# Towards a generalized monaural and binaural auditory model for psychoacoustics and speech intelligibility
**Authors**: Thomas Biberger, Stephan D. Ewert
This work has been submitted to Acta Acustica for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.
## Towards a generalized monaural and binaural auditory model for psychoacoustics and speech intelligibility
Thomas Biberger a) and Stephan D. Ewert Medizinische Physik and Cluster of Excellence Hearing4all, Universität Oldenburg, 26111 Oldenburg, Germany.
a) Electronic mail: thomas.biberger@uni-oldenburg.de
Running title: Modeling masking and speech intelligibility
## ABSTRACT
Auditory perception involves cues in the monaural auditory pathways as well as binaural cues based on differences between the ears. So far auditory models have often focused on either monaural or binaural experiments in isolation. Although binaural models typically build upon stages of (existing) monaural models, only a few attempts have been made to extend a monaural model by a binaural stage using a unified decision stage for monaural and binaural cues. In such approaches, a typical prototype of binaural processing has been the classical equalization-cancelation mechanism, which either involves signal-adaptive delays and provides a single channel output or can be implemented with tapped delays providing a highdimensional multichannel output. This contribution extends the (monaural) generalized envelope power spectrum model by a non-adaptive binaural stage with only a few, fixed output channels. The binaural stage resembles features of physiologically motivated hemispheric binaural processing, as simplified signal processing stages, yielding a 5-channel monaural and binaural matrix feature 'decoder' (BMFD). The back end of the existing monaural model is applied to the 5-channel BMFD output and calculates short-time envelope power and power features. The model is evaluated and discussed for a baseline database of monaural and binaural psychoacoustic experiments from the literature.
## I. INTRODUCTION
Auditory perception is typically binaural, involving signals at both ears. Besides enabling localization based on interaural time and intensity differences, interaural disparities can also be exploited to better detect a target stimulus in spatially separated or spatially differently distributed maskers (spatial release from masking, SRM; e.g., [1, 2]) or an antiphasic tone in diotic noise (binaural masking level difference, BMLD; e.g., [3, 4]). Auditory models have been used to explain and analyze monaural and binaural psychoacoustic phenomena (e.g., [59), and as supportive tools offering instrumental assessment of, e.g., speech intelligibility (SI) and audio quality, applicable for development and control of signal processing (e.g., [10-16]). In such applications typically monaural phenomena and perceptive cues involved in, e.g., spectral and temporal masking [17, 18], as well as binaural cues involved in, e.g., sound source location, apparent source width [15], occur in combination [19, 20]. Auditory models as well as psychoacoustic experiments have often focused on either monaural or binaural aspects of perception in isolation, having led to a variety of monaural models (e.g., [ 5, 6, 9, 21, 22, 23, 24, 25, 26]) and binaural models (e.g., [8, 12, 27, 28, 29, 31, 32, 33, 34]). The binaural models typically share 'common ground' assumptions of essential monaural preprocessing steps followed by a binaural interaction (BI) stage. In many of these binaural models, the prototype binaural interaction is based on the equalization-cancelation mechanism (EC; [28]) providing a 'monaural', single channel output signal after a signal-adaptive binaural noise cancelation. This single channel output either uses the optimal internal delay to compensate for external interaural delays in connection with an optimal level compensation (equalization) to cancel undesired noise, comparable to an adaptive binaural (or bilateral) beamformer (for an overview, see [35]), or simply selects the better ear (referred to as 'betterear glimpsing' if applied in time-frequency frames, see [1]). Thus, the EC mechanism can be easily applied as binaural front end to an existing monaural model (for speech intelligibility see, e.g., [12, 13, 14, 36, 37]). Providing a monaural or diotic input, reverts such models to
monaural ones, although they are typically applied to binaural (dichotic) stimuli. Focusing on a large variety of basic binaural psychoacoustic experiments, Breebaart et al. [8, 38, 39] combined a number of internal delays and interaural gains in a matrix of (excitatoryinhibitory) cancelation elements. By this, a signal-adaptive mechanism to equalize prior to is required to 'select' optimal matrix elements by applying weights in the form of a template for a given psychoacoustic experiment. Both the monaural front end and the templatematching procedure used in the Breebaart model have been taken from the (monaural) perception model of Dau et al. [5, 6].
The question arises whether a simpler, non-adaptive approach is sufficient to model binaural simple addition of the left and right input channel can explain a large part of the observed spatial release from masking (SRM). Such a simplistic binaural interaction has also been suggested by [40] as midline spatial channel in the human auditory cortex. Additionally, the existence of delay lines as utilized in the EC and Breebaart approach has been questioned in mammals (for a review see [41]) and physiologic studies (e.g., [42, 43]) suggest a simpler hemispheric model without delay lines to account for binaural interaction, involving fixed phase delays and excitation as well as inhibition from the contralateral ear. Regarding the cancelation as in the EC approach is avoided, however, a signal-adaptive template mechanism The above mentioned models show successful concepts for combining monaural and binaural model stages in a combined model, however, they have been either explicitly applied to binaural psychoacoustics or speech intelligibility whereas their front and back ends without binaural stage have been explicitly applied to the respective monaural experiments. Moreover, the models require a signal-adaptive mechanism in the EC stage and a selection from 3 output channels (EC approach: Left, EC output, right) or a signal-adaptive template to extract information from the high-dimensional matrix of delay-gain elements. interaction. For speech intelligibility in symmetrically placed interferers, e.g., [2] found that a
development of effective auditory signal processing models, such a fixed binaural interaction could be beneficial for applications where computational efficiency is important. Moreover, it appears desirable to evaluate the same model both in monaural and binaural experiments as well as in basic psychoacoustic tasks and speech intelligibility. The advantage of such a unified modelling approach (see, e.g., [9, 26] for monaural models) is the applicability of the model to a wide variety of stimuli as well as the potential of the model to directly link performance and cues in basic psychoacoustic tasks, such as detection and discrimination thresholds, to higher level processes involved in speech intelligibility. In the long run, such a link might help to understand and disentangle peripheral and central deficits in hearing impaired and elderly persons (e.g., [44 - 48]) and in the context of model-driven stimulus design for psychoacoustics and physiology (e.g., [49]).
Here we suggest and examine a combined monaural and binaural model in a variety of 'benchmark' psychoacoustic and speech intelligibility experiments. The combined approach uses the monaural front end and back end of the generalized power spectrum model (GPSM; [26]) which has been successfully applied to monaural psychoacoustics, speech intelligibility and audio quality ([9, 16, 19, 20, 26]). A binaural processing stage with five fixed (nonadaptive) output channels is suggested prior to the model back end, referred to as binaural matrix feature decoder (BMFD). The output comprises the left (L) and right (R) channels, the L+R channel and the L-R and R-L channels, incorporating a fixed phase delay and gain. L and R enable better ear glimpsing in connection with a selection of time-frequency frames across the BMFD output channels in the back end (better ear channels). The three other channels realize a binaural interaction: L+R represents a midline channel, enhancing coherent (frontal) signals at both ears. The L-R and R-L channels effectively mimic the outputs expected in hemispheric models of binaural interaction in a highly simplified manner. These channels are comparable to two elements in the delay-gain matrix of the Breebaart model, or to two according parameter choices in the EC approach. The ability of the suggested model to
account for the monaural and binaural data and the relevance of the five BMFD output channels are assessed in the following.
## II. Model description
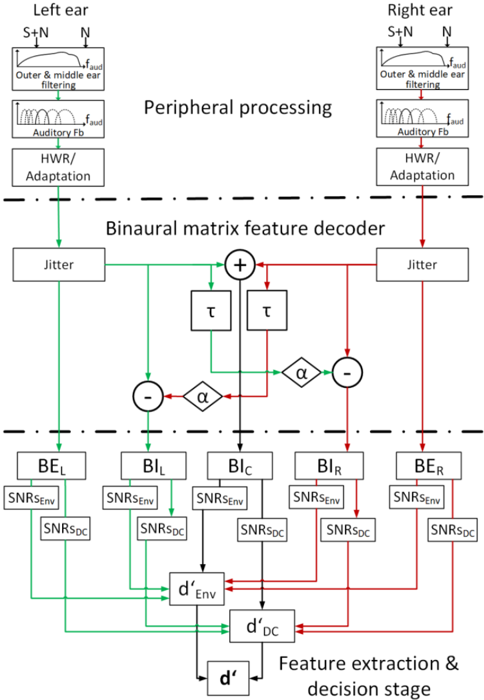
The front end of the proposed GPSM with BMFD extension calculates short-time power and envelope power features for each of two better-ear (BE) channels (L: BEL, R: BER) and the three binaural interaction (BI) channels (L-R: BIL, L+R: BIC, R-L: BIR), comprising the binaural matrix feature decoder. Signal-to-noise ratios based on these features are assessed by a task-dependent decision stage (psychoacoustics or speech intelligibility) in the model back end. The model processes two input stimuli, the target-plus-masker (signal) and masker alone (noise).
## A. Monaural processing stages
The peripheral processing, feature extraction and decision stage of the GPSM with BMFD extension, illustrated in Figure 1 are similar to that of the monaural mr-GPSM proposed in [26]. In the following, the processing stages related to the envelope power pathway are only roughly described here, and for a more comprehensive description the reader is referred to [9, 26].
Figure 1: Block diagram of the GPSM with BMFD extension. After peripheral processing, the left and right ear signals are binaurally processed by using the BMFD that provides two better-ear channels BEL and BER and three binaural interaction channels BIL, BIC, BIR. For each of the five BMFD outputs, envelope power and power SNRs are calculated in short-time frames and then combined across the five channels of the BMFD and across auditory and modulation channels, resulting in a sensitivity index denv ' based on envelope power SNRs and dDC ' based on power SNRs. The final combined d ' is then compared to a threshold criterion that assumes that a signal is detected if d ' > (0.5) 1 2 / .
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Binaural Processing Model
### Overview
This diagram illustrates a model of binaural processing, depicting the flow of auditory information from the left and right ears through peripheral processing, a binaural matrix feature decoder, and finally to feature extraction and a decision stage. The diagram uses boxes to represent processing stages and arrows to indicate the direction of information flow. Green arrows represent signal flow, while red arrows indicate inhibitory connections.
### Components/Axes
The diagram is structured into three main sections:
1. **Peripheral Processing:** Includes stages for both the left and right ears.
2. **Binaural Matrix Feature Decoder:** The central processing unit.
3. **Feature Extraction & Decision Stage:** The final stage.
Key components and labels include:
* **Left Ear:** S+N (Signal + Noise), Outer & middle ear filtering, f<sub>aud</sub>, Auditory Fb, HWR/Adaptation.
* **Right Ear:** S+N (Signal + Noise), Outer & middle ear filtering, f<sub>aud</sub>, Auditory Fb, HWR/Adaptation.
* **Peripheral processing:** Title for the first section.
* **Binaural matrix feature decoder:** Title for the central section.
* **Jitter:** Present in both left and right ear pathways.
* **τ (Tau):** Delay element.
* **α (Alpha):** Gain element.
* **BE<sub>L</sub>, BE<sub>R</sub>:** Binaural Envelope - Left and Right.
* **BI<sub>L</sub>, BI<sub>R</sub>:** Binaural Intensity - Left and Right.
* **BI<sub>C</sub>:** Binaural Intensity - Center.
* **SNR<sub>Env</sub>:** Signal-to-Noise Ratio - Envelope.
* **SNR<sub>DC</sub>:** Signal-to-Noise Ratio - DC.
* **d'<sub>Env</sub>:** Prime d - Envelope.
* **d'<sub>DC</sub>:** Prime d - DC.
* **d':** Prime d.
* **Feature extraction & decision stage:** Title for the final section.
### Detailed Analysis or Content Details
The diagram shows a parallel processing pathway for the left and right ears.
1. **Peripheral Processing:** Both ears receive a signal plus noise (S+N). This signal undergoes outer and middle ear filtering, characterized by the frequency f<sub>aud</sub>. The filtered signal then passes through an Auditory Filterbank (Fb) and a stage for HWR/Adaptation. Jitter is introduced after this stage.
2. **Binaural Matrix Feature Decoder:** The outputs from the left and right ear pathways converge. The signals pass through delay elements (τ) and gain elements (α). The outputs of these elements feed into the binaural envelope (BE) and binaural intensity (BI) calculations. Specifically:
* BE<sub>L</sub> and BE<sub>R</sub> receive inputs from the left and right pathways, respectively.
* BI<sub>L</sub> and BI<sub>R</sub> receive inputs from the left and right pathways, respectively.
* BI<sub>C</sub> receives inputs from both pathways.
* Each of BE<sub>L</sub>, BE<sub>R</sub>, BI<sub>L</sub>, BI<sub>R</sub>, and BI<sub>C</sub> is associated with SNR<sub>Env</sub> and SNR<sub>DC</sub>.
3. **Feature Extraction & Decision Stage:** The outputs from the binaural intensity and envelope calculations (d'<sub>Env</sub> and d'<sub>DC</sub>) are combined to produce d', which represents the final feature used in the decision stage. Red arrows indicate inhibitory connections from BI<sub>L</sub> and BI<sub>R</sub> to d'<sub>Env</sub> and d'<sub>DC</sub>.
### Key Observations
* The diagram emphasizes parallel processing of auditory information from both ears.
* The use of delay (τ) and gain (α) elements suggests that interaural time and level differences are crucial for binaural processing.
* The SNR calculations (SNR<sub>Env</sub> and SNR<sub>DC</sub>) indicate that the model considers both the envelope and DC components of the signal-to-noise ratio.
* The inhibitory connections (red arrows) suggest a mechanism for suppressing irrelevant or competing signals.
* The diagram does not provide specific numerical values or quantitative data. It is a conceptual model.
### Interpretation
This diagram represents a computational model of how the brain processes binaural auditory information to extract features relevant for sound localization and speech intelligibility. The model highlights the importance of both temporal (delay) and intensity cues in binaural hearing. The SNR calculations suggest that the model accounts for the effects of noise on auditory perception. The inhibitory connections likely represent neural mechanisms for selective attention and noise reduction. The model suggests that the brain extracts features (d') from the binaural signal that are then used to make decisions about the location and characteristics of sound sources. The diagram is a high-level representation and does not delve into the specific neural circuits or algorithms involved in each processing stage. It is a conceptual framework for understanding the principles of binaural hearing.
</details>
The initial Outer & middle ear filtering stage (see Figure 1) weights the input signal with the hearing threshold in quiet [50], followed by the Auditory Fb , reflecting basilar membrane filtering by applying a fourth-order Gammatone filterbank with bandwidth equal to the
equivalent rectangular bandwidth of the auditory filter (ERBN; [51]) and third octave spacing from 63 to 12500 Hz. In contrast to Hilbert envelope extraction in [26], each auditory channel is half-wave rectified to simulate that inner hair cells primarily respond only to one direction of deflection. The half-wave rectified signals are divided by an integrator with time constant of 2 ms, realized as a first-order low pass filter with cut-off frequency of 500 Hz, to simulate effects of neural adaptation of the auditory system in a simple feed-forward manner.
## B. Binaural processing stages
The adapted signals from the monaural processing of the left and right ear serve as input for the binaural processor. First, amplitude and phase jitter are applied independently for each auditory channel to the input signals, to limit the performance of the BI. Amplitude and time jitters are generated as zero-mean Gaussian processes with a standard deviation of σϵ = 0.25 and σδ = 105 µs, as suggested by [28] and also applied by [36] and [37]. Based on the jittered signals three BI channels BIL, BIC, and BIR are calculated according to Eq. 1-3:
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
BIL results from subtracting the time delayed and amplified right ear channel 𝛼 ∙
𝑅(𝑝, 𝑡 - 𝜏(𝑝)) from the left ear channel 𝐿(𝑝, 𝑡) in each auditory channel p . BIR is calculated
vice versa to BIL. Based on physiologic findings and preliminary tests, a frequency-dependent delay τ equal to a phase shift of π/4 was chosen, resulting in longer delays for lower frequencies. The amplification factor α equals 3 (see discussion for further details). BIC accounts for the effect of adding the left and right ear signals prior to auditory processing. Taking the half-wave rectified signal representation into account, this is achieved by the square root of the product 𝐿(𝑝, 𝑡) and 𝑅(𝑝, 𝑡) , making BIC a midline channel most sensitive to sound images spatially placed in the median plane. In addition to the three BI channels, the (monaural) left and right channel 𝐿(𝑝, 𝑡) and 𝑅(𝑝, 𝑡) are passed unaltered as output of the five channel BMFD stage. They can be used for better-ear glimpsing in the following feature extraction stage (referred to as BEL, BER).
## C. Power and envelope power feature extraction stage
A first-order low-pass filter with cut-off frequency of 150 Hz [7, 52] is applied to the five output channels of the BMFD. The consecutive processing stages in each of the five BMFD channels are separated into two independent pathways where envelope power SNRs (EPSM; left-hand side of Figure 1), and power SNRs (PSM; right-hand side of Figure 1) are calculated. Indices for the BMFD channels are omitted for clarity in the following equations.
In the PSM path, the intensity (DC-power) features PDC,j(p) are calculated in short-time windows j by taking the squared mean of the Hilbert envelope within each auditory channel p
<!-- formula-not-decoded -->
The duration of the windows depends on the center frequency of the auditory channel, where the lowest center frequency of 63 Hz corresponds to window length of 45 ms and the highest center frequency provides a window length of 8 ms. As proposed by Rhebergen and
Versfeld [11] values for the window duration were taken from [53] and multiplied by 2.5. Intensities P DC ,j(p) falling below the hearing threshold are set to 1e-10. Then the SNRDC ,j(p) is calculated between target-plus-masker intensities P DC,targ+mask ,j(p) and the masker intensities P DC,mask ,j(p) according to
<!-- formula-not-decoded -->
For speech intelligibility predictions, optionally a band importance function (BIF) as used in the ESII, is multiplicatively applied to the intensity SNRDC (p) . Note that the here applied BIF is normalized by its highest value and thus the SNRDC within this auditory channel remains unaffected from the (normalized) BIF, while all other channels become attenuated. In the EPSM path, the envelopes are initially processed by a modulation filterbank consisting of bandpass filters ranging from 2 to 256 Hz with a Q-value of 1 and a third-order low-pass filter with cut-off frequency of 1 Hz. Hereby, based on [54], only modulation filter center frequencies up to one fourth of the corresponding auditory channel center frequency are considered. Then the AC-coupled envelope power P env ,j(p,n) is calculated for each auditory channel p , modulation channel n , and time window i , as it was proposed in [25], by applying a lower limit of -27 dB for the envelope power, reflecting the limitation in human sensitivity to amplitude modulation (AM) [22, 52]. The envelope power based signal-to-noise ratio SNRenv ,i(p,n) between the target-plus-masker and masker envelope power is calculated according to [25] and then a logarithmic weighting of envelope power SNRs is applied for auditory channels with intensity levels of the target-plus-masker stimuli below 35 dB, while envelope power SNRs above that level are unaffected from weighting.
Taken together, the output of the model front end consists of intensity weighted envelope power SNRs, SNRenvW ,i(p,n) , and power SNRs, SNRDC ,j(p) , for each of the five BMFD output channels.
## D. Decision stage
The envelope power and power based SNRs are subjected to a task-specific decision stage for predicting psychoacoustic detection or discrimination thresholds and SI data.
## 1. Psychoacoustics
In the first step, SNRenvW ,i(p,n) in each of the five front end output channels are combined by taking the largest value for each time frame within each auditory and modulation channel resulting in SNRenvWC ,i(p,n) . SNRenvWC ,i(p,n) is then averaged across temporal segments i per modulation filter, resulting in a two-dimensional representation of envelope power SNRenv (p,n). The same procedure is applied to combine SNRDC ,j(p) across the five channels resulting in the SNRDCW ,j(p) which is then is averaged across temporal segments j , resulting in a 1-dimensional representation of power SNRs over auditory channels denoted as SNRDC (p)
Finally, the envelope power and power SNRs [SNRenv (p,n) , SNRDC (p) ] are combined in the same manner as proposed in [26]:
<!-- formula-not-decoded -->
At first envelope power and power SNRs are combined across auditory and modulation channels (in case of envelope power) and auditory channels [inner brackets in Eq. 6] and then multiplied with empirical determined correction factors β = 0.21 and γ = 0.45. Both correction factors are identical to those proposed in [9, 26] and are used due to violation of the
assumption of independent observations in the auditory and modulation channels, because of using overlapping bandpass filter. Finally, the domain (envelope or power), providing the highest SNR-value is chosen.
As in [9, 26] the decision criterion used in this study is based on [7] assuming that a signal is detected if the SNR > -6 dB (equivalent to a power ratio of 0.25), which can, according to [55] also be expressed as sensitivity index d ' = (2 ∙ SNR) 1 2 / ≈ (0.5) 1 2 / .
## 2. Speech intelligibility
The overall SNR is obtained by applying the same procedure as described for psychoacoustic predictions. The overall SNR is converted to the sensitivity index d ' by using equation (6) from [25] and finally transformed into percent correct responses.
## E. Model configurations
All model versions with binaural extension tested in this study had the same settings as the monaural GPSM-versions in [9, 26]: For psychoacoustic experiments, auditory filters had a third-octave spacing ranging from 63 to 12500 Hz, while auditory filters range from 63 to 8000 Hz for SI experiments. For SI predictions, the band-importance weighting, as it was proposed by Table 3 of [56] was exclusively applied to the power SNRs. Each of the models used exactly the same set of parameters for all experiments.
## III. Psychoacoustic evaluation
## A. Monaural experiments
In this study the same set of headphone-based monaural psychoacoustic experiments were applied for model evaluation as in [9, 26]. Thus, these experiments are only briefly explained in the following. For more detailed information the reader is referred to [9] or the respective original publications.
Experiment 1 (Intensity discrimination and hearing thresholds). Just noticeable intensity level differences (JNDs) as a function of the reference level (20, 30, 40, 50, 60, 70 dB) were measured for a 1-kHz pure-tone (in quiet) and broadband noise ranged from 0.1 to 8 kHz [57]. The target interval contained an increased level 𝐿𝑡 = 𝐿0 +∆𝐿 where L0 corresponds to the reference level and ∆L corresponds to the JND, which can be rewritten in terms of intensities as ∆𝐿 = 10 log10 𝐼 𝑡 𝐼 𝑜 = ∆𝐼+𝐼0 𝐼 𝑜 . Hearing thresholds ranging from 50 Hz to 10 kHz were taken from [50].
In Experiment 2 (Spectral masking with narrow-band and pure-tone maskers) the masking patterns for four different signal-masker combinations of noise-in-tone (NT), noise-in-noise (NN), tone-in-tone (TT) and tone-in-noise (TN) originated from [58]. The noise corresponds to a Gaussian noise with a bandwidth of 80 Hz, while the tone refers to a sinusoidal stimulus. The masker had a fixed center frequency at 1 kHz, while the signal had frequencies of 0.25, 0.5, 0.75, 0.9, 1.0, 1.1, 1.25, 1.5, 2, 3, and 4 kHz. All signal-masker combinations, with exception of the TT condition, where each stimulus had a fixed phase of 90°, had random phases. Data for the masker levels of 45 and 85 dB are considered here.
Experiment 3 (Tone in noise masker) was taken from [24] and reflects detection thresholds of a 2-kHz pure tone signal in the presence of a band limited (0.02 to 5 kHz) Gaussian noise masker for signal durations from 5 to 200 ms. The masker had a duration of 500 ms and the
signal was temporally centered in the masker. The presentation level of the masker was 65 dB SPL.
Experiment 4 (AM-depth discrimination) is based on the study from [59] where AM-depth discrimination function for a 16 Hz sinusoidal AM with respect to fixed reference AM-depths was measured for sinusoidally modulated broadband noise (1.952-4 kHz) and pure-tone carriers (4 kHz) at an overall presentation level of 65 dB SPL. The AM depth of the (standard) reference signal ms ranged, in 5-dB steps, from -28 to -3 dB. The increased AM depth of the target signal is given by 𝑚𝑐 = 𝑚𝑠√1 + 𝑚𝑖𝑛𝑐 . Within the measurement the fractional increment 𝑚𝑖𝑛𝑐 = (𝑚𝑐 2 -𝑚𝑠 2 ) 𝑚𝑠 2 / was varied in dB ( 10log𝑚𝑖𝑛𝑐 ).
In Experiment 5 (AM detection) temporal modulation transfer functions (TMTF) for three narrow band noise carriers of 3, 31, and 314 Hz [5] and broadband noise carriers [22] were considered. The narrow band noise carriers were centered at 5 kHz and a sinusoidal AM of 3, 5, 10, 20, 30, 50, and 100 Hz was used. The narrow band carrier level was 65 dB SPL and the stimuli were adjusted to have equal power after AM. The broadband noise carriers ranged from 0.001 to 6 kHz and a sinusoidal AM of 4, 8, 16, 32, 64, 128, 256, 512, and 1024 Hz was applied. The level of the broadband carriers was 77 dB SPL.
Experiment 7 (Amplitude modulation masking) was taken from [9] and measured AM masking and detection thresholds for a target sinusoidal amplitude modulation (SAM) in the presence of a sinusoidal or squarewave masker modulation. The effect of varying the carrier type (broadband and pure-tone carriers), masker waveform (sinusoidal or squarewave), and modulation rate of the target (4 and 16 Hz) and masker (16 and 64 Hz) were examined in four different stimulus configurations which can be seen in Table 1 of [9].
## B. Binaural experiments
Six binaural headphone experiments from literature were used for the model evaluation. The maskers used in the binaural experiments had a duration of 400 ms unless otherwise stated. In several binaural experiments target and masker signals comprise interaural manipulations indicated by subscripts: The subscript 0 indicates no interaural phase shift (in phase), the subscript π indicates an interaural phase shift of π (out of phase), and the subscript m indicates that the corresponding signal was presented monaurally. Accordingly, a N0Sπ stimulus indicates that the noise signal N0 is interaurally in phase, while the target signal Sπ is interaurally out of phase. The experiments are only briefly described in the following and the reader is referred to [38, 39] for experiment 1-5 or the original literature for further details.
Experiment 1 (ITD discrimination) is based on the ITD experiments from [60, 61], where discrimination threshold for ITDs were measured for pure tone stimuli at various frequencies. The reference stimuli were presented diotically at a level of 65 dB SPL, while the target stimuli were presented at the same level but had an ITD. The tested frequencies ranged from 90 to 1500 Hz.
Experiment 2 (IID discrimination) is based on the IID experiments from [62, 63], where thresholds for IID were measured for pure tones at various frequencies ranging from 62.5 to 4000 Hz. The reference stimuli were presented diotically at a level of 65 dB SPL. The target stimuli had an IID, resulting in an overall level of (65+IID/2) dB SPL for the left channel and (65 - IID/2) dB SPL for the right channel.
Experiment 3 (Frequency and interaural phase relationships in wideband conditions) is based on experiments of [3, 4, 64, 65], where thresholds of the four binaural conditions N0Sπ, NπS0, N0Sm, and NπSm, were measured as a function of the frequency of the pure tone signal (125, 250, 500, 1000, 2000, and 4000 Hz). The masker was a low-pass noise with a cutoff frequency of 8 kHz and a spectral level of 40 dB/Hz.
Experiment 4 (N0Sπ depending on signal duration) is based on experiments of [66-69], where N0Sπ detection thresholds were measured as a function of the target signal (Sπ)
duration. The masker signal (N0) was a 500-ms wideband noise with a spectral density of 36.2 dB/Hz. The target signal was a pure tone of either 500 Hz or 4 kHz with signal durations ranging from 2 to 256 ms.
Experiment 5 (Temporal phase transition) is based on the experiments of Kollmeier and Gilky [70] where N0NπSπ, NπN0Sπ, NπNπ,-15dBSπ, Nπ,-15dBNπSπ, thresholds were measured as a function of the temporal position of the target signal (Sπ) relative to the masker-phase transition (NπN0 or N0Nπ) to estimate the temporal resolution of the binaural auditory system. The broadband noise maskers with a duration of 750 ms were bandpass filtered from 100 to 2000 Hz and had a spectral level of 40 dB/Hz. The N0Nπ masker started with an interaural phase of N0 that switched to Nπ after 375 ms. Accordingly, NπN0 started with a 375 ms interaurally out of phase segment followed by a 375 ms in phase segment. The interaurally out of phase masker NπNπ,-15dB was attenuated by 15 dB 375 ms after its onset. The interaurally out of phase masker Nπ,-15dBNπ was amplified by 15 dB 375 ms after its onset. Sπ was an interaurally out of phase pure tone of 500 Hz with a duration of 20 ms. The masked threshold was measured as a function of the delay time between the transition of the noise segments and the signal offset.
Experiment 6 (Time-intensity-trading) is based on experiments of Hafter and Carrier [71], where d ' was measured for several combinations of fixed ITDs (0, +10, +20, +30, and +40 µs; positive sign indicates left ear leading) and varying IIDs (ranging from 0 to -3 dB; negative sign indicates right ear more intense) to examine to which extent time differences can be traded against level differences. The reference signal was a diotic pure tone of 500 Hz (centered sound image). The test signal had a ITD promoting lateralization to the left side, and a IID promoting lateralization to the right side. The lowest d ' measured for a certain IID at a fixed ITD indicates that the test signal was most similar to a centered image.
## C. Results and discussion
Predictions from three model versions were compared to disentangle the contribution of the binaural interaction (BIL, BIC, BIL) and better-ear (BEL, BER) BMFD channels. Model predictions based on all five channels are abbreviated as BMFD and represented by open circles. Model predictions based on the three binaural interaction channels are abbreviated as BIL,C,R (open squares), while predictions based on only the left and right BI channel are abbreviated as BIL,R (open diamonds).
## 1. Monaural Experiments
The upper part of Table 1 reports root-mean squared errors (RMSEs) and the coefficient of determination (R²) between experimental data and predictions based on BMFD, BIL,R, and the monaural mr-GPSM [26]. For the monaural experiments stimuli were only provided to the left-ear input channel of the BMFD and the right-ear input channel was set to zero. As obvious from the RMSE- and R²-values, BMFD predictions largely agree with those from the monaural mr-GPSM. Given the similarity of both models for the monaural data, detailed figures to compare the subjective and predicted data are not shown here. The similarity is expected as the BMFD has only a few modifications which potentially influence monaural prediction performance. As shown in Table 1, prediction performance was not degraded when only BIL and BIR (BIL,R) were used instead of all five BMFD outputs. This result was also expected, because when the right input channel is set to zero, BIL only depends on the left ear channel, and in such monaural conditions BIL is equal to BEL. Accordingly, reducing the number of output channels of the BMFD would be sufficient to capture important monaural psychoacoustic effects, but may not sufficient to account for all the binaural aspects assumed to be important to explain a variety of data from binaural psychoacoustic and SI experiments.
To summarize, for monaural experiments tested in this study the GPSM with binaural BMFD extension largely maintains the prediction performance of the monaural mr-GPSM.
## 2. Binaural Experiments
In Figures 2 - 6, subjective and predicted data for the binaural experiments are represented by closed and open symbols, respectively. The lower part of Table 1 reports root-mean square errors (RMSE) and the coefficient of determination (R²) between experimental data and predictions based on BMFD, BIL,C,R, and BIL,R.
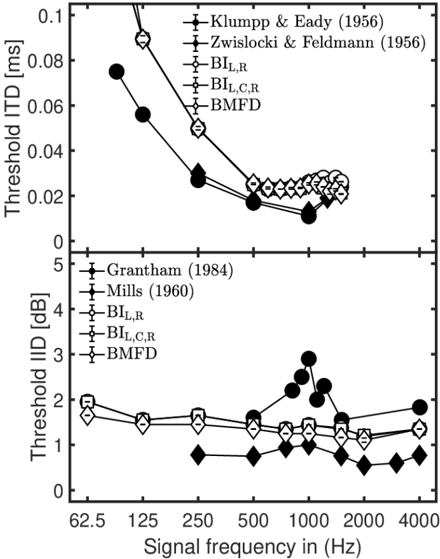
As illustrated in the upper panel of Figure 2, data of [60, 61] showed that ITD thresholds decreases with increasing target tone frequency, where the smallest ITD threshold of about 0.012 ms was found at 1 kHz. These decreasing threshold ITDs represent a more or less constant IPD of about 0.05 rad (~ 3°). For frequencies above 1 kHz, measured ITD thresholds increase, which is due to a reduced phase-locking ability of the IHCs for higher frequencies. For all three model versions, predicted ITD thresholds are higher than observed in the data, particularly at low frequencies. Here a nearly constant IPD of about 0.07 - 0.08 rad (~ 4°-5°) was predicted, which is higher than the nearly constant IPD of about 3° in the data. In agreement with the data, predicted ITD thresholds decrease with increasing frequency reaching a plateau at 500 Hz and above. At about 700 Hz, all three models predicted the lowest ITD threshold of about 0.023 µs. For frequencies above 900 Hz BIL,R predictions showed increased ITD thresholds, while predictions based on BIL,C,R and BMFD showed increased thresholds up to about 1200 Hz followed by slightly decreased threshold up to 1500 Hz. For all three model versions ITD thresholds slightly decrease for frequencies above 1.5 kHz.
Figure 2: Empirical data (filled symbols) and model predictions (open symbols) for ITD thresholds in ms (upper panel) and IID thresholds in dB (lower panel).
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Chart: Threshold vs. Signal Frequency for Temporal and Interaural Differences
### Overview
The image presents a dual-panel chart illustrating the relationship between signal frequency and threshold values for Temporal Difference (TD) and Interaural Intensity Difference (IID). The top panel displays Threshold TD [ms] against Signal frequency [Hz], while the bottom panel shows Threshold IID [dB] against Signal frequency [Hz]. Multiple data series, representing different studies, are plotted on each panel.
### Components/Axes
* **X-axis (Both Panels):** Signal frequency in Hz. Scale ranges from approximately 62.5 Hz to 4000 Hz. Markers are placed at 62.5, 125, 250, 500, 1000, 2000, and 4000 Hz.
* **Y-axis (Top Panel):** Threshold TD [ms]. Scale ranges from 0 to 0.1 ms.
* **Y-axis (Bottom Panel):** Threshold IID [dB]. Scale ranges from 0 to 5 dB.
* **Legend (Top-Left):**
* Klump & Eady (1956) - Black circles with error bars.
* Zwislocki & Feldmann (1956) - Black squares with error bars.
* BILR - Black triangles pointing up with error bars.
* BILC,R - Black diamonds with error bars.
* BMFD - Black triangles pointing down with error bars.
* **Legend (Bottom-Left):**
* Grantham (1984) - Black circles with error bars.
* Mills (1960) - Black squares with error bars.
* BILR - Black triangles pointing up with error bars.
* BILC,R - Black diamonds with error bars.
* BMFD - Black triangles pointing down with error bars.
### Detailed Analysis or Content Details
**Top Panel (Threshold TD vs. Signal Frequency):**
* **Klump & Eady (1956):** The line starts at approximately 0.09 ms at 62.5 Hz, decreases rapidly to around 0.025 ms at 250 Hz, and then plateaus around 0.02 ms for frequencies above 500 Hz.
* **Zwislocki & Feldmann (1956):** The line begins at approximately 0.085 ms at 62.5 Hz, decreases to around 0.03 ms at 250 Hz, and then levels off around 0.02 ms for frequencies above 500 Hz.
* **BILR:** The line starts at approximately 0.07 ms at 62.5 Hz, decreases to around 0.025 ms at 250 Hz, and then remains relatively constant around 0.02 ms for higher frequencies.
* **BILC,R:** The line begins at approximately 0.065 ms at 62.5 Hz, decreases to around 0.02 ms at 250 Hz, and then plateaus around 0.018 ms for frequencies above 500 Hz.
* **BMFD:** The line starts at approximately 0.06 ms at 62.5 Hz, decreases to around 0.02 ms at 250 Hz, and then remains relatively constant around 0.018 ms for higher frequencies.
**Bottom Panel (Threshold IID vs. Signal Frequency):**
* **Grantham (1984):** The line starts at approximately 2.2 dB at 62.5 Hz, decreases to around 1.5 dB at 250 Hz, increases to approximately 2.2 dB at 1000 Hz, and then decreases slightly to around 2 dB at 4000 Hz.
* **Mills (1960):** The line begins at approximately 1.8 dB at 62.5 Hz, remains relatively constant around 1.5 dB up to 500 Hz, and then increases to around 2 dB at 2000 Hz, decreasing to approximately 1.8 dB at 4000 Hz.
* **BILR:** The line starts at approximately 1.5 dB at 62.5 Hz, remains relatively constant around 1.2 dB up to 1000 Hz, and then increases to around 1.8 dB at 4000 Hz.
* **BILC,R:** The line begins at approximately 1.2 dB at 62.5 Hz, remains relatively constant around 1 dB up to 1000 Hz, and then increases to around 1.6 dB at 4000 Hz.
* **BMFD:** The line starts at approximately 1.0 dB at 62.5 Hz, remains relatively constant around 0.8 dB up to 1000 Hz, and then increases to around 1.4 dB at 4000 Hz.
### Key Observations
* In the top panel, all data series show a similar trend: a rapid decrease in Threshold TD with increasing signal frequency up to 250 Hz, followed by a plateau.
* In the bottom panel, the Threshold IID values are generally lower than the Threshold TD values. The lines exhibit more fluctuation, but generally show a slight increase with increasing signal frequency.
* The data from Klump & Eady (1956) and Zwislocki & Feldmann (1956) are very close to each other in the top panel.
* The BMFD and BILC,R lines are consistently lower than the other lines in both panels.
### Interpretation
The chart demonstrates the frequency dependence of auditory thresholds for detecting temporal and interaural differences. The rapid decrease in Threshold TD at lower frequencies suggests that humans are more sensitive to temporal differences at lower frequencies. The plateau at higher frequencies indicates a limit to this sensitivity. The relatively stable Threshold IID values suggest a consistent ability to detect interaural intensity differences across the frequency spectrum, with a slight improvement at higher frequencies.
The consistency between the studies of Klump & Eady and Zwislocki & Feldmann suggests a robust finding regarding temporal thresholds. The differences between the data series likely reflect variations in experimental methodology or subject populations. The lower thresholds for BMFD and BILC,R may indicate a specific sensitivity related to the binaural processing mechanisms being investigated in those studies.
The chart provides valuable insights into the mechanisms of sound localization and the neural processing of auditory information. The data supports the idea that the auditory system utilizes both temporal and interaural cues to determine the location of sound sources, and that the relative importance of these cues varies with frequency.
</details>
The lower panel of Figure 2 shows measured IID thresholds adopted from the studies of [62, 63]. Across frequencies ranging from 250 Hz to 4 kHz, Mills [62] measured rather similar IID thresholds (average threshold of about 0.8 dB), where the maximum of about 1 dB was reached at 1 kHz. Grantham [63] observed overall about 1.3 dB higher IID thresholds with substantially increased thresholds around 1 kHz. Predicted IID thresholds for the three model versions slightly decreased from about 2 dB at 62.5 Hz to about 1.1 dB at 2 kHz, and increased again for higher frequencies. The predicted IID pattern agrees well with the average of both data sets. Predicted thresholds for BIL,R, and BIL,C,R between frequencies from 62.5 Hz to 2 kHz are on average 0.2 dB higher than those from BMFD.
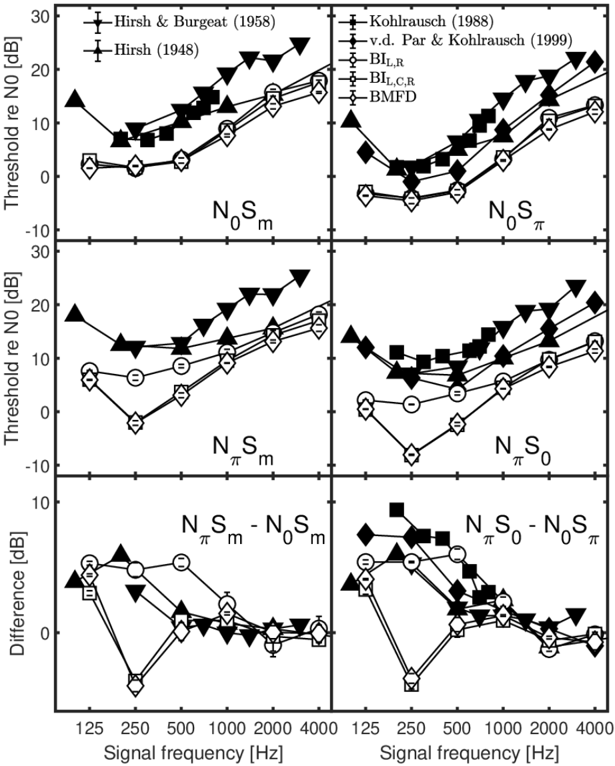
The upper four panels of Figure 3 show measured N0Sm, NπSm N0Sπ, NπS0, thresholds adopted from the studies of [3, 4, 64, 65]. All threshold patterns show a V shape with a minimum at 250 Hz. For the monaural target (Sm) thresholds are lower for N0Sm than for NπSm,
while for the binaural target (Sπ or S0) thresholds are lower for N0Sπ than for NπS0. The resulting threshold differences of NπSm-N0Sm and NπS0-N0Sπ are shown in both lower panels of Figure 3. The largest differences, up to about 9.5 dB, occur for signal frequencies below 500 Hz. BIL,R predictions (open circles) show a similar overall pattern to the data, and accordingly the predicted NπSm-N0Sm and NπS0-N0Sπ patterns largely agree with data. For NπSm and NπS0, both middle panels in Figure 3 show larger deviations between the data and the BIL,C,R and BMFD predictions at 250 Hz and 500 Hz. This deviation is based on the contribution of the BIC channel that overestimates human performance for the NπSm and NπS0 conditions. Accordingly large deviations between data and predictions are observed in the difference patterns in the lower two panels for BIL,C,R and BMFD at 250 Hz.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Line Chart: Thresholds and Differences in Signal Detection
### Overview
The image presents a series of line charts comparing signal detection thresholds under different noise conditions. There are six charts arranged in a 2x3 grid. The charts plot "Threshold re N0 [dB]" (decibels relative to noise power spectral density) against "Signal frequency [Hz]". The bottom two charts display the difference in thresholds between different noise conditions.
### Components/Axes
* **X-axis:** Signal frequency [Hz], ranging from 125 Hz to 4000 Hz. Marked at 125, 250, 500, 1000, 2000, and 4000 Hz.
* **Y-axis:** Threshold re N0 [dB], ranging from -10 dB to 30 dB. Marked at -10, 0, 10, 20, and 30 dB.
* **Legends:** Each chart has a legend identifying different models/studies.
* **Top Row:**
* Hirsch & Burgeat (1958) - Red
* Hirsch (1948) - Black
* Kohlrausch (1988) - Dark Grey
* v.d. Par & Kohlrausch (1999) - Light Grey
* BIL<sub>R</sub> - Grey with X marker
* BIL<sub>C,R</sub> - Grey with Triangle marker
* BMFD - Grey with Diamond marker
* **Middle Row:** Same as Top Row
* **Bottom Row:** Same as Top Row
* **Titles:** Each chart is labeled with a noise condition:
* N<sub>S0m</sub>
* N<sub>S0π</sub>
* N<sub>Smπ</sub>
* N<sub>Sπ</sub> - N<sub>S0π</sub>
* N<sub>Sπm</sub> - N<sub>S0m</sub>
* N<sub>S0π</sub> - N<sub>S0m</sub>
### Detailed Analysis or Content Details
**Chart 1: N<sub>S0m</sub>**
* Hirsch & Burgeat (1958) (Red): Starts at approximately 18 dB at 125 Hz, rises to approximately 22 dB at 500 Hz, then decreases to approximately 19 dB at 4000 Hz.
* Hirsch (1948) (Black): Starts at approximately 12 dB at 125 Hz, rises to approximately 18 dB at 500 Hz, then decreases to approximately 14 dB at 4000 Hz.
* Kohlrausch (1988) (Dark Grey): Starts at approximately 8 dB at 125 Hz, rises to approximately 14 dB at 500 Hz, then increases to approximately 18 dB at 4000 Hz.
* v.d. Par & Kohlrausch (1999) (Light Grey): Starts at approximately 7 dB at 125 Hz, rises to approximately 12 dB at 500 Hz, then increases to approximately 16 dB at 4000 Hz.
* BIL<sub>R</sub> (Grey with X): Starts at approximately 10 dB at 125 Hz, rises to approximately 16 dB at 500 Hz, then increases to approximately 20 dB at 4000 Hz.
* BIL<sub>C,R</sub> (Grey with Triangle): Starts at approximately 8 dB at 125 Hz, rises to approximately 14 dB at 500 Hz, then increases to approximately 18 dB at 4000 Hz.
* BMFD (Grey with Diamond): Starts at approximately 6 dB at 125 Hz, rises to approximately 10 dB at 500 Hz, then increases to approximately 14 dB at 4000 Hz.
**Chart 2: N<sub>S0π</sub>**
* Hirsch & Burgeat (1958) (Red): Starts at approximately 16 dB at 125 Hz, rises to approximately 20 dB at 500 Hz, then decreases to approximately 17 dB at 4000 Hz.
* Hirsch (1948) (Black): Starts at approximately 10 dB at 125 Hz, rises to approximately 16 dB at 500 Hz, then decreases to approximately 12 dB at 4000 Hz.
* Kohlrausch (1988) (Dark Grey): Starts at approximately 6 dB at 125 Hz, rises to approximately 12 dB at 500 Hz, then increases to approximately 16 dB at 4000 Hz.
* v.d. Par & Kohlrausch (1999) (Light Grey): Starts at approximately 5 dB at 125 Hz, rises to approximately 10 dB at 500 Hz, then increases to approximately 14 dB at 4000 Hz.
* BIL<sub>R</sub> (Grey with X): Starts at approximately 8 dB at 125 Hz, rises to approximately 14 dB at 500 Hz, then increases to approximately 18 dB at 4000 Hz.
* BIL<sub>C,R</sub> (Grey with Triangle): Starts at approximately 6 dB at 125 Hz, rises to approximately 12 dB at 500 Hz, then increases to approximately 16 dB at 4000 Hz.
* BMFD (Grey with Diamond): Starts at approximately 4 dB at 125 Hz, rises to approximately 8 dB at 500 Hz, then increases to approximately 12 dB at 4000 Hz.
**Chart 3: N<sub>Smπ</sub>**
* Hirsch & Burgeat (1958) (Red): Starts at approximately 14 dB at 125 Hz, rises to approximately 18 dB at 500 Hz, then decreases to approximately 15 dB at 4000 Hz.
* Hirsch (1948) (Black): Starts at approximately 8 dB at 125 Hz, rises to approximately 14 dB at 500 Hz, then decreases to approximately 10 dB at 4000 Hz.
* Kohlrausch (1988) (Dark Grey): Starts at approximately 4 dB at 125 Hz, rises to approximately 10 dB at 500 Hz, then increases to approximately 14 dB at 4000 Hz.
* v.d. Par & Kohlrausch (1999) (Light Grey): Starts at approximately 3 dB at 125 Hz, rises to approximately 8 dB at 500 Hz, then increases to approximately 12 dB at 4000 Hz.
* BIL<sub>R</sub> (Grey with X): Starts at approximately 6 dB at 125 Hz, rises to approximately 12 dB at 500 Hz, then increases to approximately 16 dB at 4000 Hz.
* BIL<sub>C,R</sub> (Grey with Triangle): Starts at approximately 4 dB at 125 Hz, rises to approximately 10 dB at 500 Hz, then increases to approximately 14 dB at 4000 Hz.
* BMFD (Grey with Diamond): Starts at approximately 2 dB at 125 Hz, rises to approximately 6 dB at 500 Hz, then increases to approximately 10 dB at 4000 Hz.
**Chart 4: N<sub>Sπ</sub> - N<sub>S0π</sub>**
* Hirsch & Burgeat (1958) (Red): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
* Hirsch (1948) (Black): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
* Kohlrausch (1988) (Dark Grey): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
* v.d. Par & Kohlrausch (1999) (Light Grey): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
* BIL<sub>R</sub> (Grey with X): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
* BIL<sub>C,R</sub> (Grey with Triangle): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
* BMFD (Grey with Diamond): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 0 dB at 4000 Hz.
**Chart 5: N<sub>Sπm</sub> - N<sub>S0m</sub>**
* Hirsch & Burgeat (1958) (Red): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* Hirsch (1948) (Black): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* Kohlrausch (1988) (Dark Grey): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* v.d. Par & Kohlrausch (1999) (Light Grey): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* BIL<sub>R</sub> (Grey with X): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* BIL<sub>C,R</sub> (Grey with Triangle): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* BMFD (Grey with Diamond): Starts at approximately 4 dB at 125 Hz, remains relatively flat around 4 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
**Chart 6: N<sub>S0π</sub> - N<sub>S0m</sub>**
* Hirsch & Burgeat (1958) (Red): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* Hirsch (1948) (Black): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* Kohlrausch (1988) (Dark Grey): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* v.d. Par & Kohlrausch (1999) (Light Grey): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* BIL<sub>R</sub> (Grey with X): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* BIL<sub>C,R</sub> (Grey with Triangle): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
* BMFD (Grey with Diamond): Starts at approximately 2 dB at 125 Hz, remains relatively flat around 2 dB until 2000 Hz, then decreases to approximately 2 dB at 4000 Hz.
### Key Observations
* The thresholds generally increase with signal frequency up to around 500-1000 Hz, then tend to plateau or decrease at higher frequencies.
* The differences in thresholds (bottom two charts) are relatively small and consistent across different models, suggesting a similar pattern of change in thresholds between the noise conditions.
* The models generally agree with each other, with some minor variations in the absolute threshold values.
### Interpretation
The data suggests that signal detection thresholds are influenced by both signal frequency and noise conditions. The increase in thresholds with frequency up to a certain point likely reflects the increasing difficulty of detecting signals at higher frequencies. The differences in thresholds between noise conditions (N<sub>Sπ</sub> - N<sub>S0π</sub>, etc.) indicate that the type of noise affects the detectability of signals. The consistency across different models suggests that the observed patterns are robust and not specific to any particular model or study. The small differences between the models could be due to variations in experimental setup, subject populations, or data analysis techniques. The overall pattern suggests that the models are capturing the fundamental relationship between signal frequency, noise, and detection thresholds.
</details>
Figure 3: Empirical data (filled symbols) and model predictions (open symbols) for masked thresholds for wideband N0Sm (upper-left panel), N0Sπ (upper-right panel), NπSm (middle-left panel), and NπS0 (middle-right panel) conditions as a function of the frequency of the signal. Differences in thresholds between the NπSm and N0Sm are shown in the lower-left panel, while the lower-right panel represents differences in threshold between NπS0 and N0Sπ.
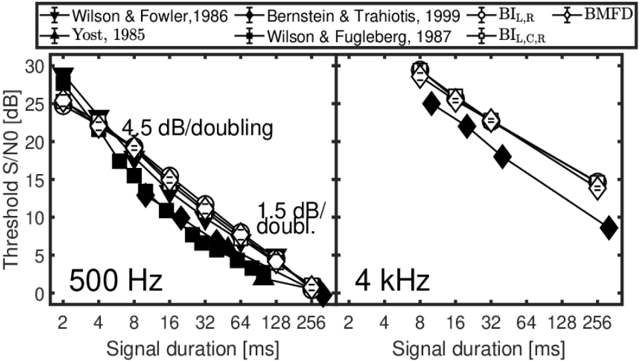
Measured N0Sπ thresholds as a function of signal duration adopted from [66-69] are shown in Figure 4. For the target signal with frequency of 500 Hz, thresholds decrease with a slope of about 4.5 dB per duration doubling, while for longer signal durations a slope of about 1.5 dB per duration doubling is observed. For the 4 kHz target signal, the data shows a slope of about 3 dB per duration doubling. For all three model versions, nearly identical thresholds were observed with on average higher thresholds than observed in the data. For both signal frequencies predicted thresholds decreased with about 3 dB per doubling of the signal duration, as the signal's energy increases by 3 dB per duration doubling. Such increase in signal duration means that more short-time frames of the model provide an SNR-advantage, that effectively lowers the threshold.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Chart: Threshold Signal-to-Noise Ratio vs. Signal Duration
### Overview
This chart presents the relationship between threshold Signal-to-Noise Ratio (S/NO) in decibels (dB) and signal duration in milliseconds (ms) at two different frequencies: 500 Hz and 4 kHz. The data is presented as multiple lines representing results from different studies. The chart is divided into two sections, one for each frequency.
### Components/Axes
* **X-axis:** Signal duration [ms]. Scale ranges from 2 to 256 ms. Markers are at 2, 4, 8, 16, 32, 64, 128, and 256 ms.
* **Y-axis:** Threshold S/NO [dB]. Scale ranges from 0 to 30 dB. Markers are at 0, 5, 10, 15, 20, 25, and 30 dB.
* **Legend:** Located at the top-center of the chart. Contains the following data series labels and corresponding symbols/colors:
* Wilson & Fowler, 1986 (Black circle with cross)
* Bernstein & Trahiotis, 1999 (Black diamond)
* Yost, 1985 (White triangle with black border)
* Wilson & Fugleberg, 1987 (Black square)
* BI<sub>L,R</sub> (White diamond with black border)
* BMFD (Black triangle)
* **Annotations:** Two annotations are present:
* "4.5 dB/doubling" – positioned near the Wilson & Fowler, 1986 and Yost, 1985 lines at 500 Hz.
* "1.5 dB/doubling" – positioned near the Bernstein & Trahiotis, 1999 and Wilson & Fugleberg, 1987 lines at 500 Hz.
* **Chart Division:** A vertical dashed line separates the 500 Hz data (left side) from the 4 kHz data (right side).
### Detailed Analysis or Content Details
**500 Hz Data (Left Side)**
* **Wilson & Fowler, 1986:** Line slopes downward, starting at approximately 28 dB at 2 ms and decreasing to approximately 2 dB at 256 ms.
* **Bernstein & Trahiotis, 1999:** Line slopes downward, starting at approximately 26 dB at 2 ms and decreasing to approximately 3 dB at 256 ms.
* **Yost, 1985:** Line slopes downward, starting at approximately 27 dB at 2 ms and decreasing to approximately 2 dB at 256 ms.
* **Wilson & Fugleberg, 1987:** Line slopes downward, starting at approximately 26 dB at 2 ms and decreasing to approximately 3 dB at 256 ms.
* **BI<sub>L,R</sub>:** Line slopes downward, starting at approximately 25 dB at 2 ms and decreasing to approximately 2 dB at 256 ms.
* **BMFD:** Line slopes downward, starting at approximately 26 dB at 2 ms and decreasing to approximately 2 dB at 256 ms.
**4 kHz Data (Right Side)**
* **Wilson & Fowler, 1986:** Line slopes downward, starting at approximately 22 dB at 2 ms and decreasing to approximately 12 dB at 256 ms.
* **Bernstein & Trahiotis, 1999:** Line slopes downward, starting at approximately 20 dB at 2 ms and decreasing to approximately 10 dB at 256 ms.
* **Yost, 1985:** Line slopes downward, starting at approximately 21 dB at 2 ms and decreasing to approximately 11 dB at 256 ms.
* **Wilson & Fugleberg, 1987:** Line slopes downward, starting at approximately 20 dB at 2 ms and decreasing to approximately 10 dB at 256 ms.
* **BI<sub>L,R</sub>:** Line slopes downward, starting at approximately 19 dB at 2 ms and decreasing to approximately 9 dB at 256 ms.
* **BMFD:** Line slopes downward, starting at approximately 20 dB at 2 ms and decreasing to approximately 10 dB at 256 ms.
### Key Observations
* All data series show a negative correlation between signal duration and threshold S/NO – as signal duration increases, the required S/NO decreases.
* The slope of the lines is steeper at 500 Hz than at 4 kHz, indicating a more rapid decrease in required S/NO with increasing signal duration at lower frequencies.
* The annotations "4.5 dB/doubling" and "1.5 dB/doubling" suggest that for every doubling of signal duration, the threshold S/NO decreases by approximately 4.5 dB at 500 Hz and 1.5 dB at 4 kHz.
* The data series are generally clustered together, suggesting a degree of consistency across different studies.
### Interpretation
This chart demonstrates the temporal integration effect in auditory perception. The data suggests that the human auditory system is more sensitive to longer-duration signals, requiring a lower S/NO for detection. The steeper slope at 500 Hz indicates that this effect is more pronounced at lower frequencies. The annotations quantify this effect, showing the rate of S/NO reduction with increasing signal duration. The consistency among the different studies (represented by the clustered lines) lends credibility to the findings. The separation into 500 Hz and 4 kHz data allows for a comparison of the temporal integration effect at different frequencies, revealing that it is frequency-dependent. The chart provides valuable insights into the mechanisms of auditory processing and has implications for understanding hearing loss and designing effective hearing aids.
</details>
Figure 4: Empirical data (filled symbols) and model predictions (open symbols) for N0Sπ thresholds as a function of the signal duration. Data and predictions are shown for signal frequencies of 500 Hz (left panel) and 4 kHz (right panel).
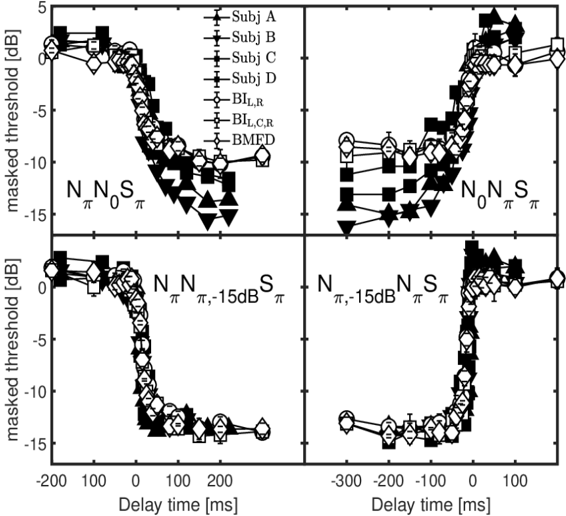
In Figure 5, masked thresholds from four subjects measured by Kollmeier and Gilky [70] are shown. In N0NπSπ and NπN0Sπ conditions lower thresholds (large BMLD) were measured for target signals (Sπ) in the interaurally in phase masker segments (N0) than for Sπ in interaurally out of phase masker segments (Nπ). Similarly for the corresponding 'monaural' NπNπ,-15dBSπ and Nπ,-15dBNπSπ conditions, Sπ in attenuated Nπ segments resulted in lower thresholds compared to Sπ in not attenuated Nπ segments. While a gradual release from masking was observed when shifting Sπ from the Nπ segment into the N0 segment (upper-left panel), a very steep release from masking was observed for the corresponding 'monaural' NπNπ,-15dBSπ condition (lower-left-panel). A similar behavior was found for the N0NπSπ and the Nπ,-15dBNπSπ conditions. Similar predicted masked thresholds are observed for the three model versions and the predicted steepness of the transition is the same for all four conditions. The predicted BMLD in NπN0Sπ (upper-left panel) and the predicted masking effect in N0NπSπ (upper-right panel) are somewhat smaller than observed in data. Overall, the predictions largely agree to experimental data, which is also indicated by reasonable RMSE and R² values of about 2.7 dB and 0.8, respectively.
Figure 5: Empirical data (filled symbols) and model predictions (open symbols) for NπN0Sπ (upper-left panel) and NπN0Sπ (upper-right panel) thresholds as a function of the temporal position of the signal center relative to the masker-phase transition. Monaural thresholds for NπNπ,-15dBSπ and Nπ,-15dBNπSπ are shown in the lower-left and lower-right panels. Filled symbols represent four subjects measured by Kollmeier and Gilky [70].
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Chart: Masked Threshold vs. Delay Time
### Overview
The image presents two plots displaying masked threshold [dB] as a function of delay time [ms]. The plots appear to represent psychoacoustic data, likely from auditory experiments. Each plot shows data for multiple subjects and a model (BMED). The top plot shows data for a 0 dB signal-to-noise ratio, while the bottom plot shows data for a -15 dB signal-to-noise ratio.
### Components/Axes
* **X-axis (both plots):** Delay time [ms]. Scale ranges from -200 ms to 200 ms in the top plot and -300 ms to 100 ms in the bottom plot.
* **Y-axis (both plots):** Masked threshold [dB]. Scale ranges from -15 dB to 5 dB.
* **Legend (top-right):**
* Subj A (Black squares)
* Subj B (Black circles)
* Subj C (Black triangles pointing up)
* Subj D (Black diamonds)
* BIL<sub>R</sub> (Gray squares)
* BIL<sub>C,R</sub> (Gray circles)
* BMED (Black squares)
* **Labels (top plot):** N N S<sub>π</sub>, N<sub>0</sub> S<sub>π</sub>
* **Labels (bottom plot):** N N<sub>π,-15dB</sub> S<sub>π</sub>, N<sub>π,-15dB</sub> N S<sub>π</sub>
### Detailed Analysis or Content Details
**Top Plot (0 dB SNR):**
* **Subj A (Black squares):** The line slopes downward from approximately 2 dB at -200 ms to approximately -14 dB at 150 ms, then rises again to approximately -8 dB at 200 ms.
* Approximate data points: (-200, 2), (-100, -6), (0, -10), (100, -14), (200, -8)
* **Subj B (Black circles):** The line slopes downward from approximately 1 dB at -200 ms to approximately -13 dB at 150 ms, then rises again to approximately -7 dB at 200 ms.
* Approximate data points: (-200, 1), (-100, -5), (0, -9), (100, -13), (200, -7)
* **Subj C (Black triangles):** The line slopes downward from approximately 0 dB at -200 ms to approximately -12 dB at 150 ms, then rises again to approximately -6 dB at 200 ms.
* Approximate data points: (-200, 0), (-100, -4), (0, -8), (100, -12), (200, -6)
* **Subj D (Black diamonds):** The line slopes downward from approximately 1 dB at -200 ms to approximately -15 dB at 150 ms, then rises again to approximately -9 dB at 200 ms.
* Approximate data points: (-200, 1), (-100, -6), (0, -11), (100, -15), (200, -9)
* **BIL<sub>R</sub> (Gray squares):** The line slopes downward from approximately 0 dB at -200 ms to approximately -10 dB at 150 ms, then rises again to approximately -5 dB at 200 ms.
* Approximate data points: (-200, 0), (-100, -4), (0, -7), (100, -10), (200, -5)
* **BIL<sub>C,R</sub> (Gray circles):** The line slopes downward from approximately 0 dB at -200 ms to approximately -9 dB at 150 ms, then rises again to approximately -4 dB at 200 ms.
* Approximate data points: (-200, 0), (-100, -3), (0, -6), (100, -9), (200, -4)
* **BMED (Black squares):** The line slopes downward from approximately 0 dB at -200 ms to approximately -12 dB at 150 ms, then rises again to approximately -7 dB at 200 ms.
* Approximate data points: (-200, 0), (-100, -5), (0, -9), (100, -12), (200, -7)
**Bottom Plot (-15 dB SNR):**
* **Subj A (Black squares):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
* **Subj B (Black circles):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
* **Subj C (Black triangles):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
* **Subj D (Black diamonds):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
* **BIL<sub>R</sub> (Gray squares):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
* **BIL<sub>C,R</sub> (Gray circles):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
* **BMED (Black squares):** The line remains relatively flat around -1 dB to -2 dB from -300 ms to 0 ms, then rises to approximately 0 dB at 100 ms.
* Approximate data points: (-300, -1), (-200, -1), (-100, -2), (0, -2), (100, 0)
### Key Observations
* In the top plot (0 dB SNR), all curves exhibit a U-shaped pattern, indicating a minimum in masked threshold at around 100-150 ms delay.
* In the bottom plot (-15 dB SNR), the curves are much flatter, suggesting that the masked threshold is less sensitive to delay time at this lower SNR.
* The individual subject data (Subj A, B, C, D) generally follows similar trends, with some variability.
* The BMED model appears to align well with the average trend of the subject data.
* The BIL models (BIL<sub>R</sub> and BIL<sub>C,R</sub>) show slightly different responses compared to the individual subjects and BMED.
### Interpretation
The data suggests that the masking effect of a tone is dependent on the delay between the tone and the masker. At a 0 dB SNR, there is a clear temporal window where masking is most effective (around 100-150 ms delay). This is likely due to the interaction of the signals in the auditory system, potentially related to temporal integration or forward masking.
At a -15 dB SNR, the masking effect is less pronounced, and the masked threshold is less sensitive to delay time. This is expected, as the weaker signal is more easily masked regardless of the delay.
The BMED model provides a reasonable approximation of the observed data, suggesting that it captures some of the key mechanisms underlying masking. The differences between the BIL models and the subject data may indicate that these models do not fully account for the complexity of human auditory processing. The labels N N S<sub>π</sub>, N<sub>0</sub> S<sub>π</sub>, N N<sub>π,-15dB</sub> S<sub>π</sub>, N<sub>π,-15dB</sub> N S<sub>π</sub> likely refer to the conditions of the experiment, potentially related to the type of signal (N) and masker (S) and their relative phases (π). Further context about the experimental setup would be needed to fully interpret these labels.
</details>
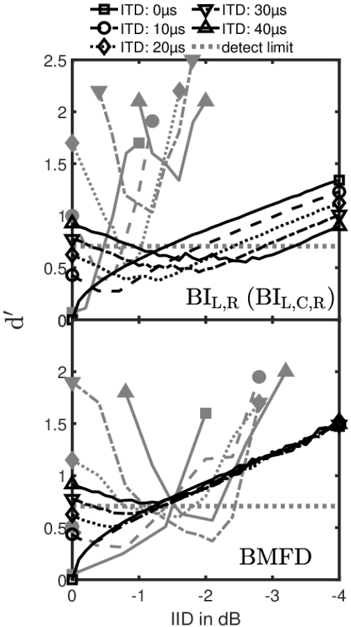
The upper and lower panel of Figure 6 show measured d ' s from the time-intensity-trading experiment of subject S1 and S4 from Hafter and Carrier [71], respectively (see their Figure 1). For clarity only these two subjects with the largest difference in performance are shown in different panels. Likewise, the model predictions for the BI channels and all five channels are split to the two panels for better visibility. Both subjects show that for increasing ITD of 0, 10, 20, 30, and 40 µs a larger opposing ILD was required for 'trading' yielding the lowest sensitivity index d ' for discrimination of the trading stimulus from the diotic reference signal. It is obvious that the model based on only the BI channels (upper panel of Figure 6) can only mimic the general pattern while there are large differences in the sensitivity and the ILD required for trading as a function of ITD. Moreover, the model with all five BMFD output
channels (lower panel of Figure 6) shows even larger deviations to the data and fails to predict a clear dependency of ILD on ITD. Overall the model is closer to the performance of subject S4 than to S1.
Figure 6: Empirical data (grey lines, closed symbols) and model predictions (black lines, open symbols) for the time-intensity trading experiment of Hafter and Carrier [71] with different ITDs of 0, 10, 20, 30, and 40 µs. The ordinate represents d ' , while the abscissa represents the IID in dB. Since BIL,R and BIL,C,R predicts nearly identical d ' only BIL,R predictions are shown in the upper panel for improved clarity. The lower panel represents predictions from BMFD. The dashed horizontal lines indicate the decision criterion of the models, e.g., differences between test and reference signals resulting in d ' values below the criterion are not assumed to be detectable.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Chart: d' vs. IID for Different ITDs
### Overview
The image presents two line graphs displaying the relationship between d' (a measure of sensitivity) and Interaural Intensity Difference (IID) in dB, for different Interaural Time Differences (ITDs) in microseconds. The top graph represents data for BI<sub>L,R</sub> (BI<sub>L,C,R</sub>), and the bottom graph represents data for BMFD. Arrows indicate the direction of increasing ITD. A dashed horizontal line represents the detect limit.
### Components/Axes
* **X-axis (Both Graphs):** IID in dB, ranging from 0 to -4 dB.
* **Y-axis (Both Graphs):** d', ranging from 0 to 2.5.
* **Legend (Top-Left):**
* ITD: 0 µs (represented by a black square)
* ITD: 10 µs (represented by a white circle)
* ITD: 20 µs (represented by a grey diamond)
* ITD: 30 µs (represented by a black triangle pointing up)
* ITD: 40 µs (represented by a black triangle pointing down)
* detect limit (represented by a dashed grey line)
* **Labels:**
* Top Graph: BI<sub>L,R</sub> (BI<sub>L,C,R</sub>)
* Bottom Graph: BMFD
### Detailed Analysis or Content Details
**Top Graph (BI<sub>L,R</sub> (BI<sub>L,C,R</sub>))**
* **ITD: 0 µs (Black Square):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.2 at IID = -1 dB, then plateaus around d' = 1.3 to 1.4 from IID = -1 dB to -4 dB.
* **ITD: 10 µs (White Circle):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.0 at IID = -0.5 dB, then decreases to approximately d' = 0.6 at IID = -4 dB.
* **ITD: 20 µs (Grey Diamond):** The line starts at approximately d' = 0 at IID = 0 dB, increases rapidly to approximately d' = 2.0 at IID = -0.5 dB, then decreases to approximately d' = 1.2 at IID = -4 dB.
* **ITD: 30 µs (Black Triangle Up):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.6 at IID = -1 dB, then plateaus around d' = 1.5 to 1.6 from IID = -1 dB to -4 dB.
* **ITD: 40 µs (Black Triangle Down):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.4 at IID = -0.5 dB, then decreases to approximately d' = 0.8 at IID = -4 dB.
* **Detect Limit (Dashed Grey Line):** A horizontal line at approximately d' = 0.5.
**Bottom Graph (BMFD)**
* **ITD: 0 µs (Black Square):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.2 at IID = -1 dB, then plateaus around d' = 1.3 to 1.4 from IID = -1 dB to -4 dB.
* **ITD: 10 µs (White Circle):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 0.8 at IID = -0.5 dB, then decreases to approximately d' = 0.5 at IID = -4 dB.
* **ITD: 20 µs (Grey Diamond):** The line starts at approximately d' = 0 at IID = 0 dB, increases rapidly to approximately d' = 1.8 at IID = -0.5 dB, then decreases to approximately d' = 1.0 at IID = -4 dB.
* **ITD: 30 µs (Black Triangle Up):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.5 at IID = -1 dB, then plateaus around d' = 1.4 to 1.5 from IID = -1 dB to -4 dB.
* **ITD: 40 µs (Black Triangle Down):** The line starts at approximately d' = 0 at IID = 0 dB, increases to approximately d' = 1.2 at IID = -0.5 dB, then decreases to approximately d' = 0.7 at IID = -4 dB.
* **Detect Limit (Dashed Grey Line):** A horizontal line at approximately d' = 0.5.
### Key Observations
* In both graphs, increasing ITD generally leads to a higher d' value at smaller negative IID values, but this effect diminishes or reverses at more negative IID values.
* The 20 µs ITD consistently shows the highest d' values at smaller negative IID values in both graphs.
* The detect limit appears to be crossed by all ITD curves at some point, indicating that the stimulus is detectable under those conditions.
* The lines for ITD 0 µs and 30 µs are very similar in both graphs.
### Interpretation
The data suggests that sensitivity (d') to sound localization cues is influenced by both IID and ITD. The optimal ITD for detection appears to be around 20 µs, as evidenced by the highest d' values at smaller negative IID values. However, as IID becomes more negative, the benefit of this optimal ITD diminishes, and other ITDs may become more effective. The detect limit indicates the minimum level of sensitivity required for a stimulus to be reliably detected. The differences between the BI<sub>L,R</sub> (BI<sub>L,C,R</sub>) and BMFD graphs suggest that the specific processing mechanism (represented by these labels) influences the relationship between IID, ITD, and sensitivity. The arrows indicate that as ITD increases, the sensitivity increases, but this effect is not linear and is dependent on the IID. The data could be used to model human auditory perception and to understand how the brain integrates IID and ITD to localize sounds.
</details>
The lower part of Table 1 summarizes RMSE and R² between experimental data and predictions for the three model versions. Is it observed that for most binaural experiments the three model versions BMFD, BIL,C,R, and BIL,R achieve a comparable prediction performance. Only in experiment 3 (Frequency and interaural phase relationships in wideband conditions) BIL,R achieved a substantially better performance compared to the other two versions. Therefore, it can be stated that BIL and BIR are sufficient to explain most of the data of the binaural psychoacoustic experiments used in this study.
Overall, Table 1 showed that the GPSM with binaural BMFD extension, accounts for several monaural and binaural psychoacoustic experiments.
Table 1 about here
## IV. Speech intelligibility evaluation
The binaural model extension was also tested for the headphone-based binaural (dichotic) speech intelligibility experiments of Ewert et al. [2], where SRTs were measured for frontal target speech [German Oldenburger Satztest (OLSA), [72]] in the presence of two co-located or spatially separated maskers with different spectro-temporal characteristics, but identical long-term spectrum.
Four stationary speech-shaped noise (SSN) based maskers, SSN, SAM, BB, and AFS with different spectro-temporal stimulus properties and two speech maskers were used in [2]: The SAM masker was obtained by applying an 8-Hz sinusoidal amplitude modulation with 100% modulation depth to the SSN masker yielding regular temporal modulations coherent across all auditory channels (co-modulation). For the BB masker, the SSN was multiplied with the Hilbert envelope of a broadband speech signal (ten randomly selected OLSA sentences), introducing temporal gaps that reflect the modulations of intact speech. Temporal
irregularities of the speech envelope are coherent across all auditory channels. For the acrossfrequency shifted (AFS) masker, the speech envelope was randomly shifted in eight groups (each consisting of four adjacent auditory frequency channels) resulting in incoherent AMs across auditory channels. As speech maskers, a male version of the International Speech Test Signal (ISTS; [73]), composed of intact continuous speech uttered by six different female talkers in different languages, was used as 'nonsense' speech. A single talker (ST) masker used randomly cut parts of ten concatenated OLSA sentences spoken by a different male speaker than in the target OLSA material.
Two spatial target-masker configurations were measured for each masker: In the colocated configuration target and masker sources were placed in front of the receiver (0°). In the spatially separated configuration, the masker positions were changed two both sides at ±60° relative to the frontal direction. Speech intelligibility improvements depending on the spatial separation between target and masker are expressed as SRM. A single masker had a level of 65 dB SPL, and accordingly the presentation of two statistically independent masker sequences resulting in an overall masker level of 68 dB SPL. A detailed description of the experiment can be found in [2].
## A. Results and discussion
Measured and predicted SRTs are represented by gray and black symbols, respectively. Co-located maskers are indicated by closed symbols and separated maskers by open symbols. Predicted SRTs shown in Figure 7 are averaged over 5 repeated simulations each based on 20 OLSA sentences. Each model version was calibrated to the speech material as proposed in [25] by setting the parameters k, q, m, 𝜎𝑠 in order to match the SSN data, which are shown in Table 2.
Table 2 about here
Figure 7: The upper panel shows SRT50 results, while the lower panel shows the respective SRM. Data is represented by squares, while predictions are given by circles, triangles, and diamonds, respectively. The spatially co-located (front) and separated masker conditions are indicated by closed and open symbols, respectively.
<details>
<summary>Image 7 Details</summary>
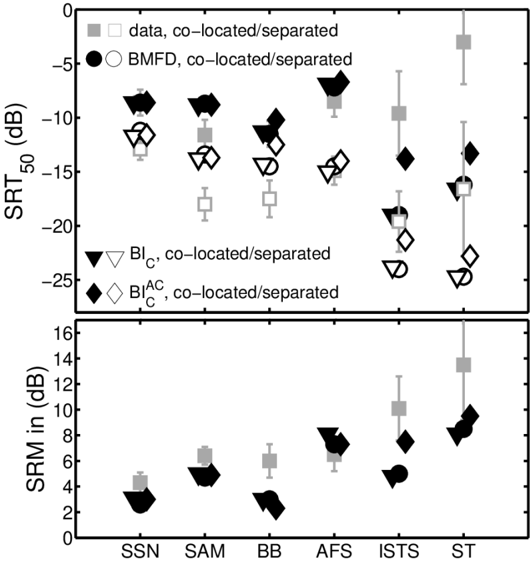
### Visual Description
\n
## Charts: Speech Reception Thresholds (SRT)
### Overview
The image contains two separate charts displaying Speech Reception Thresholds (SRT) in decibels (dB) under different conditions. The top chart shows SRT50 values, while the bottom chart shows SRT in dB. Both charts compare different hearing aid processing strategies across several acoustic conditions. Error bars are present in both charts, indicating variability in the data.
### Components/Axes
**Top Chart:**
* **Y-axis:** SRT50 (dB), ranging from -25 dB to 0 dB.
* **X-axis:** Labeled with acoustic conditions: SSN, SAM, BB, AFS, ISTS, ST.
* **Legend:** Located in the top-left corner.
* Light gray squares: "data, co-located/separated"
* Light gray circles: "BMFD, co-located/separated"
* White triangles: "BIc, co-located/separated"
* Black diamonds: "BIAC, co-located/separated"
**Bottom Chart:**
* **Y-axis:** SRT in (dB), ranging from 0 dB to 16 dB.
* **X-axis:** Labeled with acoustic conditions: SSN, SAM, BB, AFS, ISTS, ST.
* **Legend:** The legend is represented by the shape of the data points.
* Black squares: "SSN"
* Black circles: "SAM"
* Black triangles: "BB"
* Black diamonds: "AFS"
* Black pentagons: "ISTS"
* Black hexagons: "ST"
### Detailed Analysis or Content Details
**Top Chart (SRT50):**
* **SSN:**
* Data: Approximately -10 dB with an error bar ranging from -13 dB to -7 dB.
* BMFD: Approximately -11 dB with an error bar ranging from -14 dB to -8 dB.
* BIc: Approximately -16 dB with an error bar ranging from -19 dB to -13 dB.
* BIAC: Approximately -17 dB with an error bar ranging from -20 dB to -14 dB.
* **SAM:**
* Data: Approximately -16 dB with an error bar ranging from -19 dB to -13 dB.
* BMFD: Approximately -13 dB with an error bar ranging from -16 dB to -10 dB.
* BIc: Approximately -18 dB with an error bar ranging from -21 dB to -15 dB.
* BIAC: Approximately -20 dB with an error bar ranging from -23 dB to -17 dB.
* **BB:**
* Data: Approximately -16 dB with an error bar ranging from -19 dB to -13 dB.
* BMFD: Approximately -12 dB with an error bar ranging from -15 dB to -9 dB.
* BIc: Approximately -18 dB with an error bar ranging from -21 dB to -15 dB.
* BIAC: Approximately -22 dB with an error bar ranging from -25 dB to -19 dB.
* **AFS:**
* Data: Approximately -10 dB with an error bar ranging from -13 dB to -7 dB.
* BMFD: Approximately -6 dB with an error bar ranging from -9 dB to -3 dB.
* BIc: Approximately -14 dB with an error bar ranging from -17 dB to -11 dB.
* BIAC: Approximately -17 dB with an error bar ranging from -20 dB to -14 dB.
* **ISTS:**
* Data: Approximately -12 dB with an error bar ranging from -15 dB to -9 dB.
* BMFD: Approximately -8 dB with an error bar ranging from -11 dB to -5 dB.
* BIc: Approximately -16 dB with an error bar ranging from -19 dB to -13 dB.
* BIAC: Approximately -21 dB with an error bar ranging from -24 dB to -18 dB.
* **ST:**
* Data: Approximately -5 dB with an error bar ranging from -8 dB to -2 dB.
* BMFD: Approximately -2 dB with an error bar ranging from -5 dB to 1 dB.
* BIc: Approximately -12 dB with an error bar ranging from -15 dB to -9 dB.
* BIAC: Approximately -15 dB with an error bar ranging from -18 dB to -12 dB.
**Bottom Chart (SRT in dB):**
* **SSN:** Approximately 6 dB with an error bar ranging from 5 dB to 7 dB.
* **SAM:** Approximately 5 dB with an error bar ranging from 4 dB to 6 dB.
* **BB:** Approximately 5 dB with an error bar ranging from 4 dB to 6 dB.
* **AFS:** Approximately 7 dB with an error bar ranging from 6 dB to 8 dB.
* **ISTS:** Approximately 8 dB with an error bar ranging from 7 dB to 9 dB.
* **ST:** Approximately 10 dB with an error bar ranging from 9 dB to 11 dB.
### Key Observations
* In the top chart (SRT50), BIAC consistently shows the lowest (most negative) values across all conditions, indicating the best performance. Data and BMFD generally perform similarly, with values slightly higher than BIAC.
* In the bottom chart (SRT in dB), the SRT values increase across the acoustic conditions from SSN to ST, suggesting that speech understanding becomes more difficult in more challenging listening environments.
* The error bars indicate substantial variability in the data, particularly for the BIAC condition in the top chart.
### Interpretation
The data suggests that the BIAC processing strategy yields the best speech understanding performance (lowest SRT50) across various acoustic conditions. The BMFD and "data" conditions provide intermediate performance, while the BIc strategy shows the worst performance. The bottom chart demonstrates that speech understanding becomes more challenging as the acoustic environment becomes more complex (moving from SSN to ST). The large error bars suggest that individual listener variability plays a significant role in SRT measurements. The difference between the top and bottom charts likely reflects different measures of speech perception sensitivity – SRT50 represents a threshold for 50% correct detection, while the bottom chart represents the threshold for any detection. The co-located/separated designation in the legend suggests that the data was collected under conditions where the sound source and listener were either in the same location or separated, potentially influencing the results. The consistent trend of BIAC outperforming other strategies suggests a robust benefit of this approach, despite the variability in individual responses.
</details>
For noise maskers (SSN, SAM, AFS, and BB) presented co-located to target speech, the highest SRT50s were measured for stationary SSN and fluctuating AFS maskers, and listeners took only advantage from listen into dips when speech was presented in fluctuating SAM and BB maskers. The highest SRT50 was measured when speech was masked by the single talker (ST), resulting in about 5.5 dB higher thresholds compared to the SSN masker. A spatial separation of target speech and maskers resulted in SRM values ranging between 4.3 and 13.5 dB. The smallest SRM of about 4.3 dB was observed for the SSN maskers, while the largest SRM values of 10.1 and 13.5 dB were observed for ISTS and ST masker.
All model versions were calibrated to account for the co-located SSN masker, while all other thresholds use the same parameters. For co-located predictions based on the BMFD
(closed circles in the upper panel of Figure 7) for fluctuating noise maskers BB and AFS largely agree with data, while the predicted SRT50 for the SAM maskers is about 3 dB higher than measured SRT50. For BMFD the largest differences between predicted and measured SRTs of up to 13 dB can be observed for co-located ISTS and ST maskers. Particularly the ST masker is very similar to the target sentences and makes it difficult for the listener to separate the target from the interfering speech (informational masking, e.g. [74]), which results in high SRTs and high variability across listeners. In contrast to human listeners, the current model, as other intrusive SI models, has a-priori knowledge about the target speech and the masker signals and is only limited by aspects of amplitude modulation and energetic masking (and not informational masking), yielding to substantially lower thresholds for the speech like maskers. For the spatially separated conditions (open circles in the upper panel of Figure 7) BMFD predictions fit well for SSN and AFS while in overestimates the thresholds for SAM and BB and again underestimates thresholds for the speech like maskers ISTS and ST as can be expected (see above). Regarding the SRM (lower panel of Figure 7), BMFD predictions show a good agreement with the data for SSN, SAM (about 2 dB reduced SRM) and AFS. For BB the predicted SRM is about 3 dB lower and for ISTS and ST up to 5 dB lower than the measured SRM. For ISTS and ST these differences are partly caused by larger discrepancies between predicted and measured SRTs in co-located conditions.
In a further step, each of the five BMFD outputs was analyzed to identify the most contributing channel. Here, BIC with highest sensitivity to the hemispheric midline denoted as BIC in Figure 7, gave most contribution to SI predictions, that is clearly shown by very similar predictions of BMFD and BIC in Figure 7. This agrees well with the findings of Ewert et al. [2], where a simple binaural summation of the left and right ear signals (prior to the model) showed similar results for predictions using the binaural speech intelligibility model (BSIM; [12]). For this summed diotic input, BSIM effectively reduces to a similar processing as suggested in the monaural ESII [11] model, using a short-time assessment of power-based
SNRs. In contrast the current BIC predictions are based on both short-time envelope power and power SNRs. It should be noted that although predictions of both the power pathway of BMFD and BSIM are based on power SNRs, substantial differences exist, like the SNR combination across time frames and auditory channels, which could have an influence on predicted SRTs.
Analyzing the contribution of envelope power and power SNRs, revealed that AM cues are mostly dominant. Predictions only based on envelope power SNRs provided by the center binaural interaction channel are denoted as BI C AC and shown as diamonds in Figure 7. With exception of the BB masker condition BI C AC -based predictions already explain most of the SRM observed in the data.
Although BIC does not play an important role for the binaural psychoacoustic experiments in this study, it can successfully account for a large part of the SRM in the speech intelligibility experiments.
## VI. General discussion
The suggested model explores the ability of a strongly simplified, fixed (non-adaptive) binaural interaction stage to account for key aspects of binaural psychoacoustics and speech intelligibility with spatially separated interferers. The investigated 5-channel BMFD stage was incorporated in an existing monaural model using power and envelope power SNR cues. It was demonstrated that the suggested model maintains the ability of the former monaural approach to account for monaural psychoacoustic key phenomena. Binaural psychoacoustics was well covered except for larger discrepancies for time-intensity trading. For speech intelligibility, the key aspects where also predicted with larger discrepancies for speech-like interferers. Here aspects of informational masking which are generally not covered by signal-
processing models play a role, as has been previously shown for other speech intelligibility models.
It is conceivable that the current simplified approach might not reach the performance of other 'specialist', dedicated monaural and binaural models for psychoacoustics and speech intelligibility for each of the experiments considered here. The value of the current approach is that i) based on former work [9, 16, 19, 20, 26] the suggested model can be assumed to generalize well for other unknown data. This makes the model interesting also in the context of instrumental (spatial) audio quality predictions. ii) Another consideration is that the simple processing in the BMFD stage is generally advantageous for real-time applications, e.g., for control of signal processing algorithms in hearing supportive devices or as hearing aid processing stage itself. iii) The current approach demonstrates that the physiologically motivated hemispheric interaural interaction in mammals (e.g., [42, 43]), as realized here in the two binaural interaction channels BIL and BIR, is suited to explain a broad variety of perception experiments.
## A. Contribution of binaural interaction and better ear channels
For the binaural psychoacoustic experiments used in this study, the two BIL and BIR channels appear sufficient to account for the data. BIC has only a negligible effect on the predicted data as also indicated by very similar RMSE and R² values shown in Table I for the model versions including BIc (BIL,C,R) and excluding BIc (BIL,R), except for the binaural experiment 3 on interaural phase effects in wideband conditions: Here predicted thresholds based on BIC are significantly better than human performance in NπSm and NπS0 conditions (see middle panels in Figure 6) and accordingly predicted difference pattern for NπSm-N0Sm and NπS0-N0Sπ show a large deviation of up to 10 dB at 250 Hz from measured data. In
general, both better ear channels BEL and BER did not make any substantial contribution in the binaural psychoacoustic experiments.
For speech intelligibility, the importance of the five BMFD channels is different and BIC has been shown to account for a large part of the data (see Figure 7). In the current SI conditions, a frontal target was presented in either co-located or spatially separated maskers. In view of the psychoacoustic conditions, the co-located condition can be regarded as N0S0, while the separated condition can be considered as S0 plus noise with frequency-dependent interaural phase difference. In the separated conditions, the BIC channel amplifies the coherent frontal target speaker (S0), while spatially separated maskers with IPDs ≠ 0 are incoherently added or might be partially cancelled.
The role of the five BMFD channels for speech intelligibility can be further assessed by analyzing the distribution of most contributing envelope power and power SNRs across frequency and over the five binaural processing channels (not shown): For all spatially separated conditions, BIC shows the highest contribution (in agreement with the additive approach in [2]). For the co-located conditions, no large differences in the contributions of all channels are observed. BIL and BIR contribute slightly more, resulting in about 1 dB lower SRTs for BIL and BIR than for the other three channels. Regarding the SRM, in line with the psychoacoustic experiments, the two better-ear channels contributed less resulting in consistently lower predicted SRM than the three binaural interaction channels. Although BIL and BIR might be less important in the current spatial configuration with frontal target where BIC was most beneficial, they can be assumed to be more important when the target is placed to either side of the head. Moreover, both BIL and BIR are also assumed to be important for the evaluation of spatial audio quality as inaccuracies in the audio rendering of sound reproduction systems may alter the spatial properties, e.g., location, apparent source width, of an auditory object.
## B. Comparison of the binaural stage to other literature models
The outputs of the suggested BMFD stage can be considered as a simplification of the delay-gain matrix and the left/right channel in Breebaart et al. [8] or as specific fixed states of the EC model [28]. Given the conceptual similarity of these two models itself and the widespread use of the EC approach as binaural processing stage in numerous auditory models (e.g., [12, 36, 37]), might make the current results interesting for other literature models.
The three BIL,C,R channels are comparable to elements in the matrix of the Breebaart model with according delay and gain in the respective auditory frequency channel. The BEL,R channels are directly comparable to the individual ear signals passed to the detector stage in the Breebaart model, in parallel to outputs of the delay-gain matrix. In the Breebaart model, internal delays up to 5 ms (π phase shift at 100 Hz) and a gain difference up to 10 dB between both ears are realized. These parameters broadly cover the current choice in the BIL,R channels. Thus the difference between the suggested model and the Breebaart model is the reduction of degrees of freedom in the binaural interaction stage to parameters that are directly motivated by physiology in mammals.
Similarly, each of the five BMFD outputs represents a specific state of the EC approach. Again the difference is that the EC stage can realize arbitrary delays and gains (for the equalization of the noise in the left and right channel) to optimally cancel the noise at the output, while BIL,C,R represents a fixed, potentially suboptimal, realization of the EC process. Alternatively, the left or right ear input can be directly routed to the EC output, comparable to the better-ear channels BEL,R in the current BMFD stage.
Based on the five BMFD outputs, envelope power and power SNRs are calculated and combined to give an overall d ' . In contrast to other models like the B-sEPSM [37] and BSIM [12] where SI prediction are either based on envelope power SNRs or power SNRs, this approach combines both types of SNRs. As shown in Figure 7, envelope power SNRs capture most of the measured SRM. It should be noted that predictions only based on power SNRs
also agree with the measured SRM pattern, but tend to overestimate measured SRM. For fluctuating maskers, SRTs predicted by power SNRs are often substantially lower than measured SRTs, which was also observed in Biberger and Ewert [26]. As suggested in [26], a forward masking function or SNR limitation could be applied to counteract that effect.
The envelope power SNRenvW ,i(p,n) and SNRDC ,j(p) are combined across the five BMFD outputs by taking the largest value for each time frame within each auditory and modulation channel. Such a procedure allows fast switching between the five BMFD outputs, in line with findings of Siveke et al. [75]. However, psychophysical studies (e.g., [70], also considered here, see Fig 5.) and a recent SI study of Hauth and Brand [76] implied some limitations of the binaural auditory system in following temporal changes of ITDs (or IPDs). This is often referred to as binaural sluggishness, and suggests binaural temporal windows with time constants of up to about 200 ms. The current model has the same time constants for monaural and binaural interaction channels, resulting in the same slope of the transition in the data of Kollmeier and Gilky [70], see Figure 5. Thus, for some conditions prediction performance could be improved when aspects of (task dependent) binaural sluggishness are integrated into the suggested model by using a temporal window as suggested in [8].
## C. Model limitations and simplification of physiological processes
The current L-R and R-L processing after delay and amplification in the current BIL,R channels represents a strongly simplified realization of hemispheric processing as suggested in more detailed models (e.g., [41, 77]) based on (simulated) neuronal responses. A key feature of these approaches is the characteristic (hemispheric) net neural activation as a function of ITD for high frequencies in the lateral superior olive (LSO) and for low frequencies in the medial superior olive (MSO), see, e.g., bottom row in Figure 5 of [41].
Figure 8: Response of the BIL and BIR channels as a function of IPD (left panel) and ILD (right panel) for a 500 Hz pure tone. Negative IPDs indicate left ear leading, while negative ILDs indicate right ear more intense. Note that for clarity, amplitude and phase jitter were turned off.
<details>
<summary>Image 8 Details</summary>
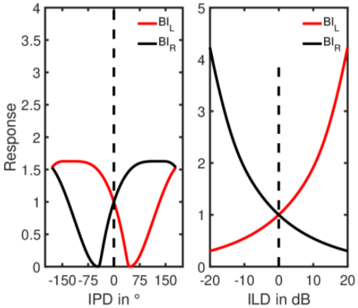
### Visual Description
## Charts: Binaural Response Curves
### Overview
The image presents two separate charts displaying response curves for binaural cues: Interaural Phase Difference (IPD) and Interaural Level Difference (ILD). Both charts share a common legend indicating two data series: BI<sub>L</sub> (red line) and BI<sub>R</sub> (black line). The charts aim to illustrate how the brain processes spatial audio information based on these cues.
### Components/Axes
**Chart 1 (IPD):**
* **X-axis:** IPD in degrees (°), ranging from approximately -160° to 160°. Marked with tick marks at -150°, -75°, 0°, 75°, and 150°.
* **Y-axis:** Response, ranging from 0 to 4. Marked with tick marks at 0, 1, 2, 3, and 4.
* **Legend:** Located in the top-right corner.
* BI<sub>L</sub> (Red line)
* BI<sub>R</sub> (Black line)
* **Vertical dashed line:** Present at x = 0°.
**Chart 2 (ILD):**
* **X-axis:** ILD in dB, ranging from approximately -20 dB to 20 dB. Marked with tick marks at -20, -10, 0, 10, and 20.
* **Y-axis:** Response, ranging from 0 to 5. Marked with tick marks at 0, 1, 2, 3, 4, and 5.
* **Legend:** Located in the top-right corner.
* BI<sub>L</sub> (Red line)
* BI<sub>R</sub> (Black line)
* **Vertical dashed line:** Present at x = 0°.
### Detailed Analysis or Content Details
**Chart 1 (IPD):**
* **BI<sub>L</sub> (Red Line):** The curve starts at approximately 1.6 at -160°, decreases to a minimum of approximately 0.2 at -80°, increases to a maximum of approximately 1.7 at 80°, and then decreases to approximately 0.4 at 160°. The curve is roughly symmetrical around the y-axis.
* **BI<sub>R</sub> (Black Line):** The curve starts at approximately 0.1 at -160°, increases to a maximum of approximately 1.6 at -40°, decreases to a minimum of approximately 0 at 40°, and then increases to approximately 1.5 at 160°. The curve is not symmetrical.
**Chart 2 (ILD):**
* **BI<sub>L</sub> (Red Line):** The curve starts at approximately 4.2 at -20 dB, decreases monotonically to approximately 0.3 at 20 dB. The curve appears to be exponential in nature.
* **BI<sub>R</sub> (Black Line):** The curve starts at approximately 0.2 at -20 dB, increases to a maximum of approximately 1.5 at 0 dB, and then decreases to approximately 0.5 at 20 dB. The curve is roughly symmetrical around the y-axis.
### Key Observations
* In the IPD chart, the BI<sub>L</sub> curve exhibits a broader peak and a more symmetrical shape compared to the BI<sub>R</sub> curve.
* In the ILD chart, the BI<sub>L</sub> curve shows a strong negative correlation between ILD and response, while the BI<sub>R</sub> curve shows a peak response at 0 dB ILD.
* Both charts have a vertical dashed line at x=0, potentially indicating a reference point or the point of binaural symmetry.
### Interpretation
These charts likely represent the response of neurons or auditory pathways to different interaural cues. The IPD chart demonstrates how the brain encodes sound source location based on the difference in arrival time of sound at each ear. The ILD chart shows how the brain uses differences in sound intensity to localize sounds.
The differing shapes of the curves for BI<sub>L</sub> and BI<sub>R</sub> suggest that the left and right ears may have different sensitivities or processing mechanisms for these cues. The exponential decay of the BI<sub>L</sub> curve in the ILD chart indicates that even small differences in ILD can significantly affect the perceived location of a sound.
The vertical dashed line at 0°/0 dB likely represents the midline or a reference point for sound localization. Sounds originating directly in front of the listener would have an IPD and ILD close to zero. The charts provide insights into the neural mechanisms underlying spatial hearing and how the brain constructs a three-dimensional auditory scene.
</details>
The (hemispheric) net neural activation is only partly resembled with the current subtraction process of the half-wave rectified continuous time signal as illustrated in Figure 8 and is reminiscent of to that observed in the LSO (first two rows in Figure 5 of [41]). The left panel of Figure 8 shows the linear response of BIL (red lines) and BIR (black lines), normalized to the response at 0° IPD, as a function of the IPD (negative sign indicates left ear leading, no ILD) for τ (delay) of π 4 / and α of 3. The strongest contralateral inhibition occurs when the contralateral ear is leading with an IPD of τ. The least inhibition occurs when the ipsilateral ear is leading with an IPD of π -τ, resulting in internal phase differences of π between the excitatory and inhibitory channels. The current τ value of 𝜋 4 / provides a sufficient steep slope around zero IPD to ensure a sufficient sensitivity for small interaural phase differences and is in line with physiological findings. Smaller values would further increase IPD sensitivity and would improve predictions for data of the ITD experiment shown in Figure 2. The α factor of 3 was selected empirically and leads to a complete inhibition by a contralateral leading ear with an up to 10 dB lower level. Larger values would widen the
troughs in the response pattern in the left panel of Figure 8, while smaller values would result in narrower troughs. α values ranging between 3 and 5 resulted in similar prediction performance. The current α agrees well with range of interaural gain differences applied in the Breebaart model. The right panel of Figure 8 represents the linear response as a function of the ILD (negative sign indicates right ear more intense, no IPD). The response of the ipsilateral ear increases as the ipsilateral ear is more intense while inhibition occurs for contralaterally more intense sounds.
In more detailed neural model assumptions (e.g., [41, 42]), the hypothesis of timed inhibition is that the contralateral inhibitory post-synaptic potential (IPSPcontra) precedes the contralateral excitatory PSP for low-frequency processing in the MSO, resulting in a delay of the contralaterally evoked net excitation and the observed hemispheric excitation as a function of ITD. The delayed excitatory interaction, as well as the temporal smearing of excitatory and inhibitory effects represented in the PSPs are not covered by the current (over) simplified model. Moreover, different processing in the LSO and MSO for low and high frequencies, respectively, is observed in the physiology. Conversely, the current model only uses subtraction of the waveforms, disregarding details of PSP simulation, resembling (envelope) ITD processing assumed in the LSO for high frequencies (see center panel of Figure 5 in [41]). This inhibitory processing is used for all frequencies, involving interaural temporal fine structure (TFS) differences at low frequencies and temporal envelope differences at high frequencies. An improvement of the current model can be expected when incorporating both excitatory and inhibitory effects more faithfully, however, at the cost of simplicity.
To compare inhibitory vs excitatory interaction in the context of the current model, we replaced the current subtractive (inhibitory) processing by an additive (excitatory) processing, resulting in an overall similar prediction performance for the psychoacoustic experiments. However, large τ values above about 3π 4 / had to be used to ensure sufficiently large response differences between stimuli with and without interaural phase shifts. Although, the
additive processing also explained most of data from the binaural psychoacoustic experiments used in this study, the SRM predictions in SI experiments were often substantially lower than observed in data. Accordingly, the RMSE between predicted and measured SRM was higher for the additive processing (RMSE of 5.5 dB) than for the current subtractive processing (RMSE of 3.3 dB).
## D. Relation to binaural signal processing algorithms
The five outputs of the suggested fixed BMFD stage can be translated to binaural signal processing, potentially applicable in hearing supportive devices. The difference between the model stage and audio signal processing is that the model operates on a half-wave rectified internal representation, whereas audio signal processing operates on the input waveform at the ears. This difference is important for the binaural interaction channels where the ear signals are combined after nonlinear processing in the model. As outlined in the introduction, the processing of BIC was designed to resemble the effect of summation of the waveform in the ears. For BIL and BIR, the subtraction of the unipolar (half-wave rectified) signals is followed by a maximum operation with zero, which makes the result more comparable to a subtraction of the waveforms. Thus, as a signal processing algorithm, BIC represents a (spatially broadly tuned) fixed broadside beamformer (tuning to front and back). Taking the phase delays and subtraction into account, BIL and BIR conceptually represent fixed (non-adaptive) first-order differential microphone beamformers with a (frequency-dependent) steering vector. Finally, taking the head shadow effect into account, BEL and BER can be interpreted as beamformers pointing to the left and the right. Thus, the BMFD in the current model suggest that the auditory system selects the favorable output of five beamformers in time-frequency frames, depending on the task and spatial configuration of the input.
In comparison to the adaptive EC model, the current approach cannot optimize parameters to specifically cancel certain signal parts (or directions) as in the adaptive differential microphone. Further simplifying the current selection of the optimal BMFD channel in timefrequency frames to the selection of a single broadband channel, the BMFD might be applicable in hearing aid processing as five spatially broadly tuned binaural beamformers from which the optimal output is selected, e.g., based on direction of arrival of the intended target. Such simplistic beamformers might also be better suited in ecologically valid situations with head movements where the additional benefit of more elaborated processing might be limited (e.g., [78]). Indicated by the current speech intelligibility results for a frontal (speech) target, humans appear to just use a simple broadside binaural beamformer (BIC).
## VII. Summary and conclusions
The main goal of this study was to examine how well a modelling approach with strongly simplified assumptions about a fixed (non-adaptive) binaural interaction processing can predict data from both binaural psychoacoustic and speech intelligibility experiments. For this, the generalized power spectrum model [26] was extended by a five channel binaural matrix feature decoder, comprising two better-ear and three binaural interaction channels, to account for monaural and binaural aspects in psychoacoustic and speech intelligibility experiments. The binaural processing comprises the left (L) and right (R) better ear channels, the L+R channel (BIC) and two L-R (BIL) and R-L (BIR) channels incorporating a fixed phase delay (π/4). The model was tested in a monaural and binaural 'benchmark' of overall 13 psychoacoustic experiments and 6 conditions of a speech intelligibility experiment from literature. The following conclusion can be drawn:
- The suggested binaural model accounts for several temporal and spectral key aspects in classical binaural experiments from literature and also explains a large amount of spatial
release from masking in speech intelligibility experiments. The model maintains the predictive power of the earlier monaural approach for monaural psychoacoustics.
- In the psychoacoustic experiments of this study, the L-R and R-L binaural interaction channels, physiologically motivated by hemispheric processing, were most important as the target signal often contained an interaural phase shift (Sπ). The L+R 'midline' channel played no important role.
- For the current speech intelligibility predictions, with a frontal target and spatially separated maskers (somewhat similar to a S0 plus noise with frequency-dependent interaural phase difference condition in psychoacoustics), the L+R channel was most important to account for SRT and the spatial release from masking.
- Overall, the results show that human performance in binaural task might be based on a smart selection of spectro-temporal segments at the output of only a few fixed binaural interaction channels.
## VIII. ACKNOWLEDGMENTS
We would like to thank M. Dietz, B. Eurich, and J. Encke for helpful remarks. We would also like to thank the members of the Medizinische Physik and Birger Kollmeier for continued support. This work was supported by the Deutsche Forschungsgemeinschaft (DFG - 352015383 - SFB1330 A2 and DFG - 390895286 - EXC 2177/1).
## IX. REFERENCES
- [1] D. S. Brungart, N. Iyer: Better-ear glimpsing efficiency with symmetrically-placed interfering talkers. J. Acoust. Soc. Am. 132 (2012) 2545-2556. Doi: 10.1121/1.4747005
- [2] S. D. Ewert, W. Schubotz, T. Brand, B. Kollmeier: Binaural masking release in symmetric listening conditions with spectro-temporally modulated maskers. J. Acoust. Soc. Am. 142 (2017) 12-28. Doi: https://doi.org/10.1121/1.381578
- [3] I. Hirsh: The influence of interaural phase on interaural summation and inhibition. J. Acoust. Soc. Am. 20 (1948) 536-544. Doi: https://doi.org/10.1121/1.1916992
- [4] S. van de Par, A. Kohlrausch: Dependence of binaural masking level differences on center frequency, masker bandwidth and interaural parameters. J. Acoust. Soc. Am. 106 (1999) 1940-1947. Doi: https://doi.org/10.1121/1.427942
- [5] T. Dau, B. Kollmeier, A. Kohlrausch: Modeling auditory processing of amplitude modulation. I. Detection and masking with narrow-band carriers. J. Acoust. Soc. Am. 102 (1997) 2892-2905. Doi: https://doi.org/10.1121/1.420344
- [6] T. Dau, B. Kollmeier, A. Kohlrausch: Modeling auditory processing of amplitude modulation. II. Spectral and temporal integration. J. Acoust. Soc. Am. 102 (1997) 2906-2919. Doi: https://doi.org/10.1121/1.420345
- [7] S. D. Ewert, T. Dau: Characterizing frequency selectivity for envelope fluctuations. J. Acoust. Soc. Am. 108 (2000) 1181-1196. Doi: https://doi.org/10.1121/1.1288665
- [8] J. Breebaart, S. van de Par, A. Kohlrausch: Binaural processing model based on contralateral inhibition. I. Model setup. J. Acoust. Soc. Am. 110 (2001) 1074-1088. Doi: https://doi.org/10.1121/1.1383297
- [9] T. Biberger, S. D. Ewert: Envelope and intensity based prediction of psychoacoustic masking and speech intelligibility. J. Acoust. Soc. Am. 140 (2016) 1023-1038. doi: http://dx.doi.org/10.1121/1.4960574
- [10] B. C. J. Moore, C.-T. Tan: Development and validation of a method for predicting the perceived naturalness of sounds subjected to spectral distortion. J. Audio Eng. Soc. 52 (2004) 900-914.
- [11] K. S. Rhebergen, N. J. Versfeld: A speech intelligibility index-based approach to predict the speech reception threshold for sentences in fluctuating noise for normal-hearing listeners. J. Acoust. Soc. Am. 117 (2005) 2181-2192. Doi: https://doi.org/10.1121/1.1861713
- [12] R. Beutelmann, T. Brand, B. Kollmeier: Revision, extension and evaluation of a binaural speech intelligibility model. J. Acoust. Soc. Am. 127 (2010) 2479-2497. Doi: https://doi.org/10.1121/1.3295575
- [13] M. Lavandier, J. F. Culling: Prediction of binaural speech intelligibility against noise in rooms. J. Acoust. Soc. Am. 127 (2010) 387-399. Doi: https://doi.org/10.1121/1.3268612
- [14] A. H. Andersen, J. M. de Haan, Z.-H. Tan, J. Jensen: Predicting the intelligibility of noisy and non-linearly processed binaural speech. IEEE/ACM Transactions on speech, Audio and Language Processing. 24 (2016) 1908-1920. Doi: 10.1109/TASLP.2016.2588002
- [15] J.-H. Fleßner, R. Huber, S. D. Ewert: Assessment and prediction of binaural aspects of audio quality. J. Audio Eng. Soc. 65 (2017) 929-942. Doi: https://doi.org/10.17743/jaes.2017.0037
- [16] T. Biberger, J.-H. Fleßner, R. Huber, S. D. Ewert: An objective audio quality measure based on power and envelope power cues. J. Audio Eng. Soc. 66 (2018) 578-593. doi: https://doi.org/10.17743/jaes.2018.0031
- [17] R. D. Patterson, B. C. J. Moore: Auditory filters and excitation patterns as representations of frequency resolution, in Frequency selectivity in hearing Moore BCJ, Editor London, Academic Press. 1986.
- [18] C. J. Plack, A. J. Oxenham: Basilar-membrane nonlinearity and the growth of forward masking. J. Acoust. Soc. Am. 103 (1998) 1598-1608. Doi: https://doi.org/10.1121/1.421294
- [19] J.-H. Fleßner, T. Biberger, S. D. Ewert: Subjective and objective assessment of monaural and binaural aspects of audio quality. IEEE Transactions on Audio, Speech and Language Processing. 27 (2019) 1112-1125. Doi: https://doi.org/10.1109/TASLP.2019.2904850
- [20] T. Biberger, H. Schepker, F. Denk, S. D. Ewert: Instrumental quality predictions and analysis of auditory cues for algorithms in modern headphone technology. Trends in Hearing, 25 (2021) 1-22. doi: 10.1177/23312165211001219
- [21] H. Fletcher: Auditory patterns. Reviews of Modern Physics 12 (1940) 47-65. Doi: https://doi.org/10.1103/RevModPhys.12.47
- [22] N. F. Viemeister: Temporal modulation transfer functions based upon modulation thresholds. J. Acoust. Soc. Am. 66 (1979) 1364-1380. Doi: https://doi.org/10.1121/1.383531
- [23] B. R. Glasberg, B. C. J. Moore: Development and evaluation of a model for predicting the audibility of time-varying sounds in the presence of background sounds. J. Audio Eng. Soc. 53 (2005) 906-918.
- [24] M. L. Jepsen, S. D. Ewert, T. Dau: A computational model of human auditory signal processing and perception. J. Acoust. Soc. Am. 124 (2008) 422-438. Doi: https://doi.org/10.1121/1.2924135
- [25] S. Jørgensen, S. D. Ewert, T. Dau: A multi-resolution envelope-power based model for speech intelligibility. J. Acoust. Soc. Am . 134 (2013) 436-446. Doi: https://doi.org/10.1121/1.4807563
- [26] T. Biberger, S. D. Ewert: The role of short-time intensity and envelope power for speech intelligibility and psychoacoustic masking. J. Acoust. Soc. Am. 142 (2017) 10981111. doi: http://dx.doi.org/10.1121/1.4999059
- [27] L. A. Jeffress: A place theory of sound localization. J. Comp. Physiol. Psychol. 41 (1948) 35-39. Doi: 10.1037/h0061495
- [28] N. I. Durlach: Equalization and cancellation theory of binaural masking-level differences. J. Acoust. Soc. Am. 35 (1963) 1206-1218. Doi: https://doi.org/10.1121/1.1918675
- [29] W. Lindemann: Extension of a binaural cross-correlation model by contralateral inhibition. J. Acoust. Soc. Am. 80 (1986) 1608-1622. Doi: https://doi.org/10.1121/1.394325
- [30] R. M. Stern, G. D. Shear: Lateralization and detection of low-frequency binaural stimuli: Effects of distribution of internal delay. J. Acoust. Soc. Am. 100 (1996) 2278-2288. Doi: https://doi.org/10.1121/1.417937
- [31] L. R. Bernstein, C. Trahiotis: Enhancing interaural-delay-based extents of laterality at high frequencies by using 'transposed stimuli'. J. Acoust. Soc. Am. 113 (2003) 33353347. Doi: https://doi.org/10.1121/1.1570431
- [32] L. R. Bernstein, C. Trahiotis: Lateralization produced by interaural temporal and intensitive disparities of high-frequency, raised-sine stimuli: Data and modeling. J. Acoust. Soc. Am. 131 (2012) 409-415. Doi: https://doi.org/10.1121/1.3662056
- [33] M. Dietz, S. D. Ewert, V. Hohmann, B. Kollmeier: Coding of temporally fluctuating interaural timing disparities in a binaural processing model based on phase differences. Brain Res. 1220 (2008) 234-245. Doi: 10.1016/j.brainres.2007.09.026
- [34] J. Klug, L. Schmors, G. Ashida, M. Dietz: Neural rate difference model can account for lateralization of high frequency stimuli. J. Acoust. Soc. Am. 148 (2020) 678-691. Doi: https://doi.org/10.1121/10.0001602
- [35] S. Doclo, S. Gannot, D. Marquardt, E. Hadad: Binaural speech processing with application to hearing devices, in Audio source separation and speech enhancement Vincent E, Virtanen T, Gannot S, Editors, Wiley. 2018. Doi: https://doi.org/10.1002/9781119279860.ch18
- [36] R. Wan, N. I. Durlach, H. S. Colburn: Application of a short-time version of the equalization-cancellation model to speech intelligibility experiments with speech maskers. J. Acoust. Soc. Am. 136 (2014) 768-776. Doi: https://doi.org/10.1121/1.4884767
- [37] A. Chabot-Leclerc, E. N. MacDonald, T. Dau: Predicting binaural speech intelligibility using the signal-to-noise ratio in the envelope power spectrum domain. J. Acoust. Soc. Am. 140 (2016) 192-205. Doi: https://doi.org/10.1121/1.4954254
- [38] J. Breebaart, S. van de Par, A. Kohlrausch: Binaural processing model based on contralateral inhibition. II. Dependence on spectral parameters. J. Acoust. Soc. Am. 110 (2001) 1089-1104. Doi: https://doi.org/10.1121/1.1383298
- [39] J. Breebaart, S. van de Par, A. Kohlrausch: Binaural processing model based on contralateral inhibition. III. Dependence on temporal parameters. J. Acoust. Soc. Am. 110 (2001) 1105-1117. Doi: https://doi.org/10.1121/1.1383299
- [40] P. M. Briley, A. M. Goman, A. Q. Summerfield: Physiological evidence for a midline spatial channel in human auditory cortex. J. Assoc. Res. Otolaryngol. 17 (2016) 331340. Doi: 10.1007/s10162-016-0571-y
- [41] B. Grothe, M. Pecka: The natural history of sound localization in mammals - a story of neuronal inhibition. Frontiers in Neural Circuits 8 (2014) 116. Doi: 10.3389/fncir.2014.00116
- [42] M. Pecka, A. Brand, O. Behrend, B. Grothe: Interaural time difference processing in the mammalian medial superior olive: The role of glycinergic inhibition. J. Neurosci. 28 (2008) 6914-6925. Doi: 10.1523/JNEUROSCI.1660-08.2008
- [43] B. Grothe, M. Pecka, D. McAlpine: Mechanisms of sound localization in mammals. Physiol. Rev. 90 (2010) 983-1012. Doi: https://doi.org/10.1152/physrev.00026.2009
- [44] S. Kortlang, M. Mauermann, S. D. Ewert: Suprathreshold auditory processing deficits in noise: Effects of hearing loss and age. Hearing Research 331 (2016) 27-40. Doi: 10.1016/j.heares.2015.10.004
- [45] N. Paraouty, S. D. Ewert, N. Wallaert, C. Lorenzi: Interactions between amplitude modulation and frequency modulation processing: Effects of age and hearing loss. J. Acoust. Soc. Am. 140 (2016) 121-131. Doi: https://doi.org/10.1121/1.4955078
- [46] N. Wallaert, B. C. J. Moore, C. Lorenzi: Comparing the effects of age on amplitude modulation detection. J. Acoust. Soc. Am. 139 (2016) 3088-3096. Doi: https://doi.org/10.1121/1.4953019
- [47] N. Wallaert, B. C. J. Moore, S. D. Ewert, C. Lorenzi: Sensorineural hearing loss enhances auditory sensitivity and temporal integration for amplitude modulation. J. Acoust. Soc. Am. 141 (2017) 971-980. Doi: https://doi.org/10.1121/1.4976080
- [48] S. D. Ewert, N. Paraouty, C. Lorenzi: A two-path model of auditory modulation detection using temporal fine structure and envelope cues. Eur J Neurosci. 51 (2018) 1265-1278. Doi: 10.1111/ejn.13846
- [49] S. D. Ewert: Defining the proper stimulus and its ecology - mammals, in The senses: A comprehensive reference Fritzsch B, Editor, Elsevier. 2020. Doi:10.1016/B978-0-12809324-5.24238-7
- [50] ISO 389-7: Acoustics-Reference Zero for the Calibration of Audiometric Equipment. Part 7: Reference Threshold of hearing under free-field and diffuse-field listening conditions. International Organization for Standardization. Geneva, Switzerland. 2005.
- [51] B. C. J. Moore, B. R. Glasberg: Suggested formulae for calculating auditory filter bandwidth and excitation patterns. J. Acoust. Soc. Am. 74 (1983) 750-753. Doi: https://doi.org/10.1121/1.389861
- [52] A. Kohlrausch, R. Fassel, T. Dau: The influence of carrier level and frequency on modulation and beat-detection thresholds for sinusoidal carriers. J. Acoust. Soc. Am. 108 (2000) 723-734. Doi: https://doi.org/10.1121/1.429605
- [53] B. C. J. Moore: An Introduction to the psychology of. Hearing. 4 th Edition. London, Academic. 1997.
- [54] J. L. Verhey, T. Dau, B. Kollmeier: Within-channel cues in comodulation masking release (CMR): Experiments and model predictions using a modulation-filterbank model. J. Acoust. Soc. Am. 106 (1999) 2733-2745. Doi: https://doi.org/10.1121/1.428101
- [55] W. P. Tanner, R. D. Sorkin: The Theory of signal detectability, in Foundation of modern auditory function Tobias JV, Editor New York, Academic. 1972.
- [56] ANSI, 1997: S3.5, Methods for calculation of the speech intelligibility index (Standards Secreteriat. Acoustical Society of America, New York.
- [57] A. J. M. Houtsma, N. I. Durlach, L. D. Braida: Intensity perception. XI. Experimental results on the relation of intensity resolution to loudness matching. J. Acoust. Soc. Am. 68 (1998) 807-813. Doi: https://doi.org/10.1121/1.384819
- [58] B. C. J. Moore, J. I. Alcántara, T. Dau: Masking patterns for sinusoidal and narrow-band noise maskers. J. Acoust. Soc. Am. 104 (1998) 1023-1038. Doi: https://doi.org/10.1121/1.423321
- [59] S. D. Ewert, T. Dau: External and internal limitations in amplitude-modulation processing. J. Acoust. Soc. Am. 116 (2004) 478-490. Doi: https://doi.org/10.1121/1.1737399
- [60] R. G. Klumpp, H. R. Eady: Some measurements of interaural time difference thresholds. J. Acoust. Soc. Am. 28 (1956) 859-860. Doi: https://doi.org/10.1121/1.1908493
- [61] J. Zwislocki, R. S. Feldman: Just noticeable differences in dichotic phase. J. Acoust. Soc. Am. 28 (1956) 860-864. Doi: https://doi.org/10.1121/1.1908495
- [62] A. Mills: Lateralization of high-frequency tones. J. Acoust. Soc. Am. 32 (1960) 132-134. Doi: https://doi.org/10.1121/1.1907864
- [63] D. W. Grantham: Interaural intensity discrimination: insensitivity at 1000 Hz. J. Acoust. Soc. Am. 75 (1984) 1191-1194. Doi: https://doi.org/10.1121/1.390769
- [64] I. Hirsh, M. Burgeat: Binaural effects in remote masking. J. Acoust. Soc. Am. 30 (1958) 827-832. Doi: https://doi.org/10.1121/1.1930084
- [65] A. Kohlrausch: Auditory filter shape derived from binaural masking experiments. J. Acoust. Soc. Am. 84 (1988) 573-583. Doi: https://doi.org/10.1121/1.396835
- [66] W. A. Yost: Prior stimulation and the masking-level difference. J. Acoust. Soc. Am. 78 (1985) 901-906. Doi: https://doi.org/10.1121/1.392920
- [67] R. Wilson, C. Fowler: Effects of signal duration on the 500-Hz masking-level difference. Scand. Audiol. 15 (1986) 209-215. Doi: 0.3109/01050398609042145
- [68] R. Wilson, R. Fugleberg: Influence of signal duration on the masking-level difference. J. Speech Hear. Res. 30 (1987) 330-334. Doi: 10.1044/jshr.3003.330
- [69] L. R. Bernstein, C. Trahiotis: The effects of signal duration on N0S0 and N0Sπ thresholds at 500 Hz and 4 kHz. J. Acoust. Soc. Am. 105 (1999) 1776-1783. Doi: https://doi.org/10.1121/1.426715
- [70] B. Kollmeier, R. H. Gilkey: Binaural forward and backward masking: evidence for sluggishness in binaural detection. J. Acoust. Soc. Am. 87 (1990) 1709-1719. Doi: https://doi.org/10.1121/1.399419
- [71] E. R. Hafter, S. C. Carrier: Binaural interaction in low-frequency stimuli: The inability to trade time and intensity completely. J. Acoust. Soc. Am. 51(1972) 1852-1862. Doi: https://doi.org/10.1121/1.1913044
- [72] K. C. Wagner, T. Brand, B. Kollmeier: Entwicklung und Evaluation eines Satztests für die deutsche Sprache III: Evaluation des Oldenburger Satztests (Development and evaluation of a sentence test for german language III: Design, optimization and evaluation of the Oldenburger sentence test). Z. Audiol. 38 (1999) 86-95
- [73] I. Holube, S. Fredelake, M. Vlaming, B. Kollmeier: Development and analysis of an International Speech Test Signal (ISTS). Int. J. Audiol. 49 (2010) 891-903. Doi: 10.3109/14992027.2010.506889
- [74] D. S. Brungart: Informational and energetic masking effects in the perception of two simultaneous talkers. J. Acoust. Soc. Am. 109 (2001) 1101-1109. Doi: https://doi.org/10.1121/1.1345696
- [75] I. Siveke, S. D. Ewert, B. Grothe, L. Wiegrebe: Psychophysical and physiological evidence for fast binaural processing. J. Neurosc. 28 (2008) 2043-2052. Doi: https://doi.org/10.1523/JNEUROSCI.4488-07.2008
- [76] C. F. Hauth, T. Brand: Modelling sluggishness in binaural unmasking of speech for maskers with time-vaying interaural phase differences. Trends in Hearing 22 (2018) 110. Doi: 10.1177/2331216517753547
- [77] J. Encke, W. Hemmert: Extraction of interaural time differences using a spiking neuron network model of the medial superior olive. Front. Neurosci. 12 (2018) 140. Doi: 10.3389/fnins.2018.00140
- [78] M. M. E. Hendrikse, G. Grimm, V. Hohmann: Evaluation of the influence of head movement on hearing aid algorithm performance using acoustic simulations. Trends in Hearing 24 (2020) 1-20. Doi: 10.1177/2331216520916682.
## X. Tables
Table 1: Root-mean square errors (RMSE) and coefficient of determination (R²; squared cross-correlation coefficient) between data and model predictions for the monaural and binaural psychoacoustic experiments.
| Experiments | BMFD | BMFD | BI L,R | BI L,R | mr-GPSM [26] | mr-GPSM [26] |
|------------------------------------------------------------------------|----------------------|----------------------|----------------------|----------------------|----------------------|----------------------|
| Experiments | RMSE | R² | RMSE | R² | RMSE | R² |
| 1. Hearing threshold | 3.3 dB | 0.99 | 3.3 | 0.99 | 1.7 dB | 0.99 |
| 2. Intensity JNDs | 0.2 dB | 0.66 | 0.2 | 0.64 | 0.3 dB | 0.57 |
| 3. Tone in noise | 1.3 dB | 0.99 | 1.3 | 0.99 | 2.1 dB | 0.99 |
| 4. Spectral masking | 9.5 dB | 0.82 | 9.5 | 0.8 | 7.9 dB | 0.9 |
| 5. AMdetection | 4.0 dB | 0.71 | 4 | 0.78 | 4.5 dB | 0.68 |
| 6.AM discrimination | 2.4 dB | 0.94 | 2.4 | 0.92 | 1.6 dB | 0.94 |
| 7 AMmasking | 4.6 dB | 0.77 | 4.7 | 0.79 | 6.2 dB | 0.73 |
| Binaural Experiments | Binaural Experiments | Binaural Experiments | Binaural Experiments | Binaural Experiments | Binaural Experiments | Binaural Experiments |
| Experiments | BMFD | BMFD | BI L,C,R | BI L,C,R | BI L,R | BI L,R |
| | RMSE | R² | RMSE | R² | RMSE | R² |
| 1. ITD discrimination | 0.019 ms | 0.89 | 0.019 | 0.9 | 0.019 ms | 0.93 |
| 2. IID discrimination | 0.5 dB | 0.002 | 0.5 | 0.0014 | 0.5 dB | 0.005 |
| 3. Frequency and interaural phase relationships in wideband conditions | 9.1 dB | 0.86 | 8.5 dB | 0.85 | 6.7 | 0.88 |
| 4. N 0 S π depending on signal duration | 2.9 dB | 0.92 | 3.0 | 0.92 | 3.2 dB | 0.9 |
|-------------------------------------------|----------|--------|--------|--------|----------|-------|
| 5. Temporal phase transition | 2.6 dB | 0.8 | 2.7 dB | 0.8 | 2.7 dB | 0.81 |
| 6. Time- intensity- trading | 0.5 | 0.38 | 0.6 | 0.58 | 0.6 | 0.61 |
Table 2: Parameter settings of the three model versions to match the co-located SSN data.
The k value results from averaging the individual k values from five repeated simulations.
| | k | q | m | 𝜎 𝑠 |
|---------|------|-----|-----|-------|
| BMFD | 0.6 | 0.5 | 50 | 0.6 |
| BI C | 0.72 | 0.5 | 50 | 0.6 |
| BI C AC | 0.72 | 0.5 | 50 | 0.6 |
## XI. Figure captions
Figure 1: Block diagram of the GPSM with BMFD extension. After peripheral processing, the left and right ear signals are binaurally processed by using the BMFD that provides two better-ear channels BEL and BER and three binaural interaction channels BIL, BIC, BIR. For each of the five BMFD outputs, envelope power and power SNRs are calculated on short-time frames and then combined across the five channels of the BMFD and across auditory and modulation channels, resulting in a sensitivity index denv ' based on envelope power SNRs and dDC ' based on power SNRs. The final combined d ' was then compared to a threshold criterion that assumes that a signal is detected if d' > (0.5) 1/2 .
Figure 2: empirical data (filled symbols) and model predictions (open symbols) for ITD thresholds in ms (upper panel) and IID thresholds in dB (lower panel).
Figure 3: Empirical data (filled symbols) and model predictions (open symbols) for masked thresholds for wideband N0Sm (upper-left panel), N0Sπ (upper-right panel), NπSm (middle-left panel), and NπS0 (middle-right panel) conditions as a function of the frequency of the signal. Differences in thresholds between the NπNm and N0Sm are shown in the lower-left panel, while the lower-right panel represents differences in threshold between NπS0 and N0Sπ.
Figure 4: Empirical data (filled symbols) and model predictions (open symbols) for N0Sπ thresholds as a function of the signal duration. Data and predictions are shown for signal frequencies of 500 Hz (left panel) and 4 kHz (right panel).
Figure 5: Empirical data (filled symbols) and model predictions (open symbols) for NπN0Sπ (upper-left panel) and NπN0Sπ (upper-right panel) thresholds as a function of the temporal position of the signal center relative to the masker-phase transition. Monaural thresholds for NπNπ,-15dBSπ and Nπ,-15dBNπSπ are shown in the lower-left and lower-right panels. Filled symbols represent four subjects measured by Kollmeier and Gilky [70].
Figure 6: Empirical data (grey lines, closed symbols) and model predictions (black lines, open symbols) for the time-intensity trading experiment of Hafter and Carrier [71] with different ITDs of 0, 10, 20, 30, and 40 µs. The ordinate represents d ' , while the abscissa represents the ILD in dB. Since BIL,R and BIL,C,R predicts nearly identical d ' only BIL,R predictions are shown in the upper panel for improved clarity. The lower panel represents predictions from BMFD. The dashed horizontal lines indicate the decision criterion of the models, e.g. differences between test and reference signals resulting in d ' values below the criterion are not assumed to be detectable.
Figure 7: The upper panel shows SRT50 results, while the lower panel shows the respective SRM. Data is represented by squares, while predictions are given by circles, triangles, and diamonds, respectively. The spatially co-located (front) and separated masker conditions are indicated by closed and open symbols, respectively.
Figure 8: Response of the BIL and BIR channels as a function of IPD (left panel) and ILD (right panel) for a 500 Hz pure tone. Negative IPDs indicate left ear leading, while negative ILDs indicate right ear more intense. Response shown in both panels are based on the same τ and α values of 𝜋 4 / and 3 as they were used for all simulations in this study. Note that for clarity, amplitude and phase jitter were turned off.