# Automatic Change-Point Detection in Time Series via Deep Learning
**Authors**: Jie Li111Addresses for correspondence: Jie Li, Department of Statistics, London School of Economics and Political Science, London, WC2A 2AE.Email: j.li196@lse.ac.uk, Paul Fearnhead, Piotr Fryzlewicz, Tengyao Wang
> Department of Statistics, London School of Economics and Political Science, London, UK
> Department of Mathematics and Statistics, Lancaster University, Lancaster, UK
## Abstract
Detecting change-points in data is challenging because of the range of possible types of change and types of behaviour of data when there is no change. Statistically efficient methods for detecting a change will depend on both of these features, and it can be difficult for a practitioner to develop an appropriate detection method for their application of interest. We show how to automatically generate new offline detection methods based on training a neural network. Our approach is motivated by many existing tests for the presence of a change-point being representable by a simple neural network, and thus a neural network trained with sufficient data should have performance at least as good as these methods. We present theory that quantifies the error rate for such an approach, and how it depends on the amount of training data. Empirical results show that, even with limited training data, its performance is competitive with the standard CUSUM-based classifier for detecting a change in mean when the noise is independent and Gaussian, and can substantially outperform it in the presence of auto-correlated or heavy-tailed noise. Our method also shows strong results in detecting and localising changes in activity based on accelerometer data.
Keywords— Automatic statistician; Classification; Likelihood-free inference; Neural networks; Structural breaks; Supervised learning
12.5[0,0](2,1) [To be read before The Royal Statistical Society at the Society’s 2023 annual conference held in Harrogate on Wednesday, September 6th, 2023, the President, Dr Andrew Garrett, in the Chair.] 12.5[0,0](2,2) [Accepted (with discussion), to appear]
## 1 Introduction
Detecting change-points in data sequences is of interest in many application areas such as bioinformatics (Picard et al., 2005), climatology (Reeves et al., 2007), signal processing (Haynes et al., 2017) and neuroscience (Oh et al., 2005). In this work, we are primarily concerned with the problem of offline change-point detection, where the entire data is available to the analyst beforehand. Over the past few decades, various methodologies have been extensively studied in this area, see Killick et al. (2012); Jandhyala et al. (2013); Fryzlewicz (2014, 2023); Wang and Samworth (2018); Truong et al. (2020) and references therein. Most research on change-point detection has concentrated on detecting and localising different types of change, e.g. change in mean (Killick et al., 2012; Fryzlewicz, 2014), variance (Gao et al., 2019; Li et al., 2015), median (Fryzlewicz, 2021) or slope (Baranowski et al., 2019; Fearnhead et al., 2019), amongst many others. Many change-point detection methods are based upon modelling data when there is no change and when there is a single change, and then constructing an appropriate test statistic to detect the presence of a change (e.g. James et al., 1987; Fearnhead and Rigaill, 2020). The form of a good test statistic will vary with our modelling assumptions and the type of change we wish to detect. This can lead to difficulties in practice. As we use new models, it is unlikely that there will be a change-point detection method specifically designed for our modelling assumptions. Furthermore, developing an appropriate method under a complex model may be challenging, while in some applications an appropriate model for the data may be unclear but we may have substantial historical data that shows what patterns of data to expect when there is, or is not, a change. In these scenarios, currently a practitioner would need to choose the existing change detection method which seems the most appropriate for the type of data they have and the type of change they wish to detect. To obtain reliable performance, they would then need to adapt its implementation, for example tuning the choice of threshold for detecting a change. Often, this would involve applying the method to simulated or historical data. To address the challenge of automatically developing new change detection methods, this paper is motivated by the question: Can we construct new test statistics for detecting a change based only on having labelled examples of change-points? We show that this is indeed possible by training a neural network to classify whether or not a data set has a change of interest. This turns change-point detection in a supervised learning problem. A key motivation for our approach are results that show many common test statistics for detecting changes, such as the CUSUM test for detecting a change in mean, can be represented by simple neural networks. This means that with sufficient training data, the classifier learnt by such a neural network will give performance at least as good as classifiers corresponding to these standard tests. In scenarios where a standard test, such as CUSUM, is being applied but its modelling assumptions do not hold, we can expect the classifier learnt by the neural network to outperform it. There has been increasing recent interest in whether ideas from machine learning, and methods for classification, can be used for change-point detection. Within computer science and engineering, these include a number of methods designed for and that show promise on specific applications (e.g. Ahmadzadeh, 2018; De Ryck et al., 2021; Gupta et al., 2022; Huang et al., 2023). Within statistics, Londschien et al. (2022) and Lee et al. (2023) consider training a classifier as a way to estimate the likelihood-ratio statistic for a change. However these methods train the classifier in an un-supervised way on the data being analysed, using the idea that a classifier would more easily distinguish between two segments of data if they are separated by a change-point. Chang et al. (2019) use simulated data to help tune a kernel-based change detection method. Methods that use historical, labelled data have been used to train the tuning parameters of change-point algorithms (e.g. Hocking et al., 2015; Liehrmann et al., 2021). Also, neural networks have been employed to construct similarity scores of new observations to learned pre-change distributions for online change-point detection (Lee et al., 2023). However, we are unaware of any previous work using historical, labelled data to develop offline change-point methods. As such, and for simplicity, we focus on the most fundamental aspect, namely the problem of detecting a single change. Detecting and localising multiple changes is considered in Section 6 when analysing activity data. We remark that by viewing the change-point detection problem as a classification instead of a testing problem, we aim to control the overall misclassification error rate instead of handling the Type I and Type II errors separately. In practice, asymmetric treatment of the two error types can be achieved by suitably re-weighting misclassification in the two directions in the training loss function. The method we develop has parallels with likelihood-free inference methods Gourieroux et al. (1993); Beaumont (2019) in that one application of our work is to use the ability to simulate from a model so as to circumvent the need to analytically calculate likelihoods. However, the approach we take is very different from standard likelihood-free methods which tend to use simulation to estimate the likelihood function itself. By comparison, we directly target learning a function of the data that can discriminate between instances that do or do not contain a change (though see Gutmann et al., 2018, for likelihood-free methods based on re-casting the likelihood as a classification problem). For an introduction to the statistical aspects of neural network-based classification, albeit not specifically in a change-point context, see Ripley (1994). We now briefly introduce our notation. For any $n∈ℤ^+$ , we define $[n]\coloneqq\{1,…,n\}$ . We take all vectors to be column vectors unless otherwise stated. Let $\boldsymbol{1}_n$ be the all-one vector of length $n$ . Let $\mathbbm{1}\{·\}$ represent the indicator function. The vertical symbol $|·|$ represents the absolute value or cardinality of $·$ depending on the context. For vector $\boldsymbol{x}=(x_1,…,x_n)^⊤$ , we define its $p$ -norm as $\|\boldsymbol{x}\|_p\coloneqq\big{(}∑_i=1^n|x_i|^p\big{)}^1/p,p≥ 1$ ; when $p=∞$ , define $\|\boldsymbol{x}\|_∞\coloneqq\max_i|x_i|$ . All proofs, as well as additional simulations and real data analyses appear in the supplement.
## 2 Neural networks
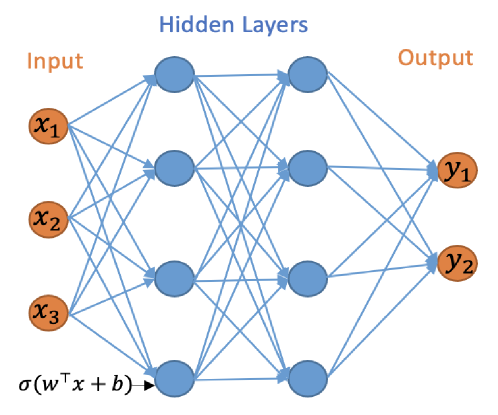
The initial focus of our work is on the binary classification problem for whether a change-point exists in a given time series. We will work with multilayer neural networks with Rectified Linear Unit (ReLU) activation functions and binary output. The multilayer neural network consists of an input layer, hidden layers and an output layer, and can be represented by a directed acyclic graph, see Figure 1.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Neural Network Architecture
### Overview
This image depicts a feedforward neural network with an input layer, two hidden layers, and an output layer. It illustrates the flow of information through the network, with connections between neurons in adjacent layers.
### Components/Axes
* **Input Layer:** Represented by three orange circles labeled $x_1$, $x_2$, and $x_3$. These are the input features to the network.
* **Hidden Layers:** Two layers of blue circles, each containing three neurons. These layers process the input data. The label "Hidden Layers" is positioned above these layers.
* **Output Layer:** Represented by two orange circles labeled $y_1$ and $y_2$. These are the final outputs of the network. The label "Output" is positioned to the right of this layer.
* **Connections:** Blue lines with arrows indicate the direction of information flow from one layer to the next. Every neuron in a layer is connected to every neuron in the subsequent layer.
* **Activation Function Notation:** A single arrow points to the bottom neuron of the first hidden layer, accompanied by the mathematical notation $\sigma(w^T x + b)$. This indicates that the output of each neuron is the result of applying an activation function (represented by $\sigma$) to a weighted sum of inputs ($w^T x$) plus a bias ($b$).
### Detailed Analysis or Content Details
* **Input Layer:** Consists of 3 input nodes ($x_1, x_2, x_3$).
* **First Hidden Layer:** Consists of 3 neurons. Each of the 3 input nodes is connected to each of these 3 neurons.
* **Second Hidden Layer:** Consists of 3 neurons. Each of the 3 neurons in the first hidden layer is connected to each of these 3 neurons.
* **Output Layer:** Consists of 2 output nodes ($y_1, y_2$). Each of the 3 neurons in the second hidden layer is connected to each of these 2 output nodes.
* **Activation Function:** The diagram explicitly shows the application of an activation function $\sigma(w^T x + b)$ to the weighted sum of inputs and bias for at least one neuron, implying this process occurs for all neurons in the hidden layers.
### Key Observations
* The network is fully connected between adjacent layers.
* There are 3 input features, 2 hidden layers with 3 neurons each, and 2 output predictions.
* The diagram visually represents a multi-layer perceptron (MLP) architecture.
### Interpretation
This diagram illustrates a fundamental structure of a deep learning model, specifically a feedforward neural network. The input layer receives raw data ($x_1, x_2, x_3$). This data is then processed through two sequential hidden layers, where complex patterns and features are extracted and transformed. The connections between neurons, weighted by parameters ($w$) and influenced by biases ($b$), along with the non-linear activation functions ($\sigma$), allow the network to learn intricate relationships within the data. Finally, the output layer produces the desired predictions ($y_1, y_2$) based on the processed information from the hidden layers. The notation $\sigma(w^T x + b)$ highlights the core computational step within each neuron: a linear transformation followed by a non-linear activation, which is crucial for the network's ability to model non-linear phenomena. This architecture is commonly used for tasks such as classification and regression.
</details>
Figure 1: A neural network with 2 hidden layers and width vector $m=(4,4)$ .
Let $L∈ℤ^+$ represent the number of hidden layers and $\boldsymbol{m}={(m_1,…,m_L)}^⊤$ the vector of the hidden layers widths, i.e. $m_i$ is the number of nodes in the $i$ th hidden layer. For a neural network with $L$ hidden layers we use the convention that $m_0=n$ and $m_L+1=1$ . For any bias vector $\boldsymbol{b}={(b_1,b_2,…,b_r)}^⊤∈ℝ^r$ , define the shifted activation function $σ_\boldsymbol{b}:ℝ^r→ℝ^r$ :
$$
σ_\boldsymbol{b}((y_1,…,y_r)^⊤)=(σ(y_1-b_1),
…,σ(y_r-b_r))^⊤,
$$
where $σ(x)=\max(x,0)$ is the ReLU activation function. The neural network can be mathematically represented by the composite function $h:ℝ^n→\{0,1\}$ as
$$
h(\boldsymbol{x})\coloneqqσ^*_λW_Lσ_\boldsymbol{b_L}
W_L-1σ_\boldsymbol{b_L-1}⋯ W_1σ_\boldsymbol{b_1}W_
0\boldsymbol{x}, \tag{1}
$$
where $σ^*_λ(x)=\mathbbm{1}\{x>λ\}$ , $λ>0$ and $W_\ell∈ℝ^m_\ell+1× m_\ell$ for $\ell∈\{0,…,L\}$ represent the weight matrices. We define the function class $H_L,\boldsymbol{m}$ to be the class of functions $h(\boldsymbol{x})$ with $L$ hidden layers and width vector $\boldsymbol{m}$ . The output layer in (1) employs the shifted heaviside function $σ^*_λ(x)$ , which is used for binary classification as the final activation function. This choice is guided by the fact that we use the 0-1 loss, which focuses on the percentage of samples assigned to the correct class, a natural performance criterion for binary classification. Besides its wide adoption in machine learning practice, another advantage of using the 0-1 loss is that it is possible to utilise the theory of the Vapnik–Chervonenkis (VC) dimension (see, e.g. Shalev-Shwartz and Ben-David, 2014, Definition 6.5) to bound the generalisation error of a binary classifier equipped with this loss; indeed, this is the approach we take in this work. The relevant results regarding the VC dimension of neural network classifiers are e.g. in Bartlett et al. (2019). As in Schmidt-Hieber (2020), we work with the exact minimiser of the empirical risk. In both binary or multiclass classification, it is possible to work with other losses which make it computationally easier to minimise the corresponding risk, see e.g. Bos and Schmidt-Hieber (2022), who use a version of the cross-entropy loss. However, loss functions different from the 0-1 loss make it impossible to use VC-dimension arguments to control the generalisation error, and more involved arguments, such as those using the covering number (Bos and Schmidt-Hieber, 2022) need to be used instead. We do not pursue these generalisations in the current work.
## 3 CUSUM-based classifier and its generalisations are neural networks
### 3.1 Change in mean
We initially consider the case of a single change-point with an unknown location $τ∈[n-1]$ , $n≥ 2$ , in the model
| | $\displaystyle\boldsymbol{X}$ | $\displaystyle=\boldsymbol{μ}+\boldsymbol{ξ},$ | |
| --- | --- | --- | --- |
where $μ_L,μ_R$ are the unknown signal values before and after the change-point; $\boldsymbol{ξ}∼ N_n(0,I_n)$ . The CUSUM test is widely used to detect mean changes in univariate data. For the observation $\boldsymbol{x}$ , the CUSUM transformation $C:ℝ^n→ℝ^n-1$ is defined as $C(\boldsymbol{x}):=(\boldsymbol{v}_1^⊤\boldsymbol{x},…, \boldsymbol{v}_n-1^⊤\boldsymbol{x})^⊤$ , where $\boldsymbol{v}_i\coloneqq\bigl{(}√{\frac{n-i}{in}}\boldsymbol{1}_i^ ⊤,-√{\frac{i}{(n-i)n}}\boldsymbol{1}_n-i^⊤\bigr{)}^⊤$ for $i∈[n-1]$ . Here, for each $i∈[n-1]$ , $(\boldsymbol{v}_i^⊤\boldsymbol{x})^2$ is the log likelihood-ratio statistic for testing a change at time $i$ against the null of no change (e.g. Baranowski et al., 2019). For a given threshold $λ>0$ , the classical CUSUM test for a change in the mean of the data is defined as
$$
h^CUSUM_λ(\boldsymbol{x})=\mathbbm{1}\{\|C(
\boldsymbol{x})\|_∞>λ\}.
$$
The following lemma shows that $h^CUSUM_λ(\boldsymbol{x})$ can be represented as a neural network.
**Lemma 3.1**
*For any $λ>0$ , we have $h^CUSUM_λ(\boldsymbol{x})∈H_1,2n-2$ .*
The fact that the widely-used CUSUM statistic can be viewed as a simple neural network has far-reaching consequences: this means that given enough training data, a neural network architecture that permits the CUSUM-based classifier as its special case cannot do worse than CUSUM in classifying change-point versus no-change-point signals. This serves as the main motivation for our work, and a prelude to our next results.
### 3.2 Beyond the mean change model
We can generalise the simple change in mean model to allow for different types of change or for non-independent noise. In this section, we consider change-point models that can be expressed as a change in regression problem, where the model for data given a change at $τ$ is of the form
$$
\boldsymbol{X}=\boldsymbol{Z}\boldsymbol{β}+\boldsymbol{c}_τφ+
\boldsymbol{Γ}\boldsymbol{ξ}, \tag{2}
$$
where for some $p≥ 1$ , $\boldsymbol{Z}$ is an $n× p$ matrix of covariates for the model with no change, $\boldsymbol{c}_τ$ is an $n× 1$ vector of covariates specific to the change at $τ$ , and the parameters $\boldsymbol{β}$ and $φ$ are, respectively, a $p× 1$ vector and a scalar. The noise is defined in terms of an $n× n$ matrix $\boldsymbol{Γ}$ and an $n× 1$ vector of independent standard normal random variables, $\boldsymbol{ξ}$ . For example, the change in mean problem has $p=1$ , with $\boldsymbol{Z}$ a column vector of ones, and $\boldsymbol{c}_τ$ being a vector whose first $τ$ entries are zeros, and the remaining entries are ones. In this formulation $β$ is the pre-change mean, and $φ$ is the size of the change. The change in slope problem Fearnhead et al. (2019) has $p=2$ with the columns of $\boldsymbol{Z}$ being a vector of ones, and a vector whose $i$ th entry is $i$ ; and $\boldsymbol{c}_τ$ has $i$ th entry that is $\max\{0,i-τ\}$ . In this formulation $\boldsymbol{β}$ defines the pre-change linear mean, and $φ$ the size of the change in slope. Choosing $\boldsymbol{Γ}$ to be proportional to the identity matrix gives a model with independent, identically distributed noise; but other choices would allow for auto-correlation. The following result is a generalisation of Lemma 3.1, which shows that the likelihood-ratio test for (2), viewed as a classifier, can be represented by our neural network.
**Lemma 3.2**
*Consider the change-point model (2) with a possible change at $τ∈[n-1]$ . Assume further that $\boldsymbol{Γ}$ is invertible. Then there is an $h^*∈H_1,2n-2$ equivalent to the likelihood-ratio test for testing $φ=0$ against $φ≠ 0$ .*
Importantly, this result shows that for this much wider class of change-point models, we can replicate the likelihood-ratio-based classifier for change using a simple neural network. Other types of changes can be handled by suitably pre-transforming the data. For instance, squaring the input data would be helpful in detecting changes in the variance and if the data followed an AR(1) structure, then changes in autocorrelation could be handled by including transformations of the original input of the form $(x_tx_t+1)_t=1,…,n-1$ . On the other hand, even if such transformations are not supplied as the input, a neural network of suitable depth is able to approximate these transformations and consequently successfully detect the change (Schmidt-Hieber, 2020, Lemma A.2). This is illustrated in Figure 7 of appendix, where we compare the performance of neural network based classifiers of various depths constructed with and without using the transformed data as inputs.
## 4 Generalisation error of neural network change-point classifiers
In Section 3, we showed that CUSUM and generalised CUSUM could be represented by a neural network. Therefore, with a large enough amount of training data, a trained neural network classifier that included CUSUM, or generalised CUSUM, as a special case, would perform no worse than it on unseen data. In this section, we provide generalisation bounds for a neural network classifier for the change-in-mean problem, given a finite amount of training data. En route to this main result, stated in Theorem 4.3, we provide generalisation bounds for the CUSUM-based classifier, in which the threshold has been chosen on a finite training data set. We write $P(n,τ,μ_L,μ_R)$ for the distribution of the multivariate normal random vector $\boldsymbol{X}∼ N_n(\boldsymbol{μ},I_n)$ where $\boldsymbol{μ}\coloneqq{(μ_L\mathbbm{1}\{i≤τ\}+μ_ R\mathbbm{1}\{i>τ\})}_i∈[n]$ . Define $η\coloneqqτ/n$ . Lemma 4.1 and Corollary 4.1 control the misclassification error of the CUSUM-based classifier.
**Lemma 4.1**
*Fix $ε∈(0,1)$ . Suppose $\boldsymbol{X}∼ P(n,τ,μ_L,μ_R)$ for some $τ∈ℤ^+$ and $μ_L,μ_R∈ℝ$ .
1. If $μ_L=μ_R$ , then $ℙ\bigl{\{}\|C(\boldsymbol{X})\|_∞>√{2\log(n/ ε)}\bigr{\}}≤ε.$
1. If $|μ_L-μ_R|√{η(1-η)}>√{8\log(n/ ε)/n}$ , then $ℙ\bigl{\{}\|C(\boldsymbol{X})\|_∞≤√{2\log(n/ ε)}\bigr{\}}≤ε.$*
For any $B>0$ , define
$$
Θ(B)\coloneqq≤ft\{(τ,μ_L,μ_R)∈[n-1]
×ℝ×ℝ:|μ_L-μ_R|√{τ
(n-τ)}/n∈\{0\}∪≤ft(B,∞\right)\right\}.
$$
Here, $|μ_L-μ_R|√{τ(n-τ)}/n=|μ_L-μ _R|√{η(1-η)}$ can be interpreted as the signal-to-noise ratio of the mean change problem. Thus, $Θ(B)$ is the parameter space of data distributions where there is either no change, or a single change-point in mean whose signal-to-noise ratio is at least $B$ . The following corollary controls the misclassification risk of a CUSUM statistics-based classifier:
**Corollary 4.1**
*Fix $B>0$ . Let $π_0$ be any prior distribution on $Θ(B)$ , then draw $(τ,μ_L,μ_R)∼π_0$ and $\boldsymbol{X}∼ P(n,τ,μ_L,μ_R)$ , and define $Y=\mathbbm{1}\{μ_L≠μ_R\}$ . For $λ=B√{n}/2$ , the classifier $h^CUSUM_λ$ satisfies
$$
ℙ(h^CUSUM_λ(\boldsymbol{X})≠ Y)≤ ne^-nB^{2
/8}.
$$*
Theorem 4.2 below, which is based on Corollary 4.1, Bartlett et al. (2019, Theorem 7) and Mohri et al. (2012, Corollary 3.4), shows that the empirical risk minimiser in the neural network class $H_1,2n-2$ has good generalisation properties over the class of change-point problems parameterised by $Θ(B)$ . Given training data $(\boldsymbol{X}^(1),Y^(1)),…,(\boldsymbol{X}^(N),Y^(N))$ and any $h:ℝ^n→\{0,1\}$ , we define the empirical risk of $h$ as
$$
L_N(h)\coloneqq\frac{1}{N}∑_i=1^N\mathbbm{1}\{Y^(i)≠ h(
\boldsymbol{X}^(i))\}.
$$
**Theorem 4.2**
*Fix $B>0$ and let $π_0$ be any prior distribution on $Θ(B)$ . We draw $(τ,μ_L,μ_R)∼π_0$ , $\boldsymbol{X}∼ P(n,τ,μ_L,μ_R)$ , and set $Y=\mathbbm{1}\{μ_L≠μ_R\}$ . Suppose that the training data $D:=\bigl{(}(\boldsymbol{X}^(1),Y^(1)),…,(\boldsymbol{X}^(N ),Y^(N))\bigr{)}$ consist of independent copies of $(\boldsymbol{X},Y)$ and $h_ERM\coloneqq\operatorname*{arg min}_h∈H_1,2n-2L_ {N}(h)$ is the empirical risk minimiser. There exists a universal constant $C>0$ such that for any $δ∈(0,1)$ , (3) holds with probability $1-δ$ .
$$
ℙ(h_ERM(\boldsymbol{X})≠ Y\midD)≤ ne^-nB^
{2/8}+C√{\frac{n^2\log(n)\log(N)+\log(1/δ)}{N}}. \tag{3}
$$*
The theoretical results derived for the neural network-based classifier, here and below, all rely on the fact that the training and test data are drawn from the same distribution. However, we observe that in practice, even when the training and test sets have different error distributions, neural network-based classifiers still provide accurate results on the test set; see our discussion of Figure 2 in Section 5 for more details. The misclassification error in (3) is bounded by two terms. The first term represents the misclassification error of CUSUM-based classifier, see Corollary 4.1, and the second term depends on the complexity of the neural network class measured in its VC dimension. Theorem 4.2 suggests that for training sample size $N\gg n^2\log n$ , a well-trained single-hidden-layer neural network with $2n-2$ hidden nodes would have comparable performance to that of the CUSUM-based classifier. However, as we will see in Section 5, in practice, a much smaller training sample size $N$ is needed for the neural network to be competitive in the change-point detection task. This is because the $2n-2$ hidden layer nodes in the neural network representation of $h^CUSUM_λ$ encode the components of the CUSUM transformation $(±\boldsymbol{v}_t^⊤\boldsymbol{x}:t∈[n-1])$ , which are highly correlated. By suitably pruning the hidden layer nodes, we can show that a single-hidden-layer neural network with $O(\log n)$ hidden nodes is able to represent a modified version of the CUSUM-based classifier with essentially the same misclassification error. More precisely, let $Q:=\lfloor\log_2(n/2)\rfloor$ and write $T_0:=\{2^q:0≤ q≤ Q\}∪\{n-2^q:0≤ q≤ Q\}$ . We can then define
$$
h^CUSUM_*_λ^*(\boldsymbol{X})=\mathbbm{1}\Bigl{\{}\max_
{t∈ T_0}|\boldsymbol{v}_t^⊤\boldsymbol{X}|>λ^*\Bigr{\}}.
$$
By the same argument as in Lemma 3.1, we can show that $h^CUSUM_*_λ^*∈H_1,4\lfloor\log_{2(n)\rfloor}$ for any $λ^*>0$ . The following Theorem shows that high classification accuracy can be achieved under a weaker training sample size condition compared to Theorem 4.2.
**Theorem 4.3**
*Fix $B>0$ and let the training data $D$ be generated as in Theorem 4.2. Let $h_ERM\coloneqq\operatorname*{arg min}_h∈H_L, \boldsymbol{m}L_N(h)$ be the empirical risk minimiser for a neural network with $L≥ 1$ layers and $\boldsymbol{m}=(m_1,…,m_L)^⊤$ hidden layer widths. If $m_1≥ 4\lfloor\log_2(n)\rfloor$ and $m_rm_r+1=O(n\log n)$ for all $r∈[L-1]$ , then there exists a universal constant $C>0$ such that for any $δ∈(0,1)$ , (4) holds with probability $1-δ$ .
$$
ℙ(h_ERM(\boldsymbol{X})≠ Y\midD)≤ 2\lfloor
\log_2(n)\rfloor e^-nB^{2/24}+C√{\frac{L^2n\log^2(Ln)\log(N)+\log(
1/δ)}{N}}. \tag{4}
$$*
Theorem 4.3 generalises the single hidden layer neural network representation in Theorem 4.2 to multiple hidden layers. In practice, multiple hidden layers help keep the misclassification error rate low even when $N$ is small, see the numerical study in Section 5. Theorems 4.2 and 4.3 are examples of how to derive generalisation errors of a neural network-based classifier in the change-point detection task. The same workflow can be employed in other types of changes, provided that suitable representation results of likelihood-based tests in terms of neural networks (e.g. Lemma 3.2) can be obtained. In a general result of this type, the generalisation error of the neural network will again be bounded by a sum of the error of the likelihood-based classifier together with a term originating from the VC-dimension bound of the complexity of the neural network architecture. We further remark that for simplicity of discussion, we have focused our attention on data models where the noise vector $\boldsymbol{ξ}=\boldsymbol{X}-E\boldsymbol{X}$ has independent and identically distributed normal components. However, since CUSUM-based tests are available for temporally correlated or sub-Weibull data, with suitably adjusted test threshold values, the above theoretical results readily generalise to such settings. See Theorems A.3 and A.5 in appendix for more details.
## 5 Numerical study
We now investigate empirically our approach of learning a change-point detection method by training a neural network. Motivated by the results from the previous section we will fit a neural network with a single layer and consider how varying the number of hidden layers and the amount of training data affects performance. We will compare to a test based on the CUSUM statistic, both for scenarios where the noise is independent and Gaussian, and for scenarios where there is auto-correlation or heavy-tailed noise. The CUSUM test can be sensitive to the choice of threshold, particularly when we do not have independent Gaussian noise, so we tune its threshold based on training data. When training the neural network, we first standardise the data onto $[0,1]$ , i.e. $\tilde{\boldsymbol{x}}_i=((x_ij-x_i^min)/(x_i^max -x_i^min))_j∈[n]$ where $x_i^max:=\max_jx_ij,x_i^min:=\min_jx_ij$ . This makes the neural network procedure invariant to either adding a constant to the data or scaling the data by a constant, which are natural properties to require. We train the neural network by minimising the cross-entropy loss on the training data. We run training for 200 epochs with a batch size of 32 and a learning rate of 0.001 using the Adam optimiser (Kingma and Ba, 2015). These hyperparameters are chosen based on a training dataset with cross-validation, more details can be found in Appendix B. We generate our data as follows. Given a sequence of length $n$ , we draw $τ∼Unif\{2,…,n-2\}$ , set $μ_L=0$ and draw $μ_R|τ∼Unif([-1.5b,-0.5b]∪[0.5b,1.5b])$ , where $b:=√{\frac{8n\log(20n)}{τ(n-τ)}}$ is chosen in line with Lemma 4.1 to ensure a good range of signal-to-noise ratios. We then generate $\boldsymbol{x}_1=(μ_L\mathbbm{1}_\{t≤τ\}+μ_R \mathbbm{1}_\{t>τ\}+ε_t)_t∈[n]$ , with the noise $(ε_t)_t∈[n]$ following an $AR(1)$ model with possibly time-varying autocorrelation $ε_t|ρ_t=ξ_1$ for $t=1$ and $ρ_tε_t-1+ξ_t$ for $t≥ 2$ , where $(ξ_t)_t∈[n]$ are independent, possibly heavy-tailed noise. The autocorrelations $ρ_t$ and innovations $ξ_t$ are from one of the three scenarios:
1. $n=100$ , $N∈\{100,200,…,700\}$ , $ρ_t=0$ and $ξ_t∼ N(0,1)$ .
1. $n=100$ , $N∈\{100,200,…,700\}$ , $ρ_t=0.7$ and $ξ_t∼ N(0,1)$ .
1. $n=100$ , $N∈\{100,200,…,1000\}$ , $ρ_t∼Unif([0,1])$ and $ξ_t∼ N(0,2)$ .
1. $n=100$ , $N∈\{100,200,…,1000\}$ , $ρ_t=0$ and $ξ_t∼Cauchy(0,0.3)$ .
The above procedure is then repeated $N/2$ times to generate independent sequences $\boldsymbol{x}_1,…,\boldsymbol{x}_N/2$ with a single change, and the associated labels are $(y_1,…,y_N/2)^⊤=1_N/2$ . We then repeat the process another $N/2$ times with $μ_R=μ_L$ to generate sequences without changes $\boldsymbol{x}_N/2+1,…,\boldsymbol{x}_N$ with $(y_N/2+1,…,y_N)^⊤=0_N/2$ . The data with and without change $(\boldsymbol{x}_i,y_i)_i∈[N]$ are combined and randomly shuffled to form the training data. The test data are generated in a similar way, with a sample size $N_test=30000$ and the slight modification that $μ_R|τ∼Unif([-1.75b,-0.25b]∪[0.25b,1.75b])$ when a change occurs. We note that the test data is drawn from the same distribution as the training set, though potentially having changes with signal-to-noise ratios outside the range covered by the training set. We have also conducted robustness studies to investigate the effect of training the neural networks on scenario S1 and test on S1 ${}^\prime$ , S2 or S3. Qualitatively similar results to Figure 2 have been obtained in this misspecified setting (see Figure 6 in appendix).
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image displays a line chart comparing the "MER Average" on the y-axis against "N" on the x-axis for five different methods. The methods are represented by distinct colored lines with markers, and their labels are provided in a legend. The chart shows how the MER Average changes as N increases for each method.
### Components/Axes
* **Y-axis Title:** MER Average
* **Scale:** Linear, ranging from approximately 0.05 to 0.17.
* **Markers:** 0.06, 0.08, 0.10, 0.12, 0.14, 0.16.
* **X-axis Title:** N
* **Scale:** Linear, ranging from 100 to 700.
* **Markers:** 100, 200, 300, 400, 500, 600, 700.
* **Legend:** Located in the top-right quadrant of the chart.
* **CUSUM:** Blue line with circular markers.
* **m⁽¹⁾, L=1:** Orange line with triangular markers.
* **m⁽²⁾, L=1:** Green line with diamond markers.
* **m⁽¹⁾, L=5:** Red line with square markers.
* **m⁽¹⁾, L=10:** Purple line with star markers.
### Detailed Analysis
The chart presents data points for five series at N values of 100, 200, 300, 400, 500, 600, and 700.
**1. CUSUM (Blue line with circles):**
* **Trend:** The CUSUM line generally slopes upward from N=400 to N=500, then plateaus, and slightly decreases towards N=700. It shows a slight dip between N=100 and N=200.
* **Data Points (approximate):**
* N=100: 0.060
* N=200: 0.082
* N=300: 0.068
* N=400: 0.062
* N=500: 0.076
* N=600: 0.076
* N=700: 0.060
**2. m⁽¹⁾, L=1 (Orange line with triangles):**
* **Trend:** This line starts at its highest point at N=100 and then sharply decreases until N=400, after which it shows a slight upward trend until N=600, followed by a decrease.
* **Data Points (approximate):**
* N=100: 0.165
* N=200: 0.085
* N=300: 0.070
* N=400: 0.062
* N=500: 0.065
* N=600: 0.058
* N=700: 0.059
**3. m⁽²⁾, L=1 (Green line with diamonds):**
* **Trend:** This line shows a steep downward trend from N=100 to N=200, and then a gradual decrease as N increases, with a slight increase between N=400 and N=500.
* **Data Points (approximate):**
* N=100: 0.128
* N=200: 0.085
* N=300: 0.072
* N=400: 0.065
* N=500: 0.068
* N=600: 0.055
* N=700: 0.058
**4. m⁽¹⁾, L=5 (Red line with squares):**
* **Trend:** This line starts at a moderate value at N=100, increases slightly to N=200, then decreases steadily as N increases, with a slight dip at N=400 and N=600.
* **Data Points (approximate):**
* N=100: 0.078
* N=200: 0.074
* N=300: 0.065
* N=400: 0.058
* N=500: 0.060
* N=600: 0.053
* N=700: 0.055
**5. m⁽¹⁾, L=10 (Purple line with stars):**
* **Trend:** This line shows a general upward trend from N=100 to N=200, followed by a decrease until N=400, and then a slight increase and plateauing.
* **Data Points (approximate):**
* N=100: 0.060
* N=200: 0.074
* N=300: 0.068
* N=400: 0.060
* N=500: 0.062
* N=600: 0.055
* N=700: 0.055
### Key Observations
* The **m⁽¹⁾, L=1** method exhibits the highest MER Average at N=100 (approximately 0.165).
* As N increases, most methods show a general decreasing trend in MER Average, particularly between N=100 and N=400.
* The **CUSUM** method shows a relatively stable MER Average for N > 400, hovering around 0.076 before decreasing slightly.
* The **m⁽¹⁾, L=5** and **m⁽¹⁾, L=10** methods tend to have the lowest MER Averages for larger values of N (N >= 400), often falling below 0.060.
* At N=200, several lines converge around an MER Average of 0.074-0.085.
* At N=700, the MER Averages for most methods are clustered between 0.055 and 0.060, with CUSUM being slightly higher.
### Interpretation
This chart likely demonstrates the performance of different anomaly detection or change detection algorithms (indicated by the method names like CUSUM and the parameterized 'm' methods) across varying sample sizes (N). The "MER Average" could represent a metric like Mean Error Rate or a similar measure of performance.
* **Initial High Performance:** The high MER Average for `m⁽¹⁾, L=1` at N=100 suggests that this method might be very sensitive to initial anomalies or variations but may not generalize well to larger datasets.
* **Convergence and Stability:** The convergence of several lines at higher N values indicates that for larger sample sizes, the performance of these methods becomes more similar. The general decrease in MER Average as N increases suggests that most methods become more robust or accurate with more data.
* **Method-Specific Behavior:** The distinct trends for each method highlight their different characteristics. For instance, CUSUM appears to maintain a moderate performance level for larger N, while `m⁽¹⁾, L=5` and `m⁽¹⁾, L=10` seem to achieve lower error rates at larger sample sizes. The parameters L=5 and L=10 in the 'm' methods likely represent different window sizes or look-ahead periods, influencing their behavior. A larger L might lead to smoother detection or a different trade-off between false positives and negatives.
* **Trade-offs:** The chart implicitly shows trade-offs. For example, `m⁽¹⁾, L=1` might detect anomalies very quickly (low N), but at the cost of higher average error over time or larger datasets. Conversely, methods with lower MER at higher N might be slower to detect initial changes but are more reliable overall.
* **Peircean Investigative Reading:** The data suggests an investigation into the optimal choice of algorithm and its parameters (like L) based on the expected size of the data stream (N) and the desired performance metric (MER Average). If the goal is to detect anomalies in a large, stable dataset, methods like `m⁽¹⁾, L=5` or `m⁽¹⁾, L=10` might be preferred. If rapid detection of early anomalies is critical, `m⁽¹⁾, L=1` might be considered, but with an awareness of its potential for higher average error. The CUSUM method appears to offer a balanced approach, especially for larger N.
</details>
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image displays a line chart that plots the "MER Average" on the y-axis against "N" on the x-axis. Five different data series, representing various methods, are shown, each with a distinct color and marker. The chart illustrates how the MER Average changes with increasing values of N for each method.
### Components/Axes
* **Y-axis Label**: MER Average
* **Scale**: Ranges from 0.18 to 0.32, with major ticks at 0.18, 0.20, 0.22, 0.24, 0.26, 0.28, 0.30, and 0.32.
* **X-axis Label**: N
* **Scale**: Ranges from 100 to 700, with major ticks at 100, 200, 300, 400, 500, 600, and 700.
* **Legend**: Located in the top-right quadrant of the chart. It associates colors and markers with specific data series:
* **Blue line with circles**: CUSUM
* **Orange line with triangles**: $m^{(1)}, L=1$
* **Green line with diamonds**: $m^{(2)}, L=1$
* **Red line with squares**: $m^{(1)}, L=5$
* **Purple line with crosses**: $m^{(1)}, L=10$
### Detailed Analysis
**Data Series Trends and Points:**
1. **CUSUM (Blue line with circles)**:
* **Trend**: The CUSUM line generally shows a slight decrease from N=100 to N=400, then a slight increase from N=400 to N=500, followed by a slight decrease from N=500 to N=700.
* **Approximate Data Points**:
* N=100: 0.285
* N=200: 0.250
* N=300: 0.245
* N=400: 0.248
* N=500: 0.255
* N=600: 0.250
* N=700: 0.248
2. **$m^{(1)}, L=1$ (Orange line with triangles)**:
* **Trend**: This series starts at its highest point at N=100 and shows a consistent downward trend as N increases, with a slight upward fluctuation around N=400.
* **Approximate Data Points**:
* N=100: 0.322
* N=200: 0.250
* N=300: 0.235
* N=400: 0.230
* N=500: 0.215
* N=600: 0.205
* N=700: 0.198
3. **$m^{(2)}, L=1$ (Green line with diamonds)**:
* **Trend**: This series shows a sharp decrease from N=100 to N=200, then a gradual decrease until N=300, followed by an increase at N=400, and then a consistent decrease from N=400 to N=700.
* **Approximate Data Points**:
* N=100: 0.315
* N=200: 0.230
* N=300: 0.218
* N=400: 0.225
* N=500: 0.208
* N=600: 0.200
* N=700: 0.190
4. **$m^{(1)}, L=5$ (Red line with squares)**:
* **Trend**: This series exhibits a downward trend from N=100 to N=300, a sharp increase at N=400, and then a general downward trend from N=400 to N=700.
* **Approximate Data Points**:
* N=100: 0.278
* N=200: 0.215
* N=300: 0.198
* N=400: 0.225
* N=500: 0.205
* N=600: 0.200
* N=700: 0.195
5. **$m^{(1)}, L=10$ (Purple line with crosses)**:
* **Trend**: This series shows a steep decline from N=100 to N=300, followed by an increase at N=400, and then a consistent downward trend from N=400 to N=700.
* **Approximate Data Points**:
* N=100: 0.285
* N=200: 0.215
* N=300: 0.195
* N=400: 0.228
* N=500: 0.202
* N=600: 0.195
* N=700: 0.188
### Key Observations
* **General Trend**: Most of the methods show a general decrease in MER Average as N increases, particularly from N=100 to N=300.
* **Peak at N=100**: The highest MER Average values are observed at N=100 for all methods, with $m^{(1)}, L=1$ having the highest value (approx. 0.322).
* **N=400 Anomaly**: There is a noticeable upward spike in MER Average for $m^{(2)}, L=1$, $m^{(1)}, L=5$, and $m^{(1)}, L=10$ at N=400. The CUSUM method shows a slight increase at this point as well.
* **Lowest MER Average**: The lowest MER Average values are generally observed at N=700, with $m^{(2)}, L=1$ reaching approximately 0.190 and $m^{(1)}, L=10$ reaching approximately 0.188.
* **Comparison of Methods**:
* The $m^{(1)}, L=1$ method generally exhibits higher MER Averages compared to other methods for larger values of N, although it starts with the highest value at N=100.
* The CUSUM method shows a more stable, albeit slightly fluctuating, MER Average across the range of N compared to the other methods, which exhibit more pronounced decreases and increases.
* The methods with $L=5$ and $L=10$ ($m^{(1)}, L=5$ and $m^{(1)}, L=10$) show similar trends, with $m^{(1)}, L=10$ generally having slightly lower MER Averages than $m^{(1)}, L=5$ for N > 300.
### Interpretation
The chart suggests that the "MER Average" is sensitive to the parameter "N" across all tested methods. The initial high MER Average at N=100 for all methods might indicate a period of higher uncertainty or variability when the sample size (N) is small. As N increases, most methods tend to stabilize or decrease their MER Average, implying improved performance or reduced error in estimating the MER.
The upward spike at N=400 for several methods is a significant observation. This could indicate a specific point where the underlying data distribution or the method's assumptions are challenged, leading to a temporary increase in error before it potentially stabilizes again at larger N. This anomaly warrants further investigation into the nature of the data or the method's behavior at this particular N value.
The CUSUM method appears to be the most robust or stable across the range of N, showing less dramatic fluctuations compared to the other methods. This could imply that CUSUM is less sensitive to changes in N or exhibits a more consistent performance.
The comparison between $m^{(1)}, L=5$ and $m^{(1)}, L=10$ suggests that increasing the parameter L (from 5 to 10) for the $m^{(1)}$ method generally leads to a lower MER Average for larger N, indicating potentially better performance or accuracy with a larger L value in this range. However, the initial values at N=100 are similar.
Overall, the data demonstrates a trade-off or relationship between the sample size (N) and the MER Average for different detection or estimation methods. The choice of method and its parameters (like L) can significantly influence the MER Average, and understanding these trends is crucial for selecting the most appropriate method for a given application and data size. The anomaly at N=400 is a key point of interest for deeper analysis.
</details>
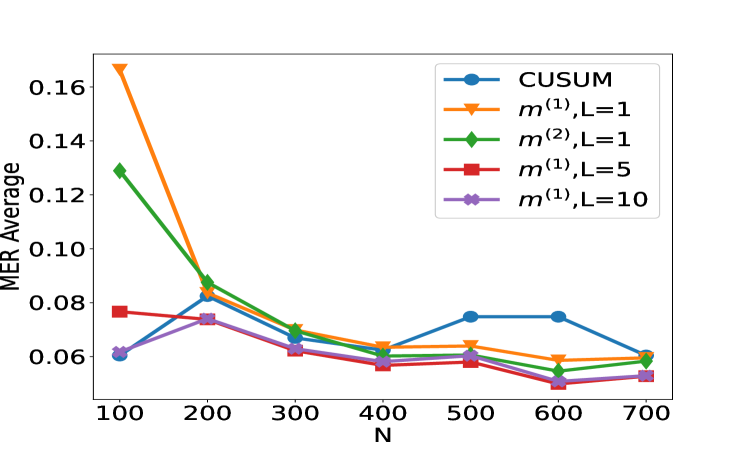
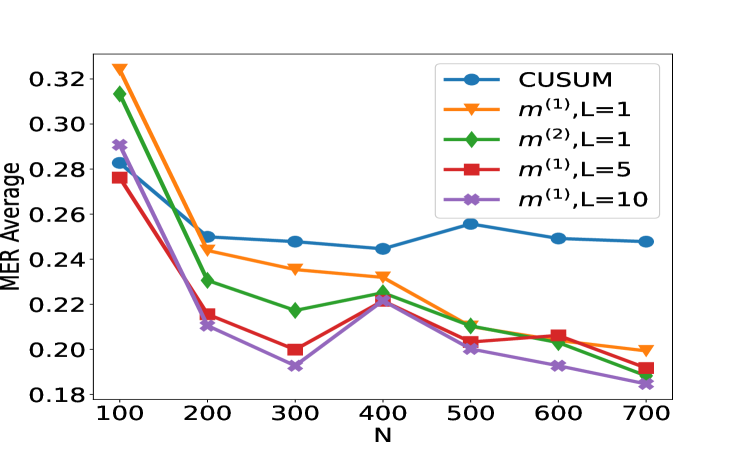
(a) Scenario S1 with $ρ_t=0$ (b) Scenario S1 ${}^\prime$ with $ρ_t=0.7$
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image is a line chart displaying the "MER Average" on the y-axis against "N" on the x-axis. Five different data series, representing different methods or configurations, are plotted. The chart shows how the MER Average changes as N increases from approximately 100 to 1000.
### Components/Axes
* **Y-axis Label**: "MER Average"
* **Scale**: Linear, ranging from approximately 0.18 to 0.36.
* **Tick Marks**: 0.18, 0.20, 0.22, 0.24, 0.26, 0.28, 0.30, 0.32, 0.34, 0.35.
* **X-axis Label**: "N"
* **Scale**: Linear, ranging from approximately 100 to 1000.
* **Tick Marks**: 200, 400, 600, 800, 1000.
* **Legend**: Located in the top-right quadrant of the chart. It maps colors and markers to different data series:
* **Blue circles**: CUSUM
* **Orange inverted triangles**: $m^{(1)}, L=1$
* **Green diamonds**: $m^{(2)}, L=1$
* **Red squares**: $m^{(1)}, L=5$
* **Purple crosses**: $m^{(1)}, L=10$
### Detailed Analysis or Content Details
The chart displays data points at approximate N values of 100, 200, 300, 400, 500, 600, 700, 800, 900, and 1000.
**1. CUSUM (Blue circles):**
* **Trend**: This series shows a relatively stable trend, starting around 0.24, slightly decreasing to around 0.235, then increasing to around 0.245, and fluctuating between 0.24 and 0.245 for the rest of the N values.
* **Data Points (approximate N, MER Average):**
* (100, 0.24)
* (200, 0.245)
* (300, 0.235)
* (400, 0.24)
* (500, 0.245)
* (600, 0.245)
* (700, 0.24)
* (800, 0.245)
* (900, 0.24)
* (1000, 0.24)
**2. $m^{(1)}, L=1$ (Orange inverted triangles):**
* **Trend**: This series starts at a high MER Average of approximately 0.35 at N=100, then sharply decreases to around 0.25 at N=200, and continues to decrease to around 0.19 at N=400. It then fluctuates between approximately 0.20 and 0.22 before ending around 0.195 at N=1000.
* **Data Points (approximate N, MER Average):**
* (100, 0.35)
* (200, 0.25)
* (300, 0.21)
* (400, 0.19)
* (500, 0.205)
* (600, 0.22)
* (700, 0.20)
* (800, 0.215)
* (900, 0.195)
* (1000, 0.195)
**3. $m^{(2)}, L=1$ (Green diamonds):**
* **Trend**: This series begins at approximately 0.36 at N=100, drops significantly to around 0.26 at N=200, and further to around 0.22 at N=300. It then fluctuates, reaching a low of around 0.19 at N=400, then rising to around 0.205 at N=500, dropping to 0.19 at N=700, rising to 0.205 at N=800, and ending around 0.195 at N=1000.
* **Data Points (approximate N, MER Average):**
* (100, 0.36)
* (200, 0.26)
* (300, 0.22)
* (400, 0.19)
* (500, 0.205)
* (600, 0.19)
* (700, 0.185)
* (800, 0.205)
* (900, 0.185)
* (1000, 0.195)
**4. $m^{(1)}, L=5$ (Red squares):**
* **Trend**: This series starts at approximately 0.30 at N=100, drops to around 0.23 at N=200, and continues to decrease to around 0.21 at N=300. It then fluctuates between approximately 0.19 and 0.22, ending around 0.185 at N=1000.
* **Data Points (approximate N, MER Average):**
* (100, 0.30)
* (200, 0.23)
* (300, 0.21)
* (400, 0.22)
* (500, 0.205)
* (600, 0.215)
* (700, 0.195)
* (800, 0.185)
* (900, 0.19)
* (1000, 0.185)
**5. $m^{(1)}, L=10$ (Purple crosses):**
* **Trend**: This series begins at approximately 0.28 at N=100, drops to around 0.23 at N=200, and further to around 0.18 at N=300. It then fluctuates between approximately 0.18 and 0.21, ending around 0.19 at N=1000.
* **Data Points (approximate N, MER Average):**
* (100, 0.28)
* (200, 0.23)
* (300, 0.18)
* (400, 0.19)
* (500, 0.205)
* (600, 0.195)
* (700, 0.21)
* (800, 0.185)
* (900, 0.19)
* (1000, 0.19)
### Key Observations
* **Initial High Values**: The methods $m^{(2)}, L=1$, $m^{(1)}, L=1$, and $m^{(1)}, L=5$ all start with significantly higher MER Average values at N=100 compared to CUSUM and $m^{(1)}, L=10$.
* **Rapid Decrease**: For most methods (except CUSUM), there is a sharp decrease in MER Average as N increases from 100 to around 300-400.
* **Convergence/Stabilization**: After the initial drop, most of the methods (except CUSUM, which is already relatively stable) tend to converge to lower MER Average values, generally between 0.18 and 0.22, as N increases towards 1000.
* **CUSUM Stability**: The CUSUM method exhibits the most stable MER Average across the range of N, fluctuating only slightly around 0.24.
* **Lowest Values**: The lowest MER Average values (around 0.18-0.19) are achieved by $m^{(1)}, L=5$, $m^{(1)}, L=10$, and $m^{(2)}, L=1$ at various points for N >= 300.
### Interpretation
The chart suggests that for the tested methods, the "MER Average" generally decreases as the parameter "N" increases, especially in the initial range of N. This indicates that a larger sample size or a longer observation period (represented by N) might lead to a more stable or accurate measurement of MER (likely Mean Error Rate or a similar metric).
The CUSUM method appears to be the most robust or least sensitive to changes in N, maintaining a consistent MER Average. In contrast, the other methods, particularly $m^{(1)}, L=1$ and $m^{(2)}, L=1$, show a significant improvement (reduction in MER Average) as N increases from 100. The parameter L (which might represent a lookback window or a similar parameter) also seems to influence the performance, with $m^{(1)}, L=5$ and $m^{(1)}, L=10$ generally achieving lower MER averages than $m^{(1)}, L=1$ for larger N.
The initial high MER Average values for some methods at small N could indicate instability or a higher rate of errors when the system is less observed. The subsequent decrease suggests that with more data, the methods become more adept at identifying or mitigating errors, leading to a lower average error rate. The convergence of several lines at lower MER Average values for larger N implies that beyond a certain point, increasing N might yield diminishing returns in terms of MER reduction for these specific methods.
</details>
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image displays a line chart comparing the "MER Average" (Mean Error Rate Average) against "N" (likely representing sample size or number of observations) for five different methods: CUSUM, m⁽¹⁾,L=1, m⁽²⁾,L=1, m⁽¹⁾,L=5, and m⁽¹⁾,L=10. The chart visualizes how the average MER changes as N increases for each of these methods.
### Components/Axes
* **Chart Type**: Line Chart
* **Title**: Implicitly, the chart title relates to the comparison of MER Average across different methods as N varies.
* **X-axis**:
* **Label**: N
* **Scale**: Numerical, ranging from approximately 100 to 1000.
* **Markers**: 100, 200, 400, 600, 800, 1000.
* **Y-axis**:
* **Label**: MER Average
* **Scale**: Numerical, ranging from 0.25 to 0.50.
* **Markers**: 0.25, 0.30, 0.35, 0.40, 0.45, 0.50.
* **Legend**: Located in the top-right quadrant of the chart. It maps colors and markers to specific methods:
* Blue circles: CUSUM
* Orange triangles: m⁽¹⁾,L=1
* Green diamonds: m⁽²⁾,L=1
* Red squares: m⁽¹⁾,L=5
* Purple crosses: m⁽¹⁾,L=10
### Detailed Analysis or Content Details
The chart displays data points for each method at various values of N. The approximate values for each data series are as follows:
**1. CUSUM (Blue circles):**
* **Trend**: This line generally shows a slight upward trend, with some minor fluctuations. It starts around 0.36 at N=100, dips slightly, and then rises to around 0.36 at N=1000.
* **Data Points (approximate N, MER Average):**
* (100, 0.36)
* (200, 0.35)
* (300, 0.35)
* (400, 0.35)
* (500, 0.355)
* (600, 0.35)
* (700, 0.348)
* (800, 0.35)
* (900, 0.348)
* (1000, 0.353)
**2. m⁽¹⁾,L=1 (Orange triangles):**
* **Trend**: This line shows a significant downward trend from N=100 to N=600, after which it fluctuates. It starts at a high value and decreases substantially.
* **Data Points (approximate N, MER Average):**
* (100, 0.425)
* (200, 0.365)
* (300, 0.355)
* (400, 0.35)
* (500, 0.315)
* (600, 0.29)
* (700, 0.285)
* (800, 0.265)
* (900, 0.27)
* (1000, 0.28)
**3. m⁽²⁾,L=1 (Green diamonds):**
* **Trend**: This line exhibits a generally decreasing trend, with some fluctuations. It starts high and ends lower than its initial value.
* **Data Points (approximate N, MER Average):**
* (100, 0.40)
* (200, 0.37)
* (300, 0.32)
* (400, 0.31)
* (500, 0.305)
* (600, 0.28)
* (700, 0.27)
* (800, 0.26)
* (900, 0.255)
* (1000, 0.255)
**4. m⁽¹⁾,L=5 (Red squares):**
* **Trend**: This line shows a clear downward trend, particularly from N=100 to N=500, and then it fluctuates.
* **Data Points (approximate N, MER Average):**
* (100, 0.365)
* (200, 0.32)
* (300, 0.29)
* (400, 0.285)
* (500, 0.31)
* (600, 0.275)
* (700, 0.26)
* (800, 0.26)
* (900, 0.27)
* (1000, 0.275)
**5. m⁽¹⁾,L=10 (Purple crosses):**
* **Trend**: This line shows significant fluctuations, with an initial decrease, a peak, and then a general downward trend with a slight increase at the end.
* **Data Points (approximate N, MER Average):**
* (100, 0.34)
* (200, 0.29)
* (300, 0.295)
* (400, 0.315)
* (500, 0.295)
* (600, 0.28)
* (700, 0.27)
* (800, 0.30)
* (900, 0.275)
* (1000, 0.275)
### Key Observations
* **Initial Performance**: At N=100, the m⁽¹⁾,L=1 method has the highest MER Average (approx. 0.425), while CUSUM and m⁽¹⁾,L=10 have the lowest (approx. 0.36 and 0.34 respectively).
* **General Trend**: Most methods, except for CUSUM, show a general decreasing trend in MER Average as N increases, especially in the initial range of N.
* **CUSUM Stability**: The CUSUM method exhibits a relatively stable MER Average across the range of N, hovering around 0.35. It does not show a significant decrease or increase.
* **Convergence**: As N approaches 1000, several methods (m⁽¹⁾,L=1, m⁽¹⁾,L=5, m⁽¹⁾,L=10, and m⁽²⁾,L=1) appear to converge to a MER Average in the range of 0.25 to 0.28.
* **Outlier/Peak**: The m⁽¹⁾,L=10 method shows a notable peak at N=400 (approx. 0.315), which is higher than its neighboring data points.
### Interpretation
This chart likely demonstrates the performance of different anomaly detection or change detection algorithms (indicated by CUSUM and the 'm' notations, possibly representing different variants or parameters of a method). The "MER Average" is a performance metric, where a lower value is generally better, indicating fewer errors on average.
The data suggests that for most of the tested methods (m⁽¹⁾,L=1, m⁽²⁾,L=1, m⁽¹⁾,L=5, and m⁽¹⁾,L=10), increasing the sample size (N) leads to a reduction in the average MER, implying that these methods become more effective or reliable with more data. This is a common characteristic of many statistical and machine learning algorithms.
The CUSUM method, however, appears to be less sensitive to the increase in N, maintaining a relatively consistent MER Average. This could indicate that CUSUM is either already performing optimally within this range of N, or it has a different operational characteristic that makes its performance less dependent on sample size compared to the other methods.
The parameters 'L' in the 'm' methods (e.g., L=1, L=5, L=10) likely represent a window size or a threshold parameter. The comparison between m⁽¹⁾,L=1, m⁽¹⁾,L=5, and m⁽¹⁾,L=10 suggests that the choice of 'L' can influence the performance, with some values of 'L' leading to better (lower) MER Averages than others, especially at larger N. For instance, m⁽²⁾,L=1 and m⁽¹⁾,L=5 seem to achieve lower MER Averages at higher N compared to m⁽¹⁾,L=10.
The peak observed in m⁽¹⁾,L=10 at N=400 might represent a point where the algorithm's performance temporarily degrades, possibly due to specific data characteristics at that sample size or an interaction between the algorithm's parameters and the data distribution.
In summary, the chart illustrates a trade-off between different methods and their sensitivity to sample size, with most methods showing improvement as N increases, while CUSUM remains relatively stable. The parameter 'L' also plays a role in the performance of the 'm' methods.
</details>
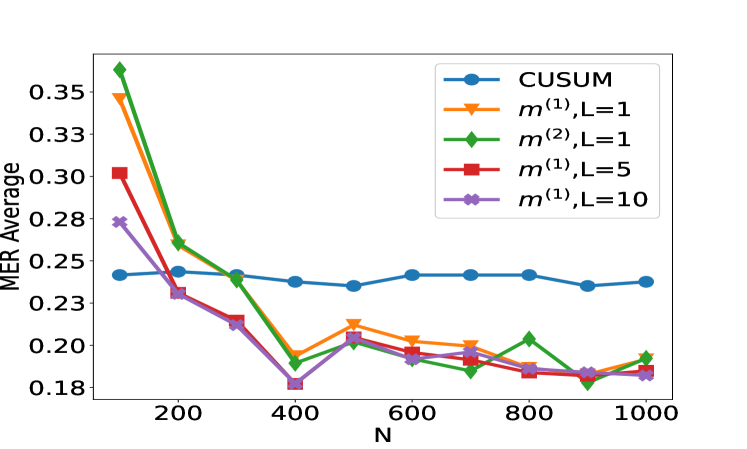
(c) Scenario S2 with $ρ_t∼Unif([0,1])$ (d) Scenario S3 with Cauchy noise
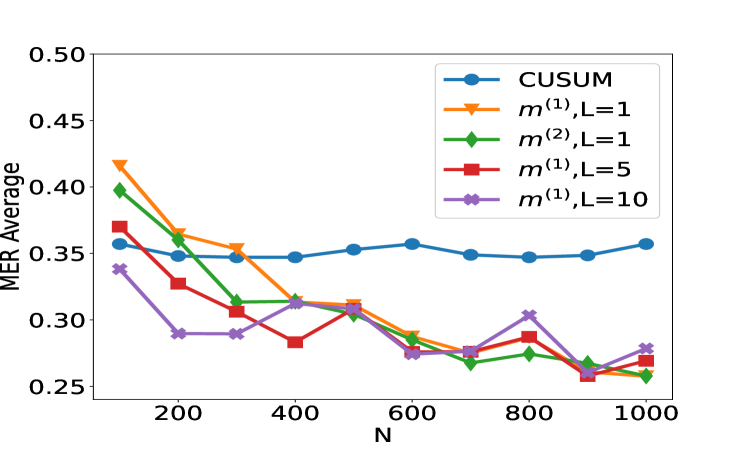
Figure 2: Plot of the test set MER, computed on a test set of size $N_test=30000$ , against training sample size $N$ for detecting the existence of a change-point on data series of length $n=100$ . We compare the performance of the CUSUM test and neural networks from four function classes: $H_1,m^(1)$ , $H_1,m^(2)$ , $H_5,m^(1)1_5$ and $H_10,m^(1)1_10$ where $m^(1)=4\lfloor\log_2(n)\rfloor$ and $m^(2)=2n-2$ respectively under scenarios S1, S1 ${}^\prime$ , S2 and S3 described in Section 5.
We compare the performance of the CUSUM-based classifier with the threshold cross-validated on the training data with neural networks from four function classes: $H_1,m^(1)$ , $H_1,m^(2)$ , $H_5,m^(1)1_5$ and $H_10,m^(1)1_10$ where $m^(1)=4\lfloor\log_2(n)\rfloor$ and $m^(2)=2n-2$ respectively (cf. Theorem 4.3 and Lemma 3.1). Figure 2 shows the test misclassification error rate (MER) of the four procedures in the four scenarios S1, S1 ${}^\prime$ , S2 and S3. We observe that when data are generated with independent Gaussian noise ( Figure 2 (a)), the trained neural networks with $m^(1)$ and $m^(2)$ single hidden layer nodes attain very similar test MER compared to the CUSUM-based classifier. This is in line with our Theorem 4.3. More interestingly, when noise has either autocorrelation ( Figure 2 (b, c)) or heavy-tailed distribution ( Figure 2 (d)), trained neural networks with $(L,m)$ : $(1,m^(1))$ , $(1,m^(2))$ , $(5,m^(1)1_5)$ and $(10,m^(1)1_10)$ outperform the CUSUM-based classifier, even after we have optimised the threshold choice of the latter. In addition, as shown in Figure 5 in the online supplement, when the first two layers of the network are set to carry out truncation, which can be seen as a composition of two ReLU operations, the resulting neural network outperforms the Wilcoxon statistics-based classifier (Dehling et al., 2015), which is a standard benchmark for change-point detection in the presence of heavy-tailed noise. Furthermore, from Figure 2, we see that increasing $L$ can significantly reduce the average MER when $N≤ 200$ . Theoretically, as the number of layers $L$ increases, the neural network is better able to approximate the optimal decision boundary, but it becomes increasingly difficult to train the weights due to issues such as vanishing gradients (He et al., 2016). A combination of these considerations leads us to develop deep neural network architecture with residual connections for detecting multiple changes and multiple change types in Section 6.
## 6 Detecting multiple changes and multiple change types – case study
From the previous section, we see that single and multiple hidden layer neural networks can represent CUSUM or generalised CUSUM tests and may perform better than likelihood-based test statistics when the model is misspecified. This prompted us to seek a general network architecture that can detect, and even classify, multiple types of change. Motivated by the similarities between signal processing and image recognition, we employed a deep convolutional neural network (CNN) (Yamashita et al., 2018) to learn the various features of multiple change-types. However, stacking more CNN layers cannot guarantee a better network because of vanishing gradients in training (He et al., 2016). Therefore, we adopted the residual block structure (He et al., 2016) for our neural network architecture. After experimenting with various architectures with different numbers of residual blocks and fully connected layers on synthetic data, we arrived at a network architecture with 21 residual blocks followed by a number of fully connected layers. Figure 9 shows an overview of the architecture of the final general-purpose deep neural network for change-point detection. The precise architecture and training methodology of this network $\widehat{NN}$ can be found in Appendix C. Neural Architecture Search (NAS) approaches (see Paaß and Giesselbach, 2023, Section 2.4.3) offer principled ways of selecting neural architectures. Some of these approaches could be made applicable in our setting. We demonstrate the power of our general purpose change-point detection network in a numerical study. We train the network on $N=10000$ instances of data sequences generated from a mixture of no change-point in mean or variance, change in mean only, change in variance only, no-change in a non-zero slope and change in slope only, and compare its classification performance on a test set of size $2500$ against that of oracle likelihood-based classifiers (where we pre-specify whether we are testing for change in mean, variance or slope) and adaptive likelihood-based classifiers (where we combine likelihood based tests using the Bayesian Information Criterion). Details of the data-generating mechanism and classifiers can be found in Appendix B. The classification accuracy of the three approaches in weak and strong signal-to-noise ratio settings are reported in Table 1. We see that the neural network-based approach achieves similar classification accuracy as adaptive likelihood based method for weak SNR and higher classification accuracy than the adaptive likelihood based method for strong SNR. We would not expect the neural network to outperform the oracle likelihood-based classifiers as it has no knowledge of the exact change-type of each time series.
Table 1: Test classification accuracy of oracle likelihood-ratio based method (LR ${}^oracle$ ), adaptive likelihood ratio method (LR ${}^adapt$ ) and our residual neural network (NN) classifier for setups with weak and strong signal-to-noise ratios (SNR). Data are generated as a mixture of no change-point in mean or variance (Class 1), change in mean only (Class 2), change in variance only (Class 3), no-change in a non-zero slope (Class 4), change in slope only (Class 5). We report the true positive rate of each class and the accuracy in the last row.
Weak SNR Strong SNR LR ${}^oracle$ LR ${}^adapt$ NN LR ${}^oracle$ LR ${}^adapt$ NN Class 1 0.9787 0.9457 0.8062 0.9787 0.9341 0.9651 Class 2 0.8443 0.8164 0.8882 1.0000 0.7784 0.9860 Class 3 0.8350 0.8291 0.8585 0.9902 0.9902 0.9705 Class 4 0.9960 0.9453 0.8826 0.9980 0.9372 0.9312 Class 5 0.8729 0.8604 0.8353 0.9958 0.9917 0.9147 Accuracy 0.9056 0.8796 0.8660 0.9924 0.9260 0.9672
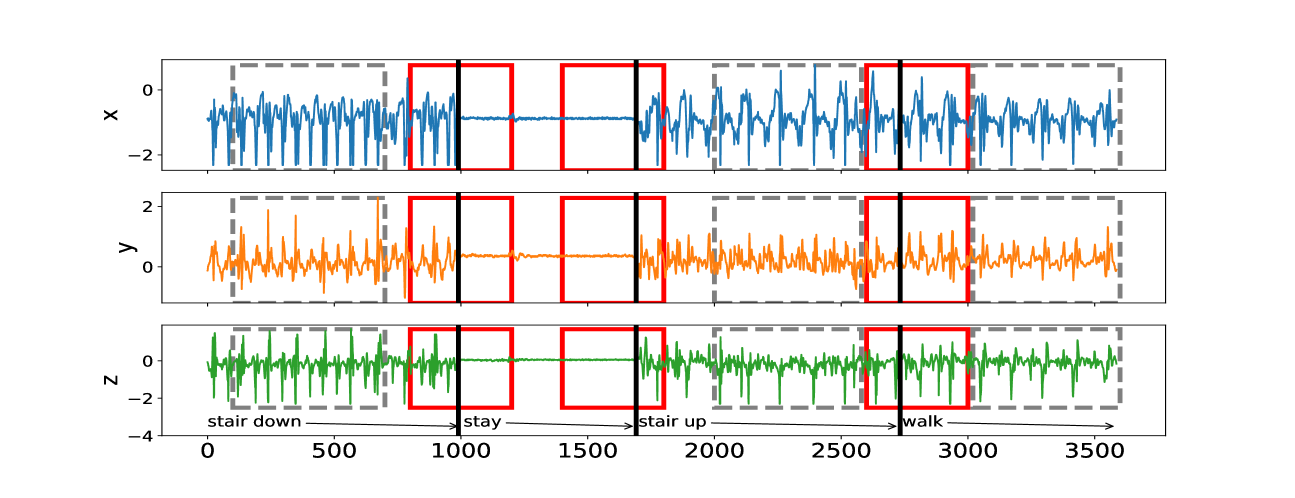
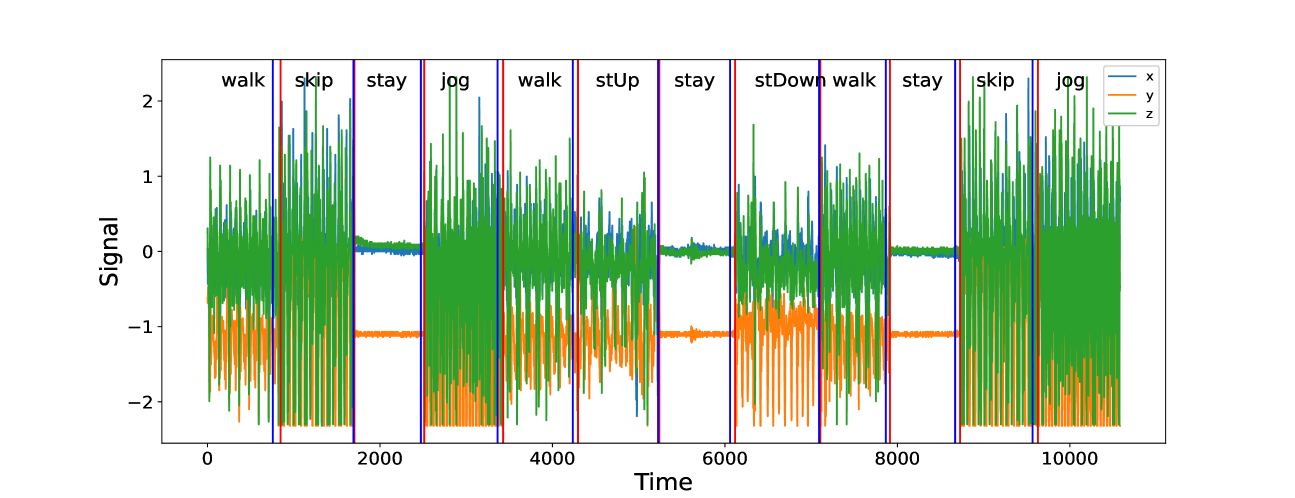
We now consider an application to detecting different types of change. The HASC (Human Activity Sensing Consortium) project data contain motion sensor measurements during a sequence of human activities, including “stay”, “walk”, “jog”, “skip”, “stair up” and “stair down”. Complex changes in sensor signals occur during transition from one activity to the next (see Figure 3). We have 28 labels in HASC data, see Figure 10 in appendix. To agree with the dimension of the output, we drop two dense layers “Dense(10)” and “Dense(20)” in Figure 9. The resulting network can be effectively applied for change-point detection in sensory signals of human activities, and can achieve high accuracy in change-point classification tasks (Figure 12 in appendix). Finally, we remark that our neural network-based change-point detector can be utilised to detect multiple change-points. Algorithm 1 outlines a general scheme for turning a change-point classifier into a location estimator, where we employ an idea similar to that of MOSUM (Eichinger and Kirch, 2018) and repeatedly apply a classifier $ψ$ to data from a sliding window of size $n$ . Here, we require $ψ$ applied to each data segment $\boldsymbol{X}^*_[i,i+n)$ to output both the class label $L_i=0$ or $1$ if no change or a change is predicted and the corresponding probability $p_i$ of having a change. In our particular example, for each data segment $\boldsymbol{X}^*_[i,i+n)$ of length $n=700$ , we define $ψ(\boldsymbol{X}^*_[i,i+n))=0$ if $\widehat{NN}(\boldsymbol{X}^*_[i,i+n))$ predicts a class label in $\{0,4,8,12,16,22\}$ (see Figure 10 in appendix) and 1 otherwise. The thresholding parameter $γ∈ℤ^+$ is chosen to be $1/2$ .
Input: new data $\boldsymbol{x}_1^*,…,\boldsymbol{x}_n^*^*∈ℝ^d$ , a trained classifier $ψ:ℝ^d× n→\{0,1\}$ , $γ>0$ .
1 Form $\boldsymbol{X}_[i,i+n)^*:=(\boldsymbol{x}_i^*,…,\boldsymbol{x}_i +n-1)$ and compute $L_i←ψ(\boldsymbol{X}^*_[i,i+n))$ for all $i=1,…,n^*-n+1$ ;
2 Compute $\bar{L}_i← n^-1∑_j=i-n+1^iL_j$ for $i=n,…,n^*-n+1$ ;
3 Let $\{[s_1,e_1],…,[s_\hat{ν},e_\hat{ν}]\}$ be the set of all maximal segments such that $\bar{L}_i≥γ$ for all $i∈[s_r,e_r]$ , $r∈[\hat{ν}]$ ;
4 Compute $\hat{τ}_r←\operatorname*{arg max}_i∈[s_{r,e_r]}\bar{L}_i$ for all $r∈[\hat{ν}]$ ;
Output: Estimated change-points $\hat{τ}_1,…,\hat{τ}_\hat{ν}$
Algorithm 1 Algorithm for change-point localisation
Figure 4 illustrates the result of multiple change-point detection in HASC data which provides evidence that the trained neural network can detect both the multiple change-types and multiple change-points.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Activity Recognition Data
### Overview
This image displays three line charts, stacked vertically, representing data from sensors along the x, y, and z axes over time. The charts are annotated with dashed grey boxes and solid red boxes, indicating different segments of activity. Additionally, text labels below the charts identify specific activities such as "stair down," "stay," "stair up," and "walk." The x-axis represents time, with markers at 0, 500, 1000, 1500, 2000, 2500, 3000, and 3500. The y-axis for the top chart (x-axis data) ranges from approximately -2 to 0. The y-axis for the middle chart (y-axis data) ranges from approximately 0 to 2. The y-axis for the bottom chart (z-axis data) ranges from approximately -4 to 2.
### Components/Axes
* **X-axis (Time):**
* **Labels:** 0, 500, 1000, 1500, 2000, 2500, 3000, 3500. The axis extends from 0 to approximately 3600.
* **Title:** Implicitly "Time" based on the numerical progression.
* **Y-axes (Sensor Readings):**
* **Top Chart (x-axis data):**
* **Labels:** 0, -2. The axis extends from approximately -2.5 to 0.5.
* **Title:** "x"
* **Middle Chart (y-axis data):**
* **Labels:** 2, 0. The axis extends from approximately -0.5 to 2.5.
* **Title:** "y"
* **Bottom Chart (z-axis data):**
* **Labels:** 2, 0, -2, -4. The axis extends from approximately -4.5 to 2.5.
* **Title:** "z"
* **Data Series:**
* **Blue Line:** Represents data from the x-axis sensor.
* **Orange Line:** Represents data from the y-axis sensor.
* **Green Line:** Represents data from the z-axis sensor.
* **Annotations:**
* **Dashed Grey Boxes:** These boxes appear to demarcate broader periods of activity. They are present at the beginning of each chart, and then at approximately:
* x-axis: 0-500, 1500-2000, 2500-3000, 3000-3500
* y-axis: 0-500, 1500-2000, 2500-3000, 3000-3500
* z-axis: 0-500, 1500-2000, 2500-3000, 3000-3500
* **Solid Red Boxes:** These boxes highlight specific, shorter segments within the broader periods. They are present at approximately:
* x-axis: 750-1000, 1000-1250, 1250-1500, 1750-2000, 2750-3000, 3250-3500
* y-axis: 750-1000, 1000-1250, 1250-1500, 1750-2000, 2750-3000, 3250-3500
* z-axis: 750-1000, 1000-1250, 1250-1500, 1750-2000, 2750-3000, 3250-3500
* **Solid Black Vertical Lines:** These lines appear to mark the boundaries between different activities. They are located at approximately 1000, 1500, 2000, 2500, 3000, and 3500.
* **Activity Labels (below the z-axis chart):**
* "stair down": Centered around the range 0-500.
* "stay": Centered around the range 750-1500.
* "stair up": Centered around the range 1750-2000.
* "walk": Centered around the range 2500-3500.
### Detailed Analysis
**Data Series Trends and Approximate Values:**
* **Blue Line (x-axis data):**
* **Trend:** The blue line exhibits a generally periodic pattern with significant amplitude variations. It shows a high frequency of sharp peaks and troughs, suggesting rapid movements.
* **Segment 1 (approx. 0-750):** Characterized by frequent, high-amplitude oscillations, peaking around 0 and dipping to approximately -2. This segment is labeled "stair down."
* **Segment 2 (approx. 750-1000):** Shows a transition with slightly reduced amplitude oscillations.
* **Segment 3 (approx. 1000-1500):** This segment, labeled "stay," shows a near-flat line with very low amplitude oscillations, centered around 0. The values are approximately between -0.2 and 0.2.
* **Segment 4 (approx. 1750-2000):** Labeled "stair up," this segment shows a return to higher amplitude oscillations, similar to the "stair down" phase but potentially with slightly different characteristics. Peaks are around 0, troughs around -2.
* **Segment 5 (approx. 2000-2500):** Shows a transition period.
* **Segment 6 (approx. 2500-3500):** Labeled "walk," this segment displays a consistent, rhythmic pattern of oscillations with moderate amplitude, peaking around 0 and dipping to approximately -1.5.
* **Orange Line (y-axis data):**
* **Trend:** The orange line shows more irregular, but still somewhat periodic, fluctuations. The amplitude is generally lower than the x-axis data during movement phases.
* **Segment 1 (approx. 0-750):** Exhibits moderate amplitude oscillations, ranging from approximately 0 to 2. This segment is associated with "stair down."
* **Segment 2 (approx. 750-1000):** Shows a decrease in amplitude.
* **Segment 3 (approx. 1000-1500):** Labeled "stay," this segment is characterized by very low amplitude oscillations, close to 0, with values ranging from approximately -0.2 to 0.2.
* **Segment 4 (approx. 1750-2000):** Labeled "stair up," this segment shows increased oscillations, similar to the initial phase, ranging from approximately 0 to 2.
* **Segment 5 (approx. 2000-2500):** Transition period.
* **Segment 6 (approx. 2500-3500):** Labeled "walk," this segment shows consistent, rhythmic oscillations with moderate amplitude, ranging from approximately 0 to 1.5.
* **Green Line (z-axis data):**
* **Trend:** The green line displays a highly periodic pattern with sharp, distinct peaks and troughs, particularly during movement phases.
* **Segment 1 (approx. 0-750):** Characterized by very sharp, high-amplitude peaks, reaching up to approximately 2, and deep troughs, down to approximately -4. This segment is labeled "stair down."
* **Segment 2 (approx. 750-1000):** Shows a decrease in the sharpness and amplitude of peaks.
* **Segment 3 (approx. 1000-1500):** Labeled "stay," this segment shows very low amplitude oscillations, close to 0, with values ranging from approximately -0.5 to 0.5.
* **Segment 4 (approx. 1750-2000):** Labeled "stair up," this segment shows a return to sharp, high-amplitude peaks, similar to the "stair down" phase, reaching up to approximately 2 and down to approximately -4.
* **Segment 5 (approx. 2000-2500):** Transition period.
* **Segment 6 (approx. 2500-3500):** Labeled "walk," this segment displays a consistent, rhythmic pattern of sharp peaks and troughs, with moderate amplitude, peaking around 1.5 and dipping to approximately -2.
**Annotation Placement and Correlation:**
* The dashed grey boxes generally encompass the periods labeled with activities. For instance, the first grey box (0-500) aligns with "stair down." The grey boxes from 1500-2000 align with "stair up," and from 2500-3500 align with "walk."
* The solid red boxes appear to highlight specific sub-segments within these activities, possibly representing individual steps or distinct phases of movement. For example, within the "stay" period (1000-1500), there are multiple red boxes, each containing a near-flat line.
* The solid black vertical lines clearly delineate the transitions between the labeled activities. For example, the line at 1000 marks the end of "stair down" and the beginning of "stay." The line at 1500 marks the end of "stay" and the beginning of the transition to "stair up." The line at 2000 marks the end of "stair up." The line at 2500 marks the beginning of "walk." The line at 3000 and 3500 mark further points within the "walk" period.
### Key Observations
* **Activity Signatures:** Each labeled activity ("stair down," "stay," "stair up," "walk") has a distinct signature across the x, y, and z sensor data.
* **"Stay"** is characterized by very low amplitude oscillations across all three axes, indicating minimal movement.
* **"Stair down" and "Stair up"** show high-amplitude, sharp oscillations, particularly in the z-axis, suggesting significant vertical movement. The x-axis also shows high-amplitude, rapid oscillations.
* **"Walk"** exhibits a more consistent, rhythmic pattern with moderate amplitudes across all axes, distinct from the more erratic or sharp movements of stair climbing.
* **Axis Dominance:** The z-axis data appears to be the most sensitive to vertical movements like stair climbing, showing the sharpest and highest amplitude peaks. The x-axis data is also highly dynamic during movement, reflecting forward/backward or side-to-side motion. The y-axis data shows more subtle variations.
* **Transitions:** The transitions between activities are visually represented by changes in the amplitude and frequency of the sensor readings. The solid black lines mark these distinct shifts.
* **Segmentation:** The use of dashed grey and solid red boxes suggests a hierarchical segmentation of the data, with grey boxes defining broader activity periods and red boxes highlighting finer-grained events within those periods.
### Interpretation
This chart demonstrates the effectiveness of using multi-axis sensor data (likely from an accelerometer or similar inertial measurement unit) to distinguish between different human activities. The distinct patterns observed in the x, y, and z sensor readings for "stair down," "stay," "stair up," and "walk" suggest that these activities have unique kinematic profiles.
The "stay" activity, with its near-zero amplitude across all axes, clearly represents a period of inactivity. The sharp, high-amplitude spikes in the z-axis data during "stair down" and "stair up" are indicative of the impact and vertical displacement associated with climbing stairs. The "walk" activity shows a more regular, cyclical pattern, reflecting the repetitive nature of gait.
The annotations (dashed grey boxes, solid red boxes, and black vertical lines) are crucial for understanding the temporal segmentation of these activities. They likely represent the output of an activity recognition algorithm that has identified and labeled these distinct behavioral states. The red boxes, in particular, might represent individual steps or micro-movements within a larger activity.
In essence, the data suggests that by analyzing the temporal dynamics of sensor readings along multiple axes, it is possible to reliably classify human activities. This type of data visualization is fundamental in the field of wearable technology, human-computer interaction, and health monitoring, where understanding user activity is paramount. The clear differentiation between activities implies that a machine learning model trained on such data could achieve high accuracy in activity recognition.
</details>
Figure 3: The sequence of accelerometer data in $x,y$ and $z$ axes. From left to right, there are 4 activities: “stair down”, “stay”, “stair up” and “walk”, their change-points are 990, 1691, 2733 respectively marked by black solid lines. The grey rectangles represent the group of “no-change” with labels: “stair down”, “stair up” and “walk”; The red rectangles represent the group of “one-change” with labels: “stair down $→$ stay”, “stay $→$ stair up” and “stair up $→$ walk”.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Time Series of Sensor Signals During Various Activities
### Overview
This image displays a line chart showing the time series of three sensor signals (labeled x, y, and z) recorded over a period of approximately 11,000 time units. The chart is segmented by vertical colored lines and labeled with different human activities, indicating changes in the signal patterns corresponding to these activities.
### Components/Axes
* **X-axis**: Labeled "Time", with tick marks at 0, 2000, 4000, 6000, 8000, and 10000. The axis represents the progression of time.
* **Y-axis**: Labeled "Signal", with tick marks at -2, -1, 0, 1, and 2. The axis represents the amplitude or magnitude of the sensor signals.
* **Legend**: Located in the top-right corner of the chart. It indicates the color mapping for each signal:
* Blue line: 'x'
* Orange line: 'y'
* Green line: 'z'
* **Activity Labels**: Text labels are placed above the chart, indicating specific activities at different time intervals. These labels are: "walk", "skip", "stay", "jog", "walk", "stUp", "stay", "stDown", "walk", "stay", "skip", "jog".
* **Vertical Dividers**: Colored vertical lines (primarily red and blue) demarcate the time intervals corresponding to the labeled activities.
### Detailed Analysis or Content Details
The chart displays three distinct signal lines (x, y, z) over time. The signals exhibit varying patterns and amplitudes, which change significantly with different activities.
**Activity Segments and Signal Characteristics:**
1. **"walk" (approx. 0 to 1500):**
* **x (blue):** Relatively low amplitude, oscillating around 0, with some minor fluctuations.
* **y (orange):** Moderate amplitude, oscillating with a noticeable pattern, generally between -1 and -0.5.
* **z (green):** High amplitude, showing a consistent, rhythmic pattern of peaks and troughs, ranging from approximately -1.5 to 2.
2. **"skip" (approx. 1500 to 2200):**
* **x (blue):** Slightly increased amplitude compared to "walk", oscillating around 0.
* **y (orange):** High amplitude, with sharp, rapid oscillations, reaching peaks around -0.5 and troughs around -1.5.
* **z (green):** Very high amplitude, with a more intense and rapid rhythmic pattern than "walk", reaching peaks around 2 and troughs around -1.5.
3. **"stay" (approx. 2200 to 3000):**
* **x (blue):** Low amplitude, oscillating very close to 0.
* **y (orange):** Very low amplitude, oscillating very close to 0.
* **z (green):** Low amplitude, oscillating very close to 0, with minimal variation. This indicates a period of stillness.
4. **"jog" (approx. 3000 to 4500):**
* **x (blue):** Moderate amplitude, oscillating around 0, with a more pronounced pattern than "walk".
* **y (orange):** High amplitude, with a rhythmic pattern, generally between -1 and -0.5.
* **z (green):** High amplitude, with a strong, rhythmic pattern, similar to "walk" but with slightly higher frequency and amplitude, reaching peaks around 2 and troughs around -1.5.
5. **"walk" (approx. 4500 to 5500):**
* **x (blue):** Similar to the first "walk" segment, low to moderate amplitude around 0.
* **y (orange):** Similar to the first "walk" segment, moderate amplitude, oscillating between -1 and -0.5.
* **z (green):** Similar to the first "walk" segment, high amplitude, rhythmic pattern, ranging from approximately -1.5 to 2.
6. **"stUp" (approx. 5500 to 6200):**
* **x (blue):** Shows a brief spike and then settles to a low amplitude around 0.
* **y (orange):** Shows a brief period of higher amplitude oscillations before settling to a low amplitude around 0.
* **z (green):** Shows a brief period of higher amplitude oscillations before settling to a low amplitude around 0. This segment appears to represent a transition, possibly standing up from a seated position.
7. **"stay" (approx. 6200 to 7000):**
* **x (blue):** Low amplitude, oscillating very close to 0.
* **y (orange):** Very low amplitude, oscillating very close to 0.
* **z (green):** Low amplitude, oscillating very close to 0, indicating stillness.
8. **"stDown" (approx. 7000 to 7700):**
* **x (blue):** Shows a brief spike and then settles to a low amplitude around 0.
* **y (orange):** Shows a brief period of higher amplitude oscillations before settling to a low amplitude around 0.
* **z (green):** Shows a brief period of higher amplitude oscillations before settling to a low amplitude around 0. Similar to "stUp", this likely represents sitting down.
9. **"walk" (approx. 7700 to 8500):**
* **x (blue):** Moderate amplitude, oscillating around 0.
* **y (orange):** Moderate to high amplitude, with a rhythmic pattern.
* **z (green):** High amplitude, with a strong, rhythmic pattern, similar to previous "walk" segments.
10. **"stay" (approx. 8500 to 9200):**
* **x (blue):** Low amplitude, oscillating very close to 0.
* **y (orange):** Very low amplitude, oscillating very close to 0.
* **z (green):** Low amplitude, oscillating very close to 0, indicating stillness.
11. **"skip" (approx. 9200 to 9800):**
* **x (blue):** Increased amplitude compared to "walk", oscillating around 0.
* **y (orange):** High amplitude, with sharp, rapid oscillations.
* **z (green):** Very high amplitude, with an intense and rapid rhythmic pattern, similar to the first "skip" segment.
12. **"jog" (approx. 9800 to 10800):**
* **x (blue):** Moderate amplitude, oscillating around 0.
* **y (orange):** High amplitude, with a rhythmic pattern.
* **z (green):** High amplitude, with a strong, rhythmic pattern, similar to previous "jog" segments.
**General Trends:**
* The 'z' signal (green) consistently shows the highest amplitude during dynamic activities like walking, skipping, and jogging, suggesting it might be capturing the primary motion axis.
* The 'y' signal (orange) also shows significant activity during dynamic movements, particularly during skipping and jogging, and exhibits a distinct pattern during walking.
* The 'x' signal (blue) generally has the lowest amplitude during dynamic activities, often oscillating around zero, but shows some variation.
* Periods labeled "stay" consistently show very low signal amplitudes across all three axes, indicating minimal movement.
* The "stUp" and "stDown" segments show a transition from a low-amplitude "stay" state to a brief period of increased signal activity before returning to a low-amplitude state, which is characteristic of the motion involved in standing up or sitting down.
### Key Observations
* The "stay" periods are clearly distinguishable by their near-zero signal values across all axes.
* "Skip" and "jog" activities exhibit higher signal amplitudes and more rapid oscillations compared to "walk".
* The "stUp" and "stDown" activities show a characteristic transient signal pattern, distinct from continuous movement or stillness.
* The repetition of activities (e.g., "walk", "stay", "skip", "jog") allows for comparison of signal patterns under similar conditions.
### Interpretation
This chart demonstrates the ability of multi-axis sensor data to differentiate between various human physical activities. The distinct signal patterns observed for each activity (walk, skip, stay, jog, stUp, stDown) suggest that these signals can be used as features for activity recognition systems.
* **Signal Dynamics and Activity:** The amplitude and frequency of the signals, particularly the 'z' and 'y' axes, are directly correlated with the intensity and type of physical movement. Higher intensity activities like skipping and jogging produce larger and more rapid signal variations.
* **Baseline for Stillness:** The "stay" segments provide a clear baseline, showing minimal sensor noise when the body is at rest. This is crucial for distinguishing between actual movement and sensor drift or background noise.
* **Transitional Movements:** The "stUp" and "stDown" segments highlight how sensor data can capture the dynamics of transitions between states (e.g., sitting to standing). The brief bursts of activity indicate the forces and movements involved in these actions.
* **Potential for Classification:** The clear visual separation of activity patterns suggests that machine learning models could be trained on this type of data to automatically classify human activities based on sensor readings. The consistency of patterns for repeated activities (e.g., multiple "walk" segments) reinforces this potential.
* **Peircean Investigative Reading:** The data can be interpreted as a semiotic representation of human motion. The sensor signals act as signs, where the specific patterns (the interpretant) allow us to infer the object (the activity). The chart presents a series of indices (the signals) that point to the underlying physical actions. The repetition of activities allows for the establishment of a more robust indexical relationship, moving towards a symbolic understanding of the data. The chart effectively demonstrates a form of embodied cognition, where the physical act of movement is translated into a digital signal that can be interpreted. The underlying assumption is that each activity has a unique kinetic signature.
</details>
Figure 4: Change-point detection in HASC data. The red vertical lines represent the underlying change-points, the blue vertical lines represent the estimated change-points. More details on multiple change-point detection can be found in Appendix C.
## 7 Discussion
Reliable testing for change-points and estimating their locations, especially in the presence of multiple change-points, other heterogeneities or untidy data, is typically a difficult problem for the applied statistician: they need to understand what type of change is sought, be able to characterise it mathematically, find a satisfactory stochastic model for the data, formulate the appropriate statistic, and fine-tune its parameters. This makes for a long workflow, with scope for errors at its every stage. In this paper, we showed how a carefully constructed statistical learning framework could automatically take over some of those tasks, and perform many of them ‘in one go’ when provided with examples of labelled data. This turned the change-point detection problem into a supervised learning problem, and meant that the task of learning the appropriate test statistic and fine-tuning its parameters was left to the ‘machine’ rather than the human user. The crucial question was that of choosing an appropriate statistical learning framework. The key factor behind our choice of neural networks was the discovery that the traditionally-used likelihood-ratio-based change-point detection statistics could be viewed as simple neural networks, which (together with bounds on generalisation errors beyond the training set) enabled us to formulate and prove the corresponding learning theory. However, there are a plethora of other excellent predictive frameworks, such as XGBoost, LightGBM or Random Forests (Chen and Guestrin, 2016; Ke et al., 2017; Breiman, 2001) and it would be of interest to establish whether and why they could or could not provide a viable alternative to neural nets here. Furthermore, if we view the neural network as emulating the likelihood-ratio test statistic, in that it will create test statistics for each possible location of a change and then amalgamate these into a single classifier, then we know that test statistics for nearby changes will often be similar. This suggests that imposing some smoothness on the weights of the neural network may be beneficial. A further challenge is to develop methods that can adapt easily to input data of different sizes, without having to train a different neural network for each input size. For changes in the structure of the mean of the data, it may be possible to use ideas from functional data analysis so that we pre-process the data, with some form of smoothing or imputation, to produce input data of the correct length. If historical labelled examples of change-points, perhaps provided by subject-matter experts (who are not necessarily statisticians) are not available, one question of interest is whether simulation can be used to obtain such labelled examples artificially, based on (say) a single dataset of interest. Such simulated examples would need to come in two flavours: one batch ‘likely containing no change-points’ and the other containing some artificially induced ones. How to simulate reliably in this way is an important problem, which this paper does not solve. Indeed, we can envisage situations in which simulating in this way may be easier than solving the original unsupervised change-point problem involving the single dataset at hand, with the bulk of the difficulty left to the ‘machine’ at the learning stage when provided with the simulated data. For situations where there is no historical data, but there are statistical models, one can obtain training data by simulation from the model. In this case, training a neural network to detect a change has similarities with likelihood-free inference methods in that it replaces analytic calculations associated with a model by the ability to simulate from the model. It is of interest whether ideas from that area of statistics can be used here. The main focus of our work was on testing for a single offline change-point, and we treated location estimation and extensions to multiple-change scenarios only superficially, via the heuristics of testing-based estimation in Section 6. Similar extensions can be made to the online setting once the neural network is trained, by retaining the final $n$ observations in an online stream in memory and applying our change-point classifier sequentially. One question of interest is whether and how these heuristics can be made more rigorous: equipped with an offline classifier only, how can we translate the theoretical guarantee of this offline classifier to that of the corresponding location estimator or online detection procedure? In addition to this approach, how else can a neural network, however complex, be trained to estimate locations or detect change-points sequentially? In our view, these questions merit further work.
## Availability of data and computer code
The data underlying this article are available in http://hasc.jp/hc2011/index-en.html. The computer code and algorithm are available in Python Package: AutoCPD.
## Acknowledgement
This work was supported by the High End Computing Cluster at Lancaster University, and EPSRC grants EP/V053590/1, EP/V053639/1 and EP/T02772X/1. We highly appreciate Yudong Chen’s contribution to debug our Python scripts and improve their readability.
## Conflicts of Interest
We have no conflicts of interest to disclose.
## References
- Ahmadzadeh (2018) Ahmadzadeh, F. (2018). Change point detection with multivariate control charts by artificial neural network. J. Adv. Manuf. Technol. 97 (9), 3179–3190.
- Aminikhanghahi and Cook (2017) Aminikhanghahi, S. and D. J. Cook (2017). Using change point detection to automate daily activity segmentation. In 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), pp. 262–267.
- Baranowski et al. (2019) Baranowski, R., Y. Chen, and P. Fryzlewicz (2019). Narrowest-over-threshold detection of multiple change points and change-point-like features. J. Roy. Stat. Soc., Ser. B 81 (3), 649–672.
- Bartlett et al. (2019) Bartlett, P. L., N. Harvey, C. Liaw, and A. Mehrabian (2019). Nearly-tight VC-dimension and pseudodimension bounds for piecewise linear neural networks. J. Mach. Learn. Res. 20 (63), 1–17.
- Beaumont (2019) Beaumont, M. A. (2019). Approximate Bayesian computation. Annu. Rev. Stat. Appl. 6, 379–403.
- Bengio et al. (1994) Bengio, Y., P. Simard, and P. Frasconi (1994). Learning long-term dependencies with gradient descent is difficult. IEEE T. Neural Networ. 5 (2), 157–166.
- Bos and Schmidt-Hieber (2022) Bos, T. and J. Schmidt-Hieber (2022). Convergence rates of deep ReLU networks for multiclass classification. Electron. J. Stat. 16 (1), 2724–2773.
- Breiman (2001) Breiman, L. (2001). Random forests. Mach. Learn. 45 (1), 5–32.
- Chang et al. (2019) Chang, W.-C., C.-L. Li, Y. Yang, and B. Póczos (2019). Kernel change-point detection with auxiliary deep generative models. In International Conference on Learning Representations.
- Chen and Gupta (2012) Chen, J. and A. K. Gupta (2012). Parametric Statistical Change Point Analysis: With Applications to Genetics, Medicine, and Finance (2nd ed.). New York: Birkhäuser.
- Chen and Guestrin (2016) Chen, T. and C. Guestrin (2016). XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794.
- De Ryck et al. (2021) De Ryck, T., M. De Vos, and A. Bertrand (2021). Change point detection in time series data using autoencoders with a time-invariant representation. IEEE T. Signal Proces. 69, 3513–3524.
- Dehling et al. (2015) Dehling, H., R. Fried, I. Garcia, and M. Wendler (2015). Change-point detection under dependence based on two-sample U-statistics. In D. Dawson, R. Kulik, M. Ould Haye, B. Szyszkowicz, and Y. Zhao (Eds.), Asymptotic Laws and Methods in Stochastics: A Volume in Honour of Miklós Csörgő, pp. 195–220. New York, NY: Springer New York.
- Dürre et al. (2016) Dürre, A., R. Fried, T. Liboschik, and J. Rathjens (2016). robts: Robust Time Series Analysis. R package version 0.3.0/r251.
- Eichinger and Kirch (2018) Eichinger, B. and C. Kirch (2018). A MOSUM procedure for the estimation of multiple random change points. Bernoulli 24 (1), 526–564.
- Fearnhead et al. (2019) Fearnhead, P., R. Maidstone, and A. Letchford (2019). Detecting changes in slope with an $l_0$ penalty. J. Comput. Graph. Stat. 28 (2), 265–275.
- Fearnhead and Rigaill (2020) Fearnhead, P. and G. Rigaill (2020). Relating and comparing methods for detecting changes in mean. Stat 9 (1), 1–11.
- Fryzlewicz (2014) Fryzlewicz, P. (2014). Wild binary segmentation for multiple change-point detection. Ann. Stat. 42 (6), 2243–2281.
- Fryzlewicz (2021) Fryzlewicz, P. (2021). Robust narrowest significance pursuit: Inference for multiple change-points in the median. arXiv preprint, arxiv:2109.02487.
- Fryzlewicz (2023) Fryzlewicz, P. (2023). Narrowest significance pursuit: Inference for multiple change-points in linear models. J. Am. Stat. Assoc., to appear.
- Gao et al. (2019) Gao, Z., Z. Shang, P. Du, and J. L. Robertson (2019). Variance change point detection under a smoothly-changing mean trend with application to liver procurement. J. Am. Stat. Assoc. 114 (526), 773–781.
- Glorot and Bengio (2010) Glorot, X. and Y. Bengio (2010). Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 249–256. JMLR Workshop and Conference Proceedings.
- Gourieroux et al. (1993) Gourieroux, C., A. Monfort, and E. Renault (1993). Indirect inference. J. Appl. Econom. 8 (S1), S85–S118.
- Gupta et al. (2022) Gupta, M., R. Wadhvani, and A. Rasool (2022). Real-time change-point detection: A deep neural network-based adaptive approach for detecting changes in multivariate time series data. Expert Syst. Appl. 209, 1–16.
- Gutmann et al. (2018) Gutmann, M. U., R. Dutta, S. Kaski, and J. Corander (2018). Likelihood-free inference via classification. Stat. Comput. 28 (2), 411–425.
- Haynes et al. (2017) Haynes, K., I. A. Eckley, and P. Fearnhead (2017). Computationally efficient changepoint detection for a range of penalties. J. Comput. Graph. Stat. 26 (1), 134–143.
- He and Sun (2015) He, K. and J. Sun (2015). Convolutional neural networks at constrained time cost. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5353–5360.
- He et al. (2016) He, K., X. Zhang, S. Ren, and J. Sun (2016, June). Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778.
- Hocking et al. (2015) Hocking, T., G. Rigaill, and G. Bourque (2015). PeakSeg: constrained optimal segmentation and supervised penalty learning for peak detection in count data. In International Conference on Machine Learning, pp. 324–332. PMLR.
- Huang et al. (2023) Huang, T.-J., Q.-L. Zhou, H.-J. Ye, and D.-C. Zhan (2023). Change point detection via synthetic signals. In 8th Workshop on Advanced Analytics and Learning on Temporal Data.
- Ioffe and Szegedy (2015) Ioffe, S. and C. Szegedy (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, pp. 448–456. JMLR.org.
- James et al. (1987) James, B., K. L. James, and D. Siegmund (1987). Tests for a change-point. Biometrika 74 (1), 71–83.
- Jandhyala et al. (2013) Jandhyala, V., S. Fotopoulos, I. MacNeill, and P. Liu (2013). Inference for single and multiple change-points in time series. J. Time Ser. Anal. 34 (4), 423–446.
- Ke et al. (2017) Ke, G., Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu (2017). LightGBM: A highly efficient gradient boosting decision tree. Adv. Neur. In. 30, 3146–3154.
- Killick et al. (2012) Killick, R., P. Fearnhead, and I. A. Eckley (2012). Optimal detection of changepoints with a linear computational cost. J. Am. Stat. Assoc. 107 (500), 1590–1598.
- Kingma and Ba (2015) Kingma, D. P. and J. Ba (2015). Adam: A method for stochastic optimization. In Y. Bengio and Y. LeCun (Eds.), ICLR (Poster).
- Kuchibhotla and Chakrabortty (2022) Kuchibhotla, A. K. and A. Chakrabortty (2022). Moving beyond sub-Gaussianity in high-dimensional statistics: Applications in covariance estimation and linear regression. Inf. Inference: A Journal of the IMA 11 (4), 1389–1456.
- Lee et al. (2023) Lee, J., Y. Xie, and X. Cheng (2023). Training neural networks for sequential change-point detection. In IEEE ICASSP 2023, pp. 1–5. IEEE.
- Li et al. (2015) Li, F., Z. Tian, Y. Xiao, and Z. Chen (2015). Variance change-point detection in panel data models. Econ. Lett. 126, 140–143.
- Li et al. (2023) Li, J., P. Fearnhead, P. Fryzlewicz, and T. Wang (2023). Automatic change-point detection in time series via deep learning. submitted, arxiv:2211.03860.
- Li et al. (2023) Li, M., Y. Chen, T. Wang, and Y. Yu (2023). Robust mean change point testing in high-dimensional data with heavy tails. arXiv preprint, arxiv:2305.18987.
- Liehrmann et al. (2021) Liehrmann, A., G. Rigaill, and T. D. Hocking (2021). Increased peak detection accuracy in over-dispersed ChIP-seq data with supervised segmentation models. BMC Bioinform. 22 (1), 1–18.
- Londschien et al. (2022) Londschien, M., P. Bühlmann, and S. Kovács (2022). Random forests for change point detection. arXiv preprint, arxiv:2205.04997.
- Mohri et al. (2012) Mohri, M., A. Rostamizadeh, and A. Talwalkar (2012). Foundations of Machine Learning. Adaptive Computation and Machine Learning Series. Cambridge, MA: MIT Press.
- Ng (2004) Ng, A. Y. (2004). Feature selection, l 1 vs. l 2 regularization, and rotational invariance. In Proceedings of the Twenty-First International Conference on Machine Learning, ICML ’04, New York, NY, USA, pp. 78. Association for Computing Machinery.
- Oh et al. (2005) Oh, K. J., M. S. Moon, and T. Y. Kim (2005). Variance change point detection via artificial neural networks for data separation. Neurocomputing 68, 239–250.
- Paaß and Giesselbach (2023) Paaß, G. and S. Giesselbach (2023). Foundation Models for Natural Language Processing: Pre-trained Language Models Integrating Media. Artificial Intelligence: Foundations, Theory, and Algorithms. Springer International Publishing.
- Picard et al. (2005) Picard, F., S. Robin, M. Lavielle, C. Vaisse, and J.-J. Daudin (2005). A statistical approach for array CGH data analysis. BMC Bioinform. 6 (1).
- Reeves et al. (2007) Reeves, J., J. Chen, X. L. Wang, R. Lund, and Q. Q. Lu (2007). A review and comparison of changepoint detection techniques for climate data. J. Appl. Meteorol. Clim. 46 (6), 900–915.
- Ripley (1994) Ripley, B. D. (1994). Neural networks and related methods for classification. J. Roy. Stat. Soc., Ser. B 56 (3), 409–456.
- Schmidt-Hieber (2020) Schmidt-Hieber, J. (2020). Nonparametric regression using deep neural networks with ReLU activation function. Ann. Stat. 48 (4), 1875–1897.
- Shalev-Shwartz and Ben-David (2014) Shalev-Shwartz, S. and S. Ben-David (2014). Understanding Machine Learning: From Theory to Algorithms. New York, NY, USA: Cambridge University Press.
- Truong et al. (2020) Truong, C., L. Oudre, and N. Vayatis (2020). Selective review of offline change point detection methods. Signal Process. 167, 107299.
- Verzelen et al. (2020) Verzelen, N., M. Fromont, M. Lerasle, and P. Reynaud-Bouret (2020). Optimal change-point detection and localization. arXiv preprint, arxiv:2010.11470.
- Wang and Samworth (2018) Wang, T. and R. J. Samworth (2018). High dimensional change point estimation via sparse projection. J. Roy. Stat. Soc., Ser. B 80 (1), 57–83.
- Yamashita et al. (2018) Yamashita, R., M. Nishio, R. K. G. Do, and K. Togashi (2018). Convolutional neural networks: an overview and application in radiology. Insights into Imaging 9 (4), 611–629.
This is the appendix for the main paper Li, Fearnhead, Fryzlewicz, and Wang (2023), hereafter referred to as the main text. We present proofs of our main lemmas and theorems. Various technical details, results of numerical study and real data analysis are also listed here.
## Appendix A Proofs
### A.1 The proof of Lemma 3.1
Define $W_0\coloneqq(\boldsymbol{v}_1,…,\boldsymbol{v}_n-1,-\boldsymbol{v}_ {1},…,-\boldsymbol{v}_n-1)^⊤$ and $W_1\coloneqq\boldsymbol{1}_2n-2$ , $\boldsymbol{b}_1\coloneqqλ\boldsymbol{1}_2n-2$ and $b_2\coloneqq 0$ . Then $h(\boldsymbol{x})\coloneqqσ^*_b_2W_1σ_\boldsymbol{b_1}W_ {0}\boldsymbol{x}∈H_1,2n-2$ can be rewritten as
$$
h(\boldsymbol{x})=\mathbbm{1}\biggl{\{}∑_i=1^n-1\bigl{\{}(\boldsymbol{v
}_i^⊤\boldsymbol{x}-λ)_++(-\boldsymbol{v}_i^⊤\boldsymbol
{x}-λ)_+\bigr{\}}>b_2\biggr{\}}=\mathbbm{1}\{\|C(
\boldsymbol{x})\|_∞>λ\}=h_λ^CUSUM(\boldsymbol{
x}),
$$
as desired.
### A.2 The Proof of Lemma 3.2
As $\boldsymbol{Γ}$ is invertible, (2) in main text is equivalent to
$$
\boldsymbol{Γ}^-1\boldsymbol{X}=\boldsymbol{Γ}^-1\boldsymbol{Z}
\boldsymbol{β}+\boldsymbol{Γ}^-1\boldsymbol{c}_τφ+
\boldsymbol{ξ}.
$$
Write $\tilde{\boldsymbol{X}}=\boldsymbol{Γ}^-1\boldsymbol{X}$ , $\tilde{\boldsymbol{Z}}=\boldsymbol{Γ}^-1\boldsymbol{Z}$ and $\tilde{\boldsymbol{c}}_τ=\boldsymbol{Γ}^-1\boldsymbol{c}_τ$ . If $\tilde{\boldsymbol{c}}_τ$ lies in the column span of $\tilde{\boldsymbol{Z}}$ , then the model with a change at $τ$ is equivalent to the model with no change, and the likelihood-ratio test statistic will be 0. Otherwise we can assume, without loss of generality that $\tilde{\boldsymbol{c}}_τ$ is orthogonal to each column of $\tilde{\boldsymbol{Z}}$ : if this is not the case we can construct an equivalent model where we replace $\tilde{\boldsymbol{c}}_τ$ with its projection to the space that is orthogonal to the column span of $\tilde{\boldsymbol{Z}}$ . As $\boldsymbol{ξ}$ is a vector of independent standard normal random variables, the likelihood-ratio statistic for a change at $τ$ against no change is a monotone function of the reduction in the residual sum of squares of the model with a change at $τ$ . The residual sum of squares of the no change model is
$$
\tilde{\boldsymbol{X}}^⊤\tilde{\boldsymbol{X}}-\tilde{\boldsymbol{X}}^
⊤\tilde{\boldsymbol{Z}}(\tilde{\boldsymbol{Z}}^⊤\tilde{\boldsymbol{Z}
})^-1\tilde{\boldsymbol{Z}}^⊤\tilde{\boldsymbol{X}}.
$$
The residual sum of squares for the model with a change at $τ$ is
$$
\tilde{\boldsymbol{X}}^⊤\tilde{\boldsymbol{X}}-\tilde{\boldsymbol{X}}^
⊤[\tilde{\boldsymbol{Z}},\tilde{\boldsymbol{c}}_τ]([\tilde{
\boldsymbol{Z}},\tilde{\boldsymbol{c}}_τ]^⊤[\tilde{\boldsymbol{Z}},
\tilde{\boldsymbol{c}}_τ])^-1[\tilde{\boldsymbol{Z}},\tilde{\boldsymbol
{c}}_τ]^⊤\tilde{\boldsymbol{X}}=\tilde{\boldsymbol{X}}^⊤\tilde{
\boldsymbol{X}}-\tilde{\boldsymbol{X}}^⊤\tilde{\boldsymbol{Z}}(\tilde{
\boldsymbol{Z}}^⊤\tilde{\boldsymbol{Z}})^-1\tilde{\boldsymbol{Z}}^⊤
\tilde{\boldsymbol{X}}-\tilde{\boldsymbol{X}}^⊤\tilde{\boldsymbol{c}}_
τ(\tilde{\boldsymbol{c}}_τ^⊤\tilde{\boldsymbol{c}}_τ)^-1
\tilde{\boldsymbol{c}}_τ^⊤\tilde{\boldsymbol{X}}.
$$
Thus, the reduction in residual sum of square of the model with the change at $τ$ over the no change model is
$$
\tilde{\boldsymbol{X}}^⊤\tilde{\boldsymbol{c}}_τ(\tilde{\boldsymbol{
c}}_τ^⊤\tilde{\boldsymbol{c}}_τ)^-1\tilde{\boldsymbol{c}}_
τ^⊤\tilde{\boldsymbol{X}}=≤ft(\frac{1}{√{\tilde{\boldsymbol{c}}
_τ^⊤\tilde{\boldsymbol{c}}_τ}}\tilde{\boldsymbol{c}}_τ^
⊤\tilde{\boldsymbol{X}}\right)^2
$$
Thus if we define
$$
\boldsymbol{v}_τ=\frac{1}{√{\tilde{\boldsymbol{c}}_τ^⊤
\tilde{\boldsymbol{c}}_τ}}\tilde{\boldsymbol{c}}_τ^⊤\boldsymbol
{Γ}^-1,
$$
then the likelihood-ratio test statistic is a monotone function of $|\boldsymbol{v}_τ\boldsymbol{X}|$ . This is true for all $τ$ so the likelihood-ratio test is equivalent to
$$
\max_τ∈[n-1]|\boldsymbol{v}_τ\boldsymbol{X}|>λ,
$$
for some $λ$ . This is of a similar form to the standard CUSUM test, except that the form of $\boldsymbol{v}_τ$ is different. Thus, by the same argument as for Lemma 3.1 in main text, we can replicate this test with $h(\boldsymbol{x})∈H_1,2n-2$ , but with different weights to represent the different form for $\boldsymbol{v}_τ$ .
### A.3 The Proof of Lemma 4.1
* Proof*
(a) For each $i∈[n-1]$ , since ${\|\boldsymbol{v}_i\|_2}=1$ , we have $\boldsymbol{v}_i^⊤\boldsymbol{X}∼ N(0,1)$ . Hence, by the Gaussian tail bound and a union bound,
$$
ℙ\Bigl{\{}\|C(\boldsymbol{X})\|_∞>t\Bigr{\}}≤∑
_i=1^n-1ℙ≤ft(≤ft|\boldsymbol{v}_i^⊤\boldsymbol{X}
\right|>t\right)≤ n\exp(-t^2/2).
$$
The result follows by taking $t=√{2\log(n/ε)}$ . (b) We write $\boldsymbol{X}=\boldsymbol{μ}+\boldsymbol{Z}$ , where $\boldsymbol{Z}∼ N_n(0,I_n)$ . Since the CUSUM transformation is linear, we have $C(\boldsymbol{X})=C(\boldsymbol{μ})+C( \boldsymbol{Z})$ . By part (a) there is an event $Ω$ with probability at least $1-ε$ on which $\|C(\boldsymbol{Z})\|_∞≤√{2\log(n/ε)}$ . Moreover, we have $\|C(\boldsymbol{μ})\|_∞=|\boldsymbol{v}_τ^⊤ \boldsymbol{μ}|=|μ_L-μ_R|√{nη(1-η)}$ . Hence on $Ω$ , we have by the triangle inequality that
$$
\|C(\boldsymbol{X})\|_∞≥\|C(\boldsymbol{μ})\|_
{∞}-\|C(\boldsymbol{Z})\|_∞≥|μ_L-μ_
R|√{nη(1-η)}-√{2\log(n/ε)}>√{2\log(n/
ε)},
$$
as desired. ∎
### A.4 The Proof of Corollary 4.1
* Proof*
From Lemma 4.1 in main text with $ε=ne^-nB^{2/8}$ , we have
$$
ℙ(h_λ^CUSUM(\boldsymbol{X})≠ Y\midτ,μ_
L,μ_R)≤ ne^-nB^{2/8},
$$
and the desired result follows by integrating over $π_0$ . ∎
### A.5 Auxiliary Lemma
**Lemma A.1**
*Define $T^\prime\coloneqq\{t_0∈ℤ^+:{≤ft\lvert t_0-τ\right \rvert}≤\min(τ,n-τ)/2\}$ , for any $t_0∈ T^\prime$ , we have
$$
\min_t_{0∈ T^\prime}|\boldsymbol{v}_t_0^⊤\boldsymbol{μ}|≥
\frac{√{3}}{3}|μ_L-μ_R|√{nη(1-η)}.
$$*
* Proof*
For simplicity, let $Δ\coloneqq|μ_L-μ_R|$ , we can compute the CUSUM test statistics $a_i=|\boldsymbol{v}_i^⊤\boldsymbol{μ}|$ as:
$$
a_i=\begin{cases}Δ≤ft(1-η\right)√{\frac{ni}{n-i}}&1≤ i≤
τ\\
Δη√{\frac{n≤ft(n-i\right)}{i}}&τ<i≤ n-1\end{cases}
$$
It is easy to verified that $a_τ\coloneqq\max_i(a_i)=Δ√{nη(1-η)}$ when $i=τ$ . Next, we only discuss the case of $1≤τ≤\lfloor n/2\rfloor$ as one can obtain the same result when $\lceil n/2\rceil≤τ≤ n$ by the similar discussion. When $1≤τ≤\lfloor n/2\rfloor$ , ${≤ft\lvert t_0-τ\right\rvert}≤\min(τ,n-τ)/2$ implies that $t_l≤ t_0≤ t_u$ where $t_l\coloneqq\lceilτ/2\rceil,t_u\coloneqq\lfloor 3τ/2\rfloor$ . Because $a_i$ is an increasing function of $i$ on $[1,τ]$ and a decreasing function of $i$ on $[τ+1,n-1]$ respectively, the minimum of $a_t_0,t_l≤ t_0≤ t_u$ happens at either $t_l$ or $t_u$ . Hence, we have
| | $\displaystyle a_t_{l}$ | $\displaystyle≥ a_τ/2=a_τ√{\frac{n-τ}{2n-τ}}$ | |
| --- | --- | --- | --- |
Define $f(x)\coloneqq√{\frac{n-x}{2n-x}}$ and $g(x)\coloneqq√{\frac{2n-3x}{3(n-x)}}$ . We notice that $f(x)$ and $g(x)$ are both decreasing functions of $x∈[1,n]$ , therefore $f(\lfloor n/2\rfloor)≥ f(n/2)=√{3}/3$ and $g(\lfloor n/2\rfloor)≥ g(n/2)=√{3}/3$ as desired. ∎
### A.6 The Proof of Theorem 4.2
* Proof*
Given any $L≥ 1$ and $\boldsymbol{m}=(m_1,…,m_L)^⊤$ , let $m_0:=n$ and $m_L+1:=1$ and set $W^*=∑_r=1^L+1m_r-1m_r$ . Let $d\coloneqqVCdim(H_L,\boldsymbol{m})$ , then by Bartlett et al. (2019, Theorem 7), we have $d=O(LW^*\log(W^*))$ . Thus, by Mohri et al. (2012, Corollary 3.4), for some universal constant $C>0$ , we have with probability at least $1-δ$ that
$$
ℙ(h_ERM(\boldsymbol{X})≠ Y\midD)≤\min_h
∈H_L,\boldsymbol{m}ℙ(h(\boldsymbol{X})≠ Y)+√{
\frac{8d\log(2eN/d)+8\log(4/δ)}{N}}. \tag{5}
$$
Here, we have $L=1$ , $m=2n-2$ , $W^*=O(n^2)$ , so $d=O(n^2\log(n))$ . In addition, since $h^CUSUM_λ∈H_1,2n-2$ , we have $\min_h∈H_L,\boldsymbol{m}≤ℙ(h^CUSUM_ λ(\boldsymbol{X})≠ Y)≤ ne^-nB^{2/8}$ . Substituting these bounds into (5) we arrive at the desired result. ∎
### A.7 The Proof of Theorem 4.3
The following lemma, gives the misclassification for the generalised CUSUM test where we only test for changes on a grid of $O(\log n)$ values.
**Lemma A.2**
*Fix $ε∈(0,1)$ and suppose that $\boldsymbol{X}∼ P(n,τ,μ_L,μ_R)$ for some $τ∈[n-1]$ and $μ_L,μ_R∈ℝ$ .
1. If $μ_L=μ_R$ , then
$$
ℙ\Bigl{\{}\max_t∈ T_0|\boldsymbol{v}_t^⊤\boldsymbol{X}|>
√{2\log(|T_0|/ε)}\Bigr{\}}≤ε.
$$
1. If $|μ_L-μ_R|√{η(1-η)}>√{24\log(|T_0|/ ε)/n}$ , then we have
$$
ℙ\Bigl{\{}\max_t∈ T_0|\boldsymbol{v}_t^⊤\boldsymbol{X}|
≤√{2\log(|T_0|/ε)}\Bigr{\}}≤ε.
$$*
* Proof*
(a) For each $t∈[n-1]$ , since ${\|\boldsymbol{v}_t\|_2}=1$ , we have $\boldsymbol{v}_t^⊤\boldsymbol{X}∼ N(0,1)$ . Hence, by the Gaussian tail bound and a union bound,
$$
ℙ\Bigl{\{}\max_t∈ T_0|\boldsymbol{v}_t^⊤\boldsymbol{X}|>
y\Bigr{\}}≤∑_t∈ T_0ℙ≤ft(≤ft|\boldsymbol{v}_t^⊤
\boldsymbol{X}\right|>y\right)≤|T_0|\exp(-y^2/2).
$$
The result follows by taking $y=√{2\log(|T_0|/ε)}$ . (b) There exists some $t_0∈ T_0$ such that $|t_0-τ|≤\min\{τ,n-τ\}/2$ . By Lemma A.1, we have
$$
|\boldsymbol{v}_t_0^⊤E\boldsymbol{X}|≥\frac{√{3}}{3}
\|C(E\boldsymbol{X})\|_∞≥\frac{√{3}}{3}|μ_
L-μ_R|√{nη(1-η)}≥ 2√{2\log(|T_0|/
ε)}.
$$
Consequently, by the triangle inequality and result from part (a), we have with probability at least $1-ε$ that
$$
\max_t∈ T_0|\boldsymbol{v}_t^⊤\boldsymbol{X}|≥|\boldsymbol{v}_
{t_0}^⊤\boldsymbol{X}|≥|\boldsymbol{v}_t_0^⊤E
\boldsymbol{X}|-|\boldsymbol{v}_t_0^⊤(\boldsymbol{X}-E
\boldsymbol{X})|≥√{2\log(|T_0|/ε)},
$$
as desired. ∎
Using the above lemma we have the following result.
**Corollary A.1**
*Fix $B>0$ . Let $π_0$ be any prior distribution on $Θ(B)$ , then draw $(τ,μ_L,μ_R)∼π_0$ , $\boldsymbol{X}∼ P(n,τ,μ_L,μ_R)$ , and define $Y=\mathbbm{1}\{μ_L≠μ_R\}$ . Then for $λ^*=B√{3n}/6$ , the test $h^CUSUM_*_λ^*$ satisfies
$$
ℙ(h^CUSUM_*_λ^*(\boldsymbol{X})≠ Y)≤ 2
\lfloor\log_2(n)\rfloor e^-nB^{2/24}.
$$*
* Proof*
Setting $ε=|T_0|e^-nB^{2/24}$ in Lemma A.2, we have for any $(τ,μ_L,μ_R)∈Θ(B)$ that
$$
ℙ(h^CUSUM_*_λ^*(\boldsymbol{X})≠\mathbbm{1}
\{μ_L≠μ_R\})≤|T_0|e^-nB^{2/24}.
$$
The result then follows by integrating over $π_0$ and the fact that $|T_0|=2\lfloor\log_2(n)\rfloor$ . ∎
* Proof ofTheorem4.3*
We follow the proof of Theorem 4.2 up to (5). From the conditions of the theorem, we have $W^*=O(Ln\log n)$ . Moreover, we have $h^CUSUM_*_λ^*∈H_1,4\lfloor\log_{2(n) \rfloor}⊆H_L,\boldsymbol{m}$ . Thus,
| | $\displaystyleℙ(h_ERM(\boldsymbol{X})≠ Y\midD)$ | $\displaystyle≤ℙ(h^CUSUM_*_λ^*(\boldsymbol{X })≠ Y)+C√{\frac{L^2n\log n\log(Ln)\log(N)+\log(1/δ)}{N}}$ | |
| --- | --- | --- | --- |
as desired. ∎
### A.8 Generalisation to time-dependent or heavy-tailed observations
So far, for simplicity of exposition, we have primarily focused on change-point models with independent and identically distributed Gaussian observations. However, neural network based procedures can also be applied to time-dependent or heavy-tailed observations. We first considered the case where the noise series $ξ_1,…,ξ_n$ is a centred stationary Gaussian process with short-ranged temporal dependence. Specifically, writing $K(u):=cov(ξ_t,ξ_t+u)$ , we assume that
$$
∑_u=0^n-1K(u)≤ D. \tag{6}
$$
**Theorem A.3**
*Fix $B>0$ , $n>0$ and let $π_0$ be any prior distribution on $Θ(B)$ . We draw $(τ,μ_L,μ_R)∼π_0$ , set $Y:=\mathbbm{1}\{μ_L≠μ_R\}$ and generate $\boldsymbol{X}:=\boldsymbol{μ}+\boldsymbol{ξ}$ such that $\boldsymbol{μ}:=(μ_L\mathbbm{1}\{i≤τ\}+μ_R \mathbbm{1}\{i>τ\})_i∈[n]$ and $\boldsymbol{ξ}$ is a centred stationary Gaussian process satisfying (6). Suppose that the training data $D:=\bigl{(}(\boldsymbol{X}^(1),Y^(1)),…,(\boldsymbol{X}^(N ),Y^(N))\bigr{)}$ consist of independent copies of $(\boldsymbol{X},Y)$ and let $h_ERM:=\operatorname*{arg min}_h∈L_L,\boldsymbol{m }L_N(h)$ be the empirical risk minimiser for a neural network with $L≥ 1$ layers and $\boldsymbol{m}=(m_1,…,m_L)^⊤$ hidden layer widths. If $m_1≥ 4\lfloor\log_2(n)\rfloor$ and $m_rm_r+1=O(n\log n)$ for all $r∈[L-1]$ , then for any $δ∈(0,1)$ , we have with probability at least $1-δ$ that
$$
ℙ(h_ERM(\boldsymbol{X})≠ Y\midD)≤ 2\lfloor
\log_2(n)\rfloor e^-nB^{2/(48D)}+C√{\frac{L^2n\log^2(Ln)\log(N)+
\log(1/δ)}{N}}.
$$*
* Proof*
By the proof of Wang and Samworth (2018, supplementary Lemma 10),
$$
ℙ\bigl{\{}\max_t∈ T_0|\boldsymbol{v}_t^⊤\boldsymbol{ξ}
|>B√{3n}/6\bigr{\}}≤|T_0|e^-nB^{2/(48D)}.
$$
On the other hand, for $t_0$ defined in the proof of Lemma A.1, we have that $|μ_L-μ_R|√{τ(n-τ)}/n>B$ , then $|\boldsymbol{v}_t_0^⊤EX|≥ B√{3n}/3$ . Hence for $λ^*=B√{3n}/6$ , we have $h_λ^*^CUSUM_*$ satisfying
$$
ℙ(h_λ^*^CUSUM_*(\boldsymbol{X}≠ Y))≤|T_
0|e^-nB^{2/(48D)}.
$$
We can then complete the proof using the same arguments as in the proof of Theorem 4.3. ∎
We now turn to non-Gaussian distributions and recall that the Orlicz $ψ_α$ -norm of a random variable $Y$ is defined as
$$
\|Y\|_ψ_{α}:=∈f\{η:E\exp(|Y/η|^α)≤ 2\}.
$$
For $α∈(0,2)$ , the random variable $Y$ has heavier tail than a sub-Gaussian distribution. The following lemma is a direct consequence of Kuchibhotla and Chakrabortty (2022, Theorem 3.1) (We state the version used in Li et al. (2023, Proposition 14)).
**Lemma A.4**
*Fix $α∈(0,2)$ . Suppose $\boldsymbol{ξ}=(ξ_1,…,ξ_n)^⊤$ has independent components satisfying $Eξ_t=0$ , $Var(ξ_t)=1$ and $\|ξ_t\|_ψ_{α}≤ K$ for all $t∈[n]$ . There exists $c_α>0$ , depending only on $α$ , such that for any $1≤ t≤ n/2$ , we have
$$
ℙ\bigl{(}|\boldsymbol{v}_t^⊤\boldsymbol{ξ}|≥ y\bigr{)}
≤\exp\biggl{\{}1-c_α\min\biggl{\{}\biggl{(}\frac{y}{K}\biggr{)}^2,
\biggl{(}\frac{y}{K\|\boldsymbol{v}_t\|_β(α)}\biggr{)}^α
\biggr{\}}\biggr{\}},
$$
where $β(α)=∞$ for $α≤ 1$ and $β(α)=α/(α-1)$ when $α>1$ .*
**Theorem A.5**
*Fix $α∈(0,2)$ , $B>0$ , $n>0$ and let $π_0$ be any prior distribution on $Θ(B)$ . We draw $(τ,μ_L,μ_R)∼π_0$ , set $Y:=\mathbbm{1}\{μ_L≠μ_R\}$ and generate $\boldsymbol{X}:=\boldsymbol{μ}+\boldsymbol{ξ}$ such that $\boldsymbol{μ}:=(μ_L\mathbbm{1}\{i≤τ\}+μ_R \mathbbm{1}\{i>τ\})_i∈[n]$ and $\boldsymbol{ξ}=(ξ_1,…,ξ_n)^⊤$ satisfies $Eξ_i=0$ , $Var(ξ_i)=1$ and $\|ξ_i\|_ψ_{α}≤ K$ for all $i∈[n]$ . Suppose that the training data $D:=\bigl{(}(\boldsymbol{X}^(1),Y^(1)),…,(\boldsymbol{X}^(N ),Y^(N))\bigr{)}$ consist of independent copies of $(\boldsymbol{X},Y)$ and let $h_ERM:=\operatorname*{arg min}_h∈L_L,\boldsymbol{m }L_N(h)$ be the empirical risk minimiser for a neural network with $L≥ 1$ layers and $\boldsymbol{m}=(m_1,…,m_L)^⊤$ hidden layer widths. If $m_1≥ 4\lfloor\log_2(n)\rfloor$ and $m_rm_r+1=O(n\log n)$ for all $r∈[L-1]$ , then there exists a constant $c_α>0$ , depending only on $α$ such that for any $δ∈(0,1)$ , we have with probability at least $1-δ$ that
$$
ℙ(h_ERM(\boldsymbol{X})≠ Y\midD)≤ 2\lfloor
\log_2(n)\rfloor e^1-c_α(√{nB/K)^α}+C√{\frac{L^2n
\log^2(Ln)\log(N)+\log(1/δ)}{N}}.
$$*
* Proof*
For $α∈(0,2)$ , we have $β(α)>2$ , so $\|\boldsymbol{v}_t\|_β(α)≥\|\boldsymbol{v}_t\|_2=1$ . Thus, from Lemma A.4, we have $ℙ(|\boldsymbol{v}_t^⊤\boldsymbol{ξ}|≥ y)≤ e^1-c_ α(y/K)^{α}$ . Thus, following the proof of Corollary A.1, we can obtain that $ℙ(h_λ^*^CUSUM_*(\boldsymbol{X}≠ Y))≤ 2 \lfloor\log_2(n)\rfloor e^1-c_α(√{nB/K)^α}$ . Finally, the desired conclusion follows from the same argument as in the proof of Theorem 4.3. ∎
### A.9 Multiple change-point estimation
Algorithm 1 is a general scheme for turning a change-point classifier into a location estimator. While it is theoretically challenging to derive theoretical guarantees for the neural network based change-point location estimation error, we motivate this methodological proposal here by showing that Algorithm 1, applied in conjunction with a CUSUM-based classifier have optimal rate of convergence for the change-point localisation task. We consider the model $x_i=μ_i+ξ_i$ , where $ξ_i\stackrel{{\scriptstyleiid}}{{∼}}N(0,1)$ for $i∈[n^*]$ . Moreover, for a sequence of change-points $0=τ_0<τ_1<⋯<τ_ν<n=τ_ν+1$ satisfying $τ_r-τ_r-1≥ 2n$ for all $r∈[ν+1]$ we have $μ_i=μ^(r-1)$ for all $i∈[τ_r-1,τ_r]$ , $r∈[ν+1]$ .
**Theorem A.6**
*Suppose data $x_1,…,x_n^*$ are generated as above satisfying $|μ^(r)-μ^(r-1)|>2√{2}B$ for all $r∈[ν]$ . Let $h_λ^*^CUSUM_*$ be defined as in Corollary A.1. Let $\hat{τ}_1,…,\hat{τ}_\hat{ν}$ be the output of Algorithm 1 with input $x_1,…,x_n^*$ , $ψ=h_λ^*^CUSUM_*$ and $γ=\lfloor n/2\rfloor/n$ . Then we have
$$
ℙ\biggl{\{}\hat{ν}=ν and |τ_i-\hat{τ}_i|≤
\frac{2B^2}{|μ^(r)-μ^(r-1)|^2}\biggr{\}}≥ 1-2n^*\lfloor\log_
2(n)\rfloor e^-nB^{2/24}.
$$*
* Proof*
For simplicity of presentation, we focus on the case where $n$ is a multiple of 4, so $γ=1/2$ . Define
| | $\displaystyle I_0$ | $\displaystyle:=\{i:μ_i+n-1=μ_i\},$ | |
| --- | --- | --- | --- |
By Lemma A.2 and a union bound, the event
$$
Ω=\bigl{\{}h_λ^*^CUSUM_*(\boldsymbol{X}^*_[i,i+
n))=k, for all $i∈ I_k$, $k=0,1$\bigr{\}}
$$
has probability at least $1-2n^*\lfloor\log_2(n)\rfloor e^-nB^{2/24}$ . We work on the event $Ω$ henceforth. Denote $Δ_r:=2B^2/|μ^(r)-μ^(r-1)|^2$ . Since $|μ^(r)-μ^(r-1)|>2√{2}B$ , we have $Δ_r<n/4$ . Note that for each $r∈[ν]$ , we have $\{i:τ_r-1<i≤τ_r-n or τ_r<i≤τ_r+1-n\}⊆ I _0$ and $\{i:τ_r-n+Δ_r<i≤τ_r-Δ_r\}⊆ I_1$ . Consequently, $\bar{L}_i$ defined in Algorithm 1 is below the threshold $γ=1/2$ for all $i∈(τ_r-1+n/2,τ_r-n/2]∪(τ_r+n/2,τ_r+1-n/2]$ , monotonically increases for $i∈(τ_r-n/2,τ_r-Δ]$ and monotonically decreases for $i∈(τ_r+Δ,τ_r+n/2]$ and is above the threshold $γ$ for $i∈(τ_r-Δ,τ_r+Δ]$ . Thus, exactly one change-point, say $\hat{τ}_r$ , will be identified on $(τ_r-1+n/2,τ_r+1-n/2]$ and $\hat{τ}_r=\operatorname*{arg max}_i∈(τ_{r-1+n/2,τ_r+1-n/2]} \bar{L}_i∈(τ_r-Δ,τ_r+Δ]$ as desired. Since the above holds for all $r∈[ν]$ , the proof is complete. ∎
Assuming that $\log(n^*)\asymp\log(n)$ and choosing $B$ to be of order $√{\log n}$ , the above theorem shows that using the CUSUM-based change-point classifier $ψ=h_λ^*^CUSUM_*$ in conjunction with Algorithm 1 allows for consistent estimation of both the number of locations of multiple change-points in the data stream. In fact, the rate of estimating each change-point, $2B^2/|μ^(r)-μ^(r-1)|^2$ , is minimax optimal up to logarithmic factors (see, e.g. Verzelen et al., 2020, Proposition 6). An inspection of the proof of Theorem A.6 reveals that the same result would hold for any $ψ$ for which the event $Ω$ holds with high probability. In view of the representability of $h_λ^*^CUSUM_*$ in the class of neural networks, one would intuitively expect that a similar theoretical guarantee as in Theorem A.6 would be available to the empirical risk minimiser in the corresponding neural network function class. However, the particular way in which we handle the generalisation error in the proof of Theorem 4.3 makes it difficult to proceed in this way, due to the fact that the distribution of the data segments obtained via sliding windows have complex dependence and no longer follow a common prior distribution $π_0$ used in Theorem 4.2.
## Appendix B Simulation and Result
### B.1 Simulation for Multiple Change-types
In this section, we illustrate the numerical study for one-change-point but with multiple change-types: change in mean, change in slope and change in variance. The data set with change/no-change in mean is generated from $P(n,τ,μ_L,μ_R)$ . We employ the model of change in slope from Fearnhead et al. (2019), namely
$$
x_t=f_t+ξ_t=\begin{cases}φ_0+φ_1t+ξ_t& if 1
≤ t≤τ\\
φ_0+(φ_1-φ_2)τ+φ_2t+ξ_t& τ+1≤ t≤ n,
\end{cases}
$$
where $φ_0,φ_1$ and $φ_2$ are parameters that can guarantee the continuity of two pieces of linear function at time $t=τ$ . We use the following model to generate the data set with change in variance.
$$
y_t=\begin{cases}μ+ε_t ε_t∼ N(0,σ_1^
{2}),& if t≤τ\\
μ+ε_t ε_t∼ N(0,σ_2^2),&
otherwise \end{cases}
$$
where $σ_1^2,σ_2^2$ are the variances of two Gaussian distributions. $τ$ is the change-point in variance. When $σ_1^2=σ_2^2$ , there is no-change in model. The labels of no change-point, change in mean only, change in variance only, no-change in variance and change in slope only are 0, 1, 2, 3, 4 respectively. For each label, we randomly generate $N_sub$ time series. In each replication of $N_sub$ , we update these parameters: $τ,μ_L,μ_R,σ_1,σ_2,α_1,φ_ 1,φ_2$ . To avoid the boundary effect, we randomly choose $τ$ from the discrete uniform distribution $U(n^\prime+1,n-n^\prime)$ in each replication, where $1≤ n^\prime<\lfloor n/2\rfloor,n^\prime∈ℕ$ . The other parameters are generated as follows:
- $μ_L,μ_R∼ U(μ_l,μ_u)$ and $μ_dl≤≤ft|μ_L-μ_R\right|≤μ_du$ , where $μ_l,μ_u$ are the lower and upper bounds of $μ_L,μ_R$ . $μ_dl,μ_du$ are the lower and upper bounds of $≤ft|μ_L-μ_R\right|$ .
- $σ_1,σ_2∼ U(σ_l,σ_u)$ and $σ_dl≤≤ft|σ_1-σ_2\right|≤σ_du$ , where $σ_l,σ_u$ are the lower and upper bounds of $σ_1,σ_2$ . $σ_dl,σ_du$ are the lower and upper bounds of $≤ft|σ_1-σ_2\right|$ .
- $φ_1,φ_2∼ U(φ_l,φ_u)$ and $φ_dl≤≤ft|φ_1-φ_2\right|≤φ_du$ , where $φ_l,φ_u$ are the lower and upper bounds of $φ_1,φ_2$ . $φ_dl,φ_du$ are the lower and upper bounds of $≤ft|φ_1-φ_2\right|$ .
Besides, we let $μ=0$ , $φ_0=0$ and the noise follows normal distribution with mean 0. For flexibility, we let the noise variance of change in mean and slope be $0.49$ and $0.25$ respectively. Both Scenarios 1 and 2 defined below use the neural network architecture displayed in Figure 9. Benchmark. Aminikhanghahi and Cook (2017) reviewed the methodologies for change-point detection in different types. To be simple, we employ the Narrowest-Over-Threshold (NOT) (Baranowski et al., 2019) and single variance change-point detection (Chen and Gupta, 2012) algorithms to detect the change in mean, slope and variance respectively. These two algorithms are available in R packages: not and changepoint. The oracle likelihood based tests $LR^oracle$ means that we pre-specified whether we are testing for change in mean, variance or slope. For the construction of adaptive likelihood-ratio based test $LR^adapt$ , we first separately apply 3 detection algorithms of change in mean, variance and slope to each time series, then we can compute 3 values of Bayesian information criterion (BIC) for each change-type based on the results of change-point detection. Lastly, the corresponding label of minimum of BIC values is treated as the predicted label. Scenario 1: Weak SNR. Let $n=400$ , $N_sub=2000$ and $n^\prime=40$ . The data is generated by the parameters settings in Table 2. We use the model architecture in Figure 9 to train the classifier. The learning rate is 0.001, the batch size is 64, filter size in convolution layer is 16, the kernel size is $(3,30)$ , the epoch size is 500. The transformations are ( $x,x^2$ ). We also use the inverse time decay technique to dynamically reduce the learning rate. The result which is displayed in Table 1 of main text shows that the test accuracy of $LR^oracle$ , $LR^adapt$ and NN based on 2500 test data sets are 0.9056, 0.8796 and 0.8660 respectively.
Table 2: The parameters for weak and strong signal-to-noise ratio (SNR).
Chang in mean $μ_l$ $μ_u$ $μ_dl$ $μ_du$ Weak SNR -5 5 0.25 0.5 Strong SNR -5 5 0.6 1.2 Chang in variance $σ_l$ $σ_u$ $σ_dl$ $σ_du$ Weak SNR 0.3 0.7 0.12 0.24 Strong SNR 0.3 0.7 0.2 0.4 Change in slope $φ_l$ $φ_u$ $φ_dl$ $φ_du$ Weak SNR -0.025 0.025 0.006 0.012 Strong SNR -0.025 0.025 0.015 0.03
Scenario 2: Strong SNR. The parameters for generating strong-signal data are listed in Table 2. The other hyperparameters are same as in Scenario 1. The test accuracy of $LR^oracle$ , $LR^adapt$ and NN based on 2500 test data sets are 0.9924, 0.9260 and 0.9672 respectively. We can see that the neural network-based approach achieves higher classification accuracy than the adaptive likelihood based method.
### B.2 Some Additional Simulations
#### B.2.1 Simulation for simultaneous changes
In this simulation, we compare the classification accuracies of likelihood-based classifier and NN-based classifier under the circumstance of simultaneous changes. For simplicity, we only focus on two classes: no change-point (Class 1) and change in mean and variance at a same change-point (Class 2). The change-point location $τ$ is randomly drawn from $Unif\{40,…,n-41\}$ where $n=400$ is the length of time series. Given $τ$ , to generate the data of Class 2, we use the parameter settings of change in mean and change in variance in Table 2 to randomly draw $μ_L,μ_R$ and $σ_1,σ_2$ respectively. The data before and after the change-point $τ$ are generated from $N(μ_L,σ_1^2)$ and $N(μ_R,σ_2^2)$ respectively. To generate the data of Class 1, we just draw the data from $N(μ_L,σ_1^2)$ . Then, we repeat each data generation of Class 1 and 2 $2500$ times as the training dataset. The test dataset is generated in the same procedure as the training dataset, but the testing size is 15000. We use two classifiers: likelihood-ratio (LR) based classifier (Chen and Gupta, 2012, p.59) and a 21-residual-block neural network (NN) based classifier displayed in Figure 9 to evaluate the classification accuracy of simultaneous change v.s. no change. The result are displayed in Table 3. We can see that under weak SNR, the NN has a good performance than LR-based method while it performs as well as the LR-based method under strong SNR.
Table 3: Test classification accuracy of likelihood-ratio (LR) based classifier (Chen and Gupta, 2012, p.59) and our residual neural network (NN) based classifier with 21 residual blocks for setups with weak and strong signal-to-noise ratios (SNR). Data are generated as a mixture of no change-point (Class 1), change in mean and variance at a same change-point (Class 2). We report the true positive rate of each class and the accuracy in the last row. The optimal threshold value of LR is chosen by the grid search method on the training dataset.
Weak SNR Strong SNR LR NN LR NN Class 1 0.9823 0.9668 1.0000 0.9991 Class 2 0.8759 0.9621 0.9995 0.9992 Accuracy 0.9291 0.9645 0.9997 0.9991
#### B.2.2 Simulation for heavy-tailed noise
In this simulation, we compare the performance of Wilcoxon change-point test (Dehling et al., 2015), CUSUM, simple neural network $H_L,\boldsymbol{m}$ as well as truncated $H_L,\boldsymbol{m}$ for heavy-tailed noise. Consider the model: $X_i=μ_i+ξ_i, i≥ 1,$ where $(μ_i)_i≥ 1$ are signals and $(ξ_i)_i≥ 1$ is a stochastic process. To test the null hypothesis
$$
H:μ_1=μ_2=⋯=μ_n
$$
against the alternative
$$
A:~{}There exists 1≤ k≤ n-1~{}such that μ_1=
⋯=μ_k≠μ_k+1=⋯=μ_n.
$$
Dehling et al. (2015) proposed the so-called Wilcoxon type of cumulative sum statistic
$$
T_n\coloneqq\max_1≤ k<n{≤ft\lvert\frac{2√{k(n-k)}}{n}\frac{1}{n^
3/2}∑_i=1^k∑_j=k+1^n≤ft(1_\{X_{i<X_j\}}-1/2
\right)\right\rvert} \tag{7}
$$
to detect the change-point in time series with outlier or heavy tails. Under the null hypothesis $H$ , the limit distribution of $T_n$ The definition of $T_n$ in Dehling et al. (2015, Theorem 3.1) does not include $2√{k(n-k)}/n$ . However, the repository of the R package robts (Dürre et al., 2016) normalises the Wilcoxon test by this item, for details see function wilcoxsuk in here. In this simulation, we adopt the definition of (7). can be approximately by the supreme of standard Brownian bridge process $(W^(0)(λ))_0≤λ≤ 1$ up to a scaling factor (Dehling et al., 2015, Theorem 3.1). In our simulation, we choose the optimal thresh value based on the training dataset by using the grid search method. The truncated simple neural network means that we truncate the data by the $z$ -score in data preprocessing step, i.e. given vector $\boldsymbol{x}=(x_1,x_2,…,x_n)^⊤$ , then $x_i[{≤ft\lvert x_i-\bar{x}\right\rvert}>Zσ_x]=\bar{x}+sgn( x_i-\bar{x})Zσ_x$ , $\bar{x}$ and $σ_x$ are the mean and standard deviation of $\boldsymbol{x}$ . The training dataset is generated by using the same parameter settings of Figure 2 (d) of the main text. The result of misclassification error rate (MER) of each method is reported in Figure 5. We can see that truncated simple neural network has the best performance. As expected, the Wilcoxon based test has better performance than the simple neural network based tests. However, we would like to mention that the main focus of Figure 2 of the main text is to demonstrate the point that simple neural networks can replicate the performance of CUSUM tests. Even though, the prior information of heavy-tailed noise is available, we still encourage the practitioner to use simple neural network by adding the $z$ -score truncation in data preprocessing step.
<details>
<summary>x8.png Details</summary>
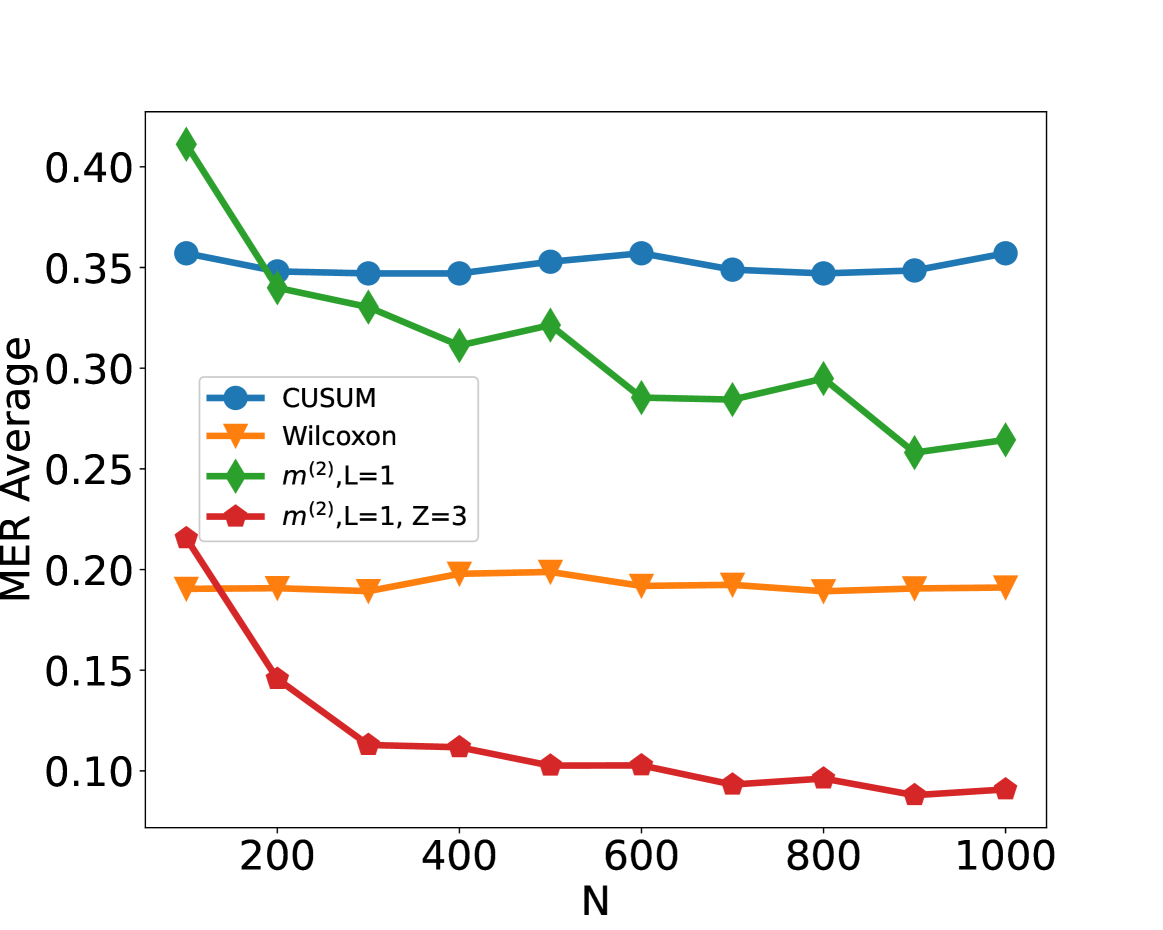
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image is a line chart displaying the "MER Average" on the y-axis against "N" on the x-axis. Four different data series, representing different methods, are plotted. The chart shows how the MER Average changes as N increases for each method.
### Components/Axes
* **Y-axis Title**: MER Average
* **Scale**: Linear, ranging from approximately 0.05 to 0.45.
* **Markers**: 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40.
* **X-axis Title**: N
* **Scale**: Linear, ranging from approximately 100 to 1000.
* **Markers**: 200, 400, 600, 800, 1000.
* **Legend**: Located in the top-left quadrant of the chart.
* **CUSUM**: Blue circles.
* **Wilcoxon**: Orange inverted triangles.
* **m⁽²⁾,L=1**: Green diamonds.
* **m⁽²⁾,L=1, Z=3**: Red diamonds.
### Detailed Analysis
**Data Series Trends and Points:**
1. **CUSUM (Blue circles)**:
* **Trend**: The line generally fluctuates slightly around a value of 0.35, with a slight upward trend towards the end.
* **Data Points (approximate N, MER Average)**:
* (100, 0.355)
* (200, 0.350)
* (300, 0.348)
* (400, 0.350)
* (500, 0.355)
* (600, 0.352)
* (700, 0.350)
* (800, 0.350)
* (900, 0.350)
* (1000, 0.357)
2. **Wilcoxon (Orange inverted triangles)**:
* **Trend**: The line starts at approximately 0.195 and then remains relatively flat, fluctuating slightly around 0.195 to 0.200.
* **Data Points (approximate N, MER Average)**:
* (100, 0.195)
* (200, 0.195)
* (300, 0.195)
* (400, 0.198)
* (500, 0.198)
* (600, 0.195)
* (700, 0.198)
* (800, 0.198)
* (900, 0.195)
* (1000, 0.195)
3. **m⁽²⁾,L=1 (Green diamonds)**:
* **Trend**: The line starts at a high value and generally slopes downward as N increases, with some fluctuations.
* **Data Points (approximate N, MER Average)**:
* (100, 0.410)
* (200, 0.345)
* (300, 0.330)
* (400, 0.345)
* (500, 0.315)
* (600, 0.285)
* (700, 0.295)
* (800, 0.300)
* (900, 0.260)
* (1000, 0.265)
4. **m⁽²⁾,L=1, Z=3 (Red diamonds)**:
* **Trend**: The line starts at approximately 0.225 and shows a significant downward trend as N increases, stabilizing at a low value.
* **Data Points (approximate N, MER Average)**:
* (100, 0.225)
* (200, 0.155)
* (300, 0.118)
* (400, 0.115)
* (500, 0.105)
* (600, 0.105)
* (700, 0.095)
* (800, 0.100)
* (900, 0.090)
* (1000, 0.095)
### Key Observations
* The "m⁽²⁾,L=1, Z=3" method shows the most significant decrease in MER Average as N increases, starting high and ending low.
* The "Wilcoxon" method exhibits a consistently high and stable MER Average across all values of N.
* The "CUSUM" method maintains a relatively stable MER Average, hovering around 0.35, with a slight increase at the highest N value.
* The "m⁽²⁾,L=1" method shows a general downward trend but with more pronounced fluctuations compared to the other methods.
* At N=100, "m⁽²⁾,L=1" has the highest MER Average (approx. 0.410), while "m⁽²⁾,L=1, Z=3" has the second highest (approx. 0.225).
* At N=1000, "CUSUM" has the highest MER Average (approx. 0.357), followed by "Wilcoxon" (approx. 0.195), "m⁽²⁾,L=1" (approx. 0.265), and "m⁽²⁾,L=1, Z=3" (approx. 0.095).
### Interpretation
This chart appears to be evaluating the performance of different statistical methods (CUSUM, Wilcoxon, and two variations of m⁽²⁾) in terms of their "MER Average" as a function of sample size "N". The MER Average likely represents some measure of error or performance metric.
* **Method Performance**: The data suggests that for larger sample sizes (higher N), the "m⁽²⁾,L=1, Z=3" method is the most effective, achieving the lowest MER Average. Conversely, the "CUSUM" method consistently shows a higher MER Average, indicating it might be less sensitive or perform less optimally in this context, especially at smaller N. The "Wilcoxon" method appears to be consistently mediocre, with a stable but relatively high MER Average.
* **Impact of N**: The trend for "m⁽²⁾,L=1, Z=3" strongly indicates that increasing the sample size "N" significantly improves its performance, reducing the MER Average. This suggests that this method benefits from more data to converge to a better estimate or decision. The "m⁽²⁾,L=1" method also shows improvement with N, but its performance is more erratic.
* **Methodological Differences**: The different behaviors of the methods highlight their underlying statistical principles. CUSUM is often used for change detection, while Wilcoxon is a rank-based test. The m⁽²⁾ variations likely represent more complex or specialized metrics. The parameter Z=3 in one of the m⁽²⁾ methods seems to have a substantial impact, leading to a much lower MER Average compared to the m⁽²⁾,L=1 method without this parameter.
* **Potential Applications**: This type of analysis is common in fields like signal processing, quality control, or anomaly detection, where one needs to choose a method that performs well across varying data sizes and provides a reliable measure of performance. The results suggest that "m⁽²⁾,L=1, Z=3" is a strong candidate for applications where a low MER Average is desired and sufficient data is available.
</details>
Figure 5: Scenario S3 with Cauchy noise by adding Wilcoxon type of change-point detection method (Dehling et al., 2015) and simple neural network with truncation in data preprocessing. The average misclassification error rate (MER) is computed on a test set of size $N_test=15000$ , against training sample size $N$ for detecting the existence of a change-point on data series of length $n=100$ . We compare the performance of the CUSUM test, Wilcoxon test, $H_1,m^(2)$ and $H_1,m^(2)$ with $Z=3$ where $m^(2)=2n-2$ and $Z=3$ means the truncated $z$ -score, i.e. given vector $\boldsymbol{x}=(x_1,x_2,…,x_n)^⊤$ , then $x_i[{≤ft|x_i-\bar{x}\right|}>Zσ_x]=\bar{x}+sgn(x_i- \bar{x})Zσ_x$ , $\bar{x}$ and $σ_x$ are the mean and standard deviation of $\boldsymbol{x}$ .
#### B.2.3 Robustness Study
This simulation is an extension of numerical study of Section 5 in main text. We trained our neural network using training data generated under scenario S1 with $ρ_t=0$ (i.e. corresponding to Figure 2 (a) of the main text), but generate the test data under settings corresponding to Figure 2 (a, b, c, d). In other words, apart the top-left panel, in the remaining panels of Figure 6, the trained network is misspecified for the test data. We see that the neural networks continue to work well in all panels, and in fact have performance similar to those in Figure 2 (b, c, d) of the main text. This indicates that the trained neural network has likely learned features related to the change-point rather than any distributional specific artefacts.
<details>
<summary>x9.png Details</summary>
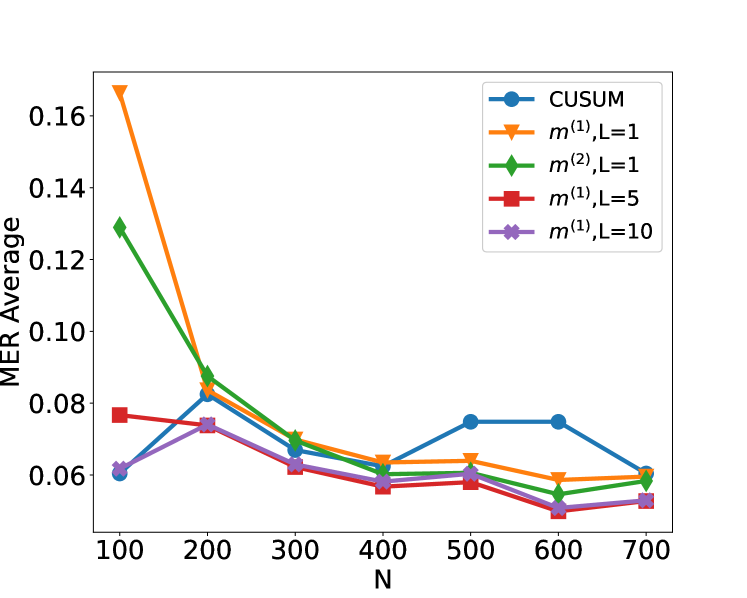
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image displays a line chart illustrating the "MER Average" on the y-axis against "N" on the x-axis. Five different data series, representing various methods, are plotted, each with distinct markers and colors. The chart shows how the MER Average changes with increasing values of N for each method.
### Components/Axes
* **X-axis Title:** N
* **X-axis Markers:** 100, 200, 300, 400, 500, 600, 700
* **Y-axis Title:** MER Average
* **Y-axis Markers:** 0.06, 0.08, 0.10, 0.12, 0.14, 0.16
* **Legend:** Located in the top-right quadrant of the chart.
* **CUSUM:** Blue circles (•)
* **m⁽¹⁾, L=1:** Orange inverted triangles (▼)
* **m⁽²⁾, L=1:** Green diamonds (◆)
* **m⁽¹⁾, L=5:** Red squares (■)
* **m⁽¹⁾, L=10:** Purple crosses (×)
### Detailed Analysis
**Data Series Trends and Points:**
1. **CUSUM (Blue circles •):**
* **Trend:** Initially slopes upward from N=100 to N=500, then plateaus between N=500 and N=600, and finally slopes downward to N=700.
* **Data Points (approximate):**
* N=100: 0.060
* N=200: 0.082
* N=300: 0.070
* N=400: 0.065
* N=500: 0.077
* N=600: 0.077
* N=700: 0.062
2. **m⁽¹⁾, L=1 (Orange inverted triangles ▼):**
* **Trend:** Starts at its highest value at N=100 and then consistently slopes downward as N increases.
* **Data Points (approximate):**
* N=100: 0.165
* N=200: 0.085
* N=300: 0.073
* N=400: 0.065
* N=500: 0.060
* N=600: 0.058
* N=700: 0.059
3. **m⁽²⁾, L=1 (Green diamonds ◆):**
* **Trend:** Starts at a high value at N=100 and then consistently slopes downward as N increases, generally following a similar pattern to m⁽¹⁾, L=1 but with lower initial values.
* **Data Points (approximate):**
* N=100: 0.128
* N=200: 0.085
* N=300: 0.072
* N=400: 0.065
* N=500: 0.062
* N=600: 0.057
* N=700: 0.058
4. **m⁽¹⁾, L=5 (Red squares ■):**
* **Trend:** Starts at a moderate value at N=100, dips slightly at N=200, then generally slopes downward as N increases, reaching its lowest point at N=600 before a slight increase at N=700.
* **Data Points (approximate):**
* N=100: 0.078
* N=200: 0.074
* N=300: 0.065
* N=400: 0.059
* N=500: 0.063
* N=600: 0.055
* N=700: 0.057
5. **m⁽¹⁾, L=10 (Purple crosses ×):**
* **Trend:** Starts at a moderate value at N=100, rises slightly at N=200, then generally slopes downward as N increases, reaching its lowest point at N=600 before a slight increase at N=700. This trend is very similar to m⁽¹⁾, L=5.
* **Data Points (approximate):**
* N=100: 0.062
* N=200: 0.075
* N=300: 0.067
* N=400: 0.062
* N=500: 0.060
* N=600: 0.055
* N=700: 0.056
### Key Observations
* The **m⁽¹⁾, L=1** method exhibits the highest MER Average at N=100 (approximately 0.165) and shows a significant decrease as N increases.
* All methods generally show a decreasing trend in MER Average as N increases, particularly after N=200.
* The **CUSUM** method shows a different pattern, with an initial increase and then a plateau before a decrease, unlike the other methods which mostly decrease monotonically.
* The **m⁽¹⁾, L=5** and **m⁽¹⁾, L=10** methods have very similar trends and values, especially for N >= 300, with both reaching their minimum MER Average around N=600.
* At N=100, the MER Average values range from approximately 0.060 (CUSUM) to 0.165 (m⁽¹⁾, L=1).
* At N=700, the MER Average values are much closer, ranging from approximately 0.056 (m⁽¹⁾, L=10) to 0.062 (CUSUM).
### Interpretation
The chart suggests that for most of the methods presented (m⁽¹⁾, L=1, m⁽²⁾, L=1, m⁽¹⁾, L=5, and m⁽¹⁾, L=10), the MER Average tends to decrease as the sample size (N) increases. This is a common observation in statistical analysis, where larger sample sizes often lead to more stable and potentially lower error metrics.
The **m⁽¹⁾, L=1** method starts with a very high MER Average at N=100, indicating a significant amount of error or variability at smaller sample sizes. However, it rapidly improves as N grows.
The **CUSUM** method's behavior is distinct. Its initial rise and subsequent plateau suggest a different mechanism of error accumulation or detection compared to the other methods. The plateau between N=500 and N=600 might indicate a point where the CUSUM statistic stabilizes or reaches a steady state before potentially detecting changes at larger N.
The similarity between **m⁽¹⁾, L=5** and **m⁽¹⁾, L=10** suggests that for these specific methods, the parameter L (which likely represents a look-ahead or window size) might have a diminishing impact on the MER Average beyond L=5, or that the optimal L is around 5 or 10 for the tested range of N.
Overall, the data demonstrates a trade-off between sample size and MER Average for most methods. The choice of method and its parameters (like L) significantly influences the MER Average, especially at smaller sample sizes. The CUSUM method's unique trend warrants further investigation into its specific application and behavior.
</details>
<details>
<summary>x10.png Details</summary>
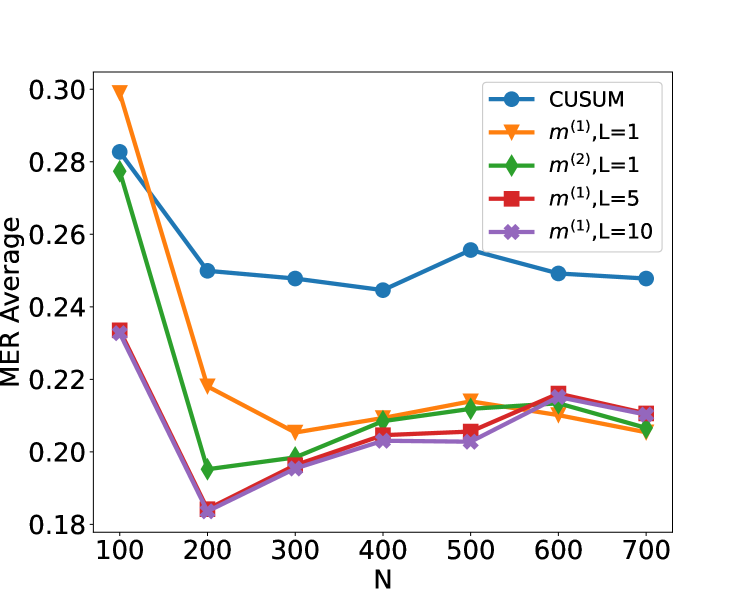
### Visual Description
## Line Chart: MER Average vs. N
### Overview
This image is a line chart displaying the "MER Average" on the y-axis against "N" on the x-axis. Several data series, representing different methods (CUSUM, m^(1),L=1, m^(2),L=1, m^(1),L=5, m^(1),L=10), are plotted. The chart shows how the MER Average changes with increasing values of N for each method.
### Components/Axes
* **Y-axis Title**: MER Average
* **Scale**: Ranges from 0.18 to 0.30, with major tick marks at 0.22, 0.24, 0.26, 0.28, and 0.30. Minor tick marks are present at intervals of 0.01.
* **X-axis Title**: N
* **Scale**: Ranges from 100 to 700, with major tick marks at 100, 200, 300, 400, 500, 600, and 700.
* **Legend**: Located in the top-right quadrant of the chart. It maps colors and markers to the different data series:
* **Blue circles**: CUSUM
* **Orange inverted triangles**: m^(1),L=1
* **Green diamonds**: m^(2),L=1
* **Red squares**: m^(1),L=5
* **Purple crosses**: m^(1),L=10
### Detailed Analysis
**Data Series Trends and Points:**
1. **CUSUM (Blue circles)**:
* **Trend**: The line initially increases sharply from N=100 to N=200, then shows a general downward trend with minor fluctuations.
* **Data Points (approximate)**:
* N=100: 0.281
* N=200: 0.251
* N=300: 0.248
* N=400: 0.244
* N=500: 0.255
* N=600: 0.248
* N=700: 0.246
2. **m^(1),L=1 (Orange inverted triangles)**:
* **Trend**: The line starts at its highest point at N=100, drops significantly to N=200, and then shows a gradual upward trend with some leveling off.
* **Data Points (approximate)**:
* N=100: 0.300
* N=200: 0.217
* N=300: 0.207
* N=400: 0.213
* N=500: 0.215
* N=600: 0.217
* N=700: 0.212
3. **m^(2),L=1 (Green diamonds)**:
* **Trend**: The line starts at a high value, drops sharply to N=200, and then shows a generally upward trend, fluctuating slightly.
* **Data Points (approximate)**:
* N=100: 0.281
* N=200: 0.195
* N=300: 0.203
* N=400: 0.207
* N=500: 0.215
* N=600: 0.217
* N=700: 0.207
4. **m^(1),L=5 (Red squares)**:
* **Trend**: The line starts at a moderate value, drops to N=200, and then shows a generally upward trend, with some fluctuations.
* **Data Points (approximate)**:
* N=100: 0.235
* N=200: 0.184
* N=300: 0.198
* N=400: 0.205
* N=500: 0.205
* N=600: 0.217
* N=700: 0.212
5. **m^(1),L=10 (Purple crosses)**:
* **Trend**: The line starts at a moderate value, drops to N=200, and then shows a generally upward trend, with some fluctuations.
* **Data Points (approximate)**:
* N=100: 0.235
* N=200: 0.184
* N=300: 0.198
* N=400: 0.205
* N=500: 0.205
* N=600: 0.217
* N=700: 0.212
**Note on m^(1),L=5 and m^(1),L=10**: These two series appear to overlap significantly, particularly at N=100 and N=200, and follow very similar trends and values throughout the plotted range.
### Key Observations
* **Initial Drop**: All plotted series, except CUSUM, exhibit a significant drop in MER Average between N=100 and N=200.
* **CUSUM's Behavior**: The CUSUM method shows a different pattern, with an initial increase and then a general decrease, maintaining a higher MER Average than the other methods for N > 200.
* **Convergence**: For N >= 300, the MER Average for m^(1),L=1, m^(2),L=1, m^(1),L=5, and m^(1),L=10 tend to converge, fluctuating within a narrower range of approximately 0.20 to 0.217.
* **Lowest MER Average**: The lowest MER Average values are observed around N=200 for m^(2),L=1 (approx. 0.195) and for m^(1),L=5 and m^(1),L=10 (approx. 0.184).
* **Highest MER Average**: The highest MER Average is observed for m^(1),L=1 at N=100 (approx. 0.300).
### Interpretation
The chart demonstrates the performance of different methods (CUSUM and variations of 'm' with different L parameters) in terms of their "MER Average" as a function of "N".
* **CUSUM's Robustness/Stability**: The CUSUM method, while starting with a higher MER Average at N=100 compared to some other methods, shows a more stable or decreasing trend for larger N. This suggests it might be more robust or efficient in maintaining a lower average error as the sample size (N) increases beyond a certain point, or it might be less sensitive to initial variations.
* **Initial Sensitivity of Other Methods**: The sharp drop observed for m^(1),L=1, m^(2),L=1, m^(1),L=5, and m^(1),L=10 between N=100 and N=200 indicates that these methods are highly sensitive to initial sample sizes. They perform poorly at very small N but improve significantly as N increases to 200.
* **Parameter Impact (L)**: The comparison between m^(1),L=5 and m^(1),L=10 suggests that for these specific configurations, the parameter L (which likely represents a lookahead or lookback window) has a minimal impact on the MER Average, as their performance curves are nearly identical. The difference between m^(1),L=1 and m^(2),L=1 is more pronounced, especially at smaller N values.
* **Trade-offs**: The data suggests a trade-off. Methods like m^(1),L=5 and m^(1),L=10 achieve their best performance (lowest MER Average) at N=200, but their performance plateaus or slightly degrades for larger N compared to CUSUM. CUSUM, on the other hand, might require a larger N to reach its optimal performance or maintain a consistently low error rate.
In essence, the chart allows for a comparative analysis of different anomaly detection or statistical monitoring methods, highlighting their performance characteristics across varying sample sizes. The choice of method would depend on the specific requirements, such as the acceptable MER Average, the expected range of N, and the desired stability of the metric.
</details>
(a) Trained S1 ( $ρ_t=0$ ) $→$ S1 ( $ρ_t=0$ ) (b)Trained S1 ( $ρ_t=0$ ) $→$ S1 ${}^\prime$ ( $ρ_t=0.7$ )
<details>
<summary>x11.png Details</summary>
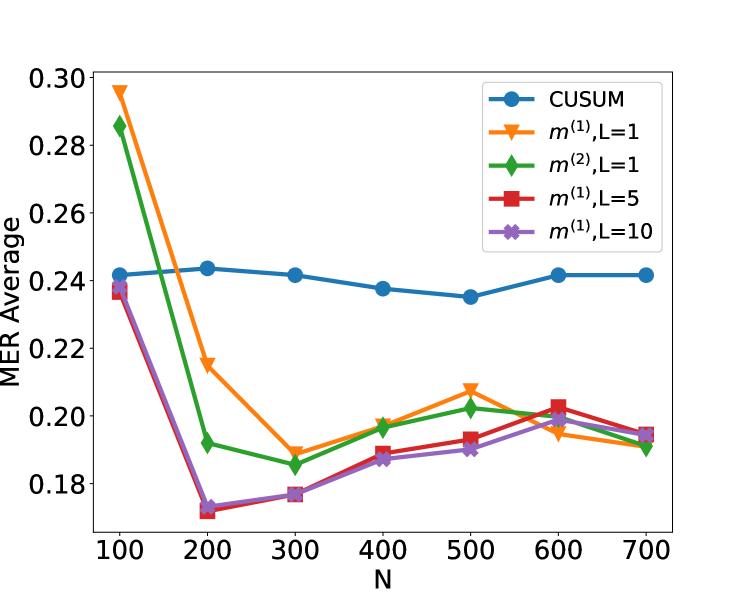
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image displays a line chart comparing the "MER Average" on the y-axis against "N" on the x-axis for five different methods: CUSUM, $m^{(1), L=1}$, $m^{(2), L=1}$, $m^{(1), L=5}$, and $m^{(1), L=10}$. The chart shows how the MER Average changes as N increases for each of these methods.
### Components/Axes
* **Chart Type**: Line Chart
* **Title**: Not explicitly stated, but implied by the axes and legend.
* **X-axis**:
* **Label**: N
* **Scale**: Numerical, ranging from 100 to 700.
* **Markers**: 100, 200, 300, 400, 500, 600, 700.
* **Y-axis**:
* **Label**: MER Average
* **Scale**: Numerical, ranging from approximately 0.18 to 0.30.
* **Markers**: 0.18, 0.20, 0.22, 0.24, 0.26, 0.28, 0.30.
* **Legend**: Located in the top-right quadrant of the chart.
* **CUSUM**: Blue line with circular markers.
* **$m^{(1), L=1}$**: Orange line with triangular markers.
* **$m^{(2), L=1}$**: Green line with diamond markers.
* **$m^{(1), L=5}$**: Red line with square markers.
* **$m^{(1), L=10}$**: Purple line with cross markers.
### Detailed Analysis
**Data Series Trends and Points:**
1. **CUSUM (Blue, Circles)**:
* **Trend**: The CUSUM line starts at approximately 0.242 at N=100, then slightly increases to around 0.244 at N=200, remains relatively stable between 0.240 and 0.242 from N=300 to N=500, then increases slightly to approximately 0.243 at N=600, and finally stays at approximately 0.242 at N=700. Overall, it shows a relatively flat trend with minor fluctuations.
* **Approximate Data Points**:
* N=100: 0.242
* N=200: 0.244
* N=300: 0.240
* N=400: 0.238
* N=500: 0.237
* N=600: 0.243
* N=700: 0.242
2. **$m^{(1), L=1}$ (Orange, Triangles)**:
* **Trend**: This line starts at a high value of approximately 0.298 at N=100. It then drops sharply to approximately 0.215 at N=200. The trend continues downwards to approximately 0.195 at N=300. After N=300, it begins to increase, reaching approximately 0.200 at N=400, then 0.210 at N=500, and 0.202 at N=600. Finally, it decreases slightly to approximately 0.195 at N=700.
* **Approximate Data Points**:
* N=100: 0.298
* N=200: 0.215
* N=300: 0.195
* N=400: 0.200
* N=500: 0.210
* N=600: 0.202
* N=700: 0.195
3. **$m^{(2), L=1}$ (Green, Diamonds)**:
* **Trend**: This line starts at approximately 0.285 at N=100. It then decreases sharply to approximately 0.192 at N=200. The trend continues downwards to approximately 0.185 at N=300. After N=300, it begins to increase, reaching approximately 0.198 at N=400, then 0.205 at N=500, and 0.195 at N=600. Finally, it decreases slightly to approximately 0.192 at N=700.
* **Approximate Data Points**:
* N=100: 0.285
* N=200: 0.192
* N=300: 0.185
* N=400: 0.198
* N=500: 0.205
* N=600: 0.195
* N=700: 0.192
4. **$m^{(1), L=5}$ (Red, Squares)**:
* **Trend**: This line starts at approximately 0.240 at N=100. It then drops sharply to approximately 0.175 at N=200. The trend continues slightly upwards to approximately 0.177 at N=300, then to 0.185 at N=400, and 0.198 at N=500. It then increases to approximately 0.202 at N=600, before decreasing to approximately 0.195 at N=700.
* **Approximate Data Points**:
* N=100: 0.240
* N=200: 0.175
* N=300: 0.177
* N=400: 0.185
* N=500: 0.198
* N=600: 0.202
* N=700: 0.195
5. **$m^{(1), L=10}$ (Purple, Crosses)**:
* **Trend**: This line starts at approximately 0.238 at N=100. It then drops sharply to approximately 0.175 at N=200. The trend continues slightly upwards to approximately 0.178 at N=300, then to 0.190 at N=400, and 0.195 at N=500. It then decreases slightly to approximately 0.192 at N=600, before decreasing further to approximately 0.190 at N=700.
* **Approximate Data Points**:
* N=100: 0.238
* N=200: 0.175
* N=300: 0.178
* N=400: 0.190
* N=500: 0.195
* N=600: 0.192
* N=700: 0.190
### Key Observations
* **Initial High Values**: The methods $m^{(1), L=1}$ and $m^{(2), L=1}$ exhibit significantly higher MER Average values at N=100 compared to CUSUM, $m^{(1), L=5}$, and $m^{(1), L=10}$.
* **Sharp Decrease**: All methods except CUSUM show a dramatic decrease in MER Average from N=100 to N=200.
* **Convergence**: For N values greater than or equal to 300, the MER Average values for $m^{(1), L=1}$, $m^{(2), L=1}$, $m^{(1), L=5}$, and $m^{(1), L=10}$ tend to converge, fluctuating within a narrower range (approximately 0.175 to 0.210).
* **CUSUM Stability**: The CUSUM method maintains a relatively stable MER Average throughout the observed range of N, hovering around 0.24.
* **Lowest MER Average**: The methods $m^{(1), L=5}$ and $m^{(1), L=10}$ achieve the lowest MER Average values, particularly around N=200 and N=300, with values as low as approximately 0.175.
* **Crossings**: The lines for $m^{(1), L=5}$ and $m^{(1), L=10}$ are very close for most of the N range, with slight crossings occurring. Similarly, $m^{(1), L=1}$ and $m^{(2), L=1}$ also show some proximity in their trends after the initial drop.
### Interpretation
The chart demonstrates the performance of different methods (CUSUM and various $m$ functions with different parameters L) in terms of their "MER Average" as the sample size "N" increases.
* **Initial Performance**: At a small sample size (N=100), $m^{(1), L=1}$ and $m^{(2), L=1}$ appear to be less optimal, showing very high MER Averages. This could indicate that these methods are more sensitive to initial data or require more data to stabilize. CUSUM, $m^{(1), L=5}$, and $m^{(1), L=10}$ perform better at N=100.
* **Adaptability**: The sharp decline in MER Average for most methods from N=100 to N=200 suggests that they become more efficient or accurate as more data becomes available. This is a common characteristic of many statistical or machine learning methods.
* **Long-term Behavior**: For larger N, the convergence of $m^{(1), L=1}$, $m^{(2), L=1}$, $m^{(1), L=5}$, and $m^{(1), L=10}$ indicates that their performance becomes similar. The choice between these methods might then depend on other factors not shown in this chart, such as computational cost or specific error profiles.
* **CUSUM's Consistency**: The CUSUM method's stable performance across different N values suggests it is robust and less affected by sample size variations. However, its MER Average is consistently higher than the other methods for N > 200. This implies that while CUSUM is stable, it might not be as efficient in minimizing the MER Average as the other methods when sufficient data is available.
* **Parameter Impact**: Comparing $m^{(1), L=5}$ and $m^{(1), L=10}$, their performance is very similar, suggesting that increasing L from 5 to 10 for the $m^{(1)}$ method has a minimal impact on the MER Average in this context. The slight differences might be within the margin of error or represent minor trade-offs.
In essence, the chart suggests that for achieving a low MER Average, methods like $m^{(1), L=5}$ and $m^{(1), L=10}$ are effective, especially with increasing N. CUSUM offers stability but at a higher MER Average. The initial high values for $m^{(1), L=1}$ and $m^{(2), L=1}$ at small N highlight the importance of sample size for these specific configurations.
</details>
<details>
<summary>x12.png Details</summary>
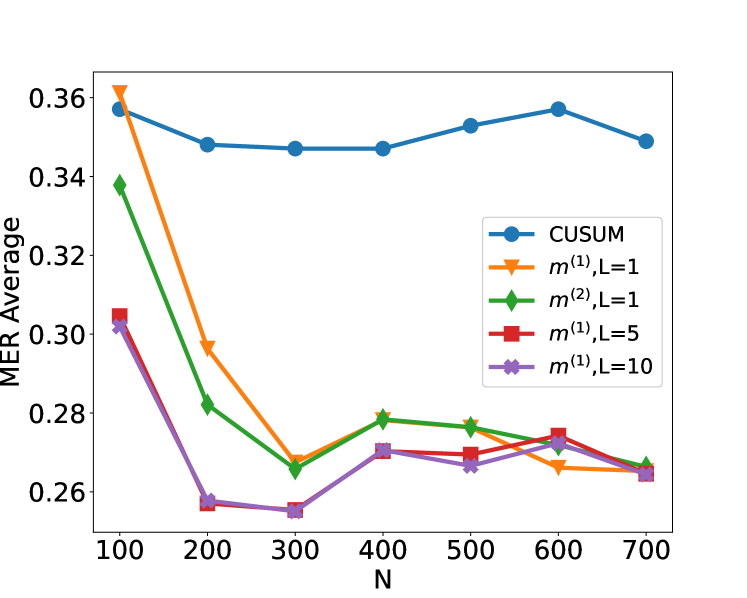
### Visual Description
## Line Chart: MER Average vs. N for Different Methods
### Overview
This image displays a line chart illustrating the "MER Average" on the y-axis against "N" on the x-axis. Five different data series, representing various methods (CUSUM, m⁽¹⁾,L=1, m⁽²⁾,L=1, m⁽¹⁾,L=5, and m⁽¹⁾,L=10), are plotted. The chart shows how the MER Average changes with increasing values of N for each method.
### Components/Axes
* **Y-axis Label**: "MER Average"
* **Scale**: Ranges from approximately 0.25 to 0.36, with major tick marks at 0.26, 0.28, 0.30, 0.32, 0.34, and 0.36.
* **X-axis Label**: "N"
* **Scale**: Ranges from 100 to 700, with major tick marks at 100, 200, 300, 400, 500, 600, and 700.
* **Legend**: Located in the top-right quadrant of the chart. It maps colors and markers to the different data series:
* **Blue circles**: CUSUM
* **Orange inverted triangles**: m⁽¹⁾,L=1
* **Green diamonds**: m⁽²⁾,L=1
* **Red squares**: m⁽¹⁾,L=5
* **Purple crosses**: m⁽¹⁾,L=10
### Detailed Analysis
**Data Series Trends and Values:**
1. **CUSUM (Blue circles)**:
* **Trend**: The CUSUM line generally shows a slight upward trend from N=100 to N=500, then a slight dip and another slight rise. It remains relatively stable across the range of N.
* **Approximate Data Points**:
* N=100: ~0.358
* N=200: ~0.347
* N=300: ~0.345
* N=400: ~0.345
* N=500: ~0.352
* N=600: ~0.355
* N=700: ~0.348
2. **m⁽¹⁾,L=1 (Orange inverted triangles)**:
* **Trend**: This line starts at its highest MER Average at N=100 and then shows a sharp downward trend until N=300, followed by a slight upward trend.
* **Approximate Data Points**:
* N=100: ~0.362
* N=200: ~0.298
* N=300: ~0.267
* N=400: ~0.278
* N=500: ~0.273
* N=600: ~0.270
* N=700: ~0.265
3. **m⁽²⁾,L=1 (Green diamonds)**:
* **Trend**: This line begins with a significant drop from N=100 to N=200, then shows a gradual upward trend with some fluctuations.
* **Approximate Data Points**:
* N=100: ~0.339
* N=200: ~0.280
* N=300: ~0.267
* N=400: ~0.279
* N=500: ~0.277
* N=600: ~0.275
* N=700: ~0.267
4. **m⁽¹⁾,L=5 (Red squares)**:
* **Trend**: This line starts at a moderate MER Average and shows a general downward trend until N=300, followed by a slight increase and then a decrease.
* **Approximate Data Points**:
* N=100: ~0.304
* N=200: ~0.257
* N=300: ~0.255
* N=400: ~0.270
* N=500: ~0.273
* N=600: ~0.275
* N=700: ~0.266
5. **m⁽¹⁾,L=10 (Purple crosses)**:
* **Trend**: This line shows a sharp initial decrease from N=100 to N=200, then remains relatively stable with minor fluctuations, generally trending downwards slightly towards the end.
* **Approximate Data Points**:
* N=100: ~0.303
* N=200: ~0.257
* N=300: ~0.255
* N=400: ~0.268
* N=500: ~0.270
* N=600: ~0.272
* N=700: ~0.265
### Key Observations
* **Initial Performance**: At N=100, the m⁽¹⁾,L=1 method shows the highest MER Average (~0.362), while CUSUM is also high (~0.358). The other methods (m⁽¹⁾,L=5, m⁽¹⁾,L=10, and m⁽²⁾,L=1) start at lower MER Averages, around 0.30 to 0.34.
* **Convergence**: For N values between 200 and 300, several lines (m⁽¹⁾,L=1, m⁽²⁾,L=1, m⁽¹⁾,L=5, and m⁽¹⁾,L=10) converge to similar low MER Average values, around 0.255 to 0.267.
* **CUSUM Stability**: The CUSUM method exhibits the most stable MER Average across the range of N, fluctuating within a narrow band of approximately 0.345 to 0.358.
* **Lowest MER Averages**: The lowest MER Average values are generally observed for N=300 and N=700, with values around 0.265-0.267 for m⁽¹⁾,L=1, m⁽²⁾,L=1, and m⁽¹⁾,L=10 at N=700.
* **L Parameter Impact**: Comparing m⁽¹⁾,L=1, m⁽¹⁾,L=5, and m⁽¹⁾,L=10, it appears that increasing L (from 1 to 5 and 10) initially leads to lower MER Averages for smaller N (e.g., N=200), but the performance becomes more similar for larger N.
### Interpretation
The chart suggests a comparative analysis of different methods for calculating or estimating some metric (MER Average) as a function of a parameter N.
* **Method Performance**: The CUSUM method appears to be the most robust and stable across varying N, maintaining a consistently moderate MER Average. In contrast, methods like m⁽¹⁾,L=1 show a significant initial drop in MER Average, indicating a potential sensitivity to initial data points or a rapid adaptation.
* **Parameter Influence**: The parameter L in the m⁽¹⁾ method seems to influence its performance. For smaller N, a higher L (like 5 or 10) might lead to a lower MER Average, suggesting better initial performance or stability. However, for larger N, the differences between different L values for m⁽¹⁾ become less pronounced, and they tend to perform similarly to m⁽²⁾,L=1.
* **Trade-offs**: The initial high MER Average for m⁽¹⁾,L=1 at N=100 might be a trade-off for its rapid decrease to lower values at N=200 and N=300. This could imply that it is more sensitive to changes or anomalies early on but becomes more efficient later.
* **Overall Goal**: The data likely aims to demonstrate which method or parameter setting provides the lowest and most consistent MER Average for a given N, which could be crucial in applications where minimizing this metric is important (e.g., in statistical process control, anomaly detection, or signal processing). The convergence of several lines at lower N values suggests that for certain ranges, different methods might achieve similar levels of performance. The CUSUM method's consistent performance might be desirable in scenarios where predictability and stability are prioritized over achieving the absolute lowest MER Average.
</details>
(c) Trained S1 ( $ρ_t=0$ ) $→$ S2 (d) Trained S1 ( $ρ_t=0$ ) $→$ S3
Figure 6: Plot of the test set MER, computed on a test set of size $N_test=30000$ , against training sample size $N$ for detecting the existence of a change-point on data series of length $n=100$ . We compare the performance of the CUSUM test and neural networks from four function classes: $H_1,m^(1)$ , $H_1,m^(2)$ , $H_5,m^(1)1_5$ and $H_10,m^(1)1_10$ where $m^(1)=4\lfloor\log_2(n)\rfloor$ and $m^(2)=2n-2$ respectively under scenarios S1, S1 ${}^\prime$ , S2 and S3 described in Section 5. The subcaption “A $→$ B” means that we apply the trained classifier “A” to target testing dataset “B”.
#### B.2.4 Simulation for change in autocorrelation
In this simulation, we discuss how we can use neural networks to recreate test statistics for various types of changes. For instance, if the data follows an AR(1) structure, then changes in autocorrelation can be handled by including transformations of the original input of the form $(x_tx_t+1)_t=1,…,n-1$ . On the other hand, even if such transformations are not supplied as the input, a deep neural network of suitable depth is able to approximate these transformations and consequently successfully detect the change (Schmidt-Hieber, 2020, Lemma A.2). This is illustrated in Figure 7, where we compare the performance of neural network based classifiers of various depths constructed with and without using the transformed data as inputs.
<details>
<summary>x13.png Details</summary>
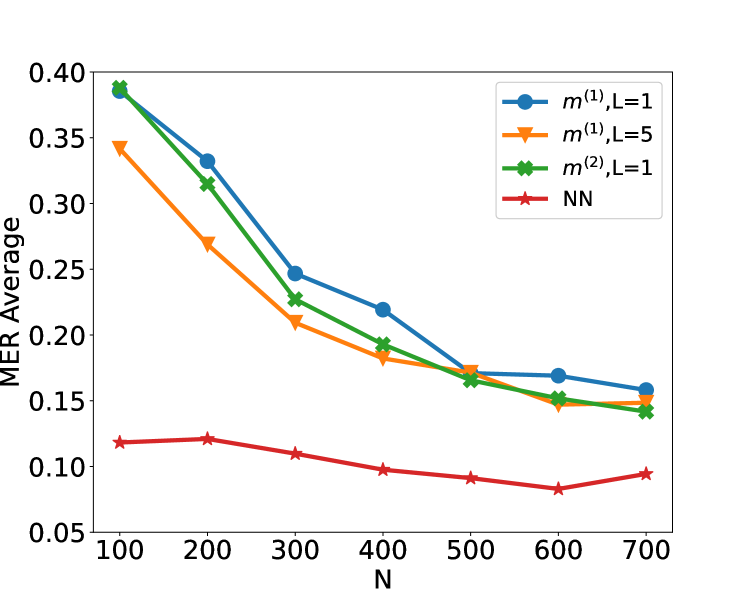
### Visual Description
## Line Chart: MER Average vs. N for Different Models
### Overview
This image is a line chart displaying the "MER Average" on the y-axis against "N" on the x-axis. Four different data series are plotted, each representing a different model or configuration, indicated by distinct colors and markers. The chart shows how the MER Average changes as N increases for each of these series.
### Components/Axes
* **Y-axis Title**: MER Average
* **Scale**: Linear, ranging from 0.05 to 0.40.
* **Tick Marks**: 0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40.
* **X-axis Title**: N
* **Scale**: Linear, ranging from 100 to 700.
* **Tick Marks**: 100, 200, 300, 400, 500, 600, 700.
* **Legend**: Located in the top-right quadrant of the chart.
* **Blue circles with solid line**: $m^{(1)}, L=1$
* **Orange triangles with solid line**: $m^{(1)}, L=5$
* **Green crosses with solid line**: $m^{(2)}, L=1$
* **Red stars with solid line**: NN
### Detailed Analysis
**Data Series: $m^{(1)}, L=1$ (Blue circles)**
* **Trend**: This data series starts at a high MER Average and generally slopes downward as N increases.
* **Data Points (approximate)**:
* N=100: 0.39
* N=200: 0.33
* N=300: 0.25
* N=400: 0.22
* N=500: 0.17
* N=600: 0.16
* N=700: 0.155
**Data Series: $m^{(1)}, L=5$ (Orange triangles)**
* **Trend**: This data series also starts at a high MER Average and slopes downward as N increases, generally staying below the $m^{(1)}, L=1$ series for N > 200.
* **Data Points (approximate)**:
* N=100: 0.345
* N=200: 0.27
* N=300: 0.225
* N=400: 0.19
* N=500: 0.165
* N=600: 0.15
* N=700: 0.155
**Data Series: $m^{(2)}, L=1$ (Green crosses)**
* **Trend**: This data series starts at the highest MER Average and slopes downward as N increases, closely tracking the $m^{(1)}, L=1$ series for N > 300.
* **Data Points (approximate)**:
* N=100: 0.39
* N=200: 0.32
* N=300: 0.23
* N=400: 0.175
* N=500: 0.165
* N=600: 0.15
* N=700: 0.145
**Data Series: NN (Red stars)**
* **Trend**: This data series starts at the lowest MER Average and shows a generally downward trend, with a slight increase at the end. It consistently remains below the other three series.
* **Data Points (approximate)**:
* N=100: 0.12
* N=200: 0.115
* N=300: 0.105
* N=400: 0.095
* N=500: 0.09
* N=600: 0.085
* N=700: 0.095
### Key Observations
* All four data series exhibit a decreasing trend in MER Average as N increases, suggesting that performance generally improves with a larger value of N for all tested models.
* The "NN" series consistently shows the lowest MER Average across all values of N, indicating it is the most performant model among those plotted.
* The $m^{(1)}, L=1$ and $m^{(2)}, L=1$ series are very close in performance, especially for N values of 300 and above.
* The $m^{(1)}, L=5$ series performs worse than $m^{(1)}, L=1$ for N values up to 600, but converges at N=700.
* The initial MER Average at N=100 for $m^{(1)}, L=1$ and $m^{(2)}, L=1$ is approximately 0.39, which is the highest observed value.
### Interpretation
The chart demonstrates the relationship between a parameter "N" and the "MER Average" for four different models or configurations. The consistent downward trend across all series indicates that increasing "N" leads to a reduction in the MER Average, which is likely a desirable outcome, implying improved performance or accuracy.
The "NN" model stands out as the most effective, achieving the lowest MER Average throughout the observed range of N. This suggests that the neural network approach is superior in this context compared to the other models represented by $m^{(1)}$ and $m^{(2)}$.
The close proximity of $m^{(1)}, L=1$ and $m^{(2)}, L=1$ suggests that for these specific configurations, the difference in performance is minimal, particularly as N grows. The comparison between $m^{(1)}, L=1$ and $m^{(1)}, L=5$ indicates that a smaller value of L (i.e., L=1) is more beneficial for the $m^{(1)}$ model when N is not excessively large. However, at N=700, their performance becomes comparable.
This data could be used to inform model selection and parameter tuning. For instance, if the goal is to minimize MER Average, the "NN" model would be the preferred choice. If computational resources or other constraints limit the maximum value of N, the chart provides insights into the expected MER Average for each model at different N values, allowing for a trade-off analysis between performance and resource utilization. The convergence of some lines at higher N values might suggest a saturation point in performance improvement for those models.
</details>
<details>
<summary>x14.png Details</summary>
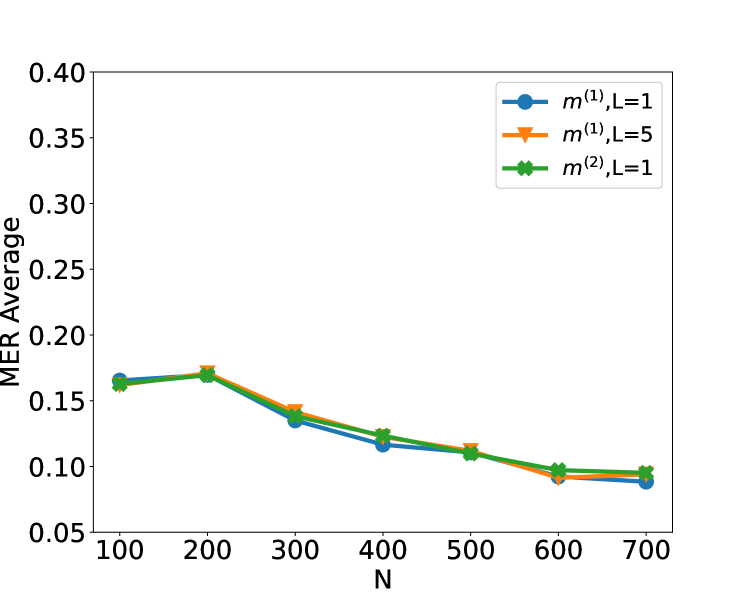
### Visual Description
## Line Chart: MER Average vs. N
### Overview
This image displays a line chart showing the "MER Average" on the y-axis against "N" on the x-axis. Three distinct data series are plotted, each representing a different configuration denoted by `m` and `L` values. All three series exhibit a general downward trend as N increases.
### Components/Axes
* **Y-axis Title**: MER Average
* **Y-axis Scale**: Ranges from 0.05 to 0.40, with major tick marks at 0.05 intervals (0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40).
* **X-axis Title**: N
* **X-axis Scale**: Ranges from 100 to 700, with major tick marks at 100 intervals (100, 200, 300, 400, 500, 600, 700).
* **Legend**: Located in the top-right quadrant of the chart. It uses colored markers and lines to identify the data series:
* **Blue line with circular markers**: `m⁽¹⁾, L=1`
* **Orange line with triangular markers**: `m⁽¹⁾, L=5`
* **Green line with cross markers**: `m⁽²⁾, L=1`
### Detailed Analysis
**Data Series 1: `m⁽¹⁾, L=1` (Blue line with circles)**
* **Trend**: This line starts at a relatively high MER Average and generally decreases as N increases.
* **Data Points (approximate values with uncertainty +/- 0.01)**:
* N=100: MER Average ≈ 0.165
* N=200: MER Average ≈ 0.170
* N=300: MER Average ≈ 0.140
* N=400: MER Average ≈ 0.120
* N=500: MER Average ≈ 0.110
* N=600: MER Average ≈ 0.095
* N=700: MER Average ≈ 0.085
**Data Series 2: `m⁽¹⁾, L=5` (Orange line with triangles)**
* **Trend**: This line also shows a decreasing trend as N increases, closely following the blue line for most of the range.
* **Data Points (approximate values with uncertainty +/- 0.01)**:
* N=100: MER Average ≈ 0.165
* N=200: MER Average ≈ 0.170
* N=300: MER Average ≈ 0.145
* N=400: MER Average ≈ 0.125
* N=500: MER Average ≈ 0.110
* N=600: MER Average ≈ 0.095
* N=700: MER Average ≈ 0.090
**Data Series 3: `m⁽²⁾, L=1` (Green line with crosses)**
* **Trend**: This line exhibits a similar decreasing trend as N increases, and it is very close to the other two lines, particularly at lower values of N.
* **Data Points (approximate values with uncertainty +/- 0.01)**:
* N=100: MER Average ≈ 0.165
* N=200: MER Average ≈ 0.170
* N=300: MER Average ≈ 0.140
* N=400: MER Average ≈ 0.125
* N=500: MER Average ≈ 0.110
* N=600: MER Average ≈ 0.095
* N=700: MER Average ≈ 0.090
### Key Observations
* All three data series show a consistent decrease in MER Average as N increases from 100 to 700.
* The MER Average values for all three series are very similar, especially at N=100 and N=200, where they are almost indistinguishable.
* The series `m⁽¹⁾, L=1` and `m⁽²⁾, L=1` appear to be nearly identical across the entire range of N.
* The series `m⁽¹⁾, L=5` shows slightly higher MER Average values than the other two series for N between 300 and 700, though the difference is marginal.
* The most significant drop in MER Average occurs between N=200 and N=300 for all series.
### Interpretation
The chart demonstrates that the "MER Average" metric generally improves (decreases) as the parameter "N" increases, across all tested configurations of `m` and `L`. This suggests that a larger value of N is beneficial for reducing the MER Average.
The close proximity of the three data series indicates that the specific configurations tested (`m⁽¹⁾, L=1`, `m⁽¹⁾, L=5`, and `m⁽²⁾, L=1`) have a similar impact on the MER Average with respect to N. The slight divergence at higher N values for `m⁽¹⁾, L=5` might suggest a minor difference in performance, but the overall trend is consistent. The near-identical performance of `m⁽¹⁾, L=1` and `m⁽²⁾, L=1` implies that the difference between `m⁽¹⁾` and `m⁽²⁾` might be negligible for L=1 in this context, or that the parameter L=1 is the dominant factor.
The initial plateau or slight increase from N=100 to N=200, followed by a steeper decline, could indicate an initial phase where the system is stabilizing or adapting before benefiting more significantly from larger N. The data suggests that for practical purposes, increasing N beyond 300 yields diminishing returns in terms of MER Average reduction, as the rate of decrease slows down.
</details>
(a) Original Input (b) Original and $x_tx_t+1$ Input
Figure 7: Plot of the test set MER, computed on a test set of size $N_test=30000$ , against training sample size $N$ for detecting the existence of a change-point on data series of length $n=100$ . We compare the performance of neural networks from four function classes: $H_1,m^(1)$ , $H_1,m^(2)$ , $H_5,m^(1)1_5$ and neural network with 21 residual blocks where $m^(1)=4\lfloor\log_2(n)\rfloor$ and $m^(2)=2n-2$ respectively. The change-points are randomly chosen from $Unif\{10,…,89\}$ . Given change-point $τ$ , data are generated from the autoregressive model $x_t=α_tx_t-1+ε_t$ for $ε_t\stackrel{{\scriptstyleiid}}{{∼}}N(0,0.25^2)$ and $α_t=0.21_\{t<τ\}+0.81_\{t≥τ\}$ .
#### B.2.5 Simulation on change-point location estimation
Here, we describe simulation results on the performance of change-point location estimator constructed using a combination of simple neural network-based classifier and Algorithm 1 from the main text. Given a sequence of length $n^\prime=2000$ , we draw $τ∼Unif\{750,…,1250\}$ . Set $μ_L=0$ and draw $μ_R|τ$ from 2 different uniform distributions: $Unif([-1.5b,-0.5b]∪[0.5b,1.5b])$ (Weak) and $Unif([-3b,-b]∪[b,3b])$ (Strong), where $b\coloneqq√{\frac{8n^\prime\log(20n^\prime)}{τ(n^\prime-τ)}}$ is chosen in line with Lemma 4.1 to ensure a good range of signal-to-noise ratio. We then generate $\boldsymbol{x}=(μ_L\mathbbm{1}_\{t≤τ\}+μ_R \mathbbm{1}_\{t>τ\}+ε_t)_t∈[n^\prime]$ , with the noise $\boldsymbol{ε}=(ε_t)_t∈[n^\prime]∼ N_n^\prime (0,I_n^\prime)$ . We then draw independent copies $\boldsymbol{x}_1,…,\boldsymbol{x}_N^\prime$ of $\boldsymbol{x}$ . For each $\boldsymbol{x}_k$ , we randomly choose 60 segments with length $n∈\{300,400,500,600\}$ , the segments which include $τ_k$ are labelled ‘1’, others are labelled ‘0’. The training dataset size is $N=60N^\prime$ where $N^\prime=500$ . We then draw another $N_test=3000$ independent copies of $\boldsymbol{x}$ as our test data for change-point location estimation. We study the performance of change-point location estimator produced by using Algorithm 1 together with a single-layer neural network, and compare it with the performance of CUSUM, MOSUM and Wilcoxon statistics-based estimators. As we can see from the Figure 8, under Gaussian models where CUSUM is known to work well, our simple neural network-based procedure is competitive. On the other hand, when the noise is heavy-tailed, our simple neural network-based estimator greatly outperforms CUSUM-based estimator.
<details>
<summary>x15.png Details</summary>

### Visual Description
## Line Chart: RMSE vs. n for Different Algorithms
### Overview
This image displays a line chart comparing the Root Mean Squared Error (RMSE) for three different algorithms (CUSUM, MOSUM, and Alg. 1) across varying values of 'n'. The x-axis represents 'n', and the y-axis represents RMSE.
### Components/Axes
* **X-axis Title**: 'n'
* **X-axis Markers**: 300, 350, 400, 450, 500, 550, 600
* **Y-axis Title**: 'RMSE'
* **Y-axis Markers**: 50, 100, 150, 200, 250
* **Legend**: Located in the top-right corner of the chart.
* **CUSUM**: Represented by blue circles (•).
* **MOSUM**: Represented by orange triangles (▼).
* **Alg. 1**: Represented by green crosses (x).
### Detailed Analysis or Content Details
**Data Series: CUSUM (Blue Circles)**
* **Trend**: The CUSUM line generally slopes upward slightly from n=300 to n=500, then dips slightly at n=600.
* **Data Points**:
* At n = 300, RMSE ≈ 58
* At n = 400, RMSE ≈ 53
* At n = 500, RMSE ≈ 67
* At n = 600, RMSE ≈ 57
**Data Series: MOSUM (Orange Triangles)**
* **Trend**: The MOSUM line shows a clear downward trend as 'n' increases.
* **Data Points**:
* At n = 300, RMSE ≈ 270
* At n = 400, RMSE ≈ 200
* At n = 500, RMSE ≈ 175
* At n = 600, RMSE ≈ 150
**Data Series: Alg. 1 (Green Crosses)**
* **Trend**: The Alg. 1 line shows a downward trend from n=300 to n=400, then plateaus or slightly decreases as 'n' increases further.
* **Data Points**:
* At n = 300, RMSE ≈ 98
* At n = 400, RMSE ≈ 70
* At n = 500, RMSE ≈ 70
* At n = 600, RMSE ≈ 58
### Key Observations
* The MOSUM algorithm consistently exhibits the highest RMSE across all tested values of 'n'.
* The CUSUM algorithm shows the lowest RMSE at n=400 and n=600, and is comparable to Alg. 1 at n=600.
* Alg. 1 demonstrates a significant reduction in RMSE from n=300 to n=400, after which its performance stabilizes.
* Both CUSUM and Alg. 1 show a convergence in RMSE values at n=600, with both being approximately 57-58.
### Interpretation
The chart suggests that for the given range of 'n', the MOSUM algorithm is the least effective in terms of minimizing RMSE, indicating higher error rates. Conversely, both CUSUM and Alg. 1 perform significantly better, especially at larger values of 'n'. The convergence of CUSUM and Alg. 1 at n=600 implies that for larger sample sizes, their performance in terms of RMSE becomes comparable. The initial sharp decrease in RMSE for Alg. 1 from n=300 to n=400 might indicate a sensitivity to sample size in its early stages, after which it reaches a more stable performance level. The slight upward trend for CUSUM between n=300 and n=500, followed by a decrease, could suggest a more complex relationship with 'n' or potential variability in its error. Overall, the data demonstrates a trade-off between algorithms and their performance as the sample size ('n') increases, with CUSUM and Alg. 1 appearing to be more robust or efficient for larger datasets.
</details>
<details>
<summary>x16.png Details</summary>
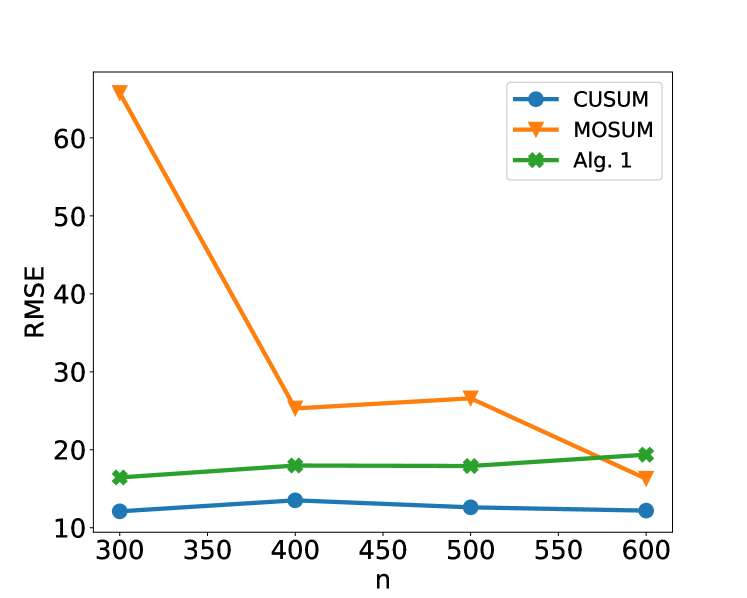
### Visual Description
## Line Chart: RMSE vs. n for Different Algorithms
### Overview
This image displays a line chart comparing the Root Mean Square Error (RMSE) for three different algorithms (CUSUM, MOSUM, and Alg. 1) across a range of 'n' values. The x-axis represents 'n', and the y-axis represents RMSE.
### Components/Axes
* **Chart Type**: Line Chart
* **Title**: Implicitly, the chart compares RMSE performance of algorithms against 'n'.
* **X-axis Label**: 'n'
* **X-axis Markers**: 300, 350, 400, 450, 500, 550, 600
* **Y-axis Label**: 'RMSE'
* **Y-axis Markers**: 10, 20, 30, 40, 50, 60
* **Legend**: Located in the top-right quadrant of the chart.
* **CUSUM**: Represented by a blue line with circular markers (•).
* **MOSUM**: Represented by an orange line with triangular markers (▲).
* **Alg. 1**: Represented by a green line with cross markers (x).
### Detailed Analysis
**Data Series: CUSUM (Blue line with •)**
* **Trend**: The CUSUM line generally slopes slightly downward, indicating a decrease in RMSE as 'n' increases, with minor fluctuations.
* **Data Points (approximate values)**:
* At n=300: RMSE ≈ 12.5
* At n=400: RMSE ≈ 13.5
* At n=500: RMSE ≈ 12.5
* At n=600: RMSE ≈ 12.5
**Data Series: MOSUM (Orange line with ▲)**
* **Trend**: The MOSUM line shows a sharp initial decrease in RMSE from n=300 to n=400, followed by a slight increase from n=400 to n=500, and then a significant decrease from n=500 to n=600.
* **Data Points (approximate values)**:
* At n=300: RMSE ≈ 65
* At n=400: RMSE ≈ 25
* At n=500: RMSE ≈ 27
* At n=600: RMSE ≈ 18
**Data Series: Alg. 1 (Green line with x)**
* **Trend**: The Alg. 1 line shows a slight upward trend in RMSE from n=300 to n=500, and then a slight decrease from n=500 to n=600.
* **Data Points (approximate values)**:
* At n=300: RMSE ≈ 16.5
* At n=400: RMSE ≈ 18
* At n=500: RMSE ≈ 18.5
* At n=600: RMSE ≈ 19
### Key Observations
* The MOSUM algorithm exhibits the highest RMSE at n=300, but shows a dramatic improvement by n=400.
* The CUSUM algorithm consistently maintains the lowest RMSE across all observed values of 'n'.
* Alg. 1 shows a relatively stable but slightly increasing RMSE as 'n' increases, before a minor dip at n=600.
* The MOSUM algorithm's performance is the most variable, with a large drop and then a rise and another drop.
### Interpretation
The chart demonstrates the performance of three algorithms (CUSUM, MOSUM, and Alg. 1) in terms of Root Mean Square Error (RMSE) as a function of a parameter 'n'. RMSE is a common metric for evaluating the accuracy of a model or algorithm; lower RMSE values indicate better performance (i.e., less error).
* **CUSUM** appears to be the most robust and consistently performs best, maintaining a low RMSE across the tested range of 'n'. This suggests it is a reliable choice for this particular problem.
* **MOSUM** shows a very interesting and potentially problematic behavior. Its extremely high RMSE at n=300 suggests it is highly sensitive to initial conditions or small sample sizes. The sharp drop to n=400 indicates a significant improvement, but the subsequent rise and fall suggest instability or a complex relationship with 'n' that warrants further investigation. The large initial error might be an outlier or indicative of a specific failure mode for small 'n'.
* **Alg. 1** shows a steady, albeit slight, increase in error as 'n' grows, before a minor improvement at the largest 'n'. This suggests that for larger datasets, its performance might degrade slightly, or it reaches a plateau.
In summary, CUSUM is the most stable and accurate algorithm shown. MOSUM is highly variable and performs poorly at small 'n', but can achieve moderate performance at larger 'n'. Alg. 1 is moderately accurate and shows a slight tendency towards increased error with larger 'n'. The choice of algorithm would depend on the specific requirements for accuracy, stability, and the expected range of 'n'. The behavior of MOSUM, in particular, suggests it might be suitable only for specific ranges of 'n' or might require careful tuning.
</details>
(a) S1 with $ρ_t=0$ , weak SNR (b) S1 with $ρ_t=0$ , strong SNR
<details>
<summary>x17.png Details</summary>
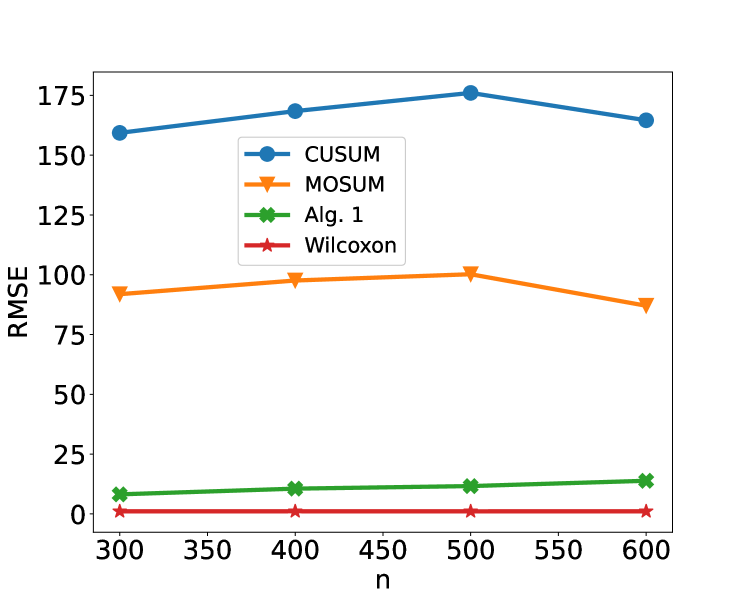
### Visual Description
## Line Chart: RMSE vs. n for Different Algorithms
### Overview
This image displays a line chart that plots the Root Mean Square Error (RMSE) against a variable 'n' for four different algorithms: CUSUM, MOSUM, Alg. 1, and Wilcoxon. The chart shows how the RMSE changes for each algorithm as 'n' increases.
### Components/Axes
* **Y-axis Label**: RMSE
* **Scale**: Linear, ranging from 0 to 175, with major ticks at 0, 25, 50, 75, 100, 125, 150, and 175.
* **X-axis Label**: n
* **Scale**: Linear, ranging from approximately 300 to 600, with major ticks at 300, 350, 400, 450, 500, 550, and 600.
* **Legend**: Located in the top-center of the chart, it identifies the four data series with corresponding markers and colors:
* **CUSUM**: Blue line with circular markers (●).
* **MOSUM**: Orange line with triangular markers (▼).
* **Alg. 1**: Green line with 'x' markers (x).
* **Wilcoxon**: Red line with star markers (★).
### Detailed Analysis or Content Details
**Data Series Trends and Points:**
1. **CUSUM (Blue line with ● markers):**
* **Trend**: The CUSUM line generally slopes upward from n=300 to n=500, and then slightly slopes downward from n=500 to n=600.
* **Data Points (approximate):**
* At n = 300: RMSE ≈ 158
* At n = 400: RMSE ≈ 170
* At n = 500: RMSE ≈ 175
* At n = 600: RMSE ≈ 168
2. **MOSUM (Orange line with ▼ markers):**
* **Trend**: The MOSUM line shows a consistent upward trend from n=300 to n=500, and then a downward trend from n=500 to n=600.
* **Data Points (approximate):**
* At n = 300: RMSE ≈ 95
* At n = 400: RMSE ≈ 99
* At n = 500: RMSE ≈ 101
* At n = 600: RMSE ≈ 90
3. **Alg. 1 (Green line with x markers):**
* **Trend**: The Alg. 1 line shows a very slight upward trend across the observed range of 'n'.
* **Data Points (approximate):**
* At n = 300: RMSE ≈ 8
* At n = 400: RMSE ≈ 10
* At n = 500: RMSE ≈ 11
* At n = 600: RMSE ≈ 13
4. **Wilcoxon (Red line with ★ markers):**
* **Trend**: The Wilcoxon line remains relatively flat and consistently low across the observed range of 'n'.
* **Data Points (approximate):**
* At n = 300: RMSE ≈ 2
* At n = 400: RMSE ≈ 2
* At n = 500: RMSE ≈ 2
* At n = 600: RMSE ≈ 2
### Key Observations
* **Performance Hierarchy**: The Wilcoxon algorithm consistently exhibits the lowest RMSE across all values of 'n', indicating the best performance in terms of accuracy. Alg. 1 shows the next lowest RMSE, followed by MOSUM, and then CUSUM, which has the highest RMSE.
* **CUSUM and MOSUM Behavior**: Both CUSUM and MOSUM show a peak in RMSE around n=500, after which their RMSE decreases. This suggests a potential non-monotonic relationship between 'n' and RMSE for these algorithms, or that the optimal 'n' for these methods might be around 500 in this context.
* **Alg. 1 Stability**: Alg. 1 demonstrates a stable and gradually increasing RMSE, suggesting consistent performance with a slight degradation as 'n' increases.
* **Wilcoxon Stability**: The Wilcoxon algorithm shows remarkable stability with a very low and nearly constant RMSE, indicating robust performance irrespective of 'n'.
### Interpretation
This chart demonstrates the comparative performance of four different algorithms (CUSUM, MOSUM, Alg. 1, and Wilcoxon) in terms of Root Mean Square Error (RMSE) as a function of a parameter 'n'. The RMSE is a common metric for evaluating the accuracy of a model or algorithm; a lower RMSE generally indicates better performance.
The data suggests a clear hierarchy of performance: **Wilcoxon** is the most accurate, followed by **Alg. 1**, then **MOSUM**, and finally **CUSUM** is the least accurate among the tested algorithms. The stability of the Wilcoxon algorithm, with its consistently low RMSE, makes it a highly reliable choice. Alg. 1 also shows good stability, with a slight increase in error as 'n' grows, which might be acceptable depending on the application's tolerance for error.
The behavior of CUSUM and MOSUM, with their RMSE peaking around n=500 and then decreasing, is particularly interesting. This could imply that for these specific algorithms, there's an optimal range of 'n' for performance, and values significantly deviating from this optimum (either lower or higher) might lead to increased error. This non-monotonic trend warrants further investigation into the underlying mechanisms of these algorithms.
In essence, the chart provides valuable insights for selecting the most appropriate algorithm based on the desired level of accuracy and the expected range of the parameter 'n'. For applications prioritizing accuracy, Wilcoxon is the clear frontrunner. For scenarios where a slight increase in error is tolerable for potentially other benefits (not shown here), Alg. 1 is a strong contender. The performance characteristics of CUSUM and MOSUM suggest they might be more sensitive to the choice of 'n' and require careful tuning.
</details>
<details>
<summary>x18.png Details</summary>
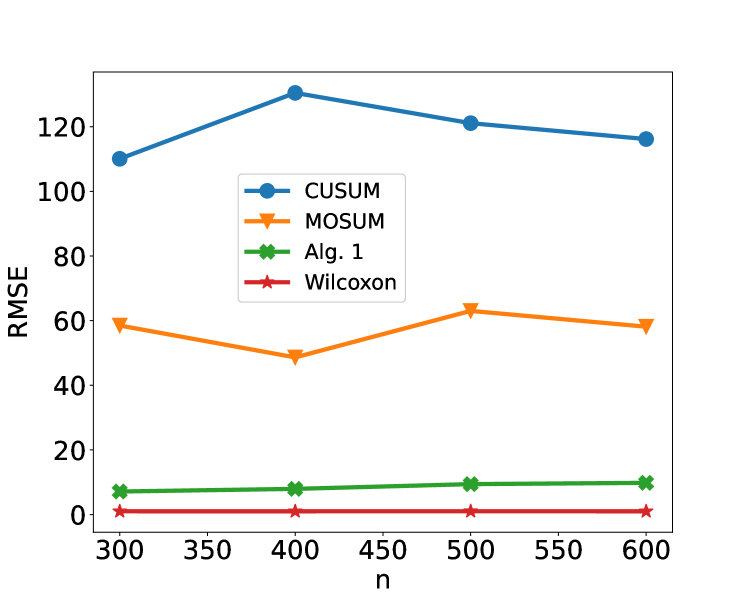
### Visual Description
## Line Chart: RMSE vs. n for Different Algorithms
### Overview
This image displays a line chart comparing the Root Mean Squared Error (RMSE) for four different algorithms (CUSUM, MOSUM, Alg. 1, and Wilcoxon) across varying values of 'n'. The x-axis represents 'n', and the y-axis represents RMSE.
### Components/Axes
* **Chart Type**: Line Chart
* **Title**: Implicitly, the chart shows the performance of different algorithms based on RMSE as a function of 'n'.
* **X-axis Label**: 'n'
* **X-axis Markers**: 300, 350, 400, 450, 500, 550, 600
* **Y-axis Label**: 'RMSE'
* **Y-axis Markers**: 0, 20, 40, 60, 80, 100, 120
* **Legend**: Located in the top-right quadrant of the chart.
* **CUSUM**: Represented by a blue line with circular markers.
* **MOSUM**: Represented by an orange line with triangular markers.
* **Alg. 1**: Represented by a green line with 'x' shaped markers.
* **Wilcoxon**: Represented by a red line with star shaped markers.
### Detailed Analysis or Content Details
**Data Series Trends and Points:**
1. **CUSUM (Blue Line with Circles):**
* **Trend**: The CUSUM line generally slopes upward from n=300 to n=400, reaching a peak, and then slopes downward slightly for larger values of n.
* **Data Points (approximate):**
* n=300: RMSE ≈ 110
* n=400: RMSE ≈ 128
* n=500: RMSE ≈ 120
* n=600: RMSE ≈ 116
2. **MOSUM (Orange Line with Triangles):**
* **Trend**: The MOSUM line shows a decrease in RMSE from n=300 to n=400, followed by an increase to n=500, and then a slight decrease to n=600.
* **Data Points (approximate):**
* n=300: RMSE ≈ 60
* n=400: RMSE ≈ 48
* n=500: RMSE ≈ 64
* n=600: RMSE ≈ 59
3. **Alg. 1 (Green Line with 'x' Markers):**
* **Trend**: The Alg. 1 line shows a relatively stable and low RMSE across all observed values of n, with a very slight upward trend.
* **Data Points (approximate):**
* n=300: RMSE ≈ 6
* n=400: RMSE ≈ 7
* n=500: RMSE ≈ 7
* n=600: RMSE ≈ 7
4. **Wilcoxon (Red Line with Stars):**
* **Trend**: The Wilcoxon line maintains a consistently low and stable RMSE across all observed values of n.
* **Data Points (approximate):**
* n=300: RMSE ≈ 2
* n=400: RMSE ≈ 2
* n=500: RMSE ≈ 2
* n=600: RMSE ≈ 2
### Key Observations
* **Alg. 1 and Wilcoxon** consistently exhibit the lowest RMSE values, indicating they are the most accurate or performant algorithms in terms of this metric across the tested range of 'n'. Their RMSE values are very close to zero.
* **CUSUM** shows the highest RMSE values among all algorithms, with a peak around n=400.
* **MOSUM** performs moderately, with RMSE values significantly lower than CUSUM but higher than Alg. 1 and Wilcoxon. Its performance shows some fluctuation with changes in 'n'.
* The trend for CUSUM suggests that its performance might degrade slightly for very large 'n' after an initial increase.
* The trends for Alg. 1 and Wilcoxon are remarkably flat, suggesting robustness to changes in 'n' within the observed range.
### Interpretation
This chart demonstrates the comparative performance of four different algorithms (CUSUM, MOSUM, Alg. 1, and Wilcoxon) as measured by Root Mean Squared Error (RMSE) for varying sample sizes ('n').
The data strongly suggests that **Alg. 1 and Wilcoxon are superior algorithms** for the task represented by this RMSE metric, as they consistently produce the lowest error rates. Their stability across different 'n' values indicates they are reliable.
The **CUSUM algorithm appears to be the least effective**, exhibiting the highest RMSE. The observed peak at n=400 and subsequent slight decrease might suggest a complex relationship between sample size and CUSUM's error, possibly related to its detection mechanism.
The **MOSUM algorithm falls in the middle**, showing a more variable performance than Alg. 1 and Wilcoxon, but still outperforming CUSUM. Its dip in RMSE at n=400 and rise at n=500 could indicate specific sample sizes where it is more or less effective.
In essence, the chart provides evidence for selecting Alg. 1 or Wilcoxon for applications where minimizing RMSE is critical, while CUSUM should be approached with caution, and MOSUM offers a compromise with some variability. The choice of algorithm would depend on the specific requirements of the application, balancing accuracy (RMSE) with other potential factors not shown here (e.g., computational cost, interpretability).
</details>
(c) S3, weak SNR (d) S3, strong SNR
Figure 8: Plot of the root mean square error (RMSE) of change-point estimation (S1 with $ρ_t=0$ and S3), computed on a test set of size $N_test=3000$ , against bandwidth $n$ for detecting the existence of a change-point on data series of length $n^*=2000$ . We compare the performance of the change-point detection by CUSUM, MOSUM, Algorithm 1 and Wilcoxon (only for S3) respectively. The RMSE here is defined by $√{1/N∑_i=1^N(\hat{τ}_i-τ_i)^2}$ where $\hat{τ}_i$ is the estimator of change-point for the $i$ -th observation and $τ_i$ is the true change-point. The weak and strong signal-to-noise ratio (SNR) correspond to $μ_R|τ∼Unif([-1.5b,-0.5b]∪[0.5b,1.5b])$ and $μ_R|τ∼Unif([-3b,-b]∪[b,3b])$ respectively.
## Appendix C Real Data Analysis
The HASC (Human Activity Sensing Consortium) project aims at understanding the human activities based on the sensor data. This data includes 6 human activities: “stay”, “walk”, “jog”, “skip”, “stair up” and “stair down”. Each activity lasts at least 10 seconds, the sampling frequency is 100 Hz.
### C.1 Data Cleaning
The HASC offers sequential data where there are multiple change-types and multiple change-points, see Figure 3 in main text. Hence, we can not directly feed them into our deep convolutional residual neural network. The training data fed into our neural network requires fixed length $n$ and either one change-point or no change-point existence in each time series. Next, we describe how to obtain this kind of training data from HASC sequential data. In general, Let $\boldsymbol{x}={(x_1,x_2,…,x_d)}^⊤,d≥ 1$ be the $d$ -channel vector. Define $\boldsymbol{X}\coloneqq(\boldsymbol{x}_t_1,\boldsymbol{x}_t_2,…, \boldsymbol{x}_t_{n^*})$ as a realization of $d$ -variate time series where $\boldsymbol{x}_t_{j},j=1,2,…,n^*$ are the observations of $\boldsymbol{x}$ at $n^*$ consecutive time stamps $t_1,t_2,…,t_n^*$ . Let $\boldsymbol{X}_i,i=1,2,…,N^*$ represent the observation from the $i$ -th subject. $\boldsymbol{τ}_i\coloneqq(τ_i,1,τ_i,2,…,τ_i,K)^⊤ ,K∈ℤ^+,τ_i,k∈[2,n^*-1],1≤ k≤ K$ with convention $τ_i,0=0$ and $τ_i,K+1=n^*$ represents the change-points of the $i$ -th observation which are well-labelled in the sequential data sets. Furthermore, define $n\coloneqq\min_i∈[N^*]\min_k∈[K+1](τ_i,k-τ_i,k-1)$ . In practice, we require that $n$ is not too small, this can be achieved by controlling the sampling frequency in experiment, see HASC data. We randomly choose $q$ sub-segments with length $n$ from $\boldsymbol{X}_i$ like the gray dash rectangles in Figure 3 of main text. By the definition of $n$ , there is at most one change-point in each sub-segment. Meanwhile, we assign the label to each sub-segment according to the type and existence of change-point. After that, we stack all the sub-segments to form a tensor $X$ with dimensions of $(N^*q,d,n)$ . The label vector is denoted as $Y$ with length $N^*q$ . To guarantee that there is at most one change-point in each segment, we set the length of segment $n=700$ . Let $q=15$ , as the change-points are well labelled, it is easy to draw 15 segments without any change-point, i.e., the segments with labels: “stay”, “walk”, “jog”, “skip”, “stair up” and “stair down”. Next, we randomly draw 15 segments (the red rectangles in Figure 3 of main text) for each transition point.
### C.2 Transformation
Section 3 in main text suggests that changes in the mean/signal may be captured by feeding the raw data directly. For other type of change, we recommend appropriate transformations before training the model depending on the interest of change-type. For instance, if we are interested in changes in the second order structure, we suggest using the square transformation; for change in auto-correlation with order $p$ we could input the cross-products of data up to a $p$ -lag. In multiple change-types, we allow applying several transformations to the data in data pre-processing step. The mixture of raw data and transformed data is treated as the training data. We employ the square transformation here. All the segments are mapped onto scale $[-1,1]$ after the transformation. The frequency of training labels are list in Figure 11. Finally, the shapes of training and test data sets are $(4875,6,700)$ and $(1035,6,700)$ respectively.
### C.3 Network Architecture
We propose a general deep convolutional residual neural network architecture to identify the multiple change-types based on the residual block technique (He et al., 2016) (see Figure 9). There are two reasons to explain why we choose residual block as the skeleton frame.
- The problem of vanishing gradients (Bengio et al., 1994; Glorot and Bengio, 2010). As the number of convolution layers goes significantly deep, some layer weights might vanish in back-propagation which hinders the convergence. Residual block can solve this issue by the so-called “shortcut connection”, see the flow chart in Figure 9.
- Degradation. He et al. (2016) has pointed out that when the number of convolution layers increases significantly, the accuracy might get saturated and degrade quickly. This phenomenon is reported and verified in He and Sun (2015) and He et al. (2016).
<details>
<summary>x19.png Details</summary>
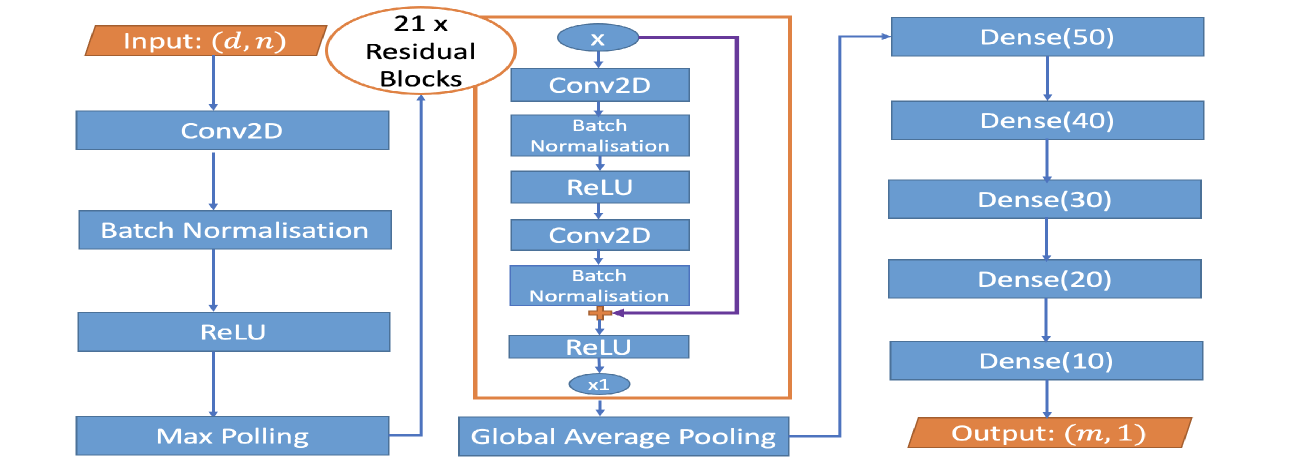
### Visual Description
## Diagram: Neural Network Architecture
### Overview
This diagram illustrates a neural network architecture. It begins with an input layer, followed by convolutional layers, batch normalization, ReLU activation, and max pooling. A significant portion of the network consists of 21 residual blocks, which are themselves composed of convolutional layers, batch normalization, and ReLU activations, with a skip connection. After the residual blocks, a global average pooling layer is applied, leading to a series of dense (fully connected) layers, culminating in an output layer.
### Components/Axes
The diagram is a flowchart-style representation of a neural network. There are no explicit axes or legends in the traditional sense of a chart. The components are represented by rectangular boxes for layers and operations, and an oval for a repeated block structure. Arrows indicate the flow of data through the network.
**Input/Output:**
* **Input:** Indicated by an orange trapezoidal shape labeled "Input: (d, n)". This signifies the input data has dimensions 'd' and 'n'.
* **Output:** Indicated by an orange trapezoidal shape labeled "Output: (m, 1)". This signifies the output data has dimensions 'm' and '1'.
**Layers and Operations (Blue Rectangles):**
* **Conv2D:** Convolutional layer (appears multiple times).
* **Batch Normalisation:** Batch Normalization layer (appears multiple times).
* **ReLU:** Rectified Linear Unit activation function (appears multiple times).
* **Max Polling:** Max Pooling layer.
* **Dense(50):** Fully connected layer with 50 neurons.
* **Dense(40):** Fully connected layer with 40 neurons.
* **Dense(30):** Fully connected layer with 30 neurons.
* **Dense(20):** Fully connected layer with 20 neurons.
* **Dense(10):** Fully connected layer with 10 neurons.
**Special Components:**
* **21 x Residual Blocks:** An orange oval enclosing a repeated structure, indicating that this block is instantiated 21 times.
* **x:** An oval representing a variable or intermediate output, used as input to the residual block.
* **x1:** An oval indicating a single instance or output of the residual block structure.
* **Global Average Pooling:** A rectangular box representing the global average pooling operation.
**Connections:**
* Arrows indicate the sequential flow of data.
* A purple arrow forms a skip connection within the residual block, bypassing some layers and adding its output to a later stage.
* A '+' symbol within the residual block indicates the addition operation for the skip connection.
### Detailed Analysis or Content Details
The network processing can be broken down as follows:
1. **Initial Feature Extraction:**
* Input data with dimensions `(d, n)` is fed into a `Conv2D` layer.
* The output of `Conv2D` is processed by `Batch Normalisation`.
* The normalized output is passed through a `ReLU` activation function.
* This is followed by a `Max Polling` operation.
2. **Residual Blocks:**
* The output from the initial feature extraction (or the output of the previous residual block) is fed into a structure labeled "21 x Residual Blocks".
* **Inside a single Residual Block:**
* An input `x` is received.
* It passes through a `Conv2D` layer.
* Followed by `Batch Normalisation`.
* Then a `ReLU` activation.
* Another `Conv2D` layer.
* Followed by `Batch Normalisation`.
* A `ReLU` activation.
* Crucially, a skip connection (purple arrow) bypasses the first `Conv2D`, `Batch Normalisation`, and `ReLU` layers. The output of the first `Batch Normalisation` layer is added (indicated by '+') to the output of the second `Batch Normalisation` layer.
* The result of this addition is then passed through a `ReLU` activation.
* This entire block is repeated 21 times. The output of the final residual block is labeled `x1`.
3. **Downsampling and Feature Aggregation:**
* The output `x1` from the residual blocks is fed into a `Global Average Pooling` layer.
4. **Classification/Regression Head:**
* The output of `Global Average Pooling` is then passed through a series of fully connected (Dense) layers:
* `Dense(50)`
* `Dense(40)`
* `Dense(30)`
* `Dense(20)`
* `Dense(10)`
* The final layer produces an output with dimensions `(m, 1)`.
### Key Observations
* The architecture heavily relies on residual connections, a common technique in deep learning to facilitate the training of very deep networks by mitigating the vanishing gradient problem.
* The network employs a combination of convolutional layers for feature extraction and dense layers for final prediction or classification.
* The presence of 21 residual blocks suggests a deep network designed to learn complex hierarchical features.
* Batch Normalization and ReLU activations are used throughout the network, which are standard practices for improving training stability and performance.
* Global Average Pooling is used before the dense layers, which can help reduce the number of parameters and prevent overfitting compared to traditional fully connected layers after convolutional layers.
### Interpretation
This diagram depicts a deep convolutional neural network architecture, likely designed for a task such as image classification or regression. The initial convolutional layers extract low-level features, which are then processed and refined through a substantial stack of 21 residual blocks. The residual connections are a key design choice, enabling the network to learn identity mappings and thus making it easier to train very deep models. The repeated application of `Conv2D`, `Batch Normalisation`, and `ReLU` within each residual block allows for the learning of increasingly complex and abstract features. The `Global Average Pooling` layer effectively summarizes the spatial feature maps into a fixed-size vector, reducing dimensionality and making the network more robust to spatial variations. Finally, the series of `Dense` layers acts as a classifier or regressor, mapping the learned features to the desired output dimensions `(m, 1)`. The specific number of neurons in the dense layers (50, 40, 30, 20, 10) suggests a multi-class classification problem or a regression task with multiple output values, where the final layer with 10 neurons might represent classes or specific output features. The input dimensions `(d, n)` and output dimensions `(m, 1)` are generic placeholders, indicating that the network is adaptable to different input data shapes and output requirements.
</details>
Figure 9: Architecture of our general-purpose change-point detection neural network. The left column shows the standard layers of neural network with input size $(d,n)$ , $d$ may represent the number of transformations or channels; We use 21 residual blocks and one global average pooling in the middle column; The right column includes 5 dense layers with nodes in bracket and output layer. More details of the neural network architecture appear in the supplement.
There are 21 residual blocks in our deep neural network, each residual block contains 2 convolutional layers. Like the suggestion in Ioffe and Szegedy (2015) and He et al. (2016), each convolution layer is followed by one Batch Normalization (BN) layer and one ReLU layer. Besides, there exist 5 fully-connected convolution layers right after the residual blocks, see the third column of Figure 9. For example, Dense(50) means that the dense layer has 50 nodes and is connected to a dropout layer with dropout rate 0.3. To further prevent the effect of overfitting, we also implement the $L_2$ regularization in each fully-connected layer (Ng, 2004). As the number of labels in HASC is 28, see Figure 10, we drop the dense layers “Dense(20)” and “Dense(10)” in Figure 9. The output layer has size $(28,1)$ . We remark two discussable issues here. (a) For other problems, the number of residual blocks, dense layers and the hyperparameters may vary depending on the complexity of the problem. In Section 6 of main text, the architecture of neural network for both synthetic data and real data has 21 residual blocks considering the trade-off between time complexity and model complexity. Like the suggestion in He et al. (2016), one can also add more residual blocks into the architecture to improve the accuracy of classification. (b) In practice, we would not have enough training data; but there would be potential ways to overcome this via either using Data Argumentation or increasing $q$ . In some extreme cases that we only mainly have data with no-change, we can artificially add changes into such data in line with the type of change we want to detect.
### C.4 Training and Detection
<details>
<summary>x20.png Details</summary>

### Visual Description
## Textual Data Extraction
### Overview
The image contains a block of text that appears to be a dictionary or a mapping of string keys to integer values. The keys represent different states or transitions between states, likely related to human activity or movement.
### Components/Axes
This section is not applicable as the image does not contain a chart or diagram with axes.
### Content Details
The following key-value pairs are extracted:
* `'jog'`: 0
* `'jog→skip'`: 1
* `'jog→stay'`: 2
* `'jog→walk'`: 3
* `'skip'`: 4
* `'skip→jog'`: 5
* `'skip→stay'`: 6
* `'skip→walk'`: 7
* `'stDown'`: 8
* `'stDown→jog'`: 9
* `'stDown→stay'`: 10
* `'stDown→walk'`: 11
* `'stUp'`: 12
* `'stUp→skip'`: 13
* `'stUp→stay'`: 14
* `'stUp→walk'`: 15
* `'stay'`: 16
* `'stay→jog'`: 17
* `'stay→skip'`: 18
* `'stay→stDown'`: 19
* `'stay→stUp'`: 20
* `'stay→walk'`: 21
* `'walk'`: 22
* `'walk→jog'`: 23
* `'walk→skip'`: 24
* `'walk→stDown'`: 25
* `'walk→stUp'`: 26
* `'walk→stay'`: 27
### Key Observations
* The keys are predominantly strings representing a single state (e.g., 'jog', 'skip', 'stay') or a transition between two states (e.g., 'jog→skip', 'stay→walk').
* The integer values range from 0 to 27.
* There appears to be a systematic assignment of integer values to these states and transitions. For example, single states are assigned lower numbers, and transitions are assigned subsequent numbers.
* The notation '→' likely signifies a transition from one state to another.
* 'stDown' and 'stUp' are likely abbreviations for 'sit down' and 'stand up' respectively.
### Interpretation
This data likely represents a state machine or a lookup table for a system that tracks or models human movement or activity. Each key defines a specific action or state, and the associated integer value could serve as an identifier, a code, or a numerical representation for that state/transition. This could be used in various applications such as:
* **Activity Recognition:** In wearable devices or computer vision systems, these codes could represent recognized activities.
* **Simulation:** In simulations of human behavior or biomechanics, these could define possible transitions and their associated costs or probabilities.
* **Data Encoding:** For efficient storage or processing of activity data, these integer codes would be more compact than string representations.
The structure suggests a discrete set of possible actions and their sequential mapping to numerical identifiers. The presence of both single states and transitions implies a system that can represent both being in a particular posture/activity and the act of changing between them. The numerical progression from 0 to 27 indicates a defined order or enumeration of these states and transitions.
</details>
Figure 10: Label Dictionary
<details>
<summary>x21.png Details</summary>

### Visual Description
## Textual Data Extraction: Activity Transition Counts
### Overview
The image contains a block of text representing a data structure, likely a dictionary or a map, that enumerates counts for various activities and transitions between activities. The data is presented in a key-value format, where the keys are strings representing activities or transitions (e.g., 'walk', 'stay', 'walk->jog'), and the values are integers representing the frequency or count of those activities/transitions.
### Components/Axes
This is not a chart or diagram, but a direct transcription of textual data. There are no explicit axes, legends, or labels in the conventional sense. The data is structured as a series of key-value pairs within a `Counter` object.
### Content Details
The following key-value pairs were extracted:
* **Single Activities:**
* 'walk': 570
* 'stay': 525
* 'jog': 495
* 'skip': 405
* 'stDown': 225
* 'stUp': 225
* **Transitions (from -> to):**
* 'walk->jog': 210
* 'stay->stDown': 180
* 'walk->stay': 180
* 'stay->skip': 180
* 'jog->walk': 165
* 'jog->stay': 150
* 'walk->stUp': 120
* 'skip->stay': 120
* 'stay->jog': 120
* 'stDown->stay': 105
* 'stay->stUp': 105
* 'stUp->walk': 105
* 'jog->skip': 105
* 'skip->walk': 105
* 'walk->skip': 75
* 'stUp->stay': 75
* 'stDown->walk': 75
* 'skip->jog': 75
* 'stUp->skip': 45
* 'stay->walk': 45
* 'walk->stDown': 45
* 'stDown->jog': 45
### Key Observations
* **Most Frequent Single Activity:** 'walk' with a count of 570.
* **Least Frequent Single Activity:** 'skip' with a count of 405.
* **Most Frequent Transition:** 'walk->jog' with a count of 210.
* **Least Frequent Transitions:** Several transitions have the lowest count of 45, including 'stUp->skip', 'stay->walk', 'walk->stDown', and 'stDown->jog'.
* **Symmetry in Transitions:** Some transitions appear to have symmetrical counts (e.g., 'walk->stay' is 180, and 'stay->walk' is 45, indicating asymmetry). However, 'stay->stDown' (180) and 'stDown->stay' (105) show a difference. 'stay->skip' (180) and 'skip->stay' (120) also show a difference.
* **Activity vs. Transition Counts:** The counts for single activities are generally higher than the counts for transitions, which is expected as transitions represent a change from one state to another, implying a preceding state.
### Interpretation
This data likely represents the output of a system that tracks user activity or state changes over time. The `Counter` object suggests a tally of occurrences.
* **Activity Distribution:** The counts for single activities ('walk', 'stay', 'jog', 'skip', 'stDown', 'stUp') indicate the overall prevalence of each activity. 'walk' and 'stay' are the most common states.
* **Transition Dynamics:** The transition counts reveal how frequently users move between different activities. For example, the high count for 'walk->jog' (210) suggests that transitioning from walking to jogging is a common behavior. Conversely, transitions with lower counts might represent less frequent or more specific behavioral patterns.
* **Behavioral Patterns:** By analyzing these transition probabilities (counts divided by the total occurrences of the originating activity), one could infer behavioral patterns. For instance, if 'walk->stay' is high and 'stay->walk' is low, it might suggest that once a user stops walking to stay, they are less likely to resume walking immediately.
* **Potential Applications:** This type of data is crucial for applications involving activity recognition, user behavior modeling, predictive analytics, and personalized user experiences. It could be used to train machine learning models to predict the next activity or to understand user engagement patterns. The presence of 'stDown' and 'stUp' suggests these might represent standing down and standing up, or perhaps specific types of movement like stairs. The distinct counts for transitions like 'walk->stDown' (45) versus 'stDown->walk' (75) could indicate different probabilities of initiating or resuming these actions.
</details>
Figure 11: Label Frequency
<details>
<summary>x22.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Epochs for Kernel Size 25
### Overview
This image displays a line chart illustrating the accuracy of a model over a number of epochs. Two data series are plotted: "Kernel Size=25 Train" and "Kernel Size=25 Validation". Both series show a rapid increase in accuracy in the initial epochs, followed by a plateau at a high accuracy level.
### Components/Axes
* **X-axis**:
* **Title**: Epochs
* **Scale**: Linear, ranging from 0 to 400.
* **Markers**: 0, 50, 100, 150, 200, 250, 300, 350, 400.
* **Y-axis**:
* **Title**: Accuracy
* **Scale**: Linear, ranging from 0.3 to 1.0.
* **Markers**: 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0.
* **Legend**:
* Located in the bottom-left quadrant of the chart.
* **"Kernel Size=25 Train"**: Represented by a solid blue line.
* **"Kernel Size=25 Validation"**: Represented by a dashed blue line.
### Detailed Analysis
**Data Series 1: Kernel Size=25 Train (Solid Blue Line)**
* **Trend**: The solid blue line shows a steep upward trend from approximately 0.3 accuracy at epoch 0. It rapidly increases, reaching around 0.95 accuracy by epoch 50. The trend then continues to rise more gradually, plateauing at approximately 1.0 accuracy by epoch 150. From epoch 150 onwards, the accuracy remains consistently at or very near 1.0.
* **Key Data Points (Approximate)**:
* Epoch 0: ~0.30
* Epoch 25: ~0.75
* Epoch 50: ~0.95
* Epoch 100: ~0.99
* Epoch 150: ~1.00
* Epoch 200: ~1.00
* Epoch 400: ~1.00
**Data Series 2: Kernel Size=25 Validation (Dashed Blue Line)**
* **Trend**: The dashed blue line also exhibits a rapid upward trend from epoch 0, starting at a slightly higher accuracy than the training data, around 0.35. It quickly climbs, reaching approximately 0.98 accuracy by epoch 50. The trend then flattens out, reaching and maintaining an accuracy of approximately 1.0 from around epoch 100 onwards.
* **Key Data Points (Approximate)**:
* Epoch 0: ~0.35
* Epoch 25: ~0.85
* Epoch 50: ~0.98
* Epoch 100: ~1.00
* Epoch 150: ~1.00
* Epoch 200: ~1.00
* Epoch 400: ~1.00
### Key Observations
* Both training and validation accuracy converge to a very high level (close to 1.0).
* The validation accuracy is consistently slightly higher than the training accuracy, especially in the initial epochs.
* Both curves reach their plateau around the same epoch range (100-150 epochs).
* The model appears to be well-trained and generalizes effectively, as indicated by the close alignment and high accuracy of both training and validation curves.
### Interpretation
The chart demonstrates the learning progress of a model with a kernel size of 25 over 400 epochs. The rapid increase in accuracy for both training and validation sets suggests that the model is effectively learning the underlying patterns in the data. The plateauing of both curves at a high accuracy level (close to 1.0) indicates that the model has converged and is performing very well.
The fact that validation accuracy is slightly higher than training accuracy, particularly in the early stages, is an interesting observation. This could suggest that the validation set might be slightly easier for the model to learn from initially, or that the regularization techniques (if any) are effectively preventing overfitting. However, the strong convergence of both curves to near-perfect accuracy implies that the model is not significantly overfitting the training data. The consistency of the accuracy at 1.0 for both sets beyond epoch 150 suggests that the model has reached its optimal performance for this configuration and dataset. This indicates a successful training run for the specified kernel size.
</details>
Figure 12: The Accuracy Curves
<details>
<summary>x23.png Details</summary>
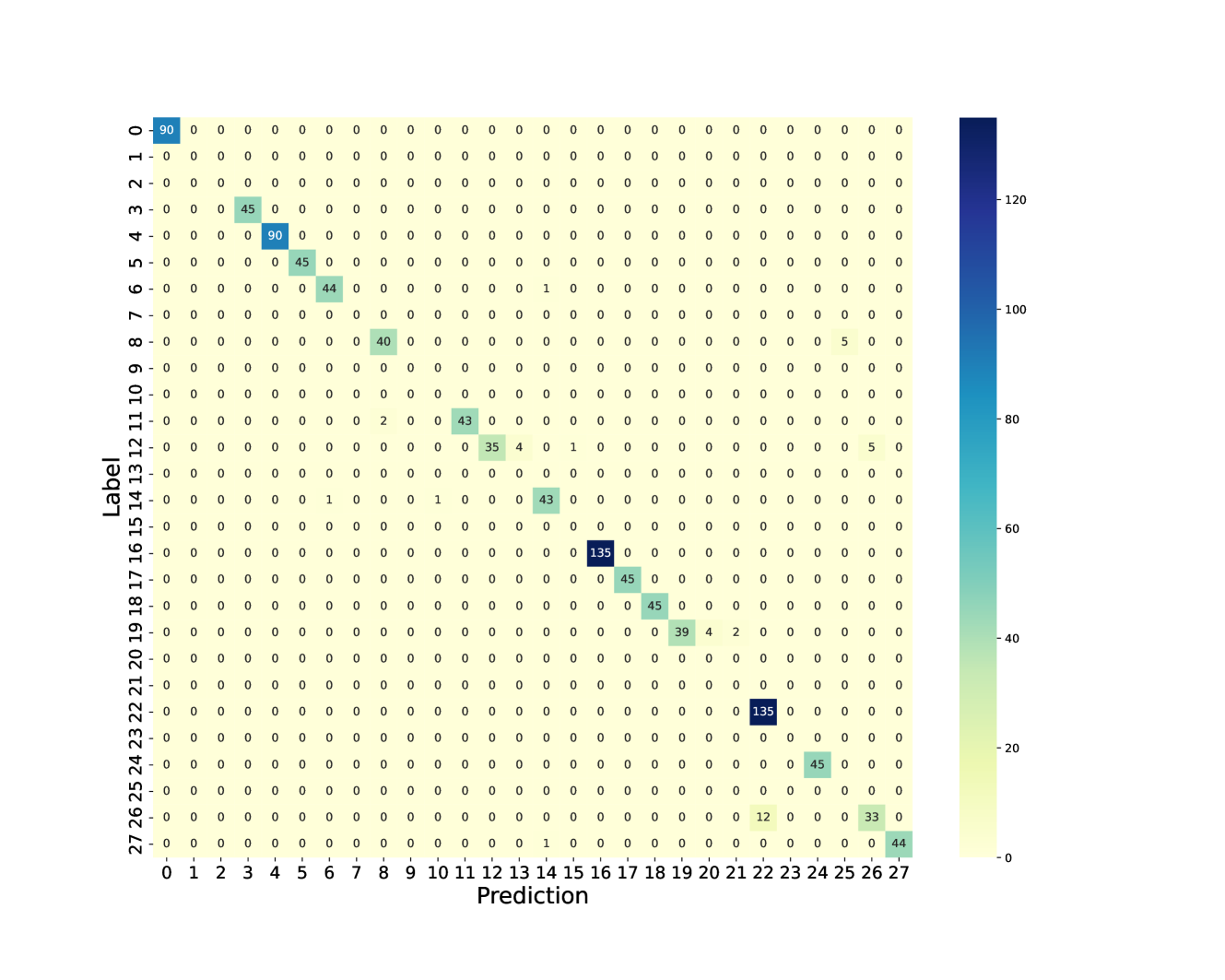
### Visual Description
## Confusion Matrix: Model Performance Evaluation
### Overview
The image displays a confusion matrix, a visualization tool used to evaluate the performance of a classification model. It shows the counts of true positive, true negative, false positive, and false negative predictions for each class. The matrix is presented as a heatmap, where the intensity of the color in each cell corresponds to the number of instances. The rows represent the true labels, and the columns represent the predicted labels.
### Components/Axes
* **Chart Type**: Heatmap (Confusion Matrix)
* **X-axis Title**: Prediction
* **Y-axis Title**: Label
* **Axis Markers (X and Y)**: Both axes are labeled with integers from 0 to 27, representing the different classes.
* **Colorbar**: A vertical colorbar is present on the right side of the matrix.
* **Colorbar Range**: The colorbar ranges from 0 to 120.
* **Colorbar Ticks**: Ticks are present at 0, 20, 40, 60, 80, 100, and 120.
* **Color Mapping**: The color scheme transitions from a light yellow (low values) through light green and teal to dark blue (high values). This indicates that darker colors represent higher counts.
### Detailed Analysis or Content Details
The confusion matrix is a 28x28 grid, with both the 'Label' (true class) and 'Prediction' (predicted class) axes ranging from 0 to 27. The cells contain numerical values representing the count of instances.
**Key non-zero entries and their corresponding (Label, Prediction) coordinates:**
| Label | Prediction | Count |
| :---- | :--------- | :---- |
| 0 | 0 | 90 |
| 2 | 2 | 45 |
| 4 | 4 | 90 |
| 5 | 5 | 45 |
| 6 | 6 | 44 |
| 8 | 8 | 40 |
| 11 | 11 | 2 |
| 12 | 12 | 43 |
| 13 | 13 | 35 |
| 13 | 14 | 4 |
| 13 | 15 | 1 |
| 14 | 14 | 43 |
| 14 | 16 | 5 |
| 15 | 15 | 1 |
| 16 | 16 | 135 |
| 17 | 17 | 45 |
| 19 | 19 | 39 |
| 19 | 20 | 4 |
| 19 | 21 | 2 |
| 22 | 22 | 135 |
| 23 | 23 | 45 |
| 24 | 24 | 45 |
| 25 | 25 | 12 |
| 25 | 26 | 33 |
| 26 | 26 | 44 |
**Observations on Off-Diagonal Entries (Misclassifications):**
* A notable misclassification occurs for Label 13, where 4 instances are predicted as 14 and 1 instance as 15.
* Label 14 has 5 instances misclassified as 16.
* Label 19 shows misclassifications with 4 instances predicted as 20 and 2 instances as 21.
* Label 25 has 33 instances misclassified as 26.
### Key Observations
* **Diagonal Dominance**: The majority of the counts are concentrated along the main diagonal, indicating that the model correctly classifies a significant number of instances for many classes. The highest counts are observed for classes 0, 4, 16, and 22, with values of 90, 90, 135, and 135 respectively.
* **High Accuracy for Certain Classes**: Classes 0, 4, 16, and 22 appear to be well-learned by the model, as evidenced by the high counts on the diagonal.
* **Specific Misclassification Patterns**: There are specific patterns of misclassification. For instance, class 13 is sometimes confused with classes 14 and 15. Class 14 is confused with class 16. Class 19 is confused with classes 20 and 21. Class 25 is frequently confused with class 26.
* **Low Counts for Most Off-Diagonal Cells**: Most off-diagonal cells have very low counts (0, 1, 2, 4, 5), suggesting that the model generally does not confuse most classes with each other.
### Interpretation
This confusion matrix suggests that the classification model performs well overall, with a strong ability to correctly identify instances for many classes, as indicated by the high values on the diagonal. The presence of high counts on the diagonal for classes like 0, 4, 16, and 22 points to robust learning for these specific categories.
However, the off-diagonal entries reveal areas where the model struggles. The specific misclassification patterns observed (e.g., 13 with 14/15, 14 with 16, 19 with 20/21, 25 with 26) suggest that these classes might be visually similar, share common features, or have insufficient distinguishing characteristics in the training data. This could be an opportunity for model improvement by:
1. **Data Augmentation**: Generating more diverse training examples for the confused classes.
2. **Feature Engineering**: Exploring or creating features that better differentiate these classes.
3. **Model Architecture**: Investigating if a different model architecture or fine-tuning existing parameters could improve discrimination.
4. **Class Balancing**: If the dataset is imbalanced, addressing this could help.
The colorbar's scale, ranging up to 120, with the highest values at 135, indicates that the model's performance is generally strong, but there's room for refinement, particularly for the classes exhibiting significant off-diagonal confusion. The Peircean investigative approach would involve further examining the instances that fall into these misclassified categories to understand the underlying reasons for the model's errors, thereby refining the classification process. The relative positioning of the high counts on the diagonal and the scattered, lower counts off-diagonal visually reinforce the interpretation of good general performance with specific weaknesses.
</details>
Figure 13: Confusion Matrix of Real Test Dataset
<details>
<summary>x24.png Details</summary>
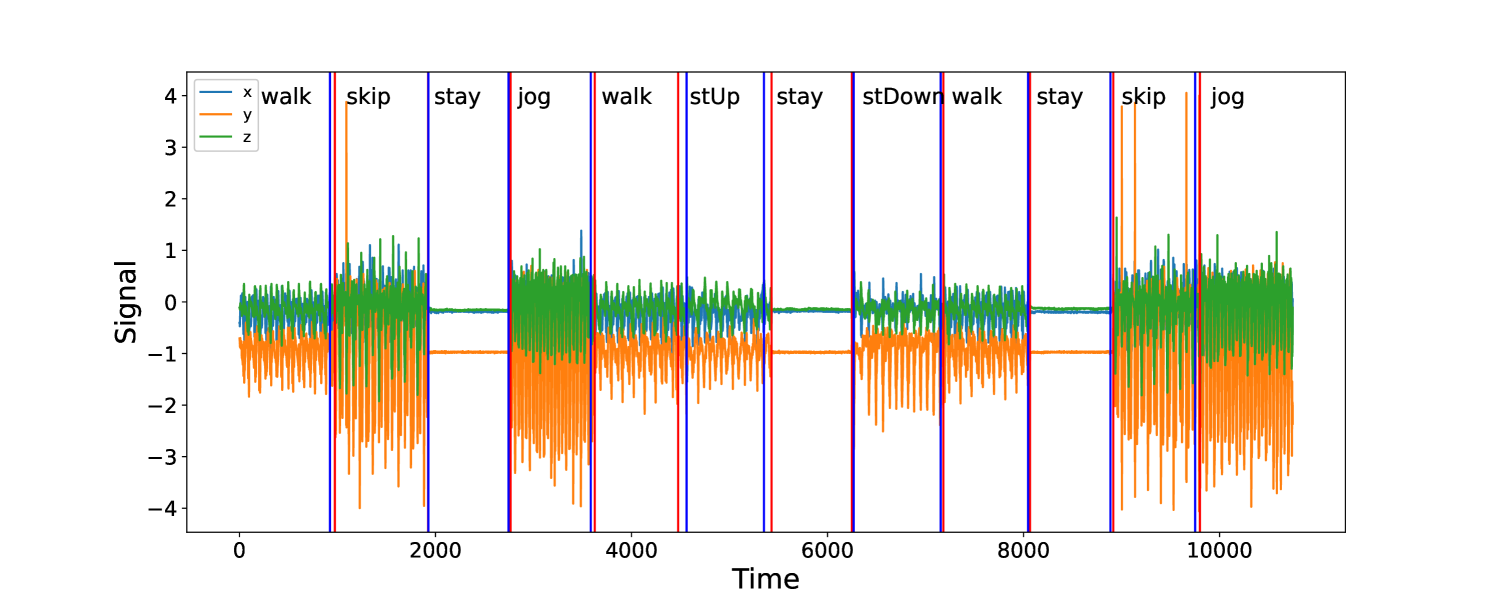
### Visual Description
## Line Chart: Activity Signal Over Time
### Overview
This image displays a line chart showing sensor signals (labeled 'x', 'y', and 'z') over time. The chart is segmented by vertical lines, each indicating a different human activity. The activities are labeled above the corresponding time segments.
### Components/Axes
* **X-axis:** Labeled "Time". The axis ranges from approximately 0 to 11000. Major tick marks are present at 0, 2000, 4000, 6000, 8000, and 10000.
* **Y-axis:** Labeled "Signal". The axis ranges from -4 to 4. Major tick marks are present at -4, -3, -2, -1, 0, 1, 2, 3, and 4.
* **Legend:** Located in the top-left corner of the chart. It indicates the color mapping for the three signal lines:
* 'x': Blue line
* 'y': Orange line
* 'z': Green line
* **Activity Labels:** Text labels are positioned above the chart, indicating the type of activity occurring within specific time intervals. These labels are: "walk", "skip", "stay", "jog", "walk", "stUp", "stay", "stDown", "walk", "stay", "skip", "jog".
* **Vertical Dividers:** Red and blue vertical lines segment the chart, visually separating the different activity periods.
### Detailed Analysis or Content Details
The chart displays three distinct signal lines (blue for 'x', orange for 'y', and green for 'z') that fluctuate over time. The amplitude and pattern of these fluctuations vary significantly depending on the activity.
**Activity Segments and Signal Characteristics:**
1. **walk (approx. Time 0 to 1500):**
* 'x' (blue): Exhibits moderate oscillations, generally between -0.5 and 0.5.
* 'y' (orange): Shows strong, regular oscillations, ranging from approximately -1.5 to -0.5.
* 'z' (green): Displays smaller, more frequent oscillations, mostly between 0 and 0.5.
2. **skip (approx. Time 1500 to 2200):**
* 'x' (blue): Becomes more erratic with larger amplitude spikes, reaching up to 1.5.
* 'y' (orange): Shows very high amplitude, regular oscillations, ranging from approximately -3.5 to -1.5.
* 'z' (green): Exhibits high amplitude, regular oscillations, ranging from approximately 0.5 to 1.5.
3. **stay (approx. Time 2200 to 3000):**
* 'x' (blue): Signal is relatively flat, oscillating slightly around 0, with values between -0.2 and 0.2.
* 'y' (orange): Signal is very flat, close to -1, with minimal fluctuation.
* 'z' (green): Signal is relatively flat, oscillating slightly around 0.2, with values between 0 and 0.4.
4. **jog (approx. Time 3000 to 3800):**
* 'x' (blue): Shows moderate, somewhat regular oscillations, ranging from approximately -0.5 to 0.5.
* 'y' (orange): Exhibits strong, regular oscillations, ranging from approximately -2.5 to -0.5.
* 'z' (green): Displays moderate to high amplitude, regular oscillations, ranging from approximately 0 to 1.5.
5. **walk (approx. Time 3800 to 4500):**
* 'x' (blue): Similar to the first "walk" segment, with oscillations between -0.5 and 0.5.
* 'y' (orange): Similar to the first "walk" segment, with oscillations between -1.5 and -0.5.
* 'z' (green): Similar to the first "walk" segment, with oscillations between 0 and 0.5.
6. **stUp (approx. Time 4500 to 5200):**
* 'x' (blue): Shows a gradual increase in signal, peaking around 1.5, then returning to near 0.
* 'y' (orange): Exhibits a sharp drop to approximately -1, then a gradual rise back to near -0.5.
* 'z' (green): Shows a gradual increase, peaking around 0.5, then returning to near 0.
7. **stay (approx. Time 5200 to 6000):**
* 'x' (blue): Signal is relatively flat, oscillating slightly around 0, with values between -0.2 and 0.2.
* 'y' (orange): Signal is very flat, close to -1, with minimal fluctuation.
* 'z' (green): Signal is relatively flat, oscillating slightly around 0.2, with values between 0 and 0.4.
8. **stDown (approx. Time 6000 to 6800):**
* 'x' (blue): Shows a gradual decrease in signal, reaching a minimum around -1.5, then returning to near 0.
* 'y' (orange): Exhibits a sharp rise to approximately 0.5, then a gradual drop back to near -0.5.
* 'z' (green): Shows a gradual decrease, reaching a minimum around -0.5, then returning to near 0.
9. **walk (approx. Time 6800 to 7500):**
* 'x' (blue): Similar to previous "walk" segments, with oscillations between -0.5 and 0.5.
* 'y' (orange): Similar to previous "walk" segments, with oscillations between -1.5 and -0.5.
* 'z' (green): Similar to previous "walk" segments, with oscillations between 0 and 0.5.
10. **stay (approx. Time 7500 to 8200):**
* 'x' (blue): Signal is relatively flat, oscillating slightly around 0, with values between -0.2 and 0.2.
* 'y' (orange): Signal is very flat, close to -1, with minimal fluctuation.
* 'z' (green): Signal is relatively flat, oscillating slightly around 0.2, with values between 0 and 0.4.
11. **skip (approx. Time 8200 to 9000):**
* 'x' (blue): Exhibits high amplitude spikes, similar to the first "skip" segment.
* 'y' (orange): Shows very high amplitude, regular oscillations, similar to the first "skip" segment.
* 'z' (green): Displays high amplitude, regular oscillations, similar to the first "skip" segment.
12. **jog (approx. Time 9000 to 10500):**
* 'x' (blue): Shows moderate, somewhat regular oscillations, similar to the first "jog" segment.
* 'y' (orange): Exhibits strong, regular oscillations, similar to the first "jog" segment.
* 'z' (green): Displays moderate to high amplitude, regular oscillations, similar to the first "jog" segment.
### Key Observations
* **Distinct Activity Signatures:** Each activity (walk, skip, stay, jog, stUp, stDown) has a unique and recognizable pattern in the 'x', 'y', and 'z' signals.
* **"Stay" Activity:** Characterized by very low signal variance across all three axes, indicating minimal movement. The 'y' signal is consistently around -1, while 'x' and 'z' are close to 0.
* **"Skip" and "Jog" Activities:** Show the highest signal amplitudes, particularly in the 'y' and 'z' signals, indicating vigorous movement. "Skip" appears to have slightly higher peak amplitudes than "jog".
* **"Walk" Activity:** Exhibits moderate signal amplitudes, with distinct oscillatory patterns.
* **Vertical Transitions:** The transitions between activities are marked by abrupt changes in signal patterns, especially when moving from "stay" to a more active state or vice-versa.
* **"stUp" and "stDown" Activities:** These activities show more gradual changes in signal compared to the abrupt shifts between other activities, suggesting a controlled movement. "stUp" shows an overall increase in 'x' and 'z' signals and a decrease in 'y', while "stDown" shows the opposite trend.
### Interpretation
This chart demonstrates the effectiveness of using multi-axis sensor data (likely from an accelerometer or gyroscope) to differentiate between various human physical activities. The distinct patterns observed for each activity suggest that these signals can be used as features for activity recognition algorithms.
The "stay" periods serve as a baseline, showing minimal signal noise, while more dynamic activities like "skip" and "jog" generate significant signal variations. The "walk" pattern is a moderate intermediate. The "stUp" and "stDown" segments are particularly interesting as they show a directional change in the signals, which could be indicative of changes in body orientation or acceleration due to gravity.
The clear segmentation and labeling of activities allow for a direct correlation between the sensor readings and the physical actions performed. This type of data is crucial for applications such as wearable health trackers, sports performance analysis, and human-computer interaction. The consistency of patterns for repeated activities (e.g., multiple "walk" segments) suggests the reliability of the sensor data and the distinctiveness of the activities.
</details>
Figure 14: Change-point Detection of Real Dataset for Person 7 (2nd sequence). The red line at 4476 is the true change-point, the blue line on its right is the estimator. The difference between them is caused by the similarity of “Walk” and “StairUp”.
<details>
<summary>x25.png Details</summary>
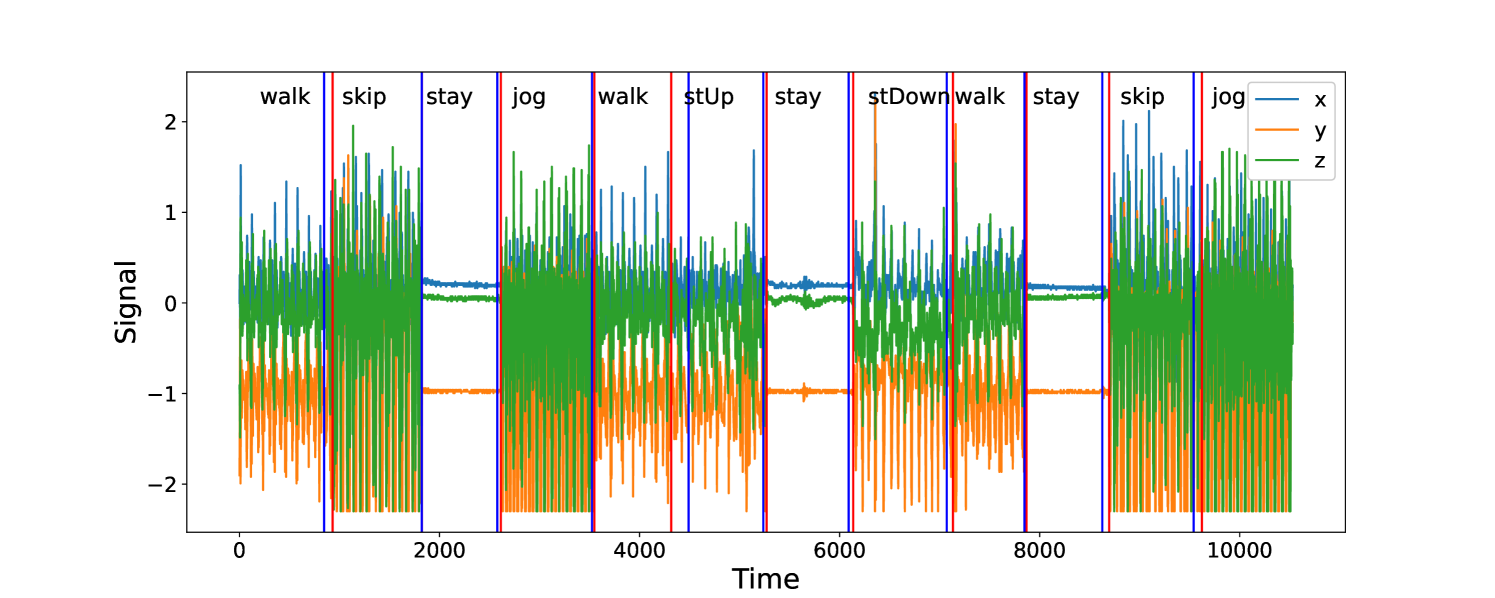
### Visual Description
## Line Chart: Sensor Signal Over Time During Various Activities
### Overview
This image displays a line chart showing sensor signal data over time. The chart is segmented by vertical lines, with labels indicating different human activities performed during the recorded time. Three distinct signal lines, representing x, y, and z axes, are plotted.
### Components/Axes
* **X-axis Title:** Time
* **X-axis Scale:** Numerical, ranging from 0 to approximately 10500. Major tick marks are present at 0, 2000, 4000, 6000, 8000, and 10000.
* **Y-axis Title:** Signal
* **Y-axis Scale:** Numerical, ranging from -2 to 2. Major tick marks are present at -2, -1, 0, 1, and 2.
* **Legend:** Located in the top-right quadrant of the chart.
* Blue line: 'x'
* Orange line: 'y'
* Green line: 'z'
* **Activity Labels:** Text labels positioned above the chart, indicating specific activities. These labels are associated with vertical colored lines (blue and red) that demarcate the time intervals for each activity.
* walk
* skip
* stay
* jog
* walk
* stUp (likely "stand up")
* stay
* stDownwalk (likely "stand down walk")
* stay
* skip
* jog
### Detailed Analysis or Content Details
The chart displays three distinct signal lines (x, y, and z) over a time period of approximately 10500 units. The signals exhibit varying patterns corresponding to different activities.
**Activity Segments and Signal Characteristics:**
1. **"walk" (approx. Time 0 to 1800):**
* **x (blue):** Oscillates between approximately 0.2 and 1.5, with a generally upward trend within this segment.
* **y (orange):** Shows strong, regular oscillations between approximately -1.5 and -0.5.
* **z (green):** Exhibits high-frequency oscillations, with peaks reaching around 1.5 and troughs around -1.5.
2. **"skip" (approx. Time 1800 to 2600):**
* **x (blue):** Oscillates between approximately 0.5 and 1.5, with a slightly higher average than the previous "walk" segment.
* **y (orange):** Shows strong, regular oscillations between approximately -1.5 and -0.5, similar to the previous "walk" segment but with slightly higher amplitude.
* **z (green):** Exhibits very high-frequency and high-amplitude oscillations, reaching peaks around 2 and troughs around -2.
3. **"stay" (approx. Time 2600 to 3500):**
* **x (blue):** Remains relatively stable, fluctuating around 0.3.
* **y (orange):** Remains relatively stable, fluctuating around -0.7.
* **z (green):** Shows very low amplitude oscillations, fluctuating around 0.
4. **"jog" (approx. Time 3500 to 4500):**
* **x (blue):** Oscillates between approximately 0.5 and 1.5, with a pattern similar to "skip" but with slightly lower peak amplitude.
* **y (orange):** Shows strong, regular oscillations between approximately -1.5 and -0.5.
* **z (green):** Exhibits high-frequency oscillations, with peaks reaching around 1.5 and troughs around -1.5.
5. **"walk" (approx. Time 4500 to 5500):**
* **x (blue):** Oscillates between approximately 0.2 and 1.2.
* **y (orange):** Shows regular oscillations between approximately -1.5 and -0.5.
* **z (green):** Exhibits high-frequency oscillations, with peaks reaching around 1.5 and troughs around -1.5.
6. **"stUp" (approx. Time 5500 to 5800):**
* **x (blue):** Shows a sharp increase from around 0.3 to 0.5, then a slight decrease.
* **y (orange):** Shows a sharp increase from around -0.7 to -0.1, then a slight decrease.
* **z (green):** Shows a sharp increase from around 0 to 1.5, then a decrease. This segment appears to represent a transition.
7. **"stay" (approx. Time 5800 to 6500):**
* **x (blue):** Remains relatively stable, fluctuating around 0.3.
* **y (orange):** Remains relatively stable, fluctuating around -0.7.
* **z (green):** Shows very low amplitude oscillations, fluctuating around 0.
8. **"stDownwalk" (approx. Time 6500 to 7500):**
* **x (blue):** Shows a pattern of oscillations between approximately 0.5 and 1.5.
* **y (orange):** Shows strong, regular oscillations between approximately -1.5 and -0.5.
* **z (green):** Exhibits high-frequency oscillations, with peaks reaching around 1.5 and troughs around -1.5. This segment appears similar to "jog" or "walk".
9. **"stay" (approx. Time 7500 to 8200):**
* **x (blue):** Remains relatively stable, fluctuating around 0.3.
* **y (orange):** Remains relatively stable, fluctuating around -0.7.
* **z (green):** Shows very low amplitude oscillations, fluctuating around 0.
10. **"skip" (approx. Time 8200 to 9000):**
* **x (blue):** Oscillates between approximately 0.5 and 1.5.
* **y (orange):** Shows strong, regular oscillations between approximately -1.5 and -0.5.
* **z (green):** Exhibits very high-frequency and high-amplitude oscillations, reaching peaks around 2 and troughs around -2.
11. **"jog" (approx. Time 9000 to 10500):**
* **x (blue):** Oscillates between approximately 0.5 and 1.5.
* **y (orange):** Shows strong, regular oscillations between approximately -1.5 and -0.5.
* **z (green):** Exhibits high-frequency oscillations, with peaks reaching around 1.5 and troughs around -1.5.
### Key Observations
* The "stay" periods are characterized by very low signal variance across all three axes, indicating minimal movement.
* Activities involving significant movement like "skip", "jog", and "walk" show high-amplitude and high-frequency oscillations, particularly in the 'z' signal.
* The "skip" activity appears to generate the highest signal amplitudes, especially in the 'z' axis, reaching approximately +/- 2.
* The "stUp" and "stDownwalk" segments show distinct transitional patterns, with a noticeable increase in signal amplitude compared to the "stay" periods.
* The 'y' signal consistently shows strong, regular oscillations during dynamic activities, with troughs around -1.5 and peaks around -0.5.
* The 'x' signal generally shows moderate oscillations during dynamic activities, with a range of approximately 0.2 to 1.5.
* The 'z' signal is the most dynamic, showing the highest amplitudes and frequencies during activities like "skip" and "jog".
### Interpretation
This chart demonstrates the distinct sensor signal signatures associated with different human activities. The data suggests that accelerometers or similar motion sensors can effectively differentiate between static states (like "stay") and dynamic movements (like "walk", "skip", "jog").
The high variance in the 'z' signal during activities like "skip" and "jog" likely corresponds to the vertical acceleration experienced during these movements. The consistent oscillations in the 'y' signal might represent the forward or backward motion, while the 'x' signal could capture lateral movements or a combination of forces.
The "stay" periods serve as a baseline, showing minimal sensor activity, which is crucial for identifying periods of rest or inactivity. The transitional periods ("stUp", "stDownwalk") highlight the dynamic changes in sensor readings as a person transitions between states of rest and motion.
Overall, this data could be used to train machine learning models for activity recognition, enabling devices to automatically detect and classify human actions based on sensor data. The clear differentiation between activities suggests a robust system for motion sensing and interpretation. The repetition of activities (e.g., "walk" appears multiple times) allows for comparison and verification of consistent signal patterns for each activity type.
</details>
Figure 15: Change-point Detection of Real Dataset for Person 7 (3rd sequence). The red vertical lines represent the underlying change-points, the blue vertical lines represent the estimated change-points.
There are 7 persons observations in this dataset. The first 6 persons sequential data are treated as the training dataset, we use the last person’s data to validate the trained classifier. Each person performs each of 6 activities: “stay”, “walk”, “jog”, “skip”, “stair up” and “stair down” at least 10 seconds. The transition point between two consecutive activities can be treated as the change-point. Therefore, there are 30 possible types of change-point. The total number of labels is 36 (6 activities and 30 possible transitions). However, we only found 28 different types of label in this real dataset, see Figure 10. The initial learning rate is 0.001, the epoch size is 400. Batch size is 16, the dropout rate is 0.3, the filter size is 16 and the kernel size is $(3,25)$ . Furthermore, we also use 20% of the training dataset to validate the classifier during training step. Figure 12 shows the accuracy curves of training and validation. After 150 epochs, both solid and dash curves approximate to 1. The test accuracy is 0.9623, see the confusion matrix in Figure 13. These results show that our neural network classifier performs well both in the training and test datasets. Next, we apply the trained classifier to 3 repeated sequential datasets of Person 7 to detect the change-points. The first sequential dataset has shape $(3,10743)$ . First, we extract the $n$ -length sliding windows with stride 1 as the input dataset. The input size becomes $(9883,6,700)$ . Second, we use Algorithm 1 to detect the change-points where we relabel the activity label as “no-change” label and transition label as “one-change” label respectively. Figures 14 and 15 show the results of multiple change-point detection for other 2 sequential data sets from the 7-th person.