## CryptoEmu: An Instruction Set Emulator for Computation Over Ciphers
Xiaoyang Gong xgong35@wisc.edu Dan Negrut negrut@wisc.edu
## Abstract
Fully homomorphic encryption (FHE) allows computations over encrypted data. This technique makes privacy-preserving cloud computing a reality. Users can send their encrypted sensitive data to a cloud server, get encrypted results returned and decrypt them, without worrying about data breaches.
This project report presents a homomorphic instruction set emulator, CryptoEmu, that enables fully homomorphic computation over encrypted data. The software-based instruction set emulator is built upon an open-source, state-of-the-art homomorphic encryption library that supports gate-level homomorphic evaluation. The instruction set architecture supports multiple instructions that belong to the subset of ARMv8 instruction set architecture. The instruction set emulator utilizes parallel computing techniques to emulate every functional unit for minimum latency. This project report includes details on design considerations, instruction set emulator architecture, and datapath and control unit implementation. We evaluated and demonstrated the instruction set emulator's performance and scalability on a 48-core workstation. CryptoEmu has shown a significant speedup in homomorphic computation performance when compared with HELib, a state-of-the-art homomorphic encryption library.
## Index Terms
Fully Homomorphic Encryption, Parallel Computing, Homomorphic Instruction Set, Homomorphic Processor, Computer Architecture.
## I. INTRODUCTION
I N the conventional cloud service model, users share data with their service provide (cloud) to outsource computations. The cloud receives encrypted data and decrypts it with the cloud's private key or the private key shared between the user and the cloud. Thus, the service provider has access to user data, which might contain sensitive information like health records, bank statements, or trade secrets. Privacy concerns have been raised along with the wide adoption of cloud services. In 2019, over 164.68 million sensitive records were exposed in the United States [1].
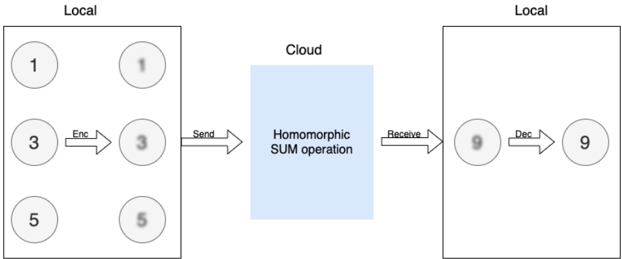
In the worst-case scenario, the cloud service provider cannot be trusted. User data is inherently unsafe if it is in plain text. Even if the service provider is honest, cloud service is prone to fail victims of cybercrime. Security loopholes or sophisticated social engineering attacks expose user privacy on the cloud, and a successful attack usually results in a massive user data leak. One way to eliminate this type of risk is to allow the cloud to operate on the encrypted user data without decrypting it. Fully Homomorphic Encryption (FHE) is a special encryption scheme that allows arbitrary computation over encrypted data without knowing the private key. An FHE enabled cloud service model shown in Fig. 1. In this example, the user wants to compute the sum of 1, 3, 5 in the cloud. The user first encrypts data with FHE, then sends the cipher (shown in Fig. 1 as bubbles with blurry text) to the cloud. When the cloud receives encrypted data, it homomorphically adds all encrypted data together to form an encrypted sum and returns the encrypted sum to the user. The user decrypts the encrypted sum with a secret key, and the result in cleartext is 9 - the sum of 1, 3, and 5. In the entire process, the cloud has no knowledge of user data input and output. Therefore, user data is safe from the insecure cloud or any attack targeted at the cloud service provider.
Fig. 1: Homomorphic Encryption
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram Type: Flowchart
### Overview
The image is a flowchart that illustrates the process of data transmission and processing between a local system and a cloud-based system. The flowchart is divided into three main sections: Local, Cloud, and Local again.
### Components/Axes
- **Local**: This section contains two rectangles, each with a circle inside. The circles are labeled with numbers 1, 3, 5, and 9. The rectangles are labeled "Local" at the top.
- **Cloud**: This section contains a rectangle labeled "Cloud" with a blue background. Inside the rectangle, there is text that reads "Homomorphic SUM operation."
- **Local**: This section contains two rectangles, each with a circle inside. The circles are labeled with numbers 1, 3, 5, and 9. The rectangles are labeled "Local" at the top.
### Detailed Analysis or ### Content Details
- The flowchart shows a process where data is transmitted from a local system to a cloud-based system and then processed by the cloud system.
- The "Homomorphic SUM operation" is performed by the cloud system on the data received from the local system.
- The data is then transmitted back to the local system for further processing or storage.
### Key Observations
- The flowchart demonstrates the concept of homomorphic encryption, which allows for data to be processed in the cloud without being decrypted.
- The use of homomorphic encryption ensures that the data remains secure and private during transmission and processing.
### Interpretation
The data suggests that the flowchart is illustrating the process of data transmission and processing between a local system and a cloud-based system using homomorphic encryption. The use of homomorphic encryption ensures that the data remains secure and private during transmission and processing. The flowchart demonstrates the concept of data processing in the cloud without being decrypted, which is a key advantage of cloud computing.
</details>
Blurry text in the figure denotes encrypted data.
Over the years, the research community has developed various encryption schemes that enable computation over ciphers. TFHE [2] is an open-source FHE library that allows fully homomorphic evaluation on arbitrary Boolean circuits. TFHE library
supports FHE operations on unlimited numbers of logic gates. Using FHE logic gates provided by TFHE, users can build an application-specific FHE circuit to perform arbitrary computations over encrypted data. While TFHE library has a good performance in gate-by-gate FHE evaluation speed and memory usage [3], a rigid logic circuit has reusability and scalability issues for general-purpose computing. Also, evaluating a logic circuit in software is slow. Because bitwise FHE operations on ciphers are about one billion times slower than the same operations on plain text, computation time ramps up as the circuit becomes complex.
Herein, we propose a solution that embraces a different approach that draws on a homomorphic instruction set emulator called CryptoEmu. CryptoEmu supports multiple FHE instructions (ADD, SUB, DIV, etc.). When CryptoEmu decodes an instruction, it invokes a pre-built function, referred as functional unit, to perform an FHE operation on input ciphertext. All functional units are built upon FHE gates from TFHE library, and they are accelerated using parallel computing techniques. During execution, the functional units fully utilize a multi-core processor to achieve an optimal speedup. A user would simply reprogram the FHE assembly code for various applications, while relying on the optimized functional units.
This report is organized as follows. Section 2 provides a primer on homomorphic encryption and summarizes related work. Section 3 introduces TFHE, an open-source library for fully homomorphic encryption. TFHE provides the building blocks for CryptoEmu. Section 4 describes CryptoEmu's general architecture. Section 5 and 6 provide detailed instruction set emulator implementations and gives benchmark results on Euler, a CPU/GPU supercomputer. Section 7 analyzes CryptoEmu's scalability and vulnerability, and compared CryptoEmu with a popular FHE software library, HELib [4]. Conclusions and future directions of investigation/development are provided in Section 8.
## II. BACKGROUND
Homomorphic Encryption. Homomorphic encryption (HE) is an encryption scheme that supports computation on encrypted data and generates an encrypted output. When the encrypted output is decrypted, its value is equal to the result when applying equivalent computation on unencrypted data. HE is formally defined as follows: let Enc () be an HE encryption function, Dec () be an HE decryption function, f () be a function, g () be a homomorphic equivalent of f () , and a and b be input data in plaintext. The following equation holds:
$$f ( a , b ) = D e c \left ( g ( E n c ( a ) , E n c ( b ) ) \right ) .$$
An HE scheme is a partially homomorphic encryption (PHE) scheme if g () supports only either addition or multiplication. An HE scheme is a somewhat homomorphic encryption (SWHE) scheme if a limited number of g () is allowed to be applied to encrypted data. An HE scheme is a fully homomorphic encryption (FHE) scheme if any g () can be applied for an unlimited number of times over encrypted data [5].
The first FHE scheme was proposed by Gentry [6]. In HE schemes, the plaintext is encrypted with Gaussian noise. The noise grows after every homomorphic evaluation until the noise becomes too large for the encryption scheme to work. This is the reason that SWHE only allows a limited number of homomorphic evaluations. Gentry introduced a novel technique called 'bootstrapping' such that a ciphertext can be homomorphically decrypted and homomorphically encrypted with the secret key to reduce Gaussian noise [6], [7]. Building off [6], [8] improved bootstrapping to speedup homomorphic evaluations. The TFHE library based on [3] and [9] is one of the FHE schemes with a fast bootstrapping procedure.
Related work. This project proposed a software-based, multiple-instruction ISA emulator that supports fully homomorphic, general-purpose computation. Several general-purpose HE computer architecture implementations exist in both software and hardware. HELib [10] is an FHE software library the implements the Brakerski-Gentry-Vaikuntanathan (BGV) homomorphic encryption scheme [11]. HELib supports HE arithmetic such as addition, subtraction, multiplication, and data movement operations. HELib can be treated as an assembly language for general-purpose HE computing. Cryptoleq [12] is a softwarebased one-instruction set computer (OISC) emulator for general-purpose HE computing. Cryptoleq uses Paillier partially homomorphic scheme [13] and supports Turing-complete SUBLEQ instruction. HEROIC [14] is another OISC architecture implemented on FPGA, based on Paillier partially homomorphic scheme. Cryptoblaze [15] is a multiple-instruction computer based on non-deterministic Paillier encryption that supports partially homomorphic computation. Cryptoblaze is implemented on the FPGA.
## III. TFHE LIBRARY
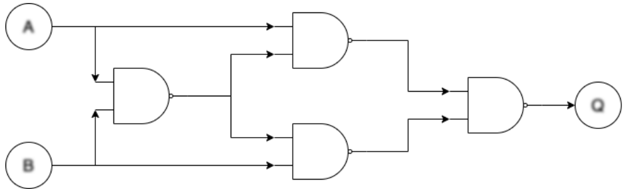
TFHE [2] is an FHE C/C++ software library used to implement fast gate-by-gate bootstrapping. The idea of TFHE is straightforward: if one can homomorphically evaluate a universal logic gate and homomorphically evaluate the next universal logic gate that uses the previous logic gate's output as its input, one can homomorphically evaluate arbitrary Boolean functions, essentially allowing arbitrary FHE computations on encrypted binary data. Figure 2 demonstrates a minimum FHE gate-level library: NAND gate. Bootstrapped NAND gates are used to construct an FHE XOR gate. Similarly, any FHE logic circuit can be constructed with a combination of bootstrapped NAND gates.
Fig. 2: Use of bootstrapped NAND gate to form arbitrary FHE logic circuit. Blurry text in the figure denotes encrypted data.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Circuit Diagram
### Overview
The image depicts a circuit diagram consisting of logic gates. The diagram includes two input signals, labeled A and B, and an output signal, labeled Q. The logic gates used are AND gates and OR gates.
### Components/Axes
- **Input Signals**: A and B
- **AND Gates**: Two AND gates are present in the circuit.
- **OR Gate**: One OR gate is present in the circuit.
- **Output Signal**: Q
### Detailed Analysis or ### Content Details
The circuit diagram shows the following connections:
- Input A is connected to the first AND gate and the second AND gate.
- Input B is connected to the first AND gate and the second AND gate.
- The output of the first AND gate is connected to the input of the OR gate.
- The output of the second AND gate is also connected to the input of the OR gate.
- The output of the OR gate is labeled as Q.
### Key Observations
- The circuit uses a combination of AND and OR gates to process the input signals A and B.
- The output signal Q is determined by the combination of the outputs from the AND gates and the OR gate.
- The circuit appears to be a basic logic circuit used for signal processing or decision-making.
### Interpretation
The circuit diagram represents a simple logic circuit that takes two input signals, A and B, and produces an output signal, Q. The output Q is determined by the logical operations performed by the AND and OR gates. The AND gates ensure that both input signals must be high for the output to be high, while the OR gate allows the output to be high if at least one of the input signals is high. This type of circuit is commonly used in digital electronics for various applications such as data processing, control systems, and signal processing.
</details>
TFHE API. TFHE library contains a comprehensive gate bootstrapping API for the FHE scheme [2], including secret-keyset and cloud-keyset generation; Encryption/decryption with secret-keyset; and FHE evaluation on a binary gate netlist with cloudkeyset. TFHE API's performance is evaluated on a single core of Intel Xeon CPU E5-2650 v3 @ 2.30GHz CPU, running CentOS Linux release 8.2.2004 with 128 GB memory. Table I shows the benchmark result of TFHE APIs that are critical to CryptoEmu's performance. TFHE gate bootstrapping parameter setup, Secret-keyset, and cloud-keyset generation are not included in the table.
TABLE I: TFHE API Benchmark
| API | Category | Bootstrapped? | Latency (ms) |
|-----------------|------------------------|-----------------|----------------|
| Encrypt | Encrypt decrypt | N/A | 0.0343745 |
| Decrypt | Encrypt decrypt | N/A | 0.000319556 |
| CONSTANT | Homomorphic operations | No | 0.00433995 |
| NOT | Homomorphic operations | No | 0.000679717 |
| COPY | Homomorphic operations | No | 0.000624117 |
| NAND | Homomorphic operations | Yes | 25.5738 |
| OR | Homomorphic operations | Yes | 25.618 |
| AND | Homomorphic operations | Yes | 25.6176 |
| XOR | Homomorphic operations | Yes | 25.6526 |
| XNOR | Homomorphic operations | Yes | 25.795 |
| NOR | Homomorphic operations | Yes | 25.6265 |
| ANDNY | Homomorphic operations | Yes | 25.6982 |
| ANDYN | Homomorphic operations | Yes | 25.684 |
| ORNY | Homomorphic operations | Yes | 25.7787 |
| ORYN | Homomorphic operations | Yes | 25.6957 |
| MUX | Homomorphic operations | Yes | 49.2645 |
| CreateBitCipher | Ciphertexts | N/A | 0.001725 |
| DeleteBitCipher | Ciphertexts | N/A | 0.002228 |
| ReadBitFromFile | Ciphertexts | N/A | 0.0175304 |
| WriteBitToFile | Ciphertexts | N/A | 0.00960664 |
In Table I, outside the 'Homomorphic operations' category, all other operations are relatively fast. In general, the latency is around 25ms, with exceptions of MUX that takes around 50ms, and CONSTANT, NOT, COPY that are relatively fast. The difference in speed is from gate bootstrapping. Unary gates like CONSTANT, NOT and COPY do not need to be bootstrapped. Binary gates need to be bootstrapped once. MUX needs to be bootstrapped twice. The bootstrapping procedure is manifestly the most computationally expensive operation in TFHE. This overhead is alleviated in CryptoEmu via parallel computing as detailed below.
## IV. CRYPTOEMU ARCHITECTURE OVERVIEW
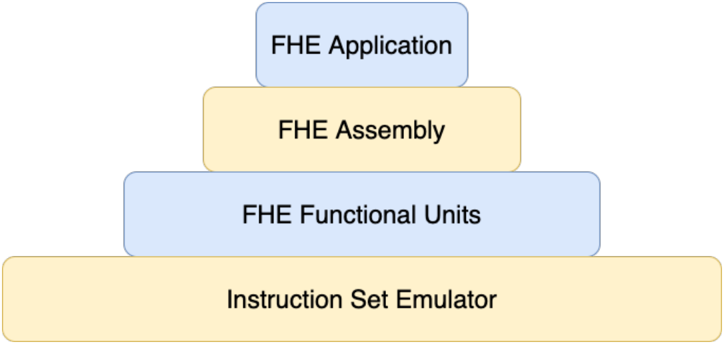
CryptoEmu is a C/C++ utility that emulates the behavior of Fully Homomorphic Encryption (FHE) instructions. The instruction set that CryptoEmu supports is a subset of ARMv8 A32 instructions for fully homomorphic computation over encrypted data. Figure 3 shows the abstract layer for an FHE application. For an FHE application that performs computation over encrypted data, the application will be compiled into FHE assembly that the instruction emulator supports. The instruction set emulator coordinates control units and functional units to decode and execute FHE assembly and returns final results. The design and implementation of CryptoEmu are anchored by two assumptions:
Assumption 1. The instruction set emulator runs on a high-performance multi-core machine.
Assumption 2. The cloud service provider is honest. However, the cloud is subject to cyber-attacks on the user's data.
In §VII-C we will discuss modification on CryptoEmu's implementation when Assumption 2 does not hold.
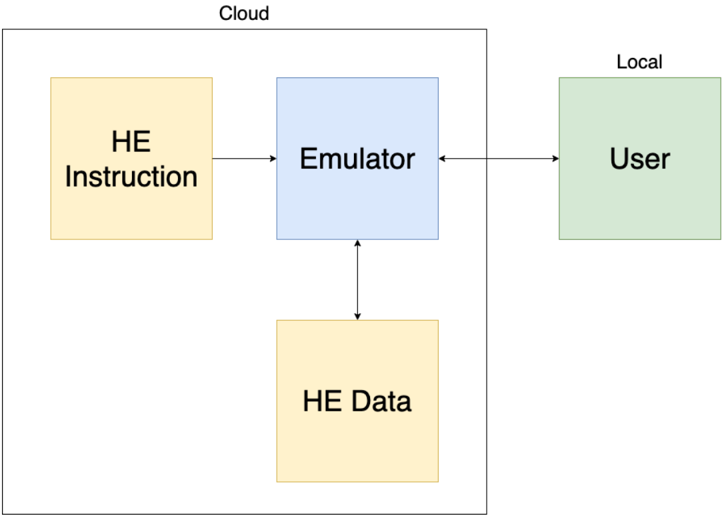
Cloud service model. Figure 4 shows the cloud service model. The instruction set emulator does what an actual hardware asset for encrypted execution would do: it reads from an unencrypted memory space an HE instruction ; i.e., it fetches
Fig. 3: Abstract Layers
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram Type: Hierarchical Structure
### Overview
The image displays a hierarchical structure diagram that represents the components of an Instruction Set Emulator (ISE). The diagram is organized in a top-down manner, with each level indicating a different component of the ISE.
### Components/Axes
- **Instruction Set Emulator**: The bottom level of the diagram, representing the entire system.
- **FHE Functional Units**: The second level, indicating the functional units within the ISE.
- **FHE Assembly**: The third level, representing the assembly process within the ISE.
- **FHE Application**: The top level, indicating the application of the ISE.
### Detailed Analysis or ### Content Details
The diagram uses different colors to differentiate between the levels and components. The Instruction Set Emulator is represented by a large, light yellow rectangle. The FHE Functional Units are represented by a medium blue rectangle, the FHE Assembly by a light blue rectangle, and the FHE Application by a dark blue rectangle.
### Key Observations
- The diagram is well-organized, with each level clearly separated from the others.
- The colors used for each level are distinct, making it easy to distinguish between them.
- The diagram does not contain any numerical values or data points.
### Interpretation
The diagram provides a clear representation of the hierarchical structure of an Instruction Set Emulator. It shows how the ISE is composed of different functional units, which are then assembled to form the complete system. The application of the ISE is at the top level, indicating that it is the final output of the system. The diagram is useful for understanding the architecture of the ISE and how its components interact with each other.
</details>
instruction that needs to be executed. The instruction set emulator also reads and writes HE data from an encrypted memory space, to process the user's data and return encrypted results to the encrypted memory space. The user, or any device that owns the user's secret key, will communicate with the cloud through an encrypted channel. The user provides all encrypted data to cloud. The user can send unencrypted HE instructions to the cloud through a secure channel. The user is also responsible for resolving branch directions for the cloud, based on the encrypted branch taken/non-taken result provided by the cloud.
Fig. 4: Cloud service model
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram Type: Flowchart
### Overview
The image is a flowchart that illustrates the process of how HE (High-Energy) instructions are processed and executed. It shows the flow from HE instruction to emulator, then to user, and finally to HE data.
### Components/Axes
- **HE Instruction**: A yellow box representing the high-energy instruction.
- **Emulator**: A blue box representing the emulator that processes the HE instruction.
- **User**: A green box representing the user who interacts with the emulator.
- **HE Data**: A yellow box representing the high-energy data generated by the emulator.
- **Cloud**: A label at the top of the diagram indicating the cloud environment.
- **Local**: A label at the top right of the diagram indicating the local environment.
### Detailed Analysis or ### Content Details
The flowchart shows a linear process where HE instructions are first sent to the emulator. The emulator processes the HE instruction and generates HE data, which is then sent to the user. The user interacts with the emulator, and the process is repeated.
### Key Observations
- The flowchart is simple and clear, making it easy to understand the process.
- The use of different colors for each component helps to distinguish between them.
- The labels "Cloud" and "Local" indicate the different environments in which the process takes place.
### Interpretation
The flowchart demonstrates the process of how HE instructions are processed and executed. It shows that the HE instructions are first sent to the emulator, which processes them and generates HE data. The HE data is then sent to the user, who interacts with the emulator. The process is repeated, indicating that the HE instructions are continuously processed and executed. The use of different colors for each component helps to distinguish between them, making it easy to understand the process. The labels "Cloud" and "Local" indicate the different environments in which the process takes place.
</details>
## A. Data Processing
In actuality, the HE instruction and HE data can be text files or arrays of data bits stored in buffers, if sufficient memory is available. CryptoEmu employs a load-store architecture. All computations occur on virtual registers (vReg), where a vReg is an array of 32 encrypted data bits. Depending on the memory available on the machine, the number of total vReg is configurable. However, it is the compiler's responsibility to recycle vRegs and properly generate read/write addresses. A snippet of possible machine instructions is as follows:
LOAD R1
```
READ_ADDR1
READ_ADDR2
```
LOAD R2
```
ADD R0 R1, R2
STORE R0 WRITE_ADDR
```
Above, to perform a homomorphic addition, CryptoEmu fetches the LOAD instruction from the instruction memory. Because the instruction itself is in cleartext, CryptoEmu decodes the instruction, loads a piece of encrypted data from HE data memory indexed by READ ADDR1, and copies the encrypted data into vReg R1. Then, CryptoEmu increments its program counter by 4 bytes, reads the next LOAD instruction, and loads encrypted data from HE data memory into vReg R2. After the two operands are ready, CryptoEmu invokes a 32-bit adder and passes R1, R2 to it. The adder returns encrypted data in R0. Finally, CryptoEmu invokes the STORE operation and writes R0 data into the HE data memory pointed to by WRITE ADDR. Under Assumption 2, the honest cloud could infer some user information from program execution because HE instructions are in cleartext. However, all user data stays encrypted and protected from malicious attackers. Vulnerabilities are discussed in §VII-C.
## B. Branch and Control Flow
CryptoEmu can perform a homomorphic comparison and generate N (negative), Z (zero), C (Unsigned overflow), and V (signed overflow) conditional flags. Based on conditional flags, the branch instruction changes the value of the program counter and therefore changes program flow. Because branches are homomorphically evaluated on the encrypted conditional flag, the branch direction is also encrypted. To solve this problem, CryptoEmu employs a client-server communication model from CryptoBlaze [15]. Through a secure communication channel, the cloud server will send an encrypted branch decision to a machine (client) that owns the user's private key. The client deciphers the encrypted branch decision and sends the branch decision encrypted with the server's public key to the server. The cloud server finally decrypts the branch decision, and CryptoEmu will move forward with a branch direction. Under assumption 2, the honest cloud will not use branch decision query and binary search to crack user's encrypted data, nor will the honest cloud infer user information from the user. In §VII-C, the scenario that assumption 2 does not hold will be discussed.
## V. DATA PROCESSING UNITS
Data processing units are subroutines that perform manipulation on encrypted data, including homomorphic binary arithmetic, homomorphic bitwise operation, and data movement. Under Assumption 1, data processing units are implemented with OpenMP [16] and are designed for parallel computing. If the data processing units exhaust all cores available, the rest of the operations will be serialized. We benchmarked the performance of data processing units with 16-bit and 32-bit vReg size. Benchmarks are based an computing node on Euler. The computing node has 2 NUMA nodes. Each NUMA nodes has two sockets, and each socket has a 12-core Intel Xeon CPU E5-2650 v3 @ 2.30GHz CPU. The 48-core computing node runs CentOS Linux release 8.2.2004 with 128 GB memory.
## A. Load/Store Unit
CryptoEmu employs a load/store architecture. A LOAD instruction reads data from data memory; a STORE instruction writes data to data memory. The TFHE library [2] provides the API for load and store operations on FHE data. If data memory is presented as a file, CryptoEmu invokes the specific LD/ST subroutine, moves the file pointer to the right LD/ST address, and calls the appropriate file IO API, i.e.,
```
import_gate_bootstrapping_ciphertext_fromFile()
or
export_gate_bootstrapping_ciphertext_toFile()
```
Preferably, if the machine has available memory, the entire data file is loaded into a buffer as this approach significantly improves LD/ST instruction's performance. Table II shows LD/ST latency for 16-bit and 32-bit. LD/ST on a buffer is significantly faster than LD/ST on a file. The performance speedup is even more when the data file size is large because LD/ST on file needs to use fseek() function to access data at the address specified by HE instructions.
TABLE II: LD/ST latencies.
| | 16-bit (ms) | 32-bit (ms) |
|----------------|---------------|---------------|
| Load (file) | 0.027029 | 0.0554521 |
| Store (file) | 0.0127804 | 0.0276899 |
| Load (buffer) | 0.0043463 | 0.00778488 |
| Store (buffer) | 0.0043381 | 0.0077692 |
```
#pragma omp parallel sections num_threads(2)
{
#pragma omp section
{
bootsAND(&g_o[0], &a_i[0], &b_i[0], bk);
}
#pragma omp section
{
bootsXOR(&p_o[0], &a_i[0], &b_i[0], bk);
}
}
```
Fig. 5: Parallel optimization for bitwise (g,p) calculation, get gp ()
## B. Adder
CryptoEmu supports a configurable adder unit of variable width. As for the ISA that CryptoEmu supports, adders are either 16-bit or 32-bit. Operating under an assumption that CryptoEmu runs on a host that supports multi-threading, the adder unit is implemented as a parallel prefix adder [17]. The parallel prefix adder has a three-stage structure: pre-calculation of generate and propagate bit; carry propagation; and sum computation. Each stage can be divided into sub-stages and can leverage a multi-core processor. Herein, we use the OpenMP [16] library to leverage parallel computing.
Stage 1: Propagate and generate calculation. Let a and b be the operands to adder, and let a [ i ] and b [ i ] be the i th bit of a and b . In carry-lookahead logic, a [ i ] and b [ i ] generates a carry if a [ i ] AND b [ i ] is 1 and propagates a carry if a [ i ] XOR b [ i ] is 1. This calculation requires an FHE AND gate and an FHE XOR gate, see §III and Fig. 2 for gate bootstrapping. An OpenMP parallel region is created to handle two parallel sections. As shown in Fig. 5, CryptoEmu spawns two threads to execute two OpenMP sections in parallel.
For a 16-bit adder, get gp() calculations are applied on every bit. This process is parallelizable: as shown in Fig. 6, CryptoEmu spawns 16 parallel sections [16], one per bit. Inside each parallel section, the code starts another parallel region that uses two threads. Because of nested parallelism, 32 threads in total are required to calculate every generation and propagate a bit concurrently. If there is an insufficient number of cores, parallel sections will be serialized, which will only affect the efficiency of the emulator.
Stage 2: Carry propagation. Let G i be the carry signal at i th bit, P i be the accumulated propagation bit at i th bit, g i and p i be outputs from propagate and generate calculation. We define operator such that
$$( g _ { x } , p _ { x } ) \odot ( g _ { y } , p _ { y } ) = ( g _ { x } + p _ { x } \cdot g _ { y } , p _ { x } \cdot p _ { y } ) \, .$$
Carry signal G i and accumulated propagation P i can be recursively defined as
$$( G _ { i } , P _ { i } ) = ( g _ { i } , p _ { i } ) \odot ( G _ { i - 1 } , P _ { i - 1 } ) , w h e r e ( G _ { 0 } , P _ { 0 } ) = ( g _ { 0 } , p _ { 0 } ) \, .$$
The above recursive formula is equivalent to
$$( G _ { i \colon j } , P _ { i \colon j } ) = ( G _ { i \colon n } , G _ { i \colon n } ) \odot ( G _ { m \colon j } , P _ { m \colon j } ) , w h e r e i \geq j a n d m \geq n \, .$$
Therefore, carry propagation can be reduced to a parallel scan problem. In CryptoEmu, we defined a routine, get carry() to perform operation . As shown in Fig. 7 , the requires two FHE AND gate and an FHE OR gate. CryptoEmu spawns two threads to perform the operation in parallel.
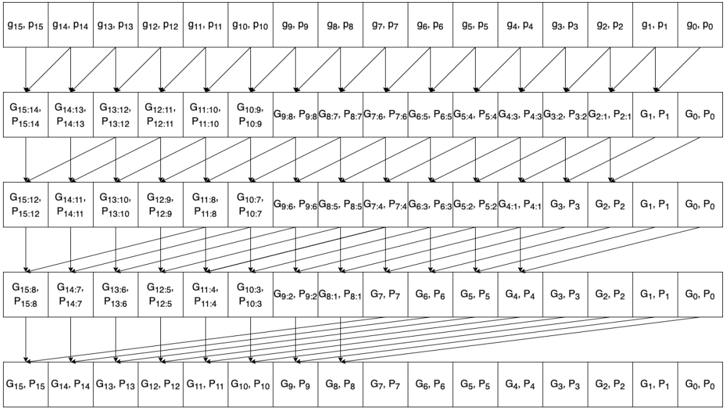
For a 16-bit adder, we need 4 levels to compute the carry out from the most significant bit. As shown in fig 8, every two arrows that share an arrowhead represents one operation. The operations at the same level can be executed in parallel. In the case of a 16-bit adder, the maximum number of concurrent is 15 at level 1. Because of nested parallelism within the operation, the maximum number of threads required is 30. With a sufficient number of cores, parallel scan reduced carry propagation time from 16 times operation latency, to 4 times operation latency.
Stage 3: Sum calculation. The last stage for parallel prefix adder is sum calculation. Let s i be the sum bit at i th bit, p i be the propagation bit at i th bit, G i be the carry signal at i th bit. Then
$$s _ { i } = p _ { i } \, X O R \, G _ { i } \, .$$
One FHE XOR gate is needed to calculate 1-bit sum. For 16-bit adder, 16 FHE XOR gates are needed. All FHE XOR evaluation are independent, therefore can be executed in parallel. In total 16 threads are required for the best parallel optimization on sum calculation stage.
```
<loc_66><loc_61><loc_379><loc_273><_C++_>#pragma omp parallel sections num_threads(N)
{
#pragma omp section
{
get_gp(&g[0], &p[0], &a[0], &b[0], bk);
}
#pragma omp section
{
get_gp(&g[1], &p[1], &a[1], &b[1], bk);
}
...
#pragma omp section
{
get_gp(&g[14], &p[14], &a[14], &b[14], bk);
}
#pragma omp section
{
get_gp(&g[15], &p[15], &a[15], &b[15], bk);
}
}
```
Fig. 7: Parallel optimization for bitwise carry calculation, get carry ()
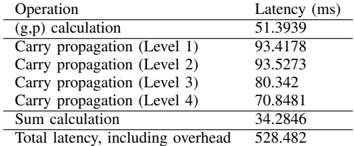
a) Benchmark: the 16-bit adder.: Table III shows benchmarking results for a 16-bit adder unit executed on the target machine describe earlier in the document. If parallelized, the 1-bit get gp() shown in Fig. 5 has one FHE gate latency around 25ms as shown in Table I. Ideally, if sufficient cores are available and there is no overhead from parallel optimization, (g,p) calculation should run 16 get gp() concurrently, and total latency should be 25ms. In reality, 16-bit (g,p) calculation uses 32 threads and takes 51.39ms to complete due to overhead in parallel computing.
For carry propagation calculation, the 1-bit get carry() shown in Fig. 7 has two FHE gate latency of around 50ms when parallelized. In an ideal scenario, each level for carry propagation should run get carry() in parallel, and total latency should be around 50ms. In reality, the 16-bit carry propagation calculation uses 30 threads on level 1 and takes 93.42ms. A collection of 28 threads are used on carry propagation level 2; the operation takes 93.58ms. A collection of 24 threads are used on carry propagation level 3; the operation takes 80.34ms. Finally, 16 threads are used on carry propagation level 4; the operation takes 70.85ms.
Fig. 8: Parallel scan for carry signals
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Heatmap: Network Traffic Analysis
### Overview
The heatmap displays the network traffic flow between different nodes in a network. The rows represent different nodes, and the columns represent different time intervals. The color intensity indicates the volume of traffic between the nodes.
### Components/Axes
- **Nodes**: Represented by rows, labeled from G15 to G1.
- **Time Intervals**: Represented by columns, labeled from P15 to P0.
- **Traffic Volume**: Indicated by color intensity, ranging from light blue (low traffic) to dark red (high traffic).
### Detailed Analysis or ### Content Details
- **G15 to G1**: The highest traffic volume is observed between G15 and G1, with the traffic volume peaking at P10.
- **G14 to G1**: The traffic volume between G14 and G1 is consistently high, with the peak at P10.
- **G13 to G1**: The traffic volume between G13 and G1 is moderate, with the peak at P10.
- **G12 to G1**: The traffic volume between G12 and G1 is low, with the peak at P10.
- **G11 to G1**: The traffic volume between G11 and G1 is consistently low, with the peak at P10.
- **G10 to G1**: The traffic volume between G10 and G1 is consistently low, with the peak at P10.
- **G9 to G1**: The traffic volume between G9 and G1 is consistently low, with the peak at P10.
- **G8 to G1**: The traffic volume between G8 and G1 is consistently low, with the peak at P10.
- **G7 to G1**: The traffic volume between G7 and G1 is consistently low, with the peak at P10.
- **G6 to G1**: The traffic volume between G6 and G1 is consistently low, with the peak at P10.
- **G5 to G1**: The traffic volume between G5 and G1 is consistently low, with the peak at P10.
- **G4 to G1**: The traffic volume between G4 and G1 is consistently low, with the peak at P10.
- **G3 to G1**: The traffic volume between G3 and G1 is consistently low, with the peak at P10.
- **G2 to G1**: The traffic volume between G2 and G1 is consistently low, with the peak at P10.
- **G1 to G1**: The traffic volume between G1 and G1 is consistently low, with the peak at P10.
### Key Observations
- The highest traffic volume is between G15 and G1.
- The traffic volume between G14 and G1 is consistently high.
- The traffic volume between G13 and G1 is moderate.
- The traffic volume between G12 and G1 is low.
- The traffic volume between G11 and G1 is consistently low.
- The traffic volume between G10 and G1 is consistently low.
- The traffic volume between G9 and G1 is consistently low.
- The traffic volume between G8 and G1 is consistently low.
- The traffic volume between G7 and G1 is consistently low.
- The traffic volume between G6 and G1 is consistently low.
- The traffic volume between G5 and G1 is consistently low.
- The traffic volume between G4 and G1 is consistently low.
- The traffic volume between G3 and G1 is consistently low.
- The traffic volume between G2 and G1 is consistently low.
- The traffic volume between G1 and G1 is consistently low.
### Interpretation
The heatmap suggests that the network is heavily trafficked between G15 and G1, with the highest traffic volume occurring at P10. The traffic volume between G14 and G1 is consistently high, indicating a significant flow of data between these two nodes. The traffic volume between G13 and G1 is moderate, suggesting a moderate flow of data between these two nodes. The traffic volume between G12 and G1 is low, indicating a low flow of data between these two nodes. The traffic volume between G11 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G10 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G9 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G8 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G7 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G6 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G5 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G4 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G3 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G2 and G1 is consistently low, indicating a low flow of data between these two nodes. The traffic volume between G1 and G1 is consistently low, indicating a low flow of data between these two nodes.
</details>
TABLE III: 16-bit adder latency
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Table: Latency Analysis
### Overview
The table provides a breakdown of latency measurements for various operations in a computational system. The operations include (g,p) calculation, carry propagation at different levels, and sum calculation. The total latency, including overhead, is also included.
### Components/Axes
- **Operation**: The type of operation being measured.
- **Latency (ms)**: The time taken to complete the operation in milliseconds.
### Detailed Analysis or ### Content Details
| Operation | Latency (ms) |
|----------------------------|---------------|
| (g,p) calculation | 51.3939 |
| Carry propagation (Level 1)| 93.4178 |
| Carry propagation (Level 2)| 93.5273 |
| Carry propagation (Level 3)| 80.342 |
| Carry propagation (Level 4)| 70.8481 |
| Sum calculation | 34.2846 |
| **Total latency, including overhead** | **528.482** |
### Key Observations
- The (g,p) calculation has the lowest latency at 51.3939 ms.
- Carry propagation at Level 1 has the highest latency at 93.4178 ms.
- The latency decreases as the level of carry propagation increases.
- The sum calculation has the lowest latency at 34.2846 ms.
- The total latency, including overhead, is significantly higher than the sum calculation latency.
### Interpretation
The data suggests that the (g,p) calculation is the most efficient operation in terms of latency. The carry propagation operations have varying latencies, with the highest latency at Level 1. The sum calculation is the most efficient operation, with the lowest latency. The total latency, including overhead, is significantly higher than the sum calculation latency, indicating that overhead costs are a significant factor in the overall latency of the system.
</details>
| Operation | Latency (ms) |
|-----------------------------------|----------------|
| (g,p) calculation | 51.3939 |
| Carry propagation (Level 1) | 93.4178 |
| Carry propagation (Level 2) | 93.5273 |
| Carry propagation (Level 3) | 80.342 |
| Carry propagation (Level 4) | 70.8481 |
| Sum calculation | 34.2846 |
| Total latency, including overhead | 528.482 |
For sum calculation, 1-bit sum calculation uses one FHE XOR gate, with latency around 25ms. Ideally, if CryptoEmu runs all 16 XOR gates in parallel without parallel computing overhead, the latency for 16-bit sum calculation should be around 25ms. In reality, due to OpenMP overhead, the 16-bit sum calculation uses 16 threads and takes 34.28ms to complete.
In total, a 16-bit adder's latency is 486.66ms. This result includes latency for all stages, plus overheads like variable declaration, memory allocation, and temporary variable manipulation.
b) Benchmark: the 32-bit adder.: Table IV shows benchmarking results for a 32-bit adder unit executed on the target machine describe earlier in the document. Note that get gp() and get carry() have the same performance as the 16-bit adder. If sufficient cores are available, in the absence of OpenMP overhead, the (g,p) calculation should run 32 get gp() concurrently for 32-bit adder at a total latency of 25ms. In reality, the 32-bit (g,p) calculation uses 32 threads and takes 94.92ms to complete.
TABLE IV: 32-bit adder latency
| Operation | Latency (ms) |
|-----------------------------------|----------------|
| (g,p) calculation | 94.9246 |
| Carry propagation (Level 1) | 147.451 |
| Carry propagation (Level 2) | 133.389 |
| Carry propagation (Level 3) | 127.331 |
| Carry propagation (Level 4) | 112.268 |
| Carry propagation (Level 5) | 91.5781 |
| Sum calculation | 49.0098 |
| Total latency, including overhead | 941.12 |
For carry propagation calculation, if sufficient cores are available, each level for carry propagation should run get carry() in parallel. Without parallel computing overhead, total latency should be around 50ms. Level 0 of 32-bit carry propagation calculation uses 62 threads. Because the platform on which CryptoEmu is tested has only 48 cores, level 0 carry propagation calculation is serialized and takes 147.45ms to complete. Level 1 carry propagation calculation uses 60 threads, and similar to level 0, its calculation is serialized. Level 1 carry propagation calculation takes 133.39ms. Level 3 carry propagation calculation that uses 56 threads is serialized and takes 127.33ms to complete. Level 4 carry propagation calculation uses 48 threads, and it is possible to run every get carry() in parallel on our 48-core workstation. Level 4 carry propagation calculation takes 112.27ms. Level 5 carry propagation calculation uses 32 threads. It is able to execute all get carry() concurrently; level 5 takes 91.58ms to complete.
For sum calculation, the 32-bit adder spawns 32 threads in parallel to perform FHE XOR operation if sufficient cores are available. The latency for the 32-bit sum calculation should be around 25ms. In reality, the 32-bit sum calculation uses 32 threads and takes 49ms to complete.
In total, 32-bit adder's latency is 941.12ms. This result includes latency for all stages, plus overheads like variable declaration, memory allocation, and temporary variable manipulation.
## C. Subtractor
The subtractor unit supports variable ALU size. CryptoEmu supports subtractors with 16-bit operands or 32-bit operands. Let a be the minuend, b be the subtrahend, and diff be the difference. Formula for 2's complement subtraction is:
$$a + N O T ( b ) + 1 = d i f f \, .$$
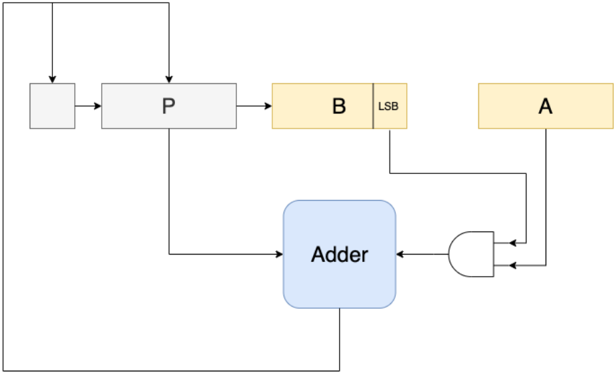
As shown in Fig. 9, CryptoEmu reuses adder units in §V-B to perform homomorphic subtractions. On the critical path, extra homomorphic NOT gates are used to create subtrahend's complement. For a subtractor with N-bit operands, N homomorphic NOT operations need to be applied on the subtrahend. While all FHE NOT gates can be evaluated in parallel, in §III we showed that FHE NOT gates do not need bootstrapping, and is relatively fast (around 0.0007ms latency per gate) comparing to bootstrapped FHE gates. Therefore, parallel execution is not necessary. Instead, the homomorphic NOT operation is implemented in an iterative for-loop, as shown below:
$$\begin{array} { r l } & { f o r ( i n t \, i = 0 ; \, i < N ; \, + + i ) } \\ & { b o o t s N O T ( \& b _ { - } n e g [ i ] , \, & b k [ i ] , \, b k ) ; } \end{array}$$
In addition to homomorphic NOT operation on subtrahend, the carry out bit from bit 0 needs to be evaluated with an OR gate because carry in is 1. Therefore, the adder in §V-B is extended to take a carry in bit. When sufficient cores are available on the machine, a subtractor units adds negation and carry bit calculation to the adder unit's critical path.
Fig. 9: Subtractor architecture. Blurry text in the figure denotes encrypted data.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Diagram Type: Flowchart
### Overview
The image depicts a flowchart illustrating the process of addition with carry. It shows the input of two numbers, 'a' and 'b', which are added together by an "Adder with carry" block. The result of the addition is then carried out, and the final result is displayed.
### Components/Axes
- **Input**: Two circles labeled 'a' and 'b' represent the input numbers.
- **Adder with carry**: A rectangular block labeled "Adder with carry" performs the addition.
- **Carry in**: An arrow pointing from the input circles to the adder block indicates the input of the numbers.
- **Carry out**: An arrow pointing from the adder block to the right side of the image indicates the output of the carry.
- **Result**: An arrow pointing from the adder block to the bottom of the image indicates the final result of the addition.
### Detailed Analysis or ### Content Details
- The flowchart shows a simple addition process with carry.
- The input numbers 'a' and 'b' are added together by the "Adder with carry" block.
- The carry from the addition is then carried out, which is indicated by the arrow pointing to the right.
- The final result of the addition is displayed at the bottom of the image.
### Key Observations
- The flowchart is straightforward and easy to understand.
- It clearly shows the process of addition with carry.
- The use of arrows indicates the direction of the flow of data.
### Interpretation
The flowchart demonstrates the process of addition with carry, which is a fundamental concept in arithmetic. The addition of two numbers 'a' and 'b' is performed by the "Adder with carry" block, and the carry from the addition is then carried out. The final result of the addition is displayed at the bottom of the image. This flowchart is useful for understanding the process of addition with carry and can be used as a reference for implementing this process in programming or other applications.
</details>
a) Benchmark.: Tables V and VI report benchmark results for the 16-bit and 32-bit subtractors on the target machine. Negation on the subtrahend takes a trivial amount of time to complete. The homomorphic addition is the most time-consuming operation in the subtractor unit. The homomorphic addition is a little slower than the homomorphic additions in §V-B because the adder needs to use extra bootstrapped FHE gates to process carry in and calculate carry out from sum bit 0.
TABLE V: 16-bit subtractor latency
<details>
<summary>Image 8 Details</summary>

### Visual Description
## Table: Latency Measurements
### Overview
The table provides latency measurements for different operations, including negation and add with carry, as well as the total latency including overhead.
### Components/Axes
- **Operation**: The type of operation being measured (negation or add with carry).
- **Latency (ms)**: The time taken to complete the operation in milliseconds.
### Detailed Analysis or ### Content Details
- **Negation**: The latency for the negation operation is 0.0341106 ms.
- **Add with carry**: The latency for the add with carry operation is 680.59 ms.
- **Total latency, including overhead**: The total latency, including overhead, is 715.015 ms.
### Key Observations
- The latency for the add with carry operation is significantly higher than the negation operation.
- The total latency, including overhead, is the highest among the three operations.
### Interpretation
The data suggests that the add with carry operation is the most time-consuming operation, taking approximately 680.59 ms to complete. The negation operation takes significantly less time, with a latency of only 0.0341106 ms. The total latency, including overhead, is the highest among the three operations, indicating that there may be additional factors contributing to the increased latency.
</details>
| Operation | Latency (ms) |
|-----------------------------------|----------------|
| Negation | 0.0341106 |
| Add with carry | 680.59 |
| Total latency, including overhead | 715.015 |
## D. Shifter
CryptoEmu supports three types of shifters: logic left shift (LLS), logic right shift (LRS), and arithmetic right shift (ARS). Each shifter type has two modes: immediate and register mode. In immediate mode, the shift amount is in cleartext. For example, the following instruction shifts encrypted data in R0 to left by 1 bit and assigns the shifted value to R0.
<details>
<summary>Image 9 Details</summary>

### Visual Description
Icon/Small Image (238x17)
</details>
This instruction is usually issued by the cloud to process user data. Shift immediate implementation is trivial. The shifter calls bootCOPY() API to move all data to the input direction by the specified amount. The LSB or MSB will be assigned to an encrypted constant using the bootCONSTANT() API call. Because neither bootCOPY() nor bootCONSTANT() need to be bootstrapped, they are fast operations, see Table III. Therefore, an iterative loop is used for shifting. Parallel optimization is unnecessary.
In register mode, the shift amount is an encrypted data stored in the input register. For example, the following instruction shifts encrypted data in R0 to left by the value stored in R1 and assign shifted value to R0.
```
LLS R0 R0 R1
```
Because the shifting amount stored in R1 is encrypted, the shifter can't simply move all encrypted bits left/right by a certain amount. The shifter is implemented as a barrel shifter, with parallel computing enabled.
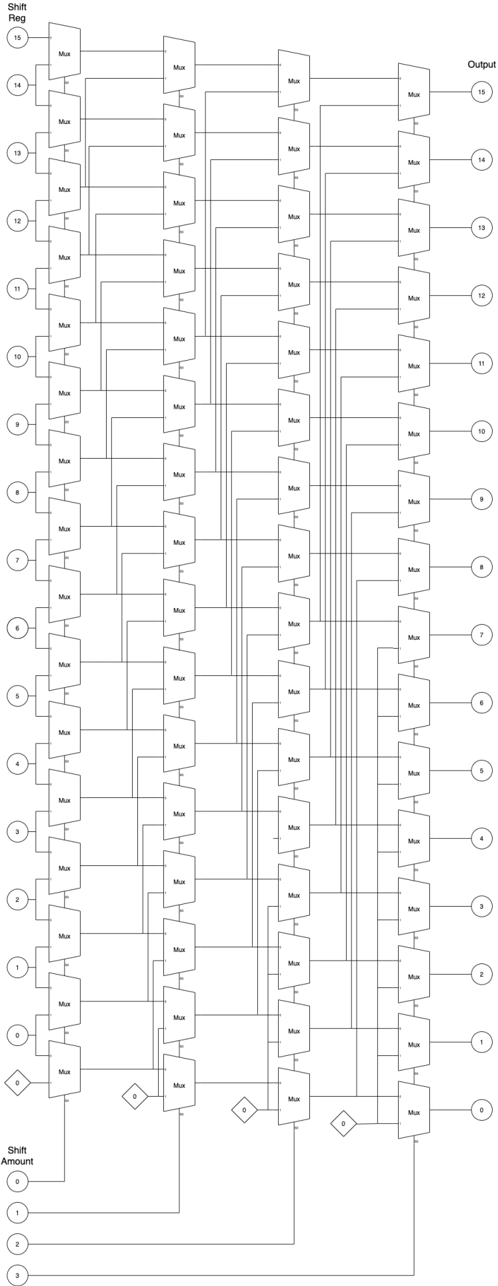
a) Logic left shift.: Figure 10 shows the architecture for the 16-bit LLS. In the figure, numbers in the bubbles denote encrypted data in the shift register and the shift amount register. Numbers in the diamond denote an encrypted constant value generated by the bootsCONSTANT() API. The 16-bit LLS has four stages. In each stage, based on the encrypted shift amount, the FHE MUX homomorphically selects an encrypted bit from the shift register. In the end, the LLS outputs encrypted shifted data. FHE MUX is an elementary logic unit provided by TFHE library [2]. FHE MUX needs to be bootstrapped twice, and its latency is around 50ms. Therefore, it is reasonable to spawn multiple threads to execute all MUX select in parallel in each stage. For the 16-bit LLS, each stage needs 16 threads to perform a homomorphic MUX select, as shown in the following code:
```
its latency is around 50ms. Therefore, it is reasonable to spawn multiple threads to execute all MUX select stage. For the 16-bit LLS, each stage needs 16 threads to perform a homomorphic MUX select, as show code:
{
#pragma omp parallel sections num_threads(16)
{
#pragma omp section
{
bootsMUX(&out[0], &amt[0], &zero[0], &in[0], bk);
}
#pragma omp section
{
bootsMUX(&out[1], &amt[0], &in[0], &in[1], bk);
}
...
#pragma omp section
{
bootsMUX(&out[14], &amt[0], &in[13], &in[14], bk);
}
#pragma omp section
{
bootsMUX(&out[15], &amt[0], &in[14], &in[15], bk);
}
}
```
TABLE VI: 32-bit subtractor latency
<details>
<summary>Image 10 Details</summary>

### Visual Description
## Table: Latency Comparison
### Overview
The table provides a comparison of latency for two operations: Negation and Add with carry. It also includes a total latency figure that includes overhead.
### Components/Axes
- **Operation**: The two operations being compared are Negation and Add with carry.
- **Latency (ms)**: The time taken for each operation in milliseconds.
### Detailed Analysis or ### Content Details
- **Negation**: The latency for the Negation operation is 0.0347466 ms.
- **Add with carry**: The latency for the Add with carry operation is 1058.65 ms.
- **Total latency, including overhead**: The total latency, which includes overhead, is 1115.25 ms.
### Key Observations
- The latency for the Add with carry operation is significantly higher than that for the Negation operation.
- The total latency, including overhead, is the highest among the three operations.
### Interpretation
The data suggests that the Add with carry operation is much slower than the Negation operation. This could be due to the complexity of the operation, which involves carrying over values from one digit to the next. The total latency, including overhead, indicates that the operation is not only slow but also resource-intensive. This information is crucial for optimizing the performance of the system in which these operations are used.
</details>
| Operation | Latency (ms) |
|-----------------------------------|----------------|
| Negation | 0.0347466 |
| Add with carry | 1058.65 |
| Total latency, including overhead | 1115.25 |
Fig. 10: LLS architecture
<details>
<summary>Image 11 Details</summary>
### Visual Description
## Circuit Diagram
### Overview
The image depicts a complex circuit diagram consisting of multiple components connected in a series of pathways. The diagram is labeled with various elements such as input, output, and intermediate nodes. The circuit appears to be a digital or electronic circuit, possibly related to signal processing or data transmission.
### Components/Axes
- **Input**: Located at the top left of the diagram, labeled "Shift Reg".
- **Output**: Located at the top right of the diagram, labeled "Output".
- **Intermediate Nodes**: Multiple nodes labeled "Mux" (Multiplexer) are connected in series, with each node receiving input from the previous one and sending output to the next.
- **Shift Amount**: A vertical axis on the left side of the diagram, labeled "Shift Amount", indicating the number of bits to shift the data.
### Detailed Analysis or ### Content Details
- **Multiplexer (Mux)**: Each "Mux" node is connected to the next, with the input signal passing through each Mux before reaching the output. The Muxes are labeled with numbers from 0 to 15, indicating the possible input signals.
- **Shift Amount**: The vertical axis on the left side of the diagram shows the shift amount, which is a binary number. The shift amount is used to determine the position of the data bits in the output signal.
- **Circuit Pathways**: The pathways between the Muxes and the output are clearly defined, with arrows indicating the direction of data flow.
### Key Observations
- **Data Shifting**: The circuit appears to be designed for data shifting, as indicated by the "Shift Reg" and "Shift Amount" labels.
- **Multiplexing**: The use of multiple Muxes suggests that the circuit is capable of selecting and routing multiple input signals to a single output.
- **Binary Shift**: The vertical axis on the left side of the diagram indicates that the data is being shifted in binary format.
### Interpretation
The circuit diagram represents a digital shift register circuit, which is used to shift data bits in a binary format. The circuit is designed to take an input signal, shift it by a specified amount, and output the shifted data. The use of multiple Muxes allows for the selection and routing of multiple input signals to the output, making the circuit versatile and capable of handling complex data processing tasks. The vertical axis on the left side of the diagram indicates that the data is being shifted in binary format, which is a common format for digital data transmission and processing.
</details>
In a parallel implementation with zero overhead, each stage should have one FHE MUX latency of around 50ms. Therefore, in an ideal scenario, four stages would have a latency of around 200ms.
b) Benchmark: Logic left shift.: Table VII shows the benchmark results for the 16-bit LLS on the target platform. Each stage spawns 16 threads to run all FHE MUX in parallel with latency from 50-90ms, a latency that is in between 1 FHE MUX latency to 2 FHE MUX latency, due to parallel computing overhead. In total, it takes around 290ms to carry out a homomorphic LLS operation on 16-bit encrypted data.
TABLE VII: 16-bit LLS latency
| Operation | Latency (ms) |
|-----------------------------------|----------------|
| Mux select (Stage 1) | 87.3295 |
| Mux select (Stage 2) | 82.2656 |
| Mux select (Stage 3) | 76.6871 |
| Mux select(Stage 4) | 55.5396 |
| Total latency, including overhead | 287.92 |
Table VIII shows the benchmark result for the 32-bit LLS. Each stage spawns 32 threads and takes around 90-100ms to complete. In total, it takes around 450-500ms for a homomorphic LLS operation on 32-bit encrypted data.
TABLE VIII: 32-bit LLS latency
| Operation | Latency (ms) |
|-----------------------------------|----------------|
| Mux select (Stage 1) | 101.92 |
| Mux select (Stage 2) | 89.7695 |
| Mux select (Stage 3) | 98.8634 |
| Mux select(Stage 4) | 91.3939 |
| Mux select (Stage 5) | 91.8491 |
| Total latency, including overhead | 474.739 |
c) Logic right shift/Arithmetic right shift.: LRS has an architecture that is similar to the architecture of LLS. Figure 11 shows the architecture for the 16-bit LRS. Compared to Fig. 10, the only difference between LLS and LRS is the bit order of the input register and output register. To reuse the LRS architecture for ARS, one should simply pass MSB of the shift register as the shift-in value, shown as the numbers in the diamond in Fig. 11. The LRS and ARS shifter implementation is similar to that of LLS. For 16-bit LRS/ARS, CryptoEmu spawns 16 parallel threads to perform a homomorphic MUX select at each stage.
Table IX shows the benchmark result for the 16-bit LRS and ARS. LRS and ARS have similar performance. At each stage, LRS/ARS utilizes 16 threads, and each stage takes 50-90ms to complete. Single stage latency is between 1 FHE MUX latency to 2 FHE MUX latency, due to parallel computing overhead. In total, 16-bit LRS/ARS latency is around 290-300ms.
TABLE IX: 16-bit LRS, ARS latency
| Operation | LRS Latency (ms) | ARS Latency (ms) |
|-----------------------------------|--------------------|--------------------|
| Mux select (Stage 1) | 88.1408 | 87.7689 |
| Mux select (Stage 2) | 85.5154 | 79.6416 |
| Mux select (Stage 3) | 75.0295 | 75.2938 |
| Mux select(Stage 4) | 55.9639 | 54.9246 |
| Total latency, including overhead | 290.517 | 296.124 |
Table X shows the benchmark result for the 32-bit LRS and ARS. The 32-bit LRS/ARS has five stages. Each stage creates 32 parallel threads to evaluate FHE MUX and takes 90-100ms to complete. Single stage latency is around 2 FHE MUX latency. In total, the 32-bit LRS/ARS takes around 470-500ms to complete a homomorphic LRS/ARS operation on 32-bit encrypted data.
TABLE X: 32-bit LRS, ARS latency
| Operation | LRS Latency (ms) | ARS Latency (ms) |
|-----------------------------------|--------------------|--------------------|
| Mux select (Level 1) | 104.33 | 106.132 |
| Mux select (Level 2) | 104.75 | 95.3209 |
| Mux select (Level 3) | 90.2377 | 90.1364 |
| Mux select(Level 4) | 89.7183 | 90.5383 |
| Mux select(Level 5) | 90.6315 | 94.4654 |
| Total latency, including overhead | 472.896 | 491.787 |
Fig. 11: LRS architecture
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Circuit Diagram
### Overview
The image depicts a complex circuit diagram consisting of multiple components and connections. The diagram is organized into several sections, including the input, processing units, and output.
### Components/Axes
- **Input**: The input section is labeled "Shift Amount" and has a series of numbers ranging from 0 to 15.
- **Processing Units**: There are multiple processing units labeled "MUX" (Multiplexer), which are connected in a series.
- **Output**: The output section is labeled "Output" and has a series of numbers ranging from 0 to 15.
### Detailed Analysis or ### Content Details
The diagram shows a series of MUX units connected in a parallel configuration. Each MUX unit takes an input from the "Shift Amount" section and outputs a signal to the "Output" section. The input signals are processed through the MUX units, and the output signals are combined and sent to the "Output" section.
### Key Observations
- The diagram shows a total of 15 MUX units, each with a different input signal.
- The output signals are combined through a series of MUX units, and the final output signal is sent to the "Output" section.
- The diagram does not show any specific values or numerical data, but it does show a clear flow of signals through the circuit.
### Interpretation
The diagram demonstrates a complex circuit that takes an input signal, processes it through multiple MUX units, and produces an output signal. The circuit is designed to handle a large number of input signals and produce a single output signal. The diagram is a useful tool for understanding the flow of signals through a complex circuit and for designing and troubleshooting circuits.
</details>
## E. Multiplier
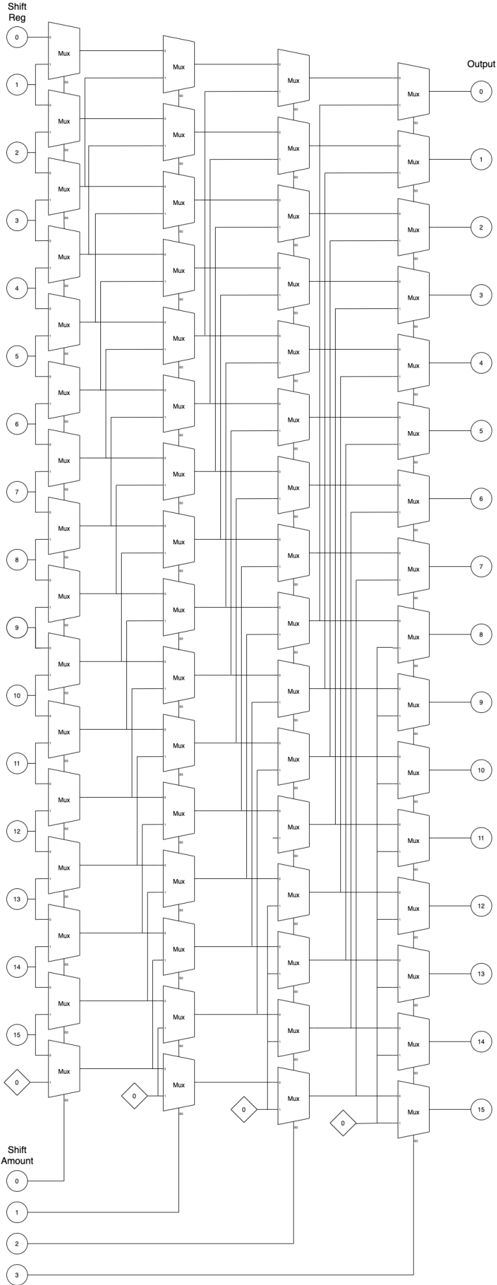
Design consideration. Binary multiplication can be treated as a summation of partial products [18], see Fig. 12. Therefore, adder units mentioned in §V-B can be reused for partial sum computation. Summing up all partial products is a sum reduction operation, and therefore can be parallelized.
Fig. 12: Binary multiplication
<details>
<summary>Image 13 Details</summary>
### Visual Description
## Table: Data Points
| | A3 | A2 | A1 | A0 |
|---|----|----|----|----|
| x | + | - | * | / |
| B3| - | + | / | * |
| B2| * | / | + | - |
| B1| / | * | - | + |
| B0| + | - | * | / |
### Overview
The image displays a table with four columns labeled A3, A2, A1, and A0, and four rows labeled x, B3, B2, B1, and B0. The table contains numerical values and symbols that represent different data points.
### Components/Axes
- **Columns**: A3, A2, A1, A0
- **Rows**: x, B3, B2, B1, B0
- **Symbols**: +, -, *, /
### Detailed Analysis or ### Content Details
- **A3**: The value in the A3 column is +.
- **A2**: The value in the A2 column is -.
- **A1**: The value in the A1 column is *.
- **A0**: The value in the A0 column is /.
- **x**: The value in the x column is +.
- **B3**: The value in the B3 column is -.
- **B2**: The value in the B2 column is *.
- **B1**: The value in the B1 column is /.
- **B0**: The value in the B0 column is +.
### Key Observations
- The table contains a mix of positive and negative values, as well as symbols that represent different operations.
- The values in the A3 and A0 columns are positive, while the values in the A2 and A1 columns are negative.
- The values in the B3 and B0 columns are positive, while the values in the B2 and B1 columns are negative.
### Interpretation
The table appears to represent a set of data points with different values and symbols. The positive and negative values could indicate different categories or conditions, while the symbols could represent different operations or relationships between the data points. Without additional context, it is difficult to determine the exact meaning of the table.
</details>
However, the best parallel optimization cannot be achieved on our 48-core computing node. For a 16-bit wide multiplier, the product is a 32-bit encrypted value. Therefore, a 32-bit adder is required to carry out the homomorphic addition. Each 32-bit adder has peak thread usage of 64 threads: 31 threads with nested parallel (g,p) calculation that uses two threads. Thus, on the server used (with 48 cores), the 32-bit adder has to be partially serialized. For the 16-bit multiplier's parallel sum reduction, at most eight summation occur in parallel and each summation uses a 32-bit adder. The peak thread usage is 512 threads. For a 32-bit multiplier, maximum thread usage is 2048 threads. Thus, because homomorphic multiplication is a computationally demanding process, the server used does not have sufficient resources to do all operations in parallel. Homomorphic multiplication will thus show suboptimal performance on the server used in this project.
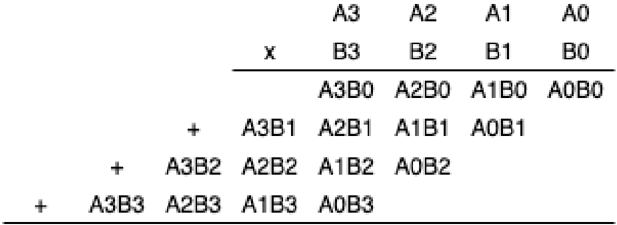
Based on the design consideration above, CryptoEmu implements a carry-save multiplier [19] that supports variable ALU width. Carry-save multiplier uses an adder described in V-B to sum up partial products in series.
- 1) Unsigned multiplication: Figure 13 shows the multiplier's architecture. For a 16-bit multiplier, A and B are 16-bit operands stored in vRegs. P is an intermediate 16-bit vReg to store partial products. Adder is a 16-bit adder with a carry in bit, see §V-B.
On startup, vReg P is initialized to encrypted 0 using TFHE library's bootCONSTANT() API. Next, we enter an iterative loop and homomorphically AND all bits in vReg A with LSB of vReg B , and use the result as one of the operands to the 16-bit adder. Data stored in vReg P is then passed to the 16-bit adder as the second operand. The adder performs the homomorphic addition to output an encrypted carry out bit. Next, we right shift carry out, vReg P and vReg B , and reached the end of the iterative for-loop. We repeat the for-loop 16 times, and the final product is a 32-bit result stored in vReg P and vReg B . The pseudo-code below shows the 16-bit binary multiplication algorithm.
```
P = 0;
for 16 times:
(P, carry out) = P + (B[0] ? A : 0)
[carry out, P, B] = [carry out, P, B] >> 1;
return [P, B]
```
For implementation, an N-bit multiplier uses N threads to concurrently evaluate all the FHE AND gates. The adder is already parallel optimized. The rest of the multiplication subroutine is executed sequentially. Therefore, the multiplier is a computationally expensive unit in CryptoEmu.
- a) Benchmark: Unsigned multiplication.: Table XI shows benchmark for 16-bit unsigned multiplication and 32-bit unsigned multiplication. A single pass for partial product summation takes around 715ms and 925ms, respectively. Total latency is roughly equal to N times single iteration's latency because summation operations are in sequence.
- 2) Signed multiplication: Signed multiplication is implemented using the carry-save multiplier in Figure 13, with slight modifications. For N-bit signed multiplication, partial products need to be signed extended to 2N bit. Figure 14 shows the partial product summation for 4-bit signed multiplication. This algorithm requires a 2N-bit adder and a 2N-bit subtractor for
TABLE XI: Unsigned multiplication latency
| | 16-bit multiplier (ms) | 32-bit multiplier (ms) |
|-----------------------------------|--------------------------|--------------------------|
| Single iteration | 715.812 | 926.79 |
| Total latency, including overhead | 11316.8 | 36929.2 |
Fig. 13: Carry save multiplier
<details>
<summary>Image 14 Details</summary>
### Visual Description
## Circuit Diagram
### Overview
The image depicts a simple electronic circuit diagram consisting of various components connected by wires. The diagram includes a power source, a switch, a resistor, an inductor, a capacitor, and a voltage divider. The components are labeled with their respective symbols and names.
### Components/Axes
- **Power Source**: Represented by a battery symbol, labeled as Vcc.
- **Switch**: Symbolized by a switch, labeled as S.
- **Resistor**: Shown as a rectangle with a zigzag line, labeled as R.
- **Inductor**: Depicted as a coiled wire, labeled as L.
- **Capacitor**: Represented by two parallel lines, labeled as C.
- **Voltage Divider**: Shown as two resistors in series, labeled as R1 and R2.
- **Voltage Measurement**: Indicated by a voltmeter symbol, labeled as Vout.
### Detailed Analysis or ### Content Details
The circuit diagram illustrates a voltage divider configuration, where the input voltage (Vcc) is divided into two output voltages (Vout) across the two resistors (R1 and R2). The voltage across each resistor can be calculated using the voltage divider formula:
\[ V_{out} = V_{cc} \times \frac{R_2}{R_1 + R_2} \]
The switch (S) can be used to control the flow of current in the circuit, allowing the user to turn the voltage divider on or off. The resistor (R) and inductor (L) can be used to filter or limit the current in the circuit, while the capacitor (C) can be used to store and release energy.
### Key Observations
- The voltage divider configuration is commonly used in electronic circuits to provide a stable output voltage from a variable input voltage.
- The switch allows for easy control of the circuit, enabling the user to adjust the output voltage as needed.
- The resistors and inductor can be used to filter or limit the current, while the capacitor can be used to store and release energy.
### Interpretation
The circuit diagram demonstrates a basic voltage divider configuration, which is a fundamental component in electronic circuits. The voltage divider is used to provide a stable output voltage from a variable input voltage, which is essential in many electronic applications. The switch allows for easy control of the circuit, enabling the user to adjust the output voltage as needed. The resistors and inductor can be used to filter or limit the current, while the capacitor can be used to store and release energy. Overall, the circuit diagram illustrates a simple yet essential electronic component that is widely used in various applications.
</details>
N-bit signed multiplication. The algorithm is further simplified with a 'magic number' [19]. Figure 15 shows the simplified signed multiplication. Based on this algorithm, the unsigned carry-save multiplier is modified to adopt signed multiplication.
| | | | | A3 | A2 | A1 | AO |
|------|------|-----------|------|----------------|-----------|------|----------|
| A3B0 | A3B0 | | X | B3 | B2 | B1 | BO |
| A3B1 | | A3B0 A3B1 | A3B0 | A3B0 | A2B0 A1B1 | | A1B0A0B0 |
| | A3B1 | | A3B1 | A2B1 | | A0B1 | |
| A3B2 | A3B2 | A3B2 | A2B2 | A1B2 | A0B2 | | |
| A3B3 | A3B3 | | | A2B3 A1B3 A0B3 | | | |
Fig. 15: Simplified signed binary multiplication
<details>
<summary>Image 15 Details</summary>

### Visual Description
## Heatmap: Signified Binary Multiplication
### Overview
The image displays a heatmap representing the results of a binary multiplication operation. The heatmap is organized into a grid with rows and columns, each cell containing a value that corresponds to the product of the binary digits in the respective row and column.
### Components/Axes
- **Rows**: Represent the binary digits A0, A1, A2, A3, from top to bottom.
- **Columns**: Represent the binary digits B0, B1, B2, B3, from left to right.
- **Values**: Each cell contains a binary digit (0 or 1) or a sum of binary digits (indicated by a plus sign).
- **Legend**: The legend at the bottom right corner indicates the meaning of the values, with 0 representing a product of 0 and 1 representing a sum of binary digits.
### Detailed Analysis or ### Content Details
The heatmap shows the results of multiplying two binary numbers. Each cell contains a value that is the product of the corresponding binary digits in the row and column. For example, the cell in the first row and first column contains a 0, indicating that the product of A0 and B0 is 0. The cell in the first row and second column contains a 1, indicating that the product of A0 and B1 is 1.
The heatmap also includes a sum of binary digits in each cell, indicated by a plus sign. For example, the cell in the first row and second column contains a 1, indicating that the sum of A0 and B1 is 1. The cell in the first row and third column contains a 0, indicating that the sum of A0 and B2 is 0.
### Key Observations
- The heatmap shows that the product of A0 and B0 is 0, and the product of A0 and B1 is 1.
- The heatmap also shows that the sum of A0 and B1 is 1, and the sum of A0 and B2 is 0.
- The heatmap indicates that the product of A0 and B3 is 0, and the product of A0 and B4 is 0.
- The heatmap also shows that the sum of A0 and B3 is 0, and the sum of A0 and B4 is 0.
### Interpretation
The heatmap demonstrates the results of a binary multiplication operation. The values in the heatmap represent the product of the corresponding binary digits in the row and column. The legend indicates the meaning of the values, with 0 representing a product of 0 and 1 representing a sum of binary digits. The heatmap shows that the product of A0 and B0 is 0, and the product of A0 and B1 is 1. The heatmap also shows that the sum of A0 and B1 is 1, and the sum of A0 and B2 is 0. The heatmap indicates that the product of A0 and B3 is 0, and the product of A0 and B4 is 0. The heatmap also shows that the sum of A0 and B3 is 0, and the sum of A0 and B4 is 0.
</details>
a) Benchmark: Signed multiplication.: The unsigned multiplication was modified for signed multiplication based on the simplified algorithm outlined above. Table XII shows benchmark results for the 16-bit and 32-bit signed multiplications. A single pass for partial product summation takes roughly 745ms and 1155ms, respectively. The total latency for signed multiplication is around N times that of the single iteration.
TABLE XII: Signed multiplication latency
<details>
<summary>Image 16 Details</summary>

### Visual Description
Icon/Small Image (574x53)
</details>
| | 16-bit multiplier (ms) | 32-bit multiplier (ms) |
|-----------------------------------|--------------------------|--------------------------|
| Single iteration | 742.8 | 1154.77 |
| Total latency, including overhead | 13120.6 | 34826 |
## F. Divider
CryptoEmu supports unsigned division over encrypted data. Figure 16 shows the flow chart for a non-restoring division algorithm for unsigned integer [20].
The division algorithm is based on sequential addition/subtraction. In every iteration, the MSB of vReg A decides whether the divider takes an addition or subtraction. This function is implemented building off the adder in §V-B. The MSB of vReg A is passed as the SUB bit into the adder. In the adder, the second operand b is homomorphically XORed with the SUB bit and then added with the first operand A and SUB bit. If FHE XOR gates are evaluated in parallel and parallel computing overhead is ignored, the adder with add/sub select is about 1 FHE XOR gate slower than regular adders. Note that, the integer divide instruct does not care about the value of remainder because the result will be rounded down (floor) to the closest integer, and therefore remainder calculation is skipped to save computation time.
The unsigned division algorithm is a sequential algorithm. Within each iteration, a parallel optimized adder subroutine is invoked. Like multiplication, the unsigned division algorithm is computationally expensive. Pseudocode for the 16-bit unsigned division is shown below.
```
invoked. Like multiplication, the unsigned division is shown below.
Non-restoring Division:
A = 0;
D = Divisor
Q = Dividend
for 16 times:
[A, Q] = [A, Q] << 1
if A < 0:
A = A + D
else:
A = A - D
if A < 0:
Q[0] = 0;
else:
Q[0] = 1;
```
a) Benchmark.: Table XIII provides benchmark results for the 16-bit and 32-bit unsigned integer divisions. Performance for a single iteration is slightly slower than homomorphic addition because one iteration uses an adder-subtractor unit. The division algorithm is sequential, and the total latency for N-bit division is around N times that of a single iteration's latency.
TABLE XIII: Unsigned division latency
<details>
<summary>Image 17 Details</summary>

### Visual Description
Icon/Small Image (536x53)
</details>
| | 16-bit divider (ms) | 32-bit divider (ms) |
|-----------------------------------|-----------------------|-----------------------|
| Single iteration | 769.063 | 1308.67 |
| Total latency, including overhead | 11659.5 | 38256.5 |
## G. Bitwise operations and data movement
CryptoEmu supports several homomorphic bitwise operations and data movement of configurable data size. The instruction set supports 16-bit and 32-bit bitwise operation and data movement.
The collection of bitwise operations includes homomorphic NOT, AND, OR, XOR, and ORN, in both immediate mode and register mode. All homomorphic bitwise operations except bitwise NOT are implemented with parallel computing optimizations. For the N-bit bitwise operation, CryptoEmu spawns N threads to carry out all FHE gate evaluation in parallel. Bitwise NOT operation is an exception because the FHE NOT gate does not need to be bootstrapped and is relatively fast. Parallel computing cannot be justified because of its overhead. The following code shows a generic way to implement N-bit parallel bitwise operations using the TFHE and OpenMP libraries.
```
#pragma omp parallel sections num_threads(16)
{
#pragma omp section
{
bootsAND(&out[0], &a[0], &b[0], bk);
}
```
<details>
<summary>Image 18 Details</summary>
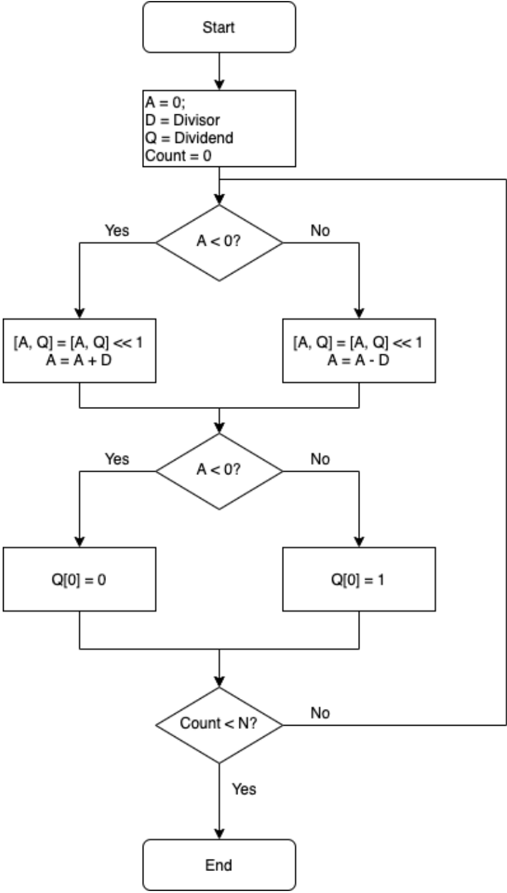
### Visual Description
## Flowchart: Division Algorithm
### Overview
The flowchart illustrates the division algorithm, which is a method for dividing two integers. The algorithm involves a series of steps to determine the quotient and remainder of the division.
### Components/Axes
- **Start**: The beginning of the flowchart.
- **A = 0**: Initialization of the dividend (A) to 0.
- **D = Divisor**: Initialization of the divisor (D).
- **Q = Dividend**: Initialization of the quotient (Q) to the dividend (A).
- **Count = 0**: Initialization of the count (Count) to 0.
- **A < 0?**: A decision point to check if the dividend (A) is negative.
- **[A, Q] = [A, Q] << 1**: A bitwise left shift operation to update the dividend (A) and quotient (Q).
- **A = A + D**: Addition of the divisor (D) to the dividend (A).
- **Q[0] = 0**: Initialization of the first element of the quotient array (Q[0]) to 0.
- **Q[0] = 1**: Initialization of the first element of the quotient array (Q[0]) to 1.
- **Count < N?**: A decision point to check if the count (Count) is less than the number of bits in the dividend (N).
- **End**: The end of the flowchart.
### Detailed Analysis or ### Content Details
The flowchart begins with the initialization of the dividend (A) to 0 and the divisor (D). The quotient (Q) is initialized to the dividend (A), and the count (Count) is initialized to 0. The algorithm then enters a loop that continues until the count is less than the number of bits in the dividend (N).
Inside the loop, the algorithm checks if the dividend (A) is negative. If it is, the dividend (A) and quotient (Q) are updated using a bitwise left shift operation. The dividend (A) is then updated by adding the divisor (D) to it.
The algorithm also initializes the first element of the quotient array (Q[0]) to 0 and 1, depending on the sign of the dividend (A). The count is then incremented by 1.
The loop continues until the count is less than the number of bits in the dividend (N). At this point, the algorithm ends.
### Key Observations
The flowchart demonstrates the division algorithm in a step-by-step manner. It shows how the dividend (A) and quotient (Q) are updated at each iteration of the loop. The algorithm also handles the sign of the dividend (A) and initializes the quotient array (Q) accordingly.
### Interpretation
The flowchart provides a clear and concise explanation of the division algorithm. It demonstrates how the algorithm works by updating the dividend (A) and quotient (Q) at each iteration of the loop. The algorithm also handles the sign of the dividend (A) and initializes the quotient array (Q) accordingly. The flowchart is a useful tool for understanding the division algorithm and its implementation.
</details>
Fig. 16: Binary division algorithm
```
Fig. 16: Binary division algorithm
#pragma omp section
{
bootsAND(&out[1], &a[1], &b[1], bk);
}
...
#pragma omp section
{
bootsAND(&out[N-2], &a[N-2], &b[N-2], bk);
}
#pragma omp section
{
bootsAND(&out[N-1], &a[N-1], &b[N-1], bk);
}
}
```
Data movement instructions support homomorphic operations such as bit field clear, bit field insert, bit-order reverse, and byteorder reverse. Because data movement uses TFHE library's non-bootstrapped APIs like bootsCOPY() and bootsCONSTANT() , they are not implemented via OpenMP parallel sections.
a) Benchmark.: Table XIV provides benchmark results for 16-bit and 32-bit bitwise operation and data movement instructions. When parallel optimized, an N-bit bitwise operation spawns N threads. For bitwise operation with bootstrapped FHE gate, latency is between 1-2 FHE gates when all threads are in parallel. The performance of the N-bit bitwise NOT and data movement instructions that are implemented sequentially is proportional to N times the corresponding TFHE API's latency.
TABLE XIV: Bitwise operation and data movement latency
| Operation | Category | Parallel? | 16-bit latency (ms) | 32-bit latency (ms) |
|-------------|--------------------|-------------|-----------------------|-----------------------|
| AND(imm) | Bitwise operations | Yes | 26.9195 | 27.1288 |
| AND(reg) | Bitwise operations | Yes | 47.7228 | 55.4597 |
| OR(imm) | Bitwise operations | Yes | 28.1923 | 27.8774 |
| OR(reg) | Bitwise operations | Yes | 47.6171 | 50.089 |
| XOR(imm) | Bitwise operations | Yes | 29.2375 | 27.9389 |
| XOR(reg) | Bitwise operations | Yes | 47.1986 | 50.3683 |
| ORN(imm) | Bitwise operations | Yes | 27.8467 | 27.776 |
| ORN(reg) | Bitwise operations | Yes | 47.6422 | 57.0639 |
| NOT(imm) | Bitwise operations | Yes | 0.0072794 | 0.0116968 |
| NOT(reg) | Bitwise operations | No | 0.006089 | 0.01232 |
| BFC | Bitwise operations | No | 0.0028094 | 0.0026892 |
| BFI | Bitwise operations | No | 0.003278 | 0.0033974 |
| RBIT | Bitwise operations | No | 0.0104582 | 0.0216222 |
| REV | Bitwise operations | No | 0.0097926 | 0.0187618 |
## VI. CONTROL UNITS
A control unit decides and/or changes the value of the program counter (PC), which in CryptoEmu is an integer in cleartext. CryptoEmu supports conditional execution that generates encrypted conditional flags defined in the ARM ISA. Based on conditional flags, the branch unit decides the branch direction to take. The PC is set to a cleartext that points to an HE instruction address when branch is taken, or increased by 4 if the branch is not taken.
## A. Conditional Flags
The conditional unit handles NZCV flags defined in the ARM architecture. The N (negative) flag is set if an instruction's result is negative. The Z (zero) flag is set if an instruction's result is zero. The C (carry) flag is set if an instruction's results in an unsigned overflow. The V (overflow) flag is set if an instruction's results in an signed overflow. NZCV values are stored as encrypted data in a vReg. An instruction can be conditionally executed to update NZCV's value. The following code shows HE assembly for a while loop. Note that all data in this example is encrypted.
```
HE assembly for a while loop. Note that
C++:
int i = 42;
while(i != 0)
i--;
HE assembly:
MOV R0 R0 42
Loop_label:
SUBS R0 R0 1
B_NE Loop_label
```
After the SUBS instruction is executed, the NZCV vReg is updated with results in R0. Based on the value of the Z flag, the program counter either updates its value to SUBS' instruction address (branch taken) or increases by 4 (branch non-taken).
Because the homomorphic evaluation of a conditional flag is computationally expensive, an ordinary data processing unit does not have a mechanism to update a conditional flag. In reality, instructions like ADDS, SUBS, and MULS are treated as micro-ops and completed in two steps: homomorphic data processing and homomorphic conditional flag calculation.
The N flag calculation is straight forward. CryptoEmu takes the MSB of result vReg and assigns it to the NZCV vReg. For the C flag, CryptoEmu takes the carry out result from previous unsigned computation and assigns it to the NZCV vReg. For the Z flag, the conditional unit performs an OR reduction on the input vReg, and assigns a negated result to the NZCV vReg. OR reduction can be parallelized. For a 16-bit conditional unit, OR reduction has four stages and maximum thread usage is eight. For a 32-bit conditional unit, OR reduction has five stages and maximum thread usage is 16. Finally, for the V flag, we
take the sign bit (MSB) of two operands and the result for a signed computation, denoted as a , b , and s , respectively. Overflow is then evaluated as
$$o v = \left ( \bar { a } \cdot \bar { b } \cdot s \right ) + \left ( a \cdot b \cdot \bar { s } \right ) .$$
Note that the conditional unit calculates overflow in parallel by executing (¯ a · ¯ b · s ) and ( a · b · ¯ s ) concurrently.
a) Benchmark.: Table XV shows benchmark results for the 16-bit and 32-bit conditional units. The N flag and C flag calculations are fast because they do not have bootstrapped FHE gates. The Z flags and V flags are calculated at the same time. For conditional flag calculation on N-bit result, the maximum thread usage is N/ 2 + 2 threads. Z flag and V flag's latency dominates the total latency.
TABLE XV: Conditional flag latency
| | 16-bit (ms) | 32-bit (ms) |
|-----------------------------------|---------------|---------------|
| N flag | 0.0214161 | 0.0204952 |
| C flag | 0.0007251 | 0.0002539 |
| Z flag and V flag | 115.811 | 168.728 |
| Total latency, including overhead | 115.901 | 169.843 |
## B. Branch
CryptoEmu has a vReg virtual register reserved for the program counter (PC). The PC stores a cleartext value that points at an HE instruction address. CryptoEmu loads an HE instruction from PC, decodes the instruction, invokes the data processing unit to execute the instruction, and repeats. Normally when using the ARM A32 ISA, the next instruction address that CryptoEmu is at the current PC plus 4. However, branch instructions can modify the PC value based on conditional flags, and therefore decide the next instruction address CryptoEmu fetches from. For example, the following code branches to ADDRESS LABEL because SUBS instruction sets the Z flag.
```
MOV R0 R0 1
SUBS R0 R0 1
B_NE ADDRESS_LABEL
```
§VI-A discussed conditional flag calculation. The NZCV flag is stored in a vReg as encrypted data. The cloud needs to know the value of the NZCV flags to decide which branch direction to take. However, the cloud has no knowledge of NZCV value unless it is decrypted by the user. CryptoEmu adopts a server-client communication model from CryptoBlaze [15]. As demonstrated in Fig. 17, the cloud (server) first homomorphically evaluates an HE instruction and updates the NCZV vReg. Next, the cloud sends the encrypted NCZC value and branch condition to the client. User deciphers the encrypted NCZC value, and sends a branch taken/non-taken decision back to the cloud through a secure channel. Once the cloud learns the branch decision, the PC will either be updated to PC+4, or to the branch address.
Fig. 17: Server-client model for branch resolution Blurry text in the figure denotes encrypted data.
<details>
<summary>Image 19 Details</summary>
### Visual Description
## Diagram Type: Flowchart
### Overview
The image is a flowchart that illustrates the relationship between the Cloud, User, and various flags and directions. The flowchart uses arrows to indicate the direction of data flow or process.
### Components/Axes
- **Cloud**: Represented by a blue rectangle on the left side of the flowchart.
- **User**: Represented by a yellow rectangle on the right side of the flowchart.
- **NCZV Flags**: Represented by an oval shape with the text "NCZV Flags" inside it, located above the Cloud.
- **Branch Direction**: Represented by an oval shape with the text "Branch Direction" inside it, located below the Cloud.
- **Arrows**: Used to indicate the direction of data flow or process between the Cloud and User.
### Detailed Analysis or ### Content Details
- The Cloud is connected to the User with two arrows, one pointing from the Cloud to the User and another pointing from the User to the Cloud.
- The NCZV Flags are connected to the Cloud with an arrow pointing from the NCZV Flags to the Cloud.
- The Branch Direction is connected to the User with an arrow pointing from the Branch Direction to the User.
### Key Observations
- The flowchart suggests a two-way relationship between the Cloud and User, with data or process flowing in both directions.
- The NCZV Flags and Branch Direction are connected to the Cloud, indicating that they may influence or be influenced by the Cloud.
- The arrows indicate that the data or process is moving from the Cloud to the User and vice versa.
### Interpretation
The flowchart suggests a complex system where the Cloud and User are interconnected through various flags and directions. The NCZV Flags and Branch Direction may play a role in determining the flow of data or process between the Cloud and User. The two-way relationship between the Cloud and User suggests that the system is dynamic and responsive to changes in either component.
</details>
## VII. RESULTS
This section reports on ( i ) the scalability with respect to bit count when the core count is a fixed number; ( ii ) the scalability with respect to core count when the data size is a fixed number; ( iii ) on CryptoEmu's potential vulnerabilities; and ( iv ) comparison against the state of the art.
## A. Scalability with respect to bit count
Table I shows the latency of the TFHE library API. Non-bootstrapped gates such as CONSTANT, NOT, and COPY are three to four orders of magnitude faster than bootstrapped gates. Therefore, compared to bootstrapped gates, non-bootstrapped
gates are considered as negligible in the CryptoEmu's performance equation. Functional units without bootstrapped gates are not included in our scalability analysis.
The latency of a single bootstrapped gate is denoted as G . In the rest of the subsection, we analyzed the scalability of functional unit subroutines with respect to data size N. Two scenarios are considered: single core mode, and multi-core mode with a sufficient number of cores to do all intended parallel computation concurrently. CryptoEmu uses all available cores to concurrently perform homomorphic computation on encrypted data with multi-core mode latency. When CryptoEmu exhausted all core resources, the rest of the program will be serialized with single-core mode latency.
a) Adder.: An adder has 3 stages: Generate and propagate calculation, carry calculation, and sum calculation. Let the available core number be 1 (single core mode); then, the time complexity for each stage is:
Generate and propagate calculation : To compute generate and propagate for one bit, two bootstrapped FHE gates evaluations are required. With N-bit operands, total latency is 2 · G · N .
Carry calculation : Three bootstrapped FHE gates evaluations are required to calculate the carry out bit. With N-bit operands, total latency is 3 · G · N .
Sum calculation : One bootstrapped XOR gate is needed to calculate one sum bit. With N-bit operands, total latency is G · N Total latency : The latency for adder with single core is 6 · G · N . Time complexity is O ( N ) .
Table XVI summarizes the discussion above for the N-bit adder with one core available.
TABLE XVI: Adder scalability, single core
| Operation | Latency | Time complexity |
|-------------------|-----------|-------------------|
| (g,p) calculation | 2 GN | O ( N ) |
| Carry calculation | 3 GN | O ( N ) |
| Sum calculation | GN | O ( N ) |
| Total latency | 6 GN | O ( N ) |
Assume a sufficient but fixed number of processors are available. Then, the latencies become:
Generate and propagate : Calculation for generate and propagate for one bit can be executed in parallel, with a latency of one bootstrapped FHE gate. Given N-bit operands, N calculations can be carried out concurrently. Therefore, the latency for the (g,p) calculation is G .
Carry calculation : Carry out computation for one bit can be executed in parallel, with a latency of two bootstrapped FHE gates. For N-bit operands, carry calculation is divided into log ( N ) stages. Operations in the same stage are executed in parallel. Therefore, latency for carry calculation is 2 · G · log ( N ) .
Sum calculation : Each sum bit needs one bootstrapped XOR gate. For N-bit operands, N computations can be executed in parallel. Total latency for sum calculation is G .
Total latency : The total latency for an adder with sufficient yet fixed number of cores is 2 · G · log ( N )+2 G . Time complexity is O ( log ( N )) .
Table XVII summarizes the scalability analysis discussion for the N-bit adder with sufficient, yet fixed number of cores available.
TABLE XVII: Adder scalability, multiple core
| Operation | Latency | Time complexity |
|-------------------|---------------------|-------------------|
| (g,p) calculation | G | O (1) |
| Carry calculation | 2 G · log ( N ) | O ( log ( N )) |
| Sum calculation | G | O (1) |
| Total latency | 2 G · log ( N )+2 G | O ( log ( N )) |
b) Subtractor.: A subtractor performs homomorphic negation on subtrahend, and homomorphically adds subtrahend's complement to minuend using an adder with carry in of one.
Negation uses TFHE library's non-bootstrapped NOT gate, and its latency is negligible. Adding a carry to the adder uses two extra bootstrapped gates. Therefore, the total latency for subtractor is Latency ( Adder ) + 2 · G .
Table XVIII summarizes key scalability aspects for the N-bit subtractor with single core and with sufficient yet fixed number of cores available.
TABLE XVIII: Subtractor scalability
| # of cores | Latency | Time complexity |
|--------------|------------------|-------------------|
| Single core | 6 GN +2 G | O ( N ) |
| Multi-core | 2 Glog ( N )+4 G | O ( log ( N )) |
Shifter. For shifting with cleartext immediate, the operation is essentially a homomorphic data movement operation using the TFHE library's COPY and CONSTANT API. Shifting with immediate latency is therefore negligible compared to the rest of function units in CryptoEmu.
.
Shifting with encrypted vReg is implemented as a barrel shifter. For vReg N-bit shift, the operation has log ( N ) stages. In each stage, individual bits are selected by bits in the shifting amount vReg moves to the next stage through a MUX. The TFHE MUX has latency around 2 · G .
When a single core is used, each stage has N MUXs. Latency in one stage is 2 · G · N . There are log ( N ) stages, therefore total shifter latency for a single core processor is 2 · G · N · log ( N ) .
When sufficient cores are given, MUXs of the same stage can be evaluated in parallel, resulting in a latency of 2 · G . There are log ( N ) stages, therefore total shifter latency for processor with sufficient cores is 2 · G · log ( N ) .
Table XIX summarizes key scalability aspects for the shifter with respect to bit count N, in single core and multi-core mode.
TABLE XIX: Shifter scalability
| # of cores | Latency | Time complexity |
|--------------|---------------|-------------------|
| Single core | 2 GNlog ( N ) | O ( Nlog ( N )) |
| Multi-core | 2 Glog ( N ) | O ( log ( N )) |
c) Multiplier.: The multiplier is implemented with iterative multiplication algorithms. A multiplier with N-bit operands requires N times iterations.
N-bit unsigned multiplication contains an N-bit FHE AND evaluation and invokes an N-bit adder for every iteration. When running unsigned multiplication with a single core, sequential latency for N-bit FHE AND is N · G . Sequential latency for the N-bit adder is 6 · G · N . Latency for one iteration is 7 · G · N . Total latency for the N-bit unsigned multiplication 7 · G · N 2 .
When sufficient number of cores are provided to run subroutines in parallel, parallel latency for the N-bit FHE AND is G . Parallel latency for N-bit adder is 2 · G · log ( N ) + 2 G . One iteration takes 2 · G · log ( N ) + 3 G to complete. Total latency for N-bit unsigned multiplication is 2 · G · N · log ( N ) + 3 · G · N .
Signed multiplication has the same latency per iteration as in unsigned multiplication. N-bit signed multiplication involves an N-bit addition that adds an offset to the upper half of the 2N-bit product. This operation has sequential latency of 6 · G · N and parallel latency of 2 · G · log ( N ) + 3 G . Total latency for signed multiplication is therefore 7 · G · N 2 +6 · G · N for single core, and 2 · G · N · log ( N ) + 3 · G · N +2 · G · log ( N ) + 3 G if a sufficient number of cores is available.
Table XX summarizes key scalability aspects (latency and time complexity) for the unsigned and signed multiplication with respect to bit count N, in single core and multi-core mode.
TABLE XX: Multiplier scalability
| unsigned? | # of cores | Latency | Time complexity |
|-------------|--------------|--------------------------------------|-------------------|
| Yes | Single core | 7 GN 2 | O ( N 2 )) |
| Yes | Multi-core | 2 GNlog ( N )+3 GN | O ( Nlog ( N )) |
| No | Single core | 7 GN 2 +6 GN | O ( N 2 )) |
| No | Multi-core | 2 GNlog ( N )+3 GN +2 Glog ( N )+3 G | O ( Nlog ( N )) |
d) Divider.: The divider is implemented with iterative non-restoring division algorithm. A divider with N-bit operands requires N iterations. Every iteration involves negligible non-bootstrapped gates and an adder-subtractor unit. The addersubtractor selectively inverts the second operand based on the value in the SUB bit. Then the subroutine invokes an adder to add the first operand, processes the second operand, and SUB bit together to form a result.
For computation on single core, selective inversion for an N-bit operand uses N FHE XOR gates, and therefore has a latency of G · N . Adder with carry in has 6 · G · N +2 · G latency. Latency per iteration is 7 · G · N +2 · G , and total latency is 7 · G · N 2 +2 · G · N for single core.
If enough cores are available, the N-bit selective inversion can be executed in parallel, resulting in G latency. Adder with carry in parallel computing mode has 2 · G · log ( N ) + 4 · G latency. Latency per iteration is 2 · G · log ( N ) + 5 · G , and total latency is 2 · G · N · log ( N ) + 5 · G · N .
Table XXI shows latency and time complexity results for the unsigned division with respect to bit count N, in single core and multi-core modes.
TABLE XXI: Divider scalability
| # of cores | Latency | Time complexity |
|--------------|--------------------|-------------------|
| Single core | 7 GN 2 +2 GN | O ( N 2 )) |
| Multi-core | 2 GNlog ( N )+5 GN | O ( Nlog ( N )) |
e) Bitwise operations.: Bitwise operation evaluates all input bits with one FHE gate. Latency per bit is G . For N-bit bitwise operation in single core mode, total latency is G · N . In multi-core mode, because all FHE gate evaluations are in parallel, the total latency is G .
Table XXI shows latency and time complexity data for bitwise operation with respect to bit count N, in single core and multi-core mode.
TABLE XXII: Bitwise ops scalability
| # of cores | Latency | Time complexity |
|--------------|-----------|-------------------|
| Single core | GN | O ( N ) |
| Multi-core | G | O (1) |
f) Conditional Flags.: Conditional flags calculation involves four sub-calculations: N flag, Z flag, C flag, and V flag. N flag and C flag calculations are trivial. Z flag calculation contains an OR reduction operation. In single core mode, the N-bit Z flag calculation has a latency of G · N . In multi-core mode, the OR reduction is executed in parallel. N-bit OR reduction is broken down into log ( N ) stages, and in each stage, the FHE OR gates are evaluated in parallel. The N-bit Z flag latency for parallel computing is Glog ( N ) .
The V flag calculation uses five gates regardless of the size of the input vReg. In single core mode, V flag calculation has 5 · G latency. In multi-core mode because V flag calculation can be partially optimized with parallel computing, the latency is 3 · G . Therefore, total latency for single core mode is G · N +5 · G , and total latency for multi-core mode is G · log ( N ) +3 · G .
Table XXIII shows latency and time complexity data for conditional flag calculation with respect to the bit count N, in single core and multi-core mode.
TABLE XXIII: Conditional flags scalability
| # of cores | Latency | Time complexity |
|--------------|----------------|-------------------|
| Single core | GN +5 G | O ( N ) |
| Multi-core | Glog ( N )+3 G | O ( log ( N )) |
## B. Scalability with respect to core count
CryptoEmu's performance is dictated by the extent to which it can rely on parallel computing. In ideal scenario, the processor has enough cores to enable any collection of tasks that can be performed in parallel to be processed as such. Sometimes, a part of the execution of an instruction takes place in parallel, but the rest is sequential because all CPU core resources are exhausted. In the worst case scenario, the processor has only one core and all computations are sequential/serialized.
Assume that the size of the functional units is 16-bit. Peak thread usage is then 32 threads, where each thread performance an FHE gate evaluation. On the server used in this study, which has 48 cores distributed over four CPUs, we vary the number of cores available to carry our emulation from 1 core to 48 cores. This amounts to a strong scaling analysis. We created scenarios where ( i ) the instruction set can draw on one core only and therefore the computation is sequential; ( ii ) the instruction set has insufficient cores and parallel computation is mixed with sequential computation; and ( iii ) the instruction set can count on sufficient cores to do all emulation in parallel.
a) Adder.: Figure 18 shows the 16-bit adder's compute time with respect to core count. From the chart, the adder's latency decreases when the core count increases from 1 to 32. The adder reached its optimal speed at around 32 core count and has a slight decrease in speed when the core count exceeds 32. Adder's maximum speedup from parallel computing is around 7.78x.
Fig. 18: Time vs Core count
<details>
<summary>Image 20 Details</summary>
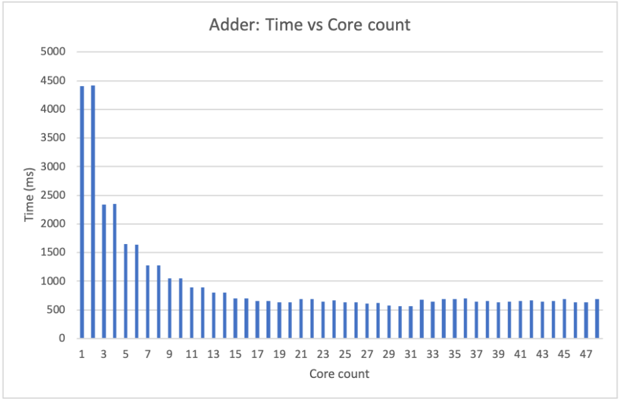
### Visual Description
## Bar Chart: Adder: Time vs Core count
### Overview
The bar chart displays the time taken by the Adder to process various core counts. The x-axis represents the core count, ranging from 1 to 47, while the y-axis represents the time in milliseconds, ranging from 0 to 5000 ms.
### Components/Axes
- **Title**: Adder: Time vs Core count
- **X-axis**: Core count (ranging from 1 to 47)
- **Y-axis**: Time (milliseconds, ranging from 0 to 5000 ms)
- **Legend**: No legend is present in the image.
### Detailed Analysis or ### Content Details
The chart shows a clear trend where the time taken by the Adder increases as the core count increases. The highest time recorded is approximately 4500 ms at a core count of 1. The time then decreases as the core count increases, reaching a minimum of around 500 ms at a core count of 47.
### Key Observations
- The time taken by the Adder increases with the core count.
- The highest time recorded is approximately 4500 ms at a core count of 1.
- The time then decreases as the core count increases, reaching a minimum of around 500 ms at a core count of 47.
### Interpretation
The data suggests that the Adder's processing time is directly proportional to the core count. As the number of cores increases, the time taken to process the data also increases. This could be due to the fact that more cores require more resources to process the data, leading to increased time taken. The minimum time recorded at a core count of 47 suggests that the Adder is optimized for high-core counts, as it can process data quickly even with a large number of cores.
</details>
b) Subtractor.: Figure 19 shows the 16-bit subtractor's compute time with respect to core count. The 16-bit subtractor uses at most 32 cores to compute in parallel. The subtractor's latency decreases as the core count increases from 1-32, and reaches its maximum performance at around 32 core count. At and beyond 32 core count, all parallel optimizations are enabled. When the core counts saturate the subtractor's parallel computing requirement, the latency of the subtractor is around 700ms. The subtractor's maximum speedup from parallel computing is about 8.49x.
Fig. 19: Time vs Core count
<details>
<summary>Image 21 Details</summary>
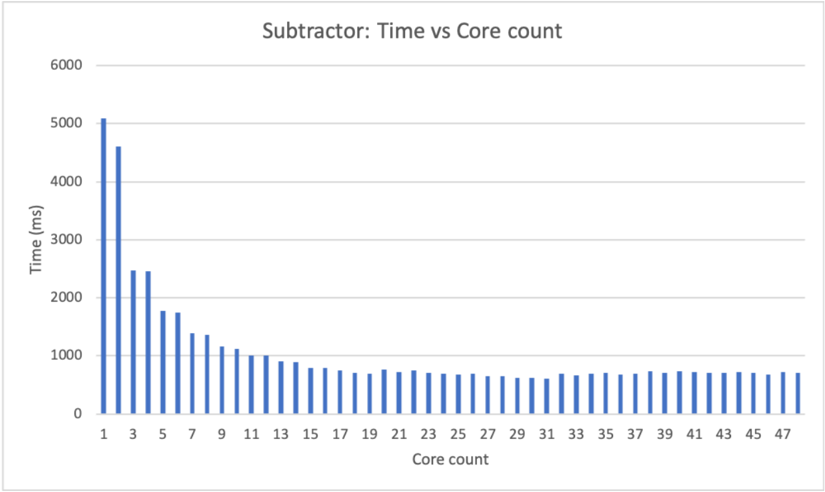
### Visual Description
## Bar Chart: Subtractor: Time vs Core count
### Overview
The bar chart displays the time taken by a subtractor in milliseconds (ms) as a function of the core count. The x-axis represents the core count, which ranges from 1 to 47, while the y-axis represents the time taken in milliseconds, ranging from 0 to 6000 ms.
### Components/Axes
- **Title**: Subtractor: Time vs Core count
- **X-axis**: Core count, ranging from 1 to 47
- **Y-axis**: Time (ms), ranging from 0 to 6000 ms
- **Legend**: No legend is present in the image
### Detailed Analysis or ### Content Details
The chart shows a clear trend where the time taken by the subtractor decreases as the core count increases. The highest time taken is approximately 5000 ms at a core count of 1, and the time taken decreases gradually as the core count increases. The time taken at a core count of 47 is approximately 1000 ms.
### Key Observations
- The time taken by the subtractor decreases as the core count increases.
- The highest time taken is at a core count of 1.
- The time taken at a core count of 47 is significantly lower than at a core count of 1.
### Interpretation
The data suggests that the subtractor's performance improves as the number of cores increases. This is because the subtractor can utilize multiple cores to perform the subtraction operation in parallel, reducing the overall time taken. The trend is consistent across the entire range of core counts, indicating that the subtractor is designed to take advantage of multiple cores to improve performance.
</details>
c) Shifter.: Figure 20 shows the 16-bit shifter's compute time with respect to core count. A 16-bit shifter has a maximum core usage of 16. The 16-bit shifter's latency decreases as the core count increases from 1-16. The shifter's performance reaches its peak at core count 16. For core counts higher than 16, its stays stable at around 300ms. The maximum speedup yielded by parallel computing is around 10.94x.
Fig. 20: Time vs Core count
<details>
<summary>Image 22 Details</summary>
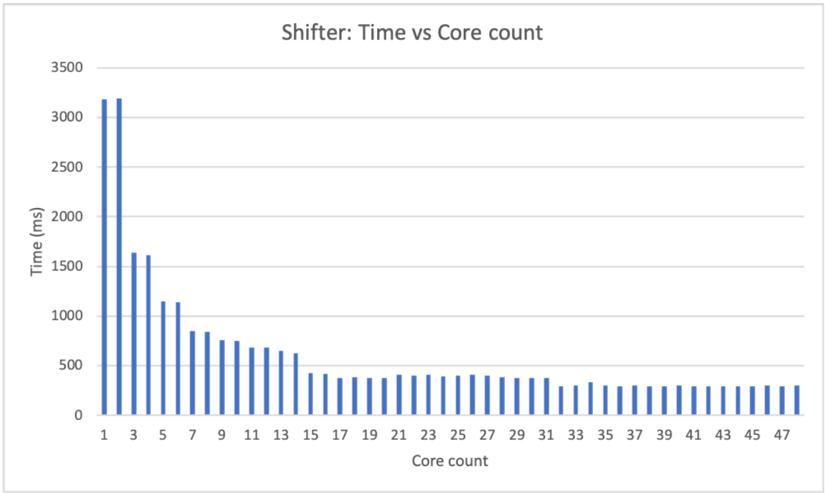
### Visual Description
## Bar Chart: Shifter: Time vs Core count
### Overview
The bar chart displays the relationship between the time taken by a shifter and the core count. The x-axis represents the core count, ranging from 1 to 47, while the y-axis represents the time in milliseconds (ms), ranging from 0 to 3500 ms.
### Components/Axes
- **Title**: Shifter: Time vs Core count
- **X-Axis**: Core count, with values from 1 to 47
- **Y-Axis**: Time (ms), with values from 0 to 3500 ms
- **Legend**: No legend is present in the image
### Detailed Analysis or ### Content Details
The chart shows a clear trend where the time taken by the shifter increases as the core count increases. The highest time recorded is approximately 3000 ms at a core count of 1. The time then decreases as the core count increases, reaching a minimum of around 500 ms at a core count of 47.
### Key Observations
- The time taken by the shifter increases with the core count.
- There is a significant decrease in time as the core count increases from 1 to 47.
- The time taken by the shifter is relatively consistent across different core counts, with minor fluctuations.
### Interpretation
The data suggests that the shifter's performance is directly related to the number of cores it can utilize. As the number of cores increases, the time taken by the shifter decreases, indicating improved performance. This trend is consistent across the entire range of core counts displayed in the chart. The slight fluctuations in time could be due to variations in the workload or other factors not shown in the chart. Overall, the data demonstrates that increasing the number of cores can lead to faster performance of the shifter.
</details>
d) Multiplier.: Figure 21 shows the 16-bit multiplier's compute time with respect to core count. A 16-bit multiplier requires 32 cores to enable all parallel computing optimization. From the chart, both unsigned and signed multiplication's latency decrease as the number of cores increases from 1 to 32. The multiplier reached its top speed at around 32 cores. Beyond that, the multiplier's latency stays around 11000-12000ms. Unsigned multiplication has a maximum parallel computing speedup of 8.3x; signed multiplication has a maximum parallel computing speedup of 8.4x.
Fig. 21: Time vs Core count
<details>
<summary>Image 23 Details</summary>
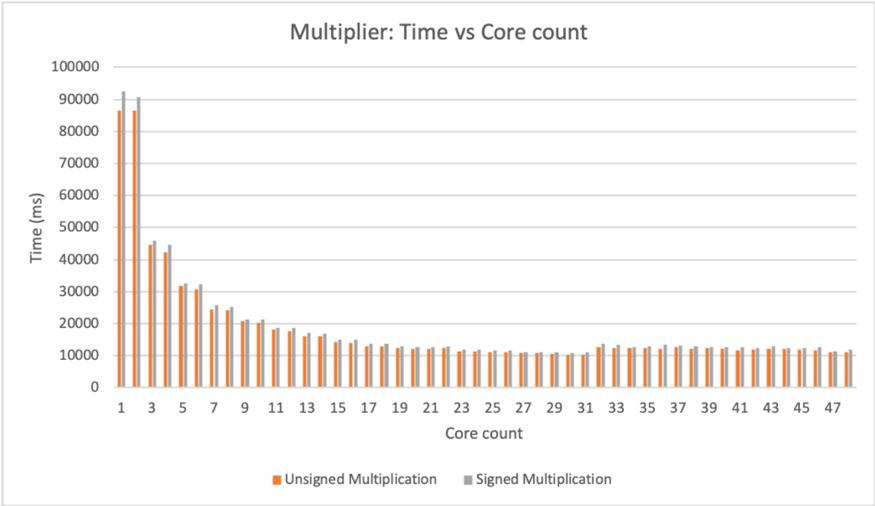
### Visual Description
## Bar Chart: Multiplier: Time vs Core count
### Overview
The bar chart displays the relationship between the core count and the time taken for multiplication operations. The x-axis represents the core count, ranging from 1 to 47, while the y-axis represents the time in milliseconds, ranging from 0 to 100,000 ms.
### Components/Axes
- **X-axis (Core count)**: Ranges from 1 to 47, with each bar representing a different core count.
- **Y-axis (Time (ms))**: Ranges from 0 to 100,000 ms, with each bar representing the time taken for multiplication operations at a specific core count.
- **Legend**: Two bars represent the time taken for unsigned multiplication (orange) and signed multiplication (gray).
### Detailed Analysis or ### Content Details
- **Unsigned Multiplication**: The bars for unsigned multiplication are consistently higher than those for signed multiplication across all core counts.
- **Signed Multiplication**: The bars for signed multiplication are generally lower than those for unsigned multiplication, indicating that signed multiplication is faster.
- **Time Distribution**: The time taken for multiplication operations decreases as the core count increases, suggesting that more cores can process multiplication operations more efficiently.
- **Core Count 1**: The time taken for multiplication operations is the highest, indicating that the core count has a significant impact on the time taken.
- **Core Count 47**: The time taken for multiplication operations is the lowest, indicating that the core count has a significant impact on the time taken.
### Key Observations
- **Unsigned Multiplication is Faster**: The bars for unsigned multiplication are consistently higher than those for signed multiplication, indicating that unsigned multiplication is faster.
- **Core Count Impact**: The time taken for multiplication operations decreases as the core count increases, suggesting that more cores can process multiplication operations more efficiently.
- **Core Count 1 is the Slowest**: The time taken for multiplication operations is the highest at core count 1, indicating that the core count has a significant impact on the time taken.
### Interpretation
The data suggests that the time taken for multiplication operations is significantly influenced by the core count. Unsigned multiplication is faster than signed multiplication, and the time taken decreases as the core count increases. Core count 1 is the slowest, indicating that the core count has a significant impact on the time taken. This information is crucial for optimizing the performance of multiplication operations in parallel processing environments.
</details>
e) Divider.: Figure 22 shows the 16-bit divider's compute time with respect to core count. A 16-bit divider requires 32 cores to achieve the best parallel computing performance. From the chart, divider's latency decreases as the core count increases from 1 to 32. From 32 cores on, the divider's latency stays at around 12000ms. The 16-bit divider has a maximum parallel computing speedup of 8.43x, reached when it can draw on 32 cores.
Fig. 22: Time vs Core count
<details>
<summary>Image 24 Details</summary>
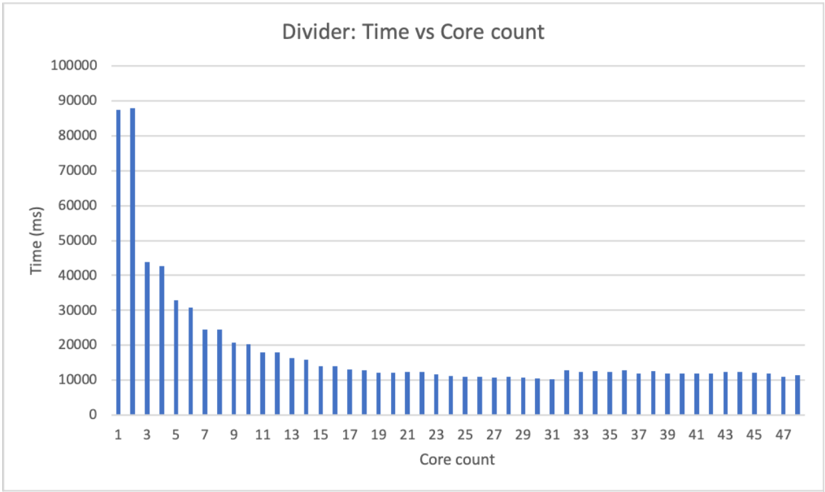
### Visual Description
## Bar Chart: Divider: Time vs Core count
### Overview
The bar chart displays the relationship between the time taken by a divider and the core count. The x-axis represents the core count, ranging from 1 to 47, while the y-axis represents the time in milliseconds, ranging from 0 to 100,000 ms.
### Components/Axes
- **Title**: Divider: Time vs Core count
- **X-axis**: Core count (ranging from 1 to 47)
- **Y-axis**: Time (milliseconds, ranging from 0 to 100,000 ms)
- **Legend**: No legend is present in the image.
### Detailed Analysis or ### Content Details
The chart shows a clear inverse relationship between the core count and the time taken by the divider. As the core count increases, the time taken decreases. The highest time taken is observed at a core count of 1, with a time of approximately 85,000 ms. The time taken decreases as the core count increases, reaching its lowest point at a core count of 47, with a time of approximately 10,000 ms.
### Key Observations
- The highest time taken is at a core count of 1.
- The time taken decreases as the core count increases.
- The lowest time taken is at a core count of 47.
### Interpretation
The data suggests that as the number of cores increases, the time taken by the divider decreases. This could be due to the parallel processing capabilities of multi-core systems, where multiple tasks can be executed simultaneously, reducing the overall time taken. However, it is important to note that the relationship is not linear, as the time taken decreases more rapidly at lower core counts and then levels off at higher core counts. This could be due to the overhead of managing multiple cores and the diminishing returns of additional cores.
</details>
f) Bitwise operations.: Figure 23 shows 16-bit bitwise operation's compute time with respect to the core count. 16-bit bitwise ops requires 16 cores to have the best parallel computing performance. From the graph, at core count 16 the bitwise operation reached its top speed. At 16 cores and beyond, the latency stays around 50ms. 16-bit bitwise op has a maximum parallel computing speedup of 8.63x.
Fig. 23: Time vs Core count
<details>
<summary>Image 25 Details</summary>
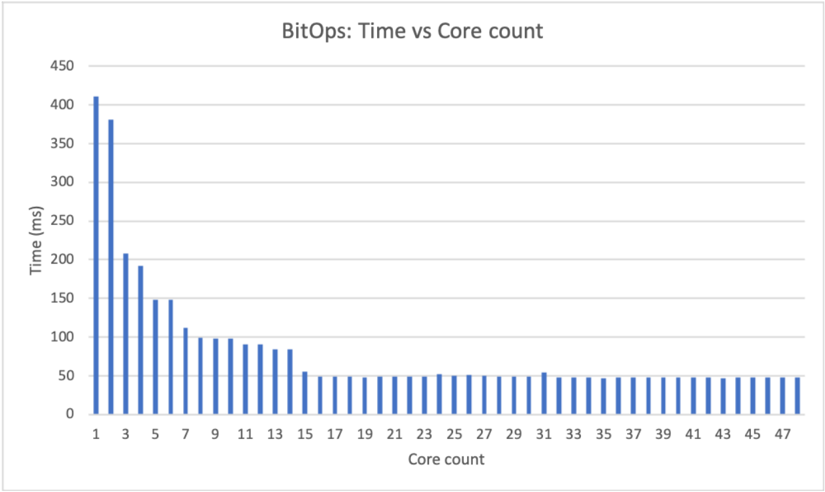
### Visual Description
## Bar Chart: BitOps: Time vs Core count
### Overview
The bar chart displays the relationship between the number of cores and the time taken to perform a certain operation, measured in milliseconds (ms). The x-axis represents the number of cores, ranging from 1 to 47, while the y-axis represents the time taken, ranging from 0 to 450 ms.
### Components/Axes
- **Title**: BitOps: Time vs Core count
- **X-axis**: Core count, with values ranging from 1 to 47
- **Y-axis**: Time (ms), with values ranging from 0 to 450 ms
- **Legend**: No legend is present in the image
### Detailed Analysis or ### Content Details
The chart shows a clear trend where the time taken increases as the number of cores increases. The highest time taken is 400 ms, which corresponds to a core count of 1. The time taken decreases as the core count increases, with the lowest time taken being 50 ms, which corresponds to a core count of 47.
### Key Observations
- The chart shows a positive correlation between the number of cores and the time taken.
- The time taken decreases as the core count increases.
- The highest time taken is 400 ms, which corresponds to a core count of 1.
- The lowest time taken is 50 ms, which corresponds to a core count of 47.
### Interpretation
The data suggests that the time taken to perform the operation increases as the number of cores increases. This could be due to the fact that more cores mean more processing power, but also more communication overhead between the cores. The positive correlation between the number of cores and the time taken suggests that the operation is not highly parallelizable. The highest time taken is 400 ms, which corresponds to a core count of 1, suggesting that the operation is not highly parallelizable even with a single core. The lowest time taken is 50 ms, which corresponds to a core count of 47, suggesting that the operation is highly parallelizable even with a large number of cores.
</details>
- g) Conditional Flags.: Figure 24 shows the 16-bit conditional flag unit's compute time with respect to core count. A 16-bit conditional flag unit runs a maximum of 18 threads in parallel. On the chart from core count 15 onward, the latency of the conditional flag unit hovers at around 120-130ms. The maximum parallel computing speedup is 4.7x.
Fig. 24: Time vs Core count
<details>
<summary>Image 26 Details</summary>
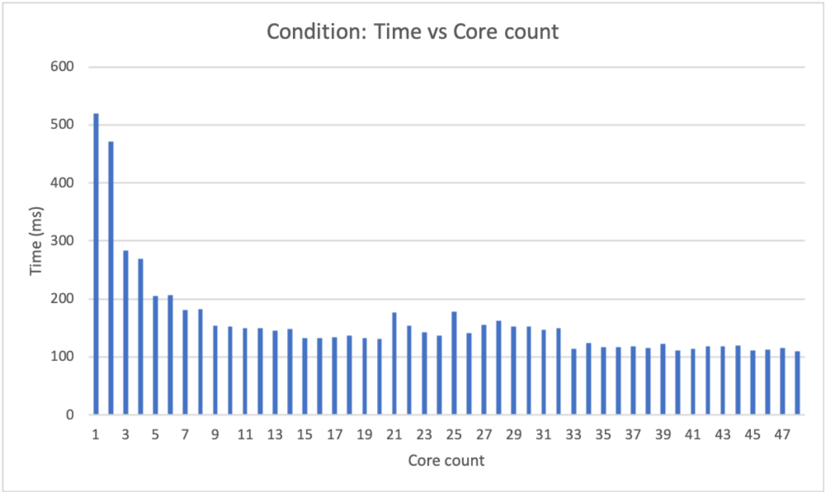
### Visual Description
## Bar Chart: Condition: Time vs Core count
### Overview
The bar chart displays the relationship between time (in milliseconds) and the core count of a system under a specific condition. The x-axis represents the core count, ranging from 1 to 47, while the y-axis represents the time taken, ranging from 0 to 600 milliseconds.
### Components/Axes
- **Title**: Condition: Time vs Core count
- **X-axis**: Core count, with values ranging from 1 to 47
- **Y-axis**: Time (ms), with values ranging from 0 to 600 milliseconds
- **Legend**: No legend is present in the image
### Detailed Analysis or ### Content Details
The chart shows a clear trend where the time taken increases as the core count increases. The highest time recorded is approximately 500 milliseconds, which corresponds to a core count of 1. The time then decreases as the core count increases, reaching a minimum of around 100 milliseconds at a core count of 47.
### Key Observations
- The time taken increases with the core count, indicating that more cores may lead to longer processing times.
- There is a significant increase in time at a core count of 1, which could be due to the overhead of managing multiple cores.
- The time then decreases as the core count increases, suggesting that adding more cores can improve performance.
### Interpretation
The data suggests that the system's performance is influenced by the number of cores used. With a single core, the system takes the longest time to complete tasks, likely due to the overhead of managing a single core. As the number of cores increases, the time taken decreases, indicating improved performance. This trend is consistent with the concept of parallel processing, where multiple cores can work together to complete tasks faster than a single core. However, there is a point of diminishing returns, where adding more cores does not significantly improve performance, as seen at a core count of 47. This could be due to the complexity of the tasks being performed or the limitations of the system's architecture.
</details>
## C. Vulnerability
There are two source of vulnerability associated with the current CryptoEmu implementation: ( i ) the unencrypted HE instruction memory; and ( ii ) the branch resolution process.
Because HE instruction memory is in cleartext, the cloud knows exactly what assembly code is being executed. Assumption 2 assumes that the cloud is honest, so cloud visible instructions to the cloud do not pose a security issue. However, it is possible that the cloud's execution pipeline is compromised by attackers. If an attacker obtains control over the instruction set emulator, or performs a side-channel attack, user data can be breached.
If Assumption 2 is lifted, then the unencrypted HE instruction memory becomes a security loophole.Note that, we still assume the cloud will not start a denial of service attack on user. For example, if user send an encrypted number such as age, credit score or salaries, the cloud can also use binary search to actively query the value of an encrypted data using conditional unit implemented in CryptoEmu, and eventually find out the cleartext. User can counter the attack by sending HE instructions with anti-disassembly techniques, making it difficult for side-channel attack. However, this approach does not eliminate an active attack from cloud.
The cloud is able to actively find encrypted data's value because the cloud can abuse the branch resolution process. The problem can be solved by having the user assume control over the branch resolution process [15]. The user can ask for encrypted data from cloud, decrypt and process the data, send data back to cloud and inform the cloud which is the next instruction to fetch. With some extra overhead in data transmission, the user can make branch resolution unknown to the cloud and has full control over branch resolution.
## D. Comparison against the state of the art
HELib [4] is one of the most widely adopted FHE software libraries. HELib implements the Brakerski-Gentry-Vaikuntanathan (BGV) scheme and supports basic homomorphic operations [21]. HELib has native support for binary negation, addition/subtraction, multiplication, binary condition, shift immediate, bitwise operation and binary comparison. CryptoEmu supports all these operation and a few more: left shift/right shift with encrypted amount, unsigned binary division, and NZCV condition flag computation. This section compares the performance of the operations supported by both HELib and CryptoEmu.
TABLE XXIV: HELib vs CryptoEmu
| Operation | HELib | CryptoEmu (single core) | CryptoEmu (multi-core) | Speedup |
|---------------------------|------------|---------------------------|--------------------------|-----------|
| Addition | 10484.1ms | 4400.67ms | 566.149ms | 18.518x |
| Subtraction | 10962.2ms | 5088.57ms | 599.396ms | 18.289x |
| Multiplication (unsigned) | 69988.9ms | 86389.8ms | 10396.1ms | 6.732x |
| Multiplication (signed) | 81707.2ms | 92408.4ms | 10985.4ms | 7.438x |
| LLS (immediate) | 0.534724ms | 0.0040335ms | 0.0040335ms | 132.571x |
| Bitwise XOR | 1.52444ms | 416.013 ms | 47.1986ms | -30.9613x |
| Bitwise OR | 771.12ms | 416.146 ms | 47.6171ms | 16.194x |
| Bitwise AND | 756.641ms | 411.014ms | 47.6001ms | 15.90x |
| Bitwise NOT | 1.8975ms | 0.012508 ms | 0.012508 ms | 151.703x |
| Comparison | 4706.07ms | 519.757ms | 110.416ms | 42.62x |
As reported in Table XXIV, for addition and subtraction, CryptoEmu's single core performance is about two times faster than HELib's. With sufficient cores, CryptoEmu yields maximum 18x speed up compare to HELib. For both signed and unsigned multiplication, CryptoEmu in single core mode is slightly slower than HELib. CryptoEmu yields a maximum 7x speed up in multiple core mode compare to HELib.
HELib supports logic left shift (LLS) with immediate. This operation is not computationally intensive compared to addition/subtraction. LLS with immediate is not implemented without parallel computing optimizations on CryptoEmu, and therefore single core latency is the same as multi-core latency. Because of the excellent support provided by TFHE library, LLS with immediate on CryptoEmu is about 132x faster than on HELib.
For bitwise operation, HELib's bitwise XOR is in fact 31x faster than CryptoEmu. This is expected because the implementation for HELib's bitwise XOR is not computationally expensive. For bitwise OR and bitwise AND, CryptoEmu's single core speed is faster than HELib's. When maximum cores are enabled, CryptoEmu yields 16x speed up on bitwise OR and bitwise AND compared to HELib.
Bitwise NOT is not a computationally expensive operation on both CryptoEmu and HELib. Because bitwise NOT is implemented without parallel computing techniques, single core and multi-core performance are the same on CryptoEmu. By comparison, CryptoEmu is 151x faster than HELib on bitwise NOT operation.
For comparison/conditional operations, we benchmarked HELib's CompareTwo() function and CryptoEmu's conditional unit. HELib's compare routine compares two encrypted values and returns the greater/lesser number and comparison result. Our CryptoEmu compares two encrypted data and returns N, Z, C, and V flags. Because the Z-flag computation is on conditional unit's critical path, it is justified to compare latencies of two functionally equivalent operations that are on both unit's critical
paths. CryptoEmu's comparison is much faster than HELib's in single core mode. When multiple cores are enabled, CryptoEmu yields maximum speedup of 42x.
## VIII. CONCLUSION AND FUTURE WORK
CryptoEmu successfully supports multiple homomorphic instructions on a multi-core host. With function units built upon the TFHE bootstrapped gate library, CryptoEmu is reconfigurable and reusable for general purpose computing. Through parallel computing algorithms that significantly reduces time complexity, CryptoEmu has a scalable implementation and achieves parallel computing speedup from 4.7x to 10.94x on functional units. Compare to HELib, CryptoEmu has maximum 18x speedup on addition/subtraction, 7x speedup on multiplication, 16x speed up on bitwise AND/OR, 42x speedup on comparison, 130x speedup on left shift with immediate, and 151x speedup on bitwise NOT.
Scalability of CryptoEmu can be further improved. The current design only supports single instruction set emulator process that runs on multiple cores. Therefore maximum core count is bounded by number of cores on one CPU. With more cores available, CryptoEmu can draw on more parallelism through pipelining, multiple instruction issue and dynamic instruction scheduling. Another aspect that could provide further speed improvements is the use of AVX instructions.
## REFERENCES
- [1] J. Clement, 'Cyber crime: number of breaches and records exposed 2005-2020.' https://www.statista.com/statistics/273550, 2020. Accessed on 2020Dec-01.
- [2] I. Chillotti, N. Gama, M. Georgieva, and M. Izabach` ene, 'TFHE: Fast fully homomorphic encryption library,' August 2016, Accessed on 2020-Dec-01. https://tfhe.github.io/tfhe.
- [3] I. Chillotti, N. Gama, M. Georgieva, and M. Izabachene, 'Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds,' in international conference on the theory and application of cryptology and information security , pp. 3-33, Springer, 2016.
- [4] S. Halevi and V. Shoup, 'An implementation of homomorphic encryption,' 2013, Accessed on 2020-Dec-17. https://github.com/shaih/HElib.
- [5] A. Acar, H. Aksu, A. S. Uluagac, and M. Conti, 'A survey on homomorphic encryption schemes: Theory and implementation,' ACM Computing Surveys (CSUR) , vol. 51, no. 4, pp. 1-35, 2018.
- [6] C. Gentry, 'Fully homomorphic encryption using ideal lattices,' in Proceedings of the forty-first annual ACM symposium on Theory of computing , pp. 169-178, 2009.
- [7] I. Chillotti, N. Gama, M. Georgieva, and M. Izabach` ene, 'Tfhe: fast fully homomorphic encryption over the torus,' Journal of Cryptology , vol. 33, no. 1, pp. 34-91, 2020.
- [8] L. Ducas and D. Micciancio, 'Fhew: bootstrapping homomorphic encryption in less than a second,' in Annual International Conference on the Theory and Applications of Cryptographic Techniques , pp. 617-640, Springer, 2015.
- [9] I. Chillotti, N. Gama, M. Georgieva, and M. Izabach` ene, 'Faster packed homomorphic operations and efficient circuit bootstrapping for tfhe,' in International Conference on the Theory and Application of Cryptology and Information Security , pp. 377-408, Springer, 2017.
- [10] S. Halevi and V. Shoup, 'Design and implementation of a homomorphic-encryption library,' IBM Research (Manuscript) , vol. 6, pp. 12-15, 2013.
- [11] Z. Brakerski, C. Gentry, and V. Vaikuntanathan, '(leveled) fully homomorphic encryption without bootstrapping,' ACM Transactions on Computation Theory (TOCT) , vol. 6, no. 3, pp. 1-36, 2014.
- [12] O. Mazonka, N. G. Tsoutsos, and M. Maniatakos, 'Cryptoleq: A heterogeneous abstract machine for encrypted and unencrypted computation,' IEEE Transactions on Information Forensics and Security , vol. 11, no. 9, pp. 2123-2138, 2016.
- [13] P. Paillier, 'Public-key cryptosystems based on composite degree residuosity classes,' in International conference on the theory and applications of cryptographic techniques , pp. 223-238, Springer, 1999.
- [14] N. G. Tsoutsos and M. Maniatakos, 'Heroic: homomorphically encrypted one instruction computer,' in 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE) , pp. 1-6, IEEE, 2014.
- [15] F. Irena, D. Murphy, and S. Parameswaran, 'Cryptoblaze: A partially homomorphic processor with multiple instructions and non-deterministic encryption support,' in 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC) , pp. 702-708, IEEE, 2018.
- [16] OpenMP, 'Specification Standard 5.1.' Available online at http://openmp.org/wp/, 2020.
- [17] K. Vitoroulis, 'Parallel prefix adders,' Concordia university , 2006.
- [18] A. D. Booth, 'A signed binary multiplication technique,' The Quarterly Journal of Mechanics and Applied Mathematics , vol. 4, no. 2, pp. 236-240, 1951.
- [19] C. Terman, '6.004 computation structures.' MIT OpenCourseWare, https://ocw.mit.edu, Spring 2017.
- [20] geeksforgeeks.org, 'Non-restoring division for unsigned integer.' https://www.geeksforgeeks.org/non-restoring-division-unsigned-integer, 2018, Accessed on 2020-Dec-09.
- [21] S. Halevi and V. Shoup, 'Algorithms in helib,' in Annual Cryptology Conference , pp. 554-571, Springer, 2014.
<details>
<summary>Image 27 Details</summary>

### Visual Description
## [Chart/Diagram Type]: [Brief Title]
### Overview
The image is a black and white portrait of a young man. He has short hair, is smiling, and is wearing a dark sweater over a white collared shirt. The background is plain and does not contain any additional details.
### Components/Axes
- There are no axes or labels visible in the image. The image is a portrait and does not contain any data or graphical elements that would require axes or labels.
### Detailed Analysis or ### Content Details
- The image does not contain any numerical data or trends. It is a simple portrait of a person.
### Key Observations
- The image does not provide any information about the subject's occupation, age, or any other personal details.
- The image is a static portrait and does not contain any dynamic elements or trends.
### Interpretation
- The image does not provide any information that can be interpreted or analyzed. It is a simple portrait of a person and does not contain any data or trends that can be used for analysis.
</details>
<details>
<summary>Image 28 Details</summary>

### Visual Description
## Image Description
### Overview
The image is a black and white photograph of a man. He appears to be in his middle years, with short hair and a neutral expression on his face. He is wearing a light-colored shirt with a collar. The background is nondescript and blurred, making it difficult to discern any specific details.
### Components/Axes
- **Labels**: There are no visible labels on the image.
- **Axes**: There are no axes present in the image.
- **Legends**: There are no legends visible in the image.
- **Axis Markers**: There are no axis markers visible in the image.
### Detailed Analysis or ### Content Details
- **Specific Values**: There are no specific numerical values visible in the image.
- **Trends**: There are no trends visible in the image.
- **Distributions**: There are no distributions visible in the image.
### Key Observations
- **Notable Patterns**: There are no notable patterns visible in the image.
- **Outliers**: There are no outliers visible in the image.
- **Trends**: There are no trends visible in the image.
### Interpretation
- **What the Data Means**: The image does not contain any data or information that can be interpreted.
- **Why It Matters**: The image does not provide any context or reason for its significance.
- **Peircean Investigative, Reading Between the Lines**: The image does not provide any clues or hints that require further interpretation.
### Conclusion
The image is a simple black and white photograph of a man without any visible data, trends, or patterns. It does not provide any information that can be used for further analysis or interpretation.
</details>
Xiaoyang Gong is a graduate student in the Department of Electrical and Computer Engineering at the University of WisconsinMadison. Xiaoyang received his MS in Electrical Engineering in 2020 and BS in Computer Engineering in 2019 from the University of Wisconsin-Madison. He worked as an intern at Arm Ltd.'s CPU team in 2019. His interests are in computer architecture and processor design.
Dan Negrut is a Mead Witter Foundation Professor in the Department of Mechanical Engineering at the University of WisconsinMadison. He has courtesy appointments in the Department of Computer Sciences and the Department of Electrical and Computer Engineering. Dan received his Ph.D. in Mechanical Engineering in 1998 from the University of Iowa under the supervision of Professor Edward J. Haug. He spent six years working for Mechanical Dynamics, Inc., a software company in Ann Arbor, Michigan. In 2004 he served as an Adjunct Assistant Professor in the Department of Mathematics at the University of Michigan, Ann Arbor. He spent 2005 as a Visiting Scientist at Argonne National Laboratory in the Mathematics and Computer Science Division. He joined University of Wisconsin-Madison in 2005. His interests are in Computational Science and he leads the Simulation-Based Engineering Lab. The lab's projects focus on high performance computing, computational dynamics, artificial intelligence, terramechanics, autonomous vehicles, robotics, and fluid-solid interaction problems. Dan received the National Science Foundation Career Award in 2009. Since 2010 he is an NVIDIA CUDA Fellow.