## Federated and Transfer Learning: A Survey on Adversaries and Defense Mechanisms
Ehsan Hallaji, Roozbeh Razavi-Far and Mehrdad Saif
Abstract The advent of federated learning has facilitated large-scale data exchange amongst machine learning models while maintaining privacy. Despite its brief history, federated learning is rapidly evolving to make wider use more practical. One of the most significant advancements in this domain is the incorporation of transfer learning into federated learning, which overcomes fundamental constraints of primary federated learning, particularly in terms of security. This chapter performs a comprehensive survey on the intersection of federated and transfer learning from a security point of view. The main goal of this study is to uncover potential vulnerabilities and defense mechanisms that might compromise the privacy and performance of systems that use federated and transfer learning.
## 1 Introduction
Machine learning has exploded in popularity as the information era has matured. As a sub-discipline of machine learning, deep learning (DL) is responsible for a number of achievements that have helped popularise the area. The hierarchical feature extraction within the DL models enables them to learn complex underlying patterns in the observed input space. This makes DL models suitable for processing various data types and facilitating different tasks such as prediction [47], detection
Ehsan Hallaji
Department of Electrical and Computer Engineering, University of Windsor, 401 Sunset Avenue, Windsor, ON N9B 3P4, Canada, e-mail: hallaji@uwindsor.ca
Roozbeh Razavi-Far
Department of Electrical and Computer Engineering and School of Computer Science, University of Windsor, 401 Sunset Avenue, Windsor, ON N9B 3P4, Canada, e-mail: roozbeh@uwindsor.ca
Mehrdad Saif
Department of Electrical and Computer Engineering, University of Windsor, 401 Sunset Avenue, Windsor, ON N9B 3P4, Canada, e-mail: msaif@uwindsor.ca
[93], imputation [43], and data reduction [46]. Although the success of DL-based projects is contingent on several factors, one of the most important requirements is usually to have access to abundant training samples.
With the advancement of technologies such as internet of things and increasing number of intelligent devices, the diversity and volume of generated data is growing at an astonishing pace [88]. This abundant data stream is dispersed and diverse in character. When this data is evaluated as a whole, it may provide knowledge and discoveries that might possibly accelerate technological and scientific advancements. Nonetheless, the privacy hazards associated with data ownership are increasingly becoming a major problem. The conflict between user privacy and high-quality services is driving need for new technologies and research to enable knowledge extraction from data without jeopardising data-holding parties' privacy.
Federated learning (FL) is perhaps the most recent approach presented to potentially resolve this issue. FL allows for the collaborative training of a DL model across a network of client devices. This multi-party collaboration is accomplished by communication with a central server and decentralisation of training data [71]. In other words, the FL design requires that the training data be retained on the client, or local device, that generated or recorded it. FL's data decentralisation addresses a significant portion of data and user privacy concerns, since model training at the network's edge eliminates the need for direct data sharing. Nevertheless, in FL systems one should strike a balance between data privacy and model performance. The appropriate balance is determined by a number of criteria, including the model architecture, data type, and intended application. Beyond FL restrictions, ensuring the confidentiality and security of the FL infrastructure is critical for establishing trust amongst diverse clients of the federated network.
The conventional FL imposes a constraint by requiring customers' training data to use similar attributes. However, most industries such as banking and healthcare do not comply with this assumption. In centralized machine learning, this was addressed by Transfer Learning (TL), which enables a model obtained from a specific domain to be used in other domains of with the same application [93]. Inspired by this, Federated TL (FTL) emerged as a way to overcome this constraint [64]. FTL clients may differ in the employed attributes, which is more practical for industrial application. TL effectiveness is heavily reliant on inter-domain interactions. It is worthwhile to mention that organizations joined in a FTL network are often comparable in the service they provide and the data they use. As a result, including TL within the FL architecture can be quite advantageous.
FTL is at the crossroads of two distinct and rapidly expanding research areas of privacy-preserving and distributed machine learning. For this reason, it is crucial to investigate more on these two topics to make best use of FTL. Hence, this chapter studies different security and privacy aspects of FTL.
Information privacy and machine learning are distinct and rapidly expanding research areas that derive FTL, and, thus, going through their connections to FTL is necessary. Understanding the interplay between TL and FL, as well as identifying potential risks to FTL in real-world applications, is crucial. Knowing compatible diffense mechanisms with FTL is also vital for mitigating potential cyber-threats.
Hence, in this chapter, we present a comprehensive survey on possible threats to FTL and the available defense mechanisms.
The rest of the chapter is organized as follows. The preliminaries of this survey are explained in Section 2. Section 3 reviews known attack scenarios on FL and TL w.r.t. performance and privacy. Section 4 presents tools and defense mechanisms that are undertook in the literature for mitigating threats to FL and TL. Section 5 explains the future directions in defending FTL. Finally, Chapter 6 concludes the conducted survey.
## 2 Background
This chapter concisely reviews preliminaries of federated and transfer learning to facilitate the discussions in the following sections.
## 2.1 Federated Learning
FL paradigm allows for collaborative model training across several participants (i.e., also referred to as clients or devices). This multi-party collaboration is accomplished by communication with a central server and decentralization of training data [71]. Data decentralization of FL mitigates a major part of user privacy issues. Moreover, the efficiency of FL reduces the communication overhead in the network. FL can be categorizes from different perspectives, as explained in the following.
## 2.1.1 Categories of Federated Learning
FLvariations generally fall under three categories depending on the portion of feature and sample space they share [114]:
1. Horizontal Federated Learning: Participants exchange data with comparable properties captured from various users [55]. For instance, clinical information of various patients is recorded using the same features across several hospitals. Therefore, similar deep learning structures can be trained on these datasets since they all process the same number and types of features.
2. Vertical Federated Learning: The vertical variation is utilized in applications where participant datasets have considerable overlaps in the sample space but each has a separate set of attributes [104].
3. Federated Transfer Learning: FTL facilitates knowledge transfer between participants when the overlap between sample and feature space is minimal [64]. FTL is discussed in further detail later in this section.
## 2.2 Transfer Learning
Most machine learning approaches work on the premise that the training and test data are in the same feature space. In industry, data may be hard to collect in certain applications, and, thus, there is a preference for using the available data shared by large companies and organizations. The challenge, however, is the difference between the data distributions despite the similarity of the applications. In other words, the ideal model needs to model from one domain with limited data resources, while abundant training data is available in another domain. For instance, consider a factory that trained a model to predict the market demand to adjust it production rate for different items. However, it may be time consuming to obtain enough samples for each produced item separately. Instead, TL can enable the model to be trained on the data of other organizations that produce similar products, albeit samples may not be recorded using the same features. The past decade has witnessed an increasing attraction towards research on TL, which resulted in proposing different variations TL under different names [78].
## 2.3 Federated Transfer Learning
Similar to TL, clients of FTL may not use the same attributes in the training data. This is mostly the case in organizations that are similar in nature but are not identical [92]. Due to such differences, these organizations share only a small portion of each other's feature space. Therefore, under this condition, both samples and features are different in the dataset. Note that the considered condition in FTL is in contrast to the other variants of FL.
FTL takes a model that has been constructed on source data, and then aligns it to be employed in a target domain. This allows the model to be utilized for uncorrelated data points while exploiting the information gained from non-overlapping features in the source domain. As a result, FTL transmits information from the source domain's non-overlapping attributes to new samples within the target domain.
Existing literature on FTL mainly studies the customization of FTL for certain applications [20, 113]. From a learning stand-point, only a limited number of works present distinct FTL protocols. A secure FTL framework is proposed in [64] that uses secret sharing and homomorphic encrypton to protect privacy without sacrificing accuracy, which is a typical issue in privacy-preserving techniques. Other benefits of this method include the simplicity of homomorphic encryption and the fact that secret sharing ensures zero accuracy loss and quick processing time. On the other had, Homomorphic encryption, imposes significant computing overhead, and secret sharing necessitated offline operations prior to online computation. A following research [98] tackles the computation overhead of previous protocols and extends the FTL model beyond the semi-honset setting by taking malicious users into count as well. The authors use secret-sharing in the designed algorithm to enhance the security and efficiency of multi-party communications in FTL. An scalable heterogeneous
FTLframeworkisalsopresentedin[36], which uses secret sharing and homomorphic encryption.
## 3 Threats to Federated Learning
Threats to FL and TL often compromise the functionality or privacy of the system. Table 1 lists the sources of threats for common attacks to FL. FL enables a distributed learning process without requiring data exchange, allowing members to freely join and exit federations. Recent research has shown, however, that resilience of FL against the mentioned threats in Table 1 can be questionable.
Existing FL protocol designs are vulnerable to rough servers and adversarial parties. While both infer confidential information from participants' updates, the former mainly tampers with the model training whereas the latter resorts to poisoning attacks to deviate the aggregation procedure.
During the training process, communicating model updates might divulge critical information and lead to deep leakage. This can consequently jeopardize the privacy of local data or lead to high-jacking the training data [118]. The robustness of FL systems, on the other hand, can be degraded using poisoning attacks on the model to corrupt the model or training data [107, 8, 13]. In turn, these attacks lead to planting a backdoor into the global model or degrade its convergence.
## 3.1 Threat Models
Attacks on FL can be launched in different fashions [68, 69]. To have a better grasp of the nature of FL attacks, we will first go through the most frequent threat models in the following:
Table 1 Identification of sources of attacks on FL systems.
| Attacks | Source of Attack |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Data poisoning Model poisoning Backdoor attack Evasion attack Non-robust aggregation Training rule manipulation Inference attacks GAN reconstruction Free-riding attack Man-in-the-middle attack | Malicious client Malicious client Malicious client and malicious server Malicious client and model deployment Aggregation algorithm Malicious client Malicious server and communication Malicious server and communication Malicious client Communication |
- Outsider Adversaries include attacks by eavesdroppers on the line of communication between clients and the FL server, as well as attacks by clients of the FL model once it is provided as a service.
- Semi-HonestAdversaries are non-aggressive adversaries that attempt to discover the hidden states of other users while being honest to the FL protocol. Only the received information such as the global model's parameters is visible to the attackers.
- Insider Adversaries involve attacks initiated from the server or the edge of the network. Byzantine [15] and Sybil [35] attacks can be mentioned as two most important insider attacks.
- Training Manipulation is the process of learning, affecting, or distorting the FL model itself [14]. The attacker can damage the integrity of the learning process by attacking the training data or the model during the training phase [13].
- Inference Manipulation mainly consists of evasion or inference attacks [10]. They usually deceive the model into making incorrect decisions or gather information regarding the model's properties. These opponents' efficacy is determined by the amount of knowledge given to the attacker, which classifies them into white-box and black-box variations.
## 3.2 Attacks on Performance
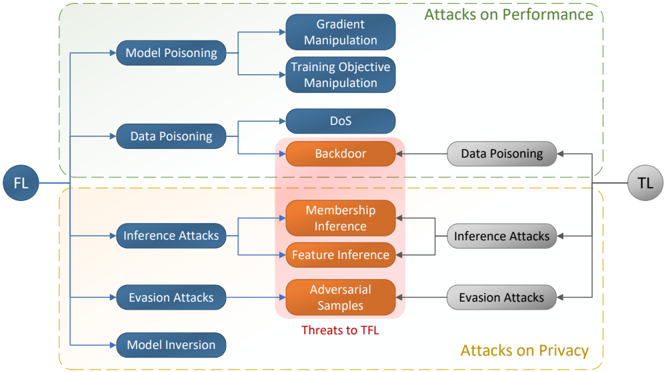
Figure 1 shows the taxonomy of attacks on FL and TL. The common threats between FL and TL that can jeopardize FTL are also specified within the red area.
Fig. 1 Taxonomy of the attacks on Federated and Transfer Learning. The common threats between FL and TL are specified in red area.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Attacks on Federated Learning and Transfer Learning
### Overview
This diagram illustrates the various attack vectors targeting Federated Learning (FL) and Transfer Learning (TL) systems. The diagram is structured with "FL" on the left and "TL" on the right, representing the flow of potential attacks. Attacks are categorized into three main groups: Attacks on Performance (top), Attacks on Privacy (bottom), and Threats to Transfer Learning (center). The diagram uses a flowchart-like structure with boxes representing attack types and arrows indicating potential attack paths.
### Components/Axes
The diagram consists of the following components:
* **FL:** Located in the top-left corner, representing Federated Learning.
* **TL:** Located in the top-right corner, representing Transfer Learning.
* **Attacks on Performance:** A header at the top, indicating the category of attacks affecting model performance.
* **Attacks on Privacy:** A header at the bottom, indicating the category of attacks affecting data privacy.
* **Threats to TFL:** A header in the center, indicating the category of attacks specific to Transfer Federated Learning.
* **Attack Boxes:** Rectangular boxes containing the names of specific attack types. These are color-coded: blue for attacks on performance and privacy, orange for threats to TFL, and pink for attacks that bridge both performance and privacy.
* **Arrows:** Lines connecting the attack boxes, indicating the flow or relationship between attacks.
### Detailed Analysis or Content Details
The diagram details the following attacks:
**Attacks on Performance (Top)**
* **Model Poisoning:** Connected to Gradient Manipulation and Training Objective Manipulation.
* **Gradient Manipulation:** Receives input from Model Poisoning.
* **Training Objective Manipulation:** Receives input from Model Poisoning.
* **Data Poisoning:** Connected to DoS and Backdoor.
* **DoS (Denial of Service):** Receives input from Data Poisoning.
* **Backdoor:** Receives input from Data Poisoning, and also connects to Data Poisoning on the TL side.
**Attacks on Privacy (Bottom)**
* **Inference Attacks:** Connected to Membership Inference and Feature Inference.
* **Membership Inference:** Receives input from Inference Attacks, and also connects to Feature Inference.
* **Feature Inference:** Receives input from Inference Attacks and Membership Inference.
* **Evasion Attacks:** Connected to Adversarial Samples.
* **Adversarial Samples:** Receives input from Evasion Attacks, and also connects to Evasion Attacks on the TL side.
* **Model Inversion:** No direct connections shown.
**Threats to TFL (Center)**
* **Membership Inference:** Bridging attacks on performance and privacy.
* **Feature Inference:** Bridging attacks on performance and privacy.
* **Adversarial Samples:** Bridging attacks on performance and privacy.
The diagram shows a flow from FL to TL, with attacks originating on the FL side potentially impacting the TL side. Data Poisoning and Evasion Attacks have direct connections to their counterparts on the TL side. The pink boxes (Membership Inference, Feature Inference, and Adversarial Samples) represent attacks that simultaneously threaten both performance and privacy.
### Key Observations
* The diagram highlights the interconnectedness of different attack types. For example, Model Poisoning can lead to both Gradient Manipulation and Training Objective Manipulation.
* The central "Threats to TFL" section emphasizes the unique vulnerabilities introduced when combining Federated Learning and Transfer Learning.
* The color-coding effectively distinguishes between different categories of attacks.
* The diagram does not provide any quantitative data or specific metrics related to the severity or likelihood of these attacks.
### Interpretation
The diagram illustrates the complex security landscape of Federated Learning and Transfer Learning. It demonstrates that these systems are vulnerable to a wide range of attacks, spanning both performance and privacy concerns. The flow from FL to TL suggests that vulnerabilities in the federated learning process can propagate to the transfer learning stage. The diagram serves as a valuable tool for researchers and practitioners to understand the potential threats and develop appropriate mitigation strategies. The inclusion of "Threats to TFL" highlights the need for specialized security measures when deploying these combined techniques. The diagram is a conceptual overview and does not provide details on the specific mechanisms or implementations of these attacks. It is a high-level representation of the attack surface, intended to raise awareness and guide further investigation.
</details>
## 3.2.1 Data Poisoning
Poisoning training data in FL often affect the integrity of the training data, compromising model performance by injecting a backdoor for particular triggers during inference and degrading the overall model accuracy. The most common types of data poisoning attacks are as follows:
- Denial-of-Service (DoS) attacks generally attempt to minimize the target overall performance, impacting the recognition rate of all classes. In a FL system, label noise in the training data may be induced to create a poisoned model that cannot accurately predict any of the classes. This is also referred to as label flipping [54] in the literature. When the parameters of this model are sent to the server, the performance of other devices diminishes.
- Backdoor attacks are designed to impose intentional and particular false predictions for specific data patterns. [54]. Backdoor attacks, unlike DoS attacks, only influence the model's recognition ability for a specific group of samples or classes.
## 3.2.2 Model Poisoning
Poisoning a model refers to a wide range of techniques for tampering with the FL training procedure. It is worth mentioning that in some literature data poisoning is categorized as a type of model poisoning [52]. However, here, we mainly target gradient and learning objective manipulation when referring to model poisoning.
- Gradient Manipulation: Local model gradients may be manipulated by adversaries to degrade overall performance of the central model, for example, by lowering detection accuracy [54]. For instance, this approach is used to inject hidden global model backdoors [8].
- Training Objective Manipulation: involve manipulating model training rules [54]. Training rule manipulation, for example, is used to successfully carry out a covert poisoning operation by appending a deviating term to the loss function to penalize the difference of benign and malicious updates [13].
## 3.3 Attacks on Privacy
## 3.3.1 Model Inversion Attacks
It has been demonstrated that model inversion attacks can successfully define sensitive characteristics of the classes and instances covered by the model [54, 52]. [32] states that using these attacks in a white-box setting on decision trees enables reveal sensitive variables such as survey responses, which may be identified with no false
positives. Another study demonstrates that a hacker may anticipate genetic data of a person simply using their demographic information [54].
## 3.3.2 Membership Inference Attacks
Membership inference aims at disclosing the membership of a particular sample to the training dataset or a certain class. Furthermore, this form of attack can work even if the objective is unrelated to the basic characteristics of the class [72].
## 3.3.3 GAN Reconstruction Attacks
Model inversion is similar to GAN reconstruction; however, the latter is substantially more potent and have been demonstrated to create artificial samples that statistically resemble of the training data [48]. Traditional model inversion approaches utterly fail when attacking more sophisticated DL architectures, whereas GAN reconstruction attacks may effectively create desirable outputs. It has been shown that even with the presence of differential privacy, GAN may be able to reach the objective. As a result, an adversary may be able to persuade benign clients to mistakenly commit gradient modifications that leak more confidential details than planned during collaborative learning [48].
## 4 Threats to Transfer Learning
## 4.1 Backdoor Attacks
Plenty of the pre-trained Teacher models ( T ) employed for TL are openly available, making them vulnerable to backdoor attacks [108, 116]. In a white-box setup, the intruder has access to T , as is prevalent in modern applications. The intruder intends to cause a erroneous decision making for a Student model ( S ) that has been calibrated via TL using a publicly available pre-trained T model.
Theattacker may breach the publicly accessible pre-trained T modelprior to the S system deployment phase. Because the regulations of third-party platforms that store diverse T models are often inadequate, the platforms contain multiple variations of the same pre-trained neural networks. Since weights of a neural network are not selfexplanatory, distinguishing damaging models from refined models is complicated, if not impossible. In this situation, we suppose that the intruder is familiar with the structure and parameters of the T and has black-box access to S , but is unaware of the specific T who trained this model and which layers were fixed for training S [106].
Adversaries might potentially get around the fine-tuning technique by leveraging openly accessible pre-trained T models to construct S models. The S models must
be optimized using particular T models, in which a portion of the T structure must be incorporated and retrained frequently. In a white-box setting, we presume the intruder knows the certain T that trained S and which layers were unchanged throughout the S training. The adversary, in particular, has access to the architecture and weights of the S model and may change them.
## 4.2 Adversarial Attacks
In contrast to conventional adversarial attacks, which optimize false data to be mistaken for benign samples, the central notion of adversarial attacks against TL is to optimize a data matrix to imitate the intrinsic representation of the target data. Models transferred by re-learning the last linear layer have recently been shown to be sensitive to adversarial instances produced exclusively using a pre-trained model [89]. It has been demonstrated that such an attack can fool models that have been transported with end-to-end fine-tuning [21]. This discovery raises questions about the security of the extensively employed fine-tuning approach.
## 4.3 Inference Attacks
An inference attack resorts to data analysis to gather unauthorized information about a subject or database. If an attacker can confidently estimate the true worth of a subject's confidential information, it can be termed as leaked. The most frequent variants of this approach are membership inference and attribute inference.
## 4.3.1 Membership Inference
The goal of membership inference in machine learning is to establish whether a sample was employed to train the target model. Discovering the membership status of a particular user data might lead to serious information theft [119]. For instance, revealing that a patient's medical records were utilized to train a model linked with an illness might disclose that the patient has the condition.
In contrast with conventional machine learning, there are two attack surfaces for membership inference in TL setting, that is discovering the membership status of samples for both S and T models. Furthermore, depending on the abilities of certain adversaries, access to either the T or S model may be possible. Given both attack surfaces and the extent of attackers' access to the models, there are three possible attack scenarios:
1. The attackers can observe T and aim at ascertaining the state of the T dataset's membership. This approach is analogous to the traditional membership inference attack, in which the target model is trained from the ground up.
2. The S model is visible to the attackers, and they attempt to ascertain the status of the T dataset's membership The target model is not directly trained from the target dataset in this scenario.
3. The attackers observes the S model and try to deduce the S dataset's membership status. In contrast to the first scenario, here the target model is transferred from the T model.
## 4.3.2 Feature Inference
An adversary with partial prior knowledge of a target's record can devise feature inference to fill in the missing features by monitoring the model's behaviour [117, 33, 32]. For instance, a description of attribute inference attack is given in [117] and it has been demonstrated that by incorporating membership inference as a subroutine, this attack may deduce missing attribute values. Based on the missing attributes, a set of distinct feature vectors are generated and passed to the membership inference adversary as input. The output of this process is attribute values that correspond to the vector whose membership is confirmed via membership inference. Experimental validations for the effectiveness of an attribute inference of regression models are also available [117].
## 5 Defense Mechanisms
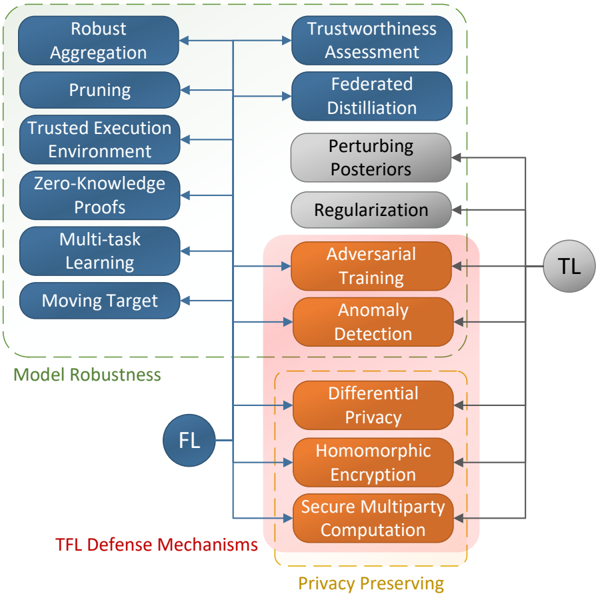
Various defense mechanisms are proposed to fortify FL against privacy and performance related threats. Figure 2 illustrates the taxonomy of the defense mechanisms in TL and FL, and the common approaches between the two that can be used to defend FTL.
## 5.1 Privacy Preserving
Despite the wide diversity of previous efforts on safeguarding FL privacy, suggested methods typically fall into one of these categories: homomorphic encryption, secure multiparty computation, and differential privacy. The following paragraphs go through each of these groups.
## 5.1.1 Homomorphic Encryption
By processing on cyphertext, homomorphic encryption is commonly used to secure the learning process. Clients can use homomorphic encryption to perform arithmetic operations on encrypted data (i.e., cyphertext) without having to decode it. The most
Fig. 2 Taxonomy of the defense mechanisms for FTL. The common defense mechanisms between FL and TL are specified in red area.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: TFL Defense Mechanisms
### Overview
The image is a diagram illustrating defense mechanisms for Trusted Federated Learning (TFL). It categorizes these mechanisms into two main areas: Model Robustness and Privacy Preserving, with connections indicating relationships between different techniques. The diagram uses rounded rectangles to represent individual defense mechanisms and arrows to show dependencies or influences. Two circular labels, "TL" and "FL", are placed on the right side of the diagram.
### Components/Axes
The diagram is structured around two main categories, visually separated by dashed lines:
* **Model Robustness:** Located in the upper portion of the diagram, enclosed by a dashed rectangle.
* **Privacy Preserving:** Located in the lower portion of the diagram, enclosed by a dashed rectangle.
The individual defense mechanisms are:
* Robust Aggregation
* Pruning
* Trusted Execution Environment
* Zero-Knowledge Proofs
* Multi-task Learning
* Moving Target
* Trustworthiness Assessment
* Federated Distillation
* Perturbing Posteriors
* Regularization
* Adversarial Training
* Anomaly Detection
* Differential Privacy
* Homomorphic Encryption
* Secure Multiparty Computation
The labels "TL" and "FL" are positioned on the right side of the diagram.
### Detailed Analysis or Content Details
The diagram shows a flow of influence between the defense mechanisms.
**Model Robustness:**
* Robust Aggregation is connected to Trustworthiness Assessment.
* Pruning is connected to Federated Distillation.
* Trusted Execution Environment is connected to Perturbing Posteriors.
* Zero-Knowledge Proofs is connected to Regularization.
* Multi-task Learning is connected to Adversarial Training.
* Moving Target is connected to Anomaly Detection.
**Privacy Preserving:**
* Adversarial Training is connected to Differential Privacy.
* Anomaly Detection is connected to Homomorphic Encryption.
* Differential Privacy is connected to Secure Multiparty Computation.
The "TL" label is connected to Adversarial Training, Anomaly Detection, Differential Privacy, Homomorphic Encryption, and Secure Multiparty Computation.
The "FL" label is connected to Differential Privacy, Homomorphic Encryption, and Secure Multiparty Computation.
### Key Observations
The diagram highlights the interconnectedness of different defense mechanisms. The "TL" and "FL" labels suggest these are key areas or goals that the defense mechanisms aim to support. The diagram suggests that Model Robustness techniques feed into Privacy Preserving techniques, and both are ultimately linked to "TL" and "FL".
### Interpretation
This diagram illustrates a layered approach to securing Trusted Federated Learning systems. The "Model Robustness" section focuses on protecting the model itself from attacks or manipulation, while the "Privacy Preserving" section focuses on protecting the data used to train the model. The connections between these sections suggest that a robust model is essential for effective privacy preservation, and vice versa.
The labels "TL" and "FL" likely stand for "Trusted Learning" and "Federated Learning" respectively, indicating that these defense mechanisms are designed to enhance both the trustworthiness and privacy of the learning process. The diagram suggests a hierarchical structure, where techniques in the "Model Robustness" category contribute to the techniques in the "Privacy Preserving" category, ultimately supporting the broader goals of "TL" and "FL".
The diagram doesn't provide quantitative data, but rather a conceptual framework for understanding the relationships between different defense mechanisms. It implies that a comprehensive security strategy for TFL requires a combination of techniques from both categories. The connections between the mechanisms suggest that they are not independent, but rather work together to provide a more robust and secure system.
</details>
prevalent techniques in Homomorphic encryption are explained as in the following [76].
Fully homomorphic encryption is capable of doing arbitrary calculations on the encrypted data [37]. This is while partially homomorphic encryption can only execute one operation (e.g., addition or multiplication), and substantially homomorphic encryption can do several operations [23, 91, 77]. The latter, on the other hand, has a restricted amount of additions and multiplications. While completely homomorphic encryption offers greater flexibility, it is inefficient when compared to other forms of homomorphic encryption [37].
Despite the benefits of homomorphic encryption, executing arithmetic on the encrypted integers increases the memory and processing time costs. For this reason, one of the main problems in homomorphic encryption is to find a proper balance between privacy and utility [6, 56]. In [82], for instance, additive homomorphic encryption is used to secure distributed learning by securing model changes and maintaining
gradient privacy. Another example is [45], which uses an additive homomorphic architecture to defeat honest-but-curious adversaries using federated logistic regression on the encrypted vertical FL data. However, the overburdening of the system with additional computational and communication costs is a typical downside of such systems.
## 5.1.2 Secure Multiparty Computation
Secure Multiparty Computation (SMC) [115] is a sub-field of cryptography, in which multiple parties cooperate to estimate a function on their input, without compromising privacy between participants. As an example of SMC is proposed in [74], which enables collaborative training without compromising privacy. Nevertheless, SMC is followed by considerable computational and communication burden, which may deter parties from collaborating. This dramatic rise in communication and processing costs makes SMC undesirable for large-scale FL.
For safe aggregation of individual model updates, [16] suggested a protocol based on SMC that is secure, communication-efficient, and failure-resistant. Their technique makes the communicating information perceivable only when they are aggregated. Thus, their protocol is secured in honest-but-curious and malicious setups. In other words, none of the participants learns anything beyond the aggregate of the inputs of numerous honest users [16].
Aside from the efficiency-related issues of SMC, another major problem for SMC-based systems is the necessity for all participants to coordinate at the same time during the training process. In practise, such multiparty interactions may not be ideal, especially in FL contexts where the client-server design is typical. Moreover, while the privacy of client data is preserved, malicious parties may still infer sensitive information from the final output [40, 90]. As a result, SMC cannot guarantee information leakage protection, necessitating the incorporation of additional differential privacy mechanisms within the multiparty protocol to overcome these issues [85, 2]. In addition, all cryptography-based protocols preclude the audition of updates, during which a hacker can covertly inject backdoor features into the shared model [13].
## 5.1.3 Differential Privacy
The idea of Diffrential Privacy (DP) is to inject random noise into the generating updates so that the data interpretation becomes infeasible for malicious entities. DP is primarily used to safeguard DFL communications against privacy attacks (e.g., inference attacks); however, the literature also shows that DP is also beneficial against data poisoning, as these attacks are usually designed based on the communicated gradients [70, 1, 38].
In contrast to homomorphic encryption and SMC whose main disadvantage was communication overhead, DP does not overburden the system in this sense. Instead,
DP comes at the cost of deteriorating the model quality since the injected noise can potentially add up to the noise within the constructed model. Moreover, DP provides resistance to poisoning attempts due to its group privacy trait. As a result, as the number of attackers increases, this defense will reduce significantly.
DP can be centralized, local, or distributed. In centralized DP, the noise addition is performed via a server, which makes it impractical in FDL. On the other hand, local [24] and distributed DP [11, 25] both assume that the aggregator is not trusted, which perfectly complies with the FDL paradigm. In the local variant, participants inject noise to their estimated gradients before sharing them over the blockchain. However, research on local DP indicates its impotency to provide privacy guarantee on large-scale and heterogeneous models with numerous parameters [102, 79]. In FDL, the injected noise should be calibrated to ensure successful DP. Despite the appealing security qualities of local DP, its practicality becomes questionable when dealing with immense number of users.
It is also possible to integrate TL into DP. For instance, private aggregation of T ensembles [79, 80] initially training an ensemble of T s on disjoint subsets of private data, then perturbs the ensemble's information by introducing noise to the aggregated T votes before transferring the information to a S . The aggregated output of the ensemble then is used to train a S model, which learns to precisely replicate the ensemble. To meet the desired accuracy, this method requires a large number of clients, and each of them must have sufficient training records. On the other hand, most industrial applications deal with imbalanced data [86], and similarly, FL data is often imbalanced among parties that does not comply with this assumption.
It has been established that the usage of DP helps prevent inference attacks in TL [1, 51], albeit at the cost of potential utility loss [51, 7]. By definition, DP seeks to conceal the presence or absence of a record in a dataset, which works against the objective of membership inference attacks. [59] draws attention to the fact that these two concepts seem to counteract each other and establishes a link between DP and membership inference attacks. This has been often carried out by minimizing the bias of the model towards any individual sample or feature by including adequate differential privacy noise. The existing connection between records and features is elaborated in [117].
## 5.2 Model Robustness
Defenses are classified into two types: proactive and reactive. The former is an inexpensive method of anticipating attacks and associated consequences. The reactive defense operates by detecting an invasion and taking preventative steps. In the production environment, it is often deployed as a patch-up. FL presents multiple additional attack surfaces throughout training, resulting in complicated and unique countermeasures. In this part, we will look at some of the most common types of FL defensive tactics and investigate their usefulness and limits.
## 5.2.1 Anomaly Detection
Anomaly detection methods actively identify and stops malicious updates from affecting the system [44, 9]. These methods may be also used in FL systems to identify potential threats [17]. One frequent technique for handling untargeted adversaries is to calculate a specific test error rate on updates and reject those disadvantageous or neutral to the global model [9].
In [99], a protection mechanism is proposed that clusters participants based on their submitted suggestive attributes to identify malicious updates. It produces groups of benign and malicious users with each indicator attribute. Another detector monitors drifts in updates using a distance measure for different participants [15]. [60] proposed producing low-dimensional model weight surrogates to recognise anomalous updates from participants. An outlier detection-based paradigm presented in [50] selects a number of updates that work in favour of objective function among others. DL-based anomaly detection is often performed using autoencoders [84]. These neural network models represent data in a latent space, in which anomalies can be discriminated. Examples of anomaly detection in FL are given in [27, 61].
Backdoor attacks in TL may also be mitigated via anomaly detection. As an example, [65] employs an anomaly detection technique to determine whether the input is a possible Trojan trigger. If the input is identified as an anomaly, it will not be passed to the neural network. This approach employs support vector machines and decision trees to find anomalies.
## 5.2.2 Robust Aggregation
The security of FL aggregation techniques is of paramount importance. Extensive research endeavours has been dedicated to research on robust aggregation that can recognize and dismiss inaccurate or malicious updates during training [83, 41]. Furthermore, strong aggregation approaches must be able to withstand communications disturbances, client dropout, and incorrect model updates on top of hostile participants [5]. Existing constraints [54] of aggregation methods for integration with FL lead to the emergence of more mature techniques such as adaptive aggregation, have been developed. This technique incorporates repeated median regression into an iteratively re-weighted least squares [34] and a resilient aggregation oracle [83]. This form of aggregation has been shown to be resistant to distortion rates distortion up to fifty percent of the users. To assess participants' prospective contributions, [66] recommends employing a Gaussian distribution. They also provided layer-by-layer optimization procedures to ensure that the aggregation works effectively. Experiments reveal that this aggregation method surpasses the well-known FedAvg in terms of robustness and convergence. Aggregation methods can also help with the problem of FL client heterogeneity. FedProx was designed as a re-parametrization and generalisation of FedAvg [94]. In comparison to FedAvg, it exhibits substantially more consistent and accurate convergence behaviour in highly heterogeneous FL systems.
Pruning also eliminates backdoors in TL by removing duplicate neurons that are no longer relevant for normal classification [63]. However, it has been discovered that when applied to particular models, it significantly degrades the model performance [105].
## 5.2.3 Pruning
Pruning decreases the size of a deep learning model by removing neurons in order to reduce complexity, increase accuracy, and eliminate backdoors Clients in the FL environment are abundant, and they are frequently linked to the server via unreliable or costly connections. When it comes to training large-scale deep neural networks (DNN), engineers encounter a huge challenge due to the restricted processing power on some edge devices. Federated dropout [18] demonstrates that a good generalization can be achieved by allowing users to perform partial training on the global model. Both transmission and local processing costs are reduced by means of federated dropout. Discarding inactive nodes of a network also make it robust against backdoors [63]. Passing benign and malicious behaviour into the same set of activations, one can combine pruning with fine-tuning. It has been shown that using this approach the backdoor task accuracy is reduced to zero in several circumstances.
## 5.2.4 Trusted Execution Environment
Trusted Execution Environment (TEE) secures linked devices in FL, establishing digital trust [17]. By using an isolated and encrypted part of the main processor, it safeguards devices from inserting incorrect training results. TEE can be used in FL to mitigate algorithmic threats [19, 73]. The validity of a participating device in a TEE Authentication should be checked by the connected service with which it is attempting to enroll. Furthermore, until the matching party provides a message, the status of code execution stays hidden. The execution route of the code cannot be changed until it takes explicit input or a validated interruption. The TEE is in charge of all data access privileges. Cryptographic technologies are used to secure TEE communications. Only the TEE secure environment stores, maintains, and uses private and public encryption keys. The TEE can show a remote client what code is presently being executed as well as the starting state. TEE can aid in resolving a key challenge for FL security since it is becoming progressively important in securing the central server and clients against hackers and preventing data theft.
## 5.2.5 Zero-Knowledge Proofs
Zero-knowledge proofs allow one party to verify assertions made by another party without exchanging or exposing underlying data [81]. In the mid-1980s, MIT researchers initially promoted the notion of zero-knowledge proofs [39]. Zero-
knowledge procedures are probabilistic evaluations, meaning they cannot guarantee something with 100 percent certainty that it will be discovered. Instead, they supply unconnected bits of information that might add up to suggest that an statement's truth is overwhelmingly likely. Thus, zero-knowledge proofs offer a practical answer to the problem of private data verifiability. For instance, zero-knowledge proofs can be employed in FL to make sure the clients' model used authentic feature for training and generating an update. Even though this approach has many appealing potentials for transforming secure update monitoring, we need to better understand how to use these approaches and discover problems in how the modules are constructed and deployed. Zero-knowledge proofs protocols mostly maintain their performance regardless of the volume of data.
## 5.2.6 Adversarial Training
Adversarial training denotes a min-max optimization problem in which the adversarial samples and model parameters are updated alternately. Generally, adversarial samples are generated through maximizing a classification loss, and model parameters are attained via minimizing a loss w.r.t. the generated adversarial samples [94, 87, 42]. This approach can provide an acceptable resilience against evasion attacks [97, 110]. While there are different approaches to carry out adversarial training, including the so-called generative adversarial networks [31, 28, 30, 29], non of them are flawless. To begin with, this approach was mainly designed for independent and identically distributed data. This is while FL data do not comply with this assumption, and, thus, further research is required to investigate the practicality of adversarial training in FL [49]. Furthermore, this approach can be very time-consuming. In addition, adversarial training often improves resilience for cases utilized during the training. Furthermore, it can possibly exhaust FL participants' limited computational capabilities and leaving the trained model exposed to various forms of adversarial noise [26, 103].
Adversarial training also aids in the prevention of TL inference attacks [119, 75]. For example, [75] presents a technique for training models with membership privacy, which assures that a model's predictions are indistinguishable on both training and unobserved samples of similar distributions. This technique formulates a min-max problem and develops an adversarial training procedure that minimizes the model's prediction loss along with the attack maximum gain. This method, which ensures membership privacy, also functions as a powerful regularizer and aids in model generalization.
Mitigating adversarial attacks is another use-case of adversarial training. As an example, [4] investigates the approach of introducing white noise to DL results to counter these assaults and emphasises on the noise-cost balance. The query count of the attacker is calculated analytically based on the noise standard deviation. Consequently, the degree of noise required to prevent attacks can be easily determined while maintaining the appropriate extent of security defined by query count and limiting performance deterioration.
## 5.2.7 Multi-Task Learning
The statistical and system difficulties of FL such as efficiency and fault fault tolerance are addressed using Federated Multi-task Learning (FML) [101, 62]. The goal of FML is to learn models for numerous related activities at the same time. It can perfectly handle statistical problems since it can immediately infer associations among non-i.i.d. and imbalanced data. For instance, [101] designs a FML approach to accelerate convergence while managing devices that disconnect on a regular basis. This approach is also flexible against data heterogeneity.
## 5.2.8 Moving Target Defense
Moving target defense [22, 111, 57, 96] confuses malevolent adversaries by constantly re-configuring the system and make it harder for intruders to infer system states. This may be accomplished by randomly shifting the FL system's components and nullify their knowledge of the system. This defense mechanism also creates complexity and expense for attackers and reduces the disclosure of vulnerabilities and the possibility of an attack. It also improves the system resilience, specially against sniffing attacks. This dynamic mechanisms disables intruders to make accurate estimations regarding the required resources for attacking the FL training process.
## 5.2.9 Client Trustworthiness Assessment
Poisoning attacks in FL are mostly studied in a centralized context. Only a limited number of research endeavours, however, address these attacks in decentralized systems [109], where several adversarial parties follow the same objective and attempt to poison the training data. Although these attacks pose a greater risk in FL, their efficiency remains unknown compared to their centralized variants. This protection approach works by detecting authorized clients and drastically increasing the rate of failure for poisoning attacks, even when the attack is initiated in a distributed fashion.
## 5.2.10 Federated Distillation
Exchanging model parameters becomes prohibitively expensive when communication resources are limited, especially for contemporary big DNNs. In this sense, federated distillation [102] is an appealing FL option since it only transmits model outputs, which are often considerably less in size than the model sizes. Knowledge distillation is a fundamental algorithm in federated distillation [58]. The goal of knowledge distillation is to perform TL from a large model ( T ) to a compact model ( S ). In FL, this idea translates into sharing the knowledge of a model rather than
the parameters, which improve FL's resilience while reducing communication and computing costs.
## 5.2.11 Regularization
Classifiers make more confident predictions when confronted with data samples they have been trained on before. For this reasons, overfitting of a model can lead to a successful membership inference. Classifiers make more reliable predictions when confronted with records they have been trained on before. To tackle this issue, researchers have investigated the usage of regularization for preventing overfitting, which in turn eliminates membership inference. The conventional 𝐿 2 regularizer, as an example, is examined during the training process of a target classifier [100].
Dropout is another regularization strategy intended to counter membership inference attacks. It was employed in [95] to counter membership inference attacks. In each training cycle, dropout dismisses a neuron with a particular probability.
Model stacking is a conventional ensemble approach that combines the findings of multiple weak classifiers to form a strong model. [95] investigated the use of this method to counter membership inference. The target classifier, in particular, is comprised of three models grouped into a tree structure (i.e., one model at top and two models at the bottom of the tree).
The original data samples are fed to leafs of the tree, while the results obtained from the leafs are inputs to the top of the tree. The tree models are trained using separate sets of data samples, which decreases the likelihood that the target classifier will recall any particular point, which in turn reduces overfitting.
## 5.2.12 Perturbing Posteriors
Rather than meddling with the target classifier's training procedure, one can introduce noise to the classifiers' outputs [53]. This concept is referred to as perturbing posteriors. For instance, [53], designs a method to protect against membership inference launched in a black-box setting. This defensive approach operates in two stages and offers theoretical robustness guarantee. The first stage involves locating a generated noise vector that may be used to convert a vector of confidence scores into an adversarial example. This noise vector is added to the confidence scores with a probability in the next stage.
## 6 Future Research
As mentioned previously, it is anticipated that FTL is most vulnarible against backdoor, membership inference, feature inference, and adversarial samples (refer back
to Fig. 1). In this section, we outline future development requirements that we believe will be promising for FTL in this sense.
## 6.1 Decentralized Federated Transfer Learning
Decentralized FL is a new study topic in which the system has no singular central server. Decentralized FL may be more beneficial in business-based FL instances when third parties are not trusted by the clients. Each client might be selected as a server in a turn-based fashion. As of now, there are no decentralized FTL protocols in the literature. It would be fascinating to see if the same risks that exist in server-based FL also arise in decentralized FTL.
## 6.2 Flaws in Current Defense Mechanisms
Because FL cannot review updates for privacy reasons, it is vulnerable to poisoning attacks, which is often used to counter adversarial attacks in ML, remains a questionable choice in FL since it was designed particularly for i.i.d. data and its effectiveness in non-i.i.d. scenarios is unknown. This can become problematic in the case of FTL furthermore. Besides, adversarial training is computationally expensive and may degrade efficiency, regardless of the type of FL.
Available privacy defenses for FTL are mostly based on homomorphic encryption and secret sharing. Nevertheless, since DP is used as a privacy-preserving method in both FL and TL, it may be also used for FTL. If future works extend DP to FTL, there are a number of points to consider. Firstly, DP cannot handle attribute inference. Secondly, client-level DP is designed for large-scale systems with numerous clients, and using it in smaller systems may affect it performance.
## 6.3 Optimizing Defense Mechanism Deployment
The servers will require additional computational resources while implementing defense mechanisms to verify if any attacker is targeting the FTL system. Additionally, different forms of defense systems may have varying degrees of efficiency against different types of threats, as well as varying costs. It is crucial to look into how to optimize the deployment of defensive systems or the declaration of deterrent measures for FTL.
## 6.4 Achieving Simultaneous Objectives
There are no extant research on FL or FTL that can achieve the following objectives at the same time [68]:
1. Rapid model convergence.
2. Descent generalization of model.
3. Efficient communication.
4. Preserving privacy.
5. Resilience to targeted and untargeted attacks.
6. Fault tolerance.
Past efforts sought to tackle several objectives simultaneously [67]. [112] tackled cooperative fairness and privacy at the same time, and a architecture has been developed to solve mitigate these problems. To cut communication overhead and provide privacy perks, [3] integrated DP with model compression approaches. Another research [12] concentrates on enhancing convergence and preventing gradient leakage. Nevertheless, it is crucial to remember that privacy and robustness are incompatible by nature, as protecting against performance attacks typically necessitates full access to the training samples, which is irreconcilable with FTL's privacy requirements. Even though encryption and DP-based approaches can guarantee verifiably privacy-preserving, they are vulnerable to poisoning techniques and may result in models with unfavourable privacy-performance trade-off. Finding a cohesive design that meets all of the aforementioned criteria is indeed undiscovered in the FTL domain.
## 6.5 Heterogeneity of Federated Transfer Learning
The vast majority of privacy and robustness studies have been conducted on FL with homogenous designs. On the other hand, there is a common assumption of feature co-occurrence among most of the available work on heterogeneous FL. For FTL to be secure, the existing defense mechanisms should be compatible with fully heterogeneous feature space [36].
## 7 Conclusion
FTL is one of the latest fields of machine learning, it is evolving at a rapid pace and will be a focal point of research in machine learning and privacy. As FL and TL evolve, so will the dangers to FTL's privacy and security. It is critical to conduct a wide assessment of present FL and TL threats and countermeasures so that upcoming FTL designs consider the possible weaknesses in existing models. This survey provides a clear and straightforward review of the privacy and robustness attack and possible
defense mechanisms that may be used in FTL. Designing a coherent FTL defensive mechanismthatcanwithstand various attacks without decreasing model performance would demand multidisciplinary collaboration in the scientific community.
## Acknowledgements
This work is supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) under funding reference numbers CGSD3-569341-2022 and RGPIN-2021-02968.
## References
1. Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep learning with differential privacy. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS '16, p. 308-318 (2016)
2. Ács, G., Castelluccia, C.: I have a dream! (differentially private smart metering). In: Information Hiding, pp. 118-132. Springer Berlin Heidelberg (2011)
3. Agarwal, N., Suresh, A.T., Yu, F., Kumar, S., McMahan, H.B.: Cpsgd: Communicationefficient and differentially-private distributed sgd. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems, p. 7575-7586 (2018)
4. Aithal, M.B., Li, X.: Mitigating black-box adversarial attacks via output noise perturbation (2021). ArXiv:2109.15160
5. Ang, F., Chen, L., Zhao, N., Chen, Y., Wang, W., Yu, F.R.: Robust federated learning with noisy communication. IEEE Transactions on Communications 68 (6), 3452-3464 (2020)
6. Aono, Y., Hayashi, T., Trieu Phong, L., Wang, L.: Scalable and secure logistic regression via homomorphic encryption. In: Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, p. 142-144 (2016)
7. Backes, M., Berrang, P., Humbert, M., Manoharan, P.: Membership privacy in microrna-based studies. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, p. 319-330 (2016)
8. Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., Shmatikov, V.: How to backdoor federated learning. In: Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research , vol. 108, pp. 2938-2948. PMLR (2020)
9. Barreno, M., Nelson, B., Joseph, A., Tygar, J.: The security of machine learning. Machine Learning 81 , 121-148 (2010)
10. Barreno, M., Nelson, B., Sears, R., Joseph, A.D., Tygar, J.D.: Can machine learning be secure? In: Proceedings of the ACM Symposium on Information, Computer and Communications Security, p. 16-25 (2006)
11. Benhamouda, F., Joye, M., Libert, B.: A new framework for privacy-preserving aggregation of time-series data. ACM Trans. Inf. Syst. Secur. 18 (3) (2016)
12. Bernstein, J., Zhao, J., Azizzadenesheli, K., Anandkumar, A.: signsgd with majority vote is communication efficient and fault tolerant (2019). ArXiv:1810.05291
13. Bhagoji, A.N., Chakraborty, S., Mittal, P., Calo, S.: Analyzing federated learning through an adversarial lens. In: Proceedings of the 36th International Conference on Machine Learning, vol. 97, pp. 634-643 (2019)
14. Biggio, B., Nelson, B., Laskov, P.: Support vector machines under adversarial label noise. In: C.N. Hsu, W.S. Lee (eds.) Proceedings of the Asian Conference on Machine Learning, Proceedings of Machine Learning Research , vol. 20, pp. 97-112. PMLR (2011)
15. Blanchard, P., El Mhamdi, E.M., Guerraoui, R., Stainer, J.: Machine learning with adversaries: Byzantine tolerant gradient descent. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
16. Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., McMahan, H.B., Patel, S., Ramage, D., Segal, A., Seth, K.: Practical secure aggregation for privacy-preserving machine learning. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, CCS '17, p. 1175-1191 (2017)
17. Bouacida, N., Mohapatra, P.: Vulnerabilities in federated learning. IEEE Access 9 , 6322963249 (2021)
18. Caldas, S., Konečný, J., McMahan, H.B., Talwalkar, A.: Expanding the reach of federated learning by reducing client resource requirements (2018). ArXiv:1812.07210
19. Chen, Y., Luo, F., Li, T., Xiang, T., Liu, Z., Li, J.: A training-integrity privacy-preserving federated learning scheme with trusted execution environment. Information Sciences 522 , 69-79 (2020)
20. Chen, Y., Qin, X., Wang, J., Yu, C., Gao, W.: Fedhealth: A federated transfer learning framework for wearable healthcare. IEEE Intelligent Systems 35 (4), 83-93 (2020)
21. Chin, T., Zhang, C., Marculescu, D.: Improving the adversarial robustness of transfer learning via noisy feature distillation. CoRR (2020). ArXiv:2002.02998
22. Colbaugh, R., Glass, K.: Moving target defense for adaptive adversaries. In: IEEE International Conference on Intelligence and Security Informatics, pp. 50-55 (2013)
23. Damgård, I., Pastro, V., Smart, N., Zakarias, S.: Multiparty computation from somewhat homomorphic encryption. In: Advances in Cryptology - CRYPTO, pp. 643-662 (2012)
24. Duchi, J.C., Jordan, M.I., Wainwright, M.J.: Local privacy and statistical minimax rates. In: 1st Annual Allerton Conference on Communication, Control, and Computing (Allerton), pp. 1592-1592 (2013)
25. Dwork, C., Kenthapadi, K., McSherry, F., Mironov, I., Naor, M.: Our data, ourselves: Privacy via distributed noise generation. In: Advances in Cryptology (EUROCRYPT 2006), Lecture Notes in Computer Science , vol. 4004, pp. 486-503. Springer Verlag (2006)
26. Engstrom, L., Tran, B., Tsipras, D., Schmidt, L., Madry, A.: Exploring the landscape of spatial robustness. In: K. Chaudhuri, R. Salakhutdinov (eds.) Proceedings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research , vol. 97, pp. 1802-1811. PMLR (2019)
27. Fang, M., Cao, X., Jia, J., Gong, N.: Local model poisoning attacks to byzantine-robust federated learning. In: 29th USENIX Security Symposium (USENIX Security 20), pp. 1605-1622 (2020)
28. Farajzadeh-Zanjani, M., Hallaji, E., Razavi-Far, R., Saif, M.: Generative-adversarial classimbalance learning for classifying cyber-attacks and faults - a cyber-physical power system. IEEE Transactions on Dependable and Secure Computing pp. 1-1 (2021). DOI 10.1109/ TDSC.2021.3118636
29. Farajzadeh-Zanjani, M., Hallaji, E., Razavi-Far, R., Saif, M.: Generative adversarial dimensionality reduction for diagnosing faults and attacks in cyber-physical systems. Neurocomputing 440 , 101-110 (2021)
30. Farajzadeh-Zanjani, M., Hallaji, E., Razavi-Far, R., Saif, M., Parvania, M.: Adversarial semisupervised learning for diagnosing faults and attacks in power grids. IEEE Transactions on Smart Grid 12 (4), 3468-3478 (2021)
31. Farajzadeh-Zanjani, M., Razavi-Far, R., Saif, M., Palade, V.: Generative adversarial networks: A survey on training, variants, and applications. In: Generative Adversarial Learning: Architectures and Applications, pp. 7-29. Springer International Publishing, Cham (2022)
32. Fredrikson, M., Jha, S., Ristenpart, T.: Model inversion attacks that exploit confidence information and basic countermeasures. In: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, p. 1322-1333. Association for Computing Machinery (2015)
33. Fredrikson, M., Lantz, E., Jha, S., Lin, S., Page, D., Ristenpart, T.: Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. In: Proceedings of the 23rd USENIX Conference on Security Symposium, p. 17-32 (2014)
34. Fu, S., Xie, C., Li, B., Chen, Q.: Attack-resistant federated learning with residual-based reweighting. CoRR (2019). ArXiv:1912.11464
35. Fung, C., Yoon, C.J.M., Beschastnikh, I.: Mitigating sybils in federated learning poisoning. CoRR (2018). ArXiv:1808.04866
36. Gao, D., Liu, Y., Huang, A., Ju, C., Yu, H., Yang, Q.: Privacy-preserving heterogeneous federated transfer learning. In: IEEE International Conference on Big Data, pp. 2552-2559 (2019)
37. Gentry, C.: Fully homomorphic encryption using ideal lattices. In: Proceedings of the FortyFirst Annual ACM Symposium on Theory of Computing, STOC '09, p. 169-178. Association for Computing Machinery (2009)
38. Geyer, R.C., Klein, T., Nabi, M.: Differentially private federated learning: A client level perspective abs/1712.07557 (2017). ArXiv:1712.07557
39. Goldwasser, S., Micali, S., Rackoff, C.: The knowledge complexity of interactive proof systems. SIAM Journal on Computing 18 (1), 186-208 (1989)
40. Goryczka, S., Xiong, L.: A comprehensive comparison of multiparty secure additions with differential privacy. IEEE Transactions on Dependable and Secure Computing 14 (5), 463-477 (2017)
41. Grama, M., Musat, M., Muñoz-González, L., Passerat-Palmbach, J., Rueckert, D., Alansary, A.: Robust aggregation for adaptive privacy preserving federated learning in healthcare (2020). ArXiv:2009.08294
42. Hallaji, E., Farajzadeh-Zanjani, M., Razavi-Far, R., Palade, V., Saif, M.: Constrained generative adversarial learning for dimensionality reduction. IEEE Transactions on Knowledge and Data Engineering pp. 1-1 (2021). DOI 10.1109/TKDE.2021.3126642
43. Hallaji, E., Razavi-Far, R., Saif, M.: DLIN: Deep ladder imputation network. IEEE Transactions on Cybernetics pp. 1-13 (2021). DOI 10.1109/TCYB.2021.3054878
44. Hallaji, E., Razavi-Far, R., Saif, M.: Embedding time-series features into generative adversarial networks for intrusion detection in internet of things networks. In: Generative Adversarial Learning: Architectures and Applications, pp. 169-183. Springer International Publishing, Cham (2022)
45. Hardy, S., Henecka, W., Ivey-Law, H., Nock, R., Patrini, G., Smith, G., Thorne, B.: Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption (2017). ArXiv:1711.10677
46. Hassani, H., Hallaji, E., Razavi-Far, R., Saif, M.: Unsupervised concrete feature selection based on mutual information for diagnosing faults and cyber-attacks in power systems. Engineering Applications of Artificial Intelligence 100 , 104150 (2021)
47. Hassani, H., Razavi-Far, R., Saif, M.: Real-time out-of-step prediction control to prevent emerging blackouts in power systems: A reinforcement learning approach. Applied Energy 314 , 118861 (2022). DOI https://doi.org/10.1016/j.apenergy.2022.118861
48. Hitaj, B., Ateniese, G., Perez-Cruz, F.: Deep models under the gan: Information leakage from collaborative deep learning. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, p. 603-618. Association for Computing Machinery (2017)
49. Jacobsen, J., Behrmann, J., Carlini, N., Tramèr, F., Papernot, N.: Exploiting excessive invariance caused by norm-bounded adversarial robustness (2019). ArXiv:1903.10484
50. Jagielski, M., Oprea, A., Biggio, B., Liu, C., Nita-Rotaru, C., Li, B.: Manipulating machine learning: Poisoning attacks and countermeasures for regression learning. In: IEEE Symposium on Security and Privacy (SP), pp. 19-35 (2018)
51. Jayaraman, B., Evans, D.: Evaluating differentially private machine learning in practice. In: 28th USENIX Security Symposium, pp. 1895-1912 (2019)
52. Jere, M.S., Farnan, T., Koushanfar, F.: A taxonomy of attacks on federated learning. IEEE Security Privacy 19 (2), 20-28 (2021)
53. Jia, J., Salem, A., Backes, M., Zhang, Y., Gong, N.Z.: Memguard: Defending against blackbox membership inference attacks via adversarial examples. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, p. 259-274 (2019)
54. Kairouz, P., et al.: Advances and open problems in federated learning (2019). ArXiv:1912.04977
55. Kantarcioglu, M., Clifton, C.: Privacy-preserving distributed mining of association rules on horizontally partitioned data. IEEE Transactions on Knowledge and Data Engineering 16 (9), 1026-1037 (2004)
56. Kim, M., Song, Y., Wang, S., Xia, Y., Jiang, X.: Secure logistic regression based on homomorphic encryption: Design and evaluation. JMIR Med Inform 6 (2), e19 (2018)
57. Lei, C., Zhang, H.Q., Jinglei, T., Zhang, Y.C., Liu, X.H.: Moving target defense techniques: A survey. Security and Communication Networks 2018 , 1-25 (2018)
58. Li, D., Wang, J.: Fedmd: Heterogenous federated learning via model distillation (2019). ArXiv:1910.03581
59. Li, N., Qardaji, W., Su, D., Wu, Y., Yang, W.: Membership privacy: A unifying framework for privacy definitions. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, p. 889-900. Association for Computing Machinery (2013)
60. Li, S., Cheng, Y., Liu, Y., Wang, W., Chen, T.: Abnormal client behavior detection in federated learning abs/1910.09933 (2019). ArXiv:1910.09933
61. Li, S., Cheng, Y., Wang, W., Liu, Y., Chen, T.: Learning to detect malicious clients for robust federated learning (2020). ArXiv:2002.00211
62. Li, T., Hu, S., Beirami, A., Smith, V.: Ditto: Fair and robust federated learning through personalization. In: M. Meila, T. Zhang (eds.) Proceedings of the 38th International Conference on Machine Learning, Proceedings of Machine Learning Research , vol. 139, pp. 6357-6368. PMLR (2021)
63. Liu, K., Dolan-Gavitt, B., Garg, S.: Fine-pruning: Defending against backdooring attacks on deep neural networks. In: M. Bailey, T. Holz, M. Stamatogiannakis, S. Ioannidis (eds.) Research in Attacks, Intrusions, and Defenses, pp. 273-294. Springer International Publishing, Cham (2018)
64. Liu, Y., Kang, Y., Xing, C., Chen, T., Yang, Q.: A secure federated transfer learning framework. IEEE Intelligent Systems 35 (4), 70-82 (2020)
65. Liu, Y., Xie, Y., Srivastava, A.: Neural trojans. In: IEEE 35th International Conference on Computer Design, pp. 45-48 (2017)
66. Lu, Y., Fan, L.: An efficient and robust aggregation algorithm for learning federated cnn. In: Proceedings of the 3rd International Conference on Signal Processing and Machine Learning, p. 1-7 (2020)
67. Lyu, L., Li, Y., Nandakumar, K., Yu, J., Ma, X.: How to democratise and protect ai: Fair and differentially private decentralised deep learning. IEEE Transactions on Dependable and Secure Computing pp. 1-1 (2020)
68. Lyu, L., Yu, H., Ma, X., Sun, L., Zhao, J., Yang, Q., Yu, P.S.: Privacy and robustness in federated learning: Attacks and defenses (2020). ArXiv:2012.06337
69. Lyu, L., Yu, H., Yang, Q.: Threats to federated learning: A survey (2020). ArXiv:2003.02133
70. Ma, Y., Zhu, X., Hsu, J.: Data poisoning against differentially-private learners: Attacks and defenses. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence,
- p. 4732-4738 (2019)
71. McMahan, B., Moore, E., Ramage, D., Hampson, S., Arcas, B.A.y.: Communication-Efficient Learning of Deep Networks from Decentralized Data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research , vol. 54, pp. 1273-1282. PMLR (2017)
72. Melis, L., Song, C., De Cristofaro, E., Shmatikov, V.: Exploiting unintended feature leakage in collaborative learning. In: EEE Symposium on Security and Privacy (SP), pp. 691-706 (2019)
73. Mo, F., Haddadi, H., Katevas, K., Marin, E., Perino, D., Kourtellis, N.: Ppfl: Privacypreserving federated learning with trusted execution environments. In: Proceedings of the
- 19th Annual International Conference on Mobile Systems, Applications, and Services, p. 94-108 (2021)
74. Mohassel, P., Zhang, Y.: Secureml: A system for scalable privacy-preserving machine learning. In: IEEE Symposium on Security and Privacy, pp. 19-38 (2017)
75. Nasr, M., Shokri, R., Houmansadr, A.: Machine learning with membership privacy using adversarial regularization. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, p. 634-646. Association for Computing Machinery (2018)
76. Ogburn, M., Turner, C., Dahal, P.: Homomorphic encryption. Procedia Computer Science 20 , 502-509 (2013). Complex Adaptive Systems
77. Paillier, P.: Public-key cryptosystems based on composite degree residuosity classes. In: J. Stern (ed.) Advances in Cryptology - EUROCRYPT '99, pp. 223-238. Springer Berlin Heidelberg (1999)
78. Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering 22 (10), 1345-1359 (2010)
79. Papernot, N., Abadi, M., Úlfar Erlingsson, Goodfellow, I., Talwar, K.: Semi-supervised knowledge transfer for deep learning from private training data (2017). ArXiv:1610.05755
80. Papernot, N., Song, S., Mironov, I., Raghunathan, A., Talwar, K., Úlfar Erlingsson: Scalable private learning with pate (2018). ArXiv:1802.08908
81. Parno, B., Howell, J., Gentry, C., Raykova, M.: Pinocchio: Nearly practical verifiable computation. In: EEE Symposium on Security and Privacy, pp. 238-252 (2013)
82. Phong, L.T., Aono, Y., Hayashi, T., Wang, L., Moriai, S.: Privacy-preserving deep learning via additively homomorphic encryption. IEEE Transactions on Information Forensics and Security 13 (5), 1333-1345 (2018)
83. Pillutla, K., Kakade, S.M., Harchaoui, Z.: Robust aggregation for federated learning (2019). ArXiv:1912.13445
84. Preuveneers, D., Rimmer, V., Tsingenopoulos, I., Spooren, J., Joosen, W., Ilie-Zudor, E.: Chained anomaly detection models for federated learning: An intrusion detection case study. Applied Sciences 8 (12) (2018)
85. Rastogi, V., Nath, S.: Differentially private aggregation of distributed time-series with transformation and encryption. In: Proceedings of the CM SIGMOD International Conference on Management of Data, p. 735-746. Association for Computing Machinery (2010)
86. Razavi-Far, R., Farajzadeh-Zanajni, M., Wang, B., Saif, M., Chakrabarti, S.: Imputationbased ensemble techniques for class imbalance learning. IEEE Transactions on Knowledge and Data Engineering 33 (5), 1988-2001 (2021)
87. Razavi-Far, R., Ruiz-Garcia, A., Palade, V., Schmidhuber, J. (eds.): Generative Adversarial Learning: Architectures and Applications. Springer, Cham (2022)
88. Razavi-Far, R., Wan, D., Saif, M., Mozafari, N.: To tolerate or to impute missing values in v2x communications data? IEEE Internet of Things Journal pp. 1-1 (2021). DOI 10.1109/JIOT.2021.3126749
89. Rezaei, S., Liu, X.: A target-agnostic attack on deep models: Exploiting security vulnerabilities of transfer learning (2020). ArXiv:1904.04334
90. Riazi, M.S., Weinert, C., Tkachenko, O., Songhori, E.M., Schneider, T., Koushanfar, F.: Chameleon: A hybrid secure computation framework for machine learning applications. In: Proceedings of the Asia Conference on Computer and Communications Security, ASIACCS '18, p. 707-721 (2018)
91. Rivest, R.L., Shamir, A., Adleman, L.: A method for obtaining digital signatures and publickey cryptosystems. Commun. ACM 21 (2), 120-126 (1978)
92. Saha, S., Ahmad, T.: Federated transfer learning: concept and applications (2020). ArXiv:2010.15561
93. Saha, S., Bovolo, F., Bruzzone, L.: Unsupervised deep change vector analysis for multiplechange detection in vhr images. IEEE Transactions on Geoscience and Remote Sensing 57 (6), 3677-3693 (2019)
94. Sahu, A.K., Li, T., Sanjabi, M., Zaheer, M., Talwalkar, A., Smith, V.: On the convergence of federated optimization in heterogeneous networks (2018). ArXiv:1812.06127
95. Salem, A., Zhang, Y., Humbert, M., Fritz, M., Backes, M.: Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models (2018). ArXiv:1806.01246
96. Sengupta, S., Chowdhary, A., Sabur, A., Alshamrani, A., Huang, D., Kambhampati, S.: A survey of moving target defenses for network security. IEEE Communications Surveys Tutorials 22 (3), 1909-1941 (2020)
97. Shafahi, A., Najibi, M., Ghiasi, M.A., Xu, Z., Dickerson, J., Studer, C., Davis, L.S., Taylor, G., Goldstein, T.: Adversarial training for free! In: Advances in Neural Information Processing Systems, vol. 32 (2019)
98. Sharma, S., Xing, C., Liu, Y., Kang, Y.: Secure and efficient federated transfer learning. In: IEEE International Conference on Big Data (Big Data), pp. 2569-2576 (2019)
99. Shen, S., Tople, S., Saxena, P.: A<span class="smallcaps smallercapital">uror</span>: Defending against poisoning attacks in collaborative deep learning systems. In: Proceedings of the 32nd Annual Conference on Computer Security Applications, ACSAC '16, p. 508-519 (2016)
100. Shokri, R., Stronati, M., Song, C., Shmatikov, V.: Membership inference attacks against machine learning models. In: IEEE Symposium on Security and Privacy, pp. 3-18 (2017)
101. Smith, V., Chiang, C.K., Sanjabi, M., Talwalkar, A.S.: Federated multi-task learning. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
102. Sun, L., Lyu, L.: Federated model distillation with noise-free differential privacy (2020). ArXiv:2009.05537
103. Tramer, F., Boneh, D.: Adversarial training and robustness for multiple perturbations. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
104. Vaidya, J., Clifton, C.: Privacy preserving association rule mining in vertically partitioned data. In: Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, p. 639-644 (2002)
105. Wang, B., Yao, Y., Shan, S., Li, H., Viswanath, B., Zheng, H., Zhao, B.Y.: Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In: IEEE Symposium on Security and Privacy, pp. 707-723 (2019)
106. Wang, B., Yao, Y., Viswanath, B., Zheng, H., Zhao, B.Y.: With great training comes great vulnerability: Practical attacks against transfer learning. In: Proceedings of the 27th USENIX Conference on Security Symposium, SEC'18, p. 1281-1297. USENIX Association (2018)
107. Wang, H., Sreenivasan, K., Rajput, S., Vishwakarma, H., Agarwal, S., Sohn, J., Lee, K., Papailiopoulos, D.S.: Attack of the tails: Yes, you really can backdoor federated learning (2020). ArXiv:2007.05084
108. Wang, S., Nepal, S., Rudolph, C., Grobler, M., Chen, S., Chen, T.: Backdoor attacks against transfer learning with pre-trained deep learning models. IEEE Transactions on Services Computing pp. 1-1 (2020)
109. Xie, C., Huang, K., Chen, P.Y., Li, B.: Dba: Distributed backdoor attacks against federated learning. In: International Conference on Learning Representations (2020)
110. Xie, C., Wu, Y., van der Maaten, L., Yuille, A.L., He, K.: Feature denoising for improving adversarial robustness (2018). ArXiv:1812.03411
111. Xu, J., Guo, P., Zhao, M., Erbacher, R.F., Zhu, M., Liu, P.: Comparing different moving target defense techniques. In: Proceedings of the First ACM Workshop on Moving Target Defense, MTD '14, p. 97-107. Association for Computing Machinery (2014)
112. Xu, X., Lyu, L.: A reputation mechanism is all you need: Collaborative fairness and adversarial robustness in federated learning (2021). ArXiv:2011.10464
113. Yang, H., He, H., Zhang, W., Cao, X.: Fedsteg: A federated transfer learning framework for secure image steganalysis. IEEE Transactions on Network Science and Engineering 8 (2), 1084-1094 (2021)
114. Yang, Q., Liu, Y., Chen, T., Tong, Y.: Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology 10 (2) (2019)
115. Yao, A.C.: Protocols for secure computations. In: 23rd Annual Symposium on Foundations of Computer Science, pp. 160-164 (1982)
116. Yao, Y., Li, H., Zheng, H., Zhao, B.Y.: Latent backdoor attacks on deep neural networks. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, CCS '19, p. 2041-2055. Association for Computing Machinery, New York, NY, USA (2019)
117. Yeom, S., Giacomelli, I., Fredrikson, M., Jha, S.: Privacy risk in machine learning: Analyzing the connection to overfitting (2018). ArXiv:1709.01604
118. Zhu, L., Liu, Z., Han, S.: Deep leakage from gradients. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
119. Zou, Y., Zhang, Z., Backes, M., Zhang, Y.: Privacy analysis of deep learning in the wild: Membership inference attacks against transfer learning (2020). ArXiv:2009.04872