeated `print(x, y)` calls.
- Orange dashed lines highlight the conditional `break` path.
- Blue wavy line indicates post-loop execution.
#### Right Flowchart
- **Color-Coded Paths**:
- **Green**: Primary loop iterations (`while x > 0`).
- **Red**: `break` termination.
- **Blue**: Post-loop execution.
- **Orange**: Conditional `if y > 10` path.
### Key Observations
1. **Loop Termination**: The loop exits either when `x ≤ 0` or `y > 10`.
2. **Variable Updates**: `x` decrements by 1 per iteration; `y` increments by 1 after the loop.
3. **Print Statements**:
- Initial and final `print(x, y)` capture state before/after loop.
- Intermediate `print(x, y)` inside the loop (annotated with yellow/blue boxes).
### Interpretation
The flowchart and annotations illustrate a function that:
1. Prints initial `(x, y)` values.
2. Iterates while `x > 0`, decrementing `x` each iteration.
3. Breaks early if `y > 10`, skipping remaining iterations.
4. Prints final `(x, y)` after loop termination.
5. Increments `y` post-loop, suggesting a secondary effect outside the loop.
The annotations and flowchart emphasize **control flow dependencies**:
- The `break` condition (`y > 10`) overrides the `x > 0` loop condition.
- The final `print(x, y)` occurs regardless of loop termination reason.
- The post-loop `y = y + 1` implies a side effect independent of the loop's logic.
This visualization aids in understanding how variable updates and conditional breaks interact in nested control structures.
</details>
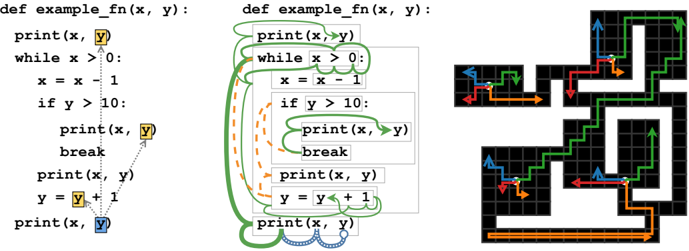
- (a) LASTREAD edges for an example function.
- (b) Learned behavior of GFSA on LASTREAD task.
- (c) Learned behavior of GFSA on grid-world task.
Figure 1: (a) Target edges for the LASTREAD task starting from the final use of y on a handwritten example function. (b) Learned behavior starting at the final use of y (blue circle). Thickness represents probability mass, color and style represent the finite-state memory, and boxes represent AST nodes in the graph. The automaton changes to a reverse-execution mode (green) and steps backward to the while loop, then nondeterministically either looks at the condition or switches to a break-finding mode (orange) and jumps to the body. In the first case, it checks for uses of y in the condition, then splits again between the previous print and the loop body. In the second, it walks upward until finding a break statement, then transitions back to the reverse-execution mode. For simplicity, we hide backtracking trajectories and combine some intermediate steps. Note that only the start and end locations (colored boxes in (a)) are supervised; all intermediate steps are learned. (c) Colored arrows denote the path taken by the GFSA policy for each option, shown starting from four arbitrary start positions (white) on a grid-world layout not seen during training. The tabular agent can jump from each start position to the endpoint of any of its arrows in a single step.
Finite-State Automaton (GFSA), can be trained end-to-end to add derived relationships (edges) to arbitrary graph-structured data based on performance on a downstream task. 2 We show empirically that the GFSA layer has favorable inductive biases relative to baseline methods for learning edge structures in graph-based neural networks.
## 2 Background
## 2.1 Neural Networks on Graphs
Many neural architectures have been proposed for graph-structured data. We focus on two general families of models: first, message-passing neural networks (MPNNs), which compute sums of messages sent across each edge [17], including recurrent models such as Gated Graph Neural Networks (GGNNs) [27]; second, transformer-like models operating on the nodes of a graph, which include the Relation-Aware Transformer (RAT) [42] and Graph Relational Embedding Attention Transformer (GREAT) [19] models along with other generalizations of relative attention [37]. All of these models assume that each node is associated with a feature vector, and each edge is associated with a feature vector or a discrete type.
## 2.2 Derived Relationships as Constrained Reachability
Compilers and static analysis tools use a variety of techniques to analyze programs, many of which are based on fixed-point analysis over a problem-specific abstract lattice (see for instance Cousot and Cousot [10]). However, it is possible to recast many of these analyses within a different framework: graph reachability under formal language constraints [34].
Consider a directed graph G where the nodes and edges are annotated with labels from finite sets N and E . Let L be a formal language over alphabet Σ = N ∪ E , i.e. L ⊆ Σ ∗ is a set of words (finite
2 An implementation is available at https://github.com/google-research/google-research/ tree/master/gfsa .
sequences of labels from Σ ) built using formal rules. One useful family of languages is the set of regular languages : a regular language L consists of the words that match a regular expression, or equivalently the words that a finite-state automaton (FSA) accepts [20]. Note that each path in G corresponds to a word in Σ ∗ , obtained by concatenating the node and edge labels along the path. We say that a path from node n 1 to n 2 is an L -path if this word is in L .
Using a construction similar to Reps [34], one can construct a regular language L such that, if n 1 is the location of a variable and n 2 is the location of a previous read from that variable, then there is an L -path from n 1 to n 2 (and every L -path is of this form); roughly, L contains paths that trace backward through the program's execution. This corresponds to edge type LASTREAD as described by Allamanis et al. [1], which is visualized in Figure 1a. Similarly, one can define edges and corresponding regular languages that connect each use of a variable to the possible locations of the previous assignment to it (the LASTWRITE edge type from [1]) or connect each statement to the statements that could execute directly afterward (which we denote NEXTCONTROLFLOW since it corresponds to the control flow graph); see appendix A.1 for details. More generally, the existence of L -paths summarizes the presence of longer chains of relationships with a single pairwise relation. Depending on L , this can represent transitive closures, compositions of edges, or other more complex patterns. We may not always know which language L would be useful for a task of interest; our approach makes it possible to jointly learn L and use the L -paths as an abstraction for the downstream task.
## 3 Approach
Consider, as a motivating example, a graph representing the abstract syntax tree for a Python program. Each of the nodes of this tree has a type, for instance 'identifier', 'binary operation' or 'if statement', and edges correspond to AST fields such as 'X is the left child of Y' or 'X is the loop condition of Y'. Section 2.2 suggests that L -paths on this graph are a useful abstraction for higher-level reasoning, but we do not know what the best choice of L is; we seek a mechanism to learn it end-to-end.
We propose placing an agent on a node of this tree, with actions corresponding to the possible fields of each node (e.g. 'go to parent node' or 'go to left child'), and observations giving local information about each node (e.g. 'this is an identifier, but not the one we are trying to analyze'). Note that the trajectories of this agent then correspond to paths in the graph. We allow the agent to terminate the episode and add an edge from its initial to its current location, thus 'accepting" the path it has taken. By averaging over all trajectories, we obtain an expected adjacency matrix for these edges that summarizes the paths that the agent tends to accept, which we use as an output edge type.
If the agent's actions were determined by a finite-state automaton for a regular language L , the added edges would correspond to L -paths. We propose parameterizing the agent with a learnable finite-state automaton, so that it can learn to do the kinds of analyses that a regular language can express. As long as the actions and observations are shared across all ASTs, we can then apply this policy to many different ASTs, even ones not seen at training time.
In this section, we formalize and generalize this intuition by describing a transformation from graphs into partially-observable Markov decision processes (POMDPs). We show that, for agents with a finite-state hidden memory, we can efficiently compute and differentiate through the distribution of trajectory endpoints. We propose using this distribution to define a new edge type, and demonstrate that any regular-language-constrained reachability problem (and in particular, basic program analyses) can be expressed as a policy of this form.
## 3.1 From Graphs to POMDPs
Suppose we have a family of graphs G with an associated set of node types N . Our approach is to transform each graph G ∈ G to a rewardless POMDP, in which an agent takes a sequence of actions to move between nodes of the graph while observing only local information about its current location. To ensure that all graphs have compatible action and observation spaces, for each node type τ ( n ) ∈ N we choose a finite set M τ ( n ) of movement actions associated with that node type (e.g. the set of possible fields that can be followed) and a finite set Ω τ ( n ) of observations (which include the node type as well as other task-specific information). These choices may depend on domain knowledge about the graph family or the task to be solved; see appendix B for the specific choices we used in our experiments.
At each node n t ∈ N of a graph G ∈ G , the agent selects an action a t from the set
$$\mathcal { A } _ { t } = \left \{ \left ( M o v E , m \right ) \, | \, m \in \mathcal { M } _ { \tau ( n _ { t } ) } \right \} \sqcup \left \{ A D D E G E A N D S T O P , S T O P , B A C K T R A C K \right \}$$
according to some policy π . If a t = ADDEDGEANDSTOP, the episode terminates by adding an edge ( n 0 , n t ) to the output adjacency matrix. If a t = STOP, the episode terminates without adding an edge. If a t = ( MOVE , m ) , the agent is either moved to an adjacent node n t +1 ∈ N in the graph by the environment or stays at node n t (and thus n t +1 = n t ), and then receives an observation ω t +1 with ω t +1 ∈ Ω τ ( n t +1 ) . The MDP is partially observable because the agent does not see node identities or the global structure; instead, ω t +1 encodes only node types and other local information. Since derived edge types may depend on existing pairwise relationships between nodes (for instance, whether two variables have the same name), we allow the observations to depend on the initial node n 0 as well as the current node n t and most recent transition; in effect, each choice of n 0 ∈ N specifies a different version of the POMDP for graph G . Finally, if a t = BACKTRACK is selected, the agent is reset to its initial state. We note that, since the action and observation spaces are shared between all graphs in G , a single policy π can be applied to any graph G ∈ G .
We would like our agent to be powerful enough to extract useful information from this POMDP, but simple enough that we can efficiently compute and differentiate through the learned trajectories. Since our motivating program analyses can be represented as regular languages, which correspond to finite-state automata (see section 2.2), we focus on agents augmented with a finite-state memory.
## 3.2 Computing Absorbing Probabilities
Here we describe an efficient way to compute and differentiate through the distribution over trajectory endpoints for a finite-state memory policy over a graph. Let Z be a finite set of memory states, and consider a specific policy π θ ( a t , z t +1 | ω t , z t ) parameterized by θ (see appendix C.1 for details regarding the parameterization we use). Combining the policy π θ with the environment dynamics for a single graph G yields an absorbing Markov chain over tuples ( n t , ω t , z t ) , with transition distribution
$$\begin{array} { r l } & { p ( n _ { t + 1 } , \omega _ { t + 1 } , z _ { t + 1 } | n _ { t } , \omega _ { t } , z _ { t } , n _ { 0 } ) = \sum _ { m _ { t } } \pi _ { \theta } \left ( a _ { t } = \left ( M O V E , m _ { t } \right ) , z _ { t + 1 } | \omega _ { t } , z _ { t } \right ) } \\ & { \quad \cdot p ( n _ { t + 1 } | n _ { t } , m _ { t } ) \cdot p ( \omega _ { t + 1 } | n _ { t + 1 } , n _ { t } , m _ { t } , n _ { 0 } ) } \end{array}$$
and halting distribution π θ ( a t ∈ { ADDEDGEANDSTOP , STOP , BACKTRACK } | n t , ω t , z t ) . We can represent this distribution via a transition matrix Q n 0 ∈ R K × K where K is the set of possible ( n, ω, z ) tuples, along with a halting matrix H ∈ R (3 ×| N | ) × K (keeping track of the final node n T ∈ N as well as the halting action). We can then compute probabilities for each final action by summing over each possible trajectory length i :
$$p ( a _ { T } , n _ { T } | n _ { 0 } , \pi _ { \theta } ) = \left [ \sum _ { i \geq 0 } H Q _ { n _ { 0 } } ^ { i } \delta _ { n _ { 0 } } \right ] _ { ( a _ { T } , n _ { T } ) } = H _ { ( a _ { T } , n _ { T } ) , \colon } \left ( I - Q _ { n _ { 0 } } \right ) ^ { - 1 } \delta _ { n _ { 0 } } , \quad ( 1 )$$
where δ n 0 is a vector with a 1 at the position of the initial state tuple ( n 0 , ω 0 , z 0 ) . Note that, since the matrix depends on the initial state n 0 , it would be inefficient to analytically invert this matrix for every n 0 . We thus use T max iterations (typically 128) of the the Richardson iterative solver [3] to obtain an approximate solution using only efficient matrix-vector products; this is equivalent to truncating the sum to include only paths of length at most T max .
To compute gradients with respect to θ , we use implicit differentiation to express the gradients as the solution to another (transposed) linear system and use the same iterative solver; this ensures that the memory cost of this procedure is independent of T max (roughly the cost of a single propagation step for a message-passing model). We implement the forward and backward passes using the automatic differentiation package JAX [8], which makes it straightforward to use implicit differentiation with an efficient matrix-vector product implementation that avoids materializing the full transition matrix Q n 0 for each value of n 0 (see appendix C for details).
## 3.3 Absorbing Probabilities as a Derived Adjacency Matrix
Finally, we construct an output weighted adjacency matrix by averaging over trajectories:
$$\begin{array} { r l } & { \widehat { A } _ { n , n ^ { \prime } } = p ( a _ { T } = A D D E D G E A N D S T O P , n _ { T } = n ^ { \prime } | n _ { 0 } = n , a _ { T } \neq B A C K T R A C K , z _ { 0 } , \pi _ { \theta } ) , } \\ & { A _ { n , n ^ { \prime } } = \sigma \left ( a \, \sigma ^ { - 1 } \left ( \widehat { A } _ { n , n ^ { \prime } } \right ) + b \right ) } \end{array} \quad ( 2 )$$
where a, b ∈ R are optional learned adjustment parameters, σ denotes the logistic sigmoid, and σ -1 denotes its inverse. Note that, since they are derived from a probability distribution, the columns of ̂ A n,n ′ sum to at most 1. The adjustment parameters a and b remove this restriction, allowing the model to express one-to-many relationships.
Given a fixed initial automaton state z 0 , A n,n ′ can be viewed as a new weighted edge type. Since A n,n ′ is differentiable with respect to the policy parameters θ , this adjacency matrix can either be supervised directly or passed to a downstream graph model and trained end-to-end.
## 3.4 Connections to Constrained Reachability Problems
As described in section 2.2, many interesting derived edge types can be expressed as the solutions to constrained reachability problems. Here, we describe a correspondence between constrained reachability problems on graphs and trajectories within the POMDPs defined in section 3.1.
Proposition 1. Let G be a family of graphs annotated with node and edge types. There exists an encoding of graphs G ∈ G into POMDPs as described in section 3.1 and a mapping from regular languages L into finite-state policies π L such that, for any G ∈ G , there is an L -path from n 0 to n T in G if and only if p ( a T = ADDEDGEANDSTOP , n T | n 0 , π L ) > 0 .
In other words, for any ordered pair of nodes ( n 0 , n T ) , determining if there is a path in G that satisfies regular-language reachability constraints is equivalent to determining if a specific policy takes the ADDEDGEANDSTOP action at node n T with nonzero probability when started at node n 0 , under a particular POMDP representation. See appendix A.2 for a proof. As a specific consequence:
Corollary. There exists an encoding of program AST graphs into POMDPs and a specific policy π NEXT-CF with finite-state memory such that p ( a T = ADDEDGEANDSTOP , n T | n 0 , π ) > 0 if and only if ( n 0 , n T ) is an edge of type NEXTCONTROLFLOW in the augmented AST graph. Similarly, there are policies π LAST-READ and π LAST-WRITE for edges of type LASTREAD and LASTWRITE , respectively.
## 3.5 Connections to Reinforcement Learning and the Successor Representation
The GFSA layer deterministically computes continuous edge weights by marginalizing over trajectories. These weights can then be transformed nonlinearly (e.g. f ( E [ τ ]) where f is the downstream model and loss and τ are edge additions from trajectories). In contrast, standard RL approaches produce stochastic discrete samples. As such, is not possible to 'drop in' an RL approach instead of GFSA; one must first reformulate the model and task in terms of an expected reward E [ f ( τ )] .
Even so, there are interesting connections between the gradient updates for GFSA and traditional RL. In particular, the columns of the matrix ( I -Q n 0 ) -1 are known in the RL literature as the successor representation . If immediate rewards are described by r , then taking a product r T ( I -Q n 0 ) -1 corresponds to computing the value function [13]. In our case, instead of specifying a reward, we use the GFSA layer for a downstream task that requires optimizing some loss L . When computing gradients of our parameters with respect to L , backpropagation computes a linear approximation of the downstream network and loss function and then uses it in the intermediate expression
$$\frac { \partial \mathcal { L } } { \partial p ( \cdot | n _ { 0 } , \pi _ { \theta } ) } ^ { T } H \left ( I - Q _ { n _ { 0 } } \right ) ^ { - 1 } .$$
This is analogous to a non-stationary 'reward function' for the GFSA policy, which assigns reward to the absorbing states that produce useful edges for the rest of the model. Unlike in standard RL, however, this quantity depends on the full marginal distribution over behaviors. As such, the 'reward' assigned to a given trajectory may depend on the probability of other, mutually exclusive trajectories.
## 4 Related Work
Some prior work has explored learning edges in graphs. Kipf et al. [25] propose a neural relational inference model, which infers pairwise relationships from observed particle trajectories but does not add them to a base graph. Franceschi et al. [15] infer missing edges in a single fixed graph by jointly optimizing the edge structure and a classification model; this method only infers edges of a predefined type, and does not generalize to new graphs at test time. Yun et al. [48] propose adding
new edge types to a graph family by learning to compose a fixed number of existing edge types, which can be seen as a special case of GFSA where each state is visited once. The MINERVA model, described in Das et al. [12], uses an RL agent trained with REINFORCE to add edges to a knowledge base, but requires direct supervision of edges. Wang et al. [43] use a RL policy to remove existing edges from a noisy graph, with reward coming from a downstream classification task.
Bielik et al. [7] apply decision trees to program traces with a counterexample-guided program generator in order to learn static analyses of programs. Their method is provably correct, but cannot be used as a component of an end-to-end differentiable model or applied to general graph structures.
Our work shares many commonalities with reinforcement learning techniques. Section 3.5 describes a connection between the GFSA computation and the successor representation [13]. Our work is also conceptually similar to methods for learning options. For instance, Bacon et al. [4] describe an endto-end architecture for learning options by differentiating through a primary policy's reward. Their option policies and primary policy are analogous to our GFSA edge types and downstream model; on the other hand, they apply policy gradient methods to trajectory samples instead of optimizing over full marginal distributions, and their full architecture is still a policy, not a general model on graphs.
Existing graph embedding methods have used stochastic walks on graphs [47, 23, 49, 24, 21, 9], but generally assume uniform random walks. Alon et al. [2] propose representing ASTs by sampling random paths and concatenating their node labels, then attending over the resulting sequences. Dai et al. [11] describe a framework of MDPs over graphs, but focus on a 'learning to explore' task, where the goal is to visit many nodes and the agent can see the entire subgraph it has already visited. Hudson and Manning [22] propose treating the nodes of an inferred scene graph as states of a learned state machine, and learning to update the current active node based on natural-language inputs.
Self-attention can be viewed as constructing a weighted adjacency matrix similar to GFSA, but only considers pairwise relationships and not longer paths. Existing approaches to learning multi-step path-based relationships include iterating a graph neural network until convergence [36] and using a learned stopping criterion as in Universal Transformers [14]. The algorithm in section 3.2 in particular resembles running a separate graph neural network model to convergence for each start node and training with recurrent backpropagation [36, 28], and is also similar to other uses of implicit differentiation [45, 5, 32]. The GFSA layer enables multi-step relationships to be efficiently computed for every start node in parallel and provides good expressivity and inductive biases for learning edges, in contrast to previous techniques that focus on learning node representations and must learn from scratch to propagate multi-step information without letting distinct paths interfere with each other.
Weiss et al. [44] describe a method for extracting a discrete finite-state automaton from a RNN; this assumes access to an existing trained RNN for the task, and is intended for recognizing sequences, not adding edges to graphs. See also Mohri [31] for a framework of weighted automata on sequences.
## 5 Experiments
## 5.1 Grid-World Options
As an illustrative example, we consider the task of discovering useful navigation strategies in gridworld environments. We generate grid-world layouts using the LabMaze generator [6], 3 and interpret each cell as a node in a graph G , where edges represent cardinal directions. We augment this graph with additional edges from a GFSA layer, using four independent GFSA policies to add four additional edge types; let G ′ θ ( G ) denote the augmented graph using GFSA parameters θ . Next, we construct a pathfinding task on the augmented graph G ′ θ ( G ) , in which a graph-specific agent finds the shortest path to some goal node g . We assign an equal cost to all edges (including those that the GFSA layer adds); when the agent follows a GFSA edge, it ends up at a destination cell with probability proportional to the edge weights from the GFSA layer.
Inspired by existing work on meta-learning options [16], we interpret the GFSA-derived edges as a kind of option for this agent: given a random graph, the edges added by the GFSA layer should make it possible to quickly reach any goal node g from any start location n 0 . More specifically, we train the graph-independent GFSA layer (in an outer loop) to minimize the number of steps that a
3 https://github.com/deepmind/labmaze
graph-specific policy (trained in an inner loop) takes to reach the goal g , i.e. we minimize
$$\mathcal { L } = \mathbb { E } _ { G , n _ { 0 } , g } \left [ \mathbb { E } _ { n _ { t } \sim \pi ^ { * } ( \cdot | n _ { t - 1 } , g , G _ { \theta } ^ { \prime } ( G ) ) } \left [ T | n _ { T } = g \right ] \right ]$$
where π ∗ ( ·| g, G ′ θ ( G )) is an optimal tabular policy for graph G ′ θ ( G ) and goal g . In order to differentiate this with respect to the GFSA parameters θ , we use entropy regularization to ensure π ∗ ( ·| g, G ′ θ ( G )) is smooth, and solve for it by iterating the soft Bellman equation until convergence [18], again using implicit differentiation to backpropagate through that solution (see appendix D.1).
Figure 1c shows the derived edges learned by the GFSA layer on a graph not seen during training; we find that the edges learned by the GFSA layer are discrete and roughly correspond to diagonal motions in the grid. Over the course of training the GFSA layer, the average number of steps taken by the (optimal) primary policy (on a validation set of unseen layouts) decreases from 40.1 steps to 11.5 steps, a substantial improvement in the end-to-end performance. This example illustrates the kind of relationships the GFSA layer can learn from end-to-end supervision; note that we do not claim these options are optimal for this task or would be practical in a more traditional RL context.
## 5.2 Learning Static Analyses of Python Code
Proposition 1 ensures that a GFSA is theoretically capable of performing simple static analyses of code. We demonstrate that the GFSA can practically learn to do these analyses by casting them as pairwise binary classification problems. We first generate a synthetic dataset of Python programs by sampling from a probabilistic context-free grammar over a subset of Python. We then transform the corresponding ASTs into graphs, and compute the three edge types NEXTCONTROLFLOW, LASTREAD, and LASTWRITE, which are commonly used for program understanding tasks [1, 19] and which we describe in section 2.2. Note that there may be multiple edges from the same statement or variable, since there are often multiple possible execution paths through the program.
For each of these edge types, we train a GFSA layer to classify whether each ordered pair of nodes is connected with an edge of that type. We use the focal-loss objective [29], a more stable variant of the cross-entropy loss for highly unbalanced classification problems, minimizing
$$\mathcal { L } = \mathbb { E } _ { ( N , E ) \sim \mathcal { D } } \left [ \sum _ { n _ { 1 } , n _ { 2 } \in N } \begin{cases} - ( 1 - A _ { n _ { 1 } , n _ { 2 } } ) ^ { \gamma } \log ( A _ { n _ { 1 } , n _ { 2 } } ) & i f \, ( n _ { 1 } \to n _ { 2 } ) \in E , \\ - ( A _ { n _ { 1 } , n _ { 2 } } ) ^ { \gamma } \log ( 1 - A _ { n _ { 1 } , n _ { 2 } } ) & o t h e r w i s e \end{cases} \right ]$$
where the expectation is taken over graphs in the training dataset D .
We compare against four graph model baselines: a GGNN [27], a GREAT model over AST graphs [19], a RAT model [42], and an NRI-style encoder [25]. For the GGNN, GREAT, and RAT models, we present results for two methods of computing output adjacency matrices: the first computes a learned key-value dot product (similar to dot-product attention) and interprets it as an adjacency matrix, and the second runs the model separately for each possible source node, tagging that source with an extra node feature, and computing an output for each possible destination (denoted 'nodewise'). For the NRI encoder model, the output head is an MLP over node feature pairs as described by Kipf et al. [25]; we extend the NRI model with residual connections and layer normalization to improve stability, similar to a transformer model [40]. All baselines use a logistic sigmoid as a final activation, and are trained with the focal-loss objective. See appendix D.2 for more details.
As an ablation, we also train a standard RL agent with the same parameterization as GFSA, inspired by MINERVA [12]. We replace the cross-entropy loss with a reward of +1 for adding a correct edge (or correctly not adding any) and 0 otherwise, and train using REINFORCE with 20 rollouts per start node and a leave-one-out control variate [46, 26]. Since edges are added by single trajectories rather than marginals over trajectories, this RL agent can add at most one edge from each start node.
Table 1 shows results of each of these models on the three edge classification tasks. We present results after training on a dataset of 100,000 examples as well as on a smaller dataset of only 100 examples, and report F1 scores at the best classification threshold; we choose the model with the best validation performance from a 32-job random hyperparameter search. To assess generalization, we also show results on two modified data distributions: programs of half the size of those in the training set (0.5x), and programs twice the size (2x). When trained on 100,000 examples, all models achieve high accuracy on examples of the training size, but some fail to generalize, especially to larger programs. When trained on 100 examples, only the GFSA layer and RL ablation consistently achieve
Table 1: Results on the program analysis edge-classification tasks. Values are F1 scores (in percent), with bold indicating overlapping 95% confidence intervals with the best model; see appendix D.2.3 for full-precision results. 'nw' denotes nodewise output, and 'dp' denotes dot-product output.
| 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples |
|-----------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|
| Task | Next Control Flow | Next Control Flow | Next Control Flow | Last Read | Last Read | Last Read | Last Write | Last Write | Last Write |
| Example size | 1x | 2x | 0.5x | 1x | 2x | 0.5x | 1x | 2x | 0.5x |
| RAT nw | 99.98 | 99.94 | 99.99 | 99.86 | 96.29 | 99.98 | 99.83 | 94.87 | 99.97 |
| GREAT nw | 99.98 | 99.87 | 99.98 | 99.91 | 95.12 | 99.98 | 99.75 | 93.22 | 99.93 |
| GGNN nw | 99.98 | 93.90 | 97.77 | 95.52 | 9.22 | 86.24 | 98.82 | 40.69 | 88.28 |
| RAT dp | 99.99 | 92.53 | 96.59 | 99.96 | 42.58 | 91.96 | 99.98 | 68.96 | 99.76 |
| GREAT dp | 99.99 | 96.32 | 98.36 | 99.99 | 47.07 | 99.78 | 99.99 | 68.46 | 99.88 |
| GGNN dp | 99.94 | 62.75 | 98.51 | 98.44 | 0.99 | 63.77 | 99.35 | 38.40 | 94.52 |
| NRI encoder | 99.98 | 85.91 | 99.92 | 99.83 | 43.44 | 99.39 | 99.87 | 52.73 | 99.84 |
| RL ablation | 94.24 | 93.56 | 94.83 | 96.69 | 94.85 | 97.85 | 98.08 | 96.64 | 98.93 |
| GFSA (ours) | 100.00 | 99.99 | 100.00 | 99.66 | 98.94 | 99.90 | 99.47 | 98.73 | 99.78 |
| 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples |
| RAT nw | 98.63 | 95.93 | 96.32 | 80.28 | 1.12 | 83.49 | 79.27 | 8.91 | 83.79 |
| GREAT nw | 98.23 | 97.98 | 98.52 | 78.88 | 6.96 | 60.90 | 80.19 | 40.22 | 84.54 |
| GGNN nw | 99.37 | 98.36 | 98.60 | 79.36 | 28.28 | 5.66 | 91.13 | 71.62 | 91.79 |
| RAT dp | 81.81 | 68.46 | 87.05 | 59.53 | 28.91 | 62.27 | 75.99 | 48.10 | 81.63 |
| GREAT dp | 86.60 | 62.98 | 80.58 | 57.02 | 27.13 | 64.48 | 73.69 | 46.27 | 80.03 |
| GGNN dp | 76.85 | 22.99 | 28.91 | 44.37 | 9.64 | 38.34 | 53.82 | 17.84 | 55.08 |
| NRI encoder | 81.74 | 69.08 | 88.87 | 68.69 | 26.64 | 73.52 | 65.38 | 36.43 | 73.86 |
| RL ablation | 91.70 | 91.14 | 92.29 | 98.48 | 97.03 | 99.17 | 98.32 | 96.96 | 99.07 |
| GFSA (ours) | 99.99 | 99.99 | 100.00 | 98.81 | 97.82 | 99.22 | 98.71 | 96.98 | 99.55 |
high accuracy, highlighting the strong inductive bias for constrained-reachability-based reasoning tasks. The GFSA layer trained with exact marginals and cross-entropy loss obtains higher accuracy than the RL ablation, and also converges more reliably: 82% of GFSA layer training jobs achieve at least 90% accuracy on the validation set, compared to only 11% of RL ablation jobs.
Figure 1b shows an example of the behavior that the GFSA layer learns for the LASTREAD task based on only input-output supervision. We note that the GFSA layer discovers separate modes for break statements and regular control flow, and also learns to split probability mass across multiple trajectories in order to account for multiple paths through the program, closely following the program semantics. The paths learned by this policy are also quite long; the policy shown takes an average of 35 actions before accepting (on the 1x test set). More generally, this shows that the GFSA layer is able to learn many-hop reasoning that covers large distances in the graph by breaking down the reasoning into subcomponents defined by the learned automaton states.
## 5.3 Variable Misuse
Finally, we investigate performance on the variable misuse task [1, 39]. Following Hellendoorn et al. [19], we use a dataset of small code samples from a permissively-licenced subset of the ETH 150k Python dataset [33], where synthetic variable misuse bugs have been introduced in half of the examples by randomly replacing one of the identifiers with a different identifier in that program. 4 We train a model to predict the location of the incorrect identifier, as well as another location in the program containing the correct replacement that would restore the original program; we use a special 'no-bug' location for the unmodified examples, similar to Vasic et al. [39] and Hellendoorn et al. [19].
We consider two graph neural network architectures: either an eight-layer RAT model [42] or eight GGNN blocks [27] with two message passing iterations per block (similar to Hellendoorn et al. [19]). For each, we investigate adding different types of edges to the base AST graph: no extra edges, hand-engineered edges used by Allamanis et al. [1] and Hellendoorn et al. [19], weighted
4 https://github.com/google-research-datasets/great
Table 2: Accuracy on the variable misuse task, in percent. 'Start' indicates that edges are added to the base graph before running the graph model, and 'middle' indicates they are added halfway through, conditioned on the output of the first half. Bold indicates overlapping 95% confidence intervals with the best model for each metric. See appendix D.3.3 for standard error estimates and additional details.
| Example type: | All | All | No bug | No bug | With bug | With bug | With bug | With bug |
|---------------------------|---------------|---------------|----------------|----------------|----------------|----------------|-------------|-------------|
| Metric: | Full accuracy | Full accuracy | Classification | Classification | Classification | Classification | Loc &Repair | Loc &Repair |
| Graph model family: | RAT | GGNN | RAT | GGNN | RAT | GGNN | RAT | GGNN |
| Base AST graph only | 88.22 | 83.52 | 92.05 | 91.26 | 93.03 | 88.15 | 88.30 | 81.63 |
| Base AST graph, +2 layers | 87.85 | 84.38 | 92.45 | 88.80 | 92.03 | 91.92 | 87.76 | 83.97 |
| Hand-engineered edges | 88.50 | 84.78 | 92.93 | 90.19 | 92.48 | 91.56 | 88.39 | 83.52 |
| NRI head @start | 88.71 | 84.47 | 92.55 | 91.49 | 93.21 | 89.38 | 88.73 | 82.73 |
| NRI head @middle | 88.42 | 84.41 | 92.83 | 88.29 | 92.31 | 92.20 | 88.62 | 84.44 |
| Random walk @start | 88.91 | 84.52 | 93.22 | 91.35 | 92.77 | 89.28 | 88.73 | 82.96 |
| RL ablation @middle | 87.28 | 84.96 | 90.36 | 90.44 | 93.71 | 90.64 | 87.73 | 84.30 |
| GFSA layer (ours) @start | 89.47 | 85.01 | 93.10 | 90.08 | 93.56 | 91.80 | 89.58 | 83.91 |
| GFSA layer (ours) @middle | 89.63 | 84.72 | 92.66 | 90.98 | 94.25 | 89.81 | 89.93 | 83.63 |
edges learned by a GFSA layer, weighted edges output by an NRI-like pairwise MLP, weighted edges produced by an ablation of GFSA consisting of a uniform random walk with a learned halting probability, and a single edge per start state sampled by a GFSA-based RL agent. For the NRI and GFSA layers, we investigate adding the edges either before the graph neural network model (building from the base graph), or halfway through the model (conditioned on the node embeddings from the first half). For the RL agent, we train with REINFORCE and a learned scalar reward baseline, and use the downstream cross-entropy loss as the reward. To show the effect of just increasing model capacity, we also present results for ten-layer models on the base graph. In all models, we initialize node embeddings based on a subword tokenization of the program (using the Tensor2Tensor library by Vaswani et al. [41]), and predict a joint distribution over the bug and repair locations, with softmax normalization and the standard cross entropy objective. See appendix D.3 for additional details on each of the above models, as well as results using an eight-layer GREAT model [19].
The results are shown in Table 2. We report overall accuracy, along with a breakdown by example type: for non-buggy examples, we report the fraction of examples the model predicts as non-buggy, and for buggy examples, we report both accuracy of the classification and accuracy of the predicted error and replacement identifier locations conditioned on the classification. Consistent with prior work, adding the hand-engineered features from Allamanis et al. [1] improves performance over only using the base graph. Interestingly, adding weighted edges using a random walk on the base graph yields similar performance to adding hand-engineered edges, suggesting that, for this task, improving connectivity may be more important than the specific program analyses used. We find that the GFSA layer combined with the RAT graph model obtains the best performance, outperforming the hand-engineered edges. Interestingly, we observe that the GFSA layer does not seem to converge to a discrete adjacency matrix, but instead assigns continuous weights. We conjecture that the output edge weights may provide additional representative power to the base model.
## 6 Conclusion
Inspired by ideas from programming languages and reinforcement learning, we propose the differentiable GFSA layer, which learns to add new edges to a base graph. We show that the GFSA layer can learn sophisticated behaviors for navigating grid-world environments and analyzing program behavior, and demonstrate that it can act as a viable replacement for hand-engineered edges in the variable misuse task. In the future, we plan to apply the GFSA layer to other domains and tasks, such as molecular structures or larger code repositories. We also hope to investigate the interpretability of the edges learned by the GFSA layer to determine whether they correspond to useful general concepts, which might allow the GFSA edges to be shared between multiple tasks.
## Broader Impact
We consider this work to be a general technical and theoretical contribution, without well-defined specific impacts. If applied to real-world program understanding tasks, extensions of this work might lead to reduced bug frequency or improved developer productivity. On the other hand, those benefits might accrue mostly to groups with sufficient resources to incorporate machine learning into their development practices. Additionally, if users put too much trust in the output of the model, they could inadvertently introduce bugs in their code because of incorrect model predictions. If applied to other tasks involving structured data, the impact would depend on the specific application; we leave the exploration of these other applications and their potential impacts to future work.
## Acknowledgments
We would like to thank Aditya Kanade and Charles Sutton for pointing out the connection to Reps [34], and Petros Maniatis for help with the variable misuse dataset. We would also like to thank Dibya Ghosh and Yujia Li for their helpful comments and suggestions during the writing process, and the Brain Program Learning, Understanding, and Synthesis team at Google for useful feedback throughout the course of the project. Finally, we thank the reviewers for their feedback and for pointing out relevant related work.
## References
- [1] Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi. Learning to represent programs with graphs. In International Conference on Learning Representations , 2018.
- [2] Uri Alon, Shaked Brody, Omer Levy, and Eran Yahav. code2seq: Generating sequences from structured representations of code. In International Conference on Learning Representations , 2019.
- [3] RS Anderssen and GH Golub. Richardson's non-stationary matrix iterative procedure. rep. Technical report, STAN-CS-72-304, Computer Science Dept., Stanford University Report, 1972.
- [4] Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. In Thirty-First AAAI Conference on Artificial Intelligence , 2017.
- [5] Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. In Advances in Neural Information Processing Systems , pages 688-699, 2019.
- [6] Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Heinrich Küttler, Andrew Lefrancq, Simon Green, Víctor Valdés, Amir Sadik, et al. Deepmind lab. arXiv preprint arXiv:1612.03801 , 2016.
- [7] Pavol Bielik, Veselin Raychev, and Martin Vechev. Learning a static analyzer from data. In International Conference on Computer Aided Verification , pages 233-253. Springer, 2017.
- [8] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, and Skye Wanderman-Milne. JAX: composable transformations of Python+NumPy programs. http: //github.com/google/jax , 2018.
- [9] Julian Busch, Jiaxing Pi, and Thomas Seidl. Pushnet: Efficient and adaptive neural message passing. arXiv preprint arXiv:2003.02228 , 2020.
- [10] Patrick Cousot and Radhia Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Proceedings of the 4th ACM SIGACT-SIGPLAN symposium on Principles of programming languages , pages 238-252, 1977.
- [11] Hanjun Dai, Yujia Li, Chenglong Wang, Rishabh Singh, Po-Sen Huang, and Pushmeet Kohli. Learning transferable graph exploration. In Advances in Neural Information Processing Systems , pages 2514-2525, 2019.
- [12] Rajarshi Das, Shehzaad Dhuliawala, Manzil Zaheer, Luke Vilnis, Ishan Durugkar, Akshay Krishnamurthy, Alex Smola, and Andrew McCallum. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. In International Conference on Learning Representations , 2018.
- [13] Peter Dayan. Improving generalization for temporal difference learning: The successor representation. Neural Computation , 5(4):613-624, 1993.
- [14] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819 , 2018.
- [15] Luca Franceschi, Mathias Niepert, Massimiliano Pontil, and Xiao He. Learning discrete structures for graph neural networks. arXiv preprint arXiv:1903.11960 , 2019.
- [16] Kevin Frans, Jonathan Ho, Xi Chen, Pieter Abbeel, and John Schulman. Meta learning shared hierarchies. In International Conference on Learning Representations , 2018.
- [17] Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine LearningVolume 70 , pages 1263-1272. JMLR. org, 2017.
- [18] Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In Proceedings of the 34th International Conference on Machine Learning-Volume 70 , pages 1352-1361. JMLR. org, 2017.
- [19] Vincent J Hellendoorn, Charles Sutton, Rishabh Singh, and Petros Maniatis. Global relational models of source code. In International Conference on Learning Representations , 2020.
- [20] John E Hopcroft, Rajeev Motwani, and Jeffrey D Ullman. Introduction to automata theory, languages, and computation. Acm Sigact News , 32(1):60-65, 2001.
- [21] Xiao Huang, Qingquan Song, Yuening Li, and Xia Hu. Graph recurrent networks with attributed random walks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages 732-740, 2019.
- [22] Drew Hudson and Christopher D Manning. Learning by abstraction: The neural state machine. In Advances in Neural Information Processing Systems , pages 5903-5916, 2019.
- [23] Sergey Ivanov and Evgeny Burnaev. Anonymous walk embeddings. In International Conference on Machine Learning , pages 2186-2195, 2018.
- [24] Bo Jiang, Doudou Lin, Jin Tang, and Bin Luo. Data representation and learning with graph diffusionembedding networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 10414-10423, 2019.
- [25] T Kipf, E Fetaya, K-C Wang, M Welling, R Zemel, et al. Neural relational inference for interacting systems. Proceedings of Machine Learning Research , 80, 2018.
- [26] Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 REINFORCE samples, get a baseline for free! ICLR workshop: Deep RL Meets Structured Prediction , 2019.
- [27] Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard Zemel. Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493 , 2015.
- [28] Renjie Liao, Yuwen Xiong, Ethan Fetaya, Lisa Zhang, KiJung Yoon, Xaq Pitkow, Raquel Urtasun, and Richard Zemel. Reviving and improving recurrent back-propagation. In International Conference on Machine Learning , pages 3082-3091, 2018.
- [29] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision , pages 2980-2988, 2017.
- [30] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602 , 2013.
- [31] Mehryar Mohri. Weighted automata algorithms. In Handbook of weighted automata , pages 213-254. Springer, 2009.
- [32] Aravind Rajeswaran, Chelsea Finn, Sham M Kakade, and Sergey Levine. Meta-learning with implicit gradients. In Advances in Neural Information Processing Systems , pages 113-124, 2019.
- [33] Veselin Raychev, Pavol Bielik, and Martin Vechev. Probabilistic model for code with decision trees. ACM SIGPLAN Notices , 51(10):731-747, 2016.
- [34] Thomas Reps. Program analysis via graph reachability. Information and software technology , 40(11-12): 701-726, 1998.
- [35] Yousef Saad. Iterative methods for sparse linear systems , volume 82. SIAM, 2003.
- [36] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks , 20(1):61-80, 2008.
- [37] Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) , pages 464-468, 2018.
- [38] Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence , 112(1-2):181-211, 1999.
- [39] Marko Vasic, Aditya Kanade, Petros Maniatis, David Bieber, and Rishabh Singh. Neural program repair by jointly learning to localize and repair. In International Conference on Learning Representations , 2019.
- [40] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems , pages 5998-6008, 2017.
- [41] Ashish Vaswani, Samy Bengio, Eugene Brevdo, Francois Chollet, Aidan Gomez, Stephan Gouws, Llion Jones, Łukasz Kaiser, Nal Kalchbrenner, Niki Parmar, et al. Tensor2tensor for neural machine translation. In Proceedings of the 13th Conference of the Association for Machine Translation in the Americas (Volume 1: Research Papers) , pages 193-199, 2018.
- [42] Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers. arXiv preprint arXiv:1911.04942 , 2019.
- [43] Lu Wang, Wenchao Yu, Wei Wang, Wei Cheng, Wei Zhang, Hongyuan Zha, Xiaofeng He, and Haifeng Chen. Learning robust representations with graph denoising policy network. In 2019 IEEE International Conference on Data Mining (ICDM) , pages 1378-1383. IEEE, 2019.
- [44] Gail Weiss, Yoav Goldberg, and Eran Yahav. Extracting automata from recurrent neural networks using queries and counterexamples. In International Conference on Machine Learning , pages 5247-5256. PMLR, 2018.
- [45] Bryan Wilder, Eric Ewing, Bistra Dilkina, and Milind Tambe. End to end learning and optimization on graphs. In Advances in Neural Information Processing Systems , pages 4674-4685, 2019.
- [46] Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning , 8(3-4):229-256, 1992.
- [47] Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages 974-983, 2018.
- [48] Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. Graph transformer networks. In Advances in Neural Information Processing Systems , pages 11960-11970, 2019.
- [49] Zhen Zhang, Mianzhi Wang, Yijian Xiang, Yan Huang, and Arye Nehorai. Retgk: Graph kernels based on return probabilities of random walks. In Advances in Neural Information Processing Systems , pages 3964-3974, 2018.
## A Details on Constrained Reachability
In this section we describe how program analyses can be converted to regular languages, and provide the proofs for the statements in section 2.2.
## A.1 Example: Regular Languages For Program Analyses
The following grammar defines a regular language for the LASTWRITE edge type as described by Allamanis et al. [1], where n 2 is the last write to variable n 1 if there is a path from n 1 to n 2 whose label sequence matches the nonterminal Last-Write . We denote node type labels with capitals, edge type labels in lowercase, and nonterminal symbols in boldface. For simplicity we assume a single target variable name with its own node type TargetVariable, and only consider a subset of possible AST nodes.
<details>
<summary>Image 2 Details</summary>

### Visual Description
## Flowchart: Pseudocode for Variable Decompilation Process
### Overview
The image depicts a flowchart outlining a recursive algorithm for tracing the origin of a target variable's value in code. It starts from the last use of the variable and steps backward through the code, handling control structures like loops and conditionals.
### Components/Axes
- **Blocks**: Rectangular nodes representing functions/steps (e.g., "Last-Write", "Find-Current-Statement").
- **Arrows**: Directed edges indicating control flow between blocks.
- **Text**: Descriptive instructions within each block (e.g., "Assign Step-Backward", "While in an expression, step out").
### Detailed Analysis
1. **Last-Write**
- Title: "Last-Write"
- Text: "All LASTWRITE edges start from a use of the target variable."
- Action: TargetVariable →-parent-→ Find-Current-Statement
2. **Find-Current-Statement**
- Title: "Find-Current-Statement"
- Text: "Once we find a statement, go backward."
- Substeps:
- ExprStmt Step-Backward
- Assign Step-Backward
- While in an expression, step out
- BinOp →-parent-→ Find-Current-Statement
- Call →-parent-→ Find-Current-Statement
3. **Check-Stmt**
- Title: "Check-Stmt"
- Text: "Stop if we find an assignment to the target variable."
- Substeps:
- Assign →-target-→ TargetVariable → Step-Backward
- ExprStmt Step-Backward
- If →-last-child-→ Check-Stmt
- If Step-Backward →-last-child-→ Check-Stmt
- While Step-Backward →-last-child-→ Check-Stmt
- While →-last-child-→ Find-Break-A
4. **Step-Backward**
- Title: "Step-Backward"
- Text: "If we have a previous statement, check it."
- Substeps:
- prev-stmt Check-Stmt
- If first If-block → Step-Backward
- If first While-block → Step-Backward or exit loop
- from-first-child →-last-child-→ Check-Stmt
5. **Find-Break-A**
- Title: "Find-Break-A"
- Text: "If we find a Break, this is a possible previous loop exit point."
- Substeps:
- Break Step-Backward
- Break Find-Break-B
- ExprStmt Find-Break-B
- If →-last-child-→ Find-Break-A
- While Find-Break-B
6. **Find-Break-B**
- Title: "Find-Break-B"
- Text: "prev-stmt Find-Break-A"
- Substeps:
- from-first-child If Find-Break-B
### Key Observations
- **Recursive Flow**: The process repeatedly steps backward through code, prioritizing assignments to the target variable.
- **Control Structure Handling**:
- Loops (While) and conditionals (If) are traversed backward, with special handling for `break` statements.
- `break` statements only affect the innermost loop, requiring separate tracking (Find-Break-A vs. Find-Break-B).
- **Termination**: Stops when an assignment to the target variable is found.
### Interpretation
This flowchart represents a **decompilation algorithm** for reverse-engineering code to trace variable origins. It systematically navigates backward through the code, accounting for nested control structures. The separation of `Find-Break-A` and `Find-Break-B` ensures accurate handling of loop exits, as `break` statements only terminate the nearest enclosing loop. The algorithm’s recursive nature allows it to resolve complex code paths, making it useful for tasks like debugging or understanding obfuscated code.
**Note**: No numerical data or visual trends are present; the focus is on procedural logic and control flow.
</details>
The constructions for NEXTCONTROLFLOW and LASTREAD are similar. Note that for LASTREAD, instead of skipping entire statements until finding an assignment, the path must iterate over all expressions used within each statement and check for uses of the variable. For NEXTCONTROLFLOW, instead of stepping backward, the path steps forward, and instead of searching for break statements
after entering a loop, it searches for the containing loop when reaching a break statement. (This is because NEXTCONTROLFLOW simulates program execution forward instead of in reverse. Note that regular languages are closed under reversal [20], so such a transformation between forward and reverse paths is possible in general; we could similarly construct a language for LASTCONTROLFLOW if desired.)
## A.2 Proof of Proposition 1
We recall proposition 1:
Proposition 1. Let G be a family of graphs annotated with node and edge types. There exists an encoding of graphs G ∈ G into POMDPs as described in section 3.1 and a mapping from regular languages L into finite-state policies π L such that, for any G ∈ G , there is an L -path from n 0 to n T in G if and only if p ( a T = ADDEDGEANDSTOP , n T | n 0 , π L ) > 0 .
Proof. We start by defining a generic choice of POMDP conversion that depends only on the node and edge types. Let G ∈ G be a directed graph with node types N , edge types E , nodes N , and edges E ⊆ N × N ×E . We convert it to a POMDP by choosing Ω τ ( n ) = { ( τ ( n ) , TRUE ) , ( τ ( n ) , FALSE ) } , M τ ( n ) = E ,
$$p ( n _ { t + 1 } | n _ { t } , a _ { t } = ( M O V E , m _ { t } ) ) = \begin{cases} 1 / | A _ { n _ { t } } ^ { m _ { t } } | & i f \, n _ { t + 1 } \in A _ { n _ { t } } ^ { m _ { t } } , \\ 1 & i f \, n _ { t + 1 } = n _ { t } \ a n d \ A _ { n _ { t } } ^ { m _ { t } } = \varnothing , \\ 0 & o t h e r w i s e , \end{cases}$$
ω 0 = ( τ ( n 0 ) , TRUE ) , and ω t +1 = ( τ ( n t +1 ) , n t +1 ∈ A m t n t ) , where we let A m t n t = { n t +1 | ( n t , n t +1 , m t ) ∈ E } be the set of neighbors adjacent to n t via an edge of type m t .
Nowsuppose L is a regular language over sequences of node and edge types. Construct a deterministic finite automaton M that accepts exactly the words in L (for instance, using the subset construction) [20]. Let Q denote its state space, q 0 denote its initial state, δ : Q × Σ → Q be its transition function, and F ⊆ Q be its set of accepting states. We choose Q as the finite state memory of our policy π L , i.e. at each step t we assume our agent is associated with a memory state z t ∈ Q . We let z 0 = q 0 be the initial memory state of π L .
Consider an arbitrary memory state z t ∈ Q and observation ω t = ( τ ( n t ) , e t ) . We now construct a set of possible next actions and memories N t ⊆ A t × Q . If e t = FALSE, let N t = ∅ . Otherwise, let z t +1 / 2 = δ ( z t , τ ( n t )) . If z t +1 / 2 ∈ F , add ( ADDEDGEANDSTOP , z t +1 / 2 ) to N t . Next, for each m ∈ E , add (( MOVE , m ) , δ ( z t +1 / 2 , m )) to N t . Finally, let
$$\pi _ { L } ( a _ { t } , z _ { t + 1 } | z _ { t } , \omega _ { t } ) = \begin{cases} 1 / | N _ { t } | & i f \, ( a _ { t } , z _ { t + 1 } ) \in N _ { t } , \\ 1 & i f \, N _ { t } = \varnothing , a _ { t } = S T O P , z _ { t + 1 } = z _ { t } \\ 0 & o t h e r w i s e . \end{cases}$$
The e t = FALSE = ⇒ N t = ∅ constraint ensures that the partial sequence of labels along any accepting trajectory matches the sequence of node type observations and movement actions produced by π L . Since π L starts in the same state as M , and assigns nonzero probability to exactly the state transitions determined by δ , it follows that the memory state of the agent along any partial trajectory [ n 0 , m 0 , n 1 , m 1 , . . . , n t ] corresponds to the state of M after processing the label sequence [ τ ( n 0 ) , m 0 , τ ( n 1 ) , m 1 , . . . , τ ( n t )] .
Since π L assigns nonzero probability to the ADDEDGEANDSTOP action exactly when memory state is an accepting state from F , and M is in an accepting state from F exactly when the label sequence is in L , we conclude that desired property holds.
Corollary. There exists an encoding of program AST graphs into POMDPs and a specific policy π NEXT-CF with finite-state memory such that p ( a T = ADDEDGEANDSTOP , n T | n 0 , π ) > 0 if and only if ( n 0 , n T ) is an edge of type NEXTCONTROLFLOW in the augmented AST graph. Similarly, there are policies π LAST-READ and π LAST-WRITE for edges of type LASTREAD and LASTWRITE , respectively.
Proof. This corollary follows directly from Proposition 1 and the existence of regular languages for these edge types (see appendix A.1).
Note that equivalent policies also exist for POMDPs encoded differently than the proof of proposition 1 describes. For instance, instead of having 'TargetVariable' as a node type and constructing edges for each target variable name separately, we can extend the observation ω t to contain information on whether the current variable name matches the initial variable name and then find all edges at once, which we do for our experiments. Additionally, if an action would cause the policy to transition into an absorbing but non-accepting state (i.e. a failure state) in the discrete finite automaton for L , the policy can immediately take a BACKTRACK or STOP action instead, or reallocate probability to other states, instead of just cycling forever in that state. This allows the policy π to more evenly allocate probability across possible answers, and we observe that the GFSA policies learn to do this in our experiments.
## B Graph to POMDP Dataset Encodings
Here we describe the encodings of graphs as POMDPs that we use for our experiments.
## B.1 Python Abstract Syntax Trees
We convert all of our code samples into the unified format defined by the gast library, 5 which is a slightly-modified version of the abstract syntax tree provided with Python 3.8 that is backwardcompatible with older Python versions. We then use a generic mechanism to convert each AST node into one or more graph nodes and corresponding POMDP states.
Each AST node type τ (such as FunctionDef , If , While , or Call ) has a fixed set F of possible field names. We categorize these fields into four categories: optional fields F opt, exactly-one-child fields F one, nonempty sequence fields F nseq, and possibly empty sequence fields F eseq. We define the observation space at nodes of type τ as
$$\Omega _ { \tau } = \{ \tau \} \times \Gamma \times \Psi _ { \tau }$$
where Γ is a task-specific extra observation space, and Ψ τ indicates the result of the previous action:
$$\Psi _ { \tau } = \{ \left ( F R O M , f \right ) | f \in F \cup \{ P A R E N T \} \cup \{ ( M I S S I N G , f ) | f \in F _ { o p t } \cup F _ { e s e q } \} .$$
The ( τ, γ, ( FROM , f )) observations are used when the agent moves to an edge of type τ from a child from field f (or from the parent node), and the ( τ, γ, ( MISSING , f )) observations are used when the agent attempts to move to a child for field f but no such child exists. We define the movement space as
$$\begin{array} { r l } & { \mathcal { M } _ { \tau } = \left \{ G O P A R E N T \right \} \cup \left \{ ( G O , f ) | f \in F _ { o n e } \cup F _ { o p t } \right \} \right \} } \\ & { \quad \cup \left \{ ( x , f ) | x \in \left \{ G O F I R S T , G O L A S T , G O - A L L \right \} , f \in F _ { n s e q } \cup F _ { e s e q } \right \} . } \end{array}$$
GO moves the agent to the single child for that field, GO-FIRST moves it to the first child, GO-LAST moves it to the last child, and GO-ALL distributes probability evenly among all children. GO-PARENT moves the agent to the parent node; we omit this movement action for the root node ( τ = Module).
For each sequence field f ∈ F nseq ∪ F eseq, we also define a helper node type τ f , which is used to construct a linked list of children. This helper node has the fixed observation space
$$\Psi _ { \tau _ { f } } = \left \{ \begin{array} { l l } { F R O M - P A R E N T , F R O M - I T E M , F R O M - N E X T , F R O M - P R E V , } \\ { M I S S I N G - N E X T , M I S S I N G - P R E V \right \} } \end{array}$$
and action space
$$\mathcal { M } _ { \tau _ { f } } = \{ G O P A R E N T , G O I T E M , G O - N E X T , G O - P R E V \} .$$
When encoding the AST as a graph, helper nodes of this type are inserted between the AST node of type τ and the children for field f : the 'parent' of a helper node is the original AST node, and the 'item' of the n th helper node is the n th child of the original AST node for field f .
We note that this construction differs from the construction in the proof of proposition 1, in that movement actions are specific to the node type of the current node. When the agent takes the GOPARENT action, the observation for the next step informs it what field type it came from. This helps
5 https://github.com/serge-sans-paille/gast/releases/tag/0.3.3
keep the state space of the GFSA policy small, since it does not have to guess what its parent node is and then remember the results; it can instead simply walk to the parent node and then condition its next action on the observed field. The construction described here still allows encoding the edges from NEXTCONTROLFLOW, LASTREAD, and LASTWRITE as policies, as we empirically demonstrate by training the GFSA layer to replicate those edges.
## B.2 Grid-world Environments
For the grid-world environments, we represent each traversable grid cell as a node, and classify the cells into eleven node types corresponding to which movement directions (left, up, right, and down) are possible:
$$\mathcal { N } = \{ L U , L R , L D , U R , U D , R D , L U R , L U D , L R D , U R D , L U R D \}$$
Note that in our dataset, no cell has fewer than two neighbors.
For each node type τ ∈ N the movement actions M τ correspond exactly to the possible directions of movement; for instance, cells of type LD have M LD = { L , D } . We use a trivial observation space Ω τ = { τ } , i.e. the GFSA automaton sees the type of the current node but no other information.
When converting grid-world environments into POMDPs, we remove the BACKTRACK action to encourage the GFSA edges to match more traditional RL option sub-policies.
## C GFSA Layer Implementation
Here we describe additional details about the implementation of the GFSA layer.
## C.1 Parameters
We represent the parameters θ of the GFSA layer as a table indexed by feasible observation and action pairs Φ as well as state transitions:
$$\Phi = \left ( \bigcup _ { \tau \in N } \Omega _ { \tau } \times \mathcal { A } _ { \tau } \right ) , \quad \theta \colon Z \times \Phi \times Z \to \mathbb { R } ,$$
where Z = { 0 , 1 , . . . , | Z |-1 } is the set of memory states. We treat the elements of θ as unnormalized log-probabilities and then set π = softmax( θ ) , normalizing separately across actions and new memory states for each possible current memory state and observation.
To initialize θ , we start by defining a 'base distribution' p , which chooses a movement action at random with probability 0.95 and a special action (ADDEDGEANDSTOP, STOP, BACKTRACK) otherwise, and which stays in the same state with probability 0.8 and changes states randomly otherwise. Next, we sample our initial probabilities q from a Dirichlet distribution centered on p (with concentration parameters α i = p i /β where β is a temperature parameter), and then take a (stabilized) logarithm θ i = log( q i +0 . 001) . This ensures that the initial policy has some initial variation, while still biasing it toward staying in the same state and taking movement actions most of the time.
## C.2 Algorithmic Details
As a preprocessing step, for each graph in the dataset, we compute the set X of all ( n, ω ) nodeobservation pairs for the corresponding MDP. We then compute 'template transition matrices', which specify how to convert the probability table θ into a transition matrix by associating transitions X × X and halting actions X × { ADDEDGEANDSTOP , STOP , BACKTRACK } with their appropriate indicies into Φ . Then, when running the model, we retrieve blocks of θ according to those indices to construct the transition matrix for that graph (implemented with 'gather' and 'scatter' operations).
Conceptually, each possible starting node n 0 could produce a separate transition matrix Q n 0 : X × Z × X × Z → R because part of the observation in each state (which we denote γ ∈ Γ and leave out of X ) may depend on the starting node or other learned parameters. We address this by instead computing an 'observation-conditioned' transition tensor
$$Q \colon \Gamma \times X \times Z \times X \times Z \rightarrow \mathbb { R }$$
that specifies transition probabilities for each observation γ , along with a start-node-conditioned observation tensor
$$C \colon N \times X \times \Gamma \to \mathbb { R }$$
that specifies the probability of observing γ for a given start node n 0 and current ( n, ω ) tuple. In order to compute a matrix-vector product Q n 0 v we can then use the tensor product
$$\sum _ { i , z , \gamma } C _ { n _ { 0 } , i , \gamma } \, Q _ { \gamma , i , z , i ^ { \prime } , z ^ { \prime } } \, v _ { i , z }$$
which can be computed efficiently without having to materialize a separate transition matrix for every start node n 0 ∈ N .
During the forward pass through the GFSA layer, to solve for the absorbing probabilities in equation 1, we iterate
$$x _ { 0 } = \delta _ { n _ { 0 } } , \quad x _ { k + 1 } = \delta _ { n _ { 0 } } + Q _ { n _ { 0 } } x _ { k }$$
$$c _ { 0 } = o _ { n _ { 0 } } ,$$
until a fixed number of steps K , then approximate
$$p ( a _ { T } , n _ { T } | n _ { 0 } , \pi ) = H _ { ( a _ { T } , n _ { T } ) , ; } \left ( I - Q _ { n _ { 0 } } \right ) ^ { - 1 } \delta _ { n _ { 0 } } \approx H _ { ( a _ { T } , n _ { T } ) , ; } x _ { K } .$$
To efficiently compute the backwards pass without saving all of the values of x k , we use the jax.lax.custom\_linear\_solve function from JAX [8], which converts the gradient equations into a transposed matrix system
$$\left ( I - Q _ { n _ { 0 } } ^ { T } \right ) ^ { - 1 } H ^ { T } \frac { \partial \mathcal { L } } { \partial p ( \cdot | n _ { 0 } , \pi ) }$$
that we similarly approximate with
$$y _ { 0 } = H ^ { T } \frac { \partial \mathcal { L } } { \partial p ( \cdot | n _ { 0 } , \pi ) } , \quad y _ { k + 1 } = H ^ { T } \frac { \partial \mathcal { L } } { \partial p ( \cdot | n _ { 0 } , \pi ) } + Q _ { n _ { 0 } } ^ { T } y _ { k } .$$
Note that both iteration procedures are guaranteed to converge because the matrix I -Q n 0 is diagonally dominant [35]. Conveniently, we implement Q n 0 x k using the tensor product described above, and JAX automatically translates this into a computation of the transposed matrix-vector product Q T n 0 y k using automatic differentiation.
If the GFSA policy assigns a very large probability to the BACKTRACK action, this can lead to numerical instability when computing the final adjacency matrix, since we condition on non-backtracking trajectories when computing our final adjacency matrix. We circumvent this issue by constraining the policy such that a small fraction of the time ( ε bt-stop), if it attempts to take the BACKTRACK action, it instead takes the STOP action; this ensures that, if the policy backtracks with high probability, the weight of the produced edges will be low. Additionally, we attempt to mitigate floating-point precision issues during normalization by summing over ADDEDGEANDSTOP and STOP actions instead of computing 1 -p ( a t = BACKTRACK | · · · ) directly.
When computing an adjacency matrix from the outputs of the GFSA layer, there are two ways to extract multiple edge types. The first is to associate each edge type with a distinct starting state in Z . The second way is to compute a different version of the parameter vector θ for each edge type. For the variable misuse experiments, we use the first method, since sharing states uses less memory. For the grid-world experiments, we use the second method, as we found that using non-shared states gives slightly better performance and results in more interpretable learned options.
## C.3 Asymptotic Complexity
We now give a brief complexity analysis for the GFSA layer implementation. Let n be the number of nodes, e be the number of edges, z be the number of memory states, ω be the number of 'static' observations per node (such as FROM-PARENT), and γ be the number of 'dynamic' observations per node (for instance, observations conditioned on learned node embeddings).
Memory: Storing the probability of visiting each state in X × Z for a given source node takes memory O ( nωz ) , so storing it for all source nodes takes O ( n 2 ωz ) . For a dense representation of Q and C , Q takes O ( n 2 ω 2 z 2 γ ) memory and C takes O ( n 2 ωγ ) . Since memory usage is independent of
$$x _ { k + 1 } = o _ { n _ { 0 } } + \Omega _ { n _ { 0 } } x _ { k }$$
the number of iterations, the overall memory cost is thus O ( n 2 ω 2 z 2 γ ) . We note that memory scales proportional to the square of the number of nodes, but this is in a sense unavoidable since the output of the GFSA layer is a dense n × n matrix even if Q is sparse.
Time: Computing the tensor product for all starting nodes requires computing n × nωz × nωz × γ elements. Since we do this at every iteration, we end up with a time cost of O ( T max n 3 ω 2 z 2 γ ) . We note that a sparse representation of Q might reduce this to O ( T max ( n 2 z + nez 2 ) ωγ ) (since we could first contract with C with cost n × nω × z × γ and then iterate over edges, start nodes, observations, and states, with cost n × e × ωz × z × γ ). However, in practice we use a dense implementation to take advantage of fast accelerator hardware.
## D Experiments, Hyperparameters, and Detailed Results
Here we describe additional details for each of our experiments and the corresponding evaluation results. For all of our experiments, we train and evaluate on TPU v2 accelerators. 6 Each training job uses 8 TPU v2 cores, evenly dividing the batch size between the cores and averaging gradients across them at each step.
## D.1 Grid-world Task
We use the LabMaze generator ( https://github.com/deepmind/labmaze ) from DeepMind Lab [6] to generate our grid-world layouts. We configure it with a width and height of 19 cells, a maximum of 6 rooms, and room sizes between 3 and 6 cells on each axis. We then convert the generated grids into graphs, and filter out examples with more than 256 nodes or 512 node-observation tuples. We generate 100,000 training graphs and 100,000 validation graphs. For each graph, we then pick 32 goal locations uniformly at random.
We configure the GFSA layer to use four independent policies to produce four derived edge types. For each policy, we set the memory space to the two-element set Z = { 0 , 1 } , where z 0 = 0 . We initialize parameters using temperature β = 0 . 2 , but use the Dirichlet sample directly as a logit, i.e. θ i = q i . (We found that applying the logarithm from appendix C during initialization yields similar numerical performance but makes the learned policies harder to visualize.)
Since the interpretation of the edges as options requires them to be properly normalized (i.e. the distribution p ( s t +1 | s t , a t ) must be well defined), we make a few modifications to the output adjacency matrix produced by the GFSA layer. In particular, we do not use the learned adjustment parameters described in section 3.3, instead fixing a = 1 , b = 0 . We also ensure that the edge weights are normalized to 1 for each source node by assigning any missing mass to the diagonal. In other words, if the GFSA sub-policy agent takes a STOP action or fails to take the ADDEDGEANDSTOP action before T max iterations, we instead treat the option as a no-op that causes the primary agent to remain in place. We also remove the BACKTRACK action.
At each training iteration, we sample a graph G from our training set, and in parallel compute approximate entropy-regularized optimal policies π ∗ for each of the 32 goal locations for G . Mathematically, for each goal g , we seek
$$\pi ^ { * } = \arg \max _ { \pi } \mathbb { E } _ { ( s _ { t } , a _ { t } ) \sim p ( \cdot | \pi ) } \left [ \sum _ { 0 \leq t \leq T } - 1 + \mathcal { H } ( \pi ( \cdot | s _ { t } ) ) \, \right | s _ { T } = g \right ] ,$$
where H ( π ( · | s t )) denotes the entropy of the distribution over actions, and we have fixed the reward to -1 for all timesteps. We use an entropy-regularized objective here so that the policy π ∗ is nondeterministic and thus has a useful derivative with respect to the option distribution. As described by Haarnoja et al. [18], we can compute this optimal policy by doing soft-Q iteration using the update equations
$$Q _ { \text {soft} } ( s _ { t } , a _ { t } ) & \leftarrow \mathbb { E } _ { s _ { t + 1 } \sim p ( \cdot | s _ { t } , a _ { t } ) } \left [ V _ { \text {soft} } ( s _ { t + 1 } ) \right ] - 1 , \\ V _ { \text {soft} } ( s _ { t } ) & \leftarrow \log \sum _ { a _ { t } } \exp \left ( Q _ { \text {soft} } ( s _ { t } , a _ { t } ) \right ) .$$
6 https://cloud.google.com/tpu/
until reaching a fixed point, and then letting
$$\pi ^ { * } ( a _ { t } | s _ { t } ) = \exp ( Q _ { s o f t } ( s _ { t } , a _ { t } ) - V _ { s o f t } ( s _ { t } ) ) .$$
Since our graphs are small, we can store Q soft and V soft in tabular form, and directly solve for their optimal values by iterating the above equations. In practice, we approximate the solution by using 512 iterations.
After computing Q ( g ) soft , V ( g ) soft , and π ∗ ( g ) for each choice of g , we then define a minimization objective for the full task as
$$\mathcal { L } = - \mathbb { E } _ { s _ { 0 } , g } \left [ V _ { s o f t } ^ { ( g ) } ( s _ { 0 } ) \right ] ,$$
i.e. we seek to maximize the soft value function across randomly chosen sources and goals, or equivalently to minimize the expected number of steps taken by π ∗ ( g ) before reaching the goal. We compute gradients by using implicit differentiation twice: first to differentiate through the fixed point to the soft-Q iteration, and second to differentiate through the computation of the GFSA edges. Implicitly differentiating through the soft-Q equations is conceptually similar to implicit MAML [32] except that the parameters we optimize in the outer loop (the GFSA parameters) are not the same as the parameters we optimize in the inner loop (the graph-specific tabular policy).
Note that differentiating through the soft-Q fixed point requires first linearizing the equations around the fixed point. More specifically, if we express the fixed point equations in terms of a function V soft = f ( V soft , θ ) where θ represents the GFSA parameters, we have
$$\partial V _ { s o f t } = \partial f ( V _ { s o f t } , \theta ) = f _ { V } ( V _ { s o f t } , \theta ) \partial V _ { s o f t } + f _ { \theta } ( V _ { s o f t } , \theta ) \partial \theta$$
(where f V ( V soft , θ ) denotes the Jacobian of f with respect to V , and similarly for f θ ) and thus
$$\partial V _ { s o f t } = \left ( I - f _ { V } ( V _ { s o f t } , \theta ) \right ) ^ { - 1 } f _ { \theta } ( V _ { s o f t } , \theta ) \partial \theta$$
which leads to gradient equations
$$\frac { \partial \mathcal { L } } { \partial \theta } = f _ { \theta } ( V _ { s o f t } , \theta ) ^ { T } \left ( I - f _ { V } ( V _ { s o f t } , \theta ) ^ { T } \right ) ^ { - 1 } \frac { \partial \mathcal { L } } { \partial V _ { s o f t } } .$$
As before, JAX makes it possible to easily express these gradient computations and automatically handles the computation of the relevant partial derivatives and Jacobians. In this case, due to the small number of goal locations and lack of diagonal dominance guarantees, we simply compute and invert the matrix I -f V ( V soft , θ ) T during the backward pass instead of using an iterative solver. (See Liao et al. [28] for additional information about implicitly differentiating through fixed points.)
We trained the model using the Adam optimizer, with a learning rate of 0.001 and a batch size of 32 graphs with 32 goals each, for approximately 50,000 iterations, until the validation loss plateaued. We then picked a grid from the validation set, and chose four possible starting locations manually to give a summary of the overall learned behavior.
## D.2 Static Analyses
## D.2.1 Datasets
For the static analysis tasks, we first generate a dataset of random Python programs using a probabilistic context free grammar. This grammar contains a variety of nonterminals and associated production rules:
- Number : An integer or float expression. Either a variable dereference, a constant integer, an arithmetic operation, or a function call with numeric arguments.
- Boolean : A boolean expression. Either a comparison between numbers, a constant True or False , or a boolean combination using and or or .
- Statement : A single statement. Either an assignment, a call to print , an if, if-else, for, or while block, or a pass statement.
- Block : A contiguous sequence of statements that may end in a return , break , or continue , or with a normal statement; we only allow these statements at the end of a block to avoid producing dead code.
```
def generated_function(a, b):
for v2 in range(int(bar_2(a, b))):
v3 = foo_4(v2, b, bar_1(b), a) / 42
v3 = (b + 8) * foo_1((v2 * v3))
pass
v3 = b
while False:
a = v3
a = v3
v2 = 34
break
if bar_1((b * b)) != v2:
v4 = foo_4(bar_2(56, bar_1(v2)),
foo_4(b, a, a, 39) - v2,
bar_1(a), 32)
for v5 in range(int(v4)):
v6 = v4
pass
break
print(69)
v2 = v2
b = (b + 96) + 89) - a
b = ((a + 96) + 89) - a
v2 = foo_4(b, 21, 26, foo_4(85, a, a - b, a))
b = v2 - (a - v2)
```
Figure D.1: Example of a program from the '1x' program distribution.
```
def generated_function(a, b):
if bar_1(b) > b:
b = a
print(b)
else:
a = a + a
a = bar_1(62 - 35)
if b <= bar_1(54):
b = b
while a >= 58:
b = foo_1(a)
pass
pass
else:
a = bar_4(b, bar_1(b), bar_1(a * a), bar_1(a))
b = 88
```
Figure D.2: Example of a program from the '0.5x' program distribution.
```
def generated_function(a, b):
v2 = b
pass
b = v2
pass
v2 = b
b = bar_1(v2)
v3 = v2
print(b)
b = bar_1(v3) + (bar_1(20)-v2)
print(56)
if (foo_2(v2 + v3, foo_1(a)) == a) or ((foo_2(b, v2)< 22) or (v2 >= a or 37 <= v3)):
v3 = b
print(v2)
print(foo_1(a))
a = v3
b = foo_1(a)
v4 = foo_1(b)
print(foo_1(v3) * bar_1(v2))
b = a
print(bar_1(v2))
v2 = v2
v4 = 67
v5 = bar_2((v4 + v2) / (a / b), b)
else:
v4 = v3
b = v4
while ((v2 + (a / v4)) * (foo_2(93, v2) + v2)) < ((a - v2)-18):
v5 = v2
v6 = bar_2(v3, (a - v4) + v3)
a = v2 + v2
break
v5 = 71 / v2
v6 = (a + (b + 47)) - (foo_2(v2, a) / (v5 * v3))
b = v5
b = foo_2(v3, v4)
v5 = 14
v3 = v3
v4 = b * foo_1(b)
v5 = bar_4(v2, v3, v4, b)
v6 = a
v3 = v5
b = 11
v7 = foo_1(v2)
v8 = v4
v4 = foo_1(foo_1(b))
v4 = bar_1(bar_1(bar_2(32, v5)))
v5 = bar_1(bar_2(v2, v2))
```
Figure D.3: Example of a program from the '2x' program distribution.
We apply constraints to the generation process such that variable names are only used after they have been defined, expressions are limited to a maximum depth, and statements continue to be generated until reaching a target number of AST nodes. For the training dataset, we set this target number of nodes to 150, and convert each generated AST into a graph according to B.1; we then throw out graphs with more than 256 graph nodes or 512 node-observation tuples. For our test datasets, we use a target AST size of 300 AST nodes and cutoffs of 512 graph nodes or 1024 node-observation tuples for the '2x' dataset, and a target of 75 AST nodes and cutoffs of 128 graph nodes and 512 tuples for the '0.5x' dataset. For each dataset, the graph size cutoff results in keeping approximately 95% of the generated ASTs. Figures D.1, D.2, and D.3 show example programs from these distributions.
We generated a training dataset with 100,000 programs, a validation dataset of 1024 programs, and a test dataset of 100,000 programs for each of the three sizes (1x, 0.5x, 2x).
## D.2.2 Architectures and Hyperparameters
We configure the GFSA layer to produce a single edge type, corresponding to the target edge of interest. For this task, we specify the the task-specific observation γ referenced in appendix B.1 such that the agent can observe when its current node is a variable with the same identifier as the initial node. We treat | Z | as a hyperparameter, varying between 2, 4, and 8, with a fixed starting state z 0 . We additionally randomly sample the backtracking stability hyperparameter ε bt-stop according to a log-uniform distribution within the range [0 . 001 , 0 . 1] (see appendix C). We initialize parameters with
temperature β = 0 . 01 . Since we choose an optimal threshold while computing the F1 score, we do not use the learned adjustment parameters described in section 3.3, and instead fix a = 1 , b = 0 .
For the GGNN, GREAT, and RAT baselines, we evaluate with both 'nodewise" and 'dot-product" heads. For the "nodewise" head, we compute outputs as
$$A _ { n , n ^ { \prime } } = \sigma \left ( \left [ f _ { \theta } ( X _ { n o d e } + b ^ { T } \delta _ { n } , X _ { e d g e } ) \right ] _ { n ^ { \prime } } \right )$$
where the learned model f θ : R d ×| N | × R e ×| N |×| N | → R | N | produces a scalar output for each node, X node ∈ R d ×| N | and X edge ∈ R e ×| N |×| N | are embeddings of the node and edge features, δ n is a one-hot vector indicating the start node, and b is a learned start node embedding. For the 'dot-product' head, we instead compute
$$Y = f _ { \theta } ( X _ { n o d e } , X _ { e d g e } ) , \quad A _ { n , n ^ { \prime } } = \sigma \left ( y _ { n } ^ { T } W y _ { n ^ { \prime } } + b \right ) ,$$
where the learned model f θ : R d ×| N | × R e ×| N |×| N | → R d ×| N | produces updated node embeddings y n , W is a learned d × d matrix, and b is a learned scalar bias. Since the nodewise models require | N | times as many more forward passes to compute edges for a single example, we keep training time manageable by reducing the width relative to the dot-product models.
The RAT and GREAT models are both variants of a transformer applied to the nodes of a graph. Both models use a set of attention heads, each of which compute query and key vectors q n , k n ∈ R d for each node n as linear transformations of the node features x n : q n = W Q x n , k n = W K x n . The RAT model computes attention logits as
$$y _ { ( n , n ^ { \prime } ) } = \frac { q _ { n } ^ { T } \left ( k _ { n ^ { \prime } } + W ^ { E K } e _ { ( n , n ^ { \prime } ) } \right ) } { \sqrt { d } }$$
where we transform the edge features e ( n,n ′ ) into an 'edge key' that can be attended to by the query in addition to the content-based key. This corresponds to the attention equations as described by Shaw et al. [37], but with a graph-based mechanism for choosing the pairwise key vector. The GREAT model uses an easier-to-compute formulation
$$y _ { ( n , n ^ { \prime } ) } = \frac { q _ { n } ^ { T } k _ { n ^ { \prime } } + w ^ { T } e _ { ( n , n ^ { \prime } ) } \cdot 1 ^ { T } k _ { n ^ { \prime } } } { \sqrt { d } }$$
where the attention logits are biased by a (learned) linear projection of the edge features, scaled by a (fixed) linear projection of the key ( 1 denotes a vector of ones). In both models, the y ( n,n ′ ) are converted to attention weights α ( n,n ′ ) using softmax, and used to compute a weighed average of embedded values. However, in the RAT model, both nodes and edges contribute to values ( z n = ∑ n ′ α ( n,n ′ ) ( v n ′ + W EV e ( n,n ′ ) ) ), whereas in GREAT this sum is only over nodes ( z n = ∑ n ′ α ( n,n ′ ) v n ′ ).
For the NRI-encoder-based model, we make multiple adjustments to the formulation from Kipf et al. [25] in order to apply it to our setting. Since we are adding edges to an existing graph, the first part of our NRI model combines aspects from the encoder and decoder described in Kipf et al. [25]; we express our version in terms of blocks that each compute
$$h _ { ( n , n ^ { \prime } ) } ^ { i + 1 } = \sum _ { k } e _ { k , ( n , n ^ { \prime } ) } f _ { e } ^ { i , k } ( h _ { n } ^ { i } , h _ { n ^ { \prime } } ^ { i } ) , \quad h _ { n } ^ { i + 1 } = f _ { v } ^ { i } \left ( \sum _ { n ^ { \prime } } h _ { ( n , n ^ { \prime } ) } ^ { i + 1 } \right ) .$$
where h i n denotes the vector of node features after layer i , h i +1 ( n,n ′ ) denotes the vector of hidden pairwise features, and e k, ( n,n ′ ) is the k th edge feature between n and n ′ from the base graph. To enable deeper models, we apply layer normalization and residual connections after each of these blocks, as in Vaswani et al. [40]. We then compute the final output head by applying the sigmoid activation to the final layer's hidden pairwise feature matrix h I ( n,n ′ ) (which we constrain to have feature dimension 1), replacing the softmax used in the original NRI encoder (since we are doing binary classification, not computing a categorical latent variable). All versions of f are learned MLPs with ReLU activations.
The RL agent baseline uses the same parameterization as the GFSA layer. However, instead of exactly solving for marginals, we sample a discrete transition at every step. Given a particular start node, the
agent gets a reward of +1 if it takes the ADDEDGEANDSTOP action at any of the correct destination nodes, or if it takes the STOP action and there was no correct destination node. We use 20 rollouts per start node, and train with REINFORCE and a leave-one-out control variate. During final evaluation, we compute exact marginals as for the GFSA layer; thus, differences in evaluation results reflect differences in the learning algorithm only.
For all of our baselines, we convert the Python AST into a graph by transforming the AST nodes into graph nodes and the field relationships into edges. For parity with the GFSA layer, the helper nodes defined in appendix B.1 are also used in the the baseline graph representation, and we add an extra edge type connecting variables that use the same identifier. All edges are embedded in both forward and reverse directions. We include hyperparameters for whether the initial node embeddings X node contain positional encodings computed as in Vaswani et al. [40] according to a depth-first tree traversal, and whether edges are embedded using a learned vector or using a one-hot encoding.
For the GGNN model, we choose a number of GGNN iterations (between 4 and 12 iterations using the same parameters) and a hidden state dimension (from { 16 , 32 , 128 } for the nodewise models or { 128 , 256 , 512 } for the dot-product models).
For the GREAT and RAT models, we choose a number of layers (between 4 and 12, but not sharing parameters), a hidden state dimension (from { 16 , 32 , 128 } for the nodewise models or { 128 , 256 , 512 } for the dot-product models), and a number of self-attention heads (from { 2 , 4 , 8 , 16 } ), with query, key, and value sizes chosen so that the sum of sizes across all heads matches the hidden state dimension.
For the NRI encoder model, we choose whether to allow communication between non-adjacent nodes, a hidden size for node features (from { 128 , 256 , 512 } ), a hidden size for intermediate pairwise features (from { 16 , 32 , 64 } ), a hidden size for initial base-graph edge features (from { 16 , 32 , 64 } ), a depth for each MLP (from 1 to 5 layers), and a number of NRI-style blocks (between 4 and 12).
## D.2.3 Training and Detailed Results
For all of our models, we train using the Adam optimizer for either 500,000 iterations or 24 hours, whichever comes first; this is enough time for all models to converge to their final accuracy. For each model version and task, we randomly sample 32 hyperparameter settings, and then select the model and early-stopping point with the best F1 score on a validation set of 1024 functions. In addition to the hyperparameters described above, all models share the following hyperparameters: batch size (either 8, 32, or 128), learning rate (log-uniform in [10 -5 , 10 -2 ] ), gradient clipping threshold (log-uniform in [1 , 10 4 ] ), and focal-loss temperature γ (uniform in [0 , 5] ). Hyperparameter settings that result in out-of-memory errors are not counted toward the 32 samples.
After selecting the best performing model for each model type and task based on performance on the validation set, we evaluated the model on each of our test datasets. For each example size (1x, 2x, 0.5x), we partitioned the 100,000 test examples into 10 equally-sized folds. We used the first fold to tune the final classifier threshold to maximize F1 score (using a different threshold for each example size to account for shifts in the distribution of model outputs). We then fixed that threshold and evaluated the F1 score on each of the other splits. We report the mean of the F1 score across those folds, along with an approximate standard error estimate (computed by dividing the standard deviation of the F1 score across folds by √ 9 = 3 ).
To assess robustness of convergence, we also compute the fraction of training runs that achieve at least 90% accuracy on the validation set. Note that each training job has different hyperparameters but also a different parameter initialization and a different dataset iteration order; we do not attempt to distinguish between these sources of variation.
Table D.1 contains higher-precision results for the edge-classification tasks, along with the standard error estimates computed as above. Additionally, figure D.4 shows precision-recall curves, computed for a subset of the experiments that shows the most interesting variation in performance.
Table D.1: Full-precision results on static analysis tasks. Expressed as mean F1 score (in %) ± standard error on test set. For 1x dataset size, we also report fraction of training jobs across hyperparameter sweep that achieved 90% validation accuracy.
| Task | Next Control Flow | Next Control Flow | Next Control Flow | Next Control Flow | Next Control Flow | Next Control Flow | Next Control Flow |
|-------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|------------------------------------------------|
| Example size | 1x | | 2x | 0.5x | | | |
| training examples | training examples | training examples | training examples | training examples | training examples | training examples | training examples |
| RAT nw | 99.9837 ± 0.0006 (25/32 | @90%) | 99.9367 ± 0.0012 | 99.9880 ± 0.0007 | | | |
| GREAT nw | 99.9770 ± 0.0011 (26/32 | @90%) | 99.8709 ± 0.0013 | 99.9834 ± 0.0010 | | | |
| GGNN nw | 99.9823 ± 0.0007 | (31/32 @90%) | 93.9034 ± 0.0304 | 97.7723 ± 0.0246 | | | |
| RAT dp | 99.9945 ± 0.0004 | (26/32 @90%) | 92.5278 ± 0.0080 | 96.5901 ± 0.0150 | | | |
| GREAT dp | 99.9941 ± 0.0006 | (24/32 @90%) | 96.3243 ± 0.0092 | 98.3557 ± 0.0081 | | | |
| GGNN dp | 99.9392 ± 0.0014 | (26/32 @90%) | 62.7524 ± 0.0195 | 98.5104 ± 0.0176 | | | |
| NRI encoder | 99.9765 ± 0.0010 | (31/32 @90%) | 85.9087 ± 0.0156 | 99.9161 ± 0.0021 | | | |
| RL ablation Layer (ours) | 94.2419 ± 0.0118 99.9972 ± 0.0001 | (02/32 @90%) | 93.5616 ± 0.0087 | 94.8329 ± 0.0241 99.9985 ± 0.0002 | | | |
| GFSA | | (29/32 @90%) | 99.9941 ± 0.0002 | | | | |
| training examples | training examples | training examples | training examples | training examples | training examples | training examples | training examples |
| RAT nw | 98.6324 ± 0.0090 | (13/32 @90%) | 95.9320 ± 0.0092 | 96.3167 ± 0.0249 | | | |
| GREAT nw | 98.2327 ± 0.0054 | (13/32 @90%) | 97.9814 ± 0.0071 | 98.5181 ± 0.0065 | | | |
| GGNN nw | 99.3749 ± 0.0060 | (25/32 @90%) | 98.3590 ± 0.0050 | 98.6022 ± 0.0141 | | | |
| RAT dp | 81.8068 ± 0.0296 | (00/32 @90%) | 68.4592 ± 0.0187 | 87.0517 ± 0.0334 | | | |
| GREAT dp | 86.5967 ± 0.0216 | (00/32 @90%) | 62.9828 ± 0.0245 | 80.5810 ± 0.0192 | | | |
| GGNN dp | 76.8530 ± 0.0388 | (00/32 @90%) | 22.9947 ± 0.0083 | 28.9142 ± 0.0520 | | | |
| NRI encoder | 81.7358 ± 0.0347 | (00/32 @90%) | 69.0823 ± 0.0216 | 88.8749 ± 0.0452 | | | |
| RL ablation | 91.6981 ± 0.0122 | (03/32 @90%) | 91.1424 ± 0.0120 | 92.2917 ± 0.0215 | | | |
| GFSA Layer (ours) | 99.9944 ± 0.0002 | | | | | | |
| | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 | (29/32 @90%) 99.9890 ± 0.0003 99.9971 ± 0.0004 |
| Example | Task size | 1x | | Last Read 2x | 0.5x | | |
| | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples |
| | RAT nw | 99.8602 ± 0.0020 | (11/32 @90%) | 96.2865 ± 0.0083 | 99.9785 ± 0.0008 | | |
| | GREAT nw | 99.9099 ± 0.0015 | (14/32 @90%) | 95.1157 ± 0.0100 | 99.9801 ± 0.0006 | | |
| | GGNN nw | 95.5197 ± 0.0121 | (04/32 @90%) | 9.2216 ± 0.0658 | 86.2371 ± 0.0310 | | |
| | RAT | 99.9579 ± 0.0011 | (18/32 @90%) | 42.5754 ± 0.0139 | 91.9595 ± 0.0325 | | |
| | dp | | | 47.0747 ± 0.0193 | | | |
| | GREAT dp | 99.9869 ± 0.0005 | (18/32 @90%) | 0.9925 ± 0.0004 | 99.7819 ± 0.0028 63.7686 ± 0.0940 | | |
| | GGNN dp NRI encoder | 98.4356 ± 0.0063 99.8306 ± 0.0024 | (05/32 @90%) | 43.4380 ± 0.0220 | 99.3851 ± 0.0051 | | |
| | RL ablation | 96.6928 ± 0.0131 | (14/32 @90%) (02/32 @90%) | 94.8530 ± 0.0164 | | | |
| | | 99.6561 ± | | | 97.8541 ± 0.0091 | | |
| GFSA | Layer (ours) | | (25/32 @90%) | 98.9355 ± 0.0056 | 99.8973 ± | | |
| 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples | 0.0030 0.0020 100 training examples |
| | RAT nw | 80.2832 ± 0.0257 | (00/32 @90%) | 1.1217 ± 0.0021 | 83.4938 ± 0.0284 | | |
| | GREAT nw | 78.8755 ± 0.0220 | (00/32 @90%) | 6.9583 ± 0.0157 | 60.9003 ± 0.0375 | | |
| | GGNN nw | 79.3594 ± 0.0350 | (00/32 @90%) | 28.2760 ± 0.3023 | 5.6617 ± 0.0095 | | |
| | | 59.5289 ± 0.0174 | (00/32 @90%) | 28.9121 ± 0.0076 | 62.2680 ± 0.0500 | | |
| | RAT dp | | | 27.1285 ± 0.0161 | 64.4819 ± 0.0339 | | |
| | GREAT dp | 57.0199 ± 0.0378 | (00/32 @90%) | 9.6449 ± 0.0060 | 38.3370 ± 0.0223 | | |
| | GGNN dp NRI encoder | 44.3653 ± 0.0182 68.6947 ± 0.0390 | (00/32 @90%) (00/32 @90%) | 26.6422 ± 0.0172 | 73.5216 ± 0.0312 | | |
| | RL ablation | 98.4823 ± 0.0087 | (06/32 @90%) | 97.0341 ± 0.0141 | 99.1689 ± 0.0089 99.2172 ± 0.0048 | | |
| GFSA | Layer (ours) | 98.8141 ± 0.0069 | (25/32 @90%) | 97.8198 ± 0.0079 | | | |
| | Task | | | Last | Write | | |
| | | Example size | | | | | |
| | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples | 100,000 training examples |
| | | RAT nw | ± 0.0021 | | ± 0.0172 | 99.9741 ± 0.0012 | 99.9741 ± 0.0012 |
| | | | 99.8333 | (22/32 @90%) | 94.8665 | | |
| | | GREAT nw | 99.7538 ± 0.0043 | (16/32 @90%) | 93.2187 ± 0.0181 99.9343 40.6941 ± 0.0302 | | |
| | | GGNN nw | 98.8240 ± 0.0080 | (09/32 @90%) | ± | 88.2834 ± 0.0281 ± | 88.2834 ± 0.0281 ± |
| | | RAT dp | 99.9815 ± 0.0006 | (19/32 @90%) | 68.9617 0.0169 ± | 99.7626 0.0045 | 99.7626 0.0045 |
| | | GREAT dp | 99.9868 ± 0.0007 | (18/32 @90%) | 68.4564 0.0188 38.3976 ± 0.0772 | 99.8809 ± 0.0029 94.5246 ± 0.0576 | 99.8809 ± 0.0029 94.5246 ± 0.0576 |
| | | GGNN dp | 99.3488 ± 0.0040 | (13/32 @90%) @90%) | 52.7272 ± 0.0226 | | |
| | NRI | encoder | 99.8710 ± 0.0019 | (24/32 | | 99.8390 ± 0.0058 | 99.8390 ± 0.0058 |
| | RL | ablation | 98.0828 ± 0.0109 | (03/32 @90%) | 96.6400 ± 0.0185 | 98.9277 ± 0.0076 | 98.9277 ± 0.0076 |
| | GFSA Layer | (ours) | 99.4653 ± 0.0040 | (25/32 @90%) | 98.7259 ± 0.0111 | 99.7763 ± 0.0033 | 99.7763 ± 0.0033 |
| | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples | 100 training examples |
| | | RAT nw | 79.2705 ± 0.0212 | (00/32 | ± | ± | ± |
| | | | | @90%) | 8.9069 0.0165 | 83.7914 0.0379 | 83.7914 0.0379 |
| | | GREAT nw | 80.1879 ± 0.0273 | (00/32 @90%) | 40.2206 ± 0.0386 | 84.5417 ± 0.0312 | 84.5417 ± 0.0312 |
| | | GGNN nw | 91.1302 ± 0.0196 | (01/32 @90%) | 71.6216 ± 0.0163 | 91.7911 ± 0.0272 | 91.7911 ± 0.0272 |
| | | RAT dp | 75.9944 ± 0.0352 | (00/32 @90%) (00/32 | 48.0974 ± 0.0331 | 81.6254 ± 0.0312 | 81.6254 ± 0.0312 |
| | | GREAT dp | 73.6926 ± 0.0391 | @90%) | 46.2676 ± 0.0334 | 80.0267 ± 0.0511 | 80.0267 ± 0.0511 |
| | | GGNN dp | 53.8178 ± 0.0282 | (00/32 @90%) | 17.8435 ± 0.0101 | 55.0784 ± 0.0481 | 55.0784 ± 0.0481 |
| | NRI | encoder | ± 0.0498 | @90%) | ± 0.0301 | 73.8556 ± 0.0106 | 73.8556 ± 0.0106 |
| | RL | ablation (ours) | 98.3220 ± 0.0098 98.7144 ± 0.0072 | @90%) @90%) | ± 0.0150 | 99.0671 ± | 99.0671 ± |
| | GFSA Layer | | | | ± 0.0120 | 99.5543 ± | 99.5543 ± |
| | | | | (24/32 | | | |
| | | | | (06/32 | | | |
| | | | | | 96.9613 96.9758 | | |
| | | | | | (00/32 | (00/32 | (00/32 |
| | | | | | 36.4278 | 0.0074 0.0068 | 0.0074 0.0068 |
| | 65.3841 | | | | | | |
Figure D.4: Precision-recall curves for a subset of the static analysis experiments that reveals interesting differences in performance: training on 100 examples and evaluating on the same data distribution, and training on 100,000 examples but evaluating on examples of twice the size. Crosshatches indicate candidate thresholds that were evaluated at test time. Best viewed in color.
<details>
<summary>Image 3 Details</summary>
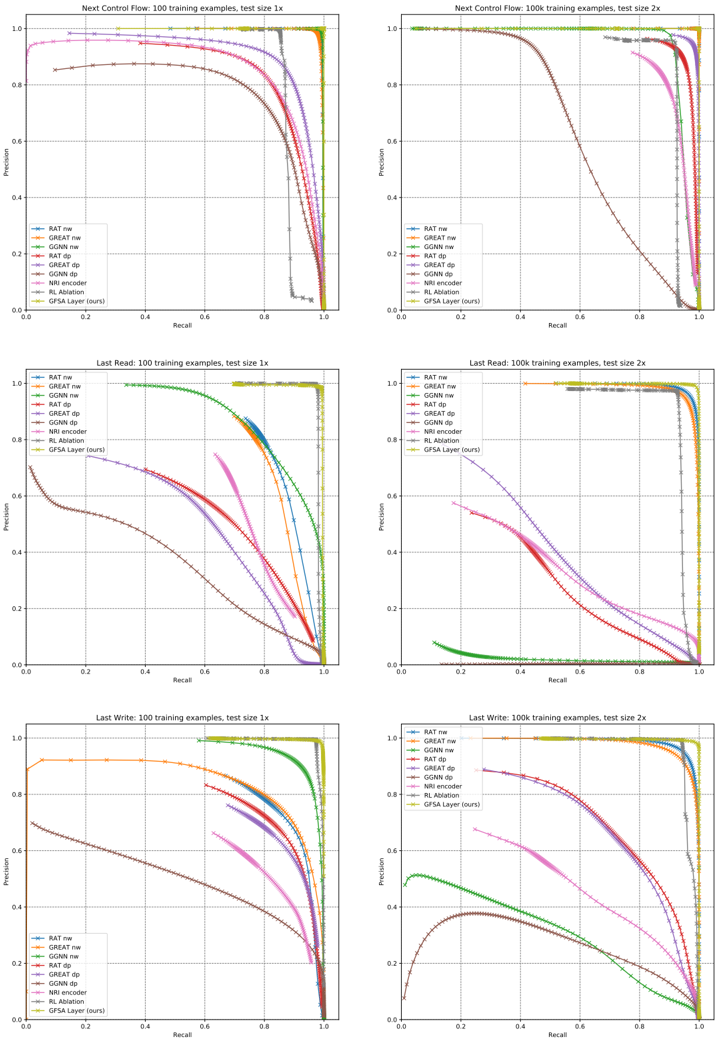
### Visual Description
## Precision-Recall Curves for Different Models
### Overview
The image contains six precision-recall (PR) curves comparing the performance of various machine learning models across different tasks and configurations. Each graph represents a specific task (e.g., "Next Control Flow," "Last Read," "Last Write") with varying training example counts (100 or 100k) and test sizes (1x or 2x). The curves illustrate the trade-off between precision and recall for each model.
### Components/Axes
- **X-axis**: Recall (0.0 to 1.0)
- **Y-axis**: Precision (0.0 to 1.0)
- **Legends**:
- RAT nw (blue solid)
- GREAT nw (orange solid)
- GGNN nw (green solid)
- RAT dp (red dashed)
- GREAT dp (purple dashed)
- GGNN dp (brown dashed)
- NRI encoder (pink dash-dot)
- RL Ablation (gray dotted)
- GFSA Layer (ours) (yellow dotted)
- **Task Labels**:
- Top row: "Next Control Flow"
- Middle row: "Last Read"
- Bottom row: "Last Write"
- **Test Size**:
- Left column: 1x
- Right column: 2x
- **Training Examples**:
- 100 (top row)
- 100k (bottom row)
### Detailed Analysis
#### Next Control Flow (100 training examples, test size 1x)
- **GFSA Layer (ours)**: Starts at ~0.95 precision, drops sharply to ~0.8 at recall 0.2, then plateaus.
- **RAT nw**: Begins at ~0.9, declines gradually to ~0.7 at recall 0.8.
- **GREAT nw**: Starts at ~0.85, drops to ~0.6 at recall 0.6.
- **GGNN nw**: Declines slowly from ~0.8 to ~0.5 at recall 0.8.
- **RAT dp**: Sharp drop from ~0.9 to ~0.5 at recall 0.4.
- **GREAT dp**: Gradual decline from ~0.85 to ~0.4 at recall 0.7.
- **GGNN dp**: Starts at ~0.75, drops to ~0.3 at recall 0.6.
- **NRI encoder**: Flat at ~0.6 precision until recall 0.8, then drops.
- **RL Ablation**: Declines from ~0.7 to ~0.2 at recall 0.8.
#### Next Control Flow (100k training examples, test size 2x)
- **GFSA Layer (ours)**: Maintains ~0.95 precision until recall 0.3, then drops sharply.
- **RAT nw**: Starts at ~0.9, declines to ~0.75 at recall 0.6.
- **GREAT nw**: Begins at ~0.85, drops to ~0.65 at recall 0.5.
- **GGNN nw**: Declines from ~0.8 to ~0.5 at recall 0.7.
- **RAT dp**: Sharp drop from ~0.9 to ~0.5 at recall 0.4.
- **GREAT dp**: Gradual decline from ~0.85 to ~0.4 at recall 0.7.
- **GGNN dp**: Starts at ~0.75, drops to ~0.3 at recall 0.6.
- **NRI encoder**: Flat at ~0.6 precision until recall 0.8, then drops.
- **RL Ablation**: Declines from ~0.7 to ~0.2 at recall 0.8.
#### Last Read (100 training examples, test size 1x)
- **GFSA Layer (ours)**: Starts at ~0.9, drops to ~0.7 at recall 0.3, then plateaus.
- **RAT nw**: Begins at ~0.85, declines to ~0.6 at recall 0.5.
- **GREAT nw**: Starts at ~0.8, drops to ~0.5 at recall 0.4.
- **GGNN nw**: Declines from ~0.75 to ~0.4 at recall 0.6.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
#### Last Read (100k training examples, test size 2x)
- **GFSA Layer (ours)**: Maintains ~0.9 precision until recall 0.2, then drops sharply.
- **RAT nw**: Starts at ~0.9, declines to ~0.75 at recall 0.4.
- **GREAT nw**: Begins at ~0.85, drops to ~0.65 at recall 0.3.
- **GGNN nw**: Declines from ~0.8 to ~0.5 at recall 0.5.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
#### Last Write (100 training examples, test size 1x)
- **GFSA Layer (ours)**: Starts at ~0.9, drops to ~0.7 at recall 0.3, then plateaus.
- **RAT nw**: Begins at ~0.85, declines to ~0.6 at recall 0.5.
- **GREAT nw**: Starts at ~0.8, drops to ~0.5 at recall 0.4.
- **GGNN nw**: Declines from ~0.75 to ~0.4 at recall 0.6.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
#### Last Write (100k training examples, test size 2x)
- **GFSA Layer (ours)**: Maintains ~0.9 precision until recall 0.2, then drops sharply.
- **RAT nw**: Starts at ~0.9, declines to ~0.75 at recall 0.4.
- **GREAT nw**: Begins at ~0.85, drops to ~0.65 at recall 0.3.
- **GGNN nw**: Declines from ~0.8 to ~0.5 at recall 0.5.
- **RAT dp**: Sharp drop from ~0.85 to ~0.4 at recall 0.3.
- **GREAT dp**: Gradual decline from ~0.8 to ~0.3 at recall 0.5.
- **GGNN dp**: Starts at ~0.7, drops to ~0.2 at recall 0.5.
- **NRI encoder**: Flat at ~0.5 precision until recall 0.7, then drops.
- **RL Ablation**: Declines from ~0.6 to ~0.1 at recall 0.6.
### Key Observations
1. **GFSA Layer (ours)** consistently outperforms other models across all tasks and configurations, maintaining high precision even at high recall levels.
2. **Test size (1x vs 2x)** has minimal impact on model performance, with slight improvements in precision for most models at larger test sizes.
3. **Training example count (100 vs 100k)** significantly improves model performance, with higher precision and recall across all models.
4. **DP (data processing) models** (e.g., RAT dp, GREAT dp) generally underperform compared to their non-DP counterparts (e.g., RAT nw, GREAT nw).
5. **NRI encoder** shows flat precision-recall curves, indicating limited adaptability to varying recall levels.
6. **RL Ablation** (gray dotted line) consistently performs poorly, with steep declines in precision as recall increases.
### Interpretation
The data suggests that the **GFSA Layer (ours)** is the most robust model, maintaining high precision across varying recall levels and training conditions. The consistent performance of GFSA Layer across tasks and configurations indicates its generalizability. The underperformance of DP models (e.g., RAT dp, GREAT dp) suggests that data processing steps may introduce noise or reduce model effectiveness. The flat curves of the NRI encoder imply it struggles to adapt to different recall requirements, while RL Ablation's poor performance highlights the importance of reinforcement learning components in these tasks. The minimal impact of test size on performance suggests that model robustness is more influenced by training data quantity and architecture than test size.
</details>
## D.3 Variable Misuse
## D.3.1 Dataset
We use the dataset released by Hellendoorn et al. [19], which is derived from a redistributable subset of the ETH 150k Python dataset [33]. 7 For each top-level function and class definition extracted from the original dataset, this derived dataset includes up to three modified copies introducing synthetic variable misuse errors, along with an equal number of unmodified copies. For our experiments, we do additional preprocessing to support the GFSA layer: we encode the examples as graphs, and throw out examples with more than 256 nodes or 512 node-observation tuples, which leaves us with 84.5% of the dataset from Hellendoorn et al. [19].
## D.3.2 Model Architectures
As in the edge classification task, we convert the AST nodes into graph nodes, using the same helper nodes and connectivity structure described in appendix B.1. For this task, when an AST node has multiple children, we add extra edges specifying the index of each child; this is used only by the attention model, not by the GFSA layer. In addition to node features based on the AST node type, we include features based on a bag-of-subtokens representation of each AST node. We use a 10,000-token subword encoder implemented in the Tensor2Tensor library by Vaswani et al. [41], pretrain it on GitHub Python code, and use it to tokenize the syntax for each AST node. We then compute node features by summing over the embedding vectors of all subtokens that appear in each node. The learned embedding vectors are of dimension 128, which we project out to 256 before using as node features.
To ensure that we can compare results across different edge types in a fair way, we fix the sizes of the base models. For the RAT and GREAT model families, we use a hidden dimension of 256 and 8 attention heads with a per-head query and value dimension of 32. For the GGNN model family, we use a hidden dimension of 256 and a message dimension of 128. For all models, we use positional embeddings for node features, and edge types embedded as 64-dimensional vectors. We embed all edge types separately in the forward and reverse directions, including both the base AST edges as well as any edges added by learned edge layers; for learned edges we compute new edge features by weighting each embedding vector by the associated edge weight. For the '@ start' edge types, the edges are all embedded at the same time, and for the '@ middle' edge types, we modify the edge features after adding the new edges and use the modified edge features for all following model layers. We compute our final outputs by performing a learned dot-product operation on our final node embeddings Y and then taking a softmax transformation to obtain a distribution over node pairs:
$$Y = f _ { \theta } ( X _ { n o d e } , X _ { e d g e } ) , \quad Z = s o f t \max \left ( \{ y _ { n } ^ { T } W y _ { n ^ { \prime } } \} _ { n , n ^ { \prime } \in N } \right ) .$$
As described in Vasic et al. [39], we compute a mask that indicates the location of all local variables that could be either bug locations or repair targets (along with the sentinel no-bug location). We then set the entries of Z n,n ′ to zero for the locations not contained in the mask, and renormalize so that it sums to 1 across node pairs. Note that there is always exactly one correct bug location n but there could be more than one acceptable repair location n ′ ; we thus sum over all correct repair locations to compute the total probability assigned to correct bug-repair pairs, and then use the standard cross-entropy loss.
For the GFSA edges, we use an initialization temperature of β = 0 . 2 , and fix | Z | = 4 . We use a single finite-state automaton policy to generate two edge types by computing the trajectories when z 0 = 0 as well as when z 0 = 1 . We set T max = 128 .
For the NRI head edges, we use a 3-layer MLP (with hidden sizes [32, 32] and output size 2), and take a logistic sigmoid of the outputs, interpreting it as a weighted adjacency matrix for two edge types.
For the uniform random walk edges, we learn a single halting probability p halt = σ ( θ halt ) along with adjustment parameters a, b ∈ R as defined in section 3.3. The output adjacency matrix is defined
7 Original Python corpus (from Raychev et al. [33]): https://www.sri.inf.ethz.ch/py150
Redistributable subset: https://github.com/google-research-datasets/eth\_py150\_open With synthetic errors (as released by Hellendoorn et al. [19]):
https://github.com/google-research-datasets/great
similarly to the GFSA model, but with all of the policy parameters fixed to move to a random neighbor with probability 1 -p halt and take the ADDEDGEANDSTOP action with probability p halt. For this model, we only add a single edge type.
The RL agent uses the same parameterization as the GFSA layer, but samples a single trajectory for each start node and uses it to add a single edge (or no edge) from each start node. The downstream cross-entropy loss for the classification model is used as the reward for all of these trajectories. Since simply computing this reward requires a full downstream model forward pass, we run only one rollout per example with a learned scalar reward baseline ˆ R . We add an additional loss term α ( R -ˆ R ) 2 so that this learned baseline approximates the expected reward, and scale the REINFORCE gradient term by a hyperparameter β .
The 'Hand-engineered edges' baseline uses the base AST edges and adds the following edge types from Allamanis et al. [1] and Hellendoorn et al. [19]: NextControlFlow, ComputedFrom, FormalArgName, LastLexicalUse, LastRead, LastWrite, NextToken (connecting syntactically adjacent nodes), Calls (connecting function calls to their definitions), and ReturnsTo (connecting return statements to the function they return from).
## D.3.3 Training and Detailed Results
For all of our models, we train using the Adam optimizer for 400,000 iterations; this is enough time for all models to converge to their final accuracy. We use a batch size of 64 examples, grouping examples of similar size to avoid excessive padding.
For each model, we randomly sample 32 hyperparameter settings for the learning rate (log-uniform in [10 -5 , 10 -2 ] ) and gradient clipping threshold (log-uniform in [1 , 10 4 ] ). For the GFSA models, we also tune ε bt-stop (log-uniform in [0 . 001 , 0 . 1] ). For the RL ablation, we tune the weight of the relative weights of different gradient terms: α is chosen log-uniformly in [0 . 00001 , 0 . 1] and β is chosen in [0 . 001 , 2 . 0] . Over the course of training, we take a subset of approximately 7000 validation examples and compute the top-1 accuracy of each model on this subset. We then choose the hyperparameter settings and early-stopping point with the highest accuracy.
We evaluate the selected models on the size-filtered test set, containing 818,560 examples. For each example and each model, we determine the predicted classification by determining whether 50% or more probability is assigned to the no-bug location. For incorrect examples, we then find the pair of predicted bug location and repair identifier with the highest probability (summing over all locations for each candidate repair identifier), and check whether the bug location and replacement identifier are correct. Note that if the model assigns >50% probability to the no-bug location, but still ranks the true bug and replacement highest with the remaining probability mass, we count that as an incorrect classification but a correct localization and repair.
To compute standard error estimates, we assume that predictions are independent across different functions, but may be correlated across modified copies of the same function; we thus estimate standard error by using the analytic variance for a binomial distribution, adjusted by a factor of 3 (for buggy or non-buggy examples analyzed separately) or 6 (for averages across all examples) to account for the multiple copies of each function in the dataset. Table D.2 contains higher-precision results for the variable misuse tasks, along with standard error estimates, a breakdown of marginal localization and repair scores (examples where the model gets one of the locations correct but possibly the other incorrect), and an overall accuracy score capturing classification, localization, and repair.
Table D.2: Full-precision results on variable misuse task, with additional breakdown of accuracy for buggy examples. Expressed as accuracy (in %) ± standard error.
| Example type: | All | All | No bug | With bug |
|----------------------------------------------|-------------------------------|-------------------------------|-------------------------------|-------------------------------|
| | Classification | Class &Loc &Rep | Classification | Classification |
| RAT | | | | |
| Base AST graph only | 92.540 ± 0.071 | 88.225 ± 0.087 | 92.051 ± 0.073 | 93.030 ± 0.069 |
| Base AST graph, +2 layers | 92.245 ± 0.072 | 87.846 ± 0.088 | 92.455 ± 0.072 | 92.035 ± 0.073 |
| edges | | | | |
| Hand-engineered | 92.704 ± 0.070 | 88.496 ± 0.086 | 92.932 ± 0.069 | 92.477 ± 0.071 |
| NRI head @start | 92.880 ± 0.070 | 88.710 ± 0.085 | 92.551 ± 0.071 | 93.208 ± 0.068 ± |
| NRI head @middle | 92.572 ± 0.071 92.997 ± 0.069 | 88.423 ± 0.086 | 92.834 ± 0.070 93.224 ± 0.068 | 92.310 0.072 92.770 ± 0.070 |
| Random walk @start RL ablation @middle | 92.036 ± 0.073 | 88.907 ± 0.084 87.278 ± 0.090 | 90.361 ± 0.080 | 93.711 ± 0.066 |
| GFSA layer (ours) @start | 93.328 ± 0.068 | | 93.101 ± 0.069 | 93.555 ± 0.066 |
| GFSA layer (ours) @middle | 93.456 ± 0.067 | 89.472 ± 0.083 89.627 ± 0.082 | 92.662 ± 0.071 | 94.250 ± 0.063 |
| GREAT | | | | |
| Base AST graph only | 91.662 ± 0.075 | 86.906 ± 0.091 | 90.849 ± 0.078 | 92.475 ± 0.071 |
| Base AST graph, +2 | 92.307 ± 0.072 | 87.902 ± 0.087 | 92.711 ± 0.070 | 91.903 ± 0.074 |
| layers Hand-engineered edges | 92.287 ± 0.072 | 87.646 ± 0.088 | 92.577 ± 0.071 | 91.996 ± 0.073 |
| NRI head @start | 92.061 ± 0.073 | 87.447 ± 0.089 | 91.112 ± 0.077 | 93.009 ± 0.069 |
| NRI head @middle | 92.074 ± 0.073 | 87.552 ± 0.088 | 92.800 ± 0.070 | 91.347 ± 0.076 |
| Random walk @start | 92.644 ± 0.071 | 88.283 ± 0.087 | 91.872 ± 0.074 | 93.417 ± 0.067 |
| RL ablation @middle | 91.707 ± 0.075 | 86.939 ± 0.091 | 89.951 ± 0.081 | 93.464 ± 0.067 |
| GFSA layer (ours) @start | 92.963 ± 0.069 | 88.825 ± 0.085 | 92.872 ± 0.070 | 93.055 ± 0.069 |
| GFSA layer (ours) @middle | 93.019 ± 0.069 | 88.806 ± 0.085 | 92.427 ± 0.072 | 93.612 ± 0.066 |
| GGNN | | | | |
| Base AST graph only | 89.704 ± 0.082 | 83.521 ± 0.098 | 91.257 ± 0.076 | 88.152 ± 0.087 |
| Base AST graph, +2 layers | 90.359 ± 0.080 | 84.383 ± 0.098 | 88.795 ± 0.085 | 91.922 ± 0.074 |
| Hand-engineered edges | 90.874 ± 0.078 | 84.776 ± 0.096 | 90.187 ± 0.081 | 91.560 ± 0.075 |
| | | | 91.486 ± 0.076 | 89.380 ± 0.083 |
| NRI head @start | 90.433 ± 0.080 | 84.473 ± 0.096 | | |
| NRI head @middle | 90.243 ± 0.080 | 84.412 ± 0.098 | 88.289 ± 0.087 | 92.198 ± 0.073 |
| Random walk @start | 90.315 ± 0.080 | 84.519 ± 0.096 | 91.351 ± 0.076 | 89.278 ± 0.084 |
| RL ablation @middle | 90.540 ± 0.079 | 84.959 ± 0.096 | 90.437 ± 0.080 90.083 ± 0.081 | 90.643 ± 0.079 91.796 ± 0.074 |
| GFSA layer (ours) @start | 90.939 ± 0.078 | 85.012 ± 0.096 | | |
| GFSA layer (ours) @middle | 90.394 ± 0.080 | 84.723 ± 0.096 | 90.983 ± 0.078 | 89.805 ± 0.082 |
| Example type: | With bug | With bug | With bug | With bug |
| | Localization | Repair | Loc &Repair | Class &Loc &Rep |
| RAT | | | | |
| Base AST graph only | 92.936 ± 0.069 | 91.892 ± 0.074 | 88.300 ± 0.087 | 84.399 ± 0.098 |
| Base AST graph, +2 layers | 92.638 ± 0.071 | 91.541 ± 0.075 | 87.764 ± 0.089 | 83.238 ± 0.101 |
| Hand-engineered edges | 93.100 ± 0.069 | 92.007 ± 0.073 | 88.388 ± 0.087 | 84.060 ± 0.099 |
| NRI head @start | 93.180 ± 0.068 | 92.304 ± 0.072 | 88.731 ± 0.086 | 84.869 ± 0.097 |
| NRI head @middle Random walk @start | 93.013 ± 0.069 93.227 ± 0.068 | 92.176 ± 0.073 | 88.619 ± 0.086 88.726 ± 0.086 | 84.011 ± 0.099 84.590 ± 0.098 |
| RL ablation @middle | 92.553 ± 0.071 | 92.282 ± 0.072 91.606 ± 0.075 | 87.730 ± 0.089 | 84.195 ± 0.099 |
| GFSA layer (ours) @start | 93.820 ± 0.065 | ± | 89.577 ± 0.083 | 85.843 ± 0.094 |
| | | 92.834 0.070 | | |
| GFSA layer (ours) @middle | 94.058 ± 0.064 | 93.083 ± 0.069 | 89.932 ± 0.081 | 86.593 ± 0.092 |
| GREAT | | | | |
| Base AST graph only | 92.030 ± 0.073 | 91.156 ± 0.077 | 87.179 ± 0.091 | 82.964 ± 0.102 |
| Base AST graph, +2 layers | 92.585 ± 0.071 | 91.477 ± 0.076 | 87.698 ± 0.089 | 83.093 ± 0.101 |
| Hand-engineered edges | 92.174 ± 0.073 | 91.287 ± 0.076 | 87.168 ± 0.091 | 82.715 ± 0.102 |
| NRI head @start | 92.446 ± 0.072 | 91.520 ± 0.075 | 87.628 ± 0.089 | 83.781 ± 0.100 |
| NRI head @middle | 92.213 ± 0.073 | 91.166 ± 0.077 | 87.258 ± 0.090 | 82.303 ± 0.103 |
| Random walk @start | 92.849 ± 0.070 | 91.949 ± 0.074 | 88.272 ± 0.087 | 84.694 ± 0.097 |
| RL ablation @middle | 92.383 ± 0.072 | 91.295 ± 0.076 | 87.486 ± 0.090 | 83.927 ± 0.099 |
| GFSA layer (ours) @start | 93.466 ± 0.067 | 92.279 ± 0.072 | 88.845 ± 0.085 | 84.779 ± 0.097 |
| GFSA layer (ours) @middle | 93.266 ± 0.068 | 92.394 ± 0.072 | 88.863 ± 0.085 | 85.186 ± 0.096 |
| GGNN | | | | |
| Base AST graph | 89.243 ± 0.084 | 87.703 ± 0.089 | 81.633 ± 0.105 | 75.785 ± 0.116 |
| only | 90.633 ± 0.079 | 88.948 ± 0.085 | 83.969 ± 0.099 | 79.972 ± 0.108 |
| Base AST graph, +2 layers | 90.681 ± 0.079 | ± | ± | 79.365 ± 0.110 |
| Hand-engineered edges | 89.915 ± 0.082 | 88.770 0.085 88.151 ± 0.087 | 83.524 0.100 82.731 ± 0.102 | 77.460 ± 0.113 |
| NRI head @start NRI head @middle | 90.352 ± 0.080 | 89.613 ± 0.083 | 84.443 ± 0.098 | 80.535 ± 0.107 |
| | 89.729 ± 0.082 | 88.611 ± 0.086 | 82.956 ± 0.102 | 77.688 ± 0.113 |
| Random walk @start | | | | 79.480 ± 0.109 |
| RL ablation @middle GFSA layer (ours) @start | 90.560 ± 0.079 90.939 ± 0.078 | 89.269 ± 0.084 88.960 ± 0.085 | 84.301 ± 0.098 83.909 ± 0.099 | 79.942 ± 0.108 |
| GFSA layer (ours) @middle | 90.217 ± 0.080 | 88.886 ± 0.085 | 83.633 ± 0.100 | 78.463 ± 0.111 |