# Visually Informed Binaural Audio Generation without Binaural Audios
**Authors**: Xudong Xu, Hang Zhou, Ziwei Liu, Bo Dai, Xiaogang Wang, Dahua Lin
## Visually Informed Binaural Audio Generation without Binaural Audios
Xudong Xu 1 * Hang Zhou 1 * Ziwei Liu 2 Bo Dai 2 Xiaogang Wang 1 Dahua Lin 1 1 CUHK - SenseTime Joint Lab, The Chinese University of Hong Kong 2 S-Lab, Nanyang Technological University
{xx018@ie,zhouhang@link,xgwang@ee,dhlin@ie}.cuhk.edu.hk , {ziwei.liu,bo.dai}@ntu.edu.sg
## Abstract
Stereophonic audio, especially binaural audio, plays an essential role in immersive viewing environments. Recent research has explored generating visually guided stereophonic audios supervised by multi-channel audio collections. However, due to the requirement of professional recording devices, existing datasets are limited in scale and variety, which impedes the generalization of supervised methods in real-world scenarios. In this work, we propose PseudoBinaural , an effective pipeline that is free of binaural recordings. The key insight is to carefully build pseudo visual-stereo pairs with mono data for training. Specifically, we leverage spherical harmonic decomposition and head-related impulse response (HRIR) to identify the relationship between spatial locations and received binaural audios. Then in the visual modality, corresponding visual cues of the mono data are manually placed at sound source positions to form the pairs. Compared to fully-supervised paradigms, our binaural-recording-free pipeline shows great stability in cross-dataset evaluation and achieves comparable performance under subjective preference. Moreover, combined with binaural recordings, our method is able to further boost the performance of binaural audio generation under supervised settings 1 .
## 1. Introduction
Auditory and visual experiences are implicitly but strongly connected. In immersive environments, the perception of sound is impacted by visual scenes [48]. Therefore, researchers have explored ways to generate stereophonic audios with visual guidance, in order to improve the user experience in multimedia products. Specifically, supervised learning methods [22, 14, 20, 49] have been considered for this purpose.
* Equal contribution.
1 Code, models and demo videos are available at https:// sheldontsui.github.io/projects/PseudoBinaural .
However, it is noteworthy that fully-supervised learning methods, despite the positive results that they achieve under constrained settings, would face significant difficulties in real-world applications. 1) They rely on videos associated with stereophonic recordings, which we refer to as 'visualstereo' pairs [22, 14]. Obtaining a high-quality collection of real stereo data requires complicated and professional recording systems ( e.g. microphone arrays or dummy heads), thus is both resource-demanding and time-consuming. 2) The models trained on datasets collected under controlled environments may overfit to the layout of the rooms, rather than capturing the general associations between sound effects and the visual locations of the sound sources. The resultant models would also have poor generalization capability.
The privilege of learning representations from unlabeled data has been well discussed in different fields of deep learning [43, 18, 3, 23, 25]. This inspires us to explore an alternative approach, namely, to use only mono audios which can be acquired much more easily compared to binaural audios. We note that mono audios have been successfully applied in learning visually informed sound separation [9, 1, 13, 46, 45, 15]. Zhou et al. [49] recently leverage mono audios for stereo generation. However, their stereophonic learning procedure still depends on stereo data.
In this work, we propose PseudoBinaural , a novel pipeline that generates visually coherent binaural audios without accessing any recorded binaural data. Our key insight is to carefully build pseudo visual-stereo pairs from mono data. Two questions need to be identified in order to achieve our goal. Given a spatial location, 1) what is the relationship between a mono audio and its binaural counterpart sourcing from that location? 2) How should visual cues be organized to represent the source visually? Our solution is to utilize two mappings. A Mono-Binaural-Mapping to reproduce binaural audios of a single source positioned at any spatial location, and a Visual-Coordinate-Mapping that associates visual modality with spatial locations. Specifically, the Mono-Binaural-Mapping is achieved by adopting spherical harmonic decomposition [8]. A head-related impulse response (HRIR) [6] is then used to render binaural
̂
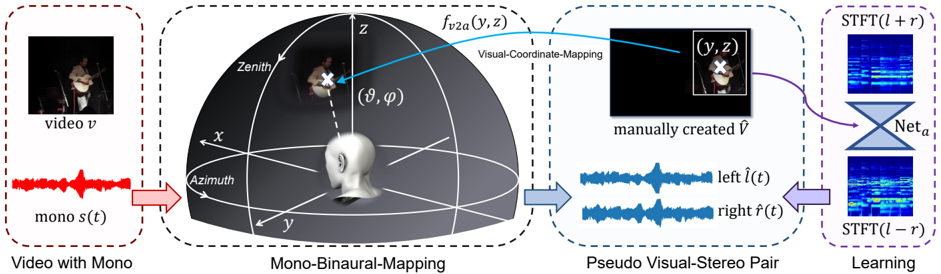
Figure 1: The pipeline of our method. Given one mono source, we create a pseudo visual-stereo pair { ˆ V , ( ˆ l, ˆ r ) } by assigning the source direction ϑ = ( ϑ, ϕ ) in the spherical coordinates according to our manually created ˆ V . Then mono source s ( t ) is converted to binaural channels ( ˆ l ( t, ϑ ) , ˆ r ( t, ϑ )) through our Mono-Binaural-Mapping procedure by leveraging spherical harmonics decomposition. Within this pipeline, multiple sources can be linearly blended together to build training pairs. Then mono-to-binaural networks can be trained on the created pseudo data.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Audio-Visual Processing Pipeline with Spatial Mapping and Learning
### Overview
The diagram illustrates a technical pipeline for processing audio-visual data, integrating spatial coordinate mapping, pseudo stereo pair generation, and machine learning. It connects four primary components:
1. **Video with Mono** (input)
2. **Mono-Binaural-Mapping** (spatial transformation)
3. **Pseudo Visual-Stereo Pair** (audio-visual synthesis)
4. **Learning** (neural network refinement)
### Components/Axes
#### 1. Video with Mono
- **Visual Input**: Labeled "video v" (top-left corner).
- **Audio Input**: Red waveform labeled "mono s(t)" (bottom-left corner).
- **Spatial Coordinates**:
- 3D coordinate system with axes labeled **X**, **Y**, **Z**.
- **Zenith** (top of Z-axis), **Azimuth** (horizontal plane).
- Angles **θ** (polar angle) and **φ** (azimuthal angle) marked near a 3D head model.
#### 2. Mono-Binaural-Mapping
- **Visual-Coordinate-Mapping**: Blue arrow labeled **f<sub>v2a</sub>(y,z)** connects the 3D head model to a pseudo stereo pair.
- **Manually Created Visual**: Labeled **Ṽ** (black square with crosshair).
#### 3. Pseudo Visual-Stereo Pair
- **Left Audio**: Blue waveform labeled **left l̂(t)**.
- **Right Audio**: Blue waveform labeled **right r̂(t)**.
- **Visual Output**: Black square with crosshair (mirroring the manually created **Ṽ**).
#### 4. Learning
- **STFT Visualizations**:
- **STFT(l + r)**: Blue spectrogram (top-right).
- **STFT(l - r)**: Blue spectrogram (bottom-right).
- **Neural Network**: Labeled **Net<sub>a</sub>** (gray diamond connecting STFT outputs).
### Detailed Analysis
- **Spatial Mapping**: The 3D coordinate system (X, Y, Z) defines a spherical coordinate framework for mapping audio-visual relationships. The head model anchors the origin, with **θ** and **φ** defining directional vectors.
- **Pseudo Stereo Generation**: The left/right audio waveforms (**l̂(t)**, **r̂(t)**) are derived from the mono input **s(t)** via coordinate transformations.
- **Learning Phase**: The STFT visualizations (**STFT(l + r)**, **STFT(l - r)**) represent frequency-domain analysis of the synthesized stereo pair, refined by **Net<sub>a</sub>**.
### Key Observations
- **Color Coding**:
- Red: Mono audio (**s(t)**).
- Blue: Pseudo stereo audio and STFT outputs.
- Purple: Learning phase (STFT and network).
- **Flow Direction**: Arrows indicate sequential processing from input (video/audio) to spatial mapping, stereo synthesis, and finally learning.
- **Missing Elements**: No explicit numerical values or data tables; the diagram focuses on conceptual relationships.
### Interpretation
This pipeline demonstrates a method for enhancing mono audio-visual data by:
1. Mapping spatial coordinates to simulate binaural hearing.
2. Generating pseudo stereo pairs to enrich audio depth.
3. Using STFT and neural networks to refine frequency-domain representations.
The absence of numerical data suggests the diagram emphasizes architectural design over empirical results. The use of **Net<sub>a</sub>** implies a focus on adaptive learning for audio-visual synchronization. The crosshair in **Ṽ** may indicate a focal point for coordinate alignment, critical for accurate spatial mapping.
</details>
audios from the zero- and first-order terms of the decomposition. As for the Visual-Coordinate-Mapping, we pre-define a correspondence between pixel coordinates and spherical coordinates, so that we can easily manipulate visual content to meet the designation of the corresponding source direction.
Existing models for visually informed binaural audio generation can be readily adapted to train on our pseudo visual-stereo pairs. In order to make the best use of mono data, we further propose a new way of leveraging the task of audio-visual source separation [46, 15] to assist the training. The inference procedure is to simply apply the trained models to videos with mono audios and generate corresponding binaural audios. Our framework renders stable performances on two datasets and in-the-wild scenarios. Moreover, we can mix our pseudo data with real stereophonic recordings to further boost the performance of binaural audio generation under the supervised setting.
Our contributions can be summarized as follows: 1) We identify the mapping between source directions and binaural audios with theoretical analysis. 2) By manipulating the visual modality, pseudo visual-stereo pairs can be generated for model training without relying on any recorded binaural data. 3) Extensive experiments validate the effectiveness and stability of our method on a variety of scenes. Moreover, our pseudo visual-stereo data can serve as a strong augmentation under the supervised setting.
## 2. Related Work
Visually Informed Stereophonic Audio Generation. While stereo is strongly correlated with visual information, only few papers have proposed to guide the generation of stereo with vision. Li et al. [19] combine a synthesized early reverberation and a measured late reverberation tail for the generation of stereo sound in the desired room. However, the usage of such method is restricted to specific rooms and serves for 360 ◦ videos. Morgado et al. [22] propose to recover ambisonics based on the datasets collected from YouTube. They assume that their end-to-end network is able to separate sound sources and reformulate them with learnable weights. Lu et al. [20] leverage flow with corresponding classifier for stereo generation. Specifically, Gao et al. [14] collect the FAIR-Play dataset using professional bianural audio collecting mics in a music room. Then they propose the Mono2bianural pipeline for converting mono audios to bianural ones in a U-Net framework. Their data is precious yet limited, models trained on their lab-collected data are difficult to generalize well on in-the-wild scenarios. Very recently, Zhou et al. [49] leverage mono data and propose to tackle stereophonic audio generation and source separation at the same time. Nevertheless, their method uses mono data to train separation only. All the above methods rely on recorded stereophonic data and visual-stereo pairs for training. We target to generate visually guided binaural audios without any binaural data.
Visually Indicated Sound Source Separation. The task of visually guided sound source separation aims at separating a mixed audio into independent ones, according to their sound source's visual appearances. It has long been an interest of research for both human speech [10, 21, 26, 9, 1] and music [27, 13, 46, 45, 15, 11, 38, 35]. Recent learningbased methods [1, 46, 45, 15, 42] all leverage the Mix-andSeparate training pipeline that creates training pairs using collected solo data. Our work also exploits the same type of data to build training samples for binaural generation. We also adopt the setting of separating two sources [49] to boost the final performance.
Sound Source Localization. One of the most important features for human auditory system is to localize sound by the subtle differences of intensity, spectral and time cues between ears [7]. In the audio domain, previous research
mostly relies on microphone arrays to perform direction of arrival estimation [44]. Multi-modality works learn audiovisual associations [4, 5, 37, 36, 47, 41, 50] and propose to localize the responses of sound in the visual domains [46, 32, 28, 17] a different type of 'source localization". Recent works [12, 39] propose to detect the position of vehicles with stereo audio, which deals with the opposite of our task. Normally, the visualization of activation is used to show auditorily associated visual information [4, 26, 25, 5, 45, 22, 14]. Our model also shows the ability of source localization by training only on our pseudo visual-stereo pairs.
## 3. Methodology
Different from previous completely learning-based and data-driven methods that rely on the ground-truth stereo, we train networks on self-created pseudo visual-stereo pairs. Our method is thus called PseudoBinaural . The overall pipeline is illustrated in Fig. 1.
## 3.1. Mapping Mono to Binaural
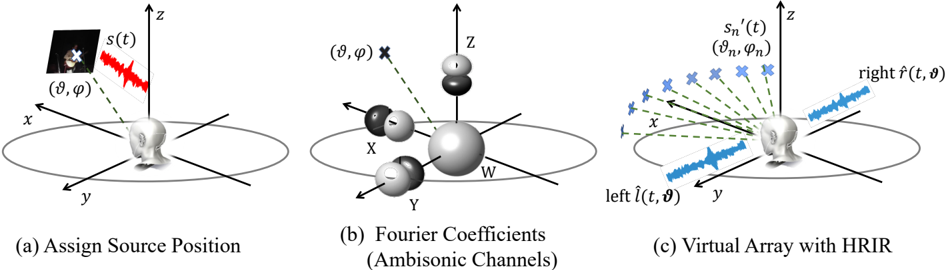
The key of our method relies on identifying the relationship between mono and stereo. This whole procedure, as illustrated in Fig. 2, is called Mono-Binaural-Mapping . Given a mono audio with an arbitrarily assigned source position ϑ = ( ϑ, ϕ ) (Fig. 2 a ), our goal is to first convert it to binaural channels with correct auditory sense of location. We empirically choose spherical harmonic decomposition for its expressive ability and its substantial connection with ambisonics (Fig. 2 b ). Finally, the decomposed coefficients are transformed to virtual array and rendered to audios with HRIR (Fig. 2 c ).
Spherical Harmonic Decomposition. The Laplace spherical harmonics represent a complete set of orthonormal basis defined on sphere surface [8]. The normalized form of spherical harmonics defined at azimuth angle ϑ and zenith angle ϕ in spherical coordinates can be represented as:
<!-- formula-not-decoded -->
where P | m | l (cos ϕ ) is the associated Legendre polynomials, integer l is its order and m is the degree, limited to [ -l, l ] . N | m | l is a normalization factor. Real spherical harmonics can serve as a type of generalized Fourier series, to decompose any function f :
<!-- formula-not-decoded -->
The coefficients Ψ l m are the analogs of Fourier coefficients which can be represented as ( ∗ denotes the conjunction):
<!-- formula-not-decoded -->
Decomposed Coefficients for Mono Source. Here we follow the simplest assumption that only the impulse response from the direction ϑ = ( ϑ, ϕ ) of a single sound source s ( t ) is received, the Fourier coefficients can be derived from Eq. (3) as:
<!-- formula-not-decoded -->
This is the same as the encoding of ambisonics, where the Ψ l m ( ϑ ) can also be regarded as ambisonics' components. For simplicity, ϑ is omitted in the following representations associated with this pre-defined direction.
The zero- and first-order components ( l = 0 , 1 ) that contribute most to 3D audio effect are leveraged in our model. Based on Eq. (1) and Eq. (4), the coefficients { Ψ 0 0 , Ψ 1 1 , Ψ -1 1 , Ψ 0 1 } ( ϑ omitted) can be written as:
<!-- formula-not-decoded -->
which correspond to the W, X, Y and Z channels of ambisonics, respectively. W is the omnidirectional base channel, X, Y and Z are the orthogonal channels lie along 3D Cartesian axes as illustrated in Fig. 2 (b).
Weadopt the Schmidt semi-normalization (SN3D) [40] to Eq. (1), which can be written as N l m = √ (2 -δ m ) ( l -| m | )! ( l + | m | )! , where δ m = 1 if m = 0 else 0 .
Binaural Decoding. Regarding the decomposed coefficients as ambisonic channels, we can roughly predict the left and right binaural channels ˆ l ( t ) and ˆ r ( t ) using simple transformation: ˆ l ( t ) = W + Yand ˆ r ( t ) = W -Y. However, this paradigm is unable to recover real binaural.
On the other hand, binaural sound can be directly synthesized given a source position with the head-related impulse response (HRIR). One set of HRIR data can serve as filters h r ( ϑ ) and h l ( ϑ ) with respect to the direction ϑ of the sound source. The transferred binaural sound can be represented as ˆ l ( t ) = h l ( ϑ ) s ( t ) and ˆ r ( t ) = h r ( ϑ ) s ( t ) , where is the convolution operation. However, open-sourced HRIR [2] are recorded in the free-field, thus cannot recover binaurals in a normal scene owing to reverberations.
Our solution is to leverage the binaural rendering technique that combines ambisonics with HRIR [24]. A virtual speaker array is pre-defined to make up for the reverberations as shown in Fig. 2 (c). Denoting the Fourier coefficients (ambisonic channels) as vectors Ψ( ϑ ) = s ( t ) Y ( ϑ ) = [Ψ 0 0 , Ψ 1 1 , Ψ -1 1 , Ψ 0 1 ] T (Refer to Eq. 5), we can further decompose Ψ( ϑ ) into M virtual speakers at directions Θ = [ ϑ ′ 1 , . . . , ϑ ′ M ] to analog the multi-source effect caused by room reverberations. We define the matrix D (Θ) = [ Y ( ϑ ′ 1 ) , . . . , Y ( ϑ ′ M )] , each column representing
𝑧𝑧
̂
Figure 2: The steps for the Mono-Binaural-Mapping procedure. (a) Firstly the mono sound source s ( t ) is assigned at direction ϑ = ( ϑ, ϕ ) . (b) Then through spherical harmonics decomposition of the source, we can derive the zero- and first-order spherical-based Fourier coefficients (which are also ambisonic channels). The figure represents the directions of the channels. (c) Finally, the Fourier coefficients can be transferred to a set of speaker array with fixed positions, and generate binaural with HRIR.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Spatial Audio Processing Components
### Overview
The image presents three interconnected diagrams illustrating spatial audio processing concepts: source positioning, ambisonic channel representation, and virtual array implementation with Head-Related Impulse Responses (HRIR). Each diagram uses 3D coordinate systems and vector representations to model acoustic phenomena.
### Components/Axes
**Diagram (a): Assign Source Position**
- 3D coordinate system (x, y, z axes)
- Spherical coordinate markers (θ, φ) for source direction
- Waveform label: s(t) (red waveform)
- Human head silhouette facing positive z-axis
**Diagram (b): Fourier Coefficients (Ambisonic Channels)**
- Central sphere (W) representing first-order ambisonics
- Four directional spheres (X, Y, Z, W) with vectors
- Spherical coordinate markers (θ, φ) for each channel
- Cross mark (×) indicating reference point
**Diagram (c): Virtual Array with HRIR**
- 3D coordinate system (x, y, z axes)
- Multiple blue crosses (×) labeled (θ_n, φ_n) representing virtual sources
- Waveforms: s'_n(t) (blue) and h(t, θ) (blue)
- Human head silhouette with left/right channel labels
- Legend: Blue = Virtual Array Elements
### Detailed Analysis
**Diagram (a)**
- Source position defined by spherical coordinates (θ, φ) in 3D space
- Waveform s(t) originates from source position
- Human head orientation aligned with z-axis (frontal view)
**Diagram (b)**
- Ambisonic channels represented by four spheres:
- X: Rightward vector
- Y: Forward vector
- Z: Upward vector
- W: Central omnidirectional channel
- Vectors show directional sensitivity of each channel
- Spherical coordinates (θ, φ) define angular relationships
**Diagram (c)**
- Virtual array implementation with N virtual sources (N ≥ 3)
- Each virtual source has:
- Directional coordinates (θ_n, φ_n)
- Associated HRIR waveform h(t, θ)
- Modified source waveform s'_n(t)
- Left/right channel representation with directional waveforms
### Key Observations
1. Spatial coordinate systems consistently use right-handed 3D axes
2. Ambisonic channels (X,Y,Z,W) form orthogonal basis for first-order ambisonics
3. Virtual array elements (blue crosses) are distributed around the head's coordinate system
4. HRIR waveforms (h(t, θ)) show directional filtering characteristics
5. Waveform transformations (s(t) → s'_n(t)) indicate spatial processing
### Interpretation
This diagram set demonstrates the mathematical and physical foundations of spatial audio processing:
1. **Source Localization**: Diagram (a) shows how sound sources are positioned in 3D space using spherical coordinates
2. **Ambisonic Encoding**: Diagram (b) illustrates the four-channel ambisonic representation, where each channel captures sound from a specific direction
3. **Virtual Source Synthesis**: Diagram (c) demonstrates how HRIR-based virtual arrays can create spatially localized sound sources through directional filtering
The progression from source positioning to ambisonic encoding to virtual array implementation reveals the complete pipeline for creating spatially accurate audio experiences. The use of consistent coordinate systems across diagrams emphasizes the mathematical relationships between physical space and acoustic representation.
</details>
the harmonics for each virtual source. The virtual audio signals s ′ ( t ) = [ s ′ 1 ( t ) , . . . , s ′ M ( t )] T can be constraint as:
<!-- formula-not-decoded -->
As the matrix D (Θ) T D (Θ) is of full-column rank, the virtual signals can be computed:
<!-- formula-not-decoded -->
Finally, we take advantage of HRIR filters to acquire the desired left and right channels:
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
The above is the binaural audio generated from a single mono source s ( t ) from direction ϑ .
## 3.2. Creating Pseudo Visual-Stereo Pairs
With the Mono-Binaural-Mapping. there are two questions left to achieve visually informed binaural generation: 1) How to leverage the visual information, and 2) how to connect the direction of the sound source with visual information. To this end, we create pseudo visual information and define a Visual-Coordinate-Mapping .
Pseudo Visual Information Creation. As illustrated in Fig. 1, assuming that the listener is facing towards the x axis in 3D Cartesian coordinates, frontal-view scenes can thus be projected to the y -z image plane. Given a video v k with a single sound source, we can place the center of the sound source v ′ k to a random position in the image plane. More specifically, the cropped frames v ′ k are placed to a background image ˆ V according to ˆ V ( y, z ) = v ′ k .
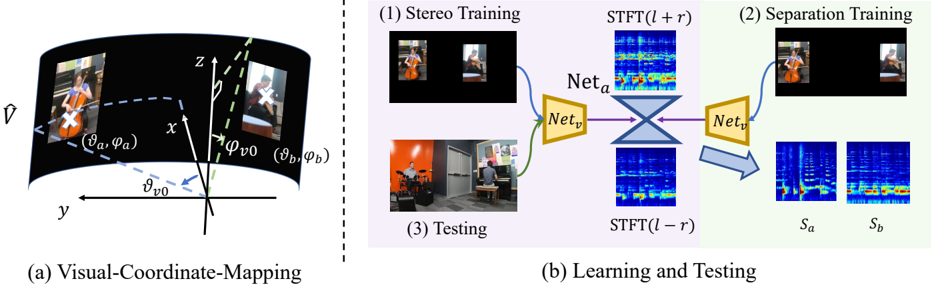
Visual-Coordinate-Mapping. We then define the mapping f v 2 a from pixel position ( y, z ) on frontal-view images to spherical angles ϑ = f v 2 a ( y, z ) . In the spherical coordinate, the frontal-view image plane is defined as part of a cylinder centered at the coordinate origin as shown in Fig. 3 (a).
Based on the fact that the effective visual field of humans is approximately 120 degrees [34], we define the border azimuth angle as ϑ v 0 = π/ 3 . So that objects within ˆ V are distributed within ϑ ∈ [ -ϑ v 0 , ϑ v 0 ] . The ratio between the height and width of the background image is set to H/W = 1 / 2 , thus the top edge of the image is corresponding to ϕ v 0 = π/ 2 -arctan( π/ 3) . The range is ϕ ∈ [ π/ 2 -arctan( π/ 3) , π/ 2 + arctan( π/ 3)] . In this way, for each point in the image plane, we can find an angle in the spherical coordinate. We have also explored other field of view settings and find subtle differences.
Create Pseudo Visual-Stereo Pairs. By calculating the corresponding angle ϑ k in spherical coordinates, a pair of binaural audios { ˆ r k ( t, ϑ k ) , ˆ l k ( t, ϑ k ) } can be recovered from the mono audio s k ( t ) accompanying v k ( t ) through Eq. (8).
Audio recordings collected in real-world scenarios are mostly mixed,therefore, we propose to mix multiple solo videos together in one scene to create pseudo visual-stereo pairs { ˆ V , ( ˆ l, ˆ r ) } . Each time, we assemble a random number of K independent mono videos s ( t ) = { s 1 ( t ) , . . . , s K ( t ) } together to form a pseudo visual-stereo pair. The self-created binaural can be written as ˆ l ( t ) = ∑ K k =1 ˆ l k ( t, ϑ k ) and ˆ r ( t ) = ∑ K k =1 ˆ r k ( t, ϑ k ) . The manually built visual information is ˆ V , where ˆ V ( ϑ k ) = v k , k ∈ [1 , K ] .
Note that the patch size and audio amplitude are both directly proportional to the reciprocal of the depth. Therefore, the mono audio is firstly normalized according to its wave amplitude, and the corresponding cropped patch v ′ k is normalized in the same scale as the audio. When the pseudo scene is assembled, v ′ k is randomly resized and placed on ˆ V
Figure 3: (a) Mapping from visual positions in the image domain to spherical angles. Normally we place the image ˆ V at the frontal-view to be part of a cylinder. The borders of the image are corresponding to the angles ϕ v 0 and ϑ v 0 . (b) Network details. The input to the audio UNet Net a is the STFT of a mono audio. The output is the prediction of the STFT difference between the left and right channels. During training, Net v extract the visual feature f v from our self-created image ˆ V , and concatenate it to the audio UNet. During testing, this network can be applied to normal frames.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Audio-Visual Processing Framework
### Overview
The image depicts a two-part technical framework for audio-visual processing. Part (a) illustrates a **Visual-Coordinate-Mapping** system using 3D coordinate transformations, while part (b) outlines a **Learning and Testing** pipeline involving stereo training, separation training, and testing phases with neural networks and STFT (Short-Time Fourier Transform) operations.
---
### Components/Axes
#### Part (a): Visual-Coordinate-Mapping
- **Axes**:
- **x, y, z**: 3D spatial axes.
- **θ (theta)** and **φ (phi)**: Angular coordinates for elevation and azimuth, respectively.
- **Labels**:
- **(θ_a, φ_a)**: Coordinates for the first visual element (e.g., a person playing a cello).
- **(θ_b, φ_b)**: Coordinates for the second visual element (e.g., a person in a different setting).
- **(θ_v0, φ_v0)**: Reference coordinates for the origin or baseline.
- **Visual Elements**:
- Two images of individuals (one with a cello, one in a room with a drum set).
- Dashed lines connecting angular coordinates to 3D space.
#### Part (b): Learning and Testing
- **Stages**:
1. **Stereo Training**: Inputs two stereo images (e.g., cello player and drummer).
2. **Separation Training**: Processes outputs through networks (`Net_a`, `Net_v`) and STFT operations.
3. **Testing**: Final output separation into `S_a` and `S_b`.
- **Networks**:
- `Net_a`: Processes the first input (e.g., cello player).
- `Net_v`: Processes the second input (e.g., drummer).
- **STFT Operations**:
- **STFT(l + r)**: Combines left (`l`) and right (`r`) audio channels.
- **STFT(l - r)**: Subtracts right from left audio channels.
- **Outputs**:
- `S_a` and `S_b`: Separated audio components (e.g., cello and drum sounds).
---
### Detailed Analysis
#### Part (a): Visual-Coordinate-Mapping
- **Angular Coordinates**:
- **(θ_a, φ_a)** and **(θ_b, φ_b)** map to distinct 3D positions, suggesting stereo vision or multi-view geometry.
- **(θ_v0, φ_v0)** likely represents a reference point (e.g., camera origin).
- **Dashed Lines**: Indicate geometric relationships between angular coordinates and 3D positions.
#### Part (b): Learning and Testing
- **Stereo Training**:
- Inputs two stereo images, processed by `Net_a` and `Net_v`.
- **Separation Training**:
- `Net_v` combines outputs from `Net_a` and `Net_v` via an X-shaped architecture.
- STFT operations (`l + r` and `l - r`) suggest audio feature extraction for separation.
- **Testing Phase**:
- Final outputs `S_a` and `S_b` represent isolated audio sources (e.g., cello and drum sounds).
---
### Key Observations
1. **Coordinate Mapping**: The 3D angular coordinates in part (a) imply a system for aligning visual and spatial data.
2. **Network Architecture**: The X-shaped connection between `Net_a` and `Net_v` suggests a fusion of features for separation.
3. **STFT Operations**: The use of `l + r` and `l - r` indicates a focus on phase and amplitude differences for audio separation.
4. **Output Separation**: `S_a` and `S_b` likely correspond to distinct audio sources derived from the input images.
---
### Interpretation
This framework appears to address **audio-visual source separation** using stereo imagery and neural networks. The 3D coordinate mapping in part (a) may enable spatial alignment of visual and audio data, while part (b) outlines a pipeline where:
- **Stereo Training** teaches the network to associate visual inputs with audio features.
- **Separation Training** refines the model to isolate individual audio sources (e.g., instruments).
- **Testing** validates the separation by producing `S_a` and `S_b`.
The STFT operations (`l + r` and `l - r`) are critical for capturing temporal and spectral differences between audio channels, enabling effective separation. The angular coordinates in part (a) suggest a geometric foundation for aligning visual and auditory data in 3D space.
---
**Note**: No explicit numerical values or data tables are present. The diagram focuses on conceptual relationships and architectural design.
</details>
to represent objects at different depths. Only mono audios are used in building the data.
## 3.3. Learning
We leverage neural networks for learning from mono and visual guidance to pseudo binaural output. Previous networks and training paradigms from Mono2Binaural [14] and Sep-Stereo [49] can be readily adapted to train on our data. The learning procedure is depicted in Fig. 3 (b).
Stereo Training. The main part of our learning procedure is to directly train networks using our pseudo visual-stereo pairs. The whole training procedure is basically following [14, 49]. It consists of a backbone U-Net [31] audio network Net a , and a ResNet18 [16] visual network Net v . The audios are all processed in the complex TimeFrequency domain in form of Short-Time Fourier Transformation (STFT). Mono is created from the left and right channels s m ( t ) = ˆ l ( t ) + ˆ r ( t ) and the input to Net a is the transformed mono spectrum S m = STFT ( s m ( t )) . Net a returns the complex mask M for final predictions. The training objective is the difference of the left and right spectrums S D = STFT ( ˆ l ( t ) -ˆ r ( t )) , which can be written as:
<!-- formula-not-decoded -->
Then the predicted difference spectrum is transferred back to the difference audio ˜ s D = ISTFT ( M∗ S m ) . The predicted left and right can be computed as ˜ l ( t ) = ( s m ( t ) + ˜ s D ( t )) / 2 and ˜ r ( t ) = ( s m ( t ) -˜ s D ( t )) / 2 .
Separation Training. Specifically, we leverage the task of separating two sources inspired by Sep-Stereo [49]. We care less about the performance on separation, but more about its benefits on distinguishing sound sources. Thus different from their visual feature rearrangement, we directly place two sources at separate edges when creating the pseudo visual input ˆ V (as shown in Fig. 3 (b)). The network input would be the pseudo pair { ˆ V , ( s a , s b ) } , where s a and s b are the individual mono audio signals. Then we leverage one APNet branch from [49] to predict the original STFTs S a and S b . In this way, the backbone network can learn better the association between the sources' visual and audio information. Please refer to the supplementary materials for details.
## 4. Experiments
## 4.1. Datasets
We emphasize creating binaurals for music, which is an important scenario for stereo production. We will at first show our analysis on the FAIR-Play dataset, then introduce other datasets we use.
Revisiting FAIR-Play. Collected in a music room, FAIRPlay [14] is one of the most influential datasets in this field. However, by carefully examining the dataset, we find that the original train-test splits are somewhat problematic. The whole dataset contains 1 , 871 clips cut from several different long camera recordings with approximately the same camera view and scene layouts. The clips are randomly divided into 10 different train-test splits. As a result, the scenes within train and test splits are overlapped, probably originate from the same recording. This would lead to serious overfitting problems. The models might learn layouts of the room instead of visual-stereo association that we desired.
In order to evaluate the true generalization ability of different models on this dataset, we take efforts to re-organize the FAIR-Play dataset through reconstructing the original videos and re-splitting them. Specifically, we first run a clustering algorithm on all the clips to roughly group them according to the scenes. Then by matching the first and last
Table 1: Quantitative results of binaural audio generation on FAIR-Play and MUSIC-Stereo dataset.Except for SNR, the lower the score, the better the results. The upper half shows the results of standard benchmarks and our PseudoBinaural method. The lower half shows the augmentation results and our ablation studies on different binaural decoding schemes (Sec. 3.1). Our method outperforms previous methods when augmented with binaural recordings. Moreover, our chosen decoding scheme achieves the best performance among three decoding methods.
| | FAIR-Play | FAIR-Play | FAIR-Play | FAIR-Play | FAIR-Play | MUSIC-Stereo | MUSIC-Stereo | MUSIC-Stereo | MUSIC-Stereo | MUSIC-Stereo |
|---------------------------|-------------|-------------|-------------|-------------|-------------|----------------|----------------|----------------|----------------|----------------|
| Method | STFT | ENV | Mag | D phase | SNR ↑ | STFT | ENV | Mag | D phase | SNR ↑ |
| Mono-Mono | 1.024 | 0.145 | 2.049 | 1.571 | 4.968 | 1.014 | 0.144 | 2.027 | 1.568 | 7.858 |
| Mono2Binaural [14] | 0.917 | 0.137 | 1.835 | 1.504 | 5.203 | 0.942 | 0.138 | 1.885 | 1.550 | 8.255 |
| PseudoBinaural (w/o sep.) | 0.951 | 0.140 | 1.914 | 1.539 | 5.037 | 0.953 | 0.139 | 1.902 | 1.564 | 8.129 |
| PseudoBinaural (Ours) | 0.944 | 0.139 | 1.901 | 1.522 | 5.124 | 0.943 | 0.139 | 1.886 | 1.562 | 8.198 |
| Sep-Stereo [49] | 0.906 | 0.136 | 1.811 | 1.495 | 5.221 | 0.929 | 0.135 | 1.803 | 1.544 | 8.306 |
| Augment-HRIR | 0.896 | 0.137 | 1.791 | 1.472 | 5.255 | 0.940 | 0.138 | 1.866 | 1.550 | 8.259 |
| Augment-ambisonic | 0.912 | 0.139 | 1.823 | 1.477 | 5.220 | 0.909 | 0.137 | 1.817 | 1.546 | 8.277 |
| Augment-PseudoBinaural | 0.878 | 0.134 | 1.768 | 1.467 | 5.316 | 0.891 | 0.132 | 1.762 | 1.539 | 8.419 |
frame of each clip within groups, we find the original order of the clips and concatenate them to recover the recorded videos. Finally, we select the videos whose scenes are completely absent in other videos as the validate and test sets. In this way, we create 5 different splits in which train and test sets are not overlapped. In our experiments, we re-train all supervised models (including Mono2Binaural [14] and Sep-Stereo [49]) and report the average results on the five splits. Please be noted that our model is also trained on this dataset, using only the solo part and mono audios .
MUSIC-Stereo [46, 45]. Containing 21 different types of instruments, MUSIC(21) is originally collected for visually guided sound separation. We select all the videos with binaural audio from MUSIC(21) and MUSIC-duet [46] to form a new dataset MUSIC-Stereo. Composed of solo and duet parts, it includes 1 , 120 unique videos of different musical performances. MUSIC-Stereo lasts 49.7 hours in total, which is 10 times larger than the FAIR-Play dataset. Following the post-processing steps in [14], we cut these videos into 17 , 940 10s clips and split them into training, validation, and test sets in an 8:1:1 ratio. Similar to FAIR-Play, only the solo part and mono audios are exploited for our model's training.
YT-Music [22]. This dataset is collected from 360 ◦ videos on YouTube in the ambisonic format. The audios are transferred to binaural in the same way as our decoding scheme. With distinct vision configurations and stereo audio characteristics, YT-MUSIC is the most challenging dataset.
## 4.2. Evaluation Metrics
Previous Metrics. The evaluation protocol within this field is basically the STFT distance and the envelope distance (ENV) between recovered audios and recorded ones [22, 14]. The STFT distance represents the mean square error com- puted on predicted spectrums, and the ENV distance is performed on raw audio waves through Hilbert transform [33]. To evaluate the predicted binaural audios more comprehensively, we also adopt two widely-used metrics Magnitude Distance (Mag) and Signal-to-noise Ratio (SNR) from [22]. The Mag distance reflects the L 2 deviation on the magnitude of spectrums and SNR is operated on the waveform directly. Newly Proposed Metric. In 3D audio sensation, audiences care more about sensing the source direction, where the phase of binaural audio is the key. As illustrated in [30], phase errors will introduce perceivable distortions but are always neglected during the optimization. Inspired by this, we further propose a new metric named Difference Phase Distance ( D phase ), which is performed on the Time-Frequency domain. Note that, the binaural audio is completely determined by the difference between left and right spectrums 3.3. Hence, D phase is to evaluate the phase distortion between the ground-truth difference S D and the predicted one ˜ S D = M∗ S m :
<!-- formula-not-decoded -->
where the phase is represented by the angle values, thus D phase ∈ [0 , 2 π ] . It's worth emphasizing that D phase is sensitive to the audio directions, i.e. , switching left and right channels would bring a significant change on this metric.
## 4.3. Quantitative Results
Binaural-Recording-Free Evaluation. Since no binauralrecording-free method has been proposed before, supervised method Mono2Binaural [14] whose backbone we borrow from, can be served as our baseline and upper bound. The evaluation is made on our newly-split FAIR-Play [14] and MUSIC-Stereo. For comparison, Mono2Binaural is trained with both visual frames and binaural audio, whereas our
Table 2: Cross-dataset evaluation results on five metrics. While the model trained on FAIR-Play is used for testing on the others, the model trained on MUSIC-Stereo is for the evaluation on FAIR-Play. PseudoBinaural presents better generalization ability than the supervised method Mono2Binaural on all datasets.
| | Mono2Binaural [14] | Mono2Binaural [14] | Mono2Binaural [14] | Mono2Binaural [14] | Mono2Binaural [14] | PseudoBinaural (Ours) | PseudoBinaural (Ours) | PseudoBinaural (Ours) | PseudoBinaural (Ours) | PseudoBinaural (Ours) |
|--------------|----------------------|----------------------|----------------------|----------------------|----------------------|-------------------------|-------------------------|-------------------------|-------------------------|-------------------------|
| Dataset | STFT | ENV | Mag | D phase | SNR ↑ | STFT | ENV | Mag | D phase | SNR ↑ |
| FAIR-Play | 0.996 | 0.142 | 1.993 | 1.562 | 5.876 | 0.959 | 0.140 | 1.917 | 1.496 | 6.057 |
| MUSIC-Stereo | 0.971 | 0.140 | 1.942 | 1.552 | 7.933 | 0.952 | 0.139 | 1.904 | 0.574 | 8.099 |
| YT-MUSIC | 0.717 | 0.118 | 1.435 | 1.597 | 9.214 | 0.653 | 0.111 | 1.306 | 1.357 | 9.848 |
method PseudoBinaural only leverages frames and mono audio to do the training. Please be noted that we do not rely on an extra dataset. The result of Mono-Mono is also listed, which copies the mono input two times as the stereo channels. This method should have no stereo effect at all, thus outperforming it means the success of generating the sense of directions. As the whole model of ours includes the separation training described in Sec. 3.3, we also evaluation the ablation of this module (w/o sep.) . Table 1 shows the results of these methods on all metrics.
With no supervision, it is reasonable that our PseudoBinaural cannot outperform the supervised setting. However, the fact that our model outperforms Mono-Mono on all metrics proves the effectiveness of our proposed method. In line with previous work [49], introducing the separation task in the training framework can further improve the overall performance of generated binaural audio.
Augmentation to Binaural Audio Training. Since our method just relies on the pseudo visual-stereo pairs, a natural idea is to leverage both pseudo data and recorded ones to boost the performance of the traditional fully-supervised approach. As demonstrated in the lower half of Table 1, our method, denoted as Augment-PseudoBinaural , can surpass the traditional setting Mono2Binaural [14] on all 5 metrics. Moreover, compared to Sep-Stereo [49], which incorporates extra data, we create pseudo pairs with the same set of collected data, providing more effective and complementary information to guide the training. Consequently, our method outperforms theirs on both FAIR-Play and MUSIC-Stereo.
Cross-Dataset Evaluation. Wespecifically show the results of cross-dataset evaluation in Table. 2 to prove that 1) supervised methods can easily overfit to a specific domain and 2) the generalization ability of our method. YT-MUSIC [22] with special 360 ◦ videos and ambisonics sounds is also used for evaluation. Here we use the non-augmented version of PseudoBinaural for evaluation. For Mono2Binaural , the model evaluated on FAIR-Play is trained on MUSIC-Stereo, and the model tested on MUSIC-Stereo and YT-MUSIC is trained on FAIR-Play. During cross-testing on FAIR-Play and MUSIC-Stereo, the visual to angle mapping f v 2 a is defined in the frontal view. But when cross-testing on YTMUSIC, the video is defined in the form of 360 ◦ .
Table 3: Ablation study on the number K of mono videos to mix based on FAIR-Play dataset. When K is a mixture of the three different numbers, the ratio is empirically set to 1 : 2 : 3 = 0 . 4 : 0 . 5 : 0 . 1 .
| K | STFT | ENV | Mag | D phase | SNR ↑ |
|-------|--------|-------|-------|-----------|---------|
| 1 | 0.965 | 0.143 | 1.914 | 1.483 | 4.976 |
| 2 | 0.935 | 0.141 | 1.871 | 1.48 | 5.026 |
| 3 | 0.967 | 0.142 | 1.936 | 1.527 | 5.004 |
| 1,2 | 0.895 | 0.136 | 1.793 | 1.479 | 5.282 |
| 1,2,3 | 0.878 | 0.134 | 1.768 | 1.467 | 5.316 |
We can see from the table that our method stably outperforms Mono2Binaural in all cross-dataset evaluations. The supervised method tends to perform badly when testing in a different domain, while our recording-free method generalizes well by training only on mono data.
Ablation Study. The lower half of Table 1 presents our ablation studies on different binaural decoding schemes. As written in Sec. 3.1, binaural audios can be decoded directly from HRIR or ambisonic . It can be seen that our way of combining both leads to the best results.
When preparing pseudo visual-stereo pairs, the number of mono videos to mix is also another important hyperparameter for consideration. As shown in Table 3, a fixed mixing number K always fails to construct various training samples, introducing inconsistency with those naturally collected datasets. Hence, an empirical ratio of 1 : 2 : 3 = 0 . 4 : 0 . 5 : 0 . 1 for the number K is applied to ensure the diversity of generated visual-stereo pairs.
Additionally, we evaluate the choice of visual field-ofview (FOV) when building the Visual-Coordinate-Mapping . The influential parameter is the border azimuth angle ϑ v 0 which is set to π/ 3 (Sec. 3.2). The results are shown in Table 4, that our choice achieves the best results.
## 4.4. Qualitative Results
User Study 2 . In total 30 users with normal hearing participated in our study to perform the quality evaluation. There
2 Please refer to https : / / sheldontsui . github . io / projects/PseudoBinaural for demo videos.
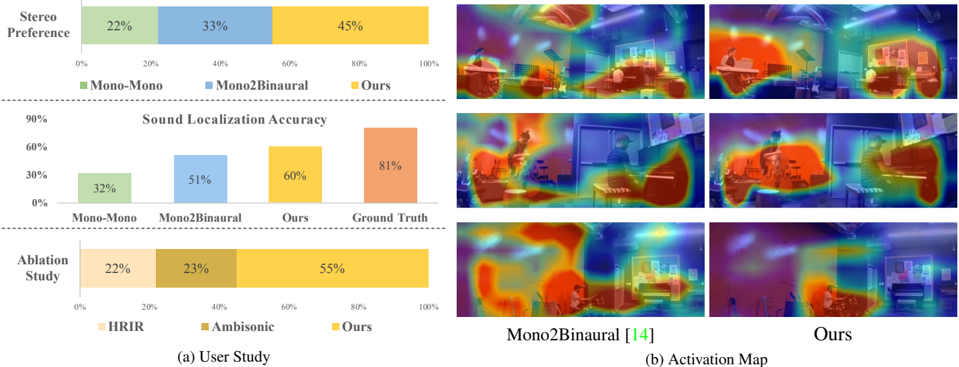
Figure 4: Qualitative results. (a) shows the results of our user studies. It can be seen that the users slightly prefer our approach over supervised Mono2Binaural [14]. (b) is the visualization of the activation maps of ours and Mono2Binaural. While the attention of theirs is messier, the results of ours are more compact. We focus more on sound sources.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Bar Charts and Heatmaps: User Study and Activation Map Analysis
### Overview
The image contains two primary sections:
1. **User Study** (left side): Three bar charts comparing user preferences, sound localization accuracy, and ablation study results.
2. **Activation Map** (right side): Six heatmaps visualizing spatial activation patterns for "Mono2Binaural" and "Ours" methods.
---
### Components/Axes
#### User Study (Bar Charts)
1. **Stereo Preference**
- **X-axis**: Categories: Mono-Mono (22%), Mono2Binaural (33%), Ours (45%).
- **Y-axis**: Percentage (0%–100%).
- **Legend**: Located at the bottom, with colors:
- Green: Mono-Mono
- Blue: Mono2Binaural
- Yellow: Ours
2. **Sound Localization Accuracy**
- **X-axis**: Categories: Mono-Mono (32%), Mono2Binaural (51%), Ours (60%), Ground Truth (81%).
- **Y-axis**: Percentage (0%–90%).
- **Legend**: Located at the bottom, with colors:
- Green: Mono-Mono
- Blue: Mono2Binaural
- Yellow: Ours
- Orange: Ground Truth
3. **Ablation Study**
- **X-axis**: Categories: HRIR (22%), Ambisonic (23%), Ours (55%).
- **Y-axis**: Percentage (0%–100%).
- **Legend**: Located at the bottom, with colors:
- Light orange: HRIR
- Brown: Ambisonic
- Yellow: Ours
#### Activation Map (Heatmaps)
- **Labels**:
- Top row: "Mono2Binaural [14]" (left), "Ours" (right).
- Bottom row: "Mono2Binaural [14]" (left), "Ours" (right).
- **Color Scheme**:
- Red: High activation.
- Green: Moderate activation.
- Blue: Low activation.
- Purple: Minimal activation.
---
### Detailed Analysis
#### User Study
1. **Stereo Preference**
- "Ours" (45%) outperforms "Mono2Binaural" (33%) and "Mono-Mono" (22%).
- **Trend**: Increasing preference from left to right.
2. **Sound Localization Accuracy**
- "Ground Truth" (81%) is the highest, followed by "Ours" (60%), "Mono2Binaural" (51%), and "Mono-Mono" (32%).
- **Trend**: "Ours" improves accuracy by 9% over "Mono2Binaural" and 28% over "Mono-Mono".
3. **Ablation Study**
- "Ours" (55%) significantly outperforms "HRIR" (22%) and "Ambisonic" (23%).
- **Trend**: Removing components (HRIR/Ambisonic) reduces performance by ~50%.
#### Activation Map
- **Mono2Binaural [14]**:
- Activation is diffuse, with scattered red/green regions.
- **Ours**:
- Activation is more concentrated, with larger red/yellow regions.
- Suggests stronger spatial focus compared to "Mono2Binaural".
---
### Key Observations
1. **User Preference**: "Ours" is the most preferred method (45% vs. 33% for "Mono2Binaural").
2. **Accuracy**: "Ours" achieves 60% accuracy, 28% higher than "Mono-Mono" and 9% higher than "Mono2Binaural".
3. **Ablation**: Removing components (HRIR/Ambisonic) halves performance, highlighting their importance.
4. **Activation Maps**: "Ours" shows more localized activation, aligning with higher user preference and accuracy.
---
### Interpretation
- **User Preference vs. Accuracy**: "Ours" excels in both metrics, suggesting it balances perceptual quality and technical performance.
- **Ablation Impact**: The 55% accuracy of "Ours" vs. 22–23% for simplified methods indicates that integrating HRIR and Ambisonic components is critical.
- **Activation Maps**: The concentrated activation in "Ours" implies better spatial awareness, likely contributing to its superior performance.
- **Ground Truth Benchmark**: "Ground Truth" (81%) sets a high standard, but "Ours" (60%) is the closest among user-tested methods.
This data demonstrates that "Ours" is the most effective method for spatial audio tasks, combining user preference, accuracy, and focused activation patterns.
</details>
are three sets of studies, each with 20 videos selected from the test set of FAIR-Play [14] and MUSIC-Stereo [45], most of which are duets. 1) The users are asked to watch one video and listen to the binaural audios generated by PseudoBinaural , Mono2Binaural [14] or Mono-Mono . The question is which one of the three methods creates the best stereo sensation. The results show the percentage of the users' Stereo Preferences. 2) The users are asked to listen to the audio generated by the above methods without viewing videos, and decide where is the specific instrument (left, right, or center). Ground truth audios are also included for reference. The results show the Sound Localization Accuracy of these methods. 3) A subjective Ablation Study is conducted to show the influence of different choices of binaural decoding methods. The users are asked to tell which decoding diagram, direct HRIR, ambisonic, or ours, creates the best 3D hearing experience.
The results are shown in Fig 4 (a). From the first and second experiments, we can see that users find our method slightly better than supervised Mono2Binaural on both the two measurements. This is enough to validate that our results are highly competitive to supervised methods in subjective evaluations, which is extremely important for auditory tasks. In the sound localization experiment, users can only achieve 81% accuracy even given the ground-truth audio, which demonstrates the misguiding caused by the room reverberations. The subjective ablation study shows that our decoding procedure apparently creates the best sense of hearing among all decoding choices.
Visualization. We also visualize the activation map generated by our method and Mono2Binaural [14] on the visual domain. In Fig. 4 (b) we can see that Pseu-
Table 4: Ablation study on the border azimuth angle ϑ v 0 . The horizontal visual field-of-view is 2 ϑ v 0 .
| ϑ v 0 | π/ 6 | π/ 4 | π/ 3 | 5 π/ 12 | π/ 2 |
|---------|--------|--------|--------|-----------|--------|
| STFT ↓ | 0.923 | 0.896 | 0.878 | 0.884 | 0.886 |
| SNR ↑ | 5.138 | 5.181 | 5.316 | 5.302 | 5.271 |
doBinaural can successfully attend to sound sources while Mono2Binaural [14] would focus on less important areas. For example, their approach would attend to the ceiling for all three scenes shown, which is not the sound source.
## 5. Conclusion
In this work, we propose PseudoBinaural, a binauralrecording-free method for generating binaural audios from corresponding mono audios and visual cues. For the first time, the problem of visually informed binaural audio generation is tackled without binaural audio recordings. Based on the theoretical analysis of Mono-BinauralMapping, the created pseudo visual-stereo pairs can be capitalized to train models for binaural audio generation. Extensive experiments validate that our framework can be very competitive both quantitatively and qualitatively. More impressively, augmented with real binaural audio recordings, our PseudoBinaural could outperform current state-of-the-art methods on various standard benchmarks.
Acknowledgements. This work is supported by the Collaborative Research Grant from SenseTime (CUHK Agreement No. TS1712093), the General Research Fund (GRF) of Hong Kong (No. 14205719, 14202217, 14203118, 14208619), NTU NAP and A*STAR through the Industry Alignment Fund - Industry Collaboration Projects Grant.
## References
- [1] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman. The conversation: Deep audio-visual speech enhancement. Proceedings of the Interspeech , 2018. 1, 2
- [2] V Ralph Algazi, Richard O Duda, Dennis M Thompson, and Carlos Avendano. The cipic hrtf database. In Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No. 01TH8575) , 2001. 3
- [3] Humam Alwassel, Dhruv Mahajan, Lorenzo Torresani, Bernard Ghanem, and Du Tran. Self-supervised learning by cross-modal audio-video clustering. Advances in neural information processing systems (NeurIPS) , 2020. 1
- [4] Relja Arandjelovic and Andrew Zisserman. Look, listen and learn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2017. 3
- [5] Relja Arandjelovic and Andrew Zisserman. Objects that sound. In Proceedings of the European Conference on Computer Vision (ECCV) , 2018. 3
- [6] Durand R Begault and Leonard J Trejo. 3-d sound for virtual reality and multimedia. 2000. 1
- [7] Jens Blauert. Spatial hearing: the psychophysics of human sound localization . MIT press, 1997. 2
- [8] R. Courant and D. Hilbert. Methods of mathematical physics . Wiley classics library. Interscience Publishers, 1962. 1, 3
- [9] Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein. Looking to listen at the cocktail party: a speakerindependent audio-visual model for speech separation. ACM Transactions on Graphics (TOG) , 2018. 1, 2
- [10] John W Fisher III, Trevor Darrell, William T Freeman, and Paul A Viola. Learning joint statistical models for audiovisual fusion and segregation. In Advances in neural information processing systems (NeurIPS) , 2001. 2
- [11] Chuang Gan, Deng Huang, Hang Zhao, Joshua B Tenenbaum, and Antonio Torralba. Music gesture for visual sound separation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2020. 2
- [12] Chuang Gan, Hang Zhao, Peihao Chen, David Cox, and Antonio Torralba. Self-supervised moving vehicle tracking with stereo sound. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2019. 3
- [13] Ruohan Gao, Rogerio Feris, and Kristen Grauman. Learning to separate object sounds by watching unlabeled video. In Proceedings of the European Conference on Computer Vision (ECCV) , 2018. 1, 2
- [14] Ruohan Gao and Kristen Grauman. 2.5 d visual sound. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2019. 1, 2, 3, 5, 6, 7, 8, 11, 12
- [15] Ruohan Gao and Kristen Grauman. Co-separating sounds of visual objects. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2019. 1, 2, 11
- [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) , 2016. 5
- [17] Di Hu, Rui Qian, Minyue Jiang, Xiao Tan, Shilei Wen, Errui Ding, Weiyao Lin, and Dejing Dou. Discriminative sounding objects localization via self-supervised audiovisual matching. In Advances in Neural Information Processing Systems (NeurIPS) , 2020. 3
- [18] Bruno Korbar, Du Tran, and Lorenzo Torresani. Cooperative learning of audio and video models from self-supervised synchronization. In Advances in Neural Information Processing Systems (NeurIPS) , 2018. 1
- [19] Dingzeyu Li, Timothy R. Langlois, and Changxi Zheng. Scene-aware audio for 360 videos. ACM Transactions on Graphics (TOG) , 2018. 2
- [20] Yu-Ding Lu, Hsin-Ying Lee, Hung-Yu Tseng, and MingHsuan Yang. Self-supervised audio spatialization with correspondence classifier. In 2019 IEEE International Conference on Image Processing (ICIP) , 2019. 1, 2
- [21] Hari Krishna Maganti, Daniel Gatica-Perez, and Iain McCowan. Speech enhancement and recognition in meetings with an audio-visual sensor array. IEEE Transactions on Audio, Speech, and Language Processing (TASLP) , 2007. 2
- [22] Pedro Morgado, Nuno Nvasconcelos, Timothy Langlois, and Oliver Wang. Self-supervised generation of spatial audio for 360 video. In Advances in Neural Information Processing Systems (NeurIPS) , 2018. 1, 2, 3, 6, 7
- [23] Pedro Morgado, Nuno Vasconcelos, and Ishan Misra. Audiovisual instance discrimination with cross-modal agreement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2021. 1
- [24] Markus Noisternig, Alois Sontacchi, Thomas Musil, and Robert Holdrich. A 3d ambisonic based binaural sound reproduction system. In Audio Engineering Society Conference: 24th International Conference: Multichannel Audio, The New Reality . Audio Engineering Society, 2003. 3
- [25] Andrew Owens and Alexei A Efros. Audio-visual scene analysis with self-supervised multisensory features. Proceedings of the European Conference on Computer Vision (ECCV) , 2018. 1, 3
- [26] Andrew Owens, Phillip Isola, Josh McDermott, Antonio Torralba, Edward H Adelson, and William T Freeman. Visually indicated sounds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016. 2, 3
- [27] Sanjeel Parekh, Slim Essid, Alexey Ozerov, Ngoc QK Duong, Patrick Pérez, and Gaël Richard. Motion informed audio source separation. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2017. 2
- [28] Rui Qian, Di Hu, Heinrich Dinkel, Mengyue Wu, Ning Xu, and Weiyao Lin. Multiple sound sources localization from coarse to fine. Proceedings of the European Conference on Computer Vision (ECCV) , 2020. 3
- [29] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (NeurIPS) , 2015. 11
- [30] Alexander Richard, Dejan Markovic, Israel D. Gebru, Steven Krenn, Gladstone Alexander Butler, Fernando Torre, and Yaser Sheikh. Neural synthesis of binaural speech. In Interna-
tional Conference on Learning Representations (ICLR) , 2021. 6
- [31] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention , 2015. 5
- [32] Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, and In So Kweon. Learning to localize sound source in visual scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018. 3
- [33] Julius Orion Smith. Mathematics of the discrete Fourier transform (DFT): with audio applications . 2007. 6
- [34] John Smythies. A note on the concept of the visual field in neurology, psychology, and visual neuroscience. Perception , 1996. 4
- [35] Yapeng Tian, Di Hu, and Chenliang Xu. Cyclic co-learning of sounding object visual grounding and sound separation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2021. 2
- [36] Yapeng Tian, Dingzeyu Li, and Chenliang Xu. Unified multisensory perception: weakly-supervised audio-visual video parsing. Proceedings of the European Conference on Computer Vision (ECCV) , 2020. 3
- [37] Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu. Audio-visual event localization in unconstrained videos. In Proceedings of the European Conference on Computer Vision (ECCV) , 2018. 3
- [38] Yapeng Tian, Chenliang Xu, and Dingzeyu Li. Deep audio prior. arXiv preprint arXiv:1912.10292 , 2019. 2
- [39] Arun Balajee Vasudevan, Dengxin Dai, and Luc Van Gool. Semantic object prediction and spatial sound super-resolution with binaural sounds. Proceedings of the European Conference on Computer Vision (ECCV) , 2020. 3
- [40] DE Winch, DJ Ivers, JPR Turner, and RJ Stening. Geomagnetism and schmidt quasi-normalization. Geophysical Journal International , 2005. 3
- [41] Yu Wu, Linchao Zhu, Yan Yan, and Yi Yang. Dual attention matching for audio-visual event localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2019. 3
- [42] Xudong Xu, Bo Dai, and Dahua Lin. Recursive visual sound separation using minus-plus net. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2019. 2
- [43] Karren Yang, Bryan Russell, and Justin Salamon. Telling left from right: Learning spatial correspondence of sight and sound. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2020. 1, 12
- [44] Qilin Zhang, Habti Abeida, Ming Xue, William Rowe, and Jian Li. Fast implementation of sparse iterative covariancebased estimation for source localization. The Journal of the Acoustical Society of America (JASA) , 2012. 3
- [45] Hang Zhao, Chuang Gan, Wei-Chiu Ma, and Antonio Torralba. The sound of motions. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2019. 1, 2, 3, 6, 8
- [46] Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, and Antonio Torralba. The sound of pixels. In Proceedings of the European Conference on Computer Vision (ECCV) , 2018. 1, 2, 3, 6, 11
- [47] Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , 2019. 3
- [48] Hang Zhou, Ziwei Liu, Xudong Xu, Ping Luo, and Xiaogang Wang. Vision-infused deep audio inpainting. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2019. 1
- [49] Hang Zhou, Xudong Xu, Dahua Lin, Xiaogang Wang, and Ziwei Liu. Sep-stereo: Visually guided stereophonic audio generation by associating source separation. Proceedings of the European Conference on Computer Vision (ECCV) , 2020. 1, 2, 5, 6, 7, 11
- [50] Ye Zhu, Yu Wu, Hugo Latapie, Yi Yang, and Yan Yan. Learning audio-visual correlations from variational cross-modal generation. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2021. 3
## Appendices
## A. Demo Video Descriptions
In the demo video, we show our prediction results and the comparisons between our predictions and that of the baseline method [14] on FAIR-Play, MUSIC-Stereo and Youtube-ASMR E, respectively. The video is encoded in H.264 codec.
## B. Separation Training Details
The task of visually guided sound source separation [46, 15] aims at separating a mixed audio into independent ones, according to their sound source's visual appearances. We adopt the setting with a mixture of two sources, which is kept the same as Sep-Stereo [49] for fair comparisons. The backbone audio network Net a is shared across stereo and separation learning, following [49].
During training, we follow the Mix-and-Separate pipeline [46, 15] to mix two mono audios ( s a and s b ) of two solo videos as input in the form of STFTs. This can be written as S mix = S a + S b . The network renders complex masks M a and M b to predict the STFTs of the audios themselves. We use two APNet [49] structures for the prediction of complex masks. The loss function can be written as:
<!-- formula-not-decoded -->
This training is done in parallel with stereo, thus the overall loss function is:
<!-- formula-not-decoded -->
The weight λ sep is empirically set to 1 in our experiments. We observe that it would not affect the results much when λ sep ∈ [0 . 5 , 1 . 5] .
## C. Implementation Details
Following [14], we use Python package Audiolab to resample the audio at 16kHz, which significantly accelerates the IO process during training. Besides, our follow the same details for our network structure and the training protocol as in Mono2Binaural [14] and Sep-Stereo [49]. The spectrograms are of size 257 × 64 × 2 , and the visual inputs are 224 × 448 × 3 images. During testing, we find an inappropriate normalization operation in the demo-generating script presented in the public code of [14] and [49]. Specifically, since the ground-truth binaural audio is unknown in advance, the normalization step should be implemented in the mono audio instead. After fixing this bug, we discover the hop length of sliding window will not affect the inference performance. Hence, the sliding window is set to 0.1s for all the experiments.
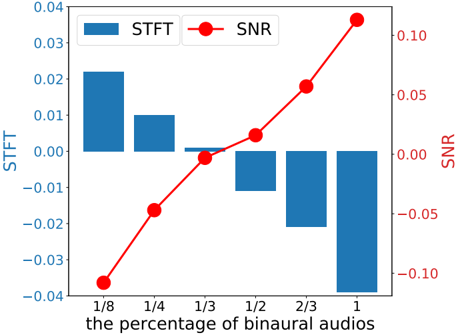
Figure 5: The curve of our relative performances w.r.t the percentage of binaural audios we use on FAIR-Play. It can be observed that our approach can reach their full performance using only 1 / 3 of the ground-truth binaural audios.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Line/Bar Chart: STFT and SNR vs Percentage of Binaural Audios
### Overview
The chart compares two metrics—Short-Time Fourier Transform (STFT) and Signal-to-Noise Ratio (SNR)—across varying percentages of binaural audio input. STFT is represented by blue bars, while SNR is shown as a red line with circular markers. The x-axis ranges from 1/8 (12.5%) to 1 (100%) binaural audio, and the y-axes are normalized to [-0.10, 0.10] for SNR and [-0.04, 0.04] for STFT.
### Components/Axes
- **X-axis**: "the percentage of binaural audios" (labeled as fractions: 1/8, 1/4, 1/3, 1/2, 2/3, 1).
- **Left Y-axis (STFT)**: Ranges from -0.04 to 0.04, labeled "STFT".
- **Right Y-axis (SNR)**: Ranges from -0.10 to 0.10, labeled "SNR".
- **Legend**: Located in the top-right corner, with blue squares for STFT and red circles for SNR.
- **Bars**: Blue vertical bars for STFT values at each x-axis interval.
- **Line**: Red line with circular markers for SNR values, connecting data points across the x-axis.
### Detailed Analysis
- **STFT (Blue Bars)**:
- At **1/8**: ~0.02
- At **1/4**: ~0.01
- At **1/3**: ~0.00
- At **1/2**: ~-0.01
- At **2/3**: ~-0.02
- At **1**: ~-0.03
- **SNR (Red Line)**:
- At **1/8**: ~-0.04
- At **1/4**: ~-0.02
- At **1/3**: ~0.00
- At **1/2**: ~0.01
- At **2/3**: ~0.05
- At **1**: ~0.10
### Key Observations
1. **STFT Decreases Linearly**: STFT values start positive (~0.02 at 1/8) and decrease steadily to negative values (-0.03 at 100% binaural audio).
2. **SNR Increases Linearly**: SNR values start negative (-0.04 at 1/8) and rise sharply to positive values (0.10 at 100% binaural audio).
3. **Inverse Relationship**: As the percentage of binaural audio increases, STFT decreases while SNR increases, suggesting a trade-off between these metrics.
4. **Outlier at 100%**: The SNR value at 100% binaural audio (0.10) is the highest observed, while STFT reaches its lowest (-0.03).
### Interpretation
The data suggests that increasing the proportion of binaural audio improves SNR (better signal quality) but degrades STFT (potentially reducing temporal resolution or other STFT-related properties). The sharp rise in SNR at 100% binaural audio indicates a critical threshold where binaural processing significantly enhances signal clarity. Conversely, the linear decline in STFT implies a cost to this improvement, possibly related to computational complexity or loss of specific audio features. This trade-off highlights the need to balance binaural audio usage based on application priorities (e.g., SNR optimization vs. STFT fidelity).
</details>
While creating the pseudo visual-stereo pairs, we leverage the off-the-shelf human detector and instrument detector of Faster RCNN [29, 15] to crop the visual patches from the videos with mono audios. The center of the cropped patches is placed in an arbitrary position on a blank background. For the generation of pseudo binaurals, the number of speakers in the virtual array is defined as N = 8 following the common practice. The speakers are uniformly placed around the frontal part of the head.
As for the activation map in Fig.4, it comes from the feature map of the last convolutional layer in the visual network. For a specific image input, the corresponding feature map is averagely pooled along the channel dimension and normalized to [0 , 1] . And then, we deploy a bilinear upsampling operation on the feature map, making the size align with the original input image. In the end, we set the transparency ratio of upsampled feature map as 0.4, and combine it with the input image to obtain the final activation map.
## D. More Ablation Studies
## D.1. Ablation Study on the Amount of Binaural Recordings
Similar to the extensive analysis in [49], we provide an ablation study on the amount of binaural recording audios used in the augmentation experiments. Fig 5 shows the relative performance gains w.r.t the percentage of binaural audios used on FAIR-Play. The curve is drawn in a relative setting, where the performance of Mono2Binaural serves as the reference (zero in both metrics). As illustrated in Fig 5, Augment-PseudoBinaural can achieve the comparable performance based on only 1 / 3 of the ground-truth binaural
Table 5: Quantitative results of binaural audio generation on Youtube-ASMR dataset with five evaluation metrics. Note that, our method PseudoBinaural still outperforms Mono-Mono on the non-musical dataset. Owing to the huge data amount and relatively simpler scenarios in Youtube-ASMR dataset, Augment-PseudoBinaural can only achieve a minor improvement over the supervised counterpart [14].
| Method | STFT | ENV | Mag | D phase | SNR ↑ |
|------------------------|--------|-------|-------|-----------|---------|
| Mono-Mono | 0.286 | 0.07 | 0.571 | 1.57 | 2.111 |
| Mono2Binaural [14] | 0.198 | 0.055 | 0.395 | 1.396 | 3.855 |
| PseudoBinaural (Ours) | 0.252 | 0.064 | 0.504 | 1.517 | 2.634 |
| Augment-PseudoBinaural | 0.196 | 0.055 | 0.394 | 1.394 | 3.86 |
Table 6: Results for different mixes of K on FAIR-Play.
| Mix ratio | 1 : 1 : 1 | 4 : 5 : 1 | 4 : 1 : 5 | 1 : 5 : 4 |
|-------------|-------------|-------------|-------------|-------------|
| STFT ↓ | 0.88 | 0.878 | 0.884 | 0.885 |
| SNR ↑ | 5.312 | 5.316 | 5.31 | 5.306 |
audios, which further demonstrates the effectiveness of our proposed method.
## D.2. Ablation Study on Mix Ratios of K
We conduct an ablation study on the selection of different mix ratios. The portions are the partitions of videos with one, two and three mixed sources used during training. During our implementation, the ratios are selected as 4 : 5 : 1. The ablation results on FAIR-Play are listed in Table 6. It indicates that the influence of different mix ratios is minor.
## E. Experiment on Youtube-ASMR Dataset
Youtube-ASMR introduced by Yang et al . [43] is a largescale video dataset collected from YouTube. It consists of approximately 300K 10-second video clips with spatial audio and lasts about 904 hours in total. In an ASMR video, only an individual actor or 'ASMRtist' is speaking or making different sounds towards a dummy head or the microphone arrays while facing the cameras. Compared to FAIR-Play or MUSIC-Stereo, the binaural scenarios in Youtube-ASMR dataset are relatively simpler since a typical sample just contains one sound source and the visual scene only involves a face in most cases. Similarly, the supervised method Mono2Binaural [14] and our approach are also implemented on this non-musical dataset. As shown in Tabel 5, PseudoBinaural can still surpass Mono-Mono on all the metrics, while the augmentation version only improves modestly over the supervised paradigm [14].
## F. Limitations
There are also certain limitations in our work. The first is the domain gap between self-created images and real images.
One direction towards solving this problem is through better blending techniques to the background. The second is that we do not specifically model room reverberations, particularly cannot be adapted to any given environment. Domain adaptation techniques for vision might be useful for it. Moreover, our method does rely on the videos that contains only one visual and auditory sound source.