# PQK: Model Compression via Pruning, Quantization, and Knowledge Distillation
## PQK: Model Compression via Pruning, Quantization, and Knowledge Distillation
Jangho Kim ∗ , 1 , 2 , Simyung Chang 1 , Nojun Kwak 2
1 Qualcomm AI Research † , Qualcomm Korea YH
2 Seoul National University kjh91@snu.ac.kr, simychan@qti.qualcomm.com, nojunk@snu.ac.kr
## Abstract
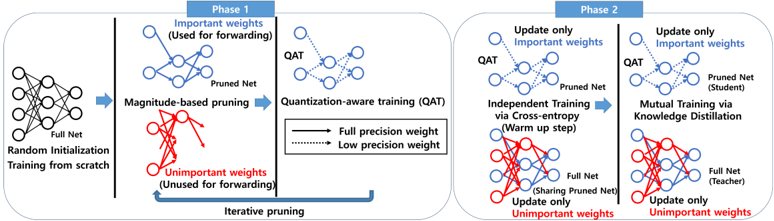
As edge devices become prevalent, deploying Deep Neural Networks (DNN) on edge devices has become a critical issue. However, DNN requires a high computational resource which is rarely available for edge devices. To handle this, we propose a novel model compression method for the devices with limited computational resources, called PQK consisting of pruning, quantization, and knowledge distillation (KD) processes. Unlike traditional pruning and KD, PQK makes use of unimportant weights pruned in the pruning process to make a teacher network for training a better student network without pre-training the teacher model. PQK has two phases. Phase 1 exploits iterative pruning and quantization-aware training to make a lightweight and power-efficient model. In phase 2, we make a teacher network by adding unimportant weights unused in phase 1 to a pruned network. By using this teacher network, we train the pruned network as a student network. In doing so, we do not need a pre-trained teacher network for the KD framework because the teacher and the student networks coexist within the same network (See Fig. 1). We apply our method to the recognition model and verify the effectiveness of PQK on keyword spotting (KWS) and image recognition.
Index Terms : keyword spotting, model pruning, model quantization, knowledge distillation.
## 1. Introduction
Nowadays, Deep Neural Networks (DNNs) have shown astonishing capabilities in various domains such as computer vision and signal processing. Although DNN shows remarkably high performance, it requires high computational cost and memory. Also, DNN models are spreading from personal computers or servers into edge devices. Deploying DNN on edge devices such as smartphones and IoT devices is still a challenge due to its computational resource constraint and restricted memory.
In recent years, model compression has been actively studied to deal with the above issues. In general, model compression can be categorized into three: pruning, quantization, and knowledge distillation. (1) Pruning method prunes the unimportant weights or channels based on different criteria [1, 2, 3, 4]. Pruning method can reduce model memory and the number of flops by eliminating unimportant weights or channels. (2) Quantization method quantizes floating point values into discrete values to approximate them by a set of integers and scaling factors [5]. Quantization allows for more power-efficient operations and convolution computations at the expense of lower bitwidth representation. Recently, hardware accelerators such
∗ Author completed the research in part during an internship at Qualcomm Technologies, Inc. † Qualcomm AI Research is an initiative of Qualcomm Technologies, Inc.
as NVIDIA's Tensor Core and CIM (Compute-in-memory) devices have launched for 4-bit processing to improve the power efficiency [6, 7]. (3) Knowledge distillation is a learning framework using teacher and student networks. Teacher network transfers its knowledge to student network to enhance the performance of student network. Feature maps [8, 9, 10] and logits of a network [11, 12] are widely used as knowledge. Model compression has actively been studied mainly on computer vision tasks. However, with the increase of various voice assistants such as Siri, Hey Google, and Alexa on IoT devices, model compression has also become an important research topic in speech processing [13, 14, 15, 16, 17].
In this work, we aim to design the PQK to leverage pruning, quantization, and knowledge distillation by considering each method's characteristics. In contrast with traditional pruning and knowledge distillation, we use unimportant weights considered in the pruning process to make a teacher network, so PQK does not need a pre-trained teacher model. We propose PQK to compress the keyword spotting (KWS) recognition model. PQK can also be used for the image recognition model because the design of PQK is focused on the training framework regardless of datatype and model, which has high applicability. PQK consists of two phases. In the first phase, we train the model from scratch using both iterative pruning and quantization-aware training (QAT). We prune the model and quantize the pruned model with a learnable step-size for QAT. This phase focus on finding a pruned model from scratch together with quantizing the model. In phase 2, we make a teacher network called full net shown in Fig. 1 by combining the pruned net and the unused weights considered unimportant in phase 1. Then, we train the pruned network as a student network. This phase improves the performance of the pruned net (student) by knowledge distillation with the full net (teacher). The details of PQK are explained in Sec. 2 and Fig. 1.
## 2. Proposed Method
In this section, we first explain the pruning and quantization method used in PQK and then describe the proposed PQK.
## 2.1. Preliminaries
Pruning Iterative pruning [1] is widely used in machine learning because it generally outperforms the one-shot pruning method [2]. One-shot pruning just prunes the model once with specific sparsity after model training. Then, it finetunes the model to improve the performance of the pruned model. On the other hand, iterative pruning gradually prunes the model while training and the final model contains unpruned important weights. In this work, we use iterative pruning and adopt the gradually increasing pruning ratio scheme based on the current
Figure 1: The overall process of PQK. Phase 1 trains the model from scratch with iterative pruning and quantization-aware training (QAT). The blue nodes and arrows corresponds to important weights used for the QAT, and the red ones are unimportant weights based on pruning method. The solid line and dotted line represent the full precision and k -bit quantized weights, respectively. At phase 2, we make a teacher network with a full network (Blue graph+Red graph). After some warm-up steps, we train the pruned net (student) and the full net (teacher) using KD framework. At teacher training, The blue graph from the student is fixed and shared in the full net, and the the red graph is only updated. However, the blue graph is shared at the forwarding of the full net.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Two-Phase Neural Network Pruning and Training Process
### Overview
The image is a technical flowchart illustrating a two-phase methodology for training a neural network with pruning and quantization. The process begins with a full network trained from scratch and proceeds through iterative pruning (Phase 1) followed by two alternative training strategies (Phase 2). The diagram uses color-coding (blue for "Important weights," red for "Unimportant weights") and line styles (solid for "Full precision weight," dotted for "Low precision weight") to distinguish components.
### Components/Axes
The diagram is divided into two main panels, labeled **Phase 1** and **Phase 2**, connected by a large arrow indicating sequential flow.
**Phase 1: Pruning and Quantization-Aware Training (QAT)**
* **Initial State:** A "Full Net" with "Random Initialization" and "Training from scratch."
* **Process:** "Magnitude-based pruning" separates weights into two groups:
* **Important weights (Used for forwarding):** Shown in blue. These form the "Pruned Net."
* **Unimportant weights (Unused for forwarding):** Shown in red.
* **Legend (Center):** Defines the visual language:
* Solid line: "Full precision weight"
* Dotted line: "Low precision weight"
* **Next Step:** The "Pruned Net" undergoes "Quantization-aware training (QAT)."
* **Feedback Loop:** An arrow labeled "Iterative pruning" loops back from the QAT step to the magnitude-based pruning step, indicating this process repeats.
**Phase 2: Training Strategies**
This phase presents two parallel training paths, both starting from the QAT model produced in Phase 1.
* **Left Path: Independent Training via Cross-entropy (Warm up step)**
* **Action:** "Update only Important weights" (blue lines) in the "Pruned Net (Student)."
* **Action:** "Update only Unimportant weights" (red lines) in the "Full Net."
* **Note:** The Full Net is shown "Sharing Pruned Net" for its important weights.
* **Right Path: Mutual Training via Knowledge Distillation**
* **Action:** "Update only Important weights" (blue lines) in the "Pruned Net (Student)."
* **Action:** "Update only Unimportant weights" (red lines) in the "Full Net (Teacher)."
* **Note:** The Full Net (Teacher) provides guidance to the Student.
### Detailed Analysis
The diagram details a structured pipeline for creating efficient neural networks.
**Phase 1 Flow:**
1. A full-sized network is initialized and trained.
2. Weights are pruned based on magnitude, creating a sparse "Pruned Net" containing only the "Important weights" (blue).
3. The Pruned Net undergoes Quantization-Aware Training (QAT), which simulates the effects of low-precision (quantized) inference during training, preparing the model for deployment.
4. The "Iterative pruning" loop suggests steps 2 and 3 are repeated, progressively refining the pruned and quantized model.
**Phase 2 Flow (Two Alternatives):**
* **Independent Training:** The pruned student network is fine-tuned using a standard cross-entropy loss. Concurrently, the unimportant weights (red) in the original full network are also updated, but they remain unused for forwarding. This appears to be a warm-up or preparatory stage.
* **Mutual Training:** This is a more advanced stage employing knowledge distillation. The full network acts as a "Teacher," and the pruned network is the "Student." The Student's important weights are updated to mimic the Teacher's behavior, while the Teacher's own unimportant weights are also updated. This suggests a co-adaptation or mutual refinement process.
### Key Observations
1. **Weight Role Separation:** The core concept is the strict separation of weights into "Important" (blue, used for inference) and "Unimportant" (red, unused for inference but potentially updated during training).
2. **Precision Differentiation:** The legend explicitly distinguishes between full-precision and low-precision weights, highlighting that quantization is a key part of the pipeline.
3. **Iterative Refinement:** Phase 1 is not a single pass but an iterative loop, suggesting the pruning and QAT process is repeated to achieve an optimal sparse, quantized model.
4. **Two-Stage Training:** Phase 2 is not a single method but presents a progression from a simpler "Independent Training" warm-up to a more complex "Mutual Training" distillation scheme.
5. **Spatial Layout:** The legend is centrally placed between the two phases for easy reference. Phase 1 flows left-to-right, while Phase 2 presents two side-by-side alternatives.
### Interpretation
This diagram outlines a sophisticated methodology for **model compression and efficient training**. The process aims to produce a neural network that is both **sparse** (pruned) and **quantized** (low-precision), which drastically reduces its memory footprint and computational cost for deployment.
* **Phase 1** focuses on **structural efficiency**: identifying and retaining only the most critical connections (pruning) and adapting the model to operate with lower numerical precision (QAT). The iterative nature implies that finding the optimal sparse structure is an ongoing search.
* **Phase 2** focuses on **performance recovery and enhancement**: After aggressive pruning and quantization, model accuracy typically drops. The two strategies shown are methods to recover that accuracy. The "Independent Training" warms up the model, while "Mutual Training via Knowledge Distillation" uses the original, larger network as a teacher to guide the compressed student network, potentially recovering performance lost during compression.
The overall narrative is one of **creating a lightweight, efficient model without sacrificing excessive accuracy**, by carefully managing which weights are used, at what precision, and how they are trained in relation to a larger teacher model. The separation of "important" and "unimportant" weights throughout the process is the central, defining principle.
</details>
epoch ( c ) [1]:
$$\frac { c - c _ { 0 } } { n } ) ^ { 3 } \cdot ( 1 )$$
We increase the pruning ratio from an initial ratio ( p i = 0 ) to a target pruning ratio p t over the training epoch ( n ). p c represents the current pruning ratio per epoch c ∈ { c 0 , ..., c 0 + n } , where c 0 means an initial epoch ( c 0 = 0 ).
Quantization After pruning step, we train the model with quantization-aware training (QAT) using important weights. We choose the uniform symmetric quantization method and the perlayer quantization scheme considering hardware friendliness [5, 18]. Consider the range of model weight [ min w , max w ]. The weight w is quantized to an integer value ˆ w with the range of [ -2 k -1 +1 , 2 k -1 -1 ] according to k -bit. Quantization and dequantization for the weight are defined with the learnable stepsize S w . The overall quantization process is as follows:
$$\omega = C \lim _ { S \rightarrow w } [ \frac { w ^ { 2 } - 1 } { S } ] , - 2 k - 1 , ( 2 )$$
where · is the round operation and
$$where { } is the round operation and$$
Dequantization step just brings the quantized value back to the original range by multiplying the step-size:
$$1 1 \times 5 1$$
These quantization and dequantization processes are nondifferentiable, so we utilize a straight-through estimator (STE) [19] for backpropagation. STE approximates the gradient d ¯ w dw by 1. Therefore, we can approximate gradients L , d L dw , with d L d ¯ w .
## 2.2. PQK
$$\frac { d L } { d u } = \frac { d C _ { 0 } L _ { 0 } } { d u } = \frac { d C } { d u }$$
Notations Consider a Convolutional Neural Network (CNN) with L layers 1 as an example. Then, we can represent the weights of the CNN model as { w l : 1 ≤ l ≤ L } . To represent the pruned model with a binary matrix, we use {M l : 1 ≤ l ≤ L } . Each M l , is a binary matrix indicating whether they
1 In our notation, a layer contains the corresponding weights.
## Algorithm 1 PQK
```
```
are pruned or not. Set I l is all indices of w l at the l -th layer. I M l and I ∼M l indicate indices of the important weights (Blue graph in Fig. 1) and unimportant weights (Red graph in Fig. 1) at the l -th layer, respectively ( I l = I M l ∪ I ∼M l ).
Assuming that we handle a recognition task with m classes, the logit vector of a model is defined as z t , where t ∈ { S, T } is the type of the network, i.e. either the student or the teacher. The network can have different paths depending on the target bitwidth k . We can consider the pruned network as a student network whose path is determined by the masks {M l } L l =1 and the full network as a teacher network which utilizes all weights (important + unimportant weights). At phase 2, we make a teacher network using both unimportant weights and important weights. Then, we make a soft probability distribution with temperature T as:
$$a _ { t } ( z ^ { \prime } ; T ) = \frac { e ^ { z ^ { \prime } } / T } { \sum _ { b } e ^ { z ^ { \prime } } / T } .$$
Here, z S is the logit forwarded by blue graph and z T is the logit from blue+red graph, shown in Fig. 1. Based on this notation, we can define the cross-entropy loss as below:
$$c _ { t } = - \sum _ { a = 1 } ^ { m } y _ { a } \log ( a _ { t } ( z )$$
where y is a ground truth and the subscript a denotes the a -th element of the corresponding vector.
Phase 1 Generally, phase 1 has the same number of epochs compared to conventional training and trains model from scratch. At phase 1, PQK combines iterative pruning and the quantization-aware training. First, PQK prunes the model at some epochs based on the pruning ratio in Eq. (1) by magnitudebased unstructured pruning [2]. It calculates the pruning mask M which acts as gate functions. Note that, PQK update the pruning mask every p u -th iteration similar to [1]. Then, QAT is performed with important weights using trainable step-size S w . By using STE and the chain rule, the update rule at the l -th layer becomes
$$\frac { w _ { 1 } ^ { ( i , j ) } } { \leftarrow w _ { 1 } ^ { ( i , j ) } - n \rightarrow }$$
where, ( i, j ) is a index of weight matrix. Note that, PQK also updates S w with L S ce . As depicted in Fig 1, L S ce is calculated by forwarding only important weights.
Phase 2 At phase 2, PQK trains the full network and pruned network with additional epochs. Commonly, to leverage knowledge distillation, a pre-trained teacher model is needed. Unlike traditional KD, PQK makes a teacher model with unimportant weights which means unused weights at phase 1 (See Fig 1). Note that there is no pre-trained teacher network because the teacher and student network are in the same network (full net).
We can compute the Kullback-Leibler divergence (KL) between student and teacher network.
$$\sum _ { a = 1 } ^ { n } o _ { a } ( z ^ { T } ; T ) = K L ( z ^ { T } \vert z ^ { S } ; T ) =$$
Then, we update each network with cross entropy and KL loss as below:
$$L _ { K D } = o L _ { S e } + B ( T ^ { 2 } *$$
$$L _ { k D } = o L ^ { 2 } _ { c e } + \beta ( T ^ { 2 } *$$
L S KD and L T KD are the KD loss of pruned net (student) and full net (teacher), respectively. α and β are hyper-parameters for balancing between KL and cross-entropy losses. T 2 is multiplied to the KL loss because the gradient with respect to the logit decrease as much as 1 / T 2 . The update rules at the l -th layer becomes
$$\frac { w _ { i } ( i , j ) } { 1 - w _ { i } ^ { \prime } ( i , j ) - n }$$
$$w _ { 1 } ^ { ( i , j ) } \rightarrow w _ { 1 } ^ { ( i - j ) } - n \frac { a L T } { d W _ { 1 } ^ { ( i , j ) } }$$
Note that, with respect to the pruned network, based on Eq. (11) keeping the same bitwidth of phase 1, phase 2 updates only important weights unlike phase 1 (Eq. (7)) updating all weights. Analogous to the pruned network, in terms of the full network, phase 2 updates only unimportant weights (Eq. (12)). At the forwarding path of the full network, pruned network is shared and the full network does not use QAT. Also, we fix S w at phase 2 for a stable training.
At first few epochs, we set the hyper-parameters as α = 1 , β = 0 meaning that both pruned and full nets are trained by cross-entropy only because initial unimportant weights are not trained well at phase 1. Thus, it needs a warm up stage. The overall process of PQK is depicted in Fig 1 and Algorithm 1.
## 3. Experiments
We verify the proposed PQK on a keyword spotting task. Also, we conduct additional experiments on an image recognition task to show the applicability and generality of the proposed PQK. We set the target pruning ratio p t (Eq. (1)) as 0.9 that means we only use 10% parameters of the baseline model. For ResNet-8 [20], we also conduct various target pruning ratio ( p t ∈ { 0 . 9 , 0 . 7 , 0 . 5 } ). We quantize the model by 8-bit and 4bit ( k ∈ { 8 , 4 } , Eq. (2)) compared to the 32-bit baseline model. Although we have one network in PQK, at phase 2, we have twice forwarding for pruned net and full net, so they need different batch statistics in phase 2. Therefore, we use different batchnorm parameters for each net in phase 2.
## 3.1. Experimental Setup
In all experiments, we use pytorch framework and set the same hyper-parameters. We update the pruning mask per 32 iterations ( p u ) at phase 1. After the warm up stage in phase 2, we set T = 2 , α = 0 , 5 , β = 0 . 5 . We did not conduct a grid search for finding hyper-parameters but choose them based on recommendations from related works [21, 12, 1]. For the learning rate of learnable step-size S w , we multiply 10 -4 to the initial learning rate of model parameters because of its sensitivity.
Keyword Spotting We use Google's Speech Commands Dataset v1 [22], choosing ResNet-8 and ResNet-8-narrow [20] as baselines using the official code in pytorch 2 . At phase 1, we follow overall training details from [20]. At phase 2, we run 9 epochs for additional training. We start learning rate of 0.1 and decay it at 1000 and 2000 iteration by multiplying 0.1. We set the warm up iteration ( s ) as 1500.
Image Recognition We use CIFAR100 Dataset [23] and choose ResNet-32 [24] for the baseline. We follow the training details same as [24]. At phase 2, we use 60 additional epochs. We train the model with an initial learning rate of 0.2 and decay it at 20,40 epochs with a factor of 0.1. We start KD after 30 epochs ( s = 30 ).
## 3.2. Experimental Results
In this section, we show the results of PQK with various methods, bitwidths, and pruning ratios. We will refer to the baseline network which is trained with cross-entropy as vanilla in all experiments. There are two forwarding paths in the output of phase 2. The first one, pruned net (student), uses (1 -p t ) × 100 % and quantized parameters. The other one, full net (teacher), uses the whole parameters same as the vanilla. At every table, we refer to our method at the end of each phase and network type ∈ { P, F } , where P and F represent pruned net and full net, respectively. Full net contains and shares the pruned net so the bitwidth of full net is 32-bit containing the pruned net trained with k bitwidth QAT. For example, at the 4-th row in Table 1, phase2F and 32 ( P = 8 ) means full net of phase 2 with 32bitwidth, sharing pruned net trained with 8-bitwidth QAT.
Keyword Spotting As shown in Table ( p t = 0 . 9 ), the performance of phase1P decreases compared to vanilla. This is
2 https://github.com/castorini/honk
Table 1: Test accuracy with various setting on speech and image dataset.
| | | | CIFAR100 | Google's Speech Commands Dataset | Google's Speech Commands Dataset | Google's Speech Commands Dataset | Google's Speech Commands Dataset |
|-----------|--------------|---------------|------------------------|------------------------------------------|------------------------------------|------------------------------------|------------------------------------|
| Method | Bitwidth | Pruning ratio | ResNet-32 Accuracy (%) | p t = 0 . 9 ResNet-8-narrow Accuracy (%) | ResNet-8 Accuracy (%) | p t = 0 . 7 ResNet-8 Accuracy (%) | p t = 0 . 5 ResNet-8 Accuracy (%) |
| Vanilla | 32 | 0 | 69.7 | 91.4 | 94.3 | 94.3 | 94.3 |
| Phase1- P | 8 | p t | 67.4 | 81.7 | 92.6 | 94.3 | 94.3 |
| Phase2- P | 8 | p t | 69.8 | 86.4 | 94.0 | 94.6 | 94.7 |
| Phase2- F | 32 ( P = 8 ) | 0 | 71.1 | 90.1 | 94.4 | 94.8 | 94.9 |
| Phase1- P | 4 | p t | 66.2 | 74.1 | 91.7 | 94.3 | 94.1 |
| Phase2- P | 4 | p t | 67.7 | 83.1 | 93.6 | 94.1 | 94.6 |
| Phase2- F | 32 ( P = 4 ) | 0 | 69.8 | 85.1 | 93.4 | 93.2 | 93.7 |
because, in this phase, we pruned unimportant 90% weights of full net and quantize important 10% weights from 32-bit to 8bit or 4-bit using iterative pruning and QAT. A compact model, ResNet-8-narrow using fewer channels than ResNet-8, is more sensitive to the model compression. It degrades 9.7% and 17.3% at 8-bit and 4-bit in phase1P . Such severe performance degradation of the compact model with quantization is also reported in other researches [25, 12]. At phase 2, by training unimportant 90% weights of the full net, it becomes a teacher to improve the performance of the pruned net. Surprisingly, there is a large performance gap between phase 1 and 2 in the pruned model of ResNet-8-narrow compared to that of ResNet-8. Table 1 shows that PQK is more effective at the compact model in terms of recovering the decreased performance at phase 1, where performance enhancements are 4.7% and 9% at 8- and 4-bit in ResNet-8-narrow. Concerning bitwidth and accuracy, 8-bit consistently outperforms 4-bit because of its high representative power from more bitwidth. In ResNet-8, Regardless of bitwidth, as pruning ratio decreases, the performance of pruned net increases. These numbers show the usage of model parameters is important to the performance. In ResNet-8 with 4-bit, although pruned net performs well, accuracies of phase2-F are lower than those of phase2-P. ResNet-8 with 8-bit shows the opposite trend, meaning that combining 32-bit and 4-bit trained model is more unstable than combining 32-bit and 8-bit trained model.
Image Recognition In this experiment, we can show the applicability of PQK. The design of PQK is not dependent on dataset and model architecture because PQK prunes and quantizes the model regardless of dataset and model architecture. Image recognition task has a similar tendency with KWS task. Interestingly, the performance of phase2F containing 8-bit pruned net outperforms vanilla by 1.4%. At phase 2, the teacher network is also trained with KD using the student network (Eq. (10)). In doing so, the full net can outperform the vanilla.
Ablation study To show the effectiveness of phase 2 in PQK, we conduct an ablation study in Table 2. At phase 2, we have additional epochs for the boosting performance of the pruned net. We make various baselines using the same training budget as phase 2. Finetune in Table 2 represents the performance of finetuning 4-bit ResNet-8-narrow model from phase1P (Table 1) with additional training using various learning rates. We use the same experiment setting with phase2P using 9 epochs and decay learning rate at 1000 and 2000 iteration. The only difference is the existence of KD with full net. In finetuning methods, the high learning rate is more efficient than the lower one, where 0.1 shows the best performance along with various learning rates. However, phase 2 using KD framework utilizing unused weights in phase 1 outperforms the best finetuning method by 3.9%. We also plot the validation accuracy of fine-
Table 2: Ablation study on PQK: comparing PQK (phase2P ) with finetuning using same training budget on various learning rate, where all methods start from phase1P .
| Google's Speech Commands Dataset ResNet-8-narrow | Google's Speech Commands Dataset ResNet-8-narrow | Google's Speech Commands Dataset ResNet-8-narrow | Google's Speech Commands Dataset ResNet-8-narrow |
|----------------------------------------------------|----------------------------------------------------|----------------------------------------------------|----------------------------------------------------|
| Method | Bitwidth | Accuracy (%) | Pruning ratio |
| Phase1- P | 4 | 74.1 | 0.9 |
| Finetune (lr=0.1) | 4 | 79.2 | 0.9 |
| Finetune (lr=0.01) | 4 | 78.0 | 0.9 |
| Finetune (lr=0.001) | 4 | 73.8 | 0.9 |
| Phase2- P | 4 | 83.1 | 0.9 |
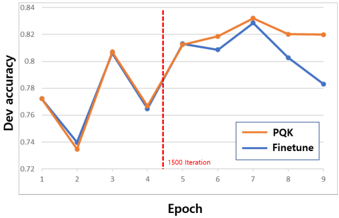
Figure 2: Dev accuracy of ResNet-8-narrow on google's speech command dataset at every epoch :Orange line represents PQK (Phase2-P) and blue line shows the finetune (lr=0.1). Red dot line means the end of warm up iteration.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Line Chart: Dev Accuracy Comparison (PQK vs. Finetune)
### Overview
The image is a line chart comparing the development set accuracy ("Dev accuracy") of two machine learning training methods, labeled "PQK" and "Finetune," over a series of training epochs. The chart includes a vertical dashed line marking a specific iteration milestone.
### Components/Axes
* **Chart Type:** Line chart with two data series.
* **X-Axis:**
* **Label:** "Epoch"
* **Scale:** Linear, integer markers from 1 to 9.
* **Y-Axis:**
* **Label:** "Dev accuracy"
* **Scale:** Linear, ranging from 0.72 to 0.84, with major gridlines at intervals of 0.02.
* **Legend:**
* **Position:** Bottom-right corner of the plot area.
* **Series 1:** "PQK" - Represented by an orange line.
* **Series 2:** "Finetune" - Represented by a blue line.
* **Annotations:**
* A vertical red dashed line is positioned between Epoch 4 and Epoch 5 (approximately at x=4.5).
* Text label next to the red line: "1500 iteration".
### Detailed Analysis
**Data Series Trends & Approximate Points:**
1. **PQK (Orange Line):**
* **Trend:** Shows significant volatility in early epochs, with a general upward trend after Epoch 4, peaking at Epoch 7 before a slight decline.
* **Approximate Data Points:**
* Epoch 1: ~0.775
* Epoch 2: ~0.735 (local minimum)
* Epoch 3: ~0.805 (local peak)
* Epoch 4: ~0.780
* Epoch 5: ~0.815
* Epoch 6: ~0.820
* Epoch 7: ~0.830 (global maximum)
* Epoch 8: ~0.820
* Epoch 9: ~0.820
2. **Finetune (Blue Line):**
* **Trend:** Follows a very similar volatile pattern to PQK for the first 7 epochs, closely tracking it. After Epoch 7, it diverges with a sharp downward trend.
* **Approximate Data Points:**
* Epoch 1: ~0.770
* Epoch 2: ~0.740 (local minimum)
* Epoch 3: ~0.805 (local peak, matches PQK)
* Epoch 4: ~0.765
* Epoch 5: ~0.815 (matches PQK)
* Epoch 6: ~0.810
* Epoch 7: ~0.825 (global maximum, slightly below PQK)
* Epoch 8: ~0.805
* Epoch 9: ~0.785
**Key Spatial & Visual Relationships:**
* The two lines are nearly superimposed from Epoch 1 to Epoch 7, indicating very similar performance during this phase.
* The red "1500 iteration" line at Epoch 4.5 appears to mark a transition point. After this line, both methods show a more consistent upward climb until Epoch 7.
* The most significant divergence occurs after Epoch 7, where the PQK line plateaus while the Finetune line declines steeply.
### Key Observations
1. **High Correlation Pre-Divergence:** The performance of PQK and Finetune is almost identical for the first 7 epochs, suggesting they respond similarly to training data up to that point.
2. **Post-Peak Divergence:** After reaching their respective peaks at Epoch 7, the methods behave differently. PQK maintains its accuracy (~0.82), while Finetune's accuracy degrades significantly (dropping ~0.04 by Epoch 9).
3. **Volatility:** Both methods exhibit a "sawtooth" pattern in early epochs (dips at Epoch 2 and 4), which may indicate instability in training or the effect of specific data batches.
4. **Milestone Marker:** The "1500 iteration" annotation suggests a change in training protocol (e.g., switching from a pre-training to a fine-tuning phase, adjusting learning rate) occurred at that point, after which both models began a more sustained improvement.
### Interpretation
This chart likely illustrates a comparison between a novel training method (PQK) and a standard fine-tuning approach. The data suggests:
* **Initial Parity:** For the majority of the training process (up to Epoch 7), PQK performs equivalently to standard fine-tuning. This demonstrates that PQK is a viable alternative that does not sacrifice performance during the main training phase.
* **Superior Stability/Generalization:** The critical finding is the behavior after Epoch 7. The fact that PQK's accuracy plateaus at a high level while Finetune's drops suggests that PQK may lead to a more robust model that is less prone to **overfitting** on the development set as training continues. The Finetune method's decline could indicate it is beginning to memorize training data at the expense of generalizability.
* **The "1500 iteration" Point:** This marker is crucial context. It implies the experiment was designed with a two-stage process. The improved, steadier climb for both models after this point indicates the protocol change was effective. The subsequent divergence highlights PQK's advantage in the later, potentially more delicate, stages of optimization.
**Conclusion:** The chart provides evidence that the PQK method matches the performance of standard fine-tuning during active learning and may offer significant advantages in maintaining model performance and preventing degradation in later training stages, leading to a more stable and potentially better-generalizing final model.
</details>
tuning and phase-2 of PQK per every epoch in Fig. 2. In this figure, orange and blue line represent the validation accuracy of phase2P and finetune (lr=0.1) in Table 2. During the warm up step, two methods show very similar trends because they are trained with only cross-entropy. After warm up step, the performance gap between them increases because mutual KD training helps to enhance the performance of both pruned and full net.
## 4. Conclusions
Wepropose a novel model compression framework to cope with the limited computational resource. This is a new way of model compression by leveraging pruning, quantization, and knowledge distillation. In phase 1, we are combining pruning and quantization to make a lightweight and power-efficient model. Then, in phase 2, we boost the performance of a efficient model by KD. We verify the efficiency of PQK on KWS and image recognition tasks.
## 5. References
- [1] T. Lin, S. U. Stich, L. Barba, D. Dmitriev, and M. Jaggi, 'Dynamic model pruning with feedback,' International Conference on Learning Representations , 2020.
- [2] S. Han, J. Pool, J. Tran, and W. J. Dally, 'Learning both weights and connections for efficient neural networks,' International Conference on Learning Representations , 2015.
- [3] Y. He, P. Liu, Z. Wang, Z. Hu, and Y. Yang, 'Filter pruning via geometric median for deep convolutional neural networks acceleration,' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , June 2019.
- [4] J. Kim, S. Chang, S. Yun, and N. Kwak, 'Prototype-based personalized pruning,' in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2021, pp. 3925-3929.
- [5] R. Krishnamoorthi, 'Quantizing deep convolutional networks for efficient inference: A whitepaper,' arXiv preprint arXiv:1806.08342 , 2018.
- [6] Y. Pan, P. Ouyang, Y. Zhao, W. Kang, S. Yin, Y. Zhang, W. Zhao, and S. Wei, 'A multilevel cell stt-mram-based computing inmemory accelerator for binary convolutional neural network,' IEEE Transactions on Magnetics , vol. 54, no. 11, pp. 1-5, 2018.
- [7] S. Markidis, S. W. Der Chien, E. Laure, I. B. Peng, and J. S. Vetter, 'Nvidia tensor core programmability, performance & precision,' in 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW) . IEEE, 2018, pp. 522-531.
- [8] J. Kim, S. Park, and N. Kwak, 'Paraphrasing complex network: Network compression via factor transfer,' in Advances in Neural Information Processing Systems , vol. 31, 2018.
- [9] B. Heo, J. Kim, S. Yun, H. Park, N. Kwak, and J. Y. Choi, 'A comprehensive overhaul of feature distillation,' in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2019, pp. 1921-1930.
- [10] J. Kim, M. Hyun, I. Chung, and N. Kwak, 'Feature fusion for online mutual knowledge distillation,' in 2020 25th International Conference on Pattern Recognition (ICPR) . IEEE, 2021, pp. 4619-4625.
- [11] G. Hinton, O. Vinyals, and J. Dean, 'Distilling the knowledge in a neural network,' arXiv preprint arXiv:1503.02531 , 2015.
- [12] J. Kim, Y. Bhalgat, J. Lee, C. Patel, and N. Kwak, 'Qkd: Quantization-aware knowledge distillation,' arXiv preprint arXiv:1911.12491 , 2019.
- [13] Y. Bai, J. Yi, J. Tao, Z. Tian, Z. Wen, and S. Zhang, 'Listen Attentively, and Spell Once: Whole Sentence Generation via a NonAutoregressive Architecture for Low-Latency Speech Recognition,' in Proc. Interspeech 2020 , 2020, pp. 3381-3385.
- [14] C. Jose, Y. Mishchenko, T. S´ en´ echal, A. Shah, A. Escott, and S. N. P. Vitaladevuni, 'Accurate Detection of Wake Word Start and End Using a CNN,' in Proc. Interspeech 2020 , 2020, pp. 3346-3350.
- [15] S. Adya, V. Garg, S. Sigtia, P. Simha, and C. Dhir, 'Hybrid Transformer/CTC Networks for Hardware Efficient Voice Triggering,' in Proc. Interspeech 2020 , 2020, pp. 3351-3355.
- [16] H. D. Nguyen, A. Alexandridis, and A. Mouchtaris, 'Quantization Aware Training with Absolute-Cosine Regularization for Automatic Speech Recognition,' in Proc. Interspeech 2020 , 2020, pp. 3366-3370.
- [17] G. Chen, C. Parada, and G. Heigold, 'Small-footprint keyword spotting using deep neural networks,' in 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2014, pp. 4087-4091.
- [18] J. Kim, K. Yoo, and N. Kwak, 'Position-based scaled gradient for model quantization and pruning,' in Advances in Neural Information Processing Systems , vol. 33, 2020, pp. 20 415-20 426.
- [19] Y. Bengio, N. L´ eonard, and A. Courville, 'Estimating or propagating gradients through stochastic neurons for conditional computation,' arXiv preprint arXiv:1308.3432 , 2013.
- [20] R. Tang and J. Lin, 'Deep residual learning for small-footprint keyword spotting,' in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2018, pp. 5484-5488.
- [21] G. Tucker, M. Wu, M. Sun, S. Panchapagesan, G. Fu, and S. Vitaladevuni, 'Model compression applied to small-footprint keyword spotting.' in Interspeech , 2016, pp. 1878-1882.
- [22] P. Warden, 'Launching the speech commands dataset,' in Google Research Blog , 2017.
- [23] A. Krizhevsky, G. Hinton et al. , 'Learning multiple layers of features from tiny images,' 2009.
- [24] K. He, X. Zhang, S. Ren, and J. Sun, 'Deep residual learning for image recognition,' in Proceedings of the IEEE conference on computer vision and pattern recognition , 2016, pp. 770-778.
- [25] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, 'Binarized neural networks,' in Advances in neural information processing systems , 2016, pp. 4107-4115.