# A Survey of Multi-Agent Deep Reinforcement Learning with Communication
**Authors**:
- Changxi Zhu (Department of Information and Computing Sciences)
- &Mehdi Dastani (Department of Information and Computing Sciences)
- Shihan Wang (Department of Information and Computing Sciences)
## Abstract
Communication is an effective mechanism for coordinating the behaviors of multiple agents, broadening their views of the environment, and to support their collaborations. In the field of multi-agent deep reinforcement learning (MADRL), agents can improve the overall learning performance and achieve their objectives by communication. Agents can communicate various types of messages, either to all agents or to specific agent groups, or conditioned on specific constraints. With the growing body of research work in MADRL with communication (Comm-MADRL), there is a lack of a systematic and structural approach to distinguish and classify existing Comm-MADRL approaches. In this paper, we survey recent works in the Comm-MADRL field and consider various aspects of communication that can play a role in designing and developing multi-agent reinforcement learning systems. With these aspects in mind, we propose 9 dimensions along which Comm-MADRL approaches can be analyzed, developed, and compared. By projecting existing works into the multi-dimensional space, we discover interesting trends. We also propose some novel directions for designing future Comm-MADRL systems through exploring possible combinations of the dimensions.
K eywords Multi-Agent Reinforcement Learning $·$ Deep Reinforcement Learning $·$ Communication $·$ Survey
## 1 Introduction
Many real-world scenarios, such as autonomous driving [1], sensor networks [2], robotics [3] and game-playing [4, 5], can be modeled as multi-agent systems. Such multi-agent systems can be designed and developed using multi-agent reinforcement learning (MARL) techniques to learn the behavior of individual agents, which can be cooperative, competitive, or a mixture of them. As agents are often distributed in the environment where they only have access to their local observations rather than the complete state of the environment, partial observability becomes an essential assumption in MARL [6, 7, 8]. Moreover, MARL suffers from the non-stationary issue [9], since each agent faces a dynamic environment that can be influenced by the changing and adapting policies of other agents. Communication has been viewed as a vital means to tackle the problems of partial observability and non-stationary in MARL. Agents can communicate individual information, e.g., observations, intentions, experiences, or derived features, to have a broader view of the environment, which in turn allows them to make well-informed decisions [9, 10].
Due to the recent success of deep learning [11] and its application to reinforcement learning [12], multi-agent deep reinforcement learning (MADRL) has witnessed great achievements in recent years, where agents can process high-dimensional data and have generalization ability in large state and action spaces [7, 8]. We notice that a large number of research works focus on learning tasks with communication, which aim at learning to solve domain-specific tasks, such as navigation, traffic, and video games, by communicating and sharing information. To the best of our knowledge, there is a lack of survey literature that can cover recent works on learning tasks with communication in multi-agent deep reinforcement learning (Comm-MADRL). Early surveys consider the role of communication in MARL but assume it to be predefined rather than a subject of learning [13, 14, 15]. Most Comm-MADRL surveys cover only a small number of research works without proposing a fine-grained classification system to compare and analyze them. We provide a detailed comparison of recent surveys on MADRL which involves communication in Section 2.3. In cooperative scenarios, Hernandez-Leal et al. [16] use learning communication to denote the area of learning communication protocols to promote the cooperation of agents. In our survey, we extend the concept of learning communication to general multi-agent tasks and use the term learning tasks with communication to emphasize that the primary goal of recent research, which is centered on solving specific domain tasks through the use of communication. The only survey that we found classifying some early works in Comm-MADRL is from Gronauer and Diepold [17], which is based on distinguishing whether messages are received by all agents, a set of agents, or a network of agents. However, other aspects of Comm-MADRL, such as the type of messages and training paradigms, which are essential for communication and can help characterize existing communication protocols, are ignored. As a result, the reviewed papers in recent surveys regarding learning tasks with communication are rather limited and the proposed categorizations are too narrow to distinguish existing works in Comm-MADRL. On the other hand, there is a closely related research area, emergent language/communication, which also considers learning communication through various reinforcement learning techniques [18]. Different from Comm-MADRL, the primary goal of emergent language studies is to learn a symbolic language. In the literature, emergent language and emergent communication are used interchangeably. In our survey, we use emergent language for referring to both terms. However, a subset of emergent language research works pursues an additional goal to leverage learnable symbolic language to enhance task-level performance. Notably, these research works have not been encompassed within existing Comm-MADRL surveys but included in our survey, referred to learning tasks with emergent language. In summary, our survey overlaps in scope with surveys of emergent language (i.e., in learning tasks with emergent language), but our survey focuses on different primary goals (i.e., achieving domain-specific tasks rather than learning a symbolic language). We further clarify the differences between learning tasks with communication and emergent language in Section 2.2.
In our survey paper, we review the Comm-MADRL literature by focusing on how communication can be utilized to improve the performance of multi-agent deep reinforcement learning techniques. Specifically, we focus on learnable communication protocols, which are aligned with recent works that emphasize the development of dynamic and adaptive communication, including learning when, how, and what to communicate with deep reinforcement learning techniques. Through a comprehensive review of recent Comm-MADRL literature, we propose a systematic and structured classification methodology designed to differentiate and categorize various Comm-MADRL approaches. Such a methodology will also provide guidance for the design and advancement of new Comm-MADRL systems. Suppose we plan to develop a Comm-MADRL system for a domain task at hand. Starting with the questions of when, how, and what to communicate, the system can be characterized from various aspects. Agents need to learn when to communicate, with whom to communicate, what information to convey, how to integrate received information, and, lastly, what learning objectives can be achieved through communication. We propose 9 dimensions that correspond to unique aspects of Comm-MADRL systems: Controlled Goals, Communication Constraints, Communicatee Type, Communication Policy, Communicated Messages, Message Combination, Inner Integration, Learning Methods, and Training Schemes. These dimensions, which form the skeleton of a Comm-MADRL system, can be used to analyze and gain insights into designed Comm-MADRL approaches thoroughly. By mapping recent Comm-MADRL approaches into this multi-dimensional structure, we not only provide insight into the current state of the art in this field but also determine some important directions for designing future Comm-MADRL systems.
The remaining sections of this paper are organized as follows. In Section 2 the preliminaries of multi-agent RL are discussed, together with existing extensions regarding communication and a detailed comparison of recent surveys. In Section 3, we present our proposed dimensions, explaining how we group the recent works in the categories of each dimension. In Section 4, we discuss the trends that we found in the literature, and, driven by the proposed dimensions, we propose possible research directions in this research area. We finalize the paper with some conclusions in Section 5.
## 2 Background
In this section, we first provide the necessary background on multi-agent reinforcement learning. Then, we show how multi-agent reinforcement learning can be extended to consider communication between agents. Finally, we present and compare recent surveys involving communication, from which we can directly see our motivations to fill the gaps among existing surveys.
### 2.1 Multi-agent Reinforcement Learning
Real-world applications often contain more than one agent that operate in the environment. Agents are generally assumed to be autonomous and required to learn their strategies for achieving their goals. A multi-agent environment can be formalized in several ways [19], depending on whether the environment is fully observable, how agents’ goals are correlated, etc. Among them, the Partially Observable Stochastic Game (POSG) [20, 21] is one of the most flexible formalizations. A POSG is defined by a tuple $≤ft⟨I,S,ρ^0,≤ft\{A_i\right\},P, ≤ft\{O_i\right\},O,≤ft\{R_i\right\}\right⟩$ , where $I$ is a (finite) set of agents indexed as $\{1,...,n\}$ , $S$ is a set of environment states, $ρ^0$ is the initial state distribution over state space $S$ , $A_i$ is a set of actions available to agent $i$ , and $O_i$ is a set of observations of agent $i$ . We denote a joint action space as $\boldsymbol{A}=×_i∈IA_i$ and a joint observation space of agents as $\boldsymbol{O}=×_i∈IO_i$ . Therefore, $P:S×\boldsymbol{A}→Δ(S)$ denotes the transition probability from a state $s∈S$ to a new state $s^\prime∈S$ given agents’ joint action $\vec{a}=⟨ a_1,...,a_n⟩$ , where $\vec{a}∈\boldsymbol{A}$ . With the environment transitioning to the new state $s^\prime$ , the probability of observing a joint observation $\vec{o}=⟨ o_1,...,o_n⟩$ (where $\vec{o}∈\boldsymbol{O}$ ) given the joint action $\vec{a}$ is determined according to the observation probability function $O:S×\boldsymbol{A}→Δ(\boldsymbol{ O})$ . Each agent then receives an immediate reward according to their own reward functions $R_i:S×\boldsymbol{A}×S→ ℝ$ . Similar to the joint action and observation, we could denote $\vec{r}=⟨ r_1,...,r_n⟩$ as a joint reward. If agents’ reward functions happen to be the same, i.e., they have identical goals, then $r_1=r_2=...=r_n$ holds for every time step. In this setting, the POSG is reduced to a Dec-POMDP [19]. If at every time step the state is uniquely determined from the current set of observations of agents, i.e., $s≡\vec{o}$ , the Dec-POMDP is reduced to a Dec-MDP. If each agent knows what the true environment state is, the Dec-MDP is reduced to a Multi-agent MDP. If there is only one single agent in the set of agents, i.e., $I=\{1\}$ , then the Multi-agent MDP is reduced to an MDP and the Dec-POMDP is reduced to a POMDP. Due to the partial observability, MARL methods often use the observation-action history $τ_i,t=\{o_i,0,a_i,0,o_i,1,...,o_i,t\}$ up to time step $t$ for each agent to approximate the environment state. Note that time step $t$ is often omitted for the sake of simplification.
In the multi-agent reinforcement learning setting, agents can learn their policies in either a decentralized or a centralized fashion. In decentralized learning (e.g., decentralized Q-learning [22, 23]), an $n$ -agent MARL problem is decomposed into $n$ decentralized single-agent problems where each agent learns its own policy by considering all other agents as a part of the environment [24, 25]. In such a decentralized setting, the learned policy of each agent is conditioned on its local observation and history. A major problem with decentralized learning is the so-called non-stationarity of the environment, i.e., the fact that each agent learns in an environment where other agents are simultaneously exploring and learning. Centralized learning enables the training of either a single joint policy for all agents or a centralized value function to facilitate the learning of $n$ decentralized policies. While centralized (joint) learning removes or mitigates issues of partial observability and non-stationarity, it faces the challenge of joint action (and observation) spaces that expand exponentially with the number of agents and their actions. For a deeper dive into various training schemes used in MARL, we recommend the comprehensive survey by [17], which offers valuable insights into the training and execution of policies. Based on whether policies are derived from value functions or directly learned, multi-agent reinforcement learning methods can be categorized into value-based and policy-based methods. Both methods have been largely utilized in Comm-MADRL.
Value-based
Value-based methods in the multi-agent case borrow considerable ideas from the single-agent case. As one of the most popular value-based algorithms, the decentralized Q-learning learns a local Q-function for each agent. In the cooperative setting where agents share a common reward, the update rule for agent $i$ is as follows:
$$
Q_i(s,a_i)← Q_i(s,a_i)+α(\underbrace{r+γ\max_a^
\prime_iQ_i(s^\prime,a^\prime_i)}_new estimate-
\underbrace{\vphantom{≤ft(\frac{a^0.3}{b}\right)}Q_i(s,a_i)}_
current estimate) \tag{1}
$$
where $r$ is the shared reward, and $a^\prime_i$ is the action with the highest Q-value in the next state $s^\prime$ . In partially observable environments, the environment state is not fully observable and is usually replaced by the individual observation or history of each agent. The Q-values for each state-action pair are incrementally updated according to the TD error. This error, i.e., $r+γ\max_a^\prime_iQ_i(s^\prime,a^\prime_i)-Q_i(s,a_i)$ , represents the difference between a new estimate (i.e., $r+γ\max_a^\prime_iQ_i(s^\prime,a^\prime_i)$ ) and the current estimate (i.e., $Q_i(s,a_i)$ ) based on the Bellman equation [26]. As the state and action space could be too large to be encountered frequently for accurate estimation, function approximation methods, like deep neural networks, have become popular for endowing value or policy models with generalization abilities across both discrete and continuous states and actions [12]. For example, the Deep Q-network (DQN) [12] minimizes the difference between the new estimate calculated from sampled rewards and the current estimate of a parameterized Q-function. In DQN-based methods, the Q-function in Equation 1 is notated as $Q_i(s,a_i;θ_i)$ , which depends on learnable parameters $θ_i$ . On the other hand, centralized learning in value-based methods learns a joint Q-function $Q(s,\vec{a};θ)$ with parameters $θ$ . However, this approach can be challenging to scale with an increasing number of agents. Value decomposition methods [27, 28, 29, 30] are popular MARL methods that decompose a joint Q-function to enable efficient training. These methods are also widely employed in research works in Comm-MADRL [31, 32, 33]. In partially observable environments, linear value decomposition methods decompose history-based joint Q-functions as follows:
$$
Q^joint(\vec{τ},\vec{a})=∑_i^nw_iQ^i(τ_i,a_i) \tag{2}
$$
where the joint Q-function is based on the joint history of all agents and is decomposed into local Q-functions based on individual histories. The weight $w_i$ can either be a fixed value [27, 29] or a learnable parameter subject to certain constraints [30]. Advantage functions can also replace the Q-function in the above equation to reduce variance [34].
Policy-based
Policy-based methods directly search over the policy space instead of obtaining the policy through value functions implicitly. The policy gradient theorem [26] provides an analytical expression of the gradients for a stochastic policy with learnable parameters in single-agent cases. In the multi-agent case with centralized learning, the policy gradient theorem is expressed as follows:
$$
∇_θJ(θ)=E_\vec{a∼π(·\mid s),s∼ρ^
π}[∇_θ\logπ(\vec{a}\mid s;θ)Q^π(s,\vec{a})] \tag{3}
$$
where $J(θ)$ represents the learning objective, and $π(\vec{a}\mid s;θ)$ denotes a stochastic policy parameterized by $θ$ (abbreviated as $π$ ). Additionally, $ρ^π$ signifies the state distribution under the policy $π$ , and $∇_θJ(θ)$ represents the expected gradient with respect to all possible actions and states. Due to the computational intractability of the expected gradient, stochastic gradient ascent can be applied to update the parameters $θ$ at every learning step $l$ as follows:
$$
θ_l+1=θ_l+α\widehat{∇_θJ(θ)}
$$
where $α$ is the learning rate, and $\widehat{∇_θJ(θ)}$ is an estimate of the expected gradient based on sampled actions and states. Moreover, the Q-function in Equation 3 can be replaced by average returns over episodes to form REINFORCE algorithms [26], or by an estimated value function to form actor-critic algorithms [35, 36]. In actor-critic methods, the policy and value function are termed the actor and the critic, respectively. The critic will, therefore, guide the learning of the actor.
Actor-critic methods have undergone various adaptations for multi-agent environments [7, 8, 37, 38]. A typical extension is the multi-agent deep deterministic policy gradient (MADDPG) [7]. In MADDPG, the critic is a centralized Q-function designed to capture global information and coordinate learning signals. Meanwhile, the actors are local policies, ensuring decentralized execution. MADDPG assumes deterministic actors with continuous actions, allowing for the backpropagation of gradients from the value function to the policies. The gradient of each parameterized actor $μ_θ_{i}(a_i\mid o_i)$ with learnable parameters $θ_i$ , abbreviated as $μ_i$ , is defined as follows:
$$
∇_θ_{i}J≤ft(θ_i\right)=E_\vec{o,\vec{a}∼
D}≤ft[∇_θ_{i}μ_i≤ft(a_i\mid o_i\right)∇
_a_{i}Q_i^μ≤ft(\vec{o},a_1,…,a_N\right)\mid_a_{i=μ_i
≤ft(o_i\right)}\right]
$$
where $D$ is the experience buffer that contains joint observation-action tuples $⟨\vec{o},\vec{a},\vec{r},\vec{o^\prime}⟩$ . Each agent’s Q-function, denoted as $Q_i^μ(\vec{o},a_1,…,a_N)$ , takes joint observations and actions as inputs, while decentralized actors use local observations as inputs. Contrary to Equation 3, gradients with respect to the current action of agent $i$ (specifically, $μ_i(o_i)$ ) are utilized to guide the update of the policy parameter $θ_i$ . Both MADDPG and its single-agent counterpart, DDPG, have seen widespread application in Comm-MADRL [39, 40, 41, 42, 43].
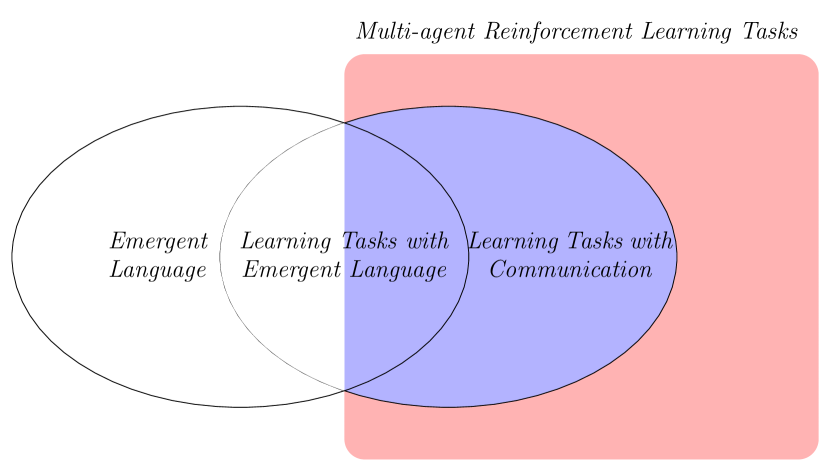
### 2.2 Extensions with Communication
In the MADRL literature where communication is used, we notice two closely related research areas, which we will refer to with the terms emergent language and learning tasks with communication. The emergent language research area [18, 44, 45, 46, 47] aims at learning a language grounded on symbols in communities of interacting/communicating agents. This line of research tries to understand the evolution of the language in agents equipped with neural networks. On the other hand, learning tasks with communication [16, 48, 49, 50] focuses primarily on solving multi-agent reinforcement learning tasks with the aid of communication. Communication is often regarded as information exchange rather than learning a (human-like) language. Despite the distinction, when using MADRL techniques on specific domain tasks, languages might emerge, which can potentially enhance the learning system’s explainability in accomplishing those tasks. We illustrate the research areas, emergent language and learning tasks with communication, along with their intersection learning tasks with emergent language in Figure 1. Notably, our survey focuses on learning tasks with communication in multi-agent deep reinforcement learning, including the intersection with emergent language. Throughout the remainder of our survey, Comm-MADRL will be used to specifically refer to the areas of our focus. Within this focus, multiple agents often operate in partially observable environments and learn to share information encoded through neural networks. Furthermore, communication protocols, determining when and with whom to communicate, often leverage deep learning models to find the optimal choices that minimize communication overhead and yield more targeted communication. A multitude of works have been proposed to handle these subproblems inherent in Comm-MADRL. Most research works model only one or a few aspects of Comm-MADRL while selecting a default approach for other aspects. Given that the common goal of Comm-MADRL approaches is to design an effective and efficient communication protocol to improve agents’ learning performance in the environment, the proposed Comm-MADRL approaches inevitably share similarities to some extent. Consequently, establishing a classification system for Comm-MADRL becomes crucial. Such a system would aid in categorizing critical elements like contributions, targeted problems, and learning objectives, from which we can compare and analyse existing Comm-MADRL approaches.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Venn Diagram: Multi-agent Reinforcement Learning Tasks
### Overview
The image is a conceptual Venn diagram illustrating the relationships between different categories of tasks in the field of multi-agent reinforcement learning. It uses overlapping shapes and color coding to show set relationships and intersections.
### Components/Axes
The diagram consists of three primary geometric shapes, each with a distinct color and label:
1. **Gray Circle (Left):** Positioned on the left side of the diagram. It is labeled **"Emergent Language"**.
2. **Blue Circle (Right):** Positioned on the right side, overlapping with the gray circle. It is labeled **"Learning Tasks with Communication"**.
3. **Pink Rectangle (Background):** A large, rounded rectangle that encompasses the entire blue circle and the overlapping region between the two circles. It is labeled at the top-right as **"Multi-agent Reinforcement Learning Tasks"**.
The overlapping region between the gray and blue circles is labeled **"Learning Tasks with Emergent Language"**.
### Detailed Analysis
The diagram defines three distinct but related conceptual sets:
* **Set A (Gray Circle):** Represents the domain of "Emergent Language." This is a standalone concept.
* **Set B (Blue Circle):** Represents "Learning Tasks with Communication." This is a broader category that includes tasks where communication is a designed or given component.
* **Intersection (A ∩ B):** The area where the gray and blue circles overlap is explicitly labeled "Learning Tasks with Emergent Language." This signifies that tasks in this intersection are a subset of both Emergent Language and Learning Tasks with Communication. They are tasks where communication protocols are not pre-defined but emerge during the learning process.
* **Superset (Pink Rectangle):** The "Multi-agent Reinforcement Learning Tasks" rectangle acts as a superset. It fully contains the blue circle ("Learning Tasks with Communication") and the intersection ("Learning Tasks with Emergent Language"). It does *not* fully contain the gray circle ("Emergent Language"), indicating that not all emergent language research falls under the specific umbrella of multi-agent RL tasks as defined by this diagram.
### Key Observations
1. **Hierarchical Containment:** The diagram establishes a clear hierarchy. "Learning Tasks with Communication" is a subset of "Multi-agent Reinforcement Learning Tasks." "Learning Tasks with Emergent Language" is a further subset of both.
2. **Partial Overlap of "Emergent Language":** A significant portion of the "Emergent Language" circle lies outside the pink rectangle. This visually argues that the study of emergent language is a broader field that extends beyond the specific context of multi-agent reinforcement learning tasks.
3. **Color-Coded Regions:** The blue circle is filled with a semi-transparent blue, the overlapping region is a blend of blue and gray, and the pink rectangle provides a background context. This color coding helps distinguish the sets and their intersections.
### Interpretation
This diagram serves as a conceptual map to clarify terminology and scope within a research area. It makes several key arguments:
* **Communication vs. Emergent Language:** It distinguishes between tasks where communication is an engineered component ("Learning Tasks with Communication") and the more specific phenomenon where language-like protocols arise spontaneously from agent interactions ("Emergent Language").
* **Scope of Multi-agent RL:** It posits that the field of multi-agent reinforcement learning explicitly includes the study of communication and, by extension, the study of emergent language within that communication framework.
* **Broader Context of Emergent Language:** By placing part of the "Emergent Language" circle outside the multi-agent RL rectangle, the diagram acknowledges that emergent language is a topic studied in other disciplines (e.g., linguistics, complex systems, evolutionary biology) and is not solely the domain of RL.
The diagram is likely used to frame a research paper or presentation, helping the audience understand where the authors' work on "Learning Tasks with Emergent Language" fits within the larger landscape of related concepts. It emphasizes that this work is at the intersection of two fields and is a specific instance of multi-agent RL.
</details>
Figure 1: An illustration depicting the scope of this survey. The focus of our survey is represented by the blue part.
In the emergent language literature, numerous works employ various forms of the Lewis game, often referred to as referential games and operate under a cheap-talk setting [51], as highlighted in several surveys [10, 18]. In the emergent language research area, research works that do not adopt the cheap-talk setting but communicate through observable (domain-level) actions, are not included in our survey. Our survey focuses on explicit message transfer between agents. In these games, a goal, often represented as a target location, an image, or a semantic concept, is given to a sender agent but remains unrevealed from a receiver agent. The receiver agent must then either identify the correct goal based on the sender’s signaling [52, 53, 54, 47, 55, 56, 57, 58] or accomplish its single-agent task using the received signals (messages) [59, 60]. Research works in learning tasks with emergent language are grounded in a multi-agent environment where the joint actions of both sender and receiver agents impact environment transitions. Consequently, the learning tasks with emergent language literature considers multi-agent domain tasks [61, 62, 63, 64, 65], building on foundational concepts from MARL such as Dec-POMDPs or POSGs.
We further distinguish explicit versus non-explicit communication [19] in the literature of MADRL with communication. Explicit communication refers to communication through a set of messages separate from domain-level actions. Here, agents’ action policies are influenced by both their observations and the messages they receive. Such messages, crucial for supporting agents’ decision-making, are essential in both the training and execution phases. MADRL frameworks without explicit communication can still allow for communication through domain-level actions, such as the act of influencing the observations of one agent through the actions of another. Furthermore, without explicit communication, agents can transmit gradient signals, which facilitate centralized training (and decentralized execution) but are not utilized during execution phases. Specifically, in our survey, we focus on explicit and learnable communication.
Dec-POMDPs and POSGs are often extended to accommodate explicit communication. The communication can be integrated into the action set, adding a collection of communication acts alongside domain-level actions. Alternatively, a Dec-POMDP or a POSG can be extended to explicitly include a set of messages [19]. For instance, the POSG can be expanded with a (shared) message space $M$ , resulting in a POSG-Comm, defined as $≤ft⟨I,S,ρ^0,≤ft\{A_i\right\},P, ≤ft\{O_i\right\},O,≤ft\{R_i\right\},M\right⟩$ , where all components remain unchanged except for the added message space $M$ . A Dec-POMDP-Comm can be defined as similar to the POSG-Comm with shared rewards. In both POSG-Comm and Dec-POMDP-Comm, action policies take into account both environmental observations and inter-agent messages. Research works in Comm-MADRL that expand upon a POSG or a Dec-POMDP can be seen in references such as [61, 63, 66, 65, 67].
### 2.3 Communication in Recent Surveys
Communication has attracted much attention in the field of multi-agent reinforcement learning (MARL). Previous surveys mentioning communication in MARL primarily focus on providing an overview of MARL’s development. These surveys view communication as a subfield in MARL, and no extensive and substantial progress is reported. In an early survey, Stone and Veloso [13] classify MARL based on whether agents communicate and whether agents are homogeneous or not. Homogeneous agents have the same internal structure including goals, domain knowledge, and possible actions. They view learnable communication as a future research opportunity. Busoniu et al. [15] consider communication as a means to negotiate action choices and select equilibrium in the research direction of explicit coordination, without further classifying communication. With the advancement of deep learning, MARL has gradually incorporated deep neural networks such that recent developments are dominated by multi-agent deep reinforcement learning (MADRL). In the MADRL context, Hernandez-Leal et al. [16], Nguyen et al. [68], and Papoudakis et al. [9] briefly review early Comm-MADRL methods, which have now become baselines in many recent works. Specifically, Hernandez-Leal et al. [16] use learning communication to denote a new branch in MADRL. Papoudakis et al. [9] consider communication as an approach to handle the non-stationary problem in MADRL, as agents can exchange information to stabilize their training. Compared to the aforementioned surveys, OroojlooyJadid and Hajinezhad [37] provide a more detailed review of Comm-MADRL, covering a significant number of existing works. They view communication as a way to solve cooperative MADRL problems but did not propose a categorization model for Comm-MADRL. Zhang et al. [69] and Yang et al. [21] review communication from a theoretical perspective. Their primary focus is on communication within networked multi-agent systems. In these systems, agents share information through a time-varying network, aiming to reach consensus on learned value functions or policies. Despite this, no further classification of communication is made.
Two more recent surveys in MADRL, proposed by Gronauer and Diepold [17] and Wong et al. [70], focus on classifying existing works on communication. Gronauer and Diepold classify early research works in Comm-MADRL into Broadcasting, Targeted, and Networked communication, based on whether messages are received from all agents, a subset of agents, or a network of agents. Wong et al., similar to the survey of Papoudakis et al. [9], view communication as a method to address the issues of non-stationarity and partial observability. In the survey of Wong et al., research works on communication are categorized into three groups from a high-level perspective: communication as the primary learning goal, communication as an instrument to learn a specific task, and peer-to-peer teaching. However, they do not delve into how agents utilize communication to enhance learning. These surveys focus on limited aspects of communication, making their categorizations too narrow to distinguish recent works effectively, given the fact that many existing works share similar assumptions and conditions. To the best of our knowledge, only one survey [71] exclusively focuses on communication issues in MADRL. They review algorithms for communication and cooperation, including efforts to interpret languages developed through communication. Despite this, their survey mainly covers early models without proposing a categorization framework.
The literature has investigated communication from other perspectives. Shoham and Leyton-Brown [72] investigate communication from a game-theoretic perspective. They introduce several theories of communication in multi-agent systems, with the particular concern that agents can be self-motivated to convey information, driven by underlying incentives (e.g., the knowledge of game structure), or communicate in a pragmatic way analogous to human communication. Deep neural networks and deep reinforcement learning techniques have greatly widened the scope of language development in multi-agent systems. Lazaridou and Baroni [18] provide an extensive survey focused on emergent language, aiming to establish effective human-machine communication. As highlighted in section 2.2, the primary goal of emergent language research is to learn a human-like language from scratch. The goal of our survey is, however, to classify the literature on learning tasks with communication that aims at exploiting communication to accomplish multi-agent tasks.
In summary, existing surveys in Comm-MADRL lack coverage of the latest developments. These surveys also do not elaborate on the fact that communication itself is a combinatorial problem. Importantly, communication models engage with MADRL algorithms across various processes, including learning and decision-making. To effectively distinguish between existing Comm-MADRL approaches, it is crucial to analyze and classify them from a wider range of perspectives. In the following section, we delve into the field of Comm-MADRL through multiple dimensions, each linked to a unique research question pertinent to system design. These dimensions allow us to provide a fine-grained classification, highlighting the differences between Comm-MADRL approaches even within similar domains.
## 3 Learning Tasks with Communication in MADRL
In our survey, we consider explicit communication where action policies of agents are conditioned on communication that is learnable and dynamic, rather than static and predefined. Therefore, both the content of the messages and the chances of communication occurrences are subject to learning. As agents engage in multi-agent tasks, they learn domain-specific action policies and their communication protocols concurrently. As a result, learning tasks with communication becomes a joint learning challenge, where agents employ reinforcement learning to maximize environmental rewards and simultaneously utilize various machine learning techniques to develop efficient and effective communication protocols.
Learning tasks with communication in multi-agent deep reinforcement learning (Comm-MADRL) is a significant research problem, particularly as communication can lead to higher rewards. Numerous studies have emerged, developing effective and efficient Comm-MADRL systems, often sharing similarities. Our review begins with the seminal works such as DIAL [73], RIAL [73], and CommNet [48], and then expands to include the most relevant research works presented at major AI conferences and journals like AAMAS, AAAI, NeurIPS, and ICML, totaling 41 models in Comm-MADRL. To better distinguish among these models, we propose classifying them based on several dimensions in Comm-MADRL system design. These dimensions aim to comprehensively cover the current literature, allowing us to project the research works into a space where their similarities and differences become clear. We start by focusing on three key components of Comm-MADRL systems: problem settings, communication processes, and training processes. Problem settings encompass both communication-specific settings (e.g., communication constraints) and non-communication-specified settings (e.g., reward structures). Communication processes include common communication procedures, such as deciding whether to communicate and what messages to communicate. Training processes cover the learning of both agents and communication within MADRL. Based on the three key components, we identify and summarize 9 research questions that commonly arise in Comm-MADRL system design, corresponding to 9 dimensions as detailed in Table 1. These research questions and dimensions are designed to capture various aspects of Comm-MADRL, covering the learning objectives of agents and communication, the processes by which messages are generated, transmitted, integrated, and learned within the MADRL framework. We outline a systematic procedure for providing a guideline to effectively navigate through these dimensions when developing Comm-MADRL systems. The procedure allows us to organize the dimensions, demonstrate their relevance in system design, and guide the creation of customized Comm-MADRL systems in a step-by-step manner.
Table 1: Proposed dimensions and associated research questions.
| Key Components | Target Questions | Dimensions | Index |
| --- | --- | --- | --- |
| Problem Settings | What kind of behaviors are desired to emerge with communication? | Controlled Goals | ① |
| How to fulfill realistic requirements? | Communication Constraints | ② | |
| Which type of agents to communicate with? | Communicatee Type | ③ | |
| Communication Processes | When and how to build communication links among agents? | Communication Policy | ④ |
| Which piece of information to share? | Communicated Messages | ⑤ | |
| How to combine received messages? | Message Combination | ⑥ | |
| How to integrate combined messages into learning models? | Inner Integration | ⑦ | |
| Training Processes | How to train and improve communication? | Learning Methods | ⑧ |
| How to utilize collected experience from agents? | Training Schemes | ⑨ | |
As outlined in Procedure 1, $N$ reinforcement learning agents employ communication throughout their learning and decision-making. Initially, the learning objective for the $N$ agents is set, defining rewards that induce cooperative, competitive, or mixed behaviors, as captured by dimension 1. We then consider potential communication-specified settings like limited resources, addressing the need for realistic scenarios as described in dimension 2. Dimension 3 identifies potential communicatees, determining the agents for messages to be received, which varies across domains. At each time step, agents decide when and with whom to communicate, as highlighted in dimension 4. The patterns of communication occurrences are structured like a graph, where links, either undirected or directed, aid information exchange. Subsequently, messages that encapsulate agents’ understanding of the environment are generated and shared, relating to dimension 5. Given that agents often receive multiple messages, they must decide on how to combine these messages effectively. This process, crucial for integrating messages into their policies or value functions, is captured in dimensions 6 and 7. In cases of Comm-MADRL studies focusing on emergent language (i.e., learning tasks with emergent language), where messages are modeled as communicative acts emitted alongside domain-level actions, a specific rearrangement of the procedure is required. Here, messages are not observed by other agents until the next time step. Therefore, the processes outlined in dimensions 6 and 7 (lines 8 and 9) are moved to the front of those in dimension 4 (line 6). This rearrangement allows agents to combine and integrate messages from the previous time step before initiating new communication. As a result, agents make decisions and perform actions in the environment based not only on their environmental observations but also on information obtained from other agents (lines 10 and 11). During the training phase, experiences from both environmental interactions and inter-agent communication are utilized to train how agents will behave and communicate, i.e., agents’ policies, value functions, and communication processes, as characterized in dimensions 8 and 9 (line 14).
In the following sections, we make an extensive survey on Comm-MADRL based on each dimension and classify the literature when we focus on a specific dimension. We finally provide a comprehensive table to frame recent works with the aid of the 9 dimensions.
Procedure 1 A guideline of Comm-MADRL systems
1: $N$ reinforcement learning agents
2: Set goals for reinforcement learning agents $\triangleright$ Dimension ①
3: Set possible communication constraints $\triangleright$ Dimension ②
4: Set the type of communicatees $\triangleright$ Dimension ③
5: for $episode=1,2,...$ do
6: for every environment step do
7: Decide with whom and whether to communicate $\triangleright$ Dimension ④
8: Decide which piece of information to share $\triangleright$ Dimension ⑤
9: Combine received information shared from others $\triangleright$ Dimension ⑥
10: Integrate messages into agents’ internal models $\triangleright$ Dimension ⑦
11: Select actions based on communication
12: Perform in the environment (and store experiences)
13: end for
14: if training is enablled then
15: Update agents’ policies, value function, and communication processes $\triangleright$ Dimensions ⑧ & ⑨
16: end if
17: end for
Procedure 1: A guideline of Comm-MADRL systems. The guideline positions dimensions where communication influences interaction with the environment and training phases.
### 3.1 Controlled Goal
Table 2: The category of controlled goals.
| Types | Configurations | Methods |
| --- | --- | --- |
| Cooperative | Global Rewards | DIAL [73]; RIAL [73]; CommNet [48]; GCL [61]; MAGNet-SA-GS-MG [40]; MADDPG-M [41]; SchedNet [43]; Agent-Entity Graph [74]; VBC [31]; NDQ [75]; IMAC [66]; Gated-ACML [76]; Bias [63]; LSC [77]; Diff Discrete [78]; I2C [79]; TMC [32]; GAXNet [80]; DCSS [64]; MAIC [33]; |
| Local Rewards | BiCNet [50]; DGN [81]; IC3Net [49]; MD-MADDPG [42]; DCC-MD [82]; GA-Comm [83]; NeurComm [84]; IP [85]; ETCNet [86]; Variable-length Coding [87]; AE-Comm [65]; | |
| Global or Local Rewards | MS-MARL-GCM [88]; ATOC [39]; TarMAC [89]; IS [90]; HAMMER [91]; MAGIC [92]; FlowComm [93]; FCMNet [94]; | |
| Competitive | Conflict Rewards | IC3Net [49]; R-MACRL [95]; |
| Mixed | Self-interested Rewards | IC [62]; DGN [81]; TarMAC [89]; IC3Net [49]; NDQ [75]; LSC [77]; MAGIC [92]; |
With a given reward configuration, reinforcement learning agents are guided to achieve their designated goals and interests. As agents communicate in order to obtain higher rewards, the goal of communication and the goal of achieving domain-specific tasks are inherently aligned. The emergent behaviors of agents can be summarized into three types: cooperative, competitive, and mixed [96, 23], each corresponding to different reward configurations and goals. Notably, some Comm-MADRL methods have been tested in more than one benchmark environment to show their flexibility and scalability, where the reward configurations may vary [49, 81, 89, 77, 92]. Furthermore, a multi-agent environment may consist of both fixed opponents and teammates, which typically do not participate in communication. Therefore, we exclude fixed agents when identifying reward configurations. Consequently, we focus on (learnable) agents involved in communication and classify their behaviors that are desired to emerge, aligning them with associated reward configurations (summarized in Table 2).
Cooperative
In cooperative scenarios, agents have the incentive to communicate to achieve better team performance. Cooperative settings can be characterized by either a global reward that all agents share or a sum of local rewards that could be different among agents. Communication is usually used to promote cooperation as a team. Thus, in the literature, a team of agents can receive a global reward [73, 48, 61, 88, 39, 89, 40, 41, 43, 74, 31, 75, 66, 76, 63, 77, 78, 79, 90, 32, 91, 92, 93, 80, 64, 33, 94], which does not account for the contribution of each agent. The agents can also receive local rewards, with designs to make the reward depend on teammates’ collective performance [50, 88, 81, 49, 42, 82, 83, 87, 91], to penalize collisions [39, 81, 82, 83, 90, 86, 92, 93], or to share the reward with other agents for encouraging mutual cooperation [84, 85, 65].
There are a variety of cooperative environments where communication has shown performance improvements, from small-scale games to complex video games. In early works, Foerster et al. [73] developed two simple games, named Switch Riddle and MNIST Games, for their proposed models, DIAL and RIAL. Sukhbaatar et al. [48] used Traffic Junction for evaluating CommNet, which has become a popular testbed in recent works [88, 89, 49, 83, 79, 90, 92]. Among them, MAGIC [92] achieved higher performance on Traffic Junction with local rewards compared to two early works, CommNet [48], IC3Net [49], and one recent work, GA-Comm [83]. StarCraft [97, 98, 99] is another benchmark environment in cooperative MARL with relatively flexible settings. BiCNet [50] and MS-MARL-GCM [88] are evaluated on an early version of StarCraft [97]. Then, a new version of StarCraft, SMAC, has become popular in recent works [31, 75, 66, 32, 33, 94]. By controlling a team of agents, the cooperative goal in SMAC is to defeat enemies on easy, hard, and super hard maps. FCMNet [94] and MAIC are two recent works that surpass multiple communication methods and value decomposition methods (e.g., QMIX) on different maps. Google research football [100] is an even more challenging game with a physics-based 3D soccer simulator. Only MAGIC has reported performance on this platform with communication, and more investigations on this environment are needed. Compared to the above approaches in Comm-MADRL, ATOC [39] has been examined using a significantly larger number of learning agents in the predator-prey domain. Predator-prey is a grid world game with a long history in MARL. It has been developed with several versions [101, 102, 7], while still viewed as a standard test environment due to its flexibility and customizability. ATOC reports performance on this platform with continuous state and action spaces. In the subfield learning tasks with emergent language, cooperative scenarios are popularly used. They are mostly based on grid world or particle environments and have explicit role assignments, e.g., senders and receivers [61, 63, 65, 64].
Competitive
In case agents need to compete with each other to occupy limited resources, they are assigned competitive learning objectives. In some competitive games, such as zero-sum games, one player wins and the others lose and therefore rational agents do not have the incentive to communicate. Nevertheless, in other competitive scenarios where agents compete for long-term goals, communication can allow for low-level cooperation among agents before the (long-term) goals are achieved. Based on our observations, only one work, IC3Net [49], tests competitive settings and enables agents to compete for rewards. IC3Net has been tested in several settings, including cooperative, competitive, and mixed scenarios, with different reward configurations. IC3Net shows that competitive agents communicate only when it is profitable, e.g., before catching prey in the predator-prey domain. $\mathfrak{R}$ -MACRL [95] considers communication from malicious agents to improve the worst-case performance. In $\mathfrak{R}$ -MACRL, the whole environment is cooperative while agents learn to defend against malicious messages. Although the environment is cooperative, we classify this work under the competitive category as the learning goal between malicious agents and other agents is competitive.
Mixed
For a MAS where we care about self-interest agents, individual rewards can be designed and distributed to each agent [81, 89, 49, 75, 77, 92, 94]. Therefore, cooperative and competitive behaviors coexist during learning, which may show more complex communication patterns. Specifically, DGN [81] considers a game where each agent gets positive rewards by eating food but gets higher rewards by attacking other agents. However, being attacked will get a high punishment. With communication, agents can learn to share resources collaboratively rather than attacking each other. IC3Net [49], TarMAC [89] and MAGIC [92] are evaluated on a mixed version of Predator-prey, and agents learn to communicate only when necessary. NDQ [75] is examined in an independent search scenario, where two agents are rewarded according to their own goals, and shows that agents learn to not communicate in independent scenarios. IC [62] considers a scenario in which sender and receiver agents have different abilities to complete the goal. The sender agents have more vision but cannot clean obstacles, while receiver agents have limited vision but are able to clear obstacles. With communication, agents show collaborative behaviors to get higher rewards.
### 3.2 Communication Constraints
Practical concerns such as communication cost and noisy environment impair Comm-MADRL systems from embracing realistic applications more than simulations. This dimension, Communication Constraints, determines which type of communication concerns are handled in a Comm-MADRL system. We categorize recent works on this dimension into the following categories (summarized in Table 3).
Unconstrained Communication
In this category, communication processes, including communication channels, the content and transmission of messages, and the decisions of whether to communicate or not, are not explicitly restricted. In principle, agents can communicate as much as information they can without any decision to disallow communication in order to prevent communication overhead [48, 50, 88, 81, 89, 40, 42, 90, 91, 80, 94]. Specifically, several works consider blocking communication through predefined or learnable decisions of whether to communicate or not, while aiming to differentiate useful communicated information [39, 41, 49, 82, 74, 83, 77, 84, 85, 79, 92, 93]. We also put those works under this category as they do not explicitly assume that communication is limited by cost.
Constrained Communication
In this category, communication processes are explicitly constrained by cost or noise. Thus, agents need to utilize communication resources efficiently to promote learning. We further identify two practical concerns that have been considered in the literature.
Table 3: The category of communication constraints.
| Types | Subtypes | Methods |
| --- | --- | --- |
| Unconstrained Communication | | CommNet [48]; BiCNet [50]; MS-MARL-GCM [88]; ATOC [39]; DGN [81]; TarMAC [89]; MAGNet-SA-GS-MG [40]; MADDPG-M [41]; IC3Net [49]; MD-MADDPG [42]; DCC-MD [82]; Agent-Entity Graph [74]; GA-Comm [83]; LSC [77]; NeurComm [84]; IP [85]; I2C [79]; IS [90]; HAMMER [91]; MAGIC [92]; FlowComm [93]; GAXNet [80]; FCMNet [94]; |
| Constrained Communication | Limited Bandwidth | RIAL [73]; DIAL [73]; GCL [61]; IC [62]; SchedNet [43]; VBC [31]; NDQ [75]; IMAC [66]; Gated-ACML [76]; Bias [63]; ETCNet [86]; Variable-length Coding [87]; TMC [32]; AE-Comm [65]; MAIC [33]; |
| Corrupted Messages | DIAL [73]; Diff Discrete [78]; DCSS [64]; $\mathfrak{R}$ -MACRL [95]; | |
- Limited Bandwidth. In this category, communication bandwidth is limited by channel capacity. Thus, communication needs to be used more efficiently, both in the number of times that agents can communicate and the size of communicated information. Early works focus on transmitting succinct messages to avoid communication overhead. RIAL and DIAL [73] are proposed to communicate very little information (i.e., a binary value or a real number) at every time step to reduce the bandwidth needed. MD-MADDPG [42] considers a fixed-size memory, which is shared by all agents. Agents communicate through the shared memory instead of ad hoc channels. VBC [31] and TMC [32] reduce communication costs by using predefined thresholds to filter unnecessary communication, and both show lower communication overhead. NDQ [75] cuts 80% of messages by ordering the distributions of messages according to their means and drops accordingly to prevent meaningless messages. MAIC [33] also cuts messages by examining several message pruning rates. In MAIC, messages are encoded to consider their respective importance. Sent messages are ordered and then pruned with a given pruning rate. IMAC [66] explicitly models bandwidth limitation as a constraint to optimization. An upper bound of the mutual information between messages and observations is derived according to bandwidth constraint, which turns out to minimize the entropy of messages. Then agents learn not only to maximize cumulative rewards but also to generate low-entropy messages. The number of agents to communicate can also be restricted to reduce the total amount of communication. SchedNet [43] considers a scenario of a shared channel together with limited bandwidth. Only a subset of agents are chosen to convey their messages according to their importance. Gated-ACML [76] learns a probabilistic gate unit to block messages transmitting between each agent and a centralized message coordinator, with the extra cost of learning optimal gates. Inspired by Gated-ACML and IMAC, ETCNet [86] puts constraints on the behaviors of deciding whether to send messages or not. A penalty term is added to the environment rewards, and an additional reinforcement learning algorithm is used to optimize the sending behaviors. Variable-length Coding [87] also utilizes a penalty term while encouraging short messages. When learning tasks with emergent language, symbolic languages are acquired for communication through a limited number of tokens. Therefore, we classify those works under limited bandwidth [61, 62, 63, 65].
- Corrupted Messages. In this category, messages transmitted among agents can be corrupted due to environmental noise or malicious intentions. DIAL [73] shows that during training, adding Gaussian noise to the communication channel can push the distribution of messages into two modes to convey different types of information. Diff Discrete [78] considers how to backpropagate gradients through a discrete communication channel (between 2 agents) with unknown noise. An encoder/channel/decoder system is modeled, where the encoder is used to discretize a real-valued signal into a discrete message to pass through the discrete communication channel, and the decoder is used to compute an approximation of the original signal. Later they show that the encoder/channel/decoder system is equivalent to an analog communication channel with additive noise. With the additional assumption that training is centralized, the gradient of the receiver with respect to real-value messages from the sender can be computed to allow backpropagation. DCSS [64] also considers a noisy setting. They prove that representing messages as one-hot vectors may not be optimal when the environment becomes noisy. Inspired by word embedding in the NLP field, they propose to generate a semantic representation of discrete tokens that are communicated among agents. The results show that such representation is robust in noisy environments and benefits human understanding of communication. Different from noisy environments, $\mathfrak{R}$ -MACRL [95] assumes that an agent holds a malicious messaging policy, producing adversarial messages that can mislead other agents’ action selections. Therefore, other agents need to prevent being exploited by learning a defense policy in order to filter the messages.
### 3.3 Communicatee Type
Communicatee Type determines which type of agents are assumed to receive messages in a Comm-MADRL system. We found that in the literature, communicatee type can be classified into the following categories based on whether agents in the environment communicate with each other directly or not.
Agents in the MAS
In this category, the set of communicatees consists of agents in the environment, and they directly communicate with each other. Nevertheless, due to partial observability, agents may not be able to communicate with every agent in the MAS, and thus we further distinguish the types of communicatees as follows:
- Nearby Agents. In many Comm-MADRL systems, communication is only allowed between neighbors. Nearby agents can be defined as observable agents [80], agents within a certain distance [81, 74, 77] or neighboring agents on a graph [84]. GAXNet [80] labels observable agents and enables communication between them. DGN [81] limits communication within 3 closest neighbors while using a distance metric to find them. Agent-Entity Graph [74] also uses distance to measure whether agents are nearby or not. As long as two agents are close to each other, they will be allowed to communicate. LSC [77] enables agents within a cluster radius to decide whether to become a leader agent. Then all non-leader agents in the same cluster will only communicate with the leader agent. NeurComm [84] and IP [85] preset a graph structure among agents built upon networked multi-agent systems. In both NeurComm and IP, communicatees are restricted to neighbors on the graph. MAGNet-SA-GS-MG [40] uses a pre-trained graph to limit communication and restricts communication on neighboring agents. Neighboring agents can also emerge during learning instead of being predetermined, as proposed in GA-Comm [83], MAGIC [92] and FlowComm [93], which explicitly learn a graph structure among agents. Specifically, in GA-Comm [83] and MAGIC [92], a central unit (e.g., GNN) learns a graph inside and coordinates messages based on the (complete) graph simultaneously. In this case, agents do not communicate with each other directly; instead, they communicate through a virtual agent who does not affect the environment. Therefore, we categorize these two works into the proxy category.
- Other (Learning) Agents. If nearby agents are not identified, the set of communicatees typically consists of other (learning) agents. Specifically, IC3Net [49] enables communication between learning agents and their opponents. Experiments indicate that these opponents eventually learn to not communicate to avoid being exploited. Some works assume explicit role assignments, i.e., senders and receivers. The role of the receiver can be taken by a disjoint set of agents separate from the senders [62, 63, 64] or by all other agents in the environment [61, 65]. In both cases, agents communicate with each other directly.
Table 4: The category of communicatee type.
| Types | Subtypes | Methods |
| --- | --- | --- |
| Agents in the MAS | Nearby Agents | DGN [81]; MAGNet-SA-GS-MG [40]; Agent-Entity Graph [74]; LSC [77]; NeurComm [84]; IP [85]; FlowComm [93]; GAXNet [80]; |
| Other Agents | DIAL [73]; RIAL [73]; CommNet [48]; GCL [61]; BiCNet [50]; IC [62]; TarMAC [89]; MADDPG-M [41]; IC3Net [49]; SchedNet [43]; DCC-MD [82]; VBC [31]; NDQ [75]; Bias [63]; Diff Discrete [78]; I2C [79]; IS [90]; ETCNet [86]; Variable-length Coding [87]; TMC [32]; AE-Comm [65]; DCSS [64]; R-MACRL [95]; MAIC [33]; FCMNet [94]; | |
| Proxy | | MS-MARL-GCM [88]; ATOC [39]; MD-MADDPG [42]; IMAC [66]; GA-Comm [83]; Gated-ACML [76]; HAMMER [91]; MAGIC [92]; |
Proxy
A proxy is a virtual agent that plays an essential role (e.g., as a medium) in facilitating communication but does not directly affect the environment. Using a proxy as the communicatee means that agents will not directly communicate with each other, instead viewing the proxy as a medium, coordinating and transforming messages for specific purposes. MS-MARL-GCM [88] utilizes a master agent that collects local observations and hidden states from agents in the environment and sends a common message back to each of them. Similarly, HAMMER [91] employs a central proxy that gathers local observations from agents and sends a private message to each agent. MD-MADDPG [42] maintains a shared memory among agents, learning to selectively store and retrieve local observations from the memory. IMAC [66] defines a scheduler that aggregates encoded information from all agents and sends individual messages to each agent. These works primarily focus on how to encode messages through the proxy without determining whether to send or receive messages. By contrast, ATOC [39], Gated-ACML [103], GA-Comm [83] and MAGIC [92] are all designed for agents to decide whether to communicate with a message coordinator. In ATOC and Gated-ACML, each agent’s decisions are made locally based on individual observations, with messages aggregated from nearby agents and from the entire MAS, respectively. Both GA-Comm and MAGIC develop a global communication graph, coupled with a graph neural network (GNN) to aggregate messages by weights and send new messages back to each agent, informing action selection in the environment.
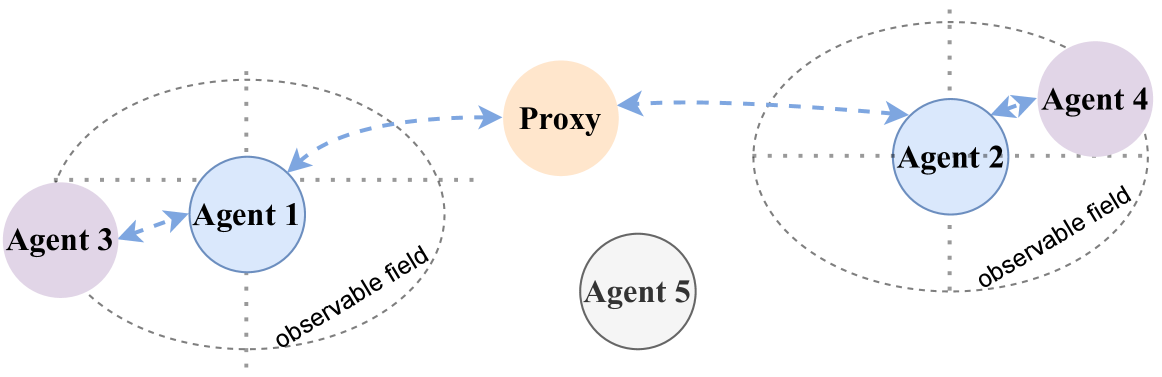
Table 4 summarizes recent works on communication types in MAS. To illustrate these categories, we present an example of different communication methods used in a Comm-MADRL system in Figure 2. The system consists of five agents and one proxy. Agent 3 is the nearby agent of Agent 1, while Agent 4 is the nearby agent of Agent 2. Agent 5 is out of the view range of Agents 1 and 2. If communication is limited to nearby agents, Agent 1 will communicate only with Agent 3, and Agent 2 will communicate only with Agent 4. However, if communication involves a proxy, all agents can send their messages to the proxy and receive coordinated messages.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Multi-Agent Communication Network
### Overview
The image is a schematic diagram illustrating a network of five agents (Agent 1 through Agent 5) and a central "Proxy" node. It depicts communication pathways and observational boundaries within a multi-agent system. The diagram uses color-coded circles for entities and dashed arrows to represent directional communication links.
### Components/Axes
**Entities (Circles):**
* **Agent 1:** Light blue circle, positioned in the left-center region.
* **Agent 2:** Light blue circle, positioned in the right-center region.
* **Agent 3:** Light purple circle, positioned to the left of Agent 1.
* **Agent 4:** Light purple circle, positioned to the right of Agent 2.
* **Agent 5:** White circle with a black outline, positioned below and between the Proxy and Agent 2.
* **Proxy:** Light orange circle, positioned centrally between the two main agent clusters.
**Communication Links (Dashed Blue Arrows):**
* A bidirectional arrow connects **Agent 3** and **Agent 1**.
* A unidirectional arrow points from **Agent 1** to the **Proxy**.
* A unidirectional arrow points from the **Proxy** to **Agent 2**.
* A bidirectional arrow connects **Agent 2** and **Agent 4**.
**Observable Fields (Dashed Ellipses):**
* A large dashed ellipse encircles **Agent 1** and **Agent 3**. The label "observable field" is written along its lower-right curve.
* A second large dashed ellipse encircles **Agent 2** and **Agent 4**. The label "observable field" is written along its lower-right curve.
**Background Grid:**
* Faint, dashed gray lines form a crosshair or grid pattern behind the elements, suggesting a coordinate system or spatial reference frame.
### Detailed Analysis
**Spatial Layout & Relationships:**
* The diagram is organized into two primary clusters separated by the central Proxy.
* **Left Cluster:** Contains Agent 3 (leftmost) and Agent 1, enclosed within an "observable field." Agent 3 communicates directly with Agent 1.
* **Central Mediator:** The Proxy sits between the two clusters. It receives information from Agent 1 (left cluster) and sends information to Agent 2 (right cluster).
* **Right Cluster:** Contains Agent 2 and Agent 4 (rightmost), enclosed within a separate "observable field." Agent 2 communicates directly with Agent 4.
* **Isolated Agent:** Agent 5 is positioned outside both observable fields and has no depicted communication links, suggesting it is either inactive, in a different scope, or an observer.
**Flow Direction:**
The communication flow is asymmetric. Information appears to originate in the left cluster (Agent 3 -> Agent 1), pass through the Proxy for mediation or translation, and then be disseminated to the right cluster (Agent 2 -> Agent 4). The bidirectional links within each cluster suggest local, reciprocal communication.
### Key Observations
1. **Proxy as a Bridge:** The Proxy is the sole connection point between the two agent clusters, indicating a hub-and-spoke or mediated communication architecture.
2. **Separation of Observability:** The two "observable field" ellipses explicitly define the perceptual or operational boundaries for each cluster. Agents within a field can likely perceive each other directly.
3. **Color Coding:** Agents are color-coded by role or type: light blue for primary cluster nodes (Agent 1, Agent 2), light purple for peripheral nodes (Agent 3, Agent 4), and white for the isolated node (Agent 5). The Proxy has a unique color (light orange).
4. **Agent 5's Isolation:** Agent 5's lack of connections and placement outside the defined fields is a significant anomaly, implying it is not integrated into the current communication process.
### Interpretation
This diagram models a **decentralized yet partitioned multi-agent system**. The key insight is the use of a **Proxy to facilitate controlled, indirect communication between two otherwise isolated groups of agents**. Each group operates within its own "observable field," meaning agents within a group have direct awareness of each other, but cross-group awareness is mediated.
The structure suggests a design for scalability, security, or specialization. For example:
* The Proxy could be a gateway translating protocols or filtering information between different sub-networks.
* The observable fields might represent physical proximity, network subnets, or task-specific domains.
* Agent 5's isolation could represent a monitoring agent, a new agent not yet integrated, or a node that has lost connectivity.
The overall system prioritizes modularity and controlled interaction over fully connected, flat communication. The flow from left to right (Agent 3 -> Agent 1 -> Proxy -> Agent 2 -> Agent 4) may indicate a specific data pipeline or command chain within this snapshot of the system's operation.
</details>
Figure 2: Three communicatee types in the same system.
### 3.4 Communication Policy
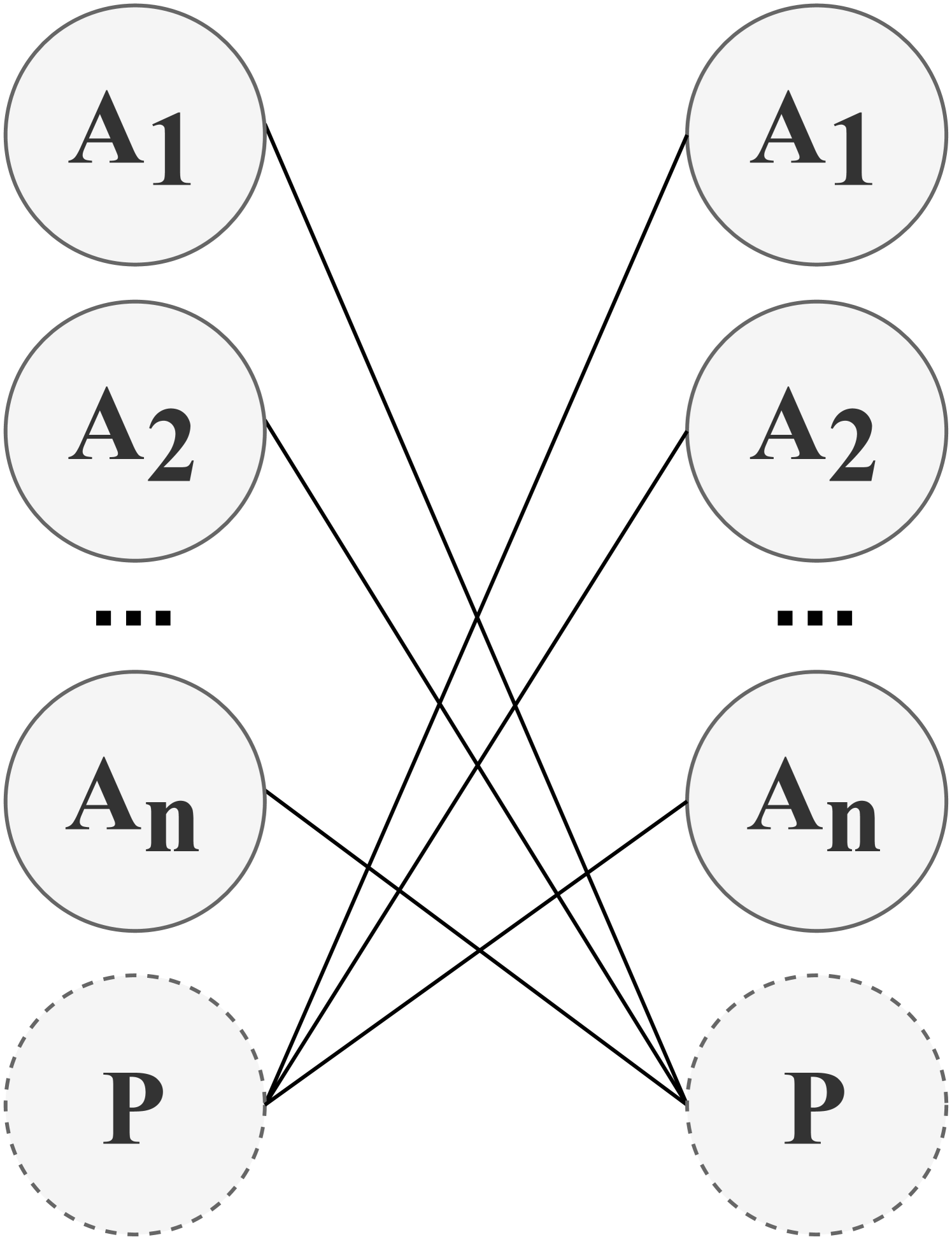
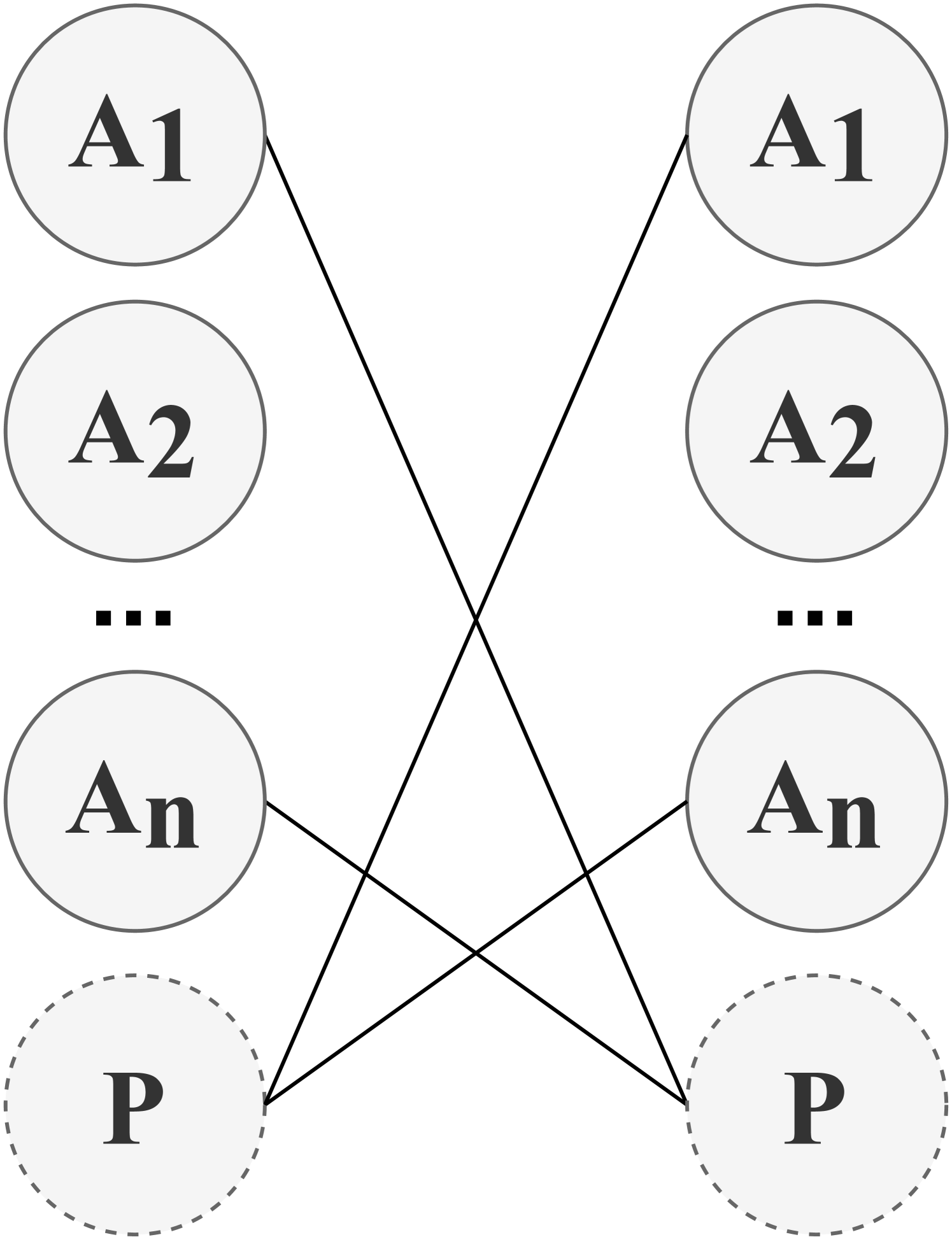
Communication Policy determines when and with which agents (i.e., communicatees) to communicate in order to enable message transmission. A Communication Policy defines a set of communication actions, which can be modeled in different ways. For example, a communication action can be represented as a vector of binary values, where each value indicates whether communication with one of the other agents is allowed at a certain time step. These actions form communication links between pairs of agents, which can be represented as a communication graph among agents. In the literature, communication policies can be either predefined or learned, allowing communication with all other agents or only a subset of agents. Furthermore, communication policies can be centralized, controlling communication among all agents, or decentralized, enabling individual agents to control whether to communicate. Therefore, we first categorize the literature based on whether communication policies are predefined or learned. We find that in predefined communication policies, the literature often uses either full communication among agents, where the communication graph becomes complete, or a partial graph structure to incorporate constraints on communication policies. On the other hand, in learnable communication policies, we identify two distinct categories: individual control and global control. In individual control, communication policies are learned by each agent independently, whereas in global control, these policies are learned and implemented centrally, applying to all agents in Comm-MADRL systems. As a result, we have identified four subcategories within the dimension of communication policy: Full Communication, (Predefined) Partial Structure, Individual Control, and Global Control. These categorizations are summarized in Table 5.
We present examples of how agents form communication links in the four categories of communication policy, as illustrated in Figure 3. Both Full Communication and Partial Structure rely on a predefined communication policy to determine communication actions. In contrast, Individual Control and Global Control involve the learning of a local communication policy and a global communication policy, respectively, to establish communication links between agents or a potential proxy. If a proxy is involved, it coordinates messages from agents choosing to communicate through this proxy. The categories and their associated research works are introduced as follows:
Table 5: The category of communication policy
| Types | Subtypes | Methods |
| --- | --- | --- |
| Predefined | Full Communication | DIAL [73]; RIAL [73]; CommNet [48]; GCL [61]; BiCNet [50]; MS-MARL-GCM [88]; TarMAC [89]; MD-MADDPG [42]; DCC-MD [82]; IMAC [66]; Diff Discrete [78]; IS [90]; Variable-length Coding [87]; HAMMER [91]; AE-Comm [65]; R-MACRL [95]; FCMNet [94]; |
| Partial Structure | IC [62]; DGN [81]; MAGNet-SA-GS-MG [40]; Agent-Entity Graph [74]; VBC [31]; NDQ [75]; Bias [63]; NeurComm [84]; IP [85]; TMC [32]; GAXNet [80]; DCSS [64]; MAIC [33]; | |
| Learnable | Individual Control | ATOC [39]; MADDPG-M [41]; IC3Net [49]; Gated-ACML [76]; LSC [77]; I2C [79]; ETCNet [86]; |
| Global Control | SchedNet [43]; GA-Comm [83]; MAGIC [92]; FlowComm [93]; | |
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Bipartite Mapping Network
### Overview
The image displays a schematic diagram representing a bipartite graph or mapping between two distinct sets of nodes arranged in two vertical columns. The diagram illustrates a many-to-many relationship or connection pattern between elements of the left set and elements of the right set.
### Components/Axes
**Structure:** Two parallel vertical columns of circular nodes.
**Left Column Nodes (Top to Bottom):**
1. A solid-outlined circle labeled **A₁**.
2. A solid-outlined circle labeled **A₂**.
3. An ellipsis (**...**), indicating a sequence of intermediate nodes.
4. A solid-outlined circle labeled **Aₙ**.
5. A dashed-outlined circle labeled **P**.
**Right Column Nodes (Top to Bottom):**
1. A solid-outlined circle labeled **A₁**.
2. A solid-outlined circle labeled **A₂**.
3. An ellipsis (**...**), indicating a sequence of intermediate nodes.
4. A solid-outlined circle labeled **Aₙ**.
5. A dashed-outlined circle labeled **P**.
**Connections:** Straight black lines connect nodes from the left column to nodes in the right column. The connections are not one-to-one but form a crisscrossing network.
### Detailed Analysis
**Node Labels and Types:**
* **A₁, A₂, ..., Aₙ:** These labels use subscript notation (₁, ₂, ₙ) to denote a sequence or series of similar entities. The ellipsis confirms the sequence extends from index 2 to index n.
* **P:** This label is distinct, appearing in a circle with a dashed outline, suggesting it may represent a different type of entity (e.g., a placeholder, a special node, or a different category) compared to the "A" nodes.
**Connection Pattern (Visible Lines):**
The diagram shows a partial but illustrative set of connections. Tracing the visible lines reveals the following mappings:
* Left **A₁** connects to Right **A₂** and Right **P**.
* Left **A₂** connects to Right **A₁** and Right **P**.
* Left **Aₙ** connects to Right **A₁** and Right **A₂**.
* Left **P** connects to Right **A₁**, Right **A₂**, and Right **Aₙ**.
**Spatial Grounding:** The legend (node labels) is integrated directly into the diagram within each node. The connections are drawn as straight lines crossing the central space between the two columns.
### Key Observations
1. **Symmetry and Repetition:** The two columns are identical in their composition and labeling, suggesting a mapping between two instances of the same set or a reflection.
2. **Dense Interconnection:** The visible lines show that each node on the left is connected to multiple nodes on the right, and vice-versa. This indicates a complex, non-hierarchical relationship.
3. **Special Status of 'P':** The node labeled 'P' is visually distinct (dashed outline) and appears to be highly connected, linking to multiple 'A' nodes in the opposite column.
4. **Ellipsis Implication:** The ellipses (...) signify that the diagram is a generalized representation. The actual number of 'A' nodes (n) is variable and could be large, making the full connection pattern potentially very dense.
### Interpretation
This diagram is a conceptual model, not a data chart. It visually communicates the architecture of a system where two groups of entities (the left and right columns) interact.
* **What it Demonstrates:** It illustrates a **bipartite graph** where connections only exist between nodes of different columns, not within the same column. This is common in modeling relationships like users-to-permissions, inputs-to-outputs, or clients-to-services.
* **Relationship Between Elements:** The crisscrossing lines emphasize that the mapping is arbitrary and complex. There is no implied order or hierarchy; any 'A' or 'P' node on one side can potentially connect to any node on the other side.
* **Role of 'P':** The dashed outline and central connectivity suggest 'P' may represent a **proxy, a processor, a shared resource, or a special gateway node** that interacts with all or many of the standard 'A' entities. Its distinct styling marks it as functionally different.
* **Generalization:** The use of 'Aₙ' and ellipses makes this a template diagram. It is meant to be applicable to any system with this bipartite structure, regardless of the specific number of 'A' components. The specific connections shown are for illustrative purposes only; the actual connectivity in a real system would be defined by its rules.
**In essence, the image provides a structural blueprint for a networked system characterized by two mirrored sets of components and a complex, many-to-many connection scheme between them, with a special component 'P' playing a highly interconnected role.**
</details>
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Diagram: Bipartite Mapping with Cross-Connections
### Overview
The image displays a schematic diagram representing a bipartite relationship or mapping between two sets of nodes. The diagram is composed of two vertical columns of circular nodes, with lines indicating specific connections between nodes from the left column to the right column. The visual style is minimal, using black lines and text on a light gray background.
### Components/Axes
* **Structure:** Two parallel vertical columns of nodes.
* **Left Column Nodes (Top to Bottom):**
* A solid-outlined circle labeled **A1**.
* A solid-outlined circle labeled **A2**.
* An ellipsis (**...**) indicating a sequence of omitted nodes.
* A solid-outlined circle labeled **An**.
* A dashed-outlined circle labeled **P**.
* **Right Column Nodes (Top to Bottom):**
* A solid-outlined circle labeled **A1**.
* A solid-outlined circle labeled **A2**.
* An ellipsis (**...**) indicating a sequence of omitted nodes.
* A solid-outlined circle labeled **An**.
* A dashed-outlined circle labeled **P**.
* **Connections (Lines):** Four straight black lines connect specific nodes between the columns:
1. From left **A1** to right **An**.
2. From left **An** to right **A1**.
3. From left **P** to right **A2**.
4. From right **P** to left **A2**.
### Detailed Analysis
The diagram defines a specific, non-sequential mapping between two identical sets of elements {A1, A2, ..., An, P}. The connections form a cross-pattern:
* The first element (A1) of the left set maps to the last 'A' element (An) of the right set.
* The last 'A' element (An) of the left set maps to the first element (A1) of the right set.
* The special element P on the left maps to the second element (A2) on the right.
* The special element P on the right maps to the second element (A2) on the left.
The ellipsis (...) between A2 and An in both columns signifies that this is a generalized diagram for an arbitrary number 'n' of 'A'-type elements. The dashed outline for the 'P' nodes visually distinguishes them from the solid-outlined 'A' nodes, suggesting 'P' may represent a different category, a placeholder, or a parameter.
### Key Observations
1. **Symmetry and Inversion:** The connections between A1 and An are perfectly inverted (left A1 → right An, left An → right A1).
2. **Asymmetric Role of P:** The 'P' nodes are involved in a different connection pattern (to/from A2) compared to the 'A' nodes.
3. **Visual Distinction:** The use of a dashed outline for 'P' is a critical visual cue indicating a different status or property.
4. **Generalized Structure:** The ellipsis confirms the diagram is a template, not a depiction of a fixed, small set.
### Interpretation
This diagram is an abstract representation of a **specific permutation or mapping rule** between two ordered sets. It is likely used in contexts such as:
* **Mathematics/Computer Science:** Illustrating a specific bijective function, a permutation cycle, or a network routing pattern. The cross-connection of A1 and An is a classic "swap" operation.
* **Systems Theory or Logic:** Modeling a relationship where certain elements (the 'A's) follow one set of rules (the cross-swap), while a distinct element ('P') follows a different rule (mapping to A2). The dashed outline for 'P' emphasizes its unique role in the system.
* **Algorithm Design:** Could represent a step in an algorithm where specific indices are swapped and a special value is handled separately.
The diagram's power lies in its abstraction. It conveys a precise relational structure without specifying the concrete nature of the 'A' or 'P' elements, making it applicable to various fields where such mapping logic is relevant. The key takeaway is the defined, non-sequential correspondence between the two sets, highlighted by the visual distinction of the 'P' element.
</details>
<details>
<summary>x5.png Details</summary>
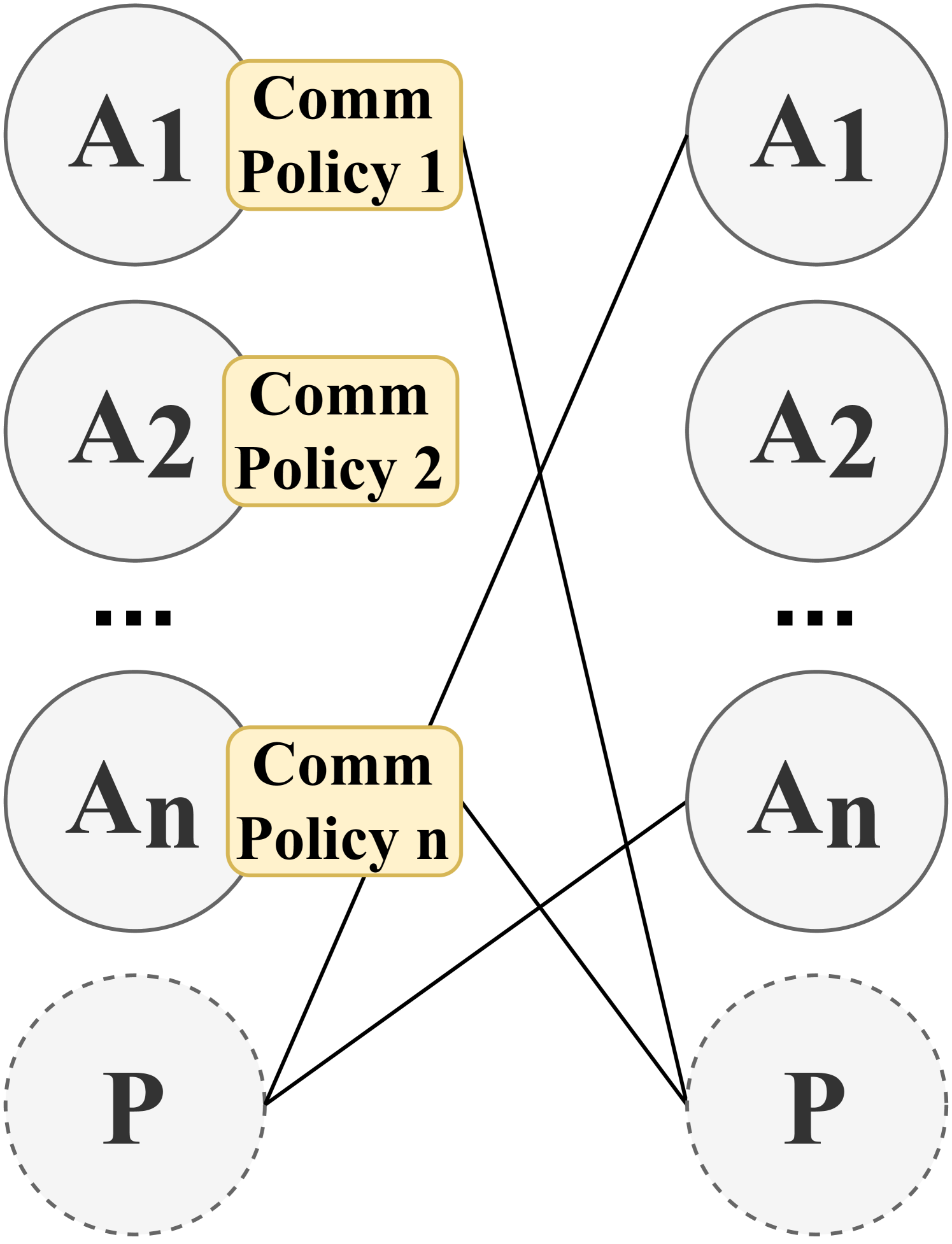
### Visual Description
## Diagram: Communication Policy Network
### Overview
The image is a schematic diagram illustrating a network of communication policies connecting two sets of entities. It depicts a one-to-many or many-to-many relationship where specific policies on the left side are linked to multiple entities on the right side. The diagram uses circles to represent entities and labeled boxes to represent policies, with lines indicating connections.
### Components/Axes
The diagram is organized into two vertical columns of circular nodes, with policy labels attached to the left column.
**Left Column (Top to Bottom):**
1. **Circle A1:** Solid gray border, containing the text "A1".
2. **Circle A2:** Solid gray border, containing the text "A2".
3. **Ellipsis (...):** Three black squares indicating a sequence continues (A3, A4, etc.).
4. **Circle An:** Solid gray border, containing the text "An".
5. **Circle P:** Dashed gray border, containing the text "P".
**Attached Policy Labels (Left Column):**
* A yellow, rounded rectangle with a thin black border is attached to the right side of each solid-bordered circle (A1, A2, An).
* **Label on A1:** "Comm Policy 1"
* **Label on A2:** "Comm Policy 2"
* **Label on An:** "Comm Policy n"
**Right Column (Top to Bottom):**
1. **Circle A1:** Solid gray border, containing the text "A1".
2. **Circle A2:** Solid gray border, containing the text "A2".
3. **Ellipsis (...):** Three black squares indicating a sequence continues.
4. **Circle An:** Solid gray border, containing the text "An".
5. **Circle P:** Dashed gray border, containing the text "P".
**Connections (Lines):**
Black lines originate from the yellow policy boxes and connect to circles in the right column.
* **From "Comm Policy 1":** A line connects to the right-column circle **A1**.
* **From "Comm Policy 2":** A line connects to the right-column circle **P**.
* **From "Comm Policy n":** Two lines originate from this box:
* One line connects to the right-column circle **A2**.
* Another line connects to the right-column circle **P**.
### Detailed Analysis
The diagram establishes a clear mapping:
* **Entity Types:** There are two types of entities: "A" types (A1, A2, ..., An) and a "P" type. The "P" type is visually distinguished by a dashed border.
* **Policy Assignment:** Each "A" entity on the left (A1, A2, An) is assigned a specific, numbered communication policy ("Comm Policy 1", "Comm Policy 2", "Comm Policy n").
* **Connection Logic:** The policies dictate connections to entities on the right. The connections are not strictly one-to-one:
* Policy 1 connects only to its namesake (A1).
* Policy 2 connects to a different entity type (P).
* Policy n connects to two entities: one "A" type (A2) and the "P" type.
* **Spatial Layout:** The policy boxes are positioned to the immediate right of their source circles. The connection lines cross the central space diagonally to reach their target circles in the right column.
### Key Observations
1. **Asymmetric Connections:** The connection pattern is not uniform. "Comm Policy 1" has a direct, self-referential link, while "Comm Policy n" has divergent links to two different entities.
2. **Role of Entity P:** The entity "P" (dashed circle) is a common connection point, receiving links from both "Comm Policy 2" and "Comm Policy n". This suggests "P" may be a central, privileged, or different class of agent (e.g., a Primary agent, a Process, or a Policy server).
3. **Generalization:** The use of "n" and ellipses (...) indicates this is a generalized model for an arbitrary number of "A" entities and their associated policies.
### Interpretation
This diagram models a system where individual agents or components (A1 through An) are governed by distinct communication policies. These policies determine their interaction partners within a network.
The data suggests a flexible or complex communication architecture:
* **Specialization:** Agents may have specialized roles, as different policies lead to different connection targets.
* **Centralization:** The frequent connection to the "P" entity implies a centralized component that multiple policies interact with, possibly for coordination, authentication, or logging.
* **Policy-Driven Networking:** The core concept is that communication pathways are not hardcoded between agents but are dynamically defined by the policies assigned to them. This is common in multi-agent systems, network security models, or microservice architectures where policy engines control service-to-service communication.
The diagram effectively conveys that understanding the system requires knowing both the assignment of policies to source agents and the specific connection rules encoded within each policy.
</details>
<details>
<summary>x6.png Details</summary>
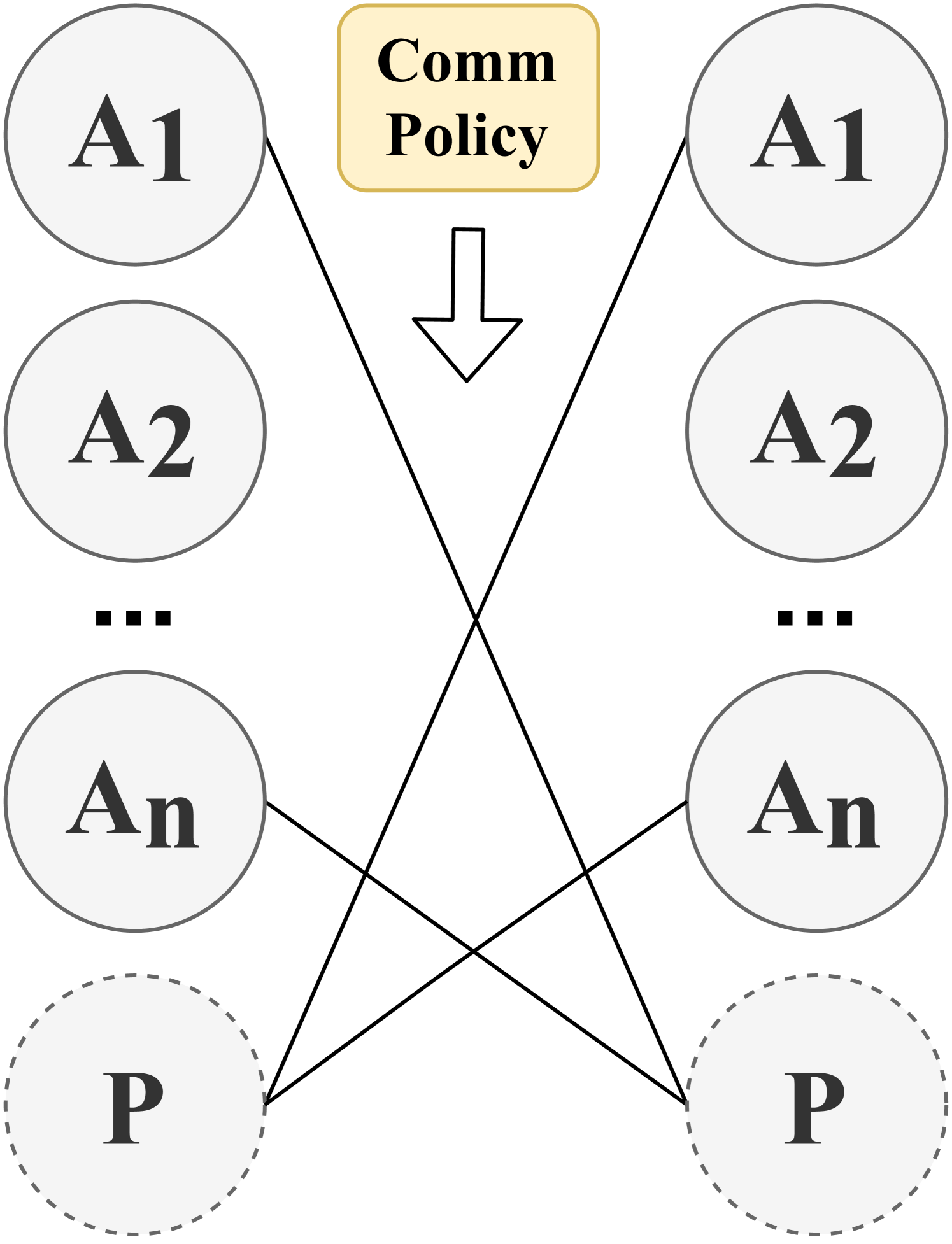
### Visual Description
## Diagram: Communication Policy Network
### Overview
The image is a schematic diagram illustrating a communication policy framework. It depicts two symmetrical columns of agent nodes (labeled A1, A2, ..., An) and a distinct process or entity node (labeled P) at the bottom of each column. A central "Comm Policy" box governs the connections, which are shown as crossing lines linking agents from one column to the P node on the opposite side.
### Components/Axes
* **Central Policy Element:** A rectangular box with a light yellow fill and a gold border, located at the top-center of the diagram. It contains the text "**Comm Policy**" in a bold, serif font. A large, downward-pointing arrow originates from this box, indicating its governing influence over the connections below.
* **Agent Nodes (A):** Two vertical columns of circular nodes with solid grey outlines.
* **Left Column:** Contains nodes labeled **A1**, **A2**, an ellipsis (**...**), and **An**.
* **Right Column:** Contains an identical set of nodes labeled **A1**, **A2**, an ellipsis (**...**), and **An**.
* The ellipsis indicates a sequence, implying there are multiple agents (A3, A4, etc.) between A2 and An.
* **Process/Entity Nodes (P):** Two circular nodes with dashed grey outlines, located at the bottom of each column. Each is labeled with a bold, serif **P**.
* **Connections:** Solid black lines represent communication or interaction pathways. The lines form a crisscross pattern:
* A line connects the left **A1** node to the right **P** node.
* A line connects the right **A1** node to the left **P** node.
* A line connects the left **An** node to the right **P** node.
* A line connects the right **An** node to the left **P** node.
* The connections for intermediate agents (A2, etc.) are implied by the ellipsis and the crossing pattern but are not explicitly drawn.
### Detailed Analysis
The diagram is structured with clear spatial grounding:
* **Header Region:** Contains the "Comm Policy" box and its downward arrow, establishing the overarching rule set.
* **Main Chart Region:** Contains the two agent columns and the P nodes. The connections are drawn diagonally across the central space.
* **Footer Region:** The P nodes are positioned at the bottom of each column.
The visual trend is one of **cross-communication**. Agents in one column do not connect to the P node in their own column. Instead, the policy mandates that they connect to the P node in the *opposite* column. This creates a symmetrical, X-shaped flow of interactions.
### Key Observations
1. **Symmetry and Mirroring:** The left and right sides of the diagram are perfect mirrors of each other in terms of node labels and structure.
2. **Node Differentiation:** Agent nodes (A) have solid outlines, while the P nodes have dashed outlines, suggesting a categorical difference (e.g., P may represent a "Principal," "Process," or "Public" entity distinct from the "Agents").
3. **Selective Connection:** Only the first (A1) and last (An) agents in each sequence have their connections explicitly drawn. This is a common diagrammatic shorthand to avoid visual clutter while implying that all agents in the sequence follow the same connection rule.
4. **Centralized Control:** The "Comm Policy" box is placed above and central to the entire network, with its arrow pointing down into the connection matrix, visually asserting its authority over all depicted interactions.
### Interpretation
This diagram models a structured communication system governed by a central policy. The data suggests a design where agents are partitioned into two groups, and the policy enforces a rule of **cross-group reporting or interaction**. Each group of agents is accountable to a different instance of "P" (which could be a manager, a database, a regulatory body, or a service endpoint).
The key takeaway is the **enforced separation and cross-connection**. This could be a security architecture (e.g., agents in one network segment can only access resources in another), an organizational chart (teams reporting to a different department's lead), or a distributed system design (services in one availability zone connecting to a coordinator in another). The dashed outline of "P" might indicate it is a logical or virtual entity, or that its connection is conditional. The absence of connections between agents (A-to-A) implies that all communication must be mediated through the P entities and is subject to the overarching "Comm Policy."
</details>
Figure 3: Four types of communication policy with agents (shown as A) in the environment and a possible proxy (shown as P).
Full Communication
In this category, every pair of agents is connected so that messages are transmitted in a broadcast manner. Full communication can be regarded as a fully connected graph, often used in early works on Comm-MADRL. DIAL [73], RIAL [73], CommNet [48], and BiCNet [50] learn a communication protocol which connect all agents together. Inspired by BiCNet, FCMNet [94] uses multiple RNNs to link all agents together with different sequences, allowing agents to benefit from communication flow from various directions. In contrast, Diff Discrete [78] and Variable-length Coding [87] focus on two-agent cases but do not learn to block messages from each other. TarMAC [89] and IS [90] learn meaningful messages while using a broadcast way to share messages, thus still adhering to full communication. DCC-MD [82] and $\mathfrak{R}$ -MACRL [95] introduce a strategy to drop out received messages without specifying whether to send messages. Specifically, DCC-MD drops out messages with a fixed probability to reduce input dimensions, and $\mathfrak{R}$ -MACRL learns to drop out adversary messages through a defense policy. In Comm-MADRL methods like IMAC [66], MS-MARL-GCM [88] and HAMMER [91], a central proxy that receives local observations or encoded messages is always connected with agents in the MAS. In addition, GCL [61] and AE-Comm [65] learn a language grounded on discrete tokens among agents, where all agents have the capability to send and receive messages.
(Predefined) Partial Structure
In this category, the communication between agents is captured by a predetermined partial graph to reduce overall communication. Then, each agent communicates with a limited number of agents within the MAS, rather than with every agent. NeurComm [84] and IP [85] operate in a networked multi-agent environment, randomly generating a communication network while maintaining a fixed average number of connections per agent during the learning process. DGN [81], MAGNet-SA-GS-MG [40], and GAXNet [80] restrict communication to a certain proximity of agents. The Agent-Entity Graph [74] employs a pre-trained graph to capture agent relationships. Comm-MADRL approaches like VBC [31], NDQ [75], TMC [32], and MAIC [33] utilize handcrafted thresholds or pruning rates to limit communication opportunities. In IC [62], Bias [63], and DCSS [64], disjoint sets of agents are designated as either senders or receivers, facilitating unidirectional communication from senders to receivers only.
Individual Control
In this category, each agent actively and individually determines whether to communicate with other agents, implicitly forming a graph structure. A common method employed in Comm-MADRL studies within this category is a learnable gate mechanism, which aids agents in making the decision to communicate. For instance, IC3Net [49] and ATOC [39] use a gate mechanism that enables agents to decide whether to broadcast their messages, in a deterministic and probabilistic manner, respectively. ETCNet [86] also implements a gate unit but limits the overall probability of message-sending behaviors. If a proxy, such as a message coordinator, is present, Gated-ACML [76] introduces a learning mechanism for each agent to decide whether to communicate with the proxy, as opposed to direct communication with other agents. Diverging from the gate function approach, I2C [79] allows each agent to unilaterally decide on communication with other agents, based on evaluating the impact of those agents on its own policy. LSC [77] allows each group of agents, defined by a specific radius, to compare their weights in order to elect a leader. This system then facilitates communication from each group to their respective leaders and from leader to leader. Notably, the leader agent in this model is not considered a proxy, as it still directly interacts with the environment.
Global Control
In this category, a globally shared communication policy is learned, providing more complete control over the communication links between agents. SchedNet [43] employs a global scheduler that limits the number of agents allowed to broadcast their messages, thereby reducing overall communication. FlowComm [93] learns a directed graph among agents, enabling unilateral or bilateral communication between them. Similarly, GA-Comm [83] and MAGIC [92] develop an undirected and a directed graph for communication, respectively. These Comm-MADRL systems incorporate an additional message coordinator to coordinate and transform messages sent by the agents.
### 3.5 Communicated Messages
After establishing communication links among agents through a communication policy, agents should determine which specific information to communicate. This information can derive from historical experiences, intended actions, or future plans, enriching the messages with valuable insights. Consequently, the communicated information can expand the agents’ understanding of the environment and enhance the coordination of their behaviors. In the dimension of communicated messages, an important consideration is whether the communication includes future information, such as intentions and plans. This kind of information, being inherently private, often requires an (estimated) model of the environment to effectively simulate and generate conjectured intentions and plans. Accordingly, we categorize recent studies in this dimension into two categories, as summarized in Table 6.
Existing Knowledge
In this category, agents share their knowledge of the environment (e.g., past observations), previous movements, or policies to assist other agents in selecting actions. As historical information accumulates, agents use a low-dimensional encoding of their knowledge as messages to reduce communication overhead. Notably, the RNN family (e.g., LSTM and GRU) is commonly used as an encoding function, capable of selectively retaining and forgetting historical observations [48, 50, 88, 89, 49, 42, 83, 79, 92, 93, 33, 94], action-observation histories [73, 50], or action-observation-message histories [62, 63]. When a proxy is present, messages are generated and transformed from agents to the proxy, and then from the proxy to agents. Thus, local observations can either be encoded [42, 66, 83, 76, 92] or directly sent [88, 91] to the proxy. The proxy, after gathering these local (encoded) observations, can generate a unified message for all agents [88], or individualized messages for each agent [42, 66, 83, 76, 91, 92]. Both methods provide a message containing global information, relieving agents from the task of combining multiple received messages. In Comm-MADRL systems without a proxy, messages are sent directly to each agent. Specifically, in MADDPG-M [41], agents communicate local observations without an encoding of them. On the other hand, DIAL and RIAL [73] encode past observations, actions, and current observations as messages. BiCNet [50] encodes both local observations of each agent and a global view of the environment. Other research works employ various methods such as simple feed-forward networks [43, 78, 86, 87], MLP [40, 31, 32, 95], autoencoders [82], CNNs [81], RNNs [48, 89, 49, 79, 93, 33, 94], or GNNs [74, 77] to encode local observations as messages. Furthermore, agents can communicate more specific information, such as in GAXNet [80], where agents coordinate their local attention weights, integrating hidden states from neighboring agents. Messages can also be modeled as random variables, as seen in NDQ [75], where messages are drawn from a multivariate Gaussian distribution to maximize expressiveness by maximizing mutual information between messages and receivers’ action selection. In learning tasks with emergent language, agents often communicate goal-related information, such as the goal’s location [61, 62, 63, 65, 64].
Table 6: The category of communicated messages.
| Types | Methods |
| --- | --- |
| Existing Knowledge | DIAL [73]; RIAL [73]; CommNet [48]; GCL [61]; BiCNet [50]; MS-MARL-GCM [88]; IC [62]; DGN [81]; TarMAC [89]; MAGNet-SA-GS-MG [40]; MADDPG-M [41]; IC3Net [49]; MD-MADDPG [42]; SchedNet [43]; DCC-MD [82]; Agent-Entity Graph [74]; VBC [31]; NDQ [75]; IMAC [66]; GA-Comm [83]; Gated-ACML [76]; Bias [63]; LSC [77]; Diff Discrete [78]; I2C [79]; ETCNet [86]; Variable-length Coding [87]; TMC [32]; HAMMER [91]; MAGIC [92]; FlowComm [93]; AE-Comm [65]; GAXNet [80]; DCSS [64]; R-MACRL [95]; MAIC [33]; FCMNet [94]; |
| Imagined Future Knowledge | ATOC [39]; NeurComm [84]; IP [85]; IS [90]; |
Imagined Future Knowledge
In this context, Imagined Future Knowledge refers to aspects such as intended actions [39], policy fingerprints (i.e., action probabilities in a given state) [85, 84], or future plans [90]. Since intentions are related to the current environment state, recent works often combine intended actions with local observations to produce more relevant messages. The concept of future plans extends this idea further by utilizing an approximated model of the environment and the behavior models of other agents. This approach enables the generation of a sequence of possible future observations and actions [90]. Such knowledge is shared among agents, allowing the receivers to consider the potential future outcomes of the senders’ actions.
### 3.6 Message Combination
Table 7: The category of message combination.
| Types | Methods |
| --- | --- |
| Equally Valued | DIAL [73]; RIAL [73]; CommNet [48]; GCL [61]; IC [62]; MADDPG-M [41]; IC3Net [49]; SchedNet [43]; VBC [31]; NDQ [75]; Bias [63]; Diff Discrete [78]; IS [90]; ETCNet [86]; Variable-length Coding [87]; FlowComm [93]; AE-Comm [65]; DCSS [64]; |
| Unequally Valued | BiCNet [50]; MS-MARL-GCM [88]; ATOC [39]; DGN [81]; TarMAC [89]; MAGNet-SA-GS-MG [40]; MD-MADDPG [42]; DCC-MD [82]; Agent-Entity Graph [74]; IMAC [66]; GA-Comm [83]; Gated-ACML [76]; LSC [77]; NeurComm [84]; IP [85]; I2C [79]; TMC [32]; HAMMER [91]; MAGIC [92]; GAXNet [80]; R-MACRL [95]; MAIC [33]; FCMNet [94]; |
When agents receive more than one message, current works often aggregate all received messages to reduce the input for the action policy. Message Combination determines how to integrate multiple messages before they are processed by an agent’s internal model. If a proxy is involved, each agent receives already coordinated and combined messages from the proxy, eliminating the need for further message combination. If no proxy is presented, each agent independently determines how to combine multiple messages. Since communicated messages encode the senders’ understanding of the learning process or the environment, some messages can be more valuable than others. As shown in Table 7, recent works in the dimension of message combination are categorized based on how agents prioritize received messages.
Equally Valued
In this category, messages received by agents are treated without preference, meaning they are assigned equal weights or simply no weights at all. Without having preferences, agents can concatenate all messages, ensuring no loss of information, though it may significantly expand the input space for the action policy [73, 61, 62, 41, 43, 75, 78, 90, 86, 87]. Recent research involving concatenated messages typically represent the sent messages either as single values [73, 62, 87, 86] or as short vectors [61, 41, 43, 75, 78, 90]. Alternatively, messages can be combined by averaging [48, 49, 31] or summing [93], under the assumption that messages from different agents have the same dimension. In some cases, particularly in two-agent scenarios, no explicit preferences are assigned to messages [63, 65, 64].
Unequally Valued
In this category, messages are assigned distinct preferences, which potentially impose differences on sender agents. DCC-MD [82] and TMC [32] use handcrafted rules to prune received messages. In DCC-MD, each received message can be dropped out with a certain probability. TMC stores the received messages and checks whether they are expired or not within a preset time window. Only valid messages are integrated into an agent’s model. Instead of using fixed rules, $\mathfrak{R}$ -MACRL [95] learns a gate unit to decide whether to use a received message. An attention mechanism can also be learned to assign weights to received messages and then combine them, rather than filtering messages out, as seen in research works [89, 40, 74, 33]. Moreover, a neural network can aggregate received messages into a single message or a low-dimensional vector, which implicitly imposes preferences on messages during the mapping. Feedforward neural networks [66, 76, 91], CNNs [81], LSTMs (or RNNs) [50, 88, 39, 42, 84, 79, 80, 94], and GNNs [83, 77, 85, 92] have been used as aggregators. Among them, GNNs utilize a learned graph structure of agents and assign different weights to neighboring agents.
Table 8: The category of inner integration.
| Types | Methods |
| --- | --- |
| Policy-level | CommNet [48]; GCL [61]; MS-MARL-GCM [88]; ATOC [39]; MAGNet-SA-GS-MG [40]; IC3Net [49]; MD-MADDPG [42]; SchedNet [43]; IMAC [66]; GA-Comm [83]; Gated-ACML [76]; Diff Discrete [78]; IP [85]; I2C [79]; IS [90]; ETCNet [86]; Variable-length Coding [87]; HAMMER [91]; FlowComm [93]; GAXNet [80]; R-MACRL [95]; |
| Value-level | DIAL [73]; RIAL [73]; DGN [81]; DCC-MD [82]; VBC [31]; NDQ [75]; LSC [77]; TMC [32]; MAIC [33]; |
| Policy- and Value-level | BiCNet [50]; IC [62]; TarMAC [89]; MADDPG-M [41]; Agent-Entity Graph [74]; Bias [63]; NeurComm [84]; MAGIC [92]; AE-Comm [65]; DCSS [64]; FCMNet [94]; |
### 3.7 Inner Integration
Inner Integration determines how to integrate (combined) messages into an agent’s learning model, such as a policy or a value function. In most existing literature, messages are viewed as additional observations. Agents take messages as extra input to a policy function, a value function, or both. Thus, in the dimension of inner integration, we classify recent works into categories based on the learning model that is used to integrate messages. These categories are summarized in Table 8.
Policy-level
By exploiting information from other agents, each agent will no longer act independently. Policies can be learned through policy gradient methods like REINFORCE, as seen in studies [48, 61, 88, 49, 83], which collect rewards during episodes and train the policy models at the end of episodes. Moreover, the Comm-MADRL approaches that utilize actor-critic methods [39, 40, 42, 43, 66, 76, 78, 85, 79, 90, 86, 87, 91, 93, 80, 95] assume that a critic model (i.e., a Q-function) guides the learning of an actor model (i.e., a policy network).
Value-level
In this category, a value function incorporates messages as input, and a policy is derived by selecting the action with the highest Q-value. Most works in this category employ DQN-like methods to train their value functions [73, 81, 82, 31, 75, 77, 32, 33]. Specifically, Comm-MADRL approaches like VBC [31], NDQ [75], TMC [32], and MAIC [33] are based on value decomposition methods in cooperative scenarios (with global rewards). These methods involve learning to decompose a joint Q-function.
Policy- and Value-level
Integrating messages using both a policy function and a value function typically relies on actor-critic methods. In Comm-MADRL approaches within this category, received messages can be treated as extra inputs for both the actor and critic models [50, 74, 64]. Alternatively, messages can be combined with local observations to generate new internal states, which are then shared with both the actor and critic models [62, 89, 41, 63, 84, 92, 65, 94].
### 3.8 Learning Methods
Learning methods determine which type of machine learning techniques is used to learn a communication protocol. The learning of communication is at the center of modern Comm-MADRL and can benefit from the advancements in the machine learning field. If proper assumptions about communication are made, such as being able to calculate the derivatives with respect to the message generator function and the communication policy, then the training of communication can be integrated into the overall learning process of agents. This integration allows for the use of fully differentiable methods for backpropagation. Other machine learning techniques, including reinforcement learning, supervised learning, and regularizations, can also be utilized to incorporate our requirements and available ground truth into the learning of communication, each carrying respective assumptions. The assumptions used in the literature are summarized in Table 9. For instance, supervised methods require defining true labels for communication (e.g., the correct information to share or the right agents to communicate with). In contrast, reinforced methods use rewards as learning signals. Regularized methods, which use neither true labels nor rewards, employ an additional learning objective by using regularizers, such as minimizing the entropy of messages to reduce stochasticity. Therefore, we classify recent works based on how they differ in the learning of communication (summarized in Table 10).
Table 9: The assumptions behind different learning methods.
| Types | Assumptions |
| --- | --- |
| Fully differentiable | The messages or the communication actions are generated by a differentiable function and thus backpropagation is used everywhere. |
| Supervised learning | True labels (or the ground truth) are assumed to be given or defined to guide the learning of communication policy or messages. |
| Reinforcement learning | Environment rewards or self-defined rewards are used to update communication policy or messages incrementally. |
| Regularizers | Regularizations such as entropy inspired from information theory are added to agents’ optimization objectives to regularize the learning of communication. |
Table 10: The category of learning methods.
| Types | Methods |
| --- | --- |
| Differentiable | GCL [61]; DIAL [73]; CommNet [48]; BiCNet [50]; MS-MARL-GCM [88]; DGN [81]; TarMAC [89]; MAGNet-SA-GS-MG [40]; MD-MADDPG [42]; DCC-MD [82]; Agent-Entity Graph [74]; VBC [31]; GA-Comm [83]; Diff Discrete [78]; NeurComm [84]; IP [85]; IS [90]; Variable-length Coding [87]; TMC [32]; MAGIC [92]; FlowComm [93]; GAXNet [80]; DCSS [64]; FCMNet [94]; |
| Supervised | DCSS [64]; ATOC [39]; Gated-ACML [76]; I2C [79]; R-MACRL [95]; |
| Reinforced | GCL [61]; RIAL [73]; IC [62]; MADDPG-M [41]; IC3Net [49]; SchedNet [43]; LSC [77]; ETCNet [86]; HAMMER [91]; |
| Regularized | NDQ [75]; IMAC [66]; Bias [63]; AE-Comm [65]; MAIC [33]; |
Differentiable
In this category, communication is learned and improved by backpropagating gradients from agent to agent. When the communication policy is predefined, such as in full communication [73, 48, 61, 50, 88, 89, 42, 82, 78, 90, 87, 94] or by communicating with a subset of agents [81, 40, 74, 31, 84, 85, 32, 80, 64], agents learn the content of messages through backpropagation. Several recent studies [61, 83, 92, 93, 64] address the issue of non-differentiable communication actions by utilizing gradient estimators like Gumbel-softmax [104], which replaces non-differentiable samples with a differentiable approximation during training, albeit requiring additional parameter tuning. Specifically, both GCL [61] and DCSS [64] employ a differential message function in their approaches. Additionally, GCL integrates auxiliary rewards, and DCSS utilizes labeled messages for training communication policies. Thus, they are categorized under the Differentiable category, each additionally aligning with the Reinforced and Supervised categories respectively. Freed et al. [78] propose an alternative method, Diff Discrete, to address the challenge of continuous messages versus discrete channels. This method models message transmitting as an encoder/channel/decoder system, where the receiver decodes the messages and reconstructs the original signals. These reconstructed signals enable the calculation of derivatives with respect to the sender, allowing gradients to be sent back to the sender.
Supervised
In this category, additional efforts need to be made to define the true label for when and what information to communicate. ATOC [39] and Gated-ACML [76] use the difference in Q-values between actions chosen with and without a message to define a label of communication actions. If the difference exceeds a threshold, the message is deemed valuable, indicating a high probability of sending it; otherwise, the probability is 0. This process sets up a classification task to decide whether to communicate. Similarly, I2C [79] trains a classifier to determine communication but relies on the causal effect between two agents, using a threshold to tag effective communication. $\mathfrak{R}$ -MACRL [95] learns a classifier to identify malicious messages, using the status of a message (malicious or not) as a label. DCSS [64] learns message content by using a small dataset that maps observations to desired communication symbols. In DCSS, the gradient from the supervised loss is added to the policy loss, leading agents to use communication that aligns with the grounding data and enables high task performance.
Reinforced
In this category, reinforcement learning is utilized to train communication in addition to the learning of action policies. RIAL [73] and HAMMER [91] focus on learning the content of messages through reinforcement learning, without addressing the decision of whether to communicate. In GCL [61], auxiliary rewards are used for predicting goals and consolidating symbols, facilitating the development of a compositional language for communication. IC [62] employs the difference in outcomes from using and not using communication on action policies as rewards. Maximizing the rewards can enhance the influence of communication on the receivers’ action policies. Other studies [41, 49, 43, 77, 86] consider both the learning of communication content and the decision to communicate. Notably, MADDPG-M [41] suggests using intrinsic rewards to train the communication policy instead of relying solely on environmental rewards. ETCNet [86] shapes environmental rewards by introducing a penalty term to discourage unnecessary communication.
Regularized
Regularized methods are used to reduce redundant information in communication [75, 66, 33]. NDQ [75] calculates a lower bound of the mutual information between received messages and the receivers’ action selection. This approach suggests that messages can be optimized to decrease the uncertainty in the action-value functions of the receivers. IMAC [66] establishes an upper bound on the mutual information between messages and the senders’ observations, and minimizing this upper bound helps agents send messages with lower uncertainty. MAIC [33] employs an estimated model of teammates and aims to maximize the mutual information between teammates’ actions and hidden variables from this model. This model then guides the encoding of messages, resulting in tailored communications for different agents. Bias [63] focuses on the long-term impact of messages on agents’ decision-making to enhance signaling and listening effectiveness. AE-Comm [65] adopts an autoencoder to learn a low-dimensional encoding of observations.
### 3.9 Training Schemes
This dimension focuses on how to utilize the collected experiences (such as observations, actions, rewards, and messages) of agents to train their action policies and communication architectures in a Comm-MADRL system. Agents can train their models in a fully decentralized manner using only their local experience. Alternatively, when global information is accessible, the experiences of all agents can be collected to centrally train a single (centralized) model that controls all agents. However, each approach has inherent challenges. Fully decentralized learning must cope with a non-stationary environment due to the changing and adapting behaviors of agents, while fully centralized learning faces the complexities of joint observation and policy spaces. As a balanced solution, Centralized Training and Decentralized Execution (CTDE) [105, 73] has emerged as a popular training schemes in MADRL. CTDE approaches allow agents to learn their local policies using guidance from central information. Therefore, in the dimension of training schemes, we categorize recent works based on how agents’ experiences are collected and utilized, as detailed in Table 11.
Table 11: The category of training schemes.
| Types | Subtypes | Methods |
| --- | --- | --- |
| Fully Decentralized Learning | | IC [62]; MAGNet-SA-GS-MG [40]; MADDPG-M [41]; DCC-MD [82]; Agent-Entity Graph [74]; Bias [63]; NeurComm [84]; IP [85]; AE-Comm [65]; R-MACRL [95]; |
| Centralized Training and Decentralized Execution | Individual Parameters | MS-MARL-GCM [88]; SchedNet [43]; IMAC [66]; Gated-ACML [76]; GAXNet [80]; DCSS [64]; |
| Parameter Sharing | DIAL [73]; RIAL [73]; CommNet [48]; GCL [61]; BiCNet [50]; ATOC [39]; DGN [81]; TarMAC [89]; IC3Net [49]; VBC [31]; NDQ [75]; GA-Comm [83]; LSC [77]; Diff Discrete [78]; I2C [79]; ETCNet [86]; Variable-length Coding [87]; TMC [32]; HAMMER [91]; MAGIC [92]; FlowComm [93]; MAIC [33]; FCMNet [94]; | |
| Concurrent | MD-MADDPG [42]; IS [90]; | |
<details>
<summary>x7.png Details</summary>
### Visual Description
## Diagram: Multi-Policy Reinforcement Learning Loop
### Overview
The image is a technical diagram illustrating a system where multiple policies interact with a shared environment in a reinforcement learning framework. The diagram depicts a cyclical process involving action, observation, and reward-based updates.
### Components/Axes
The diagram consists of three primary components arranged vertically:
1. **Top Component (Environment):** A parallelogram labeled **"Environment"**.
2. **Middle Component (Policy Set):** A large, rounded rectangle containing a series of smaller, rounded rectangles labeled **"Policy 1"**, **"Policy 2"**, **"..."**, and **"Policy n"**. This represents a set of *n* distinct policies.
3. **Bottom Text (Update Mechanism):** Text at the bottom of the diagram reads **"Update with <r₁, r₂, ..., rₙ>"**.
**Flow and Connections (Arrows):**
* A vertical, double-headed arrow connects the **Environment** and the **Policy Set**.
* To the left of this central arrow, text indicates the flow from policies to environment: **"<a₁, a₂, ..., aₙ>"**. This represents a vector of actions from the *n* policies.
* To the right of the central arrow, text indicates the flow from environment to policies: **"<o₁, o₂, ..., oₙ>"**. This represents a vector of observations sent to the *n* policies.
* A feedback loop arrow originates from the right side of the **Policy Set** rectangle, curves downward, and points back into the left side of the same rectangle. This loop is associated with the bottom text **"Update with <r₁, r₂, ..., rₙ>"**, indicating a vector of rewards used for updating the policies.
### Detailed Analysis
The diagram explicitly defines the following data flows:
* **Action Vector (`<a₁, a₂, ..., aₙ>`):** A set of *n* actions, where `aᵢ` is the action generated by Policy *i*. This vector is sent to the Environment.
* **Observation Vector (`<o₁, o₂, ..., oₙ>`):** A set of *n* observations, where `oᵢ` is the observation provided by the Environment to Policy *i*. This vector is received from the Environment.
* **Reward Vector (`<r₁, r₂, ..., rₙ>`):** A set of *n* rewards, where `rᵢ` is the reward signal associated with Policy *i*. This vector is used in the update step.
The spatial layout is hierarchical and cyclical:
* The **Environment** is positioned at the top, acting as the external system.
* The **Policy Set** is centrally located, acting as the decision-making agent(s).
* The **Update** mechanism is shown as a feedback loop at the bottom, closing the cycle.
### Key Observations
1. **Multi-Agent/Multi-Policy Structure:** The diagram is not for a single agent but for a system with *n* policies (`Policy 1` to `Policy n`). This could represent multiple agents, an ensemble of policies, or a single agent with multiple policy components.
2. **Vectorized Communication:** All interactions (actions, observations, rewards) are explicitly shown as vectors of length *n*, implying a one-to-one correspondence between policies and their respective signals.
3. **Centralized Environment:** All policies interact with a single, shared **Environment**.
4. **Closed Learning Loop:** The diagram clearly shows a complete reinforcement learning cycle: Policies -> Actions -> Environment -> Observations -> Policies, with a separate Reward -> Update loop modifying the policies.
### Interpretation
This diagram models a **centralized multi-policy reinforcement learning system**. It visually answers the question: "How do multiple policies learn from a shared environment?"
* **What it demonstrates:** The core process of distributed decision-making and learning. Each policy `i` generates an action `aᵢ`, which collectively influence the environment. The environment responds with observations `oᵢ` and, crucially, provides individual reward signals `rᵢ` for each policy. These rewards are then used to update the respective policies, aiming to improve their future action selection.
* **Relationships:** The Environment is the source of truth and feedback (observations and rewards). The Policy Set is the learning component. The update loop is the learning algorithm (e.g., policy gradient, Q-learning) applied to each policy based on its own reward signal.
* **Notable Implications:**
* **Credit Assignment:** The structure suggests each policy receives its own reward `rᵢ`, which is essential for determining which policy's actions were effective. This is a key challenge in multi-agent learning.
* **Scalability:** The use of `n` and ellipses (`...`) indicates the framework is designed to be general for any number of policies.
* **Potential Scenarios:** This could model a team of cooperative agents, a population of competing agents, or a single agent using multiple sub-policies (like options in hierarchical RL). The diagram is abstract and does not specify the relationship (cooperative, competitive, etc.) between the policies.
**Language Note:** All text in the image is in English. Mathematical notation uses standard subscripts (₁, ₂, ₙ).
</details>
(a) Fully Centralized Learning
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## Diagram: Multi-Agent Reinforcement Learning Framework
### Overview
The image is a technical diagram illustrating a multi-agent reinforcement learning (MARL) framework. It depicts multiple independent learning agents (policies) interacting with a shared environment. Each agent operates in parallel, receiving observations and sending actions to the environment, and updates its policy based on its own reward signal.
### Components/Axes
The diagram is structured into three main vertical sections, with a clear hierarchical flow.
1. **Top Section (Environment):**
* A large, light-gray parallelogram spanning the top of the diagram.
* Contains the single label: **"Environment"**.
2. **Middle Section (Agents/Policies):**
* Three rounded rectangles are shown, representing individual learning agents.
* Labels from left to right: **"Policy 1"**, **"Policy 2"**, **"Policy n"**.
* An ellipsis (**"..."**) is placed between "Policy 2" and "Policy n", indicating a sequence that can be extended to an arbitrary number of agents.
* **Interaction Arrows:** Each policy box has two vertical arrows connecting it to the Environment parallelogram above.
* An upward-pointing arrow labeled with an action: **"a₁"** (for Policy 1), **"a₂"** (for Policy 2), **"aₙ"** (for Policy n).
* A downward-pointing arrow labeled with an observation: **"o₁"** (for Policy 1), **"o₂"** (for Policy 2), **"oₙ"** (for Policy n).
* **Update Loop:** Each policy box has a self-referential arrow forming a loop on its left side, indicating an internal update process.
3. **Bottom Section (Update Instructions):**
* Text is placed directly below each corresponding policy box.
* Labels from left to right: **"Update with r₁"**, **"Update with r₂"**, **"Update with rₙ"**.
* The "r" variables (r₁, r₂, rₙ) represent the reward signals used by each respective policy for its learning update.
### Detailed Analysis
* **Spatial Layout:** The Environment is the central, top-level entity. The policies are arranged horizontally below it, suggesting parallel and independent operation. The update instructions are anchored at the bottom, directly linked to their respective policies.
* **Flow of Information:**
1. Each Policy `i` sends an action `aᵢ` to the Environment.
2. The Environment returns an observation `oᵢ` to that same Policy `i`.
3. Policy `i` then performs an internal update using its dedicated reward signal `rᵢ`.
* **Notation:** The diagram uses subscript notation (`1, 2, ..., n`) to generalize the framework for any number of agents. The variables follow a consistent pattern: `a` for action, `o` for observation, `r` for reward.
### Key Observations
* **Independent Learning:** There are no arrows connecting the different Policy boxes to each other. This visually emphasizes that the agents are learning independently, without direct communication or shared parameters.
* **Shared Environment:** All policies interact with the same, singular "Environment" block, indicating a shared state space or world that all agents influence and observe.
* **Scalability:** The use of "Policy n" and the ellipsis explicitly denotes that the framework is designed to scale to a variable number of agents.
* **Closed-Loop Systems:** Each agent-environment pair forms a classic reinforcement learning feedback loop (state -> policy -> action -> new state/reward). The diagram shows `n` such loops operating in parallel.
### Interpretation
This diagram represents a **decentralized** or **independent learners** approach to multi-agent reinforcement learning. The core concept is that multiple agents coexist and learn within a common environment, but their learning processes are isolated from one another.
* **What it demonstrates:** It models scenarios like a group of robots navigating a shared space, multiple trading algorithms in a market, or non-player characters (NPCs) in a game world, where each entity learns its own strategy based solely on its personal experiences (its own actions, observations, and rewards).
* **Relationships:** The primary relationship is between each individual agent and the environment. The lack of inter-agent connections is the defining feature, distinguishing this from cooperative or communication-based MARL frameworks.
* **Potential Challenges (Implied):** While not stated in the diagram, this setup is known to face challenges like **non-stationarity**. From the perspective of any single agent, the environment appears to change unpredictably because the other agents are also learning and altering their behavior simultaneously. This can make stable learning difficult. The diagram's clean, parallel structure elegantly captures the independent learning paradigm while implicitly highlighting the complexity that arises from their shared impact on the environment.
</details>
(b) Fully Decentralized Learning
<details>
<summary>x9.png Details</summary>
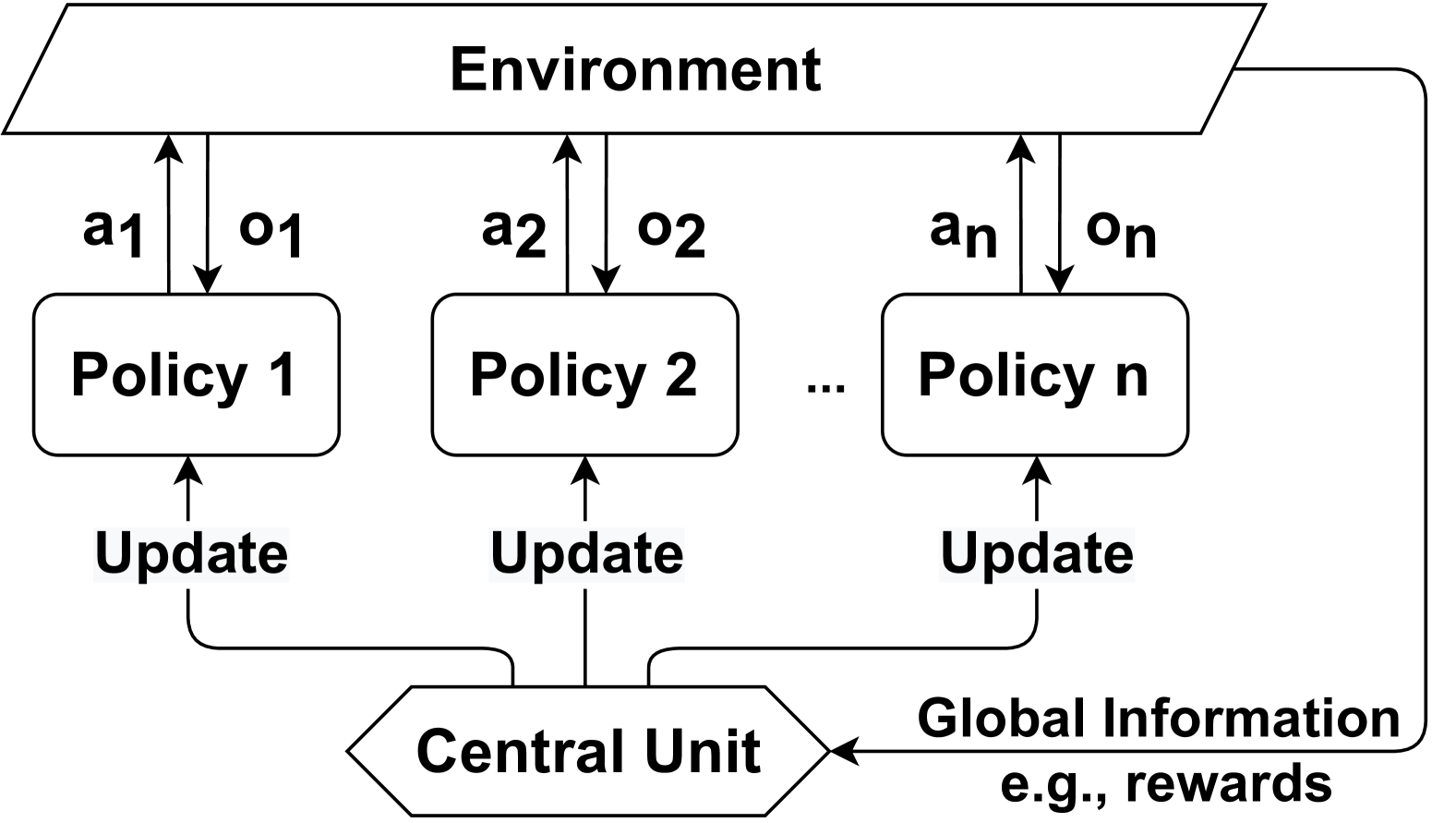
### Visual Description
## Diagram: Multi-Agent Reinforcement Learning Architecture
### Overview
The image is a technical block diagram illustrating a multi-agent reinforcement learning (MARL) system architecture. It depicts a centralized training with decentralized execution (CTDE) framework, where multiple independent policies interact with a shared environment and are updated by a central unit using global information.
### Components/Axes
The diagram is composed of three primary horizontal layers and a feedback loop.
**1. Top Layer: Environment**
* A single, wide parallelogram block labeled **"Environment"**.
* This represents the external system or problem space with which the agents interact.
**2. Middle Layer: Policy Agents**
* A series of rounded rectangular blocks representing individual agent policies.
* **Labels:** "Policy 1", "Policy 2", "Policy n". An ellipsis ("...") between "Policy 2" and "Policy n" indicates a variable number of such policies.
* **Interactions with Environment:**
* Each policy block has an upward-pointing arrow labeled with an action: **"a1"**, **"a2"**, **"an"**.
* Each policy block has a downward-pointing arrow labeled with an observation: **"o1"**, **"o2"**, **"on"**.
* This shows each policy `i` sends an action `ai` to the Environment and receives an observation `oi` from it.
**3. Bottom Layer: Central Unit**
* A hexagonal block at the bottom center labeled **"Central Unit"**.
* **Inputs:**
* A long, curved arrow originates from the right side of the "Environment" block, travels down the right edge of the diagram, and points into the right side of the "Central Unit". This arrow is labeled **"Global Information e.g., rewards"**.
* **Outputs:**
* Three arrows originate from the top of the "Central Unit" block.
* Each arrow splits and points upward to a corresponding policy block.
* The label **"Update"** is placed on the vertical segment of each of these three arrows, just before they reach their respective policy blocks ("Policy 1", "Policy 2", "Policy n").
### Detailed Analysis
**Flow and Relationships:**
1. **Decentralized Execution:** Each policy (`Policy 1` through `Policy n`) operates independently during interaction with the environment. They each receive their own local observation (`o1`, `o2`, `on`) and decide on their own action (`a1`, `a2`, `an`).
2. **Centralized Information Gathering:** The "Central Unit" receives "Global Information" from the environment. The example given is "rewards," which could include global state information, joint rewards, or other system-wide metrics not available to individual policies.
3. **Centralized Training/Update:** Using this global information, the "Central Unit" computes and sends an "Update" signal to each individual policy. This update likely contains training gradients, value function estimates, or other parameters to improve the policies' performance. The diagram shows this as a one-way flow from the Central Unit to the policies.
**Spatial Grounding:**
* The **"Environment"** block is positioned at the top, spanning the width of the diagram.
* The **Policy blocks** are arranged horizontally in the middle, evenly spaced.
* The **"Central Unit"** is centered at the bottom.
* The **"Global Information"** label and its associated arrow are located on the right side of the diagram, forming a large feedback loop from the Environment's output back to the Central Unit's input.
* The **"Update"** labels are positioned on the vertical lines connecting the Central Unit to each policy, clearly indicating the direction of the update flow.
### Key Observations
* **Architectural Pattern:** This is a classic representation of the **Centralized Training with Decentralized Execution (CTDE)** paradigm in multi-agent reinforcement learning.
* **Scalability:** The use of "Policy n" and an ellipsis explicitly indicates the architecture is designed to scale to an arbitrary number of agents.
* **Information Asymmetry:** A key design feature is the asymmetry in information. Policies have access only to local observations (`oi`) during execution, while the Central Unit has access to global information for training. This is crucial for learning cooperative behaviors without requiring agents to share all their internal states during deployment.
* **Feedback Loop:** The diagram clearly shows a closed-loop system: Environment -> Policies (Actions) -> Environment -> Global Info -> Central Unit -> Policy Updates -> Policies (improved behavior).
### Interpretation
This diagram illustrates a solution to a fundamental challenge in multi-agent systems: how to train agents to achieve a common goal when they only have a local view of the world. The "Central Unit" acts as a critic or a trainer with a god's-eye view. It uses global success metrics (like total reward) to evaluate the collective performance and then provides targeted feedback ("Update") to each agent to adjust its individual policy.
The architecture suggests a focus on **cooperative tasks**. The policies are not shown competing for resources from the environment; instead, they all feed into a single "Central Unit" that processes "Global Information," implying their actions are coordinated towards a shared objective. The "e.g., rewards" note is critical—it specifies that the global information is not necessarily the full environment state, but could be a distilled signal like the team's cumulative reward, which is more scalable and often sufficient for learning coordination.
In essence, the diagram maps out a learning loop where decentralized actors explore the environment, and a centralized critic uses the outcomes of that exploration to teach them how to act more effectively as a team.
</details>
(c) Individual Parameters
<details>
<summary>x10.png Details</summary>
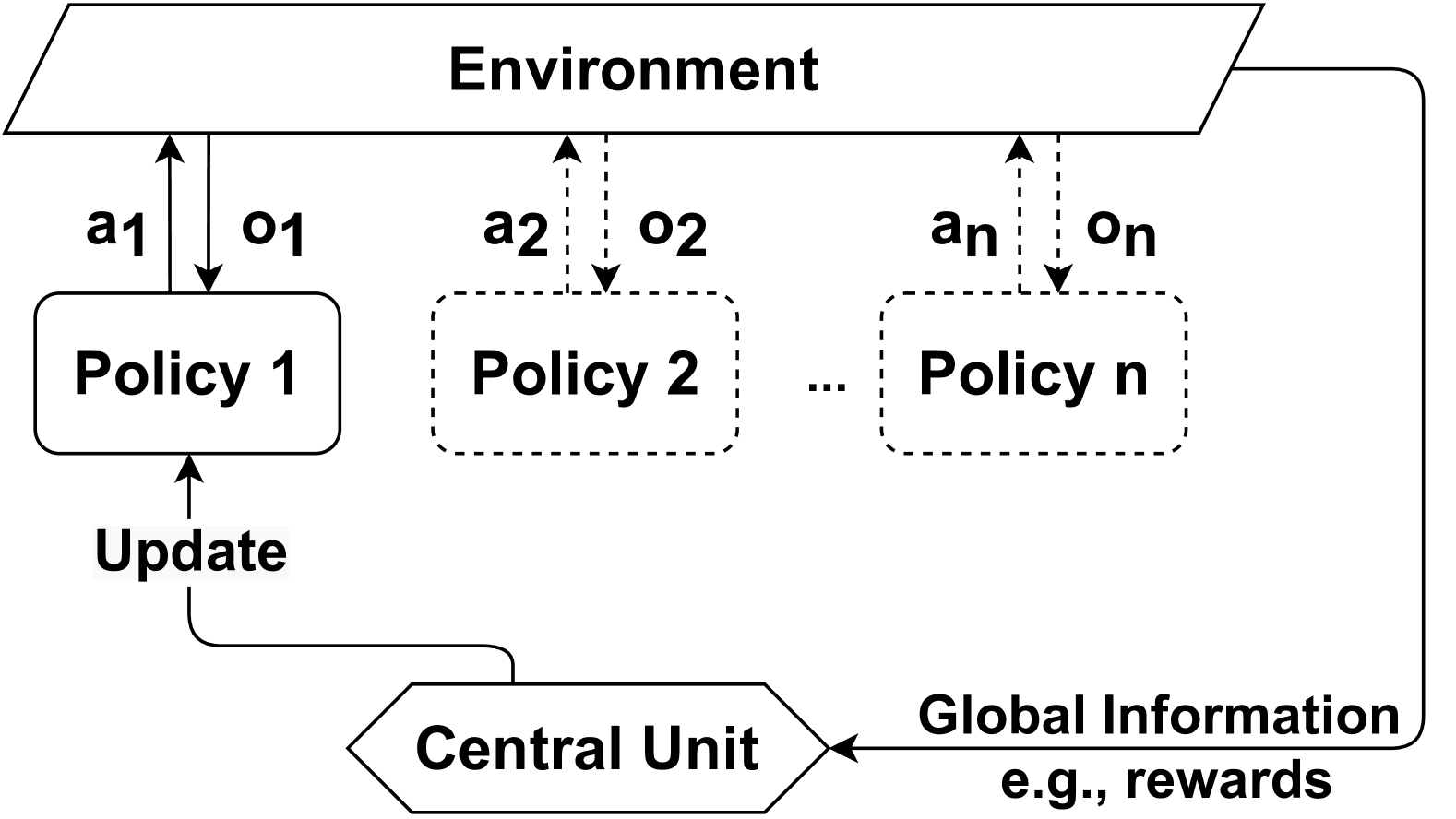
### Visual Description
## Diagram: Multi-Agent Policy Architecture with Centralized Coordination
### Overview
The image is a technical system architecture diagram illustrating a multi-agent or multi-policy control system interacting with a shared environment. It depicts a centralized learning or coordination framework where multiple policies operate in parallel, with a central unit facilitating updates based on global information. The diagram uses standard flowchart symbols and directional arrows to denote information flow and control relationships.
### Components/Axes
The diagram is composed of the following labeled components and connections, arranged in a hierarchical flow:
1. **Environment** (Top, Center): Represented by a parallelogram. This is the external system or context with which the policies interact.
2. **Policy Blocks** (Middle Row):
* **Policy 1**: A solid-lined, rounded rectangle on the left.
* **Policy 2**: A dashed-lined, rounded rectangle in the center.
* **Policy n**: A dashed-lined, rounded rectangle on the right.
* An ellipsis (`...`) between Policy 2 and Policy n indicates a sequence of policies from 2 to n.
3. **Central Unit** (Bottom, Center): Represented by a hexagon. This is the coordinating entity.
4. **Interaction Arrows (Environment ↔ Policies):**
* **From Environment to Policy 1**: A solid downward arrow labeled `o1` (observation 1).
* **From Policy 1 to Environment**: A solid upward arrow labeled `a1` (action 1).
* **From Environment to Policy 2**: A dashed downward arrow labeled `o2`.
* **From Policy 2 to Environment**: A dashed upward arrow labeled `a2`.
* **From Environment to Policy n**: A dashed downward arrow labeled `on`.
* **From Policy n to Environment**: A dashed upward arrow labeled `an`.
5. **Control & Information Flow Arrows:**
* **Update**: A solid arrow originates from the Central Unit, curves left, and points upward to **Policy 1**. The label `Update` is placed on the vertical segment of this arrow.
* **Global Information**: A solid arrow originates from the right side of the **Environment** block, curves down, and points left into the **Central Unit**. The label `Global Information` is placed above this arrow, with the sub-label `e.g., rewards` below it.
### Detailed Analysis
* **Spatial Layout**: The diagram has a clear top-down flow. The Environment is the top-level entity. The Policies are arranged horizontally in the middle layer, suggesting parallel operation. The Central Unit is at the bottom, acting as a foundational coordinator.
* **Line Style Semantics**: The solid lines for Policy 1 and its connections contrast with the dashed lines for Policy 2 through Policy n. This visually distinguishes Policy 1, possibly indicating it is the primary, active, or currently highlighted policy in the sequence, while the others represent a generalized set.
* **Data Flow**:
1. Each policy `i` receives an observation `oi` from the Environment.
2. Each policy `i` outputs an action `ai` to the Environment.
3. The Environment provides `Global Information` (e.g., rewards) to the Central Unit.
4. The Central Unit processes this global information and sends an `Update` signal specifically to Policy 1. The diagram implies this update mechanism could apply to all policies, but only the connection to Policy 1 is explicitly drawn.
### Key Observations
* **Centralized Training, Decentralized Execution (CTDE) Pattern**: The architecture strongly suggests a CTDE paradigm common in multi-agent reinforcement learning. Policies act independently (decentralized execution) based on local observations (`oi`), but are trained or updated (centralized training) using global information (`Global Information`) processed by a Central Unit.
* **Asymmetric Representation**: Policy 1 is visually emphasized with solid lines and a direct update link, while Policies 2..n are generalized with dashed lines. This is a common diagrammatic technique to show one instance of a repeated component.
* **Closed-Loop System**: The diagram forms a closed loop: Environment → Policies → Environment → Central Unit → Policies. This represents a continuous cycle of interaction, evaluation, and adaptation.
### Interpretation
This diagram models a sophisticated control or learning system designed for scenarios involving multiple agents or decision-making modules. The key insight is the separation of **execution** (handled by individual policies interacting directly with the environment) from **coordination and learning** (handled by the Central Unit using global feedback).
The `Global Information` (e.g., rewards) is critical. It allows the Central Unit to assess the overall system performance, not just the performance of individual policies. The `Update` signal likely contains optimized parameters, gradients, or instructions derived from this global assessment, which are then used to improve the policies.
The use of `n` policies indicates scalability. The system is designed to handle an arbitrary number of agents or sub-processes. The dashed lines for policies 2 through n abstract away repetitive detail, focusing the viewer on the architectural pattern rather than each individual component.
**In essence, the diagram answers the question: "How can multiple independent agents learn to cooperate or optimize a shared goal?"** The answer is by employing a central critic or coordinator (Central Unit) that uses system-wide data to guide the learning of all individual actors (Policies). This is a foundational concept in fields like multi-agent systems, swarm robotics, and distributed AI.
</details>
(d) Parameter Sharing
<details>
<summary>x11.png Details</summary>
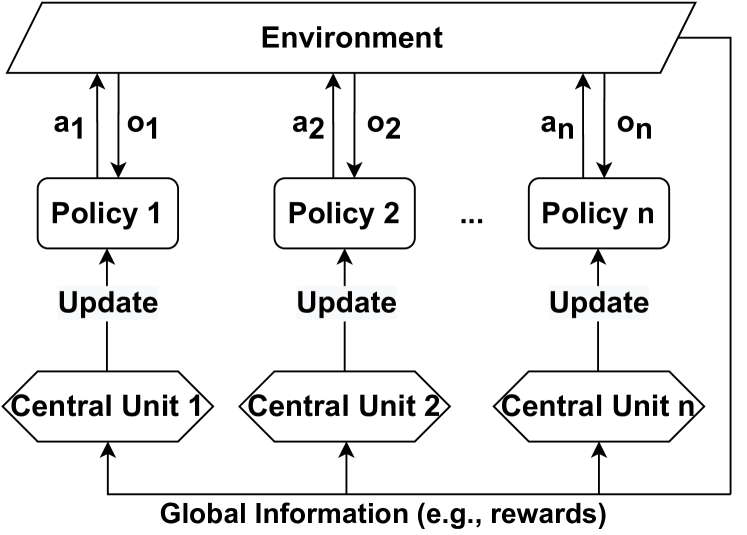
### Visual Description
## Diagram: Multi-Agent Reinforcement Learning Architecture
### Overview
The image is a technical diagram illustrating a multi-agent reinforcement learning (MARL) system architecture. It depicts a centralized training with decentralized execution framework where multiple independent policies interact with a shared environment, and their updates are coordinated by separate central units using global information.
### Components/Axes
The diagram is structured into three main horizontal layers, with vertical columns representing individual agents.
**1. Top Layer (Environment):**
* **Component:** A single parallelogram spanning the top of the diagram.
* **Label:** `Environment`
* **Function:** Represents the external world or simulation with which all agents interact.
**2. Middle Layer (Agents/Policies):**
* **Components:** Three rectangular boxes arranged horizontally, representing a scalable number of agents.
* **Labels (from left to right):** `Policy 1`, `Policy 2`, `Policy n`
* **Ellipsis:** The notation `...` between `Policy 2` and `Policy n` indicates a sequence, implying there are multiple policies (from 1 to n).
* **Interactions with Environment:**
* Each Policy box has a pair of vertical arrows connecting it to the Environment above.
* **Upward Arrow (Action):** Labeled `a1`, `a2`, `an` respectively. Represents the action output from the policy to the environment.
* **Downward Arrow (Observation):** Labeled `o1`, `o2`, `on` respectively. Represents the observation or state input from the environment to the policy.
**3. Bottom Layer (Central Units & Global Information):**
* **Components:** Three hexagonal boxes arranged horizontally, each directly below a corresponding Policy box.
* **Labels (from left to right):** `Central Unit 1`, `Central Unit 2`, `Central Unit n`
* **Update Mechanism:** Each Central Unit has an upward-pointing arrow labeled `Update` directed at its corresponding Policy box above. This indicates the central unit is responsible for updating the parameters of its assigned policy.
* **Global Information Source:** A text label at the very bottom of the diagram.
* **Label:** `Global Information (e.g., rewards)`
* **Flow:** Three upward-pointing arrows originate from this label, one pointing to the base of each Central Unit. This shows that global information (such as shared rewards or system-wide state) is fed into each central unit to inform the policy updates.
### Detailed Analysis
**Spatial Layout & Flow:**
* The diagram is organized in a top-down flow: Environment → Policies → Central Units.
* The primary data flow is vertical within each column (e.g., Environment ↔ Policy 1 ↔ Central Unit 1).
* A secondary, horizontal flow of "Global Information" feeds into all Central Units from the bottom, creating a many-to-one relationship from global data to the decentralized update units.
**Component Relationships:**
* **Policy-Environment Loop:** Each `Policy i` engages in a direct, independent interaction loop with the `Environment`, sending actions (`ai`) and receiving observations (`oi`).
* **Centralized Update:** Each `Policy i` is not updated by its own interaction data alone. Instead, its update is mediated by a dedicated `Central Unit i`.
* **Global Coordination:** The `Central Units` do not operate in isolation. They all receive the same `Global Information`, which likely includes aggregated rewards or global state information. This allows for coordinated learning across all agents, even though their execution (the Policy-Environment interaction) is decentralized.
### Key Observations
1. **Scalability:** The use of `n` and the ellipsis (`...`) explicitly denotes that this architecture is designed for a variable and potentially large number of agents (`n`).
2. **Separation of Concerns:** The diagram cleanly separates the *execution* component (Policy) from the *learning/update* component (Central Unit) for each agent.
3. **Hybrid Information Flow:** The system combines local, agent-specific information (the `ai`/`oi` loop) with global, shared information (the `Global Information` feed) for the learning process.
4. **Symmetry:** The structure is perfectly symmetric across all `n` columns, indicating a homogeneous agent architecture where each agent follows the same interaction and update protocol.
### Interpretation
This diagram represents a specific paradigm in multi-agent reinforcement learning, often referred to as **Centralized Training with Decentralized Execution (CTDE)**.
* **What it demonstrates:** The architecture enables agents to learn cooperative or competitive behaviors by leveraging global information during training (via the Central Units), while allowing them to act independently based on their local observations during deployment (the Policy-Environment loop).
* **Relationship between elements:** The `Environment` is the shared testing ground. The `Policies` are the individual agents' brains. The `Central Units` are the trainers or critics that improve each agent's brain using both the agent's own experiences and a global perspective (`Global Information`). The `Update` arrow is the critical learning signal.
* **Purpose and Implications:** This design aims to solve the non-stationarity problem in MARL (where one agent's learning changes the environment for others) by providing a stable, global learning signal. It suggests a system where individual agents can be deployed efficiently (decentralized execution) but are trained intelligently with system-wide awareness (centralized training). The "e.g., rewards" note implies that the global information is likely used to shape a shared or team-based objective function.
</details>
(e) Concurrent
Figure 4: Five types of Training Schemes.
Centralized Learning
As shown in Figure 4(a), experiences are gathered into a central unit, then learning to control all agents. Based on our observations, recent works on Comm-MADRL usually do not assume a central controller.
Fully Decentralized Learning
As illustrated in Figure 4(b), in fully decentralized learning, experiences are collected individually by each agent, and they undergo independent training processes. Recent works in this category often employ actor-critic based methods for each agent [40, 41, 82, 74, 84, 85, 95]. Specifically, decentralized learning has gained much attention in learning tasks with emergent language, as it most closely resembles language learning in nature [62, 63, 65].
Centralized Training and Decentralized Execution
In CTDE approaches, the experiences of all agents are collectively used for optimization. Gradients derived from the joint experiences of agents guide the learning of local policies. However, once training is complete, only the policies are needed and gradients can be discarded, facilitating decentralized execution. When agents are assumed to be homogeneous, meaning they have identical sensory inputs, actuators, and model structures, they can share parameters. Parameters sharing reduces the overall number of parameters, potentially enhancing learning efficiency compared to training in separate processes. Despite sharing parameters, agents can still exhibit distinct behaviors because they are likely to receive different observations at the same time step. Based on these considerations, recent works in this field can be further divided into the following subcategories.
- Independent Policies. In this category, each local policy is trained with its own set of learning parameters. A central unit collects experiences from all agents to provide global information and guidance, such as gradients, as depicted in Figure 4(c). The training of the entire system can employ policy gradient algorithms (e.g., using REINFORCE) [88], or actor-critic methods [43, 66, 76, 80, 64].
- Parameter Sharing. In this category, all local policies (or local value functions) utilize a shared set of parameters, as illustrated in Figure 4(d). Commonly used algorithms in this scenario include DQN-like algorithms, actor-critic methods, and policy gradient algorithms with REINFORCE. When employing a DQN-like algorithm, a shared local Q-function, which processes each agent’s individual experience, is learned collectively across agents [73, 81, 77]. Additionally, DQN-based methods can be integrated with value decomposition models (e.g., QMIX [28]) in cooperative environments, which enable learning from factorized rewards (value functions) [31, 75, 32, 33]. In the case of actor-critic methods, a shared actor (i.e., policy model) is trained using all individual experiences, supported by gradient guidance from a central critic [50, 39, 89, 78, 79, 86, 87, 91, 92, 93, 94]. Policy gradient with REINFORCE can alternatively be used, requiring the collection of sampled rewards over episodes [48, 61, 49, 83].
- Concurrent. In scenarios where storing all experiences in a central unit is not feasible, agents can alternatively create backups of all experiences, with the assumption that they are able to observe other agents’ actions and observations. The concurrent approaches differ inherently from fully decentralized learning. In CTDE with concurrent approaches, each agent maintains an individual set of policy parameters and receives the guidance from a local unit that collects global information (with additional assumptions on observability), as depicted in Figure 4(e). Concurrent CTDE often employs actor-critic methods, where each agent has its own central critic to guide its local actor (policy) [42, 90].
### 3.10 Possible Relations of Dimensions
We have introduced 9 dimensions for Comm-MADRL and identified a range of categories within each dimension. It is crucial to consider the potential interdependencies among these dimensions. We realize that the dimensions do not inherently depend on one another based on the criteria used for classifying the literature. However, specific implementations of Comm-MADRL systems may create dependencies between dimensions. For instance, limited bandwidth constraints (defined in the communication constraints dimension) can be realized by setting a limited number of times to communicate, rendering the full communication category (within the communication policy dimension) infeasible. This scenario illustrates how the dimensions of communication constraints (Section 3.2) and communication policy (Section 3.4) become interdependent due to specific implementations. Another example about communicated messages shows that the classification criteria we used do not depend on each other. During implementation, a proxy (in the communicatee type dimension) or corrupted message constraints (in the communication constraints dimension) may change the value of message content. However, we categorize communicated messages as Existing Knowledge or Imagined Future Knowledge, based on whether future knowledge is simulated and utilized. This classification criterion is not inherently linked to a specific type of communicatee or communication constraint. Thus, the dimensions of communicatee type (Section 3.3) and communication constraints (Section 3.2) are independent from the viewpoint of classification criteria. Consequently, the proposed categories and dimensions effectively encapsulate the literature from their unique perspectives.
## 4 Findings, Discussions, and Research Directions
In this section, we discuss the trend of the current literature and provide our observations and findings based on the proposed dimensions and categorizations. We also dive into the dimensions and suggest possible future research directions.
### 4.1 Findings and Discussions
To provide a more comprehensive overview of the literature, we have utilized the proposed 9 dimensions to categorize existing works, thereby creating an extensive table. For ease of reference, we introduce notations for these dimensions and their associated categories in Table 12. These notations are subsequently employed to categorize research works in Table LABEL:tab:allworks. In Table LABEL:tab:allworks, research works are sorted based on their publication or archival dates (e.g., on arXiv). Our proposed 9 dimensions offer different perspectives for analyzing and comparing recent works in the field of Comm-MADRL. Through these dimensions and categories, we have observed several intriguing findings.
Table 12: The notations of all categories.
| Dimensions | Notations |
| --- | --- |
| Controlled Goals (CG) | $C_oo$ : Cooperative; $C_om$ : Competitive; $M$ : Mixed |
| Communication Constraints (CC) | $U$ : Unconstrained Communication; $L_b$ : Limited Bandwidth; $C_m$ : Corrupted Messages; |
| Communicatee Type (CT) | $N_a$ : Nearby Agents; $A$ : Other (Learning) Agents; $P$ : Proxy |
| Communication Policy (CP) | $F_c$ : Full Communication; $P_s$ : Predefined (Partial) Structure; $I_c$ : Individual Control; $G_c$ : Global Control |
| Communicated Messages (CM) | $E$ : Existing Knowledge; $I$ : Imagined Future Knowledge |
| Message Combination (MC) | $V_e$ : Equally Valued; $V_u$ : Unequally Valued |
| Inner Integration (II) | $P_l$ : Policy-level; $V_l$ : Value-level; $PV$ : Policy-level & Value-level |
| Learning Methods (LM) | $D$ : Differentiable; $S_p$ : Supervised; $R_e$ : Reinforced; $R_g$ : Regularized |
| Training Schemes (TS) | $CL$ : Centralized Learning; $DL$ : Decentralized Learning; $CTDE_ip$ : CTDE with Individual (Policy) Parameters; $CTDE_ps$ : CTDE with Parameter Sharing; $CTDE_c$ : Concurrent CTDE |
- In the dimension of Controlled Goals, recent research has focused on various cooperative settings, together with a few mixed scenarios. Communication in non-cooperative multi-agent tasks, however, has not been extensively explored. In such (non-cooperative) environments, the goals of different agents may conflict. In the emergent language literature, Noukhovitch et al. [47] have investigated how communication emerges between sender and receiver agents when they exhibit different levels of competitiveness, ranging from full cooperation to full competition. The results reveal that both sender and receiver agents can obtain higher rewards through communication when the level of competition is not high. However, their research primarily focuses on a simplified game without considering state transitions. The effectiveness of communication in MARL tasks with large state spaces, particularly in partial competitive settings where agents can still gain mutual benefits through low-level cooperation, remains an area for further exploration. Moreover, in non-cooperative settings, agents may be motivated to deceive or manipulate the communication channel to mislead others. The notion of trust in multi-agent systems introduces the possibility of establishing a truthful communication protocol [106, 107]. Agents could assess the reliability of opponents and defend against malicious messages. Additionally, agents might evaluate interactions of opponents with other agents to determine their reputations, which could influence the priorities of communicating with other agents.
- In the dimension of Communication Constraints, many existing works do not account for communication constraints, which may limit their applicability in realistic scenarios that have such limitations. For instance, transmitting messages in a large multi-agent system across long distances can result in delays, losses, or even be infeasible. Communication might be asynchronous, requiring several time steps for information exchange. These factors introduce new challenges to Comm-MADRL systems, such as validating previously sent messages and integrating messages from different time steps. Moreover, if communication resources are limited due to budget or capacity constraints, agents must decide how to allocate these resources effectively, especially when their goals vary. Conveying too much information might benefit others while sacrificing the agent’s own learning opportunities. The concept of fairness, which has been extensively studied in multi-agent systems, focuses on developing fair solutions for resource allocation. The ideas of maximizing the utility of worse-off agents and decreasing the difference in utilities between agents in the fairness study can be utilized to distribute communication resources equally. For instance, agents with lower utilities could be allotted more resources to facilitate their communication with others.
- In the dimension of Communicatee Type, the concept of a proxy is utilized to facilitate message coordination. When global observability is available, a proxy often considers all agents within the environment. This proxy can be particularly effective and targeted by utilizing the independence among agents, coordinating messages among only a subset of agents as necessary.
- In the dimension of Communication Policy, current works often assume a binary communication action regarding whether or not to communicate with other agents (or a specific agent). However, communication actions can be more fine-grained and descriptive. For instance, agents might opt to send only a portion of their messages due to uncertainty or lack of confidence. Additionally, a communication action could be defined more specifically, such as communicate with others if the budget exceeds a predetermined threshold. Thus, a communication policy can encompass a variety of communication actions, tailored to align with human heuristics and specific system requirements.
- In the dimension of Communicated Messages, various methods have been proposed to utilize the existing knowledge of agents for message generation. Some existing works consider incorporating agents’ intentions or future plans. However, intentions or future plans may lead to catastrophic errors due to insufficient understanding of the underlying (transition) dynamics. Model-based Reinforcement Learning (RL) could assist agents in making more accurate predictions about future situations, thereby enabling the agents to communicate information with more certainty regarding upcoming changes. Additionally, current literature often assumes that messages are conveyed as single values or vectors. In contrast, modern devices allow for more complex formats, such as graphs and logical expressions. These formats can convey a substantial amount of knowledge or facts concisely, facilitating fast coordination. However, the challenge lies in effectively encoding and decoding complex information structures, which requires more sophisticated learning signals.
- In the dimension of Message Combination, as messages often contain information related to each agent’s individual experiences, goals, etc., many recent works consider the varying importance of these messages. These research works mostly rely on attention mechanisms to impose weights on received messages. Furthermore, agents can incorporate their prior knowledge or preferences about other agents’ capabilities into these weights, enhancing the relevance and effectiveness of message combination.
- In the dimension of Inner Integration, many recent works have focused on integrating messages into the policy model. This trend is likely due to the growing interest in policy-based methods, particularly actor-critic algorithms, within the field of MADRL, where significant advancements have been achieved. Given that neural networks typically feature a hierarchical structure, there is potential for agents to effectively integrate messages into different layers. This approach would allow for considering varying levels of abstraction, potentially enhancing the decision-making process.
- In the dimension of Learning Methods, the learning process for communication typically requires instantaneous feedback from agents who receive and act upon messages. This feedback could be in the form of gradient information or changes in the policies or rewards of the receiving agents. However, obtaining instantaneous feedback from other agents might not always be feasible in real-time decision-making systems. Despite this challenge, agents can still observe changes in the environment and their rewards to self-evaluate the effectiveness of their communication. This self-evaluation process enables agents to update and learn their communication protocols over time.
- In the dimension of Training Schemes, parameter sharing combined with centralized training and decentralized execution is widely adopted in Comm-MADRL to reduce the number of learning parameters. However, accessing other agents’ memories and parameters might raise privacy concerns. On the other hand, fully decentralized learning presents significant challenges and remains a key research area in MARL. In fully decentralized learning, agents have limited knowledge about the environment and must deal with non-stationarity, a problem that intensifies with an increasing number of agents. Nonetheless, Comm-MADRL can benefit from advancements in MARL, potentially leading to the development of novel training paradigms that better balance knowledge sharing, privacy, and learning efficiency.
Based on the proposed dimensions, we have identified a range of findings and potential issues in the field of Comm-MADRL. Among these issues, achieving fully decentralized learning and self-evaluated communication protocols remains a significant challenge. This difficulty arises because each agent has access only to their own data collected from the environment, adding complexity to message evaluation without the help of other agents. Decentralized action policies and self-evaluated communication protocols, however, could be advantageous in areas like Electronic Commerce [108], Networks [109], and Blockchain [110], where synchronizing knowledge and information among users or agents can be computationally demanding. Another open question involves how to effectively communicate using more complex message formats and implement efficient training methods, potentially leading to more sophisticated communication architectures. Importantly, advancements in multi-agent systems and multi-agent reinforcement learning can significantly contribute to the progress of Comm-MADRL.
Table 13: An overview of recent works in Comm-MADRL. $a+b$ denotes that the research work considers categories $a$ and $b$ simultaneously in the environment. $a/b$ denotes that the research work has been examined in multiple categories but in separate environments or settings.
| DIAL [73] | $C_oo$ | $L_b$ + $C_m$ | $A$ | $F_c$ | $E$ | $V_e$ | $V_l$ | $D$ | $CTDE_ps$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RIAL [73] | $C_oo$ | $L_b$ | $A$ | $F_c$ | $E$ | $V_e$ | $V_l$ | $R_e$ | $CTDE_ps$ |
| CommNet [48] | $C_oo$ | $U$ | $A$ | $F_c$ | $E$ | $V_e$ | $P_l$ | $D$ | $CTDE_ps$ |
| GCL [61] | $C_oo$ | $L_b$ | $A$ | $F_c$ | $E$ | $V_e$ | $P_l$ | $D$ + $R_e$ | $CTDE_ps$ |
| BiCNet [50] | $C_oo$ | $U$ | $A$ | $F_c$ | $E$ | $V_u$ | $PV$ | $D$ | $CTDE_ps$ |
| MS-MARL-GCM [88] | $C_oo$ | $U$ | $P$ | $F_c$ | $E$ | $V_u$ | $P_l$ | $D$ | $CTDE_ip$ |
| ATOC [39] | $C_oo$ | $U$ | $P$ | $I_c$ | $I$ | $V_u$ | $P_l$ | $S_p$ | $CTDE_ps$ |
| IC [62] | $C_oo$ | $L_b$ | $A$ | $F_c$ | $E$ | $V_e$ | $PV$ | $R_e$ | $DL$ |
| DGN [81] | $C_oo$ / $M$ | $U$ | $N_a$ | $P_s$ | $E$ | $V_u$ | $V_l$ | $D$ | $CTDE_ps$ |
| TarMAC [89] | $C_oo$ / $M$ | $U$ | $A$ | $F_c$ | $E$ | $V_u$ | $PV$ | $D$ | $CTDE_ps$ |
| MAGNet-SA-GS-MG [40] | $C_oo$ | $U$ | $N_a$ | $P_s$ | $E$ | $V_u$ | $P_l$ | $D$ | $DL$ |
| MADDPG-M [41] | $C_oo$ | $U$ | $A$ | $I_c$ | $E$ | $V_e$ | $PV$ | $R_e$ | $DL$ |
| IC3Net [49] | $C_oo$ / $C_om$ / $M$ | $U$ | $A$ | $I_c$ | $E$ | $V_e$ | $P_l$ | $R_e$ | $CTDE_ps$ |
| MD-MADDPG [42] | $C_oo$ | $U$ | $P$ | $F_c$ | $E$ | $V_u$ | $P_l$ | $D$ | $CTDE_c$ |
| SchedNet [43] | $C_oo$ | $L_b$ | $A$ | $G_c$ | $E$ | $V_e$ | $P_l$ | $R_e$ | $CTDE_ip$ |
| DCC-MD [82] | $C_oo$ | $U$ | $A$ | $F_c$ | $E$ | $V_u$ | $V_l$ | $D$ | $DL$ |
| Agent-Entity Graph [74] | $C_oo$ | $U$ | $N_a$ | $P_s$ | $E$ | $V_u$ | $PV$ | $D$ | $DL$ |
| VBC [31] | $C_oo$ | $L_b$ | $A$ | $P_s$ | $E$ | $V_e$ | $V_l$ | $D$ | $CTDE_ps$ |
| NDQ [75] | $C_oo$ / $M$ | $L_b$ | $A$ | $P_s$ | $E$ | $V_e$ | $V_l$ | $R_g$ | $CTDE_ps$ |
| IMAC [66] | $C_oo$ | $L_b$ | $P$ | $F_c$ | $E$ | $V_u$ | $P_l$ | $R_g$ | $CTDE_ip$ |
| GA-Comm [83] | $C_oo$ | $U$ | $P$ | $G_c$ | $E$ | $V_u$ | $P_l$ | $D$ | $CTDE_ps$ |
| Gated-ACML [76] | $C_oo$ | $L_b$ | $P$ | $I_c$ | $E$ | $V_u$ | $P_l$ | $S_p$ | $CTDE_ip$ |
| Bias [63] | $C_oo$ | $L_b$ | $A$ | $F_c$ | $E$ | $V_e$ | $PV$ | $R_g$ | $DL$ |
| LSC [77] | $C_oo$ / $M$ | $U$ | $N_a$ | $I_c$ | $E$ | $V_u$ | $V_l$ | $R_e$ | $CTDE_ps$ |
| Diff Discrete [78] | $C_oo$ | $C_m$ | $A$ | $F_c$ | $E$ | $V_e$ | $P_l$ | $D$ | $CTDE_ps$ |
| NeurComm [84] | $C_oo$ | $U$ | $N_a$ | $P_s$ | $I$ | $V_u$ | $PV$ | $D$ | $DL$ |
| IP [85] | $C_oo$ | $U$ | $N_a$ | $P_s$ | $I$ | $V_u$ | $P_l$ | $D$ | $DL$ |
| I2C [79] | $C_oo$ | $U$ | $A$ | $I_c$ | $E$ | $V_u$ | $P_l$ | $S_p$ | $CTDE_ps$ |
| IS [90] | $C_oo$ | $U$ | $A$ | $F_c$ | $I$ | $V_e$ | $P_l$ | $D$ | $CTDE_c$ |
| ETCNet [86] | $C_oo$ | $L_b$ | $A$ | $I_c$ | $E$ | $V_e$ | $P_l$ | $R_e$ | $CTDE_ps$ |
| Variable-length Coding [87] | $C_oo$ | $L_b$ | $A$ | $F_c$ | $E$ | $V_e$ | $P_l$ | $D$ | $CTDE_ps$ |
| TMC [32] | $C_oo$ | $L_b$ | $A$ | $P_s$ | $E$ | $V_u$ | $V_l$ | $D$ | $CTDE_ps$ |
| HAMMER [91] | $C_oo$ | $U$ | $P$ | $F_c$ | $E$ | $V_u$ | $P_l$ | $R_e$ | $CTDE_ps$ |
| MAGIC [92] | $C_oo$ / $M$ | $U$ | $P$ | $G_c$ | $E$ | $V_u$ | $PV$ | $D$ | $CTDE_ps$ |
| FlowComm [93] | $C_oo$ | $U$ | $N_a$ | $G_c$ | $E$ | $V_e$ | $P_l$ | $D$ | $CTDE_ps$ |
| AE-Comm [65] | $C_oo$ | $L_b$ | $A$ | $F_c$ | $E$ | $V_e$ | $PV$ | $R_g$ | $DL$ |
| GAXNet [80] | $C_oo$ | $U$ | $N_a$ | $P_s$ | $E$ | $V_u$ | $P_l$ | $D$ | $CTDE_ip$ |
| DCSS [64] | $C_oo$ | $C_m$ | $P$ | $F_c$ | $E$ | $V_e$ | $PV$ | $D$ + $S_p$ | $CTDE_ip$ |
| R-MACRL [95] | $C_om$ | $C_m$ | $A$ | $F_c$ | $E$ | $V_u$ | $P_l$ | $S_p$ | $DL$ |
| MAIC [33] | $C_oo$ | $L_b$ | $A$ | $P_s$ | $E$ | $V_u$ | $V_l$ | $R_g$ | $CTDE_ps$ |
| FCMNet [94] | $C_oo$ | $U$ | $A$ | $F_c$ | $E$ | $V_u$ | $PV$ | $D$ | $CTDE_ps$ |
In addition to these findings, the evaluation metrics used in Comm-MADRL research are of significant interest. It is noteworthy that existing works have been evaluated across various platforms and games, employing different metrics to assess performance. Crucially, Comm-MADRL studies often use varying settings of experiments, such as the number of agents or the use of parameter sharing. These settings can make it challenging to fairly compare the relative strengths and limitations of algorithms based on their performance outcomes [111]. We have identified four evaluation metrics commonly used in Comm-MADRL studies as follows:
- Reward-based: This metric employs the converged return or average rewards per episode or time step to demonstrate the profit gained by agents.
- Win or Fail Rate: This metric calculates the percentage that agents achieve their goal or fail the game during learning. It is often used in episodic tasks.
- Steps Taken: This metric evaluates the number of time steps learned to reach the goal. It is often used in episodic tasks and essential in scenarios where time efficiency is key.
- Communication Efficiency: This metric evaluates how much communication resource has been used, such as the frequency of communication between agents.
- Emergence Degree: Originating from the field of emergent language, this metric evaluates and detects the emergence of language [112, 45]. It is often used in learning tasks with emergent language. Positive signaling and positive listening are two common approaches. Positive signaling measures the correlation between a message and the sender’s observation or intended action. Positive listening assesses the impact of an observed message on the receiver’s beliefs or behavior.
We have analyzed the number of times that the above performance metrics are used in existing Comm-MADRL studies, as illustrated in Figure 5. It is shown that the metric of communication efficiency has not been extensively used in the literature, requiring further investigation into the use of communication resources in Comm-MADRL approaches. The Emergence Degree metric, intended to measure whether a language is emergent, is primarily utilized in emergent language studies. Nonetheless, this metric can also yield significant insights for other Comm-MADRL systems. By analyzing the correlation between communication and the observations and behaviors of both senders and receivers, we could obtain a deeper understanding and explanation of communication for Comm-MADRL.
<details>
<summary>x12.png Details</summary>
### Visual Description
\n
## Bar Chart: Count of Metrics or Categories
### Overview
The image displays a vertical bar chart showing the count associated with five distinct categories. The chart has a clean, minimalist design with a light gray background and horizontal grid lines. The bars are colored in a gradient from light beige to dark purple, but no legend is provided to explain the color coding. The data appears to represent a frequency or occurrence count for each category.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **Y-Axis (Vertical):**
* **Label:** "Count"
* **Scale:** Linear scale from 0 to 30.
* **Major Ticks/Gridlines:** At intervals of 5 (0, 5, 10, 15, 20, 25, 30).
* **X-Axis (Horizontal):**
* **Categories (from left to right):**
1. Reward-based
2. Win or Fail Rate
3. Steps Taken
4. Communication Efficiency
5. Emergence Degree
* **Legend:** None present. The color gradient of the bars (light beige to dark purple) does not have an explanatory key.
* **Title:** No chart title is visible.
### Detailed Analysis
The chart presents a clear descending trend in count from the first category to the last. Below is the approximate value for each bar, determined by visual alignment with the y-axis gridlines.
| Category (X-axis) | Approximate Count (Y-axis) | Visual Trend & Color Description |
| :--- | :--- | :--- |
| **Reward-based** | ~29 | The tallest bar, colored light beige. It nearly reaches the 30 mark. |
| **Win or Fail Rate** | ~16 | The second tallest bar, colored a muted rose/taupe. It sits just above the 15 gridline. |
| **Steps Taken** | ~10 | The third bar, colored a dusty mauve. Its top aligns exactly with the 10 gridline. |
| **Communication Efficiency** | ~5 | The fourth bar, colored a dark plum. Its top aligns exactly with the 5 gridline. |
| **Emergence Degree** | ~3 | The shortest bar, colored a very dark purple/black. It is slightly more than half the height of the 5 gridline. |
**Trend Verification:** The visual trend is a strict, stepwise decrease in bar height from left to right. Each subsequent category has a lower count than the one before it.
### Key Observations
1. **Dominant Category:** "Reward-based" is the most frequent or highly counted metric by a significant margin, with a count nearly double that of the next category.
2. **Clear Hierarchy:** The data establishes a strict order of prevalence: Reward-based > Win or Fail Rate > Steps Taken > Communication Efficiency > Emergence Degree.
3. **Precise Mid-Point:** The "Steps Taken" bar sits exactly at the midpoint of the y-axis scale (10 out of 0-30).
4. **Low-End Clustering:** The last two categories, "Communication Efficiency" and "Emergence Degree," have relatively low counts (5 and ~3), suggesting they are less frequently observed or measured.
5. **Color Gradient:** The bar colors transition smoothly from light to dark, which may be an aesthetic choice or could imply an ordinal relationship between the categories (e.g., from more concrete to more abstract concepts).
### Interpretation
This chart likely summarizes the frequency of different evaluation metrics, performance indicators, or behavioral categories within a dataset or a body of research, possibly related to multi-agent systems, reinforcement learning, or complex systems analysis.
* **What the data suggests:** The overwhelming count for "Reward-based" indicates that reward mechanisms are the most commonly tracked or reported element in the context this data was drawn from. Metrics related to outcomes ("Win or Fail Rate") and process efficiency ("Steps Taken") are moderately common. More complex, systemic properties like "Communication Efficiency" and especially "Emergence Degree" are measured or reported far less frequently.
* **Relationship between elements:** The descending order could reflect a hierarchy of measurement difficulty or research focus. Reward-based metrics are often fundamental and easier to quantify in AI systems. In contrast, "Emergence Degree" is a complex, higher-order property that is notoriously difficult to define and measure, which aligns with its low count.
* **Notable anomaly:** The lack of a chart title or legend is a significant omission for a technical document. The color gradient, while visually appealing, remains unexplained, leaving the viewer to speculate whether it carries semantic meaning (e.g., representing a spectrum from simple to complex) or is purely decorative.
* **Underlying implication:** The data implies a potential research or monitoring bias towards easily quantifiable, direct performance metrics (reward, win rate, steps) over more nuanced, interaction-based, or systemic properties (communication, emergence). This could highlight a gap in evaluation methodologies for the studied system.
</details>
Figure 5: The Statistics of Evaluation Metrics in existing Comm-MADRL systems.
In the next section, inspired by the proposed dimensions, we demonstrate the potential for discovering new ideas through our survey. We identify several possible research directions that jointly explore multiple dimensions, aiming to bridge the gaps in current works.
### 4.2 Research Directions
Comm-MADRL is a young but rapidly enlarging field. There are still lots of possibilities to develop new Comm-MADRL systems. Our proposed dimensions encapsulate several aspects of Comm-MADRL, from which we can identify new research directions. Therefore, we showcase four research directions motivated by leveraging the possible combinations of dimensions and the extensions of corresponding categories. We also point out further challenges for Comm-MADRL.
#### 4.2.1 Multimodal Communication
A versatile robot can hear by sound sensors, read text or talk with human partners. Intelligent agents may be surrounded by different data sources and act based on multimodal input. By jointly considering the dimensions of communicatee type and communicated messages, we can imagine a fertile scenario where communication is not limited to images or handcrafted features but encompasses multimodal data, such as speech, videos, and text from humans or domestic robots, to prosper applications like smart home. To the best of our knowledge, existing works in Comm-MADRL do not consider communicating multimodal data or encoding them. Recent works often use encoded images as messages, which only cover visually-based applications. Therefore, we believe exploring multimodal communication represents a promising research direction and introduces several challenges that need to be addressed. In multimodal communication, agents have to coordinate heterogeneous modalities and encode various types of information into messages. A possible solution is to use separate channels to communicate specific modalities, while agents must decide on the right channel to communicate and merge data from different channels. A more efficient way is to learn a joint representation of multimodal observations and communicate on one channel. Due to the progress of Multimodal machine learning [113], we can bring ideas from this area to equip agents with the ability to create a single representation of multimodal data. Nevertheless, it is unclear how the solutions from Multimodal machine learning can be extended to multi-agent reinforcement learning. Poklukar et al. [114] propose learning an aligned representation from multiple modalities, although their tests are conducted in a single-agent reinforcement learning task. The multi-agent scenarios, however, may need to consider the individual abilities and preferences of different agents. For example, a voice-activated agent may favor voice data for interaction, while a monitoring agent may only access video data. Therefore, in multi-agent settings, agents need to align their individual preferences regarding multimodality when learning a joint representation of the multimodal data. Another crucial technical issue is how to represent multimodal messages in low-dimensional vectors without losing essential information from each modality, as Comm-MADRL systems often consider reducing communication costs. Eventually, we expect the progress of multimodal communication will benefit human-agent interaction and diverse communicating agents.
The emergence of new research works would introduce new categories under each dimension. For example, with developments in multimodal communication, we can extend the categories of communicated messages with speech, image, text, and video data. Nevertheless, our proposed dimensions can be adaptive and robust to cover new Comm-MADRL research in this direction.
#### 4.2.2 Structural Communication
Through the Internet, electronic devices like routers can process and transmit information. On social media, chatbots can be community members [115, 116], to engage in conversations with users and share information/opinions. In those large-scale multi-agent systems [117, 118], agents may belong to different groups, where their relationships can be complicated. For example, local area networks create boundaries of communication and interaction between devices. Chatbots may not be able to reach some users because of limited permission or the lack of friendship relations. These restricted connectivities among agents require more efficient usage of communication structure. Therefore, we think that the research direction focusing on structural communication opens up possibilities for enabling communication among a larger number of agents. In the current literature in Comm-MADRL, ATOC [39] and LSC [77] have investigated communication with multiple groups, where agents can only communicate with other agents who belong to the same group. In both approaches, different groups may share common member agents, i.e., bridge agents, which are used to enable information to flow from group to group. However, communication through bridge agents is not targeted and each agent unconsciously shares their information with other groups. In terms of the dimension of controlled goals, agents may have individualized goals and require collaboration with a specific set of agents. Therefore, an important future direction of structural communication is to send critical information and opinions to target agents. For example, agent 1 may observe the goal location of agent 2 while they belong to different groups. If agent 3 happens to be a common friend of agent 1 and 2, agent 1 can actively send the goal information to agent 2 with the help of agent 3. If communication is costly and information is private, agents need to make thoughtful decisions about which bridge agents to be used to find the shortest and safe path to reach targeted agents. At the same time, bridge agents need to agree on the communication path to transmit information successfully. If a complex and hierarchical friendship network is identified, another important question is how to prioritize and schedule different communication paths to make communication fluent. Regarding communicated messages, agents need to build a common protocol with targeted agents so that information can be encoded and decoded successfully. As a result, agents can more actively utilize the communication structure among agents to achieve better collaboration and agreements.
#### 4.2.3 Robust Centralized Unit
Robustness has been widely considered in the field of reinforcement learning [119, 120], where an agent needs to cope with disturbances in learning in order to achieve a robust policy that can generalize under changes in training/test data. In MARL, agents’ policies can be sensitive to environmental noise or malicious intentions of opponents, and thus robust policies are required [121, 122]. With communication, opponents may produce malicious messages, implying adversary intentions. Preventing malicious messages is important in non-cooperative settings as adversary agents may manipulate communication to achieve their own goals at the expense of other agents’ benefits. Existing works on Comm-MADRL, such as $\mathfrak{R}$ -MACRL [95], have investigated how to detect adversary information and reconstruct original messages. However, as we discussed in the dimensions of communicatee type and training paradigm, proxy and critics are often centralized and gather information from all agents. Robustness becomes essential for these centralized units as all agents involved in communication can be misled by polluted feedback, for example, incorrect gradient signals from critics or malicious messages from a proxy. Moreover, malicious messages can easily spread through the (centralized) proxy. Therefore, we think building a robust centralized unit is a promising and underdeveloped direction for safe communication in MADRL, where proxies and critics need to avoid communication being exploited by adversaries or affected by harmful environmental changes. By considering the dimension of communication policy, sender agents can learn a versatile communication policy. For example, the communication policy can be defined to select different encoding protocols for different groups of agents, in case malicious agents may easily find a solution to cheat on a specific encoding protocol. Besides, as malicious or noisy messages can be hidden in the centralized proxy, it is important to figure out which messages are malicious and how to reconstruct the original messages. Nonetheless, developing robust centralized units is vital for reliable and protected Comm-MADRL systems.
#### 4.2.4 Learning Tasks with Emergent Language
In this survey, we have identified the intersection between learning tasks with communication and emergent language in the field of MADRL, which we have called learning tasks with emergent language. We also observed that there is only a limited number of research works concerning this sub-area learning tasks with emergent language, which learns a language while achieving a MADRL task. We believe this area can be further expanded and investigated, by considering several dimensions proposed by our survey. First, the communicated messages, as we discussed earlier, can be encoded into more complex symbolic formats, such as graphs or logical expressions. Existing works in the field only learn how to communicate through atomic symbols or a combination [61, 63, 64]. However, it is important to learn the relation between symbols. For example, symbol A is on the left of symbol B. Those messages can express facts about what agents know or conjecture. Therefore, receivers can quickly adapt their behaviors by successfully decoding the messages. The important question is how to learn both encoding and decoding with complex expressions of messages, which can have a significant number of possibilities. The senders should also properly encapsulate their knowledge and the receivers should reason on the messages correctly. In addition, how complex symbolic formats can emerge in non-cooperative settings is an interesting but unexplored research area. What’s more, the combination of complex messages will not be as easy as handling single values or vectors. Therefore, learning together with complicated communication is still challenging.
#### 4.2.5 Further Challenges
In the field of Comm-MADRL, there are further challenges. For instance, the design of neural network architectures plays a critical role in performance and communication. A deeper neural network may be effective in some domains while failing in other domains. For example, LSTM is effective in capturing history information while may require much time to train the parameters [123, 124], which could greatly slow down the learning in tasks with high complexity. The choice of architectures and fine-tuning hyperparameters are significant problems of Comm-MADRL. With communication, another crucial issue is the explainability of communicated messages. Emergent language has made a step towards human-like language. However, whether machines communicate in a human-like way and can learn a human-interpretable language is still unclear. A great number of existing works regarding learning tasks with communication seek hidden, deep, and obscure codes for messages [48, 49, 79, 92], which still need to be further interpreted and understood.
## 5 Conclusions
Our survey proposes to classify the literature based on 9 dimensions. These dimensions constitute the basis of designing Comm-MADRL systems. We further categorize existing works under each dimension, where readers can easily compare research works from a unique perspective. Based on those dimensions, we also observe findings through the trend of the literature and identify new research directions by filling the gap among recent works. Our survey concludes that while the number of works in Comm-MADRL is notable and represents significant achievements, communication can be more fruitful and versatile to incorporate non-cooperative settings, heterogeneous players, and many more agents. Agents can communicate information not only from raw image inputs or handcrafted features but also from diverse data sources such as voice and text. Furthermore, we can explore novel metrics to better understand the contribution of communication to the overall learning process. Ultimately, Comm-MADRL can benefit from the MARL community and take advantage of good solutions from MARL.
## References
- [1] Shai Shalev-Shwartz, Shaked Shammah, and Amnon Shashua. Safe, multi-agent, reinforcement learning for autonomous driving. CoRR, abs/1610.03295, 2016.
- [2] Meritxell Vinyals, Juan A. Rodríguez-Aguilar, and Jesús Cerquides. A survey on sensor networks from a multiagent perspective. Comput. J., 54(3):455–470, 2011.
- [3] Jens Kober, J. Andrew Bagnell, and Jan Peters. Reinforcement learning in robotics: A survey. Int. J. Robotics Res., 32(11):1238–1274, 2013.
- [4] David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy P. Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of go without human knowledge. Nature, 550(7676):354–359, 2017.
- [5] Noam Brown and Tuomas Sandholm. Superhuman ai for multiplayer poker. Science, 365(6456):885–890, 2019.
- [6] Frans A. Oliehoek and Christopher Amato. A Concise Introduction to Decentralized POMDPs. Springer Briefs in Intelligent Systems. 2016.
- [7] Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6379–6390, 2017.
- [8] Jakob N. Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Sheila A. McIlraith and Kilian Q. Weinberger, editors, Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 2974–2982, 2018.
- [9] Georgios Papoudakis, Filippos Christianos, Arrasy Rahman, and Stefano V. Albrecht. Dealing with non-stationarity in multi-agent deep reinforcement learning. CoRR, abs/1906.04737, 2019.
- [10] Mohamed Salah Zaïem and Etienne Bennequin. Learning to communicate in multi-agent reinforcement learning : A review. CoRR, abs/1911.05438, 2019.
- [11] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521(7553):436–444, 2015.
- [12] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
- [13] Peter Stone and Manuela M. Veloso. Multiagent systems: A survey from a machine learning perspective. Auton. Robots, 8(3):345–383, 2000.
- [14] Liviu Panait and Sean Luke. Cooperative multi-agent learning: The state of the art. Auton. Agents Multi Agent Syst., 11(3):387–434, 2005.
- [15] Lucian Busoniu, Robert Babuska, and Bart De Schutter. A comprehensive survey of multiagent reinforcement learning. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 38(2):156–172, 2008.
- [16] Pablo Hernandez-Leal, Bilal Kartal, and Matthew E. Taylor. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi Agent Syst., 33(6):750–797, 2019.
- [17] Sven Gronauer and Klaus Diepold. Multi-agent deep reinforcement learning: a survey. Artificial Intelligence Review, pages 1–49, 2021.
- [18] Angeliki Lazaridou and Marco Baroni. Emergent multi-agent communication in the deep learning era. CoRR, abs/2006.02419, 2020.
- [19] Frans A. Oliehoek and Christopher Amato. A Concise Introduction to Decentralized POMDPs. Springer Briefs in Intelligent Systems. 2016.
- [20] Eric A. Hansen, Daniel S. Bernstein, and Shlomo Zilberstein. Dynamic programming for partially observable stochastic games. In Deborah L. McGuinness and George Ferguson, editors, Proceedings of the Nineteenth National Conference on Artificial Intelligence, Sixteenth Conference on Innovative Applications of Artificial Intelligence, July 25-29, 2004, San Jose, California, USA, pages 709–715, 2004.
- [21] Yaodong Yang and Jun Wang. An overview of multi-agent reinforcement learning from game theoretical perspective. CoRR, abs/2011.00583, 2020.
- [22] Ming Tan. Multi-agent reinforcement learning: Independent versus cooperative agents. In Paul E. Utgoff, editor, Machine Learning, Proceedings of the Tenth International Conference, University of Massachusetts, Amherst, MA, USA, June 27-29, 1993, pages 330–337, 1993.
- [23] Laëtitia Matignon, Guillaume J. Laurent, and Nadine Le Fort-Piat. Independent reinforcement learners in cooperative markov games: a survey regarding coordination problems. Knowledge Engineering Revie, 27(1):1–31, 2012.
- [24] Caroline Claus and Craig Boutilier. The dynamics of reinforcement learning in cooperative multiagent systems. In Jack Mostow and Chuck Rich, editors, Proceedings of the Fifteenth National Conference on Artificial Intelligence and Tenth Innovative Applications of Artificial Intelligence Conference, AAAI 98, IAAI 98, July 26-30, 1998, Madison, Wisconsin, USA, pages 746–752, 1998.
- [25] Ardi Tampuu, Tambet Matiisen, Dorian Kodelja, Ilya Kuzovkin, Kristjan Korjus, Juhan Aru, Jaan Aru, and Raul Vicente. Multiagent cooperation and competition with deep reinforcement learning. CoRR, abs/1511.08779, 2015.
- [26] Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction, 2nd Edition. The MIT Press. 2018.
- [27] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinícius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-decomposition networks for cooperative multi-agent learning based on team reward. In Elisabeth André, Sven Koenig, Mehdi Dastani, and Gita Sukthankar, editors, Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS 2018, Stockholm, Sweden, July 10-15, 2018, pages 2085–2087, 2018.
- [28] Tabish Rashid, Mikayel Samvelyan, Christian Schröder de Witt, Gregory Farquhar, Jakob N. Foerster, and Shimon Whiteson. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. In Jennifer G. Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pages 4292–4301, 2018.
- [29] Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Hostallero, and Yung Yi. QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 5887–5896, 2019.
- [30] Yihan Wang, Beining Han, Tonghan Wang, Heng Dong, and Chongjie Zhang. DOP: off-policy multi-agent decomposed policy gradients. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021.
- [31] Sai Qian Zhang, Qi Zhang, and Jieyu Lin. Efficient communication in multi-agent reinforcement learning via variance based control. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems 32 (NeurIPS), pages 3230–3239, 2019.
- [32] Sai Qian Zhang, Qi Zhang, and Jieyu Lin. Succinct and robust multi-agent communication with temporal message control. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33 (NIPS), 2020.
- [33] Lei Yuan, Jianhao Wang, Fuxiang Zhang, Chenghe Wang, Zongzhang Zhang, Yang Yu, and Chongjie Zhang. Multi-agent incentive communication via decentralized teammate modeling. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), 2022.
- [34] Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, and Chongjie Zhang. QPLEX: duplex dueling multi-agent q-learning. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, 2021.
- [35] Vijay R. Konda and John N. Tsitsiklis. Actor-critic algorithms. In Sara A. Solla, Todd K. Leen, and Klaus-Robert Müller, editors, Advances in Neural Information Processing Systems 12, NIPS Conference, pages 1008–1014, 1999.
- [36] John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. In Yoshua Bengio and Yann LeCun, editors, 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016.
- [37] Afshin Oroojlooyjadid and Davood Hajinezhad. A review of cooperative multi-agent deep reinforcement learning. CoRR, abs/1908.03963, 2019.
- [38] Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V Albrecht. Comparative evaluation of cooperative multi-agent deep reinforcement learning algorithms. arXiv: 2006.07869, 2020.
- [39] Jiechuan Jiang and Zongqing Lu. Learning attentional communication for multi-agent cooperation. In Advances in Neural Information Processing Systems 31 (NIPS), pages 7265–7275, 2018.
- [40] Aleksandra Malysheva, Tegg Tae Kyong Sung, Chae-Bong Sohn, Daniel Kudenko, and Aleksei Shpilman. Deep multi-agent reinforcement learning with relevance graphs. CoRR, abs/1811.12557, 2018.
- [41] Ozsel Kilinc and Giovanni Montana. Multi-agent deep reinforcement learning with extremely noisy observations. CoRR, abs/1812.00922, 2018.
- [42] Emanuele Pesce and Giovanni Montana. Improving coordination in small-scale multi-agent deep reinforcement learning through memory-driven communication. Machine Learning, 109(9-10):1727–1747, 2020.
- [43] Daewoo Kim, Sangwoo Moon, David Hostallero, Wan Ju Kang, Taeyoung Lee, Kyunghwan Son, and Yung Yi. Learning to schedule communication in multi-agent reinforcement learning. In 7th International Conference on Learning Representations (ICLR), 2019.
- [44] Kris Cao, Angeliki Lazaridou, Marc Lanctot, Joel Z. Leibo, Karl Tuyls, and Stephen Clark. Emergent communication through negotiation. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings, 2018.
- [45] Ryan Lowe, Jakob N. Foerster, Y-Lan Boureau, Joelle Pineau, and Yann N. Dauphin. On the pitfalls of measuring emergent communication. In Edith Elkind, Manuela Veloso, Noa Agmon, and Matthew E. Taylor, editors, Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’19, Montreal, QC, Canada, May 13-17, 2019, pages 693–701, 2019.
- [46] Kalesha Bullard, Douwe Kiela, Joelle Pineau, and Jakob N. Foerster. Quasi-equivalence discovery for zero-shot emergent communication. CoRR, abs/2103.08067, 2021.
- [47] Michael Noukhovitch, Travis LaCroix, Angeliki Lazaridou, and Aaron C. Courville. Emergent communication under competition. In Frank Dignum, Alessio Lomuscio, Ulle Endriss, and Ann Nowé, editors, AAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems, Virtual Event, United Kingdom, May 3-7, 2021, pages 974–982, 2021.
- [48] Sainbayar Sukhbaatar, Arthur Szlam, and Rob Fergus. Learning multiagent communication with backpropagation. In Advances in Neural Information Processing Systems 29 (NIPS), pages 2244–2252, 2016.
- [49] Amanpreet Singh, Tushar Jain, and Sainbayar Sukhbaatar. Learning when to communicate at scale in multiagent cooperative and competitive tasks. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019.
- [50] Peng Peng, Quan Yuan, Ying Wen, Yaodong Yang, Zhenkun Tang, Haitao Long, and Jun Wang. Multiagent bidirectionally-coordinated nets for learning to play starcraft combat games. CoRR, abs/1703.10069, 2017.
- [51] Joseph Farrell and Matthew Rabin. Cheap talk. Journal of Economic perspectives, 10(3):103–118, 1996.
- [52] Hyowoon Seo, Jihong Park, Mehdi Bennis, and Mérouane Debbah. Semantics-native communication with contextual reasoning. CoRR, abs/2108.05681, 2021.
- [53] Tadahiro Taniguchi, Yuto Yoshida, Akira Taniguchi, and Yoshinobu Hagiwara. Emergent communication through metropolis-hastings naming game with deep generative models. CoRR, abs/2205.12392, 2022.
- [54] Rahma Chaabouni, Florian Strub, Florent Altché, Eugene Tarassov, Corentin Tallec, Elnaz Davoodi, Kory Wallace Mathewson, Olivier Tieleman, Angeliki Lazaridou, and Bilal Piot. Emergent communication at scale. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022, 2022.
- [55] Rahma Chaabouni, Eugene Kharitonov, Diane Bouchacourt, Emmanuel Dupoux, and Marco Baroni. Compositionality and generalization in emergent languages. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 4427–4442, 2020.
- [56] Cinjon Resnick, Abhinav Gupta, Jakob N. Foerster, Andrew M. Dai, and Kyunghyun Cho. Capacity, bandwidth, and compositionality in emergent language learning. In Amal El Fallah Seghrouchni, Gita Sukthankar, Bo An, and Neil Yorke-Smith, editors, Proceedings of the 19th International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’20, Auckland, New Zealand, May 9-13, 2020, pages 1125–1133, 2020.
- [57] Rahma Chaabouni, Eugene Kharitonov, Emmanuel Dupoux, and Marco Baroni. Anti-efficient encoding in emergent communication. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 6290–6300, 2019.
- [58] Serhii Havrylov and Ivan Titov. Emergence of language with multi-agent games: Learning to communicate with sequences of symbols. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 2149–2159, 2017.
- [59] Alexander Imani Cowen-Rivers and Jason Naradowsky. Emergent communication with world models. CoRR, abs/2002.09604, 2020.
- [60] Ivana Kajic, Eser Aygün, and Doina Precup. Learning to cooperate: Emergent communication in multi-agent navigation. In Stephanie Denison, Michael Mack, Yang Xu, and Blair C. Armstrong, editors, Proceedings of the 42th Annual Meeting of the Cognitive Science Society - Developing a Mind: Learning in Humans, Animals, and Machines, CogSci 2020, virtual, July 29 - August 1, 2020, 2020.
- [61] Igor Mordatch and Pieter Abbeel. Emergence of grounded compositional language in multi-agent populations. In Sheila A. McIlraith and Kilian Q. Weinberger, editors, Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 1495–1502, 2018.
- [62] Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Çaglar Gülçehre, Pedro A. Ortega, DJ Strouse, Joel Z. Leibo, and Nando de Freitas. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 3040–3049, 2019.
- [63] Tom Eccles, Yoram Bachrach, Guy Lever, Angeliki Lazaridou, and Thore Graepel. Biases for emergent communication in multi-agent reinforcement learning. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 13111–13121, 2019.
- [64] Mycal Tucker, Huao Li, Siddharth Agrawal, Dana Hughes, Katia P. Sycara, Michael Lewis, and Julie A. Shah. Emergent discrete communication in semantic spaces. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 10574–10586, 2021.
- [65] Toru Lin, Jacob Huh, Christopher Stauffer, Ser-Nam Lim, and Phillip Isola. Learning to ground multi-agent communication with autoencoders. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 15230–15242, 2021.
- [66] Rundong Wang, Xu He, Runsheng Yu, Wei Qiu, Bo An, and Zinovi Rabinovich. Learning efficient multi-agent communication: An information bottleneck approach. In Proceedings of the 37th International Conference on Machine Learning (ICML), volume 119 of Proceedings of Machine Learning Research, pages 9908–9918, 2020.
- [67] Wanqi Xue, Wei Qiu, Bo An, Zinovi Rabinovich, Svetlana Obraztsova, and Chai Kiat Yeo. Mis-spoke or mis-lead: Achieving robustness in multi-agent communicative reinforcement learning. CoRR, abs/2108.03803, 2021.
- [68] Thanh Thi Nguyen, Ngoc Duy Nguyen, and Saeid Nahavandi. Deep reinforcement learning for multi-agent systems: A review of challenges, solutions and applications. CoRR, abs/1812.11794, 2018.
- [69] Kaiqing Zhang, Zhuoran Yang, and Tamer Basar. Multi-agent reinforcement learning: A selective overview of theories and algorithms. CoRR, abs/1911.10635, 2019.
- [70] Annie Wong, Thomas Bäck, Anna V. Kononova, and Aske Plaat. Multiagent deep reinforcement learning: Challenges and directions towards human-like approaches. CoRR, abs/2106.15691, 2021.
- [71] Mohamed Salah Zaïem and Etienne Bennequin. Learning to communicate in multi-agent reinforcement learning : A review. CoRR, abs/1911.05438, 2019.
- [72] Yoav Shoham and Kevin Leyton-Brown. Multiagent Systems - Algorithmic, Game-Theoretic, and Logical Foundations. Cambridge University Press. 2009.
- [73] Jakob N. Foerster, Yannis M. Assael, Nando de Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning. In Advances in Neural Information Processing Systems 29 (NIPS), pages 2137–2145, 2016.
- [74] Akshat Agarwal, Sumit Kumar, Katia P. Sycara, and Michael Lewis. Learning transferable cooperative behavior in multi-agent teams. In Proceedings of the 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 1741–1743, 2020.
- [75] Tonghan Wang, Jianhao Wang, Chongyi Zheng, and Chongjie Zhang. Learning nearly decomposable value functions via communication minimization. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, 2020.
- [76] Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. Learning agent communication under limited bandwidth by message pruning. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, pages 5142–5149, 2020.
- [77] Junjie Sheng, Xiangfeng Wang, Bo Jin, Junchi Yan, Wenhao Li, Tsung-Hui Chang, Jun Wang, and Hongyuan Zha. Learning structured communication for multi-agent reinforcement learning. CoRR, abs/2002.04235, 2020.
- [78] Benjamin Freed, Guillaume Sartoretti, Jiaheng Hu, and Howie Choset. Communication learning via backpropagation in discrete channels with unknown noise. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, pages 7160–7168, 2020.
- [79] Ziluo Ding, Tiejun Huang, and Zongqing Lu. Learning individually inferred communication for multi-agent cooperation. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33 (NeurIPS), 2020.
- [80] Won Joon Yun, Byungju Lim, Soyi Jung, Young-Chai Ko, Jihong Park, Joongheon Kim, and Mehdi Bennis. Attention-based reinforcement learning for real-time UAV semantic communication. CoRR, abs/2105.10716, 2021.
- [81] Jiechuan Jiang, Chen Dun, Tiejun Huang, and Zongqing Lu. Graph convolutional reinforcement learning. In 8th International Conference on Learning Representations (ICLR), 2020.
- [82] Woojun Kim, Myungsik Cho, and Youngchul Sung. Message-dropout: An efficient training method for multi-agent deep reinforcement learning. In The Thirty-Third AAAI Conference on Artificial Intelligence, pages 6079–6086, 2019.
- [83] Yong Liu, Weixun Wang, Yujing Hu, Jianye Hao, Xingguo Chen, and Yang Gao. Multi-agent game abstraction via graph attention neural network. In The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), pages 7211–7218, 2020.
- [84] Tianshu Chu, Sandeep Chinchali, and Sachin Katti. Multi-agent reinforcement learning for networked system control. In 8th International Conference on Learning Representations (ICLR), 2020.
- [85] Chao Qu, Hui Li, Chang Liu, Junwu Xiong, James Zhang, Wei Chu, Yuan Qi, and Le Song. Intention propagation for multi-agent reinforcement learning. CoRR, abs/2004.08883, 2020.
- [86] Guangzheng Hu, Yuanheng Zhu, Dongbin Zhao, Mengchen Zhao, and Jianye Hao. Event-triggered multi-agent reinforcement learning with communication under limited-bandwidth constraint. CoRR, abs/2010.04978, 2020.
- [87] Benjamin Freed, Rohan James, Guillaume Sartoretti, and Howie Choset. Sparse discrete communication learning for multi-agent cooperation through backpropagation. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7993–7998, 2020.
- [88] Xiangyu Kong, Bo Xin, Fangchen Liu, and Yizhou Wang. Revisiting the master-slave architecture in multi-agent deep reinforcement learning. CoRR, abs/1712.07305, 2017.
- [89] Abhishek Das, Théophile Gervet, Joshua Romoff, Dhruv Batra, Devi Parikh, Mike Rabbat, and Joelle Pineau. Tarmac: Targeted multi-agent communication. In Proceedings of the 36th International Conference on Machine Learning (ICML), pages 1538–1546, 2019.
- [90] Woojun Kim, Jongeui Park, and Youngchul Sung. Communication in multi-agent reinforcement learning: Intention sharing. In 9th International Conference on Learning Representations (ICLR), 2021.
- [91] Nikunj Gupta, G. Srinivasaraghavan, Swarup Kumar Mohalik, and Matthew E. Taylor. HAMMER: multi-level coordination of reinforcement learning agents via learned messaging. CoRR, abs/2102.00824, 2021.
- [92] Yaru Niu, Rohan R. Paleja, and Matthew C. Gombolay. Multi-agent graph-attention communication and teaming. In 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 964–973, 2021.
- [93] Yali Du, Bo Liu, Vincent Moens, Ziqi Liu, Zhicheng Ren, Jun Wang, Xu Chen, and Haifeng Zhang. Learning correlated communication topology in multi-agent reinforcement learning. In 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pages 456–464, 2021.
- [94] Yutong Wang and Guillaume Sartoretti. Fcmnet: Full communication memory net for team-level cooperation in multi-agent systems. CoRR, abs/2201.11994, 2022.
- [95] Wanqi Xue, Wei Qiu, Bo An, Zinovi Rabinovich, Svetlana Obraztsova, and Chai Kiat Yeo. Mis-spoke or mis-lead: Achieving robustness in multi-agent communicative reinforcement learning. CoRR, abs/2108.03803, 2021.
- [96] Lucian Busoniu, Robert Babuska, and Bart De Schutter. Multi-agent reinforcement learning: A survey. In Ninth International Conference on Control, Automation, Robotics and Vision (ICARCV), pages 1–6, 2006.
- [97] Gabriel Synnaeve, Nantas Nardelli, Alex Auvolat, Soumith Chintala, Timothée Lacroix, Zeming Lin, Florian Richoux, and Nicolas Usunier. Torchcraft: a library for machine learning research on real-time strategy games. CoRR, abs/1611.00625, 2016.
- [98] Oriol Vinyals, Timo Ewalds, Sergey Bartunov, Petko Georgiev, Alexander Sasha Vezhnevets, Michelle Yeo, Alireza Makhzani, Heinrich Küttler, John P. Agapiou, Julian Schrittwieser, John Quan, Stephen Gaffney, Stig Petersen, Karen Simonyan, Tom Schaul, Hado van Hasselt, David Silver, Timothy P. Lillicrap, Kevin Calderone, Paul Keet, Anthony Brunasso, David Lawrence, Anders Ekermo, Jacob Repp, and Rodney Tsing. Starcraft II: A new challenge for reinforcement learning. CoRR, abs/1708.04782, 2017.
- [99] Mikayel Samvelyan, Tabish Rashid, Christian Schröder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob N. Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. In Edith Elkind, Manuela Veloso, Noa Agmon, and Matthew E. Taylor, editors, Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’19, Montreal, QC, Canada, May 13-17, 2019, pages 2186–2188, 2019.
- [100] Karol Kurach, Anton Raichuk, Piotr Stanczyk, Michal Zajac, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, and Sylvain Gelly. Google research football: A novel reinforcement learning environment. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, pages 4501–4510, 2020.
- [101] Laëtitia Matignon, Guillaume J. Laurent, and Nadine Le Fort-Piat. Independent reinforcement learners in cooperative markov games: a survey regarding coordination problems. Knowl. Eng. Rev., 27(1):1–31, 2012.
- [102] Tim Brys, Ann Nowé, Daniel Kudenko, and Matthew E. Taylor. Combining multiple correlated reward and shaping signals by measuring confidence. In Carla E. Brodley and Peter Stone, editors, Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, July 27 -31, 2014, Québec City, Québec, Canada, pages 1687–1693, 2014.
- [103] Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. Learning agent communication under limited bandwidth by message pruning. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 5142–5149, 2020.
- [104] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In 5th International Conference on Learning Representations (ICLR), 2017.
- [105] Landon Kraemer and Bikramjit Banerjee. Multi-agent reinforcement learning as a rehearsal for decentralized planning. Neurocomputing, 190:82–94, 2016.
- [106] Jones Granatyr, Vanderson Botelho, Otto Robert Lessing, Edson Emílio Scalabrin, Jean-Paul A. Barthès, and Fabrício Enembreck. Trust and reputation models for multiagent systems. ACM Comput. Surv., 48(2):27:1–27:42, 2015.
- [107] Dogan Gunes, Taha. Strategic and Adaptive Behaviours in Trust Systems. PhD thesis, University of Southampton, 2021.
- [108] Jörg P. Müller and Klaus Fischer. Application impact of multi-agent systems and technologies: A survey. In Onn Shehory and Arnon Sturm, editors, Agent-Oriented Software Engineering - Reflections on Architectures, Methodologies, Languages, and Frameworks, pages 27–53. 2014.
- [109] Manuel Herrera, Marco Pérez-Hernández, Ajith Kumar Parlikad, and Joaquín Izquierdo. Multi-agent systems and complex networks: Review and applications in systems engineering. Processes, 8(3), 2020.
- [110] Davide Calvaresi, Alevtina Dubovitskaya, Jean-Paul Calbimonte, Kuldar Taveter, and Michael Schumacher. Multi-agent systems and blockchain: Results from a systematic literature review. In Yves Demazeau, Bo An, Javier Bajo, and Antonio Fernández-Caballero, editors, Advances in Practical Applications of Agents, Multi-Agent Systems, and Complexity: The PAAMS Collection - 16th International Conference, PAAMS 2018, Toledo, Spain, June 20-22, 2018, Proceedings, volume 10978 of Lecture Notes in Computer Science, pages 110–126, 2018.
- [111] Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V. Albrecht. Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks. In Joaquin Vanschoren and Sai-Kit Yeung, editors, Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 2021.
- [112] Ben Bogin, Mor Geva, and Jonathan Berant. Emergence of communication in an interactive world with consistent speakers. CoRR, abs/1809.00549, 2018.
- [113] Tadas Baltrusaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell., 41(2):423–443, 2019.
- [114] Petra Poklukar, Miguel Vasco, Hang Yin, Francisco S. Melo, Ana Paiva, and Danica Kragic. Geometric multimodal contrastive representation learning. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 17782–17800, 2022.
- [115] Joseph Seering, Michal Luria, Geoff Kaufman, and Jessica Hammer. Beyond dyadic interactions: Considering chatbots as community members. In Stephen A. Brewster, Geraldine Fitzpatrick, Anna L. Cox, and Vassilis Kostakos, editors, Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, CHI 2019, Glasgow, Scotland, UK, May 04-09, 2019, page 450, 2019.
- [116] Joseph Seering, Michal Luria, Connie Ye, Geoff Kaufman, and Jessica Hammer. It takes a village: Integrating an adaptive chatbot into an online gaming community. In Regina Bernhaupt, Florian ’Floyd’ Mueller, David Verweij, Josh Andres, Joanna McGrenere, Andy Cockburn, Ignacio Avellino, Alix Goguey, Pernille Bjøn, Shengdong Zhao, Briane Paul Samson, and Rafal Kocielnik, editors, CHI ’20: CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, April 25-30, 2020, pages 1–13, 2020.
- [117] Asbjørn Følstad and Petter Bae Brandtzæg. Chatbots and the new world of HCI. Interactions, 24(4):38–42, 2017.
- [118] Romit Roy Choudhury, Krishna Paul, and Somprakash Bandyopadhyay. Marp: a multi-agent routing protocol for mobile wireless ad hoc networks. Autonomous Agents and Multi-Agent Systems, 8(1):47–68, 2004.
- [119] Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. Robust adversarial reinforcement learning. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 2817–2826, 2017.
- [120] Anay Pattanaik, Zhenyi Tang, Shuijing Liu, Gautham Bommannan, and Girish Chowdhary. Robust deep reinforcement learning with adversarial attacks. In Elisabeth André, Sven Koenig, Mehdi Dastani, and Gita Sukthankar, editors, Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS 2018, Stockholm, Sweden, July 10-15, 2018, pages 2040–2042, 2018.
- [121] Shihui Li, Yi Wu, Xinyue Cui, Honghua Dong, Fei Fang, and Stuart Russell. Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, pages 4213–4220, 2019.
- [122] Kaiqing Zhang, Tao Sun, Yunzhe Tao, Sahika Genc, Sunil Mallya, and Tamer Basar. Robust multi-agent reinforcement learning with model uncertainty. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020.
- [123] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, 1997.
- [124] Jakob N. Foerster, Nantas Nardelli, Gregory Farquhar, Triantafyllos Afouras, Philip H. S. Torr, Pushmeet Kohli, and Shimon Whiteson. Stabilising experience replay for deep multi-agent reinforcement learning. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 1146–1155, 2017.