## Towards Artificial Virtuous Agents: Games, Dilemmas and Machine Learning
Ajay Vishwanath 1* , Einar Duenger Bøhn 1 , Ole-Christoffer Granmo 1 , Charl Maree 1,2 and Christian Omlin 1
1* Center for Artificial Intelligence Research, University of Agder, Jon Lilletuns vei, Grimstad, 4672, Aust-Agder, Norway.
2 Chief Technology Office, Sparebank 1 SR-Bank, Postboks 250, Stavanger, 4066, Rogaland, Norway.
*Corresponding author(s). E-mail(s): ajay.vishwanath@uia.no; Contributing authors: einar.d.bohn@uia.no; ole.granmo@uia.no; charl.maree@uia.no; christian.omlin@uia.no;
## Abstract
Machine ethics has received increasing attention over the past few years because of the need to ensure safe and reliable artificial intelligence (AI). The two dominantly used theories in machine ethics are deontological and utilitarian ethics. Virtue ethics, on the other hand, has often been mentioned as an alternative ethical theory. While this interesting approach has certain advantages over popular ethical theories, little effort has been put into engineering artificial virtuous agents due to challenges in their formalization, codifiability, and the resolution of ethical dilemmas to train virtuous agents. We propose to bridge this gap by using role-playing games riddled with moral dilemmas. There are several such games in existence, such as Papers, Please and Life is Strange , where the main character encounters situations where they must choose the right course of action by giving up something else dear to them. We draw inspiration from such games to show how a systemic role-playing game can be designed to develop virtues within an artificial agent. Using modern day AI techniques, such as affinity-based reinforcement learning and explainable AI, we motivate the implementation of virtuous agents that play such role-playing games, and the examination of their decisions through a virtue ethical lens. The development of such agents and environments is a first step towards practically formalizing and demonstrating the value of virtue ethics in the development of ethical agents.
Keywords: machine ethics, role-playing games, deep reinforcement learning, virtue ethics
## 1 Introduction
The rapid increase in the usage of artificial intelligence (AI) in critical applications has brought about a need to consider the ethics of how AI is used, and, whether it would make the right choice while encountering ethical dilemmas [1, 2]. The ethics of AI usage has been studied extensively by lawyers, philosophers, and technologists to develop policies to account for the ethical implications of an AI application. However, the development of inherent ethics in AI is still in its infancy; it has been discussed and debated in the last couple of decades [3-5], resulting in few real-world implementations [6, 7]. This question of how to make AI inherently ethical falls under the umbrella of machine ethics , often referred to as artificial morality or AI alignment . The majority of the frameworks discussed in machine ethics are based on rule-based (deontological), or consequentialist ethical theories [6]. In deontological implementations, an artificial agent abides by a set of rules which dictate its action, regardless of what happens as a result of this action. On the other hand, a consequentialist agent tends to focus on the utility value as a deciding factor of the goodness of an action. While there are advantages from using these theories, they have shortcomings, and we argue how these could be overcome by using virtue ethics.
Virtue ethics centers morality on an individual's character, an individual who behaves such that he/she exercises virtues to manifest the character of a virtuous person. Generosity, truthfulness and bravery are examples of virtues; a virtuous person will know how to balance the extremes of these virtues, by striving towards a golden mean . An important advantage is that a virtuous person strives to make better choices when similar situations present themselves in the future. We posit that the trait of life-long learning in virtue ethics makes it compatible with modern day artificial intelligence, whose goal is also to learn from experiences to give the best possible predictions given its environment or data.
There are several implementations of the dominant ethical theories mentioned above. However, these have been developed by demonstration on toy examples and very specific problems [1]. To expand the conversation and to apply these theories in more general scenarios, we propose to seek inspiration from the world of gaming, in particular role-playing games that compel a player to make ethical choices. Some examples of such games are Witcher 3 [8], Fallout [9], Batman: The Telltale Series [10] and Papers, Please [11]. These video games are usually based on a mechanism where game-play is dictated by the players' choices. One such mechanism follows a scripted approach, where the developer handcrafts moral dilemmas based on the story-line of the game [12]. A systemic approach, where the player makes choices where, initially, there
are no specific moral dilemmas; but as the story unfolds, the dilemmas become apparent [13].
With respect to implementation of virtues, previous works [7, 14, 15] have advocated for the RL paradigm because it fits well with virtue ethics, since an agent can learn behaviour from experience. We motivate the use of affinitybased RL where agents can be incentivized to learn virtues by modifying the objective function using policy regularization [16], rather than designing the reward function itself. And since virtue ethics involves performing the right action in the right situation for the right reasons [17], we also highlight the importance of interpretability, especially since we opt for the usage of opaque deep neural networks.
In the subsequent sections, we will discuss state-of-the-art machine ethics, and make the case of artificial virtuous agents as a viable alternative to the dominant theories. Next, we review the literature from role-playing games which integrate aspects from ethics and morality, in particular, we will discuss Papers, please . Finally, we explain how systemic environments in role-playing games can be used to train artificial agents to develop virtues, and, how RL can be leveraged to train such agents.
## 2 Background and Related Work
Most of the machine ethics literature [1] refers to artificial agents with inherent morals as artificial moral agents (AMA). In this section, we introduce artificial morality and argue for the development of artificial virtuous agents (AVA), where an artificial agent reasons in terms of virtues instead of labelling an act as right or wrong . We first talk about the current implementations of AMAs, then introduce virtue ethics as an alternative paradigm, and finally make the case for AVAs.
## 2.1 Artificial Morality
In machine ethics, the conversation revolves mainly around morality: whether an artificial agent's choice is right or wrong. If an agent violates certain rules or fails to meet certain standards, it is said to be morally wrong. A famous example of rules for moral agents is Asimov's Laws, which formulates a set of laws that a robot must never violate. This approach is inspired by deontological ethics [18], where the right actions are chosen based on specific rules regardless of consequences of the action. In contrast, the utilitarians believe that the action which has the best consequences are moral; e.g., the action with the maximum pleasure and minimum pain. For example, a utilitarian might prioritize the needs of the majority over that of the few through utility maximization. For a computer or an artificial agent, following rules or calculating the best consequence is straightforward; this may be one of the reasons why most of the implementations in machine ethics are based on the deontological and consequentialist ethics [6].
Approaches to machine ethics include top-down, bottom-up and hybrid approaches [3]. As the name suggests, a top-down approach defines a set of rules for an artificial agent to follow. The environment gives no feedback for learning; the rules are presumed to be adequate for ensure an agent's moral behavior. Bottom-up approaches are preferred, in the sense that they allow for the agent to learn and adapt to new situations, while not having much control over how learning happens. This coincides with the premise of the use of machine learning: it is the preferred system design paradigm when not all future situations can be defined and thus accounted for during the design phase. Lastly, a hybrid approach strives to integrate the strengths of topdown and bottom-up approaches while mitigating their respective weaknesses. See [1] and [6] for reviews on machine ethics implementations based on their approaches.
It is still early days for this field; while there have been several attempts to develop machine ethics systems, the challenges relating to machine ethics have not yet been adequately addressed. The disagreements among scientists and philosophers about ethical artificial intelligence design have not yet been resolved. Therefore, there is no obvious direction for the research to proceed in. Some may go as far to claim that the state of the art AI cannot be ethical, either because artificial agents lack moral agency or because they did not program themselves [19]. Deontological or consequentialist ethics, are thus unable to circumvent the limitations posed by these ethical theories and the dominance of these ethical theories mean that most implementations are top-down [6] or hybrid, rather than bottom-up. Given this current state, we suggest virtue ethics as a strong bottom-up alternative.
## 2.2 Virtue Ethics
In his classic, The Nicomachean Ethics [20], Aristotle defined virtues as an excellent trait of character that enables a person to perform the right actions in the right situations for the right reasons. A person can behave virtuously in a given situation by asking themselves: 'What would a virtuous person do in the same situation?'. Such a person practices virtues by habituation, thus striving towards excellence in character. According to Aristotle, a child or a young person is inexperienced and thus lacks the wisdom to make virtuous decisions. However, with learning experiences from consistent practice of virtues, the youth will exhibit practical wisdom (phronesis).
In virtue ethics, virtues are central and practical wisdom is a must, thus providing a framework to achieve eudaimonia, which translates to flourishing or happiness. Eudaimonia may sound like the utilitarian pleasure, but it is not. Eudaimonia refers to well-being of the individual and the overall society; it thus differs from consequentialist thinking [21]. Unlike a consequentialist, a virtuous person does not practice virtues for the sake of eudaimonia, but for the sake of the virtues in themselves. Some examples of virtues are honesty, bravery, and temperance. Another feature of a virtue is that there are often no absolute right or wrong actions in a given situation; a virtue is exercised
in degree. A virtuous person knows to live by this golden mean, while a nonvirtuous person might not find that balance. For example, a brave person would exercise the right amount of bravery required for a situation (golden mean), rather than being absolutely cowardly or reckless. This is unlike deontological ethics, where an action is deemed right or wrong based on its adherence to pre-defined rules.
We propose that virtue ethics is the more felicitous ethical theory. For instance, consequentialism is about maximizing net utility of a given situation. As a result of the utility oriented approach, an action may favor the majority at the cost of the few. In such situations, a deontologist may vehemently disagree with the consequentialist means to such an end; to deontologists, the end is irrelevant but the means to such ends is vital. The means of such actions based on universal norms are said to be of moral worth. 'Always speak the truth' is an example of a deontological norm, where speaking the truth must be the means, regardless of the end. While universal norms may inform moral behaviour, opponents of deontology may point out that we cannot define rules for every single situation; it is practically impossible. A bottom-up approach of learning and improving, may thus, offer a viable alternative paradigm, and this is where virtue ethics will be relevant [22].
Moor [23] distinguished artificial agents into four different levels: ethical impact agents (e.g., ATM machines), implicit ethical agents (e.g., airplane auto-pilot), explicit ethical agents (e.g., ethical knowledge and reasoning), and fully ethical agents (e.g., humans). Aristotelean virtue ethical agents are implicit ethical agents, which are agents that come preloaded with safety features, e.g. airplane autopilots. An issue with such a categorization is that Moor [23] excludes the possibility that a virtuous agent may have the ability to learn from experience and exhibit virtues based on the situation. We thus place AVAs within the categorization of explicit ethical agents which are presumably able to gather knowledge and reason about ethical behavior.
## 2.3 Related Works: Artificial Intelligence and Virtues
Virtue ethics was resurrected in a powerful piece by Elizabeth Anscombe [24] in 1958, where she highlighted the weaknesses in contemporary ethics. Thereafter, philosophers such as Foot [21], MacIntyre [22] and Hursthouse [25] followed suit to develop a modern account of virtue ethics. In parallel, virtue ethics was introduced in the form of teleology (central to Aristotelean ethics) developed in cybernetics during the mid-twentieth century [14, 26]. Artificial intelligence developed around this time in the form of symbolic AI and the scientific conversation started to expand to value alignment [27].
The symbolic, rule-based AI was followed by the connectionist architectures. The former was heavily criticized by Dreyfus [28] for being limited in its learning and perception; however, he was sympathetic towards connectionist architectures, and motivated the development of a Heideggerian AI. The rebirth of virtue ethics, and the birth of artificial intelligence followed by value alignment, may seem like a coincidence, but it was not. A manuscript titled
Android arete [29], a name given to virtuous machines inspired from the Greek word for virtues (arete) used by Aristotle [20], spoke about machines and possible virtues they can exhibit; this is a good point of departure towards artificial virtues in intelligent systems. In this context, Berberich and Diepold [14] took inspiration from Aristotelean virtue ethics, where they drew parallels with lifelong learning in virtue ethics and the RL paradigm. They define how virtues such as temperance and friendship can be realised in contemporary AI.
Stenseke [7] argued further and advocated for a connectionist approach towards realisation of artificial virtues where, depending on the application of the ethical agent, dedicated neural networks for specific virtues can combine to form an artificial virtuous agent. Such architectures, inspired by cognitive science and philosophy, serve to motivate research in and progression towards virtues approaches of machine ethics to address formalization, codifiability, and resolution of ethical dilemmas within the virtue ethics framework. While [7] defined a framework, we propose an alternative paradigm to the above architecture, and the use of role-playing game environments to train artificial virtuous agents. In the following sections, we shed further light on our hypothesis.
## 3 Design of Games with Ethical Dilemmas
In this section, we explore morality in games and look at some examples of how these can be used to invoke moral reasoning in players. Video games, especially role-player games, that force players to make difficult choices in moral dilemmas have become widespread. For example, Witcher 3 [8], Batman: The Telltale series [10] and Life is Strange [30] have become popular for enabling moral engagement among players [31] [13]. We will briefly discuss how these games are designed to invoke moral engagement and go through examples of games such as Papers, Please (PP) [11].
## 3.1 Mechanisms of Choices and Narratives
Ultima IV: The Quest of the Avatar [32] was one of the earliest role-playing computer games. It featured player choices based on virtues such as compassion, honor, humility, etc. [33]. In this game, a player is successful when he/she consistently makes virtuous choices; failure to do so brings with it undesirable consequences. Ultima IV is based on scripted choices, where the developer has designed sophisticated scenarios to test whether the right virtues are exercised.
Today, video games with moral dilemmas following a scripted narrative are the most popular. For instance, in Batman: The Telltale Series , the player assumes the role of Batman. A series of interactions with non-playing characters (NPCs) is followed by the player's selection of dialogue. This choice determines the reaction of the NPC and how subsequent scenes are presented. Overall, the game follows a linear narrative with scripted choices, since the ending is the same regardless of the player's choices. The alternative to linear narratives is the branching narrative with different endings possible within the game. Examples of branching narratives are Fallout 4 and PP [11]. However,
unlike Fallout 4 , where choices are hardcoded by the developer, PP is based on systemic choices presented to the player, where the ethical considerations within the game become evident as the game progresses [12]. Below, we analyze the game mechanism in PP to understand why systemic choices in moral dilemmas are interesting.
## 3.2 Case Study: Papers, Please
In PP, the player assumes the role of an immigration officer whose job is to assess documents and decide whether the entrant is legal or illegal (Fig 1). For each correct evaluation, the player is rewarded, but for an incorrect decision, they are penalized. The reward takes the form of salary, which is then used to pay the rent and cover other family expenses. If the player does not make the correct decisions as an officer, the family gets sick and hungry, and eventually a family member dies. If the player has no family members left, then the game is over. Also, there is the dichotomy between loyalty and justice: the player could choose to take bribes from illegal entrants, thus increasing their income. At the same time, these illegal entrants might be spies sent by revolutionaries trying to overthrow the ruling government. For more details, see [12].
Fig. 1 An example scenario from Papers, Please , where the player looks at multiple documents to make a decision on whether to allow or reject the entrant. Source: [12]
<details>
<summary>Image 1 Details</summary>

### Visual Description
\n
## Screenshot: Border Control/Immigration Scene
### Overview
The image depicts a pixelated scene resembling a border control or immigration checkpoint. It features a person being processed, various documents, and a chart-like display on the left side. The overall aesthetic suggests a retro or stylized video game. The scene is divided into three main horizontal sections: a top section with silhouettes, a central section with a person and a chart, and a bottom section filled with documents.
### Components/Axes
* **Chart (Left Side):** This appears to be a vertical bar chart.
* Y-axis: Labeled with numbers from 4 to 20, in increments of 4.
* X-axis: Not clearly labeled, but appears to represent different categories.
* Bars: Multiple bars of varying heights are visible.
* **Documents (Bottom Section):** Several documents are present, including:
* "Work Permit"
* "Vaccination Certificate"
* "Entry Permit"
* "Entry Visa"
* **Person (Center):** A person with purple skin tone is positioned behind a counter.
* **Silhouettes (Top Section):** A row of small, silhouetted figures.
### Detailed Analysis or Content Details
**Chart Data (Approximate):**
* Bar 1: Approximately 16
* Bar 2: Approximately 12
* Bar 3: Approximately 8
* Bar 4: Approximately 4
* Bar 5: Approximately 12
* Bar 6: Approximately 16
* Bar 7: Approximately 20
**Work Permit:**
* Ministry of Labor
* This pass grants limited rights.
* Height: 173cm
* Weight: 63kg
* Description: Dark Hair
**Vaccination Certificate:**
* Name: Orcuni Kocakova
* 4THMH
* Date: 81.10.26
* 81.10.28 POLIO
* Valid for 3 years
**Entry Permit:**
* M.O.A.
* Conditional entry to the sovereign nation of Arst is hereby granted to: Orcuni Kocakova bearing passport number 4THMH-JD4E6
* Purpose: WORK
* Duration: 2 MONTHS
* Enter by: 1983.01.07
* Ministry of A4
**Entry Visa:**
* Kocakova, Orcuni
* 1957.11.11
* True Glorian
* 1984.09.07
* REPUBLIA
* 4THMH-JD4E6
**Text on the left side of the image:**
* id card
* Foreigners require an entry permit
* Workers must have a work pass
**Text on the right side of the image:**
* As
* En:
### Key Observations
* The chart shows varying values, peaking at approximately 20 and bottoming out at approximately 4. The bars do not appear to follow a clear increasing or decreasing trend.
* The documents all pertain to Orcuni Kocakova, suggesting she is the individual being processed.
* The dates on the documents span several years (1957, 1981, 1983, 1984), indicating a complex travel history or a time-lapse scenario.
* The presence of both an "Entry Permit" and an "Entry Visa" suggests a multi-stage immigration process.
* The pixelated style and the somewhat unusual color palette contribute to a distinct visual aesthetic.
### Interpretation
The image likely represents a scene from a game or interactive narrative focused on immigration, border control, or political themes. The chart could represent statistics related to immigration, such as approval rates, demographic data, or economic indicators. The documents provide specific details about the individual being processed, including her identity, purpose of entry, and duration of stay. The combination of these elements suggests a bureaucratic process with potential for scrutiny and control. The dates on the documents hint at a potentially complex backstory or a narrative spanning multiple years. The overall atmosphere is somewhat sterile and impersonal, reflecting the nature of bureaucratic procedures. The "4THMH-JD4E6" code appears on multiple documents, suggesting a unique identifier for the individual or the case. The presence of "Arst" and "Republica" suggests fictional nations within the game's world. The text "As" and "En:" could indicate language options or translation fields. The image is not providing factual data, but rather a constructed scene for narrative purposes.
</details>
Prior to Formosa et al. [12], Heron et al. [34] wrote a critique of scripted approaches and how PP is a refreshing deviation from the plethora of script oriented games. Farmosa et al. [12] then analyzed the inner mechanisms where the impact of scripted and systemic approaches are distinguished along four dimensions: moral focus, sensitivity, judgement and action. These dimensions are based on the four component model in moral psychology and education [35]. However, since our focus is on game mechanisms rather than a player's moral engagement, we refrain from discussing the model details; instead, we examine the systemic and scripted approaches and their impact on moral choices. We summarize the ethical dimensions within PP below:
- Dehumanization : performing document checks for an extended period of time can challenge the human element in the game, thus affecting how a player assesses entrants.
- Fairness : An important aspect of the game, which allows a player to bend the rules for humane reasons. This makes the game more interesting.
- Privacy : The use of X-ray on the entrants to check for their gender or weapons might unnecessarily violate privacy.
- Loyalty : Whether the player is loyal to the country, their family or themselves.
These moral aspects of PP become evident as we play the game, which is characteristic of a systemic approach. For example, only after processing around 30 entrants at the immigration office, the officer's loyalty is tested, where a spy asks to enter the country to overthrow the current corrupt regime. The player (officer) will assess their situation based on their finances, family situation and job, and all these aspects develop in the game over time.
Formosa et al. [12] also highlight the pros and cons of systemic approaches. While systemic approaches allow morality to arise from the aggregation of choices made over a period of time where players are expected to explore moral themes, they prevent the formulation of apparent ethical problems. For example, a player who is presented with a single instance of having to choose between the interests of the ruling party and the country's safety and security may not be aware of the high-stakes nature of the decision; but a sequence of many such choices will make this obvious. While this may be considered as a disadvantage, it can be an advantage where such deep exploration of ethics may encourage a player to develop creative solutions to these problems.
## 4 Development of Virtues through Games
This section aims to briefly demonstrate how artificial virtues can be brought about using a systemic approach in role-playing game environment and how virtues could be implemented using deep RL methods. We bring together the various concepts discussed in Sections 2 and 3, by outlining possible ways to design a suitable environment, to solve such environments, and finally, explain their decisions.
## 4.1 Environment Design
Since we aim to design an environment, a starting point could be to ponder about how we would judge a player (X) as being virtuous. We might observe how X responds to different situations, or perhaps a series of ethical dilemmas that gives us an impression that X is either just , truthful or courageous , for example, on a consistent basis. By ethical dilemmas, we do not refer to extreme dilemmas, such as the trolley problem or Sophie's Choice . Instead, we consider situations in everyday life, such as choosing between individual and collective goals when there is a conflict between the two. Such scenarios can be witnessed in some of the games discussed earlier. By presenting similar sequential dilemmas, we hypothesize that an artificial agent can learn to be virtuous in such environments.
Training an artificial agent to play a linear narrative with scripted player choices is straightforward for, say, a utilitarian RL agent. We need to think about a state-space complex enough to bring about learning and, at the same time, introduce moral dilemmas into the environment. Hence, a branching narrative with systemic player choices will ensure complexity of the state space. For example, in PP an artificial agent might process dozens of immigrants and as the game progresses, encounters dilemmas that test virtues such as loyalty and honesty. And through repeated encounters with such dilemmas, the agent is incentivized to develop an inclination towards specific virtues.
In addition to the branching narrative, the ability to go back in time and redo the choices make a game more sophisticated and allow the agent to make virtuous choices [31]. This can be witnessed in games like Life is Strange [30] where better choices can be made with hindsight that lead to similar outcomes. Overall, these design elements make it difficult for an agent to hack the game, thus creating an environment with a complex state space. In such environments, agents that use optimization algorithms cannot explore the entire state space; instead require more sophisticated architectures.
## 4.2 Artificial Virtuous Agents
In addition to the existence of virtues that could be applied across domains, virtuous behavior is also dependent on the situation, Aristotle argues:
'[...] a young man of practical wisdom cannot be found. The cause is that such wisdom is concerned not only with universals but with particulars, which become familiar from experience' (NE 1141b 10)
Through practice and habituation of virtues, an agent can fulfill their quest for eudaimonia -which translates to 'a combination of well-being, happiness and flourishing' [25]. In other words, it is not about getting the behavior right every time, but to strive towards virtuous behavior and to improve onself when the opportunity presents itself. Similarly, Berberich and Diepold [14] use
Aristotle's teleological form of virtue ethics to make the link to goal-oriented RL. An RL agent strives towards maximizing a reward function, given the states and actions available in its environment; the agents will improves it actions over time through learning. Here, we use the word goal cautiously as Aristotle uses it: no one strives for eudaimonia for the sake of some higher goal, instead, eudaimonia itself is the highest goal, and other ends, such as physical health, money, and career success, are only possible means to being eudaimon . When it comes to an RL agent, the reward function should be defined in a similar fashion, but the objective function of the agent is to strive for excellence in the virtues.
For example, in a simplified version of the game PP, an artificial agent acts as an immigration officer with a family. The environment with states S = { Office, Restaurant, Home } , and actions A = { Allow, Deny, Feed, Don't Feed, Heat, Don't Heat, Accept Bribe, Reject Bribe } . A dilemma can be introduced in the form of bribery or loyalty to family. Since this is a systemic game, the dilemmas are not apparent until the agent has processed multiple entrants. The virtues in this context are honesty (accepting or rejecting bribes) and compassion (allow or deny food/heat).
Note that an artificial agent playing PP does not understand the concept of immigration, family, compassion, or food; it does not have to. The goal of a virtuous agent playing the game is to achieve excellence in relevant virtues, by processing inputs in the form of binary and numeric values, and then to output a decision in the form of discrete or continuous actions (which are again, numbers). The agent must strive to be virtuous, given such a context. In addition to being an inspiration for developing environments that teach artificial agents virtues, the purpose of using a role-player game is to give meaning to these binary and numeric inputs and outputs, thus making it easier for developers, researchers, and philosophers to understand the artificial virtuous agents.
## 4.3 Deep Reinforcement Learning
In a single agent RL setting, the states S , actions A , transition probabilities T , and rewards R are modeled in a Markov Decision Process (MDP) S, A, T, R framework. Using optimization algorithms, an RL agent learns the best policy by either optimizing the policy, or a value function (the return from being in a particular state S , or a state-action pair [ S, A ]). When the state-space is very large, for example in Chess (10 43 complexity), approximations are applied to simplify this state-space. These approximations are possible using neural networks whose inputs are the states and outputs are either the predicted value or the policy. These networks are optimize an objective function parameterized by θ using algorithms such as backpropagation. Various RL agents can be deployed to play systemic role-playing games, ranging from deep Q-learners (value optimizers) to actor-critic models (policy optimizers).
Deep deterministic policy gradients algorithm (DDPG [36]) is a RL algorithm that learns, by trial and error, the value of state-action pairs. It uses
this learned state-action value function to select those actions that maximize the expected discounted future rewards. The value function is learned by a neural network Q ( θ Q ) (critic), while the policy is learned by a distinct and separate neural network µ ( θ µ ) (actor). It uses a duplicate pair of neural networks Q ′ ( θ Q ′ ) and µ ′ ( θ µ ′ ) during learning, for which the network parameters θ Q ′ and θ µ ′ are updated slowly according to a soft-update function: θ i ← τθ i +(1 -τ ) θ ′ i , where τ ∈ [0 , 1] is usually a small number. In the following subsection, we briefly discuss affinity-based RL and how it may be applied to represent virtues in AI.
## 4.4 Affinity-Based Reinforcement Learning
Affinity-based RL learns policies that are, at least partially, disjoint from the reward function resulting in a homogeneous set of locally-optimal policies for solving the same problem [37]. Contrary to constrained RL, which discourages agents from visiting given states [38, 39], affinity-based learning encourages behavior that mimics a defined prior. It is a calculus that is suitable for modelling situations where the desirable behavior is somewhat decoupled from the global optimum. For example, a delivery van in Manhattan may prefer to take right turns over left turns, on the premise that this is a prudent safety measure [40]. While it reaches the destination in the end, it navigates along a different route than the global optimum: the shortest distance is typically promoted by reward functions. The reasoning is that the deviation from the global optimum, and any corresponding penalty, is justified by other incentives, such as reduced risk in this case. It is compelling to thus motivate an agent to behave according to a given virtue either globally, or in a state dependent fashion. For example in PP, the prior might define an action distribution that favors honesty 95% of the time and loyalty 5% of the time. An agent that selects actions according to this distribution can be classified as honest, compared to an agent that was encouraged to act more loyally during learning.
Affinity-based learning uses policy regularization with significant potential for this application. It expedites learning by encouraging exploration of the state space and is never detrimental to convergence [41, 42]. Haarnoja et al. [43] proposed an entropy-based regularization method that penalizes any deviation from a uniform action distribution; it increases the entropy in the policy thereby encouraging exploration of the entire state space. Galashov et al. [44] generalizes this method with a regularization term that penalizes the Kullback-Leibler (KL) divergence D KL between the state-action distribution of the policy and that of a given prior: D KL ( P | Q ) = ∑ x ∈ X P ( x ) log ( P ( x ) Q ( x ) ). Maree and Omlin [16] extended this concept to, rather than improving learning performance, instill a global action affinity into learned policies. They extended the DDPG objective function with a regularization term based on a specific prior:
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
where J is the objective function governed by parameters θ , D is the replay buffer, R ( s, a ) is the expected reward for action a in state s , λ is a hyperparameter that scales the effect of the regularization term L , M is the number of actions in the action space π θ is the current policy, and π 0 is the prior action distribution that defines the desired behavior. Maree and Omlin [45] demonstrated their method in a financial advisory application, where they trained several prototypical agents to invest according to the preferences from a set of personality traits; each agent invested in those assets that might appeal to a given personality trait. For instance, a highly conscientious agent preferred to invest in property while an extraverted agent preferred buying stocks. While these agents optimized a singular reward function-the maximization of profitthey learned vastly different strategies. To personalize investment strategies, Maree and Omlin [45] combined these agents according to individual customers' personality profiles. The final strategy was a unique linear combination of the investment actions of the prototypical agents.
## Deep RL-based virtuous agent
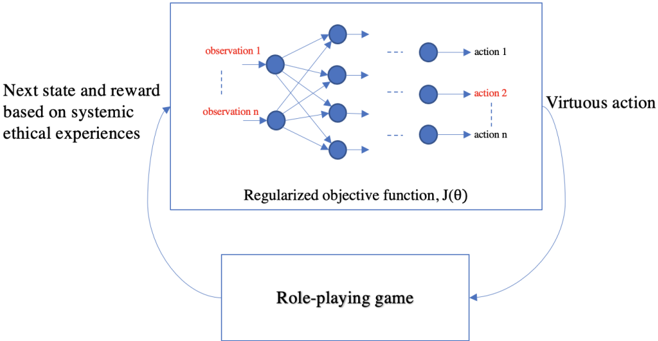
Fig. 2 Affinity-based RL agent solving a systemic role-playing game. The agent takes virtuous action by optimizing the regularized objective function and receives next state and reward information from the game. Here, the observations 1 to n represents the state. The text highlighted in red represents the affinity of the agent for taking action 2 when encountering a particular combination of observations.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Systemic Ethical Experiences and Virtuous Action
### Overview
The image depicts a diagram illustrating the relationship between a role-playing game and a "Regularized objective function, J(θ)". The diagram shows a flow of information from the role-playing game to the objective function, and back, representing a feedback loop. The objective function appears to be a neural network-like structure with observations and actions.
### Components/Axes
The diagram consists of two main rectangular blocks connected by curved arrows.
* **Top Block:** Contains a network of nodes labeled "observation 1" through "observation n" and "action 1" through "action n". Below this network is the text "Regularized objective function, J(θ)".
* **Bottom Block:** Contains the text "Role-playing game".
* **Arrows:** Two curved arrows connect the blocks. One arrow originates from the bottom block and points towards the top block, labeled "Next state and reward based on systemic ethical experiences". The other arrow originates from the top block and points towards the bottom block, labeled "Virtuous action".
### Detailed Analysis or Content Details
The top block represents a network. The left side of the network contains nodes labeled "observation 1" through "observation n". These nodes are connected to nodes on the right side labeled "action 1" through "action n". The connections appear to be fully connected, meaning each observation node is connected to each action node. The number of observation and action nodes is not precisely defined, but "n" suggests a variable number.
The text "Regularized objective function, J(θ)" is positioned below the network. J(θ) is a standard notation in machine learning, representing an objective function with parameters θ.
The arrow from the "Role-playing game" to the "Regularized objective function" is labeled "Next state and reward based on systemic ethical experiences". This suggests the role-playing game provides input to the objective function in the form of a new state and a reward signal, informed by ethical considerations within the game.
The arrow from the "Regularized objective function" to the "Role-playing game" is labeled "Virtuous action". This indicates that the objective function outputs an action that is considered "virtuous" and is then implemented within the role-playing game.
### Key Observations
The diagram illustrates a closed-loop system where the role-playing game provides ethical experiences, which are processed by the objective function to generate virtuous actions, which then influence the game state and subsequent ethical experiences. The network structure within the objective function suggests a learning or decision-making process based on observations and actions.
### Interpretation
This diagram likely represents a reinforcement learning system designed to train an agent (represented by the objective function) to behave ethically within a role-playing game environment. The "systemic ethical experiences" suggest that the game is designed to present the agent with complex ethical dilemmas. The objective function, J(θ), is regularized, implying constraints are placed on the learning process to encourage ethical behavior. The feedback loop allows the agent to learn from its actions and improve its ability to make virtuous decisions. The diagram highlights the interplay between game design, ethical considerations, and machine learning algorithms. The use of a role-playing game as the environment suggests a focus on complex, nuanced ethical scenarios that are difficult to model using traditional methods. The diagram does not provide specific data or numerical values, but rather a conceptual framework for understanding the system.
</details>
The combination of prototypical agents seems a promising approach to learning virtuous behavior: while individual virtues can be learned using policy regularization, a combination of these virtues might represent a rational
agent; we are not equally brave or honorable all the time. This way, an agent actually becomes virtuous rather than utilitarian by being solely dependent on the reward function. The other aspect in virtue ethics is practical wisdom , which is to know to what degree an agent must exhibit a virtue depending on the situation. As opposed to the work done in [45], the combinations of virtues may therefore vary in time as well as between individuals. One way of attaining such combinations could be through decision trees with a (partially observable) state vector as input. Another approach could be to extend the policy regularization term in Equation 1 to specify a state-specific action distribution (Fig 2), resembling KL-regularization. Formally, the regularization term L in Equation 1 could be replaced by:
<!-- formula-not-decoded -->
Thus, an agent may learn to act honorably in certain states, and bravely in others. Such a prior π 0 should specify the desired action distribution as a function of the state variables, e.g., in PP a sick family member might prompt an agent to consider bravery 50% of the time, whereas a dying family member might elicit a higher rate. This is a compelling generalization of global affinitybased RL to local affinity-based RL. Fig 2 illustrates the flow of information from the systemic role-playing game to the policy-regularized deep RL agent. Finally, once the agent is trained to make virtuous decisions in the game, it is crucial to investigate what the agent has learned from these experiences.
## 4.5 Interpretation of Reinforcement Learning Agents
A virtuous agent is required to perform the right actions for the right reasons; it becomes critical that the decisions made be scrutinized. At the same time, black-box architectures such as recurrent neural networks (RNN) within the RL framework, are necessary to maintain a good performance. Such a trade-off between interpretability and performance means that an agent must learn to balance between these. In this paper, we use the words 'explainability' and 'interpretability' interchangably, but we acknowledge the differences expressed in literature [46]. The composition of prototypical agents is one way of achieving RL interpretability; other methods including causal lens [47], reward decomposition [48] and reward redistribution [49].
The action influence model, introduced by Madumal et al. [47], takes inspiration from cognitive science to encode cause-effect relations by using counterfactuals, i.e., events that could have happened along with the ones that did. We may define the causal model for PP and, based on the action influence model, explain the decisions made by the agent. An alternative approach is the reward decomposition technique, where, in addition to the rewards associated with winning a game, the agent is also incentivised to maximize other reward functions. This maximization is done by decomposing the overall Qfunction into multiple elemental Q-functions and calculating differences in
rewards using a reward difference explanation technique introduced in [48]. Finally, another interesting approach is the reward redistribution [49], where the expected return is approximated using an LSTM or alignment methods. In reward redistribution, the agent receives delayed rewards at the end of an episode, after every sub-goal, until, finally, the full reward after achieving the main goal. Hence, this approach useful in episodic games such as PP, where salary (reward) is paid at the end of the day, and the main goal of the agent is to keep their family alive using the salary.
## 5 Conclusions and Future Research Directions
In this section, we outline some questions that arise as a result of our work, for instance: how could an artificial agent possibly exhibit virtuous behavior when it clearly lacks human agency and consciousness? At the same time, which virtues are artificial, and which are not? While these questions deserve articles of their own, we attempt to briefly discuss them here. After making the case for virtue ethics, we presented examples of role-playing games such as Papers, Please which include ethics as moral dilemmas and we suggested possible approaches to solving such games. Here, we also suggest fruitful directions for future research in virtuous game design and learning algorithms.
We have purposely side-stepped the question of consciousness and moral agency. We are not concerned with conscious artificial agents, but with AI that exists today . And once again we stress that the virtues we present here are different from human virtues. For example, in the Nicomachean ethics [20], Aristotle argues for the existence of virtues such as temperance and bravery. Such virtues can be thought of exclusively for humans, because we show emotions such as anger and fear, whereas at this point, one cannot fathom an artificial agent exhibiting such emotions. Thus, it makes sense to think about a different set of virtues for artificial agents.
Artificial virtues can be thought of as character traits for current day artificial intelligence. A starting point is to consider virtues such as honesty (degree of truthfulness), perseverance (how much to compute), and optimization (how much to fine-tune), demonstrated in [29]. However, unlike [29], we are compelled to progress from mere machine learning towards designing virtuous AI. We consider virtues to be continuous variables; an agent's challenge is to find the golden mean for a given virtue. We will elaborate on this aspect of virtues in a future work.
Previous work has proposed POMDP [15], inverse RL [14] and deep neural network frameworks [7] as possible means to implement artificial virtues. While these are widely adopted models of machine learning, we do recognize that there is a danger that these models might be perceived as consequentialist. There needs to be something more besides the reward function motivating virtuous behaviour. Techniques that work directly on the objective function to encourage certain behaviours may be needed to work in tandem with the reward function. For example, [16] have shown theoretical evidence of agent
characterization through policy regularization. Such affinity-based RL methods also aid towards improving the explainability of models, and this is crucial with respect to virtues, as we highlighted in earlier sections.
Finally, it is important to consider the data or environment used to train such agents, as these influence the model's performance. The framework of systemic role-player games highlighted in Papers, Please [12], provides a reasonable model on how to integrate ethical dilemmas into an environment, such that these ethical aspects arise as the agent plays the game and learns to adjust its decision-making based on feedback received from the environment. Depending on the model and the environment used, it may be fruitful to see how multiple virtuous agents behave when they are at odds. Overall, this paper furthers the conversation on the implementation of ethical machines, which is a nascent research area.
## Acknowledgments
Financial support for this project is provided by the University of Agder. We would like to thank Marija Slavkovik, Department of Information Science and Media Studies, University of Bergen, and, Henrik Martin Hansen Torjusen, Department of Foreign Languages and Translation, University of Agder, for useful discussions and feedback on this manuscript.
## Declarations
The authors have no competing interests.
## References
- [1] Cervantes, J.-A., L´ opez, S., Rodr´ ıguez, L.-F., Cervantes, S., Cervantes, F., Ramos, F.: Artificial Moral Agents: A Survey of the Current Status. Science and Engineering Ethics 26 (2), 501-532 (2020). https://doi.org/ 10.1007/s11948-019-00151-x
- [2] Formosa, P., Ryan, M.: Making Moral Machines: Why We Need Artificial Moral Agents. AI & SOCIETY 36 (3), 839-851 (2021). https://doi.org/ 10.1007/s00146-020-01089-6
- [3] Allen, C., Smit, I., Wallach, W.: Artificial Morality: Top-down, Bottomup, and Hybrid Approaches. Ethics and Information Technology 7 (3), 149-155 (2005). https://doi.org/10.1007/s10676-006-0004-4. Accessed 2022-04-05
- [4] Fisher, M., List, C., Slavkovik, M., Winfield, A.: Engineering Moral Agents - from Human Morality to Artificial Morality (Dagstuhl Seminar 16222), 24 (2016). https://doi.org/10.4230/DAGREP.6.5.114
- [5] Gips, J.: Towards the Ethical Robot. In: Anderson, M., Anderson, S.L. (eds.) Machine Ethics, pp. 244-253. Cambridge University Press, Cambridge (2011). https://doi.org/10.1017/CBO9780511978036.019. https:// www.cambridge.org/core/product/identifier/CBO9780511978036A028/ type/book part
- [6] Tolmeijer, S., Kneer, M., Sarasua, C., Christen, M., Bernstein, A.: Implementations in Machine Ethics: A Survey. ACM Computing Surveys 53 (6), 1-38 (2021). https://doi.org/10.1145/3419633
- [7] Stenseke, J.: Artificial Virtuous Agents: from Theory to Machine Implementation. AI & SOCIETY (2021). https://doi.org/10.1007/ s00146-021-01325-7
- [8] Red, C.P.: The Witcher 3: Wild Hunt - Official Website (2015). https: //www.thewitcher.com/en Accessed 2022-04-11
- [9] Bethesda Game Studios: Fallout 4 (2015). https://fallout.bethesda.net/ en/games/fallout-4 Accessed 2022-04-12
- [10] Telltale Games: Batman: The Telltale Series (2016). https://telltale.com/ Accessed 2022-04-11
- [11] Lucas Pope: Papers, Please (2013). https://papersplea.se/ Accessed 202204-11
- [12] Formosa, P., Ryan, M., Staines, D.: Papers, Please and the Systemic Approach to Engaging Ethical Expertise in Videogames. Ethics and Information Technology 18 (3), 211-225 (2016). https://doi.org/10.1007/ s10676-016-9407-z
- [13] Tancred, N., Vickery, N., Wyeth, P., Turkay, S.: Player Choices, Game Endings and the Design of Moral Dilemmas in Games. In: Proceedings of the 2018 Annual Symposium on Computer-Human Interaction in Play Companion Extended Abstracts, pp. 627-636. ACM, Melbourne VIC Australia (2018). https://doi.org/10.1145/3270316.3271525. https: //dl.acm.org/doi/10.1145/3270316.3271525
- [14] Berberich, N., Diepold, K.: The Virtuous Machine - Old Ethics for New Technology? (2018). http://arxiv.org/abs/1806.10322
- [15] Abel, D., MacGlashan, J., Littman, M.L.: Reinforcement Learning As a Framework for Ethical Decision Making. In: Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, p. 8. AAAI Publications, Phoenix, Arizona, USA (2016). https://www.aaai.org/ocs/index.php/ WS/AAAIW16/paper/view/12582
- [16] Maree, C., Omlin, C.: Reinforcement Learning Your Way: Agent Characterization through Policy Regularization. AI 3 (2), 250-259 (2022). https://doi.org/10.3390/ai3020015
- [17] Annas, J.: Virtue Ethics (2007). https://doi.org/10.1093/oxfordhb/ 9780195325911.003.0019
- [18] Alexander, L., Moore, M.: Deontological Ethics. The Stanford Encyclopedia of Philosophy (2021). Accessed 2022-04-05
- [19] Hew, P.C.: Artificial Moral Agents are Infeasible with Foreseeable Technologies. Ethics and Information Technology 16 (3), 197-206 (2014). https: //doi.org/10.1007/s10676-014-9345-6
- [20] Ross, W.D., Brown, L. (eds.): Oxford World's Classics: Aristotle: The Nicomachean Ethics (Revised Edition) (1980). https://doi.org/10.1093/ actrade/9780199213610.book.1
- [21] Foot, P.: Virtues and Vices (2002). https://doi.org/10.1093/0199252866. 001.0001
- [22] MacIntyre, A.C.: After Virtue: A Study in Moral Theory, (2007)
- [23] Moor, J.H.: The Nature, Importance, and Difficulty of Machine Ethics. IEEE Intelligent Systems 21 (4), 18-21 (2006). https://doi.org/10.1109/ MIS.2006.80
- [24] Anscombe, G.E.M.: Modern Moral Philosophy, 20 (2022)
- [25] Hursthouse, R.: On Virtue Ethics (2001). https://doi.org/10.1093/ 0199247994.001.0001
- [26] Rosenblueth, A., Wiener, N., Bigelow, J.: Behavior, Purpose and Teleology. Philosophy of Science 10 (1), 18-24 (1943)
- [27] Wiener, N.: Some Moral and Technical Consequences of Automation. Science 131 (3410), 1355-1358 (1960). https://doi.org/10.1126/science.131. 3410.1355
- [28] Dreyfus, H.L.: What Computers Still Can't Do: A Critique of Artificial Reason. MIT Press, Cambridge, MA, USA (1992)
- [29] Coleman, K.G.: Android Arete: Toward a Virtue Ethic for Computational Agents. Springer 3 (4), 247-265 (2001)
- [30] Dotnod Entertainment: Life is Strange (2022). https://lifeisstrange. square-enix-games.com/en-gb/ Accessed 2022-04-11
- [31] Nay, J.L., Zagal, J.P.: Meaning Without Consequence: Virtue Ethics and Inconsequential Choices in Games. In: Proceedings of the 12th International Conference on the Foundations of Digital Games, pp. 1-8. ACM, Hyannis Massachusetts (2017). https://doi.org/10.1145/3102071. 3102073. https://dl.acm.org/doi/10.1145/3102071.3102073
- [32] Origin Systems: Ultima IV: Quest of the Avatar. Origin Systems (1985). https://en.wikipedia.org/wiki/Ultima IV: Quest of the Avatar# Development Accessed 2022-08-11
- [33] Zagal, J.P.: Ethically Notable Videogames: Moral Dilemmas and Gameplay, vol. 5, p. 9. Brunel University, Brunei (2009). http://www.digra.org/ wp-content/uploads/digital-library/09287.13336.pdf
- [34] Heron, M.J., Belford, P.H.: Do You Feel Like a Hero Yet? Externalized Morality in Video Games. Journal of Games Criticism 1 (2), 25 (2014)
- [35] Narvaez, D., Vaydich, J.L.: Moral Development and Behaviour Under the Spotlight of the Neurobiological Sciences. Journal of Moral Education 37 (3), 289-312 (2008). https://doi.org/10.1080/03057240802227478
- [36] Lillicrap, T.P., Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., Wierstra, D.: Continuous Control with Deep Reinforcement Learning. arXiv 1509.02971 (2019)
- [37] Aubret, A., Matignon, L., Hassas, S.: A Survey on Intrinsic Motivation in Reinforcement Learning. arXiv 1908.06976 (2019)
- [38] Miryoosefi, S., Brantley, K., Daume III, H., Dudik, M., Schapire, R.E.: Reinforcement Learning with Convex Constraints. In: Advances in Neural Information Processing Systems, vol. 32, pp. 1-10 (2019)
- [39] Chow, Y., Ghavamzadeh, M., Janson, L., Pavone, M.: Risk-Constrained Reinforcement Learning with Percentile Risk Criteria. Journal of Machine Learning Research 18 , 1-51 (2015)
- [40] Lu, J., Dissanayake, S., Castillo, N., Williams, K.: Safety Evaluation of Right Turns Followed by U-Turns as an Alternative to Direct Left Turns - Conflict Analysis. Technical report, CUTR Research Reports (2001)
- [41] Andres, A., Villar-Rodriguez, E., Ser, J.D.: Collaborative Training of Heterogeneous Reinforcement Learning Agents in Environments with Sparse Rewards: What and When to Share? arXiv 2202.12174 (2022)
- [42] Vieillard, N., Kozuno, T., Scherrer, B., Pietquin, O., Munos, R., Geist, M.: Leverage the Average: An Analysis of KL Regularization in Reinforcement Learning. In: Advances in Neural Information Processing Systems (NIPS),
- vol. 33, pp. 12163-12174. Curran Associates, Virtual-only (2020). https: //doi.org/10.48550/ARXIV.2003.14089
- [43] Haarnoja, T., Tang, H., Abbeel, P., Levine, S.: Reinforcement Learning with Deep Energy-Based Policies. In: Proceedings of the 34th International Conference on Machine Learning, pp. 1352-1361 (2017)
- [44] Galashov, A., Jayakumar, S., Hasenclever, L., Tirumala, D., Schwarz, J., Desjardins, G., Czarnecki, W.M., Teh, Y.W., Pascanu, R., Heess, N.: Information Asymmetry in KL-Regularized RL. In: International Conference on Learning Representations (ICLR), New Orleans, Louisiana, United States, pp. 1-25 (2019)
- [45] Maree, C., Omlin, C.W.: Can Interpretable Reinforcement Learning Manage Prosperity Your Way? AI 3 (2), 526-537 (2022)
- [46] Heuillet, A., Couthouis, F., D´ ıaz-Rodr´ ıguez, N.: Explainability in Deep Reinforcement Learning. Knowledge-Based Systems 214 , 106685 (2021). https://doi.org/10.1016/j.knosys.2020.106685
- [47] Madumal, P., Miller, T., Sonenberg, L., Vetere, F.: Explainable Reinforcement Learning through a Causal Lens. Proceedings of the AAAI Conference on Artificial Intelligence 34 (03), 2493-2500 (2020). https: //doi.org/10.1609/aaai.v34i03.5631
- [48] Juozapaitis, Z., Koul, A., Fern, A., Erwig, M., Doshi-Velez, F.: Explainable Reinforcement Learning via Reward Decomposition. In: in Proceedings at the International Joint Conference on Artificial Intelligence. A Workshop on Explainable Artificial Intelligence. (2019)
- [49] Patil, V.P., Hofmarcher, M., Dinu, M.-C., Dorfer, M., Blies, P.M., Brandstetter, J., Arjona-Medina, J.A., Hochreiter, S.: Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution. arXiv (2022). http://arxiv.org/abs/2009.14108