## Extreme Compression for Pre-trained Transformers Made Simple and Efficient
Xiaoxia Wu ∗ , Zhewei Yao ∗ , Minjia Zhang ∗ Conglong Li, Yuxiong He
Microsoft
{xiaoxiawu, zheweiyao, minjiaz, conglong.li, yuxhe} @microsoft.com
## Abstract
Extreme compression, particularly ultra-low bit precision (binary/ternary) quantization, has been proposed to fit large NLP models on resource-constraint devices. However, to preserve the accuracy for such aggressive compression schemes, cutting-edge methods usually introduce complicated compression pipelines, e.g., multi-stage expensive knowledge distillation with extensive hyperparameter tuning. Also, they oftentimes focus less on smaller transformer models that have already been heavily compressed via knowledge distillation and lack a systematic study to show the effectiveness of their methods. In this paper, we perform a very comprehensive systematic study to measure the impact of many key hyperparameters and training strategies from previous works. As a result, we find out that previous baselines for ultra-low bit precision quantization are significantly under-trained. Based on our study, we propose a simple yet effective compression pipeline for extreme compression, named XTC. XTC demonstrates that (1) we can skip the pre-training knowledge distillation to obtain a 5-layer BERT while achieving better performance than previous state-of-the-art methods, e.g., the 6-layer TinyBERT; (2) extreme quantization plus layer reduction is able to reduce the model size by 50x, resulting in new state-of-the-art results on GLUE tasks.
## 1 Introduction
Over the past few years, we have witnessed the model size has grown at an unprecedented speed, from a few hundred million parameters (e.g., BERT [10], RoBERTa [28], DeBERTA [15], T5 [37],GPT-2 [36]) to a few hundreds of billions of parameters (e.g., 175B GPT-3 [6], 530B MT-NLT [46]), showing outstanding results on a wide range of language processing tasks. Despite the remarkable performance in accuracy, there have been huge challenges to deploying these models, especially on resource-constrained edge or embedded devices. Many research efforts have been made to compress these huge transformer models including knowledge distillation [20, 54, 53, 63], pruning [57, 43, 8], and low-rank decomposition [30]. Orthogonally, quantization focuses on replacing the floating-point weights of a pre-trained Transformer network with low-precision representation. This makes quantization particularly appealing when compressing models that have already been optimized in terms of network architecture.
Recently, several QAT works further push the limit of BERT quantization to the extreme via ternarized (2-bit) ([61]) and binarized (1-bit) weights ([3]) together with 4-/8-bit quantized activation. These compression
Popular quantization methods include post-training quantization [45, 33, 29], quantization-aware training (QAT) [23, 4, 31, 22], and their variations [44, 24, 12]. The former directly quantizes trained model weights from floating-point values to low precision values using a scalar quantizer, which is simple but can induce a significant drop in accuracy. To address this issue, quantization-aware training directly quantizes a model during training by quantizing all the weights during the forward and using a straight-through estimator (STE) [5] to compute the gradients for the quantizers.
∗ Equal contribution. Code will be released soon as a part of https://github.com/microsoft/DeepSpeed
Figure 1: The left figure summarizes how to do 1-bit quantization for a layer-reduced model based on [20, 3]. It involves expensive pretraining on an fp-32 small model, task-specific training on 32-bit and 2-bit models, weight-splitting, and the final 1-bit model training. Along the way, it applies multi-stage knowledge distillation with data augumentation, which needs considerable hyperparameter tuning efforts. The right figure is our proposed method, XTC (see details in § 5), a simple while effective pipeline (see Figure 2 for highlighted results). Better read with a computer screen.
<details>
<summary>Image 1 Details</summary>

### Visual Description
## Diagram: Knowledge Distillation Strategies
### Overview
The image presents two diagrams illustrating different knowledge distillation strategies for BERT models. The left diagram shows a multi-stage knowledge distillation process, while the right diagram depicts a single-stage approach. Both diagrams highlight the transfer of knowledge from a larger "teacher" BERT model to a smaller "student" BERT model.
### Components/Axes
**Left Diagram:**
* **Horizontal Axis:** Represents the progression of knowledge distillation stages.
* **Labels along the axis:**
* "Task-agnostic Smaller BERT FP32"
* "Task-specific Smaller BERT FP32"
* "Task-specific Smaller BERT 2-bit"
* "Task-specific Smaller BERT 1-bit"
* **Data Source:** "Large-scale Text Corpus" (represented as a cylinder on the left)
* **Teacher Model:** "Task-specific BERT (Teacher)" (top-left, in a rounded rectangle)
* **(DA) Task Dataset:** "(DA) Task Dataset" (top-center, in a rounded rectangle)
* **Knowledge Distillation Stages (represented as colored rectangles):**
* "General KD" (brown)
* "Stage-I KD" (red)
* "Stage-II KD" (purple)
* "KD Weight-Splitting" (green)
* "Stage-I KD" (red)
* "Stage-II KD" (purple)
**Right Diagram:**
* **Vertical Arrow:** "Initialization" (indicating the transfer of knowledge from the teacher to the student)
* **Teacher Model:** "Task-specific BERT (Teacher)" (top-left, in a rounded rectangle)
* **Student Model:** "Task-specific Smaller BERT" (below the teacher model, in a rounded rectangle)
* **Horizontal Axis:** Represents the progression of knowledge distillation stages.
* **Labels along the axis:**
* "Task-specific Smaller BERT FP32"
* "Task-specific Smaller BERT 1-bit"
* **Knowledge Distillation Stages (represented as colored rectangles):**
* "Single Stage KD" (red)
* "Single Stage KD" (red)
### Detailed Analysis
**Left Diagram:**
1. **Data Source:** The process begins with a "Large-scale Text Corpus."
2. **General KD:** The first stage involves "General KD," resulting in a "Task-agnostic Smaller BERT FP32."
3. **Multi-Stage KD:** Subsequent stages involve "Stage-I KD," "Stage-II KD," "KD Weight-Splitting," "Stage-I KD," and "Stage-II KD," leading to increasingly compressed models: "Task-specific Smaller BERT FP32," "Task-specific Smaller BERT 2-bit," and finally "Task-specific Smaller BERT 1-bit."
4. **Teacher and Dataset:** The "Task-specific BERT (Teacher)" and "(DA) Task Dataset" are connected to the KD stages via dotted lines, indicating their role in guiding the distillation process.
**Right Diagram:**
1. **Initialization:** The "Task-specific Smaller BERT" is initialized from the "Task-specific BERT (Teacher)."
2. **Single-Stage KD:** Two "Single Stage KD" steps are shown, resulting in "Task-specific Smaller BERT FP32" and "Task-specific Smaller BERT 1-bit."
3. **Teacher and Dataset:** The "Task-specific BERT (Teacher)" and "(DA) Task Dataset" are connected to the KD stages via dotted lines, indicating their role in guiding the distillation process.
### Key Observations
* The left diagram illustrates a more complex, multi-stage knowledge distillation process, while the right diagram shows a simpler, single-stage approach.
* Both diagrams aim to compress a larger "teacher" BERT model into a smaller "student" BERT model, reducing the model size from FP32 to 1-bit.
* The "Task-specific BERT (Teacher)" and "(DA) Task Dataset" are crucial components in both distillation strategies.
### Interpretation
The diagrams demonstrate two different strategies for knowledge distillation, a technique used to transfer knowledge from a large, complex model (the teacher) to a smaller, more efficient model (the student). The multi-stage approach (left) allows for finer-grained control over the distillation process, potentially leading to better performance in some cases. The single-stage approach (right) is simpler and may be more suitable for scenarios where computational resources are limited. The progression from FP32 to 1-bit models indicates a focus on extreme model compression, likely for deployment on resource-constrained devices. The use of a "Task-specific BERT (Teacher)" and "(DA) Task Dataset" suggests that the distillation process is tailored to a specific task, which can improve the performance of the smaller model on that task.
</details>
methods have been referred to as extreme quantization since the limit of weight quantization, in theory, can bring over an order of magnitude compression rates (e.g., 16-32 times). One particular challenge identified in [3] was that it was highly difficult to perform binarization as there exits a sharp performance drop from ternarized to binarized networks. To address this issue, prior work proposed multiple optimizations where one first trains a ternarized DynaBert [17] and then binarizes with weight splitting. In both phases, multi-stage distillation with multiple learning rates tuning and data augmentation [20] are used. Prior works claim these optimizations are essential for closing the accuracy gap from binary quantization.
While the above methodology is promising, several unanswered questions are related to these recent extreme quantization methods. First, as multiple ad-hoc optimizations are applied at different stages, the compression pipeline becomes very complex and expensive, limiting the applicability of extreme quantization in practice. Moreover, a systematical evaluation and comparison of these optimizations are missing, and the underlying question remains open for extreme quantization:
what are the necessities of ad-hoc optimizations to recover the accuracy los?
Second, prior extreme quantization primarily focused on reducing the precision of the network. Meanwhile, several advancements have also been made in the research direction of knowledge distillation, where large teacher models are used to guide the learning of a small student model. Examples include DistilBERT [42], MiniLM [54, 53], MobileBERT [49], which demonstrate 2-4 × model size reduction by reducing the depth or width without much accuracy loss through pre-training distillation with an optional fine-tuning distillation. Notably, TinyBERT [20] proposes to perform deep distillation in both the pre-training and finetuning stages and shows that this strategy achieves state-of-the-art results on GLUE tasks. However, most of these were done without quantization, and there are few studies about the interplay of extreme quantization with these heavily distilled models, which poses questions on to what extent, a smaller distilled model benefits from extreme quantization?
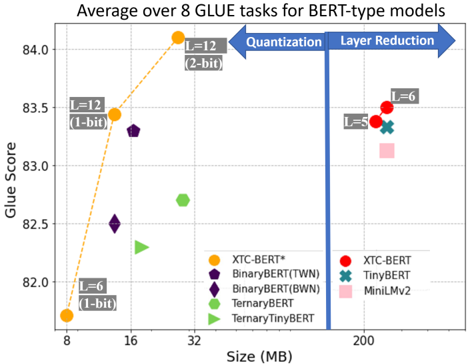
Figure 2: The comparison between XTC with other SOTA results.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Scatter Chart: Average GLUE Score vs. Model Size for BERT-type Models
### Overview
The image is a scatter plot comparing the size (in MB) of various BERT-type models against their average GLUE score (a measure of language understanding performance). The plot highlights the impact of quantization and layer reduction techniques on model size and performance.
### Components/Axes
* **Title:** Average over 8 GLUE tasks for BERT-type models
* **X-axis:** Size (MB). Scale: 8, 16, 32, 200
* **Y-axis:** Glue Score. Scale: 82.0, 82.5, 83.0, 83.5, 84.0
* **Legend:** Located in the bottom-left and bottom-right of the chart.
* **XTC-BERT*:** Orange circle
* **BinaryBERT(TWN):** Purple pentagon
* **BinaryBERT(BWN):** Purple diamond
* **TernaryBERT:** Green triangle pointing right
* **TernaryTinyBERT:** Green triangle pointing left
* **XTC-BERT:** Red circle
* **TinyBERT:** Teal X
* **MiniLMv2:** Pink square
* **Annotations:**
* "L=12 (1-bit)" near the orange XTC-BERT* data point at approximately (12, 83.5)
* "L=6 (1-bit)" near the orange XTC-BERT* data point at approximately (8, 81.8)
* "L=12 (2-bit)" near the orange XTC-BERT* data point at approximately (28, 84.1)
* "L=6" near the red XTC-BERT data point at approximately (200, 83.5)
* "L=5" near the red XTC-BERT data point at approximately (200, 83.3)
* **Vertical Blue Bar:** Separates "Quantization" (left) from "Layer Reduction" (right).
* **Dashed Orange Line:** Connects the XTC-BERT* data points.
### Detailed Analysis
* **XTC-BERT* (Orange Circles):**
* Trend: As size increases, Glue Score increases.
* Data Points:
* (8, approximately 81.8), labeled "L=6 (1-bit)"
* (approximately 12, approximately 83.5), labeled "L=12 (1-bit)"
* (approximately 28, approximately 84.1), labeled "L=12 (2-bit)"
* **BinaryBERT(TWN) (Purple Pentagons):**
* Data Point: (approximately 16, approximately 83.3)
* **BinaryBERT(BWN) (Purple Diamonds):**
* Data Point: (approximately 16, approximately 82.5)
* **TernaryBERT (Green Triangles pointing right):**
* Data Point: (approximately 32, approximately 82.7)
* **TernaryTinyBERT (Green Triangles pointing left):**
* Data Point: (approximately 16, approximately 82.3)
* **XTC-BERT (Red Circles):**
* Data Point: (approximately 200, approximately 83.5), labeled "L=6"
* Data Point: (approximately 200, approximately 83.3), labeled "L=5"
* **TinyBERT (Teal X):**
* Data Point: (approximately 200, approximately 83.3)
* **MiniLMv2 (Pink Square):**
* Data Point: (approximately 200, approximately 83.1)
### Key Observations
* The XTC-BERT* model shows a clear improvement in Glue Score as size increases with quantization.
* Layer reduction techniques (right side of the plot) generally result in larger models (200 MB) but varying Glue Scores.
* The vertical blue bar visually separates the impact of quantization (left) from layer reduction (right).
### Interpretation
The chart suggests that quantization can effectively reduce model size while maintaining or even improving performance, as seen with the XTC-BERT* model. However, layer reduction, while resulting in larger models, does not guarantee a higher Glue Score, indicating a trade-off between model size and performance. The different models employing layer reduction techniques cluster around the 200 MB size, but their performance varies, suggesting that the specific layer reduction strategy significantly impacts the final Glue Score. The XTC-BERT model appears in both the quantization and layer reduction sections, suggesting it was used as a baseline for both sets of experiments.
</details>
Contribution. To investigate the above questions,
- (1) We present a systematic study of extreme quantization methods by fine-tuning ≥ 1000 pre-trained Transformer models, which includes a careful evaluation of the effects of hyperparameters and several methods introduced in extreme quantization.
we make the following contributions:
- (2) We find that previous extreme quantization studies overlooked certain design choices, which lead to under-trained binarized networks and unnecessarily complex optimizations. Instead, we derive a celebrating recipe for extreme quantization, which is not only simpler but also allows us to achieve an even larger compression ratio and higher accuracy than existing methods (see Figure 1, right).
Our evaluation results, as illustrated in Figure 2, show that our simple yet effective method can:
- (3) We find that extreme quantization can be effectively combined with lightweight layer reduction, which allows us to achieve greater compression rates for pre-trained Transformers with better accuracy than prior methods while enjoying the additional benefits of flexibly adjusting the size of the student model for each use-case individually, without the expensive pre-training distillation.
- (1) compress BERT base to a 5-layer BERT base while achieving better performance than previous state-of-theart distillation methods, e.g., the 6-layer TinyBERT [20], without incurring the computationally expensive pre-training distillation;
- (2) reduce the model size by 50 × via performing robust extreme quantization on lightweight layer reduced models while obtaining better accuracy than prior extreme quantization methods, e.g., the 12-layer 1-bit BERT base , resulting in new state-of-the-art results on GLUE tasks.
## 2 Related Work
Quantization becomes practically appealing as it not only reduces memory bandwidth consumption but also brings the additional benefit of further accelerating inference on supporting hardware [44, 24, 12]. Most quantization works focus on INT8 quantization [21] or mixed INT8/INT4 quantization [44]. Our work differs from those in that we investigate extreme quantization where the weight values are represented with only 1-bit or 2-bit at most. There are prior works that show the feasibility of using only ternary or even binary weights [61, 3]. Unlike those work, which uses multiple optimizations with complex pipelines, our investigation leads us to introduce a simple yet more efficient method for extreme compression with more excellent compression rates.
On a separate line of research, reducing the number of parameters of deep neural networks models with full precision (no quantization) has been an active research area by applying the powerful knowleadge distillation (KD) [16, 54], where a stronger teacher model guides the learning of another small student model to minimize the discrepancy between the teacher and student outputs. Please see Appendix A for a comprehensive literature review on KD. Instead of proposing a more advanced distillation method, we perform a well-rounded comparative study on the effectiveness of the recently proposed multiple-stage distillation [20].
## 3 Extreme Compression Procedure Analysis
This section presents several studies that have guided the proposed method introduced in Section 5. All these evaluations are performed with the General Language Understanding Evaluation (GLUE) benchmark [51], which is a collection of datasets for evaluating natural language understanding systems. For the subsequent studies, we report results on the development sets after compressing a pre-trained model (e.g., BERT base and TinyBERT) using the corresponding single-task training data.
Previous works [61, 3] on extreme quantization of transformer models state three hypotheses for what can be related to the difficulty of performing extreme quantization:
- Directly training a binarized BERT is complicated due to its irregular loss landscape, so it is better to first to train a ternarized model to initialize the binarized network.
- Specialized distillation that transfers knowledge at different layers (e.g., intermediate layer) and multiple stages is required to improve accuracy.
- Small training data sizes make extreme compression difficult.
## 3.1 Is staged ternary-binary training necessary to mitigate the sharp performance drop?
Previous works demonstrate that binary networks have more irregular loss surface than ternary models using curvature analysis. However, given that rough loss surface is a prevalent issue when training neural networks, we question whether all of them have a causal relationship with the difficulty in extreme compression.
It is not surprising that binarization leads to further accuracy drop as prior studies from computer vision also observe similar phenomenon [18, 50]. However, prior works also identified that the difficulty of training binarized networks mostly resides in training with insufficient number of iterations or having too large learning rates, which can lead to frequent sign changes of the weights that make the learning of binarized networks unstable [50]. Therefore, training a binarized network the same way as training a full precision network consistently achieves poor accuracy. Would increasing the training iterations and let the binarized network train longer under smaller learning rates help mitigate the performance drop from binarization?
We are first interested in the observation from previous work [3] that shows directly training a binarized network leads to a significant accuracy drop (e.g., up to 3.8%) on GLUE in comparison to the accuracy loss from training a ternary network (e.g., up to 0.6%). They suggest that this is because binary networks have a higher training loss and overall more complex loss surface. To overcome this sharp accuracy drop, they propose a staged ternary-binary training strategy in which one needs first to train a ternarized network and use a technique called weight splitting to use the trained ternary weights to initialize the binary model.
To investigate this, we perform the following experiment: We remove the TernaryBERT training stage and weight splitting and directly train a binarized network. We use the same quantization schemes as in [3], e.g., a binary quantizer to quantize the weights: w i = α · sign ( w i ) , α = 1 n || w || 1 , and a uniform symmetric INT8 quantizer to quantize the activations. We apply the One-Stage quantizationaware KD that will be explained in § 3.2 to train the model. Nevertheless, without introducing the details of KD here, it does not affect our purpose of understanding the phenomena of a sharp performance drop since we only change the training iteration and learning rates while fixing other setups.
We consider three budgets listed in Table 1, which cover the practical scenarios of short, standard, and long training time, where Budget-A and Budget-B take into account the training details that appeared in BinaryBERT [3], TernaryBERT [61]. Budget-C has a considerably larger training budget but smaller than TinyBert [3]. Meanwhile, we also perform a grid search of peak learning rates {2e-5, 1e-4, 5e-4}. For more
Table 1: Different training budgets for the GLUE tasks.
| Dataset | Data | Training epochs: | Training epochs: | Training epochs: |
|-----------------|--------|--------------------|--------------------|--------------------|
| | Aug. | Budget-A | Budget-B | Budget-C |
| QQP/MNLI | 7 | 3 | 9 | 18 or 36 |
| QNLI | 3 | 1 | 3 | 6 or 9 |
| SST-2/STS-B/RTE | 3 | 1 | 3 | 12 |
| CoLA/MRPC | 3 | 1 | 3 | 12 or 18 |
training details on iterations and batch size per iteration, please see Table C.1.
Table 2: 1-bit quantization for BERT base with various Budget-A, Budget-B and Budget-C.
| # | Cost | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Acc Drop |
|-----|----------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|------------|
| 0 | Teacher | 59.7 | 84.9/85.6 | 90.6/86.3 | 92.1 | 88.6/91.5 | 72.2 | 93.2 | 90.1/89.6 | 83.95 | - |
| 1 | Budget-A | 50.4 | 83.7/84.6 | 90.0/85.8 | 91.3 | 88.0/91.1 | 72.9 | 92.8 | 88.8/88.4 | 82.38 | 1.57 |
| 2 | Budget-B | 55.6 | 84.1/84.4 | 90.4/86.0 | 90.8 | 88.3/91.3 | 72.6 | 93.1 | 88.9/88.5 | 82.98 | 0.97 |
| 3 | Budget-C | 57.3 | 84.2/84.4 | 90.7/86.5 | 91 | 88.3/91.3 | 74 | 93.1 | 89.2/88.8 | 83.44 | 0.51 |
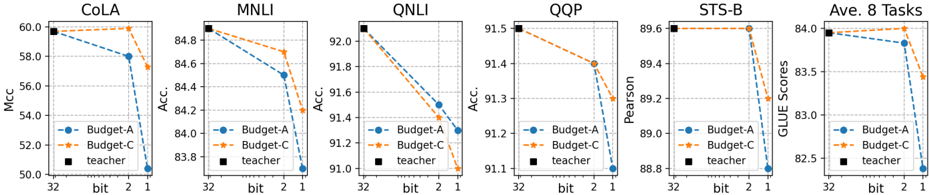
Figure 3: Performance of quantized BERT base with different weight bits and 8-bit activation on the GLUE Benchmarks. The results for orange and blue curves respectively represent the costs: (limited) Budget-A and (sufficient) Budget-C. The fp32-teacher scores are shown by black square marker.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Chart Type: Multiple Line Graphs Comparing Model Performance
### Overview
The image presents six line graphs arranged horizontally, each evaluating the performance of different models (Budget-A, Budget-C, and Teacher) on various tasks (CoLA, MNLI, QNLI, QQP, STS-B, and Average of 8 Tasks). The x-axis represents the bit size (32, 2, 1), and the y-axis represents the performance metric specific to each task (Mcc, Accuracy, Pearson, GLUE Scores). The graphs compare the performance of two budget models (A and C) against a teacher model.
### Components/Axes
* **X-Axis:** "bit" with values 32, 2, and 1. The x-axis is consistent across all six graphs.
* **Y-Axis:** Varies depending on the task:
* **CoLA:** "Mcc" (Matthews correlation coefficient), scale from 50.0 to 60.0.
* **MNLI:** "Acc." (Accuracy), scale from 83.8 to 84.8.
* **QNLI:** "Acc." (Accuracy), scale from 91.0 to 92.0.
* **QQP:** "Acc." (Accuracy), scale from 91.1 to 91.5.
* **STS-B:** "Pearson", scale from 88.8 to 89.6.
* **Ave. 8 Tasks:** "GLUE Scores", scale from 82.5 to 84.0.
* **Legend:** Located below each graph, indicating:
* **Blue Line with Circle Markers:** "Budget-A"
* **Orange Dashed Line with Star Markers:** "Budget-C"
* **Black Square Marker:** "teacher"
### Detailed Analysis
**1. CoLA**
* **Budget-A (Blue):** Starts at approximately 60.0 at bit=32, decreases to approximately 58.0 at bit=2, and further decreases to approximately 50.5 at bit=1.
* **Budget-C (Orange):** Remains relatively constant at approximately 60.0 across all bit values.
* **Teacher (Black):** Constant at approximately 60.0.
**2. MNLI**
* **Budget-A (Blue):** Starts at approximately 84.8 at bit=32, decreases to approximately 84.5 at bit=2, and further decreases to approximately 83.7 at bit=1.
* **Budget-C (Orange):** Starts at approximately 84.8 at bit=32, decreases to approximately 84.7 at bit=2, and further decreases to approximately 84.2 at bit=1.
* **Teacher (Black):** Constant at approximately 84.8.
**3. QNLI**
* **Budget-A (Blue):** Starts at approximately 92.1 at bit=32, decreases to approximately 91.6 at bit=2, and further decreases to approximately 91.2 at bit=1.
* **Budget-C (Orange):** Starts at approximately 92.1 at bit=32, decreases to approximately 91.8 at bit=2, and further decreases to approximately 91.1 at bit=1.
* **Teacher (Black):** Constant at approximately 92.1.
**4. QQP**
* **Budget-A (Blue):** Starts at approximately 91.5 at bit=32, decreases to approximately 91.3 at bit=2, and further decreases to approximately 91.2 at bit=1.
* **Budget-C (Orange):** Starts at approximately 91.5 at bit=32, decreases to approximately 91.4 at bit=2, and further decreases to approximately 91.3 at bit=1.
* **Teacher (Black):** Constant at approximately 91.5.
**5. STS-B**
* **Budget-A (Blue):** Remains relatively constant at approximately 89.6 at bit=32, decreases to approximately 89.3 at bit=2, and further decreases to approximately 89.1 at bit=1.
* **Budget-C (Orange):** Remains relatively constant at approximately 89.6 across all bit values.
* **Teacher (Black):** Constant at approximately 89.6.
**6. Ave. 8 Tasks**
* **Budget-A (Blue):** Starts at approximately 83.9 at bit=32, decreases to approximately 83.8 at bit=2, and further decreases to approximately 82.6 at bit=1.
* **Budget-C (Orange):** Starts at approximately 84.0 at bit=32, decreases to approximately 83.9 at bit=2, and further decreases to approximately 83.4 at bit=1.
* **Teacher (Black):** Constant at approximately 84.0.
### Key Observations
* The "teacher" model consistently performs at the highest level across all tasks and bit sizes.
* Both "Budget-A" and "Budget-C" models generally show a decrease in performance as the bit size decreases from 32 to 1.
* The performance drop is more pronounced for "Budget-A" in some tasks (e.g., CoLA, Ave. 8 Tasks).
* For the CoLA task, Budget-C maintains a constant performance across all bit sizes, matching the teacher model.
### Interpretation
The graphs illustrate the impact of bit size reduction on the performance of different models across various natural language processing tasks. The "teacher" model serves as a benchmark, demonstrating the potential performance ceiling. The "Budget-A" and "Budget-C" models, presumably smaller or more efficient versions, experience performance degradation as the bit size is reduced, indicating a trade-off between model size/efficiency and accuracy. The extent of this degradation varies depending on the task and the specific budget model. The CoLA task shows a unique case where Budget-C maintains performance, suggesting it may be more robust to bit size reduction for this particular task. Overall, the data suggests that reducing bit size can negatively impact model performance, and the choice of model architecture (Budget-A vs. Budget-C) can influence the extent of this impact.
</details>
We present our main results in Table 2 and Figure 3 (see Table C.2 a full detailed results including three learning rates). We observe that although training binarized BERT with more iterations does not fully close the accuracy gap to the uncompressed full-precision model, the sharp accuracy drop from ternarization to binarization (the blue curve v.s. the orange curve in Figure 3) has largely been mitigated, leaving a much smaller accuracy gap to close. For example, when increasing the training time from Budget-A to Budget-C, the performance of CoLA boosts from 50.4 to 57.3, and the average score improves from 82.38 to 83.44 (Table 2). These results indicate that previous studies [3] on binarized BERT were significantly under-trained. It also suggests that the observed sharp accuracy drop from binarization is primarily an optimization problem. We note that in the context of fine-tuning BERT models, Mosbach et al. [32] also observe that fine-tuning BERT can suffer from vanishing gradients, which causes the training converges to a "bad" valley with sub-optimal training loss. As a result, the authors also suggest increasing the number of iterations to train the BERT model to have stable and robust results.
Finding 1. A longer training iterations with learning rate decay is highly preferred for closing the accuracy gap of extreme quantization.
Finding 1 seems natural. However, we argue that special considerations need to be taken for effectively doing extreme quantization before resorting to more complex solutions.
## 3.2 The role of multi-stage knowledge distillation
The above analysis shows that the previous binarized BERT models were severely undertrained. In this section, we further investigate the necessity of multi-stage knowledge distillation, which is quite complex because each stage has its own set of hyperparameters. Still, prior works claim to be crucial for improving the accuracy of extreme quantization. Investigating this problem is interesting because it can potentially admit a more straightforward solution with a cheaper cost.
Generally, the knowledge distillation for transformer models can be formulated as minimizing the following
Prior work proposes an interesting knowledge distillation (KD), and here we call it Two-Stage KD (2S-KD) [20], which has been applied for extreme quantization [3]. The 2S-KD minimizes the losses of hidden states L hidden and attention maps L att and losses of prediction logits L logit in two separate steps, where different learning rates are used in these two stages, e.g., a × 2 . 5 larger learning rate is used for Stage-I than that for Stage-II. However, how to decide the learning rates and training epochs for these two stages is not well explained and will add additional hyperparameter tuning costs. We note that this strategy is very different from the deep knowledge distillation strategy used in [48, 53, 49], where knowledge distillation is performed with a single stage that minimizes the sum of the losses from prediction logits, hidden states, and attention maps. Despite the promising results in [3], the mechanism for why multi-stage KD improves accuracy is not well understood.
objective:
<!-- formula-not-decoded -->
where L logit denote the loss (e.g., KL divergence or mean square error) between student's and teacher's prediction logits, and L hidden and L att ) measures the loss of hidden states and attention maps. γ ∈ { 0 , 1 } , β ∈ { 0 , 1 } are hyperparameters. See the detailed mathematical definition in § B
To investigate the effectiveness of multi-stage, we compare three configurations (shown in Figure 4):
- (1) 1S-KD (One-stage KD): ( γ, β ) = (1 , 1) for t ≤ T ;
- (2) 2S-KD (Two-stage KD): ( γ, β ) = (0 , 1) if t < T / 2 ; ( γ, β ) = (1 , 0) if T / 2 ≤ t ≤ T ;
- (3) 3S-KD (Three-stage KD): ( γ, β ) = (0 , 1) if t < T / 3 ; ( γ, β ) = (1 , 1) if T / 3 ≤ t ≤ 2 T / 3 ; ( γ, β ) = (1 , 0) if 2 T / 3 ≤ t ≤ T .
where T presents the total training budget and t represents the training iterations.
Table 3 shows the results under Budget-A (see Table C.2 for Budget-B/C). We note that when the learning rate is fixed to 2e-5 (i.e., Row 1, 5, and 9), the previously proposed 2S-KD [20] (81.46) does show performance benefits over 1S-KD (80.33). Our newly created 3S-KD (81.57) obtains even better accuracy under the same learning rate. However, multi-stage makes the extreme compression procedure complex and inefficient because it needs to set the peak learning rates differently for different stages. Surprisingly, the simple 1S-KD easily outperforms both 2S-KD and 3S-KD (Row 6 and 8) when we slightly increase the search space of the learning rates (e.g., 1e-4 and 5e-4). This means we can largely omit the burden of tuning learning rates and training epochs for each stage in multi-stage by using single-stage but with the same training iteration budget.
Notably, we created the 3S-KD, where we add a transition stage: L hidden + L att + L logit in between the first and second stage of the 2S-KD. The idea is to make the transition of the training objective smoother in comparison to the 2S-KD. In this case, the learning rate schedules will be correspondingly repeated in three times, and the peak learning rate of Stage-I is × 2 . 5 higher than that of Stage-II and Stage-III. We apply all three KD methods independently (under a fixed random seed) for binary quantization across different learning rates {2e-5, 1e-4, 5e-4} under the same training budget. We do not tune any other hyperparameters.
Finding 2. Single-stage knowledge distillation with more training budgets and search of learning rates is sufficient to match or even exceed accuracy from multi-stage ones.
Table 3: 1-bit quantization for BERT base with three different KD under the training Budget-A.
| # | Stages | learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all |
|-----|-------------|-----------------|------------|----------------------|---------------------|----------------|---------------------|-----------|-------------|-------------------|-------------|
| 1 | One-Stage | 2e-5 | 44.6 | 83.1/83.7 | 88.8/83.1 90.1/85.3 | 91.1 91.3 89.5 | 87.4/90.7 88.0/91.1 | 66.1 71.5 | 92.8 92.7 | 87.8/87.5 | 80.33 82.16 |
| 2 | | 1e-4 | 50.4 | 83.7/84.6 | | | | | | 88.8/88.4 | |
| 3 | | 5e-4 | 42.3 | 83.3/84.1 | 90.0/85.8 | | 87.8/90.9 | 72.9 | 92.5 | 88.1/87.8 | 81.04 |
| 4 | | Best (above) | 50.4 | 83.7/84.6 | 90.0/85.8 | 91.3 | 88.0/91.1 | 72.9 | 92.8 | 88.8/88.4 | 82.38 |
| 5 | Two-Stage | 2e-5 | 48.2 | 83.3/83.8 | 89.3/84.6 | 90.7 | 87.7/90.9 | 70.4 | 92.5 | 88.7/88.4 | 81.46 |
| 6 | | 1e-4 | 48.5 | 83.3/83.4 | 90.0/85.5 | 90.4 | 87.4/90.7 | 70.4 | 92.4 | 88.6/88.2 | 81.47 |
| 7 | | 5e-4 | 16.2 | 74.9/76.4 | 89.7/84.8 | 87.8 | 85.0/89.0 | 68.2 | 91.6 | 86.2/86.5 | 75.01 |
| 8 | | Best (above) | 48.5 | 83.3/83.8 | 90.0/85.5 | 90.7 | 87.7/90.9 | 70.4 | 92.5 | 88.7/88.4 | 81.59 |
| 9 | Three-Stage | 2e-5 | 49.3 | 83.1/83.6 | 89.5/84.3 | 91.0 | 87.6/90.9 | 70.8 | 92.4 | 88.7/88.3 | 81.57 |
| 10 | | 1e-4 | 49 | 83.2/83.4 | 89.7/84.8 | 90.9 | 87.6/90.7 | 73.6 | 92.2 | 88.8/88.5 | 81.84 |
| 11 | | 5e-4 | 29.5 | 81.3/81.9 | 89.1/83.6 | 88.4 | 85.0/89.3 | 66.1 | 91.9 | 84.1/83.9 | 77.34 |
| 12 | | Best (above) | 49.3 | 83.2/83.4 | 89.7/84.8 | 91.0 | 87.6/90.9 | 73.6 | 92.4 | 88.8/88.5 | 81.93 |
## 3.3 The importance of data augmentation
Prior works augment the task-specific datasets using a text-editing technique by randomly replacing words in a sentence with their synonyms, based on their similarity measure on GloVe embeddings [20]. They then use the augmented dataset for task-specific compression of BERT models, observing improved accuracy for extreme quantization [61, 3]. They hypothesized that data augmentation (DA) is vital for compressing transformer models. However, as we have observed that the binarized networks were largely under-trained and had no clear advantage of multi-stage versus single-stage under a larger training budget, it raises the question of the necessity of DA.
To better understand the importance of DA for extreme compression, we compare the end-task performance of both 1-bit quantized BERT base models with and without data augmentation, based on previous findings in this paper that make extreme compression more robust. Table 4 shows results for the comparison of the 1-bit BERT base model under two different training budgets. Note that MNLI /QQP does not use DA; we repeat the results. We find that regardless of whether shorter or longer iterations, removing DA leads to an average of 0.66 and 0.77 points drop in average GLUE score. Notably, the accuracy drops more than 1 point on smaller tasks such as CoLA, MPRC, RTE, STS-B. Furthermore, similar performance degradation is observed when removing DA from training an FP32 half-sized BERT model (more details will be introduced in § 4), regardless of whether using 1S-KD or 2S-KD. These results indicate that DA is helpful, especially for extreme compressed models; DA significantly benefits from learning more diverse/small data to mitigate accuracy drops.
Table 4: The Comparison between the results with and without data augmentation (DA). Row 1-4 is for BERT base under 1-bit quantization using 1S-KD. Row 5-8 is for a layer-reduced BERT base (six-layer) under Budget-C without quantization (please see § 4 for more details).
| # | Cost or Stages | Data Aug. | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | DIFF |
|-----|------------------|-------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|------------|--------|
| 1 | Budget-A | 3 7 | 50.4 | 83.7/84.6 | 90.0/85.8 | 91.3 | 88.0/91.1 | 72.9 | 92.8 | 88.8/88.4 | 82.38 | -0.77 |
| 2 | | | 48.9 | 83.7/84.6 | 89.0/83.6 | 91 | 88.0/91.1 | 71.5 | 92.5 | 87.6/87.5 | 81.61 | -0.77 |
| 3 | Budget-C | 3 | 57.3 | 84.2/84.4 | 90.7/86.5 | 91 | 88.3/91.3 | 74 | 93.1 | 89.2/88.8 | 83.44 | -0.66 |
| 4 | | 7 | 55 | 84.2/84.4 | 90.0/85.0 | 90.7 | 88.3/91.3 | 73.3 | 92.9 | 88.2/87.9 | 82.78 | -0.66 |
| 5 | One-stage | 3 | 56.9 | 84.5/84.9 | 89.7/84.8 | 91.7 | 88.5/91.5 | 71.8 | 93.5 | 89.8/89.4 | 83.27 | -2.18 |
| 6 | | 7 | 52.2 | 84.5/84.9 | 88.4/82.4 | 91.4 | 88.5/91.5 | 63.9 | 92.9 | 86.5/86.3 | 81.09 | -2.18 |
| 7 | Two-stage | 3 | 56 | 84.1/84.2 | 89.7/84.8 | 91.5 | 88.2/91.3 | 71.8 | 93.3 | 89.4/89.1 | 82.93 | -2.03 |
| 8 | | 7 | 50.2 | 84.1/84.2 | 88.7/83.1 | 90.8 | 88.2/91.3 | 64.6 | 92.9 | 86.9/86.7 | 80.9 | -2.03 |
Finding 3. Training without DA hurts performance on downstream tasks for various compression tasks, especially on smaller tasks.
We remark that although our conclusion for DA is consistent with the finding in [3], we have performed a far more well-through experiment than [3] where they consider a single budget and 2S-KD only.
## 4 Interplay of KD, Long Training, Data Augmentation and Layer Reduction
In the previous section, we found strong evidence for statistically significant benefits from 1S-KD compared to 2S-KD and 3S-KD. Moreover, a considerable long training can greatly lift the score to the level same as the full precision teacher model. Although 1-bit BERT base already achieves × 32 smaller size than its full-precision counterpart, a separate line of research focuses on changing the model architecture to reduce the model size. Notably, one of the promising methods - reducing model sizes via knowledge distillation has long been studied and shown good performances [13, 60, 42, 53, 49].
While many works focus on innovating better knowledge distillation methods for higher compression ratio and better accuracy, given our observations in Section 3 that extreme quantization can effectively reduce the model size, we are interested in to what extent can extreme quantization benefit state-of-the-art distilled models?
To investigate this issue, we perform the following experiments: We prepare five student models, all having 6 layers with the same hidden dimension 768: (1) a pretrained TinyBERT 6 [20] 1 ; (2) MiniLMv2 6 [53] 2 ; (3) Top-BERT 6 : using the top 6 layers of the fine-tuned BERT-base model to initialize the student model; (4) Bottom-BERT 6 : using the bottom six layers of the fine-tuned BERT-base model to initialize the student; (5) Skip-BERT 6 : using every other layer of the fine-tuned BERT-based model to initialize the student. In all cases, we fine-tune BERT base for each task as the teacher model (see the teachers' performance in Table 5, Row 0). We choose TinyBERT and MiniLM because they are the state-of-the-art for knowledge distillation of BERT models. We choose the other three configurations because prior work [48, 34] also suggested that layer pruning is also a practical approach for task-specific compression. For the initialization of the student model, both TinyBERT 6 and MiniLM 6 are initialized with weights distilled from BERT base through pretraining distillation, and the other three students (e.g., top, bottom, skip) are obtained from the fine-tuned teacher model without incurring any pretraining training cost . We apply 1S-KD as we also verify that 2S-KD and
Table 5: Pre-training does not show benefits for layer reduction. Row 3 (rep.*) is a reproduced result by following the training recipe in [20].
| # | Model | size | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Acc. Drop |
|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|--------------------------------------------------------|
| 1 | BERT-base fp32 | 417.2 | 59.7 | 84.9/85.6 | 90.6/86.3 | 92.1 | 88.6/91.5 | 72.2 | 93.2 | 90.1/89.6 | 83.95 | - |
| Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) | Training cost: greater than Budget-C (see [20] or § B) |
| 2 | Pretrained TinyBERT 6 ([20]) | 255.2 ( × 1 . 6 ) | 54.0 | 84.5/84.5 | 90.6/86.3 | 91.1 | 88.0/91.1 | 73.4 | 93.0 | 90.1/89.6 | 83.11 | -0.84 |
| 3 | Pretrained TinyBERT 6 (rep.*) | 255.2 ( × 1 . 6 ) | 56.9 | 84.4/84.8 | 90.1/85.5 | 91.3 | 88.4/91.4 | 72.2 | 93.2 | 90.3/90.0 | 83.33 | -0.62 |
| Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C | Training cost: Budget-C |
| 4 | Pretrained TinyBERT 6 | 255.2 ( × 1 . 6 ) | 54.4 | 84.6/84.3 | 90.4/86.3 | 91.5 | 88.5/91.5 | 69.7 | 93.3 | 89.2/89.0 | 82.76 | -1.19 |
| 5 | Pretrained MiniLM 6 -v2 | 255.2 ( × 1 . 6 ) | 55.4 | 84.4/84.5 | 90.7/86.5 | 91.4 | 88.5/91.5 | 71.8 | 93.3 | 89.4/89.0 | 83.13 | -0.82 |
| 6 | Skip-BERT 6 (ours) | 255.2 ( × 1 . 6 ) | 56.9 | 84.6/84.9 | 90.4/85.8 | 91.8 | 88.6/91.6 | 72.6 | 93.5 | 89.8/89.4 | 83.50 | -0.45 |
| 7 | Skip-BERT 5 (ours) | 228.2 ( × 1 . 8 ) | 57.9 | 84.3/85.1 | 90.1/85.5 | 91.4 | 88.5/91.5 | 72.2 | 93.3 | 89.2/88.9 | 83.38 | -0.57 |
| 8 | Skip-BERT 4 (ours) | 201.2 ( × 2 . 1 ) | 53.3 | 83.2/83.4 | 90.0/85.3 | 90.8 | 88.2/91.3 | 70.0 | 93.5 | 88.8/88.4 | 82.18 | -1.77 |
3S-KD are under-performed (See Table C.7 in the appendix). We set Budget-C as our training cost because the training budget in reproducing the results for TinyBert is greatly larger than Budget-C illustrated above. We report their best validation performances in Table 5 across the three learning rate {5e-5, 1e-4, 5e-4}. We apply 1S-KD and budget-C for this experiment. We report their best validation performances in Table 5 across three learning rates {5e-5, 1e-4, 5e-4}. For complete statistics with these learning rates, please refer to Table C.5. We make a few observations:
One noticeable fact in Table 5 is that under the same budget (Budget-C), the accuracy drop of Skip-BERT 6 is about 0.74 (0.37) higher than TinyBERT 6 in Row 5 (MINILM 6 -v2 in Row 6). Note that layer reduction without pretraining has also been addressed in [41]. However, their KD is limited to logits without DA, and the performance is not better a trained DistillBERT.
First, perhaps a bit surprisingly, the results in Table 5 show that there are no significant improvements from using the more computationally expensive pre-pretraining distillation in comparison to lightweight layer reduction: Skip-BERT 6 (Row 7) achieves the highest average score 83.50. This scheme achieves the highest score on larger and more robust tasks such as MNLI/QQP/QNLI/SST-2.
Second, with the above encouraging results from a half-size model (Skip-BERT 6 ), we squeeze the depths into five and four layers. The five-/four-layer student is initialized from -layer of teacher with ∈ { 3 , 5 , 7 , 9 , 11 } or ∈ { 3 , 6 , 9 , 12 } . We apply the same training recipe as Skip-BERT 6 and report the results in Row 8 and 9 in Table 5. There is little performance degradation in our five-layer model (83.28) compared to its six-layer counterpart (83.50); Interestingly, CoLA and MNLI-mm even achieve higher accuracy with smaller model
1 The checkpoint of TinyBert is downloaded from their uploaded huggingface.co.
2 The checkpoint of miniLMv2 is from their github.
sizes. Meanwhile, when we perform even more aggressive compression by reducing the depth to 4, the result is less positive as the average accuracy drop is around 1.3 points.
Third, among three lightweight layer reduction methods, we confirm that a Skip-# student performs better than those using Top-# and Bottom-#. We report the full results of this comparison in the Appendix Table C.6. This observation is consistent with [20]. However, their layerwise distillation method is not the same as ours, e.g, they use the non-adapted pretrained BERT model to initialize the student, whereas we use the fine-tuned BERT weights. We remark that our finding is in contrast to [41] which is perhaps because the KD in [41] only uses logits distillation without layerwise distillation.
Finding 4. Lightweight layer reduction matches or even exceeds expensive pre-training distillation for task-specific compression.
## 5 Proposed Method for Further Pushing the Limit of Extreme Compression
Based on our studies, we propose a simple yet effective method tailored for extreme lightweight compression. Figure 1 (right) illustrates our proposed method: XTC, which consists of only 2 steps:
Step II: 1-bit quantization by applying 1S-KD with DA and long training. Once we obtain the layer-reduced model, we apply the quantize-aware 1S-KD, proven to be the most effective in § 3.2. To be concrete, we use an ultra-low bit (1-bit/2-bit) quantizer to compress the layer-reduced model weights for a forward pass and then use STE during the backward pass for passing gradients. Meanwhile, we minimize the single-stage deep knowledge distillation objective with data augmentation enabled and longer training Budget-C (such that the training loss is close to zero).
Step I: Lightweight layer reduction. Unlike the common layer reduction method where the layerreduced model is obtained through computationally expensive pre-training distillation, we select a subset of the fine-tuned teacher weights as a lightweight layer reduction method (e.g., either through simple heuristics as described in Section 4 or search-based algorithm as described in [34]) to initialize the layer-reduced model. When together with the other training strategies identified in this paper, we find that such a lightweight scheme allows for achieving a much larger compression ratio while setting a new state-of-the-art result compared to other existing methods.
Table 6: 1-/2-bit quantization of the layer-reduced model. The last column (Acc. drop) is the accuracy drop from their own fp-32 models. See full details in Table C.8.
| # | Method | bit (#-layer) | size (MB) | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Acc. drop |
|-----|----------|-----------------|-------------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|------------|-------------|
| 1 | [61] | 2 (6L) | 16.0 ( × 26 . 2 ) | 53 | 83.4/83.8 | 91.5/88.0 | 89.9 | 87.2/90.5 | 71.8 | 93 | 86.9/86.5 | 82.26 | -0.76 |
| 2 | Ours | 2 (6L) | 16.0 ( × 26 . 2 ) | 53.8 | 83.6/84.2 | 90.5/86.3 | 90.6 | 88.2/91.3 | 73.6 | 93.6 | 89.0/88.7 | 82.89 | -0.44 |
| 3 | Ours | 2 (5L) | 14.2 ( × 29 . 3 ) | 53.9 | 83.3/84.1 | 90.4/86.0 | 90.4 | 88.2/91.2 | 71.8 | 93 | 88.4/88.0 | 82.46 | -0.72 |
| 4 | Ours | 2 (4L) | 12.6 ( × 33 . 2 ) | 50.3 | 82.5/83.0 | 90.0/85.3 | 89.2 | 87.8/91.0 | 69 | 92.8 | 87.9/87.4 | 81.22 | -0.9 |
| 5 | Ours | 1 (6L) | 8.0 ( × 52 . 3 ) | 52.3 | 83.4/83.8 | 90.0/85.3 | 89.4 | 87.9/91.1 | 68.6 | 93.1 | 88.4/88.0 | 81.71 | -1.51 |
| 6 | Ours | 1 (5L) | 7.1 ( × 58 . 5 ) | 52.2 | 82.9/83.2 | 89.9/85.0 | 88.5 | 87.6/90.8 | 69.3 | 92.9 | 87.3/87.0 | 81.34 | -1.84 |
| 7 | Ours | 1 (4L) | 6.3 ( × 66 . 4 ) | 48.3 | 82.0/82.3 | 89.9/85.5 | 87.7 | 86.9/90.4 | 63.9 | 92.4 | 87.1/86.7 | 79.96 | -2.01 |
Evaluation Results. The results of our approach are presented in Table 6, which we include multiple layer-reduced models with both 1-bit and 2-bit quantization. We make the following two observations: (1) For the 2-bit + 6L model (Row 1 and Row 2), XTC achieves 0.63 points higher accuracy than 2-bit quantized model TernaryBERT [61]. This remarkable improvement consists of two factors: (a) our fp-32 layer-reduced model is better (b) when binarization, we train longer under three learning rate searches. To understand how much the factor-(b) benefits, we may refer to the accuracy drop from their fp32 counterparts (last col.) where ours only drops 0.44 points and TinyBERT 6 drops 0.76.
- (2) When checking between our 2-bit five-layer (Row 3, 82.46) in Table 6 and 2-bit TinyBERT 6 (Row 1, 82.26), our quantization is much better, while our model size is 12.5% smaller, setting a new state-of-the-art result for 2-bit quantization with this size.
Besides the reported results above, we have also done a well-thorough investigation on the effectiveness of adding a low-rank (LoRa) full-precision weight matrices to see if it will further push the accuracy for the 1-bit layer-reduced models. However, we found a negative conclusion on using LoRa. Interestingly, if we repeat another training with the 1-bit quantization after the single-stage long training, there is another 0.3 increase in the average GLUE score (see Table C.14). Finally, we also verify that prominent teachers can indeed help to improve the results (see appendix).
(3) Let us take a further look at accuracy drops (last column) for six/five/four layers, which are 0.44 (1.51), 0.72 (1.84), and 0.9 (2.01) respectively. It is clear that smaller models become much more brittle for extreme quantization than BERT base , especially the 1-bit compression as the degradation is × 3 or × 4 higher than the 2-bit quantization.
## 6 Conclusions
We carefully design and perform extensive experiments to investigate the contemporary existing extreme quantization methods [20, 3] by fine-tuning pre-trained BERT base models with various training budgets and learning rate search. Unlike [3], we find that there is no sharp accuracy drop if long training with data augmentation is used and that multi-stage KD and pretraining introduced in [20] is not a must in our setup. Based on the finding, we derive a user-friendly celebrating recipe for extreme quantization (see Figure 1, right), which allows us to achieve a larger compression ratio and higher accuracy. See our summarized results in Table 7. 3
Table 7: Summary of task-specific performance of MNLI and GLUE scores. Also see Figure 2.
| # | Model (8-bit activation) | size (MB) | MNLI-m/-mm | GLUE Score |
|-----|----------------------------|-------------------|--------------|--------------|
| 1 | BERT base (Teacher) | 417.2 ( × 1 . 0 ) | 84.9/85.6 | 83.95 |
| 2 | TinyBERT 6 (rep*) | 255.2 ( × 1 . 6 ) | 84.4/84.8 | 83.33 |
| 3 | XTC-BERT 6 (ours) | 255.2 ( × 1 . 6 ) | 84.6 /84.9 | 83.5 |
| 4 | XTC-BERT 5 (ours) | 228.2 ( × 1 . 8 ) | 84.3/ 85.1 | 83.38 |
| 5 | 2-bit BERT [61] | 26.8 ( × 16 . 0 ) | 83.3/83.3 | 82.73 |
| 6 | 2-bit XTC-BERT (ours) | 26.8 ( × 16 . 0 ) | 84.6/84.7 | 84.1 |
| 7 | 1-bit BERT (TWN) [3] | 16.5 ( × 25 . 3 ) | 84.2/ 84.7 | 82.49 |
| 8 | 1-bit BERT (BWN) [3] | 13.4 ( × 32 . 0 ) | 84.2/84.0 | 82.29 |
| 9 | 1-bit XTC-BERT (ours) | 13.4 ( × 32 . 0 ) | 84.2/84.4 | 83.44 |
| 10 | 2-bit TinyBERT 6 [61] | 16.0 ( × 26 . 2 ) | 83.4/83.8 | 82.26 |
| 11 | 2-bit XTC-BERT 6 (ours) | 16.0 ( × 26 . 2 ) | 83.6/84.2 | 82.89 |
| 12 | 2-bit XTC-BERT 5 (ours) | 14.2 ( × 29 . 3 ) | 83.3/84.1 | 82.46 |
| 13 | 1-bit XTC-BERT 6 (ours) | 8.0 ( × 52 . 3 ) | 83.4/83.8 | 81.71 |
| 14 | 1-bit XTC-BERT 5 (ours) | 7.1 ( × 58 . 5 ) | 82.9/83.2 | 81.34 |
Discussion and future work. Despite our encouraging results, we note that there is a caveat in our Step I when naively applying our method (i.e., initializing the student model as a subset of the teacher) to reduce the width of the model as the weight matrices dimension of teacher do not fit into that of students. We found that the accuracy drop is considerably sharp. Thus, in this domain, perhaps pertaining distillation [20] could be indeed useful, or Neural Architecture Search (AutoTinyBERT [58]) could be another promising direction. We acknowledge that, in order to make a fair comparison with [61, 3], our investigations are based on the classical 1-bit [39] and 2-bit [27] algorithms and without quantization on layernorm [2].
or without quantization on layer norm) would be of potential interests [24, 35]. Finally, as our experiments focus on BERT base model, future work can be understanding how our conclusion transfers to decoder models such as GPT-2/3 [36, 6].
Exploring the benefits of long training on an augmented dataset with different 1-/2-bit algorithms (with
## Acknowledgments
This work is done within the DeepSpeed team in Microsoft. We appreciate the help from the DeepSpeed team members. Particularly, we thank Jeff Rasley for coming up with the name of our method and Elton Zheng for solving the engineering issues. We thank the engineering supports from the Turing team in Microsoft.
3 We decide not to include many other great works [26, 59, 42, 35] since they do not use data augmentation or their setups are not close.
## References
- [1] Gustavo Aguilar, Yuan Ling, Yu Zhang, Benjamin Yao, Xing Fan, and Chenlei Guo. Knowledge distillation from internal representations. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020 , pages 7350-7357. AAAI Press, 2020.
- [2] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450 , 2016.
- [3] Haoli Bai, Wei Zhang, Lu Hou, Lifeng Shang, Jin Jin, Xin Jiang, Qun Liu, Michael Lyu, and Irwin King. BinaryBERT: Pushing the limit of BERT quantization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 4334-4348, Online, August 2021. Association for Computational Linguistics.
- [4] Ron Banner, Itay Hubara, Elad Hoffer, and Daniel Soudry. Scalable methods for 8-bit training of neural networks. Advances in neural information processing systems , 31, 2018.
- [5] Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 , 2013.
- [6] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. CoRR , abs/2005.14165, 2020.
- [7] Daniel Cer, Mona Diab, Eneko Agirre, Inigo Lopez-Gazpio, and Lucia Specia. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055 , 2017.
- [8] Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. The lottery ticket hypothesis for pre-trained bert networks. Advances in neural information processing systems , 33:15834-15846, 2020.
- [9] Ido Dagan, Dan Roth, Mark Sammons, and Fabio Massimo Zanzotto. Recognizing textual entailment: Models and applications. Synthesis Lectures on Human Language Technologies , 6(4):1-220, 2013.
- [10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019) , pages 4171-4186, 2019.
- [11] William B Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005) , 2005.
- [12] Zhen Dong, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Hawq: Hessian aware quantization of neural networks with mixed-precision. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 293-302, 2019.
- [13] Angela Fan, Edouard Grave, and Armand Joulin. Reducing transformer depth on demand with structured dropout. In International Conference on Learning Representations , 2020.
- [14] Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision , 129(6):1789-1819, 2021.
- [15] Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention. In International Conference on Learning Representations , 2020.
- [16] Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. CoRR , abs/1503.02531, 2015.
- [17] Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, and Qun Liu. Dynabert: Dynamic bert with adaptive width and depth. Advances in Neural Information Processing Systems , 33:9782-9793, 2020.
- [18] Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett, editors, Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain , pages 4107-4115, 2016.
- [19] Shankar Iyer, Nikhil Dandekar, and Kornl Csernai. First quora dataset release: Question pairs, 2017. URL https://data. quora. com/First-Quora-Dataset-Release-Question-Pairs , 2017.
- [20] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: Distilling BERT for natural language understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020 , pages 4163-4174, Online, November 2020. Association for Computational Linguistics.
- [21] Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. Is BERT really robust? A strong baseline for natural language attack on text classification and entailment. In The Thirty-Fourth AAAI Conference on Artificial Intelligence , pages 8018-8025. AAAI Press, 2020.
- [22] Felix Juefei-Xu, Vishnu Naresh Boddeti, and Marios Savvides. Local binary convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 19-28, 2017.
- [23] Minje Kim and Paris Smaragdis. Bitwise neural networks. arXiv preprint arXiv:1601.06071 , 2016.
- [24] Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. I-bert: Integer-only bert quantization. In International conference on machine learning , pages 5506-5518. PMLR, 2021.
- [25] François Lagunas, Ella Charlaix, Victor Sanh, and Alexander M Rush. Block pruning for faster transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 10619-10629, 2021.
- [26] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942 , 2019.
- [27] Fengfu Li, Bo Zhang, and Bin Liu. Ternary weight networks. arXiv preprint arXiv:1605.04711 , 2016.
- [28] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR , abs/1907.11692, 2019.
- [29] Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, and Wen Gao. Post-training quantization for vision transformer. Advances in Neural Information Processing Systems , 34, 2021.
- [30] Yihuan Mao, Yujing Wang, Chufan Wu, Chen Zhang, Yang Wang, Quanlu Zhang, Yaming Yang, Yunhai Tong, and Jing Bai. Ladabert: Lightweight adaptation of BERT through hybrid model compression. In Donia Scott, Núria Bel, and Chengqing Zong, editors, Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020 , pages 3225-3234. International Committee on Computational Linguistics, 2020.
- [31] Naveen Mellempudi, Abhisek Kundu, Dheevatsa Mudigere, Dipankar Das, Bharat Kaul, and Pradeep Dubey. Ternary neural networks with fine-grained quantization. arXiv preprint arXiv:1705.01462 , 2017.
- [32] Marius Mosbach, Maksym Andriushchenko, and Dietrich Klakow. On the stability of fine-tuning {bert}: Misconceptions, explanations, and strong baselines. In International Conference on Learning Representations , 2021.
- [33] Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. In International Conference on Machine Learning , pages 7197-7206. PMLR, 2020.
- [34] David Peer, Sebastian Stabinger, Stefan Engl, and Antonio Rodríguez-Sánchez. Greedy-layer pruning: Speeding up transformer models for natural language processing. Pattern Recognition Letters , 157:76-82, 2022.
- [35] Haotong Qin, Yifu Ding, Mingyuan Zhang, Qinghua YAN, Aishan Liu, Qingqing Dang, Ziwei Liu, and Xianglong Liu. BiBERT: Accurate fully binarized BERT. In International Conference on Learning Representations , 2022.
- [36] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- [37] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR , abs/1910.10683, 2019.
- [38] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250 , 2016.
- [39] Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. In European conference on computer vision , pages 525-542. Springer, 2016.
- [40] Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550 , 2014.
- [41] Hassan Sajjad, Fahim Dalvi, Nadir Durrani, and Preslav Nakov. Poor man's BERT: smaller and faster transformer models. CoRR , abs/2004.03844, 2020.
- [42] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. CoRR , abs/1910.01108, 2019.
- [43] Victor Sanh, Thomas Wolf, and Alexander Rush. Movement pruning: Adaptive sparsity by fine-tuning. Advances in Neural Information Processing Systems , 33:20378-20389, 2020.
- [44] Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Q-bert: Hessian based ultra low precision quantization of bert. In Proceedings of the AAAI Conference on Artificial Intelligence , 2020.
- [45] Gil Shomron, Freddy Gabbay, Samer Kurzum, and Uri Weiser. Post-training sparsity-aware quantization. Advances in Neural Information Processing Systems , 34, 2021.
- [46] Shaden Smith, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, et al. Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. arXiv e-prints , pages arXiv-2201, 2022.
- [47] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing , pages 1631-1642, 2013.
- [48] Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for BERT model compression. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019 , pages 4322-4331, 2019.
- [49] Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. Mobilebert: a compact task-agnostic bert for resource-limited devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 2158-2170, 2020.
- [50] Wei Tang, Gang Hua, and Liang Wang. How to train a compact binary neural network with high accuracy? In Satinder Singh and Shaul Markovitch, editors, Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA , pages 2625-2631. AAAI Press, 2017.
- [51] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations , 2019.
- [52] Lin Wang and Kuk-Jin Yoon. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. CoRR , abs/2004.05937, 2020.
- [53] Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers. CoRR , abs/2012.15828, 2020.
- [54] Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep selfattention distillation for task-agnostic compression of pre-trained transformers. In Hugo Larochelle, Marc'Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , 2020.
- [55] Alex Warstadt, Amanpreet Singh, and Samuel R Bowman. Neural network acceptability judgments. arXiv preprint arXiv:1805.12471 , 2018.
- [56] Adina Williams, Nikita Nangia, and Samuel R Bowman. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426 , 2017.
- [57] Zhewei Yao, Linjian Ma, Sheng Shen, Kurt Keutzer, and Michael W Mahoney. Mlpruning: A multilevel structured pruning framework for transformer-based models. arXiv preprint arXiv:2105.14636 , 2021.
- [58] Yichun Yin, Cheng Chen, Lifeng Shang, Xin Jiang, Xiao Chen, and Qun Liu. Autotinybert: Automatic hyper-parameter optimization for efficient pre-trained language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 5146-5157, 2021.
- [59] Ali Hadi Zadeh, Isak Edo, Omar Mohamed Awad, and Andreas Moshovos. Gobo: Quantizing attentionbased nlp models for low latency and energy efficient inference. In 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) , pages 811-824. IEEE, 2020.
- [60] Minjia Zhang and Yuxiong He. Accelerating training of transformer-based language models with progressive layer dropping. Advances in Neural Information Processing Systems , 33:14011-14023, 2020.
- [61] Wei Zhang, Lu Hou, Yichun Yin, Lifeng Shang, Xiao Chen, Xin Jiang, and Qun Liu. TernaryBERT: Distillation-aware ultra-low bit BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 509-521, Online, November 2020. Association for Computational Linguistics.
- [62] Sanqiang Zhao, Raghav Gupta, Yang Song, and Denny Zhou. Extremely small BERT models from mixed-vocabulary training. In Paola Merlo, Jörg Tiedemann, and Reut Tsarfaty, editors, Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021 , pages 2753-2759, 2021.
- [63] Minjia Zhng, Niranjan Uma Naresh, and Yuxiong He. Adversarial data augmentation for task-specific knowledge distillation of pre-trained transformers. Association for the Advancement of Artificial Intelligence , 2022.
## A Additional Related Work
KD has been extensively applied to computer vision and NLP tasks [52] since its debut. On the NLP side, several variants of KD have been proposed to compress BERT [10], including how to define the knowledge that is supposed to be transferred from the teacher BERT model to the student variations. Examples of such knowledge definitions include output logits (e.g., DistilBERT [42]) and intermediate knowledge such as feature maps [48, 1, 62] and self-attention maps [54, 49] (we refer KD using these additional knowledge as deep knowledge distillation [54]). To mitigate the accuracy gap from reduced student model size, existing work has also explored applying knowledge distillation in the more expensive pre-training stage, which aims to provide a better initialization to the student for adapting to downstream tasks. As an example, MiniLM [54] and MobileBERT [49] advance the state-of-the-art by applying deep knowledge distillation and architecture change to pre-train a student model on the general-domain corpus, which then can be directly fine-tuned on downstream tasks with good accuracy. TinyBERT [20] proposes to perform deep distillation in both the pre-training and fine-tuning stage and shows that these two stages of knowledge distillation are complementary to each other and can be combined to achieve state-of-the-art results on GLUE tasks. Our work differs from these methods in that we show how lightweight layer reduction without expensive pre-training distillation can be effectively combined with extreme quantization to achieve another order of magnitude reduction in model sizes for pre-trained Transformers.
## B Additional Details on Methodology, Experimental Setup and Results
## B.1 Knowledge Distillation
Knowledge Distillation (KD) [16] has been playing the most significant role in overcoming the performance degradation of model compression as the smaller models (i.e., student models) can absorb the rich knowledge of those uncompressed ones (i.e., teacher models) [40, 25, 43, 14]. In general, KD can be expressed as minimizing the difference ( L kd ) between outputs of a teacher model T and a student model S . As we are here studying transformer-based model and that the student and teacher models admit the same number (denoted as h ) of attention heads, our setup focuses on a particular widely-used paradigm, layerwise KD [20, 61, 3]. That is, for each layer of a student model S , the loss in the knowledge transferred from teacher T consist of three parts:
- (1) the fully-connected hidden states: L hidden = MSE ( H S , H T ) , where H S , H T ∈ R l × d h ;
- (2) the attention maps: L att = 1 h ∑ h i =1 MSE ( A S i , A T i ) , where A S i , A T i ∈ R l × l ;
- (3) the prediction logits: L logit = CE ( p S , p T ) where p S , p T ∈ R c ;
where MSE stands for the mean square error and CE is a cross entropy loss. Notably, for the first part in the above formulation, H S ( H T ) corresponds to the output matrix of the student's (teacher's) hidden states; l is the sequence length of the input (in our experiments, it is set to be 64 or 128 ); d h is the hidden dimension (768 for BERT base ). For the second part A S i ( A T i ) is the attention matrix corresponds to the i -th heads (in our setting, h = 12 ). In the final part, the dimension c in logit outputs ( p S and p T ) is either to be 2 or 3 for GLUE tasks. For more details on how the weight matrices involved in the output matrices, please see [20].
We have defined the three types of KD: 1S-KD, 2S-KD, and 3S-KD in main text. See Figure 4 for a visualization. Here we explain in more details. One-Stage KD means we naively minimize the sum of teacher-student differences on hidden-states, attentions and logits. In this setup, a single one-time learning rate schedule is used; in our case, it is a linear-decay schedule with warm-up steps 10% of the total training time. Two-Stage KD first minimizes the losses of hidden-states L hidden and attentions L att , then followed by the loss of logits L logit . This type of KD is proposed in [20] and has been used in [3] for extreme quantization. During the training, the (linear-decay) learning rate schedule will be repeated from the first stage to the
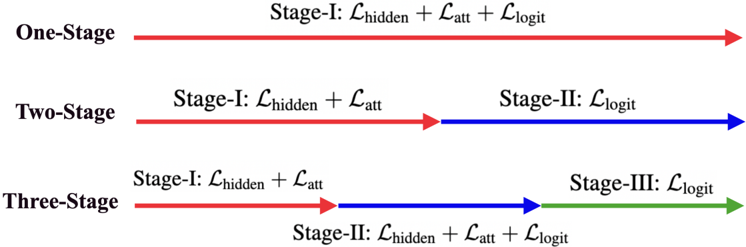
Figure 4: Three types of knowledge distillation. 1S-KD KD (top red arrow line) involves all the outputs of hidden-states, attentions and logits from the beginning of the training to the end. 2S-KD KD (middle red and blue arrow line) separates hidden-states and attentions from the logits part. While 3S-KD KD (bottom red, blue and green arrow line) succeed 2S-KD one, it also adds a transition phase in the middle of the training.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: Multi-Stage Process Comparison
### Overview
The image illustrates a comparison of one-stage, two-stage, and three-stage processes, likely in the context of a machine learning or computational workflow. Each process is represented by a horizontal arrow, with different colors indicating different stages and associated loss functions.
### Components/Axes
* **Process Labels (Left):**
* One-Stage
* Two-Stage
* Three-Stage
* **Stages (Above Arrows):** Stage-I, Stage-II, Stage-III
* **Loss Functions (Above Arrows):** L<sub>hidden</sub>, L<sub>att</sub>, L<sub>logit</sub>
* **Arrows:** Represent the flow of the process. Arrow color indicates the stage.
### Detailed Analysis
* **One-Stage:**
* A single red arrow labeled "Stage-I: L<sub>hidden</sub> + L<sub>att</sub> + L<sub>logit</sub>".
* **Two-Stage:**
* A red arrow labeled "Stage-I: L<sub>hidden</sub> + L<sub>att</sub>" transitions into a blue arrow labeled "Stage-II: L<sub>logit</sub>".
* **Three-Stage:**
* A red arrow labeled "Stage-I: L<sub>hidden</sub> + L<sub>att</sub>" transitions into a blue arrow labeled "Stage-II: L<sub>hidden</sub> + L<sub>att</sub> + L<sub>logit</sub>", which then transitions into a green arrow labeled "Stage-III: L<sub>logit</sub>".
### Key Observations
* The One-Stage process involves all three loss functions (hidden, attention, and logit) in a single stage.
* The Two-Stage process separates the hidden and attention loss functions from the logit loss function.
* The Three-Stage process further divides the loss functions, with the second stage including all three loss functions and the final stage focusing solely on the logit loss function.
### Interpretation
The diagram visually represents the decomposition of a process into multiple stages, each potentially focusing on different aspects or loss functions. The progression from one-stage to three-stage suggests an increasing level of modularity or specialization in the process. The loss functions (L<sub>hidden</sub>, L<sub>att</sub>, L<sub>logit</sub>) likely represent different components of the overall objective function being optimized in the process. The diagram highlights how these loss functions are distributed across different stages in each process.
</details>
second one; particularly, in [20] they used a × 2 . 5 peak learning rate for Stage-I than that for Stage-II. Finally, Three-Stage KD succeeds the properties of 1S-KD and 2S-KD. That is, after minimizing the losses of hidden-states L hidden and attentions L att , we add a transition phase: L hidden + L att + L logit , instead of directly optimizing L logit . The learning rate schedules will be correspondingly repeated in three times and the peak learning rate of Stage-I is × 2 . 5 higher than that of Stage-II and Stage-III.
## B.2 Experimental Setup
Similar to [20, 3], we fine-tune on GLUE tasks, namely, MRPC [11], STS-B [7], SST-2 [47], QNLI [38], QQP [19], MNLI [56], CoLA [55], RTE [9]). We recorded their validation performances over the training and report the best validation value. The maximum sequence length is set to 64 for CoLA/SST-2, and 128 for the rest sequence pair tasks. See Table C.1 for the size of each (augmented) dataset and training batch size. Each independent experiment is ran on a single A100 GPU with a fixed random seed 42. To understand how much the variance can bring with various random seed, we include a set of experiments by only varying the random seeds 111 and 222 . The results are given in Table C.16 and Table C.17. We overall find the standard deviation are within 0.1 on the GLUE score.
The 2-bit algorithm and distillation code are based on the official implementation of [61] 4 and the 1-bit algorithm is based only on the binary code 5 in [3] as explained in the main text. Finally, we comment on the reproduced result shown in Row 3 of Table 5. We apply the 2S-KD where Stage-I distillation requires much longer epochs than Budget-C as ColA requires 50 epochs, MNLI/QQP/QNLI requires 10 epochs, and others 20 epochs. All are trained on augmented datasets; Note that 10-epoch augmented MNLI/QQP is much longer than 18/36-epoch standard ones. Stage-II KD is similar to Budget B but needs to search with three learning rates and two batch sizes.
## B.3 Exploration of LoRa
As we see in § 5 (i.e.,Table 6), smaller models is much more brittle on extreme quantization than BERT base , especially the 1-bit compression. We now investigate whether adding low-rank (LoRa) matrices to the quantize weights would help improve the situation. That is, we introduce two low-rank matrices U ∈ R d in × r
4 https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TernaryBERT
5 https://github.com/huawei-noah/Pretrained-Language-Model/blob/master/BinaryBERT/transformer/ut ils\_quant.py#L347
and V ∈ R r × d out for a quantized weight ˜ W ∈ R d in × d out such that the weight we used for input is
<!-- formula-not-decoded -->
Here U and V are computed in full precision. In our experiments for the layer-reduced model (Skip-Bert 6 ), we let r ∈ { 1 , 8 } . We use 1S-KD and also include the scenarios for the three budgets and three learning rates {5e-5,1e-4,5e-4}. The full results for 1-bit and 2-bit Skip-Bert 6 are presented in Table C.11 and Table C.12. Correspondingly, we summarized the results in Table C.9 and Table C.10 for clarity.
To further verify the claim of "marginal or none" benefit using LoRa under a sufficient training budget, we include more experiments for five-/four-layer BERT (Skip-BERT 5 and Skip-BERT 4 ), and the results are shown in Table C.13. The observation is similar to what we have found for Skip-BERT 6 .
Overall, we see that LoRa can boost performance when the training time is short. For instance, as shown in Table C.9 ( Table C.10) under Budget-A, the average score for 1-bit (2-bit) is 80.81 (82.14) without LoRa, compared with 81.09 (82.31) with LoRa. However, the benefit becomes marginal when training is long. Here, under Budget-B, the average score for 1-bit (2-bit) is 81.37 (82.51) without LoRa, compared with 81.59 (82.41) with LoRa.
Interestingly, we find that in Table C.14, instead of adding these full-precision low-rank matrices, there is a considerable improvement by continuing training with another Budget-C iteration based on the checkpoints obtained under Budget-C. Particularly, there is 0 . 09 in GLUE score's improvement for 1-bit SkipBERT 5 (from 81.34 (Row 1) to 81.63 (Row 2)) and 0 . 28 for 1-bit SkipBERT 4 . On the other hand, if we trained a 2-bit SkipBERT 5 /SkipBERT 4 first and then continue training them into 1-bit, the final performance (see Row 5 and Row 11) is even worse than a direct 1-bit quantization (see Row 1 and Row 7). In addition to the results above, we also tried to see if continuing training by adding LoRa (rank=1) matrices would help or not. However, the results are negative.
## B.4 Exploration of Smaller Teacher
As shown in previous works, such as [53, 25], there is a clear advantage to using larger teacher models. Here shown in Table C.15 under Budget-C, we apply 1-/2-bit quantization on Skip-BERT 6 and compare the teachers between BERT base and the full-precision Skip-BERT 6 .
We verify that a better teacher can boost the performance, particularly for 1-bit quantization on the smaller tasks such as CoLA, MRPC, RTE, and STS-B. However, when adding LoRa, the advantage of using better teacher diminishes as the gain on average GLUE score decreases from 0.31 (without LoRa) to 0.11 (with LoRa) on 1-/2-bit quantization.
## C Tables
Table C.1: Training details. DA is short for data augmentation.
| | CoLA | MNLI | MRPC | QNLI | QQP | RTE | SST-2 | STS-B |
|------------------|----------|-----------|----------|------------------|--------|----------|-----------------|----------|
| Dev data | 1043 | 9815/9832 | 408 | 5463 | 40430 | 277 | 872 | 1500 |
| Train (noDA) | 8551 | 392702 | 3668 | 104743 | 363846 | 2490 | 67349 | 5749 |
| Train (DA) | 218844 | 392702 | 226123 | 4.27377e+06 | 363846 | 145865 | 1.13383e+06 | 327384 |
| DA/noDA | 25.6 | 1 | 61.6 | 40.8 | 1 | 58.6 | 16.8 | 56.9 |
| Train batch-size | 16 | 32 | 32 | 32 | 32 | 32 | 32 | 32 |
Table C.2: 1-bit quantization for BERT base with size 13 . 0 MB ( × 32 . 0 smaller than the fp32 version).
| Training Cost | Stages | learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|-----------------|-------------|-----------------|------------|----------------------|---------------|------------|---------------------|-----------|-------------|-------------------|--------|-----------------|
| Budget-A | One-Stage | 2e-5 | 44.6 | 83.1/83.7 | 88.8/83.1 | 91.1 | 87.4/90.7 | 66.1 | 92.8 | 87.8/87.5 | 80.33 | 84.8 |
| Budget-A | One-Stage | 1e-4 | 50.4 | 83.7/84.6 | 90.1/85.3 | 91.3 | 88.0/91.1 | 71.5 | 92.7 | 88.8/88.4 | 82.16 | 86.12 |
| Budget-A | One-Stage | 5e-4 | 42.3 | 83.3/84.1 | 90.0/85.8 | 89.5 | 87.8/90.9 | 72.9 | 92.5 | 88.1/87.8 | 81.04 | 85.89 |
| Budget-A | One-Stage | Best (above) | 50.4 | 83.7/84.6 | 90.0/85.8 | 91.3 | 88.0/91.1 | 72.9 | 92.8 | 88.8/88.4 | 82.38 | 86.37 |
| Budget-A | Two-Stage | 2e-5 | 48.2 | 83.3/83.8 | 89.3/84.6 | 90.7 | 87.7/90.9 | 70.4 | 92.5 | 88.7/88.4 | 81.46 | 85.61 |
| Budget-A | Two-Stage | 1e-4 | 48.5 | 83.3/83.4 | 90.0/85.5 | 90.4 | 87.4/90.7 | 70.4 | 92.4 | 88.6/88.2 | 81.47 | 85.59 |
| Budget-A | Two-Stage | 5e-4 | 16.2 | 74.9/76.4 | 89.7/84.8 | 87.8 | 85.0/89.0 | 68.2 | 91.6 | 86.2/86.5 | 75.01 | 82.36 |
| Budget-A | Two-Stage | Best (above) | 48.5 | 83.3/83.8 | 90.0/85.5 | 90.7 | 87.7/90.9 | 70.4 | 92.5 | 88.7/88.4 | 81.59 | 85.72 |
| Budget-A | Three-Stage | 2e-5 | 49.3 | 83.1/83.6 | 89.5/84.3 | 91 | 87.6/90.9 | 70.8 | 92.4 | 88.7/88.3 | 81.57 | 85.6 |
| Budget-A | Three-Stage | 1e-4 | 49 | 83.2/83.4 | 89.7/84.8 | 90.9 | 87.6/90.7 | 73.6 | 92.2 | 88.8/88.5 | 81.84 | 85.95 |
| Budget-A | Three-Stage | 5e-4 | 29.5 | 81.3/81.9 | 89.1/83.6 | 88.4 | 85.0/89.3 | 66.1 | 91.9 | 84.1/83.9 | 77.34 | 83.32 |
| Budget-A | Three-Stage | Best (above) | 49.3 | 83.2/83.4 | 89.7/84.8 | 91 | 87.6/90.9 | 73.6 | 92.4 | 88.8/88.5 | 81.93 | 86.01 |
| Budget-B | One-Stage | 2e-5 | 51.8 | 84.1/84.4 | 89.6/84.6 | 90.8 | 88.0/91.1 | 70.8 | 92.8 | 88.8/88.4 | 82.13 | 85.92 |
| Budget-B | One-Stage | 1e-4 | 55.6 | 83.9/84.6 | 90.4/86.0 | 90.8 | 88.3/91.3 | 72.6 | 93.1 | 88.9/88.5 | 82.98 | 86.4 |
| Budget-B | One-Stage | 5e-4 | 45.7 | 82.9/83.4 | 90.4/86.0 | 89.2 | 87.7/90.8 | 72.6 | 92.8 | 87.8/87.5 | 81.24 | 85.69 |
| Budget-B | One-Stage | Best (above) | 55.6 | 84.1/84.4 | 90.4/86.0 | 90.8 | 88.3/91.3 | 72.6 | 93.1 | 88.9/88.5 | 82.98 | 86.4 |
| Budget-B | One-Stage | 2e-5 | 52.4 | 84.0/84.5 | 89.7/85.0 | 90.5 | 88.0/91.1 | 72.2 | 92.7 | 89.2/88.8 | 82.4 | 86.15 |
| Budget-B | Two-Stage | 1e-4 | 51.3 | 83.3/83.6 | 90.3/85.8 | 90.2 | 87.0/90.6 | 72.9 | 92.5 | 88.6/88.3 | 82.09 | 85.94 |
| Budget-B | Two-Stage | 5e-4 | 29.7 | 78.4/79.6 | 89.2/84.3 | 88.8 | 83.2/88.2 | 69.7 | 91.3 | 84.8/85.1 | 77.2 | 83.14 |
| Budget-B | Two-Stage | Best (above) | 52.4 | 84.0/84.5 | 90.3/85.8 | 90.5 | 88.0/91.1 | 72.9 | 92.7 | 89.2/88.8 | 82.57 | 86.34 |
| Budget-B | Three-Stage | 2e-5 | 53 | 83.8/84.4 | 90.1/85.3 | 90.7 | 88.0/91.1 | 72.2 | 93.2 | 89.2/88.8 | 82.54 | 86.24 |
| Budget-B | Three-Stage | 1e-4 | 51.5 | 83.4/83.9 | 90.4/86.0 | 90.2 | 87.9/91.1 | 72.6 | 92.9 | 88.7/88.4 | 82.26 | 86.1 |
| Budget-B | Three-Stage | 5e-4 | 35.6 | 80.2/80.9 | 89.1/84.6 | 88.5 | 86.1/89.7 | 69.3 | 90.6 | 86.4/86.2 | 78.42 | 83.78 |
| Budget-B | Three-Stage | Best (above) | 53 | 83.8/84.4 | 90.4/86.0 | 90.7 | 88.0/91.1 | 72.6 | 93.2 | 89.2/88.8 | 82.67 | 86.38 |
| Budget-C | One-Stage | 2e-5 | 57.3 | 84.1/84.0 | 90.7/86.5 | 91 | 88.2/91.2 | 74 | 93.1 | 89.2/88.8 | 83.38 | 86.64 |
| Budget-C | One-Stage | 1e-4 | 55.6 | 84.2/84.4 | 90.4/86.0 | 90.4 | 88.3/91.3 | 73.6 | 93 | 88.8/88.4 | 83.03 | 86.46 |
| Budget-C | One-Stage | 5e-4 | 46.1 | 82.8/82.9 | 89.9/86.0 | 89.5 | 87.7/90.8 | 71.1 | 92.4 | 88.2/88.0 | 81.09 | 85.46 |
| Budget-C | One-Stage | Best (above) | 57.3 | 84.2/84.4 | 90.7/86.5 | 91 | 88.3/91.3 | 74 | 93.1 | 89.2/88.8 | 83.44 | 86.71 |
| Budget-C | Two-Stage | 2e-5 | 55.9 | 84.2/83.9 | 90.6/86.5 | 90.7 | 88.3/91.3 | 73.3 | 93.1 | 89.2/88.9 | 83.12 | 86.52 |
| Budget-C | Two-Stage | 1e-4 | 52 | 83.2/83.8 | 90.9/86.5 | 90.1 | 88.0/91.0 | 74 | 93.1 | 87.8/87.8 | 82.39 | 86.19 |
| Budget-C | Two-Stage | 5e-4 | 32.2 | 79.3/80.3 | 90.6/86.5 | 89.6 | 85.3/89.1 | 70 | 91.2 | 87.0/86.8 | 78.36 | 84.12 |
| Budget-C | | Best (above) | 55.9 | 84.2/83.9 | 90.6/86.5 | 90.7 | 88.3/91.3 | 74 | 93.1 | 89.2/88.9 | 83.2 | 86.61 |
| Budget-C | Three-Stage | 2e-5 | 57.1 | 84.0/84.4 | 90.6/86.5 | 90.9 | 88.1/91.1 | 72.6 | 92.9 | 89.5/89.2 | 83.22 | 86.49 |
| Budget-C | | 1e-4 | 53.8 | 83.5/84.1 | 90.8/86.8 | 90.1 | 88.3/91.3 | 72.6 | 92.8 | 88.2/87.9 | 82.58 | 86.18 |
| Budget-C | | 5e-4 | 31.3 | 80.0/81.3 | 89.8/85.3 | 89.2 | | 70.8 | 91.3 | 86.4/86.8 | 78.4 | 84.29 |
| Budget-C | | Best (above) | 57.1 | 84.0/84.4 | 90.8/86.8 | 90.9 | 86.7/90.0 88.3/91.3 | 72.6 | 92.9 | 89.5/89.2 | 83.28 | 86.55 |
Table C.3: 2-bit quantization for BERT base with size 26 . 8 MB ( × 16 . 0 smaller than the fp32 version).
| Training Cost | Stages | learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|-----------------|-------------|-----------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|-----------------|
| Budget-A | One-Stage | 2e-5 | 58 | 84.2/84.6 | 89.8/84.8 | 91.5 | 88.4/91.4 | 72.2 | 93.5 | 89.4/89.0 | 83.29 | 86.45 |
| Budget-A | One-Stage | 1e-4 | 55.8 | 84.5/85.0 | 90.9/87.0 | 91.5 | 88.4/91.4 | 74 | 93.5 | 89.6/89.2 | 83.59 | 87.06 |
| Budget-A | One-Stage | 5e-4 | 46.1 | 83.8/84.7 | 89.6/85.0 | 90.9 | 88.0/91.2 | 71.8 | 92.8 | 88.8/88.4 | 81.68 | 86.12 |
| Budget-A | One-Stage | Best (above) | 58 | 84.5/85.0 | 90.9/87.0 | 91.5 | 88.4/91.4 | 74 | 93.5 | 89.6/89.2 | 83.83 | 87.06 |
| Budget-A | Two-Stage | 2e-5 | 56.6 | 84.3/85.0 | 91.0/87.3 | 91.3 | 88.3/91.3 | 71.5 | 93.5 | 89.6/89.1 | 83.38 | 86.72 |
| Budget-A | Two-Stage | 1e-4 | 52.3 | 84.2/84.8 | 90.2/85.5 | 91 | 87.9/91.1 | 72.2 | 92.8 | 89.4/89.1 | 82.59 | 86.38 |
| Budget-A | Two-Stage | 5e-4 | 29 | 78.1/78.8 | 90.3/85.8 | 90.3 | 86.2/89.9 | 68.2 | 91.7 | 87.6/87.5 | 77.71 | 83.8 |
| Budget-A | Two-Stage | Best (above) | 56.6 | 84.3/85.0 | 91.0/87.3 | 91.3 | 88.3/91.3 | 72.2 | 93.5 | 89.6/89.1 | 83.46 | 86.81 |
| Budget-A | Three-Stage | 2e-5 | 58.8 | 84.3/84.7 | 90.4/86.8 | 91.4 | 88.0/91.2 | 72.6 | 93.5 | 89.6/89.1 | 83.66 | 86.76 |
| Budget-A | Three-Stage | 1e-4 | 55.2 | 84.1/84.9 | 90.6/86.3 | 91.1 | 87.9/91.2 | 74 | 93.1 | 89.2/88.9 | 83.23 | 86.74 |
| Budget-A | Three-Stage | 5e-4 | 33.3 | 83.1/83.8 | 88.5/83.6 | 89.8 | 86.4/90.0 | 47.3 | 91.2 | 84.4/84.0 | 76.28 | 81.65 |
| Budget-A | Three-Stage | Best (above) | 58.8 | 84.3/84.7 | 90.4/86.8 | 91.4 | 88.0/91.2 | 74 | 93.5 | 89.6/89.1 | 83.81 | 86.94 |
| | One-Stage | 2e-5 | 58.2 | 84.6/84.7 | 91.3/87.7 | 91.4 | 88.4/91.4 | 73.6 | 93.3 | 89.6/89.2 | 83.83 | 87.04 |
| | One-Stage | 1e-4 | 56.3 | 84.3/84.9 | 90.5/86.3 | 91.3 | 88.4/91.4 | 75.8 | 93.5 | 89.5/89.1 | 83.7 | 87.12 |
| | One-Stage | 5e-4 | 47.3 | 84.0/84.3 | 90.1/86.3 | 90.5 | 88.3/91.2 | 72.6 | 92.9 | 88.7/88.2 | 81.98 | 86.31 |
| | One-Stage | Best (above) | 58.2 | 84.6/84.7 | 91.3/87.7 | 91.4 | 88.4/91.4 | 75.8 | 93.5 | 89.6/89.2 | 84.1 | 87.34 |
| Budget-B | Two-Stage | 2e-5 | 58.4 | 84.3/84.9 | 90.5/86.3 | 91.4 | 88.4/91.3 | 74 | 93.5 | 89.7/89.4 | 83.76 | 86.93 |
| Budget-B | Two-Stage | 1e-4 | 53.6 | 84.0/84.6 | 91.1/87.3 | 91 | 88.0/91.2 | 73.3 | 93.5 | 89.0/88.6 | 83.06 | 86.74 |
| Budget-B | Two-Stage | 5e-4 | 34.7 | 81.5/82.3 | 90.1/85.5 | 90.5 | 85.5/89.2 | 71.1 | 91.6 | 87.6/87.4 | 79.33 | 84.91 |
| Budget-B | Two-Stage | Best (above) | 58.4 | 84.3/84.9 | 91.1/87.3 | 91.4 | 88.4/91.3 | 74 | 93.5 | 89.7/89.4 | 83.87 | 87.05 |
| Budget-B | Three-Stage | 2e-5 | 59.6 | 84.5/84.7 | 90.9/86.5 | 91.3 | 88.3/91.3 | 73.3 | 93.3 | 89.7/89.3 | 83.8 | 86.82 |
| Budget-B | Three-Stage | 1e-4 | 55.9 | 84.6/84.8 | 90.7/86.5 | 91.1 | 88.3/91.4 | 74.4 | 93.3 | 89.3/89.0 | 83.48 | 86.92 |
| Budget-B | Three-Stage | 5e-4 | 35.3 | 81.4/81.8 | 89.9/85.5 | 90.6 | 86.9/90.2 | 72.9 | 91.6 | 87.8/87.6 | 79.68 | 85.22 |
| Budget-B | Three-Stage | Best (above) | 59.6 | 84.6/84.8 | 90.9/86.5 | 91.3 | 88.3/91.4 | 74.4 | 93.3 | 89.7/89.3 | 83.96 | 87 |
| Budget-C | One-Stage | 2e-5 | 59.9 | 84.7/84.4 | 91.0/86.7 | 91.4 | 88.4/91.4 | 74 | 93.5 | 89.6/89.2 | 84 | 87.01 |
| Budget-C | Two-Stage | 2e-5 | 59.9 | 84.9/84.7 | 91.2/87.3 | 91.2 | 88.2/91.3 | 73.3 | 93.5 | 89.7/89.4 | 83.98 | 86.99 |
| Budget-C | Three-Stage | 2e-5 | 59.6 | 84.7/84.3 | 91.0/87.0 | 91.2 | 88.4/91.3 | 74.4 | 93.7 | 89.6/89.2 | 83.98 | 87.03 |
Table C.4: Results without data augmentation. Details of Table 4 for 1-bit quantization on BERT base with three learning rates.
| Cost | learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Avg. w/o CoLA |
|--------------------|-----------------|------------|----------------------|---------------------|------------|---------------------|-----------|-------------|-------------------|------------|-----------------|
| Budget-A One-Stage | 2e-5 1e-4 | 47.3 | 83.1/83.7 | 87.2/80.1 89.0/83.6 | 90.8 91.0 | 87.4/90.7 88.0/91.1 | 66.8 | 92.2 | 85.5/85.3 | 80.02 | 84.11 |
| Budget-A One-Stage | | 48.9 | 83.7/84.6 | | | | 71.5 | 92.5 | 87.6/87.5 | 81.61 | 85.7 |
| Budget-A One-Stage | 5e-4 | 38.1 | 83.3/84.1 | 88.4/83.6 | 90.1 | 87.8/90.9 | 69.7 | 92 | 85.0/85.0 | 79.64 | 84.84 |
| Budget-A One-Stage | Best (above) | 48.9 | 83.7/84.6 | 89.0/83.6 | 91.0 | 88.0/91.1 | 71.5 | 92.5 | 87.6/87.5 | 81.61 | 85.7 |
| Budget-C One-Stage | 2e-5 | 55 | 84.1/84.0 | 90.0/85.0 | 90.7 | 88.2/91.2 | 73.3 | 92.9 | 88.2/87.9 | 82.71 | 86.18 |
| Budget-C One-Stage | 1e-4 | 52.9 | 84.2/84.4 | 89.2/85.0 | 90.4 | 88.3/91.3 | 72.9 | 92.7 | 87.7/87.7 | 82.39 | 86.08 |
| Budget-C One-Stage | 5e-4 | 42.2 | 82.8/82.9 | 88.7/83.6 | 89.8 | 87.7/90.8 | 71.1 | 91.4 | 87.0/86.8 | 80.18 | 84.92 |
| Budget-C One-Stage | Best (above) | 55 | 84.2/84.4 | 90.0/85.0 | 90.7 | 88.3/91.3 | 73.3 | 92.9 | 88.2/87.9 | 82.78 | 86.25 |
Table C.5: Details of Table 5: Layer reduction with different learning rates (i.e., the 2nd column).
| Model (MB) | Learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|--------------|-----------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|-----------------|
| BERT-base | n/a | 59.7 | 84.9/85.6 | 90.6/86.3 | 92.1 | 88.6/91.5 | 72.2 | 93.2 | 90.1/89.6 | 83.95 | 86.98 |
| TinyBERT 6 | 5e-5 | 53.6 | 84.3/84.3 | 90.4/86.3 | 91.2 | 88.5/91.5 | 67.9 | 93.2 | 89.2/88.8 | 82.39 | 85.99 |
| TinyBERT 6 | 1e-4 | 54.4 | 84.6/84.3 | 90.1/85.8 | 91.5 | 88.4/91.5 | 68.6 | 93.3 | 89.1/89.0 | 82.57 | 86.09 |
| TinyBERT 6 | 5e-4 | 45.1 | 84.1/84.2 | 90.1/85.8 | 91.3 | 88.5/91.5 | 69.7 | 93.2 | 89.1/88.7 | 81.56 | 86.11 |
| MiniLM 6 | 5e-5 | 55.1 | 84.4/84.4 | 90.4/86.0 | 91.3 | 88.3/91.4 | 70.8 | 93 | 89.4/89.0 | 82.87 | 86.34 |
| MiniLM 6 | 1e-4 | 55.4 | 84.2/84.5 | 89.5/85.3 | 91.3 | 88.4/91.5 | 70.8 | 93.2 | 89.4/89.0 | 82.84 | 86.28 |
| MiniLM 6 | 5e-4 | 49.5 | 84.1/83.9 | 90.7/86.5 | 91.4 | 88.5/91.5 | 71.8 | 93.3 | 89.1/88.7 | 82.34 | 86.45 |
| Skip-BERT 6 | 5e-5 | 56.9 | 84.5/84.9 | 89.7/84.8 | 91.7 | 88.5/91.5 | 71.8 | 93.5 | 89.8/89.4 | 83.27 | 86.56 |
| Skip-BERT 6 | 1e-4 | 56.6 | 84.6/84.7 | 90.4/85.8 | 91.8 | 88.5/91.6 | 72.6 | 93.5 | 89.7/89.4 | 83.43 | 86.79 |
| Skip-BERT 6 | 5e-4 | 48.5 | 84.3/84.2 | 90.0/85.5 | 91.5 | 88.6/91.6 | 71.5 | 93.5 | 89.4/88.9 | 82.22 | 86.44 |
| Skip-BERT 5 | 5e-5 | 57.9 | 84.3/85.1 | 89.8/84.8 | 91.4 | 88.3/91.4 | 72.2 | 93.3 | 89.2/88.9 | 83.29 | 86.46 |
| Skip-BERT 5 | 1e-4 | 56.7 | 84.2/84.8 | 90.1/85.5 | 91.4 | 88.3/91.4 | 72.2 | 93.2 | 89.2/88.8 | 83.18 | 86.49 |
| Skip-BERT 5 | 5e-4 | 53.6 | 84.1/84.4 | 90.1/85.5 | 91.4 | 88.5/91.5 | 70.4 | 93.3 | 88.6/88.2 | 82.53 | 86.15 |
| Skip-BERT 4 | 5e-5 | 53.3 | 83.0/83.3 | 89.9/85.0 | 90.8 | 88.1/91.3 | 70 | 93.2 | 88.8/88.4 | 82.08 | 85.67 |
| Skip-BERT 4 | 1e-4 | 52.2 | 83.2/83.4 | 90.0/85.3 | 90.7 | 88.2/91.3 | 70 | 93.5 | 88.6/88.3 | 82.02 | 85.75 |
| Skip-BERT 4 | 5e-4 | 46.8 | 82.9/83.0 | 89.6/85.0 | 90.4 | 87.8/91.0 | 67.9 | 93.1 | 88.3/87.8 | 80.93 | 85.2 |
Table C.6: Selection for student networks from their teacher networks (fine-tuned BERT base ). The following results follow the same hyperparamters and the learning rate 5e-5.
| Layer Selection | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Avg. w/o CoLA |
|-------------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|------------|-----------------|
| BERT-base fp32 | 59.7 | 84.9/85.6 | 90.6/86.3 | 92.1 | 88.6/91.5 | 72.2 | 93.2 | 90.1/89.6 | 83.95 | 86.98 |
| (1) Skip-6 | 56.9 | 84.5/84.9 | 89.7/84.8 | 91.7 | 88.5/91.5 | 71.8 | 93.5 | 89.8/89.4 | 83.27 | 86.56 |
| (2) Top-6 | 52 | 83.9/84.2 | 90.0/85.3 | 91.5 | 88.2/91.3 | 69.3 | 93 | 88.2/87.9 | 82.08 | 85.84 |
| (3) Bottom-6 | 51.2 | 83.2/83.6 | 89.5/84.6 | 90.1 | 87.8/90.9 | 67.9 | 92.7 | 89.5/89.1 | 81.5 | 85.29 |
Table C.7: Compare between different stages KD. All learning rate set to be 5e-5.
| # | Model (255.2MB) | #-Stage Same Budget | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Avg. w/o CoLA |
|-------|-------------------|-----------------------|----------------|-------------------------------|-------------------------------|----------------|-------------------------------|----------------|----------------|-------------------------------|-------------------|-------------------|
| 1 2 3 | TinyBERT 6 | One Two Three | 53.6 55.3 54.2 | 84.3/84.3 84.2/84.2 84.2/84.4 | 90.4/86.3 89.9/85.3 89.9/85.0 | 91.2 91.1 91.3 | 88.5/91.5 88.4/91.4 88.5/91.5 | 67.9 68.6 70.8 | 93.2 92.9 93.1 | 89.2/88.8 89.2/88.9 89.2/88.8 | 82.39 82.47 82.63 | 85.99 85.86 86.19 |
| 4 5 6 | MiniLM 6 -v2 | One Two Three | 55.1 53.8 54.0 | 84.4/84.4 84.4/84.5 84.4/84.6 | 90.4/86.0 90.7/87.3 89.1/85.3 | 91.3 91.2 91.3 | 88.3/91.4 88.3/91.3 88.5/91.5 | 70.8 67.9 70.4 | 93.0 93.1 93.0 | 89.4/89.0 89.7/89.3 89.6/89.2 | 82.87 82.58 82.68 | 86.34 86.18 86.26 |
| 7 8 9 | Skip-BERT 6 | One Two Three | 56.9 56.0 55.3 | 84.5/84.9 84.1/84.2 84.4/84.6 | 89.7/84.8 89.7/84.8 89.7/84.8 | 91.7 91.5 91.7 | 88.5/91.5 88.2/91.3 88.5/91.5 | 71.8 71.8 72.2 | 93.5 93.3 93.6 | 89.8/89.4 89.4/89.1 89.6/89.2 | 83.27 82.93 83.08 | 86.56 86.30 86.55 |
Table C.8: 1-/2-bit quantization of smaller model.
| # | Model #-layer | bit | size (MB) | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Acc. drop |
|---------|-----------------|--------|------------------------------------------------------|----------------|-------------------------------|-------------------------------|----------------|-------------------------------|----------------|----------------|-------------------------------|-------------------|---------------|
| 1 2 | TinyBERT 6 [61] | 32 2 | 255.2 ( × 1 . 6 ) 16.0 ( × 26 . 2 ) | 54.1 53.0 | 84.5/84.5 83.4/83.8 | 91.0/87.3 91.5/88.0 | 91.1 89.9 | 88.0/91.1 87.2/90.5 | 71.8 71.8 | 93.0 93.0 | 89.8/89.6 86.9/86.5 | 83.02 82.26 | - -0.76 |
| 3 4 5 | XTC-BERT 6 SIX | 32 2 1 | 255.2 ( × 1 . 6 ) 16.0 ( × 26 . 2 ) 8.0 ( × 52 . 3 ) | 56.9 53.8 52.3 | 84.4/84.8 83.6/84.2 83.4/83.8 | 90.1/85.5 90.5/86.3 90.0/85.3 | 91.3 90.6 89.4 | 88.4/91.4 88.2/91.3 87.9/91.1 | 72.2 73.6 68.6 | 93.2 93.6 93.1 | 90.3/90.0 89.0/88.7 88.4/88.0 | 83.33 82.89 81.71 | - -0.44 -1.51 |
| 6 7 8 | XTC-BERT 5 FIVE | 32 2 1 | 228.2 ( × 1 . 8 ) 14.2 ( × 29 . 3 ) 7.1 ( × 58 . 5 ) | 56.7 53.9 52.2 | 84.2/84.8 83.3/84.1 82.9/83.2 | 90.1/85.5 90.4/86.0 89.9/85.0 | 91.4 90.4 88.5 | 88.3/91.4 88.2/91.2 87.6/90.8 | 72.2 71.8 69.3 | 93.2 93.0 92.9 | 89.2/88.8 88.4/88.0 87.3/87.0 | 83.18 82.46 81.34 | - -0.72 -1.84 |
| 9 10 11 | XTC-BERT 4 FOUR | 32 2 1 | 201.2 ( × 2 . 1 ) 12.6 ( × 33 . 2 ) 6.3 ( × 66 . 4 ) | 52.2 50.3 48.3 | 83.2/83.4 82.5/83.0 82.0/82.3 | 90.0/85.3 90.0/85.3 89.9/85.5 | 90.7 89.2 87.7 | 88.2/91.3 87.8/91.0 86.9/90.4 | 70.0 69.0 63.9 | 93.5 92.8 92.4 | 88.6/88.3 87.9/87.4 87.1/86.7 | 82.02 81.22 79.96 | - -0.90 -2.01 |
Table C.9: 1-bit quantization for Skip-BERT 6 .
| # | Cost | LoRa (Y/N) | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|-------|----------|-----------------------|----------------|-------------------------------|-------------------------------|----------------|-------------------------------|----------------|----------------|-------------------------------|-------------------|-------------------|
| 1 2 3 | Budget-A | N Y (DIM=1) Y (DIM=8) | 47.9 48.1 49.7 | 82.9/83.2 82.9/83.2 83.4/83.6 | 90.5/86.3 89.4/84.3 89.8/85.0 | 89.7 89.6 89.9 | 87.8/90.9 87.6/90.8 87.5/90.8 | 65.7 65.3 66.8 | 92.7 92.4 92.8 | 88.0/87.6 88.1/87.7 87.8/87.5 | 80.81 80.52 81.09 | 84.92 84.58 85.01 |
| 4 5 6 | Budget-B | N Y (DIM=1) Y (DIM=8) | 50.3 49.9 50.9 | 83.2/83.7 83.3/83.8 | 90.9/86.8 90.5/86.0 | 89.3 89.3 89.4 | 87.9/91.0 88.0/91.1 | 67.1 67.5 | 92.7 92.7 | 88.2/88.0 88.3/87.9 | 81.37 81.32 | 85.25 85.25 |
| 7 8 | | | | 83.2/83.7 83.1/83.6 | 90.3/85.8 90.5/86.0 | 89.3 89.4 | 88.1/91.2 88.2/91.2 | 69.0 | 92.8 | 88.3/88.0 | 81.59 | 85.42 |
| | Budget-C | N Y | 51.9 52.0 | 83.2/83.8 | 89.8/86.0 | | | 69.0 | 93.1 | 88.1/87.7 | 81.70 | 85.42 |
| 9 | | (DIM=1) Y (DIM=8) | 52.6 | 83.3/83.8 | 89.9/85.5 | 89.2 | 88.0/91.1 88.2/91.2 | 69.3 69.3 | 93.0 92.8 | 88.2/88.0 88.2/87.9 | 81.78 81.77 | 85.50 85.41 |
Table C.10: 2-bit quantization for Skip-BERT 6 .
| # | Cost | LoRa (Y/N) | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|-----|----------|--------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|-----------------|
| 1 | | N | 51.8 | 83.8/83.7 | 90.2/85.8 | 90.6 | 88.2/91.3 | 70.4 | 93.2 | 88.7/88.3 | 82.14 | 85.94 |
| 2 | Budget-A | Y (DIM=1) | 51.4 | 83.7/84.2 | 90.3/85.8 | 90.5 | 88.2/91.3 | 70.8 | 93.5 | 88.9/88.5 | 82.23 | 86.09 |
| 3 | | Y (DIM=8) | 51.6 | 83.6/84.2 | 90.6/86.3 | 90.7 | 88.2/91.3 | 71.1 | 93.1 | 88.9/88.5 | 82.31 | 86.15 |
| 4 | | N | 52.7 | 83.8/84.5 | 90.0/85.3 | 90.3 | 88.4/91.4 | 72.6 | 93 | 89.0/88.6 | 82.51 | 86.24 |
| 5 | Budget-B | Y (DIM=1) | 53.6 | 83.6/83.9 | 90.5/86.0 | 90.2 | 88.4/91.4 | 71.1 | 93.2 | 88.9/88.5 | 82.43 | 86.04 |
| 6 | | Y (DIM=8) | 53.3 | 83.9/84.4 | 90.3/85.8 | 90.2 | 88.3/91.3 | 70.8 | 93 | 89.0/88.7 | 82.41 | 86.05 |
Table C.11: 1-bit quantization for Skip-BERT 6 .
| Training Cost | LoRa | learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|-----------------|---------|-----------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|-----------------|
| Budget-A | N | 5e-5 | 45.6 | 82.6/83.0 | 89.3/84.3 | 89.7 | 87.5/90.8 | 63.5 | 92.4 | 87.6/87.3 | 79.94 | 84.24 |
| Budget-A | N | 1e-4 | 47.9 | 82.9/83.2 | 89.4/84.6 | 89.4 | 87.8/90.9 | 64.3 | 92.4 | 88.0/87.6 | 80.4 | 84.46 |
| Budget-A | N | 5e-4 | 40.6 | 81.9/82.6 | 90.5/86.3 | 88.4 | 87.6/90.8 | 65.7 | 92.7 | 86.9/86.7 | 79.54 | 84.41 |
| Budget-A | N | Best (above) | 47.9 | 82.9/83.2 | 90.5/86.3 | 89.7 | 87.8/90.9 | 65.7 | 92.7 | 88.0/87.6 | 80.81 | 84.92 |
| Budget-A | (DIM=1) | 5e-5 | 46.9 | 82.9/83.2 | 88.9/83.6 | 89.6 | 87.6/90.8 | 63.2 | 92.4 | 87.7/87.4 | 80.03 | 84.18 |
| Budget-A | (DIM=1) | 1e-4 | 48.1 | 82.6/83.5 | 89.4/84.3 | 89.2 | 87.6/90.8 | 65.3 | 92.3 | 88.1/87.7 | 80.47 | 84.51 |
| Budget-A | (DIM=1) | 5e-4 | 39.3 | 82.1/82.8 | 89.2/84.3 | 88.6 | 87.5/90.7 | 65 | 92.2 | 87.0/86.8 | 79.11 | 84.09 |
| Budget-A | (DIM=1) | Best (above) | 48.1 | 82.9/83.2 | 89.4/84.3 | 89.6 | 87.6/90.8 | 65.3 | 92.4 | 88.1/87.7 | 80.52 | 84.58 |
| Budget-A | (DIM=8) | 5e-5 | 49.7 | 82.8/83.5 | 88.7/83.1 | 89.9 | 87.5/90.8 | 66.8 | 92.7 | 87.7/87.4 | 80.78 | 84.66 |
| Budget-A | (DIM=8) | 1e-4 | 49.6 | 83.4/83.6 | 89.8/85.0 | 89.4 | 87.6/90.8 | 65.7 | 92.8 | 87.8/87.5 | 80.9 | 84.81 |
| Budget-A | (DIM=8) | 5e-4 | 38.4 | 82.3/83.0 | 89.4/84.1 | 88.9 | 87.6/90.8 | 66.4 | 92 | 86.8/86.6 | 79.19 | 84.29 |
| Budget-A | (DIM=8) | Best (above) | 49.7 | 83.4/83.6 | 89.8/85.0 | 89.9 | 87.5/90.8 | 66.8 | 92.8 | 87.8/87.5 | 81.09 | 85.01 |
| Budget-B | N | 5e-5 | 50.3 | 83.1/83.7 | 89.2/84.1 | 89.3 | 87.9/91.0 | 66.8 | 92.7 | 88.2/88.0 | 81.02 | 84.86 |
| Budget-B | N | 1e-4 | 49.7 | 83.2/83.7 | 90.9/86.8 | 88.8 | 87.9/91.0 | 67.1 | 92.7 | 88.1/87.8 | 81.23 | 85.18 |
| Budget-B | N | 5e-4 | 45 | 81.9/81.9 | 89.1/84.3 | 88.1 | 87.4/90.7 | 66.1 | 92.5 | 85.9/85.7 | 79.6 | 83.92 |
| Budget-B | N | Best (above) | 50.3 | 83.2/83.7 | 90.9/86.8 | 89.3 | 87.9/91.0 | 67.1 | 92.7 | 88.2/88.0 | 81.37 | 85.25 |
| Budget-B | N | 5e-5 | 49.4 | 83.0/83.6 | 89.7/85.0 | 89.3 | 88.1/91.0 | 67.5 | 92.7 | 88.3/87.9 | 81.09 | 85.05 |
| Budget-B | (DIM=1) | 1e-4 | 49.9 | 83.3/83.8 | 90.5/86.0 | 88.8 | 88.0/91.1 | 67.1 | 92.4 | 88.2/87.9 | 81.18 | 85.09 |
| Budget-B | (DIM=1) | 5e-4 | 41.8 | 81.8/82.5 | 89.7/84.8 | 88 | 87.7/90.8 | 63.9 | 92.1 | 86.0/85.9 | 79.08 | 83.74 |
| Budget-B | (DIM=1) | Best (above) | 49.9 | 83.3/83.8 | 90.5/86.0 | 89.3 | 88.0/91.1 | 67.5 | 92.7 | 88.3/87.9 | 81.32 | 85.25 |
| Budget-B | (DIM=8) | 5e-5 | 50.9 | 83.2/83.7 | 90.3/85.8 | 89.4 | 87.9/91.0 | 69 | 92.8 | 88.3/88.0 | 81.57 | 85.4 |
| Budget-B | (DIM=8) | 1e-4 | 50.6 | 83.2/83.4 | 89.7/84.8 | 89.1 | 88.1/91.2 | 67.5 | 92.8 | 88.1/87.9 | 81.19 | 85.01 |
| Budget-B | (DIM=8) | 5e-4 | 41.7 | 82.2/82.8 | 89.2/84.1 | 88.6 | 87.7/90.8 | 65.3 | 92.1 | 86.0/85.7 | 79.29 | 83.99 |
| Budget-B | (DIM=8) | Best (above) | 50.9 | 83.2/83.7 | 90.3/85.8 | 89.4 | 88.1/91.2 | 69 | 92.8 | 88.3/88.0 | 81.59 | 85.42 |
| Budget-C | N | 5e-5 | 51.9 | 82.9/83.6 | 90.2/85.8 | 89.3 | 88.2/91.2 | 69 | 93.1 | 88.1/87.7 | 81.66 | 85.38 |
| Budget-C | N | 1e-4 | 50.3 | 83.1/83.6 | 90.5/86.0 | 88.9 | 87.9/91.0 | 67.9 | 92.7 | 87.6/87.4 | 81.23 | 85.1 |
| Budget-C | N | 5e-4 | 44.4 | 81.7/81.9 | 89.6/84.6 | 88.4 | 87.5/90.7 | 64.6 | 92.9 | 87.1/87.0 | 79.59 | 83.99 |
| Budget-C | N | Best (above) | 51.9 | 83.1/83.6 | 90.5/86.0 | 89.3 | 88.2/91.2 | 69 | 93.1 | 88.1/87.7 | 81.7 | 85.42 |
| Budget-C | (DIM=1) | 5e-5 | 52 | 83.2/83.8 | 89.8/86.0 | 89.4 | 87.9/91.0 | 69.3 | 93 | 88.2/88.0 | 81.77 | 85.49 |
| Budget-C | (DIM=1) | 1e-4 | 48.9 | 83.2/83.5 | 90.4/85.8 | 89.1 | 88.0/91.1 | 68.6 | 92.5 | 87.8/87.5 | 81.17 | 85.2 |
| Budget-C | (DIM=1) | 5e-4 | 42.5 | 81.8/82.3 | 89.5/84.6 | 88.4 | 87.6/90.7 | 65.7 | 92.5 | 87.1/86.8 | 79.51 | 84.14 |
| Budget-C | | Best (above) | 52 | 83.2/83.8 | 89.8/86.0 | 89.4 | 88.0/91.1 | 69.3 | 93 | 88.2/88.0 | 81.78 | 85.5 |
| Budget-C | (DIM=8) | 5e-5 | 52.6 | 83.3/83.8 | 89.9/85.5 | 89.2 | 88.1/91.1 | 69.3 | 92.8 | 88.2/87.9 | 81.76 | 85.4 |
| Budget-C | | 1e-4 | 50.2 | 83.0/83.8 | 89.9/85.5 | 89 | 88.2/91.2 | 69 | 92.7 | 87.9/87.6 | 81.37 | 85.26 |
| Budget-C | | 5e-4 | 43 | 82.1/82.5 | 90.2/85.5 | 88.7 | 87.5/90.7 | 67.5 | 92.4 | 87.2/86.9 | 79.96 | 84.58 |
| Budget-C | | Best (above) | 52.6 | 83.3/83.8 | 89.9/85.5 | 89.2 | 88.2/91.2 | 69.3 | 92.8 | 88.2/87.9 | 81.77 | 85.41 |
Table C.12: 2-bit quantization for Skip-BERT 6 with various learning rates.
| Training Cost | LoRa | learning rate | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|-----------------|---------|-----------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|-----------------|
| Budget-A | N | 5e-5 | 50.8 | 83.8/83.7 | 90.0/85.3 | 90.4 | 88.2/91.3 | 70.4 | 93.2 | 88.6/88.2 | 81.94 | 85.84 |
| Budget-A | N | 1e-4 | 51.8 | 83.6/84.2 | 90.2/85.8 | 90.6 | 88.2/91.3 | 70.4 | 92.9 | 88.7/88.3 | 82.14 | 85.94 |
| Budget-A | N | 5e-4 | 41.4 | 83.2/83.5 | 90.1/85.5 | 89.8 | 87.9/91.0 | 68.2 | 92.5 | 87.8/87.4 | 80.32 | 85.19 |
| Budget-A | N | Best (above) | 51.8 | 83.8/83.7 | 90.2/85.8 | 90.6 | 88.2/91.3 | 70.4 | 93.2 | 88.7/88.3 | 82.14 | 85.94 |
| Budget-A | (DIM=1) | 5e-5 | 51.4 | 83.7/84.2 | 90.3/85.8 | 90.5 | 88.2/91.3 | 70.8 | 93.5 | 88.8/88.4 | 82.22 | 86.07 |
| Budget-A | (DIM=1) | 1e-4 | 51.2 | 83.7/84.0 | 90.3/85.8 | 90.4 | 88.1/91.2 | 70.8 | 92.9 | 88.9/88.5 | 82.1 | 85.96 |
| Budget-A | | 5e-4 | 43.8 | 83.6/83.5 | 89.6/84.8 | 89.5 | 87.8/91.1 | 69.3 | 92.7 | 87.8/87.5 | 80.68 | 85.29 |
| Budget-A | | Best (above) | 51.4 | 83.7/84.2 | 90.3/85.8 | 90.5 | 88.2/91.3 | 70.8 | 93.5 | 88.9/88.5 | 82.23 | 86.09 |
| Budget-A | (DIM=8) | 5e-5 | 51.6 | 83.6/84.2 | 90.1/85.3 | 90.7 | 88.2/91.3 | 71.1 | 93 | 88.9/88.5 | 82.19 | 86.01 |
| Budget-A | (DIM=8) | 1e-4 | 51 | 83.6/84.1 | 90.6/86.3 | 90.3 | 88.3/91.3 | 71.1 | 93.1 | 88.8/88.5 | 82.18 | 86.08 |
| Budget-A | | 5e-4 | 43.8 | 83.3/83.7 | 89.3/84.1 | 89.8 | 88.1/91.2 | 69 | 92.2 | 88.0/87.7 | 80.57 | 85.16 |
| Budget-A | | Best (above) | 51.6 | 83.6/84.2 | 90.6/86.3 | 90.7 | 88.2/91.3 | 71.1 | 93.1 | 88.9/88.5 | 82.31 | 86.15 |
| | N | 5e-5 | 52.5 | 83.5/84.3 | 89.7/84.8 | 90.3 | 88.3/91.3 | 71.5 | 93 | 89.0/88.6 | 82.24 | 85.96 |
| | N | 1e-4 | 52.7 | 83.8/84.5 | 90.0/85.3 | 90.1 | 88.4/91.4 | 72.6 | 93 | 88.9/88.6 | 82.48 | 86.2 |
| | N | 5e-4 | 45.2 | 83.3/83.4 | 89.7/85.0 | 89.9 | 88.0/91.1 | 69 | 92.7 | 88.3/87.9 | 80.88 | 85.34 |
| | N | Best (above) | 52.7 | 83.8/84.5 | 90.0/85.3 | 90.3 | 88.4/91.4 | 72.6 | 93 | 89.0/88.6 | 82.51 | 86.24 |
| Budget-B | (DIM=1) | 5e-5 | 52.8 | 83.6/83.9 | 90.0/85.3 | 90.2 | 88.4/91.3 | 71.1 | 93.1 | 88.9/88.5 | 82.24 | 85.92 |
| Budget-B | (DIM=1) | 1e-4 | 53.6 | 83.6/83.8 | 90.5/86.0 | 89.9 | 88.4/91.4 | 71.1 | 93.2 | 88.8/88.4 | 82.38 | 85.98 |
| Budget-B | | 5e-4 | 46.1 | 83.1/83.9 | 89.7/85.0 | 89.7 | 88.0/91.1 | 68.2 | 92.9 | 88.1/87.9 | 80.9 | 85.25 |
| Budget-B | | Best (above) | 53.6 | 83.6/83.9 | 90.5/86.0 | 90.2 | 88.4/91.4 | 71.1 | 93.2 | 88.9/88.5 | 82.43 | 86.04 |
| Budget-B | (DIM=8) | 5e-5 | 53.3 | 83.9/84.4 | 89.8/85.0 | 90.2 | 88.3/91.3 | 70.8 | 93 | 88.9/88.5 | 82.31 | 85.94 |
| Budget-B | | 1e-4 | 53.1 | 83.9/84.0 | 90.3/85.8 | 90.1 | 88.4/91.3 | 70.8 | 92.9 | 89.0/88.7 | 82.32 | 85.98 |
| Budget-B | | 5e-4 | 48.7 | 83.2/83.5 | 89.7/85.5 | 90 | 88.3/91.3 | 70.4 | 92.8 | 88.0/87.7 | 81.49 | 85.59 |
| Budget-B | | Best (above) | 53.3 | 83.9/84.4 | 90.3/85.8 | 90.2 | 88.3/91.3 | 70.8 | 93 | 89.0/88.7 | 82.41 | 86.05 |
Table C.13: LoRa and quantization of five-/four-layer model.
| #- layer | #- bit | loRa Y/N | size (MB) | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. all | Avg. w/o CoLA |
|------------|----------|------------|-------------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|------------|-----------------|
| | 32 | | 228.2 ( × 1 . 8 ) | 56.7 | 84.2/84.8 | 90.1/85.5 | 91.4 | 88.3/91.4 | 72.2 | 93.2 | 89.2/88.8 | 83.18 | 86.49 |
| | 1 | N | 7.1 ( × 58 . 5 ) | 52.2 | 82.9/83.2 | 89.9/85.0 | 88.5 | 87.6/90.8 | 69.3 | 92.9 | 87.3/87.0 | 81.34 | 84.99 |
| Five | | Y | 7.3 ( × 57 . 4 ) | 51.8 | 81.8/81.9 | 90.2/85.5 | 88.6 | 87.1/90.3 | 68.6 | 92.8 | 87.5/87.2 | 80.98 | 84.62 |
| | 2 | N | 14.2 ( × 29 . 3 ) | 53.9 | 83.3/84.1 | 90.4/86.0 | 90.4 | 88.2/91.2 | 71.8 | 93 | 88.4/88.0 | 82.46 | 86.02 |
| | | Y | 14.6 ( × 28 . 7 ) | 54.2 | 83.5/83.9 | 90.4/86.0 | 90 | 88.0/91.1 | 72.9 | 93.1 | 88.5/88.1 | 82.58 | 86.12 |
| | 32 | | 201.2 ( × 2 . 1 ) | 52.2 | 83.2/83.4 | 90.0/85.3 | 90.7 | 88.2/91.3 | 70 | 93.5 | 88.6/88.3 | 82.02 | 85.75 |
| | 1 | N | 6.3 ( × 66 . 4 ) | 48.3 | 82.0/82.3 | 89.9/85.5 | 87.7 | 86.9/90.4 | 63.9 | 92.4 | 87.1/86.7 | 79.96 | 83.91 |
| Four | | Y | 6.4 ( × 65 . 2 ) | 48.5 | 81.5/80.8 | 89.8/85.3 | 87.6 | 86.9/90.3 | 64.3 | 92.8 | 87.0/86.7 | 79.79 | 83.7 |
| | 2 | N | 12.6 ( × 33 . 2 ) | 50.3 | 82.5/83.0 | 90.0/85.3 | 89.2 | 87.8/91.0 | 69 | 92.8 | 87.9/87.4 | 81.22 | 85.09 |
| | | Y | 12.8 ( × 32 . 6 ) | 49.8 | 82.8/82.6 | 90.1/85.5 | 89.1 | 87.8/91.0 | 68.6 | 92.9 | 87.9/87.5 | 81.13 | 85.05 |
Table C.14: More quantization of five-/four-layer model.
| # | Model | size | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. | Avg. w/o CoLA |
|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|---------------------------------------------|
| 1 | 1-bit SkipBERT 5 | 7.1 ( × 58 . 5 ) | 52.2 | 82.9/83.2 | 89.9/85.0 | 88.5 | 87.6/90.8 | 69.3 | 92.9 | 87.3/87.0 | 81.34 | 84.99 |
| Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage |
| 2 | 1-bit | 7.1 ( × 58 . 5 ) | 52.8 | 83.0/83.4 | 89.8/84.8 | 89.6 | 87.8/91.0 | 69.3 | 93.2 | 87.6/87.3 | 81.63 | 85.24 |
| 3 | 1-bit+LoRa1 | 7.3 ( × 57 . 4 ) | 53.0 | 83.0/83.5 | 89.5/84.6 | 89.6 | 87.9/91.0 | 69.3 | 93.2 | 87.6/87.3 | 81.64 | 85.23 |
| 4 | 2-bit SkipBERT 5 | 14.2 ( × 29 . 3 ) | 53.9 | 83.3/84.1 | 90.4/86.0 | 90.4 | 88.2/91.2 | 71.8 | 93.0 | 88.4/88.0 | 82.46 | 86.02 |
| Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage |
| 5 | 1-bit | 7.1 ( × 58 . 5 ) | 49.7 | 82.4/83.0 | 89.9/85.3 | 88.2 | 87.8/90.9 | 66.8 | 92.7 | 86.4/86.1 | 80.60 | 84.46 |
| 6 | 1-bit+LoRa1 | 7.3 ( × 57 . 4 ) | 48.6 | 82.6/83.1 | 89.9/85.0 | 88.2 | 87.7/90.8 | 66.4 | 92.9 | 86.5/86.2 | 80.46 | 84.44 |
| 7 | 1-bit SkipBERT 4 | 6.3 ( × 66 . 4 ) | 48.3 | 82.0/82.3 | 89.9/85.5 | 87.7 | 86.9/90.4 | 63.9 | 92.4 | 87.1/86.7 | 79.96 | 83.91 |
| Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage |
| 8 | 1-bit | 6.3 ( × 66 . 4 ) | 49.8 | 82.4/82.3 | 89.5/84.8 | 88.4 | 87.6/90.8 | 63.5 | 92.9 | 87.2/86.9 | 80.23 | 84.04 |
| 9 | 1-bit+LoRa1 | 6.4 ( × 65 . 2 ) | 49.6 | 82.4/82.1 | 89.6/85.0 | 88.5 | 87.5/90.8 | 63.5 | 93.1 | 87.2/86.9 | 80.24 | 84.08 |
| 10 | 2-bit SkipBERT 4 | 12.6 ( × 33 . 2 ) | 50.3 | 82.5/83.0 | 90.0/85.3 | 89.2 | 87.8/91.0 | 69.0 | 92.8 | 87.9/87.4 | 81.22 | 85.09 |
| Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage | Continue with above using another one-stage |
| 11 | 1-bit | 6.3 ( × 66 . 4 ) | 46.2 | 81.8/82.0 | 89.1/84.6 | 87.2 | 87.3/90.6 | 63.2 | 92.5 | 85.7/85.4 | 79.31 | 83.45 |
| 12 | 1-bit+LoRa1 | 6.4 ( × 65 . 2 ) | 47.9 | 81.4/82.0 | 89.4/85.0 | 87.1 | 87.4/90.6 | 64.3 | 92.9 | 85.7/85.4 | 79.66 | 83.63 |
Table C.15: Compare between teachers: a twelve-layer BERT base vs a six-layer SkipBERT 6 .
| #- bit | LoRa (Size) Y/N (MB) | Teacher | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. w/o CoLA |
|------------|-----------------------------------------------|-----------------------------------------------|------------|----------------------|---------------------|------------|---------------------|-----------|-------------|---------------------|-------------------|
| 1-bit | N (8.0MB) BERT base Skip-BERT Difference BERT | N (8.0MB) BERT base Skip-BERT Difference BERT | +0.3 | +0.2/+0.3 | 90.0/85.3 89.7/85.0 | 89.4 89.3 | 87.9/91.1 87.7/91.0 | 68.6 67.5 | 93.1 | 88.4/88.0 | 85.39 85.08 +0.31 |
| 1-bit | | | 52.3 52.0 | 83.4/83.8 83.2/83.5 | | | | | 93.2 | 87.9/87.6 | |
| 1-bit | | 6 base | 52.1 | 83.3/84.0 | +0.3/+0.3 89.9/85.5 | +0.1 89.5 | +0.2/+0.1 88.0/91.1 | +1.1 68.2 | -0.1 93.0 | +0.5/+0.4 88.5/88.1 | 85.39 |
| 1-bit | Y (8.1MB) | Skip-BERT 6 | 52.4 | 83.2/83.5 | 90.4/85.8 | 89.1 | 87.8/91.0 | 68.2 | 93.1 | 87.9/87.6 | 85.22 |
| 1-bit | Difference | Difference | -0.3 | +0.1/+0.5 | -0.5/-0.3 | +0.1 | +0.2/+0.1 | 0.0 | -0.1 | +0.6/+0.5 | +0.17 |
| 2-bit | N (16.0MB) | BERT base | 53.8 | 83.6/84.2 | 90.5/86.3 | 90.6 | 88.2/91.3 | 73.6 | 93.6 | 89.0/88.7 | 86.53 |
| 2-bit | | Skip-BERT 6 | 54.5 | 83.7/83.8 | 90.5/86.0 | 90.3 | 88.1/91.2 | 71.5 | 93.3 | 88.8/88.4 | 86.07 |
| 2-bit | Difference | Difference | -0.7 | -0.1/+0.4 | +0.0/+0.3 | +0.3 | +0.1/+0.1 | +2.1 | +0.3 | +0.2/+0.3 | +0.46 |
| 2-bit | Y (16.2MB) | BERT base | 55.2 | 83.7/84.4 | 90.3/86.0 | 90.5 | 88.2/91.3 | 71.8 | 93.2 | 89.0/88.6 | 86.24 |
| 2-bit | | Skip-BERT 6 | 54.3 | 83.7/83.8 | 90.4/86.0 | 90.4 | 88.0/91.2 | 72.6 | 93.2 | 88.9/88.5 | 86.22 |
| Difference | Difference | Difference | -0.9 | 0.0/+0.6 | -0.1/+0.0 | +0.1 | +0.2/+0.1 | -0.8 | +0.0 | +0.1/+0.1 | +0.02 |
Table C.16: 1-bit quantization with various random seeds (learning rate here all set to be 2e-5).
| Model Cost | KD #-Stage | Random seed | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. |
|---------------------|--------------|----------------------|------------|-----------------------|-----------------------|------------|-----------------------|-----------|-------------|------------------------|-------------|
| TinyBERT 6 Budget-B | fp32 | fp32 | 54.2 | 84.25/84.38 | 89.85/85.05 | 91.3 | 88.49/91.45 | 70.8 | 93.1 | 89.18/88.79 | 82.64 |
| TinyBERT 6 Budget-B | | 42 | 50.5 | 82.72/82.95 | 89.08/84.07 | 89.3 | 87.72/90.82 | 65.0 | 92.7 | 87.93/87.64 | 80.66 |
| TinyBERT 6 Budget-B | | 111 | 49.6 | 82.75/83.15 | 89.04/84.07 | 89.4 | 87.8/90.97 | 65.0 | 92.4 | 87.95/87.75 | 80.59 |
| TinyBERT 6 Budget-B | One | 222 | 48.4 | 82.72/83.08 | 89.11/84.07 | 89.4 | 87.61/90.84 | 64.6 | 92.7 | 88.14/87.75 | 80.43 |
| TinyBERT 6 Budget-B | | Ave. above | 49.5 | 82.73/83.06 | 89.08/84.07 | 89.4 | 87.71/90.88 | 64.9 | 92.6 | 88.01/87.71 | 80.56 |
| TinyBERT 6 Budget-B | | std above | 0.9 | 0.01/0.08 | 0.03/0 | 0.0 | 0.08/0.07 | 0.2 | 0.1 | 0.09/0.05 | 0.09 |
| TinyBERT 6 Budget-B | | 42 | 48.8 | 82.58/82.81 | 88.74/83.58 | 89.2 | 87.75/90.87 | 65.0 | 92.4 | 88.2/87.82 | 80.37 |
| TinyBERT 6 Budget-B | | 111 | 48.9 | 82.84/83.31 | 88.93/83.82 | 89.0 | 87.72/90.87 | 64.3 | 92.7 | 88.4/88.06 | 80.45 |
| TinyBERT 6 Budget-B | Two | 222 | 48.6 | 82.72/83.27 | 89.56/84.8 | 88.9 | 87.68/90.89 | 65.7 | 92.6 92.6 | 88.2/87.87 88.27/87.92 | 80.62 80.48 |
| TinyBERT 6 Budget-B | | Ave. above std above | 48.8 0.1 | 82.71/83.13 0.11/0.23 | 89.08/84.07 0.35/0.53 | 89.0 0.1 | 87.72/90.88 0.03/0.01 | 65.0 0.6 | 0.1 | 0.09/0.1 89.56/89.19 | 0.10 82.67 |
| MiniLM 6 Budget-B | fp32 | fp32 | 54.0 | 84.42/84.58 | 89.13/85.29 | 91.3 | 88.53/91.46 | 70.4 | 93.0 | | |
| MiniLM 6 Budget-B | | 42 | 48.2 | 83.03/83.24 | 88.47/83.33 | 89.2 | 87.85/90.87 | 64.3 | 92.6 | 88.37/88.06 | 80.34 |
| MiniLM 6 Budget-B | | 111 | 47.7 | 83.2/83.42 | 88.56/82.84 | 89.4 | 87.76/90.9 | 65.3 | 92.6 | 88.48/88.17 | 80.43 |
| MiniLM 6 Budget-B | Three | 222 | 47.2 | 83.36/83.44 | 89.04/83.82 | 89.4 | 87.88/90.97 | 64.6 | 92.6 | 88.57/88.23 | 80.43 |
| MiniLM 6 Budget-B | | Ave. above | 47.7 | 83.2/83.37 | 88.69/83.33 | 89.3 | 87.83/90.91 | 64.7 | 92.6 | 88.47/88.15 | 80.40 |
| MiniLM 6 Budget-B | | std above | 0.4 | 0.13/0.09 | 0.25/0.4 | 0.1 | 0.05/0.04 | 0.5 | 0.0 | 0.08/0.07 | 0.04 |
| SkipBERT 6 Budget-B | fp32 | fp32 | 56.1 | 84.37/84.53 | 90.52/86.03 | 91.6 | 88.34/91.42 | 73.7 | 93.5 | 89.3/88.92 | 83.39 |
| SkipBERT 6 Budget-B | | 42 | 51.1 | 82.79/83.59 | 89.95/85.05 | 89.4 | 88.01/91.07 | 67.5 | 92.9 | 88.09/87.73 | 81.28 |
| SkipBERT 6 Budget-B | | 111 | 50.7 | 82.96/83.2 | 90.02/85.54 | 89.4 | 87.96/91.04 | 67.9 | 92.9 | 88.35/87.99 | 81.32 |
| SkipBERT 6 Budget-B | Three | 222 | 51.8 | 83.02/83.58 | 90.54/86.27 | 89.4 | 87.91/91 | 67.2 | 92.6 | 88.23/87.98 | 81.43 |
| SkipBERT 6 Budget-B | | Ave. above | 51.2 | 82.92/83.46 | 90.17/85.62 | 89.4 | 87.96/91.04 | 67.5 | 92.8 | 88.22/87.9 | 81.35 |
| SkipBERT 6 Budget-B | std above | std above | 0.4 | 0.1/0.18 | 0.26/0.5 | 0.0 | 0.04/0.03 | 0.3 | 0.2 | 0.11/0.12 | 0.06 |
Table C.17: 2-bit quantization with various random seeds (learning rate here all set to be 2e-5).
| Model Cost | KD #-Stage | Random seed | CoLA Mcc | MNLI-m/-mm Acc/Acc | MRPC F1/Acc | QNLI Acc | QQP F1/Acc | RTE Acc | SST-2 Acc | STS-B Pear/Spea | Avg. |
|---------------------|--------------|---------------|------------|----------------------|---------------|------------|--------------|-----------|-------------|-------------------|--------|
| SkipBERT 6 Budget-B | Three | 42 | 53.2 | 83.67/83.79 | 91.25/87.25 | 90.4 | 88.42/91.4 | 72.2 | 93.6 | 88.77/88.36 | 82.7 |
| SkipBERT 6 Budget-B | Three | 111 | 53.3 | 83.63/83.59 | 90.91/86.76 | 90.4 | 88.32/91.38 | 72.2 | 93.5 | 88.65/88.32 | 82.6 |
| SkipBERT 6 Budget-B | Three | 222 | 54.1 | 83.65/84.27 | 90.82/86.52 | 90.6 | 88.29/91.4 | 71.5 | 93.6 | 88.69/88.38 | 82.7 |
| SkipBERT 6 Budget-B | Three | Ave. above | 53.6 | 83.65/83.88 | 90.99/86.84 | 90.4 | 88.34/91.39 | 72 | 93.5 | 88.7/88.35 | 82.66 |
| SkipBERT 6 Budget-B | Three | std above | 0.4 | 0.02/0.29 | 0.19/0.3 | 0.1 | 0.06/0.01 | 0.3 | 0.1 | 0.05/0.02 | 0.05 |