## Fairness and Randomness in Machine Learning: Statistical Independence and Relativization *
Rabanus Derr University of Tübingen rabanus.derr@uni-tuebingen.de
Robert C. Williamson University of Tübingen and Tübingen AI Centre
bob.williamson@uni-tuebingen.de
November 17, 2022
## Abstract
Fair Machine Learning endeavors to prevent unfairness arising in the context of machine learning applications embedded in society. Despite the variety of definitions of fairness and proposed 'fair algorithms,' there remain unresolved conceptual problems regarding fairness. In this paper, we dissect the role of statistical independence in fairness and randomness notions regularly used in machine learning. Thereby, we are led to a suprising hypothesis: randomness and fairness can be considered equivalent concepts in machine learning.
In particular, we obtain a relativized notion of randomness expressed as statistical independence by appealing to Von Mises' century-old foundations for probability. This notion turns out to be 'orthogonal' in an abstract sense to the commonly used i.i.d.-randomness. Using standard fairness notions in machine learning, which are defined via statistical independence, we then link the ex ante randomness assumptions about the data to the ex post requirements for fair predictions. This connection proves fruitful: we use it to argue that randomness and fairness are essentially relative and that both concepts should reflect their nature as modeling assumptions in machine learning.
## 1 Introduction
Underthe name 'Fair Machine Learning' researchers have attempted to tackle problems of injustice, fairness, discrimination arising in the context of machine learning applications embedded in society [Barocas et al., 2017]. Despite the variety of definitions of fairness and proposed 'fair algorithms,' we still lack a conceptual understanding of fairness in machine learning [Passi and Barocas, 2019, Scantamburlo, 2021]. What does it mean for predictions to be fair? How does the statistical frame influence fairness? Is there fair data and what would it look like?
Wefocus on a collection of widely used fairness notions which are based on statistical independence e.g. [Calders and Verwer, 2010, Hardt et al., 2016, Chouldechova, 2017], but examine them from a new perspective. Surprisingly, debates concerning these notions have not questioned the role and meaning of statistical independence upon which they are based. As we shall argue, statistical independence is far from being a mathematical concept linked to one unique interpretation (see §4.2). This paper, in contrast to much of the literature on fairness in machine learning, e.g. [Calders
* This paper has been presented at the Philosophy of Science meets Machine Learning Conference in Tübingen in October 2022.
and Verwer, 2010, Dwork et al., 2012, Hardt et al., 2016, Chouldechova, 2017], investigates what many definitions of fairness take for granted: a well-defined and meaningful notion of statistical independence.
Another, less popular, strand of research investigates the role of randomness in machine learning [Steinwart et al., 2009]. The standard randomness notion, independently and often identically distributed data points, suffers the longstanding critique of being inadequate (cf. [Shafer, 2007]). Again, statistical independence lies at the foundation of this, hitherto unrelated to fairness, concept. (We will justify below our use of 'randomness' as used here.)
At the core of both our observations is the unreflective use of a convenient mathematical theory of probability. Kolmogorov's axiomatization of probability theory, developed 1933 in his book [Kolmogorov, 1933] (translated in [Kolmogorov, 1956]), dominates most research in machine learning. As Kolmogorov explicitly stated, his theory was designed as a purely axiomatic, mathematical theory detached from meaning and interpretation. In particular, Kolmogorov's statistical independence lacks such reference. However, the modeling nature of machine learning and the arising ethical complications within machine learning applied in society ask for semantics of probabilistic notions.
In this work, we focus on statistical independence. We leverage a theory of probability axiomatized by Von Mises [Von Mises and Geiringer, 1964] in order to obtain meaningful access to probabilistic notions. (In leaning on Von Mises we are directly following the explicit advice of Kolmogorov [1956, page 3, footnote 4].) This theory construes probability theory as 'scientific' 1 (as opposed to purely mathematical) with the aim to describe the world and provide interpretations and verifiability [Von Mises and Geiringer, 1964, pages 1 and 14].
Von Mises' theory of probability provides a mathematical definition of statistical independence which describes statistical phenomena observable in the world. In particular, Von Mises' statistical independence is mathematically, but not conceptually, related to Kolmogorov's definition.
In this paper, we, to the best of our knowledge, are the first to apply Von Mises' randomness to machine learning and to interpret randomness in machine learning in a Von Mises' way. The paper is structured as follows:
In Section 2, we outline our statistical perspective on machine learning. We present the 'independent and identically distributed'-assumption (i.i.d.-assumption) as one commonly used choice for modeling randomness. The further occurrence of statistical independence as fundamental ingredient of fairness notions in machine learning (§3) pushes us to the question: 'How to interpret statistical independence in (fair) machine learning?'
We first dissect Kolmogorov's widely used definition of statistical independence in Section 4 before we propose another mathematical notion following Von Mises. Von Mises uses his notion of independence in order to define randomness We contrast his definition and the i.i.d.-assumption in Section 5. This reveals a general typification of mathematical definitions of randomness which most importantly differ in the absoluteness respectively relativity to the problem under consideration (§5.2).
Finally, we leverage Von Mises' definition of statistical independence to redefine three fairness notions from machine learning (§6). Against the background of Von Mises' probability theory, we then link randomness and fairness both expressed as statistical independence (§7). Thereby, we reveal an unexpected hypothesis: randomness and fairness can be considered equivalent concepts in machine learning. Randomness becomes a relative , even an ethical choice. Fairness, however,
1 We further use the term 'scientific' in order to describe a theory modeling a phenomenon in the world providing interpretations and verifiability in the sense of Von Mises (spelled out more concretely in Section 4.3). Any more detailed discussion, e.g. along the lines of Popper [2010], is out of the scope of this paper.
turns out to be a modeling assumption about the data used in the machine learning system.
Due to the frequent use of the word 'independence' with different meanings in this paper, we differentiate. By 'independence' we mean an abstract concept of unrelatedness and non-influence [Simpson and Weine, 1989]. We use it interchangeably with 'statistical independence' which emphasizes the probabilistic and statistical context. When referring to the later introduced, formal definitions of statistical independence following Kolmogorov or Von Mises we explicitly state this. Finally, we assign 'Independence' (capital 'I') to one of the fairness criteria in machine learning which demands for statistical independence of predictions and sensitive attribute [Barocas et al., 2017, Räz, 2021].
## 2 AStatistical Perspective on Machine Learning
Machine Learning ingests data and provides decisions or inferences. In this sense, at its core, it is statistics 2 . Adopting this perspective, we understand machine learning as 'modeling data generative processes'. Statistics, respectively machine learning, asks for properties of data generating processes given a collection of data [Wasserman, 2004, p. ix] [Bandyopadhyay and Forster, 2011, p. 1].
We assume that a data generative process occurs somehow in the world. We are confronted with a collection of numbers, the data, produced by the process and acquired by measurement. A 'model' is a mathematical description of such a data generating process. This description should allow us to make predictions in an algorithmic fashion. Thus, we require, inter alia , a mathematical description of data - 'a model for data collection' [Casella and Berger, 2002, p. 207].
What is arguably the standard model of data is stated in [Devroye et al., 1996, p. 11]
Weshall assume in this book that ( X 1, Y 1),..., ( Xn , Yn ), the data, is a sequence of independent identically distributed (i.i.d.) random pairs with the same distribution...
Similar definitions can be found in many machine learning or statistics textbooks (e.g. [Casella and Berger, 2002, Def. 5.1.1]). Data (measurements from the world) is conceived of (mathematically) as a collection of random variables which share the same distribution and which are (statistically) independent to each other. Implicit in this definition is that the data indeed has a stable distribution. The assumed independence can be interpreted as presumption of randomness of the data. Each data point was 'drawn independently' 3 from all others, with the obvious interpretation that each data point does not give a hint about the value of any other.
The i.i.d. assumption is two-fold: 1) the assumption of identical distributions of a sample, and 2) the mutual independence of points in the sample. The second assumption alone captures and pertains to randomness [Humphreys, 1977, Section 3]. However, since the use of i.i.d. is more common, we refer to this more specific assumption.
Even though many results in statistics and machine learning rely on the i.i.d. assumption (e.g. law of large numbers and central limit theorem in statistics [Casella and Berger, 2002], generalization
2 Machine learning could be viewed as classical statistics with a stronger focus on algorithmic realizations (cf. [ShalevShwartz and Ben-David, 2014, p. 6] or [Lafferty and Wasserman, 2006]). While there are ML approaches that do not seem statistical in the classical sense (e.g. worst case online sequence prediction), our general description still holds.
3 Observe that as a mathematical theory of data this already leaves a lot to be desired: you will not find in any text a precise and constructive explanation of this process of 'drawn independently'. To be sure, the notion of 'statistical independence' is well defined (see further below), as is a collection of random variables. But not the mysterious process of 'drawing from'. The closest we can come to such a description of mechanism is the indirect version: the data are created (by the world) in a manner that the (mathematical theorem) of the law of large numbers holds, and that their empirical distribution converges to the distribution which was given in the first place.
bounds in statistical learning theory [Shalev-Shwartz and Ben-David, 2014] and computationally feasible expressions in probabilistic machine learning [Devroye et al., 1996]), it has always been subject of fundamental critique 4 . Other randomness definitions are rarely applied, but exceptions exist [Vovk, 1993, Tadaki, 2014].
In summary, statistical conclusions often rely on the i.i.d.-description of data. This description embraces a model of randomness making randomness a substantial assumption about the data in statistics and machine learning. Interestingly, statistical independence lies at the foundation of another, hitherto unrelated, concept: many fairness criteria in fair machine learning are expressed in terms of statistical independence.
## 3 Fair Machine Learning Relies on Statistical Independence
With the broad use of machine learning algorithms in many socially relevant domains, e.g. recidivism risk prediction or algorithmic hiring, machine learning algorithms turned out to be part of discriminatory practices [Chouldechova, 2017, Raghavan et al., 2020]. These revelations were accompanied by the rise of an entire research field, called 'fair machine learning' (cf. [Calders and Verwer, 2010, Chouldechova, 2017, Barocas et al., 2017]). We do not attempt to summarize this large literature here. Instead, we simply take a snapshot of the most widely known fairness criteria in machine learning [Barocas et al., 2017, p. 45].
## 3.1 Three Fairness Criteria in Machine Learning
The three so called observational fairness criteria, which are expressed in terms of statistical independence, encompass a large part of fair machine learning literature: 5
- Independence demands that the predictions ˆ Y are statistically independent of group membership S in socially salient, morally relevant groups [Calders and Verwer, 2010, Kamishima et al., 2012, Dwork et al., 2012].
- Separation is formalized as ˆ Y ? S ϕ Y , i.e. the prediction ˆ Y is conditionally independent of the sensitive attribute S given the true label Y [Hardt et al., 2016].
Sufficiency is fullfilled if and only if Y ? S ϕ ˆ Y [Kleinberg et al., 2017].
For the sake of distinguishing between the fairness criteria 'Independence' and statistical independence, we henceforth mark all fairness criteria by a leading capital letter. Each of the notions appear in a variety of ways and under different names [Barocas et al., 2017, p. 45ff]. From the perspective of ethics, the fairness criteria have been substantiated via loss egalitarianism [Binns, 2018, Williamson and Menon, 2019], absence of discrimination [Binns, 2018], affirmative action [Biddle, 2006, Räz, 2021] or equality of opportunity [Hardt et al., 2016].
Certainly, statistical independence is not equivalent to fairness in general (a constellation of concepts sharing a common name, and perhaps little else agreed by all) [Dwork et al., 2012, Hardt et al., 2016, Räz, 2021]. The nature of fairness has been discussed for decades, e.g. in political philosophy [Rawls, 1971], moral philosophy [Lippert-Rasmussen, 2006] and actuarial science [Abraham,
4 Nicely summarized by Glenn Shafer in a comment on [Gammerman and Vovk, 2007] 'The i.i.d. case has also been central to statistics ever since Jacob Bernoulli proved the law of large numbers at the end of the 17th century, but its inadequacy was always obvious.' [Shafer, 2007].
5 Obviously, there are other fairness notions in machine learning which we have not listed above and which are not expressed as statistical independence, e.g. [Dwork et al., 2012, Kilbertus et al., 2017].
1985]. The 'essentially contested' nature of fairness suggests that no universal, statistical criterion of fairness exists [Gallie, 1955]. How fairness should be defined is a context-specific decision [Scantamburlo, 2021, Hertweck et al., 2021].
Nevertheless, in order to incorporate fairness notions into algorithmic tools we require mathematical formalisations of fairness definitions. The three named criteria dominate most of the practical fair machine learning tools [Barocas et al., 2017, p. 45], presumably because their simple definitions make it easy to incorporate them in learning procedures in a pre-, in- or post-processing way [Barocas et al., 2017, Chapter 3, p. 20]. Regarding both the reductionist definition of fairness and the pragmatic justification, we emphasize that our argumentation is solely with respect to the fairness criteria named above .
The three fairness criteria are described as group fairness notions since each of the definitions is intrinsically relativized with respect to sensitive groups. The definition of sensitive groups substantially influences the notion of fairness. For instance, via custom categorization one can provide fairness by group-design (see [Menon and Williamson, 2018, Section H.3] for a detailed discussion of the question of choice of groups). In addition, the meaning of groups in a societal context influences the choice of groups as elaborated in [Hu and Kohler-Hausmann, 2020], and as explored in a long line of work in social psychology [Campbell, 1958, Tajfel, 1974, Hogg and Abrams, 1998, McGarty, 1999, Castano et al., 2002]. We contribute to the debate by drawing a connection between the choice of groups and the choice of randomness in §7.1.1.
## 3.2 Independence in mathematics and the world
Behind the formalization of fairness as statistical independence, there is an apparently rigid, mathematical definition of statistical independence. The fairness criteria presume that we have the machinery of probability theory at our disposal and the relationship of mathematics and the world is clear and unambiguous. However, as we elaborate further in the following, there is no single notion of 'the' mathematical theory of probability [Fine, 1973]. Furthermore, it is not clear what it means to be statistically independent when talking of measurements in the world. Respectively, it is not obvious that the standard formulation of statistical independence is the right one to use.
If we desire statistical independence to capture a fairness notion applicable to the world, we ought to understand what the mathematical formulae signify in the world. Thus, in addition to the debate about the fairness criteria, a debate on the interpretation of statistical concepts in ethical context is required.
In this work, we contribute to the understanding by scrutinizing the standard definition of statistical independence. Motivated by the occurrence of statistical independence as fundamental ingredient in randomness as well as fairness in machine learning, we first detail the standard account due to Kolmogorov. What is statistical independence? How does statistical independence relate to an independence in the world?
## 4 Statistical Independence Revisited
To make any sense of phenomena in our world, we need to ignore large parts of it in order to avoid being overwhelmed. Hence, we usually assume or presume the phenomena of interest depends only on a few factors and to be independent of everything else [Naylor, 1981]. Thus the concept of independence is inherent in a variety of subjects ranging from causal reasoning [Spohn, 1980], to logic [Grädel and Väänänen, 2013], accounting [Cook, 2020], public law [Murchison, 1992] and
many more. Independence, as we understand it, grasps the concept of incapability of an entity to be expressed, derived or deduced by something else [Simpson and Weine, 1989].
## 4.1 From Independence to Statistical Independence
Of special interest to us is the concept of independence in probability theories and statistics [Levin, 1980][Fine, 1973, Section IIF , IIIG and VH]. Independence in a probabilistic context should somehow capture the unrelatedness between the occurrence of events, as has been understood for centuries:
Two Events are independent, when they have no connexion [sic] one with the other, and that the happening of one neither forwards nor obstructs the happening of the other. [De Moivre, 1738/1967, Introduction, p. 6].
Modern probability theory loosely follows this intuition as we see in the following.
## 4.2 Statistical Independence as we know it lacks semantics
Since the axiomatization of probability theory developed by Kolmogorov [1933] (translated in [Kolmogorov, 1956]), it displaced many other approaches. Mathematically, Kolmogorov's measuretheoretic axiomatization dominates all other mathematical formalizations to probability and related concepts. 6 In particular, his definition of statistical independence developed a well-accepted, ubiquitous notion. In a simple form it is given by 7 :
Definition 1 (Simplified Statistical Independence following Kolmogorov) . Two events A , B are statistically independent iff
<!-- formula-not-decoded -->
Independence plays a central role in Kolmogorov's probability theory: 'measure theory ends and probability begins with the definition of independence' [Durrett, 2019, p. 37] (quoted in [Tao, 2015]). However, Kolmogorov's definition of independence is subtle and requires closer investigation.
Let us look onto a small toy example: consider the experiment of throwing a die. The events under observation are A ∅ {1,2}, seeing one or two pips, respectively B ∅ {2,3}, seeing two or three pips. If the die were fair, so each face has equal probability 1 6 to show up, the events A and B would turn out not to be independent. In contrast, if the die were loaded in a very special way p 1 ∅ 1 3 , p 2 ∅ 1 6 , p 3 ∅ 1 2 , p 4 ∅ p 5 ∅ p 6 ∅ 0, where pi refers to the probability of seeing i pips, the events A and B would be independent following Kolmogorov's definition.
Thus, statistical independence, even though defined over events, manifests in the correspondence of how probabilities are mapped to events and why. The definition focuses on events. But, the crucial ingredient is the probabilities. Thus, there is no unique interpretation of statistical independence. A more detailed interpretation and meaning heavily depends on the interpretation of probability in the first place.
Given this observation, we may ask for a notion of independence in the world, which is somehow captured by Kolmogorov's definition. Kolmogorov himself underlined the avowedly mathematical, axiomatic nature of probability. His theory is in principle detached from any meaning of probabilistic concepts such as statistical independence in the world [Kolmogorov, 1956, p. 1]. He even
6 Exceptions exist, e.g. in quantum theory [Gudder, 1979] or in statistics [Vovk, 1993].
7 For a rigorous definition see Appendix 5.
questions the validity of his axioms as reasonable descriptions of the world [Kolmogorov, 1956, p. 17].
However, one can possibly construct a notion of independence in world which is captured by Kolmogorov's definition. If one assumes one's calculations about one's beliefs on the happening of events are governed by the mathematical rules laid out by Kolmogorov, then Kolmogorov's definition of statistical independence captures one's (in-the-world) understanding of an independence of beliefs on the happening of events. This sketch of a purely subjectivist account to statistical independence neglects a justification for the choice of mathematical formulation and skips over any reference to an objective world. In conclusion, Kolmorogov's independence might capture a worldly concept. But, this independence in the world is not uniquely attached to Kolmogorov's definition.
There is a third major irritation arising from Kolmogorov's definition. As observed already above, Kolmogorov treats events as the entities of independence. Though, against the background of De Moivre [1738/1967]'s intuition on statistical independence, we wonder about this focus. Statistical independence, as De Moivre [1738/1967] already emphasized, refers to altering 'the happening of the event,' but not the event itself. It is not the independence between the shown numbers of the die (whatever this means), but the independence of the processes how the number showed up (loading the die, throwing the die, etc.) which are captured by statistical independence.
This critique is not new. Von Mises already criticized the measure theoretical definition by Kolmogorov in his book [Von Mises and Geiringer, 1964, p. 36-39]. In summary, he argued that there is no interpretation of statistical independence of 'single events.' The unrelatedness, which the probabilistic notion of statistical independence is trying to capture, locates in the process of reoccuring events, but not single events themselves. More recently, Von Collani [2006] argued in a similar way. It is probability which brings the definition of statistical independence to life and it is the question what probability means and why we use it which links the mathematical definition to a concept in the real world.
In machine learning and statistics it is often presumed that the mathematical definition of independence captures a worldly concept. As we argued in this section, this link is far from being well-defined. However, if we consider machine learning as worldly data modeling, then the natural question arises: what do we model when we leverage Kolmogorov's statistical independence? What do we mean by independence of events? In order to circumvent these questions, we propose to look into another mathematical theory of probability. This theory was led by the idea of modeling statistical phenomena in the world.
## 4.3 Statistical Independence and a Probability Theory with inherent Semantics
Around 15 years before Kolmogorov's Grundbegriffe der Wahrscheinlichkeitsrechnung [Kolmogorov, 1933] (translated as [Kolmogorov, 1956]), Von Mises proposed an earlier axiomatization of probability theory [Von Mises, 1919]. His less known theory approached the problem of a mathematical theory of probability through the lens of physics. Von Mises aimed for a 'mathematical theory of repetitive events.'
This aim included the emphasis on the link between real-world and mathematical idealization. In particular, he offers interpretability and verifiability of his theory [Von Mises and Geiringer, 1964, p. 1 and 14]. 8 For interpretation he defined probabilities in a frequency-based way (see
8 Von Mises' discussion pre-dates most of the modern work done in the philosophy of science. Popper [2010], for instance, was inspired by Von Mises' conception of randomness and probability. While Von Mises' definition of verifiability and interpretability is arguably somewhat ill-conceived, nevertheless, he works, in contrast to Kolmorogov's theory which
Definition 2). This inherently reflects the repetitive nature of the phenomena under description. By verifiability he referred to the ability to approximately verify the probabilistic statements made about the world [Von Mises and Geiringer, 1964, p. 45].
In summary, Von Mises' theory, in our conception of machine learning, starts the 'modeling of data generating processes' on an even more fundamental level then it is currently done via the use of Kolmogorov's axiomatization. His aim for a mathematical description of data-generating processes (the sequence of repetitive events) aligns to our perspective on machine learning as laid out earlier (cf. Section 2). With Von Mises we obtain access to meaningful foundations for statistical concepts in machine learning. In particular, we redefine and reinterpret statistical independence in a Von Misesean way. This suggests new perspectives on the problem of fair machine learning and the concepts of fairness and randomness themselves.
For the further discussion, we summarize the major ingredients of Von Mises' theory. Fortunately, it turns out that Von Mises' notion of statistical independence, central to our discussion, is mathematically analogous to the well-known Kolmogorovian definition. Thus, one's intuition on statistical independence is refined but its mathematical applicability remains.
## 4.4 Von Mises' theory of Probability and Randomness in a Nutshell
Von Mises' axiomatization of probability theory is based on random sequences of events and the interpretation of probability as the limiting frequency that an event occurs in such a sequence [Von Mises, 1919]. These random sequences, called collectives, are the main ingredients of his theory. For the sake of simplicity, we stick to binary collectives. Thus, collectives are 0-1-sequences with certain randomness properties which define probabilities for the labels 0 and 1. Nevertheless, it is possible to define collectives respectively probabilities on richer label sets. Collectives can be extended up to a continuum [Von Mises and Geiringer, 1964, II.B ].
For notational economy, we note that a sequence taking values in {0,1}, ( si ) i 2 N can be identified with a function s : N ! {0,1}.
Definition 2 (Collective [Von Mises and Geiringer, 1964, p. 12]) . Let S be a set of sequences s : N ! {0,1} with s ( j ) ∅ 1 for infinitely many j 2 N . In mathematical terms, collectives with respect to S are sequences x : N ! {0,1} for which the following two conditions hold.
## 1. The limit of relative frequencies of 1 s,
<!-- formula-not-decoded -->
exists. 9 If it exists, then the limit of relative frequencies of 0 s exists, too. We define p 1 , respectively p 0 ∅ 1 ϒ p 1 , to be its value.
2. For all s 2 S ,
<!-- formula-not-decoded -->
is of purely syntactical nature, on a semantical project, where the connection of the real world and the mathematical formulation is of vital importance.
9 The mathematically inclined reader might notice the requirement for an order structure to obtain a definition of limit here. We use x as sequences with the standard order structure on the natural numbers. However, x can be generalized to be a net on more abitrary base sets [Ivanenko, 2010] .
Wecall p 0 the probability of label 0. Conversely, p 1 is the probability of label 1. 10 The existence of the limit (Condition 1) is a non-vacuous condition. One can easily construct sequences whose frequencies do not converge.
The sequences s 2 S are called selection rules. A selection rule selects the j th element of x whenever s ( j ) ∅ 1. 11 Informally, a collective (w.r.t S ) is a sequence which has invariant frequency limits with respect to all selection rules in S . Wecall any selection rule which does not change the frequency limit of a collective admissible . This invariance property of collectives is often called 'law of excluded gambling strategy' [Von Mises and Geiringer, 1964]. When thinking of a sequence of coin tosses, a gambler is not able to gain an advantage by just considering specific selected coin tosses. The probability of seeing 'heads' or 'tails' remains unchanged.
Von Mises introduced the 'law of excluded gambling strategy' with the goal to define randomness of a collective [Von Mises and Geiringer, 1964, p. 8]. A collective is called random with respect to S . Consequently, Von Mises integrated randomness and probability into one theory. In fact, admissibility of selection rules is equivalent to statistical independence in the sense of Von Mises. But it is defined with respect to collectives instead of selection rules.
Definition 3 (Von Mises' Definition of Statistical Independence of Collectives [Von Mises and Geiringer, 1964, p. 30 Def. 2]) . A collective x with respect to S x is called statistically independent to the collective y with respect to S y iff the following limits exist and
<!-- formula-not-decoded -->
where 0 0 : ∅ 0 . When two collectives are independent of each other we write
<!-- formula-not-decoded -->
In comparison to admissibility, the collective y adopts the role of a selection rule. It is in fact an admissible selection rule with the difference that a potentially finite number of elements in x are selected (cf. [Gillies, 2010, p. 120f]). Conversely, Von Mises' randomness is statistical independence with respect to sequences with infinitely many ones and potentially no frequency limit. (For a general comparison between Kolmogorov's and Von Mises' theory of probability see Appendix A and Table 2.)
## 4.5 Kolmogorov's Independence versus Von Mises' Independence
What is the relationship between Kolmorogov's and Von Mises' definition of statistical independence? On a conceptual level, the critique posed earlier, which questioned the meaning of statistical independence between events following Kolmogorov, gets resolved.
Von Mises adopted a strong frequential perspective on probabilities which clarifies the mapping from real world to mathematical definition. He idealized repetitive observations by infinite
10 Von Mises called p 0 chance as long as x is a sequence. When x is a collective, he called it probability.
11 We sweep under the carpet a substantial difference in Von Mises' definition of selection rules and our definition. Von Mises allowed the selection rules to 'see' the first n elements of the collective when deciding whether to choose the n ⊕ 1th element [Von Mises and Geiringer, 1964, p. 9]. Our definition is more restrictive. We require the selected position to be determined before 'seeing' the entire sequence. We focus on the ex ante nature of Von Mises randomness but neglect his recursive formalism.
sequences and defined probabilities as limiting frequencies. 12 Von Mises' independence states that there is no difference in counting the frequency of occurrences of an event in the entirety of the sequences or in a subselected sequence. His independence forbids any statistical interference between processes described as sequences. No statistical patterns can be derived from one sequence by leveraging the other. Von Mises' definition formalizes the concept of statistical independence between processes of reoccuring events.
In contrast to Kolmogorov, Von Mises' definition does not evoke the conceptual obscurity. His focus on idealized sequences of repetitive events restricts his definition of statistical independence to specific applications with the gain of clarity in the goal of the mathematical description.
Onamoreformal level, Kolmogorov defined statistical independence via the factorization of measure (cf. Definition 5), whereas Von Mises defined statistical independence via conditionalization of measures. The invariance of the frequency limit of a collective with regard to the subselection via another collective can be interpreted as the invariance of a probability of an event with regard to the conditioning on another event, i.e. 'selecting with respect to' is 'conditioning on' (cf. Theorem 1 and Theorem 2).
Mathematically, it turns out that Kolmogorov's definition and Von Mises' definition are both special cases (modulo the measure zero problem in conditioning) of a more general form of measuretheoretic statistical independence. A selection rule with converging frequency limit is admissible (respectively, statistically independent), to a collective if and only if the two are statistically independent of each other in the sense of Kolmogorov, when generalized to finitely additive probability spaces (see Appendix A for a formal statement of this claim). Thus, we can replace the known definition of statistical independence by Kolmogorov with the definition by Von Mises. Thereby, we give a specific meaning to statistical independence.
Wehave been motivated to dissect the notion of statistical independence for its central role in fair machine learning. Von Mises' definition drew us closer to a more transparent mathematical formalization of statistical independence for fairness notions in machine learning. However, our discussion of Von Mises' theory skipped over a substantial part of his work so far. Von Mises included a definition of randomness in his theory of probability. This is much in contrast to Kolmogorov: There is no definition of 'randomness' in Kolmogorov's Grundbegriffe der Wahrscheinlichkeitsrechnung [Kolmogorov, 1933] (translated as [Kolmogorov, 1956]). Even more interestingly, Von Mises' definition of randomness is stated in terms of statistical independence. The reader might notice that in Section 2 we already stumbled upon a heavily used notion of randomness in machine learning, which is expressed as statistical independence (i.i.d.). How do i.i.d. and Von Mises' randomness relate to each other? How does the close connection between statistical independence and randomness complement our picture of the three fairness criteria from machine learning?
## 5 Randomness as Statistical Independence
The nature and definition of randomness seems as 'random' as the term itself [Eagle, 2021, Ornstein, 1989, Muchnik et al., 1998, Volchan, 2002, Berkovitz et al., 2006]. Usually, a very broad distinction between two approaches to randomness is made: process randomness versus outcome randomness [Eagle, 2021]. In this work, we focus on outcome randomness and more specifically the role of
12 Without the idealization, again the mathematical description would miss a link to a worldly phenomenon. The idealization in terms of infinite sequences is substantial. In fact, the legitimacy of this idealization is the subject of another debate [Hájek, 2009]. Nevertheless, the idealization taken in Von Mises' framework is explicitly and transparently stated. Kolmogorov's axioms do not possess such a statement.
randomness in statistics and machine learning.
Randomness is a modeling assumption in statistics (cf. Section 2). Upon looking into statistics and machine learning textbooks one often finds the assumption of independent and identically distributed (i.i.d.) data points as the expression of randomness [Casella and Berger, 2002, p. 207] [Devroye et al., 1996, p. 4].
Weadopt Von Mises' differing account of randomness. The expression of randomness relative to the problem at hand, particularly in settings with data models such as statistics, turns out to be substantial.
## 5.1 Orthogonal Perspectives on Randomness as Independence in Machine Learning and Statistics
Von Mises defined a random sequence as a sequence which is statistically independent to a (prespecified) set of selection rules respectively other sequences. In contrast, an i.i.d.-sequence consists of elements each statistically independent to all others.
Both definitions are stated in terms of statistical independence. But, the relationship of independence and randomness in terms of i.i.d. and in Von Mises' theory differ substantially. Von Mises' randomness is stated relative with respect to a set of selection rules. Furthermore, it is stated between sequences, respectively collectives. Whereas, in an i.i.d. sequence randomness is expressed between random variables. The randomness definitions are in an abstract sense 'orthogonal.' We consider a concrete example for better understanding.
- Horizontal Randomness. Let › ∅ N be a penguin colony. Let s , f be two attributes of a penguin, namely sex and whether a penguin has the penguin flu or not. Mathematically: s : › ! {0,1}, f : › ! {0,1}. So, penguins are individuals n 2 › which we do not know individually, but we know some attributes of them. Suppose we are given a sequence f (1), f (2), f (3),... of flu values with existing frequency limit. This allows us to state randomness of f with respect to the corresponding sequence of sex values s , containing infinitely many ones and having a frequency limit, by: the sequence of sex values s is admissible on f . Respectively, s and f are statistically independent of each other. In the context of colony › a penguin having flu is random with respect to the sex of the penguin.
- Vertical Randomness. This is different to the i.i.d.-setting in which each penguin i 2 N obtains its own random variable Fi : › ! {0,1} on some probability space ( › , F , P ). Here, Fi encodes whether penguin i has the penguin flu or not. The sequence F 1, F 2, F 3,... somehow represents the colony. The included random variables share their distribution and are statistically independent to each other. The attribute flu is not random with respect to the attribute sex here, but the penguins are random with respect to each other. The random variables are (often implicitly) defined on a standard probability space on › . The set › here does not model the colony. It shrivels to an abstract source of randomness and probability.
The choice of perspective, horizontal or vertical, on randomness expressed as statistical independence is a question of the data model. The two types of randomness definitions are distinct in a number of ways. For a summary see Table 1. Most importantly, horizontal randomness is inherently expressed with respect to some mathematical object. Vertical randomness lacks this explicit relativization. This typification of horizontal and vertical, mathematical definitions of randomness is actually more broadly applicable.
Table 1: Typification of horizontal and vertical randomness ('RV'='random variable').
| | Horizontal Randomness | Vertical Randomness |
|-------------------------------------------|-------------------------|-----------------------|
| Data points are modelled as: | Evaluations of RVs | RVs |
| Mathematical definition of randomness of: | Sequences | Sequences of RVs |
| Explicit relativization: | Yes | No |
To the set of vertical randomness notions one can add: exchangeability [De Finetti, 1929], fi -mixing, fl -mixing [Steinwart et al., 2009] and possibly many more. The set of horizontal randomness notions is spanned up by an entire branch of computer science and mathematics: algorithmic randomness.
Algorithmic randomness poses the question whether a sequence is random or not. This question arose in [Von Mises, 1919] within the attempt to axiomatize probability theory [Bienvenu et al., 2009, p. 3]. In algorithmic randomness further definitions of random sequences have been proposed. For the sake of simplicity the considered sequences consist only of zeros and ones.
Four intuitions for random sequences crystallized [Porter, 2012, pp.280ff]: typicality, incompressibility, unpredictability and independence (see Appendix B). For our purposes, the key point to note is that a random sequence is typical, incompressible, unpredictable or independent with respect to 'something' (they are all relativised in some way). Each of these intuitions has been expressed in various mathematical terms. In particular, formalizations of the same intuitions are not necessarily equivalent, and formalizations of different intuitions sometimes coincide or are logically related (see Appendix C). 13 Wemainly stick to the intuition of independence in this paper. A random sequence is independent of 'some' other sequences [Von Mises, 1919, Church, 1940].
## 5.2 Relative Randomness Instead of Absolute, Universal Randomness
The definition of randomness for sequences is inherently relative. Even though, the notion is relative with respect to 'something,' most of the effort has been spent on finding the set of statistically independent sequences defining randomness [Church, 1940, Muchnik et al., 1998]. 14
Naively, one could attempt to define a random sequence as: a sequence is random if and only if it is independent with respect to all sequences. However, this approach is doomed to fail. There is no sequence fulfilling this condition except for trivial ones such as endless repetitions of zeros or ones (see Kamke's critique of von Mises' notion of randomness [Van Lambalgen, 1987]).
So instead, research focused on computability expressed in various ways (because it was felt by those investigating these matters that computability was somehow given, or more primitive, and thus a natural way to resolve the relativity of the notion of randomness). Intuitively, randomness is considered the antithesis of computability [Porter, 2012, p. 288]: something which is computable is not random. Something which is random is not computable. If we then informally update the definition above we obtain: a sequence is random if and only if it is independent with respect to all computable sequences [Church, 1940] 15 . Analogous to the definition of computability [Porter, 2012, p. 165], this is taken as an argument for the existence of the definition of randomness [Porter, 2012, p. 287].
13 For an overview of algorithmic randomness see [Uspenskii et al., 1990, Muchnik et al., 1998, Volchan, 2002, Downey and Hirschfeldt, 2010].
14 The analogous observation holds for all four intuitions (see Appendix B and [Muchnik et al., 1998]).
15 To be precise, a random sequence following Church [1940] is independent to all partially computable selection rules following Von Mises (see Footnote 11).
In our work, we argue towards a relativized conception of randomness in line with work by Porter [2012], Humphreys [1977] and Von Mises and Geiringer [1964] 16 . A relative definition of randomness is a definition of randomness which is relative with respect to the problem under consideration. 17 In contrast, an absolute and universal definition of randomness would preserve its validity in all problems. It presupposes the existence of the randomness.
Relative randomness with respect to the problem which we want to describe aligns to Von Mises' theory of probability and randomness. Von Mises emphasized the ex ante choice of randomness [Von Mises, 1981, p. 89] relative to the problem at hand [Von Mises and Geiringer, 1964, p. 12]. First, one formalizes randomness with respect to the underlying problem, then one can consider a sequence to be random or not. Otherwise, if we are given a sequence, it is easy to construct a set of selection rules, such that the sequence is random with respect to this set. 18 This, however, undermines the concept of randomness, which should capture the pre-existing typicality, incompressibility, unpredictability or independence of a sequence (cf. [Vovk, 1993, p. 321]). Von Mises' randomness intrinsically possesses a modeling character, similar to our needs in machine learning and statistics.
Given its role as modeling assumption in statistics, randomness lacks substantial justification to be expressed in any absolute and universal manner in this context. Neither, there are reasons why computability 19 is the only mathematical, expressive way to encode one of the four intuitions of randomness. The i.i.d. assumption, an absolute and universal definition of randomness, does not fits thpi purpose. To appropriately model data we require adjustable notions of randomness. Otherwise, we restrict our modeling choice without reason or gain. 20
Equipped with the interpretation of statistical independence as randomness we now return to our motivation for investigating statistical independence. ML-friendly fairness criteria are built upon statistical independence. In contrast to Kolmogorov, Von Mises' statistical independence transparently refers to a concept of independence in the real world. To clarify the meaning of fairness expressed as statistical independence, we directly apply Von Mises' independence to the fairness criteria listed in Section 3 in the following.
## 6 Von Mises' Fairness
With Von Mises' definition of statistical independence we have a notion at our disposal which is conceptually focused on a more 'scientific' perspective (i.e. making claims about the world) of statistical concepts. Since it is mathematically related to Kolmogorov's standard account of statistical independence, Kolmogorov's definition can, at many places, be easily replaced by Von Mises' definition.
Let us denote the three presented fairness criteria in a Von Mises' way (cf. Section 4.5).
16 Humphreys [1977] presented randomness as relativized to a probabilistic hypothesis or reference class. Porter [2012, p. 169] even postulated the 'No-Thesis'-Thesis: Any notion of randomness neither defines a well-defined collection of random sequences nor captures all mathematical conceptions of randomness; confer the logic of 'essentially contested' concepts [Gallie, 1955], which, presumably, are unavoidably contested for the same reason.
17 In machine learning, a problem under consideration is, for instance, animal classification via neural networks.
18 This idea is transferable to other intuitions of randomness, for instance [Ville, 1939].
19 Computability is often taken (at least by computer scientists) as a purely mathematical notion, detached from the world. An alternate view, close in spirit to Von Mises, is that computation is part of physics, and thus needs to be viewed in a scientific , and not merely mathematical manner [Deutsch, 2011].
20 This is not entirely true, as specific computability notions of randomness and the i.i.d.-assumption deliver convergence results for random sequences, which can be used to guarantee low estimation error in the long run.
Definition 4 (Fairness as Statistical Independence) . A collective x : N ! {0,1} (with respect to a family of selection rules S ) is fair with respect to a set of sensitive groups G ∅ { s j : N ! {0,1} ϕ j 2 J } if
<!-- formula-not-decoded -->
The 0-1-sequences s j determine for each individual i whether it is part of the group or not (according to whether s j ( i ) ∅ 1 or s j ( i ) ∅ 0). We call these groups 'sensitive,' as these are the groups which are of moral and ethical concern. In philosophical literature these groups are often called 'socially salient groups' [Altman, 2020, Loi et al., 2019]. 21 Wesee that the connection between Von Misean independence and fairness arises from the observation that the set of sensitive groups G is a family of selection rules, so that if G ∝ S , then indeed the collective x will be fair for G .
Following Von Mises' interpretation of independence, the given definition reads as follows: we assume, we are in the idealized setting of infinitely many individuals with values xi , e.g. binary predictions. The predictions are fair if and only if there is no difference in counting the frequency of 1-predictions in the entirety or in a sensitive group. (For an illustration see Appendix E.) A proper conceptualization of fairness requires such immediate semantics, but a purely mathematical theory of probability cannot offer these (see Section 4.2).
Each of the three fairness criteria is captured in Definition 4; the choice of fairness criterion manifests in the collective under consideration:
Independence The collective x : N ! {0,1} consists of predictions; i.e. {0,1} is the set of predictions.
- Separation The collective x : N ! {0,1} is obtained via the subselection of predictions based on the sequence of true labels corresponding to the predictions. 22
Sufficiency The true labels are subselected by predictions.
The three fairness criteria Independence, Separation and Sufficiency encompass a large part of fair machine learning [Barocas et al., 2017, p. 45]. Von Mises' statistical independence gives a consistent interpretation to all of them. In fact, Von Mises' independence opens the door to further investigations. To this end, we we recapitulate the strong linkage between statistical independence and randomness in Von Mises' theory.
## 7 The Ethical Implications of Modeling Assumptions
Machine learning methods try to model data in complex ways. Derived statements, such as predictions, then potentially get applied in society. In these cases one is obliged to ask which ought-state the machine learning model should reflect [Passi and Barocas, 2019, Räz, 2021]. To enable a justified choice, statistical concepts in machine learning require relations to the real world. Furthermore, modeling even requires understanding of the entanglement of societal and statistical concepts.
We proposed one specific meaningful definition of statistical independence which can be directly applied to the three observational fairness criteria from fair machine learning. In addition, this Von Mises' independence is key to a relativized notion of randomness. Pulling these threads together, we are now able to establish the following link: Randomness is fairness. Fairness is randomness.
21 Intersections of sensitive groups are not necessarily independent.
22 'Selecting with respect to' is 'conditioning on.'
## 7.1 Randomness is Fairness. Fairness is Randomness.
The concepts fairness and randomness frequently appear jointly: Broome [1984] argues that a random allocation of goods is fair under certain conditions. Literature on sortition argues for just representation of society by random selection of people [Parker, 2011, Stone, 2011]. 23 Bennett [2011, p. 633] even states that randomness encompasses fairness.
With Von Mises' axiom 2 and Definition 4 we can now tighten the conceptual relationship of fairness and randomness. The proposition directly follows from the definition of randomness respectively fairness in the sense of Von Mises.
Proposition 1 (Randomness is fairness. Fairness is randomness.) . Let x be a collective with respect to ; (the empty set). It is fair with respect to a set of sensitive groups (0-1-sequences) { s j } j 2 J , if and only if it is is random with respect to { s j } j 2 J .
The given proposition establishes a helpful link. It gives insights into both of the concepts. In particular, it substantiates the relativized conception of randomness in machine learning as it presents randomness as an ethical choice.
## 7.1.1 Randomness as Ethical Choice
Randomness in machine learning is a modeling assumption (Section 2). Fairness is an ethical choice. 24 In light of Proposition 1 randomness gets an ethical choice and fairness a modeling assumption. We now further detail this perspective.
We assume that we are given a fixed set of selection rules, which defines 'the' randomness. As far-fetched as this may sound, if we, for example, accept the so called Martin-Löf randomness as absolute and universal definition, then we exactly do this and fix the set of selection rules to the partial computable ones (see Appendix C.1). A sequence which is random with respect to this specified set of selection rules is fair with respect to the groups defined by the selection rules. Rephrased in terms of Martin-Löf randomness: a Martin-Löf random sequence is fair with respect to all partial computable groups. Only non-partial-computable groups (respectively sequences) can be discriminated against in this setting. If we interpret statistical independence as fairness (Section 3), then fairness is as absolute and universal as randomness here. Where did the 'essentially contested' nature of fairness [Gallie, 1955] leave the picture?
The set of admissible selection rules specifies the choice of sensitive groups, which indeed is a fraught and contestable choice [Menon and Williamson, 2018, Section H.3]. Thus each selection rule gets ethically loaded. Furthermore, the choice of collective, which we consider as random, fixes the fairness criterion. In summary, the determination of randomness is analogous to the determination of fairness.
However one defines randomness, it is an ethical choice. For symmetry reasons one can equivalently state in machine learning: fairness is a modeling assumption. The randomness assumption has an ethical, moral and potentially legal implication. We need non-mathematical, contextual arguments to each problem at hand which justify the adjustable and explicit randomness assumptions.
Given that randomness is an ethical choice, an absolute, universal conception of randomness counteracts any ethical debate in machine learning. Discussions about sexism, racism and other kinds of discrimination and injustice persist over time without ever arrogating the discovery of 'the'
23 Representativity here can be interpreted as typicality, thus one of the four intuitions for randomness.
24 More specifically, the choice of operationalized fairness, one of the fairness criteria, and the choice of groups.
fairness [Gallie, 1955]. But if 'the' randomness as statistical independence would exist, then 'the' fairness as statistical independence would be an accessible notion. For illustration, we reconsider Martin-Löf randomness. A Martin-Löf random sequence is independent, respectively fair, to the set of all partial computable selection rules. But, it is completely unclear what the ethical meaning of partial computable groups is. And, it remains unsolved whether the groups given by gender are partial computable, when we desire to be fair with respect to them. We conceive Proposition 1 as further counterargument to an absolute, universal definition of randomness. Randomness is, like fairness, better interpreted as a relative notion.
Further concluding, the equivalence of randomness and fairness highlights the deficiency of fairness notions in machine learning. The equivalence only holds due to the very reductionist perspective on fairness in fair machine learning. Despite their regular co-occurrence [Broome, 1984, Parker, 2011] [Bennett, 2011, p. 633], fairness and randomness are more multi-facetted and non-overlapping concepts as illustrated in Proposition 1.
## 7.1.2 Fairy Tales of Fairness: 'Perfectly Fair' Data
With the relationship between fairness and randomness in mind, we now turn towards random data as primitive. Discussions in fair machine learning sometimes seemingly presume the existence of 'perfectly fair' data (e.g. as highlighted in [Räz, 2021, p. 134]), as if fair machine learning merely tackles the cases where 'perfectly fair' data is not available.
Weinterpret 'perfectly fair' data as a collective with respect to all possible selection rules. The data does not depend on any (sensitive) group at all. In other words, 'perfectly fair' data is 'totally random' data. As we saw in Section 5.2 this is self-contradicting except of the trivial constant case. 'Perfectly fair' data does not exist or is statistically useless.
## 7.2 Demanding Fairness is Randomization: Fair Predictors are Randomizers
In practice, it is often unreasonable to assume random or fair data as in Proposition 1. Instead one demands for fairness respectively randomness of predictions. In these settings, fair machine learning techniques are deployed to exhibit ex post fulfillment of fairness criteria.
Weassume for the following discussion that the collective x consists of predictions, as in the fairness criteria Independence or Separation. Fair machine learning techniques enforce statistical independence of predictions and sensitive attributes. Rephrased, fair machine learning techniques actually introduce randomness post-hoc into the predictions. Thus, fair machine learning techniques can potentially be interpreted as randomization techniques.
## 7.2.1 Fairness-Accuracy Trade-Off - Another Perspective
Wenoticed that fair predictions are random predictions with respect to the sensitive attribute. In contrast, accurate predictions exploit all dependencies between given attributes and predictive goal, including the sensitive attributes. Thus, in fair machine learning morally wrongful discriminative potential of sensitive attributes is thrown away by purpose. On these grounds, it is not surprising that an increase in fairness respectively randomness (usually) goes hand in hand with a decrease in accuracy [Wick et al., 2020]. Randomization of predictions leads to the so called fairness-accuracy trade-off.
Concluding, via Von Mises' axiomatization we established: Randomness is fairness. Fairness is randomness . Exploiting this new perspective, we unlock another perspective on fair predictors
as randomizers, demonstrate the nonexistence of 'perfectly fair' data and treat randomness as an ethical choice, which can be neither universal nor total. In particular, the 'essentially contested' nature of fairness is tied to the 'essentially relative ' nature of randomness.
## 8 Conclusion
Fair machine learning attained an increasing interest in the last years. However, its conceptual maturity lags behind. In particular, the interplay between data, its mathematical representation and their relation to fairness is encompassed by a veil of nescience. In this paper, we contribute towards a better understanding of randomness and fairness in machine learning.
Westarted from the most commonly used definition of statistical independence and questioned its representation due to a lack of semantics. Generally, we observe that in machine learning, as in statistics, probability and its related concepts should be interpreted as modeling assumptions about the world (of data). Von Mises aimed for exactly this 'scientific' perspective on probability theory. We lean on his statistical independence, which clarifies the relation to the real world, and his definition of randomness, which is relative and orthogonal to the i.i.d. assumption, but similarly expressed as statistical independence. Then by the three fairness criteria in machine learning we obtain a further interpretation of independence, which we finally exploit to argue for a relative conception of randomness, randomness as an ethical choice in machine learning and fair predictors as randomizers.
## 8.1 Future Work: Approximate Randomness and Fairness, Randomness as Fairness via Calibration
Despite future conclusions in-between the topics fairness and randomness in other research subjects as machine learning, we claim that a significant dimension is missing in the present discussion. Practitioners usually deal with approximate versions of randomness, statistical independence or fairness. Yet, approximation spans another dimension of choice beset with pitfalls [Putnam, 1990, Lohaus et al., 2020]. Several questions ranging from the choice of approximation to the interference of concepts arise. Future work should detail the implications of this choice.
Second, we conjecture that ' Randomness is Fairness. Fairness is randomness. ' can be substantiated via the intuition of unpredictability. Starting from [Shafer and Vovk, 2019] definition of unpredictability randomness, which is closely related to the calibration idea presented in [Dawid, 2017], we can bridge to fairness as calibration as given in [Chouldechova, 2017]. In particular, this chain of arguments entails a more thorough discussion of the concepts of individual versus group fairness in machine learning [Binns, 2020]. As a subproblem, which is contained therein, the categorization into (sensitive) groups in fair machine learning deserves its own work.
Third, regarding a more thorough definition of statistical independence within the fairness criteria, we are convinced that a subjectivist interpretation of probability might reveal yet another perspective on the problem. We assume that the interplay between different interpretations of probability and ethical concepts such as fairness still leaves room for many important investigations.
Last but not least, we already referred to sortition literature and random allocation. The somewhat different relation between fairness and randomness in this literature leads us to speculate that further fruitful discussions between the two concepts may develop.
In the jungle of statistical concepts such as probability, uncertainty, randomness, independence
etc. further relations to social and ethical concepts wait to be brought to light. And machine learning research should care:
The arguments that justify inference from a sample to a population should explicitly refer to the variety of non-mathematical considerations involved. [Battersby, 2003, p. 11]
## Acknowledgements
Many thanks to Christian Fröhlich, Eric Raidl, Sebastian Zezulka, Thomas Grote and Benedikt Höltgen for helpful discussions and feedback. Futhermore, the authors thank all participants of the Philosophy of Science meets Machine Learning Conference 2022 in Tübingen, for all helpful comments and debates.
This work was was funded in part by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy - EXC number 2064/1 - Project number390727645; it was also supported by the German Federal Ministry of Education and Research (BMBF): Tübingen AI Center. The authors thank the International Max Planck Research School for Intelligent System (IMPRS-IS) for supporting Rabanus Derr.
## References
- Kenneth S. Abraham. Efficiency and fairness in insurance risk classification. Virginia Law Review , 71(3):403-451, 1985.
- Andrew Altman. Discrimination. In Edward N. Zalta, editor, The Stanford Encyclopedia of Philosophy (Summer 2020 Edition) . Stanford University, 2020. URL https://plato.stanford.edu/entri es/discrimination/ .
- Klaus Ambos-Spies, Elvira Mayordomo, Yongge Wang, and Xizhong Zheng. Resource-bounded balanced genericity, stochasticity and weak randomness. In Annual Symposium on Theoretical Aspects of Computer Science , pages 61-74. Springer, 1996.
- Prasanta S. Bandyopadhyay and Malcolm R. Forster. Philosophy of statistics: An introduction. In Prasanta S. Bandyopadhyay and Malcolm R. Forster, editors, Philosophy of Statistics , volume 7. Elsevier, 2011.
- Solon Barocas, Moritz Hardt, and Arvind Narayanan. Fairness in machine learning. NIPS tutorial , 1: 2, 2017.
- MarkBattersby. The rhetoric of numbers: Statistical inference as argumentation. In OSSAConference Archive , 2003.
- Deborah Bennett. Defining randomness. In Prasanta S. Bandyopadhyay and Malcolm R. Forster, editors, Philosophy of Statistics , volume 7. Elsevier, 2011.
- Joseph Berkovitz, Roman Frigg, and Fred Kronz. The ergodic hierarchy, randomness and hamiltonian chaos. Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics , 37(4):661-691, 2006.
- Dan Biddle. Adverse Impact and Test Validation: A Practitioner's Guide to Valid and Defensible Employment Testing. Gower Publishing, Ltd., 2006.
- Laurent Bienvenu, Glenn Shafer, and Alexander Shen. On the history of martingales in the study of randomness. Electronic Journal for History of Probability and Statistics , 5(1):1-40, 2009.
- Reuben Binns. Fairness in machine learning: Lessons from political philosophy. In Conference on Fairness, Accountability and Transparency , pages 149-159. PMLR, 2018.
- Reuben Binns. On the apparent conflict between individual and group fairness. In Proceedings of the 2020 conference on fairness, accountability, and transparency , pages 514-524, 2020.
- Norbert Blum. Einführung in Formale Sprachen, Berechenbarkeit, Informations-und Lerntheorie . Oldenbourg Wissenschaftsverlag, 2009.
- John Broome. Selecting people randomly. Ethics , 95(1):38-55, 1984.
- Sam Buss and Mia Minnes. Probabilistic algorithmic randomness. The Journal of Symbolic Logic , 78 (2):579-601, 2013.
- Toon Calders and Sicco Verwer. Three naive Bayes approaches for discrimination-free classification. Data Mining and Knowledge Discovery , 21(2):277-292, 2010.
- Donald T. Campbell. Common fate, similarity, and other indices of the status of aggregates of persons as social entities. Behavioral Science , 3(1):14-25, 1958.
- George Casella and Roger L. Berger. Statistical Inference: Second Edition . Duxbury Advanced Series, 2002.
- Emanuele Castano, Vincent Yzerbyt, Maria-Paolo Paladino, and Simona Sacchi. I belong, therefore, I exist: Ingroup identification, ingroup entitativity, and ingroup bias. Personality and Social Psychology Bulletin , 28(2):135-143, 2002.
- Gregory J. Chaitin. On the length of programs for computing finite binary sequences. Journal of the ACM(JACM) , 13(4):547-569, 1966.
- Graciela Chichilnisky. The foundations of statistics with black swans. Mathematical Social Sciences , 59(2):184-192, 2010.
- Alexandra Chouldechova. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data , 5(2):153-163, 2017.
- Alonzo Church. On the concept of a random sequence. Bulletin of the American Mathematical Society , 46(2):130-135, 1940.
- Donald C. Cook. The concept of independence in accounting. In Federal Securities Law and Accounting 1933-1970: Selected Addresses , pages 198-222. Routledge, 2020.
- Philip Dawid. On individual risk. Synthese , 194(9):3445-3474, 2017.
- Gert De Cooman and Jasper De Bock. Randomness is inherently imprecise. International Journal of Approximate Reasoning , 141:28-68, 2022.
- Bruno De Finetti. Funzione caratteristica di un fenomeno aleatorio. In Atti del Congresso Internazionale dei Matematici: Bologna del 3 al 10 de settembre di 1928 , pages 179-190, 1929.
- Abraham De Moivre. The Doctrine of Chances: A Method of Calculating the Probabilities of Events in Play . Frank Cass and Company Limited, 2nd edition, 1738/1967.
- David Deutsch. The beginning of infinity: Explanations that transform the world . Penguin, 2011.
- Luc Devroye, László Györfi, and Gábor Lugosi. A probabilistic theory of pattern recognition . Springer Science & Business Media, 1996.
- Rodney G. Downey and Denis R. Hirschfeldt. Algorithmic randomness and complexity . Springer Science & Business Media, 2010.
- Rick Durrett. Probability: Theory and Examples . Cambridge University Press, 5th edition, 2019.
- Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference ITCS 2012 , pages 214-226, 2012.
- Antony Eagle. Chance versus Randomness. In Edward N. Zalta, editor, The Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford University, Spring 2021 edition, 2021.
- Terrence L. Fine. Theories of probability: An examination of foundations . Academic Press, 1973.
- Rafael M. Frongillo and Andrew B. Nobel. Memoryless sequences for general losses. J. Mach. Learn. Res. , 21:80-1, 2020.
- Walter Bryce Gallie. Essentially contested concepts. In Proceedings of the Aristotelian society , volume 56, pages 167-198, 1955.
- Alexander GammermanandVladimirVovk. Hedging predictions in machine learning. TheComputer Journal , 50(2):151-163, 2007.
- Donald Gillies. An Objective Theory of Probability . Routledge, 2010. (first published 1973).
- Erich Grädel and Jouko Väänänen. Dependence and independence. Studia Logica , 101(2):399-410, 2013.
- Stanley P . Gudder. Quantum probability spaces. Proceedings of the American Mathematical Society , 21(2):296-302, 1969.
- Stanley P . Gudder. Stochastic methods in quantum mechanics . Dover Publications Inc., 1979.
- Alan Hájek. Fifteen arguments against hypothetical frequentism. Erkenntnis , 70(2):211-235, 2009.
- Moritz Hardt, Eric Price, and Nathan Srebro. Equality of opportunity in supervised learning. Advances in Neural Information Processing Systems , pages 3323-3331, 2016.
- Corinna Hertweck, Christoph Heitz, and Michele Loi. On the moral justification of statistical parity. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages 747-757, 2021.
- Michael A. Hogg and Dominic Abrams. Social Identifications: A Social Psychology of Intergroup Relations and Group Processes . Routledge, 1998.
- Lily Hu and Issa Kohler-Hausmann. What's sex got to do with fair machine learning? arXiv preprint arXiv:2006.01770 , 2020.
- Paul W. Humphreys. Randomness, independence, and hypotheses. Synthese , pages 415-426, 1977.
- Victor I. Ivanenko. Decision systems and nonstochastic randomness . Springer, 2010.
- Toshihiro Kamishima, Shotaro Akaho, Hideki Asoh, and Jun Sakuma. Fairness-aware classifier with prejudice remover regularizer. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) , 7524 LNAI(PART 2):35-50, 2012.
- Niki Kilbertus, Mateo Rojas Carulla, Giambattista Parascandolo, Moritz Hardt, Dominik Janzing, and Bernhard Schölkopf. Avoiding discrimination through causal reasoning. Advances in neural information processing systems , 30, 2017.
- Jon Kleinberg, Sendhil Mullainathan, and Manish Raghavan. Inherent trade-offs in the fair determination of risk scores. Leibniz International Proceedings in Informatics, LIPIcs , 67:1-22, 2017.
- Andre˘ ı Nikolaevich Kolmogorov. Grundbegriffe de Wahrscheinlichkeitsrechnung . Julius Springer, 1933.
- Andre˘ ı Nikolaevich Kolmogorov. Foundations of the theory of probability: Second English Edition . Chelsea Publishing Company, 1956.
- Andre˘ ı Nikolaevich Kolmogorov. Three approaches to the definition of the concept 'quantity of information'. Problemy peredachi informatsii , 1(1):3-11, 1965.
- John Lafferty and Larry Wasserman. Challenges in statistical machine learning. Statistica Sinica , 16 (2):307, 2006.
- Leonid A. Levin. The concept of random sequence. Soviet Mathemathics Doklady 14 , pages 14131416, 1973.
- Leonid A. Levin. A concept of independence with applications in various fields of mathematics. Technical Report MIT/LCS/TR-235, MIT, Laboratory for Computer Science, April 1980.
- Kasper Lippert-Rasmussen. The badness of discrimination. Ethical Theory and Moral Practice , 9(2): 167-185, 2006.
- Vitali Liskevich. Analysis 1 Lecture Notes 2013/2014 . University of Bristol, 2014.
- Michael Lohaus, Michael Perrot, and Ulrike Von Luxburg. Too relaxed to be fair. In International Conference on Machine Learning , pages 6360-6369. PMLR, 2020.
- Michele Loi, Anders Herlitz, and Hoda Heidari. A philosophical theory of fairness for predictionbased decisions. Technical report, Politecnico di Milano, 2019. URL https://ssrn.com/abstr act=3450300 .
Per Martin-Löf. The definition of random sequences. Information and control , 9(6):602-619, 1966.
Craig McGarty. Categorization in Social Psychology . Sage Publications, 1999.
- Aditya Krishna Menon and Robert C. Williamson. The cost of fairness in binary classification. In Conference on Fairness, Accountability and Transparency , pages 107-118. PMLR, 2018.
- Andrei A. Muchnik, Alexei L. Semenov, and Vladimir A. Uspensky. Mathematical metaphysics of randomness. Theoretical Computer Science , 207(2):263-317, 1998.
- Brian C. Murchison. The concept of independence in public law. Emory Law Journal , 41:961, 1992.
- Louis Narens. An introduction to lattice based probability theories. Journal of Mathematical Psychology , 74:66-81, 2016.
- Melvyn B. Nathanson. Elementary methods in number theory , volume 195. Springer Science & Business Media, 2008.
- Arch W. Naylor. On decomposition theory: generalized dependence. IEEE Transactions on Systems, Man, and Cybernetics , 11(10):699-713, 1981.
- Donald S. Ornstein. Ergodic theory, randomness, and 'chaos'. Science , 243(4888):182-187, 1989.
- Joel Matthew Parker. Randomness and legitimacy in selecting democratic representatives . The University of Texas at Austin, 2011.
- Samir Passi and Solon Barocas. Problem formulation and fairness. In Proceedings of the conference on fairness, accountability, and transparency , pages 39-48, 2019.
- Karl Popper. The logic of scientific discovery . Routledge, 2010.
- Christopher P . Porter. Mathematical and philosophical perspectives on algorithmic randomness . PhD thesis, University of Notre Dame, 2012.
- Pavel Pták. Concrete quantum logics. International Journal of Theoretical Physics , 39(3):827-837, 2000.
- Hilary Putnam. The Meaning of the Concept of Probability in Application to Finite Sequences (Routledge Revivals) . Garland Publishing, 1990.
- Manish Raghavan, Solon Barocas, Jon Kleinberg, and Karen Levy. Mitigating bias in algorithmic hiring: Evaluating claims and practices. In Proceedings of the 2020 conference on fairness, accountability, and transparency , pages 469-481, 2020.
- K.P .S. Bhaskara Rao and M. Bhaskara Rao. Theory of charges: a study of finitely additive measures . Academic Press, 1983.
- John Rawls. A theory of justice . The Belknap Press of Harvard University Press, 1971.
- Tim Räz. Group fairness: Independence revisited. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages 129-137, 2021.
- Teresa Scantamburlo. Non-empirical problems in fair machine learning. Ethics and Information Technology , 23(4):703-712, 2021.
- Claus-Peter Schnorr. Zufälligkeit und Wahrscheinlichkeit: eine algorithmische Begründung der Wahrscheinlichkeitstheorie , volume 218 of Lecture Notes in Mathematics . Springer-Verlag, 1971.
- Claus-Peter Schnorr. The process complexity and effective random tests. In Proceedings of the fourth annual ACM symposium on Theory of computing , pages 168-176, 1972.
- Claus-Peter Schnorr. A survey of the theory of random sequences. In Basic Problems in Methodology and Linguistics , pages 193-211. Springer, 1977.
- Gerhard Schurz and Hannes Leitgeb. Finitistic and frequentistic approximation of probability measures with or without -additivity. Studia Logica , 89(2):257-283, 2008.
- Glenn Shafer. Discussion on Hedging Predictions in Machine Learning by A. Gammerman and V. Vovk . The Computer Journal , 50(2):164-172, 02 2007. URL https://doi.org/10.1093/comjnl /bxl066 .
- Glenn Shafer and Vladimir Vovk. Game-Theoretic Foundations for Probability and Finance , volume 455. John Wiley & Sons, 2019.
- Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: From theory to algorithms . Cambridge university press, 2014.
- John Simpson and Edmund Weine. 'independence, n.". In Oxford English Dictionary - Second Edition . Oxford University Press, 1989.
- Wolfgang Spohn. Stochastic independence, causal independence, and shieldability. Journal of Philosophical logic , 9(1):73-99, 1980.
- Ingo Steinwart, Don Hush, and Clint Scovel. Learning from dependent observations. Journal of Multivariate Analysis , 100(1):175-194, 2009.
- Peter Stone. The Luck of the Draw: The Role of Lotteries in Decision-Making . Oxford University Press, 2011.
- Kohtaro Tadaki. An operational characterization of the notion of probability by algorithmic randomness. In Proceedings of the 37th Symposium on Information Theory and its Applications (SITA2014) , volume 5, pages 389-394, 2014.
- Henri Tajfel. Social identity and intergroup behaviour. Social Science Information , 13(2):65-93, 1974.
- Terence Tao. 275a, notes 2: Product measures and independence, October 2015. URL https: //terrytao.wordpress.com/2015/10/12/275a-notes-2-product-measures-and-indepe ndence/ .
- Vladimir A. Uspenskii, Alexei L. Semenov, and A Kh. Shen. Can an individual sequence of zeros and ones be random? Russian Mathematical Surveys , 45(1):121, 1990.
- Michiel Van Lambalgen. Von Mises' definition of random sequences reconsidered. The Journal of Symbolic Logic , 52(3):725-755, 1987.
- Michiel Van Lambalgen. The axiomatization of randomness. The Journal of Symbolic Logic , 55(3): 1143-1167, 1990.
Jean Ville. Étude critique de la notion de collectif . Gauthier-Villars, 1939.
- Sérgio B. Volchan. What is a random sequence? The American mathematical monthly , 109(1):46-63, 2002.
- Elart Von Collani. A note on the concept of independence. Economic Quality Control , 21(1):155-164, 2006.
- Richard Von Mises. Grundlagen der Wahrscheinlichkeitsrechnung. Mathematische Zeitschrift , 5(1): 52-99, 1919.
Richard Von Mises. Probability, statistics, and truth . Dover Publications, Inc., 1981.
- Richard Von Mises and Hilda Geiringer. Mathematical theory of probability and statistics . Academic press, 1964.
- Vladimir G. Vovk. A logic of probability, with application to the foundations of statistics. Journal of the Royal statistical society: series B (Methodological) , 55(2):317-341, 1993.
- Larry Wasserman. All of statistics: a concise course in statistical inference . Springer, 2004.
- Michael Wick, Swetasudha Panda, and Jean-Baptiste Tristan. Unlocking fairness: a trade-off revisited. Proceedings of the 37th International Conference on Machine Learning , 32, 2020.
- Robert C. Williamson and Aditya Menon. Fairness risk measures. In International Conference on Machine Learning , pages 6786-6797. PMLR, 2019.
## A Generalized Von Misesean Probability Theory
In this appendix we outline a theory of probability subsuming that of Kolmogorov and Von Mises.
## A.1 Kolmogorov's notion of Independence
Kolmogorov axiomatized probability theory in his book [Kolmogorov, 1956] in a measure theoretical way. He defined a probability space ( › , F , P ) as a measure space with base set › , -algebra F and normalized measure P . Events are elements of F , i.e. subsets of › , which obtain a probability via P . Statistical independence is defined as a specific assignment of probability to an intersection event.
Definition 5 (Kolmogorov's Definition of Statistical Independence of Events [Kolmogorov, 1956, p. 9 Def. 1]) . Let ( › , F , P ) be a probability space. Two events A , B 2 F are called statistically independent iff
<!-- formula-not-decoded -->
As we highlighted above, Kolmogorov's axiomatization is, despite its success, not the only mathematical theory of probability. Specifically, one can weaken the structure of the probability space and still work with concepts such as statistical independence, expectation, conditioning (e.g. [Gudder, 1969, Chichilnisky, 2010, Narens, 2016]).
## A.2 Finitely Additive Probability Space
Weintroduce a weaker measure structure, which we call finitely additive probability space. Interestingly, this weaker structure includes the axiomatization of Kolmogorov and Von Mises as special cases. We define a finitely additive probability space modified from [Rao and Rao, 1983, Def. 2.1.1 (7)]) as
Definition 6 (Finitely Additive Probability Space) . The tuple ( N , A , ' ) is called a finitely additive probability space for a base set N, a set of measurable sets A P ( N ) containing the empty set ;2 A and a finitely additive probability measure ' : A ! [0,1] satisfying the following conditions: (1) ' ( ; ) ∅ 0 ,
(2) if A 1, A 2, A 1 [ A 2 2 A and A 1 ∴ A 2 ∅; then ' ( A 1 [ A 2) ∅ ' ( A 1) ⊕ ' ( A 2) .
Observe that this definition does not impose any structural restrictions on the set of subsets A . Kolmogorov's probability space is certainly a specific finitely additive probability space in our sense, as every set -algebra contains the empty set and every countably additive probability is finitely additive.
Analogously, Von Mises implicitly uses a finitely additive probability space. This space is given by ( N , A vM, ' vM), where N are the natural numbers and A vM, ' vM are defined in the following.
First, we consider the finitely additive base measure
<!-- formula-not-decoded -->
where A N and N n ∅ {1,..., n }. ' vM is called the 'natural density' in the number theory literature [Nathanson, 2008, p. 256]. From this definition is not clear whether the given limit exists. Thus, we define the set of measurable sets by
<!-- formula-not-decoded -->
which is called the 'density logic' in [Pták, 2000]. It is a pre-Dynkin-system [Schurz and Leitgeb, 2008].
Wegeneralize Kolmogorov's definition of statistical independence of events to finitely additive probability spaces.
Definition 7 (Statistical Independence of Events on a Finitely Additive Probability Space) . Let ( N , A , ' ) be a finitely additive probability space. Two measurable sets A , B 2 A are independent iff
1. A ∴ B 2 A
2. ' ( A ∴ B ) ∅ ' ( A ) ' ( B )
Observe that the first condition is naturally fulfilled in Kolmogorov's -algebra. In the case of Von Mises' density logic, this constraint is strict. A pre-Dynkin-system is not closed under arbitrary intersections.
## A.3 Von Mises' Admissibility and Kolmogorov's Independence are Analogues
We now reconsider the definition of collectives and selection rules. Both are 0,1-sequences on the natural numbers, with the restriction that selection rules contain infinitely many 1's and their frequency limit does not have to exist. Both sequences can be interpreted as indicator functions on
the natural numbers. So for x : N ! {0,1} and s : N ! {0,1} we write X ∅ x ϒ 1 (1) and S ∅ s ϒ 1 (1) for the corresponding subsets of the natural numbers.
Wewant to show that Von Mises' admissibility condition is equivalent to the given definition of statistical independence on finitely additive probability spaces. Actually, the equivalence only holds for the slightly restricted case in which the selection rule itself possesses converging frequencies.
Theorem 1 (Admissibility in Von Mises setting implies Statistical Independence on Finitely Additive Probability Spaces) . Let x be a collective with respect to s. Suppose furthermore that s has a converging frequency limit. Then X and S, the indexed sets corresponding to the collective (respectively selection rule) on the finitely additive probability space ( N , A vM, ' vM) are statistically independent.
Proof. Weknow that
<!-- formula-not-decoded -->
which we can rewrite as
This gives
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
by help of a standard result for the multiplication of sequence limits [Liskevich, 2014, Theorem 3.1.7].
Theorem 2. Let X and S be two statistically independent events on the finitely additive probability space ( N , A vM, ' vM) with ' vM( S ) ∪ 0 , then the corresponding collective x, indicator function of X , has the admissible selection rule s, indicator function of S.
Proof. It is given that
<!-- formula-not-decoded -->
Furthermore ' vM( S ) ∪ 0 implies that the corresponding selection rules selects infinitely many elements and lim n !1 n ϕ S ∴ N n ϕ ∅ 1 ' vM( S ) .
This implies
<!-- formula-not-decoded -->
Wenote some caveats regarding the preceding discussion.
1. Werequire the frequency limit for s to exist in Theorem 1. So the sequence S is not an entirely general selection rule.
2. The condition ' vM( S ) ∪ 0 in Theorem 2 ensures that we do not condition on measure zero events. Furthermore, it guarantees at this point, that the indicator function of S is a selection rule containing infinitely many ones. Besides that, its frequency limit exists.
3. Even though given here only for the binary case. The argumentation can be extended to continuum labeled collectives [Von Mises and Geiringer, 1964, II.B].
4. In our discussion, we focus on admissibility instead of statistical independence in the sense of Von Mises, since our argument finally focuses on the randomness interpretation of statistical independence. Admissibility and Von Mises' statistical independence are, despite the objects on which they are defined, equivalent.
5. Statistical independence in Von Mises' setting and Kolmogorov's setting are not equivalent. They are special cases of a more general form of statistical independence. So they are mathematically analogous under mild conditions. But we emphasize the conceptual difference. Von Mises refused to define statistical independence between mere events [Von Mises and Geiringer, 1964, p. 35]. Instead he demanded statistical independence to be defined between collectives underlining that independence is a concept about aggregates, the collectives, not single occurring events.
## B Four Intuitions of Randomness
- Typicality A sequence is called random if it shares 'some' characteristics of any possible sequence. Martin-Löf and Schnorr formalized this idea via statistical tests [Martin-Löf, 1966, Schnorr, 1977].
- Incompressibility The information contained in a random sequences is (approximately) as large as the sequence itself. The sequences cannot be compressed by 'some' procedure [Kolmogorov, 1965, Chaitin, 1966, Schnorr, 1972, Levin, 1973].
- Unpredictability In a random sequence one can know all foregoing elements without being able to predict by 'some' procedure the next element [Ville, 1939, Muchnik et al., 1998, Shafer and Vovk, 2019, Frongillo and Nobel, 2020, De Cooman and De Bock, 2022].
Independence A random sequence is independent of 'some' other sequences [Von Mises, 1919, Church, 1940].
## C Relations between Randomness Definitions
Webriefly outline some of the known relationships between various notions of randomness.
Onone hand, there are mathematical expressions capturing the same randomness intuitions meanwhile being mathematically distinct to each other.
For instance, the definition of a typical sequence following [Martin-Löf, 1966] implies Schnorr's definition of typicality [Schnorr, 1971, 1977] but not vice versa [Uspenskii et al., 1990, p. 143]. Cooman and De Bock's imprecise unpredictability randomness [De Cooman and De Bock, 2022] is strictly more expressive than Vovk and Shafer's unpredictability randomness [Shafer and Vovk, 2019, Section 1.1] [De Cooman and De Bock, 2022, Theorem 37].
On the other hand, there are mathematical expressions capturing differing randomness intuitions meanwhile being necessary, sufficient or even equivalent to each other. For instance, the Levin-Schnorr theorem, simultaneously proven by Levin [Levin, 1973] and Schnorr [Schnorr, 1972, 1977], established an equivalence of typicality following Martin-Löf [Martin-Löf, 1966] and incompressibility following Levin [Levin, 1973] and Schnorr [Schnorr, 1972] based on the idea of [Kolmogorov, 1965] (e.g. see in [Volchan, 2002, Theorem 5.3] and references therein). Cooman and de Bock expressed Schnorr [Schnorr, 1971, 1977] and Martin-Löf randomness [Martin-Löf, 1966] in terms of an unpredictability approach [De Cooman and De Bock, 2022]. Muchnik showed in [Muchnik et al., 1998] that all incompressible sequences, again following Levin and Schnorr's prefix-complexity approach [Schnorr, 1972, Levin, 1973] are unpredictable in his sense.
In his thesis Ville [1939] attempted to generalize the idea of 'excluding a gambling strategy' (see Section 4.4) via a game-theoretic approach. He showed [Ville, 1939, p. 76] that for any set of admissible selection rules S he could construct a gambling strategy, more exactly a capital process associated to a gambling strategy, which captures the same randomness definition. The opposite direction is, however, impossible [Ville, 1939, p. 39]. But Ambos-Spies et al. [1996] introduced a weaker form of Ville [1939]'s randomness as unpredictability which is equivalent to Church [1940]'s randomness as independence [Downey and Hirschfeldt, 2010, Section 12.3]. Finally, van Lambalgen observed an abstract interpretation of 'random with respect to something' as 'independent to' in [Van Lambalgen, 1990].
## C.1 Aprototypical, absolute and universal Notion of Randomness
One often referred absolute and universal definition of randomness is Martin-Löf's typicality approach [Buss and Minnes, 2013]. Martin-Löf's randomness as typicality has been equivalently formalized in terms of incompressibility and unpredictability (see Section C). Furthermore, a sequence, which is Martin-Löf random [Martin-Löf, 1966], is statistically independent to all partial computable selection rules [Church, 1940] [Tadaki, 2014, Theorem 11]. Contrarily, not every collective with respect to all partial computable selection rules is a Martin-Löf random sequence [Blum, 2009, p. 193]. So Martin-Löf's definition is linked to all four intuitions.
## D Kolmogorov's versus Von Mises' Probability Theories in a Table
Table 2: Summary of main difference between Kolmogorov's and Von Mises' probability theories.
| | Kolmogorov | Von Mises |
|--------------------------|--------------------------------------------------------|------------------------------------------------------------|
| fundamental structure | probability space ( › , F , P ) | collectives ( x i ) i 2 N , implicitly ( N , A vM , ' vM ) |
| base set | (almost arbitrary) set › | N |
| set of events | -algebra F | Dynkin-system A vM |
| probability | finite positive measure | limit of frequency sequence |
| probability measure | countably additive | finitely additive ' vM |
| randomness | noexplicit mathematical definition | explicit mathematical definition |
| statistical independence | factorization of joint distribution | frequency limit doesn't change under subselection |
| data model | each data point a random variable X i on ( › , F , P ) | each data point an element in a collective ( x i ) i 2 N |
## E Penguin Colony Example for Fair Collective
n
<details>
<summary>Image 1 Details</summary>
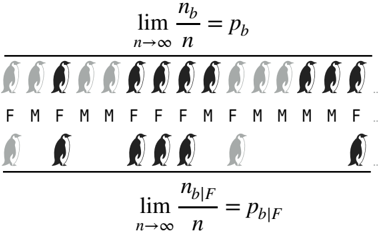
### Visual Description
## Diagram: Penguin Population Representation
### Overview
The image is a diagram illustrating a concept related to population statistics, specifically focusing on the proportion of black penguins within a larger penguin population and within a subset of female penguins. The diagram uses penguin illustrations to represent the population and mathematical notation to express the proportions.
### Components/Axes
* **Penguin Illustrations:** Penguins are used to represent individuals in the population. Black penguins represent a specific characteristic (presumably being black), while gray penguins represent the absence of that characteristic.
* **Labels (F, M):** The letters "F" and "M" are placed below some of the penguins, likely representing female and male penguins, respectively.
* **Mathematical Notation (Top):** The expression "lim (n\_b / n) = p\_b" is present, where:
* "lim" denotes the limit as n approaches infinity.
* "n\_b" represents the number of black penguins.
* "n" represents the total number of penguins.
* "p\_b" represents the proportion of black penguins in the overall population.
* **Mathematical Notation (Bottom):** The expression "lim (n\_{b|F} / n) = p\_{b|F}" is present, where:
* "lim" denotes the limit as n approaches infinity.
* "n\_{b|F}" represents the number of black penguins that are female.
* "n" represents the total number of penguins.
* "p\_{b|F}" represents the proportion of black penguins among the female penguins.
### Detailed Analysis
* **Top Row of Penguins:** The top row shows a sequence of penguins, alternating between gray and black, with some variation. The sequence is labeled with "F" or "M" below each penguin. The sequence appears to continue indefinitely, indicated by the ellipsis (...).
* **Bottom Row of Penguins:** The bottom row shows a smaller sample of penguins, also labeled with "F" or "M". This row seems to represent a subset of the population, specifically focusing on the female penguins.
* **Proportions:** The mathematical expressions indicate that the diagram is illustrating the concept of proportions within a population and within a subset of that population. The top expression calculates the overall proportion of black penguins, while the bottom expression calculates the proportion of black penguins specifically among the female penguins.
### Key Observations
* The diagram uses visual representation (penguins) to illustrate a statistical concept.
* The mathematical notation provides a formal definition of the proportions being represented.
* The use of "F" and "M" labels suggests that gender is a relevant factor in the analysis.
### Interpretation
The diagram is designed to visually explain the concept of conditional probability or proportions within a population. It demonstrates how the proportion of a certain characteristic (being black) can differ between the overall population and a specific subset of that population (female penguins). The mathematical notation formalizes this concept, showing how the proportions are calculated as the population size approaches infinity. The diagram is likely intended for educational purposes, to help visualize and understand statistical concepts.
</details>
→∞
Figure 1: Example for a subselection and fair collective. nb denotes the number of black penguins among the first n -penguins. Blackness of penguins is distributed fairly with respect to sex if pb ∅ pb ϕ F .
…
…
…