## Knowledge-based Analogical Reasoning in Neuro-symbolic Latent Spaces
Vishwa Shah 1 , Aditya Sharma 1 , Gautam Shroff 2 , Lovekesh Vig 2 , Tirtharaj Dash 1 and Ashwin Srinivasan 1
1 APPCAIR, BITS Pilani, K.K. Birla Goa Campus
2 TCS Research, New Delhi
## Abstract
Analogical Reasoning problems pose unique challenges for both connectionist and symbolic AI systems as these entail a carefully crafted solution combining background knowledge, deductive reasoning and visual pattern recognition. While symbolic systems are designed to ingest explicit domain knowledge and perform deductive reasoning, they are sensitive to noise and require inputs be mapped to a predetermined set of symbolic features. Connectionist systems on the other hand are able to directly ingest rich input spaces such as images, text or speech and can perform robust pattern recognition even with noisy inputs. However connectionist models struggle to incorporate explicit domain knowledge and perform deductive reasoning. In this paper, we propose a framework that combines the pattern recognition capabilities of neural networks with symbolic reasoning and background knowledge for solving a class of Analogical Reasoning problems where the set of example attributes and possible relations across them are known apriori. We take inspiration from the 'neural algorithmic reasoning' approach [DeepMind 2020] and exploit problem-specific background knowledge by (i) learning a distributed representation based on a symbolic model of the current problem (ii) training neural-network transformations reflective of the relations involved in the problem and finally (iii) training a neural network encoder from images to the distributed representation in (i). These three elements enable us to perform search-based reasoning using neural networks as elementary functions manipulating distributed representations. We test our approach on visual analogy problems in RAVENs Progressive Matrices, and achieve accuracy competitive with human performance and, in certain cases, superior to initial end-to-end neural-network based approaches. While recent neural models trained at scale currently yield the overall SOTA, we submit that our novel neuro-symbolic reasoning approach is a promising direction for this problem, and is arguably more general, especially for problems where sufficient domain knowledge is available.
## Keywords
neural reasoning, visual analogy, neuro-symbolic learning, RPMs
## 1. Introduction
Many symbolic reasoning algorithms can be viewed as searching for a solution in a space defined by prior domain knowledge. Given sufficient domain knowledge represented in symbolic form, 'difficult' reasoning problems, such as analogical reasoning, can be 'solved' via exhaustive search, even though they are challenging for the average human. However, such algorithms operate on a symbolic space, whereas humans are easily able to consume rich data such as images or speech.
Accepted at NeSy 2022, 16th International Workshop on Neural-Symbolic Learning and Reasoning, Cumberland Lodge, Windsor, UK
/envelope-open f20180109@goa.bits-pilani.ac.in (V. Shah)
<details>
<summary>Image 1 Details</summary>

### Visual Description
Icon/Small Image (64x23)
</details>
Neural networks on the other end are proficient in encoding high-dimensional continuous data and are robust to noisy inputs, but struggle with deductive reasoning and absorbing explicit domain knowledge. 'Neural Algorithmic Reasoning'[1], presents an approach to jointly model neural and symbolic learning, wherein rich inputs are encoded to a latent representation that has been learned using from symbolic inputs. This design allows neural learners and algorithms to complement each other's weaknesses. Through this work, we aim to investigate a variation of the neural algorithmic reasoning approach applied to analogical reasoning, using RAVENs Progressive Matrices [2] problems as a test case.
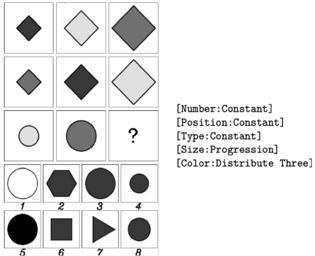
Our approach essentially exploits the domain knowledge to train a suite of neural networks, one for each known domain predicate. For RAVENs problems, these predicates represent rules that might apply to ordered sets (rows) of images in a particular problem. Further, these neural predicates are trained to operate on a special highdimensional representation space ('symbolic latent space') that is derived, via self-supervised learning, from the symbolic input space. Note that a purely symbolic algorithm can consume symbolic inputs to solve the problem exactly, however a distributed representation can allow for real world analogical reasoning for rich input spaces such as images or speech (see Fig 1 for a RAVENs problem; one can
Figure 1.: RPM : Problem Matrix (Top), Answer Options (Bottom)
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Pattern Recognition Puzzle: Visual Sequence
### Overview
The image presents a visual pattern recognition puzzle consisting of a 3x3 grid of shapes, with the bottom-right cell left blank. Adjacent to the grid is a list of attributes describing the pattern's characteristics. The puzzle appears to test the ability to identify and extrapolate visual sequences based on defined rules.
### Components/Axes
The image is divided into two main sections:
1. **The Grid:** A 3x3 grid containing geometric shapes (diamonds, circles, hexagons, squares, triangles). Each shape varies in color (white, light gray, dark gray, black).
2. **Attribute List:** A list of attributes defining the rules governing the pattern. These are:
* Number: Constant
* Position: Constant
* Type: Constant
* Size: Progression
* Color: Distribute Three
The grid cells are numbered 1 through 8, starting from the top-left and proceeding row by row.
### Detailed Analysis or Content Details
Let's analyze the shapes in each cell:
* **Cell 1:** Dark gray diamond.
* **Cell 2:** Light gray diamond.
* **Cell 3:** Dark gray diamond.
* **Cell 4:** Light gray diamond.
* **Cell 5:** Dark gray diamond.
* **Cell 6:** Black square.
* **Cell 7:** Black triangle.
* **Cell 8:** ? (Empty)
Based on the attribute list:
* **Number:** The number of shapes in each cell is constant (one shape per cell).
* **Position:** The position of the shape within the cell is constant (centered).
* **Type:** The type of shape is not constant. We see diamonds, circles, hexagons, squares, and triangles.
* **Size:** The size of the shapes appears to be progressing.
* **Color:** The colors are distributed among three shades: white, gray, and black.
Looking at the rows:
* **Row 1:** Diamond, Diamond, Diamond. Color sequence: Dark Gray, Light Gray, Dark Gray.
* **Row 2:** Diamond, Diamond, Diamond. Color sequence: Light Gray, Dark Gray, Light Gray.
* **Row 3:** Circle, Hexagon, Circle. Color sequence: Light Gray, Black, ?
Looking at the columns:
* **Column 1:** Diamond, Diamond, Circle. Color sequence: Dark Gray, Light Gray, Light Gray.
* **Column 2:** Diamond, Diamond, Hexagon. Color sequence: Light Gray, Dark Gray, Black.
* **Column 3:** Diamond, Diamond, ?. Color sequence: Dark Gray, Light Gray, ?.
The shapes in the third row are: Circle, Hexagon, ?. The shapes in the third column are: Diamond, Diamond, ?.
### Key Observations
* The first two rows consist entirely of diamonds, with alternating shades of gray.
* The third row introduces different shapes (circle and hexagon).
* The color distribution seems to follow a pattern, but it's not immediately obvious.
* The attribute "Size: Progression" is not visually apparent in the provided image.
* The attribute "Type: Constant" is incorrect, as the shapes change.
### Interpretation
The puzzle is designed to test pattern recognition skills. The attributes provided are partially misleading or incomplete. The "Type: Constant" attribute is demonstrably false. The "Size: Progression" attribute is not visible. The most apparent pattern is the alternating color scheme within each row. The third row introduces new shapes, suggesting the missing shape in cell 8 should be a shape not yet seen (likely a triangle or square) and its color should continue the alternating pattern. Given the shapes in the third row, and the shapes in the third column, the missing shape is likely a black diamond.
The puzzle highlights the importance of critically evaluating provided information and identifying inconsistencies. The attributes are intended to guide the solution, but their inaccuracy requires the solver to rely on visual observation and deduction. The puzzle is not about finding a single "correct" answer, but about identifying the underlying rules and applying them logically.
</details>
also imagine tasks with speech inputs where the analogous example signals are high pitch transformed versions of the original). Our approach differs from [1] where the symbolic latent space is derived via a supervised approach; by using a self-supervised learning approach we are able to use the same representation space to train multiple neural predicates, unlike in [1] where only a single function is learned. Next, we train a neural network encoder to map real-world images (here sub-images of the RAVENs matrices) to the 'symbolic latent space'. Finally, using the above elements together we are able to perform symbolic search-based reasoning, albeit using neural-networks as primitive predicates, to solve analogical reasoning problems.
Contributions (1) We adapt and extend Neural Algorithmic Reasoning to propose a neurosymbolic approach for a class of visual analogical reasoning problems (2) We present experimental results on the RAVENs Progressive Matrices dataset and compare our neuro-symbolic approach to purely connectionist approaches, and analyse the results. In certain cases, our approach is superior to initial neural approaches, as well as to human performance (though more recent neural approaches trained at scale remain SOTA) (3) We submit that our approach can be viewed as a novel and more general neuro-symbolic procedure that uses domain knowledge to train neural network predicates operating on a special, 'symbolically-derived latent space', which are then used as elementary predicates in a symbolic search process.
## 2. Problem Definition
In general, 'RAVEN-like' analogical reasoning tasks can be viewed as comprising of 𝑛 ordered sets 𝑠 1 , 𝑠 2 , ..., 𝑠 𝑛 containing 𝑚 input samples each, an additional test set containing 𝑚 -1 samples and a target 𝑚 𝑡ℎ sample. Each sample 𝐼 𝑗𝑘 where 𝑗 ∈ [1 ...𝑛 ] , 𝑖 ∈ [1 ...𝑚 ] is comprised of a set of entities 𝐸 𝑗𝑘 and each entity 𝑒 ∈ 𝐸 𝑗𝑘 has attributes from a set 𝐴 of 𝑘 predefined attributes 𝑎 1 , 𝑎 2 , ..., 𝑎 𝑘 ∈ 𝐴 . Assume a predefined set of all possible rules 𝑅 = 𝑟 1 , 𝑟 2 ..., 𝑟 𝑢 that can hold over sample attributes in an example set(s). For a given task the objective is to infer which rules hold across the 𝑚 samples in each of the 𝑛 example sets in order to subsequently predict the analogous missing sample for the test set, either by generating the target sample as in the ARC challenge [3], or by classifying from a set of possible choices as in RPMs. Note that the problem definition assumes prior domain knowledge about possible sample entities, their possible attribute values, and possible rules over sample attributes within the example sets. It is worth mentioning that while here we investigate visual analogies, the problem definition can accommodate input samples of any datatype such as audio or text as long as the problem structure is unchanged.
## 3. Proposed Approach
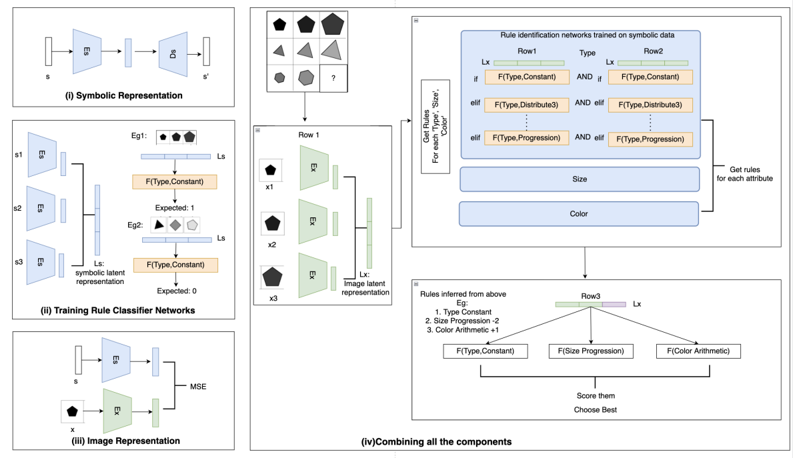
Figure 2.: Overview of our approach for RAVEN's RPM
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Rule Identification Networks with Symbolic Representation
### Overview
This diagram illustrates a process for identifying rules from image data, combining symbolic representation with rule classifier networks. The diagram is divided into four main sections: (i) Symbolic Representation, (ii) Training Rule Classifier Networks, (iii) Image Representation, and (iv) Combining all the components. It depicts a flow of information from initial image input to rule inference and scoring.
### Components/Axes
The diagram consists of several interconnected blocks representing different stages of the process. Key components include:
* **Input Images (s, s1, s2, s3):** Represent initial image inputs.
* **Symbolic Representation (Ls):** Represents the symbolic output of the image processing.
* **Rule Classifier Networks:** Networks trained to identify rules based on symbolic data.
* **Image Latent Representation (Lx):** Represents the learned representation of the image.
* **MSE (Mean Squared Error):** Used for evaluating the image representation.
* **Rule Identification Networks:** Networks trained on symbolic data to identify rules.
* **Rows 1, 2, 3:** Represent different stages of rule inference and scoring.
* **Attributes (Type, Size, Color):** Represent the attributes used for rule identification.
* **Functions (F(Type, Constant), F(Size, Progression), F(Color, Arithmetic)):** Represent the functions used to define rules.
### Detailed Analysis or Content Details
**(i) Symbolic Representation:**
* An input image 's' is processed through a series of blocks (represented by rectangles with arrows) resulting in a symbolic representation 's''.
* A grid of pentagonal shapes is shown, representing the symbolic output. The grid contains a mix of filled and unfilled pentagons.
**(ii) Training Rule Classifier Networks:**
* Three input images (s1, s2, s3) are processed.
* Each image is associated with an expected symbolic representation (Eg1, Eg2, Eg3) and a loss function (Ls).
* Eg1 and Eg2 show a grid of filled pentagons. Eg3 shows a grid of unfilled pentagons.
* The loss function Ls is associated with F(Type, Constant).
**(iii) Image Representation:**
* An input image is processed through a series of blocks, resulting in an image representation.
* The image representation is compared to the expected symbolic representation using MSE.
* The output is a grid of pentagonal shapes.
**(iv) Combining all the components:**
* **Rule Identification Networks:** A table is shown with "Type", "Size", and "Color" as attributes. The table contains conditional statements (if/elif) using functions like F(Type, Constant), F(Type, Distribute), and F(Type, Progression).
| Attribute | Function Example |
|---|---|
| Type | F(Type, Constant) |
| Size | F(Size, Progression) |
| Color | F(Color, Arithmetic) |
* **Rules Inferred from above:** Three rules are listed:
1. Type Constant
2. Size Progression - 2
3. Color Arithmetic + 1
* **Row X3:** Contains F(Type, Constant), F(Size, Progression), and F(Color, Arithmetic).
* A scoring mechanism is indicated, with the goal of choosing the best rule.
### Key Observations
* The diagram emphasizes the integration of symbolic representation with neural networks for rule identification.
* The use of MSE suggests a learning process where the image representation is refined to match the expected symbolic output.
* The rule identification networks appear to operate based on conditional logic, considering attributes like type, size, and color.
* The scoring mechanism indicates a process for selecting the most appropriate rule based on the inferred rules.
### Interpretation
The diagram presents a system for extracting and representing rules from visual data. The process begins with converting images into symbolic representations, which are then used to train rule classifier networks. These networks learn to identify rules based on attributes like type, size, and color. The system then infers rules from new images and scores them to determine the best match. This approach could be used for tasks such as object recognition, scene understanding, or automated reasoning. The use of MSE suggests a supervised learning approach, where the system is trained on labeled data. The combination of symbolic representation and neural networks allows the system to leverage both the interpretability of symbolic logic and the learning capabilities of neural networks. The diagram suggests a complex system with multiple stages of processing and learning, designed to extract meaningful rules from visual data. The diagram does not provide any numerical data, but rather illustrates a conceptual framework.
</details>
We adapt a variation of the neural algorithmic reasoning approach to the problem defined in Section 2, where we (i) learn a latent representation based on the symbolic representation of the tasks, via self-supervised learning; (ii) train neural networks to infer the rules involved in the problem; (iii) train a neural encoder from images to align with the symbolic latent representations in (i), and (iv) use the above elements to solve a given task via a neuro-symbolic search procedure, i.e., where the elementary predicates are neural networks. We assume the presence of a training dataset 𝐷 𝑡𝑟𝑎𝑖𝑛 with correct answer labels for the analogical reasoning tasks. The components (i), (ii) and (iii) are trained independently as for each of them we know or can determine the inputs and the targets depending on their function. We also evaluate an alternative of (v) encoding an image to the symbolic latent space via the neural encoder in (iii) above, and decode it to symbolic form using the decoder trained in (i) on the symbolic space, on which purely symbolic search is used to solve a problem instance.
## 3.1. Learning a Distributed Representation from the Symbolic Space
We begin with a symbolic multihot task representation 𝑠 , which is a series of concatenated one-hots, one for each image entity attribute. Each attribute can take a value from a finite set and hence is represented using a one-hot vector. To obtain the latent representations of the tasks, we train an auto-encoder on the symbolic task definitions S as L ( S ) = ( 𝐸 S 𝜃 , 𝐷 S 𝜑 ) where the encoder 𝐸 S 𝜃 maps from the symbolic space to the latent space and the decoder 𝐷 S 𝜑 maps the representation from the latent space back to the symbolic space as shown in component (i) of Fig. 2. As we want to reconstruct the multihot representation, a sum of negative-log likelihood is computed for each one-hot encoding present in the multihot representation. We provide an example in C.1 where the parameters 𝜃 and 𝜑 are obtained via gradient descent on a combination of negative log-likelihood loss functions as shown in equation 1 and 2 in the appendix.
## 3.2. Training Rule Identification Neural Networks
Next for every attribute, and for each applicable rule for that attribute, we train a Rule Identification neural network classifier to predict if the rule (pattern) holds for the example set. As mentioned in 2, we know the rules that can hold over attributes, giving us a definite set of networks to be trained. We refer to any rule identification network 𝐹 using the ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒, 𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) pair for which it is trained. The latent representations obtained after encoding the symbolic representations of each of the samples in the example set are concatenated and sent as input to the rule identification networks. While training a neural net for a ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒, 𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) pair, we categorize each example set with the specific label for that particular rule and attribute, labeling it with 0 if the rule-type is not followed, 1 if the rule-type is followed or a rule-value indicating the level of the rule-type when being followed. As each of these rule-types is deterministic, we can obtain the rule-type and value for each row using their symbolic representations. The overview can be seen in component (ii) of Fig. 2 where we see the input for these elementary neural networks and the expected output determined for the ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒, 𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) pair. We see in Fig. 2 that type (shape) changes in row 𝐸𝑔 1 , hence the expected target for 𝐹 ( 𝑡𝑦𝑝𝑒, 𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡 ) should be 1 as type stays constant and in case of 𝐸𝑔 2 as the type changes, we expect 𝐹 ( 𝑡𝑦𝑝𝑒, 𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡 ) to predict 0, indicating the rule is not obeyed. With these labels, each network is optimized using cross-entropy loss. For parameterized rules we train additional networks to predict the parameters. 1
1 Examples provided in appendix section C.2
## 3.3. Sample representation
As our objective to apply our approach on samples in an unstructured (image, text, speech) format, we want to develop a representation for the samples that resembles the latent representation of symbolic inputs. For this we train any neural network encoder 𝐸 X 𝜓 over the rich input space X which encodes each sample to a latent space. We want to minimize the disparity in the latent representations from the sample 𝑥 and its corresponding symbolic representation 𝑠 . For this we use 𝐸 S 𝜃 trained in 3.1. We minimize the mean squared error over all pairs of symbolic and input representations (equation shown in C.1). This enables us to use the previously learned neural networks for rule inference on our image data.
## 3.4. Combining the Elements
As shown in component (iv) of Fig. 2, we first use 𝐸 X 𝜓 ( 𝑥 ) as inputs to find the underlying rules using the neural networks trained in section 3.2. Once we obtain the set of (rule-type, value) pairs for each attribute, we apply these neural networks for each of the answer choices by adding them to the test set. For each attribute, we obtain the output probability score for that rule-type and value. The final score is the sum of these probability scores for all the inferred rules 2 . The choice with the highest score is returned as the answer.
## 4. Empirical Evaluation
Raven's Progressive Matrices (RPM): is a widely accepted visual reasoning puzzle used to test human intelligence [2]. The idea is to infer multiple patterns to be able to find the answer from the options, an example of the same from the RAVEN[4] dataset is seen in Fig 1. In this dataset, for every problem, each independent attribute follows an algorithmic rule. The task here is to deduce the underlying rules applied over each row for the first two rows; followed by selecting the option that validates all the inferred rules when aligned with the images in the last row. As seen in the first two rows in the Fig 1 we observe the attributes: Number, Position and Type stay constant across the rows. We observe an increasing progression in Size and a fixed set of 3 Colors are permuted within the row indicating distribute three. Hence option 3 is the only solution that satisfies all the rules 3 . For our experiments, We use the 'Relational and Analogical Visual rEasoNing' dataset (RAVEN)[4], which was introduced to drive reasoning ability in current models. RAVEN consists of 10,000 problems for each of the 7 different configurations of the RPM problem shown in Fig 3. Each problem has 16 images (8 : problem matrix and 8 : target options).
Figure 3.: Examples of 7 different configurations of the RAVEN dataset
<details>
<summary>Image 4 Details</summary>

### Visual Description
\n
## Diagram: Shape Arrangement Visualization
### Overview
The image presents a visual arrangement of geometric shapes within a grid-like structure. It appears to be a demonstration of different shape placements and patterns, labeled with descriptive names. The arrangement is organized into two rows, each containing seven distinct configurations.
### Components/Axes
The diagram consists of the following labeled configurations, positioned horizontally across two rows:
* **Center:** A hexagon and a diamond.
* **2x2Grid:** Four triangles (two dark, two light) arranged in a 2x2 grid.
* **3x3Grid:** Nine circles (some dark, some light) arranged in a 3x3 grid.
* **Left-Right:** Two hexagons (one dark, one light) and two circles (one dark, one light) arranged horizontally.
* **Up-Down:** A dark circle, a triangle, and a dark circle arranged vertically.
* **Out-InCenter:** A pentagon and a square, with a dark circle in the center.
* **Out-InGrid:** A triangle and a hexagon, with three dark circles arranged in a grid.
The shapes used are: hexagons, diamonds, triangles, circles, squares, and pentagons. The shapes are filled with either a dark or light gray color.
### Detailed Analysis / Content Details
Each configuration displays a unique arrangement of shapes and colors.
* **Center:** Contains one dark hexagon and one light diamond.
* **2x2Grid:** Contains two dark triangles and two light triangles.
* **3x3Grid:** Contains five light circles and four dark circles.
* **Left-Right:** Contains one dark hexagon, one light hexagon, one dark circle, and one light circle.
* **Up-Down:** Contains one dark circle, one light triangle, and one dark circle.
* **Out-InCenter:** Contains one light pentagon, one light square, and one dark circle.
* **Out-InGrid:** Contains one light triangle, one light hexagon, and three dark circles.
### Key Observations
The diagram focuses on the spatial relationships between shapes and the use of color to differentiate them. The configurations vary in complexity, from simple arrangements of two shapes to more intricate grids. The labels suggest an exploration of how shapes can be organized within different spatial constraints.
### Interpretation
This diagram likely serves as a visual aid for understanding concepts related to spatial arrangement, pattern recognition, or visual design. It could be used to illustrate principles of composition, balance, or hierarchy in visual communication. The use of both dark and light shapes may represent different levels of emphasis or importance. The labels ("Center", "Grid", "Left-Right", etc.) indicate the organizing principle behind each arrangement. The diagram doesn't present numerical data or trends, but rather a qualitative exploration of visual possibilities. It is a demonstration of visual elements and their arrangement, rather than a representation of data.
</details>
2 We explain the complete pseudo-algorithm along with the scoring function in the appendix.
3 Weprovide the dataset overview, set of rule and attribute definitions for the RAVENs problems used in the appendix.
## 4.1. Experimental Details
As each image in a RAVENs problem can be represented symbolically in terms of the entities (shapes) involved and their attributes: Type, Size, and Color; and multiple entities in the same image have Number and Position attributes. Such attributes are also rule-governing in that rules based on these can be applied to each row and the combination of rules from all rows is used to solve a given problem. Example: for each entity, the multihot representation 𝑠 is of size | 𝑇 | + | 𝑆 | + | 𝐶 | where 𝑇 , 𝑆 and 𝐶 are the set of shapes, possible sizes and possible colors respectively. The multi-hot vector is made up of 3 concatenated one-hot vectors, one each for type, size, and color. In case of multiple components, e.g: Left-Right, we concatenate the multihots of both the entities. For our auto-encoder architecture, we train simple MLPs with a single hidden layer for both 𝐸 𝑠 and 𝐷 𝑠 (using loss function 1,2) in appendix. The dimensions of the layers and latent representations are chosen based on the RPM configuration.
Following [2]'s description of RPM, there are four types of rules: Constant, Distribute Three, Arithmetic, and Progression. In a given problem, there is a one rule applied to each rulegoverning attribute across all rows, and the answer image is chosen so that this holds. We aim to find a set of rules being obeyed by both the rows.
So for every attribute and its rule-type, we train an elementary neural network classifier 𝐹 ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒,𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) , to verify if the rule is satisfied in a given row, or pair of rows. The rules of Progression and Arithmetic are further associated with a value (e.g., Progression could have increments or decrements of 1 or 2). For rule-type Constant and 'Distribute-three' we train a binary classifier, and for rule-type Arithmetic and Progression, we train a multi-class classifier to also predict the value associated with the rule. An example is described in the appendix along with further details on the neural networks used.
We train a CNN-based image encoder 𝐸 X 𝜓 over the image space X which encodes each image of the problem to a latent space and minimize the disparity with the corresponding symbolic latent space as described in Section 3.3. Finally, as shown in component (iv) of Fig. 2, we find the underlying rules using the neural networks trained in section 3.2. Once we obtain the set of (rule-type, value) pairs for each attribute, we apply these neural networks for each of the 8 options by placing them in the last row. We obtain the output probability score for that attribute, rule-type and value and sum the probability scores for all the inferred rules 4 and the image with the highest score is returned as the answer.
## 4.2. Results
We use the test set provided by RAVEN to evaluate rule classification networks and the final accuracy. Table 2 lists the F1 of each 𝐹 ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒,𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) classification network across all configurations. We observe that 85% of the neural networks have an F1-score ≥ 0.90. This is corroborated by the idea that these networks are trained on latent representations of symbolic data to perform elementary functions and do well on specialized reasoning components.
Table 1 shows end-to-end accuracy for different RAVENs problem configurations. Our proposed neural reasoning approach ( A ) is where we have image input encoded by 𝐸 𝑥 ( 𝑥 ) and neural reasoning in the latent space, i.e. steps (i)-(iv) in Section 3. We also show results for
4 We explain the complete pseudo-algorithm along with the scoring function in the appendix.
Table 1. Configuration Wise Accuracy
| | Center | Left-Right | Up-Down | Out-In Center | 2x2 Grid | 3x3 Grid | Out-In Grid |
|--------------------------|----------|--------------|-----------|-----------------|------------|------------|---------------|
| Input/Reasoning | | | | | | | |
| A: Image/Neural(ours) | 89.40% | 85.00% | 89.10 % | 89.80% | 53.10% | 33.90% | 31.90% |
| B: Image/Symbolic(ours) | 97.30% | 98.35% | 98.95% | 96.95% | 88.40% | 19.15% | 34.15% |
| c: Symbolic/Neural(ours) | 94.60% | 90.65% | 91.90% | 93.85% | 62.20% | 54.10% | 59.40% |
| RAVEN(ResNet+DRT)[4] | 58.08% | 65.82% | 67.11% | 69.09% | 46.53% | 50.40% | 60.11% |
| CoPINet[5] | 95.05% | 99.10% | 99.65% | 98.50% | 77.45% | 78.85% | 91.35% |
| SCL[6] | 98.10% | 96.80% | 96.50 % | 96.00% | 91.00% | 82.50% | 80.10% |
| DCNet[7] | 97.80% | 99.75% | 99.75% | 98.95% | 81.70% | 86.65% | 91.45% |
| Human [4] | 95.45% | 86.36% | 81.81% | 86.36% | 81.82% | 79.55% | 81.81% |
an alternative ( B ), (v) mentioned in Section 3, i.e., image inputs decoded to symbolic space via 𝐷 𝑠 ( 𝐸 𝑥 ( 𝑥 )) followed by purely symbolic reasoning (algorithmic solving). Results using neural reasoning in the latent space but using the correct symbolic inputs mapped via 𝐸 𝑠 ( 𝑠 ) are also shown as ( c ) to highlight the loss in accuracy incurred while encoding images using 𝐸 𝑥 ( 𝑥 ) .
We use ResNet+DRT from RAVEN as our baseline, human performance (provided in [4] ) as a reference and other SOTA methods for comparison. We note that the RAVEN baseline is bested by A : neural reasoning on image inputs for 4 out of the 7 configurations, and by B : symbolic reasoning on image inputs for one of the more difficult cases (2x2). At the same time we observe that approach B is better than A except for the difficult case of 3x3 grid, where the encoder-decoder combination 𝐷 𝑠 ( 𝐸 𝑥 ( 𝑥 )) produces too many errors, adversely affecting purely symbolic reasoning.
Neural reasoning from symbolic inputs, i.e. ( c ), accuracy consistently exceeds approach A , which can be attributed to the closer relation of the latent space to the algorithmic symbolic space. We also observe lower performance for the configurations 2x2 Grid, 3x3 Grid, and Out-In grid. Upon analysis, we find that the performance of 𝐸 𝑥 for these configurations is relatively lower as each of these components have multiple entities and the task to transform the image into the latent space and identifying rules becomes difficult.
While more recent purely neural-network based approaches remain SOTA, we note that for the simpler configurations our neuro-symbolic approaches are competitive. We speculate that because of the complex nature and difficulty of these configurations, using more powerful neural architectures (such as transformers) for self-supervised learning of the symbolic latent space as well as for learning predicates can be useful. More generally our results provide evidence that a neuro-symbolic search using neural-network based elementary predicates, trained on a symbolic latent space, may be a promising approach for learning complex reasoning tasks, especially where domain knowledge is available.
## 5. Discussion
While the results presented in this paper pertain to visual analogical reasoning problems, it should be noted that the procedure presented in Section 3 is agnostic to the input modality.
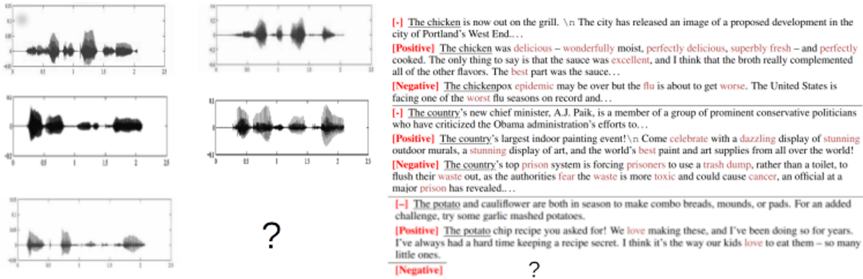
Figure 4 illustrates analogical reasoning problems in speech and text respectively; the first task involves analogical reasoning in speech, where the input corresponds to a speech sample in a male voice and the output samples correspond to the same utterance in a female voice: The task is to infer that this is the transformation involved and analogously generate the output speech signal for the target query. Possible attributes for rules on a speech signal can include discrete values of pitch, tone, volume or others. In the second, text-based example, inputs correspond to positive reflections of an input passage, and the outputs correspond to negative reflections of the same passage. Attributes for text rule identification can similarly include textual aspects like language, sentiment and style. Note that both these examples require generation of the missing target output which is a harder task than classification from a set of possible choices. However, given the recent progress in conditional generation for images [8] and text[9], this seems entirely feasible.
Figure 4.: Analogical reasoning problems across different input modalities.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Spectrograms & Text Snippets: Sentiment Analysis Visualization
### Overview
The image presents six spectrograms arranged in a 2x3 grid, alongside corresponding text snippets. Each spectrogram appears to visually represent audio data, likely speech, with time on the x-axis (ranging from approximately 0 to 15) and amplitude or intensity on the y-axis (ranging from approximately 0 to 1). Each spectrogram is paired with a text excerpt labeled with sentiment: "[+]" for positive, "[-]" for negative, or "[?]" for unknown/unlabeled. The spectrograms are grayscale, with darker areas indicating lower intensity and lighter areas indicating higher intensity.
### Components/Axes
* **Spectrograms:** Six individual visualizations of audio data.
* **X-axis:** Represents time, scaled from approximately 0 to 15.
* **Y-axis:** Represents amplitude or intensity, scaled from approximately 0 to 1.
* **Sentiment Labels:** "[+]", "[-]", "[?]" indicating positive, negative, or unknown sentiment respectively.
* **Text Snippets:** Short excerpts of text associated with each spectrogram.
### Detailed Analysis or Content Details
**Row 1:**
* **Spectrogram 1 (Top-Left):** The spectrogram shows a relatively consistent, low-amplitude signal for the first ~8 time units, followed by a burst of higher-amplitude activity around time unit 9, then a decline.
* **Text 1 (Top-Left):** "[+]" "The chicken is now out on the grill. \n The city has released an image of a proposed development in the city of Portland’s West End…"
* **Spectrogram 2 (Top-Right):** The spectrogram shows a more dispersed signal with varying amplitude throughout the time range. There are several distinct bands of energy.
* **Text 2 (Top-Right):** "[Positive]" "The chicken was delicious – wonderfully moist, perfectly delicious, superbly fresh – and perfectly cooked. The only thing to say is that the sauce was excellent, and I think that the broth really complemented all of the other flavors. The best part was the sauce."
**Row 2:**
* **Spectrogram 3 (Middle-Left):** The spectrogram shows a relatively consistent, low-amplitude signal for the first ~5 time units, followed by a burst of higher-amplitude activity around time unit 6, then a decline.
* **Text 3 (Middle-Left):** "[-]" "The chickenpox epidemic may be over but the flu is about to get worse. The United States is facing one of the worst flu seasons on record…"
* **Spectrogram 4 (Middle-Right):** The spectrogram shows a more dispersed signal with varying amplitude throughout the time range. There are several distinct bands of energy.
* **Text 4 (Middle-Right):** "[+]" "The country’s new chief minister, A.J. Paik, is a member of a group of prominent conservative politicians who have criticized the Obama administration’s efforts to…"
**Row 3:**
* **Spectrogram 5 (Bottom-Left):** The spectrogram shows a relatively consistent, low-amplitude signal for the first ~5 time units, followed by a burst of higher-amplitude activity around time unit 6, then a decline.
* **Text 5 (Bottom-Left):** "[+]" "The potato chip recipe you asked for! We love making these, and I’ve been doing so for years. We always had a hard time keeping a recipe secret. I think it’s the way our kids love to eat them – so many little ones."
* **Spectrogram 6 (Bottom-Right):** Spectrogram is present, but the associated text is missing, indicated by a question mark "[?]" for both the text and sentiment.
### Key Observations
* The spectrograms appear to correlate with the sentiment of the associated text. Positive sentiment text ("delicious," "love") is paired with spectrograms that have more distinct and potentially energetic patterns. Negative sentiment text ("epidemic," "worse") is paired with spectrograms that have more consistent, lower-amplitude patterns.
* The spectrograms do not have clear, easily interpretable features. The visual patterns are subtle and require analysis.
* The last spectrogram has no associated text, indicating incomplete data.
### Interpretation
This image likely represents a visualization of sentiment analysis applied to audio data. The spectrograms are visual representations of speech, and the associated text snippets provide the content of that speech. The sentiment labels indicate whether the speech expresses positive, negative, or neutral/unknown sentiment. The goal is likely to demonstrate a correlation between the acoustic features of speech (as represented by the spectrograms) and the emotional tone of the content.
The varying patterns in the spectrograms suggest that different emotional states are associated with different acoustic characteristics. For example, positive sentiment might be associated with more variation in pitch and amplitude, while negative sentiment might be associated with a more monotone or subdued delivery.
The missing text for the last spectrogram highlights a potential limitation of the analysis: the inability to determine sentiment when the content is unknown. This could be due to errors in speech recognition or a lack of context.
The image suggests that it is possible to automatically detect sentiment from audio data using machine learning techniques. This has applications in areas such as customer service, market research, and mental health monitoring. The image is a demonstration of a system that attempts to correlate audio features with sentiment labels.
</details>
## 6. Related Work
The 'neural algorithmic reasoning'[1] approach presents a procedure for building neural networks that can mimic algorithms. It includes training processor networks that can operate over high-dimensional latent spaces to align with fundamental computations. This improves generalization and reasoning in neural networks. RAVEN[4] combines both visual understanding and structural reasoning using a Dynamic Residual tree (DRT) graph developed from structural representation and aggregates latent features in a bottom-up manner. This provides a direction suggesting that augmenting networks with domain knowledge performs better than black-box neural networks. Scattering Compositional learner(SCL)[6] presents an approach where the model learns a compositional representation by learning independent networks for encoding object, attribute representations and relationship networks for inferring rules, and using their composition to make a prediction. Our work bears similarity with this approach as both utilize background knowledge in composing a larger mechanism from elementary networks. CoPINet[5] presents the Contrastive Perceptual Inference network which is built on the idea of contrastive learning, i.e. to teach concepts by comparing cases. The Dual-Contrast Network (DCNet)[7] works on similar lines as it uses 2 contrasting modules: rule contrast and choice contrast for its training. We draw inspiration from [10] which also presents a variation of the Neural Algorithmic Reasoning approach applied to visual reasoning.
## 7. Conclusion
In this work, we have proposed a novel neuro-symbolic reasoning approach where we learn neural-network based predicates operating on a 'symbolically-derived latent space' and use these in a symbolic search procedure to solve complex visual reasoning tasks, such as RAVENs Progressive Matrices. Our experimental results (though preliminary, in that our predicates are composition of simple MLPs) indicate that our the approach points to a promising direction for neuro-symbolic reasoning research.
## Acknowledgments
This work is supported by 'The DataLab' agreement between BITS Pilani, K.K. Birla Goa Campus and TCS Research, India.
## References
- [1] P. Veličković, C. Blundell, Neural algorithmic reasoning, Patterns 2 (2021) 100273.
- [2] P. Carpenter, M. Just, P. Shell, What one intelligence test measures: A theoretical account of the processing in the raven progressive matrices test, Psychological review 97 (1990) 404-31. doi: 10.1037/0033-295X.97.3.404 .
- [3] F. Chollet, On the measure of intelligence, arXiv preprint arXiv:1911.01547 (2019).
- [4] C. Zhang, F. Gao, B. Jia, Y. Zhu, S.-C. Zhu, Raven: A dataset for relational and analogical visual reasoning, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [5] C. Zhang, B. Jia, F. Gao, Y. Zhu, H. Lu, S.-C. Zhu, Learning perceptual inference by contrasting, in: Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [6] Y. Wu, H. Dong, R. Grosse, J. Ba, The scattering compositional learner: Discovering objects, attributes, relationships in analogical reasoning, 2020. arXiv:2007.04212 .
- [7] T. Zhuo, M. Kankanhalli, Effective abstract reasoning with dual-contrast network, in: International Conference on Learning Representations, 2021. URL: https://openreview.net/ forum?id=ldxlzGYWDmW.
- [8] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, I. Sutskever, Zeroshot text-to-image generation, 2021. URL: https://arxiv.org/abs/2102.12092. doi: 10.48550/ ARXIV.2102.12092 .
- [9] S. Dathathri, A. Madotto, J. Lan, J. Hung, E. Frank, P. Molino, J. Yosinski, R. Liu, Plug and play language models: A simple approach to controlled text generation, 2019. URL: https://arxiv.org/abs/1912.02164. doi: 10.48550/ARXIV.1912.02164 .
- [10] A. Sonwane, G. Shroff, L. Vig, A. Srinivasan, T. Dash, Solving visual analogies using neural algorithmic reasoning, CoRR abs/2111.10361 (2021). URL: https://arxiv.org/abs/2111.10361. arXiv:2111.10361 .
## A. Overview of RAVEN dataset generation
To give an overview of how the RAVEN dataset was generated, the authors used an A-SIG (Attributed Stochastic Grammar) to generate the structural representation of RPM. Each RPM is a parse tree that instantiates from this A-SIG. After this, rules and the initial attributes for that structure are sampled. The rules are applied to produce a valid row. This process is repeated 3 times to generate a valid problem matrix. The answer options are generated by breaking some set of rules. This structured representation is then used to generate images.
The RAVEN dataset provides a structural representation that is semantically linked with the image representation. The structural representation of the image space available in RAVEN makes it generalizable. As each image in a configuration follows a fixed structure, we use this knowledge to generate the corresponding symbolic representations. RAVEN has 10,000 problems for each configuration split into 6000: Train, 2000:Val and 2000:Test. We use the same split for training and validation and provide the results on the test set.
## B. Rule and Attribute definitions
## B.1. Attributes
Number
: The number of entities in a given layout. It could take integer values from [1; 9].
Position
: Possible slots for each object in the layout. Each Entity could occupy one slot.
Type
: Entity types could be triangle, square, pentagon, hexagon, and circle.
Size
: 6 scaling factors uniformly distributed in [0:4; 0:9].
Color
: 10 grey-scale colors
## B.2. Rules
4 different rules can be applied over rule-governing attributes.
Constant : Attributes governed by this rule would not change in the row. If it is applied on Number or Position, attribute values would not change across the three panels. If it is applied on Entity level attributes, then we leave 'as is' the attribute in each object across the three panels.
Progression : Attribute values monotonically increase or decrease in a row. The increment or decrement could be either 1 or 2, resulting in 4 instances in this rule.
Arithmetic : There are 2 instantiations in this rule, resulting in either a rule of summation or one of subtraction. Arithmetic derives the value of the attribute in the third panel from the first 2 panels. For Position, this rule is implemented as set arithmetics.
Distribute Three : This rule first samples 3 values of an attribute in a problem instance and permutes the values in different rows.
## C. Autoencoder, Neural Predicates and Image Encoder
## C.1. Autoencoder
The symbolic encoder 𝐸 S 𝜃 ( 𝑠 ) is trained using the following losses as described in Section 3. As we want to reconstruct the multihot representation, a sum of negative-log likelihood is computed for each one-hot encoding present in the multihot representation. Here 𝑝 𝑘 denotes the output nodes from the decoder corresponding to the 𝑘 𝑡ℎ attribute and 𝑡 𝑘 denotes the one-hot input for the same attribute. In equations 1 and 2 we use the example from RAVEN where the attributes are type, size, color, etc.
<!-- formula-not-decoded -->
<!-- formula-not-decoded -->
## C.2. Neural Predicates for Rule Classification
For every attribute, for each of its rule-type, we train an elementary neural network classifier to verify if the rule is satisfied in the row- this acts as our Rule Identification network. In this work, we refer to any rule identification network 𝐹 using a ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒, 𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) pair for which it is trained. For rule-type Constant and Distribute Three we train a binary classifier. The rules of Progression and Arithmetic are also associated with a value (e.g., Progression could have increments or decrements of 1 or 2), hence for rule-type Arithmetic and Progression, we train a multi-class classifier to also predict the value associated with the rule. Example: A neural network for Center: 𝐹 ( 𝑇𝑦𝑝𝑒,𝐶𝑜𝑛𝑠𝑡𝑎𝑛𝑡 ) is a binary classifier trained to identify if the row from the configuration Center has constant type (shape) across the 3 panels. Similarly a neural network for Left: 𝐹 ( 𝑆𝑖𝑧𝑒,𝑃𝑟𝑜𝑔𝑟𝑒𝑠𝑠𝑖𝑜𝑛 ) is a five-class classifier trained to classify if there is a progression in size in the Left component. This predicts 0 if there is no progression and predicts the progression value: increment or decrement (-2, -1, 1, 2) otherwise.
The latent representations 𝐸 S 𝜃 ( 𝑠 ) obtained after encoding the symbolic representations of each of the three panels in the row are concatenated and sent as input to the neural networks. While training a neural net for a ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒, 𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) pair, we categorize each row with the specific label for that particular rule and attribute, labeling it with 0 if the rule-type is not followed and with 1 or rule-value indicating the level of the rule-type when being followed. As each of these rule-types is deterministic, we can obtain the rule-type and value for each row using their symbolic representations. The overview can be seen in component (ii) of Fig. 2 where we see the input for these elementary neural networks and the expected output determined for the ( 𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒, 𝑟𝑢𝑙𝑒 -𝑡𝑦𝑝𝑒 ) pair. With these labels, each network is optimized using cross-entropy loss. Each network is a shallow MLP classifier with 1 or 2 hidden layers whose dimensions are chosen depending on the configuration and validation set. These classifiers are trained using symbolic representations for each component across the various configurations and we provide the results in Table. 2.
## C.3. Image Encoder
To learn the latent representation of the unstructured data such that it mimics the symbolic latent space, we minimize the mean squared error over all pairs of symbolic and input representations obtained from 𝐸 S 𝜃 ( 𝑠 )) and 𝐸 X 𝜓 ( 𝑥 ) respectively. This enables us to use the previously learned neural networks for rule inference on our image data.
<!-- formula-not-decoded -->
Table 2. component. Blank entries indicate that the rule setting does not exist for that particular component. Eg:
F1-score of rule classification networks. Note: Different components have different set of rules as in the case of Left-Right, Out-In Center, and Out-In Grid, wherein we train a separate set of networks for each Number attribute is always 1 in Center configuration.
| | Center | Left-Right | Left-Right | Up-Down | Up-Down | Out-In Center | Out-In Center | 2x2 Grid | 3x3 Grid | Out-In Grid | Out-In Grid |
|--------------|----------|--------------|--------------|-----------|-----------|-----------------|-----------------|------------|------------|---------------|---------------|
| | | Left | Right | Up | Down | Out | In | | | Out | In Grid |
| Constant | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.99 | 1.0 | 0.94 | 0.94 | 0.99 | 0.91 |
| Distri Three | 1.0 | 0.99 | 0.99 | 0.99 | 1.0 | 0.99 | 0.99 | 0.92 | 0.91 | 0.99 | 0.88 |
| Progression | 0.96 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | 0.96 | 0.99 | 0.97 |
| Constant | 1.0 | 0.99 | 1.00 | 0.99 | 1.0 | 0.99 | 1.0 | 0.91 | 0.90 | 1.0 | 0.95 |
| Distri Three | 1.0 | 0.97 | 0.96 | 0.98 | 0.98 | 1.0 | 0.98 | 0.77 | 0.72 | 0.99 | 0.94 |
| Progression | 0.95 | 0.99 | 0.99 | 0.99 | 0.99 | 0.97 | 0.99 | 0.93 | 0.94 | 0.96 | 0.98 |
| Arithmetic | 0.91 | 0.96 | 0.96 | 0.96 | 0.97 | - | 0.96 | 0.90 | 0.84 | - | 1.0 |
| Constant | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | - | 0.99 | 0.82 | 0.87 | - | 0.86 |
| Distri Three | 0.98 | 0.99 | 0.97 | 0.98 | 0.98 | - | 0.98 | 0.61 | 0.74 | - | 0.63 |
| Progression | 0.99 | 1.0 | 0.99 | 0.99 | 0.98 | - | 0.99 | 0.95 | 0.92 | - | 0.95 |
| Arithmetic | 0.93 | 0.91 | 0.93 | 0.92 | 0.95 | - | 0.94 | 0.78 | 0.68 | - | 0.78 |
| Constant | - | - | - | - | - | - | - | 0.93 | 0.92 | - | 0.96 |
| Distri Three | - | - | - | - | - | - | - | 0.81 | 0.77 | - | 0.83 |
| Progression | - | - | - | - | - | - | - | 0.97 | 0.85 | - | 0.95 |
| Arithmetic | - | - | - | - | - | - | - | 0.96 | 0.84 | - | 0.94 |
| Constant | - | - | - | - | - | - | - | 0.93 | 0.92 | - | 0.96 |
| Distri Three | - | - | - | - | - | - | - | 0.87 | 0.94 | - | 0.89 |
| Progression | - | - | - | - | - | - | - | 0.95 | 0.96 | - | 0.93 |
| Arithmetic | - | - | - | - | - | - | - | 0.95 | 0.92 | - | 0.93 |
## D. Search Algorithm
## Algorithm 1. Search Overview
```
```