# Inferring Past Human Actions in Homes with Abductive Reasoning
## Abstract
Abductive reasoning aims to make the most likely inference for a given set of incomplete observations. In this paper, we introduce “Abductive Past Action Inference", a novel research task aimed at identifying the past actions performed by individuals within homes to reach specific states captured in a single image, using abductive inference. The research explores three key abductive inference problems: past action set prediction, past action sequence prediction, and abductive past action verification. We introduce several models tailored for abductive past action inference, including a relational graph neural network, a relational bilinear pooling model, and a relational transformer model. Notably, the newly proposed object-relational bilinear graph encoder-decoder (BiGED) model emerges as the most effective among all methods evaluated, demonstrating good proficiency in handling the intricacies of the Action Genome dataset. The contributions of this research significantly advance the ability of deep learning models to reason about current scene evidence and make highly plausible inferences about past human actions. This advancement enables a deeper understanding of events and behaviors, which can enhance decision-making and improve system capabilities across various real-world applications such as Human-Robot Interaction and Elderly Care and Health Monitoring. Code and data available at https://github.com/LUNAProject22/AAR
## 1 Introduction
Reasoning is an inherent part of human intelligence as it allows us to draw conclusions and construct explanations from existing knowledge when dealing with an uncertain scenario. One of the reasoning abilities that humans possess is abductive reasoning. Abductive reasoning aims to infer the most compelling explanation for a given set of observed facts based on a logical theory. In this work, we study the new problem of inferring past human actions from visual information using abductive inference. It is an extremely useful tool in our daily life, as we often rely on a set of facts to form the most probable conclusion. In fact, a comprehensive understanding of a situation requires considering both past and future information. The ability to perform abductive reasoning about past human actions is vital for human-robot collaboration AI-assisted accident and crime investigation and assistive robotics. Furthermore, robots working in dynamic environments benefit from understanding previous human actions to better anticipate future behaviour or adapt their actions accordingly. Imagine the scenario where a rescue robot enters an elderly person’s house to check on why he or she is not responding to the routine automated phone call. Upon entering the house, the robot observes its surroundings and notices that the back door is left open but nothing else is out of the ordinary. These observations may form a basis for a rational agent – the elderly might have opened the door and went into the garden. The robot can immediately make its way to search for him/her in the back garden. This example illustrates how a social rescue robot can utilize observed facts from the scene to infer past human actions, thereby reasoning about the individual’s whereabouts and ensuring their safety through abductive reasoning.
In recent years, there have been some great initiatives made in abductive reasoning for computer vision [25, 48, 19]. In particular, [25] generates the description of the hypothesis and the premises in the natural language given a video snapshot of events. Without the generation of a hypothesis description, these methods boil down to dense video captioning. A similar task is also presented in [19] where given an image, the model must perform logical abduction to explain the observation in natural language. The use of natural language queries in these tasks presents challenges related to language understanding, making the abductive reasoning task more complicated.
In contrast to these recent works, we challenge a model to infer multiple human actions that may have occurred in the past from a given image. Based on the visual information from the image, objects such as a person, glass and cabinet, may provide clues from which humans can draw conclusions – see Fig. 1. We term this new task, Abductive Past Action Inference and further benchmark how deep learning models perform on this challenging new task. For this task, the models are not only required to decipher the effects of human actions resulting in different environment states but also solve causal chains of action effects, a task that can be challenging even for humans. Furthermore, the task relies on the model’s ability to perform abductive reasoning based on factual evidence i.e., determining what actions may have or have not been performed based on visual information in the image. Humans can solve this task by using prior experience (knowledge) about actions and their effects and using reasoning to make logical inferences. Are deep learning models able to perform abductive past action inference by utilizing visual knowledge present in a given image and a learned understanding of the domain? We aim to answer this question in this paper.
Human action can be viewed as an evolution of human-object relationships over time. Therefore, the state of human-object relations in a scene may give away some cues about the actions that may have been executed by the human. We hypothesize that deep learning models are able to perform logical abduction on past actions using visual and semantic information of human-object relations in the scene. As these human-object relations provide substantial visual cues about actions and the effects of past actions, it makes it easier for the models to infer past actions. On the other hand, there is also the duality in which the evidence should support those conclusions (the actions inferred by the model). If a human executed a set of actions $\mathcal{A}$ which resulted in a state whereby a human-object relation set $\mathcal{R}$ is formed as an effect of those executed actions (i.e., $\mathcal{A}\rightarrow\mathcal{R}$ ), then using the relational information, we can formulate the task by aiming to infer $\mathcal{A}$ from $\mathcal{R}$ . Therefore, we argue that human-object relational representations are vital for abductive past action inference and provide further justifications in our experiments.
In this work, our models rely on the human-centric object relation tuples such as (person, glass) and (person, closet) obtainable from a single image at the current point in time to perform abductive past action inference. One can see why these human-centric relations are vital for identifying past actions: the (person, glass) relation may lead to deriving actions such as (person-pouring-water, person-took-glass-from-somewhere) while (person, closet) may imply actions such as (person-opening-closet, person-closing-closet) see – Figure 1. Therefore, we use objects and their relationships in the scene to construct human-centric object relations within each image. These relations are made up of both visual and semantic features of recognized objects. To effectively model relational information, we use bilinear pooling and to model inter-relational reasoning, we use a new relational graph neural network (GNN). We propose a new model called BiGED that uses both bilinear pooling and GNNs to effectively reason over human-object relations and inter-relational information of an image to perform abductive inference on past actions effectively.
Our contributions are summarized as follows: (1) To the best of our knowledge, we are the first to propose the abductive past action inference task, which involves predicting past actions through abductive inference. (2) We benchmark several image, video, vision-language, and object-relational models on this problem, thereby illustrating the importance of human-object relational representations. Additionally, we develop a new relational rule-based inference model which serve as relevant baseline models for the abductive past action inference task. (3) We propose a novel relational bilinear graph dncoder-decoder model (BiGED) to tackle this challenging reasoning problem and show the effectiveness of this new design.
## 2 Related Work
Our work is different from action recognition [20, 18] in a fundamental way. First, in action recognition, the objective is to identify the actions executed in the visible data (e.g., a video or an image in still image action recognition [15]). In action recognition, the models can learn from visual cues what the action looks like and what constitutes an action. In our work, we aim to infer past actions that the model has never seen the human performing. The model only sees visual evidence (e.g. human-object relations) in the scene which is the outcome of executed actions. There are no motion cues or visual patterns of actions that the model can rely on to predict past actions. From a single static image, the machine should infer what actions may have been executed. This is drastically different from classical action recognition and action anticipation tasks.
Abductive past action inference shares some similarity to short-term action anticipation [11, 9] and long-term action anticipation [1]. However, there are several notable differences between the two tasks. Firstly, in abductive past action inference, the goal of the model is to identify the most plausible actions executed by a human in the past based on the current evidence, whereas, in action anticipation, the model learns to predict future action sequences from current observations. The primary distinction lies in abductive past action inference, where observations (evidence) may imply certain past actions, contrasting with action anticipation tasks that predict future actions without certainty. In other words, in abductive past action inference, the evidence and clues indicate possible actions executed in the past that resulted in the evidence or clues. However, in action anticipation, the clues [37], context [14], current actions [13], and knowledge about the task [49] are used to infer probable future actions, but there is no guarantee that the predicted actions will be executed by a human. For instance, observing a person cleaning a room with a broom suggests prior actions such as picking up the broom from somewhere must have happened among many others. Even if putting away the broom is anticipated somewhere in the future, other actions such as holding the broom and opening a window are also possible. Therefore, while action anticipation addresses the uncertainty of future human behavior, abductive past action inference models can utilize scene evidence (such as objects in the scene) to infer the most likely past actions. Additionally, in abductive past action inference, the uncertainty arises from the fact that several different actions may have resulted in similar states $\mathcal{R}$ . In our task, models should comprehend the consequences of each executed action and engage in abductive reasoning to infer the most probable set or sequence of past actions. Another key difference between action anticipation and abductive past action inference is that in action anticipation, predictions made at time $t$ can leverage all past observations. In contrast, abductive past action inference relies solely on present and future information, where new future observations can potentially alter the evidence about past actions, making the inference process more challenging.
Visual Commonsense Reasoning (VCR) [47, 45] and causal video understanding [30, 31] are also related to our work. In VCR [47], given an image, object regions, and a question, the model should answer the question regarding what is happening in the given frame. The model has to also provide justifications for the selected answer in relation to the question. Authors in [29] also studied a similar problem where a dynamic story underlying the input image is generated using commonsense reasoning. In particular, VisualCOMET [29] extends VCR and attempts to generate a set of textual descriptions of events at present, a set of commonsense inferences on events before, a set of commonsense inferences on events after, and a set of commonsense inferences on people’s intents at present. In this vein, given the complete visual commonsense graph representing an image, they propose two tasks; (1) generate the rest of the visual commonsense graph that is connected to the current event and (2) generate a complete set of commonsense inferences. In contrast, given an image without any other natural language queries, we recognize visual objects in the scene and how they are related to the human, then use the human-centric object relational representation to infer the most likely actions executed by the human.
Recently, there are machine learning models that can also perform logical reasoning [6, 50, 4, 16, 22]. Visual scene graph generation [42] and spatial-temporal scene graph generation [5] are also related to our work. Graph neural networks are also related to our work [39, 46, 40]. Our work is also related to bilinear pooling methods such as [12, 10].
<details>
<summary>extracted/6142422/images/tasks_without.png Details</summary>
### Visual Description
## Diagram: Three-Stage Action Inference Pipeline
### Overview
The image is a technical diagram illustrating a three-stage pipeline for inferring human actions from visual data. The process flows from left to right, starting with raw visual input and culminating in a verified sequence of actions. The diagram is divided into three main colored panels, each representing a distinct stage: Object Detection (grey), Relational Modelling (purple), and Abductive Action Inference (blue).
### Components/Axes
The diagram is structured as a horizontal flowchart with three primary stages connected by large, right-pointing arrows.
1. **Stage 1: Object Detection (Left Panel)**
* **Header:** "Object Detection" in white text on a grey background.
* **Visual Content:** A photograph of a person in a kitchen setting. The person is holding a white bottle (with a blue cap) in their right hand and an orange glass in their left hand.
* **Annotations:** Three colored bounding boxes are drawn on the image:
* A **cyan box** around the white bottle.
* A **red box** around the orange glass.
* A **green box** around the person's torso and arms.
2. **Stage 2: Relational Modelling (Middle Panel)**
* **Header:** "Relational Modelling" in white text on a purple background.
* **Visual Content:** This panel contains cropped and isolated elements from the first image, with arrows indicating relationships.
* Top: The cropped image of the white bottle (cyan border).
* Bottom Left: The cropped image of the orange glass (red border).
* Bottom Right: The cropped image of the person's torso/arms (green border).
* **Annotations:** Two green, double-headed arrows show relationships:
* One arrow connects the bottle (top) to the person (bottom right).
* Another arrow connects the glass (bottom left) to the person (bottom right).
3. **Stage 3: Abductive Action Inference (Right Panel)**
* **Header:** "Abductive Action Inference" in white text on a blue background.
* **Sub-Stages:** This panel is further divided into three numbered sub-steps, each with a black header and a white content box.
* **Sub-step 1:** Header "Set of actions". Content is a bulleted list.
* **Sub-step 2:** Header "Sequence of actions". Content is a numbered list.
* **Sub-step 3:** Header "Language query-based action verification". Content is a bulleted list with verification answers.
### Detailed Analysis
**Text Transcription from Stage 3 (Abductive Action Inference):**
* **Sub-step 1: Set of actions**
* Take glass
* Hold glass
* Open cabinet
* Close cabinet
* Pour into glass
* **Sub-step 2: Sequence of actions**
1. Open cabinet
2. Take glass
3. Close cabinet
4. Hold glass
5. Pour into glass
* **Sub-step 3: Language query-based action verification**
* Open cabinet? **Yes.** (Answer in green)
* Take glass? **Yes.** (Answer in green)
* Close cabinet? **Yes.** (Answer in green)
* Hold glass? **Yes.** (Answer in green)
* Pour into glass? **Yes.** (Answer in green)
* Drinking? **No.** (Answer in red)
* Washing glass? **No.** (Answer in red)
### Key Observations
1. **Process Flow:** The pipeline moves from low-level perception (detecting objects) to mid-level understanding (modeling relationships between objects and the person) to high-level reasoning (inferring and verifying a logical sequence of actions).
2. **Color Consistency:** The bounding box colors (cyan for bottle, red for glass, green for person) are consistently maintained from the Object Detection stage into the Relational Modelling stage, providing clear visual tracking of entities.
3. **Action Logic:** The inferred "Sequence of actions" (Sub-step 2) presents a plausible, temporally ordered narrative that is a subset of the broader "Set of actions" (Sub-step 1). The sequence logically progresses from accessing a cabinet to manipulating the glass.
4. **Verification Outcome:** The verification step (Sub-step 3) confirms all actions in the inferred sequence ("Open cabinet", "Take glass", etc.) as present ("Yes"). It also explicitly rules out two related but absent actions ("Drinking?", "Washing glass?") with "No" answers, demonstrating the system's discriminative capability.
### Interpretation
This diagram outlines a technical approach for an AI system to understand human activity. It demonstrates a **Peircean abductive reasoning** process: starting with observed evidence (detected objects), the system forms a hypothesis about the relationships between them, and then infers the most likely *explanation*—a coherent sequence of actions that could have produced the observed scene.
The pipeline's strength lies in its structured progression. Object Detection provides the raw "what." Relational Modelling adds the "how they interact." Abductive Action Inference then answers the "why" by constructing a plausible story (the action sequence) and rigorously testing it against language-based queries. The final verification step is crucial, as it moves beyond mere pattern matching to a form of commonsense validation, distinguishing between actions that are part of the narrative (pouring) and those that are contextually similar but not occurring (drinking). This suggests a system designed not just for recognition, but for robust, explainable activity understanding.
</details>
Figure 1: Proposed object-relational approach for abductive past action inference. Models are tasked to: 1) abduct the set of past actions, 2) abduct the sequence of past actions, and 3) perform abductive past action verification.
## 3 Abductive Past Action Inference
Task: Given a single image, models have to infer past actions executed by humans up to the current moment in time. We name this task Abductive Past Action Inference. Let us denote a human action by $a_{i}\in A$ where $A$ is the set of all actions and $E_{1},E_{2},\cdots$ is a collection of evidence from the evidence set $\mathcal{E}$ . As the evidence is a result of actions, we can write the logical implication $\mathcal{A}\rightarrow\mathcal{E}$ where $\mathcal{A}$ is the set of actions executed by a human which resulted in a set of evidence $\mathcal{E}$ . Then, the task aims to derive 1) the set of past actions, 2) the sequence of past actions that resulted in the current evidence shown in the image, and 3) abductive past action verification. The abductive past action verification is a binary task where the model is given a single image and is required to answer a yes or no to an action query (did the person execute action $a_{x}$ in the past?).
### 3.1 Object-Relational Representation Approach
Our primary hypothesis is that human-object relations are essential for abductive past action inference. Therefore, we propose a human-object relational approach for the task. In all three tasks, our general approach is as follows. We make use of detected humans and objects in the image and then generate a representation for human-centric object relations. Then, using these human-centric object relations, we summarize the visual image, and using neural models, we infer the most likely actions executed by the human. The overview of this approach is shown in Figure 1. Next, we first discuss abductive past action set inference, followed by the details of abductive past action verification.
#### Abductive past action set prediction.
Let us denote the object by $o\in O$ , the predicate category by $p\in P$ , and the human by $h$ . The $j^{th}$ relation $R_{j}$ is a triplet of the form $\left<h,p,o\right>$ . In the $i^{th}$ image, we observe $n$ number of relations $\mathcal{R}_{i}=\{R_{1},R_{2},\cdots R_{n}\}$ where $\mathcal{R}_{i}$ is the relation set present in the situation shown in that image. These relations constitute the evidence ( $\mathcal{E}$ ). The relation set $\mathcal{R}_{i}$ is an effect of a person executing an action set/sequence $\mathcal{A}_{i}=\{a_{1},\cdots a_{K}\}$ . Therefore, the following association holds.
$$
\mathcal{A}_{i}\rightarrow\mathcal{R}_{i} \tag{1}
$$
However, we do not know which action caused which relation (evidence), as this information is not available. The association reveals that there is a lack of specific knowledge about the exact effects of individual actions and when multiple actions have been executed, the resulting effect is a combined effect of all executed actions. Consequently, the learning mechanism must uncover the probable cause-and-effect relationships concerning actions. Therefore, given $\mathcal{R}$ we aim to perform abductive past action inference to infer the most likely set of actions executed by the human using neural network learning.
We learn this abduction using the deep neural network functions $\phi()$ , and $\phi_{c}()$ . The relational model, $\phi$ takes relation set as input and outputs a summary of relational information as a vector $x_{r}$ .
$$
x_{r}=\phi(R_{1},\cdots,R_{n};\theta_{\phi}) \tag{2}
$$
The parameters of the relational model are denoted by $\theta_{\phi}$ . The linear classifier ( $\phi_{c}$ ) having the parameters $\theta_{{c}}$ , takes relational information as a vector $x_{r}$ as input and returns the conditional probability of actions given the relational evidence as follows:
$$
P(a_{1},\cdots,a_{K}|R_{1},\cdots,R_{n})=\phi_{c}(x_{r};\theta_{{c}}) \tag{3}
$$
The training and inference sets comprise images and corresponding action set $\mathcal{A}_{i}$ . From each image, we extract the relation set $\mathcal{R}_{i}$ . Therefore, the dataset consists of $\mathcal{D}=\bigcup_{i}\{\mathcal{R}_{i},\mathcal{A}_{i}\}$ . Given the training set ( $\mathcal{D}$ ), we learn the model function in Equations 2 and 3 using backpropagation as follows:
$$
\theta_{\phi}^{*},\theta_{{c}}^{*}=\texttt{argmin}_{\theta_{\phi},\theta_{{c}}
}\sum_{i}-log(P(\mathcal{A}_{i}|\mathcal{R}_{i})) \tag{4}
$$
where $\theta_{\phi}^{*},\theta_{{c}}^{*}$ are the optimal parameters. As this is a multi-label-multi-class classification problem, we utilize the max-margin multi-label loss from PyTorch where the margin is set to 1, during training.
#### Abductive past action verification.
Abductive verification model $\phi_{ver}()$ takes the evidence $\mathcal{E}$ and the semantic representation of the past action (e.g. textual encoding of the action name) $y_{a}$ as inputs and outputs a binary classification score indicating if the evidence supports the action or not, i.e. $\phi_{ver}(\mathcal{E},y_{a})\rightarrow[0,1]$ . Specifically, we encode the past action name using the CLIP [33] text encoder to obtain the textual encoding $y_{a}$ for action class $a$ . Then, we concatenate $y_{a}$ with $x_{r}$ and utilize a two-layer MLP to perform binary classification to determine whether action $a$ was executed or not. We use the max-margin loss to train $\phi_{ver}()$ . Note that semantic embedding of action classes ( $y_{a}$ ) is not a necessity here. For example, one might learn the class embeddings from scratch removing the dependency on language or use one-hot-vectors.
### 3.2 Relational Representation
To obtain the relation representation, we extract features from the human and object regions of each image using a FasterRCNN [36] model with a ResNet101 backbone [17]. Let us denote the human feature by $x_{h}$ , the object feature by $x_{o}$ , and the features extracted from taking the union region of both human and object features by $x_{u}$ . As we do not know the predicate or the relationship label for the relation between $x_{h}$ and $x_{o}$ , we use the concatenation of all three visual features $x_{h}$ , $x_{o}$ , and $x_{u}$ as the joint relational visual feature $x_{v}=[x_{h},x_{o},x_{u}]$ . Using FasterRCNN, we can also obtain the object and human categories. We use Glove [32] embedding to acquire a semantic representation of each human and object in the image. Let us denote the Glove embedding of the human by $y_{h}$ and the object by $y_{o}$ . Then, the semantic representation of the relation is given by $y_{s}=[y_{h},y_{o}]$ . Using both visual and semantic representations, we obtain a joint representation for each human-centric object relation in a given image. Therefore, the default relation representation for a relation $R=<h,p,o>$ is given by $r=[x_{v},y_{s}]$ . Note that we do not have access to the predicate class or any information about the predicate. Next, we present several neural and non-neural models that we developed in this paper that uses relational representations for the abductive past action inference task.
The details of abductive past action sequence inference are provided in the supplementary materials (section 4.1). Next, we present our graph neural network model to infer past actions based on relational information.
### 3.3 GNNED: Relational Graph Neural Network
The graph neural network-based encoder-decoder model summarizes relational information for abductive past action inference. Given the relational data with slight notation abuse, let us denote the relational representations by a $n\times d$ matrix $\mathcal{R}=[r_{1},r_{2},\cdots,r_{n}]$ , where $r_{n}$ has $d$ dimensions. In our graph neural network encoder-decoder (GNNED) model, we first project the relational data using a linear function as follows:
$$
\mathcal{R^{\prime}}=\mathcal{R}W_{l}+b_{l} \tag{5}
$$
where $\mathcal{R^{\prime}}=[r^{\prime}_{1},r^{\prime}_{2},\cdots,r^{\prime}_{n}]$ . Then, we construct the affinity matrix $W_{A}(i,j)$ using Jaccard Vector similarity, where $W_{A}(i,j)$ shows the similarity/affinity between the i-th relation and the j-th relation in the set. Here, we use Jaccard Vector Similarity which is a smooth and fully differentiable affinity [9]. Note that Jaccard Vector Similarity is bounded by [-1,1]. Thereafter, we obtain the graph-encoded relational representation as follows:
$$
G_{e}=ReLU((W_{A}\mathcal{R^{\prime}})W_{g}+b_{g}) \tag{6}
$$
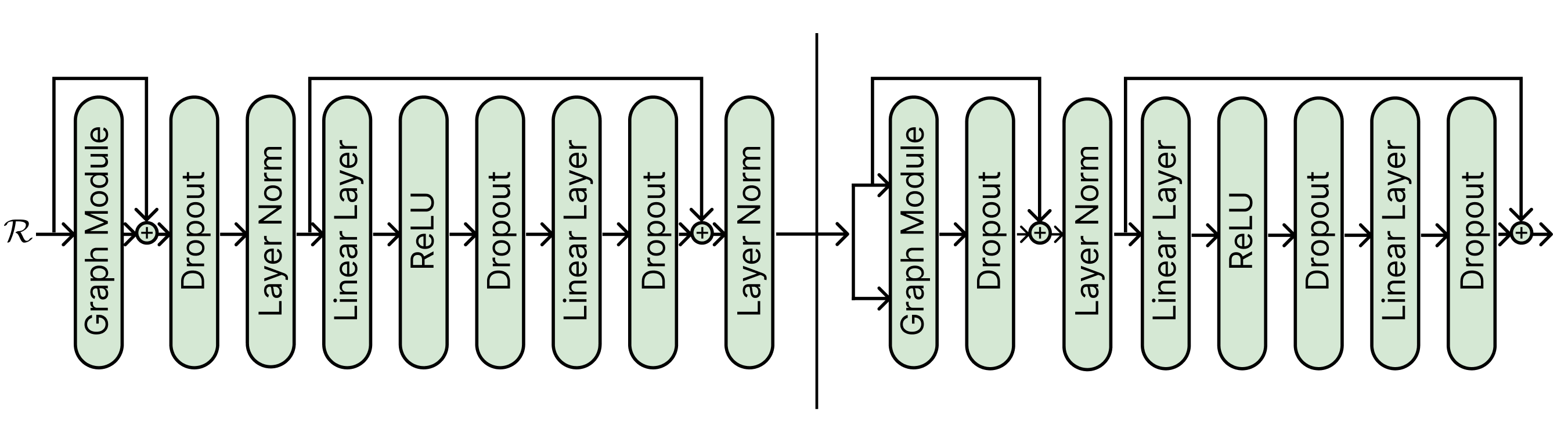
where $W_{g}$ and $b_{g}$ are the weight matrix and bias term respectively. We call equations 5 - 6 the graph module. Using the graph module as a base model, we develop a graph encoding layer. The relational graph neural network encoder-decoder architecture we proposed is shown in Figure 2. Our graph encoder-decoder model consists of one graph encoder and three graph decoders by default. The graph module is able to model the inter-relations between human-object relations and reasons about them to perform abduction on past actions. The graph encoding layer (left) is very similar to the Transformer encoder layer [43]. The graph encoding layer consists of drop-out layers, layer norm [2], linear layers, and residual connections [17]. The graph decoder layer (right) is also similar to a Transformer decoder layer except for the graph module. Finally, we apply max-pooling at the end of the graph encoder-decoder model to obtain the final image representation $x_{r}$ .
<details>
<summary>extracted/6142422/images/graphed_updated.png Details</summary>
### Visual Description
## Diagram: Neural Network Architecture Block Diagram
### Overview
The image displays a detailed block diagram of a neural network architecture, specifically illustrating the data flow and layer composition of two sequential processing blocks or stages. The diagram uses rounded rectangular nodes to represent different layer types, connected by directional arrows indicating the forward pass. A vertical line separates the diagram into two distinct, but structurally similar, major sections. The overall flow is from left to right.
### Components/Axes
**Input:**
* **ℛ**: Located at the far left, this symbol (likely representing a representation, feature map, or tensor) is the input to the entire architecture.
**Layer Types (Nodes):**
The following layer types are used as building blocks, listed in the order they first appear:
1. **Graph Module**
2. **Dropout**
3. **Layer Norm**
4. **Linear Layer**
5. **ReLU**
6. **Linear Layer** (second instance)
7. **Dropout** (second instance)
8. **Layer Norm** (second instance)
**Connectivity Elements:**
* **Arrows**: Indicate the primary sequential data flow between layers.
* **Skip Connections / Residual Paths**: Represented by arrows that bypass one or more layers. These paths originate before a block of layers and terminate at a summation point (⊕) after the block, where the bypassed signal is added to the processed signal.
* **⊕ (Summation Point)**: A circle with a plus sign, indicating element-wise addition of the main path and a skip connection.
* **Vertical Line**: A solid black line dividing the diagram into a left section (first block) and a right section (second block).
### Detailed Analysis
**Left Section (First Block):**
1. The input **ℛ** splits into two paths:
* **Main Path**: Flows into a **Graph Module**.
* **Skip Connection**: Bypasses the Graph Module.
2. The outputs of the Graph Module and the skip connection meet at a **summation point (⊕)**.
3. The summed signal then flows sequentially through: **Dropout** → **Layer Norm** → **Linear Layer** → **ReLU** → **Dropout** → **Linear Layer** → **Dropout**.
4. After the final Dropout in this sequence, another **skip connection** originates from the point *after the first Layer Norm* (i.e., before the first Linear Layer) and connects to a second **summation point (⊕)**.
5. The output of this second summation flows into a final **Layer Norm**.
6. The output of this Layer Norm is the output of the left section and becomes the input to the right section.
**Right Section (Second Block):**
1. The input from the left section splits into two paths:
* **Main Path**: Flows into a **Graph Module**.
* **Skip Connection**: Bypasses the Graph Module.
2. The outputs meet at a **summation point (⊕)**.
3. The summed signal flows sequentially through: **Dropout** → **Layer Norm** → **Linear Layer** → **ReLU** → **Dropout** → **Linear Layer** → **Dropout**.
4. After the final Dropout, a **skip connection** originates from the point *after the Layer Norm* (i.e., before the first Linear Layer in this block) and connects to a final **summation point (⊕)**.
5. The output of this final summation is the output of the entire depicted architecture.
### Key Observations
1. **Residual Learning Framework**: The architecture heavily utilizes residual (skip) connections, a hallmark of modern deep networks (e.g., ResNets) designed to mitigate the vanishing gradient problem and enable training of deeper models.
2. **Two-Stage Processing**: The vertical line suggests the model is composed of at least two major, potentially repeated, blocks or stages. The second block is not an exact copy of the first; its first skip connection bypasses only the Graph Module and Dropout, whereas the first block's initial skip bypasses only the Graph Module.
3. **Layer Composition**: Each block combines:
* **Graph-based processing** (Graph Module).
* **Regularization** (Dropout layers appear frequently).
* **Normalization** (Layer Norm).
* **Linear transformations** (Linear Layers).
* **Non-linear activation** (ReLU).
4. **Pattern of Operations**: A common sub-pattern within each block is: `Linear Layer -> ReLU -> Dropout -> Linear Layer -> Dropout`, which is a standard feed-forward network structure often found in Transformer architectures.
### Interpretation
This diagram represents a sophisticated deep learning model designed for tasks where relational or graph-structured data is important, as indicated by the "Graph Module." The architecture is engineered for stability and depth through the extensive use of Layer Normalization and residual connections.
The flow suggests a hybrid model: it first processes input through a graph-aware operation, then passes the result through a series of transformations that resemble a Transformer's feed-forward sublayer (Linear-ReLU-Dropout-Linear-Dropout). The residual connections are strategically placed to allow gradients to flow directly through the network during backpropagation, facilitating the training of a deep stack of such blocks.
The separation into two blocks by the vertical line could indicate a hierarchical feature extraction process, where the first block processes low-level graph features and the second block processes higher-level abstractions. The slight variation in skip connection topology between the two blocks might be an architectural choice to create different levels of feature refinement or to control the information flow. Overall, this is a blueprint for a deep graph neural network with strong regularization and normalization components.
</details>
Figure 2: The graph neural network encoder (left) and graph neural network decoder (right) architecture. The residual connections are shown with the $+$ sign.
<details>
<summary>extracted/6142422/images/biged.png Details</summary>
### Visual Description
## Diagram: Neural Network Architecture for Human-Object Interaction Feature Processing
### Overview
The image displays a technical block diagram of a neural network architecture designed to process and combine features related to human-object interactions. The diagram illustrates the flow of data from three input feature sets through various processing modules to produce a final classification output. The overall flow is from left to right, with inputs on the left, intermediate processing in the center, and the final output on the right.
### Components/Axes
The diagram is composed of labeled blocks (modules), feature representations (colored 3D blocks), and directional arrows (solid and dashed) indicating data flow and operations.
**Input Features (Left Side):**
1. **Human Feature**: Represented by a red 3D block. Labeled with the text "Human Feature" and the mathematical notation \( x_h \).
2. **Object Feature**: Represented by a green 3D block. Labeled with the text "Object Feature" and the mathematical notation \( [x_o, y_o] \).
3. **Union Feature**: Represented by an orange 3D block. Labeled with the text "Union Feature" and the mathematical notation \( x_u \).
**Processing Modules (Center):**
1. **GNNED**: A light green rounded rectangle. This acronym likely stands for Graph Neural Network Encoder-Decoder or similar. It appears twice in the diagram.
2. **Bilinear Module**: A pink rounded rectangle.
3. **Linear Layer**: A light purple rounded rectangle.
4. **Classifier MLP**: A light purple rounded rectangle. MLP stands for Multi-Layer Perceptron.
**Intermediate and Output Features:**
1. A green 3D block (output of the first GNNED).
2. A yellow 3D block (output of the Bilinear Module).
3. A blue 3D block (output of the second GNNED).
4. **Relational Features**: A composite 3D block made of yellow, blue, and orange segments. Labeled with the text "Relational Features".
5. \( x_r \): A composite 3D block (yellow, blue, orange) representing the final relational feature vector.
6. **Past Actions**: The final output text label.
**Operations:**
1. **Concat**: Labeled twice, indicating a concatenation operation. One instance combines the red (Human) and green (Object) features. The other combines the yellow, blue, and orange features to form the "Relational Features".
### Detailed Analysis
**Data Flow and Connections:**
1. **Path 1 (Top Branch):**
* The **Human Feature** (\( x_h \), red) is fed directly into the **Bilinear Module** via a solid arrow.
* The **Human Feature** (\( x_h \)) is also fed into the first **GNNED** module via a dashed arrow.
* The **Object Feature** (\( [x_o, y_o] \), green) is fed into the first **GNNED** module via a solid arrow.
* The output of the first **GNNED** (a green 3D block) is fed into the **Bilinear Module** via a solid arrow.
* The **Bilinear Module** processes the direct human feature and the GNNED-processed object feature, outputting a **yellow 3D block**.
2. **Path 2 (Bottom Branch):**
* The **Human Feature** (\( x_h \), red) and the **Object Feature** (\( [x_o, y_o] \), green) are combined via a **Concat** operation (dashed arrow) to form a composite red-green 3D block.
* This concatenated feature is passed through a **Linear Layer** (solid arrow).
* The output of the Linear Layer is fed into a second **GNNED** module (solid arrow).
* The second **GNNED** module outputs a **blue 3D block**.
3. **Feature Fusion and Classification:**
* The **yellow block** (from Path 1), the **blue block** (from Path 2), and the original **Union Feature** (\( x_u \), orange) are combined via a **Concat** operation (dashed arrows converging) to form the **Relational Features** block.
* This combined feature is represented as \( x_r \).
* The feature vector \( x_r \) is fed into the **Classifier MLP** (solid arrow).
* The final output of the Classifier MLP is labeled **Past Actions**.
### Key Observations
* **Dual-Path Processing:** The architecture employs two distinct pathways to process the relationship between human and object features. One path uses a bilinear interaction after separate GNNED processing, while the other uses early concatenation followed by a linear layer and GNNED.
* **Feature Re-use:** The Human Feature (\( x_h \)) is used in three places: directly in the Bilinear Module, as input to the first GNNED, and as part of the concatenation for the bottom branch.
* **Union Feature Integration:** The Union Feature (\( x_u \)) is not processed through any intermediate modules; it is directly concatenated with the outputs of the two processing branches to form the final relational representation.
* **Notation:** The use of mathematical notation (\( x_h, [x_o, y_o], x_u, x_r \)) suggests this diagram is from a formal research paper or technical report.
* **Visual Coding:** Colors are used consistently to track feature types: red for human, green for object, orange for union, yellow for bilinear-path output, and blue for concatenation-path output.
### Interpretation
This diagram represents a sophisticated model for understanding human-object interactions, likely for tasks such as action recognition or anticipation in computer vision. The core idea is to learn a rich "relational feature" (\( x_r \)) that encapsulates the interaction between a human and an object by fusing multiple perspectives:
1. **Bilinear Perspective:** Captures multiplicative interactions between human features and object features that have been contextualized by a graph network (GNNED).
2. **Concatenation Perspective:** Captures additive, joint representations of human and object features after linear transformation and graph-based processing.
3. **Contextual Perspective:** Directly includes the "Union Feature" (\( x_u \)), which likely represents the visual context or the bounding box encompassing both the human and the object.
By combining these three streams, the model aims to create a comprehensive representation (\( x_r \)) that is then classified by an MLP to predict **Past Actions**. The architecture suggests that understanding an action requires analyzing the human, the object, their direct interaction, and the surrounding context in an integrated manner. The use of GNNED modules implies that the features themselves may have a graph structure (e.g., body joints for the human, object parts).
</details>
Figure 3: The Bilinear Graph Encoder-Decoder (BiGED) architecture.
### 3.4 RBP: Relational Bilinear Pooling
To effectively model the higher-order relational information between human and object features, we use bilinear pooling. Given the human representation $x_{h}$ and the object representation $x_{o}$ , we use bilinear pooling with a weight matrix $W_{b}$ of size $d\times d\times d$ and linear projection matrices $W_{bl},W_{jb}$ as follows:
$$
\displaystyle o^{\prime} \displaystyle=ReLU(W_{o}x_{o}+b_{o}) \displaystyle h^{\prime} \displaystyle=ReLU(W_{h}x_{h}+b_{h}) \displaystyle r_{b} \displaystyle=ReLU([h^{\prime}W_{b}o^{\prime};([h^{\prime};o^{\prime}]W_{bl}+b
_{bl})])W_{jb}+b_{jb} \tag{7}
$$
where [;] represents the vector concatenation and $h^{\prime}W_{b}o^{\prime}$ is the bilinear pooling operator applied over human and object features. $([h^{\prime};o^{\prime}]W_{bl}+b_{bl})$ is the output of concatenated human and object features followed by a linear projection using weight matrix $W_{bl}$ and bias term $b_{bl}$ . In contrast to bilinear pooling, the concatenated linear projection captures direct relational information between human and object features. Then, we concatenate the bilinear pooled vector ( $h^{\prime}W_{b}o^{\prime}$ ) and the output of the linear projection ( $([h^{\prime};o^{\prime}]W_{bl}+b_{bl})$ ). Next, we use ReLU and apply another linear projection ( $W_{jb}+b_{jb}$ ). Finally, we concatenate the overlap feature $x_{u}$ with the overall model output ( $r_{b}$ ) and apply max-pooling across all relational features ( $[r_{b};x_{u}]$ ) in the image to obtain $x_{r}$ .
### 3.5 BiGED: Bilinear Graph Encoder-Decoder
Finally, to take advantage of both bilinear relational modeling and graph neural network encoder-decoder models, we combine both strategies as shown in Fig 3. The main idea is to replace the projection function in Equation 7 with a graph neural network encoder-decoder model. Let us denote the graph neural network encoder-decoder model by $f_{Ged}()$ . Then, equation 7 will be replaced as follows:
$$
\displaystyle O^{\prime} \displaystyle=f_{Ged}(X_{o}) \tag{10}
$$
where $X_{o}$ is all the object features in the image. Afterward, we apply equation 9 before using bilinear modeling to obtain the relational representation. Note that as there are only one or two humans in the image, we do not use the GNNED to model human semantic features. The inputs to the BiGED model are the visual human features $x_{h}$ , concatenated visual and semantic object features $[x_{o},y_{o}]$ as well as the union features $x_{u}$ . Next, we concatenate the human and object features $[x_{h},x_{o},y_{o}]$ to obtain a joint feature and then pass it through a linear layer and another GNNED model. The outputs of the bilinear, joint feature-based GNNED models and overlap union feature $x_{u}$ are concatenated to obtain the final relational representation. Afterward, we use max-pooling to obtain the representation $x_{r}$ for the image. For all models, we employ a linear classifier to infer past actions using the representation vector $x_{r}$ .
## 4 Experiments and Results
### 4.1 Action Genome Past Action Inference dataset
We extend the Action Genome (AG) dataset [21] and benchmark all models on the AG dataset for the abductive past action inference task. Built upon the Charades dataset [41], the AG dataset contains 9,848 videos with 476,000+ object bounding boxes and 1.72 million visual relationships annotated across 234,000+ frames. It should be noted that not all video frames in the Charades dataset are used in the AG dataset. Only a handful of keyframes are used in AG, and we follow the same. The AG dataset does not provide action annotations. To obtain action annotations for images of AG, we leverage the Charades dataset which contains 157 action classes. The process of generating action sets and sequences using images from the Action Genome and action labels from the Charades dataset for the abductive past action inference task is detailed in Section 2 of the supplementary materials.
### 4.2 Experimental Setup
After obtaining the action annotations of images for a given video, we drop videos having only one image as there are no past images and therefore, no past actions. For the remaining images, we assign action labels from the previous images in two different evaluation setups:
1. Abduct at $T$ : Given a image at time $T$ , we add action labels from all the previous images to the ground truth (including actions from the current image) where $\mathcal{A}_{t}$ denotes all past actions of the $t^{th}$ image. Therefore, the ground truth action set $\mathcal{A}$ is given by $\mathcal{A}=\mathop{\cup}\limits_{t=1}^{T}\mathcal{A}_{t}$ .
2. Abduct last image: Based on the first setup, we add an additional task where the model has to perform inference only on the last image of each video which contains all past actions. If the last image is $T^{\prime}$ , then the action set is $\mathcal{A}=\mathop{\cup}\limits_{t=1}^{T^{\prime}}\mathcal{A}_{t}$ . Note that in the Action Genome dataset, the images are sampled non-homogeneously from the Charades dataset videos. Therefore, the previous image occurs several seconds before the current image. In our abductive past action inference task, the ground truth past action sets are confined to the length of each video. We provide details on the number of images for a set of $n$ past actions in the AG dataset for these setups in the supplementary materials – section 2 and figure 4.
### 4.3 Evaluation Metrics
We utilize the mean Average Precision (mAP), Recall@K (R@K), and mean Recall@K (mR@K) metrics to evaluate the models for the abductive action set prediction and action verification tasks. Each image contains 8.9 and 8.2 actions for the Abduct at $T$ and Abduct last image setups respectively. Therefore, K is set to 10 based on the average number of actions contained in a image. Please see the supplementary material Section 3 for more implementation details. We will also release all our codes and models for future research.
### 4.4 Baseline Models
We benchmark several publicly available image (Resnet101-2D [17], ViT [7]) and video models (Slow-Fast [8] and Resnet50-3D) using the surrounding 8 frames of a image from the Charades dataset, and Video-Swin-S [27], Mvitv2 [24] and InternVideo [44] models using future $K$ images from Action Genome to explore video based methods. The value of $K$ is set to the minimum possible frame size for each model, with the default being 5 frames. Image models are pre-trained on ImageNet [38] while video models are pre-trained on Kinetics400 [23] dataset and we fine-tune these models on our task. We use a batch size of 32 with a learning rate of 1e-5. As for ViT, we use a batch size of 2042 using A100 GPUs. All video-based methods are fine-tuned end-to-end. We also use CLIP linear-probe and zero-shot to perform abduction using several variants of the CLIP model [33]. The details of all other baseline models (Relational Rule-based inference, Relational MLP, and Relational Transformers) are presented in supplementary material Section 1.
### 4.5 Human Performance Evaluation
Human performance for the abductive past action set inference and verification tasks in the Abduct at $T$ setup is presented in Tables 1 and 3. Performance on the abductive past action sequence inference is provided in the supplementary materials–see Table 1 and Section 4.1. All human experiments for the three sub-problems in the Abduct at $T$ setup follow the same procedure. Evaluators are asked to review 100 randomly sampled test images and manually assess all action classes in the Charades dataset without viewing the ground truth. They then select the likely past actions for each image.
### 4.6 Results: Abductive Past Action Set Prediction
| Model Human Performance End-to-end training | mAP – | R@10 80.60 | mR@10 82.81 |
| --- | --- | --- | --- |
| ResNet101-2D [17] | 9.27 | 18.63 | 11.51 |
| ViT B/32 [7] | 7.27 | 16.84 | 8.82 |
| Resnet50-3D [8] | 8.16 | 16.08 | 7.83 |
| Slow-Fast [8] | 7.91 | 14.42 | 7.65 |
| Video-Swin-S [27] - (K= 5) | 14.86 | 34.18 | 19.05 |
| MvitV2 [24] - (K=16) | 14.01 | 34.38 | 15.17 |
| InternVideo [44] - (K=8) | 12.29 | 30.72 | 12.37 |
| Vision-language models | | | |
| CLIP-ViT-B/32 (zero-shot) [33] | 14.07 | 14.88 | 20.88 |
| CLIP-ViT-L/14 (zero-shot) [33] | 19.79 | 21.88 | 27.77 |
| CLIP-ViT-B/32 (linear probe) [33] | 16.16 | 31.25 | 16.38 |
| CLIP-ViT-L/14 (linear probe) [33] | 22.06 | 40.18 | 20.01 |
| Object-relational methods - using GT human/objects | | | |
| Relational Rule-based inference | 26.27 | 48.94 | 36.89 |
| Relational MLP | 27.73 $\pm$ 0.20 | 42.50 $\pm$ 0.68 | 25.80 $\pm$ 0.61 |
| Relational Self Att. Transformer | 33.59 $\pm$ 0.17 | 56.03 $\pm$ 0.40 | 40.04 $\pm$ 1.15 |
| Relational Cross Att. Transformer | 34.73 $\pm$ 0.05 | 56.89 $\pm$ 0.47 | 40.75 $\pm$ 0.57 |
| Relational GNNED | 34.38 $\pm$ 0.36 | 57.17 $\pm$ 0.35 | 42.83 $\pm$ 0.21 |
| Relational Bilinear Pooling (RBP) | 35.55 $\pm$ 0.30 | 59.98 $\pm$ 0.68 | 43.53 $\pm$ 0.63 |
| BiGED | 35.75 $\pm$ 0.15 | 60.55 $\pm$ 0.41 | 44.37 $\pm$ 0.21 |
| BiGED - (K=3) | 36.00 $\pm$ 0.12 | 60.17 $\pm$ 0.44 | 42.82 $\pm$ 0.90 |
| BiGED - (K=5) | 37.34 $\pm$ 0.21 | 61.16 $\pm$ 0.56 | 44.07 $\pm$ 0.87 |
| BiGED - (K=7) | 36.57 $\pm$ 0.38 | 60.65 $\pm$ 0.52 | 43.12 $\pm$ 0.47 |
| Object-relational method - using FasterRCNN labels | | | |
| BiGED | 24.13 $\pm$ 0.04 | 43.59 $\pm$ 0.88 | 30.12 $\pm$ 0.23 |
Table 1: Abductive past action set inference performance using the proposed methods on the Abduct at $T$ setup.
| Relational Rule-based inference Relational MLP Relational Self Att. Transformer | 26.18 25.99 $\pm$ 0.10 30.13 $\pm$ 0.11 | 44.34 38.79 $\pm$ 0.86 47.55 $\pm$ 0.14 | 33.94 23.54 $\pm$ 0.72 35.05 $\pm$ 0.55 |
| --- | --- | --- | --- |
| Relational Cross Att. Transformer | 31.07 $\pm$ 0.20 | 48.33 $\pm$ 0.15 | 35.32 $\pm$ 0.50 |
| Relational GNNED | 30.95 $\pm$ 0.30 | 48.18 $\pm$ 0.17 | 36.36 $\pm$ 0.12 |
| RBP | 31.48 $\pm$ 0.20 | 49.79 $\pm$ 0.55 | 36.96 $\pm$ 0.36 |
| BiGED | 31.41 $\pm$ 0.15 | 49.62 $\pm$ 0.64 | 36.15 $\pm$ 0.61 |
| Object-relational method - using FasterRCNN labels | | | |
| BiGED | 22.01 $\pm$ 0.26 | 37.06 $\pm$ 0.52 | 25.01 $\pm$ 0.37 |
Table 2: Abductive past action set inference performance using the proposed methods on the Abduct last image setup.
Our results for the abductive past action inference set prediction task are shown in Table 1. These results are obtained based on the Abduct at $T$ setup. During training, the model learns from every single image in the video sequence independently. Likewise, during inference, the model predicts the past action set on every single image. The end-to-end trained models such as Slow-Fast [8], ResNet50-3D, Resnet101-2D, and ViT perform poorly as it may be harder for these models to find clues that are needed for the abductive inference task. As there are no direct visual cues to infer previous actions (unlike object recognition or action recognition) from a given image, end-to-end learning becomes harder or near impossible for these models. The Video-Swin-S Transformer model [27] shows promise in end-to-end models due to its use of future context (K future snapshots) and strong video representation capabilities.
On the other hand, multi-modal foundational models such as the CLIP [33] variants are able to obtain better results than vanilla CNN models on this task perhaps due to the quality of the visual representation. Interestingly, object-relational models such as MLP and rule-based inference obtain decent performance. One might argue that the performance of human-object relational models is attributed to the use of ground truth object labels in the scene. However, when we tried to incorporate ground truth objects using object bounding boxes with red colored boxes as visual prompts in the CLIP [33] model, the performance was poor. The poor performance of the CLIP might be attributed to their training approach, which aims to align overall image features with corresponding text features. During their training, CLIP assumes that the text in the captions accurately describes the visual content of the image. However, when it comes to abductive past action inference, no explicit visual cues are available to indicate the execution of certain actions. We also note that the CLIP model demonstrates reasonable zero-shot performance. This may be because the CLIP model learns better vision features.
We experimented with generative models like ViLA [26] (instruction tuning) and BLIP (question answering). Details are in the supplementary materials sections 1.4 for GPT-3.5 and section 1.5 for ViLA. After instruction tuning on our dataset, ViLA achieved 10.5 mAP, 29.3 R@10, and 19.8 mR@10. We also tested GPT-3.5 with human-object relations as context, yielding 9.98 mAP, 25.22 R@10, and 20.32 mR@10. Due to the challenges of unconstrained text generation, models like BLIP, ViLA, and GPT-3.5 are excluded from the main comparison table.
The results also suggest that the human-object relational representations provide valuable evidence (cues) about what actions may have been executed in contrast to holistic vision representations. Among object-relational models, the MLP model and rule-based inference perform the worst across all three metrics. The rule-based inference does not use any parametric learning and therefore it can only rely on statistics. Interestingly, the rule-based method obtains similar performance to the MLP model indicating the MLP model merely learns from the bias of the dataset.
The relational transformer model improves results over MLP. Furthermore, the relational GNNED performance is comparable to the relational transformers. The transformer variants and GNNED have similar architectural properties and have better relational modeling capacity than the MLP model. These models exploit the interrelation between visual and semantic relational representations to better understand the visual scene. This potentially helps to boost the performance of abductive past action inference.
Surprisingly, Relational Bilinear Pooling (RBP) obtains particularly good results outperforming the transformer and GNNED models. The way relational reasoning is performed in RBP is fundamentally different from transformers and GNNED. The RBP models interactions between the human and object features within a relation more explicitly than the GNNED and Transformer. However, unlike the GNNED or Transformer, RBP is unable to model interactions between relations. Finally, the combination of GNNED and RBP, i.e., BiGED performs even better. This result is not surprising as BiGED takes advantage of better inter and intra-relation modelling. We also experimented with a BiGED model, that takes $K$ future frames starting from frame at $T$ (i.e. Action Genome frames from $T$ to $T+K$ ) as inputs. The results of this experiment suggests that use of future snapshots helps improve performance.
All object-relational models utilize the ground truth object labels from the AG dataset to obtain semantic representations. We observe a drop in performance when we use predicted objects from the FasterRCNN model. Additionally, FasterRCNN-based object-semantic prediction performs worse than the visual-only BiGED model (Table 4), indicating that incorrect semantics significantly harm performance. Nevertheless, the performance of BiGED with FasterRCNN labels is significantly better than end-to-end trained models and vision-language models. Finally, it should be emphasized that human performance on this task is significantly better than any of the modern AI models, highlighting a substantial research gap in developing AI systems capable of effectively performing abductive past action inference.
### 4.7 Results: Abduction on the Last Image
We evaluated object-relational models on the second setup, where we perform abduction on the last image of each video, using models trained in the previous setup. Due to the variety of possible actions in a video sequence, this setup is more challenging. It should be noted that this is a special case of abduct at T. This additional experiment allows us to observe and select the longest time horizon to determine whether the models are still able to abduct actions. Results in Table 2 show lower performance across all models compared to the previous setup, indicating the task’s increased difficulty. The MLP model and rule-based inference perform poorly. The GNNED, RBP, and BiGED methods outperform the Transformer model, despite GNNED’s similar architecture to the Transformer. BiGED achieves the highest mAP, while RBP excels in R@10 and mR@10.
| Human Performance Relational MLP Relational Self Att. Transformer | – 26.58 $\pm$ 0.37 27.94 $\pm$ 0.35 | 92.26 41.71 $\pm$ 0.82 45.72 $\pm$ 1.42 | 93.71 25.40 $\pm$ 0.66 30.12 $\pm$ 2.30 |
| --- | --- | --- | --- |
| RBP | 32.19 $\pm$ 0.44 | 53.76 $\pm$ 0.89 | 38.44 $\pm$ 0.67 |
| BiGED | 34.13 $\pm$ 0.39 | 57.39 $\pm$ 0.10 | 41.97 $\pm$ 0.36 |
Table 3: Abductive past action verification performance using the proposed methods on the Abduct at $T$ setup.
### 4.8 Results: Abductive Past Action Verification
We present abductive past action verification results in Table 3 using the object-relational approach. We use the ground truth human and object class names to obtain the semantic representation. As the query is in textual form (i.e. the action class name), we suggest that the abductive past action verification resembles a human-like task. It is easy to answer yes, or no to the question “Did the person execute action $a_{i}$ in this image to arrive at this state?" Interestingly, the performance of this task is slightly lower than the main results we obtained in Table 1. Even though this task is mentally more straightforward for the human, it seems the task is slightly difficult for the machine as it now has to understand the complexities of human languages.
### 4.9 Ablation on semantic vs visual
We use both visual and semantic features (Glove embedding of object names) to obtain the relational features –see Section 3.2. We ablate the impact of visual and semantic features on each model on Abductive Past Action Set Prediction (abduct at T) and the results are shown in Table 4. While RBP achieves the best performance using ground truth object semantics, BiGED is the best-performing model for visual data alone by a considerable margin, making it the overall best method. We can conclude while semantic features are effective, both visual and semantic features are complementary.
| Rule-based inference MLP Transformer | – 17.82 21.30 | 26.27 18.55 32.81 | – 27.73 33.59 |
| --- | --- | --- | --- |
| Relational GNNED | 21.55 | 32.82 | 34.38 |
| RBP | 22.15 | 33.03 | 35.55 |
| BiGED | 24.62 | 30.25 | 35.75 |
Table 4: mAP on Abductive Past Action Set Prediction (Abduct at T) using visual and semantic features.
Qualitative Results. The qualitative results in supplementary material Section 4.4 demonstrate RBP and BiGED infer past actions more accurately. Generalizability of BiGED. A visual-only BiGED model trained to infer past actions was evaluated for action recognition at the video level. We obtained 50.5 mAP on the Charades dataset without any tuning. Although not state-of-the-art, these results suggest the value of the abductive past action inference model for general action understanding using only visual features.
## 5 Discussion & Conclusion
This paper introduces abductive past action inference, a task involving past action set prediction, sequence prediction, and verification, all formulated as closed-set classification tasks. Our experiments show that while deep learning models can perform these tasks to some extent, holistic end-to-end models are ineffective. Large multi-modal models like CLIP show promise, but our proposed human-object relational approaches—such as relational graph neural networks, bilinear pooling, and the BiGED model—outperform them, demonstrating the value of object-relational modelling. We find conditional text generation unsuitable for this task due to limited control, and even advanced foundational models fail after instruction tuning. Overall, human-object-centric video representations emerge as the most effective approach, and abductive past action inference may enhance general human action understanding.
Acknowledgment. This research/project is supported by the National Research Foundation, Singapore, under its NRF Fellowship (Award NRF-NRFF14-2022-0001) and this research is partially supported by MOE grant RG100/23. It was also partly funded by an ASTAR CRF award to Cheston Tan and supported by the ASTAR CIS (ACIS) Scholarship awarded to Clement Tan. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not reflect the views of these organizations.
## References
- [1] Yazan Abu Farha, Alexander Richard, and Juergen Gall. When will you do what?-anticipating temporal occurrences of activities. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5343–5352, 2018.
- [2] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [3] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [4] Le-Wen Cai, Wang-Zhou Dai, Yu-Xuan Huang, Yu-Feng Li, Stephen H Muggleton, and Yuan Jiang. Abductive learning with ground knowledge base. In IJCAI, pages 1815–1821, 2021.
- [5] Yuren Cong, Wentong Liao, Hanno Ackermann, Bodo Rosenhahn, and Michael Ying Yang. Spatial-temporal transformer for dynamic scene graph generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16372–16382, 2021.
- [6] Wang-Zhou Dai, Qiuling Xu, Yang Yu, and Zhi-Hua Zhou. Bridging machine learning and logical reasoning by abductive learning. Advances in Neural Information Processing Systems, 32, 2019.
- [7] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [8] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019.
- [9] Basura Fernando and Samitha Herath. Anticipating human actions by correlating past with the future with jaccard similarity measures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13224–13233, 2021.
- [10] Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv preprint arXiv:1606.01847, 2016.
- [11] Antonino Furnari and Giovanni Maria Farinella. What would you expect? anticipating egocentric actions with rolling-unrolling lstms and modality attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6252–6261, 2019.
- [12] Yang Gao, Oscar Beijbom, Ning Zhang, and Trevor Darrell. Compact bilinear pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [13] Rohit Girdhar and Kristen Grauman. Anticipative video transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13505–13515, October 2021.
- [14] Dayoung Gong, Joonseok Lee, Manjin Kim, Seong Jong Ha, and Minsu Cho. Future transformer for long-term action anticipation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3052–3061, 2022.
- [15] Guodong Guo and Alice Lai. A survey on still image based human action recognition. Pattern Recognition, 47(10):3343–3361, 2014.
- [16] Zhongyi Han, Le-Wen Cai, Wang-Zhou Dai, Yu-Xuan Huang, Benzheng Wei, Wei Wang, and Yilong Yin. Abductive subconcept learning. Science China Information Sciences, 66(2):122103, 2023.
- [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [18] Samitha Herath, Mehrtash Harandi, and Fatih Porikli. Going deeper into action recognition: A survey. Image and vision computing, 60:4–21, 2017.
- [19] Jack Hessel, Jena D Hwang, Jae Sung Park, Rowan Zellers, Chandra Bhagavatula, Anna Rohrbach, Kate Saenko, and Yejin Choi. The abduction of sherlock holmes: A dataset for visual abductive reasoning. arXiv preprint arXiv:2202.04800, 2022.
- [20] Hueihan Jhuang, Juergen Gall, Silvia Zuffi, Cordelia Schmid, and Michael J Black. Towards understanding action recognition. In Proceedings of the IEEE international conference on computer vision, pages 3192–3199, 2013.
- [21] Jingwei Ji, Ranjay Krishna, Li Fei-Fei, and Juan Carlos Niebles. Action genome: Actions as compositions of spatio-temporal scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10236–10247, 2020.
- [22] Yang Jin, Linchao Zhu, and Yadong Mu. Complex video action reasoning via learnable markov logic network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3242–3251, 2022.
- [23] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017.
- [24] Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Mvitv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4804–4814, 2022.
- [25] Chen Liang, Wenguan Wang, Tianfei Zhou, and Yi Yang. Visual abductive reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15565–15575, 2022.
- [26] Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models, 2023.
- [27] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3202–3211, 2022.
- [28] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [29] Jae Sung Park, Chandra Bhagavatula, Roozbeh Mottaghi, Ali Farhadi, and Yejin Choi. Visualcomet: Reasoning about the dynamic context of a still image. In European Conference on Computer Vision, pages 508–524. Springer, 2020.
- [30] Paritosh Parmar, Eric Peh, Ruirui Chen, Ting En Lam, Yuhan Chen, Elston Tan, and Basura Fernando. Causalchaos! dataset for comprehensive causal action question answering over longer causal chains grounded in dynamic visual scenes. arXiv preprint arXiv:2404.01299, 2024.
- [31] Paritosh Parmar, Eric Peh, and Basura Fernando. Learning to visually connect actions and their effects. arXiv preprint arXiv:2401.10805, 2024.
- [32] Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- [33] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [34] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- [35] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [36] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- [37] Debaditya Roy, Ramanathan Rajendiran, and Basura Fernando. Interaction region visual transformer for egocentric action anticipation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6740–6750, January 2024.
- [38] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. CoRR, abs/1409.0575, 2014.
- [39] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE transactions on neural networks, 20(1):61–80, 2008.
- [40] Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. In European semantic web conference, pages 593–607. Springer, 2018.
- [41] Gunnar A Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In European Conference on Computer Vision, pages 510–526. Springer, 2016.
- [42] Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. Unbiased scene graph generation from biased training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3716–3725, 2020.
- [43] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [44] Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning. arXiv preprint arXiv:2212.03191, 2022.
- [45] Aming Wu, Linchao Zhu, Yahong Han, and Yi Yang. Connective cognition network for directional visual commonsense reasoning. Advances in Neural Information Processing Systems, 32, 2019.
- [46] Changqian Yu, Yifan Liu, Changxin Gao, Chunhua Shen, and Nong Sang. Representative graph neural network. In European Conference on Computer Vision, pages 379–396. Springer, 2020.
- [47] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6720–6731, 2019.
- [48] Hao Zhang, Yeo Keat Ee, and Basura Fernando. Rca: Region conditioned adaptation for visual abductive reasoning. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 9455–9464, 2024.
- [49] Qi Zhao, Shijie Wang, Ce Zhang, Changcheng Fu, Minh Quan Do, Nakul Agarwal, Kwonjoon Lee, and Chen Sun. Antgpt: Can large language models help long-term action anticipation from videos? In ICLR, 2024.
- [50] Tianyang Zhong, Yaonai Wei, Li Yang, Zihao Wu, Zhengliang Liu, Xiaozheng Wei, Wenjun Li, Junjie Yao, Chong Ma, Xiang Li, et al. Chatabl: Abductive learning via natural language interaction with chatgpt. arXiv preprint arXiv:2304.11107, 2023.
## 6 Supplementary - Other Baseline Methods
In this section, we give the details of all other baseline methods used in the paper.
### 6.1 Rule-based Abductive Past Action Inference
In abductive past action inference, we assume the following logical association holds,
$$
\{a_{1},a_{2},a_{3},\cdots,a_{K}\}\rightarrow\{R_{1},R_{2},\cdots,R_{N}\} \tag{11}
$$
where $\{R_{1},R_{2},\cdots,R_{N}\}$ is the relation set $\mathcal{R}$ present in an image and $\{a_{1},a_{2},a_{3},\cdots,a_{K}\}$ is the action set $\mathcal{A}$ executed by the human to arrive at the image. Note the set of all actions is denoted by $A$ where $\mathcal{A}\subset A$ .
In rule-based inference, each relation is in the symbolic form $R_{k}=<H,o_{k}>$ where $H$ and $o_{k}$ are the human feature and $k^{th}$ object label in the image. As the human feature is common in all relations, we omit the human feature in each relation. Then, the relational association is updated as follows:
$$
\{a_{1},a_{2},a_{3},\cdots,a_{K}\}\rightarrow\{o_{1},o_{2},\cdots,o_{N}\} \tag{12}
$$
for any image. In rule-based abductive past action set inference, for each given object pattern $\{o_{1},o_{2},\cdots,o_{N}\}$ , we count the occurrence of each action $a_{j}$ . Let us denote the frequency of action $a_{j}$ for object pattern $\mathcal{O}_{q}=\{o_{1},o_{2},\cdots,o_{N}\}$ from the entire training set by $C_{j}^{q}$ . Therefore, for each object pattern $\mathcal{O}_{q}$ , we obtain a frequency vector over all past actions denoted by:
$$
\mathbf{C^{q}}=[C_{1}^{q},C_{2}^{q},\cdots,C_{|A|}^{q}] \tag{13}
$$
Then, we can convert these frequencies into probabilities using softmax:
$$
P(A|\mathcal{O}_{q})=softmax([C_{1}^{q},C_{2}^{q},\cdots,C_{|A|}^{q}]) \tag{14}
$$
We use this to perform abductive past action set inference using the test set. Given a test image, we first obtain the object pattern $\mathcal{O}$ . Next, we obtain the action probability vector for the object pattern from the training set using Equation 14. If an object pattern does not exist in the training set, we assign equal probability to each action.
### 6.2 Relational MLP
The MLP consists of 2-layers. The human feature $x_{h}$ , object feature $x_{o}$ , and union region of both human and feature $x_{u}$ obtained from the ResNet-101 FasterRCNN backbone are concatenated to form the joint relational visual features $x_{v}$ . The semantic representation $y_{s}$ is formed via a concatenation of the Glove [32] embedding of the human $y_{h}$ and object $y_{o}$ . We perform max pooling on the relational features, $\mathcal{R}_{i}=r_{1},r_{2},...,r_{n}$ in a given image, where each $r_{n}=[x_{v},y_{s}]$ is the concatenation of visual and semantic features. Afterward, we pass these features into the 2-layer MLP. The inputs and outputs of the first layer are D-dimensional and we apply dropout with $p$ = 0.5. The last layer of the MLP is the classification layer. Lastly, we apply a sigmoid function before applying multi-label margin loss to train the model.
### 6.3 Relational Transformer
Transformers [43] are a popular class of models in deep learning. They are effective at capturing relationships between far-apart elements in a set or a sequence. In this work, we use transformers as a set summarization model. Multi-head self-attention Transformer: Specifically, we utilize a multi-head self-attention (MSHA) transformer model. The MHSA transformer contains one encoder and three decoder layers by default. We do not use any positional encoding as we are summarising a set. Given the set of relational representation of an image $\mathcal{R}_{i}=r_{1},r_{2},\cdots,r_{n}$ , the transformer model outputs a Tensor of size $n\times d$ where $d$ is the size of the relational representation. Afterward, we use max-pooling to obtain an image representation vector $x_{r}$ . A visual illustration of this model is shown in Fig. 4 (left). Cross-attention Transformer: Similar to the multi-head self-attention transformer, we use one encoder and three decoder layers. The inputs to the transformer encoder comprise concatenated visual and semantic features of a human and objects $[x_{h},y_{h},x_{o},y_{o}]$ , excluding the union features $x_{u}$ .
<details>
<summary>extracted/6142422/images/sat.png Details</summary>
### Visual Description
## Diagram: Transformer-Based Relational Feature Processing Architecture
### Overview
The image is a technical diagram illustrating a neural network architecture designed to process relational features between human and object entities. The system takes human features, object features, and union features as input, processes them through an encoder-decoder transformer block, and outputs relational features which are then classified to predict past actions. The flow is from left to right, with data represented as 3D block tensors.
### Components/Axes
The diagram is composed of several distinct components connected by arrows indicating data flow:
1. **Input Features (Left Side):**
* **Human Feature:** Represented by a pink 3D block tensor. Labeled with the mathematical notation `[x_o, y_o]`.
* **Object Feature:** Represented by a green 3D block tensor. Labeled with the mathematical notation `[x_h, y_h]`.
* **Union Feature:** Represented by an orange 3D block tensor. Labeled with the mathematical notation `x_u`.
* **Concatenation Operation:** A dashed line connects the Human and Object features to a combined tensor labeled `r`. The text "Concat" with an upward arrow indicates these features are concatenated. The resulting tensor `r` is a multi-colored block (pink, green, orange).
2. **Core Processing Block (Center):**
* **Encoder:** A large, blue, rounded rectangle labeled "Encoder". It receives three inputs labeled `Q`, `K`, and `V` (Query, Key, Value), which are standard components of a transformer attention mechanism.
* **Decoder:** A second large, blue, rounded rectangle labeled "Decoder", positioned to the right of the Encoder. It also receives `Q`, `K`, and `V` inputs from the Encoder's output.
* **Data Flow:** A solid arrow points from the concatenated tensor `r` into the Encoder. Another solid arrow points from the Encoder to the Decoder.
3. **Output and Classification (Right Side):**
* **Relational Features:** The output of the Decoder is a 3D block tensor with yellow, blue, and orange segments. It is labeled "Relational Features".
* **Feature Vector `x_r`:** A downward arrow points from the "Relational Features" tensor to a smaller, single yellow-and-blue 3D block labeled `x_r`.
* **Classifier MLP:** A downward arrow points from `x_r` to a light purple rounded rectangle labeled "Classifier MLP" (Multi-Layer Perceptron).
* **Final Output:** An arrow points left from the "Classifier MLP" to the text "Past Actions", indicating the model's prediction target.
### Detailed Analysis
* **Data Representation:** All features (Human, Object, Union, Relational) are visualized as 3D block tensors, suggesting multi-dimensional data (e.g., feature maps with spatial or channel dimensions).
* **Mathematical Notation:**
* Human Feature: `[x_o, y_o]`
* Object Feature: `[x_h, y_h]`
* Union Feature: `x_u`
* Concatenated Tensor: `r`
* Processed Feature Vector: `x_r`
* **Transformer Components:** The explicit labeling of `Q`, `K`, and `V` inputs to both the Encoder and Decoder confirms the use of a transformer architecture with self-attention (in the Encoder) and likely cross-attention (in the Decoder).
* **Color Coding:** Colors are used consistently to track data types:
* Pink: Associated with the Human Feature.
* Green: Associated with the Object Feature.
* Orange: Associated with the Union Feature.
* Yellow/Blue: Appear in the final "Relational Features" and `x_r`, suggesting a transformation or combination of the input features.
### Key Observations
1. **Input Fusion:** The model begins by explicitly fusing (concatenating) separate human and object features with a union feature into a single tensor `r` before any complex processing.
2. **Symmetrical Transformer Core:** The architecture uses a standard Encoder-Decoder transformer stack, which is effective for learning complex relationships and dependencies within the fused input data.
3. **Dimensionality Reduction:** There is a clear reduction in data dimensionality from the high-dimensional "Relational Features" tensor to the more compact feature vector `x_r` before classification.
4. **Task-Specific Output:** The final classifier is explicitly directed towards predicting "Past Actions," defining the model's purpose as action recognition or forecasting based on human-object interactions.
### Interpretation
This diagram outlines a sophisticated model for understanding human-object interactions. The core idea is to learn "relational features" that capture the meaningful context between a human and an object. The process works as follows:
1. **Context Creation:** By concatenating individual human (`[x_o, y_o]`) and object (`[x_h, y_h]`) features with a union feature (`x_u`), the model creates an initial combined representation (`r`) that contains all necessary raw information about the entities and their spatial or contextual overlap.
2. **Relationship Modeling:** The Encoder-Decoder transformer is the engine for reasoning. It processes the fused input `r` to model complex, non-linear relationships. The attention mechanisms (`Q`, `K`, `V`) allow the model to dynamically weigh the importance of different parts of the human and object features relative to each other, effectively learning "how they relate."
3. **Action Inference:** The output "Relational Features" represent the distilled understanding of the interaction. This is compressed into a vector `x_r` and fed to a simple classifier (MLP). The classifier's job is to map this learned relational understanding to a discrete output: the "Past Actions." This suggests the model is trained on a dataset where human-object interactions are labeled with the actions that occurred.
**Notable Implication:** The architecture implies that predicting past actions requires not just recognizing the human and object in isolation, but explicitly modeling the *relationship* between them. The transformer is well-suited for this, as it can capture long-range dependencies and contextual nuances within the interaction. The flow from high-dimensional tensors to a final action label is a classic pattern in deep learning for video understanding, robotics, or human-computer interaction tasks.
</details>
<details>
<summary>extracted/6142422/images/cat.png Details</summary>
### Visual Description
## Diagram: Transformer-Based Relational Feature Extraction Architecture
### Overview
The image displays a technical block diagram of a neural network architecture designed to process and relate human and object features. The system uses an encoder-decoder structure with attention mechanisms to generate relational features, which are then classified to predict past actions. The flow moves from left (inputs) to right (outputs).
### Components/Axes
The diagram is composed of several interconnected blocks and data representations:
**Input Features (Left Side):**
* **Human Feature:** Represented by a pink 3D block. Labeled as `Human Feature` with the mathematical notation `[x_h, y_h]`.
* **Object Feature:** Represented by a green 3D block. Labeled as `Object Feature` with the mathematical notation `[x_o, y_o]`.
* **Union Feature:** Represented by an orange 3D block. Labeled as `Union Feature` with the mathematical notation `x_u`.
**Processing Blocks (Center):**
* **Concat:** A dashed arrow indicates the concatenation of the Human and Object features, resulting in a combined pink-and-green block.
* **Encoder:** A large, blue, rounded rectangle labeled `Encoder`. It receives three inputs: `Q` (Query), `K` (Key), and `V` (Value), which are derived from the concatenated features.
* **Decoder:** A large, blue, rounded rectangle labeled `Decoder`. It receives three inputs: `K` and `V` from the Encoder's output, and `Q` from a separate path.
* **Proj. Layer:** A smaller, light purple, rounded rectangle labeled `Proj. Layer` (Projection Layer). It processes the `Union Feature (x_u)` and outputs the `Q` (Query) for the Decoder.
**Output Features (Right Side):**
* **Relational Features:** Represented by a multi-colored (yellow, blue, orange) 3D block. Labeled as `Relational Features`.
* **Feature `x_r`:** A smaller, multi-colored block derived from the Relational Features, labeled with the mathematical notation `x_r`.
* **Classifier MLP:** A light purple, rounded rectangle labeled `Classifier MLP` (Multi-Layer Perceptron). It takes `x_r` as input.
* **Past Actions:** The final output of the system, indicated by an arrow from the Classifier MLP.
### Detailed Analysis
The architecture processes information in the following sequence:
1. **Input Preparation:** Two primary input features, `Human Feature [x_h, y_h]` and `Object Feature [x_o, y_o]`, are concatenated. A third input, the `Union Feature x_u`, is processed separately.
2. **Encoding:** The concatenated human-object features are used to generate Query (`Q`), Key (`K`), and Value (`V`) vectors. These are fed into the **Encoder** block.
3. **Decoding with External Query:** The Encoder outputs its own `K` and `V` vectors, which are sent to the **Decoder**. Simultaneously, the separate `Union Feature x_u` passes through a **Projection Layer** to generate a Query (`Q`) vector. This `Q` is the third input to the Decoder.
4. **Feature Generation:** The Decoder processes its inputs (`K`, `V` from Encoder; `Q` from Union Feature) to produce the **Relational Features**.
5. **Classification:** A specific feature vector, `x_r`, is extracted from the Relational Features. This vector is passed to a **Classifier MLP**, which outputs a prediction for **Past Actions**.
### Key Observations
* **Dual-Path Input:** The model has two distinct input pathways: one for the direct human-object pair (concatenated) and another for a "union" feature, which likely represents a combined or contextual representation of the scene.
* **Attention Mechanism:** The use of `Q`, `K`, and `V` labels strongly indicates an attention mechanism (likely self-attention in the Encoder and cross-attention in the Decoder).
* **Decoder Query Source:** A critical architectural detail is that the Decoder's Query (`Q`) does not come from the Encoder's output but from the independently processed `Union Feature`. This suggests the model is using the union context to "query" the relational information between the human and object.
* **Color Coding:** Colors are used consistently to trace data flow: pink (human), green (object), orange (union), blue (core processing), and light purple (projection/classification).
### Interpretation
This diagram illustrates a sophisticated model for understanding relationships, likely for tasks like human-object interaction (HOI) recognition or action anticipation in computer vision.
The architecture's core innovation appears to be the separation and specialized processing of the "union" feature. Instead of simply feeding all information into a single transformer, it uses the union context to actively guide (via the Query) the extraction of relational features from the encoded human-object representation. This implies that the model learns to ask specific questions about the relationship (e.g., "What is the person doing with this object in this context?") based on the broader scene information (`x_u`).
The final classification into "Past Actions" suggests the model is designed for temporal reasoning, using the extracted relational features to infer what actions have already occurred. This is valuable for applications in video understanding, robotics, and assistive technology where understanding past interactions is key to predicting future behavior or intent. The model effectively translates raw visual features (`x_h, y_o, x_u`) into a high-level semantic understanding of an event (`Past Actions`).
</details>
Figure 4: (left) The relational multi-head self-attention transformer. (right) The relational cross-attention transformer.
### 6.4 Relational GPT-3.5 Past Action Inference
GPT and later versions [34, 35, 3] have revolutionized the AI field by solving many natural language processing and reasoning tasks. Here, we use the GPT-3.5 turbo version to perform abductive past action inference. To do this, we generate a query prompt as well as a contextual description for each image using the ground truth relational annotations based on the subject-predicate-object triplet relation. In contrast to the all other methods, we utilize the ground truth predicate label for GPT-3.5. An example of the contextual description and textual prompt is shown in Figure 5. In addition, an answer generated by GPT-3.5 is shown in Figure 6. We specifically created the prompt such that GPT-3.5 responses are constrained to the ground truth action sets within the dataset. Based on the responses from the GPT-3.5 model, we construct the score vector where the predicted action is marked with a score of 1 or 0 otherwise. We call this hard matching as we add 1 if and only if the GPT-3.5 model outputs the exact action class name given in the input prompt.
<details>
<summary>extracted/6142422/images/chatgpt.png Details</summary>
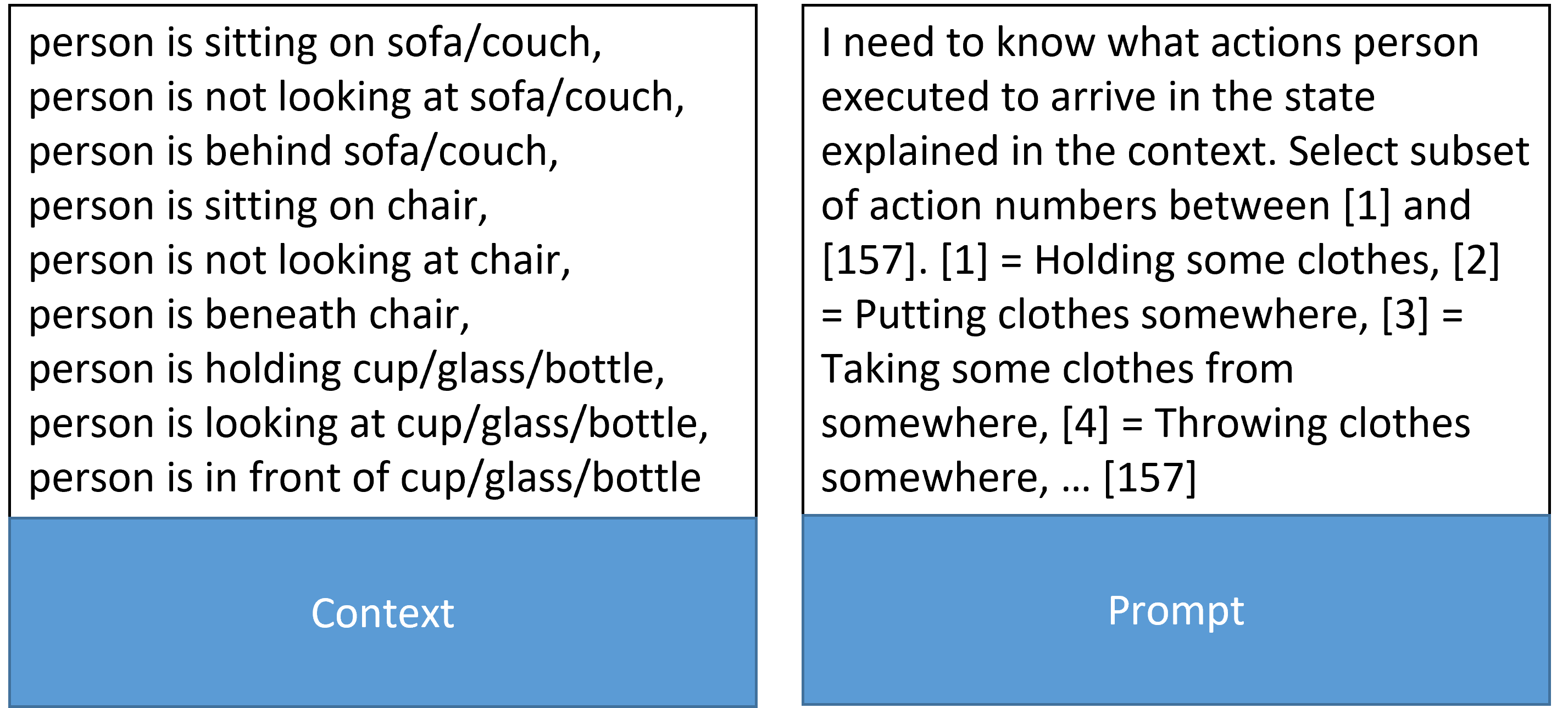
### Visual Description
## Screenshot: Context and Prompt Text Boxes
### Overview
The image displays two adjacent rectangular text boxes, each with a white content area and a solid blue label bar at the bottom. The left box is labeled "Context" and contains a list of descriptive statements about a person's state relative to various objects. The right box is labeled "Prompt" and contains a task instruction referencing a numbered list of actions. The overall layout is simple, with a light gray background surrounding the two boxes.
### Components/Axes
The image is composed of two primary components arranged side-by-side:
1. **Left Component (Context Box):**
* **Content Area (White):** Contains a list of nine text lines.
* **Label Bar (Blue):** Contains the centered white text "Context".
2. **Right Component (Prompt Box):**
* **Content Area (White):** Contains a single paragraph of text.
* **Label Bar (Blue):** Contains the centered white text "Prompt".
### Detailed Analysis
**Text Transcription:**
**Left Box (Context):**
The following statements are listed, each on a new line:
1. person is sitting on sofa/couch,
2. person is not looking at sofa/couch,
3. person is behind sofa/couch,
4. person is sitting on chair,
5. person is not looking at chair,
6. person is beneath chair,
7. person is holding cup/glass/bottle,
8. person is looking at cup/glass/bottle,
9. person is in front of cup/glass/bottle
**Right Box (Prompt):**
The text reads:
"I need to know what actions person executed to arrive in the state explained in the context. Select subset of action numbers between [1] and [157]. [1] = Holding some clothes, [2] = Putting clothes somewhere, [3] = Taking some clothes from somewhere, [4] = Throwing clothes somewhere, ... [157]"
### Key Observations
* The "Context" box defines a specific, multi-faceted state of a person using relational predicates (e.g., "sitting on," "behind," "holding").
* The "Prompt" box defines a task: to infer a sequence of actions (from a predefined list of 157) that would result in the state described in the Context.
* The action list in the Prompt is truncated with an ellipsis ("..."), indicating that only the first four examples ([1] through [4]) are shown, and the list continues up to action [157].
* The language is precise and technical, resembling a formal problem statement for an AI planning, reasoning, or activity recognition task.
### Interpretation
This image presents a structured problem setup, likely for a computational or logical reasoning system. The **Context** serves as the *goal state* or *observed condition*—a snapshot of a person's spatial relationships with furniture (sofa, chair) and an object (cup/glass/bottle). The **Prompt** defines the *problem*: to reverse-engineer the sequence of primitive actions (from a large, fixed vocabulary) that led to this state.
The relationship is causal and investigative. The system must bridge the gap between high-level, relational state descriptions and a low-level, numbered action vocabulary. The notable gap between the simple, example actions listed (e.g., "Holding some clothes") and the complex, multi-object state in the Context suggests the required action sequence could be long and non-trivial. The ellipsis in the action list implies the full vocabulary is extensive, making the selection task a search or inference problem over a large space of possibilities. This setup is characteristic of benchmarks or challenges in areas like procedural knowledge reasoning, action anticipation, or explainable AI.
</details>
Figure 5: The context description and the textual prompt used for the GPT-3.5 turbo model.
<details>
<summary>extracted/6142422/images/chatgpt_answer.png Details</summary>

### Visual Description
## Diagram: Comparison of Context, GPT Answer, and Ground Truth for Action Recognition
### Overview
The image is a three-panel diagram comparing textual descriptions of a person's actions and states. The left panel provides raw observational context, the middle panel shows a structured answer generated by a GPT model, and the right panel lists the ground truth actions. The diagram appears to be from a technical evaluation or research context, likely assessing the performance of an AI model in interpreting contextual data to identify human actions.
### Components/Axes
The diagram consists of three vertically aligned rectangular panels, each with a blue footer label.
1. **Left Panel (Labeled "Context"):** Contains a block of plain text describing a person's spatial relationships and interactions with objects.
2. **Middle Panel (Labeled "GPT Answer"):** Contains a structured list of actions with associated numerical identifiers in brackets. The text uses color coding (red and green).
3. **Right Panel (Labeled "Ground truth"):** Contains a list of actions, also using color coding (green and red).
### Detailed Analysis
#### Panel 1: Context
This panel contains a continuous block of English text. The text is a list of observational statements about a person. The full transcription is:
"person is leaning on window, person is looking at window, person is on the side of window, person is holding food, person is not looking at food, person is in front of food, person is holding dish, person is not looking at dish, person is in front of dish, person is holding sandwich, person is not looking at sandwich, person is in front of sandwich,"
#### Panel 2: GPT Answer
This panel presents a structured interpretation of the context. It begins with an introductory sentence and lists five actions with numerical codes.
* **Introductory Text:** "Based on the context provided, the actions executed by the person are as follows:"
* **Listed Actions (with color and code):**
* `[90] = Opening a window` (Text in **red**)
* `[93] = Watching/Looking outside of a window` (Text in **green**)
* `[62] = Holding some food` (Text in **green**)
* `[68] = Holding a sandwich` (Text in **green**)
* `[119] = Holding a dish` (Text in **green**)
#### Panel 3: Ground truth
This panel lists the correct or reference actions. The text is color-coded, likely indicating correctness relative to the GPT Answer.
* **Listed Actions (with color):**
* `Holding some food` (Text in **green**)
* `Holding a sandwich` (Text in **green**)
* `Watching/Looking outside of a window` (Text in **green**)
* `Drinking from a cup/glass/bottle` (Text in **red**)
* `Holding a dish` (Text in **green**)
### Key Observations
1. **Color Coding Discrepancy:** The color meaning appears inverted between the "GPT Answer" and "Ground truth" panels.
* In the **GPT Answer**, "Opening a window" is in **red**, while the other four actions are in **green**.
* In the **Ground truth**, "Drinking from a cup/glass/bottle" is in **red**, while the other four actions are in **green**.
* This suggests that in the GPT Answer panel, **red** may indicate an action the model predicted that is *not* in the ground truth (a false positive). In the Ground truth panel, **red** may indicate an action that is correct but was *missed* by the GPT model (a false negative).
2. **Action Comparison:**
* **Matches (True Positives):** Three actions appear in both lists with green text in the Ground Truth: "Holding some food," "Holding a sandwich," "Watching/Looking outside of a window," and "Holding a dish." (Note: "Holding a dish" is green in both).
* **GPT False Positive:** The action "Opening a window" (red in GPT Answer) is not present in the Ground Truth list.
* **GPT False Negative:** The action "Drinking from a cup/glass/bottle" (red in Ground Truth) is not present in the GPT Answer.
3. **Context vs. Inference:** The "Context" panel describes states ("holding," "in front of," "not looking at") but does not explicitly state the action "Opening a window" or "Drinking." The GPT model inferred "Opening a window" from the context about the window, which the ground truth does not support. The ground truth includes "Drinking," which is not directly supported by the provided context statements.
### Interpretation
This diagram illustrates a common challenge in AI evaluation: mapping ambiguous, descriptive context to a discrete set of action labels. The comparison reveals the strengths and weaknesses of the GPT model's reasoning.
* **What the data suggests:** The model successfully extracted several core actions directly mentioned or strongly implied by the context (holding food/sandwich/dish, looking out a window). However, it also hallucinated an action ("Opening a window") based on associative reasoning (person near window -> might be opening it) and failed to infer an action ("Drinking") that may have been present in the original scene but was not described in the provided context snippet.
* **Relationship between elements:** The "Context" is the input, the "GPT Answer" is the model's output, and the "Ground truth" is the benchmark. The color coding visually highlights the model's precision (avoiding false positives like "Opening a window") and recall (capturing all true actions like "Drinking").
* **Notable anomaly:** The most significant finding is the model's confidence in an action ("Opening a window") that is entirely absent from the ground truth. This indicates a potential bias in the model's training or reasoning, where it over-interprets spatial proximity as interaction. The missed "Drinking" action suggests the model may rely too heavily on explicit textual cues and struggles with actions that are contextually plausible but not stated. This evaluation is crucial for improving the model's reliability in real-world applications like video understanding or assistive technology.
</details>
Figure 6: Answer generated by GPT-3.5 turbo model. The correct answers are shown in green color whereas false positives and negatives are shown in red. This example is cherry-picked.
The GPT-3.5 model is able to generate reasonable answers in some images (see Fig 6). However, most of the time GPT-3.5 answers are either overly conservative or aggressive. For example, GPT responds “There is not enough information given in the context to determine the specific actions the person executed to arrive in the described state" and in some instances, it selects all action classes. This may be the main reason for the poor performance of GPT-3.5. However, it should be noted that the GPT model is fed with more information than all other baselines as we also provide the predicate relation to the GPT-3.5 model. We also note that the GPT-3.5 + CLIP (Text) model with both soft and hard scores performs better than the hard score method. Assuming that large language models such as GPT-3.5 are capable of human-like reasoning, we can perhaps suggest that abductive inference requires more than text-based reasoning and commonsense reasoning. Given the fact that pure rule-based inference performs better than GPT-3.5 with lesser information may suggest that GPT-3.5 is not suited for abductive past action inference due to it not having a detailed understanding of some of the human behaviors and effects of human actions.
### 6.5 VILA Fine-tuning for Past Action Infernce
With the proven success of Large Language Models (LLMs) across various NLP tasks, recent research has extended their capabilities towards vision tasks, resulting in the development of Visual Language Models (VLMs). These models are typically enhanced through prompt-tuning (where LLMs are frozen) or fine-tuning methods. We employ a fine-tuned VLM, VILA [26], which has not only advanced state-of-the-art performance in vision tasks but also retains robust capabilities in text processing. VILA demonstrates strong reasoning abilities in multi-image analysis, contextual learning, and zero/few-shot learning scenarios. Hence, we leverage VILA for the task of abductive past action set inference.
## 7 Details on Dataset Creation
<details>
<summary>extracted/6142422/images/bar_chart_nf_inference.png Details</summary>
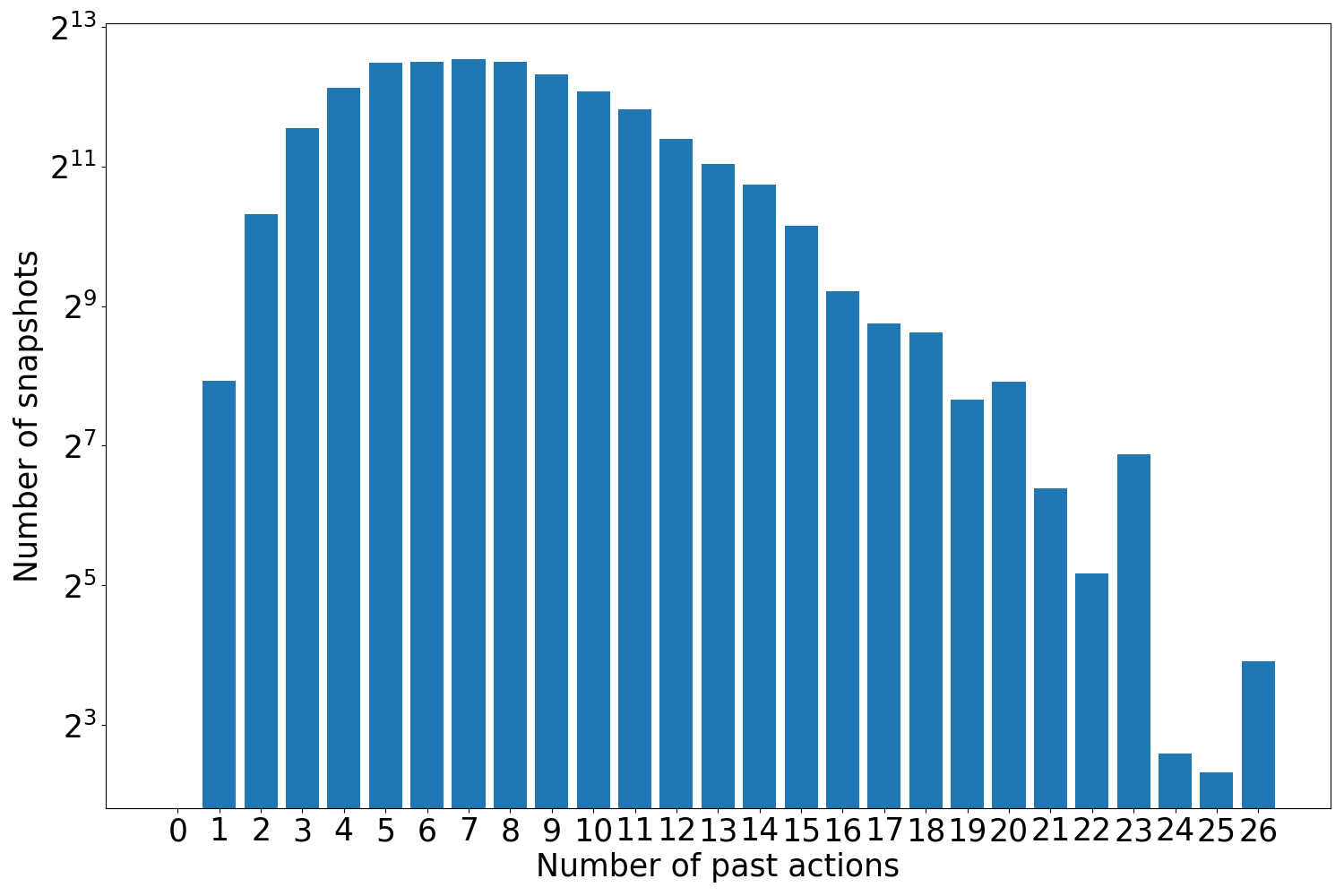
### Visual Description
## Bar Chart: Distribution of Snapshots by Number of Past Actions
### Overview
The image displays a vertical bar chart illustrating the frequency distribution of "snapshots" across a range of "Number of past actions." The chart uses a logarithmic scale on the y-axis, indicating that the data spans several orders of magnitude. The overall shape of the distribution is unimodal and right-skewed, with a peak in the lower-middle range of the x-axis.
### Components/Axes
* **Chart Type:** Vertical Bar Chart (Histogram-like).
* **X-Axis:**
* **Label:** "Number of past actions"
* **Scale:** Linear, integer values from 0 to 26.
* **Tick Marks:** Present for every integer from 0 to 26.
* **Y-Axis:**
* **Label:** "Number of snapshots"
* **Scale:** Logarithmic (base 2).
* **Major Tick Marks & Labels:** 2³, 2⁵, 2⁷, 2⁹, 2¹¹, 2¹³.
* **Data Series:** A single series represented by blue bars. There is no legend, as only one category of data is plotted.
* **Spatial Layout:** The chart is contained within a standard rectangular frame with axes on the left and bottom. The bars are evenly spaced along the x-axis.
### Detailed Analysis
The chart shows the count of snapshots (y-axis) for each discrete number of past actions (x-axis). Due to the logarithmic y-axis, the height of each bar represents an approximate power of two.
**Approximate Data Points (y ≈ 2^k):**
* **x=1:** y ≈ 2⁸ (256)
* **x=2:** y ≈ 2¹⁰ (1,024)
* **x=3:** y ≈ 2¹¹·⁵ (~2,896)
* **x=4:** y ≈ 2¹² (4,096)
* **x=5:** y ≈ 2¹²·⁵ (~5,792)
* **x=6:** y ≈ 2¹²·⁵ (~5,792)
* **x=7:** y ≈ 2¹²·⁶ (~6,452) **[Peak Region]**
* **x=8:** y ≈ 2¹²·⁵ (~5,792)
* **x=9:** y ≈ 2¹² (4,096)
* **x=10:** y ≈ 2¹¹·⁵ (~2,896)
* **x=11:** y ≈ 2¹¹ (2,048)
* **x=12:** y ≈ 2¹⁰·⁸ (~1,740)
* **x=13:** y ≈ 2¹⁰·⁵ (~1,448)
* **x=14:** y ≈ 2¹⁰ (1,024)
* **x=15:** y ≈ 2⁹·⁵ (~724)
* **x=16:** y ≈ 2⁹ (512)
* **x=17:** y ≈ 2⁸·⁸ (~445)
* **x=18:** y ≈ 2⁸·⁵ (~362)
* **x=19:** y ≈ 2⁷·⁵ (~181)
* **x=20:** y ≈ 2⁸ (256)
* **x=21:** y ≈ 2⁶·⁵ (~91)
* **x=22:** y ≈ 2⁵·² (~37)
* **x=23:** y ≈ 2⁶·⁹ (~119)
* **x=24:** y ≈ 2²·⁶ (~6)
* **x=25:** y ≈ 2²·⁴ (~5)
* **x=26:** y ≈ 2³·⁷ (~13)
**Trend Verification:**
The visual trend shows a rapid increase from x=1 to a plateau/peak between x=5 and x=8. Following this peak, there is a consistent, gradual decline in bar height (number of snapshots) as the number of past actions increases from x=9 to x=22. The trend becomes irregular at the tail end (x=23 to x=26), with a small spike at x=23 and a significant drop at x=24 and x=25, before a slight rise at x=26.
### Key Observations
1. **Peak Region:** The highest concentration of snapshots occurs for systems/states with approximately 5 to 8 past actions.
2. **Right Skew:** The distribution has a long tail to the right, meaning snapshots with a high number of past actions (e.g., >20) are relatively rare.
3. **Logarithmic Scale:** The use of a log₂ y-axis is crucial. It reveals that the difference between the peak (~6,000 snapshots) and the tail (~5-13 snapshots) is over three orders of magnitude.
4. **Tail Anomalies:** The data does not decline smoothly at the extreme right. The values for x=24 and x=25 are notably lower than their neighbors, suggesting these specific counts of past actions are particularly uncommon in the dataset. The value at x=26 is higher than at x=25.
5. **Zero Actions:** There is no bar for x=0, indicating either zero snapshots with zero past actions or that this category was not plotted.
### Interpretation
This chart likely represents the state distribution of a system where "snapshots" are taken, and each snapshot records the number of preceding "actions." The data suggests the system spends most of its time in states with a moderate history (5-8 actions). States with very short histories (1-3 actions) are less common, possibly representing initialization phases. States with very long histories (>20 actions) are rare, which could indicate that the system is frequently reset, pruned, or that long sequences naturally terminate or become unstable.
The logarithmic scale emphasizes that the system's behavior is dominated by states in the middle of the distribution. The anomalies in the tail (x=24,25) might be artifacts of the data collection process, specific constraints in the system's design, or simply statistical noise due to the very low counts. The overall pattern is characteristic of many natural and computational processes where intermediate complexity is most stable or frequently observed.
</details>
<details>
<summary>extracted/6142422/images/bar_chart_nf_inference_infer_last.png Details</summary>
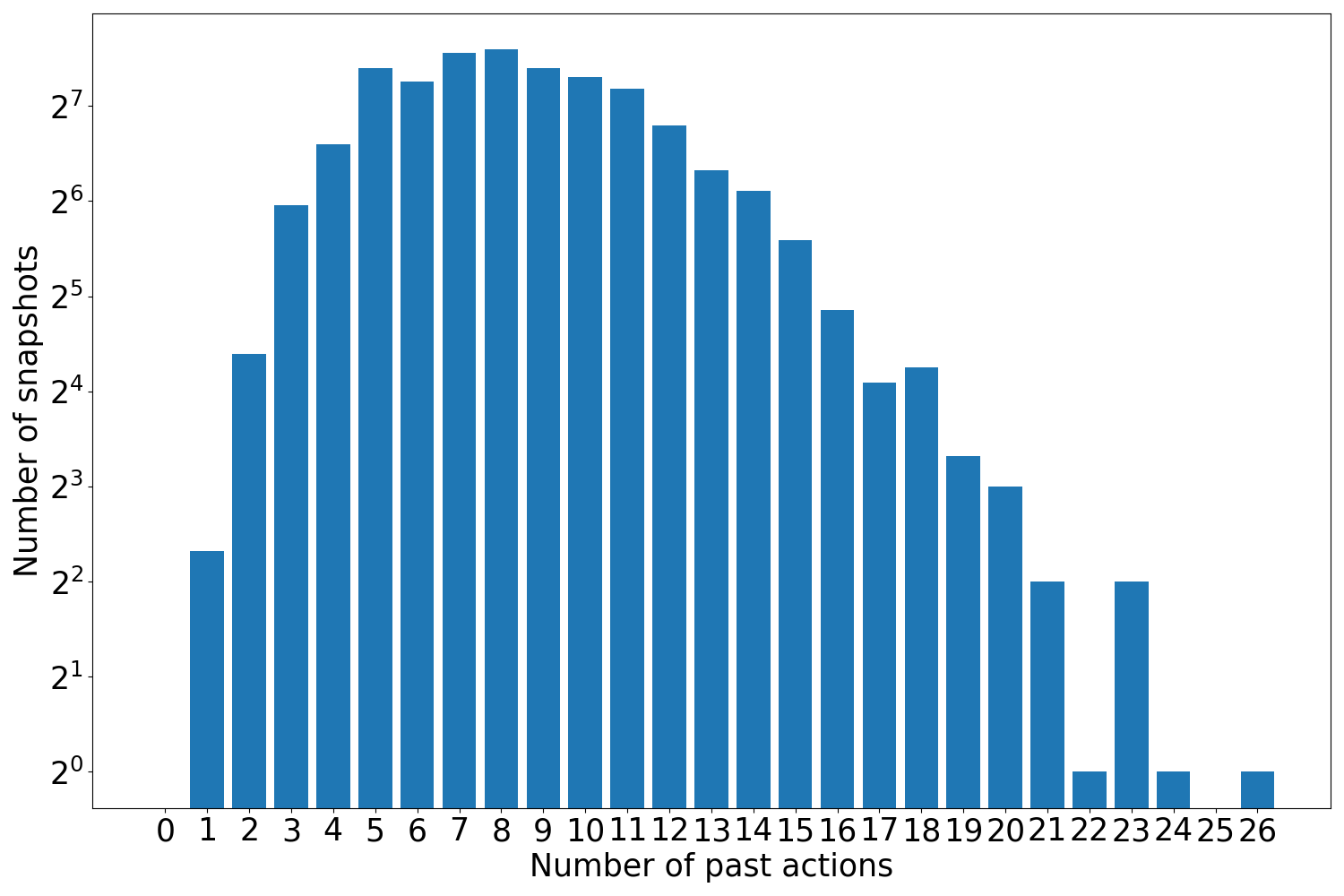
### Visual Description
## Bar Chart: Distribution of Snapshots by Number of Past Actions
### Overview
The image displays a bar chart illustrating the frequency distribution of "snapshots" across a range of "Number of past actions." The chart uses a logarithmic scale (base 2) on the vertical axis to accommodate a wide range of values. The overall shape of the distribution is right-skewed, peaking at a moderate number of past actions and tapering off with a long tail to the right.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **X-Axis (Horizontal):**
* **Label:** "Number of past actions"
* **Scale:** Linear, discrete integer values from 0 to 26.
* **Markers:** Each integer from 0 to 26 is explicitly labeled below its corresponding bar position.
* **Y-Axis (Vertical):**
* **Label:** "Number of snapshots"
* **Scale:** Logarithmic (base 2). Major tick marks and labels are at `2^0`, `2^1`, `2^2`, `2^3`, `2^4`, `2^5`, `2^6`, and `2^7`.
* **Legend:** Not present. All bars are the same solid blue color.
* **Spatial Layout:** The chart area is clean with no gridlines. The axes form a standard L-shape at the bottom and left. The bars are evenly spaced.
### Detailed Analysis
The following table reconstructs the approximate data from the chart. Values are estimated based on the bar height relative to the logarithmic y-axis. **Note:** All values are approximate due to visual estimation from a log-scale chart.
| Number of Past Actions (X) | Approx. Number of Snapshots (Y) | Y as Power of 2 (Approx.) |
| :--- | :--- | :--- |
| 0 | 0 | N/A |
| 1 | ~5 | ~2^2.3 |
| 2 | ~22 | ~2^4.5 |
| 3 | ~64 | 2^6 |
| 4 | ~100 | ~2^6.6 |
| 5 | ~200 | ~2^7.6 |
| 6 | ~180 | ~2^7.5 |
| 7 | ~220 | ~2^7.8 |
| 8 | ~230 | ~2^7.9 |
| 9 | ~200 | ~2^7.6 |
| 10 | ~190 | ~2^7.6 |
| 11 | ~170 | ~2^7.4 |
| 12 | ~120 | ~2^6.9 |
| 13 | ~80 | ~2^6.3 |
| 14 | ~70 | ~2^6.1 |
| 15 | ~45 | ~2^5.5 |
| 16 | ~30 | ~2^4.9 |
| 17 | ~16 | 2^4 |
| 18 | ~19 | ~2^4.2 |
| 19 | ~10 | ~2^3.3 |
| 20 | ~8 | 2^3 |
| 21 | ~4 | 2^2 |
| 22 | ~1 | 2^0 |
| 23 | ~4 | 2^2 |
| 24 | ~1 | 2^0 |
| 25 | 0 | N/A |
| 26 | ~1 | 2^0 |
**Trend Verification:**
The data series shows a clear unimodal distribution. The number of snapshots increases rapidly from 1 past action, reaches a broad peak between 5 and 11 past actions (with the absolute maximum at 8), and then generally decreases as the number of past actions increases further. The decline is not perfectly monotonic; there is a small local increase at 18 past actions. The tail extends to 26, with very low frequencies (1-4 snapshots) for values above 21.
### Key Observations
1. **Peak Region:** The highest concentration of snapshots occurs for sequences with 5 to 11 past actions. The single highest bar is at 8 past actions.
2. **Right Skew:** The distribution is heavily right-skewed. The majority of snapshots are associated with a relatively low number of past actions (less than ~15).
3. **Long Tail:** There is a long, sparse tail extending to 26 past actions, indicating that while rare, sequences with a very high number of past actions do occur in the dataset.
4. **Logarithmic Scale Necessity:** The use of a log scale is crucial for visualization. On a linear scale, the bars for values >15 would be nearly invisible compared to the peak, and the detail in the lower range (1-4) would be lost.
5. **Zero Values:** There are no snapshots recorded for 0 or 25 past actions.
### Interpretation
This chart likely represents the distribution of episode lengths or historical context windows in a sequential dataset, such as from a reinforcement learning environment, a user interaction log, or a process mining record.
* **What the data suggests:** The system or phenomenon being measured most commonly operates with a moderate amount of recent history (5-11 past actions). This could indicate an optimal or typical context length for decision-making or state representation.
* **Relationship between elements:** The "Number of past actions" is the independent variable (the length of history considered), and the "Number of snapshots" is the dependent variable (the frequency of observing that specific history length). The relationship is non-linear and peaked.
* **Notable patterns/anomalies:**
* The sharp drop-off after the peak suggests a strong constraint or preference against maintaining very long histories, possibly due to computational limits, noise, or the nature of the task (e.g., only recent history is relevant).
* The small bump at 18 past actions is an interesting deviation from the smooth decline. This could be a statistical artifact or hint at a secondary, less common mode of operation or a specific sub-task that requires a longer context.
* The presence of values at the extreme end (22, 23, 24, 26) shows that the system is capable of, or occasionally encounters, scenarios requiring very extensive history, even if they are rare outliers.
**In summary, the chart reveals a dataset where the typical case involves a medium-length history, with a rapid fall-off in frequency for both very short and very long histories, visualized effectively through a logarithmic scale.**
</details>
Figure 7: Number of snapshots (in $log_{2}$ ) for sets of $n$ past actions in the Action Genome test set. (a) – Abduct at $T$ , (b) – Abduct last snapshot
.
How to generate action sets and sequences? To obtain the ground truth action set $\mathcal{A}$ for an image in the Action Genome dataset using the Charades action labels, we first compute the time $t$ for each individual frame within a video sequence by using the formula: ${t}=\frac{v_{d}}{n}$ , where $v_{d}$ and $n$ denote the video duration and the number of frames in the video respectively. Then, we multiply the current frame number $f_{n}$ with ${t}$ to obtain the current time, $t_{c}=t\times f_{n}$ .
Action sets: As each video contains multiple actions, we check whether the current time of the frame $t_{c}$ , falls within the start $t_{s}$ and end $t_{e}$ time of the action. If it does, we add the ground truth action label to the action set $\mathcal{A}_{n}$ for the image. To obtain the ground truth action set for the $t^{th}$ image, we combine all previous action sets from $t=1$ up to and including the $t^{th}$ image to form the set.
Action sequences: We sort the start time $t_{s}$ of the actions contained in the video in ascending order. Then, for each image, if the current time of the frame is greater than the start time of the action ( $t_{c}\geq t_{s}$ ), we add it to the sequence.
We provide details on the number of images for a set of $n$ past actions in the AG dataset for these setups in Figure 7. As can be seen from these statistics, the majority of the images have more than five actions and some images have as many as 26 actions.
## 8 Implementation Details
We use FasterRCNN [36] with a ResNet-101 [17] backbone to extract human and object features from each image based on the ground truth person and object bounding boxes provided by AG for all object-relational models. We load pre-trained weights provided by [5] that were trained on the training set of AG which obtained 24.6 mAP at 0.5 IoU with COCO metrics. The parameters of the FasterRCNN during training and inference are fixed for the abductive past action inference task. Our default human and object visual representations have 512 dimensions obtained from 2048 dimensional visual features from the FasterRCNN. We use linear mappings to do this. During training, we train the models for 10 epochs and set the batch size to 1 video (there are many frames in a video). We assume the frames are i.i.d. Note that even though there are multiple images in a batch, the images are processed in parallel and individually for the transformer and graph models respectively. There is no sharing of information between images. We use the AdamW [28] optimizer with an initial learning rate of 1e-5 along with a scheduler to decrease the learning rate by a factor of 0.5 to a minimum of 1e-7. We utilize Glove [32] word embedding of size 200 for the human and object semantic features. In addition, gradient clipping with a maximal norm of 5 is applied. Moreover, we report the mean across 3 different runs for each configuration to ensure we report the most accurate performance of our models. All models (except end-to-end and ViT) are trained on a single RTX3090 or A5000 GPU. For CLIP, we use publicly available implementations [33]. We use the public API of OpenAI for GPT 3.5 models.
## 9 Additional Experiments
### 9.1 Abductive Past Action Sequence Prediction
Next, we formulated the abductive past action sequence prediction task based on the Abduct at T setup. We attached a GRU / transformer decoder to our existing object-relational models. To train both sequence prediction models, we freeze the object detector and relational model ( $\phi()$ ). Then, we use the relational vector $x_{r}$ and action distribution obtained from $\phi_{c}()$ as the initial hidden state and pass it to the GRU respectively. The transformer decoder takes non-pooled relational features (a matrix of size $n\times d$ ) as the key, value, and max-pooled relational features $x_{r}$ as the query. The output of these models is fed into a linear classifier to produce action sequences autoregressively. The results of these models are reported in Table 5. The BiGED model obtains slightly better performance than the rest. Although the performances of these models are suboptimal, we note that humans are also unable to obtain satisfactory results (only 14.00% accuracy). As we are constrained to only utilize available information in a single frame, the solution contains a substantial amount of sequence permutations. Therefore, the task is extremely challenging. The poor human performance also suggests how humans may use abduction. Perhaps humans do not resolve causal chains when performing abduction as it is a very challenging task.
We use the Hamming Loss to evaluate the action sequence prediction models as follows:
$$
H=\frac{1}{N*L}\sum_{n=1}^{N}\sum_{l=1}^{L}\left[y_{l}\neq\hat{y}_{l}\right] \tag{15}
$$
where $N$ is the total number of samples and $L$ is the sequence length. Finally, for a given sample, the accuracy is $(1-H)\times 100$ .
Table 5: Abductive past action sequence prediction using the proposed methods on the Abduct at $T$ setup.
| Model Human performance | Accuracy 14.00 GRU | Transformer |
| --- | --- | --- |
| Relational MLP | 9.43 $\pm$ 0.13 | 9.59 $\pm$ 0.06 |
| Relational Self Att. Transformer | 9.72 $\pm$ 0.06 | 9.95 $\pm$ 0.07 |
| Relational Cross Att. Transformer | 9.69 $\pm$ 0.18 | 9.96 $\pm$ 0.12 |
| Relational GNNED | 9.81 $\pm$ 0.05 | 10.11 $\pm$ 0.19 |
| RBP | 10.48 $\pm$ 0.05 | 10.22 $\pm$ 0.12 |
| BiGED | 10.54 $\pm$ 0.15 | 10.1 $\pm$ 0.14 |
### 9.2 Ablation Study
Ablation on graph affinity function: By default, we use the Jaccard Vector Similarity as the affinity $W_{A}(i,j)$ for the GNNED and BiGED models. Here, we ablate the impact of this design choice by comparing it with cosine similarity and dot product. As can be seen from the results in Table 6, the Jaccard Vector Similarity (JVS) obtains better results than cosine similarity and dot product. This behavior can be attributed to the fully differentiable and bounded nature of JVS in contrast to the dot product or cosine similarity.
Table 6: Ablation on graph affinity using Abduct at T setup.
| Jaccard Vector Similarity Cosine Similarity Dot product | 35.75 34.17 28.81 | 60.55 57.98 54.68 | 44.37 41.97 38.38 |
| --- | --- | --- | --- |
Impact of semantic features and learning scheduler: Apart from the two different setups mentioned, we also use a third setup for ablations. In the third setup, the action sets are formed from the current and previous images which form the ground truth denoted by $\mathcal{A}=\{\mathcal{A}_{t-1}\bigcup\mathcal{A}_{t}\}$ for faster experimentation. We retrain all object-relational models with the corresponding past action set obtained from the current and previous images. We perform ablation studies on the relational self-attention transformer based on this setup. These findings can also be generalized to the other setups as mentioned earlier.
We evaluate the effect of visual and semantic (Glove [32]) features in Table 7. The use of semantic features provides a huge performance boost across all metrics. We attribute the performance increase to the contextual information provided by the semantics. The semantics of objects enable the model to effectively identify and relate actions, providing a more intuitive means for reasoning about these actions. It is also interesting to see the impact of the learning rate scheduler which provides considerable improvement for the transformer model. Therefore, we use semantics and the learning rate scheduler for all our models.
Table 7: Ablation study for the impact of semantic features and scheduler on the abductive past action set inference for the Abduct from current and previous images setup using self-attention transformer.
| Visual only Visual + scheduler Visual + semantic | 21.42 $\pm$ 0.13 21.93 $\pm$ 0.16 35.40 $\pm$ 0.16 | 46.44 $\pm$ 0.12 47.04 $\pm$ 0.44 68.47 $\pm$ 0.06 | 34.24 $\pm$ 0.42 34.80 $\pm$ 0.47 54.90 $\pm$ 0.52 |
| --- | --- | --- | --- |
| Visual + semantic + scheduler | 35.77 $\pm$ 0.30 | 69.16 $\pm$ 0.50 | 55.70 $\pm$ 0.47 |
### 9.3 Object-Relational Model Parameters
Table 8: The object-relational model parameters for the abductive past action inference task.
| Relational MLP Relational Self Att. Transformer Relational Cross Att. Transformer | 13.4M 101.2M 65.9M |
| --- | --- |
| Relational GNNED | 80.7M |
| RBP | 373.4M |
| BiGED | 213.6M |
The proposed object-relational model parameters are shown in Table 8. The rule-based inference model does not have any parameters and is therefore omitted from the table. Based on the results shown earlier, we note that the GNNED model obtains better performance than the transformer model even though it has lesser parameters. In addition, our proposed BiGED model has lesser parameters and performs comparable to or better than the RBP model. These further demonstrate the effectiveness of the proposed GNNED, RBP, and BiGED models for the challenging task of abductive past action inference.
|
<details>
<summary>extracted/6142422/images/Comparison/000138_bbox.png Details</summary>

### Visual Description
## Object Detection Screenshot: Kitchen Scene with Bounding Boxes
### Overview
This image is a screenshot from an object detection system, showing a person in a kitchen environment. The system has identified and labeled several objects with colored bounding boxes and text labels. The scene is a typical domestic kitchen with wooden cabinets, countertops, and appliances.
### Components/Labels
The image contains five distinct object detection labels, each with a specific color and bounding box:
1. **Label: `person`**
* **Color:** Magenta (bright pink)
* **Bounding Box:** A large vertical rectangle encompassing the central figure.
* **Position:** Centered in the frame, extending from near the top edge to the bottom edge.
2. **Label: `laptop`**
* **Color:** Yellow
* **Bounding Box:** A horizontal rectangle on the left side of the image.
* **Position:** Left-center, on the kitchen counter.
3. **Label: `cup`**
* **Color:** Cyan (light blue)
* **Bounding Box:** A small square near the person's hands.
* **Position:** Center, slightly to the left, overlapping the person's bounding box.
4. **Label: `cable`**
* **Color:** Blue
* **Bounding Box:** A long, thin horizontal rectangle spanning the lower portion of the image.
* **Position:** Bottom third of the frame, running from the left edge to the right edge.
5. **Label: `microwave`**
* **Color:** Cyan (light blue) - *Note: Same color as the `cup` label.*
* **Bounding Box:** A rectangle in the background on the right side.
* **Position:** Right-center, on the kitchen counter behind the person.
### Detailed Analysis
* **Person:** The primary subject is a person with shoulder-length brown hair, wearing a red and black plaid shirt and blue jeans. They are standing at the kitchen counter, facing left, and appear to be interacting with an object (likely the cup).
* **Laptop:** A silver or light-colored laptop is open on the counter to the person's left.
* **Cup:** The person is holding or interacting with a white cup or mug.
* **Cable:** A black cable or cord runs horizontally along the front edge of the kitchen counter.
* **Microwave:** A white microwave oven is visible on the counter in the background, to the right of the person.
* **Kitchen Environment:** The background features light brown wooden cabinets (upper and lower), a white tiled backsplash, a white stove/oven, and various kitchen items on the counters (e.g., a kettle, a toaster).
### Key Observations
1. **Detection Focus:** The object detection system has prioritized the person and items directly related to their immediate action (cup, laptop) and prominent foreground/background objects (cable, microwave).
2. **Color Coding:** Two objects (`cup` and `microwave`) share the same cyan bounding box color, which could indicate they belong to the same category (e.g., "kitchenware") in the model's classification schema.
3. **Spatial Relationships:** The bounding boxes clearly show spatial relationships: the `cup` is within the `person`'s box, the `laptop` is adjacent to the person, and the `cable` runs beneath the main scene.
4. **Partial Label:** The text for the `microwave` label is partially cut off by the right edge of the image, but remains legible.
### Interpretation
This image demonstrates the output of a computer vision model performing object detection and localization in a complex, real-world indoor scene. The model successfully identifies discrete objects (`person`, `laptop`, `cup`, `microwave`) and a continuous feature (`cable`), assigning each a bounding box that approximates its spatial extent.
The detection suggests the model is trained to recognize common household objects and people. The inclusion of the `cable` is notable, as it is a less common object for general detection models, possibly indicating a specialized training set or a focus on identifying potential hazards or clutter. The overlapping boxes (person/cup) show the model's ability to handle occlusion and nested objects. The scene captures a moment of human activity, with the detections providing a machine-readable summary of the scene's composition and the entities involved.
</details>
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Taking a cup/glass/bottle from somewhere | | | | | | | |
| Holding a cup/glass/bottle of something | | | | | | | |
| Working/Playing on a laptop | | | | | | | |
| Working at a table | | | | | | | |
| Watching a laptop or something on a laptop | | | | | | | |
| Drinking from a cup/glass/bottle | | | | | | | |
| Taking a cup/glass/bottle from somewhere | | | | | | | |
| Sitting at a table | | | | | | | |
| Working at a table | | | | | | | |
| Working/Playing on a laptop | | | | | | | |
| Holding a laptop | | | | | | | |
| Opening a laptop | | | | | | | |
| Sitting in a chair | | | | | | | |
| Drinking from a cup/glass/bottle | | | | | | | |
| Taking a dish/es from somewhere | | | | | | | |
| Putting something on a shelf | | | | | | | |
| Walking through a doorway | | | | | | | |
| Closing a closet/cabinet | | | | | | | |
| Opening a closet/cabinet | | | | | | | |
| Putting a dish/es somewhere | | | | | | | |
| Taking a dish/es from somewhere | | | | | | | |
| Someone is smiling | | | | | | | |
| Someone is sneezing | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
| Taking a cup/glass/bottle from somewhere | | | | | | | |
| Putting something on a table | | | | | | | |
| Closing a closet/cabinet | | | | | | | |
| Opening a closet/cabinet | | | | | | | |
| Putting a dish/es somewhere | | | | | | | |
| Taking a dish/es from somewhere | | | | | | | |
| Someone is cooking something | | | | | | | |
| Someone is smiling | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
| Taking a cup/glass/bottle from somewhere | | | | | | | |
| Putting something on a table | | | | | | | |
| Working/Playing on a laptop | | | | | | | |
| Tidying up a table | | | | | | | |
| Putting a cup/glass/bottle somewhere | | | | | | | |
| Drinking from a cup/glass/bottle | | | | | | | |
| Putting a dish/es somewhere | | | | | | | |
| Taking a dish/es from somewhere | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
| Taking a cup/glass/bottle from somewhere | | | | | | | |
| Holding a cup/glass/bottle of something | | | | | | | |
| Working/Playing on a laptop | | | | | | | |
| Putting something on a table | | | | | | | |
| Watching a laptop or something on a laptop | | | | | | | |
| Drinking from a cup/glass/bottle | | | | | | | |
| Putting a cup/glass/bottle somewhere | | | | | | | |
| Opening a closet/cabinet | | | | | | | |
| Taking a dish/es from somewhere | | | | | | | |
| Taking a cup/glass/bottle from somewhere | | | | | | | |
| Holding a cup/glass/bottle of something | | | | | | | |
| Working/Playing on a laptop | | | | | | | |
| Putting something on a table | | | | | | | |
| Walking through a doorway | | | | | | | |
| Putting a cup/glass/bottle somewhere | | | | | | | |
| Putting a dish/es somewhere | | | | | | | |
| Taking a dish/es from somewhere | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
|
<details>
<summary>extracted/6142422/images/Comparison/XOOTA.mp4/000102_bbox.png Details</summary>
### Visual Description
\n
## Object Detection Diagram: Indoor Scene with Bounding Boxes
### Overview
This image is a screenshot from an object detection or computer vision system. It displays a real-world indoor scene with several objects identified and enclosed by colored bounding boxes, each accompanied by a text label. The system has detected and localized four distinct object classes within the frame.
### Components/Axes
The image is a standard photographic frame. The primary informational components are the overlaid graphical elements from the detection system:
1. **Bounding Boxes & Labels:**
* **Person:** A pink bounding box encloses a person sitting on the floor. The label "person" is in pink text at the top-left corner of this box.
* **Fan:** A blue bounding box encloses a handheld fan being held by the person. The label "fan" is in blue text at the top-left corner of this box.
* **Blanket:** A green bounding box encloses a patterned blanket on the floor in front of the person. The label "blanket" is in green text at the top-left corner of this box.
* **Floor:** A white bounding box outlines a section of the floor on the left side of the image. The label "floor" is in white text at the top-left corner of this box.
2. **Scene Context (Background):**
* The setting is a room with light-colored carpet.
* **Left Side:** A wooden bed frame with a white mattress/box spring is visible. A black chair is partially in the foreground.
* **Center/Background:** A dark green tapestry with a forest or nature scene hangs on the wall.
* **Right Side:** A white shelving unit holds a television (screen is on, displaying a blue image). An acoustic guitar leans against the shelf. A wooden door is visible in the background.
### Detailed Analysis
* **Spatial Grounding & Placement:**
* The **"person"** box (pink) is centrally located, dominating the middle of the frame.
* The **"fan"** box (blue) is positioned within the upper-right quadrant of the "person" box, indicating the object is being held at chest level.
* The **"blanket"** box (green) is located directly below the "person" box, covering the floor area immediately in front of the seated individual.
* The **"floor"** box (white) is placed on the far left side of the image, highlighting a patch of carpet near the bed and chair. This is a segmentation of a surface rather than a discrete object.
* **Object Relationships:** The diagram shows a clear interaction: the detected **person** is holding the detected **fan**. The **blanket** is placed on the **floor** near the person, suggesting a casual, seated activity. The **floor** label explicitly identifies the ground plane.
### Key Observations
1. **Detection Specificity:** The system distinguishes between the general surface ("floor") and a specific object on it ("blanket").
2. **Interaction Recognition:** The placement of the "fan" box within the "person" box correctly implies the fan is being manipulated by the person.
3. **Contextual Awareness:** The detection occurs within a cluttered, realistic environment containing furniture (bed, shelf), electronics (TV), and personal items (guitar), demonstrating the system's ability to operate in non-sterile conditions.
4. **Label Consistency:** The color of each label text matches the color of its corresponding bounding box, providing a clear visual link.
### Interpretation
This image serves as a visualization of an object detection model's output. The primary data it conveys is not numerical but **spatial and categorical**: it answers "what is where" within the scene.
* **What it Demonstrates:** The system successfully performs multi-class object detection and localization. It identifies discrete objects (person, fan, blanket) and a surface region (floor), providing bounding box coordinates for each.
* **Relationships:** The spatial arrangement of the boxes encodes relationships. The containment of the "fan" box within the "person" box is a strong visual cue for interaction. The proximity of the "blanket" to the "person" suggests association.
* **Anomalies/Notes:** The "floor" detection is interesting as it segments a region of a continuous surface. This could be for training purposes (to teach the model what the floor looks like) or as a precursor to tasks like navigation or scene understanding. The detection appears accurate based on the visual evidence; no obvious misclassifications or poor localizations are present in this frame.
* **Underlying Purpose:** Such visualizations are critical for debugging and validating computer vision models. They allow engineers to assess if the model's internal representations (its "understanding" of the scene) align with reality. The clear labeling and boxing provide immediate, interpretable feedback on the model's performance for this specific input.
</details>
| | | | | | | |
| Holding a bag | | | | | | | |
| Snuggling with a blanket | | | | | | | |
| Sitting on the floor | | | | | | | |
| Lying on the floor | | | | | | | |
| Holding a vacuum | | | | | | | |
| Someone is awakening somewhere | | | | | | | |
| Taking a broom from somewhere | | | | | | | |
| Throwing a broom somewhere | | | | | | | |
| Tidying up with a broom | | | | | | | |
| Fixing a light | | | | | | | |
| Turning on a light | | | | | | | |
| Turning off a light | | | | | | | |
| Drinking from a cup/glass/bottle | | | | | | | |
| Holding a cup/glass/bottle of something | | | | | | | |
| Pouring something into a cup/glass/bottle | | | | | | | |
| Holding some clothes | | | | | | | |
| Putting clothes somewhere | | | | | | | |
| Holding a towel/s | | | | | | | |
| Putting a blanket somewhere | | | | | | | |
| Taking a blanket from somewhere | | | | | | | |
| Walking through a doorway | | | | | | | |
| Someone is smiling | | | | | | | |
| Someone is sneezing | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
| Holding a bag | | | | | | | |
| Holding some clothes | | | | | | | |
| Putting clothes somewhere | | | | | | | |
| Taking some clothes from somewhere | | | | | | | |
| Opening a bag | | | | | | | |
| Taking a bag from somewhere | | | | | | | |
| Walking through a doorway | | | | | | | |
| Someone is smiling | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
| Holding a bag | | | | | | | |
| Snuggling with a blanket | | | | | | | |
| Opening a bag | | | | | | | |
| Putting a bag somewhere | | | | | | | |
| Taking a bag from somewhere | | | | | | | |
| Putting a blanket somewhere | | | | | | | |
| Taking a blanket from somewhere | | | | | | | |
| Tidying up a blanket/s | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
| Holding a bag | | | | | | | |
| Snuggling with a blanket | | | | | | | |
| Sitting on the floor | | | | | | | |
| Holding a vacuum | | | | | | | |
| Opening a bag | | | | | | | |
| Taking a bag from somewhere | | | | | | | |
| Taking a blanket from somewhere | | | | | | | |
| Drinking from a cup/glass/bottle | | | | | | | |
| Tidying something on the floor | | | | | | | |
| Holding a bag | | | | | | | |
| Snuggling with a blanket | | | | | | | |
| Sitting on the floor | | | | | | | |
| Holding a vacuum | | | | | | | |
| Opening a bag | | | | | | | |
| Taking a bag from somewhere | | | | | | | |
| Throwing a blanket somewhere | | | | | | | |
| Fixing a vacuum | | | | | | | |
| Someone is standing up from somewhere | | | | | | | |
Figure 8: Manually selected qualitative results produced by each model on the abductive past action set inference: Abduct last image setup on the AG test dataset. The first column shows the image followed by their corresponding ground truth past actions. The remaining columns display the actions predicted by each model, with correct predictions highlighted in green and incorrect predictions highlighted in red.
### 9.4 Qualitative Results
We compare qualitative results for the abductive past action set prediction task in Figure 8. Depending on the number of past action labels an image has, we take the same number of top-k predicted actions from each model. All models demonstrate their ability to perform abductive past action inference. In the first image, there are objects such as a person, laptop, table, cup, and dish. In the second image, there are objects such as a person, floor, blanket, bag, and vacuum. In both scenarios, RBP and BiGED demonstrate that they can infer past actions more accurately.