# On the Need and Applicability of Causality for Fairness: A Unified Framework for AI Auditing and Legal Analysis
Ruta Binkyte ruta.binkyte@gmail.com CISPA, Helmholtz Center for Information Security Ljupcho Grozdanovski grozdanovski@uliege.be University of Liège Sami Zhioua sami.zhioua@gmail.com INRIA, Saclay Ile-de-France
## Abstract
As Artificial Intelligence (AI) increasingly influences decisions in critical societal sectors, understanding and establishing causality becomes essential for evaluating the fairness of automated systems. This article explores the significance of causal reasoning in addressing algorithmic discrimination, emphasizing both legal and societal perspectives. By reviewing landmark cases and regulatory frameworks, particularly within the European Union, we illustrate the challenges inherent in proving causal claims when confronted with opaque AI decision-making processes. The discussion outlines practical obstacles and methodological limitations in applying causal inference to real-world fairness scenarios, proposing actionable solutions to enhance transparency, accountability, and fairness in algorithm-driven decisions.
keywords: Fairness, Discrimination, Causality, Anti-discrimination law
## 1 Introduction
Artificial Intelligence (AI) systems increasingly shape decisions across critical sectors, including finance, employment, healthcare, and justice. While AI promises efficiency and objectivity, its deployment also raises significant concerns about algorithmic discrimination, particularly when automated decisions perpetuate biases or unjustly disadvantage specific groups. Central to addressing these concerns is establishing causality—accurately identifying whether and how discriminatory harm arises from algorithmic processes.
This article examines the challenges and opportunities involved in applying principles of causality to ensure fairness in AI-driven decision-making from both legal and technical perspectives. The core objective is to develop a unified analytical framework that integrates causal reasoning with procedural fairness, aiding courts and regulators in effectively addressing algorithmic discrimination.
To achieve this, the article first explores foundational legal principles regarding causality and fairness, emphasizing procedural safeguards essential for fair adjudication. It then critically reviews landmark cases involving AI discrimination—such as Cook vs. HSBC, Pickett, Loomis, and Ewert—to illustrate the practical difficulties of proving causation when faced with opaque AI systems.
Subsequently, the discussion delves into causal inference methodologies, highlighting their potential for establishing direct or indirect evidence of discrimination through techniques such as causal discovery algorithms, counterfactual analysis, and the but-for test. The article also evaluates recent legislative efforts, particularly the European Union’s AI Act and AI Liability Directive, analyzing their impact on evidentiary standards and procedural fairness in algorithmic discrimination cases.
Ultimately, by clearly identifying the limitations and assumptions underlying causal approaches, the article outlines practical considerations and future research directions. The proposed framework thus serves as a comprehensive resource for policymakers, legal practitioners, and AI developers committed to fostering transparency, accountability, and fairness in algorithmic decision-making.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Causal Analysis for Auditing Algorithmic Fairness
### Overview
The image is a conceptual diagram outlining a three-part framework for using causal analysis to audit algorithmic fairness. It presents a structured approach, moving from measurement to analysis and finally to legal application. The diagram is contained within a single, rounded rectangular border on a plain white background.
### Components/Axes
The diagram is organized into three distinct, horizontally aligned columns, each representing a core component of the framework. Each component consists of a bold title, a descriptive subtitle, and a representative icon.
1. **Left Column: Measuring Discrimination**
* **Title:** "Measuring Discrimination"
* **Subtitle:** "Distinguishing discrimination from spurious correlations"
* **Icon:** A blue line-art icon depicting a clipboard with a document. Superimposed on the clipboard are a magnifying glass (left) and a balance scale (right). The magnifying glass has a checkmark inside its lens.
2. **Center Column: Path Specific Analysis**
* **Title:** "Path Specific Analysis"
* **Subtitle:** "Distinguishing Explaining variables from Proxy discrimination."
* **Icon:** A purple line-art icon showing two dashed, curved arrows. The arrows originate from the left, cross over each other in the middle, and point to the right, suggesting the separation or tracing of different causal pathways.
3. **Right Column: Legal Evidence**
* **Title:** "Legal Evidence"
* **Subtitle:** "Establishing causal evidence in court."
* **Icon:** A blue line-art icon of a classical courthouse building with columns and a triangular pediment. Inside the building's facade is a prominent balance scale.
### Detailed Analysis
The diagram presents a logical progression:
* **Stage 1 (Measuring Discrimination):** The foundational step involves using causal methods to move beyond simple statistical correlation. The goal is to isolate and measure actual discriminatory effects from coincidental or spurious associations in data. The icon combines symbols of investigation (magnifying glass), documentation (clipboard), and justice (scales).
* **Stage 2 (Path Specific Analysis):** This is the analytical core. It involves decomposing the causal pathways within an algorithmic system. The purpose is to differentiate between variables that legitimately explain an outcome ("Explaining variables") and those that act as stand-ins for protected attributes, thereby enabling indirect discrimination ("Proxy discrimination"). The crossing arrows visually represent the untangling of these intertwined causal paths.
* **Stage 3 (Legal Evidence):** The final application. The results from the causal analysis are structured to form admissible evidence that can demonstrate a causal link between an algorithmic process and a discriminatory outcome in a legal setting. The courthouse icon directly symbolizes this judicial context.
### Key Observations
* The framework is linear and sequential, suggesting a process that moves from technical measurement to analytical decomposition and finally to legal justification.
* The color scheme is minimal, using blue for the first and last icons (associated with measurement and law) and purple for the central analytical step, possibly to highlight its distinct, technical nature.
* The icons are metaphorical: the magnifying glass for scrutiny, the crossing arrows for path analysis, and the courthouse for legal application. The balance scale appears in both the first and last icons, bookending the process with the theme of fairness and justice.
* The text is concise and uses technical terminology ("spurious correlations," "proxy discrimination," "causal evidence") appropriate for an audience familiar with statistics, machine learning, and law.
### Interpretation
This diagram advocates for a rigorous, causality-based methodology to address algorithmic bias. It argues that simply observing disparate outcomes is insufficient; one must *prove* a causal link to discrimination.
* **What it suggests:** The framework implies that current fairness audits may be flawed if they rely only on correlations. True fairness auditing requires dissecting the "how" and "why" of an algorithm's decisions (Path Specific Analysis) to build a defensible case (Legal Evidence).
* **Relationships:** The three components are interdependent. Measurement without specific path analysis cannot pinpoint the source of bias. Path analysis without the goal of producing legal evidence may remain an academic exercise. Legal evidence is only as strong as the causal measurement and analysis that precedes it.
* **Notable Implication:** The inclusion of "Legal Evidence" as a core component signals a proactive, compliance-oriented approach. It suggests this framework is designed not just for internal model improvement but for external accountability, potentially in response to emerging regulations (like the EU AI Act) or litigation risks. The entire process is framed as building a "causal chain" of evidence suitable for a courtroom, moving algorithmic fairness from a technical metric to a legal standard of proof.
</details>
Figure 1: Causality is crucial for auditing algorithmic fairness because it accurately identifies whether automated systems produce genuinely discriminatory outcomes or merely reflect correlations; helps to disentangle the paths relating sensitive attribute and the outcome and justifiable dependency from proxy discrimination; causal analysis aligns with causal evidence for establishing liability in court-practice.
### 1.1 Related Work
Over the last decade, causal fairness has emerged as a important approach in the quest for equitable AI. One of the most influential works in counterfactual fairness, introduced by [Kusner et al. (2017)]. They formalized the idea that a decision is fair “if it is the same in the actual world and in a counterfactual world where the individual belonged to a different demographic group” [Kusner et al. (2017)]. Building on this, subsequent research refined causal fairness notions by distinguishing fair and unfair pathways of influence. [Nabi and Shpitser (2018)] proposed defining discrimination as the presence of a causal effect of a sensitive attribute on the outcome along certain disallowed paths. Similarly, [Chiappa (2019)] introduced a method to compute path-specific counterfactual fairness, explicitly quantifying the information flow along particular causal paths and ensuring that protected attributes do not impact the outcome via forbidden channels . [Zhang and Bareinboim (2018)] further contributed a causal explanation formula to decompose observed outcome disparities into portions attributable to different causal factors, enabling one to explain and quantify unfairness in decision-making. [Loftus et al. (2018b)] argued for the importance of causal reasoning when designing fair algorithms, pointing out that purely correlation-based fairness criteria may be misleading if the data is biased by historical discrimination. [Plečko et al. (2024)] enumerates which causal assumptions are needed to test for disparate impact versus disparate treatment and connect causal fairness to legal disparate treatment framework. Carey and Wu (2022) discusses the relationship between causality-based fairness notions to legal principles, noting that many fairness criteria in machine learning echo concepts from discrimination law when interpreted causally. However, they do not link causal fairness in ML and court practice in the context of AI auditing.
### Main Contributions
This paper makes several key contributions to the study of auditing fairness in AI through a causal inference perspective. Specifically, we:
- Establish the connection between causal fairness analysis and legal frameworks. We analyze how causal methods align with judicial practices, particularly within the European legal framework, and discuss the admissibility and role of causal evidence in proving algorithmic discrimination in court.
- Consolidate the arguments for causality in fairness evaluation. We provide systematization of knowledge on scenarios where purely statistical approaches can misrepresent discrimination.
- Discuss limitations of applying causality for fairness evaluation. We critically examine assumptions such as ignorability, positivity, SUTVA, and path-specific identifiability in fairness contexts.
By bridging the gap between causal inference, fairness in AI, and legal accountability, this work provides a comprehensive framework for evaluating and mitigating algorithmic discrimination.
### Paper Structure
This paper is structured as follows. In sec:background we introduce making concepts of causality; in sec:measure we discuss when causality is crucial for reliably measuring discrimination; In sec:mediation we lay out the importance of mediation analysis in the context of fairness evaluation; In sec:legal we delve into the concept of causality in European law and court practice, and link to causal AI auditing. Finally, we conclude in sec:conclusion.
## 2 Background on Causality
In this work, we primarily adopt the structural probabilistic models framework (Pearl, 2009a) and the potential outcomes framework (Rubin, 2005). Below, we provide a technical preliminaries for causal framework and causal fairness notions.
### 2.1 Causal Graph
A causal graph, denoted as $G=(V,E)$ , is a Directed Acyclic Graph (DAG) consisting of a set of variables or nodes $V$ and edges $E$ . Each edge $X→ Y$ signifies a causal relationship, meaning changes in $X$ directly influence $Y$ . Importantly, altering $X$ impacts $Y$ , but modifying $Y$ does not affect $X$ . fig:simpleColliderJobHiring shows three basic DAG structures - confounder, mediator and collider.
### 2.2 Causal Fairness Notions
Causal fairness aims to ensure that sensitive attributes, such as race or gender, do not unfairly influence outcomes. Below, we describe key causal fairness notions and their formal definitions.
#### 2.2.1 Total Effect (TE)
Total Effect (TE) (Pearl, 2009b) is a causal fairness notion that quantifies the overall effect of a sensitive attribute $X$ on an outcome $Y$ . Formally, TE is defined as:
$$
TE_x_{1,x_0}(y)=ℙ(Y=y\mid do(X=x_1))-ℙ(Y=y\mid do(X=x_
{0})),
$$
where $do(X=x)$ denotes an intervention that sets $X$ to $x$ . TE measures the causal impact of changing $X$ from $x_0$ to $x_1$ on $Y$ across all causal paths connecting $X$ to $Y$ .
#### 2.2.2 Mediation Analysis: NDE, NIE, and PSE
Mediation analysis decomposes the causal effect of $X$ on $Y$ into direct and indirect effects. This is essential for identifying the pathways through which $X$ influences $Y$ .
Natural Direct Effect (NDE) (Pearl, 2001): The NDE quantifies the direct effect of $X$ on $Y$ , bypassing any mediators. For a binary variable $X$ with values $x_0$ and $x_1$ , the NDE is:
$$
NDE_x_{1,x_0}(y)=ℙ(y_x_{1,Z_x_0})-ℙ(y_x_
{0}),
$$
where $Z$ represents the set of mediator variables, and $ℙ(y_x_{1,Z_x_0})$ is the probability of $Y=y$ if $X$ is set to $x_1$ while the mediators are set to values they would take under $X=x_0$ .
Natural Indirect Effect (NIE) (Pearl, 2001): The NIE captures the influence of $X$ on $Y$ through mediators. It is given by:
$$
NIE_x_{1,x_0}(y)=ℙ(y_x_{0,Z_x_1})-ℙ(y_x_
{0}),
$$
where $ℙ(y_x_{0,Z_x_1})$ represents the probability of $Y=y$ when $X=x_0$ but mediators take values they would under $X=x_1$ .
Path-Specific Effect (PSE) (Pearl, 2009b; Chiappa, 2019; Wu et al., 2019): The PSE isolates the causal effect of $X$ on $Y$ transmitted through a specific path or set of paths $π$ . Formally, it is defined as:
$$
PSE^π_x_{1,x_0}(y)=ℙ(y_x_{1\mid_π,x_0\mid_\overline{
π}})-ℙ(y_x_0),
$$
where $ℙ(y_x_{1\mid_π,x_0\mid_\overline{π}})$ is the probability of $Y=y$ if $X=x_1$ along path $π$ , while other paths ( $\overline{π}$ ) remain unaffected by the intervention.
## 3 When Causality is Needed for Reliably measuring discrimination?
Measuring discrimination without accounting for the underlying causal structure of variable relationships can lead to misleading conclusions and biased estimations of discrimination. In extreme cases, such as Simpson’s paradox, this bias can even reverse conclusions—for example, a biased estimation may suggest positive discrimination when, in reality, an unbiased analysis would reveal negative discrimination.
Figures 4 - 4 illustrate the three fundamental causal structures that can result in statistical anomalies, making common fairness metrics unreliable.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Directed Acyclic Graph (DAG): Causal Model of SES, Political Belief, and Job Hiring
### Overview
The image displays a simple directed acyclic graph (DAG), a type of diagram used in statistics, causal inference, and social sciences to represent hypothesized causal relationships between variables. The diagram consists of three nodes (variables) connected by three directed arrows (causal paths), forming a triangular structure.
### Components/Axes
The diagram has three labeled nodes, each represented by a black dot with text labels:
1. **Node A (Bottom-Left):**
* **Label:** `A`
* **Description:** `Political Belief`
* **Position:** Bottom-left corner of the triangular layout.
2. **Node Z (Top-Center):**
* **Label:** `Z`
* **Description:** `SES (Socio-Economic Status)`
* **Position:** Top-center, forming the apex of the triangle.
3. **Node Y (Bottom-Right):**
* **Label:** `Y`
* **Description:** `Selection for Job Hiring`
* **Position:** Bottom-right corner.
**Directed Arrows (Causal Paths):**
* An arrow originates from **Z** and points to **A**.
* An arrow originates from **Z** and points to **Y**.
* An arrow originates from **A** and points to **Y**.
### Detailed Analysis
The diagram explicitly defines the following causal relationships:
1. **Z → A:** Socio-Economic Status (SES) is modeled as a cause of Political Belief.
2. **Z → Y:** Socio-Economic Status (SES) is modeled as a direct cause of Selection for Job Hiring.
3. **A → Y:** Political Belief is modeled as a cause of Selection for Job Hiring.
This structure implies that **Z (SES)** is a common cause (a confounder) for both **A (Political Belief)** and **Y (Job Hiring)**. The path **Z → A → Y** represents an *indirect effect* of SES on job hiring that is mediated through political belief.
### Key Observations
* **No Reverse Causality:** All arrows are unidirectional. The model does not allow for feedback loops (e.g., job hiring outcome affecting political belief or SES).
* **No Direct Link from A to Z:** The model assumes political belief does not influence one's socio-economic status.
* **Complete Mediation Assumption:** The model suggests that the *only* way political belief (A) affects job hiring (Y) is directly (A → Y). It does not account for political belief potentially influencing SES, which in turn influences hiring.
* **Visual Clarity:** The triangular layout cleanly separates the three variables and makes the two distinct pathways from Z to Y (one direct, one indirect via A) immediately apparent.
### Interpretation
This diagram is a formal representation of a causal hypothesis, likely used to frame a research question or analysis in social science, economics, or public policy. It suggests that when studying the effect of political belief on job hiring outcomes, one must account for socio-economic status as a confounding variable. SES influences both the belief itself and the hiring outcome independently.
The model implies that any observed correlation between political belief and hiring success could be partially or wholly due to the underlying influence of SES, rather than being a direct causal relationship. To isolate the true effect of political belief (A → Y), a researcher would need to "control for" or adjust for the variable Z (SES) in their analysis. This is a classic setup for discussing selection bias or confounding in observational studies.
</details>
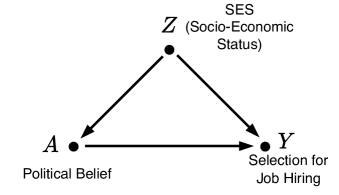
Figure 2: Confounder structure.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Directed Acyclic Graph (DAG): Causal Model of College Admission
### Overview
The image displays a simple directed acyclic graph (DAG) or causal diagram. It consists of three nodes (represented by black dots) connected by three directed arrows, forming a triangular structure. The diagram illustrates hypothesized causal relationships between three variables: Gender, Department, and Admission in College.
### Components/Axes
The diagram has no traditional axes, legends, or scales. Its components are nodes and directed edges (arrows).
**Nodes (Variables):**
1. **Node A**: Located at the bottom-left of the diagram. It is labeled with the letter "**A**" and the descriptive text "**Gender**".
2. **Node M**: Located at the top-center of the diagram. It is labeled with the letter "**M**" and the descriptive text "**Department**".
3. **Node Y**: Located at the bottom-right of the diagram. It is labeled with the letter "**Y**" and the descriptive text "**Admission in College**".
**Directed Edges (Arrows):**
1. An arrow originates from **Node A (Gender)** and points to **Node M (Department)**.
2. An arrow originates from **Node M (Department)** and points to **Node Y (Admission in College)**.
3. An arrow originates from **Node A (Gender)** and points directly to **Node Y (Admission in College)**.
### Detailed Analysis
The diagram is a visual representation of a causal model. The arrows indicate the direction of hypothesized influence or causation.
* **Path 1 (Indirect Effect):** `A (Gender) → M (Department) → Y (Admission in College)`. This path suggests that Gender may influence which Department a person applies to or is assigned to, and that Department, in turn, influences the likelihood of Admission.
* **Path 2 (Direct Effect):** `A (Gender) → Y (Admission in College)`. This path suggests a direct influence of Gender on Admission outcomes, independent of Department.
The structure implies that the variable "Department" (M) is a potential **mediator** for the effect of "Gender" (A) on "Admission" (Y). It also allows for a direct effect of Gender on Admission.
### Key Observations
1. **Triangular Structure:** The three nodes form a closed triangle, indicating a system where all variables are interconnected.
2. **Dual Pathways:** There are two distinct pathways from Gender (A) to Admission (Y): one direct and one indirect via Department (M).
3. **No Confounding Shown:** The diagram does not include any "backdoor" paths or common causes (confounders) influencing more than one variable. It presents a simplified, clean causal structure.
### Interpretation
This diagram is a foundational tool in causal inference, likely used to frame a research question or statistical analysis about bias in college admissions.
* **What it Suggests:** The model posits that observed differences in admission rates between genders could be explained by two mechanisms: (1) a direct bias in the admission process itself, and/or (2) an indirect bias where gender influences department choice, and department choice then influences admission chances (e.g., if some departments are more competitive or have different acceptance rates).
* **Why it Matters:** This framework is critical for designing a fair analysis. To isolate the *direct* effect of gender on admission (the `A → Y` arrow), a researcher would need to statistically control for or stratify by Department (M). Failing to account for the mediating path (`A → M → Y`) could lead to incorrect conclusions about the presence or magnitude of direct discrimination.
* **Underlying Assumption:** The diagram assumes no unmeasured confounding variables (e.g., socioeconomic status, academic preparation) that affect both Department choice and Admission outcomes. In a real-world scenario, such variables would likely exist and would need to be added to the model for a more accurate representation.
</details>
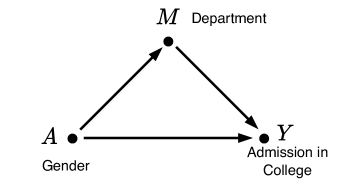
Figure 3: Mediator structure.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Causal Diagram: Political Belief, Job Hiring, and Labor Union Activism
### Overview
The image displays a directed acyclic graph (DAG) or causal diagram illustrating hypothesized relationships between three variables: Political Belief, Selection for Job Hiring, and Labor Union Activism. The diagram uses nodes (points) and directed edges (arrows) to represent causal or influential pathways.
### Components/Axes
The diagram consists of three labeled nodes and three directed arrows connecting them.
**Nodes (Variables):**
1. **A**: Located at the top-left. Labeled "Political Belief".
2. **Y**: Located at the top-right. Labeled "Selection for Job Hiring".
3. **W**: Located at the bottom-center, enclosed within a square box. Labeled "Labor Union Activism".
**Directed Edges (Arrows):**
1. An arrow originates from node **A** and points directly to node **Y**.
2. An arrow originates from node **A** and points directly to node **W**.
3. An arrow originates from node **Y** and points directly to node **W**.
### Detailed Analysis
The diagram presents a specific causal structure:
* **Political Belief (A)** is positioned as an exogenous variable, influencing both **Selection for Job Hiring (Y)** and **Labor Union Activism (W)**.
* **Selection for Job Hiring (Y)** is an intermediate variable, influenced by **A** and in turn influencing **W**.
* **Labor Union Activism (W)** is the endogenous outcome variable, influenced by both **A** and **Y**. The square box around **W** may signify it is the primary dependent variable or outcome of interest in the model.
The flow of influence is unidirectional: A → Y → W, with an additional direct path from A → W. This creates a triangular structure where A has both a direct effect on W and an indirect effect on W mediated through Y.
### Key Observations
1. **Model Structure**: This is a classic mediation model diagram. It suggests that the effect of Political Belief on Labor Union Activism is partially mediated by the Selection for Job Hiring process.
2. **Variable Roles**: The diagram explicitly defines the roles: A is a predictor, Y is a mediator, and W is an outcome.
3. **Visual Emphasis**: The variable **W (Labor Union Activism)** is uniquely highlighted with a surrounding box, drawing attention to it as the focal point of the analysis.
### Interpretation
This diagram represents a theoretical or statistical model, likely from social science research (e.g., political science, sociology, labor economics). It proposes a specific hypothesis about how individual political beliefs translate into labor activism.
The model suggests two pathways:
1. **Direct Path**: A person's political belief directly influences their propensity for labor union activism.
2. **Indirect (Mediated) Path**: A person's political belief influences the hiring selection process they experience (or perhaps the type of job/sector they enter), which in turn influences their level of labor union activism.
The inclusion of the mediated path implies that the hiring process is not a neutral event but is itself shaped by political beliefs, and this filtered experience subsequently affects activist behavior. The diagram does not provide empirical data but outlines a conceptual framework for testing these relationships statistically (e.g., using regression analysis or structural equation modeling). The absence of numerical values indicates this is a schematic representation of a theory, not a presentation of results.
</details>
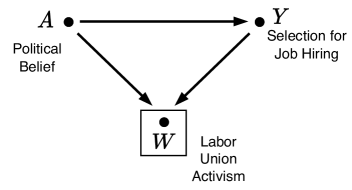
Figure 4: Collider structure.
### 3.1 Confounder structure
The first scenario in which ignoring the causal structure of the data can lead to an unreliable estimation of discrimination arises from failing to account for a confounding variable. Consider the hypothetical example in Figure 4, which depicts an automated system used to select candidates for job positions.
Suppose the system takes two input features: socio-economic status (SES), denoted as $Z$ , and the candidate’s political belief, denoted as $A$ . The outcome, $Y$ , represents whether the candidate is selected for the next stage of hiring (or the probability of selection). The SES influences the hiring outcome because candidates from higher SES backgrounds may have greater access to reputable academic institutions and expensive training programs.
Both SES ( $Z$ ) and political belief ( $A$ ) can be either binary (e.g., rich vs. poor for SES, liberal vs. conservative for political belief) or continuous (e.g., the degree of wealth for SES and the extent of conservatism for political belief). In this example, we assume that a candidate’s political belief is influenced solely by their SES.
Now, suppose the automated decision system is suspected of being biased against candidates with a particular political belief. The claim is that the system is more likely to select candidates who hold a specific political ideology. However, failing to account for the confounding effect of SES may lead to incorrect conclusions about whether the system is truly biased.
A simple approach to assessing the fairness of the automated selection process, represented by $Y$ , with respect to the sensitive attribute $A$ , is to compare the conditional probabilities:
$$
ℙ(Y=1\mid A=0) and ℙ(Y=1\mid A=1)
$$
This comparison, known as statistical disparity, quantifies the difference in selection rates between the two groups (e.g., conservatives and liberals). However, such an estimation of discrimination is biased due to the confounding effect of $Z$ .
Since $Z$ influences both the sensitive variable $A$ and the outcome $Y$ , it introduces a correlation between $A$ and $Y$ that is not causal. In other words, candidates with a high socio-economic status (SES) are more likely to have conservative political beliefs and, at the same time, have a higher probability of being selected due to their access to better academic institutions and training opportunities. This results in an observed correlation in the data: employers will see a greater proportion of candidates with conservative political beliefs and a lower proportion of those with liberal beliefs. However, this correlation is driven by the confounder $Z$ and should not be misinterpreted as discrimination.
Most statistical fairness metrics, such as equal opportunity and predictive parity, fail to account for such confounding effects, making them unsuitable for measuring discrimination in the presence of these statistical anomalies.
### 3.2 Mediator structure
The second scenario in which failing to account for the causal structure of data leads to unreliable discrimination estimation arises from the presence of one or more mediator variables. The core issue is whether discrimination transmitted through a mediator variable should be considered justifiable or not. Similar to confounding structures, a mediator variable can result in Simpson’s paradox.
A well-known example of Simpson’s paradox caused by a mediator structure is the gender bias observed in the 1973 Berkeley graduate admissions study (Bickel et al., 1975; Loftus et al., 2018a). Figure 4 illustrates the causal graph underlying the data, where the sensitive variable ( $A$ ) represents gender, the outcome ( $Y$ ) represents admission to Berkeley graduate programs, and a single mediator variable ( $M$ ) represents the department to which a candidate applied.
In 1973, 44% of male applicants were admitted, compared to only 34% of female applicants. At first glance, this appears to indicate a bias against female candidates. However, when the data was analyzed separately by department, acceptance rates were found to be approximately equal across genders.
In a simple mediator structure, there are two possible causal paths from $A$ to $Y$ : a direct path, $A→ Y$ , and an indirect path, $A→ M→ Y$ . Comparing the overall admission rates of male and female candidates considers both paths in the discrimination measure. In contrast, comparing admission rates within each department isolates only the direct path, $A→ Y$ . Consequently, whether or not to account for mediator paths when measuring discrimination can lead to contradictory conclusions, as demonstrated by Simpson’s paradox.
### 3.3 Collider structure
A biased estimation of discrimination can also arise due to the presence of a common effect (collider) variable and implicit conditioning on that variable during the data generation process. Using the same hypothetical job selection example, consider the causal graph in Figure 4, where $A$ and $Y$ retain the same meanings as in the previous example.
Assume that the data used to train the automated decision system is collected from various sources, but primarily from labor union records. Let $W$ represent a candidate’s labor union activism, which is influenced by both $A$ and $Y$ . On one hand, political belief ( $A$ ) affects whether a candidate becomes an active labor union member, as individuals with liberal political beliefs are more likely to join labor unions. On the other hand, if a candidate is selected (hired), they are more likely to become a labor union member, increasing the likelihood that their case appears in labor union records. Following prior work, a box around a variable ( $W$ ) indicates that data is implicitly conditioned on that variable during the data collection process.
Once again, the simple approach of comparing selection rates between the two groups (conservatives and liberals) leads to a biased estimation of discrimination due to the colliding path through $W$ . Intuitively, an individual appears in the collected data either because they hold liberal political beliefs or because they were selected for the job. Candidates who are both liberal and selected remain in the data, but conditioning on labor union activism introduces a non-causal correlation between $A$ and $Y$ . Specifically, the dataset drawn from labor union records includes fewer liberal candidates who were selected for the job compared to conservative candidates. This pattern may misleadingly suggest discrimination against liberal candidates. However, this correlation arises from the collider structure and should not be mistaken for actual discrimination.
## 4 Mediation Analysis for Disentangling Explaining Variables and Proxy Discrimination
<details>
<summary>x5.png Details</summary>
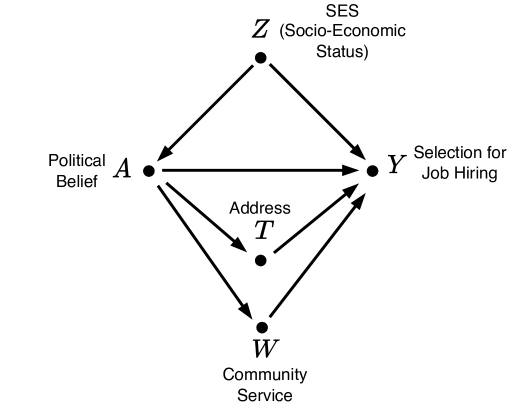
### Visual Description
## Directed Acyclic Graph (DAG): Causal Model of Job Hiring Selection
### Overview
The image displays a directed acyclic graph (DAG), a type of causal diagram used in statistics and social sciences to represent hypothesized causal relationships between variables. The diagram consists of five nodes (variables) connected by directed arrows (causal paths). The layout is hierarchical, with one variable at the top, two in the middle tier, and two in the lower tier.
### Components/Axes
The diagram contains five labeled nodes and seven directed arrows. There are no numerical axes, scales, or legends as this is a conceptual model, not a data chart.
**Nodes (Variables):**
1. **Z** (Top-center): Labeled "SES (Socio-Economic Status)".
2. **A** (Middle-left): Labeled "Political Belief".
3. **Y** (Middle-right): Labeled "Selection for Job Hiring".
4. **T** (Lower-center, below A): Labeled "Address".
5. **W** (Bottom-center): Labeled "Community Service".
**Directed Arrows (Causal Paths):**
The arrows indicate the direction of hypothesized causal influence.
* From **Z** to **A**.
* From **Z** to **Y**.
* From **A** to **Y**.
* From **A** to **T**.
* From **A** to **W**.
* From **T** to **Y**.
* From **W** to **Y**.
### Detailed Analysis
The graph structures the relationships between the five variables as follows:
* **Z (SES)** is positioned as an exogenous variable (no incoming arrows). It has direct causal paths to both **A (Political Belief)** and **Y (Selection for Job Hiring)**.
* **A (Political Belief)** is a central node with multiple outgoing paths. It is influenced by **Z** and, in turn, influences **Y**, **T (Address)**, and **W (Community Service)**.
* **Y (Selection for Job Hiring)** is the primary outcome variable. It receives direct causal inputs from four other variables: **Z**, **A**, **T**, and **W**.
* **T (Address)** and **W (Community Service)** are intermediate variables. They are both influenced by **A** and both directly influence **Y**. They do not have a direct connection to each other.
### Key Observations
1. **Multiple Pathways to Outcome:** The outcome variable **Y** is influenced by four distinct direct causes.
2. **Central Role of Political Belief (A):** Variable **A** acts as a key mediator and confounder. It is influenced by **Z** and transmits that influence to **Y** through three separate pathways: directly, via **T**, and via **W**.
3. **Confounder Structure:** **Z (SES)** is a common cause of both **A** and **Y**, making it a potential confounder for the relationship between **A** and **Y** if not controlled for.
4. **Mediator Chain:** There is a clear mediator chain: **A → T → Y** and **A → W → Y**. This suggests that Political Belief may affect job hiring outcomes indirectly through its influence on an individual's Address and Community Service activities.
### Interpretation
This DAG represents a theoretical model for investigating factors that influence job hiring selection. It posits that Socio-Economic Status (SES) has both a direct effect on hiring and an indirect effect through shaping Political Belief. Political Belief itself is modeled as having a direct effect on hiring, as well as indirect effects mediated by a person's residential Address and their involvement in Community Service.
The diagram is a tool for research design. It helps identify which variables must be measured and controlled for to estimate the "true" causal effect of one variable on another. For example, to study the direct effect of Political Belief (A) on Hiring (Y), a researcher would need to statistically control for SES (Z) to block the confounding path Z → A and Z → Y. They might also need to consider whether Address (T) and Community Service (W) are mediators (part of the causal pathway) or confounders (common causes of A and Y), which would require different analytical approaches. The model suggests that simply observing a correlation between Political Belief and Hiring outcomes could be misleading without accounting for these complex interrelationships.
</details>
Figure 5: Causal graph with two mediated paths.
In the presence of one or more mediator variables, it is important to determine how much of the observed discrimination is direct and how much is mediated. More specifically, understanding the extent to which discrimination is transmitted through each mediator variable is crucial. Mediation analysis aims to distinguish the different causal pathways through which discrimination propagates and quantify the proportion of discrimination conveyed through each path.
Consider a variation of the job hiring example, illustrated in Figure 5, which includes two mediator variables: address ( $T$ ) and community service participation ( $W$ ). In this scenario, there are four distinct causal paths from the sensitive variable $A$ (political belief) to the outcome variable $Y$ (job hiring):
- $A← Z→ Y$ : confounding path
- $A→ Y$ : direct path
- $A→ T→ Y$ : indirect path through $T$
- $A→ W→ Y$ : indirect path through $W$ .
The first confounding path is non-causal, meaning that any effect transmitted through it should not be considered when estimating discrimination. As discussed in Section 3.1, this spurious effect arises from the way data is generated or collected and, therefore, should not be counted as actual discrimination.
The direct path exists whenever there is an edge between $A$ and $Y$ . The effect through $A→ Y$ is always discriminatory—it can never be justified or considered acceptable discrimination.
The two remaining paths are indirect paths passing through mediator variables. Whether discrimination along an indirect path is justifiable depends on the nature of the mediator variable. For instance, in the job hiring example shown in Figure 5, $T$ (home address) acts as a mediator because, on one hand, political inclination may influence where a candidate lives, and on the other hand, hiring decisions may be influenced by a candidate’s address. Similarly, $W$ (community service) is a mediator because a candidate’s political beliefs may impact their level of involvement in community service, while an employer may consider community service records as an indicator of suitability for a given position.
Discrimination along the path $A→ W→ Y$ can be considered justifiable, as an employer may argue that disparities between candidates with different political beliefs arise from differences in their community service records. However, discrimination through the path $A→ T→ Y$ is typically not acceptable, as an employer cannot justify hiring decisions based on candidates’ addresses. In this context, $T$ is referred to as a proxy variable, whereas $W$ is called an explaining variable. If a single causal path consists of two or more mediator variables, the presence of at least one explaining variable among the mediators makes discrimination along that path justifiable and, therefore, acceptable.
Causality, through the concepts of intervention and counterfactual reasoning, provides the necessary tools to distinguish between different types of discrimination based on their causal pathways. By intervening on $A$ , all paths that include an incoming edge to $A$ —such as confounding paths between $A$ and $Y$ —are blocked. Discrimination transmitted through causal paths is quantified by the total effect ( $TE$ ) ( eq:TE). In the causal graph depicted in Figure 5, the $TE$ expression captures discrimination along all causal paths except for the non-causal confounding path $A← Z→ Y$ .
To distinguish between direct and indirect discrimination, two key expressions can be used: the natural direct effect ( $NDE$ ) (eq:NDE) and the natural indirect effect ( $NIE$ ) (eq:NIE) (Pearl, 2001). Intuitively, $NDE$ is counterfactual quantity because it corresponds to a candidate who is conservative ( $A=1$ ) along the direct path $A→ Y$ but liberal ( $A=0$ ) along all indirect paths. This isolates the direct effect of $A$ on $Y$ while holding indirect pathways constant.
Here, $NIE$ represents the probability of a counterfactual situation where $Y=y^\scriptscriptstyle+$ had $A$ been $0 0$ along the direct path while indirect path took the value it would naturally have if $A=1$ . This captures the portion of discrimination that is mediated through indirect paths.
Finally, discrimination conveyed through specific indirect paths can be identified using the path-specific effect ( $PSE$ ) (eq:PSE) (Pearl, 2001; Chiappa, 2019). For example, $PSE$ quantifies the extent to which a sensitive attribute influences a decision through the mediator ’address’ compared to the mediator ’community service.’ This has direct implications for fairness assessment.
Mediation analyis allows for a more granular analysis of discrimination by isolating the contribution of specific causal pathways, enabling a deeper understanding of the mechanisms through which bias is propagated in automated decision-making systems.
## 5 Uncovering causality through legal evidence: the regulatory approach in the European Union
The method of using mediator structures to uncover causation, as discussed in the previous section, is undoubtedly a valuable model for establishing causality in judicial cases involving algorithmic discrimination. However, an important question arises: does procedural law, particularly within the European Union (EU), support such an analysis?
As a preliminary observation, it is essential to clarify that in legal contexts, the term causal fairness generally refers to the procedural conditions under which instances of fairness (or unfairness) are causally represented. With this in mind, this section focuses on two critical and interrelated issues: evidence and procedural fairness. In the EU, the Independent High-Level Expert Group on AI, established by the European Commission, defines procedural fairness as the ability to contest and seek effective redress against decisions made by AI systems and their human operators. See HLEG, Ethics Guidelines for Trustworthy AI, available at https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai, p. 13.
From a legal perspective, causality is a question of fact, requiring legally established discovery procedures and corresponding reasoning models designed to yield accurate causal representations—i.e., to distinguish genuine causation from a myriad of correlations (positive associations between candidate causes and a harm suffered) (Haack, 2014).
However, in adjudicatory contexts, causality is established primarily to serve the purpose of fairness, typically in the form of compensation as a fair remedy for harm suffered. Legal systems committed to the rule of law In the EU, the concept of the rule of law encompasses the following principles: legality, legal certainty, prohibition of arbitrariness by executive powers, independent and impartial courts, effective judicial review (including respect for fundamental rights), and equality before the law. See Communication from the Commission to the European Parliament and the Council, ‘A New EU Framework to Strengthen the Rule of Law,’ COM(2014) 158 final, p. 4. share a commitment to procedural fairness, based on the normative principle that only fairly designed procedures can lead to fair outcomes.
In contemporary systems of evidence and judicial remedies, including those within EU law, the parallelism between fair procedures and fair outcomes is epitomized in fair trial safeguards. These procedural entitlements are intended to uphold basic equality (or procedural parity) and ensure the effectiveness of litigants’ participation in dispute resolution (Solum, 2004). This principle applies not only to equal access to judicial remedies but also to equal access to and the ability to present evidence. The fundamental idea is that neither party should be advantaged or disadvantaged in terms of access to the facts necessary to present their case—typically before a court.
In summary, causal fairness in law requires accurate—or at the very least, plausible (Rescher, 1980) —evidence of causality, presented under conditions of procedural fairness.
The proof of causality in cases of algorithmic discrimination has profoundly challenged longstanding legal postulates. From a procedural fairness perspective, a major issue arises from the opacity—whether relative or total—of AI systems, which renders their decision-making processes inscrutable and obstructs victims’ ability to properly establish and argue causation.
One prominent example in this regard is Cook v. HSBC North America, U.S. District Court for the Northern District of Illinois, 21 March 2014, County of Cook v. HSBC North America Holdings Inc et al., 1:2014cv02031. a credit scoring case in which the system used applicants’ places of residence as a relevant variable, ultimately favoring predominantly white neighborhoods while discriminating against ethnic minorities. The association of subtly discriminatory variables—such as zip code and ethnic background—combined with practical difficulties in accessing information about how the AI system weighted different variables, severely undermined fundamental fair trial safeguards, particularly the right to access evidence and courts.
To address these challenges, regulators worldwide, including in the EU, have sought to answer two key questions:
1. What evidence must litigants have access to in order to effectively prove causation?
1. Once that evidence is identified, how should legal procedures be (re)designed to ensure victims’ access to it?
These questions are central to ensuring that legal systems remain capable of addressing algorithmic discrimination while upholding principles of procedural fairness.
### 5.1 Methods for Establishing Causality in Algorithmic Discrimination Cases
Regarding the first question, emerging—though not yet consolidated—global AI liability case law reveals an interesting trend. While numerous judicial instances could be citepd, for the purpose of this article, we highlight three cases that illustrate the ‘new approach’ to proving causation in AI-related disputes. These cases are Pickett, Superior Court of New Jersey (Appellate Division), 2 February 2021, State of New Jersey v. Corey Pickett, Docket N° A-4207-19T4. (which concerns the use of a DNA matching system—TrueAllele—by law enforcement to track down suspects), Loomis, Supreme Court of Wisconsin, 13 July 2016, State of Wisconsin v. Eric L. Loomis, 881 N.W.2d 749 (2016) 2016 WI 68. (which involves COMPAS, a recidivism-prediction system used by courts), and Ewert, Ewert v. Canada, 2018 SCC 30, File N° 37233, 13 June 2018. (which also deals with the use of recidivism-predicting systems by Canadian correctional services).
In all three cases, the plaintiffs argued that the automated decisions were inaccurate because they were unfair—that is, they contained unfair biases: gender bias in Pickett and Loomis, and ethnic bias in Ewert. To uncover the bias-inducing variable associations (i.e., the causal link), the plaintiffs requested that the systems be reverse-engineered. However, this proved nearly impossible. For instance, in Pickett, independent experts confirmed that reverse-engineering the system would take up to 8.5 years to complete. See Superior Court of New Jersey (Appellate Division), 2 February 2021, State of New Jersey v. Corey Pickett, Docket N° A-4207-19T4, at 17. The emerging field of mechanistic interpretability offers methods to inspect models, such as LLMs internal representations without full reverse engineering (Bereska and Gavves, 2024). However, the causal relationship between concepts and representations is hard to establish and is still an open problem for the future research (Sharkey et al., 2025; Binkyte et al., 2025).
Faced with the practical infeasibility of reverse-engineering, the courts in Pickett (and in Loomis) turned to general expertise as a faute de mieux solution. The absence of direct evidence (through reverse-engineering) that could reveal unfair bias was ‘compensated’ by relying on pre-existing expert assessments of the system’s general functionality. If the majority of experts agreed that a system—such as TrueAllele in Pickett or COMPAS in Loomis —was generally well-performing (i.e., unbiased and therefore accurate), courts were inclined to presume that the system’s decisions in the specific cases under dispute were also unbiased.
Thus, the role of experts is to assess the strength of the causal link between sensitive variables and the decision. In the presence of different causal structures (Section 3), which may lead to various types of bias, a zero causal effect would indicate the absence of discrimination. A possible approach to uncovering this causal link is to first identify the causal graph that represents the relationships between variables. This can be achieved by:
1. Using causal discovery techniques to infer an initial causal graph.
1. Consulting domain experts to refine the discovered graph—such as adding or removing causal links and enforcing domain-specific assumptions.
Expert input is also essential for clarifying the role of each variable, particularly in classifying mediator variables as either explaining (leading to justifiable discrimination) or proxy (leading to unjustifiable discrimination) variables. This classification is crucial for selecting the appropriate causal fairness metric (Section 4) to assess discrimination.
From the perspectives of procedural fairness and the mediator structure model, this trend is open to criticism. First, general expert opinions on a system’s accuracy are not as probative as direct evidence (such as reverse engineering), which could provide highly reliable information on the mediator associations leading to a discriminatory outcome. Second, the inability to prove causation through reliable evidence appears to have led to a peculiar application of the so-called but-for test.
In principle, the but-for test employs counterfactual reasoning to determine whether a harm would have occurred if an alleged cause had not been present. For example, in Cook v. HSBC (a credit scoring case), a standard application of this test would involve determining whether the same loan applicants would have been approved had the system not considered their place of residence as a relevant variable.
However, the cases cited in this section (particularly Pickett and Loomis) reveal a shift in how the but-for test is applied. In conventional (non-AI-related) disputes, the test seeks to answer a factual question about causal association: would the outcome have been the same (or different) if certain facts (such as address, gender, or age) were absent from the causal structure? In AI-related disputes, however, the but-for test is reframed to address a different causal question: would a human decision relying on AI output have been the same or different if the AI system had not been used at all?
In this context, statistical causality tools can be applied to detect discrimination in data reflecting previous hiring or loan-granting practices within the company. If an association between the sensitive attribute and the outcome is identified, one can infer that the decision would remain the same even without algorithmic assistance. This shifts the focus from scrutinizing the AI system (and its designers) to assessing broader company practices. Here, causality analysis helps differentiate between spurious associations, explainable disparities, and actual discrimination.
Conversely, if the data used to train the AI system contains ingrained discrimination, compliance with AI design guidelines warrants further examination. Finally, causality tools offer formal mathematical expressions that capture the otherwise intangible concept of counterfactual reasoning (Shpitser and Pearl, 2007, 2008), making them particularly useful for directly verifying the but-for test.
This allows us to raise the second issue mentioned above: should systems of evidence include a right to access/to request disclosure of evidence?
### 5.2 Disclosing causal evidence to victims of discrimination
Given these practical and theoretical challenges associated with the but-for test and counterfactual reasoning in AI-related discrimination cases, an important question emerges regarding how evidence disclosure mechanisms might facilitate fairer judicial outcomes. In particular, should litigants possess a specific right to access evidence that would allow effective causal analysis? From a procedural fairness perspective, the right to request evidence disclosure is crucial for a victim of algorithmic discrimination, providing at least an opportunity to seek the lifting of the opacity veil that may obscure a causal chain (Grozdanovski, 2021). In the EU, recent regulatory developments appear—at least on the surface—to be moving toward recognizing such a right.
The first major step was the introduction of the AI Act, Proposal for a Regulation of the European Parliament and of the Council laying down harmonized rules on Artificial Intelligence (AI Act) and amending certain Union legislative acts, COM(2021) 206 final. a horizontal, cross-sectoral legislation that makes two significant contributions. First, it establishes a four-level taxonomy of AI-related risks: non-high, limited, high, and unacceptable. Second, based on this risk classification, the AI Act introduces a set of technical standards—including transparency, data governance, and risk-mitigation strategies—specifically targeting high-risk AI systems deployed in eight key market sectors. The ‘high-risk’ sectors, listed in Annex III of the AI Act, include employment, education, healthcare, transport, energy, public sector (including asylum, migration, border controls, judiciary, and social security services), defense and security, finance, banking, and insurance.
To complement the AI Act and to provide procedural avenues for compensating harm caused by high-risk AI systems, the EU introduced the AI Liability Directive (AILD). Proposal for a Directive of the European Parliament and of the Council on adapting non-contractual civil liability rules to Artificial Intelligence (AI Liability Directive), COM(2022)496 final. This directive establishes an evidentiary framework granting victims the right to request disclosure of evidence. Under the AILD, if the defendant (a programmer or user) refuses to disclose the requested evidence, or if a national or EU court finds that the disclosed evidence is both probative and plausible, the defendant is presumed responsible for the harm (e.g., discrimination) suffered by the claimant.
However, it is important to note that the type of evidence a victim may request under the AILD does not include the kind of evidence previously identified as necessary (i.e., expert analysis) in the cases discussed earlier. The AILD permits disclosure only of evidence related to the defendant’s compliance with the technical standards outlined in the AI Act. In other words, defendants would not be required to provide information such as access to the AI system’s code or, where feasible, allow for reverse engineering to support a proper causal analysis. Instead, they would merely be asked to demonstrate compliance with obligations such as ensuring human oversight and control.
The rationale behind this limitation is that the AILD operates under the assumption that if harm—such as discrimination—occurs, it is because the AI Act was not fully adhered to. As a result, the AILD effectively narrows the scope of evidentiary debates in AI discrimination cases. Instead of compelling parties to uncover the actual causal structure underlying a discriminatory AI outcome, legal proceedings will primarily focus on identifying the human agent who failed to meet a legally prescribed duty of care.
## 6 Challenges and Opportunities in Using Causality for Fairness
While recent regulatory developments such as the AI Act and AI Liability Directive represent significant progress in addressing algorithmic discrimination, their implementation relies fundamentally on the practical feasibility of causal analysis. Thus, understanding the methodological constraints and opportunities of causal inference becomes essential to ensure that regulatory efforts lead to meaningful improvements in fairness. Many causal requirements can, in principle, be satisfied through specific experimental designs—ideally, through random assignment. However, in fairness-related scenarios, such experimental setups are often impractical or ethically infeasible. As a result, discrimination is typically evaluated using observational data.
In this section, we outline some key requirements for applying causal inference, particularly those most relevant to fairness applications.
### 6.1 Availability of Causal Graph
The effective use of causal inference in fairness applications is shaped by several critical methodological requirements and assumptions. Among these, one of the most significant is the availability of an accurate directed acyclic graph (DAG) representing relationships among variables. The DAG is subject to additional assumptions, including the causal Markov condition, causal faithfulness, and causal sufficiency. Together, these conditions encode the same requirements as SUTVA and ignorability in the potential outcome framework and, therefore, will not be discussed separately. (Pearl, 2009a). Research by (Binkytė-Sadauskienė et al., 2022) highlights significant disagreements in causal fairness estimations due to minor variations in the assumed causal structure.
The availability of a DAG is particularly crucial in the presence of collider structures, as conditioning on a collider induces bias in causal effect estimation (Pearl, 1988). Additionally, DAGs are essential for evaluating path-specific effects, which play a key role in distinguishing between redlining and explaining variables in fairness scenarios.
Causal structures (or causal graphs) can be obtained through two main approaches: expert consultation or learning from observational data. However, both approaches have limitations. Domain experts may hold differing views or introduce biased assumptions.
Learning causal relationships from data, on the other hand, often requires additional assumptions regarding data distribution, functional dependencies, relationships between exogenous unobserved variables, and an informed choice of the learning algorithm. Research by (Binkytė-Sadauskienė et al., 2022) demonstrates how different causal discovery algorithms, when applied to the same dataset, can yield significantly different causal structures. This variability raises concerns about the reliability of causality learned purely from observational data (Guyon et al., 2011).
Expert-driven causal graphs, while useful, are not easily scalable and may be prone to human error. However, recent advancements in causal discovery with large language models (LLMs) offer a promising alternative (Kıcıman et al., 2023; Kasetty et al., 2024; Vashishtha et al., 2023). Hybrid approaches that combine LLM-driven insights with statistical causal discovery methods appear to be particularly promising in bridging the gap between expert-driven and data-driven causal inference (Afonja et al., 2024).
### 6.2 Causal Transportability
Beyond the accurate identification of causal graphs, another crucial consideration when applying causal inference to fairness is whether causal findings obtained in one context remain valid and generalizable across diverse populations—an issue addressed by the concept of causal transportability. Currently, the application of causal knowledge across populations relies heavily on assumptions about general causal structures that remain relatively stable across different contexts. Examples include physical laws, such as ”altitude causes temperature,” or well-established medical principles, such as ”bacteria cause disease.”
However, the principles underlying ethical AI are often deeply intertwined with cultural values and societal norms, which are neither immutable nor universally consistent. These variations present significant challenges in transferring causal insights across different demographic or geographic populations.
The framework developed by Pearl and Bareinboim utilizes directed acyclic graphs (DAGs) to adjust causal knowledge for new settings through targeted data collection (Bareinboim and Pearl, 2014; Pearl and Bareinboim, 2011). Building on this, Binkyte et al. (2024) propose an expectation-maximization (EM) approach to adapt causal knowledge for applications in target demographic groups, further enhancing the practicality of causal transportability in real-world scenarios.
### 6.3 Possibility for Intervention
In fairness estimation, the sensitive attribute is typically considered the exposure or treatment variable, with the goal of measuring its impact on the outcome.
Most definitions of causal effect are based on the notion of intervention or manipulation of a cause variable (exposure) (VanderWeele and Hernán, 2012; Holland, 1986). This presents a challenge when making causal claims about non-manipulable attributes, such as race or gender.
Some approaches in the literature suggest shifting the focus from actual manipulation to changes in perception (Rahmattalabi and Xiang, 2022). For instance, instead of altering the gender of candidates to estimate its effect on hiring decisions, researchers could manipulate the employer’s perception of gender. This could be achieved by submitting two otherwise identical résumés with different names or titles indicating different genders. Such an approach aligns with methodologies used in social experiments examining the impact of race or gender on hiring decisions (Neumark, 2018).
(VanderWeele and Hernán, 2012) further differentiates immutable sensitive attributes into those that are randomized at birth (e.g., biological sex) and those that are not (e.g., race, social gender). This distinction is important when estimating the causal effect of a sensitive attribute. If the attribute is randomized, its causal effect on an outcome can be estimated by directly comparing exposure levels. For example, the total causal effect of biological sex on an outcome can be estimated by comparing observed differences between men and women (VanderWeele and Hernán, 2012).
In contrast, race is not randomly assigned but influenced by ancestral and socio-cultural factors, making causal effect estimation more complex. Even at the biological level, estimating the effect of race requires a thorough understanding of the causal structure of relevant covariates. Such estimation is particularly relevant in medical scenarios, where assuming independence between the sensitive attribute and the outcome (e.g., disease probability) is unreasonable.
Similarly, in potential discrimination scenarios, (VanderWeele and Hernán, 2012) and (Rahmattalabi and Xiang, 2022) suggest shifting the focus to the direct effect of the perceived gender or race on decision-making. This perspective aligns with causal fairness approaches that assess discrimination based on how sensitive attributes are perceived and acted upon within decision-making processes.
### 6.4 Causal assumptions
The Stable Unit Treatment Value Assumption (SUTVA) (Rubin, 1986) imposes two key requirements: no interference and consistency.
The no interference assumption states that the effect of the sensitive attribute on the outcome should not be influenced by interactions between individuals. However, in social sciences research—where interactions and feedback loops are common—this assumption is often challenged, necessitating careful discussion and restricted interpretations of causal estimates (Morgan and Winship, 2015).
Since fairness is typically evaluated within a social context, potential interactions must be carefully assessed. For example, in the hiring scenario, a violation of the no interference assumption would occur if hiring individuals from one political spectrum increased the likelihood of favoring candidates with the same political beliefs in future hiring decisions. This scenario is plausible because current employees may prefer candidates who share their political ideology, creating a feedback loop that perpetuates bias.
The consistency assumption requires that each treatment level leads to the same potential outcomes (Keele, 2015). In fairness evaluation, the treatment variable is replaced by the sensitive attribute, which is often a socially constructed category such as race or gender. Identifying the causal effect of gender on hiring becomes problematic if gender itself does not have a consistent effect on hiring decisions. For instance, discrimination may not apply uniformly to all women; rather, only women who exhibit a certain level of ”femininity” might experience bias. If this possibility cannot be ruled out, it should be considered in studies aiming for a fine-grained causal analysis.
In summary, SUTVA assumptions are likely to be violated in fairness scenarios. However, causal approaches can still be applied if the results are interpreted with caution. Some methods for identifying causal effects despite SUTVA violations are discussed in (Laffers and Mellace, 2020).
The ignorability assumption (Rubin, 1986) requires that the sensitive attribute and the outcome be independent, given the observable variables. In other words, no unobserved variables should create a significant link between the sensitive attribute and the outcome.
In fairness evaluation, the presence of such a link could indicate that a portion of the observed discrimination is, in fact, a spurious effect induced by a confounding variable. For example, if education is a confounder but is not included in the dataset, its confounding effect cannot be controlled. Consequently, it becomes impossible to estimate the causal effect of political belief on hiring decisions separately from the effect of education.
Unobserved confounders are less likely to exist for immutable sensitive attributes such as sex or race, as these attributes generally do not have temporally prior causes. However, dependency between noise terms related to the sensitive attribute and the outcome can still violate ignorability.
(Fawkes et al., 2022) highlight the implications of assuming ignorability when using causal counterfactuals. Following their reasoning, consider the case of college admissions (illustrated in Figure 4). Under the ignorability assumption, an average male applicant to a technical profession could be counterfactually replaced with an average female applicant to the same profession. However, due to social expectations tied to gender roles, a woman applying to a technical profession is likely to be more motivated and hardworking than an average male applicant with the same professional aspirations. This example illustrates how violations of ignorability can introduce bias into causal estimations.
The positivity assumption (Rubin, 1986) is violated if certain combinations of a sensitive attribute and a covariate have zero probability. Violations of positivity can be either deterministic or random (Westreich and Cole, 2010).
For example, positivity would be violated if a specific level of education always corresponded to liberal political beliefs. In this scenario, the violation would likely be random, as it is improbable that education would have a strictly deterministic relationship with political beliefs. In such cases, statistical methods exist for handling analysis under violations of positivity (Westreich and Cole, 2010).
However, consider a case where obtaining a Harvard degree is treated as an explanatory mediator between ethnicity and hiring. Due to historical patterns of discrimination and socioeconomic disparities, certain ethnic groups may have near zero probability of obtaining a Harvard degree. This constitutes a deterministic violation of positivity. In such cases, it is essential to reconsider whether possessing a Harvard degree should be an absolute requirement for the job in question, given its potential for exclusion and disparate impact.
The identifiability of path-specific effects in the presence of multiple mediators requires the absence of causal links between the mediators (VanderWeele and Vansteelandt, 2014). Evaluating path-specific effects is particularly important for understanding the mechanism through which the sensitive attribute influences the outcome. As discussed earlier (Section 4), the effect of the sensitive attribute can be considered either justifiable or discriminatory depending on the mediating variables along the causal path.
However, in fairness scenarios, causal dependencies between mediators are common. For example, consider a case where the relationship between race and hiring decisions is mediated by both social status (e.g., redlining) and education (an explaining variable). It is highly probable that education level is influenced by social status. In such a scenario, the indirect effects of race through social status and education separately are not identifiable, as the mediators are causally dependent.
To address this challenge, (VanderWeele and Vansteelandt, 2014) proposed a method that treats multiple mediators jointly. In some cases, this approach can help disentangle and identify individual indirect effects in the presence of causal links between the mediators.
Recognizing these methodological challenges underscores the importance of carefully balancing technical rigor and practical applicability. With these considerations in mind, we now summarize our findings and highlight future directions for research.
## 7 Conclusions
This article has outlined the critical role of causality in evaluating the fairness of AI-driven decisions. We demonstrated that relying exclusively on statistical tools without causal analysis can lead to significant inaccuracies, such as overestimating, underestimating, or even reversing discrimination effects. Furthermore, we highlighted the essential connections between reliable evidence of algorithmic discrimination, legal practices in courts, and evolving regulatory frameworks, particularly within the European Union.
Specifically, we examined how causal reasoning influences legal assessments of discrimination and identified two primary forms of evidence— direct evidence, derived from reverse engineering AI systems, and indirect evidence. Given that direct evidence is often practically unattainable due to AI opacity, the article explores alternative causal analyses through indirect evidence. Two approaches based on but-for counterfactual reasoning were presented:
The first approach evaluates the impact of sensitive attributes or redlining mediators in algorithmic decision-making, using test data to investigate causal relationships.
The second approach assesses whether decisions would differ if AI systems were not employed at all, placing emphasis on historical decision-making practices within organizations.
We also critically discussed the causal assumptions underlying fairness assessments, emphasizing the inherent challenges, such as dependency on accurate causal graphs, practical limitations in conducting robust causal analyses, and potential biases arising from untestable assumptions.
### 7.1 Limitations and Future Research Directions
Several important limitations constrain the practical application of causal fairness evaluations. Most of the challenges are related to accurately specifying causal structures, the infeasibility of reverse engineering complex AI systems, and the limitations inherent in observational data. These factors restrict the effectiveness of existing causal inference methodologies. Future research should address these limitations by:
- Establishing causality in mechanistic interpretability methods allowing reliable and legally binding conclusions on fairness of model’s internal representations.
- Refining regulatory frameworks to better align legal evidentiary standards with technical realities, thereby enhancing procedural fairness.
- Exploring hybrid approaches combining expert knowledge, causal discovery algorithms, and insights from large language models (LLMs) to improve the reliability and scalability of causal fairness assessments.
- Investigating cross-cultural validity and adaptability of causal fairness concepts, ensuring their global applicability and effectiveness in diverse societal contexts.
This work of Ruta Binkyte and Sami Zhioua was supported by the European Research Council (ERC) project HYPATIA under the European Union’s Horizon 2020 research and innovation programme. Grant agreement n. 835294. The work of Ruta Binkyte is funded in part by PriSyn: Representative, synthetic health data with strong privacy guarantees (BMBF), grant No. 16KISAO29K. It is also supported by Integrated Early Warning System for Local Recognition, Prevention, and Control for Epidemic Outbreaks (LOKI / Helmholtz) grant. The work is also partially funded by Medizininformatik-Plattform ”Privatsphären-schutzende Analytik in der Medizin” (PrivateAIM), grant No. 01ZZ2316G, and ELSA – European Lighthouse on Secure and Safe AI funded by the European Union under grant agreement No. 101070617. Views and opinions expressed are, however, those of the authors only and do not necessarily reflect those of the European Union or European Commission. Neither the European Union nor the European Commission can be held responsible for them.
## References
- Afonja et al. (2024) Tejumade Afonja, Ivaxi Sheth, Ruta Binkyte, Waqar Hanif, Thomas Ulas, Matthias Becker, and Mario Fritz. LLM4GRN: Discovering Causal Gene Regulatory Networks with LLMs–Evaluation through Synthetic Data Generation. arXiv preprint arXiv:2410.15828, 2024.
- Bareinboim and Pearl (2014) Elias Bareinboim and Judea Pearl. Transportability from multiple environments with limited experiments: Completeness results. Advances in neural information processing systems, 27, 2014.
- Bereska and Gavves (2024) Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082, 2024.
- Bickel et al. (1975) Peter J Bickel, Eugene A Hammel, and J William O’Connell. Sex bias in graduate admissions: Data from berkeley. Science, 187(4175):398–404, 1975.
- Binkyte et al. (2024) Ruta Binkyte, Daniele Gorla, and Catuscia Palamidessi. BaBE: Enhancing Fairness via Estimation of Explaining Variables. In The 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1917–1925, 2024.
- Binkyte et al. (2025) Ruta Binkyte, Ivaxi Sheth, Zhijing Jin, Muhammad Havaei, Bernhardt Schölkopf, and Mario Fritz. Causality Is Key to Understand and Balance Multiple Goals in Trustworthy ML and Foundation Models. arXiv preprint arXiv:2502.21123, 2025.
- Binkytė-Sadauskienė et al. (2022) Rūta Binkytė-Sadauskienė, Karima Makhlouf, Carlos Pinzón, Sami Zhioua, and Catuscia Palamidessi. Causal Discovery for Fairness. arXiv preprint arXiv:2206.06685, 2022.
- Carey and Wu (2022) Alycia N. Carey and Xintao Wu. The causal fairness field guide: perspectives from social and formal sciences. Frontiers in Big Data, 5:892837, 2022. 10.3389/fdata.2022.892837.
- Chiappa (2019) Silvia Chiappa. Path-specific counterfactual fairness. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 7801–7808, 2019.
- Fawkes et al. (2022) Jake Fawkes, Robin Evans, and Dino Sejdinovic. Selection, ignorability and challenges with causal fairness. In Conference on Causal Learning and Reasoning, pages 275–289. PMLR, 2022.
- Grozdanovski (2021) Ljupcho Grozdanovski. In search of effectiveness and fairness in proving algorithmic discrimination in eu law. Common Market Law Review, 58(1), 2021.
- Guyon et al. (2011) Isabelle Guyon, Constantin Aliferis, Gregory Cooper, André Elisseeff, Jean Philippe Pellet, Peter Spirtes, and Alexander Statnikov. Causality workbench. In Causality in the sciences. Oxford University Press, 2011.
- Haack (2014) Susan Haack. Evidence matters: Science, proof, and truth in the law. Cambridge University Press, 2014.
- Holland (1986) Paul W Holland. Statistics and causal inference. Journal of the American statistical Association, 81(396):945–960, 1986.
- Kasetty et al. (2024) Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, and Dhanya Sridhar. Evaluating interventional reasoning capabilities of large language models. arXiv preprint arXiv:2404.05545, 2024.
- Keele (2015) Luke Keele. The statistics of causal inference: A view from political methodology. Political Analysis, 23(3):313–335, 2015.
- Kıcıman et al. (2023) Emre Kıcıman, Robert Ness, Amit Sharma, and Chenhao Tan. Causal reasoning and large language models: Opening a new frontier for causality. arXiv preprint arXiv:2305.00050, 2023.
- Kusner et al. (2017) Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. Counterfactual fairness. Advances in neural information processing systems, 30, 2017.
- Laffers and Mellace (2020) Lukas Laffers and Giovanni Mellace. Identification of the average treatment effect when sutva is violated. Discussion Papers on Business and Economics, University of Southern Denmark, 3, 2020.
- Loftus et al. (2018a) Joshua R Loftus, Chris Russell, Matt J Kusner, and Ricardo Silva. Causal reasoning for algorithmic fairness. arXiv preprint arXiv:1805.05859, 2018a.
- Loftus et al. (2018b) Joshua R Loftus, Chris Russell, Matt J Kusner, and Ricardo Silva. Causal reasoning for algorithmic fairness. arXiv preprint arXiv:1805.05859, 2018b.
- Morgan and Winship (2015) Stephen L Morgan and Christopher Winship. Counterfactuals and causal inference. Cambridge University Press, 2015.
- Nabi and Shpitser (2018) Razieh Nabi and Ilya Shpitser. Fair inference on outcomes. In Proceedings of the… AAAI Conference on Artificial Intelligence. AAAI Conference on Artificial Intelligence, volume 2018, page 1931. NIH Public Access, 2018.
- Neumark (2018) David Neumark. Experimental research on labor market discrimination. Journal of Economic Literature, 56(3):799–866, 2018.
- Pearl (1988) Judea Pearl. Probabilistic reasoning in intelligent systems: networks of plausible inference. Morgan kaufmann, 1988.
- Pearl (2001) Judea Pearl. Direct and indirect effects. In Proceedings of the Seventeenth conference on Uncertainty in artificial intelligence, pages 411–420, 2001.
- Pearl (2009a) Judea Pearl. Causality. Cambridge university press, 2009a.
- Pearl (2009b) Judea Pearl. Causality. Cambridge University Press, Cambridge, 2009b. ISBN 978-0-521-89560-6. 10.1017/CBO9780511803161. URL https://www.cambridge.org/core/books/causality/B0046844FAE10CBF274D4ACBDAEB5F5B.
- Pearl and Bareinboim (2011) Judea Pearl and Elias Bareinboim. Transportability of causal and statistical relations: A formal approach. In Twenty-fifth AAAI conference on artificial intelligence, 2011.
- Plečko et al. (2024) Drago Plečko, Elias Bareinboim, et al. Causal fairness analysis: a causal toolkit for fair machine learning. Foundations and Trends® in Machine Learning, 17(3):304–589, 2024.
- Rahmattalabi and Xiang (2022) Aida Rahmattalabi and Alice Xiang. Promises and challenges of causality for ethical machine learning. arXiv preprint arXiv:2201.10683, 2022.
- Rescher (1980) Nicholas Rescher. Plausible reasoning: An introduction to the theory and practice of plausibilistic inference. Philosophy and Rhetoric, 13(3), 1980.
- Rubin (1986) Donald B Rubin. Statistics and causal inference: Comment: Which ifs have causal answers. Journal of the American Statistical Association, 81(396):961–962, 1986.
- Rubin (2005) Donald B Rubin. Causal inference using potential outcomes: Design, modeling, decisions. Journal of the American Statistical Association, 100(469):322–331, 2005.
- Sharkey et al. (2025) Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability. arXiv preprint arXiv:2501.16496, 2025.
- Shpitser and Pearl (2007) Ilya Shpitser and Judea Pearl. What counterfactuals can be tested. In 23rd Conference on Uncertainty in Artificial Intelligence, UAI 2007, pages 352–359, 2007.
- Shpitser and Pearl (2008) Ilya Shpitser and Judea Pearl. Complete identification methods for the causal hierarchy. Journal of Machine Learning Research, 9(Sep):1941–1979, 2008.
- Solum (2004) Lawrence B Solum. Procedural justice. S. CAl. l. reV., 78:181, 2004.
- VanderWeele and Vansteelandt (2014) Tyler VanderWeele and Stijn Vansteelandt. Mediation analysis with multiple mediators. Epidemiologic methods, 2(1):95–115, 2014.
- VanderWeele and Hernán (2012) Tyler J VanderWeele and Miguel A Hernán. Causal effects and natural laws: towards a conceptualization of causal counterfactuals for nonmanipulable exposures, with application to the effects of race and sex. Causality: statistical perspectives and applications, pages 101–113, 2012.
- Vashishtha et al. (2023) Aniket Vashishtha, Abbavaram Gowtham Reddy, Abhinav Kumar, Saketh Bachu, Vineeth N Balasubramanian, and Amit Sharma. Causal inference using llm-guided discovery. arXiv preprint arXiv:2310.15117, 2023.
- Westreich and Cole (2010) Daniel Westreich and Stephen R Cole. Invited commentary: positivity in practice. American journal of epidemiology, 171(6):674–677, 2010.
- Wu et al. (2019) Yongkai Wu, Lu Zhang, Xintao Wu, and Hanghang Tong. Pc-fairness: A unified framework for measuring causality-based fairness. In Advances in Neural Information Processing Systems, pages 3404–3414, 2019.
- Zhang and Bareinboim (2018) Junzhe Zhang and Elias Bareinboim. Fairness in decision-making—the causal explanation formula. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.