# End-to-End Binaural Speech Synthesis
**Authors**: Wen Chin Huang, Dejan Markovic, Alexander Richard, Israel Dejene Gebru, Anjali Menon
## End-to-End Binaural Speech Synthesis
Wen-Chin Huang 1 ∗ , Dejan Markovi´ c 2 , Israel D. Gebru 2 , Anjali Menon 2 , Alexander Richard 2
Nagoya University, Japan 2 Meta Reality Labs Research, USA
wen.chinhuang@g.sp.m.is.nagoya-u.ac.jp { dejanmarkovic,idgebru,aimenon,richardalex } @fb.com
## Abstract
In this work, we present an end-to-end binaural speech synthesis system that combines a low-bitrate audio codec with a powerful binaural decoder that is capable of accurate speech binauralization while faithfully reconstructing environmental factors like ambient noise or reverb. The network is a modified vectorquantized variational autoencoder, trained with several carefully designed objectives, including an adversarial loss. We evaluate the proposed system on an internal binaural dataset with objective metrics and a perceptual study. Results show that the proposed approach matches the ground truth data more closely than previous methods. In particular, we demonstrate the capability of the adversarial loss in capturing environment effects needed to create an authentic auditory scene.
Index Terms : binaural speech synthesis, spatial audio, audio codec, neural speech representation
## 1. Introduction
Augmented and virtual reality technologies promise to revolutionize remote communications by achieving spatial and social presence, i.e., the feeling of shared space and authentic face-toface interaction with others. High-quality, accurately spatialized audio is an integral part of such an AR/VR communication platform. In fact, binaural audio guides us to effortlessly focus on a speaker in multi-party conversation scenarios, from formal meetings to causal chats [1]. It also provides surround understanding of space and helps us navigate 3D environments.
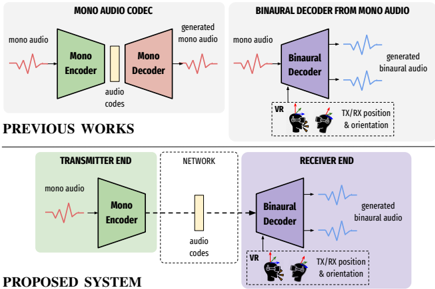
Our goal is to create a pipeline for a binaural communication system, as shown at the bottom of Fig. 1. At the transmitter end, monaural audio is first encoded by an audio encoder, and then transmitted over the network. At the receiver end, the transmitted audio code is decoded, and the binaural audio is synthesized according to transmitter and receiver positions in the virtual space. Specifically, such a system should be capable of (a) encoding transmitter audio into a low-bitrate neural code and (b) synthesizing binaural audio from these codes including environmental factors such as room reverb and noise floor, which are crucial for acoustic realism and depth perception.
Although binaural synthesis has recently experienced a breakthrough based on neural audio rendering techniques [2-4] that allow to learn binauralization and spatial audio in a datadriven way, these approaches fall short in their ability to faithfully model environmental factors such as room reverb and noise floor. The reason these models fail to model stochastic processes is their reliance on direct reconstruction losses on waveforms. Additionally, this reliance on metric losses makes the joint optimization of neural spatial renderers and neural audio codecs a difficult task. In fact, given their high sensitivity
∗ Work done while interning at Meta Reality Labs Research.
Figure 1: Illustration of previous works and the proposed system. Top left : Standard audio codec which encodes and reconstructs mono audio. Top right : binaural decoder that spatializes mono audio by conditioning on orientation and relative position between the transmitter and receiver. Bottom : proposed end-to-end binaural system that combines previous modules.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Audio Processing System Architecture
### Overview
The image compares two audio processing systems: "PREVIOUS WORKS" and "PROPOSED SYSTEM". Both involve encoding/decoding audio, but the proposed system introduces spatial and virtual reality (VR) context for binaural audio generation.
### Components/Axes
#### PREVIOUS WORKS
1. **MONO AUDIO CODEC**
- **Mono Encoder**: Converts mono audio to audio codes.
- **Mono Decoder**: Reconstructs mono audio from audio codes.
- **Flow**: Mono audio → Mono Encoder → Audio codes → Mono Decoder → Generated mono audio.
2. **BINAURAL DECODER FROM MONO AUDIO**
- **Binaural Decoder**: Converts mono audio to binaural audio.
- **Inputs**:
- Mono audio.
- VR (virtual reality) context.
- TX/RX position & orientation (transmitter/receiver spatial data).
- **Output**: Generated binaural audio.
#### PROPOSED SYSTEM
1. **TRANSMITTER END**
- **Mono Encoder**: Same as previous works.
- **Flow**: Mono audio → Mono Encoder → Audio codes → Network.
2. **NETWORK**
- Transmits audio codes between transmitter and receiver.
3. **RECEIVER END**
- **Binaural Decoder**: Uses audio codes, VR context, and TX/RX position/orientation to generate binaural audio.
- **Output**: Generated binaural audio.
### Detailed Analysis
- **Color Coding**:
- Green: Mono Encoder (both systems).
- Purple: Binaural Decoder (proposed system).
- Red: Mono audio signals.
- Blue: Binaural audio signals.
- **Key Differences**:
- Previous works lack spatial/VR context in decoding.
- Proposed system integrates TX/RX position/orientation and VR to enhance binaural audio generation.
### Key Observations
1. The proposed system adds spatial awareness (TX/RX position/orientation) and VR context to the decoding process, enabling more immersive audio.
2. The network acts as a neutral intermediary for audio codes in both systems.
3. Binaural audio generation in the proposed system depends on both audio codes and environmental/spatial data.
### Interpretation
The proposed system advances audio processing by incorporating spatial and VR context into binaural decoding. This suggests a shift from generic mono-to-binaural conversion to context-aware audio rendering, which could improve realism in applications like VR/AR. The integration of TX/RX position/orientation implies dynamic adaptation to the listener’s environment, a feature absent in prior work.
</details>
to phase shifts that do not necessarily correlate with perceptual quality, metric losses are known to perform badly in pure generative tasks, including speech synthesis from compressed representations. Yet, efficient compression and encoding are required in a practical setting like an AR/VR communication system.
In this work, we demonstrate that these shortcomings of existing binauralization systems can be overcome with adversarial learning which is more powerful at matching the generator distribution with the real data distribution. Simultaneously, this paradigm shift in training spatial audio systems naturally allows their fusion with neural audio codecs for efficient transmission over a network. We present a fully end-to-end, waveform-towaveform system based on a state-of-the-art neural codec [5] and binaural decoder [2]. The proposed model borrows the codec architecture from [5] and physics-inspired elements, such as view conditioning and time warping, from [2]. We propose loss functions and a training strategy that allows for efficient training, natural sounding outputs and accurate audio spatialization. In summary, our contributions are as follows:
- we propose a first fully end-to-end binaural speech transmission system that combines low-bitrate audio codecs with high-quality binaural synthesis;
- we show that our end-to-end trained system performs better than a baseline that cascades a monaural audio codec system (top left of Fig. 1) and a binaural decoder (top right of Fig. 1);
- we demonstrate that adversarial learning allows to faithfully reconstruct realistic audio in an acoustic scene, including stochastic noise and reverberation effects that existing approaches fail to model.
## 2. Related Work.
Audio codecs have long relied on traditional signal processing and in-domain knowledge of psychoacoustics in order to perform encoding of speech [6] or general audio signals [7, 8]. More recently, following advances in speech synthesis [9-11], data-driven neural audio codecs were developed [12-16], and Soundstream [5], a novel neural audio codec, has shown to be capable of operating on bitrates as low as 3kbps with state-ofthe-art sound reconstruction quality. None of these approaches, however, was developed with spatial audio in mind, focusing solely on reconstructing monaural signals, as illustrated at the top left of Fig. 1.
Binaural audio synthesis has traditionally relied on signal processing techniques that model the physics of human spatial hearing as a linear time-invariant system [17-20]. More recently, there has been a line of studies on neural synthesis of binaural audio that showed the advantages of the data-driven approaches [2-4,21-25]. We will refer to these models, illustrated at the top right of Fig. 1, as binaural decoders . All these approaches, however, are trained as regression models with pointwise, metric losses such as mean squared error. Consequently, they fail to model stochastic processes on the receiver side that are not observable on the mono transmitter input. Examples of these processes are noise floor and reverberant effects in the virtual receiver environment.
## 3. Proposed system
## 3.1. Model architecture
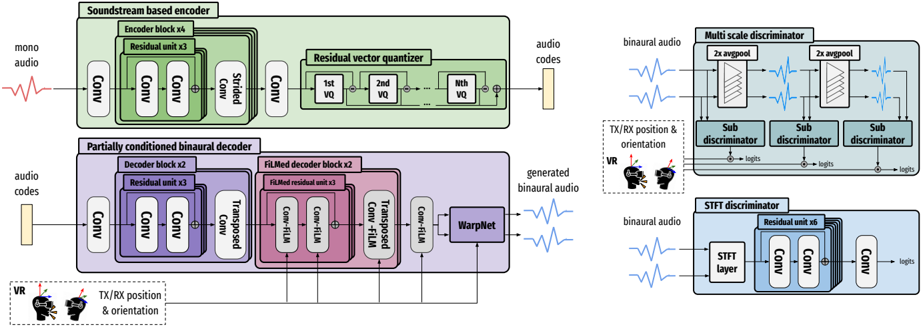
Formally, we aim to find a model f that takes as input a mono audio signal x ∈ R T , and generates the left and right binaural signals ˆ y = ( ˆ y ( l ) , ˆ y ( r ) ) (both of length T ) by conditioning on a temporal signal c of length T which contains the transmitter and receiver position and orientation. Our model, depicted in Fig. 2, is based on Soundstream [5], with a series of modifications for generating binaural signals. The input signal x is first encoded with a convolutional (conv) neural network, Enc , and then discretized with a residual vector quantizer (RVQ) to obtain the audio codes, h ∈ R T M × D , where M is the downsampling rate and D is the dimension of a single code. The decoder, Dec , which consists of a convnet and a warpnet [2], then generates the binaural signals by conditioning on the position information. The process can be formulated as follows:
<!-- formula-not-decoded -->
In order to facilitate adversarial training, a set of discriminators is trained together with the entire network in an end-to-end fashion. We describe each component in detail below, and because we mostly followed the specifications described in [5], we omit detailed hyperparameters due to space constraints.
## 3.1.1. Soundstream-based encoder
The first part of the encoder is a stack of four 1D conv blocks, with each block containing three residual units and a downsampling strided conv layer. After the input mono signal is transformed into a series of continuous vectors, they are thereafter discretized through a RVQ [5, 26] of N VQ layers, which represents each vector with a sum of codewords from a set of finite codebooks. These final vectors are denoted as the audio codes . Note that in [5], several techniques are used to improve codebook usage and bitrate scalability including k-means based initialization, codeword revival and quantization dropout, which we did not find necessary in our work. During training, the codebooks are updated with exponential moving averages, following [5,27].
## 3.1.2. Partially conditioned binaural decoder
The first part of the decoder is a reverse mirror of the encoder, with the downsampling strided conv layers replaced by upsampling transposed conv layers. Because it was orginally proposed for mono audio reconstruction, we carefully designed the decoder to capture the required fidelity of the binaural signals by conditioning on the position information c . First, a FiLMbased affine layer [28] was added to the output of each conv layer. Specifically, the position information is first processed through a three-layered MLP with ReLU activation, which is then upsampled to be used as the scale and shift parameters to perform feature-wise affine transformation. Second, due to the low dimension and low frequency nature of the position vector, we further adopt a Gaussian Fourier encoding layer [29] at the beginning of the position input to learn the implicit, high frequency correlation between the position vector and the binaural audio. Moreover, we empirically discovered that it is sufficient to condition only the last few decoder blocks with position information to get high-quality binaural signals. This is because interaural differences are typically determined within a short temporal window ( ≤ 100 samples), and the position information is only needed to accurately shift and scale the binaural signals by such a small amount. Since the temporal resolution of the audio codes (determined by the encoder downsampling rate) is greater than this difference, introducing the conditioning at the start of the decoder is ineffective.
Additionally, we added a neural time warping layer proposed in [2] at the end of the decoder to model the temporal shifts from mono to binaural signals caused by sound propagation delays. The layer is a fully differentiable implementation of the monotonous dynamic time warping algorithm.
## 3.1.3. Multi-scale and single-scale discriminators
Following [5], we used two types of discriminators. The first type is a single-scale STFT discriminator, which operates on the STFT spectrogram. The architecture is based on a stack of conv layer-based residual units. The second type, originally proposed in [10], is a multi-scale discriminator (MSD) with three sub-discriminator operating on different temporal scales: 1/2/4 × downsampled version of the input signal. Each subdiscriminator is composed of a sequence of strided and grouped convolutional layers. In addition, we adopted the projection discriminator proposed in [30] to inform the multi-scale discriminator to make use of the conditional information when approximating the underlying probabilistic model given in Eq. 1. We empirically found that this significantly improves the quality of spatialization.
## 3.2. Loss function
Let the target binaural signals be y = ( y ( l ) , y ( r ) ) . Given the importance of interaural time and level differences for human auditory perception [31], we optimize the difference between the left and right predicted signal against the target signal,
<!-- formula-not-decoded -->
We additionally use a phase loss L pha that directly optimizes the phase in angular space, which has been proven crucial for accurate phase modeling in [2].
Figure 2: Model architecture. Top left : Soundstream-based encoder, consists of a stack of conv layer-based encoder blocks and a residual vector quantizer. Bottom left : Partially conditioned binaural decoder, consists of a stack of partially FiLMed decoder blocks and a WarpNet. Top right : Multi-scale projection discriminator. Bottom right : STFT discriminator.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Neural Architecture Diagram: Audio Processing System
### Overview
The diagram illustrates a complex neural network architecture for binaural audio generation, featuring three main components: a soundstream-based encoder, a partially conditioned binaural decoder, and two discriminator systems (multi-scale and STFT). The architecture includes spatial audio processing elements (VR/TX/RX position & orientation) and demonstrates a GAN-like framework for audio synthesis and evaluation.
### Components/Axes
1. **Left Section (Encoder/Decoder Flow)**
- **Input**: Mono audio waveform (red sine wave)
- **Encoder Blocks**:
- Green blocks: "Soundstream based encoder" with residual units (x3), strided convolution, and residual vector quantizer (VQ)
- Output: Audio codes (yellow block)
- **Decoder Blocks**:
- Purple blocks: "Partially conditioned binaural decoder" with FiLM decoder units (x3), transposed convolutions, and WarpNet
- Inputs: Audio codes + VR/TX/RX position & orientation
- Output: Generated binaural audio (blue waveform)
2. **Right Section (Discriminators)**
- **Multi-scale Discriminator**:
- Blue blocks with 2x avgpool layers
- Sub-discriminators (3 instances)
- Input: Binaural audio + VR/TX/RX position & orientation
- **STFT Discriminator**:
- Blue blocks with residual units (x6) and convolutional layers
- Input: Binaural audio
- Output: Logits
3. **Spatial Elements**:
- VR headset icon with directional arrows
- TX/RX position & orientation indicators
### Detailed Analysis
- **Encoder Flow**:
- Mono audio → 4 Conv layers → 3 Residual units → Strided Conv → 4 Conv layers → Residual Vector Quantizer (VQ1-VQn) → Audio codes
- Color coding: Green for encoder components
- **Decoder Flow**:
- Audio codes + VR/TX/RX → 2 Conv layers → 3 Residual units → 2 Conv layers → FiLM decoder blocks (x3) → Transposed Conv → WarpNet → Binaural audio
- Color coding: Purple for decoder components
- **Discriminator Structure**:
- Multi-scale: 2x avgpool → 3 sub-discriminators (each with 2x avgpool)
- STFT: Residual unit (x6) → 3 Conv layers → Logits
- Color coding: Blue for discriminator components
### Key Observations
1. **Hierarchical Processing**:
- Encoder uses residual units and VQ for feature extraction
- Decoder employs FiLM conditioning for spatial audio generation
- Discriminators use multi-scale and spectral (STFT) analysis
2. **Spatial Conditioning**:
- VR/TX/RX position/orientation inputs appear in both encoder and decoder paths
- Critical for binaural audio spatialization
3. **GAN Architecture**:
- Encoder-decoder generates audio
- Discriminators evaluate quality through:
- Multi-scale temporal analysis
- Spectral/temporal STFT analysis
4. **Color Coding**:
- Green: Encoder components
- Purple: Decoder components
- Blue: Discriminator components
### Interpretation
This architecture represents a state-of-the-art approach for spatial audio generation using VQ-VAE-GAN principles. The encoder compresses audio into discrete codes while preserving spatial information through residual units. The decoder reconstructs binaural audio by conditioning on VR/TX/RX data through FiLM mechanisms, enabling precise spatial audio reproduction. The dual discriminator system ensures high-quality generation by evaluating both temporal (multi-scale) and spectral (STFT) characteristics. The architecture's strength lies in its ability to maintain spatial coherence while generating high-fidelity binaural audio, making it suitable for VR/AR applications and immersive audio experiences.
</details>
We also adopted a mix of losses used in [5]. The first loss is a hinge adversarial loss, where the respective losses for the generator (the model f in Eq. 1) and the discriminator D 1 are defined as:
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
Second, the feature matching loss [10, 11] is introduced as an implicit similarity metric defined as the differences of the intermediate features from the discriminator between a ground truth and a generated sample:
<!-- formula-not-decoded -->
where L denotes the total number of layers in D and D i denotes the features from the i -th layer. Finally, the mel spectrogram loss is applied, as in [11]:
<!-- formula-not-decoded -->
where φ denotes the transform from audio to mel spectrogram.
The overall generator loss is a weighted sum of the different loss components:
<!-- formula-not-decoded -->
Our initial experiments with weights suggested in [5] ( λ fm = 100 , λ mel = 1 ) yielded poor results. Instead, we discovered that it is critical to give the mel spectrogram loss a higher weight. The final weight combination we used is: λ diff = λ adv = 1 , λ pha = 0 . 01 , λ fm = 2 , λ mel = 45 .
## 3.3. Mono pretraining
From Eq. 1, the Dec is responsible for (1) upsampling h to match the temporal resolution of x , and (2) spatialization using information from c . If the model is trained from scratch, the Dec struggles to achieve both tasks concurrently. As a result, we propose a pretraining strategy, which we found to be
1 For simplicity we assume that D outputs the average logits of all sub-discriminators in this section.
important for fast convergence and high-quality output. In the pretraining step the model is trained to generate two copies of the monaural input signals. The primary objective is to train the decoder to upsample while ignoring the condition information via a constant zero vector. Following that, the fine-tuning step is performed using the acutal binaural signals and position condition information. Once the model has been initialised to perform well at upsampling, it can be trained to spatialize and is expected to retain the ability to upsample.
## 4. Experiments
## 4.1. Experimental settings
Datasets. We re-recorded the VCTK corpus [32] using a binaural microphone setup comprised of three 3Dio Omni Pro rigs, which were placed at the center of a non-anechoic room. Speech signals were played back on a loudspeaker, which was carried by a person walking randomly around the room to cover various areas. The 3D position and orientation of the loudspeaker as well as the static 3DIO rigs were tracked using Motive Optitrack system. We recorded 42 hours of binaural audio data, covering a distance of 4.6 m horizontally and 2.4 m vertically. The audio was sampled at 48kHz and the tracking data was recorded at 240 frames per second. For mono-pretraining, we used the original monaural version of VCTK.
Competing systems. We first consider the state-of-the-art binaural decoder only system [2]. It is trained on the same binaural speech dataset. We then consider a baseline system, where we directly cascade the Soundstream [5] and the binaural decoder [2] models trained separately on VCTK and the binaural speech datasets, respectively.
Objective metrics. The 2 distance of the predicted and ground truth audio is calculated in the waveform and mel spectrogram domains. To assess the spatialization accuracy, we report the deep perceptual spatial-audio localization metric (DPLM) [33]. Subjective evaluation protocol. This evaluation is divided into two parts. In the first part, participants were presented the result of our system and a competing system (either the decoder only or the baseline system) and were asked to determine which of them is closer to the ground truth. The second part focuses on spatialization. The reference and synthetic samples are played alternating, switching between the one and the other every few
Table 1: Objective evaluation results on the competing systems and variations of the proposed systems.
| System | Wave- 2 ↓ | Mel spec- 2 ↓ | DPLM ↓ |
|-----------------|----------------------------|--------------------------------|----------|
| Decoder only | 0.228 | 1.22 | 0.108 |
| Baseline | 0.75 | 1.173 | 0.105 |
| Proposed system | 0.807 | 0.631 | 0.106 |
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Bar Chart: Performance Comparison of Approaches
### Overview
The image is a horizontal bar chart comparing the performance of two approaches ("our approach" and "baseline"/"decoder only") across two scenarios. Each scenario includes three categories: "our approach," "baseline/decoder only," and "both are bad." The chart uses color-coded bars to represent percentages, with a legend on the left.
### Components/Axes
- **Legend**:
- Green: "our approach"
- Red: "baseline" (top section) / "decoder only" (bottom section)
- Gray: "both are bad"
- **X-axis**: Labeled "Approach" (categories: "our approach," "baseline," "both are bad" for the top section; "our approach," "decoder only," "both are bad" for the bottom section).
- **Y-axis**: Labeled "Percentage (%)" (values range from 0% to 100%).
### Detailed Analysis
#### Top Section (Baseline Comparison)
- **Our approach**: 82.0% (green bar, longest)
- **Baseline**: 14.9% (red bar, medium length)
- **Both are bad**: 3.1% (gray bar, shortest)
#### Bottom Section (Decoder-Only Comparison)
- **Our approach**: 79.4% (green bar, longest)
- **Decoder only**: 17.2% (red bar, medium length)
- **Both are bad**: 3.4% (gray bar, shortest)
### Key Observations
1. **"Our approach" dominates** in both sections, with 82.0% in the top section and 79.4% in the bottom section.
2. **"Baseline" (top) and "decoder only" (bottom)** show lower performance, with "decoder only" slightly outperforming "baseline" (17.2% vs. 14.9%).
3. **"Both are bad"** categories are minimal in both sections (3.1% and 3.4%), indicating rare instances of poor performance.
### Interpretation
The data suggests that "our approach" consistently outperforms both the baseline and decoder-only methods. The slight decrease in "our approach" from 82.0% to 79.4% in the bottom section may reflect a minor trade-off in a different context (e.g., a more complex task or dataset). The "decoder only" method shows a modest improvement over the baseline, but it remains significantly less effective than "our approach." The near-identical "both are bad" percentages across sections imply that the approaches are generally reliable, with minimal failure rates. This highlights the superiority of "our approach" in the evaluated scenarios.
</details>
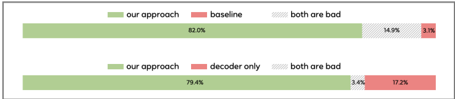
(a) Evaluation 1: participants were asked if our system or the baseline (top)/decoder only (bottom) system are closer to the ground truth.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Horizontal Bar Chart: Comparison of Approaches
### Overview
The image contains two horizontal bar charts comparing the performance of different approaches ("our approach," "baseline," "decoder only") against a "no difference" category. The charts use color-coded bars (green, red, gray) to represent proportions of outcomes, with percentages labeled on the bars.
### Components/Axes
- **Legend**: Located on the right side of the chart.
- **Green**: "our approach"
- **Red**: "baseline"
- **Gray**: "no difference"
- **Y-Axis**: Categories (e.g., "our approach," "baseline," "decoder only," "no difference").
- **X-Axis**: Labeled "percentage," representing the proportion of outcomes.
### Detailed Analysis
#### Top Chart: "Our Approach" vs. "Baseline"
- **Our Approach (Green)**: 30.3%
- **Baseline (Red)**: 60.7%
- **No Difference (Gray)**: 9.0%
#### Bottom Chart: "Our Approach," "Decoder Only," and "No Difference"
- **Our Approach (Green)**: 17.6%
- **Decoder Only (Red)**: 58.0%
- **No Difference (Gray)**: 17.6%
### Key Observations
1. In the top chart, the "baseline" approach dominates with 60.7%, while "our approach" accounts for 30.3%, and "no difference" is minimal (9.0%).
2. In the bottom chart, "decoder only" is the largest category (58.0%), with "our approach" and "no difference" tied at 17.6%.
3. The "no difference" category is consistently smaller in both charts, suggesting most outcomes are distinguishable between approaches.
### Interpretation
- The data highlights that "our approach" performs better than the baseline in the top chart but is less dominant than the "decoder only" approach in the bottom chart. This could indicate that the baseline is a strong default, while the "decoder only" method excels in specific scenarios.
- The near-equal split between "our approach" and "no difference" in the bottom chart suggests that the additional components of "our approach" (beyond the decoder) may not always provide a significant advantage.
- The "no difference" category’s low percentage in both charts implies that most outcomes are clearly attributable to one of the tested approaches, reducing ambiguity in comparisons.
</details>
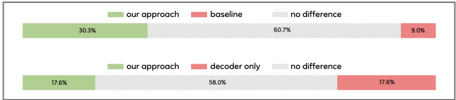
(b) Evaluation 2: participants were asked if our system or the baseline (top)/decoder only (bottom) system are more accurately spatialized.
Figure 3: Subjective evaluation results.
seconds, so the listeners can observe the change in the sound source position when the switch happens. Participants are asked which of the synthetic samples has source position closer to the reference. Participants annotated more than 350 test examples.
## 4.2. Empirical Evaluation
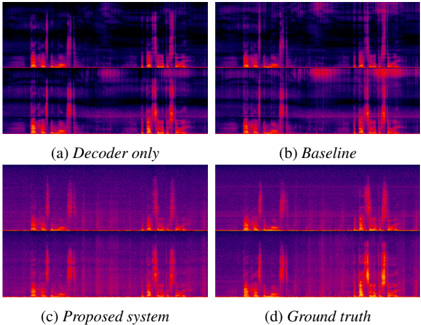
Objective Evaluation. The objective evaluation results are shown in Tab. 1. Unsurprisingly, being optimized in the waveform domain, the decoder only model outperforms others on wave 2 metric. However, the 2 -loss is not a good indicator of signal quality and can result in highly distorted signals even if the loss itself is low. The proposed system is superior in terms of mel spec 2 . We note that the mel spectrogram loss is more indicative of signal quality than the waveform 2 . In fact, spectrogram visualizations in Fig. 4 show that the proposed system matches the ground truth much better than both baseline and decoder only models. Finally, the DPLM scores shows that the proposed approach achieves the same spatialization quality as the state-of-the art binaural decoders.
User study. The subjective evaluation results are shown in Fig. 3. The first evaluation confirms that the proposed approach generates more natural outputs that are closer to the ground truth recordings than both baseline and decoder-only models. When listening to outputs generated by the baseline and decoder-only models, we found that these models have difficulty reconstructing output that is uncorrelated or only weakly correlated to the input such as room noise floor and reverberation. As a result, these effects are masked out, whereas our approach models them accurately. The second evaluation confirm that the proposed approach achieves the same level of spatialization quality as the state-of-the art binaural decoders. The results also correlated well with DPLM scores presented in Tab. 1. 2
Ablation study. We conducted ablation studies to understand
2 Audio samples can be found at https://unilight. github.io/Publication-Demos/publications/ e2e-binaural-synthesis
Figure 4: Visualizations of spectrograms from the decoder only, baseline, proposed system and the ground truth.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Heatmap Visualization: Comparative Analysis of Audio Processing Systems
### Overview
The image presents four comparative heatmaps visualizing audio processing performance across different system configurations. Each heatmap uses a color gradient from dark purple (low intensity) to bright orange (high intensity) to represent measurement values. The configurations compared are: (a) Decoder only, (b) Baseline, (c) Proposed system, and (d) Ground truth. No explicit axis labels or numerical scales are visible in the image.
### Components/Axes
- **Labels**:
- (a) Decoder only (top-left)
- (b) Baseline (top-right)
- (c) Proposed system (bottom-left)
- (d) Ground truth (bottom-right)
- **Color Gradient**:
- Dark purple → Bright orange (intensity scale, no explicit legend)
- **Spatial Arrangement**:
- 2x2 grid layout with equal-sized heatmaps
- Labels positioned directly below each heatmap
- No axis markers or numerical scales visible
### Detailed Analysis
1. **Decoder only (a)**:
- Vertical streaks dominate the left half
- Faint horizontal bands in the upper region
- Intensity peaks concentrated in the lower third
2. **Baseline (b)**:
- More diffuse vertical patterns compared to (a)
- Additional horizontal intensity bands in the middle region
- Broader orange regions in the upper-right quadrant
3. **Proposed system (c)**:
- Sharper vertical peaks than (a) and (b)
- Reduced horizontal banding
- Intensity distribution more concentrated in the central region
4. **Ground truth (d)**:
- Most defined vertical peaks
- Minimal horizontal artifacts
- Highest intensity concentration in the central region
### Key Observations
- The proposed system (c) shows the closest visual alignment to the ground truth (d)
- Decoder-only (a) exhibits the most pronounced horizontal artifacts
- Baseline (b) demonstrates intermediate characteristics between (a) and (c)
- All configurations show vertical intensity patterns consistent with audio signal representation
### Interpretation
The heatmaps suggest a progression in performance from (a) to (c), with the proposed system (c) achieving the highest fidelity to the ground truth (d). The vertical intensity patterns across all configurations likely represent temporal audio features, while horizontal artifacts may indicate processing errors or noise. The proposed system's reduced horizontal banding and sharper peaks suggest improved temporal resolution and noise suppression compared to baseline approaches. The absence of explicit axis labels prevents quantitative analysis, but the qualitative comparison demonstrates the proposed system's superiority in maintaining ground truth characteristics. The consistent vertical patterning across all configurations implies successful capture of fundamental audio signal components, with the proposed system optimizing secondary artifacts.
</details>
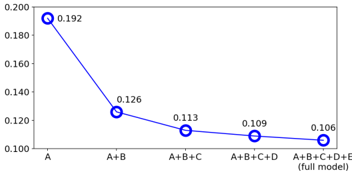
Figure 5: Distances calculated by the deep perceptual spatialaudio localization metric (DPLM) from different variations of the model. Smaller the better. A : mel spectrogram loss ( L mel ). B : adversarial-related loss ( L adv + L fm ). C : mono pretraining. D : partially-conditioned decoder. E : projection discriminator.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Line Graph: Cumulative Component Impact on Measured Value
### Overview
The image depicts a line graph illustrating a downward trend in a measured value as additional components (B, C, D, E) are added to a base component (A). The graph includes five data points connected by a blue line, with numerical values decreasing progressively from left to right. The x-axis represents incremental combinations of components, while the y-axis shows the measured value in decimal form. The final data point is labeled as the "full model" (A+B+C+D+E).
---
### Components/Axes
- **X-Axis (Horizontal)**:
- Labels: "A", "A+B", "A+B+C", "A+B+C+D", "A+B+C+D+E (full model)".
- Positioning: Left to right, with equal spacing between categories.
- **Y-Axis (Vertical)**:
- Labels: Numerical values ranging from 0.100 to 0.200 in increments of 0.020.
- Positioning: Top to bottom, with gridlines for reference.
- **Legend**:
- Not explicitly visible in the image. However, the blue line and circular markers are consistent with standard line graph conventions.
- **Data Points**:
- Blue circular markers with white centers, positioned at the following coordinates:
- (A, 0.192)
- (A+B, 0.126)
- (A+B+C, 0.113)
- (A+B+C+D, 0.109)
- (A+B+C+D+E, 0.106)
---
### Detailed Analysis
- **Trend**: The line graph shows a **consistent downward slope** from left to right, indicating a steady decline in the measured value as more components are added.
- **Data Points**:
- **A (0.192)**: Highest value, representing the base component alone.
- **A+B (0.126)**: A significant drop of 0.066 (34.8% decrease) from the base.
- **A+B+C (0.113)**: Further decrease of 0.013 (10.3% decrease) from A+B.
- **A+B+C+D (0.109)**: Minimal drop of 0.004 (3.5% decrease) from A+B+C.
- **Full Model (A+B+C+D+E, 0.106)**: Final value, a 0.003 (2.8% decrease) from the previous step.
- **Line Behavior**: The line connecting the points is smooth, suggesting a linear or near-linear relationship between component additions and the measured value.
---
### Key Observations
1. **Steep Initial Decline**: The largest drop occurs between "A" and "A+B", suggesting that adding component B has the most significant impact on reducing the measured value.
2. **Diminishing Returns**: Subsequent additions (C, D, E) result in progressively smaller reductions, indicating diminishing returns as more components are included.
3. **Full Model Value**: The final value (0.106) is the lowest, implying that the cumulative effect of all components maximizes the reduction in the measured metric.
---
### Interpretation
The graph demonstrates a **cumulative reduction effect** of adding components to a base system. The sharp decline after adding component B suggests it plays a critical role in lowering the measured value, while later components contribute less incrementally. This could imply:
- **Efficiency Gains**: If the measured value represents a cost or error rate, the full model achieves optimal performance.
- **Component Interactions**: The diminishing returns may indicate that later components have overlapping or redundant effects.
- **Model Robustness**: The full model’s value (0.106) is notably lower than the base (0.192), highlighting the importance of including all components for maximum impact.
The absence of a legend or explicit units for the y-axis limits contextual interpretation, but the trend itself is clear. The data suggests a systematic relationship between component inclusion and the target metric, with potential applications in optimization or system design.
</details>
the impact of various design choices in the proposed system by gradually adding components and calculating the DPLM distances of different model variations. Results are shown in Fig. 5. We see that all model components contribute to the DPLM metric, demonstrating the significance of our design choices.
Effectiveness of the adversarial loss. Note especially the importance of the adversarial loss for spatialization (A vs. A+B in Fig. 5). Due to the information bottleneck in the quantized audio codes, not all phase information is sufficiently maintained and reconstructable using a metric loss only. With the addition of adversarial loss, the model is able to generate a plausible phase, resulting in a significant improvement in spatialization quality. In addition, we found that the adversarial loss to be effective at capturing effects such as background noise and reverberation. This can be observed from the spectrograms shown in Figure 4. Because the decoder-only and baseline methods are trained without adversarial loss, the generated speech lacks background noise and reverb details, making the output binaural sound uncanny.
## 5. Conclusions
Wedescribed in detail an the end-to-end binaural speech synthesis system capable of (1) transmitting source monaural speech in the form of compressed speech codes, and (2) synthesizing accurate spatialized binaural speech by conditioning on source and receiver position/orientation information in virtual space. We tested our method on a real-world binaural dataset and found it to be objectively and subjectively superior to a cascade baseline. Finally, we conducted ablation studies to justify various design choices.
## 6. References
- [1] C. Hendrix and W. Barfield, 'The Sense of Presence within Auditory Virtual Environments,' Presence: Teleoper. Virtual Environ. , vol. 5, no. 3, p. 290-301, 1996.
- [2] A. Richard, D. Markovic, I. D. Gebru, S. Krenn, G. A. Butler, F. Torre, and Y. Sheikh, 'Neural Synthesis of Binaural Speech From Mono Audio,' in Proc. ICLR , 2021.
- [3] I. D. Gebru, D. Markovi´ c, A. Richard, S. Krenn, G. A. Butler, F. De la Torre, and Y. Sheikh, 'Implicit HRTF Modeling Using Temporal Convolutional Networks,' in Proc. ICASSP , 2021, pp. 3385-3389.
- [4] A. Richard, P. Dodds, and V. K. Ithapu, 'Deep impulse responses: Estimating and parameterizing filters with deep networks,' in IEEE International Conference on Acoustics, Speech and Signal Processing , 2022.
- [5] N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, 'SoundStream: An End-to-End Neural Audio Codec,' IEEE/ACM TASLP , vol. 30, pp. 495-507, 2022.
- [6] D. O'Shaughnessy, 'Linear predictive coding,' IEEE Potentials , vol. 7, no. 1, pp. 29-32, 1988.
- [7] J. Valin, M. Corporation, K. Vos, and T. Terriberry, 'Definition of the Opus Audio Codec,' 2012.
- [8] M. Dietz, M. Multrus, V. Eksler, V. Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z. Wang, L. Laaksonen, A. Vasilache, Y. Kamamoto, K. Kikuiri, S. Ragot, J. Faure, H. Ehara, V. Rajendran, V. Atti, H. Sung, E. Oh, H. Yuan, and C. Zhu, 'Overview of the EVS codec architecture,' in Proc. ICASSP , 2015, pp. 5698-5702.
- [9] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, 'Wavenet: A generative model for raw audio,' arXiv preprint arXiv:1609.03499 , 2016.
- [10] K. Kumar, R. Kumar, T. de Boissiere, L. Gestin, W. Teoh, J. Sotelo, A. de Br´ ebisson, Y . Bengio, and A. C. Courville, 'MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis,' in Proc. NeurIPS , vol. 32, 2019.
- [11] J. Kong, J. Kim, and J. Bae, 'HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,' in Proc. NeurIPS , vol. 33, 2020, pp. 17 022-17 033.
- [12] W. B. Kleijn, F. S. C. Lim, A. Luebs, J. Skoglund, F. Stimberg, Q. Wang, and T. C. Walters, 'Wavenet Based Low Rate Speech Coding,' in Proc. ICASSP , 2018, pp. 676-680.
- [13] C. Gˆ arbacea, A. v. den Oord, Y. Li, F. S. C. Lim, A. Luebs, O. Vinyals, and T. C. Walters, 'Low Bit-rate Speech Coding with VQ-VAE and a WaveNet Decoder,' in Proc. ICASSP , 2019, pp. 735-739.
- [14] K. Zhen, M. S. Lee, J. Sung, S. Beack, and M. Kim, 'Efficient And Scalable Neural Residual Waveform Coding with Collaborative Quantization,' in Proc. ICASSP , 2020.
- [15] W. B. Kleijn, A. Storus, M. Chinen, T. Denton, F. S. C. Lim, A. Luebs, J. Skoglund, and H. Yeh, 'Generative Speech Coding with Predictive Variance Regularization,' in Proc. ICASSP , 2021, pp. 6478-6482.
- [16] A. Polyak, Y. Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, 'Speech Resynthesis from Discrete Disentangled Self-Supervised Representations,' in Proc. Interspeech , 2021.
- [17] L. Savioja, J. Huopaniemi, T. Lokki, and R. V¨ a¨ an¨ anen, 'Creating Interactive Virtual Acoustic Environments,' Journal of the Audio Engineering Society , vol. 47, no. 9, pp. 675-705, 1999.
- [18] D. Zotkin, R. Duraiswami, and L. Davis, 'Rendering localized spatial audio in a virtual auditory space,' IEEE Transactions on Multimedia , vol. 6, no. 4, pp. 553-564, 2004.
- [19] K. Sunder, J. He, E. L. Tan, and W.-S. Gan, 'Natural Sound Rendering for Headphones: Integration of signal processing techniques,' IEEE Signal Processing Magazine , vol. 32, no. 2, pp. 100-113, 2015.
- [20] W. Zhang, P. Samarasinghe, H. Chen, and T. Abhayapala, 'Surround by Sound: A Review of Spatial Audio Recording and Reproduction,' Applied Sciences , vol. 7, p. 532, 05 2017.
- [21] P. Morgado, N. Nvasconcelos, T. Langlois, and O. Wang, 'SelfSupervised Generation of Spatial Audio for 360° Video,' in Proc. NeurIPS , vol. 31, 2018.
- [22] R. Gao and K. Grauman, '2.5 d Visual Sound,' in Proc. CVPR , 2019, pp. 324-333.
- [23] Y.-D. Lu, H.-Y. Lee, H.-Y. Tseng, and M.-H. Yang, 'SelfSupervised Audio Spatialization with Correspondence Classifier,' in Proc. ICIP , 2019, pp. 3347-3351.
- [24] K. Yang, B. Russell, and J. Salamon, 'Telling Left From Right: Learning Spatial Correspondence of Sight and Sound,' in Proc. CVPR , 2020.
- [25] H. Zhou, X. Xu, D. Lin, X. Wang, and Z. Liu, 'Sep-stereo: Visually guided stereophonic audio generation by associating source separation,' in Proc. ECCV , 2020.
- [26] A. van den Oord, O. Vinyals, and k. Kavukcuoglu, 'Neural Discrete Representation Learning,' in Proc. NIPS , 2017, pp. 63066315.
- [27] A. Razavi, A. Van den Oord, and O. Vinyals, 'Generating Diverse High-fidelity Images with VQ-VAE-2,' in Proc. NeurIPS , 2019.
- [28] E. Perez, F. Strub, H. De Vries, V. Dumoulin, and A. Courville, 'FiLM: Visual Reasoning with a General Conditioning Layer,' in Proc. AAAI , vol. 32, no. 1, 2018.
- [29] M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, and R. Ng, 'Fourier features let networks learn high frequency functions in low dimensional domains,' in Proc. NeurIPS , 2020, pp. 75377547.
- [30] T. Miyato and M. Koyama, 'cGANs with Projection Discriminator,' in Proc. ICLR , 2018.
- [31] C. Darwin and R. Hukin, 'Auditory objects of attention: the role of interaural time differences.' Journal of Experimental Psychology: Human perception and performance , vol. 25, no. 3, p. 617, 1999.
- [32] C. Veaux, J. Yamagishi, and K. MacDonald, 'CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit,' 2017.
- [33] P. Manocha, A. Kumar, B. Xu, A. Menon, I. D. Gebru, V. K. Ithapu, and P. Calamia, 'DPLM: A Deep Perceptual SpatialAudio Localization Metric,' in Proc. Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) , 2021, pp. 6-10.