## FastSecAgg: Scalable Secure Aggregation for Privacy-Preserving Federated Learning
Swanand Kadhe, Nived Rajaraman, O. Ozan Koyluoglu, and Kannan Ramchandran
University of California Berkeley
Department of Electrical Engineering and Computer Sciences f swanand.kadhe,nived,ozan.koyluoglu,kannanr g @berkeley.edu
## ABSTRACT
Recent attacks on federated learning demonstrate that keeping the training data on clients' devices does not provide sufficient privacy, as the model parameters shared by clients can leak information about their training data. A secure aggregation protocol enables the server to aggregate clients' models in a privacy-preserving manner. However, existing secure aggregation protocols incur high computation/communication costs, especially when the number of model parameters is larger than the number of clients participating in an iteration - a typical scenario in federated learning.
subset of clients, and sends them the current global model. Each client runs several steps of mini-batch stochastic gradient descent, and communicates its model update-the difference between the local model and the received global model-to the server. The server aggregates the model updates from the clients to obtain an improved global model, and moves to the next iteration.
In this paper, we propose a secure aggregation protocol, FastSecAgg, that is efficient in terms of computation and communication, and robust to client dropouts. The main building block of FastSecAgg is a novel multi-secret sharing scheme, FastShare, based on the Fast Fourier Transform (FFT), which may be of independent interest. FastShare is information-theoretically secure, and achieves a trade-off between the number of secrets, privacy threshold, and dropout tolerance. Riding on the capabilities of FastShare, we prove that FastSecAgg is (i) secure against the server colluding with any subset of some constant fraction (e.g. 10%) of the clients in the honest-but-curious setting; and (ii) tolerates dropouts of a random subset of some constant fraction (e.g. 10%) of the clients. FastSecAgg achieves significantly smaller computation cost than existing schemes while achieving the same (orderwise) communication cost. In addition, it guarantees security against adaptive adversaries, which can perform client corruptions dynamically during the execution of the protocol.
## CCS CONCEPTS
· Security and privacy ! Privacy-preserving protocols;
## KEYWORDS
secret sharing, secure aggregation, federated learning, machine learning, data sketching, privacy-preserving protocols
## 1 INTRODUCTION
Federated Learning (FL) is a distributed learning paradigm that enables a large number of clients to coordinate with a central server to learn a shared model while keeping all the training data on clients' devices. In particular, training a neural net in a federated manner is an iterative process. In each iteration of FL, the server selects a
A shorter version of this paper has been accepted in ICML Workshop on Federated Learning for User Privacy and Data Confidentiality, July 2020, and CCS Workshop on Privacy-Preserving Machine Learning in Practice, November 2020.
Secure aggregation protocols can be used to provide strong privacy guarantees in FL. At a high level, secure aggregation is a secure multi-party computation (MPC) protocol that enables the server to compute the sum of clients' model updates without learning any information about any client's individual update [9]. Secure aggregation can be efficiently composed with differential privacy to further enhance privacy guarantees [9, 22, 45].
FL ensures that every client keeps their local data on their own device, and sends only model updates that are functions of their dataset. Even though any update cannot contain more information than the client's local dataset, the updates may still leak significant information making them vulnerable to inference and inversion attacks [17, 19, 33, 40]. Even well-generalized deep models such as DenseNet can leak a significant amount of information about their training data [33]. In fact, certain neural networks (e.g., generative text models) trained on sensitive data (e.g., private text messages) can memorize the training data [13].
The secure aggregation problem for securely computing the summation has received significant research attention in the past few years, see [22] for a survey. However, the FL setup presents unique challenges for a secure aggregation protocol [8, 28]:
- (1) Massive scale: Up to 10,000 users can be selected to participate in an iteration.
- (3) Dropouts: Clients are mobile devices which can drop out at any point. The percentage of dropouts can go up to 10%.
- (2) Communication costs: Model updates can be high-dimensional vectors, e.g., the ResNet model consists of hundreds of millions of parameters [23].
- (4) Privacy: It is crucial to provide strongest possible privacy guarantees since malicious servers can launch powerful attacks by using sybils [14], wherein the adversary simulates a large number of fake client devices [18].
Due to these challenges, existing secure aggregation protocols for FL [3, 9, 43, 45, 47] either incur heavy computation and communication costs or provide only weaker forms of privacy guarantees, which limits their scalability (see Table 1).
Secret sharing [2] is an elegant primitive that is used as a building block in a large number of secure summation (and in general secure MPC) protocols, see, e.g., [15, 22]. Secret sharing based secure aggregation protocols are often more efficient than other approaches such as homomorphic encryption and Yao's garbled
Table 1: Comparison of the proposed FastSecAgg with SecAgg [9], TurboAgg [43], and SecAgg+ [3]. Here N is the total number of clients and L is the length of model updates (i.e., client inputs). An adaptive adversary can choose which clients to corrupt during the protocol execution, whereas the corruptions happen before the protocol execution starts for a non-adaptive adversary. Worst-case (resp. average-case) dropout guarantee ensures that any (resp. a random) subset of clients of a bounded size may drop out without affecting the correctness and security. TurboAgg requires at least log N rounds, which increases the overheads. The protocols in [45, 47] assume a trusted third party for key distribution (see Sec. 5.3 for details).
| Protocol | Computation (Server) | Communication (Server) | Computation (Client) | Communication (Client) | Adversary | Dropouts |
|---------------|------------------------------------------|------------------------------|-----------------------------------------|--------------------------|--------------|--------------|
| SecAgg [9] | O LN 2 | O LN + N 2 | O LN + N 2 | O' L + N ' | Adaptive | Worst-case |
| TurboAgg [43] | O L log N log 2 log N | O' LN log N ' | O L log N log 2 log N | O' L log N ' | Non-adaptive | Average-case |
| SecAgg+ [3] | O LN log N + N log 2 N | O' LN + N log N ' | O L log N + log 2 N | O' L + log N ' | Non-adaptive | Average-case |
| FastSecAgg | O' L log N ' | O LN + N 2 | O' L log N ' | O' L + N ' | Adaptive | Average-case |
circuits [1, 11, 22]. However, na¨ ıvely using the popular Shamir's secret sharing scheme [39] for aggregating lengthL updates from N clients incurs O LN 2 communication and computation cost, which is intractable at the envisioned scale of FL.
Using FastShare as a building block, we propose FastSecAgg - a scalable secure aggregation protocol for FL that has low computation and communication costs and strong privacy guarantees (see Table 1 for a comparison of costs). FastSecAgg achieves low costs by riding on the capabilities of FastShare and leveraging the following unique attribute of FL. Privacy breaches in FL are inflicted by malicious/adversarial actors (e.g., a server using sybils), requiring worst-case guarantees; whereas dropouts occur due to non-adversarial/natural causes (e.g., system dynamics and wireless outages) [8], making statistical or average-case guarantees sufficient. FastShare achieves O' N log N ' computation cost by relaxing the dropout constraint from worst-case to random.
In this paper, we propose FastShare-a novel secret sharing scheme based on a finite-field version of the Fast Fourier Transform (FFT)-that is designed to leverage the FL setup. FastShare is a multi-secret sharing scheme, which can simultaneously share S secrets to N clients such that (i) it is information-theoretically secure against a collusion of any subset of some constant fraction (e.g. 10%) of the clients; and (ii) with overwhelming probability, it is able to recover the secrets with O' N log N ' complexity even if a random subset of some constant fraction (e.g. 10%) of the clients drop out. In general, FashShare can achieve a trade-off between the security and dropout parameters (see Theorem 3.3); thresholds of 10% are chosen to be well-suited in the FL setup. We note that a larger number of arbitrary (or even adversarial) dropouts does not affect security, and may only result in a failure to recover the secrets (i.e, affects only correctness). FastShare uses ideas from sparsegraph codes [27, 29, 38] and crucially exploits insights derived from a spectral view of codes [6, 34], which enables us to prove strong privacy guarantees.
For N clients, each having a lengthL update vector, FastSecAgg requires O' L log N ' computation and O LN + N 2 communication at the server, and O' L log N ' computation and O' L + N ' communication per client. We compare the costs and setups with existing protocols in Table 1 (see Sec. 5.3 for details). We point out that the computation cost at the server was observed to be the key barrier to scalability in [8, 9]. FastSecAgg significantly reduces the computation cost at the server as compared to prior works. When the length of model updates L is larger than the number of clients N , FastSecAgg achieves the same (order-wise) communication cost as the prior works. We note that, in typical FL applications, the number of model parameters ' L ' is in millions, whereas the number of clients ' N ' is up to tens of thousands [8, 32]. In addition, FastSecAgg guarantees security against an adaptive adversary, which can corrupt clients adaptively during the execution of the protocol. This is in contrast with the protocols in [3, 43], which are secure only against non-adaptive (or static) adversaries, wherein client corruptions happen before the protocol executions begins.
We note that, although FastShare secret sharing scheme is inspired from the federated learning setup, it may be of independent interest. In fact, FastShare is a cryptographic primitive that can be used for secure aggregation (and secure multi-party computation in general) in wide applications including smart meters [26], medical data collection [12], and syndromic surveillance [46].
## 2 PROBLEM SETUP AND PRELIMINARIES
## 2.1 Federated Learning
We consider the setup in which a fixed set of M clients, each having their local dataset, coordinate with the server to jointly train a model. The i -th client's data is sampled from a distribution D i . The federated learning problem can be formalized as minimizing a sum of stochastic functions defined as
<!-- formula-not-decoded -->
where ' i ' w ' = E ζ D i » ' i ' w ; ζ '… is the expected loss of the prediction on the i -th client's data made with model parameters w .
Federated Averaging (FedAvg) is a synchronous update scheme that proceeds in rounds of communication [32]. At the beginning of each round (called iteration), the server selects a subset C of N clients (for some N M ). Each of these clients i 2 C copies the current model parameters w t i ; 0 = w t , and performs T steps of (minibatch) stochastic gradient descent steps to obtain its local model w t i ; T ; each local step k is of the form w t i ; k w t i ; k 1 η l д t i ; k 1 , where д t i ; k 1 is an unbiased stochastic gradient of ' i at w t i ; k 1 ,
and η l is the local step-size. 1 Then, each client i 2 C sends their update as ∆ w t i = w t i ; L w t . At the server, the clients' updates ∆ w t i are aggregated to form the new server model as w t + 1 = w t + 1 j C j ˝ i 2C ∆ w t i .
Our focus is on one iteration of FedAvg and we omit the explicit dependence on the iteration t hereafter. We assume that each client potentially compresses and suitably quantizes their model update ∆ w t i 2 R d to obtain u i 2 Z L R , where L d . Our goal is to design a protocol that enables the server to securely compute ˝ i 2C u i . We describe the threat model and the objectives in the next section.
## 2.2 Threat Model
Federated learning can be considered as a multi-party computation consisting of N parties (i.e., the clients), each having their own private dataset, and an aggregator (i.e., the server), with the goal of learning a model using all of the datasets.
Honest-but-curious model: The parties honestly follow the protocol, but attempt to learn about the model updates from other parties by using the messages exchanged during the execution of the protocol. The honest-but-curious (aka semi-honest) adversarial model is commonly used in the field of secure MPC, including prior works on secure federated learning [9, 43, 45].
Colluding parties: In every iteration of federated averaging, the server first samples a set C of clients. The server may collude with any set of up to T clients from C . The server can view the internal state and all the messages received/sent by the clients with whom it colludes. We refer to the internal state along with the messages received/sent by colluding parties (including the server) as their joint view . (see Sec. 5.1 for details)
Dropouts: Arandom subset of up to D clients may drop out at any point of time during the execution of secure aggregation.
Objective: Our objective is to design a protocol to securely aggregate clients' model updates such that the joint view of the server and any set of up to T clients must not leak any information about the other clients' model updates, besides what can be inferred from the output of the summation. In addition, even if a random set of up to D clients drop out during an iteration, the server with high probability should be able to compute the sum of model updates (of the surviving clients) while maintaining the privacy. We refer to T as the privacy threshold and D as the dropout tolerance .
## 2.3 Cryptographic Primitives
2.3.1 Key Agreement. A key agreement protocol consists of three algorithms (KA.param, KA.gen, KA.agree). Given a security parameter λ , the parameter generation algorithm pp KA.param ' λ ' generates some public parameters, over which the protocol will be parameterized. The key generation algorithm allows a client i to generate a private-public key pair ' pk i ; sk i ' KA.gen ' pp ' . The key agreement procedure allows clients i and j to obtain a private shared key k i ; j KA.agree ' sk i ; pk j ' . Correctness requires that, for any key pairs generated by clients i and j
1 In practice, clients can make multiple training passes (called epochs) over its local dataset with a given step size. Further, typically client datasets are of different size, and the server takes a weighted average with weight of a client proportional to the size of its dataset. See [32] for details.
(using KA.gen with the same parameters pp ), KA.agree ' sk i ; pk j ' = KA.agree ' sk j ; pk i ' . Security requires that there exists a simulator Sim KA, which takes as input an output key sampled uniformly at random and the public key of the other client, and simulates the messages of the key agreement execution such that the simulated messages are computationally indistinguishable from the protocol transcript.
2.3.2 Authenticated Encryption. An authenticated encryption allows two parties to communicate with data confidentially and data integrity. It consists of an encryption algorithm AE.enc that takes as input a key and a message and outputs a ciphertext, and a decryption algorithm AE.dec that takes as input a ciphertext and a key and outputs the original plaintext, or a special error symbol ? . For correctness, we require that for all keys k i 2 f 0 ; 1 g λ and all messages m , AE.dec '' k i ; AE.enc ' k i ; m '' = m . For security, we require semantic security under a chosen plaintext attack (INDCPA) and ciphertext integrity (IND-CTXT) [4].
## 3 FASTSHARE: FFT BASED SECRET SHARING
In this section, we present a novel, computationally efficient multisecret sharing scheme FastShare which forms the core of our proposed secure aggregation protocol FastSecAgg (described in the next section).
A multi-secret sharing scheme splits a set of secrets into shares (with one share per client) such that coalitions of clients up to certain size have no information on the secrets, and a random 2 set of clients of large enough size can jointly reconstruct the secrets from their shares. In particular, we consider information-theoretic (perfect) security. A secret sharing scheme is said to be linear if any linear combination of valid share-vectors result in a valid share-vector of the linear combination applied to the respective secret-vectors. We summarize this in the following definition.
Definition 3.1 (Multi-secret Sharing). Let F q be a finite field, and let S , T , D and N be positive integers such that S + T + D < N q . A linear multi-secret sharing scheme over F q consists of two algorithms Share and Recon. The sharing algorithm f' i ; » s … i 'g i 2C Share ' s ; C' is a probabilistic algorithm that takes as input a set of secrets s 2 F S q and a set C of N clients (client-IDs), and produces a set of N shares, each in F q , where share » s … i is assigned to client i in C . For a set D C , the reconstruction algorithm f s ; ?g Recon f' i ; » s … i 'g i 2CnD takes as input the shares corresponding to C n D , and outputs either a set of S field elements s or a special symbol ? . The scheme should satisfy the following requirements.
- (1) T -Privacy: For all s ; s 0 2 F S q and every P C of size at most T , the shares of s and s 0 restricted to P are identically distributed.
- (2) D -Dropout-Resilience: For every s 2 F S q and any random set D C of size at most D , Recon f' i ; » s … i 'g i 2CnD = s with probability at least 1 poly ' N ' .
2 Secret sharing [2] and multi-secret sharing [7, 16] schemes conventionally consider worst-case dropouts. We consider random dropouts to exploit the FL setup.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Secret Sharing Scheme using DFT/IDFT
### Overview
The image depicts a diagram illustrating a secret sharing scheme based on the Discrete Fourier Transform (DFT) and its inverse, the Inverse Discrete Fourier Transform (IDFT). The diagram shows the process of encoding a secret into shares and then reconstructing the secret from those shares. It consists of two main flows: encoding (top) and decoding (bottom).
### Components/Axes
The diagram contains the following components:
* **Input:** `x` - Represents the secret plus random masks with careful zero padding.
* **DFT Block:** A rectangular block labeled "DFT".
* **Output (Encoding):** `X` - Represents the shares.
* **Input (Decoding):** `X_y` - Represents a random subset of shares.
* **Peeling Decoder Block:** A rectangular block labeled "Peeling Decoder".
* **IDFT Block:** A rectangular block labeled "IDFT".
* **Output (Decoding):** `x` - Represents the reconstructed secret plus random masks.
* **Text Labels:** Descriptive text accompanying each component, explaining the input and output.
### Detailed Analysis or Content Details
The diagram shows a two-step process:
**Encoding (Top Row):**
1. The secret `x` (along with random masks and zero padding) is input into the DFT block.
2. The DFT block transforms `x` into `X`, which represents the shares. An arrow indicates the flow from `x` to DFT, and from DFT to `X`.
**Decoding (Bottom Row):**
1. A random subset of shares `X_y` is input into the Peeling Decoder block.
2. The Peeling Decoder block processes `X_y` to produce `X` (all shares). An arrow indicates the flow from `X_y` to Peeling Decoder, and from Peeling Decoder to `X`.
3. `X` is then input into the IDFT block.
4. The IDFT block transforms `X` back into `x`, reconstructing the original secret plus the random masks. An arrow indicates the flow from `X` to IDFT, and from IDFT to `x`.
The text labels provide additional context:
* "Secret + random masks with careful zero padding" describes the input `x`.
* "Shares" describes the output `X`.
* "Random subset of shares" describes the input `X_y`.
* "All shares" describes the output of the Peeling Decoder.
* "Secret + random masks" describes the output `x`.
### Key Observations
The diagram illustrates a method for distributing a secret among multiple parties (shares) such that the secret can only be reconstructed if a sufficient number of shares are combined. The use of DFT and IDFT suggests a frequency-domain approach to secret sharing. The "Peeling Decoder" is a key component in reconstructing the full set of shares from a subset.
### Interpretation
This diagram represents a cryptographic technique for secure secret sharing. The DFT and IDFT are used to transform the secret into a different domain (frequency domain) where it can be split into shares. The Peeling Decoder is a crucial step in recovering the complete set of shares from a random subset. This scheme leverages the properties of the DFT to ensure that the secret remains hidden unless a sufficient number of shares are available. The addition of random masks and zero padding likely enhances the security of the scheme by obscuring the original secret and preventing attacks based on known plaintext. The diagram demonstrates a mathematical approach to information security, relying on the properties of signal processing to achieve confidentiality. The diagram does not provide any specific numerical data or parameters, but rather illustrates the conceptual flow of the secret sharing process.
</details>
of shares
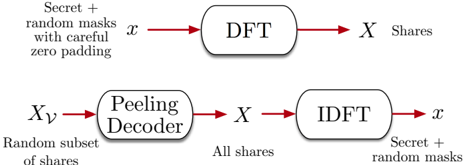
Figure 1: FastShare to generate shares, and FastRecon to recover the secrets from a subset of shares.
- (3) Linearity: If f' i ; » s 1 … i 'g i 2C and f' i ; » s 2 … i 'g i 2C are sharings of s 1 and s 2, then f' i ; a » s 1 … i + b » s 2 … i 'g i 2C is a sharing of a s 1 + b s 2 for any a ; b 2 F q .
Next, we describe FastShare which can achieve a trade-off between S , T , and D for a given N . We begin with setting up the necessary notation. FastShare leverages the finite-field Fourier transform and Chinese Remainder Theorem. Towards this end, let f n 0 ; n 1 g be co-prime positive integers of the same order, such that n 0 n 1 divides ' q 1 ' . Without loss of generality, assume that n 0 < n 1. E.g., n 0 = 10, n 1 = 13, and q = 131. We consider N of the form N = n 0 n 1, and choose the field size q as a power of a prime such that N divides q 1. By the co-primeness of n 0 and n 1, applying the Chinese Remainder Theorem, any number j 2 f 0 ; ; n 1 g can be uniquely represented in a 2-dimensional (2D) grid as a tuple ' a ; b ' where a = j mod n 0 and b = j mod n 1.
## 3.1 FastShare to Generate Shares
The sharing algorithm f' i ; » s … i 'g i 2C FastShare ' s ; C' is a probabilistic algorithm that takes as input a set of secrets s 2 F S q , and a set C of N clients (client-IDs), and produces a set of N shares, each in F q , where share » s … i is assigned to client i . At a high level, FastShare consists of two stages. First, it constructs a lengthN 'signal' consisting of the secrets and random masks with zeros placed at judiciously chosen locations. Second, it takes the fast Fourier transform of the signal to generate the shares (see Fig. 1). The shares can be considered as the 'spectrum' of the signal constructed in the first stage.
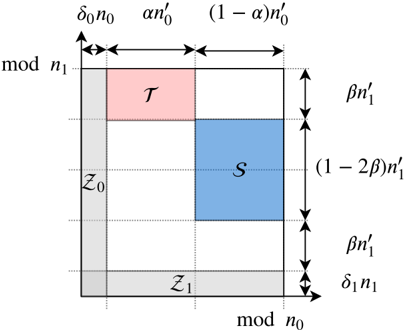
In particular, the 'signal' is constructed as follows. Given fractions δ 0 ; δ 1 ; α 2 ' 0 ; 1 ' and β 2 ' 0 ; 1 2 ' , we define the sets of tuples Z 0, Z 1, S , and T using the grid representation as depicted in Fig. 2. We give the formal definitions below. Here, we round any real number to the largest integer no larger than it, i.e., round x to b x c , and omit the floor sign for the sake of brevity.
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
S
=
f'
a
δ
;
b
n
'
:
δ
+
β
n
'
+
δ
α
'
'
n
δ
b
'
n
δ
a
n
+
n
'
β
;
''
δ
'
n
g
;
(4)
<!-- formula-not-decoded -->
We place zeros at indices in Z 0 and Z 1, and secrets at indices S . Each of the remaining indices is assigned a uniform random mask from F q (independent of other masks and the secrets). We use T
Figure 2: Indices assigned to a grid using the Chinese remainder theorem, and sets Z 0 , Z 1 , S , and T . Here, we define n 0 i = ' 1 δ i ' n i for i 2 f 0 ; 1 g . Set S is used for secrets, and sets Z 0 and Z 1 are used for zeros, and the remaining locations are used for random masks. Set T is used in our privacy proof.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Geometric Representation of Regions
### Overview
The image presents a geometric diagram depicting a square divided into four rectangular regions, labeled with mathematical expressions and symbols. The diagram appears to illustrate a spatial arrangement with defined dimensions and areas, likely representing a model or a component within a larger system.
### Components/Axes
The diagram consists of a large square with the following labeled elements:
* **Axes:**
* Horizontal axis labeled "mod n₀" at the bottom.
* Vertical axis labeled "mod n₁" on the left.
* **Regions:**
* Top-left region: Labeled "T", filled with a light red color.
* Top-right region: Unlabeled, white.
* Bottom-left region: Labeled "Z₀", filled with a light gray color.
* Bottom-right region: Labeled "S", filled with a light blue color.
* Bottom region: Labeled "Z₁", filled with a light gray color.
* **Dimensions:**
* Horizontal dimension of T: "αn'₀"
* Horizontal dimension of the remaining top region: "(1 - α)n'₀"
* Vertical dimension of T and S: "βn'₁"
* Vertical dimension of Z₀ and Z₁: "δ₁n₁"
* Vertical dimension of the central region: "(1 - 2β)n'₁"
### Detailed Analysis
The diagram shows a square divided into four rectangular regions. The dimensions of each region are defined in terms of variables α, β, δ, and n₀, n₁.
* **Region T:** Occupies the top-left corner. Its width is αn'₀ and its height is βn'₁.
* **Region S:** Occupies the bottom-right corner. Its width is (1 - α)n'₀ and its height is βn'₁.
* **Region Z₀:** Occupies the bottom-left corner. Its width is αn'₀ and its height is δ₁n₁.
* **Region Z₁:** Occupies the bottom region. Its width is (1 - α)n'₀ and its height is δ₁n₁.
* The total height of the square is βn'₁ + (1 - 2β)n'₁ + δ₁n₁ = n'₁.
* The total width of the square is αn'₀ + (1 - α)n'₀ = n₀.
### Key Observations
The diagram illustrates a partitioning of a square into four rectangular regions, with the dimensions of each region defined by parameters α and β. The parameters α and β appear to control the relative sizes of the regions. The variables n₀ and n₁ represent the overall dimensions of the square.
### Interpretation
This diagram likely represents a model for a system where a total area (represented by the square) is divided into different components (T, S, Z₀, Z₁). The parameters α and β could represent probabilities, proportions, or other factors that determine the allocation of resources or space within the system. The diagram could be used to analyze the relationships between the different components and to optimize the overall performance of the system. The use of "mod" in the axis labels suggests that the diagram might be related to modular arithmetic or a periodic system. The diagram is a visual representation of a mathematical model, and its meaning depends on the context in which it is used. It is a schematic representation, and the specific values of α, β, δ, n₀, and n₁ would determine the exact dimensions and areas of the regions.
</details>
in our privacy proof. Let x denote the resulting lengthN vector, which we refer to as the 'signal'. (See Fig. 3 for a toy example.)
Let ω be a primitive N -th root of unity in F q . FastShare computes the (fast) Fourier transform X of the signal x generated by ω . 3 The coefficients of X represent shares of s , i.e., » s … i = X i . The details are given in Algorithm 1.
## 3.2 FastRecon to Reconstruct the Secrets
Let D C denote a random subset of size at most D . The reconstruction algorithm f s ; ?g FastRecon f' i ; » s … i 'g i 2CnD takes as input the shares corresponding to C n D , and outputs either a set of S field elements s or a special symbol ? . At a high level, FastRecon consists of two stages. First, it iteratively recovers all the missing shares by leveraging a linear-relationship between the shares (as described next). Second, it takes the inverse Fourier transform of the shares (i.e., the 'spectrum') to obtain the 'signal', which contains the secrets at appropriate locations (see Fig. 1).
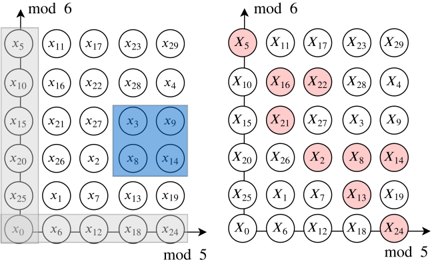
The key ingredient of FastRecon is a computationally efficient iterative algorithm, rooted in the field of coding theory, to recover the missing shares. Towards this end, we show that the shares satisfy certain 'parity-check' constraints, which are induced by the careful placement of zeros in x . (See Fig. 3 for a toy example.)
Lemma 3.2. Let f X j g N 1 j = 0 denote the shares produced by the FastShare scheme for an arbitrary secret s . Then, for each i 2 f 0 ; 1 g , for every c 2 f 0 ; 1 ; : : : ; N n i g and v 2 f 0 ; 1 ; : : : ; δ i n i 1 g , it holds that
<!-- formula-not-decoded -->
3 See Appendix A for a brief overview of the finite field Fourier transform.
Figure 3: Example with ' = 4 secrets, and co-prime integers n 0 = 5 , n 1 = 6 , yielding N = n 0 n 1 = 30 . Zeros are placed at gray locations, and the secrets at blue locations. Careful zero padding induces parity checks on the shares in each row and column due to aliasing , i.e., » X 0 + X 5 + + X 25; X 1 + + X 26; ; X 4 + + X 29 … = » 0 ; ; 0 … and » X 0 + X 6 + + X 24; ; X 5 + + X 29 … = » 0 ; ; 0 … . Any one missing share in a row or column can be recovered using the parity-check structure. E.g., dropped out red shares can be recovered by iteratively decoding the missing shares in rows and columns.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Lattice Representation of a Modular System
### Overview
The image presents two lattice diagrams, side-by-side, representing a modular system. Each diagram consists of a grid of circles, labeled with variables 'x' followed by a number. The axes are labeled "mod 6" (vertical) and "mod 5" (horizontal). The left diagram shows a subset of circles highlighted in blue, while the right diagram highlights a different subset in red. The diagrams visually represent a mapping or transformation between the two highlighted sets.
### Components/Axes
* **Axes:**
* Vertical Axis: "mod 6" - representing values modulo 6 (0, 1, 2, 3, 4, 5).
* Horizontal Axis: "mod 5" - representing values modulo 5 (0, 1, 2, 3, 4).
* **Grid Elements:** Circles labeled x₀ to x₂₉.
* **Highlighting:**
* Left Diagram: Blue highlighting indicates a specific subset of circles.
* Right Diagram: Red highlighting indicates a different subset of circles.
### Detailed Analysis / Content Details
The left diagram shows the following circles highlighted in blue:
* x₃
* x₈
* x₉
* x₁₀
* x₁₅
* x₁₆
* x₁₇
* x₂₁
* x₂₂
* x₂₇
The right diagram shows the following circles highlighted in red:
* x₅
* x₁₀
* x₁₆
* x₂₁
* x₂₂
* x₂₄
* x₁₉
* x₁₈
* x₁₇
* x₂₉
The grid is organized as follows:
* Row 0: x₀, x₁, x₂, x₃, x₄
* Row 1: x₅, x₆, x₇, x₈, x₉
* Row 2: x₁₀, x₁₁, x₁₂, x₁₃, x₁₄
* Row 3: x₁₅, x₁₆, x₁₇, x₁₈, x₁₉
* Row 4: x₂₀, x₂₁, x₂₂, x₂₃, x₂₄
* Row 5: x₂₅, x₂₆, x₂₇, x₂₈, x₂₉
### Key Observations
The red highlighted set in the right diagram appears to be a transformation of the blue highlighted set in the left diagram. There is no immediately obvious simple arithmetic relationship between the indices of the blue and red sets. The highlighted sets do not have an obvious pattern or symmetry.
### Interpretation
The diagrams likely represent a mapping between two modular spaces (mod 5 and mod 6). The blue set on the left represents an initial selection of elements, and the red set on the right represents the result of applying some transformation to those elements. The transformation is not a simple shift or scaling, as the indices do not follow a consistent pattern. This could represent a more complex function or operation within the modular arithmetic system. The diagrams are likely illustrating a concept in number theory, cryptography, or coding theory, where modular arithmetic is frequently used. The specific meaning of the transformation would require additional context.
</details>
The proof essentially follows from the subsampling and aliasing properties of the Fourier transform and is deferred to Appendix B.
Remark 1. When translated in coding theory parlance, the above lemma essentially states that the shares form a codeword of a product code with Reed-Solomon component codes [31]. In particular, when the shares are represented on a 2D-grid using the Chinese remainder theorem, each row (resp. column) forms a codeword of a Reed-Solomon code with block-length n 0 (resp. n 1 ) and dimension ' 1 δ 0 ' n 0 (resp. ' 1 δ 1 ' n 1 ). In other words, ¯ X c = h X c X N n i + c X ' n i 1 ' N n i + c i is a codeword of an ' n i ; ' 1 δ i ' n i ' Reed-Solomon code for every c = 0 ; 1 ; : : : ; N n i 1 . To see this, observe that when the constraints in (6) , for a fixed c , are written in a matrix form, the resulting matrix is a Vandermonde matrix, and it is straightforward to show that ¯ X c corresponds to the evaluations of a polynomial of degree ' 1 δ i ' n i 1 at ω uN n i for u = 0 ; 1 ; : : : ; n i 1 . We present a comparison with the Shamir's scheme in Appendix F.
These parity-check constraints on the shares make it possible to iteratively recover missing shares from each row and column until all the missing shares can be recovered. We present a toy example for this in Fig. 3. It is worth noting that this way of recovering the missing symbols of a codeword is known in coding theory as an iterative (bounded distance) decoder [27, 38].
In particular, codewords of a Reed-Solomon code with blocklength n i and dimension ' 1 δ i ' n i are evaluations of a polynomial of degree at most ' 1 δ i ' n i 1. Therefore, any δ i fraction of erasures can be recovered via polynomial interepolation. Therefore, if a row (resp. column) has less than δ 0 n 0 (resp. δ 1 n 1) missing shares, then they can be recovered. This process is repeated for a fixed number if iterations, or until all the missing shares are recovered.
## Algorithm 1 FastShare Secret Sharing
procedure FastShare( s ; C ) parameters: finite field F q of size q , a primitive root of unity ω in F q , privacy threshold T , dropout resilience D inputs: secret s 2 F L q , set of N clients C (client-IDs) initialize: sets Z 0, Z 1, S as per (2), (2), (4), respectively; an arbitrary bijection σ : S ! f 0 ; 1 ; : : : ; S 1 g for j = 0 to n 1 do if j 2 Z 0 [ Z 1 then x j 0 else if j 2 S then x j s σ ' j ' . s i is the i -th coordinate of s else x j $ F q end if end for X FFT ω ' x ' Output: f' i ; » s … i 'g i 2C f' i ; X i 'g N 1 i = 0 end procedure procedure FastRecon( f' i ; » s … i 'g i 2R ) parameters: finite field F q of size q , a primitive root of unity ω in F q , privacy threshold T , dropout resilience D , number of iterations J , bijection σ and set S used in FastShare input: subset of shares with client-IDs f' i ; » s … i 'g i 2R for iterations j = 1 to J do for rows r = 0 to n 1 1 in parallel do if r has fewer than δ 0 n 0 missing shares then Decode the missing share values by polynomial interpolation end if end for for columns c = 0 to n 0 1 in parallel do if c has fewer than δ 1 n 1 missing shares then Decode the missing share values by polynomial interpolation end if end for end for if any missing share then Output: ? else x I F FT ω ' X ' Output: s X ' σ 'S'' end if end procedure
Putting things together, FastRecon first uses an iterative decoder to obtain the missing shares. If the peeling decoder fails, it outputs ? , and declares failure. Otherwise, it takes the inverse (fast) Fourier transform of X (generated by ω ) to obtain x . Finally, it output the coordinates of x indexed by S (in the 2D-grid representation) as the secret. The details are given in Algorithm 1.
## 3.3 Analysis of FastShare
First, we analyze the security and correctness of FastShare in the honest-but-curious setting. We defer the proof to Appendix C.
Theorem 3.3. Given fractions δ 0 ; δ 1 ; α 2 ' 0 ; 1 ' and β 2 ' 0 ; 1 2 ' , FastShare generates N shares from S = ' 1 α '' 1 2 β '' 1 δ 0 '' 1 δ 1 ' N secrets such that it satisfies
- (1) T -privacy for T = αβ ' 1 δ 0 '' 1 δ 1 ' N ,
- (2) D -dropout resilience for D = ' 1 ' 1 δ 0 '' 1 δ 1 '' N 2 , and
- (3) linearity.
For example, choosing α = 1 2, β = 1 4, δ 0 = δ 1 = 1 10, yields S = 0 : 2 N , T = 0 : 1 N , and D = 0 : 095 N .
Computation Cost: FastShare runs in O' N log N ' time, since constructing the signal takes O' N ' time and the Fourier transform can be computed in O' N log N ' time using a Fast Fourier Transform (FFT). FastRecon also runs in O ' N log N ' time, when computations are parallelized. Specifically, recovering the missing shares in a row or column of shares (when arranged in the 2D-grid) can be done in O n 2 i = O' N ' complexity by leveraging that rows and columns are Reed-Solomon codewords, which are evaluations of a degree-' n i δ i n i 1 ' polynomial. Since all rows and columns can be decoded in parallel, and decoding is carried out for a constant number of iterations, the iterative decoder runs in O' N ' time. The second step is the inverse Fourier transform, which can be computed in O' N log N ' time using an FFT.
Next, we present the computation cost in terms of the number of (basic) arithmetic operations in F q .
Note that in practical FL scenarios, the number of clients typically scales up to ten thousand [8]. Therefore, in order to gain full parallelism, one needs to have p N 100 processors/cores. In the next section, we present a variant of FastShare that removes the requirement of parallelism for sufficiently large N . Moreover, this variant also allows us to achieve a more favorable trade-off between the number of shares, privacy threshold, and dropout tolerance.
## 3.4 Improving the Performance for Large Number of Clients
FastShare ensures that when the shares are arranged in a 2Dgrid using the Chinese remainder theorem, each row and column satisfies certain parity-check constraints (cf. Remark 1). As we show next, when N is sufficiently large, it suffices to ensure that only rows (or columns) satisfy the parity-check constraints. In this case, the FastShare algorithm remains the same as before except for the placement of secrets, zeros, and random masks changes slightly.
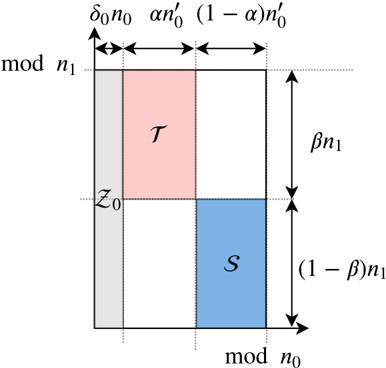
Let q be a power of a prime, and let N be a positive integer such that N divides q 1. Let c 1 be a constant. We consider N of the form N = n 0 n 1 such that n 0 = c log N . Given fractions δ 0 ; α ; β 2 ' 0 ; 1 ' , we define the sets of tuples Z 0, S , and T using the grid representation determined by the Chinese remainder theorem, as depicted in Fig. 4. We give the formal definitions below. Note that we round any rational number x to b x c , and omit the floor sign for the sake of brevity.
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
Figure 4: Indices assigned to a grid, and sets Z , S , and T . Here, we define n 0 0 = ' 1 δ 0 ' n 0 . Set S is used for secrets, Z 0 is used for zeros, and the remaining locations are used for random masks. Set T is used in our privacy proof.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Rectangular Partition with Labels
### Overview
The image depicts a rectangular area partitioned into four regions: a gray strip on the left, a pink rectangle in the top-right, a blue rectangle in the bottom-right, and a white space in the bottom-left. The diagram is labeled with mathematical expressions and variables indicating dimensions and regions.
### Components/Axes
* **Axes:** The diagram uses two axes labeled "mod n₁" (vertical) and "mod n₀" (horizontal).
* **Labels:**
* "δ₀n₀" - Label for the width of the gray strip.
* "αn₀¹" - Label for the width of the pink rectangle.
* "(1 - α)n₀¹" - Label for the width of the blue rectangle.
* "βn₁" - Label for the height of the pink rectangle.
* "(1 - β)n₁" - Label for the height of the blue rectangle.
* "z₀" - Label for the vertical position of the top edge of the gray strip.
* "τ" - Label within the pink rectangle.
* "S" - Label within the blue rectangle.
### Detailed Analysis or Content Details
The diagram represents a rectangular area with dimensions defined by "mod n₀" and "mod n₁". The area is divided as follows:
* **Gray Strip:** Located on the left side, with a width of approximately "δ₀n₀". It extends vertically from "z₀" to "mod n₁".
* **Pink Rectangle (τ):** Located in the top-right quadrant. Its width is approximately "αn₀¹" and its height is approximately "βn₁".
* **Blue Rectangle (S):** Located in the bottom-right quadrant. Its width is approximately "(1 - α)n₀¹" and its height is approximately "(1 - β)n₁".
* **White Space:** Located in the bottom-left quadrant.
The sum of the widths of the pink and blue rectangles equals "n₀¹" (approximately). The sum of the heights of the pink and blue rectangles equals "n₁" (approximately).
### Key Observations
The diagram illustrates a partitioning of a rectangular area into four regions, with the dimensions of each region defined by parameters α, β, δ₀, n₀, and n₁. The labels "τ" and "S" suggest these regions represent distinct sets or areas within a larger space.
### Interpretation
This diagram likely represents a modular arithmetic or geometric partitioning problem. The variables suggest a division of a space defined by "mod n₀" and "mod n₁" into regions based on parameters α and β. The gray strip could represent a boundary or a region of interest. The labels "τ" and "S" could represent two different sets or areas within the partitioned space. The diagram could be used to visualize a sampling process, a probability distribution, or a cryptographic operation. The use of "mod" suggests a cyclical or periodic nature to the space being partitioned. The diagram is a visual representation of a mathematical relationship, likely used in a theoretical context.
</details>
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
We construct the signal by placing zeros at indices in Z 0, and secrets at indices in S . Each of the remaining indices is assigned a uniform random mask from F q (independent of other masks and the secrets). We then take the Fourier transform (generated by a primitive N -th root of unity in F q ) of the signal to obtain the shares.
Using the same arguments as in the proof of Lemma 3.2, it is straightforward to show that, for every c 2 f 0 ; : : : ; n 1 1 g and v 2 f 0 ; 1 ; : : : ; δ 0 n 0 1 g , it holds that
<!-- formula-not-decoded -->
When translated in coding theory parlance, the above condition states that when the shares are represented in a 2D-grid using the Chinese remainder theorem, then each row forms a codeword of a Reed-Solomon code with block-length n 0 and dimension ' 1 δ 0 ' n 0. 4
FastRecon first recovers the missing shares by decoding each row. If every row has less than δ 0 fraction of erasures, then it recovers all the missing shares. Otherwise, it outputs ? , and declares failure. Next, it takes the inverse (fast) Fourier transform of the shares to obtain the signal. The coordinates of the signal indexed by S (in the 2D-grid representation) gives the secrets.
Security and Correctness: Given fractions δ 0 ; α ; β 2 ' 0 ; 1 ' , this variant of FastShare generates N shares from
<!-- formula-not-decoded -->
4 We note that this variant of FastShare is related to a class of erasure codes called Locally Recoverable Codes (LRCs) (see [21, 37, 44], and references therein). See Appendix F for details.
secrets such that it satisfies T -privacy for
<!-- formula-not-decoded -->
D -dropout-resilience for
<!-- formula-not-decoded -->
and linearity. (The proof is similar to Theorem 3.3, and is omitted.) Observe that this variant achieves a better trade-off between S , T , and D . For instance, choosing δ 0 = 1 10, α = 1 2, and β = 1 2, yields S = 0 : 225 N , T = 0 : 225, and D = 0 : 1.
Computation Cost: In this case, FastShare also has O' N log N ' computational cost, since constructing the signal takes O' N ' time and the Fourier transform can be computed in O' N log N ' time using an FFT. FastRecon has O' N log N ' computational cost without requiring any parallelism. In particular, recovering the missing shares in a row (when arranged in the 2D-grid) can be done in O n 2 0 = O log 2 N complexity by leveraging that the rows are Reed-Solomon codewords, which are evaluations of a degree-' n 0 δ 0 n 0 1 ' polynomial. Since there are O' N log N ' rows, the decoder to recover the missing shares has O' N log N ' complexity. The second step is the inverse FFT, which also has O' N log N ' complexity.
## 4 FASTSECAGG BASED ON FASTSHARE
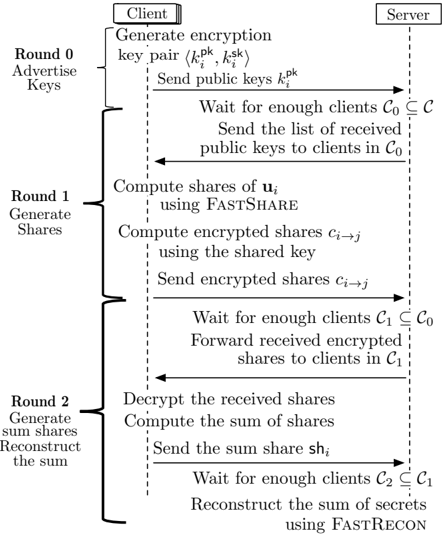
In this section, we present our proposed protocol FastSecAgg, which allows the server to securely compute the summation of clients' model updates. We begin with a high-level overview of FastSecAgg (see Fig. 5). Each client generates shares for its lengthL input (by breaking it into a sequence of d L S e vectors, each of length at most S , and treating each vector as S secrets) using FastShare, and distributes the shares to N clients. Since all the communication in FL is mediated by the server, clients encrypt their shares before sending it to the server to prevent the server from reconstructing the secrets. Each client then decrypts and sums the shares it receives from other clients (via the server). The linearity property of FastShare ensures that the sum of shares is a share of the sum of secret vectors (i.e., client inputs). Each client then sends the sum-share to the server (as a plaintext). The server can then recover the sum of secrets (i.e., client inputs) with high probability as long as it receives the shares from a random set of clients of sufficient size. We note that FastSecAgg uses secret sharing as a primitive in a standard manner, similar to several secure aggregation protocols [5, 11, 22].
Round 0 consists of generating and advertising encryption keys. Specifically, each client i uses the key agreement protocol to generate a public-private key pair ' pk i ; sk i ' KA.gen ' pp ' , and sends their public key pk i to the server. The server waits for at least N D clients (denoted as C 0 C ), and forwards the received public keys to clients in C 0.
FastSecAgg is a three round interactive protocol. See Fig. 5 for a high-level overview, and Algorithm 2 for the detailed protocol. Recall that the model update for client i 2 C is assumed to be u i 2 Z L R , for some R q . In practice, this can be achieved by appropriately quantizing the updates.
Round 1 consists of generating secret shares for the updates. Each client i partitions their update u i into d L S e vectors, u 1 , u 2 , : : : ,
i
i
Figure 5: High-lever overview of FastSecAgg protocol.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Diagram: Secure Multi-Party Computation Protocol Flow
### Overview
The image depicts a flowchart illustrating a secure multi-party computation protocol involving a client and a server, executed over three rounds. The protocol appears to focus on key exchange, share generation, and sum reconstruction, likely for a privacy-preserving computation. The diagram uses arrows to indicate the flow of information between the client and server.
### Components/Axes
The diagram is structured into three main sections, labeled "Round 0: Advertise Keys", "Round 1: Generate Shares", and "Round 2: Generate sum/shares Reconstruct the sum". These sections are vertically aligned and separated by horizontal lines. The diagram features two primary actors: "Client" (positioned at the top-left) and "Server" (positioned at the top-right). The flow of communication is indicated by dashed arrows. Mathematical notations and algorithm names (FASTSHARE, FASTRECON) are embedded within the process steps. The diagram also includes set notation (C₀, C₁, C₂) to represent client subsets.
### Detailed Analysis or Content Details
**Round 0: Advertise Keys**
1. **Client:** "Generate encryption key pair (kₚᵏ, kₛᵏ)"
2. **Client → Server:** "Send public keys kₚᵏ" (dashed arrow)
3. **Server:** "Wait for enough clients C₀ ⊆ C"
4. **Server → Clients in C₀:** "Send the list of received public keys to clients in C₀" (dashed arrow)
**Round 1: Generate Shares**
1. **Client:** "Compute shares of uᵢ using FASTSHARE"
2. **Client:** "Compute encrypted shares cᵢ→ⱼ using the shared key"
3. **Client → Server:** "Send encrypted shares cᵢ→ⱼ" (dashed arrow)
4. **Server:** "Wait for enough clients C₁ ⊆ C₀"
5. **Server → Clients in C₁:** "Forward received encrypted shares to clients in C₁" (dashed arrow)
**Round 2: Generate sum/shares Reconstruct the sum**
1. **Client:** "Decrypt the received shares"
2. **Client:** "Compute the sum of shares"
3. **Client → Server:** "Send the sum share shᵢ" (dashed arrow)
4. **Server:** "Wait for enough clients C₂ ⊆ C₁"
5. **Server:** "Reconstruct the sum of secrets using FASTRECON"
**Notations:**
* kₚᵏ: Public key
* kₛᵏ: Secret key
* uᵢ: Shares of a value
* cᵢ→ⱼ: Encrypted shares
* shᵢ: Sum share
* C₀, C₁, C₂: Subsets of clients, with C₂ ⊆ C₁ ⊆ C₀ ⊆ C
### Key Observations
The protocol is iterative, progressing through three rounds. Each round involves waiting for a sufficient number of clients to participate, indicated by the set notation (C₀, C₁, C₂). The use of FASTSHARE and FASTRECON suggests optimized algorithms for share generation and reconstruction. The encryption and decryption steps highlight the privacy-preserving nature of the protocol. The server acts as a facilitator, forwarding shares between clients.
### Interpretation
This diagram illustrates a secure multi-party computation (MPC) protocol. The goal is to allow multiple clients to jointly compute a function (likely a sum in this case) on their private inputs without revealing those inputs to each other or the server.
* **Round 0 (Key Exchange):** Establishes a secure communication channel between clients and the server through public key exchange.
* **Round 1 (Share Generation):** Clients generate shares of their inputs using FASTSHARE and encrypt them using shared keys. This distributes the input data among the clients, preventing any single client from knowing the complete input.
* **Round 2 (Sum Reconstruction):** Clients decrypt the received shares, compute the sum of shares, and send sum shares to the server. The server then reconstructs the final sum using FASTRECON.
The use of subsets (C₀, C₁, C₂) suggests a threshold scheme, where a minimum number of clients must participate in each round to ensure the protocol's security and correctness. The server's role is limited to forwarding messages, minimizing its potential to compromise the computation. The FASTSHARE and FASTRECON algorithms likely employ techniques like secret sharing and homomorphic encryption to achieve privacy and efficiency.
The diagram does not provide specific details about the function being computed or the security guarantees of the protocol. However, it clearly demonstrates a structured approach to secure multi-party computation. The diagram is a high-level overview and does not delve into the mathematical details of the algorithms.
</details>
u d L S e i , such that the last vector has length at most S and all others have length S . Treating each u ' i as S secrets, the client computes N shares as f' j ; u ' i j 'g j 2C FastShare ' u ' i ; C' for 1 ' d L S e . For simplicity, we denote client i 's share for client j as sh i ! j = ' u 1 i j j u 2 i j j j j » u d L S e … ' .
j i The server waits for at least N D clients to respond (denoted as C 1 C 0). 5 Then, the server sends to each client i 2 C 1, all ciphertexts encrypted for it: f c j ! i g j 2C 1 nf i g .
j j i j In addition, every client receives the list of public keys from the server. Client i generates a shared key k i ; j KA.agree ' sk i ; pk j ' for each j 2 C 0 n f i g , and encrypts sh i ! j using the shared key k i ; j as c i ! j AE.enc k i ; j ; sh i ! j . The client then sends all the encrypted shares f c i ! j g 2C 0 nf g to the server.
Round 2 consists of generating sum-shares and reconstructing the approximate sum. Every surviving client receives the list of encrypted shares from the server. Each client i then decrypts the ciphertexts c j ! i using the shared key k j ; i to obtain the shares sh j ! i , i.e., sh j ! i AE.dec ' k j ; i ; c j ! i ' where k j ; i KA.agree ' sk j ; pk i ' . Then, each client i computes the sum (over F q ) of all the shares including its own share as: sh i = ˝ j 2C 1 sh j ! i . Each client i sends the sum-share sh i to the server (as a plaintext).
The server waits for at least N D clients to respond (denoted as C 2 C 1). Let sh ' i denote the ' -th coefficient of sh i for 1 ' d L S e . The server computes f z ' ; ?g FastRecon f' i ; sh ' i 'g i 2C 2 ,
5 For simplicity, we assume that a client does not drop out after initiating communication with the server, i.e., while sending or receiving messages from the server. The same assumption is also made in [3, 9, 43]. This is not a critical assumption, and the protocol and the analysis can be easily adapted if it does not hold.
## Algorithm 2 FastSecAgg Protocol
- Parties: Clients 1 ; 2 ; : : : ; N and the server
- Input: u i 2 Z L (for each client i )
- Public Parameters: Update length L , input domain Z R , key agreement parameter pp KA.param ' λ ' , finite field F q for FastShare secret sharing with primitive N -th root of unity ω
- R Output: z 2 Z L (for the server)
R
- Round 0 (Advertise Keys)
- -Generate key pairs ' pk ; sk i ' KA.gen ' pp '
Client i :
- i -Send pk to the server and move to the next round
i
- -Wait for at least N D clients to respond (denote this set as C 0 C ); otherwise, abort
## Server:
- -Send to all clients in C 0 the list f' i ; pk i 'g i 2C 0 , and move to the next round
Client i :
## Round 1 (Generate shares)
- -Receive the list f' j ; pk j 'g j 2C 0 from the server; Assert that jC 0 j N D , otherwise abort
- -Compute N shares by treating each u ' i as S secrets as f' j ; u ' i j 'g j 2C FastShare ' u ' i ; C' for 1 ' d L S e (by using independent private randomness for each ' ); Denote client i 's share for client j as sh i ! j = u 1 j j u 2 j j j j » u d L S e …
- -Partition the input u i 2 Z L R into d L S e vectors, u 1 i , u 2 i , : : : , u d L S e i , such that u d L S e i has length at most S and all others have length S
i
i
- -Send all the ciphertexts f c i ! j g 2C 0 nf g to the server by adding the addressing information i ; j as metadata
- j j j -For each client j 2 C 0 n f i g , compute encrypted share: c i ! j AE.enc ' k i ; j ; i j j j j j sh i ! j ' , where k i ; j = KA.agree ' sk i ; pk j '
- j i -Store all the messages received and values generated in this round and move to the next round
- -Wait for at least N D clients to respond (denote this set as C 1 C 0)
## Server:
- -Send to each client i 2 C 1, all ciphertexts encrypted for it: c j ! i 2C 1 nf g , and move to the next round
Client i :
- Round 2 (Recover the aggregate update)
- -Receive from the server the list of ciphertexts c j ! i j 2C 1 nf i g
- -Compute the sum of shares over F q as sh i = ˝ j 2C 1 sh j ! i
- -Decrypt the ciphertext ' i 0 j j j 0 j j sh j ! i ' Dec ' sk i ; c j ! i ' for each client j 2 C 1 n f i g , and assert that ' i = i 0 ' ^ ' j = j 0 '
- -Send the share sh i to the server
- -Wait for at least N D clients to respond (denote this set as C 2 C 1)
i
## Server:
- -Run the reconstruction algorithm to obtain z ' ; ? FastRecon ' n ' i ; sh ' i ' o i 2C 2 ' for 1 ' d L S e , where sh ' i is the ' -th coefficient of sh ; Denote z = » z 1 z 2 z d L S e …
- -Output the aggregate result z
- -If the reconstruction algorithm returns ? for any ' , then abort
for 1 ' d L S e . If the reconstruction fails (i.e., outputs ? ) for any ' , then the server aborts the current FL iteration and moves to the next one. Otherwise, it outputs z = » z 1 z 2 z d L S e … .
## 5 ANALYSIS
## 5.1 Correctness and Security
First we state the correctness of FastSecAgg, which essentially follows from the linearity and D -dropout tolerance of FastShare. The proof is given in D.
Theorem 5.1 (Correctness). Let f u i g i 2C denote the client inputs for FastSecAgg. If a random set of at most D clients drop out during the execution of FastSecAgg, i.e., jC 2 j N D , then the server does not abort and obtains z = ˝ i 2C 1 u i with probability at least 1 1 poly N , where the probability is over the randomness in dropouts.
Next, we show that FastSecAgg is secure against the server colluding with up to T clients in the honest-but-curious setting, irrespective of how and when clients drop out. Specifically, we prove that the joint view of the server and any set of clients of bounded size does not reveal any information about the updates of the honest clients, besides what can be inferred from the output of the summation.
We will consider executions of FastSecAgg where FastShare has privacy threshold T , and the underlying cryptographic primitives are instantiated with security parameter λ . We denote the server (i.e., the aggregator) as A , and the set of of N clients as C .
j
i
i
Clients may drop out (or, abort) at any point during the execution, and we denote with C i the subset of the clients that correctly sent their message to the server in round i . Therefore, we have C C 0 C 1 C 2. For example, the set C 0 n C 1 are the clients that abort before sending the message to the server in Round 1, but after sending the message in Round 0. Let u i 2 Z L R denote the model update of client i (i.e., u i the i -th client's input to the secure aggregation protocol), and for any subset C 0 C , let u C 0 = f u i g i 2C 0 .
In such a protocol execution, the view of a participant consists of their internal state (including their update, encryption keys, and randomness) and all messages they received from other parties. Note that the messages sent by the participant are not included in the view, as they can be determined using the other elements of their view. If a client drops out (or, aborts), it stops receiving messages and the view is not extended past the last message received.
Given any subset M C , let REAL C ; T ; λ M ' u C ; C 0 ; C 1 ; C 2 ' be a random variable representing the combined views of all parties in M[f A g in an execution of FastSecAgg, where the randomness is over the internal randomness of all parties, and the randomness in the setup phase. We show that for any such set M of honest-butcurious clients of size up to T , the joint view of M[f A g can be simulated given the inputs of the clients in M , and only the sum of the values of the remaining clients.
Theorem 5.2 (Security). There exists a probabilistic polynomial time (PPT) simulator SIM such that for all C , u C , C 0 , C 1 , C 2 , and M such that M C , jMj T , C C 0 C 1 C 2 , the output of SIM is computationally indistiguishable from the joint view REAL C ; T ; λ M of the server and the corrupted clients M , i.e.,
<!-- formula-not-decoded -->
where
<!-- formula-not-decoded -->
The security and correctness of FastSecAgg critically relies on the guarantees provided by FastShare proved in Theorem 3.3. We present the proofs of the above theorem in Appendices E.
## 5.2 Computation and Communication Costs
We assume that the addition and multiplication operations in F q are O' 1 ' each.
Computation Cost at a Client: O' max f L ; N g log N ' . Each client's computation cost can be broken as computing shares using FastShare which is O'd L S e N log N ' = O' max f L ; N g log N ' ; encrypting and decrypting shares, which is O'd L S e N ' ; and adding the received shares, which is O'd L S e N ' = O' max f L ; N g' .
CommunicationCostataClient: O' max f L ; N g' . Each client sends and receives N 1 shares (each having d L S e elements in F q ), resulting in O'd L S e N ' = O' max f L ; N g' communication. In addition, each client sends the sum-share consisting of d L S e elements in F q .
Computation Cost at the Server: O' max f L ; N g log N ' . The server first recovers missing sum-shares using FastRecon, each has d L S e elements in F q . This results in O'd L S e N log N ' complexity.
The second step is the inverse FFT on N shares, each has of d L S e elements in F q , resulting in O'd L S e N log N ' complexity.
Communication Cost at the Server: O' N max f L ; N g' . The server communicates N times of what each client communicates.
## 5.3 Comparison with Prior Works
Bonawitz et al. [9] presented the first secure aggregation protocol SecAgg for FL, wherein clients use a key exchange protocol to agree on pairwise additive masks to achieve privacy. SecAgg, in the honest-but-curious setting, can achieve T = αN for any α 2 ' 0 ; 1 ' and D = N T 1, and provides worst-case dropout resilience, i.e., it can tolerate any D users dropping out. However, SecAgg incurs significant computation cost of O LN 2 at the server. This limits its scalability to several hundred clients as observed in [8].
The scheme by So et al. [43], which we call TurboAgg, uses additive secret sharing for security combined with erasure codes for dropout tolerance. TurboAgg allows T = D = αN for any α 2 ' 0 ; 1 2 ' . However, it has two main drawbacks. First, it divides N clients into N log N groups, and each client in a group needs to communicate to every client in the next group. This results in per client communication cost of O' L log N ' . Moreover, processing in groups requires at least log N rounds. Second, it can tolerate only non-adaptive adversaries, i.e., client corruptions happen before the clients are partitioned into groups. On the other hand, FastSecAgg results in O' L ' communication per client, runs in 3 rounds, and is robust against an adaptive adversary which can corrupt clients during the protocol execution.
Truex et al. [45] uses threshold homomorphic encryption and Xu et al. [47] uses functional encryptionto perform secure aggregation. However, these schemes assume a trusted third party for key distribution, which typically does not hold in the FL setup.
Recently, Bell et al. [3] proposed an improved version of SecAgg, which we call SecAgg+. Their key idea is to replace the complete communication graph of SecAgg by a sparse random graph to reduce the computation and communication costs. FastSecAgg achieves smaller computation cost than SecAgg+ at the server and the same (orderwise) communication cost per client as SecAgg+ when L = Ω ' N ' . Moreover, FastSecAgg is robust against adaptive adversaries, whereas SecAgg+ can mitigate only non-adaptive adversaries where client corruptions happen before the protocol execution starts. On the other hand, SecAgg+ achieves smaller communication cost in absolute numbers than FastSecAgg.
There are several recent works [24, 35, 42] which consider secure aggregation when a fraction of clients are Byzantine. Our focus, on the other hand, is on honest-but-curious setting, and we leave the case of Byzantine clients as a future work.
The performance comparison between FastSecAgg and SecAgg [9], TurboAgg [43], and SecAgg+ [3] is summarized in Table 1.
## ACKNOWLEDGEMENTS
Swanand Kadhe was introduced to the secure aggregation problem in the Decentralized Security course by Raluca Ada Popa in Fall 2019. He would like to thank Raluca for an excellent course. Swanand would like to thank Mukul Kulkarni for immensely helpful discussions and for providing feedback on drafts of this paper.
This work is supported in part by the National Science Foundation grant CNS-1748692.
## REFERENCES
- [1] Gergely ´ Acs and Claude Castelluccia. 2011. I Have a DREAM! Differentially Private Smart Metering. In Proceedings of the 13th International Conference on Information Hiding (IH'11) . Springer-Verlag, Berlin, Heidelberg, 118-132.
- [3] James Bell, K. A. Bonawitz, Adri` a Gasc´ on, Tancr` ede Lepoint, and Mariana Raykova. 2020. Secure Single-Server Aggregation with (Poly)Logarithmic Overhead. Cryptology ePrint Archive, Report 2020/704. (2020). https://eprint.iacr. org/2020/704.
- [2] Amos Beimel. 2011. Secret-Sharing Schemes: A Survey. In Coding and Cryptology , Yeow Meng Chee, Zhenbo Guo, San Ling, Fengjing Shao, Yuansheng Tang, Huaxiong Wang, and Chaoping Xing (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 11-46.
- [4] Mihir Bellare and Chanathip Namprempre. 2000. Authenticated Encryption: Relations among Notions and Analysis of the Generic Composition Paradigm. In Advances in Cryptology - ASIACRYPT 2000 , Tatsuaki Okamoto (Ed.). 531-545.
- [6] R. E. Blahut. 1979. Transform Techniques for Error Control Codes. IBM Journal of Research and Development 23, 3 (1979), 299-315.
- [5] Michael Ben-Or, Shafi Goldwasser, and Avi Wigderson. 1988. Completeness Theorems for Non-Cryptographic Fault-Tolerant Distributed Computation. In Proceedings of the Twentieth Annual ACM Symposium on Theory of Computing (STOC '88) . Association for Computing Machinery, New York, NY, USA, 1-fi/question\_exclam10. https://doi.org/10.1145/62212.62213
- [7] Carlo Blundo, Alfredo De Santis, Giovanni Di Crescenzo, Antonio Giorgio Gaggia, and Ugo Vaccaro. 1994. Multi-Secret Sharing Schemes. In Advances in Cryptology - CRYPTO '94 , Yvo G. Desmedt (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 150-163.
- [9] Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS '17) . 1175-1191.
- [8] Keith Bonawitz, Hubert Eichner, Wolfgang Grieskamp, Dzmitry Huba, Alex Ingerman, Vladimir Ivanov, Chlo M Kiddon, Jakub Koneff\_hn, Stefano Mazzocchi, Brendan McMahan, Timon Van Overveldt, David Petrou, Daniel Ramage, and Jason Roselander. 2019. Towards Federated Learning at Scale: System Design. In Proceedings of the 2nd SysML Conference .
- [10] A. Borodin and R. Moenck. 1974. Fast modular transforms. J. Comput. System Sci. 8, 3 (1974), 366 - 386. https://doi.org/10.1016/S0022-0000(74)80029-2
- [12] B. Cakici, K. Hebing, M Grunewald, P. Saretok, and A. Hulth. 2010. CASE: a framework for computer supported outbreak detection. In BMC Medical Information and Decision Making .
- [11] Martin Burkhart, Mario Strasser, Dilip Many, and Xenofontas Dimitropoulos. 2010. SEPIA: Privacy-Preserving Aggregation of Multi-Domain Network Events and Statistics. In Proceedings of the 19th USENIX Conference on Security (USENIX Security'10) . USENIX Association, USA, 15.
- [13] Nicholas Carlini, Chang Liu, ´ Ulfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks. In 28th USENIX Security Symposium (USENIX Security 19) . 267-284.
- [15] David Evans, Vladimir Kolesnikov, and Mike Rosulek. 2018. A Pragmatic Introduction to Secure Multi-Party Computation. Foundations and Trends in Privacy and Security 2 (2018), 70-246.
- [14] John R. Douceur. 2002. The Sybil Attack. In Peer-to-Peer Systems . Springer Berlin Heidelberg, Berlin, Heidelberg, 251-260.
- [16] Matthew Franklin and Moti Yung. 1992. Communication Complexity of Secure Computation (Extended Abstract). In Proceedings of the Twenty-Fourth Annual ACM Symposium on Theory of Computing . 699-710.
- [18] Clement Fung, Chris J. M. Yoon, and Ivan Beschastnikh. 2018. Mitigating Sybils in Federated Learning Poisoning. CoRR abs/1808.04866 (2018). arXiv:1808.04866 http://arxiv.org/abs/1808.04866
- [17] Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. 2015. Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security . 1322-1333.
- [19] Karan Ganju, Qi Wang, Wei Yang, Carl A. Gunter, and Nikita Borisov. 2018. Property Inference Attacks on Fully Connected Neural Networks Using Permutation Invariant Representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security . 619-633.
- [21] P. Gopalan, Cheng Huang, H. Simitci, and S. Yekhanin. 2012. On the Locality of Codeword Symbols. Information Theory, IEEE Transactions on 58, 11 (Nov 2012), 6925-6934.
- [20] Joachim Von Zur Gathen and Jurgen Gerhard. 2003. Modern Computer Algebra (2 ed.). Cambridge University Press, USA.
- [22] S. Goryczka and L. Xiong. 2017. A Comprehensive Comparison of Multiparty Secure Additions with Differential Privacy. IEEE Transactions on Dependable and Secure Computing 14, 5 (2017), 463-477.
- [24] Lie He, Sai Praneeth Karimireddy, and Martin Jaggi. 2020. Secure ByzantineRobust Machine Learning. (2020). arXiv:cs.LG/2006.04747
- [23] K. He, X. Zhang, S. Ren, and J. Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . 770-778.
- [25] Ellis Horowitz. 1972. A fast method for interpolation using preconditioning. Inform. Process. Lett. 1, 4 (1972), 157 - 163. https://doi.org/10.1016/0020-0190(72) 90050-6
- [27] J. Justesen. 2011. Performance of Product Codes and Related Structures with Iterated Decoding. IEEE Transactions on Communications 59, 2 (2011), 407-415.
- [26] Marek Jawurek, Martin Johns, and Florian Kerschbaum. 2011. Plug-In Privacy for Smart Metering Billing. In Privacy Enhancing Technologies , Simone Fischer-H¨ ubner and Nicholas Hopper (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 192-210.
- [28] Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aur´ elien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Keith Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, Rafael G. L. D'Oliveira, Salim El Rouayheb, David Evans, Josh Gardner, Zachary A. Garrett, Adri` a Gasc´ on, Badih Ghazi, Phillip B. Gibbons, Marco Gruteser, Za¨ ıd Harchaoui, Chaoyang He, Lie He, Zhouyuan Huo, Ben Hutchinson, Justin Hsu, Martin Jaggi, Tara Javidi, Gauri Joshi, Mikhail Khodak, Jakub Konecn´ y, Aleksandra Korolova, Farinaz Koushanfar, Oluwasanmi Koyejo, Tancr` ede Lepoint, Yang Liu, Prateek Mittal, Mehryar Mohri, Richard Nock, Ayfer ¨ Ozg¨ ur, Rasmus Pagh, Mariana Raykova, Hang Qi, Daniel Ramage, Ramesh Raskar, Dawn Xiaodong Song, Weikang Song, Sebastian U. Stich, Ziteng Sun, Ananda Theertha Suresh, Florian Tram` er, Praneeth Vepakomma, Jianyu Wang, Li Xiong, Zheng Xu, Qiang Yang, Felix X. Yu, Han Yu, and Sen Zhao. 2019. Advances and Open Problems in Federated Learning. ArXiv abs/1912.04977 (2019).
- [30] M. G. Luby, M. Mitzenmacher, M. A. Shokrollahi, and D. A. Spielman. 2001. Efficient erasure correcting codes. IEEE Transactions on Information Theory 47, 2 (2001), 569-584.
- [29] M. G. Luby, M. Amin Shokrolloahi, M. Mizenmacher, and D. A. Spielman. 1998. Improved low-density parity-check codes using irregular graphs and belief propagation. In Proceedings. 1998 IEEE International Symposium on Information Theory . 117-121.
- [31] F.J. MacWilliams and N.J.A. Sloane. 1978. The Theory of Error-Correcting Codes (2nd ed.). North-holland Publishing Company.
- [33] M. Nasr, R. Shokri, and A. Houmansadr. 2019. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In 2019 IEEE Symposium on Security and Privacy (SP) . 739-753.
- [32] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics . 1273-1282.
- [34] S. Pawar and K. Ramchandran. 2018. FFAST: An Algorithm for Computing an Exactly k -Sparse DFT in O ' k log k ' Time. IEEE Transactions on Information Theory 64, 1 (2018), 429-450.
- [36] John M. Pollard. 1971. The fast Fourier transform in a finite field. Math. Comp. 25 (1971), 365-374.
- [35] Krishna Pillutla, Sham M. Kakade, and Zaid Harchaoui. 2019. Robust Aggregation for Federated Learning. (2019). arXiv:stat.ML/1912.13445
- [37] N. Prakash, G.M. Kamath, V. Lalitha, and P.V. Kumar. 2012. Optimal linear codes with a local-error-correction property. In Information Theory Proceedings (ISIT), 2012 IEEE International Symposium on . 2776-2780.
- [39] Adi Shamir. 1979. How to Share a Secret. Commun. ACM 22, 11 (Nov. 1979), 612-613.
- [38] T. J. Richardson and R. L. Urbanke. 2001. The capacity of low-density parity-check codes under message-passing decoding. IEEE Transactions on Information Theory 47, 2 (2001), 599-618.
- [40] R. Shokri, M. Stronati, C. Song, and V. Shmatikov. 2017. Membership Inference Attacks Against Machine Learning Models. In 2017 IEEE Symposium on Security and Privacy (SP) . 3-18.
- [42] Jinhyun So, Basak Guler, and A. Salman Avestimehr. 2020. Byzantine-Resilient Secure Federated Learning. (2020). arXiv:cs.CR/2007.11115
- [41] D. Silva and F. R. Kschischang. 2011. Universal Secure Network Coding via Rank-Metric Codes. IEEE Transactions on Information Theory 57, 2 (Feb. 2011), 1124-1135.
- [43] Jinhyun So, Basak Guler, and Amir Salman Avestimehr. 2020. Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. CoRR abs/2002.04156 (2020). https://arxiv.org/abs/2002.04156
- [45] Stacey Truex, Nathalie Baracaldo, Ali Anwar, Thomas Steinke, Heiko Ludwig, Rui Zhang, and Yi Zhou. 2019. A Hybrid Approach to Privacy-Preserving Federated Learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and
- [44] I. Tamo and A. Barg. 2014. A Family of Optimal Locally Recoverable Codes. Information Theory, IEEE Transactions on 60, 8 (Aug 2014), 4661-4676.
Security . 1-11.
- [47] Runhua Xu, Nathalie Baracaldo, Yi Zhou, Ali Anwar, and Heiko Ludwig. 2019. HybridAlpha: An Efficient Approach for Privacy-Preserving Federated Learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security (AISec'19) . Association for Computing Machinery, New York, NY, USA, 13-fi/question\_exclam23. https://doi.org/10.1145/3338501.3357371
- [46] Michael M. Wagner. 2006. CHAPTER 1 - Introduction. In Handbook of Biosurveillance , Michael M. Wagner, Andrew W. Moore, and Ron M. Aryel (Eds.). Academic Press, Burlington, 3 - 12. https://doi.org/10.1016/B978-012369378-5/50003-X
## A FINITE FIELD FOURIER TRANSFORM
Here, we review the basics of the finite field Fourier transform, for details, see, e.g., [36]. Let q be a power of a prime, and consider a finite field F q of order q . Let N be a positive integer such that N divides ' q 1 ' and ω be a primitive N -th root of unity in F q . The discrete Fourier transform (DFT) of length N generated by ω is a mapping from F N q to F N q defined as follows. Let x = » x 0 x 1 : : : x N 1 … be a vector over F q . Then, the DFT of x generated by ω , denoted as DFT ω ' x ' , is the vector over F q , X = » X 0 X 1 : : : X N 1 … , given by
<!-- formula-not-decoded -->
The inverse DFT (IDFT), denoted as I DFT ω ' X ' , is given by
<!-- formula-not-decoded -->
where 1 N denotes the reciprocal of the sum of N ones in the field F q . We refer to x as the 'time-domain signal' and index i as time, and X as the 'frequency-domain signal' or the 'spectrum' and j as frequency.
If a signal is subsampled in the time-domain, its frequency components mix together, i.e., alias , in a pattern that depends on the sampling procedure. In particular, let n be a positive integer that divides N . Let x '# n ' denote the subsampled version of x with period n , i.e., x '# n ' = f x ni : 0 i N n 1 g . Then, ' N n ' -length DFT of x '# n ' , X '# n ' , (generated by ω n ) is related to the N -length DFT of x , X , (generated by ω ) as
<!-- formula-not-decoded -->
where 1 n is the reciprocal of the sum of n ones in F q .
A circular shift in the time-domain results in a phase shift in the frequency-domain. Given a signal x , consider its circularly shifted version x ' 1 ' defined as x ' 1 ' i = x ' i + 1 ' mod N . Then, the DFTs of x ' 1 ' and x (both generated by ω ) are related as X ' 1 ' j = ω j X j . In general, a circular shift of t results in
<!-- formula-not-decoded -->
## B PROOF OF LEMMA
Proof of Lemma 3.2. For i 2 f 0 ; 1 g , for v 2 f 0 ; 1 ; : : : ; δ i n i 1 g , let us denote x ' v ''# n i ' as x circularly shifted (in advance) by v and then subsampled by n i . That is, x ' v ''# n i ' j = x ' jn i + v ' mod n i for j = 0 ; 1 ; : : : ; N n i 1. Let X ' v ''# n i ' denote the DFT of x ' v ''# n i '
generated by ω n i . Now, from the aliasing property (18), it holds that
<!-- formula-not-decoded -->
for v = 0 ; 1 ; : : : ; δ i n i 1 and c = 0 ; 1 ; : : : ; N n i 1 : However, from the circular shift property (19), we have X ' v ' j = ω vj X j for j = 0 ; 1 ; : : : ; N 1. Thus, we have
<!-- formula-not-decoded -->
for v = 0 ; 1 ; : : : ; δ i n i 1, and c = 0 ; 1 ; : : : ; N n i 1. Note that, by construction, x ' v ''# n i ' is a length-' N n i ' zero vector for v = 0 ; 1 ; : : : ; δ i n i 1 for each i 2 f 0 ; 1 g . Therefore, X ' v ''# n i ' is also a length-' N n i ' zero vector for v = 0 ; 1 ; : : : ; δ i n i 1 for each i 2 f 0 ; 1 g . Hence, from (21), we get
<!-- formula-not-decoded -->
for v = 0 ; 1 ; : : : ; δ i n i 1, and c = 0 ; 1 ; : : : ; N n i 1. Simplifying the above, we get
<!-- formula-not-decoded -->
for u = 0 ; 1 ; : : : ; n i 1, v = 0 ; 1 ; : : : ; δ i n i 1, and c = 0 ; 1 ; ; : : : ; N n i 1.
## C ANALYSIS OF FASTSHARE
We first focus on the correctness, i.e., dropout tolerance. To prove that FastShare has a dropout tolerance of D , we need to show that FastRecon can recover the secrets from a random subset of N D shares. This is equivalent to showing that the iterative peeling decoder of FastRecon can recover all the shares from a random subset of N D shares. Note that the shares generated by FastShare form a codeword of a product code. From the density evolution analysis of the iterative peeling decoder of product codes in [27, 34], it follows that, when D ' 1 ' 1 δ 0 '' 1 δ 1 '' N 2 , the decoder recovers all the shares from a random subset of N D shares with probability at least 1 poly N . Therefore, FastShare has the dropout tolerance of D = ' 1 ' 1 δ 0 '' 1 δ 1 '' N 2 .
First, we show that the information-theoretic security condition is equivalent to a specific linear algebraic condition. To this end, we first observe that the vector of N shares can be written as,
To prove the privacy threshold of T , we consider the informationtheoretic equivalent of the security definition [7]. In particular, we need to show the following: for any P C such that jPj T , it holds that H ' s j f» s … i g i 2P ' = H ' s ' , where H denotes the Shannon entropy. For simplicity, let us denote » s … i = X i for all i . In the remainder of the proof, we denote random variables by boldface letters.
<!-- formula-not-decoded -->
where s 2 F ' q is the vector of secrets, m 2 F K ' q is a vector with each element chosen independently and uniformly from F q , and G is a particular submatrix of the DFT matrix whose formal definition we defer later on. We then show that information theoretic security is equivalent to a particular linear algebraic condition on submatrices of G . To prove this condition we leverage the fact that G is derived from a DFT matrix and consider an alternate representation based on the Chinese Remainder theorem (CRT). We furnish more details while formally discussing the lemmas.
Recall that n 0 and n 1 are co-prime. By the CRT, we may conclude that any number j 2 f 0 ; ; N 1 g can be uniquely represented in a 2D-grid as a tuple ' a ; b ' where a = j mod n 0 and b = j mod n 1. First, define the set of indices
<!-- formula-not-decoded -->
Similarly, define
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
For a pictorial representation of these indices, refer to Fig. 2. These sets correspond to points in the grid, and by the CRT map back to integers in the range f 0 ; ; N 1 g .
Remark 2. In Theorem 3.3, the number of secrets ' , is chosen to be equal to ' 1 α '' 1 2 β '' 1 δ 0 '' 1 δ 1 ' n 0 n 1 . By design this coincides with the size of S .
With these definition, we next describe the construction of the matrix G is obtained by starting with the N N DFT matrix, removing the columns corresponding to Z 0 [ Z 1, and permuting the remaining columns so that the columns corresponding to S are ordered as the first ' columns in S (in arbitrary sequence).
The proof is similar to Lemma 6 in [41], and thus omitted.
Having defined the matrix G , in the following lemma we show that information theoretic security can be guaranteed by a particular rank condition satisfied by submatrices of G . In particular, In addition, define K = N jZ 0 [ Z 1 j .
Lemma C.1. Let s 2 F ' q , m 2 F k ' q , and X = G » s m … T be random variables representing the secrets, random masks, and shares, respectively. Let X P be an arbitrary set of shares corresponding to the indices in P f 1 ; 2 ; : : : ; N g . Let G P denote the sub-matrix of G corresponding to the rows indexed by P . Let G P = » G 1 G 2 … , where G 1 consists of the first ' columns of G P and G 2 consists of the last K ' columns of G P . If m is uniform over F K ' q , then it holds that
<!-- formula-not-decoded -->
Now, to prove the information-theoretic security, it suffices to prove that for any P of size at most T = αβ ' 1 δ 0 '' 1 δ 1 ' N , rank ' G 2 ' = rank ' G P ' . We prove this by showing that, for any D with jPj T , the columns of G 1 lie in the span of the columns of G 2. Note that columns of G 1 are the columns of the DFT matrix indexed by S .
Proof of rank ' G P ' = rank ' G 2 ' : Assume that f ω @ : @ 2 Pg are the set of primitive elements generating the rows of G P . For the rest of the proof we are guided by the grid representation of fig. 2 - the Chinese remainder theorem (CRT) furnishes a representation of the columns of G P , indexed by f 0 ; ; n 1 g as points on a 2D-grid, f' p 0 ; p 1 ' : p 0 2 f 0 ; ; n 0 1 g ; p 1 2 f 0 ; ; n 1 1 gg .
Notation: In the grid representation, consider the set of points T in fig. 2. Formally,
<!-- formula-not-decoded -->
Define G 2 'T' as the matrix G 2 only populated by the columns whose indices belong to T . Henceforth, we use the terminology 'points' to refer to a column of G P in its representation as a tuple in the 2D-grid. Moreover we use the terminology 'span' and 'rank' of the points to indicate the span and rank of the corresponding columns. Consider a column index p 2 f 0 ; ; n 1 g and ∆ 2 f 0 ; ; n 1 g where p 7!' p 0 ; p 1 ' and ∆ 7!' ∆ 0 ; ∆ 1 ' under the CRT bijection. Then, the notation ' p 0 ; p 1 ' + ' ∆ 0 ; ∆ 1 ' returns the point '' p 0 + ∆ 0 ' mod n 0 ; ' p 1 + ∆ 1 ' mod n 1 ' .
Observe that P + ∆ corresponds to multiplying the columns indexed by P by a full-rank matrix. Then, using the structure of G P inherited from the DFT (Vandermonde) matrix structure, we get the following result immediately.
Since G P is derived from a DFT matrix, this in fact corresponds to multiplying the column corresponding to p by the matrix diag '' ω ∆ @ : @ 2 P'' . The notations (i) p + ∆ , (ii) p + ' ∆ 0 ; ∆ 1 ' are defined analogously. We also use the terminology 'shift p horizontally by ∆ 0' and 'shift p vertically by ∆ 1' to respectively denote p + ' ∆ 0 ; 0 ' and p + ' 0 ; ∆ 1 ' . Given a set of points P , we overload notation and use P + ∆ as the set of points f p + ∆ : p 2 Pg .
Lemma C.2. If p 2 span 'P' for some set of points P , then for any ∆ 2 f 0 ; ; n 1 g , p + ∆ 2 span 'P + ∆ ' .
Proof. If p 2 span 'P' this implies that there exists weights f α q : q 2 Pg such that for each @ 2 P , ω p @ = ˝ q 2P α q ω q @ . Fixing any @ 2 P , and multiplying both sides by ω ∆ ,
@
<!-- formula-not-decoded -->
Since this is true for each @ 2 P the proof follows immediately.
By construction of the set, observe that the number of points in T equals αβ ' 1 δ 0 '' 1 δ 1 ' n 0 n 1. Moreover, recalling the choice of the privacy threshold T in Theorem 3.3, observe that jT j = T . By this fact, we have that rank ' G P ' T . This implies two possibilities:
Case I. If rank ' G 2 'T'' = rank ' G P ' , then the remaining columns in G 1 must lie in the span of G 2 'T' , and the proof concludes.
Case II. If not, then the columns of G 2 'T' must have at least one column dependent on the others.
We can identify one such column by the following procedure: starting at the top left corner of T in the grid, sequentially collect the points in T in a top-to-bottom, left-to-right sequence. Stop at the first point y = ' y 0 ; y 1 ' which lies in the span of the previously collected points (by assumption, such a point must exist as we are in Case II). Figure 6 illustrates this procedure where we collect the black points sequentially until the yellow point is reached which is the first point that lies in the span of the previously collected points. Let B be defined as the set of black points which are enumerated
Figure 6: Enumerating the columns in the bottom-right sequence until the first column (yellow) is reached which lies in the span of the previous columns
<details>
<summary>Image 6 Details</summary>
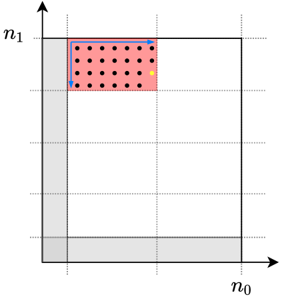
### Visual Description
\n
## Diagram: Phase Space Representation
### Overview
The image depicts a two-dimensional phase space diagram, likely representing a system's state based on two variables, n₀ and n₁. A rectangular region within the phase space is highlighted with a red fill containing black dots, and is bordered by a blue rectangle with arrows indicating a direction of movement. The diagram appears to illustrate a specific region of accessible states or a trajectory within the phase space.
### Components/Axes
* **Axes:** The diagram has two axes labeled n₀ (horizontal) and n₁ (vertical). The axes appear to be linearly scaled, with no explicit numerical values indicated.
* **Highlighted Region:** A rectangular region in the top-left quadrant is filled with red dots. This region is enclosed by a blue rectangle.
* **Arrows:** Two blue arrows are present along the sides of the blue rectangle, indicating a direction of movement or flow. One arrow points upwards, and the other points to the right.
* **Shaded Areas:** The areas to the right of the n₁ axis and below the n₀ axis are shaded in gray.
### Detailed Analysis
The diagram shows a rectangular region in the n₀-n₁ phase space. The red dots within the rectangle suggest discrete states or points within that region. The blue rectangle outlines the region, and the arrows indicate a possible trajectory or flow direction within that region. The shaded areas represent regions of the phase space that are not currently considered or are inaccessible.
The dimensions of the rectangle are approximately 2 units along the n₀ axis and 3 units along the n₁ axis. The red dots appear to be randomly distributed within the rectangle, with an approximate density of 15-20 dots per unit area. The arrows are approximately the same length as the sides of the rectangle.
### Key Observations
* The diagram focuses on a specific region of the phase space, defined by the blue rectangle.
* The red dots suggest a set of discrete states within that region.
* The arrows indicate a direction of movement or flow within the region.
* The shaded areas represent regions outside the current focus.
### Interpretation
This diagram likely represents a system's behavior in a two-dimensional phase space. The n₀ and n₁ variables could represent any two relevant state variables of the system (e.g., position and momentum, concentration of two species). The red dots represent possible states of the system, and the blue rectangle defines a region of interest. The arrows suggest that the system is evolving or moving within this region, potentially following a specific trajectory.
The shaded areas could represent regions of the phase space that are energetically unfavorable or inaccessible to the system under the given conditions. The diagram could be used to illustrate the dynamics of a system, the stability of certain states, or the possible pathways the system can take. The lack of numerical values on the axes suggests that the diagram is intended to be a qualitative representation of the system's behavior rather than a precise quantitative analysis. The diagram is a conceptual illustration of a system's state and its evolution in phase space.
</details>
until y is found. By definition, this implies that there exist (not necessarily unique) weights f α b g b 2B such that,
<!-- formula-not-decoded -->
This implies that y ' 0 ; 1 ' 2 span 'B ' 0 ; 1 '' . Define Y as the set of points,
<!-- formula-not-decoded -->
Note that the set of points Y implicitly depends on the location of point y . Next, we define L and C to be the set of points,
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
In addition, we define Q to be the set of points,
<!-- formula-not-decoded -->
Pictorially these points are represented in Figs 7 and 8.
Claim 1. Y span 'C' .
Proof. We prove this result by induction sequentially iterating over all the points from top to bottom in Y . Clearly B C , therefore the induction holds for the first point in Y , which is y = ' y 0 ; y 1 ' .
Suppose for some k 1 that for each t k 1 the point y ' 0 ; t ' lies in span 'C' . Then we show that y ' 0 ; k ' 2 span 'C' as long as k y 1 n 1 ' 1 δ 1 '' 1 β ' + 1. Indeed, observe first that,
<!-- formula-not-decoded -->
The key observation is that B ' 0 ; k ' is always C[f y ' 0 ; t ' : 0 t k 1 g (unless k > y 1 n 1 ' 1 δ 1 '' 1 β ' + 1, in which case B' 0 ; k ' shifts far enough down that it includes points in Z 1 - this has null intersection with C and Y so the assertion is clearly false). For a pictorial presentation of this fact, refer to Fig. 9. By the induction hypothesis, for each t k 1, y ' 0 ; t ' 2 span 'C' . Therefore, span 'B ' 0 ; k '' span 'C' . Plugging into eq. (36) completes the proof of the claim.
Claim 2. L span 'Q' .
Proof. Recall that L = [ n 0 y 0 1 k = 0 'Y + ' k ; 0 '' . Wefollow a similar proof by induction strategy as Claim 1 to result in the assertion. In particular, for k = 0 the statement follows directly from the fact that C Q and using Claim 1 to claim that Y span 'C' . Assuming the induction hypothesis that for all 0 t k 1, Y + ' t ; 0 ' span 'Q' we show that Y + ' k ; 0 ' span 'Q' as long as k n 0 y 0 1. In particular, observe that from Claim 1,
<!-- formula-not-decoded -->
Next observe that unless k > n 0 y 0 1,
<!-- formula-not-decoded -->
if k > n 0 y 0 1, then C + ' k ; 0 ' shifts far enough that it wraps around and include points in Z 0 - this has null intersection with Q and Y + ' t ; 0 ' for any t n 0 y 0 1 and the assertion becomes false. A pictorial representation of this fact is provided in Fig. 10. By the induction hypothesis for each 0 t k 1, Y + ' t ; 0 ' span 'Q' . Combining this fact with eqs. (37) and (38) implies that Y + ' 0 ; k ' span 'Q' and completes the induction step for k .
Recall from eq. (33) that L is defined as the set of points, [ n 0 y 0 1 k = 0 'Y + ' k ; 0 '' . More explicitly, noting that the set of points Y is defined as f' y 0 ; θ ' : y 1 n 1 ' 1 δ 1 '' 1 β ' + 1 θ y 1 g ,
<!-- formula-not-decoded -->
Claim 3. The set of points S L irrespective of the location of the point y = ' y 0 ; y 1 ' (note that the set of points L is a function of y 0 and y 1 ).
Proof. Before furnishing the details of the proof, note that a pictorial representation of this statement is provided in Fig. 10. First recall that y = ' y 0 ; y 1 ' is a point in the set T . Therefore, δ 0 n 0 y 0 δ 0 n 0 + α ' 1 δ 0 ' n 0 1 and n 1 β ' 1 δ 1 ' n 1 y 1 n 1 1. In particular, this means that for any y ,
<!-- formula-not-decoded -->
Furthermore, we see that (i) y 1 n 1 β ' 1 δ 1 ' n 1, and (ii) y 1 n 1 ' 1 δ 1 '' 1 β ' + 1 n 1 n 1 ' 1 δ 1 '' 1 β ' = n 1 δ 1 + β ' 1 δ 1 ' n 1. Therefore, we have that,
:
;
<!-- formula-not-decoded -->
: ; The LHS is exactly the definition of S in eq. (25).
From Claims 2 and 3 and the definition of L in eq. (33), we see that S span 'Q' . In particular this implies that the each column indexed by points in S can be expressed as a linear combination of some set of remaining columns that do not belong to Z 0 or Z 1.
Figure 7: Definition of B ; Y and C
<details>
<summary>Image 7 Details</summary>
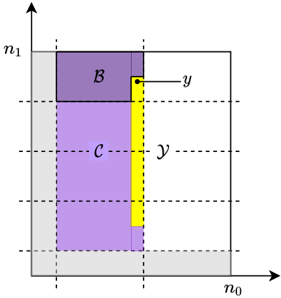
### Visual Description
\n
## Diagram: Rectangular Region Partitioning
### Overview
The image depicts a rectangular region partitioned into several areas, likely representing a geometric or mathematical concept. The region is defined by axes labeled *n₀* and *n₁*. Within this region, there are three distinct colored areas: a purple rectangle labeled *B* at the top-left, a larger purple rectangle labeled *C* below *B*, and a yellow rectangle positioned to the right of *C*. Dashed lines indicate boundaries and relationships between the areas. The variable *y* is labeled twice, once at the top-right corner of *B* and once in the middle of the yellow rectangle.
### Components/Axes
* **Axes:**
* *n₀* (horizontal axis)
* *n₁* (vertical axis)
* **Regions:**
* *B* (purple rectangle, top-left)
* *C* (purple rectangle, below *B*)
* Yellow rectangle (right of *C*)
* **Labels:**
* *y* (appears twice, associated with both *B* and the yellow rectangle)
* **Lines:**
* Solid lines defining the rectangular boundaries.
* Dashed lines indicating internal boundaries and potentially relationships between regions.
### Detailed Analysis
The diagram shows a rectangular area with dimensions defined by the axes *n₀* and *n₁*. The purple rectangle *B* is positioned in the upper-left quadrant. Below *B* is a larger purple rectangle *C*. A yellow rectangle is positioned to the right of *C*, sharing a vertical boundary with it. The variable *y* is marked at the top-right corner of *B* and at the center of the yellow rectangle. The dashed lines suggest a possible relationship or partitioning within the overall rectangular area.
There are no numerical values provided on the axes, so precise dimensions or coordinates cannot be determined. The relative sizes of the rectangles can be estimated visually: *C* appears to be approximately twice the height of *B*, and the yellow rectangle's width is roughly comparable to the width of *B*.
### Key Observations
* The diagram focuses on the spatial relationship between the three colored regions.
* The repeated label *y* suggests a common parameter or variable associated with both the purple rectangle *B* and the yellow rectangle.
* The dashed lines imply a partitioning or division of the overall rectangular area.
* The absence of numerical values limits quantitative analysis.
### Interpretation
This diagram likely represents a geometric problem or a visual illustration of a mathematical concept. The partitioning of the rectangular area into regions *B*, *C*, and the yellow rectangle could represent different sets, areas, or quantities. The variable *y* might represent a coordinate, a length, or some other parameter relevant to both the purple rectangle *B* and the yellow rectangle. The dashed lines could indicate boundaries or relationships between these regions, potentially defining constraints or dependencies.
Without additional context, it's difficult to determine the specific meaning of the diagram. However, it appears to be a visual representation of a problem involving areas, boundaries, and a common variable *y*. It could be related to optimization, area calculation, or geometric modeling. The diagram is a qualitative representation, and further information would be needed to perform a quantitative analysis or derive a specific solution.
</details>
Figure 8: Definition of Q and L
<details>
<summary>Image 8 Details</summary>
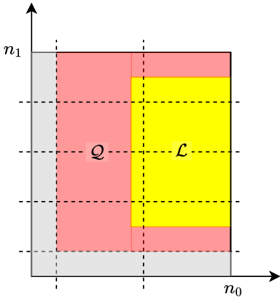
### Visual Description
\n
## Diagram: Phase Diagram Representation
### Overview
The image depicts a two-dimensional diagram representing a phase space or a region divided into different phases. The diagram uses color-coding to distinguish between different regions, labeled 'Q' and 'L'. The axes are labeled 'n₀' and 'n₁'. The diagram appears to illustrate a conceptual partitioning of a space based on two variables.
### Components/Axes
* **Axes:**
* Horizontal axis: labeled 'n₀'
* Vertical axis: labeled 'n₁'
* **Regions:**
* Yellow region: Labeled 'L' in the center-right.
* Pink/Red region: Labeled 'Q' in the center-left.
* Gray region: Surrounding the pink and yellow regions, forming a border along the axes.
* **Grid:** Dashed lines create a grid pattern within the diagram, dividing the regions into smaller squares.
### Detailed Analysis or Content Details
The diagram shows a rectangular area defined by the axes n₀ and n₁. The area is partitioned into three distinct regions:
* **Region Q (Pink/Red):** Occupies the left half of the rectangle. It is further divided into 9 equal squares by the dashed grid lines.
* **Region L (Yellow):** Occupies the right half of the rectangle. It is also divided into 9 equal squares by the dashed grid lines.
* **Gray Region:** Forms a border around the pink and yellow regions, extending along the n₀ and n₁ axes. This region appears to represent a boundary or transition zone.
There are no numerical values provided on the axes, so the scale and range of n₀ and n₁ are unknown. The diagram is purely qualitative, illustrating the relative positions and areas of the different regions.
### Key Observations
* The diagram visually represents two distinct phases, 'Q' and 'L', separated by a boundary.
* The areas of regions 'Q' and 'L' appear to be equal, each occupying approximately half of the total area.
* The gray region suggests a transition or boundary between the two phases.
* The grid lines indicate a uniform partitioning of the space within each phase.
### Interpretation
This diagram likely represents a phase diagram in a physical or chemical system. The variables n₀ and n₁ could represent concentrations, temperature, pressure, or other relevant parameters. The regions 'Q' and 'L' represent different phases of the system, and the gray region represents a phase boundary where the two phases coexist.
The equal areas of 'Q' and 'L' might suggest that the two phases are equally probable or stable under the conditions represented by the diagram. The grid lines could indicate a discrete or quantized nature of the system.
Without further context, it is difficult to determine the specific meaning of the diagram. However, it clearly illustrates a partitioning of a space into different phases based on two variables. The diagram is a conceptual representation and does not provide any quantitative data. It is a schematic illustration of a system's state space.
</details>
This implies that for any choice of P (note that we do not specify a particular choice of P in the proof as long as it has size T ) that rank ' G 2 ' = rank ' G P ' .
Moreover, we do not specify the particular choice of P in the proof, so it holds for all sets of size T .
## D CORRECTNESS OF FASTSECAGG
Correctness essentially follows from the correctness of key agreement and authenticated encryption protocols together with the linearity and D -dropout tolerance of FastShare.
Specifically, using the correctness of key agreement and authenticated encryption, it is straightforward to show that, in Round 2, each client i 2 C 1 computes and sends to the server the sum of shares it receives in Round 1 as follows
<!-- formula-not-decoded -->
«
‹
Figure 9: Showing that B' 0 ; k ' is a subset of the intersection of C and f y ' 0 ; t ' : 0 t k 1 g .
<details>
<summary>Image 9 Details</summary>
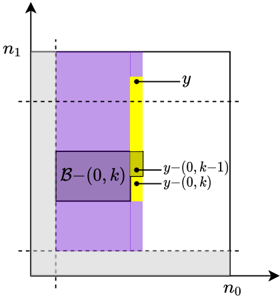
### Visual Description
\n
## Diagram: Spatial Representation with Rectangular Regions
### Overview
The image depicts a two-dimensional space defined by axes labeled *n₀* and *n₁*. The space is partitioned into several rectangular regions colored in shades of gray, yellow, and purple. Annotations indicate specific points and a labeled region *B−(0, k)*. Dashed lines are present, suggesting boundaries or levels within the space. This appears to be a visual representation of a mathematical or computational concept involving spatial partitioning.
### Components/Axes
* **Axes:**
* *n₀* (horizontal axis)
* *n₁* (vertical axis)
* **Regions:**
* Light Gray: Occupies the bottom and left portions of the space.
* Yellow: A vertical strip in the center-right.
* Purple: The largest region, filling the majority of the space.
* **Annotations:**
* "y": A point within the yellow region, near the top.
* "y−(0, k−1)": A point within the purple region, below "y".
* "y−(0, k)": A point within the purple region, below "y−(0, k−1)".
* "B−(0, k)": A rectangular region within the purple area, near the bottom-left.
* **Lines:**
* Dashed horizontal lines: Two dashed lines are present, defining levels or boundaries within the space.
* Dashed vertical line: A dashed vertical line separates the gray and purple regions.
### Detailed Analysis or Content Details
The diagram shows a partitioning of a two-dimensional space. The axes *n₀* and *n₁* define the coordinate system. The purple region dominates the space, with the yellow region acting as a vertical strip intersecting it. The gray region occupies the bottom-left corner.
The annotations indicate specific points within these regions. The point "y" is located in the yellow region. The points "y−(0, k−1)" and "y−(0, k)" are located within the purple region, positioned vertically below "y". The region "B−(0, k)" is a rectangular area within the purple region.
There are no numerical values provided on the axes, so the scale is unknown. The positions of the points are relative to the regions and the dashed lines.
### Key Observations
* The points "y", "y−(0, k−1)", and "y−(0, k)" appear to be aligned vertically, suggesting a relationship based on the *n₀* coordinate.
* The region "B−(0, k)" is contained entirely within the purple region.
* The dashed lines may represent boundaries or levels of a process or function.
* The diagram is purely geometric and does not contain any quantitative data.
### Interpretation
This diagram likely represents a state space or a domain partitioning in a mathematical or computational context. The regions could represent different states or categories, and the points could represent specific instances or values within those states. The notation "B−(0, k)" suggests a set or region indexed by *k*. The points "y−(0, k−1)" and "y−(0, k)" might represent previous or current states in a sequence.
The absence of numerical values on the axes indicates that the diagram is intended to illustrate a conceptual relationship rather than a precise quantitative one. The diagram could be used to visualize an algorithm, a decision tree, or a state transition diagram. The dashed lines could represent thresholds or boundaries that determine the state of a system.
Without further context, it is difficult to determine the exact meaning of the diagram. However, it clearly demonstrates a spatial partitioning and the relationships between different regions and points within that space.
</details>
Figure 10: Showing that C + ' k ; 0 ' is a subset of the intersection of Q and -k 1 t = 0 'Y + ' t ; 0 '' .
<details>
<summary>Image 10 Details</summary>
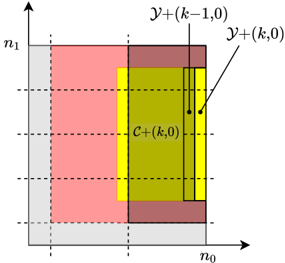
### Visual Description
\n
## Diagram: Representation of a Computational Region
### Overview
The image depicts a rectangular region divided into several sub-regions, likely representing a computational domain or a data structure. The region is defined by axes labeled *n₀* and *n₁*. Within this region, there are areas colored in pink, yellow, and green, with dotted lines indicating boundaries and labels pointing to specific points or areas. The diagram appears to illustrate a partitioning or decomposition of a larger space.
### Components/Axes
* **Axes:**
* *n₀* (Horizontal axis)
* *n₁* (Vertical axis)
* **Regions:**
* Pink region: Occupies the left side and bottom of the overall rectangle.
* Yellow region: Located in the center, partially overlapping with the green region.
* Green region: Occupies the central area, partially overlapping with the yellow region.
* **Labels:**
* *y+(k,0)*: Points to a location on the right edge of the green region.
* *y+(k-1,0)*: Points to a location on the right edge of the green region, slightly below *y+(k,0)*.
* *c+(k,0)*: Located in the center of the green region.
* **Dotted Lines:** Vertical dotted lines divide the region into sections.
### Detailed Analysis or Content Details
The diagram shows a rectangular area defined by the axes *n₀* and *n₁*. The pink region occupies the space to the left and below the central regions. The yellow and green regions are positioned centrally, with the yellow region appearing to be a subset of the green region. The labels indicate specific points within the green region.
* *y+(k,0)* and *y+(k-1,0)* are positioned vertically adjacent to each other on the right edge of the green region. The label *y+(k,0)* is slightly above *y+(k-1,0)*.
* *c+(k,0)* is located in the center of the green region.
* The dotted lines suggest a partitioning of the space, potentially representing boundaries between different computational elements or data blocks.
There are no numerical values provided in the image. The labels use the variable *k*, suggesting a parameter or index.
### Key Observations
The diagram illustrates a hierarchical or nested structure. The green region contains the yellow region, and both are situated within the larger rectangular area defined by *n₀* and *n₁*. The labels *y+(k,0)* and *y+(k-1,0)* suggest a sequence or iteration, potentially related to a time step or a computational loop.
### Interpretation
This diagram likely represents a computational domain or a data structure used in a numerical method or algorithm. The different colored regions could represent different states, data types, or computational tasks. The labels *y+(k,0)* and *y+(k-1,0)* suggest a time-stepping or iterative process, where *k* represents the current iteration. *c+(k,0)* could represent a central point or value within the current iteration. The dotted lines indicate boundaries between different computational elements or data blocks.
The diagram is abstract and does not provide specific numerical data. It serves as a visual representation of a conceptual framework or a computational process. Without additional context, it is difficult to determine the exact meaning of the diagram. It could be related to finite element analysis, computational fluid dynamics, or other numerical simulations. The use of "+" in the labels suggests a positive or increasing value. The diagram is likely part of a larger technical document explaining a specific algorithm or method.
</details>
The linearity property of FastShare ensures that the sum of shares is a share of the sum of secret vectors (i.e., client inputs). In other words, by linearity of FastShare, it holds that
<!-- formula-not-decoded -->
Recall that sh ' i denotes the ' -th coefficient of sh i . Therefore, from (43), it holds, for 1 ' d L S e , that
<!-- formula-not-decoded -->
Let C 2 be a random subset of at least N D clients that survive in Round 2, i.e., clients in C 2 send their sum-shares to the server. Now, from (44) and the D -dropout tolerance of FastShare, it holds that FastRecon f' i ; sh ' i 'g i 2C 2 = ˝ j 2C 1 u ' j with probability at least 1 1 poly N for all 1 ' d L S e . Note that we do not need to use a union bound here because if FastRecon succeeds (i.e., does not output ? ) for ' = 1, then it succeeds for each 1 ' d L S e ,
Figure 11: The S is indeed a subset of L . For the particular choice of y this figure shows that the inclusion is true. More generally we in construct S as the intersection of L over all the possible locations of y 2 T .
<details>
<summary>Image 11 Details</summary>
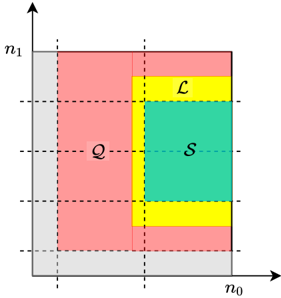
### Visual Description
\n
## Diagram: Partitioned Rectangle with Labels
### Overview
The image depicts a rectangle partitioned into several regions, likely representing a two-dimensional space. The rectangle is bounded by axes labeled 'n₀' (horizontal) and 'n₁' (vertical). Four regions are visually distinguished by color and labeled with letters: 'Q', 'L', 'S', and areas shaded in light gray. Dashed lines indicate the boundaries between the regions.
### Components/Axes
* **Axes:**
* Horizontal axis: labeled 'n₀'
* Vertical axis: labeled 'n₁'
* **Regions:**
* Light Gray: Occupies the left and bottom portions of the rectangle.
* Light Yellow: Forms a border around the central green region and extends along the top and bottom.
* Light Green: A central square region.
* Light Red: Occupies the remaining space, surrounding the yellow and green regions.
* **Labels:**
* 'Q': Located in the light red region, approximately in the center-left portion.
* 'L': Located in the light yellow region, approximately in the top-right portion.
* 'S': Located in the light green region, approximately in the center.
### Detailed Analysis or Content Details
The diagram shows a rectangular area divided into four distinct regions. The axes 'n₀' and 'n₁' define a coordinate system. The regions are arranged as follows:
* The light gray regions are located in the bottom-left and top-left corners.
* The light red region ('Q') occupies the majority of the left side and extends partially into the center.
* The light yellow region ('L') forms a border around the light green region ('S') and extends along the top and bottom edges.
* The light green region ('S') is a square located in the center-right portion of the rectangle.
There are no numerical values or scales provided on the axes. The diagram is purely qualitative, illustrating a partitioning of space.
### Key Observations
The diagram visually represents a partitioning of a two-dimensional space into four regions, labeled Q, L, and S, with the remaining areas shaded gray. The arrangement suggests a hierarchical or nested structure, with 'S' being contained within 'L', and both being surrounded by 'Q'. The gray areas appear to be outside of the primary regions of interest.
### Interpretation
This diagram likely represents a conceptual partitioning of a state space or a feature space. The labels 'Q', 'L', and 'S' could represent different states, categories, or regions of interest within a larger system. The axes 'n₀' and 'n₁' likely represent two key parameters or features that define the space.
Without further context, it's difficult to determine the specific meaning of the diagram. However, the arrangement suggests that 'S' is a subset of 'L', which is in turn a subset of 'Q'. The gray areas could represent regions outside the scope of the analysis or areas with low probability or relevance.
The diagram could be used to illustrate concepts in various fields, such as:
* **Probability and Statistics:** 'Q', 'L', and 'S' could represent regions of different probabilities.
* **Machine Learning:** 'Q', 'L', and 'S' could represent different clusters or classes.
* **Control Theory:** 'Q', 'L', and 'S' could represent different states of a system.
* **Signal Processing:** 'Q', 'L', and 'S' could represent different frequency bands.
</details>
since the locations of missing indices (among N ) of shares for every 1 ' d L S e are the same.
Hence, we get
<!-- formula-not-decoded -->
with probability at least 1 1 poly N . In other words, z = ˝ i 2C 1 u i with probability at least 1 1 poly N . This concludes the proof.
## E SECURITY OF FASTSECAGG
In FastSecAgg, each client i first partitions their input u i to d L S e vectors u 1 i , u 2 i , : : : , u d L S e i , each of length at most S , and computes shares for each u ' , 1 ' d L S e . In other words, we have
i
<!-- formula-not-decoded -->
where independent private randomness is used for each 1 ' d L S e . Let us denote the set of shares that client i generates for client j as » u i … j , i.e., we have
<!-- formula-not-decoded -->
It is straightforward to show that for any set of up to T clients P C , the shares f» u i … j g j 2P reveal no information about u i .
Lemma E.1. For every u i ; v i 2 F L q , for any P C such that jPj T , the distribution of f» u i … j g j 2P is identical to that of f» v i … j g j 2P .
Proof. Here we treat u i to be a random variable (with arbitrary distribution), and f» u i … j g j 2P to be a conditional random variable given a realization of u i . By slightly abusing the notation for simplicity, denote u i as a set u i = f u 1 ; u 2 ; : : : ; u d L S e g (instead of a
i
i
i
vector). Further, for simplicity, define
<!-- formula-not-decoded -->
Now, observe that, given u ' i , the distribution of u ' i P is conditionally independent of u i n f u ' i g and » u i … P n n u ' i P o . This is because, for the ' -th instantiation, 1 ' d L S e , FastShare takes only u ' i as its input and uses independent private randomness. Therefore, the distribution of » u i … P factors into the product of the distributions of u ' i P . The proof then follows by applying the T -privacy property for each instantiation of FastShare.
We prove Theorem 5.2 by a standard hybrid argument. We will present a sequence of hybrids starting that start from the real execution and transition to the simulated execution where each two consecutive hybrids are computationally indistinguishable. Hybrid 0 : This random variable is REAL C ; T ; λ M ' u C ; C 0 ; C 1 ; C 2 ' , the joint view of the parites M in the real execution of the protocol. Hybrid 1 : In this hybrid, we change the behavior of honest clients in C 1 nM so that instead of using KA.agree ' sk i ; pk j ' to encrypt and decrypt messages, we run the key agreement simulator Sim KA ' s i ; j ; pk j ' , where s i ; j is chosen uniformly at random. The security of the key agreement protocol guarantees that this hybrid is indistinguishable from the previous one.
Hybrid 3 : In this hybrid, for every client i 2 C 1 n M , we replace the shares of u i sent to the corrupt clients in M in Round 1 with shares of v i , which are chosen as follows depending on z . If z = ? , then f v i g i 2C 1 nM are chosen uniformly at random. Otherwise, f v i g i 2C 1 nM are chosen uniformly at random subject to ˝ i 2C 1 nM v i = z = ˝ i 2C 1 nM u i . The joint view of corrupt parties contains only jMj T shares of each v i . From Lemma E.1, it follows that this hybrid is identically distributed to the previous one.
Hybrid 2 : In this hybrid, for every client i 2 C 1 n M , we replace the shares of u i sent to other honest clients in Round 1 with zeros, which the adversary observes encrypted as c i ! j . Since only the contents of the ciphertexts are changed, the IND-CPA security of the encryption scheme guarantees that this hybrid is indistinguishable from the previous one.
If z = ? , then we do not need to consider the further hybrids, and let SIM is defined to sample from Hybrid 3 . This distribution can be computed from the inputs z , C 0, and C 1. In the following hybrids, we assume z , ? .
Hybrid 4 : Partition z into d L S e vectors, z 1 , z 2 , : : : , z d L S e , each of length at most S . In this hybrid, for every client i 2 C 2 nM and each 1 ' d L S e , we replace the share sh ' i with the i -th share of z ' + ˝ j 2M u ' j , i.e., h z ' + ˝ j 2M u ' j i . Since z = ˝ i 2C 1 nM u i , from (43)
i and (44), it follows that the distribution of n z + ˝ j 2M u j i o i 2C 2 is identical to that of f sh i g i 2C 2 . Therefore, this hybrid is identically distributed to the previous one.
We define a PPT simulator SIM to sample from the distribution described in the last hybrid. This distribution can be computed from the inputs z , u M , C 0, C 1, and C 2. The argument above proves that
the output of the simulator is computationally indistinguishable from the output of REAL , which concludes the proof.
## F COMPARISON OF FASTSHARE WITH SHAMIR'S SCHEME AND RELATION TO LOCALLY RECOVERABLE CODES
Comparison with the Shamir's scheme: Amulti-secret sharing variant of the Shamir's scheme can be constructed as follows (see, e.g., [16]). We consider the case of generating N shares (each in F q , q N ) from S secrets (each in F q ) such that the privacy threshold is T and dropout tolerance is N S T . Construct a polynomial of degree-' S + T 1 ' with the secrets and T random masks (each in F q ) as coefficients. Its evaluations on N distinct non-zero points in F q yield the N shares for the Shamir's scheme.
Since the shares generated by Shamir are evaluations of a degree-' S + T 1 ' polynomial on N distinct non-zero points, it is easy to see that the shares form a codeword of a Reed-Solomon code of blocklength N and dimension S + T . On the other hand, FastShare constructs a polynomial of degree-' N 1 ' , and evaluates it on primitive N -th roots of unity. The shares generated by FastShare form a codeword of a product code with Reed-Solomon codes as component codes (see Remark 1).
Note that it is possible to recover the secrets from any S + T shares via polynomial interpolation. Although there exist fast polynomial interpolation algorithms that can interpolate a degreen polynomial in O n log 2 n time (see, e.g., [10, 20, 25]), the actual complexity of these algorithms is typically large due to huge constants hidden by the big-Oh notation as noted in [10, 20, 30]. This limits the scalability of such fast interpolation algorithms.
Suppose we choose primitive N -th roots of unity as the evaluation points for the Shamir's multi-secret sharing scheme. Then, the Shamir's scheme essentially computes the Fourier transform of the 'signal' consisting of S secrets, concatenated with T random masks followed by N S T zeros. In contrast, in case of FastShare, we construct the signal by judiciously placing zeros, which ensures the product code structure on the shares.
Relation to LRCs: The variant of FastShare described in 3.4 is related to a class of erasure codes called Locally Recoverable Codes (LRCs) (see [21, 37, 44], and references therein). Specifically, consider LRCs with ' '; r ' locality [37] in which coordinates can be partitioned into several subsets of cardinality ' such that the coordinates in each subset form a maximum distance separable (MDS) code of length ' and dimension r . An efficient construction of such LRCs is presented in [44, Section V-C]. Note that the shares generated by FastShare (as described in 3.4) form codewods of an LRC with ' n 0 ; ' 1 δ 0 ' n 0 ' locality. Moreover, it is not difficult to show that FastShare as an evaluation code is isomorphic to the LRC constructed in [44, Section V-C] when the good polynomial is x ' (see [44, Sections III-A] for the definition of a good polynomial) and the evaluation points are primitive N -th roots of unity.