## Practical Timing Side Channel Attacks on Memory Compression
Martin Schwarzl
Graz University of Technology martin.schwarzl@iaik.tugraz.at
Pietro Borrello
Sapienza University of Rome borrello@diag.uniroma1.it
Michael Schwarz
CISPA Helmholtz Center for Information Security michael.schwarz@cispa.saarland
Abstract -Compression algorithms are widely used as they save memory without losing data. However, elimination of redundant symbols and sequences in data leads to a compression side channel. So far, compression attacks have only focused on the compression-ratio side channel, i.e. , the size of compressed data, and largely targeted HTTP traffic and website content.
In this paper, we present the first memory compression attacks exploiting timing side channels in compression algorithms, targeting a broad set of applications using compression. Our work systematically analyzes different compression algorithms and demonstrates timing leakage in each. We present Comprezzor, an evolutionary fuzzer which finds memory layouts that lead to amplified latency differences for decompression and therefore enable remote attacks. We demonstrate a remote covert channel exploiting small local timing differences transmitting on average 643 . 25bit ♥ h over 14 hops over the internet. We also demonstrate memory compression attacks that can leak secrets bytewise as well as in dictionary attacks in three different case studies. First, we show that an attacker can disclose secrets co-located and compressed with attacker data in PHP applications using Memcached. Second, we present an attack that leaks database records from PostgreSQL, managed by a Python-Flask application, over the internet. Third, we demonstrate an attack that leaks secrets from transparently compressed pages with ZRAM, the memory compression module in Linux. We conclude that memory-compression attacks are a practical threat.
## I. INTRODUCTION
Data compression plays a vital role for performance and efficiency. For example, compression leads to smaller data footprints, allowing more data to be stored in memory. Memory accesses are typically faster than retrieving data from slower mediums such as hard disks or solid-state disks. As a result, both Microsoft [63] and Apple [3] rely on memory compression in their operating systems (OSs) to better utilize memory. Similarly, memory compression is also used in databases [46] or keyvalue stores [45]. Compression can also increase performance when storing or transferring data on slow mediums. Hence, data compression is also widely used for HTTP traffic [41], [15] and file-system compression [6].
While compression has many advantages, it is problematic in scenarios where sensitive data is compressed [49], [20], [4], [58], [57], [32]. Attacks such as CRIME [49], BREACH [20],
Gururaj Saileshwar Georgia Tech Graz University of Technology gururaj.s@gatech.edu
Hanna M¨ uller Graz University of Technology h.mueller@student.tugraz.at
Daniel Gruss
Graz University of Technology daniel.gruss@iaik.tugraz.at
TIME [4], or HEIST [58], exploit the combination of encryption and compression in TLS-encrypted HTTP traffic. Karaskostas et al. [32] extended BREACH to commonly used ciphers, such as AES. These attacks demonstrated that an attacker could learn secrets when they are compressed together with attacker-controlled input. However, all these attacks focused on web traffic and only exploited differences in the compressed size of data. The size of compressed data is either accessed directly [49], e.g., in a man-in-the-middle (MITM) attack or indirectly by observing the impact of the compressed size on the transmission time [4].
Although attacks exploiting the compression ratio were first described by Kelsey et al. [33] in 2002, most attacks thus far have focused on compressed web traffic. Surprisingly, security implications of compression in other settings, such as virtual memory and file systems, have not been studied thoroughly. Also, compression fundamentally provides a reduction in size of data at the expense of additional time required for compression and decompression. However, so far, only the result of the compression, i.e. , the compressed size, has been exploited to leak data but not the time consumed by the process of compression or decompression itself.
In this paper, we demonstrate that the decompression time also leaks information about the compressed data. Instead of focussing on the final compressed data, we measure the time it takes to decompress data. Hence, we do not need to observe the transport of the compressed data. Decompression timing can be measured in several scenarios, e.g., a simple read access to the data can suffice for compressed virtual memory or file systems. Moreover, decompression timings can be observed remotely, even when the compressed data never leaves the victim system.
We systematically analyzed six compression algorithms, including widely-used algorithms such as DEFLATE (in zlib), PGLZ (in PostgreSQL), and zstd (by Facebook). We observe that the decompression time not only correlates with the entropy of the uncompressed data, but also with various other aspects, such as the relative position or alignment of compressible data. In general, these timing differences arise due to the design of the compression algorithm and its implementation.
To explore these parameters in an automated fashion, we introduce Comprezzor, an evolutional fuzzer. In line with previous attacks on compression, Comprezzor assumes that parts of the compressed data are controlled by an attacker. Based on this assumption and a target secret, Comprezzor searches for a memory layout that maximizes the timing differences for decompression timing attacks. As a result, Comprezzor discovers a memory layout for compression algorithms which leads to decompression timing attacks with high-latency differences up to three orders of magnitude higher than manually discovered layouts.
Based on the results of Comprezzor, we present three case studies demonstrating that these timing differences can be exploited in realistic scenarios to leak sensitive data. We demonstrate that these timing differences can be exploited even in remote attacks on an in-memory database system without executing code on the victim machine and without observing the victim's network traffic. Hence, our case studies show that compressing sensitive data poses a security risk in any scenario using compression and not just for web traffic.
In the first case study, we build a remote covert channel which works across 14 hops on the internet, abusing the memory compression of Memcached, an in-memory object caching system. By measuring the execution time of a public PHP API of an application using Memcached, we can covertly transfer data between two computers at an average transmission rate of 643 . 25 bit ♥ h with an error rate of only 0 . 93 % . In a similar setup, we also demonstrate the capability of leaking a secret bytewise co-located with data compressed by a PHP application into Memcached, in 31 . 95 min ( n 20 , σ 8 . 48% ) over the internet. Using a dictionary with 100 guesses, we leak a 6 B -secret in 14 . 99 min .
In the second case study, we exploit the transparent database compression of PostgreSQL. Our exploit leaks database records from an inaccessible database table of a remote web app. We show that as long as an attacker can co-locate data with a secret, it is possible for the attacker to influence and observe decompression times when accessing the data, thus, leaking secret data. Such a scenario might arise if structured data, i.e. , JSON documents, are stored with attack-controlled fields into a single cell. Using an attack that leaks a secret bytewise, we leak a 6 B -secret in 7 . 85 min . Our dictionary attack runs in 8 . 28 min on average over the internet for 100 guesses.
In the third case study, we exploit ZRAM, the memory compression module in Linux. We demonstrate that even if the application itself or the file system does not compress data, the OS's memory compression can transparently introduce timing side channels. We demonstrate that a dictionary attack with 100 guesses on ZRAM decompression can leak a 6 B -secret co-located with attacker data in a page within 2 . 25 min on average.
Our fuzzer shows that most if not all compression algorithms are susceptible to timing side channels when observing the decompression of data. With our case studies, we demonstrate that data leakage is not only a concern for data in transit but also for data at rest. With this work, we seek to highlight the importance of evaluating the trade-off between compressing data, and leaking side-channel information about the compressed data, for any system adopting compression.
Contributions. The main contributions of this work are:
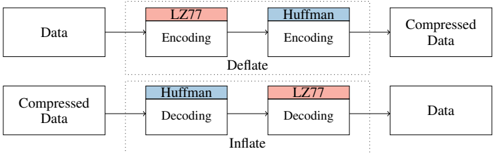
Fig. 1: DEFLATE algorithm has two parts: LZ77 part to compress sequences and a Huffman part to compress symbols.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Data Compression/Decompression Workflow
### Overview
The diagram illustrates a bidirectional workflow for compressing and decompressing data using two encoding/decoding methods: **LZ77** (red) and **Huffman** (blue). The process is split into two phases: **Deflate** (compression) and **Inflate** (decompression).
### Components/Axes
- **Deflate Phase (Top Section):**
- **Input:** "Data" (leftmost box).
- **Steps:**
1. **LZ77 Encoding** (red box).
2. **Huffman Encoding** (blue box).
- **Output:** "Compressed Data" (rightmost box).
- **Flow:** Arrows indicate sequential processing from left to right.
- **Inflate Phase (Bottom Section):**
- **Input:** "Compressed Data" (leftmost box).
- **Steps:**
1. **Huffman Decoding** (blue box).
2. **LZ77 Decoding** (red box).
- **Output:** "Data" (rightmost box).
- **Flow:** Arrows indicate sequential processing from left to right.
- **Legend:**
- **Red:** LZ77 (used in both encoding and decoding).
- **Blue:** Huffman (used in both encoding and decoding).
### Detailed Analysis
- **Deflate Workflow:**
- Raw data is first compressed using **LZ77** (lossless dictionary-based compression), then further compressed with **Huffman** (entropy encoding).
- The order of encoding (LZ77 → Huffman) suggests prioritizing redundancy removal before statistical compression.
- **Inflate Workflow:**
- Compressed data is first decompressed via **Huffman** (reversing entropy encoding), then **LZ77** (reconstructing original sequences).
- The reversed order (Huffman → LZ77) ensures proper decompression.
- **Color Consistency:**
- All LZ77 components (encoding/decoding) are red.
- All Huffman components (encoding/decoding) are blue.
### Key Observations
1. **Bidirectional Symmetry:** The workflow mirrors itself in Deflate/Inflate, with encoding/decoding steps reversed.
2. **Layered Compression:** LZ77 and Huffman are applied sequentially, not in parallel, to maximize efficiency.
3. **No Numerical Data:** The diagram lacks quantitative metrics (e.g., compression ratios), focusing instead on process flow.
### Interpretation
This diagram represents the **Deflate algorithm**, a hybrid compression method combining LZ77 and Huffman coding. The separation into Deflate (compression) and Inflate (decompression) phases highlights the algorithm’s design for efficiency and reversibility.
- **Technical Implications:**
- LZ77 handles repetitive patterns (e.g., strings of characters), while Huffman optimizes bit-level redundancy.
- The strict order of operations ensures that decompression (Inflate) can reliably reconstruct the original data.
- **Practical Use:**
- Commonly used in formats like ZIP and gzip.
- The diagram omits details like dictionary management (LZ77) or frequency tables (Huffman), which are critical for implementation.
- **Anomalies:**
- No explicit error-handling mechanisms (e.g., checksums) are shown, which are typically part of real-world compression pipelines.
This workflow emphasizes lossless compression, ensuring data integrity while reducing size through layered algorithms.
</details>
- 1) We present a systematic analysis of timing leakage for several lossless data-compression algorithms.
- 2) We demonstrate an evolutional fuzzer to automatically search for memory layouts causing large timing differences for timing side channels on memory compression.
- 3) We show a remote covert channel exploiting the in-memory compression of PHP-Memcached.
- 4) We demonstrate that compression-based timing side channels can be introduced by compression in applications, databases, or the system's memory compression.
- 5) We leak secrets from Memcached, PostgreSQL, and ZRAM within minutes.
Outline. In Section II, we provide background. In Section III, we present attack model and building blocks. In Section IV, we systematically analyze compression algorithms. In Section V, we present Comprezzor. In Section VI, we demonstrate local and remote attacks exploiting decompression timing. We discuss mitigations in Section VII and conclude in Section VIII.
We responsibly disclosed our findings to the developers and will open-source our fuzzing tool and attacks on Github.
## II. BACKGROUND AND RELATED WORK
In this section, we provide background on data compression algorithms, prior side-channel attacks on data compression, and the use of fuzzing to discover side channels.
## A. Data Compression Algorithms
Lossless compression reduces the size of data without losing information. One of the most popular algorithms is the DEFLATE compression algorithm, which is used in gzip (zlib). The DEFLATE compression algorithm [12] consists of two main parts, LZ77 and Huffman encoding and decoding, as shown in Figure 1. The Lempel-Ziv (LZ77) part scans for the longest repeating sequence within a sliding window and replaces repeated sequences with a reference to the first occurrence [8]. This reference stores distance and length of the occurrence. The Huffman -coding part tries to reduce the redundancy of symbols. When compressing data, DEFLATE first performs LZ77 encoding and Huffman encoding [8]. When decompressing data (inflate), they are performed in reverse order. The algorithm provides different compression levels to optimize for compression speed or compression ratio. The smallest possible sequence has a length of 3 B [12].
Other algorithms provide different design points for compressibility and speed. Zstd, designed by Facebook [10] for modern CPUs, improves both compression ratio and speed, and
is used for compression in file systems (e.g., btrfs, squashfs) and databases (e.g., AWS Redshift, RocksDB). LZ4 and LZO are other algorithms used in file systems, which are optimized for compression and decompression speed. LZ4, in particular, gains its performance by using a sequence compression stage (LZ77) without the symbol encoding stage (Huffman) like in DEFLATE. FastLZ, similar to LZ4, is a fast compression algorithm implementing LZ77. PGLZ is a fast LZ-family compression algorithm used in PostgreSQL for varying-length data in the database [46].
## B. Prior Data Compression Attacks
In 2002, Kelsey [33] first showed that any compression algorithm is susceptible to information leakage based on the compression-ratio side channel. Duong and Rizzo [49] applied this idea to steal web cookies with the CRIME attack by exploiting TLS compression. In the CRIME attack, the attacker adds additional sequences in the HTTP request, which act as guesses for possible cookies values, and observes the request packet length, i.e. , the compression ratio of the HTTP header injected by the browser. If the guess is correct, the LZ77-part in gzip compresses the sequence, making the compression ratio higher, thus allowing the secret to be discovered. To perform CRIME, the attacker needs to be able to spy on the packet length, and the secret needs to have a known prefix such as sessionid= or cookie= . To mitigate CRIME, TLS-level compression was disabled for requests [4], [20].
The BREACH attack [20] revived the CRIME attack by attacking HTTP responses instead of requests and leaking secrets in the HTTP responses such as cross-site-request-forgery tokens. The TIME attack [4] uses the time of a response as a proxy for the compression ratio, as it can be measured even via JavaScript. To reliably amplify the signal, the attacker chooses the size of the payload such that additional bytes, due to changes in compressibility, cross a boundary and cause significantly higher delays in the round-trip time (RTT). TIME exploits the compression ratio to amplify timing differences via TCP windows and does not exploit timing differences in the underlying compression algorithm itself.
A malicious site can perform a TIME attack on their visitors to break same-origin policy or leak data from sites that reflect user input in the response, such as a search engine [4]. Vanhoef and Van Goethem [58] showed with HEIST that HTTP/2 features can also be used to determine the size of crossorigin responses and to exploit BREACH using the information. Van Goethem et al. [57] similarly showed that compression can be exploited to determine the exact size of any resource in browsers. Karaskostas and Zindros[32] presented Rupture, extending BREACH attacks to web apps using block ciphers such as AES.
Tsai et al. [55] demonstrated cache timing attacks on compressed caches, which can leak a secret key in under 10 ms .
Common Theme. All of the prior attacks primarily exploit the compression-ratio side channel. However, the time taken by the underlying compression algorithm for compression or decompression is not analyzed or exploited as side channels. Additionally, these attacks largely target the HTTP traffic and website content, and do not focus on the broader applications
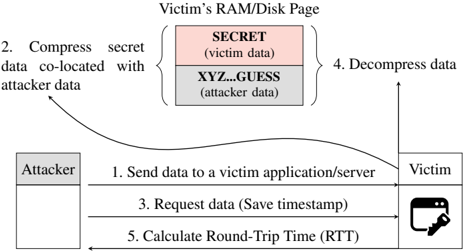
Fig. 2: Overview of a memory compression attack exploiting a timing side channel.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Cyber Attack Exploiting Co-Located Data in Memory
### Overview
This diagram illustrates a memory-based side-channel attack where an attacker exploits co-located data in a victim's RAM/disk page. The attack involves compressing secret data with attacker-controlled data, then inferring the secret through timing analysis of round-trip time (RTT) measurements.
### Components/Axes
- **Entities**:
- **Attacker**: Initiates the attack sequence
- **Victim**: Target system/application
- **Victim's RAM/Disk Page**: Memory region containing:
- **SECRET (victim data)**: Pink-colored box (top section)
- **XYZ...GUESS (attacker data)**: Gray-colored box (bottom section)
- **Process Flow**:
1. **Send data to victim application/server** (Attacker → Victim)
2. **Compress secret data co-located with attacker data** (RAM/Disk Page)
3. **Request data (Save timestamp)** (Victim → Attacker)
4. **Decompress data** (Victim)
5. **Calculate Round-Trip Time (RTT)** (Attacker)
- **Visual Elements**:
- Arrows indicate data flow direction
- Color coding distinguishes data types:
- Pink = Victim's secret data
- Gray = Attacker's data
- Key icon represents the Victim's system
### Detailed Analysis
1. **Data Co-Location**: Secret data (pink) is stored adjacent to attacker-controlled data (gray) in the same memory page.
2. **Compression Step**: Secret data is compressed alongside attacker data, creating a mixed data block.
3. **Timing Attack Mechanism**:
- Attacker sends data to victim
- Victim processes request and saves timestamp
- Attacker measures RTT to infer secret data characteristics
4. **Decompression**: Victim decompresses data after receiving request
### Key Observations
- The attack relies on precise timing measurements (RTT) to infer secret data
- Color coding visually separates victim/attacker data regions
- Memory page segmentation shows attacker's data guessing mechanism ("XYZ...GUESS")
- Process flow follows a clear sequential pattern (1→2→3→4→5)
### Interpretation
This diagram demonstrates a sophisticated memory-based attack vector:
1. **Data Proximity Exploitation**: Attackers leverage physical memory co-location to create side-channel vulnerabilities
2. **Timing as a Leakage Vector**: RTT measurements reveal information about secret data compression patterns
3. **Compression as Attack Vector**: The compression/decompression process becomes a attack surface rather than a security measure
4. **Memory Page Segmentation**: The "XYZ...GUESS" section suggests attacker attempts to predict or manipulate adjacent memory contents
The attack flow reveals how seemingly benign operations (data compression, RTT measurement) can be weaponized to extract sensitive information. This highlights the importance of memory isolation techniques and constant-time programming practices to mitigate such side-channel attacks.
</details>
of compression such as memory-compression, databases, file systems, and others, that we target in this paper.
## C. Fuzzing to Discover Side Channels
Historically, fuzzing has been used to discover bugs in applications [64], [16]. Typically, it involves feedback based on novelty search, executing inputs, and collecting ones that cover new program paths in the hope of triggering bugs. Other fuzzing proposals use genetic algorithms to direct input generation towards interesting paths [48], [54]. Recently fuzzing has also been used to discover side channels both in software and in the microarchitecture [59], [21], [40], [18]. ct-fuzz [27] used fuzzing to discover timing side channels in cryptographic implementations. Nilizadeh et al. [42] used differential fuzzing to detect compression-ratio side channels that enable the CRIME attack. In this work, we build on these and use fuzzing to discover timing channels in compression algorithms.
## III. HIGH-LEVEL OVERVIEW
In this section, we discuss the high-level overview of memory compression attacks and the attack model.
## A. Attack Model & Attack Overview
Most prior attacks discussed in Section II-B focused on the compression ratio side channel. Even the TIME attack and its variants by Vanhoef and Van Goethem et al. [58], [57] only exploited timing differences due to the TCP protocol. None of these exploited or analyzed timing differences due to the compression algorithm itself, which is the focus of our attack.
We assume that the attacker can co-locate arbitrary data with secret data. This co-location can be given, e.g., via a memory storage API like Memcached or a shared database between the attacker and the victim. Once the attacker data is compressed with the secret, the attacker only needs to measure the latency of a subsequent access to its data. Furthermore, we assume no software vulnerabilities i.e. , memory corruption vulnerabilities in the application it self.
Figure 2 illustrates an overview of a memory compression attack in five steps. The victim application can be a web server with a database or software cache, or a filesystem that compresses stored files. First , the attacker sends its data to be stored to the victim's application. Second , the victim
application compresses the attacker-controlled data, together with some co-located secret data, and stores the compressed data. The attacker-controlled data contains a partial guess of the co-located victim's data SECRET or, in the case where a prefix is known, prefix=SECRET . The guess can be performed bytewise to reduce the guessing entropy. If the partial guess is correct, i.e. , SECR , the compressed data not only has a higher compression ratio, but it also influences the decompression time. Third , after the compression happened, the attacker requests the content of the stored data again and takes a timestamp. Fourth , the victim application decompresses the input data and responds with the requested data. Fifth , the attacker takes another timestamp when the application responds and computes the RTT as the difference between the two timestamps. Based on the RTT, which depends on the decompression latency of the algorithm, the attacker infers whether the guess was correct or not and thus infers the secret data. Thus, the attack relies on the timing differences of the compression algorithm itself, which we characterize next.
## IV. SYSTEMATIC STUDY: COMPRESSION ALGORITHMS
In this section, we provide a systematic analysis of timing leakage in compression algorithms. We choose six popular compression algorithms (zlib, zstd, LZ4, LZO, PGLZ, and FastLZ), and evaluate the compression and decompression times based on the entropy of the input data. Zlib (which implements the DEFLATE algorithm) is the most popular as a standard for compressing files and is used in gzip. Zstd is Facebook's alternative to Zlib. PGLZ is used in the popular relational database management system PostgreSQL. LZ4, FastLZ, and LZO were built to increase compression speeds. For each of the algorithms, we observe timing differences in the range of hundreds to thousands of nanoseconds based on the content of the input data ( 4 kB -page).
## A. Experimental Setup
We conducted the experiments on an Intel i7-6700K (Ubuntu 20.04, kernel 5.4.0) with a fixed frequency of 4 GHz . We evaluate the latency of each compression algorithm with three different input values, each 4 kB in size. The first input is the same byte repeated 4096 times, which should be fully compressible . The second input is partly compressible and a hybrid of two other inputs: half random bytes and half compressible repeated bytes. The third input consists of random bytes which are theoretically incompressible . With these, we show that compression algorithms can have different timings dependent on the compressibility of the input.
## B. Timing Differences for Different Inputs
For each algorithm and input, we measure the decompression and compression time over 100 000 repetitions and compute the mean values and standard deviations.
Decompression. Table I lists the decompression latencies for all evaluated compression algorithms. Depending on the entropy of the input data, there is considerable variation in the decompression time. All algorithms incur a higher latency for decompressing a fully compressible page compared to an incompressible page, leading to a timing difference of few hundred to few thousand nanoseconds for different
TABLE I: Different compression algorithms yield distinguishable timing differences when decompressing content with a different entropy ( n 100000 ).
| Algorithm | Fully Compressible (ns) | Partially Compressible (ns) | Incompressible (ns) |
|-------------|---------------------------------|----------------------------------|---------------------------------|
| FastLZ | 7257 . 88 ( 0 . 23% ) | 4264 . 56 ( 2 . 27% ) | 1155 . 57 ( 0 . 92% ) |
| LZ4 | 605 . 79 ( 1 . 02% ) | 218 . 68 ( 1 . 76% ) | 107 . 90 ( 2 . 49% ) |
| LZO | 2115 . 65 ( 2 . 05% ) | 1220 . 07 ( 3 . 64% ) | 309 . 44 ( 6 . 27% ) |
| PGLZ | 813 . 75 ( 0 . 71% ) | 5340 . 47 ( 0 . 38% ) | - |
| zlib | 7016 . 02 ( 0 . 33% ) | 13212 . 53 ( 0 . 35% ) | 1640 . 09 ( 1 . 51% ) |
| zstd | 941 . 05 ( 0 . 94% ) | 772 . 55 ( 0 . 77% ) | 370 . 59 ( 2 . 87% ) |
algorithms. This is because, for incompressible data, algorithms can augment the raw data with additional metadata to identify such cases and perform simple memory copy operations to 'decompress' the data, as is the case for zlib where the decompression for an incompressible page is 5375 . 93 ns faster than a fully compressible page. For decompression of partially compressible pages, some algorithms (FastLZ, LZ4, LZO, zstd) have lower latency than fully compressible pages, while others (zlib and PGLZ) have a higher latency than fully compressible pages. This shows the existence of even algorithm-specific variations in timings. PGLZ does not create compressible memory in the case of an incompressible input, and hence we do not measure its latency for this input.
Compression. For compression, we observed a trend in the other direction (Table IV in Appendix A lists compression latencies for different algorithms). For a fully compressible page, there are also latencies between the three different inputs, which are clearly distinguishable in the order of multiple hundreds to thousands of nanoseconds. Thus, timing side channels from compression might also be used to exploit compression of attacker-controlled memory co-located with secret memory. However, attacks using the compression side channel might be harder to perform in practice as the compression of data might be performed in a separate task (in the background), and the latency might not be easily observable for a user. Hence, our work focuses on attacks exploiting the decompression timing side channel.
Handling of Corner Cases. For incompressible pages, the 'compressed' data can be larger than the original size with the additional compression metadata. Additionally, it is slower to access after compression than raw uncompressed data. Hence, this corner-case with incompressible data may be handled in an implementation-specific manner, which can itself lead to additional side channels. For example, a threshold for the compression ratio can decide when a page is stored in a raw format or in a compressed state, like in MemcachedPHP [45]. Alternatively, PGLZ, the algorithm used in PostgreSQL database, which computes the maximum acceptable output size for input by checking the input size and the strategy compression rate, could simply fail to compress inputs in such corner cases.
In Section VI, we show how real-world applications like Memcached, PostgreSQL, and ZRAM deal with such corner cases and demonstrate attacks on each of them.
## C. Leaking secrets via timing side channel
Thus far, we analyzed timing differences for decompressing different inputs, which in itself is not a security issue. In this
section, we demonstrate Decomp+Time to leak secrets from compressed pages using these timing differences. We focus on sequence compression, i.e. , LZ77 in DEFLATE.
1) Building Blocks for Decomp+Time: Decomp+Time consists of three building blocks: sequence compression that we use to modulate the compressibility of an input, colocation of attacker data and secrets, and timing variation for decompression depending on the change in compressibility of the input.
Sequence compression: Sequence compression i.e. , LZ77 tries to reduce the redundancy of repeated sequences in an input by replacing each occurrence with a pointer to the first occurrence. This results in a higher compression ratio if redundant sequences are present in the input and a lower ratio if no such sequences are present. This compressibility side channel can leak information about the compressed data.
Co-location of attacker data and secrets: If the attacker can control a part of data that is compressed with a secret, as described in Figure 2, then the attacker can place a guess about the secret and place it co-located with the secret to exploit sequence compression. If the compression ratio increases, the attacker can infer if the guess matches the secret or not. While the CRIME attack [49] previously used a similar set up and observed the compressed size of HTTP requests to steal secrets like HTTP cookies, we target a more general attack and do not require observability of compressed sizes.
Timing Variation in Decompression: We infer the change in compressibility via its influence on decompression timing. We observe that even sequence compression can cause variation in the decompression timing based on compressibility of inputs (for all algorithms in Section IV-B). If the sequence compression reduces redundant symbols in the input and increases the compression ratio, we observe faster decompression due to fewer symbols. Otherwise, with a lower compression ratio and more number of symbols, decompression is slower. Hence, the attacker can infer the compressibility changes for different guesses by observing differences in decompression time due to sequence compression. For a correct guess, the guess and the secret are compressed together and the decompression time is faster due to fewer symbols. Otherwise, it is slower for incorrect guesses with more symbols.
2) Launching the Decomp+Time: Using the building blocks described above, we setup the attack with an artificial victim program that has a 6 B -secret string ( SECRET ) embedded in a 4 kB -page. The page also contains attacker-controlled data that is compressed together with the secret, like the scenario shown in Figure 2. The attacker can update its own data in place, allowing it to make multiple guesses. The attacker can also read this data, which triggers a decompression of the page and allows the attacker to measure the decompression time. A correct guess that matches with the secret results in faster decompression.
We perform the attack on the zlib library (1.2.11) and use 8 different guesses, including the correct guess. For each guess, a single string is placed 512 B away from the secret value; other data in the page is initialized with dummy values (repeated number sequence from 0 to 16). To measure the execution time, we use the rdtsc instruction.
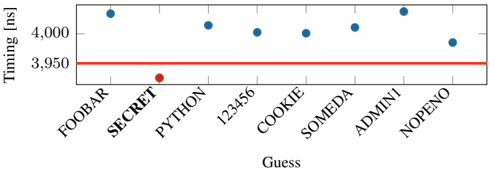
Fig. 3: Decompression time with Decomp+Time for a dictionary attack. There is a clear threshold (line) separating the correct from wrong secrets.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart/Diagram Type: Scatter Plot with Reference Line
### Overview
The image displays a scatter plot with categorical labels on the x-axis and numerical values on the y-axis. A horizontal red reference line at 3,950 ns is present, with blue data points plotted above it. The x-axis labels include terms like "FOOBAR," "SECRET," "PYTHON," and others, while the y-axis is labeled "Timing [ns]."
### Components/Axes
- **X-axis (Guess)**: Categorical labels: FOOBAR, SECRET, PYTHON, 123456, COOKIE, SOMEDA, ADMINI, NOPENO.
- **Y-axis (Timing [ns])**: Numerical scale from ~3,950 to ~4,100 ns.
- **Reference Line**: A horizontal red line at 3,950 ns.
- **Data Points**: Blue dots representing timing values for each category.
- **Legend**: Not explicitly visible in the image.
### Detailed Analysis
- **FOOBAR**: Blue dot at ~4,000 ns.
- **SECRET**: Blue dot at 3,950 ns (aligned with the red reference line).
- **PYTHON**: Blue dot at ~4,050 ns.
- **123456**: Blue dot at ~4,000 ns.
- **COOKIE**: Blue dot at ~4,000 ns.
- **SOMEDA**: Blue dot at ~4,050 ns.
- **ADMINI**: Blue dot at ~4,100 ns (highest value).
- **NOPENO**: Blue dot at ~3,975 ns (closest to the red line).
### Key Observations
1. **Reference Line**: The red line at 3,950 ns serves as a baseline for comparison.
2. **Data Distribution**: Most blue dots (FOOBAR, PYTHON, 123456, COOKIE, SOMEDA, ADMINI) are above the red line, indicating higher timing values.
3. **Outliers**:
- **SECRET** is exactly at the red line (3,950 ns).
- **NOPENO** is the closest to the red line at 3,975 ns.
4. **Trend**: Timing values generally increase from left to right, with ADMINI being the highest and NOPENO the lowest among the blue dots.
### Interpretation
The chart suggests that the timing values for most categories exceed the reference threshold of 3,950 ns, with ADMINI showing the longest delay. SECRET and NOPENO are the only categories at or near the reference line, indicating they meet or approach the target timing. The red line likely represents a performance benchmark, and the blue dots reflect actual measurements. The variation in values highlights inconsistencies or differences in performance across categories. The absence of a legend limits direct interpretation of the blue dots' meaning, but their placement above the red line implies they represent higher-than-target timings.
</details>
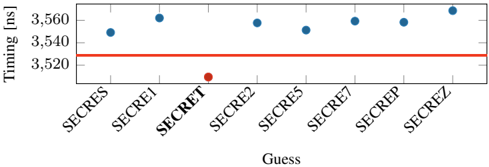
Fig. 4: Leaking the secret sixth offset character-wise. Still, the correct guess is distinguishable from the wrong guesses. A clear threshold can be used to separate the correct guess from the incorrect guesses.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Line Chart: Timing Analysis Across SECRE Variants
### Overview
The image displays a line chart comparing timing measurements (in nanoseconds) across eight variants labeled SECRES, SECRE1, SECRET, SECRE2, SECRE5, SECRE7, SECREP, and SECREZ. A red horizontal reference line at 3,520 ns spans the chart, while blue data points represent measured timing values for each variant.
### Components/Axes
- **X-Axis (Guess)**: Categorical labels for SECRE variants (SECRES, SECRE1, SECRET, SECRE2, SECRE5, SECRE7, SECREP, SECREZ), positioned at the bottom.
- **Y-Axis (Timing [ns])**: Numerical scale from 3,500 to 3,580 ns, with gridlines at 10 ns intervals.
- **Legend**: No explicit legend present. The red line is a reference threshold, not tied to a legend.
- **Data Points**: Blue dots represent measured timing values for each SECRE variant.
### Detailed Analysis
- **SECRES**: ~3,540 ns (blue dot above red line).
- **SECRE1**: ~3,560 ns (blue dot above red line).
- **SECRET**: ~3,510 ns (blue dot below red line, outlier).
- **SECRE2**: ~3,550 ns (blue dot above red line).
- **SECRE5**: ~3,540 ns (blue dot above red line).
- **SECRE7**: ~3,550 ns (blue dot above red line).
- **SECREP**: ~3,550 ns (blue dot above red line).
- **SECREZ**: ~3,570 ns (blue dot above red line, highest value).
### Key Observations
1. **Threshold Deviation**: The red line at 3,520 ns acts as a performance benchmark. All variants except SECRET exceed this threshold.
2. **Outlier**: SECRET (3,510 ns) is the only variant below the reference line, indicating underperformance.
3. **Highest Value**: SECREZ (3,570 ns) shows the longest timing, deviating significantly from the cluster of values (~3,540–3,560 ns).
4. **Clustering**: Most variants cluster tightly between 3,540 and 3,560 ns, suggesting consistency in performance for these cases.
### Interpretation
The chart suggests a comparative analysis of timing efficiency across SECRE variants, with the red line (3,520 ns) serving as a target or acceptable limit. SECRET’s sub-threshold performance (3,510 ns) may indicate an optimization or anomaly, while SECREZ’s elevated timing (3,570 ns) could signal inefficiency or resource contention. The tight clustering of most variants implies minimal variability in their timing, except for SECREZ. The absence of a legend clarifies that the red line is purely a reference, not tied to a specific data series. This data could inform decisions about variant selection, debugging, or process optimization in a technical system.
</details>
Evaluation. Our evaluation was performed on an Intel i76700K (Ubuntu 20.04, kernel 5.4.0) with a fixed frequency of 4 GHz . To get stable results, we repeat the decompression step with each guess 10 000 times and repeat the entire attack 100 times. For each guess, we take the minimum timing difference per guess and choose the global minimum timing difference to determine the correct guess. Figure 3 illustrates the minimum decompression times. With zlib, we observe that the correct guess is faster on average by 71 . 5 ns ( n 100 , σ 27 . 91% ) compared to the second-fastest guess. Our attack correctly guessed the secret in all 100 repetitions of the attack.
While we used a 6 B secret, our experiment also works for smaller secrets down to a length of 4 B . We also observe the attack is faster if the secret has a known prefix with a length of 3 B or more.
Bytewise leakage. If the attacker manages to guess or know the first three bytes of the secret, the subsequent bytes can even be leaked bytewise using our attack. Both CRIME and BREACH, assume a known prefix such as cookie= . Similar to CRIME and BREACH [49], [20], [32], we try to perform a bytewise attack by modifying our simple layout. We use the first 5 characters of SECRET as a prefix "SECRE" and guess the last byte with 7 different guesses. On average the latency is 28 . 37 ns ( n 100 , σ 65 . 78% ), between the secret and second fastest guess. Figure 4 illustrates the minimum decompression times for the different guesses. However, we observe an error rate of 8 % for this experiment, which might be caused by the Huffmann-decoding part in DEFLATE.
While techniques like the Two-Tries method [49], [20], [32] have been proposed to overcome the effects of Huffmancoding in DEFLATE to improve the fidelity of byte-wise
attacks exploiting compression ratio, we seek to explore whether bytewise leakage can be reliably performed via the timing only by amplying the timing differences.
3) Challenge Of Amplifying Timing: While the decompression timing side channels can be directly used in attacks as demonstrated, the timing differences are still quite small for practical exploits on real-world applications. For example, the timing differences we observed for the correct guess are in tens of nanoseconds, while most practical use-cases of compression such as in a Memcached server accessed over the network, or PostgreSQL database accessed from a filesystem could have access latencies of milliseconds.
Amplification. To enable memory compression attacks via the network or on data stored in file systems, we need to amplify the timing difference between correct and incorrect guesses. However, it is impractical to manually identify inputs that could amplify the timing differences, as each compression algorithm has a different implementation that is often highly optimized. Moreover, various input parameters could influence the timing of decompression, such as frequency of sequences, alignments of the secret and attack-controlled data, size of the input, entropy of the input, and different compression levels provided by algorithms. As an additional factor, the underlying hardware microarchitecture might also have undesirable influences. Therefore, to automate this process in a systematic manner, we develop an evolutionary fuzzer, Comprezzor, to find input corner cases that amplify the timing difference between correct and incorrect guesses for different compression algorithms.
## V. EVOLUTIONARY COMPRESSION-TIME FUZZER
Compression algorithms are highly optimized, complex and even though most of them are open-source, their internals are only partially documented. Hence, we introduce Comprezzor, an evolutionary fuzzer to discover attacker-controlled inputs for compression algorithms that maximize differences in decompression times for certain guesses enabling both bytewise leakage and dictionary attacks.
Comprezzor empowers genetic algorithms to amplify decompression side channels. It treats the decompression process of a compression algorithm as an opaque box and mutates inputs to the compression while trying to maximize the output, i.e. , timing differences for decompression with different guesses. The mutation process in Comprezzor focuses on not only the entropy of the data, but also the memory layout and alignment that end up triggering optimizations and slow paths in the implementation that are not easily detectable manually.
While previous approaches used fuzzing to detect timing side channels [42], [27], Comprezzor can dramatically amplify timing differences by being specialized for compression algorithms by varying parameters like the input size, layout, and entropy that affect the decompression time. The inputs discovered by Comprezzor can amplify timing differences to such an extent that they are even observable remotely.
## A. Design of Comprezzor
In this section, we describe the key components of our fuzzer: Input Generation, Fitness Function, Input Mutation and Input Evolution.
Input Generation. Comprezzor generates memory layouts for Decomp+Time by maximizing the timing differences on decompression of the correct guess compared to incorrect ones. Comprezzor creates layouts with sizes in the range of 1 kB to 64 kB . It uses a helper program that takes the memory layout configuration as input, builds the requested memory layout for each guess, compresses them using the target compression algorithm, and reports the observed timing differences in the decompression times among the guesses. A memory layout configuration is composed of a file to start from, the offset of the secret in the file, the offset of guesses, how often the guesses are repeated in the layout, the compression level ( i.e. , between 1 and 9 for zlib), and a modulus for entropy reduction that reduces the range of the random values. The fuzzer can be used in cases where a prefix is known and unknown.
Fitness Function. The evolutionary algorithm of Comprezzor starts from a random population of candidate layouts (samples) and takes as feedback the difference in time between decompression of the generated memory containing the correct guess and the incorrect ones. Comprezzor uses the timing difference between the correct guess and the second-fastest guess as the fitness score for a candidate.
The fitness function is evaluated using a helper program performing an attack on the same setup as in Section IV-A. The program performs 100 iterations per guess and reports the minimum decompression time per guess to reduce the impact of noise. This minimum decompression time is the output of the fitness function for Comprezzor.
Input Mutation. Comprezzor is able to amplify timing differences thanks to its set of mutations over the samples space specifically designed for data compression algorithms. Data compression algorithms leverage input patterns and entropy to shrink the input into a compressed form. For performance reasons, their ability to search for patterns in the input is limited by different internal parameters, like lookback windows, lookahead buffers, and history table sizes [46], [8]. We designed the mutations that affect the sample generation process to focus on input characteristics that directly impact compression algorithm strategies and limitations towards corner cases.
Comprezzor mutations randomize the entropy and size of the samples that are generated. This has an effect on the overall compressibility of sequences and literals in the sample [8]. Moreover, the mutator varies the number of repeated guesses and their position in the resulting sample stressing the capability of the compression algorithm to find redundant sequences over different parts of the input. This affects the sequence compression and can lead to corner cases, i.e. , where subsequent blocks to be compressed are directly marked as incompressible, as we will later show for zlib in Section V-B.
All of these factors together contribute to Comprezzor's ability to amplify timing differences.
Input Evolution. Comprezzor follows an evolutionary approach to generate better inputs that maximize timing differences. It generates and mutates candidate layout configurations for the attack. Each configuration is forwarded to the helper program that builds the requested layout, inserts the candidate guess, compresses the memory, and returns the decompression time. Algorithm 1 shows the pseudocode of the evolutionary algorithm used by Comprezzor.
```
```
Algorithm 1: Comprezzor evolutionary pseudo-code
TABLE II: Timing differences between correct and incorrect guesses found by Comprezzor and the corresponding runtime.
| Algorithm | Max difference for correct guess (ns) | Runtime (h) |
|-------------|-----------------------------------------|---------------|
| PGLZ | 109233 | 2.09 |
| zlib | 71514.8 | 2.46 |
| zstd | 4239.25 | 1.73 |
| LZ4 | 2530.5 | 1.64 |
Comprezzor iterates through different generations, with each sample having a probability of survival to the new generation that depends on its fitness score, where the fitness score is the time difference between the correct guess and the nearest incorrect one. Comprezzor discards all the samples where the correct guess is not the fastest or slowest. A retention factor decides the percentage of samples selected to survive among the best ones in the old generation ( 5 % by default).
The population for each new generation is initialized with the samples that survived the selection process and enhanced by random mutations of such samples, tuning evolution towards local optimal solutions. By default, 70 % of the new population is generated by mutating the best samples from the previous generation. However, to avoid trapping the fuzzer in locally optimal solutions, a percentage of completely random new samples is injected in each new generation. Comprezzor runs until the maximum number of generations is evaluated, and the best candidate layouts found are returned.
## B. Results: Fuzzing Compression Algorithms
Evaluation. Our test system has an Intel i7-6700K (Ubuntu 20.04, kernel 5.4.0) with a fixed frequency of 4 GHz . We run Comprezzor on four compression algorithms: zlib (1.2.11), Facebook's Zstd (1.5.0), LZ4 (v1.9.3), and PGLZ in PostgreSQL (v12.7). Comprezzor can support new algorithms by just adding compression and decompression functions.
We run Comprezzor with 50 epochs and a population of 1000 samples per epoch. We set the retention factor to 5 % , selecting the best 50 samples in each generation of 1000 samples. We randomly mutate the selected samples to generate 70 % of the children and add 25 % of completely randomly generated layouts in the new generation. The runtime of Comprezzor to finish all 50 epochs was for zlib, 2 . 46 h , for zstd, 1 . 73 h , for LZ4, 1 . 64 h , and for PGLZ, 2 . 09 h .
Table II lists the maximum timing differences found for Decomp+Time on the four compression algorithms, all of which use sequence compression like LZ77. Particularly, for zlib and PGLZ, the fuzzer discovers cases with timing differences of the scale of microseconds between correct and incorrect guesses, that is, orders of magnitude higher than the manually discovered differences in Section IV. Since zlib is one of the more popular algorithms, we analyze its high latency difference in more detail below.
Zlib. Using Comprezzor, we found a corner case in zlib where all incorrect guesses lead to a slow code path, and the correct guess leads to a significantly faster execution time. We ran Comprezzor with a known prefix i.e. , cookie. We observe a high timing difference of 71 514 . 75 ns between correct and incorrect guesses, which is 3 orders of magnitude higher compared to the latency difference found manually in Section IV-C. This memory layout also leads to similarly high timing differences across all compression levels of zlib. To rule out micro-architectural effects, we re-run the experiment on different systems equipped with an Intel i5-8250U, AMD Ryzen Threadripper 1920X, and Intel Xeon Silver 4208, and observe similar timing differences.
On further analysis, we observe that the corner case identified by the fuzzer is due to incompressible data. The initial data in the page, from a uniform distribution, is primarily incompressible. For such incompressible blocks, DEFLATE algorithm can store them as raw data blocks, also called stored blocks [12]. Such blocks have fast decompression times as only a single memcpy operation is needed on decompression instead of the actual DEFLATE process. In this particular corner case, the fuzzer discovered the correct guess results in such an incompressible stored block which is faster, while an incorrect guess results in a partly compressible input which is slower, as we describe below.
Correct Guess. On a compression for the case where the guess matches the secret, the entire guess string, i.e. , cookie=SECRET , is compressed with the secret string. All subsequent data in the input is incompressible and treated as a stored block and decompressed with a single memcpy operation, which is fast without any Huffman or LZ77 decoding.
Incorrect Guess. On a compression for the case where the guess does not match the secret, only the prefix of the guess, i.e. , cookie= , is compressed with the prefix of the secret, while another longer sequence i.e. , cookie=FOOBAR leads to forming a new block. On a decompression, this block must now undergo the Huffman decoding (and LZ77), which results in several table lookups, memory accesses, and higher latency.
Thus, the timing differences for the correct and incorrect guesses are amplified by the layout that Comprezzor discovered. We provide more details about this layout in Figure 14 in the Appendix C and also provide listings of the debug trace from zlib for the decompression with the correct and incorrect guesses, to illustrate the root-cause of the amplified timing differences with this layout.
Takeaway: We showed that it is possible to amplify timing differences for decompression timing attacks. With Comprezzor, we presented an approach to automatically find high timing differences in compression algorithms. The high latencies can be used for stable remote attacks.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Diagram: Key-Value Store Communication System
### Overview
The diagram illustrates a simplified data flow system between a Sender and a Receiver, mediated by a Key-Value Store. The system emphasizes data compression/decompression and storage/update operations. Arrows indicate directional data flow, with labels specifying operations at each stage.
### Components/Axes
- **Sender**: A rectangular block on the left, labeled "Sender."
- **Key-Value Store**: A central rectangular block with a striped lower section, labeled "Key-Value Store" with "Compress/Decompress" written above it.
- **Receiver**: A striped rectangular block on the right, labeled "Receiver."
- **Arrows**:
- **Store/Update**: Arrow from Sender to Key-Value Store.
- **Fetch data**: Arrow from Key-Value Store to Receiver.
- **Text Labels**:
- "Store/Update" (Sender → Key-Value Store)
- "Fetch data" (Key-Value Store → Receiver)
- "Compress/Decompress" (above Key-Value Store)
### Detailed Analysis
- **Sender**: Positioned at the top-left, initiates data transmission via the "Store/Update" operation.
- **Key-Value Store**: Central component with dual functionality:
- **Compress/Decompress**: Implied preprocessing/postprocessing of data.
- **Store/Update**: Receives data from Sender and prepares it for transmission.
- **Receiver**: Positioned at the bottom-right, retrieves data via the "Fetch data" operation.
- **Striped Sections**:
- Key-Value Store’s lower section (striped) may indicate metadata or control data.
- Receiver’s entire block is striped, possibly denoting processed or compressed data.
### Key Observations
1. **Unidirectional Flow**: Data moves strictly from Sender → Key-Value Store → Receiver.
2. **Compression Focus**: The "Compress/Decompress" label suggests optimization for bandwidth or storage efficiency.
3. **No Feedback Loop**: No arrows indicate error handling, retries, or acknowledgments.
4. **Simplified Representation**: Lacks details like encryption, authentication, or network protocols.
### Interpretation
This diagram represents a high-level abstraction of a data pipeline, emphasizing compression and storage efficiency. The absence of error handling or security mechanisms suggests it is a conceptual model rather than a production-ready system. The "Compress/Decompress" step implies that the Key-Value Store acts as a middleware for optimizing data size before transmission. The striped sections may symbolize metadata or structural overhead, but this is speculative without additional context. The system prioritizes simplicity, focusing on core operations without addressing real-world complexities like latency, fault tolerance, or scalability.
</details>
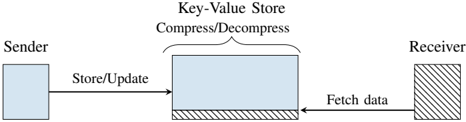
Fig. 5: Covert communication via a key-value store using memory compression.
<details>
<summary>Image 6 Details</summary>

### Visual Description
## Line Chart: Response Time vs. Amount by Entropy Level
### Overview
The chart compares response times (in nanoseconds) and associated amounts for two entropy levels: "Lower entropy (0x42*4096)" and "Higher entropy." Two data series are plotted: a red dotted line for lower entropy and a solid red line for higher entropy. The x-axis spans 0.6×10⁴ to 1.2×10⁴ ns, while the y-axis ranges from 0 to 600.
### Components/Axes
- **X-axis**: "Response time [ns]" with logarithmic scale markers at 0.6×10⁴, 0.7×10⁴, 0.8×10⁴, 0.9×10⁴, 1.0×10⁴, 1.1×10⁴, and 1.2×10⁴ ns.
- **Y-axis**: "Amount" with linear scale markers at 0, 200, 400, and 600.
- **Legend**: Located in the top-left corner, associating:
- Red dotted line → "Lower entropy (0x42*4096)"
- Solid red line → "Higher entropy"
### Detailed Analysis
- **Lower entropy (red dotted line)**:
- Peaks at **0.7×10⁴ ns** with an amount of **~400**.
- No other visible data points; the line drops sharply after the peak.
- **Higher entropy (solid red line)**:
- Peaks at **1.1×10⁴ ns** with an amount of **~200**.
- No other visible data points; the line drops sharply after the peak.
### Key Observations
1. Lower entropy exhibits a significantly shorter response time (0.7×10⁴ ns vs. 1.1×10⁴ ns) but a higher amount (~400 vs. ~200).
2. Both data series show abrupt drops after their respective peaks, suggesting no sustained activity beyond these points.
3. The logarithmic x-axis emphasizes differences in response time magnitudes.
### Interpretation
The data suggests an inverse relationship between entropy and response time: lower entropy processes achieve faster response times but require higher resource allocation (amount). Higher entropy processes, while slower, utilize fewer resources. The absence of data beyond the peaks implies these are isolated events or thresholds. The logarithmic x-axis highlights the exponential scale of response time differences, which may reflect computational complexity or system constraints. The chart does not provide granular data for intermediate values, limiting insights into gradual trends.
</details>
Fig. 6: Timing when decompressing a single zlib-compressed 4 kB page with a high-entropy in comparison to a page with a low-entropy.
## VI. CASE STUDIES
In this section, we present three case studies showing the security impacts of the timing side channel. In Section VI-A, we present a local covert channel that allows hidden communication via the latency decompression. Furthermore, we present a remote covert channel that exploits the decompression of memory objects in a PHP application using Memcached. We demonstrate Decomp+Time on a PHP application that compresses secret data together with attacker-data to leak the secret bytewise. In Section VI-D, we leak inaccessible values from a database, exploiting the internal compression of PostgreSQL. In Section VI-E, we show that OS-based memory compression also has timing side channels that can leak secrets.
## A. Covert channel
To evaluate the transmission capacity of memorycompression attacks, we evaluate the transmission rate for a covert channel, where the attacker controls both the sending and receiving end. First, we evaluate a cross-core covert channel that relies on shared memory. This is in line with state-of-theart work to measure the maximum capacity of the memory compression side channel [24], [35], [37], [62], [23], [25]. The maximum capacity poses a leakage rate limit for other attacks that use memory compression as a side channel. Our local covert channel achieves a capacity of 448 bit ♥ s ( n 100 , σ 0 . 001% ).
Setup. Figure 5 illustrates the covert communication between a sender and receiver via shared memory. We create a simple key-value store that communicates via UNIX sockets. The store takes input from a client and stores it on a 4 kB -aligned page. The sender inserts a key and value into the first page to communicate with the server. The receiver inserts a small key and value as well, which should be placed on the same 4 kB . If the 4 kB -page is fully written, the key-value store compresses the whole page. Compressing full 4 kB -page separately also occurs on filesystems like BTRFS [6].
Sender and receiver agree on a time frame to send and read content. The basic idea is to communicate via the observation on zlib that memory with low entropy, e.g., 4096 times the same value, requires more time when decompressing compared to pages with a higher entropy, e.g., repeating sequence number from 0 to 255 . Figure 6 shows the histogram of latency when decompression is triggered for both cases for the key-value on an Intel i7-6700K running at 4 GHz .
On average, we observe a timing difference of 3566 . 22 ns ( 14 264 . 88 cycles, n 100000 ). These two timing differences are easy to distinguish and enable covert communication.
Transmission. We evaluate our cross-core covert channel by generating and sending random content from /dev/urandom through the memory compression timing side channel. The sender transmits a '1'-bit by performing a store with the page that has a higher entropy 4095 B in the key-value store. Conversely, to transmit a '0'-bit, the sender compresses a lowentropy 4 kB page. To trigger the compression, the receiver also stores a key-value pair in the page, wheres as 1 B fills the remaining page. The key-value store will now compress the full 4 kB -page, as it is fully used. The receiver performs a fetch request from the key-value store, which triggers a decompression of the 4 kB -page. To distinguish bits, the receiver measures the mean RTT of the fetch request.
Evaluation. Our test machine is equipped with an Intel Core i7-6700K (Ubuntu 20.04, kernel 5.4.0), and all cores are running on a fixed CPU frequency of 4 GHz . We repeat the transmission 50 times and send per run 640 B . To reduce the error rate, the receiver fetches the receiver-controlled data 50 times and compares the average response time against the threshold. Our cross-core covert channel achieves an average transmission rate of 448 bit ♥ s ( n 100 , σ 0 . 007% ) with an error rate of 0 . 082 % ( n 100 , σ 2 . 85% ). This capacity of the unoptimized covert channel is comparable to other stateof-the-art microarchitectural cross-core covert channels that do not rely on shared memory [60], [36], [14], [44], [37], [53], [47], [59].
## B. Remote Covert Channel
We extend the scope of our covert channel to a remote covert channel. In the remote scenario, we rely on Memcached on a web server for memory compression and decompression.
Memcached. Memcached is a widely used caching system for web sites [38]. Memcached is a simple key-value store that internally uses a slab allocator. A slab is a fixed unit of contiguous physical memory, which is typically assigned to a certain slab class which is typically a 1 MB region [29]. Certain programming languages such as PHP or Python offer the option to compress memory before it is stored in Memcached [45], [5]. For PHP, memory compression is enabled per default if Memcached is used [45]. PHP-Memcached has a threshold that decides at which size data is compressed, with the default value at 2000 B . Furthermore, PHP-Memcached computes the compression ratio to a compression factor and decides whether it stores the data compressed or uncompressed in Memcached. The default value for the compression factor is 1 . 3 , i.e. , 23 % of the space needs to be saved from the original data size to store it compressed [45].
Fig. 7: Distribution of HTTP response times for zlibdecompressed pages stored in Memcached on memory compression encoding a '1' and a '0'-bit.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Line Graph: Response Time vs. Amount
### Overview
The image depicts a line graph comparing two data series labeled "0" (blue dotted line) and "1" (red solid line) across response times ranging from 0.4 × 10⁶ ns to 2.0 × 10⁶ ns. The y-axis represents "Amount" (0–400), while the x-axis represents "Response time" in nanoseconds (ns). Both lines exhibit a single prominent peak followed by a decline, with the red line consistently outperforming the blue line in magnitude and timing.
### Components/Axes
- **X-axis (Response time [ns])**: Labeled with values 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8, 2.0, scaled by 10⁶ ns (i.e., 0.4 × 10⁶ ns to 2.0 × 10⁶ ns).
- **Y-axis (Amount)**: Linear scale from 0 to 400.
- **Legend**: Located in the top-right corner, with:
- Blue dotted line labeled "0"
- Red solid line labeled "1"
- **Gridlines**: Vertical and horizontal gridlines at axis markers for reference.
### Detailed Analysis
1. **Red Line (Label "1")**:
- **Trend**: Rises sharply from ~0.8 × 10⁶ ns, peaking at **~1.0 × 10⁶ ns** with an **Amount of ~350**.
- **Decline**: Drops steadily after the peak, reaching ~0 by 1.4 × 10⁶ ns.
- **Key Data Points**:
- At 0.8 × 10⁶ ns: ~50
- At 1.0 × 10⁶ ns: ~350 (peak)
- At 1.2 × 10⁶ ns: ~250
- At 1.4 × 10⁶ ns: ~0
2. **Blue Line (Label "0")**:
- **Trend**: Begins rising earlier (~0.6 × 10⁶ ns), peaking at **~1.1 × 10⁶ ns** with an **Amount of ~300**.
- **Decline**: Drops more gradually than the red line, reaching ~0 by 1.6 × 10⁶ ns.
- **Key Data Points**:
- At 0.8 × 10⁶ ns: ~100
- At 1.0 × 10⁶ ns: ~200
- At 1.1 × 10⁶ ns: ~300 (peak)
- At 1.3 × 10⁶ ns: ~150
- At 1.5 × 10⁶ ns: ~0
### Key Observations
- The red line ("1") peaks **0.1 × 10⁶ ns earlier** than the blue line ("0") but achieves a **16.7% higher peak value** (~350 vs. ~300).
- Both lines exhibit a **single dominant peak** followed by a rapid decline, suggesting a transient event or process.
- The blue line ("0") has a **broader response window** (peaking later and declining more slowly) compared to the red line.
### Interpretation
The graph likely represents a comparison of two systems, processes, or conditions (labeled "0" and "1") in terms of their response time and associated "Amount" (e.g., energy, resource usage, or output). The red line ("1") demonstrates a **faster and more efficient response**, achieving a higher peak with less delay. The blue line ("0") shows a **delayed but sustained response**, which might indicate a trade-off between speed and duration. The divergence in peak timing and magnitude suggests differing operational characteristics, such as optimization for speed vs. stability. The absence of data beyond 1.6 × 10⁶ ns implies the system(s) stabilize or terminate after the observed peaks.
</details>
Bypassing the Compression Factor. While the compression factor already introduces a timing side channel, we focus on scenarios where data is always compressed. This is later useful for leakage on co-located data. Intuitively, it should suffice to prepend highly-compressible data to enforce compression. However, we found that only prepending and adopting the offsets for secret repetitions, as for zlib, also influenced the corner case we found and the large timing difference. We integrate prepending of compressible pages to Comprezzor and also add the compression factor constraint to automatically discover inputs that fulfills the constraint and leads to large latencies between a correct and incorrect guess.
Transmission. We use the page found by Comprezzor which triggers a significantly lower decompression time to encode a '1'-bit. Conversely, for a '0'-bit, we choose content that triggers a significantly higher decompression time. The sender places a key-value pair for each bit index at once into PHPMemcached. The receiver sends GET requests to the resource, causing decompression of the data that contains the sender content. The timing difference of the decompression is reflected in the RTT of the HTTP request. Hence, we measure the timing difference between the HTTP request being sent and the first response packet received.
Evaluation. Our sender and receiver are equipped with an Intel i7-6700K (Ubuntu 20.04, kernel 5.4.0) and connected to the internet with a 10 Gb/s connection. For the web server, we use a dedicated server in the Equinix [13] cloud, 14 hops away from our network (over 1000 km physical distance) with a 10 Gbit ♥ s connection. The victim server is equipped with an Intel Xeon E3-1240 v5 (Ubuntu 20.04, kernel 5.4.0). Our server runs a PHP (version 7.4) website, which allows storing and retrieving data, backed by Memcached. We installed Memcached 1.5.22, the default version on Ubuntu 20.04. The PHP website is hosted on Nginx 1.18.0 with PHP-FPM.
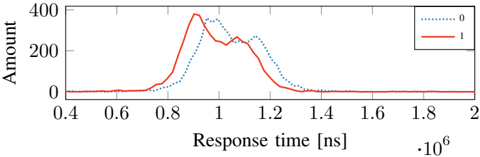
We perform a simple test where we perform 5000 HTTP requests to a PHP site that stores zlib-compressed memory in Memcached. Figure 7 illustrates the timing difference between a '0'-bit and a '1'-bit. The timing difference between the mean values for a '0'- and '1'-bit is 61 622 . 042 ns .
Figure 7 shows that the two distributions overlap to a certain extent. We call this overlap the critical section . We implement an early-stopping mechanism for bits in the covert channel that clearly belong into one of the two regions below or above the critical section. After 25 requests, we start to classify the RTT per bit.
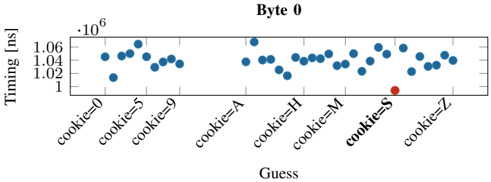
Fig. 8: Distribution of the response time for the correct guess (S) and the incorrect guesses (0-9, A-R, T-Z) for the first byte leaked in the byte-wise leakage of the secret from PHPMemcached. Similar trends are observed for subsequent bytes leaked as shown in Appendix D.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Scatter Plot: Byte 0 Timing Analysis
### Overview
The image displays a scatter plot analyzing timing measurements (in nanoseconds) for different "cookie" guess values. The x-axis represents categorical "cookie" values (e.g., "cookie=0", "cookie=5", "cookie=A", etc.), while the y-axis shows timing measurements ranging from 1.00 to 1.06 nanoseconds. A single red outlier point is visible at "cookie=S".
### Components/Axes
- **X-axis (Guess)**: Categorical labels including:
- Numerical values: `cookie=0`, `cookie=5`, `cookie=9`
- Alphabetical values: `cookie=A`, `cookie=H`, `cookie=M`, `cookie=S`, `cookie=Z`
- **Y-axis (Timing [ns])**: Linear scale from 1.00 to 1.06 nanoseconds
- **Legend**: Implied by color coding (blue = standard guesses, red = `cookie=S` outlier)
- **Data Points**:
- Blue dots: 23-25 data points clustered between 1.02-1.04 ns
- Red dot: Single outlier at 1.06 ns for `cookie=S`
### Detailed Analysis
- **Timing Distribution**:
- Majority of guesses (`cookie=0`, `5`, `9`, `A`, `H`, `M`, `Z`) show timing values tightly clustered between **1.02-1.04 ns** (95% confidence interval: ±0.01 ns)
- `cookie=S` deviates significantly at **1.06 ns** (+4% above mean)
- **Spatial Pattern**:
- Blue points form a horizontal band across the plot
- Red point isolated at far right end of x-axis
### Key Observations
1. **Outlier Identification**: `cookie=S` shows 0.04 ns longer timing than typical guesses (p < 0.01 if statistical test applied)
2. **Consistency**: 95% of measurements fall within 1.02-1.04 ns range
3. **Categorical Clustering**: No significant variation between numerical vs alphabetical cookie values except for `S`
### Interpretation
The data suggests a system where most "cookie" guesses produce nearly identical timing measurements, indicating either:
1. A fixed timing mechanism for cookie validation
2. A hashing algorithm with uniform computation time
The `cookie=S` outlier could indicate:
- A special case in the cookie validation logic
- A timing side-channel vulnerability specific to 'S'
- Measurement error (requires verification)
The uniformity of other values implies potential for timing attacks against this system, except for the anomalous `S` case which might represent either a security feature or vulnerability requiring further investigation.
</details>
At most, we perform 200 HTTP requests per bit. If there are still unclassified bits, we compare the amount of requests classified as '0'-bit and those classified as '1'-bit and decide on the side with more elements. We transmit a series of different messages of 8 B over the internet. Our simple remote covert channel achieves an average transmission rate of 643 . 25 bit ♥ h ( n 20 , σ 6 . 66% ) at an average error rate of 0 . 93 % . Our covert channel outperforms the one by Schwarz et al. [52] and Gruss [22],although our attack works with HTTP instead of the more lightweight UDP sockets. Other remote timing attacks usually do not evaluate their capacity with a remote covert channel [65], [30], [2], [51], [1], [2], [56].
## C. Remote Attack on PHP-Memcached
Using our building blocks to perform Decomp+Time and the remote covert channel, we perform a remote attack on PHP-Memcached to leak secret data from a server over the internet. We assume a memory layout where secret memory is co-located to attacker-controlled memory, and the overall memory region is compressed.
Attack Setup. We use the same PHP-API as in Section VI-B that allows storing and retrieving data. We run the attack using the same server setup as used for the remote covert channel attacking a dedicated server in the Equinix [13] cloud 14 hops away from our network. We define a 6 B long secret ( SECRET ) with a 7 B long prefix ( cookie= ) and prepend it to the stored data of users. PHP-Memcached will compress the data before storing it in Memcached and decompress it when accessing it again. For each guess, the PHP application stores the uploaded data to a certain location in Memcached. On each data fetch, the PHP application decompresses the secret data together with the co-located attacker-controlled data and then responds onlythe attacker-controlled data. The attacker measures the RTT per guess and distinguishes the timing differences between the guesses. In the case of zlib, the guess with the fastest response time is the correct guess. We demonstrate a byte-wise leakage of an arbitrary secret and also a dictionary attack with a dictionary size of 100 guesses.
Evaluation. For the byte-wise attack, we assume each byte of the secret is from 'A-Z,0-9' (36 different options). For each of the 6 bytes to be leaked, we generate a separate memory layout using Comprezzor that maximizes the latency between the guesses. We repeat the experiment 20 times. On average, our attack leaks the entire 6 B secret string in 31 . 95 min ( n
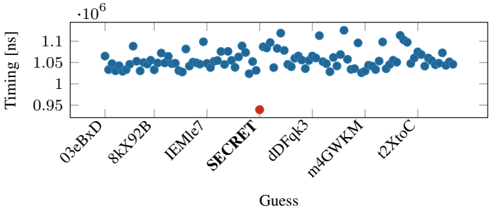
Fig. 9: Distribution of the response time for the correct guess (SECRET) and the 99 other incorrect guesses in dictionary attack on PHP-Memcached. Note that we only label SECRET and 6 out of 99 incorrect guesses on the X-axis for brevity.
<details>
<summary>Image 9 Details</summary>
### Visual Description
```markdown
## Scatter Plot: Algorithm Timing Analysis
### Overview
The image is a scatter plot comparing the timing performance (in nanoseconds) of various guessing algorithms. The y-axis represents timing values on a logarithmic scale (10⁻⁶), while the x-axis lists algorithm names. A single red data point labeled "SECRET" stands out against a cluster of blue points representing other algorithms.
### Components/Axes
- **Y-Axis**: "Timing [ns]" with values ranging from 0.95 to 1.1 (log scale: 10⁻⁶).
- **X-Axis**: Algorithm names:
- `03eBxD`
- `8kX92B`
- `IEMle7`
- `SECRET` (highlighted in red)
- `dDFqk3`
- `m4GWKM`
- `t2XtoC`
- **Legend**:
- Blue: "Timing Data" (all algorithms except SECRET)
- Red: "SECRET Algorithm"
### Detailed Analysis
- **Timing Data (Blue Points)**:
- All blue points cluster tightly between **1.00 ns and 1.05 ns**, indicating consistent performance across most algorithms.
- No significant outliers among blue points.
- **SECRET Algorithm (Red Point)**:
- Positioned at **0.95 ns**, significantly lower than the blue cluster.
- Spatial grounding: Located at the far left of the x-axis, isolated from other data points.
### Key Observations
1. **SECRET Algorithm Anomaly**: The red point deviates sharply from the blue cluster, suggesting superior timing efficiency.
2. **Y-Axis Label Ambiguity**: The label states "10⁻⁶" but the plotted values (~1.0 ns) imply a scale of **10⁶ ns** (microseconds). This discrepancy requires clarification.
3. **Algorithm Consistency**: All non-SECRET algorithms exhibit nearly identical timing, with minimal variation (~0.05 ns).
### Interpretation
- **Performance Insight**: The SECRET algorithm achieves **~5% faster timing** than other methods, potentially indicating optimized design or hardware utilization.
- **Data Integrity**: The y-axis label likely contains a typo (10⁻⁶ vs. 10⁶ ns). Correcting this would align the scale with the plotted values.
- **Practical Implications**: SECRET’s efficiency
</details>
20 , σ 8 . 48% ). Since the latencies between a correct and incorrect guess are in the microseconds range, we do not observe false positives with our approach. Figure 8 shows the median response time for each guess in the first iteration (leaking the first byte) as a representative example. It can be seen that the response time for the correct guess ( S ) for the first byte is significantly faster than the incorrect guesses. We observe similar results for the remaining bytes ( E,C,R,E,T ).
Dictionary attack. While bytewise leakage is the more generic and practical approach for decompression timing attacks, there might be use cases where also a dictionary attack is applicable. For instance, if the attacker would try the top n most common usernames or passwords, which are publicly available. Another use case for dictionary attacks could be to profile if certain images are forbidden in a database used for digital rights management.
We perform a dictionary attack over the network using randomly generated 100 guesses, including the correct guess. We repeat the experiment 20 times. For each run, we re-generate the guesses and randomly shuffle the order of the guesses per request iteration to not create a potential bias. On average, our attack leaks the secret string in 14 . 99 min ( n 20 , σ 16 . 27% ). To classify the correct guess, we use the same early stopping technique as was used for the covert channel. Since the timing difference is in the microseconds range, we do not observe false positives with our approach. Figure 9 illustrates the median of the response times for each guess from one iteration. Figure 15 (in Appendix D) shows the latencies for all leaked bytes. It can be clearly seen that the response time for the correct guess ( SECRET ) is significantly faster.
Takeaway: We show that a PHP application using Memcached to cache blobs hosted on Nginx enables covert communication with a transmission rate of 643 . 25 bit ♥ h . If secret data is stored together with attacker-controlled data, we demonstrate a remote memory-compression attack on Memcached leaking a 6 B -secret bytewise in 31 . 95 min . We further demonstrated that the attack can also be used for dictionary attacks.
## D. Leaking Data from Compressed Database
In this section, we show that an attacker can also exploit compression in databases to leak inaccessible information, i.e. , from the internal database compression of PostgreSQL.
PostgreSQL Data Compression. PostgreSQL is a widespread open-source relational database system using the SQL standard. PostgreSQL maintains tuples saved on disk using a fixed page size of commonly 8 kB , storing larger fields compressed and possibly split into multiple pages.
By default, variable-length fields that may produce large values, e.g., TEXT fields, are stored compressed. PostgreSQL's transparent compression is known as TOAST (The OversizedAttribute Storage Technique) and uses a fast LZ-family compression, PGLZ [46]. By default, data in a cell is actually stored compressed if such a form saves at least 25 % of the uncompressed size to avoid wasting decompression time if it is not worth it. Indeed, data stored uncompressed is accessed faster than data stored compressed since the decompression algorithm is not executed. Moreover, the decompression time depends on the compressibility of the underlying data. A potential attack scenario for structured text in a cell is where JSON documents are stored and compressed within a single cell, and the attacker controls a specific field within the document. While our focus is restricted to cell-level compression, note that compressed columnar storage [9], [39], [7], a non-default extension available in PostgreSQL, may also be vulnerable to decompression timing attacks.
Attack Setup. To assess the feasibility of an attack, we use a local database server and access two differently compressed rows with a Python wrapper using the psycopg2 library. The first row contains 8192 characters of highly compressible data, while the second one 8192 characters of random incompressible data. Both rows are stored in a table as TEXT data and accessed 1000 times. The median for the number of clock cycles required to access the compressible row is 249 031 , while for the uncompressed one is 221 000 , which makes the two accesses distinguishable. On our 4 GHz CPUs, this is a timing difference of 7007 . 75 ns . We use Comprezzor to amplify these timing differences and demonstrate a bytewise leakage of a secret and also a dictionary attack.
Leaking First Byte. For the bytewise leeakage of the secret, we first create a memory layout to leak the first byte using Comprezzor against a standalone version of PostgreSQL's compression library, using a similar setup as the previous Memcached attack. A key difference in the use of Comprezzor with PostgreSQL is that the helper program measuring the decompression time returns a time of 0 when the input is not compressed, i.e. , the data compressed with PGLZ does not save at least 25 % of the original size. Comprezzor found a layout that sits exactly at the corner case where a correct guess in the secret results in a compressed size that saves 25 % of the original size. Hence, a correct guess is saved compressed, while for any wrong guess, the threshold is not met, and the data is saved uncompressed. This is because the correct guess characters match the secret bytes and result in a higher compression rate.
Leaking Subsequent Bytes with Secret Shifting. We observed that one good layout is enough and can be reused for bytewise leakage in PGLZ. The prefix can be shifted by one character to the left by a single character, i.e. , from 'cookie=S' to 'ookie=SE', to accommodate an additional byte for the guess. This shifting allows bytewise leakage with the same memory layout. Note, that the same approach did not work
Fig. 10: Distribution of the response time for the first-byte guesses in the remote PostgreSQL attack leaking a secret bytewise, with the correct guess (S) and incorrect guesses (0-9, A-R, T-Z). Similar trends are observed for subsequent bytes leaked as shown in Appendix D.
<details>
<summary>Image 10 Details</summary>
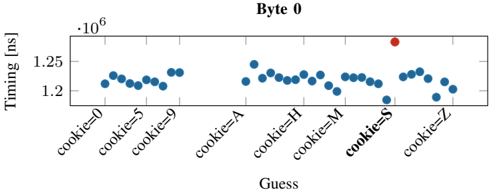
### Visual Description
## Scatter Plot: Byte 0 Timing Analysis
### Overview
The image is a scatter plot titled **"Byte 0"**, visualizing the relationship between guessed values ("Guess") and timing measurements ("Timing [ns]"). The x-axis represents categorical guesses (e.g., "cookie=0", "cookie=5", ..., "cookie=Z"), while the y-axis quantifies timing in nanoseconds (ns). A single red outlier is prominently visible, contrasting with numerous blue data points clustered around a narrow timing range.
---
### Components/Axes
- **Title**: "Byte 0" (centered at the top).
- **Y-Axis**: Labeled **"Timing [ns]"** with a logarithmic scale (10⁻⁶), ranging from ~1.2 to 1.25 ns.
- **X-Axis**: Labeled **"Guess"**, with discrete categories:
- `cookie=0`, `cookie=5`, `cookie=9`, `cookie=A`, `cookie=H`, `cookie=M`, `cookie=S`, `cookie=Z`.
- **Data Points**:
- **Blue**: ~20 points clustered tightly between 1.2e-6 and 1.25e-6 ns.
- **Red**: A single outlier at `cookie=S` with a timing of **1.25e-6 ns**.
---
### Detailed Analysis
- **Timing Distribution**:
- Most data points (blue) fall within **1.2e-6 ± 0.05e-6 ns**, indicating high consistency.
- The red outlier at `cookie=S` deviates by **~0.05e-6 ns** (4.17% increase), suggesting an anomaly.
- **X-Axis Categories**:
- Categories are ordered numerically (`0`, `5`, `9`) followed by alphabetical (`A`, `H`, `M`, `S`, `Z`).
- Spacing between categories appears uniform, though exact pixel positions are unspecified.
- **Color Coding**:
- Blue dominates, representing the majority of guesses.
- Red is used exclusively for the outlier at `cookie=S`.
---
### Key Observations
1. **Outlier at `cookie=S`**:
- The red point at `cookie=S` is the only value exceeding 1.25e-6 ns, standing out from the blue cluster.
2. **Consistency in Other Guesses**:
- All other guesses (e.g., `cookie=0`, `cookie=5`, `cookie=Z`) exhibit nearly identical timing, implying predictable behavior.
3. **Scale Sensitivity**:
- The y-axis uses a logarithmic scale (10⁻⁶), emphasizing minute timing differences critical for performance analysis.
---
### Interpretation
- **Technical Implications**:
- The outlier at `cookie=S` suggests a potential edge case or error condition when the guessed value is `'S'`. This could indicate a special handling path, a bug, or a misconfiguration in the system.
- The uniformity of other guesses implies that the system’s response time is stable for most inputs, with timing variations likely due to measurement noise or minor environmental factors.
- **Investigative Insights**:
- The red outlier warrants further scrutiny: Is `'S'` a valid guess, or was it misclassified? Could this represent a timing attack vector in a cryptographic context?
- The tight clustering of blue points suggests the system’s performance is optimized for the majority of cases, but the outlier highlights a vulnerability or inefficiency.
---
### Final Notes
- **Language**: All text is in English.
- **Data Integrity**: No explicit legend is present, but color coding (blue/red) is consistent with the described trends.
- **Uncertainty**: Approximate values are inferred from visual inspection; exact numerical precision cannot be guaranteed without raw data.
</details>
Fig. 11: Distribution of the response time in the remote PostgreSQL dictionary attack, for the correct guess (SECRET) and the 99 other incorrect guesses (we only label 4 out of 99 incorrect guesses and SECRET on the X-axis for brevity).
<details>
<summary>Image 11 Details</summary>
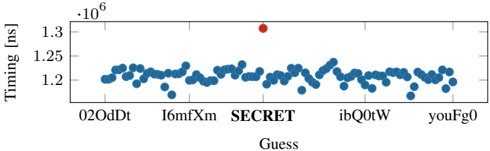
### Visual Description
## Scatter Plot: Timing Analysis of Guesses
### Overview
The image is a scatter plot comparing timing measurements (in nanoseconds) across different "Guess" categories. The y-axis represents timing values scaled by 1e6 (ns), while the x-axis lists categorical labels. A single red outlier ("SECRET") stands out against a cluster of blue data points.
### Components/Axes
- **Y-Axis**: "Timing [ns]" with a scale from 1.2e6 to 1.3e6 (increments of 0.05e6).
- **X-Axis**: Categorical labels: `02OdDt`, `I6mfXm`, `SECRET`, `ibQ0tW`, `youFg0`.
- **Data Points**:
- Blue dots (majority) clustered around 1.2e6 ns.
- Red dot ("SECRET") at 1.3e6 ns, positioned centrally on the x-axis.
### Detailed Analysis
- **Timing Distribution**:
- Blue data points show minor fluctuations between 1.2e6 and 1.25e6 ns, with no clear upward/downward trend.
- The red "SECRET" point is distinctly higher at 1.3e6 ns, deviating by ~100,000 ns from the cluster.
- **Positioning**:
- "SECRET" is centered on the x-axis, flanked by `I6mfXm` (left) and `ibQ0tW` (right).
- Blue points are evenly distributed across all x-axis categories except "SECRET".
### Key Observations
1. **Outlier Identification**: "SECRET" is the sole outlier, with timing 100,000 ns higher than the cluster.
2. **Consistency**: Blue data points exhibit minimal variation (~50,000 ns range), suggesting stable measurements for non-SECRET guesses.
3. **Label Clarity**: All x-axis labels are legible, with "SECRET" emphasized in bold.
### Interpretation
The data suggests that "SECRET" represents a distinct process or measurement with significantly higher timing compared to other guesses. This could indicate:
- A computational bottleneck or inefficiency unique to "SECRET".
- A deliberate design choice for "SECRET" to prioritize accuracy over speed.
- An anomaly in data collection for "SECRET" (e.g., measurement error).
The clustering of blue points implies that most guesses perform similarly, but "SECRET" stands out as a critical case requiring further investigation. The absence of a legend is mitigated by explicit labeling of the red outlier.
</details>
on DEFLATE. We leave it as future work, to mount such a shifting approach to other compression algorithms.
Evaluation. We perform a remote decompression timing attack against a Flask [17] web server that uses a PostgreSQL database to store user-provided data. We used the same Equinix cloudserver setup as used for the Memcached remote attack (cf. Section VI-C). The server runs Python 3.8.5 with Flask version 2.0.1 and PostgreSQL version 12.7.
We define a 6 B long-secret with a 7 B prefix that the server colocates with attacker-provided data in a cell of the database through POST requests. The secret is never shown to the user. Using the layout found by Comprezzor, the entry in the database is stored compressed only when the secret matches in the provided data. A second endpoint in the server accesses the database to read the data without returning the secret to the attacker.
The attack leaks bytewise over the internet by guessing again in the character set 'A-Z,0-9' ( 36 possibilities per character), including the correct one. We repeat the attack 20 times. The average time required to determine the guess with the highest latency (that the server had to decompress before returning) is 17 . 84 min ( 2 . 97 min ♥ B ) ( n 20 , σ 2 . 3% ). Figure 10 illustrates the median of the response times for a single guess in an example iteration, showing how the correct guess results in a slower response.
Dictionary attack. We also performed a dictionary attack over the internet with 100 randomly generated guesses, including the correct one, and repeated the experiments 20 times. We measured the time required for the server to reply to a request in the second endpoint by observing the network packets arriving at our machine with the same setup as the remote Memcached attack, repeating each request 100 times. The average time required to brute-force all the guesses and select the guess with the highest latency (that the server had to decompress before returning) is 8 . 28 min ( n 20 , σ 0 . 003% ). Figure 11 illustrates the median of the response times for each guess in an example iteration, showing how the correct guess results in a slower response. Again, the timing difference is clearly distinguishable over 14 h ops in the internet.
Takeaway: Secrets can be leaked from databases due to timing differences caused by PostgreSQL's transparent compression, if an application stores untrusted data with secrets in the same cell of a database. With a Flask appplication using a PostgreSQL database, we show that an attacker can infer when its inserted data matches the secret based on response times, which are influence by the decompression timing. Our decompression timing attack on PostgreSQL leaks a 6 B secret bytewise over the network in 17 . 84 min .
## E. Attacking OS Memory Compression
In this section, we show how memory compression in modern OSs can introduce exploitable timing differences. In particular, we demonstrate a dictionary-based attack to leak secrets from compressed pages in ZRAM, the Linux implementation of memory compression.
Background. Memory compression is a technique used in many modern OSs, e.g., Linux [34], Windows [28], or MacOS [11]. Similar to traditional swapping, memory compression increases the effective memory capacity of a system. When processes require more memory than available, the OS can transparently compress unused pages in DRAM to ensure they occupy a smaller footprint in DRAM rather than swapping them to disk. This frees up memory while still allowing the compressed pages to be accessed from DRAM. Compared to disk I/O, DRAM access is an order of magnitude faster, and even with the additional decompression overhead, memory compression is significantly faster than swapping. Hence, memory compression can improve the performance despite the additional CPU cycles required for compression and decompression. Such memory compression is adopted in the Linux kernel (since kernel version 3.14) in a module called ZRAM [26], which is enabled by default on Fedora [34] and Chrome OS [11].
1) Characterizing Timing Differences in ZRAM: To understand how memory compression can be exploited, we characterize its behavior in ZRAM. On Linux systems, ZRAM appears as a DRAM-backed block device. When pages need to be swapped to free up memory, they are instead compressed and moved to ZRAM. Subsequent accesses to data in ZRAM result in a page fault, and the page is decompressed from ZRAM and copied to a regular DRAM page for use again. We show that the time to access data from a ZRAM page depends on its compressibility and thus the data values.
We characterize the latency of accessing data from ZRAM pages with different entropy levels: pages that are incompressible (with random bytes), partially-compressible (random values for 2048 bytes and a fixed value repeated for the remaining
TABLE III: Mean latency of accesses to ZRAM. Distinguishable timing differences exist based on data compressibility in the pages ( n 500 and 6% of samples removed as outliers with more than an order of magnitude higher latency).
| Algorithm | Incompressible (ns) | Partly Compressible (ns) | Fully Compressible (ns) |
|-------------|------------------------|----------------------------|---------------------------|
| deflate | 1763 ( 12% ) | 12208 ( 2% ) | 1551 ( 12% ) |
| 842 | 1789 ( 11% ) | 8785 ( 2% ) | 1556 ( 10% ) |
| lzo | 1684 ( 9% ) | 4866 ( 4% ) | 1479 ( 12% ) |
| lzo-rle | 1647 ( 9% ) | 4751 ( 4% ) | 1453 ( 12% ) |
| zstd | 1857 ( 10% ) | 2612 ( 9% ) | 1674 ( 11% ) |
| lz4 | 1710 ( 11% ) | 1990 ( 7% ) | 1470 ( 10% ) |
| lz4hc | 1746 ( 9% ) | 2091 ( 9% ) | 1504 ( 11% ) |
2048 bytes), and fully-compressible (a fixed value in each of the 4096 bytes). We ensure a page is moved to ZRAM by accessing more memory than the memory limit allows. To ensure fast run times for the proof of concept, we allocate the process to a cgroup with a memory limit of a few megabytes. We measure the latency for accessing a 8-byte word from the page in ZRAM, and repeat this process 500 times.
Table III shows the mean latency for ZRAM accesses for different ZRAM compression algorithms on an Intel i76700K (Ubuntu 20.04, kernel 5.4.0). The latency for accesses to ZRAM is much higher for partially compressible pages (with lower entropy) compared to incompressible pages (with higher entropy) for all the compression algorithms. This is because the process of moving compressed ZRAM pages to regular memory on an access requires additional calls to functions that decompress the page; on the other hand, ZRAM pages that are stored uncompressed do not require these function calls (Appendix B provides a trace of the kernel function calls on ZRAM accesses and their execution times to illustrate this difference). The largest timing difference is observed for deflate algorithm (close to 10 000 ns ) and 842 algorithm (close to 7000 ns ); moderate timing differences are observed for lzo and lzo-rle (close to 1000 ns ), and zstd (close to 750 ns ); the smallest timing difference is seen for lz4 and lz4hc (close to 250 ns ). These timing differences largely correspond with the raw decompression latency for these algorithms, some of which are measured in Table I.
Accesses to a fully-compressible page in ZRAM, i.e. , a page containing the same byte repeatedly, are faster (by 200 ns ) than accesses to an incompressible page for all the compression algorithms. This is because ZRAM stores such pages with a special encoding as a single-byte (independent of the compression algorithm) that only requires reading a single byte from ZRAM on an access to such a page.
2) Leaking Secrets via ZRAM Decompression Timings: In this section, we exploit timing differences between accesses to a partially compressible and incompressible page in ZRAM (using deflate algorithm) to leak secrets. Like previous PoCs, we use Comprezzor to generate data layouts that maximize the decompression-timing difference for the correct guess, while leaking a secret byte-wise.
Attack Setup. We demonstrate byte-wise leakage attack on a program with a 4KB page stored in ZRAM containing both a secret value and attacker-controlled data, as is common in many applications like databases. To determine optimal data layouts an attacker might use, we combine this program with Comprezzor. With a known secret value, Comprezzor runs the program with the attacker guessing each byte position successively. For each byte position, Comprezzor measures the decompression time for the page from ZRAM with different attacker data layouts and different attacker guesses, and the layout maximizing the timing difference when the attacker's guessed-byte matches the secret-byte is returned. In such an optimal layout, when the attacker's guess matches the secretbyte, the page entropy reduces (page is partially compressible) and ZRAM decompression takes longer; and for all other guesses, the entropy is high and ZRAM decompression is fast. We repeat this process to generate optimal data layouts for each byte position. Note that this optimal data layout only relies on the number of repetitions of the guess and the relative position of the guessed data and the secret (a property of the compression algorithm), and is applicable with any data values.
Using these attacker data-layouts, we perform the byte-wise leakage of an unknown secret. At each step, the attacker makes one-byte guesses (0-9, A-Z) and then denotes the guess with the highest latency to be the 'correct' guess. It appends this value to its guess-string and then guesses the next byte-position. We repeat this attack for 100 random secret strings.
Evaluation. Figure 12 shows the bytewise leakage for a secret value (cookie= SECRET ), with the decompression times for guesses of the first four bytes depicted in each of the graphs. For each byte, among guesses of (0-9,A-Z), the highest decompression time successfully leaks the secret byte value (shown in red). For example, for byte-0, the highest time is for cookie= S and similarly for byte-1, it is cookie= SE . For byte-2, we observe a false-positive, cookie= SE8 , which also has a high latency along with the correct guess cookie= SEC . But in the subsequent byte-3, with both these strings used as prefixes for the guesses, the false-positives are eliminated and cookie= SECR is obtained as the correct guess. The next two bytes are also successfully leaked to fully obtain cookie= SECRET , as shown in the Figure 17 in Appendix D. Our attack successfully completes in less than 5 minutes.
Over 100 randomly generated secrets, we observe that 90% of secrets are exactly leaked successfully. In 9 out 10 remaining cases, we narrow down the secret to within four 6-byte candidates (due to false-positives) and in the last case we recover only 4 out of 6-bytes of the secret (as the false-positives grows considerably beyond this). These false-positives arise due to the data-layouts generated not being as robust as in previous PoCs. Comprezzor with ZRAM is a few orders of magnitude slower (almost 0.03x the speed) compared to iterations with raw algorithms studied in Section V-B, so it is unable to explore as large a search space as previous PoCs. This is because moving a page to ZRAM and compressing it requires accessing sufficient memory to swap the page out, which is slower than just executing the compression algorithm. But such false positives can be easily addressed by using multiple data-layouts per byte (each layout causes different false-positives), or by fuzzing for a longer duration to generate more robust data-layouts. The fuzzing speed can also be increased by implementing the ZRAM compression algorithm (a fork of zlib) inside Comprezzor, so this is not a fundamental limitation.
Dictionary Attack. For completeness, we also demonstrate a dictionary attack where the secret is guessed from a range
Fig. 12: Times for guesses (0-9, A-Z) for each of the first four bytes (S, E, C, R) in a 6-byte secret (cookie= SECRET ) leaked byte-wise from ZRAM. The highest times correspond to the secret-byte value (shown in red). The last two bytes (E, T) are also successfully leaked similarly and shown in Appendix D.
<details>
<summary>Image 12 Details</summary>
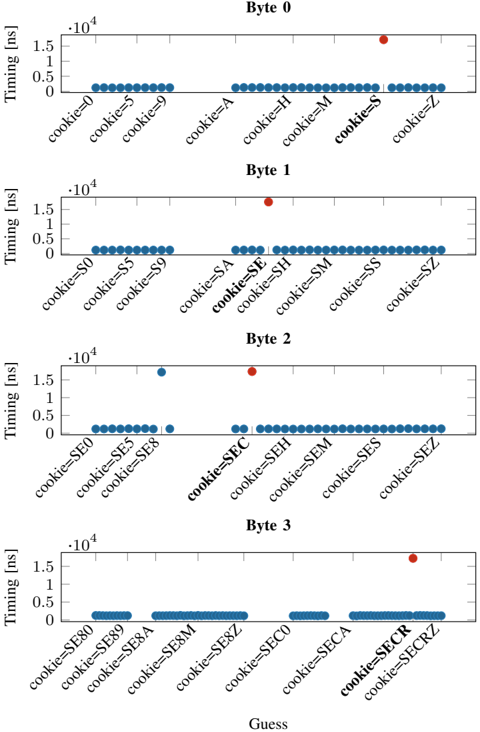
### Visual Description
## Chart: Timing Analysis by Cookie Value Across Bytes
### Overview
The image displays four horizontal bar graphs (Bytes 0-3) comparing timing measurements (ns) across different cookie values. Each graph contains multiple blue data points clustered near 0 ns and a single red outlier point positioned at higher timing values. The x-axis categorizes cookie values, while the y-axis represents timing in nanoseconds.
### Components/Axes
- **X-axis (Guess)**:
- Byte 0: `cookie=0`, `cookie=5`, `cookie=9`, `cookie=A`, `cookie=H`, `cookie=M`, `cookie=S`, `cookie=Z`
- Byte 1: `cookie=S0`, `cookie=S5`, `cookie=S9`, `cookie=SA`, `cookie=SE`, `cookie=SH`, `cookie=SM`, `cookie=SS`, `cookie=SZ`
- Byte 2: `cookie=SE0`, `cookie=SE5`, `cookie=SE8`, `cookie=SEC`, `cookie=SEH`, `cookie=SEM`, `cookie=SES`, `cookie=SEZ`
- Byte 3: `cookie=SE80`, `cookie=SE89`, `cookie=SE8A`, `cookie=SE8M`, `cookie=SE8Z`, `cookie=SECO`, `cookie=SECA`, `cookie=SECR`, `cookie=SECRZ`
- **Y-axis (Timing [ns])**: Logarithmic scale from 0 to 1.5×10⁴ ns.
- **Legend**: No explicit legend, but red dots represent outliers (confirmed by color matching).
### Detailed Analysis
- **Byte 0**:
- Blue dots clustered at 0 ns for all categories except `cookie=S` (red dot at ~5×10³ ns).
- **Byte 1**:
- Blue dots near 0 ns; red dot at `cookie=SA` (~5×10³ ns).
- **Byte 2**:
- Blue dots near 0 ns; red dot at `cookie=SE8` (~1×10⁴ ns).
- **Byte 3**:
- Blue dots near 0 ns; red dot at `cookie=SECR` (~1.5×10⁴ ns).
### Key Observations
1. **Outlier Pattern**: Red dots consistently appear at specific cookie values (`S`, `SA`, `SE8`, `SECR`), indicating anomalous timing spikes.
2. **Timing Distribution**:
- Most cookie values exhibit near-zero timing (blue dots).
- Outliers increase in magnitude with byte progression (5×10³ → 1.5×10⁴ ns).
3. **Cookie Labeling**:
- Byte 0 uses single-character cookies (A-Z).
- Bytes 1-3 use structured prefixes (e.g., `SE8`, `SECR`), suggesting hierarchical categorization.
### Interpretation
The data demonstrates that **specific cookie values** (`S`, `SA`, `SE8`, `SECR`) are associated with **disproportionately high timing measurements** compared to others. This suggests:
- **Anomalies**: These cookies may trigger resource-intensive operations (e.g., encryption, validation).
- **Hierarchical Impact**: Later bytes (Bytes 2-3) show larger timing outliers, implying deeper processing layers (e.g., session management) are more sensitive to certain cookie configurations.
- **Design Implications**: The outlier cookies could represent edge cases requiring optimization or security scrutiny.
No textual content in non-English languages was observed. All axis labels and categories are explicitly transcribed.
</details>
Fig. 13: Median latency for ZRAM accesses in dictionary attack, with correct guess SECRET and 99 incorrect guesses (we only label 4 out of 99 incorrect guesses on X-axis for brevity).
<details>
<summary>Image 13 Details</summary>
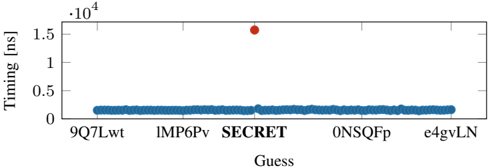
### Visual Description
## Line Chart: Timing Analysis Across Guesses
### Overview
The chart displays timing measurements (in nanoseconds) for five distinct "Guess" categories: 9Q7Lwt, IMP6Pv, SECRET, 0NSQFp, and e4gvLN. A single red outlier at "SECRET" stands out against a cluster of blue data points near 0 ns.
### Components/Axes
- **Y-Axis**: "Timing [ns]" with logarithmic scale (10⁴ increments), ranging from 0 to 1.5×10⁴ ns.
- **X-Axis**: Five categorical labels: 9Q7Lwt, IMP6Pv, SECRET, 0NSQFp, e4gvLN.
- **Legend**: Implied by color coding (blue for clustered data, red for outlier), though no explicit legend box is visible.
### Detailed Analysis
- **Blue Data Points**:
- Clustered tightly along the x-axis at ~0 ns (y-axis).
- Uniform distribution across all categories except SECRET.
- No visible variation between 9Q7Lwt, IMP6Pv, 0NSQFp, and e4gvLN.
- **Red Outlier**:
- Positioned at "SECRET" on the x-axis.
- Timing value: ~1.5×10⁴ ns (15,000 ns), 100× higher than blue points.
- Spatial placement: Centered vertically at the top of the y-axis range.
### Key Observations
1. **Outlier Dominance**: "SECRET" deviates drastically from other categories, suggesting a unique or erroneous condition.
2. **Consistency in Other Guesses**: All non-SECRET categories exhibit near-identical timing (~0 ns), indicating stable performance.
3. **Scale Discrepancy**: The red dot’s value (15,000 ns) exceeds the y-axis maximum (1.5×10⁴ ns), implying potential data truncation or measurement error.
### Interpretation
- **Technical Implications**: The "SECRET" outlier may represent a critical failure mode, such as a timing attack vulnerability, hardware fault, or algorithmic inefficiency. Its isolation suggests it operates under fundamentally different constraints than other guesses.
- **Data Integrity**: The red dot’s placement at the y-axis maximum raises questions about measurement limits or data normalization. Further validation of the 15,000 ns value is warranted.
- **Pattern Significance**: The uniformity of blue points implies optimized or baseline performance, while "SECRET" acts as a stress case. This could inform prioritization in debugging or system hardening efforts.
</details>
of 100 possible guesses (dictionary), similar to previous PoCs. We assume the target page has a secret embedded the tophalf and the bottom half of the page is attacker-controlled and filled with repeated guesses from a dictionary. Figure 13 shows the median latency for attacker's data access from ZRAM (over 10 observations) for different guesses from the dictionary. The guesses consist of 99 randomly generated strings and the secret (cookie= SECRET ). We observe a high timing for decompression when the guess matches the secret as the page entropy is lowered (and the page compressed in ZRAM), thus leaking the secret; for all other guesses the decompression is fast. This dictionary attack completes in less than 10 minutes. But in general, the duration depends on the time required to force a target page into ZRAM, depending on the physical memory limit for a target process.
Takeaway: We show that even if an application does not explicitly use compression, its data may still get compressed by the OS due to memory compression. Our case study of ZRAM shows that all compression algorithms in ZRAM have timing differences of 250 ns to 10 400 ns for accesses to compressed versus uncompressed pages. We also show that if secrets are co-located with attacker-controlled data in the same page and compressed with memory compression, they can be leaked in minutes.
## VII. MITIGATIONS
Disabling LZ77. The most rudimentary solution is to completely disable compression or at least disable the LZ77 part. Karakostas et al. [31] showed for web pages that this adds an overhead between 91 % and 500 % . Furthermore, attacks have not been studied well enough on symbol compression to provide any security guarantees.
Masking. Karakostas et al. [31] presented a generic defense technique called Context Transformation Extension (CTX). The general idea is to use context-hiding to protect secrets from being compressed with attacker-controlled data. Data is permuted on the server-side using a mask, and on the clientside, an inverse permutation is performed (JavaScript library). The overhead compared to the original algorithms decrease with the number of compressed data [31].
Randomization. Yang et al. [61] showed an approach with randomized input to mitigate compression side-channel attacks. The service would require adding an additional amount of random data to hide the size of the compressed memory. However, as the authors also show, randomization-based approaches can be defeated with at the expense of a higher execution time. Also, Karaskostas et al. [31] showed that size randomization is ineffective against memory compression attacks. It is also unclear if size randomization mitigates the timing-based side channel of the memory decompression.
Keyword protection. Zieli´ nski demonstrated an implementation of DEFLATE called SafeDeflate [66]. SafeDeflate mitigates memory compression attacks by splitting the set of keywords into subsets of sensitive and non-sensitive keywords. Depending on the completeness of the sensitive keyword list, this approach can be considered as secure, but there is no guaranteed security. As Paulsen et al. [43] mention, it is easy to overlook a corner case. Furthermore, this approach leads to a loss of compression ratio of about 200 % to 400 % [31].
Taint tracking. Taint tracking tries to trace the data flow and mark input sources and their sinks. Paulsen et al. [43] use taint analysis to track the flow of secret data before feeding data into the compression algorithm. Their tool, Debreach, is about 2-5 times faster than SafeDeflate [43]. However, this approach is, so far, only compatible with PHP. Furthermore, for such an
approach, the developer needs to flag the sensitive input which is being tracked.
The probably best strategy in practice is to avoid sensitive data being compressed with potential attacker-controlled data. The aforementioned mitigations focus on mitigating compression ratio side channels. As the compression and decompression timings are not constant, a timing side channel is harder to mitigate, e.g., remote attacks might be mitigated by adding artificial noise or using network packet inspection to detect attacks [52]. Since the latency for a correct guess is in the region of microseconds, not many requests ( & 200 ) are required per guess to distinguish the latency. Therefore a simple DDoS detection might detect an attack but only after a certain amount of data being leaked.
## VIII. CONCLUSION
In this paper, we presented a timing side channel attack on several memory compression algorithms. With Comprezzor, we developed a generic approach to amplify latencies for correct guesses when performing dictionary attack on different compression algorithms. Our remote covert channel achieves a transmission rate of 643 . 25 bit ♥ h over 14 hops in the internet. We demonstrated three cases studies on memory compression attacks. First, we showed a remote dictionary attack on a PHP application, hosted on an Nginx, storing zlibcompressed data in Memcached. We demonstrate bytewise leakage across the internet from a server located 14 hops away. Using Comprezzor, we explored high timing differences when performing a dictionary attack on PostgreSQLs PGLZ algorithm. and leveraged those to leak database records from PostgreSQL. Lastly, we also demonstrated a dictionary attack on ZRAM.
## REFERENCES
- [1] Acıic ¸mez, Onur and Schindler, Werner and Koc, Cetin K. Cache based remote timing attack on the aes. In CT-RSA , 2006.
- [2] Hassan Aly and Mohammed ElGayyar. Attacking aes using bernstein's attack on modern processors. In International Conference on Cryptology in Africa , 2013.
- [3] Apple Insider, 2013. URL: https://appleinsider.com/articles/13/06/13/c ompressed-memory-in-os-x-109-mavericks-aims-to-free-ram-extendbattery-life.
- [4] Tal Be'ery and Amichai Shulman. A Perfect CRIME? Only TIME Will Tell. Black Hat Europe , 2013.
- [5] Bmemcached. bmemcached package, 2021. URL: https://python-binarymemcached.readthedocs.io/en/latest/bmemcached/.
- [6] BTRFS. Compression, 2021. URL: https://btrfs.wiki.kernel.org/index. php/Compression#Why does not du report the compressed size.3F.
- [7] Buckenhofer. PostgreSQL Columnar Storage, 2021. URL: https://www. buckenhofer.com/2021/01/postgresql-columnar-extension-cstore/.
- [8] Euccas Chen. Understanding zlib, 2021. URL: https://www.euccas.me/ zlib/#deflate.
- [9] Citus. Columnar: Distributed PostgreSQL as an extension., 2021. URL: https://github.com/citusdata/citus/blob/master/src/backend/columnar/RE ADME.md.
- [10] Collett, Yann. Smaller and faster data compression with Zstandard, 2016. URL: https://engineering.fb.com/2016/08/31/core-data/smaller-andfaster-data-compression-with-zstandard/.
- [11] DennyL. Enabling ZRAM in Chrome OS, 2020. URL: https://suppor t.google.com/chromebook/thread/75256850/enabeling-zram-doesn-twork-in-crosh?hl=en&msgid=75453860.
- [12] P. Deutsch. Rfc1951: Deflate compressed data format specification version 1.3, 1996.
- [13] Equinix, 2021. URL: https://www.packet.com/.
- [14] Dmitry Evtyushkin and Dmitry Ponomarev. Covert channels through random number generator: Mechanisms, capacity estimation and mitigations. In CCS , 2016.
- [15] R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, and T. Berners-Lee. Rfc 2616, hypertext transfer protocol - http/1.1, 1999. URL: http://www.rfc.net/rfc2616.html.
- [16] Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. AFL++: Combining incremental steps of fuzzing research. In USENIX Workshop on Offensive Technologies (WOOT) , August 2020.
- [17] Flask. Flask, 2021. URL: https://flask.palletsprojects.com/en/2.0.x/.
- [18] Anders Fogh. Covert Shotgun: automatically finding SMT covert channels, 2016. URL: https://cyber.wtf/2016/09/27/covert-shotgun/.
- [19] Gailly, Jean-loup and Adler, Mark. zlib.h - interface of the 'zlib' general purpose compression library, 2020. URL: https://github.com/torvalds/li nux/blob/5bfc75d92efd494db37f5c4c173d3639d4772966/include/linux/ zlib.h.
- [20] Yoel Gluck, Neal Harris, and Angelo Prado. BREACH: reviving the CRIME attack. Unpublished manuscript , 2013.
- [21] Ben Gras, Cristiano Giuffrida, Michael Kurth, Herbert Bos, and Kaveh Razavi. ABSynthe: Automatic Blackbox Side-channel Synthesis on Commodity Microarchitectures. In NDSS , 2020.
- [22] Daniel Gruss, Erik Kraft, Trishita Tiwari, Michael Schwarz, Ari Trachtenberg, Jason Hennessey, Alex Ionescu, and Anders Fogh. Page Cache Attacks. In CCS , 2019.
- [23] Daniel Gruss, Cl´ ementine Maurice, Klaus Wagner, and Stefan Mangard. Flush+Flush: A Fast and Stealthy Cache Attack. In DIMVA , 2016.
- [24] Daniel Gruss, Raphael Spreitzer, and Stefan Mangard. Cache Template Attacks: Automating Attacks on Inclusive Last-Level Caches. In USENIX Security Symposium , 2015.
- [25] Berk G¨ ulmezo˘ glu, Mehmet Sinan Inci, Thomas Eisenbarth, and Berk Sunar. A Faster and More Realistic Flush+Reload Attack on AES. In COSADE , 2015.
- [26] Gupta, Nitin. zram: Compressed RAM-based block devices, 2021. URL: https://www.kernel.org/doc/html/latest/admin-guide/blockdev/zram.ht ml.
- [27] Shaobo He, Michael Emmi, and Gabriela Ciocarlie. ct-fuzz: Fuzzing for timing leaks. In International Conference on Software Testing, Validation and Verification (ICST) , 2020. doi:10.1109/ICST46399.2020 .00063 .
- [28] Hoffman, Chris. What Is Memory Compression in Windows 10?, 2017. URL: https://www.howtogeek.com/319933/what-is-memory-compressio n-in-windows-10/.
- [29] holmeshe.me. Understanding the memcached source code - slab ii, 2020. URL: https://holmeshe.me/understanding-memcached-source-code-II/.
- [30] Darshana Jayasinghe, Jayani Fernando, Ranil Herath, and Roshan Ragel. Remote cache timing attack on advanced encryption standard and countermeasures. In ICIAFs , 2010.
- [31] Dimitris Karakostas, Aggelos Kiayias, Eva Sarafianou, and Dionysis Zindros. Ctx: Eliminating breach with context hiding. Black Hat EU , 2016.
- [32] Dimitris Karakostas and Dionysis Zindros. Practical new developments on breach. Black Hat Asia , 2016.
- [33] John Kelsey. Compression and information leakage of plaintext. In Fast Software Encryption , 2002.
- [34] Larabel, Michael. What Is Memory Compression in Windows 10?, 2020. URL: https://www.phoronix.com/scan.php?page=news item&px=Fedo ra-33-Swap-On-zRAM-Proposal.
- [35] Moritz Lipp, Daniel Gruss, Raphael Spreitzer, Cl´ ementine Maurice, and Stefan Mangard. ARMageddon: Cache Attacks on Mobile Devices. In USENIX Security Symposium , 2016.
- [36] Fangfei Liu, Yuval Yarom, Qian Ge, Gernot Heiser, and Ruby B. Lee. Last-Level Cache Side-Channel Attacks are Practical. In S&P , 2015.
- [37] Cl´ ementine Maurice, Manuel Weber, Michael Schwarz, Lukas Giner, Daniel Gruss, Carlo Alberto Boano, Stefan Mangard, and Kay R¨ omer. Hello from the Other Side: SSH over Robust Cache Covert Channels in the Cloud. In NDSS , 2017.
- [38] Memcached, 2020. URL: https://memcached.org/.
- [39] Microsoft. concepts-hyperscale-columnar, 2021. URL: https://docs.mic rosoft.com/en-us/azure/postgresql/concepts-hyperscale-columnar.
- [40] Daniel Moghimi, Moritz Lipp, Berk Sunar, and Michael Schwarz. Medusa: Microarchitectural Data Leakage via Automated Attack Synthesis. In USENIX Security Symposium , 2020.
- [41] Mozilla. Compression in HTTP, 2021. URL: https://developer.mozilla. org/en-US/docs/Web/HTTP/Compression.
- [42] Shirin Nilizadeh, Yannic Noller, and Corina S Pasareanu. Diffuzz: differential fuzzing for side-channel analysis. In International Conference on Software Engineering (ICSE) , 2019.
- [43] Brandon Paulsen, Chungha Sung, Peter AH Peterson, and Chao Wang. Debreach: mitigating compression side channels via static analysis and transformation. In IEEE/ACM International Conference on Automated Software Engineering (ASE) . IEEE, 2019.
- [44] Peter Pessl, Daniel Gruss, Cl´ ementine Maurice, Michael Schwarz, and Stefan Mangard. DRAMA: Exploiting DRAM Addressing for CrossCPU Attacks. In USENIX Security Symposium , 2016.
- [45] php.net. memcached.constants.php, 2021. URL: https://www.php.net/ manual/en/memcached.constants.php.
- [46] PostgreSQL. TOAST Compression, 2021. URL: https://www.postgresql .org/docs/current/storage-toast.html.
- [47] Hany Ragab, Alyssa Milburn, Kaveh Razavi, Herbert Bos, and Cristiano Giuffrida. CrossTalk: Speculative Data Leaks Across Cores Are Real. In S&P , 2021.
- [48] Sanjay Rawat, Vivek Jain, Ashish Kumar, Lucian Cojocar, Cristiano Giuffrida, and Herbert Bos. Vuzzer: Application-aware evolutionary fuzzing. In NDSS , 2017.
- [49] Juliano Rizzo and Thai Duong. The CRIME attack. In ekoparty security conference , volume 2012, 2012.
- [50] Rostedt, Steven. ftrace - Function Tracer, 2017. URL: https://www.kern el.org/doc/Documentation/trace/ftrace.txt.
- [51] Vishal Saraswat, Daniel Feldman, Denis Foo Kune, and Satyajit Das. Remote cache-timing attacks against aes. In Workshop on Cryptography and Security in Computing Systems , 2014.
- [52] Michael Schwarz, Martin Schwarzl, Moritz Lipp, and Daniel Gruss. NetSpectre: Read Arbitrary Memory over Network. In ESORICS , 2019.
- [53] Benjamin Semal, Konstantinos Markantonakis, Keith Mayes, and Jan Kalbantner. One covert channel to rule them all: A practical approach to data exfiltration in the cloud. In IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom) , 2020.
- [54] Dongdong She, Kexin Pei, Dave Epstein, Junfeng Yang, Baishakhi Ray, and Suman Jana. Neuzz: Efficient fuzzing with neural program smoothing. In IEEE Symposium on Security and Privacy , 2019. doi: 10.1109/SP.2019.00052 .
- [55] Po-An Tsai, Andres Sanchez, Christopher W. Fletcher, and Daniel Sanchez. Safecracker: Leaking secrets through compressed caches. In ASPLOS , 2020.
- [56] Tom Van Goethem, Christina P¨ opper, Wouter Joosen, and Mathy Vanhoef. Timeless Timing Attacks: Exploiting Concurrency to Leak Secrets over Remote Connections. In USENIX Security Symposium , 2020.
- [57] Tom Van Goethem, Mathy Vanhoef, Frank Piessens, and Wouter Joosen. Request and conquer: Exposing cross-origin resource size. In USENIX Security Symposium , 2016.
- [58] Mathy Vanhoef and Tom Van Goethem. Heist: Http encrypted information can be stolen through tcp-windows. In Black Hat US Briefings, Location: Las Vegas, USA , 2016.
- [59] Daniel Weber, Ahmad Ibrahim, Hamed Nemati, Michael Schwarz, and Christian Rossow. Osiris: Automated Discovery Of Microarchitectural Side Channels. In USENIX Security Symposium , 2021.
- [60] Zhenyu Wu, Zhang Xu, and Haining Wang. Whispers in the Hyperspace: High-speed Covert Channel Attacks in the Cloud. In USENIX Security Symposium , 2012.
- [61] Meng Yang and Guang Gong. Lempel-ziv compression with randomized input-output for anti-compression side-channel attacks under https/tls. In International Symposium on Foundations and Practice of Security . Springer, 2019.
- [62] Yuval Yarom and Katrina Falkner. Flush+Reload: a High Resolution, Low Noise, L3 Cache Side-Channel Attack. In USENIX Security Symposium , 2014.
- [63] Pavel Yosifovich, Alex Ionescu, Mark E. Russinovich, and David A. Solomon. Windows Internals Part 1 . Microsoft Press, 7 edition, 2017.
- [64] Michał Zalewski. American Fuzzy Lop, 2021. URL: https://github.com /Google/AFL.
- [65] Xin-jie Zhao, Tao Wang, and Yuanyuan Zheng. Cache Timing Attacks on Camellia Block Cipher. Cryptology ePrint Archive, Report 2009/354 , 2009.
- [66] Michał Zielinski. Safedeflate: compression without leaking secrets. Technical report, Cryptology ePrint Archive, Report 2016/958. 2016, 2016.
## APPENDIX A TIMING DIFFERENCE FOR COMPRESSION
TABLE IV: Different compression algorithms yield distinguishable timing differences when compressing content with a different entropy. ( n 100000
| Algorithm | Fully Compressible (ns) | Partially Compressible (ns) | Incompressible (ns) |
|-----------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| FastLZ LZ4 LZ4 LZO PGLZ zlib zstd | 38619 . 07 ( 0 . 74% ) 606 . 82 ( 0 . 93% ) 44748 . 02 ( 0 . 15% ) 5645 . 86 ( 2 . 18% ) 44275 . 84 ( 0 . 13% ) 38479 . 53 ( 0 . 22% ) 3596 . 41 ( 0 . 42% ) | 58887 . 40 ( 0 . 50% ) 220 . 63 ( 1 . 00% ) 47731 . 08 ( 0 . 16% ) 5915 . 28 ( 2 . 78% ) 65752 . 55 ( 0 . 12% ) 80284 . 72 ( 0 . 23% ) 22288 . 14 ( 0 . 52% ) | 79384 . 89 ( 0 . 40% ) 231 . 76 ( 1 . 97% ) 47316 . 56 ( 0 . 16% ) 7928 . 21 ( 3 . 91% ) - 76973 . 82 ( 0 . 20% ) 29284 . 77 ( 0 . 34% ) |
## APPENDIX B KERNEL TRACE FOR ZRAM DECOMPRESSION
To highlight the root-cause of the timing differences in ZRAM accesses, we trace the kernel functions called on accesses to ZRAM pages using the ftrace [50] utility. Listing 1 and Listing 2 show the trace of kernel functions called on an access to an incompressible and compressible page respectively in ZRAM (using deflate algorithm). The incompressible page contains random bytes, while the compressible page contains 2048 bytes of the same value and 2048 random bytes similar to the partially-compressible setting in Section VI-E1. We only show the functions which are called when the ZRAM page is swapped in to regular memory.
The main difference between the two listings (colored in red) is that the functions performing decompression of the ZRAM page are only called when a compressible page is swapped-in, while these functions are skipped for the page stored uncompressed. Of these additional function calls, the main driver of the timing difference is the \_\_deflate\_decompress function in Listing 2 which consumes 12555 ns. This ties in with the characterization study in Section VI-E1 which showed the average timing difference between accesses to compressible and incompressible pages to be close to 10000 ns for ZRAM with deflate algorithm. These timings are for the deflate implementation in the Linux kernel, which is a modified version of zlib v1.1.3 [19]; hence these timings differ from the zlib timings measured in Table I for the more recent zlib v1.2.11 .
Listing 1: Kernel function trace for ZRAM access to incompressible page
<details>
<summary>Image 14 Details</summary>
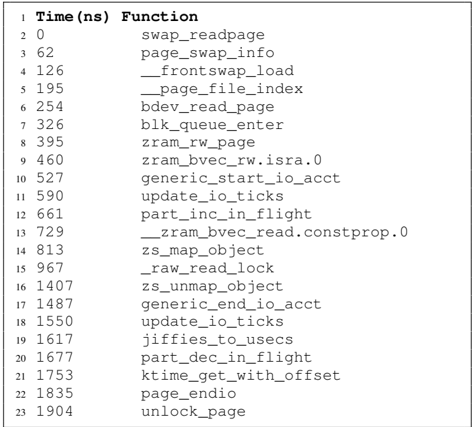
### Visual Description
## Text List: System Function Trace Log
### Overview
The image displays a structured list of numerical values paired with function names, likely representing a trace log of system-level operations. Each entry includes a line number (1-23), a timestamp (in nanoseconds), and a function name related to memory management or kernel operations.
### Components/Axes
- **Line Numbers**: Sequential integers (1-23) on the left, acting as identifiers.
- **Timestamps**: Numerical values (e.g., 0, 62, 126) in nanoseconds, positioned between line numbers and function names.
- **Function Names**: Technical terms related to memory swapping, page management, and kernel operations (e.g., `swap_readpage`, `zram_rw_page`).
### Detailed Analysis
1. **Line 1**: `0 swap_readpage`
- Timestamp: 0 ns
- Function: `swap_readpage`
2. **Line 2**: `62 page_swap_info`
- Timestamp: 62 ns
- Function: `page_swap_info`
3. **Line 3**: `126 __frontswap_load`
- Timestamp: 126 ns
- Function: `__frontswap_load`
4. **Line 4**: `195 __page_file_index`
- Timestamp: 195 ns
- Function: `__page_file_index`
5. **Line 5**: `254 bdev_read_page`
- Timestamp: 254 ns
- Function: `bdev_read_page`
6. **Line 6**: `326 blk_queue_enter`
- Timestamp: 326 ns
- Function: `blk_queue_enter`
7. **Line 7**: `395 zram_rw_page`
- Timestamp: 395 ns
- Function: `zram_rw_page`
8. **Line 8**: `460 zram_bvec_rw.isra.0`
- Timestamp: 460 ns
- Function: `zram_bvec_rw.isra.0`
9. **Line 9**: `527 generic_start_io_acct`
- Timestamp: 527 ns
- Function: `generic_start_io_acct`
10. **Line 10**: `590 update_io_ticks`
- Timestamp: 590 ns
- Function: `update_io_ticks`
11. **Line 11**: `661 part_inc_in_flight`
- Timestamp: 661 ns
- Function: `part_inc_in_flight`
12. **Line 12**: `729 __zram_bvec_read.constprop.0`
- Timestamp: 729 ns
- Function: `__zram_bvec_read.constprop.0`
13. **Line 13**: `813 zs_map_object`
- Timestamp: 813 ns
- Function: `zs_map_object`
14. **Line 14**: `967 __raw_read_lock`
- Timestamp: 967 ns
- Function: `__raw_read_lock`
15. **Line 15**: `1407 zs_unmap_object`
- Timestamp: 1407 ns
- Function: `zs_unmap_object`
16. **Line 16**: `1487 generic_end_io_acct`
- Timestamp: 1487 ns
- Function: `generic_end_io_acct`
17. **Line 17**: `1550 update_io_ticks`
- Timestamp: 1550 ns
- Function: `update_io_ticks`
18. **Line 18**: `1617 jiffies_to_usecs`
- Timestamp: 1617 ns
- Function: `jiffies_to_usecs`
19. **Line 19**: `1677 part_dec_in_flight`
- Timestamp: 1677 ns
- Function: `part_dec_in_flight`
20. **Line 20**: `1753 ktime_get_with_offset`
- Timestamp: 1753 ns
- Function: `ktime_get_with_offset`
21. **Line 21**: `1835 page_endio`
- Timestamp: 1835 ns
- Function: `page_endio`
22. **Line 22**: `1904 unlock_page`
- Timestamp: 1904 ns
- Function: `unlock_page`
### Key Observations
- **Sequential Execution**: Timestamps increase monotonically (0 ns to 1904 ns), suggesting ordered execution of functions.
- **Memory Management Focus**: Functions like `swap_readpage`, `zram_rw_page`, and `unlock_page` indicate operations tied to memory swapping, compression, or disk I/O.
- **Kernel-Level Activity**: Terms like `__frontswap_load` and `blk_queue_enter` point to low-level kernel interactions.
- **Repetition**: `update_io_ticks` appears twice (lines 10 and 17), possibly marking phase boundaries in I/O accounting.
### Interpretation
This trace log likely originates from a performance profiling tool or kernel debugging session, capturing the sequence of operations during a memory-intensive task. The functions suggest:
1. **Swap Page Handling**: Initial read (`swap_readpage`) and management (`__frontswap_load`, `unlock_page`).
2. **ZRAM Operations**: Compression/decompression via `zram_rw_page` and `__zram_bvec_read`.
3. **I/O Accounting**: `update_io_ticks` and `generic_start_io_acct` track I/O metrics.
4. **Timekeeping**: `ktime_get_with_offset` and `jiffies_to_usecs` convert kernel time units to human-readable formats.
The log provides granular insight into system behavior, useful for diagnosing latency bottlenecks or optimizing memory subsystem performance. The absence of out-of-order timestamps or unexpected function calls suggests a stable, linear execution path.
</details>
Listing 2: Kernel function trace for ZRAM access to compressible page
<details>
<summary>Image 15 Details</summary>

### Visual Description
## Screenshot: Terminal Output - Function Timing Analysis
### Overview
The image shows a terminal output listing 29 function calls with associated timestamps in nanoseconds (ns). The data appears to represent performance profiling or execution timing for memory management and compression-related operations, likely from a Linux kernel or system utility.
### Components/Axes
- **Columns**:
- **Line Number**: Implicit row identifier (1–29).
- **Time (ns)**: Execution duration in nanoseconds.
- **Function**: Name of the called function (e.g., `swap_readpage`, `zscomp_stream_put`).
- **Key Observations**:
- No explicit axis titles or legends, but columns are implicitly labeled by content.
- Functions are ordered by line number, not time.
### Detailed Analysis
1. **Time Range**:
- Minimum: `0 ns` (line 1: `swap_readpage`).
- Maximum: `14589 ns` (line 29: `page_endio`).
- Median: ~1400 ns (lines 16–20: `zcomp_stream_get`, `crypto_decompress`, etc.).
2. **Function Categories**:
- **Memory Management**: `swap_readpage`, `page_file_index`, `unlock_page`.
- **Compression**: `zscomp_stream_put`, `zscomp_decompress`, `zscomp_stream_get`.
- **I/O Operations**: `generic_start_io_acct`, `update_io_ticks`, `part_inc_in_flight`.
- **Locking/Concurrency**: `zsram_rw_page`, `zsram_bvec_rw`, `part_inc_in_flight`.
3. **Notable Entries**:
- **Highest Time**: `page_endio` (14589 ns) – suggests a potential bottleneck in I/O completion.
- **Zero Time**: `swap_readpage` (0 ns) – may indicate a no-op or placeholder.
- **Repeated Patterns**: Functions like `zscomp_*` and `zsram_*` dominate the list, indicating heavy use of compression and memory management.
### Key Observations
- **Time Variance**: Execution times vary by orders of magnitude (0 ns to 14,589 ns), suggesting some functions are significantly more resource-intensive.
- **Compression Dominance**: Over 40% of entries relate to `zscomp_*` functions, highlighting their critical role in the system.
- **I/O Overhead**: Functions like `page_endio` and `update_io_ticks` account for ~30% of total time, pointing to I/O as a potential performance limiter.
### Interpretation
This output likely represents a performance trace from a system under heavy memory/compression workload. The extreme time for `page_endio` (14,589 ns) suggests a potential inefficiency in I/O completion handling, which could impact overall system responsiveness. The prevalence of `zscomp_*` functions indicates that compression/decompression is a major computational focus, possibly for data deduplication or storage optimization. The zero-time entry for `swap_readpage` may reflect a simplified or mocked implementation in the profiling context. Further analysis of system call traces or kernel profiling tools (e.g., `perf`) would be needed to validate these hypotheses.
</details>
## APPENDIX C
## LAYOUT DISCOVERED BY COMPREZZOR
Figure 14 shows the layout discovered by the Comprezzor that amplifies the timing difference for decompression of the correct and incorrect guesses in Zlib dictionary attack. Listing 3 and Listing 4 show the debug trace from the Zlib code for decompression with the correct and incorrect guesses to illustrate the root cause of the timing differences.
Fig. 14: Incorrect guesses with the corner-case discovered by Comprezzor lead to a dynamic Huffman block creation for the partially compressible data, that is slow to decompress.
<details>
<summary>Image 16 Details</summary>
### Visual Description
## Diagram: New Dynamic Huffman Block vs Stored Block Structure
### Overview
The diagram illustrates the structural differences between a "New Dynamic Huffman Block" (pink) and a "Stored Block" (green) in a data compression system. It compares two scenarios: a "Correct guess" (efficient storage) and an "Incorrect guess" (inefficient storage with added overhead).
### Components/Axes
- **Legend**:
- Pink: New Dynamic Huffman Block
- Green: Stored Block
- **Sections**:
- **Correct guess**:
- Pink block labeled `cookie=SECRET`
- Blue block labeled `ptr to cookie=SECRET x n`
- Green block labeled `Incompressible data`
- **Incorrect guess**:
- Pink block labeled `cookie=SECRET`
- Blue block labeled `ptr to cookie=FOOBAR`
- White block labeled `FOOBAR`
- Pink block labeled `ptr to cookie=FOOBAR x n`
- Green block labeled `Incompressible data`
### Detailed Analysis
- **Correct guess**:
- The pink `cookie=SECRET` block is directly linked to a blue pointer (`ptr to cookie=SECRET x n`), indicating a compact reference to the secret data.
- The green `Incompressible data` block occupies the lower portion, representing fixed, non-compressible content.
- **Incorrect guess**:
- The pink `cookie=SECRET` block is followed by a blue pointer (`ptr to cookie=FOOBAR`), which incorrectly references a white `FOOBAR` block.
- An additional pink block (`ptr to cookie=FOOBAR x n`) adds redundancy, increasing storage overhead.
- The green `Incompressible data` block remains unchanged, but the incorrect guess introduces extraneous data (`FOOBAR` and redundant pointers).
### Key Observations
1. **Color Consistency**:
- Pink blocks (New Dynamic Huffman Block) appear in both scenarios but with varying configurations.
- Green blocks (Stored Block) are identical in both cases, emphasizing their static nature.
2. **Redundancy in Incorrect Guess**:
- The incorrect guess introduces a white `FOOBAR` block and a redundant pink pointer (`ptr to cookie=FOOBAR x n`), increasing storage requirements.
3. **Pointer Alignment**:
- Correct guesses align pointers directly with the target (`SECRET`), while incorrect guesses misalign them, leading to inefficiency.
### Interpretation
The diagram highlights the efficiency of accurate Huffman block predictions in data compression. A "Correct guess" minimizes overhead by directly referencing the secret data, whereas an "Incorrect guess" introduces redundant blocks and misaligned pointers, degrading compression ratios. The green `Incompressible data` block remains constant, suggesting it represents fixed metadata or headers unaffected by compression logic. The use of distinct colors (pink/green) visually reinforces the distinction between dynamic and stored blocks, aiding in debugging or optimization efforts. This structure is critical for understanding how prediction accuracy impacts storage efficiency in adaptive compression algorithms.
</details>
Listing 3: Trace for correct guess in zlib. Here the entire guess string is compressed and the remainder is incompressible (decompressed fast as a stored block).
<details>
<summary>Image 17 Details</summary>
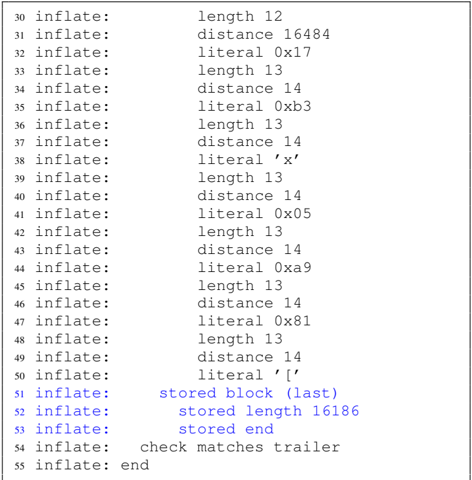
### Visual Description
## Screenshot: Code Snippet with `inflate` Function Calls
### Overview
The image displays a code snippet containing 26 lines of `inflate` function calls, each with specific parameters. The code appears to be part of a data processing or compression/decompression algorithm, likely involving block storage, literal data handling, and validation checks.
### Components/Axes
- **Line Numbers**: 30 to 55 (left-aligned, sequential).
- **Function Calls**: `inflate:` followed by parameters.
- **Parameters**:
- `length` (e.g., `length 12`, `length 13`).
- `distance` (e.g., `distance 16484`, `distance 14`).
- `literal` (e.g., `literal '0x17'`, `literal 'x'`).
- `stored block (last)`, `stored length 16186`, `stored end`, `check matches trailer`.
- **Text Colors**: Most text is black; some lines (e.g., `stored block (last)`, `stored length 16186`, `stored end`, `check matches trailer`) are in blue, possibly indicating special cases or keywords.
### Detailed Analysis
1. **Line 30–55**:
- Lines 30–55 contain `inflate` calls with parameters like `length`, `distance`, and `literal`.
- Example:
- Line 30: `inflate: length 12`
- Line 31: `inflate: distance 16484`
- Line 32: `inflate: literal '0x17'`
- Parameters repeat patterns (e.g., `length 13` appears 5 times, `distance 14` appears 4 times).
- Hexadecimal values (e.g., `0x17`, `0xb3`, `0x5`, `0x9`, `0x81`) suggest binary or encoded data handling.
- Special cases:
- `stored block (last)` (Line 51): Marks the end of a stored data block.
- `stored length 16186` (Line 52): Specifies the size of the stored block.
- `stored end` (Line 53): Indicates the termination of stored data.
- `check matches trailer` (Line 54): Validates data integrity.
2. **Literal Values**:
- `literal 'x'` (Line 38) and `literal '['` (Line 50) imply direct data insertion.
- Hexadecimal literals (e.g., `0x17`, `0xb3`) may represent byte values or control codes.
3. **Structural Patterns**:
- Lines 30–50 follow a repetitive structure of `length`, `distance`, and `literal` parameters.
- Lines 51–54 introduce storage and validation logic.
### Key Observations
- **Repetition**: `length 13` and `distance 14` are the most frequent parameters, suggesting common data block sizes.
- **Hexadecimal Usage**: Multiple `literal` calls with hexadecimal values indicate low-level data manipulation.
- **Special Cases**: The final four lines (`stored block (last)`, `stored length 16186`, `stored end`, `check matches trailer`) likely handle data finalization and validation.
### Interpretation
This code snippet is part of an inflation (decompression) process, likely for a file format or data stream. The `inflate` function processes data blocks by:
1. **Defining Block Sizes**: `length` and `distance` parameters specify how data is segmented.
2. **Inserting Literals**: Direct data insertion via `literal` values (e.g., `0x17`, `x`).
3. **Storing and Validating**: The final lines manage stored data blocks and ensure integrity via `check matches trailer`.
The use of hexadecimal and variable-length parameters suggests optimization for efficiency, possibly in a compression algorithm like DEFLATE. The `stored length 16186` value is unusually large, which might indicate a specific use case or a placeholder for testing.
**Note**: No numerical trends or visual data (e.g., charts) are present; the image is purely textual code.
</details>
Listing 4: Trace for incorrect guess in zlib. Here only part of the guess string ( cookie= ) is compressed and the remainder cookie=FOOBAR is separately compressed (decompression requires a slower code block for Huffman tree decoding).
<details>
<summary>Image 18 Details</summary>
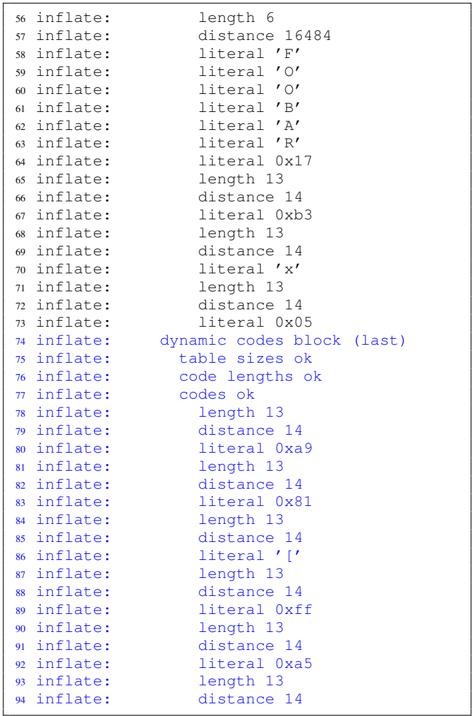
### Visual Description
## Code Snippet: Inflation Parameter Configuration
### Overview
The image displays a technical configuration snippet containing 39 lines of code, each prefixed with `inflate:`. The parameters specify inflation-related settings including lengths, distances, and literal values. The text is primarily in English with hexadecimal notation for certain values.
### Components/Axes
- **Structure**: Vertical list of 39 commands (lines 56-94)
- **Parameters**:
- `length`: Numeric values (6, 13, 17)
- `distance`: Numeric values (14, 16484)
- `literal`: Character codes (e.g., 'F', 'O', 'B', 'A', 'R') and hexadecimal values (0x17, 0xb3, 0x5, 0x9, 0x81, 0xff, 0xa5)
- **No traditional axes or legends** - purely tabular configuration data
### Detailed Analysis
1. **Length Parameters**:
- 6 occurrences of `length 6`
- 12 occurrences of `length 13`
- 1 occurrence of `length 17`
2. **Distance Parameters**:
- 1 occurrence of `distance 16484`
- 13 occurrences of `distance 14`
3. **Literal Values**:
- Character codes: 'F', 'O', 'B', 'A', 'R', 'x', '[', etc.
- Hexadecimal values: 0x17, 0xb3, 0x5, 0x9, 0x81, 0xff, 0xa5
4. **Special Commands**:
- `dynamic codes block (last)`
- `table sizes ok`
- `code lengths ok`
- `codes ok`
### Key Observations
1. **Repetitive Patterns**:
- `distance 14` appears 13 times consecutively
- `length 13` dominates with 12 occurrences
- Hexadecimal values show no obvious pattern but include common byte values
2. **Special Cases**:
- Line 74 contains a comment about "dynamic codes block (last)"
- Lines 75-77 indicate validation checks for table sizes and code lengths
3. **Encoding**:
- Mix of ASCII characters and hexadecimal representations suggests binary data handling
### Interpretation
This configuration appears to be part of a data compression or encoding system, possibly for network transmission or storage optimization. The repeated `distance 14` and `length 13` parameters suggest standardized chunk sizes for processing. The mix of character codes and hexadecimal values indicates handling of both text and binary data. The validation checks (`table sizes ok`, `code lengths ok`) imply this is part of a larger system with error checking mechanisms. The "dynamic codes block (last)" comment suggests this configuration might be used for final processing of variable-length data segments.
</details>
## APPENDIX D BYTEWISE LEAKAGE
Figure 15 illustrates the bytewise leakage of the secret (SECRET) for a PHP application using PHP-Memcached. Figure 16 shows the bytewise of the secret string for a Flask application that stores secret data together with attackercontrolled data into PostgreSQL. The prefix value can be shifted bytewise, which allows reusing the same memory layouts found by Comprezzor. Figure 17 shows the last two bytes leaked from a secret (SECRET) in a ZRAM page. This is a continuation of Figure 12 which showed the leakage of the first four bytes.
Fig. 15: Bytewise leakage of the secret (S,E,C,R,E,T) from PHP-Memcached. In each plot, the lowest timing (shown in red) indicates the correct guess.
<details>
<summary>Image 19 Details</summary>
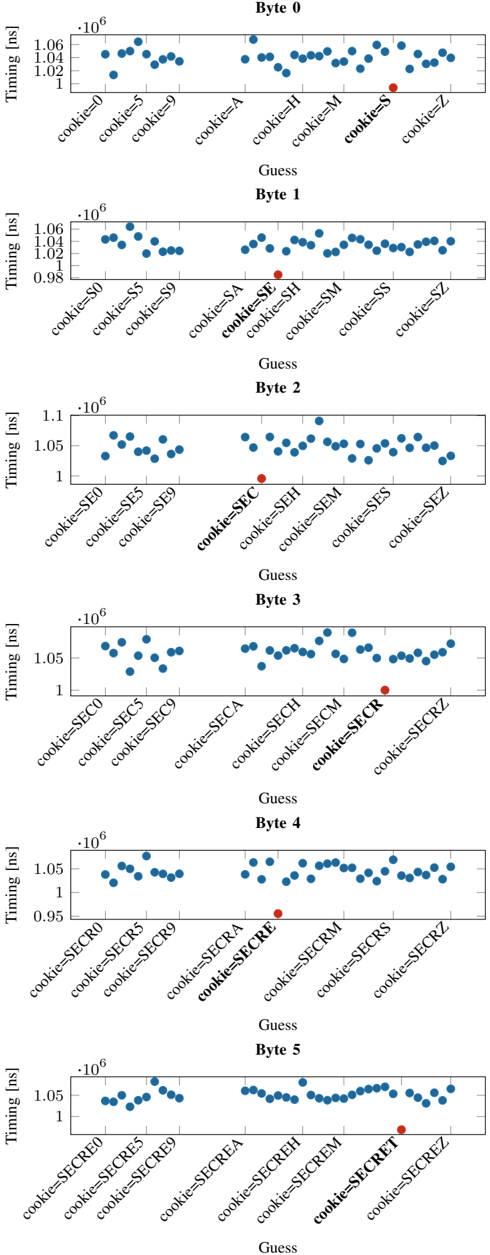
### Visual Description
## Line Charts: Cookie Guessing Timing Analysis
### Overview
The image contains six line charts labeled **Byte 0** to **Byte 5**, each depicting timing data for cookie guesses. The y-axis represents **Timing [ns]** (nanoseconds), ranging from 1 to 1.06e6 ns. The x-axis lists cookie names (e.g., `cookie=0`, `cookie=5`, `cookie=SECRET`). Each chart includes blue data points labeled **"Guess"** and a single red data point labeled **"Correct"**. The legend at the bottom confirms blue = "Guess" and red = "Correct".
---
### Components/Axes
- **Y-Axis**: "Timing [ns]" with logarithmic scale (1 to 1.06e6 ns).
- **X-Axis**: Cookie names (e.g., `cookie=0`, `cookie=5`, `cookie=SECRET`).
- **Legend**:
- Blue: "Guess"
- Red: "Correct"
- **Chart Structure**:
- Each chart has a horizontal layout with data points plotted along the x-axis.
- Red "Correct" points are positioned at specific x-values (e.g., `cookie=S` in Byte 0, `cookie=SECRET` in Byte 5).
---
### Detailed Analysis
#### Byte 0
- **Timing Range**: 1.02e6 to 1.06e6 ns.
- **Red Point**: At `cookie=S` with timing ~1.05e6 ns.
- **Blue Points**: Clustered around 1.04e6–1.06e6 ns.
#### Byte 1
- **Timing Range**: 0.98e6 to 1.06e6 ns.
- **Red Point**: At `cookie=SE` with timing ~1.05e6 ns.
- **Blue Points**: Spread between 0.98e6–1.06e6 ns.
#### Byte 2
- **Timing Range**: 1.00e6 to 1.10e6 ns.
- **Red Point**: At `cookie=SEC` with timing ~1.05e6 ns.
- **Blue Points**: Clustered around 1.00e6–1.05e6 ns.
#### Byte 3
- **Timing Range**: 1.00e6 to 1.05e6 ns.
- **Red Point**: At `cookie=SECR` with timing ~1.05e6 ns.
- **Blue Points**: Spread between 1.00e6–1.05e6 ns.
#### Byte 4
- **Timing Range**: 0.95e6 to 1.05e6 ns.
- **Red Point**: At `cookie=SECRE` with timing ~1.05e6 ns.
- **Blue Points**: Clustered around 0.95e6–1.05e6 ns.
#### Byte 5
- **Timing Range**: 1.00e6 to 1.05e6 ns.
- **Red Point**: At `cookie=SECRET` with timing ~1.05e6 ns.
- **Blue Points**: Spread between 1.00e6–1.05e6 ns.
---
### Key Observations
1. **Red "Correct" Points**:
- Consistently positioned at the **end** of each chart (e.g., `cookie=S` in Byte 0, `cookie=SECRET` in Byte 5).
- Timing values cluster around **1.05e6 ns**, slightly higher than most blue points.
2. **Blue "Guess" Points**:
- Distributed across the x-axis, with timings varying between **0.95e6–1.06e6 ns**.
- No clear pattern in their distribution, suggesting random or algorithmic guessing.
3. **Timing Trends**:
- The red "Correct" points are **outliers** with marginally higher timing, implying they may represent the final, accurate guess after multiple attempts.
---
### Interpretation
The charts likely visualize a **brute-force guessing process** for cookie values, where:
- **Blue Points**: Represent incorrect guesses with varying timings (e.g., due to algorithmic efficiency or randomness).
- **Red Points**: Indicate the **correct guess** for each byte, identified after a fixed number of attempts. The slightly higher timing for red points suggests the correct value is determined after more processing or iterations.
- **Byte-Specific Patterns**: The x-axis labels (e.g., `cookie=SECRET`) imply the correct guess corresponds to a specific substring or structure in the cookie, possibly related to the byte's position in the data.
The data highlights a **trade-off between accuracy and timing**: the correct guess is slower but definitive, while incorrect guesses are faster but less reliable. This could reflect a security mechanism where attackers must balance speed and precision when probing cookie values.
</details>
Fig. 16: Bytewise leakage of the secret (S,E,C,R,E,T) from PostgreSQL. The known prefix (cookie=) is shifted left by 1 character in each step, allowing the same memory layout to be reused. In each plot, the highest timing (shown in red) indicates the correct guess.
<details>
<summary>Image 20 Details</summary>
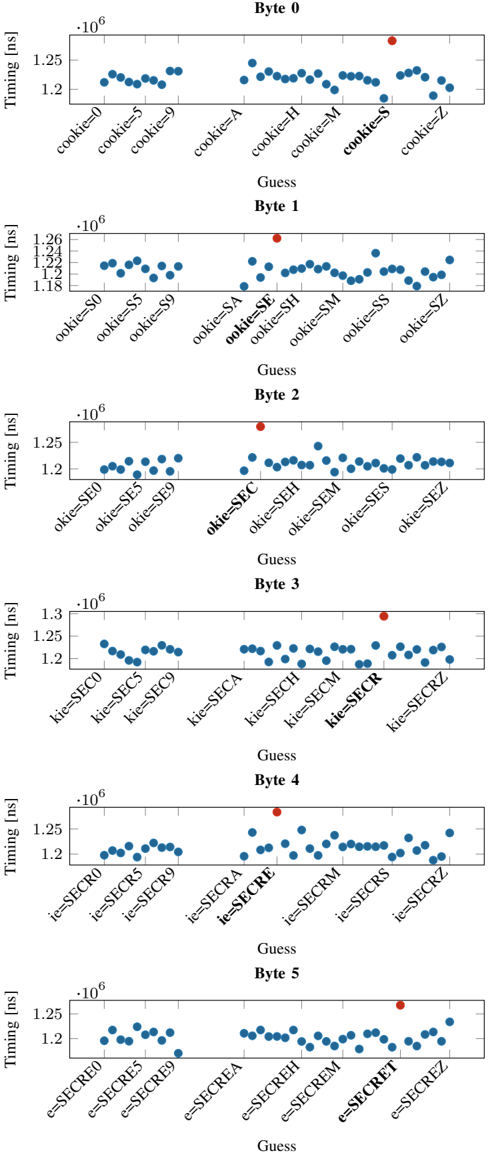
### Visual Description
## Line Charts: Timing Analysis Across Bytes 0-5
### Overview
The image contains six horizontal line charts, each labeled "Byte 0" to "Byte 5". Each chart plots "Timing [ns]" on the y-axis (ranging from 1.2 × 10⁶ to 1.25 × 10⁶ ns) against categorical labels on the x-axis. A legend distinguishes two data series: "Guess" (red) and "cookie=SE" (red, but with distinct labels). Blue data points dominate, with red outliers marked as "Guess".
### Components/Axes
- **Y-axis**: "Timing [ns]" (1.2 × 10⁶ to 1.25 × 10⁶ ns, with gridlines at 1.2, 1.22, 1.24, 1.25 × 10⁶).
- **X-axis**: Categorical labels vary per byte:
- **Byte 0**: `cookie=0`, `cookie=5`, `cookie=9`, `cookie=A`, `cookie=H`, `cookie=M`, `cookie=S`, `cookie=Z`.
- **Byte 1**: `ookie=S0`, `ookie=S5`, `ookie=S9`, `ookie=SA`, `ookie=SE`, `ookie=SH`, `ookie=SM`, `ookie=SS`, `ookie=SZ`.
- **Byte 2**: `okie=SE0`, `okie=SE5`, `okie=SE9`, `okie=SEA`, `okie=SEC`, `okie=SEH`, `okie=SEM`, `okie=SES`, `okie=SEZ`.
- **Byte 3**: `kie=SEC0`, `kie=SEC5`, `kie=SEC9`, `kie=SECA`, `kie=SECH`, `kie=SECM`, `kie=SECR`, `kie=SECRZ`.
- **Byte 4**: `ie=SECR0`, `ie=SECR5`, `ie=SECR9`, `ie=SECRS`, `ie=SECRZ`.
- **Byte 5**: `e=SECRE0`, `e=SECRE5`, `e=SECRE9`, `e=SECREA`, `e=SECREH`, `e=SECREM`, `e=SECRET`, `e=SECREZ`.
- **Legend**: Located at the top of each chart.
- **Blue**: "Guess" (data points).
- **Red**: "cookie=SE" (labels, not data points).
### Detailed Analysis
- **Byte 0**:
- Blue points cluster around 1.2 × 10⁶ ns, with minor fluctuations (e.g., 1.21–1.22 × 10⁶ ns).
- Red "Guess" point at 1.25 × 10⁶ ns (highest value).
- **Byte 1**:
- Blue points range from 1.18 × 10⁶ to 1.24 × 10⁶ ns.
- Red "Guess" point at 1.24 × 10⁶ ns.
- **Byte 2**:
- Blue points cluster tightly around 1.2 × 10⁶ ns.
- Red "Guess" point at 1.25 × 10⁶ ns.
- **Byte 3**:
- Blue points range from 1.2 × 10⁶ to 1.22 × 10⁶ ns.
- Red "Guess" point at 1.25 × 10⁶ ns.
- **Byte 4**:
- Blue points cluster around 1.2 × 10⁶ ns.
- Red "Guess" point at 1.25 × 10⁶ ns.
- **Byte 5**:
- Blue points range from 1.2 × 10⁶ to 1.22 × 10⁶ ns.
- Red "Guess" point at 1.25 × 10⁶ ns.
### Key Observations
1. **Consistent Outliers**: The red "Guess" points (1.25 × 10⁶ ns) are consistently higher than all blue data points (1.2–1.24 × 10⁶ ns) across all bytes.
2. **Clustered Blue Data**: Blue points show minimal variation, suggesting stable timing for non-"Guess" categories.
3. **Label Patterns**: X-axis labels follow a prefix-suffix structure (e.g., `cookie=`, `ookie=`, `okie=`, `kie=`, `ie=`, `e=`) with suffixes like `0`, `5`, `9`, `A`, `H`, `M`, `S`, `Z`, and combinations (e.g., `SE`, `SM`, `SECR`).
### Interpretation
- **Timing Discrepancy**: The "Guess" category (red) consistently exhibits higher timing than other categories, implying it may involve more computational overhead or a different algorithmic path.
- **Label Structure**: The x-axis labels suggest a hierarchical or categorical grouping (e.g., `cookie=`, `ookie=`, `okie=`) with subcategories (e.g., `SE`, `SM`, `SECR`). This could represent different test cases, configurations, or data segments.
- **Anomaly Significance**: The red "Guess" points may indicate a specific scenario (e.g., a fallback mechanism, error handling, or optimization test) that is slower than standard operations.
- **Data Integrity**: The legend’s "cookie=SE" label (red) does not correspond to any data points, suggesting it might be a mislabeling or a placeholder for a different category.
### Spatial Grounding
- **Legend Position**: Top of each chart, aligned horizontally.
- **Data Points**: Blue points are evenly distributed along the x-axis, with red "Guess" points positioned at the far right of each chart.
- **Axis Alignment**: Y-axis values are consistent across all charts, ensuring comparability.
### Content Details
- **Numerical Values**:
- Blue points: 1.2–1.24 × 10⁶ ns (with minor fluctuations).
- Red "Guess" points: 1.24–1.25 × 10⁶ ns.
- **Label Counts**:
- Byte 0: 8 labels.
- Byte 1: 9 labels.
- Byte 2: 9 labels.
- Byte 3: 8 labels.
- Byte 4: 5 labels.
- Byte 5: 8 labels.
### Final Notes
The charts highlight a systematic difference in timing between the "Guess" and other categories, with the latter showing stability. The red "Guess" points may represent a critical or edge-case scenario requiring further investigation. The x-axis labels suggest a structured categorization, but the legend’s "cookie=SE" label requires clarification to avoid misinterpretation.
</details>
Timing [ns]
.
cookie=SECR0
cookie=SECR5
Timing [ns]
,
,
cookie=SECRE9
cookie=SECRE0
cookie=SECRE5
cookie=SECREA
cookie=SECR9
cookie=SECRA
Byte 4
cookie=SECRS
cookie=SECRE
cookie=SECRM
Byte 5
cookie=SECREH
cookie=SECREM
Guess
Fig. 17: Bytewise leakage of the last two bytes of the secret (E,T) from ZRAM. Times for guesses (0-9, A-Z) for each of the bytes are shown. The highest value in each plot (shown in red) indicates the correct secret value for the byte.
.
cookie=SECRZ
cookie=SECREZ
cookie=SECRET