## Bridging Level-K to Nash Equilibrium
Accepted at The Review of Economics and Statistics
DAN LEVIN ∗† and LUYAO ZHANG ∗†‡
We introduce NLK, a model that connects the Nash equilibrium (NE) and Level-K. It allows a player in a game to believe that her opponent may be either less or as sophisticated as, she is, a view supported in psychology. Weapply NLK to data from five published papers on static, dynamic, and auction games. NLK provides different predictions than those of the NE and Level-K; moreover, a simple version of NLK explains the experimental data better in many cases, with the same or lower number of parameters. We discuss extensions to games with more than two players and heterogeneous beliefs.
JEL: D01, C72, C92; ACM-class: J.4,
Additional Key Words and Phrases: Nash equilibrium, Level-K, Bayesian Nash Equilibrium, Sub-game Perfect Bayesian Nash Equilibrium, Bounded rationality, psychology, behavioral economics, false consensus effects, centipede Game, the 11-20 money request game, Common Value Auction, experienced and inexperienced bidders, learning in games, equilibrium solution concepts, strategic thinking, chess players
## 1 INTRODUCTION
There is mounting, robust evidence from laboratory experiments of substantial discrepancies between the prediction of Nash equilibrium (NE) and the behavior of agents. 1 . Among all the alternative models that retain the individual rationality, but relax correct beliefs, Level-K is probably the most prominent model. 2 First proposed by Stahl and Wilson [1995], Stahl II and Wilson [1994] and Nagel [1995], Level-K introduces a non-equilibrium, structural model of strategic thinking, which admits possible cognitive limitations of players that are not allowed in NE. 3 This model has a hierarchy of levels of sophistication that are constructed iteratively, starting with an exogenous, nonstrategic, and least-sophisticated level 0 player. Higher levels are then constructed by assuming that a level k player best responds to level k -1 opponents, k = 1 , 2 , . . . . Absent in NE, the Level-K model explicitly allows players to consider their opponents as less (strategically) sophisticated than themselves; however, it does not allow players to use a critical element of strategic thinking, namely, "put yourself in the other's shoes."
Our paper introduces NLK, which bridges the NE and the Level-K model. Whereas a Nash player believes that the other player is another Nash player, and a Level-K player believes that the other player is less sophisticated than herself, NLK allows the player to believe, with a probability 𝜆 , the
∗ Corresponding authors: Luyao Zhang (email:lz183@duke.edu, institution: Data Science Research Center and Social Science Division, Duke Kunshan University, address: No.8 Duke Ave. Kunshan, Jiangsu 215316, China.) and Dan Levin (email: levin.36@osu.edu, institution: Ohio State University, address:433B Arps Hall, 1945 N. High St, Columbus, Ohio, 43210 USA
‡ Also with SciEcon CIC, London, United Kingdom, WC2H 9JQ
† Acknowledgements : We thank the editor and two anonymous referees for valuable comments. We have benefited from the comments of participants in the Texas Experimental Economics Symposium, Midwest Economic Theory, and Trade Conference, D-TEA workshop and from conversations with Yaron Azrieli, Pierpaolo Battigali, Tobias Brünner, Paul Healy, Philippe Jehiel, and James Peck. We thank John H. Kagel for generously providing the data for the Common Value Auction [Avery and Kagel, 1997].
1 There is much experimental evidence that predictions of both (Bayesian) NE in static games and subgame perfect Nash equilibrium (SPNE) in dynamic games fail miserably. For instance, see McKelvey and Palfrey [1992] and Kagel et al. [2002]
3 There are many variations and extensions of the Level-K model, and we refer the reader to [Crawford et al., 2013] and the references therein.
2 Another strand of models such as quantal response equilibrium McKelvey and Palfrey [1995] retains correct beliefs but allow errors in the best response.
other player can be a naïve player, less sophisticated, than herself, and with a probability of (1𝜆 ), another NLK player, as sophisticated as herself. However, the NLK player still best responds to her subjective beliefs such as those in both NE and Level-K. 4 Next, we discuss how to construct a hierarchy of levels as Level-K does.
There are two possible interpretations of our model:
- (1) A population game with inconsistent beliefs: 5 In this interpretation, an NLK player behaves as if facing a population composed of naïve and NLK agents. In equilibrium, an NLK player best responds to her belief that with a subjective probability 𝜆 , each of the other players in the game is a naïve player, and with a probability of (1𝜆 ), each of the other players in the game is another NLK player (like herself). Being subjective, 𝜆 does not have to coincide with the objective proportions of naïve players in the population, denoted by 𝜌 . Thus, with 𝜆 ≠ 𝜌 , NLK is not a 'full-equilibrium' 6 because it allows an NLK player to hold inconsistent beliefs regarding the proportion of naïve players in the population. As such, NLK belongs to the 'bounded rationality' or behavioral models proposed to help reconcile the theoretical predictions and experimental and field evidence by maintaining the maximization and best response parts of individual rationality but allowing relaxation, in some form, of consistent beliefs, for example, CI 2007 and the other variations of the original Level-k model and the Eyster and Rabin [2005] model of cursed equilibrium . Such inconsistency has been supported in psychology: The 'False Consensus Effect,' first introduced by Ross et al. [1977], claims that individuals overestimate the proportion of individuals similar to themselves ( 𝜆 < 𝜌 ). 7 More recent works in psychology and experimental economics, have re-evaluated the 'False Consensus Effect.' Some of those works have provided evidence in support of such effect [Jimenez-Gomez, 2019, Krueger and Clement, 1994], but other works have demonstrated evidence of an opposite effect ( 𝜆 < 𝜌 ; [Dawes, 1990, Sherman et al., 1984]) or the absence of a biased belief ( [Engelmann and Strobel, 2000]). Of course, an individual may insist on consistency by requiring that in a 'full-equilibrium,' 𝜆 = 𝜌 . 8 With 0 1, the sophistication of Level-K and NLK players are different and not easily
< 𝜆 < ranked because NLK is a hybrid model 'bridging' Level-K to the NE. The behavior of NLK is determined endogenously by having a player best respond to a mix of the naïve players, whose behavior is determined exogenously by the level 0 player in Level-K and of the NLK players. As an equilibrium model, it uses similar assumptions as in the NE, for example, all NLK players have mutual knowledge of rationality. In principle, the strategy of the naïve player can be specified as context based as long as it is exogenously given; and all levels of
4 The formal definition of NLK and its extensions to Bayesian and dynamic games are in Section 2.
6 Stahl and Wilson [1995] include a rational expectation type along with different types of level-k and Nash players in analyzing experimental data of a 3×3 symmetric game. Their results reject the existence of a rational expectation type.
5 The population game interpretation provided in this section is simplified to the case where NLK model has only NLK players (i.e., NLK 1 ) facing Level 0 players. This is the simplest case that guides most of our data analysis. To coincide with the second interpretations as a model of hierarchy of heterogeneous players the population game needs elaboration and is much less intuitive, so it is committed.
7 In the psychology literature, we found much support for the finding of FCE and the 'self-anchoring' argument. Mullen et al. [1985] report on 115 studies that show FCE. For a more detailed empirical and theoretical discussion, refer to Marks and Miller [1987] and all the listed references therein.
-
𝑚
8 An alternative approach is to construct the naïve player's strategy based on the Poisson cognitive hierarchy ( P -CH ) model ( [Camerer et al., 2004]). 9 We let 𝑓 ( 𝑚 ) = 𝑒 -𝜏 𝜏 𝑚 𝑚 ! denote the probability function of a Poisson distribution, and in a similar way as in the P -CH model treatment of truncated probability distributions, we let an NLKm player believe that she faces a naïve player of level ℎ = 0 , 1 , . . . , 𝑚 -1 with probability 𝑔 ( ℎ ) = 𝑓 ( ℎ ) ˝ 𝑚 𝑙 = 0 𝑓 ( 𝑙 ) and another NLK m player with probability -1 𝑓 ( 𝑚 )
˝
ℎ
=
𝑚
˝
𝑙
=
𝑓
(
𝑙
)
𝑔
(
ℎ
)
=
.
NLK are sophisticated compared with naïve players because their strategies are endogenously by (solving) by best responses.
- (2) A hierarchy of heterogeneous players (as an analog to the Level-K model): A player is an NLK player of type 𝑚 , denoted by NLK 𝑚 , who best responds to the belief that each of the other players is an NLK 𝑚 -1 player with probability 𝜆 and another NLK 𝑚 (like herself) with probability 1𝜆 . Thus, an NLK 𝑚 player coincides with a levelm player when 𝜆 =1, and the NLK equilibrium reduces to NE when 𝜆 =0.
To illustrate the NLK equilibrium, we consider a simple example of the chicken game introduced by Rapoport and Chammah [1966]. In this two-player symmetric game, each player chooses either a 'Dove' or 'Hawk,' and the player's payoffs depend on her action and that of the opponents as follows:
Dove
Hawk
Table 1. Dove and Hawk Game.
| Dove | 30,30 | 20,70 |
|--------|---------|---------|
| Hawk | 70,20 | 0,0 |
A random level0 chooses to play either Dove or Hawk with equal probability. A level 1 best responds to the level 0 player by choosing Hawk, a level 2 best responds to the level 1 player by choosing Dove, a level 3 best responds to the level 2 player by choosing Hawk, and so forth. There are two pure NE strategies - (Hawk, Dove) and (Dove, Hawk) -and a third mixed strategy where Dove and Hawk are played with the probability of ( 1 / 3 ) and ( 2 / 3 ) , respectively. Now, we consider an NLK1 player who faces a naïve random level 0 player with the probability of 𝜆 and another NLK1 player with the probability of ( 1 -𝜆 ) . For 2 3 ≤ 𝜆 ≤ 1, and only one pure strategy NLK equilibrium exists, where each player chooses Hawk. For 0 ≤ 𝜆 < 2 3 , there exist two pure strategy NLK equilibria-(Hawk, Dove) and (Dove, Hawk)-and a mixed strategy where Dove and Hawk are played with the probabilities of 2 -3 𝜆 6 ( 1 -𝜆 ) and 4 -3 𝜆 6 ( 1 -𝜆 ) , respectively.
Empirically , we compare the performance of NLK to that of NE and some versions of Level-K by applying it to data from four experimental papers published in top economic journals and to data from one field study. These studies allow us to test the NLK on a static game with complete information, a static game with incomplete information, and a dynamic game of perfect information and on field data. For the experiments that we analyzed, NLK provides several insightful implications.
NLK helps bridge Level-K to the NE both theoretically and empirically : Theoretically , it shares a similar foundation with NE but is also applicable to games with players of different cognitive or reasoning abilities. For example, in the experiment of Alaoui, Larbi and Penta, Antonio [2016], math and science students who interact with students from the humanities field, may adopt a different subjective 𝜆 than when they play with fellow math and science students. Such a conjecture, (e.g., larger 𝜆 ) is reasonable and can be tested. We also adapt our basic definition of NLK to Bayesian games and dynamic games, as extensions of the Bayesian NE (BNE) and subgame perfect NE (SPNE). In the dynamic game, we show that NLK can characterize belief updating, which is absent in Level-K.
First, in the static guessing game by Arad and Rubinstein [2012], a simple version of NLK with one parameter, 𝜆 ∈ ( 0 , 1 ) , that is chosen optimally, fits data better than both the NE and Level-K models with an optimal distribution among three types of players, namely, two parameters. When we allow for an error structure that is sensitive to payoffs but uses only one parameter, NLK still
outperforms Level-K models. However, when we allow Level-K to freely choose more parameters, it fits better than the simple NLK, suggesting that in some cases, NLK can also be an analytical tool.
Third, we compare predictions of NLK to those of Level-K for the data from the common value auction experiment by Avery and Kagel [1997]. For inexperienced bidders, NLK's performance coincides with that of Level-K; but for experienced bidders, NLK with 𝜆 ∈ ( 0 , 1 ) provides the most accurate prediction. Moreover, because the estimated 𝜆 is smaller for the data of experienced bidders compared with that of inexperienced bidders, NLK may also be used to track dynamic learning from experience, for example, learning in repeated games and convergence to a 'full-equilibrium,' 𝜆 = 𝜌 = 0.
Second, when we apply the data from a centipede game experiment by Palacios-Huerta and Volij [2009], NLK's predictions, adapted to dynamic games, are different and more precise than those of the SPNE and Level-K models, with only a few exceptions when they coincide, or when Level-K adopts more parameters. Also reassuring that the optimal 𝜆 < 1is the largest when the players are all students, the smallest when only chess players are involved, and in the middle when one chess player is matched with o student. Thus, the optimal 𝜆 for NLK seems to track and capture the shift in subjective beliefs that can be expected in the different mixes of subject populations. The better performance of NLK than Level-K in the centipede game is reconfirmed by using the data from Levitt et al. [2011]. Moreover, NLK can capture belief updating in every round of a game that a dynamic Level-K cannot. Notably, although the results of the data from the centipede game in the two aforementioned papers are drastically different, NLK predicts both quite well with different optimal 𝜆𝑠 , which implies that the difference in behavioral data can be explained by the difference in beliefs of subjects between two datasets.
Forth, in recent experimental work on a rank-order tournament with an outside option - a dynamic game with imperfect information - Brünner [2020] finds that a mixture of Level-K and NLK predicts both the population of types in the tournament and the mean-variance of efforts remarkably well. That paper shows that NLK predicts the experimental data better than a Level-K model without the updating of beliefs, which highlights the importance of the belief updating that PBNLK added to the Level-K and the validity of NLK for outside sample predictions. 9
Related Literature: Level-K and its related extension, the cognitive hierarchy models by Camerer et al. [2004], have been applied to many laboratory experiments and field data. The survey by Crawford et al. [2013] documents many successes of Level-K and its extensions over other solution concepts, including NE. However, as we observed in the chicken game and in several examples in the following paper, NLK can be more useful than Level-K in certain games.
Finally, we also looked at data from the experimental work on the beauty contest game by Gill and Prowse [2016] but concluded that there are no 'winners' as the simplest Level-K and NLK models poorly predict behavior and Nash equilibrium performs much worse.
Theoretically, Level-K has been extended in two ways. Strzalecki [2014] allows beliefs to vary arbitrarily for players at a certain level. Specifically, a level k player can believe the opponent to be level j < k, by any arbitrary subjective distribution. However, and here as well, beliefs are restricted to lower levels. Building on Strzalecki [2014], Jimenez-Gomez [2019] innovatively allows a level k player to believe the opponent to be also a level k player, but only when their beliefs coincide, and adopts the solution concept of interim correlated rationality to games of incomplete information that endogenize level-0 behavior. However, in the application to the e-mail game , the case where the player allows the opponent to be at the same level is not considered.
Alaoui, Larbi and Penta, Antonio [2016] use another approach and show how cognitive bounds, beliefs about opponents, and beliefs about opponents' beliefs vary according to incentives by using
9 Brünner [2020] shows that the Nash equilibrium performs even worse than the Levelk without belief updating.
a cost-benefit analysis. In their model, if agents believe that their opponents behave at lower levels than their own cognitive bound, they would behave at one level higher than these opponents; but if they believe that the strategies of their opponents are reaching or exceeding their own cognitive bound, they would act within their own cognitive bound. Thus, although the aforementioned researchers have considered a situation where the opponents have the same or even a higher cognitive level than the agents, they treated it as if the opponents were nevertheless one level below the agents. Thus, according to our review of the literature, no extension of the Level-K model allows either the player to believe she faces the same level as herself or apply such belief structure in the analysis of games. More recently, [Koriyama and Ozkes, 2018] introduce a model of inclusive cognitive hierarchy that extends the cognitive hierarchy (CH) model in normal form games. Their model allows the most sophisticated player to consider the possibility that other players are of the same level as themselves. However, their model, unlike ours, requests that the belief of the most sophisticated player be consistent with objective distributions of player types. Our model subsumed their model in the extreme case where the strategy of the NLK naïve player is constructed as in CH and requires consistent belief. They explicitly recognize that such a requirement restricts the applicability of their model to most strategic environments such as beauty contests games, market-entry games, coordination games, and centipede games. They also do not characterize dynamic games and belief updates, which are covered in ours.
Motivation : KMRW's works have been motivated by Selten [1978] chain-store paradox (CSP) and by vast experimental evidence of cooperation in finitely repeated prisoner's dilemma (PD) games. Deterrence strategy in CSP and cooperation in PD games contradict the logic of backward induction that implies unraveling to the one-shot, stage game, solution. KMRW's objective is to resolve the paradoxes of using a deterrence strategy in the CSP 10 game and cooperation in the finitely repeated PD game. To do so, they transform these complete games, into incomplete, information games by introducing a 'tiny' probability of exogenous type and showing that it is sufficient to 'choke off' the otherwise unavoidable logic of unraveling. The emphasis on tiny probability is a critical novelty, because otherwise, the deterrence strategy in the CSP game or cooperation in the PD game may be rationalized even in a one-shot game. In NLK, the probability 𝜆 of such an exogenous type is typically quite large and similar to, but maybe smaller than, that in Level-K model. Thus, whereas the motivation of KMRW's models is to 'defend' the standard NE, NLK is a behavioral model of bounded rationality.
NLK is not the first equilibrium solution concept to introduce an exogenous type; Kreps et al. [1982], Kreps and Wilson [1982a,b], Milgrom and Roberts [1982], Milgrom and Weber [1982] (KMRW)havealready used an exogenous type. However, NLK and KMRW's models differ drastically in motivation and generality.
Generality : NLK introduces one nonstrategic exogenous type to be applied to all, or at least to a large class of different, games. By contrast, KMRW admit that their 'defense' of the standard NE requires a particular exogenous type for each case. 11 For instance, in the CSP case, Kreps and Wilson use a 'strong' monopoly that is hard-wired to fight; in the finitely repeated PD game, KMRW use two nonstrategic types for two cases, respectively: the one who plays Tit-for-Tat in the one-sided incomplete information game, and the one who prefers the stage payoffs from joint cooperation over those of defection when the other player cooperates, for their two-sided case. 12
10 Deterrence strategy , where the monopoly fights an early entrant, although it is not the best response in the stage game, was offered by Selten [1978], as a sensible, though not an equilibrium, strategy to deter later entrant.
12 In addition, NLK can require that 𝜆 matches the probability of the exogenous type in the population, making the model an equilibrium model with rational expectations.
11 KMRW explicitly acknowledge that a particular, and different, exogenous type may be necessary for different cases.
Similar to other models that use 'relaxed beliefs,' NLK has its limitations. For example, NLK cannot explain deviations from theoretical predictions in games with a dominant strategy solution, such as overbidding the value in second-price sealed-bid auctions with private values, first reported by Kagel et al. [1987].
In Section 2, we present our basic solution concepts as used in different types of games (static or dynamic, with complete or incomplete information). In Sections 3, 4, and 5, we provide the NLK solutions and compare them to those of the NE and Level-K models for a static guessing game, a dynamic centipede game, and a common value auction. We conclude in Section 6. Readers can refer to Appendix A.3 for an extended discussion for solution concepts related to NLK.
## 2 THE SOLUTION CONCEPT
In this section, we define the NLK equilibrium in a simple case with symmetric beliefs for three types of games and prove existence. We discuss several extensions in Section 5.
## 2.1 Basic Case
We consider that an N-player normal form game 𝐺 = ( 𝑖, 𝑆 𝑖 , 𝑢 𝑖 ) 𝑖 ∈ 𝐼 comprises a set 𝐼 = { 1 , 2 , . . . , 𝑁 } players, where ( 𝑆 𝑖 , 𝑢 𝑖 ) are the strategy set and the utility function of player 𝑖 , respectively. The strategy of a naïve player 𝑖 is given exogenously by 𝜎 𝑜 𝑖 ∈ Δ ( 𝑆 𝑖 ) , 𝑖 ∈ 𝐼 . In our strategic environment, an NLK player believes that each of the opponents is either a naïve player with probability 𝜆 , or another NLK player with probability ( 1 -𝜆 ) , 𝜆 ∈ [ 0 , 1 ] . In equilibrium, an NLK player chooses an optimal strategy by best responding to her belief. A formal definition of the NLK equilibrium is as follows:
Definition 1. A mixed strategy profile 𝜎 ∗ 𝑖 𝑖 ∈ 𝐼 , is a 𝜆 -𝑁𝐿𝐾 equilibrium if for each 𝑖 ∈ 𝐼 , and each 𝑠 ′ 𝑖 ∈ 𝑆 𝑖 , 𝜆𝑢 𝑖 𝜎 ∗ 𝑖 , 𝜎 0 -𝑖 + ( 1 -𝜆 ) 𝑢 𝑖 𝜎 ∗ 𝑖 , 𝜎 ∗ -𝑖 ≥ 𝜆𝑢 𝑖 𝑠 ′ 𝑖 , 𝜎 0 -𝑖 + ( 1 -𝜆 ) 𝑢 𝑖 𝑠 ′ 𝑖 , 𝜎 ∗ -𝑖 . 13
## 2.2 Bayesian Games
We consider a Bayesian game of incomplete information, 𝐵 = ( 𝑆 𝑖 , 𝑢 𝑖 , Θ 𝑖 , 𝑝 ) 𝑖 ∈ 𝐼 , where Θ 𝑖 denotes the set of player 𝑖 's types and 𝑝 denotes the joint density function of the probability distribution over ˛ 𝑖 ∈ 𝐼 Θ 𝑖 . Similar to the relationship between NE and BNE, a BNLK is the NLK equilibrium of the "extended game" in which each player 𝑖 's space of pure strategies, 𝑆 𝑖 Θ 𝑖 , denotes the set of mappings from Θ 𝑖 to 𝑆 𝑖 . Again, we let 𝜎 0 𝑖 ∈ Δ ( 𝑆 𝑖 ) , 𝑖 ∈ 𝐼 , denote the strategy of a naïve player 𝑖 , which is independent of that player type. A formal definition of BNLK with symmetric subjective belief 𝜆 is as follows.
Definition 2. A profile of strategies 𝑠 ∗ 𝑖 (·) 𝑖 ∈ 𝐼 , is a 𝜆 -𝐵𝑁𝐿𝐾 equilibrium, if for each 𝑖, 𝑖 ∈ 𝐼 , and each 𝜃 𝑖 ∈ Θ 𝑖 ,
<!-- formula-not-decoded -->
## 2.3 Dynamic Games
Consider a dynamic game with perfect information and perfect recall, 14 𝑃 = ( 𝑢 𝑖 , Υ ) 𝑖 ∈ 𝐼 , where Υ denotes a game tree and 𝐼 is the set of players. A node in Υ is denoted by ℎ 𝑡 , and the set of nodes is denoted by 𝐻 . The set of nodes at which player 𝑖 must move is denoted by 𝐻 𝑖 . An NLK player holds a prior belief that the each of the other players is either a naïve player with probability 𝜆 or
13 This version has homogenous NLK players; allowing heterogonous players may help better fit the model to the data it also introduces additional parameter(s) and reduces the transparency that we wish to maintain.
14 That is, at any decision node, all previous moves are assumed to be known to every player.
another NLK player with probability ( 1 -𝜆 ) , 𝜆 ∈ [ 0 , 1 ] . At every decision node with history ℎ 𝑡 , as more information is revealed, beliefs are updated. We denote the updated belief that the opponent is a naïve player by 𝑝 𝑖 ℎ 𝑡 . In equilibrium, an NLK player chooses an optimal strategy according to her belief at every decision node and the choice is sequentially rational as in Definition 3:
Definition 3. (Sequential rationality). A strategy profile 𝜎 ∗ 𝑖 𝑖 ∈ 𝐼 is sequentially rational with respect to the profile of beliefs 𝑝 𝑖 ℎ 𝑡 𝑖 ℎ 𝑡 𝑖 ∈ 𝐻 𝑖 , 𝑖 ∈ 𝐼 if for 𝑖 ∈ 𝐼 all strategies 𝜎 ′ 𝑖 , and all nodes ℎ 𝑡 𝑖 ∈ 𝐻 𝑖 :
<!-- formula-not-decoded -->
We also require that the beliefs of NLK players be consistent. That is, they may start with a subjective prior distribution and then be updated by the Bayes' rule at each succeeding decision node. To present formally the consistency restriction, we let 𝑝 ℎ 𝑡 | 𝜎 𝑖 , 𝜎 -𝑖 denote the probability that decision node ℎ 𝑡 is reached according to the strategy profile, ( 𝜎 𝑖 , 𝜎 -𝑖 ) .
Definition 4. (Consistency). A profile of beliefs 𝑝 ∗ 𝑖 ℎ 𝑡 𝑖 ℎ 𝑡 𝑖 ∈ 𝐻 𝑖 𝑖 ∈ 𝐼 is consistent with the subjective prior 𝜆 and the strategy profile { 𝜎 𝑖 } 𝑖 = 1 , 2 if and only if for 𝑖 ∈ 𝐼 , and all nodes ℎ 𝑡 𝑖 ∈ 𝐻 𝑖 :
<!-- formula-not-decoded -->
Where, 𝑝 ℎ 𝑡 𝑖 | 𝜎 𝑖 , 𝜎 0 -𝑖 > 0 or 𝑝 ℎ 𝑡 𝑖 | 𝜎 𝑖 , 𝜎 -𝑖 > 0 . 16 15
Although the game has perfect information, the belief structure in our strategic environment makes our solution concept more similar to an analogy of a perfect Bayesian equilibrium; thus, we denote it as PBNLK and formally treat it as follows:
<!-- formula-not-decoded -->
- (1) the strategy profile 𝜎 ∗ 𝑖 𝑖 ∈ 𝐼 is sequentially rational with respect to the profile of beliefs 𝑝 ∗ 𝑖 ℎ 𝑡 𝑖 ℎ 𝑡 𝑖 ∈ 𝐻 𝑖 , 𝑖 ∈ 𝐼 , and
- (2) the profile of beliefs 𝑝 ∗ 𝑖 ℎ 𝑡 𝑖 ℎ 𝑡 𝑖 ∈ 𝐻 𝑖 , 𝑖 ∈ 𝐼 is consistent with the subjective prior 𝜆 and the strategy profile 𝜎 ∗ 𝑖 𝑖 ∈ 𝐼
## 2.4 Existence
Proposition 1. for any 𝜆 ∈ [ 0 , 1 ] :
- a) In every finite strategic-form game, there exists an NLK equilibrium.
- c) In every finite extensive form game, there exists a PBNLK equilibrium.
- b) In every finite Bayesian game, there exists a BNLK equilibrium.
## Proof: See Appendix A.1.
In the following sessions, we compare the performance of NLK. We employ only k=1 to that NE or Level-K model with k ≥ 1, where the naïve player is a random level 0 player that chooses uniformly among her strategy set across all games.
15 Notably, Definition 1.4 places no restrictions on player i's expectations on those decision nodes that cannot be reached according to 𝜎 , regardless of whether the player faces a naïve player or another NLK player. A stronger notion of consistency could be defined in the spirit of a trembling hand or a sequential equilibrium Kreps and Wilson [1982b]. Such a stronger restriction and its impact on prediction are discussed in Section 5.
## 3 ARAD-RUBINSTEIN MONEY REQUEST GAME.
In the basic version of the money request game by Arad and Rubinstein [2012], there are two risk-neutral players, and each can request and receive an integer amount of money from $11 to $20, plus an extra $20 if she asks for exactly one integer less than the other player.
Table 2. NLK equilibrium strategy for different subjective beliefs.
| NLK (%) ( 𝜆 ) | 15 | 16 | 17 | 18 | 19 | 20 |
|-------------------------------------|----------------------|-----------------------|-----------------------|-----------------------|---------------------|---------------------|
| 0 ≤ 𝜆 ≤ 1 2 | 5 ( 5 - 10 𝜆 ) 1 - 𝜆 | 5 ( 5 - 2 𝜆 ) 1 - 𝜆 | 5 ( 4 - 2 𝜆 ) 1 - 𝜆 | 5 ( 3 - 2 𝜆 ) 1 - 𝜆 | 5 ( 2 - 2 𝜆 ) 1 - 𝜆 | 5 ( 1 - 2 𝜆 ) 1 - 𝜆 |
| 1 2 ≤ 𝜆 ≤ 14 20 | 0 | 5 ( 14 - 20 𝜆 ) 1 - 𝜆 | 15 1 - 𝜆 | 10 1 - 𝜆 | 5 1 - 𝜆 | 0 |
| 14 20 ≤ 𝜆 ≤ 17 20 | 0 | 0 | 5 ( 17 - 20 𝜆 ) 1 - 𝜆 | 10 1 - 𝜆 | 5 1 - 𝜆 | 0 |
| 17 20 ≤ 𝜆 ≤ 19 20 | 0 | 0 | 0 | 5 ( 19 - 20 𝜆 ) 1 - 𝜆 | 5 1 - 𝜆 | 0 |
| 19 20 ≤ 𝜆 ≤ 1 | 0 | 0 | 0 | 0 | 100 | 0 |
Consider the Level-K model with a level0 payer who randomizes uniformly within the strategy set: $11,$12,...,$20. A level 1 player that requests $20 earns $20. Alternatively, if she asks for $19, she earns $19 for sure and a $20 bonus with a probability of 1/10, for a total expected payoff of $21. 16 Thus, level 1 picks $19, level 2 picks $18,..., and level 9 picks $11; but then, level 10 picks $20, level 11 picks $19, and so forth. Thus, it is difficult to infer from players' actions their sophistication level: A player who requests $19 can be a level 1 player or a highly sophisticated level 11 player.
the MSE. 19 As expected, it increases the unrestricted MSE, from 28.39 to 38.20, which is higher than 35.93 (by about 6%) obtained by the Level-K model with 𝑘 = 1 , 2 , 3 , and picking the optimal distribution of those levels, i.e., using 3 parameters. In contrast, the Level-K model that optimal distribution of those levels, i.e., using 3 parameters. In contrast, the Level-K model that uses only one level, 𝐾 = 1,or 𝐾 = 2 or 𝐾 = 3, results in MSE that is between 15 to 20 times higher. We also include prediction of NLK using MSE minimizer pair of 𝜆 =0.734 and 𝜌 =0.344 and this results in MSE of 5.58, which one fifth of the aforementioned MSE of Level-K. 20
Table 2 shows the unique mixed strategy 𝜆 -NLK equilibrium for each 𝜆 ∈ [ 0 , 19 / 20 ) and the unique pure strategy for 𝜆 ∈ [ 19 / 20 , 1 ] . 17 Table 3 compares the performance of the Level-K model; k=1,2,3; NE; and NLK 18 by using the mean squared error (MSE). NLK with the best 𝜆 =0.6585, fits the data better than NE and any type of the Level-K model; moreover, it also outperforms Level-K with the optimal distribution of levels 1, 2 and 3, that is, two parameters, because it reduces MSE by 23.457%. (from MSE being 35.93 to 28.39.) We include the prediction of NLK where 𝜆 is restricted to match 𝜌 , but allowing 𝜆 = 𝜌 = 0 . 70, that minimizes
16 To ask for any amount of money less than $19 leads to a strictly lower payoff.
18 Our level0, player is defined as a player who pick each available action with equal probability.
17 See Appendix A.2 for detail of the argument.
19 Here is how the entry of 22 in this row is calculated: For 𝜆 = 0 . 7, we obtain from Table 2, that an NLK player pick the #17 , 5 ( 17 -20 𝜆 ) 1 -𝜆 = 50 .𝜌 = 0 . 7 implies that 30% are NLK players, resulting in 15 ( % ) coming from NLK players. We add 7 ( % )
20 Observing that the data from Arad and Rubinstein [2012] in Table 3, a referee noted, that 30% to 40% of the players "look like" Level-0 players and suggested having those prediction. Our "best" fitting 𝜌 = 0 . 344 is in the middle of that range.
coming from the 70% of Level-0 players who uniformly randomize over the ten numbers.
Table 3. 11-20 Game: Comparison of different solution concepts by MSE.
| Action | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | MSE |
|-------------------------------------------|------|------|------|------|------|------|-------|-------|-------|------|-------|
| level 1 (%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 980.2 |
| level 2 (%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 620.2 |
| level 3 (%) | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 580.2 |
| level 𝑘 , k =1,2,3, optimal distribution | 0 | 0 | 0 | 0 | 0 | 0 | 40.7 | 38.7 | 20.6 | 0 | 35.93 |
| NE (%) | 0 | 0 | 0 | 0 | 25 | 25 | 20 | 15 | 10 | 5 | 137.2 |
| NLK (%) 𝜆 =0.6585 | 0 | 0 | 0 | 0 | 0 | 12.1 | 43.9 | 29.4 | 14.6 | 0 | 28.39 |
| 𝑙𝑒𝑣𝑒𝑙 0 and NLK (%) ( 𝜆 = 𝜌 = 0 . 70) | 7 | 7 | 7 | 7 | 7 | 7 | 22 | 17 | 12 | 7 | 38.20 |
| 𝑙𝑒𝑣𝑒𝑙 0 and NLK (%) ( 𝜌 =0.344, 𝜆 =0.734) | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | 32 | 28.1 | 15.7 | 3.4 | 5.58 |
| Data (%) | 4 | 0 | 3 | 6 | 1 | 6 | 32 | 30 | 12 | 6 | |
Finally, we test the robustness of our results by using an alternative statistical method. Our econometric specification follows the mixture-of-types models of Stahl and Wilson [1995], Stahl II and Wilson [1994]. 21
Both level k and our NLK types are assumed to make logistic errors as follows. The decision rule suggests that the choice probabilities of type t players are positive but imperfect and related to expected payoffs according to the specific beliefs of type t. Formally, we denote the expected payoff player i of type t, given strategy s by 𝜋 𝑡 𝑖 ( 𝑠 ) . Then, the probability of observing s by such players is specified as follows:
<!-- formula-not-decoded -->
Exceptionally, random level 0 directly specifies a uniform distribution of decisions and thus has no precision parameter. Alternatively, it is equivalent by specifying the precision parameter to be 0 for a random level 0 player. The likelihood of observing a sample { 𝑠 𝑖 } 𝑁 𝑖 = 1 , given type 𝑡 , is 𝐿 𝑡 ({ 𝑠 𝑖 } | 𝜂 ) = ˛ 𝑁 𝑖 = 1 𝑝 𝑡 𝑖 ( 𝑠 𝑖 )
where 𝑆 𝑖 and 𝜂 are respectfully the strategy set for player 𝑖 , and the precision parameter. Specifically, 𝜂 determines the sensitivity of the choice probabilities to payoff differences. 22
Let denote the proportion of type in the population, with 1. The likelihood of
𝛼 𝑡 𝑡 ˝ 𝑡 𝛼 𝑡 = observing the sample unconditional on type is ˛ 𝑁 𝑖 = 1 ˝ 𝑡 𝛼 𝑡 𝑝 𝑡 𝑖 ( 𝑠 𝑖 ) . Table 4 reports the results. With An error structure, the best single type Level-K model, with 𝑘 ∗ = 3 has a smaller log-likelihood and a precision parameter, 𝐿𝐿 = -221 . 275 , 𝜂 = 0 . 075 than those of NLK with the best 𝜆 ∗ = 0.85: 𝐿𝐿 = -210 . 05 , 𝜂 = 0 . 359 . NLK also outperforms Level-K model with the optimal distribution of level 1 an'd level 2 of 𝐿𝐿 = -218 . 093 , 𝜂 = 0 . 252 . 25 However, we let Level-K use two parameters, and
21 The same econometric specification was also adopted by Camerer et al. [2004], Costa-Gomes et al. [2001], Costa-Gomes and Crawford [2006], Crawford and Iriberri [2007]. The error model is developed from quantal response equilibrium (See Goeree et al. [2008] and discussed in Goeree and Holt [2001].
25 It is estimated to be the 85% level 1 and 15% level2 types.
22 As 𝜂 goes to ∞ , the probability of the optimal decision converges to 1, i.e., the choice is error-free and fully characterized by the model under consideration. In contrast, as 𝜂 goes to 0, the choice probability converges to a uniformly random choice, such as that of the random level 0 players.
Table 4. Comparison of different solution concepts by maximum log-likelihood
| Action | Log-Likelihood (LL) | Precision parameter ( 𝜂 ) | BIC 23 | AIC 24 |
|---------------------------------------|-----------------------|-----------------------------|----------|----------|
| level 1 | -233.97 | 0.296 (0.039) | 472.622 | 469.94 |
| level 2 | -226.245 | 0.066 (0.009) | 457.172 | 454.49 |
| level 3 | -221.22 | 0.075 (0.010) | 447.122 | 444.44 |
| level_k,k=1,2 optimal distribution | -218.1 | 0.252 (0.052) | 445.564 | 440.2 |
| level_k,k=1,2,3, optimal distribution | -197.77 | 0.207 (0.051) | 409.586 | 401.54 |
| NE | -230.04 | 0.231 (0.046) | 464.762 | 462.08 |
| NLK ( 𝜆 =0.85) | -210.05 | 0.359 (0.025) | 429.464 | 424.1 |
optimal distribution, of level 1 level 2 and level 3 , and this raises its LL to -197 . 77, which is larger than that of NLK with only one parameter, -210 . 05 . However, NLK still has higher precision, 𝜂 = 0 . 231, than that of Level-K, 𝜂 = 0 . 207 . 26 The results are robust when considering the Bayesian information criterion (BIC) and AIC instead of LL.
## 4 CENTIPEDE GAME
Introduced by [Rosenthal, 1981], the centipede game is an example where deviations from backward induction (or SPNE) seem reasonable. 27 We follow the bulk of the literature and study a version of the centipede game where the total payout doubles when the game continues to the next stage, which subsumes the game in the experiments of Palacios-Huerta and Volij [2009] and Levitt et al. [2011], as a special case (with six decision nodes).
Based on the dynamic Level-K model by Ho and Su [2013], it is equally likely that a level0 player chooses T or P at each decision node, and strategies of 𝐾 > 0 are generated from iterative best responses to a player of one level below. A level 1 Player B would choose T at the last node. 28
There are two players, A and B, with an initial pot worth $5. At Node 1, Player A moves and chooses either to stop the game (T) by taking 80% of the pot and leaving 20% of it to Player B or passes the game (P) to Player B, doubling the pot. If Player A chooses P, at Node 2, Player B faces a similar decision but with a pot now worth $10. Unless one of the players chooses T earlier, the game ends after S=2N stages, with Player B either choosing T, taking 80% of the pot and leaving the other 20% to Player A, or choosing P and doubling the pot, with the result that 20% of the pot goes to Player B and 80% of it goes to Player A. The payoffs for Players A and B are ( $2 2 𝑘 , $2 𝑠𝑘 -2 if the game ends at an odd decision node, 2 k -1, and $2 2 𝑘 -1 , $2 𝑠𝑘 + 1 if the game ends at an even decision node, 2 𝑘, 𝑘 = 1 , 2 , ..., 𝑁 -1. By backward induction, the unique SPNE strategy profile for Player A is to play T immediately, at Node 1, and off equilibrium, the active player always chooses T at each Node.
26 It is estimated to be the 46% level1, 24.45% level2, and 28.98% level 3 types.
28 To end the game at Node 2N, Player B receives a payoff of $2 2 𝑁 + 1 , and he only ends up with $2 2 𝑁 if he chooses P instead.
27 For additional literature, see Bornstein et al. [2004], Fey et al. [1996], McKelvey and Palfrey [1992], Nagel and Tang [1998], Rapoport et al. [2003]. These papers show that even in high-stakes situations, involving altruism or group decisions, Backward Induction remains inadequate to explain players' behavior.
We denote the whole pie at each decision node by 𝑥. A level 1 Player A is playing T at node ( 2 𝑁 -1 ) yields 4 𝑥 5 , and playing P yields 9 𝑥 5 ; thus, a level 1 Player A would choose P at the decision node ( 2 𝑁 -1 ) Similarly, a level 2 Player A would choose 𝑇 at the penultimate node ( 2 𝑁 -1 )
Table 5 summarizes the solution for the Level-K model for a game of length 𝑆 = 2 𝑁 . For a certain level of players (indicated in the second column), there exists a corresponding threshold stage (indicated in the first column). A level k player chooses P before the threshold stage 𝑠 ∗ but chooses T at stage 𝑠 ∗ and afterward. For example, in a six-stage game ( 𝑁 = 3 ) , the threshold stage for a level 3 ( 𝑘 = 3 , ℎ = 1 ) Player A is 2 ( 3 -1 ) + 1 = 5 . Thus, a level 3 Player A chooses P before Node 5 and T at Node 5 .
| Role | Threshold stage s | Level of players |
|----------|---------------------|----------------------------------------|
| Player A | 2(N-h)+1 | 𝑘 = 2 ℎ ∗ or 2 ℎ + 1 ( 1 ≤ ℎ ≤ 𝑁 - 1 ) |
| Player B | 2(N-h)+2 | 𝑘 = 2 ℎ ∗ - 1 or 2 ℎ ( 1 ≤ ℎ ≤ 𝑁 ) |
ℎ ∗ is an auxiliary parameter for indicating the same threshold stage of two adjacent levels.
Table 5. Threshold stage for different levels of players.
In general, a Player A, at level 𝑘 = 2 𝑁 or higher, and a Player B at 𝑘 = ( 2 𝑁 -1 ) or higher, ought to choose T at each decision node. The Level-K solution requires relatively high levels 29 to rationalize terminating the game at earlier stages, especially for longer games, because the strategies of different level players are independent of the length of the game. For example, regardless of the duration of the game, a level1 Player A ought to keep passing to the last decision node, and regardless of the observed history, a level k player never updates his belief. 30
Consider a simple version of PBNLK with symmetric beliefs, 0 < 𝜆 < 1. At the last stage, T is the best response for Player B regardless of his belief about his opponents' type. We now assume that Player B first chooses T at Stage 2 𝑛 and Player A plans to choose T at Stage (2 𝑛 + 1). Then, at stage (2 𝑛 -1), Player A's posterior belief of the opponent being level 0 is
<!-- formula-not-decoded -->
If Player B first plays T at Stage 2 𝑛 , at Stage (2 𝑛 -1), Player A receives 4x/5 by playing T, whereas by playing P now and T at (2 𝑛 + 1) yields the expected payoff:
<!-- formula-not-decoded -->
Thus, Player A plays P whenever 2 7 < 𝑝 𝜆 𝐴 ( 2 𝑛 -1 ) ≤ 1 and plays T otherwise. Moreover, because 𝑝 𝜆 𝐴 ( 2 𝑁 -1 ) decreases in 𝑁 for a given 𝜆 , in a longer game, NLK Player A (with a certain 𝜆 ) is more likely to play T at stage ( 2 𝑁 -1 ) . This result is a key difference between NLK and the Level-K model where a level 1 Player A always passes at stage ( 2 𝑁 -1 ) regardless of the game's duration.
29 Table 5 also entails that to increase the level by just 1 would not necessarily predict earlier termination. Two adjacent levels of players might behave in the same manner.
30 Note that in a more general CH solution concept may produce qualitatively different predictions. However, because beliefs put more weight on lower levels according to a Poisson distribution in CH and lower levels continue passing to later stages, an even higher level of players than in the Level-K model would be required to rationalize early termination.
Because 𝑝 𝜆 𝐴 ( 2 𝑛 -1 )(≤ 𝜆 ) is strictly decreasing in 𝑛 , and 𝑝 𝜆 𝐴 ( 2 𝑛 -1 ) 𝑛 →∞ = 0, for 𝜆 ≤ 2 7 , Player A would always play T, given that Player B plays T in the next sage. For 𝜆 > 2 7 , by continuity, there is a critical value 𝑛 𝐴 , such that 𝑝 𝜆 𝐴 ( 2 𝑛 -1 ) > 2 7 for 𝑛 < 𝑛 𝐴 , and 𝑝 𝜆 𝐴 ( 2 𝑛 -1 ) ≤ 2 7 for 𝑛 ≥ 𝑛 𝐴 .
Similarly, we assume that Player A first chooses T at Stage ( 2 𝑛 + 1 ) , ( 𝑛 ≤ 𝑁 -1 ) and Player B plans to choose T at stage ( 2 𝑛 + 2 ) . Then, at Stage 2 𝑛 , Player B's posterior belief that the opponent is level 0 is
$$p _ { B } ^ { \lambda } ( 2 n ) = \frac { \lambda \left ( \frac { 1 } { 2 } \right ) ^ { n - 1 } } { \lambda \left ( \frac { 1 } { 2 } \right ) ^ { n - 1 } + ( 1 - \lambda ) } = p _ { A } ^ { \lambda } ( 2 n + 1 )$$
We use these arguments to construct our PBNLK equilibrium. For 𝜆 = 0, the game ends at the first stage (the same result as in SPNE). 31 For 𝜆 > 0, there are two possibilities. In a short game with a relatively larger 𝜆 satisfying 𝑝 𝜆 𝐴 ( 2 𝑁 -1 ) > 2 7 , Player A plays P to the end, and Player B first plays T at the last stage (the same result as when both players are level 1 ). In a longer game with 𝑝 𝜆 𝐴 ( 2 𝑁 -1 ) ≤ 2 7 , the game would end earlier. For similar arguments as in the papers of KMRW (1982), 32 PBNLK must be in mixed strategies for this range of 𝜆 . The reason for this is that in a presumed pure strategy, PBNLK and an NLK player (who ought to play T earlier than the other player) would rather deviate in the first node, that is, she ought to play T and lay P instead. Completing this action would mislead the other player to believe that he is facing a levelo player (as only a levelo player would have played P in the last node); thus, the other NLK player would play P. 33
This implies that the threshold stage for Player B, 𝑠 ∗ 𝐵 , is one stage earlier than that of Player A, 𝑠 ∗ 𝐴 , that is, 𝑠 ∗ 𝐵 = ( 2 𝑛 𝐵 ) = ( 2 𝑛 𝐴 -1 ) -1 = 𝑠 ∗ 𝐴 -1
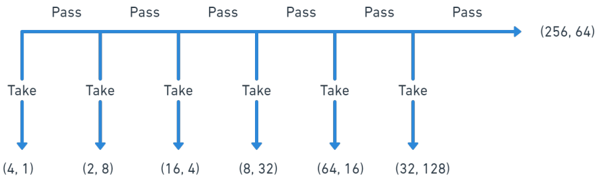
We apply our model to experiment by Palacios-Huerta and Volij [2009] and Levitt et al. [2011] on the centipede game , where N = 3 (Figure 1).
Fig. 1. The Centipede game 34
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Flowchart: Sequential Decision Process
### Overview
The image depicts a horizontal flowchart with a central "Pass" line and six vertical "Take" arrows branching downward. Each "Take" arrow leads to a pair of numerical values in parentheses. The final arrow points to the pair **(256, 64)**. The flowchart uses blue lines for both "Pass" and "Take" elements, with no explicit legend or color differentiation.
### Components/Axes
- **Horizontal Line**: Labeled "Pass" in blue, spanning the entire width of the chart.
- **Vertical Arrows**: Six blue arrows labeled "Take," each connecting the "Pass" line to a numerical pair below.
- **Numerical Pairs**: Six pairs of integers in parentheses, positioned directly below each "Take" arrow.
- **Final Arrow**: A seventh "Take" arrow extends beyond the main line to the pair **(256, 64)**.
### Detailed Analysis
1. **Numerical Pairs**:
- **(4, 1)**
- **(2, 8)**
- **(16, 4)**
- **(8, 32)**
- **(64, 16)**
- **(32, 128)**
- **(256, 64)** (final pair)
2. **Trends**:
- The first number in each pair alternates between **halving** and **doubling**:
- 4 → 2 (halve) → 16 (multiply by 8) → 8 (halve) → 64 (multiply by 8) → 32 (halve) → 256 (multiply by 8).
- The second number alternates between **multiplying by 8** and **halving**:
- 1 → 8 (×8) → 4 (÷2) → 32 (×8) → 16 (÷2) → 128 (×8) → 64 (÷2).
3. **Flow Logic**:
- The "Pass" line represents a continuous process, while each "Take" decision modifies the numerical state.
- The final pair **(256, 64)** suggests a cyclical or exponential pattern, with the first number doubling and the second halving relative to the previous step.
### Key Observations
- The numerical pairs follow a strict alternating pattern of operations (halving/doubling and multiplying/halving).
- The final pair **(256, 64)** is the only one where both numbers are powers of 2, reinforcing the exponential theme.
- No explicit labels or legends clarify the purpose of the numbers or the "Pass"/"Take" decisions.
### Interpretation
This flowchart likely represents a **binary or exponential process** where each "Take" decision alters the state of two variables in a predictable, alternating manner. The final pair **(256, 64)** could symbolize a terminal state or a reset condition, given its alignment with powers of 2. The lack of contextual labels (e.g., "Time," "Value," "State") limits direct interpretation, but the pattern suggests a computational or algorithmic workflow, such as:
- A **binary tree traversal** with alternating operations.
- A **state machine** where "Pass" represents inaction and "Take" triggers state transitions.
- A **simplified model** of exponential growth/decay in a system with two interdependent variables.
The absence of a legend or axis labels makes it challenging to assign real-world meaning, but the structured numerical pattern implies a deliberate, rule-based process.
</details>
31 The off-equilibrium path will not be reached by an A or B NLK player whether her opponent is an NLK or a naive player; thus, it is not restricted by Definition 1.4 of consistency. We assume that an NLK player believes the other NLK player would always play T off the equilibrium path.
33 For example, in the case when the threshold stage of Player B is 4 and (it follows) that of Player A is 5, now, at Node 5, which is reachable for Player A when facing a level0 player, since Player B first choose T at 4, not 6, the belief 𝑃 𝜆 𝐴 (5) represented by Equation 1.3 no longer satisfies our consistency requirement. Upon reaching Node 5, by Bayes' rule, an NLK Player A confirms that her opponent is a level0 player for sure, so she would pass instead. Thus, at decision Node 4, an NLK Player B has an incentive to pass with a positive probability to mimic the level 0 player, which motivates an NLK Player A to pass with a positive probability at decision Node 5, as well.
32 Inserting a 'crazy' type even with a slight probability can rationalize long cooperation in the finitely repeated prisoners' dilemma games.
34 This is the same example from Palacios-Huerta and Volij [2009]. Source: Drawn using https://whimsical.com/.
The prediction of our PBNLK with all 𝜆 ∈ { 0 . 05 𝑛 } 𝑛 = 0 , 1 , 2 ,..., 20 and the Level-K model with all k ∈ ℵ + and data from the aforementioned two papers are summarized in Table 6 . When 𝜆 = 0, PBNLK coincides with SPNE and level 𝑘 , 𝑘 ≥ 6, and when 𝜆 ∈ [ 0 . 615 , 1 ] , PBNLK coincides with level 1 . For all other 𝜆 ∈ ( 0 , 0 . 615 ) , PBNLK generates different predictions. We first compare our predictions to data from Palacios-Huerta and Volij's laboratory experiment with four treatments. Unlike other experiments of the centipede game, in their work, the composition of two opponents varies 35 across treatments, and it is common knowledge among all players. This allows us to explore how beliefs represented by 𝜆 and the results change as the nature of the subject pool changes. Next, we compare predictions| to data from Levitt et al. [2011]'s field experiments of chess players to further evaluate the predictions of NLK, because the data are different from the data of the former experiment.
| Data or Prediction | Node 1 | Node 2 | Node 3 | Node 4 | Node 5 | Node 6 |
|------------------------------------|----------|----------|----------|----------|----------|----------|
| NLK or 𝑙𝑒𝑣𝑒𝑙 𝑘 ( 𝜆 =0) k ≥ 6 | 1* | 1 | 1 | 1 | 1 | 1 |
| NLK ( 𝜆 =0.05) | 0 | 0.704 | 0.867 | 0.899 | 0.892 | 1 |
| NLK ( 𝜆 =0.1) | 0 | 0.375 | 0.877 | 0.889 | 0.938 | 1 |
| NLK ( 𝜆 =0.15) | 0 | 0.007 | 0.889 | 0.889 | 0.999 | 1 |
| NLK ( 𝜆 =0.2) | 0 | 0 | 0 | 0.844 | 0.879 | 1 |
| NLK ( 𝜆 =0.25) | 0 | 0 | 0 | 0.792 | 0.887 | 1 |
| NLK ( 𝜆 =0.3) | 0 | 0 | 0 | 0.732 | 0.895 | 1 |
| NLK ( 𝜆 =0.35) | 0 | 0 | 0 | 0.663 | 0.905 | 1 |
| NLK ( 𝜆 =0.4) | 0 | 0 | 0 | 0.583 | 0.916 | 1 |
| NLK ( 𝜆 =0.45) | 0 | 0 | 0 | 0.489 | 0.93 | 1 |
| NLK | 0 | 0 | 0 | 0.375 | 0.946 | 1 |
| ( 𝜆 =0.5) NLK ( 𝜆 =0.55) | 0 | 0 | 0 | 0.236 | 0.966 | 1 |
| NLK ( 𝜆 =0.6) | 0 | 0 | 0 | 0.0625 | 0.991 | 1 |
| NLK or 𝑙𝑒𝑣𝑒𝑙 1 ( 0 . 615 ≤ 𝜆 ≤ 1 ) | 0 | 0 | 0 | 0 | 0 | 1 |
| 𝑙𝑒𝑣𝑒𝑙 2 | 0 | 0 | 0 | 0 | 1 | 1 |
| 𝑙𝑒𝑣𝑒𝑙 3 | 0 | 0 | 0 | 1 | 1 | 1 |
| 𝑙𝑒𝑣𝑒𝑙 4 | | | | | | |
|-------------------|----------|-------|-------|-------|-------|-------|
| 𝑙𝑒𝑣𝑒𝑙 5 | 0 | 1 | 1 | 1 | 1 | 1 |
| Data ∗∗ (S vs. S) | 0.030*** | 0.17 | 0.42 | 0.65 | 0.82 | 0.83 |
| Data ∗∗ (S vs. S) | (200) | (194) | (161) | (93) | (33) | (6) |
| Data (S vs. C) | 0.30 | 0.52 | 0.61 | 0.69 | 1.00 | - |
| Data (S vs. C) | (200) | (140) | (67) | (26) | (8) | - |
| Data (C vs. S) | 0.375 | 0.44 | 0.56 | 0.61 | 1.00 | - |
| Data (C vs. S) | (200) | (125) | (70) | (31) | (12) | - |
| Data (C vs. C) | 0.725 | 0.64 | 0.90 | 1.00 | - | - |
| Data (C vs. C) | (200) | (55) | (20) | (2) | - | - |
| Data ∗∗∗ (Field) | 0.039 | 0.102 | 0.193 | 0.352 | 0.587 | 0.632 |
| Data ∗∗∗ (Field) | (102) | (98) | (88) | (71) | (46) | (19) |
Table 6. Centipede game-Prediction and Data
∗ presents the predicted probabilities of playing T at each node by the model. Columns correspond to the probability that a player is predicted to play T upon reaching that node. Odd nodes refer to Player A's choices; even nodes refer to Player B's choices.
∗∗∗ shows the distribution of implied stop probabilities for players in the centipede game. The number of opportunities observed is displayed in the parentheses.
∗∗ Data are from Palacios-Huerta and Volij [2009]. S represents students, and C represents chess players. S vs. C represents the situation when Player A is a student and Player B is a chess player. C vs. S is when Player A is a chess player and Player B is a student.
∗∗∗∗ Data are from the field Centipede game of chess players by Levitt, List, and Sadoff (2011).
Referring to Ho and Su [2013], we define a measure, 𝐷 ( 𝐻, 𝑀,𝐺 𝑆 ) , to quantify the deviation of data H from the model's prediction, 𝑀 in centipede game 𝐺 𝑆 with S decision nodes as follows:
$$D \left ( H , M , G _ { S } \right ) = \sum _ { s = 1 } ^ { S } w _ { s } ^ { H } d _ { s } \left ( p _ { s } ^ { H } , p _ { s } ^ { M } \right ) , w _ { s } ^ { H } = \frac { n _ { s } ^ { H } } { \sum _ { k = 1 } ^ { S } n _ { k } ^ { H } } , d _ { s } \left ( p _ { s } ^ { H } , p _ { s } ^ { M } \right ) = \left | p _ { s } ^ { H } - p _ { s } ^ { M } \right |$$
where 𝑛 𝐻 𝑠 is the number of observations at each stage, given by data H, 𝑑 𝑠 ( 𝑝 𝐻 𝑠 , 𝑝 𝑀 𝑠 ) is the distance of stopping probabilities at stage s between data H and the prediction of model M measured by their absolute difference | 𝑝 𝐻 𝑠 -𝑝 𝑀 𝑠 | .
| Models | Data (S vs. S) | Data (S vs. C) | Data (C vs. S) | Data (C vs. C) | Data (Field) |
|------------------------------|------------------|------------------|------------------|------------------|----------------|
| NLK or 𝑙𝑒𝑣𝑒𝑙 𝑘 ( 𝜆 =0) k ≥ 6 | 0.7102 | 0.5474 | 0.5431 | 0.2773 # ∗ | 0.776 |
| NLK ( 𝜆 =0.05) | 0.3016 | 0.2478 | 0.3191 | 0.5393 | 0.4296 |
| NLK ( 𝜆 =0.1) | 0.2132 | 0.2361 # | 0.2619 # | 0.5785 | 0.3589 |
| NLK ( 𝜆 =0.15) | 0.2071 | 0.3536 | 0.3672 | 0.6500 | 0.3269 |
NLK
Table 7. Centipede game-prediction for different models
| ( 𝜆 =0.2) | 0.1857 | 0.4051 | 0.4062 | 0.7166 | 0.2036 |
|----------------------------------------------------------------------|----------|----------|----------|----------|----------|
| NLK ( 𝜆 =0.25) | 0.1791 | 0.4019 | 0.4023 | 0.717 | 0.1946 |
| NLK ( 𝜆 =0.3) | 0.1714 | 0.3982 | 0.3978 | 0.7175 | 0.1866 |
| NLK ( 𝜆 =0.35) | 0.1625 # | 0.3971 | 0.3927 | 0.7181 | 0.1761 |
| NLK ( 𝜆 =0.4) | 0.1703 | 0.4016 | 0.3905 | 0.7185 | 0.1638 |
| NLK ( 𝜆 =0.45) | 0.1837 | 0.4069 | 0.3968 | 0.7192 | 0.1497 |
| NLK ( 𝜆 =0.5) | 0.1999 | 0.4134 | 0.4044 | 0.72 | 0.1323 # |
| NLK ( 𝜆 =0.55) | 0.2197 | 0.4212 | 0.4137 | 0.721 | 0.150 |
| NLK ( 𝜆 =0.6) | 0.2444 | 0.4310 | 0.4253 | 0.7222 | 0.1818 |
| NLK or 𝑙𝑒𝑣𝑒𝑙 1 ( 0 . 615 ≤ 𝜆 ≤ 1 ) | 0.2840 | 0.4526 | 0.4569 | 0.7227 | 0.2121 |
| 𝑙𝑒𝑣𝑒𝑙 2 | 0.2533 | 0.4345 | 0.4295 | 0.7227 | 0.1933* |
| 𝑙𝑒𝑣𝑒𝑙 3 | 0.2127* | 0.4121 | 0.4139 | 0.7155 | 0.2428 |
| 𝑙𝑒𝑣𝑒𝑙 4 | 0.2502 | 0.3787* | 0.3947* | 0.6578 | 0.3703 |
| 𝑙𝑒𝑣𝑒𝑙 5 | 0.4366 | 0.3660 | 0.4290 | 0.6022 | 0.5540 |
| 𝑙𝑒𝑣𝑒𝑙 𝑘 ,𝑘 = 1 , 2 | 0.2446 | 0.4345 | 0.4295 | 0.7227 | 0.1484 |
| (optimal distribution) 𝑙𝑒𝑣𝑒𝑙 𝑘 ,𝑘 = 1 , 2 , 3 (optimal distribution) | 0.1567 | 0.3946 | 0.3872 | 0.7155 | 0.0895 |
* and # indicate the best prediction of a single type Level-K and NLK, respectively.
Table 7 presents the result of 𝐷 ( 𝐻, 𝑀,𝐺 𝑆 ) calculated using PBNLK and the Level-K model with the five different aforementioned data sets. In the lab experiments, when opponents are students (Column 2), PBNLK with 𝜆 =0.35 provides the most precise prediction (D=0.1625), which is better than the best prediction of the single type Level-K model (k=3,D=0.2127); in the treatment when chess players and students play with each other (Column 3 and 4), PBNLK with 𝜆 =0.1 fits the data the best ( 𝐷 𝑆𝑣𝑠𝐶 = 0 . 2361 , 𝐷 𝐶𝑣𝑠𝑆 = 0 . 2619 ) , which is more accurate than the Level-K model with an optimal k=4 ( 𝐷 𝑆𝑣𝑠𝐶 = 0 . 3787 , 𝐷 𝐶𝑣𝑠𝑆 = 0 . 3947 ) ; when the opponents are chess players, the best fit is the case when PBNLK ( 𝜆 = 0), SPNE, and the 𝑙𝑒𝑣𝑒𝑙 𝑘 type, ( 𝑘 ≥ 6 ) , coincide ( 𝐷 = 0 . 2773). For the field data, PBNLK with 𝜆 =0.5 provides the most precise prediction ( 𝐷 = 0 . 1323), which is more accurate than the best prediction of the Level-K model with an optimal 𝑘 = 2 ( 𝐷 = 0 . 1933). Moreover, in all
five datasets, the optimal PBNLK performs better than the Level-K with an optimal distribution of level 1 and level 2 types. When we allow the Level-K model to have one more parameter, the optimal PBNLK still performs better the Level-K with an optimal distribution of level 1 , level 2 , and level 3 in three datasets (Column 2, 3, 4) except for the lab experiments when opponents are students and the field data.
Our solution concept provides an alternative explanation for cases where neither the original Level-K model nor backward induction applies. Notably, we constrain NLK by using only symmetric beliefs. However, it is reasonable for each group to have a different subjective 𝜆 in cases where students interact with chess players, and we conjecture that NLK would perform even better by allowing for heterogeneous beliefs while accounting for additional parameters.
## 5 COMMONVALUE AUCTION
Avery and Kagel [1997](AK) conducted a laboratory experiment using a common value, secondprice auction, and the wallet game . Their design has two bidders, 𝑖 = 1 , 2, and each privately observes a signal 𝑋 𝑖 drawn i.i.d from a uniform distribution on [ 1 , 4 ] . The common value is the sum of the two private signals, i.e., 𝑣 𝑖 ( 𝑥 1 , 𝑥 2 ) = 𝑣 ( 𝑥 1 , 𝑥 2 ) = 𝑥 1 + 𝑥 2 . Let 𝑣 ( 𝑥,𝑦 ) = 𝑥 + 𝑦 , and r ( x ) = x + E [ 𝑋 2 ] = 𝑥 + 2 . 5 .𝑣 ( 𝑥, 𝑥 ) ≡ 𝑏 ( 𝑥 ) = 2 𝑥 is the unique symmetric BNE 36 and with just two bidders, 𝑏 ( 𝑥 ) = 2 𝑥 , is an ex-post equilibrium , independent of signals distribution and risk attitude and with no regret. AK defines naïve bidding by 𝑟 ( 𝑥 ) = 𝑥 + 2 . 5, representing a naive bidder who assumes that whenever she wins, the other bidder's signal is at its expected value ( 2 . 5 ). Notably, 𝑟 ( 𝑥 ) is also the level player's strategy in Crawford and Iriberri ( CI;2007 ) , the best response to a levelo player who bids uniformly randomly on [ 1 , 4 ] . We denote by 𝑏 𝜆 (·) the strategy in a 𝜆 -𝐵𝑁𝐿𝐾 equilibrium and solve the symmetric linear strategy. (The details are provided in Appendix A.3.)
Table ?? compares the prediction of 𝜆 -BNLK (with all 𝜆 ∈ { 0 . 05 𝑛 } 𝑛 = 0 , 1 , 2 ,.., 20 ) and the Level-K model. The optimal bidding of a level2 player already reduces to a boundary solution (the objective function becomes a linear function), where all bidders with a value lower than 2.5 bid 3.5 and the others (with a value higher than 2.5) bid 6.5. For a level3 player, when her signal is smaller than 2.5, she bids any number below 3.5 (expecting to lose), and she bids any number above 6.5 when her signal is larger than 2.5 (expecting to win). The predictions are ambiguous for higher levels. By contrast, there always exists a symmetric linear strategy for our 𝜆 -BNLK players.
The data produced by 𝐴𝐾 is evaluated using the cursed equilibrium (CE) model by Eyster and Rabin [2005](ER) and the Level-K by [Crawford and Iriberri, 2007] (CI). ER show that for any cursed level, 0 < 𝜒 ≤ 1, their CE predicts better than BNE (i.e., CE with 𝜒 = 0 ) and that for a given 𝜒, CE fits better for experienced, rather than for inexperienced subjects, with respect to the MSE. For data on only inexperienced bidders, CI use Level-K with a logistic error structure and a subject-specific precision. They compare their model using the best mixture of five types, including random level 1 and level 2 , 37 truthful level 1 and level 2 , 38 and BNE players, and show that it outperforms CE (with the best mixture of types, such that 𝜒 ∈ 0 . 1 , 0 . 2 , ..., 0 . 9 , 1 . 0 ) , using both likelihood and the BIC. 39
36 Refer to Milgrom and Roberts [1982].
38 Truthful level1 and level2 are generated iteratively by best responding to a truthful level0 who always bids her signal: 𝑏 ( 𝑥 ) = 𝑥 .
37 Random level1 and level2 are generated iteratively by best responding to a random level0 , as considered in this paper.
39 BIC penalizes models with more parameters to adjust the likelihood.
| Models | b(x) | MSE (inexperienced) | MSE (experienced) |
|--------------------------|--------------|-----------------------|---------------------|
| NLK or NE ( 𝜆 =0) | 2x | 2.897 | 1.171 |
| NLK ( 𝜆 =0.05) | 1.951x+0.122 | 2.823 | 1.124 |
| NLK ( 𝜆 =0.1) | 1.904x+0.239 | 2.756 | 1.082 |
| NLK ( 𝜆 =0.15) | 1.859x+0.352 | 2.693 | 1.042 |
| NLK ( 𝜆 =0.2) NLK | 1.815x+0.462 | 2.634 | 1.010 |
| ( 𝜆 =0.25) | 1.772x+0.570 | 2.579 | 0.978 |
| NLK ( 𝜆 =0.3) | 1.730x+0.676 | 2.531 | 0.953 |
| NLK ( 𝜆 =0.35) | 1.688x+0.781 | 2.484 | 0.927 |
| NLK ( 𝜆 =0.4) | 1.646x+0.886 | 2.44 | 0.906 |
| NLK ( 𝜆 =0.45) | 1.604x+0.990 | 2.396 | 0.889 |
| NLK | 1.562x+1.096 | 2.356 | 0.872 |
| ( 𝜆 =0.5) NLK ( 𝜆 =0.55) | 1.519x+1.203 | 2.32 | 0.859 |
| NLK ( 𝜆 =0.6) | 1.475x+1.313 | 2.286 | 0.848 |
| NLK ( 𝜆 =0.65) | 1.430x+1.426 | 2.25 | 0.840 |
| NLK ( 𝜆 =0.7) | 1.383x+1.543 | 2.22 | 0.835 |
| NLK ( 𝜆 =0.75) | 1.333x+1.667 | 2.19 | 0.834* |
| NLK ( 𝜆 =0.8) | 1.281x+1.798 | 2.164 | 0.835 |
| NLK ( 𝜆 =0.85) | 1.224x+1.940 | 2.137 | 0.843 |
| NLK ( 𝜆 =0.9) | 1.161x+2.098 | 2.117 | 0.857 |
NLK
Table 8. Model comparison for the wallet game.
| ( 𝜆 =0.95) | 1.088x+2.280 | 2.097 | 0.882 |
|------------------------|-------------------------------------------------|-----------|-----------|
| NLK or level 1 ( 𝜆 =1) | x+2.5 | 2.085 # ∗ | 0.922 # ∗ |
| level 2 | ( 3 . 5 if 𝑥 < 2 . 5 6 . 5 if 𝑥 > 2 . 5 | 2.955 | 1.381 |
| level 3 | ( < 3 . 5 if 𝑥 < 2 . 5 > 6 . 5 if 𝑥 > 2 . 5 | - | |
| Data (inexperienced) | 0 . 997 ( 0 . 079 ) x + 2 . 950 ( 0 . 203 ) 023 | 1.899 | |
| Data (experienced) | 1 . 313 ( 0 . 053 ) x + 2 . ( 0 . 150 ) | - | 0.745 |
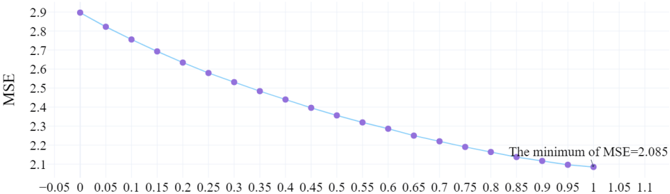
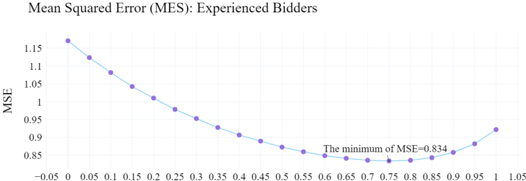
Table 8 and Figures 2 and 3 show that for inexperienced bidders (using the first 18 periods), the most accurate prediction of BNLK is with 𝜆 =1, and it coincides with level1 (MSE=2.085). 40 For experienced bidders (using periods 19-42), BNLK with 𝜆 =0.75 fits the data the best (MSE=0.834), which is better than the most precise prediction of Level-K (k=1,MSE=0.922).
## Mean Squared Error (MES): Inexperienced Bidders
Fig. 2. MSEs of BNLK with Different 𝜆 : inexperienced bidders.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Line Graph: Mean Squared Error (MSE) vs. Variable Value
### Overview
The image depicts a line graph illustrating the relationship between a variable (x-axis) and Mean Squared Error (MSE, y-axis). The graph shows a consistent downward trend in MSE as the variable increases, with a labeled minimum MSE value of 2.085 at a specific variable value.
### Components/Axes
- **X-axis**: Labeled with values ranging from -0.05 to 1.1 in increments of 0.05. No explicit label for the variable is provided.
- **Y-axis**: Labeled "MSE" with values from 2.1 to 2.9 in increments of 0.1.
- **Legend**: Not visible in the image.
- **Data Line**: Blue line with purple circular markers at each data point.
- **Annotation**: Text stating "The minimum of MSE=2.085" positioned near the bottom-right of the graph.
### Detailed Analysis
- **Data Points**:
- At x = -0.05, MSE ≈ 2.9.
- At x = 0, MSE ≈ 2.8.
- At x = 0.05, MSE ≈ 2.7.
- At x = 0.1, MSE ≈ 2.6.
- At x = 0.15, MSE ≈ 2.5.
- At x = 0.2, MSE ≈ 2.4.
- At x = 0.25, MSE ≈ 2.3.
- At x = 0.3, MSE ≈ 2.2.
- At x = 0.35, MSE ≈ 2.1.
- At x = 0.4, MSE ≈ 2.0.
- At x = 0.45, MSE ≈ 1.9.
- At x = 0.5, MSE ≈ 1.8.
- At x = 0.55, MSE ≈ 1.7.
- At x = 0.6, MSE ≈ 1.6.
- At x = 0.65, MSE ≈ 1.5.
- At x = 0.7, MSE ≈ 1.4.
- At x = 0.75, MSE ≈ 1.3.
- At x = 0.8, MSE ≈ 1.2.
- At x = 0.85, MSE ≈ 1.1.
- At x = 0.9, MSE ≈ 1.0.
- At x = 0.95, MSE ≈ 0.9.
- At x = 1.0, MSE ≈ 0.8.
- At x = 1.05, MSE ≈ 0.7.
- At x = 1.1, MSE ≈ 0.6.
### Key Observations
- The MSE decreases monotonically as the variable increases from -0.05 to 1.1.
- The minimum MSE of 2.085 is annotated near x = 1.05, though the plotted data suggests a lower value (≈0.7) at this point. This discrepancy may indicate a labeling error or misinterpretation of the annotation.
- The trend is linear, with no visible outliers or anomalies.
### Interpretation
The graph demonstrates a strong negative correlation between the variable and MSE, suggesting that increasing the variable reduces prediction error. The annotated minimum MSE of 2.085 conflicts with the plotted data, which shows a lower value (≈0.7) at x = 1.05. This inconsistency warrants verification of the annotation's accuracy. The optimal variable value for minimizing MSE appears to be near x = 1.05, but further validation is needed to resolve the discrepancy between the annotation and the plotted data.
</details>
Thus far, we have used the in-sample of various versions of NLK, including BNLK and PBNLK, to compare to other models. However, in a recent paper, Brünner [2020], who studies experimental tournament games, compares the performance of PBNLK to that of the other models for out-ofsample predictions. We cite his findings as follows:
Levin and Zhang (2019) have already shown that their PBNLK solution concept explains behavior in centipede games better than Nash equilibrium and Level-K thinking. this study finds that in a tournament context, PBNLK has the greatest out-of-sample predictive power in a modified version of the tournament among all the alternatives
40 We choose the value of 𝜆 that minimizes the mean squared errors (MSEs), that is, the nonlinear least squares estimate of 𝜆 .
Fig. 3. MSEs of BNLK with different 𝜆 : experienced bidders.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Line Graph: Mean Squared Error (MSE) for Experienced Bidders
### Overview
The image is a line graph depicting the relationship between an unspecified x-axis variable and Mean Squared Error (MSE) for "Experienced Bidders." The graph shows a U-shaped curve, with MSE decreasing to a minimum value before increasing again. Key annotations include the minimum MSE value and axis labels.
### Components/Axes
- **X-Axis**: Labeled with values from **-0.05 to 1.05** in increments of **0.05**. No explicit label for the x-axis variable is provided.
- **Y-Axis**: Labeled **"MSE"** (Mean Squared Error), with values ranging from **0.85 to 1.15** in increments of **0.05**.
- **Legend**: Located at the **bottom-right corner**, indicating the line color is **blue**.
- **Line**: A single blue line representing MSE values across the x-axis range.
### Detailed Analysis
- **Trend**: The line starts at **MSE = 1.15** when x = -0.05, decreases monotonically to a **minimum MSE = 0.834** at x = 0.75, then increases again. The curve is smooth, with no abrupt changes.
- **Key Data Points**:
- x = -0.05 → MSE ≈ 1.15
- x = 0.00 → MSE ≈ 1.10
- x = 0.05 → MSE ≈ 1.05
- x = 0.10 → MSE ≈ 1.00
- x = 0.15 → MSE ≈ 0.95
- x = 0.20 → MSE ≈ 0.90
- x = 0.25 → MSE ≈ 0.87
- x = 0.30 → MSE ≈ 0.85
- x = 0.35 → MSE ≈ 0.84
- x = 0.40 → MSE ≈ 0.83
- x = 0.45 → MSE ≈ 0.83
- x = 0.50 → MSE ≈ 0.83
- x = 0.55 → MSE ≈ 0.83
- x = 0.60 → MSE ≈ 0.83
- x = 0.65 → MSE ≈ 0.83
- x = 0.70 → MSE ≈ 0.83
- x = 0.75 → MSE ≈ 0.834 (minimum)
- x = 0.80 → MSE ≈ 0.84
- x = 0.85 → MSE ≈ 0.85
- x = 0.90 → MSE ≈ 0.87
- x = 0.95 → MSE ≈ 0.90
- x = 1.00 → MSE ≈ 0.93
- x = 1.05 → MSE ≈ 0.95
### Key Observations
1. **Minimum MSE**: The lowest MSE value (**0.834**) occurs at **x = 0.75**, marked explicitly on the graph.
2. **Symmetry**: The U-shaped curve suggests a quadratic relationship between the x-axis variable and MSE, with the minimum at x = 0.75.
3. **Asymmetry in Recovery**: After the minimum, MSE increases more gradually compared to the steeper decline before x = 0.75.
4. **Negative X-Values**: The graph includes x-values below zero (-0.05), though their practical interpretation is unclear without context.
### Interpretation
The data suggests that the MSE for experienced bidders is minimized when the x-axis variable is approximately **0.75**. This could represent an optimal threshold or parameter value (e.g., bid amount, risk tolerance, or experience level) that balances error minimization. The U-shape implies diminishing returns beyond this point, where further increases in the x-axis variable lead to higher errors. The inclusion of negative x-values raises questions about the domain of the x-axis variable—it may represent a normalized or transformed metric. The graph emphasizes the importance of identifying optimal points in decision-making processes for experienced bidders, potentially guiding strategies to minimize prediction or estimation errors.
</details>
considered. Thus, PBNLK and its updating of beliefs during a game seem to be important concepts that promise to be valuable for the design of new policies and deserve more attention in future research.
Finally, we looked at experimental data from the work of [Gill and Prowse, 2016] (G&P) on the beauty contest game, and compared to the predictions of Nash equilibrium, Level-K and NLK. 41 In this experiment there are three players, and guesses are from the set, I={0,1,2,...,100}. The winner of a prize of $6 (normalized here to 1) is the player whose guess, 𝑔 𝑖 , 𝑖 = 1 , 2 , 3, is the closest to 70% of the target T, 𝑇 = 7 10 𝑔 1 + 𝑔 2 + 𝑔 3 3 , ties (of two or three) are equally divided. 42 We used data only from the first round behavior, 43 and applied only the simplest versions of Level-K and NLK models. This is, in Level-K model, 𝑙𝑒𝑣𝑒𝑙 0 randomizes 𝑢𝑛𝑖𝑓 𝑜𝑟𝑚𝑙𝑦 on the set 𝐼 and player 𝑙𝑒𝑣𝑒𝑙 𝑘 + 1 best responds by assuming all rivals are 𝑙𝑒𝑣𝑒𝑙 𝑘 players, and the NLK player believes that each one (of the two rivals) is either a 𝑙𝑒𝑣𝑒𝑙 0 player, or an NLK player with probabilities 𝜆 , and (1𝜆 ) respectively. We consider only symmetric NLK solutions.
Case 1: 𝜆 =0: In this case the NLK player faces two other NLK players, thus the solution coincides with Nash equilibrium, and the unique dominance solvable outcome is: 𝑔 ∗ 2 = 0.
Case 2: 𝜆 = 1 : In this case the NLK player faces two level 0 players and the NLK model is identical to the Level-K model, where the, 𝑁𝐿𝐾 , or level 1 , players maximize the probability of winning. (For now we ignore the integer constraint and solve as if on uniform [ 0 , 1 ] ). For 𝑔 < 7 16 , the probability of NLK winning with a guess of 𝑔 is given by: 44 ( 1 -𝑔 ) 2 -1 56 ( 7 -16 𝑔 ) 2 + 8 7 𝑔 2 + 2 7 7 𝑔 -16 𝑔 2 = ( 1 -𝑔 ) 2 -1 56 ( 7 -16 𝑔 ) 2 + 2 7 ( 7 -12 𝑔 ) 𝑔 , with first-order-condition for maximization being 2 [ 2 -7 𝑔 ] = 0, yielding a guess of 𝑔 ∗ = 2 7 = 0 . 2857 as being (optimal) the best response for level 1 and NLK, and with 273 392 = 0 . 6964, being the probability of winning. In the simple version of Level-K the best response of a level 2 player facing two level 1 rivals is any guess below 𝑔 ∗ .
41 We thank a referee of the journal who suggested looking into the beauty contest game.
42 The main objective of their paper is to 'study how cognitive ability measured in a nonstrategic setting affects how people perform and learn in a strategic environment.' They used a careful design and protocols to first classify exogenously experimental subjects to two groups of Low and High cognitive ability, and their treatments included playing 10 rounds of the game with the same three players that were of the same homogeneous group or a mixed of players from the two groups.
and overbidding in independent-private-value auctions using a non-equilibrium
Crawford and Iriberri [2007], mid of page 7, 'In this paper we reconsider the winner's curse in common-value auctions model of initial responses
based on studies and non-auction experiments on strategic thinking, and thereby to bring a large body of auction evidence to bear on
"level-k" thinking, introduced by...' and bottom of page 7, 'It also promises to establish a link between empirical auction the issue
of how best to model initial responses to games.
' Both bold added.
44 For 7 8 ≤ 𝑔 and for 7 16 ≤ 𝑔 < 7 8 , the probability of the DM winning with 𝑔 are given by ( 1 -𝑔 ) 2 , and by ( 1 -𝑔 ) 2 + 1 56 ( 7 -8 𝑔 ) 2 , respectively and both strictly decline in 𝑔 .
The average first round guesses in G&P among players who were classified as having High and Low cognitive abilities are 42 . 9 and 43 . 6 respectively. Neither the NLK, nor the Level-K models predict subjects' behavior well, with Nash equilibrium being much worse. 45
Case 3: 0 < 𝜆 < 1: Ignoring the constraint imposed by restricting guesses only to integers we show (omitted) that an NLK player would undercut any presumed strictly positive, g > 0 solution, thus eliminating the possibility of a pure strategy solution. Yet, the reason is telling: the tiniest undercutting from a presumed g > 0 solution induces a positive, discontinuous increase in payoffs of 2 3 , when the NLK player is matched with two other NLK players, (as the player wins 1 rather than 1 3 by a using the same guess), and a gaining 1 rather than 1 2 when the NLK player is matched with one NLK player and one 𝑙𝑒𝑣𝑒𝑙 0 player whose guess is larger than the presumed 𝑔 > 0. On the other hand, when the NLK is matched with two 𝑙𝑒𝑣𝑒𝑙 0 players, undercutting hurts, as a lower guess is even further from the optimal guess of 0.2857. However, because that loss is 'continuous,' (at 0.2857 it vanishes), there is 𝜖 > 0 undercutting, small enough, to validate such intuition. In G&P paper, guesses are restricted to be integers and cannot be as small as we wish and the loss is not infinitesimal and we can always find small enough 𝛿 > 0, such that 𝜆 ′ 𝑠 satisfying, 1 -𝛿 < 𝜆 < 1, will rationalize (say) a guess of 28 as a pure strategy NLK solution. 46
We conclude that with 0 < 𝜆 < 1, NLK does better than 𝑙𝑒𝑣𝑒𝑙 1 , 𝑙𝑒𝑣𝑒𝑙 2 , that predicts a guess of 0.2857, or 0 respectively, but we do not call it a winner as it uses an extra parameter. 48
Solving NLK's mix strategy equilibrium for each 𝜆 , 0 < 𝜆 < 1, is a computational nightmare and we have not done it. We conjecture it has the following qualitative property. 47 For a given 𝜆 there is an interval, [ 𝑙 𝜆 , 0 . 2857 ] , from which NLK players pick their guess using endogenously determined distribution. The mix strategy equilibrium implies that a tiny undercutting induces continuous change that thus must be 'balanced' against moving further from the optimal NLK guess in the event where the NLK player is matched with two 𝑙𝑒𝑣𝑒𝑙 0 players. Qualitatively, it results in predictions that resembles the behavior of 𝑙𝑒𝑣𝑒𝑙 2 , player, but provides a precise mixing whereas the Level-K model allows any guess under below 𝑔 ∗ .
## 6 CONCLUSION
This introduces NLK, a model that connects NE and Level-K. NLK allows a player to believe that her opponent may be less or as sophisticated as herself. NLK is well-defined in both static and dynamic games, making it easy to apply to the data from four published papers on static, dynamic, and auction games. In all four cases, NLK provides better predictions than those of the NE and Level-K, except for few cases when predictions coincide or when we allow Level-K to freely choose more parameters NLK allows other beliefs about the naïve player and can be extended to manage heterogeneous beliefs about opponents (e.g., who are from distinct populations) and to games with more than two players.
Comparing across applications to experimental data from different games with different cognitive requirements of the tasks, we observe that the 'best fitting' 𝜆 depends on the game played and the population of players. Based on our intuition and the limited evidence, ceteris paribus, the expectation should be a smaller 𝜆 in simpler games requiring less cognitive/strategical sophistication,
45 From their figure 2. On page 1632 it seems that the corresponding average guesses for rounds 6 -10 is about 10.4 and 12.6 for High and Low cognitive abilities, respectively.
47 We made enough computation to have fate in this conjecture.
46 It suggests that in a beauty contest game with guesses allowed only from the set, 𝐼 = { 0 , 10 , 20 , ..., 100 } , a guess of 30 can be 'supported' as a pure strategy NLK for a 'larger' interval of 𝜆 < 1. Such design may be better suited for comparing Level-K and NLK without sacrificing much of the original motivation of that game.
48 If we allow a 𝑙𝑒𝑣𝑒𝑙 2 player in the Level-K model best respond to a mix of rivals who are 𝑙𝑒𝑣𝑒𝑙 1 and 𝑙𝑒𝑣𝑒𝑙 0 , we will have similar qualitative predictions.
or with more sophisticated/experienced (e.g., chess) players. For instance, in the common value auction with inexperienced bidders, 𝜆 =1 provides the best fit, but with experienced bidders, 𝜆 =0.75 fits better. We also find that in the centipede game, the best 𝜆𝑠 are smaller than those in the common value auction. This finding suggests that further experimental research is necessary with the same, or similar, games with similar populations, to estimate the optimal 𝜆 , to provide more evidence and tests for external validity. [Alaoui, Larbi and Penta, Antonio, 2016]
49 For instance, Brünner (2018) documents the consistently good performance of NLK in two similar games with the same 𝜆 : a regular rank-order tournament and the version with an outside option.
## REFERENCES
- Alaoui, Larbi and Penta, Antonio. 2016. Endogenous depth of reasoning. The Review of Economic Studies 83, 4 (2016), 1297-1333.
- Geir Asheim and Martin Dufwenberg. 2003. Deductive Reasoning In Extensive Games. The Economic Journal 113 (03 2003). https://doi.org/10.1111/1468-0297.00121
- Ayala Arad and Ariel Rubinstein. 2012. The 11-20 money request game: A level-k reasoning study. American Economic Review 102, 7 (2012), 3561-73.
- Robert Aumann and Adam Brandenburger. 1995. Epistemic conditions for Nash equilibrium. Econometrica: Journal of the Econometric Society (1995), 1161-1180.
- Christopher Avery and John H Kagel. 1997. Second-Price Auctions with Asymmetric Payoffs: An Experimental Investigation. Journal of Economics & Management Strategy 6, 3 (1997), 573-603.
- Robert J Aumann. 1992. Irrationality in game theory. Economic analysis of markets and games (1992), 214-227.
- Pierpaolo Battigalli and Giacomo Bonanno. 1999. Recent results on belief, knowledge and the epistemic foundations of game theory. Research in Economics 53, 2 (1999), 149-225.
- Gary Bornstein, Tamar Kugler, and Anthony Ziegelmeyer. 2004. Individual and group decisions in the centipede game: Are groups more 'rational' players? Journal of Experimental Social Psychology 40, 5 (2004), 599-605.
- Elchanan Ben-Porath. 1997. Rationality, Nash equilibrium and backwards induction in perfect-information games. The Review of Economic Studies 64, 1 (1997), 23-46.
- Antoni Bosch-Domenech, Jose G Montalvo, Rosemarie Nagel, and Albert Satorra. 2002. One, two,(three), infinity,...: Newspaper and lab beauty-contest experiments. American Economic Review 92, 5 (2002), 1687-1701.
- Colin F Camerer, Teck-Hua Ho, and Juin-Kuan Chong. 2004. A cognitive hierarchy model of games. The Quarterly Journal of Economics 119, 3 (2004), 861-898.
- Tobias Brünner. 2020. Self-selection with non-equilibrium beliefs: Predicting behavior in a tournament experiment. Journal of Economic Behavior & Organization 169 (2020), 389-396.
- Miguel Costa-Gomes, Vincent P Crawford, and Bruno Broseta. 2001. Cognition and behavior in normal-form games: An experimental study. Econometrica 69, 5 (2001), 1193-1235.
- Vincent P Crawford, Miguel A Costa-Gomes, and Nagore Iriberri. 2013. Structural models of nonequilibrium strategic thinking: Theory, evidence, and applications. Journal of Economic Literature 51, 1 (2013), 5-62.
- Miguel A Costa-Gomes and Vincent P Crawford. 2006. Cognition and Behavior in Two-person Guessing Games: An Experimental Study. American Economic Review 96, 5 (2006), 1737-1768.
- Vincent P Crawford and Nagore Iriberri. 2007. Level-k auctions: Can a nonequilibrium model of strategic thinking explain the winner's curse and overbidding in private-value auctions? Econometrica 75, 6 (2007), 1721-1770.
- Dirk Engelmann and Martin Strobel. 2000. The false consensus effect disappears if representative information and monetary incentives are given. Experimental Economics 3, 3 (2000), 241-260.
- Robyn M Dawes. 1990. The potential nonfalsity of the false consensus effect. Insights in decision making: A tribute to Hillel J. Einhorn (1990), 179-199.
- Erik Eyster and Matthew Rabin. 2005. Cursed equilibrium. Econometrica 73, 5 (2005), 1623-1672.
- Drew Fudenberg and Jean Tirole. 1991. Perfect Bayesian equilibrium and sequential equilibrium. journal of Economic Theory 53, 2 (1991), 236-260.
- Mark Fey, Richard D McKelvey, and Thomas R Palfrey. 1996. An experimental study of constant-sum centipede games. International Journal of Game Theory 25, 3 (1996), 269-287.
- David Gill and Victoria Prowse. 2016. Cognitive ability, character skills, and learning to play equilibrium: A level-k analysis. Journal of Political Economy 124, 6 (2016), 1619-1676.
- Jacob K Goeree and Charles A Holt. 2001. Ten little treasures of game theory and ten intuitive contradictions. American Economic Review 91, 5 (2001), 1402-1422.
- Irving L Glicksberg. 1952. A further generalization of the Kakutani fixed point theorem, with application to Nash equilibrium points. Proc. Amer. Math. Soc. 3, 1 (1952), 170-174.
- Jacob K Goeree, Charles A Holt, and Thomas R Palfrey. 2008. Quantal response equilibrium. The New Palgrave Dictionary of Economics (2008).
- Teck-Hua Ho and Xuanming Su. 2013. A dynamic level-k model in sequential games. Management Science 59, 2 (2013), 452-469.
- John C Harsanyi. 1973. Games with randomly disturbed payoffs: A new rationale for mixed-strategy equilibrium points. International journal of game theory 2, 1 (1973), 1-23.
- Philippe Jehiel. 2005. Analogy-based expectation equilibrium. Journal of Economic theory 123, 2 (2005), 81-104.
- Philippe Jehiel and Frédéric Koessler. 2008. Revisiting games of incomplete information with analogy-based expectations. Games and Economic Behavior 62, 2 (2008), 533-557.
- David Jimenez-Gomez. 2019. False Consensus in Games: Embedding Level-k Models into Games of Incomplete Information. Available at SSRN 3216040 (2019).
- John H Kagel, Ronald M Harstad, and Dan Levin. 2002. Information impact and allocation rules in auctions with affiliated private values: A laboratory study. Common Value Auctions and the Winner's Curse (2002), 177.
- John H. Kagel, Ronald M. Harstad, and Dan Levin. 1987. Information Impact and Allocation Rules in Auctions with Affiliated Private Values: A Laboratory Study. Econometrica 55, 6 (1987), 1275-1304.
- John H Kagel and Dan Levin. 2009. Common value auctions and the winner's curse . Princeton University Press.
Duke mathematical journal
Shizuo Kakutani. 1941. A generalization of Brouwer's fixed point theorem.
- David A Kenny. 1994. Interpersonal perception: A social relations analysis . Guilford Press.
- Toshiji Kawagoe and Hirokazu Takizawa. 2012. Level-k analysis of experimental centipede games. Journal of Economic Behavior & Organization 82, 2-3 (2012), 548-566.
8, 3 (1941), 457-459.
- Willemien Kets. 2012. Bounded reasoning and higher-order uncertainty. Available at SSRN 2116626 (2012).
- David M Kreps, Paul Milgrom, John Roberts, and Robert Wilson. 1982. Rational cooperation in the finitely repeated prisoners' dilemma. Journal of Economic theory 27, 2 (1982), 245-252.
- Yukio Koriyama and Ali Ozkes. 2018. Inclusive Cognitive Hierarchy in Collective Decisions. (2018).
- David M Kreps and Robert Wilson. 1982a. Reputation and imperfect information. Journal of economic theory 27, 2 (1982), 253-279.
- Joachim Krueger and Russell W Clement. 1994. The truly false consensus effect: an ineradicable and egocentric bias in social perception. Journal of personality and social psychology 67, 4 (1994), 596.
- David M Kreps and Robert Wilson. 1982b. Sequential equilibria. Econometrica: Journal of the Econometric Society (1982), 863-894.
- Steven D Levitt, John A List, and Sally E Sadoff. 2011. Checkmate: Exploring backward induction among chess players. American Economic Review 101, 2 (2011), 975-90.
- Richard D McKelvey and Thomas R Palfrey. 1992. An experimental study of the centipede game. Econometrica: Journal of the Econometric Society (1992), 803-836.
- Gary Marks and Norman Miller. 1987. Ten years of research on the false-consensus effect: An empirical and theoretical review. Psychological bulletin 102, 1 (1987), 72.
- Richard D McKelvey and Thomas R Palfrey. 1995. Quantal response equilibria for normal form games. Games and economic behavior 10, 1 (1995), 6-38.
- Paul R Milgrom and Robert J Weber. 1982. A theory of auctions and competitive bidding. Econometrica: Journal of the Econometric Society (1982), 1089-1122.
- Paul Milgrom and John Roberts. 1982. Predation, reputation, and entry deterrence. Journal of economic theory 27, 2 (1982), 280-312.
- Brian Mullen, Jennifer L Atkins, Debbie S Champion, Cecelia Edwards, Dana Hardy, John E Story, and Mary Vanderklok. 1985. The false consensus effect: A meta-analysis of 115 hypothesis tests. Journal of Experimental Social Psychology 21, 3 (1985), 262-283.
- Rosemarie Nagel and Fang Fang Tang. 1998. Experimental results on the centipede game in normal form: an investigation on learning. Journal of Mathematical psychology 42, 2-3 (1998), 356-384.
- Rosemarie Nagel. 1995. Unraveling in guessing games: An experimental study. The American economic review 85, 5 (1995), 1313-1326.
- Ignacio Palacios-Huerta and Oscar Volij. 2009. Field centipedes. American Economic Review 99, 4 (2009), 1619-35.
- Amnon Rapoport, William E. Stein, James E. Parco, and Thomas E. Nicholas. 2003. Equilibrium play and adaptive learning
- Anatol Rapoport and Albert M Chammah. 1966. The game of chicken. American Behavioral Scientist 10, 3 (1966), 10-28.
- in a three-person centipede game. Games and Economic Behavior 43, 2 (2003), 239-265. https://doi.org/10.1016/S08998256(03)00009-5
- Robert W Rosenthal. 1981. Games of perfect information, predatory pricing and the chain-store paradox. Journal of Economic theory 25, 1 (1981), 92-100.
- Philip J Reny. 1992. Rationality in extensive-form games. Journal of Economic perspectives 6, 4 (1992), 103-118.
- Lee Ross, David Greene, and Pamela House. 1977. The 'false consensus effect': An egocentric bias in social perception and attribution processes. Journal of experimental social psychology 13, 3 (1977), 279-301.
- Steven J Sherman, Clark C Presson, and Laurie Chassin. 1984. Mechanisms underlying the false consensus effect: The special role of threats to the self. Personality and Social Psychology Bulletin 10, 1 (1984), 127-138.
- Reinhard Selten. 1978. The Chain Store Paradox. Theory and Decision 9, 2 (1978), 127-159.
- Dale O Stahl and Paul W Wilson. 1995. On players' models of other players: Theory and experimental evidence. Games and Economic Behavior 10, 1 (1995), 218-254.
- Dale O Stahl II and Paul W Wilson. 1994. Experimental evidence on players' models of other players. Journal of economic behavior & organization 25, 3 (1994), 309-327.
Tomasz Strzalecki. 2014. Depth of reasoning and higher order beliefs. Journal of Economic Behavior & Organization 108 (2014), 108-122.
## A APPENDIX A
## A.1 Solve for 𝜆 -NLK equilibrium in the Money Request Game
We only go through the solution for 0 ≤ 𝜆 < 1 2 because a similar argument follows for 1 2 ≤ 𝜆 < 1. We first claim that when 0 ≤ 𝜆 < 1 2 , $20 must be played by an NLK player. We assume for contraction that $20 will not be played; then, deviation to $20 would end up with $20 for sure, whereas choosing $19 generates $19 + 𝜆 × 1 10 × 20 ( < 20 ) . Thus, $19 will not be played by an NLK player. By induction, no strategy is valid for an NLK player. This is a contradiction. 50 Thus, $20 must be played by an NLK player. However, $20 could not be the only pure strategy of an NLK player because he has an incentive to deviate to $19. We assume that 𝑗 < 19 is the largest number played with positive probability. Hence, deviating to $19 generates a strictly larger payoff. Then, $19 must be played with positive probability. We denote the probability of playing $ j in the NLK equilibrium by 𝛽 𝑗 , 𝛽 𝑗 ∈ [ 0 , 1 ] and ˝ 𝛽 𝑗 = 1. The expected payoff of all strategies in equilibrium should be the same, and because playing $20 yields $20 for sure, it follows that 19 + ( 1 -𝜆 ) 𝛽 2020 + 𝜆 20 10 = 20 . Then, 𝛽 ∗ 20 = 1 -2 𝜆 ( 1 -𝜆 ) 20 < 1 . By the same argument, 18 + ( 1 -𝜆 ) 𝛽 1920 + 𝜆 20 10 = 20 . Then, 𝛽 ∗ 19 = 2 -2 𝜆 ( 1 -𝜆 ) 20 Because 𝛽 ∗ 20 + 𝛽 ∗ 19 < 1 , $18 has to be played in equilibrium (otherwise, there would be an incentive to deviate to $18 ) ; thus, iteratively, we obtain 𝛽 ∗ 18 = 3 -2 𝜆 ( 1 -𝜆 ) 20 , 𝛽 ∗ 17 = 4 -2 𝜆 ( 1 -𝜆 ) 20 , 𝛽 ∗ 16 = 5 -2 𝜆 ( 1 -𝜆 ) 20 . We suppose that $14 is played in equilibrium too; then, 14 + ( 1 -𝜆 ) 𝛽 1520 + 𝜆 20 10 = 20 implies that 𝛽 15 = 6 -2 𝜆 ( 1 -𝜆 ) 20 . However, in this case, ˝ 20 𝑗 = 15 𝛽 𝑗 > 1. This is a contradiction. Thus, $14 (and all lower numbers) would not be played by an NLK player. Then, 𝛽 ∗ 15 = 1 -˝ 20 𝑗 = 16 𝛽 𝑗 = 5 -10 𝜆 ( 1 -𝜆 ) 20 . In conclusion, when 0 ≤ 𝜆 < 1 2 , there is a unique mixed strategy for an NLK player where 𝜎 ∗ 𝑖 = 𝛽 ∗ 15 , 𝛽 ∗ 16 , 𝛽 ∗ 17 , 𝛽 ∗ 18 , 𝛽 ∗ 19 , 𝛽 ∗ 20 = n 5 -10 𝜆 ( 1 -𝜆 ) 20 , 5 -2 𝜆 ( 1 -𝜆 ) 20 , 4 -2 𝜆 ( 1 -𝜆 ) 20 , 3 -2 𝜆 ( 1 -𝜆 ) 20 , 2 -2 𝜆 ( 1 -𝜆 ) 20 , 1 -2 𝜆 ( 1 -𝜆 ) 20 o .
## A.2 Solve for 𝜆 -NLK equilibrium in the common value auction
We assume there is a linear pure strategy for a 𝜆 -NLK player and denote it as 𝑏 𝜆 ( 𝑥 ) = 𝑏 𝜆 ( 1 ) + 𝑏 𝜆 ( 4 )-𝑏 𝜆 ( 1 ) 3 ( 𝑥 -1 ) , 𝑥 ∈ [ 1 , 4 ] . Wedenote 𝑑 𝜆 = 𝑏 𝜆 ( 4 )-𝑏 𝜆 ( 1 ) . The probability that the opponent is level 0 conditional on a tie is 𝑞 𝜆 = Pr ( rival = level 0 | tie at bid = 𝑏 ) = 𝜆 / 6 𝜆 / 6 +( 1 -𝜆 )/ 𝑑 𝜆 , 𝑏 ∈ 𝑏 𝜆 ( 1 ) , 𝑏 𝜆 ( 4 ) ⊆ [ 2 , 8 ] . Then, by indifference, in the case of the maximum willingness to pay conditional on a tie, we denote it by 𝑀𝑊𝑃 ( 𝑋 ) = 𝑏 ( 𝑥 ) :
$$M W P ( 1 ) = q ^ { \lambda } ( 1 + 2 . 5 ) + \left ( 1 - q ^ { \lambda } \right ) 2 = 1 . 5 q ^ { \lambda } + 2 = b ^ { \lambda } ( 1 )$$
$$M W P ( 4 ) = q ^ { \lambda } ( 4 + 2 . 5 ) + \left ( 1 - q ^ { \lambda } \right ) 8 = 8 - 1 . 5 q ^ { \lambda } = b ^ { \lambda } ( 4 )$$
$$T h e n , d ^ { \lambda } = b ^ { \lambda } ( 4 ) - b ^ { \lambda } ( 1 ) = 1 - 3 q ^ { \lambda } = \frac { \lambda / 6 } { \lambda / 6 + ( 1 - \lambda ) / d ^ { \lambda } }$$
$$T h e n , \, \left ( d ^ { \lambda } \right ) ^ { 2 } + 3 \frac { 2 - 3 \lambda } { \lambda } d ^ { \lambda } - \frac { 3 6 ( 1 - \lambda ) } { \lambda } = 0$$
<!-- formula-not-decoded -->
## A.3 Comparisons with Other Related Solution Concepts
Eyster and Rabin [2005] propose CE that also relaxes the restriction on beliefs in NE, while maintaining the equilibrium concepts for players' strategies. They show that CE rationalizes behavior (data) from experiments where BNE fails. In particular. this rationalization occurs in
50 Because the game is finite, by Proposition 1, NLK exists.
common value auctions, where [Kagel et al., 2002] observe systematic overbidding and losses, a phenomenon called the winner's curse. CE also fits experimental data from voting and signaling models better than BNE. In one extreme version of CE, entitled "fully CE," individuals correctly predict other players' distribution of actions but ignore the correlation between actions and the specific players' types who chose those actions. In their general model, 𝜒 -CE, beliefs are a weighted average of beliefs in fully cursed opponents (with weight 𝜒 ) and Bayesian Nash opponents (with weight ( 1 -𝜒 ) ). The CE characterizes heterogeneous behaviors by different cursed levels (with 𝜒 = 1 being fully cursed, and 𝜒 = 0 being BNE). However, CE reduces to NE when there is complete information. Hence, it cannot be applied to explain deviations from NE in both static and dynamic games with complete information. Conceptually, the CE models bounded rational agents as only partially taking.into.account how other players' actions depend on their type. By contrast, NLK allows a player to consider the possibility that the other player is a naive player or another NLK player like herself. [Kets, 2012] extends the type space of [Harsanyi, 1973], by allowing players to have a finite instead of infinite depth of reasoning. However, different from NLK, it required that the depth of reasoning be the same for all players, and beliefs that the other player might be less sophisticated are not allowed.
anchored at the beginning of the game and are updated at each stage using Bayes' rule. Analytically, ABEE coincides with SPNE for the finest analogy partition, and similar to NLK, ABEE can also rationalize passing, in the centipede game, to the last few stages for a large range of partitions, in violation of the backward induction predictions. However, ABEE does not provide a specific means to choose an analogy class, whereas NLK offers a means of parametric estimation to specify beliefs in equilibrium. 53
For applications to dynamic games with perfect information and recall, analogy-based expectation equilibrium (ABEE), a solution concept proposed by Jehiel [2005], is the most closely related to ours. 51 In ABEE, agents first group the set of opponents' decision nodes into a partition, namely, an analogy class. Next, they form expectations of each opponent's average behavior at every element of the analogy class rather than, more precisely, at each decision node. Although conceptually, ABEE is similar to CE, when applied to a different type of games, ABEE also suggests that individuals might not fully consider how others' choices depend on their information, and such deficiency in reasoning is common knowledge among all players. 52 By contrast, our model allows NLK players to consider heterogeneity in their opponents' inference process. In our adaptation of NLK equilibrium to dynamic games, beliefs about different types of opponents are
As with all of the aforementioned solution concepts, NLK maintains the best response to beliefs but relaxes NE's requirement of a player's consistent beliefs about other players. In dynamic games, [Aumann, 1992], similar to several other writers in the subsequent literature, has shown that a failure of backward induction does not imply a failure of individual rationality. For example, in the centipede game, backward induction implies that the first mover ought to use stop at the first decision node, which has rarely been demonstrated in experimental data. These papers show that
51 Jehiel and Koessler [2008]) extends his analogy-based concept to Bayesian games.
53 As an extension of the Level-K model to dynamic games, Ho and Su [2013] apply their model to the experiment data of the centipede game. However, they intend to study learning across repetitions, whereas ours explains strategic behavior better even for novel games. Moreover, unlike their model, NLK does not restrict the strategy set, which allows NLK to capture Bayesian updating for beliefs across stages within one round.
52 More specifically, information means the history upon reaching a decision node at which the choice is made.
some relaxations of the "common knowledge of rationality" explain several rounds of passing, although all of the players are individually rational. 54 , 55
54 An individual must be careful about the terminology according to the epistemic condition of NE. Aumann and Brandenburger [1995] prove that in a two-person game, mutual knowledge of preferences and payoffs, rationality, and beliefs regarding the other players' strategies are sufficient for NE. This common knowledge of rationality is unnecessary for NE in a two-person game. Moreover, Battigalli and Bonanno [1999] argue that there is a contradiction between the results of backward induction and a common belief in sequential rationality at later stages. Thus, in this paper, by 'common knowledge of rationality,' we mean, in general, the extra assumptions necessary for NE/BNE/SPNE other than individual rationality.
55 Aumann [1992] shows that continuation of the game beyond the first node for several rounds could occur even with 'mutual knowledge' of high degrees. Considering that some sequentially rational behaviors off the equilibrium path are only reachable by the violation of sequential rationality, Reny [1992] defines a weaker version of sequential rationality in light of forward induction. Ben-Porath [1997] proves that cooperation in the centipede game is consistent with the common certainty of rationality, a weaker concept than the common knowledge of rationality. [Asheim and Dufwenberg, 2003] introduce the concept of 'fully permissible sets' to the extensive form game, where players reason deductively by attempting to determine one another's moves. They show that deductive reasoning does not necessarily imply backward induction.