## SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
Xuezhi Wang †‡ Jason Wei † Dale Schuurmans † Quoc Le † Ed H. Chi † Sharan Narang † Aakanksha Chowdhery † Denny Zhou †§
xuezhiw@google.com dennyzhou@google.com
## ABSTRACT
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency , to replace the naive greedy decoding used in chain-of-thought prompting. It first samples a diverse set of reasoning paths instead of only taking the greedy one, and then selects the most consistent answer by marginalizing out the sampled reasoning paths. Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer. Our extensive empirical evaluation shows that self-consistency boosts the performance of chain-of-thought prompting with a striking margin on a range of popular arithmetic and commonsense reasoning benchmarks, including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%) and ARC-challenge (+3.9%).
## 1 INTRODUCTION
Although language models have demonstrated remarkable success across a range of NLP tasks, their ability to demonstrate reasoning is often seen as a limitation, which cannot be overcome solely by increasing model scale (Rae et al., 2021; BIG-bench collaboration, 2021, inter alia ). In an effort to address this shortcoming, Wei et al. (2022) have proposed chain-of-thought prompting , where a language model is prompted to generate a series of short sentences that mimic the reasoning process a person might employ in solving a task. For example, given the question 'If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?' , instead of directly responding with '5' , a language model would be prompted to respond with the entire chain-of-thought: 'There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5. ' . It has been observed that chain-of-thought prompting significantly improves model performance across a variety of multi-step reasoning tasks (Wei et al., 2022).
In this paper, we introduce a novel decoding strategy called self-consistency to replace the greedy decoding strategy used in chain-of-thought prompting (Wei et al., 2022), that further improves language models' reasoning performance by a significant margin. Self-consistency leverages the intuition that complex reasoning tasks typically admit multiple reasoning paths that reach a correct answer (Stanovich & West, 2000). The more that deliberate thinking and analysis is required for a problem (Evans, 2010), the greater the diversity of reasoning paths that can recover the answer.
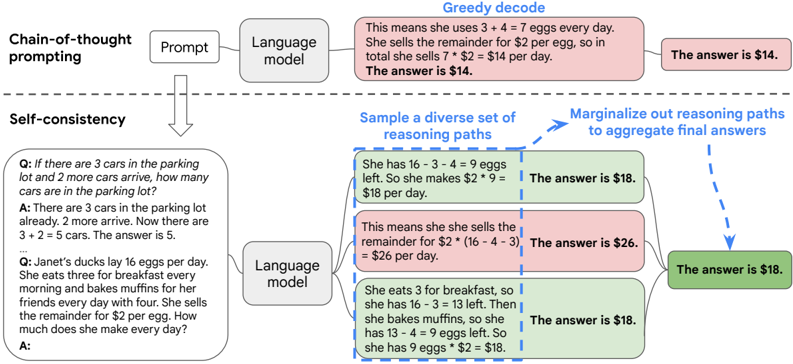
Figure 1 illustrates the self-consistency method with an example. We first prompt the language model with chain-of-thought prompting, then instead of greedily decoding the optimal reasoning path, we propose a 'sample-and-marginalize' decoding procedure: we first sample from the language model's decoder to generate a diverse set of reasoning paths; each reasoning path might lead to a different final answer, so we determine the optimal answer by marginalizing out the sampled reasoning paths to find the most consistent answer in the final answer set. Such an approach is analogous to the human experience that if multiple different ways of thinking lead to the same answer, one has greater confidence that the final answer is correct. Compared to other decoding methods, self-consistency avoids the repetitiveness and local-optimality that plague greedy decoding, while mitigating the stochasticity of a single sampled generation.
† Google Research, Brain Team ‡ , §
Figure 1: The self-consistency method contains three steps: (1) prompt a language model using chain-of-thought (CoT) prompting; (2) replace the 'greedy decode' in CoT prompting by sampling from the language model's decoder to generate a diverse set of reasoning paths; and (3) marginalize out the reasoning paths and aggregate by choosing the most consistent answer in the final answer set.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Chain-of-Thought Prompting and Self-Consistency
### Overview
This diagram illustrates the process of Chain-of-Thought prompting and Self-Consistency in the context of Large Language Models (LLMs). It shows how a prompt is fed into a language model, generating reasoning paths, and how these paths are aggregated to arrive at a final answer. The diagram highlights two main approaches: Greedy Decode and Self-Consistency.
### Components/Axes
The diagram is structured into three main sections:
1. **Chain-of-Thought Prompting:** This section shows the initial prompt and the language model.
2. **Self-Consistency:** This section demonstrates sampling diverse reasoning paths and marginalizing them to aggregate final answers.
3. **Reasoning Paths & Answers:** This section displays several reasoning paths generated by the language model, along with their corresponding answers.
Key labels include:
* "Chain-of-thought prompting"
* "Prompt"
* "Language model"
* "Greedy decode"
* "Self-consistency"
* "Sample a diverse set of reasoning paths"
* "Marginalize out reasoning paths to aggregate final answers"
* "Q:" (Question)
* "A:" (Answer)
### Detailed Analysis or Content Details
**1. Chain-of-Thought Prompting & Greedy Decode:**
* A prompt is sent to a "Language model".
* The language model generates a single reasoning path: "This means she uses 3 + 4 = 7 eggs every day. She sells the remainder for $2 per egg, so in total she sells 7 * $2 = $14 per day. The answer is $14."
* The final answer is stated as "$14".
**2. Self-Consistency:**
* The process begins with a "Language model" receiving a prompt.
* The model is instructed to "Sample a diverse set of reasoning paths".
* These paths are then "Marginalize out reasoning paths to aggregate final answers".
**3. Reasoning Paths & Answers (Self-Consistency Examples):**
* **Example 1 (Parking Lot):**
* Q: "If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?"
* A: "There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5."
* Answer: 5
* **Example 2 (Eggs & Muffins - Path 1):**
* Q: "Janet's ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder for $2 per egg. How much does she make every day?"
* A: "She has 16 - 3 - 4 = 9 eggs left. So she makes $2 * 9 = $18 per day."
* Answer: $18
* **Example 3 (Eggs & Muffins - Path 2):**
* A: "This means she sells the remainder for $2" (16 - 4 - 3) = $26 per day."
* Answer: $26
* **Example 4 (Eggs & Muffins - Path 3):**
* A: "She eats 3 for breakfast, so she has 16 - 3 = 13 left. Then she bakes muffins, so she has 13 - 4 = 9 eggs left. So she has 9 eggs *$2 = $18."
* Answer: $18
**4. Aggregated Answer:**
* The final aggregated answer, after marginalizing the reasoning paths, is "$18".
### Key Observations
* The Self-Consistency approach generates multiple reasoning paths to the same question.
* The answers from the different reasoning paths vary (e.g., $18, $26).
* The final answer is determined by aggregating these paths, resulting in a more robust and potentially accurate answer ($18).
* The Greedy Decode approach provides a single answer, which may not be the most reliable.
### Interpretation
The diagram demonstrates the benefits of using Self-Consistency in LLMs. By generating multiple reasoning paths and aggregating them, the model can mitigate the risk of relying on a single, potentially flawed, line of reasoning. This approach leads to a more reliable and accurate final answer. The diagram highlights the importance of exploring diverse reasoning paths to improve the performance of LLMs, particularly in tasks requiring complex reasoning. The variation in answers from different paths suggests that the model is exploring different interpretations of the problem, and the aggregation process helps to identify the most plausible solution. The contrast between Greedy Decode and Self-Consistency underscores the value of considering multiple perspectives when solving problems with LLMs.
</details>
Self-consistency is far simpler than prior approaches that either train an additional verifier (Cobbe et al., 2021) or train a re-ranker given additional human annotations to improve generation quality (Thoppilan et al., 2022). Instead, self-consistency is entirely unsupervised , works off-the-shelf with pre-trained language models, requires no additional human annotation, and avoids any additional training, auxiliary models or fine-tuning. Self-consistency also differs from a typical ensemble approach where multiple models are trained and the outputs from each model are aggregated, it acts more like a 'self-ensemble' that works on top of a single language model.
We evaluate self-consistency on a wide range of arithmetic and commonsense reasoning tasks over four language models with varying scales: the public UL2-20B (Tay et al., 2022) and GPT-3-175B (Brown et al., 2020), and two densely-activated decoder-only language models: LaMDA-137B (Thoppilan et al., 2022) and PaLM-540B (Chowdhery et al., 2022). On all four language models, self-consistency improves over chain-of-thought prompting by a striking margin across all tasks. In particular, when used with PaLM-540B or GPT-3, self-consistency achieves new state-of-the-art levels of performance across arithmetic reasoning tasks, including GSM8K (Cobbe et al., 2021) (+17.9% absolute accuracy gains), SV AMP (Patel et al., 2021) (+11.0%), AQuA (Ling et al., 2017) (+12.2%), and across commonsense reasoning tasks such as StrategyQA (Geva et al., 2021) (+6.4%) and ARCchallenge (Clark et al., 2018) (+3.9%). In additional experiments, we show self-consistency can robustly boost performance on NLP tasks where adding a chain-of-thought might hurt performance compared to standard prompting (Ye & Durrett, 2022). We also show self-consistency significantly outperforms sample-and-rank, beam search, ensemble-based approaches, and is robust to sampling strategies and imperfect prompts.
## 2 SELF-CONSISTENCY OVER DIVERSE REASONING PATHS
A salient aspect of humanity is that people think differently. It is natural to suppose that in tasks requiring deliberate thinking, there are likely several ways to attack the problem. We propose that such a process can be simulated in language models via sampling from the language model's decoder. For instance, as shown in Figure 1, a model can generate several plausible responses to a math question that all arrive at the same correct answer (Outputs 1 and 3). Since language models are not perfect reasoners, the model might also produce an incorrect reasoning path or make a mistake in one of the reasoning steps (e.g., in Output 2), but such solutions are less likely to arrive at the same answer. That is, we hypothesize that correct reasoning processes, even if they are diverse, tend to have greater agreement in their final answer than incorrect processes.
We leverage this intuition by proposing the following self-consistency method. First, a language model is prompted with a set of manually written chain-of-thought exemplars (Wei et al., 2022). Next,
Table 1: Accuracy comparison of different answer aggregation strategies on PaLM-540B.
| | GSM8K | MultiArith | AQuA | SVAMP | CSQA | ARC-c |
|--------------------------------|------------|--------------|------------|------------|------------|------------|
| Greedy decode | 56.5 | 94.7 | 35.8 | 79.0 | 79.0 | 85.2 |
| Weighted avg (unnormalized) | 56.3 ± 0.0 | 90.5 ± 0.0 | 35.8 ± 0.0 | 73.0 ± 0.0 | 74.8 ± 0.0 | 82.3 ± 0.0 |
| Weighted avg (normalized) | 22.1 ± 0.0 | 59.7 ± 0.0 | 15.7 ± 0.0 | 40.5 ± 0.0 | 52.1 ± 0.0 | 51.7 ± 0.0 |
| Weighted sum (unnormalized) | 59.9 ± 0.0 | 92.2 ± 0.0 | 38.2 ± 0.0 | 76.2 ± 0.0 | 76.2 ± 0.0 | 83.5 ± 0.0 |
| Weighted sum (normalized) | 74.1 ± 0.0 | 99.3 ± 0.0 | 48.0 ± 0.0 | 86.8 ± 0.0 | 80.7 ± 0.0 | 88.7 ± 0.0 |
| Unweighted sum (majority vote) | 74.4 ± 0.1 | 99.3 ± 0.0 | 48.3 ± 0.5 | 86.6 ± 0.1 | 80.7 ± 0.1 | 88.7 ± 0.1 |
we sample a set of candidate outputs from the language model's decoder, generating a diverse set of candidate reasoning paths. Self-consistency is compatible with most existing sampling algorithms, including temperature sampling (Ackley et al., 1985; Ficler & Goldberg, 2017), topk sampling (Fan et al., 2018; Holtzman et al., 2018; Radford et al., 2019), and nucleus sampling (Holtzman et al., 2020). Finally, we aggregate the answers by marginalizing out the sampled reasoning paths and choosing the answer that is the most consistent among the generated answers.
In more detail, assume the generated answers a i are from a fixed answer set, a i ∈ A , where i = 1 , . . . , m indexes the m candidate outputs sampled from the decoder. Given a prompt and a question, self-consistency introduces an additional latent variable r i , which is a sequence of tokens representing the reasoning path in the i -th output, then couples the generation of ( r i , a i ) where r i → a i , i.e., generating a reasoning path r i is optional and only used to reach the final answer a i . As an example, consider Output 3 from Figure 1: the first few sentences ' She eats 3 for breakfast ... So she has 9 eggs * $2 = $18. ' constitutes r i , while the answer 18 from the last sentence, ' The answer is $18 ', is parsed as a i . 1 After sampling multiple ( r i , a i ) from the model's decoder, self-consistency applies a marginalization over r i by taking a majority vote over a i , i.e., arg max a ∑ m i =1 ✶ ( a i = a ) , or as we defined as the most 'consistent' answer among the final answer set.
In Table 1, we show the test accuracy over a set of reasoning tasks by using different answer aggregation strategies. In addition to majority vote, one can also weight each ( r i , a i ) by P ( r i , a i | prompt , question ) when aggregating the answers. Note to compute P ( r i , a i | prompt , question ) , we can either take the unnormalized probability of the model generating ( r i , a i ) given ( prompt , question ) , or we can normalize the conditional probability by the output length (Brown et al., 2020), i.e.,
<!-- formula-not-decoded -->
where log P ( t k | prompt , question , t 1 , . . . , t k -1 ) is the log probability of generating the k -th token t k in ( r i , a i ) conditioned on the previous tokens, and K is the total number of tokens in ( r i , a i ) . In Table 1, we show that taking the 'unweighted sum', i.e., taking a majority vote directly over a i yields a very similar accuracy as aggregating using the 'normalized weighted sum'. We took a closer look at the model's output probabilities and found this is because for each ( r i , a i ) , the normalized conditional probabilities P ( r i , a i | prompt , question ) are quite close to each other, i.e., the language model regards those generations as 'similarly likely'. 2 Additionally, when aggregating the answers, the results in Table 1 show that the 'normalized' weighted sum (i.e., Equation 1) yields a much higher accuracy compared to its unnormalized counterpart. For completeness, in Table 1 we also report the results by taking a 'weighted average', i.e., each a gets a score of its weighted sum divided by ∑ m i =1 ( a i = a ) , which results in a much worse performance.
✶ Self-consistency explores an interesting space between open-ended text generation and optimal text generation with a fixed answer. Reasoning tasks typically have fixed answers, which is why researchers have generally considered greedy decoding approaches (Radford et al., 2019; Wei et al., 2022; Chowdhery et al., 2022). However, we have found that even when the desired answer is fixed, introducing diversity in the reasoning processes can be highly beneficial; therefore we leverage
1 The parser is task dependent. For arithmetic reasoning, we parse the first numerical part as the final answer after the model generates 'The answer is '. For commonsense reasoning, we parse the full string answer as the final answer after the model generates 'The answer is '. Most generated outputs have a consistent format of '{Reasoning paths}. The answer is X.' if we prompt the language model in this format.
2 This also means that the language model is not well calibrated and thus cannot distinguish well between correct solutions and wrong solutions, which also explains why additional re-rankers were trained to better judge the quality of the solutions in previous work (Cobbe et al., 2021; Thoppilan et al., 2022).
sampling, as commonly used for open-ended text generation (Radford et al., 2019; Brown et al., 2020; Thoppilan et al., 2022), to achieve this goal. One should note that self-consistency can be applied only to problems where the final answer is from a fixed answer set, but in principle this approach can be extended to open-text generation problems if a good metric of consistency can be defined between multiple generations, e.g., whether two answers agree or contradict each other.
## 3 EXPERIMENTS
We conducted a series of experiments to compare the proposed self-consistency method with existing approaches on a range of reasoning benchmarks. We find that self-consistency robustly improves reasoning accuracy for every language model considered, spanning a wide range of model scales.
## 3.1 EXPERIMENT SETUP
Tasks and datasets. We evaluate self-consistency on the following reasoning benchmarks. 3
- Arithmetic reasoning . For these tasks, we used the Math Word Problem Repository (KoncelKedziorski et al., 2016), including AddSub (Hosseini et al., 2014), MultiArith (Roy & Roth, 2015), and ASDiv (Miao et al., 2020). We also included AQUA-RAT (Ling et al., 2017), a recently published benchmark of grade-school-math problems (GSM8K; Cobbe et al., 2021), and a challenge dataset over math word problems (SVAMP; Patel et al., 2021).
- Commonsense reasoning . For these tasks, we used CommonsenseQA (Talmor et al., 2019), StrategyQA (Geva et al., 2021), and the AI2 Reasoning Challenge (ARC) (Clark et al., 2018).
- Symbolic Reasoning . We evaluate two symbolic reasoning tasks: last letter concatenation (e.g., the input is 'Elon Musk' and the output should be 'nk'), and Coinflip (e.g., a coin is heads-up, after a few flips is the coin still heads-up?) from Wei et al. (2022).
Language models and prompts. We evaluate self-consistency over four transformer-based language models with varying scales:
- UL2 (Tay et al., 2022) is an encoder-decoder model trained on a mixture of denoisers with 20billion parameters. UL2 is completely open-sourced 4 and has similar or better performance than GPT-3 on zero-shot SuperGLUE, with only 20B parameters and thus is more compute-friendly;
- GPT-3 (Brown et al., 2020) with 175-billion parameters. We use two public engines code-davinci001 and code-davinci-002 from the Codex series (Chen et al., 2021) to aid reproducibility; 5
- LaMDA-137B (Thoppilan et al., 2022) is a dense left-to-right, decoder-only language model with 137-billion parameters, pre-trained on a mixture of web documents, dialog data and Wikipedia;
- PaLM-540B (Chowdhery et al., 2022) is a dense left-to-right, decoder-only language model with 540-billion parameters, pre-trained on a high quality corpus of 780 billion tokens with filtered webpages, books, Wikipedia, news articles, source code, and social media conversations.
We perform all experiments in the few-shot setting, without training or fine-tuning the language models. For a fair comparison we use the same prompts as in Wei et al. (2022): for all arithmetic reasoning tasks we use the same set of 8 manually written exemplars; for each commonsense reasoning task, 4-7 exemplars are randomly chosen from the training set with manually composed chain-of-thought prompts. 6 Full details on the prompts used are given in Appendix A.3.
Sampling scheme. To sample diverse reasoning paths, we followed similar settings to those suggested in Radford et al. (2019); Holtzman et al. (2020) for open-text generation. In particular, for UL2-20B and LaMDA-137B we applied temperature sampling with T = 0 . 5 and truncated at the topk ( k = 40 ) tokens with the highest probability, for PaLM-540B we applied T = 0 . 7 , k = 40 , and for GPT-3 we use T = 0 . 7 without topk truncation. We provide an ablation study in Section 3.5 to show that self-consistency is generally robust to sampling strategies and parameters.
3 By default we use the test split for all datasets if the labels are available for evaluation. For CommonsenseQA we use the dev split; for StrategyQA we use the question-only set from BIG-bench collaboration (2021): https://github.com/google/BIG-bench/tree/main/bigbench/benchmark\_tasks/strategyqa .
4 Model checkpoints at https://github.com/google-research/google-research/tree/master/ul2 .
5 Public API available at https://openai.com/api/ .
6 Self-consistency is robust to different sets of prompts and we provide a study in Appendix A.1.2.
## 3.2 MAIN RESULTS
We report the results of self-consistency averaged over 10 runs, where we sampled 40 outputs independently from the decoder in each run. The baseline we compare to is chain-of-thought prompting with greedy decoding (Wei et al., 2022), referred to as CoT-prompting , which has been previously used for decoding in large language models (Chowdhery et al., 2022).
Arithmetic Reasoning The results are shown in Table 2. 7 Self-consistency improves the arithmetic reasoning performance over all four language models significantly over chain-of-thought prompting. More surprisingly, the gains become more significant when the language model's scale increases, e.g., we see +3%-6% absolute accuracy improvement over UL2-20B but +9%-23% for LaMDA137B and GPT-3. For larger models that already achieve high accuracy on most tasks (e.g., GPT-3 and PaLM-540B), self-consistency still contributes significant additional gains with +12%-18% absolute accuracy on tasks like AQuA and GSM8K, and +7%-11% on SVAMP and ASDiv. With self-consistency, we achieve new state-of-the-art results on almost all tasks: despite the fact that selfconsistency is unsupervised and task-agnostic, these results compare favorably to existing approaches that require task-specific training, or fine-tuning with thousands of examples (e.g., on GSM8K).
Table 2: Arithmetic reasoning accuracy by self-consistency compared to chain-of-thought prompting (Wei et al., 2022). The previous SoTA baselines are obtained from: a : Relevance and LCA operation classifier (Roy & Roth, 2015), b : Lan et al. (2021), c : Amini et al. (2019), d : Pi et al. (2022), e : GPT-3 175B finetuned with 7.5k examples (Cobbe et al., 2021), g : GPT-3 175B finetuned plus an additional 175B verifier (Cobbe et al., 2021). The best performance for each task is shown in bold.
| | Method | AddSub | MultiArith | ASDiv | AQuA | SVAMP | GSM8K |
|------------------------|--------------------------------|-------------------|-------------------|------------------|-------------------|-------------------|-------------------|
| | Previous SoTA | 94.9 a | 60.5 a | 75.3 b | 37.9 c | 57.4 d | 35 e / 55 g |
| UL2-20B | CoT-prompting Self-consistency | 18.2 24.8 (+6.6) | 10.7 15.0 (+4.3) | 16.9 21.5 (+4.6) | 23.6 26.9 (+3.3) | 12.6 19.4 (+6.8) | 4.1 7.3 (+3.2) |
| LaMDA-137B | CoT-prompting Self-consistency | 52.9 63.5 (+10.6) | 51.8 75.7 (+23.9) | 49.0 58.2 (+9.2) | 17.7 26.8 (+9.1) | 38.9 53.3 (+14.4) | 17.1 27.7 (+10.6) |
| PaLM-540B | CoT-prompting Self-consistency | 91.9 93.7 (+1.8) | 94.7 99.3 (+4.6) | 74.0 81.9 (+7.9) | 35.8 48.3 (+12.5) | 79.0 86.6 (+7.6) | 56.5 74.4 (+17.9) |
| GPT-3 Code-davinci-001 | CoT-prompting Self-consistency | 57.2 67.8 (+10.6) | 59.5 82.7 (+23.2) | 52.7 61.9 (+9.2) | 18.9 25.6 (+6.7) | 39.8 54.5 (+14.7) | 14.6 23.4 (+8.8) |
| GPT-3 Code-davinci-002 | CoT-prompting Self-consistency | 89.4 91.6 (+2.2) | 96.2 100.0 (+3.8) | 80.1 87.8 (+7.6) | 39.8 52.0 (+12.2) | 75.8 86.8 (+11.0) | 60.1 78.0 (+17.9) |
Table 3: Commonsense and symbolic reasoning accuracy by self-consistency compared to chainof-thought prompting (Wei et al., 2022). The previous SoTA baselines are obtained from: a : DeBERTaV3-large + KEAR (Xu et al., 2021b), b : Chowdhery et al. (2022), c : UnifiedQA-FT (Khashabi et al., 2020). The best performance for each task is shown in bold.
| | Method | CSQA | StrategyQA | ARC-e | ARC-c | Letter (4) | Coinflip (4) |
|------------------------|--------------------------------|------------------|------------------|------------------|-------------------|------------------|------------------|
| | Previous SoTA | 91.2 a | 73.9 b | 86.4 c | 75.0 c | N/A | N/A |
| UL2-20B | CoT-prompting Self-consistency | 51.4 55.7 (+4.3) | 53.3 54.9 (+1.6) | 61.6 69.8 (+8.2) | 42.9 49.5 (+6.8) | 0.0 0.0 (+0.0) | 50.4 50.5 (+0.1) |
| LaMDA-137B | CoT-prompting Self-consistency | 57.9 63.1 (+5.2) | 65.4 67.8 (+2.4) | 75.3 79.3 (+4.0) | 55.1 59.8 (+4.7) | 8.2 8.2 (+0.0) | 72.4 73.5 (+1.1) |
| PaLM-540B | CoT-prompting Self-consistency | 79.0 80.7 (+1.7) | 75.3 81.6 (+6.3) | 95.3 96.4 (+1.1) | 85.2 88.7 (+3.5) | 65.8 70.8 (+5.0) | 88.2 91.2 (+3.0) |
| GPT-3 Code-davinci-001 | CoT-prompting Self-consistency | 46.6 54.9 (+8.3) | 56.7 61.7 (+5.0) | 63.1 72.1 (+9.0) | 43.1 53.7 (+10.6) | 7.8 10.0 (+2.2) | 71.4 75.9 (+4.5) |
| GPT-3 | CoT-prompting | 79.0 81.5 (+2.5) | 73.4 (+6.4) | 94.0 96.0 (+2.0) | 87.5 (+3.9) | 73.4 (+3.0) | 99.0 99.5 (+0.5) |
| Code-davinci-002 | Self-consistency | | 79.8 | | 83.6 | 70.4 | |
7 The standard deviation of self-consistency is ≤ 0 . 5 for all tasks and is thus omitted in the table. Please refer to Figure 2, Figure 7 and 8 for the standard deviations under varying numbers of sampled paths.
Commonsense and Symbolic Reasoning Table 3 shows the results on commonsense and symbolic reasoning tasks. Similarly, self-consistency yields large gains across all four language models, and obtained SoTA results on 5 out of 6 tasks. For symbolic reasoning, we test the out-of-distribution (OOD) setting where the input prompt contains examples of 2-letters or 2-flips but we test examples of 4-letters and 4-flips (this setting is more challenging as PaLM-540B or GPT-3 can already achieve perfect in-distribution accuracy). In this challenging OOD setting, the gain of self-consistency is still quite significant compared to CoT-prompting with sufficient model sizes.
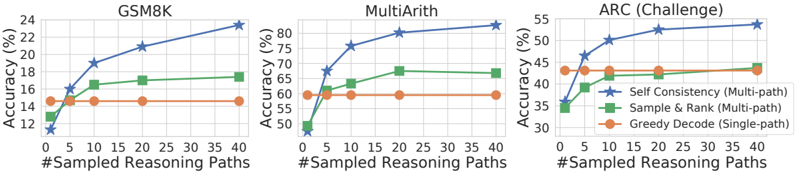
To show the effect of the number of sampled reasoning paths, we plot the accuracy (mean and standard deviation over 10 runs) with respect to varying numbers of sampled paths (1, 5, 10, 20, 40) in Figure 2. The results show that sampling a higher number (e.g., 40) of reasoning paths leads to a consistently better performance, further emphasizing the importance of introducing diversity in the reasoning paths. In Table 4, we show self-consistency yields a richer set of reasoning paths compared to greedy decoding with a few example questions from two tasks.
Figure 2: Self-consistency (blue) significantly improves accuracy over CoT-prompting with greedy decoding (orange) across arithmetic and commonsense reasoning tasks, over LaMDA-137B. Sampling a higher number of diverse reasoning paths consistently improves reasoning accuracy.
<details>
<summary>Image 2 Details</summary>

### Visual Description
\n
## Line Chart: Accuracy vs. Sampled Reasoning Paths for Different Datasets
### Overview
The image presents four separate line charts, each depicting the relationship between "Accuracy (%)" and "#Sampled Reasoning Paths" for different datasets: MultiArith, SVAMP, Commonsense QA, and ARC (Challenge). Each chart compares two methods: "Greedy Decode (Single-path)" and "Self Consistency (Multi-path)". The charts visually demonstrate how accuracy changes as the number of sampled reasoning paths increases for each method and dataset.
### Components/Axes
* **X-axis:** "#Sampled Reasoning Paths" - Ranges from 0 to 40, with markers at 0, 5, 10, 15, 20, 25, 30, 35, and 40.
* **Y-axis:** "Accuracy (%)" - Ranges from approximately 30% to 75%, with markers at 30, 35, 40, 45, 50, 55, 60, 65, 70, and 75.
* **Datasets (Chart Titles):** MultiArith, SVAMP, Commonsense QA, ARC (Challenge).
* **Legend:**
* Orange Line with Circle Markers: "Greedy Decode (Single-path)"
* Blue Line with Cross Markers: "Self Consistency (Multi-path)"
### Detailed Analysis or Content Details
**1. MultiArith:**
* **Self Consistency (Multi-path):** The blue line starts at approximately 68% accuracy at 0 paths, rises sharply to around 73% at 10 paths, plateaus around 74% between 15 and 40 paths.
* **Greedy Decode (Single-path):** The orange line remains relatively flat around 52% accuracy across all sampled reasoning paths, with slight fluctuations between 51% and 53%.
**2. SVAMP:**
* **Self Consistency (Multi-path):** The blue line begins at approximately 36% accuracy at 0 paths, increases rapidly to around 51% at 20 paths, and then plateaus around 53% between 20 and 40 paths.
* **Greedy Decode (Single-path):** The orange line starts at approximately 39% accuracy at 0 paths, and remains relatively stable around 39-40% across all sampled reasoning paths.
**3. Commonsense QA:**
* **Self Consistency (Multi-path):** The blue line starts at approximately 56% accuracy at 0 paths, increases to around 61% at 10 paths, and then plateaus around 62% between 15 and 40 paths. There is a visible error bar at 0 paths, indicating some variance.
* **Greedy Decode (Single-path):** The orange line remains relatively flat around 58% accuracy across all sampled reasoning paths, with slight variations between 57% and 59%.
**4. ARC (Challenge):**
* **Self Consistency (Multi-path):** The blue line starts at approximately 57% accuracy at 0 paths, increases to around 60% at 15 paths, and then plateaus around 60-61% between 20 and 40 paths.
* **Greedy Decode (Single-path):** The orange line starts at approximately 55% accuracy at 0 paths, and remains relatively stable around 55-56% across all sampled reasoning paths.
### Key Observations
* In all four datasets, the "Self Consistency (Multi-path)" method consistently outperforms the "Greedy Decode (Single-path)" method.
* The performance gains from increasing the number of sampled reasoning paths diminish after a certain point (around 15-20 paths) for all datasets.
* The SVAMP dataset shows the most significant improvement with increased reasoning paths for the "Self Consistency" method.
* The "Greedy Decode" method exhibits minimal improvement with increased reasoning paths across all datasets.
### Interpretation
The data suggests that utilizing multiple reasoning paths ("Self Consistency") significantly improves accuracy in these reasoning tasks compared to a single, greedy approach. The diminishing returns observed after a certain number of paths indicate that there's a point where adding more reasoning paths doesn't yield substantial benefits. This could be due to redundancy in the reasoning process or limitations in the underlying model. The varying degrees of improvement across datasets suggest that the effectiveness of multi-path reasoning is dependent on the complexity and nature of the task. The consistent outperformance of "Self Consistency" highlights the value of exploring multiple possible solutions or reasoning chains to enhance the robustness and accuracy of AI systems. The error bar on the Commonsense QA chart at 0 paths suggests that the initial accuracy of the "Self Consistency" method may have some variability.
</details>
Table 4: Examples where self-consistency helps repair the errors over greedy decode, on PaLM-540B. Two sampled reasoning paths that are consistent with the ground truth are shown.
| | GSM8K | StrategyQA |
|----------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Question | Henry made two stops during his 60-mile bike trip. He first stopped after 20 miles. His second stop was 15 miles before the end of the trip. How many miles did he travel between his first and second stops? | Yes or no: Is Albany, Georgia the most populous US Albany? |
| Greedy Decode | He traveled 60 miles in total. He stopped after 20 miles, so he traveled 60 - 20 = 40 miles between the first and second stops. The answer is 40. | Albany, Georgia is the most populous US Al- bany. Thus, the answer is yes. |
| Sampled Path 1 | Henry travelled a total of 60 miles. His first stop was 20 miles in, and his second stop was 15 miles before the end. So between his first and second stops he travelled 60 - 20 -15 = 25 miles. The answer is 25. | The most populous US Albany is Albany, New York. Thus, Albany, Georgia is not the most populous US Albany. So the answer is no. |
| Sampled Path 2 | He made two stops during a 60-mile trip. The first was 20 miles into the trip. The second was 15 miles before the end of the trip. This means the second stop was 60 - 15 = 45 miles into the trip. Since he made the stops in order, the second stop must have been 45 - 20 = 25 miles after the first stop. The answer is 25. | Albany, Georgia has a population of about 88,000. Albany, New York has a population of about 95,000. Thus, Albany, Georgia is not the most populous US Albany. So the answer is no. |
## 3.3 SELF-CONSISTENCY HELPS WHEN CHAIN-OF-THOUGHT HURTS PERFORMANCE
Ye & Durrett (2022) show that sometimes chain-of-thought prompting could hurt performance compared to standard prompting in few-shot in-context learning. Here we perform a study using self-consistency to see if it can help fill in the gap, over a set of common NLP tasks, including (1) Closed-Book Question Answering: BoolQ (Clark et al., 2019), HotpotQA (Yang et al., 2018), and (2) Natural Language Inference: e-SNLI (Camburu et al., 2018), ANLI (Nie et al., 2020) and RTE (Dagan et al., 2005; Bar-Haim et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., 2009).
The results over PaLM-540B are shown in Table 5. For some tasks (e.g., ANLI-R1, e-SNLI, RTE), adding chain-of-thought does hurt performance compared to standard prompting (Brown et al., 2020), but self-consistency is able to robustly boost the performance and outperform standard prompting, making it a reliable way to add rationales in few-shot in-context learning for common NLP tasks.
Table 5: Compare Standard/CoT prompting with self-consistency on common NLP tasks.
| | ANLI R1 / R2 / R3 | e-SNLI | RTE | BoolQ | HotpotQA (EM/F1) |
|-----------------------------------|---------------------|----------|-------|---------|--------------------|
| Standard-prompting (no-rationale) | 69.1 / 55.8 / 55.8 | 85.8 | 84.8 | 71.3 | 27.1 / 36.8 |
| CoT-prompting (Wei et al., 2022) | 68.8 / 58.9 / 60.6 | 81 | 79.1 | 74.2 | 28.9 / 39.8 |
| Self-consistency | 78.5 / 64.5 / 63.4 | 88.4 | 86.3 | 78.4 | 33.8 / 44.6 |
## 3.4 COMPARE TO OTHER EXISTING APPROACHES
We conduct a set of additional studies and show that self-consistency significantly outperforms existing methods including sample-and-rank, beam search, and ensemble-based approaches.
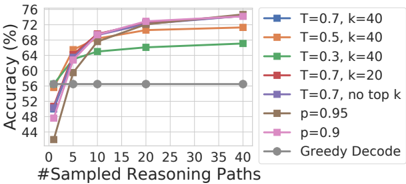
Comparison to Sample-and-Rank One commonly used approach to improve generation quality is sample-and-rank, where multiple sequences are sampled from the decoder and then ranked according to each sequence's log probability (Adiwardana et al., 2020). We compare self-consistency with sample-and-rank on GPT-3 code-davinci-001 , by sampling the same number of sequences from the decoder as self-consistency and taking the final answer from the top-ranked sequence. The results are shown in Figure 3. While sample-and-rank does improve the accuracy with additionally sampled sequences and ranking, the gain is much smaller compared to self-consistency.
Figure 3: Self-consistency significantly outperforms sample-and-rank with the same # of samples.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart: Accuracy vs. Number of Sampled Reasoning Paths
### Overview
This image presents three line charts, each displaying the relationship between "Accuracy (%)" and "#Sampled Reasoning Paths" for different datasets: GSM8K, MultiArith, and ARC (Challenge). Each chart includes three data series representing different decoding methods: "Self Consistency (Multi-path)", "Sample & Rank (Multi-path)", and "Greedy Decode (Single-path)".
### Components/Axes
* **X-axis:** "#Sampled Reasoning Paths" - ranging from 0 to 40, with markers at 0, 5, 10, 15, 20, 25, 30, 35, and 40.
* **Y-axis:** "Accuracy (%)" - ranging from approximately 12% to 80%, depending on the chart.
* **Datasets (Charts):** GSM8K, MultiArith, ARC (Challenge) - each chart represents one dataset.
* **Legend:** Located in the top-left corner of each chart, identifying the data series by color and name.
* Blue: "Self Consistency (Multi-path)"
* Green: "Sample & Rank (Multi-path)"
* Orange: "Greedy Decode (Single-path)"
### Detailed Analysis or Content Details
**GSM8K Chart:**
* **Self Consistency (Blue):** The line slopes sharply upward from approximately 14% at 0 paths to approximately 23% at 35 paths. Data points (approximate): (0, 14%), (5, 17%), (10, 19%), (15, 21%), (20, 22%), (25, 22.5%), (30, 23%), (35, 23%).
* **Sample & Rank (Green):** The line shows a moderate upward trend, leveling off after 15 paths. Data points (approximate): (0, 12%), (5, 15%), (10, 16%), (15, 17%), (20, 17.5%), (25, 17.5%), (30, 17.5%), (35, 17.5%).
* **Greedy Decode (Orange):** The line is relatively flat, fluctuating around 14-15%. Data points (approximate): (0, 14%), (5, 14%), (10, 14.5%), (15, 14.5%), (20, 14.5%), (25, 14.5%), (30, 14.5%), (35, 14.5%).
**MultiArith Chart:**
* **Self Consistency (Blue):** The line exhibits a strong upward trend, increasing rapidly from approximately 50% to approximately 82% as the number of paths increases. Data points (approximate): (0, 50%), (5, 62%), (10, 70%), (15, 75%), (20, 78%), (25, 80%), (30, 81%), (35, 82%).
* **Sample & Rank (Green):** The line shows a moderate upward trend, but remains significantly below the "Self Consistency" line. Data points (approximate): (0, 50%), (5, 58%), (10, 63%), (15, 65%), (20, 66%), (25, 67%), (30, 67%), (35, 67%).
* **Greedy Decode (Orange):** The line is relatively flat, fluctuating around 54-56%. Data points (approximate): (0, 54%), (5, 55%), (10, 55%), (15, 55.5%), (20, 55.5%), (25, 55.5%), (30, 55.5%), (35, 55.5%).
**ARC (Challenge) Chart:**
* **Self Consistency (Blue):** The line shows a strong upward trend, increasing from approximately 32% to approximately 53% as the number of paths increases. Data points (approximate): (0, 32%), (5, 40%), (10, 45%), (15, 47%), (20, 49%), (25, 50%), (30, 52%), (35, 53%).
* **Sample & Rank (Green):** The line shows a moderate upward trend, leveling off after 20 paths. Data points (approximate): (0, 30%), (5, 36%), (10, 40%), (15, 42%), (20, 42.5%), (25, 42.5%), (30, 42.5%), (35, 42.5%).
* **Greedy Decode (Orange):** The line is relatively flat, fluctuating around 41-42%. Data points (approximate): (0, 41%), (5, 41%), (10, 41.5%), (15, 41.5%), (20, 41.5%), (25, 41.5%), (30, 41.5%), (35, 41.5%).
### Key Observations
* "Self Consistency" consistently outperforms both "Sample & Rank" and "Greedy Decode" across all three datasets.
* The benefit of increasing the number of sampled reasoning paths diminishes after a certain point, particularly for "Sample & Rank" and "Greedy Decode".
* "Greedy Decode" shows minimal improvement with increased reasoning paths, suggesting it is not effectively utilizing additional information.
* The MultiArith dataset shows the most significant improvement in accuracy with increased reasoning paths, especially for "Self Consistency".
### Interpretation
The charts demonstrate the effectiveness of multi-path reasoning techniques, specifically "Self Consistency", in improving accuracy on mathematical and reasoning tasks. The superior performance of "Self Consistency" suggests that sampling multiple reasoning paths and aggregating their results leads to more robust and accurate solutions. The diminishing returns observed with increasing paths indicate that there is a point where the computational cost outweighs the marginal gains in accuracy. The relatively flat performance of "Greedy Decode" highlights the limitations of single-path reasoning, which may be susceptible to errors or suboptimal solutions. The differences in performance across datasets suggest that the effectiveness of these techniques may vary depending on the complexity and characteristics of the task. The data suggests that for complex reasoning tasks, exploring multiple reasoning paths is crucial for achieving high accuracy, and "Self Consistency" is a particularly promising approach.
</details>
Comparison to Beam Search In Table 6, we compare self-consistency with beam search decoding on the UL2-20B model. For a fair comparison we report the accuracy under the same number of beams and reasoning paths. On both tasks self-consistency outperforms beam search significantly. Note self-consistency can also adopt beam search to decode each reasoning path (results are shown as 'Self-consistency using beam search'), but its performance is worse compared to self-consistency with sampling. The reason is that beam search yields a lower diversity in the outputs (Li & Jurafsky, 2016), while in self-consistency the diversity of the reasoning paths is the key to a better performance.
Table 6: Compare self-consistency with beam search decoding on the UL2-20B model.
| | Beam size / Self-consistency paths | 1 | 5 | 10 | 20 | 40 |
|------------|--------------------------------------|------------|------------|------------|------------|------------|
| | Beam search decoding (top beam) | 23.6 | 19.3 | 16.1 | 15.0 | 10.2 |
| AQuA | Self-consistency using beam search | 23.6 | 19.8 ± 0.3 | 21.2 ± 0.7 | 24.6 ± 0.4 | 24.2 ± 0.5 |
| AQuA | Self-consistency using sampling | 19.7 ± 2.5 | 24.9 ± 2.6 | 25.3 ± 1.8 | 26.7 ± 1.0 | 26.9 ± 0.5 |
| MultiArith | Beam search decoding (top beam) | 10.7 | 12.0 | 11.3 | 11.0 | 10.5 |
| MultiArith | Self-consistency using beam search | 10.7 | 11.8 ± 0.0 | 11.4 ± 0.1 | 12.3 ± 0.1 | 10.8 ± 0.1 |
| MultiArith | Self-consistency using sampling | 9.5 ± 1.2 | 11.3 ± 1.2 | 12.3 ± 0.8 | 13.7 ± 0.9 | 14.7 ± 0.3 |
Comparison to Ensemble-based Approaches We further compare self-consistency to ensemblebased methods for few-shot learning. In particular, we consider ensembling by: (1) prompt order permutation: we randomly permute the exemplars in the prompt 40 times to mitigate model's sensitivity to prompt order (Zhao et al., 2021; Lu et al., 2021); and (2) multiple sets of prompts (Gao et al., 2021): we manually write 3 different sets of prompts. We took majority vote of the answers from greedy decoding in both approaches as an ensemble. Table 7 shows that compared to self-consistency, existing ensemble-based approaches achieve a much smaller gain. 8 In addition, note that self-consistency is different from a typical model-ensemble approach, where multiple models are trained and their outputs are aggregated. Self-consistency acts more like a 'self-ensemble' on top of a single language model. We additionally show the results of ensembling multiple models in Appendix A.1.3 where the model-ensembles perform much worse compared to self-consistency.
Table 7: Self-consistency outperforms prompt-order and multi-prompt ensembles on LaMDA-137B.
| | GSM8K | MultiArith | SVAMP | ARC-e | ARC-c |
|-------------------------------------|------------|--------------|------------|------------|------------|
| CoT (Wei et al., 2022) | 17.1 | 51.8 | 38.9 | 75.3 | 55.1 |
| Ensemble (3 sets of prompts) | 18.6 ± 0.5 | 57.1 ± 0.7 | 42.1 ± 0.6 | 76.6 ± 0.1 | 57.0 ± 0.2 |
| Ensemble (40 prompt permutations) | 19.2 ± 0.1 | 60.9 ± 0.2 | 42.7 ± 0.1 | 76.9 ± 0.1 | 57.0 ± 0.1 |
| Self-Consistency (40 sampled paths) | 27.7 ± 0.2 | 75.7 ± 0.3 | 53.3 ± 0.2 | 79.3 ± 0.3 | 59.8 ± 0.2 |
8 Self-consistency is compatible with both ensemble approaches and we show the results in Appendix A.1.4.
## 3.5 ADDITIONAL STUDIES
We conducted a number of additional experiments to analyze different aspects of the self-consistency method, including its robustness to sampling strategies and parameters, and how it works with imperfect prompts and non-natural-language reasoning paths.
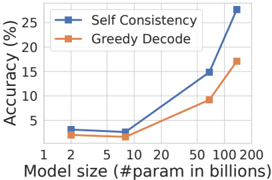
Self-Consistency is Robust to Sampling Strategies and Scaling We show self-consistency is robust to sampling strategies and parameters, by varying T in temperature sampling (Ackley et al., 1985; Ficler & Goldberg, 2017), k in topk sampling (Fan et al., 2018; Holtzman et al., 2018; Radford et al., 2019), and p in nucleus sampling (Holtzman et al., 2020), over PaLM-540B in Figure 4 (left). Figure 4 (right) shows that self-consistency robustly improves performance across all scales for the LaMDA-137B model series. The gain is relatively lower for smaller models due to certain abilities (e.g., arithmetic) only emerge when the model reaches a sufficient scale (Brown et al., 2020).
Figure 4: GSM8K accuracy. (Left) Self-consistency is robust to various sampling strategies and parameters. (Right) Self-consistency improves performance across language model scales.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Sampled Reasoning Paths
### Overview
This image presents a line chart illustrating the relationship between the number of sampled reasoning paths and the resulting accuracy, for various decoding strategies. The chart compares several configurations of temperature (T) and top-k sampling (k), along with probability (p) values, against a "Greedy Decode" baseline.
### Components/Axes
* **X-axis:** "#Sampled Reasoning Paths" - Ranging from 0 to 40, with markers at 0, 5, 10, 15, 20, 25, 30, 35, and 40.
* **Y-axis:** "Accuracy (%)" - Ranging from 44% to 76%, with markers at 44, 48, 52, 56, 60, 64, 68, 72, and 76.
* **Legend:** Located in the top-right corner, containing the following lines and their corresponding colors:
* T=0.7, k=40 (Blue)
* T=0.5, k=40 (Orange)
* T=0.3, k=40 (Green)
* T=0.7, k=20 (Red)
* T=0.7, no top k (Dark Blue)
* p=0.95 (Brown)
* p=0.9 (Magenta)
* Greedy Decode (Gray)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points:
* **T=0.7, k=40 (Blue):** The line slopes upward, showing increasing accuracy with more sampled reasoning paths.
* 0 Paths: ~54%
* 5 Paths: ~60%
* 10 Paths: ~67%
* 15 Paths: ~70%
* 20 Paths: ~72%
* 25 Paths: ~73%
* 30 Paths: ~73.5%
* 35 Paths: ~74%
* 40 Paths: ~75%
* **T=0.5, k=40 (Orange):** The line also slopes upward, but starts lower and plateaus earlier than the blue line.
* 0 Paths: ~44%
* 5 Paths: ~54%
* 10 Paths: ~65%
* 15 Paths: ~69%
* 20 Paths: ~71%
* 25 Paths: ~72%
* 30 Paths: ~72%
* 35 Paths: ~72%
* 40 Paths: ~72%
* **T=0.3, k=40 (Green):** This line shows a moderate upward slope, but remains lower than the blue and orange lines.
* 0 Paths: ~50%
* 5 Paths: ~58%
* 10 Paths: ~64%
* 15 Paths: ~66%
* 20 Paths: ~68%
* 25 Paths: ~68%
* 30 Paths: ~68%
* 35 Paths: ~68%
* 40 Paths: ~68%
* **T=0.7, k=20 (Red):** This line exhibits a similar upward trend to the blue line, but with slightly lower accuracy values.
* 0 Paths: ~54%
* 5 Paths: ~62%
* 10 Paths: ~68%
* 15 Paths: ~70%
* 20 Paths: ~71%
* 25 Paths: ~72%
* 30 Paths: ~72%
* 35 Paths: ~73%
* 40 Paths: ~73%
* **T=0.7, no top k (Dark Blue):** This line shows a strong upward trend, reaching the highest accuracy values.
* 0 Paths: ~56%
* 5 Paths: ~64%
* 10 Paths: ~71%
* 15 Paths: ~73%
* 20 Paths: ~74%
* 25 Paths: ~75%
* 30 Paths: ~75%
* 35 Paths: ~75%
* 40 Paths: ~76%
* **p=0.95 (Brown):** This line shows a moderate upward trend, similar to the green line.
* 0 Paths: ~54%
* 5 Paths: ~60%
* 10 Paths: ~66%
* 15 Paths: ~69%
* 20 Paths: ~70%
* 25 Paths: ~71%
* 30 Paths: ~71%
* 35 Paths: ~71%
* 40 Paths: ~72%
* **p=0.9 (Magenta):** This line exhibits the strongest upward trend and achieves the highest accuracy values, closely following the "T=0.7, no top k" line.
* 0 Paths: ~54%
* 5 Paths: ~62%
* 10 Paths: ~70%
* 15 Paths: ~72%
* 20 Paths: ~73%
* 25 Paths: ~74%
* 30 Paths: ~74%
* 35 Paths: ~75%
* 40 Paths: ~75%
* **Greedy Decode (Gray):** This line remains flat at approximately 56% accuracy, regardless of the number of sampled reasoning paths.
* All Paths: ~56%
### Key Observations
* Increasing the number of sampled reasoning paths generally improves accuracy for most decoding strategies.
* The "Greedy Decode" strategy consistently performs the worst and does not benefit from increased sampling.
* The "T=0.7, no top k" and "p=0.9" strategies achieve the highest accuracy, particularly with a larger number of sampled reasoning paths.
* Lower temperature values (T=0.3) result in lower accuracy compared to higher temperature values (T=0.5, T=0.7).
* Reducing the top-k value (k=20 vs k=40) appears to slightly decrease accuracy.
### Interpretation
The data suggests that employing sampling techniques during decoding significantly enhances the accuracy of the model, especially when combined with appropriate temperature and probability settings. The "Greedy Decode" approach, which lacks sampling, demonstrates a clear performance limitation. The superior performance of the "T=0.7, no top k" and "p=0.9" strategies indicates that removing constraints on the sampling process (no top k) or using a higher probability threshold (p=0.9) allows the model to explore a wider range of reasoning paths, leading to more accurate results. The plateauing of some lines (e.g., T=0.5, k=40) suggests diminishing returns from increasing the number of sampled paths beyond a certain point. This implies an optimal balance between sampling effort and accuracy gain. The differences in performance between the various temperature settings suggest that temperature plays a crucial role in controlling the exploration-exploitation trade-off during decoding.
</details>
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Line Chart: Accuracy vs. Model Size
### Overview
This line chart compares the accuracy of two decoding methods, "Self Consistency" and "Greedy Decode", across varying model sizes. Accuracy is measured in percentage (%) and model size is measured in billions of parameters. The chart demonstrates how accuracy scales with model size for each method.
### Components/Axes
* **X-axis:** "Model size (#param in billions)". Markers are present at 1, 2, 5, 10, 20, 50, 100, and 200.
* **Y-axis:** "Accuracy (%)". Scale ranges from 0 to 25, with increments of 5.
* **Legend:** Located in the top-right corner.
* "Self Consistency" - Represented by a blue line with triangle markers.
* "Greedy Decode" - Represented by an orange line with square markers.
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
**Self Consistency (Blue Line):**
The blue line representing "Self Consistency" shows a generally upward trend.
* At Model Size = 1 billion parameters, Accuracy ≈ 2%.
* At Model Size = 2 billion parameters, Accuracy ≈ 3%.
* At Model Size = 5 billion parameters, Accuracy ≈ 3%.
* At Model Size = 10 billion parameters, Accuracy ≈ 4%.
* At Model Size = 20 billion parameters, Accuracy ≈ 8%.
* At Model Size = 50 billion parameters, Accuracy ≈ 12%.
* At Model Size = 100 billion parameters, Accuracy ≈ 16%.
* At Model Size = 200 billion parameters, Accuracy ≈ 25%.
**Greedy Decode (Orange Line):**
The orange line representing "Greedy Decode" also shows an upward trend, but is generally lower than "Self Consistency".
* At Model Size = 1 billion parameters, Accuracy ≈ 2%.
* At Model Size = 2 billion parameters, Accuracy ≈ 3%.
* At Model Size = 5 billion parameters, Accuracy ≈ 3%.
* At Model Size = 10 billion parameters, Accuracy ≈ 3%.
* At Model Size = 20 billion parameters, Accuracy ≈ 5%.
* At Model Size = 50 billion parameters, Accuracy ≈ 8%.
* At Model Size = 100 billion parameters, Accuracy ≈ 10%.
* At Model Size = 200 billion parameters, Accuracy ≈ 18%.
### Key Observations
* "Self Consistency" consistently outperforms "Greedy Decode" across all model sizes.
* The accuracy gap between the two methods widens as the model size increases.
* Both methods show relatively little improvement in accuracy between 1 and 10 billion parameters.
* The most significant gains in accuracy for both methods occur when the model size exceeds 20 billion parameters.
* The "Self Consistency" method shows a particularly steep increase in accuracy between 50 and 200 billion parameters.
### Interpretation
The data suggests that increasing model size generally improves accuracy for both decoding methods. However, "Self Consistency" is a more effective decoding strategy, especially as model size grows. This could be because "Self Consistency" leverages multiple generated outputs to arrive at a more robust and accurate answer, which becomes more beneficial with larger, more complex models. The relatively flat performance curve for both methods at smaller model sizes (1-10 billion parameters) indicates that the benefits of increased model capacity are limited until a certain threshold is reached. The substantial gains observed at larger model sizes (50-200 billion parameters) suggest that these models have the capacity to learn more complex patterns and relationships, but require a more sophisticated decoding strategy like "Self Consistency" to fully realize their potential. The difference in performance between the two methods is likely due to the inherent limitations of "Greedy Decode", which selects the most probable token at each step without considering alternative possibilities. This can lead to suboptimal results, especially in complex tasks where multiple valid solutions exist.
</details>
Self-Consistency Improves Robustness to Imperfect Prompts For few-shot learning with manually constructed prompts, human annotators sometimes make minor mistakes when creating the prompts. We further study if self-consistency can help improve a language model's robustness to imperfect prompts. 9 We show the results in Table 8: while imperfect prompts decrease accuracy with greedy decoding (17.1 → 14.9), self-consistency can fill in the gaps and robustly improve the results.
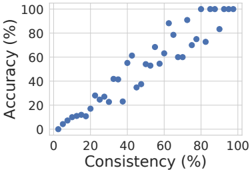
Additionally, we found that the consistency (in terms of % of decodes agreeing with the final aggregated answer) is highly correlated with accuracy (Figure 5, over GSM8K). This suggests that one can use self-consistency to provide an uncertainty estimate of the model in its generated solutions. In other words, one can use low consistency as an indicator that the model has low confidence; i.e., self-consistency confers some ability for the model to 'know when it doesn't know'.
| LaMDA-137B | Prompt with correct chain-of-thought | 17.1 14.9 |
|--------------|----------------------------------------------------------------------|-------------|
| LaMDA-137B | Prompt with imperfect chain-of-thought + Self-consistency (40 paths) | 23.4 |
| LaMDA-137B | Prompt with equations | 5 |
| LaMDA-137B | + Self-consistency (40 paths) | 6.5 |
| PaLM-540B | Zero-shot CoT (Kojima et al., 2022) | 43 |
| PaLM-540B | + Self-consistency (40 paths) | 69.2 |
Figure 5: The consistency is correlated with model's accuracy.
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Scatter Plot: Accuracy vs. Consistency
### Overview
The image presents a scatter plot illustrating the relationship between Accuracy and Consistency, both measured as percentages. The plot displays a generally positive correlation, with accuracy increasing as consistency increases.
### Components/Axes
* **X-axis:** Labeled "Consistency (%)", ranging from 0% to 100%. The axis is marked with increments of 20%.
* **Y-axis:** Labeled "Accuracy (%)", ranging from 0% to 100%. The axis is marked with increments of 20%.
* **Data Points:** A series of blue circular data points are scattered across the plot.
* **Gridlines:** A light gray grid is present to aid in reading values.
### Detailed Analysis
The data points show a clear trend: as Consistency increases, Accuracy also tends to increase.
Here's a breakdown of approximate data points, reading from left to right:
* At approximately 10% Consistency, Accuracy is around 5%.
* At approximately 20% Consistency, Accuracy is around 10-15%.
* At approximately 30% Consistency, Accuracy is around 20-25%.
* At approximately 40% Consistency, Accuracy is around 40%.
* At approximately 50% Consistency, Accuracy is around 50-60%.
* At approximately 60% Consistency, Accuracy is around 60-70%.
* At approximately 70% Consistency, Accuracy is around 70-80%.
* At approximately 80% Consistency, Accuracy is around 80-90%.
* At approximately 90% Consistency, Accuracy is around 90-100%.
* At approximately 100% Consistency, Accuracy is consistently around 95-100%.
The data points are relatively sparse at lower consistency values (below 30%) and become more densely populated as consistency increases.
### Key Observations
* **Positive Correlation:** A strong positive correlation exists between Consistency and Accuracy.
* **Non-Linearity:** The relationship appears to be non-linear. The rate of increase in Accuracy slows down as Consistency approaches 100%.
* **Threshold Effect:** Accuracy remains low (below 20%) until Consistency reaches approximately 30%, after which it begins to increase more rapidly.
* **Saturation:** Accuracy seems to plateau around 90-100% as Consistency reaches 100%.
### Interpretation
This data suggests that a higher degree of consistency is strongly associated with higher accuracy. This could represent a system or process where reliable, repeatable results (high consistency) lead to more correct outcomes (high accuracy). The non-linear relationship indicates that there's a threshold effect – a certain level of consistency must be achieved before significant gains in accuracy are observed. The saturation effect at high consistency suggests that there are diminishing returns; further improvements in consistency may not yield substantial improvements in accuracy.
This plot could be illustrating the performance of a machine learning model, a quality control process, or any system where both consistency and accuracy are important metrics. The data implies that focusing on improving consistency is a key strategy for enhancing accuracy, but that there may be a point of diminishing returns.
</details>
Self-Consistency Works for Non-Natural-Language Reasoning Paths and Zero-shot CoT We also tested the generality of the self-consistency concept to alternative forms of intermediate reasoning like equations (e.g., from ' There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. ' to ' 3 + 2 = 5 '). The results are shown in Table 8 ('Prompt with equations'): self-consistency still improves accuracy by generating intermediate equations; however, compared to generating natural language reasoning paths, the gain is smaller since the equations are much shorter and less opportunity remains for generating diversity in the decoding process. In addition, we tested self-consistency with zero-shot chain-of-thought (Kojima et al., 2022) and show that self-consistency works for zero-shot CoT as well and improves the results significantly (+26.2%) in Table 8.
9 We use the same prompts as before, but swap all the numbers in the reasoning paths with random numbers except the final answer, e.g., from ' There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. ' to ' There are 7 cars in the parking lot already. 6 more arrive. Now there are 7 + 6 = 5 cars. '.
## 4 RELATED WORK
Reasoning in language models. Language models are known to struggle in Type 2 tasks, such as arithmetic, logical and commonsense reasoning (Evans, 2010). Previous work has primarily focused on specialized approaches for improving reasoning (Andor et al., 2019; Ran et al., 2019; Geva et al., 2020; Pi˛ ekos et al., 2021). Compared to prior work, self-consistency is applicable to a wide range of reasoning tasks without any additional supervision or fine-tuning, while still substantially improving the performance of the chain-of-thought prompting approach proposed in Wei et al. (2022).
Sampling and re-ranking in language models. Multiple decoding strategies for language models have been proposed in the literature, e.g., temperature sampling (Ackley et al., 1985; Ficler & Goldberg, 2017), topk sampling (Fan et al., 2018; Holtzman et al., 2018; Radford et al., 2019), nucleus sampling (Holtzman et al., 2020), minimum Bayes risk decoding (Eikema & Aziz, 2020; Shi et al., 2022), and typical decoding (Meister et al., 2022). Other work has sought to explicitly promote diversity in the decoding process (Batra et al., 2012; Li et al., 2016; Vijayakumar et al., 2018).
Re-ranking is another common approach to improve generation quality in language models (Adiwardana et al., 2020; Shen et al., 2021). Thoppilan et al. (2022) collect additional human annotations to train a re-ranker for response filtering. Cobbe et al. (2021) train a 'verifier' to re-rank generated solutions, which substantially improves the solve rate on math tasks compared to just fine-tuning the language model. Elazar et al. (2021) improve the consistency of factual knowledge extraction by extending pre-training with an additional consistency loss. All these methods require either training an additional re-ranker or collecting additional human annotation, while self-consistency requires no additional training, fine-tuning, nor extra data collection.
Extract reasoning paths. Some previous work has considered task-specific approaches for identifying reasoning paths, such as constructing semantic graphs (Xu et al., 2021a), learning an RNN to retrieve reasoning paths over the Wikipedia graph (Asai et al., 2020), fine-tuning with human annotated reasoning paths on math problems (Cobbe et al., 2021), or training an extractor with heuristic-based pseudo reasoning paths (Chen et al., 2019). More recently, the importance of diversity in the reasoning processes has been noticed, but only leveraged via task-specific training, either through an additional QA model over extracted reasoning paths (Chen et al., 2019), or by the introduction of latent variables in a commonsense knowledge graph (Yu et al., 2022). Compared to these approaches, self-consistency is far simpler and requires no additional training. The approach we propose simply couples the generation of reasoning paths and a final answer by sampling from the decoder, using aggregation to recover the most consistent answer without additional modules.
Consistency in language models. Some prior work has shown that language models can suffer from inconsistency in conversation (Adiwardana et al., 2020), explanation generation (Camburu et al., 2020), and factual knowledge extraction (Elazar et al., 2021). Welleck et al. (2020) use 'consistency' to refer to generating an infinite-length sequence in recurrent language models. Nye et al. (2021) improve the logical consistency of samples from a System 1 model by adding a System 2-inspired logical reasoning module. In this paper we focus on a slightly different notion of 'consistency', i.e., utilizing answer consistency among diverse reasoning paths to improve accuracy.
## 5 CONCLUSION AND DISCUSSION
We introduced a simple yet effective method called self-consistency, and observed that it significantly improves accuracy in a range of arithmetic and commonsense reasoning tasks, across four large language models with varying scales. Beyond accuracy gains, self-consistency is also useful for collecting rationales when performing reasoning tasks with language models, and for providing uncertainty estimates and improved calibration of language model outputs.
One limitation of self-consistency is that it incurs more computation cost. In practice people can try a small number of paths (e.g., 5 or 10) as a starting point to realize most of the gains while not incurring too much cost, as in most cases the performance saturates quickly (Figure 2). As part of future work, one could use self-consistency to generate better supervised data to fine-tune the model, such that the model can give more accurate predictions in a single inference run after fine-tuning. In addition, we observed that language models can sometimes generate incorrect or nonsensical reasoning paths (e.g., the StrategyQA example in Table 4, the two population numbers are not exactly correct), and further work is needed to better ground models' rationale generations.
## REPRODUCIBILITY STATEMENT
In experiments, we included four different language models with varying scales. Two of them are public models: UL2 is a completely open-sourced model with model checkpoints available at https:// github.com/google-research/google-research/tree/master/ul2 ; GPT-3 is also a public model with public API available at https://openai.com/api/ . For GPT-3, we have included two public engines ('code-davinci-001' and 'code-davinci-002') to further aid reproducibility, as Codex is currently free so anyone can reproduce the results. In addition, as our results make use of LaMDA-137B and PaLM-540B that are not publicly available, we provide the exact input prompts for all tasks in Appendix A.3 (and note that we do not perform any finetuning and only apply prompting to off-the-shelf language models).
## ETHICS STATEMENT
As we stated in the discussion, language models can sometimes generate nonsensical or non-factual reasoning paths, so one should use language models' outputs with extra caution. We deal with reasoning tasks mostly and the generated rationales are only used for inspecting how a model reaches its answer. One could potentially use the generated rationales to further check why the model makes certain mistakes or whether the model contains any biases when performing a certain task. For language model in real-world use, further work is needed to better ground models' predictions and improve model's factuality and safety, to ensure the models do not cause harms to users.
## REFERENCES
- David H. Ackley, Geoffrey E. Hinton, and Terrence J. Sejnowski. A learning algorithm for boltzmann machines. Cognitive Science , 9(1):147-169, 1985. ISSN 0364-0213. URL https://www. sciencedirect.com/science/article/pii/S0364021385800124 .
- Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, and Quoc V. Le. Towards a human-like open-domain chatbot, 2020.
- Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pp. 2357-2367. Association for Computational Linguistics, June 2019. URL https://aclanthology.org/N19-1245 .
- Daniel Andor, Luheng He, Kenton Lee, and Emily Pitler. Giving BERT a calculator: Finding operations and arguments with reading comprehension. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , 2019. URL https://aclanthology. org/D19-1609 .
- Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. Learning to retrieve reasoning paths over wikipedia graph for question answering. In International Conference on Learning Representations , 2020. URL https://openreview.net/forum? id=SJgVHkrYDH .
- Roy Bar-Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. The second pascal recognising textual entailment challenge. In Proceedings of the second PASCAL challenges workshop on recognising textual entailment , 2006.
- Dhruv Batra, Payman Yadollahpour, Abner Guzman-Rivera, and Gregory Shakhnarovich. Diverse m-best solutions in markov random fields. In Proceedings of the 12th European Conference on Computer Vision - Volume Part V , ECCV'12, pp. 1-16, Berlin, Heidelberg, 2012. Springer-Verlag. ISBN 9783642337147. URL https://doi.org/10.1007/978-3-642-33715-4\_1 .
- Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. The fifth pascal recognizing textual entailment challenge. In TAC , 2009.
- BIG-bench collaboration. Beyond the imitation game: Measuring and extrapolating the capabilities of language models. In preparation , 2021. URL https://github.com/google/ BIG-bench/ .
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems , 2020. URL https://proceedings.neurips.cc/paper/2020/ file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf .
- Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom. esnli: Natural language inference with natural language explanations. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (eds.), Advances in Neural Information Processing Systems 31 , pp. 9539-9549. Curran Associates, Inc., 2018. URL http://papers.nips.cc/paper/ 8163-e-snli-natural-language-inference-with-natural-language-explanations. pdf .
- Oana-Maria Camburu, Brendan Shillingford, Pasquale Minervini, Thomas Lukasiewicz, and Phil Blunsom. Make up your mind! adversarial generation of inconsistent natural language explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pp. 4157-4165, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020. acl-main.382. URL https://aclanthology.org/2020.acl-main.382 .
- Jifan Chen, Shih-Ting Lin, and Greg Durrett. Multi-hop question answering via reasoning chains. CoRR , abs/1910.02610, 2019. URL http://arxiv.org/abs/1910.02610 .
- Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 , 2021.
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways, 2022. URL https://arxiv.org/abs/2204.02311 .
- Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL , 2019.
- Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv , abs/1803.05457, 2018.
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Machine Learning Challenges Workshop , pp. 177-190. Springer, 2005.
- Bryan Eikema and Wilker Aziz. Is MAP decoding all you need? the inadequacy of the mode in neural machine translation. In Proceedings of the 28th International Conference on Computational Linguistics , pp. 4506-4520, Barcelona, Spain (Online), December 2020. International Committee on Computational Linguistics. URL https://aclanthology.org/2020.coling-main. 398 .
- Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. Measuring and improving consistency in pretrained language models. Transactions of the Association for Computational Linguistics , 9:1012-1031, 2021. doi: 10.1162/tacl\_a\_00410. URL https://aclanthology.org/2021.tacl-1.60 .
- Jonathan St BT Evans. Intuition and reasoning: A dual-process perspective. Psychological Inquiry , 21(4):313-326, 2010.
- Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pp. 889-898, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1082. URL https://aclanthology.org/P18-1082 .
- Jessica Ficler and Yoav Goldberg. Controlling linguistic style aspects in neural language generation. In Proceedings of the Workshop on Stylistic Variation , pp. 94-104, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/W17-4912. URL https: //aclanthology.org/W17-4912 .
- Tianyu Gao, Adam Fisch, and Danqi Chen. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pp. 3816-3830, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.295. URL https://aclanthology.org/2021.acl-long. 295 .
- Mor Geva, Ankit Gupta, and Jonathan Berant. Injecting numerical reasoning skills into language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , 2020. doi: 10.18653/v1/2020.acl-main.89. URL https://aclanthology.org/2020. acl-main.89 .
- Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics , 2021. URL https://aclanthology.org/ 2021.tacl-1.21 .
- Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing , pp. 1-9. Association for Computational Linguistics, 2007.
- Ari Holtzman, Jan Buys, Maxwell Forbes, Antoine Bosselut, David Golub, and Yejin Choi. Learning to write with cooperative discriminators. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pp. 1638-1649, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1152. URL https://aclanthology.org/P18-1152 .
- Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In International Conference on Learning Representations , 2020. URL https: //openreview.net/forum?id=rygGQyrFvH .
- Mohammad Javad Hosseini, Hannaneh Hajishirzi, Oren Etzioni, and Nate Kushman. Learning to solve arithmetic word problems with verb categorization. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2014. doi: 10.3115/v1/D14-1058. URL https://aclanthology.org/D14-1058 .
- Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. UNIFIEDQA: Crossing format boundaries with a single QA system. In Findings of the Association for Computational Linguistics: EMNLP 2020 , pp. 1896-1907, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.171. URL https://aclanthology.org/2020.findings-emnlp.171 .
- Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems , 2022. URL https://openreview.net/forum?id=e2TBb5y0yFf .
- Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. MAWPS: A math word problem repository. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , 2016. doi: 10.18653/v1/N16-1136. URL https://aclanthology.org/N16-1136 .
- Yihuai Lan, Lei Wang, Qiyuan Zhang, Yunshi Lan, Bing Tian Dai, Yan Wang, Dongxiang Zhang, and Ee-Peng Lim. MWPToolkit: An open-source framework for deep learning-based math word problem solvers. arXiv preprint arXiv:2109.00799 , 2021. URL https://arxiv.org/abs/ 2109.00799 .
- Jiwei Li and Dan Jurafsky. Mutual information and diverse decoding improve neural machine translation, 2016. URL https://arxiv.org/abs/1601.00372 .
- Jiwei Li, Will Monroe, and Dan Jurafsky. A simple, fast diverse decoding algorithm for neural generation. CoRR , abs/1611.08562, 2016. URL http://arxiv.org/abs/1611.08562 .
- Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , 2017. doi: 10.18653/v1/P17-1015. URL https://aclanthology.org/P17-1015 .
- Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. ArXiv , abs/2104.08786, 2021.
- Clara Meister, Tiago Pimentel, Gian Wiher, and Ryan Cotterell. Typical decoding for natural language generation. arXiv preprint arXiv:2202.00666 , 2022.
- Shen Yun Miao, Chao Chun Liang, and Keh Yih Su. A diverse corpus for evaluating and developing English math word problem solvers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , 2020. URL https://aclanthology.org/2020. acl-main.92 .
- Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial NLI: A new benchmark for natural language understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics . Association for Computational Linguistics, 2020.
- Maxwell Nye, Michael Henry Tessler, Joshua B. Tenenbaum, and Brenden M. Lake. Improving coherence and consistency in neural sequence models with dual-system, neuro-symbolic reasoning. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems , 2021. URL https://openreview.net/forum?id= uyKk\_avJ-p4 .
- Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pp. 2080-2094, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main. 168. URL https://aclanthology.org/2021.naacl-main.168 .
- Xinyu Pi, Qian Liu, Bei Chen, Morteza Ziyadi, Zeqi Lin, Yan Gao, Qiang Fu, Jian-Guang Lou, and Weizhu Chen. Reasoning like program executors, 2022.
- Piotr Pi˛ ekos, Mateusz Malinowski, and Henryk Michalewski. Measuring and improving BERT's mathematical abilities by predicting the order of reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) , 2021. doi: 10.18653/v1/2021.acl-short.49. URL https://aclanthology.org/2021.acl-short.49 .
- Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446 , 2021.
- Qiu Ran, Yankai Lin, Peng Li, Jie Zhou, and Zhiyuan Liu. NumNet: Machine reading comprehension with numerical reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , 2019. doi: 10.18653/v1/D19-1251. URL https://aclanthology. org/D19-1251 .
- Subhro Roy and Dan Roth. Solving general arithmetic word problems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , 2015. doi: 10.18653/v1/ D15-1202. URL https://aclanthology.org/D15-1202 .
- Jianhao Shen, Yichun Yin, Lin Li, Lifeng Shang, Xin Jiang, Ming Zhang, and Qun Liu. Generate & rank: A multi-task framework for math word problems. In Findings of the Association for Computational Linguistics: EMNLP 2021 , pp. 2269-2279, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. URL https://aclanthology. org/2021.findings-emnlp.195 .
- Freda Shi, Daniel Fried, Marjan Ghazvininejad, Luke Zettlemoyer, and Sida I. Wang. Natural language to code translation with execution. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pp. 3533-3546, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology. org/2022.emnlp-main.231 .
- Keith E Stanovich and Richard F West. Individual differences in reasoning: Implications for the rationality debate? Behavioral and brain sciences , 23(5):645-665, 2000. URL https: //pubmed.ncbi.nlm.nih.gov/11301544/ .
- Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , 2019. URL https://aclanthology. org/N19-1421 .
- Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, Denny Zhou, Neil Houlsby, and Donald Metzler. Unifying language learning paradigms, 2022. URL https://arxiv.org/abs/2205.05131 .
- Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239 , 2022. URL https://arxiv.org/abs/ 2201.08239 .
- Ashwin Vijayakumar, Michael Cogswell, Ramprasaath Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search for improved description of complex scenes. Proceedings of the AAAI Conference on Artificial Intelligence , 32, Apr. 2018. URL https: //ojs.aaai.org/index.php/AAAI/article/view/12340 .
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. Conference on Neural Information Processing Systems (NeurIPS) , 2022. URL https://arxiv. org/pdf/2201.11903 .
- Sean Welleck, Ilia Kulikov, Jaedeok Kim, Richard Yuanzhe Pang, and Kyunghyun Cho. Consistency of a recurrent language model with respect to incomplete decoding. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 5553-5568, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020. emnlp-main.448. URL https://aclanthology.org/2020.emnlp-main.448 .
- Weiwen Xu, Yang Deng, Huihui Zhang, Deng Cai, and Wai Lam. Exploiting reasoning chains for multi-hop science question answering. In Findings of the Association for Computational Linguistics: EMNLP 2021 , pp. 1143-1156, Punta Cana, Dominican Republic, November 2021a. Association for Computational Linguistics. URL https://aclanthology.org/2021. findings-emnlp.99 .
- Yichong Xu, Chenguang Zhu, Shuohang Wang, Siqi Sun, Hao Cheng, Xiaodong Liu, Jianfeng Gao, Pengcheng He, Michael Zeng, and Xuedong Huang. Human parity on commonsenseqa: Augmenting self-attention with external attention, 2021b. URL https://arxiv.org/abs/ 2112.03254 .
- Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pp. 2369-2380, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. URL https://aclanthology.org/D18-1259 .
- Xi Ye and Greg Durrett. The unreliability of explanations in few-shot prompting for textual reasoning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems , 2022. URL https://openreview.net/forum? id=Bct2f8fRd8S .
- Wenhao Yu, Chenguang Zhu, Lianhui Qin, Zhihan Zhang, Tong Zhao, and Meng Jiang. Diversifying content generation for commonsense reasoning with mixture of knowledge graph experts. In Findings of Annual Meeting of the Association for Computational Linguistics (ACL) , 2022.
- Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning , volume 139 of Proceedings of Machine Learning Research . PMLR, 2021. URL https://proceedings.mlr.press/ v139/zhao21c.html .
## A APPENDIX
## A.1 ADDITIONAL EXPERIMENT RESULTS
## A.1.1 ROBUSTNESS TO SAMPLING STRATEGIES AND PARAMETERS
In Figure 6 we ablate the results with respect to different sampling strategies and parameters by varying T in temperature sampling and k in Topk sampling, on LaMDA-137B. We show that self-consistency is robust to various sampling strategies and parameters.
Figure 6: GSM8K accuracy over LaMDA-137B. Self-consistency works under various sampling strategies and sampling parameters.
<details>
<summary>Image 7 Details</summary>
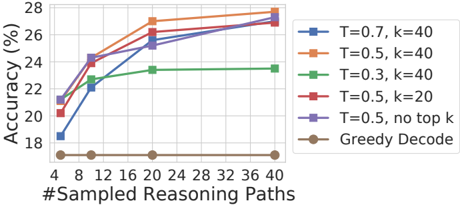
### Visual Description
## Line Chart: Accuracy vs. Sampled Reasoning Paths
### Overview
This line chart depicts the relationship between the number of sampled reasoning paths and the resulting accuracy (in percentage) for different parameter settings (T and k). The chart compares several decoding strategies, including varying temperature (T) and top-k sampling (k) values, against a "Greedy Decode" baseline.
### Components/Axes
* **X-axis:** "#Sampled Reasoning Paths" with values: 4, 8, 12, 16, 20, 24, 28, 32, 36, 40.
* **Y-axis:** "Accuracy (%)" with a scale ranging from approximately 18% to 28%.
* **Legend:** Located in the top-right corner, listing the following data series:
* T = 0.7, k = 40 (Blue, Triangle Marker)
* T = 0.5, k = 40 (Orange, Square Marker)
* T = 0.3, k = 40 (Green, Diamond Marker)
* T = 0.5, k = 20 (Red, Triangle Down Marker)
* T = 0.5, no top k (Purple, Circle Marker)
* Greedy Decode (Brown, Circle Marker)
### Detailed Analysis
* **Greedy Decode (Brown):** This line remains relatively flat, starting at approximately 16% accuracy at 4 sampled paths and increasing slightly to around 17% at 40 sampled paths.
* **T = 0.5, no top k (Purple):** This line shows a steady increase in accuracy, starting at approximately 20% at 4 sampled paths and reaching around 26% at 40 sampled paths.
* **T = 0.5, k = 20 (Red):** This line exhibits a rapid increase in accuracy from approximately 21% at 4 sampled paths to around 27% at 20 sampled paths, then plateaus, remaining around 27% at 40 sampled paths.
* **T = 0.3, k = 40 (Green):** This line shows a moderate increase in accuracy, starting at approximately 21% at 4 sampled paths and reaching around 23% at 40 sampled paths.
* **T = 0.7, k = 40 (Blue):** This line demonstrates a significant increase in accuracy, starting at approximately 19% at 4 sampled paths and reaching around 27% at 40 sampled paths.
* **T = 0.5, k = 40 (Orange):** This line shows a strong increase in accuracy, starting at approximately 21% at 4 sampled paths and reaching around 27.5% at 20 sampled paths, then plateaus, remaining around 27.5% at 40 sampled paths.
### Key Observations
* Increasing the number of sampled reasoning paths generally improves accuracy for all decoding strategies except for Greedy Decode, which remains consistently low.
* The combination of T = 0.7 and k = 40 yields the highest accuracy, particularly at higher numbers of sampled paths.
* The "Greedy Decode" strategy consistently performs the worst across all sampled path values.
* The lines for T = 0.5, k = 40 (Orange) and T = 0.5, k = 20 (Red) show a plateau in accuracy after 20 sampled paths, suggesting diminishing returns beyond that point.
### Interpretation
The data suggests that employing sampling techniques (increasing the number of sampled reasoning paths) significantly improves the accuracy of the model compared to a greedy decoding approach. The temperature (T) and top-k (k) parameters play a crucial role in balancing exploration and exploitation during the decoding process. A higher temperature (T = 0.7) combined with a larger k value (k = 40) appears to be the most effective configuration for maximizing accuracy, indicating that allowing for more diverse reasoning paths leads to better results. The plateau observed in some lines suggests that there's a point of diminishing returns where increasing the number of sampled paths no longer provides substantial accuracy gains. This could be due to the model converging on a limited set of optimal reasoning paths. The consistently poor performance of "Greedy Decode" highlights the importance of exploration in the reasoning process, as it tends to get stuck in local optima.
</details>
In Figure 7 and Figure 8, we show the results of self-consistency compared with greedy decoding a single path over LaMDA-137B and PaLM-540B, respectively. Self-consistency improves over greedy decode by a quite significant margin on both models, on top of high accuracy already achieved by scaling up model sizes.
Figure 7: Self-consistency (blue) significantly improves accuracy across various arithmetic and commonsense reasoning tasks, over LaMDA-137B. Sampling a higher number of diverse reasoning paths consistently improves reasoning accuracy.
<details>
<summary>Image 8 Details</summary>
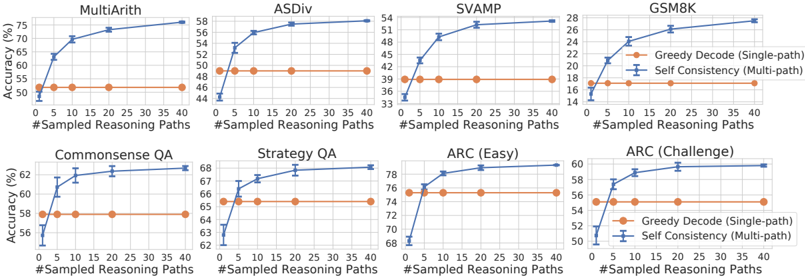
### Visual Description
\n
## Line Chart: Accuracy vs. Sampled Reasoning Paths for Different Datasets
### Overview
The image presents a series of line charts, each representing the accuracy of a model on a different dataset as a function of the number of sampled reasoning paths. Two methods are compared: "Greedy Decode (Single-path)" and "Self Consistency (Multi-path)". The charts visually demonstrate how accuracy changes with an increasing number of reasoning paths for each dataset and method.
### Components/Axes
* **X-axis:** "#Sampled Reasoning Paths" - Ranges from 0 to 35, with markers at 0, 5, 10, 15, 20, 25, 30, and 35.
* **Y-axis:** "Accuracy (%)" - Ranges from approximately 40% to 62%, with markers at 40, 45, 50, 55, 60.
* **Datasets (Chart Titles):** MultiArith, ASDiv, SVAMP, GSM8K, Commonsense QA, Strategy QA, ARC (Easy), ARC (Challenge).
* **Legend:**
* Orange Line with Circle Markers: "Greedy Decode (Single-path)"
* Blue Line with Cross Markers: "Self Consistency (Multi-path)"
### Detailed Analysis or Content Details
**MultiArith:**
* Self Consistency (Blue): Starts at approximately 55% accuracy at 0 paths, rises sharply to around 58% at 10 paths, and plateaus around 58.5% from 20 paths onwards.
* Greedy Decode (Orange): Starts at approximately 55% accuracy at 0 paths, rises slightly to around 56% at 10 paths, and remains relatively flat around 56% for the rest of the paths.
**ASDiv:**
* Self Consistency (Blue): Starts at approximately 46% accuracy at 0 paths, increases rapidly to around 56% at 15 paths, and plateaus around 57% from 20 paths onwards.
* Greedy Decode (Orange): Starts at approximately 46% accuracy at 0 paths, rises slightly to around 48% at 10 paths, and remains relatively flat around 48% for the rest of the paths.
**SVAMP:**
* Self Consistency (Blue): Starts at approximately 38% accuracy at 0 paths, increases rapidly to around 52% at 15 paths, and plateaus around 52.5% from 20 paths onwards.
* Greedy Decode (Orange): Starts at approximately 38% accuracy at 0 paths, rises slightly to around 40% at 10 paths, and remains relatively flat around 40% for the rest of the paths.
**GSM8K:**
* Self Consistency (Blue): Starts at approximately 18% accuracy at 0 paths, increases rapidly to around 26% at 15 paths, and plateaus around 26.5% from 20 paths onwards.
* Greedy Decode (Orange): Starts at approximately 18% accuracy at 0 paths, rises slightly to around 20% at 10 paths, and remains relatively flat around 20% for the rest of the paths.
**Commonsense QA:**
* Self Consistency (Blue): Starts at approximately 60% accuracy at 0 paths, rises to around 62% at 10 paths, and plateaus around 62% from 15 paths onwards.
* Greedy Decode (Orange): Starts at approximately 60% accuracy at 0 paths, rises slightly to around 61% at 10 paths, and remains relatively flat around 61% for the rest of the paths.
**Strategy QA:**
* Self Consistency (Blue): Starts at approximately 66% accuracy at 0 paths, rises to around 68% at 10 paths, and plateaus around 68.5% from 15 paths onwards.
* Greedy Decode (Orange): Starts at approximately 66% accuracy at 0 paths, rises slightly to around 67% at 10 paths, and remains relatively flat around 67% for the rest of the paths.
**ARC (Easy):**
* Self Consistency (Blue): Starts at approximately 70% accuracy at 0 paths, increases rapidly to around 77% at 15 paths, and plateaus around 77.5% from 20 paths onwards.
* Greedy Decode (Orange): Starts at approximately 70% accuracy at 0 paths, rises slightly to around 72% at 10 paths, and remains relatively flat around 72% for the rest of the paths.
**ARC (Challenge):**
* Self Consistency (Blue): Starts at approximately 52% accuracy at 0 paths, increases rapidly to around 58% at 15 paths, and plateaus around 58.5% from 20 paths onwards.
* Greedy Decode (Orange): Starts at approximately 52% accuracy at 0 paths, rises slightly to around 54% at 10 paths, and remains relatively flat around 54% for the rest of the paths.
### Key Observations
* The "Self Consistency (Multi-path)" method consistently outperforms the "Greedy Decode (Single-path)" method across all datasets.
* The performance gains from increasing the number of sampled reasoning paths diminish after approximately 15-20 paths for most datasets.
* The GSM8K dataset shows the largest performance gap between the two methods, indicating that it benefits the most from multi-path reasoning.
* The Commonsense QA and Strategy QA datasets show the smallest performance gap, suggesting that single-path reasoning is relatively effective for these tasks.
### Interpretation
The data strongly suggests that employing a "Self Consistency" approach with multiple sampled reasoning paths significantly improves the accuracy of the model across a diverse range of tasks. The diminishing returns observed after a certain number of paths indicate an optimal point where further increasing the number of paths does not yield substantial improvements. The varying degrees of improvement across datasets suggest that the complexity and nature of the task influence the effectiveness of multi-path reasoning. Datasets like GSM8K, which require more complex reasoning, benefit more from the increased exploration of solution paths. The consistent outperformance of "Self Consistency" highlights the value of considering multiple perspectives and aggregating results to arrive at a more robust and accurate solution. The charts provide empirical evidence supporting the hypothesis that exploring a wider solution space through multiple reasoning paths enhances the model's ability to solve complex problems.
</details>
We further show additional sampled reasoning paths from the LaMDA-137B model in Table 12, and sampled reasoning paths from the PaLM-540B model in Table 13. We see that the diversity in the additionally sampled reasoning paths indeed helps the model arrive at a more correct final answer after aggregation.
## A.1.2 ROBUSTNESS TO DIFFERENT SETS OF PROMPTS
In Table 9, we further show that self-consistency is quite robust to different sets of input prompts. We manually wrote 3 different sets of chain-of-thought as prompts to the model. Across all sets of prompts, self-consistency yields consistent gains over the original CoT approach.
## A.1.3 COMPARED TO MODEL ENSEMBLES
Additionally, we provide results of directly ensembling the outputs from multiple language models . The results are shown in Table 10, by greedily decoding sequences from 3 language models and
Figure 8: Self-consistency (blue) significantly improves accuracy across various arithmetic and commonsense reasoning tasks, over PaLM-540B. Sampling a higher number of diverse reasoning paths consistently helps reasoning accuracy.
<details>
<summary>Image 9 Details</summary>
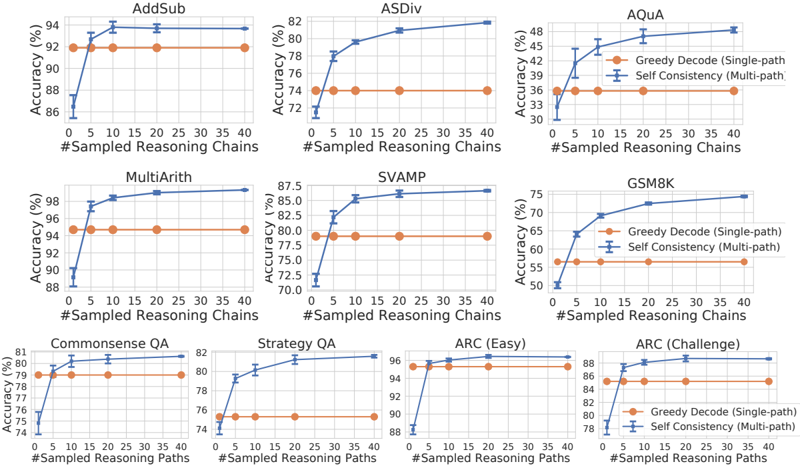
### Visual Description
\n
## Charts: Accuracy vs. Sampled Reasoning Chains
### Overview
The image presents a series of nine line charts, each depicting the relationship between "Accuracy (%)" and "#Sampled Reasoning Chains". Each chart represents a different benchmark dataset used for evaluating language model performance. Two data series are plotted on each chart: "Greedy Decode (Single-path)" and "Self Consistency (Multi-path)". The charts aim to demonstrate how increasing the number of sampled reasoning chains affects the accuracy of these two decoding methods across various tasks.
### Components/Axes
* **X-axis:** "#Sampled Reasoning Chains" - Ranges from 0 to 40, with markers at 0, 5, 10, 15, 20, 25, 30, 35, and 40.
* **Y-axis:** "Accuracy (%)" - Ranges from approximately 70% to 98%, varying slightly between charts.
* **Data Series:**
* "Greedy Decode (Single-path)" - Represented by a yellow line with circular markers.
* "Self Consistency (Multi-path)" - Represented by a blue line with triangular markers.
* **Chart Titles (Datasets):** AddSub, ASDiv, AQUA, MultiArith, SVAMP, GSM8, Commonsense QA, Strategy QA, ARC (Easy), ARC (Challenge).
* **Legend:** Located in the top-right corner of the AQUA chart, and is consistent across all charts.
### Detailed Analysis or Content Details
Here's a breakdown of each chart, including approximate data points. Note that due to the image resolution, values are estimated.
1. **AddSub:**
* Greedy Decode: Starts at ~91.5%, increases to ~92.5% at 10 chains, then plateaus around ~92.5%.
* Self Consistency: Starts at ~87%, increases to ~92% at 10 chains, then plateaus around ~92%.
2. **ASDiv:**
* Greedy Decode: Starts at ~75%, increases steadily to ~81% at 40 chains.
* Self Consistency: Starts at ~76%, increases rapidly to ~82% at 20 chains, then plateaus.
3. **AQUA:**
* Greedy Decode: Starts at ~32%, increases to ~36% at 10 chains, then plateaus.
* Self Consistency: Starts at ~30%, increases to ~46% at 40 chains.
4. **MultiArith:**
* Greedy Decode: Starts at ~96%, increases to ~97% at 10 chains, then plateaus.
* Self Consistency: Starts at ~90%, increases to ~98% at 40 chains.
5. **SVAMP:**
* Greedy Decode: Starts at ~83%, increases to ~85% at 20 chains, then plateaus.
* Self Consistency: Starts at ~72%, increases to ~86% at 40 chains.
6. **GSM8:**
* Greedy Decode: Starts at ~52%, increases rapidly to ~72% at 20 chains, then plateaus.
* Self Consistency: Starts at ~50%, increases rapidly to ~75% at 40 chains.
7. **Commonsense QA:**
* Greedy Decode: Starts at ~78%, increases to ~80% at 20 chains, then plateaus.
* Self Consistency: Starts at ~77%, increases to ~81% at 40 chains.
8. **Strategy QA:**
* Greedy Decode: Starts at ~76%, increases to ~80% at 20 chains, then plateaus.
* Self Consistency: Starts at ~74%, increases to ~82% at 40 chains.
9. **ARC (Easy):**
* Greedy Decode: Starts at ~92%, increases to ~94% at 10 chains, then plateaus.
* Self Consistency: Starts at ~90%, increases to ~96% at 40 chains.
10. **ARC (Challenge):**
* Greedy Decode: Starts at ~80%, increases to ~84% at 20 chains, then plateaus.
* Self Consistency: Starts at ~78%, increases to ~86% at 40 chains.
### Key Observations
* **Self Consistency generally outperforms Greedy Decode:** Across most datasets, the "Self Consistency" method achieves higher accuracy, especially as the number of sampled reasoning chains increases.
* **Diminishing Returns:** The accuracy gains from increasing the number of reasoning chains tend to diminish beyond a certain point (around 20-30 chains) for most datasets.
* **Dataset Sensitivity:** The impact of sampled reasoning chains varies significantly depending on the dataset. Some datasets (e.g., AQUA, GSM8, SVAMP) show substantial improvements with more chains, while others (e.g., AddSub, MultiArith) show minimal gains.
* **AQUA is the lowest performing dataset:** The accuracy scores for both methods are significantly lower on the AQUA dataset compared to others.
### Interpretation
The data suggests that employing a "Self Consistency" decoding strategy, which leverages multiple reasoning paths, generally leads to improved accuracy in language model performance across a range of mathematical and reasoning tasks. The benefit of this approach is particularly pronounced in more complex datasets like AQUA, GSM8, and SVAMP, where the model needs to perform more intricate reasoning steps.
The diminishing returns observed with increasing reasoning chains indicate a trade-off between accuracy and computational cost. While more chains can initially improve performance, the gains eventually plateau, suggesting that there's a point where the added computational effort doesn't yield significant improvements.
The dataset sensitivity highlights the importance of tailoring decoding strategies to the specific characteristics of the task. Some tasks may be more amenable to multi-path reasoning than others. The low performance on AQUA suggests that this dataset presents unique challenges for the models being evaluated, potentially requiring specialized techniques or architectures.
The charts provide valuable insights into the effectiveness of different decoding strategies and the impact of reasoning chain sampling on language model performance. This information can be used to optimize model configurations and improve the accuracy of language models on various reasoning tasks. The consistent outperformance of Self Consistency suggests it is a robust strategy for improving performance, but the diminishing returns and dataset sensitivity require careful consideration when applying it in practice.
</details>
Table 9: GSM8K accuracy over PaLM-540B. The results show robustness of self-consistency with respect to different prompts in the input.
| | Prompt set 1 (used in the main text) | Prompt set 2 | Prompt set 3 |
|------------------------|----------------------------------------|----------------|----------------|
| CoT (Wei et al., 2022) | 56.5 | 54.6 | 54.0 |
| Self-consistency | 74.4 (+17.9) | 72.1 (+17.5) | 70.4 (+16.4) |
taking the majority vote (averaged over 10 runs). Note this is a typical ensemble approach (averaging over the predictions over multiple models) and it achieves a performance significantly worse than self-consistency (self-consistency over PaLM-540B gets an accuracy of 74.4%), as lower-capacity models drag down the performance of higher-capacity models. In addition, this approach is limited in two ways: 1) It requires multiple models for an ensemble which might not always be available, while self-consistency only requires one single model to 'self-ensemble'; 2) If one of the models is much weaker, it can actually hurt the final performance.
Table 10: Comparison of GSM8K accuracy over multiple-model ensembles.
| Method | Method | GSM8K accuracy |
|--------------------|---------------------------------------------------------|------------------|
| Single model | PaLM-540B, greedy / self-consistency | 56.5 / 74.4 |
| | LaMDA-137B + PaLM-540B | 36.9 ± 0.5 |
| Ensemble of models | PaLM-540B + GPT-3 (code-davinci-001, 175B) | 36.6 ± 0.4 |
| Ensemble of models | LaMDA-137B + GPT-3 (code-davinci-001, 175B) | 16.0 ± 0.8 |
| Ensemble of models | LaMDA-137B + PaLM-540B + GPT-3 (code-davinci-001, 175B) | 33.3 ± 0.7 |
## A.1.4 COMBINING SELF-CONSISTENCY WITH OTHER ENSEMBLING STRATEGIES
Self-consistency is completely compatible with other ensemble strategies, although the gains achieved by self-consistency are significantly higher than other ensemble strategies (and can 'override' the performance gains achieved by other ensemble strategies). We further performed experiments and include the results in Table 11 (for a fair comparison, we use 40 sets of prompts, or 40 prompt permutations to compare with self-consistency with 40 paths, all experiments are based on PaLM540B).
Table 11: Combining self-consistency with other ensembling strategies.
| | GSM8K accuracy |
|----------------------------------------------------|------------------|
| Different sets of prompts (x40) | 58.9 |
| Prompt-permutation (x40) | 59.6 |
| Self-consistency (x40) | 74.4 |
| Self-consistency + different sets of prompts (x40) | 75.4 |
| Self-consistency + prompt-permutation (x40) | 73.8 |
## A.2 DETAILS ON RESOURCES AND INFERENCE
For all four language models we perform prompting-based inference only. For UL2 we use TPU v3 (2x2 configuration, 4 chips, 8 cores). For GPT-3 models the experiments are done though the public API. 10 For LaMDA-137B we use TPU v3 (8x8 configuration, 64 chips, 128 cores). For PaLM-540B we use TPU v4 (4x4x12 configuration, 192 chips, 384 cores). Most inference jobs take 1 to 4 hours (over about 1,000 examples) for each task on UL2 and LaMDA-137B, and about 2 to 12 hours on PaLM-540B. Some tasks (e.g., commonsense reasoning) take longer but do not exceed 2 days for each task.
For GPT-3 models, we use 128 max tokens for all methods, without frequency penalty or presence penalty. For all models, we take the generated outputs until the start of the next 'Q:" to parse the final answers, consistent with our prompting format.
Table 12: Additional examples where self-consistency helps repair the errors over greedy decode on LaMDA-137B. Two sampled reasoning paths that are consistent with the ground truth are shown.
| Question | Greedy Decode | Sampled Path 1 | Sampled Path 2 |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [MultiArith] Sam had 10 socks. If he threw away 3 old ones that didn't fit and bought 36 new ones, how many socks would he have? | Sam had 10 socks. He threw away 3 old ones that didn't fit. He bought 36 new ones. That means he has 10 + 36 - 3 = 41 socks. The answer is 41. | Sam had 10 socks. He threw away 3 old ones. So now he has 7 left. Then he bought 36 new ones. So now he has 7 + 36 = 43 socks. The answer is 43. | He had 10 socks. He threw away 3 old ones that didn't fit. He bought 36 new ones. So in total he has 10 - 3 + 36 = 43 socks. The answer is 43. |
| [SVAMP] In a school there are 697 girls and the rest are boys. If there are 228 more girls than boys. How many boys are there in that school? | There are 697 girls and the rest are boys. That means there are 697 + 228 = 925 girls. The rest are boys. So the number of boys is 925 - 697 = 228. The answer is 228. | The number of boys is the difference between 697 and 228. This is 697 - 228 = 469. The answer is 469. | In the beginning there are 697 girls and the rest are boys. So, the number of boys must be 697 - 228 = 469 boys. The answer is 469. |
| [AQuA] There are 10 oranges in a basket. Find the no. of ways in which 2 oranges are chosen from the basket? (a) 45 (b) 90 (c) 120 (d) 150 (e) 180 | There are 10 oranges in a bas- ket. So there are 10 ways in which 2 oranges are chosen from the basket. | There are 10 oranges in a basket. We need to choose 2 oranges from the basket. So the number of ways are 10C2. So the answer is (a). | There are 10 oranges in the bas- ket. If you choose 2 oranges, you have 10C2 = 45 ways of choosing 2 oranges. So the answer is (a). |
| [CommonsenseQA] The man laid on the soft moss and looked up at the trees, where was the man? (a) niagra falls (b) forest (c) waterfall (d) ground (e) tree | The answer must be something that is soft and mossy. Of the above choices, only ground is soft and mossy. So the answer is (d). | The answer must be somewhere where moss is found. Of the above choices, only forests are known for having moss. So the answer is (b). | The answer must be a place where the man is laying down and look- ing up at trees. Of the above choices, only forest is a place where people lay down and look at trees. So the answer is (b). |
| [ARC] Which of these will most likely harm a habitat? (a) plant- ing trees. (b) water pollution. (c) rainfall. (d) sunlight. | Planting trees will not harm a habitat. So the answer is (a). | The answer is (b), water pollution, because it will most likely harm the habi- tat. The other answers are not likely to harm the habi- tat. | The answer is (b), water pollution. Trees are good for a habitat, rain- fall is necessary for a habitat, and sunlight is necessary for a habitat. So the answer is (b). |
| [ARC-challenge] Which pro- cess in the carbon cycle takes the longest to complete? (a) emis- sion of waste. (b) respiration in animals. (c) photosynthesis in plants. (d) formation of fossil fu- els. | The process of photosynthesis in plants takes the longest to complete. So the answer is (c). | The formation of fossil fu- els takes the longest time to complete. So the an- swer is (d). | The process that takes the longest time to complete is the forma- tion of fossil fuels, which hap- pens over millions of years. So the answer is (d). |
10 https://beta.openai.com/docs/api-reference/making-requests
| Question | Greedy Decode | Sampled Path 1 | Sampled Path 2 |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [GSM8K] Kyle bought last year's best-selling book for $19.50. This is with a 25% dis- count from the original price. What was the original price of the book? | The book was sold for $19.50. This is 25% less than the origi- nal price. This means the original price was 100%. 25% of 100% is 25%. So the original price was 100% - 25% = 75%. The original price was 75% of $19.50. 75% of $19.50 is 75% * $19.50 = $14.625. The answer is $14.625. | The original price of the book is $19.50. Since it was dis- counted by 25%, the original price was 19.50 / 0.75 = 26. The answer is 26. | Kyle bought a book that is sold for $19.50. With a 25% discount, the original price must be higher. If we call the original price x, then the discounted price is 0.75x. Since this is $19.50, we can write 0.75x = 19.50. Solving this, we find that the original price is x = 19.50 / 0.75 = $26. The answer is $26. |
| [AQuA] The capacity of a tank of dimensions (8 m x 6 m x 2.5 m) is (a) 120 litres (b) 1200 litres (c) 12000 litres (d) 120000 litres (e) None of these | The volume of the tank is 8 m * 6 m * 2.5 m = 120 m 3 . So the capacity of the tank is120m 3 . So the answer is (c). | The volume of the tank is 8m * 6m* 2.5m = 120m 3 . This is equal to 120000 litres. So the answer is (d) | The volume of the tank is 8 m * 6 m * 2.5 m = 120 m3. One cu- bic meter contains 1000 litres, so the tank contains 120 m3 * 1000 liters/m3 = 120,000 liters. So the answer is (d). |
| [StrategyQA] Yes or no: Can the Great Depression be treated with Prozac? | The Great Depression was an economic depression. Prozac is a drug used to treat depression. Thus, the Great Depression could be treated with Prozac. So the an- swer is yes. | Prozac is an anti-depressant medication. The Great Depres- sion is not a disease. Thus, Prozac cannot treat the Great Depression. So the answer is no. | The Great Depression is a time pe- riod. Prozac is used to treat de- pression (the mental illness). Thus, the Great Depression can not be treated with Prozac. So the answer is no. |
| [ARC-easy] Which source of energy is nonrenewable? (a) coal. (b) sunlight. (c) water. (d) wood. | Coal, sunlight, and water are all renewable sources of energy. Woodis a nonrenewable source of energy. So the answer is (d). | A nonrenewable source of en- ergy is one in which the source is not replenished in a short amount of time. Thus, the only option that is nonrenewable is coal. So the answer is (a). | Coal is a fossil fuel and is formed from dead organisms from the past. Coal cannot be produced in a short period of time, so it is considered a nonrenewable source of energy. So the answer is (a). |
| [ARC-challenge] Students studied the revolution of Earth around the Sun. During which month will Florida have the most sunlight energy avail- able? (a) March. (b) June. (c) September. (d) December. | The Earth is closest to the Sun in December, hence Florida will have the most sunlight energy available in December. So the an- swer is (d). | Earth is closest to the Sun on June 21, the summer solstice. So the answer is (b). | Florida is closer to the sun during June, so it will have the most sun- light energy during that month. So the answer is (b). |
Table 13: Additional examples where self-consistency helps repair the errors over greedy decode on PaLM-540B. Two sampled reasoning paths that are consistent with the ground truth are shown.
## A.3 FULL SETS OF PROMPTS
We list the full details of the prompts used for two newly-introduced datasets, AQUA-RAT (Ling et al., 2017) and AI2 Reasoning Challenge (ARC) (Clark et al., 2018), where we manually composed the example chain-of-thought in this paper, in Table 14 and Table 15, respectively.
Table 14: Few-shot exemplars for AQUA-RAT.
Q: John found that the average of 15 numbers is 40. If 10 is added to each number then the mean of the numbers is? Answer Choices: (a) 50 (b) 45 (c) 65 (d) 78 (e) 64
A: If 10 is added to each number, then the mean of the numbers also increases by 10. So the new mean would be 50. The answer is (a).
Q: If a / b = 3/4 and 8a + 5b = 22,then find the value of a. Answer Choices: (a) 1/2 (b) 3/2 (c) 5/2 (d) 4/2 (e) 7/2
A: If a / b = 3/4, then b = 4a / 3. So 8a + 5(4a / 3) = 22. This simplifies to 8a + 20a / 3 = 22, which means 44a / 3 = 22. So a is equal to 3/2. The answer is (b).
Q: Aperson is traveling at 20 km/hr and reached his destiny in 2.5 hr then find the distance? Answer Choices: (a) 53 km (b) 55 km (c) 52 km (d) 60 km (e) 50 km
A: The distance that the person traveled would have been 20 km/hr * 2.5 hrs = 50 km. The answer is (e).
Q: How many keystrokes are needed to type the numbers from 1 to 500? Answer Choices: (a) 1156 (b) 1392 (c) 1480 (d) 1562 (e) 1788
A: There are 9 one-digit numbers from 1 to 9. There are 90 two-digit numbers from 10 to 99. There are 401 three-digit numbers from 100 to 500. 9 + 90(2) + 401(3) = 1392. The answer is (b).
## Table 15: Few-shot exemplars for ARC easy/challenge.
Q: George wants to warm his hands quickly by rubbing them. Which skin surface will produce the most heat? (a) dry palms. (b) wet palms. (c) palms covered with oil. (d) palms covered with lotion.
A: Dry surfaces will more likely cause more friction via rubbing than other smoother surfaces, hence dry palms will produce the most heat. The answer is (a).
Q: Which factor will most likely cause a person to develop a fever? (a) a leg muscle relaxing after exercise. (b) a bacterial population in the bloodstream. (c) several viral particles on the skin. (d) carbohydrates being digested in the stomach.
A: Option (b), bacterial population is the most likely cause for a person developing fever. The answer is (b).
Q: Which change in the state of water particles causes the particles to become arranged in a fixed position? (a) boiling. (b) melting. (c) freezing. (d) evaporating.
A: When water is freezed, the particles are arranged in a fixed position; the particles are still moving for all other options. The answer is (c).
Q: When a switch is used in an electrical circuit, the switch can (a) cause the charge to build. (b) increase and decrease the voltage. (c) cause the current to change direction. (d) stop and start the flow of current.
A: The function of a switch is to start and stop the flow of a current. The answer is (d).
Table 16: Few-shot exemplars for HotpotQA (closed-book setting).
Q: Which magazine was started first Arthur's Magazine or First for Women?
A: Arthur's Magazine started in 1844. First for Women started in 1989. So Arthur's Magazine was started first. The answer is Arthur's Magazine.
Q: The Oberoi family is part of a hotel company that has a head office in what city?
A: The Oberoi family is part of the hotel company called The Oberoi Group. The Oberoi Group has its head office in Delhi. The answer is Delhi.
Q: What nationality was James Henry Miller's wife?
A: James Henry Miller's wife is June Miller. June Miller is an American. The answer is American.
Q: The Dutch-Belgian television series that "House of Anubis" was based on first aired in what year?
A: "House of Anubis" is based on the Dutch-Belgian television series Het Huis Anubis. Het Huis Anubis is first aired in September 2006. The answer is 2006.
As additional information, we also list the exact set of prompts used for all arithmetic reasoning tasks in Table 17, since there are multiple sets of prompts introduced in Wei et al. (2022). The prompts for CommonsenseQA and StrategyQA are the same as used in Wei et al. (2022).
We provide the exact prompts used for common NLP tasks in the following tables as well, including NLI (Table 18, Table 19, Table 20) and Closed-Book Question-Answering tasks (Table 16, Table 21).
Table 17: Few-shot exemplars for all arithmetic reasoning tasks, from Wei et al. (2022).
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted. So, they must have planted 21 - 15 = 6 trees. The answer is 6.
Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5.
Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
A: Leah had 32 chocolates and Leah's sister had 42. That means there were originally 32 + 42 = 74 chocolates. 35 have been eaten. So in total they still have 74 - 35 = 39 chocolates. The answer is 39.
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
A: Jason had 20 lollipops. Since he only has 12 now, he must have given the rest to Denny. The number of lollipops he has given to Denny must have been 20 - 12 = 8 lollipops. The answer is 8.
Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now?
A: He has 5 toys. He got 2 from mom, so after that he has 5 + 2 = 7 toys. Then he got 2 more from dad, so in total he has 7 + 2 = 9 toys. The answer is 9.
Q: There were nine computers in the server room. Five more computers were installed each day, from monday to thursday. How many computers are now in the server room?
A: There are 4 days from monday to thursday. 5 computers were added each day. That means in total 4 * 5 = 20 computers were added. There were 9 computers in the beginning, so now there are 9 + 20 = 29 computers. The answer is 29.
Q: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many golf balls did he have at the end of wednesday?
A: Michael initially had 58 balls. He lost 23 on Tuesday, so after that he has 58 - 23 = 35 balls. On Wednesday he lost 2 more so now he has 35 - 2 = 33 balls. The answer is 33.
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
A: She bought 5 bagels for $3 each. This means she spent 5 * $3 = $15 on the bagels. She had $23 in beginning, so now she has $23 - $15 = $8. The answer is 8.
Premise:
"Conceptually cream skimming has two basic dimensions - product and geography."
Based on this premise, can we conclude the hypothesis "Product and geography are what make cream skimming work." is true?
OPTIONS:
- yes
- no
- it is not possible to tell
A: Based on "cream skimming has two basic dimensions" we can't infer that these two dimensions are what make cream skimming work. The answer is it is not possible to tell.
Premise:
"One of our member will carry out your instructions minutely."
Based on this premise, can we conclude the hypothesis "A member of my team will execute your orders with immense precision." is true?
OPTIONS:
- yes
- no
- it is not possible to tell
A: "one of" means the same as "a member of", "carry out" means the same as "execute", and "minutely" means the same as "immense precision". The answer is yes.
Premise:
"Fun for adults and children."
Based on this premise, can we conclude the hypothesis "Fun for only children." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: "adults and children" contradicts "only children". The answer is no.
Premise:
"He turned and smiled at Vrenna."
Based on this premise, can we conclude the hypothesis "He smiled at Vrenna who was walking slowly behind him with her mother." is true?
OPTIONS:
- yes
- no
- it is not possible to tell
A: the premise does not say anything about "Vrenna was walking". The answer is it is not possible to tell.
Premise:
"well you see that on television also"
Based on this premise, can we conclude the hypothesis "You can see that on television, as well." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: "also" and "as well" mean the same thing. The answer is yes.
Premise:
"Vrenna and I both fought him and he nearly took us."
Based on this premise, can we conclude the hypothesis "Neither Vrenna nor myself have ever fought him." is true?
OPTIONS:
- yes
- no
- it is not possible to tell
A: "Vrenna and I both" contradicts "neither Vrenna nor myself". The answer is no.
## Table 18: Few-shot exemplars for ANLI.
Table 19: Few-shot exemplars for e-SNLI (the rationales are crowd-sourced annotations from the original dataset).
Premise:
"A person on a horse jumps over a broken down airplane."
Based on this premise, can we conclude the hypothesis "A person is training his horse for a competition." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: The person is not necessarily training his horse. The answer is it is not possible to tell.
Premise:
"A person on a horse jumps over a broken down airplane."
Based on this premise, can we conclude the hypothesis "A person is at a diner, ordering an omelette." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: One jumping horse cannot be in a diner ordering food. The answer is no.
Premise:
"A person on a horse jumps over a broken down airplane."
Based on this premise, can we conclude the hypothesis "A person is outdoors, on a horse." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: A broken down airplane is outdoors. The answer is yes.
Premise:
"Children smiling and waving at camera."
Based on this premise, can we conclude the hypothesis "They are smiling at their parents." is true?
OPTIONS:
- yes
- no
- it is not possible to tell
A: Just because they are smiling and waving at a camera does not imply their parents or anyone is anyone behind it. The answer is it is not possible to tell.
Premise:
"Children smiling and waving at camera."
Based on this premise, can we conclude the hypothesis "The kids are frowning." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: One cannot be smiling and frowning at the same time. The answer is no.
Premise:
"Children smiling and waving at camera."
Based on this premise, can we conclude the hypothesis "There are children present." is true? OPTIONS:
- yes
- no
- it is not possible to tell
A: The children must be present to see them smiling and waving. The answer is yes.
Premise:
"No Weapons of Mass Destruction Found in Iraq Yet."
Based on this premise, can we conclude the hypothesis "Weapons of Mass Destruction Found in Iraq." is true?
A: "No Weapons of Mass Destruction Found" contradicts "Weapons of Mass Destruction Found". The answer is no.
Premise:
"A place of sorrow, after Pope John Paul II died, became a place of celebration, as Roman Catholic faithful gathered in downtown Chicago to mark the installation of new Pope Benedict XVI."
Based on this premise, can we conclude the hypothesis "Pope Benedict XVI is the new leader of the Roman Catholic Church." is true?'
A: "installation of new Pope Benedict XVI." means "Pope Benedict XVI is the new leader". The answer is yes.
Premise:
"A man is due in court later charged with the murder 26 years ago of a teenager whose case was the first to be featured on BBC One's Crimewatch. Colette Aram, 16, was walking to her boyfriend's house in Keyworth, Nottinghamshire, on 30 October 1983 when she disappeared. Her body was later found in a field close to her home. Paul Stewart Hutchinson, 50, has been charged with murder and is due before Nottingham magistrates later."
Based on this premise, can we conclude the hypothesis "Paul Stewart Hutchinson is accused of having stabbed a girl." is true?
A: The premise does not say Paul Stewart Hutchinson "stabbed" this girl. The answer is no.
Premise:
"Herceptin was already approved to treat the sickest breast cancer patients, and the company said, Monday, it will discuss with federal regulators the possibility of prescribing the drug for more breast cancer patients." Based on this premise, can we conclude the hypothesis "Herceptin can be used to treat breast cancer." is true?
A: "Herceptin was approved to treat breast cancer" implies that "Herceptin can be used to treat breast cancer". The answer is yes.
Table 21: Few-shot exemplars for BoolQ (closed-book setting).
Q: does system of a down have 2 singers?
A: System of a Down currently consists of Serj Tankian, Daron Malakian, Shavo Odadjian and John Dolmayan. Serj and Daron do vocals, so the band does have two singers. The answer is yes.
Q: do iran and afghanistan speak the same language?
A: Iran and Afghanistan both speak the Indo-European language Persian. The answer is yes.
Q: is a cello and a bass the same thing?
A: The cello is played sitting down with the instrument between the knees, whereas the double bass is played standing or sitting on a stool. The answer is no.
Q: can you use oyster card at epsom station?
A: Epsom railway station serves the town of Epsom in Surrey and is not in the London Oyster card zone. The answer is no.
## Table 20: Few-shot exemplars for RTE.