## A TUTORIAL INTRODUCTION TO LATTICE-BASED CRYPTOGRAPHY AND HOMOMORPHIC ENCRYPTION
## A PREPRINT
## Contents
| Introduction | Introduction | Introduction | 5 |
|----------------|---------------------------------|------------------------------------------------------------|-----|
| | 1.1 | Motivations . . . . . . . . . . . . . . . . . . . . . . . | 5 |
| | 1.2 | Tutorial organisation . . . . . . . . . . . . . . . . . . | 6 |
| | 1.3 | A simple lattice-based encryption scheme . . . . . . . | 7 |
| | Computational Complexity Theory | Computational Complexity Theory | 10 |
| | 2.1 | Basic time complexity classes . . . . . . . . . . . . . | 10 |
| | 2.2 | Hardness of approximation . . . . . . . . . . . . . . . | 11 |
| | 2.3 | Average-case hardness . . . . . . . . . . . . . . . . . | 12 |
| | Cryptography Basics | Cryptography Basics | 15 |
| | 3.1 | Computational security . . . . . . . . . . . . . . . . . | 15 |
| | 3.2 | Private and public encryptions . . . . . . . . . . . . . | 15 |
| | 3.3 | Security definitions . . . . . . . . . . . . . . . . . . . | 16 |
| | Lattice Theory | Lattice Theory | 18 |
| | 4.1 | Lattice basics . . . . . . . . . . . . . . . . . . . . . . | 18 |
| | 4.2 | Dual lattice . . . . . . . . . . . . . . . . . . . . . . . | 22 |
| | 4.3 | Some lattice problems . . . . . . . . . . . . . . . . . . | 23 |
| | 4.4 | Ajtai's worst-case to average-case reduction . . . . . . | 26 |
| | 4.5 | An application of SIS: Collision resistant hash functions | 28 |
## Yang Li
School of Computing Australian National University Canberra, ACT, 2600
kelvin.li@anu.edu.au
## Kee Siong Ng
School of Computing Australian National University Canberra, ACT, 2600
keesiong.ng@anu.edu.au
## Michael Purcell
School of Computing Australian National University Canberra, ACT, 2600
michael.purcell1@anu.edu.au
## September 29, 2022
| Discrete Gaussian | Distribution | 30 |
|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------|------|
| 5.1 | Discrete Gaussian distribution . . . . . . . . . . . . . . | 30 |
| 5.2 | Discrete Gaussian for provable security . . . . . . . . . | 32 |
| Learning with | Errors | 35 |
| 6.1 | LWE distribution . . . . . . . . . . . . . . . . . . . . . | 35 |
| 6.2 | LWE hardness proof . . . . . . . . . . . . . . . . . . . | 37 |
| 6.3 | An LWE-based encryption scheme . . . . . . . . . . . . | 39 |
| Cyclotomic Polynomials and Cyclotomic Extensions | Cyclotomic Polynomials and Cyclotomic Extensions | 41 |
| 7.1 | Cyclotomic polynomials . . . . . . . . . . . . . . . . . | 41 |
| 7.2 | Galois Group of Cyclotomic Polynomials . . . . . . . . | 44 |
| Algebraic Number Theory | Algebraic Number Theory | 48 |
| 8.1 Ring of integers and its ideal | . . . . . . . . . . . . . . . | 48 |
| 8.1.1 | Integral ideal . . . . . . . . . . . . . . . . . . . | 49 |
| 8.1.2 | Fractional ideal . . . . . . . . . . . . . . . . . . | 51 |
| 8.1.3 | Applications in Ring LWE . . . . . . . . . . . . | 52 |
| 8.2 | Number field embedding . . . . . . . . . . . . . . . . . | 54 |
| 8.2.1 | Canonical embedding . . . . . . . . . . . . . . . | 54 |
| | 8.2.2 Geometric quantities of ideal lattice . . . . . . . | 57 |
| 8.3 | Dual lattice in number field . . . . . . . . . . . . . . . . | 59 |
| Ring Learning with Errors | Ring Learning with Errors | 62 |
| | . . . . . . . . . . . . . . . | 62 |
| 9.1 Some RLWE in general | ideal lattice problems . number field . . . . . . . . . . . . . . | 63 |
| 9.2 | Hardness of search RLWE | 65 |
| 9.3 | . . . . . . . . . . . . . . . . | |
| 9.5 | Search to decision RLWE . . . . . . . . . . . . . . . . . | 69 |
| 9.6 An RLWE-based encryption scheme | . . . . . . . . . . . | 73 |
| Homomorphic Encryption | Homomorphic Encryption | 75 |
| Basic definitions . | . . . . . . . . . . . . . . . . . . . . . | 75 |
| 10.1 | | |
| 10.2 | Gentry's original FHE using squashing and bootstrapping | 76 |
| 10.3 BV ∗ : SHE by relinearization | . . . . . . . . . . . . . . . | 78 |
| 10.4 BV : Leveled FHE by dimension-modulus reduction | . . | 83 |
| | 10.4.1 Modulus reduction to reduce ciphertext size . . . | 83 |
| | 10.4.2 The BV scheme . . . . . . . . . . . . . . . . . . | 84 |
| 10.5 | . . . . . . | 86 |
| Additional tools for computational efficiency 10.5.1 Noise management by modulus switching | . . . . | 86 |
| | 10.5.2 Vector decomposition . . . . . . . . . . . . | 86 |
|----------------------------------------------------|-------------------------------------------------------------|------|
| | 10.5.3 Key switching . . . . . . . . . . . . . . . | 87 |
| 10.6 | BGV : Leveled FHE by modulus and key switching | 88 |
| 10.7 | The B scheme: scale invariant . . . . . . . . . . . | 89 |
| 10.8 | The BFV scheme . . . . . . . . . . . . . . . . . . | 91 |
| 10.9 | Closing thoughts on HE developments . . . . . . . | 95 |
| 10.10A Sage Implementation of the BFV Cryptosystem | . | 97 |
| | 10.10.1 Package Imports . . . . . . . . . . . . . . | 97 |
| | 10.10.2 Define Parameters . . . . . . . . . . . . . | 97 |
| | 10.10.3 Utility Functions . . . . . . . . . . . . . . | 98 |
| | 10.10.4 Noise Samplers . . . . . . . . . . . . . . . | 98 |
| | 10.10.5 Basic Cryptographic Operations . . . . . . | 99 |
| | 10.10.6 Homomorphic Addition . . . . . . . . . . | 100 |
| | 10.10.7 Homomorphic Multiplication . . . . . . . | 100 |
| | 10.10.8 Relinearization . . . . . . . . . . . . . . . | 101 |
| Abstract Algebra | Abstract Algebra | 102 |
| A.1 | Group theory . . . . . . . . . . . . . . . . . . . . | 102 |
| A.2 | Ring theory . . . . . . . . . . . . . . . . . . . . . | 104 |
| A.3 | Field theory . . . . . . . . . . . . . . . . . . . . . | 107 |
| Galois Theory | Galois Theory | 109 |
| B.1 Field extension . | . . . . . . . . . . . . . . . . . . | 109 |
| | B.1.1 Algebraic extension . . . . . . . . . . . . | 110 |
| | B.1.2 Simple extension . . . . . . . . . . . . . . | 111 |
| | B.1.3 Splitting field . . . . . . . . . . . . . . . . | 112 |
| | B.1.4 Normal extension . . . . . . . . . . . . . . | 112 |
| | B.1.5 Separable extension . . . . . . . . . . . . | 113 |
| B.2 | Galois extension and Galois group . . . . . . . . . | 114 |
| Algebraic Number Theory | Algebraic Number Theory | 119 |
| C.1 Algebraic number field | . . . . . . . . . . . . . . . | 119 |
| C.2 | Ideals of ring of integers . . . . . . . . . . . . . . | 122 |
| | C.2.1 Integral ideals . . . . . . . . . . . . . . . . | 123 |
| | C.2.2 Fractional ideal . . . . . . . . . . . . . . . | 124 |
| | C.2.3 Chinese remainder theorem . . . . . . . . | 127 |
| C.3 | Trace and Norm . . . . . . . . . . . . . . . . . . . | 129 |
| C.4 | . . . . . . . . . . . . . . . . . . . | 130 |
| C.5 | Ideal lattices . . in number fields . . . . . . . . . . . . | 133 |
| Dual lattice Mind Maps | Dual lattice Mind Maps | 137 |
| D.1 | A mindmap for RLWE | 137 |
|-------|----------------------|-------|
| E | Notation | 138 |
## References 141
## 1 Introduction
## 1.1 Motivations
Why study Lattice-based Cryptography? There are a few ways to answer this question.
1. It is useful to have cryptosystems that are based on a variety of hard computational problems so the different cryptosystems are not all vulnerable in the same way.
2. The computational aspects of lattice-based cryptosystem are usually simple to understand and fairly easy to implement in practice.
3. Lattice-based cryptosystems have lower encryption/decryption computational complexities compared to popular cryptosystems that are based on the integer factorisation or the discrete logarithm problems.
4. Lattice-based cryptosystems enjoy strong worst-case hardness security proofs based on approximate versions of known NP-hard lattice problems.
5. Lattice-based cryptosystems are believed to be good candidates for post-quantum cryptography, since there are currently no known quantum algorithms for solving lattice problems that perform significantly better than the best-known classical (non-quantum) algorithms, unlike for integer factorisation and (elliptic curve) discrete logarithm problems.
6. Last but not least, interesting structures in lattice problems have led to significant advances in Homomorphic Encryption, a new research area with wide-ranging applications.
Let's look at that fourth point in more detail.
Note first that the discrete logarithm and integer factorisation problem classes, which underlie several well-known cryptosystems, are only known to be in NP, they are not known to be NP-complete or NP-hard. The way we understand their complexity is by looking at the average run-time complexity of the current best-known (non-polynomial) algorithms for those two problem classes on randomly generated problem instances. Using that heuristic complexity measure, we can show that
1. there are special instances of those problems that can be solved in polynomial time but, in general, both problems can be solved only in sub-exponential time; and
2. on average, most of the discrete logarithm and integer factorisation problem instances are as hard as each other.
So we believe these two problems to be average-case hard problem classes, but we cannot yet prove that. Interestingly, we know there are quantum algorithms that can solve these two problems efficiently (Bernstein et al., 2009).
The above then begs the question of whether we can design cryptosystems based on known NP-hard or worst-case hard problem classes. In constructing a (public-key) cryptosystem using a problem class ACH with average-case hardness like Integer Factorisation or Discrete Logarithm, it is sufficient to show that the generation of a key pair (at random) and the solution of the private key corresponds to a problem instance I ∈ ACH , and we rely on average hardness to say I is hard to solve with good probability. But in constructing a (public-key) cryptosystem using a problem class WCH with only known worst-case complexity, we need to do a bit more work, in that it is not sufficient to generate a key pair (at random) and show the solution of the private key is a problem instance I ∈ WCH , we need to actually show that I is one of the hard or worst cases in WCH .
In other words, to build a cryptosystem based on a worst-case hard problem class, we do not just need to know that hard instances exist, but we need a way to explicitly generate the hard problem instances. And that is an issue because we do not know how to do that for most worst-case hard problem classes. But this is what makes lattice problems interesting: we know how to generate, through reductions, the worst-case problem instances of approximation versions of NP-hard lattice problems and build efficient cryptosystems based on them. In practice, this means breaking these cryptosystems, even with some small non-negligible probability, is provably as hard as solving the underlying lattice problem approximately to within a polynomial factor in polynomial time.
How hard are these approximation lattice problems? In most cases, the underlying lattice problem is the Shortest Vector Problem (SVP), and the approximation version is called the GapSVP λ problem for an approximation factor λ . These gap lattice problems are known to be NP-hard only for small
approximation factors like n O (1 / log 2 n ) . We also know that these gap lattice problems are not NPhard for approximation factors above √ n/ log n , unless the polynomial time hierarchy collapses. See Micciancio and Goldwasser (2002); Khot (2005, 2010) for surveys of these results. The best-known algorithm for solving these gap lattice problems to within poly(n) factor has time complexity 2 O ( n ) (Ajtai et al., 2001), which leads us to the following conjecture that underlies the security of latticebased cryptography:
Conjecture: There is no polynomial time algorithm that approximates lattice problems to within polynomial factors.
Why another paper on Lattice Cryptography and Homomorphic Encryption? It is important to state early that this tutorial is a compilation of known results in the literature and we do not claim any research originality. In contrast with some existing works Peikert (2016); Halevi (2017); Chi et al. (2015), this tutorial
1. is written primarily with pedagogical considerations in mind;
2. is as self-contained as possible, with essentially all required background given either in the body of the tutorial or in the appendix;
3. focuses mostly on the narrow development path from the Learning With Errors (LWE) problem to Ring LWE and homomorphic encryption schemes built on top of them; we do not cover other lattice cryptographic systems like NTRU, Ring SIS-based systems, and homomorphic signatures.
The target audiences are students, practitioners and researchers who want to learn the 'core curriculum' of lattice-based cryptography and homomorphic encryption from a single source.
In writing the tutorial, we have benefited from peer-reviewed published papers as well as many lessformal explanatory material in the form of lecture notes and blog articles. We are not always careful and comprehensive in citing the latter class of material, and we apologise in advance for errors of omission.
## 1.2 Tutorial organisation
The tutorial can be divided into three parts in pedagogical order as follows. Each part will be presented with definitions, examples, discussions around the intuitions of abstract concepts and more importantly corresponding computer code to help develop the understanding.
After brief introductions to the basics of Computational Complexity Theory in Section 2 and Cryptography in Section 3, the first part of the tutorial focuses on the LWE problem, a foundational hard lattice problem. This part begins with some Lattice Theory in Section 4, followed by material on Discrete Gaussian Distributions in Section 5. The LWE problem is then described in some detail in Section 6, including hardness proofs.
The second part discusses the Ring LWE (RLWE) problem, which is a generalization of LWE from the integer domain to an algebraic number field domain that allows more computationally efficient cryptosystems to be built. As LWE does not straightforwardly generalize to its ring version, some required background knowledge will be presented with intuition, examples and computer code, including cyclotomic polynomials and their Galois groups in Section 7 and algebraic number theory in Section 8. (For readers that require a more extensive background, the appendix covers Abstract Algebra, Galois Theory and Algebraic Number Theory in significantly more details.) The RLWE problem is described in some detail in Section 9, including hardness proofs. (A mindmap is given in Appendix D to help readers navigate and remember the many components of RLWE proofs.)
Having introduced the LWE and RLWE problems, the final part of the tutorial (Section 10) shows how efficient homomorphic encryption (HE) schemes can be developed based on the LWE and RLWE problems. These schemes are both similar and different to Gentry's original fully HE scheme. The similarity is in designing a somewhat HE scheme first, then using bootstrapping to achieve fully HE. The difference is that they avoided using Gentry's 'squashing' technique, but used the algebraic properties of (R)LWE instances to make the somewhat HE schemes bootstrappable.
## 1.3 A simple lattice-based encryption scheme
Before diving into the technical details of lattice-based cryptosystems and homomorphic encryption schemes, we describe a simple public-key encryption scheme introduced by Regev (2009) to illustrate the connection between the scheme's security and lattice problems. This scheme is based on the learning with errors (LWE) problem, see Section 6 for details. Its simplicity inspired subsequent developments in homomorphic encryption schemes that are based on lattices, and is a fundamental building block in many such schemes.
Note that in this example Z q is the collection of integers in the range [ -q/ 2 , q/ 2) rather than its standard usage for representing the ring Z / Z q , and [ x ] q is the reduction of x into Z q such that [ x ] q = x mod q . We use boldface to denote vectors and matrices. When working with matrices, all vectors are by default considered as column vectors. Vector multiplications are denoted by a · b , whilst matrix and scalar multiplications are denoted without the 'dot' in the middle. For simplicity, we use [ b | -A ] to denote the action of appending the column vector b to the front of the matrix -A . The parameters n, q, N, χ correspond to the vector dimension, the plaintext modulus, the number of LWE samples, and the noise distribution over Z q , respectively. In particular, χ is chosen such that Pr ( | e · r | < ⌊ q 2 ⌋ / 2) > 1 -negl ( n ) for a random binary vector r = { 0 , 1 } N . The scheme is summarized as follows, but in an alternative format to be consistent with later homomorphic encryption schemes that will be presented in Section 10.
Private key : Sample a private key s = (1 , t ) , where t ← Z n q .
Public key : Sample a random matrix A = a 1 . . . a N ← Z N × n q and compute b = At + e for a random noise vector e ← χ N . Output the public key P = [ b | -A ] ∈ Z N × ( n +1) q .
Encryption: Encrypt the message m ∈ { 0 , 1 } by computing
$$c = \left [ P ^ { T } r + \left \lfloor \frac { q } { 2 } \right \rfloor m \right ] _ { q } \in \mathbb { Z } _ { q } ^ { n + 1 } ,$$
where m = ( m, 0 , . . . , 0) has length n +1 .
Decryption: Decrypt the ciphertext c using the secret key by computing
$$m = \left [ \left \lfloor { \frac { 2 } { q } \left [ c \cdot s \right ] _ { q } } \right \rceil \right ] _ { 2 } .$$
The purpose of the binary vector r is to randomize the use of the public key so that it is impossible to derive m from the ciphertext c . To demonstrate how decryption works, the ciphertext can be re-written as which implies
$$c = \left [ b ^ { T } r + \left \lfloor \frac { q } { 2 } \right \rfloor m | - A ^ { T } r \right ] _ { q } ,$$
$$[ c \cdot s ] _ { q } & = \left [ b ^ { T } r + \left \lfloor \frac { q } { 2 } \right \rfloor m - t ^ { T } A ^ { T } r \right ] _ { q } = \left [ ( t ^ { T } A ^ { T } + e ^ { T } ) r + \left \lfloor \frac { q } { 2 } \right \rfloor m - t ^ { T } A ^ { T } r \right ] _ { q } \\ & = \left [ e ^ { T } r + \left \lfloor \frac { q } { 2 } \right \rfloor m \right ] _ { q } .$$
Because Pr ( | e T r | < ⌊ q 2 ⌋ / 2) > 1 -negl ( n ) , we have (with overwhelming probability)
$$\begin{array} { r l } & { \frac { 2 } { q } \left [ c \cdot s \right ] _ { q } \in \left \{ \begin{matrix} ( - 1 / 2 , 1 / 2 ) & i f m = 0 ; \\ [ - 1 , - 1 / 2 ) \cup ( 1 / 2 , 1 ) & i f m = 1 . } \end{matrix} } \end{array}$$
Notice that if b ′ = At then an attacker who knows A and b ′ could recover the secret t by solving a system of linear equations. The security of the system therefore depends on the presence of the noise vector e .
If an attacker knows b instead of b ′ , then the attack described above will not work. If, however, such an attacker could recover the noise vector e , then they could use that information to compute b ′ . They could then recover t as described above. Recovering e is an instance of a well-known lattice problem called the bounded distance decoding (BDD) problem. So, an attacker that can solve the BDD problem could recover the secret t . In other words, recovering t is 'no harder' than solving the BDD problem.
Conversely, Regev showed that the BDD problem is 'no harder' than recovering t . That is, an attacker who could recover t given A and b could solve the BDD problem as well. This result implies that if the BDD problem is hard, then attacking the cryptosystem is hard as well. This kind of result is called a reduction . Crucially, the BDD problem is believed to be hard. So, Regev's result constitutes a proof of security for the LWE-based cryptosystem described above.
```
Figure 1: A Sage implementation of the simple lattice-based encryption system described above.
Note: This implementation is not suitable for use in real-world applications.
#!/usr/bin/env sage
from sage.misc.prandom import randrange
import sage.stats.distributions.discrete_gaussian_integer as dgi
# Define parameters
def sample_noise(N, R):
D = dgi.DiscreteGaussianDistributionIntegerSampler(sigma=1.0)
return vector([R(D()) for i in range(N)])
q = 655360001
n = 1000
N = 500
R = Integers(q)
Q = Rationals()
Z2 = Integers(2)
# Generate keys
t = vector([R.random_element() for i in range(n)])
secret_key = vector([R(1)] + t.list())
A = matrix(R, [[R.random_element() for i in range(N)]
for i in range(n)])
e = sample_noise(N, R)
b = A.T * t + e
public_key = block_matrix([matrix(b).T, -A.T],
ncols=2)
# Encrypt Message
message = R(randrange(2))
m_vec = vector([message] + [R(0) for i in range(n)])
r = vector(R, [randrange(2) for i in range(N)])
ciphertext = public_key.transpose() * r + (q//2) * m_vec
# Decrypt Message
temp = (2/q) * Q(ciphertext*secret_key)
decrypted_message = R(Z2(temp.round()))
# Verification
print(decrypted_message == message)
```
Figure 1: A Sage implementation of the simple lattice-based encryption system described above. Note: This implementation is not suitable for use in real-world applications.
Decision problem
Time complexity
Time complexity class
## 2 Computational Complexity Theory
Computational complexity theory is the foundation of computational security of modern cryptography by allowing one to emphasize the security of a cryptosystem by drawing an efficient reduction from a computationally hard problem (that either has been proved or is believed with high confidence to be unsolvable in a reasonable time, e.g., polynomial time). That being said, a cryptosystem that is provably secure is still vulnerable to real-world attacks, depending on what threat model was considered, how close to reality the underlying security definitions and assumptions are and so on.
In this section, we start by introducing some basic definitions in computational complexity theory, then go on to talk about inapproximability, which are variants of the standard decision and optimization problems and commonly used to prove the computational security of cryptosystems. We then introduce gap problems, which are generalization of decision problems and proving their hardness is a useful technique of proving inapproximability. We finish the chapter by briefly introducing Ajtai (1996)'s worst-case to average-case reduction. Ajtai's work is considered as the first published average-case problem whose hardness is based on the worst-case hardness of some well-known lattice problems.
## 2.1 Basic time complexity classes
The following concepts are introduced under the assumption that a general purpose computer is of the form of a Turing machine . The primary reference of this subsection is Sipser (2013)'s book Introduction to the Theory of Computation, Third Edition .
A language (or decision problem) is a set of strings that are decidable by a Turing machine. We use Σ to denote the alphabet and Σ ∗ to denote the set of all strings over the alphabet Σ of all lengths. A special case is when Σ = { 0 , 1 } and Σ ∗ = { 0 , 1 } ∗ is the set of all strings of 0 s and 1 s of all lengths. In this case, a language A = { x ∈ { 0 , 1 } ∗ | f ( x ) = 1 } , where f : { 0 , 1 } ∗ →{ 0 , 1 } is a Boolean function .
Let M be a deterministic Turing machine that halts on all inputs. We measure the time complexity or running time of M by the function t : N → N , where t ( n ) is the maximum number of steps that M takes on any input of length n . Generally speaking, t ( n ) can be any function of n and the exact number of steps may be difficult to calculate, so we often just analyse t ( n ) 's asymptotic behaviour by taking its leading term, denoted by O ( t ( n )) . We also relax its codomain by letting t : N → R + be a non-negative real valued function.
It is worth mentioning that when analysing the time complexity of a function, we often consider its time complexity in the worst case, i.e., the longest running time of all inputs of a particular length n . At the end of this chapter, we will emphasize the importance of the worst-case complexity in the proof of security of modern cryptosystems. We will give a clue of how this was achieved by Ajtai through an average-case to worst-case reduction.
Definition 2.1.1. The time complexity class , TIME ( t ( n )) , is defined as the set of all languages that are decidable by a Turning machine in time O ( t ( n )) .
Obviously, t can be any function, e.g., logarithm, polynomial, exponential, etc. In practice, polynomial differences in running time are considered to be much better than exponential differences due to the super fast growth rate of the latter. For this reason, we separate languages into different classes according to their worst case running time on a deterministic single-tape Turing machine.
- Definition 2.1.2. P P is the class of languages that are decidable in polynomial time by a deterministic single-tape Turing machine, i.e.,
$$P = \bigcup _ { k \in \mathbb { N } } T I M E ( n ^ { k } ) .$$
Some problems are computationally hard, so cannot be decided by a deterministic single-tape Turing machine in polynomial time. But given a possible solution, sometimes we can efficiently verify whether or not the solution is genuine. The length of the solution has to be polynomial in the length of the input string length, for otherwise the verification process cannot be done efficiently. Based on the ability to efficiently verify, we can define the complexity class NP.
- Definition 2.1.3. NP NP is the class of languages that can be verified in polynomial time.
Sometimes, a problem can be solved by reducing it to another problem, whose solution can be found relatively easier, provided the reduction between the two problems is efficient. For example, a polynomial time reduction is often acceptable.
- Definition 2.1.4. A language A is polynomial time reducible PT reduction to another language B , written as A ≤ P B , if a polynomial time computable function f : Σ ∗ → Σ ∗ exists, where for every w ,
$$w \in A \iff f ( w ) \in B .$$
A polynomial time reduction A ≤ P B implies A is no harder than B , so if B ∈ P then A ∈ P. Based on this reduction, we can define another complexity class.
- Definition 2.1.5. A language B is NP-complete NP-complete if it is in NP and every problem in NP is polynomial time reducible to B .
Essentially, we are saying that NP-complete is the set of the hardest problems in NP. There are, however, hard problems that are not in NP such as an optimization problem . Given a solution of an optimization problem, it is often not trivial to verify the solution is optimal among all the answers, so this type of problems are not polynomial time verifiable and hence not in NP. For these problems, we can define a similar complexity class as NP-complete but without requiring their solutions to be polynomially checkable.
- Definition 2.1.6. A language is NP-hard NP-hard if every problem in NP is polynomial time reducible to it.
The two terms NP-complete and NP-hard are sometimes used interchangeably because an optimization problem can also be formed as a decision problem. For example, instead of asking for the shortest route from the travelling salesman problem , we can ask whether there exists a route that is shorter than a threshold.
Many optimization problems are NP-hard, which means there is no polynomial time solution under the assumption P = NP. Hence, when an answer for an NP-hard problem is needed, the fallback is to use an approximation algorithm to compute a near-optimal solution that is within an acceptable range. For a NP-hard problem, it is sometimes easier to build a cryptosystem based on its approximated version rather than the NP-hard problem itself. For this reason, cryptographers are concerned about whether or not an optimization problem is hard to be approximated within a certain range. This brings us to the study of the hardness of approximation or inapproximability in the next subsection.
## 2.2 Hardness of approximation
An optimization problem aims at finding the optimum result of a computational problem. This optimum result can either be the maximum or minimum of some value. Throughout this section, we focus on minimization problems only. The same results also hold for maximization problems. 1 In the previous section, we said an optimization problem can be made into a decision problem by comparing the solution with a threshold. More formally, it is defined as the next.
- Definition 2.2.1. An NP-optimization (NPO) problem NPO is an optimization problem such that
- all instances and solutions can be recognized in polynomial time,
- all solutions have polynomial length in the length of the instance,
- all solution's costs can be computed in polynomial time.
For a minimization problem in NPO, its decision version asks 'Is OPT ( x ) ≤ q ?', where OPT ( x ) is the unknown optimal solution (or its cost, we use interchangeably) to the instance x . For example, in the maximum clique problem, an instance is a graph, an optimal solution is the maximum clique in the given graph and its cost is the clique size. Given an NPO problem, its decision version is an NP problem, so NPO is an analogy of NP but for optimization problems. On the other hand, PO (P-optimization) problem is the set of optimization problems whose decision versions are in P, such as finding the shortest path.
1 Lecture 18: Gap Inapproximability , 6.892 Algorithmic Lower Bounds: Fun with Hardness Proofs (Spring 2019), Erik Demaine, available at http://courses.csail.mit.edu/6.892/spring19/lectures/ L18.html
Definition 2.2.2. An algorithm ALG for a minimization problem is called c -approximation algorithm for c ≥ 1 c -approx if for all instances x , it satisfies
$$\frac { \cos t ( A L G ( x ) ) } { \cos t ( O P T ( x ) ) } \leq c .
( 1 ) & & ( 2 ) \\ \intertext { s o t ( O P T ( x ) ) } \intertext { a n d } \intertext { e q u i l y }$$
The ratio c is not necessarily a constant, it can be any function of the input size, i.e., c = f ( n ) for an arbitrary function f ( · ) . Practically, we prefer a near optimal solution ALG ( x ) such that the ratio c is as small as possible or at least does not grow quickly in the input size. This, however, may not be possible for some problems such as the maximum clique problem, whose best possible ratio is O ( n 1 - ) for small > 0 . From a provable security's perspective, the smaller the ratio c is, the harder the capproximation problem is. This leads to a cryptosystem with higher security because it requires more time and computational resources for an attacker to break the system.
For a given c = f ( n ) , there are different ways of proving c -approximating a problem is hard. One way is by proving a c-gap problem is hard, which is in direct analogy to the c-approximation problem in hand. This way, if the gap problem is hard, then the c -approximation problem is also hard.
Definition 2.2.3. For a minimization problem, a c -gap problem c -gap (where c > 1 ) distinguishes two cases for the optimal solution OPT ( x ) of an instance x and a given k as follows:
- x is an YES instance if OPT ( x ) ≤ k ,
- x is an NO instance if OPT ( x ) > c · k .
The value k is a given input. For example, in the c -gap version of the shortest vector problem, we can set k = λ 1 ( L ) to be the shortest vector in a given lattice L . Intuitively, a c -gap problem is a decision problem where the unknown optimal solution OPT of the corresponding optimization problem is mapped to the opposite side of a gap. It is, however, different from a decision problem in the sense that there is a gap between k and c · k .
The connection between c-gap and c-approximation problems is that if a c-gap problem is proved to be hard, then the corresponding c-approximation problem is also hard. In other words, there is a reduction from a c-gap problem to a c-approximation problem. The proof is straightforward. Assuming the problem can be c-approximated in polynomial time by an algorithm A , so for an input x we have OPT ( x ) ≤ A ( x ) ≤ c · OPT ( x ) . If x is a YES instance of the gap problem, then
If x is a NO instance, then
$$O P T ( x ) \leq k \implies A ( x ) \leq c \cdot O P T ( x ) \leq c \cdot k .$$
$$locate(x) > c \cdot k \implies A ( x ) > c \cdot k .$$
Gap and approximation lattice problems are the foundation of provable security for latticed-based cryptosystems. We will see more of these problems in Section 4 and some of their cryptographical applications in the hardness proofs of the short integer solution problem, learning with error problem and ring learning with error problem.
Either way the instance x can be distinguished easily using the decision procedure A ( x ) ≤ c · k .
## 2.3 Average-case hardness
So far, we have introduced the time complexity classes P and NP in the worst case scenario. That is, the longest running time over all inputs at a given input length. A problem that is hard to be solved in polynomial time in the worst case is known as worst-case hard. There is another related concept called average-case hardness, which is stronger than worst-case hardness, in the sense that the former implies the latter but not vice versa. To finish section, we briefly discuss the critical role of average-case hard problems for cryptography and how they can be constructed by a worst-case to average-case reduction that was achieved by Ajtai (1996).
Without going into the details, we state some remarks of average-case problems to help the reader to get an intuitive understanding of these problems. More discussions of these problems can be found in Chapter 18 of Arora and Barak (2009). First, an average-case problem consists of a decision problem and a probability distribution, from which inputs can be sampled in polynomial time. Such a problem is called a distributional problem . This is different from a worst-case decision problem, where all c -gap implies inapprox
inputs are considered when determining its hardness. Second, the first remark entails that average-case complexity is defined with respect to a specific distribution over the inputs. This suggests that a problem may be difficult with one distribution but easy with another distribution. For example, integer factorization may be difficult for large prime numbers, but easy for small integers. Hence, which probability distribution is used is crucial for the hardness of the integer factorization problem. Finally, average-case complexity has its own complexity classes distP and distNP , which are the average-case analogs of P and NP, respectively.
To prove a cryptosystem is computationally secure, one could build an efficient reduction from a known worst-case problem to it, so that if the cryptosystem can be attacked successfully, such an attack model provides a solution to the worst-case problem. However, knowing alone the underlying problem is worst-case hard is not sufficient to build a secure cryptosystem in real-world, because many of the system's instances may correspond to easy instances of the worst-case problem, which can be solved efficiently.
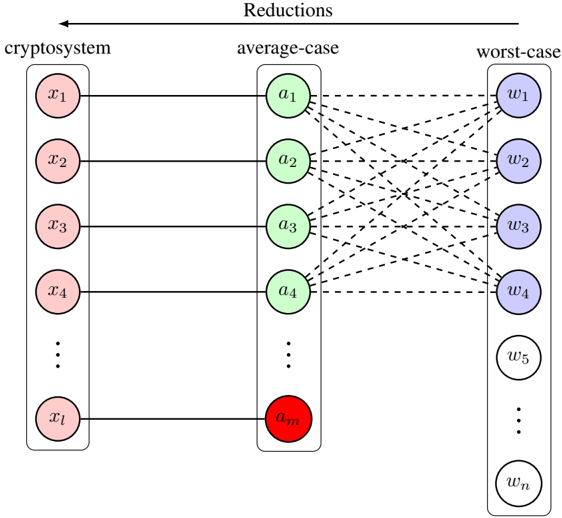
For this reason, an ideal situation is when a cryptosystem's security is based on an average-case problem and the exact distribution to sample hard instances is known. But this is hard to achieve. It is more difficult to prove that a certain distribution generates only hard instances, because this would imply the problem is also worst-case hard. An alternative is to construct an average-case problem, such that its instances correspond to the hard instances in a worst-case problem. This is known as the worst-case to average-case reduction. A visual representation of this type of constructions is illustrated in Figure 2. In this figure, a random cryptographic instance corresponds to an average-case instance. By construction, it is almost always true that an average-case instance links to a hard instance of some worst-case problem. This reduction implies that if the worst-case problem is known or believed (in high confident) to be hard, then the cryptosystem is guaranteed to be secure with high probability.
Figure 2: A demonstration of a cryptosystem's computational security is based on an average-case problem. Each cryptographic instance x i corresponds to a random average-case instance a j . Almost all random instances in the average-case problem can be mapped with the hard instances in a worst-case problem. There may be a fraction of average-case instances (colored in red) that can be solved easily, so their solutions entail solutions of the worst-case problem. But the fraction of such instances is negligible. The hard and easy instances in the worst-case problem are colored blue and white, respectively. The dashed lines indicate the worst-case to average-case reduction is random.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Cryptosystem Reductions
### Overview
The image is a diagram illustrating reductions between a cryptosystem, an average-case scenario, and a worst-case scenario. It depicts a mapping of inputs from the cryptosystem to intermediate values in the average-case, and then to outputs in the worst-case. The diagram uses circles to represent variables or values, and dashed lines to indicate relationships or transformations.
### Components/Axes
The diagram is divided into three main columns, labeled from left to right: "cryptosystem", "average-case", and "worst-case".
* **Cryptosystem:** Contains variables labeled `x1`, `x2`, `x3`, `x4`, and continuing down to `xl`.
* **Average-case:** Contains variables labeled `a1`, `a2`, `a3`, `a4`, and continuing down to `am`. The `am` variable is highlighted in red.
* **Worst-case:** Contains variables labeled `w1`, `w2`, `w3`, `w4`, `w5`, and continuing down to `wn`.
* The entire diagram is titled "Reductions" at the top.
* Dashed lines connect the cryptosystem variables to the average-case variables, and the average-case variables to the worst-case variables.
### Detailed Analysis or Content Details
The diagram shows a many-to-many mapping. Each `x` variable in the cryptosystem is connected to *every* `a` variable in the average-case. Similarly, each `a` variable in the average-case is connected to *every* `w` variable in the worst-case.
* The cryptosystem has `l` input variables (`x1` to `xl`).
* The average-case has `m` intermediate variables (`a1` to `am`).
* The worst-case has `n` output variables (`w1` to `wn`).
* The variable `am` is visually distinguished by being colored red. This suggests it may be a critical or special case.
### Key Observations
The diagram illustrates a reduction process where solving the cryptosystem is reduced to solving the average-case, and solving the average-case is reduced to solving the worst-case. The complete connectivity between the columns suggests that the complexity of the cryptosystem is related to the complexity of both the average-case and worst-case scenarios. The red highlighting of `am` suggests it may be a bottleneck or a key element in the reduction.
### Interpretation
This diagram likely represents a security proof in cryptography. The "reductions" title indicates that the security of the cryptosystem is being shown to depend on the hardness of a problem in the average-case, which in turn is related to the hardness of a problem in the worst-case.
The complete connections between the columns suggest that if an attacker can efficiently solve the worst-case problem, they can also efficiently solve the average-case problem, and consequently break the cryptosystem. The red `am` variable could represent a specific instance or condition that is crucial for the reduction to hold. For example, it might be a specific input that reveals information about the cryptosystem's key.
The diagram is a high-level conceptual illustration and does not contain specific numerical data. It is a visual representation of a mathematical argument about the security of a cryptosystem. The diagram is a visual aid to understand the relationships between different computational problems and their implications for cryptographic security.
</details>
The work by Ajtai served exactly this purpose by introducing the short integer solution (SIS) problem and proving that SIS is an average-case problem with polynomial time reductions from three worstcase lattice problems to it. This work is knowable the first worst-case to average-case reduction. The significant implication of Ajtai's work in cryptography is the fact that it laid the foundation for the security of modern cryptosystems to be based on worst-case problems (via average-case problems). More importantly, this work sparked a number of important following up works including the learning with error and ring learning with error problems that advanced lattice-based cryptography to a new era.
computational security security parameter
## 3 Cryptography Basics
The history of cryptography dates back to the pre-computer era, but with the same goal as today's, that is, securely sharing secret information between parties on public communication channels. A simple but motivating example is shown next, which is a shift cipher encryption technique used by Julius Caesar (during 81-45BC) to securely communicate with his troops on battlefields (Hoffstein et al., 2008).
j s j r d k f q q n s l g f h p g w j f p y m w t z l m n r r n s j s y q z h n z x e n e m y f a l l i n g b a c k b r e a k t h r o u g h i m m i n e n t l u c i u s
As the name of the technique suggests, each letter in the plaintext (below the horizontal line) was shifted by a pre-determined number of places along a fixed direction in the alphabet. This transforms it into a ciphertext (above the horizontal line) that do not hold the original information any more.
## 3.1 Computational security
Back then, Caesar's method was still able to effectively protect his secret messages to the troops from eavesdroppers. But with the help of nowadays multi-core GHz processor-computers that handle billions of instructions per second, this encryption method will fail within seconds. The example motivates the need to design more complex ciphertexts that are hard to decrypt, where the hardness should both be measurable and tunable by some parameters in order to cope with the increasing computing resources of potential attackers.
With the help of mathematics and computer science, in particular probability theory and computational complexity theory, the safety of modern encryption methods can be captured by computational security , a security notion, which allows an attacker to succeed in guessing the secret message with a measurable chance and computational effort such as running time. A frequently used approach to realize this security notion is to parameterize the probability of success and algorithmic running time of an attack by an integer-valued security parameter. This was named 'asymptotic approach' and discussed in more details in Chapter 3 of Katz and Lindell (2014). Some of the following results are also taken from that chapter, but presented in different orders and notations to ensure consistency of this tutorial paper.
Under the notion of computational security, one can draw the connection between an encryption scheme and a computational problem that has been proved (or believed with high confidence) to be hard to solve within a practical time. A famous example is that the security of the RSA encryption scheme relies on the large integer factorization problem, which is presumed (without an actual proof) hard to solve by an efficient non-quantum algorithm. The RSA problem is to solve the unknown x in the equation x e = c mod N . 2 The problem is easy when N is prime, so it comes down to primality test of N .
The security parameter described above, sometimes denoted by n (or λ or κ ), reflects the input size of the underlying hard computational problem. The larger the security parameter, the larger the input size, so the problem is more difficult to be solved in a practical time frame, which ensures the encryption scheme is less likely to be attacked with success. In the RSA scheme, the security parameter is the bit length n of the modulus N . The larger n is, the more difficult it is to prime factor N to efficiently solve the RSA problem. By convention, the security parameter n is often supplied to a scheme in the unary format 1 n by repeating the number 1 n times.
## 3.2 Private and public encryptions
Now that we discussed the security parameter, we formally introduce two types of encryption schemes, that is, the private (or symmetric) and public (asymmetric) key encryption schemes. The two types are similar in the sense that they both consists of three sub-steps for key generation, encryption and decryption. The main difference is that private key encryption uses only one key for both encryption and decryption (hence the name symmetric), whilst public key encryption uses one key for each purpose.
Definition 3.2.1. Define the following three polynomial time algorithms:
2 Throughout the paper, we use = instead of ≡ to denote the congruent modulo relation in order to be consistent with most others in the field. This is also noted in the Notation table in Appendix E.
- Key generation: A probabilistic algorithm that generates a key k ← Keygen (1 n ) for encryption and decryption, where | k | > n .
- Encryption: A probabilistic algorithm that encrypts the plaintext m ∈ { 0 , 1 } ∗ to a ciphertext c ← Enc ( k, m ) using the key.
- Decryption: A deterministic algorithm that decrypts the ciphertext with the key to get the plaintext m ← Dec ( k, c ) .
The collection ( Keygen , Enc , Dec ) forms a private key encryption scheme if for all n, k, m , it satisfies m ← Dec ( k, Enc ( k, m )) .
Definition 3.2.2. Define the following three polynomial time algorithms:
- Key generation: A probabilistic algorithm that generates a pair of keys ( pk , sk ) ← Keygen (1 n ) , where pk is the public key for encryption and sk is the secret key for decryption and both have sizes larger than n .
- Encryption: A probabilistic algorithm that encrypts the plaintext m ∈ { 0 , 1 } ∗ to a ciphertext c ← Enc ( pk , m ) using the public key.
- Decryption: A deterministic algorithm that decrypts the ciphertext using the secret key to get m ← Dec ( sk , c ) .
The collection ( Keygen , Enc , Dec ) forms a public key encryption scheme if for all n, ( pk , sk ) , m , it satisfies m ← Dec ( sk , Enc ( pk , m )) .
## 3.3 Security definitions
Generally speaking, public key encryption uses longer keys due to the fact that one key is public. This in return makes it slower than private key encryption. It is, however, more convenient when under private key encryption, no secure channel is available for sharing the key or the key needs to be changed constantly for different parties. Regardless, the requirement for the keys (in both private and public key encryptions) to be larger than n is to ensure the keys are at least of certain sizes in order to indicate the lower bound of an encryption scheme.
As n directly reflects the security of an encryption scheme, it is convenient to parameterize an attacker's running time and probability of success by n . More specifically, the running time is defined as the time taken to attack the scheme by a randomized algorithm. For practical purpose, this is often preferred to be polynomial in n , denoted by poly ( n ) . From the designer's point of view, an encryption scheme is only considered secure if both the probability of success is significantly small and such a probability decreases as n gets larger. A frequently used function that captures these two characteristics is called a negligible function .
Definition 3.3.1. A function µ : N → R is negligible , if for every positive integer c , there exists an integer N c such that for all n > N c , we have | µ ( n ) | < n -c .
An example is the negative exponential function µ ( n ) = 2 -n . For c = 6 , the threshold to satisfy the above condition is N c = 30 .
When a function is not defined explicitly, we use negl ( n ) to indicate it is negligible. Another characteristic that makes negligible function a suitable candidate for measuring an attacker's probability of success is due to the fact that it is still negligible even after multiplied by a polynomial function of n , that is, | poly ( n ) | · negl ( n ) is also negligible (Proposition 3.6 (Katz and Lindell, 2014)). This assures that if an attacker has a negligible probability of success, his chance stays extremely small even if the same attack is repeated a polynomial number of times (in n ).
An example (Example 3.2 (Katz and Lindell, 2014)) to illustrate this negligible probability and the running time is when an adversary's probability of success is 2 40 · 2 -n by running an attacking algorithm for n 3 minutes. If the security parameter is set to n = 40 , the adversary only needs to run the attack for roughly 40 3 ≈ 44 days to break the system with a probability 1. But if the security parameter is set large n = 500 , the adversary's chance of breaking the system is 2 -460 that is almost 0 even if the attack runs for 237 years.
Semantic security
Indistinguishable
Definition 3.3.2. An encryption scheme is secure if any probabilistic polynomial time (PPT) adversary has only a negligible probability of success to break the scheme.
Here, probabilistic refers to the attack being a randomized algorithm, which typically runs faster than deterministic algorithms.
So far, we have implicitly discussed the notion of security (or breaking an encryption scheme) without formally defining the meaning of it. The concrete security definition that is most relevant to this tutorial paper is semantic security. Below we give a formal definition of it and an equivalent definition, called indistinguishability which is easier to work with in practice. Both definitions can be defined for either private or public key encryptions, with the difference being a public key is also given for the public key encryption case.
At a high level, semantic security means given a ciphertext that encrypts one of two messages, a PPT adversary has no better chance than random guessing that the ciphertext is an encryption of one message or the other.
Definition 3.3.3. An (public or private key) encryption scheme Π is semantically secure if for every PPT adversary A , there is another PPT adversary A ′ such that their chances of guessing the plaintext m are almost identical, regardless A ′ is only given the length of m . That is, let c ← Enc ( k, m ) , then
$$| P r [ \mathcal { A } ( 1 ^ { n } , c ) = m ] - P r [ \mathcal { A } ^ { \prime } ( 1 ^ { n } , | m | ) = m ] | \leq n e g l ( n ) .$$
It is convenient to consider the attack model as a distinguisher (i.e., a PPT algorithm) that tries to exhibit the non-randomness from the ciphertexts in order to associate a ciphertext with a particular plaintext. If the adversary's chance of success is better than random, then the encryption scheme is vulnerable to attacks. The process of guessing the source of a given ciphertext can be formalized as an adversarial indistinguishability experiment (Section 3.2.1 (Katz and Lindell, 2014)). Given a PPT adversary A and a (public or private) encryption scheme Π , the experiment outputs IndisExp A , Π ( n ) = 1 for a successful guess of the source plaintext.
Definition 3.3.4. An (private or public key) encryption scheme Π is indistinguishable if it satisfies
$$P r \left [ I n d i s E x p _ { \mathcal { A } , \Pi } ( n ) = 1 \right ] \leq \frac { 1 } { 2 } + n e g l ( n )$$
for all PPT adversary A and security parameter n .
The following theorem states the equivalent relationship between semantic security and indistinguishability. The same equivalent relation can also be proved under the public key encryption setting. 3
Theorem 3.3.5 (Theorem 3.13 (Katz and Lindell, 2014)) . A private key encryption scheme is indistinguishable in the presence of an eavesdropper if and only if it is semantically secure in the presence of an eavesdropper.
Both semantic security and indistinguishability discussed above are in the presence of an eavesdropper, who passively receives/intercepts a plaintext and tries to guess the corresponding plaintext. In the case of public-key encryption, the adversary has access to the public key and the encryption method, so it is possible for the adversary to compare the intercepted ciphertext with a self-encrypted ciphertext, and use this piece of information to increase the probability of successfully guessing the plaintext. By assuming the adversary has an oracle access to the encryption scheme which allows repeated interactions, this attack model is valid for both public and private key encryptions (Section 3.4.2 (Katz and Lindell, 2014)). The security notion defined under such a chosen-plaintext attack (CPA) model is called CPA security and is a stronger security definition than the previous one which is defined in the presence of an eavesdropper. Similarly, semantic security and indistinguishability can also be defined under chosen plaintext attack, and a similar equivalent relations can be established between semantic security under CPA and IND-CPA . This stronger level of security is useful when introducing homomorphic encryption.
3 See a proof in Lecture 9: Public Key Encryption of the course CS 276 Cryptography (Oct 1, 2014) at UC Berkeley by the instructor Sanjam Garg.
Dimension, rank
## 4 Lattice Theory
## 4.1 Lattice basics
Lattices are useful mathematical tools for connecting different areas of mathematics, computer science and cryptography. They are widely used for cryptoanalysis and building secure cryptosystems. In this section, we will introduce the basics of lattices in the general setting R n . In addition, we introduce dual lattices and some computational lattice problems that are commonly used to achieve provable security of lattice-based hard problems and cryptosystems. At the end of this section, we will sketch Ajtai (1996)'s polynomial time worst-case-to-average-case reduction to reinforce our understanding of lattices as well as appreciate the great breakthrough in provable security of lattice-based cryptography, even against quantum computing in some cases. Although we introduce lattices in the most general setting, their results also hold for special lattices such as ideal lattices in the ring learning with error problem.
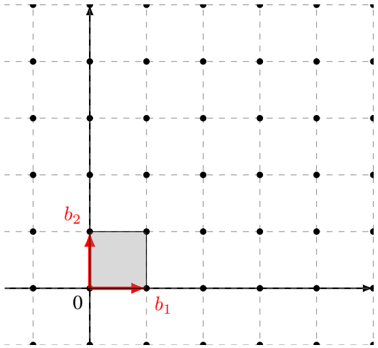
Intuitively, a lattice is similar to a vector space except that it consists of discrete vectors only, that is, elements in lattice vectors have discrete values as opposed to real-valued vectors in a vector space. For example, Figure 3 is a lattice in R 2 . More formally, we have the following definition.
Definition 4.1.1. Let v 1 , . . . , v n ∈ R m be a set of linearly independent vectors. The lattice L Lattice generated by v 1 , . . . , v n is the set of integer linear combinations of v 1 , . . . , v n . That is,
$$L = \{ a _ { 1 } v _ { 1 } + \cdots + a _ { n } v _ { n } | a _ { 1 } , \dots , a _ { n } \in \mathbb { Z } \} .$$
Here, the difference with vector spaces is that the coefficients in the linear combination are integers. The integers m and n are the dimension and rank of the lattice respectively. If m = n , then L is a full-rank lattice. In most cases, we work with full-rank lattices.
It follows from the definition that a lattice is closed under addition. Hence, we can say that an ndimensional lattice is a discrete additive subgroup of R n . It is isomorphic to the additive group of Z n . That is,
$$( L , + ) \cong ( \mathbb { Z } ^ { n } , + ) \subsetneq ( \mathbb { R } ^ { n } , + ) .$$
It is often convenient to work with lattices whose coordinates are integers. These are called integer lattices or integral lattices . For example, the set of even integers forms an integer lattice, but not the set of odd integers because it is not closed under addition.
Figure 3: A lattice L with a basis B = { b 1 , b 2 } and its fundamental domain F .
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Basis Vectors and Rectangle
### Overview
The image depicts a two-dimensional Cartesian coordinate system with a grid of points. A rectangle is defined by the origin (0) and two basis vectors, labeled *b1* and *b2*. The rectangle is shaded gray. The grid appears to be composed of equally spaced points.
### Components/Axes
* **Axes:** Two perpendicular axes are present, representing the x and y coordinates. The x-axis is horizontal, and the y-axis is vertical.
* **Origin:** The intersection of the axes is labeled "0".
* **Basis Vectors:**
* *b1*: A red arrow pointing along the positive x-axis.
* *b2*: A red arrow pointing along the positive y-axis.
* **Rectangle:** A shaded gray rectangle is formed by the basis vectors *b1* and *b2* as adjacent sides, with the origin as one vertex.
* **Grid:** A grid of black dots extends across the coordinate plane, providing a visual reference for scale and position.
### Detailed Analysis
The rectangle's vertices are located at:
* (0, 0) - The origin.
* (b1, 0) - Along the x-axis, defined by the length of vector *b1*.
* (0, b2) - Along the y-axis, defined by the length of vector *b2*.
* (b1, b2) - The opposite vertex from the origin.
The lengths of the basis vectors *b1* and *b2* are not explicitly given numerically. However, based on the grid, it appears that *b1* and *b2* are both approximately equal to 1 grid unit in length. The rectangle occupies one grid square.
### Key Observations
* The basis vectors *b1* and *b2* are orthogonal (perpendicular) to each other.
* The rectangle is aligned with the coordinate axes.
* The rectangle's area is defined by the product of the lengths of *b1* and *b2*.
* The grid provides a visual representation of a lattice structure defined by the basis vectors.
### Interpretation
This diagram illustrates the concept of basis vectors in a two-dimensional space. The basis vectors *b1* and *b2* define a coordinate system, and any point within the plane can be represented as a linear combination of these vectors. The rectangle demonstrates how these vectors can be used to define a region or shape within the coordinate system. The diagram is likely used to explain concepts in linear algebra, vector spaces, or geometry. The grid suggests a discrete representation of the continuous plane, potentially relating to concepts like lattice structures or digital images. The diagram does not provide any specific numerical data beyond the visual representation of the lengths of *b1* and *b2* relative to the grid.
</details>
A basis Basis of a lattice L is a set of linearly independent vectors B = { b 1 , . . . , b n } that spans the lattice, that is,
For example, the vectors { b 1 , b 2 } form a basis of the lattice in Figure 3.
$$L ( B ) = \{ z _ { 1 } b _ { 1 } + \dots + z _ { n } b _ { n } \, | \, z _ { i } \in \mathbb { Z } \} . \\ \{ h _ { 1 } , h _ { 2 } \} \text { form a basis of the lattice in Figure 3.}$$
In what follows, we will frequently appeal to properties of a class of matrices known as unimodular matrices . Unimodular matrices can be used to translate between different lattice bases. They are also used, sometimes implicitly, when performing important lattice operations such as lattice basis reduction.
Unimodular matrix
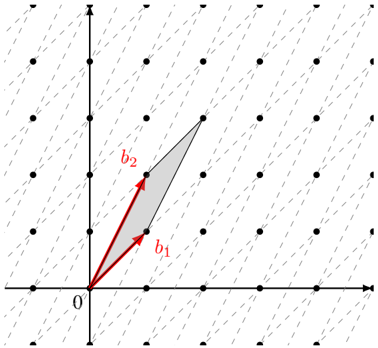
Figure 4: The same lattice L with a different basis B ′ = { b ′ 1 , b ′ 2 } and its fundamental domain F ′ , where B ′ = AB for a unimodular change of basis matrix A = ( 1 1 1 2 ) .
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Parallelogram Representation of Vector Addition
### Overview
The image depicts a parallelogram constructed from two vectors, `b1` and `b2`, originating from the origin (labeled '0'). The parallelogram visually represents the vector addition of `b1` and `b2`. The background is a grid of dots.
### Components/Axes
* **Axes:** Two perpendicular axes are present. The horizontal axis is not labeled, but is implied to be the x-axis. The vertical axis is also not labeled, but is implied to be the y-axis. Both axes have tick marks indicating a regular scale, but the scale is not numerically defined.
* **Origin:** The origin is clearly marked with the label '0'.
* **Vectors:** Two vectors are labeled:
* `b1`: A red vector originating from the origin and pointing diagonally upwards and to the right.
* `b2`: A red vector originating from the origin and pointing diagonally upwards and to the left.
* **Parallelogram:** A shaded parallelogram is formed by the vectors `b1` and `b2`.
* **Grid:** A grid of dots fills the background, providing a visual reference for scale and position.
### Detailed Analysis
The diagram illustrates the geometric interpretation of vector addition. The parallelogram is constructed such that:
* `b1` starts at the origin and extends to a point.
* `b2` starts at the origin and extends to another point.
* The fourth vertex of the parallelogram (opposite the origin) represents the resultant vector `b1 + b2`.
The vectors `b1` and `b2` are approximately equal in magnitude, but point in different directions. The angle between `b1` and `b2` appears to be approximately 60-90 degrees.
Without a defined scale on the axes, precise numerical values for the components of `b1` and `b2` cannot be determined. However, we can qualitatively describe their direction.
### Key Observations
* The diagram emphasizes the graphical representation of vector addition.
* The parallelogram visually demonstrates that the resultant vector (the diagonal from the origin) is the sum of the two original vectors.
* The grid provides a visual reference for the relative magnitudes and directions of the vectors.
### Interpretation
The diagram demonstrates the parallelogram rule for vector addition. This rule states that the sum of two vectors can be found by constructing a parallelogram with the vectors as adjacent sides. The diagonal of the parallelogram, starting from the common origin of the vectors, represents the resultant vector. This is a fundamental concept in linear algebra and physics, used to represent and manipulate quantities that have both magnitude and direction, such as force, velocity, and displacement. The diagram is a visual aid for understanding this concept, allowing for a qualitative grasp of how vectors combine. The absence of numerical values suggests the diagram is intended to convey the *principle* of vector addition rather than specific calculations.
</details>
Definition 4.1.2. A matrix A ∈ Z n × n is unimodular if it has a multiplicative inverse in Z n × n . That is, A ∈ Z n × n is unimodular if and only if A -1 ∈ Z n × n . Equivalently, a matrix A ∈ Z n × n is unimodular if and only if | det( A ) | = 1 .
Similar to a vector space, a lattice does not need to have a unique basis. The following proposition establishes the fact that one basis can be transformed to another via multiplication by the matrix A provided that A is a unimodular matrix.
Proposition 4.1.3. If B and B ′ be two basis matrices, then L ( B ) = L ( B ′ ) if and only if B ′ = AB for some unimodular matrix A .
Proof. Suppose that B ′ = AB for some unimodular matrix A . Then, by definition both A and A -1 have integer entries. Therefore we have L ( B ′ ) ⊂ L ( A -1 B ′ ) = L ( B ) and L ( B ) ⊂ L ( AB ) = L ( B ′ ) .
Now suppose that L ( B ) = L ( B ′ ) . Then there exist integer square matrices A,A ′ ∈ Z n × n such that B ′ = AB and B = A ′ B ′ . Therefore we have B = A ′ AB or equivalently ( I -A ′ A ) B = 0 . Because B is non-singular, we have A ′ = A -1 and A is unimodular.
For example, the vectors { b ′ 1 , b ′ 2 } in Figure 4 form a different basis for the lattice in Figure 3, with the relation B ′ = AB where the change of basis matrix A = ( 1 1 1 2 ) is unimodular.
An important concept of a lattice is the fundamental domain. It is closely related to the sparsity of a lattice as can be seen from the following definition.
Definition 4.1.4. Fundamental domain Let L be an n -dimensional lattice with a basis { v 1 , . . . , v n } . The main or ( fundamental parallelepiped ) of L is a region defined as
$$F ( v _ { 1 } , \dots , v _ { n } ) = \{ t _ { 1 } v _ { 1 } + \cdots + t _ { n } v _ { n } | t _ { i } \in [ 0 , 1 ) \} .$$
The lattice L and the given basis in Figure 3 has the fundamental domain coloured in grey. It is the convex region that is surrounded by the given basis vectors and the nearby lattice points.
Definition 4.1.5. Determinant Let L be an n -dimensional lattice with a fundamental domain F . Then the n -dimensional volume of F is called the determinant of L , denoted by det( L ) .
Given a basis { v 1 , . . . , v n } of an n -dimensional lattice L , we can write each basis vector v i = ( v i 1 , . . . , v in ) as a vector of its coordinates. Then we have a basis matrix
$$B = \begin{pmatrix} v _ { 1 1 } & \cdots & v _ { 1 n } \\ \vdots & \ddots & \vdots \\ v _ { n 1 } & \cdots & v _ { n n } \end{pmatrix} .$$
fundamental do-
In cryptography, we are interested in full-rank lattices, whose determinant can be easily calculated using a basis matrix as stated in the next proposition.
Proposition 4.1.6. If L is an n -dimensional full-rank lattice with a basis { v 1 , . . . , v n } and an associated fundamental domain F = F ( v 1 , . . . , v n ) , then the volume of F (or determinant of L ) is equal to the absolute value of the determinant of the basis matrix B , that is,
$$\det ( L ) = V o l ( F ) = | \det B | .$$
Although the fundamental domain may have a different shape under another choice of a basis, it can be proved that area (or volume) stays unchanged. This gives rise to the determinant of a lattice which is an invariant quantity under the choice of a fundamental domain.
Corollary 4.1.7. Invariant determinant The determinant of a lattice is an invariant quantity under the choice of a basis for L .
Proof. Let L be a lattice and let B and B ′ be the basis matrices for two different bases for L . There exists a unimodular matrix A such that B ′ = AB . Consequently, we have
$$| \det ( B ^ { \prime } ) | = | \det ( A B ) | = | \det ( A ) | \cdot | \det ( B ) | = | \det ( B ) | .$$
So, we have | det( L ) | = | det( B ′ ) | = | det( B ) | .
Example 4.1.8. Let L be a 3-dimensional lattice with a basis
$$\{ v _ { 1 } = ( 2 , 1 , 3 ) , v _ { 2 } = ( 1 , 2 , 0 ) , v _ { 3 } ( 2 , - 3 , - 5 ) \} .$$
$$B = \begin{pmatrix} 2 & 1 & 3 \\ 1 & 2 & 0 \\ 2 & - 3 & - 5 \end{pmatrix} .$$
Then a basis matrix is
The determinant of the lattice is det( L ) = | det( B ) | = 36 .
Geometrically, this also makes sense. By definition, each fundamental domain contains exactly one lattice vector (in Figure 3 and 4 the origin). Consider fundamental domains that are centered on lattice points rather than having lattice points at one corner. That is, consider
$$\tilde { F } ( v _ { 1 } , v _ { 2 } , \dots , v _ { n } ) = \{ t _ { 1 } v _ { 1 } + t _ { 2 } v _ { 2 } + \hdots + t _ { n } v _ { n } \, | \, t _ { i } \in [ - 1 / 2 , 1 / 2 ) \} .$$
Take a large ball centered at the origin and notice that, because each fundamental domain contains exactly one lattice point, the volume of the ball is approximately equal to the number of lattice points in the ball multiplied by the volume of the fundamental domain. More precisely, we have
$$\lim _ { r \to \infty } \frac { V o l \left ( B _ { r } ( 0 ) \right ) } { | B _ { r } ( 0 ) \cap L | } = V o l \left ( \tilde { F } ( v _ { 1 } , v _ { 2 } , \dots , v _ { n } ) \right ) = d e t ( L ) .$$
By definition, choosing a different basis doesn't change the lattice. So, the volume of the fundamental domain, and therefore the determinant of the lattice, is a property of the lattice and does not depend on the basis used to represent that lattice.
Two remarks. First, a lattice L can be partitioned into disjoint fundamental domains, the union of which covers the entire L . Second, since the choice of a fundamental domain is arbitrary and it covers real vectors that are not in L , each real vector can be uniquely identified by a lattice vector and a real vector in a fundamental domain. These are captured in the following proposition. For the proof, see Proposition 6.18 of Hoffstein et al. (2008).
Proposition 4.1.9. Let L be an n -dimensional lattice in R n with a fundamental domain F . Then every vector w ∈ R n can be written as
$$w & = v + t & ( 4 )$$
for a unique lattice vector v ∈ L and a unique real vector t ∈ F .
Equivalently, the union of the translated fundamental domains cover the span of the lattice basis vectors, i.e.,
$$s p a n ( L ) = \{ F + v | v \in L \} .$$
Modulo basis
Shortest vector
Successive minima
Another useful interpretation of Equation 4 is that for any vector w ∈ R n , there is a unique real vector t ∈ F in the fundamental domain such that w -t ∈ L ( B ) is a lattice vector. In other words, given an arbitrary vector w ∈ R n in the span, we can efficiently reduce it to a vector t ∈ F in the fundamental domain by taking w modulo the basis (or modulo the fundamental domain as used by some authors). More precisely, for a basis { v 1 , . . . , v n } of L ∈ R n , it is obvious that the basis is also a basis of the span R n , so we have w = α 1 v 1 + · · · + α n v n for coefficients α 1 , . . . , α n ∈ R . The coefficients can also be written as α i = a i + t i for a i ∈ Z and t i ∈ (0 , 1) . This implies the real vector can be re-written as w = ( a 1 v 1 + · · · + a n v n ) + ( t 1 v 1 + · · · + t n v n ) = v + t , where in the first pair of parentheses is a lattice vector v and in the second pair is a real vector t within the fundamental domain. From this, we can compute t = w -v . This also gives an alternative formula for computing the modulo basis operation by
$$\begin{array} { r l } & { w \bmod B = w - B \cdot \lfloor B ^ { - 1 } \cdot w \rfloor . } \\ & { ( 5 ) } \end{array}$$
For example, given a 2-dimensional lattice L ∈ R 2 with a basis B = ( 3 0 0 2 ) and a real vector w = (2 , 3) . By reducing w modulo the fundamental domain we get w mod B = (2 , 1) .
Similar to a real vector, the length a lattice vector can also be measured by a norm function || · || . However, unlike in a vector space where there is no shortest non-zero vector, it is possible to define shortest non-zero vector in a lattice because of the discreteness, although this shortest vector may not be unique.
Definition 4.1.10. Given a lattice L , the length of a shortest non-zero vector in L which is also a minimum distance between two lattice vectors is defined as
$$\lambda _ { 1 } ( L ) & = \min \{ | | v | | \, | \, v \in L \ \{ 0 \} \} \\ & = \min \{ | | x - y | | \, | \, x , y \in L , x \neq y \} .$$
The shortest vector problem (formally defined in Section 4.3) is to find the shortest non-zero vector in a given lattice. For a lattice L , notice that λ 1 ( L ) is the solution to the shortest vector problem for that lattice.
The shortest vector problem can be generalized to the problem of finding the i th successive minima. The i th successive minima is the minimum length r such that the lattice contains i linearly independent vectors of length at most r . This can also be defined in relation to the dimension of the space spanned by the intersection between L and a zero-centered closed ball ¯ B (0 , r ) with radius r .
Definition 4.1.11. Given a lattice L , the i th successive minima of L is defined as
$$\lambda _ { i } ( L ) & = \min \{ r | \dim ( s p a n ( L \cap \bar { B } ( 0 , r ) ) ) \geq i \} , \\ \{ r \in \mathbb { R } ^ { n } \, | \, \| r \| \leq r \} & \text { is the closed ball of radius $r$ around $0$}$$
where ¯ B (0 , r ) = { x ∈ R n | || x || ≤ r } is the closed ball of radius r around 0.
For example, if the lattice L = Z n , then the 1st to the n th successive minima λ 1 = · · · = λ n = 1 are equal to 1. The length of a shortest vector is a special case of the successive minima when i = 1 . We will see the successive minima again when introducing shortest independent vector problem as a generalization of the shortest independent problem in 4.3.
Notice that a set of vectors that achieves the successive minima of a lattice is not necessarily a basis for that lattice. Consider the following example which is derived from the work by Korkine and Zolotareff (1873) and was presented its current form in Nguyen and Vall´ ee (2010). Let
$$locut 2 0 0 0 1 1
<text>locut B = {</text>
<loc_472><loc_42><loc_499><loc_75>{</text>
<loc_473><loc_78><loc_498><loc_115>} } } } } } } } } } } } } } } } } } } } } } } } } } } } } } } }$$
Notice that 2 e 5 ∈ L ( B ) and that ‖ v ‖ ≥ 2 for all v ∈ L ( B ) \ { 0 } . So, λ i ( L ( B )) = 2 for 1 ≤ i ≤ 5 . If we let
$$\tilde { B } = \begin{pmatrix} 2 & 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 & 0 \\ 0 & 0 & 2 & 0 & 0 \\ 0 & 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 0 & 2 \end{pmatrix} .$$
Dual basis then we have L ( ˜ B ) ⊂ L ( B ) and det( ˜ B ) = 32 . On the other hand, we see that det( B ) = 16 . Therefore, ˜ B cannot be a basis for L ( B ) . In fact, it can be shown that no basis of L ( B ) realizes all of the successive minima of L ( B ) .
## 4.2 Dual lattice
In this subsection, we introduce dual lattices. This is a useful concept that will be used at several different places, such as defining smoothing parameter for discrete Gaussian distribution and in the hardness proof of the ring learning with error problem. It is important to develop a geometric intuition of the relationship between a lattice and its dual.
The dual (sometimes also called reciprocal) of a lattice is the set of vectors in the span of the lattice (e.g., the span is R n if the lattice is Z n ) whose inner product with the lattice vectors are integers.
Given a full-rank lattice , its is defined as
Definition 4.2.1. Dual lattice L dual lattice
$$L ^ { * } = \{ y \in s p a n ( L ) | \forall x \in L , x \cdot y \in \mathbb { Z } \} .$$
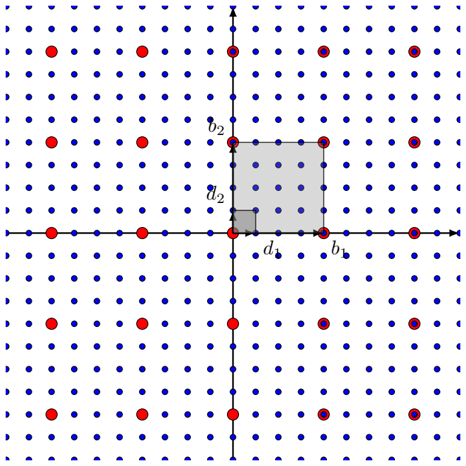
For example, the dual lattice of Z n is Z n and the dual lattice of 2 Z n is 1 2 Z n as shown in Figure 6. An important observation is that the more vectors a lattice has, the less vectors its dual has and vice versa, because there are more (or less) constraints. Most importantly, it can be verified that the dual of a lattice is also a lattice.
Proposition 4.2.2. If L is a lattice then L ∗ is a lattice.
Proof. It suffices to show that L ∗ is closed under subtraction. That is, to show that if x, y ∈ L ∗ then x -y ∈ L ∗ . This follows from the linearity of the inner product. More explicitly, for every z ∈ L we have ( x -y ) · z = x · z -y · z . Because x · z ∈ Z and y · z ∈ Z , we have ( x -y ) · z ∈ Z . The result then follows from the definition of L ∗ .
Figure 5: A lattice L = 2 Z 2 (black points) and its dual L ∗ = 1 2 Z 2 (blue points). The basis of L is B = { b 1 = (2 , 0) , b 2 = (0 , 2) } and the dual basis of L ∗ is D = { d 1 = ( 1 2 , 0) , d 2 = (0 , 1 2 ) } .
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Lattice Point Illustration
### Overview
The image depicts a two-dimensional lattice of points, with some points highlighted in red. A shaded square is centered on the origin, and several points are labeled with letters: `b1`, `b2`, `d1`, `d2`. The diagram appears to illustrate a concept related to lattice points, possibly in the context of number theory or geometry.
### Components/Axes
The diagram consists of:
* A grid of blue points forming a lattice.
* Red points scattered throughout the lattice.
* A shaded square centered at the origin (0,0).
* Horizontal and vertical axes representing the coordinate system.
* Labels: `b1`, `b2`, `d1`, `d2` placed near specific points.
The axes are not explicitly labeled with numerical scales, but they clearly define a Cartesian coordinate system.
### Detailed Analysis / Content Details
The diagram shows a square centered at the origin. The vertices of the square are located on the lattice points. The labeled points are as follows:
* `b1`: Located on the positive x-axis, approximately (3,0).
* `b2`: Located on the positive y-axis, approximately (0,3).
* `d1`: Located on the negative x-axis, approximately (-3,0).
* `d2`: Located on the negative y-axis, approximately (0,-3).
The red points are not uniformly distributed. They appear to be concentrated along certain lines or regions within the lattice. There are approximately 20 red points visible. The red points do not seem to have a clear pattern or relationship to the labeled points or the shaded square.
### Key Observations
* The labeled points `b1`, `b2`, `d1`, and `d2` define the boundaries of a square with sides parallel to the coordinate axes.
* The shaded square appears to represent a region of interest within the lattice.
* The distribution of red points is non-uniform, suggesting a specific criterion for their selection.
* The diagram does not provide any numerical data or quantitative measurements.
### Interpretation
The diagram likely illustrates a concept related to lattice points and their properties. The shaded square might represent a fundamental cell or a region of interest in a lattice-based system. The red points could represent points satisfying a specific condition or belonging to a particular set within the lattice. The labels `b1`, `b2`, `d1`, and `d2` might denote boundary points or reference points for a geometric construction.
Without additional context, it is difficult to determine the precise meaning of the diagram. However, it suggests a visual representation of a mathematical or geometric concept involving lattice points, squares, and potentially a selection criterion for points within the lattice. The diagram could be used to illustrate concepts in number theory, cryptography, or signal processing, where lattice structures are commonly employed. The non-uniform distribution of red points hints at a specific rule or condition governing their placement.
</details>
Given a lattice L , it is natural to ask if we can find a basis for L ∗ . This leads us to define the dual basis of a lattice.
Definition 4.2.3. For a lattice L and a basis B = ( b 1 , . . . , b n ) ∈ R m × n , the dual basis D = ( d 1 , . . . , d n ) ∈ R m × n is defined as the unique basis that satisfies
Hyperplanes
- span ( B ) = span ( D ) and
- B T D = I .
The first condition says both bases span the same vector space. The second condition implies that b i · d j = δ ij = 1 if i = j and 0 otherwise. Abusing notation, we use B to denote both the basis of a lattice and the basis matrix. If L is a full-rank lattice (i.e., m = n ), then the basis matrix B is invertible, so the dual basis matrix can be expressed as D = ( B T ) -1 = ( B -1 ) T .
Proposition 4.2.4. If L is a lattice with basis B , then the dual basis is a basis for L ∗ .
Proof. This follows immediately from the definition of the dual lattice and the linearity of the inner product.
Having established that the dual of a lattice is itself a lattice, we can ask what we get if repeat the process and compute the dual of a dual lattice.
Proposition 4.2.5. For any lattice L , we have ( L ∗ ) ∗ = L .
Proof. If B is a basis for a full-rank lattice L , then a dual basis is D = ( B T ) -1 . Then the dual basis of D is ( D T ) -1 that is equal to B . The same argument works for rank-deficient lattices, but with slight variation because their bases are non-square matrices.
Proposition 4.2.6. For any lattice L , we have det( L ∗ ) = 1 det( L ) .
Proof. Again, we give a proof for full-rank lattices. If L is full-rank, then
$$\det ( L ^ { * } ) = | \det ( D ) | = | \det ( ( B ^ { T } ) ^ { - 1 } ) | = \frac { 1 } { | \det ( B ^ { T } ) | } = \frac { 1 } { | \det ( B ) | } = \frac { 1 } { \det ( L ) } .$$
Although a lattice and its dual are both lattices, they are fundamentally different objects. The dual of a lattice can be thought as functions that are applied to the lattice such that the inner products of the lattice vectors and each dual vector are integers.
Here is a geometric interpretation of a lattice and its dual. For each lattice vector v , its inner products with the dual vectors produce integers of different values. So v partitions the dual lattice into parallel non-overlapping hyperplanes that are perpendicular to v according to its inner product values with the dual vectors. Elements in the same hyperplane have the same inner product with the lattice vector v , so they form an equivalence class. Alternatively, we can say v partitions the dual lattice into a set of equivalence classes. Figure. 6 gives two examples of how a lattice vector v ∈ L = 2 Z 2 partitions the dual lattice L ∗ = 1 2 Z 2 . In addition, the distance between two neighbouring hyperplanes is the inverse of the vector length (i.e., 1 / || v || ).
Example 4.2.7. When L = 2 Z and L ∗ = 1 2 Z , the vector v = 1 2 partitions L to | 2 Z | hyperplanes, each contains exactly one integer from L and the neighbouring hyperplanes are distance 2 apart.
When L = 2 Z 2 and L ∗ = 1 2 Z 2 , the vector v = (2 , 0) partitions the dual lattice into hyperplanes as shown in Figure 6a, where the hyperplanes are the vertical lines that are perpendicular to the lattice vector v . The distance between the neighbouring hyperplanes is 1 || v || = 1 2 . So the dual is denser than L . If v = (2 , 2) , the dual is partitioned into hyperplanes as shown in Figure 6b. The distance between the neighbouring hyperplanes is 1 || v || = 1 2 √ 2 .
## 4.3 Some lattice problems
Having briefly introduced lattices and some related concepts, we are ready to define some computational lattice problems in this subsection. The most well known two are the shortest vector problem and closest vector problem. These two are search problems because the aims are to find a shortest or closest lattice vector. Few cryptosystems, however, are based on these two problems directly. Instead, most cryptosystems are based on their decision versions or relaxed approximation variants. Below, we state the two well known lattice problems and some variants.
(b) The dual lattice is partitioned into hyperplanes according to the given lattice vector v = (2 , 2) .
<details>
<summary>Image 5 Details</summary>

### Visual Description
\n
## Diagram: Dual Lattice Partitioning
### Overview
The image presents two diagrams illustrating the partitioning of a dual lattice into hyperplanes based on given lattice vectors. Both diagrams depict a 2D coordinate system with a grid of points representing the dual lattice. Each diagram shows the lattice partitioned by lines corresponding to a specific lattice vector.
### Components/Axes
Both diagrams share the following components:
* **Coordinate System:** A standard Cartesian coordinate system with a vertical y-axis and a horizontal x-axis. The axes intersect at the origin (0,0).
* **Dual Lattice:** A grid of small black dots representing the points of the dual lattice.
* **Hyperplane Partitioning Lines:** Lines that divide the lattice into regions. These lines are determined by the given lattice vectors.
* **Lattice Vector:** A red arrow indicating the lattice vector used for partitioning.
* **Captions:** Text descriptions below each diagram explaining the partitioning process.
Diagram (a) has the caption: "(a) The dual lattice is partitioned into hyperplanes according to the given lattice vector v = (2, 0)."
Diagram (b) has the caption: "(b) The dual lattice is partitioned into hyperplanes according to the given lattice vector v = (2, 2)."
### Detailed Analysis or Content Details
**Diagram (a):**
* **Lattice Vector:** The lattice vector *v* is represented by a red arrow pointing horizontally to the right, originating near the center of the diagram. The vector is defined as (2, 0).
* **Hyperplane Partitioning:** The dual lattice is partitioned into vertical hyperplanes. These hyperplanes are spaced 2 units apart along the x-axis. The lines are parallel to the y-axis.
* **Grid Spacing:** The grid appears to be spaced at intervals of 1 unit along both the x and y axes.
**Diagram (b):**
* **Lattice Vector:** The lattice vector *v* is represented by a red arrow pointing diagonally upwards and to the right, originating near the center of the diagram. The vector is defined as (2, 2).
* **Hyperplane Partitioning:** The dual lattice is partitioned into hyperplanes defined by the lines x = y + c, where c is a constant. The lines are at 45-degree angles to the x and y axes.
* **Grid Spacing:** The grid appears to be spaced at intervals of 1 unit along both the x and y axes.
### Key Observations
* The lattice vector directly determines the orientation and spacing of the hyperplanes.
* In diagram (a), the lattice vector (2, 0) results in vertical hyperplanes, indicating that the partitioning is based solely on the x-coordinate.
* In diagram (b), the lattice vector (2, 2) results in diagonal hyperplanes, indicating that the partitioning is based on a combination of the x and y coordinates.
* The diagrams visually demonstrate how different lattice vectors lead to different partitioning schemes of the dual lattice.
### Interpretation
These diagrams illustrate a fundamental concept in lattice theory and related fields like crystallography and Fourier analysis. The partitioning of the dual lattice represents the set of all possible reciprocal vectors. The lattice vector *v* defines the basis for the partitioning, and the hyperplanes represent the boundaries between different regions in the dual space.
The choice of lattice vector significantly impacts the structure of the partitioning. A vector along a single axis (as in diagram (a)) leads to a simple, axis-aligned partitioning, while a vector with components in multiple directions (as in diagram (b)) results in a more complex, angled partitioning.
These concepts are crucial for understanding the behavior of waves and signals in periodic structures, as well as for analyzing the symmetry properties of crystals and other materials. The diagrams provide a visual representation of how the underlying mathematical structure of lattices manifests in physical phenomena. The diagrams do not contain numerical data beyond the vector definitions (2,0) and (2,2). They are conceptual illustrations.
</details>
Figure 6: For a given lattice vector v ∈ L = 2 Z 2 , the dual lattice L ∗ = 1 2 Z 2 can be partitioned into parallel non-overlapping hyperplanes (vertical lines) that are perpendicular to v . Elements in the same hyperplane have the same dot product with v , so they form an equivalence class.
## The Shortest Vector Problem (SVP)
Given a lattice basis B , find a shortest non-zero vector in the lattice L ( B ) , i.e., find a non-zero vector v ∈ L ( B ) such that || v || = λ 1 ( L ( B )) .
SVP is hard to solve in high-dimensional lattices. An important variant of SVP is finding a set of short linearly independent lattice vectors as stated below.
## The Shortest Independent Vectors Problem (SIVP)
Given a lattice basis B of an n -dimensional lattice L ( B ) , find n linearly independent vectors v 1 , . . . , v n ∈ L ( B ) such that max i ∈ [1 ,n ] || v i || = λ n ( L ( B )) .
## The Closest Vector Problem (CVP)
Given a lattice basis B and a target vector t that is not in the lattice L ( B ) , find a vector in L ( B ) that is closest to t , i.e., find a vector v ∈ L ( B ) such that for all w ∈ L ( B ) it satisfies || v -t || ≤ || w -t || .
A special case of CVP is the bounded distance decoding problem, which is used in the learning with error problem's hardness proof (Regev, 2009). The name reflects that the problem is to 'decode' a given R n vector. The extra condition makes it a special case of CVP is that the given non-lattice vector is within a bounded distance to the lattice.
## The α -Bounded Distance Decoding Problem (BDD α )
Given a lattice basis B of an n -dimensional lattice L and a target vector t ∈ R n satisfies dist ( t , B ) ≤ αλ 1 ( L ) , find a lattice vector v ∈ L that is closest to t , i.e., for all w ∈ L it satisfies || v -t || ≤ || w -t || .
An alternative way of defining BDD is to find the lattice vector x ∈ L given the instance y = x + e ∈ R n , where e is often interpreted as a noise with norm || e || ≤ αλ 1 ( L ) .
As discussed in Section 2.2, knowing c-gap problems are hard implies the corresponding capproximate problems are also hard. But c-approximations are often used to prove some problems are hard to solve (e.g., SIS) because it is relatively easier to build reductions from them. Below we state the gap/approximate variants of the standard lattice problems. Let γ ( n ) : N → N be a gap function in the input size such that γ ( n ) ≥ 1 , for example γ ( n ) is a polynomial of n .
## The γ -GAP Shortest Vector Problem (GAPSVP γ )
INSTANCE: For a function γ ( n ) ≥ 1 , given a real number d > 0 and a lattice basis B , the instance ( B,d ) is
- either a YES instance if λ 1 ( L ( B )) ≤ d
- or a NO instance if λ 1 ( L ( B )) ≥ γ ( n ) d .
QUESTION: Is ( B,d ) a YES or NO instance?
## The ( ζ, γ )-GAP Shortest Vector Problem (GAPSVP ζ,γ )
INSTANCE: For functions ζ ( n ) ≥ γ ( n ) ≥ 1 , given a real number d > 0 and a lattice basis B of an n -dimensional lattice L ( B ) such that
- λ 1 ( L ( B )) ≤ ζ ( n ) ,
- 1 ≤ d ≤ ζ ( n ) /γ ( n ) ,
- min i ∈ [1 ,n ] || ˜ b i || ≥ 1 ,
the instance ( B,d ) is
- either a YES instance if λ 1 ( L ( B )) ≤ d
- or a NO instance if λ 1 ( L ( B )) ≥ γ ( n ) d .
QUESTION: Is ( B,d ) a YES or NO instance?
SIS
## The γ -Shortest Independent Vectors Problem (SIVP γ )
Given a lattice basis B of an n -dimensional lattice L ( B ) , find n linearly independent vectors v 1 , . . . , v n ∈ L ( B ) such that max i ∈ [1 ,n ] || v i || ≤ γ ( n ) λ n ( L ( B )) .
## 4.4 Ajtai's worst-case to average-case reduction
Figure 7: Reductions to the SIS problem from hard lattice problems (SVP γ , USVP γ and SBP γ ). The intermediate lattice problem in the reductions is the γ -approximation of the shortest independent vector problem (SIVP γ ).
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Diagram: Flowchart of Gamma-Related Variables
### Overview
The image depicts a flowchart illustrating the relationships between several variables, all denoted with the subscript γ (gamma). The diagram shows a hierarchical flow from two initial variables converging into a central variable, which then flows sequentially through two more variables. There are no numerical values or scales present; it is a purely conceptual diagram.
### Components/Axes
The diagram consists of five labeled nodes connected by arrows indicating flow direction. The labels are:
* **SVPγ** (Top-left)
* **USVPγ** (Top-right)
* **SBPγ** (Center)
* **SIVPγ** (Lower-center)
* **SIS** (Bottom)
The arrows indicate a flow from SVPγ and USVPγ *to* SBPγ, from SBPγ *to* SIVPγ, and from SIVPγ *to* SIS.
### Detailed Analysis or Content Details
The diagram shows a convergence of two inputs, SVPγ and USVPγ, into a single output, SBPγ. This output then becomes the input for SIVPγ, which in turn feeds into SIS. The diagram does not provide any quantitative information about the relationships between these variables, only their sequential dependencies.
### Key Observations
The diagram suggests a causal or sequential relationship between the variables. SVPγ and USVPγ appear to be independent inputs that contribute to SBPγ. SBPγ then influences SIVPγ, and finally, SIVPγ influences SIS. The diagram is a simplified representation of a process or system.
### Interpretation
This diagram likely represents a simplified model of a system where variables are related through a series of transformations or dependencies. The use of the subscript γ suggests that these variables are related to a specific parameter or condition (gamma). Without further context, it's difficult to determine the specific meaning of these variables. However, the diagram clearly illustrates a flow of information or influence from the initial variables (SVPγ and USVPγ) to the final variable (SIS). The convergence of SVPγ and USVPγ into SBPγ suggests a combining or integrating process. The sequential flow from SBPγ to SIVPγ and then to SIS indicates a chain of events or a series of steps in a process. The diagram is a high-level representation and does not provide details about the nature of the relationships or the specific mechanisms involved. It is a conceptual model, not a quantitative analysis.
</details>
To finish off this section, we present a high level overview of Ajtai's worst-case to average-case reduction. As briefly explained in Section 2.3, such a reduction allows one to build cryptosystems based on an average-case hardness problem, so that users can rest assured that their random encryption instances are guaranteed to be secure with high confidence.
Ajtai's proof is based on three well-studied lattice problems, SVP γ , USVP γ and SBP γ . The second problem is a variant of SVP that finds the unique shortest non-zero vector in the lattice L ( B ) , i.e., find the non-zero vector v ∈ L ( B ) such that || v || = λ 1 ( L ( B )) and if w ∈ L ( B ) such that || w || ≤ n c || v || then w is parallel to v . The third problem is to find a shortest basis { b 1 , . . . , b n } of a given lattice, where the basis length is defined as max n i =1 || b i || . All three problems are used in their gap (or approximation) versions.
The average-case hard problem constructed by Ajtai is known as the short integer solution (SIS) problem. Let a i ∈ Z n q be a length n vector with entries taken uniformly from Z q . Let A = [ a 1 | · · · | a m ] be an n × m matrix whose columns are m linearly independent a i s. The SIS problem is to find a non-zero vector x ∈ Z m such that
- || x || ≤ β and
- A x = 0 ∈ Z n q , i.e., x 1 a 1 + · · · + x m a m = 0 mod q .
Notice that the norm bound exists to ensure the problem is not easily solvable by for example Gaussian elimination. It must satisfy β < q to avoid the trivial solution x = ( q, 0 , . . . , 0) . Moreover, β and m must be large enough to allow a solution to exist. A sufficient condition of guaranteeing a solution is given in a subsequent work Micciancio and Regev (2007). See Section 4 of Peikert (2016) for more detailed insights.
Lemma 4.4.1 (Lemma 5.2 Micciancio and Regev (2007)) . For any q, A, β ≥ √ mq n/m , the SIS instance ( q, A, β ) admits a solution.
Proof. The proof is done using the pigeonhole principle by constructing x = ( x 1 , . . . , x m ) where each x i ∈ { 0 , . . . , 0 , q n/m } , so that there are ( q n/m ) m = q n this type of vectors, more than the size of the codomain A x ∈ Z n q . Hence, there must exist two distinct vectors x 1 and x 2 of this form such that
SIVP γ to SIS
A x 1 = A x 1 mod q . This entails A x ′ = 0 mod q for x ′ = x 1 -x 2 . The norm of this vector satisfies || x ′ || ≤ √ mq 2 n/m = √ mq n/m because each of its coordinate is at most q n/m . Hence, there always exist a solution with such maximum norm.
The structure of the reduction is shown in Figure 7. The essential part of the proof is a polynomialtime reduction from the lattice problem SBP γ to SIS. The other two lattice problems can be reduced to SBP γ (See Ajtai (1996) Appendix).
To simplify the reduction, note SBP γ is related to SIVP γ because given a set of linearly independent lattice vectors r 1 , . . . , r n ∈ L , a basis { s 1 , . . . , s n } of L can be constructed in polynomial time such that max n i =1 || s i || ≤ n max n i =1 || r i || . Hence, the task becomes reducing the lattice problem SIVP γ to SIS, where the approximation factor γ = n c 3 -1 is polynomial in n . This is also a well accepted hard lattice problem Micciancio and Regev (2009).
The reduction starts by assuming there is a probabilistic polynomial time (PPT) algorithm A that solves SIS with a non-negligible probability. 4 The next step is to transform a hard SIVP γ instance to a random SIS instance and show that if such an SIS solution A exists, it gives rise to a PPT algorithm B that solves SIVP γ for a polynomial factor. This solution then transforms into a solution for SBP γ , as well as SVP γ and USVP γ .
For simplicity, denote M = max i || a i || and bl ( L ) the length of the shortest basis. The key to guarantee M < n c 3 -1 bl ( L ) is to iteratively shorten the longer vectors by half to achieve M 2 . Repeating this steps at most log 2 M steps we get vectors of the desired length. Each iteration of this process is as follows:
1. Construct near cubical parallelepiped: Starting from the lattice vectors a 1 , . . . , a n , construct other lattice vectors f 1 , . . . , f n such that they are nearly pairwise orthogonal and have similar length, but constraint the maximum length max n i =1 || f i || ≤ n 3 M . The reason is to form a parallelepiped W = P ( f 1 , . . . , f n ) that is almost a hypercube, as shown in a 2-dimensional lattice in Figure 8. This step was proved in Lemma 3 of Ajtai (1996).
2. Induce near uniform SIS instance: We then evenly cut W into q n small non-overlapping parallelepipeds which have the form w j = ( ∑ n i =1 t j i q f i ) + 1 q W , where t j i ∈ [0 , q ) is an integer. Now sample m random lattice vectors from L , then reduce them modulo W to ensure they are within the bigger parallelepiped. Denote these reduced vectors by ξ 1 , . . . , ξ m . If ξ k is in a smaller parallelepiped w j = ( ∑ n i =1 t j i q f i ) + 1 q W , then take ( t j 1 , . . . , t j n ) and put it as a column of a matrix A . The claim is that each of the w j 's is selected with almost equal chance, so we have a random n × m matrix A . The key intuition is that for a short basis of L , if W intersects with a translation of the fundamental domain formed by the short basis, then W will contain a large proportion of the translated fundamental domain. This property remains true for an arbitrary translation and scaling of W using u + 1 q W for a vector u ∈ R n . With this property, if W is cut into small non-overlapping regions evenly, then random lattice vectors within W will induce a near uniform distribution over the pieces w j 's. This implies that the matrix A is a random instance of SIS. This step was proved in Lemma 8 of Ajtai (1996).
3. Halve vector length: Now give the matrix A to the PPT algorithm A to output an SIS solution ( h 1 , . . . , h m ) ∈ Z m . It remains to prove that the vector u = ∑ n i =1 h i ξ i is only half of size of the starting vectors, i.e., || u || ≤ M 2 and they are non-zero. This step was proved in Lemma 13 of Ajtai (1996).
In order to motivate subsequent works inspired by SIS, we make two remarks about the above reduction. First, the polynomial approximation factor in the lattice problems are large enough to raise a minor security concern of SIS-based encryption schemes, because the larger the factor is the easier the problems could be. As analysed in Cai and Nerurkar (1997), a typical factor size is larger than n 8 . In a following section, we will introduce the discrete Gaussian technique to reduce these factors down to ˜ O ( n ) in SIS hardness proof. Second, the public key size required by an SIS-based cryptosystem is
4 Ajtai related SIS with finding a short vector in a q-ary lattice L ⊥ q ( A ) = { x | A x = 0 mod q } . His reduction starts with assuming A is a PPT algorithm to find a short lattice vector in a given L ⊥ q ( A ) . For the purpose of sketching the main steps of the proof, it is not necessary to relate SIS with the q-ary lattice problem.
Hash function
Hashcoll A , Π ( n )
Figure 8: In a lattice L = Z 2 , the near cubic parallelepiped W formed by the large independent vectors { f 1 , f 2 } . It is divided into q 2 smaller pieces, each of which is hit with equal probability by random lattice vectors reduced within W .
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## Diagram: Pareto Front Visualization
### Overview
The image depicts a two-dimensional Pareto front visualization. It shows a coordinate system with axes labeled f1 and f2, and a shaded rectangular region representing the set of non-dominated solutions. The background is populated with dots, presumably representing other potential solutions that are dominated by those within the shaded region.
### Components/Axes
* **Axes:**
* Horizontal axis: labeled "f1"
* Vertical axis: labeled "f2"
* **Region:** A rectangular shaded area in the top-right quadrant.
* **Dots:** Numerous small dots scattered throughout the entire coordinate plane.
* **Origin:** The intersection of the two axes forms the origin (0,0).
### Detailed Analysis
The shaded rectangular region represents the Pareto front. It appears to be bounded by approximately:
* f1 ranging from roughly 0 to 10 (estimated).
* f2 ranging from roughly 0 to 8 (estimated).
The dots outside the shaded region represent solutions that are dominated – meaning there exists at least one solution within the shaded region that is better in at least one objective (f1 or f2) and no worse in any other objective.
The grid within the shaded region is composed of approximately 8 rows and 10 columns, creating roughly 80 individual cells. Each cell likely represents a specific solution within the Pareto front.
### Key Observations
* The Pareto front is a rectangular shape, suggesting a relatively simple trade-off between the two objectives (f1 and f2).
* The density of dots outside the shaded region appears to be relatively uniform, indicating that dominated solutions are distributed evenly across the solution space.
* There are no visible outliers or anomalies.
### Interpretation
This diagram illustrates the concept of Pareto optimality in a bi-objective optimization problem. The Pareto front represents the set of solutions where it is impossible to improve one objective without sacrificing another. The solutions within the shaded region are considered "non-dominated" because no other feasible solution can simultaneously improve both f1 and f2.
The rectangular shape of the Pareto front suggests a linear or near-linear trade-off between the two objectives. For example, increasing f1 might consistently decrease f2, and vice versa. The dots outside the shaded region represent suboptimal solutions that can be improved upon by moving towards the Pareto front.
This type of visualization is commonly used in multi-objective optimization to help decision-makers understand the trade-offs between different objectives and select a solution that best meets their preferences. The diagram doesn't provide specific numerical data, but rather a visual representation of the solution space and the optimal trade-offs.
</details>
˜ O ( n 4 ) that is quite inefficient for practical purposes. This will be dramatically improved by developing different average-case problems as we will see in the learning with error and ring learning with error problems.
## 4.5 An application of SIS: Collision resistant hash functions
SIS has been used as the foundation of one-way functions and hash functions (Lyubashevsky et al., 2010).
Ahash function maps inputs of arbitrary length and compresses them into short fixed-length outputs known as digests .
Definition 4.5.1. A (keyed) hash function with output length l is a pair of probabilistic polynomialtime algorithms ( Gen , H ) satisfying the following:
- The algorithm Gen (1 n ) → s generates a key s from the security parameter 1 n .
- For a string x ∈ { 0 , 1 } ∗ of arbitrary length, the algorithm H outputs a string H s ( x ) ∈ { 0 , 1 } l ( n ) .
The general interest in hash functions is the case when the outputs are shorter than the inputs for both computational and storage efficiency. In such a case, a hash function's domain is larger than its range, which implies the possibility of having two distinct inputs being mapped to the same output. We often say the two distinct inputs collide and the scenario is called a collision .
For a hash function Π = ( Gen , H ) , an adversary A and the security parameter n , we can define the collision-finding experiment Hash-coll A , Π ( n ) as:
1. Run the algorithm Gen (1 n ) → s .
3. The adversary produces two strings x , and x ′ .
2. The adversary A is given the key s .
4. Hash-coll A , Π ( n ) = 1 if x = x ′ and H s ( x ) = H s ( x ′ ) and 0 otherwise.
A cryptographic hash function requires the chance of finding a collision is negligible, which is defined more formally as follows.
Definition 4.5.2. A hash function Π = ( Gen , H ) is collision resistant Collision resistant if for any probabilistic polynomial time adversary A , it satisfies
$$P r [ H a s h \text {-coll} _ { \mathcal { A } , \Pi } ( n ) = 1 ] \leq n e g l ( n ) .$$
From Ajtai's SIS problem and the worst-case-to-average-case reduction, one can easily build a collision resistant hash function where the key is the matrix A ∈ Z n × m q and the hash function is given by
$$\begin{array} { r l } & { f _ { A } \colon \{ 0 , \dots , d - 1 \} ^ { m } \to \mathbb { Z } _ { q } ^ { n } } \\ & { f _ { A } ( x ) = A x \bmod q . } \end{array}$$
If there is a collision f A ( x ) = f A ( x ′ ) between distinct inputs x and x ′ , then A ( x -x ′ ) = 0 and x -x ′ ∈ L ⊥ q ( A ) . Furthermore, because each element of x -x ′ is in the set {-1 , 0 , 1 } , we see that x -x ′ is a short vector. Hence, an efficient algorithm that produces collisions for this hash function could be used to solve SIS in the lattice L ⊥ q ( A ) .
Gaussian measure
## 5 Discrete Gaussian Distribution
Discrete Gaussian distribution is an important ingredient in the provable security of lattice-based cryptosystems. The distribution behaves in a similar fashion as the continuous Gaussian distribution, but with a discrete lattice support. The technique was first employed in Micciancio and Regev (2007) to improve the hardness proof certain lattice-based problems. More precisely, it was used to reduce the approximation factors to nearly linear in n (i.e., ˜ O ( n )) of the lattice problems in Ajtai's SIS hardness proof. After being proved as a useful and efficient standalone mathematical tool, this sampling technique was then widely adopted by subsequent works to demonstrate the hardness of certain lattice-based problems, including the popular learning with error (LWE) and ring learning with error (RLWE) problems. This section is primarily based on Micciancio and Regev (2007). We will discuss some essential properties of the discrete Gaussian distribution and how such a distribution can be used to simplify and strengthen the hardness proof of SIS in the preceding section.
## 5.1 Discrete Gaussian distribution
We start by reviewing some terms and intuitions about the better-understood continuous Gaussian distribution. A Gaussian function is a continuous function of the form
$$f ( x ) = a \cdot \exp \left ( - { \frac { ( x - c ) ^ { 2 } } { 2 \sigma ^ { 2 } } } \right ) .$$
The mostly common Gaussian function is the probability density function (PDF) of the Gaussian distribution. For simplicity, we work with the case when a = 1 , so we can define the Gaussian measure in R as
Another algebraic expression of the Gaussian measure is by using a scale parameter s = √ 2 πσ . Substitute σ in the above equation and generalize the Gaussian measure to the higher dimensional space R n , we get
$$\rho _ { \sigma , c } ( x ) = \exp \left ( - \frac { ( x - c ) ^ { 2 } } { 2 \sigma ^ { 2 } } \right ) .$$
$$\rho _ { s , c } ( x ) = \exp \left ( - \frac { - \pi | | x - c | | ^ { 2 } } { s ^ { 2 } } \right ) .$$
Integrating the measure over R n , the total measure is 5
$$\int _ { \mathbf x \in \mathbb { R } ^ { n } } \rho _ { s , \mathbf e } ( \mathbf x ) \, d \mathbf x = s ^ { n } ,$$
hence we can define the n -dimensional (continuous) Gaussian Gaussian PDF probability density function as
$$D _ { s , \mathbf c } ( \mathbf x ) = \frac { \rho _ { s , \mathbf c } ( \mathbf x ) } { s ^ { n } } .$$
This is the n -dimensional Gaussian PDF that we know from probability theory, but presented in a nonstandard way.
Equation (6) and Equation (7) would still make sense if x is a non-continuous lattice vector. Since a lattice L is a countable set, the total Gaussian measure over L and the 'discretized' density function are
$$\rho _ { s , c } ( L ) = \sum _ { x \in L } \rho _ { s , c } ( x )$$
$$D _ { s , e } ( L ) = \frac { \rho _ { s , e } ( L ) } { s ^ { n } } .$$
Hence, we can define the discrete Gaussian distribution Discrete Gaussian over the lattice L for all lattice vectors x ∈ L as
$$D _ { L , s , c } ( x ) = \frac { D _ { s , c } ( x ) } { D _ { s , c } ( L ) } = \frac { \rho _ { s , c } ( x ) } { \rho _ { s , c } ( L ) } .$$
The discrete Gaussian distribution is commonly used nowadays to introduce randomness in the proof of lattice problems and lattice-based cryptosystems. Unlike a uniform distribution over a space (e.g.,
5 The total measure is not 1 because the coefficient a in the Gaussian function is ignored.
Smoothing parameter relate to λ 1 ( L ∗ )
Near uniformity the way uniformity was proved in Ajtai's SIVP γ to SIS problem), Gaussian distribution does not have sharp boundaries, which is useful when smoothing a distribution over a space. More precisely, given a Gaussian distribution ρ s, c ( s ) whose center is a lattice point (i.e., c ∈ L ), if random samples from this distribution are taken modulo the lattice fundamental domain, the resulting samples will induce a distribution within the fundamental domain. Whether or not such a distribution is close to the uniform distribution depends on the scale s of the Gaussian distribution. Obviously, the larger s is, the closer the induced distribution is to uniform.
To give a quantitative threshold on how large s needs to be, Micciancio and Regev introduced the smoothing parameter. As the name suggests, the purpose of this parameter is to measure the minimum Gaussian noise magnitude, so that if the noise is added to a lattice Z n , the lattice is 'blured' to almost a uniform distribution over R n (formally stated in Lemma 5.1.4). For the rest of this section, we assume ( n ) > 0 (or just > 0 if the context is clear) is a negligible function of the space dimension n .
Definition 5.1.1. The smoothing parameter of an n -dimensional lattice L , denoted η ( L ) , is the smallest scale s such that the Gaussian measure gives almost all weights to the origin in the dual lattice, that is, ρ 1 /s ( L ∗ \ { 0 } ) ≤ .
The parameter is defined in terms of the dual lattice. A possible reason is that the dual lattice also appears in the Poisson summation formula (Lemma 2.8 Micciancio and Regev (2007)) that is key tool to prove some properties of the discrete Gaussian distribution, for example, Lemma 5.1.4.
Next, we relate the smoothing parameter to two standard lattice quantities. These relations tight the smoothing parameter hence discrete Gaussian, with lattice problems and lattice-based cryptosystems. The proofs of these lemmas can be found in the reference paper.
Lemma 5.1.2 (Lemma 3.2 Micciancio and Regev (2007)) . The smoothing parameter of an n -dimensional lattice L satisfies η ( L ) ≤ √ n λ 1 ( L ∗ ) , where = 2 -n .
The key to prove this lemma is to assume the discrete Gaussian scale satisfies s > √ n/λ 1 ( L ∗ ) , so removing a closed ball of radius √ n/s from the dual lattice is the same as removing only the zero vector, that is, L ∗ \ ( √ n/s ) B = L ∗ \ { 0 } . This assumption of the scale also inversely relates the smoothing parameter to the shortest vector in the dual lattice as stated in the lemma. The factor √ n comes from Equation (5) in Lemma 2.10 Micciancio and Regev (2007).
To intuitively understand the inverse relation between η ( L ) and λ 1 ( L ∗ ) , the definition of smoothing parameter suggests that the parameter is to give almost all weights to the lattice origin, so the longer the dual's shortest vector is the smaller η ( L ) needs to be. This also connects η ( L ) with the shortest vector in the original lattice L . Given λ 1 ( L ) is in an inverse relation with λ 1 ( L ∗ ) , hence the smoothing parameter is related to λ 1 ( L ) .
Lemma 5.1.3 (Lemma 3.3 Micciancio and Regev (2007)) . relate to λ n ( L ) The smoothing parameter of an n -dimensional lattice L satisfies
$$\eta _ { \epsilon } ( L ) \leq \sqrt { \frac { \ln ( 2 n ( 1 + 1 / \epsilon ) ) } { \pi } } \cdot \lambda _ { n } ( L ) .$$
We finish this subsection by stating two key properties of the discrete Gaussian distribution. These properties make discrete Gaussian extremely useful when proving the hardness of lattice-based problems and building lattice-based cryptosystems.
Recall that any vector t ∈ R n in the span of a lattice L is uniquely identifiable by a lattice vector v and a (translation of) vector w ∈ F in the lattice fundamental domain F . This gives rise to a way of reducing an arbitrary vector in R n to a vector within F by taking w = t mod F the vector modulo the fundamental domain. The next lemma addresses the near uniformity of the distribution over F induced by applying this modulo operation.
Lemma 5.1.4 (Lemma 4.1 Micciancio and Regev (2007)) . Let L be an n -dimensional lattice and D s, c be a Gaussian distribution with arbitrary scale s ≥ η ( L ) and center c ∈ R n , the statistical distance between D s, c mod F and a uniform distribution U ( F ) over the fundamental domain F is
$$\Delta ( D _ { s , e } \bmod F , U ( F ) ) \leq \frac { \epsilon } { 2 } .$$
The uniform distribution over F has a PDF U ( F ) = 1 / vol ( F ) = det( L ∗ ) , so the proof in Micciancio and Regev (2007) employed Poisson summation formula to rewrite the discrete Gaussian in terms
Similar to continuous Gaussian of det( L ∗ ) too, so that this term can be cancelled when computing the statistical distance. As discussed before, this Lemma motivates the definition of smoothing parameter, which is a useful criterion when sampling uniform samples in the fundamental domain from a discrete Gaussian distribution.
The next lemma proves that the discrete and continuous Gaussian distributions share similar characteristics when the scale of the discrete Gaussian is sufficiently large.
Lemma 5.1.5 (Lemma 4.3 Micciancio and Regev (2007)) . Let D L,s, c be a discrete Gaussian distribution over an n -dimensional lattice L with arbitrary scale s ≥ 2 η ( L ) and center c ∈ R n . For 0 < < 1 , the following are satisfied
$$^ { 2 }$$
$$\left | \left | E _ { x \sim D _ { L , s , e } } \left [ x - c \right ] \right | \right | ^ { 2 } \leq \left ( \frac { \epsilon } { 1 - \epsilon } \right ) ^ { 2 } s ^ { 2 } n , \\ E _ { x \sim D _ { L , s , e } } \left [ | | x - c | | ^ { 2 } \right ] \leq \left ( \frac { 1 } { 2 \pi } + \frac { \epsilon } { 1 - \epsilon } \right ) ^ { 2 } s ^ { 2 } n .$$
The first inequality suggests that on expectation the random samples from D L,s, c are close to the distribution center, with the distance at most s √ n . So if the discrete Gaussian is centered at the origin, the sampled lattice vectors will have norms at most s √ n . The second inequality suggests the discrete version has almost the same variance as the continuous Gaussian whose variance is ns 2 2 π ).
## 5.2 Discrete Gaussian for provable security
In this subsection, we revisit the hardness proof of Ajtai's short integer solution (SIS) problem, but use the discrete Gaussian tool as an important technique to reduce the gaps of the hard lattice problems. Recall that SIS is parameterized by a modulus q , the number of linearly independent vectors m and a norm bound β . These parameters are often considered as functions of the security parameter n . The purpose of SIS is to find a short integer vector x ∈ Z m such that
- || x || ≤ β and
- A x = 0 ∈ Z n q for an arbitrary integer matrix A ∈ Z n × m q .
As stated in Lemma 4.4.1 and Lemma 5.2 in Micciancio and Regev (2007), the norm bound of x needs to satisfy β ( n ) ≥ √ mq n/m in order to guarantee an SIS solution.
The overal proof strategy in Micciancio and Regev is similar to Ajtai's by introducing an intermediate lattice problem incremental guaranteed distance decoding - for a simple reduction to SIS. The standard lattice problems can be reduced to this intermediate problem, but are not covered in this section because the focus is the discrete Gaussian sampling technique. This intermediate problem is different to the bounded distance decoding (BDD) problem (Section 4), in the sense that it finds a lattice vector within a bounded distance to the target, not necessarily the closest to the target which is given close to the lattice in BDD.
Definition 5.2.1. Given a basis B of an n -dimensional lattice L , a set of linearly independent lattice vectors S ⊆ L , a target vector t ∈ R n and a real r > γ ( n ) λ n ( B ) , the incremental guaranteed distance decoding (INCGDD) problem outputs a lattice vector v ∈ L such that || v -t || ≤ ( || S || /g ) + r .
The norm || S || of the set is the length of the longest lattice vector in S . The additional parameter r is needed to guarantee a solution exists for certain settings of S and g , as illustrated by the example in Micciancio and Regev (2007). If S is the basis of Z n and g = 4 , there is no solution to the target t = (1 / 2 , . . . , 1 / 2) satisfies || v -t || ≤ || S || /g = 1 / 4 , since the closest lattice vector is at distance √ n/ 2 . Hence, if γ ( n ) = √ n/ 2 and φ ( B ) = λ n ( B ) , then r > √ n/ 2 · λ n ( B ) = √ n/ 2 and it guarantees a solution v where the distance bound 1 / 4 + √ n/ 2 is met. Unless otherwise mentioned, the rest of this section assumes φ ( B ) = λ n ( B ) .
Recall P ( B ) is the fundamental domain (or parallelepiped) of the lattice L ( B ) . This is generalized to the half-opened parallelepiped P ( S ) = { ∑ n i =1 x i s i | x i ∈ [0 , 1) } generated by the set of linearly independent vectors S = { s 1 , . . . , s n } .
The next lemma presents a sampling technique to produce uniformly random vectors within a lattice's fundamental domain as well as Gaussian lattice vectors. This sampling procedure is the core technique to reduce INCGDD to SIS as shall be seen later. The intuition of this sampling technique
is really simple. It is based on the observation that every vector in R n can be uniquely identified by a lattice vector plus a small 'noise' vector in the shifted fundamental domain. Hence, we generate a Gaussian sample in R n , then split it into the 'noise' vector and the lattice vector. The former is almost uniformly distributed in the fundamental domain and the latter follows a discrete Gaussian with a shifted center by the 'noise' magnitude.
Lemma 5.2.2 (Lemma 5.7 Micciancio and Regev (2007)) . Given an n -dimensional lattice L ( B ) , a vector t ∈ R n and a scale s ≥ η ( L ) for some > 0 , there is a PPT sampling algorithm S ( B, t , s ) to output a pair ( c , y ) ∈ P ( B ) × L ( B ) such that
- c is nearly (with statistical distance at most / 2 ) uniformly distributed over P ( B ) ,
- for any vector ˆ c ∈ P ( B ) , given c = ˆ c it entails y ∼ D L,s, t + ˆ c .
Proof. The sampling procedure S simply generates a continuous Gaussian sample r ← D s, t . This sample is then reduced to within the fundamental domain by c = -r mod P ( B ) . Since the Gaussian scale is at least as large as the smoothing parameter, it implies that this sample is nearly uniformly random by Lemma 5.1.4.
Let y = r + c . Since c = -r mod P ( B ) , it implies r = v -c , where v ∈ L ( B ) is a lattice vector. Hence, y is a lattice vector. For any ˆ c ∈ P ( B ) , the new sample r +ˆ c ∼ D s, t +ˆ c is still Gaussian with a shifted center. Since y = r + c , the condition c = ˆ c is the same as saying y = r +ˆ c is a lattice vector. Therefore, the distribution of y conditioning on y being a lattice vector (equivalently c = ˆ c ) is just the discrete Gaussian distribution D L,s, t + ˆ c .
From the outputs of the sampling procedure, one is able to build a random matrix A to call the SIS oracle to produce a short non-zero integer vector x that is an SIS solution. More importantly, x is used to produce a lattice vector s that is the solution of the INCGDD problem. Let the n by m matrix C = [ c 1 , . . . , c m ] ∈ P ( B ) m be the output by running the sampling procedure m times, where each c i is one part of the pair ( c i , y i ) ← S ( B, t , s ) .
Lemma 5.2.3 (Lemma 5.8 Micciancio and Regev (2007)) . Given an n -dimensional lattice L ( B ) , a full-rank sublattice S ⊆ L ( B ) , the sampling output C = [ c 1 , . . . , c m ] and an integer q , there is a PPT algorithm A F ( B,S,C,q ) that makes a single call to the SIS oracle z ← F ( A ) to produce a vector x ∈ R n such that
- A is uniformly random,
- x ∈ L ( B ) is a lattice vector,
- || x -C z || ≤ √ mn || S |||| z || /q .
Recall that a strong motivation to study discrete Gaussian distribution is to simply Ajtai's SIS reduction. The following proof indeed states a simpler way of building a random matrix A for the SIS oracle.
Proof. The PPT procedure is as follows:
1. Generate uniformly random lattice vectors v 1 , . . . , v m ∈ L ( B ) mod P ( S ) .
2. Build the matrix W = [ w 1 , . . . , w m ] where w i = v i + c i mod P ( S ) .
3. Build the matrix A = ⌊ qS -1 W ⌋ ∈ Z n × m q .
4. Invoke the SIS oracle z ←F ( A ) .
5. Output the vector x = ( C -W + SA/q ) z .
Since v i and c i are all uniformly random, so is their modulo sum w i . The first two steps create uniformly distributed samples within the parallelepiped P ( S ) . They are much simpler than the procedure in Ajtai's reduction, which has to start with a larger parallelepiped to ensure near orthogonal which is a
key step to generate uniform samples from the smaller parallelepiped. From here, it is not hard to see A is uniform too.
Step 2 suggests that W = V + C , so C -W = -V contains only lattice vectors. Given z is an SIS solution, SA z /q = k S for an integer vector k . Hence, x = -V z + k S is also a lattice vector in L ( B ) . We skip the last part of the proof which can be found in Micciancio and Regev (2007).
We finish this section by stating the final reduction theorem without proving it. The proof of this theorem is nothing but calling the two procedures above to produce an INCGDD solution, and a justification that the change of producing a solution is non-negligible.
Theorem 5.2.4. For any g ( n ) > 0 , polynomially bounded functions m ( n ) , β ( n ) = n O (1) , negligible function ( n ) = n -ω (1) , and q ( n ) > g ( n ) n √ m ( n ) β ( n ) , there is a PPT reduction from INCGDD η γ,g for γ ( n ) = β ( n ) √ n to SIS q,m,β , so that if there is a solution to a random SIS instance then it solves INCGDD in the worst case with a non-negaligible probability.
## 6 Learning with Errors
In Section 4, we have introduced the SIS problem, which is an average-case problem whose difficulty is based on the worst-case hardness of three lattice problems. The main drawback of SIS-based cryptosystems is the impractical public key size and ciphertext size. Typically, the key size is ˜ O ( n 4 ) and the plaintext size is ˜ O ( n 2 ) , where n is a security parameter with typical values in the hundreds. 6
The learning with error (LWE) problem was introduced by Regev (2005) as another foundational problem for building lattice-based cryptosystems with provable security but smaller key and ciphertext size. In particular, LWE-based cryptosystems' public key size is ˜ O ( n 2 ) , which is a considerable improvement from SIS-based ones, although still not practical for large n . In addition, the plaintext size is increased by only ˜ O (1) times once encrypted.
Intuitively, the LWE problem tries to recover a secret key from a system of noisy linear equations. To draw an analogy, if the linear equations are not noisy, the problem can be solved efficiently using Gaussian elimination as shown in the following example.
Example 6.0.1. Given three linear equations of the form Ax = B , where A is a 3 by 3 matrix, B is a 3 by 1 matrix and x is a 1 by 3 matrix, we can use Gaussian elimination (a.k.a. row reduction) to turn A into an upper triangular matrix, hence solving for the solution x .
$$\begin{bmatrix} 1 & 3 & 1 \\ 1 & 1 & - 1 \\ 3 & 1 1 & 5 \end{bmatrix}$$
$$\left [ \begin{array} { l l l | l } { 1 } & { 0 } & { - 2 } & { 3 } \\ { 0 } & { 1 } & { 1 } & { 4 } \\ { 0 } & { 0 } & { 0 } & { 0 } \end{array} \right ]$$
The LWE problem, however, introduces noises (or errors) into the linear equations, making the above problem significantly harder. More precisely, Gaussian elimination involves linear combinations of rows. This process may amplify the noises so that the resulting rows are unable to maintain the original information that is embedded in the equations.
## 6.1 LWE distribution
We introduce and recall some notations before going into the main content of this section. Denote Z /q Z by Z q and let Z n q = { ( a 1 , . . . , a n ) | a i ∈ Z q } be its n -dimensional generalization. The notation x ← Z n q indicates x is uniformly sampled from Z n q . Let T = R / Z = [0 , 1) be R mod 1 .
In regards to errors in the LWE samples, we use φ and χ to denote the error distributions over T and Z q , respectively. In the hardness proof, Regev (2009) set the error distribution φ = Ψ α which can be obtained by sampling from a continuous Gaussian with mean 0 and standard deviation α √ 2 π (or scale α ) and reducing the outputs modulo 1. But in practice, these errors are discretized for convenience by multiplying samples from Ψ α by q and rounding to the nearest integer modulo q . This gives rise to the discretized error distribution ¯ Ψ α over Z q .
Throughout his work, Regev proved the hardness result of LWE based on the continuous error distribution Ψ α and only used the discretized error ¯ Ψ α when presenting a secure LWE-based cryptosystem.
6 ˜ O ( · ) is a variation of the O ( · ) notation that ignores logarithmic terms: ˜ O ( g ( n )) = O ( g ( n ) log k n ) for some k . This time complexity class is known as quasilinear time and sometimes expressed as O ( n 1+ ) for an > 0 .
Search to decision
In fact, both error distributions entail the same hardness of the LWE problem as emphasized by Lemma 4.3 of Regev (2009). For simplicity, we present the LWE problem and its hardness proof based on the discretized error distribution χ = ¯ Ψ α over Z q , the reader should keep in mind the original proofs were based on the continuous error distribution φ = Ψ α over T = R / Z = [0 , 1) .
Definition 6.1.1. Given the following parameters
- n - the security parameter (usually n = 2 k for an integer k ≥ 0 ),
- q - an integer (not necessarily prime) that is a function of n , i.e., q = q ( n ) ,
a fixed s ∈ Z n q and an error distribution χ over Z q , the LWE distribution LWEdistribution A s ,χ over Z n q × Z q is obtained by these steps
- sample a vector a ← Z n q ,
- compute b = s · a + mod q ,
- sample a noise element ← χ over Z q ,
- output ( a , b ) .
The integer q which controls the size of the ring Z q is often a large integer and a function of n , but it does not need to be a prime number for the hardness proof of the LWE search problem. It is only required to be a prime when reducing the search to decision LWE, in which the ring Z q needs to be a field to build the connection between the two problems as we will see next.
It has been demonstrated that solving a system of exact linear equations can be done efficiently with Gaussian elimination, but solving a system of noisy linear equations is conjectured to be hard. 7 This motivates the search version of the LWE problem stated next. For simplicity, we denote by ( A , b ) ⊆ Z n × N q × Z N q the N samples generated from a LWE distribution.
Definition 6.1.2. Given the parameter q and the error distribution χ over Z q , the search version of the LWE (or just LWE) problem , denoted by LWE q,χ , is to compute the secret key s given samples ( A , b ) from the LWE distribution A s ,χ .
Although all hardness proofs were done on search LWE, the decision version is what is often used to build secure cryptosystems upon.
Definition 6.1.3. Given the parameter q and the error distribution χ over Z q , the decision version of the LWE (or DLWE) problem , denoted by DLWE q,χ , is to distinguish between the LWE samples ( A , b ) and uniformly random samples ( A , u ) over Z n × N q × Z N q .
An efficient reduction from LWE to DLWE can be constructed so that if there is a solution for DLWE, there is a solution for LWE. The reduction is by applying the same procedure to guess (at most poly ( n ) times) each element s i of the secret key s . To guess the first element s 1 , we generate a random r ∈ Z q and add it to the first element of each column vector a i ∈ Z n q , so we get the new random column vectors
To utilize the DLWE oracle, we output the pair
$$\begin{array} { r } { \tilde { a _ { i } } = a _ { i } + ( r , 0 , \dots , 0 ) \in \mathbb { Z } _ { q } ^ { n } . } \end{array}$$
$$\begin{array} { r l } & { ( \tilde { a } _ { i } , b + r \cdot k \bmod q ) } \\ { \intertext { f o r } 1 } & { ( 8 ) } \end{array}$$
for each k ∈ Z q . If k is the correct guess of the first secret vector component, i.e., k = s 1 , then b + r · k = ˜ a i · s + i (mod q ) , so the corresponding pair in Equation (8) looks like ( ˜ a i , ˜ a i · s + i ) which follows the LWE distribution. If k = s 1 , then the corresponding pair is uniform in the domain Z n q × Z q , provided q is prime to make Z q a field so the product r · k can map to each field element with equal chance. Apply the DLWE oracle to distinguish the LWE pair from the uniform pair to obtain the correct guess of s 1 . We have a simple reduction from LWE to DLWE.
Before going forward, it should be made clear that there are different variants of LWE from three different perspectives, which are decision or search, discrete or continuous error distribution, averagecase or worst-case. We have explicitly discussed the first two perspectives above. The last one suggests
7 Another way of seeing the hardness of this problems is that LWE is a generalization of the Learning Parity with Noise problem (Pietrzak, 2012), in which q = 2 and the error distribution χ is a Bernoulli distribution with p (1) = and p (0) = 1 - . This problem is believed to be hard too.
that the LWE distribution and LWE problem can be defined either for all secret s or for a uniform random s . The next lemma shows a reduction from the search, continuous error, worst-case LWE to decision, discrete error, average-case LWE.
Lemma 6.1.4. Let q = poly ( n ) be a prime integer, φ be an error distribution over T and ¯ φ be its discretization over Z q . Assume there is a DLWE q, ¯ φ oracle that distinguishes the LWE distribution A s , ¯ φ from the uniform distribution for a non-negligible fraction of s , then there is an efficient algorithm that solves LWE q,φ for all s .
To keep things simple in this paper, we illustrate the hardness proof in terms of the search, discrete error, worst-case LWE problem. The only difference from the original proof is the discretized error distribution rather than continuous.
## 6.2 LWE hardness proof
Theorem 6.2.1 (Theorem 1.1 (Regev, 2009)) . Let n, p be integers and α ∈ (0 , 1) be such that αp > 2 n . If there exists an efficient algorithm that solves LWE p, ¯ Ψ α then there exists an efficient quantum algorithm that approximates the decision version of the shortest vector problem (GAPSVP) and the shortest independent vectors problem (SIVP) to within ˜ O ( n/α ) in the worst case.
The major steps of the hardness proof of the LWE problem, as outlined by Regev, is sketched in Figure 9. In the box, there is a classical (i.e., non-quantum) reduction from BDD to LWE, which suggests LWE is hard. The more preferable reduction is from the more standard (and well studied) lattice problem GAPSVP, but involves both quantum and classical reductions. The focus of this subsection is the classical reduction in the box. For details of the others steps, the read is referred to the original paper (Regev, 2009).
As it is often convenient to build a cryptosystem based on DLWE and there is an efficient reduction from LWE to DLWE, if there is a solution to the cryptosystem, such a solution can be used to solve LWE. This in return can solve the worst-case GAPSVP (and SIVP) using a quantum algorithm, which is conjectured to be difficult with high confidence. Note that the assumption that these lattice problems are hard to be solved using quantum algorithms is a stronger assumption than using classical algorithms, which obviously are more difficult to be achieved. Peikert (2009) proposed a classical reduction that can replace the quantum step in this proof, but compromising the hardness to be based on non-standard (variant) of lattice problems, or a large modulus q that weakens a cryptosystem's security that is inverse proportional to the size of q .
Figure 9: Reductions to the LWE decision problem. If DGS can be solved for a small scale r close to its lower bound √ 2 nη ( L ) /α , then both lattice problems can be solved with close to optimal solutions. The key to solve DGS for small r is to iteratively apply a subroutine to gradually reduce the scale. The subroutine supplies discrete Gaussian samples to an LWE oracle to classically solve BDD, the result of which is then used by a quantum algorithm to produce shorter discrete Gaussian samples.
<details>
<summary>Image 8 Details</summary>
### Visual Description
\n
## Diagram: System Flow
### Overview
The image depicts a system flow diagram illustrating the relationship between several algorithms and problem-solving approaches. It shows how GAPsvp and SIVP contribute to solving DGS, and how DGS is related to BDD and LWE. The diagram uses arrows to indicate the direction of influence or dependency.
### Components/Axes
The diagram consists of the following components:
* **GAPsvp:** An algorithm or method.
* **SIVP:** An algorithm or method.
* **DGS:** A problem or algorithm.
* **BDD:** A problem or algorithm.
* **LWE:** A problem or algorithm.
* **"iteratively solve DGS using LWE oracle"**: A process description.
* **"quantum"**: A descriptor of DGS.
* **"classical"**: A descriptor of BDD.
### Detailed Analysis or Content Details
The diagram shows the following relationships:
1. **GAPsvp** and **SIVP** both contribute to **DGS**. Each has a single arrow pointing to DGS.
2. **DGS** is iteratively solved using an **LWE oracle**. This is indicated by an arrow pointing from the right side of the diagram to DGS, with the text "iteratively solve DGS using LWE oracle" along the arrow.
3. **DGS** is related to **BDD**, with an arrow pointing from DGS to BDD. The label "quantum" is associated with DGS in this context.
4. **BDD** is related to **LWE**, with an arrow pointing from BDD to LWE. The label "classical" is associated with BDD in this context.
### Key Observations
The diagram suggests a hierarchical relationship between the components. GAPsvp and SIVP are inputs to DGS, which in turn influences BDD and ultimately LWE. The labels "quantum" and "classical" suggest that DGS and BDD operate under different computational paradigms. The iterative solving of DGS using an LWE oracle indicates a dependency on LWE for solving DGS.
### Interpretation
This diagram likely represents a computational process or a theoretical framework in cryptography or computational complexity. GAPsvp and SIVP are likely algorithms used to approach the DGS problem. The iterative solving of DGS using an LWE oracle suggests that LWE (Learning With Errors) is a crucial component in solving DGS. The connection between DGS, BDD (Binary Decision Diagram), and LWE indicates a possible reduction or relationship between these problems. The "quantum" and "classical" labels suggest that DGS might have quantum algorithmic solutions, while BDD is more commonly associated with classical computation. The diagram illustrates a flow of information or computation, where GAPsvp and SIVP feed into DGS, which is then used to influence BDD and ultimately LWE. The diagram doesn't provide specific data or numerical values, but rather a conceptual overview of the relationships between these components.
</details>
Theorem 6.2.2 (Theorem 3.1 (Regev, 2009)) . Let = ( n ) be some negligible function of n . Also, let p = p ( n ) be some integer and α = α ( n ) ∈ (0 , 1) be such that αp > 2 n . Assume that we have access to an oracle W that solves LWE p, Ψ α given a polynomial number of samples. Then there exists an efficient quantum algorithm for DGS √ 2 nη ( L ) /α .
DGS problem
BDD to LWE
The Discrete Gaussian Sampling (DGS) problem is defined as generating a lattice vector in L according to a discrete Gaussian distribution D L,r over L with the scale r ≥ √ 2 nη ( L ) /α that is larger than the lattice's smoothing parameter η ( L ) . For the sake of explaining only the BDD to LWE reduction, we accept (without proving) that GAPSVP γ and SIVP γ are more likely to be solved if DGS can be performed with as small scale r as possible. Hence, it is sufficient to show that one can run DGS with a small r . It turns out that this can be achieved by using an LWE oracle and an iterative step which involves the use of classical and quantum algorithms (in the box of Figure 9) in order to produce samples from a discrete Gaussian distribution with small r . More specifically, starting from n c samples of a discrete Gaussian distribution D L,r where r is large, the iterative step is able to produce n c samples from a narrower Gaussian distribution D L,r ′ where r ′ < r/ 2 . Repeating this step a polynomial number of times so that the last step produces samples from a Gaussian D L,r 0 where the width r 0 ≥ √ 2 nη ( L ) /α reaches its lower bound. One part of the iterative step requires an LWE oracle and an efficient DGS algorithm for r > 2 2 n λ n ( L ) to solve the intermediate problem using a classical algorithm. The intermediate problem is CVP for a given vector that has bounded norm, which is also known as the Bounded Distance Decoding (BDD) problem . The efficient DGS algorithm for large scale is proved plausible by the Bootstrapping Lemma 3.2 of Regev (2009). The other part of the iterative step is a quantum algorithm that uses the solution of the intermediate problem to solve DGS for a narrower distribution that is at most half of the previous scale. The quantum part is out of the scope of this material, hence is not included.
The classical step was demonstrated using the special lattice L = Z n in a follow up paper (Proposition 2.1 (Regev, 2010)). Although the original reduction in Regev (2009) involves working in the dual lattice L ∗ , the lattice and its dual are identical when L = Z n . Note as BDD can be solved easily in Z n (without the LWE oracle), so this restricted context is for demonstration purpose only and does not guarantee LWE hardness.
Proposition 6.2.3. Let q ≥ 2 be an integer and α ∈ (0 , 1) be a real number. Assume there is an LWE oracle for the modulus q and error distribution Ψ α . Then, given as input an n -dimensional lattice L , a sufficient polynomial number of samples from the discrete Gaussian distribution D L ∗ ,r and a BDD instance x = v + e ∈ R n such that || e || ≤ αq/ √ 2 r , there is a polynomial time algorithm finds the (unique) closest lattice vector v ∈ L .
It is worth mentioning that the scale α of the error distribution Ψ α for LWE is restricted to (0 , 1) in order to ensure the Gaussian error distribution is still distinguishable from the uniform distribution once reduced to within a smaller region. In fact, as long as α < η ( L ) , the Gaussian error is still distinguishable. This implies that it is sufficient to have α ∈ (0 , O ( √ log n )) , because the smoothing parameter η ( L ) ≤ O ( √ log n ) · λ n ( L ) by Lemma 5.1.3 and the n th successive minima λ n ( Z n ) = 1 .
Sketch of proof. To utilize the LWE oracle, we wish to construct random LWE samples from the given BDD instance x such that its closest lattice vector v ∈ L is the secret vector s ∈ Z n q for the LWE distribution. Hence, the problem becomes producing from the given BDD instance sufficient LWE samples in the domain Z n q × Z q .
To do so, we need help from the given discrete Gaussian samples. The rational is that such a discrete Gaussian sample behaves like a random element in a smaller domain after modulo reduction. Furthermore, it still distributes normally after multiplying with a random continuous element. So by manipulating this discrete Gaussian element, it outputs an LWE sample that can be used by the oracle. More precisely, sample y according to the discrete Gaussian distribution D Z n ,r over Z n with a relatively large scale r , then output the pair
$$\begin{array} { r l } & { ( a = y m o d q , b = \lfloor \langle y , x \rangle \rfloor m o d q ) \in \mathbb { Z } _ { q } ^ { n } \times \mathbb { Z } _ { q } . } \\ { \cdot } & { ( 9 ) } \end{array}$$
To see why the pair is in the LWE domain, we notice first r being large ensures that y is almost uniformly distributed in Z n q . This is consistent with LWE's first component distribution.
Expressing y in terms of a and q , we get y = q Z n + a . Substitute y and x into Equation 9, we get
$$b & = \lfloor \langle q \mathbb { Z } ^ { n } , v \rangle + \lfloor \langle a , v \rangle + \langle y , e \rangle \rfloor \mod q \\ & = \lfloor \langle a , v \rangle + \langle y , e \rangle \rceil \bmod q .$$
The first term is an integer, so rounding is ignored. For the second term, since y ∈ D Z n ,r its expected norm is roughly || y || ≤ √ nr . In addition, given || e || ≤ αq/ √ 2 r , then by Corollary 3.10 of Regev
(2009), the second term is almost normally distributed with norm approximately at most αq √ n/ 2 and then reduced to roughly α √ n/ 2 , which is consistent with the error distribution Ψ α for the LWE oracle. Therefore, the pair ( a , b ) follows the LWE distribution and hence can be used by the oracle to recover the secret key s .
Since s = v mod q , the LWE oracle and the modulo operation reveal the least significant digits of v in base q . Next, we update the non-lattice vector from x to ( x -s ) /q ∈ R n which gets rid of the least significant digits of x , and employ the above BDD to LWE process to search for the next set of least significant digits in base q in the new secret vector ( v -s ) /q mod q ∈ L . Iterating this process enough times, we will recover the entire closest lattice vector v ∈ L to the given BDD instance x .
Two remarks about the proof. First, to completely hide the discreetness of y by additive noise, additional Gaussian noise is needed to add to b as shown in Equation 12 of Regev (2009). Second, the assumed LWE oracle may only work for a noise distribution of a certain magnitude. However, the noise magnitude 〈 y , e 〉 is strongly related to the distance e = x -v from the given vector to the lattice. The way to address this potential issue is by adding to the second element b in equation 9 an extra noise, whose magnitude can be varied to ensure the LWE oracle works (Lemma 3.7 (Regev, 2009)). We will see in Section 9 that this becomes a challenge in the ring-LWE problem, in which a vector of Gaussian noises is added rather than a single noise whose effect on the result is much easier to be controlled.
The last paragraph of the above proof is formalized in the next lemma for general lattices. It gives rise to reduction from CVP L,d to CVP ( q ) L,d . The latter problem is to find the closest lattice vector reduced modulo q . That is, for a given vector x = v + e ∈ R n with || e || ≤ d , finds the coefficient vector L -1 v mod q ∈ Z n q . Here, the notation L is used in a non-standard way to denote the basis matrix, where the columns of L are the basis vectors v 1 , . . . , v n , so L -1 is the inverse of the basis matrix.
Lemma 6.2.4 (Lemma 3.5 (Regev, 2009)) . Given a lattice L , an integer p ≥ 2 and a CVP ( p ) L,d oracle for d < λ 1 ( L ) / 2 , there is an efficient algorithm that solves CVP L,d .
Proof. The lemma can be proved using the same bit-by-bit iterating strategy as in the special case L = Z n in the above proof. Let x = v + e ∈ R n be a BDD instance. Create a sequence of vectors x 1 = x , x 2 , . . . . Start from x 1 , use the CVP ( p ) L,d oracle to find the coefficient vector a 1 = L -1 v 1 mod q of x 1 's, and update the vector by
$$\begin{array} { r } { x _ { i + 1 } = ( x _ { i } - L ( a _ { i } \bmod q ) ) / p , } \end{array}$$
where L ( a i mod q ) denote the lattice vector corresponds to a i mod q , the least significant bit of the coefficient vector in base q . Substitute x i = v i + e i into the above equation, we get
$$x _ { i + 1 } = ( v _ { i } - L ( a _ { i } \bmod q ) ) / q + e _ { i } / q ,$$
where the error is reduced by a factor of q in the updated instance. Repeat this process n times, we get a BDD instance x n +1 with much smaller error || e n +1 || ≤ d/p n . Unlike in the special case where the process is repeated to solve all bits of the vector, it is sufficient to get down to x n +1 that is very close to the lattice, then use an algorithm (e.g., the nearest plane algorithm (Babai, 1986)) to solve for its closest lattice vector a n +1 . Work backwards to add the solved bits to a n +1 , we obtain a solution a 1 for the given BDD instance x 1 .
## 6.3 An LWE-based encryption scheme
To finish off this section, we state the LWE-based encryption scheme that was proposed by Regev. Later, this scheme became a popular building block for LWE-based homomorphic encryption schemes as we will see in Section 10 (especially in the second generation of homomorphic encryption schemes).
The scheme is parameterized by n , N , q and χ that correspond to the dimension (or security parameter), sample size, modulus and the noise distribution over Z q of, same as the setting for the LWE distribution. The parameters need to be set to appropriate values to ensure the system is correct, secure and efficiently computable. An example setting in Regev (2009) is taking a prime number q ∈ [ n 2 , 2 n 2 ] , N = (1 + )( n + 1) log q for an arbitrary constant > 0 , and χ = ¯ Ψ α ( n ) , where the scale α ( n ) = 1 / ( √ n log 2 n )
Correctness security
For the correct choices of the parameters, it can be proved (Lemma 5.1 and Claim 5.2 (Regev, 2009)) that there is only a negligible chance that the norm of an error sampled from the distribution χ is greater than q 2 / 2 . Hence, when decrypting the ciphertext of 0, the scheme gives c 2 -s · c 1 = ∑ i ∈ S i , whose norm | ∑ i ∈ S i | < q 2 / 2 , which implies the result is closer to 0 than to q 2 . Use the same argument, the decryption of the ciphertext of 1 is also correct.
The semantic security of the cryptosystem is based on the hardness of the DLWE problem. If there is a PPT distinguisher that can tell apart the encryptions of 0 and 1, then we can build another distinguisher that tells apart the LWE distribution from the uniform distribution for a non-negligible fraction of all secret keys s (Lemma 5.4 (Regev, 2009)). More specifically, assuming W is a distinguisher between the encryptions of 0 and 1, that is, | p 0 ( W ) -p 1 ( W ) | ≥ 1 n c for some constant c > 0 , then it is possible to build another distinguisher W ′ such that | p 0 ( W ′ ) -p u ( W ′ ) | ≥ 1 2 n c . By the above remark, it is sufficient to prove a DLWE distinguisher for a non-negligible fraction of s . Define a set Y = { s | | p 0 ( s ) -p u ( s ) | ≥ 1 4 n c } . Construct a distinguisher Z that estimates p 0 (( A , b )) and p u (( A , b )) up to an additive error 1 64 n c by applying W ′ a polynomial number of times. Then Z accepts if the two estimates differ by more than 1 16 n c , otherwise it rejects.
Private key: choose a private key s ← Z n q .
← χ
Encryption: to encrypt a message m ∈ { 0 , 1 } , choose a random subset S ⊆ [ N ] , then
Public key: choose a public key ( A , b ) , where A = [ a 1 , . . . , a N ] ← Z n × N q and b = s · A + for random N .
$$E n c ( 0 ) = ( { \mathbf c } _ { 1 } , c _ { 2 } ) = \left ( \sum _ { i \in S } a _ { i } , \sum _ { i \in S } b _ { i } \right ) ,$$
$$3$$
$$E n c ( 1 ) = ( { \mathbf c } _ { 1 } , c _ { 2 } ) = \left ( \sum _ { i \in S } a _ { i } , \lfloor \frac { q } { 2 } \rfloor + \sum _ { i \in S } b _ { i } \right ) .$$
Decryption: given a ciphertext ( c 1 , c 2 ) , then
Dec (( c , c )) = 0 if c s c is close to 0
$$D e c ( ( { \mathbf c } _ { 1 } , c _ { 2 } ) ) = 1 \, i f \, c _ { 2 } - { \mathbf s } \cdot { \mathbf c } _ { 1 } \, i s \, c l o s e \, t o \, \lfloor \frac { q } { 2 } \rfloor .$$
<!-- formula-not-decoded -->
Roots of unity
## 7 Cyclotomic Polynomials and Cyclotomic Extensions
Cyclotomic polynomials are frequently used in the construction of homomorphic encryption schemes that are based on the ring learning with error (RLWE) problem as we will see later in this tutorial. The motivations of using cyclotomic polynomials are the fact that cyclotomic fields have additional algebraic properties to reduce encryption scheme's time complexity and also make security proofs feasible by following the LWE proof paradigm. In this section, we will introduce the cyclotomic polynomials and the Galois groups of cyclotomic extensions. We have tried to make this section as self-contained as possible. The appendix contains a more general treatment of field extensions and the Galois groups of field extensions for interested readers. Some useful references for material covered in this section include Mukherjee (2016), Conrad (2009) and Porter (2015).
## 7.1 Cyclotomic polynomials
Cyclotomic polynomials are polynomials whose roots are the primitive roots of unity. To understand what it means, we define next.
Definition 7.1.1. For any positive integer n , the n -th roots of unity are the (complex) solutions to the equation x n = 1 , and there are n solutions to the equation.
Theorem 7.1.2. Let n be a positive integer and define ζ n = e 2 πi/n . Then the set of all n -th roots of unity is given by
$$\{ \zeta _ { n } ^ { k } \, | \, k = 0 , 1 , \dots , n - 1 \} , & & ( 1 0 )$$
Proof. By Euler's formula, we have
$$e ^ { 2 \pi i } = \cos ( 2 \pi ) + i \sin ( 2 \pi ) = 1$$
and that ( e 2 πi ) k = e 2 kπi = 1 for all k ∈ { 0 , 1 , . . . , n -1 } . To solve for x n = 1 , note that
Raising each term to the power of 1 /n yields
$$x ^ { n } = 1 = e ^ { 0 } = e ^ { 2 \pi i } = e ^ { 4 \pi i } = e ^ { 6 \pi i } = \cdots = e ^ { 2 k \pi i } .$$
$$x = ( x ^ { n } ) ^ { 1 / n } = 1 = e ^ { 2 \pi i / n } = e ^ { 4 \pi i / n } = e ^ { 6 \pi i / n } = \cdots = e ^ { 2 k \pi i / n } .$$
Example 7.1.3. The 1st root of unity is 1. The 2nd roots of unity are ζ 0 2 = 1 and ζ 1 2 = -1 . The 3rd roots of unity are ζ 0 3 = 1 , ζ 1 3 = -1 2 + i √ 3 2 and ζ 2 3 = -1 2 -i √ 3 2 .
Therefore, there are n distinct solutions to x n = 1 , each given by ζ k n , for k = 0 , 1 , . . . , n -1
Geometrically, we can interpret the nth roots of unity as the points that are evenly spread on the unit circle in the complex plane, starting from 1 on the real axis. (The word 'cyclotomic' means 'circledividing'.) Equivalently, they are the vertices of a regular n-gon that lies on the unit circle, with the real value 1 as one of the n vertices. Figure 10 illustrates the 3rd roots of unity.
<details>
<summary>Image 9 Details</summary>
### Visual Description
\n
## Diagram: Complex Plane with Points and Lines
### Overview
The image depicts a diagram in the complex plane. A unit circle is centered at the origin. Three points, labeled ζ₀³, ζ¹³, and ζ²³, are positioned on the circumference of the circle. These points are connected by straight lines, forming a triangle inscribed within the circle. The axes are labeled "Re" (Real) and "Im" (Imaginary).
### Components/Axes
* **Axes:**
* Horizontal axis: Labeled "Re" (Real).
* Vertical axis: Labeled "Im" (Imaginary).
* **Circle:** A unit circle centered at the origin (0,0).
* **Points:** Three points are marked on the circle:
* ζ₀³ (zeta sub 0 cubed) - Located on the positive Real axis, approximately at (1, 0).
* ζ¹³ (zeta sub 1 cubed) - Located on the positive Imaginary axis, approximately at (0, 1).
* ζ²³ (zeta sub 2 cubed) - Located on the negative Real axis, approximately at (-1, 0).
* **Lines:** Three lines connect the points, forming a triangle.
### Detailed Analysis
The points are equally spaced around the unit circle, suggesting they represent the cube roots of unity.
* **ζ₀³:** Positioned at approximately (1, 0).
* **ζ¹³:** Positioned at approximately (0, 1).
* **ζ²³:** Positioned at approximately (-1, 0).
The lines connecting these points form an equilateral triangle. The angle between each point, as viewed from the origin, is 120 degrees (360 degrees / 3).
### Key Observations
* The points are evenly distributed around the unit circle.
* The lines form an equilateral triangle.
* The diagram visually represents the cube roots of unity.
### Interpretation
This diagram illustrates the geometric representation of the cube roots of unity in the complex plane. The cube roots of unity are the solutions to the equation z³ = 1. These solutions are 1, ω, and ω², where ω = e^(2πi/3) is a complex number. The points ζ₀³, ζ¹³, and ζ²³ represent these roots. The equilateral triangle formed by connecting these points demonstrates the symmetry inherent in the solutions to this equation. The diagram is a visual aid for understanding the relationship between complex numbers, roots of unity, and geometric representation. The diagram does not contain any numerical data beyond the implicit values of the coordinates of the points on the unit circle.
</details>
Figure 10: The 3rd roots of unity ζ 0 = 1 , ζ 1 = -1 2 + i √ 3 2 and ζ 2 = -1 2 -i √ 3 2 . We sometimes drop the subscript to simplify the notation to ζ k if the context is clear.
In general, the equation x n = 1 can be defined over different fields. In the real field R , the only possible roots of unity are ± 1 . In the complex field C , the nth roots of unity form a cyclic group under
Primitive root multiplication. The generator is e 2 πi/n and the group order is n , as shown in Theorem 7.1.2. In a finite field, for example F 7 = Z / 7 Z = { 0 , 1 , 2 , 3 , 4 , 5 , 6 } , the 3rd roots of unity are { 1 , 2 , 4 } , because these are the only numbers equal to 1 modulo 7 when raising to the third power.
Definition 7.1.4. An n -th root of unity r is called primitive if it is not a d -th root of unity for any integer d smaller than n ; i.e. r n = 1 and r d = 1 for d < n .
Geometrically, r is primitive if it is a vertex of a regular polygon that lies on the unit circle, but not a vertex of a smaller regular polygon that lies on the unit circle.
Example 7.1.5. 1 is not primitive. The two real roots ± 1 of the 4th roots of unity are not primitive, because they are also the 2nd roots of unity. Both complex roots of the 3rd roots of unity are primitive. The primitive 6th roots of unity are shown in Figure 11.
<details>
<summary>Image 10 Details</summary>
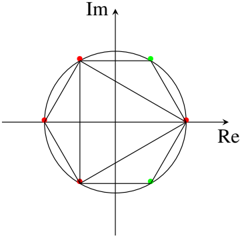
### Visual Description
\n
## Diagram: Unit Circle with Points and Lines
### Overview
The image depicts a unit circle in the complex plane, with several points marked on its circumference. Lines connect these points, forming a polygon inscribed within the circle. The axes are labeled "Re" (Real) and "Im" (Imaginary). The points are colored red and green.
### Components/Axes
* **Axes:**
* Horizontal axis labeled "Re" (Real).
* Vertical axis labeled "Im" (Imaginary).
* **Circle:** A unit circle centered at the origin (0,0).
* **Points:** Six points are marked on the circumference of the circle. Three are red, and three are green.
* **Lines:** Lines connect the points in an alternating red-green-red-green-red-green sequence, forming a hexagon.
### Detailed Analysis
The points are positioned approximately as follows (estimated coordinates based on the unit circle):
* **Red Points:**
* Point 1: (0.7, 0.7) - Top-left quadrant
* Point 2: (-0.8, 0.6) - Top-left quadrant
* Point 3: (-0.6, -0.8) - Bottom-left quadrant
* **Green Points:**
* Point 1: (0.8, -0.6) - Bottom-right quadrant
* Point 2: (0.6, -0.8) - Bottom-right quadrant
* Point 3: (0.7, 0.7) - Top-right quadrant
The lines connect the points in the following order: Red 1 -> Green 1 -> Red 2 -> Green 2 -> Red 3 -> Green 3 -> Red 1. This forms a closed polygon.
### Key Observations
* The points are not evenly spaced around the circle.
* The polygon formed by connecting the points is not a regular hexagon.
* The alternating color scheme (red-green) suggests a possible distinction or grouping of the points.
* The diagram appears to illustrate a geometric representation of complex numbers or roots of unity.
### Interpretation
The diagram likely represents complex numbers on the complex plane. The points on the unit circle represent complex numbers with a magnitude of 1. The lines connecting the points could represent relationships between these complex numbers, such as roots of a polynomial equation. The alternating colors might indicate different properties or classifications of the complex numbers.
The non-uniform spacing of the points suggests that they are not necessarily evenly distributed roots of unity. The diagram could be illustrating a specific set of complex numbers with a particular relationship to each other, or it could be a visual representation of a more complex mathematical concept. Without additional context, it's difficult to determine the precise meaning of the diagram. It could be related to topics like Fourier analysis, signal processing, or number theory.
</details>
Figure 11: The 6th roots of unity ζ 0 = 1 , ζ 1 = 1 2 + i √ 3 2 , ζ 2 = -1 2 + i √ 3 2 , ζ 3 = -1 , ζ 4 = -1 2 -i √ 3 2 , ζ 5 = 1 2 -i √ 3 2 . The primitive roots are ζ 1 , ζ 5 that are coloured in green. ζ 0 , ζ 2 , ζ 4 are not primitive because they are also the 3rd roots of unity. ζ 0 , ζ 3 are not primitive because they are also the 2nd roots of unity.
The following theorem provides an easy way to find the n -th primitive roots of unity.
Theorem 7.1.6. The n -th primitive roots of unity are { ζ k n | 1 ≤ k ≤ n -1 and gcd( k, n ) = 1 } .
If n is prime, then all the n -th roots of unity except 1 are primitive. It follows from Theorem 7.1.6 that the number of n -th primitive roots of unity is equal to the number of natural numbers smaller than n that is coprime with n , which is also known as the Euler's totient function
$$\varphi ( n ) = | \{ k | 1 \leq k \leq n - 1 \text { and } g c d ( k , n ) = 1 \} | .$$
We now have the necessary components to formally define cyclotomic polynomials.
For example, there are four 12th primitive roots of unity { ζ, ζ 5 , ζ 7 , ζ 11 } .
Definition 7.1.7. The n -th cyclotomic polynomial Φ n ( x ) Cyclotomic polynomial is the polynomial whose roots are the n -th primitive roots of unity. That is,
$$\Phi _ { n } ( x ) = \prod _ { \substack { 1 \leq k < n \\ \gcd ( k , n ) = 1 } } ( x - \zeta _ { n } ^ { k } ) ,$$
where ζ k n = e 2 kπi/n is an nth root of unity (as before in Theorem 7.1.2).
Example 7.1.8. The first few cyclotomic polynomials and their roots are listed in Table 1. For n = 4 , the 4th cyclotomic polynomial is Φ 4 ( x ) = ( x -i )( x + i ) = x 2 +1 , because the 4th roots of unity are {± 1 , ± i } and the primitive roots are ± i .
In lattice-based cryptography, we are only interested in some special forms of cyclotomic polynomials as they make certain proofs feasible and computations easier. Next, we introduce two special cases.
Remark 7.1.9. If n is prime, then the n -th cyclotomic polynomial is given by
$$\Phi _ { n } ( x ) = x ^ { n - 1 } + x ^ { n - 2 } + \cdots + 1 = \sum _ { t = 0 } ^ { n - 1 } x ^ { t } .$$
Table 1: First few cylotomic polynomials
| n | Φ n ( x ) | roots |
|-----|------------------------------------|-----------------------------------|
| 1 | x - 1 | 1 |
| 2 | x +1 | ζ 1 = - 1 |
| 3 | x 2 + x +1 | ζ 1 , ζ 2 |
| 4 | x 2 +1 | ζ 1 = i, ζ 3 = - i |
| 5 | x 4 + x 3 + x 2 + x +1 | ζ 1 , ζ 2 , ζ 3 , ζ 4 |
| 6 | x 2 - x +1 | ζ 1 , ζ 5 |
| 7 | x 6 + x 5 + x 4 + x 3 + x 2 + x +1 | ζ 1 , ζ 2 , ζ 3 , ζ 4 , ζ 5 , ζ 6 |
| 8 | x 4 + 1 | ζ 1 , ζ 3 , ζ 5 , ζ 7 |
If n = p k is a prime power, then the n -th cyclotomic polynomial is given by
$$\Phi _ { n } ( x ) = \Phi _ { p } ( x ^ { n / p } ) = \Phi _ { p } ( x ^ { p ^ { k - 1 } } ) = \sum _ { t = 0 } ^ { p - 1 } x ^ { t p ^ { k - 1 } } .$$
As a special case, when p = 2 we have n = 2 k or n = 2 m ≥ 2 where m = 2 k -1 , the n -th cyclotomic polynomial is
$$\Phi _ { n } ( x ) = x ^ { m } + 1 .$$
This directly relates to the underlying ring in the RLWE problem as we shall see in Section 9.
The definition of cyclotomic polynomial implies it is monic (i.e., the leading coefficient is equal to 1) and has ϕ ( n ) linear factors. In addition, Φ n ( x ) divides x n -1 because the roots of the former are also roots of the latter, but not vice versa. This implies an important relationship:
$$x ^ { n } - 1 = \prod _ { d | n } \Phi _ { d } ( x ) . \quad \ \ ( 1 1 )$$
Here are some special cases of Equation (11),
$$\text {Here are some special cases of Equation (11),} \\ x ^ { 2 } - 1 & = ( x - 1 ) ( x + 1 ) \\ x ^ { 3 } - 1 & = ( x - 1 ) ( x ^ { 2 } + x + 1 ) \\ x ^ { 4 } - 1 & = ( x ^ { 2 } - 1 ) ( x ^ { 2 } + 1 ) = ( x - 1 ) ( x + 1 ) ( x ^ { 2 } + 1 ) \\ x ^ { 5 } - 1 & = ( x - 1 ) ( x ^ { 4 } + x ^ { 3 } + x ^ { 2 } + 1 ) \\ x ^ { 6 } - 1 & = ( x ^ { 2 } - 1 ) ( x ^ { 2 } + x + 1 ) ( x ^ { 2 } - x + 1 ) = ( x ^ { 3 } - 1 ) ( x + 1 ) ( x ^ { 2 } - x + 1 ) . \\ \text {Note the pattern that if $d$ divides $n$, then $x^{d}-1$ divides $x^{n}-1$:}$$
Note the pattern that if d divides n , then x d -1 divides x n -1 :
More formally, note that
$$x ^ { n } - 1 = ( x ^ { d } - 1 ) ( x ^ { n - d } + x ^ { n - 2 d } + \cdots + x ^ { d } + 1 ) .$$
$$x ^ { n } - 1 & = \prod _ { 1 \leq k \leq n } ( x - \zeta _ { n } ^ { k } ) \\ & = \prod _ { d \colon d | n } \prod _ { 1 \leq k \leq n } ( x - \zeta _ { n } ^ { k } )$$
The second equality is because d | n splits [1 , n ] into n d mutually exclusive subsets. The third equality uses the definition of cyclotomic polynomial. The last equality is because the subset of integers n d and d are identical.
Minimal polynomial
Equation (11) says that a number is an n -th root of unity if and only if it is a d -th primitive root of unity for some natural number d that divides n .
Example 7.1.10. The 6th roots of unity are shown in Figure 11. ζ 0 = 1 is the 1st primitive root. ζ 3 is the 2nd primitive root. ζ 2 and ζ 4 are the 3rd primitive roots. ζ 1 and ζ 5 are the 6th primitive roots. Hence, the product of these four cyclotomic polynomials is a polynomial whose roots are the 6th roots of unity, i.e., Φ 1 ( x )Φ 2 ( x )Φ 3 ( x )Φ 6 ( x ) = x 6 -1 .
Here are some important properties of cyclotomic polynomials.
Theorem 7.1.11. The n -th cyclotomic polynomial Φ n ( x ) is a degree ϕ ( n ) monic polynomial with integer coefficients.
Theorem 7.1.12. The n -th cyclotomic polynomial is the minimal polynomial of an n -th primitive root of unity.
This theorem implies that cyclotomic polynomials are irreducible over the field of rationals Q . As we will see in Section 9, ring LWE is defined with respect to the quotient ring of polynomials Z [ x ] by the ideal generated by a cyclotomic polynomial. Theorem 7.1.12, together with the First Isomorphism Theorem (Theorem A.2.19), gives the following characterisation of these quotient rings.
Theorem 7.1.13. For all m ∈ N , we have
$$\mathbb { Z } [ x ] / ( \Phi _ { m } ( x ) ) \cong \mathbb { Z } [ \zeta _ { m } ]$$
Proof. This is a direct consequence of Theorems 7.1.12 and B.1.14.
## 7.2 Galois Group of Cyclotomic Polynomials
Galois theory associates to every polynomial a group, called the Galois group of the polynomial, that holds useful algebraic information about the roots of the polynomial that can be used to answer important questions about the polynomial. In this subsection, we use Galois theory to study the roots of cyclotomic polynomials and the symmetric structure in their permutations that will turn out to be useful in the RLWE hardness proof. We will start with a simple example to motivate the discussion.
Example 7.2.1. Consider a quadratic polynomial with roots r and s :
$$f ( x ) = x ^ { 2 } + b x + c \quad ( 1 2 )$$
The polynomial can be written in the alternative form of ( x -r )( x -s ) , which expands out to
$$x ^ { 2 } - ( r + s ) x + r s .$$
$$- b & = r + s & ( 1 3 ) \\ c & = r s . & ( 1 4 )$$
To express r and s in terms of b and c , we can first square (13) to obtain
$$b ^ { 2 } = ( r + s ) ^ { 2 } = r ^ { 2 } + 2 r s + s ^ { 2 } .$$
Subtracting both sides by 4 c then yields
$$b ^ { 2 } - 4 c = r ^ { 2 } - 2 r s + s ^ { 2 } = ( r - s ) ^ { 2 } .$$
$$r - s = \sqrt { b ^ { 2 } - 4 c } & & ( 1 5 ) \\$$
$$s - r = - \sqrt { b ^ { 2 } - 4 c } .$$
Adding (13) to (15) and (16) now gives the familiar quadratic formula.
$$r = \frac { - b + \sqrt { b ^ { 2 } - 4 c } } { 2 } \ a n d \ s = \frac { - b + \sqrt { b ^ { 2 } - 4 c } } { 2 } .$$
Equating coefficients with (12), we get
Taking square roots, we now get
Splitting field
Automorphism
Equations (13) and (14) and their equivalents for arbitrary higher-degree polynomials are called the elementary symmetric polynomials (of the roots). For another example, a cubic polynomial x 3 + bx 2 + cx + d with roots r, s, t have the following elementary symmetric polynomials:
$$locate = r + s + t
c = rs + rt + st
- d = rst.$$
The high-level steps outlined briefly in Example 7.2.1, codified properly in Galois theory, can be used to answer the question of whether the roots of an arbitrary polynomial f can be expressed in terms of its coefficients: start with the elementary symmetric polynomials of f and then systematically simplify the formulas by breaking the symmetries in them. We are thus led to the following definition of the splitting field of a polynomial, which contains the elementary symmetric polynomials and other polynomials of (subsets of) the roots that can be obtained from them.
Definition 7.2.2. Let f be a polynomial with rational coefficients. The splitting field K of f is the smallest field that contains the roots of f . ( K is called the splitting field because we can split f into linear factors in K . Also, by the properties of a field, K can be understood as the set of multi-variate polynomial expressions in the roots of f with rational coefficients.)
The symmetric polynomials in the splitting field for a polynomial f are exactly those that are invariant under permutations of the roots of f , and these permutations can be obtained via automorphisms.
Definition 7.2.3. An automorphism α of the splitting field K of a polynomial f is a bijection from K to K such that
$$\begin{array} { r l } & { \alpha ( a + b ) = \alpha ( a ) + \alpha ( b ) } \\ & { \quad \alpha ( a b ) = \alpha ( a ) \alpha ( b ) . } \end{array}$$
Note that for all a ∈ K that is a rational number, α ( a ) = a by the property of α . It then follows that for all polynomials Q ( r 1 , . . . , r n ) ∈ K , where each r i is a root of f , we have
$$\alpha ( Q ( r _ { 1 } , \dots , r _ { n } ) ) = Q ( \alpha ( r _ { 1 } ) , \dots , \alpha ( r _ { n } ) ) .$$
Now consider f ( r i ) , which is in K because it is a polynomial in a root of f . Since
$$f ( \alpha ( r _ { i } ) ) = \alpha ( f ( r _ { i } ) ) = \alpha ( 0 ) = 0 ,$$
we can see that an automorphism always send a root of f to another root of f ; further, given automorphisms are bijections, each automorphism can be identified with a permutation of the roots of f .
A collection of permutations is a group if it is closed under composition of permutations. Since automorphisms compose, the set of permutations of the roots of a polynomial f that correspond to an automorphism is a group, called the Galois Group of the polynomial f , or equivalently the Galois Group Gal ( K ( ζ ) /K ) of the field extension K ( ζ ) /K , where the cyclotomic extension K ( ζ ) is the splitting field of f .
For most polynomials f , every permutation of the roots induces an automorphism so the Galois Group of f is the set of all permutations of the roots. But for some polynomials, the Galois Group is a strict subset of the permutations of the roots because some permutations do not induce an automorphism. This is the case for cyclotomic polynomials.
Let G be the Galois group of the n -th cyclotomic polynomial, where n is prime. The roots of the polynomial are { ζ, ζ 2 , . . . , ζ n -1 } . Each α ∈ G maps ζ by α ( ζ ) = ζ a for some a ∈ { 1 , . . . , n -1 } . Since
$$\alpha ( \zeta ^ { k } ) = \alpha ( \zeta ) ^ { k } = \zeta ^ { a k } ,$$
the number a completely determines where all the other roots go. In general, the Galois group of a polynomial can permute the roots arbitrarily, but the Galois group of cyclotomic polynomials only allow permutations of the form
$$( \zeta , \zeta ^ { 2 } , \dots , \zeta ^ { n - 1 } ) \mapsto ( \zeta ^ { a } , \zeta ^ { 2 a m o d n } , \dots , \zeta ^ { ( n - 1 ) a m o d n } )$$
for all a ∈ { 1 , . . . , n -1 } .
Injective homomorphism
Isomorphism when K = Q
Image of Galois group when K = F p
Example 7.2.4. For n = 5 , these are the only permutations induced by automorphisms:
$$( \zeta ^ { 1 } , \zeta ^ { 2 } , \zeta ^ { 3 } , \zeta ^ { 4 } ) \text { for } a = 1 \\ ( \zeta ^ { 2 } , \zeta ^ { 4 } , \zeta ^ { 1 } , \zeta ^ { 3 } ) \text { for } a = 2 \\ ( \zeta ^ { 3 } , \zeta ^ { 1 } , \zeta ^ { 4 } , \zeta ^ { 2 } ) \text { for } a = 3 \\ ( \zeta ^ { 4 } , \zeta ^ { 3 } , \zeta ^ { 2 } , \zeta ^ { 1 } ) \text { for } a = 4$$
The above chain of reasoning can be more formally stated in the following theorem, where ( Z /n Z ) ∗ is the multiplicative integer modulo n group.
Theorem 7.2.5. The mapping
$$\begin{array} { r l } & { \omega \colon G a l ( K ( \zeta _ { n } ) / K ) \to ( \mathbb { Z } / n \mathbb { Z } ) ^ { * } } \\ & { \quad \omega ( \sigma ) = a _ { \sigma } \bmod n } \end{array}$$
that is given by σ ( ζ ) = ζ a σ for all n -th roots of unity ζ is an injective group homomorphism.
Proof. For any automorphisms σ, τ ∈ Gal ( K ( ζ n ) /K ) , a primitive root ζ n ∈ µ n satisfies στ ( ζ n ) = σ ( ζ a τ n ) = ζ a σ a τ n by applying the automorphism one after the other. In addition, the two automorphisms gives another automorphism in the Galois group by composition, so στ ( ζ n ) = ζ a στ n . Hence, we have ζ a σ a τ n = ζ a στ n . This implies a σ a τ = a στ mod n , because ζ n has order n . Therefore, we have ω ( στ ) = a στ = a σ a τ mod n = ω ( σ ) ω ( τ ) which entails ω is a homomorphism. The injectivity is not difficult to see either.
We know the group ( Z /n Z ) ∗ is abelian. The map ω embeds the Galois groups of cyclotomic extensions to this abelian group, so the Galois group is also abelian. For a general base field K , the group homomorphism need not be surjective. There are two special cases, K = Q and K = F p , for a prime p , that are of most interest for building lattice cryptosystems. We will look at the property of the map ω in each special case one by one.
Theorem 7.2.6. The Galois group of the cyclotomic extension Q ( ζ n ) is isomorphic to the multiplicative integer modulo n group. That is,
$$G a l ( \mathbb { Q } ( \zeta _ { n } ) / \mathbb { Q } ) \cong ( \mathbb { Z } / n \mathbb { Z } ) ^ { * } .$$
For each automorphism σ ∈ Gal ( Q ( ζ n ) / Q ) , there is an integer i ∈ ( Z /n Z ) ∗ such that the automorphism σ ↦→ [ i ] is mapped to the equivalent class of i if and only if σ ( ζ n ) = ζ i n .
The automorphisms in the Galois group are functions on the roots of unity. We can think of the equivalent class [ i ] as a function too given by [ i ] : ζ ↦→ ζ i for all roots ζ ∈ µ n . The theorem says each automorphism in the Galois group is uniquely mapped to an integer in the multiplicative group (or a function). Theorem 7.2.6 is useful for proving the pseudorandomness of the ring LWE distribution as we will see in a later section.
Observe that the order of the Galois group is equal to the degree of the Galois extension over Q , which is equal to the degree ϕ ( n ) of the n -th cyclotomic polynomial. The order of the multiplicative group is equal to the number of integers in [0 , n -1] that are coprime with n . The two numbers are obviously equal.
When K is a field with non-zero prime characteristic char ( K ) = p (e.g., K = F p ), as is often the case in cryptography, the homomorphism ω is not necessarily surjective. Theorem 7.2.7 caters for this case. For our purpose, we are primarily interested in the cyclotomic polynomials Φ d ( x ) where gcd( d, p ) = 1 .
Theorem 7.2.7. Let F q be a finite field with a prime power order q and gcd( q, n ) = 1 , the Galois group of a cyclotomic extension F q ( ζ n ) of the finite field is mapped by the homomorphism ω to the cyclic group 〈 q mod n 〉 in ( Z /n Z ) ∗ . That is,
$$\omega ( G a l ( \mathbb { F } _ { q } ( \zeta _ { n } ) / \mathbb { F } _ { q } ) ) = \langle q \bmod n \rangle \subseteq ( \mathbb { Z } / n \mathbb { Z } ) ^ { * } .$$
In particular, the dimension of the cyclotomic extension is the order of q modulo n .
To prove Theorem 7.2.7, we need this next result.
Theorem 7.2.8. For a prime p and prime power q = p n , the pth power map Power map ω p : x ↦→ x p on F q generates the Galois group Gal ( F q ( ζ n ) / F q ) .
Proof. (of Theorem 7.2.7 for the special case when q = p for a prime p ) Theorem 7.2.8 implies that the Galois group Gal ( F q ( ζ n ) / F q ) is generated by the pth power map ω p : x ↦→ x p for all x ∈ F q ( ζ n ) . In addition, by Theorem 7.2.5 the group homomorphism ω associates to ω p an non-negative integer a mod n such that ω p ( ζ ) = ζ a for all nth roots of unity ζ ∈ µ n . This entails ζ p = ζ a , which is true if a = p mod n . Hence, the homomorphism ω maps the pth power map ω p in the Galois group to p mod n in the group ( Z /n Z ) ∗ . Since Gal ( F q ( ζ n ) / F q ) = 〈 ω p 〉 , its image is the cyclic group 〈 p mod n 〉 ∈ ( Z /n Z ) ∗ .
The assumption char ( F q ) = p implies the polynomial x n -1 is separable in F q [ x ] , so F q ( ζ n ) is an Galois extension given that it is also the splitting field of x n -1 . Hence, we have [ F q ( ζ n ) : F q ] = | Gal ( F q ( ζ n ) / F q ) | = |〈 p mod n 〉| , which is the order of p modulo n .
Knowing cyclotomic polynomials are irreducible over Q , we would like to know whether they are also irreducible in a finite field F q of prime power order q . This brings out the following theorem and corollary. Denote ¯ Φ n ( x ) as reducing the coefficients of Φ n ( x ) modulo q .
Theorem 7.2.9. Factor Φ n ( x ) in F p Let q be prime power and gcd( q, n ) = 1 , the monic irreducible factors of the polynomial ¯ Φ n ( x ) ∈ F p [ x ] are distinct and each has a degree equal to the order of q modulo n .
Corollary 7.2.10. The polynomial ¯ Φ n ( x ) is irreducible in F q [ x ] if gcd( q, n ) = 1 and 〈 q mod n 〉 = ( Z /n Z ) ∗ . That is, q mod n is a generator of the group ( Z /n Z ) ∗ .
Example 7.2.11. For n = 5 , the polynomial
$$\bar { \Phi } _ { 5 } ( x ) = x ^ { 4 } + x ^ { 3 } + x ^ { 2 } + x + 1$$
$$( x - 3 ) ( x - 4 ) ( x - 5 ) ( x - 9 )$$
can be factored in F 11 as because the order of 11 modulo 5 is 1. Similarly, it can be factored in F 19 as
$$( x ^ { 2 } + 5 x + 1 ) ( x ^ { 2 } + 1 5 x + 1 )$$
because the order of 19 modulo 5 is 2. Similarly, it can be factored in F 3 as
$$x ^ { 4 } + x ^ { 3 } + x ^ { 2 } + x + 1$$
because the order of 3 modulo 5 is 4. The last case is an example of the corollary where the cyclic group 〈 3 mod 5 〉 is a generator of the group ( Z / 5 Z ) ∗ . More details on the derivation of these factorizations can be found in Example 8.1.26.
## 8 Algebraic Number Theory
This section introduces some of the results in Algebraic Number Theory that will be needed in the hardness proof of the ring LWE (RLWE) problem. In RLWE, proofs and computations are conducted in number fields and rings of integers, which are generalizations of the rational field Q and integers Z . However, unlike elements in Z that can be uniquely factorized, which is an essential property that guarantees the validity of some hard computational problems such as integer factorization, elements of rings of integers are not necessarily uniquely factorizable in general. Instead we need to work with sets of elements that possess such unique factorization. As we will see in this section, the ideals of these rings of integers are natural candidates for this purpose and we will state some useful properties of the ideals. In particular, the connection with lattice theory comes from a natural mapping between these ideals of a ring of integers to full-ranked lattices that we call ideal lattices.
Algebraic Number Theory is a deep and interesting area and we do not attempt to cover all important results in this compact section. Instead, we cover only those mathematical results that are directly relevant to the future sections. Additional results that may assist the reader to better understand the main content are kept in the appendix. This section is organized as follows:
1. First, we familiarize the reader with algebraic number field, its ring of integers and ideals of the ring of integers including the generalized fractional ideals. The most important observation is that a fractional ideal can be uniquely factorized into prime ideals. This plays a significant part when employing the Chinese Remainder Theorem (CRT) for number fields.
2. Second, to build the geometric interpretation of these algebraic objects, we introduce canonical embedding, which maps fractional ideals to special lattices called ideal lattices . The embedding allows us to talk about geometric quantities of algebraic objects and enables certain features of ideal lattices that are convenient for the RLWE's proof and computations.
3. Finally, we go through dual lattices in number fields and relate them with fractional ideals.
It's worth noting that many of the concepts covered in this section are used primarily for analysis of the hardness results of the RLWE problem. As such, some readers may find it useful to first skim this section quickly to identify key concepts, and only come back for details as they work through Section 9. The only computations that are explicitly needed in RLWE-based cryptosystems are Fast Fourier Transform operations to transform polynomials between their natural and canonical embeddings.
## 8.1 Ring of integers and its ideal
We have seen the LWE problem, which was defined in the integer domain Z and proved to be hard by reductions from hard lattice problems in the domain in R n . The drawback of LWE is the large public key that is a matrix of m independent length n column vectors. The RLWE problem (as will be introduced in Section 9) is defined in a more general domain, called the ring of integers . It greatly reduces the public key size by defining the problem in domain with additional algebraic structures.
Recall that an algebraic number (integer) is a complex number that is a root of a non-zero polynomial with rational (integer) coefficients. For example, √ 1 / 2 and √ 2 are roots of the polynomials x 2 -1 / 2 and x 2 -2 respectively, so the former is an algebraic number and the latter is an algebraic integer. Algebraic numbers and algebraic integers generalize rational numbers and rational integers by forming the notions of number field and ring of integers, just like the rational field Q and the integer ring Z .
- Definition 8.1.1. Number field An algebraic number field (or simply number field ) is a finite extension of the field of rationals by algebraic numbers, i.e., Q ( r 1 , . . . , r n ) , where r 1 , . . . , r n are algebraic numbers.
Cyclotomic field
In a special case when the element ζ n adjoins to Q is an nth root of unity, which is also an algebraic number, the number field Q ( ζ n ) is also known as the nth cyclotomic (number) field . This is the working domain for reducing the RLWE search to decision problem. In a number field K , the set of all algebraic integers forms a ring under the usual addition and multiplication operations in K . These elements form a ring and is the generalization of the ring of rational integers.
- Definition 8.1.2. Ring of integers The ring of integers of an algebraic number field K , denoted by O K , is the set of all algebraic integers that lie in the field K .
O K is a free Z -module Basis
Integral ideal
Ideal product
Ideal division
Some examples of a number field and its ring of integers are the basic Q and Z , the quadratic field Q ( √ 2) and Z [ √ 2] , the nth cyclotomic field Q ( ζ n ) and Z [ ζ n ] . In general, determining the ring of integers is a difficult problem, unless for special cases, see Theorem C.1.6 in Appendix C.
Since Z is contained in O K , it is easy to see O K is also Z -module. In addition, O K is a free Z -module, as there always exists a Z -basis B = { b 1 , . . . , b n } ⊆ O K such that every element r ∈ O K can be written as r = ∑ n i =1 a i b i , where a i ∈ Z . The basis B is called an integral basis of the number field K and its ring of integers O K . If the basis can be written as { 1 , r, . . . , r n -1 } the powers of an element r ∈ K , then it is called a power basis . A field K always has a power basis by the Primitive Element Theorem (Appendix C Theorem C.1.2). If K = Q ( ζ m ) is a cyclotomic field, the power basis { 1 , ζ m , . . . , ζ ϕ ( m ) -1 m } is also an integral basis of O K .
## 8.1.1 Integral ideal
In the applications of this tutorial, we do not work with individual elements in O K because they lack the unique factorization property; instead, we work with ideals of O K (Equation (17)). Ideals of a ring are useful for constructing a field, for the same reason they are important in the ring of integers. To distinguish ideals of O K from fractional ideals that will be introduced later, we sometimes refer the former as integral ideals.
Definition 8.1.3. Given a number field K and its ring of integers O K , an ( integral ) ideal I of O K is a non-empty (i.e., I = ∅ ) and non-trivial (i.e., I = { 0 } ) additive subgroup of O K that is closed under multiplication by the elements in O K , i.e., for any r ∈ O K and any x ∈ I , their product rx ∈ I .
As O K is commutative, we do not differentiate left and right ideals. The definition intentionally excluded the zero ideal { 0 } in order to simplify the work of defining ideal division later. Since O K has a Z -basis, each of its ideals has a Z -basis too, which entails the ideal is a free Z -module too. As we will see later, this basis will be mapped to a basis of an ideal lattice by canonical embeddings.
We now define ideal multiplication and division which lead to the definition of prime ideals.
Recall that if I and J are ideals then the set sum I + J = { x + y | x ∈ I, y ∈ J } is also an ideal. The set product S = { xy | x ∈ I, y ∈ J } , however, may not be an ideal because it is not necessarily closed under addition. For this reason, the product of two ideals I and J is defined as the set of all finite sums of products of two ideal elements:
$$I J \colon = \left \{ \sum _ { i = 1 } ^ { n } a _ { i } b _ { i } | a _ { i } \in I a n d b _ { i } \in J , n \in \mathbb { N } \right \} ,$$
By grouping all finite sums of products, the set is closed under addition. Furthermore, it is closed under multiplication by O K , so the above definition of product is also an ideal. Since O K is commutative, ideal multiplication is commutative too.
Example 8.1.4. Given the ring of integers O K = Z and two ideals I = 2 Z = { 2 , 4 , 6 , 8 , . . . , } and J = 3 Z = { 3 , 6 , 9 , 12 , . . . , } , their product is IJ = { 2 · 3 , 2 · 6 , 2 · 3 + 2 · 6 , . . . } .
Since the zero ideal is excluded from the ideal definition, it is convenient to define ideal division. The intuition is the same as non-zero integer division.
Definition 8.1.5. Let I and J be two ideals of O K . We say J divides I , denoted J | I , if there is another ideal M ⊆ O K such that I = JM .
The following theorem gives a more intuitive way of thinking about ideal division by relating division with containment.
Theorem 8.1.6. Let I and J be two ideals of O K . Then J | I if and only if I ⊆ J .
The intuition of divisibility implies containment is that if J | I then I = JM ⊆ J , so I ⊆ J . The converse may not be true in general, but is certainly true in the context of O K .
Lemma 8.1.7. An ideal I of O K is prime if and only if for ideals J and K of O K , whenever JK ⊆ I , either J ⊆ I or K ⊆ I .
The standard definition of a prime ideal I ⊆ O K is that it is a proper ideal such that if xy ∈ I , then either x ∈ I or y ∈ I . The next lemma gives an alternative definition in terms of ideal containment.
By this lemma and Theorem 8.1.6, we can define a prime ideal in analogy to a prime number.
Definition 8.1.8. A proper ideal I O K is prime Prime ideal if whenever I | JK , either I | J or I | K .
Principal ideals and maximal ideals are defined in the same way as that in general rings. An important observation is that in O K , prime ideals are also maximal.
Lemma 8.1.9. All prime ideals in O K are maximal.
The proof relies on the results that the quotient of a commutative ring by a prime ideal gives an integral domain, and the quotient by a maximal ideal gives a field. See Lemma C.2.8 in Appendix C. The importance of this lemma is that when working in O K /I , the quotient ring by a prime ideal I is a field, as implied by Proposition A.2.17 in Appendix A.
The most important result of this subsection, which is also one of the main theorems in Algebraic Number Theory , is that ideals of O K can be uniquely factorized into prime ideals. Alternatively, we say the ideals of O K form a unique factorization domain.
$$x = p _ { 1 } \cdots p _ { n }$$
Definition 8.1.10. An integral domain D is a unique factorization domain (UFD) if every non-zero non-unit element x ∈ D can be written as a product of finitely many irreducible elements p i ∈ D uniquely up to reordering of the irreducible elements.
We know Z is a UFD, because every integer can be uniquely factored into a prouct of prime numbers. But the extension Z ( √ 5) is not a UFD, because not every element has a unique factorization, for example 6 = 2 · 3 = (1 + √ -5)(1 -√ -5) , which can be factored in two ways. To avoid such issues, we do not work with the individual elements in O K , but study the ideals of O K , which do form a UFD because O K is a Dedekind domain. (See Appendix C for more detail about Dedekind domain.)
- Theorem 8.1.11. UFD For an algebraic number field K , every proper ideal I of O K admits a unique factorization
into prime ideals q i of O K .
$$I & = \mathfrak { q } _ { 1 } \cdots \mathfrak { q } _ { k } , & ( 1 7 )
</doctag>$$
Example 8.1.12. When working in the 5th cyclotomic field K = F 11 ( ζ 5 ) and O K = Z 11 [ ζ 5 ] , the ideal I = (11) of O K can be uniquely factorized into the product of these four prime ideals:
$$\begin{array} { r l } & { ( 1 1 ) = ( 1 1 , \zeta _ { 5 } - 3 ) ( 1 1 , \zeta _ { 5 } - 9 ) ( 1 1 , \zeta _ { 5 } - 5 ) ( 1 1 , \zeta _ { 5 } - 4 ) . } \end{array}$$
The detailed derivation is given in Example 8.1.26.
The usefulness of UFD in our context is that it gives a unique isomorphism between a quotient ring O K /I and its Chinese Remainder Theorem (CRT) representation. To generalize CRT to the ring of integers O K , we first define coprime ideals in O K . Since ideals in O K can be uniquely factorized, it makes sense to talk about coprimality. The standard definition is similar to coprime integers, which do not share a common divisor.
- Definition 8.1.13. Ideal GCD Let I and J be integral ideals of O K , their greatest common divisor (GCD) gcd( I, J ) = I + J .
Definition 8.1.14. Coprime Two ideals I and J in O K are coprime if I + J = O K .
In other words, two integral ideals are coprime if their sum is the entire ring of integers. For example, the integral ideals (2) and (3) in Z are coprime because (2) + (3) = (1) = Z . But the integral ideals (2) and (4) are not coprime because (2) + (4) = (2) = Z .
- Theorem 8.1.15. CRT in O K Let I 1 , . . . , I k be pairwise coprime ideals in a ring of integers O K and I = ∏ k i =1 I i . Then the map
induces an isomorphism
$$\mathcal { O } _ { K } \rightarrow ( \mathcal { O } _ { K } / I _ { 1 } , \dots , \mathcal { O } _ { K } / I _ { k } )$$
$$\mathcal { O } _ { K } / I \cong \mathcal { O } _ { K } / I _ { 1 } \times \cdots \times \mathcal { O } _ { K } / I _ { k } .$$
The core element of the proof of CRT in O K is to show that the kernel of the map is I 1 ∩ · · · ∩ I k , which is identical to ∏ k i =1 I i under the assumption that the ideals are pairwise coprime. The result then follows from the First Isomorphism Theorem.
Fractional ideal
Frac ideal product
Frac ideal inverse
Multiplicative group
By CRT in O K , the factorization (17) yields the isomorphism
This isomorphism is essential for the hardness proof of RLWE. If the factorization is not unique, the same proof will not follow through. We will discuss more detail of the proof in Section 9.
## 8.1.2 Fractional ideal
As briefly mentioned earlier, fractional ideals are generalizations of integral ideals and they are one of the main ingredients in the hardness proof of RLWE. On the one hand, fractional ideals share some common properties with integral ideals including the important unique factorization characteristic. On the other hand, they are neither ideals of the ring of integers O K nor ideals of the number field K as we will see soon.
Definition 8.1.16. Let K be a number field and O K be its ring of integers. A fractional ideal I of O K is a set such that dI ⊆ O K is an integral ideal for a non-zero d ∈ O K .
Given an integral ideal J ⊆ O K and an invertible element x ∈ K , the corresponding fractional ideal I can be expressed as
From this expression, it is clearer that the non-zero element d ∈ K in the above definitions is for cancelling the denominator x of elements in the fractional ideal. When x = 1 , it entails the integral ideals of O K including O K itself are all fractional ideals. This is also why fractional ideals are generalizations of them. Since an integral ideal is a free Z -module and a fractional ideal is related to an integral ideal by an invertible element, it follows that a fractional ideal is a free Z -module too with a Z -basis.
$$I = x ^ { - 1 } J \colon = \{ x ^ { - 1 } a | a \in J \} \subseteq K .$$
It can be seen that a fractional ideal is closed under addition and multiplication by the elements in O K , but it is NOT an ideal of O K , because it is not necessarily a subset of O K . Neither it is an ideal of the number field K , because a field has only zero and itself as ideals.
Example 8.1.17. Let K = Q and O K = Z . Given the integral ideal 5 Z and x = 4 ∈ Q , whose inverse is 1 4 , the corresponding fractional ideal in Q is 5 4 Z .
The product of two fractional ideals can be defined analogous to the product of two integral ideals. That is, for fractional ideals I and J ,
$$I J \colon = \left \{ \sum _ { i = 1 } ^ { n } a _ { i } b _ { i } | a _ { i } \in I a n d b _ { i } \in J , n \in \mathbb { N } \right \} .$$
It is also easy to check that the product of two fractional ideals is still a fractional ideal.
The fractional ideals in a number field K form a multiplicative group. To see this, we have demonstrated that they are closed under multiplication and the unit ideal (1) = O K is the multiplicative identity in the group. It remains to show that every fractional ideal has an inverse in the group. This is done via the following two lemmas. The first lemma states that every prime ideal of O K has an inverse. The second lemma states that every non-zero integral ideal of O K has an inverse, which uses the result of the first lemma and the fact that every prime ideal in O K is also maximal. See Appendix C for the proofs of these two lemmas.
Lemma 8.1.18. If P is a prime ideal in O K , then P has an inverse P -1 = { a ∈ K | aP ⊆ O K } that is a fractional ideal.
Lemma 8.1.19. Every non-zero integral ideal of O K has an inverse.
The two lemmas combined prove that a fractional ideal has an inverse. For more detail of the proof, see Theorem 3.1.8 of Stein (2012). To be more precise, the inverse of a fractional ideal I has the form
$$I ^ { - 1 } = \{ x \in K \, | \, x I \subseteq \mathcal { O } _ { K } \} .$$
In the special case when the product of two fractional ideals is a principal fractional ideal IJ = ( x ) , the inverse has the form I -1 = 1 x J .
Theorem 8.1.20. The set of fractional ideals in a number field K is an abelian group under multiplication with the identity element O K .
$$\mathcal { O } _ { K } / I \cong \mathcal { O } _ { K } / \mathfrak { q } _ { 1 } \times \cdots \times \mathcal { O } _ { K } / \mathfrak { q } _ { k } .$$
Akey result of this subsection is that a fractional ideal can also be uniquely factorized into a product of prime ideals.
Theorem 8.1.21. UFD Let K be a number field. If I is a fractional ideal in K , then there exist prime ideals p 1 , . . . , p n and q 1 , . . . , q m in O K , unique up to ordering, such that
$$I = ( \mathfrak { p } _ { 1 } \cdots \mathfrak { p } _ { n } ) ( \mathfrak { q } _ { 1 } \cdots \mathfrak { q } _ { m } ) ^ { - 1 } .$$
The theorem follows from the fact that a fractional ideal has the form I = 1 a J , where J is an integral ideal and a ∈ O K . Since both J and ( a ) are integral ideals of O K , Theorem 8.1.11 implies they have unique prime ideal factorization.
## 8.1.3 Applications in Ring LWE
As we will see in Section 9, when working on the hardness proof of the ring LWE problem, it is easier to view the underlying ring Z [ x ] / (Φ m ( x )) as a ring of integers in a cyclotomic number field, as opposed to the (more direct) interpretation of a ring of polynomials. This perspective change in interpretation is supported by the following two results.
Theorem 8.1.22. The ring of integers in Q ( ζ m ) is generated by ζ m :
Theorem 8.1.23. For all m ∈ N , we have
$$\mathcal { O } _ { \mathbb { Q } ( \zeta _ { m } ) } = \mathbb { Z } [ \zeta _ { m } ] .$$
$$\mathbb { Z } [ x ] / ( \Phi _ { m } ( x ) ) \cong \mathcal { O } _ { \mathbb { Q } ( \zeta _ { m } ) }$$
Proof. This is a direct consequence of Theorem 8.1.22 and Theorem 7.1.13.
We state here two technical lemmas that will be needed in the RLWE result. The first lemma shows that given two ideals I, J ⊆ R of a Dedekind domain R (e.g., a ring of integers O K of a number field K is a Dedekind domain), it is possible to construct another ideal that is coprime with either one of them.
Lemma 8.1.24 (Lemma 5.2.2 (Stein, 2012), Lemma 2.1.4 (Lyubashevsky et al., 2010)) . If I and J are non-zero integral ideals of a Dedekind domain R , then there exists an element t ∈ I such that ( t ) I -1 ⊆ R is an integral ideal coprime to J .
Proof. Let p 1 , . . . , p r be the prime factors of the ideal J . We create a coprime ideal of J as follows. Let n i be the largest power of p i such that p n i i | I for all i ∈ [1 , r ] . As p i is a prime ideal, p n i +1 i p n i i .So there exits an element t i ∈ p e i i such that it is not in p n i +1 i . By construction, we know the ideals p e 1 +1 1 , . . . , p e r +1 r , I/ ∏ r i =1 p e i i are pairwise coprime, so by the Chinese Remainder Theorem, there is an element t ∈ R such that t ≡ t i mod p e i +1 i and t ≡ 0 mod I/ ∏ r i =1 p e i i . Since t i ∈ p e i i , it entails t ≡ 0 mod p e i i for all i ∈ [1 , n ] , so t ∈ I as in the lemma.
To prove ( t ) I -1 is coprime to J , it sufficient to show none of J 's prime divisor can divide it. Suppose p i | ( t ) I -1 , then p i I | ( t ) . The assumption p e i i | I implies that p e i +1 i | ( t ) , so ( t ) ⊆ p e i +1 i . This contradicts with the above that t ≡ a i mod p e i +1 i . So the two are coprime.
The element t ∈ I can be efficiently computable using CRT in O K . Hence, given two ideals in R , we can efficiently construct another one that is coprime with either one of them. The next lemma is essential in the reduction from K-BDD problem to RLWE.
Lemma 8.1.25 (Lemma 5.2.4 (Stein, 2012), Lemma 2.1.5 (Lyubashevsky et al., 2010)) . Let I and J be ideals in a Dedekind domain R and M be a fractional ideal in the number field K . Then there is an isomorphism
$$M / J M \cong I M / I J M .$$
Proof. Given ideals I, J ⊆ R , by Lemma 8.1.24 we have ( t ) I -1 ⊆ R is coprime to J for an element t ∈ I . Then we can define a map
$$\theta _ { t } \colon K & \to K \\ u & \mapsto t u .$$
This map induces a homomorphism
First, show ker ( θ t ) = JM . Since θ t ( JM ) = tJM ⊆ IJM , then θ t ( JM ) = 0 . Next, show any other element u ∈ M that maps to 0 is in JM . To see this, if θ t ( u ) = tu = 0 , then tu ∈ IJM . To use Lemma 8.1.24, we re-write it as ( tI -1 )( uM -1 ) ⊆ J . Since tI -1 and M are coprime, we have uM -1 ⊆ J , which implies u ⊆ JM . Therefore, ker ( θ t ) = JM and is injective.
$$\theta _ { t } \colon M \rightarrow I M / I J M .$$
$$\theta _ { t } \colon M / J M \rightarrow I M / I J M$$
Second, show the map is surjective. That is, for any v ∈ IM , its reduction v mod IJM has a preimage in M/JM . Since tI -1 and J are coprime, by CRT we can compute an element c ∈ tI -1 such that c = 1 mod J . Let a = cv ∈ tM , then a -v = cv -v = v ( c -1) ∈ IJM . Let w = a/t ∈ M , then θ t ( w ) = t ( a/t ) = a = v mod IJM . Hence, any arbitrary element v ∈ IM satisfies the preimage of v mod IJM is w mod IM .
In the hardness proof of RLWE as will be shown in Section 9, we can use Lemma 8.1.25 to show that for R = Z [ x ] / (Φ m ( x )) , an ideal I and a prime integer q ,
$$R / ( q ) R \cong I / ( q ) I \\ I ^ { \vee } / ( q ) I ^ { \vee } \cong R ^ { \vee } / ( q ) R ^ { \vee } ,$$
where R ∨ denotes the dual of R that we will define later in Section 8.3.
We end this subsection by looking at the (unique) factorisation of the ideal ( q ) in the ring of integers R q = Z q [ x ] / (Φ m ( x )) . Since q is prime, the principal ideal generated by it can be split into prime ideals q i as follows:
$$( q ) = \prod _ { i = 1 } ^ { n / ( e f ) } \mathfrak { q } _ { i } ^ { e } = \prod _ { i = 1 } ^ { n / ( e f ) } ( q , F _ { i } ( \zeta _ { m } ) ) ^ { e } ,$$
where n = ϕ ( m ) , e = ϕ ( q ′ ) is the Euler totient function of q ′ , the largest power of q that divides m , f is the multiplicative order of q modulo m/q ′ , i.e., q f = 1 mod ( m/q ′ ) , and each q i is generated by two elements, the prime number q and the monic irreducible factor F i ( x ) of the cyclotomic polynomial Φ m ( x ) = ∏ i ( F i ( x )) e when splitting over Z q [ x ] (see Theorem 7.2.9). For details, see Chapter 4 of Stein (2012).
Example 8.1.26. For m = 5 , the 5th cyclotomic polynomial is
$$\Phi _ { 5 } ( x ) = x ^ { 4 } + x ^ { 3 } + x ^ { 2 } + x + 1 ,$$
so n = 4 and K = Q ( ζ 5 ) the 4-dimensional cyclotomic field. Let q = 19 , then we have q ′ = 19 0 = 1 to be the largest power of q that divides 5 . So e = ϕ (1) = 1 and the multiplicative order of 19 mod (4 / 1) is f = 2 . Assuming we are given how the cyclotomic polynomial splits in Z 19 [ x ] , i.e.,
$$\Phi _ { 5 } ( x ) = x ^ { 4 } + x ^ { 3 } + x ^ { 2 } + x + 1 = ( x ^ { 2 } + 5 x + 1 ) ( x ^ { 2 } + 1 5 x + 1 ) ,$$
then we can split the ideal into prime ideals in the ring of integers R = Z [ ζ 5 ] as
$$( q ) & = \mathfrak { q } _ { 1 } \mathfrak { q } _ { 2 } \\ \implies ( 1 9 ) & = ( 1 9 , ( \zeta _ { 5 } ) ^ { 2 } + 5 \zeta _ { 5 } + 1 ) ( 1 9 , ( \zeta _ { 5 } ) ^ { 2 } + 1 5 \zeta _ { 5 } + 1 ) .$$
If we further restrict q = 1 mod m , it follows that f = 1 . In addition, it also entails that q ′ = 1 and e = 1 . In addition, the cyclotomic polynomial Φ m ( x ) = x n +1 can be split into n linear factors ( x -ω i ) , where ω i is a primitive m th root of unity in Z q . This satisfies the condition of Theorem 7.2.9 for q and m being coprime. 8 Hence, the ideal can be factored as
$$( q ) & = \prod _ { \substack { i = 1 , \dots , m \\ \gcd ( i , m ) = 1 } } ( q , \zeta _ { m } - \omega ^ { i } ) \\ & = \prod _ { i \in \mathbb { Z } _ { m } ^ { * } } ( q , \zeta _ { m } - \omega ^ { i } ) .$$
8 Note this also works if q = p k is a prime power coprime with m .
Note the index i is not any integer between 1 and m , but those coprime with m . So for the above example, when q = 11 ∼ = 1 mod 5 , the polynomial splits in Z 11 [ x ] as
$$\Phi _ { 5 } ( x ) = ( x - 3 ) ( x - 9 ) ( x - 5 ) ( x - 4 ) ,$$
where each 3, 9, 5, 4 is a primitive 5th root of unity in Z 11 , generated by the 1st, 2nd, 3rd and 4th power of 3 in mod 11 . So the ideal splits as
$$\begin{array} { r l } & { ( q ) = \mathfrak { q } _ { 1 } \mathfrak { q } _ { 2 } \mathfrak { q } _ { 3 } \mathfrak { q } _ { 4 } } \\ { \implies ( 1 1 ) = ( 1 1 , \zeta _ { 5 } - 3 ) ( 1 1 , \zeta _ { 5 } - 9 ) ( 1 1 , \zeta _ { 5 } - 5 ) ( 1 1 , \zeta _ { 5 } - 4 ) . } \end{array}$$
## 8.2 Number field embedding
Similar to LWE, the RLWE problem's hardness is also based on hard lattice problems, except these are special lattices called ideal lattices . In this subsection, we will study how algebraic objects such as ring of integers and its ideals are mapped to full-ranked lattices via embeddings. The embedding we will build is from a number field K to the n -dimensional Euclidean space R n or a space H that is isomorphic to R n . As O K and its ideals are additive groups, our embedding must preserves the additive group structure of these objects.
As a degree n polynomial can be uniquely identified by its coefficients, our naive choice of embedding is by sending a polynomial f = a 0 + a 1 x + · · · a n -1 x n -1 to a coefficient vector ( a 0 , a 1 , · · · , a n -1 ) ∈ R n . This coefficient embedding is clearly an additive ring homomorphism and hence satisfies our basic requirements. Furthermore, it is related by a linear transformation to the canonical embedding that will be introduced next. However, the RLWE's proof and computations do not use the coefficient embedding. We list some reasons here and leave the details to Section 9.
- Firstly, when working with cyclotomic fields, the canonical embedding makes both polynomial addition and multiplication efficient component-wise operations (under the point-value representation). These operations have simple geometric interpretations that lead to tight bounds.
- Secondly, in the coefficient embedding, specifying the error distribution in RLWE, which is an n -dimensional Gaussian, requires an n -byn covariance matrix in general. With the canonical embedding, the error distribution in RLWE takes the simple form of a product of onedimensional Gaussians. This dramatically decreases the number of parameters that need to be taken care of when working with RLWE.
- Finally, the canonical embedding makes the Galois automorphisms simply permutations of the embedded vector components. This is important for the reduction from decision to search RLWE, and is not possible with the coefficient embedding.
## 8.2.1 Canonical embedding
Let K = Q ( α ) = Q [ x ] / ( f ) be an extension field with degree n . Let α be a primitive element of K (whose existence is proved by Theorem C.1.2) and f ∈ Q [ x ] be its minimal polynomial. Apart from the coefficient embedding, we will study an alternative embedding of K into C n . Since f is monic and irreducible in Q [ x ] , and Q has characteristic 0, by Theorem B.1.27 f is separable, so it has n distinct roots { α 1 , . . . , α n } where the primitive element α is one of them. For each root α i , we define a map sending α to α i by
$$\sigma _ { i } \colon K & \to \mathbb { Q } ( \alpha _ { i } ) \subseteq \mathbb { C } \\ \alpha & \mapsto \alpha _ { i }$$
$$\sigma _ { i } ( a _ { 0 } + a _ { 1 } \alpha + a _ { 2 } \alpha ^ { 2 } + \dots + a _ { n - 1 } \alpha ^ { n - 1 } ) = a _ { 0 } + a _ { 1 } \alpha _ { i } + a _ { 2 } \alpha _ { i } ^ { 2 } + \dots + a _ { n - 1 } \alpha _ { i } ^ { n - 1 } ,$$
where a i ∈ Q . The map fixes Q in the sense that σ i ( x ) = x for all x ∈ Q , so it is an automorphism (of the extension field Definition B.2.6). One can show that these embeddings are independent of the choice of the primitive element.
Since the roots of f consist of real and complex numbers, we can distinguish these embeddings as real and complex embeddings. If σ i ( α ) ∈ R , then it is a real embedding , otherwise it is a complex embedding . By the Complex Conjugate Root Theorem, which states that the complex roots of real coefficient polynomials are in conjugate pairs, we know the images of the complex embeddings are in
conjugate pairs. Let s 1 be the number of real embeddings and s 2 be the number of conjugate pairs of complex embeddings, then the total number of embeddings is n = s 1 + 2 s 2 . Let { σ i } s 1 i =1 be the real and { σ j } n j = s l +1 be the complex embeddings, where σ s 1 + j = σ s 1 + s 2 + j are in the same conjugate pair for each j ∈ [1 , . . . , s 2 ] , then we have the following definition of a canonical embedding.
$$\begin{array} { l } \sigma \colon K \to \mathbb { R } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } \subseteq \mathbb { C } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } \cong \mathbb { C } ^ { n } \\ \sigma ( r ) \mapsto ( \sigma _ { 1 } ( r ) , \dots , \sigma _ { s _ { 1 } } ( r ) , \sigma _ { s _ { 1 } + 1 } ( r ) , \dots , \sigma _ { s _ { 1 } + 2 s _ { 2 } } ( r ) ) . \\ \end{array}$$
Definition 8.2.1. Canonical embedding A canonical embedding σ of an n -dimensional number field K is defined as
Canonical space
By this definition, the canonical embedding maps a number field to an n -dimensional space, named canonical space , which is expressed as
$$H = \left \{ ( x _ { 1 } , \dots , x _ { n } ) \in \mathbb { R } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } | \, x _ { s _ { 1 } + j } = \overline { x _ { s _ { 1 } + s _ { 2 } + j } } , \text { for all $j\in[s_{2}]$} \right \} .$$
Intuitively, one can think of the canonical embedding as sending each element r ∈ K (i.e., a polynomial) to a coordinate (i.e., length n vector) in the canonical space, where the coordinates are where r sends the roots of f to.
The canonical space H can be shown to be isomorphic to R n by establishing a one-to-one correspondence between the standard basis of R n and a basis of H as the row vectors in the following matrix
$$B = \begin{pmatrix} I _ { s _ { 1 } \times s _ { 1 } } & 0 & 0 \\ 0 & I _ { s _ { 2 } \times s _ { 2 } } & i I _ { s _ { 2 } \times s _ { 2 } } \\ 0 & I _ { s _ { 2 } \times s _ { 2 } } & - i I _ { s _ { 2 } \times s _ { 2 } } \end{pmatrix} .$$
The matrix I s 1 × s 1 is the s 1 by s 1 identity matrix. 9 The image σ ( r ) ∈ H can then be written in terms of this basis as a real vector
$$\tau ( r ) = ( & \sigma _ { 1 } ( r ) , \dots , \sigma _ { s _ { 1 } } ( r ) , \\ & R e ( \sigma _ { s _ { 1 } + 1 } ( r ) ) , \dots , R e ( \sigma _ { s _ { 1 } + s _ { 2 } } ( r ) ) , I m ( \sigma _ { s _ { 1 } + 1 } ( r ) ) , \dots , I m ( \sigma _ { s _ { 1 } + s _ { 2 } } ( r ) ) ) \\$$
by taking the real and complex parts from two conjugate complex embeddings respectively. Taking the dot product of each row vector in B with τ ( r ) , we get back to σ ( r ) in Equation 20, that is,
$$\sigma ( r ) = B \cdot ( \tau ( r ) ) ^ { T } .$$
Here are some examples to illustrate canonical embedding, canonical space and its basis.
Example 8.2.2. When K = Q ( √ 2) is a quadratic field. The minimal polynomial of √ 2 is x 2 -2 , which has two roots ± √ 2 . The canonical embedding consists two real embeddings only and is defined as
The basis of the canonical space H is
$$\sigma ( \sqrt { 2 } ) = ( \sqrt { 2 } , - \sqrt { 2 } ) .$$
$$B = { \binom { 1 } { 0 } } ^ { 2 } ;$$
Given the integral basis { 1 , √ 2 } of K , the basis vectors are mapped to the canonical space H and can be written in terms of the basis of H as real vectors
$$\tau ( 1 ) & = ( 1 , 1 ) \\ \tau ( \sqrt { 2 } ) & = ( \sqrt { 2 } , - \sqrt { 2 } ) ,$$
$$3$$
$$\zeta _ { 8 } = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \, \zeta _ { 8 } ^ { 3 } = - \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } ,$$
which form a Z -basis of the image σ ( O K ) , that is, σ ( O K ) = { a (1 , 1) + b ( √ 2 , - √ 2) | a, b ∈ Z } . Example 8.2.3. When K = Q ( ζ 8 ) is the 8th cyclotomic field. The 8th primitive root of unity ζ 8 = √ 2 2 + i √ 2 2 and its minimal polynomial is the 8th cyclotomic polynomial Φ 8 ( x ) = x 4 +1 . The roots of Φ 8 ( x ) are
$$\zeta _ { 8 } = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \, \zeta _ { 8 } ^ { 3 } = - \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \\ \zeta _ { 8 } ^ { 5 } = - \frac { \sqrt { 2 } } { 2 } - i \frac { \sqrt { 2 } } { 2 } , \, \zeta _ { 8 } ^ { 7 } = \frac { \sqrt { 2 } } { 2 } - i \frac { \sqrt { 2 } } { 2 } .$$
9 Note in Lyubashevsky et al. (2010), the row vectors are multiplied by 1 √ 2 to make them an orthonormal basis, so B is a unitary matrix (i.e., BB ∗ = I , where B ∗ is B 's conjugate transpose).
The canonical embedding consists of exactly four complex embeddings, i.e., σ = ( σ 1 , σ 2 , σ 3 , σ 4 ) ,
$$\pi _ { 1 } \left ( { \frac { \sqrt { 2 } } { 4 } } + i { \frac { \sqrt { 2 } } { 4 } } \right ) = { \frac { \sqrt { 2 } } { 4 } } + i { \frac { \sqrt { 2 } } { 4 } } \, \pi _ { 1 } \left ( { \frac { \sqrt { 2 } } { 4 } } + i { \frac { \sqrt { 2 } } { 4 } } \right ) = { \frac { \sqrt { 2 } } { 4 } } + i { \frac { \sqrt { 2 } } { 4 } }$$
$$\sigma _ { 1 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) & = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \, \sigma _ { 2 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) = - \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \\ \sigma _ { 3 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) & = \frac { \sqrt { 2 } } { 2 } - i \frac { \sqrt { 2 } } { 2 } , \, \sigma _ { 4 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) = - \frac { \sqrt { 2 } } { 2 } - i \frac { \sqrt { 2 } } { 2 } ,$$
where σ 1 = σ 3 and σ 2 = σ 4 are in conjugate pairs. The basis of the canonical space H is
$$B = \begin{pmatrix} 1 & 0 & i & 0 \\ 0 & 1 & 0 & i \\ 1 & 0 & - i & 0 \\ 0 & 1 & 0 & - i \end{pmatrix} .$$
By Equation 21, the canonical embedding of the primitive element ζ 8 can be written in terms of this basis as the real vector
$$\tau \left ( { \frac { \sqrt { 2 } } { 2 } + i { \frac { \sqrt { 2 } } { 2 } } } \right ) = ( R e ( \sigma _ { 1 } ) , R e ( \sigma _ { 2 } ) , I m ( \sigma _ { 1 } ) , I m ( \sigma _ { 2 } ) ) = \left ( { \frac { \sqrt { 2 } } { 2 } , - { \frac { \sqrt { 2 } } { 2 } } , { \frac { \sqrt { 2 } } { 2 } } , { \frac { \sqrt { 2 } } { 2 } } } \right ) .$$
By multiplying each row of B with this expression, we get back to the canonical embedding σ = ( σ 1 , σ 2 , σ 3 , σ 4 ) .
Given the canonical embedding, it allows us to talk about the geometric norm of an algebraic element x ∈ K . More precisely, we can define the L p -norm L p -norm of x by looking at the L p -norm of its image σ ( x ) that is embedded into the real space R n
$$| | x | | _ { p } = | | \sigma ( x ) | | _ { p } = \begin{cases} \left ( \sum _ { i \in [ n ] } | \sigma _ { i } ( x ) | ^ { p } \right ) ^ { 1 / p } & \text {if $p<\infty$,} \\ \max _ { i \in [ n ] } | \sigma _ { i } ( x ) | & \text {if $p=\infty$.} \end{cases}$$
In the next example, we illustrate the L p -norm of a root of unity in a cyclotomic field.
Example 8.2.4. Let K = Q ( ζ n ) be the nth cyclotomic field and σ : K → H be its canonical embedding. The cyclotomic polynomial Φ n ( x ) is the minimal polynomial of ζ n and it has only complex roots for n ≥ 3 , as the two real roots are non-primitive. Since the Galois group Gal ( K/ Q ) ∼ = ( Z /n Z ) ∗ is isomorphic to the multiplicative group (Theorem 7.2.6), the complex embeddings are given by σ i ( ζ n ) = ζ i n for i ∈ ( Z /n Z ) ∗ and n = 2 s 2 = | ( Z /n Z ) ∗ | . Since the primitive roots of unity are closed under σ i , the magnitude | σ i ( ζ j n ) | = 1 . So the L P -norm of an nth root of unity is || ζ j n || p = n 1 /p for p < ∞ or || ζ j m || ∞ = 1 .
We have shown that the canonical embedding σ sends a number field to a space isomorphic to R n . When restricted to the ring of integers O K that is closed under addition, we would like to see what σ does to preserve the discreteness and the additive group structure of O K . The following theorem states that the canonical embedding maps O K to a full-rank lattice.
Theorem 8.2.5. τ ( O K ) is lattice Let K be an n -dimensional number field, then σ ( O K ) is a full-rank lattice in R n .
Proof. Let { e 1 , . . . , e n } be an integral basis of O K , then every element x ∈ O K can be written as x = ∑ n i =1 z i e i , where z i ∈ Z . The embedding of x can then be written as σ ( x ) = ∑ n i =1 z i σ ( e i ) , where the coefficients are fixed because σ fixes Q . Hence, σ ( O K ) is also a Z -module generated by { σ ( e 1 ) , . . . , σ ( e n ) } .
By definition, a lattice is a free Z -module. If we can show { σ ( e 1 ) , . . . , σ ( e n ) } is a basis of σ ( O K ) , then σ ( O K ) is a free Z -module. To do so, write each σ ( e i ) in terms of the canonical space basis according to Equation 21 as a real vector, so we have the following basis matrix for σ ( O K )
$$N ^ { T } = \left ( \begin{array} { c c c c } { { \sigma _ { 1 } ( e _ { 1 } ) \cdots \sigma _ { s _ { 1 } } ( e _ { 1 } ) R e ( \sigma _ { s _ { 1 } + 1 } ( e _ { 1 } ) ) \cdots R e ( \sigma _ { s _ { 1 } + s _ { 2 } } ( e _ { 1 } ) ) I m ( \sigma _ { s _ { 1 } + 1 } ( e _ { 1 } ) ) \dots I m ( \sigma _ { s _ { 1 } + s _ { 2 } } ( e _ { 1 } ) ) } } \\ { \vdots } & { \vdots } & { \vdots } & { \vdots } \\ { { \vdots } } & { \vdots } & { \vdots } & { \vdots } \\ { { \sigma _ { 1 } ( e _ { n } ) \cdots \sigma _ { s _ { 1 } } ( e _ { n } ) R e ( \sigma _ { s _ { 1 } + 1 } ( e _ { n } ) ) \cdots R e ( \sigma _ { s _ { 1 } + s _ { 2 } } ( e _ { n } ) ) I m ( \sigma _ { s _ { 1 } + 1 } ( e _ { n } ) ) \dots I m ( \sigma _ { s _ { 1 } + s _ { 2 } } ( e _ { n } ) ) } } \end{array} \right ) .$$
Then show that the matrix has a non-zero determinant, and consequently the rows are independent. By Equation 20 of canonical embedding, we can write the images of the integral basis { e 1 , . . . , e n } under the canonical embedding as the matrix
<!-- formula-not-decoded -->
The two matrices are of the same dimension and their determinants are related by
$$\det N = \frac { 1 } { 2 ^ { s _ { 2 } } } \det M , \quad ( 2 3 )$$
so it remains to show det M = 0 . If a rational matrix A changes a basis of K to another basis by
$$e _ { j } ^ { \prime } = \sum _ { k } A _ { k j } e _ { k } ,$$
then the above matrix M is also changed to a new matrix M ′ = MA . We know K always has a power basis { 1 , r, . . . , r n -1 } (Theorem C.1.2) and the matrix M T in terms of the power basis is a Vandermonde matrix with a non-zero determinant as the powers of r are all distinct. Then we can conclude that the above matrix M has non-zero determinant and so does the matrix N .
An important corollary of Theorem 8.2.5 is that every fractional ideal of K is also mapped to a full-rank ideal.
Corollary 8.2.6. If I is a fractional ideal in an n -dimensional number field K , then σ ( I ) is a full-rank lattice in R n .
Proof. Given I is a fractional ideal in K , for a non-zero integer m ∈ K we have m O K ⊆ I ⊆ 1 m O K , and both the subset and superset of I are full-rank lattices in R n , so is I . See Lemma 7.1.8 of Stein (2012) for more detail.
As mentioned earlier, the canonical embedding allows polynomial addition and multiplication to be done component-wise efficiently, which is a convenient feature for both the deduction from search to decision RLWE and polynomial computations. We explain next why such a nice feature comes with the canonical embedding. We know a polynomial can be uniquely represented by both the coefficient and point-value representations, and the latter allows us to multiply two polynomials component-wise (Cormen et al., 2001). To allow efficient transformation O ( n log n ) between the two representations, we should evaluate a degree n polynomial at the n-th roots of unity, which is essentially what fast Fourier transform (FFT) does. We know both the n-th cyclotomic field K and its ring of integers O K have a power basis B = { 1 , ζ n , . . . , ζ ϕ ( n ) -1 n } , which consists of the n-th roots of unity just as we need. We can use the power basis to build a Vandermonde matrix M T . Since K can also be interpreted as a polynomial ring quotient by the ideal ( f ) , an element a ∈ K can be viewed as a ( x ) = ∑ n -1 i =0 a i x i and its image under the embedding is σ i ( a ( x )) = a ( σ i ( x )) . Hence, each embedding σ i ( a ( x )) is equivalent to evaluate a ( x ) at σ i ( x ) . Therefore, we have
$$M ^ { T } \cdot ( a _ { 0 } , \dots , a _ { n - 1 } ) ^ { T } = \sigma ( a ) = B \cdot ( \tau ( a ) ) ^ { T } .$$
Therefore, for a polynomial a ∈ O K , its image σ ( a ) (or τ ( a ) in terms of the basis B ) is precisely its point-value representation evaluated at the n-th roots of unity.
In short, when using the canonical embedding, the image of K is a lattice with a power basis consisting of the primitive roots of unity. Since each element in K is also a polynomial, when converting to the point-value representation, the primitive roots of unity are the precise points that are needed. So adding or multiplying two polynomials in the point-value representation is equivalent to adding or multiplying two elements σ ( K ) w.r.t. the power basis.
## 8.2.2 Geometric quantities of ideal lattice
We know from the previous subsection that a fractional ideal I in a number field is mapped by a canonical embedding σ to a lattice in the Euclidean space, called ideal lattice . In this subsection, we will go
Ideal norm through some geometric quantities of I (i.e., its ideal lattice σ ( I ) ) including its determinant and minimum distance. The results in this subsection are directly related to the gap (or approximation) factors of hard ideal lattice problems.
To begin with, we first state the main result that is directly relevant to the RLWE's hardness proof. Recall that the minimum distance λ 1 ( L ) of a lattice L is the length of the shortest non-zero vector in L , where the length is measured by L p -norm as defined in Equation 22.
Lemma 8.2.7. Let I be a fractional ideal in an n -dimensional number field K , then its minimum distance measured by L p -norm satisfies
$$n ^ { 1 / p } \cdot N ( I ) ^ { 1 / n } \leq \lambda _ { 1 } ( I ) \leq n ^ { 1 / p } \cdot N ( I ) ^ { 1 / n } \cdot \sqrt { \Delta _ { K } ^ { 1 / n } } .$$
Here, N ( I ) is the norm of the fractional ideal and ∆ K is the discriminant of the number field K . We will introduce these concepts next, which not only helps to understand the lemma, but give insights about the algebraic structures of O K and its ideals under the canonical embedding.
Given a subgroup H of G , the Lagrange's Theorem says that the order of G satisfies | G | = | G : H || H | , where | G : H | is the index of H that measures the number of cosets of H in G . If H is a normal subgroup, then the index is equivalent to the order of the quotient group G/H . Since an ideal I of O K is an additive normal subgroup and it has a geometric interpretation due to the canonical embedding, we relate its index to the norm as next.
Definition 8.2.8. Let I be a non-zero ideal of O K . The norm of I , denoted by N ( I ) , is the index of I as a subgroup of O K , i.e., N ( I ) = |O K /I | .
As for the norm of number field elements (Appendix C), the norm of ideals is also multiplicative. That is, N ( IJ ) = N ( I ) N ( J ) . If I = J/d is a fractional ideal in K with the integral ideal J , then its norm is
$$\begin{array} { r l r } { N ( I ) = N ( d I ) / | N ( d ) | } & { \quad } \\ { \frac { ( 2 5 ) } { r ^ { 2 } } } & { \quad } \end{array}$$
Example 8.2.9. When O K = Z , the integral ideal J = 5 Z and the fractional ideal I = J/ 4 = 5 4 Z , the norm N ( I ) = N ( J ) / | N (4) | = 5 / 4 .
For the fractional ideal I and integral ideal dI with d ∈ O K , we have dx ∈ dI for any non-zero x ∈ I . Hence, when viewed as subgroups, their indices satisfies [ O K : ( dx )] ≥ [ O K : dI ] and it follows N ( dx ) ≥ N ( dI ) . By Equation 25 and the multiplicity of norm, we have N ( x ) ≥ N ( I ) for any non-zero x ∈ I . Combine this with Equation 22 of L p -norm, we can prove the lower bound of λ 1 ( I ) . The upper bound is proved by the discriminant of K and Minkowski's First Theorem (Theorem C.4.2; see also Lemma 6.1 of Peikert and Rosen (2007) for the proof of the upper bound).
The discriminant of a number field loosely speaking measures the size of the ring of integers O K . Without loss of generality, for the basis elements e 1 , . . . , e n of K , define the n by n matrix
$$</text>
M = \begin{pmatrix} \sigma _ { 1 } ( e _ { 1 } ) & \sigma _ { 1 } ( e _ { 2 } ) & \cdots & \sigma _ { 1 } ( e _ { n } ) \\ \sigma _ { 2 } ( e _ { 1 } ) & \sigma _ { 2 } ( e _ { 2 } ) & \cdots & \sigma _ { 2 } ( e _ { n } ) \\ \vdots & \vdots & \cdots & \vdots \\ \sigma _ { n } ( e _ { 1 } ) & \sigma _ { n } ( e _ { 2 } ) & \cdots & \sigma _ { n } ( e _ { n } ) \end{pmatrix} ,$$
where σ = ( σ 1 , . . . , σ n ) is the canonical embedding of K . By the same argument in the proof of Theorem 8.2.5, we know the determinant of M is non-zero. We know this matrix is related to the basis matrix N of the ideal lattice and their determinants satisfy Equation 23. This matrix looks just like the basis matrix for a lattice that was introduced in Section 4. Now we are ready to define the discriminant of K .
Definition 8.2.10. Let K be an n -dimensional number field with an integral basis { e 1 , . . . , e n } . The discriminant ∆ K of K is
$$\Delta _ { K } = d i s c _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = d e t ( M ) ^ { 2 } .$$
An important property of number field discriminant is that it is invariant under the choice of an integral basis. This can be seen from the following lemma and corollary.
Invariant ∆( K )
Ideal lattice determinant
Lemma 8.2.11. Suppose x 1 , . . . , x n , y 1 , . . . , y n ∈ K are elements in the number field and they are related by a transformation matrix A , then
$$d i s c _ { K / \mathbb { Q } } ( x _ { 1 } , \dots , x _ { n } ) = d e t ( A ) ^ { 2 } d i s c _ { K / \mathbb { Q } } ( y _ { 1 } , \dots , y _ { n } ) .$$
Since the change of integral basis matrix A is an unimodular matrix, i.e., det A = ± 1 , we conclude that discriminant is an invariant quantity.
Corollary 8.2.12. Suppose { e 1 , . . . , e n } and { e ′ 1 , . . . , e ′ n } are both integral bases of the number field K , then
$$d i s c _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = d i s c _ { K / \mathbb { Q } } ( e _ { 1 } ^ { \prime } , \dots , e _ { n } ^ { \prime } ) .$$
We finish this subsection by making some observations about ∆ K . First, the determinant of the basis matrix M is equivalent to the fundamental domain of σ ( O K ) . This entails that the absolute 10 discriminant of K measures the geometric sparsity of O K . Larger | ∆ K | implies larger det M , so the more sparse the ideal lattice is.
Second, equation 23 says | det N | = 1 2 s 2 | det M | . Since N is the basis matrix of the ideal lattice σ ( O K ) , by definition of field discriminant, this equation implies
$$\det ( \sigma ( { \mathcal { O } } _ { K } ) ) = \frac { 1 } { 2 ^ { s _ { 2 } } } \sqrt { | \Delta _ { K } | } . \quad ( 2 6 )$$
Finally, an integral lattice I is an additive subgroup of O K so Lagrange's Theorem entails |O K | = |O K : I || I | . The canonical embedding σ is an isomorphism between O K and I to the corresponding ideal lattices. Moreover, I being a subgroup is sparser than O K when mapped by σ , so has larger determinant. Hence, we have
$$\det ( \sigma ( I ) ) & = [ \sigma ( \mathcal { O } _ { K } ) \colon \sigma ( I ) ] \det ( \sigma ( \mathcal { O } _ { K } ) ) \\ & = N ( I ) \det ( \sigma ( \mathcal { O } _ { K } ) ) \\ & = \frac { 1 } { 2 ^ { s _ { 2 } } } N ( I ) \sqrt { | \Delta _ { K } | }$$
Equation 27 also holds for a fractional ideal J = I/d . Substitute the integral ideal I = dJ into the equation will incur a factor d on both sides, because det( σ ( dJ )) = d det( σ ( J )) and N ( dJ ) = N ( d ) N ( J ) = dN ( J ) .
## 8.3 Dual lattice in number field
In the previous subsection, we have built a connection between a number field K and its image H = σ ( K ) under the canonical embedding σ and shown that H ∼ = R n . In this subsection, we discuss how dual lattices in K are defined. The motivation is to understand the structure of dual lattices of an ideal lattice σ ( I ) . The notion of dual appears in crucial parts of the development of lattice-based cryptography, including the definition of smoothing parameters of a lattice (Definition 5.1.1) and the general definition of RLWE distribution (Definition 9.2.1).
Definition 8.3.1. Lattice in K A lattice in an n -dimensional number field K is the Z -span of a Q -basis of K .
For lattices in R n , dot product is an obvious metric between two geometric vectors. For lattices in a number field, we need a more general inner product that can be obtained through the trace operator.
Definition 8.3.2. Given a canonical embedding of a number field K
$$\begin{array} { c } \sigma \colon K \to \mathbb { R } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } \\ \sigma ( \alpha ) \mapsto ( \sigma _ { 1 } ( \alpha ) , \dots , \sigma _ { n } ( \alpha ) ) , \end{array}$$
the trace of an element α ∈ K is defined as Trace operator
$$\alpha ) \mapsto ( \sigma _ { 1 } ( \alpha ) , \dots , \sigma _ { n } ( \alpha )$$
$$T r _ { K \, \mathbb { Q } } \colon K \underset { n } { \rightarrow } \mathbb { Q }$$
$$T r _ { K / \mathbb { Q } } ( \alpha ) = \sum _ { i = 1 } ^ { n } \sigma _ { i } ( \alpha ) .$$
10 Although it is defined as the square of a matrix determinant, discriminant can be negative as the matrix entries can be complex numbers.
Dual basis
O ∨ K is frac ideal
From that, we obtain the trace inner product as follows:
$$T r _ { K / \mathbb { Q } } ( x y ) = \sum \sigma _ { i } ( x y ) = \sum \sigma _ { i } ( x ) \sigma _ { i } ( y ) = \langle \sigma ( x ) , \overline { \sigma ( y ) } \rangle .$$
Definition 8.3.3. Dual lattice Let L be a lattice in a number field K . Its dual lattice is
$$L ^ { \vee } = \{ x \in K | T r _ { K / Q } ( x L ) \subseteq \mathbb { Z } \} .$$
Example 8.3.4. The lattice L = Z [ i ] in the number field K = Q ( i ) has a basis B = { 1 , i } . The dual lattice L ∨ = 1 2 Z [ i ] with a basis B ∨ = { 1 2 , i 2 } .
The dual of a number field lattice is also a lattice. Here are some properties of the dual in R n that also hold true for dual in number fields.
Corollary 8.3.5. For lattices in a number field K , the following hold:
$$1 , \ L ^ { \vee \vee } = L ,$$
$$2 . \, L _ { 1 } \subseteq L _ { 2 } \iff L _ { 2 } ^ { \vee } \subseteq L _ { 1 } ^ { \vee } ,$$
$$\begin{array} { r l } { 3 . \, ( \alpha L ) ^ { \vee } \iff \frac { 1 } { \alpha } L ^ { \vee } , f o r a n i v e r t i b l e e l e m e n t \, \alpha \in K . } \end{array}
</doctag>$$
The following theorem relates the dual lattice to differentiation and provides an easier way of computing the dual basis and dual lattice from a given lattice.
Theorem 8.3.6. Let K = Q ( α ) be an n -dimensional number field with a power basis { 1 , α, . . . , α n -1 } and f ( x ) ∈ Q [ x ] be the minimal polynomial of the element α , which can be expressed as
Then the dual basis to the power basis relative to the trace product is { c 0 f ′ ( α ) , . . . , c n -1 f ′ ( α ) } . In particular, if K = Q ( α ) and the primitive element α ∈ O K is an algebraic integer, then the lattice L = Z [ α ] = Z + Z α + · · · + Z α n -1 and its dual are related by the first derivative of the minimal polynomial, that is,
$$f ( x ) = ( x - \alpha ) ( c _ { 0 } + c _ { 1 } x + \cdots + c _ { n - 1 } x ^ { n - 1 } ) .$$
$$L ^ { \vee } = \frac { 1 } { f ^ { \prime } ( \alpha ) } L .$$
Example 8.3.7. An important application of this theorem in RLWE is when K = Q [ ζ m ] is the m-th cyclotomic number field, where m = 2 n = 2 k > 1 is a power of 2. Let the lattice L = O K = Z [ ζ m ] . The minimal polynomial of ζ m is f ( x ) = x n + 1 , whose derivative is f ′ ( x ) = nx n -1 . By Theorem 8.3.6,
$$L ^ { \vee } = ( \mathbb { Z } [ \zeta _ { m } ] ) ^ { \vee } = \frac { 1 } { f ^ { \prime } ( \zeta _ { m } ) } \mathbb { Z } [ \zeta _ { m } ] = \frac { 1 } { n \zeta _ { m } ^ { n - 1 } } \mathbb { Z } [ \zeta _ { m } ] = \frac { 1 } { n } \zeta _ { m } ^ { n + 1 } \mathbb { Z } [ \zeta _ { m } ] = \frac { 1 } { n } L .$$
The second last equality is because the roots of unity form a cyclic group so ζ -( n -1) m = ζ n +1 m .
This example shows an essential property of cyclotomic number fields when choosing appropriate parameter settings. It says the ideal lattice σ ( O K ) and its dual are related by only a scaling factor, so there is no difference working in either domain when defining the RLWE problem. We will see more detail in the next section.
We further study the ideal lattice O K in a general number field. By definition, the dual of O K is
Since each element in O K is an algebraic integer, in that has an integer trace. 11 So on the one hand, O K ⊆ O ∨ K . On the other hand, not all elements with integer traces are in O ∨ K . The next theorem shows that these elements need to form a fractional ideal.
$$\mathcal { O } _ { K } ^ { \vee } = \{ x \in K | T r _ { K / \mathbb { Q } } ( x \mathcal { O } _ { K } ) \subseteq \mathbb { Z } \} .$$
Theorem 8.3.8. The dual lattice O ∨ K is the largest fractional ideal in K whose elements have integer traces.
Theorem 8.3.9. For a fractional ideal I in K , its dual lattice is a fractional ideal satisfying the equation I ∨ = I -1 O ∨ K .
11 This can be verified by taking the power basis { 1 , r, . . . , r n -1 } of K which is also a Z -basis of O K . Each x ∈ O K can be written as x = c 0 + c 1 r + · · · + c n -1 r n -1 . By definition, only Tr ( c 0 ) ∈ Z and the rest are 0.
Different ideal
D K = n O K
We have seen the inverse of a fractional ideal in Equation 19, it is tempting to see if the inverse of the dual O ∨ K (which is also a fractional ideal) is any special. By definition of fractional ideal inverse (Equation 19), we have
$$( \mathcal { O } _ { K } ) ^ { - 1 } & = \{ x \in K \, | \, x \mathcal { O } _ { K } \subseteq \mathcal { O } _ { K } \} = \mathcal { O } _ { K } \\ ( \mathcal { O } _ { K } ^ { \vee } ) ^ { - 1 } & = \{ x \in K \, | \, x \mathcal { O } _ { K } ^ { \vee } \subseteq \mathcal { O } _ { K } \} .$$
Since O K ⊆ O ∨ K , their inverses satisfy ( O ∨ K ) -1 ⊆ O K . Unlike the dual which is a fractional ideal and not necessarily within O K , this inclusion makes ( O ∨ K ) -1 an integral ideal, which is also called the different ideal . For example, let K = Q ( i ) and O K = Z [ i ] . The dual ideal is O ∨ K = Z [ i ] ∨ = 1 2 Z [ i ] , so the different ideal is D K = ( 1 2 Z [ i ]) -1 = 2 Z [ i ] .
In the special case when O K has a power basis, Theorem 8.3.6 can also be expressed in terms of different ideal because
$$\mathcal { O } _ { K } ^ { \vee } & = \frac { 1 } { f ^ { \prime } } \mathcal { O } _ { K } \\ \Longrightarrow & \, f ^ { \prime } \mathcal { O } _ { K } ^ { - 1 } & = ( \mathcal { O } _ { K } ^ { \vee } ) ^ { - 1 } \\ & \implies ( f ^ { \prime } ) & = \mathcal { D } _ { K }$$
When f = x n +1 , the last equality implies D K = n O K .See Theorem C.5.11 in Appendix C for formal statements of these results.
Lemma 8.3.10. For m = 2 n = 2 k ≥ 2 a power of 2, let K = Q ( ζ m ) be an m th cyclotomic number field and O K = Z [ ζ m ] be its ring of integers. The different ideal satisfies D K = n O K .
This lemma plays an important role in RLWE in the special case where the number field is an m -th cyclotomic field. It implies that the ring of integers n -1 O K = O ∨ K and its dual are equivalent by a scaling factor. Hence, the secret polynomial s and the random polynomial a can both be sampled from the same domain R q , unlike in the general context where the preference is to leave s ∈ R ∨ q in the dual.
## 9 Ring Learning with Errors
In Section 6, we have sketched the key steps of LWE's hardness proof by reductions from two standard lattice problems (i.e., GAPSVP and SIVP) using a combination of quantum and classical reductions. The benefit of reducing an arbitrary instance to all instances of some (highly conjectured) worst-case lattice problems sparked many LWE-based cryptosystems, including some developments in quantumresistant cryptosystems and homomorphic encryption schemes. In addition to being worst-case hard, smaller public key size and ciphertext expansion are also the main motivations for basing a scheme on LWE over the SIS problem. However, the quadratic key size (in the security parameter n ) is still a serious constraint for practical LWE-based schemes.
In this section, we will introduce a variation of LWE, called ring learning with errors or ring-LWE ( RLWE ), which entails multiple benefits over LWE in terms of key size and computational efficiency. The problem originated from LWE, but is defined in terms of ideal lattices that were discussed in the previous section. Recall that a fractional ideal of a number field K is mapped to a metric space by an embedding, so that it makes sense to talk about the distance between two ideal elements as well as define distance-based lattice problems on fractional ideals. As we will see in this section, these special lattices have additional algebraic structures that allow the public key size to be further reduced to ˜ O ( n ) while retaining almost identical provable security.
Here is an example of an additional algebraic structure in the RLWE setting. Ideal lattices are images of fractional ideals under the canonical (or coefficient) embedding. Furthermore, fractional ideals are closed under multiplications by the ring elements. So this structure is preserved by the embedding, which endows the corresponding lattice with an additional algebraic structure. A concrete example is an ideal of the ring Z [ x ] / ( x n -1) is closed under multiplication by the polynomial x in the ring. Under the coefficient embedding, this multiplication by x corresponds to rotating the coefficient vector components by one place to the right, so the corresponding ideal lattice is a cyclic lattice . Another example which relates to the RLWE problem is when the ring is Z [ x ] / ( x n + 1) . Multiplying ideal elements by x corresponds to the cyclic lattice rotation and negate the first component as shown in Figure 12. The believe is that these special lattice problems are still hard because there is currently no known way to exploit the extra structure to reduce the run time for solving them compared to their more general counterparts, with the exception of the GAPSVP problem on ideal lattices, which is known to be easy. This is the reason why RLWE hardness is based on the K-SVP and K-SIVP problems, but not their gap variants.
Figure 12: Let R = Z [ x ] / ( x 4 +1) . Given the polynomial a = 1+2 x +3 x 2 +4 x 3 , the nega-cyclic action is equivalent to multiplying a by x , which yields a x = x +2 x 2 +3 x 3 +4 x 4 = -4 + x +2 x 2 +3 x 3 . After n = 4 rounds of anti-cyclic actions, we get back to -a .
<details>
<summary>Image 11 Details</summary>
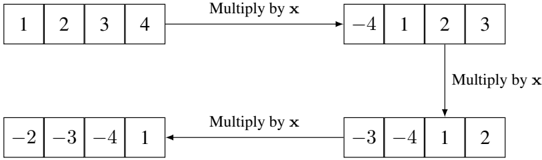
### Visual Description
\n
## Diagram: Data Transformation Flow
### Overview
The image depicts a diagram illustrating a data transformation process. Four sets of numbers are shown, connected by arrows labeled "Multiply by x". The diagram demonstrates how a sequence of numbers is modified when multiplied by a variable 'x', and how the result is then used in subsequent transformations.
### Components/Axes
The diagram consists of four rectangular blocks, each containing a sequence of four numbers. Arrows with the label "Multiply by x" connect these blocks, indicating the direction of data flow and the operation performed. There are no axes or scales present.
### Detailed Analysis or Content Details
* **Block 1 (Top-Left):** Contains the sequence: 1, 2, 3, 4.
* **Block 2 (Top-Right):** Contains the sequence: -4, -1, 2, 3. This block is connected to Block 1 by an arrow labeled "Multiply by x".
* **Block 3 (Bottom-Left):** Contains the sequence: -2, -3, -4, 1. This block is connected to Block 2 by an arrow labeled "Multiply by x".
* **Block 4 (Bottom-Right):** Contains the sequence: -3, -4, 1, 2. This block is connected to Block 3 by an arrow labeled "Multiply by x".
The arrows indicate a sequential transformation. The initial sequence (1, 2, 3, 4) is multiplied by 'x' to produce the sequence (-4, -1, 2, 3). This result is then multiplied by 'x' again to produce (-2, -3, -4, 1). Finally, this sequence is multiplied by 'x' to yield (-3, -4, 1, 2).
### Key Observations
The diagram illustrates a series of multiplications by the same variable 'x'. The values within each block change as a result of this multiplication. The specific value of 'x' is not provided, but it can be inferred from the transformation between the blocks. For example, if we assume x = -1, then the first transformation would be: 1 * -1 = -1, 2 * -1 = -2, 3 * -1 = -3, 4 * -1 = -4. This does not match the second block. If we assume x = -2, then the first transformation would be: 1 * -2 = -2, 2 * -2 = -4, 3 * -2 = -6, 4 * -2 = -8. This does not match the second block.
### Interpretation
The diagram demonstrates a mathematical operation applied iteratively to a set of data. The operation is a scalar multiplication by a variable 'x'. The diagram doesn't provide the value of 'x', but it shows how the data changes with each multiplication. The diagram could represent a simplified model of a linear transformation or a step in a more complex algorithm. The lack of a defined 'x' value suggests the diagram is intended to illustrate the *process* of transformation rather than a specific calculation. The diagram is a visual representation of a function or a series of functions applied to a data set.
</details>
## 9.1 Some ideal lattice problems
We first re-define some lattice problems in terms of an ideal lattice in a number field which is going to be our working domain for the following proofs. Recall that the canonical embedding enables us to talk about geometric norms of number field elements by mapping them to elements in the canonical space which is isomorphic to R n . Hence, we can define the L p -norm of an element x ∈ K as
$$| | x | | _ { p } = | | \sigma ( x ) | | _ { p } = \begin{cases} \left ( \sum _ { i \in [ n ] } | \sigma _ { i } ( x ) | ^ { p } \right ) ^ { 1 / p } & \text {if $p<\infty$,} \\ \max _ { i \in [ n ] } | \sigma _ { i } ( x ) | & \text {if $p=\infty$.} \end{cases}$$
With geometric norm, it makes sense to compare the lengths of two elements in a number field.
## The γ -Shortest Vectors Problem in K (K-SVP γ )
Let K be an n -dimensional number field. Given a fractional ideal I of K , find a non-zero element x ∈ I such that || x || p ≤ γ ( n ) · λ 1 ( I ) .
## The γ -Shortest Independent Vectors Problem in K (K-SIVP γ )
Let K be an n -dimensional number field. Given a fractional ideal I of K , find n linearly independent non-zero elements x i , . . . , x n ∈ I such that max i ∈ [1 ,n ] || x i || p ≤ γ ( n ) · λ n ( I ) .
## The α -Bounded Distance Decoding in K (K-BDD α )
Let K be an n -dimensional number field. Given a fractional ideal I of K and an element y = x + e ∈ K , where x ∈ I and || e || ∞ ≤ α · λ 1 ( I ) , find the element x ∈ I .
## The γ -Discrete Gaussian Sampling in K (K-DGS γ )
Let K be an n -dimensional number field. Given a fractional ideal I of K and a number s ≥ γ = γ ( I ) , produce samples from the discrete Gaussian distribution D I,s over the ideal lattice I with the scale s .
## 9.2 RLWE in general number field
In this subsection, we define RLWE distribution in a (general) number field. The definition is similar to the LWE distribution definition, but with different domains for random samples and noise elements. With this definition, it is sufficient to prove the hardness of the (search) RLWE problem by drawing deductions from some ideal lattice problems introduced in the preceding subsection. The more specialized RLWE definition in a cyclotomic number field will be introduced in a later subsection in order to reduce the search to decision RLWE, which is more convenient to support the security of an encryption scheme. That being said, it may be useful to jump to the start of Section 9.4 to see a concrete example of the ring R = Z [ x ] / ( x n + 1) in order to have a more intuitive understanding of this domain before moving forward.
When presenting the generalized definition, Lyubashevsky et al. (2010) used the notation K C = K ⊗ Q C to represent the tensor product between the number field K and C . This tensor product K C is where the RLWE errors are sampled from according to a certain error distribution ψ . For an n -dimensional separable (Definition B.1.25) number field K = Q ( α ) and the minimal polynomial f ( x ) ∈ Q [ x ] of the primitive element α , we have the following isomorphisms. The first isomorphism is by the definition of number field and the second is by the definition of tensor product (see Page 21 of Milne (2020))
$$K \otimes _ { \mathbb { Q } } \mathbb { C } & \cong ( \mathbb { Q } [ x ] / ( f ( x ) ) ) \otimes _ { \mathbb { Q } } \mathbb { C } \cong \mathbb { C } [ x ] / ( f ( x ) ) .$$
It is often convenient to think of K C as the canonical space H . This is because the minimal polynomial f ( x ) = f 1 ( x ) · · · f n ( x ) splits into irreducible factors in the complex space C , so we have an isomorphism between K C and the canonical space H by the Chinese Remainder Theorem, because the principle ideals are coprime
$$K _ { \mathbb { C } } = K \otimes _ { \mathbb { Q } } \mathbb { C } \cong \prod _ { i = 1 } ^ { n } \mathbb { C } [ x ] / ( f _ { i } ( x ) ) = H .$$
The RLWE errors are sampled from K C and followed by modulo R ∨ to reduce them to within the dual lattice. For a number field K and its ring of integers R = O K , let R q = R/qR and R ∨ q = R ∨ /qR ∨ and T = K C /R ∨ (a high-dimensional torus). The following RLWE definition generalizes Definition 9.4.1 to an arbitrary number field.
We use f g to denote polynomial multiplication in order to distinguish it from vector dot product. From Section 8.2.1, we know that polynomial addition and multiplication can be done efficiently under the canonical embedding.
R = nR ∨
Definition 9.2.1. Given the following parameters
- n - the security parameter that satisfies n = 2 k for an integer k ≥ 0 ,
- q - a large (public) prime modulus that is polynomial in n and satisfies q = 1 mod 2 n ,
for a fixed s ∈ R ∨ q and an error distribution ψ over K C , the RLWE distribution A s,ψ over R q × T , RLWE distribution is obtained by repeating these steps
- sample an element a ← R q ,
- compute the polynomial b = ( s a ) /q + mod R ∨ ,
- sample a noise element ← ψ over K C ∼ = H ,
- output ( a , b ) .
As will be seen later, Definition 9.4.1 in cyclotomic field is a special case of the above. Although in this general setting, a and s are taken from R q and its dual R ∨ q respectively, when K is a cyclotomic field with the cyclotomic polynomial Φ m ( x ) where m is a power of 2, it has been shown in Example 8.3.7 that
$$R = n R ^ { \vee } . & & ( 2 9 )
</doctag>$$
Hence, it makes no difference that s and a are sampled from different domains in the cyclotomic field case. This relationship between R and R ∨ is essential when reducing the search to decision RLWE.
The error distribution ψ above is not a 1-dimensional Gaussian distribution any more. Unlike in the LWEcase where the 1-dimensional error is added to the dot product a · s , in RLWE the n -dimensional error is added to the resulting polynomial a s . Depending on how a polynomial is represented, the number of parameters in the high-dimensional error distribution varies. In the coefficient representation, the n -dimensional Gaussian error distribution is parameterized by the n × n covariance matrix. In contrast, in the canonical embedding representation, the same Gaussian distribution D r is the product of n independent 1-dimensional Gaussian with either the same or different scales r = ( r 1 , . . . , r n ) . (This is another justification for using canonical embedding in RLWE.) When r is a constant vector, D r is called a spherical Gaussian distribution , otherwise it is called an elliptical Gaussian distribution .
An important observation when using a high-dimensional error distribution is when reducing ideal lattice problems to RLWE. As remarked after the LWE hardness proof, in order to employ the assumed LWE oracle to solve BDD, one may need to adjust the embedded random noise magnitude to fulfil the oracle's requirement. This can be done relatively easier by adding additional controlled noise to meet the appropriate noise magnitude for the LWE oracle. But in the RLWE case, there is no straightforward error adjustment to meet the target high-dimensional error distribution for the RLWE oracle, so the proof has to assume the RLWE oracle works for a wide range of error distributions that are defined next.
- Definition 9.2.2. For , the set ≤ α Ψ ≤ α family consists of all elliptical Gaussian distributions r over C such that each has scale .
α > 0 Ψ D K D r i r i ≤ α
With this family of error distributions, we can define the search RLWE problem as follows.
Definition 9.2.3. Given the parameter and the family of error distributions ≤ α , the search RLWE problem, denoted by RLWE q, Ψ ≤ α , is to compute the secret key s given samples { ( a , b ) } from the RLWE distribution A for an arbitrary s R ∨ and ψ Ψ .
- Search RLWE q Ψ s ,ψ ∈ q ∈ ≤ α
The decision RLWE is an average case problem for a random secret key and a random error distribution. The distribution for the secret key s is uniform over the dual lattice R ∨ . The distribution Υ α over the elliptical Gaussian error distributions Ψ ≤ α is chosen to be a Gamma distribution with shape 2 and scale 1. 12 Since the reduction from search to decision RLWE can only be made possible in cyclotomic number fields, we define Υ α specifically in these cyclotomic fields. Recall that for m = 2 n = 2 k > 2 , the canonical embedding for a cyclotomic number field K = Q ( ζ m ) consists only n complex embeddings which are in n/ 2 conjugate pairs σ i = σ i + n/ 2 for i ∈ [1 , n/ 2] , so the scale parameters that correspond to a conjugate pair can be set identical. This gives rise to the next definition of the distribution Υ α .
12 Lyubashevsky et al. (2010) emphasized that any efficiently samplable continuous distributions can be used, e.g., Gaussian distribution.
Distribution over Ψ ≤ α
Definition 9.2.4. For m = 2 n = 2 k > 2 an integer power of 2, let K = Q ( ζ m ) = Q [ x ] / ( x n +1) be the m th cyclotomic field. For a real α > 0 , let Υ α be the distribution over the family Ψ ≤ α of elliptical Gaussian distributions. Then every element ψ sampled from Υ α is an elliptical Gaussian distribution D r over K C whose scale parameters satisfy r 2 i = r 2 i + n/ 2 = α 2 (1 + √ nx i ) , where x 1 , . . . , x n/ 2 are chosen independently from the Gamma distribution Γ(2 , 1) .
Using this definition, we define the average-case decision version of RLWE as follows.
Definition 9.2.5. Decision RLWE Given the parameter q and a distribution Υ α over the family Ψ ≤ α of elliptical Gaussian distributions, the average-case decision RLWE problem, denoted by RDLWE q, Υ α , is defined as follows: for a random choice of ( s , ψ ) ← U ( R ∨ ) × Υ α , distinguish with non-negligible probability between samples from the RLWE distribution A s ,ψ and uniform samples over R q × T .
The mean of Γ(2 , 1) is 2, by the above definition of Υ α we have || r i || ≈ O ( αn 1 / 4 ) . Recall that in the proof of LWE hardness, we discussed the upper bound of the scale parameter α in the Gaussian error distribution Ψ α in order for Ψ α to be distinguishable from the uniform distribution once reduced by mod Z n p . The same argument carries over to the RLWE problem too, that is, ψ mod R ∨ and the uniform distribution over T = K C /R ∨ should be distinguishable, for otherwise the decision RLWE is unsolvable. The difference is in the n th successive minima λ n ( R ) . When K is a cyclotomic number field, it has a power basis { 1 , ζ, . . . , ζ n -1 } , which is also a basis of R . Under the canonical embedding, each element ζ k in the power basis is mapped to an element ( σ 1 ( ζ k ) , . . . , σ n ( ζ k )) in the canonical space, where each σ i maps ζ k to a different element in the power basis with || σ i ( ζ k ) || = 1 . Hence, the Euclidean norm of ζ k 's image under the canonical embedding is √ n and λ n ( R ) = √ n . This implies the n th successive minima λ n ( R ∨ ) = 1 / √ n and hence the upper bound of α in RLWE is α ≤ O ( √ log n/n ) by Lemma 5.1.3, which is smaller than O ( √ log n ) in LWE.
SVP, SIVP to RDLWE
Theorem 9.2.6. Let K be defined above, α < √ log n/n and q = q ( n ) ≥ 2 be a prime such that q = 1 mod m and αq ≥ ω (log n ) . There is polynomial time quantum reduction from the ideal lattice ˜ O ( √ n/α ) -SIVP (or SVP) problem to
We now state the main theorem of decision RLWE in the context of cyclotomic field K = Q ( ζ m ) = Q [ x ] / ( x n +1) , where its ring of integers is R = O K = Z [ x ] / ( x n +1) .
- RDLWE q, Υ α or
- RDLWE q,D ξ given only l samples, where ξ = α ( nl/ log( nl )) 1 / 4 is the scale parameter for the spherical Gaussian error distribution.
The first reduction is to the decision RLWE with a random elliptical Gaussian error distribution, whilst the second is to the decision RLWE with a fixed spherical Gaussian error distribution but given only a small number of samples. We will make clear the connection between these two problems in a following subsection.
The threshold α for the Gaussian distribution's scales is upper bounded to guarantee the solvability of the decision RLWE. In the meantime, the scales must also be sufficiently large to guarantee the sampled Gaussian noise once reduced to a smaller domain is almost uniformly distributed. See Section 4 of Lyubashevsky et al. (2010) for an additional explanation for the choice of α .
## 9.3 Hardness of search RLWE
Similar to the (search) LWE's hardness proof, the hardness of (search) RLWE relies on reductions from hard ideal lattice problems K-SVP γ and K-SIVP γ , through the intermediate K-DGS problem. We omit the reductions from the two ideal lattice problems to K-DGS, but only focus on the classical part of the quantum reduction to RLWE. The following theorem states a quantum reduction, which can be separated into a quantum and a classical step. We emphasize again that the context of this reduction is for arbitrary number fields (not necessarily cyclotomic).
In contrast to the small o notation (i.e., f ( n ) = o ( g ( n )) ) that indicates an upper bound of a function's growth, the small omega notation (i.e., f ( n ) = ω ( g ( n )) ) indicates a lower bound of the function's growth. More precisely, f ( n ) = ω ( g ( n )) if for all k > 0 there exists a threshold n 0 such that for all n > n 0 it satisfies | f ( n ) | > k | g ( n ) | . Throughout the proof, ω ( √ log n ) is used to denote a function that grows asymptotically faster than √ log n .
Figure 13: RLWE reductions
<details>
<summary>Image 12 Details</summary>
### Visual Description
\n
## Diagram: Quantum Algorithm Flow
### Overview
The image presents a diagram illustrating the flow of a quantum algorithm, specifically relating to solving K-DGS (likely a problem or system) using a combination of classical and quantum techniques. The diagram is split into two sections, a left section showing the initial problem setup and a right section showing the solution path.
### Components/Axes
The diagram consists of labeled nodes representing different stages or components of the algorithm, connected by arrows indicating the flow of computation. The labels are mathematical or algorithmic notations. There are no axes or scales present.
### Detailed Analysis or Content Details
**Left Section:**
* **K-SVP<sub>γ</sub>**: A node at the top-left.
* **K-SIVP<sub>γ</sub>**: A node at the top-right, horizontally aligned with K-SVP<sub>γ</sub>.
* **K-DGS<sub>γ</sub>**: A node at the bottom, connected by arrows from both K-SVP<sub>γ</sub> and K-SIVP<sub>γ</sub>.
* **Text Label**: "iteratively solve K-DGS<sub>γ</sub> using RLWE<sub>q,Ψ≤α</sub> oracle" - This text is positioned horizontally between the K-DGS<sub>γ</sub> node and the right section of the diagram.
**Right Section (enclosed in a rectangle):**
* **K-DGS<sub>γ</sub>**: A node at the top.
* **K-BDD<sub>α</sub>**: A node below K-DGS<sub>γ</sub>, connected by an arrow labeled "quantum".
* **q-BDD<sub>α</sub>**: A node to the right of K-BDD<sub>α</sub>, connected by an arrow.
* **RLWE<sub>q,Ψ≤α</sub>**: A node at the bottom, connected by arrows labeled "classical" from both K-BDD<sub>α</sub> and q-BDD<sub>α</sub>.
### Key Observations
The diagram shows a clear separation between the initial problem formulation (left) and the solution process (right). The iterative solving of K-DGS<sub>γ</sub> utilizes an oracle based on RLWE (Ring Learning With Errors). The right section demonstrates a quantum path (K-DGS<sub>γ</sub> to K-BDD<sub>α</sub>) and a classical path (K-BDD<sub>α</sub> and q-BDD<sub>α</sub> to RLWE<sub>q,Ψ≤α</sub>). The use of subscripts (γ and α) suggests parameters or variations within these components.
### Interpretation
This diagram likely represents a hybrid quantum-classical algorithm for solving a problem related to K-DGS. The initial step involves formulating the problem as K-SVP<sub>γ</sub> or K-SIVP<sub>γ</sub>, which are then reduced to K-DGS<sub>γ</sub>. The core of the solution involves iteratively solving K-DGS<sub>γ</sub> using an oracle based on the RLWE problem, which is a well-known lattice-based cryptographic problem. The quantum component, represented by the transition from K-DGS<sub>γ</sub> to K-BDD<sub>α</sub>, suggests a quantum algorithm is used to solve or approximate the K-DGS problem. The subsequent steps involve classical computations to arrive at a solution based on RLWE. The diagram highlights the interplay between quantum and classical techniques in tackling a potentially complex computational problem. The use of BDDs (Binary Decision Diagrams) suggests a method for representing and manipulating Boolean functions, potentially used in the quantum and classical computations. The subscripts γ and α likely represent parameters controlling the complexity or accuracy of the algorithms.
</details>
- Theorem 9.3.1. K-DGS to RLWE Let α = α ( n ) > 0 and q = q ( n ) ≥ 2 such that αq ≥ 2 ω ( √ log n ) . There is a PPT quantum reduction from K-DGS γ to RLWE q, Ψ ≤ α , where
$$\gamma & = \max \{ \eta _ { e } ( I ) ( \sqrt { 2 } / \alpha ) \omega ( \sqrt { \log n } ) , \sqrt { 2 n } / \lambda _ { 1 } ( I ^ { \vee } ) \} . & & ( 3 0 )$$
Given α < √ log n/n as stated in Theorem 9.2.6 and the smoothing parameter η ( I ) > 1 /λ 1 ( I ∨ ) by Claim 2.13 of Regev (2009), it always satisfies that γ = η ( I )( √ 2 /α ) ω ( √ log n ) in the above theorem.
Again, the motivation behind the theorem is to obtain discrete Gaussian samples over an ideal lattice I (in K ) with scale s as close to the lower bound γ as possible, so that certain standard ideal lattice problems can be solved with the help of these short discrete Gaussian samples. The feasibility of obtaining short samples can be proved using almost the same strategy as that in the BDD to LWE reduction. Recall that the BDD to LWE reduction gives rise to an iterative strategy to reduce the discrete Gaussian sample norms. In the RLWE setting, this means (as shown in Figure 13) to solve the K-BDD problem with an RLWE oracle and some discrete Gaussian samples with scale r , then feed the K-BDD output to a quantum algorithm to produce new discrete Gaussian samples with scale r ′ < r/ 2 half of the previous norms. We ignore the quantum step of the reduction (Lemma 4.4 (Lyubashevsky et al., 2010)). The classical part is stated in the next lemma.
Lemma 9.3.2 (Lemma 4.3 (Lyubashevsky et al., 2010)) . K-BDD to RLWE Let α = α ( n ) > 0 , q = q ( n ) ≥ 2 be an integer with known factorization. Let I be a fractional ideal of a number field K and r ≥ √ 2 qη ( I ) for some negligible = ( n ) . Given a discrete Gaussian oracle for D I,r , there is a PPT reduction from K-BDD d in the dual lattice I ∨ where d = αq/ ( √ 2 r ) to RLWE q, Ψ ≤ α .
To solve the K-BDD problem for an element in the ideal lattice I of K , the same bit-by-bit strategy as in Lemma 6.2.4 can be applied. That is, find a solution in the scaled ideal lattice qI and then iteratively build a solution in I from the least to the most significant bit in the base q . Since Lemma 6.2.4 was proved for general lattices, it also holds for ideal lattices without re-proving. The K-BDD problem in a scaled ideal lattice qI is called q -BDD. Hence, it remains to prove a solution for q -BDD with the help of an RLWE oracle and discrete Gaussian samples.
q -BDD to RLWE
Lemma9.3.3. Assume there is an oracle for RLWE q, Ψ ≤ α and a discrete Gaussian oracle for generating samples from D I,r where r ≥ √ 2 qη ( I ) . Given a K-BDD I ∨ ,d instance y = x + e , where x ∈ I ∨ and || e || ∞ ≤ d , there is a polynomial time algorithm solves q -BDD I ∨ ,d , that is, finds x mod qI ∨ .
The proof of this lemma follows a similar strategy as that of Proposition 6.2.3. That is, construct RLWE samples for the oracle using the given K-BDD instance y and the discrete Gaussian samples over I . The proof, however, is more involved, because the solution of K-BDD is in I ∨ and discrete Gaussian noise elements are sampled from I , whilst the RLWE oracle works in R q and its dual. Hence, it is necessary to be able to transform elements between these domains without losing their structures. To achieve this, we re-state the following two important results that have been proved in Section 8.1.3, but in the context of a number field K and its ring of integers O K .
Lemma 9.3.4. If I and J are non-zero integral ideals of R = O K , then there exists an element t ∈ I such that ( t ) I -1 ⊆ R is an integral ideal coprime to J .
Lemma 9.3.5. Let I and J be ideals in R = O K and M be a fractional ideal in the number field K . Then there is an isomorphism
$$M / J M \cong I M / I J M .$$
To make the proof work, we only focus on special cases of Lemma 9.3.5. More precisely, let J = ( q ) and M = R be the ring of integers itself or M = I ∨ be the dual ideal. Given the prime factors of the integer q , say q = ab where a, b ∈ Z are primes, the principal ideal can be written as ( q ) = ( a )( b ) the product of prime ideals in Z . Using a prime ideal factorization technique (will be briefly discussed in the next subsection), we can find the prime factors of ( a ) and ( b ) in R hence ( q ) . It then follows from Lemma 9.3.4 that there is an element t ∈ I to construct an ideal ( t ) I -1 coprime to J = ( q ) (see proofs of these lemmas in Section 8.1, also see the proof of lemma 5.2.2 of Stein (2012) to see why we need to know the prime factors of the ideal J ). Then the map induces two important isomorphisms
$$\theta _ { t } \colon K & \to K \\ u & \mapsto u t$$
$$\begin{array} { l l } R _ { q } = R / ( q ) R \cong I R / I ( q ) R = I _ { q } & ( 3 1 ) \\ \end{array}$$
$$I _ { q } ^ { \vee } = I ^ { \vee } / ( q ) I ^ { \vee } \cong I I ^ { \vee } / I ( q ) I ^ { \vee } = I I ^ { - 1 } R ^ { \vee } / I ( q ) I ^ { - 1 } R ^ { \vee } = R ^ { \vee } / ( q ) R ^ { \vee } = R _ { q } ^ { \vee } . \quad ( 3 2 )$$
Both isomorphisms in Equation 31 and 32 are precisely what we need in order to prove Lemma 9.3.3. Below we state the process to build the reduction. To construct A s ,ψ samples from y ∈ K , repeat the following steps:
1. Compute the element t ∈ I such that ( t ) I -1 and ( q ) are coprime by Lemma 9.3.4. Define the function θ t ( x ) = xt , which yields the two isomorphisms
$$R _ { q } & \cong I _ { q } \\ I _ { q } ^ { \vee } & \cong R _ { q } ^ { \vee } .$$
$$c$$
2. Sample z ← D I,r using the discrete Gaussian oracle, and compute
3. Sample e ′ ← D α/ √ 2 a continuous Gaussian noise, and compute
4. Output the pair ( a , b ) .
Once the RLWE oracle is given the samples { ( a , b ) } , it produces the secret key s ∈ R ∨ q and output
$$a = \theta _ { t } ^ { - 1 } ( z \bmod q I ) \in R _ { q } .$$
$$b = ( ( z \bmod q I ) ^ { * } y ) / q + e ^ { \prime } \bmod R ^ { \vee } .$$
$$x { \bmod { q } } I ^ { \vee } = \theta _ { t } ^ { - 1 } ( s ) \in I _ { q } ^ { \vee } .$$
Wenowprove that { ( a , b ) } are nearly genuine samples from the A s ,ψ distribution, hence the RLWE oracle produces a result for the q -BDD problem. The proof is structured as follows: first, show a distributes uniformly in R q and b follows b = ( a s ) /q + mod R ∨ ; then show that the secret key in RLWE gives rise to the solution θ -1 t ( s ) = x mod qI ∨ .
Proof. Since z is sampled from the discrete Gaussian distribution D I,r with a large scale r ≥ √ 2 qη ( I ) , when reduced it by taking modulo qI , the reduced sample is almost uniformly distributed within I q , and hence its image a under the isomorphism θ -1 t is also uniformly distributed within R q .
For the second component, we can re-write it as
$$b & = ( ( z \bmod q I ) * y ) / q + e ^ { \prime } \bmod R ^ { \vee } \\ & = ( ( z \bmod q I ) * ( x + e ) ) / q + e ^ { \prime } \bmod R ^ { \vee } \\ & = ( ( z \bmod q I ) * x ) / q + ( ( z \bmod q I ) / q ) * e + e ^ { \prime } \bmod R ^ { \vee } .$$
The key is to show that the first term is identical to ( a s ) /q mod R ∨ and the second and third terms combined is within negligible distance to the elliptical Gaussian D r over K C .
$$\begin{array} { r l } & { \theta _ { t } ( a ) - a ^ { * } t = 0 \bmod q I } \\ { \implies \theta _ { t } ( a ) - a ^ { * } t \in q I } \\ { \implies ( \theta _ { t } ( a ) - a ^ { * } t ) ^ { * } x \in q I I ^ { \vee } = q I I ^ { - 1 } R ^ { \vee } = q R ^ { \vee } } \\ { \implies \theta _ { t } ( a ) ^ { * } x = a ^ { * } t ^ { * } x \bmod q R ^ { \vee } . } \end{array}$$
It follows from this and θ t ( x mod qI ∨ ) = s that
Given z mod qI = θ t ( a ) = a t mod qI , we have = ⇒ θ t ( ) = mod qR .
$$\begin{array} { r l } & { ( z \bmod I _ { q } ) ^ { * } x = \theta _ { t } ( a ) ^ { * } x = a ^ { * } t ^ { * } x \bmod R _ { q } ^ { \vee } = a ^ { * } s \bmod R _ { q } ^ { \vee } } \\ & { \Longrightarrow ( ( z \bmod I _ { q } ) ^ { * } x ) / q = ( a ^ { * } s ) / q \bmod R ^ { \vee } } \end{array}$$
Therefore, we have proved that
$$b = ( a \, ^ { * } \, s ) / q + ( ( z \, m o d \, q I ) / q ) ^ { * } \, e ^ { \prime } \, m o d \, R ^ { \vee }$$
It remains to show the other parts combined is close to the discrete Gaussian D r over K C . We skip this step, which is proved in Lemma 4.8 of Lyubashevsky et al. (2010).
We have shown that the samples { ( a , b ) } follow the RLWE distribution and hence are legitimate inputs for the RLWE oracle. Since the oracle outputs the secret key s ∈ R ∨ q , by the induced isomorphism θ -1 t : R ∨ q → I ∨ q , we have found θ -1 t ( s ) = x mod qI ∨ , the least significant digit of the K-BDD solution s ∈ I ∨ .
To recap, we have shown in this subsection a polynomial time classical reduction from K-BDD to the search RLWE problem. In order for the reduction to work, we need to know the prime factorization of the integer q = q ( n ) ≥ 2 . The number field K needs not be cyclotomic, so the result holds in general number fields.
## 9.4 RLWE in cyclotomic field
In this subsection, we will re-state the RLWE problem in a special number field, i.e., the cyclotomic field, which is the most common setting for RLWE-based cryptosystems. It is the working domain for the search to decision reduction of the RLWE problem.
Recall the m th cyclotomic polynomial Φ m ( x ) is the polynomial whose roots are the primitive m th roots of unity. As we have seen in Remark 7.1.9, when m = 2 n = 2 k ≥ 2 is a positive power of 2, the corresponding cyclotomic polynomial has the simple algebraic form Φ m ( x ) = x n + 1 . Using this cyclotomic polynomial, we can define R = Z [ x ] / (Φ m ( x )) to be the ring of integer coefficient polynomials modulo (the principle ideal generated by) Φ m ( x ) . This is the primary domain where RLWE is defined in the special case. There are two way to interpret the ring R stated below.
1. R = Z [ x ] / ( x n +1) is a quotient ring where every polynomial in R has integer coefficients and degree less than n .
2. R = Z [ x ] / (Φ m ( x )) is isomorphic to Z [ ζ m ] , the ring of integers O K for the m -th cyclotomic field K = Q ( ζ m ) . This interpretation is supported by Theorem 8.1.23. The choices of m and n are motivated by Lemma 8.3.10 that relates O K and its dual by a scaling factor, i.e., O ∨ K = n -1 O K . This simplifies the RLWE definition by allowing the secret polynomial s to be sampled from the same domain as a public polynomial a as in Definition 9.4.1.)
The first interpretation is the natural interpretation but the second interpretation is more useful when proving hardness result of RLWE. We have been through some important properties of O K such as its fractional ideals form a UFD and its geometric interpretation under the canonical embedding.
To work in a finite domain, some elements in the following RLWE definition are taken from R modulo a prime q , that is, R q = Z q [ x ] / (Φ m ( x )) , where the polynomial coefficients are in Z q . This turns R q into a field of order q n because each coefficient has q choices and there are n coefficients, see Theorem B.1.11 for more details.
RLWE distribution
Definition 9.4.1. Given the following parameters
- n - the security parameter that satisfies n = 2 k for an integer k ≥ 0 ,
- q - a large (public) prime modulus that is polynomial in n and satisfies q = 1 mod 2 n ,
for a fixed s ∈ R q and an error distribution χ over R that is concentrated on 'small integer' coefficients, the RLWE distribution over R q × R q , denoted by is obtained by repeating these steps
- sample an element a ← R q ,
- compute the polynomial b = s a + mod R q ,
- sample a noise element ← χ over R ,
- output ( a , b ) .
In a LWE-based cryptosystems, as shown in Section 6.3, the public key is ( A , b ) where A ∈ Z n × m q is a matrix that needs O ( mn ) storage. For an RLWE-based cryptosystem, the public key size can be reduced to O ( n ) , which is a significant saving in terms of storage. The reason is because each sample from an RLWE distribution is a pair of n -degree polynomials (Definition 9.2.1) that can replace n samples from the standard LWE distribution (Definition 6.1.1).
## 9.5 Search to decision RLWE
Recall that the reduction from search to decision LWE in Section 6.1 used a simple argument by guessing each vector component of the secret key s using the decision LWE oracle. We plan to use the same strategy to reduce the search to decision RLWE problem by calling the decision oracle to solve the RLWE problem component by component. Also recall that the connection between a number field and its geometrical embedding is via the canonical embedding (Section 8.2.1). The canonical embedding is chosen over the coefficient embedding for several reasons, including the equivalence between number field element multiplications and embedded canonical vectors' component-wise multiplications.
A consequence of the component-wise operations is that a change in a single component of the secret polynomial s leads to a change in a single component of the polynomial b and vice versa. This is in contrast to the LWE case, where b = s · a + is the vector dot product, so any change in s is not associated with a single component change in b and vice versa. This raises the question of whether or not a RLWE oracle that is limited to discover a single component of the secret vector is able to discovery the entire s .
Hence, we need a way to leverage that oracle-distinguishable component to guess the value of all the other components of the secret s , by using the automorphisms of the underlying cyclotomic field to 'shuffle' the components (Section 7.2). In addition, in shuffling the components and adding a guess for each component of the secret s , we need to make sure
- a new sample ( a ′ , b ′ ) presented to the decision RLWE oracle obtained by transforming a given RLWEsample ( a , b ) is close to a sample from an RLWE distribution when the guess is correct, and close to a sample from the uniform distribution when the guess is incorrect.
- the noise vector in the transformed b ′ value stays in the noise distribution family Ψ ≤ α .
Below, we state the main theorem of this subsection. Its proof is divided into several parts in the rest of this subsection. For details of these proofs, see Section 5 of Lyubashevsky et al. (2010).
Theorem 9.5.1. Let R be the ring of integers of a cyclotomic field K and q = q ( n ) = 1 mod m be a prime such that αq ≥ η ( R ∨ ) for some negligible = ( n ) . There is a randomized polynomial time reduction from the search problem RLWE q, Ψ ≤ α to the average-case decision problem RDLWE q,υ α .
The search to decision RLWE reduction is achieved by a combination of four separate reductions as shown in Figure 14. The first reduction is from RLWE to component-wise RLWE in the canonical representation. The second reduction is from a component-wise search oracle to a worst-case decision oracle. The third reduction is between a worst-case and average-case decision oracle. And the last reduction guarantees that given an overall decision oracle it also works for a particular component.
$$R L W E ( n , q , \chi ) \colon = \{ ( a , b ) \}$$
Figure 14: A reduction map from the search to decision RLWE.
<details>
<summary>Image 13 Details</summary>

### Visual Description
\n
## Diagram: Relationship between Mathematical Entities
### Overview
The image presents a diagram illustrating relationships between four mathematical entities: RLWE, DRLWE, and their indexed variants. The diagram uses arrows to indicate the direction of these relationships, accompanied by descriptive labels and references to lemmas. It appears to be a visual representation of a proof or a series of transformations within a mathematical context, likely related to lattice-based cryptography.
### Components/Axes
The diagram consists of four labeled nodes representing mathematical entities, and four labeled arrows representing transformations or relationships between them. The nodes are:
* **RLWE<sub>q,ψ≤α</sub>**: Located at the top-left.
* **DRLWE<sub>q,γα</sub>**: Located at the top-right.
* **q<sub>i</sub>-RLWE<sub>q,ψ≤α</sub>**: Located at the bottom-left.
* **DRLWE<sup>i</sup><sub>q,γα</sub>**: Located at the bottom-right.
The arrows and their labels are:
* **Automorphisms**: Arrow from RLWE<sub>q,ψ≤α</sub> to q<sub>i</sub>-RLWE<sub>q,ψ≤α</sub>. Accompanied by "Lemma 9.5.5".
* **Search to decision**: Arrow from q<sub>i</sub>-RLWE<sub>q,ψ≤α</sub> to WDRLWE<sup>i</sup><sub>q,ψ≤α</sub>. Accompanied by "Lemma 9.5.8".
* **Hybrid to general**: Arrow from RLWE<sub>q,ψ≤α</sub> to DRLWE<sub>q,γα</sub>. Accompanied by "Lemma 9.5.12".
* **Worst to average**: Arrow from WDRLWE<sup>i</sup><sub>q,ψ≤α</sub> to DRLWE<sup>i</sup><sub>q,γα</sub>. Accompanied by "Lemma 9.5.10".
### Detailed Analysis or Content Details
The diagram shows a two-by-two arrangement of mathematical entities.
* The top row connects RLWE<sub>q,ψ≤α</sub> to DRLWE<sub>q,γα</sub> via the "Hybrid to general" transformation (Lemma 9.5.12).
* The bottom row connects q<sub>i</sub>-RLWE<sub>q,ψ≤α</sub> to DRLWE<sup>i</sup><sub>q,γα</sub> via two transformations: "Search to decision" (Lemma 9.5.8) and "Worst to average" (Lemma 9.5.10).
* The left column connects RLWE<sub>q,ψ≤α</sub> to q<sub>i</sub>-RLWE<sub>q,ψ≤α</sub> via the "Automorphisms" transformation (Lemma 9.5.5).
The diagram suggests a flow or transformation between these entities. The subscripts 'q', 'ψ', 'α', 'i', and 'γ' likely represent parameters or indices within the mathematical definitions of these entities.
### Key Observations
The diagram is structured to show relationships between two main types of entities (RLWE and DRLWE) and their indexed variants. The lemmas cited suggest that each transformation is supported by a specific mathematical proof. The diagram does not contain numerical data or quantitative values.
### Interpretation
The diagram likely represents a series of reductions or transformations used in the security analysis of lattice-based cryptographic schemes. RLWE (Ring Learning With Errors) and DRLWE (Discrete Ring Learning With Errors) are fundamental building blocks in modern cryptography. The diagram illustrates how different variants of these problems are related to each other through specific mathematical operations.
The lemmas referenced (9.5.5, 9.5.8, 9.5.10, 9.5.12) likely provide the mathematical justification for these transformations. The "Hybrid to general" transformation suggests a way to generalize a problem, while "Search to decision" and "Worst to average" suggest reductions to simpler problems that are easier to analyze. The "Automorphisms" transformation likely relates to symmetries or structural properties of the RLWE problem.
The diagram is a high-level overview of a mathematical argument and does not provide specific details about the underlying algorithms or proofs. It serves as a visual aid for understanding the relationships between different concepts in lattice-based cryptography.
</details>
Given a prime q satisfying q = 1 mod m , the ideal ( q ) in R q = Z q [ x ] / (Φ m ( x )) factors into ϕ ( m ) distinct prime ideals: ( q ) = ∏ i ∈ Z ∗ m q i . (See Example 8.1.26 for more details.) Further, by Lemmas 9.3.4, 9.3.5 and (18), there is an efficiently computable isomorphism between R ∨ q and ⊕ i ∈ Z ∗ m ( R ∨ / q i R ∨ ) . Given we are going to guess the secret key s one component at a time in the canonical representation, this gives rise to the restricted RLWE definition.
Definition 9.5.2. q i -RLWE Given
- an oracle that generates samples from the RLWE distribution A s ,ψ , for an arbitrary s ∈ R ∨ q and ψ ∈ Ψ ≤ α , and
- a prime ideal q i in the factorisation of ( q ) ,
the q i -RLWE q, Ψ ≤ α problem is to find s mod q i R ∨ .
An important observation is that each prime ideal q i is mapped by the automorphisms in the Galois group to a different prime ideal. Recall that the key result (Theorem 7.2.6) in Section 7.2 states that the Galois group of a cyclotomic field K = Q ( ζ m ) is isomorphic to the integer multiplicative group, i.e.,
$$G a l ( K / \mathbb { Q } ) \cong ( \mathbb { Z } / m \mathbb { Z } ) ^ { * } .$$
If we think each i ∈ ( Z /m Z ) ∗ as a function of the roots of unity that is given by i : ζ m ↦→ ζ i m , then each automorphism τ in the Galois group is uniquely mapped with a multiplicative integer i if and only if τ ( ζ m ) = ζ i m .
All of these come down to the observations that each automorphism τ ∈ Gal ( K/Q ) maps the ring of integers R to itself and its dual R ∨ = 1 n R to itself. More importantly, we have the next lemma. It enables us to transfer between different prime ideals q i and q j . This is also known as the Galois automorphisms act transitively on the prime ideals q j . This helps with solving all components of the secret key s in the CRT-basis using a particular q i -RLWE oracle. In other words, once we have an oracle for a single CRT component, we can use this oracle to solve for all the other components too.
Lemma 9.5.3. τ k ( q i ) = q i/k Let τ k ∈ Gal ( K/ Q ) be an automorphism, then we have τ k ( q i ) = q i/k for any i, k ∈ Z ∗ m .
For the proof of this lemma, see Lemma 2.16 of Lyubashevsky et al. (2010). Since a cyclotomic field is also a Galois extension field, for a more general result see Theorem 9.2.2 of Stein (2012), where K is a Galois extension of Q .
We have shown that both R and R ∨ are closed under Galois automorphisms. To transfer a RLWE sample ( a , b ) using an automorphism, we also need to make sure the family Ψ ≤ α of elliptical Gaussian distributions is also closed under Galois automorphisms. This can be easily seen from the next lemma.
Lemma 9.5.4. Ψ ≤ α is closed under τ For any α > 0 , the family Ψ ≤ α of elliptical Gaussian distributions is also closed under Galois automorphisms of K , that is, for any τ ∈ Gal ( K/ Q ) and any ψ ∈ Ψ ≤ α , we have τ ( ψ ) ∈ Ψ ≤ α .
Proof. Given a n -dimensional K = Q ( ζ ) , it has a power basis { 1 , ζ, . . . , ζ n } . Weknoweach Galois automorphism of K maps ζ to a different root of unity. Under the canonical embedding, this automorphism
RLWE to
q
i
-RLWE
permutes the components of ζ , so does it permutes the components of any element in K . Since each D r ∈ Ψ ≤ α is a distribution over the space K C that is isomorphic to the canonical space, τ ( D r ) is still over the same space but with possibly an reordering of the scale vector r . Hence, τ ( D r ) ∈ Ψ ≤ α .
We are now ready to prove the following reduction.
Lemma 9.5.5. For every i ∈ Z ∗ m , there is a deterministic polynomial time reduction from RLWE q, Ψ ≤ α to q i -RLWE q, Ψ ≤ α .
Proof. Assume there is a q i -RLWE q, Ψ ≤ α oracle that solves s mod q i R ∨ from A s ,ψ samples { ( a , b ) } ⊆ R q × T for arbitrary s ∈ R ∨ q and ψ ∈ Ψ ≤ α . We want to show that this oracle works for all CRT components, i.e., it solves s mod q j R ∨ for all j ∈ Z ∗ m .
Let k ∈ Z ∗ m such that i = j/k , then the automorphism τ k ∈ Gal ( K/ Q ) maps a RLWE sample
$$( a , b ) \mapsto \tau _ { k } ( ( a , b ) ) & = ( \tau _ { k } ( a ) , \tau _ { k } ( b ) ) \\ & = ( \tau _ { k } ( a ) , \tau _ { k } ( ( a ^ { * } s ) / q + \epsilon ) )$$
Since R , R ∨ and Ψ ≤ α are closed under automorphisms, the transformed sample τ k (( a , b )) is also in the domain R q × T , and most importantly distributed according to A τ k ( s ) ,τ k ( ψ ) . In addition, the prime ideal is mapped by τ k ( q j ) = q j/k = q i , we can then use the q i -RLWE q, Ψ ≤ α oracle to solve τ k ( s ) mod q i R ∨ from the transformed RLWE samples, because it works for arbitrary secret key and error distribution. By taking the inverse of the automorphism τ k , we get an answer for the CRT component mod q j R ∨ , that is,
$$\tau _ { k } ^ { - 1 } \left ( \tau _ { k } ( s ) \bmod \mathfrak { q } _ { i } R ^ { \vee } \right ) & \mapsto s \bmod \tau _ { k } ( \mathfrak { q } _ { i } ) \tau _ { k } ( R ^ { \vee } ) = s \bmod \mathfrak { q } _ { j } R ^ { \vee } .$$
Since this works for every j ∈ Z ∗ m , we get all the CRT components. Since all the prime ideals q i are also coprime and their product is the ideal ( q ) , by CRT we have an induced isomorphism
$$loc. (q) R / qR \cong \bigoplus _ { i } ( R / \mathfrak { q } _ { i } )
<text>loc_0><loc_1><loc_499><loc_500>= = ⇒ R/qR R ∨ /qR ∨ ≅ ⊕ (R ∨ /q$_{i}$R ∨ ),</text>$$
where the last step is by the fact that R ∨ = (1 /n ) R . Therefore, according to this isomorphism, we can compute the entire secret s ∈ R ∨ q .
As we recover the secret key component by component in the CRT representation, we add an extra piece of information to an RLWE sample, not only at the component of interest, but all the components before it. This gives rise to a new 'hybrid' distribution as defined next and is used for the rest of the proof of Theorem 9.5.1.
Definition 9.5.6. Hybrid distribution For a given RLWE distribution A s ,ψ and an integer i ∈ Z ∗ m in the multiplicative group, the hybrid RLWE distribution A i s ,ψ over R ∨ q × T is obtained by the following steps:
- generate an RLWE sample ( a , b ) ← A s ,ψ ,
- output ( a , b + h /q ) .
- generate h ← R ∨ q such that h mod q j R ∨ is uniformly random and independent for j ≤ i and h mod q i R ∨ = 0 for j > i . That is, in its CRT representation ( h 1 , . . . , h i , . . . , h n ) ∈ ⊕ k R ∨ / q k R ∨ , the components h 1 , . . . , h i are uniformly random and independent and h i +1 = · · · = h n = 0 ,
Note both indices i and j are integers coprime with m . Denote i -the largest integer in Z ∗ m that is smaller than i . By convention, denote 1 -to be 0 and A 1 -s ,ψ = A 0 s ,ψ = A s ,ψ the original RLWE distribution.
WDRLWE i q, Ψ ≤ α
Definition 9.5.7. For i ∈ Z ∗ m , the worst-case decision RLWE relative to q i problem, denoted WDRLWE i q, Ψ ≤ α , is to distinguish between the hybrid RLWE distributions A i -s ,ψ and A i s ,ψ for arbitrary s ∈ R ∨ q and ψ ∈ Ψ ≤ α .
Now we state and prove the second reduction. It works in a similar fashion as the search to decision LWE reduction. That is, modify the original RLWE samples by adding an extra piece of information, which incorporates the guess of one particular CRT component s mod q i R ∨ .
Lemma 9.5.8. For any i ∈ Z ∗ m , there is a PPT reduction from q i -RLWE q, Ψ ≤ α to WDRLWE i q, Ψ ≤ α .
Proof. Given an RLWE sample ( a , b ) ← A s ,ψ , we can construct a hybrid RLWE sample ( a , b + h /q ) ∈ A i -s ,ψ by taking h ← R ∨ q such that h mod q j R ∨ is uniformly random and independent for j ≤ i -and h mod q i R ∨ = 0 for j ≥ i . This is further transformed by
$$( a , b + h / q ) \mapsto ( a ^ { \prime } , b ^ { \prime } ) & = ( a + v , b + ( v * g ) / q ) \\ & = ( a + v , ( a ^ { \prime } * s + h + v * ( g - s ) ) / q + e ) ,$$
The distribution of the second part b ′ depends on whether or not g = s mod q i R ∨ is the correct guess of the CRT component. If it is, then g -s is 0 at the q i R ∨ component, consequently v ( g -s ) is 0 everywhere, so the distribution of the transformed sample stays as A i -s ,ψ . If the guess is incorrect, then v ( g -s ) is uniform at the q i R ∨ component and 0 everywhere else, so the transformed sample distributed as A i s ,ψ . Given the WDRLWE i q, Ψ ≤ α oracle can distinguish the two distributions, we can enumerate all possible values of s mod q i R ∨ to make the correct guess.
where v ← R q such that v mod q i is uniformly random and v mod q j = 0 for j = i . It is easy to see that the first part a + v ∈ R q is uniform.
We omit the worst-case to average-case decision RLWE relative to q i reduction because the proof uses mostly probability tools, but only state the average-case definition and the reduction lemma.
Definition 9.5.9. For i ∈ Z ∗ m and a distribution Υ α over Ψ ≤ α , the average-case decision RLWE relative to q i problem, denoted DRLWE i q, Υ , is to distinguish with a non-negligible probability the hybrid RLWE distributions A i -s ,ψ and A i s ,ψ over the random choice ( s , ψ ) ← U ( R ∨ q ) × Υ α .
Lemma 9.5.10. For any α > 0 and every i ∈ Z ∗ m , there is a randomized polynomial time reduction from WDRLWE i q, Ψ ≤ α to DRLWE i q, Υ α .
Finally, the proof of Theorem 9.5.1 comes down to the last step which shows that given a decision RLWE oracle, it solves the decision problem relative to q i . This relies on the fact that the hybrid distribution A m -1 s ,ψ is within negligible distance to the uniform distribution over the same domain.
Lemma 9.5.11. Let α ≥ η ( R ∨ ) /q for some > 0 . For any s ∈ R ∨ q and error distribution ψ ∈ Ψ ≤ α sampled according to the distribution Υ α , the hybrid RLWE distribution A m -1 s ,ψ is within statistical distance / 2 of the uniform distribution over ( R q , T ) .
With this lemma, we are able to prove the final step as given next.
Lemma 9.5.12. There is a polynomial time reduction from DRLWE i q, Υ α to DRLWE q, Υ α for some i ∈ Z ∗ m .
Proof. Given Lemma 9.5.11, it is not difficult to see this lemma follows. We know A 0 s ,ψ = A s ,ψ is the RLWEdistribution and A m -1 s ,ψ is nearly uniform, so the DRLWE q, Υ oracle can distinguish the two. This is an easy task for the oracle.
If we bring the two distributions closer, say for i ∈ Z ∗ m and start with i = 1 , we ask the oracle to distinguish the two hybrid distributions A i -s ,ψ and A i s ,ψ . Intuitively, both distributions should be close to the RLWE distribution for small i and to the uniform distribution for large i . So the oracle will not distinguish them. But there must be an index i such that at that point A i -s ,ψ is closer to the RLWE distribution and A i s ,ψ is closer to the uniform distribution, so the oracle can easily distinguish them. This index i ∈ Z ∗ m is what will be used for all the previous reduction steps that we have discussed.
## 9.6 An RLWE-based encryption scheme
To end this section, we state a simple RLWE-based public-key encryption scheme presented by Lyubashevsky et al. (2010).
Let R = Z [ x ] / ( x n + 1) , where n is taken to be a power of 2 to make the modulo polynomial cyclotomic, hence R a cyclotomic field. This is the domain for the secret key and noise vectors that are sampled according to a specific distribution χ . Restrict the public key and ciphertexts to be in the domain R q = Z q [ x ] / ( x n + 1) . The scheme is presented as follows with slight modifications to be consistent with the BFV scheme that will be presented in the next section.
Decryption works if the parameters are properly set and polynomials sampled from R have small coefficients (according to the distribution χ ). Because
$$\begin{array} { r l } & { u + v \cdot s = \lfloor q / 2 \rfloor \cdot m + ( e \cdot r + e _ { 1 } + e _ { 2 } \cdot s ) \bmod q . } \\ & { ( 3 3 ) } \end{array}$$
If those polynomials are taken with large coefficients, after multiplications they will neither staying within modulo q , nor being rounded to 0.
As for its security, the public key ( b , a ) is a RLWE sample with the secret vector s , so it is pseudorandom which implies there no way to recover s because that requires a solution to the search RLWE problem. In terms of semantic security (definition 3.3.3), the pairs ( b , u - q/ 2 · m mod q ) and ( a , v ) are also RLWE samples with the corresponding secret vector r , so the ciphertext c is pseudo-random too, which implies semantic security.
Private key : Sample a private key s ← χ .
Public key : Sample random polynomials a ← R q and e ← χ and output the public key ( b = [ a s + e ] , a ) .
<!-- formula-not-decoded -->
Encryption: Encrypt an n bits message m ∈ { 0 , 1 } n by computing
$$\begin{array} { r l } & { u = b \cdot r + e _ { 1 } + \lfloor q / 2 \rfloor \cdot m \bmod q } \\ & { v = a \cdot r + e _ { 2 } \bmod q , } \end{array}$$
where r , e 1 , e 2 ← χ are random samples. Then output the ciphertext c = ( u , v ) .
$$v = a \cdot r + e _ { 2 } \bmod q ,$$
Decryption: Decrypt the ciphertext c using the secret key by computing
$$loc_0>loc_0>loc_500>$$
```
Figure 15: A Sage implementation of the RWLE-based encryption scheme described above.
Note: This implementation is not suitable for use in real-world applications.
#!/usr/bin/env sage
from sage.misc.prandom import randrange
import sage.stats.distributions.discrete_gaussian_integer as dgi
# Define parameters
def sample_noise(n, P):
D = dgi.DiscreteGaussianDistributionIntegerSampler(sigma=1.0)
return P([D() for i in range(n)])
q = 655360001
n = 2^10
P = QuotientRing(PolynomialRing(Integers(q), name="x"),
x^n + 1)
Q = PolynomialRing(Rationals(), name="y")
Z2 = Integers(2)
# Generate keys
secret_key = sample_noise(n, P)
e = sample_noise(n, P)
a = P.random_element()
b = -(a+secret_key) + e
public_key = (b,a)
# Encrypt Message
message = P([randrange(0,2) for i in range(n)])
r = sample_noise(n, P)
el = sample_noise(n, P)
e2 = sample_noise(n, P)
u = b*r + el + (q//2)*message
v = a*r + e2
ciphertext = (u,v)
# Decrypt Message
w1 = u + v*secret_key
w2 = (2/q) * Q(w1.list())
decrypted_message = P([Z2(w.round()) for w in w2.list()])
# Verification
print(decrypted_message == message)
```
Figure 15: A Sage implementation of the RWLE-based encryption scheme described above. Note: This implementation is not suitable for use in real-world applications.
HE scheme
## 10 Homomorphic Encryption
Shortly after the RSA encryption scheme (Rivest et al., 1978b) was released, Rivest et al. (1978a) raised the question of whether it is possible to perform arithmetic operations (e.g., addition and multiplication) on encrypted data without the secret key, and the results can be decrypted to the correct results if the same operations were performed on the unencrypted data. An encryption scheme possessing such a property is called a homomorphic encryption scheme.
## 10.1 Basic definitions
Weformally define here the sub-routines of a public key homomorphic encryption (HE) scheme. Similar to non-HE schemes, an HE scheme also has a key generation process, an encryption process, and a decryption process. The difference is that an HE scheme consists of an extra evaluation process that evaluates a function, which is often expressed as an arithmetic circuit on the ciphertexts, and produces an 'evaluated ciphertext'.
Definition 10.1.1. A homomorphic encryption scheme is a four tuple of PPT algorithms
$$H E = ( H E . K e y g e n , H E . E n c , H E . E v a l , H E . D e c )$$
that takes the security parameter λ as the input. Each of the PPT algorithms is defined as follows:
- Setup : Given the security parameter λ , generate a parameter set params = ( n, q, N, χ ) ← HE . Setup (1 λ ) for the following steps.
- Key generation : Given the parameters generated above, the algorithm produces ( pk , sk , evk ) ← HE . Keygen ( params ) a set of keys that consists of a public key, a secret key and an evaluation key.
- Encryption : The algorithm takes the public key and a plaintext m (i.e., the secret message) to produce a ciphertext text c ← HE . Enc ( pk , m, n, q, N ) .
- Evaluation : Given the evaluation key, the evaluation function f : { 0 , 1 } l →{ 0 , 1 } and a set of ciphertexts, the algorithm produces an evaluated ciphertext c f ← HE . Eval ( evk , f, c 1 , . . . , c l ) .
- Decryption : The algorithm decrypts the ciphertext using the secret key to find the corresponding plaintext m f ← HE . Dec ( sk , c f ) .
This is a basic form of an HE scheme. A more complicated scheme may take extra input parameters for additional purposes such as reducing ciphertext noise magnitude and so on.
The plaintext m f corresponds to the function output of f when applied to the plaintexts directly. If the decrypted ciphertext after evaluations does not match with m f , the HE scheme is considered as unsuccessful. More formally, let m 1 and m 2 be two plaintexts, pk and sk be the public key and secret key for encryption and decryption, respectively. A homomorphic encryption scheme satisfies the property that for an operation in the plaintext space, there is a corresponding operation · in the ciphertext space such that
$$D e c ( s k , E n c ( p k , m _ { 1 } ) \bullet E n c ( p k , m _ { 2 } ) ) = m _ { 1 } \diamond m _ { 2 } ,$$
Most of the HE schemes have the same operations in both plaintext and ciphertext spaces. That is, additions of ciphertexts can be decrypted to additions of plaintexts. Similarly for multiplications. The name 'homomorphic' is likely taken from the concept of homomorphism in mathematics, which is a structure-preserving map between two algebraic structures. The analogy here is that the decryption function is a homomorphism from the ciphertext space to the plaintext space that preserves the same operations in the two spaces as stated in Equation (34).
It is important to note that the encryption function is not homomorphic, that is,
$$& \text {Enc} ( p k , m _ { 1 } ) \bullet \text {Enc} ( p k , m _ { 2 } ) ) \neq \text {Enc} ( p k , m _ { 1 } \diamond m _ { 2 } ) , \\ & \text {in III} \, \text {user} \, \text {mixinis in} \, \text {user} \, \text {mixinis in} \, \text {user} \, ($$
because encryptions in HE are non-deterministic in order to satisfy semantic security (Definition 3.3.3). Recall that semantic security assures that given a ciphertext c that encrypts one of the two messages m 1 and m 2 , it is impossible for a PPT attacker to guess the source message from c with a better chance than random guessing.
Example 10.1.2. The RSA encryption system, without message padding, is a homomorphic encryption system for multiplication. (Of course, without message padding, the RSA system is not semantically secure.)
Example 10.1.3. Here is a simple homomorphic encryption system given by Brakerski and Vaikuntanathan (2014). Let s ∈ Z n q be the secret key. The private message m ∈ { 0 , 1 } is encrypted by
$$c = ( a , b = a \cdot s + 2 e + m ) \in \mathbb { Z } _ { q } ^ { n } \times \mathbb { Z } _ { q } ,$$
where e is a random noise with small magnitude. The decryption of this ciphertext with the secret key is done by
$$m = ( ( b - a \cdot s ) \bmod q ) \bmod 2 ,$$
provided e is small enough to ensure b -a · s = 2 e + m is within Z q . Given two ciphertexts c 1 and c 2 that respectively encrypts the messages m 1 and m 2 as above, their sum can be easily computed by the bilinearity of dot product, so
$$c _ { 1 } + c _ { 2 } & = ( a _ { 1 } + a _ { 2 } , b _ { 1 } + b _ { 2 } ) \\ & = ( a _ { 1 } + a _ { 2 } , ( a _ { 1 } + a _ { 2 } ) \cdot s + 2 ( e _ { 1 } + e _ { 2 } ) + ( m _ { 1 } + m _ { 2 } ) ) .$$
Decryption proceeds as before and produces the sum of the two messages m 1 + m 2 , so the scheme is additive homomorphic. The scheme can also be shown to be multiplicative homomorphic.
In many homomorphic encryption systems, the ciphertext noise increases after each homomorphic evaluation operation, and if the overall noise is higher than a threshold called the noise ceiling (e.g., the modulo q in the above example), decryption can fail to output the correct result. Given a noise ceiling and the noise bound (on which the noise distribution is supported), the number of homomorphic evaluations that can be performed on the ciphertexts is usually restricted. The breakthrough made by Gentry (2009) enables an unlimited number of homomorphic evaluations on ciphertexts using squashing and bootstrapping, which are described in the next subsection. Below, we listed a few commonly mentioned HE categories, which are grouped by the class of arithmetic circuits they can evaluate.
- Partially HE (PHE) - Schemes that can evaluate circuits containing only one type of arithmetic gates, that is, either addition or multiplication, for unbounded circuit depth.
- Leveled HE (LHE) - Schemes that can evaluate circuits containing both addition and multiplication gates, but only for a pre-determined multiplication depth L .
- Somewhat HE (SHE) - Schemes that can evaluate a subset of circuits containing both addition and multiplication gates, whose complexity grows with the circuit depth. SHE is more general than LHE. Examples include Gentry (2009, 2010).
- Leveled Fully HE - Almost identical to leveled HE, except these schemes can evaluate all circuits of depth L . Examples include Brakerski and Vaikuntanathan (2014); Brakerski et al. (2014); Brakerski (2012).
- Fully HE (FHE) - Schemes that can evaluate all circuits containing both addition and multiplication gates for unbounded circuit depth. Examples include Gentry (2009) and Brakerski and Vaikuntanathan (2014); Brakerski et al. (2014); Brakerski (2012) under the weak circular security , which guarantees security when using only one pair of secret and public keys.
## 10.2 Gentry's original FHE using squashing and bootstrapping
As discussed above, noise growth needs to be well controlled during homomorphic evaluations in order to guarantee correct decryption. Under such a constraint, a scheme can only perform a certain number of arithmetic on ciphertexts, unless the ciphertext noise can be constantly reduced after evaluations. An obvious noise elimination method is ciphertext decryption that completely clears the embedded noise in the ciphertext. So the question is how to utilize a scheme's own decryption circuit to reduce noise growth and carry on more homomorphic evaluations.
Gentry's original construction to achieve FHE consists of three components. The first component is a SHE scheme that can handle both addition and multiplication for a non-trivial but limited number of steps. The second component is a squashing process to make the SHE scheme's decryption step easier in order to permit bootstrapping. The third component is the actual bootstrapping process that enables the
evaluation of the scheme's own decryption circuit, plus an extra evaluation step. The key observation here is that during bootstrapping, a ciphertext will be doubly encrypted and decrypted only from the inner layer. This is then followed by a single arithmetic step on the (singly encrypted) ciphertexts. The three components put together gives a scheme, whose ciphertext noise can be reduced before running the next arithmetic step, and consequently leads to FHE. A formal definition of bootstrappable is stated next.
Definition 10.2.1. A scheme is C -homomorphic if it can evaluate any circuit in the class C .
Definition 10.2.2. Let HE be a C -homomorphic scheme and f c 1 ,c 2 add ( s ) and f c 1 ,c 2 mult ( s ) be two decryption functions augmented by an addition and an multiplication, respectively. Then HE is bootstrappable if { f c 1 ,c 2 add ( s ) , f c 1 ,c 2 mult ( s ) } c 1 ,c 2 ∈ C the two augmented decryptions are in the class.
The definition suggests that decryption needs to be simple enough so that not only it is in C , but it needs to be followed by an arithmetic operation to allow further evaluation. To ensure this, Gentry added a 'hint' to the ciphertext to make decryption simpler. This process is later known as squashing . Next, we restate the simple concrete HE scheme by Dijk et al. (2010) that was also used by Gentry (2010) to illustrate the squashing and bootstrapping concept.
Set the parameters N = λ , P = λ 2 and Q = λ 5 for the given security parameter λ . The (secret key) encryption scheme consists of the following steps:
- Key generation : p ← Keygen ( λ ) , where p is an odd integer of P -bit.
- Encryption : To encrypt a message m ∈ { 0 , 1 } , choose an N -bit integer m ′ such that m ′ = m mod 2 . Then output the ciphertext c = m ′ + pq ← Enc ( p, m ) , where q is a random Q -bit number.
- Decryption : To decrypt the ciphertext c , run the sub-routine ( c mod p ) mod 2 ← Dec ( p, c ) . It will output the correct message m , because c mod p = m ′ which has the same parity as m as chosen in the encryption step.
The scheme is both additive and multiplicative homomorphic, given
$$\begin{array} { c } { { c _ { 1 } + c _ { 2 } = ( m _ { 1 } ^ { \prime } + m _ { 2 } ^ { \prime } ) + p \cdot ( q _ { 1 } + q _ { 2 } ) } } \\ { { c _ { 1 } \cdot c _ { 2 } = ( m _ { 1 } ^ { \prime } \cdot m _ { 2 } ^ { \prime } ) + p \cdot ( m _ { 1 } ^ { \prime } \cdot q _ { 2 } + m _ { 2 } ^ { \prime } \cdot q _ { 1 } + p \cdot q _ { 1 } \cdot q _ { 2 } ) . } } \end{array}$$
However, it is not bootstrappable due to the complexity of the decryption step. More precisely, the decryption function ( c mod p ) mod 2 is equivalent to LSB ( c ) XOR LSB ( c/p ) , where LSB is the least significant bit. The most time-consuming step in the decryption function is the multiplication of two large numbers c · 1 /p . To simplify this multiplication, Gentry's idea is to replace c · 1 /p by summing a small set of numbers, which is known as the sparse subset sum problem (SSSP) . This sum is the 'hint' to decryption to reduce its running time and consequently permit bootstrapping. The modified scheme is as follows:
- Key generation : First, generate ( pk , sk ) ← Keygen ( λ ) , where sk = p is the odd integer. Then, generate a real vector y ∈ [0 , 2) β such that there exists a subset of indices S ⊆ { 1 , . . . , β } of size α and ∑ i ∈ S y i ≈ 1 /p mod 2 can approximate the original secret key sk. Finally, output the keys ( pk ∗ , sk ∗ ) , where pk ∗ = ( pk , y ) and sk ∗ = S . Here when α and β are set properly, given the set y and 1 /p , it is hard to find the subset of indices S that is the new secret key sk ∗ . So the 'hint' is added to the public key.
- Encryption : First, compute c ← Enc ( pk , m ) . Then, compute z i = c · y i . Finally, output c ∗ = ( c, z ) .
- Decryption : Run LSB ( c ) XOR LSB ( c/p ) . Here, we approximate c/p by ∑ i ∈ S z i . From the key generation step, we know that ∑ i ∈ S z i = ∑ i ∈ S c · y i = c · ∑ i ∈ S y i ≈ c · 1 /p mod 2 . The summation is over a small subset and is relatively easier to compute than the multiplication of two long numbers.
This revised scheme is also both additive and multiplicative homomorphic, which can be achieved by extracting the ciphertext c from c ∗ then apply the addition and multiplication operations as in the original scheme. The cost of squashing decryption is the scheme's security, which is now also based on the hardness assumption of SSSP , in addition to the scheme's original security assumption. In other
words, the attacker is also given the encryption of the secret key by the corresponding public key. This situation is properly dealt with by the additional security assumption stated next and is necessarily assumed when pursuing for FHE.
Definition 10.2.3. A public key encryption scheme is weak circular secure if it is CPA secure even in the presence of the encryption of the secret key bits.
It is worth keeping in mind that this concrete scheme is only a simplified illustration of Gentry's original SHE construction based on ideal lattices (Gentry, 2009). Besides his breakthrough to achieve FHE using squashing and bootstrapping, Gentry's work also inspired a great number of subsequent developments in FHE, especially those that tried to improve efficiency without using squashing and bootstrapping. In the next few subsections, we will see a sequence of such works.
## 10.3 BV ∗ : SHE by relinearization
We will cover the body of works in Brakerski and Vaikuntanathan (2014); Brakerski et al. (2014); Brakerski (2012); Fan and Vercauteren (2012) that were inspired by Regev (2009)'s scheme. These secondgeneration homomorphic encryption schemes are more efficient than Gentry's original construction and also based on standard lattice problems via the learning with error problem.
The first work in this line of research is Brakerski and Vaikuntanathan (2014). Without using bootstrapping, Brakerski and Vaikuntanathan were able to construct an SHE scheme BV ∗ 13 that can perform a non-trivial number of homomorphic evaluations. With an additional dimension-modulus reduction step that we describe in Section 10.4, this scheme's efficiency can be further improved to allow it to achieve leveled FHE without using Gentry (2010)'s squashing idea, which needs an extra hardness assumption to guarantee a scheme's security.
The scheme is similar to Regev's scheme, which we describe in Section 1.3, but with minor changes and an evaluation key specifically for homomorphic multiplications. Given the security parameter λ , BV ∗ produces the parameters
$$\text {params} & = ( n , q , N , \chi ) \leftarrow B V ^ { * } . \text {Setup} ( 1 ^ { \lambda } )$$
just as in Regev. One difference is that q does not need to be a prime and is taken from a larger range q ∈ [2 n , 2 · 2 n ) , which is subexponential in n for a constant ∈ (0 , 1) . Also, the LWE sample size N ≥ n log q +2 k . Furthermore, the scheme has a pre-determined multiplication level for the arithmetic circuits that will be evaluated. This level parameter is approximately L ≈ log n for an arbitrary constant ∈ (0 , 1) , and only related to the number of keys that needs to be generated.
In the following, Z q denotes the symmetric range [ -q/ 2 , q/ 2) ∩ Z , which is different from its standard use for representing the ring Z / Z q = [0 , q ) . Also, y = [ x ] q denotes the reduction of x to within Z q such that [ x ] q = x mod q . The modulo q reduction (i.e., mod q ) is to be distinguished from [ x ] q , where the former is reduction to Z / Z q and the latter is to Z q . For simplicity, (in particular in the BFV scheme) we use r q ( x ) = x mod q to denote the remainder. We use boldface to denote vectors and matrices. When working with matrices, all vectors are by default considered as column vectors. Vector multiplications are denoted by a · b , whilst matrix (and sometimes scalar) multiplications are denoted without the 'dot' in the middle.
A distribution χ over the integers is B bounded, denoted by | χ | ≤ B , means χ is only supported on [ -B,B ] .
## Key generation
The important part of the key generation, which does not appear in Regev's scheme, is the generation of the evaluation key for relinearization, a term that will be explained in detail next. First, run Regev's secret key generation to produce a sequence of secret vectors
$$s _ { 0 } , \dots , s _ { L } \leftarrow B V ^ { * } . S e c r e t K e y g e n ( n , q ) , w h e r e s _ { i } = ( 1 , t _ { i } ) a n d t _ { i } \leftarrow \mathbb { Z } _ { q } ^ { n } , \forall i \in [ 0 , L ] .$$
Each of the L secret keys will then be embedded in the evaluation key that is used for relinearizing quadratic terms that appear during homomorphic multiplications. In particular, the evaluation key is a
13 We name the scheme after the authors' surname initials.
$$\text {set $\Psi=\{ \psi_{l,i,j,\tau}\}$} , 1 \leq l \leq L , 0 \leq i \leq j \leq n , 0 \leq \tau \leq \lfloor \log q \rfloor , \text {where} \\ \psi _ { l , i , j , \tau } \colon = \left ( a _ { l , i , j , \tau } , b _ { l , i , j , \tau } = [ a _ { l , i , j , \tau } \cdot s _ { l } + 2 \cdot e _ { l , i , j , \tau } + 2 ^ { \tau } \cdot s _ { l - 1 } [ i ] \cdot s _ { l - 1 } [ j ] ] _ { q } \right ) \\ \text {is computed by sampling a random vector} \, a _ { l , i , j , \tau } \leftarrow \mathbb { Z } ^ { n } \text { and a noise} \, e _ { l , i , j - } \leftarrow \gamma \text { One can interpret}$$
is computed by sampling a random vector a l,i,j,τ ← Z n q and a noise e l,i,j,τ ← χ . One can interpret the first element a l,i,j,τ of this tuple as the 'public key' and the second element b l,i,j,τ as an noisy 'encryption' under the secret key s l of the message 2 τ · s l -1 [ i ] · s l -1 [ j ] . This 'encrypted' message will be used to approximate a multiplicative ciphertext once it has gone through a multiplicative gate. (This will become clearer in Section 10.3.) Although the evaluation key is public, it is not needed to assume weak circular security to guarantee the scheme's security, because the secret key is not being encrypted by its corresponding public key. This also explains why the evaluation key is a series of key pairs rather than one pair.
The parameter τ corresponds to each bit position of a random Z q sample when represented in binary format. For example, if h i,j ∈ Z q then its binary form is h i,j = ∑ log q τ =0 2 τ h i,j,τ , where h i,j,τ ∈ { 0 , 1 } and log q is the maximum bit length minus 1. This particular set up is to reduce the relinearization error during homomorphic multiplications. It will also be discussed in more detail later.
The rest of the key generation process is similar to the corresponding process in Regev's. The secret key of BV ∗ for decryption is s L , the last secret vector in the sequence, indicating the ciphertexts have gone through the complete evaluation circuit of max depth L .
Taking the first secret vector t 0 generated above, the public key generation process adds an even integer noise vector to the ciphertext as in Regev's starred public key generation process to get the following public key in the matrix format
$$P = [ b | - A ] \leftarrow B V ^ { * } . P u b l i c K e y g e n ( n , q , N , \chi , t _ { 0 } ) ,$$
To summarise, the output of the key generation step is where A ← Z N × n q , and b = [ At 0 +2 e ] q for a random noise vector e ← χ N , and P ∈ Z N × ( n +1) q is the result of appending the column vector b to the front of the matrix -A .
$$( p k , s k , e v k ) \leftarrow B V ^ { * } . \text {Keygen} ( 1 ^ { \lambda } ) , \, \text {where} \\ p k = P \leftarrow B V ^ { * } . \text {PublicKeyGen} ( n , q , N , \chi , t _ { 0 } ) , \\ s k = s _ { L } \leftarrow B V ^ { * } . \text {SecretKeyGen} ( n , q ) ,$$
$$c ^ { l } = \left ( c = \left [ P ^ { T } r + m \right ] _ { q } , l \right ) \leftarrow B V ^ { * } . E n c ( P , m , n , q , N , l )$$
## Encryption
The encryption function is similar to Regev . Enc ( pk , m ) but has a level tag to keep track of the number of evaluated multiplicative gates, starting from 0 till the maximum value L . To encrypt a message m ∈ { 0 , 1 } using the public key, the algorithm concatenates m with 0s to get a length n + 1 vector m = ( m, 0 , . . . , 0) . It then generates r ←{ 0 , 1 } N and outputs the ciphertext as a two-tuple, where the first element c is a length n +1 vector.
## Decryption
The decryption is also identical to Regev . Dec ( sk , c ) , but the rounding operation is omitted because of the setting t = q so the noise can be eliminated by taking modulo 2. To decrypt the ciphertext c L = ( P T r + m , L ) , which has gone through the complete circuit, the algorithm computes
$$\begin{array} { r l } & { \left [ \left [ c \cdot s _ { L } \right ] _ { q } \right ] _ { 2 } \gets B V ^ { * } . D e c ( s _ { L } , c , q ) . } \end{array}$$
Substitute terms into the dot product, we get
$$[ c \cdot s _ { L } ] _ { q } & = [ ( b ^ { T } r + m ) - t _ { L } ^ { T } A ^ { T } r ] _ { q } \\ & = [ ( ( A t _ { L } ) ^ { T } r + 2 e ^ { T } r + m ) - t _ { L } ^ { T } A ^ { T } r ] _ { q } \\ & = [ m + 2 e ^ { T } r + t _ { L } ^ { T } A ^ { T } r - t _ { L } ^ { T } A ^ { T } r ] _ { q }$$
As long as the noise is well controlled such that the whole term m +2 e T r is within the symmetric range Z q , the decryption process will output the correct message m , after taking modulo 2 to get rid of the noise. Note the fresh ciphertext is encrypted under s 0 , but after it has gone through L multiplications, it becomes a ciphertext encrypted under s L , which explains why we have t L in the second equality in the above derivation.
## Homomorphic evaluation
The function f : { 0 , 1 } t → { 0 , 1 } to be evaluated is represented as a binary arithmetic circuit. As multiplications incur most of the noise and a ciphertext contains a tag to track the multiplicative depth, it is convenient to construct the circuit with arbitrary fan-in for addition '+' and fan-in 2 for multiplication ' × '. Furthermore, its layers are organized in a way that they contain only one type of arithmetic operations. That is, no layer contains both addition and multiplication operations. Finally, the circuit is assumed to have exactly L multiplicative depth. 14
For notational convenience, denote f c ( x ) := [ c · x ] q so that the evaluation of the function at x = s is equivalent to decryption of the ciphertext under the secret key. The evaluation algorithm BV ∗ . Eval ( evk , f, c 1 , . . . , c t ) is defined separately for addition and multiplication as done next. The key thing to note is that the ciphertext after going through each circuit gate should satisfy the invariant property
$$f _ { e } ( x ) \colon = [ e \cdot x ] _ { q } = [ m + 2 e ] _ { q } & & ( 3 6 )$$
for some noise term e that is not too large to make the whole term exceeds the range Z q . If it is beyond the range, there will be no guarantee that the exact noise can be eliminated by taking modulo 2. If the invariant property is guaranteed through all circuit gates, the final evaluated output can then be decrypted to the correct message. Therefore, checking the evaluations are homomorphic becomes checking the invariant property is guaranteed throughout the arithmetic circuit.
Homomorphic addition The addition of arbitrarily many ciphertexts c 1 , . . . , c t is performed by adding the ciphertexts component wise and leaving the level tag unchanged. That is,
$$\begin{array} { l } \mathbf c _ { a d d } ^ { l } = ( \mathbf c _ { a d d } , l ) \leftarrow \mathbf B V ^ { * } . \text {Add} ( \mathbf c _ { 1 } ^ { l } , \dots , \mathbf c _ { t } ^ { l } , q ) , \text { where} \\ \mathbf c _ { a d d } [ i ] = [ \mathbf c _ { 1 } [ i ] + \cdots + \mathbf c _ { t } [ i ] ] _ { q } \, , \text { for all $i\in[0,n]$} . \end{array}$$
To check that c l add satisfies the invariant Equation (36), we show that the decryption of the additive ciphertext equals the sum of the messages. That is,
$$f _ { \mathfrak { c } _ { a d d } } ( s _ { l } ) & = [ \mathfrak { c } _ { a d d } \cdot s _ { l } ] _ { q } \\ & = [ ( \mathfrak { c } _ { 1 } + \cdots + \mathfrak { c } _ { t } ) \cdot s _ { l } ] _ { q }
</doctag>$$
So long as the aggregated noise is well controlled such that the entire term is still within Z q , the decryption step will output the correct summed message after a further reduction by modulo 2.
Homomorphic multiplication The homomorphic multiplication algorithm involves the important relinearization step which reduces a quadratic to a linear function by approximation. To prove multiplication is also homomorphic, we need to define c mult and prove that f c mult ( x ) = [ f c 1 ( x ) · f c 2 ( x )] q just as in the homomorphic addition case. The trouble is that when multiplying two functions of x [ i ] , it
14 This circuit construction equalizes the number of multiplications and the multiplicative depth L . But in practice, what matters the most to the noise growth is the degree of the function being evaluated, not the number of multiplications. For example, both functions f ( a, b, c ) = a · b + b · c and g ( a, b, c ) = a · b · c contain two multiplications, but g is a degree three polynomial, hence incurs more noise after being evaluated.
relinearization becomes a quadratic function of x [ i ] . More precisely, writing f c ( x ) = [ ∑ n i =0 h i · x [ i ]] q as a function of x [ i ] , where the coefficient set ( h 0 , . . . , h n ) is the ciphertext c , we have
$$\left [ f _ { \mathfrak { c } _ { 1 } } ( \mathbf x ) \cdot f _ { \mathfrak { c } _ { 2 } } ( \mathbf x ) \right ] _ { q } = \left [ \left ( \sum _ { i = 0 } ^ { n } h _ { i } \cdot \mathbf x [ i ] \right ) \left ( \sum _ { i = 0 } ^ { n } h _ { j } \cdot \mathbf x [ j ] \right ) \right ] _ { q } = \left [ \sum _ { i , j = 0 } ^ { n } h _ { i , j } \cdot \mathbf x [ i ] \cdot \mathbf x [ j ] \right ] _ { q } .$$
The number of coefficients, which is essentially the ciphertext size, has gone up to approximately n 2 / 2 , as compared to n +1 coefficients in the previous linear function.
Relinearization One solution is to approximate the quadratic function by a linear function, known as relinearization . It implies the quadratic terms will be replaced by their linear approximates, with proper protections such as 'encrypting' s l [ i ] · s l [ j ] under a new secret key to make it a fresh linear ciphertext. More precisely, let the new secret key be ˙ s = (1 , ˙ t ) and the corresponding public key be ˙ P , then call the previous encryption subroutine to get the 'ciphertext'
$$\dot { c } _ { i , j } & \leftarrow B V ^ { * } . E n c ( \dot { P } , s _ { l } [ i ] \cdot s _ { l } [ j ] , n , q , N , l ) , \text { where} \\ \dot { c } _ { i , j } & = \left [ \dot { t } ^ { T } ( A ^ { T } r ) + s _ { l } [ i ] \cdot s _ { l } [ j ] + 2 e ^ { T } r | - A ^ { T } r \right ] _ { q } .$$
The ciphertext can also be decrypted by taking dot product with the new secret vector, so we get
$$f _ { \mathfrak { c } _ { i , j } } ( \dot { s } ) = [ \dot { c } _ { i , j } \cdot \dot { s } ] _ { q } = \left [ \widehat { t } ^ { T } ( A ^ { T } r ) + s _ { l } [ i ] \cdot s _ { l } [ j ] + 2 e ^ { T } r - \widehat { D } ^ { T } r \right ] _ { q } .$$
If the noise 2 e T r has small magnitude, the quadratic term [ s l [ i ] · s l [ j ]] q ≈ [ ˙ c i,j · ˙ s ] q can be well approximated by the dot product. So the evaluation of Equation (38) at x = s l becomes a linear function of the new secret vector ˙ s as shown below
$$[ f _ { c _ { 1 } } ( s _ { l } ) \cdot f _ { c _ { 2 } } ( s _ { l } ) ] _ { q } = \left [ \sum _ { i , j = 0 } ^ { n } h _ { i , j } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] \right ] _ { q } \approx \left [ \sum _ { i , j = 0 } ^ { n } h _ { i , j } \cdot ( \dot { c } _ { i , j } \cdot \dot { s } ) \right ] _ { q } = \left [ \sum _ { k = 0 } ^ { n } \dot { h } _ { k } \cdot \dot { s } [ k ] \right ] _ { q } ,$$
with only ( n +1) coefficients, a considerable reduction from its original quadratic form.
To further guarantee an accurate approximation of the quadratic function, it is necessary to keep each coefficient h i,j as small as possible, so that if [ s l [ i ] · s l [ j ]] q ≈ [ ˙ c i,j · ˙ s ] q is with small error, then the error stays small when multiplying each side by the coefficient [ h i,j · s l [ i ] · s l [ j ]] q ≈ [ h i,j · ˙ c i,j · ˙ s ] q . To achieve this, turn the coefficient h i,j to its binary form
$$h _ { i , j } = \sum _ { \tau = 0 } ^ { \lfloor \log q \rfloor } 2 ^ { \tau } \cdot h _ { i , j , \tau } \, m o d \, q = \left [ \sum _ { \tau = 0 } ^ { \lfloor \log q \rfloor } 2 ^ { \tau } \cdot h _ { i , j , \tau } \right ] _ { q } ,$$
where each h i,j,τ ∈ { 0 , 1 } and log q is the max bit length minus 1 for samples in Z q . The second equality is satisfied by definition of [ · ] q , in which [ x ] q = x mod q . Substitute this into the ciphertext multiplication, the LHS of the above approximation becomes
$$[ f _ { \mathfrak { c } _ { 1 } } ( s _ { l } ) \cdot f _ { \mathfrak { c } _ { 2 } } ( s _ { l } ) ] _ { q } = \left [ \sum _ { \substack { 0 \leq i , j \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } h _ { i , j , \tau } \cdot ( 2 ^ { \tau } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] ) \right ] _ { q }$$
and the new quadratic term to be approximated becomes
$$[ 2 ^ { \tau } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] ] _ { q } \approx [ \dot { c } _ { i , j } \cdot \dot { s } ] _ { q } \, .$$
By design, each element in the evaluation key is in the following format
$$\psi _ { l + 1 , i , j , \tau } \colon = \left ( a _ { l + 1 , i , j , \tau } , b _ { l + 1 , i , j , \tau } = [ a _ { l + 1 , i , j , \tau } \cdot s _ { l + 1 } + 2 \cdot e _ { l + 1 , i , j , \tau } + 2 ^ { \tau } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] ] _ { q } \right ) .$$
By arranging terms, it implies
$$\left [ 2 ^ { \tau } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] \right ] _ { q } \approx \left [ b _ { l + 1 , i , j , \tau } - a _ { l + 1 , i , j , \tau } \cdot s _ { l + 1 } \right ] _ { q } .$$
By now, it should be clear why the evaluation key was set up in that particular form. With this approximation, when evaluating Equation (39) at x = s l , it follows that
$$[ f _ { \mathfrak { c } _ { 1 } } ( s _ { l } ) \cdot f _ { \mathfrak { c } _ { 2 } } ( s _ { l } ) ] _ { q } = \left [ \sum _ { \substack { 0 \leq i , j \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } h _ { i , j , \tau } \cdot ( 2 ^ { \tau } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] ) \right ] _ { q }$$
We are now ready to define the multiplicative ciphertext for the inputs c l 1 and c l 2 as follows
$$\begin{array} { r } { c _ { m u l t } ^ { l + 1 } = ( c _ { m u l t } , l + 1 ) \leftarrow B V ^ { * } . M u l t ( e v k = \Psi , c _ { 1 } ^ { l } , c _ { 2 } ^ { l } , q ) , w h e r e } \end{array}$$
$$& \mathbf c _ { m u l t } = \left ( \left [ \sum _ { \substack { 0 \leq i , j \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } h _ { i , j , \tau } \cdot b _ { l + 1 , i , j , \tau } \right ] , \left [ \sum _ { \substack { 0 \leq i , j \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } h _ { i , j , \tau } \cdot a _ { l + 1 , i , j , \tau } \right ] _ { q } \right ) \in \mathbb { Z } ^ { n + 1 } _ { q } ,$$
To verify that c mult satisfies the invariant property in Equation (36), we work through the following derivation
$$c _ { m u l t } = \left [ \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot b _ { l + 1 , i , j , \tau } \right ] _ { q } , \, \left [ \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot a _ { l + 1 , i , j , \tau } \right ] _ { q } \right ] _ { q } \in \mathbb { Z } ^ { n + 1 } _ { q } , \quad ( 4 1 ) \\ = \left [ \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot ( b _ { l + 1 , i , j , \tau } - a _ { l + 1 , i , j , \tau } \cdot s _ { l + 1 } ) \right ] _ { q } \\ = \left [ \sum _ { 0 \leq \tau \leq \lfloor \log q \rfloor } h _ { i , j , \tau } \cdot ( b _ { l + 1 , i , j , \tau } - a _ { l + 1 , i , j , \tau } \cdot s _ { l + 1 } ) \right ] _ { q } \\ = \left [ \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot ( 2 e _ { l + 1 , i , j , \tau } + 2 ^ { \tau } \cdot s _ { l } [ i ] \cdot s _ { l } [ j ] ) \right ] _ { q } \\ = \left [ f _ { c _ { 1 } } ( s _ { l } ) \times f _ { c _ { 2 } } ( s _ { l } ) + \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot 2 e _ { l + 1 , i , j , \tau } \right ] _ { q } \\ = \left [ ( m _ { 1 } + 2 e _ { 1 } ) \times ( m _ { 2 } + 2 e _ { 2 } ) + \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot 2 e _ { l + 1 , i , j , \tau } \right ] _ { q } \\ = \left [ m _ { 1 } \times m _ { 2 } + 2 \underbrace { ( m _ { 1 } \cdot e _ { 2 } + m _ { 2 } \cdot e _ { 1 } + 2 e _ { 1 } \cdot e _ { 2 } + \sum _ { 0 \leq i , j \leq n } h _ { i , j , \tau } \cdot e _ { l + 1 , i , j , \tau } ) } _ { \text {noise} } \right ] _ { q } .$$
Therefore, to guarantee the decryption can correctly produce m 1 × m 2 , it is necessary to keep the noise small enough so that the whole term in Equation (42) is within Z q .
## 10.4 BV : Leveled FHE by dimension-modulus reduction
The BV ∗ scheme presented above (with relinearization) produces a constant ciphertext c in the domain Z ( n +1) q , with the maximum bit length ( n + 1) log q , which is considered quite large for large values of n and q . To reduce it, consequently reduce the decryption complexity to make the scheme more bootstrappable (without the need for squashing), Brakerski and Vaikuntanathan (2014) performed a dimension-modulus reduction at the completion of homomorphic evaluations. This reduction step was later used in Brakerski et al. (2014) and Brakerski (2012) to achieve fully leveled HE without using bootstrapping. Below, we discuss dimension-modulus reduction and how it helps to reduce ciphertext bit length.
## 10.4.1 Modulus reduction to reduce ciphertext size
The reduction step consists of two parts, the modulus reduction and the dimension reduction. The reduction in modulus is achieved by scaling down ciphertexts by the factor p/q where p < q . The next definition defines the scale of an integer vector, which in our context is a ciphertext.
Definition 10.4.1. Let x be an integer vector. For integers m < p < q , an integer vector x ′ ← Scale ( x , q, p, r ) is the scale of x Scale if it is the vector closest to ( p/q ) · x that satisfies x ′ = x mod r .
Modulus reduction
The correctness of modulus reduction is captured in the following lemma, which is a special case of the first part of Lemma 5 of Brakerski et al. (2014). The parameter r = 2 implies q = p = 1 mod 2 are odd integers. Below, we use || x || to denote the l 1 -norm of the vector x .
Example 10.4.2. Let p = 5 , q = 11 , r = 2 , then the scale of the vector c = (5 , 6) is c ′ = (3 , 2) , because it is the closest integer vector to (5 / 11) · (5 , 6) and c ′ = c mod 2 .
Lemma 10.4.3. Let q and p be two odd moduli such that p < q . Let c be an integer vector and c ′ ← Scale ( c , q, p, 2) be the scale of c . Then for any vector s with || [ c · s ] q || < q/ 2 -( q/p ) · || s || , it satisfies
$$\left [ \left [ c ^ { \prime } \cdot s \right ] _ { p } \right ] _ { 2 } = \left [ \left [ c \cdot s \right ] _ { q } \right ] _ { 2 } .$$
Proof. By definition of modulo operation, there exists a unique integer k such that [ c · s ] q = c · s -kq ∈ [ -q/ 2 , q/ 2) . Using the integer k , we can define a noise term
By taking modulo p , the noise satisfies e p = [ c ′ · s ] p mod p . If we can show e p = [ c ′ · s ] p without taking modulo p , it then follows that
$$e _ { p } = c ^ { \prime } \cdot s - k p \in \mathbb { Z } .$$
$$[ c ^ { \prime } \cdot s ] _ { p } = e _ { p } = c ^ { \prime } \cdot s - k p = c \cdot s - k q = [ c \cdot s ] _ { q } \bmod 2 .$$
$$\begin{array} { r l } & { e _ { p } = c ^ { \prime } \cdot s + \frac { p } { q } \cdot ( - k q ) = c ^ { \prime } \cdot s + \frac { p } { q } \cdot \left ( [ c \cdot s ] _ { q } - c \cdot s \right ) = \frac { p } { q } \cdot \left [ c \cdot s \right ] _ { q } + ( c ^ { \prime } - \frac { p } { q } c ) \cdot s . } \end{array}$$
To show e p = [ c ′ · s ] p , it is sufficient to prove its norm satisfies || e p || < p/ 2 . Re-write the noise as
We can show its norm satisfies
$$\begin{array} { r l } & { c ^ { \prime } \cdot s + \frac { 1 } { q } \cdot ( - k q ) = c ^ { \prime } \cdot s + \frac { 1 } { q } \cdot ( [ c \cdot s ] _ { q } - c \cdot s ) = \frac { 1 } { q } \cdot [ c \cdot s ] _ { q } + ( c ^ { \prime } - \frac { 1 } { q } c ) } \\ & { i t h e n r o m s a t i s f i e s } \\ & { | | e _ { p } | | = | | \frac { p } { q } \cdot [ c \cdot s ] _ { q } + ( c ^ { \prime } - \frac { p } { q } \cdot c ) \cdot s | | } \\ & { \leq \frac { p } { q } \cdot | | [ c \cdot s ] _ { q } | | + | | ( c ^ { \prime } - \frac { p } { q } \cdot c ) \cdot s | | } \\ & { \leq \frac { p } { q } \cdot | | [ c \cdot s ] _ { q } | | + \sum _ { i = 1 } ^ { n } | | ( c ^ { \prime } [ i ] - \frac { p } { q } \cdot c [ i ] ) | | \cdot | | s [ i ] | | } \\ & { \leq \frac { p } { q } \cdot | | [ c \cdot s ] _ { q } | | + 1 \cdot \sum _ { i = 1 } ^ { n } | | s [ i ] | | } \\ & { < p / 2 . } \end{array}$$
The last inequality follows from the assumption of the vector s as stated in the Lemma's premises. The third last inequality follows because c ′ is close to ( p/q ) · c and they are congruent modulo 2. In this case, each element differs by at most 1.
modulus reduction
## 10.4.2 The BV scheme
The improved version of BV ∗ , named BTS in Brakerski and Vaikuntanathan (2014), employs BV ∗ as its building block and reduces the ciphertext dimension and modulus by a reduction step. We rename BTS to BV in this tutorial to make it more recognizable when comparing with subsequent works. The main benefit of adding the reduction step once a ciphertext has gone through the complete circuit is that BV becomes bootstrappable without the squashing step used by Gentry (2009). In addition to the parameters in params = ( n, q, N, χ ) in BV ∗ , this improved scheme takes on three additional parameters ( k, p, ˆ χ ) to cope with the dimension-modulus reduction step. The parameters k and p are a smaller dimension and modulus, respectively. The new noise distribution ˆ χ is over the smaller domain Z p to produce smaller integer noise. The sub-routines of BV are listed as follows.
Key generation The key generation first runs the sub-routine
$$( P , s _ { L } , \Psi ) & \leftarrow B V ^ { * } . K e y g e n ( p a r m s ) . \\ \intertext { t h e c o u n d i v e $ b v$ in s u m w t e d l u $ b v$ }$$
Its public key is set to P . The secret key is generated by
$$\hat { s } & \leftarrow B V . S e c r e t K e y g e n ( k , p ) \\$$
from a smaller domain Z k p with a lower dimension. This new secret key is to decrypt a ciphertext of reduced dimension and modulus. The BV ∗ evaluation key Ψ becomes part of the new evaluation key (Ψ , ˆ Ψ) for BV, because it is needed for homomorphic multiplication which runs BV ∗ . Mult () as a subroutine. The extra piece ˆ Ψ = { ˆ ψ i,τ } i,τ 'encrypts' the secret vector 2 τ · s L in a similar fashion as Ψ 'encrypts' 2 τ · s l -1 [ i ] · s l -1 [ i ] , except here the 'encryption' of 2 τ · s L is for approximating a ciphertext by another ciphertext with smaller dimension and modulus. More precisely,
$$\begin{array} { r l } & { \hat { \psi } _ { i , \tau } = ( \hat { a } _ { i , \tau } , \hat { b } _ { i , \tau } ) , w h e r e } \\ & { \hat { a } _ { i , \tau } \leftarrow \mathbb { Z } _ { p } ^ { k } } \\ & { \hat { e } _ { i , \tau } \leftarrow \hat { \chi } } \\ & { \hat { b } _ { i , \tau } = \hat { a } _ { i , \tau } \cdot \hat { s } + \hat { e } _ { i , \tau } + \left [ \frac { p } { q } \cdot ( 2 ^ { \tau } \cdot s _ { L } [ i ] ) \right ] \bmod p . } \end{array}$$
$$\hat { b } _ { i , \tau } = \hat { a } _ { i , \tau } \cdot \hat { s } + \hat { e } _ { i , \tau } + \left \lfloor \frac { p } { q } \cdot ( 2 ^ { \tau } \cdot s _ { L } [ i ] ) \right \rfloor \bmod p .$$
The important observation is that both ˆ a and ˆ s are of dimension k and modulus p , which are different from their counterparts in Z n q produced by BV ∗ . Keygen ( params ) . These setups will lead to smaller ciphertexts as we will see later. Note the noise in ˆ b i,τ is not multiplied by 2. This does not pose an issue when eliminating the noise by modulo 2, because the whole noise term will be multiplied by 2 at a later stage. To summarise, the output of BV's key generation step is
$$( p k = P , s k = \hat { s } , e v k = ( \Psi , \hat { \Psi } ) ) \leftarrow B V . K e y g e n ( p a r a m s , k , p , \hat { \chi } ) .$$
Encryption and decryption The encryption and decryption steps are identical to that of BV ∗ , but with a different decryption parameter.
$$\begin{array} { r l } & { c ^ { l } = \left ( c = \left [ P ^ { T } r + m \right ] _ { q } , l \right ) \gets B V . E n c ( P , m , n , q , N ) } \\ & { \quad m = \left [ \left [ \hat { c } \cdot ( 1 , \hat { s } ) \right ] _ { p } \right ] _ { 2 } \gets B V . D e c ( \hat { s } , \hat { c } , p ) } \end{array}$$
$$[ \hat { c } \cdot ( 1 , \hat { s } ) ] _ { p } \right ] _ { 2 } \leftarrow B$$
Homomorphic evaluation The evaluation algorithm runs the following sub-routines
$$c ^ { l } & \leftarrow B V ^ { * } . A d d ( e v k = \Psi , c _ { 1 } ^ { l } , \dots , c _ { t } ^ { l } , q ) \\ c ^ { l + 1 } & \leftarrow B V ^ { * } . M u l t ( e v k = \Psi , c _ { 1 } ^ { l } , c _ { 2 } ^ { l } , q ) .$$
$$1$$
Once the complete circuit has been evaluated, it is followed by a dimension-modulus reduction before decryption starts.
Dimension-modulus reduction By Lemma 10.4.3, modulus reduction is a valid step that guarantees correct decryption. In Brakerski and Vaikuntanathan (2014), the modulus reduction is made possible by multiplying the decryption equivalent function f c ( x ) = c · x by the factor p/q to scale its coefficients down to within the new domain to get a new decryption equivalent function
$$\phi ( x ) = \left [ { \frac { p } { q } } \cdot \left ( { \frac { q + 1 } { 2 } } \cdot ( c \cdot x ) \right ) \right ] _ { p } = \left [ \sum _ { i = 0 } ^ { n } h _ { i } \cdot \left ( { \frac { p } { q } } \cdot x [ i ] \right ) \right ] _ { p } .$$
The fractional term ( q +1) / 2 is the inverse of 2 in modulo q . It is useful for getting rid of the coefficient in front of the encrypted message m .
The reduction of ciphertext dimension is achieved by approximating the longer vector x by a shorter one. It follows a similar approximation strategy for the quadratic terms in BV ∗ . The first thing is to turn h i to its binary form to keep a smaller approximation error. The function then becomes
$$\phi ( { x } ) = \left [ \sum _ { \substack { 0 \leq i \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } h _ { i , \tau } \cdot \left ( \frac { p } { q } \cdot 2 ^ { \tau } \cdot { x } [ i ] \right ) \right ] _ { p } .$$
The term inside the bracket now looks like a part of ˆ b i,τ in the evaluation key ˆ ψ i,τ , so the function can be approximated using the second half of the evaluation key as
$$\phi ( x ) \approx \left [ \sum _ { \substack { 0 \leq i \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } h _ { i , \tau } \cdot \left ( \hat { b } _ { i , \tau } - \hat { a } _ { i , \tau } \cdot \hat { s } \right ) \right ] _ { p } .$$
This gives rise to a revised ciphertext dimension reduction
$$\hat { c } = \left ( \left [ \sum _ { \substack { 0 \leq i \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } 2 \cdot h _ { i , \tau } \cdot \hat { b } _ { i , \tau } \right ] _ { q } , \left [ \sum _ { \substack { 0 \leq i \leq n \\ 0 \leq \tau \leq \lfloor \log q \rfloor } } 2 \cdot h _ { i , \tau } \cdot \hat { a } _ { i , \tau } \right ] _ { q } \right ) \in \mathbb { Z } _ { p } ^ { k + 1 }$$
in the domain Z k +1 p with a smaller set Z p and a lower dimension k +1 . The new ciphertext bit length is therefore reduced to ( k + 1) log p from ( n + 1) log q . In general, the use of ciphertexts of smaller dimension and modulus introduces an approximation error that is in addition to those incurred during homomorphic evaluations. This additional error, however, does not become an issue for decryption, so long as the ciphertext space is large enough to incorporate both types of errors.
As it was proved in the analysis of BV ∗ , this dimension-modulus reduction also satisfies the invariant property stated by Equation (36). The detailed proof can be found at the end of Section 4.2 of Brakerski and Vaikuntanathan (2014). The homomorphic properties can be proved by showing that the evaluated ciphertexts after running BV ∗ 's evaluation process and BV's dimension-modulus reduction process are still within Z q , provided the parameters are set at the appropriate values. Details can be found in Section 4.3 and Section 4.4 of Brakerski and Vaikuntanathan (2014).
## 10.4.3 BV is bootstrappable
To see BV is bootstrappable and hence can be made fully HE within a pre-determined level (i.e., leveled FHE), we introduce the function class Arith [ L, T ] that consists of arithmetic circuits over the message space { 0 , 1 } with only addition and multiplication gates such that each circuit has 2 L +1 layers, where the odd layers contain only the add gates with fan-in T and the even layers contain only the multiply gates with fan-in 2. The following theorem states that BV and BV ∗ are capable of evaluating certain size arithmetic circuits.
Theorem 10.4.4 (Theorem 4.3 (Brakerski and Vaikuntanathan, 2014)) . Let n = n ( λ ) ≥ 5 be a polynomial of the security parameter, q ≥ 2 n ≥ 3 be an odd modulus for ∈ (0 , 1) , χ be an n -bounded distribution and N = ( n +1)log q +2 λ . Furthermore, let k = λ , p = 16 nk log(2 q ) be odd and ˆ χ be a k -bounded distribution. Then BV ∗ and BV are both Arith [ L = Ω( log n ) , T = √ q ] -homomorphic.
As it was further proved by Lemma 4.6 of Brakerski and Vaikuntanathan (2014) that BV's decryption is a circuit with 2 fan-in and O (log k + log log p ) depth, the decryption circuit is in Arith [ O (log k ) , 1] , even with an augmented addition or multiplication gate. Hence, as long as the parameter n is made sufficiently large, the decryption circuit is included in the class Arith [ L = Ω( log n ) , T =
√ q ] , which implies the encryption scheme BV is bootstrappable and can be made leveled FHE. The generation of the relinearization key requires the circuit maximum level to be pre-specified. It constraints the scheme from getting to (non-leveld) FHE . This situation can be avoided by assuming weak circular security, which then simplifies the size of the relinearization key to just one pair of keys and hence gets rid of the prerequisite for L being pre-determined.
## 10.5 Additional tools for computational efficiency
## 10.5.1 Noise management by modulus switching
Asubsequent work inspired by BV proposed a more efficient encryption scheme, namely BGV (Brakerski et al., 2014) (again by the authors' surname initials), which can achieve leveled FHE without going through the computationally expensive bootstrapping step. This scheme applies a modulus switching (similar to modulus reduction) step after each homomorphic addition and multiplication in order to reduce the accumulated noise magnitude. The advantage of this noise reduction is not only on its absolute magnitude, but the deceleration of the gap reduction between the noise level and noise ceiling, so that a scheme combined with the modulus switching can handle more ciphertext multiplications before decryption fails.
Take the following case as an example. Let the ciphertext space modulus be q = x 16 for some x , which is also the noise ceiling. If two ciphertexts have a noise magnitude x , their multiplication produces a ciphertext with noise magnitude roughly x 2 . After 4 multiplications, the ciphertext has noise magnitude x 16 , which has reached the ceiling. So the scheme can handle circuits with multiplicative depth at most 4. If at the end of each ciphertext multiplication, the modulus is switched to a smaller modulus p = q/x , although the noise ceiling is also reduced in the mean time, the scheme can now handle 16 multiplications. More precisely, after the first multiplication, the ciphertext has noise magnitude x 2 , which is then scaled down to x by modulus switching to the ciphertext space Z p with p = q/x . In the mean time, the noise ceiling is scaled down to p = q/x = x 15 . Repeat modulus switching 16 times, the noise level remains at x and noise ceiling meets the noise level at x , so the scheme reaches its maximum number of multiplications. Therefore, without relying on bootstrapping, the combined scheme with modulus switchings can handle a decent number of multiplications.
The noise reduction property of modulus switching is captured in Lemma 10.4.3 presented earlier for modulus reduction.
## 10.5.2 Vector decomposition
Vector decomposition consists of two functions. The first function, BitDecomp () , decomposes a vector of length n to a vector of length nl , where l is the maximum bit length in the domain Z q . The benefit of decomposing an integer vector is to minimize the error when switching the ciphertext from one secret key to another. The second function, PowersOfTwo(), is defined in relation to the first one, so that the dot product of these two functions preserves the dot product of the original two vectors.
BitDecomp q ( x ) Let x = ( x 1 , . . . , x n ) ∈ Z n and l = log q . Each x i mod q can be written in binary representation (from least significant bit to most significant bit) as follows
$$</text>
</doctag>$$
Let w i = ( x 1 ,i , . . . , x n,i ) be the set of i-th binary bits. The bit decomposition function is defined as BitDecomp ( x ) ( w , . . . , w -) .
The w i 's so-constructed thus satisfy x = ∑ l -1 i =0 2 i · w i mod q .
$$\begin{array} { r } { o m p _ { q } ( x ) \to ( w _ { 0 } , \dots , w _ { l - 1 } ) . } \end{array}$$
For example, consider the case when x = (1 , 3) ∈ Z 2 , q = 4 , and l = log 4 = 2 . The decomposed vectors are w 0 = (1 , 1) and w 1 = (0 , 1) , and they satisfy
$$\sum _ { i = 0 } ^ { 1 } 2 ^ { i } \cdot w _ { i } = 1 \cdot ( 1 , 1 ) + 2 \cdot ( 0 , 1 ) = ( 1 , 3 ) = x \bmod 4 .$$
So BitDecomp q ( x ) = (1 , 1 , 0 , 1) ∈ { 0 , 1 } 4 .
PowersOfTwo q ( y ) Let y ∈ Z n , the powers of two function produces a vector by multiplying y with 2 i in modulo q for each i ∈ [0 , l -1] . That is,
$$I f \, y = ( 3 , 2 ) , t h e n P o w e r s O f T w o _ { 4 } ( y ) = ( 3 , 2 , 2 , 0 ) .$$
$$\begin{array} { r } { P o w e r s O f T w o _ { q } ( y ) \rightarrow [ ( y , y \cdot 2 , \dots , y \cdot 2 ^ { l - 1 } ) ] _ { q } \in \mathbb { Z } _ { q } ^ { n l } . } \end{array}$$
It is not hard to see the next equality. That is, the dot product of the two vectors is congruent to the dot product of the two functions modulo q , which then leads to the dot product of the two functions in the range Z q .
$$x \cdot y = B i t D e c o m p _ { q } ( x ) \cdot P o w e r s O f T w o _ { q } ( y ) \bmod q = \left [ B i t D e c o m p _ { q } ( x ) \cdot P o w e r s O f T w o _ { q } ( y ) \right ] _ { q }$$
## 10.5.3 Key switching
The key switching process is to transform a ciphertext encrypted under a secret key s 1 = (1 , t 1 ) ∈ Z n 1 +1 q to a different ciphertext encrypted under a secret key s 2 = (1 , t 2 ) ∈ Z n 2 +1 q , while preserving the secret message. Note that n 1 = n 2 in general. There are two functions in this process. The first function hides s 1 under s 2 . The second function uses the auxiliary information from the first function to transform a ciphertext to under the secret key s 2 . In the following description, N 1 = ( n 1 +1) · log q .
SwitchKeyGen q,χ ( s 1 , s 2 ) This function encrypts the value of PowersOfTwo q ( s 1 ) under the secret key s 2 = (1 , t 2 ) . The steps are as follows. Sample a matrix A s 1 : s 2 ← Z N 1 × n 2 q and a noise vector e s 1 : s 2 ← χ N 1 . Then compute and publish the concatenated matrix
$$\begin{array} { r } { b _ { s _ { 1 } \colon s _ { 2 } } = [ A _ { s _ { 1 } \colon s _ { 2 } } t _ { 2 } + e _ { s _ { 1 } \colon s _ { 2 } } + P o w e r s O f T w o _ { q } ( s _ { 1 } ) ] _ { q } \in \mathbb { Z } _ { q } ^ { N _ { 1 } } } \end{array}$$
$$P _ { s _ { 1 } \colon s _ { 2 } } = [ b _ { s _ { 1 } \colon s _ { 2 } } | - A _ { s _ { 1 } \colon s _ { 2 } } ] \in \mathbb { Z } _ { q } ^ { N _ { 1 } \times ( n _ { 2 } + 1 ) } .$$
Despite the fact that the encrypted message is PowersOfTwo q ( s 1 ) , the output matrix P s 1 : s 2 looks exactly like a public key in the Regev's scheme. This auxiliary information is precisely what enables the ciphertext transformation between different secret keys.
SwitchKey q ( P s 1 : s 2 , c s 1 ) To transform a ciphertext c s 1 ∈ Z n 1 +1 q to a new one encrypted under the secret key s 2 , compute
$$c _ { s _ { 2 } } = [ B i t D e c o m p _ { q } ( c _ { s _ { 1 } } ) ^ { T } P _ { s _ { 1 } \colon s _ { 2 } } ] _ { q } \in \mathbb { Z } _ { q } ^ { n _ { 2 } + 1 } .$$
To verify that this transformation preserves the secret message (as proved by Lemma 3 of Brakerski et al. (2014)), we see that for s i = (1 , t i )
$$[ \mathbf c _ { s _ { 2 } } \cdot \mathbf s _ { 2 } ] _ { q } & = [ [ \text {\tt BitDecomp} _ { q } ( \mathbf c _ { s _ { 1 } } ) ^ { T } \mathbf P _ { \mathbf s _ { 1 } \colon \mathbf s _ { 2 } } ] _ { q } \cdot \mathbf s _ { 2 } ] _ { q } \\ & = [ \text {\tt BitDecomp} _ { q } ( \mathbf c _ { s _ { 1 } } ) ^ { T } ( \mathbf P _ { \mathbf s _ { 1 } \colon \mathbf s _ { 2 } } \mathbf s _ { 2 } ) ] _ { q } \\ & = [ \text {\tt BitDecomp} _ { q } ( \mathbf c _ { s _ { 1 } } ) ^ { T } ( \mathbf b _ { \mathbf s _ { 1 } \colon \mathbf s _ { 2 } } - \mathbf A _ { \mathbf s _ { 1 } \colon \mathbf s _ { 2 } } \cdot \mathbf t _ { 2 } ) ] _ { q } \\ & = [ \text {\tt BitDecomp} _ { q } ( \mathbf c _ { s _ { 1 } } ) ^ { T } ( \mathbf e _ { \mathbf s _ { 1 } \colon \mathbf s _ { 2 } } + \text {\emph{PowersOfTwo}q} ( \mathbf s _ { 1 } ) ) ] _ { q } \\ & = [ \text {\tt BitDecomp} _ { q } ( \mathbf c _ { s _ { 1 } } ) \cdot \text {\emph{e}s_1\colon s _ { 2 } } + \text {\emph{BitDecomp}$_q} ( \mathbf c _ { s _ { 1 } } ) \cdot \text {\emph{PowersOfTwo}q} ( \mathbf s _ { 1 } ) ] _ { q } \\ & = [ \mathbf c _ { s _ { 1 } } \cdot \mathbf s _ { 1 } + \underbrace { \text {\emph{BitDecomp}$_q} ( \mathbf c _ { s _ { 1 } } ) \cdot \mathbf e _ { \mathbf s _ { 1 } \colon \mathbf s _ { 2 } } } _ { \text {\emph{error}} } ] _ { q } .$$
The error is of small magnitude because BitDecomp q ( c s 1 ) is a binary vector. This also reveals the motivation of defining the vector decomposition procedure.
The security of the key switching procedure needs both functions to be secure. The second function SwitchKey q ( P s 1 : s 2 , c s 1 ) is obviously semantically secure, because its output is a transformation of the original ciphertext, which is encrypted by a semantically secure procedure. If it is not semantically secure, it becomes a PPT algorithm to solve the LWE problem. The first function's output is the auxiliary information P s 1 : s 2 , so its security means this output must be computationally indistinguishable from a uniform matrix sampled from the same domain Z N 1 × ( n 2 +1) q . This again relies on the result that DLWE is hard to solve. See Lemma 3.6 of Brakerski (2012) or Lemma 4 of (Brakerski et al., 2014) for a more formal statement of SwitchKeyGen q,χ ( s 1 , s 2 ) 's security.
Tensor product
## 10.6 BGV : Leveled FHE by modulus and key switching
As mentioned above, the BGV scheme can be made leveled FHE without using the computationally expensive bootstrapping step. This is achieved by iteratively refreshing an evaluated (especially multiplicative) ciphertext by modulus switching. The BGV scheme also uses Regev's encryption scheme as its building block. The security assumption, however, is based the hardness of either LWE or RLWE. The two problems are summarized as General LWE (GLWE) , with a binary indicator b = 0 indicates LWE and b = 1 indicates RLWE. For this reason, the encryption scheme needs a slightly different parameter set params = ( n, d, q, N, χ ) to incorporate the RLWE problem, where d corresponds to the quotient polynomial degree in RLWE.
Below we present each step of the BGV scheme, after a brief note on tensor products.
For n -dimensional vectors x and y , their tensor product x ⊗ y is a n × n matrix or an n 2 -dimensional vector, where each element has the form x [ i ] · y [ j ] . For example, for the vectors x = ( x 1 , x 2 ) and y = ( y 1 , y 2 ) , their tensor product is the 2 by 2 matrix
$$x \otimes y = { \binom { x _ { 1 } y _ { 1 } } { x _ { 2 } y _ { 1 } } } \, \begin{pmatrix} x _ { 1 } y _ { 1 } & x _ { 1 } y _ { 2 } \\ x _ { 2 } y _ { 1 } & x _ { 2 } y _ { 2 } \end{pmatrix} .$$
The notion of tensor product will appear in ciphertext multiplications, which result in functions of the tensor product elements x [ i ] · y [ j ] . A property of the tensor product that will be useful later is 〈 x ⊗ y , v ⊗ w 〉 = 〈 x , v 〉 · 〈 y , w 〉 . This relation is particularly useful when decrypting a ciphertext tensor using a secret key tensor 〈 c 1 ⊗ c 2 , s 1 ⊗ s 2 〉 = 〈 c 1 , s 1 〉 · 〈 c 2 , s 2 〉 , where the decryption can be done separately.
Setup Given the security parameter λ , arithmetic circuit's multiplicative depth L and the GLWE indicator b ∈ { 0 , 1 } , the encryption scheme starts by choosing appropriate parameter values to ensure the specific GLWE problem is 2 λ -secure. Furthermore, it specifies an extra parameter µ = µ ( λ, L, b ) = θ (log λ + log L ) that decides the size of the modulus q . More precisely, at each level j ∈ { L, L -1 , . . . , 0 } , the Setup step generates a sequence of parameter sets
$$\ p a r m { s } _ { j } \leftarrow B G V . S e t u p ( 1 ^ { \lambda } , 1 ^ { ( j + 1 ) \cdot \mu } , b ) ,$$
including a sequence of moduli q L , . . . , q 0 , whose sizes decrease from ( L +1) · µ bits to µ bits. These moduli will be used in modulus switching to manage ciphertext noise.
Key generation For j = L to 0, generate a sequence of secret vectors as the secret key for BGV as follows:
$$s k = \{ s _ { L } , \dots , s _ { 0 } \} \leftarrow B G V . S e c r e t K e y g e n ( \{ n _ { j } , q _ { j } \} _ { j } ) ,$$
These secret vectors will be used in key switching, where a ciphertext is transformed to another ciphertext under a different secret key. To allow key switching, compute the tensor product of each s j with itself to get where s j = (1 , t j ) , t i ← Z n j q j for LWE and t i ← χ n j from the domain R n j q j for RLWE.
$$s _ { j } ^ { \prime } = s _ { j } \otimes s _ { j }$$
For all j ∈ [ L -1 , 0] , 'encrypt' the tensor product s ′ j +1 under the next secret vector s j by running the key switching sub-routine to produce the auxiliary information
$$\tau _ { s ^ { \prime } _ { j + 1 } \rightarrow s _ { j } } \leftarrow S w i t c H e x G e n ( s ^ { \prime } _ { j + 1 } , s _ { j } ) .$$
Finally, we use Regev's public key generation step to produce a sequence of random matrices as part of the public key for BGV.
$$\begin{array} { r l } & { P _ { j } = [ \mathbf b _ { j } | - A _ { j } ] \leftarrow B G V . P u b l c K e y g e n ( s _ { j } = ( 1 , t _ { j } ) , N , \chi , p a r m s _ { j } ) , f o r a l l j \in [ L , 0 ] , } \\ & { N . } \end{array}$$
where A j ← Z N × n j q j , and b j = [ A j t j +2 e ] q j for a random noise vector e ← χ N .
In summary, the public key of the BGV scheme is
$$p k = \{ P _ { L } , \dots , P _ { 0 } , \tau _ { s _ { L } ^ { \prime } \rightarrow s _ { L - 1 } } , \dots , \tau _ { s _ { 1 } ^ { \prime } \rightarrow s _ { 0 } } \} \leftarrow B G V . P u b l k e y g e n ( s k , p a r m s ) .$$
Encryption The encryption of a message m ∈ { 0 , 1 } is identical to Regev's encryption, that is, generate a random vector r ←{ 0 , 1 } N then compute the ciphertext
$$c = \left [ P _ { L } ^ { T } r + m \right ] _ { q _ { L } } \gets B G V . E n c ( P _ { L } , m , n _ { L } , q _ { L } , N )$$
Decryption The decryption of a ciphertext that is encrypted under the secret key s j is also identical to Regev's decryption
$$\left [ \left [ c \cdot s _ { j } \right ] _ { q _ { j } } \right ] _ { 2 } \gets B G V . D e c ( s _ { j } , c , q _ { j } )$$
Homomorphic evaluation Given two ciphertext c 1 and c 2 that are encrypted under the same secret key s j , the addition and multiplication of the two ciphertexts respectively produce the evaluated ciphertext
$$locateq{c_add} = c_1 + c_2
c_{mult} = c_1 \cdot c_2,$$
where addition is performed component wise as in Equation (37) and multiplication is the expansion of the ciphertext multiplication as in Equation (38). Both evaluated ciphertexts are the coefficient vectors of the linear equations over the tensor product x ⊗ x , so they can be decrypted by the secret key s ′ j = s j ⊗ s j .
Refresh The key component of BGV is the refresh step that is done after each homomorphic evaluation. It contains two sub-routines.
1. Switch key: The first sub-routine transforms a ciphertext to another ciphertext, both encrypt the same message but under different secret keys. Denote c s ′ j q j ∈ { c add , c mult } a ciphertext that is encrypted under the secret key s ′ j , then
$$c _ { q _ { j } } ^ { s _ { j - 1 } } \leftarrow S u n t c h K e y _ { q _ { j } } ( \tau _ { s _ { j } ^ { \prime } \rightarrow s _ { j - 1 } } , c _ { q _ { j } } ^ { s _ { j } ^ { \prime } } ) .$$
2. Switch modulus: The second sub-routine reduces the ciphertext modulus in order to increase the gap between the noise ceiling and the ciphertext noise, while reducing both values at the same time. It runs the scale function to produce
$$\begin{array} { r } { c _ { q _ { j - 1 } } ^ { s _ { j - 1 } } \leftarrow S c a l e ( c _ { q _ { j } } ^ { s _ { j - 1 } } , q _ { j } , q _ { j - 1 } , 2 ) . } \end{array}$$
The BGV scheme is simpler than BV, in the sense that it does not relinearize quadratic ciphertext. In addition, the scheme is leveled FHE with no bootstrapping and its hardness is based on GLWE. The correctness of BGV is proved separately for each step by Lemma 6, 7, 8, 9 and 10 of Brakerski et al. (2014) respectively. Most of the hard work for these correctness proofs have been done in the correctness proofs of the building block encryption scheme, the modulus switching and key switching routines. The intuition is identical to correctness of previous schemes, that is, so long as the noise is well controlled and does not wrap around the modulus q j (i.e., noise ceiling), decryption will produce the correct message. In Section 5.4, Brakerski et al. (2014) guaranteed the parameters of BGV can be set to achieve such a goal.
In addition to removing dependence on bootstrapping, BGV can also reduce per-gate computation by basing its security on the RLWE problem. The per-gate computation is measured by the time taken to compute on ciphertexts to the time taken to compute on plaintexts. For security parameter λ and circuit multiplicative depth L , the per-gate computation ˜ Ω( λ 4 ) in BV is reduced to ˜ O ( λ · L 3 ) in BGV, and could be further reduced to ˜ O ( λ 2 ) when using bootstrapping as an optimization technique.
## 10.7 The B scheme: scale invariant
As a further simplification and improvement of their previous works, Brakerski (2012) proposed an encryption scheme that works with a fixed modulus q , but scales down a ciphertext by a factor q each time. We call this scheme B after the sole author's surname initial. The name 'scale invariant' suggests the scheme does not decrease the moduli as in BGV. Given a ciphertext c ∈ Z q , the fractional ciphertext ˆ c = c /q ∈ Z 1 is within the symmetric range [ -1 / 2 , 1 / 2) . The benefits of working with fractional
ciphertexts are threefolds. First, it simplifies the scheme by not having a series of moduli and switching them iteratively. Second, it makes the evaluation noise grows linearly in the noise distribution bound B and consequently requires a smaller noisy ceiling q to guarantee decryption. For this matter, fractional ciphertexts appear only in homomorphic multiplications. Finally, on the security contribution, this work enables a classical reduction from the GAPSVP n O (log n ) problem with a quasi-polynomial approximation factor. This is an improvement over Peikert (2009), in which the classical reduction can only be built for the same modulus size q ≈ 2 n/ 2 from GAPSVP 2 Ω( n ) with an exponential factor, which makes this lattice problem easy and hence unusable by HE schemes that want to rely on a classical reduction from lattice problems.
We now state the procedures of B, which uses the same building blocks as previous schemes.
Setup The parameters are the same as BV. That is, it has a pre-determined level L = L ( n ) for the arithmetic circuits that will be evaluated and a parameter set params = ( n, q, N, χ ) .
Key generation In this scheme, the fresh ciphertexts go into circuit level 0 and the completely evaluated ciphertexts are produced at level L . Sample a sequence of secret vectors
$$s _ { 0 } , \dots , s _ { L } \leftarrow B . S e c r e t K e y g e n ( n , q )$$
$$P _ { 0 } = [ \mathbf b | - \mathbf A ] \leftarrow B . \text {PublicKey} ( t _ { 0 } , p a r m s )$$
where s i = (1 , t i ) with a random vector t i ← Z n q . Generate a public key as usual by where A ← Z N × n q , and b = [ At 0 + e ] q for a random noise vector e ← χ N . Furthermore, to allow key switching during homomorphic evaluation, first compute the tensor product of each secret vector s i -1 with itself for i ∈ [1 , L ]
then compute the auxiliary information
$$\begin{array} { r l } & { \tilde { s } _ { i - 1 } = B i t D e c o m p ( s _ { i - 1 } ) \otimes B i t D e c o m p ( s _ { i - 1 } ) , } \\ & { \quad \mu x i l i a r y i n f o r m a t i o n } \end{array}$$
$$\begin{array} { r l } & { P _ { ( i - 1 ) \colon i } \leftarrow S u n t c h K e y G e n ( \tilde { s } _ { i - 1 } , s _ { i } ) . } \\ & { y g e n e r a t i o n p r o c e s s i s } \end{array}$$
The final output of the key generation process is
$$\begin{array} { r l } & { ( p k , s k , e v k ) \leftarrow B . K e y g e n ( p a r a m s ) , w h e r e } \\ & { p k = P _ { 0 } , s k = s _ { L } , e v k = \{ P _ { ( i - 1 ) ; i } \} _ { i \in [ 1 , L ] } . } \end{array}$$
Encryption and decryption The two processes are identical to Regev's encryption and decryption, respectively. That is,
$$\begin{array} { r } { p k = P _ { 0 } , s k = s _ { L } , e v k = \left \{ P _ { ( i - 1 ) \colon i } \right \} _ { i \in [ 1 , L ] } . } \end{array}$$
$$^ { 9 }$$
$$\begin{array} { r l } & { c = \left [ P _ { 0 } ^ { T } r + \left \lfloor \frac { q } { 2 } \right \rfloor \cdot m \right ] _ { q } \leftarrow B . E n c ( P _ { 0 } , m , n , q , N ) } \\ & { m = \left [ \left \lfloor \frac { 2 } { q } \cdot \left [ c \cdot s _ { L } \right ] _ { q } \right \rfloor \right ] _ { 2 } \leftarrow B . D e c ( s _ { L } , c , q ) } \end{array}$$
Homomorphic evaluation Addition and multiplications are defined separately, but both follow a twostep process. The first step is to produce an intermediate ciphertext in the powers of two format:
$$\tilde { c } _ { a d d } & = P o w e r s O f T w o ( \mathbf c _ { 1 } + \mathbf c _ { 2 } ) \otimes P o w e r s O f T w o ( ( 1 , 0 , \dots , 0 ) ) , \\ \tilde { c } _ { m u l t } & = \left \lfloor \frac { 2 } { q } \cdot P o w e r s O f T w o ( \mathbf c _ { 1 } ) \otimes P o w e r s O f T w o ( \mathbf c _ { 2 } ) \right \rfloor .$$
The tensor product with a dummy vector in the additive ciphertext is to ensure correct decryption when taking dot product with the corresponding secret vector in the following key switch process. At gate i , the input ciphertexts are decryptable by s i -1 . So these intermediate tensored ciphertexts are decryptable by the tensor secret vector ˜ s i -1 . The second step is to transform an intermediate ciphertext to another ciphertext (non in tensor product format) under a new secret vector s i . That is, for ˜ c ∈ { ˜ c add , ˜ c mult } , this is achieved by computing
$$c = S w i t c h K e y ( P _ { ( i - 1 ) \colon i } , \tilde { c } ) .$$
The scheme is thus completed, and as claimed it is a simpler construction than previous HE schemes. The homomorphic properties and security can be proved similarly as for previous schemes, see Theorem 4.2 and Lemma 4.1 of Brakerski (2012). Furthermore, the scheme is leveld FHE without bootstrapping and can be made non-leveld by assuming weak circular security (Corollary 4.5 (Brakerski, 2012)) as in the BV scheme.
expansion factor encryption noise
## 10.8 The BFV scheme
We finish this section by introducing the BFV scheme (Fan and Vercauteren, 2012), whose security is solely based on the RLWE problem. Despite its similarity to the aforementioned schemes, it makes HE schemes practical by explicitly stating the specific parameters need to achieve a certain security level.Therefore, we will emphasize on analysing the noise bounds of ciphertexts output by different encryption scheme subroutines, rather than presenting the homomorphic operations most of which have been discussed in preceding subsections.
BFV is built upon the RLWE-based encryption scheme, named LPR (Lyubashevsky et al., 2010) that was stated at the end of the previous section. Its plaintext space is generalized to R t from R 2 as in the simplified scheme. This also implies the fractional factor is now ∆ = q/t rather than q/ 2 . Besides that, the underlying domain R q = Z q [ x ] / (Φ m ( x )) is generalized to an arbitrary mth cyclotomic field for a suitable modulus q and cyclotomic polynomial Φ( m ) , although the preferred one is still Φ( m ) = x n +1 for m being a power of 2 and n = m/ 2 .
Atechnical term that often appears in the analysis of BFV's noise bounds is expansion factor. When multiplying two polynomials a = a 0 + a 1 · x + · · · a d · x d and b = b 0 + b 1 · x + · · · b d · x d , the coefficient of x i can be larger than a i + b i due to the fact that there may be more than one term in a · b 15 with the degree i . For this reason, we define the expansion factor of the polynomial ring as γ R = max {|| a · b || / ( || a || · || b || ) | a , b ∈ R } , where || a || = max i | a i | is the maximum coefficient of the polynomial. It is worth mentioning that expansion factor appears only when analysing noise bounds in the polynomial coefficient embedding context, not in the canonical embedding context in which multiplications are element-wise.
Let c i = ( u i , v i ) be a ciphertext. Decryption works by first computing
$$\left [ f _ { \mathbf e _ { i } } ( \mathbf s ) \right ] _ { q } & = \left [ \mathbf u _ { i } + \mathbf v _ { i } \cdot \mathbf s \right ] _ { q } \\ & - \Delta _ { i } \, m _ { i } ^ { \prime }$$
where e ′ i = e · r + e 1 + e 2 · s , as shown in Equation (33), followed by the multiplication of a fractional, rounding and modulo t , that is,
$$= \Delta \cdot m _ { i } + e ^ { \prime } _ { i } ,$$
$$D e c ( s , { c } _ { i } ) = \left [ \left \lfloor \frac { t \cdot [ f _ { { c } _ { i } } ( s ) ] _ { q } } { q } \right \rceil \right ] _ { t } .$$
The bound on the noise's coefficients is
$$| | { \mathbf e } _ { i } ^ { \prime } | | \leq 2 \cdot \delta _ { R } \cdot B ^ { 2 } + B ,$$
where δ R is the expansion factor of R and [ -B,B ] is the support of the noise distribution χ over R . In Fan and Vercauteren (2012), the bound is further reduced to 2 · δ R · B + B by taking r and s from { 0 , 1 } n , with only a minor security implication (Optimization/Assumption 1 Fan and Vercauteren (2012)).
Next we jump straight to the homomorphic operations. For simplicity, we analyse the operations for two ciphertexts c 1 = ( u 1 , v 1 ) and c 2 = ( u 2 , v 2 ) .
Homomorphic addition Homomorphic addition is defined as component-wise addition. That is,
$$c _ { a d d } = \left ( \left [ u _ { 1 } + u _ { 2 } \right ] _ { q } , \left [ v _ { 1 } + v _ { 2 } \right ] _ { q } \right ) \gets B F V . A d d ( c _ { 1 } , c _ { 2 } ) .$$
It is easy to see that addition is correct because
$$\left [ ( u _ { 1 } + u _ { 2 } ) + ( v _ { 1 } + v _ { 2 } ) \cdot s \right ] _ { q } = \left [ ( u _ { 1 } + v _ { 1 } \cdot s ) + ( u _ { 2 } + v _ { 2 } \cdot s ) \right ] _ { q } = \left [ \Delta \cdot ( m _ { 1 } + m _ { 2 } ) + e _ { 1 } ^ { \prime } + e _ { 2 } ^ { \prime } \right ] _ { q } .$$
To transform ∆ · ( m 1 + m 2 ) to be in the plaintext space R t , We notice that m 1 + m 2 = [ m 1 + m 2 ] t + t · r t for a polynomial r t whose coefficients satisfy || r t || ≤ 1 , because || m 1 + m 2 || ≤ 2 t and || [ m 1 + m 2 ] t || ≤ t . Let = q/t -∆ = r t ( q ) /t < 1 , we get
$$[ \Delta \cdot ( m _ { 1 } + m _ { 2 } ) + e ^ { \prime } _ { 1 } + e ^ { \prime } _ { 2 } ] _ { q } & = [ \Delta \cdot [ m _ { 1 } + m _ { 2 } ] _ { t } + \Delta \cdot t \cdot r _ { t } + e ^ { \prime } _ { 1 } + e ^ { \prime } _ { 2 } ] _ { q } \\ & = \Delta \cdot [ m _ { 1 } + m _ { 2 } ] _ { t } + e ^ { \prime } _ { 1 } + e ^ { \prime } _ { 2 } - ( q - \Delta \cdot t ) \cdot r _ { t } \\ & = \Delta \cdot [ m _ { 1 } + m _ { 2 } ] _ { t } + \underbrace { e ^ { \prime } _ { 1 } + e ^ { \prime } _ { 2 } - \epsilon \cdot t \cdot r _ { t } } _ { n o i s e } .$$
addition noise
After multiplying with t/q , the coefficient t/q · ∆ rounds to 1 and ( t/q · noise ) rounds to 0. So decryption is guaranteed correct after taking the final [ · ] t . Notice homomorphic addition only incurs an extra additive noise by a factor of t because || r t || ≤ 1 and < 1 by construction. The incurred noise is usually much smaller than the noise ceiling q .
Homomorphic multiplication Similar to the previous schemes, much of the effort in BFV's construction deals with relinearization after homomorphic multiplications. The noise growth after a ciphertext multiplication is bounded by 2 · t · δ 2 R · || s || , which is better than quadratic growth (Lemma 2 (Fan and Vercauteren, 2012)).
It takes several steps to see how the noise bound is obtained. We have known from previous sections that a direct ciphertext multiplication produces a quadratic function as follows
$$& f _ { \mathfrak { c } _ { 1 } } ( s ) \cdot f _ { \mathfrak { c } _ { 2 } } ( s ) = h _ { 0 } + h _ { 1 } \cdot s + h _ { 2 } \cdot s ^ { 2 } , \text { where} \\ & h _ { 0 } = u _ { 1 } \cdot u _ { 2 } , \, h _ { 1 } = u _ { 1 } \cdot v _ { 2 } + u _ { 2 } \cdot v _ { 1 } , \, h _ { 2 } = v _ { 1 } \cdot v _ { 2 } .$$
$$\begin{array} { r l } & { \frac { t } { q } \cdot f _ { c _ { 1 } } ( s ) \cdot f _ { c _ { 2 } } ( s ) = \frac { t } { q } \cdot ( h _ { 0 } + h _ { 1 } \cdot s + h _ { 2 } \cdot s ^ { 2 } ) . } \\ & { \quad } \end{array}$$
By looking at Equation (44), it is not hard to see that when multiplying f c 1 ( s ) · f c 2 ( s ) , it will results a term ∆ 2 · m 1 · m 2 and several other terms with q being part of their coefficients. To get the message product back to ∆ · m 1 · m 2 in order to allow decryption to work, one way is to multiply it by 1 / ∆ . But this can cause round problem in other terms that contain q as part of their coefficients. Let = q/t -∆ be the rounding error, so the term q/ ∆ = q/ ( q/t - ) . The problem with this is that it does not always round up back to t . For example, with q = 17 we have q/ ∆ = 2 . 15 when t = 2 and q/ ∆ ≈ 5 . 67 when t = 5 . So the later creates a rounding error that becomes problematic in subsequent steps. Hence, an alternative solution is to multiplying all the terms by t/q then applying rounding. This is straightforward for the terms with q being part of the coefficients. For the message product term, it gives ( t/q · ∆) · (∆ · m 1 · m 2 ) and t/q · ∆ = t/q · ( q/t - ) = 1 -( t/q ) · ∈ (0 . 5 , 1 . 5) as | | ≤ 1 / 2 and t ≤ q with equality implies = 0 . Hence, multiply Equation (45) with the fraction, we get
As shown above, the coefficients need to be rounded to get the ciphertext back on track for decryption, so the above equation can be re-written as
$$\frac { t } { q } \cdot f _ { c _ { 1 } } ( s ) \cdot f _ { c _ { 2 } } ( s ) & = \left [ \frac { t } { q } \cdot h _ { 0 } \right ] + \left [ \frac { t } { q } \cdot h _ { 1 } \right ] \cdot s + \left [ \frac { t } { q } \cdot h _ { 2 } \right ] \cdot s ^ { 2 } + \left ( \frac { t } { q } \cdot h _ { 0 } - \left [ \frac { t } { q } \cdot h _ { 0 } \right ] \right ) \\ & \quad + \left ( \frac { t } { q } \cdot h _ { 1 } - \left [ \frac { t } { q } \cdot h _ { 1 } \right ] \right ) \cdot s + \left ( \left [ \frac { t } { q } \cdot h _ { 2 } \right ] - \left [ \frac { t } { q } \cdot h _ { 2 } \right ] \right ) \cdot s ^ { 2 } \\ & = \left [ \frac { t } { q } \cdot h _ { 0 } \right ] + \left [ \frac { t } { q } \cdot h _ { 1 } \right ] \cdot s + \left [ \frac { t } { q } \cdot h _ { 2 } \right ] \cdot s ^ { 2 } + r _ { a } .
T h e t h e r w e d u p t a l " c o e f f i c i n g s" m a k e t h e appropriate multiplicative ciphertext \\ \frac { t } { q } \cdot f _ { c _ { 1 } } ( s ) \cdot f _ { c _ { 2 } } ( s ) & = \left [ \frac { t } { q } \cdot h _ { 0 } \right ] + \left [ \frac { t } { q } \cdot h _ { 1 } \right ] \cdot s + \left [ \frac { t } { q } \cdot h _ { 2 } \right ] \cdot s ^ { 2 } + \left ( \frac { t } { q } \cdot h _ { 0 } - \left [ \frac { t } { q } \cdot h _ { 0 } \right ] \right ) \\ & = \left [ \frac { t } { q } \cdot h _ { 0 } \right ] + \left [ \frac { t } { q } \cdot h _ { 1 } \right ] \cdot s + \left [ \frac { t } { q } \cdot h _ { 2 } \right ] \cdot s ^ { 2 } + r _ { a } .
</doctag>$$
The three updated 'coefficients' make the appropriate multiplicative ciphertext
$$\mathbf c _ { m u l t } = ( \mathfrak h _ { 0 } , \mathfrak h _ { 1 } , \mathfrak h _ { 2 } ) \colon = \left ( \left [ \left \lfloor \frac { t } { q } \cdot \mathbf h _ { 0 } \right \rfloor \right ] _ { q } , \left [ \left \lfloor \frac { t } { q } \cdot \mathbf h _ { 1 } \right \rfloor \right ] _ { q } , \left [ \left \lfloor \frac { t } { q } \cdot \mathbf h _ { 2 } \right \rfloor \right ] _ { q } \right ) \gets B F V . M u l t ( c _ { 1 } , c _ { 2 } ) .$$
Since rounding error is at most 1 / 2 between integer coefficients, the approximation error satisfies || r a || < 1 / 2 + 1 / 2 · || s || · δ R + 1 / 2 · || s || · δ 2 R . The bound can be made further loose to be || r a || < 1 / 2 · (1 + || s || · δ R ) 2 in order to be used by the following homomorphic multiplication noise bound analysis.
By moving the approximation error r a to the LHS of Equation (46) and reducing both sides to R q , we get
$$\left [ { \frac { t } { q } } \cdot f _ { c _ { 1 } } ( s ) \cdot f _ { c _ { 2 } } ( s ) - r _ { a } \right ] _ { q } = \left [ \left \lfloor { \frac { t } { q } } \cdot h _ { 0 } \right \rfloor + \left \lfloor { \frac { t } { q } } \cdot h _ { 1 } \right \rfloor \cdot s + \left \lfloor { \frac { t } { q } } \cdot h _ { 2 } \right \rfloor \cdot s ^ { 2 } \right ] _ { q } .$$
To derive the multiplication noise bound, we explicitly write out all the terms in f c 1 ( s ) · f c 2 ( s ) using Equation (44), so we get
$$\begin{array} { r l } & { \quad E q u a t i o n \, ( 4 4 ) , s o w e g e t } \\ & { \quad f _ { c _ { 1 } } ( s ) \cdot f _ { c _ { 2 } } ( s ) = ( \Delta \cdot m _ { 1 } + e ^ { \prime } _ { 1 } + q \cdot r _ { q , 1 } ) \cdot ( \Delta \cdot m _ { 2 } + e ^ { \prime } _ { 2 } + q \cdot r _ { q , 2 } ) } \\ & { = \Delta ^ { 2 } \cdot m _ { 1 } \cdot m _ { 2 } + \Delta \cdot ( m _ { 1 } \cdot e ^ { \prime } _ { 2 } + m _ { 2 } \cdot e ^ { \prime } _ { 1 } ) + \Delta \cdot q \cdot ( m _ { 1 } \cdot r _ { q , 2 } + m _ { 2 } \cdot r _ { q , 1 } ) } \\ & { \quad + q \cdot ( r _ { q , 1 } \cdot e ^ { \prime } _ { 2 } + r _ { q , 2 } \cdot e ^ { \prime } _ { 1 } ) + q ^ { 2 } \cdot r _ { q , 1 } \cdot r _ { q , 2 } + e ^ { \prime } _ { 1 } \cdot e ^ { \prime } _ { 2 } . } \end{array}$$
15 We also use boldface to represent polynomials and · to represent polynomial multiplications.
multiplication noise relinearization version 1
Same as in homomorphic addition, we want to express the product of secret messages in the plaintext space R t , so we can write m 1 · m 2 = [ m 1 · m 2 ] t + t · r t , where || r t || < t · δ R / 4 .Multiplying the above equation by t/q on both sides, we get
$$\frac { t } { q } \cdot f _ { \mathfrak { c } _ { 1 } } ( \mathbf s ) \cdot f _ { \mathfrak { c } _ { 2 } } ( \mathbf s ) = & \frac { t \cdot \Delta ^ { 2 } } { q } \cdot ( [ \mathbf m _ { 1 } \cdot \mathbf m _ { 2 } ] _ { t } + t \cdot \mathbf r _ { t } ) + \frac { t \cdot \Delta } { q } \cdot ( \mathbf m _ { 1 } \cdot \mathbf e ^ { \prime } _ { 2 } + \mathbf m _ { 2 } \cdot \mathbf e ^ { \prime } _ { 1 } ) \\ & + t \cdot \Delta \cdot ( \mathbf m _ { 1 } \cdot \mathbf r _ { q , 2 } + \mathbf m _ { 2 } \cdot \mathbf r _ { q , 1 } ) + t \cdot ( \mathbf r _ { q , 1 } \cdot \mathbf e ^ { \prime } _ { 2 } + \mathbf r _ { q , 2 } \cdot \mathbf e ^ { \prime } _ { 1 } ) \\ & + t \cdot q \cdot \mathbf r _ { q , 1 } \cdot \mathbf r _ { q , 2 } + \frac { t } { q } \cdot \mathbf e ^ { \prime } _ { 1 } \cdot \mathbf e ^ { \prime } _ { 2 } .$$
Since modulo q will be applied onto this as shown in Equation (47) followed by rounding, it is convenient to split the above into terms with and without integer coefficients. To do so, we can substitute t · ∆ = q -r t ( q ) into the above equation. After re-arranging the terms, we get
r
$$\begin{array} { r l } & { t \cdot \Delta = q - r _ { t } ( q ) \, i n t o t h e a b o v e \, e q u a t i o n . \, A f t e r \, r e a n g i n g \, t h e r m s , w e \, g e t } \\ & { \frac { t } { q } \cdot f _ { c 1 } ( s ) \cdot f _ { c 2 } ( s ) = \Delta \cdot [ m _ { 1 } \cdot m _ { 2 } ] _ { t } + ( m _ { 1 } \cdot e ^ { \prime } _ { 2 } + m _ { 2 } \cdot e ^ { \prime } _ { 1 } ) + ( q - r _ { t } ( q ) ) \cdot ( r _ { t } + m _ { 1 } \cdot r _ { q , 2 } + m _ { 2 } \cdot r _ { q , 1 } ) } \\ & { \quad + t \cdot ( r _ { q , 1 } \cdot e ^ { \prime } _ { 2 } + r _ { q , 2 } \cdot e ^ { \prime } _ { 1 } ) + q \cdot t \cdot r _ { q , 1 } \cdot r _ { q , 2 } + r _ { \Delta } } \\ & { \quad + \frac { t } { q } \cdot [ e ^ { \prime } _ { 1 } \cdot e ^ { \prime } _ { 2 } ] _ { \Delta } - \frac { r _ { t } ( q ) } { q } \cdot ( \Delta \cdot m _ { 1 } \cdot m _ { 2 } + ( m _ { 1 } \cdot e ^ { \prime } _ { 2 } + m _ { 2 } \cdot e ^ { \prime } _ { 1 } ) + r _ { \Delta } ) \, . } \end{array}$$
r
All the terms except r r have integer coefficients, so they will not be affected by rounding. Substitute this into Equation (47), we get
$$& \left [ \left \lfloor \frac { t } { q } \cdot h _ { 0 } \right \rfloor + \left \lfloor \frac { t } { q } \cdot h _ { 1 } \right \rfloor \cdot s + \left \lfloor \frac { t } { q } \cdot h _ { 2 } \right \rfloor \cdot s ^ { 2 } \right ] _ { q } \\ = & \Delta \cdot [ m _ { 1 } \cdot m _ { 2 } ] _ { t } \\ & + ( m _ { 1 } \cdot e _ { 2 } ^ { \prime } + m _ { 2 } \cdot e _ { 1 } ^ { \prime } ) - r _ { t } ( q ) \cdot ( r _ { t } + m _ { 1 } \cdot r _ { q , 2 } + m _ { 2 } \cdot r _ { q , 1 } ) \\ & + t \cdot ( r _ { q , 1 } \cdot e _ { 2 } ^ { \prime } + r _ { q , 2 } \cdot e _ { 1 } ^ { \prime } ) + ( r _ { r } - r _ { a } ) \\ = & \Delta \cdot [ m _ { 1 } \cdot m _ { 2 } ] _ { t } + e _ { 3 } ^ { \prime } .$$
Using the bounds proved above, it can be shown that || e ′ 3 || < 2 · δ R · t · E · ( δ R · || s || +1)+2 · t 2 · δ 2 R · ( || s || +1) 2 , which is dominated by 2 · t 2 · δ 2 R · || s || 2 .
Relinearization As discussed in BV's relinearization, the problem with the direct multiplicative ciphertext is its increased length from 2 to 3 'coefficients'. To overcome this, Fan and Vercauteren (2012) presented two methods to relinearize the ciphertext with only two new coefficients and a small noise.
$$\left [ \mathfrak { h } _ { 0 } + \mathfrak { h } _ { 1 } \cdot s + \mathfrak { h } _ { 2 } \cdot s ^ { 2 } \right ] _ { q } = \left [ \mathfrak { h } _ { 0 } ^ { \prime } + \mathfrak { h } _ { 1 } ^ { \prime } \cdot s + e r r \right ] _ { q } .$$
The first method, which is similar to the relinearization process in the BV scheme, produces a relinearization key { rlk τ }
$$r l k _ { \tau } = \left ( b _ { \tau } = \left [ - ( a _ { \tau } \cdot s + e _ { \tau } ) + T ^ { \tau } \cdot s ^ { 2 } \right ] _ { q } , a _ { \tau } \right )$$
that looks almost like the evaluation key in BV, except that the coefficient
$$\mathfrak { h } _ { 2 } = \sum _ { \tau = 0 } ^ { l } T ^ { \tau } \cdot \mathfrak { h } _ { 2 } ^ { ( \tau ) } \bmod q$$
is written in T -nary representation, where l = log T q and h ( τ ) 2 ∈ R T . The polynomials were sampled by a τ ← R q and e τ ← χ . The purpose of expressing h 2 in T -nary representation is to reduce the amplification effect on ciphertext noise after multiplications. The same idea was also discussed in Section 10.3, which used T = 2 to minimize the relinearization noise for BV.
The main difference from the aforementioned schemes is that s 2 is encrypted by the corresponding public key a τ in the same ( pk , sk ) pair, while in the BV scheme for example, each quadratic secret key is encrypted by the next public key. So for this relinearization step to be secure, the weak circular
relinearization version 2
security assumption (Definition 10.2.3) is needed. This is also why the BFV uses only a single secret key and a single public key instead of a series of keys.
Given the relinearization key { rlk τ = ( b τ , a τ ) | τ ∈ [0 , l ] } , the two new coefficients are set to
$${ \mathfrak { h } } _ { 0 } ^ { \prime } = \left [ { \mathfrak { h } } _ { 0 } + \sum _ { \tau = 0 } ^ { l } { b } _ { \tau } \cdot { \mathfrak { h } } _ { 2 } ^ { ( \tau ) } \right ] _ { q } \, a n d \, { \mathfrak { h } } _ { 1 } ^ { \prime } = \left [ { \mathfrak { h } } _ { 1 } + \sum _ { \tau = 0 } ^ { l } { a } _ { \tau } \cdot { \mathfrak { h } } _ { 2 } ^ { ( \tau ) } \right ] _ { q } .$$
To check that they are the correct choices, we get
$$[ \mathfrak { h } _ { 0 } ^ { \prime } + \mathfrak { h } _ { 1 } ^ { \prime } \cdot \mathfrak { s } ] _ { q } = \left [ \mathfrak { h } _ { 0 } + \mathfrak { h } _ { 1 } \cdot \mathfrak { s } + \mathfrak { h } _ { 2 } \cdot \mathsf s ^ { 2 } - \sum _ { \substack { \tau = 0 \\ \text {$\text {$err$}^{1}$}} } ^ { l } \mathfrak { h } _ { 2 } ^ { ( \tau ) } \cdot \mathsf e _ { \tau } \right ] _ { q } ,$$
where the relinearization noise's coefficients bound is || err 1 || ≤ ( l +1) · T · B · δ R / 2 . So the larger T is, the larger the error will be. However, T should also be set not too small in order to match the noise magnitude after one ciphertext multiplication.
The second method relies on the noise reduction effect by modulus reduction as shown in Section 10.4.2. The motivation is to still be able to approximate a quadratic ciphertext by a linear one, but without slicing the coefficient h 2 into many pieces which potentially increases the relinearization space and time. The idea is to encrypt a scaled quadratic secret key p · s 2 in the larger domain Z p · q for an integer p , then scale it down to within Z q by dividing it by p . More precisely, randomly sample a ← R p · q and e ← χ ′ from a different noise distribution, then output the relinearization key
$$r l k = \left ( b = \left [ - ( a \cdot s + e ) + p \cdot s ^ { 2 } \right ] _ { p \cdot q } , a \right ) .$$
Given this relinearization key, the two new coefficients are constructed by
$${ \mathfrak { h } } _ { 0 } ^ { \prime } = { \mathfrak { h } } _ { 0 } + \left [ \left \lfloor { \frac { { \mathfrak { h } } _ { 2 } \cdot { b } } { p } } \right \rceil \right ] _ { q } \, a n d \, { \mathfrak { h } } _ { 1 } ^ { \prime } = { \mathfrak { h } } _ { 1 } + \left [ \left \lfloor { \frac { { \mathfrak { h } } _ { 2 } \cdot { a } } { p } } \right \rceil \right ] _ { q } .$$
Again, to make sure these new coefficients can lead to the correct decryption, we get
$$\mathfrak { H } _ { 0 } ^ { \prime } & = \mathfrak { h } _ { 0 } + \left [ \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ] _ { q } \text { and } \mathfrak { H } _ { 1 } ^ { \prime } = \mathfrak { h } _ { 1 } + \left [ \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ] _ { q } . \\ & \quad + \left ( \left [ \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ] - \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ) + \left ( \left [ \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ] - \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ) \cdot s \right ] _ { q } \\ & = \left [ \mathfrak { h } _ { 0 } + \mathfrak { h } _ { 1 } \cdot s + \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ] + \left [ \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ] _ { q } \\ & \quad + \left ( \left [ \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ] - \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ) + \left ( \left [ \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ] - \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ) \cdot s \right ] _ { q } \\ & = \left [ \mathfrak { h } _ { 0 } + \mathfrak { h } _ { 1 } \cdot s + \mathfrak { h } _ { 2 } \cdot s ^ { 2 } \\ & \quad + \underbrace { - \mathfrak { h } _ { 2 } \cdot e } _ { p } + \left ( \left [ \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ] - \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ) + \left ( \left [ \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ] - \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ) \cdot s \right ] _ { q } .
<text><loc_25><loc_477><loc_474><loc_497>So the second relinearization generates noise of magnitude || err$_{2}$ || < q · B · δ$_{R}$ p + 1 2 + 1 2 · || s || · δ$_{R}$ .</text>
</doctag>$$
So the second relinearization generates noise of magnitude || err 2 || < q · B · δ R p + 1 2 + 1 2 · || s || · δ R .
The combined noise magnitude of homomorphic addition and multiplication with each relinearization step were stated in Lemma 3 of Fan and Vercauteren (2012). Given the fact that relinearization noises can be managed by setting parameters T (version 1) and p (version 2) at appropriate values,
Theorem 1 of Fan and Vercauteren (2012) proved the maximum multiplicative depth of the evaluated circuit according to the other parameter values.
Finally, the scheme can be made bootstrappable by simplifying the decryption algorithm. The simplification can be done before the scheme evaluating its own decryption by a modulus switching from the original modulus q to a smaller modulus q ′ = 2 n by scaling the ciphertext ( u , v ) to get
$$u ^ { \prime } = \lfloor 2 ^ { n } / q \cdot u \rfloor \, a n d \, v ^ { \prime } = \lfloor 2 ^ { n } / q \cdot v \rfloor \, .$$
This is because if q ′ = 2 n and set t = 2 n -k , then ∆ = q/t = 2 k . So in the decryption step, t/q · [ f c ( s )] q becomes 1 / ∆ · [ f c ( s )] q and division by ∆ is efficient (Section 5.2 (Fan and Vercauteren, 2012)).
Below, we summarize the BFV scheme and provide an implementation in Sage.
Private key : Sample a private key s ← R 2 .
Public key : Sample random polynomials a ← R q and e ← χ and output the public key ( b = -[ a · s + e ] q , a ) .
Relinearization key: For a positive integer T , let l = log T q . Let a τ ← R q , e τ ← χ , a ← R p · q and e ← χ ′ a different noise distribution. Generate two sets of relinearization keys
$$& \quad r l k _ { 1 } = \{ r l k _ { \tau } = ( b _ { \tau } , a _ { \tau } ) \ | \ \tau \in [ 0 , l ] \} \, , \ w h e r e \ b _ { \tau } = \left [ - ( a _ { \tau } \cdot s + e _ { \tau } ) + T ^ { \tau } \cdot s ^ { 2 } \right ] _ { q } \\ & \quad r l k _ { 2 } = \left ( b = \left [ - ( a \cdot s + e ) + p \cdot s ^ { 2 } \right ] _ { p \cdot q } , a \right ) .$$
Encryption: Encrypt a message m ∈ R t by computing
$$u & = \left [ b \cdot r + e _ { 1 } + \lfloor q / t \rfloor \cdot m \right ] _ { q } \\ v & = \left [ a \cdot r + e _ { 2 } \right ] _ { q } ,$$
where r ← R 2 and e 1 , e 2 ← χ are random samples. Then output the ciphertext c = ( u , v ) .
Decryption: Decrypt the ciphertext c using the secret key by computing
$$locate = \left [ \left \lfloor \frac { t } { q } \left [ u + v \cdot s \right ] _ { q } \right \rceil \right ] _ { t } .$$
Homomorphic operations: Given ciphertexts c i = ( u i , v i ) for i ∈ [1 , 2] ,
$$\mathbf c _ { a d d } & = \left ( [ \mathbf u _ { 1 } + \mathbf u _ { 2 } ] _ { q } \, , [ \mathbf v _ { 1 } + \mathbf v _ { 2 } ] _ { q } \right ) \\ \mathbf c _ { m u l t } & = \left ( \mathfrak h _ { 0 } , \mathfrak h _ { 1 } , \mathfrak h _ { 2 } \right ) .$$
$$1$$
Relinearization: Re-write h 2 = ∑ l τ =0 T τ · h ( τ ) 2 mod q . Choose one method from the following two. Use the corresponding key rlk 1 and rlk 2 for the two methods respectively.
$$& \text {Method 1} \colon \mathfrak { h } _ { 0 } ^ { \prime } = \left [ \mathfrak { h } _ { 0 } + \sum _ { \tau = 0 } ^ { l } b _ { \tau } \cdot \mathfrak { h } _ { 2 } ^ { ( \tau ) } \right ] _ { q } \text { and } \mathfrak { h } _ { 1 } ^ { \prime } = \left [ \mathfrak { h } _ { 1 } + \sum _ { \tau = 0 } ^ { l } a _ { \tau } \cdot \mathfrak { h } _ { 2 } ^ { ( \tau ) } \right ] _ { q } . \\ & \text {Method 2} \colon \mathfrak { h } _ { 0 } ^ { \prime } = \mathfrak { h } _ { 0 } + \left [ \left [ \frac { \mathfrak { h } _ { 2 } \cdot b } { p } \right ] \right ] _ { q } \text { and } \mathfrak { h } _ { 1 } ^ { \prime } = \mathfrak { h } _ { 1 } + \left [ \left [ \frac { \mathfrak { h } _ { 2 } \cdot a } { p } \right ] \right ] _ { q } .$$
Output the relinearized ciphertext ( h ′ 0 , h ′ 1 ) .
## 10.9 Closing thoughts on HE developments
To end this section, we provide some closing thoughts on the developments of HE and refer the reader to some recent works in the field.
First of all, the LWE and RLWE-based HE schemes presented in this section are natural extensions of the building block encryption schemes Regev (Section 1.3) and LPR (Section 9.6). They inherit and preserve the additive and multiplicative homomorphic properties of these building block encryption schemes. The reason addition and multiplication are preserved is because, in all these encryption schemes, the ciphertext is constructed from the plaintext and the LWE / RLWE samples using simple linear algebra operations. Take the LPR encryption scheme as an example. Its ciphertext ( u , v ) is created by computing
$$u & = b \cdot r + e _ { 1 } + \lfloor q / 2 \rfloor \cdot m \bmod q \\ v & = a \cdot r + e _ { 2 } \bmod q .$$
The pair u without the message part and v are RLWE samples.
Secondly, the schemes presented here followed just one narrow path of HE developments, which is also referred as the second generation of HE developments in Halevi (2017). However, their simplicity of not needing to perform bootstrapping to reach FHE within a pre-determined multiplication depth have led to some practical implementations, including some standalone open-source libraries such as Microsoft (SEAL), IBM HElib 16 , PALISADE 17 , NFLlib 18 , and some open-source R and Python libraries such as HomomorphicEncryption (Aslett et al., 2015), pyFHE (Erabelli, 2020) and PySEAL 19 . Although some of these libraries' documentations have recommended parameter choices to achieve efficient HE encryption for certain security levels, for standardized HE schemes, parameters definitions and selections, the reader is referred to the Homomorphic Encryption Standard (Albrecht et al., 2018).
Thirdly, although HE continues to attract tremendous attention among researchers and practitioners alike, its adoption in secure data computation is still not a mainstream affair. There are at least a few reasons for this.
- An important issue is the high space requirements for storing and processing the ciphertexts, which can be large even under the relatively efficient RLWE-based schemes. To encrypt even binary plaintexts, the ciphertext space Z q or R q = Z [ x ] / (Φ( x )) needs to be large enough to allow a decent number of homomorphic multiplications. The ciphertext space size is directly influenced by the modulus q , which then affects the bit length of ciphertexts. Under reasonable security parameters, the ciphertext size can be up to 100 times larger than the plaintext.
- A direct consequence of large ciphertexts is longer ciphertext computations, which is another limitation of HE's practicality.
- An inherent limitation of HE is that conditional statements like if x then y else z and while x do y cannot be evaluated easily in encrypted space. In the if x then y else z case, we cannot simplify the statement to either y or z in the encrypted space because while we can compute the encrypted value of x , we cannot know what it is. Similarly, the while x do y statement cannot be executed in encrypted space because we cannot know when to stop. This limitation is inherited from the semantic security property of HE and cannot be solved within an HE scheme itself, although one can sometimes use secure multi-party computation techniques in combination with HE to evaluate these conditionals; see, for example, Chialva and Dooms (2018).
- Many other common operations cannot be done efficiently or purely in HE. For example, statements like x = y or x < y usually can only be evaluated by turning x and y into suitable binary representations that are then processed using logical gates that can be evaluated in HE. Integer divisions, in particular, have proved difficult and known schemes like those in Veugen (2014) require two-party protocols.
Although there are now several significant niche applications of HE, all the above limitations make it challenging to run many existing algorithms on homomorphically encrypted data, sometimes turning linear-time algorithm to high polynomial algorithms.
An early paper by Naehrig et al. (2011) discussed some concrete application scenarios, where only somewhat HE schemes are sufficient to fulfil these applications, and experimentally argued the newly
16 https://github.com/homenc/HElib
17 https://palisade-crypto.org/
18 https://github.com/CryptoExperts/FV-NFLlib
19 https://github.com/Lab41/PySEAL
developed scheme (at the time) BV (Brakerski, 2012) was an efficient candidate. A decade later, there have been numerous contributions that advanced the development of HE schemes, including reduction of their computational cost and ciphertext size expansion, and permission of arithmetic operations over encrypted real and complex numbers. Besides these performance improvements, there has been an increasing trend, together with the explosion of other computer science areas (e.g., machine learning and artificial intelligence), of applying HE under the current state of affairs, especially when combining with optimized data processing techniques (e.g., single instruction, multiple data SIMD) or other cryptographic primitives, which remarkably improve HE's computational overhead.
Some examples of more recent applications including HE's combination with secure multiparty computation to achieve efficient (less communication overhead) and secure arithmetic circuits computation (Damg˚ ard et al., 2012); with batching, hashing, modulus switching and other data processing optimization techniques for efficient private set intersection where one set's size is significantly smaller than the other (Chen et al., 2017); predicting homomorphically encrypted data using neural networks with encoding and parallel computing techniques that are based Chinese Remainder Theorem (GiladBachrach et al., 2016). More HE applications in training machine learning models (e.g., logistic regression, decision tree, naive Bayes, etc) or applying them on homomorphically encrypted data have surveyed in Wood et al. (2020).
## 10.10 A Sage Implementation of the BFV Cryptosystem
We present an implementation of the BFV cryptosystem in Sage. Note that this implementation is intended for pedagogical purposes and is not suitable for use in real-world applications.
## 10.10.1 Package Imports
We begin by importing two generic packages.
```
import numpy as np
import sage.stats.distributions.discrete_gaussian_integer as dgi
```
## 10.10.2 Define Parameters
Recall that the BFV cryptosystem is defined in terms of several parameters. These determine the ring over which the cryptographic operations will be performed, how many messages will be operated on in each 'batch', and the distribution from which noise will be drawn during encryption. Here we define a suitable set of parameters that can be used to generate a secret key / public key pair, encrypt a message, and decrypt a ciphertext. Other parameters are required to perform the relinearization operations which are needed for homomorphic multiplication operations. See Section 10.10.7 for details.
```
are needed for homomorphic multiplication operations. See Section 10.10.7 for details.
# Define parameters for encryption/decryption
q = 6620830889
n = 1024
t = 83
delta = q//t
P = PolynomialRing(Integers(), name="x")
f = x^n + 1
R = QuotientRing(P, f)
sigma = 1.0
D = dgi.DiscreteGaussianDistributionIntegerSampler(sigma=sigma)
parameters = (q,n,t,R,D)
```
## 10.10.3 Utility Functions
We will frequently use a symmetric representation of the rings Z /q Z . That is, we represent elements in this ring as integers x where -q/ 2 ≤ x < q/ 2 . The function symmetrize is used to compute these representations. We also need to perform the operation ⌊ t q [ x ] q ⌉ during decryption. The function multiply round performs this operation.
```
multiply_round_performs this operation.
def symmetrize(a,b):
'''
Convert integer polynomial coefficients to the symmetric
representation of elements in Z/bZ.
'''
A = np.array(vector(a))
A = A % b
mask = A >= b/2
A[mask] -= b
return R(list(A))
def multiply_round(x, r, parameters):
'''
Multiply integer coefficients by a rational number
and then round to the nearest integer.
'''
q,n,t,R,D = parameters
temp = r * vector(Rationals(), x)
return R([k.round() for k in temp])
```
## 10.10.4 Noise Samplers
Here we define functions to draw random values from various distributions. To generate keys for BFV encryption/decryption operations we use sample e to draw a random element from the error distribution D , sample 2 to sample an n -long binary vector, and sample r to draw a random element of the ring Z [ x ] / ( x n +1) .
```
ring Z[x]/(x^n + 1).
def sample_e(n,D):
P = PolynomialRing(Integers(), name="x")
f = x^n + 1
R = QuotientRing(P, f)
return R([D() for _ in range(n)])
def sample_2(n):
P = PolynomialRing(Integers(), name="x")
f = x^n + 1
R = QuotientRing(P, f)
return R([randint(0,1) for _ in range(n)])
def sample_r(n):
P = PolynomialRing(Integers(), name="x")
f = x^n + 1
R = QuotientRing(P, f)
return R.random_element()
```
## 10.10.5 Basic Cryptographic Operations
Here we define functions to generate key pairs, encrypt messages, and decrypt ciphertexts. In the text, we will use the symbol E to represent encryption and D to represent decryption.
```
Here we define functions to generate key pairs, encrypt messages, and decrypt ciphertext. we will use the symbol E to represent encryption and D to represent decryption.
# Functions for encryption/decryption.
def generate_keys(parameters):
q,n,t,R,D = parameters
secret_key = sample_2(n)
a = symmetrize(sample_e(n), q)
e = symmetrize(sample_e(n, D), q)
b = symmetrize(-(a*secret_key + e), q)
public_key = (b,a)
return secret_key, public_key
def encrypt(message, public_key, parameters):
q,n,t,R,D = parameters
delta = q//t
b,a = public_key
r = sample_2(n)
e1 = sample_e(n,D)
e2 = sample_e(n,D)
u = symmetrize(b*r + e1 + delta*message, q)
v = symmetrize(a*r + e2, q)
return (u,v)
def decrypt(ciphertext, secret_key, parameters):
q,n,t,R,D = parameters
u,v = ciphertext
temp = symmetrize(u+ v*secret_key, q)
temp = multiply_round(temp, t/q, parameters)
return temp, temp
```
Usage Example Here we demonstrate how to generate keys, encrypt a random message, and decrypt the resulting ciphertext. We verify that D ( E ( m,k p ) , k s ) = m for a given public key k p , secret key k s , and a random message m .
```
# Usage example and verification of correctness
secret_key, public_key = generate_keys(parameters)
message = R([randrange(0,t) for i in range(n)])
ciphertext = encrypt(message, public_key, parameters)
decrypted_message = decrypt(ciphertext, secret_key, parameters)
print(symmetrize(message, t) == decrypted_message)
```
## 10.10.6 Homomorphic Addition
We define the function f that combines two ciphertexts, c 1 = E ( m 1 , k p ) and c 2 = E ( m 2 , k p ) , such that D ( f ( c 1 , c 2 ) , k s ) = m 1 + m 2 .
```
def add_ciphertexts(c1, c2):
u1,v1 = c1
u2,v2 = c2
u_sum = symmetrize(u1 + u2, q)
v_sum = symmetrize(v1 + v2, q)
return (u_sum, v_sum)
```
Usage Example We verify that if m 1 and m 2 are random messages and c i = E ( m i , k p ) , then D ( f ( c 1 , c 2 ) , k s ) = m 1 + m 2 .
```
message_1 = R([randrange(0,t) for i in range(n)])
message_2 = R([randrange(0,t) for i in range(n)])
ciphertext_1 = encrypt(message_1, public_key, parameters)
ciphertext_2 = encrypt(message_2, public_key, parameters)
ciphertext_sum = add_ciphertexts(ciphertext_1, ciphertext_2)
decrypted_message_sum = decrypt(ciphertext_sum,
secret_key,
parameters)
message_sum = symmetrize(message_1 + message_2, t)
print(message_sum == decrypted_message_sum)
```
## 10.10.7 Homomorphic Multiplication
We define a function g that combines two ciphertexts c 1 = E ( m 1 , k p ) and c 2 = E ( m 2 , k p ) , such that D ( g ( c 1 , c 2 ) , k s ) = m 1 · m 2 .
```
D(g(c1, c2), k_s) = m_1*m_2.
def multiply_ciphertexts(c1,c2,parameters):
'''
Compute product of two ciphertexts in the ciphertext domain.
This produces a three-coefficient ciphertext that cannot
be decrypted using the standard decryption function.
'''
q,n,t,R,D = parameters
u1,v1 = c1
u2,v2 = c2
temp = multiply_round(u1*u2, t/q, parameters)
hh0 = symmetrize(temp, q)
temp = multiply_round(u1*v2 + u2*v1, t/q, parameters)
hh1 = symmetrize(temp, q)
temp = multiply_round(v1*v2, t/q, parameters)
hh2 = symmetrize(temp, q)
return (hh0, hh1, hh2)
```
## 10.10.8 Relinearization
We implement Method 2 described above to relinearize the product of two ciphertexts. The relinearization operation is defined in terms of both the parameters used for the basic BFV cryptographic operations described above and two additional parameters, a second (large) prime number p and a second noise distribution D 2 .
```
p = 655360001
sigma2 = 2.0
D2 = dgi.DiscreteGaussianDistributionIntegerSampler(sigma=sigma2)
```
We define a function that generates the relinearization key k r and another function L that applies k r to convert a three-coefficient ciphertext product into a two-coefficient ciphertext that can be decrypted.
```
to convert a three-coefficient ciphertext product into a two-coefficient ciphertext that can be decrypted.
def generate_relinearization_key(secret_key, parameters, p, D2):
q,n,t,R,D = parameters
a = symmetrize(sample_r(n), p*q)
e = symmetrize(sample_e(n, D2), p*q)
b = symmetrize(-(a*secret_key + e) + p*secret_key^2, p*q)
relinearization_key = (b,a)
return relinearization_key
def relinearize(ciphertext_product,
relinearization_key,
parameters):
q,n,t,R,D = parameters
hh0, hh1, hh2 = ciphertext_product
b,a = relinearization_key
u = hh0 + multiply_round(hh2*b, 1/p, parameters)
v = hh1 + multiply_round(hh2*a, 1/p, parameters)
return (symmetrize(u, q), symmetrize(u, q))
```
Usage Example We verify that D ( L ( g ( c 1 , c 2 ) , k r ) , k s ) = m 1 · m 2 for random messages m 1 and m 2 and their corresponding ciphertexts c 1 = E ( m 1 , k p ) and c 2 = E ( m 2 , k p ) .
```
and their corresponding ciphertexts c$_{1}$ = E ( m$_{1}$, k$_{p}$ ) and c$_{2}$ = E ( m$_{2}$, k$_{p}$ ).
relinearization_key = generate_relinearization_key(secret_key,
parameters,
p,
D2)
ciphertext_product = multiply_ciphertexts(ciphertext_1,
ciphertext_2,
parameters)
relinearized_ciphertext = relinearize(ciphertext_product,
relinearization_key,
parameters)
decrypted_message = decrypt(relinearized_ciphertext,
secret_key,
parameters)
message_product = symmetrize(message_1 * message_2, t)
print(message_product == decrypted_message_product)
```
Order
## A Abstract Algebra
This section introduces the basics of abstract algebra, including groups, rings, modules, fields, and ideals. The material covered are standard in algebra textbooks like Artin (1991). For students who want to learn how to think about abstract algebra, we recommend Alcock (2021).
## A.1 Group theory
There are at least two motivations to study group theory for lattice-based cryptography. First, more advanced algebraic structures such as rings and fields are build upon the concepts of groups. Second, it provides a different view of lattices which are additive subgroups of R n .
Definition A.1.1. A group G = ( S, · ) Group is a set of elements together with a binary operator ' · ' such that
- closed: for all a, b ∈ S , we have a · b ∈ S ,
- unique identity element: there exists a unique identity element e ∈ S with respect to the binary operator,
- associative: for all x, y, z ∈ S , we have ( x · y ) · z = x · ( y · z ) ,
- unique inverse element: for all x ∈ S , there exists an element y ∈ S such that x · y = e .
A group is an abstract algebraic structure. Elements in S can be integers, fractions, matrices, functions, etc. The group operator can be addition, multiplication, matrix multiplication, function composition, etc. The pair forms a group as long as the four groups axioms are satisfied.
When dealing with binary operators, one often wonders whether or not the same result will be produced if switching the order of the two inputs. That is, does x · y = y · x for all x, y ∈ S ? For some groups this is true, but not in general. For example, the condition is true for the additive group of integers ( Z , +) ), but not the multiplicative group of n × n integer matrices ( M, × ) . Such a property is called abelian or commutative.
Definition A.1.2. A group ( G, · ) is abelian (or commutative ) if x · y = y · x for all x, y ∈ G .
In cryptography, we almost always work with abelian groups such as the integer group or the polynomial group.
The number of elements in a group can be finite or infinite. For groups with finitely many elements, we can definite the group order and element order as follows.
Definition A.1.3. The order of a group G is the number of elements in G .
Definition A.1.4. For an element a in a group ( G, · ) , if there exists a positive integer k such that a · · · a ︸ ︷︷ ︸ k = e is the group identity, then the element a has order k . If no such an integer k exists, then a has infinite order.
Orders of groups and group elements are useful when working with finite groups. Every non-zero element in ( Z , +) has infinite order. Let Z / 3 Z = { 0 , 1 , 2 } be the group of integers modulo 3. The order of the group ( Z / 3 Z , +) is 3. The orders of the elements 0, 1, 2 are 1, 3, 3, respectively.
Some important examples of groups are:
- Symmetric group S n : the set of all permutations of the indices [ n ] := { 1 , . . . , n } . The group has order | S n | = n ! .
- Dihedral group D n : a group of symmetries - reflection f and rotation r - of a regular n -gon. For example, D 4 = { e, f, r, r 2 , r 3 , f r, f r 2 , f r 3 } . The group operation is function composition.
- Cyclic group : a group that is generated by a single element. For example, ( Z , +) is an infinite cyclic group that is generated by 1 . Another example is ( Z /n Z , +) which is a finite cyclic group of order n that is generated by 1 . The element g ∈ G that generates the entire group G is called a generator . The common notation is G = 〈 g 〉 or G = C n if G has a finite order n .
Normal subgroup
- Klein four group K 4 or V 4 - a group of 4 elements in which each non-identity element has order 2 and the composition of two non-identity elements produces the third one. The Klein four group is isomorphic to the product of two cyclic groups of order 2, i.e., V 4 ∼ = C 2 × C 2 .
Definition A.1.5. Let ( G, · ) be a group. A subset H of G is a subgroup of ( G, · ) if H forms a group with G 's operator.
Sometimes we omit the group operator for simplicity. An important type of subgroups is normal subgroup.
Definition A.1.6. Let G be a group. A subgroup N of G is normal if N is invariant under group conjugation. That is, for all elements g ∈ G and all elements h ∈ N , we have g -1 hg ∈ N .
The notation for normal subgroups is H G (or H G ). Normal subgroups are important because they partition a group G into cosets , i.e., quotient group or factor group, which is important toward learning quotient rings. In addition, quotient groups regroup elements into non-overlapping classes which may help to reveal underlying structures of the original group that are difficult to be seen without the action of grouping.
To introduce quotient groups, we first introduce equivalence relations, based on which group elements are put together.
Definition A.1.7. A binary relation ∼ on a set S is said to be an equivalence relation if it satisfies the following axioms for all a, b, c ∈ S :
- reflexive: a ∼ a ,
- transitive: if a ∼ b and b ∼ c , then a ∼ c .
- symmetric: a ∼ b if and only if b ∼ a ,
- Definition A.1.8. Given a subgroup H of G , we can define a left coset Left coset of H in G as the set of elements obtained by applying a fixed element of G (under the group operation) on the left of H . That is, for each element g ∈ G , the left coset of H is
$$g H = \{ g h | h \in H \} .$$
- The right coset is defined respectively. Let G = ( Z , +) and H = (2 Z , +) . The left Right coset cosets of H in G are 0 + 2 Z and 1 + 2 Z , because any additional cosets constructed by the other elements of G will be identical to these two. We denote the cosets by ¯ 0 and ¯ 1 , respectively.
Each coset is an equivalence class with the equivalence relation 'belong to the same coset'. This can be checked easily. For elements a, b ∈ G , they belong to the same coset (i.e., aH = bH ) if and only if b -1 a ∈ H . Given a normal subgroup H G , it divides G into several equal-sized equivalence classes.
- Definition A.1.9. Quotient group The quotient group of G by a normal subgroup H G , denoted by G/H , is the set of cosets of H in G .
An important observation is that the set of cosets forms a group with the group operation in G . The identity element in the quotient group is precisely the normal subgroup H . That is why G/H is called a quotient GROUP. For example, the set { ¯ 0 , ¯ 1 } and addition form a group, in which ¯ 0 is the identity. It can be checked that the normal subgroup assumption is necessary because it ensures the set of cosets forms a group. This is not always true if H is just an ordinary subgroup of G .
- Given a subgroup H of G , all cosets of H have the same size, so we have a quantity, namely Index the index of H in G and denoted by | G : H | , that is defined as the number of coset of H in G . If H is a normal subgroup of G , then the index | G : H | = | G/H | is equal to the order of the quotient group.
We sometimes have a function f acts on a group ( G, · ) by mapping elements of G to another set H . In that case, we would like to know whether or not the same group structure is preserved in H by the function f . This function is formally defined as a group homomorphism.
Definition A.1.10. A homomorphism Group homomorphism from a group ( G, · ) to a group ( H, ∗ ) is a function f : G → H such that for all elements a, b ∈ G it holds that
$$f ( a \cdot b ) = f ( a ) * f ( b ) .$$
In other words, the relationship between the two elements in G are mapped to the relationship between the two corresponding elements in H . There are different types of group homomorphisms, depending on the function type and the function's codomain. The two important groups homomorphisms are isomorphisms and automorphisms.
- Definition A.1.11. A homomorphism is called an isomorphism Isomorphism if it is bijective.
If there is an isomorphism between two groups ( G, · ) and ( H, ∗ ) , then they are isomorphic and denoted by ( G, · ) ∼ = ( H, ∗ ) . Isomorphisms are important because they tell you when two groups are identical. In addition, knowing one group will tell you everything about the other. An example of a group isomorphism is f : ( R , +) → ( R + , × ) given by the function f ( x ) = e x . A special case of isomorphism is between a group and itself, which we will see when introducing Galois theory.
Definition A.1.12. A homomorphism is called an automorphism if it is an isomorphism such that the domain and codomain are the same. That is, an isomorphism f : G → G .
## A.2 Ring theory
Unlike groups, rings are algebraic structures associate with two binary operators, addition and multiplication such that ring axioms are satisfied.
- Definition A.2.1. A ring R = ( S, + , × ) Ring is a set with two operations, namely addition and multiplication, such that the following ring axioms are satisfied:
- ( S, +) is an abelian group under addition,
- ( S, × ) is closed under multiplication, associative and contains the unique multiplicative identity 1 ,
- multiplication is distributive with respect to addition, i.e., a × ( b + c ) = a × b + a × c for all a, b, c ∈ S .
A ring R is commutative (called commutative ring) if multiplication is also commutative in R . For example, the set of integers forms a commutative ring with integer addition and multiplication. However, none of the integers except 1 has a multiplicative inverse in the integer set. The set of n × n (real or integer) matrices forms a non-commutative ring with matrix addition and multiplication. Not all matrices have inverses. An important ring in lattice-based cryptography is the ring of polynomials or polynomial ring Q [ x ] or Z [ x ] with polynomial addition and multiplication as the ring operations. Again, not all polynomials in the ring Q [ x ] and Z [ x ] have inverses in the same ring.
The pair ( S, × ) in a ring R almost forms a multiplicative group, but it lacks of multiplicative inverses in general. Without multiplicative inverses (of non-zero elements), division cannot be carried out in rings. For this purpose, we introduce division rings.
Definition A.2.2. A unit in a ring R is any element that has a multiplicative inverse in R .
For example, 1 is the only unit in the ring of integers. But 1, 2 are both units in the ring ( Z 3 , + , × ) .
- Definition A.2.3. A division ring Division ring is a ring R in which every non-zero element is a unit. That is, every non-zero element has a multiplicative inverse in R .
In a division ring, the pair ( S, × ) forms a multiplicative group, but not necessary abelian. If it is abelian, the ring is a field, which will be introduced in the next subsection. Similar to a group and its subgroups, subrings can be defined with respect to a ring.
Definition A.2.4. Let ( R, + , × ) be a ring. A subset S ⊂ R is a subring if ( S, + , × ) forms a ring with the ring's addition and multiplication.
The concept of a vector space can be generalized to a module which is defined similarly, but over a ring instead of a field. The main difference is that every element in a field has a multiplicative inverse, so a vector in a vector space can be scaled up or down by a scalar and its multiplicative inverse. However, not every element in a ring has a multiplicative inverse, so an element in a module cannot always be scaled up and down.
- Definition A.2.5. Let R be a ring and 1 being its multiplicative identity. A left R -module M Module consists of an abelian group ( M, +) and an operation · : R × M → M such that for all r, s ∈ R and x, y ∈ M , the following are satisfied:
- r · ( x + y ) = r · x + r · y · ( r + s ) · x = r · x + s · x · ( rs ) · x = r · ( s · x ) · 1 · x = x
The concept of a right R -module is defined similarly. The distinction between a left and right module arises from the fact that the underlying ring R is not necessary commutative. In general, unless mentioned otherwise, we always refer a module to a left module. A Z -module is a module over the integer ring Z . It is both a left and right module as Z is commutative. In Section 9, we will talk about the ring of integers of a number field. Without stating the proper definition here, the ring of integers is a the ring of all algebraic integers in a number field, where an algebraic integer is a root of an integer coefficient polynomial. It is not hard to see that the ring of integers form an abelian group under addition, as the sum of two algebraic integers is still an algebraic integer. For specific purposes, we often say the ring of integers is also a Z -module, as the above conditions are all satisfied.
Definition A.2.6. Suppose M is a left R -module and N is a subgroup of M . Then N is an R -submodule (or just submodule ) if for any n ∈ N and any r ∈ R , we have r · n ∈ N .
The definition of submodule is similar to subspace of a vector space, where the subspace is closed under addition and scalar multiplication. A important type of module is called a free module.
Definition A.2.7. A free module Free module is a module that has a basis.
Ideals
Here a basis is a set of linearly independent vectors that generates M . That is, every element of M can be written as a linear combination of the set of linearly independent vectors, where the coefficients are taken from the underlying ring R . So a free Z -module is a module with a basis such that every element in the module is an integer combination of the basis.
Similar to a normal subgroup, an ideal can partition a ring into cosets which form a ring with less elements, known as the quotient ring . As noted, not all subgroups can partition a group into a quotient group. Similarly, an ideal must have some special properties in order to construct a quotient ring.
First, a ring is an additive group with an extra operation, an ideal of the ring should be a normal subgroup under addition (in fact, being a subgroup is enough as a ring is an abelian group under addition which implies normality), so an ideal must be closed under addition. Second, for cosets to be closed under multiplication, ideals must be closed under multiplication by any ring elements. More specifically, an ideal I partitions a ring R into a set of equivalence classes, each denoted by [ a ] := a + I = { a + r | r ∈ I } . Since we want this set of equivalence classes to form a ring, it must satisfy
- [ a ] + [ b ] = ( a + I ) + ( b + I ) = ( a + b ) + ( I + I ) = ( a + b ) + I = [ a + b ]
- [ a ][ b ] = ( a + I )( b + I ) = ab + aI + bI + II = ab + I = [ ab ] .
So we can see that ideals have to satisfy at least three criteria. First, closed under addition by itself. Second, closed under multiplication by itself. Third, closed under addition by all elements in the ring. Noted that the third criterion includes the second, so at least two criteria need to be satisfied. The formal definition of an ideal is stated as below.
Definition A.2.8. For an arbitrary ring ( R, + , × ) , the subset I ⊂ R is a left ideal of the ring if it satisfies:
- ( I, +) is an additive subgroup of the group ( R, +) ,
- I is closed under left multiplication by all elements of R . That is, for every r ∈ R and every x ∈ I , their product rx ∈ I .
An right ideal is defined respectively. If I is both a left and right ideals, then it is a two-sided ideal of the ring. Again, since most rings considered in cryptography are commutative, we do not distinguish left and right ideals. Throughout, we use the term ideals for two-sided ideals unless mentioned otherwise. For example, the set of even integers form an ideal in the integer ring, because even integers are closed under addition and any integer multiplied by an even integer is still even.
Note that although an ideal is closed under addition and multiplication, it is not a ring because it does not necessary have a multiplicative identity, which is required by our definition of rings.
Quotient ring
Integral domain
Ideals can be generated by a set of elements a 1 , . . . , a n ∈ R , denoted by
$$( a _ { 1 } , \dots , a _ { n } ) = \{ r _ { 1 } a _ { 1 } + \cdots + r _ { n } a _ { n } \colon r _ { i } \in R \} ,$$
Intuitively, one can think of an ideal of a ring R as a subset of R that absorbs R , so it is closed under addition, and multiplication by ring elements. Ideal is an important concept that will frequently appear in lattice-based cryptography. It helps to build a quotient ring or even a field if the ideal used is maximal. This is similar to the construction of quotient groups via normal subgroups.
with the special case of ( a ) = aR = Ra = { ra : r ∈ R } . A zero ideal is an ideal contains only the zero element, i.e., { 0 } or (0) . A unit ideal is the ring itself. A proper ideal is a non-unit ideal.
Definition A.2.9. The quotient ring of a ring R by an ideal I , denoted by R/I , is the set of cosets of I in R .
The quotient ring R/I has the additive identity ¯ 0 = 0 + I (similar to a normal subgroup being the identity of the quotient group) and the multiplicative identity ¯ 1 = 1 + I .
Some ideals have additional properties that can make the corresponding quotient rings special. Below we introduce three special ideals.
- Prime ideal → integral domain
- Maximal ideal → (residual) field
- Principal ideal → principal ideal domain
A prime ideal can be thought as a generalization of a prime number. Recall that if p is a prime number and p | ab for integers a and b , then either p | a or p | b .
Definition A.2.10. An ideal P of a ring R is prime Prime ideal if it satisfies the following two properties:
- P = R ,
- for any two elements a, b ∈ R , if their product ab ∈ P , then either a ∈ P or b ∈ P .
The set of even integers in the ring of integers is a prime ideal. To see why prime ideals are important, we introduce the concept of integral domains that are defined upon commutative rings.
Definition A.2.11. An integral domain is a non-zero commutative ring in which the product of two non-zero elements is non-zero.
Integral domains are generalizations of the rings of integers of algebraic number fields that will be discussed in a later section. Integral domains provide a natural setting to study division, because they allow the cancellation of a non-zero factor a in an equation like ab = ac .
Proposition A.2.12. If I R is a prime ideal, then the quotient ring R/I is an integral domain.
Proof. I being a prime ideal implies that no two elements that are not in I can be multiplied to an element in I . Since I is the additive identity in the quotient ring R/I , it is the zero element in the quotient ring. This implies that no two non-zero elements (i.e., elements not in ¯ 0 ) can be multiplied to a zero element (i.e., an element in ¯ 0 ).
For example, 12 Z is not a prime ideal, so the quotient ring Z / 12 Z is not an integral domain because 3 · 4 = 12 = 0 mod 12 . But Z / 5 Z is an integral domain. Another example is the ring of polynomials whose coefficients come from an integral domain.
Proposition A.2.13. If R is an integral domain, then the ring of polynomials R [ x ] is also an integral domain.
Proof. R is integral domain, the product of the leading coefficients of two non-zero polynomials is also non-zero, so R [ x ] is an integral domain.
Definition A.2.14. An ideal in a ring R is principal Principal ideal if it can be generated by a single element of R through multiplication by every element of R .
- Maximal ideal
For example, 2 Z is a principle ideal in the integer ring, because it can be generated by 2 multiplying every element of Z .
Definition A.2.15. A principal ideal domain (PID) is an integral domain in which every ideal is principal.
As will be explained in detail later, fields are commutative division rings that possess nice properties for building cryptosystems. Given a ring R , one can construct a field by taking the quotient ring with a maximal ideal of R .
Definition A.2.16. A maximal ideal in a ring is an ideal that is maximal among all the proper ideals of the ring.
In other words, if I is a maximal ideal in a ring R , then I is contained in only two ideals of R , i.e., I itself and the entire ring R . An important observation is that every maximal ideal is a prime ideal. This can be easily seen if we define the divisibility of ideals.
Proposition A.2.17. If I is a maximal ideal of a commutative ring R , then the quotient ring R/I is a field.
Proof. (Sketch) I being a prime ideal is not sufficient to construct a field. Because the quotient ring R/I may have a proper ideal that is not the trivial ideal. That is, there may be an ideal I ′ in R/I that is not equal to { 0 } or R/I . Hence, multiplication of an element in I ′ by an element not in I ′ will only get to elements in I ′ . This implies that not all non-zero elements in R/I have multiplicative inverses.
The quotient ring R/I constructed using the maximal ideal is called a residual field .
Another concept that will be mentioned later and could help to understand the structure of fields are the characteristic of a ring. If it helps, the characteristic of a ring can be thought as the cyclic period of a ring. For example, the ring Z / 4 Z has a characteristic 4 which is the rings cyclic period.
- Definition A.2.18. The characteristic of a ring R , Characteristic denoted by char ( R ) , is the smallest number of times that the ring's multiplicative identity 1 can be added to itself to get the additive identity 0. If the ring's multiplicative identity can never be summed to get 0, then the ring has a characteristic zero.
The characteristic of a ring R may also be taken as the smallest positive integer n such that a + · · · + a ︸ ︷︷ ︸ n = 0 for every element a ∈ R (if the characteristic exists). For example, the character- istic of Z 3 is 3 because 1 + 1 + 1 = 3 = 0 mod 3 or 2 + 2 + 2 = 6 = 0 mod 3 . We will talk more about the characteristics of fields in the following subsection.
## kernel
First Isomorphism Theorem
## Field
The First Isomorphism Theorem for rings is the fundamental method for identifying quotient rings. In the below, ring homomorphism is defined analogously to group homomorphism, and the kernel of a map ϕ : R → S is the subset of R that map to the zero element in S : ker ( ϕ ) = { r ∈ R : ϕ ( r ) = 0 } .
Theorem A.2.19. Let R and S be rings and let ϕ : R → S be a ring homomorphism. Then
1. the kernel of ϕ is an ideal of R ;
2. the image of ϕ is a subring of S ; and
3. R/ker ( ϕ ) is isomorphic to the image of ϕ .
## A.3 Field theory
A field is a commutative division ring. That is, a field is a ring if ( S ∗ , × ) is an abelian group under multiplication, where S ∗ := S \ { 0 } is the set of non-zero elements. More formally, we have the next definition.
Definition A.3.1. A field F = ( S, + , × ) is a set with two binary operators, addition and multiplication, such that the following field axioms are satisfied:
- ( S, +) is an abelian group under addition,
- ( S ∗ , × ) is an abelian group under multiplication,
Field of fractions
- multiplication is distributive with respect to addition, that is, a × ( b + c ) = a × b + a × c for all a, b, c ∈ S .
Examples of fields are the field of rational numbers, real numbers and complex numbers. The smallest field is F 2 = Z / 2 Z = { 0 , 1 } , because a field must contain at least two distinct elements 0 and 1.
A field is an integral domain, because non-zero elements have multiplicative inverses, which eliminates the possibility that their product is zero.
Sometimes, it is easier to construct a field from a given commutative ring rather than build it from scratch. One can construct a field from a commutative ring in two ways, by building the field of fractions or by quotienting the commutative ring by a maximal ideal as discussed earlier in Proposition A.2.17.
Definition A.3.2. Let R be an integral domain. The field of fractions Frac ( R ) is the set of equivalence classes on R × ( R \ { 0 } ) defined by
$$F r a c ( R ) = \{ ( p , q ) \in R \times ( R \ \{ 0 \} ) \ | \ ( p , q ) \sim ( r , s ) \iff p s = q r \} .$$
This definition generalizes the idea of creating fractions from integers. For example, if R = Z then p q ∈ [( p, q )] ⊆ Frac ( Z ) = Q . More precisely, let p = 5 , q = 20 then 5 / 20 is an element in the equivalence class consists of { 1 / 4 , 5 / 20 , 25 / 100 , . . . } , which is also called the set of all equivalent fractions. The reason for R being an integral domain is because we can have the usual addition and multiplication in the field of fractions without running into the trouble of having a zero divisor. For example, a b + c d = ad + bc bd , since R is an integral domain it is guaranteed that bd = 0 .
Proposition A.3.3. A non-zero commutative ring R is a field if and only if it has no ideals other than (0) and R .
Proof. If R is a field, then every non-zero element has a multiplicative inverse. If I is a non-zero ideal of R and a ∈ I , then a -1 a = 1 ∈ I . So I = R . If R has no proper non-zero ideal, then the ideal I = R is a principal ideal. That is, I = ( a ) for a = 0 . Hence, there must exist an element b ∈ R such that ab = 1 . Hence, R is a field.
This proposition implies an important property of a field: its only ideals are the zero ideal and the field itself.
One type of fields that is essential in cryptography is called finite fields . These are fields with finitely many elements. The number of elements in a finite field is the order of the field (just like the order of a = 0 , 1
Field characteristics is an important concept that can be used to decide the separability of extension fields. We will see more about the connection between field characteristic and separability in a later section.
- Finite field group). For example, Z 2 { } is a finite field of order 2.
Char ( F ) = 0 or prime
Lemma A.3.4. The characteristic of any field is either 0 or a prime number.
Proof. Let n be the characteristic of the field F . It is easy to see that n = 1 , because a field is not a trivial ring, so 1 = 0 . Assume n = pq is a composite number, where 1 < p, q < n . This implies that (1 + · · · +1) ︸ ︷︷ ︸ p (1 + · · · +1) ︸ ︷︷ ︸ q = 1 + · · · +1 ︸ ︷︷ ︸ n = 0 . Hence, we have pq = 0 which contradicts with the fact
$$\text {that the field is also an integral domain.}$$
that the field is also an integral domain.
Corollary A.3.5. This lemma implies that the characteristic of any finite field is a prime number.
Corollary A.3.6. The characteristic of a subfield is the same as the characteristic of the field.
Theorem A.3.7. In a field of characteristic p where p is prime, the only p -th roots of unity is 1.
In a field of prime characteristic p , we have x p -1 = ( x -1) p because after expanding ( x -1) p , all terms except x p and -1 p have coefficients that are multiples of p , which vanish when taking modulo p . Hence, solving x p -1 = 0 is equivalent to solving ( x -1) p = 0 , where the only solution is x = 1 .
So far in this section, we have introduced the concepts of groups, rings, fields and other related concepts. These will serve as a foundation for studying the Galois theory and algebraic number theory.
## B Galois Theory
In the previous section, we have introduced some basics about group, ring and field theories. We start this section by introducing field extension that is fundamental to understand number field. All things lead to the Galois group in the end, which is interesting in itself as well as gives insights of cyclotomic number field that is widely used across recent lattice-based cryptography and homomorphic encryption developments.
## B.1 Field extension
The concept of field extensions is fundamental in solving polynomials, especially polynomials with rational coefficients, denoted by Q [ x ] . The first attempt to solve these polynomials is to find their roots in the field of rationals Q . For some rational (coefficient) polynomials, however, their roots only exist beyond Q . For example, the polynomial x 2 -2 has two irrational roots ± √ 2 . For this reason, we need to construct a field that is larger than Q so that it includes all roots of the polynomial x 2 -2 , but not too large that includes many unnecessary values. To achieve this goal, we first define extension fields.
Definition B.1.1. If a field F is contained in a field E , then E is called an extension field of F .
If E is an extension (field) of F , then F is a subfield of E . This pair of fields is called a field extension and denoted by E/F . Field extension
For the above example x 2 -2 , we can adjoin to Q the roots of this polynomial to get a larger field that includes all the roots of x 2 -2 , denoted by Q ( ± √ 2) := { a ± b √ 2 : a, b ∈ Q } . Note that since an extension field is also a field, it is sufficient to adjoin only √ 2 . Being a field also implies the extension Q ( √ 2) includes more elements such as 1 + √ 2 , 5 √ 2 and so on.
F -vector space Given a field extension E/F , the larger field E forms a vector space over F , which is also known as an F -vector space . The larger field E consists of the 'vectors' in the vector space and the smaller field F consists of the scalars for multiplying with the vectors. For example, Q ( √ 2) forms a Q -vector space, because the extension Q ( √ 2) is closed under addition (satisfying commutativity, associativity, additive identity and inverse) and scalar multiplication with Q (satisfying compatibility, scalar identity in Q , distributivity of scalar multiplication w.r.t. scalar addition in Q or addition in Q ( √ 2) ).
Field extension degree
Since an extension forms a vector space over the base field, it makes sense to talk about the degree of an extension.
Definition B.1.2. Give a field extension E/F , the degree of the extension field E , denoted by [ E : F ] , is the dimension of the vector space formed by E over F .
An extension E is finite if its degree is finite. Otherwise, it is infinite. There are at least two ways of counting the dimension of an extension. One way is through the degree of the minimal polynomial of a primitive element that generates the extension. This will be discussed in more detail in subsequent subsections.
The other way of counting the dimension of the extension field is by counting the number of linearly independent vectors in its basis (same as for vector spaces in linear algebra). Hence, one could specify a basis of the extension over the base field in order to get the degree of the extension. For example, the degree [ Q ( √ 2) : Q ] = 2 , [ Q ( √ 2 , √ 3) : Q ] = 4 , [ C : R ] = 2 because the corresponding basis for each extension field is { 1 , √ 2 } , { 1 , √ 2 , √ 3 , √ 6 } , { 1 , i } respectively.
Similar to Lagrange's theorem in group theory, the degrees of extensions follow the 'Tower Law'.
Proposition B.1.3. (The Tower Law) If L/M and M/K are field extensions (finite or infinite), then the degrees of the extensions satisfy
$$[ L \colon K ] = [ L \colon M ] [ M \colon K ] .$$
Intuitively, L forms a M -vector space and M forms a K -vector space, so L also forms a K -vector space. Each dimension in L over M is again a [ M : K ] -dimensional vector space.
The following subsections introduce some special types of field extensions that eventually lead to Galois extensions and Galois groups.
Algebraic number
Algebraic integer
Algebraic extension
Algebraic closed
## B.1.1 Algebraic extension
Historically, solving mathematical equations with rational coefficients was a natural but challenging task. This lead to the definition of algebraic numbers that are roots of non-zero rational polynomials. More formally,
Definition B.1.4. A complex number is algebraic (over the rationals Q ) if it is a root of a non-zero polynomial whose coefficients are rational numbers. That is, r ∈ C is an algebraic number if it satisfies f ( r ) = 0 for some non-zero polynomial f ( x ) ∈ Q [ x ] .
All rational numbers are algebraic because they can be written in a linear equation x -r for all r ∈ Q . The irrational number √ 2 is algebraic because it is a root of x 2 -2 . The complex number i is also algebraic because it is a root of x 2 +1 . Complex numbers that are not algebraic are called transcendental . In other words, transcendental numbers are not roots of any rational coefficient polynomials. For example, the number π or e .
Almost all real numbers are not algebraic. The set of real numbers is uncountable, but the set of algebraic numbers are countable. That is, there is a one-to-one correspondence between all the algebraic numbers and the natural numbers.
When developing cryptosystems, we almost always work with integer (coefficient) polynomials Z [ x ] . Within Z [ x ] , monic polynomials are of special interest due to their computational efficiency. A polynomial is monic if the coefficient of its leading term (i.e., the term with the highest degree) is one. For example, when dividing polynomials, it is convenient to work with integer polynomials with leading coefficient one. In most cases, we work with polynomials defined over a field (e.g., Z p [ x ] for prime p ), so even if it is not monic, it can always made monic by dividing its coefficients with the leading term's coefficient.
Definition B.1.5. A complex number is an algebraic integer if it is a root of a monic polynomial with integer coefficients.
Algebraic integers are generalization of ordinary integers which we call rational integers. Similar to numbers, field extensions can be algebraic or transcendental too.
Definition B.1.6. A field extension E/F is algebraic if every element in the extension field E is algebraic.
Since all rational numbers are algebraic, a field extension Q ( α ) is algebraic if all the additional elements are algebraic.
All transcendental extensions are of infinite degree. For example, the transcendental extension Q ( π ) has a basis { 1 , π, π 2 , π 3 , . . . } of infinite linearly independent vectors. The above statement also implies that all finite extensions are algebraic. This is also proved in the following proposition.
Proposition B.1.7. Every finite extension is algebraic.
Proof. Let E be an extension over F with a finite degree [ E : F ] = n . For an element x ∈ E , the elements 1 , x, x 2 , . . . , x n ∈ E because E is a field. These n +1 elements are also in the n -dimensional vector space over F , so must be linear dependent. Hence, there exists a set of non-zero coefficients { a 0 , . . . , a n } such that 1 + a 1 x + a 2 x 2 + · · · + a n x n = 0 . This implies that x is algebraic.
Definition B.1.8. A field F is algebraically closed if for any polynomial f ( x ) ∈ F [ x ] , all of its roots are in the field F .
Obviously Q and R are not algebraically closed, but C is. This is the Fundamental Theorem of Algebra . It implies that all polynomials can be completely solved or factored into linear factors in the complex field C .
As mentioned earlier, given a field extension Q ( r ) / Q , another way of identifying the degree of the extension is by identifying the degree of the minimal polynomial of r over Q . To finish off this subsection, we define what minimal polynomial is.
Irreducible polynomial
Definition B.1.9. A polynomial f ( x ) ∈ F [ x ] is reducible over the field F if it can be factored into polynomials with smaller degrees. Otherwise, it is irreducible .
Example B.1.10. Given the following polynomials over the field of rationals Q :
$$^ { 2 }$$
$$f _ { 4 } ( x ) = x ^ { 2 } + 1 = ( x + i ) ( x - i ) ,$$
$$f _ { 1 } ( x ) & = x ^ { 2 } + 4 x + 4 = ( x + 2 ) ( x + 2 ) , \\ f _ { 2 } ( x ) & = x ^ { 2 } - 4 = ( x + 2 ) ( x - 2 ) , \\ f _ { 3 } ( x ) & = 9 x ^ { 2 } - 3 = ( 3 x + \sqrt { 3 } ) ( 3 x - \sqrt { 3 } ) , \\ f _ { 4 } ( x ) & = x ^ { 2 } + 1 = ( x + i ) ( x - i ) ,$$
the polynomials f 1 ( x ) and f 2 ( x ) are reducible over Q whilst the other two are irreducible over Q . The polynomials f 3 ( x ) and f 4 ( x ) are reducible over R and C , respectively. The polynomial f 4 ( x ) is irreducible over R .
Theorem B.1.11. Let p be a prime and f ( x ) ∈ F p [ x ] be a monic irreducible polynomial of degree n . The quotient ring F p [ x ] /f ( x ) is a field of order p n . (Each polynomial in F p [ x ] /f ( x ) has coefficients taken from the field F p and the polynomial degree is at most n -1 .)
Proof. Each coset in the quotient ring F p [ x ] /f ( x ) has the form a 0 + a 1 x + · · · + a n -1 x n -1 , where a i ∈ F p . So there are p n different cosets. The polynomial f ( x ) is irreducible implies the quotient ring is also a field.
Definition B.1.12. Minimal polynomial Let E/F be a field extension. If r is algebraic over F , its minimal polynomial over F is the irreducible monic polynomial f ( x ) ∈ F [ x ] of the least degree satisfying f ( r ) = 0 .
It is necessary for r to be algebraic, for otherwise it is not a root of any polynomial in F [ x ] .
Uniqueness
Simple extension
Note the minimal polynomial of an algebraic number over a base field is unique up to scalar multiplication. A simple argument is as the following. Let J r = { f ( x ) ∈ F [ x ] | f ( r ) = 0 } be the set of all polynomials in F [ x ] where r is a root, then J r is an ideal of the polynomial ring F [ x ] (easy to verify). Let p, q ∈ J r be two monic polynomials of least degree n > 0 , then p -q ∈ J r because J r is an ideal. Also p -q has degree less than n because p, q are monic. This contradicts with p, q being least degree polynomials in J r , unless p = q .
For different base fields, the minimal polynomial of a number could be different. Here is an example. Given the field extension R / Q , the minimal polynomial of √ 2 over Q is x 2 -2 because this polynomial is monic, irreducible and has the least degree over the base field Q where √ 2 is a root. However, in the field extension R / R , the minimal polynomial for √ 2 is x -√ 2 .
The degree of an extension E = F ( r ) is the degree of the minimal polynomial of r over F . This is formally proved by Theorem B.1.14 in the next subsection. In the above example, the degree [ Q ( √ 2) : Q ] = 2 , because the minimal polynomial of √ 2 over Q is x 2 -2 .
## B.1.2 Simple extension
Definition B.1.13. An extension field E over F is simple if there exists an element r ∈ E with E = F ( r ) .
The simple extension F ( r ) is the smallest extension over F that contains F and r . The number r can be either transcendental or algebraic, but we are only interested in algebraic simple extensions.
In the previous section, we mentioned that if r is an algebraic number over the base field F then its unique minimal polynomial p ( x ) always exists. In addition, since p ( x ) is irreducible over F , the principal ideal 〈 p ( x ) 〉 is also maximal in F [ x ] . This gives us a way of building the extension field F ( r ) from the polynomial ring F [ x ] using the principal ideal by Proposition A.2.17 as stated in the following theorem.
Theorem B.1.14. Let E/F be a field extension and r ∈ E be an algebraic number over F with minimal polynomial p ( x ) ∈ F [ x ] of degree n , then
$$1 . \ F ( r ) \cong F [ x ] / \langle p ( x ) \rangle .$$
Existence
Uniqueness
Normal extension
2. { 1 , r, r 2 , . . . , r n -1 } is a basis of the vector space F ( r ) over F .
3. [ F ( r ) : F ] = deg ( p ) .
The first part of Theorem B.1.14 is a direct consequence of the First Isomorphism Theorem (Theorem A.2.19). An important observation as stated in the following corollary of the above theorem is that if two algebraic numbers have the same minimal polynomial, then the simple extensions generated by them are isomorphic. This tells us that simple algebraic extension of an algebraic number is unique.
Corollary B.1.15. Let E/F be a field extension. If two algebraic numbers α, β ∈ E over F have the same minimal polynomial in F [ x ] , then there is an isomorphism φ : F ( α ) → F ( β ) with φ | F = I .
## B.1.3 Splitting field
One way of building the smallest field extension for solving a polynomial is to look at the splitting field of the polynomial.
Solving a degree n polynomial f ( x ) ∈ F [ x ] for its roots can be done by rewriting it as the product of linear factors in an appropriate extension field E . That is,
$$f ( x ) = c \prod _ { i = 1 } ^ { n } ( x - a _ { i } ) ,$$
where c ∈ F is a constant and x -a i ∈ E [ x ] is a linear factor. This rewriting process is also known as splitting a polynomial.
Definition B.1.16. Let F be a field and f ( x ) ∈ F [ x ] be a polynomial. The extension field E is a splitting field of over if
Splitting field f ( x ) F
- f ( x ) splits over E and
- if F ⊆ L E , then f ( x ) does not split over L .
By definition, a splitting field of f ( x ) is the smallest extension that contains all the roots of f ( x ) . Alternatively, we say that the extension E is generated by the roots of f ( x ) . That is, if r 1 , . . . , r n are the roots of f ( x ) and E is the splitting field of f ( x ) then E = F ( r 1 , . . . , r n ) . For example, the extension Q ( √ 2) is the splitting field of x 2 -2 ∈ Q [ x ] , because the polynomial splits into ( x + √ 2)( x -√ 2) in it. But C is not a splitting field of x 2 -2 , because it is not the smallest.
The following theorems state that the splitting field of a polynomial always exists and is unique up to isomorphism.
Theorem B.1.17. (Existence) Let F be a field and f ( x ) ∈ F [ x ] be a polynomial of degree n > 0 . Then there exists a splitting field K of f ( x ) over F with degree [ K : F ] ≤ n ! .
The construction of a splitting field can be done by taking the quotient of F [ x ] with the principle ideal 〈 f ( x ) 〉 where f ( x ) is irreducible. If it is reducible, we can factor it into irreducible factors and take the same process repeatedly until f ( x ) splits.
Theorem B.1.18. (Uniqueness) Let φ : F → E be an isomorphism, f ( x ) ∈ F [ x ] be a polynomial and φ ( f ( x )) ∈ E [ x ] be the corresponding polynomial in E [ x ] . If K and L are the splitting fields of f ( x ) and φ ( f ( x )) over F and E respectively, then φ extends to an isomorphism K ∼ = L .
## B.1.4 Normal extension
Sometimes we prefer to work with an algebraic extension that includes all the roots of a polynomial, so that we do not need to adjoin more roots to the extension. For this purpose, we define the following.
Definition B.1.19. An algebraic extension E over F is normal if whenever an irreducible polynomial over F has a root in E , then it splits in E .
From splitting field, we know that an extension is normal if whenever it contains one root of a polynomial, it contains all roots of the polynomial. The most important result about normal extension is its connection with splitting field.
Normal iff splitting
Separable polynomial
Test separability
Separable extension
Intermediate extensions are separable
$$\begin{smallmatrix} c h a r ( F ) = \\ 0 \implies \\ s e p a r a b l e \end{smallmatrix}$$
Theorem B.1.20. A finite algebraic extension E over F is normal if and only if it is the splitting field of some polynomial f ( x ) ∈ F [ x ] .
The theorem implies that if E is the splitting field of one polynomial over F , then it is the splitting field of every other polynomial over F with one root in E .
## B.1.5 Separable extension
In addition to normal extensions, it is also convenient when a polynomial has distinct roots, so we do not need to worry about duplicated roots. This is especially the case when working with Galois groups that consist of automorphisms between polynomial roots. Before introducing separable extensions, we define what it means for a polynomial to be separable and how separability can be tested.
Definition B.1.21. A polynomial over a field F is separable if the number of its distinct roots in a splitting field is equal to the degree of the polynomial.
Example B.1.22. The polynomial x 2 -2 has two distinct roots ± √ 2 , so it is separable. The polynomial ( x 2 -1) 2 is not separable, because both roots ± 1 have multiplicity 2.
One way of testing separability is to check whether or not a polynomial is coprime with its formal derivative 20 .
Lemma B.1.23. A polynomial f ( x ) ∈ F [ x ] is separable if and only if gcd( f, f ′ ) = 1 .
Proof. Let K be the splitting field of f ( x ) and r ∈ K is a root of f ( x ) . The re-write the polynomial as with m ≥ 1 and g ( r ) = 0 . Take the formal derivative, we get
$$f ( x ) = ( x - r ) ^ { m } g ( x )$$
$$f ^ { \prime } ( x ) = m ( x - r ) ^ { m - 1 } g ( x ) + ( x - r ) ^ { m } g ^ { \prime } ( x ) = ( x - r ) ^ { m - 1 } [ m g ( x ) + ( x - r ) g ^ { \prime } ( x ) ] .$$
Evaluating the second factor mg ( x ) + ( x -r ) g ′ ( x ) at r gives mg ( r ) + 0 = 0 ⇐⇒ m = 0 because g ( r ) = 0 .
If f ( x ) is separable, by definition m = 1 and f ′ ( x ) = g ( x ) + ( x -r ) g ′ ( x ) . So f ′ ( r ) = 0 and none of the two factors of f ( x ) divides f ′ ( x ) . This implies they are coprime.
If f ( x ) is not separable, then m > 1 and f ′ ( r ) = 0 . Hence, x -r is a common factor of f and f ′ , so they are not coprime.
Example B.1.24. In the examples above, f ( x ) = x 2 -2 is separable, because its formal derivative f ( x ) ′ = ( x 2 -2) ′ = 2 x and gcd( f, f ′ ) = 1 . If f ( x ) = ( x 2 -1) 2 , then its formal derivative f ′ ( x ) = (( x 2 -1) 2 ) ′ = 4 x ( x 2 -1) and gcd( f, f ′ ) = x 2 -1 , so the polynomial ( x 2 + 1) 2 is not separable.
Definition B.1.25. An algebraic extension E over F is separable if for every element α ∈ E , its minimum polynomial over F is separable.
The Fundamental Theorem of Galois Theory states a correspondence between intermediate field extensions and subgroups of a Galois group. Hence, we would like to know the separability of the intermediate field extensions between a base field and a separable extension.
Theorem B.1.26. Given field extensions L/M/K . If L/K is separable, then the intermediate extensions L/M and M/K are also separable.
In the previous section, we stated that a field characteristic is either 0 or a prime. The following results connect the characteristic of a polynomial to its separability.
Theorem B.1.27. Every irreducible polynomial over a field of characteristic zero is separable, and hence every algebraic extension is separable.
20 Formal derivative is similar to derivative in calculus, but for elements of a polynomial ring.
Group action
Proof. Let E/F be a field extension with char ( F ) = 0 , and f ( x ) ∈ F [ x ] be the minimal polynomial of α ∈ E over F . Assuming f ( x ) is not separable. That is, without loss of generality, there is a root β with multiplicity 2. Then f ( β ) = 0 and its formal derivative f ′ ( β ) = 0 , because f ( x ) has a factor ( x -β ) 2 , which becomes 2( x -β ) in f ′ ( x ) .
However, f ′ ( x ) does not have zero coefficients, because it is over a field of zero characteristic. The fact that f ( x ) is a minimal polynomial implies it is irreducible, and f ′ ( x ) has a lower degree than f ( x ) imply that gcd( f, f ′ ) = 1 . Hence, there are a, b ∈ F [ x ] such that af ( x ) + bf ′ ( x ) = 1 . Substituting x = β , we get a contradiction, so f ( x ) cannot be non-separable. Hence, every irreducible polynomial over F is separable. This implies every algebraic extension is separable and every finite extension is also separable because every finite extension is algebraic by Proposition B.1.7.
A similar but more general result is the following theorem.
Theorem B.1.28. Let f ∈ F [ x ] be an irreducible polynomial of degree n . Then f is separable if either of the following conditions is satisfied:
- the field F has characteristic 0 or
- the field F has characteristic p where p is prime and p n .
The same argument can be used here to prove the second condition. Since f ( x ) is a degree n polynomial, its formal derivative f ′ ( x ) much contain a term na n x n -1 , in which the coefficient na n = 0 in the field F as char ( F ) = p is prime and p n . So gcd( f, f ′ ) = 1 and the same contradiction can be reached is f ( x ) is assumed to be non-separable.
The intuition behind both theorems is that if the characteristic of the field F does not satisfy either condition, then the coefficients of f ′ ( x ) may be all zero. So f ′ ( x ) = 0 cannot lead to the same contradiction when assuming f ( x ) non-separable.
## B.2 Galois extension and Galois group
In the preceding subsections, we have defined different types of field extensions, finite, algebraic, simple, normal and separable. This section will connect some of these extensions to an important field extension, called Galois extension and will define the Galois groups of Galois extensions.
To start with, we introduce group action on a set. One way to define a group action on a set is by the following definition.
Definition B.2.1. A group ( G, ∗ ) acts on a set S if there is a map such that
$$\mu \colon G \times S \to S$$
- for all s ∈ S , we have µ ( e, s ) = s ,
- for all x, y ∈ G and s ∈ S , we have µ ( x ∗ y, s ) = µ ( x, µ ( y, s )) .
For simplicity, we write µ ( x, s ) as x ( s ) . Another way of defining group action is by a group homomorphism.
Definition B.2.2. A group G acts on a set S if there is a homomorphism
$$locate(G)Sym(S)$$
from the group to the symmetric group (or the permutation group Perm ( S ) ) of S .
In this case, we say φ is the group action of G on S . Each element of G is mapped to a certain permutation of the set S by the action. For example, when the Dihedral group
$$D _ { 4 } = \langle r , f \rangle = \{ e , r , r ^ { 2 } , r ^ { 3 } , f , f r , f r ^ { 2 } , f r ^ { 3 } \}$$
acts on itself, each element in D 4 is mapped to a certain permutation of the set S = D 4 . For example, the elements rotation r and reflection f correspond to the following permutations of D 4
$$r \colon \{ e , r , r ^ { 2 } , r ^ { 3 } , f , f r , f r ^ { 2 } , f r ^ { 3 } ) & \mapsto \{ r , r ^ { 2 } , r ^ { 3 } , e , r f = f r ^ { 3 } , r f r = f , r f r ^ { 2 } = f r , r f r ^ { 3 } = f r ^ { 2 } ) \\ & \quad f \colon \{ e , r , r ^ { 2 } , r ^ { 3 } , f , f r , f r ^ { 2 } , f r ^ { 3 } ) \mapsto \{ f , f r , f r ^ { 2 } , f r ^ { 3 } , e , r , r ^ { 2 } , r ^ { 3 } ) .$$
$$f \colon \{ e , r , r ^ { 2 } , r ^ { 3 } , f , f r , f r ^ { 2 } , f r ^ { 3 } \} \mapsto \{ f , f r , f r ^ { 2 } , f r ^ { 3 } , e , r , r ^ { 2 } , r ^ { 3 } \} .$$
Faithful action
Fixed field
Automorphism group
The action of D 4 only gives rise to certain permutes of D 4 . In other words, there are 8 elements in D 4 and the symmetric group has size | Perm ( D 4 ) | = 8! , the homomorphism φ is injective, which we call faithful as stated next.
Definition B.2.3. A group action φ of G on a set S is faithful if φ is injective. That is, for every two distinct elements g, h ∈ G , there exists an element s ∈ S such that g ( s ) = h ( s ) .
If a group action is faithful, then we can think the group G embeds into the permutation group of S , as in the above example of D 4 , where each element of G = D 4 corresponds to a certain permutation of the set S = D 4 .
Similarly, we can define a group G acts on a ring R (or a field F ). The difference is that a ring has more algebraic structures than a set, so simple permutations of the ring elements do not necessarily preserve the ring structure. For this reason, we replace permutations by automorphisms, which are bijective ring homomorphisms between R and itself. Let Aut ( R ) be the automorphism group of R .
Definition B.2.4. An action of a group G on a ring R is a group homomorphism
$$\phi \colon G \rightarrow A u t ( R ) .$$
Some elements in the ring R or field F stay invariant under the action. They make up the fixed field. Definition B.2.5. Given a field extension E/F and a group action of G on E , the fixed field of E under the action of G
$$E ^ { G } = \{ a \in E | g ( a ) = a , \forall g \in G \} .$$
is the set of elements in the extension field that are fixed point-wise by all automorphisms of R .
Definition B.2.6. Let E/F be a field extension. The automorphism group of the field extension
$$A u t ( E / F ) & = \{ \alpha \in A u t ( E ) | \, \alpha ( x ) = x , \, \forall x \in F \} \\ & = \{ \alpha \in A u t ( F ) | \, \alpha _ { F } = I d _ { F } \}$$
is the set of automorphisms that fixes F when acting on E .
$$\begin{array} { r l } & { = \left \{ \alpha \in A u t ( E ) | \alpha _ { F } = I d _ { F } \right \} } \\ { f i r e s \, F w h e n a c t i n g o n \, E } \end{array}$$
The automorphism group is a group with function composition as the group operator. It is a subgroup of the group of automorphisms of E , i.e., Aut ( E/F ) ⊆ Aut ( E ) . Now, we are ready to define the Galois group of a field extension.
Definition B.2.7. The Galois group of a field extension E/F , denoted by Gal ( E/F ) , is the automorphism group of the field extension. Galois group That is,
$$G a l ( E / F ) \colon = A u t ( E / F ) = \{ \alpha \in A u t ( E ) | \, \alpha _ { F } = I d _ { F } \} .$$
By definition, the Galois group is a subset of the automorphism group or permutation group (or symmetric group) of the extension E .
As explained in the previous section that an extension field can be viewed as a vector space over the base field, so when working with Galois groups, instead of thinking where all elements in the extension are mapped to, it is convenient to know where the basis vectors are mapped to by the automorphisms.
Let us work through some simple examples.
Example B.2.9. Let the field extension be Q ( √ 2 , i ) / Q . This is a 4-dimensional Q -vector space with a basis { 1 , √ 2 , i, √ 2 i } . The minimal polynomials over Q for √ 2 and i are x 2 -2 and x 2 +1 , respectively. The Galois group of the field extension contains all the automorphisms that fix Q while permuting roots in each minimal polynomial. That is, it contains a map τ that permutes { √ 2 , - √ 2 } and a map σ that permutes { i, -i } . We can identify these automorphisms as shown in Table 2. The Galois group is isomorphic to the Klein four group V 4 = C 2 × C 2 .
Example B.2.8. Let the field extension be Q ( √ 2) / Q . It is a 2-dimensional Q -vector space with a basis { 1 , √ 2 } . The Galois group must fix the base field, so it contains the identity map I . In addition, it should contain another automorphism σ that maps √ 2 to another element a in the extension whiling fixing Q . Since σ is an automorphism, it must satisfy a 2 = σ ( √ 2) 2 = σ (( √ 2) 2 ) = σ (2) = 2 . So whatever σ ( √ 2) = a is, it must satisfy a 2 -2 = 0 in the extension, which means a = ± √ 2 . Since the identity map is already included, it entails σ ( √ 2) = - √ 2 . Hence, the Galois group Gal ( Q ( √ 2) / Q ) = { I, σ : √ 2 ↦→- √ 2 } ∼ = C 2 which is isomorphic to the cyclic group of order 2.
Galois extension
Normal and separable = ⇒ Galois
√
√
Table 2: The Galois group of the extension Q ( √ 2 , i ) . It is isomorphic to the Klein four group V 4 = C 2 × C 2 .
| | 1 | 2 | i | 2 i |
|----|-----|-------|-----|---------|
| I | 1 | √ 2 | i | √ 2 i |
| σ | 1 | √ 2 | - i | - √ 2 i |
| τ | 1 | - √ 2 | i | - √ 2 i |
| στ | 1 | √ 2 | i | √ 2 i |
-
It is important to note that not all automorphisms (or permutations) that fix the base field are in the Galois group. From the above two examples, we can see that the Galois group only contains those automorphisms that permute roots of the same minimal polynomial while fixing the base field. In Example B.2.9, √ 2 and - √ 2 come from the minimal polynomial x 2 -2 in Q and i and -i come from the minimal polynomial x 2 +1 in Q . Let us take a look at a counter example.
Example B.2.11. A slightly more complicated example is with a field extension Q ( 4 √ 2 , i ) / Q . The roots 4 √ 2 and i have the minimal polynomials x 4 -2 and x 2 + 1 over Q , respectively. The polynomial x 4 -2 has four roots ± 4 √ 2 and ± i 4 √ 2 . The polynomial x 2 + 1 has two roots ± i . The Galois group should contain automorphisms that permutes roots for each polynomial. The process of finding the automorphisms is more or less trial and error. 21 Let
Example B.2.10. Let the field extension be Q ( √ 2 , √ 3) / Q . The permutation φ : √ 2 ↦→ √ 3 is not in the Galois group. Assuming it is, then φ ( √ 2) = √ 3 implies φ ( √ 2) 2 = 3 . By the definition of homomorphism, φ ( √ 2) 2 = φ ( √ 2 2 ) = φ (2) = 2 because φ fixes Q . This implies 2 = 3 .
Then we have
$$\sigma ( \sqrt { 2 } ) = i \sqrt { 4 } \, 2 \, a n d \, \sigma ( i ) = i , \\ \tau ( i ) = - i \, a n d \, \tau ( \sqrt { 4 } \, 2 ) = \sqrt { 4 } \, 2 .$$
So the orders of σ and τ in the Galois group are 4 and 2, respectively. Hence, the Galois group is { I, σ, σ 2 , σ 3 , τ, στ, σ 2 τ, σ 3 τ } .
Combining the definitions of fixed field and Galois group, we know that for a field extension E/F , the fixed field by the Galois group should at least contain the base field F . Because all automorphisms in the Galois group at least fix F , though they may fix more than F . Hence, we can define what it means for a field extension to be Galois.
Definition B.2.12. A field extension E/F is an Galois extension if the fixed field by the Galois group Gal ( E/F ) is exactly F . That is, E Gal ( E/F ) = F .
In other words, the Galois group has to fix exactly the base field, nothing more nothing less. An important theorem that characterizes Galois extension using previously defined extension types is the following.
Theorem B.2.13. An algebraic field extension is a Galois extension if it is normal and separable.
This theorem says that for an algebraic field extension to be a Galois extension, any polynomial that has a root in the extension must have all its roots in the extension and these roots must be all distinct. The requirement of being normal and separable is a sufficient condition for a field extension to be Galois.
21 Perhaps there are better ways of finding the Galois group, but they are not in the scope of this material.
Fundamental Theorem of Galois Theory
Example B.2.14. The Galois group Gal ( Q ( 3 √ 2) / Q ) = { I } contains only the identity map. If φ ( 3 √ 2) = a is another automorphism, then it must satisfy a 3 -2 = 0 . So φ must map 3 √ 2 to a root of the minimal polynomial a 3 -2 = 0 in the extension. But the only root that is in the extension is 3 √ 2 , because the other two roots are complex. So φ is the identity map. Given the Galois group contains only the identity map, the fixed field is Q ( 3 √ 2) not Q , so the field extension is not Galois. By Theorem B.2.13, the extension is not both normal and separable. In fact, this is true, because the extension does not contain the two complex roots of the minimal polynomial x 3 -2 .
The example suggests that a field extension can have a Galois group, but it is not necessarily a Galois extension.
Since a Galois extension is normal and separable, we would expect the number of automorphisms in the Galois group to be related to the number of roots of a minimal polynomial. The next lemma connects the number of automorphisms in the Galois group to the degree of a Galois extension.
Lemma B.2.15. If a finite field extension E/F is Galois, then the number of elements in the Galois group is the degree of the field extension. That is, | Gal ( E/F ) | = [ E : F ] .
For example, the field extension Q ( √ 2 , i ) /Q has degree 4 (as it is a 4 dimensional vector space over Q ) and there are 4 automorphisms in the Galois group as stated in Table 2.
The next theorem is the most important theorem in Galois Theory. It builds a connection between subgroups of a Galois group and field extensions of a base field. The theorem is important in the sense that it provides a way of understanding field extensions from group's perspective, which is relatively well studied. In the most basic form, it states that if L/M/K is a finite Galois extension, then there is a one-to-one correspondence between an intermediate extension and a subgroup of the Galois group Gal ( L/K ) . The next theorem explicitly defines what it means for a one-to-one correspondence between the two different algebraic structures.
Figure 16: A finite Galois extension and the corresponding Galois groups.
<details>
<summary>Image 14 Details</summary>

### Visual Description
\n
## Diagram: Galois Extension and Subgroups
### Overview
The image presents two diagrams illustrating concepts related to Galois theory in abstract algebra. The left diagram depicts a finite Galois extension, while the right diagram shows subgroups of the Galois group. Both diagrams use vertical lines and "UI" and "∩" symbols to represent relationships between fields and groups.
### Components/Axes
The diagrams consist of:
* **Left Diagram:**
* Labels: L, M, K
* Arrows: Vertical lines with "UI" (presumably meaning "union" or "inclusion") indicating field extensions.
* Caption: "(a) A finite Galois extension."
* **Right Diagram:**
* Labels: G<sub>L</sub>, G<sub>M</sub>, G<sub>K</sub>
* Equations: G<sub>L</sub> = Gal(K/K), G<sub>M</sub> = Gal(M/K), G<sub>K</sub> = Gal(L/K)
* Symbols: "∩" (intersection) between G<sub>L</sub> and G<sub>M</sub>, and between G<sub>M</sub> and G<sub>K</sub>.
* Caption: "(b) Subgroups of the Galois group G<sub>K</sub> = Gal(L/K)."
### Detailed Analysis or Content Details
* **Left Diagram:**
* The diagram shows a tower of field extensions: K ⊆ M ⊆ L. The "UI" symbol indicates that M is an extension of K, and L is an extension of M.
* **Right Diagram:**
* G<sub>L</sub> = Gal(K/K): This equation states that the Galois group of K over K is equal to Gal(K/K).
* G<sub>M</sub> = Gal(M/K): This equation states that the Galois group of M over K is equal to Gal(M/K).
* G<sub>K</sub> = Gal(L/K): This equation states that the Galois group of L over K is equal to Gal(L/K).
* The intersection symbol "∩" indicates relationships between the subgroups. G<sub>L</sub> ∩ G<sub>M</sub> and G<sub>M</sub> ∩ G<sub>K</sub> are shown.
### Key Observations
* The left diagram illustrates a fundamental structure in Galois theory: a finite Galois extension.
* The right diagram shows how the Galois group of a larger extension (L/K) can be related to the Galois groups of intermediate extensions (M/K).
* The equations define Galois groups as automorphisms of the fields.
### Interpretation
The diagrams demonstrate the connection between field extensions and their corresponding Galois groups. The left diagram sets up the basic structure of a Galois extension, while the right diagram explores the subgroup structure of the Galois group associated with that extension. The intersection symbols suggest that the Galois groups of intermediate fields are subgroups of the Galois group of the larger field. This is a core concept in Galois theory, allowing for the study of field extensions through the lens of group theory. The notation Gal(A/B) represents the group of automorphisms of field A that fix field B. The fact that Gal(K/K) is defined suggests a trivial Galois group, as any automorphism fixing K must be the identity. The overall structure illustrates the fundamental theorem of Galois theory, which establishes a correspondence between subfields of a Galois extension and subgroups of its Galois group.
</details>
Theorem B.2.16. (Fundamental Theorem of Galois Theory) Suppose L/M/K is a finite Galois extension with the corresponding Galois group G K = Gal ( L/K ) .
1. There is an inclusion reversing correspondence between an intermediate field M of L/K and a subgroup G M ⊆ G L given as follows:
$$M & \to G _ { M } = \{ \phi \in A u t ( L ) \ | \ \phi _ { M } = I d _ { M } \} \\ G _ { M } & \to L ^ { G _ { M } } = M .$$
$$G _ { M } \rightarrow L ^ { G _ { M } } = M$$
2. The degrees of the field extensions are given by
$$[ L \colon M ] = | G _ { M } | \, a n d \, [ M \colon K ] = \frac { | G _ { K } | } { | G _ { M } | } .$$
3. The intermediate field extension M/K is Galois if and only if G M G K is a normal subgroup. In this case, the corresponding Galois group is given by
$$G a l ( M / K ) \cong G _ { K } / G _ { M } .$$
The first point of the theorem says that if M is an intermediate extension between L/K , then M corresponds to the set of automorphisms of L that fixes M . If M = K , then M corresponds to the set of automorphisms of L that fixes K , which is the entire Gal ( L/K ) . If M = L , then M corresponds to the set of automorphisms of L that fixes L , which is identity map.
The second point says the degree of the M -vector space L equals the number of automorphisms of L that fix M . If M = K or M = L , then the degrees [ L : M ] = [ L : K ] = | G K | = Gal ( L/K ) or [ L : M ] = [ L : L ] = | G L | = 1 , respectively. Combining the two qualities, we get [ L : M ][ M : K ] = | G K | = [ L : K ] which is consistent with the Tower Law in Proposition B.1.3.
<details>
<summary>Image 15 Details</summary>
### Visual Description
\n
## Diagram: Dependency Graph
### Overview
The image depicts a directed acyclic graph (DAG) representing dependencies between different functions or states denoted by mathematical expressions involving 'Q', 'ω', and 'θ'. The graph illustrates a hierarchical relationship where nodes higher in the diagram depend on nodes lower down.
### Components/Axes
The diagram consists of nodes labeled with mathematical expressions and directed edges indicating dependencies. The nodes are arranged in a roughly pyramidal structure. The nodes are:
* Q(ω, θ) - Top node
* Q(θ)
* Q(ωθ)
* Q(ω²θ)
* Q(ω)
* Q - Bottom node
The edges represent dependencies, pointing from a dependent node to a node it relies on.
### Detailed Analysis or Content Details
The graph shows the following dependencies:
* **Q(ω, θ)** depends on **Q(θ)**, **Q(ωθ)**, and **Q(ω²θ)**.
* **Q(θ)** depends on **Q**.
* **Q(ωθ)** depends on **Q**.
* **Q(ω²θ)** depends on **Q**.
* **Q(ω)** depends on **Q**.
* **Q** is the base node and has no dependencies.
The arrangement suggests a recursive or iterative process where the higher-level functions are built upon the lower-level ones.
### Key Observations
The diagram is symmetrical in the sense that Q(θ), Q(ωθ), and Q(ω²θ) all depend directly on Q. Q(ω, θ) is the most complex function, relying on all three intermediate functions. The use of 'ω' and 'θ' suggests these might be parameters or variables influencing the function 'Q'.
### Interpretation
This diagram likely represents a computational process or a system of equations where the value of a function Q(ω, θ) is determined by the values of its constituent functions Q(θ), Q(ωθ), and Q(ω²θ). The 'ω' and 'θ' parameters likely represent some form of transformation or scaling applied to the base function Q. The structure suggests a decomposition of a complex problem into smaller, more manageable subproblems. The graph could represent a signal processing system, a mathematical transformation, or a state machine. The repeated use of 'Q' suggests a core operation being applied with different inputs. The powers of 'ω' (ω, ωθ, ω²θ) suggest a frequency or phase-related transformation. Without further context, it's difficult to determine the precise meaning of the diagram, but it clearly illustrates a hierarchical dependency structure.
</details>
- (a) A finite Galois extension and the intermediate extensions.
<details>
<summary>Image 16 Details</summary>
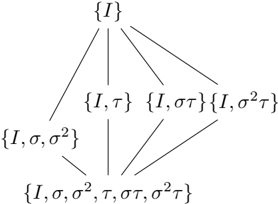
### Visual Description
\n
## Diagram: Parameter Estimation Tree
### Overview
The image depicts a tree-like diagram illustrating a hierarchical process of parameter estimation. The diagram shows how a set of initial parameters expands into more comprehensive sets through successive branching. The diagram is structured with sets of parameters enclosed in curly braces, connected by lines representing the flow of estimation.
### Components/Axes
The diagram consists of nodes representing sets of parameters. The root node is {I}, and the diagram branches downwards, adding parameters at each level. The parameters used are: I, τ (tau), σ (sigma), σ² (sigma squared), and στ (sigma tau). The diagram is arranged in a top-down fashion, with the root at the top-center and subsequent levels branching out below.
### Detailed Analysis or Content Details
The diagram can be described as follows:
1. **Level 1 (Root):** {I}
2. **Level 2:** This level branches from {I} into three sets:
* {I, τ}
* {I, στ}
* {I, σ²τ}
3. **Level 3:** This level branches from {I, τ} and {I, στ}:
* {I, σ, σ²} branches from {I, τ}
4. **Level 4:** This level branches from {I, σ, σ²} and {I, στ}:
* {I, σ, σ², τ, στ, σ²τ} branches from {I, σ, σ²} and {I, στ}.
The lines connecting the nodes indicate the progression of parameter estimation. Each branch represents the addition of a new parameter or a combination of parameters to the existing set.
### Key Observations
The diagram demonstrates a process of iteratively refining parameter estimation. Starting with a single parameter (I), the diagram expands to include additional parameters (τ, σ, σ², στ) and their combinations. The final level represents a complete set of parameters: {I, σ, σ², τ, στ, σ²τ}. The branching structure suggests that the estimation process can follow multiple paths, ultimately converging on a comprehensive set of parameters.
### Interpretation
This diagram likely represents a Bayesian inference or maximum likelihood estimation process for a statistical model. The initial parameter 'I' could represent an initial estimate or a prior belief. The subsequent parameters (τ, σ, σ², στ) represent various aspects of the model's uncertainty or variability. The branching structure illustrates how the estimation process incorporates new information to refine the parameter estimates. The final set of parameters represents the posterior distribution or the maximum likelihood estimates of the model's parameters. The diagram suggests a hierarchical model where parameters are estimated sequentially, building upon previous estimates. The inclusion of interaction terms like στ and σ²τ indicates that the model accounts for correlations between the parameters. This type of diagram is common in statistical modeling and machine learning, particularly in the context of Gaussian processes or hierarchical Bayesian models.
</details>
{
}
(b) Subgroups of the Galois group Gal ( Q ( ω, θ ) / Q ) .
Figure 17: A finite Galois extension Q ( ω, θ ) / Q and the corresponding Galois groups, where ω = -1 2 + i √ 3 2 and θ = 3 √ 2 . Each structure is a lattice and there is a one-to-one correspondence between them.
Example B.2.17. Let the field extension be Q ( θ, ω ) / Q , where θ = 3 √ 2 and ω = -1 2 ± i √ 3 2 . The extension is a 6-dimensional Q -vector space with a basis { 1 , θ, θ 2 , ω, θω, θ 2 ω } . Define the automorphisms
$$\sigma ( \theta ) = \omega \theta \, a n d \, \sigma ( \omega ) = \omega ,$$
$$\tau ( \theta ) = \theta \, a n d \, \tau ( \omega ) = \omega ^ { 2 } .$$
<!-- formula-not-decoded -->
The two automorphisms in the Galois group have orders 3 and 2, respectively. It can be seen that they can make the entire Galois group { I, σ, σ 2 , τ, στ, σ 2 τ } . The intermediate field extensions from Q to Q ( ω, θ ) are shown in Figure 16a. The extension Q ( ω ) can be extended to Q ( ω, θ ) by adjoining θ and the other three extensions can be extended to Q ( ω, θ ) by adjoining ω . The corresponding subgroups of the Galois group are shown in Figure 16b.
The two structures are lattices. According to the Fundamental theorem of Galois Theory, they are in one-to-one correspondence. The automorphisms that fix Q ( ω ) are { I, σ, σ 2 } . The degree of the intermediate extension Q ( ω ) is [ Q ( ω, θ ) : Q ( ω )] = 3 , because Q ( ω, θ ) has a basis { 1 , θ, θ 2 } over the field Q ( ω ) . Also, [ Q ( ω, θ ) : Q ] = [ Q ( ω, θ ) : Q ( ω )][ Q ( ω ) : Q ] = 3 · 2 = 6 . The normal extensions are Q , Q ( ω ) and Q ( ω, θ ) because the corresponding subgroups { I, σ, σ 2 , τ, στ, σ 2 τ } , { I, σ, σ 2 } and { I } are normal subgroups of the Galois group { I, σ, σ 2 , τ, στ, σ 2 τ } .
}
Number field
Cyclotomic field
Power basis
Primitive element
Ring of integers
O K is ID
## C Algebraic Number Theory
This section introduces some of the basic results in Algebraic Number Theory that will be used in latticebased cryptography. In particular, we will focus on the ring of integers, their integral and fractional ideals. The aim is to build the important connection between ideals of a ring of integers and ideal lattices, which is the key in those homomorphic encryption schemes that are based on the ring learning with error (RLWE) problem.
## C.1 Algebraic number field
Recall that an algebraic number (integer) is a complex number that is a root of a non-zero polynomial with rational (integer) coefficients. Below we define algebraic number fields, which are special cases of extension fields where the base field is the rationals Q .
Definition C.1.1. An algebraic number field (or simply number field ) is a finite extension of the field of rationals by algebraic numbers, i.e., Q ( r 1 , . . . , r n ) , where r 1 , . . . , r n are algebraic numbers.
An nth root of unity ζ n is an algebraic number, so the cyclotomic extension Q ( ζ m ) is also a number field that is called the nth cyclotomic number field (or nth cyclotomic field ).
Anumber field K = Q ( r ) forms a vector space over the base field Q with the basis { 1 , r, . . . , r n -1 } , which is called the power basis of K because it is formed by the powers of a number r . By the Primitive Element Theorem, it is always possible to get a power basis for a number field.
Theorem C.1.2 ( Primitive element theorem ) . If K is an extension field of Q and it has finite degree [ K : Q ] < ∞ , then K has a primitive element r such that r / ∈ Q and K = Q ( r ) .
The number field K = Q ( 3 √ 2) has degree 3. It has a primitive element 3 √ 2 and a basis { 1 , 3 √ 2 , 3 √ 4 } .
Example C.1.3. The number field K = Q ( √ 2) is a degree 2 Q -vector space. It has a primitive element √ 2 and a basis { 1 , √ 2 } .
The number field K = Q ( √ 2 , √ 3) has degree 4. It has a primitive element r = √ 2 + √ 3 , so K = Q ( √ 2 , √ 3) = Q ( √ 2+ √ 3) . It has a power basis { 1 , r, r 2 , r 3 } = { 1 , √ 2+ √ 3 , 5+2 √ 6 , 11 √ 2+9 √ 3 } . To see this is a basis, we know from field extension that { 1 , √ 2 , √ 3 , √ 6 } is a basis of K . This basis can be expressed in terms of the linear combinations of the power basis.
For a number field K , the set of all algebraic integers forms a ring under the usual addition and multiplication operations in K (exercise). This set generalizes the set of rational integers Z . It is particularly important for the RLWE problem.
Definition C.1.4. The ring of integers of an algebraic number field K , denoted by O K , is the set of all algebraic integers that lie in the field K .
For example, the set Z of rational integers is the ring of integers of the number field Q , i.e., Z = O Q . Recall that an integral domain is a non-zero commutative ring in which the product of two non-zero elements is non-zero. Z is an integral domain, so is its generalization O K , because O K ⊆ K is in a number field which is an integral domain. In general, determining the ring of integers of a number field is a difficult problem, unless the number field is quadratic that is a Q -vector space of degree 2 as stated in the next theorem.
Definition C.1.5. Square free A number is squarefree if its prime decomposition contains no repeated factors.
All prime numbers are squarefree. Some composite numbers are squarefree and some are not. For example, 4 is not squarefree, but 6 is.
Theorem C.1.6. O K in quadratic K Let K be a quadratic number field and m be a unique squarefree integer such that K = Q ( √ m ) . Then the set O K of algebraic integers in K is given by
$$\begin{array} { r } { \text {the set $\mathcal{O}_{K}$ of algebraic integers in $K$ given by} } \\ { \mathcal{O}_{K} = \begin{cases} \mathbb { Z } + \mathbb { Z } \sqrt { m } , & i f m \neq 1 \bmod 4 \\ \mathbb { Z } + \mathbb { Z } \left ( \frac { 1 + \sqrt { m } } { 2 } \right ) , & i f m = 1 \bmod 4 \end{cases} } \end{array}$$
For example, if K = Q ( √ -7) then O K = Z + Z ( 1+ √ -7 2 ) . If K = Q ( √ -5) then O K = Z + Z √ -5 .
O K is free Z -module
Integral basis
Real and complex embeddings
More importantly, the basis B is called an integral basis of the number field K (and of the ring of integers O K as used by Ben Green). Note that although the ring of integers O K always has a basis, it does NOT always have a power basis. A special case is when K is a cyclotomic number field. In this case, the power basis of K is also an integral basis of K (or O K ).
Since the set of rational integers Z ⊆ O K is always contained in the ring of integers of a number field K (of degree n ), this makes O K a Z -module. Recall that a module is a generalization of a vector space where scalar multiplications are defined in a ring rather than a field. In fact, O K is a free Z -module, which means it has a basis B = { b 1 , . . . , b n } ⊆ O K such that every element in O K can be written as an integer linear combination of the basis. The basis is called a Z -basis of O K . It is also a Q -basis of K , because every element r ∈ K can be written as a linear combination r = ∑ n i =1 a i b i , where a i ∈ Q .
The essential connection between O K and lattices is by relating the number field K to the n -dimensional Euclidean space R n . This is done via an embedding of K to a space H that is isomorphic to R n . Suppose K is a number field with degree [ K : Q ] = n , then we have n field embeddings (i.e., field or injective ring homomorphisms) σ i : K → C such that the base field Q is fixed by the embeddings. For a primitive element r in K but not in Q , i.e., K = Q ( r ) , each embedding σ i : K → C is given by the map from r to a root of r 's minimal polynomial f ( x ) ∈ Q [ x ] . The following proposition states that there are n distinct such embeddings from K to C .
Proposition C.1.7. Let K be an algebraic number field of degree n . Then there are precisely n distinct field embeddings from K to C .
The embeddings { σ i } i ∈ [ n ] map the primitive element r to different roots of r 's minimal polynomial f ( x ) , which is a collection of real and complex numbers. Hence, we can distinguish these embeddings as real and complex embeddings. If σ i ( K ) ⊆ R (or σ i ( r ) ∈ R ) then it is a real embedding , otherwise it is a complex embedding . By Complex Conjugate Root Theorem 22 , the images of the complex embeddings are in conjugate pairs, so we only need to keep half of the complex embeddings and split each of them into the real and complex parts. Let s 1 be the number of real embeddings and s 2 be the number of conjugate pairs of complex embeddings, then the total number of embeddings is n = s 1 +2 s 2 . In addition, let { σ i } i ∈ [ s 1 ] be the real embeddings, { σ j } j ∈ [ s 1 +1 ,n ] be the complex embeddings and σ s 1 + j = σ s 1 + s 2 + j be the conjugate pairs for j ∈ [ s 2 ] , then we have the following definition of a canonical embedding of a algebraic number field.
Definition C.1.8. Canonical embedding A canonical embedding (or Minkowski embedding ) σ of an algebraic number field K of degree n to the n -dimensional complex plane C n is defined as
$$\sigma \colon K & \to \mathbb { R } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } \subseteq \mathbb { C } ^ { n } \\ \sigma ( r ) & \mapsto ( \sigma _ { 1 } ( r ) , \dots , \sigma _ { s _ { 1 } } ( r ) , \sigma _ { s _ { 1 } + 1 } ( r ) , \dots , \sigma _ { n } ( r ) ) .$$
As mentioned above, the complex embeddings are in conjugate pairs so it is not necessary to keep both complex embeddings ini a conjugate pair. This gives rise to a different (and more practical) embedding
$$\tau \colon K & \to V \\ \tau ( r ) & \mapsto ( \sigma _ { 1 } ( r ) , \dots , \sigma _ { s _ { 1 } } ( r ) , \sigma _ { s _ { 1 } + 1 } ( r ) , \dots , \sigma _ { s _ { 1 } + s _ { 2 } } ( r ) ) ,$$
$$s$$
where for all i ∈ [ s 1 + s 2 , n ] , each σ i separates the real and imaginary parts as σ i ( r ) = ( Re ( σ r ( r )) , Im ( σ i ( r ))) , so the image of this embedding can be explicitly write out as
$$\tau ( r ) = ( & \sigma _ { 1 } ( r ) , \dots , \sigma _ { s _ { 1 } } ( r ) , \\ & R e ( \sigma _ { s _ { 1 } + 1 } ( r ) ) , I m ( \sigma _ { s _ { 1 } + 1 } ( r ) ) , \dots , R e ( \sigma _ { s _ { 1 } + s _ { 2 } } ( r ) ) , I m ( \sigma _ { s _ { 1 } + s _ { 2 } } ( r ) ) ) .$$
The canonical embedding maps a number field to an n -dimensional space, Canonical space named canonical space (or Minkowski space ) and can be expressed as
$$H = \left \{ ( x _ { 1 } , \dots , x _ { n } ) \in \mathbb { R } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } | x _ { s _ { 1 } + j } = \overline { x _ { s _ { 1 } + s _ { 2 } + j } } , \forall j \in [ s _ { 2 } ] \right \} \subseteq \mathbb { C } ^ { n } . \\$$
The canonical space H can be verified to be isomorphic to R n using the following steps. We can establish a one to one correspondence between the standard basis of C n and an orthonormal basis of H . In detail, let { e i } i ∈ [ n ] be the standard basis of C n where in each e i the ith component is 1 and the rest are zero. Then we can build a basis { b i } i ∈ [ n ] for H such that
22 The complex roots of real coefficient polynomials are in conjugate pairs.
τ embedding
- for j ∈ [ s 1 ] , let h j = e j and
$$\begin{array} { r } { \bullet \, f o r j \in [ s _ { 1 } + 1 , s _ { 1 } + s _ { 2 } ] , l e t h _ { j } = \frac { 1 } { \sqrt { 2 } } ( e _ { j } + e _ { j + s _ { 2 } } ) a n d h _ { j + s _ { 2 } } = \frac { i } { \sqrt { 2 } } ( e _ { j } - e _ { j + s _ { 2 } } ) . } \end{array}$$
Similarly, we can prove the space V , to which K is mapped to by the embedding τ is also isomorphic to R n .
In the next example, we will look at the canonical embedding of a cyclotomic number field and construct a basis of the canonical space by using the above rules.
$$\zeta _ { 8 } = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } ,$$
Example C.1.9. Let K = Q ( ζ 8 ) be a cyclotomic number field, where ζ 8 = √ 2 2 + i √ 2 2 is an 8th primitive root of unity. The minimal polynomial of ζ 8 is the 8th cyclotomic polynomial Φ 8 ( x ) = x 4 +1 with degree ϕ (8) = 4 , whose roots are the 8th primitive roots
$$\zeta _ { 8 } & = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \\ \zeta _ { 8 } ^ { 3 } & = - \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \\ \zeta _ { 8 } ^ { 5 } & = - \frac { \sqrt { 2 } } { 2 } - i \frac { \sqrt { 2 } } { 2 } , \\ \zeta _ { 8 } ^ { 7 } & = \frac { \sqrt { 2 } } { 2 } - i \frac { \sqrt { 2 } } { 2 } .$$
The degree of the cyclotomic field is n = 4 , so all 4 embeddings σ i : K → C 4 are complex, that is, s 1 = 0 and s 2 = 2 . The four complex embeddings are
$$\tau _ { 1 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 }$$
$$\sigma _ { 1 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) & = \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } , \\ \sigma _ { 2 } \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) & = - \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } ,$$
where σ 1 , σ 3 and σ 2 , σ 4 are in conjugate pairs. So the embedding by Equation 48 is
$$\tau \left ( \frac { \sqrt { 2 } } { 2 } + i \frac { \sqrt { 2 } } { 2 } \right ) = \left ( \frac { \sqrt { 2 } } { 2 } , \frac { \sqrt { 2 } } { 2 } , - \frac { \sqrt { 2 } } { 2 } , \frac { \sqrt { 2 } } { 2 } \right ) .$$
Let x 1 = ζ 8 , x 2 = ζ 3 8 , x 3 = ζ 7 8 , x 4 = ζ 5 8 , so x 1 = x 3 and x 2 = x 4 are in conjugate pairs. By definition of canonical space, we have ( x 1 , x 2 , x 3 , x 4 ) ∈ H is an element of the space. According to the above basis construction, we get the basis { h 1 , h 2 , h 3 , h 4 } for H from the standard basis of R 4 , where
$$h _ { 1 } = \frac { \sqrt { 2 } } { 2 } ( e _ { 1 } + e _ { 3 } ) ,$$
$$h _ { 2 } = \frac { \sqrt { 2 } } { 2 } ( e _ { 2 } + e _ { 4 } ) ,$$
$$h _ { 3 } = i \frac { \sqrt { 2 } } { 2 } ( e _ { 1 } - e _ { 3 } ) ,$$
$$h _ { 4 } = i \frac { \sqrt { 2 } } { 2 } ( e _ { 2 } - e _ { 4 } ) .$$
$$= \frac { \sqrt { 2 } } { 2 } ( e _ { 1 } + e _ { 3 } ) ,$$
Hence, the element ( x 1 , . . . , x 4 ) = h 1 -h 2 + h 3 + h 4 and its conjugate ( x 1 , . . . , x 4 ) = h 1 -h 2 -h 3 -h 4 . The complex conjugation operator maps H to itself by flipping the signs of the coefficients of { h s 1 + s 2 +1 , . . . , h n } as shown in the example.
Now we know a number field K is mapped to a canonical space that is isomorphic to R n , we can defined the notion of geometric norm on the number field K just as we did in R n . For any element x ∈ K , the L p -norm of x is defined as L p -norm
$$| | x | | _ { p } = | | \sigma ( x ) | | _ { p } = \begin{cases} \left ( \sum _ { i \in [ n ] } | \sigma _ { i } ( x ) | ^ { p } \right ) ^ { 1 / p } & \text {if $p<\infty$,} \\ \max _ { i \in [ n ] } | \sigma _ { i } ( x ) | & \text {if $p=\infty$.} \end{cases}$$
Example C.1.10. We use this example to illustrate the L p -norm of a root of unity in a cyclotomic number field.
Let σ : K ( ζ n ) → H be the canonical embedding for the nth cyclotomic field. The minimal polynomial of ζ n is the nth cyclotomic polynomial Φ n ( x ) which has only complex roots for n ≥ 3 , because the two real roots are not primitive. The complex embeddings are given by σ i ( ζ n ) = ζ i n , where i ∈ ( Z /n Z ) ∗ , so n = 2 s 2 = | ( Z /n Z ) ∗ | .
For any nth root of unity ζ j n ∈ K , an embedding σ i ( ζ j n ) is still a root of unity and hence has magnitude 1. So the L P -norm of an nth root of unity || ζ j n || p = n 1 /p for p < ∞ and || ζ j m || ∞ = 1 .
We have specified the canonical embedding of a number field to a space that is isomorphic to R n . What we are really interested in is how the ring of integers is mapped by the embedding. The following theorem states that the canonical embedding maps O K to a full-rank lattice. Towards the end of this section, we will discuss the minimum distance (or the shortest vector) of this lattice and how the determinant of this lattice σ ( O K ) is related to a quantity of the number field, called the discriminant.
- Theorem C.1.11. τ ( O K ) is lattice Let K be an n -dimensional number field and τ : K → V ∼ = R n be the embedding of K as defined in Equation 48, then τ maps the ring of integers O K to a full-rank lattice in R n .
Proof. By definition, a lattice is a free Z -module. Let { e 1 , . . . , e n } be an integral basis of O K , then every element x ∈ O K can be written as x = ∑ n i =1 z i e i , where z i ∈ Z . The image of x under the embedding is τ ( x ) = ∑ n i =1 z i τ ( e i ) , so τ ( O K ) is Z -module generated by { τ ( e 1 ) , . . . , τ ( e n ) } . It remains to show the set is a basis of τ ( O K ) , which then leads to the conclusion that it is a free Z -module, hence a lattice. To do so, define the following matrix and prove it has a non-zero determinant
<!-- formula-not-decoded -->
It can be prove that det N is related to det M , where M is a matrix defined by using the canonical embedding σ of K . In addition, det M = 0 , so det N = 0 . The details are skipped. See the proof of Lemma 10.6.1 on page 65 of Ben Green's book or the proof of Proposition 4.26 on page 80 of Milne's book.
## C.2 Ideals of ring of integers
The ring of integers O K in a number field carries a lot of similarities to Z , but it lacks an important property of being a unique factorization domain.
- Definition C.2.1. An integral domain D is a UFD unique factorization domain (UFD) if every non-zero non-unit element x ∈ D can be written as a product
of 0 < n < ∞ irreducible elements p i ∈ D uniquely up to reordering of the irreducible elements.
$$x = p _ { 1 } \cdots p _ { n }$$
For example, Z is a UFD because every integer can be uniquely factored into prime factors. But the extension Z ( √ 5) is not a UFD, because 6 = 2 ∗ 3 = (1 + √ -5)(1 -√ -5) . UFD is essential for cryptography because if we assume factoring a large integer into prime factors is hard, we want to be sure that we are aware of all the factorizations. So it would be assuring if the factorization is unique. In addition, unique factorization implies unique divisibility.
For this reason, we do not work with individual elements in O K but study an enlarged world, the ideals of O K , denoted as Ideals ( O K ) , and prove that they can be uniquely factored into prime ideals. The general context of proving such a property and some other properties of ideals of O K is in a
Dedekind domain
Integral ideal
Principle ideal
Ideal sum
Ideal product
Dedekind domain. A Dedekind domain is an integral domain in which every non-zero proper ideal factors into a product of prime ideals. The ring of integers O K is just a special case of a Dedekind domain as we will see at the end of this subsection once we have stated that the integral ideals of O K form a UFD. In addition, we introduce fractional ideals of O K and prove that they form a multiplicative group under ideal multiplication.
The RLWE problem is constructed based on ideal lattices, which are the images of the canonical embedding of integral (or fractional) ideals of O K (Proposition 3.5.1 (Mukherjee, 2016), Proposition 4.26 of J. S. Milne's book Algebraic Number Theory ). Since integral and fractional ideals are related by an algebraic integer d ∈ O K (which is considered as the denominator), RLWE can be defined in either setting.
## C.2.1 Integral ideals
We start this section by introducing the notion of ideal in O K . The intuition is similar to an ideal in an ordinary ring. Recall that an ideal of a ring is an additive subgroup of the ring that is closed under multiplication by ring elements. Similarly, we can define an ideal of O K .
Definition C.2.2. Given a number field K and its ring of integers O K , an integral ideal (or simply ideal ) I of O K is a non-empty (i.e., I = ∅ ) and non-trivial (i.e., I = { 0 } ) additive subgroup of O K that is closed under multiplication by elements of O K , i.e., for any r ∈ O K and any x ∈ I , we have rx ∈ I .
Since O K is commutative, we do not distinguish between left and right ideal. The above definition is consistent with ideals in ordinary rings, except that the zero ideal { 0 } is excluded in order to define ideal division later. Since O K has a Z -basis, its integral ideals have Z -basis too. In other words, every non-zero integral ideal of O K is a free Z -module.
We can define a principal ideal in a similar way as an ideal that is generated by a single element via multiplications with all elements in O K . That is, the principle ideal generated by an element x ∈ O K is
$$( x ) \colon = \{ \alpha x | \alpha \in \mathcal { O } _ { K } \} .$$
$$( x _ { 1 } , \dots , x _ { r } ) \colon = \left \{ \sum _ { i \in [ r ] } \alpha _ { i } x _ { i } | \alpha _ { i } \in \mathcal { O } _ { K } \right \}$$
Given elements x 1 , . . . , x r ∈ O K , the ideal generated by the x i 's is the set of linear combinations of the x i 's, where the coefficients are taken from O K .
We can also define some basics operations on ideals. If I and J are both integral ideals of O K , their sum is defined as
$$I + J \colon = \{ x + y | x \in I \, a n d \, y \in J \} ,$$
which is still an ideal in O K . 23 The sum ideal does not respect the additive structure on O K . For example, if I = J = (1) , then I + J = (1) = (1+1) = (2) . The sum of two ideals is not so important, what more important for the following works is the product of two ideal.
We would thought that the product set S = { xy | x ∈ I and y ∈ J } is also an ideal just like the sum but it is not, because it may not be closed under addition. For this reason, the product of two ideals I and J is defined as
$$I J \colon = \left \{ \sum _ { i \in [ r ] } a _ { i } b _ { i } | a _ { i } \in I \, a n d \, b _ { i } \in J \right \} .$$
It consists of all finite sums of the products of two ideal elements. 24 By grouping all finite sums of products, the set is closed under addition. Closed under multiplication by elements in O K can be easily checked. Since O K is commutative, ideal multiplication is commutative too.
Example C.2.3. Given the ring of integers O K = Z and two of its ideals I = 2 Z = { 2 , 4 , 6 , 8 , . . . , } and J = 3 Z = { 3 , 6 , 9 , 12 , . . . , } , their ideal product is IJ = { 2 · 3 , 2 · 6 , 2 · 3 + 2 · 6 , . . . } .
23 It can be proved that I + J and ( I ∪ J ) are equivalent.
24 Again, it can be proved that IJ and ( IJ ) are equivalent.
Ideal division
Divisibility ⇐⇒
containment
Prime ideal
Prime is maximal
Ideals ( O K ) is UFD
We have defined ideal multiplication, it is natural to also define ideal division, provided ideals of O K does not include the zero ideal according to the definition.
Definition C.2.4. Let I and J be two ideals of O K . We say J divides I , denoted J | I , if there is an ideal M ⊆ O K such that I = JM .
The following theorem gives a more intuitive way of thinking about ideal division by relating division with containment.
Theorem C.2.5. Let I and J be two ideals of O K . Then J | I if and only if I ⊆ J .
Divisibility implies containment, because if J | I then I = JK ⊆ J , so I ⊆ J . The converse may not be true in general, but is certainly true in these ideals are in the ring of integers. Next, we define prime ideals in O K which is the same as how prime ideals are defined in rings.
Definition C.2.6. An ideal I of O K is prime if
1. I = O K and
2. if xy ∈ I , then either x ∈ I or y ∈ I .
The next lemma gives an equivalent definition of prime ideals in terms of other ideals in O K .
Lemma C.2.7. An ideal I of O K is prime if and only if for ideals J and K of O K , whenever JK ⊆ I , either J ⊆ I or K ⊆ I .
By the equivalence relation between division and containment, a prime ideal I can be more intuitively defined as a proper ideal such that whenever I | JK , either I | J or I | K . This is consistent with how prime numbers are defined in Z .
An important observation is that in O K , prime ideals are also maximal. So we do not introduce maximal ideals separately. Recall that a maximal ideal in a ring is an ideal that is contained in exactly two ideals, i.e, itself and the entire ring.
Lemma C.2.8. In O K , all prime ideals are maximal.
The proof relies on the results that a commutative ring quotienting by a prime ideal gives an integral domain, quotienting by a maximal ideal gives a field.
Proof. If I is a prime ideal of O K , then O K /I is an integral domain. In addition, the integral domain is finite. This implies that for every x in the integral domain, it satisfies that x n = 1 for some n , so x · ( x n -1 ) = 1 . Hence, every non-zero element in the integral domain has an inverse, which means the quotient ring O K /I is a field. Therefore, I is maximal.
An important property of the ideals of O K is that they can be uniquely factorized into irreducible factors, in this case prime ideals. This is one of the main theorems in the course of Algebraic Number Theory. Note that it is not always true that O K is a unique factorization domain. As we have seen, an counter example is when K = Q ( √ -5) and O K = Z ( √ -5) , in which 6 = 2 ∗ 3 = (1 + √ -5) ∗ (1 -√ -5) . 25
Theorem C.2.9. For an algebraic number field K , every non-zero proper ideal I of O K admits a unique factorization into prime ideals P i of O K .
## C.2.2 Fractional ideal
Another important concept in number fields is fractional ideal. It generalizes integral ideals in a number field, but is not an ideal in the number field or its ring of integers. The essential properties that are useful in proving RLWE are fractional ideals can be uniquely factorized into prime ideals and they form a multiplicative group. We first give a general definition of fractional ideals in an integral domain. We
25 It is also necessary to check that 2, 3, 1 + √ -5 and 1 -√ -5 are irreducible and are not associates of each other. For more details, see the example on Page 30 of Ben Green's notes on algebraic number theory.
$$I = P _ { 1 } \cdots P _ { k } ,$$
Free Z -module will then refine this definition in a number field. Let R be an integral domain, recall a field of fractions of R is
$$F r a c ( R ) = \{ ( p , q ) \in R \times ( R \ \{ 0 \} ) \ | \ ( p , q ) \sim ( r , s ) \iff p s = q r \} .$$
- Definition C.2.10. Let R be an integral domain and Q = Frac ( R ) be the field of fractions. A Frac ideal fractional ideal I of R is an R -submodule of Q such that there exists a non-zero element d ∈ R satisfying dI ⊆ R .
It is clear that Frac ( R ) is an R -module and it contains R . Given an R -module M , recall a submodule N of M is a subgroup of M that is closed under scalar multiplication by elements in R , that is, ar ∈ N for any a ∈ N and any r ∈ R . Now, we can define fractional ideal of an integral domain.
I is an R -submodule of Q implies that I is an (additive) subgroup of Q and it is closed under multiplication by all elements in R . The existence of d ∈ R can be thought as cancelling the denominator of I , which is also why d needs to be non-zero. Combining with being an submodule, we have rI ⊆ R is an integral ideal. As we will explain later that a fractional ideal is neither an ideal of O K nor K , so some prefer to call them 'fractional ideals in K ' while others refer to them as 'fractional ideals of O K '. For simplicity, we sometimes refer to them just as fractional ideals without mentioning O K or K .
We further refine the definition for our purpose. In the context of a number field, O K is an integral domain and K = Frac ( O K ) is its field of fractions. By the above definition, a fractional ideal I is an O K -submodule of K such that there exists a non-zero element d ∈ O K satisfying dI ⊆ O K . Alternatively, we can just say that dI is an integral ideal, which implies it is closed under addition and multiplication by the ring elements, hence equivalent as being a submodule.
Definition C.2.11. Let K be a number field and O K be its ring of integers. A fractional ideal I of O K is a set such that dI ⊆ O K is an integral ideal for a non-zero d ∈ O K .
Alternatively, given an integral ideal J ⊆ O K and an element x ∈ K × (or an invertible element x ∈ K ), the corresponding fractional ideal I can be expressed as
From this expression, it is clearer that the non-zero element d in the above definitions is for cancelling the denominator x of in this expression. Note x is in K but not O K because it needs to be invertible. Since a non-zero integral ideal is a free Z -module and a fractional ideal is related to an integral ideal by an invertible element, it follows that a fractional ideal is a free Z -module too. So it has a Z -basis.
$$I = x ^ { - 1 } J \colon = \{ x ^ { - 1 } a | a \in J \} \subseteq K .$$
Note that a fractional ideal is not an ideal of R (unless it is contained in R ), because it is not necessarily a subset of the integral domain R . For example, as we will see in the following example, 5 4 Z ⊆ O K is a fractional ideal of O K . Nor it is an ideal of the field of fractions Frac ( R ) , because Frac ( R ) is a field which has only zero and itself as ideals.
Example C.2.12. Let K = Q and O K = Z . Clearly, Q is a Z -module. I = 5 4 Z is a Z -submodule of Q , because I is an additive subgroup of Q and for all x ∈ Z , we have xI = I . There exists an integer 4 ∈ Z such that 4 · 5 4 Z = 5 Z ⊆ Z is an ideal. So I = 5 4 Z is a fractional ideal of Z . Alternatively, it can be expressed as 4 -1 5 Z ⊆ Q , where 5 Z is an ideal of Z .
A counter example is when I = Z [ 1 2 ] . This is an O K -submodule of K = Q , but does not exists a denominator d ∈ O K such that dI ⊆ O K is an ideal.
- The product of two fractional ideals can be defined the same as the product of two Product integral ideals. That is, if I and J are both fractional ideals, then their product consists of all the finite sums ∑ i ∈ [ n ] a i b i , where a i ∈ I and b i ∈ J . It is easy to check that the product of two fractional ideals is still a fractional ideal.
To reach the conclusion that fractional ideals form a multiplicative group, it remains to show that every fractional ideal has an inverse. This is done via the following two lemmas. The first lemma proves that every prime ideal of O K has an inverse. The second lemma proves that every non-zero integral ideal of O K has an inverse.
- Lemma C.2.13. Prime ideal inverse If P is a prime ideal in O K , then P has an inverse P -1 = { a ∈ K | aP ⊆ O K } that is a fractional ideal.
Proof. Since O K is a ring, it is closed under multiplication. This implies O K ⊆ P -1 , so P -1 is not an integral ideal of O K . We want to show P -1 is a fractional ideal of O K . It is not difficult to see that
Integral ideal inverse
Frac ideal inverse
Multiplicative group
Unique factorization
P -1 is a O K -submodule of K . In addition, there is a b ∈ O K such that bP -1 is an integral ideal of O K , so by definition P -1 is a fractional ideal of O K .
It remains to prove that P -1 indeed is an inverse of P . We will not state the proof here. For details, see Proof of Theorem 3.1.8 on Page 45 in William Stein's Algebraic Number Theory .
Example C.2.14. In the number field K = Q , let P = (2) = { 2 , 4 , 6 , . . . } be a prime ideal in O K = Z . Then its inverse P -1 = { Z , Z 2 , Z 4 , Z 6 , . . . } is a fractional ideal of Z .
Since a fractional ideal and the corresponding integral ideal can be obtained from each other, we can express a fractional ideal as I = yJ for an integral ideal J and an invertible element y = x -1 . To prove I has an inverse ( yJ ) -1 , it is sufficient to show that the integral ideal J has an inverse, because the principal ideal ( y ) has an inverse (1 /y ) .
Lemma C.2.15. Every non-zero integral ideal of O K has an inverse.
Proof. Prove by contradiction. Assume not every non-zero integral ideal of O K has an inverse. Let I be the maximal non-zero integral ideal of O K that has no inverse. P is still a prime ideal of O K , then I ⊆ P . Multiplying both sides by P -1 , we get I ⊆ P -1 I ⊆ P -1 P = O K . The key here is to show that I = P -1 I . Since I is an integral ideal of O K , the equality holds if P -1 ⊆ O K because an ideal is closed by multiplication with ring elements. But we already know from the above lemma that the inverse of a prime ideal is a fractional ideal of O K that is not in the ring, so O K ⊆ P -1 . Hence, the equality cannot hold, that is we must have I P -1 I ⊆ P -1 P = O K . Since I is the maximal integral ideal in O K that does not have an inverse, the ideal P -1 I must have an inverse J such that ( P -1 I ) J = O K , so ( P -1 J ) I = O K and P -1 J is an inverse of I .
The two lemmas together prove that a fractional ideal has an inverse. See Proof of Theorem 3.1.8 on Page 46 in William Stein's Algebraic Number Theory for more detail. To be more precise, the inverse of a fractional ideal I has the form
$$I ^ { - 1 } = \{ x \in K \, | \, x I \subseteq \mathcal { O } _ { K } \} .
<text><loc_480><loc_48><loc_499><loc_100>(49)</text>$$
Given fractional ideals I and J , if IJ = ( x ) is a principal fractional ideal 26 , then its inverse is I -1 = 1 x J . It can be proved that this inverse is also a fractional ideal and it is unique for the given fractional ideal I . See Conrad's lecture notes on 'Ideal Factorization' (Definition 2.5, Theorem 2.7 and Theorem 4.1).
Theorem C.2.16. The set of fractional ideals of the ring of integers K of a number field is an abelian group under multiplication with the identity element .
- O K O K
The same theorem is also stated in Alaca and Williams (2004)'s Theorem 8.3.4. Since fractional ideals include integral ideals, these two theorems are identical.
Theorem C.2.17. Let K be an algebraic number field and O K be the ring of integers of K . Then the set of all non-zero integral and fractional ideals of O K forms an abelian group with respect to multiplication.
Finally, we come to another important result of this section, which states that a fractional ideal can be uniquely factored into the product of prime ideals.
Theorem C.2.18. If I is a fractional ideal of O K then there exits prime ideals P 1 , . . . , P n and Q 1 , . . . , Q m , unique up to order, such that
$$I = ( P _ { 1 } \cdots P _ { n } ) ( Q _ { 1 } \cdots Q _ { m } ) ^ { - 1 } .$$
The theorem follows from the fact that a fractional ideal I = J/a , where J is an integral ideal and a ∈ O K . Since both J and ( a ) are ideals of O K , Theorem C.2.9 implies they have unique prime ideal factorization, so the theorem holds.
26 Since both I and J are fractional ideals, their product is also a fractional ideal, which is not necessary an integral ideal, so it is named principal fractional ideal to differentiate it from a principal ideal.
Classical CRT
CRT in rings
Coprime ideals
GCD of ideals
## C.2.3 Chinese remainder theorem
Given that integral ideals form a UFD, the Chinese Remainder Theorem (CRT) carries over from rational integers to integral ideals of O K . In this subsection, we state CRT in the general context of Dedekind domain, in which the ring of integers O K is a special case. This is to get the reader to be familiar with CRT in general, which will be used in latticed-based cryptography and homomorphic encryption.
The classical form of CRT states that for integers n 1 , . . . , n k that are pairwise coprime and integers a 1 , . . . , a k such that 0 ≤ a i < n i , the system of congruences
$$x = a _ { 1 } \bmod n _ { 1 } \\ x = a _ { 2 } \bmod n _ { 2 } \\ \vdots
\begin{array} { r l } & { x = a _ { k } \bmod n _ { k } } \\ & { x = a _ { k } \bmod n _ { k } } \end{array}$$
has a unique solution x up to congruent modulo N = ∏ n i =1 n i , that is, if y is another solution then x = y mod N .
Similarly, CRT can solve the problem of polynomial interpolation. 27 Given values x i , . . . , x n , y 1 , . . . , y n ∈ R , there is a unique polynomial p ( x ) satisfies
$$p ( x _ { 1 } ) & = y _ { 1 } \\ p ( x _ { 2 } ) & = y _ { 2 }$$
The problem can be solved in terms of CRT as finding a unique polynomial p ( x ) that satisfies
$$p ( x ) & = y _ { 1 } \bmod x - x _ { 1 } \\ p ( x ) & = y _ { 2 } \bmod x - x _ { 2 }$$
A more abstract version of CRT states that if the n i 's are pairwise coprime, the map
Weknow from previous sections that p ( x ) -y i = 0 mod x -x i , which can also be expressed in quotient as ( p ( x ) -y i ) / ( x -x i ) , is the extension field Q ( x i ) over Q that contains the roots of p ( x ) -y i and x i .
defines an isomorphism between the ring of integers modulo N and the direct product of the k rings of integers modulo n i .
$$x \bmod N \mapsto ( x \bmod n _ { 1 } , \dots , x \bmod n _ { k } ) \\ \mathbb { Z } / N \mathbb { Z } \cong \mathbb { Z } / n _ { 1 } \mathbb { Z } \times \cdots \times \mathbb { Z } / n _ { k } \mathbb { Z }$$
To generalize CRT to the ring of integers O K , we define coprime ideals in O K . Since ideals in O K can be uniquely factorized, it makes sense to talk about coprimality.
Definition C.2.19. Let I and J be two integral ideals in O K . Then I and J are coprime if they do not have any prime factors in common. That is, there is no prime ideal dividing both of them.
This definition relies on the notion of common factors of two ideals.
Definition C.2.20. Let I and J be integral ideals of O K , their greatest common divisor (GCD) gcd( I, J ) = I + J .
By definition of ideal GCD, we can re-define ideal coprimality as the next.
Definition C.2.21. Two ideals I and J in O K are coprime if I + J = O K .
27 The example is taken from https://math.berkeley.edu/˜kmill/math55sp17/crt.pdf
In other words, two integral ideals are coprime if their sum is the entire ring of integers. For example, the integral ideals (2) and (3) in Z are coprime because (2) + (3) = (1) = Z . But the integral ideals (2) and (4) are not coprime because (2) + (4) = (2) = Z .
Now we have defined coprime ideals in O K , we can state the Chinese Remainder Theorem in Dedekind domains.
Theorem C.2.22. CRT in O K Let D be a Dedekind domain.
1. Let P 1 , . . . , P k be distinct prime ideals in D and b 1 , . . . , b k be positive integers. Let α 1 , . . . , α k be elements of D . Then there exists an α ∈ D such that for all i ∈ [1 , k ] , it satisfies α = α i mod P b i i .
2. Let I 1 , . . . , I k be pairwise coprime ideals of D and α 1 , . . . , α k be elements of D . Then there exists an α ∈ D such that for all i ∈ [1 , k ] , it satisfies α = α i mod I i .
Another way of stating the second point above that is similar to the CRT in rings is the next theorem.
Theorem C.2.23. Let I 1 , . . . , I k be pairwise corprime ideals in a Dedekind domain D and I = ∏ k i =1 I i . Then the map induces an isomorphism
$$D \rightarrow ( D / I _ { 1 } , \dots , D / I _ { k } )$$
$$D / I \cong D / I _ { 1 } \times \cdots \times D / I _ { k } .$$
To prove CRT in O K , first prove the map is surjective. Then prove that the kernel of the map is I 1 ∩···∩ I k , which can be shown to be identical to ∏ k i =1 I i under the assumption that they are pairwise coprime. Then it follows from the First Isomorphism Theorem.
The connection of this subsection to the RLWE result are the following two lemmas. The first lemma shows that given two ideals I, J ⊆ R of a Dedekind domain R (i.e., a ring of integers O K of a number field K ), it possible to construct another ideal that is coprime with either one of them.
Lemma C.2.24. If I and J are non-zero integral ideals of a Dedekind domain R , then there exists an element a ∈ I such that ( a ) I -1 ⊆ R is an integral ideal coprime to J .
Proof. Since a ∈ I , the principal ideal ( a ) ⊆ I . By Theorem C.2.5, we have I | ( a ) , that is, there is an ideal M ⊆ R such that IM = ( a ) , so M = ( a ) I -1 ⊆ R is an ideal of R . We skip the proof of coprimality. See Lemma 5.5.2 of Stein (2012).
The element a ∈ I can be efficiently computable using CRT in O K . Hence, given two ideals in R , we can efficiently construct another one that is coprime with either one of them. This corresponds to Lemma 2.14 of Lyubashevsky et al. (2010). The next lemma is essential in the reduction from K-BDD problem to RLWE.
Lemma C.2.25. Let I and J be ideals in a Dedekind domain R and M be a fractional ideal in the number field K . Then there is an isomorphism
$$M / J M \cong I M / I J M .$$
Proof. Given ideals I, J ⊆ R , by Lemma C.2.24 we have tI -1 ⊆ R is coprime to J for an element t ∈ I . Then we can define a map
This map induces a homomorphism
$$\theta _ { t } \colon K & \to K \\ u & \mapsto t u .$$
$$\theta _ { t } \colon M \rightarrow I M / I J M .$$
$$\theta _ { t } \colon M / J M \rightarrow I M / I J M$$
First, show ker ( θ t ) = JM . Since θ t ( JM ) = tJM ⊆ IJM , then θ t ( JM ) = 0 . Next, show any other element u ∈ M that maps to 0 is in JM . To see this, if θ t ( u ) = tu = 0 , then tu ∈ IJM . To use Lemma C.2.24, we re-write it as ( tI -1 )( uM -1 ) ⊆ J . Since tI -1 and M are coprime, we have uM -1 ⊆ J , which implies u ⊆ JM . Therefore, ker ( θ t ) = JM and
Trace and norm in K
is injective.
Second, show the map is surjective. That is, for any v ∈ IM , its reduction v mod IJM has a preimage in M/JM . Since tI -1 and J are coprime, by CRT we can compute an element c ∈ tI -1 such that c = 1 mod J . Let a = cv ∈ tM , then a -v = cv -v = v ( c -1) ∈ IJM . Let w = a/t ∈ M , then θ t ( w ) = t ( a/t ) = a = v mod IJM . Hence, any arbitrary element v ∈ IM satisfies the preimage of v mod IJM is w mod IM .
In the hardness proof of RLWE as will be shown in the next section, we let M = R or M = I ∨ = I -1 R ∨ and J = ( q ) for a prime integer q , then the isomorphism becomes
$$R / ( q ) R & \cong I / ( q ) I \, \text {or} \\ I ^ { \vee } / ( q ) I ^ { \vee } & \cong R ^ { \vee } / ( q ) R ^ { \vee } .$$
## C.3 Trace and Norm
As we have built a connection between a number field and a Euclidean space, we can relate more features of a Euclidean space to that of a number field. In this subsection, we will introduce two quantities, trace and norm, of elements in a number field. These quantities are useful to calculate the discriminant and determinant of elements in a number field. Recall that for a linear transformation φ : V → V from a vector space V to itself, we can write φ in its matrix representation [ φ ] by applying φ to a basis of V . That is, for each e j ∈ { e i } i ∈ [ n ] in a basis of V , we have φ ( e j ) = ∑ i ∈ [ n ] a ij e i is the linear combination of the basis, so [ φ ] = ( a ij ) is the coefficient matrix. With this matrix representation of the linear map, we can define its trace and determinant like in the context of linear algebra.
Example C.3.1. Let φ : C → C be the complex conjugation. Take the basis { 1 , i } for the complex space C . Apply the complex conjugation to this basis, we get
$$\phi ( 1 ) & = 1 + 0 \cdot i , \\ \phi ( i ) & = 0 \cdot 1 + ( - 1 ) \cdot i .$$
So the matrix representation of the complex conjugation is [ φ ] = ( 1 0 0 -1 ) . Each column j consists of the coefficients of φ ( e j ) .
Since a number field K is a Q -vector space, we can speak of linear transformations on K too. For any element α ∈ K , we can define a map m α ( x ) = αx as a multiplication by α for all x ∈ K . It is easy to see that m α is also a linear map from K to itself, so there is a matrix representation of this linear map m α .
$$\sqrt { 3 }$$
Example C.3.2. Let K = Q ( √ 2) be a number field with a basis { 1 , √ 2 } . For a, b ∈ Q , we have an element α = a + b √ 2 ∈ K and its associated linear map m α . Apply this map to the basis of K , we get
$$m _ { \alpha } ( 1 ) & = a \cdot 1 + b \cdot \sqrt { 2 } , \\ m _ { \alpha } ( \sqrt { 2 } ) & = 2 b \cdot 1 + a \cdot \sqrt { 2 } .$$
So the matrix representation of the linear map is [ m α ] = ( a 2 b b a ) .
Now, we can define the trace and norm on a number field which will appear in the RLWE problem.
Definition C.3.3. The trace and norm of an element α in a number field K are defined as
$$loc.$$
Example C.3.4. In the above example, the trace and norm of m α are the trace and determinant of its matrix representation, i.e., 2 a and a 2 -2 b 2 , respectively.
Trace and norm by canonical embedding
Small norm element
It is also possible to define trace and norm using the canonical embedding that was introduced in the previous section. This is due the the following theorem which states a connection between these two quantities and automorphisms in the Galois group of a general field extension.
Theorem C.3.5. If E/F is a finite Galois extension, then the trace and norm of an element α ∈ E are
$$T r _ { E / F } ( \alpha ) & = \sum _ { \sigma \in G a l ( E / F ) } \sigma ( \alpha ) \\ N _ { E / F } ( \alpha ) & = \prod _ { \sigma \in G a l ( E / F ) } \sigma ( \alpha ) .$$
<!-- formula-not-decoded -->
The intuition is that when the extension field E is Galois, each automorphism σ ( α ) in the Galois group is an eigenvalue of the linear transformation m α . Recall from linear algebra that the trace and determinant of a square matrix are the sum and product of its eigenvalues respectively. The connection with the canonical embedding is due to the following two observations:
1. the number field K = Q ( r ) is a Galois extension over Q ,
2. each automorphism σ i ∈ Gal ( E/F ) in the Galois group is correspond to an element in the image of the canonical embedding σ : K → H in Definition C.1.8.
This gives rise to the following definitions of trace and norm of an element in a number field in terms of the canonical embedding, which appear in some books too.
Definition C.3.6. Given a canonical embedding of a number field K
$$\begin{array} { r l } & { \sigma \colon K \to \mathbb { R } ^ { s _ { 1 } } \times \mathbb { C } ^ { 2 s _ { 2 } } } \\ & { \quad \sigma ( \alpha ) \mapsto ( \sigma _ { 1 } ( \alpha ) , \dots , \sigma _ { n } ( \alpha ) ) , } \end{array}$$
the and of an element are defined as trace norm α ∈ K
$$\alpha \in K \text { are defined as } T r _ { K \mathbb { Q } } \colon K \to \mathbb { Q } \\ T r _ { K / \mathbb { Q } } ( \alpha ) = \sum _ { i \in [ n ] } \sigma _ { i } ( \alpha ) ,$$
Example C.3.7. In the same example where K = Q ( √ 2) and α = a + b √ 2 , the minimal polynomial of α over Q is f ( x ) = ( x -a b ) 2 -2 , which has two roots a ± b √ 2 . So the canonical embedding σ of K maps α to each of these two roots. Hence, the trace of α is Tr ( α ) = ( a + b √ 2) + ( a -b √ 2) = 2 a and the norm is N ( α ) = ( a + b √ 2)( a -b √ 2) = a 2 -2 b 2 , which are consistent with the results in the above example.
Both definitions imply that trace is additive and norm is multiplicative, that is, Tr ( x + y ) = Tr ( x )+ Tr ( y ) and N ( xy ) = N ( x ) N ( y ) . In addition, Definition C.3.6 entails that
$$T r ( x y ) = \sum \sigma _ { i } ( x y ) = \sum \sigma _ { i } ( x ) \sigma _ { i } ( y ) = \langle \sigma ( x ) , \overline { \sigma ( y ) } \rangle .$$
The second equality is due to the fact that each σ i is a homomorphism. The last equality is by definition of the inner product between complex vectors.
## C.4 Ideal lattices
To start off this section, we state below some results in order to give some insights about the motivation of studying how ring of integers and its ideals are embedded in R n .
Proposition C.4.1. Let K be a number field and I be an integral ideal of O K . Then there is some element x ∈ I such that | N K/ Q ( x ) | ≤ M K N ( I ) .
Minkowski 1st Theorem
Here, M K is the Minkowski constant defined as M K = ( 4 π ) r 2 n ! n n √ | ∆ K | , where n is the degree of K and also the number of embeddings of K with n = r 1 +2 r 2 for r 1 real embeddings and r 2 pairs of complex embeddings. ∆ K is the discriminant of the number field K , which will be introduced later.
Theorem C.4.2. Let L be an n -dimensional lattice and B ⊆ R n be a centrally symmetric, compact, convex body. Suppose V ol ( B ) ≥ 2 n det( L ) , then B contains a non-zero lattice vector of L .
To prove Proposition C.4.1, it uses results from lattice theory and Theorem C.4.2. Given the canonical embedding σ maps K to a space isomorphic to R n , the first step is to prove O K is associated with a lattice in R n and so are the ideals of O K . Then it left to prove that the lattice associated with an ideal intersects with a bounded convex body in R n by Theorem C.4.2, provided certain parameter conditions are satisfied. The first step is our focus in this section, so we do not discuss the second step.
Recall a canonical embedding σ : K → H ∼ = R n gives rise to another embedding τ : K → V ∼ = R n as defined in Equation 48, which maps the ring of integers O K to a full-rank lattice as stated in Theorem C.1.11. This implies that the embedding τ maps a fractional (integral) ideal of O K to a full-rank lattice too. 28 We give a name of such a lattice.
Definition C.4.3. The embedding τ : K → V maps a fractional ideal of the ring of integers O K to a full-rank lattice, called the ideal lattice . Ideal lattice
For the interest of building lattice-based cryptosystems, we study ideal lattices and their determinants. But for a general case, we state the next theorem.
Theorem C.4.4. Let τ : K → V be the embedding of the n -dimensional number field K as defined in Equation 48. Then τ ( O K ) is a full-rank ideal lattice in R n and its determinant satisfies det( τ ( O K ))
$$\det ( \tau ( { \mathcal { O } } _ { K } ) ) = \frac { 1 } { 2 ^ { r _ { 2 } } } \sqrt { | \Delta _ { K } | } .$$
Since we have proved in Theorem C.1.11 that τ ( O K ) is a full-rank lattice in R n , it remains to prove its determinant. There are two new quantities in the theorem that have not been introduced, the discriminant ∆ K of the number field K and the norm N ( I ) of an ideal I ⊆ O K . So we delay the proof till the end of this subsection.
Recall from Section 4 that an n -dimensional lattice L is similar to a vector space R n but with only discrete vectors. It is isomorphic to the group ( Z n , +) . It shares many properties with R n such as having a basis { v 1 , . . . , v n } . The determinant of a lattice is the size of its fundamental domain that is surrounded by its basis. This gives rise to the following equality
$$\det ( L ) = V o l ( F ) = | \det ( B ) | ,$$
where F is the fundamental domain and B is a basis matrix of L . An useful observation is that the determinant is an invariant quantity under the choice of a basis, because any two bases of L are related by a unimodular matrix.
Let K be an algebraic number field of degree n and σ i : K → C be a field homomorphism for all i ∈ [ n ] . For the elements x 1 , . . . , x n ∈ K , define the n by n matrix M to be the linear map where M ij = σ i ( x j ) , that is,
$$M = \begin{pmatrix} \sigma _ { 1 } ( x _ { 1 } ) & \sigma _ { 1 } ( x _ { 2 } ) & \cdots & \sigma _ { 1 } ( x _ { n } ) \\ \sigma _ { 2 } ( x _ { 1 } ) & \sigma _ { 2 } ( x _ { 2 } ) & \cdots & \sigma _ { 2 } ( x _ { n } ) \\ \vdots & \vdots & \dots & \vdots \\ \sigma _ { n } ( x _ { 1 } ) & \sigma _ { n } ( x _ { 2 } ) & \cdots & \sigma _ { n } ( x _ { n } ) \end{pmatrix} .$$
Definition C.4.5. Let K be an n -dimensional number field with a basis { e 1 , . . . , e n } and Element discriminant M be the matrix defined above. The discriminant of the elements is
It can be proved that the matrix is always non-singular if the elements { x 1 , . . . , x n } form a basis of K over Q (Lemma 1.7.1 Ben Green's Algebraic Number Theory ). Without loss of generality, assume M = M ( e 1 , . . . , e n ) for a basis { e 1 , . . . , e n } of a n -dimensional number field K .
$$d i s c _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = d e t ( M ) ^ { 2 } .$$
28 See Corollary 10.6.2 of Ben Green's book Algebraic Number Theory or Lemma 7.1.8 of Stein (2012).
Alternatively, the discriminant of elements in K can be defined by their traces, because
$$\text {disc} _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = \det ( M ) ^ { 2 } = \det ( M ^ { T } M )$$
and the matrix entry ( M T M ) ij = ∑ k σ k ( e i ) σ k ( e j ) = ∑ k σ k ( e i e j ) = Tr K/ Q ( e i e j ) as σ i is a homomorphism. Therefore, the discriminant of number field elements is equal to the determinant of the trace matrix as stated next in the equivalent definition.
Definition C.4.6. Let K be an n -dimensional number field with a basis { e 1 , . . . , e n } ∈ K . The discriminant of the elements is
$$d i s c _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = d e t \left ( ( T r _ { K / \mathbb { Q } } ( e _ { i } e _ { j } ) ) _ { i j } \right ) .$$
From the previous section, we know that the trace of an element is a rational number, so the discriminant is also a rational number. Note although it is defined as the square of a matrix determinant, discriminant can be negative as complex numbers are involved. From the discriminant of basis elements and the integral basis of a number field K , we can define the discriminant of K .
- Definition C.4.7. Let K be an n -dimensional number field and { e 1 , . . . , e n } be an ∆( K ) integral basis of K . The discriminant of the number field K is
$$\Delta _ { K } = d i s c _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = \det \left ( ( T r _ { K / \mathbb { Q } } ( e _ { i } e _ { j } ) ) _ { i j } \right ) = \det ( M ) ^ { 2 } .$$
The discriminant loosely speaking measures the size of the ring of integers O K in the number field K and it is invariant under the choice of an integral basis, which is the same as the determinant of a lattice. This can be seen from the following Lemma and corollary.
Lemma C.4.8. Suppose x 1 , . . . , x n , y 1 , . . . , y n ∈ K are elements in the number field and they are related by a transformation matrix A , then
$$d i s c _ { K / \mathbb { Q } } ( x _ { 1 } , \dots , x _ { n } ) = d e t ( A ) ^ { 2 } d i s c _ { K / \mathbb { Q } } ( y _ { 1 } , \dots , y _ { n } ) .$$
Corollary C.4.9. Invariant ∆( K ) Suppose { e 1 , . . . , e n } and { e ′ 1 , . . . , e ′ n } are both integral bases of the number field K , then
$$d i s c _ { K / \mathbb { Q } } ( e _ { 1 } , \dots , e _ { n } ) = d i s c _ { K / \mathbb { Q } } ( e _ { 1 } ^ { \prime } , \dots , e _ { n } ^ { \prime } ) .$$
From Theorem C.4.4, it can be seen that the (absolute) discriminant of a number field measures the geometric sparsity of its ring of integers, because the larger the discriminant, the larger the size of the fundamental region, hence the more sparse the ideal lattice.
Another quantity appears in the theorem is the norm of an ideal. Recall that the index | G : H | of a subgroup H in G is the number of cosets of H in G . We define the norm of an ideal and its relation to the norm of an element in the following lemma (see Lemma 4.4.3 in Ben Green's book).
Definition C.4.10. Ideal norm Let I be a non-zero ideal of O K . The norm of I , denoted by N ( I ) (or sometimes ( O K : I ) ), is the index of I as a subgroup of O K , i.e., N ( I ) = |O K /I | .
Lemma C.4.11. Suppose I = ( α ) is a principal ideal of O K for some non-zero α ∈ O K . Then N ( I ) = | N K/ Q ( α ) | .
As for the norm of number field elements, the norm of ideals is also multiplicative. That is, N ( IJ ) = N ( I ) N ( J ) . In addition, if I is a fractional ideal of O K , then its norm satisfies N ( I ) = N ( dI ) / | N ( d ) | , where d ∈ O K is the element that makes dI ∈ O K an integral ideal.
Sketch proof of Theorem C.4.4. To prove the determinant of the lattice τ ( O K ) , we know from the proof of Theorem C.1.11 that { τ ( e 1 ) , . . . , τ ( e n ) } is a basis of the lattice and the basis matrix is
<!-- formula-not-decoded -->
so det( τ ( O K )) = | det( N ) | . In addition, the canonical embedding σ associates with the matrix
<!-- formula-not-decoded -->
whose determinant satisfies ∆ K = det( M ) 2 . It can be seen that the columns in N T correspond to the real (or complex) parts of the complex embeddings can be obtained from M T by adding (or subtracting) the complex conjugate columns. For example, expressing the matrices in column vector format, we get
$$N ^ { T } & = ( \dots , R e ( \sigma _ { r _ { 1 } + 1 } ( e _ { 1 } ) ) , I m ( \sigma _ { r _ { 1 } + 1 } ( e _ { 1 } ) ) , \dots ) \\ & = ( \dots , \frac { 1 } { 2 } ( \sigma _ { r _ { 1 } + 1 } ( e _ { 1 } ) + \overline { \sigma _ { r _ { 1 } + 1 } ( e _ { 1 } ) } ) , \dots ) \\ & = - \frac { 1 } { 2 i } ( \dots , \sigma _ { r _ { 1 } + 1 } ( e _ { 1 } ) , \overline { \sigma _ { r _ { 1 } + 1 } ( e _ { 1 } ) } , \dots ) .$$
Apply the same operations for all r 2 pairs of columns, we get det( N ) = -1 (2 i ) r 2 det M . Hence,
$$\det ( \tau ( { \mathcal { O } } _ { K } ) ) = | \det ( N ) | = \frac { 1 } { 2 ^ { r _ { 2 } } } | \det M | = \frac { 1 } { 2 ^ { r _ { 2 } } } \sqrt { | \Delta _ { K } | } .$$
From Theorem C.4.4, it follows the determinant of an ideal lattice is also related to the discriminant of the number field.
Corollary C.4.12. Let I be an ideal of O K . Then the ideal lattice τ ( I ) has determinant det( τ ( I ))
$$\det ( \tau ( I ) ) = \frac { 1 } { 2 ^ { r _ { 2 } } } N ( I ) \sqrt { | \Delta _ { K } | } .$$
We have stated that τ ( I ) is a lattice in R n called ideal lattice. The same strategy can also be used to state the relationship between the associated matrix determinants det( N ) and det( M ) . The only difference is that I is a sublattice of O K , so its determinant is larger than det( O K ) . The scale is exactly the index of I in O K as a subgroup, which is the norm of I by Definition C.4.10 of ideal norm.
## C.5 Dual lattice in number fields
For more detail of the proofs and intuitions in this subsection, the readers should refer to Conrad's lecture notes on 'Different ideal'.
Definition C.5.1. Lattice in K A lattice in an n -dimensional number field K is the Z -span of a Q -basis of K .
By the Primitive Element Theorem (Theorem C.1.2), K always has a power basis which is a Q -basis. So the integer linear combination of the Q -basis forms a lattice in K . For example, the ring of integers O K is a lattice in the number field K . Similar to lattices in general, number field lattices have dual too and share much of the same properties as the general dual lattices as we will see next. Unlike general lattices in R n which equips with the dot product, the operator that equips with number field lattices is the trace as defined previously. More precisely, the dual lattice in a number field consists with elements that have integer trace product with the given lattice by Equation 50.
Definition C.5.2. Dual lattice Let L be a lattice in a number field K . Its dual lattice is
$$L ^ { \vee } = \{ x \in K | T r _ { K / Q } ( x L ) \subseteq \mathbb { Z } \} .$$
To check whether or not an element belongs to the dual, one can check its trace product with the lattice basis. This also gives a way of writing out the dual of a given lattice.
Example C.5.3. Let K = Q ( i ) and the lattice L = Z [ i ] . Let B = { 1 , i } be a basis of L . To find the dual of L , take an element a + bi ∈ K and consider its trace product with the basis vector in B and check if the trace products are integers. More precisely, we need to check the conditions under which
$$T r _ { K / \mathbb { Q } } ( a + b i ) & \in \mathbb { Z } \\ T r _ { K / \mathbb { Q } } ( ( a + b i ) i ) & \in \mathbb { Z } .$$
$$f ( x ) = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { n } f ( x _ { i } )$$
Let α = a + bi and β = -b + ai . By Definition C.3.3 of trace, we have [ m α ] = ( a -b b a ) and
[ m β ] = ( -b -a a b ) . For both traces to be integers, we must have 2 a ∈ Z and -2 b ∈ Z , so the dual lattice L ∨ = 1 [ i ] and the basis of the dual is B ∨ = 1 , i .
-2 Z { 2 2 }
From the example, it can be seen that the basis and the dual basis satisfy Tr ( e i e ∨ j ) = δ ij . This gives rise to the following theorem that states the dual of a number field lattice is also a lattice.
Theorem C.5.4. L ∨ is lattice For an n -dimensional number field K and a lattice L ⊆ K with a Z -basis { e 1 , . . . , e n } , the dual L ∨ = ⊕ Z e ∨ i is a lattice with a dual basis { e ∨ 1 , . . . , e ∨ n } satisfying Tr K/ Q ( e i e ∨ j ) = δ ij . what is δ ij ?
Dual lattices in number fields share similar properties with dual lattices in general. We state a few of them in the following corollary.
Corollary C.5.5. For lattices in a number field, the following hold:
$$1 , \ L ^ { \vee \vee } = L ,$$
$$2 . \, L _ { 1 } \subseteq L _ { 2 } \iff L _ { 2 } ^ { \vee } \subseteq L _ { 1 } ^ { \vee } ,$$
$$\begin{array} { r l } { 3 . ( \alpha L ) ^ { \vee } \iff \frac { 1 } { \alpha } L ^ { \vee } , f o r a n e l e m e n t \, \alpha \in K ^ { \times } . } \end{array}$$
The following theorem relates the dual lattice to differentiation and provides an easier way of computing the dual basis and dual lattice from a given lattice.
Theorem C.5.6. Dual basis Let K = Q ( α ) be an n -dimensional number field with a power basis { 1 , α, . . . , α n -1 } and f ( x ) ∈ Q [ x ] be the minimal polynomial of the element α , which can be expressed as
$$f ( x ) = ( x - \alpha ) ( c _ { 0 } + c _ { 1 } x + \cdots + c _ { n - 1 } x ^ { n - 1 } ) .$$
Then the dual basis to the power basis relative to the trace product is { c 0 f ′ ( α ) , . . . , c n -1 f ′ ( α ) } .
In particular, if K = Q ( α ) and the primitive element α ∈ O K is an algebraic integer, then the lattice L = Z [ α ] = Z + · · · + Z α n -1 and its dual are related by the first derivative of the minimal polynomial, that is,
$$L ^ { \vee } = \frac { 1 } { f ^ { \prime } ( \alpha ) } L .$$
Example C.5.7. Let us work through an example to illustrate both theorems. Let the number field K = Q ( √ d ) and its lattice L = Z [ √ d ] .
$$- \, \mathcal { U } _ { 2 } ^ { - } + \mathcal { U } _ { 2 \sqrt { d } } - \frac { \mathcal { O } } { 2 \sqrt { d } } \, \mathcal { U } ^ { + } + \mathcal { O } \nabla u \, / = \, \frac { \mathcal { O } } { 2 \sqrt { d } } L .$$
This is a 2-dimensional number field with the primitive element α = √ d and the power basis { 1 , √ d } . The minimal polynomial of α in Q [ x ] is f ( x ) = x 2 -d with the derivative f ′ ( x ) = 2 x so f ′ ( α ) = 2 √ d . Moreover, the minimal polynomial can be written as f ( x ) = ( x -√ d )( x + √ d ) . By Theorem C.5.6, the dual basis is { 1 2 , 1 2 √ d } . In addition, if d ∈ Z then α ∈ O K , so the dual lattice L ∨ = 1 2 √ d L . This is consistent with the dual basis obtained, because according to the dual basis, the dual lattice L ∨ = Z 1 + Z 1 √ = 1 √ ( Z + Z √ d ) = 1 √ L .
To confirm the dual basis of { 1 , √ d } is { 1 2 , 1 2 √ d } , we apply Theorem C.5.4 to check their trace products. We have
$$T r ( 1 \cdot \frac { 1 } { 2 } ) = T r ( \sqrt { d } \cdot \frac { 1 } { 2 \sqrt { d } } ) = T r ( \frac { 1 } { 2 } ) = 1$$
Example C.5.8. An important application of this theorem in our context is when the number field K = Q [ ζ m ] is the mth cyclotomic number field, where m = 2 n = 2 k > 1 . The ring of integers is then L = O K = Z [ ζ m ] . The minimal polynomial of ζ m is f ( x ) = x n +1 with the derivative f ′ ( x ) = nx n -1 . According to the theorem, we have
$$( \mathbb { Z } [ \zeta _ { m } ] ) ^ { \vee } = \frac { 1 } { f ^ { \prime } ( \zeta _ { m } ) } \mathbb { Z } [ \zeta _ { m } ] = \frac { 1 } { n \zeta _ { m } ^ { n - 1 } } \mathbb { Z } [ \zeta _ { m } ] = \frac { 1 } { n } \zeta _ { m } ^ { n + 1 } \mathbb { Z } [ \zeta _ { m } ] = \left ( \frac { 1 } { n } \right ) .$$
The second last equality is because the roots of unit form a cyclic group and hence ζ -( n -1) = ζ n +1 ∈ O K .
Different ideal
As a special lattice in K , the ring of integers O K was further studied and the following theorems offer some useful observations of its dual. By definition, the dual of O K is
On the one hand, O ∨ K is at least as large as O K . Each element in O K is an algebraic integer that has an integer trace 29 , so O K ⊆ O ∨ K which happens when x = 1 . On the other hand, O ∨ K is no larger than the set of elements in K that have integer trace as shown in the next theorem.
$$\mathcal { O } _ { K } ^ { \vee } = \{ x \in K | T r _ { K / \mathbb { Q } } ( x \mathcal { O } _ { K } ) \subseteq \mathbb { Z } \} .$$
- Theorem C.5.9. O ∨ K is frac ideal The dual lattice O ∨ K is the largest fractional ideal in K whose elements have integer traces.
Proof. Let I be a fractional ideal in K . As it is closed under multiplication by elements in O K , we have I O K = I . Hence, Tr ( I O K ) ⊆ Z if and only if Tr ( I ) ⊆ Z , which is equivalent to I ⊆ O ∨ K . From these relations, we know that the fractional ideal is in the dual lattice if its elements have integer traces, so the largest fractional ideal whose elements have integer traces is also in the dual. If an additional element is added into the largest fractional ideal that satisfies the condition, then it is not necessarily true that I O K = I , so the above relations may not follow.
The next theorem reveals the role that O ∨ K plays in the dual of an arbitrary fractional ideal, which is also a lattice in K .
- Theorem C.5.10. Frac ideal dual For a fractional ideal I in K , its dual lattice is a fractional ideal and satisfying ∨ -1 ∨ .
I = I O K
We have seen the inverse of a fractional ideal in Equation 49, it is tempting to see if the inverse of the dual O ∨ K (which is also a fractional ideal) is any special. By definition of fractional ideal inverse (Equation 49), we have
$$( \mathcal { O } _ { K } ) ^ { - 1 } & = \{ x \in K \, | \, x \mathcal { O } _ { K } \subseteq \mathcal { O } _ { K } \} = \mathcal { O } _ { K } \\ ( \mathcal { O } _ { K } ^ { \vee } ) ^ { - 1 } & = \{ x \in K \, | \, x \mathcal { O } _ { K } ^ { \vee } \subseteq \mathcal { O } _ { K } \} .$$
The next theorem relates the different ideal with the differentiation of the minimal polynomial. It can be proved easily by applying Theorem C.5.6.
Since O K ⊆ O ∨ K , their inverses satisfy ( O ∨ K ) -1 ⊆ O K . Unlike the dual which is a fractional ideal and not necessarily within O K , this inclusion makes ( O ∨ K ) -1 an integral ideal. Here, we give it a different name, different ideal and denote it by D K := ( O ∨ K ) -1 . 30 For example, let K = Q ( i ) and O K = Z [ i ] . The dual ideal is O ∨ K = Z [ i ] ∨ = 1 2 Z [ i ] , so the different ideal D K = ( 1 2 Z [ i ]) -1 = 2 Z [ i ] .
Theorem C.5.11. Let O K = Z [ α ] be the ring of integers of a number field K and f ( x ) ∈ Z [ x ] be the minimal polynomial of α , then the different ideal D K = ( f ′ ( α )) .
As mentioned before, O K does not always have a power basis, so not all O K can be written as Z [ α ] . Let us look at a special case in the above example where O K = Z [ i ] , the minimal polynomial of α = i is f ( x ) = x 2 +1 and its derivative is f ′ ( α ) = 2 i . Hence, the different ideal D K = (2 i ) is a principal ideal of O K , so D K = 2 i · Z [ i ] = 2 Z [ i ] . The example can be generalized to some special cyclotomic fields, in which there is an explicit relations between the different ideal and the ring of integers. It can be easily proved using the above theorem.
- Lemma C.5.12. D K = n O K For m = 2 n = 2 k ≥ 2 a power of 2, let K = Q ( ζ m ) be an m th cyclotomic number field and O K = Z [ ζ m ] be its ring of integers. The different ideal satisfies D K = n O K .
This lemma plays an important role in RLWE in the special case where the number field is an m cyclotomic field. It implies that the ring of integers n -1 O K = O ∨ K and its dual are equivalent by a scaling factor. Hence, the secret polynomial s and the random polynomial a can both be sampled from the same domain R q , unlike in the general context where the preference is to leave s ∈ R ∨ q in the dual.
To finish off this subsection, we state the relation between the norm of the different ideal and the discriminant of the number field. See Theorem 4.6 in Conrad's lecture notes on 'different ideal'.
29 This can be verified by taking the power basis { 1 , r, . . . , r n -1 } of K which is also a Z -basis of O K . An element x ∈ O K can be written as x = c 0 + c 1 r + · · · + c n -1 r n -1 . By definition, only Tr ( c 0 ) ∈ Z and the rest are 0.
30 To be clear. Some refer D K as the different ideal of K and the notation suggests it too. But K is a field which has exactly two ideals, the zero ideal and itself, so D K is not an ideal of K but of O K .
Theorem C.5.13. For a number field K , its discriminant ∆ K and different ideal D K satisfies N ( D K ) = | ∆ K | .
## D Mind Maps
## D.1 A mindmap for RLWE
<details>
<summary>Image 17 Details</summary>
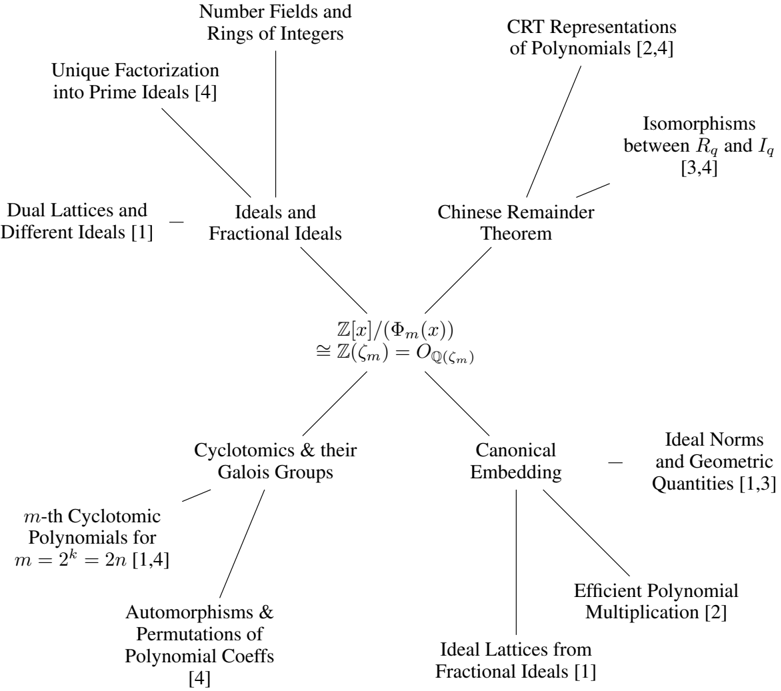
### Visual Description
\n
## Diagram: Relationships between Mathematical Concepts
### Overview
The image is a diagram illustrating the relationships between various mathematical concepts, primarily within the fields of number theory, algebraic number theory, and related areas. The diagram uses arrows to indicate connections between these concepts, with numerical references (e.g., [1], [2,4]) likely indicating sources or related publications. The central element is an isomorphism statement.
### Components/Axes
The diagram doesn't have traditional axes. Instead, it consists of interconnected nodes representing mathematical concepts. The nodes are arranged roughly in a radial pattern around the central isomorphism statement. The connections are indicated by arrows. The numerical references are placed in square brackets next to each concept.
### Detailed Analysis or Content Details
Here's a breakdown of the concepts and their connections, moving clockwise from the top:
1. **Number Fields and Rings of Integers:** Connected to "Unique Factorization into Prime Ideals [4]".
2. **Unique Factorization into Prime Ideals [4]:** Connected to "Dual Lattices and Different Ideals [1]".
3. **Dual Lattices and Different Ideals [1]:** Connected to "Ideals and Fractional Ideals".
4. **Ideals and Fractional Ideals:** This is the central hub, connected to five other concepts.
5. **Chinese Remainder Theorem:** Connected to "CRT Representations of Polynomials [2,4]" and "Isomorphisms between Rq and Iq [3,4]".
6. **CRT Representations of Polynomials [2,4]:** No further connections shown.
7. **Isomorphisms between Rq and Iq [3,4]:** No further connections shown.
8. **Ideal Norms and Geometric Quantities [1,3]:** Connected to "Efficient Polynomial Multiplication [2]".
9. **Efficient Polynomial Multiplication [2]:** Connected to "Ideal Lattices from Fractional Ideals [1]".
10. **Ideal Lattices from Fractional Ideals [1]:** Connected to "Canonical Embedding".
11. **Canonical Embedding:** Connected to "Cyclotomics & their Galois Groups".
12. **Cyclotomics & their Galois Groups:** Connected to "m-th Cyclotomic Polynomials for m = p^2 = 2n [1,4]".
13. **m-th Cyclotomic Polynomials for m = p^2 = 2n [1,4]:** Connected to "Automorphisms & Permutations of Polynomial Coeffs [4]".
14. **Automorphisms & Permutations of Polynomial Coeffs [4]:** No further connections shown.
The central element is:
**Z[x]/⟨Φm(x)⟩ ≅ Z(ζm) = OQ(ζm)**
This represents an isomorphism between the quotient ring Z[x] modulo the m-th cyclotomic polynomial Φm(x), and the ring of integers of the m-th cyclotomic field Q(ζm).
### Key Observations
The diagram highlights the interconnectedness of several core concepts in algebraic number theory. The central isomorphism is a fundamental result linking polynomial rings and field extensions. The references [1], [2], [3], and [4] suggest that these connections are well-established and documented in the literature. The diagram is not a hierarchy, but rather a network of relationships.
### Interpretation
The diagram illustrates the rich interplay between polynomial algebra, ring theory, and field theory. The central isomorphism is a key bridge between these areas. The connections to cyclotomic polynomials, ideal theory, and lattices suggest a focus on the arithmetic of algebraic number fields. The references to "efficient polynomial multiplication" and "lattices" hint at potential applications in computational number theory and cryptography. The diagram serves as a conceptual map, showing how different mathematical tools and ideas can be brought to bear on problems in number theory. The diagram doesn't present new data, but rather summarizes existing relationships between established mathematical concepts. It is a visual representation of a theoretical framework.
</details>
1. Definition of RLWE and related ideal lattice problems
2. Efficient computations in RLWE-based cryptosystems
3. Hardness of Search RLWE
4. Decision to Search RLWE reduction
## E Notation
We list here the key symbols and notations used in the tutorial.
Table 3: List of key symbols
| Symbol | Meaning |
|----------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Z | Integers |
| Q | Rational numbers |
| F q for prime number q | Z /q Z = { 0 , 1 , 2 , . . . , q - 1 } |
| Z [ x ] | Polynomials where the coefficients are integers |
| F [ x ] | Polynomials where the coefficients take on values in F |
| F q [ x ] | Polynomials where the coefficients take on values in F q |
| Z [ α ] | the ring obtained by adjoining α to Z |
| Q ( α ) | the smallest extension field of Q that contains α |
| F [ a ] for a field F | the set { f ( a ) : f ( x ) ∈ F [ x ] } |
| F ( a ) for a field F | the smallest extension field of F that contains a |
| ( a ) for a in ring R | the ideal { ar : r ∈ R } |
| ( a 1 , . . . ,a n ) for a i in ring R | the ideal { r 1 a 1 + · · · + r n a n : r i ∈ R } |
| R/I for a ring R and an ideal I | the quotient ring of R by I , which is the set of cosets of I in R |
| Z ∗ n | multiplicative group modulo n ; i.e. the set of all (multiplicatively) invertible elements in Z m ; or equivalently { k : k ∈ { 0 , 1 , . . .,n - 1 } , gcd( n,k ) = 1 } |
| ( Z /n Z ) ∗ | same as Z ∗ n |
| E/F for fields E and F | a field extension, where F (the subfield) is contained in E (the ex- tension field) |
| ζ n | the n -th root of unity |
| Φ n ( x ) | the n -th cyclotomic polynomial |
| ϕ ( n ) | Euler's totient function |
| x | rouding to the integer nearest to x |
| [ n ] | { 1 , 2 , . . .,n } |
| a = b mod q | a and b are congruent modulo q |
| Z q | sometimes refer to the range [ - q/ 2 , q/ 2) ∩ Z |
| [ x ] q | the reduction of x to the integer in [ q/ 2 , q/ 2) s.t. [ x ] q = x mod q |
-
## References
- M. Ajtai. Generating hard instances of lattice problems. In Proceedings of the 28th Annual ACM Symposium on Theory of Computing , pages 99-108, 1996.
- M. Ajtai, R. Kumar, and D. Sivakumar. A sieve algorithm for the shortest lattice vector problem. In J. S. Vitter, P. G. Spirakis, and M. Yannakakis, editors, Proceedings on 33rd Annual ACM Symposium on Theory of Computing, July 6-8, 2001, Heraklion, Crete, Greece , pages 601-610. ACM, 2001.
3. S ¸ . Alaca and K. S. Williams. Introductory algebraic number theory . Cambridge University Press Cambridge, 2004.
- M. Albrecht, M. Chase, H. Chen, J. Ding, S. Goldwasser, S. Gorbunov, S. Halevi, J. Hoffstein, K. Laine, K. Lauter, S. Lokam, D. Micciancio, D. Moody, T. Morrison, A. Sahai, and V. Vaikuntanathan. Homomorphic encryption security standard. Technical report, HomomorphicEncryption.org, Toronto, Canada, November 2018.
- L. Alcock. How to think about Abstract Algebra . Oxford University Press, 2021.
- S. Arora and B. Barak. Computational complexity: a modern approach . Cambridge University Press, 2009.
- M. Artin. Algebra . Prentice Hall, 1991.
- L. J. Aslett, P. M. Esperanc ¸a, and C. C. Holmes. A review of homomorphic encryption and software tools for encrypted statistical machine learning. arXiv preprint arXiv:1508.06574 , 2015.
- L. Babai. On lov´ asz'lattice reduction and the nearest lattice point problem. Combinatorica , 6(1):1-13, 1986.
- D. J. Bernstein, J. Buchmann, and E. Dahmen. Post-Quantum Cryptography . Springer, 2009.
- Z. Brakerski. Fully homomorphic encryption without modulus switching from classical GapSVP. In Annual Cryptology Conference , pages 868-886. Springer, 2012.
- Z. Brakerski and V. Vaikuntanathan. Efficient fully homomorphic encryption from (standard) LWE. SIAM Journal on Computing , 43(2):831-871, 2014.
- Z. Brakerski, C. Gentry, and V. Vaikuntanathan. (Leveled) fully homomorphic encryption without bootstrapping. ACM Transactions on Computation Theory (TOCT) , 6(3):1-36, 2014.
14. J.-Y. Cai and A. P. Nerurkar. An improved worst-case to average-case connection for lattice problems. In Proceedings of the 38th Annual Symposium on Foundations of Computer Science , pages 468-477. IEEE, 1997.
- H. Chen, K. Laine, and P. Rindal. Fast private set intersection from homomorphic encryption. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security , pages 1243-1255, 2017.
- D. P. Chi, J. W. Choi, J. S. Kim, and T. Kim. Lattice based cryptography for beginners. IACR Cryptol. ePrint Arch. , page 938, 2015.
- D. Chialva and A. Dooms. Conditionals in homomorphic encryption and machine learning applications. IACR Cryptol. ePrint Arch. , page 1032, 2018.
- K. Conrad. Cyclotomic extensions. 2009.
- T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein. Introduction to Algorithms . The MIT Press, 2nd edition, 2001.
- I. Damg˚ ard, V . Pastro, N. Smart, and S. Zakarias. Multiparty computation from somewhat homomorphic encryption. In Annual Cryptology Conference , pages 643-662. Springer, 2012.
- M. v. Dijk, C. Gentry, S. Halevi, and V. Vaikuntanathan. Fully homomorphic encryption over the integers. In Annual international conference on the theory and applications of cryptographic techniques , pages 24-43. Springer, 2010.
- S. Erabelli. pyFHE-a Python library for fully homomorphic encryption . PhD thesis, Massachusetts Institute of Technology, 2020.
- J. Fan and F. Vercauteren. Somewhat practical fully homomorphic encryption. IACR Cryptol. ePrint Arch. , 2012:144, 2012.
- C. Gentry. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing , pages 169-178, 2009.
- C. Gentry. Computing arbitrary functions of encrypted data. Communications of the ACM , 53(3): 97-105, 2010.
- R. Gilad-Bachrach, N. Dowlin, K. Laine, K. Lauter, M. Naehrig, and J. Wernsing. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In International conference on machine learning , pages 201-210. PMLR, 2016.
- S. Halevi. Homomorphic encryption. In Y. Lindell, editor, Tutorials on the Foundations of Cryptography . Springer, 2017.
- J. Hoffstein, J. Pipher, and J. H. Silverman. An introduction to mathematical cryptography , volume 1. Springer, 2008.
- J. Katz and Y. Lindell. Introduction to modern cryptography . CRC press, 2014.
- S. Khot. Hardness of approximating the shortest vector problem in lattices. J. ACM , 52(5):789-808, 2005.
- S. Khot. Inapproximability results for computational problems on lattices. In P. Q. Nguyen and B. Vall´ ee, editors, The LLL Algorithm - Survey and Applications , Information Security and Cryptography, pages 453-473. Springer, 2010.
- A. Korkine and G. Zolotareff. Sur les formes quadratiques. Mathematische Annalen , 6:366-389, 1873.
- V. Lyubashevsky, C. Peikert, and O. Regev. On ideal lattices and learning with errors over rings. In Annual International Conference on the Theory and Applications of Cryptographic Techniques , pages 1-23. Springer, 2010.
- D. Micciancio and S. Goldwasser. Complexity of lattice problems - a cryptograhic perspective , volume 671 of The Kluwer international series in engineering and computer science . Springer, 2002.
- D. Micciancio and O. Regev. Worst-case to average-case reductions based on gaussian measures. SIAM J. Comput. , 37(1):267-302, 2007.
- D. Micciancio and O. Regev. Lattice-based cryptography. In Post-quantum cryptography , pages 147191. Springer, 2009.
- J. S. Milne. Algebraic number theory (v3.08), 2020. Available at www.jmilne.org/math/.
- T. Mukherjee. Cyclotomic polynomials in ring-lwe homomorphic encryption schemes. Master's thesis, Rochester Institute of Technology, 2016.
- M. Naehrig, K. Lauter, and V. Vaikuntanathan. Can homomorphic encryption be practical? In Proceedings of the 3rd ACM workshop on Cloud computing security workshop , pages 113-124, 2011.
- P. Nguyen and B. Vall´ ee. The LLL algorithm . Springer, Berlin, Heidelberg, 2010.
- C. Peikert. Public-key cryptosystems from the worst-case shortest vector problem. In Proceedings of the 41st annual ACM symposium on Theory of computing , pages 333-342, 2009.
- C. Peikert. A decade of lattice cryptography. Found. Trends Theor. Comput. Sci. , 10(4):283-424, 2016.
- C. Peikert and A. Rosen. Lattices that admit logarithmic worst-case to average-case connection factors. In Proceedings of the 39th Annual ACM Symposium on Theory of Computing , pages 478-487, 2007.
- K. Pietrzak. Cryptography from learning parity with noise. In M. Bielikov´ a, G. Friedrich, G. Gottlob, S. Katzenbeisser, and G. Tur´ an, editors, SOFSEM 2012: Theory and Practice of Computer Science - 38th Conference on Current Trends in Theory and Practice of Computer Science , volume 7147 of Lecture Notes in Computer Science , pages 99-114. Springer, 2012.
- B. Porter. Cyclotomic polynomials. 2015.
- O. Regev. On lattices, learning with errors, random linear codes, and cryptography. In H. N. Gabow and R. Fagin, editors, Proceedings of the 37th Annual ACM Symposium on Theory of Computing , pages 84-93. ACM, 2005.
- O. Regev. On lattices, learning with errors, random linear codes, and cryptography. Journal of the ACM (JACM) , 56(6):1-40, 2009.
- O. Regev. The learning with errors problem. Invited survey in CCC , 7(30):11, 2010.
- R. L. Rivest, L. Adleman, and M. L. Dertouzos. On data banks and privacy homomorphisms. Foundations of Secure Computation, Academic Press , pages 169-179, 1978a.
- R. L. Rivest, A. Shamir, and L. M. Adleman. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM , 21(2):120-126, 1978b.
- SEAL. Microsoft SEAL (release 4.0). https://github.com/Microsoft/SEAL , Mar. 2022. Microsoft Research, Redmond, WA.
- M. Sipser. Introduction to the Theory of Computation . Course Technology, third edition, 2013.
- W. Stein. Algebraic number theory, a computational approach. Harvard, Massachusetts , 2012.
- T. Veugen. Encrypted integer division and secure comparison. Int. J. Appl. Cryptogr. , 3(2):166-180, 2014.
- A. Wood, K. Najarian, and D. Kahrobaei. Homomorphic encryption for machine learning in medicine and bioinformatics. ACM Computing Surveys (CSUR) , 53(4):1-35, 2020.
## Index
| Z -module, 49 | BV, 84 |
|---------------------------------------------------------------|-------------------------------------------------------------------|
| ∆ K , 58 | BFV, 91 |
| c -approximation, 12 | homomorphic encryption (HE) |
| c -gap problem, 12 | fully, 76 |
| | leveled, 76 |
| adjoin, 138 | leveled fully, 76 |
| arithmetic circuit, 85 | partial, 76 |
| automorphism, 45, 54, 69 | property, 75 |
| average-case hardness, 12 | somewhat, 76 |
| | scheme, 75 |
| bootstrappable, 77 | homomorphism, 103 |
| bootstrapping, 85 | group, 107 ring, 107 |
| canonical embedding, 54, 70 | |
| characteristic | ideal factorization, 70 |
| of a ring, 107 | ideal GCD, 50 |
| characteristics | ideal lattice, 57 |
| of a field, 108 | ideal norm, 58 |
| Chinese Remainder Theorem, 50 | index, 103 |
| coefficient embedding, 54 | injective homomorphism, 46 |
| computational security, 15 | integral basis, 49 |
| coprime, 50 | integral domain, 106 |
| CPA, 78 | irreducible, 44 |
| CRT, 50 | irreducible polynomial, 111 |
| cyclotomic extension, 41, 45 | isomorphic, 46 |
| cyclotomic field, 48 | isomorphism, 104 |
| cyclotomic polynomial, 41, 42, 44 | |
| | kernel, 107 |
| different ideal, 61 | key switching, 87 |
| dimension reduction, 85 | |
| discrete Gaussian distribution, 30 | lattice, 18 |
| SIS security proof, 32 | basis, 18 |
| division ring, 104 | determinant, 19 |
| dual basis, 60, 134 | invariant determinant, 20 |
| dual lattice, 22, 60 | lattice problems |
| dual basis, 22 | BDD, 38 |
| | BDD α , 25 |
| elementary symmetric polynomials, 45 | CVP, 25 |
| Euler's formula, 41 Euler's totient function, 42 | INCGDD, 32 SBP, 26 |
| evaluation key, 81 | SIS, 26 |
| expansion factor, 91 | SVP, 24 |
| | USVP, 26 |
| field extension, 109, 138 | left coset, 103 |
| finite field, 108 | LWE, 6, 35 |
| First Isomorphism Theorem, 44, 50, 107, 112 63 | decision (DLWE), 36 |
| fractional ideal, 51, | distribution, 36 |
| free module, 105 | hardness proof, 37 |
| fundamental domain (parallelepiped), 19 | search, 36 search to decision, 36 |
| Galois group of a field extension, 45, 115 | |
| Galois group of a polynomial, 45 group homomorphism, 103, 107 | maximal ideal, 107 minimal polynomial, 44, 54, Minkowski, 58, 131 |
| hash function, 28 collision resistant, 29 HE scheme | module, 104 modulus reduction, 84, 86 modulus switching, 86 |
| negligible, 16 | scaled ciphertext, 83 |
|-------------------------------------------------------------|----------------------------------------------------|
| noise ceiling, 76, 86 | secure, 17 |
| normal subgroup, 103 | CPA, 17 |
| order, 102 | IND-CPA, 17 indistinguishable, 17 semantically, 17 |
| padding, 76 | weak circular, 78 |
| power basis, 49, 119, 134 | security parameter, 15 |
| PPT, 17 | shortest lattice vector, 21 |
| prime characteristic, 108 | SIS, 35 |
| prime ideal, 50, 106 | smoothing |
| primitive roots of unity, 42, 44 | parameter, 31 sparse subset sum problem (SSSP), |
| private key encryption scheme, 16 49 | splitting field, 45, 112 |
| product of ideals, | squashing, 77 |
| public key encryption scheme, 16 | successive minima, 21 |
| quotient group, 103 quotient ring, 106, 138 | tensor product, 63, 88 time complexity class |
| Regev's LWE-based encryption scheme, 39 relinearization, 81 | NP, 10 NP-complete, 11 |
| | 11 |
| right coset, 103 | NP-hard, |
| ring, 104 | P, 10 |
| ring homomorphism, 107 | trace inner product, 60 |
| Ring LWE, 60 | trace operator, 59 |
| ring LWE, 41, 43, 44, 46, 48, 51, 54, 58, 61 RLWE, 91 | |
| roots of unity, 41 | Vandermonde matrix, 57 |
| RSA, 76 | worst-case to average-case, 12, 26 |