## Coherent Ising Machines with Optical Error Correction Circuits
Sam Reifenstein Satoshi Kako Farad Khoyratee Timoth´ ee Leleu Yoshihisa Yamamoto*
Sam Reifenstien, Satoshi Kako, Farad Khoyratee, Yoshihisa Yamamoto
PHI (Physics & Informatics) Laboratories, NTT Research Inc.
940 Stewart Drive, Sunnyvale, CA 94085, U.S.A.
Email Address:yoshihisa.yamamoto@ntt-research.com
Timoth´ ee Leleu
International Research Center for Neurointelligence, The University of Tokyo,
7-3-1 Hongo Bunkyo-ku, Tokyo 113-0033, JAPAN
Keywords: Coherent Ising machine, Chaotic solution search, Matrix-vector multiplication, Combinatorial optimization, Optical error correction
We propose a network of open-dissipative quantum oscillators with optical error correction circuits. In the proposed network, the squeezed/anti-squeezed vacuum states of the constituent optical parametric oscillators below the threshold establish quantum correlations through optical mutual coupling, while collective symmetry breaking is induced above the threshold as a decision-making process. This initial search process is followed by a chaotic solution search step facilitated by the optical error correction feedback. As an optical hardware technology, the proposed coherent Ising machine (CIM) has several unique features, such as programmable all-to-all Ising coupling in the optical domain, directional coupling ( J ij = J ji ) induced chaotic behavior, and low power operation at room temperature. We study the performance of the proposed CIMs and investigate how the performance scales with different problem sizes. The quantum theory of the proposed CIMs can be used as a heuristic algorithm and efficiently implemented on existing digital platforms. This particular algorithm is derived from the truncated Wigner stochastic differential equation. We find that the various CIMs discussed are effective at solving many problem types, however the optimal algorithm is different depending on the instance. We also find that the proposed optical implementations have the potential for low energy consumption when implemented optically on a thin film LiNbO 3 platform.
## 1 Introduction
Combinatorial optimization problems are ubiquitous in modern science, engineering, medicine, and business. Such problems are often NP-hard; hence, their runtime on classical digital computers is expected to scale exponentially. A representative example of NP-hard combinatorial optimization problems is the non-planar Ising model. [ 1 ] Special-purpose quantum hardware devices have been developed for finding solutions of Ising problems more efficiently compared tothan standard heuristic approaches. For example, a quantum annealing (QA) device exploits the adiabatic evolution of pure-state vectors using a timedependent Hamiltonian. [ 2 , 3 ] Another example is a coherent Ising machine (CIM), which exploits the quantumto-classical transition of mixed-state density operators in a quantum oscillator network. [ 4 , 5 , 6 , 7 ] Performance comparisons between QA devices and CIMs for various Ising models, such as complete, dense, and sparse graphs, have been reported. [ 8 ] Furthermore, theoretical performance comparisons between ideal gate-model quantum computers, implementing either Grover's search algorithm or the adiabatic quantum computing algorithm, and CIMs have been reported recently. [ 9 ] Although CIMs with all-to-all coupling among spins are highly effective, the use of an external FPGA circuit as well as an analog-todigital converter (ADC) and a digital-to-analog converter (DAC) not only results in considerable energy dissipation but also introduces a potential bottleneck for high-speed operation.
The standard linear coupling scheme of CIMs has been found to suffer from amplitude heterogeneity among the constituent quantum oscillators. Consequently, the Ising Hamiltonian is incorrectly mapped to the network loss, resulting in unsuccessful operation, especially in frustrated spin systems. [ 10 ] A novel error-correcting feedback scheme has been developed to resolve this problem [ 11 , 12 ] , which makes the solution accuracy of CIMs comparable to that of state-of-the-art heuristics such as break-out local search (BLS). [ 14 ] In this paper, we introduce a novel CIM architecture in which the error correction is implemented optically. In the proposed architecture, computationally intensive matrix-vector multiplication (MVM) and a nonlinear feedback function are implemented using phase-sensitive (degenerate) optical
parametric amplifiers, which are essentially the same device as the main-cavity optical parametric oscillator (OPO). This new CIM architecture can potentially be implemented monolithically in future photonic integrated circuits using thin-film LiNbO 3 platforms. LiNbO 3 platforms. [ 15 ]
A network of open dissipative quantum oscillators with optical error correction circuits is promising not only as a future hardware platform but also as a quantum-inspired algorithm because of its simple and efficient theoretical description. Numerical simulation of the time evolution of an N-qubit quantum system requires 2 N complex-number amplitudes. However, for a quantum oscillator network, various phasespace techniques of quantum optics have been developed over the last four decades. [ 18 , 19 , 20 ] The complete description of a network of quantum oscillators is now possible using N (or 2 N ) sets of stochastic differential equations (SDEs) based on positive-P, [ 21 ] truncated Wigner [ 22 , 23 , 24 ] or truncated Husimi [ 23 , 24 ] representations of the master equations. These SDEs can be used as heuristic algorithms on modern digital platforms. To completely described a network of low-Q quantum oscillators, a discrete map technique using a Gaussian quantum model is available, which is also computationally efficient. [ 25 ]
Similarly, a network of dissipation-less quantum oscillators with adiabatic Hamiltonian modulation is described using a set of N deterministic equations, which can also be used as a heuristic algorithm on modern digital platform. [ 27 , 28 , 29 ] Such heuristic algorithms are called simulated bifurcation machines (SBMs), [ 27 , 29 ] a variant of which will be studied in Section 6. Although the original SBM is inspired by dissipation-less adiabatic quantum computation, the version of SBM discussed in this paper (dSBM) is not a true unitary system, as dissipation is artificially added using inelastic walls to improve the performance of the algorithm. As both algorithms involve MVM as a computational bottleneck when simulated on a digital computer, we use the number of MVMs as the metric for performance comparison. We find that both types of systems have very similar performance in most cases, except graph types with great variation in vertex degree, where the SBM struggles consistently.
## 2 Semi-classical Model for Error Correction Feedback
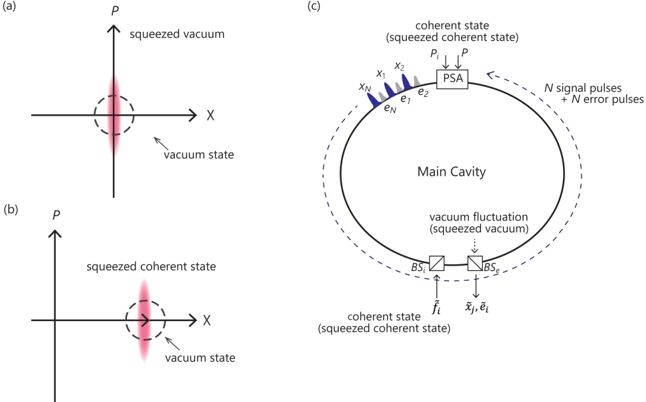
In this section, we will describe several mutual coupling and error correction feedback schemes for CIMs. To simplify our argument, we consider a semi-classical deterministic picture. [ 10 ] The semi-classical model treated in this section is an approximate theory for the following fictitious machine. At an initial time t = 0, each signal pulse field is prepared in a vacuum state (Figure 1(a)), and each error pulse field is prepared in a weak coherent state (Figure 1(b)). When the pump fields p and p i are switched on at t ≥ 0, a vacuum field incident on the extraction beam splitter BS e from an open port is squeezed/anti-squeezed by a phase-sensitive amplifier (PSA) in this optical delay line (ODL) CIM, as shown in Figure 1(c). In other words, the vacuum fluctuation in the in-phase component ˜ X = 1 2 ( ˆ a +ˆ a † ) is deamplified by a factor of 1/G, while the vacuum fluctuation in the quadrature-phase component ˆ P = 1 2 i ( ˆ a -ˆ a † ) is amplified by a factor of G. Similarly, the vacuum fluctuations incident on the OPO pulse field owing to any linear loss of the cavity are all squeezed by the respective PSA. Moreover, the pump field and feedback injection field fluctuations along the in-phase component are also deamplified by the respective PSA (Figure (c)).
The truncated Wigner stochastic differential equation (W-SDE) for such a quantum-optic CIM with squeezed reservoirs has been derived and studied previously. [ 31 ] This particular CIM achieves the maximum quantum correlation among OPO pulse fields along the in-phase component as well as the maximum success probability, [ 31 ] because the quantum correlation among OPO pulse fields is formed by the mutual coupling of the vacuum fluctuations of OPO pulse fields without the injection of uncorrelated fresh reservoir noise in such a system. The following semi-classical model is considered as an approximate theory of the above-mentioned W-SDE in the limit of a large deamplification factor ( G 1). A full quantum description of a more realistic CIM with optical error correction circuits (without reservoir engineering) is given in Section 5. To overcome the problem of amplitude heterogeneity in the CIM [ 10 ] , the addition of an auxiliary variable for error detection and correction has been proposed. [ 11 , 12 ] This system has been
Figure 1: (a) Vacuum state and squeezed vacuum state. (b) Coherent state and squeezed coherent state. (c) Conventional CIM with vacuum noise injected from reservoirs, and a modified CIM with suppressed reservoir noise.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Quantum State Representation and Optical Setup
### Overview
The image presents a diagram illustrating quantum states of light and an optical setup for generating and manipulating them. It consists of three panels: (a) and (b) depict phase space representations of quantum states, while (c) shows a schematic of an optical cavity setup. The diagram appears to relate to quantum optics, specifically squeezed states of light and their use in quantum information processing.
### Components/Axes
* **Panel (a):** Axes labeled 'X' (horizontal) and 'P' (vertical). Displays a phase space representation with a vertically elongated ellipse labeled "squeezed vacuum" and a circular shape labeled "vacuum state".
* **Panel (b):** Axes labeled 'X' (horizontal) and 'P' (vertical). Displays a phase space representation with a horizontally elongated ellipse labeled "squeezed coherent state" and a circular shape labeled "vacuum state".
* **Panel (c):** Contains several labeled components:
* "Main Cavity" – a large, shaded circular region.
* "PSA" – positioned at the top of the Main Cavity.
* "x₁", "x₂", "xN" – Input ports to the Main Cavity.
* "e₁", "e₂", "eN" – Output ports from the Main Cavity.
* "BS₁" and "BS₂" – Beam splitters positioned at the bottom of the Main Cavity.
* "h₁" and "h₂" – Input ports to the Beam Splitters.
* "x₁, e₁" – Output ports from the Beam Splitters.
* Labels indicating states: "coherent state (squeezed coherent state)", "vacuum fluctuation (squeezed vacuum)".
* Text: "N signal pulses + N error pulses" – positioned near the top of the Main Cavity.
### Detailed Analysis / Content Details
* **Panel (a):** The "squeezed vacuum" ellipse is oriented vertically, indicating squeezing in the X quadrature. The "vacuum state" is represented as a circle centered at the origin, indicating equal uncertainty in both X and P quadratures.
* **Panel (b):** The "squeezed coherent state" ellipse is oriented horizontally, indicating squeezing in the P quadrature. The "vacuum state" is again represented as a circle.
* **Panel (c):** The "Main Cavity" is a central element. A "coherent state (squeezed coherent state)" is input into the cavity via ports x₁, x₂, and xN. The cavity generates "vacuum fluctuations (squeezed vacuum)". The output is a combination of "N signal pulses + N error pulses" exiting via ports e₁, e₂, and eN. The beam splitters BS₁ and BS₂ are used to combine the input coherent state with the vacuum fluctuations. The coherent state is also input via h₁ and h₂.
### Key Observations
* The diagram illustrates the concept of squeezing, where the uncertainty in one quadrature of a quantum state is reduced at the expense of increased uncertainty in the other.
* Panel (a) shows squeezing of the vacuum state, while Panel (b) shows squeezing of a coherent state.
* Panel (c) depicts a setup for generating and manipulating squeezed states within an optical cavity.
* The presence of "N signal pulses + N error pulses" suggests the setup is used for quantum communication or computation, where errors are a consideration.
### Interpretation
The diagram demonstrates a method for generating and utilizing squeezed states of light. Squeezed states are non-classical states of light with reduced noise in one quadrature, which can be used to enhance the sensitivity of measurements or improve the performance of quantum communication protocols. The optical cavity in Panel (c) provides a means to enhance the interaction between the input coherent state and the vacuum fluctuations, leading to the generation of squeezed states. The inclusion of signal and error pulses suggests that this setup is being used in a context where quantum information is being processed, and the effects of noise and errors are being considered. The different orientations of the squeezed ellipses in Panels (a) and (b) indicate that squeezing can be achieved in different quadratures, depending on the specific setup and desired application. The diagram is a conceptual representation of a complex quantum optical system, and the specific details of the implementation would depend on the particular experimental setup.
</details>
studied as a modification of the measurement feedback CIM. [ 31 ] The spin variable (signal pulse amplitude) x i and auxiliary variable (error pulse amplitude) e i obey the following deterministic equations: [ 11 ]
$$\frac { d x _ { i } } { d t } = - x _ { i } ^ { 3 } + \left ( p - 1 \right ) x _ { i } - e _ { i } \sum _ { j } \xi J _ { i j } x _ { j } ,$$
$$\frac { d e _ { i } } { d t } = - \beta e _ { i } \left ( x _ { i } ^ { 2 } - \alpha \right ) , & & ( 2 )$$
where J ij is the Ising coupling matrix, α , β and p are system parameters and ξ is a normalizing constant for J ij (see Appendix A for parameter selection). In many cases, we may modulate these parameters over time to achieve better performance (see Section 3 and Appendix C). To use this system as an Ising solver we consider the spin configuration σ i = sign( x i ) as a possible solution to the corresponding Ising problem. Even though noise is ignored in the above-mentioned equation, we can choose the initial x i amplitude randomly to create a diverse set of possible trajectories.
In this paper, we refer to this system of equations as CIM with chaotic amplitude control (CIM-CAC). The term 'chaotic' is used because CIM-CAC exhibits chaotic behavior (as discussed in Section 3). CIMCAC may refer to either the above-mentioned system of deterministic differential equations when integrated as a digital algorithm or an optical CIM that emulates the above-mentioned equations.
While studying the CIM-CAC equations, we have made the following modification:
$$z _ { i } = e _ { i } \sum _ { j } \xi J _ { i j } x _ { j } , & & ( 3 )$$
$$\frac { d x _ { i } } { d t } = - x _ { i } ^ { 3 } + \left ( p - 1 \right ) x _ { i } - z _ { i } ,$$
$$\frac { d e _ { i } } { d t } = - \beta e _ { i } \left ( z _ { i } ^ { 2 } - \alpha \right ) ,$$
which we refer to as CIM with chaotic feedback control (CIM-CFC). The only difference between Eqs. (2) and (5) is that the time evolution of the error variable e i monitors the feedback signal z i , rather than the internal amplitude x i . The dynamics of this new equation are very similar to those of CIM-CAC, which can be understood by observing that CIM-CAC and CIM-CFC have nearly identical fixed points. The motivation for studying CIM-CFC in addition to CIM-CAC is to gain a better understanding of
how these systems work. In addition, CIM-CFC may have slightly simpler dynamics, which simplifies its numerical integration.
The third system discussed in this paper has a very different equation:
$$z _ { i } = \sum _ { j } \xi J _ { i j } x _ { j } , & & ( 6 )$$
$$\frac { d x _ { i } } { d t } = - x _ { i } ^ { 3 } + \left ( p - 1 \right ) x _ { i } - f \left ( c z _ { i } \right ) - k \left ( z _ { i } - e _ { i } \right ) ,$$
$$\frac { d e _ { i } } { d t } = - \beta \left ( e _ { i } - z _ { i } \right ) .$$
The non-linear function f is a sigmoid-like function such as f ( z ) = tanh( z ), and p , k , c and β are system parameters (See Appendix A for parameter selection). The significance of this new feedback system is that the differential equation for the error signal e i is now linear in the 'mutual coupling signal' z i . In addition, z i is calculated simply as ∑ j ξJ ij x j without the additional factor e i as in Eq. (6). This means that the only nonlinear elements in this system are the gain saturation term -x 3 i and the nonlinear function f . For the results in this paper we will use f ( z ) = tanh( z ), however if a different function with the same properties is used the system will have similar behavior.
In the above-mentioned system, the two essential aspects of CIM-CAC and CIM-CFC are separated into two different terms. The term f ( cz i ) realizes mutual coupling while passively addressing the problem of amplitude heterogeneity, while the term k ( z i -e i ) introduces the error signal e i which helps to destabilize local minima. Therefore, we refer to this system as CIM with separated feedback control (CIM-SFC) in the remainder of this paper.
Another significant aspect of CIM-SFC (Eqs. (6),(7) and (8)) compared to CIM-CAC and CIM-CFC (Eqs. (1)-(5)) is that the auxiliary variables e i in CIM-SFC have a very different meaning. In CIM-CAC and CIM-CFC, e i is meant to be a strictly positive number that varies exponentially and modulates the mutual coupling term. In CIM-SFC, e i is instead a variable that stores sign information and takes the same range of values as the mutual coupling signal z i . The error signal e i can essentially be regarded as a low pass filter on z i , and the term k ( e i -z i ) can be regarded as a high pass filter on z i (in other words k ( e i -z i ) only registers sharp changes in z i ). The similarities and differences among CIM-SFC, CIM-CAC and CIM-CFC can be understood by observing the fixed points. In CIM-CAC and CIM-CFC, the fixed points are of the form: [ 11 ]
$$x _ { i } = \lambda _ { 1 } \sigma _ { i } ,$$
$$e _ { i } = \lambda _ { 2 } \frac { 1 } { h _ { i } \sigma _ { i } } , & & ( 1 0 )$$
$$h _ { i } = \sum _ { j } \xi J _ { i j } \sigma _ { j } . & & ( 1 1 )$$
with
Here, σ i is a spin configuration corresponding to a local minimum of the Ising Hamiltonian, and λ 1 and λ 2 are constants that depend on the system parameters. In CIM-SFC, the fixed points are generally very complicated and difficult to express explicitly. However, if we consider the limit of c 1, the fixed points will take the form:
$$x _ { i } = \lambda \sigma _ { i } , \tag* { ( 1 2 ) } x _ { i } = \lambda \sigma _ { i } ,$$
$$e _ { i } = \lambda h _ { i } , \quad ( 1 3 )$$
where λ is a number such that -λ 3 + ( p -1) λ = -1. Again, σ i is a spin configuration corresponding to a local minimum. This formula is only valid if f ( cz ) is an odd function that takes the value of +1 for cz 1 and -1 for cz 1. Therefore, it is important to choose an appropriate function f .
The important difference between the fixed points of these two types of systems is that in CIM-CAC and CIM-CFC, the error signal is
$$| e _ { i } | \varpropto \frac { 1 } { | h _ { i } | } ,$$
$$| e _ { i } | \varpropto | h _ { i } | \, .$$
In Section 5, we will see that this difference makes CIM-SFC more robust to quantum noise from reservoirs and pump sources. In the next section, we will investigate the similarities and differences among these three systems using numerical simulation.
## 3 Numerical Simulation of CIM-CAC, CIM-CFC and CIM-SFC
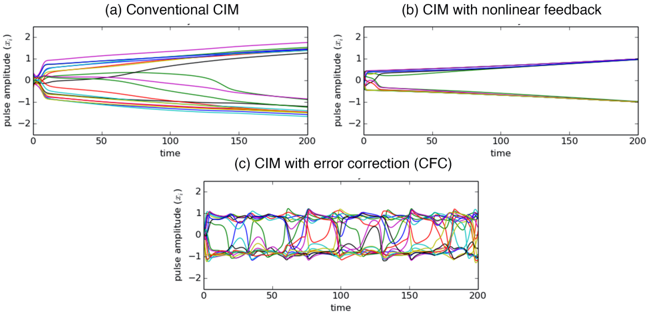
The originally proposed CIM architecture employs simple linear feedback without using an error detection/correction mechanism. In other words, the feedback term in Eq. (1) is simply ∑ j ξJ ij x j . [ 10 ] In this case, the Ising Hamiltonian cannot be properly mapped to the network loss owing to OPO amplitude heterogeneity, especially for frustrated spin systems, as shown in Figure 2 (a). Such a CIM often does not find a ground state of the Ising Hamiltonian; instead, it selects the lowest-energy eigenstate of the coupling (Jacobian) matrix [ J ij ].[10] This undesired operation is caused by a system's formation of heterogenous amplitudes.[10] We can address this problem partially by introducing a nonlinear filter function for the feedback pulse, such as tanh( ∑ j ξJ ij x j ). Thus, we can achieve the homogeneous OPO amplitudes, at least well above threshold, as shown in Figure 2 (b), and satisfy the proper mapping condition toward the end of the system's trajectory. However, such nonlinear filtering alone is not sufficiently powerful to prevent the machine from being trapped in numerous local minima. As the problem size N increases, NP-hard Ising problems are expected to have an exponentially increasing number of local minima; hence, a system that is easily trapped in these minima will be ineffective.
Figure 2: Trajectories of OPO amplitudes in CIMs with (a) linear feedback, (b) nonlinear filtering feedback, and (c) chaotic feedback control.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Charts: Pulse Amplitude vs. Time for Different CIM Configurations
### Overview
The image presents three separate line charts, labeled (a) Conventional CIM, (b) CIM with nonlinear feedback, and (c) CIM with error correction (CFC). Each chart plots pulse amplitude (x<sub>r</sub>) against time, ranging from 0 to 200. The charts visually compare the behavior of pulse amplitudes under different CIM (Computation In Memory) configurations.
### Components/Axes
* **X-axis:** Time (ranging from 0 to 200, units not specified).
* **Y-axis:** Pulse Amplitude (x<sub>r</sub>), ranging from approximately -2 to 2, units not specified.
* **Chart (a):** Conventional CIM. Multiple lines representing individual pulse amplitudes.
* **Chart (b):** CIM with nonlinear feedback. Multiple lines representing individual pulse amplitudes.
* **Chart (c):** CIM with error correction (CFC). Multiple lines representing individual pulse amplitudes.
* **No Legend:** There is no explicit legend provided for the line colors in any of the charts. Each chart contains multiple lines, each representing a different pulse amplitude, but their specific identities are not labeled.
### Detailed Analysis or Content Details
**Chart (a): Conventional CIM**
* **Trend:** The lines generally converge towards the top of the chart initially, then diverge and spread out over time. Some lines exhibit a downward trend, while others remain relatively stable or slightly increase.
* **Data Points (approximate):**
* At time = 0, most lines start around a pulse amplitude of 1.5 to 2.
* At time = 50, pulse amplitudes range from approximately -0.5 to 1.8.
* At time = 100, pulse amplitudes range from approximately -1.2 to 1.5.
* At time = 150, pulse amplitudes range from approximately -1.8 to 1.2.
* At time = 200, pulse amplitudes range from approximately -1.5 to 1.7.
* There is a line that starts at approximately 1.8 and decreases to approximately -1.5 by time = 150.
**Chart (b): CIM with nonlinear feedback**
* **Trend:** The lines converge rapidly towards a single value near the top of the chart and remain relatively stable over time.
* **Data Points (approximate):**
* At time = 0, lines start between approximately -1 and 1.5.
* At time = 50, lines are clustered around a pulse amplitude of approximately 0.8 to 1.2.
* At time = 100, lines are clustered around a pulse amplitude of approximately 0.8 to 1.2.
* At time = 150, lines are clustered around a pulse amplitude of approximately 0.8 to 1.2.
* At time = 200, lines are clustered around a pulse amplitude of approximately 0.8 to 1.2.
* There is a line that starts at approximately -1 and converges to approximately 0.8 by time = 50.
**Chart (c): CIM with error correction (CFC)**
* **Trend:** The lines oscillate rapidly and consistently around a central value, exhibiting a periodic behavior.
* **Data Points (approximate):**
* At time = 0, lines range from approximately -1.5 to 1.5.
* At time = 50, lines range from approximately -1.5 to 1.5.
* At time = 100, lines range from approximately -1.5 to 1.5.
* At time = 150, lines range from approximately -1.5 to 1.5.
* At time = 200, lines range from approximately -1.5 to 1.5.
* The oscillations appear to have a consistent amplitude and frequency throughout the duration of the chart.
### Key Observations
* The Conventional CIM (a) exhibits the most significant divergence in pulse amplitudes over time, indicating instability or varying behavior.
* The CIM with nonlinear feedback (b) demonstrates the most stable behavior, with pulse amplitudes converging to a consistent value.
* The CIM with error correction (CFC) (c) shows a consistent oscillatory behavior, suggesting a controlled and periodic response.
* The lack of a legend makes it impossible to identify specific pulse amplitudes or their corresponding lines.
### Interpretation
The data suggests that the implementation of nonlinear feedback and error correction techniques significantly improves the stability and control of pulse amplitudes in CIM systems. The conventional CIM configuration exhibits a wider range of behaviors, potentially leading to unpredictable results. The nonlinear feedback configuration effectively stabilizes the pulse amplitudes, while the error correction configuration introduces a controlled oscillatory behavior.
The oscillatory behavior in the CFC configuration might be intentional, representing a desired operational characteristic of the system. The convergence in chart (b) suggests a self-regulating mechanism, while the divergence in chart (a) indicates a lack of such control.
The absence of a legend limits the ability to draw more specific conclusions about individual pulse amplitudes. However, the overall trends clearly demonstrate the benefits of incorporating feedback and error correction mechanisms in CIM designs. The charts provide a comparative analysis of different CIM configurations, highlighting their respective strengths and weaknesses in terms of pulse amplitude stability and control.
</details>
To destabilize the attractors caused by local minima and allow the machine to continue searching for a true ground state, we can introduce an error detection/correction variable expressed by Eq. (2) or (5). As shown in Figure 2 (c), the trajectory of a CIM with error correction variables will not reach equilibrium but continue to explore many states. Conversely, the systems in Figure 2 (a) and (b), which do not have an error correction variable ( e i ), will often converge rapidly on a fixed point corresponding to a high-energy excited state of the Ising Hamiltonian. Destabilizing the local minima will inevitably make the ground state unstable as well. Although this is undesirable, we can simply allow the machine to visit whereas in CIM-SFC, the error signal is
many local minima and then determine the one that has the lowest energy subsequently. Alternatively, we have found that by modulating the system parameters, the system will have a high probability of staying in a ground state toward the end of the trajectory (see Section 4 for further details).
The addition of another N degrees of freedom allows the machine to visit a local minimum, escape from it, and continue to explore nearby states; this is not possible with a conventional CIM algorithm. In this section, we will discuss the dynamics of the error correction schemes proposed in this paper: CIM-CFC and CIM-SFC.
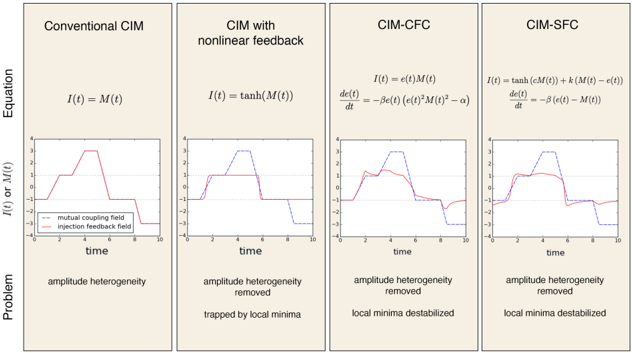
Even though CIM-CFC and CIM-SFC are described by very different equations, the two systems were originally conceived through a similar concept. To understand why CIM-CFC and CIM-SFC are similar, we can consider these systems as follows. We introduce the 'mutual coupling signal' M i ( t ) = ∑ j ξJ ij x j ( t ) and the 'injection feedback signal' I i ( t ). Then, we can write both CIM-CFC and CIM-SFC in the form:
$$M _ { i } ( t ) = \sum _ { j } \xi J _ { i j } x _ { j } ( t ) ,$$
$$\frac { d x _ { i } } { d t } = - x _ { i } ^ { 3 } + ( p - 1 ) \, x _ { i } - I _ { i } ( t ) ,$$
where I i ( t ) depends on the time evolution of M i ( t ). Figure 3 shows how I i ( t ) (red) varies with respect to a mutual coupling field M i ( t ) (blue) for four different feedback schemes.
Figure 3: Mutual coupling field (blue) and injection feedback field (red) in four different feedback systems.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Comparison of CIM Models
### Overview
The image presents a comparative analysis of four Common Information Models (CIM) used in the energy industry: IEC 61970, IEC 61968, IEC 62325, and IEEE 2017. The diagram illustrates the relationships and overlaps between these models, highlighting their respective scopes and areas of application.
### Model Details
| CIM Model | Description | Key Focus Areas | Relationships to Other Models |
|---|---|---|---|
| **IEC 61970** | Energy Management System (EMS) | Generation, Transmission, Distribution, Market Operations | Foundation for IEC 61968 and IEC 62325. Provides core objects for power system modeling. |
| **IEC 61968** | Distribution Management System (DMS) | Distribution Network, Load Management, Outage Management | Extends IEC 61970 to cover distribution-specific functionalities. Utilizes IEC 61970 objects. |
| **IEC 62325** | Market Communications | Market Transactions, Bidding, Settlement | Leverages IEC 61970 for power system data and adds market-specific information. |
| **IEEE 2017** | Power System Data Exchange Format (PSDE) | Data exchange between applications, interoperability | Aims to standardize data exchange, often referencing IEC 61970 and other CIM models. |
### Key Relationships Illustrated
* **IEC 61970 as a Foundation:** IEC 61970 serves as the base model for both IEC 61968 and IEC 62325, providing common objects and structures.
* **IEC 61968 Extending IEC 61970:** IEC 61968 builds upon IEC 61970 by adding distribution-specific elements.
* **IEC 62325 Utilizing IEC 61970:** IEC 62325 incorporates IEC 61970 objects to represent power system data within market transactions.
* **IEEE 2017 for Interoperability:** IEEE 2017 focuses on data exchange and often references the IEC CIM models to ensure interoperability.
### Use Cases
* **System Integration:** Understanding the relationships between these models is crucial for integrating different energy systems and applications.
* **Data Exchange:** Facilitates seamless data exchange between various stakeholders in the energy industry.
* **Model Development:** Provides a framework for developing new CIM-based applications and extensions.
* **Interoperability Testing:** Enables testing and validation of interoperability between different systems.
</details>
The similarity between CIM-CFC and CIM-SFC is as follows: if the mutual coupling field M i ( t ) remains constant for a certain period of time, then the injection feedback field I i ( t ) will converge on the value given by sign( M i ( t )). However, if M i ( t ) varies sharply, then I i ( t ) will deviate from its steady state values: +1 / -1. This small deviation is effective for triggering destabilization when the system is near a local minimum, which allows the machine to explore new spin configurations.
Although CIM-CFC and CIM-SFC were conceived on the basis of the same principle, the dynamics of the two systems seem to differ from each other. In particular, CIM-CFC (and CIM-CAC) nearly always features chaotic dynamics, as the trajectory is highly sensitive to the initial conditions. In the case of CIM-SFC, the trajectory will often immediately fall into a stable periodic orbit unless the parameters are dynamically modulated. At present, we do not have an exact theoretical reason for this difference in dynamics; this is purely an experimental observation. A more theoretical analysis in the case of CIMCAC can be found elsewhere. [11].
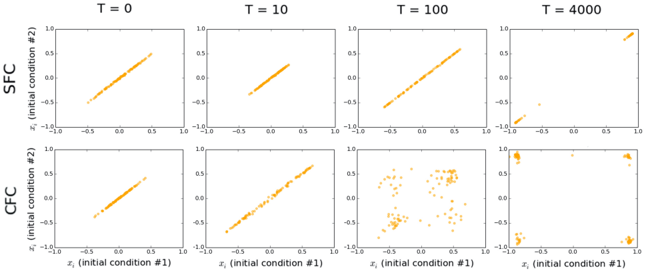
To demonstrate this difference, Figure 4 shows the correlation of pulse amplitudes between two initial conditions that are very close to each other. An initial condition for the pulse amplitude #1 (plotted on
the x-axis) is chosen from a zero-mean Gaussian with a standard deviation of 0.25, while the other initial condition for trajectory #2 (plotted in y-axis) is equal to that of trajectory #1 plus a small amount of noise (standard deviation 0.01).
Figure 4: Signal pulse amplitude correlations at different evolution time in CIM-SFC and CIM-CFC.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Scatter Plot Matrix: SFC and CFC State Evolution
### Overview
The image presents a 2x4 matrix of scatter plots. Each plot displays the relationship between `x₁` (initial condition #1) and `x₂` (initial condition #2). The plots are arranged to show the evolution of this relationship over time, with time points `T = 0`, `T = 10`, `T = 100`, and `T = 4000`. The top row represents the "SFC" (likely a system or model abbreviation), and the bottom row represents "CFC". The plots show how the initial conditions evolve over time for both SFC and CFC.
### Components/Axes
* **X-axis (all plots):** `x₁` (initial condition #1), ranging from approximately -0.10 to 0.10.
* **Y-axis (all plots):** `x₂` (initial condition #2), ranging from approximately -0.05 to 0.05.
* **Titles (above each plot):** Indicate the time point `T` at which the scatter plot is generated: `T = 0`, `T = 10`, `T = 100`, `T = 4000`.
* **Row Labels (left side):** Indicate the system being analyzed: "SFC" (top row) and "CFC" (bottom row).
* **Data Points:** Orange colored scatter points.
### Detailed Analysis or Content Details
**SFC Plots:**
* **T = 0:** The points form a nearly perfect, positive linear correlation. Approximately 50 points are visible. `x₁` ranges from -0.08 to 0.08, and `x₂` ranges from -0.03 to 0.03.
* **T = 10:** The points continue to show a strong positive linear correlation, very similar to T=0. Approximately 50 points are visible. `x₁` ranges from -0.08 to 0.08, and `x₂` ranges from -0.03 to 0.03.
* **T = 100:** The points still exhibit a strong positive linear correlation, but with slightly more scatter than at T=0 and T=10. Approximately 50 points are visible. `x₁` ranges from -0.08 to 0.08, and `x₂` ranges from -0.03 to 0.03.
* **T = 4000:** The points are now significantly scattered, no longer forming a clear linear relationship. Approximately 100 points are visible. `x₁` ranges from -0.10 to 0.10, and `x₂` ranges from -0.05 to 0.05.
**CFC Plots:**
* **T = 0:** The points form a nearly perfect, positive linear correlation, similar to the SFC plot at T=0. Approximately 50 points are visible. `x₁` ranges from -0.08 to 0.08, and `x₂` ranges from -0.03 to 0.03.
* **T = 10:** The points continue to show a strong positive linear correlation, very similar to T=0. Approximately 50 points are visible. `x₁` ranges from -0.08 to 0.08, and `x₂` ranges from -0.03 to 0.03.
* **T = 100:** The points begin to show some scatter, but still maintain a generally positive correlation. Approximately 50 points are visible. `x₁` ranges from -0.08 to 0.08, and `x₂` ranges from -0.03 to 0.03.
* **T = 4000:** The points are highly scattered, with no discernible linear relationship. Approximately 100 points are visible. `x₁` ranges from -0.10 to 0.10, and `x₂` ranges from -0.05 to 0.05.
### Key Observations
* Both SFC and CFC initially exhibit a strong, positive linear correlation between `x₁` and `x₂`.
* As time progresses, the correlation weakens.
* At `T = 4000`, both SFC and CFC show a completely randomized distribution of points, indicating a loss of predictability or a transition to chaotic behavior.
* The scatter in the SFC plots appears to increase more gradually than in the CFC plots.
### Interpretation
The data suggests that both the SFC and CFC systems start from a predictable state (strong correlation at T=0) but diverge over time. The increasing scatter in the plots indicates a loss of determinism and a potential transition to chaotic behavior. The fact that both systems eventually become completely randomized at T=4000 suggests a common underlying dynamic or sensitivity to initial conditions. The difference in the rate of divergence between SFC and CFC could indicate different sensitivities to perturbations or different underlying mechanisms driving the evolution of the system. The initial linear relationship suggests a simple, predictable relationship between the initial conditions, but the subsequent divergence implies that the systems are more complex and influenced by factors not captured by the initial conditions alone. This could be a visualization of Lyapunov exponents, where the divergence rate is related to the exponent.
</details>
Figure 4, shows the correlation of all 100 pulse amplitudes between the two initial conditions for a SherringtonKirkpatrick (SK) spin glass instance of problem size N = 100. In CIM-SFC (first row), the correlation remains even after 4000 time steps (round trips), which means that two initial conditions follow a nearly identical trajectory. However, in CIM-CFC (second row), we see that the xi variables become uncorrelated after around 100 time steps, even though the initial conditions of the two trajectories are very close. This indicates qualitatively that CIM-CFC is highly sensitive to the initial condition, whereas CIM-SFC is not.
This pattern tends to hold when different parameters and initial conditions are used. However, although CIM-SFC stays correlated in most cases, the two trajectories diverge under certain system parameters and initial conditions. This means that although CIM-SFC is less sensitive to the initial conditions compared to CIM-CFC, some chaotic dynamics likely occur during the search, especially when the parameters are modulated.
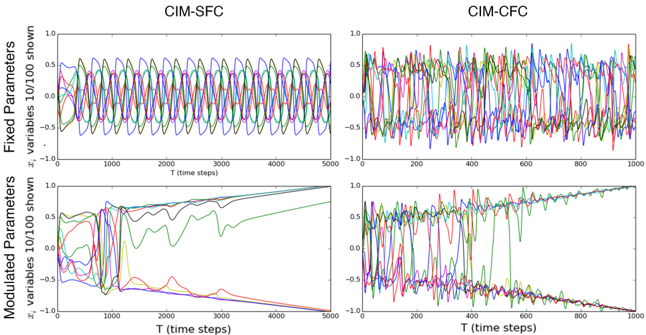
Another way to qualitatively observe the difference in dynamics is to simply observe the trajectories. Figure 5, shows examples of trajectories of both systems (10 out of 100 x i variables are shown) with fixed and linearly modulated system parameters. When the parameters are fixed, the difference between the two systems evident. CIM-SFC will rapidly become trapped in a stable periodic attractor, while CIMCFC will continue to search in an unpredictable manner. Therefore, the parameters are slowly modulated in CIM-SFC so that the system can find a ground state. CIM-CFC and CIM-CAC can find ground states with fixed parameters. However, we have found that modulation of the system parameters improves the performance of CIM-CFC and CIM-CAC considerably (see Appendix C for details).
In the lower left panel of Figure 5, the parameters c and p of CIM-SFC are linearly increased from low to high values ( p ranges from -1 to +1 and c ranges from 1 to 3). We can see that as the parameters change, the system may jump from one attractor to another and eventually end up in a fixed point/local minimum. By linearly increasing the parameters c and p from a low to high value in CIM-SFC, we are slowly transitioning the nonlinear term tanh( cz i ) from a 'soft spin' mode where the nonlinear coupling term has a continuous range of values between -1 and 1 to a 'discrete' mode where tanh( cz i ) will mostly take on the values +1 or -1. This transition is seems to be crucial for CIM-SFC to function properly.
For most fixed parameters, CIM-SFC rapidly approaches a periodic or fixed point attractor as shown in Figure 5; however, as mentioned earlier it is likely that for some specific values of c and p , CIM-SFC will feature chaotic dynamics similar to CIM-CFC. It has been shown [ 11 , 13 ] that chaotic dynamics are observed when solving hard optimization problems efficiently using a deterministic system. This trend is also observed in the simulated bifurcation machine [27, 29]. Whether or not CIM-SFC utilizes chaotic dynamics is beyond the scope of this paper. Whether CIM-SFC uses chaotic dynamics is beyond the
Figure 5: Signal pulse amplitude trajectories of CIM-SFC and CIM-CFC with fixed and modulated system parameters.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Chart: CIM Parameter Dynamics
### Overview
The image presents four time-series plots arranged in a 2x2 grid, visualizing the dynamics of parameters within two models: CIM-SFC and CIM-CFC. Each plot displays the values of 10/100 variables over time steps (T). The top row shows "Fixed Parameters", while the bottom row shows "Modulated Parameters". Each line represents the time evolution of a single parameter.
### Components/Axes
* **Titles:**
* Top-Left: "CIM-SFC"
* Top-Right: "CIM-CFC"
* Bottom-Left: "Modulated Parameters"
* Bottom-Right: "Modulated Parameters"
* **Y-axis Label (all plots):** "Σ variables 10/100 shown" (approximately)
* **X-axis Label (all plots):** "T (time steps)"
* **Y-axis Scale (all plots):** Ranges from approximately -1.0 to 1.0.
* **X-axis Scale:**
* Top plots: 0 to 5000 time steps.
* Bottom plots: 0 to 5000 time steps.
* **Legend:** There is no explicit legend, but each line color represents a different parameter.
### Detailed Analysis or Content Details
**Top-Left: CIM-SFC (Fixed Parameters)**
* The plot shows numerous oscillating lines. The oscillations appear roughly periodic.
* The amplitude of the oscillations appears relatively consistent over time.
* The lines are densely packed, making precise value extraction difficult.
* Approximate values (reading from a few lines):
* Line 1 (red): Oscillates between approximately -0.8 and 0.8, with a period of roughly 500 time steps.
* Line 2 (blue): Oscillates between approximately -0.6 and 0.6, with a period of roughly 600 time steps.
* Line 3 (green): Oscillates between approximately -0.4 and 0.4, with a period of roughly 400 time steps.
* The lines are generally centered around 0.
**Top-Right: CIM-CFC (Fixed Parameters)**
* Similar to CIM-SFC, this plot displays numerous oscillating lines.
* The oscillations are more erratic and less consistent in amplitude compared to CIM-SFC.
* Approximate values (reading from a few lines):
* Line 1 (red): Oscillates between approximately -0.9 and 0.9, with a period of roughly 200 time steps.
* Line 2 (blue): Oscillates between approximately -0.7 and 0.7, with a period of roughly 150 time steps.
* Line 3 (green): Oscillates between approximately -0.5 and 0.5, with a period of roughly 300 time steps.
**Bottom-Left: CIM-SFC (Modulated Parameters)**
* This plot shows lines that generally trend towards a stable value.
* Several lines converge towards approximately 0.2 to 0.4.
* One line (dark red) shows a clear downward trend, approaching approximately -1.0.
* Approximate values (reading from a few lines):
* Line 1 (red): Starts around 0.2 and remains relatively stable.
* Line 2 (blue): Starts around 0.1 and increases to approximately 0.3.
* Line 3 (green): Starts around -0.2 and increases to approximately 0.1.
* Line 4 (dark red): Starts around 0.0 and decreases to approximately -0.9.
**Bottom-Right: CIM-CFC (Modulated Parameters)**
* This plot also shows lines trending towards stable values, but the convergence is less pronounced than in the CIM-SFC modulated parameters plot.
* Several lines appear to converge towards approximately 0.0 to 0.2.
* One line (dark red) shows a downward trend, approaching approximately -0.8.
* Approximate values (reading from a few lines):
* Line 1 (red): Starts around 0.1 and remains relatively stable.
* Line 2 (blue): Starts around 0.2 and decreases to approximately 0.0.
* Line 3 (green): Starts around 0.3 and decreases to approximately 0.1.
* Line 4 (dark red): Starts around 0.0 and decreases to approximately -0.8.
### Key Observations
* The "Fixed Parameters" plots (top row) exhibit consistent oscillations in both models, but the oscillations are more erratic in CIM-CFC.
* The "Modulated Parameters" plots (bottom row) show a trend towards stabilization, with some parameters converging to positive values and others to negative values.
* The dark red line in both "Modulated Parameters" plots consistently shows a downward trend, indicating a parameter that is decreasing over time.
* The CIM-SFC model appears to have more stable modulated parameters than the CIM-CFC model.
### Interpretation
The plots illustrate the dynamic behavior of parameters within the CIM-SFC and CIM-CFC models. The oscillations in the "Fixed Parameters" plots suggest that these parameters are maintained within a certain range, possibly through feedback mechanisms. The convergence of the "Modulated Parameters" plots indicates that these parameters are adapting or learning over time. The downward trend of the dark red line in both models suggests a parameter that is being suppressed or reduced.
The differences between the CIM-SFC and CIM-CFC models suggest that they have different dynamic properties. The more erratic oscillations in the CIM-CFC "Fixed Parameters" plot may indicate a higher degree of instability or sensitivity to initial conditions. The less pronounced convergence in the CIM-CFC "Modulated Parameters" plot may indicate a slower learning rate or a more complex adaptation process.
The data suggests that the models are evolving over time, with some parameters remaining stable and others adapting to changing conditions. The specific meaning of these dynamics would depend on the context of the models and the parameters being visualized. The plots provide a valuable tool for understanding the behavior of these models and identifying potential areas for further investigation.
</details>
scope of this paper. To answer this question, we need to further analyze how the parameters affect the dynamics of CIM-SFC and gain a deeper understanding of how CIM-SFC finds ground states.
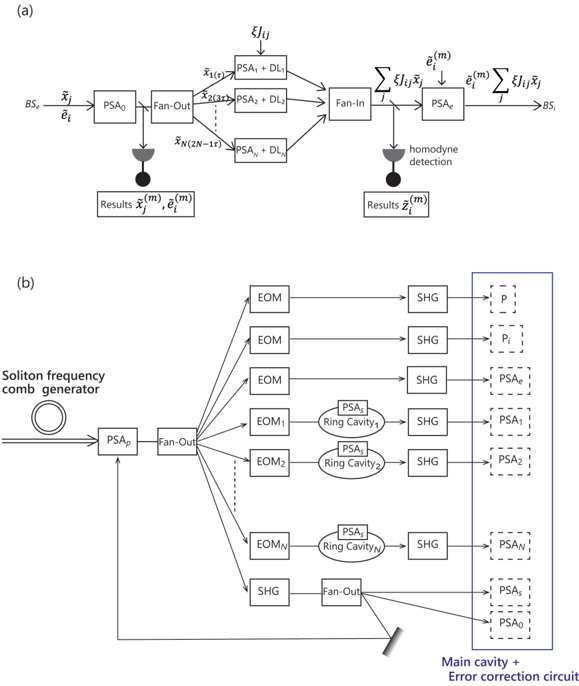
## 4 Implementation of CIM with Optical Error Correction Circuits
Figure 6, together with Figure 1(c), shows a physical setup for CIM-CAC and CIM-CFC with optical error correction circuits. In our design, the main ring cavity stores both signal pulses with normalized amplitude, x i and error pulses with normalized amplitude e i , where i = 1 , 2 , · · · N . The signal pulses start from vacuum states | 0 〉 1 | 0 〉 2 · · · | 0 〉 N and are amplified (or deamplified) along the X-coordinate by a positive (or negative) pump rate p .
The error pulses start from a coherent state | α 〉 1 | α 〉 2 · · · | α 〉 N with α > 0 and are amplified (or deamplified) along the X-coordinate by the pump rate p ′ as described below. The squared amplitude of the error pulses is kept small ( e 2 i < 1) compared to the saturation level of the main cavity OPO. Thus the error pulses are controlled in a linear amplifier/deamplifier regime while the signal pulses are controlled in both a linear amplifier/deamplifier regime ( x 2 i < 1) and a nonlinear oscillator regime ( x 2 i > 1).
An extraction beamsplitter (BS e shown in Figure 1(c)) selects partial waves of the signal and error pulses that are amplified by a noise-free phase-sensitive amplifier (PSA 0 as shown in Figure 6(a)). PSA 0 amplifies the signal and error pulses to a classical level without introducing additional noise. The extracted amplitudes ˜ x i and ˜ e i suffer from the signal-to-noise ratio (SNR) degradation owing to the vacuum noise incident on BS e . However, they are amplified by a high-gain noise-free phase-sensitive amplifier PSA 0 to classical levels; hence, no further SNR degradation occurs even with large linear losses in the optical error correction circuits.
A small part of the PSA 0 output is sent to an optical homodyne detector that measures the extracted signal and error pulses with amplitudes ˜ x i and ˜ e i , respectively. The measurement error of the homodyne detection is determined solely by the reflectivity of BS e and the vacuum fluctuation incident on BS e (as described above). Figure 6(a) shows the output of the fan-out circuit at different time instances t = τ, 3 τ, 5 τ, ... separated by a signal pulse to signal pulse interval of 2 τ .
For instance, the signal pulse ( ˜ x j ) is first input into PSA j and then sent to optical delay line DL j with a delay time of (2 N -2 j + 1) τ . The phase-sensitive gain/loss of PSA j is set to √ G j = ξJ ij so that the amplified/deamplified signal pulse that arrives in front of the fan-in circuit at time t = 2 Nτ is equal to ξJ ij ˜ x j . Therefore the fan-in circuit will output a pulse with the desired amplitude of ∑ j ξJ ij ˜ x j . Suppose that PSA j has a phase-sensitive linear gain/loss of 10dB, then we can implement an arbitrary Ising coupling of range 10 -2 < | ξJ ij | < 1.
Figure 6: (a) Optical implementation of error correction circuits for CIM-CAC and CIM-CFC. (b) Pump pulse factory providing SHG pulses to the main cavity, and the error correction circuits. The pump pulse factory carries N 2 pulses spread over N optical cavities corresponding to the elements of the Ising coupling matrix J ij .
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Diagram: Quantum Optical Circuit Schematics
### Overview
The image presents two schematic diagrams (labeled (a) and (b)) illustrating quantum optical circuits. Diagram (a) depicts a measurement scheme involving beam splitters (BS), phase-sensitive amplifiers (PSA), and fan-out elements. Diagram (b) illustrates a soliton frequency comb generator, utilizing electro-optic modulators (EOM), second harmonic generation (SHG), and ring cavities. Both diagrams use similar notation for optical components and signal flow.
### Components/Axes
**Diagram (a):**
* **Components:** BS (Beam Splitter), PSA (Phase-Sensitive Amplifier), DL (Delay Line), Fan-Out, Homodyne Detection.
* **Signals:** x̂ᵢ, êᵢ, x̂₁(m), ê¹(m), Σξj(x̂ᵢ), êᵢ(m), ξj(x̂ᵢ).
* **Labels:** "Results x̂ᵢ, êᵢ(m)", "Results êᵢ(m)".
**Diagram (b):**
* **Components:** PSA (Phase-Sensitive Amplifier), EOM (Electro-Optic Modulator), SHG (Second Harmonic Generation), Ring Cavity, Fan-Out.
* **Signals:** PSA<sub>D</sub>, x̂<sub>N</sub>, P<sub>i</sub>, PSA<sub>E</sub>, PSA<sub>1</sub>, PSA<sub>2</sub>, PSA<sub>N</sub>, PSA<sub>S</sub>, PSA<sub>0</sub>.
* **Labels:** "Soliton frequency comb generator", "Main cavity + Error correction circuit".
* **Ring Cavity Labels:** PSA<sub>1</sub> Ring Cavity<sub>1</sub>, PSA<sub>2</sub> Ring Cavity<sub>2</sub>, PSA<sub>N</sub> Ring Cavity<sub>N</sub>.
### Detailed Analysis or Content Details
**Diagram (a):**
The diagram shows a linear optical circuit. An input signal x̂ᵢ and êᵢ enters a beam splitter (BS<sub>c</sub>). The output is split via a Fan-Out element into multiple paths. Each path includes a phase-sensitive amplifier (PSA<sub>i</sub> + DL<sub>i</sub>) where 'i' ranges from 1 to N (2N-1 paths are shown). The outputs of these PSAs, x̂₁(m) and ê¹(m), are then combined using a Fan-In element. The combined signal is then fed into another PSA<sub>A</sub> and finally into a homodyne detection scheme, resulting in an output signal ξj(x̂ᵢ). The results of the measurement are labeled as x̂ᵢ and êᵢ(m).
**Diagram (b):**
The diagram depicts a more complex circuit. An input signal PSA<sub>D</sub> is split via a Fan-Out element into multiple paths. Each path contains an EOM (EOM<sub>1</sub> to EOM<sub>N</sub>), followed by a SHG stage. The output of each SHG stage is labeled P<sub>i</sub>, PSA<sub>E</sub>, PSA<sub>1</sub>, PSA<sub>2</sub>, and PSA<sub>N</sub>. These outputs are then fed into a "Main cavity + Error correction circuit" block. Within this block, there are multiple PSA stages (PSA<sub>S</sub>, PSA<sub>0</sub>) and dashed lines suggesting a feedback loop or iterative process. The ring cavities (PSA<sub>1</sub> Ring Cavity<sub>1</sub>, PSA<sub>2</sub> Ring Cavity<sub>2</sub>, PSA<sub>N</sub> Ring Cavity<sub>N</sub>) are positioned between the EOM/SHG stages and the main cavity.
### Key Observations
* Both diagrams utilize a consistent notation for optical components (boxes with labels) and signal flow (arrows).
* Diagram (b) is significantly more complex than diagram (a), suggesting a more sophisticated quantum optical process.
* The presence of ring cavities in diagram (b) indicates a resonant system, potentially used for frequency comb generation.
* The "Main cavity + Error correction circuit" in diagram (b) suggests a feedback mechanism for stabilizing or correcting the generated frequency comb.
* The use of phase-sensitive amplifiers (PSAs) in both diagrams indicates a focus on weak signal detection and amplification.
### Interpretation
Diagram (a) represents a basic quantum measurement scheme. The beam splitters and phase-sensitive amplifiers are used to perform homodyne detection, which allows for the measurement of quadrature components of the input signal. The multiple paths and fan-out/fan-in elements suggest a scheme for multi-mode or multi-channel measurement.
Diagram (b) illustrates a more advanced system for generating a soliton frequency comb. The EOMs modulate the input signal, and the SHG stages convert the signal to higher frequencies. The ring cavities provide a resonant structure for enhancing the comb generation process. The main cavity and error correction circuit likely stabilize the comb and correct for any imperfections.
The combination of these two diagrams suggests a potential application where a soliton frequency comb is generated and then measured using a homodyne detection scheme. This could be used for high-precision spectroscopy, optical metrology, or quantum communication. The error correction circuit in diagram (b) is crucial for maintaining the coherence and stability of the frequency comb, which is essential for these applications. The dashed lines in the main cavity suggest an iterative process, potentially for optimizing the comb parameters or correcting for noise.
</details>
Next, the output of the fan-in circuit is input into another phase-sensitive amplifier PSA e that amplifies with a factor of √ G e = ˜ e i . This is achieved by modulating the pump power to PSA e based on the measurement result for ˜ e i . Finally, the output of PSA e is injected back into signal pulse ( x i ) of the main cavity via BS i (see Figure 1(c)). The extraction beamsplitter BS e outputs not only signal pulses but also error pulses that are used only for homodyne detection. Thus, we switch off the pump power to PSA 0 for the error pulses and deamplify the residual error pulses by PSA 1 , PSA 2 , ... , PSA N , PSA e . In this way we avoid any spurious injection of the error pulse back into the main cavity. The dynamics of the error pulse are governed solely by the pump power p i to the main cavity PSA, which is set to satisfy p i -1 = β ( α -˜ x i 2 ) or p i -1 = β ( α -˜ z i 2 ) .
One advantage of this optical implementation of CIM-CAC and CIM-CFC is that only one type of active device, a noise-free phase-sensitive (degenerate optical parametric) amplifier, and all the other elements are passive devices. This fact may allow for on-chip monolithic integration of the CIM system as well as low-energy dissipation in the computational unit, which will be discussed in Section 5.
A similar optical implementation of CIM-SFC is shown in Appendix F.
Figure 6(b) shows a pump pulse factory that provides the second harmonic generation (SHG) pulses to the main cavity PSA, post-amplifier PSA 0 , delay line amplifiers PSA 1 , PSA 2 , · · · PSA N and exit amplifier PSA e . The purpose of this pump pulse factory is to reduce the use of EOM modulators, which consume the most energy in the entire CIM. A soliton frequency comb generator produces a pulse train at a repetition frequency of 100 GHz and wavelength of 1.56 µ m wavelength. Before it is split into many branches, the pulse train is amplified by a pump amplifier PSA p . N storage ring cavities continuously produce the pump pulses for PSA 1 , PSA 2 , · PSA N in order to implement the MVM ∑ ξJ ij ˜ x j . For this
purpose, the pulses stored in the i-th ring cavity acquire the appropriate amplitudes to realize the gain √ G ij = ξJ ij . The time duration for using N EOM arrays is only one round trip of the ring cavity, i.e., N × 10 (psec). The out-coupling loss of the storage ring cavities is compensated for by the linear gain of the internal PSA s . The pump pulses for PSA p , PSA s , and PSA 0 have constant amplitudes and are hence driven directly by the PSA p output. The pump pulses P and P i for the signal and error pulses in the main cavity, as well as the exit PSA e , must be modulated during the entire computation time.
Another detail that needs to be accounted for when considering an optical implementation is the calculation of the Ising energy. In our digital simulation for generating the results presented in this paper, the Ising energy is calculated at every time step (round trip), and the smallest energy obtained is used as the result of the computation. This means that, in an optical implementation, we must measure the ˜ x i amplitude in every round trip and calculate the Ising energy using, for instance, an external ADC/FPGA circuit. This would defeat the purpose of using optics, as the digital circuit in the ADC/FPGA would then become a bottleneck in terms of time and energy consumption.
However, we have found that with proper parameter modulation as shown in Figure 5, it is possible to use only the final state of the system for the result and still have a high success probability. For the results on 800-spin Ising instances (SK model) presented in Section 6, we calculated how often a successful trajectory is in the ground spin configuration after the final time step. We found that, for CIM-SFC, in 100% of the 7401 successful trajectories the final spin configuration was in the ground state. In other words, if CIM-SFC visits the ground state at any point during the trajectory, then it will also be in the ground state at the end of the trajectory. Meanwhile, for CIM-CFC and CIM-CAC, this was true only in 75% of the time and 48% of the time, respectively. We believe that this difference among the three systems is a result of both the intrinsic dynamics and the parameters used.
This suggests that in a CIM with optical error correction, we can simply digitize the final measurement result of x i after many round trips to obtain the computational result, and still have a high success probability. In the case of CIM-CFC and CIM-CAC, it might be beneficial to read the spin configuration multiple times during the last few round trips, as the machine usually visits the ground state close to the end of the trajectory even if it does not stay there.
## 5 Quantum Noise Analysis and Energy Cost to Solution
As we propose implementation of these dynamical systems on analog optical devices, it is important to investigate the extent to which the noise from the physical systems (in this case, quantum noise from pump sources and external reservoirs) will degrade the performance. In this section, we present quantum models based on our optical implementation.
In our optical implementation for CIM-CAC, the real-number signal pulse amplitude µ i (in unit of photon amplitude) (in units of photon amplitude) obeys the following truncated Wigner SDE: [ 22 , 23 ]
$$\frac { d } { d t } \mu _ { i } = ( p - 1 ) \, \mu _ { i } - g ^ { 2 } \mu _ { i } ^ { 3 } + \tilde { \nu } _ { i } \sum _ { j } \xi J _ { i j } \tilde { \mu } _ { j } + n _ { i } ,$$
where the term pµ i represents the parametric linear gain and the term -µ i represents the linear loss rate; this includes the cavity background loss and extraction/injection beam splitter loss for mutual coupling and error correction. The nonlinear term -g 2 µ 3 i represents gain saturation (or back-conversion from signal to pump), where g is the saturation parameter. The saturation photon number is given by 1 /g 2 , which is equal to the average photon number of a solitary OPO at a pump rate of p = 2 (two times above the threshold). Furthermore, J ij is the ( i, j ) element of the N × N Ising coupling matrix, as described in Section 2. The time t is normalized by a linear loss rate; hence, the signal amplitude decays by a factor of 1 /e at time t = 1. In addition, ˜ µ j = µ j + ∆ µ j and ˜ ν i = ν i + ∆ ν i are the inferred amplitudes for the signal pulse and error pulse, respectively, and ∆ µ j and ∆ ν i represent the additional noise governed by vacuum fluctuations incident on the extraction beam splitter. They are characterized
by √ 1 -R B 4 R B w , where R B is the reflectivity of the extraction beam splitter and w is a zero-mean Gaussian random variable with a variance of one. Finally, n i is the noise injected from external reservoirs and pump sources. [ 22 , 23 ] It is characterized by the two time correlation functions 〈 n i ( t ) n i ( t ′ ) 〉 = ( 1 2 + g 2 µ 2 i ) δ ( t -t ′ ). We assume that the external reservoirs are in vacuum states and that the pump fields are in coherent states.
The real number error pulse amplitude ν i (in units of photon amplitude) is governed by
$$\frac { d } { d t } \nu _ { i } = \left ( p ^ { \prime } _ { i } - 1 \right ) \nu _ { i } + m _ { i } ,$$
where the correlation function for the noise term is given by 〈 m i ( t ) m i ( t ′ ) 〉 = 1 2 δ ( t -t ′ ). The pump rate p ′ i for the error pulse is determined by the inferred signal pulse amplitude ˜ x i = g ˜ µ i normalized by the saturation parameter,
$$p _ { i } ^ { \prime } - 1 = \beta \left ( \alpha - \tilde { x } _ { i } ^ { 2 } \right ) .$$
The error pulses start from coherent states | γ 〉 1 | γ 〉 2 · · · | γ 〉 N , for some positive real number 1 /g γ > 0. The absence of a gain saturation term in Eq. (17) implies that the error pulses are always pumped at below the threshold. Nevertheless, the error pulses represent exponentially varying amplitudes.
The parameter β governs the time constant for the error correction dynamics, and α is the squared target amplitude. This feedback model stabilizes the squared signal pulse amplitude ˜ x 2 i = g 2 ˜ µ 2 i to α through an exponentially varying error pulse amplitude e i = gν i . Eqs. (16) and (17) are rewritten for the normalized amplitudes x i and e i as
$$\frac { d } { d t } x _ { i } = \left ( p - 1 \right ) x _ { i } - x _ { i } ^ { 3 } + \tilde { e } _ { i } \sum _ { j } \xi J _ { i j } \tilde { x } _ { j } + g n _ { i } ,$$
$$\frac { d } { d t } e _ { i } = \left ( p ^ { \prime } _ { i } - 1 \right ) e _ { i } + g m _ { i } .$$
which are nearly identical to Eqs. (1) and (2) except for the noise terms.
CIM-CFC is also realized using the experimental setup shown in Figure 6. In this case, the relevant truncated Wigner SDE for the error pulse amplitude is still given by Eq. (17) or (20); however, the pump rate p ′ should be modified to
$$p _ { i } ^ { \prime } - 1 = \beta \left ( \alpha - \tilde { z } _ { i } ^ { 2 } \right ) .$$
$$\tilde { z } _ { i } = \sum _ { j } \xi J _ { i j } \tilde { x } _ { j } & & ( 2 2 )$$
with
Finally, CIM-SFC can also be realized using the experimental setup shown in Appendix F (Figure 17). In this case, Eqs. (19) and (20) should be modified as
$$\tilde { z } _ { i } = \sum _ { j } \xi J _ { i j } \tilde { x } _ { j } & & ( 2 3 )$$
$$\frac { d } { d t } x _ { i } = \left ( p - 1 \right ) x _ { i } - x _ { i } ^ { 3 } + k \left ( \tilde { e } _ { i } - \tilde { z } _ { i } \right ) + \tanh \left ( c \tilde { z } _ { i } \right ) + g n _ { i } ,$$
$$\frac { d } { d t } e _ { i } = - \beta \left ( e _ { i } - \tilde { z } _ { i } \right ) + g m _ { i } .$$
If we compare the semi-classical nonlinear dynamical models of CIM-CAC, CIM-CFC, and CIM-SFC, represented by Eqs. (1)-(8), with the quantum nonlinear dynamical models (truncated Wigner SDE), represented by Eqs. (19)-(25), we find that the main difference is the absence or presence of the vacuum noise and pump noise terms gn i and gm i , respectively. The other important difference is that ˜ x i and ˜ e i
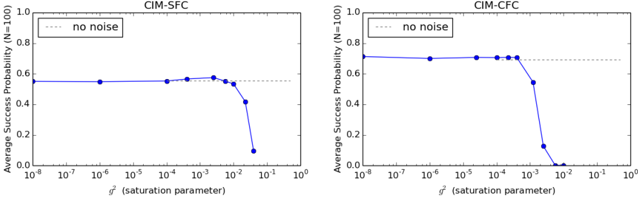
Figure 7: Success probability P s vs. saturation parameter g 2 for CIM-SFC and CIM-CFC at N=100. The success probability is averaged over 100 SK instances. CIM-CAC is not shown; however, the result is nearly identical to that of CIM-CFC.
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## Chart: Average Success Probability vs. Saturation Parameter
### Overview
The image presents two charts, side-by-side, displaying the relationship between Average Success Probability and a saturation parameter (denoted as 𝜚²). Both charts include a reference line representing the "no noise" condition. The charts are labeled "CIM-SFC" and "CIM-CFC" respectively. Both charts have the same y-axis scale and x-axis scale.
### Components/Axes
* **X-axis:** Labeled "𝜚² (saturation parameter)". The scale is logarithmic, ranging from 10⁻⁸ to 10⁰.
* **Y-axis:** Labeled "Average Success Probability (N=100)". The scale ranges from 0.0 to 1.0.
* **Legend (Top-Left of each chart):**
* "no noise" - Represented by a dotted gray line.
* **Data Series:** A single blue line representing the Average Success Probability for a given saturation parameter.
### Detailed Analysis
**Chart 1: CIM-SFC**
The blue line in the CIM-SFC chart initially remains relatively flat, hovering around 0.55, from approximately 10⁻⁸ to 10⁻³ on the x-axis. Around 10⁻³ the line begins to descend sharply.
* **Approximate Data Points:**
* 𝜚² = 10⁻⁸: Average Success Probability ≈ 0.56
* 𝜚² = 10⁻⁷: Average Success Probability ≈ 0.56
* 𝜚² = 10⁻⁶: Average Success Probability ≈ 0.56
* 𝜚² = 10⁻⁵: Average Success Probability ≈ 0.55
* 𝜚² = 10⁻⁴: Average Success Probability ≈ 0.54
* 𝜚² = 10⁻³: Average Success Probability ≈ 0.48
* 𝜚² = 10⁻²: Average Success Probability ≈ 0.35
* 𝜚² = 10⁻¹: Average Success Probability ≈ 0.12
* 𝜚² = 10⁰: Average Success Probability ≈ 0.03
The dotted gray "no noise" line is positioned horizontally at approximately 0.58.
**Chart 2: CIM-CFC**
The blue line in the CIM-CFC chart is initially flat, around 0.65, from approximately 10⁻⁸ to 10⁻³ on the x-axis. Around 10⁻³ the line begins to descend sharply.
* **Approximate Data Points:**
* 𝜚² = 10⁻⁸: Average Success Probability ≈ 0.66
* 𝜚² = 10⁻⁷: Average Success Probability ≈ 0.66
* 𝜚² = 10⁻⁶: Average Success Probability ≈ 0.66
* 𝜚² = 10⁻⁵: Average Success Probability ≈ 0.65
* 𝜚² = 10⁻⁴: Average Success Probability ≈ 0.64
* 𝜚² = 10⁻³: Average Success Probability ≈ 0.55
* 𝜚² = 10⁻²: Average Success Probability ≈ 0.35
* 𝜚² = 10⁻¹: Average Success Probability ≈ 0.12
* 𝜚² = 10⁰: Average Success Probability ≈ 0.03
The dotted gray "no noise" line is positioned horizontally at approximately 0.58.
### Key Observations
* Both charts exhibit a similar trend: a relatively stable Average Success Probability at low saturation parameters, followed by a rapid decline as the saturation parameter increases.
* The "no noise" line provides a baseline for comparison. The Average Success Probability drops below this baseline as the saturation parameter increases, indicating a degradation in performance due to the saturation effect.
* The CIM-CFC chart maintains a higher Average Success Probability than the CIM-SFC chart for most of the saturation parameter range.
### Interpretation
The charts demonstrate the impact of the saturation parameter (𝜚²) on the Average Success Probability of two different methods, CIM-SFC and CIM-CFC. The saturation parameter appears to introduce noise or instability, leading to a decrease in success probability. The "no noise" line represents the theoretical maximum success probability in the absence of this saturation effect.
The fact that both charts show a similar trend suggests that the saturation effect is a fundamental limitation of the underlying process. The difference in initial success probability between CIM-SFC and CIM-CFC indicates that CIM-CFC is more robust to the saturation effect, maintaining a higher success rate for a wider range of saturation parameters. The sharp decline in success probability at higher saturation parameters suggests a critical threshold beyond which the methods become unreliable. The logarithmic scale of the x-axis highlights the sensitivity of the success probability to changes in the saturation parameter at lower values.
</details>
are inferred amplitudes with the vacuum noise contribution in the quantum model, whereas in the semiclassical model, the amplitudes x i and e i can be reproduced without additional noise.
Next, we will discuss the impact of quantum noise on the performance of CIM. As indicated in Eqs. (19)-(25), the relative magnitude of the quantum noise in the signal and error pulses is governed by the saturation parameter g . When g increases, the ratio between the normalized pulse amplitudes ( x i , e i ) and normalized quantum noise amplitudes ( gn i , gm i ) decreases. Therefore, the CIM performance is expected to degrade as g increases. However, as g increases, the OPO threshold pump power decreases (see Figure C1 in [31]), which suggests that the OPO energy cost to solution can be potentially reduced with increasing g .
Figure 7 shows the success probability P s for N = 100 Ising problems (SK model) plotted against the saturation parameter g 2 . The reflectivity of the extraction beam splitter R B is assumed to be R B = 0 . 1. The success probability P s is almost independent of the saturation parameter g 2 as long as g 2 10 -4 . However, when g 2 exceeds 10 -3 , the success probability drops rapidly owing to the decreased signal-toquantum noise ratio, as mentioned above.
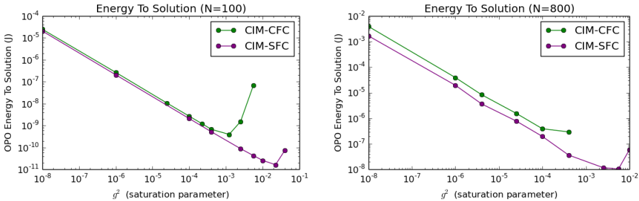
Figure 8 shows the energy cost to solution for Ising problems (SK model) with N = 100 and N = 800, where we consider only the pump power to the main cavity PSA: E main = 2 ω (MVM) N ∆ t/g 2 , where MVM is the number of matrix-vector multiplication steps to solution and ∆ t is a round-trip time normalized by the signal lifetime ( ∼ 0 . 1).
Figure 8: Energy cost to solution in joules of CIM-SFC and CIM-CFC considering only pump power to main cavity PSA. The median ETS is plotted as a function of g 2 for N=100 and N=800 SK instances to show the optimal value of g 2 in each case.
<details>
<summary>Image 8 Details</summary>
### Visual Description
\n
## Chart: Energy To Solution vs. Saturation Parameter
### Overview
The image presents two charts comparing the "Energy To Solution" for two methods, CIM-CFC (green) and CIM-SFC (purple), across varying saturation parameters (represented by 'J'). The left chart displays data for N=100, while the right chart shows data for N=800. Both charts use a logarithmic scale for the Y-axis (Energy To Solution) and a logarithmic scale for the X-axis (Saturation Parameter).
### Components/Axes
* **X-axis Label (Both Charts):** J (saturation parameter)
* **Y-axis Label (Both Charts):** OPO Energy To Solution (J)
* **Left Chart Title:** Energy To Solution (N=100)
* **Right Chart Title:** Energy To Solution (N=800)
* **Legend (Both Charts):**
* Green Line: CIM-CFC
* Purple Line: CIM-SFC
* **X-axis Scale (Both Charts):** Logarithmic, ranging from approximately 10<sup>-8</sup> to 10<sup>2</sup>.
* **Y-axis Scale (Left Chart):** Logarithmic, ranging from approximately 10<sup>-11</sup> to 10<sup>4</sup>.
* **Y-axis Scale (Right Chart):** Logarithmic, ranging from approximately 10<sup>-8</sup> to 10<sup>-2</sup>.
### Detailed Analysis or Content Details
**Left Chart (N=100):**
* **CIM-CFC (Green Line):** The line initially slopes downward from approximately 10<sup>3</sup> at J = 10<sup>-8</sup> to approximately 10<sup>-2</sup> at J = 10<sup>-3</sup>. It then increases sharply to approximately 10<sup>1</sup> at J = 10<sup>-2</sup>.
* Approximate Data Points:
* J = 10<sup>-8</sup>: 10<sup>3</sup>
* J = 10<sup>-7</sup>: 10<sup>2</sup>
* J = 10<sup>-6</sup>: 10<sup>1</sup>
* J = 10<sup>-5</sup>: 10<sup>0</sup>
* J = 10<sup>-4</sup>: 10<sup>-1</sup>
* J = 10<sup>-3</sup>: 10<sup>-2</sup>
* J = 10<sup>-2</sup>: 10<sup>1</sup>
* **CIM-SFC (Purple Line):** The line slopes downward from approximately 10<sup>2</sup> at J = 10<sup>-8</sup> to approximately 10<sup>-4</sup> at J = 10<sup>-2</sup>.
* Approximate Data Points:
* J = 10<sup>-8</sup>: 10<sup>2</sup>
* J = 10<sup>-7</sup>: 10<sup>1</sup>
* J = 10<sup>-6</sup>: 10<sup>0</sup>
* J = 10<sup>-5</sup>: 10<sup>-1</sup>
* J = 10<sup>-4</sup>: 10<sup>-2</sup>
* J = 10<sup>-3</sup>: 10<sup>-3</sup>
* J = 10<sup>-2</sup>: 10<sup>-4</sup>
**Right Chart (N=800):**
* **CIM-CFC (Green Line):** The line slopes downward from approximately 10<sup>-2</sup> at J = 10<sup>-8</sup> to approximately 10<sup>-4</sup> at J = 10<sup>-2</sup>.
* Approximate Data Points:
* J = 10<sup>-8</sup>: 10<sup>-2</sup>
* J = 10<sup>-7</sup>: 10<sup>-3</sup>
* J = 10<sup>-6</sup>: 10<sup>-3</sup>
* J = 10<sup>-5</sup>: 10<sup>-3</sup>
* J = 10<sup>-4</sup>: 10<sup>-3</sup>
* J = 10<sup>-3</sup>: 10<sup>-3</sup>
* J = 10<sup>-2</sup>: 10<sup>-4</sup>
* **CIM-SFC (Purple Line):** The line slopes downward from approximately 10<sup>-3</sup> at J = 10<sup>-8</sup> to approximately 10<sup>-5</sup> at J = 10<sup>-2</sup>.
* Approximate Data Points:
* J = 10<sup>-8</sup>: 10<sup>-3</sup>
* J = 10<sup>-7</sup>: 10<sup>-4</sup>
* J = 10<sup>-6</sup>: 10<sup>-4</sup>
* J = 10<sup>-5</sup>: 10<sup>-4</sup>
* J = 10<sup>-4</sup>: 10<sup>-4</sup>
* J = 10<sup>-3</sup>: 10<sup>-4</sup>
* J = 10<sup>-2</sup>: 10<sup>-5</sup>
### Key Observations
* For both N=100 and N=800, CIM-SFC consistently requires less energy to solution than CIM-CFC across the entire range of saturation parameters.
* The CIM-CFC method (N=100) exhibits a significant increase in energy required at higher saturation parameters (J = 10<sup>-2</sup>), which is not observed in the other datasets.
* Increasing N from 100 to 800 generally reduces the energy required for both methods, and smooths out the curve for CIM-CFC.
* Both charts show a general trend of decreasing energy to solution as the saturation parameter increases, until a certain point (especially noticeable in the N=100 chart for CIM-CFC).
### Interpretation
The charts demonstrate the relationship between energy expenditure and saturation parameter for two computational methods, CIM-CFC and CIM-SFC. The consistent lower energy requirement of CIM-SFC suggests it is a more efficient method for achieving a solution. The value of N (number of iterations or samples) significantly impacts the energy profile, with higher N values leading to lower energy consumption and smoother convergence.
The anomalous behavior of CIM-CFC at N=100 and higher saturation parameters suggests potential instability or a limitation of the method under those conditions. The increase in energy required could indicate that the algorithm struggles to converge or requires significantly more computational effort to reach a solution. The smoothing of this curve at N=800 indicates that increasing the number of iterations mitigates this instability.
The logarithmic scales on both axes highlight the wide range of energy values and saturation parameters being considered. This suggests that the methods are sensitive to the saturation parameter, and that even small changes in J can have a substantial impact on the energy required to reach a solution. The data suggests that there is an optimal range for the saturation parameter where the energy expenditure is minimized.
</details>
In Figure 8, we can see that CIM-SFC is more robust to quantum noise compared to CIM-CFC, allowing us to potentially use a larger value of g 2 . This is to be expected owing to the different roles payed by the error variable e i in each system. In CIM-CFC, the feedback signal is calculated as
$$\tilde { z } _ { i } = \tilde { e } _ { i } \sum _ { j } \xi J _ { i j } \tilde { x } _ { j } ( t )$$
which is the main cause of performance degradation when the quantum noise is increased. This is because, if the coherent excitation of ˜ e i is large, then small errors in ∑ j J ij ξ ˜ x j ( t ) will be amplified, and
Table 1: Operational power of active photonic devices in 100 GHz CIM.
| Devices | Power consumption | Reference |
|-------------------------------------------|---------------------|-------------|
| Soliton frequency comb generator | 100 mW | [16] |
| Phase sensitive ampifier (PSA) 10 dB gain | 10 mW | [15] |
| Phase sensitive ampifier (PSA) 50 dB gain | 100 mW | [15] |
| EOM modulator | 400 mW | [17] |
conversely, if the coherent excitation of ∑ j ξJ ij ˜ x j ( t ) is large, then small errors in ˜ e i will be amplified. There are no such beat noise components in CIM-SFC. Therefore, CIM-SFC is more robust to quantum noise. Moreover, the nonlinear function tanh( c ˜ z i ) can help to suppress the quantum noise.
Although they are not shown, the results for CIM-CAC are nearly identical to those for CIM-CFC.
If we include the energy cost in the optical error correction circuit and pump pulse factory (as described in Figure 6), the energy cost is increased by several orders of magnitude, as shown in Figure 9. Here, we assume that the pump pulse energy for a small signal amplification ( ∼ 10 dB) in PSA 1 , PSA 2 , ... , PSA N and PSA e in the optical error correction circuit is 100 fJ/pulse, and that for a large signal amplification ( ∼ 50 dB) in PSA 0 is 1 pJ/pulse. These numbers correspond to the experimental values for a thin-film LiNO 3 ridge waveguide DOPO at a pump wavelength of 780 nm and a pump pulse duration of 100 fs[15]. The pump energy consumed in the optical error correction circuit is estimated as E correction = [( N +1) × 10 -13 +10 -12 ] N (MVM)( J ). The energy consumption in the pump pulse factory is attributed to three components: those of a 100-GHz soliton frequency comb generator, EOM modulators, and phasesensitive amplifiers (Figure 6(b)). The 100-GHz soliton frequency comb generator requires an input power of ∼ 100 mW. [ 16 ] The 100-GHz EOM modulators require an electrical input power of ∼ 400 mW each. [ 17 ] The energy cost per pulse for PSA p is ∼ 1 pJ, while those for N PSA s for the storage ring cavities are ∼ 100 fJ each. Note that N EOMs (EOM 1 , EOM 2 , . . . EOM N ) need to be operated only for one initial round-trip time, 10 -11 N (sec). The operational powers of the active devices in the 100-GHz CIM are summarized in Table 1. The energy cost in the pump pulse factory is E factory = [1 . 3 × 10 -11 N (MVM) + 4 × 10 -Table 2 summarizes the energy costs in three parts of the CIM.
Figure 9: Estimated energy cost to solution of optical and GPU implementations of CIM-CAC vs. problem size √ N . The energy cost to solution for the optical CIM is based on the results presented in Table 2. The energy cost of the GPU is based on the ˜ 200W power consumption of the Nvidia Tesla V100 GPU used.
<details>
<summary>Image 9 Details</summary>
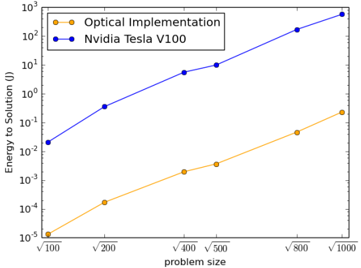
### Visual Description
\n
## Chart: Energy to Solution vs. Problem Size
### Overview
The image presents a chart comparing the energy consumption of two computational methods – an Optical Implementation and a Nvidia Tesla V100 – as a function of problem size. The chart uses a logarithmic y-axis to display the energy consumption, highlighting the differences in scaling between the two methods.
### Components/Axes
* **X-axis:** "problem size". The axis markers are √100, √200, √400, √500, √800, and √1000.
* **Y-axis:** "Energy to Solution (J)". The axis is logarithmic, ranging from 10<sup>-5</sup> to 10<sup>3</sup>.
* **Legend:** Located in the top-left corner.
* "Optical Implementation" – represented by orange circles with dashed lines.
* "Nvidia Tesla V100" – represented by blue circles with solid lines.
### Detailed Analysis
**Nvidia Tesla V100 (Blue Line):**
The blue line slopes upward consistently, indicating an increasing energy consumption with increasing problem size.
* At √100 (problem size = 10), the energy consumption is approximately 0.02 J (2 x 10<sup>-2</sup> J).
* At √200 (problem size ≈ 14.14), the energy consumption is approximately 0.05 J (5 x 10<sup>-2</sup> J).
* At √400 (problem size = 20), the energy consumption is approximately 0.2 J (2 x 10<sup>-1</sup> J).
* At √500 (problem size ≈ 22.36), the energy consumption is approximately 0.6 J (6 x 10<sup>-1</sup> J).
* At √800 (problem size ≈ 28.28), the energy consumption is approximately 2 J (2 x 10<sup>0</sup> J).
* At √1000 (problem size = 31.62), the energy consumption is approximately 6 J (6 x 10<sup>0</sup> J).
**Optical Implementation (Orange Line):**
The orange line also slopes upward, but at a much slower rate than the blue line.
* At √100 (problem size = 10), the energy consumption is approximately 0.00001 J (1 x 10<sup>-5</sup> J).
* At √200 (problem size ≈ 14.14), the energy consumption is approximately 0.0001 J (1 x 10<sup>-4</sup> J).
* At √400 (problem size = 20), the energy consumption is approximately 0.002 J (2 x 10<sup>-3</sup> J).
* At √500 (problem size ≈ 22.36), the energy consumption is approximately 0.003 J (3 x 10<sup>-3</sup> J).
* At √800 (problem size ≈ 28.28), the energy consumption is approximately 0.01 J (1 x 10<sup>-2</sup> J).
* At √1000 (problem size = 31.62), the energy consumption is approximately 0.03 J (3 x 10<sup>-2</sup> J).
### Key Observations
* The Nvidia Tesla V100 consumes significantly more energy than the Optical Implementation for all problem sizes.
* The energy consumption of the Nvidia Tesla V100 increases much more rapidly with problem size than the Optical Implementation.
* The logarithmic y-axis emphasizes the large difference in energy consumption between the two methods.
* The Optical Implementation exhibits a nearly linear increase in energy consumption on this log scale, suggesting a polynomial relationship.
### Interpretation
The chart demonstrates that the Optical Implementation is significantly more energy-efficient than the Nvidia Tesla V100, especially as the problem size increases. The steeper slope of the Nvidia Tesla V100 line indicates that its energy consumption scales poorly with problem size, making it less suitable for large-scale computations. The Optical Implementation, with its shallower slope, offers a more sustainable solution for larger problems. The use of a logarithmic scale is crucial for visualizing the large disparity in energy consumption, as a linear scale would make the Optical Implementation's energy usage appear negligible. This suggests that optical computing may be a promising avenue for reducing the energy footprint of computationally intensive tasks. The data suggests a power law relationship for the Nvidia Tesla V100, while the Optical Implementation appears closer to linear on the log-log scale.
</details>
Figure 9 shows the energy cost to solution if the CIM-CFC algorithm is implemented on GPU. The detailed description of this approach will be given in the next section. Even though the optical implementation of the error correction circuit and pump pulse factory as described in Figure 6 is technologically challenging, the energy cost can be decreased by several orders of magnitude compared to a modern GPU.
Table 2: Energy cost to solution in three subsystems in CIM. MVM: matrix-vector multiplication steps to solution, N : problem size, one round trip time: 10 -8 s, signal lifetime: 10 -7 s.
| Subsystem | Energy-to-solution |
|----------------------------------|----------------------------------------------------------------------------------------------------------------|
| Main cavity | 2 . 6 × 10 - 20 (MVM) N/g 2 |
| Optical error correction circuit | [( N +1)10 - 13 +10 - 12 ](MVM) N 10 - 13 N 2 (MVM) |
| Pump pulse factory | [ N × 10 - 13 +10 - 12 ](MVM) N +1 . 3 × 10 - 11 N (MVM)+4 × 10 - 12 N 2 10 - 13 N 2 (MVM) |
## 6 CIM - Inspired Heuristic Algorithms
## 6.1 Scaling performance of CIM-CAC, CIM-CFC, and CIM-SFC
To test whether the three classical nonlinear dynamics models given by Eqs. (1)-(8), are good Ising solvers, we can numerically integrate them on a digital platform. In this section, we will consider these CIMinspired algorithms when numerically integrated using an Euler step. In addition, to ensure numerical stability, we constrain the range of some variables, the details of which are presented in Appendix A.
The relevant performance metric is the time to solution or TTS (the number of integration time steps required to achieve a success rate of 99%). In particular, we study how the median TTS scales as a function of the problem size for randomly generated SK spin glass instances (the couplings are chosen randomly between +1 and -1). The median TTS is computed on the basis of a set of 100 randomly generated instances per problem size, and 3200 trajectories are used per instance to evaluate the TTS.
Figure 10 shows the median TTSs of the three CIM-inspired algorithms (CIM-CAC, CIM-CFC, and CIMSFC) are shown with respect to the problem size. The shaded regions represent 25th-75th percentiles. The linear behavior of the TTS with respect to √ N indicates that these algorithms have the same root exponential scaling of TTS that is also observed in physical CIMs with quantum noise from external reservoirs. [ 8 , 31 ] All three algorithms appear to have very similar scaling coefficients if the TTS is assumed to be of the form TTS ≈ A · B √ n . In addition to the similar scaling, all three algorithms show a similar spread (25th-75th percentile) in TTS, as indicated by the shaded region above. Although CIM-SFC may have a slightly larger spread in all cases, the spread does not appear to increase for larger problem sizes.
Figure 10: (left) TTSs of CIM-CAC, CIM-CFC and CIM-SFC vs. problem size √ N . The shaded regions represent the 25th-75th percentile TTS. (right) The 75th and 90th percentile TTS compared to the median TTS for all three systems as a function of the problem size.
<details>
<summary>Image 10 Details</summary>
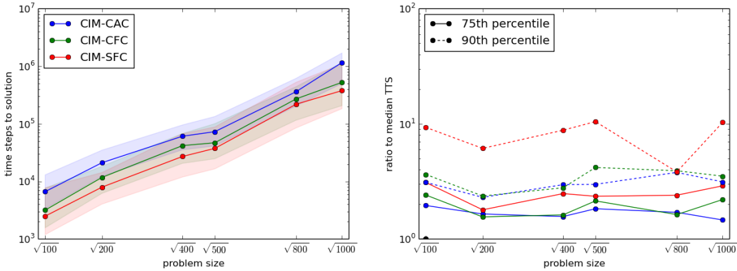
### Visual Description
## Charts: Performance Comparison of CIM Algorithms
### Overview
The image presents two charts comparing the performance of three Constraint Integer Modeling (CIM) algorithms: CIM-CAC, CIM-CFC, and CIM-SFC. The left chart displays the time steps to solution as a function of problem size, while the right chart shows the ratio to the median Time To Solution (TTS) for the 75th and 90th percentiles. Both charts use a logarithmic scale for the y-axis.
### Components/Axes
**Left Chart:**
* **X-axis:** Problem Size (labeled with values 100, 200, √400/500, 800, 1000). The x-axis is logarithmic.
* **Y-axis:** Time steps to solution (labeled with values 10^3, 10^4, 10^5, 10^6, 10^7). The y-axis is logarithmic.
* **Data Series:**
* CIM-CAC (Blue line with circles)
* CIM-CFC (Green line with triangles)
* CIM-SFC (Red line with diamonds)
* Each line has a shaded region around it, representing a confidence interval or variance. The shading is light blue for CIM-CAC, light green for CIM-CFC, and light red for CIM-SFC.
**Right Chart:**
* **X-axis:** Problem Size (labeled with values 100, 200, √400/500, 800, 1000). The x-axis is logarithmic.
* **Y-axis:** Ratio to median TTS (labeled with values 10^0, 10^1, 10^2). The y-axis is logarithmic.
* **Data Series:**
* 75th percentile (Black line with circles)
* 90th percentile (Black line with dashed circles)
* **Legend:** Located in the top-right corner, clearly labeling the data series.
### Detailed Analysis or Content Details
**Left Chart:**
* **CIM-CAC (Blue):** The line slopes upward, indicating that the time steps to solution increase with problem size.
* At problem size 100: ~1500 time steps.
* At problem size 200: ~2500 time steps.
* At problem size 500: ~7000 time steps.
* At problem size 800: ~15000 time steps.
* At problem size 1000: ~30000 time steps.
* **CIM-CFC (Green):** The line also slopes upward, but generally remains below CIM-CAC.
* At problem size 100: ~1000 time steps.
* At problem size 200: ~1500 time steps.
* At problem size 500: ~4000 time steps.
* At problem size 800: ~8000 time steps.
* At problem size 1000: ~15000 time steps.
* **CIM-SFC (Red):** The line slopes upward, and is generally the lowest of the three algorithms.
* At problem size 100: ~500 time steps.
* At problem size 200: ~800 time steps.
* At problem size 500: ~2000 time steps.
* At problem size 800: ~4000 time steps.
* At problem size 1000: ~8000 time steps.
**Right Chart:**
* **75th percentile (Black):** The line fluctuates, initially decreasing then increasing.
* At problem size 100: ~10.
* At problem size 200: ~5.
* At problem size 500: ~7.
* At problem size 800: ~10.
* At problem size 1000: ~15.
* **90th percentile (Black dashed):** The line also fluctuates, generally higher than the 75th percentile.
* At problem size 100: ~20.
* At problem size 200: ~10.
* At problem size 500: ~15.
* At problem size 800: ~20.
* At problem size 1000: ~30.
### Key Observations
* All three algorithms (CIM-CAC, CIM-CFC, CIM-SFC) exhibit an increasing trend in time steps to solution as the problem size increases (Left Chart).
* CIM-SFC consistently requires the fewest time steps to solution across all problem sizes.
* The ratio to median TTS increases with problem size for both the 75th and 90th percentiles (Right Chart), indicating greater variability in solution time for larger problems.
* The 90th percentile consistently has a higher ratio to median TTS than the 75th percentile, as expected.
### Interpretation
The data suggests that CIM-SFC is the most efficient algorithm among the three tested, consistently requiring fewer time steps to reach a solution. The logarithmic scales on both charts emphasize the exponential growth in computational effort as problem size increases. The right chart highlights that while the median solution time may be relatively stable, the tail of the distribution (75th and 90th percentiles) experiences increasing variability with larger problem sizes. This suggests that for critical applications, it may be necessary to consider the worst-case performance of these algorithms, and CIM-SFC offers the most consistent performance. The fluctuations in the ratio to median TTS could be due to the inherent stochasticity of the algorithms or variations in the problem instances used for testing. The √400/500 label on the x-axis suggests that the data points were taken at problem sizes of approximately 20 and 22.36, which is unusual and may indicate a specific experimental setup.
</details>
## 6.2 Comparison with noisy mean field annealing (NMFA)
To show the importance of the auxiliary variable (error pulse) in CIM-SFC, we compared its performance to another CIM-inspired algorithm, namely noisy mean field annealing (NMFA). [ 26 ] NMFA also applies a hyperbolic tangent function to the mutual coupling term. However, it does not have an auxiliary variable and relies on (artificial) quantum noise to escape from local minima. Figure 11, compares the scal-
ing of NMFA to CIM-SFC with different values of the feedback parameter k . As k controls the strength of the destabilization force caused by the auxiliary variable, we can measure the importance of the term k ( z i -e i ) to the scaling behavior. When k = 0, CIM-SFC is nearly identical to NMFA. The fact that CIM-SFC with k = 0 shows slightly worse performance indicates that the noise included in NMFA likely has a small effect and may help destabilize the local minima (which can also be observed in Figure 7). The case k = 0 . 15 is shown as an intermediate case, and k = 0 . 2 is the (experimentally obtained) optimal value for k in CIM-SFC.
As can be seen, the addition of the error correction feedback term k ( z i -e i ) in Eq. (7) is effective in improving both the scaling and the spread of TTS for the SK instances. This implies that the 'correlated artificial noise' provided by the auxiliary variable is more effective in finding better solutions than the 'random quantum noise' from reservoirs.
Figure 11: (left) TTSs of CIM-SFC and NMFA vs. problem size √ N . The shaded regions represent 25-75 percentile TTS. The results for NMFA are from [12]. (right) TTS for N=400 SK instances for different values of k . The 75th and 90th percentiles are not shown for smaller values of k because they were too large to be computed.
<details>
<summary>Image 11 Details</summary>
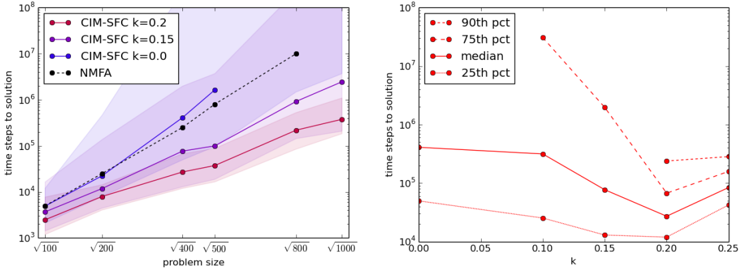
### Visual Description
\n
## Charts: Performance Comparison of Optimization Algorithms
### Overview
The image presents two charts comparing the performance of different optimization algorithms, specifically CIM-SFC with varying 'k' values and NMFA, in terms of time steps to solution. The left chart shows the relationship between time steps and problem size, while the right chart shows the relationship between time steps and the 'k' parameter.
### Components/Axes
**Left Chart:**
* **X-axis:** Problem Size (logarithmic scale, markers at 100, 200, √400 ≈ 20, √500 ≈ 22.4, 800, 1000)
* **Y-axis:** Time Steps to Solution (logarithmic scale, from 10^3 to 10^8)
* **Legend:**
* CIM-SFC k = 0.2 (Red circles with solid line)
* CIM-SFC k = 0.15 (Purple circles with solid line)
* CIM-SFC k = 0.0 (Blue circles with solid line)
* NMFA (Black dashed circles with dashed line)
**Right Chart:**
* **X-axis:** k (linear scale, from 0.00 to 0.25)
* **Y-axis:** Time Steps to Solution (logarithmic scale, from 10^3 to 10^7)
* **Legend:**
* 90th pct (Red circles with solid line)
* 75th pct (Red circles with dashed line)
* median (Blue circles with solid line)
* 25th pct (Red circles with dotted line)
### Detailed Analysis or Content Details
**Left Chart:**
* **CIM-SFC k = 0.2 (Red):** The line slopes upward, increasing from approximately 2.5 x 10^4 at problem size 100 to approximately 1.5 x 10^6 at problem size 1000.
* **CIM-SFC k = 0.15 (Purple):** The line slopes upward, increasing from approximately 1.5 x 10^4 at problem size 100 to approximately 8 x 10^5 at problem size 1000.
* **CIM-SFC k = 0.0 (Blue):** The line slopes upward, increasing from approximately 1 x 10^4 at problem size 100 to approximately 2 x 10^6 at problem size 1000.
* **NMFA (Black):** The line slopes upward, increasing from approximately 1.5 x 10^4 at problem size 100 to approximately 1.2 x 10^7 at problem size 1000.
**Right Chart:**
* **90th pct (Red, solid):** The line decreases sharply from approximately 6 x 10^6 at k = 0.00 to approximately 2 x 10^5 at k = 0.15, then increases slightly to approximately 3 x 10^5 at k = 0.25.
* **75th pct (Red, dashed):** The line decreases from approximately 2 x 10^6 at k = 0.00 to approximately 8 x 10^4 at k = 0.15, then remains relatively constant at approximately 6 x 10^4.
* **median (Blue, solid):** The line decreases from approximately 1.5 x 10^6 at k = 0.00 to approximately 2 x 10^4 at k = 0.15, then increases slightly to approximately 3 x 10^4 at k = 0.25.
* **25th pct (Red, dotted):** The line decreases sharply from approximately 5 x 10^5 at k = 0.00 to approximately 1 x 10^4 at k = 0.15, then increases to approximately 2 x 10^4 at k = 0.25.
### Key Observations
* In the left chart, NMFA consistently requires the most time steps to solution across all problem sizes.
* In the left chart, CIM-SFC with k=0.0 generally performs better than k=0.15 and k=0.2.
* In the right chart, all percentiles show a decrease in time steps as 'k' increases from 0.00 to 0.15, suggesting an optimal 'k' value around 0.15.
* In the right chart, the 90th percentile exhibits the highest time steps, indicating a wider range of performance variability.
### Interpretation
The data suggests that CIM-SFC is a more efficient optimization algorithm than NMFA, particularly for larger problem sizes. The 'k' parameter in CIM-SFC significantly impacts performance, with a value of 0.0 generally yielding the best results in terms of time steps to solution. However, the right chart indicates that there's an optimal range for 'k' (around 0.15) where performance is maximized. Beyond this point, increasing 'k' may lead to a slight increase in time steps, particularly for the 90th percentile, suggesting increased variability in performance. The difference between the 25th and 90th percentiles highlights the sensitivity of the algorithms to initial conditions or problem instances. The logarithmic scales on both axes emphasize the substantial differences in time steps required for different algorithms and parameter settings. The charts provide valuable insights for selecting the appropriate optimization algorithm and tuning its parameters for specific problem sizes and performance requirements.
</details>
## 6.3 Comparison with discrete simulated bifurcation machine (dSBM)
We compared the performance of the CIM-inspired algorithms with that of another heuristic Ising solver, namely the discrete simulated bifurcation machine (dSBM). [ 27 , 29 , 28 ] Similar to CIM, dSBM also makes use of analog spins and continuous dynamics to solve combinatorial optimization problems.
We are aware that the authors of [29] seem to claim that dSBM is algorithmically superior to CIM-CAC by comparing the required number of MVMs to solution. Although the authors of [29] discussed the wall clock TTS of their implementations on many problem sets, when making the claim of algorithmic superiority, they only used the median TTS (in units of MVM) on SK instances for two problem sizes. In this section, we will provide a more detailed comparison of the three algorithms (CIM-CAC, CIM-CFC and CIM-SFC) with dSBM using MVM to solution (or equivalently, integration time steps to solution) as the performance metric. As mentioned before, this is a good comparison because all these algorithms will have MVM as the computational bottleneck when implemented on a digital platform. As discussed in Section 4, the computation of the Ising energy can be left until the end of the trajectory in most cases; thus, for this section, we will only consider the MVM involved in the computation of the mutual coupling term when calculating the MVM to solution.
The problem instance sets used in this section are:
1. A set of 100 randomly generated 800-spin SK instances (available upon request from the authors). This instance set contains fully connected instances with weights of +1 , -1.
2. The G-set instances that have been used as a benchmark for max-cut performance (available at https://web.stanford.edu/ yyye/yyye/Gset/). In this study, we consider 50 instances with a problem size of 800-2000. These instances have varying edge density and include weights of either +1 , 0 or +1 , 0 , -1.
3. Another set of 1000 randomly generated 800-spin and 1200-spin SK instance (available upon request from the authors) used to evaluate the worst-case performance.
To compare the performance on the 800-spin SK instances, the dSBM algorithm was also implemented on GPU. The parameters for dSBM were chosen on the basis of the parameters in [29] (see Appendix D).
Figure 12: Required number of MVMs to solution for CIM-CAC, CIM-CFC, and CIM-SFC vs. that for dSBM. The median TTS is indicated by the red lines and the 25th-75th percentiles are indicated by the shaded blue regions.
<details>
<summary>Image 12 Details</summary>
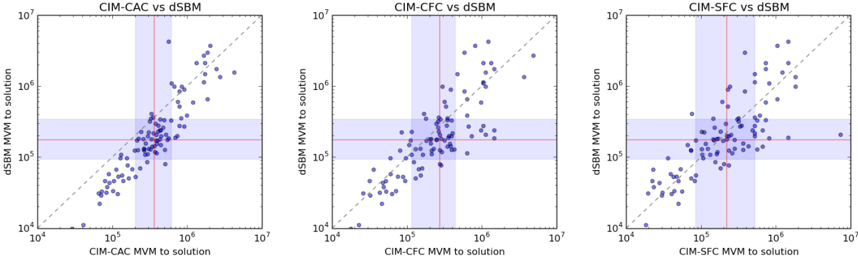
### Visual Description
## Scatter Plots: Comparison of CIM-CAC, CIM-CFC, and CIM-SFC vs dSBM
### Overview
The image presents three scatter plots arranged horizontally. Each plot compares a different CIM (presumably a computational method) – CAC, CFC, and SFC – against dSBM (another computational method). The plots visualize the relationship between the "MVM to solution" values for each method. A diagonal dashed gray line represents the ideal scenario where both methods yield the same result. A horizontal red line indicates a threshold or benchmark. Data points are color-coded: black for most points, and blue for a subset of points.
### Components/Axes
Each plot shares the following components:
* **X-axis:** Labeled as "[CIM-X] MVM to solution" where X is CAC, CFC, or SFC. Scale is logarithmic, ranging from 10<sup>4</sup> to 10<sup>7</sup>.
* **Y-axis:** Labeled as "dSBM MVM to solution". Scale is logarithmic, ranging from 10<sup>4</sup> to 10<sup>7</sup>.
* **Title:** Each plot has a title indicating the comparison being made (e.g., "CIM-CAC vs dSBM").
* **Diagonal Line:** A dashed gray line with a slope of 1, representing the line of equality.
* **Horizontal Line:** A solid red horizontal line, positioned at approximately y = 5 x 10<sup>5</sup>.
* **Data Points:** Black and blue dots representing individual data points.
### Detailed Analysis or Content Details
**Plot 1: CIM-CAC vs dSBM**
* **Trend:** The data points generally cluster around the line of equality, but with significant scatter. There's a slight upward trend, indicating a positive correlation. Points above the horizontal red line are more numerous than those below.
* **Data Points:**
* Black Points: Distributed across the plot, with a concentration in the lower-left and upper-right quadrants. Approximate values (reading from the plot, with uncertainty): (10<sup>4</sup>, 10<sup>4</sup>) to (10<sup>7</sup>, 10<sup>7</sup>).
* Blue Points: Concentrated above the horizontal red line, generally between x = 10<sup>5</sup> and x = 10<sup>6</sup>, and y = 10<sup>5</sup> and y = 10<sup>7</sup>. Approximate values: (10<sup>5</sup>, 5 x 10<sup>5</sup>), (2 x 10<sup>5</sup>, 8 x 10<sup>5</sup>), (5 x 10<sup>5</sup>, 2 x 10<sup>6</sup>), (8 x 10<sup>5</sup>, 10<sup>6</sup>).
**Plot 2: CIM-CFC vs dSBM**
* **Trend:** Similar to Plot 1, the data shows a positive correlation with scatter. Points are more tightly clustered around the line of equality than in Plot 1.
* **Data Points:**
* Black Points: Distributed across the plot, with a concentration in the lower-left and upper-right quadrants. Approximate values: (10<sup>4</sup>, 10<sup>4</sup>) to (10<sup>7</sup>, 10<sup>7</sup>).
* Blue Points: Concentrated above the horizontal red line, generally between x = 10<sup>4</sup> and x = 10<sup>6</sup>, and y = 10<sup>5</sup> and y = 10<sup>7</sup>. Approximate values: (10<sup>4</sup>, 2 x 10<sup>5</sup>), (2 x 10<sup>4</sup>, 5 x 10<sup>5</sup>), (5 x 10<sup>5</sup>, 10<sup>6</sup>), (8 x 10<sup>5</sup>, 5 x 10<sup>6</sup>).
**Plot 3: CIM-SFC vs dSBM**
* **Trend:** The data exhibits a strong positive correlation, with points generally falling above and to the right of the line of equality. The scatter is less pronounced than in the other two plots.
* **Data Points:**
* Black Points: Distributed across the plot, with a concentration in the lower-left and upper-right quadrants. Approximate values: (10<sup>4</sup>, 10<sup>4</sup>) to (10<sup>7</sup>, 10<sup>7</sup>).
* Blue Points: Concentrated above the horizontal red line, generally between x = 10<sup>4</sup> and x = 10<sup>6</sup>, and y = 10<sup>5</sup> and y = 10<sup>7</sup>. Approximate values: (10<sup>4</sup>, 5 x 10<sup>5</sup>), (2 x 10<sup>4</sup>, 10<sup>6</sup>), (5 x 10<sup>5</sup>, 2 x 10<sup>6</sup>), (8 x 10<sup>5</sup>, 5 x 10<sup>6</sup>).
### Key Observations
* The blue points consistently represent a subset of data that performs better than the overall trend (i.e., they are above the red line).
* CIM-SFC appears to have the strongest correlation with dSBM, with the data points clustering more closely around the line of equality.
* All three CIM methods show a positive correlation with dSBM, suggesting that as the MVM to solution increases for one method, it also tends to increase for the other.
* The logarithmic scales make it difficult to assess the absolute magnitude of differences, but the relative positioning of points is clear.
### Interpretation
These plots compare the performance of three different CIM methods (CAC, CFC, and SFC) against dSBM, likely in the context of solving a mathematical or computational problem. The "MVM to solution" metric likely represents the computational effort (e.g., number of matrix-vector multiplications) required to reach a solution.
The diagonal line represents the ideal scenario where both methods require the same amount of computational effort. Points above this line indicate that dSBM is more efficient, while points below indicate that the CIM method is more efficient.
The horizontal red line likely represents a performance threshold. Points above this line may be considered acceptable, while points below may indicate poor performance.
The blue points likely represent a specific subset of cases where the CIM method performs particularly well. This could be due to specific problem characteristics or optimization strategies.
The fact that CIM-SFC consistently performs closer to the line of equality suggests that it is the most reliable and efficient method among the three, in terms of matching the performance of dSBM. The other two methods exhibit more variability, indicating that their performance is more sensitive to the specific problem being solved.
The overall trend suggests that there is a trade-off between the computational effort required by the CIM methods and dSBM. In some cases, the CIM methods may be more efficient, while in others, dSBM may be more efficient. The choice of which method to use will depend on the specific problem and the desired level of performance.
</details>
In Figure 12compares the performance of the three algorithms (CIM-CAC, CIM-CFC, and CIM-SFC) instance by instance with that of dSBM on the 800-spin SK instance set. The ground-state energies used to evaluate the MVM to solution are the lowest energies found by the four algorithms. As all four algorithms found the same lowest energies, it is highly likely that these are true ground-state energies. The parameters for all four systems can be found in Appendix A. As shown in Figure 12, all four systems showed remarkably similar performance on the 800-spin instances when the parameters were optimized. It is important to note that with the parameters used in Figure 12, CIM-SFC did not find the ground state in one instance. However, if different parameters are used, CIM-SFC will find the ground state for this particular instance as well. Thus, although CIM-SFC can achieve high performance, it is highly sensitive to parameter selection.
The median TTS (in the units of MVM) of CIM-CFC, CIM-SFC and dSBM are nearly the same: around 2 × 10 5 . Furthermore, the spread in TTS of these three algorithms is similar. Although CIM-CAC shows slightly worse median TTS (by less than a factor of two), it is worth noting that the instances in which CIM-CAC performs better than dSBM tend to be the harder instances. This indicates that among the four algorithms, CIM-CAC may show slightly better worst-case performance. We investigate this further later in this section. This pattern can also be seen on the G-set.
Overall, all four algorithms show similar performance on the fully connected instance set, and it is impossible to determine which particular algorithm is the most effective one for this problem type. In addition to the similar median TTS and spread, there is a high level of correlation in the TTS among all four systems. This indicates either that instance difficulty is a universal property for all Ising heuristics or that there is something fundamentally common to the four algorithms. See Appendix E for a further discussion of the similarities and differences between these four systems.
Although CIM-SFC shows good performance on fully connected problem instances, it struggles on many G-set instances. In Appendix D, we discuss a partial reason for this failure; however, the full reason is yet to be understood. In the future, we expect to modify CIM-SFC or find better parameters so that it can solve all problem types; however, for now, we will just consider CIM-SFC as a fully connected (or densely connected) Ising solver and compare only CIM-CAC, CIM-CFC, and dSBM on the G-set. For some results of CIM- SFC on the G-set, see Appendix D.
All three algorithms (CIM-CAC, CIM-CFC, and dSBM) show fairly good performance on the G-set; however, we argue that CIM-CAC is the most consistently effective algorithm. CIM-CAC and dSBM
Q
Figure 13: (left) TTS on G-set graphs for CIM-CAC, CIM-CFC and dSBM. The best known cut values are found in [29]. The TTS for dSBM is from [29]. In this plot, the instances are separated into groups depending on the graph type and size. The dots above the plot indicate that the best known cut value was not found. (right) Histograms showing which algorithm realizes the slowest TTS and which algorithm has the fastest TTS. The column labeled 'none' indicates the two instances in which none of the three algorithms found the best known cut value. The parameters are chosen and optimized separately for each instance type. An instance-by-instance comparison and the parameters used are presented in Appendix B.
<details>
<summary>Image 13 Details</summary>
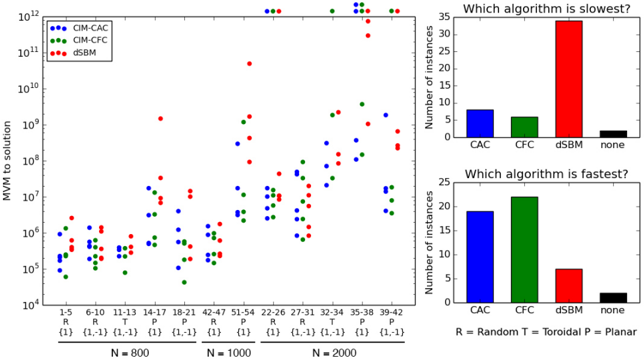
### Visual Description
## Scatter Plot & Bar Charts: Algorithm Performance Comparison
### Overview
The image presents a comparison of three algorithms – CIM-CAC, CIM-CFC, and dSBM – across different graph types (Random, Toroidal, Planar) and sizes (N=800, N=1000, N=2000). The left side displays a scatter plot showing the number of MVM (Multiplication-Vector Multiplication) operations to solution for each algorithm and instance. The right side contains two bar charts: one indicating which algorithm is slowest, and the other indicating which algorithm is fastest.
### Components/Axes
* **Left Plot:**
* **X-axis:** Instance labels, combining graph type (R=Random, T=Toroidal, P=Planar) and a numerical identifier (1-5, 6-10, etc.). The N value (800, 1000, 2000) is indicated below the x-axis.
* **Y-axis:** Number of MVM to solution, on a logarithmic scale from 10<sup>4</sup> to 10<sup>12</sup>.
* **Legend (Top-Left):**
* Blue circles: CIM-CAC
* Green triangles: CIM-CFC
* Red circles: dSBM
* **Right Plots:**
* **X-axis:** Algorithm names: CAC, CFC, dSBM, none.
* **Y-axis:** Number of instances (0-35).
* **Top Bar Chart Title:** "Which algorithm is slowest?"
* **Bottom Bar Chart Title:** "Which algorithm is fastest?"
* **Legend (Bottom-Right):** R = Random, Toroidal, P = Planar. This legend applies to the instance labels on the left plot.
### Detailed Analysis or Content Details
**Left Plot (Scatter Plot):**
* **CIM-CAC (Blue):** Generally clusters in the lower range of MVM counts (10<sup>5</sup> - 10<sup>8</sup>) for N=800 and N=1000. For N=2000, the points are more dispersed, ranging from approximately 2x10<sup>5</sup> to 8x10<sup>8</sup>.
* **CIM-CFC (Green):** Shows a wider spread than CIM-CAC. For N=800, values range from approximately 1x10<sup>5</sup> to 3x10<sup>7</sup>. For N=1000, the range is approximately 1x10<sup>5</sup> to 5x10<sup>7</sup>. For N=2000, the range expands to approximately 1x10<sup>5</sup> to 1x10<sup>9</sup>.
* **dSBM (Red):** Consistently exhibits the highest MVM counts. For N=800, values range from approximately 2x10<sup>6</sup> to 2x10<sup>8</sup>. For N=1000, the range is approximately 2x10<sup>6</sup> to 2x10<sup>9</sup>. For N=2000, the range is approximately 2x10<sup>6</sup> to 3x10<sup>10</sup>.
**Right Plots (Bar Charts):**
* **Which algorithm is slowest?**
* CAC: Approximately 8 instances.
* CFC: Approximately 6 instances.
* dSBM: Approximately 32 instances.
* none: Approximately 2 instances.
* **Which algorithm is fastest?**
* CAC: Approximately 10 instances.
* CFC: Approximately 22 instances.
* dSBM: Approximately 8 instances.
* none: Approximately 2 instances.
### Key Observations
* dSBM consistently requires the most MVM operations to reach a solution, and is identified as the slowest algorithm in the majority of instances.
* CIM-CFC is frequently the fastest algorithm, as indicated by the bar chart.
* As the graph size (N) increases, the MVM counts generally increase for all algorithms, but the increase is most pronounced for dSBM.
* The "none" category in the bar charts suggests that in some instances, no algorithm was able to find a solution within a reasonable number of MVM operations.
### Interpretation
The data suggests that CIM-CFC is the most efficient algorithm for solving these types of problems, particularly as the graph size increases. dSBM, while potentially capable of finding a solution, is significantly more computationally expensive. CIM-CAC falls between the two in terms of performance.
The logarithmic scale on the Y-axis of the scatter plot highlights the substantial differences in computational cost between the algorithms. The fact that dSBM consistently requires orders of magnitude more MVM operations than the other algorithms suggests that it may be unsuitable for large graphs.
The presence of the "none" category in the bar charts indicates that some instances are particularly challenging and may require alternative approaches or more powerful computational resources. The graph type (Random, Toroidal, Planar) also appears to influence performance, as evidenced by the varying distribution of points within each category on the scatter plot. Further analysis would be needed to determine the specific characteristics of each graph type that contribute to these differences.
</details>
were able to find the best known cut values in 47 out of 50 instances, while CIM-CFC found the best known cut value in 45 out of 50 instances. It is worth noting that the simulation time used to calculate the TTS for dSBM [ 29 ] was much longer than that used in this study. Given the same simulation time, dSBM would most likely have solved only 45 out of 50 instances. As shown in Figure 13, CIM-CAC and CIM-CFC are faster (in units of MVM) than dSBM in most instances. More importantly, among the instances in which dSBM is faster, there are no cases where dSBM is significantly faster than CIM-CAC, other than G37, in which CIM-CAC did not find the best known cut value. Meanwhile, we found that CIM-CAC was more than an order of magnitude faster than dSBM in 13 out 50 instances. Therefore, we believe that CIM-CAC is a more reliable algorithm when considering many problem types.
The difference between CIM-CAC and CIM-CFC is subtle. This is to be expected, as the dynamics of the two systems are very similar. Although the performance of the two algorithms for G-set is nearly identical in most cases, for some of the harder instances, there are some cases in which CIM-CFC cannot find the best known cut value or CIM-CFC has a significantly longer TTS. This indicates that CIMCAC is fundamentally a more promising algorithm or that precise parameter selection for CIM-CFC is required.
As noted in Figure 12, the worst case performance of CIM-CAC may be slightly better than that of dSBM. To evaluate this further we created new sets of 1000 800-spin and 1200-spin SK instances. Figure 14 shows the number of instances solved as a function of the number of MVMs required to achieve a success probability of 99%. As can be seen in both cases, dSBM can solve the easier instances with fewer MVMs; however, for the hardest instances, CIM-CAC is faster. his can be understood by observing the intersection point of the two curves in Figure 14.
In nearly all cases, the best Ising energy found was the same for both the solvers when a similar number of MVMs were used (see Appendix A for the parameters). However, for two instances in the N=1200 set, the Ising energy found by CAC was not found by dSBM. This remained true even when 50,000 dSBM trajectories were used for these instances.
Our results suggest that dSBM may struggle considerably for some harder SK instances. However, we acknowledge that this could be a result of sub-optimal parameter selection for dSBM. The parameters used (see appendix A) were optimized manually to achieve a good median TTS; however, they may not
<details>
<summary>Image 14 Details</summary>
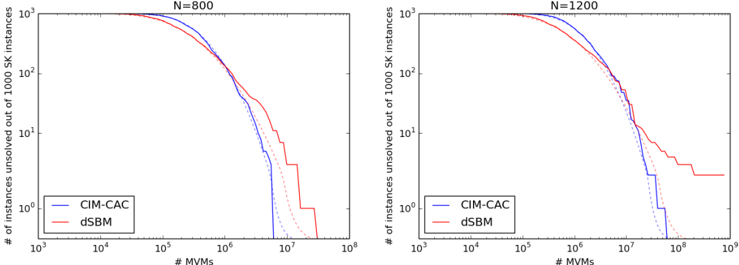
### Visual Description
\n
## Chart: Solver Performance Comparison
### Overview
The image presents two line charts comparing the performance of two solvers, CIM-CAC and dSBM, on a set of instances. Both charts depict the number of unsolved instances out of 1000 SK instances against the number of MVMs (Movements). The two charts differ in the value of 'N', representing the number of instances, with the left chart showing N=800 and the right chart showing N=1200.
### Components/Axes
* **X-axis:** "# MVMs" (Number of Movements), logarithmic scale from 10<sup>4</sup> to 10<sup>9</sup>.
* **Y-axis:** "# of instances unsolved out of 1000 SK instances", logarithmic scale from 10<sup>0</sup> to 10<sup>3</sup>.
* **Legend (Left Chart, bottom-right):**
* Blue Line: CIM-CAC
* Red Line: dSBM
* **Legend (Right Chart, bottom-right):**
* Blue Line: CIM-CAC
* Red Line: dSBM
* **Title (Left Chart, top-center):** N=800
* **Title (Right Chart, top-center):** N=1200
### Detailed Analysis or Content Details
**Left Chart (N=800):**
* **CIM-CAC (Blue Line):** The line starts at approximately 1000 unsolved instances at 10<sup>4</sup> MVMs. It gradually decreases, remaining relatively flat until approximately 5 x 10<sup>5</sup> MVMs, where it begins to decline more rapidly. Around 2 x 10<sup>7</sup> MVMs, the line drops sharply to approximately 10 unsolved instances. There is a slight increase and then decrease around 8 x 10<sup>7</sup> MVMs, ending at approximately 5 unsolved instances at 10<sup>9</sup> MVMs.
* **dSBM (Red Line):** The line begins at approximately 1000 unsolved instances at 10<sup>4</sup> MVMs. It decreases more slowly than CIM-CAC initially. Around 3 x 10<sup>6</sup> MVMs, the line begins to decline more rapidly. Around 1 x 10<sup>7</sup> MVMs, the line drops sharply to approximately 20 unsolved instances. It continues to decrease, ending at approximately 2 unsolved instances at 10<sup>9</sup> MVMs.
**Right Chart (N=1200):**
* **CIM-CAC (Blue Line):** The line starts at approximately 1000 unsolved instances at 10<sup>4</sup> MVMs. It decreases gradually, remaining relatively flat until approximately 4 x 10<sup>5</sup> MVMs, where it begins to decline more rapidly. Around 2 x 10<sup>7</sup> MVMs, the line drops sharply to approximately 10 unsolved instances. It continues to decrease, ending at approximately 2 unsolved instances at 10<sup>9</sup> MVMs.
* **dSBM (Red Line):** The line begins at approximately 1000 unsolved instances at 10<sup>4</sup> MVMs. It decreases more slowly than CIM-CAC initially. Around 3 x 10<sup>6</sup> MVMs, the line begins to decline more rapidly. Around 1 x 10<sup>7</sup> MVMs, the line drops sharply to approximately 20 unsolved instances. It continues to decrease, ending at approximately 2 unsolved instances at 10<sup>9</sup> MVMs.
### Key Observations
* Both solvers show a decreasing number of unsolved instances as the number of MVMs increases.
* For both N=800 and N=1200, dSBM initially outperforms CIM-CAC at lower MVM values, but CIM-CAC eventually surpasses dSBM in performance as the number of MVMs increases.
* The performance gap between the two solvers narrows as the number of MVMs increases.
* The sharp drops in both lines indicate a point where the solvers are able to efficiently solve a large number of instances.
* The slight fluctuations in the CIM-CAC line around 8 x 10<sup>7</sup> MVMs (N=800) might indicate a local optimum or a temporary plateau in the solver's progress.
### Interpretation
The charts demonstrate the performance of two different solvers (CIM-CAC and dSBM) in solving a set of SK instances. The number of MVMs represents the computational effort expended. The goal is to minimize the number of unsolved instances.
The data suggests that while dSBM may be more efficient at lower computational costs (fewer MVMs), CIM-CAC ultimately becomes more effective as more computational resources are allocated. This could be due to CIM-CAC employing a more sophisticated, but computationally intensive, search strategy that pays off in the long run.
The difference in performance between N=800 and N=1200 is relatively small, suggesting that the solvers' relative performance is consistent across different instance sizes. The logarithmic scales on both axes highlight the exponential nature of the problem – a small increase in MVMs can lead to a significant reduction in the number of unsolved instances, especially at higher MVM values. The fluctuations observed in the CIM-CAC line for N=800 could be indicative of the solver getting stuck in local optima, requiring additional MVMs to escape and continue the search.
</details>
# MVMs
# MVMs
Figure 14: Number of instances that remain unsolved (success probability under 99%) after a certain number of MVMs (time steps) for CIM-CAC and dSBM. The dotted lines represent the assumption of a log-normal distribution for the TTS on randomly generated SK instances. The instance sets used are 1000 randomly generated SK instances (different from the 100 instances used in Figure 12) of problem sizes N=800 (top) and N=1200 (bottom). The parameters for both systems can be found in Appendix A.
be the best parameters if one wants to solve the hardest instances. By contrast, for CIM-CAC, the optimal parameters for the median TTS appear to also perform well on the hardest instances.
To ensure that an Ising solver can find the true ground state of a given problem, the worst-case performance is very important. For this purpose, we believe that CIM-CAC is likely the more fundamentally superior algorithm, at least in the case of randomly generated SK instances. For the other CIM modifications, this is likely not true. In particular, for CIM-SFC, the worst-case performance is significantly worse than that of dSBM and CIM-CAC (as shown in Figure 10). In the future, it would be interesting to investigate the cause for this phenomenon and also to examine the spread of TTS for different problem types.
## 7 Conclusion
The new coherent Ising machines presented in this paper (CIM-CFC and CIM-SFC) have considerable potential as both digital heuristic algorithms and optically implemented physical devices. Rapid advances in the thin-film LiNbO 3 platform [ 15 , 16 , 17 ] as a photonic integrated circuit technology might enable the proposed optical CIM to surpass existing digital algorithms on a CMOS platform in terms of both speed and energy consumption.
The proposed CIM-inspired algorithms were shown to be fast and accurate Ising solvers even when implemented on an existing digital platform. In particular, we showed that their performance is very similar to that of other existing analog-system-based algorithms such as dSBM. This again brings up the question raised in [11] as to whether the simulation of analog spins on a digital computer can outperform a purely discrete heuristic algorithm. Finally, whether chaotic dynamics are necessary for a deterministic dynamical system to be a good Ising solver is left as an open issue for future research. [ 11 , 12 , 29 ]
## Appendix A: Optimization of simulation parameters
Here we summarize the simulation parameters used in our numerical experiments. The parameters are optimized empirically and thus do not necessarily reflect the true optimum values.
## Parameters used in Figure 5
| N step | CIM-SFC (upper left panel) | | CIM-CFC (upper right panel) |
|----------|------------------------------|--------|-------------------------------|
| | 500 | N step | 1000 |
| ∆ T | 0.4 | ∆ T | 0.4 |
| p | -1.0 | p | -1.0 |
| c | 1.0 | α | 1.0 |
| β | 0.3 | β | |
| k | 0.2 | | 0.2 |
| | CIM-SFC (lower left panel) | | CIM-CFC (lower right panel) |
| | | N step | 1000 |
| N step | 500 | ∆ T | 0.4 |
| ∆ T | 0.4 | T | 900 |
| p | -1.0 → 1.0 | r T | 100 |
| c | 1.0 → 3.0 | p | |
| β | 0.3 → 0.1 | p | -1.0 → 1.0 |
| | | α | 1.0 |
| k | 0.2 | β | 0.2 |
## Parameters used in Figure 10, 11, and 12
## CIM-CAC
In our simulation, the x i variables are restricted to the range [ -3 2 √ α, 3 2 √ α ] at each time step. The parameters p and α are modulated linearly from their starting to ending values during the T r time steps and are kept at the final value for an additional T p time steps. The initial value x i is set to a random value chosen from a zero-mean Gaussian distribution with a standard deviation of 10 -4 and e i = 1. Furthermore, 3200 trajectories are computed per instance to evaluate TTS. The actual parameters used for simulation are listed below:
| N step | 3200 |
|----------|------------|
| ∆ T | 0.125 |
| T r | 2880 |
| T p | 320 |
| p | -1.0 → 1.0 |
| α | 1.0 → 2.5 |
| β | 0.8 |
## CIM-CFC
In our simulation the x i variables are restricted to the range [ -1 . 5 , 1 . 5] and e i is restricted to the range [0 . 01 , ∞ ]. The parameter p is modulated linearly from its starting to ending values during the first T r time steps and kept at the final value for an additional T p time steps. The initial value x i is set to a random value chosen from a zero-mean Gaussian distribution with a standard deviation of 0 . 1 and e i = 1. Furthermore, 3200 trajectories are computed per instance to evaluate TTS. The actual parameters used for simulation are listed below:
| N step | 1000 |
|----------|------------|
| ∆ T | 0.4 |
| T r | 900 |
| T p | 100 |
| p | -1.0 → 1.0 |
| α | 1.0 |
| β | 0.2 |
## CIM-SFC
Restriction of x i and e i variables is not needed as this system is more numerically stable. The parameters p , c and β are modulated linearly from their starting to ending values during simulation. The initial value x i is set to a random value chosen from a zero-mean Gaussian distribution with standard deviation of 0 . 1 and e i = 0. 3200 trajectories are computed per instance to evaluate TTS. Actual parameters used for simulation are listed below:
| N step | 500 |
|----------|------------|
| ∆ T | 0.4 |
| p | -1.0 → 1.0 |
| c | 1.0 → 3.0 |
| β | 0.3 → 0.1 |
| k | 0.2 |
In addition to the above-mentioned parameters, it is important for the normalizing factor ξ for the mutual coupling term to be chosen as [31],
$$\xi = \sqrt { \frac { 2 N } { \sum J _ { i j } ^ { 2 } } } .$$
This choice is crucial for the successful performance of CIM-SFC but not for CIM-CAC and CIM-CFC.
Moreover, it is important to note that we used the same number of time steps for all the problem sizes in Figures 10 and 11. It is likely that the optimal number of time steps is smaller for smaller problem sizes, thus the scaling of TTS when the number of time steps is optimized separately for each problem size might be slightly worse than the reported scaling. However, we do not believe that this difference would be very significant. For the scaling of TTS for CIM-CAC when different parameters are chosen, see Appendix C.
## dSBM
For Figure 12, dSBM is implemented as described in [29]. The parameters used are
$$\frac { N \text { step} } { \Delta T } & = 2 0 0 0 \\ c & = 0 . 5$$
## Parameters used in Figure 14
The parameters for N=800 are the same as those for Figure 12. The parameters for N=1200 are listed below. The number of trajectories used for N=1200 was 3200 for most instances; however, to accurately evaluate the success probability, 10000-50000 trajectories were computed for the 10 hardest instances for both algorithms. Moreover, owing to the hardness in the case of N=1200, we are not very certain that the true ground state was found.
## CIM-CAC
| N step | 8000 |
|----------|------------|
| ∆ T | 0.125 |
| T r | 7200 |
| T p | 800 |
| p | -1.0 → 1.0 |
| α | 1.0 → 2.5 |
| β | 0.8 |
## dSBM
## Numerical Integration
An Euler step is used for integration in all the cases (except for dSBM). As described above we constrain the range of x i variables to ensure numerical stability. This is not necessary for performance but allows us to increase the integration time step by a factor of 2 or 3 without compromising the success probability. In Figure 15 we show the success probability of CIM-CAC with respect to the time step for both constrained and unconstrained systems.
The results in Section 5 for CIM-CFC do not use this numerical constraint the CIM in Section 5 is meant to be a physical machine, and a time step of 0.2 is used.
## Appendix B: Simulation Results for G-set
The results in Figure 13 for dSBM are taken directly from the GPU implementation of dSBM in [29]. The unit for TTS in Table ?? is time steps to solution, or equivalently, MVM to solution. In our simulation, 3200, 10000, or 32000 trajectories were generated to evaluate the TTS depending on the instance difficulty. The numbers in bold denote the best TTS among the three algorithms.
Figure 15: Success probability of CIM-CAC with respect to time step for both constrained and unconstrained systems. For the blue curve, the x i amplitudes are restricted to the range [ -1 . 5 √ α, 1 . 5 √ α ]
<details>
<summary>Image 15 Details</summary>
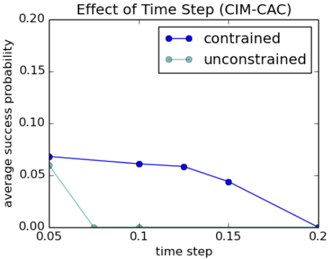
### Visual Description
\n
## Line Chart: Effect of Time Step (CIM-CAC)
### Overview
This image presents a line chart illustrating the effect of the time step on the average success probability for two scenarios: a constrained system and an unconstrained system. The chart displays how the average success probability changes as the time step varies from approximately 0.05 to 0.2.
### Components/Axes
* **Title:** "Effect of Time Step (CIM-CAC)" - positioned at the top-center of the chart.
* **X-axis:** "time step" - ranging from approximately 0.05 to 0.2, with markers at 0.05, 0.1, 0.15, and 0.2.
* **Y-axis:** "average success probability" - ranging from 0.0 to 0.2, with markers at 0.0, 0.05, 0.1, 0.15, and 0.2.
* **Legend:** Located at the top-right corner of the chart.
* "constrained" - represented by a solid blue line with circular markers.
* "unconstrained" - represented by a dashed light-blue line with circular markers.
### Detailed Analysis
**Constrained Line (Blue):**
The constrained line starts at approximately 0.075 at a time step of 0.05. It then decreases gradually to approximately 0.06 at a time step of 0.1, then to approximately 0.045 at a time step of 0.15, and finally reaches approximately 0.0 at a time step of 0.2. The line exhibits a downward trend, indicating a decreasing success probability as the time step increases.
**Unconstrained Line (Light-Blue):**
The unconstrained line begins at approximately 0.055 at a time step of 0.05. It then decreases sharply to approximately 0.0 at a time step of 0.1, and remains at approximately 0.0 for the remaining time steps (0.15 and 0.2). This line shows a rapid decline in success probability with increasing time step.
### Key Observations
* The constrained system initially has a higher success probability than the unconstrained system.
* The success probability for the constrained system decreases gradually with increasing time step.
* The success probability for the unconstrained system drops to zero very quickly as the time step increases.
* The unconstrained system is significantly more sensitive to changes in the time step than the constrained system.
### Interpretation
The chart suggests that increasing the time step negatively impacts the average success probability for both constrained and unconstrained systems. However, the unconstrained system is far more susceptible to this effect. This could indicate that the constraints in the constrained system provide stability and robustness against larger time steps. The rapid decline in success probability for the unconstrained system suggests that it may be more prone to instability or errors when using larger time steps. The data implies that for optimal performance, a smaller time step should be used, particularly for unconstrained systems. The CIM-CAC context suggests this relates to a control or simulation environment where time step selection is critical for accurate results. The fact that the constrained system maintains *some* success probability even at the largest time step suggests the constraints are effectively mitigating the negative effects of a larger time step.
</details>
## CIM-CAC parameters for G-set
The variables are restricted as described in Appendix A, and the initial conditions are set in the same way. The following parameters are the same for all the G-set instances.
$$\frac { \alpha } { \beta } | \begin{array} { c | c } 1 . 0 & 3 . 0 \\ 0 . 3 \end{array}$$
The parameters p , ∆ T , and the number of time steps used in each phase are chosen by instance type as follows:
| N step | 4000 |
|----------|--------|
| ∆ T | 1.25 |
| c | 0.5 |
| Graph Type | Edge Weight | N | Instance # | p | N step | ∆ T | T r | T p |
|--------------|---------------|------|--------------|-------------|----------|-------|-------|-------|
| Random | { +1 } | 800 | 1-5 | -0.5 → 1.0 | 6666 | 0.075 | 6000 | 666 |
| Random | { +1, -1 } | 800 | 6-10 | -0.5 → 1.0 | 6666 | 0.075 | 6000 | 666 |
| Toroidal | { +1, -1 } | 800 | 11-13 | -4.0 | 5000 | 0.1 | 4500 | 500 |
| Planar | { +1 } | 800 | 14-17 | -1.0 | 20000 | 0.05 | 18000 | 2000 |
| Planar | { +1, -1 } | 800 | 18-21 | -1.0 | 20000 | 0.05 | 18000 | 2000 |
| Random | { +1 } | 1000 | 43-46 | -0.5 → 1.0 | 10000 | 0.1 | 9000 | 1000 |
| Planar | { +1 } | 1000 | 51-54 | -1.0 | 20000 | 0.05 | 18000 | 2000 |
| Random | { +1 } | 2000 | 22-26 | -0.5 → 1.0 | 20000 | 0.1 | 19000 | 1000 |
| Random | { +1, -1 } | 2000 | 27-31 | -0.5 → 1.0 | 20000 | 0.1 | 19000 | 1000 |
| Toroidal | { +1, -1 } | 2000 | 32-34 | -4.0 → -3.0 | 20000 | 0.1 | 19000 | 1000 |
| Planar | { +1 } | 2000 | 35-38 | -1.0 → -0.5 | 80000 | 0.05 | 78000 | 2000 |
| Planar | { +1 } | 2000 | 39-42 | -1.0 → -0.5 | 80000 | 0.05 | 78000 | 2000 |
## CIM-CFC parameters for G-set
The variables are restricted as described in Appendix A, and the initial conditions are set in the same way. The following parameters are the same for all the G-set instances.
$$\frac { \alpha } { \beta } \left | \begin{array} { c c } { 1 . 0 } \\ { 0 . 1 5 } \end{array} \right |$$
The parameters p , ∆ T , and the number of time steps used in each phase are chosen by instance type as follows:
| Graph Type | Edge Weight | N | Instance # | p | N step | ∆ T | T r | T p |
|--------------|---------------|------|--------------|-------------|----------|-------|-------|-------|
| Random | { +1 } | 800 | 1-5 | -1.0 → 1.0 | 4000 | 0.125 | 3600 | 400 |
| Random | { +1, -1 } | 800 | 6-10 | -1.0 → 1.0 | 2000 | 0.25 | 1800 | 200 |
| Toroidal | { +1, -1 } | 800 | 11-13 | -3.0 → -1.0 | 2000 | 0.25 | 1800 | 200 |
| Planar | { +1 } | 800 | 14-17 | -2.0 → 0.0 | 8000 | 0.125 | 7200 | 800 |
| Planar | { +1, -1 } | 800 | 18-21 | -2.0 → 0.0 | 4000 | 0.25 | 3600 | 400 |
| Random | { +1 } | 1000 | 43-46 | -1.0 → 1.0 | 5000 | 0.2 | 4500 | 500 |
| Planar | { +1 } | 1000 | 51-54 | -2.0 → 0.0 | 16000 | 0.125 | 15200 | 800 |
| Random | { +1 } | 2000 | 22-26 | -1.0 → 1.0 | 10000 | 0.2 | 9500 | 500 |
| Random | { +1, -1 } | 2000 | 27-31 | -1.0 → 1.0 | 10000 | 0.2 | 9500 | 500 |
| Toroidal | { +1, -1 } | 2000 | 32-34 | -3.0 → -1.0 | 40000 | 0.1 | 39000 | 1000 |
| Planar | { +1 } | 2000 | 35-38 | -2.0 → 0.0 | 80000 | 0.05 | 78000 | 2000 |
| Planar | { +1 } | 2000 | 39-42 | -2.0 → 0.0 | 40000 | 0.1 | 39000 | 1000 |
## Results on G-set
Success probability and TTS of CIM-CAC, CIM-CFC and dSBM on G-set graphs. The success probability for CIM-CAC and CIM-CFC is for a single trajectory. The results for dSBM are from the GPU implementation in [29].
| Instance | CIM-CAC TTS | CIM-CAC P s | CIM-CFC TTS | CIM-CFC P s | dSBM TTS | dSBM P s * |
|------------|--------------------|---------------|---------------|---------------|---------------------|--------------|
| G1 | 90805 | 0.286875 | 60078 | 0.264062 | 339332 | 0.987 |
| G2 | 920217 | 0.0328125 | 1330454 | 0.01375 | 2578124 | 0.82 |
| G3 | 169551 | 0.165625 | 249212 | 0.07125 | 400343 | 0.996 |
| G4 | 209086 | 0.136563 | 239389 | 0.0740625 | 361673 | 0.983 |
| G5 | 226881 | 0.126562 | 226449 | 0.078125 | 618221 | 0.972 |
| G6 | 188908 | 0.15 | 104083 | 0.0846875 | 190728 | 0.979 |
| G7 | 562413 | 0.053125 | 146490 | 0.0609375 | 201889 | 0.974 |
| G8 | 431029 | 0.06875 | 399118 | 0.0228125 | 358947 | 0.954 |
| G9 | 411604 | 0.071875 | 223836 | 0.0403125 | 1095704 | 0.867 |
| G10 | 1388073 | 0.021875 | 622470 | 0.0146875 | 1410031 | 0.407 |
| G11 | 337563 | 0.0659375 | 222079 | 0.040625 | 282524 | 0.98 |
| G12 | 224452 | 0.0975 | 78562 | 0.110625 | 407997 | 0.973 |
| G13 | 391011 | 0.0571875 | 373236 | 0.024375 | 800687 | 0.996 |
| G14 | 17291018 | 0.0053125 | 13080721 | 0.0028125 | 1469967245 | 0.005 |
| G15 | 521572 | 0.161875 | 462528 | 0.0765625 | 6782113 | 0.804 |
| G16 | 494303 | 0.17 | 737146 | 0.04875 | 9156329 | 0.992 |
| G17 | 3089154 | 0.029375 | 3256332 | 0.01125 | 33222397 | 0.283 |
| G18 | 556635 | 0.1525 | 507805 | 0.035625 | 14375986 | 0.074 |
| G19 | 1218307 | 0.0728125 | 179562 | 0.0975 | 417204 | 0.995 |
| G20 | 106718 | 0.578125 | 42428 | 0.352187 | 188349 | 0.98 |
| G21 | 3991180 | 0.0228125 | 574365 | 0.0315625 | 10080921 | 0.136 |
| G43 | 174031 | 0.2325 | 145625 | 0.14625 | 228908 | 0.992 |
| G44 | 244188 | 0.171875 | 257230 | 0.085625 | 263171 | 0.985 |
| G45 | 880856 | 0.0509375 | 970877 | 0.0234375 | 1754473 | 0.985 |
| G46 | 1528073 | 0.0296875 | 717957 | 0.0315625 | 610421 | 0.992 |
| G51 | 3732360 | 0.024375 | 2189016 | 0.0331 | 424989992 | 0.067 |
| G52 | 3122871 | 0.0290625 | 3820774 | 0.0191 | 92285270 | 0.213 |
| G53 | 17291018 | 0.0053125 | 11298922 | 0.0065 | 1676440469 | 0.043 |
| G54 | 294684837 | 0.0003125 | 1178886725 | 6.25e-05 | 49107077298 | 0.0006 |
| G22 | 2516544 | 0.0359375 | 2718081 | 0.0168 | 8401394 | 0.928 |
| G23 | N/A | 0.0 | N/A | 0.0 | N/A | 0 |
| G24 | 4785454 | 0.0190625 | 5733406 | 0.008 | 10585339 | 0.648 |
| G25 | 17291018 | 0.0053125 | 15327529 | 0.003 | 43414254 | 0.399 |
| G26 | 10117012 | 0.0090625 | 10941648 | 0.0042 | 10730290 | 0.643 |
| G27 | 835530 | 0.104375 | 649972 | 0.0684 | 832465 | 0.971 |
| G28 | 2389444 | 0.0378125 | 2413498 | 0.0189 | 1455914 | 0.952 |
| G29 | 4164219 | 0.021875 | 7404644 | 0.0062 | 5516820 | 0.737 |
| G30 | 42058344 | 0.0021875 | 32871041 | 0.0014 | 11002259 | 0.738 |
| G31 | 49075749 | 0.001875 | 92080375 | 0.0005 | 19923732 | 0.199 |
| G32 | 70802710 | 0.0013 | 1841975969 | 0.0001 | 150969342 | 0.093 |
| G33 | 306965291 | 0.0003 | N/A | 0.0 | 2204950868 | 0.005 |
| G34 | 20886506 | 0.0044 | 32801883 | 0.0056 | 84156149 | 0.231 |
| G35 | N/A | 0.0 | N/A | 0.0 | N/A | 0 |
| G36 | 368321503 | 0.0005 | 3683951938 | 0.0001 | 736790387782 | 0.0001 |
| G38 | 108264816 | 0.0017 | | 0.0025 | 1046295719 | 0.068 |
| | | | 147181162 | | | 0.107 |
| G39 | 4065368 1841975969 | 0.0443 0.0001 | 3497864 N/A | 0.0513 0.0 | 651087484 264354894 | 0.154 |
| G40 G41 | 17123320 | 0.0107 | 7916531 | 0.023 | 222414431 | 0.282 |
| G42 | 13969282 | 0.0131 | 18328423 | 0.01 | N/A | 0 |
*Note that P s for dSBM taken from [29] is the success probability for a batch of 160 trajectories. To calculate the P s for a single dSBM trajectory use 1 -(1 -P s ) 1 160 .
## Appendix C: Reasoning for parameter selection
The parameters are selected numerically for the most part; however, the choice of p , α , and β can be understood as follows. It is observed that the average residual energy visited by CIM-CAC during the search process can be roughly estimated by the formula. [ 11 ]
$$\Delta E _ { a v g } \approx K \frac { 1 - p } { \alpha \beta }$$
where K is a constant depending only on the problem type and size. This formula essentially predicts the effective sampling temperature of the system (although the distribution may not be an exact Boltzmann distribution). Based on this philosophy, we gradually reduce the 'system temperature' to produce an annealing effect. This is the motivation for increasing p and α . The different choices for the range of p on different G-set instances reflects the vastly different values for the constant K depending on the structure of the max-cut problem.
In a more general setting, the value of K can be predicted on the basis of the problem type; thus, the range for p and α can be chosen accordingly.
Although it has not been verified, a similar formula most likely holds for CIM-CFC; thus, the parameters for CIM-CFC are chosen in the same way.
## Optimal parameters with respect to problem size (CIM-CAC)
Figure 16: Performance of CIM-CAC with respect to problem size for different parameters. The fixed parameters are indicated in red while the parameter modulation is indicated in blue. The red and blue dotted lines are fits for the lower envelopes of the red and blue curves, respectively
<details>
<summary>Image 16 Details</summary>
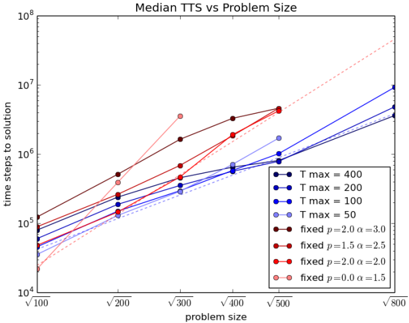
### Visual Description
\n
## Chart: Median TTS vs Problem Size
### Overview
The image presents a line chart illustrating the relationship between median Time To Solution (TTS) and Problem Size. The chart displays multiple lines, each representing a different parameter setting. The x-axis represents Problem Size, and the y-axis represents Time Steps to Solution, both on a logarithmic scale.
### Components/Axes
* **Title:** "Median TTS vs Problem Size" (centered at the top)
* **X-axis:** "problem size" (bottom-center). Scale is logarithmic, with markers at √100, √200, √300, √400, √500, and √800.
* **Y-axis:** "time steps to solution" (left-center). Scale is logarithmic, ranging from 10<sup>4</sup> to 10<sup>8</sup>.
* **Legend:** Located in the top-right corner. Contains the following labels and corresponding colors:
* T max = 400 (Black)
* T max = 200 (Dark Blue)
* T max = 100 (Light Blue)
* T max = 50 (Purple)
* fixed p = 2.0 α = 3.0 (Dark Red)
* fixed p = 1.5 α = 2.5 (Medium Red)
* fixed p = 2.0 α = 2.0 (Light Red)
* fixed p = 0.0 α = 1.5 (Red with circles)
### Detailed Analysis
The chart displays several lines representing different parameter settings. The lines generally trend upwards, indicating that as problem size increases, the time steps to solution also increase.
* **T max = 400 (Black):** The line starts at approximately 2 x 10<sup>5</sup> at √100 and increases to approximately 2 x 10<sup>6</sup> at √800. It shows a roughly linear increase.
* **T max = 200 (Dark Blue):** The line starts at approximately 1 x 10<sup>5</sup> at √100 and increases to approximately 1 x 10<sup>6</sup> at √800. It shows a roughly linear increase.
* **T max = 100 (Light Blue):** The line starts at approximately 5 x 10<sup>4</sup> at √100 and increases to approximately 5 x 10<sup>5</sup> at √800. It shows a roughly linear increase.
* **T max = 50 (Purple):** The line starts at approximately 2 x 10<sup>4</sup> at √100 and increases to approximately 2 x 10<sup>5</sup> at √800. It shows a roughly linear increase.
* **fixed p = 2.0 α = 3.0 (Dark Red):** The line starts at approximately 1 x 10<sup>5</sup> at √100 and increases to approximately 1 x 10<sup>7</sup> at √800. It shows a steeper, non-linear increase.
* **fixed p = 1.5 α = 2.5 (Medium Red):** The line starts at approximately 3 x 10<sup>4</sup> at √100 and increases to approximately 3 x 10<sup>6</sup> at √800. It shows a roughly linear increase.
* **fixed p = 2.0 α = 2.0 (Light Red):** The line starts at approximately 2 x 10<sup>4</sup> at √100 and increases to approximately 2 x 10<sup>5</sup> at √800. It shows a roughly linear increase.
* **fixed p = 0.0 α = 1.5 (Red with circles):** The line starts at approximately 1 x 10<sup>4</sup> at √100 and increases to approximately 7 x 10<sup>6</sup> at √800. It shows a steeper, non-linear increase.
### Key Observations
* The lines representing "fixed p = 2.0 α = 3.0" and "fixed p = 0.0 α = 1.5" exhibit the steepest increases in TTS with increasing problem size.
* The lines representing different "T max" values are relatively close together and show a more gradual increase.
* The logarithmic scale compresses the differences at higher values, making it difficult to discern precise differences between the lines at the upper end of the problem size range.
### Interpretation
The chart demonstrates that the time steps to solution are significantly affected by the parameter settings, particularly the "p" and "α" values. The steeper slopes for the "fixed p" lines suggest that these parameter combinations lead to a more rapid increase in computational effort as the problem size grows. The "T max" parameter appears to have a less dramatic effect, with lines representing different "T max" values remaining relatively close together.
The logarithmic scales on both axes suggest that the relationship between problem size and TTS is likely exponential or polynomial. The chart could be used to inform the selection of appropriate parameter settings for a given problem size, balancing computational cost with solution accuracy. The outliers, namely the lines with the steepest slopes, indicate parameter combinations that may be less suitable for large problem sizes due to their high computational demands. The chart suggests that the algorithm's performance is highly sensitive to the choice of parameters, and careful tuning is necessary to achieve optimal results.
</details>
Figure 16 shows the difference in scaling when the parameters are fixed (red shades) compared to when the parameters are modulated linearly (blue shades). In addition, the optimal annealing time (in other words, the optimal speed of modulation) will change with respect to the problem size, as we need long annealing times to get good results for large problem sizes. This pattern was also used when choosing parameters on the G-set.
Although Figure 16 is based on the Gaussian quantum model for CIM-CAC in MFB-CIM (see [31]), the difference in performance between this model and the noiseless model discussed in this paper is insignificant, as g 2 = 10 -4 was used. It should also be noted that a time step of 0.01 was used in Figure 16.
Therefore, the TTS in Figure 16 is an order of magnitude longer than the results presented in this study, where a time step of 0.125 was used.
## Appendix D: Results and Discussion for CIM-SFC on G-set
Based on our understanding of CIM-SFC, it is very important that the term tanh( cz i ) transitions from the 'soft spin' mode where cz i ≈ 0 and tanh( cz i ) ≈ cz i to the 'discrete spin' mode where | cz i | >> 0 and tanh( cz i ) ≈ sign( cz i ). Therefore, we use the normalizing factor ξ (as defined above) as this ensures that z i will on average be around √ 2 for a randomly chosen spin configuration, thus we can use the same value for c in all the cases and get similar results. However, this only works for instances such as SK instances where each node has equal connectivity; thus, we can expect z i to have roughly the same range of values for all i .
On some G-set instances, especially the planar graph instances, some nodes have a much larger degree; thus, cz i will be too large in some cases and too small in others regardless of the normalizing factor ξ used. This may be one of the reasons why CIM-SFC struggles on many G-set instances, especially planar graphs. This could also be the reason why dSBM struggles on planar graphs, as dSBM relies on the same normalizing factor to get good results. CIM-CAC and CIM-CFC do not need this normalizing factor, as they automatically compensate for different values of ∑ j J ij σ j , and this might be why they perform well on planar graphs.
Meanwhile, for toroidal graphs, the opposite is true, as ∑ j J ij σ j can only take on five different values for these graphs. This could mean that the transition from 'soft spin' to 'discrete spin' is rapid in the case of CIM-SFC; thus, we need to carefully tune the parameters to get good results on these graphs.
Although this observation regarding the analog/discrete transition may partially explain the poor results on the G-set, it is not a complete explanation. For example, CIM-SFC struggles on some random graphs (such as G9) that do not have the above-mentioned property, as each node has similar connectivity.
The results for CIM-SFC on the G-set as well as the parameters used are listed below (not all instances were tested).
## Results for CIM-SFC on the G-set
| Instance | TTS | P s |
|------------|----------|-----------|
| G1 | 28470 | 0.194 |
| G2 | 1531984 | 0.004 |
| G3 | 130388 | 0.046 |
| G4 | 435510 | 0.014 |
| G5 | 380685 | 0.016 |
| G6 | 112834 | 0.0202 |
| G7 | 163316 | 0.014 |
| G8 | 125360 | 0.0182 |
| G9 | 4604018 | 0.0005 |
| G10 | 395845 | 0.0058 |
| G11 | 195461 | 0.0572 |
| G12 | 128184 | 0.0859 |
| G13 | 311368 | 0.0363 |
| G43 | 1702012 | 0.0134375 |
| G44 | 1742812 | 0.013125 |
| G45 | 73671209 | 0.0003125 |
| G46 | 1927483 | 0.011875 |
For instances G14-G21 (800 node planar graphs) and G51-G54 (1000 node planar graphs), CIM-SFC shows a success probability of either zero or a very small nonzero value. Furthermore, 2000 node instances have not been tested.
## Parameters for CIM-SFC on G-set
## Common parameters
Parameters selected by problem type
| Graph Type | Edge Weight | N | Instance # | c | β | k | N step | ∆ T |
|--------------|---------------|------|--------------|-----------|------------|------|----------|-------|
| Random | { +1 } | 800 | 1-5 | 1.0 → 3.0 | 0.3 → 0.0 | 0.2 | 2666 | 0.15 |
| Random | { +1, -1 } | 800 | 6-10 | 1.0 → 3.0 | 0.3 → 0.0 | 0.2 | 500 | 0.4 |
| Toroidal | { +1, -1 } | 800 | 11-13 | 1.4 | 0.05 → 0.0 | 0.32 | 2500 | 0.4 |
| Random | { +1 } | 1000 | 43-46 | 1.4 → 4.2 | 0.2 → 0.0 | 0.2 | 5000 | 0.2 |
The parameters for CIM-SFC are chosen experimentally, and the understanding of how the parameters affect the performance and dynamics is limited. Once this system is studied more thoroughly, we will propose a more systematic method of choosing parameters so that good performance can be ensured on many different problem types.
## Appendix E: Similarities and Differences Between CIM and SBM Algorithms
Using continuous analog dynamics to solve discrete optimization problems is a somewhat new concept, and it is interesting to compare these different approaches. [ 13 , 11 , 29 ] In this appendix, we will briefly discuss some similarities and differences among the three CIM-inspired algorithms and the SBM algorithms.
All four systems discussed in Section 6, namely CIM-CAC, CIM-CAC, CIM-SFC, and dSBM, were originally inspired by the same fundamental principle:[10, 27]:
The function
$$H ( x ) = \sum _ { i } \left ( \frac { x _ { i } ^ { 2 } } { 4 } - \frac { 1 - p } { 2 } \right ) x _ { i } ^ { 2 } + c \sum _ { i } \sum _ { j } J _ { i j } x _ { i } x _ { j }$$
can be used as a continuous approximation of the Ising cost function.
In the original CIM algorithm, gradient descent is used to find the local minima of H , while H is deformed by increasing p . This system has two major drawbacks:[10]
1. local minima are stable;
2. incorrect mapping of the Ising problem to the cost function owing to amplitude heterogeneity.
All four algorithms discussed in Section 6 can be regarded as modifications of the original CIM algorithm, which aim to overcome these two flaws. [ 11 , 27 , 28 , 29 ] In all these algorithms, the first flaw is addressed by adding new degrees of freedom to the system; hence, there are now 2 N (instead of only N ) analog variables for N spins. In SBM, this is done by including both a position vector, x i , and a velocity/momentum vector y i , while in the modified CIM algorithms we add the auxiliary variable e i .
To address the second flaw, the creators of dSBM added discretization and 'inelastic walls', whereas in CIM- CFC and CIM-SFC, this discretization is not necessary. Using different mechanisms, all three algorithms ensure that the system only has fixed points at the local minima of the Ising Hamiltonian (during the end of the trajectory), something which is not true for the original CIM algorithm. Because these systems are fundamentally very similar, it should not be surprising that they achieve similar performance.
$$p \, - 1 . 0 \to 1 . 0$$
We also note that for dSBM to achieve good performance, it is necessary to use discretization and inelastic walls, which make the system discontinuous. This is particularly useful for implementation on a digital platform, which prefers discrete processes; however, when implementing these algorithms on an analog physical platform, this is not preferred. Meanwhile, in the case of CIM-CAC, CIM-CFC, and CIM-SFC, the system evolves continuously; thus, they are much more suitable for analog implementation, such as the optical CIM architecture proposed in this paper.
An interesting difference between the CIM and the original bifurcation machine [ 27 ] , which was referred to as aSBM in [29], is that aSBM is a completely unitary dissipation-less system. Because of this, aSBM relies on adiabatic evolution for computation (similar to quantum annealing), unlike the dissipative CIM and other Ising heuristics (such as simulated annealing or breakout local search [ 14 ] ) , which rely on some sort of dissipative relaxation. However, in [29], the new SBM algorithms deviate from this concept of adiabatic evolution by adding inelastic walls, thus making the new bifurcation machine a dissipative system in which information is lost over time. It would be interesting to try to understand whether dissipation is in fact necessary for a system to achieve the high performance of the algorithms discussed in this paper. For example, one could modify aSBM in a different way that addresses the problem of amplitude heterogeneity but retains the adiabatic nature. Whether this is possible is beyond the scope of this paper.
## Appendix F: Optical Implementation of CIM-SFC
Figure 17: Optical implementation of CIM-SFC.
<details>
<summary>Image 17 Details</summary>
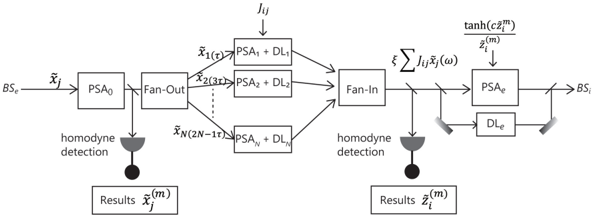
### Visual Description
\n
## Diagram: Block Diagram of a Signal Processing System
### Overview
The image presents a block diagram illustrating a signal processing system. The diagram depicts a series of processing blocks connected by arrows indicating signal flow. The system appears to involve multiple stages of processing, including power spectral analysis (PSA), delay lines (DL), fan-out and fan-in operations, and a non-linear transformation (tanh). The diagram also includes homodyne detection and result outputs.
### Components/Axes
The diagram consists of the following components:
* **BS<sub>i</sub>**: Input signal.
* **PSA<sub>0</sub>**: Power Spectral Analysis block.
* **Fan-Out**: Splits the signal into multiple paths.
* **PSA<sub>A</sub> + DL<sub>i</sub>**: Power Spectral Analysis and Delay Line blocks (indexed by 'i').
* **x<sub>1</sub>(τ)**, **x<sub>2</sub>(3τ)**, **x<sub>N</sub>(2N-1τ)**: Intermediate signals.
* **J<sub>f</sub>**: Input signal to the first PSA/DL block.
* **Fan-In**: Combines multiple signals into a single path.
* **∑ J<sub>f</sub>x<sub>j</sub>(ω)**: Summation block.
* **PSA<sub>e</sub>**: Power Spectral Analysis block.
* **DL<sub>e</sub>**: Delay Line block.
* **tanh(cz<sup>m</sup>)**: Non-linear transformation.
* **z<sup>(m)</sup>**: Intermediate signal.
* **homodyne detection**: Detection block.
* **Results x<sub>j</sub><sup>(m)</sup>**: Output results.
* **Results z<sub>j</sub><sup>(m)</sup>**: Output results.
* **BS<sub>e</sub>**: Output signal.
### Detailed Analysis or Content Details
The signal flow can be described as follows:
1. An input signal **BS<sub>i</sub>** enters the system and is processed by **PSA<sub>0</sub>**.
2. The output of **PSA<sub>0</sub>** is split into multiple parallel paths via a **Fan-Out** block.
3. Each path consists of a **PSA<sub>A</sub>** block followed by a **DL<sub>i</sub>** block. The input **J<sub>f</sub>** is also fed into the first **PSA<sub>A</sub> + DL<sub>i</sub>** block.
4. The outputs of the parallel paths are combined using a **Fan-In** block.
5. The combined signal is then processed by **PSA<sub>e</sub>** and **DL<sub>e</sub>**.
6. The output of **DL<sub>e</sub>** is passed through a non-linear transformation **tanh(cz<sup>m</sup>)**.
7. The final output signal **BS<sub>e</sub>** is generated.
8. Homodyne detection is performed on the outputs of the **Fan-Out** and **Fan-In** blocks, resulting in **Results x<sub>j</sub><sup>(m)</sup>** and **Results z<sub>j</sub><sup>(m)</sup>**, respectively.
The diagram does not provide specific numerical values or quantitative data. It is a schematic representation of a signal processing architecture.
### Key Observations
The system utilizes parallel processing with multiple PSA and DL blocks. The fan-out and fan-in operations suggest a form of signal averaging or combining. The non-linear transformation introduces a degree of complexity and potentially allows for signal shaping or feature extraction. The homodyne detection indicates that the system is sensitive to the phase of the input signal.
### Interpretation
This diagram likely represents a system for signal detection or estimation. The parallel processing and averaging operations could be used to improve signal-to-noise ratio. The non-linear transformation may be used to enhance specific signal features or to implement a decision rule. The homodyne detection suggests that the system is designed to operate with coherent signals. The overall architecture suggests a sophisticated signal processing system capable of extracting information from noisy or complex signals. The diagram is a high-level representation and does not provide details about the specific algorithms or parameters used in each block. The use of 'τ' and 'ω' suggests time and frequency domain processing, respectively. The indices 'i', 'j', 'f', 'e', and 'm' likely represent different channels, frequencies, or iterations within the system.
</details>
Figure 17 shows an optical implementation of CIM-SFC which is similar to that of CIM-CAC and CIMCFC shown in Figure 6. The feedback signal ˜ z i = ∑ j J ij ˜ x j is deamplified (rather than amplified) by PSA e with attenuation coefficient tanh( ˜ z i ( m ) ) ˜ z i ( m ) , where ˜ z i ( m ) is an optical homodyne measurement result of ˜ z i . This feedback signal is then injected back into signal pulse x i in the main cavity through BS i .
Part of the fan-in circuit output ˜ z i is delayed by a delay line DL e with delay time Nτ and combined with the error pulse e i (inside the main cavity). This implements the term e i -˜ z i in Eq. (8). The term -β ( e i -˜ z i ) on the right-hand side of Eq. (8) is implemented by a phase-sensitive amplifier PSA e of the main cavity. This is also a deamplification process. Finally, the error correction signal amplitude e i -˜ z i is coupled to the signal pulse x i inside the main cavity with a standard optical delay line.
## Conflict of Interest
The authors have no confict of interest, financial or otherwise.
## Acknowledgements
The authors wish to thank R. Hamerly, M. G. Suh, M. Jankowski, E. Ng and Y. Inui for their valuable discussions.
## References
- [1] F. Barahona, J. Phys. A 1982 , 15 , 3241.
- [2] M. W. Johnson, M. H. S. Amin, S. Gildert, T. Lanting, F. Hamze, N. Dickson, R. Harris, A. J. Berkley, J. Johansson, P. Bunyk, E. M. Chapple, C. Enderud, J. P. Hilton, K. Karimi, E. Ladizinsky, N. Ladizinsky, T. Oh, I. Perminov, C. Rich, M. C. Thom, E. Tolkacheva, C. J. S. Truncik, S. Uchaikin, J. Wang, B. Wilson, G. Rose, Nature 2011 , 473 , 194.
- [3] S. Boixo, T. F. Rønnow, S. V. Isakov, Z. Wang, D. Wecker, D. A. Lidar, J. M. Martinis, M. Troyer, Nat. Phys. 2014 , 10 , 218.
- [4] A. Marandi, Z. Wang, K. Takata, R. L. Byer, Y. Yamamoto, Nat. Photonics 2014 , 8 , 937.
- [5] T. Inagaki, K. Inaba, R. Hamerly, K. Inoue, Y. Yamamoto, H. Takesue, Nat Photon. 2016 , 10 , 415.
- [6] P. L. McMahon, A. Marandi, Y. Haribara, R. Hamerly, C. Langrock, S. Tamate, T. Inagaki, H. Takesue, S. Utsunomiya, K. Aihara, R. L. Byer, M. M. Fejer, H. Mabuchi, Y. Yamamoto, Science 2016 , 354 , 614.
- [7] T. Inagaki, Y. Haribara, K. Igarashi, T. Sonobe, S. Tamate, T. Honjo, A. Marandi, P. L. McMahon, T. Umeki, K. Enbutsu, O. Tadanaga, H. Takenouchi, K. Aihara, K. Kawarabayashi, K. Inoue, S. Utsunomiya, H. Takesue, Science 2016 , 354 , 603.
- [8] R. Hamerly, T. Inagaki, P. L. McMahon, D. Venturelli, A. Marandi, T. Onodera, E. Ng, C. Langrock, K. Inaba, T. Honjo, K. Enbutsu, T. Umeki, R. Kasahara, S. Utsunomiya, S. Kako, K. Kawarabayashi, R. L. Byer, M. M. Fejer, H. Mabuchi, D. Englund, E. Rieffel, H. Takesue, Y. Yamamoto, Sci. Adv. 2019 , 5 , eaau0823.
- [9] K. Sankar, A. Scherer, S. Kako, S. Reifenstein, N. Ghadermarzy, W. B. Krayenhoff, Y. Inui, E. Ng, T. Onodera, P. Ronagh, Y. Yamamoto, arXiv:2105.03528, v1.
- [10] Z. Wang, A. Marandi, K. Wen, R. L. Byer, Y. Yamamoto, Phys. Rev. A 2013 , 88 , 063853.
- [11] T. Leleu, Y. Yamamoto, P. L. McMahon, K. Aihara, Phys. Rev. Lett. 2019 , 122 , 040607.
- [12] T. Leleu, F. Khoyratee, T. Levi, R. Hamerly, T. Kohno, K. Aihara, arXiv:2009.04084, v3
- [13] M. Ercsey-Ravasz, Z. Toroczkai, Nature Phys , 2011 , 966 970.
- [14] U. Benlic, J. K. Hao, Eng. Appl. Artif. Intell. 2013 , 26 , 1162.
- [15] C. Wang, C. Langrock, A. Marandi, M. Jankowski, M. Zhang, B. Desiatov, M. M. Fejer, M. Lonˇ car, Optica 2018 , 5 , 1438.
- [16] B. Stern, X. Ji, Y. Okawachi, A. L. Gaeta, M. Lipson, Nature 2018 , 562 , 401.
- [17] C. Wang, M. Zhang, X. Chen, M. Bertrand, A. Shams-Ansari, S. Chandrasekhar, P. Winzer, M. Lonˇ car, Nature 2018 , 562 , 101.
- [18] P. D. Drummond, C W Gardiner, J. Phys. A 1980 , 13 , 2353.
- [19] P. D. Drummond, C. W. Gardiner, D. F. Walls, Phys. Rev. A 1981 , 24 , 914.
- [20] D. F. Walls, G. J. Milburn, Quantum Optics (Springer Science and Business Media) 2007 .
- [21] K. Takata, A. Marandi, Y. Yamamoto, Phys. Rev. A 2015 , 92 , 043821.
- [22] D. Maruo, S. Utsunomiya, Y. Yamamoto, Phys. Scr. 2016 , 91 , 083010.
- [23] Y. Inui, Y. Yamamoto, Phys. Rev. A 2020 , 102 , 062419.
- [24] Y. Inui, Y. Yamamoto, Entropy 2021 , 23 , 624.
- [25] E. Ng, T. Onodera, S. Kako, P. L. McMahon, H. Mabuchi, Y. Yamamoto, arXiv:2103.05629, v1.
- [26] A. D. King, W. Bernoudy, J. King, A. J. Berkley, T. Lanting, arXiv:1806.08422, v1
- [27] H. Goto, K. Tatsumura, A. R. Dixon, Sci. Adv. 2019 , 5 , eaav2372.
- [28] K. Tatsumura, M. Yamasaki, H. Goto, Nat. Electron. 2021 , 4 , 208.
- [29] H. Goto, K. Endo, M. Suzuki, Y. Sakai, T. Kanao, Y. Hamakawa, R. Hidaka, M. Yamasaki, K. Tatsumura, Sci. Adv. 2021 , 7 , eabe795.
- [30] Y. Inui, Y. Yamamoto, arXiv:2009.10328.
- [31] S. Kako, T. Leleu, Y. Inui, F. Khoyratee, S. Reifenstein, Y. Yamamoto, Adv. Quantum Technol. 2020 , 3 , 2000045.